mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
Compare commits
18 Commits
7720d775fa
...
31ae380b05
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
31ae380b05 | ||
|
|
61fa045fec | ||
|
|
93c6cdd981 | ||
|
|
98b7e4fc45 | ||
|
|
bbab5c5a83 | ||
|
|
95c6e3df35 | ||
|
|
9691335ca7 | ||
|
|
efbd62c90a | ||
|
|
025c4e171e | ||
|
|
de141fb2e8 | ||
|
|
9153cf255f | ||
|
|
fd2ed51771 | ||
|
|
16045e73ed | ||
|
|
2700c6f3b3 | ||
|
|
6c879e9302 | ||
|
|
81db70fbea | ||
|
|
0962170df5 | ||
|
|
8847943e50 |
@ -67,7 +67,7 @@ tag:
|
||||
|
||||
**知识越贫乏的人,相信的东西就越绝对**,因为他们从未认真了解过与自己观点相对立的角度,也缺乏对技术发展的全局认识。
|
||||
|
||||
举个例子,我刚开始学习 Java 后端开发的时候,完全没什么经验,就随便买了一本书开始看。当时看的是**《Java Web 整合开发王者归来》**这本书(梦开始的地方)。
|
||||
举个例子,我刚开始学习 Java 后端开发的时候,完全没什么经验,就随便买了一本书开始看。当时看的是 **《Java Web 整合开发王者归来》** 这本书(梦开始的地方)。
|
||||
|
||||
在我上大学那会儿,这本书的很多内容其实已经过时了,比如它花了大量篇幅介绍 JSP、Struts、Hibernate、EJB 和 SVN 等技术。不过,直到现在,我依然非常感谢这本书,带我走进了 Java 后端开发的大门。
|
||||
|
||||
|
||||
@ -191,7 +191,7 @@ tag:
|
||||
5. **子网掩码(subnet mask )**:它是一种用来指明一个 IP 地址的哪些位标识的是主机所在的子网以及哪些位标识的是主机的位掩码。子网掩码不能单独存在,它必须结合 IP 地址一起使用。
|
||||
6. **CIDR( Classless Inter-Domain Routing )**:无分类域间路由选择 (特点是消除了传统的 A 类、B 类和 C 类地址以及划分子网的概念,并使用各种长度的“网络前缀”(network-prefix)来代替分类地址中的网络号和子网号)。
|
||||
7. **默认路由(default route)**:当在路由表中查不到能到达目的地址的路由时,路由器选择的路由。默认路由还可以减小路由表所占用的空间和搜索路由表所用的时间。
|
||||
8. **路由选择算法(Virtual Circuit)**:路由选择协议的核心部分。因特网采用自适应的,分层次的路由选择协议。
|
||||
8. **路由选择算法(Routing Algorithm)**:路由选择协议的核心部分。因特网采用自适应的,分层次的路由选择协议。
|
||||
|
||||
### 4.2. 重要知识点总结
|
||||
|
||||
|
||||
@ -21,19 +21,25 @@ tag:
|
||||
|
||||
## 索引的优缺点
|
||||
|
||||
**优点**:
|
||||
**索引的优点:**
|
||||
|
||||
- 使用索引可以大大加快数据的检索速度(大大减少检索的数据量),减少 IO 次数,这也是创建索引的最主要的原因。
|
||||
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
|
||||
1. **查询速度起飞 (主要目的)**:通过索引,数据库可以**大幅减少需要扫描的数据量**,直接定位到符合条件的记录,从而显著加快数据检索速度,减少磁盘 I/O 次数。
|
||||
2. **保证数据唯一性**:通过创建**唯一索引 (Unique Index)**,可以确保表中的某一列(或几列组合)的值是独一无二的,比如用户ID、邮箱等。主键本身就是一种唯一索引。
|
||||
3. **加速排序和分组**:如果查询中的 ORDER BY 或 GROUP BY 子句涉及的列建有索引,数据库往往可以直接利用索引已经排好序的特性,避免额外的排序操作,从而提升性能。
|
||||
|
||||
**缺点**:
|
||||
**索引的缺点:**
|
||||
|
||||
- 创建和维护索引需要耗费许多时间。当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态地修改,这会降低 SQL 执行效率。
|
||||
- 索引需要使用物理文件存储,也会耗费一定空间。
|
||||
1. **创建和维护耗时**:创建索引本身需要时间,特别是对大表操作时。更重要的是,当对表中的数据进行**增、删、改 (DML操作)** 时,不仅要操作数据本身,相关的索引也必须动态更新和维护,这会**降低这些 DML 操作的执行效率**。
|
||||
2. **占用存储空间**:索引本质上也是一种数据结构,需要以物理文件(或内存结构)的形式存储,因此会**额外占用一定的磁盘空间**。索引越多、越大,占用的空间也就越多。
|
||||
3. **可能被误用或失效**:如果索引设计不当,或者查询语句写得不好,数据库优化器可能不会选择使用索引(或者选错索引),反而导致性能下降。
|
||||
|
||||
但是,**使用索引一定能提高查询性能吗?**
|
||||
**那么,用了索引就一定能提高查询性能吗?**
|
||||
|
||||
大多数情况下,索引查询都是比全表扫描要快的。但是如果数据库的数据量不大,那么使用索引也不一定能够带来很大提升。
|
||||
**不一定。** 大多数情况下,合理使用索引确实比全表扫描快得多。但也有例外:
|
||||
|
||||
- **数据量太小**:如果表里的数据非常少(比如就几百条),全表扫描可能比通过索引查找更快,因为走索引本身也有开销。
|
||||
- **查询结果集占比过大**:如果要查询的数据占了整张表的大部分(比如超过20%-30%),优化器可能会认为全表扫描更划算,因为通过索引多次回表(随机I/O)的成本可能高于一次顺序的全表扫描。
|
||||
- **索引维护不当或统计信息过时**:导致优化器做出错误判断。
|
||||
|
||||
## 索引底层数据结构选型
|
||||
|
||||
@ -386,13 +392,14 @@ EXPLAIN SELECT * FROM student WHERE name = 'Anne Henry' AND class = 'lIrm08RYVk'
|
||||
SELECT * FROM student WHERE class = 'lIrm08RYVk';
|
||||
```
|
||||
|
||||
再来看一个常见的面试题:如果有索引 `联合索引(a,b,c)`,查询 `a=1 AND c=1` 会走索引么?`c=1` 呢?`b=1 AND c=1` 呢?
|
||||
再来看一个常见的面试题:如果有索引 `联合索引(a,b,c)`,查询 `a=1 AND c=1` 会走索引么?`c=1` 呢?`b=1 AND c=1` 呢? `b = 1 AND a = 1 AND c = 1` 呢?
|
||||
|
||||
先不要往下看答案,给自己 3 分钟时间想一想。
|
||||
|
||||
1. 查询 `a=1 AND c=1`:根据最左前缀匹配原则,查询可以使用索引的前缀部分。因此,该查询仅在 `a=1` 上使用索引,然后对结果进行 `c=1` 的过滤。
|
||||
2. 查询 `c=1`:由于查询中不包含最左列 `a`,根据最左前缀匹配原则,整个索引都无法被使用。
|
||||
3. 查询 `b=1 AND c=1`:和第二种一样的情况,整个索引都不会使用。
|
||||
4. 查询 `b=1 AND a=1 AND c=1`:这个查询是可以用到索引的。查询优化器分析 SQL 语句时,对于联合索引,会对查询条件进行重排序,以便用到索引。会将 `b=1` 和 `a=1` 的条件进行重排序,变成 `a=1 AND b=1 AND c=1`。
|
||||
|
||||
MySQL 8.0.13 版本引入了索引跳跃扫描(Index Skip Scan,简称 ISS),它可以在某些索引查询场景下提高查询效率。在没有 ISS 之前,不满足最左前缀匹配原则的联合索引查询中会执行全表扫描。而 ISS 允许 MySQL 在某些情况下避免全表扫描,即使查询条件不符合最左前缀。不过,这个功能比较鸡肋, 和 Oracle 中的没法比,MySQL 8.0.31 还报告了一个 bug:[Bug #109145 Using index for skip scan cause incorrect result](https://bugs.mysql.com/bug.php?id=109145)(后续版本已经修复)。个人建议知道有这个东西就好,不需要深究,实际项目也不一定能用上。
|
||||
|
||||
|
||||
@ -786,7 +786,7 @@ dynamic-hz yes
|
||||
因为不太好办到,或者说这种删除方式的成本太高了。假如我们使用延迟队列作为删除策略,这样存在下面这些问题:
|
||||
|
||||
1. 队列本身的开销可能很大:key 多的情况下,一个延迟队列可能无法容纳。
|
||||
2. 维护延迟队列太麻烦:修改 key 的过期时间就需要调整期在延迟队列中的位置,并且还需要引入并发控制。
|
||||
2. 维护延迟队列太麻烦:修改 key 的过期时间就需要调整其在延迟队列中的位置,并且还需要引入并发控制。
|
||||
|
||||
### 大量 key 集中过期怎么办?
|
||||
|
||||
|
||||
@ -445,7 +445,7 @@ Test.parallelStream avgt 5 186345456.667 ± 3210435.590 ns/op
|
||||
|
||||
`ConcurrentHashMap` 和 `Hashtable` 的区别主要体现在实现线程安全的方式上不同。
|
||||
|
||||
- **底层数据结构:** JDK1.7 的 `ConcurrentHashMap` 底层采用 **分段的数组+链表** 实现,JDK1.8 采用的数据结构跟 `HashMap1.8` 的结构一样,数组+链表/红黑二叉树。`Hashtable` 和 JDK1.8 之前的 `HashMap` 的底层数据结构类似都是采用 **数组+链表** 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
|
||||
- **底层数据结构:** JDK1.7 的 `ConcurrentHashMap` 底层采用 **分段的数组+链表** 实现,在 JDK1.8 中采用的数据结构跟 `HashMap` 的结构一样,数组+链表/红黑二叉树。`Hashtable` 和 JDK1.8 之前的 `HashMap` 的底层数据结构类似都是采用 **数组+链表** 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
|
||||
- **实现线程安全的方式(重要):**
|
||||
- 在 JDK1.7 的时候,`ConcurrentHashMap` 对整个桶数组进行了分割分段(`Segment`,分段锁),每一把锁只锁容器其中一部分数据(下面有示意图),多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。
|
||||
- 到了 JDK1.8 的时候,`ConcurrentHashMap` 已经摒弃了 `Segment` 的概念,而是直接用 `Node` 数组+链表+红黑树的数据结构来实现,并发控制使用 `synchronized` 和 CAS 来操作。(JDK1.6 以后 `synchronized` 锁做了很多优化) 整个看起来就像是优化过且线程安全的 `HashMap`,虽然在 JDK1.8 中还能看到 `Segment` 的数据结构,但是已经简化了属性,只是为了兼容旧版本;
|
||||
|
||||
@ -273,7 +273,7 @@ public class ThreadPoolExecutorConfig {
|
||||
int maxPoolSize = (int) (processNum / (1 - 0.5));
|
||||
threadPoolExecutor.setCorePoolSize(corePoolSize); // 核心池大小
|
||||
threadPoolExecutor.setMaxPoolSize(maxPoolSize); // 最大线程数
|
||||
threadPoolExecutor.setQueueCapacity(maxPoolSize * 1000); // 队列程度
|
||||
threadPoolExecutor.setQueueCapacity(maxPoolSize * 1000); // 队列长度
|
||||
threadPoolExecutor.setThreadPriority(Thread.MAX_PRIORITY);
|
||||
threadPoolExecutor.setDaemon(false);
|
||||
threadPoolExecutor.setKeepAliveSeconds(300);// 线程空闲时间
|
||||
|
||||
@ -174,7 +174,7 @@ Java 类的继承关系由类索引、父类索引和接口索引集合三项确
|
||||
|
||||
**字段的 access_flag 的取值:**
|
||||
|
||||

|
||||

|
||||
|
||||
### 方法表集合(Methods)
|
||||
|
||||
@ -193,7 +193,7 @@ Class 文件存储格式中对方法的描述与对字段的描述几乎采用
|
||||
|
||||
**方法表的 access_flag 取值:**
|
||||
|
||||

|
||||

|
||||
|
||||
注意:因为`volatile`修饰符和`transient`修饰符不可以修饰方法,所以方法表的访问标志中没有这两个对应的标志,但是增加了`synchronized`、`native`、`abstract`等关键字修饰方法,所以也就多了这些关键字对应的标志。
|
||||
|
||||
|
||||
@ -33,7 +33,7 @@ tag:
|
||||
|
||||
虚拟机规范上面这 3 点并不具体,因此是非常灵活的。比如:"通过全类名获取定义此类的二进制字节流" 并没有指明具体从哪里获取( `ZIP`、 `JAR`、`EAR`、`WAR`、网络、动态代理技术运行时动态生成、其他文件生成比如 `JSP`...)、怎样获取。
|
||||
|
||||
加载这一步主要是通过我们后面要讲到的 **类加载器** 完成的。类加载器有很多种,当我们想要加载一个类的时候,具体是哪个类加载器加载由 **双亲委派模型** 决定(不过,我们也能打破由双亲委派模型)。
|
||||
加载这一步主要是通过我们后面要讲到的 **类加载器** 完成的。类加载器有很多种,当我们想要加载一个类的时候,具体是哪个类加载器加载由 **双亲委派模型** 决定(不过,我们也能打破双亲委派模型)。
|
||||
|
||||
> 类加载器、双亲委派模型也是非常重要的知识点,这部分内容在[类加载器详解](https://javaguide.cn/java/jvm/classloader.html "类加载器详解")这篇文章中有详细介绍到。阅读本篇文章的时候,大家知道有这么个东西就可以了。
|
||||
|
||||
|
||||
@ -101,7 +101,7 @@ JVM 中内置了三个重要的 `ClassLoader`:
|
||||
|
||||
除了 `BootstrapClassLoader` 是 JVM 自身的一部分之外,其他所有的类加载器都是在 JVM 外部实现的,并且全都继承自 `ClassLoader`抽象类。这样做的好处是用户可以自定义类加载器,以便让应用程序自己决定如何去获取所需的类。
|
||||
|
||||
每个 `ClassLoader` 可以通过`getParent()`获取其父 `ClassLoader`,如果获取到 `ClassLoader` 为`null`的话,那么该类是通过 `BootstrapClassLoader` 加载的。
|
||||
每个 `ClassLoader` 可以通过`getParent()`获取其父 `ClassLoader`,如果获取到 `ClassLoader` 为`null`的话,那么该类加载器的父类加载器是 `BootstrapClassLoader` 。
|
||||
|
||||
```java
|
||||
public abstract class ClassLoader {
|
||||
|
||||
@ -521,7 +521,7 @@ G1 收集器的运作大致分为以下几个步骤:
|
||||
|
||||
### ZGC 收集器
|
||||
|
||||
与 CMS 中的 ParNew 和 G1 类似,ZGC 也采用标记-复制算法,不过 ZGC 对该算法做了重大改进。
|
||||
与 CMS、ParNew 和 G1 类似,ZGC 也采用标记-复制算法,不过 ZGC 对该算法做了重大改进。
|
||||
|
||||
ZGC 可以将暂停时间控制在几毫秒以内,且暂停时间不受堆内存大小的影响,出现 Stop The World 的情况会更少,但代价是牺牲了一些吞吐量。ZGC 最大支持 16TB 的堆内存。
|
||||
|
||||
|
||||
@ -67,6 +67,7 @@ icon: project
|
||||
## 售票系统
|
||||
|
||||
- [12306](https://gitee.com/nageoffer/12306) :基于 JDK17 + SpringBoot3 + SpringCloud 微服务架构的高并发 12306 购票服务。
|
||||
- [大麦](https://gitee.com/java-up-up/damai):提供热门演唱会的购票功能,并且对如何解决高并发下的抢票而产生的各种问题,从而设计出了实际落地的解决方案。
|
||||
|
||||
## 权限管理系统
|
||||
|
||||
|
||||
@ -3,21 +3,17 @@ title: RestFul API 简明教程
|
||||
category: 代码质量
|
||||
---
|
||||
|
||||

|
||||
|
||||
这篇文章简单聊聊后端程序员必备的 RESTful API 相关的知识。
|
||||
|
||||
开始正式介绍 RESTful API 之前,我们需要首先搞清:**API 到底是什么?**
|
||||
|
||||
## 何为 API?
|
||||
|
||||

|
||||
|
||||
**API(Application Programming Interface)** 翻译过来是应用程序编程接口的意思。
|
||||
|
||||
我们在进行后端开发的时候,主要的工作就是为前端或者其他后端服务提供 API 比如查询用户数据的 API 。
|
||||
|
||||

|
||||

|
||||
|
||||
但是, API 不仅仅代表后端系统暴露的接口,像框架中提供的方法也属于 API 的范畴。
|
||||
|
||||
@ -66,7 +62,7 @@ POST /classes:新建一个班级
|
||||
|
||||
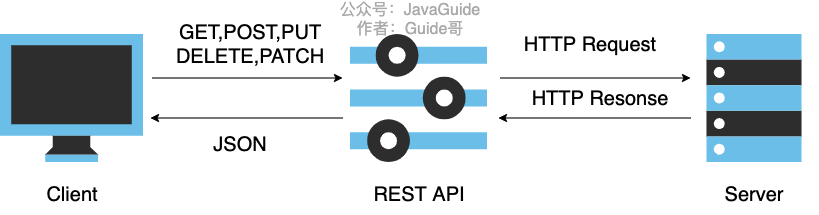
## RESTful API 规范
|
||||
|
||||
|
||||
|
||||
|
||||
### 动作
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user