mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-07-28 12:22:17 +08:00
Compare commits
9 Commits
dcd509e29f
...
5b183ee904
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
5b183ee904 | ||
|
|
a98a79b068 | ||
|
|
351a704069 | ||
|
|
0d985e2b7d | ||
|
|
e07077c4ea | ||
|
|
3a292b7edf | ||
|
|
6d40735fc4 | ||
|
|
3c2745df4a | ||
|
|
9dfd0f4ce9 |
@ -13,7 +13,7 @@ tag:
|
||||
|
||||
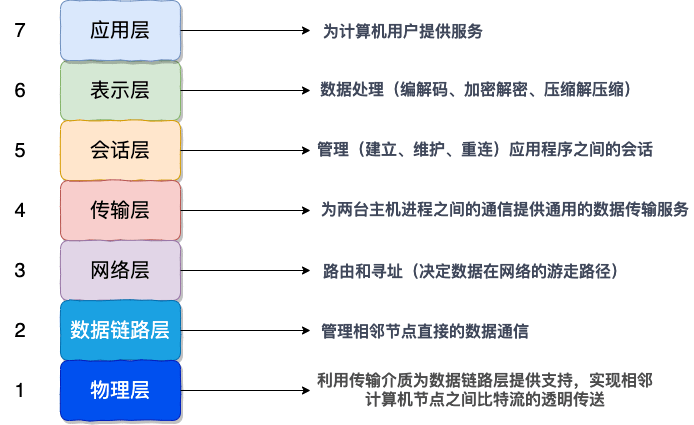
|
||||
|
||||
每一层都专注做一件事情,并且每一层都需要使用下一层提供的功能比如传输层需要使用网络层提供的路有和寻址功能,这样传输层才知道把数据传输到哪里去。
|
||||
每一层都专注做一件事情,并且每一层都需要使用下一层提供的功能比如传输层需要使用网络层提供的路由和寻址功能,这样传输层才知道把数据传输到哪里去。
|
||||
|
||||
**OSI 的七层体系结构概念清楚,理论也很完整,但是它比较复杂而且不实用,而且有些功能在多个层中重复出现。**
|
||||
|
||||
@ -113,4 +113,4 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
|
||||
|
||||
我想到了计算机世界非常非常有名的一句话,这里分享一下:
|
||||
|
||||
> 计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决,计算机整个体系从上到下都是按照严格的层次结构设计的。
|
||||
> 计算机科学领域的任何问题都可以通过增加一个间接的中间层来解决,计算机整个体系从上到下都是按照严格的层次结构设计的。
|
||||
|
||||
@ -118,7 +118,7 @@ InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索
|
||||
|
||||
**聚集索引即索引结构和数据一起存放的索引。主键索引属于聚集索引。**
|
||||
|
||||
在 Mysql 中,InnoDB 引擎的表的 `.ibd`文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
|
||||
在 MySQL 中,InnoDB 引擎的表的 `.ibd`文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
|
||||
|
||||
#### 聚集索引的优点
|
||||
|
||||
@ -135,12 +135,7 @@ InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索
|
||||
|
||||
**二级索引属于非聚集索引。**
|
||||
|
||||
> MYISAM 引擎的表的.MYI 文件包含了表的索引,
|
||||
> 该表的索引(B+树)的每个叶子非叶子节点存储索引,
|
||||
> 叶子节点存储索引和索引对应数据的指针,指向.MYD 文件的数据。
|
||||
>
|
||||
> **非聚集索引的叶子节点并不一定存放数据的指针,
|
||||
> 因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。**
|
||||
非聚集索引的叶子节点并不一定存放数据的指针,因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。
|
||||
|
||||
#### 非聚集索引的优点
|
||||
|
||||
|
||||
@ -22,7 +22,7 @@ tag:
|
||||
|
||||
- **语法形式** :从语法形式上看,成员变量是属于类的,而局部变量是在代码块或方法中定义的变量或是方法的参数;成员变量可以被 `public`,`private`,`static` 等修饰符所修饰,而局部变量不能被访问控制修饰符及 `static` 所修饰;但是,成员变量和局部变量都能被 `final` 所修饰。
|
||||
- **存储方式** :从变量在内存中的存储方式来看,如果成员变量是使用 `static` 修饰的,那么这个成员变量是属于类的,如果没有使用 `static` 修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量则存在于栈内存。
|
||||
- **生存时间** :从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动消失。
|
||||
- **生存时间** :从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动生成,随着方法的调用结束而消亡。
|
||||
- **默认值** :从变量是否有默认值来看,成员变量如果没有被赋初始值,则会自动以类型的默认值而赋值(一种情况例外:被 `final` 修饰的成员变量也必须显式地赋值),而局部变量则不会自动赋值。
|
||||
|
||||
### 创建一个对象用什么运算符?对象实体与对象引用有何不同?
|
||||
|
||||
@ -365,7 +365,7 @@ String d = str1 + str2; // 常量池中的对象
|
||||
System.out.println(c == d);// true
|
||||
```
|
||||
|
||||
被 `final` 关键字修改之后的 `String` 会被编译器当做常量来处理,编译器在程序编译期就可以确定它的值,其效果就想到于访问常量。
|
||||
被 `final` 关键字修改之后的 `String` 会被编译器当做常量来处理,编译器在程序编译期就可以确定它的值,其效果就相当于访问常量。
|
||||
|
||||
如果 ,编译器在运行时才能知道其确切值的话,就无法对其优化。
|
||||
|
||||
@ -457,7 +457,7 @@ System.out.println(s3==s4); // False
|
||||
1. 对于基本数据类型来说,==比较的是值。对于引用数据类型来说,==比较的是对象的内存地址。
|
||||
2. 在编译过程中,Javac 编译器(下文中统称为编译器)会进行一个叫做 **常量折叠(Constant Folding)** 的代码优化。常量折叠会把常量表达式的值求出来作为常量嵌在最终生成的代码中,这是 Javac 编译器会对源代码做的极少量优化措施之一(代码优化几乎都在即时编译器中进行)。
|
||||
3. 一般来说,我们要尽量避免通过 new 的方式创建字符串。使用双引号声明的 `String` 对象( `String s1 = "java"` )更利于让编译器有机会优化我们的代码,同时也更易于阅读。
|
||||
4. 被 `final` 关键字修改之后的 `String` 会被编译器当做常量来处理,编译器程序编译期就可以确定它的值,其效果就想到于访问常量。
|
||||
4. 被 `final` 关键字修改之后的 `String` 会被编译器当做常量来处理,编译器程序编译期就可以确定它的值,其效果就相当于访问常量。
|
||||
|
||||
### 4.2 String s1 = new String("abc");这句话创建了几个字符串对象?
|
||||
|
||||
|
||||
@ -48,9 +48,7 @@ category: 开源项目
|
||||
|
||||
## 开源书籍
|
||||
|
||||
- **[《Effective Java(第 3 版)各章节的中英文学习参考》](https://github.com/clxering/Effective-Java-3rd-edition-Chinese-English-bilingual)**
|
||||
- **[《On Java 8 中文版》](https://github.com/LingCoder/OnJava8)**
|
||||
- **[《DDIA(设计数据密集型应用) 中文翻译》](https://github.com/Vonng/ddia)**
|
||||
- **[《图说设计模式》](https://github.com/me115/design_patterns)**
|
||||
- **[《Java 8 简明教程 中文版》](https://github.com/wizardforcel/modern-java-zh)**
|
||||
- **[《凤凰架构》](https://github.com/fenixsoft/awesome-fenix)**
|
||||
- **[《Effective Java(第 3 版)》中英对照版](https://github.com/clxering/Effective-Java-3rd-edition-Chinese-English-bilingual)** :《Effective Java(第 3 版)各章节的中英文学习参考。
|
||||
- **[《DDIA(设计数据密集型应用)》中文版](https://github.com/Vonng/ddia)** :《Designing Data-Intensive Application》DDIA 中文翻译。
|
||||
- **[《凤凰架构》](https://github.com/fenixsoft/awesome-fenix)** :讨论如何构建一套可靠的大型分布式系统。
|
||||
- **[《分布式系统模式》中文版](https://github.com/dreamhead/patterns-of-distributed-systems)** :《Patterns of Distributed Systems》中文翻译。
|
||||
Loading…
x
Reference in New Issue
Block a user