mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
Compare commits
9 Commits
941737186b
...
6ab0909700
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
6ab0909700 | ||
|
|
b5f8894c70 | ||
|
|
a6cf71b9b5 | ||
|
|
162a17c182 | ||
|
|
a549825034 | ||
|
|
0cbe171506 | ||
|
|
26de5441d5 | ||
|
|
69d6de121c | ||
|
|
1d40675688 |
@ -25,6 +25,7 @@ export default hopeTheme({
|
||||
pure: true,
|
||||
breadcrumb: false,
|
||||
navbar,
|
||||
navbarAutoHide: "always",
|
||||
sidebar,
|
||||
footer:
|
||||
'<a href="https://beian.miit.gov.cn/" target="_blank">鄂ICP备2020015769号-1</a>',
|
||||
|
||||
@ -622,10 +622,7 @@ public class Solution {
|
||||
|
||||
**题目分析:**
|
||||
|
||||
这道题想了半天没有思路,参考了 Alias 的答案,他的思路写的也很详细应该很容易看懂。
|
||||
作者:Alias
|
||||
<https://www.nowcoder.com/questionTerminal/d77d11405cc7470d82554cb392585106>
|
||||
来源:牛客网
|
||||
这道题想了半天没有思路,参考了 [Alias 的答案](https://www.nowcoder.com/questionTerminal/d77d11405cc7470d82554cb392585106),他的思路写的也很详细应该很容易看懂。
|
||||
|
||||
【思路】借用一个辅助的栈,遍历压栈顺序,先讲第一个放入栈中,这里是 1,然后判断栈顶元素是不是出栈顺序的第一个元素,这里是 4,很显然 1≠4,所以我们继续压栈,直到相等以后开始出栈,出栈一个元素,则将出栈顺序向后移动一位,直到不相等,这样循环等压栈顺序遍历完成,如果辅助栈还不为空,说明弹出序列不是该栈的弹出顺序。
|
||||
|
||||
|
||||
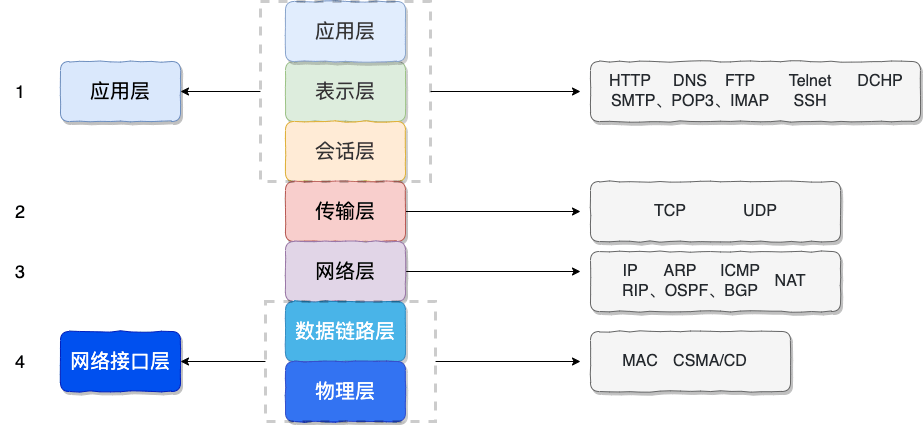
@ -15,6 +15,8 @@ DNS(Domain Name System)域名管理系统,是当用户使用浏览器访
|
||||
|
||||
|
||||
|
||||
## DNS 服务器
|
||||
|
||||
DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务器都属于以下四个类别之一):
|
||||
|
||||
- 根 DNS 服务器。根 DNS 服务器提供 TLD 服务器的 IP 地址。目前世界上只有 13 组根服务器,我国境内目前仍没有根服务器。
|
||||
@ -22,6 +24,8 @@ DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务
|
||||
- 权威 DNS 服务器。在因特网上具有公共可访问主机的每个组织机构必须提供公共可访问的 DNS 记录,这些记录将这些主机的名字映射为 IP 地址。
|
||||
- 本地 DNS 服务器。每个 ISP(互联网服务提供商)都有一个自己的本地 DNS 服务器。当主机发出 DNS 请求时,该请求被发往本地 DNS 服务器,它起着代理的作用,并将该请求转发到 DNS 层次结构中。严格说来,不属于 DNS 层级结构。
|
||||
|
||||
世界上并不是只有 13 台根服务器,这是很多人普遍的误解,网上很多文章也是这么写的。实际上,现在根服务器数量远远超过这个数量。最初确实是为 DNS 根服务器分配了 13 个 IP 地址,每个 IP 地址对应一个不同的根 DNS 服务器。然而,由于互联网的快速发展和增长,这个原始的架构变得不太适应当前的需求。为了提高 DNS 的可靠性、安全性和性能,目前这 13 个 IP 地址中的每一个都有多个服务器,截止到 2023 年底,所有根服务器之和达到了 600 多台,未来还会继续增加。
|
||||
|
||||
## DNS 工作流程
|
||||
|
||||
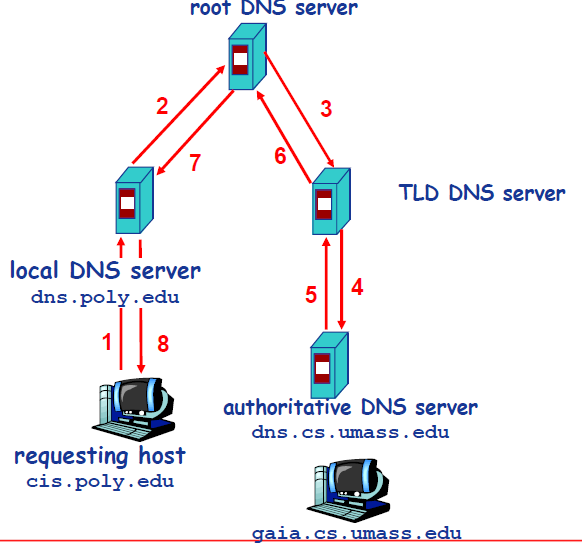
以下图为例,介绍 DNS 的查询解析过程。DNS 的查询解析过程分为两种模式:
|
||||
@ -48,7 +52,7 @@ DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务
|
||||
|
||||
|
||||
|
||||
另外,DNS 的缓存位于本地 DNS 服务器。由于全世界的根服务器甚少,只有 400 多台,分为 13 组,且顶级域的数量也在一个可数的范围内,因此本地 DNS 通常已经缓存了很多 TLD DNS 服务器,所以在实际查找过程中,无需访问根服务器。根服务器通常是被跳过的,不请求的。
|
||||
另外,DNS 的缓存位于本地 DNS 服务器。由于全世界的根服务器甚少,只有 600 多台,分为 13 组,且顶级域的数量也在一个可数的范围内,因此本地 DNS 通常已经缓存了很多 TLD DNS 服务器,所以在实际查找过程中,无需访问根服务器。根服务器通常是被跳过的,不请求的。这样可以提高 DNS 查询的效率和速度,减少对根服务器和 TLD 服务器的负担。
|
||||
|
||||
## DNS 报文格式
|
||||
|
||||
|
||||
@ -361,7 +361,7 @@ DNS(Domain Name System)域名管理系统,是当用户使用浏览器访
|
||||
|
||||
目前 DNS 的设计采用的是分布式、层次数据库结构,**DNS 是应用层协议,它可以在 UDP 或 TCP 协议之上运行,端口为 53** 。
|
||||
|
||||
### DNS 服务器有哪些?
|
||||
### DNS 服务器有哪些?根服务器有多少个?
|
||||
|
||||
DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务器都属于以下四个类别之一):
|
||||
|
||||
@ -370,10 +370,16 @@ DNS 服务器自底向上可以依次分为以下几个层级(所有 DNS 服务
|
||||
- 权威 DNS 服务器。在因特网上具有公共可访问主机的每个组织机构必须提供公共可访问的 DNS 记录,这些记录将这些主机的名字映射为 IP 地址。
|
||||
- 本地 DNS 服务器。每个 ISP(互联网服务提供商)都有一个自己的本地 DNS 服务器。当主机发出 DNS 请求时,该请求被发往本地 DNS 服务器,它起着代理的作用,并将该请求转发到 DNS 层次结构中。严格说来,不属于 DNS 层级结构
|
||||
|
||||
世界上并不是只有 13 台根服务器,这是很多人普遍的误解,网上很多文章也是这么写的。实际上,现在根服务器数量远远超过这个数量。最初确实是为 DNS 根服务器分配了 13 个 IP 地址,每个 IP 地址对应一个不同的根 DNS 服务器。然而,由于互联网的快速发展和增长,这个原始的架构变得不太适应当前的需求。为了提高 DNS 的可靠性、安全性和性能,目前这 13 个 IP 地址中的每一个都有多个服务器,截止到 2023 年底,所有根服务器之和达到了 600 多台,未来还会继续增加。
|
||||
|
||||
### DNS 解析的过程是什么样的?
|
||||
|
||||
整个过程的步骤比较多,我单独写了一篇文章详细介绍:[DNS 域名系统详解(应用层)](./dns.md) 。
|
||||
|
||||
### DNS 劫持了解吗?如何应对?
|
||||
|
||||
DNS 劫持是一种网络攻击,它通过修改 DNS 服务器的解析结果,使用户访问的域名指向错误的 IP 地址,从而导致用户无法访问正常的网站,或者被引导到恶意的网站。DNS 劫持有时也被称为 DNS 重定向、DNS 欺骗或 DNS 污染。DNS 劫持详细介绍可以参考:[黑客技术?没你想象的那么难!——DNS 劫持篇](https://cloud.tencent.com/developer/article/1197474)。
|
||||
|
||||
## 参考
|
||||
|
||||
- 《图解 HTTP》
|
||||
|
||||
@ -63,7 +63,7 @@ HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 **
|
||||
|
||||
**运行于 TCP 协议之上的协议**:
|
||||
|
||||
1. **HTTP 协议**:超文本传输协议(HTTP,HyperText Transfer Protocol)是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
|
||||
1. **HTTP 协议(HTTP/3.0 之前)**:超文本传输协议(HTTP,HyperText Transfer Protocol)是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
|
||||
2. **HTTPS 协议**:更安全的超文本传输协议(HTTPS,Hypertext Transfer Protocol Secure),身披 SSL 外衣的 HTTP 协议
|
||||
3. **FTP 协议**:文件传输协议 FTP(File Transfer Protocol)是一种用于在计算机之间传输文件的协议,可以屏蔽操作系统和文件存储方式。注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。建议在传输敏感数据时使用更安全的协议,如 SFTP。
|
||||
4. **SMTP 协议**:简单邮件传输协议(SMTP,Simple Mail Transfer Protocol)的缩写,是一种用于发送电子邮件的协议。注意 ⚠️:SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
|
||||
@ -74,9 +74,10 @@ HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 **
|
||||
|
||||
**运行于 UDP 协议之上的协议**:
|
||||
|
||||
1. **DHCP 协议**:动态主机配置协议,动态配置 IP 地址
|
||||
2. **DNS**:域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。 我们可以将其理解为专为互联网设计的电话薄。实际上,DNS 同时支持 UDP 和 TCP 协议。
|
||||
3. ……
|
||||
1. **HTTP 协议(HTTP/3.0 )**: HTTP/3.0 弃用 TCP,改用基于 UDP 的 QUIC 协议 。
|
||||
2. **DHCP 协议**:动态主机配置协议,动态配置 IP 地址
|
||||
3. **DNS**:域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。 我们可以将其理解为专为互联网设计的电话薄。实际上,DNS 同时支持 UDP 和 TCP 协议。
|
||||
4. ……
|
||||
|
||||
### TCP 三次握手和四次挥手(非常重要)
|
||||
|
||||
|
||||
@ -10,9 +10,9 @@ tag:
|
||||
1. **基于数据块传输**:应用数据被分割成 TCP 认为最适合发送的数据块,再传输给网络层,数据块被称为报文段或段。
|
||||
2. **对失序数据包重新排序以及去重**:TCP 为了保证不发生丢包,就给每个包一个序列号,有了序列号能够将接收到的数据根据序列号排序,并且去掉重复序列号的数据就可以实现数据包去重。
|
||||
3. **校验和** : TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
|
||||
4. **超时重传** : 当发送方发送数据之后,它启动一个定时器,等待目的端确认收到这个报文段。接收端实体对已成功收到的包发回一个相应的确认信息(ACK)。如果发送端实体在合理的往返时延(RTT)内未收到确认消息,那么对应的数据包就被假设为[已丢失](https://zh.wikipedia.org/wiki/丢包)并进行重传。
|
||||
4. **重传机制** : 在数据包丢失或延迟的情况下,重新发送数据包,直到收到对方的确认应答(ACK)。TCP 重传机制主要有:基于计时器的重传(也就是超时重传)、快速重传(基于接收端的反馈信息来引发重传)、SACK(在快速重传的基础上,返回最近收到的报文段的序列号范围,这样客户端就知道,哪些数据包已经到达服务器了)、D-SACK(重复 SACK,在 SACK 的基础上,额外携带信息,告知发送方有哪些数据包自己重复接收了)。关于重传机制的详细介绍,可以查看[详解 TCP 超时与重传机制](https://zhuanlan.zhihu.com/p/101702312)这篇文章。
|
||||
5. **流量控制** : TCP 连接的每一方都有固定大小的缓冲空间,TCP 的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议(TCP 利用滑动窗口实现流量控制)。
|
||||
6. **拥塞控制** : 当网络拥塞时,减少数据的发送。
|
||||
6. **拥塞控制** : 当网络拥塞时,减少数据的发送。TCP 在发送数据的时候,需要考虑两个因素:一是接收方的接收能力,二是网络的拥塞程度。接收方的接收能力由滑动窗口表示,表示接收方还有多少缓冲区可以用来接收数据。网络的拥塞程度由拥塞窗口表示,它是发送方根据网络状况自己维护的一个值,表示发送方认为可以在网络中传输的数据量。发送方发送数据的大小是滑动窗口和拥塞窗口的最小值,这样可以保证发送方既不会超过接收方的接收能力,也不会造成网络的过度拥塞。
|
||||
|
||||
## TCP 如何实现流量控制?
|
||||
|
||||
@ -101,11 +101,21 @@ ARQ 包括停止等待 ARQ 协议和连续 ARQ 协议。
|
||||
|
||||
连续 ARQ 协议可提高信道利用率。发送方维持一个发送窗口,凡位于发送窗口内的分组可以连续发送出去,而不需要等待对方确认。接收方一般采用累计确认,对按序到达的最后一个分组发送确认,表明到这个分组为止的所有分组都已经正确收到了。
|
||||
|
||||
**优点:** 信道利用率高,容易实现,即使确认丢失,也不必重传。
|
||||
- **优点:** 信道利用率高,容易实现,即使确认丢失,也不必重传。
|
||||
- **缺点:** 不能向发送方反映出接收方已经正确收到的所有分组的信息。 比如:发送方发送了 5 条 消息,中间第三条丢失(3 号),这时接收方只能对前两个发送确认。发送方无法知道后三个分组的下落,而只好把后三个全部重传一次。这也叫 Go-Back-N(回退 N),表示需要退回来重传已经发送过的 N 个消息。
|
||||
|
||||
**缺点:** 不能向发送方反映出接收方已经正确收到的所有分组的信息。 比如:发送方发送了 5 条 消息,中间第三条丢失(3 号),这时接收方只能对前两个发送确认。发送方无法知道后三个分组的下落,而只好把后三个全部重传一次。这也叫 Go-Back-N(回退 N),表示需要退回来重传已经发送过的 N 个消息。
|
||||
## 超时重传如何实现?超时重传时间怎么确定?
|
||||
|
||||
## Reference
|
||||
当发送方发送数据之后,它启动一个定时器,等待目的端确认收到这个报文段。接收端实体对已成功收到的包发回一个相应的确认信息(ACK)。如果发送端实体在合理的往返时延(RTT)内未收到确认消息,那么对应的数据包就被假设为[已丢失](https://zh.wikipedia.org/wiki/丢包)并进行重传。
|
||||
|
||||
- RTT(Round Trip Time):往返时间,也就是数据包从发出去到收到对应 ACK 的时间。
|
||||
- RTO(Retransmission Time Out):重传超时时间,即从数据发送时刻算起,超过这个时间便执行重传。
|
||||
|
||||
RTO 的确定是一个关键问题,因为它直接影响到 TCP 的性能和效率。如果 RTO 设置得太小,会导致不必要的重传,增加网络负担;如果 RTO 设置得太大,会导致数据传输的延迟,降低吞吐量。因此,RTO 应该根据网络的实际状况,动态地进行调整。
|
||||
|
||||
RTT 的值会随着网络的波动而变化,所以 TCP 不能直接使用 RTT 作为 RTO。为了动态地调整 RTO,TCP 协议采用了一些算法,如加权移动平均(EWMA)算法,Karn 算法,Jacobson 算法等,这些算法都是根据往返时延(RTT)的测量和变化来估计 RTO 的值。
|
||||
|
||||
## 参考
|
||||
|
||||
1. 《计算机网络(第 7 版)》
|
||||
2. 《图解 HTTP》
|
||||
|
||||
@ -452,11 +452,21 @@ Java 中有 8 种基本数据类型,分别为:
|
||||
|
||||
**为什么说是几乎所有对象实例都存在于堆中呢?** 这是因为 HotSpot 虚拟机引入了 JIT 优化之后,会对对象进行逃逸分析,如果发现某一个对象并没有逃逸到方法外部,那么就可能通过标量替换来实现栈上分配,而避免堆上分配内存
|
||||
|
||||
⚠️ 注意:**基本数据类型存放在栈中是一个常见的误区!** 基本数据类型的成员变量如果没有被 `static` 修饰的话(不建议这么使用,应该要使用基本数据类型对应的包装类型),就存放在堆中。
|
||||
⚠️ 注意:**基本数据类型存放在栈中是一个常见的误区!** 基本数据类型的存储位置取决于它们的作用域和声明方式。如果它们是局部变量,那么它们会存放在栈中;如果它们是成员变量,那么它们会存放在堆中。
|
||||
|
||||
```java
|
||||
class BasicTypeVar{
|
||||
private int x;
|
||||
public class Test {
|
||||
// 成员变量,存放在堆中
|
||||
int a = 10;
|
||||
// 被 static 修饰,也存放在堆中,但属于类,不属于对象
|
||||
// JDK1.7 静态变量从永久代移动了 Java 堆中
|
||||
static int b = 20;
|
||||
|
||||
public void method() {
|
||||
// 局部变量,存放在栈中
|
||||
int c = 30;
|
||||
static int d = 40; // 编译错误,不能在方法中使用 static 修饰局部变量
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
@ -431,8 +431,8 @@ public boolean equals(Object anObject) {
|
||||
|
||||
> ⚠️ 注意:该方法在 **Oracle OpenJDK8** 中默认是 "使用线程局部状态来实现 Marsaglia's xor-shift 随机数生成", 并不是 "地址" 或者 "地址转换而来", 不同 JDK/VM 可能不同在 **Oracle OpenJDK8** 中有六种生成方式 (其中第五种是返回地址), 通过添加 VM 参数: -XX:hashCode=4 启用第五种。参考源码:
|
||||
>
|
||||
> - <https://hg.openjdk.org/jdk8u/jdk8u/hotspot/file/87ee5ee27509/src/share/vm/runtime/globals.hpp(1127> 行)
|
||||
> - <https://hg.openjdk.org/jdk8u/jdk8u/hotspot/file/87ee5ee27509/src/share/vm/runtime/synchronizer.cpp(537> 行开始)
|
||||
> - <https://hg.openjdk.org/jdk8u/jdk8u/hotspot/file/87ee5ee27509/src/share/vm/runtime/globals.hpp>(1127 行)
|
||||
> - <https://hg.openjdk.org/jdk8u/jdk8u/hotspot/file/87ee5ee27509/src/share/vm/runtime/synchronizer.cpp>(537 行开始)
|
||||
|
||||
```java
|
||||
public native int hashCode();
|
||||
|
||||
@ -546,7 +546,7 @@ public E poll() {
|
||||
//上锁
|
||||
lock.lock();
|
||||
try {
|
||||
//如果队列为空直接返回null,反之出队返回元素值
|
||||
//如果队列为空直接返回null,反之出队返回元素值
|
||||
return (count == 0) ? null : dequeue();
|
||||
} finally {
|
||||
lock.unlock();
|
||||
@ -558,13 +558,12 @@ public E poll() {
|
||||
|
||||
```java
|
||||
public boolean add(E e) {
|
||||
//调用下方的add
|
||||
return super.add(e);
|
||||
}
|
||||
|
||||
|
||||
public boolean add(E e) {
|
||||
//调用offer如果失败直接抛出异常
|
||||
//调用offer方法如果失败直接抛出异常
|
||||
if (offer(e))
|
||||
return true;
|
||||
else
|
||||
|
||||
@ -461,13 +461,13 @@ public class SynchronizedDemo2 {
|
||||
|
||||
🧗🏻 进阶一下:学有余力的小伙伴可以抽时间详细研究一下对象监视器 `monitor`。
|
||||
|
||||
### JDK1.6 之后的 synchronized 底层做了哪些优化?
|
||||
### JDK1.6 之后的 synchronized 底层做了哪些优化?锁升级原理了解吗?
|
||||
|
||||
JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术来减少锁操作的开销。
|
||||
在 Java 6 之后, `synchronized` 引入了大量的优化如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销,这些优化让 `synchronized` 锁的效率提升了很多(JDK18 中,偏向锁已经被彻底废弃,前面已经提到过了)。
|
||||
|
||||
锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
|
||||
|
||||
关于这几种优化的详细信息可以查看下面这篇文章:[Java6 及以上版本对 synchronized 的优化](https://www.cnblogs.com/wuqinglong/p/9945618.html) 。
|
||||
`synchronized` 锁升级是一个比较复杂的过程,面试也很少问到,如果你想要详细了解的话,可以看看这篇文章:[浅析 synchronized 锁升级的原理与实现](https://www.cnblogs.com/star95/p/17542850.html)。
|
||||
|
||||
### synchronized 和 volatile 有什么区别?
|
||||
|
||||
|
||||
@ -91,33 +91,30 @@ ExecutorService threadPool = new ThreadPoolExecutor(corePoolSize, maximumPoolSiz
|
||||
**2、自己实现 `ThreadFactory`。**
|
||||
|
||||
```java
|
||||
import java.util.concurrent.Executors;
|
||||
import java.util.concurrent.ThreadFactory;
|
||||
import java.util.concurrent.atomic.AtomicInteger;
|
||||
|
||||
/**
|
||||
* 线程工厂,它设置线程名称,有利于我们定位问题。
|
||||
*/
|
||||
public final class NamingThreadFactory implements ThreadFactory {
|
||||
|
||||
private final AtomicInteger threadNum = new AtomicInteger();
|
||||
private final ThreadFactory delegate;
|
||||
private final String name;
|
||||
|
||||
/**
|
||||
* 创建一个带名字的线程池生产工厂
|
||||
*/
|
||||
public NamingThreadFactory(ThreadFactory delegate, String name) {
|
||||
this.delegate = delegate;
|
||||
this.name = name; // TODO consider uniquifying this
|
||||
public NamingThreadFactory(String name) {
|
||||
this.name = name;
|
||||
}
|
||||
|
||||
@Override
|
||||
public Thread newThread(Runnable r) {
|
||||
Thread t = delegate.newThread(r);
|
||||
Thread t = new Thread(r);
|
||||
t.setName(name + " [#" + threadNum.incrementAndGet() + "]");
|
||||
return t;
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
@ -555,8 +555,8 @@ public class GlobalExceptionHandler {
|
||||
|
||||
### Spring 管理事务的方式有几种?
|
||||
|
||||
- **编程式事务**:在代码中硬编码(不推荐使用) : 通过 `TransactionTemplate`或者 `TransactionManager` 手动管理事务,实际应用中很少使用,但是对于你理解 Spring 事务管理原理有帮助。
|
||||
- **声明式事务**:在 XML 配置文件中配置或者直接基于注解(推荐使用) : 实际是通过 AOP 实现(基于`@Transactional` 的全注解方式使用最多)
|
||||
- **编程式事务**:在代码中硬编码(在分布式系统中推荐使用) : 通过 `TransactionTemplate`或者 `TransactionManager` 手动管理事务,事务范围过大会出现事务未提交导致超时,因此事务要比锁的粒度更小。
|
||||
- **声明式事务**:在 XML 配置文件中配置或者直接基于注解(单体应用或者简单业务系统推荐使用) : 实际是通过 AOP 实现(基于`@Transactional` 的全注解方式使用最多)
|
||||
|
||||
### Spring 事务中哪几种事务传播行为?
|
||||
|
||||
@ -598,13 +598,9 @@ public class GlobalExceptionHandler {
|
||||
public enum Isolation {
|
||||
|
||||
DEFAULT(TransactionDefinition.ISOLATION_DEFAULT),
|
||||
|
||||
READ_UNCOMMITTED(TransactionDefinition.ISOLATION_READ_UNCOMMITTED),
|
||||
|
||||
READ_COMMITTED(TransactionDefinition.ISOLATION_READ_COMMITTED),
|
||||
|
||||
REPEATABLE_READ(TransactionDefinition.ISOLATION_REPEATABLE_READ),
|
||||
|
||||
SERIALIZABLE(TransactionDefinition.ISOLATION_SERIALIZABLE);
|
||||
|
||||
private final int value;
|
||||
@ -632,9 +628,29 @@ public enum Isolation {
|
||||
|
||||
`Exception` 分为运行时异常 `RuntimeException` 和非运行时异常。事务管理对于企业应用来说是至关重要的,即使出现异常情况,它也可以保证数据的一致性。
|
||||
|
||||
当 `@Transactional` 注解作用于类上时,该类的所有 public 方法将都具有该类型的事务属性,同时,我们也可以在方法级别使用该标注来覆盖类级别的定义。如果类或者方法加了这个注解,那么这个类里面的方法抛出异常,就会回滚,数据库里面的数据也会回滚。
|
||||
当 `@Transactional` 注解作用于类上时,该类的所有 public 方法将都具有该类型的事务属性,同时,我们也可以在方法级别使用该标注来覆盖类级别的定义。
|
||||
|
||||
在 `@Transactional` 注解中如果不配置`rollbackFor`属性,那么事务只会在遇到`RuntimeException`的时候才会回滚,加上 `rollbackFor=Exception.class`,可以让事务在遇到非运行时异常时也回滚。
|
||||
`@Transactional` 注解默认回滚策略是只有在遇到`RuntimeException`(运行时异常) 或者 `Error` 时才会回滚事务,而不会回滚 `Checked Exception`(受检查异常)。这是因为 Spring 认为`RuntimeException`和 Error 是不可预期的错误,而受检异常是可预期的错误,可以通过业务逻辑来处理。
|
||||
|
||||

|
||||
|
||||
如果想要修改默认的回滚策略,可以使用 `@Transactional` 注解的 `rollbackFor` 和 `noRollbackFor` 属性来指定哪些异常需要回滚,哪些异常不需要回滚。例如,如果想要让所有的异常都回滚事务,可以使用如下的注解:
|
||||
|
||||
```java
|
||||
@Transactional(rollbackFor = Exception.class)
|
||||
public void someMethod() {
|
||||
// some business logic
|
||||
}
|
||||
```
|
||||
|
||||
如果想要让某些特定的异常不回滚事务,可以使用如下的注解:
|
||||
|
||||
```java
|
||||
@Transactional(noRollbackFor = CustomException.class)
|
||||
public void someMethod() {
|
||||
// some business logic
|
||||
}
|
||||
```
|
||||
|
||||
## Spring Data JPA
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user