mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-05 20:31:37 +08:00
Merge branch 'main' of github.com:skeetyu/JavaGuide
This commit is contained in:
commit
69d6de121c
@ -140,6 +140,24 @@ IP 地址过滤是一种简单的网络安全措施,实际应用中一般会
|
||||
- **ICMPv6(Internet Control Message Protocol for IPv6)**:IPv6 中的 ICMPv6 相较于 IPv4 中的 ICMP 有了一些改进,如邻居发现、路径 MTU 发现等功能的改进,从而提升了网络的可靠性和性能。
|
||||
- ……
|
||||
|
||||
### 如何获取客户端真实 IP?
|
||||
|
||||
获取客户端真实 IP 的方法有多种,主要分为应用层方法、传输层方法和网络层方法。
|
||||
|
||||
**应用层方法** :
|
||||
|
||||
通过 [X-Forwarded-For](https://en.wikipedia.org/wiki/X-Forwarded-For) 请求头获取,简单方便。不过,这种方法无法保证获取到的是真实 IP,这是因为 X-Forwarded-For 字段可能会被伪造。如果经过多个代理服务器,X-Forwarded-For 字段可能会有多个值(附带了整个请求链中的所有代理服务器 IP 地址)。并且,这种方法只适用于 HTTP 和 SMTP 协议。
|
||||
|
||||
**传输层方法**:
|
||||
|
||||
利用 TCP Options 字段承载真实源 IP 信息。这种方法适用于任何基于 TCP 的协议,不受应用层的限制。不过,这并非是 TCP 标准所支持的,所以需要通信双方都进行改造。也就是:对于发送方来说,需要有能力把真实源 IP 插入到 TCP Options 里面。对于接收方来说,需要有能力把 TCP Options 里面的 IP 地址读取出来。
|
||||
|
||||
也可以通过 Proxy Protocol 协议来传递客户端 IP 和 Port 信息。这种方法可以利用 Nginx 或者其他支持该协议的反向代理服务器来获取真实 IP 或者在业务服务器解析真实 IP。
|
||||
|
||||
**网络层方法**:
|
||||
|
||||
隧道 +DSR 模式。这种方法可以适用于任何协议,就是实施起来会比较麻烦,也存在一定限制,实际应用中一般不会使用这种方法。
|
||||
|
||||
### NAT 的作用是什么?
|
||||
|
||||
**NAT(Network Address Translation,网络地址转换)** 主要用于在不同网络之间转换 IP 地址。它允许将私有 IP 地址(如在局域网中使用的 IP 地址)映射为公有 IP 地址(在互联网中使用的 IP 地址)或者反向映射,从而实现局域网内的多个设备通过单一公有 IP 地址访问互联网。
|
||||
@ -185,6 +203,7 @@ ARP 协议,全称 **地址解析协议(Address Resolution Protocol)**,
|
||||
- 《图解 HTTP》
|
||||
- 《计算机网络自顶向下方法》(第七版)
|
||||
- 什么是 Internet 协议(IP)?:<https://www.cloudflare.com/zh-cn/learning/network-layer/internet-protocol/>
|
||||
- 透传真实源 IP 的各种方法 - 极客时间:<https://time.geekbang.org/column/article/497864>
|
||||
- What Is NAT and What Are the Benefits of NAT Firewalls?:<https://community.fs.com/blog/what-is-nat-and-what-are-the-benefits-of-nat-firewalls.html>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
||||
@ -50,11 +50,16 @@ Redis 内部做了非常多的性能优化,比较重要的有下面 3 点:
|
||||
|
||||
Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来,随着 Redis 的发展,大家慢慢都转而使用更加强大的 Redis 了。
|
||||
|
||||
另外,腾讯也开源了一款类似于 Redis 的分布式高性能 KV 存储数据库,基于知名的开源项目 [RocksDB](https://github.com/facebook/rocksdb) 作为存储引擎 ,100% 兼容 Redis 协议和 Redis4.0 所有数据模型,名为 [Tendis](https://github.com/Tencent/Tendis)。
|
||||
有一些大厂也开源了类似于 Redis 的分布式高性能 KV 存储数据库,例如,腾讯开源的 [Tendis](https://github.com/Tencent/Tendis) 。Tendis 基于知名开源项目 [RocksDB](https://github.com/facebook/rocksdb) 作为存储引擎 ,100% 兼容 Redis 协议和 Redis4.0 所有数据模型。关于 Redis 和 Tendis 的对比,腾讯官方曾经发过一篇文章:[Redis vs Tendis:冷热混合存储版架构揭秘](https://mp.weixin.qq.com/s/MeYkfOIdnU6LYlsGb24KjQ) ,可以简单参考一下。
|
||||
|
||||
关于 Redis 和 Tendis 的对比,腾讯官方曾经发过一篇文章:[Redis vs Tendis:冷热混合存储版架构揭秘](https://mp.weixin.qq.com/s/MeYkfOIdnU6LYlsGb24KjQ) ,可以简单参考一下。
|
||||
不过,从 Tendis 这个项目的 Github 提交记录可以看出,Tendis 开源版几乎已经没有被维护更新了,加上其关注度并不高,使用的公司也比较少。因此,不建议你使用 Tendis 来实现分布式缓存。
|
||||
|
||||
从这个项目的 GitHub 提交记录可以看出,Tendis 开源版几乎已经没有被维护更新了,加上其关注度并不高,使用的公司也比较少。因此,不建议你使用 Tendis 来实现分布式缓存。
|
||||
目前,比较业界认可的 Redis 替代品还是下面这两个开源分布式缓存(都是通过碰瓷 Redis 火的):
|
||||
|
||||
- [Dragonfly](https://github.com/dragonflydb/dragonfly):一种针对现代应用程序负荷需求而构建的内存数据库,完全兼容 Redis 和 Memcached 的 API,迁移时无需修改任何代码,号称全世界最快的内存数据库。
|
||||
- [KeyDB](https://github.com/Snapchat/KeyDB): Redis 的一个高性能分支,专注于多线程、内存效率和高吞吐量。
|
||||
|
||||
不过,个人还是建议分布式缓存首选 Redis ,毕竟经过这么多年的生产考研,生态也这么优秀,资料也很全面。
|
||||
|
||||
### 说一下 Redis 和 Memcached 的区别和共同点
|
||||
|
||||
|
||||
@ -67,6 +67,20 @@ category: 高可用
|
||||
|
||||
令牌桶算法可以限制平均速率和应对突然激增的流量,还可以动态调整生成令牌的速率。不过,如果令牌产生速率和桶的容量设置不合理,可能会出现问题比如大量的请求被丢弃、系统过载。
|
||||
|
||||
## 针对什么来进行限流?
|
||||
|
||||
实际项目中,还需要确定限流对象,也就是针对什么来进行限流。常见的限流对象如下:
|
||||
|
||||
- IP :针对 IP 进行限流,适用面较广,简单粗暴。
|
||||
- 业务 ID:挑选唯一的业务 ID 以实现更针对性地限流。例如,基于用户 ID 进行限流。
|
||||
- 个性化:根据用户的属性或行为,进行不同的限流策略。例如, VIP 用户不限流,而普通用户限流。根据系统的运行指标(如 QPS、并发调用数、系统负载等),动态调整限流策略。例如,当系统负载较高的时候,控制每秒通过的请求减少。
|
||||
|
||||
针对 IP 进行限流是目前比较常用的一个方案。不过,实际应用中需要注意用户真实 IP 地址的正确获取。常用的真实 IP 获取方法有 X-Forwarded-For 和 TCP Options 字段承载真实源 IP 信息。虽然 X-Forwarded-For 字段可能会被伪造,但因为其实现简单方便,很多项目还是直接用的这种方法。
|
||||
|
||||
除了我上面介绍到的限流对象之外,还有一些其他较为复杂的限流对象策略,比如阿里的 Sentinel 还支持 [基于调用关系的限流](https://github.com/alibaba/Sentinel/wiki/流量控制#基于调用关系的流量控制)(包括基于调用方限流、基于调用链入口限流、关联流量限流等)以及更细维度的 [热点参数限流](https://github.com/alibaba/Sentinel/wiki/热点参数限流)(实时的统计热点参数并针对热点参数的资源调用进行流量控制)。
|
||||
|
||||
另外,一个项目可以根据具体的业务需求选择多种不同的限流对象搭配使用。
|
||||
|
||||
## 单机限流怎么做?
|
||||
|
||||
单机限流针对的是单体架构应用。
|
||||
@ -241,7 +255,11 @@ rateLimiter.acquire(1);
|
||||
boolean res = rateLimiter.tryAcquire(1, 5, TimeUnit.SECONDS);
|
||||
```
|
||||
|
||||
## 相关阅读
|
||||
## 总结
|
||||
|
||||
这篇文章主要介绍了常见的限流算法、限流对象的选择以及单机限流和分布式限流分别应该怎么做。
|
||||
|
||||
## 参考
|
||||
|
||||
- 服务治理之轻量级熔断框架 Resilience4j:<https://xie.infoq.cn/article/14786e571c1a4143ad1ef8f19>
|
||||
- 超详细的 Guava RateLimiter 限流原理解析:<https://cloud.tencent.com/developer/article/1408819>
|
||||
|
||||
@ -113,15 +113,11 @@ Java 领域主流的微服务框架 Dubbo、Spring Cloud 等都内置了开箱
|
||||
|
||||
未加权重的轮询算法适合于服务器性能相近的集群,其中每个服务器承载相同的负载。加权轮询算法适合于服务器性能不等的集群,权重的存在可以使请求分配更加合理化。
|
||||
|
||||
### 一致性 Hash 法
|
||||
在加权轮询的基础上,还有进一步改进得到的负载均衡算法,比如平滑的加权轮训算法。
|
||||
|
||||
相同参数的请求总是发到同一台服务器处理,比如同个 IP 的请求。
|
||||
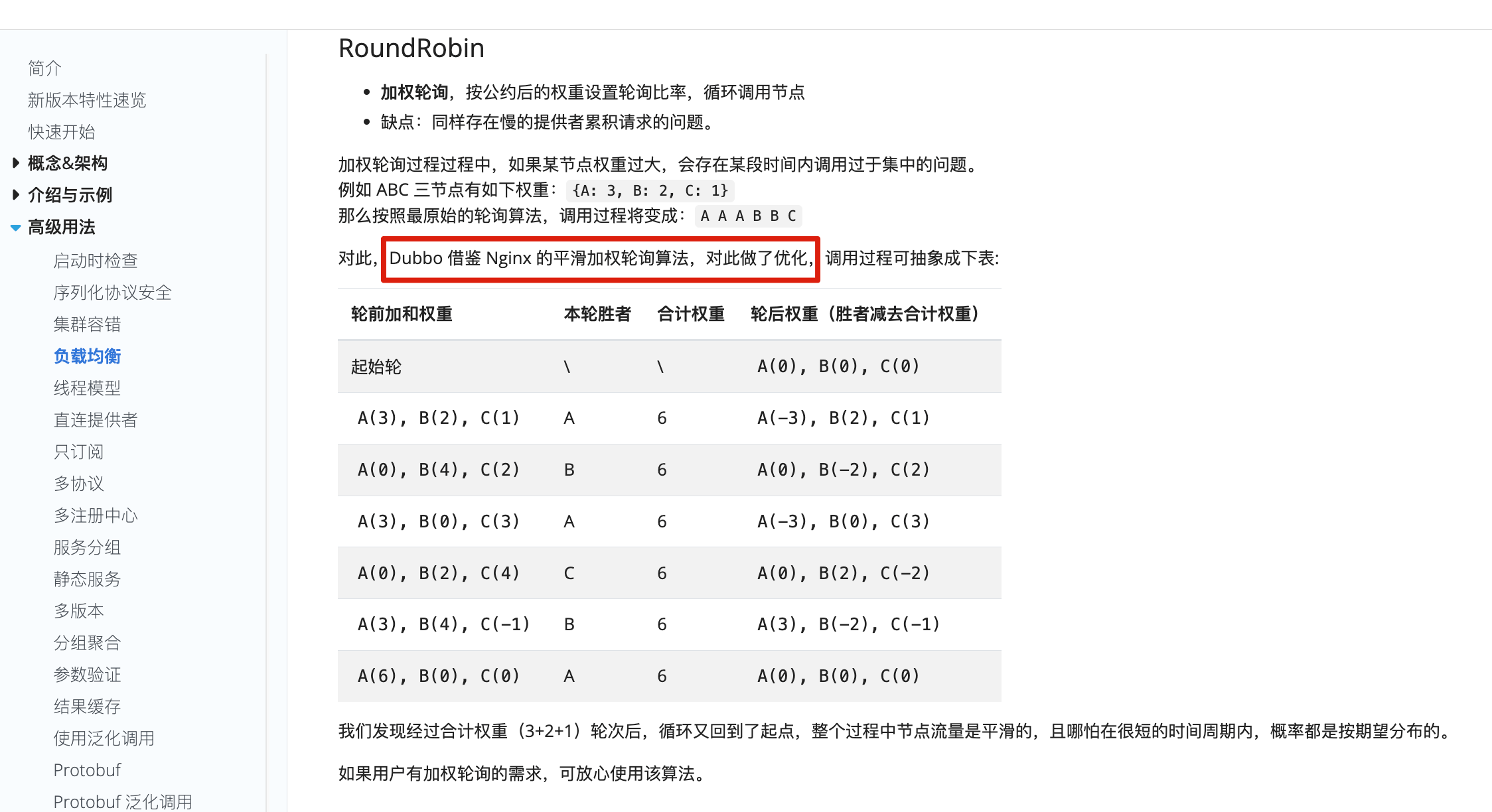
平滑的加权轮训算法最早是在 Nginx 中被实现,可以参考这个 commit:<https://github.com/phusion/nginx/commit/27e94984486058d73157038f7950a0a36ecc6e35>。如果你认真学习过 Dubbo 负载均衡策略的话,就会发现 Dubbo 的加权轮询就借鉴了该算法实现并进一步做了优化。
|
||||
|
||||
### 最小连接法
|
||||
|
||||
当有新的请求出现时,遍历服务器节点列表并选取其中活动连接数最小的一台服务器来响应当前请求。活动连接数可以理解为当前正在处理的请求数。
|
||||
|
||||
最小连接法可以尽可能最大地使请求分配更加合理化,提高服务器的利用率。不过,这种方法实现起来也最复杂,需要监控每一台服务器处理的请求连接数。
|
||||
|
||||
|
||||
### 两次随机法
|
||||
|
||||
@ -129,6 +125,34 @@ Java 领域主流的微服务框架 Dubbo、Spring Cloud 等都内置了开箱
|
||||
|
||||
两次随机法的好处是可以动态地调节后端节点的负载,使其更加均衡。如果只使用一次随机法,可能会导致某些服务器过载,而某些服务器空闲。
|
||||
|
||||
### 哈希法
|
||||
|
||||
将请求的参数信息通过哈希函数转换成一个哈希值,然后根据哈希值来决定请求被哪一台服务器处理。
|
||||
|
||||
在服务器数量不变的情况下,相同参数的请求总是发到同一台服务器处理,比如同个 IP 的请求、同一个用户的请求。
|
||||
|
||||
### 一致性 Hash 法
|
||||
|
||||
和哈希法类似,一致性 Hash 法也可以让相同参数的请求总是发到同一台服务器处理。不过,它解决了哈希法存在的一些问题。
|
||||
|
||||
常规哈希法在服务器数量变化时,哈希值会重新落在不同的服务器上,这明显违背了使用哈希法的本意。而一致性哈希法的核心思想是将数据和节点都映射到一个哈希环上,然后根据哈希值的顺序来确定数据属于哪个节点。当服务器增加或删除时,只影响该服务器的哈希,而不会导致整个服务集群的哈希键值重新分布。
|
||||
|
||||
### 最小连接法
|
||||
|
||||
当有新的请求出现时,遍历服务器节点列表并选取其中连接数最小的一台服务器来响应当前请求。相同连接的情况下,可以进行加权随机。
|
||||
|
||||
最少连接数基于一个服务器连接数越多,负载就越高这一理想假设。然而, 实际情况是连接数并不能代表服务器的实际负载,有些连接耗费系统资源更多,有些连接不怎么耗费系统资源。
|
||||
|
||||
### 最少活跃法
|
||||
|
||||
最少活跃法和最小连接法类似,但要更科学一些。最少活跃法以活动连接数为标准,活动连接数可以理解为当前正在处理的请求数。活跃数越低,说明处理能力越强,这样就可以使处理能力强的服务器处理更多请求。相同活跃数的情况下,可以进行加权随机。
|
||||
|
||||
### 最快响应时间法
|
||||
|
||||
不同于最小连接法和最少活跃法,最快响应时间法以响应时间为标准来选择具体是哪一台服务器处理。客户端会维持每个服务器的响应时间,每次请求挑选响应时间最短的。相同响应时间的情况下,可以进行加权随机。
|
||||
|
||||
这种算法可以使得请求被更快处理,但可能会造成流量过于集中于高性能服务器的问题。
|
||||
|
||||
## 七层负载均衡可以怎么做?
|
||||
|
||||
简单介绍两种项目中常用的七层负载均衡解决方案:DNS 解析和反向代理。
|
||||
|
||||
@ -52,4 +52,8 @@ JVM 线上问题排查和性能调优也是面试常问的一个问题,尤其
|
||||
|
||||
这篇文章共 2w+ 字,详细介绍了 GC 基础,总结了 CMS GC 的一些常见问题分析与解决办法。
|
||||
|
||||
[给祖传系统做了点 GC 调优,暂停时间降低了 90% - 京东云技术团队 - 2023](https://juejin.cn/post/7311623433817571365)
|
||||
|
||||
这篇文章提到了一个在规则引擎系统中遇到的 GC(垃圾回收)问题,主要表现为系统在启动后发生了一次较长的 Young GC(年轻代垃圾回收)导致性能下降。经过分析,问题的核心在于动态对象年龄判定机制,它导致了过早的对象晋升,引起了长时间的垃圾回收。
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user