201
LICENSE
Normal file
@ -0,0 +1,201 @@
|
||||
Apache License
|
||||
Version 2.0, January 2004
|
||||
http://www.apache.org/licenses/
|
||||
|
||||
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
||||
|
||||
1. Definitions.
|
||||
|
||||
"License" shall mean the terms and conditions for use, reproduction,
|
||||
and distribution as defined by Sections 1 through 9 of this document.
|
||||
|
||||
"Licensor" shall mean the copyright owner or entity authorized by
|
||||
the copyright owner that is granting the License.
|
||||
|
||||
"Legal Entity" shall mean the union of the acting entity and all
|
||||
other entities that control, are controlled by, or are under common
|
||||
control with that entity. For the purposes of this definition,
|
||||
"control" means (i) the power, direct or indirect, to cause the
|
||||
direction or management of such entity, whether by contract or
|
||||
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
||||
outstanding shares, or (iii) beneficial ownership of such entity.
|
||||
|
||||
"You" (or "Your") shall mean an individual or Legal Entity
|
||||
exercising permissions granted by this License.
|
||||
|
||||
"Source" form shall mean the preferred form for making modifications,
|
||||
including but not limited to software source code, documentation
|
||||
source, and configuration files.
|
||||
|
||||
"Object" form shall mean any form resulting from mechanical
|
||||
transformation or translation of a Source form, including but
|
||||
not limited to compiled object code, generated documentation,
|
||||
and conversions to other media types.
|
||||
|
||||
"Work" shall mean the work of authorship, whether in Source or
|
||||
Object form, made available under the License, as indicated by a
|
||||
copyright notice that is included in or attached to the work
|
||||
(an example is provided in the Appendix below).
|
||||
|
||||
"Derivative Works" shall mean any work, whether in Source or Object
|
||||
form, that is based on (or derived from) the Work and for which the
|
||||
editorial revisions, annotations, elaborations, or other modifications
|
||||
represent, as a whole, an original work of authorship. For the purposes
|
||||
of this License, Derivative Works shall not include works that remain
|
||||
separable from, or merely link (or bind by name) to the interfaces of,
|
||||
the Work and Derivative Works thereof.
|
||||
|
||||
"Contribution" shall mean any work of authorship, including
|
||||
the original version of the Work and any modifications or additions
|
||||
to that Work or Derivative Works thereof, that is intentionally
|
||||
submitted to Licensor for inclusion in the Work by the copyright owner
|
||||
or by an individual or Legal Entity authorized to submit on behalf of
|
||||
the copyright owner. For the purposes of this definition, "submitted"
|
||||
means any form of electronic, verbal, or written communication sent
|
||||
to the Licensor or its representatives, including but not limited to
|
||||
communication on electronic mailing lists, source code control systems,
|
||||
and issue tracking systems that are managed by, or on behalf of, the
|
||||
Licensor for the purpose of discussing and improving the Work, but
|
||||
excluding communication that is conspicuously marked or otherwise
|
||||
designated in writing by the copyright owner as "Not a Contribution."
|
||||
|
||||
"Contributor" shall mean Licensor and any individual or Legal Entity
|
||||
on behalf of whom a Contribution has been received by Licensor and
|
||||
subsequently incorporated within the Work.
|
||||
|
||||
2. Grant of Copyright License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
copyright license to reproduce, prepare Derivative Works of,
|
||||
publicly display, publicly perform, sublicense, and distribute the
|
||||
Work and such Derivative Works in Source or Object form.
|
||||
|
||||
3. Grant of Patent License. Subject to the terms and conditions of
|
||||
this License, each Contributor hereby grants to You a perpetual,
|
||||
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
||||
(except as stated in this section) patent license to make, have made,
|
||||
use, offer to sell, sell, import, and otherwise transfer the Work,
|
||||
where such license applies only to those patent claims licensable
|
||||
by such Contributor that are necessarily infringed by their
|
||||
Contribution(s) alone or by combination of their Contribution(s)
|
||||
with the Work to which such Contribution(s) was submitted. If You
|
||||
institute patent litigation against any entity (including a
|
||||
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
||||
or a Contribution incorporated within the Work constitutes direct
|
||||
or contributory patent infringement, then any patent licenses
|
||||
granted to You under this License for that Work shall terminate
|
||||
as of the date such litigation is filed.
|
||||
|
||||
4. Redistribution. You may reproduce and distribute copies of the
|
||||
Work or Derivative Works thereof in any medium, with or without
|
||||
modifications, and in Source or Object form, provided that You
|
||||
meet the following conditions:
|
||||
|
||||
(a) You must give any other recipients of the Work or
|
||||
Derivative Works a copy of this License; and
|
||||
|
||||
(b) You must cause any modified files to carry prominent notices
|
||||
stating that You changed the files; and
|
||||
|
||||
(c) You must retain, in the Source form of any Derivative Works
|
||||
that You distribute, all copyright, patent, trademark, and
|
||||
attribution notices from the Source form of the Work,
|
||||
excluding those notices that do not pertain to any part of
|
||||
the Derivative Works; and
|
||||
|
||||
(d) If the Work includes a "NOTICE" text file as part of its
|
||||
distribution, then any Derivative Works that You distribute must
|
||||
include a readable copy of the attribution notices contained
|
||||
within such NOTICE file, excluding those notices that do not
|
||||
pertain to any part of the Derivative Works, in at least one
|
||||
of the following places: within a NOTICE text file distributed
|
||||
as part of the Derivative Works; within the Source form or
|
||||
documentation, if provided along with the Derivative Works; or,
|
||||
within a display generated by the Derivative Works, if and
|
||||
wherever such third-party notices normally appear. The contents
|
||||
of the NOTICE file are for informational purposes only and
|
||||
do not modify the License. You may add Your own attribution
|
||||
notices within Derivative Works that You distribute, alongside
|
||||
or as an addendum to the NOTICE text from the Work, provided
|
||||
that such additional attribution notices cannot be construed
|
||||
as modifying the License.
|
||||
|
||||
You may add Your own copyright statement to Your modifications and
|
||||
may provide additional or different license terms and conditions
|
||||
for use, reproduction, or distribution of Your modifications, or
|
||||
for any such Derivative Works as a whole, provided Your use,
|
||||
reproduction, and distribution of the Work otherwise complies with
|
||||
the conditions stated in this License.
|
||||
|
||||
5. Submission of Contributions. Unless You explicitly state otherwise,
|
||||
any Contribution intentionally submitted for inclusion in the Work
|
||||
by You to the Licensor shall be under the terms and conditions of
|
||||
this License, without any additional terms or conditions.
|
||||
Notwithstanding the above, nothing herein shall supersede or modify
|
||||
the terms of any separate license agreement you may have executed
|
||||
with Licensor regarding such Contributions.
|
||||
|
||||
6. Trademarks. This License does not grant permission to use the trade
|
||||
names, trademarks, service marks, or product names of the Licensor,
|
||||
except as required for reasonable and customary use in describing the
|
||||
origin of the Work and reproducing the content of the NOTICE file.
|
||||
|
||||
7. Disclaimer of Warranty. Unless required by applicable law or
|
||||
agreed to in writing, Licensor provides the Work (and each
|
||||
Contributor provides its Contributions) on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
||||
implied, including, without limitation, any warranties or conditions
|
||||
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
||||
PARTICULAR PURPOSE. You are solely responsible for determining the
|
||||
appropriateness of using or redistributing the Work and assume any
|
||||
risks associated with Your exercise of permissions under this License.
|
||||
|
||||
8. Limitation of Liability. In no event and under no legal theory,
|
||||
whether in tort (including negligence), contract, or otherwise,
|
||||
unless required by applicable law (such as deliberate and grossly
|
||||
negligent acts) or agreed to in writing, shall any Contributor be
|
||||
liable to You for damages, including any direct, indirect, special,
|
||||
incidental, or consequential damages of any character arising as a
|
||||
result of this License or out of the use or inability to use the
|
||||
Work (including but not limited to damages for loss of goodwill,
|
||||
work stoppage, computer failure or malfunction, or any and all
|
||||
other commercial damages or losses), even if such Contributor
|
||||
has been advised of the possibility of such damages.
|
||||
|
||||
9. Accepting Warranty or Additional Liability. While redistributing
|
||||
the Work or Derivative Works thereof, You may choose to offer,
|
||||
and charge a fee for, acceptance of support, warranty, indemnity,
|
||||
or other liability obligations and/or rights consistent with this
|
||||
License. However, in accepting such obligations, You may act only
|
||||
on Your own behalf and on Your sole responsibility, not on behalf
|
||||
of any other Contributor, and only if You agree to indemnify,
|
||||
defend, and hold each Contributor harmless for any liability
|
||||
incurred by, or claims asserted against, such Contributor by reason
|
||||
of your accepting any such warranty or additional liability.
|
||||
|
||||
END OF TERMS AND CONDITIONS
|
||||
|
||||
APPENDIX: How to apply the Apache License to your work.
|
||||
|
||||
To apply the Apache License to your work, attach the following
|
||||
boilerplate notice, with the fields enclosed by brackets "[]"
|
||||
replaced with your own identifying information. (Don't include
|
||||
the brackets!) The text should be enclosed in the appropriate
|
||||
comment syntax for the file format. We also recommend that a
|
||||
file or class name and description of purpose be included on the
|
||||
same "printed page" as the copyright notice for easier
|
||||
identification within third-party archives.
|
||||
|
||||
Copyright [yyyy] [name of copyright owner]
|
||||
|
||||
Licensed under the Apache License, Version 2.0 (the "License");
|
||||
you may not use this file except in compliance with the License.
|
||||
You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
521
README.md
@ -1,8 +1,18 @@
|
||||
点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
|
||||
> 关于 JavaGuide 的相关介绍请看:[《从编程小白到做了一个接近 90k 点赞的一个国产 Java 开源项目》](https://www.yuque.com/snailclimb/dr6cvl/mr44yt#vu3ok)
|
||||
>
|
||||
> 准备面试的小伙伴可以考虑面试专版:[《Java 面试进阶指南》](https://xiaozhuanlan.com/javainterview?rel=javaguide) ,欢迎加入[我的星球](https://wx.zsxq.com/dweb2/index/group/48418884588288)获取更多实用干货。
|
||||
>
|
||||
> 阿里云最近在做活动,服务器不到 10 元/月,小伙伴们搭建一个网站提高简历质量。支持国内开源做的比较好的公司
|
||||
>
|
||||
> 项目的发展离不开你的支持,如果 JavaGuide 帮助到了你找到自己满意的 offer,那就[请作者喝杯咖啡吧](https://www.yuque.com/snailclimb/dr6cvl/mr44yt#vu3ok)☕!我会继续将项目完善下去!加油!
|
||||
|
||||
[推荐一下:阿里云高性能服务器,1核1g最低89,不限性能。](https://www.aliyun.com/minisite/goods?userCode=hf47liqn)
|
||||
如果 Github 访问速度比较慢或者图片无法刷新出来的话,可以转移到[码云](https://gitee.com/SnailClimb/JavaGuide)查看,或者[在线阅读](https://snailclimb.gitee.io/javaguide)。**如果你要提交 issue 或者 pr 的话请到 [Github](https://github.com/Snailclimb/JavaGuide) 提交。**
|
||||
|
||||
少部分原创文章更新在了知识星球,关于我为什么要弄知识星球,请看这里:**[犹豫了很久,还是做了一个很久没敢做的事情](https://javaguide.cn/2019/01/02/chat/%E5%81%9A%E4%BA%86%E4%B8%80%E4%B8%AA%E5%BE%88%E4%B9%85%E6%B2%A1%E6%95%A2%E5%81%9A%E7%9A%84%E4%BA%8B%E6%83%85/)** ,优惠卷地址:[https://t.zsxq.com/iIqZBUR](https://t.zsxq.com/iIqZBUR) 。
|
||||
《JavaGuide 面试突击版》PDF 版本+3 本 PDF Java 学习手册,在公众号 **[JavaGuide](#公众号)** 后台回复“**面试突击**”即可获取。
|
||||
|
||||
如要进群或者请教问题,请[联系我](#联系我) (备注来自 Github。请直入问题,工作时间不回复)。
|
||||
|
||||
**开始阅读之前必看** :[完结撒花!JavaGuide 面试突击版来啦!](./docs/javaguide面试突击版.md) 。
|
||||
|
||||
<p align="center">
|
||||
<a href="https://github.com/Snailclimb/JavaGuide" target="_blank">
|
||||
@ -12,7 +22,6 @@
|
||||
|
||||
<p align="center">
|
||||
<a href="https://snailclimb.gitee.io/javaguide"><img src="https://img.shields.io/badge/阅读-read-brightgreen.svg" alt="阅读"></a>
|
||||
<a href="#联系我"><img src="https://img.shields.io/badge/chat-微信群-blue.svg" alt="微信群"></a>
|
||||
<a href="#公众号"><img src="https://img.shields.io/badge/%E5%85%AC%E4%BC%97%E5%8F%B7-JavaGuide-lightgrey.svg" alt="公众号"></a>
|
||||
<a href="#公众号"><img src="https://img.shields.io/badge/PDF-Java面试突击-important.svg" alt="公众号"></a>
|
||||
<a href="#投稿"><img src="https://img.shields.io/badge/support-投稿-critical.svg" alt="投稿"></a>
|
||||
@ -20,58 +29,82 @@
|
||||
</p>
|
||||
|
||||
<h3 align="center">Sponsor</h3>
|
||||
<p align="center">
|
||||
<a href="https://mp.weixin.qq.com/s/li9_YXNVxan6Qgt3Q9FYqA">
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-7/WechatIMG1.png" style="margin: 0 auto;width:400px"/>
|
||||
</a >
|
||||
</p>
|
||||
|
||||
推荐使用 https://snailclimb.gitee.io/javaguide 在线阅读,在线阅读内容本仓库同步一致。这种方式阅读的优势在于:阅读体验会更好。
|
||||
<table>
|
||||
<tbody>
|
||||
<tr>
|
||||
<td align="center" valign="middle">
|
||||
<a href="https://mp.weixin.qq.com/s/li9_YXNVxan6Qgt3Q9FYqA">
|
||||
<img src="./media/sponsor/wangyi.png" style="margin: 0 auto;width:450px" /></a>
|
||||
</td>
|
||||
<td align="center" valign="middle">
|
||||
<a href="https://t.1yb.co/5p8J">
|
||||
<img src="./media/sponsor/xiangxue.png" style="margin: 0 auto;width:450px" /></a>
|
||||
</td>
|
||||
</tr>
|
||||
<tr>
|
||||
<td align="center" valign="middle">
|
||||
<a href="https://w.url.cn/s/AS6JeXA">
|
||||
<img src="./media/sponsor/kaikeba.png" style="margin: 0 auto;width:450px" /></a>
|
||||
</td>
|
||||
</tr>
|
||||
</tbody>
|
||||
</table>
|
||||
|
||||
## 目录
|
||||
|
||||
- [目录](#目录)
|
||||
- [Java](#java)
|
||||
- [基础](#基础)
|
||||
- [容器](#容器)
|
||||
- [并发](#并发)
|
||||
- [JVM](#jvm)
|
||||
- [I/O](#io)
|
||||
- [Java 8](#java-8)
|
||||
- [优雅 Java 代码必备实践(Java编程规范)](#优雅-java-代码必备实践java编程规范)
|
||||
- [基础](#基础)
|
||||
- [容器](#容器)
|
||||
- [并发](#并发)
|
||||
- [JVM](#jvm)
|
||||
- [其他](#其他)
|
||||
- [网络](#网络)
|
||||
- [操作系统](#操作系统)
|
||||
- [Linux相关](#linux相关)
|
||||
- [Linux](#linux)
|
||||
- [数据结构与算法](#数据结构与算法)
|
||||
- [数据结构](#数据结构)
|
||||
- [算法](#算法)
|
||||
- [数据结构](#数据结构)
|
||||
- [算法](#算法)
|
||||
- [数据库](#数据库)
|
||||
- [MySQL](#mysql)
|
||||
- [Redis](#redis)
|
||||
- [数据库扩展](#数据库扩展)
|
||||
- [MySQL](#mysql)
|
||||
- [Redis](#redis)
|
||||
- [系统设计](#系统设计)
|
||||
- [常用框架(Spring,SpringBoot,MyBatis)](#常用框架)
|
||||
- [数据通信/中间件(消息队列、RPC ... )](#数据通信中间件)
|
||||
- [权限认证](#权限认证)
|
||||
- [分布式 & 微服务](#分布式--微服务)
|
||||
- [API 网关](#api-网关)
|
||||
- [配置中心](#配置中心)
|
||||
- [唯一 id 生成](#唯一-id-生成)
|
||||
- [服务治理:服务注册与发现、服务路由控制](#服务治理服务注册与发现服务路由控制)
|
||||
- [大型网站架构](#大型网站架构)
|
||||
- [性能测试](#性能测试)
|
||||
- [高并发](#高并发)
|
||||
- [高可用](#高可用)
|
||||
- [设计模式(工厂模式、单例模式 ... )](#设计模式)
|
||||
- [必知](#必知)
|
||||
- [常用框架](#常用框架)
|
||||
- [Spring/SpringBoot](#springspringboot)
|
||||
- [MyBatis](#mybatis)
|
||||
- [Netty](#netty)
|
||||
- [认证授权](#认证授权)
|
||||
- [JWT](#jwt)
|
||||
- [SSO(单点登录)](#sso单点登录)
|
||||
- [分布式](#分布式)
|
||||
- [分布式搜索引擎](#分布式搜索引擎)
|
||||
- [RPC](#rpc)
|
||||
- [消息队列](#消息队列)
|
||||
- [API 网关](#api-网关)
|
||||
- [分布式 id](#分布式id)
|
||||
- [分布式限流](#分布式限流)
|
||||
- [分布式接口幂等性](#分布式接口幂等性)
|
||||
- [ZooKeeper](#zookeeper)
|
||||
- [其他](#其他-1)
|
||||
- [数据库扩展](#数据库扩展)
|
||||
- [大型网站架构](#大型网站架构)
|
||||
- [性能测试](#性能测试)
|
||||
- [高并发](#高并发)
|
||||
- [高可用](#高可用)
|
||||
- [微服务](#微服务)
|
||||
- [Spring Cloud](#spring-cloud)
|
||||
- [必会工具](#必会工具)
|
||||
- [Git](#git)
|
||||
- [Docker](#docker)
|
||||
- [其他](#其他-2)
|
||||
- [面试指南](#面试指南)
|
||||
- [备战面试](#备战面试)
|
||||
- [面经](#面经)
|
||||
- [Java学习常见问题汇总](#java学习常见问题汇总)
|
||||
- [工具](#工具)
|
||||
- [Git](#git)
|
||||
- [Docker](#Docker)
|
||||
- [Java 学习常见问题汇总](#java学习常见问题汇总)
|
||||
- [资源](#资源)
|
||||
- [书单](#书单)
|
||||
- [Github榜单](#Github榜单)
|
||||
- [Java 程序员必备书单](#java程序员必备书单)
|
||||
- [实战项目推荐](#实战项目推荐)
|
||||
- [Github](#github)
|
||||
- [待办](#待办)
|
||||
- [说明](#说明)
|
||||
|
||||
@ -81,82 +114,82 @@
|
||||
|
||||
**基础知识系统总结:**
|
||||
|
||||
* **[Java 基础知识回顾](docs/java/Java基础知识.md)**
|
||||
* **[Java 基础知识疑难点/易错点](docs/java/Java疑难点.md)**
|
||||
* **[一些重要的Java程序设计题](docs/java/Java程序设计题.md)**
|
||||
* [J2EE 基础知识回顾](docs/java/J2EE基础知识.md)
|
||||
1. **[Java 基础知识](docs/java/Java基础知识.md)**
|
||||
2. **[Java 基础知识疑难点/易错点](docs/java/Java疑难点.md)**
|
||||
3. [【选看】J2EE 基础知识](docs/java/J2EE基础知识.md)
|
||||
|
||||
**重要知识点详解:**
|
||||
|
||||
- [用好Java中的枚举,真的没有那么简单!](docs/java/basis/用好Java中的枚举,真的没有那么简单!)
|
||||
- [Java 常见关键字总结:final、static、this、super!](docs/java/basis/final、static、this、super.md)
|
||||
1. [枚举](docs/java/basic/用好Java中的枚举真的没有那么简单.md) (很重要的一个数据结构,用好枚举真的没有那么简单!)
|
||||
2. [Java 常见关键字总结:final、static、this、super!](docs/java/basic/final,static,this,super.md)
|
||||
3. [什么是反射机制?反射机制的应用场景有哪些?](docs/java/basic/reflection.md)
|
||||
4. [代理模式详解:静态代理+JDK/CGLIB 动态代理实战(动态代理和静态代理的区别?JDK 动态代理 和 CGLIB 动态代理的区别?)](docs/java/basic/java-proxy.md)
|
||||
|
||||
**其他:**
|
||||
|
||||
1. [JAD 反编译](docs/java/JAD反编译tricks.md)
|
||||
2. [手把手教你定位常见 Java 性能问题](./docs/java/手把手教你定位常见Java性能问题.md)
|
||||
|
||||
### 容器
|
||||
|
||||
**总结:**
|
||||
|
||||
* **[Java容器常见面试题/知识点总结](docs/java/collection/Java集合框架常见面试题.md)**
|
||||
|
||||
**源码学习:**
|
||||
|
||||
* [ArrayList 源码学习](docs/java/collection/ArrayList.md)
|
||||
* [LinkedList 源码学习](docs/java/collection/LinkedList.md)
|
||||
* [HashMap(JDK1.8)源码学习](docs/java/collection/HashMap.md)
|
||||
1. **[Java 容器常见面试题/知识点总结](docs/java/collection/Java集合框架常见面试题.md)**
|
||||
2. 源码分析:[ArrayList 源码](docs/java/collection/ArrayList.md) 、[LinkedList 源码](docs/java/collection/LinkedList.md) 、[HashMap(JDK1.8)源码](docs/java/collection/HashMap.md) 、[ConcurrentHashMap 源码](docs/java/collection/ConcurrentHashMap.md)
|
||||
|
||||
### 并发
|
||||
|
||||
**[多线程学习指南](./docs/java/Multithread/多线程学习指南.md)**
|
||||
|
||||
**面试题总结:**
|
||||
|
||||
* **[Java 并发基础常见面试题总结](docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md)**
|
||||
* **[Java 并发进阶常见面试题总结](docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md)**
|
||||
1. **[Java 并发基础常见面试题总结](docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md)**
|
||||
2. **[Java 并发进阶常见面试题总结](docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md)**
|
||||
|
||||
**必备知识点:**
|
||||
**面试常问知识点:**
|
||||
|
||||
* [并发容器总结](docs/java/Multithread/并发容器总结.md)
|
||||
* **[Java线程池学习总结](./docs/java/Multithread/java线程池学习总结.md)**
|
||||
* [乐观锁与悲观锁](docs/essential-content-for-interview/面试必备之乐观锁与悲观锁.md)
|
||||
* [JUC 中的 Atomic 原子类总结](docs/java/Multithread/Atomic.md)
|
||||
* [AQS 原理以及 AQS 同步组件总结](docs/java/Multithread/AQS.md)
|
||||
1. [并发容器总结](docs/java/Multithread/并发容器总结.md)
|
||||
2. **线程池**:[Java 线程池学习总结](./docs/java/Multithread/java线程池学习总结.md)、[拿来即用的线程池最佳实践](./docs/java/Multithread/best-practice-of-threadpool.md)
|
||||
3. [乐观锁与悲观锁](docs/essential-content-for-interview/面试必备之乐观锁与悲观锁.md)
|
||||
4. [万字图文深度解析 ThreadLocal](docs/java/Multithread/ThreadLocal.md)
|
||||
5. [JUC 中的 Atomic 原子类总结](docs/java/Multithread/Atomic.md)
|
||||
6. [AQS 原理以及 AQS 同步组件总结](docs/java/Multithread/AQS.md)
|
||||
|
||||
### JVM
|
||||
|
||||
* **[一 Java内存区域](docs/java/jvm/Java内存区域.md)**
|
||||
* **[二 JVM垃圾回收](docs/java/jvm/JVM垃圾回收.md)**
|
||||
* [三 JDK 监控和故障处理工具](docs/java/jvm/JDK监控和故障处理工具总结.md)
|
||||
* [四 类文件结构](docs/java/jvm/类文件结构.md)
|
||||
* **[五 类加载过程](docs/java/jvm/类加载过程.md)**
|
||||
* [六 类加载器](docs/java/jvm/类加载器.md)
|
||||
* **[【待完成】八 最重要的 JVM 参数指南(翻译完善了一半)](docs/java/jvm/最重要的JVM参数指南.md)**
|
||||
* [九 JVM 配置常用参数和常用 GC 调优策略](docs/java/jvm/GC调优参数.md)
|
||||
* **[【加餐】大白话带你认识JVM](docs/java/jvm/[加餐]大白话带你认识JVM.md)**
|
||||
1. **[Java 内存区域](docs/java/jvm/Java内存区域.md)**
|
||||
2. **[JVM 垃圾回收](docs/java/jvm/JVM垃圾回收.md)**
|
||||
3. [JDK 监控和故障处理工具](docs/java/jvm/JDK监控和故障处理工具总结.md)
|
||||
4. [类文件结构](docs/java/jvm/类文件结构.md)
|
||||
5. **[类加载过程](docs/java/jvm/类加载过程.md)**
|
||||
6. [类加载器](docs/java/jvm/类加载器.md)
|
||||
7. **[【待完成】最重要的 JVM 参数指南(翻译完善了一半)](docs/java/jvm/最重要的JVM参数指南.md)**
|
||||
8. [JVM 配置常用参数和常用 GC 调优策略](docs/java/jvm/GC调优参数.md)
|
||||
9. **[【加餐】大白话带你认识 JVM](docs/java/jvm/[加餐]大白话带你认识JVM.md)**
|
||||
|
||||
### I/O
|
||||
### 其他
|
||||
|
||||
* [BIO,NIO,AIO 总结 ](docs/java/BIO-NIO-AIO.md)
|
||||
* [Java IO 与 NIO系列文章](docs/java/Java%20IO与NIO.md)
|
||||
|
||||
### Java 8
|
||||
|
||||
* [Java 8 新特性总结](docs/java/What's%20New%20in%20JDK8/Java8Tutorial.md)
|
||||
* [Java 8 学习资源推荐](docs/java/What's%20New%20in%20JDK8/Java8教程推荐.md)
|
||||
* [Java8 forEach 指南](docs/java/What's%20New%20in%20JDK8/Java8foreach指南.md)
|
||||
|
||||
### 优雅 Java 代码必备实践(Java编程规范)
|
||||
|
||||
* [Java 编程规范以及优雅 Java 代码实践总结](docs/java/Java编程规范.md)
|
||||
1. **Linux IO** : [Linux IO](docs/java/Linux_IO.md)
|
||||
2. **I/O** :[BIO,NIO,AIO 总结 ](docs/java/BIO-NIO-AIO.md)
|
||||
3. **Java 8** :[Java 8 新特性总结](docs/java/What's%20New%20in%20JDK8/Java8Tutorial.md)、[Java 8 学习资源推荐](docs/java/What's%20New%20in%20JDK8/Java8教程推荐.md)、[Java8 forEach 指南](docs/java/What's%20New%20in%20JDK8/Java8foreach指南.md)
|
||||
4. **Java9~Java14** : [一文带你看遍 JDK9~14 的重要新特性!](./docs/java/jdk-new-features/new-features-from-jdk8-to-jdk14.md)
|
||||
5. Java 编程规范:**[Java 编程规范以及优雅 Java 代码实践总结](docs/java/Java编程规范.md)** 、[告别编码 5 分钟,命名 2 小时!史上最全的 Java 命名规范参考!](docs/java/java-naming-conventions.md)
|
||||
6. 设计模式 :[设计模式系列文章](docs/system-design/设计模式.md)
|
||||
|
||||
## 网络
|
||||
|
||||
* [计算机网络常见面试题](docs/network/计算机网络.md)
|
||||
* [计算机网络基础知识总结](docs/network/干货:计算机网络知识总结.md)
|
||||
* [HTTPS中的TLS](docs/network/HTTPS中的TLS.md)
|
||||
1. [计算机网络常见面试题](docs/network/计算机网络.md)
|
||||
2. [计算机网络基础知识总结](docs/network/干货:计算机网络知识总结.md)
|
||||
|
||||
## 操作系统
|
||||
|
||||
### Linux相关
|
||||
[最硬核的操作系统常见问题总结!](docs/operating-system/basis.md)
|
||||
|
||||
* [后端程序员必备的 Linux 基础知识](docs/operating-system/后端程序员必备的Linux基础知识.md)
|
||||
* [Shell 编程入门](docs/operating-system/Shell.md)
|
||||
### Linux
|
||||
|
||||
- [后端程序员必备的 Linux 基础知识](docs/operating-system/linux.md)
|
||||
- [Shell 编程入门](docs/operating-system/Shell.md)
|
||||
- [我为什么从 Windows 转到 Linux?](docs/operating-system/完全使用GNU_Linux学习.md)
|
||||
- [Linux IO 模型](docs/operating-system/Linux_IO.md)
|
||||
- [Linux 性能分析工具合集](docs/operating-system/Linux性能分析工具合集.md)
|
||||
|
||||
## 数据结构与算法
|
||||
|
||||
@ -167,116 +200,156 @@
|
||||
|
||||
### 算法
|
||||
|
||||
- [算法学习资源推荐](docs/dataStructures-algorithms/算法学习资源推荐.md)
|
||||
- [几道常见的字符串算法题总结 ](docs/dataStructures-algorithms/几道常见的子符串算法题.md)
|
||||
- [几道常见的链表算法题总结 ](docs/dataStructures-algorithms/几道常见的链表算法题.md)
|
||||
- [剑指offer部分编程题](docs/dataStructures-algorithms/剑指offer部分编程题.md)
|
||||
- [公司真题](docs/dataStructures-algorithms/公司真题.md)
|
||||
- [回溯算法经典案例之N皇后问题](docs/dataStructures-algorithms/Backtracking-NQueens.md)
|
||||
- [硬核的算法学习书籍+资源推荐](docs/dataStructures-algorithms/算法学习资源推荐.md)
|
||||
- 常见算法问题总结:
|
||||
- [几道常见的字符串算法题总结 ](docs/dataStructures-algorithms/几道常见的子符串算法题.md)
|
||||
- [几道常见的链表算法题总结 ](docs/dataStructures-algorithms/几道常见的链表算法题.md)
|
||||
- [剑指 offer 部分编程题](docs/dataStructures-algorithms/剑指offer部分编程题.md)
|
||||
- [公司真题](docs/dataStructures-algorithms/公司真题.md)
|
||||
- [回溯算法经典案例之 N 皇后问题](docs/dataStructures-algorithms/Backtracking-NQueens.md)
|
||||
|
||||
## 数据库
|
||||
|
||||
### MySQL
|
||||
|
||||
* **[【推荐】MySQL/数据库 知识点总结](docs/database/MySQL.md)**
|
||||
* **[阿里巴巴开发手册数据库部分的一些最佳实践](docs/database/阿里巴巴开发手册数据库部分的一些最佳实践.md)**
|
||||
* **[一千行MySQL学习笔记](docs/database/一千行MySQL命令.md)**
|
||||
* [MySQL高性能优化规范建议](docs/database/MySQL高性能优化规范建议.md)
|
||||
* [数据库索引总结](docs/database/MySQL%20Index.md)
|
||||
* [事务隔离级别(图文详解)](docs/database/事务隔离级别(图文详解).md)
|
||||
* [一条SQL语句在MySQL中如何执行的](docs/database/一条sql语句在mysql中如何执行的.md)
|
||||
**总结:**
|
||||
|
||||
1. **[【推荐】MySQL/数据库 知识点总结](docs/database/MySQL.md)**
|
||||
2. **[阿里巴巴开发手册数据库部分的一些最佳实践](docs/database/阿里巴巴开发手册数据库部分的一些最佳实践.md)**
|
||||
3. **[一千行 MySQL 学习笔记](docs/database/一千行MySQL命令.md)**
|
||||
4. [MySQL 高性能优化规范建议](docs/database/MySQL高性能优化规范建议.md)
|
||||
|
||||
**重要知识点:**
|
||||
|
||||
1. [数据库索引总结 1](docs/database/MySQL%20Index.md)、[数据库索引总结 2](docs/database/数据库索引.md)
|
||||
2. [事务隔离级别(图文详解)](<docs/database/事务隔离级别(图文详解).md>)
|
||||
3. [一条 SQL 语句在 MySQL 中如何执行的](docs/database/一条sql语句在mysql中如何执行的.md)
|
||||
4. **[关于数据库中如何存储时间的一点思考](docs/database/关于数据库存储时间的一点思考.md)**
|
||||
|
||||
### Redis
|
||||
|
||||
* [Redis 总结](docs/database/Redis/Redis.md)
|
||||
* [Redlock分布式锁](docs/database/Redis/Redlock分布式锁.md)
|
||||
* [如何做可靠的分布式锁,Redlock真的可行么](docs/database/Redis/如何做可靠的分布式锁,Redlock真的可行么.md)
|
||||
* [几种常见的 Redis 集群以及使用场景](docs/database/Redis/redis集群以及应用场景.md)
|
||||
|
||||
### 数据库扩展
|
||||
|
||||
待办......
|
||||
- [关于缓存的一些重要概念(Redis 前置菜)](docs/database/Redis/some-concepts-of-caching.md)
|
||||
- [Redis 常见问题总结](docs/database/Redis/redis-all.md)
|
||||
|
||||
## 系统设计
|
||||
|
||||
### 必知
|
||||
|
||||
1. **[RestFul API 简明教程](docs/system-design/restful-api.md)**
|
||||
2. **[因为命名被 diss 无数次。Guide 简单聊聊编程最头疼的事情之一:命名](docs/system-design/naming.md)**
|
||||
|
||||
### 常用框架
|
||||
|
||||
#### Spring
|
||||
#### Spring/SpringBoot
|
||||
|
||||
- [Spring 学习与面试](docs/system-design/framework/spring/Spring.md)
|
||||
- **[Spring 常见问题总结](docs/system-design/framework/spring/SpringInterviewQuestions.md)**
|
||||
- [Spring中 Bean 的作用域与生命周期](docs/system-design/framework/spring/SpringBean.md)
|
||||
- [SpringMVC 工作原理详解](docs/system-design/framework/spring/SpringMVC-Principle.md)
|
||||
- [Spring中都用到了那些设计模式?](docs/system-design/framework/spring/Spring-Design-Patterns.md)
|
||||
|
||||
#### SpringBoot
|
||||
|
||||
- **[SpringBoot 指南/常见面试题总结](https://github.com/Snailclimb/springboot-guide)**
|
||||
1. **[Spring 常见问题总结](docs/system-design/framework/spring/SpringInterviewQuestions.md)**
|
||||
2. **[SpringBoot 指南/常见面试题总结](https://github.com/Snailclimb/springboot-guide)**
|
||||
3. **[Spring/Spring 常用注解总结!安排!](./docs/system-design/framework/spring/spring-annotations.md)**
|
||||
4. **[Spring 事务总结](docs/system-design/framework/spring/spring-transaction.md)**
|
||||
5. [Spring IoC 和 AOP 详解](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486938&idx=1&sn=c99ef0233f39a5ffc1b98c81e02dfcd4&chksm=cea24211f9d5cb07fa901183ba4d96187820713a72387788408040822ffb2ed575d28e953ce7&token=1666190828&lang=zh_CN#rd)
|
||||
6. [Spring 中 Bean 的作用域与生命周期](docs/system-design/framework/spring/SpringBean.md)
|
||||
7. [SpringMVC 工作原理详解](docs/system-design/framework/spring/SpringMVC-Principle.md)
|
||||
8. [Spring 中都用到了那些设计模式?](docs/system-design/framework/spring/Spring-Design-Patterns.md)
|
||||
|
||||
#### MyBatis
|
||||
|
||||
- [MyBatis常见面试题总结](docs/system-design/framework/mybatis/mybatis-interview.md)
|
||||
- [MyBatis 常见面试题总结](docs/system-design/framework/mybatis/mybatis-interview.md)
|
||||
|
||||
### 数据通信/中间件
|
||||
#### Netty
|
||||
|
||||
- [数据通信(RESTful、RPC、消息队列)相关知识点总结](docs/system-design/data-communication/summary.md)
|
||||
1. [剖析面试最常见问题之 Netty(上)](https://xiaozhuanlan.com/topic/4028536971)
|
||||
2. [剖析面试最常见问题之 Netty(下)](https://xiaozhuanlan.com/topic/3985146207)
|
||||
|
||||
### 认证授权
|
||||
|
||||
**[认证授权基础:搞清 Authentication,Authorization 以及 Cookie、Session、Token、OAuth 2、SSO](docs/system-design/authority-certification/basis-of-authority-certification.md)**
|
||||
|
||||
#### JWT
|
||||
|
||||
- **[JWT 优缺点分析以及常见问题解决方案](docs/system-design/authority-certification/JWT-advantages-and-disadvantages.md)**
|
||||
- **[适合初学者入门 Spring Security With JWT 的 Demo](https://github.com/Snailclimb/spring-security-jwt-guide)**
|
||||
|
||||
#### SSO(单点登录)
|
||||
|
||||
SSO(Single Sign On)即单点登录说的是用户登陆多个子系统的其中一个就有权访问与其相关的其他系统。举个例子我们在登陆了京东金融之后,我们同时也成功登陆京东的京东超市、京东家电等子系统。相关阅读:**[SSO 单点登录看这篇就够了!](docs/system-design/authority-certification/sso.md)**
|
||||
|
||||
### 分布式
|
||||
|
||||
[分布式相关概念入门](docs/system-design/website-architecture/分布式.md)
|
||||
|
||||
#### 分布式搜索引擎
|
||||
|
||||
提高搜索效率。常见于电商购物网站的商品搜索于分类。
|
||||
|
||||
比较常用的是 Elasticsearch 和 Solr。
|
||||
|
||||
代办。
|
||||
|
||||
#### RPC
|
||||
|
||||
让调用远程服务调用像调用本地方法那样简单。
|
||||
|
||||
- [Dubbo 总结:关于 Dubbo 的重要知识点](docs/system-design/data-communication/dubbo.md)
|
||||
- [服务之间的调用为啥不直接用 HTTP 而用 RPC?](docs/system-design/data-communication/why-use-rpc.md)
|
||||
|
||||
#### 消息队列
|
||||
|
||||
- [消息队列总结](docs/system-design/data-communication/message-queue.md)
|
||||
- [RabbitMQ 入门](docs/system-design/data-communication/rabbitmq.md)
|
||||
- [RocketMQ 入门](docs/system-design/data-communication/RocketMQ.md)
|
||||
- [RocketMQ的几个简单问题与答案](docs/system-design/data-communication/RocketMQ-Questions.md)
|
||||
- [Kafka入门看这一篇就够了](docs/system-design/data-communication/Kafka入门看这一篇就够了.md)
|
||||
- [Kafka系统设计开篇-面试看这篇就够了](docs/system-design/data-communication/Kafka系统设计开篇-面试看这篇就够了.md)
|
||||
消息队列在分布式系统中主要是为了解耦和削峰。相关阅读: **[消息队列总结](docs/system-design/data-communication/message-queue.md)** 。
|
||||
|
||||
### 权限认证
|
||||
**RabbitMQ:**
|
||||
|
||||
- **[权限认证基础:区分Authentication,Authorization以及Cookie、Session、Token](docs/system-design/authority-certification/basis-of-authority-certification.md)**
|
||||
- **[JWT 优缺点分析以及常见问题解决方案](docs/system-design/authority-certification/JWT-advantages-and-disadvantages.md)**
|
||||
- **[适合初学者入门 Spring Security With JWT 的 Demo](https://github.com/Snailclimb/spring-security-jwt-guide)**
|
||||
1. [RabbitMQ 入门](docs/system-design/data-communication/rabbitmq.md)
|
||||
|
||||
### 分布式 & 微服务
|
||||
**RocketMQ:**
|
||||
|
||||
- [分布式应该学什么](docs/system-design/website-architecture/分布式.md)
|
||||
1. [RocketMQ 入门](docs/system-design/data-communication/RocketMQ.md)
|
||||
2. [RocketMQ 的几个简单问题与答案](docs/system-design/data-communication/RocketMQ-Questions.md)
|
||||
|
||||
#### Spring Cloud
|
||||
**Kafka:**
|
||||
|
||||
- [ 大白话入门 Spring Cloud](docs/system-design/micro-service/spring-cloud.md)
|
||||
1. **[Kafka 入门+SpringBoot 整合 Kafka 系列](https://github.com/Snailclimb/springboot-kafka)**
|
||||
2. **[Kafka 常见面试题总结](docs/system-design/data-communication/kafka-inverview.md)**
|
||||
3. [【加餐】Kafka 入门看这一篇就够了](docs/system-design/data-communication/Kafka入门看这一篇就够了.md)
|
||||
|
||||
#### API 网关
|
||||
|
||||
网关主要用于请求转发、安全认证、协议转换、容灾。
|
||||
|
||||
- [浅析如何设计一个亿级网关(API Gateway)](docs/system-design/micro-service/API网关.md)
|
||||
1. [为什么要网关?你知道有哪些常见的网关系统?](docs/system-design/micro-service/api-gateway-intro.md)
|
||||
2. [如何设计一个亿级网关(API Gateway)?](docs/system-design/micro-service/API网关.md)
|
||||
|
||||
#### 配置中心
|
||||
#### 分布式 id
|
||||
|
||||
待办......
|
||||
1. [为什么要分布式 id ?分布式 id 生成方案有哪些?](docs/system-design/micro-service/分布式id生成方案总结.md)
|
||||
|
||||
#### 唯一 id 生成
|
||||
#### 分布式限流
|
||||
|
||||
- [分布式id生成方案总结](docs/system-design/micro-service/分布式id生成方案总结.md)
|
||||
1. [限流算法有哪些?](docs/system-design/micro-service/limit-request.md)
|
||||
|
||||
#### 服务治理:服务注册与发现、服务路由控制
|
||||
#### 分布式接口幂等性
|
||||
|
||||
**ZooKeeper:**
|
||||
#### ZooKeeper
|
||||
|
||||
> 前两篇文章可能有内容重合部分,推荐都看一遍。
|
||||
|
||||
- [【入门】ZooKeeper 相关概念总结](docs/system-design/framework/ZooKeeper.md)
|
||||
- [【进阶】Zookeeper 原理简单入门!](docs/system-design/framework/ZooKeeper-plus.md)
|
||||
- [【拓展】ZooKeeper 数据模型和常见命令](docs/system-design/framework/ZooKeeper数据模型和常见命令.md)
|
||||
1. [【入门】ZooKeeper 相关概念总结 01](docs/system-design/framework/zookeeper/zookeeper-intro.md)
|
||||
2. [【进阶】ZooKeeper 相关概念总结 02](docs/system-design/framework/zookeeper/zookeeper-plus.md)
|
||||
3. [【实战】ZooKeeper 实战](docs/system-design/framework/zookeeper/zookeeper-in-action.md)
|
||||
|
||||
#### 其他
|
||||
|
||||
- 接口幂等性(代办):分布式系统必须要考虑接口的幂等性。
|
||||
|
||||
#### 数据库扩展
|
||||
|
||||
读写分离、分库分表。
|
||||
|
||||
代办.....
|
||||
|
||||
### 大型网站架构
|
||||
|
||||
- [8 张图读懂大型网站技术架构](docs/system-design/website-architecture/8%20张图读懂大型网站技术架构.md)
|
||||
- [【面试精选】关于大型网站系统架构你不得不懂的10个问题](docs/system-design/website-architecture/关于大型网站系统架构你不得不懂的10个问题.md)
|
||||
- [关于大型网站系统架构你不得不懂的 10 个问题](docs/system-design/website-architecture/关于大型网站系统架构你不得不懂的10个问题.md)
|
||||
|
||||
#### 性能测试
|
||||
|
||||
@ -288,134 +361,102 @@
|
||||
|
||||
#### 高可用
|
||||
|
||||
- [如何设计一个高可用系统?要考虑哪些地方?](docs/system-design/website-architecture/如何设计一个高可用系统?要考虑哪些地方?.md)
|
||||
高可用描述的是一个系统在大部分时间都是可用的,可以为我们提供服务的。高可用代表系统即使在发生硬件故障或者系统升级的时候,服务仍然是可用的 。相关阅读: **《[如何设计一个高可用系统?要考虑哪些地方?](docs/system-design/website-architecture/如何设计一个高可用系统?要考虑哪些地方?.md)》** 。
|
||||
|
||||
### 设计模式
|
||||
### 微服务
|
||||
|
||||
- [设计模式系列文章](docs/system-design/设计模式.md)
|
||||
#### Spring Cloud
|
||||
|
||||
## 面试指南
|
||||
- [ 大白话入门 Spring Cloud](docs/system-design/micro-service/spring-cloud.md)
|
||||
|
||||
### 备战面试
|
||||
|
||||
* **[【备战面试1】程序员的简历就该这样写](docs/essential-content-for-interview/PreparingForInterview/程序员的简历之道.md)**
|
||||
* **[【备战面试2】初出茅庐的程序员该如何准备面试?](docs/essential-content-for-interview/PreparingForInterview/interviewPrepare.md)**
|
||||
* **[【备战面试3】7个大部分程序员在面试前很关心的问题](docs/essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md)**
|
||||
* **[【备战面试4】Github上开源的Java面试/学习相关的仓库推荐](docs/essential-content-for-interview/PreparingForInterview/JavaInterviewLibrary.md)**
|
||||
* **[【备战面试5】如果面试官问你“你有什么问题问我吗?”时,你该如何回答](docs/essential-content-for-interview/PreparingForInterview/面试官-你有什么问题要问我.md)**
|
||||
* [【备战面试6】应届生面试最爱问的几道 Java 基础问题](docs/essential-content-for-interview/PreparingForInterview/应届生面试最爱问的几道Java基础问题.md)
|
||||
* **[【备战面试6】美团面试常见问题总结(附详解答案)](docs/essential-content-for-interview/PreparingForInterview/美团面试常见问题总结.md)**
|
||||
* **[【备战面试7】一些刁难的面试问题总结](https://xiaozhuanlan.com/topic/9056431872)**
|
||||
|
||||
### 真实面试经历分析
|
||||
|
||||
- [我和阿里面试官的一次“邂逅”(附问题详解)](docs/essential-content-for-interview/real-interview-experience-analysis/alibaba-1.md)
|
||||
|
||||
### 面经
|
||||
|
||||
- [5面阿里,终获offer(2018年秋招)](docs/essential-content-for-interview/BATJrealInterviewExperience/5面阿里,终获offer.md)
|
||||
- [蚂蚁金服2019实习生面经总结(已拿口头offer)](docs/essential-content-for-interview/BATJrealInterviewExperience/蚂蚁金服实习生面经总结(已拿口头offer).md)
|
||||
- [2019年蚂蚁金服、头条、拼多多的面试总结](docs/essential-content-for-interview/BATJrealInterviewExperience/2019alipay-pinduoduo-toutiao.md)
|
||||
|
||||
## Java学习常见问题汇总
|
||||
|
||||
- [Java学习路线和方法推荐](docs/questions/java-learning-path-and-methods.md)
|
||||
- [Java培训四个月能学会吗?](docs/questions/java-training-4-month.md)
|
||||
- [新手学习Java,有哪些Java相关的博客,专栏,和技术学习网站推荐?](docs/questions/java-learning-website-blog.md)
|
||||
- [Java 还是大数据,你需要了解这些东西!](docs/questions/java-big-data)
|
||||
- [Java 后台开发/大数据?你需要了解这些东西!](https://articles.zsxq.com/id_wto1iwd5g72o.html)(知识星球)
|
||||
|
||||
## 工具
|
||||
## 必会工具
|
||||
|
||||
### Git
|
||||
|
||||
* [Git入门](docs/tools/Git.md)
|
||||
- [Git 入门](docs/tools/Git.md)
|
||||
|
||||
### Docker
|
||||
|
||||
* [Docker 基本概念解读](docs/tools/Docker.md)
|
||||
* [一文搞懂 Docker 镜像的常用操作!](docs/tools/Docker-Image.md )
|
||||
1. [Docker 基本概念解读](docs/tools/Docker.md)
|
||||
2. [一文搞懂 Docker 镜像的常用操作!](docs/tools/Docker-Image.md)
|
||||
|
||||
### 其他
|
||||
|
||||
- [阿里云服务器使用经验](docs/tools/阿里云服务器使用经验.md)
|
||||
- [【原创】如何使用云服务器?希望这篇文章能够对你有帮助!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485738&idx=1&sn=f97e91a50e444944076c30b0717b303a&chksm=cea246e1f9d5cff73faf6a778b147ea85162d1f3ed55ca90473c6ebae1e2c4d13e89282aeb24&token=406194678&lang=zh_CN#rd)
|
||||
|
||||
## 面试指南
|
||||
|
||||
> 这部分很多内容比如大厂面经、真实面经分析被移除,详见[完结撒花!JavaGuide 面试突击版来啦!](./docs/javaguide面试突击版.md)。
|
||||
|
||||
1. **[【备战面试 1】程序员的简历就该这样写](docs/essential-content-for-interview/PreparingForInterview/程序员的简历之道.md)**
|
||||
2. **[【备战面试 2】初出茅庐的程序员该如何准备面试?](docs/essential-content-for-interview/PreparingForInterview/interviewPrepare.md)**
|
||||
3. **[【备战面试 3】7 个大部分程序员在面试前很关心的问题](docs/essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md)**
|
||||
4. **[【备战面试 4】Github 上开源的 Java 面试/学习相关的仓库推荐](docs/essential-content-for-interview/PreparingForInterview/JavaInterviewLibrary.md)**
|
||||
5. **[【备战面试 5】如果面试官问你“你有什么问题问我吗?”时,你该如何回答](docs/essential-content-for-interview/PreparingForInterview/面试官-你有什么问题要问我.md)**
|
||||
6. [【备战面试 6】应届生面试最爱问的几道 Java 基础问题](docs/essential-content-for-interview/PreparingForInterview/应届生面试最爱问的几道Java基础问题.md)
|
||||
7. **[【备战面试 6】美团面试常见问题总结(附详解答案)](docs/essential-content-for-interview/PreparingForInterview/美团面试常见问题总结.md)**
|
||||
|
||||
## Java 学习常见问题汇总
|
||||
|
||||
1. [Java 学习路线和方法推荐](docs/questions/java-learning-path-and-methods.md)
|
||||
2. [Java 培训四个月能学会吗?](docs/questions/java-training-4-month.md)
|
||||
3. [新手学习 Java,有哪些 Java 相关的博客,专栏,和技术学习网站推荐?](docs/questions/java-learning-website-blog.md)
|
||||
4. [Java 还是大数据,你需要了解这些东西!](docs/questions/java-big-data.md)
|
||||
|
||||
## 资源
|
||||
|
||||
### 书单
|
||||
### Java 程序员必备书单
|
||||
|
||||
- [Java程序员必备书单](docs/data/java-recommended-books.md)
|
||||
1. [「基础篇」Guide 的 Java 后端书架来啦!都是 Java 程序员必看的书籍?](./docs/books/java基础篇.md)
|
||||
|
||||
### 实战项目推荐
|
||||
|
||||
- [Github 上热门的 Spring Boot 项目实战推荐](docs/data/spring-boot-practical-projects.md)
|
||||
- **[Java、SpringBoot 实战项目推荐](https://github.com/Snailclimb/awesome-java#实战项目)**
|
||||
|
||||
### Github
|
||||
|
||||
- [Github 上非常棒的 Java 开源项目集合](https://github.com/Snailclimb/awesome-java)
|
||||
- [Github 上 Star 数最多的 10 个项目,看完之后很意外!](docs/tools/github/github-star-ranking.md)
|
||||
- [年末将至,值得你关注的16个Java 开源项目!](docs/github-trending/2019-12.md)
|
||||
- [Java 项目月榜单](docs/github-trending/JavaGithubTrending.md)
|
||||
- [年末将至,值得你关注的 16 个 Java 开源项目!](docs/github-trending/2019-12.md)
|
||||
- [Java 项目历史月榜单](docs/github-trending/JavaGithubTrending.md)
|
||||
|
||||
***
|
||||
---
|
||||
|
||||
## 待办
|
||||
|
||||
- [x] Java 多线程类别知识重构
|
||||
- [ ] Netty 总结(---正在进行中---)
|
||||
- [x] Netty 总结
|
||||
- [ ] 数据结构总结重构(---正在进行中---)
|
||||
|
||||
## 说明
|
||||
|
||||
### JavaGuide介绍
|
||||
开源项目在于大家的参与,这才使得它的价值得到提升。感谢 🙏 有你!
|
||||
|
||||
* **对于 Java 初学者来说:** 本文档倾向于给你提供一个比较详细的学习路径,让你对于Java整体的知识体系有一个初步认识。另外,本文的一些文章
|
||||
也是你学习和复习 Java 知识不错的实践;
|
||||
* **对于非 Java 初学者来说:** 本文档更适合回顾知识,准备面试,搞清面试应该把重心放在那些问题上。要搞清楚这个道理:提前知道那些面试常见,不是为了背下来应付面试,而是为了让你可以更有针对的学习重点。
|
||||
项目的 Markdown 格式参考:[Github Markdown 格式](https://guides.github.com/features/mastering-markdown/),表情素材来自:[EMOJI CHEAT SHEET](https://www.webpagefx.com/tools/emoji-cheat-sheet/)。
|
||||
|
||||
Markdown 格式参考:[Github Markdown格式](https://guides.github.com/features/mastering-markdown/),表情素材来自:[EMOJI CHEAT SHEET](https://www.webpagefx.com/tools/emoji-cheat-sheet/)。
|
||||
利用 docsify 生成文档部署在 Github pages: [docsify 官网介绍](https://docsify.js.org/#/) ,另见[《Guide 哥手把手教你搭建一个文档类型的网站!免费且高速!》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486555&idx=2&sn=8486026ee9f9ba645ff0363df6036184&chksm=cea24390f9d5ca86ff4177c0aca5e719de17dc89e918212513ee661dd56f17ca8269f4a6e303&token=298703358&lang=zh_CN#rd) 。
|
||||
|
||||
利用 docsify 生成文档部署在 Github pages: [docsify 官网介绍](https://docsify.js.org/#/)
|
||||
Logo 下的小图标是使用[Shields.IO](https://shields.io/) 生成的。
|
||||
|
||||
### 作者的其他开源项目推荐
|
||||
## 联系我
|
||||
|
||||
1. [springboot-guide](https://github.com/Snailclimb/springboot-guide) : 适合新手入门以及有经验的开发人员查阅的 Spring Boot 教程(业余时间维护中,欢迎一起维护)。
|
||||
2. [programmer-advancement](https://github.com/Snailclimb/programmer-advancement) : 我觉得技术人员应该有的一些好习惯!
|
||||
3. [spring-security-jwt-guide](https://github.com/Snailclimb/spring-security-jwt-guide) :从零入门 !Spring Security With JWT(含权限验证)后端部分代码。
|
||||

|
||||
|
||||
### 关于转载
|
||||
## 捐赠支持
|
||||
|
||||
如果你需要转载本仓库的一些文章到自己的博客的话,记得注明原文地址就可以了。
|
||||
项目的发展离不开你的支持,如果 JavaGuide 帮助到了你找到自己满意的 offer,请作者喝杯咖啡吧 ☕ 后续会继续完善更新!加油!
|
||||
|
||||
### 如何对该开源文档进行贡献
|
||||
[点击捐赠支持作者](https://www.yuque.com/snailclimb/dr6cvl/mr44yt#vu3ok)
|
||||
|
||||
1. 笔记内容大多是手敲,所以难免会有笔误,你可以帮我找错别字。
|
||||
2. 很多知识点我可能没有涉及到,所以你可以对其他知识点进行补充。
|
||||
3. 现有的知识点难免存在不完善或者错误,所以你可以对已有知识点进行修改/补充。
|
||||
## Contributor
|
||||
|
||||
### 为什么要做这个开源文档?
|
||||
下面是笔主收集的一些对本仓库提过有价值的 pr 或者 issue 的朋友,人数较多,如果你也对本仓库提过不错的 pr 或者 issue 的话,你可以加我的微信与我联系。下面的排名不分先后!
|
||||
|
||||
初始想法源于自己的个人那一段比较迷茫的学习经历。主要目的是为了通过这个开源平台来帮助一些在学习 Java 或者面试过程中遇到问题的小伙伴。
|
||||
|
||||
### 投稿
|
||||
|
||||
由于我个人能力有限,很多知识点我可能没有涉及到,所以你可以对其他知识点进行补充。大家也可以对自己的文章进行自荐,对于不错的文章不仅可以成功在本仓库展示出来更可以获得作者送出的 50 元左右的任意书籍进行奖励(当然你也可以直接折现50元)。
|
||||
|
||||
### 联系我
|
||||
|
||||
添加我的微信备注“Github”,回复关键字 **“加群”** 即可入群。
|
||||
|
||||

|
||||
|
||||
### Contributor
|
||||
|
||||
下面是笔主收集的一些对本仓库提过有价值的pr或者issue的朋友,人数较多,如果你也对本仓库提过不错的pr或者issue的话,你可以加我的微信与我联系。下面的排名不分先后!
|
||||
|
||||
<a href="https://github.com/fanofxiaofeng">
|
||||
<img src="https://avatars0.githubusercontent.com/u/3983683?s=460&v=4" width="45px">
|
||||
</a>
|
||||
<a href="https://github.com/LiWenGu">
|
||||
<img src="https://avatars0.githubusercontent.com/u/15909210?s=460&v=4" width="45px">
|
||||
</a>
|
||||
<a href="https://github.com/fanofxiaofeng">
|
||||
<img src="https://avatars0.githubusercontent.com/u/3983683?s=460&v=4" width="45px">
|
||||
</a>
|
||||
<a href="https://github.com/fanchenggang">
|
||||
<img src="https://avatars2.githubusercontent.com/u/8225921?s=460&v=4" width="45px">
|
||||
</a>
|
||||
@ -461,12 +502,12 @@ Markdown 格式参考:[Github Markdown格式](https://guides.github.com/featur
|
||||
<img src="https://avatars0.githubusercontent.com/u/20358122?s=460&v=4" width="45px">
|
||||
</a>
|
||||
|
||||
### 公众号
|
||||
## 公众号
|
||||
|
||||
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
|
||||
|
||||
**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
|
||||
**《Java 面试突击》:** 由本文档衍生的专为面试而生的《Java 面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java 面试突击"** 即可免费领取!
|
||||
|
||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
**Java 工程师必备学习资源:** 一些 Java 工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
|
||||

|
||||

|
||||
@ -1,13 +1,12 @@
|
||||
<p align="center">
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-3logo-透明.png" width=""/>
|
||||
<img src="./media/pictures/logo.png" width="200" height="200"/>
|
||||
</p>
|
||||
|
||||
|
||||
<h1 align="center">Java 学习/面试指南</h1>
|
||||
|
||||
[常用资源](https://shimo.im/docs/MuiACIg1HlYfVxrj/)
|
||||
[GitHub](<https://github.com/Snailclimb/JavaGuide>)
|
||||
[开始阅读](#java)
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
BIN
docs/books/images/0d6e5484-aea1-41cc-8417-4694c6028012.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 107 KiB |
BIN
docs/books/images/18f7bbcf-7de7-49f5-b16b-f56b5185370a.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 96 KiB |
BIN
docs/books/images/20893364-3cc6-4fe5-8cb6-4bed676ce7bd.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 102 KiB |
BIN
docs/books/images/2bb7f878-3514-4f10-99c9-7850318b33a9.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 116 KiB |
BIN
docs/books/images/3900e43f-c591-4748-acaf-affcb16d7d9d.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 93 KiB |
BIN
docs/books/images/3d2e12ad-b92e-4bb5-b330-f515750ff780.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 336 KiB |
BIN
docs/books/images/4b337376-e90d-4fdf-9a95-a3fac328b416.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 140 KiB |
BIN
docs/books/images/4fd57829-82a9-4bf4-853a-56bd7413923a.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 140 KiB |
BIN
docs/books/images/5d94f552-5815-4b9e-aed4-623b88273355.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 166 KiB |
BIN
docs/books/images/7001a206-8ac0-432c-bf62-ca7130487c12.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 554 KiB |
BIN
docs/books/images/74a29a45-b770-4fd5-8480-c46bd72464a9.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 382 KiB |
BIN
docs/books/images/7ab7af22-d9ff-4fa8-9ffb-f5ba73e8b128.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 145 KiB |
BIN
docs/books/images/7e80418d-20b1-4066-b9af-cfe434b1bf1a.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 128 KiB |
BIN
docs/books/images/8ece325c-4491-4ffd-9d3d-77e95159ec40.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 210 KiB |
BIN
docs/books/images/9b472b41-391d-42de-a210-1457c5810618.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 36 KiB |
BIN
docs/books/images/b4c03ec2-f907-47a4-ad19-731c969a499b.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 76 KiB |
BIN
docs/books/images/c7164eae-8509-4de4-af17-97933fb29f99.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 64 KiB |
BIN
docs/books/images/c8188444-68ba-4b86-a22e-d3b2bb3565d6.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 341 KiB |
BIN
docs/books/images/e2ed7d6a-1c08-4148-99f9-d284b8a7a4c1.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 85 KiB |
BIN
docs/books/images/e7e11e32-a931-4261-804f-9586ec4f8476.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 161 KiB |
BIN
docs/books/images/f16ae5d5-56a0-4b32-8e84-fb10157f3f0c.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 142 KiB |
BIN
docs/books/images/format,png.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 27 KiB |
BIN
docs/books/images/s29925598.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 13 KiB |
BIN
docs/books/images/s32277130.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 15 KiB |
BIN
docs/books/images/s32282160.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 14 KiB |
184
docs/books/java.md
Normal file
@ -0,0 +1,184 @@
|
||||
**目录:**
|
||||
|
||||
<!-- TOC -->
|
||||
|
||||
- [Java](#java)
|
||||
- [基础](#基础)
|
||||
- [并发](#并发)
|
||||
- [JVM](#jvm)
|
||||
- [Java8 新特性](#java8-新特性)
|
||||
- [代码优化](#代码优化)
|
||||
- [面试](#面试)
|
||||
- [网络](#网络)
|
||||
- [操作系统](#操作系统)
|
||||
- [数据结构](#数据结构)
|
||||
- [算法](#算法)
|
||||
- [入门](#入门)
|
||||
- [经典](#经典)
|
||||
- [面试](#面试-1)
|
||||
- [数据库](#数据库)
|
||||
- [系统设计](#系统设计)
|
||||
- [设计模式](#设计模式)
|
||||
- [常用框架](#常用框架)
|
||||
- [Spring/SpringBoot](#springspringboot)
|
||||
- [Netty](#netty)
|
||||
- [分布式](#分布式)
|
||||
- [网站架构](#网站架构)
|
||||
- [底层](#底层)
|
||||
- [软件设计之道](#软件设计之道)
|
||||
- [其他](#其他)
|
||||
|
||||
<!-- /TOC -->
|
||||
|
||||
## Java
|
||||
|
||||
### 基础
|
||||
|
||||
- **[《Head First Java》](https://book.douban.com/subject/2000732/)** : 可以说是我的 Java 启蒙书籍了,我个人觉得还是很适合稍微有一点点经验的新手来阅读的当然也适合我们用来温故 Java 知识点。*ps:刚入门编程,最好的方式还是通过看视频来学习。*
|
||||
- **[《Java 核心技术卷 1+卷 2》](https://book.douban.com/subject/25762168/)**: 很棒的两本书,建议有点 Java 基础之后再读,介绍的还是比较深入的,非常推荐。这两本书我一般也会用来巩固知识点或者当做工具书参考,是两本适合放在自己身边的好书。
|
||||
- **[《Java 编程思想 (第 4 版)》](https://book.douban.com/subject/2130190/)**(推荐,豆瓣评分 9.1,3.2K+人评价):大部分人称之为Java领域的圣经,但我不推荐初学者阅读,有点劝退的味道。稍微有点基础后阅读更好。
|
||||
- **[《JAVA 网络编程 第 4 版》](https://book.douban.com/subject/26259017/)**: 可以系统的学习一下网络的一些概念以及网络编程在 Java 中的使用。
|
||||
- **[《Java性能权威指南》](https://book.douban.com/subject/26740520/)**:O'Reilly 家族书,性能调优的入门书,我个人觉得性能调优是每个 Java 从业者必备知识,这本书的缺点就是太老了,但是这本书可以作为一个实战书,尤其是 JVM 调优!不适合初学者。前置书籍:《深入理解 Java 虚拟机》
|
||||
|
||||
### 并发
|
||||
|
||||
- **[《Java 并发编程之美》](<https://book.douban.com/subject/30351286/>)** :**我觉得这本书还是非常适合我们用来学习 Java 多线程的。这本书的讲解非常通俗易懂,作者从并发编程基础到实战都是信手拈来。** 另外,这本书的作者加多自身也会经常在网上发布各种技术文章。我觉得这本书也是加多大佬这么多年在多线程领域的沉淀所得的结果吧!他书中的内容基本都是结合代码讲解,非常有说服力!
|
||||
- **[《实战 Java 高并发程序设计》](https://book.douban.com/subject/26663605/)**: 这个是我第二本要推荐的书籍,比较适合作为多线程入门/进阶书籍来看。这本书内容同样是理论结合实战,对于每个知识点的讲解也比较通俗易懂,整体结构也比较清。
|
||||
- **[《深入浅出 Java 多线程》](https://github.com/RedSpider1/concurrent)**:这本书是几位大厂(如阿里)的大佬开源的,Github 地址:[https://github.com/RedSpider1/concurrent](https://github.com/RedSpider1/concurrent)几位作者为了写好《深入浅出 Java 多线程》这本书阅读了大量的 Java 多线程方面的书籍和博客,然后再加上他们的经验总结、Demo 实例、源码解析,最终才形成了这本书。这本书的质量也是非常过硬!给作者们点个赞!这本书有统一的排版规则和语言风格、清晰的表达方式和逻辑。并且每篇文章初稿写完后,作者们就会互相审校,合并到主分支时所有成员会再次审校,最后再通篇修订了三遍。
|
||||
- **《Java 并发编程的艺术》** :这本书不是很适合作为 Java 多线程入门书籍,需要具备一定的 JVM 基础,有些东西讲的还是挺深入的。另外,就我自己阅读这本书的感觉来说,我觉得这本书的章节规划有点杂乱,但是,具体到某个知识点又很棒!这可能也和这本书由三名作者共同编写完成有关系吧!
|
||||
- ......
|
||||
|
||||
### JVM
|
||||
|
||||
- **[《深入理解 Java 虚拟机(第 3 版)》](https://book.douban.com/subject/24722612/))**:必读!必读!必读!神书,建议多刷几篇。里面不光有丰富地JVM理论知识,还有JVM实战案例!必读!
|
||||
- **[《实战 JAVA 虚拟机》](https://book.douban.com/subject/26354292/)**:作为入门的了解 Java 虚拟机的知识还是不错的。
|
||||
|
||||
### Java8 新特性
|
||||
|
||||
- **[《Java 8 实战》](https://book.douban.com/subject/26772632/)**:面向 Java 8 的技能升级,包括 Lambdas、流和函数式编程特性。实战系列的一贯风格让自己快速上手应用起来。Java 8 支持的 Lambda 是精简表达在语法上提供的支持。Java 8 提供了 Stream,学习和使用可以建立流式编程的认知。
|
||||
- **[《Java 8 编程参考官方教程》](https://book.douban.com/subject/26556574/)**:建议当做工具书来用!哪里不会翻哪里!
|
||||
|
||||
### 代码优化
|
||||
|
||||
- **[《重构_改善既有代码的设计》](https://book.douban.com/subject/4262627/)**:豆瓣 9.1 分,重构书籍的开山鼻祖。
|
||||
- **[《Effective java 》](https://book.douban.com/subject/3360807/)**:本书介绍了在 Java 编程中很多极具实用价值的经验规则,这些经验规则涵盖了大多数开发人员每天所面临的问题的解决方案。这篇文章能够非常实际地帮助你写出更加清晰、健壮和高效的代码。本书中的每条规则都以简短、独立的小文章形式出现,并通过例子代码加以进一步说明。
|
||||
- **[《代码整洁之道》](https://book.douban.com/subject/5442024/)**:虽然是用 Java 语言作为例子,全篇都是在阐述 Java 面向对象的思想,但是其中大部分内容其它语言也能应用到。
|
||||
- **阿里巴巴 Java 开发手册** :[https://github.com/alibaba/p3c](https://github.com/alibaba/p3c)
|
||||
- **Google Java 编程风格指南:** <http://www.hawstein.com/posts/google-java-style.html>
|
||||
|
||||
### 面试
|
||||
|
||||
1. **[《JavaGuide面试突击版》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486324&idx=1&sn=e8b690ddaedabc486bd399310105aad3&chksm=cea244bff9d5cda9a627fa65235be09e7b089e92cf49c0eb0ceb35b39bbed86c1fab0125f5af&token=1745528586&lang=zh_CN&scene=21#wechat_redirect)** :我的75k+ star的开源项目 [JavaGuide ](https://github.com/Snailclimb/JavaGuide) 转为面试浓缩而成的版本,不光提供了PDF版本(我的公众号JavaGuide后台回复:“面试突击”即可获取),在线阅读版本:[https://snailclimb.gitee.io/javaguide-interview/](https://snailclimb.gitee.io/javaguide-interview/)。
|
||||
2. **[《Offer来了:Java面试核心知识点精讲》](https://book.douban.com/subject/34872163/)** : 这本书基本概括了Java程序员面试必备知识点,可以拿来准备Java面试或者夯实基础。不过,我还是更推荐我的 [JavaGuide](https://github.com/Snailclimb/JavaGuide) 和 **[《JavaGuide面试突击版》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486324&idx=1&sn=e8b690ddaedabc486bd399310105aad3&chksm=cea244bff9d5cda9a627fa65235be09e7b089e92cf49c0eb0ceb35b39bbed86c1fab0125f5af&token=1745528586&lang=zh_CN&scene=21#wechat_redirect)** ,两者配合起来学习,真香!
|
||||
|
||||
## 网络
|
||||
|
||||
- **[《图解 HTTP》](https://book.douban.com/subject/25863515/)**: 讲漫画一样的讲 HTTP,很有意思,不会觉得枯燥,大概也涵盖也 HTTP 常见的知识点。因为篇幅问题,内容可能不太全面。不过,如果不是专门做网络方向研究的小伙伴想研究 HTTP 相关知识的话,读这本书的话应该来说就差不多了。
|
||||
- **[《HTTP 权威指南》](https://book.douban.com/subject/10746113/)**:如果要全面了解 HTTP 非此书不可!
|
||||
|
||||
## 操作系统
|
||||
|
||||
- **[《鸟哥的 Linux 私房菜》](https://book.douban.com/subject/4889838/)**:本书是最具知名度的 Linux 入门书《鸟哥的 Linux 私房菜基础学习篇》的最新版,全面而详细地介绍了 Linux 操作系统。
|
||||
|
||||
## 数据结构
|
||||
|
||||
- **[《大话数据结构》](https://book.douban.com/subject/6424904/)**:入门类型的书籍,读起来比较浅显易懂,适合没有数据结构基础或者说数据结构没学好的小伙伴用来入门数据结构。
|
||||
|
||||
## 算法
|
||||
|
||||
### 入门
|
||||
|
||||
- **[《我的第一本算法书》](https://book.douban.com/subject/30357170/) (豆瓣评分 7.1,0.2K+人评价)** 一本不那么“专业”的算法书籍。和下面两本推荐的算法书籍都是比较通俗易懂,“不那么深入”的算法书籍。我个人非常推荐,配图和讲解都非常不错!
|
||||
- **[《算法图解》](https://book.douban.com/subject/26979890/)(豆瓣评分 8.4,1.5K+人评价)** :入门类型的书籍,读起来比较浅显易懂,非常适合没有算法基础或者说算法没学好的小伙伴用来入门。示例丰富,图文并茂,以让人容易理解的方式阐释了算法.读起来比较快,内容不枯燥!
|
||||
- **[《啊哈!算法》](https://book.douban.com/subject/25894685/) (豆瓣评分 7.7,0.5K+人评价)** :和《算法图解》类似的算法趣味入门书籍。
|
||||
|
||||
### 经典
|
||||
|
||||
> 下面这些书籍都是经典中的经典,但是阅读起来难度也比较大,不做太多阐述,神书就完事了!推荐先看 《算法》,然后再选下面的书籍进行进一步阅读。不需要都看,找一本好好看或者找某本书的某一个章节知识点好好看。
|
||||
|
||||
- **[《算法 第四版》](https://book.douban.com/subject/10432347/)(豆瓣评分 9.3,0.4K+人评价):** 我在大二的时候被我们的一个老师强烈安利过!自己也在当时购买了一本放在宿舍,到离开大学的时候自己大概看了一半多一点。因为内容实在太多了!另外,这本书还提供了详细的Java代码,非常适合学习 Java 的朋友来看,可以说是 Java 程序员的必备书籍之一了。再来介绍一下这本书籍吧!这本书籍算的上是算法领域经典的参考书,全面介绍了关于算法和数据结构的必备知识,并特别针对排序、搜索、图处理和字符串处理进行了论述。
|
||||
- **[编程珠玑](https://book.douban.com/subject/3227098/)(豆瓣评分 9.1,2K+人评价)** :经典名著,被无数读者强烈推荐的书籍,几乎是顶级程序员必看的书籍之一了。这本书的作者也非常厉害,Java之父 James Gosling 就是他的学生。很多人都说这本书不是教你具体的算法,而是教你一种编程的思考方式。这种思考方式不仅仅在编程领域适用,在其他同样适用。
|
||||
- **[《算法设计手册》](https://book.douban.com/subject/4048566/)(豆瓣评分9.1 , 45人评价)** :被 [Teach Yourself Computer Science](https://teachyourselfcs.com/) 强烈推荐的一本算法书籍。
|
||||
- **[《算法导论》](https://book.douban.com/subject/20432061/) (豆瓣评分 9.2,0.4K+人评价)**
|
||||
- **[《计算机程序设计艺术(第1卷)》](https://book.douban.com/subject/1130500/)(豆瓣评分 9.4,0.4K+人评价)**
|
||||
|
||||
### 面试
|
||||
|
||||
1. **[《剑指Offer》](https://book.douban.com/subject/6966465/)(豆瓣评分 8.3,0.7K+人评价)**这本面试宝典上面涵盖了很多经典的算法面试题,如果你要准备大厂面试的话一定不要错过这本书。《剑指Offer》 对应的算法编程题部分的开源项目解析:[CodingInterviews](https://github.com/gatieme/CodingInterviews)
|
||||
2. **[程序员代码面试指南:IT名企算法与数据结构题目最优解(第2版)](https://book.douban.com/subject/30422021/) (豆瓣评分 8.7,0.2K+人评价)** :题目相比于《剑指 offer》 来说要难很多,题目涵盖面相比于《剑指 offer》也更加全面。全书一共有将近300道真实出现过的经典代码面试题。
|
||||
3. **[编程之美](https://book.douban.com/subject/3004255/)(豆瓣评分 8.4,3K+人评价)**:这本书收集了约60道算法和程序设计题目,这些题目大部分在近年的笔试、面试中出现过,或者是被微软员工热烈讨论过。作者试图从书中各种有趣的问题出发,引导读者发现问题,分析问题,解决问题,寻找更优的解法。
|
||||
|
||||
## 数据库
|
||||
|
||||
**MySQL:**
|
||||
|
||||
- **[《高性能 MySQL》](https://book.douban.com/subject/23008813/)**:这本书不用多说了把!MySQL 领域的经典之作,拥有广泛的影响力。不但适合数据库管理员(dba)阅读,也适合开发人员参考学习。不管是数据库新手还是专家,相信都能从本书有所收获。如果你的时间不够的话,第5章关于索引的内容和第6章关于查询的内容是必读的!
|
||||
- [《MySQL 技术内幕-InnoDB 存储引擎》](<https://book.douban.com/subject/24708143/>)(推荐,豆瓣评分 8.7):了解 InnoDB 存储引擎底层原理必备的一本书,比较深入。
|
||||
|
||||
**Redis:**
|
||||
|
||||
- **[《Redis 实战》](https://book.douban.com/subject/26612779/)**:如果你想了解 Redis 的一些概念性知识的话,这本书真的非常不错。
|
||||
- **[《Redis 设计与实现》](https://book.douban.com/subject/25900156/)**:也还行吧!
|
||||
|
||||
## 系统设计
|
||||
|
||||
### 设计模式
|
||||
|
||||
- **[《设计模式 : 可复用面向对象软件的基础》](https://book.douban.com/subject/1052241/)** :设计模式的经典!
|
||||
- **[《Head First 设计模式(中文版)》](https://book.douban.com/subject/2243615/)** :相当赞的一本设计模式入门书籍。用实际的编程案例讲解算法设计中会遇到的各种问题和需求变更(对的,连需求变更都考虑到了!),并以此逐步推导出良好的设计模式解决办法。
|
||||
- **[《大话设计模式》](https://book.douban.com/subject/2334288/)** :本书通篇都是以情景对话的形式,用多个小故事或编程示例来组织讲解GOF(即《设计模式 : 可复用面向对象软件的基础》这本书)),但是不像《设计模式 : 可复用面向对象软件的基础》难懂。但是设计模式只看书是不够的,还是需要在实际项目中运用,在实战中体会。
|
||||
|
||||
### 常用框架
|
||||
|
||||
#### Spring/SpringBoot
|
||||
|
||||
- **[《Spring 实战(第 4 版)》](https://book.douban.com/subject/26767354/)** :不建议当做入门书籍读,入门的话可以找点国人的书或者视频看。这本定位就相当于是关于 Spring 的新华字典,只有一些基本概念的介绍和示例,涵盖了 Spring 的各个方面,但都不够深入。就像作者在最后一页写的那样:“学习 Spring,这才刚刚开始”。
|
||||
- **《[Spring源码深度解析 第2版](https://book.douban.com/subject/30452948/)》** :读Spring源码必备的一本书籍。市面上关于Spring源码分析的书籍太少了。
|
||||
- **[《Spring 5高级编程(第5版)》](https://book.douban.com/subject/30452637/)** :推荐阅读,对于Spring5的新特性介绍的很好!不过内容比较多,可以作为工具书参考。
|
||||
- **[《精通Spring4.x企业应用开发实战》](https://read.douban.com/ebook/58113975/?dcs=subject-rec&dcm=douban&dct=26767354)** :通过实战讲解,比较适合作为Spring入门书籍来看。
|
||||
- **[《Spring入门经典》](https://book.douban.com/subject/26652876/)** :适合入门,也有很多示例!
|
||||
- **[《Spring Boot实战派》](https://book.douban.com/subject/34894533/)** :这本书使用的Spring Boot 2.0+的版本,还算比较新。整本书采用“知识点+实例”的形式编写。本书通过“58个基于知识的实例+2个综合性的项目”,深入地讲解Spring Boot的技术原理、知识点和具体应用;把晦涩难懂的理论用实例展现出来,使得读者对知识的理解变得非常容易,同时也立即学会如何使用它。说实话,我还是比较推荐这本书的。
|
||||
- **[《Spring Boot编程思想(核心篇)》](https://book.douban.com/subject/33390560/)** :SpringBoot深入书,不适合初学者。书尤其的厚,这本书的缺点是书的很多知识点的讲解过于啰嗦和拖沓,优点是书中对SpringBoot内部原理讲解很清楚。
|
||||
|
||||
#### Netty
|
||||
|
||||
- **[《Netty进阶之路:跟着案例学Netty》](https://book.douban.com/subject/30381214/)** : 这本书的优点是有不少实际的案例的讲解,通过案例来学习是很不错的!
|
||||
- **[《Netty 4.x 用户指南》](https://waylau.gitbooks.io/netty-4-user-guide/content/)** :《Netty 4.x 用户指南》中文翻译(包含了官方文档以及其他文章)。
|
||||
- **[《Netty 入门与实战:仿写微信 IM 即时通讯系统》](https://juejin.im/book/5b4bc28bf265da0f60130116?referrer=59fbb2daf265da4319559f3a)** :基于 Netty 框架实现 IM 核心系统,带你深入学习 Netty 网络编程核心知识
|
||||
- **[《Netty 实战》](https://book.douban.com/subject/27038538/)** :可以作为工具书参考!
|
||||
|
||||
### 分布式
|
||||
|
||||
- **[《从 Paxos 到 Zookeeper》](https://book.douban.com/subject/26292004/)**:简要介绍几种典型的分布式一致性协议,以及解决分布式一致性问题的思路,其中重点讲解了 Paxos 和 ZAB 协议。同时,本书深入介绍了分布式一致性问题的工业解决方案——ZooKeeper,并着重向读者展示这一分布式协调框架的使用方法、内部实现及运维技巧,旨在帮助读者全面了解 ZooKeeper,并更好地使用和运维 ZooKeeper。
|
||||
- **[《RabbitMQ 实战指南》](https://book.douban.com/subject/27591386/)**:《RabbitMQ 实战指南》从消息中间件的概念和 RabbitMQ 的历史切入,主要阐述 RabbitMQ 的安装、使用、配置、管理、运维、原理、扩展等方面的细节。如果你想浅尝 RabbitMQ 的使用,这本书是你最好的选择;如果你想深入 RabbitMQ 的原理,这本书也是你最好的选择;总之,如果你想玩转 RabbitMQ,这本书一定是最值得看的书之一
|
||||
- **[《Spring Cloud 微服务实战》](https://book.douban.com/subject/27025912/)**:从时下流行的微服务架构概念出发,详细介绍了 Spring Cloud 针对微服务架构中几大核心要素的解决方案和基础组件。对于各个组件的介绍,《Spring Cloud 微服务实战》主要以示例与源码结合的方式来帮助读者更好地理解这些组件的使用方法以及运行原理。同时,在介绍的过程中,还包含了作者在实践中所遇到的一些问题和解决思路,可供读者在实践中作为参考。
|
||||
|
||||
### 网站架构
|
||||
|
||||
- **[《大型网站技术架构:核心原理与案例分析+李智慧》](https://book.douban.com/subject/25723064/)**:这本书我读过,基本不需要你有什么基础啊~读起来特别轻松,但是却可以学到很多东西,非常推荐了。另外我写过这本书的思维导图,关注我的微信公众号:“Java 面试通关手册”回复“大型网站技术架构”即可领取思维导图。
|
||||
- **[《亿级流量网站架构核心技术》](https://book.douban.com/subject/26999243/)**:一书总结并梳理了亿级流量网站高可用和高并发原则,通过实例详细介绍了如何落地这些原则。本书分为四部分:概述、高可用原则、高并发原则、案例实战。从负载均衡、限流、降级、隔离、超时与重试、回滚机制、压测与预案、缓存、池化、异步化、扩容、队列等多方面详细介绍了亿级流量网站的架构核心技术,让读者看后能快速运用到实践项目中。
|
||||
- **[《从零开始学架构(李运华)》](https://book.douban.com/subject/30335935/)** : 这本书对应的有一个极客时间的专栏—《从零开始学架构》,里面的很多内容都是这个专栏里面的,两者买其一就可以了。我看了很小一部分,内容挺全面的,是一本真正在讲如何做架构的书籍。
|
||||
- **[《架构修炼之道——亿级网关、平台开放、分布式、微服务、容错等核心技术修炼实践》](https://book.douban.com/subject/33389549/)** :非常喜欢的一本书,对一些知识点比如消息队列、API网管讲解的很好,通俗易懂。
|
||||
|
||||
### 底层
|
||||
|
||||
- **[《深入剖析 Tomcat》](https://book.douban.com/subject/10426640/)**:本书深入剖析 Tomcat 4 和 Tomcat 5 中的每个组件,并揭示其内部工作原理。通过学习本书,你将可以自行开发 Tomcat 组件,或者扩展已有的组件。 读完这本书,基本可以摆脱背诵面试题的尴尬。
|
||||
- **[《深入理解 Nginx(第 2 版)》](https://book.douban.com/subject/26745255/)**:作者讲的非常细致,注释都写的都很工整,对于 Nginx 的开发人员非常有帮助。优点是细致,缺点是过于细致,到处都是代码片段,缺少一些抽象。
|
||||
|
||||
## 软件设计之道
|
||||
|
||||
- **[《人月神话》](https://book.douban.com/subject/1102259/)** : 非常值得阅读的一本书籍。看书名感觉的第一眼感觉不像是技术类的书籍。这本书对于现代软件尤其是复杂软件的开发的规范化有深刻的意义。
|
||||
- **《领域驱动设计:软件核心复杂性应对之道》** : 这本领域驱动设计方面的经典之作一直被各种推荐,但是我还来及读。
|
||||
|
||||
## 其他
|
||||
|
||||
- **[《黑客与画家》](https://read.douban.com/ebook/387525/?dcs=subject-rec&dcm=douban&dct=2243615)**:这本书是硅谷创业之父,Y Combinator 创始人 Paul Graham 的文集。之所以叫这个名字,是因为作者认为黑客(并非负面的那个意思)与画家有着极大的相似性,他们都是在创造,而不是完成某个任务。
|
||||
|
||||
- **[《图解密码技术》](https://book.douban.com/subject/26265544/)**:本书以**图配文**的形式,第一部分讲述了密码技术的历史沿革、对称密码、分组密码模式(包括ECB、CBC、CFB、OFB、CTR)、公钥、混合密码系统。第二部分重点介绍了认证方面的内容,涉及单向散列函数、消息认证码、数字签名、证书等。第三部分讲述了密钥、随机数、PGP、SSL/TLS 以及密码技术在现实生活中的应用。关键字:JWT 前置知识、区块链密码技术前置知识。属于密码知识入门书籍。、
|
||||
- 《程序开发心理学》 、《程序员修炼之道,从小工道专家》、 《高效程序员的45个习惯,敏捷开发修炼之道》 、《高效能程序员的修炼》 、《软技能,代码之外的生存之道》 、《程序员的职业素养》 、《程序员的思维修炼》
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
246
docs/books/java基础篇.md
Normal file
@ -0,0 +1,246 @@
|
||||
|
||||
|
||||
这篇文章推荐了大部分我所读过的优秀书籍,虽然部分可能没看完。答应我,一定要看到最后,看完之后应该不会再纠结要看什么书了。走起!!!
|
||||
|
||||
*这篇文章未涵盖计算机基础比如算法和数据结构、数据库、分布式、微服务方面的书籍,这个留在下一篇文章推荐。*
|
||||
|
||||
## Java
|
||||
|
||||
### 基础
|
||||
|
||||
#### 《Head First Java》
|
||||
|
||||

|
||||
|
||||
*Guide的 Java 启蒙书籍了。因为是我学习Java看的第一本书,所以,我对其有不一样的情感。*
|
||||
|
||||
*ps:我是当时学完了 C语言之后才开始学习 Java 的,刚开始看这本书感觉很轻松有趣,可以说是我学习编程初期最喜欢的一本书了。*
|
||||
|
||||
有些人说这本书不适合编程新手阅读?(问号脸) 我个人觉得还是很适合稍微有一点点经验的新手来阅读的,当然也适合我们用来温故 Java 知识点。
|
||||
|
||||
> ps:刚入门编程,最好的方式还是通过看视频来学习。
|
||||
|
||||
#### 《Java 核心技术卷 1+卷 2》
|
||||
|
||||

|
||||
|
||||
*Guide拿来当做工具书的两本Java领域的好书!我当时在大学的时候就买了两本放在寝室,没事的时候就翻翻。*
|
||||
|
||||
建议有点 Java 基础之后再读,介绍的还是比较深入和全面的,非常推荐。
|
||||
|
||||
这两本书的内容很多,全看的话比较费时间,我一般也会用来巩固知识点或者当做工具书参考,是两本适合放在自己身边的好书。
|
||||
|
||||
#### 《Java 编程思想 (第 4 版)》
|
||||
|
||||

|
||||
|
||||
*这本书Guide第一次看的时候还觉得有点枯燥,那时候还在上大二,看了 1/3就没看下去了。*
|
||||
|
||||
大部分人称之为Java领域的圣经(*感觉有点过了~~~*),但我不推荐初学者阅读,有点劝退的味道。稍微有点基础后阅读更好。
|
||||
|
||||
这本书到现在我也才看了一半左右,内容确实也比较多,而且稍微有点枯燥,但是比较权威。我一般也是拿来当做工具书参考。
|
||||
|
||||
#### 《Java性能权威指南》
|
||||
|
||||

|
||||
|
||||
*希望能有更多这Java性能优化方面的好书!*
|
||||
|
||||
O'Reilly 家族书,性能调优的入门书,我个人觉得性能调优是每个 Java 从业者必备知识。
|
||||
|
||||
这本书介绍的实战内容很不错,尤其是 JVM 调优,缺点也比较明显,就是内容稍微有点老。市面上这种书很少。这本书不适合初学者,建议对 Java 语言已经比价掌握了再看。另外,阅读之前,最好先看看周志明大佬的《深入理解 Java 虚拟机》。
|
||||
|
||||
### 并发
|
||||
|
||||
#### 《Java 并发编程之美》
|
||||
|
||||

|
||||
|
||||
*这本书还是非常适合我们用来学习 Java 多线程的。这本书的讲解非常通俗易懂,作者从并发编程基础到实战都是信手拈来。*
|
||||
|
||||
另外,这本书的作者加多自身也会经常在网上发布各种技术文章。这本书也是加多大佬这么多年在多线程领域的沉淀所得的结果吧!他书中的内容基本都是结合代码讲解,非常有说服力!
|
||||
|
||||
#### 《实战 Java 高并发程序设计》
|
||||
|
||||

|
||||
|
||||
这个是我第二本要推荐的书籍,比较适合作为多线程入门/进阶书籍来看。这本书内容同样是理论结合实战,对于每个知识点的讲解也比较通俗易懂,整体结构也比较清。
|
||||
|
||||
#### 《深入浅出 Java 多线程》
|
||||
|
||||

|
||||
|
||||
这本书是几位大厂(如阿里)的大佬开源的,Github 地址:[https://github.com/RedSpider1/concurrent](https://github.com/RedSpider1/concurrent)
|
||||
|
||||
几位作者为了写好《深入浅出 Java 多线程》这本书阅读了大量的 Java 多线程方面的书籍和博客,然后再加上他们的经验总结、Demo 实例、源码解析,最终才形成了这本书。
|
||||
|
||||
这本书的质量也是非常过硬!给作者们点个赞!这本书有统一的排版规则和语言风格、清晰的表达方式和逻辑。并且每篇文章初稿写完后,作者们就会互相审校,合并到主分支时所有成员会再次审校,最后再通篇修订了三遍。
|
||||
|
||||
### JVM
|
||||
|
||||
JVM 这里就先只推荐一本书籍和一个关于 JVM 参数调优的免费教程(你假笨大佬将的)。
|
||||
|
||||
#### 《深入理解Java虚拟机(第3版)》
|
||||
|
||||

|
||||
|
||||
*希望国内能有更多这样的优质书籍出现!加油!💪*
|
||||
|
||||
这本书就一句话形容:**国产书籍中的战斗机,实实在在的优秀!**
|
||||
|
||||
这本书的第三版去年年底已经出来了,新增了很多实在的内容比如ZGC等新一代GC的原理剖析。目前豆瓣上是 9.6 的高分,🐂不🐂我就不多说了!
|
||||
|
||||
不论是你面试还是你想要在 Java 领域学习的更深,你都离不开这本书籍。这本书不光要看,你还要多看几遍,都是干货,里面很多实战内容自己还最好实践一篇。
|
||||
|
||||
这里额外推荐一个你假笨大佬的[《JVM 参数【Memory篇】》](https://club.perfma.com/course/438755/list)教程,很厉害了!
|
||||
|
||||

|
||||
|
||||
### 面试
|
||||
|
||||
#### 《JavaGuide面试突击版》
|
||||
|
||||

|
||||
|
||||
*谁看谁说好!哈哈!*
|
||||
|
||||
Guide自己开源的,涵盖了Java后端方面的大部分知识点比如 集合、JVM、多线程还有数据库MySQL等内容。
|
||||
|
||||
在我的公众号后台回复 :“**面试突击**”即可免费获取。
|
||||
|
||||

|
||||
|
||||
### Java 8
|
||||
|
||||
#### 《Java 8实战》
|
||||
|
||||

|
||||
|
||||
*还没用上 Java 8 的可以反思一下了,还没用过 Lambda 也可以反思一下了。*
|
||||
|
||||
现在大部分公司至少都用到了 Java 8 , Java 8算是一个里程碑式的版本,提供了很多有用的新特性比如 Lambda、流式处理等等。
|
||||
|
||||
这本书是学习 Java 8 新特性很好的选择,它内容包括 Lambda、流和函数式编程等Java8新特性。实战系列的一贯风格让自己快速上手应用起来。
|
||||
|
||||
## 软件质量
|
||||
|
||||
### 代码质量
|
||||
|
||||
#### 《重构_改善既有代码的设计》
|
||||
|
||||

|
||||
|
||||
*程序员必看!*
|
||||
|
||||
世界顶级、国宝级别的 Martin Fowler 的书籍,可以说是软件开发领域最经典的基本书之一。目前已经出了第二版,我也在不久前买了第二版。
|
||||
|
||||
这本书我觉是每一个程序员都必须要看,并且需要看很多次的!
|
||||
|
||||
#### 《Effective java 》
|
||||
|
||||

|
||||
|
||||
*程序员必看!*
|
||||
|
||||
又是一本 Java 领域国宝级别的书,非常经典。这本书主要介绍了在 Java 编程中很多极具实用价值的经验规则,这些经验规则涵盖了大多数开发人员每天所面临的问题的解决方案。这篇文章能够非常实际地帮助你写出更加清晰、健壮和高效的代码。本书中的每条规则都以简短、独立的小文章形式出现,并通过例子代码加以进一步说明。
|
||||
|
||||
#### 《代码整洁之道》
|
||||
|
||||

|
||||
|
||||
*程序员必看!*
|
||||
|
||||
每个程序员都必须要看看的一本书籍,书中很多实际可体会的例子,可以教你写出更优质代码。
|
||||
|
||||
最后再推荐两个相关的文档:
|
||||
|
||||
- **阿里巴巴 Java 开发手册** :[https://github.com/alibaba/p3c](https://github.com/alibaba/p3c)
|
||||
- **Google Java 编程风格指南:** <http://www.hawstein.com/posts/google-java-style.html>
|
||||
|
||||
### 软件设计之道
|
||||
|
||||
#### 《人月神话》
|
||||
|
||||

|
||||
|
||||
*主要描述了软件开发的基本定律:一个需要10天才能干完的活,不可能让10个人在1天干完!*
|
||||
|
||||
非常值得阅读的一本书籍。看书名感觉的第一眼感觉不像是技术类的书籍。这本书对于现代软件尤其是复杂软件的开发的规范化有深刻的意义。
|
||||
|
||||
#### 《领域驱动设计:软件核心复杂性应对之道》
|
||||
|
||||

|
||||
|
||||
这本领域驱动设计方面的经典之作一直被各种推荐,但是我还来及读。
|
||||
|
||||
## 常用框架
|
||||
|
||||
### Spring/SpringBoot
|
||||
|
||||
#### 《Spring 实战(第 5 版)》
|
||||
|
||||

|
||||
|
||||
*比较一般!*
|
||||
|
||||
不建议当做入门书籍读,入门的话可以找点国人的书或者视频看。这本定位就相当于是关于 Spring 的一个概览,只有一些基本概念的介绍和示例,涵盖了 Spring 的各个方面,但都不够深入。就像作者在最后一页写的那样:“学习 Spring,这才刚刚开始”。
|
||||
|
||||
#### 《Spring 5高级编程(第5版)》
|
||||
|
||||

|
||||
|
||||
*工具人!*
|
||||
|
||||
对于Spring5的新特性介绍的比较详细,也说不上好。另外,感觉全书翻译的有一点蹩脚的味道,还有一点枯燥。全书的内容比较多,我一般拿来当做工具书参考。
|
||||
|
||||
#### 《Spring Boot编程思想(核心篇)》
|
||||
|
||||

|
||||
|
||||
*稍微有点啰嗦,但是原理介绍的比较清楚。*
|
||||
|
||||
SpringBoot 解析,不适合初学者。我是去年入手的,现在就看了几章,后面没看下去。书很厚,感觉很多很多知识点的讲解过于啰嗦和拖沓,不过,这本书对于SpringBoot内部原理讲解的还是很清楚。
|
||||
|
||||
#### 《Spring Boot实战》
|
||||
|
||||

|
||||
|
||||
比较一般的一本书,可以简单拿来看一下。
|
||||
|
||||
#### 《Spring Boot实战派》
|
||||
|
||||

|
||||
|
||||
这本书使用的Spring Boot 2.0+的版本,还算比较新。整本书采用“知识点+实例”的形式编写。
|
||||
|
||||
另外,这本书的干货很多,作者在注意实战的过程中还不忘记对于一些重要的基础知识的讲解。
|
||||
|
||||
如果你要学习 Spring Boot 的话,我还是比较推荐这本书的。
|
||||
|
||||
### Netty
|
||||
|
||||
#### 《Netty实战》
|
||||
|
||||

|
||||
|
||||
*Guide学习Netty看的就是这本书籍,RPC框架乞丐版 Guide已经写完,Netty系列也在路上了!*
|
||||
|
||||
这本书可以用来入门 Netty ,内容从BIO聊到了 NIO、之后才详细介绍为什么有 Netty 、Netty 为什么好用以及Netty重要的知识点讲解。
|
||||
|
||||
这本书基本把 Netty 一些重要的知识点都介绍到了,而且基本都是通过实战的形式讲解。
|
||||
|
||||
#### 《Netty进阶之路:跟着案例学Netty》
|
||||
|
||||

|
||||
|
||||
*深入Netty必看!*
|
||||
|
||||
内容都是关于使用 Netty 的实践案例比如内存泄露这些东西。如果你觉得你的 Netty 已经完全入门了,并且你想要对Netty掌握的更深的话,推荐你看一下这本书。
|
||||
|
||||
#### 《Netty 入门与实战:仿写微信 IM 即时通讯系统》
|
||||
|
||||

|
||||
|
||||
*质量很高的一个小册!*
|
||||
|
||||
通过一个基于 Netty 框架实现 IM 核心系统为引子,带你学习Netty。整个小册的质量还是很高的,即使你没有 Netty 使用经验也能看懂。
|
||||
@ -1,119 +0,0 @@
|
||||
|
||||
<!-- TOC -->
|
||||
|
||||
- [Java](#java)
|
||||
- [基础](#基础)
|
||||
- [并发](#并发)
|
||||
- [JVM](#jvm)
|
||||
- [Java8 新特性](#java8-新特性)
|
||||
- [代码优化](#代码优化)
|
||||
- [网络](#网络)
|
||||
- [操作系统](#操作系统)
|
||||
- [数据结构与算法](#数据结构与算法)
|
||||
- [数据库](#数据库)
|
||||
- [系统设计](#系统设计)
|
||||
- [设计模式](#设计模式)
|
||||
- [常用框架](#常用框架)
|
||||
- [网站架构](#网站架构)
|
||||
- [软件底层](#软件底层)
|
||||
- [其他](#其他)
|
||||
|
||||
<!-- /TOC -->
|
||||
## Java
|
||||
|
||||
### 基础
|
||||
|
||||
- [《Head First Java》](https://book.douban.com/subject/2000732/)(推荐,豆瓣评分 8.7,1.0K+人评价): 可以说是我的 Java 启蒙书籍了,特别适合新手读当然也适合我们用来温故 Java 知识点。
|
||||
- [《Java 核心技术卷 1+卷 2》](https://book.douban.com/subject/25762168/)(推荐): 很棒的两本书,建议有点 Java 基础之后再读,介绍的还是比较深入的,非常推荐。这两本书我一般也会用来巩固知识点,是两本适合放在自己身边的好书。
|
||||
- [《JAVA 网络编程 第 4 版》](https://book.douban.com/subject/26259017/): 可以系统的学习一下网络的一些概念以及网络编程在 Java 中的使用。
|
||||
- [《Java 编程思想 (第 4 版)》](https://book.douban.com/subject/2130190/)(推荐,豆瓣评分 9.1,3.2K+人评价):大部分人称之为Java领域的圣经,但我不推荐初学者阅读,有点劝退的味道。稍微有点基础后阅读更好。
|
||||
- [《Java性能权威指南》](https://book.douban.com/subject/26740520/)(推荐,豆瓣评分 8.2,0.1K+人评价):O'Reilly 家族书,性能调优的入门书,我个人觉得性能调优是每个 Java 从业者必备知识,这本书的缺点就是太老了,但是这本书可以作为一个实战书,尤其是 JVM 调优!不适合初学者。前置书籍:《深入理解 Java 虚拟机》
|
||||
|
||||
### 并发
|
||||
|
||||
- [《Java 并发编程之美》](<https://book.douban.com/subject/30351286/>) (推荐):2018 年 10 月出版的一本书,个人感觉非常不错,对每个知识点的讲解都很棒。
|
||||
- [《Java 并发编程的艺术》](https://book.douban.com/subject/26591326/)(推荐,豆瓣评分 7.2,0.2K+人评价): 这本书不是很适合作为 Java 并发入门书籍,需要具备一定的 JVM 基础。我感觉有些东西讲的还是挺深入的,推荐阅读。
|
||||
- [《实战 Java 高并发程序设计》](https://book.douban.com/subject/26663605/)(推荐,豆瓣评分 8.3): 书的质量没的说,推荐大家好好看一下。
|
||||
- [《Java 高并发编程详解》](https://book.douban.com/subject/30255689/)(豆瓣评分 7.6): 2018 年 6 月出版的一本书,内容很详细,但可能又有点过于啰嗦,不过这只是我的感觉。
|
||||
|
||||
### JVM
|
||||
|
||||
- [《深入理解 Java 虚拟机(第 2 版)周志明》](https://book.douban.com/subject/24722612/)(推荐,豆瓣评分 8.9,1.0K+人评价):建议多刷几遍,书中的所有知识点可以通过 JAVA 运行时区域和 JAVA 的内存模型与线程两个大模块罗列完全。
|
||||
- [《实战 JAVA 虚拟机》](https://book.douban.com/subject/26354292/)(推荐,豆瓣评分 8.0,1.0K+人评价):作为入门的了解 Java 虚拟机的知识还是不错的。
|
||||
|
||||
### Java8 新特性
|
||||
|
||||
- [《Java 8 实战》](https://book.douban.com/subject/26772632/) (推荐,豆瓣评分 9.2 ):面向 Java 8 的技能升级,包括 Lambdas、流和函数式编程特性。实战系列的一贯风格让自己快速上手应用起来。Java 8 支持的 Lambda 是精简表达在语法上提供的支持。Java 8 提供了 Stream,学习和使用可以建立流式编程的认知。
|
||||
- [《Java 8 编程参考官方教程》](https://book.douban.com/subject/26556574/) (推荐,豆瓣评分 9.2):也还不错吧。
|
||||
|
||||
### 代码优化
|
||||
|
||||
- [《重构_改善既有代码的设计》](https://book.douban.com/subject/4262627/)(推荐):豆瓣 9.1 分,重构书籍的开山鼻祖。
|
||||
- [《Effective java 》](https://book.douban.com/subject/3360807/)(推荐,豆瓣评分 9.0,1.4K+人评价):本书介绍了在 Java 编程中 78 条极具实用价值的经验规则,这些经验规则涵盖了大多数开发人员每天所面临的问题的解决方案。通过对 Java 平台设计专家所使用的技术的全面描述,揭示了应该做什么,不应该做什么才能产生清晰、健壮和高效的代码。本书中的每条规则都以简短、独立的小文章形式出现,并通过例子代码加以进一步说明。本书内容全面,结构清晰,讲解详细。可作为技术人员的参考用书。
|
||||
- [《代码整洁之道》](https://book.douban.com/subject/5442024/)(推荐,豆瓣评分 9.1):虽然是用 Java 语言作为例子,全篇都是在阐述 Java 面向对象的思想,但是其中大部分内容其它语言也能应用到。
|
||||
- **阿里巴巴 Java 开发手册(详尽版)** [https://github.com/alibaba/p3c/blob/master/阿里巴巴 Java 开发手册(详尽版).pdf](https://github.com/alibaba/p3c/blob/master/%E9%98%BF%E9%87%8C%E5%B7%B4%E5%B7%B4Java%E5%BC%80%E5%8F%91%E6%89%8B%E5%86%8C%EF%BC%88%E8%AF%A6%E5%B0%BD%E7%89%88%EF%BC%89.pdf)
|
||||
- **Google Java 编程风格指南:** <http://www.hawstein.com/posts/google-java-style.html>
|
||||
|
||||
|
||||
## 网络
|
||||
|
||||
- [《图解 HTTP》](https://book.douban.com/subject/25863515/)(推荐,豆瓣评分 8.1 , 1.6K+人评价): 讲漫画一样的讲 HTTP,很有意思,不会觉得枯燥,大概也涵盖也 HTTP 常见的知识点。因为篇幅问题,内容可能不太全面。不过,如果不是专门做网络方向研究的小伙伴想研究 HTTP 相关知识的话,读这本书的话应该来说就差不多了。
|
||||
- [《HTTP 权威指南》](https://book.douban.com/subject/10746113/) (推荐,豆瓣评分 8.6):如果要全面了解 HTTP 非此书不可!
|
||||
|
||||
## 操作系统
|
||||
|
||||
- [《鸟哥的 Linux 私房菜》](https://book.douban.com/subject/4889838/)(推荐,,豆瓣评分 9.1,0.3K+人评价):本书是最具知名度的 Linux 入门书《鸟哥的 Linux 私房菜基础学习篇》的最新版,全面而详细地介绍了 Linux 操作系统。全书分为 5 个部分:第一部分着重说明 Linux 的起源及功能,如何规划和安装 Linux 主机;第二部分介绍 Linux 的文件系统、文件、目录与磁盘的管理;第三部分介绍文字模式接口 shell 和管理系统的好帮手 shell 脚本,另外还介绍了文字编辑器 vi 和 vim 的使用方法;第四部分介绍了对于系统安全非常重要的 Linux 账号的管理,以及主机系统与程序的管理,如查看进程、任务分配和作业管理;第五部分介绍了系统管理员 (root) 的管理事项,如了解系统运行状况、系统服务,针对登录文件进行解析,对系统进行备份以及核心的管理等。
|
||||
|
||||
## 数据结构与算法
|
||||
|
||||
- [《大话数据结构》](https://book.douban.com/subject/6424904/)(推荐,豆瓣评分 7.9 , 1K+人评价):入门类型的书籍,读起来比较浅显易懂,适合没有数据结构基础或者说数据结构没学好的小伙伴用来入门数据结构。
|
||||
- [《数据结构与算法分析:C 语言描述》](https://book.douban.com/subject/1139426/)(推荐,豆瓣评分 8.9,1.6K+人评价):本书是《Data Structures and Algorithm Analysis in C》一书第 2 版的简体中译本。原书曾被评为 20 世纪顶尖的 30 部计算机著作之一,作者 Mark Allen Weiss 在数据结构和算法分析方面卓有建树,他的数据结构和算法分析的著作尤其畅销,并受到广泛好评.已被世界 500 余所大学用作教材。
|
||||
- [《算法图解》](https://book.douban.com/subject/26979890/)(推荐,豆瓣评分 8.4,0.6K+人评价):入门类型的书籍,读起来比较浅显易懂,适合没有算法基础或者说算法没学好的小伙伴用来入门。示例丰富,图文并茂,以让人容易理解的方式阐释了算法.读起来比较快,内容不枯燥!
|
||||
- [《算法 第四版》](https://book.douban.com/subject/10432347/)(推荐,豆瓣评分 9.3,0.4K+人评价):Java 语言描述,算法领域经典的参考书,全面介绍了关于算法和数据结构的必备知识,并特别针对排序、搜索、图处理和字符串处理进行了论述。书的内容非常多,可以说是 Java 程序员的必备书籍之一了。
|
||||
|
||||
## 数据库
|
||||
|
||||
- [《高性能 MySQL》](https://book.douban.com/subject/23008813/)(推荐,豆瓣评分 9.3,0.4K+人评价):mysql 领域的经典之作,拥有广泛的影响力。不但适合数据库管理员(dba)阅读,也适合开发人员参考学习。不管是数据库新手还是专家,相信都能从本书有所收获。
|
||||
- [《Redis 实战》](https://book.douban.com/subject/26612779/):如果你想了解 Redis 的一些概念性知识的话,这本书真的非常不错。
|
||||
- [《Redis 设计与实现》](https://book.douban.com/subject/25900156/)(推荐,豆瓣评分 8.5,0.5K+人评价):也还行吧!
|
||||
- [《MySQL 技术内幕-InnoDB 存储引擎》](<https://book.douban.com/subject/24708143/>)(推荐,豆瓣评分 8.7):了解 InnoDB 存储引擎底层原理必备的一本书,比较深入。
|
||||
|
||||
## 系统设计
|
||||
|
||||
### 设计模式
|
||||
|
||||
- [《设计模式 : 可复用面向对象软件的基础》](https://book.douban.com/subject/1052241/) (推荐,豆瓣评分 9.1):设计模式的经典!
|
||||
- [《Head First 设计模式(中文版)》](https://book.douban.com/subject/2243615/) (推荐,豆瓣评分 9.2):相当赞的一本设计模式入门书籍。用实际的编程案例讲解算法设计中会遇到的各种问题和需求变更(对的,连需求变更都考虑到了!),并以此逐步推导出良好的设计模式解决办法。
|
||||
- [《大话设计模式》](https://book.douban.com/subject/2334288/) (推荐,豆瓣评分 8.3):本书通篇都是以情景对话的形式,用多个小故事或编程示例来组织讲解GOF(即《设计模式 : 可复用面向对象软件的基础》这本书)),但是不像《设计模式 : 可复用面向对象软件的基础》难懂。但是设计模式只看书是不够的,还是需要在实际项目中运用,结合[设计模式](docs/system-design/设计模式.md)更佳!
|
||||
|
||||
### 常用框架
|
||||
|
||||
- [《深入分析 Java Web 技术内幕》](https://book.douban.com/subject/25953851/): 感觉还行,涉及的东西也蛮多。
|
||||
- [《Netty 实战》](https://book.douban.com/subject/27038538/)(推荐,豆瓣评分 7.8,92 人评价):内容很细,如果想学 Netty 的话,推荐阅读这本书!
|
||||
- [《从 Paxos 到 Zookeeper》](https://book.douban.com/subject/26292004/)(推荐,豆瓣评分 7.8,0.3K 人评价):简要介绍几种典型的分布式一致性协议,以及解决分布式一致性问题的思路,其中重点讲解了 Paxos 和 ZAB 协议。同时,本书深入介绍了分布式一致性问题的工业解决方案——ZooKeeper,并着重向读者展示这一分布式协调框架的使用方法、内部实现及运维技巧,旨在帮助读者全面了解 ZooKeeper,并更好地使用和运维 ZooKeeper。
|
||||
- [《Spring 实战(第 4 版)》](https://book.douban.com/subject/26767354/)(推荐,豆瓣评分 8.3,0.3K+人评价):不建议当做入门书籍读,入门的话可以找点国人的书或者视频看。这本定位就相当于是关于 Spring 的新华字典,只有一些基本概念的介绍和示例,涵盖了 Spring 的各个方面,但都不够深入。就像作者在最后一页写的那样:“学习 Spring,这才刚刚开始”。
|
||||
- [《RabbitMQ 实战指南》](https://book.douban.com/subject/27591386/):《RabbitMQ 实战指南》从消息中间件的概念和 RabbitMQ 的历史切入,主要阐述 RabbitMQ 的安装、使用、配置、管理、运维、原理、扩展等方面的细节。如果你想浅尝 RabbitMQ 的使用,这本书是你最好的选择;如果你想深入 RabbitMQ 的原理,这本书也是你最好的选择;总之,如果你想玩转 RabbitMQ,这本书一定是最值得看的书之一
|
||||
- [《Spring Cloud 微服务实战》](https://book.douban.com/subject/27025912/):从时下流行的微服务架构概念出发,详细介绍了 Spring Cloud 针对微服务架构中几大核心要素的解决方案和基础组件。对于各个组件的介绍,《Spring Cloud 微服务实战》主要以示例与源码结合的方式来帮助读者更好地理解这些组件的使用方法以及运行原理。同时,在介绍的过程中,还包含了作者在实践中所遇到的一些问题和解决思路,可供读者在实践中作为参考。
|
||||
- [《第一本 Docker 书》](https://book.douban.com/subject/26780404/):Docker 入门书籍!
|
||||
- [《Spring Boot编程思想(核心篇)》](https://book.douban.com/subject/33390560/)(推荐,豆瓣评分 6.2):SpringBoot深入书,不适合初学者。书尤其的厚,评分低的的理由是书某些知识过于拖沓,评分高的理由是书中对SpringBoot内部原理讲解很清楚。作者小马哥:Apache Dubbo PMC、Spring Cloud Alibaba项目架构师。B站作者地址:https://space.bilibili.com/327910845?from=search&seid=17095917016893398636。
|
||||
|
||||
### 网站架构
|
||||
|
||||
- [《大型网站技术架构:核心原理与案例分析+李智慧》](https://book.douban.com/subject/25723064/)(推荐):这本书我读过,基本不需要你有什么基础啊~读起来特别轻松,但是却可以学到很多东西,非常推荐了。另外我写过这本书的思维导图,关注我的微信公众号:“Java 面试通关手册”回复“大型网站技术架构”即可领取思维导图。
|
||||
- [《亿级流量网站架构核心技术》](https://book.douban.com/subject/26999243/)(推荐):一书总结并梳理了亿级流量网站高可用和高并发原则,通过实例详细介绍了如何落地这些原则。本书分为四部分:概述、高可用原则、高并发原则、案例实战。从负载均衡、限流、降级、隔离、超时与重试、回滚机制、压测与预案、缓存、池化、异步化、扩容、队列等多方面详细介绍了亿级流量网站的架构核心技术,让读者看后能快速运用到实践项目中。
|
||||
|
||||
### 软件底层
|
||||
|
||||
- [《深入剖析 Tomcat》](https://book.douban.com/subject/10426640/)(推荐,豆瓣评分 8.4,0.2K+人评价):本书深入剖析 Tomcat 4 和 Tomcat 5 中的每个组件,并揭示其内部工作原理。通过学习本书,你将可以自行开发 Tomcat 组件,或者扩展已有的组件。 读完这本书,基本可以摆脱背诵面试题的尴尬。
|
||||
- [《深入理解 Nginx(第 2 版)》](https://book.douban.com/subject/26745255/):作者讲的非常细致,注释都写的都很工整,对于 Nginx 的开发人员非常有帮助。优点是细致,缺点是过于细致,到处都是代码片段,缺少一些抽象。
|
||||
|
||||
## 其他
|
||||
|
||||
- [《黑客与画家》](https://read.douban.com/ebook/387525/?dcs=subject-rec&dcm=douban&dct=2243615):这本书是硅谷创业之父,Y Combinator 创始人 Paul Graham 的文集。之所以叫这个名字,是因为作者认为黑客(并非负面的那个意思)与画家有着极大的相似性,他们都是在创造,而不是完成某个任务。
|
||||
- [《图解密码技术》](https://book.douban.com/subject/26265544/)(推荐,豆瓣评分 9.1,0.3K+人评价):本书以**图配文**的形式,第一部分讲述了密码技术的历史沿革、对称密码、分组密码模式(包括ECB、CBC、CFB、OFB、CTR)、公钥、混合密码系统。第二部分重点介绍了认证方面的内容,涉及单向散列函数、消息认证码、数字签名、证书等。第三部分讲述了密钥、随机数、PGP、SSL/TLS 以及密码技术在现实生活中的应用。关键字:JWT 前置知识、区块链密码技术前置知识。属于密码知识入门书籍。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,66 +0,0 @@
|
||||
最近经常被读者问到有没有 Spring Boot 实战项目可以学习,于是,我就去 Github 上找了 10 个我觉得还不错的实战项目。对于这些实战项目,有部分是比较适合 Spring Boot 刚入门的朋友学习的,还有一部分可能要求你对 Spring Boot 相关技术比较熟悉。需要的朋友可以根据个人实际情况进行选择。如果你对 Spring Boot 不太熟悉的话,可以看我最近开源的 springboot-guide:https://github.com/Snailclimb/springboot-guide 入门(还在持续更新中)。
|
||||
|
||||
### mall
|
||||
|
||||
- **Github地址**: [https://github.com/macrozheng/mall](https://github.com/macrozheng/mall)
|
||||
- **star**: 22.9k
|
||||
- **介绍**: mall项目是一套电商系统,包括前台商城系统及后台管理系统,基于SpringBoot+MyBatis实现。 前台商城系统包含首页门户、商品推荐、商品搜索、商品展示、购物车、订单流程、会员中心、客户服务、帮助中心等模块。 后台管理系统包含商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等模块。
|
||||
|
||||
### jeecg-boot
|
||||
|
||||
- **Github地址**:[https://github.com/zhangdaiscott/jeecg-boot](https://github.com/zhangdaiscott/jeecg-boot)
|
||||
- **star**: 6.4k
|
||||
- **介绍**: 一款基于代码生成器的JAVA快速开发平台!采用最新技术,前后端分离架构:SpringBoot 2.x,Ant Design&Vue,Mybatis,Shiro,JWT。强大的代码生成器让前后端代码一键生成,无需写任何代码,绝对是全栈开发福音!! JeecgBoot的宗旨是提高UI能力的同时,降低前后分离的开发成本,JeecgBoot还独创在线开发模式,No代码概念,一系列在线智能开发:在线配置表单、在线配置报表、在线设计流程等等。
|
||||
|
||||
### eladmin
|
||||
|
||||
- **Github地址**:[https://github.com/elunez/eladmin](https://github.com/elunez/eladmin)
|
||||
- **star**: 3.9k
|
||||
- **介绍**: 项目基于 Spring Boot 2.1.0 、 Jpa、 Spring Security、redis、Vue的前后端分离的后台管理系统,项目采用分模块开发方式, 权限控制采用 RBAC,支持数据字典与数据权限管理,支持一键生成前后端代码,支持动态路由。
|
||||
|
||||
### paascloud-master
|
||||
|
||||
- **Github地址**:[https://github.com/paascloud/paascloud-master](https://github.com/paascloud/paascloud-master)
|
||||
- **star**: 5.9k
|
||||
- **介绍**: spring cloud + vue + oAuth2.0全家桶实战,前后端分离模拟商城,完整的购物流程、后端运营平台,可以实现快速搭建企业级微服务项目。支持微信登录等三方登录。
|
||||
|
||||
### vhr
|
||||
|
||||
- **Github地址**:[https://github.com/lenve/vhr](https://github.com/lenve/vhr)
|
||||
- **star**: 10.6k
|
||||
- **介绍**: 微人事是一个前后端分离的人力资源管理系统,项目采用SpringBoot+Vue开发。
|
||||
|
||||
### One mall
|
||||
|
||||
- **Github地址**:[https://github.com/YunaiV/onemall](https://github.com/YunaiV/onemall)
|
||||
- **star**: 1.2k
|
||||
- **介绍**: mall 商城,基于微服务的思想,构建在 B2C 电商场景下的项目实战。核心技术栈,是 Spring Boot + Dubbo 。未来,会重构成 Spring Cloud Alibaba 。
|
||||
|
||||
### Guns
|
||||
|
||||
- **Github地址**:[https://github.com/stylefeng/Guns](https://github.com/stylefeng/Guns)
|
||||
- **star**: 2.3k
|
||||
- **介绍**: Guns基于SpringBoot 2,致力于做更简洁的后台管理系统,完美整合springmvc + shiro + mybatis-plus + beetl!Guns项目代码简洁,注释丰富,上手容易,同时Guns包含许多基础模块(用户管理,角色管理,部门管理,字典管理等10个模块),可以直接作为一个后台管理系统的脚手架!
|
||||
|
||||
### SpringCloud
|
||||
|
||||
- **Github地址**:[https://github.com/YunaiV/onemall](https://github.com/YunaiV/onemall)
|
||||
- **star**: 1.2k
|
||||
- **介绍**: mall 商城,基于微服务的思想,构建在 B2C 电商场景下的项目实战。核心技术栈,是 Spring Boot + Dubbo 。未来,会重构成 Spring Cloud Alibaba 。
|
||||
|
||||
### SpringBoot-Shiro-Vue
|
||||
|
||||
- **Github地址**:[https://github.com/Heeexy/SpringBoot-Shiro-Vue](https://github.com/Heeexy/SpringBoot-Shiro-Vue)
|
||||
- **star**: 1.8k
|
||||
- **介绍**: 提供一套基于Spring Boot-Shiro-Vue的权限管理思路.前后端都加以控制,做到按钮/接口级别的权限。
|
||||
|
||||
### newbee-mall
|
||||
|
||||
最近开源的一个商城项目。
|
||||
|
||||
- **Github地址**:[https://github.com/newbee-ltd/newbee-mall](https://github.com/newbee-ltd/newbee-mall)
|
||||
- **star**: 50
|
||||
- **介绍**: newbee-mall 项目是一套电商系统,包括 newbee-mall 商城系统及 newbee-mall-admin 商城后台管理系统,基于 Spring Boot 2.X 及相关技术栈开发。 前台商城系统包含首页门户、商品分类、新品上线、首页轮播、商品推荐、商品搜索、商品展示、购物车、订单结算、订单流程、个人订单管理、会员中心、帮助中心等模块。 后台管理系统包含数据面板、轮播图管理、商品管理、订单管理、会员管理、分类管理、设置等模块。
|
||||
|
||||
|
||||
|
||||
@ -41,7 +41,7 @@
|
||||
若 row 行的棋子和 i 行的棋子在同一对角线,等腰直角三角形两直角边相等,即 row - i == Math.abs(result[i] - column)
|
||||
|
||||
布尔类型变量 isValid 的作用是剪枝,减少不必要的递归。
|
||||
```
|
||||
```java
|
||||
public List<List<String>> solveNQueens(int n) {
|
||||
// 下标代表行,值代表列。如result[0] = 3 表示第1行的Q在第3列
|
||||
int[] result = new int[n];
|
||||
@ -104,7 +104,7 @@ row - i + n 的最大值为 2n(当row = n,i = 0时),故anti_diag的容
|
||||
|
||||
**解法二时间复杂度为O(n!),在校验相同列和相同对角线时,引入三个布尔类型数组进行判断。相比解法一,少了一层循环,用空间换时间。**
|
||||
|
||||
```
|
||||
```java
|
||||
List<List<String>> resultList = new LinkedList<>();
|
||||
|
||||
public List<List<String>> solveNQueens(int n) {
|
||||
|
||||
@ -39,7 +39,7 @@
|
||||
|
||||
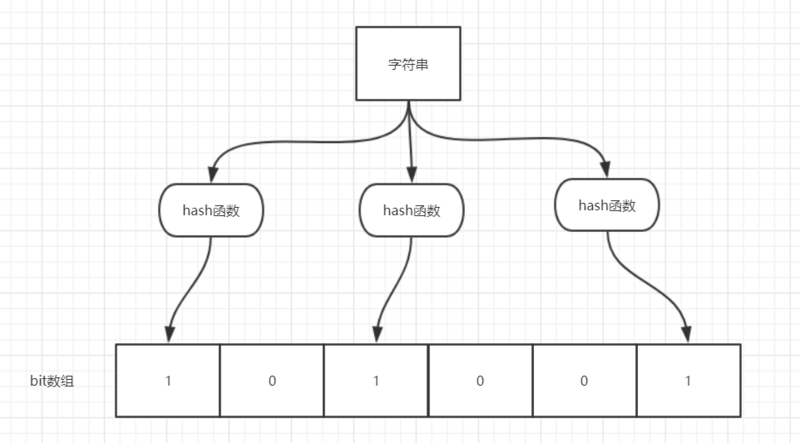
|
||||
|
||||
如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后在对应的位数组的下表的元素设置为 1(当位数组初始化时 ,所有位置均为0)。当第二次存储相同字符串时,因为先前的对应位置已设置为1,所以很容易知道此值已经存在(去重非常方便)。
|
||||
如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后在对应的位数组的下表的元素设置为 1(当位数组初始化时 ,所有位置均为0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便)。
|
||||
|
||||
如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
|
||||
|
||||
@ -49,7 +49,7 @@
|
||||
|
||||
### 3.布隆过滤器使用场景
|
||||
|
||||
1. 判断给定数据是否存在:比如判断一个数字是否在于包含大量数字的数字集中(数字集很大,5亿以上!)、 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤、黑名单功能等等。
|
||||
1. 判断给定数据是否存在:比如判断一个数字是否存在于包含大量数字的数字集中(数字集很大,5亿以上!)、 防止缓存穿透(判断请求的数据是否有效避免直接绕过缓存请求数据库)等等、邮箱的垃圾邮件过滤、黑名单功能等等。
|
||||
2. 去重:比如爬给定网址的时候对已经爬取过的 URL 去重。
|
||||
|
||||
### 4.通过 Java 编程手动实现布隆过滤器
|
||||
@ -232,9 +232,9 @@ true
|
||||
|
||||
#### 6.1介绍
|
||||
|
||||
Redis v4.0 之后有了 Module(模块/插件) 功能,Redis Modules 让 Redis 可以使用外部模块扩展其功能 。布隆过滤器就是其中的 Module。详情可以查看 Redis 官方对 Redis Modules 的介绍 :https://redis.io/modules。
|
||||
Redis v4.0 之后有了 Module(模块/插件) 功能,Redis Modules 让 Redis 可以使用外部模块扩展其功能 。布隆过滤器就是其中的 Module。详情可以查看 Redis 官方对 Redis Modules 的介绍 :https://redis.io/modules
|
||||
|
||||
另外,官网推荐了一个 RedisBloom 作为 Redis 布隆过滤器的 Module,地址:https://github.com/RedisBloom/RedisBloom。其他还有:
|
||||
另外,官网推荐了一个 RedisBloom 作为 Redis 布隆过滤器的 Module,地址:https://github.com/RedisBloom/RedisBloom. 其他还有:
|
||||
|
||||
- redis-lua-scaling-bloom-filter (lua 脚本实现):https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter
|
||||
- pyreBloom(Python中的快速Redis 布隆过滤器) :https://github.com/seomoz/pyreBloom
|
||||
|
||||
{kind=link}
|
After Width: | Height: | Size: 579 KiB |
BIN
docs/dataStructures-algorithms/images/剑指Offer.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 3.5 MiB |
BIN
docs/dataStructures-algorithms/images/啊哈!算法.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 47 KiB |
BIN
docs/dataStructures-algorithms/images/我的第一本算法书.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 128 KiB |
BIN
docs/dataStructures-algorithms/images/程序员代码面试指南.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 119 KiB |
BIN
docs/dataStructures-algorithms/images/算法-4.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 59 KiB |
BIN
docs/dataStructures-algorithms/images/算法图解.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 72 KiB |
BIN
docs/dataStructures-algorithms/images/算法导论.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 94 KiB |
BIN
docs/dataStructures-algorithms/images/算法设计手册.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 413 KiB |
BIN
docs/dataStructures-algorithms/images/编程之美.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 150 KiB |
BIN
docs/dataStructures-algorithms/images/编程珠玑.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 71 KiB |
BIN
docs/dataStructures-algorithms/images/计算机程序设计艺术.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 22 KiB |
@ -15,11 +15,13 @@
|
||||
<!-- /MarkdownTOC -->
|
||||
|
||||
|
||||
## 说明
|
||||
|
||||
- 本文作者:wwwxmu
|
||||
- 原文地址:https://www.weiweiblog.cn/13string/
|
||||
- 作者的博客站点:https://www.weiweiblog.cn/ (推荐哦!)
|
||||
> 授权转载!
|
||||
>
|
||||
> - 本文作者:wwwxmu
|
||||
> - 原文地址:https://www.weiweiblog.cn/13string/
|
||||
|
||||
|
||||
|
||||
考虑到篇幅问题,我会分两次更新这个内容。本篇文章只是原文的一部分,我在原文的基础上增加了部分内容以及修改了部分代码和注释。另外,我增加了爱奇艺 2018 秋招 Java:`求给定合法括号序列的深度` 这道题。所有代码均编译成功,并带有注释,欢迎各位享用!
|
||||
|
||||
@ -190,7 +192,7 @@ public class Main {
|
||||
我们上面已经知道了什么是回文串?现在我们考虑一下可以构成回文串的两种情况:
|
||||
|
||||
- 字符出现次数为双数的组合
|
||||
- 字符出现次数为双数的组合+一个只出现一次的字符
|
||||
- **字符出现次数为偶数的组合+单个字符中出现次数最多且为奇数次的字符** (参见 **[issue665](https://github.com/Snailclimb/JavaGuide/issues/665)** )
|
||||
|
||||
统计字符出现的次数即可,双数才能构成回文。因为允许中间一个数单独出现,比如“abcba”,所以如果最后有字母落单,总长度可以加 1。首先将字符串转变为字符数组。然后遍历该数组,判断对应字符是否在hashset中,如果不在就加进去,如果在就让count++,然后移除该字符!这样就能找到出现次数为双数的字符个数。
|
||||
|
||||
|
||||
@ -48,15 +48,6 @@ n<=39
|
||||
}
|
||||
```
|
||||
|
||||
#### **运行时间对比:**
|
||||
|
||||
假设n为40我们分别使用迭代法和递归法计算,计算结果如下:
|
||||
|
||||
1. 迭代法
|
||||

|
||||
2. 递归法
|
||||

|
||||
|
||||
### 二 跳台阶问题
|
||||
|
||||
#### **题目描述:**
|
||||
|
||||
@ -95,90 +95,102 @@ Set 继承于 Collection 接口,是一个不允许出现重复元素,并且
|
||||
|
||||
|
||||
- [集合框架源码学习之 HashMap(JDK1.8)](https://juejin.im/post/5ab0568b5188255580020e56)
|
||||
- [ConcurrentHashMap 实现原理及源码分析](https://link.juejin.im/?target=http%3A%2F%2Fwww.cnblogs.com%2Fchengxiao%2Fp%2F6842045.html)
|
||||
- [ConcurrentHashMap 实现原理及源码分析](https://www.cnblogs.com/chengxiao/p/6842045.html)
|
||||
|
||||
## 树
|
||||
* ### 1 二叉树
|
||||
|
||||
[二叉树](https://baike.baidu.com/item/%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科)
|
||||
### 1 二叉树
|
||||
|
||||
(1)[完全二叉树](https://baike.baidu.com/item/%E5%AE%8C%E5%85%A8%E4%BA%8C%E5%8F%89%E6%A0%91)——若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
|
||||
[二叉树](https://baike.baidu.com/item/%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科)
|
||||
|
||||
(2)[满二叉树](https://baike.baidu.com/item/%E6%BB%A1%E4%BA%8C%E5%8F%89%E6%A0%91)——除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
|
||||
(1)[完全二叉树](https://baike.baidu.com/item/%E5%AE%8C%E5%85%A8%E4%BA%8C%E5%8F%89%E6%A0%91)——若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
|
||||
|
||||
(3)[平衡二叉树](https://baike.baidu.com/item/%E5%B9%B3%E8%A1%A1%E4%BA%8C%E5%8F%89%E6%A0%91/10421057)——平衡二叉树又被称为AVL树(区别于AVL算法),它是一棵二叉排序树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
|
||||
(2)[满二叉树](https://baike.baidu.com/item/%E6%BB%A1%E4%BA%8C%E5%8F%89%E6%A0%91)——除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
|
||||
|
||||
* ### 2 完全二叉树
|
||||
(3)[平衡二叉树](https://baike.baidu.com/item/%E5%B9%B3%E8%A1%A1%E4%BA%8C%E5%8F%89%E6%A0%91/10421057)——平衡二叉树又被称为AVL树(区别于AVL算法),它是一棵二叉排序树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
|
||||
|
||||
[完全二叉树](https://baike.baidu.com/item/%E5%AE%8C%E5%85%A8%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科)
|
||||
### 2 完全二叉树
|
||||
|
||||
完全二叉树:叶节点只能出现在最下层和次下层,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树。
|
||||
* ### 3 满二叉树
|
||||
[完全二叉树](https://baike.baidu.com/item/%E5%AE%8C%E5%85%A8%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科)
|
||||
|
||||
[满二叉树](https://baike.baidu.com/item/%E6%BB%A1%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科,国内外的定义不同)
|
||||
完全二叉树:叶节点只能出现在最下层和次下层,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树。
|
||||
|
||||
国内教程定义:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为K,且结点总数是(2^k) -1 ,则它就是满二叉树。
|
||||
* ### 堆
|
||||
### 3 满二叉树
|
||||
|
||||
[数据结构之堆的定义](https://blog.csdn.net/qq_33186366/article/details/51876191)
|
||||
[满二叉树](https://baike.baidu.com/item/%E6%BB%A1%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科,国内外的定义不同)
|
||||
|
||||
堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。
|
||||
* ### 4 二叉查找树(BST)
|
||||
国内教程定义:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为K,且结点总数是(2^k) -1 ,则它就是满二叉树。
|
||||
|
||||
[浅谈算法和数据结构: 七 二叉查找树](http://www.cnblogs.com/yangecnu/p/Introduce-Binary-Search-Tree.html)
|
||||
### 堆
|
||||
|
||||
二叉查找树的特点:
|
||||
[数据结构之堆的定义](https://blog.csdn.net/qq_33186366/article/details/51876191)
|
||||
|
||||
1. 若任意节点的左子树不空,则左子树上所有结点的 值均小于它的根结点的值;
|
||||
2. 若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
|
||||
3. 任意节点的左、右子树也分别为二叉查找树;
|
||||
4. 没有键值相等的节点(no duplicate nodes)。
|
||||
堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。
|
||||
|
||||
* ### 5 平衡二叉树(Self-balancing binary search tree)
|
||||
### 4 二叉查找树(BST)
|
||||
|
||||
[ 平衡二叉树](https://baike.baidu.com/item/%E5%B9%B3%E8%A1%A1%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科,平衡二叉树的常用实现方法有红黑树、AVL、替罪羊树、Treap、伸展树等)
|
||||
* ### 6 红黑树
|
||||
[浅谈算法和数据结构: 七 二叉查找树](http://www.cnblogs.com/yangecnu/p/Introduce-Binary-Search-Tree.html)
|
||||
|
||||
- 红黑树特点:
|
||||
1. 每个节点非红即黑;
|
||||
2. 根节点总是黑色的;
|
||||
3. 每个叶子节点都是黑色的空节点(NIL节点);
|
||||
4. 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
|
||||
5. 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)。
|
||||
二叉查找树的特点:
|
||||
|
||||
- 红黑树的应用:
|
||||
1. 若任意节点的左子树不空,则左子树上所有结点的 值均小于它的根结点的值;
|
||||
2. 若任意节点的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
|
||||
3. 任意节点的左、右子树也分别为二叉查找树;
|
||||
4. 没有键值相等的节点(no duplicate nodes)。
|
||||
|
||||
TreeMap、TreeSet以及JDK1.8之后的HashMap底层都用到了红黑树。
|
||||
### 5 平衡二叉树(Self-balancing binary search tree)
|
||||
|
||||
- 为什么要用红黑树
|
||||
[ 平衡二叉树](https://baike.baidu.com/item/%E5%B9%B3%E8%A1%A1%E4%BA%8C%E5%8F%89%E6%A0%91)(百度百科,平衡二叉树的常用实现方法有红黑树、AVL、替罪羊树、Treap、伸展树等)
|
||||
|
||||
简单来说红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。详细了解可以查看 [漫画:什么是红黑树?](https://juejin.im/post/5a27c6946fb9a04509096248#comment)(也介绍到了二叉查找树,非常推荐)
|
||||
### 6 红黑树
|
||||
|
||||
- 推荐文章:
|
||||
- [漫画:什么是红黑树?](https://juejin.im/post/5a27c6946fb9a04509096248#comment)(也介绍到了二叉查找树,非常推荐)
|
||||
- [寻找红黑树的操作手册](http://dandanlove.com/2018/03/18/red-black-tree/)(文章排版以及思路真的不错)
|
||||
- [红黑树深入剖析及Java实现](https://zhuanlan.zhihu.com/p/24367771)(美团点评技术团队)
|
||||
* ### 7 B-,B+,B*树
|
||||
红黑树特点:
|
||||
|
||||
[二叉树学习笔记之B树、B+树、B*树 ](https://yq.aliyun.com/articles/38345)
|
||||
1. 每个节点非红即黑;
|
||||
2. 根节点总是黑色的;
|
||||
3. 每个叶子节点都是黑色的空节点(NIL节点);
|
||||
4. 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
|
||||
5. 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)。
|
||||
|
||||
[《B-树,B+树,B*树详解》](https://blog.csdn.net/aqzwss/article/details/53074186)
|
||||
|
||||
[《B-树,B+树与B*树的优缺点比较》](https://blog.csdn.net/bigtree_3721/article/details/73632405)
|
||||
红黑树的应用:
|
||||
|
||||
B-树(或B树)是一种平衡的多路查找(又称排序)树,在文件系统中有所应用。主要用作文件的索引。其中的B就表示平衡(Balance)
|
||||
1. B+ 树的叶子节点链表结构相比于 B- 树便于扫库,和范围检索。
|
||||
2. B+树支持range-query(区间查询)非常方便,而B树不支持。这是数据库选用B+树的最主要原因。
|
||||
3. B\*树 是B+树的变体,B\*树分配新结点的概率比B+树要低,空间使用率更高;
|
||||
* ### 8 LSM 树
|
||||
TreeMap、TreeSet以及JDK1.8的HashMap底层都用到了红黑树。
|
||||
|
||||
[[HBase] LSM树 VS B+树](https://blog.csdn.net/dbanote/article/details/8897599)
|
||||
**为什么要用红黑树?**
|
||||
|
||||
B+树最大的性能问题是会产生大量的随机IO
|
||||
|
||||
为了克服B+树的弱点,HBase引入了LSM树的概念,即Log-Structured Merge-Trees。
|
||||
简单来说红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。详细了解可以查看 [漫画:什么是红黑树?](https://juejin.im/post/5a27c6946fb9a04509096248#comment)(也介绍到了二叉查找树,非常推荐)
|
||||
|
||||
[LSM树由来、设计思想以及应用到HBase的索引](http://www.cnblogs.com/yanghuahui/p/3483754.html)
|
||||
推荐文章:
|
||||
|
||||
- [漫画:什么是红黑树?](https://juejin.im/post/5a27c6946fb9a04509096248#comment)(也介绍到了二叉查找树,非常推荐)
|
||||
- [寻找红黑树的操作手册](http://dandanlove.com/2018/03/18/red-black-tree/)(文章排版以及思路真的不错)
|
||||
- [红黑树深入剖析及Java实现](https://zhuanlan.zhihu.com/p/24367771)(美团点评技术团队)
|
||||
|
||||
### 7 B-,B+,B*树
|
||||
|
||||
[二叉树学习笔记之B树、B+树、B*树 ](https://yq.aliyun.com/articles/38345)
|
||||
|
||||
[《B-树,B+树,B*树详解》](https://blog.csdn.net/aqzwss/article/details/53074186)
|
||||
|
||||
[《B-树,B+树与B*树的优缺点比较》](https://blog.csdn.net/bigtree_3721/article/details/73632405)
|
||||
|
||||
B-树(或B树)是一种平衡的多路查找(又称排序)树,在文件系统中有所应用。主要用作文件的索引。其中的B就表示平衡(Balance)
|
||||
|
||||
1. B+ 树的叶子节点链表结构相比于 B- 树便于扫库,和范围检索。
|
||||
2. B+树支持range-query(区间查询)非常方便,而B树不支持。这是数据库选用B+树的最主要原因。
|
||||
3. B\*树 是B+树的变体,B\*树分配新结点的概率比B+树要低,空间使用率更高;
|
||||
|
||||
### 8 LSM 树
|
||||
|
||||
[[HBase] LSM树 VS B+树](https://blog.csdn.net/dbanote/article/details/8897599)
|
||||
|
||||
B+树最大的性能问题是会产生大量的随机IO
|
||||
|
||||
为了克服B+树的弱点,HBase引入了LSM树的概念,即Log-Structured Merge-Trees。
|
||||
|
||||
[LSM树由来、设计思想以及应用到HBase的索引](http://www.cnblogs.com/yanghuahui/p/3483754.html)
|
||||
|
||||
|
||||
## 图
|
||||
|
||||
@ -1,38 +1,128 @@
|
||||
先占个坑,说一下我觉得算法这部分学习比较好的规划:
|
||||
|
||||
1. 未入门(对算法和基本数据结构不了解)之前建议先找一本入门书籍看;
|
||||
2. 如果时间比较多可以看一下我推荐的经典部分的书籍,《算法》这本书是首要要看的,其他推荐的神书看自己时间和心情就好,不要太纠结。
|
||||
3. 如果要准备面试,时间比较紧的话,就不需要再去看《算法》这本书了,时间来不及,当然你也可以选取其特定的章节查看。我也推荐了几本不错的专门为算法面试准备的书籍比如《剑指offer》和《程序员代码面试指南》。除了这两本书籍的话,我在下面推荐了 Leetcode 和牛客网这两个常用的刷题网站以及一些比较好的题目资源。
|
||||
|
||||
## 书籍推荐
|
||||
|
||||
> 以下提到的部分书籍的 PDF 高清阅读版本在我的公众号“JavaGuide”后台回复“书籍”即可获取。
|
||||
|
||||
先来看三本入门书籍,这三本入门书籍中的任何一本拿来作为入门学习都非常好。我个人比较倾向于 **《我的第一本算法书》** 这本书籍,虽然它相比于其他两本书集它的豆瓣评分略低一点。我觉得它的配图以及讲解是这三本书中最优秀,唯一比较明显的问题就是没有代码示例。但是,我觉得这不影响它是一本好的算法书籍。因为本身下面这三本入门书籍的目的就不是通过代码来让你的算法有多厉害,只是作为一本很好的入门书籍让你进入算法学习的大门。
|
||||
|
||||
### 入门
|
||||
|
||||
<img src="images/我的第一本算法书.png" style="zoom:33%;" />
|
||||
|
||||
**[我的第一本算法书](https://book.douban.com/subject/30357170/) (豆瓣评分 7.1,0.2K+人评价)**
|
||||
|
||||
一本不那么“专业”的算法书籍。和下面两本推荐的算法书籍都是比较通俗易懂,“不那么深入”的算法书籍。我个人非常推荐,配图和讲解都非常不错!
|
||||
|
||||
<img src="images/算法图解.png" alt="img" style="zoom:50%;" />
|
||||
|
||||
**[《算法图解》](https://book.douban.com/subject/26979890/)(豆瓣评分 8.4,1.5K+人评价)**
|
||||
|
||||
入门类型的书籍,读起来比较浅显易懂,非常适合没有算法基础或者说算法没学好的小伙伴用来入门。示例丰富,图文并茂,以让人容易理解的方式阐释了算法.读起来比较快,内容不枯燥!
|
||||
|
||||

|
||||
|
||||
**[啊哈!算法](https://book.douban.com/subject/25894685/) (豆瓣评分 7.7,0.5K+人评价)**
|
||||
|
||||
和《算法图解》类似的算法趣味入门书籍。
|
||||
|
||||
### 经典
|
||||
|
||||
<img src="images/算法-4.png" style="zoom:50%;" />
|
||||
|
||||
**[《算法 第四版》](https://book.douban.com/subject/10432347/)(豆瓣评分 9.3,0.4K+人评价)**
|
||||
|
||||
我在大二的时候被我们的一个老师强烈安利过!自己也在当时购买了一本放在宿舍,到离开大学的时候自己大概看了一半多一点。因为内容实在太多了!另外,这本书还提供了详细的Java代码,非常适合学习 Java 的朋友来看,可以说是 Java 程序员的必备书籍之一了。
|
||||
|
||||
再来介绍一下这本书籍吧!这本书籍算的上是算法领域经典的参考书,全面介绍了关于算法和数据结构的必备知识,并特别针对排序、搜索、图处理和字符串处理进行了论述。
|
||||
|
||||
> **下面这些书籍都是经典中的经典,但是阅读起来难度也比较大,不做太多阐述,神书就完事了!推荐先看 《算法》,然后再选下面的书籍进行进一步阅读。不需要都看,找一本好好看或者找某本书的某一个章节知识点好好看。**
|
||||
|
||||
<img src="images/编程珠玑.png" style="zoom:67%;" />
|
||||
|
||||
**[编程珠玑](https://book.douban.com/subject/3227098/)(豆瓣评分 9.1,2K+人评价)**
|
||||
|
||||
经典名著,被无数读者强烈推荐的书籍,几乎是顶级程序员必看的书籍之一了。这本书的作者也非常厉害,Java之父 James Gosling 就是他的学生。
|
||||
|
||||
很多人都说这本书不是教你具体的算法,而是教你一种编程的思考方式。这种思考方式不仅仅在编程领域适用,在其他同样适用。
|
||||
|
||||
|
||||
|
||||
<img src="images/算法设计手册.png" style="zoom:50%;" />
|
||||
|
||||
**[《算法设计手册》](https://book.douban.com/subject/4048566/)(豆瓣评分9.1 , 45人评价)**
|
||||
|
||||
被 [Teach Yourself Computer Science](https://teachyourselfcs.com/) 强烈推荐的一本算法书籍。
|
||||
|
||||
<img src="images/算法导论.png" style="zoom:48%;" />
|
||||
|
||||
**[《算法导论》](https://book.douban.com/subject/20432061/) (豆瓣评分 9.2,0.4K+人评价)**
|
||||
|
||||

|
||||
|
||||
**[《计算机程序设计艺术(第1卷)》](https://book.douban.com/subject/1130500/)(豆瓣评分 9.4,0.4K+人评价)**
|
||||
|
||||
### 面试
|
||||
|
||||

|
||||
|
||||
**[《剑指Offer》](https://book.douban.com/subject/6966465/)(豆瓣评分 8.3,0.7K+人评价)**
|
||||
|
||||
这本面试宝典上面涵盖了很多经典的算法面试题,如果你要准备大厂面试的话一定不要错过这本书。
|
||||
|
||||
《剑指Offer》 对应的算法编程题部分的开源项目解析:[CodingInterviews](https://github.com/gatieme/CodingInterviews)
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
<img src="images/程序员代码面试指南.png" style="zoom:50%;" />
|
||||
|
||||
**[程序员代码面试指南:IT名企算法与数据结构题目最优解(第2版)](https://book.douban.com/subject/30422021/) (豆瓣评分 8.7,0.2K+人评价)**
|
||||
|
||||
题目相比于《剑指 offer》 来说要难很多,题目涵盖面相比于《剑指 offer》也更加全面。全书一共有将近300道真实出现过的经典代码面试题。
|
||||
|
||||
|
||||
|
||||
<img src="images/编程之美.png" style="zoom:55%;" />
|
||||
|
||||
|
||||
|
||||
**[编程之美](https://book.douban.com/subject/3004255/)(豆瓣评分 8.4,3K+人评价)**
|
||||
|
||||
这本书收集了约60道算法和程序设计题目,这些题目大部分在近年的笔试、面试中出现过,或者是被微软员工热烈讨论过。作者试图从书中各种有趣的问题出发,引导读者发现问题,分析问题,解决问题,寻找更优的解法。
|
||||
|
||||
## 网站推荐
|
||||
|
||||
我比较推荐大家可以刷一下 Leetcode ,我自己平时没事也会刷一下,我觉得刷 Leetcode 不仅是为了能让你更从容地面对面试中的手撕算法问题,更可以提高你的编程思维能力、解决问题的能力以及你对某门编程语言 API 的熟练度。当然牛客网也有一些算法题,我下面也整理了一些。
|
||||
|
||||
## LeetCode
|
||||
### [LeetCode](https://leetcode-cn.com/)
|
||||
|
||||
- [LeetCode(中国)官网](https://leetcode-cn.com/)
|
||||
[如何高效地使用 LeetCode](https://leetcode-cn.com/articles/%E5%A6%82%E4%BD%95%E9%AB%98%E6%95%88%E5%9C%B0%E4%BD%BF%E7%94%A8-leetcode/)
|
||||
|
||||
- [如何高效地使用 LeetCode](https://leetcode-cn.com/articles/%E5%A6%82%E4%BD%95%E9%AB%98%E6%95%88%E5%9C%B0%E4%BD%BF%E7%94%A8-leetcode/)
|
||||
- [《程序员代码面试指南》](https://leetcode-cn.com/problemset/lcci/)
|
||||
- [《剑指offer》](https://leetcode-cn.com/problemset/lcof/)
|
||||
|
||||
|
||||
## 牛客网
|
||||
### [牛客网](https://www.nowcoder.com)
|
||||
|
||||
**[在线编程](https://www.nowcoder.com/activity/oj):**
|
||||
|
||||
- [《剑指offer》](https://www.nowcoder.com/ta/coding-interviews)
|
||||
- [《程序员代码面试指南》](https://www.nowcoder.com/ta/programmer-code-interview-guide)
|
||||
- [2019 校招真题](https://www.nowcoder.com/ta/2019test)
|
||||
- [大一大二编程入门训练](https://www.nowcoder.com/ta/beginner-programmers)
|
||||
- .......
|
||||
|
||||
**[大厂编程面试真题](https://www.nowcoder.com/contestRoom?filter=0&orderByHotValue=3&target=content&categories=-1&mutiTagIds=2491&page=1)**
|
||||
|
||||
|
||||
- [牛客网官网](https://www.nowcoder.com)
|
||||
- [剑指offer编程题](https://www.nowcoder.com/ta/coding-interviews)
|
||||
|
||||
- [2017校招真题](https://www.nowcoder.com/ta/2017test)
|
||||
- [华为机试题](https://www.nowcoder.com/ta/huawei)
|
||||
|
||||
|
||||
## 公司真题
|
||||
|
||||
- [ 网易2018校园招聘编程题真题集合](https://www.nowcoder.com/test/6910869/summary)
|
||||
- [ 网易2018校招内推编程题集合](https://www.nowcoder.com/test/6291726/summary)
|
||||
- [2017年校招全国统一模拟笔试(第五场)编程题集合](https://www.nowcoder.com/test/5986669/summary)
|
||||
- [2017年校招全国统一模拟笔试(第四场)编程题集合](https://www.nowcoder.com/test/5507925/summary)
|
||||
- [2017年校招全国统一模拟笔试(第三场)编程题集合](https://www.nowcoder.com/test/5217106/summary)
|
||||
- [2017年校招全国统一模拟笔试(第二场)编程题集合](https://www.nowcoder.com/test/4546329/summary)
|
||||
- [ 2017年校招全国统一模拟笔试(第一场)编程题集合](https://www.nowcoder.com/test/4236887/summary)
|
||||
- [百度2017春招笔试真题编程题集合](https://www.nowcoder.com/test/4998655/summary)
|
||||
- [网易2017春招笔试真题编程题集合](https://www.nowcoder.com/test/4575457/summary)
|
||||
- [网易2017秋招编程题集合](https://www.nowcoder.com/test/2811407/summary)
|
||||
- [网易有道2017内推编程题](https://www.nowcoder.com/test/2385858/summary)
|
||||
- [ 滴滴出行2017秋招笔试真题-编程题汇总](https://www.nowcoder.com/test/3701760/summary)
|
||||
- [腾讯2017暑期实习生编程题](https://www.nowcoder.com/test/1725829/summary)
|
||||
- [今日头条2017客户端工程师实习生笔试题](https://www.nowcoder.com/test/1649301/summary)
|
||||
- [今日头条2017后端工程师实习生笔试题](https://www.nowcoder.com/test/1649268/summary)
|
||||
|
||||
|
||||
|
||||
|
||||
@ -1,13 +1,86 @@
|
||||
## 为什么要使用索引?
|
||||
|
||||
# 思维导图-索引篇
|
||||
1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
|
||||
2. 可以大大加快 数据的检索速度(大大减少的检索的数据量), 这也是创建索引的最主要的原因。
|
||||
3. 帮助服务器避免排序和临时表。
|
||||
4. 将随机IO变为顺序IO
|
||||
5. 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
|
||||
|
||||
> 系列思维导图源文件(数据库+架构)以及思维导图制作软件—XMind8 破解安装,公众号后台回复:**“思维导图”** 免费领取!(下面的图片不是很清楚,原图非常清晰,另外提供给大家源文件也是为了大家根据自己需要进行修改)
|
||||
## 索引这么多优点,为什么不对表中的每一个列创建一个索引呢?
|
||||
|
||||
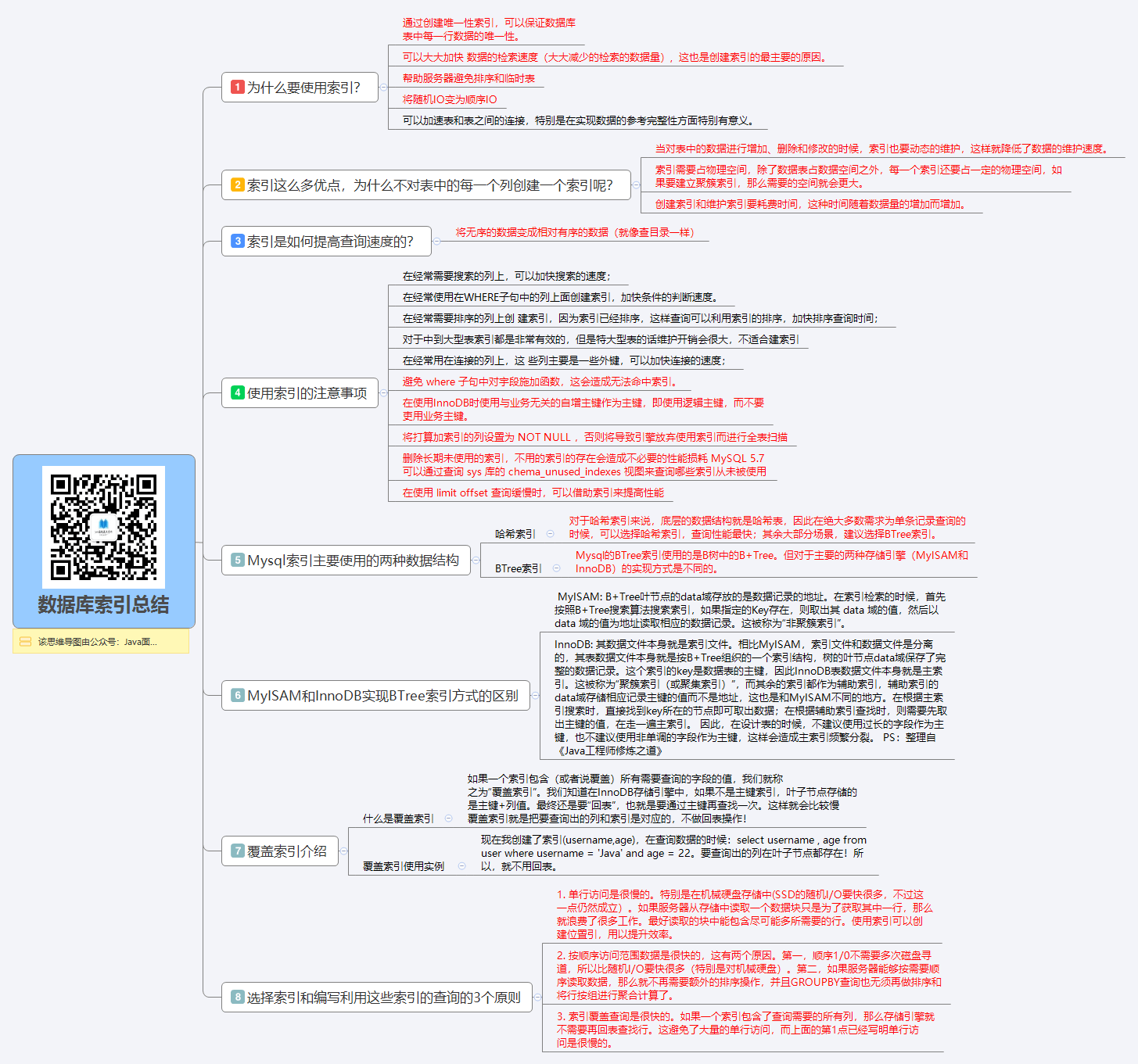
|
||||
1. 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
|
||||
2. 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
|
||||
3. 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
|
||||
|
||||
> **下面是我补充的一些内容**
|
||||
## 使用索引的注意事项?
|
||||
|
||||
# 为什么索引能提高查询速度
|
||||
1. 在经常需要搜索的列上,可以加快搜索的速度;
|
||||
|
||||
2. 在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
|
||||
|
||||
3. 在经常需要排序的列上创 建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
|
||||
|
||||
4. 对于中到大型表索引都是非常有效的,但是特大型表的话维护开销会很大,不适合建索引
|
||||
|
||||
5. 在经常用在连接的列上,这 些列主要是一些外键,可以加快连接的速度;
|
||||
|
||||
6. 避免 where 子句中对字段施加函数,这会造成无法命中索引。
|
||||
|
||||
7. 在使用InnoDB时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键。
|
||||
|
||||
8. ~~将打算加索引的列设置为 NOT NULL ,否则将导致引擎放弃使用索引而进行全表扫描。~~
|
||||
|
||||
订正,来自[issue758](https://github.com/Snailclimb/JavaGuide/issues/758) 。**将某一列设置为default null,where 是可以走索引,另外索引列是否设置 null 是不影响性能的。** 但是,还是不建议列上允许为空。最好限制not null,因为null需要更多的存储空间并且null值无法参与某些运算。
|
||||
|
||||
《高性能MySQL》第四章如是说:And, in case you’re wondering, allowing NULL values in the index really doesn’t impact performance 。NULL 值的索引查找流程参考:https://juejin.im/post/5d5defc2518825591523a1db ,相关阅读:[MySQL中IS NULL、IS NOT NULL、!=不能用索引?胡扯!](https://juejin.im/post/5d5defc2518825591523a1db) 。
|
||||
|
||||
9. 删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 chema_unused_indexes 视图来查询哪些索引从未被使用
|
||||
|
||||
10. 在使用 limit offset 查询缓慢时,可以借助索引来提高性能
|
||||
|
||||
## Mysql索引主要使用的两种数据结构
|
||||
|
||||
### 哈希索引
|
||||
|
||||
对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引。
|
||||
|
||||
### BTree索引
|
||||
|
||||
## MyISAM和InnoDB实现BTree索引方式的区别
|
||||
|
||||
### MyISAM
|
||||
|
||||
B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
|
||||
|
||||
### InnoDB
|
||||
|
||||
其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”,而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,在走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。 PS:整理自《Java工程师修炼之道》
|
||||
|
||||
## 覆盖索引介绍
|
||||
|
||||
### 什么是覆盖索引
|
||||
|
||||
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。我们知道InnoDB存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
|
||||
|
||||
### 覆盖索引使用实例
|
||||
|
||||
现在我创建了索引(username,age),我们执行下面的 sql 语句
|
||||
|
||||
```sql
|
||||
select username , age from user where username = 'Java' and age = 22
|
||||
```
|
||||
|
||||
在查询数据的时候:要查询出的列在叶子节点都存在!所以,就不用回表。
|
||||
|
||||
## 选择索引和编写利用这些索引的查询的3个原则
|
||||
|
||||
1. 单行访问是很慢的。特别是在机械硬盘存储中(SSD的随机I/O要快很多,不过这一点仍然成立)。如果服务器从存储中读取一个数据块只是为了获取其中一行,那么就浪费了很多工作。最好读取的块中能包含尽可能多所需要的行。使用索引可以创建位置引,用以提升效率。
|
||||
2. 按顺序访问范围数据是很快的,这有两个原因。第一,顺序 I/O 不需要多次磁盘寻道,所以比随机I/O要快很多(特别是对机械硬盘)。第二,如果服务器能够按需要顺序读取数据,那么就不再需要额外的排序操作,并且GROUPBY查询也无须再做排序和将行按组进行聚合计算了。
|
||||
3. 索引覆盖查询是很快的。如果一个索引包含了查询需要的所有列,那么存储引擎就
|
||||
不需要再回表查找行。这避免了大量的单行访问,而上面的第1点已经写明单行访
|
||||
问是很慢的。
|
||||
|
||||
## 为什么索引能提高查询速度
|
||||
|
||||
> 以下内容整理自:
|
||||
> 地址: https://juejin.im/post/5b55b842f265da0f9e589e79
|
||||
@ -48,7 +121,7 @@ MySQL的基本存储结构是页(记录都存在页里边):
|
||||
|
||||
其实底层结构就是B+树,B+树作为树的一种实现,能够让我们很快地查找出对应的记录。
|
||||
|
||||
# 关于索引其他重要的内容补充
|
||||
## 关于索引其他重要的内容补充
|
||||
|
||||
> 以下内容整理自:《Java工程师修炼之道》
|
||||
|
||||
@ -104,7 +177,7 @@ ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3`
|
||||
```
|
||||
|
||||
|
||||
# 参考
|
||||
## 参考
|
||||
|
||||
- 《Java工程师修炼之道》
|
||||
- 《MySQL高性能书籍_第3版》
|
||||
|
||||
@ -98,7 +98,7 @@ MyISAM是MySQL的默认数据库引擎(5.5版之前)。虽然性能极佳,
|
||||
**两者的对比:**
|
||||
|
||||
1. **是否支持行级锁** : MyISAM 只有表级锁(table-level locking),而InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
|
||||
2. **是否支持事务和崩溃后的安全恢复: MyISAM** 强调的是性能,每次查询具有原子性,其执行速度比InnoDB类型更快,但是不提供事务支持。但是**InnoDB** 提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
|
||||
2. **是否支持事务和崩溃后的安全恢复: MyISAM** 强调的是性能,每次查询具有原子性,其执行速度比InnoDB类型更快,但是不提供事务支持。但是**InnoDB** 提供事务支持,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
|
||||
3. **是否支持外键:** MyISAM不支持,而InnoDB支持。
|
||||
4. **是否支持MVCC** :仅 InnoDB 支持。应对高并发事务, MVCC比单纯的加锁更高效;MVCC只在 `READ COMMITTED` 和 `REPEATABLE READ` 两个隔离级别下工作;MVCC可以使用 乐观(optimistic)锁 和 悲观(pessimistic)锁来实现;各数据库中MVCC实现并不统一。推荐阅读:[MySQL-InnoDB-MVCC多版本并发控制](https://segmentfault.com/a/1190000012650596)
|
||||
5. ......
|
||||
@ -148,7 +148,7 @@ set global query_cache_size=600000;
|
||||
|
||||
缓存建立之后,MySQL的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
|
||||
|
||||
**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启缓存查询要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十MB比较合适。此外,**还可以通过sql_cache和sql_no_cache来控制某个查询语句是否需要缓存:**
|
||||
**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启查询缓存要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十MB比较合适。此外,**还可以通过sql_cache和sql_no_cache来控制某个查询语句是否需要缓存:**
|
||||
```sql
|
||||
select sql_no_cache count(*) from usr;
|
||||
```
|
||||
@ -164,7 +164,7 @@ select sql_no_cache count(*) from usr;
|
||||
|
||||
|
||||
1. **原子性(Atomicity):** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
|
||||
2. **一致性(Consistency):** 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
|
||||
2. **一致性(Consistency):** 执行事务后,数据库从一个正确的状态变化到另一个正确的状态;
|
||||
3. **隔离性(Isolation):** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
|
||||
4. **持久性(Durability):** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
|
||||
|
||||
@ -199,7 +199,7 @@ select sql_no_cache count(*) from usr;
|
||||
| REPEATABLE-READ | × | × | √ |
|
||||
| SERIALIZABLE | × | × | × |
|
||||
|
||||
MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看
|
||||
MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;`
|
||||
|
||||
```sql
|
||||
mysql> SELECT @@tx_isolation;
|
||||
@ -288,9 +288,9 @@ InnoDB 存储引擎在 **分布式事务** 的情况下一般会用到 **SERIALI
|
||||
|
||||
### 解释一下什么是池化设计思想。什么是数据库连接池?为什么需要数据库连接池?
|
||||
|
||||
池话设计应该不是一个新名词。我们常见的如java线程池、jdbc连接池、redis连接池等就是这类设计的代表实现。这种设计会初始预设资源,解决的问题就是抵消每次获取资源的消耗,如创建线程的开销,获取远程连接的开销等。就好比你去食堂打饭,打饭的大妈会先把饭盛好几份放那里,你来了就直接拿着饭盒加菜即可,不用再临时又盛饭又打菜,效率就高了。除了初始化资源,池化设计还包括如下这些特征:池子的初始值、池子的活跃值、池子的最大值等,这些特征可以直接映射到java线程池和数据库连接池的成员属性中。——这篇文章对[池化设计思想](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485679&idx=1&sn=57dbca8c9ad49e1f3968ecff04a4f735&chksm=cea24724f9d5ce3212292fac291234a760c99c0960b5430d714269efe33554730b5f71208582&token=1141994790&lang=zh_CN#rd)介绍的还不错,直接复制过来,避免重复造轮子了。
|
||||
池化设计应该不是一个新名词。我们常见的如java线程池、jdbc连接池、redis连接池等就是这类设计的代表实现。这种设计会初始预设资源,解决的问题就是抵消每次获取资源的消耗,如创建线程的开销,获取远程连接的开销等。就好比你去食堂打饭,打饭的大妈会先把饭盛好几份放那里,你来了就直接拿着饭盒加菜即可,不用再临时又盛饭又打菜,效率就高了。除了初始化资源,池化设计还包括如下这些特征:池子的初始值、池子的活跃值、池子的最大值等,这些特征可以直接映射到java线程池和数据库连接池的成员属性中。这篇文章对[池化设计思想](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485679&idx=1&sn=57dbca8c9ad49e1f3968ecff04a4f735&chksm=cea24724f9d5ce3212292fac291234a760c99c0960b5430d714269efe33554730b5f71208582&token=1141994790&lang=zh_CN#rd)介绍的还不错,直接复制过来,避免重复造轮子了。
|
||||
|
||||
数据库连接本质就是一个 socket 的连接。数据库服务端还要维护一些缓存和用户权限信息之类的 所以占用了一些内存。我们可以把数据库连接池是看做是维护的数据库连接的缓存,以便将来需要对数据库的请求时可以重用这些连接。为每个用户打开和维护数据库连接,尤其是对动态数据库驱动的网站应用程序的请求,既昂贵又浪费资源。**在连接池中,创建连接后,将其放置在池中,并再次使用它,因此不必建立新的连接。如果使用了所有连接,则会建立一个新连接并将其添加到池中。**连接池还减少了用户必须等待建立与数据库的连接的时间。
|
||||
数据库连接本质就是一个 socket 的连接。数据库服务端还要维护一些缓存和用户权限信息之类的 所以占用了一些内存。我们可以把数据库连接池是看做是维护的数据库连接的缓存,以便将来需要对数据库的请求时可以重用这些连接。为每个用户打开和维护数据库连接,尤其是对动态数据库驱动的网站应用程序的请求,既昂贵又浪费资源。**在连接池中,创建连接后,将其放置在池中,并再次使用它,因此不必建立新的连接。如果使用了所有连接,则会建立一个新连接并将其添加到池中**。 连接池还减少了用户必须等待建立与数据库的连接的时间。
|
||||
|
||||
### 分库分表之后,id 主键如何处理?
|
||||
|
||||
|
||||
@ -35,7 +35,7 @@
|
||||
- [2. 避免数据类型的隐式转换](#2-避免数据类型的隐式转换)
|
||||
- [3. 充分利用表上已经存在的索引](#3-充分利用表上已经存在的索引)
|
||||
- [4. 数据库设计时,应该要对以后扩展进行考虑](#4-数据库设计时应该要对以后扩展进行考虑)
|
||||
- [5. 程序连接不同的数据库使用不同的账号,进制跨库查询](#5-程序连接不同的数据库使用不同的账号进制跨库查询)
|
||||
- [5. 程序连接不同的数据库使用不同的账号,禁止跨库查询](#5-程序连接不同的数据库使用不同的账号禁止跨库查询)
|
||||
- [6. 禁止使用 SELECT * 必须使用 SELECT <字段列表> 查询](#6-禁止使用-select--必须使用-select-字段列表-查询)
|
||||
- [7. 禁止使用不含字段列表的 INSERT 语句](#7-禁止使用不含字段列表的-insert-语句)
|
||||
- [8. 避免使用子查询,可以把子查询优化为 join 操作](#8-避免使用子查询可以把子查询优化为-join-操作)
|
||||
@ -76,6 +76,8 @@ Innodb 支持事务,支持行级锁,更好的恢复性,高并发下性能
|
||||
|
||||
兼容性更好,统一字符集可以避免由于字符集转换产生的乱码,不同的字符集进行比较前需要进行转换会造成索引失效,如果数据库中有存储 emoji 表情的需要,字符集需要采用 utf8mb4 字符集。
|
||||
|
||||
参考文章:[MySQL 字符集不一致导致索引失效的一个真实案例](https://blog.csdn.net/horses/article/details/107243447)
|
||||
|
||||
### 3. 所有表和字段都需要添加注释
|
||||
|
||||
使用 comment 从句添加表和列的备注,从一开始就进行数据字典的维护
|
||||
|
||||
@ -1,370 +0,0 @@
|
||||
点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
|
||||
|
||||
<!-- TOC -->
|
||||
|
||||
- [redis 简介](#redis-简介)
|
||||
- [为什么要用 redis/为什么要用缓存](#为什么要用-redis为什么要用缓存)
|
||||
- [为什么要用 redis 而不用 map/guava 做缓存?](#为什么要用-redis-而不用-mapguava-做缓存)
|
||||
- [redis 和 memcached 的区别](#redis-和-memcached-的区别)
|
||||
- [redis 常见数据结构以及使用场景分析](#redis-常见数据结构以及使用场景分析)
|
||||
- [1.String](#1string)
|
||||
- [2.Hash](#2hash)
|
||||
- [3.List](#3list)
|
||||
- [4.Set](#4set)
|
||||
- [5.Sorted Set](#5sorted-set)
|
||||
- [redis 设置过期时间](#redis-设置过期时间)
|
||||
- [redis 内存淘汰机制(MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据?)](#redis-内存淘汰机制mysql里有2000w数据redis中只存20w的数据如何保证redis中的数据都是热点数据)
|
||||
- [redis 持久化机制(怎么保证 redis 挂掉之后再重启数据可以进行恢复)](#redis-持久化机制怎么保证-redis-挂掉之后再重启数据可以进行恢复)
|
||||
- [redis 事务](#redis-事务)
|
||||
- [缓存雪崩和缓存穿透问题解决方案](#缓存雪崩和缓存穿透问题解决方案)
|
||||
- [如何解决 Redis 的并发竞争 Key 问题](#如何解决-redis-的并发竞争-key-问题)
|
||||
- [如何保证缓存与数据库双写时的数据一致性?](#如何保证缓存与数据库双写时的数据一致性)
|
||||
|
||||
<!-- /TOC -->
|
||||
|
||||
### redis 简介
|
||||
|
||||
简单来说 redis 就是一个数据库,不过与传统数据库不同的是 redis 的数据是存在内存中的,所以读写速度非常快,因此 redis 被广泛应用于缓存方向。另外,redis 也经常用来做分布式锁。redis 提供了多种数据类型来支持不同的业务场景。除此之外,redis 支持事务 、持久化、LUA脚本、LRU驱动事件、多种集群方案。
|
||||
|
||||
### 为什么要用 redis/为什么要用缓存
|
||||
|
||||
主要从“高性能”和“高并发”这两点来看待这个问题。
|
||||
|
||||
**高性能:**
|
||||
|
||||
假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
|
||||
|
||||
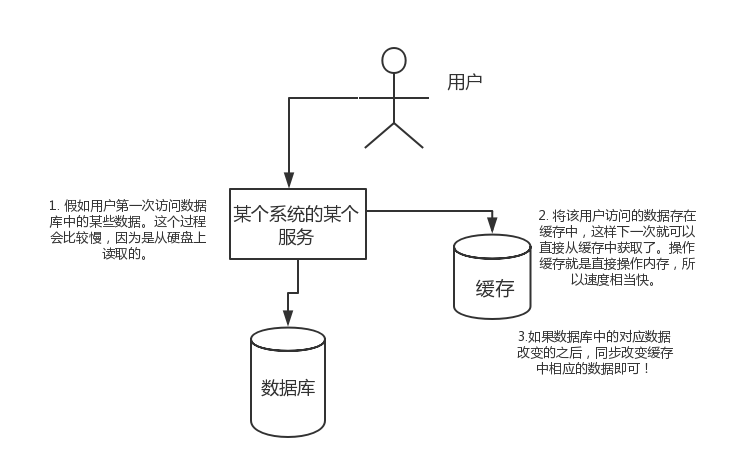
|
||||
|
||||
|
||||
**高并发:**
|
||||
|
||||
直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
|
||||
|
||||
|
||||
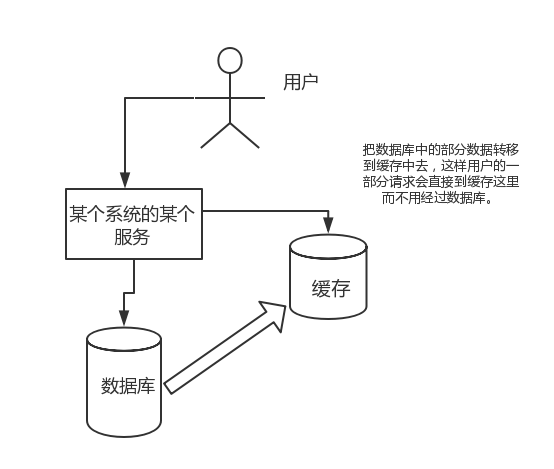
|
||||
|
||||
|
||||
### 为什么要用 redis 而不用 map/guava 做缓存?
|
||||
|
||||
|
||||
>下面的内容来自 segmentfault 一位网友的提问,地址:https://segmentfault.com/q/1010000009106416
|
||||
|
||||
缓存分为本地缓存和分布式缓存。以 Java 为例,使用自带的 map 或者 guava 实现的是本地缓存,最主要的特点是轻量以及快速,生命周期随着 jvm 的销毁而结束,并且在多实例的情况下,每个实例都需要各自保存一份缓存,缓存不具有一致性。
|
||||
|
||||
使用 redis 或 memcached 之类的称为分布式缓存,在多实例的情况下,各实例共用一份缓存数据,缓存具有一致性。缺点是需要保持 redis 或 memcached服务的高可用,整个程序架构上较为复杂。
|
||||
|
||||
### redis 的线程模型
|
||||
|
||||
> 参考地址:https://www.javazhiyin.com/22943.html
|
||||
|
||||
redis 内部使用文件事件处理器 `file event handler`,这个文件事件处理器是单线程的,所以 redis 才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 socket,根据 socket 上的事件来选择对应的事件处理器进行处理。
|
||||
|
||||
文件事件处理器的结构包含 4 个部分:
|
||||
|
||||
- 多个 socket
|
||||
- IO 多路复用程序
|
||||
- 文件事件分派器
|
||||
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
|
||||
|
||||
多个 socket 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 socket,会将 socket 产生的事件放入队列中排队,事件分派器每次从队列中取出一个事件,把该事件交给对应的事件处理器进行处理。
|
||||
|
||||
|
||||
### redis 和 memcached 的区别
|
||||
|
||||
对于 redis 和 memcached 我总结了下面四点。现在公司一般都是用 redis 来实现缓存,而且 redis 自身也越来越强大了!
|
||||
|
||||
1. **redis支持更丰富的数据类型(支持更复杂的应用场景)**:Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。memcache支持简单的数据类型,String。
|
||||
2. **Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而Memecache把数据全部存在内存之中。**
|
||||
3. **集群模式**:memcached没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 redis 目前是原生支持 cluster 模式的.
|
||||
4. **Memcached是多线程,非阻塞IO复用的网络模型;Redis使用单线程的多路 IO 复用模型。**
|
||||
|
||||
|
||||
> 来自网络上的一张图,这里分享给大家!
|
||||
|
||||
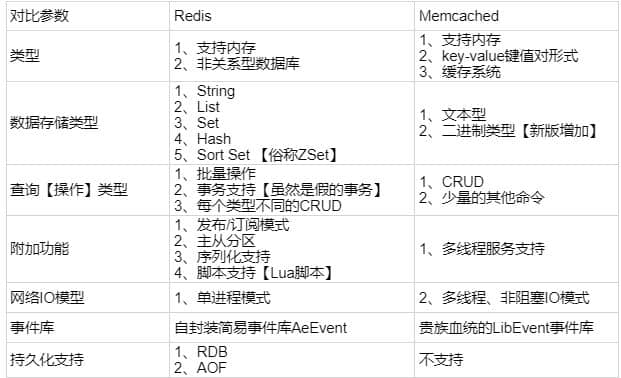
|
||||
|
||||
|
||||
### redis 常见数据结构以及使用场景分析
|
||||
|
||||
#### 1.String
|
||||
|
||||
> **常用命令:** set,get,decr,incr,mget 等。
|
||||
|
||||
|
||||
String数据结构是简单的key-value类型,value其实不仅可以是String,也可以是数字。
|
||||
常规key-value缓存应用;
|
||||
常规计数:微博数,粉丝数等。
|
||||
|
||||
#### 2.Hash
|
||||
> **常用命令:** hget,hset,hgetall 等。
|
||||
|
||||
hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象,后续操作的时候,你可以直接仅仅修改这个对象中的某个字段的值。 比如我们可以 hash 数据结构来存储用户信息,商品信息等等。比如下面我就用 hash 类型存放了我本人的一些信息:
|
||||
|
||||
```
|
||||
key=JavaUser293847
|
||||
value={
|
||||
“id”: 1,
|
||||
“name”: “SnailClimb”,
|
||||
“age”: 22,
|
||||
“location”: “Wuhan, Hubei”
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
|
||||
#### 3.List
|
||||
> **常用命令:** lpush,rpush,lpop,rpop,lrange等
|
||||
|
||||
list 就是链表,Redis list 的应用场景非常多,也是Redis最重要的数据结构之一,比如微博的关注列表,粉丝列表,消息列表等功能都可以用Redis的 list 结构来实现。
|
||||
|
||||
Redis list 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。
|
||||
|
||||
另外可以通过 lrange 命令,就是从某个元素开始读取多少个元素,可以基于 list 实现分页查询,这个很棒的一个功能,基于 redis 实现简单的高性能分页,可以做类似微博那种下拉不断分页的东西(一页一页的往下走),性能高。
|
||||
|
||||
#### 4.Set
|
||||
|
||||
> **常用命令:**
|
||||
sadd,spop,smembers,sunion 等
|
||||
|
||||
set 对外提供的功能与list类似是一个列表的功能,特殊之处在于 set 是可以自动排重的。
|
||||
|
||||
当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。可以基于 set 轻易实现交集、并集、差集的操作。
|
||||
|
||||
比如:在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程,具体命令如下:
|
||||
|
||||
```
|
||||
sinterstore key1 key2 key3 将交集存在key1内
|
||||
```
|
||||
|
||||
#### 5.Sorted Set
|
||||
> **常用命令:** zadd,zrange,zrem,zcard等
|
||||
|
||||
|
||||
和set相比,sorted set增加了一个权重参数score,使得集合中的元素能够按score进行有序排列。
|
||||
|
||||
**举例:** 在直播系统中,实时排行信息包含直播间在线用户列表,各种礼物排行榜,弹幕消息(可以理解为按消息维度的消息排行榜)等信息,适合使用 Redis 中的 Sorted Set 结构进行存储。
|
||||
|
||||
|
||||
### redis 设置过期时间
|
||||
|
||||
Redis中有个设置时间过期的功能,即对存储在 redis 数据库中的值可以设置一个过期时间。作为一个缓存数据库,这是非常实用的。如我们一般项目中的 token 或者一些登录信息,尤其是短信验证码都是有时间限制的,按照传统的数据库处理方式,一般都是自己判断过期,这样无疑会严重影响项目性能。
|
||||
|
||||
我们 set key 的时候,都可以给一个 expire time,就是过期时间,通过过期时间我们可以指定这个 key 可以存活的时间。
|
||||
|
||||
如果假设你设置了一批 key 只能存活1个小时,那么接下来1小时后,redis是怎么对这批key进行删除的?
|
||||
|
||||
**定期删除+惰性删除。**
|
||||
|
||||
通过名字大概就能猜出这两个删除方式的意思了。
|
||||
|
||||
- **定期删除**:redis默认是每隔 100ms 就**随机抽取**一些设置了过期时间的key,检查其是否过期,如果过期就删除。注意这里是随机抽取的。为什么要随机呢?你想一想假如 redis 存了几十万个 key ,每隔100ms就遍历所有的设置过期时间的 key 的话,就会给 CPU 带来很大的负载!
|
||||
- **惰性删除** :定期删除可能会导致很多过期 key 到了时间并没有被删除掉。所以就有了惰性删除。假如你的过期 key,靠定期删除没有被删除掉,还停留在内存里,除非你的系统去查一下那个 key,才会被redis给删除掉。这就是所谓的惰性删除,也是够懒的哈!
|
||||
|
||||
|
||||
但是仅仅通过设置过期时间还是有问题的。我们想一下:如果定期删除漏掉了很多过期 key,然后你也没及时去查,也就没走惰性删除,此时会怎么样?如果大量过期key堆积在内存里,导致redis内存块耗尽了。怎么解决这个问题呢? **redis 内存淘汰机制。**
|
||||
|
||||
### redis 内存淘汰机制(MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据?)
|
||||
|
||||
redis 配置文件 redis.conf 中有相关注释,我这里就不贴了,大家可以自行查阅或者通过这个网址查看: [http://download.redis.io/redis-stable/redis.conf](http://download.redis.io/redis-stable/redis.conf)
|
||||
|
||||
**redis 提供 6种数据淘汰策略:**
|
||||
|
||||
1. **volatile-lru**:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
|
||||
2. **volatile-ttl**:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
|
||||
3. **volatile-random**:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
|
||||
4. **allkeys-lru**:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
|
||||
5. **allkeys-random**:从数据集(server.db[i].dict)中任意选择数据淘汰
|
||||
6. **no-eviction**:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
|
||||
|
||||
4.0版本后增加以下两种:
|
||||
|
||||
7. **volatile-lfu**:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
|
||||
8. **allkeys-lfu**:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的key
|
||||
|
||||
**备注: 关于 redis 设置过期时间以及内存淘汰机制,我这里只是简单的总结一下,后面会专门写一篇文章来总结!**
|
||||
|
||||
|
||||
### redis 持久化机制(怎么保证 redis 挂掉之后再重启数据可以进行恢复)
|
||||
|
||||
很多时候我们需要持久化数据也就是将内存中的数据写入到硬盘里面,大部分原因是为了之后重用数据(比如重启机器、机器故障之后恢复数据),或者是为了防止系统故障而将数据备份到一个远程位置。
|
||||
|
||||
Redis不同于Memcached的很重一点就是,Redis支持持久化,而且支持两种不同的持久化操作。**Redis的一种持久化方式叫快照(snapshotting,RDB),另一种方式是只追加文件(append-only file,AOF)**。这两种方法各有千秋,下面我会详细这两种持久化方法是什么,怎么用,如何选择适合自己的持久化方法。
|
||||
|
||||
**快照(snapshotting)持久化(RDB)**
|
||||
|
||||
Redis可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本。Redis创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis主从结构,主要用来提高Redis性能),还可以将快照留在原地以便重启服务器的时候使用。
|
||||
|
||||
快照持久化是Redis默认采用的持久化方式,在redis.conf配置文件中默认有此下配置:
|
||||
|
||||
```conf
|
||||
|
||||
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
|
||||
|
||||
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
|
||||
|
||||
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
|
||||
```
|
||||
|
||||
**AOF(append-only file)持久化**
|
||||
|
||||
与快照持久化相比,AOF持久化 的实时性更好,因此已成为主流的持久化方案。默认情况下Redis没有开启AOF(append only file)方式的持久化,可以通过appendonly参数开启:
|
||||
|
||||
```conf
|
||||
appendonly yes
|
||||
```
|
||||
|
||||
开启AOF持久化后每执行一条会更改Redis中的数据的命令,Redis就会将该命令写入硬盘中的AOF文件。AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的,默认的文件名是appendonly.aof。
|
||||
|
||||
在Redis的配置文件中存在三种不同的 AOF 持久化方式,它们分别是:
|
||||
|
||||
```conf
|
||||
appendfsync always #每次有数据修改发生时都会写入AOF文件,这样会严重降低Redis的速度
|
||||
appendfsync everysec #每秒钟同步一次,显示地将多个写命令同步到硬盘
|
||||
appendfsync no #让操作系统决定何时进行同步
|
||||
```
|
||||
|
||||
为了兼顾数据和写入性能,用户可以考虑 appendfsync everysec选项 ,让Redis每秒同步一次AOF文件,Redis性能几乎没受到任何影响。而且这样即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis还会优雅的放慢自己的速度以便适应硬盘的最大写入速度。
|
||||
|
||||
**Redis 4.0 对于持久化机制的优化**
|
||||
|
||||
Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 `aof-use-rdb-preamble` 开启)。
|
||||
|
||||
如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
|
||||
|
||||
**补充内容:AOF 重写**
|
||||
|
||||
AOF重写可以产生一个新的AOF文件,这个新的AOF文件和原有的AOF文件所保存的数据库状态一样,但体积更小。
|
||||
|
||||
AOF重写是一个有歧义的名字,该功能是通过读取数据库中的键值对来实现的,程序无须对现有AOF文件进行任何读入、分析或者写入操作。
|
||||
|
||||
在执行 BGREWRITEAOF 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子进程创建新AOF文件期间,记录服务器执行的所有写命令。当子进程完成创建新AOF文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新AOF文件的末尾,使得新旧两个AOF文件所保存的数据库状态一致。最后,服务器用新的AOF文件替换旧的AOF文件,以此来完成AOF文件重写操作
|
||||
|
||||
**更多内容可以查看我的这篇文章:**
|
||||
|
||||
- [Redis持久化](Redis持久化.md)
|
||||
|
||||
|
||||
### redis 事务
|
||||
|
||||
Redis 通过 MULTI、EXEC、WATCH 等命令来实现事务(transaction)功能。事务提供了一种将多个命令请求打包,然后一次性、按顺序地执行多个命令的机制,并且在事务执行期间,服务器不会中断事务而改去执行其他客户端的命令请求,它会将事务中的所有命令都执行完毕,然后才去处理其他客户端的命令请求。
|
||||
|
||||
在传统的关系式数据库中,常常用 ACID 性质来检验事务功能的可靠性和安全性。在 Redis 中,事务总是具有原子性(Atomicity)、一致性(Consistency)和隔离性(Isolation),并且当 Redis 运行在某种特定的持久化模式下时,事务也具有持久性(Durability)。
|
||||
|
||||
补充内容:
|
||||
|
||||
> 1. redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚。(来自[issue:关于Redis事务不是原子性问题](https://github.com/Snailclimb/JavaGuide/issues/452) )
|
||||
|
||||
### 缓存雪崩和缓存穿透问题解决方案
|
||||
|
||||
#### **缓存雪崩**
|
||||
|
||||
**什么是缓存雪崩?**
|
||||
|
||||
简介:缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
|
||||
|
||||
**有哪些解决办法?**
|
||||
|
||||
(中华石杉老师在他的视频中提到过,视频地址在最后一个问题中有提到):
|
||||
|
||||
- 事前:尽量保证整个 redis 集群的高可用性,发现机器宕机尽快补上。选择合适的内存淘汰策略。
|
||||
- 事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL崩掉
|
||||
- 事后:利用 redis 持久化机制保存的数据尽快恢复缓存
|
||||
|
||||
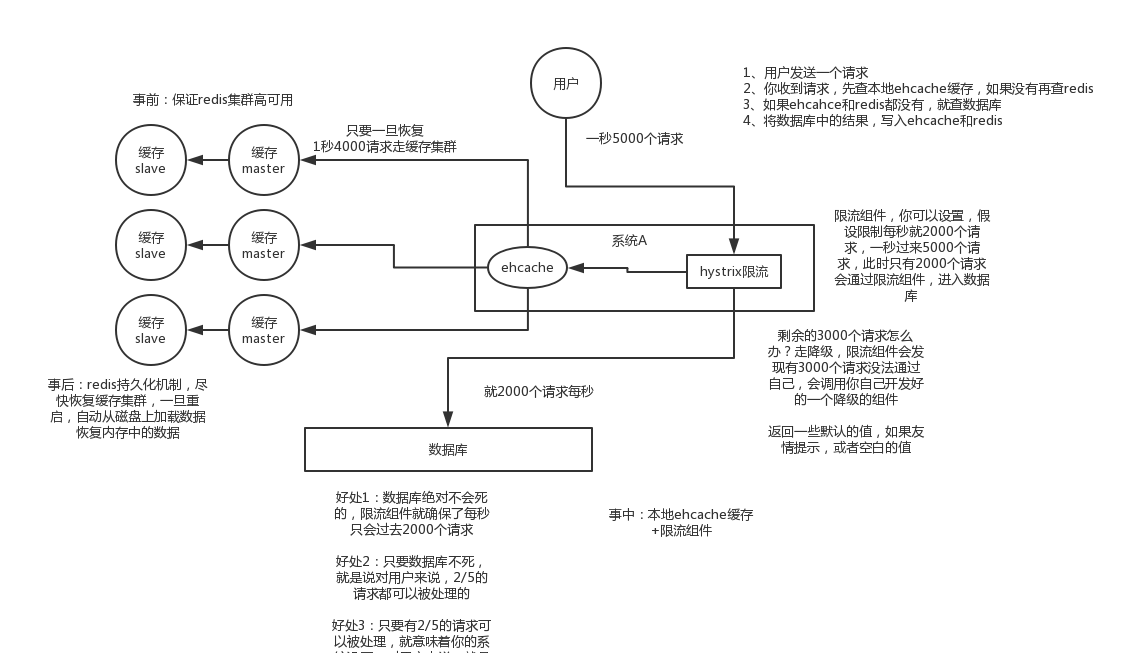
|
||||
|
||||
#### **缓存穿透**
|
||||
|
||||
**什么是缓存穿透?**
|
||||
|
||||
缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。下面用图片展示一下(这两张图片不是我画的,为了省事直接在网上找的,这里说明一下):
|
||||
|
||||
**正常缓存处理流程:**
|
||||
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/正常缓存处理流程-redis.png" style="zoom:50%;" />
|
||||
|
||||
**缓存穿透情况处理流程:**
|
||||
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/缓存穿透处理流程-redis.png" style="zoom:50%;" />
|
||||
|
||||
一般MySQL 默认的最大连接数在 150 左右,这个可以通过 `show variables like '%max_connections%'; `命令来查看。最大连接数一个还只是一个指标,cpu,内存,磁盘,网络等无力条件都是其运行指标,这些指标都会限制其并发能力!所以,一般 3000 个并发请求就能打死大部分数据库了。
|
||||
|
||||
**有哪些解决办法?**
|
||||
|
||||
最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
|
||||
|
||||
**1)缓存无效 key** : 如果缓存和数据库都查不到某个 key 的数据就写一个到 redis 中去并设置过期时间,具体命令如下:`SET key value EX 10086`。这种方式可以解决请求的 key 变化不频繁的情况,如果黑客恶意攻击,每次构建不同的请求key,会导致 redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。
|
||||
|
||||
另外,这里多说一嘴,一般情况下我们是这样设计 key 的: `表名:列名:主键名:主键值`。
|
||||
|
||||
如果用 Java 代码展示的话,差不多是下面这样的:
|
||||
|
||||
```java
|
||||
public Object getObjectInclNullById(Integer id) {
|
||||
// 从缓存中获取数据
|
||||
Object cacheValue = cache.get(id);
|
||||
// 缓存为空
|
||||
if (cacheValue == null) {
|
||||
// 从数据库中获取
|
||||
Object storageValue = storage.get(key);
|
||||
// 缓存空对象
|
||||
cache.set(key, storageValue);
|
||||
// 如果存储数据为空,需要设置一个过期时间(300秒)
|
||||
if (storageValue == null) {
|
||||
// 必须设置过期时间,否则有被攻击的风险
|
||||
cache.expire(key, 60 * 5);
|
||||
}
|
||||
return storageValue;
|
||||
}
|
||||
return cacheValue;
|
||||
}
|
||||
```
|
||||
|
||||
**2)布隆过滤器:**布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在与海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。具体是这样做的:把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,我会先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。总结一下就是下面这张图(这张图片不是我画的,为了省事直接在网上找的):
|
||||
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/布隆过滤器-缓存穿透-redis.png" style="zoom:50%;" />
|
||||
|
||||
更多关于布隆过滤器的内容可以看我的这篇原创:[《不了解布隆过滤器?一文给你整的明明白白!》](https://github.com/Snailclimb/JavaGuide/blob/master/docs/dataStructures-algorithms/data-structure/bloom-filter.md) ,强烈推荐,个人感觉网上应该找不到总结的这么明明白白的文章了。
|
||||
|
||||
### 如何解决 Redis 的并发竞争 Key 问题
|
||||
|
||||
所谓 Redis 的并发竞争 Key 的问题也就是多个系统同时对一个 key 进行操作,但是最后执行的顺序和我们期望的顺序不同,这样也就导致了结果的不同!
|
||||
|
||||
推荐一种方案:分布式锁(zookeeper 和 redis 都可以实现分布式锁)。(如果不存在 Redis 的并发竞争 Key 问题,不要使用分布式锁,这样会影响性能)
|
||||
|
||||
基于zookeeper临时有序节点可以实现的分布式锁。大致思想为:每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。完成业务流程后,删除对应的子节点释放锁。
|
||||
|
||||
在实践中,当然是从以可靠性为主。所以首推Zookeeper。
|
||||
|
||||
参考:
|
||||
|
||||
- https://www.jianshu.com/p/8bddd381de06
|
||||
|
||||
### 如何保证缓存与数据库双写时的数据一致性?
|
||||
|
||||
> 一般情况下我们都是这样使用缓存的:先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。这种方式很明显会存在缓存和数据库的数据不一致的情况。
|
||||
|
||||
你只要用缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题?
|
||||
|
||||
一般来说,就是如果你的系统不是严格要求缓存+数据库必须一致性的话,缓存可以稍微的跟数据库偶尔有不一致的情况,最好不要做这个方案,读请求和写请求串行化,串到一个内存队列里去,这样就可以保证一定不会出现不一致的情况
|
||||
|
||||
串行化之后,就会导致系统的吞吐量会大幅度的降低,用比正常情况下多几倍的机器去支撑线上的一个请求。
|
||||
|
||||
更多内容可以查看:https://github.com/doocs/advanced-java/blob/master/docs/high-concurrency/redis-consistence.md
|
||||
|
||||
**参考:** Java工程师面试突击第1季(可能是史上最好的Java面试突击课程)-中华石杉老师!公众号后台回复关键字“1”即可获取该视频内容。
|
||||
|
||||
### 参考
|
||||
|
||||
- 《Redis开发与运维》
|
||||
- Redis 命令总结:http://redisdoc.com/string/set.html
|
||||
|
||||
## 公众号
|
||||
|
||||
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
|
||||
|
||||
**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
|
||||
|
||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
|
||||

|
||||
@ -1,5 +1,4 @@
|
||||
|
||||
|
||||
非常感谢《redis实战》真本书,本文大多内容也参考了书中的内容。非常推荐大家看一下《redis实战》这本书,感觉书中的很多理论性东西还是很不错的。
|
||||
|
||||
为什么本文的名字要加上春夏秋冬又一春,哈哈 ,这是一部韩国的电影,我感觉电影不错,所以就用在文章名字上了,没有什么特别的含义,然后下面的有些配图也是电影相关镜头。
|
||||
@ -10,12 +9,10 @@
|
||||
|
||||
Redis不同于Memcached的很重一点就是,**Redis支持持久化**,而且支持两种不同的持久化操作。Redis的一种持久化方式叫**快照(snapshotting,RDB)**,另一种方式是**只追加文件(append-only file,AOF)**.这两种方法各有千秋,下面我会详细这两种持久化方法是什么,怎么用,如何选择适合自己的持久化方法。
|
||||
|
||||
|
||||
## 快照(snapshotting)持久化
|
||||
|
||||
Redis可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本。Redis创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis主从结构,主要用来提高Redis性能),还可以将快照留在原地以便重启服务器的时候使用。
|
||||
|
||||
|
||||

|
||||
|
||||
**快照持久化是Redis默认采用的持久化方式**,在redis.conf配置文件中默认有此下配置:
|
||||
@ -46,6 +43,7 @@ save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生
|
||||
|
||||
## **AOF(append-only file)持久化**
|
||||
与快照持久化相比,AOF持久化 的实时性更好,因此已成为主流的持久化方案。默认情况下Redis没有开启AOF(append only file)方式的持久化,可以通过appendonly参数开启:
|
||||
|
||||
```
|
||||
appendonly yes
|
||||
```
|
||||
|
||||
1
docs/database/Redis/images/redis-all/redis-list.drawio
Normal file
@ -0,0 +1 @@
|
||||
<mxfile host="Electron" modified="2020-07-27T06:27:52.340Z" agent="5.0 (Macintosh; Intel Mac OS X 10_15_4) AppleWebKit/537.36 (KHTML, like Gecko) draw.io/13.4.5 Chrome/83.0.4103.122 Electron/9.1.0 Safari/537.36" etag="dsqbsLB26jrO3YkREjOb" version="13.4.5" type="device"><diagram id="tTBfL0GptSJyUtbD2ZoE" name="Page-1">7VlNc5swFPw1PiaDENjmmNjpx6Gdjt1J2lNHAzKoEYgRcmzn11cYyRgJT1w3DnScU3grIaHd5b2HM4CTdP2Rozz5wiJMB64TrQdwOnBdEEAo/5TIpkICx6mAmJNITaqBOXnGCtTTliTCRWOiYIwKkjfBkGUZDkUDQ5yzVXPagtHmrjmKsQXMQ0Rt9IFEIqnQsTuq8U+YxIneGQyDaiRFerI6SZGgiK32IHg3gBPOmKiu0vUE05I8zUt134cDo7sH4zgTx9wwu/+V/H4g/myezsD35/vZ56/ulVrlCdGlOrB6WLHRDHC2zCJcLgIG8HaVEIHnOQrL0ZXUXGKJSKkaLh6xCBMVLFgmlKJgJGO1F+YCrw8eAuyokZ7CLMWCb+QUdcOVp9hUdnKhile1OL62WLInzEhhSPkh3i1dUyYvFGt/waBrMbi9BD3lUfPm2bwFLbT556INttPWc/sB035d0+i10wj7TaM77hmNw5fTIM6im7KeyCikqChI2ORMHp1vfsjA0cHPMrh2fR1P1/uj042KjiAbR1aRMqiWVRHxGIuXUr0tSSNxHqacY4oEeWo+RpsOaodvjMgHrPM2gKbk4+YaBVvyEKvb9suYuZLpHdcwRUWEtdDWF7tzn26V0f9ula4s4A0N4cbOtX+aB3zfWupNPaCb01cxAXjPF0cofGq68AJjIT8wXXdusxzRY/fbLJ0VDbPbOj1j2PXnrVOG/Z3A82WRWFaQXZUwujHB2SOeMMq4RDKW4VJLQqkBIUrirHSQVA9L/Lbs0Yj8lL1RAymJonKb1vavbhCP9M0/dYA+OFDF95zltTjLLPav1gECu5PmOcvf5aloD7qWx7fkoRf8+siiYggEuhbI/oSil/v+2Pp0/gLZ3y18u20/BTqDJp5O8VoSp2tJxvYrgxcXpIjV351PERnWv7RXPV39/wp49wc=</diagram></mxfile>
|
||||
BIN
docs/database/Redis/images/redis-all/redis-list.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 18 KiB |
BIN
docs/database/Redis/images/redis-all/redis-rollBack.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 275 KiB |
BIN
docs/database/Redis/images/redis-all/redis-vs-memcached.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 180 KiB |
BIN
docs/database/Redis/images/redis-all/redis4.0-more-thread.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 412 KiB |
BIN
docs/database/Redis/images/redis-all/redis事件处理器.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 60 KiB |
BIN
docs/database/Redis/images/redis-all/redis事务.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 336 KiB |
BIN
docs/database/Redis/images/redis-all/redis过期时间.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 399 KiB |
BIN
docs/database/Redis/images/redis-all/try-redis.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 67 KiB |
BIN
docs/database/Redis/images/redis-all/what-is-redis.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 116 KiB |
BIN
docs/database/Redis/images/redis-all/使用缓存之后.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 72 KiB |
BIN
docs/database/Redis/images/redis-all/加入布隆过滤器后的缓存处理流程.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 45 KiB |
BIN
docs/database/Redis/images/redis-all/单体架构.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 17 KiB |
BIN
docs/database/Redis/images/redis-all/缓存的处理流程.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 38 KiB |
BIN
docs/database/Redis/images/redis-all/缓存穿透情况.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 38 KiB |
BIN
docs/database/Redis/images/redis-all/集中式缓存架构.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 17 KiB |
714
docs/database/Redis/redis-all.md
Normal file
@ -0,0 +1,714 @@
|
||||
点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java 面试突击》以及 Java 工程师必备学习资源。
|
||||
|
||||
|
||||
<!-- @import "[TOC]" {cmd="toc" depthFrom=1 depthTo=6 orderedList=false} -->
|
||||
|
||||
<!-- code_chunk_output -->
|
||||
|
||||
- [1. 简单介绍一下 Redis 呗!](#1-简单介绍一下-redis-呗)
|
||||
- [2. 分布式缓存常见的技术选型方案有哪些?](#2-分布式缓存常见的技术选型方案有哪些)
|
||||
- [3. 说一下 Redis 和 Memcached 的区别和共同点](#3-说一下-redis-和-memcached-的区别和共同点)
|
||||
- [4. 缓存数据的处理流程是怎样的?](#4-缓存数据的处理流程是怎样的)
|
||||
- [5. 为什么要用 Redis/为什么要用缓存?](#5-为什么要用-redis为什么要用缓存)
|
||||
- [6. Redis 常见数据结构以及使用场景分析](#6-redis-常见数据结构以及使用场景分析)
|
||||
- [6.1. string](#61-string)
|
||||
- [6.2. list](#62-list)
|
||||
- [6.3. hash](#63-hash)
|
||||
- [6.4. set](#64-set)
|
||||
- [6.5. sorted set](#65-sorted-set)
|
||||
- [7. Redis 单线程模型详解](#7-redis-单线程模型详解)
|
||||
- [8. Redis 没有使用多线程?为什么不使用多线程?](#8-redis-没有使用多线程为什么不使用多线程)
|
||||
- [9. Redis6.0 之后为何引入了多线程?](#9-redis60-之后为何引入了多线程)
|
||||
- [10. Redis 给缓存数据设置过期时间有啥用?](#10-redis-给缓存数据设置过期时间有啥用)
|
||||
- [11. Redis是如何判断数据是否过期的呢?](#11-redis是如何判断数据是否过期的呢)
|
||||
- [12. 过期的数据的删除策略了解么?](#12-过期的数据的删除策略了解么)
|
||||
- [13. Redis 内存淘汰机制了解么?](#13-redis-内存淘汰机制了解么)
|
||||
- [14. Redis 持久化机制(怎么保证 Redis 挂掉之后再重启数据可以进行恢复)](#14-redis-持久化机制怎么保证-redis-挂掉之后再重启数据可以进行恢复)
|
||||
- [15. Redis 事务](#15-redis-事务)
|
||||
- [16. 缓存穿透](#16-缓存穿透)
|
||||
- [16.1. 什么是缓存穿透?](#161-什么是缓存穿透)
|
||||
- [16.2. 缓存穿透情况的处理流程是怎样的?](#162-缓存穿透情况的处理流程是怎样的)
|
||||
- [16.3. 有哪些解决办法?](#163-有哪些解决办法)
|
||||
- [17. 缓存雪崩](#17-缓存雪崩)
|
||||
- [17.1. 什么是缓存雪崩?](#171-什么是缓存雪崩)
|
||||
- [17.2. 有哪些解决办法?](#172-有哪些解决办法)
|
||||
- [18. 如何保证缓存与数据库双写时的数据一致性?](#18-如何保证缓存与数据库双写时的数据一致性)
|
||||
- [19. 参考](#19-参考)
|
||||
- [20. 公众号](#20-公众号)
|
||||
|
||||
<!-- /code_chunk_output -->
|
||||
|
||||
|
||||
### 1. 简单介绍一下 Redis 呗!
|
||||
|
||||
简单来说 **Redis 就是一个使用 C 语言开发的数据库**,不过与传统数据库不同的是 **Redis 的数据是存在内存中的** ,也就是它是内存数据库,所以读写速度非常快,因此 Redis 被广泛应用于缓存方向。
|
||||
|
||||
另外,**Redis 除了做缓存之外,Redis 也经常用来做分布式锁,甚至是消息队列。**
|
||||
|
||||
**Redis 提供了多种数据类型来支持不同的业务场景。Redis 还支持事务 、持久化、Lua 脚本、多种集群方案。**
|
||||
|
||||
### 2. 分布式缓存常见的技术选型方案有哪些?
|
||||
|
||||
分布式缓存的话,使用的比较多的主要是 **Memcached** 和 **Redis**。不过,现在基本没有看过还有项目使用 **Memcached** 来做缓存,都是直接用 **Redis**。
|
||||
|
||||
Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来,随着 Redis 的发展,大家慢慢都转而使用更加强大的 Redis 了。
|
||||
|
||||
分布式缓存主要解决的是单机缓存的容量受服务器限制并且无法保存通用的信息。因为,本地缓存只在当前服务里有效,比如如果你部署了两个相同的服务,他们两者之间的缓存数据是无法共同的。
|
||||
|
||||
### 3. 说一下 Redis 和 Memcached 的区别和共同点
|
||||
|
||||
现在公司一般都是用 Redis 来实现缓存,而且 Redis 自身也越来越强大了!不过,了解 Redis 和 Memcached 的区别和共同点,有助于我们在做相应的技术选型的时候,能够做到有理有据!
|
||||
|
||||
**共同点** :
|
||||
|
||||
1. 都是基于内存的数据库,一般都用来当做缓存使用。
|
||||
2. 都有过期策略。
|
||||
3. 两者的性能都非常高。
|
||||
|
||||
**区别** :
|
||||
|
||||
1. **Redis 支持更丰富的数据类型(支持更复杂的应用场景)**。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list,set,zset,hash 等数据结构的存储。Memcached 只支持最简单的 k/v 数据类型。
|
||||
2. **Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而 Memecache 把数据全部存在内存之中。**
|
||||
3. **Redis 有灾难恢复机制。** 因为可以把缓存中的数据持久化到磁盘上。
|
||||
4. **Redis 在服务器内存使用完之后,可以将不用的数据放到磁盘上。但是,Memcached 在服务器内存使用完之后,就会直接报异常。**
|
||||
5. **Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 目前是原生支持 cluster 模式的.**
|
||||
6. **Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型。** (Redis 6.0 引入了多线程 IO )
|
||||
7. **Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。**
|
||||
8. **Memcached过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除。**
|
||||
|
||||
相信看了上面的对比之后,我们已经没有什么理由可以选择使用 Memcached 来作为自己项目的分布式缓存了。
|
||||
|
||||
### 4. 缓存数据的处理流程是怎样的?
|
||||
|
||||
作为暖男一号,我给大家画了一个草图。
|
||||
|
||||

|
||||
|
||||
简单来说就是:
|
||||
|
||||
1. 如果用户请求的数据在缓存中就直接返回。
|
||||
2. 缓存中不存在的话就看数据库中是否存在。
|
||||
3. 数据库中存在的话就更新缓存中的数据。
|
||||
4. 数据库中不存在的话就返回空数据。
|
||||
|
||||
### 5. 为什么要用 Redis/为什么要用缓存?
|
||||
|
||||
_简单,来说使用缓存主要是为了提升用户体验以及应对更多的用户。_
|
||||
|
||||
下面我们主要从“高性能”和“高并发”这两点来看待这个问题。
|
||||
|
||||

|
||||
|
||||
**高性能** :
|
||||
|
||||
对照上面 👆 我画的图。我们设想这样的场景:
|
||||
|
||||
假如用户第一次访问数据库中的某些数据的话,这个过程是比较慢,毕竟是从硬盘中读取的。但是,如果说,用户访问的数据属于高频数据并且不会经常改变的话,那么我们就可以很放心地将该用户访问的数据存在缓存中。
|
||||
|
||||
**这样有什么好处呢?** 那就是保证用户下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。
|
||||
|
||||
不过,要保持数据库和缓存中的数据的一致性。 如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
|
||||
|
||||
**高并发:**
|
||||
|
||||
一般像 MySQL 这类的数据库的 QPS 大概都在 1w 左右(4 核 8g) ,但是使用 Redis 缓存之后很容易达到 10w+,甚至最高能达到 30w+(就单机 redis 的情况,redis 集群的话会更高)。
|
||||
|
||||
> QPS(Query Per Second):服务器每秒可以执行的查询次数;
|
||||
|
||||
所以,直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高的系统整体的并发。
|
||||
|
||||
### 6. Redis 常见数据结构以及使用场景分析
|
||||
|
||||
你可以自己本机安装 redis 或者通过 redis 官网提供的[在线 redis 环境](https://try.redis.io/)。
|
||||
|
||||

|
||||
|
||||
#### 6.1. string
|
||||
|
||||
1. **介绍** :string 数据结构是简单的 key-value 类型。虽然 Redis 是用 C 语言写的,但是 Redis 并没有使用 C 的字符串表示,而是自己构建了一种 **简单动态字符串**(simple dynamic string,**SDS**)。相比于 C 的原生字符串,Redis 的 SDS 不光可以保存文本数据还可以保存二进制数据,并且获取字符串长度复杂度为 O(1)(C 字符串为 O(N)),除此之外,Redis 的 SDS API 是安全的,不会造成缓冲区溢出。
|
||||
2. **常用命令:** `set,get,strlen,exists,dect,incr,setex` 等等。
|
||||
3. **应用场景** :一般常用在需要计数的场景,比如用户的访问次数、热点文章的点赞转发数量等等。
|
||||
|
||||
下面我们简单看看它的使用!
|
||||
|
||||
**普通字符串的基本操作:**
|
||||
|
||||
``` bash
|
||||
127.0.0.1:6379> set key value #设置 key-value 类型的值
|
||||
OK
|
||||
127.0.0.1:6379> get key # 根据 key 获得对应的 value
|
||||
"value"
|
||||
127.0.0.1:6379> exists key # 判断某个 key 是否存在
|
||||
(integer) 1
|
||||
127.0.0.1:6379> strlen key # 返回 key 所储存的字符串值的长度。
|
||||
(integer) 5
|
||||
127.0.0.1:6379> del key # 删除某个 key 对应的值
|
||||
(integer) 1
|
||||
127.0.0.1:6379> get key
|
||||
(nil)
|
||||
```
|
||||
|
||||
**批量设置** :
|
||||
|
||||
``` bash
|
||||
127.0.0.1:6379> mset key1 value1 key2 value2 # 批量设置 key-value 类型的值
|
||||
OK
|
||||
127.0.0.1:6379> mget key1 key2 # 批量获取多个 key 对应的 value
|
||||
1) "value1"
|
||||
2) "value2"
|
||||
```
|
||||
|
||||
**计数器(字符串的内容为整数的时候可以使用):**
|
||||
|
||||
``` bash
|
||||
|
||||
127.0.0.1:6379> set number 1
|
||||
OK
|
||||
127.0.0.1:6379> incr number # 将 key 中储存的数字值增一
|
||||
(integer) 2
|
||||
127.0.0.1:6379> get number
|
||||
"2"
|
||||
127.0.0.1:6379> decr number # 将 key 中储存的数字值减一
|
||||
(integer) 1
|
||||
127.0.0.1:6379> get number
|
||||
"1"
|
||||
```
|
||||
|
||||
**过期**:
|
||||
|
||||
``` bash
|
||||
127.0.0.1:6379> expire key 60 # 数据在 60s 后过期
|
||||
(integer) 1
|
||||
127.0.0.1:6379> setex key 60 value # 数据在 60s 后过期 (setex:[set] + [ex]pire)
|
||||
OK
|
||||
127.0.0.1:6379> ttl key # 查看数据还有多久过期
|
||||
(integer) 56
|
||||
```
|
||||
|
||||
#### 6.2. list
|
||||
|
||||
1. **介绍** :**list** 即是 **链表**。链表是一种非常常见的数据结构,特点是易于数据元素的插入和删除并且且可以灵活调整链表长度,但是链表的随机访问困难。许多高级编程语言都内置了链表的实现比如 Java 中的 **LinkedList**,但是 C 语言并没有实现链表,所以 Redis 实现了自己的链表数据结构。Redis 的 list 的实现为一个 **双向链表**,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。
|
||||
2. **常用命令:** `rpush,lpop,lpush,rpop,lrange、llen` 等。
|
||||
3. **应用场景:** 发布与订阅或者说消息队列、慢查询。
|
||||
|
||||
下面我们简单看看它的使用!
|
||||
|
||||
**通过 `rpush/lpop` 实现队列:**
|
||||
|
||||
``` bash
|
||||
127.0.0.1:6379> rpush myList value1 # 向 list 的头部(右边)添加元素
|
||||
(integer) 1
|
||||
127.0.0.1:6379> rpush myList value2 value3 # 向list的头部(最右边)添加多个元素
|
||||
(integer) 3
|
||||
127.0.0.1:6379> lpop myList # 将 list的尾部(最左边)元素取出
|
||||
"value1"
|
||||
127.0.0.1:6379> lrange myList 0 1 # 查看对应下标的list列表, 0 为 start,1为 end
|
||||
1) "value2"
|
||||
2) "value3"
|
||||
127.0.0.1:6379> lrange myList 0 -1 # 查看列表中的所有元素,-1表示倒数第一
|
||||
1) "value2"
|
||||
2) "value3"
|
||||
```
|
||||
|
||||
**通过 `rpush/rpop` 实现栈:**
|
||||
|
||||
``` bash
|
||||
127.0.0.1:6379> rpush myList2 value1 value2 value3
|
||||
(integer) 3
|
||||
127.0.0.1:6379> rpop myList2 # 将 list的头部(最右边)元素取出
|
||||
"value3"
|
||||
```
|
||||
|
||||
我专门花了一个图方便小伙伴们来理解:
|
||||
|
||||

|
||||
|
||||
**通过 `lrange` 查看对应下标范围的列表元素:**
|
||||
|
||||
``` bash
|
||||
127.0.0.1:6379> rpush myList value1 value2 value3
|
||||
(integer) 3
|
||||
127.0.0.1:6379> lrange myList 0 1 # 查看对应下标的list列表, 0 为 start,1为 end
|
||||
1) "value1"
|
||||
2) "value2"
|
||||
127.0.0.1:6379> lrange myList 0 -1 # 查看列表中的所有元素,-1表示倒数第一
|
||||
1) "value1"
|
||||
2) "value2"
|
||||
3) "value3"
|
||||
```
|
||||
|
||||
通过 `lrange` 命令,你可以基于 list 实现分页查询,性能非常高!
|
||||
|
||||
**通过 `llen` 查看链表长度:**
|
||||
|
||||
``` bash
|
||||
127.0.0.1:6379> llen myList
|
||||
(integer) 3
|
||||
```
|
||||
|
||||
#### 6.3. hash
|
||||
|
||||
1. **介绍** :hash 类似于 JDK1.8 前的 HashMap,内部实现也差不多(数组 + 链表)。不过,Redis 的 hash 做了更多优化。另外,hash 是一个 string 类型的 field 和 value 的映射表,**特别适合用于存储对象**,后续操作的时候,你可以直接仅仅修改这个对象中的某个字段的值。 比如我们可以 hash 数据结构来存储用户信息,商品信息等等。
|
||||
2. **常用命令:** `hset,hmset,hexists,hget,hgetall,hkeys,hvals` 等。
|
||||
3. **应用场景:** 系统中对象数据的存储。
|
||||
|
||||
下面我们简单看看它的使用!
|
||||
|
||||
``` bash
|
||||
127.0.0.1:6379> hset userInfoKey name "guide" description "dev" age "24"
|
||||
OK
|
||||
127.0.0.1:6379> hexists userInfoKey name # 查看 key 对应的 value中指定的字段是否存在。
|
||||
(integer) 1
|
||||
127.0.0.1:6379> hget userInfoKey name # 获取存储在哈希表中指定字段的值。
|
||||
"guide"
|
||||
127.0.0.1:6379> hget userInfoKey age
|
||||
"24"
|
||||
127.0.0.1:6379> hgetall userInfoKey # 获取在哈希表中指定 key 的所有字段和值
|
||||
1) "name"
|
||||
2) "guide"
|
||||
3) "description"
|
||||
4) "dev"
|
||||
5) "age"
|
||||
6) "24"
|
||||
127.0.0.1:6379> hkeys userInfoKey # 获取 key 列表
|
||||
1) "name"
|
||||
2) "description"
|
||||
3) "age"
|
||||
127.0.0.1:6379> hvals userInfoKey # 获取 value 列表
|
||||
1) "guide"
|
||||
2) "dev"
|
||||
3) "24"
|
||||
127.0.0.1:6379> hset userInfoKey name "GuideGeGe" # 修改某个字段对应的值
|
||||
127.0.0.1:6379> hget userInfoKey name
|
||||
"GuideGeGe"
|
||||
```
|
||||
|
||||
#### 6.4. set
|
||||
|
||||
1. **介绍 :** set 类似于 Java 中的 `HashSet` 。Redis 中的 set 类型是一种无序集合,集合中的元素没有先后顺序。当你需要存储一个列表数据,又不希望出现重复数据时,set 是一个很好的选择,并且 set 提供了判断某个成员是否在一个 set 集合内的重要接口,这个也是 list 所不能提供的。可以基于 set 轻易实现交集、并集、差集的操作。比如:你可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis 可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程。
|
||||
2. **常用命令:** `sadd,spop,smembers,sismember,scard,sinterstore,sunion` 等。
|
||||
3. **应用场景:** 需要存放的数据不能重复以及需要获取多个数据源交集和并集等场景
|
||||
|
||||
下面我们简单看看它的使用!
|
||||
|
||||
``` bash
|
||||
127.0.0.1:6379> sadd mySet value1 value2 # 添加元素进去
|
||||
(integer) 2
|
||||
127.0.0.1:6379> sadd mySet value1 # 不允许有重复元素
|
||||
(integer) 0
|
||||
127.0.0.1:6379> smembers mySet # 查看 set 中所有的元素
|
||||
1) "value1"
|
||||
2) "value2"
|
||||
127.0.0.1:6379> scard mySet # 查看 set 的长度
|
||||
(integer) 2
|
||||
127.0.0.1:6379> sismember mySet value1 # 检查某个元素是否存在set 中,只能接收单个元素
|
||||
(integer) 1
|
||||
127.0.0.1:6379> sadd mySet2 value2 value3
|
||||
(integer) 2
|
||||
127.0.0.1:6379> sinterstore mySet3 mySet mySet2 # 获取 mySet 和 mySet2 的交集并存放在 mySet3 中
|
||||
(integer) 1
|
||||
127.0.0.1:6379> smembers mySet3
|
||||
1) "value2"
|
||||
```
|
||||
|
||||
#### 6.5. sorted set
|
||||
|
||||
1. **介绍:** 和 set 相比,sorted set 增加了一个权重参数 score,使得集合中的元素能够按 score 进行有序排列,还可以通过 score 的范围来获取元素的列表。有点像是 Java 中 HashMap 和 TreeSet 的结合体。
|
||||
2. **常用命令:** `zadd,zcard,zscore,zrange,zrevrange,zrem` 等。
|
||||
3. **应用场景:** 需要对数据根据某个权重进行排序的场景。比如在直播系统中,实时排行信息包含直播间在线用户列表,各种礼物排行榜,弹幕消息(可以理解为按消息维度的消息排行榜)等信息。
|
||||
|
||||
``` bash
|
||||
127.0.0.1:6379> zadd myZset 3.0 value1 # 添加元素到 sorted set 中 3.0 为权重
|
||||
(integer) 1
|
||||
127.0.0.1:6379> zadd myZset 2.0 value2 1.0 value3 # 一次添加多个元素
|
||||
(integer) 2
|
||||
127.0.0.1:6379> zcard myZset # 查看 sorted set 中的元素数量
|
||||
(integer) 3
|
||||
127.0.0.1:6379> zscore myZset value1 # 查看某个 value 的权重
|
||||
"3"
|
||||
127.0.0.1:6379> zrange myZset 0 -1 # 顺序输出某个范围区间的元素,0 -1 表示输出所有元素
|
||||
1) "value3"
|
||||
2) "value2"
|
||||
3) "value1"
|
||||
127.0.0.1:6379> zrange myZset 0 1 # 顺序输出某个范围区间的元素,0 为 start 1 为 stop
|
||||
1) "value3"
|
||||
2) "value2"
|
||||
127.0.0.1:6379> zrevrange myZset 0 1 # 逆序输出某个范围区间的元素,0 为 start 1 为 stop
|
||||
1) "value1"
|
||||
2) "value2"
|
||||
```
|
||||
|
||||
### 7. Redis 单线程模型详解
|
||||
|
||||
**Redis 基于 Reactor 模式来设计开发了自己的一套高效的事件处理模型** (Netty 的线程模型也基于 Reactor 模式,Reactor 模式不愧是高性能 IO 的基石),这套事件处理模型对应的是 Redis 中的文件事件处理器(file event handler)。由于文件事件处理器(file event handler)是单线程方式运行的,所以我们一般都说 Redis 是单线程模型。
|
||||
|
||||
**既然是单线程,那怎么监听大量的客户端连接呢?**
|
||||
|
||||
Redis 通过**IO 多路复用程序** 来监听来自客户端的大量连接(或者说是监听多个 socket),它会将感兴趣的事件及类型(读、写)注册到内核中并监听每个事件是否发生。
|
||||
|
||||
这样的好处非常明显: **I/O 多路复用技术的使用让 Redis 不需要额外创建多余的线程来监听客户端的大量连接,降低了资源的消耗**(和 NIO 中的 `Selector` 组件很像)。
|
||||
|
||||
另外, Redis 服务器是一个事件驱动程序,服务器需要处理两类事件: 1. 文件事件; 2. 时间事件。
|
||||
|
||||
时间事件不需要多花时间了解,我们接触最多的还是 **文件事件**(客户端进行读取写入等操作,涉及一系列网络通信)。
|
||||
|
||||
《Redis 设计与实现》有一段话是如是介绍文件事件的,我觉得写得挺不错。
|
||||
|
||||
> Redis 基于 Reactor 模式开发了自己的网络事件处理器:这个处理器被称为文件事件处理器(file event handler)。文件事件处理器使用 I/O 多路复用(multiplexing)程序来同时监听多个套接字,并根据 套接字目前执行的任务来为套接字关联不同的事件处理器。
|
||||
>
|
||||
> 当被监听的套接字准备好执行连接应答(accept)、读取(read)、写入(write)、关 闭(close)等操作时,与操作相对应的文件事件就会产生,这时文件事件处理器就会调用套接字之前关联好的事件处理器来处理这些事件。
|
||||
>
|
||||
> **虽然文件事件处理器以单线程方式运行,但通过使用 I/O 多路复用程序来监听多个套接字**,文件事件处理器既实现了高性能的网络通信模型,又可以很好地与 Redis 服务器中其他同样以单线程方式运行的模块进行对接,这保持了 Redis 内部单线程设计的简单性。
|
||||
|
||||
可以看出,文件事件处理器(file event handler)主要是包含 4 个部分:
|
||||
|
||||
* 多个 socket(客户端连接)
|
||||
* IO 多路复用程序(支持多个客户端连接的关键)
|
||||
* 文件事件分派器(将 socket 关联到相应的事件处理器)
|
||||
* 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
|
||||
|
||||

|
||||
|
||||
<p style="text-align:right; font-size:14px; color:gray">《Redis设计与实现:12章》</p>
|
||||
|
||||
### 8. Redis 没有使用多线程?为什么不使用多线程?
|
||||
|
||||
虽然说 Redis 是单线程模型,但是, 实际上,**Redis 在 4.0 之后的版本中就已经加入了对多线程的支持。**
|
||||
|
||||

|
||||
|
||||
不过,Redis 4.0 增加的多线程主要是针对一些大键值对的删除操作的命令,使用这些命令就会使用主处理之外的其他线程来“异步处理”。
|
||||
|
||||
大体上来说,**Redis 6.0 之前主要还是单线程处理。**
|
||||
|
||||
**那,Redis6.0 之前 为什么不使用多线程?**
|
||||
|
||||
我觉得主要原因有下面 3 个:
|
||||
|
||||
1. 单线程编程容易并且更容易维护;
|
||||
2. Redis 的性能瓶颈不再 CPU ,主要在内存和网络;
|
||||
3. 多线程就会存在死锁、线程上下文切换等问题,甚至会影响性能。
|
||||
|
||||
### 9. Redis6.0 之后为何引入了多线程?
|
||||
|
||||
**Redis6.0 引入多线程主要是为了提高网络 IO 读写性能**,因为这个算是 Redis 中的一个性能瓶颈(Redis 的瓶颈主要受限于内存和网络)。
|
||||
|
||||
虽然,Redis6.0 引入了多线程,但是 Redis 的多线程只是在网络数据的读写这类耗时操作上使用了, 执行命令仍然是单线程顺序执行。因此,你也不需要担心线程安全问题。
|
||||
|
||||
Redis6.0 的多线程默认是禁用的,只使用主线程。如需开启需要修改 redis 配置文件 `redis.conf` :
|
||||
|
||||
``` bash
|
||||
io-threads-do-reads yes
|
||||
```
|
||||
|
||||
开启多线程后,还需要设置线程数,否则是不生效的。同样需要修改 redis 配置文件 `redis.conf` :
|
||||
|
||||
``` bash
|
||||
io-threads 4 #官网建议4核的机器建议设置为2或3个线程,8核的建议设置为6个线程
|
||||
```
|
||||
|
||||
推荐阅读:
|
||||
|
||||
1. [Redis 6.0 新特性-多线程连环 13 问!](https://mp.weixin.qq.com/s/FZu3acwK6zrCBZQ_3HoUgw)
|
||||
2. [为什么 Redis 选择单线程模型](https://draveness.me/whys-the-design-redis-single-thread/)
|
||||
|
||||
### 10. Redis 给缓存数据设置过期时间有啥用?
|
||||
|
||||
一般情况下,我们设置保存的缓存数据的时候都会设置一个过期时间。为什么呢?
|
||||
|
||||
因为内存是有限的,如果缓存中的所有数据都是一直保存的话,分分钟直接Out of memory。
|
||||
|
||||
Redis 自带了给缓存数据设置过期时间的功能,比如:
|
||||
|
||||
``` bash
|
||||
127.0.0.1:6379> exp key 60 # 数据在 60s 后过期
|
||||
(integer) 1
|
||||
127.0.0.1:6379> setex key 60 value # 数据在 60s 后过期 (setex:[set] + [ex]pire)
|
||||
OK
|
||||
127.0.0.1:6379> ttl key # 查看数据还有多久过期
|
||||
(integer) 56
|
||||
```
|
||||
|
||||
注意:**Redis中除了字符串类型有自己独有设置过期时间的命令 `setex` 外,其他方法都需要依靠 `expire` 命令来设置过期时间 。另外, `persist` 命令可以移除一个键的过期时间: **
|
||||
|
||||
**过期时间除了有助于缓解内存的消耗,还有什么其他用么?**
|
||||
|
||||
很多时候,我们的业务场景就是需要某个数据只在某一时间段内存在,比如我们的短信验证码可能只在1分钟内有效,用户登录的 token 可能只在 1 天内有效。
|
||||
|
||||
如果使用传统的数据库来处理的话,一般都是自己判断过期,这样更麻烦并且性能要差很多。
|
||||
|
||||
### 11. Redis是如何判断数据是否过期的呢?
|
||||
|
||||
Redis 通过一个叫做过期字典(可以看作是hash表)来保存数据过期的时间。过期字典的键指向Redis数据库中的某个key(键),过期字典的值是一个long long类型的整数,这个整数保存了key所指向的数据库键的过期时间(毫秒精度的UNIX时间戳)。
|
||||
|
||||

|
||||
|
||||
过期字典是存储在redisDb这个结构里的:
|
||||
|
||||
``` c
|
||||
typedef struct redisDb {
|
||||
...
|
||||
|
||||
dict *dict; //数据库键空间,保存着数据库中所有键值对
|
||||
dict *expires // 过期字典,保存着键的过期时间
|
||||
...
|
||||
} redisDb;
|
||||
```
|
||||
|
||||
### 12. 过期的数据的删除策略了解么?
|
||||
|
||||
如果假设你设置了一批 key 只能存活 1 分钟,那么 1 分钟后,Redis 是怎么对这批 key 进行删除的呢?
|
||||
|
||||
常用的过期数据的删除策略就两个(重要!自己造缓存轮子的时候需要格外考虑的东西):
|
||||
|
||||
1. **惰性删除** :只会在取出key的时候才对数据进行过期检查。这样对CPU最友好,但是可能会造成太多过期 key 没有被删除。
|
||||
2. **定期删除** : 每隔一段时间抽取一批 key 执行删除过期key操作。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对CPU时间的影响。
|
||||
|
||||
定期删除对内存更加友好,惰性删除对CPU更加友好。两者各有千秋,所以Redis 采用的是 **定期删除+惰性/懒汉式删除** 。
|
||||
|
||||
但是,仅仅通过给 key 设置过期时间还是有问题的。因为还是可能存在定期删除和惰性删除漏掉了很多过期 key 的情况。这样就导致大量过期 key 堆积在内存里,然后就Out of memory了。
|
||||
|
||||
怎么解决这个问题呢?答案就是: **Redis 内存淘汰机制。**
|
||||
|
||||
### 13. Redis 内存淘汰机制了解么?
|
||||
|
||||
> 相关问题:MySQL 里有 2000w 数据,Redis 中只存 20w 的数据,如何保证 Redis 中的数据都是热点数据?
|
||||
|
||||
Redis 提供 6 种数据淘汰策略:
|
||||
|
||||
1. **volatile-lru(least recently used)**:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
|
||||
2. **volatile-ttl**:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
|
||||
3. **volatile-random**:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
|
||||
4. **allkeys-lru(least recently used)**:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key(这个是最常用的)
|
||||
5. **allkeys-random**:从数据集(server.db[i].dict)中任意选择数据淘汰
|
||||
6. **no-eviction**:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
|
||||
|
||||
4.0 版本后增加以下两种:
|
||||
|
||||
7. **volatile-lfu(least frequently used)**:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
|
||||
8. **allkeys-lfu(least frequently used)**:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的 key
|
||||
|
||||
### 14. Redis 持久化机制(怎么保证 Redis 挂掉之后再重启数据可以进行恢复)
|
||||
|
||||
很多时候我们需要持久化数据也就是将内存中的数据写入到硬盘里面,大部分原因是为了之后重用数据(比如重启机器、机器故障之后恢复数据),或者是为了防止系统故障而将数据备份到一个远程位置。
|
||||
|
||||
Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而且支持两种不同的持久化操作。**Redis 的一种持久化方式叫快照(snapshotting,RDB),另一种方式是只追加文件(append-only file, AOF)**。这两种方法各有千秋,下面我会详细这两种持久化方法是什么,怎么用,如何选择适合自己的持久化方法。
|
||||
|
||||
**快照(snapshotting)持久化(RDB)**
|
||||
|
||||
Redis 可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本。Redis 创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis 主从结构,主要用来提高 Redis 性能),还可以将快照留在原地以便重启服务器的时候使用。
|
||||
|
||||
快照持久化是 Redis 默认采用的持久化方式,在 Redis.conf 配置文件中默认有此下配置:
|
||||
|
||||
``` conf
|
||||
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
|
||||
|
||||
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
|
||||
|
||||
save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
|
||||
```
|
||||
|
||||
**AOF(append-only file)持久化**
|
||||
|
||||
与快照持久化相比,AOF 持久化 的实时性更好,因此已成为主流的持久化方案。默认情况下 Redis 没有开启 AOF(append only file)方式的持久化,可以通过 appendonly 参数开启:
|
||||
|
||||
``` conf
|
||||
appendonly yes
|
||||
```
|
||||
|
||||
开启 AOF 持久化后每执行一条会更改 Redis 中的数据的命令,Redis 就会将该命令写入硬盘中的 AOF 文件。AOF 文件的保存位置和 RDB 文件的位置相同,都是通过 dir 参数设置的,默认的文件名是 appendonly.aof。
|
||||
|
||||
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式,它们分别是:
|
||||
|
||||
``` conf
|
||||
appendfsync always #每次有数据修改发生时都会写入AOF文件,这样会严重降低Redis的速度
|
||||
appendfsync everysec #每秒钟同步一次,显示地将多个写命令同步到硬盘
|
||||
appendfsync no #让操作系统决定何时进行同步
|
||||
```
|
||||
|
||||
为了兼顾数据和写入性能,用户可以考虑 appendfsync everysec 选项 ,让 Redis 每秒同步一次 AOF 文件,Redis 性能几乎没受到任何影响。而且这样即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis 还会优雅的放慢自己的速度以便适应硬盘的最大写入速度。
|
||||
|
||||
**相关 issue** :[783:Redis 的 AOF 方式](https://github.com/Snailclimb/JavaGuide/issues/783)
|
||||
|
||||
**拓展:Redis 4.0 对于持久化机制的优化**
|
||||
|
||||
Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 `aof-use-rdb-preamble` 开启)。
|
||||
|
||||
如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
|
||||
|
||||
**补充内容:AOF 重写**
|
||||
|
||||
AOF 重写可以产生一个新的 AOF 文件,这个新的 AOF 文件和原有的 AOF 文件所保存的数据库状态一样,但体积更小。
|
||||
|
||||
AOF 重写是一个有歧义的名字,该功能是通过读取数据库中的键值对来实现的,程序无须对现有 AOF 文件进行任何读入、分析或者写入操作。
|
||||
|
||||
在执行 BGREWRITEAOF 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子进程创建新 AOF 文件期间,记录服务器执行的所有写命令。当子进程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新旧两个 AOF 文件所保存的数据库状态一致。最后,服务器用新的 AOF 文件替换旧的 AOF 文件,以此来完成 AOF 文件重写操作
|
||||
|
||||
### 15. Redis 事务
|
||||
|
||||
Redis 可以通过 **MULTI,EXEC,DISCARD 和 WATCH** 等命令来实现事务(transaction)功能。
|
||||
|
||||
``` bash
|
||||
> MULTI
|
||||
OK
|
||||
> INCR foo
|
||||
QUEUED
|
||||
> INCR bar
|
||||
QUEUED
|
||||
> EXEC
|
||||
1) (integer) 1
|
||||
2) (integer) 1
|
||||
```
|
||||
|
||||
使用 [MULTI](https://redis.io/commands/multi)命令后可以输入多个命令。Redis不会立即执行这些命令,而是将它们放到队列,当调用了[EXEC](https://redis.io/commands/exec)命令将执行所有命令。
|
||||
|
||||
Redis官网相关介绍 [https://redis.io/topics/transactions](https://redis.io/topics/transactions) 如下:
|
||||
|
||||

|
||||
|
||||
但是,Redis 的事务和我们平时理解的关系型数据库的事务不同。我们知道事务具有四大特性: **1. 原子性**,**2. 隔离性**,**3. 持久性**,**4. 一致性**。
|
||||
|
||||
1. **原子性(Atomicity):** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
|
||||
2. **隔离性(Isolation):** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
|
||||
3. **持久性(Durability):** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
|
||||
4. **一致性(Consistency):** 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
|
||||
|
||||
**Redis 是不支持 roll back 的,因而不满足原子性的(而且不满足持久性)。**
|
||||
|
||||
Redis官网也解释了自己为啥不支持回滚。简单来说就是Redis开发者们觉得没必要支持回滚,这样更简单便捷并且性能更好。Redis开发者觉得即使命令执行错误也应该在开发过程中就被发现而不是生产过程中。
|
||||
|
||||

|
||||
|
||||
你可以将Redis中的事务就理解为 :**Redis事务提供了一种将多个命令请求打包的功能。然后,再按顺序执行打包的所有命令,并且不会被中途打断。**
|
||||
|
||||
**相关issue** :[issue452: 关于 Redis 事务不满足原子性的问题](https://github.com/Snailclimb/JavaGuide/issues/452) ,推荐阅读:[https://zhuanlan.zhihu.com/p/43897838](https://zhuanlan.zhihu.com/p/43897838) 。
|
||||
|
||||
### 16. 缓存穿透
|
||||
|
||||
#### 16.1. 什么是缓存穿透?
|
||||
|
||||
缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。
|
||||
|
||||
#### 16.2. 缓存穿透情况的处理流程是怎样的?
|
||||
|
||||
如下图所示,用户的请求最终都要跑到数据库中查询一遍。
|
||||
|
||||

|
||||
|
||||
#### 16.3. 有哪些解决办法?
|
||||
|
||||
最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
|
||||
|
||||
**1)缓存无效 key**
|
||||
|
||||
如果缓存和数据库都查不到某个 key 的数据就写一个到 Redis 中去并设置过期时间,具体命令如下: `SET key value EX 10086` 。这种方式可以解决请求的 key 变化不频繁的情况,如果黑客恶意攻击,每次构建不同的请求 key,会导致 Redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。
|
||||
|
||||
另外,这里多说一嘴,一般情况下我们是这样设计 key 的: `表名:列名:主键名:主键值` 。
|
||||
|
||||
如果用 Java 代码展示的话,差不多是下面这样的:
|
||||
|
||||
``` java
|
||||
public Object getObjectInclNullById(Integer id) {
|
||||
// 从缓存中获取数据
|
||||
Object cacheValue = cache.get(id);
|
||||
// 缓存为空
|
||||
if (cacheValue == null) {
|
||||
// 从数据库中获取
|
||||
Object storageValue = storage.get(key);
|
||||
// 缓存空对象
|
||||
cache.set(key, storageValue);
|
||||
// 如果存储数据为空,需要设置一个过期时间(300秒)
|
||||
if (storageValue == null) {
|
||||
// 必须设置过期时间,否则有被攻击的风险
|
||||
cache.expire(key, 60 * 5);
|
||||
}
|
||||
return storageValue;
|
||||
}
|
||||
return cacheValue;
|
||||
}
|
||||
```
|
||||
|
||||
**2)布隆过滤器**
|
||||
|
||||
布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在于海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。
|
||||
|
||||
具体是这样做的:把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。
|
||||
|
||||
加入布隆过滤器之后的缓存处理流程图如下。
|
||||
|
||||

|
||||
|
||||
但是,需要注意的是布隆过滤器可能会存在误判的情况。总结来说就是: **布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。**
|
||||
|
||||
_为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理来说!_
|
||||
|
||||
我们先来看一下,**当一个元素加入布隆过滤器中的时候,会进行哪些操作:**
|
||||
|
||||
1. 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
|
||||
2. 根据得到的哈希值,在位数组中把对应下标的值置为 1。
|
||||
|
||||
我们再来看一下,**当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行哪些操作:**
|
||||
|
||||
1. 对给定元素再次进行相同的哈希计算;
|
||||
2. 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
|
||||
|
||||
然后,一定会出现这样一种情况:**不同的字符串可能哈希出来的位置相同。** (可以适当增加位数组大小或者调整我们的哈希函数来降低概率)
|
||||
|
||||
更多关于布隆过滤器的内容可以看我的这篇原创:[《不了解布隆过滤器?一文给你整的明明白白!》](https://github.com/Snailclimb/JavaGuide/blob/master/docs/dataStructures-algorithms/data-structure/bloom-filter.md) ,强烈推荐,个人感觉网上应该找不到总结的这么明明白白的文章了。
|
||||
|
||||
### 17. 缓存雪崩
|
||||
|
||||
#### 17.1. 什么是缓存雪崩?
|
||||
|
||||
我发现缓存雪崩这名字起的有点意思,哈哈。
|
||||
|
||||
实际上,缓存雪崩描述的就是这样一个简单的场景:**缓存在同一时间大面积的失效,后面的请求都直接落到了数据库上,造成数据库短时间内承受大量请求。** 这就好比雪崩一样,摧枯拉朽之势,数据库的压力可想而知,可能直接就被这么多请求弄宕机了。
|
||||
|
||||
举个例子:系统的缓存模块出了问题比如宕机导致不可用。造成系统的所有访问,都要走数据库。
|
||||
|
||||
还有一种缓存雪崩的场景是:**有一些被大量访问数据(热点缓存)在某一时刻大面积失效,导致对应的请求直接落到了数据库上。** 这样的情况,有下面几种解决办法:
|
||||
|
||||
举个例子 :秒杀开始 12 个小时之前,我们统一存放了一批商品到 Redis 中,设置的缓存过期时间也是 12 个小时,那么秒杀开始的时候,这些秒杀的商品的访问直接就失效了。导致的情况就是,相应的请求直接就落到了数据库上,就像雪崩一样可怕。
|
||||
|
||||
#### 17.2. 有哪些解决办法?
|
||||
|
||||
**针对 Redis 服务不可用的情况:**
|
||||
|
||||
1. 采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。
|
||||
2. 限流,避免同时处理大量的请求。
|
||||
|
||||
**针对热点缓存失效的情况:**
|
||||
|
||||
1. 设置不同的失效时间比如随机设置缓存的失效时间。
|
||||
2. 缓存永不失效。
|
||||
|
||||
### 18. 如何保证缓存和数据库数据的一致性?
|
||||
|
||||
细说的话可以扯很多,但是我觉得其实没太大必要(小声BB:很多解决方案我也没太弄明白)。我个人觉得引入缓存之后,如果为了短时间的不一致性问题,选择让系统设计变得更加复杂的话,完全没必要。
|
||||
|
||||
下面单独对 **Cache Aside Pattern(旁路缓存模式)** 来聊聊。
|
||||
|
||||
Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删除 cache 。
|
||||
|
||||
如果更新数据库成功,而删除缓存这一步失败的情况的话,简单说两个解决方案:
|
||||
|
||||
1. **缓存失效时间变短(不推荐,治标不治本)** :我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
|
||||
2. **增加cache更新重试机制(常用)**: 如果 cache 服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。如果多次重试还是失败的话,我们可以把当前更新失败的 key 存入队列中,等缓存服务可用之后,再将 缓存中对应的 key 删除即可。
|
||||
|
||||
### 19. 参考
|
||||
|
||||
* 《Redis 开发与运维》
|
||||
* 《Redis 设计与实现》
|
||||
* Redis 命令总结:http://Redisdoc.com/string/set.html
|
||||
* 通俗易懂的 Redis 数据结构基础教程:[https://juejin.im/post/5b53ee7e5188251aaa2d2e16](https://juejin.im/post/5b53ee7e5188251aaa2d2e16)
|
||||
* WHY Redis choose single thread (vs multi threads): [https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153](https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153)
|
||||
|
||||
### 20. 公众号
|
||||
|
||||
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
|
||||
|
||||
**《Java 面试突击》:** 由本文档衍生的专为面试而生的《Java 面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java 面试突击"** 即可免费领取!
|
||||
|
||||
**Java 工程师必备学习资源:** 一些 Java 工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
|
||||

|
||||
125
docs/database/Redis/some-concepts-of-caching.md
Normal file
@ -0,0 +1,125 @@
|
||||
|
||||
|
||||
<!-- @import "[TOC]" {cmd="toc" depthFrom=1 depthTo=6 orderedList=false} -->
|
||||
|
||||
<!-- code_chunk_output -->
|
||||
|
||||
- [1. 缓存的基本思想](#1-缓存的基本思想)
|
||||
- [2. 使用缓存为系统带来了什么问题](#2-使用缓存为系统带来了什么问题)
|
||||
- [3. 本地缓存解决方案](#3-本地缓存解决方案)
|
||||
- [4. 为什么要有分布式缓存?/为什么不直接用本地缓存?](#4-为什么要有分布式缓存为什么不直接用本地缓存)
|
||||
- [5. 缓存读写模式/更新策略](#5-缓存读写模式更新策略)
|
||||
- [5.1. Cache Aside Pattern(旁路缓存模式)](#51-cache-aside-pattern旁路缓存模式)
|
||||
- [5.2. Read/Write Through Pattern(读写穿透)](#52-readwrite-through-pattern读写穿透)
|
||||
- [5.3. Write Behind Pattern(异步缓存写入)](#53-write-behind-pattern异步缓存写入)
|
||||
|
||||
<!-- /code_chunk_output -->
|
||||
|
||||
|
||||
### 1. 缓存的基本思想
|
||||
|
||||
很多朋友,只知道缓存可以提高系统性能以及减少请求相应时间,但是,不太清楚缓存的本质思想是什么。
|
||||
|
||||
缓存的基本思想其实很简单,就是我们非常熟悉的空间换时间。不要把缓存想的太高大上,虽然,它的确对系统的性能提升的性价比非常高。
|
||||
|
||||
其实,我们在学习使用缓存的时候,你会发现缓存的思想实际在操作系统或者其他地方都被大量用到。 比如 **CPU Cache 缓存的是内存数据用于解决 CPU 处理速度和内存不匹配的问题,内存缓存的是硬盘数据用于解决硬盘访问速度过慢的问题。** **再比如操作系统在 页表方案 基础之上引入了 快表 来加速虚拟地址到物理地址的转换。我们可以把快表理解为一种特殊的高速缓冲存储器(Cache)。**
|
||||
|
||||
回归到业务系统来说:**我们为了避免用户在请求数据的时候获取速度过于缓慢,所以我们在数据库之上增加了缓存这一层来弥补。**
|
||||
|
||||
当别人再问你,缓存的基本思想的时候,就把上面 👆 这段话告诉他,我觉得会让别人对你刮目相看。
|
||||
|
||||
### 2. 使用缓存为系统带来了什么问题
|
||||
|
||||
**软件系统设计中没有银弹,往往任何技术的引入都像是把双刃剑。** 但是,你使用好了之后,这把剑就是好剑。
|
||||
|
||||
简单来说,为系统引入缓存之后往往会带来下面这些问题:
|
||||
|
||||
_ps:其实我觉得引入本地缓存来做一些简单业务场景的话,实际带来的代价几乎可以忽略,下面 👇 主要是针对分布式缓存来说的。_
|
||||
|
||||
1. **系统复杂性增加** :引入缓存之后,你要维护缓存和数据库的数据一致性、维护热点缓存等等。
|
||||
2. **系统开发成本往往会增加** :引入缓存意味着系统需要一个单独的缓存服务,这是需要花费相应的成本的,并且这个成本还是很贵的,毕竟耗费的是宝贵的内存。但是,如果你只是简单的使用一下本地缓存存储一下简单的数据,并且数据量不大的话,那么就不需要单独去弄一个缓存服务。
|
||||
|
||||
### 3. 本地缓存解决方案
|
||||
|
||||
_先来聊聊本地缓存,这个实际在很多项目中用的蛮多,特别是单体架构的时候。数据量不大,并且没有分布式要求的话,使用本地缓存还是可以的。_
|
||||
|
||||
常见的单体架构图如下,我们使用 **Nginx** 来做**负载均衡**,部署两个相同的服务到服务器,两个服务使用同一个数据库,并且使用的是本地缓存。
|
||||
|
||||

|
||||
|
||||
_那本地缓存的方案有哪些呢?且听 Guide 给你来说一说。_
|
||||
|
||||
**一:JDK 自带的 `HashMap` 和 `ConcurrentHashMap` 了。**
|
||||
|
||||
`ConcurrentHashMap` 可以看作是线程安全版本的 `HashMap` ,两者都是存放 key/value 形式的键值对。但是,大部分场景来说不会使用这两者当做缓存,因为只提供了缓存的功能,并没有提供其他诸如过期时间之类的功能。一个稍微完善一点的缓存框架至少要提供:过期时间、淘汰机制、命中率统计这三点。
|
||||
|
||||
**二: `Ehcache` 、 `Guava Cache` 、 `Spring Cache` 这三者是使用的比较多的本地缓存框架。**
|
||||
|
||||
`Ehcache` 的话相比于其他两者更加重量。不过,相比于 `Guava Cache` 、 `Spring Cache` 来说, `Ehcache` 支持可以嵌入到 hibernate 和 mybatis 作为多级缓存,并且可以将缓存的数据持久化到本地磁盘中、同时也提供了集群方案(比较鸡肋,可忽略)。
|
||||
|
||||
`Guava Cache` 和 `Spring Cache` 两者的话比较像。
|
||||
|
||||
`Guava` 相比于 `Spring Cache` 的话使用的更多一点,它提供了 API 非常方便我们使用,同时也提供了设置缓存有效时间等功能。它的内部实现也比较干净,很多地方都和 `ConcurrentHashMap` 的思想有异曲同工之妙。
|
||||
|
||||
使用 `Spring Cache` 的注解实现缓存的话,代码会看着很干净和优雅,但是很容易出现问题比如缓存穿透、内存溢出。
|
||||
|
||||
**三: 后起之秀 Caffeine。**
|
||||
|
||||
相比于 `Guava` 来说 `Caffeine` 在各个方面比如性能要更加优秀,一般建议使用其来替代 `Guava` 。并且, `Guava` 和 `Caffeine` 的使用方式很像!
|
||||
|
||||
本地缓存固然好,但是缺陷也很明显,比如多个相同服务之间的本地缓存的数据无法共享。
|
||||
|
||||
_下面我们从为什么要有分布式缓存为接入点来正式进入 Redis 的相关问题总结。_
|
||||
|
||||
### 4. 为什么要有分布式缓存?/为什么不直接用本地缓存?
|
||||
|
||||
_我们可以把分布式缓存(Distributed Cache) 看作是一种内存数据库的服务,它的最终作用就是提供缓存数据的服务。_
|
||||
|
||||
如下图所示,就是一个简单的使用分布式缓存的架构图。我们使用 Nginx 来做负载均衡,部署两个相同的服务到服务器,两个服务使用同一个数据库和缓存。
|
||||
|
||||

|
||||
|
||||
本地的缓存的优势是低依赖,比较轻量并且通常相比于使用分布式缓存要更加简单。
|
||||
|
||||
再来分析一下本地缓存的局限性:
|
||||
|
||||
1. **本地缓存对分布式架构支持不友好**,比如同一个相同的服务部署在多台机器上的时候,各个服务之间的缓存是无法共享的,因为本地缓存只在当前机器上有。
|
||||
2. **本地缓存容量受服务部署所在的机器限制明显。** 如果当前系统服务所耗费的内存多,那么本地缓存可用的容量就很少。
|
||||
|
||||
使用分布式缓存之后,缓存部署在一台单独的服务器上,即使同一个相同的服务部署在再多机器上,也是使用的同一份缓存。 并且,单独的分布式缓存服务的性能、容量和提供的功能都要更加强大。
|
||||
|
||||
使用分布式缓存的缺点呢,也很显而易见,那就是你需要为分布式缓存引入额外的服务比如 Redis 或 Memcached,你需要单独保证 Redis 或 Memcached 服务的高可用。
|
||||
|
||||
### 5. 缓存读写模式/更新策略
|
||||
|
||||
**下面介绍到的三种模式各有优劣,不存在最佳模式,根据具体的业务场景选择适合自己的缓存读写模式。**
|
||||
|
||||
#### 5.1. Cache Aside Pattern(旁路缓存模式)
|
||||
|
||||
1. 写:更新 DB,然后直接删除 cache 。
|
||||
2. 读:从 cache 中读取数据,读取到就直接返回,读取不到的话,就从 DB 中取数据返回,然后再把数据放到 cache 中。
|
||||
|
||||
Cache Aside Pattern 中服务端需要同时维系 DB 和 cache,并且是以 DB 的结果为准。另外,Cache Aside Pattern 有首次请求数据一定不在 cache 的问题,对于热点数据可以提前放入缓存中。
|
||||
|
||||
**Cache Aside Pattern 是我们平时使用比较多的一个缓存读写模式,比较适合读请求比较多的场景。**
|
||||
|
||||
#### 5.2. Read/Write Through Pattern(读写穿透)
|
||||
|
||||
Read/Write Through 套路是:服务端把 cache 视为主要数据存储,从中读取数据并将数据写入其中。cache 服务负责将此数据读取和写入 DB,从而减轻了应用程序的职责。
|
||||
|
||||
1. 写(Write Through):先查 cache,cache 中不存在,直接更新 DB。 cache 中存在,则先更新 cache,然后 cache 服务自己更新 DB(**同步更新 cache 和 DB**)。
|
||||
2. 读(Read Through): 从 cache 中读取数据,读取到就直接返回 。读取不到的话,先从 DB 加载,写入到 cache 后返回响应。
|
||||
|
||||
Read-Through Pattern 实际只是在 Cache-Aside Pattern 之上进行了封装。在 Cache-Aside Pattern 下,发生读请求的时候,如果 cache 中不存在对应的数据,是由客户端自己负责把数据写入 cache,而 Read Through Pattern 则是 cache 服务自己来写入缓存的,这对客户端是透明的。
|
||||
|
||||
和 Cache Aside Pattern 一样, Read-Through Pattern 也有首次请求数据一定不再 cache 的问题,对于热点数据可以提前放入缓存中。
|
||||
|
||||
#### 5.3. Write Behind Pattern(异步缓存写入)
|
||||
|
||||
Write Behind Pattern 和 Read/Write Through Pattern 很相似,两者都是由 cache 服务来负责 cache 和 DB 的读写。
|
||||
|
||||
但是,两个又有很大的不同:**Read/Write Through 是同步更新 cache 和 DB,而 Write Behind Caching 则是只更新缓存,不直接更新 DB,而是改为异步批量的方式来更新 DB。**
|
||||
|
||||
**Write Behind Pattern 下 DB 的写性能非常高,尤其适合一些数据经常变化的业务场景比如说一篇文章的点赞数量、阅读数量。** 往常一篇文章被点赞 500 次的话,需要重复修改 500 次 DB,但是在 Write Behind Pattern 下可能只需要修改一次 DB 就可以了。
|
||||
|
||||
但是,这种模式同样也给 DB 和 Cache 一致性带来了新的考验,很多时候如果数据还没异步更新到 DB 的话,Cache 服务宕机就 gg 了。
|
||||
@ -1,4 +1,4 @@
|
||||
> 本文由 [SnailClimb](https://github.com/Snailclimb) 和 [BugSpeak](https://github.com/BugSpeak) 共同完成。
|
||||
> 本文由 [SnailClimb](https://github.com/Snailclimb) 和 [guang19](https://github.com/guang19) 共同完成。
|
||||
<!-- TOC -->
|
||||
|
||||
- [事务隔离级别(图文详解)](#事务隔离级别图文详解)
|
||||
@ -80,7 +80,7 @@ mysql> SELECT @@tx_isolation;
|
||||
+-----------------+
|
||||
```
|
||||
|
||||
这里需要注意的是:与 SQL 标准不同的地方在于InnoDB 存储引擎在 **REPEATABLE-READ(可重读)**事务隔离级别下使用的是Next-Key Lock 锁算法,因此可以避免幻读的产生,这与其他数据库系统(如 SQL Server)是不同的。所以说InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)** 已经可以完全保证事务的隔离性要求,即达到了 SQL标准的**SERIALIZABLE(可串行化)**隔离级别。
|
||||
这里需要注意的是:与 SQL 标准不同的地方在于InnoDB 存储引擎在 **REPEATABLE-READ(可重读)** 事务隔离级别下,允许应用使用 Next-Key Lock 锁算法来避免幻读的产生。这与其他数据库系统(如 SQL Server)是不同的。所以说虽然 InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**,但是可以通过应用加锁读(例如 `select * from table for update` 语句)来保证不会产生幻读,而这个加锁度使用到的机制就是 Next-Key Lock 锁算法。从而达到了 SQL 标准的 **SERIALIZABLE(可串行化)** 隔离级别。
|
||||
|
||||
因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是**READ-COMMITTED(读取提交内容):**,但是你要知道的是InnoDB 存储引擎默认使用 **REPEATABLE-READ(可重读)**并不会有任何性能损失。
|
||||
|
||||
|
||||
160
docs/database/关于数据库存储时间的一点思考.md
Normal file
@ -0,0 +1,160 @@
|
||||
我们平时开发中不可避免的就是要存储时间,比如我们要记录操作表中这条记录的时间、记录转账的交易时间、记录出发时间等等。你会发现这个时间这个东西与我们开发的联系还是非常紧密的,用的好与不好会给我们的业务甚至功能带来很大的影响。所以,我们有必要重新出发,好好认识一下这个东西。
|
||||
|
||||
这是一篇短小精悍的文章,仔细阅读一定能学到不少东西!
|
||||
|
||||
### 1.切记不要用字符串存储日期
|
||||
|
||||
我记得我在大学的时候就这样干过,而且现在很多对数据库不太了解的新手也会这样干,可见,这种存储日期的方式的优点还是有的,就是简单直白,容易上手。
|
||||
|
||||
但是,这是不正确的做法,主要会有下面两个问题:
|
||||
|
||||
1. 字符串占用的空间更大!
|
||||
2. 字符串存储的日期比较效率比较低(逐个字符进行比对),无法用日期相关的 API 进行计算和比较。
|
||||
|
||||
### 2.Datetime 和 Timestamp 之间抉择
|
||||
|
||||
Datetime 和 Timestamp 是 MySQL 提供的两种比较相似的保存时间的数据类型。他们两者究竟该如何选择呢?
|
||||
|
||||
**通常我们都会首选 Timestamp。** 下面说一下为什么这样做!
|
||||
|
||||
#### 2.1 DateTime 类型没有时区信息的
|
||||
|
||||
**DateTime 类型是没有时区信息的(时区无关)** ,DateTime 类型保存的时间都是当前会话所设置的时区对应的时间。这样就会有什么问题呢?当你的时区更换之后,比如你的服务器更换地址或者更换客户端连接时区设置的话,就会导致你从数据库中读出的时间错误。不要小看这个问题,很多系统就是因为这个问题闹出了很多笑话。
|
||||
|
||||
**Timestamp 和时区有关**。Timestamp 类型字段的值会随着服务器时区的变化而变化,自动换算成相应的时间,说简单点就是在不同时区,查询到同一个条记录此字段的值会不一样。
|
||||
|
||||
下面实际演示一下!
|
||||
|
||||
建表 SQL 语句:
|
||||
|
||||
```sql
|
||||
CREATE TABLE `time_zone_test` (
|
||||
`id` bigint(20) NOT NULL AUTO_INCREMENT,
|
||||
`date_time` datetime DEFAULT NULL,
|
||||
`time_stamp` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
|
||||
PRIMARY KEY (`id`)
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
|
||||
```
|
||||
|
||||
插入数据:
|
||||
|
||||
```sql
|
||||
INSERT INTO time_zone_test(date_time,time_stamp) VALUES(NOW(),NOW());
|
||||
```
|
||||
|
||||
查看数据:
|
||||
|
||||
```sql
|
||||
select date_time,time_stamp from time_zone_test;
|
||||
```
|
||||
|
||||
结果:
|
||||
|
||||
```
|
||||
+---------------------+---------------------+
|
||||
| date_time | time_stamp |
|
||||
+---------------------+---------------------+
|
||||
| 2020-01-11 09:53:32 | 2020-01-11 09:53:32 |
|
||||
+---------------------+---------------------+
|
||||
```
|
||||
|
||||
现在我们运行
|
||||
|
||||
修改当前会话的时区:
|
||||
|
||||
```sql
|
||||
set time_zone='+8:00';
|
||||
```
|
||||
|
||||
再次查看数据:
|
||||
|
||||
```
|
||||
+---------------------+---------------------+
|
||||
| date_time | time_stamp |
|
||||
+---------------------+---------------------+
|
||||
| 2020-01-11 09:53:32 | 2020-01-11 17:53:32 |
|
||||
+---------------------+---------------------+
|
||||
```
|
||||
|
||||
**扩展:一些关于 MySQL 时区设置的一个常用 sql 命令**
|
||||
|
||||
```sql
|
||||
# 查看当前会话时区
|
||||
SELECT @@session.time_zone;
|
||||
# 设置当前会话时区
|
||||
SET time_zone = 'Europe/Helsinki';
|
||||
SET time_zone = "+00:00";
|
||||
# 数据库全局时区设置
|
||||
SELECT @@global.time_zone;
|
||||
# 设置全局时区
|
||||
SET GLOBAL time_zone = '+8:00';
|
||||
SET GLOBAL time_zone = 'Europe/Helsinki';
|
||||
```
|
||||
|
||||
#### 2.2 DateTime 类型耗费空间更大
|
||||
|
||||
Timestamp 只需要使用 4 个字节的存储空间,但是 DateTime 需要耗费 8 个字节的存储空间。但是,这样同样造成了一个问题,Timestamp 表示的时间范围更小。
|
||||
|
||||
- DateTime :1000-01-01 00:00:00 ~ 9999-12-31 23:59:59
|
||||
- Timestamp: 1970-01-01 00:00:01 ~ 2037-12-31 23:59:59
|
||||
|
||||
> Timestamp 在不同版本的 MySQL 中有细微差别。
|
||||
|
||||
### 3 再看 MySQL 日期类型存储空间
|
||||
|
||||
下图是 MySQL 5.6 版本中日期类型所占的存储空间:
|
||||
|
||||

|
||||
|
||||
可以看出 5.6.4 之后的 MySQL 多出了一个需要 0 ~ 3 字节的小数位。Datatime 和 Timestamp 会有几种不同的存储空间占用。
|
||||
|
||||
为了方便,本文我们还是默认 Timestamp 只需要使用 4 个字节的存储空间,但是 DateTime 需要耗费 8 个字节的存储空间。
|
||||
|
||||
### 4.数值型时间戳是更好的选择吗?
|
||||
|
||||
很多时候,我们也会使用 int 或者 bigint 类型的数值也就是时间戳来表示时间。
|
||||
|
||||
这种存储方式的具有 Timestamp 类型的所具有一些优点,并且使用它的进行日期排序以及对比等操作的效率会更高,跨系统也很方便,毕竟只是存放的数值。缺点也很明显,就是数据的可读性太差了,你无法直观的看到具体时间。
|
||||
|
||||
时间戳的定义如下:
|
||||
|
||||
> 时间戳的定义是从一个基准时间开始算起,这个基准时间是「1970-1-1 00:00:00 +0:00」,从这个时间开始,用整数表示,以秒计时,随着时间的流逝这个时间整数不断增加。这样一来,我只需要一个数值,就可以完美地表示时间了,而且这个数值是一个绝对数值,即无论的身处地球的任何角落,这个表示时间的时间戳,都是一样的,生成的数值都是一样的,并且没有时区的概念,所以在系统的中时间的传输中,都不需要进行额外的转换了,只有在显示给用户的时候,才转换为字符串格式的本地时间。
|
||||
|
||||
数据库中实际操作:
|
||||
|
||||
```sql
|
||||
mysql> select UNIX_TIMESTAMP('2020-01-11 09:53:32');
|
||||
+---------------------------------------+
|
||||
| UNIX_TIMESTAMP('2020-01-11 09:53:32') |
|
||||
+---------------------------------------+
|
||||
| 1578707612 |
|
||||
+---------------------------------------+
|
||||
1 row in set (0.00 sec)
|
||||
|
||||
mysql> select FROM_UNIXTIME(1578707612);
|
||||
+---------------------------+
|
||||
| FROM_UNIXTIME(1578707612) |
|
||||
+---------------------------+
|
||||
| 2020-01-11 09:53:32 |
|
||||
+---------------------------+
|
||||
1 row in set (0.01 sec)
|
||||
```
|
||||
|
||||
### 5.总结
|
||||
|
||||
MySQL 中时间到底怎么存储才好?Datetime?Timestamp? 数值保存的时间戳?
|
||||
|
||||
好像并没有一个银弹,很多程序员会觉得数值型时间戳是真的好,效率又高还各种兼容,但是很多人又觉得它表现的不够直观。这里插一嘴,《高性能 MySQL 》这本神书的作者就是推荐 Timestamp,原因是数值表示时间不够直观。下面是原文:
|
||||
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/高性能mysql-不推荐用数值时间戳.jpg" style="zoom:50%;" />
|
||||
|
||||
每种方式都有各自的优势,根据实际场景才是王道。下面再对这三种方式做一个简单的对比,以供大家实际开发中选择正确的存放时间的数据类型:
|
||||
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/总结-常用日期存储方式.jpg" style="zoom:50%;" />
|
||||
|
||||
如果还有什么问题欢迎给我留言!如果文章有什么问题的话,也劳烦指出,Guide 哥感激不尽!
|
||||
|
||||
后面的文章我会介绍:
|
||||
|
||||
- [ ] Java8 对日期的支持以及为啥不能用 SimpleDateFormat。
|
||||
- [ ] SpringBoot 中如何实际使用(JPA 为例)
|
||||
225
docs/database/数据库索引.md
Normal file
@ -0,0 +1,225 @@
|
||||
## 什么是索引?
|
||||
**索引是一种用于快速查询和检索数据的数据结构。常见的索引结构有: B树, B+树和Hash。**
|
||||
|
||||
索引的作用就相当于目录的作用。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
|
||||
|
||||
## 为什么要用索引?索引的优缺点分析
|
||||
|
||||
### 索引的优点
|
||||
**可以大大加快 数据的检索速度(大大减少的检索的数据量), 这也是创建索引的最主要的原因。毕竟大部分系统的读请求总是大于写请求的。 ** 另外,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
|
||||
|
||||
### 索引的缺点
|
||||
1. **创建索引和维护索引需要耗费许多时间**:当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低SQL执行效率。
|
||||
2. **占用物理存储空间** :索引需要使用物理文件存储,也会耗费一定空间。
|
||||
|
||||
## B树和B+树区别
|
||||
|
||||
* B树的所有节点既存放 键(key) 也存放 数据(data);而B+树只有叶子节点存放 key 和 data,其他内节点只存放key。
|
||||
* B树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
|
||||
* B树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而B+树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
|
||||
|
||||

|
||||
|
||||
## Hash索引和 B+树索引优劣分析
|
||||
|
||||
**Hash索引定位快**
|
||||
|
||||
Hash索引指的就是Hash表,最大的优点就是能够在很短的时间内,根据Hash函数定位到数据所在的位置,这是B+树所不能比的。
|
||||
|
||||
**Hash冲突问题**
|
||||
|
||||
知道HashMap或HashTable的同学,相信都知道它们最大的缺点就是Hash冲突了。不过对于数据库来说这还不算最大的缺点。
|
||||
|
||||
**Hash索引不支持顺序和范围查询(Hash索引不支持顺序和范围查询是它最大的缺点。**
|
||||
|
||||
试想一种情况:
|
||||
|
||||
````text
|
||||
SELECT * FROM tb1 WHERE id < 500;
|
||||
````
|
||||
|
||||
B+树是有序的,在这种范围查询中,优势非常大,直接遍历比500小的叶子节点就够了。而Hash索引是根据hash算法来定位的,难不成还要把 1 - 499的数据,每个都进行一次hash计算来定位吗?这就是Hash最大的缺点了。
|
||||
|
||||
---
|
||||
|
||||
## 索引类型
|
||||
|
||||
### 主键索引(Primary Key)
|
||||
**数据表的主键列使用的就是主键索引。**
|
||||
|
||||
**一张数据表有只能有一个主键,并且主键不能为null,不能重复。**
|
||||
|
||||
**在mysql的InnoDB的表中,当没有显示的指定表的主键时,InnoDB会自动先检查表中是否有唯一索引的字段,如果有,则选择该字段为默认的主键,否则InnoDB将会自动创建一个6Byte的自增主键。**
|
||||
|
||||
### 二级索引(辅助索引)
|
||||
**二级索引又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。**
|
||||
|
||||
唯一索引,普通索引,前缀索引等索引属于二级索引。
|
||||
|
||||
**PS:不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,也可以自行搜索。**
|
||||
|
||||
1. **唯一索引(Unique Key)** :唯一索引也是一种约束。**唯一索引的属性列不能出现重复的数据,但是允许数据为NULL,一张表允许创建多个唯一索引。**建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
|
||||
2. **普通索引(Index)** :**普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和NULL。**
|
||||
3. **前缀索引(Prefix)** :前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,
|
||||
因为只取前几个字符。
|
||||
4. **全文索引(Full Text)** :全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6之前只有MYISAM引擎支持全文索引,5.6之后InnoDB也支持了全文索引。
|
||||
|
||||
二级索引:
|
||||
.png)
|
||||
|
||||
## 聚集索引与非聚集索引
|
||||
|
||||
### 聚集索引
|
||||
**聚集索引即索引结构和数据一起存放的索引。主键索引属于聚集索引。**
|
||||
|
||||
在 Mysql 中,InnoDB引擎的表的 `.ibd`文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
|
||||
|
||||
#### 聚集索引的优点
|
||||
聚集索引的查询速度非常的快,因为整个B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。
|
||||
|
||||
#### 聚集索引的缺点
|
||||
1. **依赖于有序的数据** :因为B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或UUID这种又长又难比较的数据,插入或查找的速度肯定比较慢。
|
||||
2. **更新代价大** : 如果对索引列的数据被修改时,那么对应的索引也将会被修改,
|
||||
而且况聚集索引的叶子节点还存放着数据,修改代价肯定是较大的,
|
||||
所以对于主键索引来说,主键一般都是不可被修改的。
|
||||
|
||||
### 非聚集索引
|
||||
|
||||
**非聚集索引即索引结构和数据分开存放的索引。**
|
||||
|
||||
**二级索引属于非聚集索引。**
|
||||
|
||||
>MYISAM引擎的表的.MYI文件包含了表的索引,
|
||||
>该表的索引(B+树)的每个叶子非叶子节点存储索引,
|
||||
>叶子节点存储索引和索引对应数据的指针,指向.MYD文件的数据。
|
||||
>
|
||||
**非聚集索引的叶子节点并不一定存放数据的指针,
|
||||
因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。**
|
||||
|
||||
#### 非聚集索引的优点
|
||||
**更新代价比聚集索引要小** 。非聚集索引的更新代价就没有聚集索引那么大了,非聚集索引的叶子节点是不存放数据的
|
||||
|
||||
#### 非聚集索引的缺点
|
||||
1. 跟聚集索引一样,非聚集索引也依赖于有序的数据
|
||||
2. **可能会二次查询(回表)** :这应该是非聚集索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
|
||||
|
||||
这是Mysql的表的文件截图:
|
||||
|
||||

|
||||
|
||||
聚集索引和非聚集索引:
|
||||
|
||||

|
||||
|
||||
### 非聚集索引一定回表查询吗(覆盖索引)?
|
||||
**非聚集索引不一定回表查询。**
|
||||
|
||||
>试想一种情况,用户准备使用SQL查询用户名,而用户名字段正好建立了索引。
|
||||
|
||||
````text
|
||||
SELECT name FROM table WHERE username='guang19';
|
||||
````
|
||||
|
||||
>那么这个索引的key本身就是name,查到对应的name直接返回就行了,无需回表查询。
|
||||
|
||||
**即使是MYISAM也是这样,虽然MYISAM的主键索引确实需要回表,
|
||||
因为它的主键索引的叶子节点存放的是指针。但是如果SQL查的就是主键呢?**
|
||||
|
||||
```text
|
||||
SELECT id FROM table WHERE id=1;
|
||||
```
|
||||
|
||||
主键索引本身的key就是主键,查到返回就行了。这种情况就称之为覆盖索引了。
|
||||
|
||||
## 覆盖索引
|
||||
|
||||
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。我们知道在InnoDB存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
|
||||
|
||||
**覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了,
|
||||
而无需回表查询。**
|
||||
|
||||
>如主键索引,如果一条SQL需要查询主键,那么正好根据主键索引就可以查到主键。
|
||||
>
|
||||
>再如普通索引,如果一条SQL需要查询name,name字段正好有索引,
|
||||
>那么直接根据这个索引就可以查到数据,也无需回表。
|
||||
|
||||
覆盖索引:
|
||||

|
||||
|
||||
---
|
||||
|
||||
## 索引创建原则
|
||||
|
||||
### 单列索引
|
||||
单列索引即由一列属性组成的索引。
|
||||
|
||||
### 联合索引(多列索引)
|
||||
联合索引即由多列属性组成索引。
|
||||
|
||||
### 最左前缀原则
|
||||
|
||||
假设创建的联合索引由三个字段组成:
|
||||
|
||||
```text
|
||||
ALTER TABLE table ADD INDEX index_name (num,name,age)
|
||||
```
|
||||
|
||||
那么当查询的条件有为:num / (num AND name) / (num AND name AND age)时,索引才生效。所以在创建联合索引时,尽量把查询最频繁的那个字段作为最左(第一个)字段。查询的时候也尽量以这个字段为第一条件。
|
||||
|
||||
> 但可能由于版本原因(我的mysql版本为8.0.x),我创建的联合索引,相当于在联合索引的每个字段上都创建了相同的索引:
|
||||
|
||||
.png)
|
||||
|
||||
无论是否符合最左前缀原则,每个字段的索引都生效:
|
||||
|
||||

|
||||
|
||||
## 索引创建注意点
|
||||
|
||||
### 最左前缀原则
|
||||
|
||||
虽然我目前的Mysql版本较高,好像不遵守最左前缀原则,索引也会生效。
|
||||
但是我们仍应遵守最左前缀原则,以免版本更迭带来的麻烦。
|
||||
|
||||
### 选择合适的字段
|
||||
|
||||
#### 1.不为NULL的字段
|
||||
|
||||
索引字段的数据应该尽量不为NULL,因为对于数据为NULL的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为NULL,建议使用0,1,true,false这样语义较为清晰的短值或短字符作为替代。
|
||||
|
||||
#### 2.被频繁查询的字段
|
||||
|
||||
我们创建索引的字段应该是查询操作非常频繁的字段。
|
||||
|
||||
#### 3.被作为条件查询的字段
|
||||
|
||||
被作为WHERE条件查询的字段,应该被考虑建立索引。
|
||||
|
||||
#### 4.被经常频繁用于连接的字段
|
||||
|
||||
经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
|
||||
|
||||
### 不合适创建索引的字段
|
||||
|
||||
#### 1.被频繁更新的字段应该慎重建立索引
|
||||
|
||||
虽然索引能带来查询上的效率,但是维护索引的成本也是不小的。
|
||||
如果一个字段不被经常查询,反而被经常修改,那么就更不应该在这种字段上建立索引了。
|
||||
|
||||
#### 2.不被经常查询的字段没有必要建立索引
|
||||
|
||||
#### 3.尽可能的考虑建立联合索引而不是单列索引
|
||||
|
||||
因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗B+树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
|
||||
|
||||
#### 4.注意避免冗余索引
|
||||
|
||||
冗余索引指的是索引的功能相同,能够命中 就肯定能命中 ,那么 就是冗余索引如(name,city )和(name )这两个索引就是冗余索引,能够命中后者的查询肯定是能够命中前者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
|
||||
|
||||
#### 5.考虑在字符串类型的字段上使用前缀索引代替普通索引
|
||||
|
||||
前缀索引仅限于字符串类型,较普通索引会占用更小的空间,所以可以考虑使用前缀索引带替普通索引。
|
||||
|
||||
### 使用索引一定能提高查询性能吗?
|
||||
|
||||
大多数情况下,索引查询都是比全表扫描要快的。但是如果数据库的数据量不大,那么使用索引也不一定能够带来很大提升。
|
||||
@ -21,7 +21,7 @@
|
||||
> 1. **增加了复杂性:** a.每次做DELETE 或者UPDATE都必须考虑外键约束,会导致开发的时候很痛苦,测试数据极为不方便;b.外键的主从关系是定的,假如那天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
|
||||
> 2. **增加了额外工作**: 数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗资源;(个人觉得这个不是不用外键的原因,因为即使你不使用外键,你在应用层面也还是要保证的。所以,我觉得这个影响可以忽略不计。)
|
||||
> 3. 外键还会因为需要请求对其他表内部加锁而容易出现死锁情况;
|
||||
> 4. **对分不分表不友好** :因为分库分表下外键是无法生效的。
|
||||
> 4. **对分库分表不友好** :因为分库分表下外键是无法生效的。
|
||||
> 5. ......
|
||||
|
||||
我个人觉得上面这种回答不是特别的全面,只是说了外键存在的一个常见的问题。实际上,我们知道外键也是有很多好处的,比如:
|
||||
|
||||
@ -0,0 +1,61 @@
|
||||
|
||||
|
||||
> 本文来自读者 Boyn 投稿!恭喜这位粉丝拿到了含金量极高的字节跳动实习 offer!赞!
|
||||
|
||||
## 基本条件
|
||||
|
||||
本人是底层 211 本科,现在大三,无科研经历,但是有一些项目经历,在国内监控行业某头部企业做过一段时间的实习。想着投一下字节,可以积累一下面试经验和为春招做准备.投了简历之后,过了一段时间,HR 就打电话跟我约时间,在年后进行远程面。
|
||||
|
||||
说明一下,我投的是北京 office。
|
||||
|
||||
## 一面
|
||||
|
||||
面试官很和蔼,由于疫情的原因,大家都在家里面进行远程面试
|
||||
|
||||
开头没有自我介绍,直接开始问项目了,问了比如
|
||||
|
||||
- 常用的 Web 组件有哪些(回答了自己经常用到的 SpringBoot,Redis,Mysql 等等,字节这边基本没有用 Java 的后台,所以感觉面试官不大会问 Spring,Java 这些东西,反倒是对数据库和中间件比较感兴趣)
|
||||
- Kafka 相关,如何保证不会重复消费,Kafka 消费组结构等等(这个只是凭着感觉和面试官说了,因为 Kafka 自己确实准备得不充分,但是心态稳住了)
|
||||
- **Mysql 索引,B+树(必考嗷同学们)**
|
||||
|
||||
还有一些项目中的细节,这些因人而异,就不放上来了,提示一点就是要在项目中介绍一些亮眼的地方,比如用了什么牛逼的数据结构,架构上有什么特点,并发量大小还有怎么去 hold 住并发量
|
||||
|
||||
后面就是算法题了,一共做了两道
|
||||
|
||||
1. 判断平衡二叉树(这道题总体来说并不难,但是面试官在中间穿插了垃圾回收的知识,这就很难受了,具体的就是大家要判断一下对象在什么时候会回收,可达性分析什么时候对这个对象来说是不可达的,还有在递归函数中内存如何变化,这个是让我们来对这个函数进行执行过程的建模,只看栈帧大小变化的话,应该有是两个峰值,中间会有抖动的情况)
|
||||
2. 二分查找法的变种题,给定`target`和一个升序的数组,寻找下一个比数组大的数.这道题也不难,靠大家对二分查找法的熟悉程度,当然,这边还有一个优化的点,可以看看[我的博客](https://boyn.top/2019/11/09/%E7%AE%97%E6%B3%95%E4%B8%8E%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE%E6%B3%95/)找找灵感
|
||||
|
||||
完成了之后,面试官让我等一会有二面,大概 10 分钟左右吧,休息了一会就继续了
|
||||
|
||||
## 二面
|
||||
|
||||
二面一上来就是先让我自我介绍,当然还是同样的套路,同样的香脆
|
||||
|
||||
然后问了我一些关于 Redis 的问题,比如 **zset 的实现(跳表,这个高频)** ,键的过期策略,持久化等等,这些在大多数 Redis 的介绍中都可以找到,就不细说了
|
||||
|
||||
还有一些数据结构的问题,比如说问了哈希表是什么,给面试官详细说了一下`java.util.HashMap`是怎么实现(当然里面就穿插着红黑树了,多看看红黑树是有什么特点之类的)的,包括说为什么要用链地址法来避免冲突,探测法有哪些,链地址法和探测法的优劣对比
|
||||
|
||||
后面还跟我讨论了很久的项目,所以说大家的项目一定要做好,要有亮点的地方,在这里跟面试官讨论了很多项目优化的地方,还有什么不足,还有什么地方可以新增功能等等,同样不细说了
|
||||
|
||||
一边讨论的时候劈里啪啦敲了很多,应该是对个人的面试评价一类的
|
||||
|
||||
后面就是字节的传统艺能手撕算法了,一共做了三道
|
||||
|
||||
- 一二道是连在一起的.给定一个规则`S_0 = {1} S_1={1,2,1} S_2 = {1,2,1,3,1,2,1} S_n = {S_n-1 , n + 1, S_n-1}`.第一个问题是他们的个数有什么关系(1 3 7 15... 2 的 n 次方-1,用位运算解决).第二个问题是给定数组个数下标 n 和索引 k,让我们求出 S_n(k)所指的数,假如`S_2(2) = 1`,我在做的时候没有什么好的思路,如果有的话大家可以分享一下
|
||||
- 第三道是下一个排列:[https://leetcode-cn.com/problems/next-permutation](https://leetcode-cn.com/problems/next-permutation) 的题型,不过做了一些修改,数组大小`10000<n<100000`,不能用暴力法,还有数字是在 1-9 之间会有重复
|
||||
|
||||
## hr 面
|
||||
|
||||
一些偏职业规划的话题了,实习时间,项目经历,实习经历这些。
|
||||
|
||||
## 总结
|
||||
|
||||
基础很重要!这次准备到的 Redis,Mysql,JVM 原理等等都有问到了,(网络这一块没问,但是也是要好好准备的,对于后台来说,网络知识不仅仅是面试,还是以后工作的知识基础).当然自己也有准备不足的地方,比如 Kafka 等中间件,只会用不会原理是万万不行的.并且这些基础知识不能只靠背,面试官还会融合在项目里面进行串问
|
||||
|
||||
问到了不会的不要慌,因为面试官是在试探你的技术深度,有可能会针对某一个问题,问到你不会为止,所以你出现不会的问题是很正常的,心态把控住就行.
|
||||
|
||||
无论是做题,还是回答问题的时候,牢记你不是在考试,而是在交流,和面试官有互动和沟通是很重要的,你说的一些疏漏的地方,如果你及时跟面试官反馈,还是可以补救一下的
|
||||
|
||||
最重要的一点字节的面试就是算法一定要牢固,每一轮都会有手撕算法的,这个不用想,LeetCode+剑指 Offer 走起来就对了,心态很重要,算法题不一定都是你会的,要有一定的心理准备,遇到难题可以先冷静分析一波.而且写出`Bug free`的代码也是很重要的,我前面的几题算法因为在牛客网上进行面试,所以要运行出来.
|
||||
|
||||
最后祝大家在春招取得好的 Offer,_奥力给_!
|
||||
@ -0,0 +1,125 @@
|
||||
> 本文是鄙人薛某这位老哥的投稿,虽然面试最后挂了,但是老哥本身还是挺优秀的,而且通过这次面试学到了很多东西,我想这就足够了!加油!不要畏惧面试失败,好好修炼自己,多准备一下,后面一定会找到让自己满意的工作。
|
||||
>
|
||||
|
||||
## 背景
|
||||
|
||||
前段时间家里出了点事,辞职回家待了一段时间,处理完老家的事情后就回到广州这边继续找工作,大概是国庆前几天我去面试了一家叫做Bigo(YY的子公司),面试的职位是面向3-5年的Java开发,最终自己倒在了第三轮的技术面上。虽然有些遗憾和泄气,但想着还是写篇博客来记录一下自己的面试过程好了,也算是对广大程序员同胞们的分享,希望对你们以后的学习和面试能有所帮助。
|
||||
|
||||
## 个人情况
|
||||
|
||||
先说下LZ的个人情况。
|
||||
|
||||
17年毕业,二本,目前位于广州,是一个非常普通的Java开发程序员,算起来有两年多的开发经验。
|
||||
|
||||
其实这个阶段有点尴尬,高不成低不就,比初级程序员稍微好点,但也达不到高级的程度。加上现如今IT行业接近饱和,很多岗位都是要求至少3-5年以上开发经验,所以对于两年左右开发经验的需求其实是比较小的,这点在LZ找工作的过程中深有体会。最可悲的是,今年的大环境不好,很多公司不断的在裁员,更别说招人了,残酷的形势对于求职者来说更是雪上加霜,相信很多求职的同学也有所体会。所以,不到万不得已的情况下,建议不要裸辞!
|
||||
|
||||
## Bigo面试
|
||||
|
||||
面试岗位:Java后台开发
|
||||
|
||||
经验要求:3-5年
|
||||
|
||||
由于是国庆前去面试Bigo的,到现在也有一个多月的时间了,虽然仍有印象,但也有不少面试题忘了,所以我只能尽量按照自己的回忆来描述面试的过程,不明白之处还请见谅!
|
||||
|
||||
### 一面(微信电话面)
|
||||
|
||||
bigo的第一面是微信电话面试,本来是想直接电话面,但面试官说需要手写算法题,就改成微信电话面。
|
||||
|
||||
- 自我介绍
|
||||
- 先了解一下Java基础吧,什么是内存泄漏和内存溢出?(溢出是指创建太多对象导致内存空间不足,泄漏是无用对象没有回收)
|
||||
- JVM怎么判断对象是无用对象?(根搜索算法,从GC Root出发,对象没有引用,就判定为无用对象)
|
||||
- 根搜索算法中的根节点可以是哪些对象?(类对象,虚拟机栈的对象,常量引用的对象)
|
||||
- 重载和重写的区别?(重载发生在同个类,方法名相同,参数列表不同;重写是父子类之间的行为,方法名好参数列表都相同,方法体内的程序不同)
|
||||
- 重写有什么限制没有?
|
||||
- Java有哪些同步工具?(synchronized和Lock)
|
||||
- 这两者有什么区别?
|
||||
- ArrayList和LinkedList的区别?(ArrayList基于数组,搜索快,增删元素慢,LinkedList基于链表,增删快,搜索因为要遍历元素所以效率低)
|
||||
- 这两种集合哪个比较占内存?(看情况的,ArrayList如果有扩容并且元素没占满数组的话,浪费的内存空间也是比较多的,但一般情况下,LinkedList占用的内存会相对多点,因为每个元素都包含了指向前后节点的指针)
|
||||
- 说一下HashMap的底层结构(数组 + 链表,链表过长变成红黑树)
|
||||
- HashMap为什么线程不安全,1.7版本之前HashMap有什么问题(扩容时多线程操作可能会导致链表成环的出现,然后调用get方法会死循环)
|
||||
- 了解ConcurrentHashMap吗?说一下它为什么能线程安全(用了分段锁)
|
||||
- 哪些方法需要锁住整个集合的?(读取size的时候)
|
||||
- 看你简历写着你了解RPC啊,那你说下RPC的整个过程?(从客户端发起请求,到socket传输,然后服务端处理消息,以及怎么序列化之类的都大概讲了一下)
|
||||
- 服务端获取客户端要调用的接口信息后,怎么找到对应的实现类的?(反射 + 注解吧,这里也不是很懂)
|
||||
- dubbo的负载均衡有几种算法?(随机,轮询,最少活跃请求数,一致性hash)
|
||||
- 你说的最少活跃数算法是怎么回事?(服务提供者有一个计数器,记录当前同时请求个数,值越小说明该服务器负载越小,路由器会优先选择该服务器)
|
||||
- 服务端怎么知道客户端要调用的算法的?(socket传递消息过来的时候会把算法策略传递给服务端)
|
||||
- 你用过redis做分布式锁是吧,你们是自己写的工具类吗?(不是,我们用redission做分布式锁)
|
||||
- 线程拿到key后是怎么保证不死锁的呢?(给这个key加上一个过期时间)
|
||||
- 如果这个过期时间到了,但是业务程序还没处理完,该怎么办?(额......可以在业务逻辑上保证幂等性吧)
|
||||
- 那如果多个业务都用到分布式锁的话,每个业务都要保证幂等性了,有没有更好的方法?(额......思考了下暂时没有头绪,面试官就说那先跳过吧。事后我了解到redission本身是有个看门狗的监控线程的,如果检测到key被持有的话就会再次重置过期时间)
|
||||
- 你那边有纸和笔吧,写一道算法,用两个栈模拟一个队列的入队和出队。(因为之前复习的时候对这道题有印象,写的时候也比较快,大概是用了五分钟,然后就拍成图片发给了面试官,对方看完后表示没问题就结束了面试。)
|
||||
|
||||
第一面问的不算难,问题也都是偏基础之类的,虽然答得不算完美,但过程还是比较顺利的。几天之后,Bigo的hr就邀请我去他们公司参加现场面试。
|
||||
|
||||
### 二面
|
||||
|
||||
到Bigo公司后,一位hr小姐姐招待我到了一个会议室,等了大概半个小时,一位中年男子走了进来,非常的客气,说不好意思让我等那么久了,并且介绍了自己是技术经理,然后就开始了我们的交谈。
|
||||
|
||||
- 依照惯例,让我简单做下自我介绍,这个过程他也在边看我的简历。
|
||||
- 说下你最熟悉的项目吧。(我就拿我上家公司最近做的一个电商项目开始介绍,从简单的项目描述,到项目的主要功能,以及我主要负责的功能模块,吧啦吧啦..............)
|
||||
- 你对这个项目这么熟悉,那你根据你的理解画一下你的项目架构图,还有说下你具体参与了哪部分。(这个题目还是比较麻烦的,毕竟我当时离职的时间也挺长了,对这个项目的架构也是有些模糊。当然,最后还是硬着头皮还是画了个大概,从前端开始访问,然后通过nginx网关层,最后到具体的服务等等,并且把自己参与的服务模块也标示了出来)
|
||||
- 你的项目用到了Spring Cloud GateWay,既然你已经有nginx做网关了,为什么还要用gateWay呢?(nginx是做负载均衡,还有针对客户端的访问做网关用的,gateWay是接入业务层做的网关,而且还整合了熔断器Hystrix)
|
||||
- 熔断器Hystrix最主要的作用是什么?(防止服务调用失败导致的服务雪崩,能降级)
|
||||
- 你的项目用到了redis,你们的redis是怎么部署的?(额。。。。好像是哨兵模式部署的吧。)
|
||||
- 说一下你对哨兵模式的理解?(我对哨兵模式了解的不多,就大概说了下Sentinel监控之类的,还有类似ping命令的心跳机制,以及怎么判断一个master是下线之类。。。。。)
|
||||
- 那你们为什么要用哨兵模式呢?怎么不用集群的方式部署呢?一开始get不到他的点,就说哨兵本身就是多实例部署的,他解释了一下,说的是redis-cluster的部署方案。(额......redis的环境搭建有专门的运维人员部署的,应该是优先考虑高可用吧..........开始有点心慌了,因为我也不知道为什么)
|
||||
- 哦,那你是觉得集群没有办法实现高可用吗?(不....不是啊,只是觉得哨兵模式可能比较保证主从复制安全性吧........我也不知道自己在说什么)
|
||||
- 集群也是能保证高可用的,你知道它又是怎么保证主从一致性的吗?(好吧,这里真的不知道了,只能跳过)
|
||||
- 你肯定有微信吧,如果让你来设计微信朋友圈的话,你会怎么设计它的属性成员呢?(嗯......需要有用户表,朋友圈的表,好友表之类的吧)
|
||||
- 嗯,好,你也知道微信用户有接近10亿之多,那肯定要涉及到分库分表,如果是你的话,怎么设计分库分表呢?(这个问题考察的点比较大,我答的其实一般,而且这个过程面试官还不断的进行连环炮发问,导致这个话题说了有将近20分钟,限于篇幅,这里就不再详述了)
|
||||
- 这边差不多了,最后你写一道算法吧,有一组未排序的整形数组,你设计一个算法,对数组的元素两两配对,然后输出最大的绝对值差和最小的绝对值差的"对数"。(听到这道题,我第一想法就是用HashMap来保存,key是两个元素的绝对值差,value是配对的数量,如果有相同的就加1,没有就赋值为1,然后最后对map做排序,输出最大和最小的value值,写完后面试官说结果虽然是正确的,但是不够效率,因为遍历的时间复杂度成了O(n^2),然后提醒了我往排序这方面想。我灵机一动,可以先对数组做排序,然后首元素与第二个元素做绝对值差,记为num,然后首元素循环和后面的元素做计算,直到绝对值差不等于num位置,这样效率比起O(n^2)快多了。)
|
||||
|
||||
面试完后,技术官就问我有什么要问他的,我就针对这个岗位的职责和项目所用的技术栈做了询问,然后就让我先等下,等他去通知三面的技术官。说实话,二面给我的感觉是最舒服的,因为面试官很亲切,面试的过程一直积极的引导我,而且在职业规划方面给了我很多的建议,让我受益匪浅,虽然面试时间有一个半小时,但却丝毫不觉得长,整个面试过程聊得挺舒服的,不过因为时间比较久了,很多问题我也记不清了。
|
||||
|
||||
### 三面
|
||||
|
||||
二面结束后半个小时,三面的技术面试官就开始进来了,从他的额头发量分布情况就能猜想是个大牛,人狠话不多,坐下后也没让我做自我介绍,直接开问,整个过程我答的也不好,而且面试官的问题表述有些不太清晰,经常需要跟他重复确认清楚。
|
||||
|
||||
- 对事务了解吗?说一下事务的隔离级别有哪些(我以比较了解的Spring来说,把Spring的四种事务隔离级别都叙述了一遍)
|
||||
|
||||
- 你做过电商,那应该知道下单的时候需要减库存对吧,假设现在有两个服务A和B,分别操作订单和库存表,A保存订单后,调用B减库存的时候失败了,这个时候A也要回滚,这个事务要怎么设计?(B服务的减库存方法不抛异常,由调用方也就是A服务来抛异常)
|
||||
|
||||
- 了解过读写分离吗?(额。。。大概了解一点,就是写的时候进主库,读的时候读从库)
|
||||
|
||||
- 你说读的时候读从库,现在假设有一张表User做了读写分离,然后有个线程在**一个事务范围内**对User表先做了写的处理,然后又做了读的处理,这时候数据还没同步到从库,怎么保证读的时候能读到最新的数据呢?(听完顿时有点懵圈,一时间答不上来,后来面试官说想办法保证一个事务中读写都是同一个库才行)
|
||||
|
||||
- 你的项目里用到了rabbitmq,那你说下mq的消费端是怎么处理的?(就是消费端接收到消息之后,会先把消息存到数据库中,然后再从数据库中定时跑消息)
|
||||
|
||||
- 也就是说你的mq是先保存到数据库中,然后业务逻辑就是从mq中读取消息然后再处理的是吧?(是的)
|
||||
|
||||
- 那你的消息是唯一的吗?(是的,用了唯一约束)
|
||||
|
||||
- 你怎么保证消息一定能被消费?或者说怎么保证一定能存到数据库中?(这里开始慌了,因为mq接入那一块我只是看过部分逻辑,但没有亲自参与,凭着自己对mq的了解就答道,应该是靠rabbitmq的ack确认机制)
|
||||
|
||||
- 好,那你整理一下你的消费端的整个处理逻辑流程,然后说说你的ack是在哪里返回的(听到这里我的心凉了一截,mq接入这部分我确实没有参与,硬着头皮按照自己的理解画了一下流程,但其实漏洞百出)
|
||||
|
||||
- 按照你这样画的话,如果数据库突然宕机,你的消息该怎么确认已经接收?(额.....那发送消息的时候就存放消息可以吧.........回答的时候心里千万只草泥马路过........行了吧,没玩没了了。)
|
||||
|
||||
- 那如果发送端的服务是多台部署呢?你保存消息的时候数据库就一直报唯一性的错误?(好吧,你赢了。。。最后硬是憋出了一句,您说的是,这样设计确实不好。。。。)
|
||||
|
||||
- 算了,跳过吧,现在你来设计一个map,然后有两个线程对这个map进行操作,主线程高速增加和删除map的元素,然后有个异步线程定时去删除map中主线程5秒内没有删除的数据,你会怎么设计?
|
||||
|
||||
(这道题我答得并不好,做了下简单的思考就说可以把map的key加上时间戳的标志,遍历的时候发现小于当前时间戳5秒前的元素就进行删除,面试官对这样的回答明显不太满意,说这样遍历会影响效率,ps:对这道题,大佬们如果有什么高见可以在评论区说下!)
|
||||
|
||||
......还有其他问题,但我只记住了这么多,就这样吧。
|
||||
|
||||
面完最后一道题后,面试官就表示这次面试过程结束了,让我回去等消息。听到这里,我知道基本上算是宣告结果了。回想起来,自己这一轮面试确实表现的很一般,加上时间拖得很长,从当天的2点半一直面试到6点多,精神上也尽显疲态。果然,几天之后,hr微信通知了我,说我第三轮技术面试没有通过,这一次面试以失败告终。
|
||||
|
||||
## 总结
|
||||
|
||||
以上就是面试的大概过程,不得不说,大厂的面试还是非常有技术水平的,这个过程中我学到了很多,这里分享下个人的一些心得:
|
||||
|
||||
1、**基础**!**基础**!**基础**!重要的事情说三遍,无论是什么阶段的程序员,基础都是最重要的。每个公司的面试一定会涉及到基础知识的提问,如果你的基础不扎实,往往第一面就可能被淘汰。
|
||||
|
||||
2、**简历需要适当的包装**。老实说,我的简历肯定是经过包装的,这也是我的工作年限不够,但却能获取Bigo面试机会的重要原因,所以适当的包装一下简历很有必要,不过切记一点,就是**不能脱离现实**,比如明明只有两年经验,却硬是写到三年。小厂还可能蒙混过关,但大厂基本很难,因为很多公司会在入职前做背景调查。
|
||||
|
||||
3、**要对简历上的技术点很熟悉**。简历包装可以,但一定要对简历上的技术点很熟悉,比如只是简单写过rabbitmq的demo的话,就不要写“熟悉”等字眼,因为很多的面试官会针对一个技能点问的很深入,像连环炮一样的深耕你对这个技能点的理解程度。
|
||||
|
||||
4、**简历上的项目要非常熟悉**。一般我们写简历都是需要对自己的项目做一定程序的包装和美化,项目写得好能给简历加很多分。但一定要对项目非常的熟悉,不熟悉的模块最好不要写上去。笔者这次就吃了大亏,我的简历上有个电商项目就写到了用rabbitmq处理下单,虽然稍微了解过那部分下单的处理逻辑,但由于没有亲自参与就没有做深入的了解,面试时在这一块内容上被Bigo三面的面试官逼得最后哑口无言。
|
||||
|
||||
5、**提升自己的架构思维**。对于初中级程序员来说,日常的工作就是基本的增删改查,把功能实现就完事了,这种思维不能说不好,只是想更上一层楼的话,业务时间需要提升下自己的架构思维能力,比如说如果让你接手一个项目的话,你会怎么考虑设计这个项目,从整体架构,到引入一些组件,再到设计具体的业务服务,这些都是设计一个项目必须要考虑的环节,对于提升我们的架构思维是一种很好的锻炼,这也是很多大厂面试高级程序员时的重要考察部分。
|
||||
|
||||
6、**不要裸辞**。这也是我最朴实的建议了,大环境不好,且行且珍惜吧,唉~~~~
|
||||
|
||||
总的来说,这次面试Bigo还是收获颇丰的,虽然有点遗憾,但也没什么后悔的,毕竟自己面试之前也是准备的很充分了,有些题目答得不好说明我还有很多技术盲区,不懂就是不懂,再这么吹也吹不出来。这也算是给我提了个醒,你还嫩着呢,好好修炼内功吧,毕竟菜可是原罪啊。
|
||||
@ -1,4 +1,4 @@
|
||||
本文来自 Anonymous 的投稿 ,JavaGuide 对原文进行了重新排版和一点完善。
|
||||
本文来自 Anonymous 的投稿 ,Guide哥 对原文进行了重新排版和一点完善。
|
||||
|
||||
<!-- TOC -->
|
||||
|
||||
|
||||
@ -1,81 +1,101 @@
|
||||
身边的朋友或者公众号的粉丝很多人都向我询问过:“我是双非/三本/专科学校的,我有机会进入大厂吗?”、“非计算机专业的学生能学好吗?”、“如何学习Java?”、“Java学习该学哪些东西?”、“我该如何准备Java面试?”......这些方面的问题。我会根据自己的一点经验对大部分人关心的这些问题进行答疑解惑。现在又刚好赶上考研结束,这篇文章也算是给考研结束准备往Java后端方向发展的朋友们指明一条学习之路。道理懂了如果没有实际行动,那这篇文章对你或许没有任何意义。
|
||||
身边的朋友或者公众号的粉丝很多人都向我询问过:“我是双非/三本/专科学校的,我有机会进入大厂吗?”、“非计算机专业的学生能学好吗?”、“如何学习 Java?”、“Java 学习该学哪些东西?”、“我该如何准备 Java 面试?”......这些方面的问题。我会根据自己的一点经验对大部分人关心的这些问题进行答疑解惑。现在又刚好赶上考研结束,这篇文章也算是给考研结束准备往 Java 后端方向发展的朋友们指明一条学习之路。道理懂了如果没有实际行动,那这篇文章对你或许没有任何意义。
|
||||
|
||||
<!-- TOC -->
|
||||
|
||||
- [Question1:我是双非/三本/专科学校的,我有机会进入大厂吗?](#question1我是双非三本专科学校的我有机会进入大厂吗)
|
||||
- [Question2:非计算机专业的学生能学好 Java 后台吗?我能进大厂吗?](#question2非计算机专业的学生能学好-java-后台吗我能进大厂吗)
|
||||
- [Question3: 我没有实习经历的话找工作是不是特别艰难?](#question3-我没有实习经历的话找工作是不是特别艰难)
|
||||
- [Question4: 我该如何准备面试呢?面试的注意事项有哪些呢?](#question4-我该如何准备面试呢面试的注意事项有哪些呢)
|
||||
- [Question5: 我该自学还是报培训班呢?](#question5-我该自学还是报培训班呢)
|
||||
- [Question6: 没有项目经历/博客/Github 开源项目怎么办?](#question6-没有项目经历博客github-开源项目怎么办)
|
||||
- [Question7: 大厂青睐什么样的人?](#question7-大厂青睐什么样的人)
|
||||
|
||||
<!-- /TOC -->
|
||||
|
||||
### Question1:我是双非/三本/专科学校的,我有机会进入大厂吗?
|
||||
|
||||
我自己也是非985非211学校的,结合自己的经历以及一些朋友的经历,我觉得让我回答这个问题再好不过。
|
||||
我自己也是非 985 非 211 学校的,结合自己的经历以及一些朋友的经历,我觉得让我回答这个问题再好不过。
|
||||
|
||||
首先,我觉得学校歧视很正常,真的太正常了,如果要抱怨的话,你只能抱怨自己没有进入名校。但是,千万不要动不动说自己学校差,动不动拿自己学校当做自己进不了大厂的借口,学历只是筛选简历的很多标准中的一个而已,如果你够优秀,简历够丰富,你也一样可以和名校同学一起同台竞争。
|
||||
首先,我觉得学校歧视很正常,真的太正常了,如果要抱怨的话,你只能抱怨自己没有进入名校。但是,千万不要动不动说自己学校差,动不动拿自己学校当做自己进不了大厂的借口,学历只是筛选简历的很多标准中的一个而已,如果你够优秀,简历够丰富,你也一样可以和名校同学一起同台竞争。
|
||||
|
||||
企业HR肯定是更喜欢高学历的人,毕竟985、211优秀人才比例肯定比普通学校高很多,HR团队肯定会优先在这些学校里选。这就好比相亲,你是愿意在很多优秀的人中选一个优秀的,还是愿意在很多普通的人中选一个优秀的呢?
|
||||
|
||||
双非本科甚至是二本、三本甚至是专科的同学也有很多进入大厂的,不过比率相比于名校的低很多而已。从大厂招聘的结果上看,高学历人才的数量占据大头,那些成功进入BAT、美团,京东,网易等大厂的双非本科甚至是二本、三本甚至是专科的同学往往是因为具备丰富的项目经历或者在某个含金量比较高的竞赛比如ACM中取得了不错的成绩。**一部分学历不突出但能力出众的面试者能够进入大厂并不是说明学历不重要,而是学历的软肋能够通过其他的优势来弥补。** 所以,如果你的学校不够好而你自己又想去大厂的话,建议你可以从这几点来做:**①尽量在面试前最好有一个可以拿的出手的项目;②有实习条件的话,尽早出去实习,实习经历也会是你的简历的一个亮点(有能力在大厂实习最佳!);③参加一些含金量比较高的比赛,拿不拿得到名次没关系,重在锻炼。**
|
||||
企业 HR 肯定是更喜欢高学历的人,毕竟 985、211 优秀人才比例肯定比普通学校高很多,HR 团队肯定会优先在这些学校里选。这就好比相亲,你是愿意在很多优秀的人中选一个优秀的,还是愿意在很多普通的人中选一个优秀的呢?
|
||||
|
||||
双非本科甚至是二本、三本甚至是专科的同学也有很多进入大厂的,不过比率相比于名校的低很多而已。从大厂招聘的结果上看,高学历人才的数量占据大头,那些成功进入 BAT、美团,京东,网易等大厂的双非本科甚至是二本、三本甚至是专科的同学往往是因为具备丰富的项目经历或者在某个含金量比较高的竞赛比如 ACM 中取得了不错的成绩。**一部分学历不突出但能力出众的面试者能够进入大厂并不是说明学历不重要,而是学历的软肋能够通过其他的优势来弥补。** 所以,如果你的学校不够好而你自己又想去大厂的话,建议你可以从这几点来做:**① 尽量在面试前最好有一个可以拿的出手的项目;② 有实习条件的话,尽早出去实习,实习经历也会是你的简历的一个亮点(有能力在大厂实习最佳!);③ 参加一些含金量比较高的比赛,拿不拿得到名次没关系,重在锻炼。**
|
||||
|
||||
### Question2:非计算机专业的学生能学好Java后台吗?我能进大厂吗?
|
||||
### Question2:非计算机专业的学生能学好 Java 后台吗?我能进大厂吗?
|
||||
|
||||
当然可以!现在非科班的程序员很多,很大一部分原因是互联网行业的工资比较高。我们学校外面的培训班里面90%都是非科班,我觉得他们很多人学的都还不错。另外,我的一个朋友本科是机械专业,大一开始自学安卓,技术贼溜,在我看来他比大部分本科是计算机的同学学的还要好。参考Question1的回答,即使你是非科班程序员,如果你想进入大厂的话,你也可以通过自己的其他优势来弥补。
|
||||
|
||||
我觉得我们不应该因为自己的专业给自己划界限或者贴标签,说实话,很多科班的同学可能并不如你,你以为科班的同学就会认真听讲吗?还不是几乎全靠自己课下自学!不过如果你是非科班的话,你想要学好,那么注定就要舍弃自己本专业的一些学习时间,这是无可厚非的。
|
||||
|
||||
建议非科班的同学,首先要打好计算机基础知识基础:①计算机网络、②操作系统、③数据机构与算法,我个人觉得这3个对你最重要。这些东西就像是内功,对你以后的长远发展非常有用。当然,如果你想要进大厂的话,这些知识也是一定会被问到的。另外,“一定学好数据结构与算法!一定学好数据结构与算法!一定学好数据结构与算法!”,重要的东西说3遍。
|
||||
当然可以!现在非科班的程序员很多,很大一部分原因是互联网行业的工资比较高。我们学校外面的培训班里面 90%都是非科班,我觉得他们很多人学的都还不错。另外,我的一个朋友本科是机械专业,大一开始自学安卓,技术贼溜,在我看来他比大部分本科是计算机的同学学的还要好。参考 Question1 的回答,即使你是非科班程序员,如果你想进入大厂的话,你也可以通过自己的其他优势来弥补。
|
||||
|
||||
我觉得我们不应该因为自己的专业给自己划界限或者贴标签,说实话,很多科班的同学可能并不如你,你以为科班的同学就会认真听讲吗?还不是几乎全靠自己课下自学!不过如果你是非科班的话,你想要学好,那么注定就要舍弃自己本专业的一些学习时间,这是无可厚非的。
|
||||
|
||||
建议非科班的同学,首先要打好计算机基础知识基础:① 计算机网络、② 操作系统、③ 数据机构与算法,我个人觉得这 3 个对你最重要。这些东西就像是内功,对你以后的长远发展非常有用。当然,如果你想要进大厂的话,这些知识也是一定会被问到的。另外,“一定学好数据结构与算法!一定学好数据结构与算法!一定学好数据结构与算法!”,重要的东西说 3 遍。
|
||||
|
||||
### Question3: 我没有实习经历的话找工作是不是特别艰难?
|
||||
|
||||
没有实习经历没关系,只要你有拿得出手的项目或者大赛经历的话,你依然有可能拿到大厂的 offer 。笔主当时找工作的时候就没有实习经历以及大赛获奖经历,单纯就是凭借自己的项目经验撑起了整个面试。
|
||||
没有实习经历没关系,只要你有拿得出手的项目或者大赛经历的话,你依然有可能拿到大厂的 offer 。笔主当时找工作的时候就没有实习经历以及大赛获奖经历,单纯就是凭借自己的项目经验撑起了整个面试。
|
||||
|
||||
如果你既没有实习经历,又没有拿得出手的项目或者大赛经历的话,我觉得在简历关,除非你有其他特别的亮点,不然,你应该就会被刷。
|
||||
如果你既没有实习经历,又没有拿得出手的项目或者大赛经历的话,我觉得在简历关,除非你有其他特别的亮点,不然,你应该就会被刷。
|
||||
|
||||
### Question4: 我该如何准备面试呢?面试的注意事项有哪些呢?
|
||||
|
||||
下面是我总结的一些准备面试的Tips以及面试必备的注意事项:
|
||||
下面是我总结的一些准备面试的 Tips 以及面试必备的注意事项:
|
||||
|
||||
1. **准备一份自己的自我介绍,面试的时候根据面试对象适当进行修改**(突出重点,突出自己的优势在哪里,切忌流水账);
|
||||
2. **注意随身带上自己的成绩单和简历复印件;** (有的公司在面试前都会让你交一份成绩单和简历当做面试中的参考。)
|
||||
3. **如果需要笔试就提前刷一些笔试题,大部分在线笔试的类型是选择题+编程题,有的还会有简答题。**(平时空闲时间多的可以刷一下笔试题目(牛客网上有很多),但是不要只刷面试题,不动手code,程序员不是为了考试而存在的。)另外,注意抓重点,因为题目太多了,但是有很多题目几乎次次遇到,像这样的题目一定要搞定。
|
||||
3. **如果需要笔试就提前刷一些笔试题,大部分在线笔试的类型是选择题+编程题,有的还会有简答题。**(平时空闲时间多的可以刷一下笔试题目(牛客网上有很多),但是不要只刷面试题,不动手 code,程序员不是为了考试而存在的。)另外,注意抓重点,因为题目太多了,但是有很多题目几乎次次遇到,像这样的题目一定要搞定。
|
||||
4. **提前准备技术面试。** 搞清楚自己面试中可能涉及哪些知识点、哪些知识点是重点。面试中哪些问题会被经常问到、自己该如何回答。(强烈不推荐背题,第一:通过背这种方式你能记住多少?能记住多久?第二:背题的方式的学习很难坚持下去!)
|
||||
5. **面试之前做好定向复习。** 也就是专门针对你要面试的公司来复习。比如你在面试之前可以在网上找找有没有你要面试的公司的面经。
|
||||
6. **准备好自己的项目介绍。** 如果有项目的话,技术面试第一步,面试官一般都是让你自己介绍一下你的项目。你可以从下面几个方向来考虑:①对项目整体设计的一个感受(面试官可能会让你画系统的架构图);②在这个项目中你负责了什么、做了什么、担任了什么角色;③ 从这个项目中你学会了那些东西,使用到了那些技术,学会了那些新技术的使用;④项目描述中,最好可以体现自己的综合素质,比如你是如何协调项目组成员协同开发的或者在遇到某一个棘手的问题的时候你是如何解决的又或者说你在这个项目用了什么技术实现了什么功能比如:用 redis 做缓存提高访问速度和并发量、使用消息队列削峰和降流等等。
|
||||
6. **准备好自己的项目介绍。** 如果有项目的话,技术面试第一步,面试官一般都是让你自己介绍一下你的项目。你可以从下面几个方向来考虑:① 对项目整体设计的一个感受(面试官可能会让你画系统的架构图);② 在这个项目中你负责了什么、做了什么、担任了什么角色;③ 从这个项目中你学会了那些东西,使用到了那些技术,学会了那些新技术的使用;④ 项目描述中,最好可以体现自己的综合素质,比如你是如何协调项目组成员协同开发的或者在遇到某一个棘手的问题的时候你是如何解决的又或者说你在这个项目用了什么技术实现了什么功能比如:用 redis 做缓存提高访问速度和并发量、使用消息队列削峰和降流等等。
|
||||
7. **面试之后记得复盘。** 面试遭遇失败是很正常的事情,所以善于总结自己的失败原因才是最重要的。如果失败,不要灰心;如果通过,切勿狂喜。
|
||||
|
||||
|
||||
**一些还算不错的 Java面试/学习相关的仓库,相信对大家准备面试一定有帮助:**[盘点一下Github上开源的Java面试/学习相关的仓库,看完弄懂薪资至少增加10k](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484817&idx=1&sn=12f0c254a240c40c2ccab8314653216b&chksm=fd9853f0caefdae6d191e6bf085d44ab9c73f165e3323aa0362d830e420ccbfad93aa5901021&token=766994974&lang=zh_CN#rd)
|
||||
**一些还算不错的 Java 面试/学习相关的仓库,相信对大家准备面试一定有帮助:**[盘点一下 Github 上开源的 Java 面试/学习相关的仓库,看完弄懂薪资至少增加 10k](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484817&idx=1&sn=12f0c254a240c40c2ccab8314653216b&chksm=fd9853f0caefdae6d191e6bf085d44ab9c73f165e3323aa0362d830e420ccbfad93aa5901021&token=766994974&lang=zh_CN#rd)
|
||||
|
||||
### Question5: 我该自学还是报培训班呢?
|
||||
|
||||
我本人更加赞同自学(你要知道去了公司可没人手把手教你了,而且几乎所有的公司都对培训班出生的有偏见。为什么有偏见,你学个东西还要去培训班,说明什么,同等水平下,你的自学能力以及自律能力一定是比不上自学的人的)。但是如果,你连每天在寝室坚持学上8个小时以上都坚持不了,或者总是容易半途而废的话,我还是推荐你去培训班。观望身边同学去培训班的,大多是非计算机专业或者是没有自律能力以及自学能力非常差的人。
|
||||
我本人更加赞同自学(你要知道去了公司可没人手把手教你了,而且几乎所有的公司都对培训班出生的有偏见。为什么有偏见,你学个东西还要去培训班,说明什么,同等水平下,你的自学能力以及自律能力一定是比不上自学的人的)。但是如果,你连每天在寝室坚持学上 8 个小时以上都坚持不了,或者总是容易半途而废的话,我还是推荐你去培训班。观望身边同学去培训班的,大多是非计算机专业或者是没有自律能力以及自学能力非常差的人。
|
||||
|
||||
另外,如果自律能力不行,你也可以通过结伴学习、参加老师的项目等方式来督促自己学习。
|
||||
另外,如果自律能力不行,你也可以通过结伴学习、参加老师的项目等方式来督促自己学习。
|
||||
|
||||
总结:去不去培训班主要还是看自己,如果自己能坚持自学就自学,坚持不下来就去培训班。
|
||||
总结:去不去培训班主要还是看自己,如果自己能坚持自学就自学,坚持不下来就去培训班。
|
||||
|
||||
### Question6: 没有项目经历/博客/Github开源项目怎么办?
|
||||
### Question6: 没有项目经历/博客/Github 开源项目怎么办?
|
||||
|
||||
从现在开始做!
|
||||
从现在开始做!
|
||||
|
||||
网上有很多非常不错的项目视频,你就跟着一步一步做,不光要做,还要改进,改善。另外,如果你的老师有相关 Java 后台项目的话,你也可以主动申请参与进来。
|
||||
网上有很多非常不错的项目视频,你就跟着一步一步做,不光要做,还要改进,改善。另外,如果你的老师有相关 Java 后台项目的话,你也可以主动申请参与进来。
|
||||
|
||||
如果有自己的博客,也算是简历上的一个亮点。建议可以在掘金、Segmentfault、CSDN等技术交流社区写博客,当然,你也可以自己搭建一个博客(采用 Hexo+Githu Pages 搭建非常简单)。写一些什么?学习笔记、实战内容、读书笔记等等都可以。
|
||||
如果有自己的博客,也算是简历上的一个亮点。建议可以在掘金、Segmentfault、CSDN 等技术交流社区写博客,当然,你也可以自己搭建一个博客(采用 Hexo+Githu Pages 搭建非常简单)。写一些什么?学习笔记、实战内容、读书笔记等等都可以。
|
||||
|
||||
多用 Github,用好 Github,上传自己不错的项目,写好 readme 文档,在其他技术社区做好宣传。相信你也会收获一个不错的开源项目!
|
||||
多用 Github,用好 Github,上传自己不错的项目,写好 readme 文档,在其他技术社区做好宣传。相信你也会收获一个不错的开源项目!
|
||||
|
||||
### Question7: 大厂青睐什么样的人?
|
||||
|
||||
### Question7: 大厂到底青睐什么样的应届生?
|
||||
**先从已经有两年左右开发经验的工程师角度来看:** 我们来看一下阿里官网支付宝 Java 高级开发工程师的招聘要求,从下面的招聘信息可以看出,除去 Java 基础/集合/多线程这些,这些能力格外重要:
|
||||
|
||||
从阿里、腾讯等大厂招聘官网对于Java后端方向/后端方向的应届实习生的要求,我们大概可以总结归纳出下面这 4 点能给简历增加很多分数:
|
||||
1. **底层知识比如 jvm** :不只是懂理论更会实操;
|
||||
2. 面**向对象编程能力** :我理解这个不仅包括“面向对象编程”,还有 SOLID 软件设计原则,相关阅读:[《写了这么多年代码,你真的了解 SOLID 吗?》](https://insights.thoughtworks.cn/do-you-really-know-solid/)(我司大佬的一篇文章)
|
||||
3. **框架能力** :不只是使用那么简单,更要搞懂原理和机制!搞懂原理和机制的基础是要学会看源码。
|
||||
4. **分布式系统开发能力** :缓存、消息队列等等都要掌握,关键是还要能使用这些技术解决实际问题而不是纸上谈兵。
|
||||
5. **不错的 sense** :喜欢和尝试新技术、追求编写优雅的代码等等。
|
||||
|
||||
- 参加过竞赛(含金量超高的是ACM);
|
||||
- 对数据结构与算法非常熟练;
|
||||
- 参与过实际项目(比如学校网站);
|
||||
- 参与过某个知名的开源项目或者自己的某个开源项目很不错;
|
||||
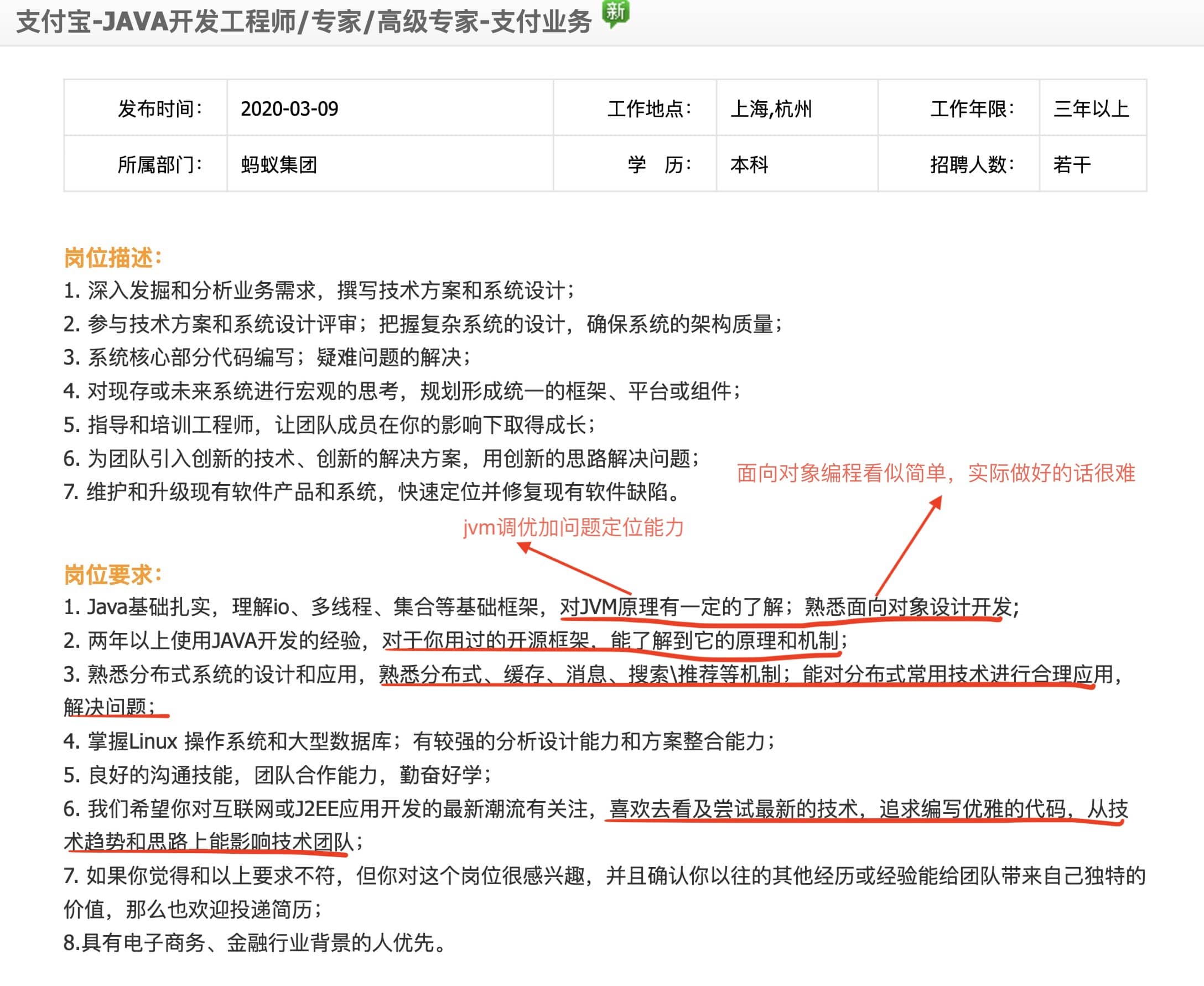
|
||||
|
||||
除了我上面说的这三点,在面试Java工程师的时候,下面几点也提升你的个人竞争力:
|
||||
**再从应届生的角度来看:** 我们还是看阿里巴巴的官网相关应届生 Java 工程师招聘岗位的相关要求。
|
||||
|
||||
- 熟悉Python、Shell、Perl等脚本语言;
|
||||
- 熟悉 Java 优化,JVM调优;
|
||||
- 熟悉 SOA 模式;
|
||||
- 熟悉自己所用框架的底层知识比如Spring;
|
||||
- 了解分布式一些常见的理论;
|
||||
- 具备高并发开发经验;大数据开发经验等等。
|
||||

|
||||
|
||||
结合阿里、腾讯等大厂招聘官网对于 Java 后端方向/后端方向的应届实习生的要求下面几点也提升你的个人竞争力:
|
||||
|
||||
1. 参加过竞赛( 含金量超高的是 ACM );
|
||||
2. 对数据结构与算法非常熟练;
|
||||
3. 参与过实际项目(比如学校网站)
|
||||
4. 熟悉 Python、Shell、Perl 其中一门脚本语言;
|
||||
5. 熟悉如何优化 Java 代码、有写出质量更高的代码的意识;
|
||||
6. 熟悉 SOA 分布式相关的知识尤其是理论知识;
|
||||
7. 熟悉自己所用框架的底层知识比如 Spring;
|
||||
8. 有高并发开发经验;
|
||||
9. 有大数据开发经验等等。
|
||||
|
||||
从来到大学之后,我的好多阅历非常深的老师经常就会告诫我们:“ 一定要有一门自己的特长,不管是技术还好还是其他能力 ” 。我觉得这句话真的非常有道理!
|
||||
|
||||
刚刚也提到了要有一门特长,所以在这里再强调一点:公司不需要你什么都会,但是在某一方面你一定要有过于常人的优点。换言之就是我们不需要去掌握每一门技术(你也没精力去掌握这么多技术),而是需要去深入研究某一门技术,对于其他技术我们可以简单了解一下。
|
||||
|
||||
@ -1,11 +1,20 @@
|
||||
不论是校招还是社招都避免不了各种面试、笔试,如何去准备这些东西就显得格外重要。不论是笔试还是面试都是有章可循的,我这个“有章可循”说的意思只是说应对技术面试是可以提前准备。 我其实特别不喜欢那种临近考试就提前背啊记啊各种题的行为,非常反对!我觉得这种方法特别极端,而且在稍有一点经验的面试官面前是根本没有用的。建议大家还是一步一个脚印踏踏实实地走。
|
||||
不论是笔试还是面试都是有章可循的,但是,一定要不要想着如何去应付面试,糊弄面试官,这样做终究是欺骗自己。这篇文章的目的也主要想让大家知道自己应该从哪些方向去准备面试,有哪些可以提高的方向。
|
||||
|
||||
网上已经有很多面经了,但是我认为网上的各种面经仅仅只能作为参考,你的实际面试与之还是有一些区别的。另外如果要在网上看别人的面经的话,建议即要看别人成功的案例也要适当看看别人失败的案例。**看面经没问题,不论是你要找工作还是平时学习,这都是一种比较好地检验自己水平的一种方式。但是,一定不要过分寄希望于各种面经,试着去提高自己的综合能力。**
|
||||
|
||||
“ 80% 的 offer 掌握在 20% 的人手 ” 中这句话也不是不无道理的。决定你面试能否成功的因素中实力固然占有很大一部分比例,但是如果你的心态或者说运气不好的话,依然无法拿到满意的 offer。
|
||||
|
||||
运气暂且不谈,就拿心态来说,千万不要因为面试失败而气馁或者说怀疑自己的能力,面试失败之后多总结一下失败的原因,后面你就会发现自己会越来越强大。
|
||||
|
||||
另外,笔主只是在这里分享一下自己对于 “ 如何备战大厂面试 ” 的一个看法,以下大部分理论/言辞都经过过反复推敲验证,如果有不对的地方或者和你想法不同的地方,请您敬请雅正、不舍赐教。
|
||||
|
||||
<!-- TOC -->
|
||||
|
||||
- [1 如何获取大厂面试机会?](#1-如何获取大厂面试机会)
|
||||
- [2 面试前的准备](#2--面试前的准备)
|
||||
- [2.1 准备自己的自我介绍](#21-准备自己的自我介绍)
|
||||
- [2.2 关于着装](#22-关于着装)
|
||||
- [2.2 搞清楚技术面可能会问哪些方向的问题](#22-搞清楚技术面可能会问哪些方向的问题)
|
||||
- [2.2 休闲着装即可](#22-休闲着装即可)
|
||||
- [2.3 随身带上自己的成绩单和简历](#23-随身带上自己的成绩单和简历)
|
||||
- [2.4 如果需要笔试就提前刷一些笔试题](#24-如果需要笔试就提前刷一些笔试题)
|
||||
- [2.5 花时间一些逻辑题](#25-花时间一些逻辑题)
|
||||
@ -13,6 +22,9 @@
|
||||
- [2.7 提前准备技术面试](#27-提前准备技术面试)
|
||||
- [2.7 面试之前做好定向复习](#27-面试之前做好定向复习)
|
||||
- [3 面试之后复盘](#3-面试之后复盘)
|
||||
- [4 如何学习?学会各种框架有必要吗?](#4-如何学习学会各种框架有必要吗)
|
||||
- [4.1 我该如何学习?](#41-我该如何学习)
|
||||
- [4.2 学会各种框架有必要吗?](#42-学会各种框架有必要吗)
|
||||
|
||||
<!-- /TOC -->
|
||||
|
||||
@ -42,13 +54,35 @@
|
||||
|
||||
### 2.1 准备自己的自我介绍
|
||||
|
||||
从HR面、技术面到高管面/部门主管面,面试官一般会让你先自我介绍一下,所以好好准备自己的自我介绍真的非常重要。网上一般建议的是准备好两份自我介绍:一份对hr说的,主要讲能突出自己的经历,会的编程技术一语带过;另一份对技术面试官说的,主要讲自己会的技术细节,项目经验,经历那些就一语带过。
|
||||
自我介绍一般是你和面试官的第一次面对面正式交流,换位思考一下,假如你是面试官的话,你想听到被你面试的人如何介绍自己呢?一定不是客套地说说自己喜欢编程、平时花了很多时间来学习、自己的兴趣爱好是打球吧?
|
||||
|
||||
我这里简单分享一下我自己的自我介绍的一个简单的模板吧:
|
||||
我觉得一个好的自我介绍应该包含这几点要素:
|
||||
|
||||
> 面试官,您好!我叫某某。大学时间我主要利用课外时间学习某某。在校期间参与过一个某某系统的开发,另外,自己学习过程中也写过很多系统比如某某系统。在学习之余,我比较喜欢通过博客整理分享自己所学知识。我现在是某某社区的认证作者,写过某某很不错的文章。另外,我获得过某某奖,我的Github上开源的某个项目已经有多少Star了。
|
||||
1. 用简单的话说清楚自己主要的技术栈于擅长的领域;
|
||||
2. 把重点放在自己在行的地方以及自己的优势之处;
|
||||
3. 重点突出自己的能力比如自己的定位的bug的能力特别厉害;
|
||||
|
||||
### 2.2 关于着装
|
||||
从社招和校招两个角度来举例子吧!我下面的两个例子仅供参考,自我介绍并不需要死记硬背,记住要说的要点,面试的时候根据公司的情况临场发挥也是没问题的。另外,网上一般建议的是准备好两份自我介绍:一份对hr说的,主要讲能突出自己的经历,会的编程技术一语带过;另一份对技术面试官说的,主要讲自己会的技术细节和项目经验。
|
||||
|
||||
**社招:**
|
||||
|
||||
> 面试官,您好!我叫独秀儿。我目前有1年半的工作经验,熟练使用Spring、MyBatis等框架、了解 Java 底层原理比如JVM调优并且有着丰富的分布式开发经验。离开上一家公司是因为我想在技术上得到更多的锻炼。在上一个公司我参与了一个分布式电子交易系统的开发,负责搭建了整个项目的基础架构并且通过分库分表解决了原始数据库以及一些相关表过于庞大的问题,目前这个网站最高支持 10 万人同时访问。工作之余,我利用自己的业余时间写了一个简单的 RPC 框架,这个框架用到了Netty进行网络通信, 目前我已经将这个项目开源,在 Github 上收获了 2k的 Star! 说到业余爱好的话,我比较喜欢通过博客整理分享自己所学知识,现在已经是多个博客平台的认证作者。 生活中我是一个比较积极乐观的人,一般会通过运动打球的方式来放松。我一直都非常想加入贵公司,我觉得贵公司的文化和技术氛围我都非常喜欢,期待能与你共事!
|
||||
|
||||
**校招:**
|
||||
|
||||
> 面试官,您好!我叫秀儿。大学时间我主要利用课外时间学习了 Java 以及 Spring、MyBatis等框架 。在校期间参与过一个考试系统的开发,这个系统的主要用了 Spring、MyBatis 和 shiro 这三种框架。我在其中主要担任后端开发,主要负责了权限管理功能模块的搭建。另外,我在大学的时候参加过一次软件编程大赛,我和我的团队做的在线订餐系统成功获得了第二名的成绩。我还利用自己的业余时间写了一个简单的 RPC 框架,这个框架用到了Netty进行网络通信, 目前我已经将这个项目开源,在 Github 上收获了 2k的 Star! 说到业余爱好的话,我比较喜欢通过博客整理分享自己所学知识,现在已经是多个博客平台的认证作者。 生活中我是一个比较积极乐观的人,一般会通过运动打球的方式来放松。我一直都非常想加入贵公司,我觉得贵公司的文化和技术氛围我都非常喜欢,期待能与你共事!
|
||||
|
||||
### 2.2 搞清楚技术面可能会问哪些方向的问题
|
||||
|
||||
你准备面试的话首先要搞清技术面可能会被问哪些方向的问题吧!
|
||||
|
||||
**我直接用思维导图的形式展示出来吧!这样更加直观形象一点,细化到某个知识点的话这张图没有介绍到,留个悬念,下篇文章会详细介绍。**
|
||||
|
||||
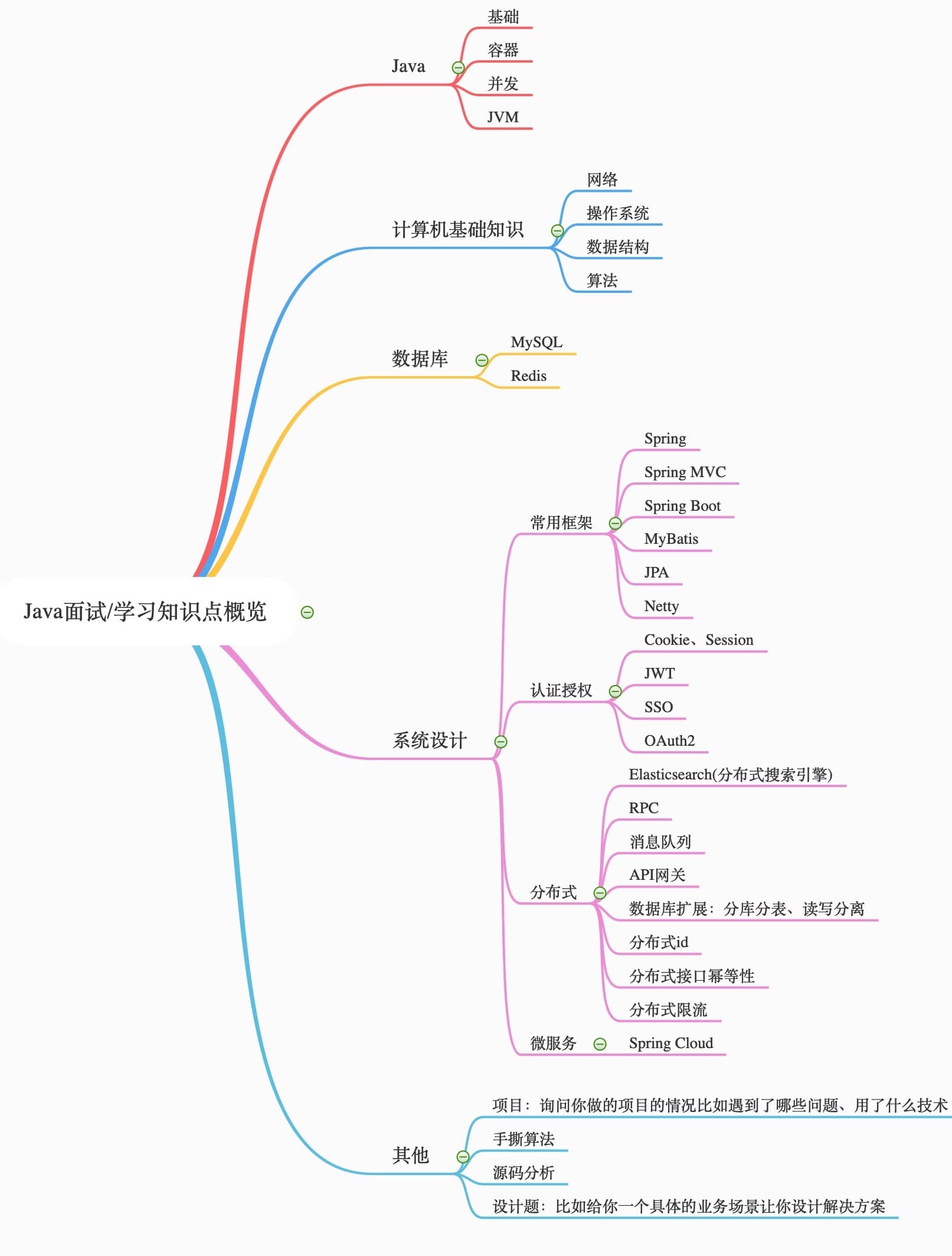
|
||||
|
||||
**上面思维导图大概涵盖了技术面试可能会设计的技术,但是你不需要把上面的每一个知识点都搞得很熟悉,要分清主次,对于自己不熟悉的技术不要写在简历上,对于自己简单了解的技术不要说自己熟练掌握!**
|
||||
|
||||
### 2.2 休闲着装即可
|
||||
|
||||
穿西装、打领带、小皮鞋?NO!NO!NO!这是互联网公司面试又不是去走红毯,所以你只需要穿的简单大方就好,不需要太正式。
|
||||
|
||||
@ -86,3 +120,32 @@
|
||||
## 3 面试之后复盘
|
||||
|
||||
如果失败,不要灰心;如果通过,切勿狂喜。面试和工作实际上是两回事,可能很多面试未通过的人,工作能力比你强的多,反之亦然。我个人觉得面试也像是一场全新的征程,失败和胜利都是平常之事。所以,劝各位不要因为面试失败而灰心、丧失斗志。也不要因为面试通过而沾沾自喜,等待你的将是更美好的未来,继续加油!
|
||||
|
||||
## 4 如何学习?学会各种框架有必要吗?
|
||||
|
||||
### 4.1 我该如何学习?
|
||||
|
||||
|
||||
|
||||
最最最关键也是对自己最最最重要的就是学习!看看别人分享的面经,看看我写的这篇文章估计你只需要10分钟不到。但这些东西终究是空洞的理论,最主要的还是自己平时的学习!
|
||||
|
||||
如何去学呢?我觉得学习每个知识点可以考虑这样去入手:
|
||||
|
||||
1. **官网(大概率是英文,不推荐初学者看)**。
|
||||
2. **书籍(知识更加系统完全,推荐)**。
|
||||
3. **视频(比较容易理解,推荐,特别是初学的时候。慕课网和哔哩哔哩上面有挺多学习视频可以看,只直接在上面搜索关键词就可以了)**。
|
||||
4. **网上博客(解决某一知识点的问题的时候可以看看)**。
|
||||
|
||||
这里给各位一个建议,**看视频的过程中最好跟着一起练,要做笔记!!!**
|
||||
|
||||
**最好可以边看视频边找一本书籍看,看视频没弄懂的知识点一定要尽快解决,如何解决?**
|
||||
|
||||
首先百度/Google,通过搜索引擎解决不了的话就找身边的朋友或者认识的一些人。
|
||||
|
||||
#### 4.2 学会各种框架有必要吗?
|
||||
|
||||
**一定要学会分配自己时间,要学的东西很多,真的很多,搞清楚哪些东西是重点,哪些东西仅仅了解就够了。一定不要把精力都花在了学各种框架上,算法、数据结构还有计算机网络真的很重要!**
|
||||
|
||||
另外,**学习的过程中有一个可以参考的文档很重要,非常有助于自己的学习**。我当初弄 JavaGuide: https://github.com/Snailclimb/JavaGuide 的很大一部分目的就是因为这个。**客观来说,相比于博客,JavaGuide 里面的内容因为更多人的参与变得更加准确和完善。**
|
||||
|
||||
如果大家觉得这篇文章不错的话,欢迎给我来个三连(评论+转发+在看)!我会在下一篇文章中介绍如何从技术面时的角度准备面试?
|
||||
@ -223,57 +223,42 @@ public class test1 {
|
||||
- String 中的 equals 方法是被重写过的,因为 object 的 equals 方法是比较的对象的内存地址,而 String 的 equals 方法比较的是对象的值。
|
||||
- 当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 String 对象。
|
||||
|
||||
## 三 hashCode 与 equals(重要)
|
||||
## 三 hashCode() 与 equals()(重要)
|
||||
|
||||
面试官可能会问你:“你重写过 hashcode 和 equals 么,为什么重写 equals 时必须重写 hashCode 方法?”
|
||||
面试官可能会问你:“你重写过 `hashcode` 和 `equals `么,为什么重写 `equals` 时必须重写 `hashCode` 方法?”
|
||||
|
||||
### 3.1 hashCode()介绍
|
||||
### 3.1 hashCode()介绍
|
||||
|
||||
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个 int 整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在 JDK 的 Object.java 中,这就意味着 Java 中的任何类都包含有 hashCode() 函数。另外需要注意的是: Object 的 hashcode 方法是本地方法,也就是用 c 语言或 c++ 实现的,该方法通常用来将对象的 内存地址 转换为整数之后返回。
|
||||
`hashCode()` 的作用是获取哈希码,也称为散列码;它实际上是返回一个 int 整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。`hashCode() `定义在 JDK 的 `Object` 类中,这就意味着 Java 中的任何类都包含有 `hashCode()` 函数。另外需要注意的是: `Object` 的 hashcode 方法是本地方法,也就是用 c 语言或 c++ 实现的,该方法通常用来将对象的 内存地址 转换为整数之后返回。
|
||||
|
||||
```java
|
||||
/**
|
||||
* Returns a hash code value for the object. This method is
|
||||
* supported for the benefit of hash tables such as those provided by
|
||||
* {@link java.util.HashMap}.
|
||||
* <p>
|
||||
* As much as is reasonably practical, the hashCode method defined by
|
||||
* class {@code Object} does return distinct integers for distinct
|
||||
* objects. (This is typically implemented by converting the internal
|
||||
* address of the object into an integer, but this implementation
|
||||
* technique is not required by the
|
||||
* Java™ programming language.)
|
||||
*
|
||||
* @return a hash code value for this object.
|
||||
* @see java.lang.Object#equals(java.lang.Object)
|
||||
* @see java.lang.System#identityHashCode
|
||||
*/
|
||||
public native int hashCode();
|
||||
public native int hashCode();
|
||||
```
|
||||
|
||||
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
|
||||
|
||||
### 3.2 为什么要有 hashCode
|
||||
### 3.2 为什么要有 hashCode?
|
||||
|
||||
**我们以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode:**
|
||||
**我们以“`HashSet` 如何检查重复”为例子来说明为什么要有 hashCode:**
|
||||
|
||||
当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的 Java 启蒙书《Head fist java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
|
||||
当你把对象加入 `HashSet` 时,`HashSet` 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,`HashSet` 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,`HashSet` 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的 Java 启蒙书《Head fist java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
|
||||
|
||||
### 3.3 hashCode()与 equals()的相关规定
|
||||
### 3.3 为什么重写 `equals` 时必须重写 `hashCode` 方法?
|
||||
|
||||
1. 如果两个对象相等,则 hashcode 一定也是相同的
|
||||
2. 两个对象相等,对两个对象分别调用 equals 方法都返回 true
|
||||
3. 两个对象有相同的 hashcode 值,它们也不一定是相等的
|
||||
4. **因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖**
|
||||
5. hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
|
||||
如果两个对象相等,则 hashcode 一定也是相同的。两个对象相等,对两个对象分别调用 equals 方法都返回 true。但是,两个对象有相同的 hashcode 值,它们也不一定是相等的 。**因此,equals 方法被覆盖过,则 `hashCode` 方法也必须被覆盖。**
|
||||
|
||||
> `hashCode()`的默认行为是对堆上的对象产生独特值。如果没有重写 `hashCode()`,则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
|
||||
|
||||
### 3.4 为什么两个对象有相同的 hashcode 值,它们也不一定是相等的?
|
||||
|
||||
在这里解释一位小伙伴的问题。以下内容摘自《Head Fisrt Java》。
|
||||
|
||||
因为 hashCode() 所使用的杂凑算法也许刚好会让多个对象传回相同的杂凑值。越糟糕的杂凑算法越容易碰撞,但这也与数据值域分布的特性有关(所谓碰撞也就是指的是不同的对象得到相同的 hashCode)。
|
||||
因为 `hashCode()` 所使用的杂凑算法也许刚好会让多个对象传回相同的杂凑值。越糟糕的杂凑算法越容易碰撞,但这也与数据值域分布的特性有关(所谓碰撞也就是指的是不同的对象得到相同的 `hashCode`。
|
||||
|
||||
我们刚刚也提到了 HashSet,如果 HashSet 在对比的时候,同样的 hashcode 有多个对象,它会使用 equals() 来判断是否真的相同。也就是说 hashcode 只是用来缩小查找成本。
|
||||
我们刚刚也提到了 `HashSet`,如果 `HashSet` 在对比的时候,同样的 hashcode 有多个对象,它会使用 `equals()` 来判断是否真的相同。也就是说 `hashcode` 只是用来缩小查找成本。
|
||||
|
||||
|
||||
更多关于 `hashcode()` 和 `equals()` 的内容可以查看:[Java hashCode() 和 equals()的若干问题解答](https://www.cnblogs.com/skywang12345/p/3324958.html)
|
||||
|
||||
## 四 String 和 StringBuffer、StringBuilder 的区别是什么?String 为什么是不可变的?
|
||||
|
||||
|
||||
@ -119,3 +119,4 @@
|
||||
|
||||
- 冷熊简历(MarkDown在线简历工具,可在线预览、编辑和生成PDF):<http://cv.ftqq.com/>
|
||||
- Typora+[Java程序员简历模板](https://github.com/geekcompany/ResumeSample/blob/master/java.md)
|
||||
- Guide哥自己写的Markdown模板:[https://github.com/Snailclimb/typora-markdown-resume](https://github.com/Snailclimb/typora-markdown-resume)
|
||||
|
||||
@ -229,7 +229,7 @@ HTTP 响应报文主要由状态行、响应头部、响应正文 3 部分组成
|
||||
|
||||
1. 避免 where 子句中对字段施加函数,这会造成无法命中索引。
|
||||
2. 在使用 InnoDB 时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键。
|
||||
3. 将打算加索引的列设置为 NOT NULL ,否则将导致引擎放弃使用索引而进行全表扫描
|
||||
3. 将打算加索引的列建议设置为 NOT NULL ,因为 NULL 比空字符串需要更多的存储空间(不仅仅是索引列,普通的列如果业务允许都建议设置为 NOT NULL)
|
||||
4. 删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 schema_unused_indexes 视图来查询哪些索引从未被使用
|
||||
5. 在使用 limit offset 查询缓慢时,可以借助索引来提高性能
|
||||
|
||||
@ -786,7 +786,7 @@ synchronized 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团
|
||||
|
||||
**④ 两者的性能已经相差无几**
|
||||
|
||||
在 JDK1.6 之前,synchronized 的性能是比 ReentrantLock 差很多。具体表示为:synchronized 关键字吞吐量岁线程数的增加,下降得非常严重。而 ReentrantLock 基本保持一个比较稳定的水平。我觉得这也侧面反映了, synchronized 关键字还有非常大的优化余地。后续的技术发展也证明了这一点,我们上面也讲了在 JDK1.6 之后 JVM 团队对 synchronized 关键字做了很多优化。JDK1.6 之后,synchronized 和 ReentrantLock 的性能基本是持平了。所以网上那些说因为性能才选择 ReentrantLock 的文章都是错的!JDK1.6 之后,性能已经不是选择 synchronized 和 ReentrantLock 的影响因素了!而且虚拟机在未来的性能改进中会更偏向于原生的 synchronized,所以还是提倡在 synchronized 能满足你的需求的情况下,优先考虑使用 synchronized 关键字来进行同步!优化后的 synchronized 和 ReentrantLock 一样,在很多地方都是用到了 CAS 操作。
|
||||
在 JDK1.6 之前,synchronized 的性能是比 ReentrantLock 差很多。具体表示为:synchronized 关键字吞吐量随线程数的增加,下降得非常严重。而 ReentrantLock 基本保持一个比较稳定的水平。我觉得这也侧面反映了, synchronized 关键字还有非常大的优化余地。后续的技术发展也证明了这一点,我们上面也讲了在 JDK1.6 之后 JVM 团队对 synchronized 关键字做了很多优化。JDK1.6 之后,synchronized 和 ReentrantLock 的性能基本是持平了。所以网上那些说因为性能才选择 ReentrantLock 的文章都是错的!JDK1.6 之后,性能已经不是选择 synchronized 和 ReentrantLock 的影响因素了!而且虚拟机在未来的性能改进中会更偏向于原生的 synchronized,所以还是提倡在 synchronized 能满足你的需求的情况下,优先考虑使用 synchronized 关键字来进行同步!优化后的 synchronized 和 ReentrantLock 一样,在很多地方都是用到了 CAS 操作。
|
||||
|
||||
## 4 线程池了解吗?
|
||||
|
||||
|
||||
@ -48,8 +48,8 @@
|
||||
|
||||
1. 操作员 A 此时将其读出( version=1 ),并从其帐户余额中扣除 $50( $100-$50 )。
|
||||
2. 在操作员 A 操作的过程中,操作员B 也读入此用户信息( version=1 ),并从其帐户余额中扣除 $20 ( $100-$20 )。
|
||||
3. 操作员 A 完成了修改工作,将数据版本号加一( version=2 ),连同帐户扣除后余额( balance=$50 ),提交至数据库更新,此时由于提交数据版本大于数据库记录当前版本,数据被更新,数据库记录 version 更新为 2 。
|
||||
4. 操作员 B 完成了操作,也将版本号加一( version=2 )试图向数据库提交数据( balance=$80 ),但此时比对数据库记录版本时发现,操作员 B 提交的数据版本号为 2 ,数据库记录当前版本也为 2 ,不满足 “ 提交版本必须大于记录当前版本才能执行更新 “ 的乐观锁策略,因此,操作员 B 的提交被驳回。
|
||||
3. 操作员 A 完成了修改工作,将数据版本号( version=1 ),连同帐户扣除后余额( balance=$50 ),提交至数据库更新,此时由于提交数据版本等于数据库记录当前版本,数据被更新,数据库记录 version 更新为 2 。
|
||||
4. 操作员 B 完成了操作,也将版本号( version=1 )试图向数据库提交数据( balance=$80 ),但此时比对数据库记录版本时发现,操作员 B 提交的数据版本号为 1 ,数据库记录当前版本也为 2 ,不满足 “ 提交版本必须等于当前版本才能执行更新 “ 的乐观锁策略,因此,操作员 B 的提交被驳回。
|
||||
|
||||
这样,就避免了操作员 B 用基于 version=1 的旧数据修改的结果覆盖操作员A 的操作结果的可能。
|
||||
|
||||
|
||||
@ -30,20 +30,23 @@
|
||||
|
||||
在讲 BIO,NIO,AIO 之前先来回顾一下这样几个概念:同步与异步,阻塞与非阻塞。
|
||||
|
||||
**同步与异步**
|
||||
关于同步和异步的概念解读困扰着很多程序员,大部分的解读都会带有自己的一点偏见。参考了 [Stackoverflow](https://stackoverflow.com/questions/748175/asynchronous-vs-synchronous-execution-what-does-it-really-mean)相关问题后对原有答案进行了进一步完善:
|
||||
|
||||
- **同步:** 同步就是发起一个调用后,被调用者未处理完请求之前,调用不返回。
|
||||
- **异步:** 异步就是发起一个调用后,立刻得到被调用者的回应表示已接收到请求,但是被调用者并没有返回结果,此时我们可以处理其他的请求,被调用者通常依靠事件,回调等机制来通知调用者其返回结果。
|
||||
> When you execute something synchronously, you wait for it to finish before moving on to another task. When you execute something asynchronously, you can move on to another task before it finishes.
|
||||
>
|
||||
> 当你同步执行某项任务时,你需要等待其完成才能继续执行其他任务。当你异步执行某些操作时,你可以在完成另一个任务之前继续进行。
|
||||
|
||||
同步和异步的区别最大在于异步的话调用者不需要等待处理结果,被调用者会通过回调等机制来通知调用者其返回结果。
|
||||
- **同步** :两个同步任务相互依赖,并且一个任务必须以依赖于另一任务的某种方式执行。 比如在`A->B`事件模型中,你需要先完成 A 才能执行B。 再换句话说,同步调用中被调用者未处理完请求之前,调用不返回,调用者会一直等待结果的返回。
|
||||
- **异步**: 两个异步的任务完全独立的,一方的执行不需要等待另外一方的执行。再换句话说,异步调用种一调用就返回结果不需要等待结果返回,当结果返回的时候通过回调函数或者其他方式拿着结果再做相关事情,
|
||||
|
||||
**阻塞和非阻塞**
|
||||
|
||||
- **阻塞:** 阻塞就是发起一个请求,调用者一直等待请求结果返回,也就是当前线程会被挂起,无法从事其他任务,只有当条件就绪才能继续。
|
||||
- **非阻塞:** 非阻塞就是发起一个请求,调用者不用一直等着结果返回,可以先去干其他事情。
|
||||
|
||||
举个生活中简单的例子,你妈妈让你烧水,小时候你比较笨啊,在那里傻等着水开(**同步阻塞**)。等你稍微再长大一点,你知道每次烧水的空隙可以去干点其他事,然后只需要时不时来看看水开了没有(**同步非阻塞**)。后来,你们家用上了水开了会发出声音的壶,这样你就只需要听到响声后就知道水开了,在这期间你可以随便干自己的事情,你需要去倒水了(**异步非阻塞**)。
|
||||
**如何区分 “同步/异步 ”和 “阻塞/非阻塞” 呢?**
|
||||
|
||||
同步/异步是从行为角度描述事物的,而阻塞和非阻塞描述的当前事物的状态(等待调用结果时的状态)。
|
||||
|
||||
## 1. BIO (Blocking I/O)
|
||||
|
||||
@ -164,8 +167,6 @@ public class IOServer {
|
||||
|
||||
在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
|
||||
|
||||
|
||||
|
||||
## 2. NIO (New I/O)
|
||||
|
||||
### 2.1 NIO 简介
|
||||
|
||||
375
docs/java/JAD反编译tricks.md
Normal file
@ -0,0 +1,375 @@
|
||||
[jad](https://varaneckas.com/jad/)反编译工具,已经不再更新,且只支持JDK1.4,但并不影响其强大的功能。
|
||||
|
||||
基本用法:`jad xxx.class`,会生成直接可读的xxx.jad文件。
|
||||
|
||||
## 自动拆装箱
|
||||
|
||||
对于基本类型和包装类型之间的转换,通过xxxValue()和valueOf()两个方法完成自动拆装箱,使用jad进行反编译可以看到该过程:
|
||||
|
||||
```java
|
||||
public class Demo {
|
||||
public static void main(String[] args) {
|
||||
int x = new Integer(10); // 自动拆箱
|
||||
Integer y = x; // 自动装箱
|
||||
}
|
||||
}
|
||||
```
|
||||
反编译后结果:
|
||||
|
||||
```java
|
||||
public class Demo
|
||||
{
|
||||
public Demo(){}
|
||||
|
||||
public static void main(String args[])
|
||||
{
|
||||
int i = (new Integer(10)).intValue(); // intValue()拆箱
|
||||
Integer integer = Integer.valueOf(i); // valueOf()装箱
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
## foreach语法糖
|
||||
|
||||
在遍历迭代时可以foreach语法糖,对于数组类型直接转换成for循环:
|
||||
|
||||
```java
|
||||
// 原始代码
|
||||
int[] arr = {1, 2, 3, 4, 5};
|
||||
for(int item: arr) {
|
||||
System.out.println(item);
|
||||
}
|
||||
}
|
||||
|
||||
// 反编译后代码
|
||||
int ai[] = {
|
||||
1, 2, 3, 4, 5
|
||||
};
|
||||
int ai1[] = ai;
|
||||
int i = ai1.length;
|
||||
// 转换成for循环
|
||||
for(int j = 0; j < i; j++)
|
||||
{
|
||||
int k = ai1[j];
|
||||
System.out.println(k);
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
对于容器类的遍历会使用iterator进行迭代:
|
||||
|
||||
```java
|
||||
import java.io.PrintStream;
|
||||
import java.util.*;
|
||||
|
||||
public class Demo
|
||||
{
|
||||
public Demo() {}
|
||||
public static void main(String args[])
|
||||
{
|
||||
ArrayList arraylist = new ArrayList();
|
||||
arraylist.add(Integer.valueOf(1));
|
||||
arraylist.add(Integer.valueOf(2));
|
||||
arraylist.add(Integer.valueOf(3));
|
||||
Integer integer;
|
||||
// 使用的for循环+Iterator,类似于链表迭代:
|
||||
// for (ListNode cur = head; cur != null; System.out.println(cur.val)){
|
||||
// cur = cur.next;
|
||||
// }
|
||||
for(Iterator iterator = arraylist.iterator(); iterator.hasNext(); System.out.println(integer))
|
||||
integer = (Integer)iterator.next();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
## Arrays.asList(T...)
|
||||
|
||||
熟悉Arrays.asList(T...)用法的小伙伴都应该知道,asList()方法传入的参数不能是基本类型的数组,必须包装成包装类型再使用,否则对应生成的列表的大小永远是1:
|
||||
|
||||
```java
|
||||
import java.util.*;
|
||||
public class Demo {
|
||||
public static void main(String[] args) {
|
||||
int[] arr1 = {1, 2, 3};
|
||||
Integer[] arr2 = {1, 2, 3};
|
||||
List lists1 = Arrays.asList(arr1);
|
||||
List lists2 = Arrays.asList(arr2);
|
||||
System.out.println(lists1.size()); // 1
|
||||
System.out.println(lists2.size()); // 3
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
从反编译结果来解释,为什么传入基本类型的数组后,返回的List大小是1:
|
||||
|
||||
```java
|
||||
// 反编译后文件
|
||||
import java.io.PrintStream;
|
||||
import java.util.Arrays;
|
||||
import java.util.List;
|
||||
|
||||
public class Demo
|
||||
{
|
||||
public Demo() {}
|
||||
|
||||
public static void main(String args[])
|
||||
{
|
||||
int ai[] = {
|
||||
1, 2, 3
|
||||
};
|
||||
// 使用包装类型,全部元素由int包装为Integer
|
||||
Integer ainteger[] = {
|
||||
Integer.valueOf(1), Integer.valueOf(2), Integer.valueOf(3)
|
||||
};
|
||||
|
||||
// 注意这里被反编译成二维数组,而且是一个1行三列的二维数组
|
||||
// list.size()当然返回1
|
||||
List list = Arrays.asList(new int[][] { ai });
|
||||
List list1 = Arrays.asList(ainteger);
|
||||
System.out.println(list.size());
|
||||
System.out.println(list1.size());
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
从上面结果可以看到,传入基本类型的数组后,会被转换成一个二维数组,而且是**new int\[1]\[arr.length]**这样的数组,调用list.size()当然返回1。
|
||||
|
||||
|
||||
|
||||
## 注解
|
||||
|
||||
Java中的类、接口、枚举、注解都可以看做是类类型。使用jad来看一下@interface被转换成什么:
|
||||
|
||||
```java
|
||||
import java.lang.annotation.Retention;
|
||||
import java.lang.annotation.RetentionPolicy;
|
||||
|
||||
@Retention(RetentionPolicy.RUNTIME)
|
||||
public @interface Foo{
|
||||
String[] value();
|
||||
boolean bar();
|
||||
}
|
||||
```
|
||||
查看反编译代码可以看出:
|
||||
|
||||
- 自定义的注解类Foo被转换成接口Foo,并且继承Annotation接口
|
||||
- 原来自定义接口中的value()和bar()被转换成抽象方法
|
||||
|
||||
```java
|
||||
import java.lang.annotation.Annotation;
|
||||
|
||||
public interface Foo
|
||||
extends Annotation
|
||||
{
|
||||
public abstract String[] value();
|
||||
|
||||
public abstract boolean bar();
|
||||
}
|
||||
```
|
||||
注解通常和反射配合使用,而且既然自定义的注解最终被转换成接口,注解中的属性被转换成接口中的抽象方法,那么通过反射之后拿到接口实例,在通过接口实例自然能够调用对应的抽象方法:
|
||||
```java
|
||||
import java.util.Arrays;
|
||||
|
||||
@Foo(value={"sherman", "decompiler"}, bar=true)
|
||||
public class Demo{
|
||||
public static void main(String[] args) {
|
||||
Foo foo = Demo.class.getAnnotation(Foo.class);
|
||||
System.out.println(Arrays.toString(foo.value())); // [sherman, decompiler]
|
||||
System.out.println(foo.bar()); // true
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## 枚举
|
||||
|
||||
通过jad反编译可以很好地理解枚举类。
|
||||
|
||||
|
||||
|
||||
### 空枚举
|
||||
|
||||
先定义一个空的枚举类:
|
||||
|
||||
```java
|
||||
public enum DummyEnum {
|
||||
}
|
||||
```
|
||||
使用jad反编译查看结果:
|
||||
|
||||
- 自定义枚举类被转换成final类,并且继承Enum
|
||||
- 提供了两个参数(name,odinal)的私有构造器,并且调用了父类的构造器。注意即使没有提供任何参数,也会有该该构造器,其中name就是枚举实例的名称,odinal是枚举实例的索引号
|
||||
- 初始化了一个private static final自定义类型的空数组 **$VALUES**
|
||||
- 提供了两个public static方法:
|
||||
- values()方法通过clone()方法返回内部$VALUES的浅拷贝。这个方法结合私有构造器可以完美实现单例模式,想一想values()方法是不是和单例模式中getInstance()方法功能类似
|
||||
- valueOf(String s):调用父类Enum的valueOf方法并强转返回
|
||||
|
||||
```java
|
||||
public final class DummyEnum extends Enum
|
||||
{
|
||||
// 功能和单例模式的getInstance()方法相同
|
||||
public static DummyEnum[] values()
|
||||
{
|
||||
return (DummyEnum[])$VALUES.clone();
|
||||
}
|
||||
// 调用父类的valueOf方法,并墙砖返回
|
||||
public static DummyEnum valueOf(String s)
|
||||
{
|
||||
return (DummyEnum)Enum.valueOf(DummyEnum, s);
|
||||
}
|
||||
// 默认提供一个私有的私有两个参数的构造器,并调用父类Enum的构造器
|
||||
private DummyEnum(String s, int i)
|
||||
{
|
||||
super(s, i);
|
||||
}
|
||||
// 初始化一个private static final的本类空数组
|
||||
private static final DummyEnum $VALUES[] = new DummyEnum[0];
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
### 包含抽象方法的枚举
|
||||
|
||||
枚举类中也可以包含抽象方法,但是必须定义枚举实例并且立即重写抽象方法,就像下面这样:
|
||||
|
||||
```java
|
||||
public enum DummyEnum {
|
||||
DUMMY1 {
|
||||
public void dummyMethod() {
|
||||
System.out.println("[1]: implements abstract method in enum class");
|
||||
}
|
||||
},
|
||||
|
||||
DUMMY2 {
|
||||
public void dummyMethod() {
|
||||
System.out.println("[2]: implements abstract method in enum class");
|
||||
}
|
||||
};
|
||||
|
||||
abstract void dummyMethod();
|
||||
|
||||
}
|
||||
```
|
||||
再来反编译看看有哪些变化:
|
||||
|
||||
- 原来final class变成了abstract class:这很好理解,有抽象方法的类自然是抽象类
|
||||
- 多了两个public static final的成员DUMMY1、DUMMY2,这两个实例的初始化过程被放到了static代码块中,并且实例过程中直接重写了抽象方法,类似于匿名内部类的形式。
|
||||
- 数组**$VALUES[]**初始化时放入枚举实例
|
||||
|
||||
还有其它变化么?
|
||||
|
||||
在反编译后的DummyEnum类中,是存在抽象方法的,而枚举实例在静态代码块中初始化过程中重写了抽象方法。在Java中,抽象方法和抽象方法重写同时放在一个类中,只能通过内部类形式完成。因此上面第二点应该说成就是以内部类形式初始化。
|
||||
|
||||
可以看一下DummyEnum.class存放的位置,应该多了两个文件:
|
||||
|
||||
- DummyEnum$1.class
|
||||
- DummyEnum$2.class
|
||||
|
||||
Java中.class文件出现$符号表示有内部类存在,就像OutClass$InnerClass,这两个文件出现也应证了上面的匿名内部类初始化的说法。
|
||||
|
||||
```java
|
||||
import java.io.PrintStream;
|
||||
|
||||
public abstract class DummyEnum extends Enum
|
||||
{
|
||||
public static DummyEnum[] values()
|
||||
{
|
||||
return (DummyEnum[])$VALUES.clone();
|
||||
}
|
||||
|
||||
public static DummyEnum valueOf(String s)
|
||||
{
|
||||
return (DummyEnum)Enum.valueOf(DummyEnum, s);
|
||||
}
|
||||
|
||||
private DummyEnum(String s, int i)
|
||||
{
|
||||
super(s, i);
|
||||
}
|
||||
|
||||
// 抽象方法
|
||||
abstract void dummyMethod();
|
||||
|
||||
// 两个pubic static final实例
|
||||
public static final DummyEnum DUMMY1;
|
||||
public static final DummyEnum DUMMY2;
|
||||
private static final DummyEnum $VALUES[];
|
||||
|
||||
// static代码块进行初始化
|
||||
static
|
||||
{
|
||||
DUMMY1 = new DummyEnum("DUMMY1", 0) {
|
||||
public void dummyMethod()
|
||||
{
|
||||
System.out.println("[1]: implements abstract method in enum class");
|
||||
}
|
||||
}
|
||||
;
|
||||
DUMMY2 = new DummyEnum("DUMMY2", 1) {
|
||||
public void dummyMethod()
|
||||
{
|
||||
System.out.println("[2]: implements abstract method in enum class");
|
||||
}
|
||||
}
|
||||
;
|
||||
// 对本类数组进行初始化
|
||||
$VALUES = (new DummyEnum[] {
|
||||
DUMMY1, DUMMY2
|
||||
});
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 正常的枚举类
|
||||
|
||||
实际开发中,枚举类通常的形式是有两个参数(int code,Sring msg)的构造器,可以作为状态码进行返回。Enum类实际上也是提供了包含两个参数且是protected的构造器,这里为了避免歧义,将枚举类的构造器设置为三个,使用jad反编译:
|
||||
|
||||
最大的变化是:现在的private构造器从2个参数变成5个,而且在内部仍然将前两个参数通过super传递给父类,剩余的三个参数才是真正自己提供的参数。可以想象,如果自定义的枚举类只提供了一个参数,最终生成底层代码中private构造器应该有三个参数,前两个依然通过super传递给父类。
|
||||
|
||||
```java
|
||||
public final class CustomEnum extends Enum
|
||||
{
|
||||
public static CustomEnum[] values()
|
||||
{
|
||||
return (CustomEnum[])$VALUES.clone();
|
||||
}
|
||||
|
||||
public static CustomEnum valueOf(String s)
|
||||
{
|
||||
return (CustomEnum)Enum.valueOf(CustomEnum, s);
|
||||
}
|
||||
|
||||
private CustomEnum(String s, int i, int j, String s1, Object obj)
|
||||
{
|
||||
super(s, i);
|
||||
code = j;
|
||||
msg = s1;
|
||||
data = obj;
|
||||
}
|
||||
|
||||
public static final CustomEnum FIRST;
|
||||
public static final CustomEnum SECOND;
|
||||
public static final CustomEnum THIRD;
|
||||
private int code;
|
||||
private String msg;
|
||||
private Object data;
|
||||
private static final CustomEnum $VALUES[];
|
||||
|
||||
static
|
||||
{
|
||||
FIRST = new CustomEnum("FIRST", 0, 10010, "first", Long.valueOf(100L));
|
||||
SECOND = new CustomEnum("SECOND", 1, 10020, "second", "Foo");
|
||||
THIRD = new CustomEnum("THIRD", 2, 10030, "third", new Object());
|
||||
$VALUES = (new CustomEnum[] {
|
||||
FIRST, SECOND, THIRD
|
||||
});
|
||||
}
|
||||
}
|
||||
```
|
||||
@ -1,23 +1,23 @@
|
||||
<!-- TOC -->
|
||||
|
||||
- [1. 基础](#1-基础)
|
||||
- [1.1. 正确使用 equals 方法](#11-正确使用-equals-方法)
|
||||
- [1.2. 整型包装类值的比较](#12-整型包装类值的比较)
|
||||
- [1.3. BigDecimal](#13-bigdecimal)
|
||||
- [1.3.1. BigDecimal 的用处](#131-bigdecimal-的用处)
|
||||
- [1.3.2. BigDecimal 的大小比较](#132-bigdecimal-的大小比较)
|
||||
- [1.3.3. BigDecimal 保留几位小数](#133-bigdecimal-保留几位小数)
|
||||
- [1.3.4. BigDecimal 的使用注意事项](#134-bigdecimal-的使用注意事项)
|
||||
- [1.3.5. 总结](#135-总结)
|
||||
- [1.4. 基本数据类型与包装数据类型的使用标准](#14-基本数据类型与包装数据类型的使用标准)
|
||||
- [2. 集合](#2-集合)
|
||||
- [2.1. Arrays.asList()使用指南](#21-arraysaslist使用指南)
|
||||
- [2.1.1. 简介](#211-简介)
|
||||
- [2.1.2. 《阿里巴巴Java 开发手册》对其的描述](#212-阿里巴巴java-开发手册对其的描述)
|
||||
- [2.1.3. 使用时的注意事项总结](#213-使用时的注意事项总结)
|
||||
- [2.1.4. 如何正确的将数组转换为ArrayList?](#214-如何正确的将数组转换为arraylist)
|
||||
- [2.2. Collection.toArray()方法使用的坑&如何反转数组](#22-collectiontoarray方法使用的坑如何反转数组)
|
||||
- [2.3. 不要在 foreach 循环里进行元素的 remove/add 操作](#23-不要在-foreach-循环里进行元素的-removeadd-操作)
|
||||
- [1. 基础](#_1-基础)
|
||||
- [1.1. 正确使用 equals 方法](#_11-正确使用-equals-方法)
|
||||
- [1.2. 整型包装类值的比较](#_12-整型包装类值的比较)
|
||||
- [1.3. BigDecimal](#_13-bigdecimal)
|
||||
- [1.3.1. BigDecimal 的用处](#_131-bigdecimal-的用处)
|
||||
- [1.3.2. BigDecimal 的大小比较](#_132-bigdecimal-的大小比较)
|
||||
- [1.3.3. BigDecimal 保留几位小数](#_133-bigdecimal-保留几位小数)
|
||||
- [1.3.4. BigDecimal 的使用注意事项](#_134-bigdecimal-的使用注意事项)
|
||||
- [1.3.5. 总结](#_135-总结)
|
||||
- [1.4. 基本数据类型与包装数据类型的使用标准](#_14-基本数据类型与包装数据类型的使用标准)
|
||||
- [2. 集合](#_2-集合)
|
||||
- [2.1. Arrays.asList()使用指南](#_21-arraysaslist使用指南)
|
||||
- [2.1.1. 简介](#_211-简介)
|
||||
- [2.1.2. 《阿里巴巴Java 开发手册》对其的描述](#_212-阿里巴巴java-开发手册对其的描述)
|
||||
- [2.1.3. 使用时的注意事项总结](#_213-使用时的注意事项总结)
|
||||
- [2.1.4. 如何正确的将数组转换为ArrayList?](#_214-如何正确的将数组转换为arraylist)
|
||||
- [2.2. Collection.toArray()方法使用的坑&如何反转数组](#_22-collectiontoarray方法使用的坑如何反转数组)
|
||||
- [2.3. 不要在 foreach 循环里进行元素的 remove/add 操作](#_23-不要在-foreach-循环里进行元素的-removeadd-操作)
|
||||
|
||||
<!-- /TOC -->
|
||||
|
||||
@ -52,9 +52,9 @@ Objects.equals(null,"SnailClimb");// false
|
||||
我们看一下`java.util.Objects#equals`的源码就知道原因了。
|
||||
```java
|
||||
public static boolean equals(Object a, Object b) {
|
||||
// 可以避免空指针异常。如果a==null的话此时a.equals(b)就不会得到执行,避免出现空指针异常。
|
||||
return (a == b) || (a != null && a.equals(b));
|
||||
}
|
||||
// 可以避免空指针异常。如果a==null的话此时a.equals(b)就不会得到执行,避免出现空指针异常。
|
||||
return (a == b) || (a != null && a.equals(b));
|
||||
}
|
||||
```
|
||||
|
||||
**注意:**
|
||||
@ -104,14 +104,18 @@ System.out.println(a == b);// false
|
||||
BigDecimal a = new BigDecimal("1.0");
|
||||
BigDecimal b = new BigDecimal("0.9");
|
||||
BigDecimal c = new BigDecimal("0.8");
|
||||
BigDecimal x = a.subtract(b);// 0.1
|
||||
BigDecimal y = b.subtract(c);// 0.1
|
||||
System.out.println(x.equals(y));// true
|
||||
|
||||
BigDecimal x = a.subtract(b);
|
||||
BigDecimal y = b.subtract(c);
|
||||
|
||||
System.out.println(x); /* 0.1 */
|
||||
System.out.println(y); /* 0.1 */
|
||||
System.out.println(Objects.equals(x, y)); /* true */
|
||||
```
|
||||
|
||||
### 1.3.2. BigDecimal 的大小比较
|
||||
|
||||
`a.compareTo(b)` : 返回 -1 表示小于,0 表示 等于, 1表示 大于。
|
||||
`a.compareTo(b)` : 返回 -1 表示 `a` 小于 `b`,0 表示 `a` 等于 `b` , 1表示 `a` 大于 `b`。
|
||||
|
||||
```java
|
||||
BigDecimal a = new BigDecimal("1.0");
|
||||
@ -167,7 +171,7 @@ Reference:《阿里巴巴Java开发手册》
|
||||
`Arrays.asList()`在平时开发中还是比较常见的,我们可以使用它将一个数组转换为一个List集合。
|
||||
|
||||
```java
|
||||
String[] myArray = { "Apple", "Banana", "Orange" };
|
||||
String[] myArray = {"Apple", "Banana", "Orange"};
|
||||
List<String> myList = Arrays.asList(myArray);
|
||||
//上面两个语句等价于下面一条语句
|
||||
List<String> myList = Arrays.asList("Apple","Banana", "Orange");
|
||||
@ -177,8 +181,9 @@ JDK 源码对于这个方法的说明:
|
||||
|
||||
```java
|
||||
/**
|
||||
*返回由指定数组支持的固定大小的列表。此方法作为基于数组和基于集合的API之间的桥梁,与 Collection.toArray()结合使用。返回的List是可序列化并实现RandomAccess接口。
|
||||
*/
|
||||
*返回由指定数组支持的固定大小的列表。此方法作为基于数组和基于集合的API之间的桥梁,
|
||||
* 与 Collection.toArray()结合使用。返回的List是可序列化并实现RandomAccess接口。
|
||||
*/
|
||||
public static <T> List<T> asList(T... a) {
|
||||
return new ArrayList<>(a);
|
||||
}
|
||||
@ -197,12 +202,12 @@ public static <T> List<T> asList(T... a) {
|
||||
`Arrays.asList()`是泛型方法,传入的对象必须是对象数组。
|
||||
|
||||
```java
|
||||
int[] myArray = { 1, 2, 3 };
|
||||
int[] myArray = {1, 2, 3};
|
||||
List myList = Arrays.asList(myArray);
|
||||
System.out.println(myList.size());//1
|
||||
System.out.println(myList.get(0));//数组地址值
|
||||
System.out.println(myList.get(1));//报错:ArrayIndexOutOfBoundsException
|
||||
int [] array=(int[]) myList.get(0);
|
||||
int[] array = (int[]) myList.get(0);
|
||||
System.out.println(array[0]);//1
|
||||
```
|
||||
当传入一个原生数据类型数组时,`Arrays.asList()` 的真正得到的参数就不是数组中的元素,而是数组对象本身!此时List 的唯一元素就是这个数组,这也就解释了上面的代码。
|
||||
@ -210,7 +215,7 @@ System.out.println(array[0]);//1
|
||||
我们使用包装类型数组就可以解决这个问题。
|
||||
|
||||
```java
|
||||
Integer[] myArray = { 1, 2, 3 };
|
||||
Integer[] myArray = {1, 2, 3};
|
||||
```
|
||||
|
||||
**使用集合的修改方法:`add()`、`remove()`、`clear()`会抛出异常。**
|
||||
@ -296,7 +301,7 @@ static <T> List<T> arrayToList(final T[] array) {
|
||||
for (final T s : array) {
|
||||
l.add(s);
|
||||
}
|
||||
return (l);
|
||||
return l;
|
||||
}
|
||||
```
|
||||
|
||||
@ -344,6 +349,14 @@ List<String> list = new ArrayList<String>();
|
||||
CollectionUtils.addAll(list, str);
|
||||
```
|
||||
|
||||
**6. 使用 Java9 的 `List.of()`方法**
|
||||
``` java
|
||||
Integer[] array = {1, 2, 3};
|
||||
List<Integer> list = List.of(array);
|
||||
System.out.println(list); /* [1, 2, 3] */
|
||||
/* 不支持基本数据类型 */
|
||||
```
|
||||
|
||||
## 2.2. Collection.toArray()方法使用的坑&如何反转数组
|
||||
|
||||
该方法是一个泛型方法:`<T> T[] toArray(T[] a);` 如果`toArray`方法中没有传递任何参数的话返回的是`Object`类型数组。
|
||||
@ -365,6 +378,16 @@ s=list.toArray(new String[0]);//没有指定类型的话会报错
|
||||
|
||||
> **fail-fast 机制** :多个线程对 fail-fast 集合进行修改的时,可能会抛出ConcurrentModificationException,单线程下也会出现这种情况,上面已经提到过。
|
||||
|
||||
Java8开始,可以使用`Collection#removeIf()`方法删除满足特定条件的元素,如
|
||||
``` java
|
||||
List<Integer> list = new ArrayList<>();
|
||||
for (int i = 1; i <= 10; ++i) {
|
||||
list.add(i);
|
||||
}
|
||||
list.removeIf(filter -> filter % 2 == 0); /* 删除list中的所有偶数 */
|
||||
System.out.println(list); /* [1, 3, 5, 7, 9] */
|
||||
```
|
||||
|
||||
`java.util`包下面的所有的集合类都是fail-fast的,而`java.util.concurrent`包下面的所有的类都是fail-safe的。
|
||||
|
||||

|
||||
|
||||
@ -84,7 +84,7 @@ protected final boolean compareAndSetState(int expect, int update) {
|
||||
- 公平锁:按照线程在队列中的排队顺序,先到者先拿到锁
|
||||
- 非公平锁:当线程要获取锁时,先通过两次 CAS 操作去抢锁,如果没抢到,当前线程再加入到队列中等待唤醒。
|
||||
|
||||
> 说明:下面这部分关于 `ReentrantLock` 源代码内容节选自:https://www.javadoop.com/post/AbstractQueuedSynchronizer-2,这是一篇很不错文章,推荐阅读。
|
||||
> 说明:下面这部分关于 `ReentrantLock` 源代码内容节选自:https://www.javadoop.com/post/AbstractQueuedSynchronizer-2 ,这是一篇很不错文章,推荐阅读。
|
||||
|
||||
**下面来看 ReentrantLock 中相关的源代码:**
|
||||
|
||||
@ -238,7 +238,9 @@ tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true
|
||||
|
||||
### 3 Semaphore(信号量)-允许多个线程同时访问
|
||||
|
||||
**synchronized 和 ReentrantLock 都是一次只允许一个线程访问某个资源,Semaphore(信号量)可以指定多个线程同时访问某个资源。** 示例代码如下:
|
||||
**synchronized 和 ReentrantLock 都是一次只允许一个线程访问某个资源,Semaphore(信号量)可以指定多个线程同时访问某个资源。**
|
||||
|
||||
示例代码如下:
|
||||
|
||||
```java
|
||||
/**
|
||||
@ -288,9 +290,9 @@ public class SemaphoreExample1 {
|
||||
当然一次也可以一次拿取和释放多个许可,不过一般没有必要这样做:
|
||||
|
||||
```java
|
||||
semaphore.acquire(5);// 获取5个许可,所以可运行线程数量为20/5=4
|
||||
test(threadnum);
|
||||
semaphore.release(5);// 获取5个许可,所以可运行线程数量为20/5=4
|
||||
semaphore.acquire(5);// 获取5个许可,所以可运行线程数量为20/5=4
|
||||
test(threadnum);
|
||||
semaphore.release(5);// 获取5个许可,所以可运行线程数量为20/5=4
|
||||
```
|
||||
|
||||
除了 `acquire`方法之外,另一个比较常用的与之对应的方法是`tryAcquire`方法,该方法如果获取不到许可就立即返回 false。
|
||||
@ -314,21 +316,21 @@ Semaphore 有两种模式,公平模式和非公平模式。
|
||||
|
||||
**这两个构造方法,都必须提供许可的数量,第二个构造方法可以指定是公平模式还是非公平模式,默认非公平模式。**
|
||||
|
||||
由于篇幅问题,如果对 Semaphore 源码感兴趣的朋友可以看下面这篇文章:
|
||||
[issue645补充内容](https://github.com/Snailclimb/JavaGuide/issues/645) :Semaphore与CountDownLatch一样,也是共享锁的一种实现。它默认构造AQS的state为permits。当执行任务的线程数量超出permits,那么多余的线程将会被放入阻塞队列Park,并自旋判断state是否大于0。只有当state大于0的时候,阻塞的线程才能继续执行,此时先前执行任务的线程继续执行release方法,release方法使得state的变量会加1,那么自旋的线程便会判断成功。
|
||||
如此,每次只有最多不超过permits数量的线程能自旋成功,便限制了执行任务线程的数量。
|
||||
|
||||
- https://blog.csdn.net/qq_19431333/article/details/70212663
|
||||
由于篇幅问题,如果对 Semaphore 源码感兴趣的朋友可以看下这篇文章:https://juejin.im/post/5ae755366fb9a07ab508adc6
|
||||
|
||||
### 4 CountDownLatch (倒计时器)
|
||||
|
||||
CountDownLatch 是一个同步工具类,它允许一个或多个线程一直等待,直到其他线程的操作执行完后再执行。在 Java 并发中,countdownlatch 的概念是一个常见的面试题,所以一定要确保你很好的理解了它。
|
||||
CountDownLatch允许 count 个线程阻塞在一个地方,直至所有线程的任务都执行完毕。在 Java 并发中,countdownlatch 的概念是一个常见的面试题,所以一定要确保你很好的理解了它。
|
||||
|
||||
#### 4.1 CountDownLatch 的三种典型用法
|
||||
CountDownLatch是共享锁的一种实现,它默认构造 AQS 的 state 值为 count。当线程使用countDown方法时,其实使用了`tryReleaseShared`方法以CAS的操作来减少state,直至state为0就代表所有的线程都调用了countDown方法。当调用await方法的时候,如果state不为0,就代表仍然有线程没有调用countDown方法,那么就把已经调用过countDown的线程都放入阻塞队列Park,并自旋CAS判断state == 0,直至最后一个线程调用了countDown,使得state == 0,于是阻塞的线程便判断成功,全部往下执行。
|
||||
|
||||
① 某一线程在开始运行前等待 n 个线程执行完毕。将 CountDownLatch 的计数器初始化为 n :`new CountDownLatch(n)`,每当一个任务线程执行完毕,就将计数器减 1 `countdownlatch.countDown()`,当计数器的值变为 0 时,在`CountDownLatch上 await()` 的线程就会被唤醒。一个典型应用场景就是启动一个服务时,主线程需要等待多个组件加载完毕,之后再继续执行。
|
||||
#### 4.1 CountDownLatch 的两种典型用法
|
||||
|
||||
② 实现多个线程开始执行任务的最大并行性。注意是并行性,不是并发,强调的是多个线程在某一时刻同时开始执行。类似于赛跑,将多个线程放到起点,等待发令枪响,然后同时开跑。做法是初始化一个共享的 `CountDownLatch` 对象,将其计数器初始化为 1 :`new CountDownLatch(1)`,多个线程在开始执行任务前首先 `coundownlatch.await()`,当主线程调用 countDown() 时,计数器变为 0,多个线程同时被唤醒。
|
||||
|
||||
③ 死锁检测:一个非常方便的使用场景是,你可以使用 n 个线程访问共享资源,在每次测试阶段的线程数目是不同的,并尝试产生死锁。
|
||||
1. 某一线程在开始运行前等待 n 个线程执行完毕。将 CountDownLatch 的计数器初始化为 n :`new CountDownLatch(n)`,每当一个任务线程执行完毕,就将计数器减 1 `countdownlatch.countDown()`,当计数器的值变为 0 时,在`CountDownLatch上 await()` 的线程就会被唤醒。一个典型应用场景就是启动一个服务时,主线程需要等待多个组件加载完毕,之后再继续执行。
|
||||
2. 实现多个线程开始执行任务的最大并行性。注意是并行性,不是并发,强调的是多个线程在某一时刻同时开始执行。类似于赛跑,将多个线程放到起点,等待发令枪响,然后同时开跑。做法是初始化一个共享的 `CountDownLatch` 对象,将其计数器初始化为 1 :`new CountDownLatch(1)`,多个线程在开始执行任务前首先 `coundownlatch.await()`,当主线程调用 countDown() 时,计数器变为 0,多个线程同时被唤醒。
|
||||
|
||||
#### 4.2 CountDownLatch 的使用示例
|
||||
|
||||
@ -377,15 +379,27 @@ public class CountDownLatchExample1 {
|
||||
|
||||
上面的代码中,我们定义了请求的数量为 550,当这 550 个请求被处理完成之后,才会执行`System.out.println("finish");`。
|
||||
|
||||
与 CountDownLatch 的第一次交互是主线程等待其他线程。主线程必须在启动其他线程后立即调用 CountDownLatch.await()方法。这样主线程的操作就会在这个方法上阻塞,直到其他线程完成各自的任务。
|
||||
与 CountDownLatch 的第一次交互是主线程等待其他线程。主线程必须在启动其他线程后立即调用 `CountDownLatch.await()` 方法。这样主线程的操作就会在这个方法上阻塞,直到其他线程完成各自的任务。
|
||||
|
||||
其他 N 个线程必须引用闭锁对象,因为他们需要通知 CountDownLatch 对象,他们已经完成了各自的任务。这种通知机制是通过 CountDownLatch.countDown()方法来完成的;每调用一次这个方法,在构造函数中初始化的 count 值就减 1。所以当 N 个线程都调 用了这个方法,count 的值等于 0,然后主线程就能通过 await()方法,恢复执行自己的任务。
|
||||
其他 N 个线程必须引用闭锁对象,因为他们需要通知 `CountDownLatch` 对象,他们已经完成了各自的任务。这种通知机制是通过 `CountDownLatch.countDown()`方法来完成的;每调用一次这个方法,在构造函数中初始化的 count 值就减 1。所以当 N 个线程都调 用了这个方法,count 的值等于 0,然后主线程就能通过 `await()`方法,恢复执行自己的任务。
|
||||
|
||||
再插一嘴:`CountDownLatch` 的 `await()` 方法使用不当很容易产生死锁,比如我们上面代码中的 for 循环改为:
|
||||
|
||||
```java
|
||||
for (int i = 0; i < threadCount-1; i++) {
|
||||
.......
|
||||
}
|
||||
```
|
||||
|
||||
这样就导致 `count` 的值没办法等于 0,然后就会导致一直等待。
|
||||
|
||||
如果对CountDownLatch源码感兴趣的朋友,可以查看: [【JUC】JDK1.8源码分析之CountDownLatch(五)](https://www.cnblogs.com/leesf456/p/5406191.html)
|
||||
|
||||
#### 4.3 CountDownLatch 的不足
|
||||
|
||||
CountDownLatch 是一次性的,计数器的值只能在构造方法中初始化一次,之后没有任何机制再次对其设置值,当 CountDownLatch 使用完毕后,它不能再次被使用。
|
||||
|
||||
#### 4.4 CountDownLatch 相常见面试题:
|
||||
#### 4.4 CountDownLatch 相常见面试题
|
||||
|
||||
解释一下 CountDownLatch 概念?
|
||||
|
||||
@ -399,6 +413,8 @@ CountDownLatch 类中主要的方法?
|
||||
|
||||
CyclicBarrier 和 CountDownLatch 非常类似,它也可以实现线程间的技术等待,但是它的功能比 CountDownLatch 更加复杂和强大。主要应用场景和 CountDownLatch 类似。
|
||||
|
||||
> CountDownLatch的实现是基于AQS的,而CycliBarrier是基于 ReentrantLock(ReentrantLock也属于AQS同步器)和 Condition 的.
|
||||
|
||||
CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。CyclicBarrier 默认的构造方法是 `CyclicBarrier(int parties)`,其参数表示屏障拦截的线程数量,每个线程调用`await`方法告诉 CyclicBarrier 我已经到达了屏障,然后当前线程被阻塞。
|
||||
|
||||
再来看一下它的构造函数:
|
||||
|
||||
@ -56,15 +56,61 @@ Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是
|
||||
**引用类型**
|
||||
|
||||
- AtomicReference:引用类型原子类
|
||||
- AtomicReferenceFieldUpdater:原子更新引用类型里的字段
|
||||
- AtomicMarkableReference :原子更新带有标记位的引用类型
|
||||
- AtomicMarkableReference:原子更新带有标记的引用类型。该类将 boolean 标记与引用关联起来,~~也可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。~~
|
||||
- AtomicStampedReference :原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
|
||||
|
||||
**对象的属性修改类型**
|
||||
|
||||
- AtomicIntegerFieldUpdater:原子更新整型字段的更新器
|
||||
- AtomicLongFieldUpdater:原子更新长整型字段的更新器
|
||||
- AtomicStampedReference :原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
|
||||
- AtomicMarkableReference:原子更新带有标记的引用类型。该类将 boolean 标记与引用关联起来,也可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
|
||||
- AtomicReferenceFieldUpdater:原子更新引用类型里的字段
|
||||
|
||||
> 修正: **AtomicMarkableReference 不能解决ABA问题** **[issue#626](https://github.com/Snailclimb/JavaGuide/issues/626)**
|
||||
|
||||
```java
|
||||
/**
|
||||
|
||||
AtomicMarkableReference是将一个boolean值作是否有更改的标记,本质就是它的版本号只有两个,true和false,
|
||||
|
||||
修改的时候在这两个版本号之间来回切换,这样做并不能解决ABA的问题,只是会降低ABA问题发生的几率而已
|
||||
|
||||
@author : mazh
|
||||
|
||||
@Date : 2020/1/17 14:41
|
||||
*/
|
||||
|
||||
public class SolveABAByAtomicMarkableReference {
|
||||
|
||||
private static AtomicMarkableReference atomicMarkableReference = new AtomicMarkableReference(100, false);
|
||||
|
||||
public static void main(String[] args) {
|
||||
|
||||
Thread refT1 = new Thread(() -> {
|
||||
try {
|
||||
TimeUnit.SECONDS.sleep(1);
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
atomicMarkableReference.compareAndSet(100, 101, atomicMarkableReference.isMarked(), !atomicMarkableReference.isMarked());
|
||||
atomicMarkableReference.compareAndSet(101, 100, atomicMarkableReference.isMarked(), !atomicMarkableReference.isMarked());
|
||||
});
|
||||
|
||||
Thread refT2 = new Thread(() -> {
|
||||
boolean marked = atomicMarkableReference.isMarked();
|
||||
try {
|
||||
TimeUnit.SECONDS.sleep(2);
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
boolean c3 = atomicMarkableReference.compareAndSet(100, 101, marked, !marked);
|
||||
System.out.println(c3); // 返回true,实际应该返回false
|
||||
});
|
||||
|
||||
refT1.start();
|
||||
refT2.start();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**CAS ABA 问题**
|
||||
- 描述: 第一个线程取到了变量 x 的值 A,然后巴拉巴拉干别的事,总之就是只拿到了变量 x 的值 A。这段时间内第二个线程也取到了变量 x 的值 A,然后把变量 x 的值改为 B,然后巴拉巴拉干别的事,最后又把变量 x 的值变为 A (相当于还原了)。在这之后第一个线程终于进行了变量 x 的操作,但是此时变量 x 的值还是 A,所以 compareAndSet 操作是成功。
|
||||
@ -268,8 +314,8 @@ public final int get(int i) //获取 index=i 位置元素的值
|
||||
public final int getAndSet(int i, int newValue)//返回 index=i 位置的当前的值,并将其设置为新值:newValue
|
||||
public final int getAndIncrement(int i)//获取 index=i 位置元素的值,并让该位置的元素自增
|
||||
public final int getAndDecrement(int i) //获取 index=i 位置元素的值,并让该位置的元素自减
|
||||
public final int getAndAdd(int delta) //获取 index=i 位置元素的值,并加上预期的值
|
||||
boolean compareAndSet(int expect, int update) //如果输入的数值等于预期值,则以原子方式将 index=i 位置的元素值设置为输入值(update)
|
||||
public final int getAndAdd(int i, int delta) //获取 index=i 位置元素的值,并加上预期的值
|
||||
boolean compareAndSet(int i, int expect, int update) //如果输入的数值等于预期值,则以原子方式将 index=i 位置的元素值设置为输入值(update)
|
||||
public final void lazySet(int i, int newValue)//最终 将index=i 位置的元素设置为newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
|
||||
```
|
||||
#### 3.2 AtomicIntegerArray 常见方法使用
|
||||
@ -306,8 +352,8 @@ public class AtomicIntegerArrayTest {
|
||||
基本类型原子类只能更新一个变量,如果需要原子更新多个变量,需要使用 引用类型原子类。
|
||||
|
||||
- AtomicReference:引用类型原子类
|
||||
- AtomicStampedReference:原子更新引用类型里的字段原子类
|
||||
- AtomicMarkableReference :原子更新带有标记位的引用类型
|
||||
- AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
|
||||
- AtomicMarkableReference :原子更新带有标记的引用类型。该类将 boolean 标记与引用关联起来,~~也可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。~~
|
||||
|
||||
上面三个类提供的方法几乎相同,所以我们这里以 AtomicReference 为例子来介绍。
|
||||
|
||||
@ -488,7 +534,7 @@ currentValue=true, currentMark=true, wCasResult=true
|
||||
|
||||
- AtomicIntegerFieldUpdater:原子更新整形字段的更新器
|
||||
- AtomicLongFieldUpdater:原子更新长整形字段的更新器
|
||||
- AtomicStampedReference :原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
|
||||
- AtomicReferenceFieldUpdater :原子更新引用类型里的字段的更新器
|
||||
|
||||
要想原子地更新对象的属性需要两步。第一步,因为对象的属性修改类型原子类都是抽象类,所以每次使用都必须使用静态方法 newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。第二步,更新的对象属性必须使用 public volatile 修饰符。
|
||||
|
||||
@ -545,6 +591,10 @@ class User {
|
||||
23
|
||||
```
|
||||
|
||||
## Reference
|
||||
|
||||
- 《Java并发编程的艺术》
|
||||
|
||||
## 公众号
|
||||
|
||||
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
|
||||
|
||||
@ -1,65 +1,118 @@
|
||||
点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
|
||||
点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java 面试突击》以及 Java 工程师必备学习资源。
|
||||
|
||||
<!-- TOC -->
|
||||
|
||||
<!-- @import "[TOC]" {cmd="toc" depthFrom=1 depthTo=6 orderedList=false} -->
|
||||
|
||||
<!-- code_chunk_output -->
|
||||
|
||||
- [Java 并发进阶常见面试题总结](#java-并发进阶常见面试题总结)
|
||||
- [1. synchronized 关键字](#1-synchronized-关键字)
|
||||
- [1.1. 说一说自己对于 synchronized 关键字的了解](#11-说一说自己对于-synchronized-关键字的了解)
|
||||
- [1.2. 说说自己是怎么使用 synchronized 关键字,在项目中用到了吗](#12-说说自己是怎么使用-synchronized-关键字在项目中用到了吗)
|
||||
- [1.3. 讲一下 synchronized 关键字的底层原理](#13-讲一下-synchronized-关键字的底层原理)
|
||||
- [1.4. 说说 JDK1.6 之后的synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗](#14-说说-jdk16-之后的synchronized-关键字底层做了哪些优化可以详细介绍一下这些优化吗)
|
||||
- [1.5. 谈谈 synchronized和ReentrantLock 的区别](#15-谈谈-synchronized和reentrantlock-的区别)
|
||||
- [2. volatile关键字](#2-volatile关键字)
|
||||
- [2.1. 讲一下Java内存模型](#21-讲一下java内存模型)
|
||||
- [2.2. 说说 synchronized 关键字和 volatile 关键字的区别](#22-说说-synchronized-关键字和-volatile-关键字的区别)
|
||||
- [3. ThreadLocal](#3-threadlocal)
|
||||
- [3.1. ThreadLocal简介](#31-threadlocal简介)
|
||||
- [3.2. ThreadLocal示例](#32-threadlocal示例)
|
||||
- [3.3. ThreadLocal原理](#33-threadlocal原理)
|
||||
- [3.4. ThreadLocal 内存泄露问题](#34-threadlocal-内存泄露问题)
|
||||
- [4. 线程池](#4-线程池)
|
||||
- [4.1. 为什么要用线程池?](#41-为什么要用线程池)
|
||||
- [4.2. 实现Runnable接口和Callable接口的区别](#42-实现runnable接口和callable接口的区别)
|
||||
- [4.3. 执行execute()方法和submit()方法的区别是什么呢?](#43-执行execute方法和submit方法的区别是什么呢)
|
||||
- [4.4. 如何创建线程池](#44-如何创建线程池)
|
||||
- [5. Atomic 原子类](#5-atomic-原子类)
|
||||
- [5.1. 介绍一下Atomic 原子类](#51-介绍一下atomic-原子类)
|
||||
- [5.2. JUC 包中的原子类是哪4类?](#52-juc-包中的原子类是哪4类)
|
||||
- [5.3. 讲讲 AtomicInteger 的使用](#53-讲讲-atomicinteger-的使用)
|
||||
- [5.4. 能不能给我简单介绍一下 AtomicInteger 类的原理](#54-能不能给我简单介绍一下-atomicinteger-类的原理)
|
||||
- [6. AQS](#6-aqs)
|
||||
- [6.1. AQS 介绍](#61-aqs-介绍)
|
||||
- [6.2. AQS 原理分析](#62-aqs-原理分析)
|
||||
- [6.2.1. AQS 原理概览](#621-aqs-原理概览)
|
||||
- [6.2.2. AQS 对资源的共享方式](#622-aqs-对资源的共享方式)
|
||||
- [6.2.3. AQS底层使用了模板方法模式](#623-aqs底层使用了模板方法模式)
|
||||
- [6.3. AQS 组件总结](#63-aqs-组件总结)
|
||||
- [7 Reference](#7-reference)
|
||||
- [1.synchronized 关键字](#1synchronized-关键字)
|
||||
- [1.1.说一说自己对于 synchronized 关键字的了解](#11说一说自己对于-synchronized-关键字的了解)
|
||||
- [1.2. 说说自己是怎么使用 synchronized 关键字](#12-说说自己是怎么使用-synchronized-关键字)
|
||||
- [1.3. 构造方法可以使用 synchronized 关键字修饰么?](#13-构造方法可以使用-synchronized-关键字修饰么)
|
||||
- [1.3. 讲一下 synchronized 关键字的底层原理](#13-讲一下-synchronized-关键字的底层原理)
|
||||
- [1.3.1. synchronized 同步语句块的情况](#131-synchronized-同步语句块的情况)
|
||||
- [1.3.2. `synchronized` 修饰方法的的情况](#132-synchronized-修饰方法的的情况)
|
||||
- [1.3.3.总结](#133总结)
|
||||
- [1.4. 说说 JDK1.6 之后的 synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗](#14-说说-jdk16-之后的-synchronized-关键字底层做了哪些优化可以详细介绍一下这些优化吗)
|
||||
- [1.5. 谈谈 synchronized 和 ReentrantLock 的区别](#15-谈谈-synchronized-和-reentrantlock-的区别)
|
||||
- [1.5.1. 两者都是可重入锁](#151-两者都是可重入锁)
|
||||
- [1.5.2.synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API](#152synchronized-依赖于-jvm-而-reentrantlock-依赖于-api)
|
||||
- [1.5.3.ReentrantLock 比 synchronized 增加了一些高级功能](#153reentrantlock-比-synchronized-增加了一些高级功能)
|
||||
- [2. volatile 关键字](#2-volatile-关键字)
|
||||
- [2.1. CPU 缓存模型](#21-cpu-缓存模型)
|
||||
- [2.2. 讲一下 JMM(Java 内存模型)](#22-讲一下-jmmjava-内存模型)
|
||||
- [2.3. 并发编程的三个重要特性](#23-并发编程的三个重要特性)
|
||||
- [2.4. 说说 synchronized 关键字和 volatile 关键字的区别](#24-说说-synchronized-关键字和-volatile-关键字的区别)
|
||||
- [3. ThreadLocal](#3-threadlocal)
|
||||
- [3.1. ThreadLocal 简介](#31-threadlocal-简介)
|
||||
- [3.2. ThreadLocal 示例](#32-threadlocal-示例)
|
||||
- [3.3. ThreadLocal 原理](#33-threadlocal-原理)
|
||||
- [3.4. ThreadLocal 内存泄露问题](#34-threadlocal-内存泄露问题)
|
||||
- [4. 线程池](#4-线程池)
|
||||
- [4.1. 为什么要用线程池?](#41-为什么要用线程池)
|
||||
- [4.2. 实现 Runnable 接口和 Callable 接口的区别](#42-实现-runnable-接口和-callable-接口的区别)
|
||||
- [4.3. 执行 execute()方法和 submit()方法的区别是什么呢?](#43-执行-execute方法和-submit方法的区别是什么呢)
|
||||
- [4.4. 如何创建线程池](#44-如何创建线程池)
|
||||
- [4.5 ThreadPoolExecutor 类分析](#45-threadpoolexecutor-类分析)
|
||||
- [4.5.1 `ThreadPoolExecutor`构造函数重要参数分析](#451-threadpoolexecutor构造函数重要参数分析)
|
||||
- [4.5.2 `ThreadPoolExecutor` 饱和策略](#452-threadpoolexecutor-饱和策略)
|
||||
- [4.6 一个简单的线程池 Demo](#46-一个简单的线程池-demo)
|
||||
- [4.7 线程池原理分析](#47-线程池原理分析)
|
||||
- [5. Atomic 原子类](#5-atomic-原子类)
|
||||
- [5.1. 介绍一下 Atomic 原子类](#51-介绍一下-atomic-原子类)
|
||||
- [5.2. JUC 包中的原子类是哪 4 类?](#52-juc-包中的原子类是哪-4-类)
|
||||
- [5.3. 讲讲 AtomicInteger 的使用](#53-讲讲-atomicinteger-的使用)
|
||||
- [5.4. 能不能给我简单介绍一下 AtomicInteger 类的原理](#54-能不能给我简单介绍一下-atomicinteger-类的原理)
|
||||
- [6. AQS](#6-aqs)
|
||||
- [6.1. AQS 介绍](#61-aqs-介绍)
|
||||
- [6.2. AQS 原理分析](#62-aqs-原理分析)
|
||||
- [6.2.1. AQS 原理概览](#621-aqs-原理概览)
|
||||
- [6.2.2. AQS 对资源的共享方式](#622-aqs-对资源的共享方式)
|
||||
- [6.2.3. AQS 底层使用了模板方法模式](#623-aqs-底层使用了模板方法模式)
|
||||
- [6.3. AQS 组件总结](#63-aqs-组件总结)
|
||||
- [6.4. 用过 CountDownLatch 么?什么场景下用的?](#64-用过-countdownlatch-么什么场景下用的)
|
||||
- [7 Reference](#7-reference)
|
||||
- [公众号](#公众号)
|
||||
|
||||
<!-- /code_chunk_output -->
|
||||
|
||||
<!-- /TOC -->
|
||||
|
||||
# Java 并发进阶常见面试题总结
|
||||
|
||||
## 1. synchronized 关键字
|
||||
## 1.synchronized 关键字
|
||||
|
||||
### 1.1. 说一说自己对于 synchronized 关键字的了解
|
||||

|
||||
|
||||
synchronized关键字解决的是多个线程之间访问资源的同步性,synchronized关键字可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行。
|
||||
### 1.1.说一说自己对于 synchronized 关键字的了解
|
||||
|
||||
另外,在 Java 早期版本中,synchronized属于重量级锁,效率低下,因为监视器锁(monitor)是依赖于底层的操作系统的 Mutex Lock 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高,这也是为什么早期的 synchronized 效率低的原因。庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对synchronized 较大优化,所以现在的 synchronized 锁效率也优化得很不错了。JDK1.6对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
|
||||
**`synchronized` 关键字解决的是多个线程之间访问资源的同步性,`synchronized`关键字可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行。**
|
||||
|
||||
另外,在 Java 早期版本中,`synchronized` 属于 **重量级锁**,效率低下。
|
||||
|
||||
### 1.2. 说说自己是怎么使用 synchronized 关键字,在项目中用到了吗
|
||||
**为什么呢?**
|
||||
|
||||
**synchronized关键字最主要的三种使用方式:**
|
||||
因为监视器锁(monitor)是依赖于底层的操作系统的 `Mutex Lock` 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高。
|
||||
|
||||
- **修饰实例方法:** 作用于当前对象实例加锁,进入同步代码前要获得当前对象实例的锁
|
||||
- **修饰静态方法:** 也就是给当前类加锁,会作用于类的所有对象实例,因为静态成员不属于任何一个实例对象,是类成员( static 表明这是该类的一个静态资源,不管new了多少个对象,只有一份)。所以如果一个线程A调用一个实例对象的非静态 synchronized 方法,而线程B需要调用这个实例对象所属类的静态 synchronized 方法,是允许的,不会发生互斥现象,**因为访问静态 synchronized 方法占用的锁是当前类的锁,而访问非静态 synchronized 方法占用的锁是当前实例对象锁**。
|
||||
- **修饰代码块:** 指定加锁对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁。
|
||||
庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对 synchronized 较大优化,所以现在的 synchronized 锁效率也优化得很不错了。JDK1.6 对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
|
||||
|
||||
**总结:** synchronized 关键字加到 static 静态方法和 synchronized(class)代码块上都是是给 Class 类上锁。synchronized 关键字加到实例方法上是给对象实例上锁。尽量不要使用 synchronized(String a) 因为JVM中,字符串常量池具有缓存功能!
|
||||
所以,你会发现目前的话,不论是各种开源框架还是 JDK 源码都大量使用了 synchronized 关键字。
|
||||
|
||||
下面我以一个常见的面试题为例讲解一下 synchronized 关键字的具体使用。
|
||||
### 1.2. 说说自己是怎么使用 synchronized 关键字
|
||||
|
||||
**synchronized 关键字最主要的三种使用方式:**
|
||||
|
||||
**1.修饰实例方法:** 作用于当前对象实例加锁,进入同步代码前要获得 **当前对象实例的锁**
|
||||
|
||||
```java
|
||||
synchronized void method() {
|
||||
//业务代码
|
||||
}
|
||||
```
|
||||
|
||||
**2.修饰静态方法:** 也就是给当前类加锁,会作用于类的所有对象实例 ,进入同步代码前要获得 **当前 class 的锁**。因为静态成员不属于任何一个实例对象,是类成员( _static 表明这是该类的一个静态资源,不管 new 了多少个对象,只有一份_)。所以,如果一个线程 A 调用一个实例对象的非静态 `synchronized` 方法,而线程 B 需要调用这个实例对象所属类的静态 `synchronized` 方法,是允许的,不会发生互斥现象,**因为访问静态 `synchronized` 方法占用的锁是当前类的锁,而访问非静态 `synchronized` 方法占用的锁是当前实例对象锁**。
|
||||
|
||||
```java
|
||||
synchronized void staic method() {
|
||||
//业务代码
|
||||
}
|
||||
```
|
||||
|
||||
**3.修饰代码块** :指定加锁对象,对给定对象/类加锁。`synchronized(this|object)` 表示进入同步代码库前要获得**给定对象的锁**。`synchronized(类.class)` 表示进入同步代码前要获得 **当前 class 的锁**
|
||||
|
||||
```java
|
||||
synchronized(this) {
|
||||
//业务代码
|
||||
}
|
||||
```
|
||||
|
||||
**总结:**
|
||||
|
||||
- `synchronized` 关键字加到 `static` 静态方法和 `synchronized(class)` 代码块上都是是给 Class 类上锁。
|
||||
- `synchronized` 关键字加到实例方法上是给对象实例上锁。
|
||||
- 尽量不要使用 `synchronized(String a)` 因为 JVM 中,字符串常量池具有缓存功能!
|
||||
|
||||
下面我以一个常见的面试题为例讲解一下 `synchronized` 关键字的具体使用。
|
||||
|
||||
面试中面试官经常会说:“单例模式了解吗?来给我手写一下!给我解释一下双重检验锁方式实现单例模式的原理呗!”
|
||||
|
||||
@ -73,7 +126,7 @@ public class Singleton {
|
||||
private Singleton() {
|
||||
}
|
||||
|
||||
public static Singleton getUniqueInstance() {
|
||||
public static Singleton getUniqueInstance() {
|
||||
//先判断对象是否已经实例过,没有实例化过才进入加锁代码
|
||||
if (uniqueInstance == null) {
|
||||
//类对象加锁
|
||||
@ -87,23 +140,30 @@ public class Singleton {
|
||||
}
|
||||
}
|
||||
```
|
||||
另外,需要注意 uniqueInstance 采用 volatile 关键字修饰也是很有必要。
|
||||
|
||||
uniqueInstance 采用 volatile 关键字修饰也是很有必要的, uniqueInstance = new Singleton(); 这段代码其实是分为三步执行:
|
||||
另外,需要注意 `uniqueInstance` 采用 `volatile` 关键字修饰也是很有必要。
|
||||
|
||||
1. 为 uniqueInstance 分配内存空间
|
||||
2. 初始化 uniqueInstance
|
||||
3. 将 uniqueInstance 指向分配的内存地址
|
||||
`uniqueInstance` 采用 `volatile` 关键字修饰也是很有必要的, `uniqueInstance = new Singleton();` 这段代码其实是分为三步执行:
|
||||
|
||||
但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 getUniqueInstance() 后发现 uniqueInstance 不为空,因此返回 uniqueInstance,但此时 uniqueInstance 还未被初始化。
|
||||
1. 为 `uniqueInstance` 分配内存空间
|
||||
2. 初始化 `uniqueInstance`
|
||||
3. 将 `uniqueInstance` 指向分配的内存地址
|
||||
|
||||
使用 volatile 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
|
||||
但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 `getUniqueInstance`() 后发现 `uniqueInstance` 不为空,因此返回 `uniqueInstance`,但此时 `uniqueInstance` 还未被初始化。
|
||||
|
||||
使用 `volatile` 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
|
||||
|
||||
### 1.3. 构造方法可以使用 synchronized 关键字修饰么?
|
||||
|
||||
先说结论:**构造方法不能使用 synchronized 关键字修饰。**
|
||||
|
||||
构造方法本身就属于线程安全的,不存在同步的构造方法一说。
|
||||
|
||||
### 1.3. 讲一下 synchronized 关键字的底层原理
|
||||
|
||||
**synchronized 关键字底层原理属于 JVM 层面。**
|
||||
|
||||
**① synchronized 同步语句块的情况**
|
||||
#### 1.3.1. synchronized 同步语句块的情况
|
||||
|
||||
```java
|
||||
public class SynchronizedDemo {
|
||||
@ -116,15 +176,25 @@ public class SynchronizedDemo {
|
||||
|
||||
```
|
||||
|
||||
通过 JDK 自带的 javap 命令查看 SynchronizedDemo 类的相关字节码信息:首先切换到类的对应目录执行 `javac SynchronizedDemo.java` 命令生成编译后的 .class 文件,然后执行`javap -c -s -v -l SynchronizedDemo.class`。
|
||||
通过 JDK 自带的 `javap` 命令查看 `SynchronizedDemo` 类的相关字节码信息:首先切换到类的对应目录执行 `javac SynchronizedDemo.java` 命令生成编译后的 .class 文件,然后执行`javap -c -s -v -l SynchronizedDemo.class`。
|
||||
|
||||

|
||||
|
||||
从上面我们可以看出:
|
||||
|
||||
**synchronized 同步语句块的实现使用的是 monitorenter 和 monitorexit 指令,其中 monitorenter 指令指向同步代码块的开始位置,monitorexit 指令则指明同步代码块的结束位置。** 当执行 monitorenter 指令时,线程试图获取锁也就是获取 monitor(monitor对象存在于每个Java对象的对象头中,synchronized 锁便是通过这种方式获取锁的,也是为什么Java中任意对象可以作为锁的原因) 的持有权。当计数器为0则可以成功获取,获取后将锁计数器设为1也就是加1。相应的在执行 monitorexit 指令后,将锁计数器设为0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
|
||||
**`synchronized` 同步语句块的实现使用的是 `monitorenter` 和 `monitorexit` 指令,其中 `monitorenter` 指令指向同步代码块的开始位置,`monitorexit` 指令则指明同步代码块的结束位置。**
|
||||
|
||||
**② synchronized 修饰方法的的情况**
|
||||
当执行 `monitorenter` 指令时,线程试图获取锁也就是获取 **对象监视器 `monitor`** 的持有权。
|
||||
|
||||
> 在 Java 虚拟机(HotSpot)中,Monitor 是基于 C++实现的,由[ObjectMonitor](https://github.com/openjdk-mirror/jdk7u-hotspot/blob/50bdefc3afe944ca74c3093e7448d6b889cd20d1/src/share/vm/runtime/objectMonitor.cpp)实现的。每个对象中都内置了一个 `ObjectMonitor`对象。
|
||||
>
|
||||
> 另外,**`wait/notify`等方法也依赖于`monitor`对象,这就是为什么只有在同步的块或者方法中才能调用`wait/notify`等方法,否则会抛出`java.lang.IllegalMonitorStateException`的异常的原因。**
|
||||
|
||||
在执行`monitorenter`时,会尝试获取对象的锁,如果锁的计数器为 0 则表示锁可以被获取,获取后将锁计数器设为 1 也就是加 1。
|
||||
|
||||
在执行 `monitorexit` 指令后,将锁计数器设为 0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
|
||||
|
||||
#### 1.3.2. `synchronized` 修饰方法的的情况
|
||||
|
||||
```java
|
||||
public class SynchronizedDemo2 {
|
||||
@ -137,78 +207,112 @@ public class SynchronizedDemo2 {
|
||||
|
||||
|
||||
|
||||
synchronized 修饰的方法并没有 monitorenter 指令和 monitorexit 指令,取得代之的确实是 ACC_SYNCHRONIZED 标识,该标识指明了该方法是一个同步方法,JVM 通过该 ACC_SYNCHRONIZED 访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。
|
||||
`synchronized` 修饰的方法并没有 `monitorenter` 指令和 `monitorexit` 指令,取得代之的确实是 `ACC_SYNCHRONIZED` 标识,该标识指明了该方法是一个同步方法。JVM 通过该 `ACC_SYNCHRONIZED` 访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。
|
||||
|
||||
#### 1.3.3.总结
|
||||
|
||||
### 1.4. 说说 JDK1.6 之后的synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗
|
||||
`synchronized` 同步语句块的实现使用的是 `monitorenter` 和 `monitorexit` 指令,其中 `monitorenter` 指令指向同步代码块的开始位置,`monitorexit` 指令则指明同步代码块的结束位置。
|
||||
|
||||
`synchronized` 修饰的方法并没有 `monitorenter` 指令和 `monitorexit` 指令,取得代之的确实是 `ACC_SYNCHRONIZED` 标识,该标识指明了该方法是一个同步方法。
|
||||
|
||||
**不过两者的本质都是对对象监视器 monitor 的获取。**
|
||||
|
||||
### 1.4. 说说 JDK1.6 之后的 synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗
|
||||
|
||||
JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术来减少锁操作的开销。
|
||||
|
||||
锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
|
||||
|
||||
关于这几种优化的详细信息可以查看笔主的这篇文章:<https://gitee.com/SnailClimb/JavaGuide/blob/master/docs/java/Multithread/synchronized.md>
|
||||
关于这几种优化的详细信息可以查看下面这几篇文章:
|
||||
|
||||
### 1.5. 谈谈 synchronized和ReentrantLock 的区别
|
||||
- [Java 性能 -- synchronized 锁升级优化](https://blog.csdn.net/qq_34337272/article/details/108498442)
|
||||
- [Java6 及以上版本对 synchronized 的优化](https://www.cnblogs.com/wuqinglong/p/9945618.html)
|
||||
|
||||
### 1.5. 谈谈 synchronized 和 ReentrantLock 的区别
|
||||
|
||||
**① 两者都是可重入锁**
|
||||
#### 1.5.1. 两者都是可重入锁
|
||||
|
||||
两者都是可重入锁。“可重入锁”概念是:自己可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果不可锁重入的话,就会造成死锁。同一个线程每次获取锁,锁的计数器都自增1,所以要等到锁的计数器下降为0时才能释放锁。
|
||||
**“可重入锁”** 指的是自己可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果不可锁重入的话,就会造成死锁。同一个线程每次获取锁,锁的计数器都自增 1,所以要等到锁的计数器下降为 0 时才能释放锁。
|
||||
|
||||
**② synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API**
|
||||
#### 1.5.2.synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API
|
||||
|
||||
synchronized 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团队在 JDK1.6 为 synchronized 关键字进行了很多优化,但是这些优化都是在虚拟机层面实现的,并没有直接暴露给我们。ReentrantLock 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock() 方法配合 try/finally 语句块来完成),所以我们可以通过查看它的源代码,来看它是如何实现的。
|
||||
`synchronized` 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团队在 JDK1.6 为 `synchronized` 关键字进行了很多优化,但是这些优化都是在虚拟机层面实现的,并没有直接暴露给我们。`ReentrantLock` 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock() 方法配合 try/finally 语句块来完成),所以我们可以通过查看它的源代码,来看它是如何实现的。
|
||||
|
||||
**③ ReentrantLock 比 synchronized 增加了一些高级功能**
|
||||
#### 1.5.3.ReentrantLock 比 synchronized 增加了一些高级功能
|
||||
|
||||
相比synchronized,ReentrantLock增加了一些高级功能。主要来说主要有三点:**①等待可中断;②可实现公平锁;③可实现选择性通知(锁可以绑定多个条件)**
|
||||
相比`synchronized`,`ReentrantLock`增加了一些高级功能。主要来说主要有三点:
|
||||
|
||||
- **ReentrantLock提供了一种能够中断等待锁的线程的机制**,通过lock.lockInterruptibly()来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。
|
||||
- **ReentrantLock可以指定是公平锁还是非公平锁。而synchronized只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。** ReentrantLock默认情况是非公平的,可以通过 ReentrantLock类的`ReentrantLock(boolean fair)`构造方法来制定是否是公平的。
|
||||
- synchronized关键字与wait()和notify()/notifyAll()方法相结合可以实现等待/通知机制,ReentrantLock类当然也可以实现,但是需要借助于Condition接口与newCondition() 方法。Condition是JDK1.5之后才有的,它具有很好的灵活性,比如可以实现多路通知功能也就是在一个Lock对象中可以创建多个Condition实例(即对象监视器),**线程对象可以注册在指定的Condition中,从而可以有选择性的进行线程通知,在调度线程上更加灵活。 在使用notify()/notifyAll()方法进行通知时,被通知的线程是由 JVM 选择的,用ReentrantLock类结合Condition实例可以实现“选择性通知”** ,这个功能非常重要,而且是Condition接口默认提供的。而synchronized关键字就相当于整个Lock对象中只有一个Condition实例,所有的线程都注册在它一个身上。如果执行notifyAll()方法的话就会通知所有处于等待状态的线程这样会造成很大的效率问题,而Condition实例的signalAll()方法 只会唤醒注册在该Condition实例中的所有等待线程。
|
||||
- **等待可中断** : `ReentrantLock`提供了一种能够中断等待锁的线程的机制,通过 `lock.lockInterruptibly()` 来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。
|
||||
- **可实现公平锁** : `ReentrantLock`可以指定是公平锁还是非公平锁。而`synchronized`只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。`ReentrantLock`默认情况是非公平的,可以通过 `ReentrantLock`类的`ReentrantLock(boolean fair)`构造方法来制定是否是公平的。
|
||||
- **可实现选择性通知(锁可以绑定多个条件)**: `synchronized`关键字与`wait()`和`notify()`/`notifyAll()`方法相结合可以实现等待/通知机制。`ReentrantLock`类当然也可以实现,但是需要借助于`Condition`接口与`newCondition()`方法。
|
||||
|
||||
如果你想使用上述功能,那么选择ReentrantLock是一个不错的选择。
|
||||
> `Condition`是 JDK1.5 之后才有的,它具有很好的灵活性,比如可以实现多路通知功能也就是在一个`Lock`对象中可以创建多个`Condition`实例(即对象监视器),**线程对象可以注册在指定的`Condition`中,从而可以有选择性的进行线程通知,在调度线程上更加灵活。 在使用`notify()/notifyAll()`方法进行通知时,被通知的线程是由 JVM 选择的,用`ReentrantLock`类结合`Condition`实例可以实现“选择性通知”** ,这个功能非常重要,而且是 Condition 接口默认提供的。而`synchronized`关键字就相当于整个 Lock 对象中只有一个`Condition`实例,所有的线程都注册在它一个身上。如果执行`notifyAll()`方法的话就会通知所有处于等待状态的线程这样会造成很大的效率问题,而`Condition`实例的`signalAll()`方法 只会唤醒注册在该`Condition`实例中的所有等待线程。
|
||||
|
||||
**④ 性能已不是选择标准**
|
||||
**如果你想使用上述功能,那么选择 ReentrantLock 是一个不错的选择。性能已不是选择标准**
|
||||
|
||||
## 2. volatile关键字
|
||||
## 2. volatile 关键字
|
||||
|
||||
### 2.1. 讲一下Java内存模型
|
||||
我们先要从 **CPU 缓存模型** 说起!
|
||||
|
||||
### 2.1. CPU 缓存模型
|
||||
|
||||
在 JDK1.2 之前,Java的内存模型实现总是从**主存**(即共享内存)读取变量,是不需要进行特别的注意的。而在当前的 Java 内存模型下,线程可以把变量保存**本地内存**(比如机器的寄存器)中,而不是直接在主存中进行读写。这就可能造成一个线程在主存中修改了一个变量的值,而另外一个线程还继续使用它在寄存器中的变量值的拷贝,造成**数据的不一致**。
|
||||
**为什么要弄一个 CPU 高速缓存呢?**
|
||||
|
||||

|
||||
类比我们开发网站后台系统使用的缓存(比如 Redis)是为了解决程序处理速度和访问常规关系型数据库速度不对等的问题。 **CPU 缓存则是为了解决 CPU 处理速度和内存处理速度不对等的问题。**
|
||||
|
||||
要解决这个问题,就需要把变量声明为**volatile**,这就指示 JVM,这个变量是不稳定的,每次使用它都到主存中进行读取。
|
||||
我们甚至可以把 **内存可以看作外存的高速缓存**,程序运行的时候我们把外存的数据复制到内存,由于内存的处理速度远远高于外存,这样提高了处理速度。
|
||||
|
||||
说白了, **volatile** 关键字的主要作用就是保证变量的可见性然后还有一个作用是防止指令重排序。
|
||||
总结:**CPU Cache 缓存的是内存数据用于解决 CPU 处理速度和内存不匹配的问题,内存缓存的是硬盘数据用于解决硬盘访问速度过慢的问题。**
|
||||
|
||||

|
||||
为了更好地理解,我画了一个简单的 CPU Cache 示意图如下(实际上,现代的 CPU Cache 通常分为三层,分别叫 L1,L2,L3 Cache):
|
||||
|
||||
|
||||
|
||||
### 2.2. 说说 synchronized 关键字和 volatile 关键字的区别
|
||||
**CPU Cache 的工作方式:**
|
||||
|
||||
synchronized关键字和volatile关键字比较
|
||||
先复制一份数据到 CPU Cache 中,当 CPU 需要用到的时候就可以直接从 CPU Cache 中读取数据,当运算完成后,再将运算得到的数据写回 Main Memory 中。但是,这样存在 **内存缓存不一致性的问题** !比如我执行一个 i++操作的话,如果两个线程同时执行的话,假设两个线程从 CPU Cache 中读取的 i=1,两个线程做了 1++运算完之后再写回 Main Memory 之后 i=2,而正确结果应该是 i=3。
|
||||
|
||||
- **volatile关键字**是线程同步的**轻量级实现**,所以**volatile性能肯定比synchronized关键字要好**。但是**volatile关键字只能用于变量而synchronized关键字可以修饰方法以及代码块**。synchronized关键字在JavaSE1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的偏向锁和轻量级锁以及其它各种优化之后执行效率有了显著提升,**实际开发中使用 synchronized 关键字的场景还是更多一些**。
|
||||
- **多线程访问volatile关键字不会发生阻塞,而synchronized关键字可能会发生阻塞**
|
||||
- **volatile关键字能保证数据的可见性,但不能保证数据的原子性。synchronized关键字两者都能保证。**
|
||||
- **volatile关键字主要用于解决变量在多个线程之间的可见性,而 synchronized关键字解决的是多个线程之间访问资源的同步性。**
|
||||
**CPU 为了解决内存缓存不一致性问题可以通过制定缓存一致协议或者其他手段来解决。**
|
||||
|
||||
### 2.2. 讲一下 JMM(Java 内存模型)
|
||||
|
||||
在 JDK1.2 之前,Java 的内存模型实现总是从**主存**(即共享内存)读取变量,是不需要进行特别的注意的。而在当前的 Java 内存模型下,线程可以把变量保存**本地内存**(比如机器的寄存器)中,而不是直接在主存中进行读写。这就可能造成一个线程在主存中修改了一个变量的值,而另外一个线程还继续使用它在寄存器中的变量值的拷贝,造成**数据的不一致**。
|
||||
|
||||
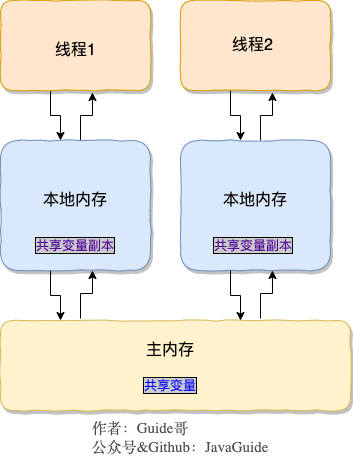
|
||||
|
||||
要解决这个问题,就需要把变量声明为**`volatile`**,这就指示 JVM,这个变量是共享且不稳定的,每次使用它都到主存中进行读取。
|
||||
|
||||
所以,**`volatile` 关键字 除了防止 JVM 的指令重排 ,还有一个重要的作用就是保证变量的可见性。**
|
||||
|
||||
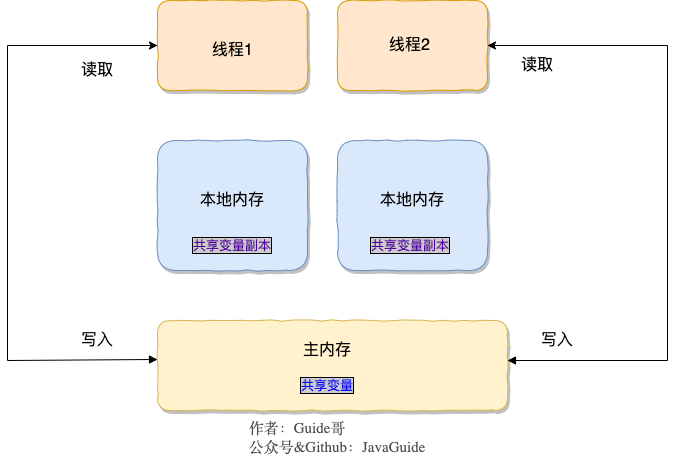
|
||||
|
||||
### 2.3. 并发编程的三个重要特性
|
||||
|
||||
1. **原子性** : 一个的操作或者多次操作,要么所有的操作全部都得到执行并且不会收到任何因素的干扰而中断,要么所有的操作都执行,要么都不执行。`synchronized` 可以保证代码片段的原子性。
|
||||
2. **可见性** :当一个变量对共享变量进行了修改,那么另外的线程都是立即可以看到修改后的最新值。`volatile` 关键字可以保证共享变量的可见性。
|
||||
3. **有序性** :代码在执行的过程中的先后顺序,Java 在编译器以及运行期间的优化,代码的执行顺序未必就是编写代码时候的顺序。`volatile` 关键字可以禁止指令进行重排序优化。
|
||||
|
||||
### 2.4. 说说 synchronized 关键字和 volatile 关键字的区别
|
||||
|
||||
`synchronized` 关键字和 `volatile` 关键字是两个互补的存在,而不是对立的存在!
|
||||
|
||||
- **volatile 关键字**是线程同步的**轻量级实现**,所以**volatile 性能肯定比 synchronized 关键字要好**。但是**volatile 关键字只能用于变量而 synchronized 关键字可以修饰方法以及代码块**。
|
||||
- **volatile 关键字能保证数据的可见性,但不能保证数据的原子性。synchronized 关键字两者都能保证。**
|
||||
- **volatile 关键字主要用于解决变量在多个线程之间的可见性,而 synchronized 关键字解决的是多个线程之间访问资源的同步性。**
|
||||
|
||||
## 3. ThreadLocal
|
||||
|
||||
### 3.1. ThreadLocal简介
|
||||
### 3.1. ThreadLocal 简介
|
||||
|
||||
通常情况下,我们创建的变量是可以被任何一个线程访问并修改的。**如果想实现每一个线程都有自己的专属本地变量该如何解决呢?** JDK中提供的`ThreadLocal`类正是为了解决这样的问题。 **`ThreadLocal`类主要解决的就是让每个线程绑定自己的值,可以将`ThreadLocal`类形象的比喻成存放数据的盒子,盒子中可以存储每个线程的私有数据。**
|
||||
通常情况下,我们创建的变量是可以被任何一个线程访问并修改的。**如果想实现每一个线程都有自己的专属本地变量该如何解决呢?** JDK 中提供的`ThreadLocal`类正是为了解决这样的问题。 **`ThreadLocal`类主要解决的就是让每个线程绑定自己的值,可以将`ThreadLocal`类形象的比喻成存放数据的盒子,盒子中可以存储每个线程的私有数据。**
|
||||
|
||||
**如果你创建了一个`ThreadLocal`变量,那么访问这个变量的每个线程都会有这个变量的本地副本,这也是`ThreadLocal`变量名的由来。他们可以使用 `get()` 和 `set()` 方法来获取默认值或将其值更改为当前线程所存的副本的值,从而避免了线程安全问题。**
|
||||
|
||||
再举个简单的例子:
|
||||
|
||||
比如有两个人去宝屋收集宝物,这两个共用一个袋子的话肯定会产生争执,但是给他们两个人每个人分配一个袋子的话就不会出现这样的问题。如果把这两个人比作线程的话,那么ThreadLocal就是用来避免这两个线程竞争的。
|
||||
比如有两个人去宝屋收集宝物,这两个共用一个袋子的话肯定会产生争执,但是给他们两个人每个人分配一个袋子的话就不会出现这样的问题。如果把这两个人比作线程的话,那么 ThreadLocal 就是用来避免这两个线程竞争的。
|
||||
|
||||
### 3.2. ThreadLocal示例
|
||||
### 3.2. ThreadLocal 示例
|
||||
|
||||
相信看了上面的解释,大家已经搞懂 ThreadLocal 类是个什么东西了。
|
||||
|
||||
@ -273,9 +377,9 @@ Thread Name= 8 formatter = yy-M-d ah:mm
|
||||
Thread Name= 9 formatter = yy-M-d ah:mm
|
||||
```
|
||||
|
||||
从输出中可以看出,Thread-0已经改变了formatter的值,但仍然是thread-2默认格式化程序与初始化值相同,其他线程也一样。
|
||||
从输出中可以看出,Thread-0 已经改变了 formatter 的值,但仍然是 thread-2 默认格式化程序与初始化值相同,其他线程也一样。
|
||||
|
||||
上面有一段代码用到了创建 `ThreadLocal` 变量的那段代码用到了 Java8 的知识,它等于下面这段代码,如果你写了下面这段代码的话,IDEA会提示你转换为Java8的格式(IDEA真的不错!)。因为ThreadLocal类在Java 8中扩展,使用一个新的方法`withInitial()`,将Supplier功能接口作为参数。
|
||||
上面有一段代码用到了创建 `ThreadLocal` 变量的那段代码用到了 Java8 的知识,它等于下面这段代码,如果你写了下面这段代码的话,IDEA 会提示你转换为 Java8 的格式(IDEA 真的不错!)。因为 ThreadLocal 类在 Java 8 中扩展,使用一个新的方法`withInitial()`,将 Supplier 功能接口作为参数。
|
||||
|
||||
```java
|
||||
private static final ThreadLocal<SimpleDateFormat> formatter = new ThreadLocal<SimpleDateFormat>(){
|
||||
@ -287,7 +391,7 @@ Thread Name= 9 formatter = yy-M-d ah:mm
|
||||
};
|
||||
```
|
||||
|
||||
### 3.3. ThreadLocal原理
|
||||
### 3.3. ThreadLocal 原理
|
||||
|
||||
从 `Thread`类源代码入手。
|
||||
|
||||
@ -303,7 +407,7 @@ ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
|
||||
}
|
||||
```
|
||||
|
||||
从上面`Thread`类 源代码可以看出`Thread` 类中有一个 `threadLocals` 和 一个 `inheritableThreadLocals` 变量,它们都是 `ThreadLocalMap` 类型的变量,我们可以把 `ThreadLocalMap` 理解为`ThreadLocal` 类实现的定制化的 `HashMap`。默认情况下这两个变量都是null,只有当前线程调用 `ThreadLocal` 类的 `set`或`get`方法时才创建它们,实际上调用这两个方法的时候,我们调用的是`ThreadLocalMap`类对应的 `get()`、`set() `方法。
|
||||
从上面`Thread`类 源代码可以看出`Thread` 类中有一个 `threadLocals` 和 一个 `inheritableThreadLocals` 变量,它们都是 `ThreadLocalMap` 类型的变量,我们可以把 `ThreadLocalMap` 理解为`ThreadLocal` 类实现的定制化的 `HashMap`。默认情况下这两个变量都是 null,只有当前线程调用 `ThreadLocal` 类的 `set`或`get`方法时才创建它们,实际上调用这两个方法的时候,我们调用的是`ThreadLocalMap`类对应的 `get()`、`set()`方法。
|
||||
|
||||
`ThreadLocal`类的`set()`方法
|
||||
|
||||
@ -323,19 +427,25 @@ ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
|
||||
|
||||
通过上面这些内容,我们足以通过猜测得出结论:**最终的变量是放在了当前线程的 `ThreadLocalMap` 中,并不是存在 `ThreadLocal` 上,`ThreadLocal` 可以理解为只是`ThreadLocalMap`的封装,传递了变量值。** `ThrealLocal` 类中可以通过`Thread.currentThread()`获取到当前线程对象后,直接通过`getMap(Thread t)`可以访问到该线程的`ThreadLocalMap`对象。
|
||||
|
||||
**每个`Thread`中都具备一个`ThreadLocalMap`,而`ThreadLocalMap`可以存储以`ThreadLocal`为key的键值对。** 比如我们在同一个线程中声明了两个 `ThreadLocal` 对象的话,会使用 `Thread`内部都是使用仅有那个`ThreadLocalMap` 存放数据的,`ThreadLocalMap`的 key 就是 `ThreadLocal`对象,value 就是 `ThreadLocal` 对象调用`set`方法设置的值。
|
||||
**每个`Thread`中都具备一个`ThreadLocalMap`,而`ThreadLocalMap`可以存储以`ThreadLocal`为 key ,Object 对象为 value 的键值对。**
|
||||
|
||||
`ThreadLocal` 内部维护的是一个类似 `Map` 的`ThreadLocalMap` 数据结构,`key` 为当前对象的 `Thread` 对象,值为 Object 对象。
|
||||
```java
|
||||
ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) {
|
||||
......
|
||||
}
|
||||
```
|
||||
|
||||

|
||||
比如我们在同一个线程中声明了两个 `ThreadLocal` 对象的话,会使用 `Thread`内部都是使用仅有那个`ThreadLocalMap` 存放数据的,`ThreadLocalMap`的 key 就是 `ThreadLocal`对象,value 就是 `ThreadLocal` 对象调用`set`方法设置的值。
|
||||
|
||||

|
||||
|
||||
`ThreadLocalMap`是`ThreadLocal`的静态内部类。
|
||||
|
||||

|
||||

|
||||
|
||||
### 3.4. ThreadLocal 内存泄露问题
|
||||
|
||||
`ThreadLocalMap` 中使用的 key 为 `ThreadLocal` 的弱引用,而 value 是强引用。所以,如果 `ThreadLocal` 没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。这样一来,`ThreadLocalMap` 中就会出现key为null的Entry。假如我们不做任何措施的话,value 永远无法被GC 回收,这个时候就可能会产生内存泄露。ThreadLocalMap实现中已经考虑了这种情况,在调用 `set()`、`get()`、`remove()` 方法的时候,会清理掉 key 为 null 的记录。使用完 `ThreadLocal`方法后 最好手动调用`remove()`方法
|
||||
`ThreadLocalMap` 中使用的 key 为 `ThreadLocal` 的弱引用,而 value 是强引用。所以,如果 `ThreadLocal` 没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。这样一来,`ThreadLocalMap` 中就会出现 key 为 null 的 Entry。假如我们不做任何措施的话,value 永远无法被 GC 回收,这个时候就可能会产生内存泄露。ThreadLocalMap 实现中已经考虑了这种情况,在调用 `set()`、`get()`、`remove()` 方法的时候,会清理掉 key 为 null 的记录。使用完 `ThreadLocal`方法后 最好手动调用`remove()`方法
|
||||
|
||||
```java
|
||||
static class Entry extends WeakReference<ThreadLocal<?>> {
|
||||
@ -353,7 +463,7 @@ ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
|
||||
|
||||
> 如果一个对象只具有弱引用,那就类似于**可有可无的生活用品**。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它 所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
|
||||
>
|
||||
> 弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。
|
||||
> 弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java 虚拟机就会把这个弱引用加入到与之关联的引用队列中。
|
||||
|
||||
## 4. 线程池
|
||||
|
||||
@ -369,9 +479,9 @@ ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
|
||||
- **提高响应速度**。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
|
||||
- **提高线程的可管理性**。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
|
||||
|
||||
### 4.2. 实现Runnable接口和Callable接口的区别
|
||||
### 4.2. 实现 Runnable 接口和 Callable 接口的区别
|
||||
|
||||
`Runnable`自Java 1.0以来一直存在,但`Callable`仅在Java 1.5中引入,目的就是为了来处理`Runnable`不支持的用例。**`Runnable` 接口**不会返回结果或抛出检查异常,但是**`Callable` 接口**可以。所以,如果任务不需要返回结果或抛出异常推荐使用 **`Runnable` 接口**,这样代码看起来会更加简洁。
|
||||
`Runnable`自 Java 1.0 以来一直存在,但`Callable`仅在 Java 1.5 中引入,目的就是为了来处理`Runnable`不支持的用例。**`Runnable` 接口**不会返回结果或抛出检查异常,但是**`Callable` 接口**可以。所以,如果任务不需要返回结果或抛出异常推荐使用 **`Runnable` 接口**,这样代码看起来会更加简洁。
|
||||
|
||||
工具类 `Executors` 可以实现 `Runnable` 对象和 `Callable` 对象之间的相互转换。(`Executors.callable(Runnable task`)或 `Executors.callable(Runnable task,Object resule)`)。
|
||||
|
||||
@ -401,7 +511,7 @@ public interface Callable<V> {
|
||||
}
|
||||
```
|
||||
|
||||
### 4.3. 执行execute()方法和submit()方法的区别是什么呢?
|
||||
### 4.3. 执行 execute()方法和 submit()方法的区别是什么呢?
|
||||
|
||||
1. **`execute()`方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;**
|
||||
2. **`submit()`方法用于提交需要返回值的任务。线程池会返回一个 `Future` 类型的对象,通过这个 `Future` 对象可以判断任务是否执行成功**,并且可以通过 `Future` 的 `get()`方法来获取返回值,`get()`方法会阻塞当前线程直到任务完成,而使用 `get(long timeout,TimeUnit unit)`方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
|
||||
@ -435,23 +545,23 @@ public interface Callable<V> {
|
||||
|
||||
### 4.4. 如何创建线程池
|
||||
|
||||
《阿里巴巴Java开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
|
||||
《阿里巴巴 Java 开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
|
||||
|
||||
> Executors 返回线程池对象的弊端如下:
|
||||
>
|
||||
> - **FixedThreadPool 和 SingleThreadExecutor** : 允许请求的队列长度为 Integer.MAX_VALUE ,可能堆积大量的请求,从而导致OOM。
|
||||
> - **CachedThreadPool 和 ScheduledThreadPool** : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致OOM。
|
||||
> - **FixedThreadPool 和 SingleThreadExecutor** : 允许请求的队列长度为 Integer.MAX_VALUE ,可能堆积大量的请求,从而导致 OOM。
|
||||
> - **CachedThreadPool 和 ScheduledThreadPool** : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致 OOM。
|
||||
|
||||
**方式一:通过构造方法实现**
|
||||

|
||||
**方式二:通过Executor 框架的工具类Executors来实现**
|
||||
我们可以创建三种类型的ThreadPoolExecutor:
|
||||
**方式二:通过 Executor 框架的工具类 Executors 来实现**
|
||||
我们可以创建三种类型的 ThreadPoolExecutor:
|
||||
|
||||
- **FixedThreadPool** : 该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
|
||||
- **SingleThreadExecutor:** 方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
|
||||
- **CachedThreadPool:** 该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
|
||||
|
||||
对应Executors工具类中的方法如图所示:
|
||||
对应 Executors 工具类中的方法如图所示:
|
||||
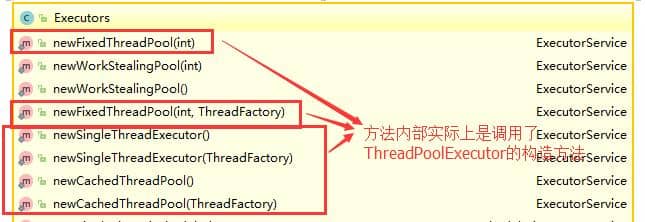
|
||||
|
||||
### 4.5 ThreadPoolExecutor 类分析
|
||||
@ -509,13 +619,13 @@ public interface Callable<V> {
|
||||
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任时,`ThreadPoolTaskExecutor` 定义一些策略:
|
||||
|
||||
- **`ThreadPoolExecutor.AbortPolicy`**:抛出 `RejectedExecutionException`来拒绝新任务的处理。
|
||||
- **`ThreadPoolExecutor.CallerRunsPolicy`**:调用执行自己的线程运行任务。您不会任务请求。但是这种策略会降低对于新任务提交速度,影响程序的整体性能。另外,这个策略喜欢增加队列容量。如果您的应用程序可以承受此延迟并且你不能任务丢弃任何一个任务请求的话,你可以选择这个策略。
|
||||
- **`ThreadPoolExecutor.CallerRunsPolicy`**:调用执行自己的线程运行任务,也就是直接在调用`execute`方法的线程中运行(`run`)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。
|
||||
- **`ThreadPoolExecutor.DiscardPolicy`:** 不处理新任务,直接丢弃掉。
|
||||
- **`ThreadPoolExecutor.DiscardOldestPolicy`:** 此策略将丢弃最早的未处理的任务请求。
|
||||
|
||||
举个例子: Spring 通过 `ThreadPoolTaskExecutor` 或者我们直接通过 `ThreadPoolExecutor` 的构造函数创建线程池的时候,当我们不指定 `RejectedExecutionHandler` 饱和策略的话来配置线程池的时候默认使用的是 `ThreadPoolExecutor.AbortPolicy`。在默认情况下,`ThreadPoolExecutor` 将抛出 `RejectedExecutionException` 来拒绝新来的任务 ,这代表你将丢失对这个任务的处理。 对于可伸缩的应用程序,建议使用 `ThreadPoolExecutor.CallerRunsPolicy`。当最大池被填满时,此策略为我们提供可伸缩队列。(这个直接查看 `ThreadPoolExecutor` 的构造函数源码就可以看出,比较简单的原因,这里就不贴代码了)
|
||||
|
||||
### 4.6 一个简单的线程池Demo:`Runnable`+`ThreadPoolExecutor`
|
||||
### 4.6 一个简单的线程池 Demo
|
||||
|
||||
为了让大家更清楚上面的面试题中的一些概念,我写了一个简单的线程池 Demo。
|
||||
|
||||
@ -702,18 +812,17 @@ pool-1-thread-1 End. Time = Tue Nov 12 20:59:54 CST 2019
|
||||
|
||||
## 5. Atomic 原子类
|
||||
|
||||
### 5.1. 介绍一下Atomic 原子类
|
||||
### 5.1. 介绍一下 Atomic 原子类
|
||||
|
||||
Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是构成一般物质的最小单位,在化学反应中是不可分割的。在我们这里 Atomic 是指一个操作是不可中断的。即使是在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰。
|
||||
|
||||
所以,所谓原子类说简单点就是具有原子/原子操作特征的类。
|
||||
|
||||
|
||||
并发包 `java.util.concurrent` 的原子类都存放在`java.util.concurrent.atomic`下,如下图所示。
|
||||
|
||||
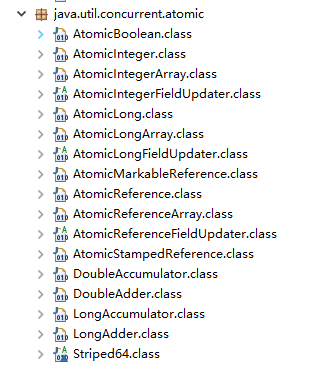
|
||||
|
||||
### 5.2. JUC 包中的原子类是哪4类?
|
||||
### 5.2. JUC 包中的原子类是哪 4 类?
|
||||
|
||||
**基本类型**
|
||||
|
||||
@ -727,7 +836,6 @@ Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是
|
||||
|
||||
使用原子的方式更新数组里的某个元素
|
||||
|
||||
|
||||
- AtomicIntegerArray:整形数组原子类
|
||||
- AtomicLongArray:长整形数组原子类
|
||||
- AtomicReferenceArray:引用类型数组原子类
|
||||
@ -744,10 +852,9 @@ Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是
|
||||
- AtomicLongFieldUpdater:原子更新长整形字段的更新器
|
||||
- AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
|
||||
|
||||
|
||||
### 5.3. 讲讲 AtomicInteger 的使用
|
||||
|
||||
**AtomicInteger 类常用方法**
|
||||
**AtomicInteger 类常用方法**
|
||||
|
||||
```java
|
||||
public final int get() //获取当前的值
|
||||
@ -759,9 +866,10 @@ boolean compareAndSet(int expect, int update) //如果输入的数值等于预
|
||||
public final void lazySet(int newValue)//最终设置为newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
|
||||
```
|
||||
|
||||
**AtomicInteger 类的使用示例**
|
||||
**AtomicInteger 类的使用示例**
|
||||
|
||||
使用 AtomicInteger 之后,不用对 increment() 方法加锁也可以保证线程安全。
|
||||
|
||||
```java
|
||||
class AtomicIntegerTest {
|
||||
private AtomicInteger count = new AtomicInteger();
|
||||
@ -800,7 +908,7 @@ AtomicInteger 类的部分源码:
|
||||
|
||||
AtomicInteger 类主要利用 CAS (compare and swap) + volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
|
||||
|
||||
CAS的原理是拿期望的值和原本的一个值作比较,如果相同则更新成新的值。UnSafe 类的 objectFieldOffset() 方法是一个本地方法,这个方法是用来拿到“原来的值”的内存地址,返回值是 valueOffset。另外 value 是一个volatile变量,在内存中可见,因此 JVM 可以保证任何时刻任何线程总能拿到该变量的最新值。
|
||||
CAS 的原理是拿期望的值和原本的一个值作比较,如果相同则更新成新的值。UnSafe 类的 objectFieldOffset() 方法是一个本地方法,这个方法是用来拿到“原来的值”的内存地址,返回值是 valueOffset。另外 value 是一个 volatile 变量,在内存中可见,因此 JVM 可以保证任何时刻任何线程总能拿到该变量的最新值。
|
||||
|
||||
关于 Atomic 原子类这部分更多内容可以查看我的这篇文章:并发编程面试必备:[JUC 中的 Atomic 原子类总结](https://mp.weixin.qq.com/s/joa-yOiTrYF67bElj8xqvg)
|
||||
|
||||
@ -808,38 +916,37 @@ CAS的原理是拿期望的值和原本的一个值作比较,如果相同则
|
||||
|
||||
### 6.1. AQS 介绍
|
||||
|
||||
AQS的全称为(AbstractQueuedSynchronizer),这个类在java.util.concurrent.locks包下面。
|
||||
AQS 的全称为(AbstractQueuedSynchronizer),这个类在 java.util.concurrent.locks 包下面。
|
||||
|
||||
|
||||
|
||||
AQS是一个用来构建锁和同步器的框架,使用AQS能简单且高效地构造出应用广泛的大量的同步器,比如我们提到的ReentrantLock,Semaphore,其他的诸如ReentrantReadWriteLock,SynchronousQueue,FutureTask等等皆是基于AQS的。当然,我们自己也能利用AQS非常轻松容易地构造出符合我们自己需求的同步器。
|
||||
AQS 是一个用来构建锁和同步器的框架,使用 AQS 能简单且高效地构造出应用广泛的大量的同步器,比如我们提到的 ReentrantLock,Semaphore,其他的诸如 ReentrantReadWriteLock,SynchronousQueue,FutureTask 等等皆是基于 AQS 的。当然,我们自己也能利用 AQS 非常轻松容易地构造出符合我们自己需求的同步器。
|
||||
|
||||
### 6.2. AQS 原理分析
|
||||
|
||||
AQS 原理这部分参考了部分博客,在5.2节末尾放了链接。
|
||||
AQS 原理这部分参考了部分博客,在 5.2 节末尾放了链接。
|
||||
|
||||
> 在面试中被问到并发知识的时候,大多都会被问到“请你说一下自己对于AQS原理的理解”。下面给大家一个示例供大家参加,面试不是背题,大家一定要加入自己的思想,即使加入不了自己的思想也要保证自己能够通俗的讲出来而不是背出来。
|
||||
> 在面试中被问到并发知识的时候,大多都会被问到“请你说一下自己对于 AQS 原理的理解”。下面给大家一个示例供大家参加,面试不是背题,大家一定要加入自己的思想,即使加入不了自己的思想也要保证自己能够通俗的讲出来而不是背出来。
|
||||
|
||||
下面大部分内容其实在AQS类注释上已经给出了,不过是英语看着比较吃力一点,感兴趣的话可以看看源码。
|
||||
下面大部分内容其实在 AQS 类注释上已经给出了,不过是英语看着比较吃力一点,感兴趣的话可以看看源码。
|
||||
|
||||
#### 6.2.1. AQS 原理概览
|
||||
|
||||
**AQS核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。**
|
||||
**AQS 核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制 AQS 是用 CLH 队列锁实现的,即将暂时获取不到锁的线程加入到队列中。**
|
||||
|
||||
> CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS是将每条请求共享资源的线程封装成一个CLH锁队列的一个结点(Node)来实现锁的分配。
|
||||
|
||||
看个AQS(AbstractQueuedSynchronizer)原理图:
|
||||
> CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS 是将每条请求共享资源的线程封装成一个 CLH 锁队列的一个结点(Node)来实现锁的分配。
|
||||
|
||||
看个 AQS(AbstractQueuedSynchronizer)原理图:
|
||||
|
||||
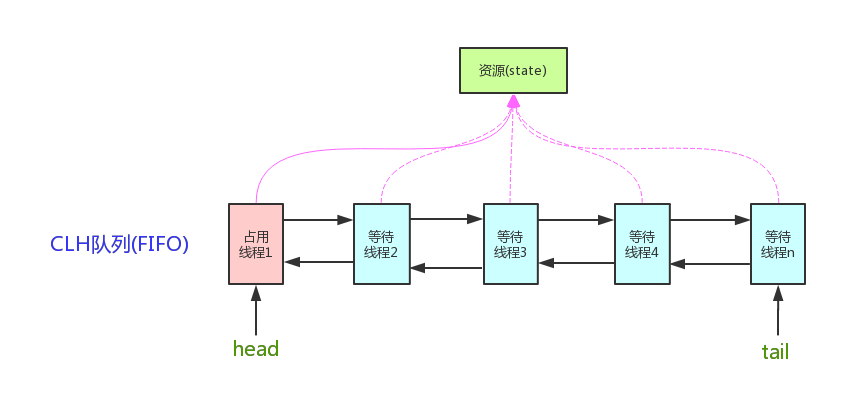
|
||||
|
||||
AQS使用一个int成员变量来表示同步状态,通过内置的FIFO队列来完成获取资源线程的排队工作。AQS使用CAS对该同步状态进行原子操作实现对其值的修改。
|
||||
AQS 使用一个 int 成员变量来表示同步状态,通过内置的 FIFO 队列来完成获取资源线程的排队工作。AQS 使用 CAS 对该同步状态进行原子操作实现对其值的修改。
|
||||
|
||||
```java
|
||||
private volatile int state;//共享变量,使用volatile修饰保证线程可见性
|
||||
```
|
||||
|
||||
状态信息通过protected类型的getState,setState,compareAndSetState进行操作
|
||||
状态信息通过 protected 类型的 getState,setState,compareAndSetState 进行操作
|
||||
|
||||
```java
|
||||
|
||||
@ -859,27 +966,27 @@ protected final boolean compareAndSetState(int expect, int update) {
|
||||
|
||||
#### 6.2.2. AQS 对资源的共享方式
|
||||
|
||||
**AQS定义两种资源共享方式**
|
||||
**AQS 定义两种资源共享方式**
|
||||
|
||||
- **Exclusive**(独占):只有一个线程能执行,如ReentrantLock。又可分为公平锁和非公平锁:
|
||||
- 公平锁:按照线程在队列中的排队顺序,先到者先拿到锁
|
||||
- 非公平锁:当线程要获取锁时,无视队列顺序直接去抢锁,谁抢到就是谁的
|
||||
- **Share**(共享):多个线程可同时执行,如Semaphore/CountDownLatch。Semaphore、CountDownLatch、 CyclicBarrier、ReadWriteLock 我们都会在后面讲到。
|
||||
- **Exclusive**(独占):只有一个线程能执行,如 ReentrantLock。又可分为公平锁和非公平锁:
|
||||
- 公平锁:按照线程在队列中的排队顺序,先到者先拿到锁
|
||||
- 非公平锁:当线程要获取锁时,无视队列顺序直接去抢锁,谁抢到就是谁的
|
||||
- **Share**(共享):多个线程可同时执行,如 Semaphore/CountDownLatch。Semaphore、CountDownLatch、 CyclicBarrier、ReadWriteLock 我们都会在后面讲到。
|
||||
|
||||
ReentrantReadWriteLock 可以看成是组合式,因为ReentrantReadWriteLock也就是读写锁允许多个线程同时对某一资源进行读。
|
||||
ReentrantReadWriteLock 可以看成是组合式,因为 ReentrantReadWriteLock 也就是读写锁允许多个线程同时对某一资源进行读。
|
||||
|
||||
不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS已经在顶层实现好了。
|
||||
不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS 已经在顶层实现好了。
|
||||
|
||||
#### 6.2.3. AQS底层使用了模板方法模式
|
||||
#### 6.2.3. AQS 底层使用了模板方法模式
|
||||
|
||||
同步器的设计是基于模板方法模式的,如果需要自定义同步器一般的方式是这样(模板方法模式很经典的一个应用):
|
||||
|
||||
1. 使用者继承AbstractQueuedSynchronizer并重写指定的方法。(这些重写方法很简单,无非是对于共享资源state的获取和释放)
|
||||
2. 将AQS组合在自定义同步组件的实现中,并调用其模板方法,而这些模板方法会调用使用者重写的方法。
|
||||
1. 使用者继承 AbstractQueuedSynchronizer 并重写指定的方法。(这些重写方法很简单,无非是对于共享资源 state 的获取和释放)
|
||||
2. 将 AQS 组合在自定义同步组件的实现中,并调用其模板方法,而这些模板方法会调用使用者重写的方法。
|
||||
|
||||
这和我们以往通过实现接口的方式有很大区别,这是模板方法模式很经典的一个运用。
|
||||
|
||||
**AQS使用了模板方法模式,自定义同步器时需要重写下面几个AQS提供的模板方法:**
|
||||
**AQS 使用了模板方法模式,自定义同步器时需要重写下面几个 AQS 提供的模板方法:**
|
||||
|
||||
```java
|
||||
isHeldExclusively()//该线程是否正在独占资源。只有用到condition才需要去实现它。
|
||||
@ -890,13 +997,13 @@ tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true
|
||||
|
||||
```
|
||||
|
||||
默认情况下,每个方法都抛出 `UnsupportedOperationException`。 这些方法的实现必须是内部线程安全的,并且通常应该简短而不是阻塞。AQS类中的其他方法都是final ,所以无法被其他类使用,只有这几个方法可以被其他类使用。
|
||||
默认情况下,每个方法都抛出 `UnsupportedOperationException`。 这些方法的实现必须是内部线程安全的,并且通常应该简短而不是阻塞。AQS 类中的其他方法都是 final ,所以无法被其他类使用,只有这几个方法可以被其他类使用。
|
||||
|
||||
以ReentrantLock为例,state初始化为0,表示未锁定状态。A线程lock()时,会调用tryAcquire()独占该锁并将state+1。此后,其他线程再tryAcquire()时就会失败,直到A线程unlock()到state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A线程自己是可以重复获取此锁的(state会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证state是能回到零态的。
|
||||
以 ReentrantLock 为例,state 初始化为 0,表示未锁定状态。A 线程 lock()时,会调用 tryAcquire()独占该锁并将 state+1。此后,其他线程再 tryAcquire()时就会失败,直到 A 线程 unlock()到 state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A 线程自己是可以重复获取此锁的(state 会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证 state 是能回到零态的。
|
||||
|
||||
再以CountDownLatch以例,任务分为N个子线程去执行,state也初始化为N(注意N要与线程个数一致)。这N个子线程是并行执行的,每个子线程执行完后countDown()一次,state会CAS(Compare and Swap)减1。等到所有子线程都执行完后(即state=0),会unpark()主调用线程,然后主调用线程就会从await()函数返回,继续后余动作。
|
||||
再以 CountDownLatch 以例,任务分为 N 个子线程去执行,state 也初始化为 N(注意 N 要与线程个数一致)。这 N 个子线程是并行执行的,每个子线程执行完后 countDown()一次,state 会 CAS(Compare and Swap)减 1。等到所有子线程都执行完后(即 state=0),会 unpark()主调用线程,然后主调用线程就会从 await()函数返回,继续后余动作。
|
||||
|
||||
一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现`tryAcquire-tryRelease`、`tryAcquireShared-tryReleaseShared`中的一种即可。但AQS也支持自定义同步器同时实现独占和共享两种方式,如`ReentrantReadWriteLock`。
|
||||
一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现`tryAcquire-tryRelease`、`tryAcquireShared-tryReleaseShared`中的一种即可。但 AQS 也支持自定义同步器同时实现独占和共享两种方式,如`ReentrantReadWriteLock`。
|
||||
|
||||
推荐两篇 AQS 原理和相关源码分析的文章:
|
||||
|
||||
@ -906,14 +1013,97 @@ tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true
|
||||
### 6.3. AQS 组件总结
|
||||
|
||||
- **Semaphore(信号量)-允许多个线程同时访问:** synchronized 和 ReentrantLock 都是一次只允许一个线程访问某个资源,Semaphore(信号量)可以指定多个线程同时访问某个资源。
|
||||
- **CountDownLatch (倒计时器):** CountDownLatch是一个同步工具类,用来协调多个线程之间的同步。这个工具通常用来控制线程等待,它可以让某一个线程等待直到倒计时结束,再开始执行。
|
||||
- **CyclicBarrier(循环栅栏):** CyclicBarrier 和 CountDownLatch 非常类似,它也可以实现线程间的技术等待,但是它的功能比 CountDownLatch 更加复杂和强大。主要应用场景和 CountDownLatch 类似。CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。CyclicBarrier默认的构造方法是 CyclicBarrier(int parties),其参数表示屏障拦截的线程数量,每个线程调用await()方法告诉 CyclicBarrier 我已经到达了屏障,然后当前线程被阻塞。
|
||||
- **CountDownLatch (倒计时器):** CountDownLatch 是一个同步工具类,用来协调多个线程之间的同步。这个工具通常用来控制线程等待,它可以让某一个线程等待直到倒计时结束,再开始执行。
|
||||
- **CyclicBarrier(循环栅栏):** CyclicBarrier 和 CountDownLatch 非常类似,它也可以实现线程间的技术等待,但是它的功能比 CountDownLatch 更加复杂和强大。主要应用场景和 CountDownLatch 类似。CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。CyclicBarrier 默认的构造方法是 CyclicBarrier(int parties),其参数表示屏障拦截的线程数量,每个线程调用 await()方法告诉 CyclicBarrier 我已经到达了屏障,然后当前线程被阻塞。
|
||||
|
||||
### 6.4. 用过 CountDownLatch 么?什么场景下用的?
|
||||
|
||||
`CountDownLatch` 的作用就是 允许 count 个线程阻塞在一个地方,直至所有线程的任务都执行完毕。之前在项目中,有一个使用多线程读取多个文件处理的场景,我用到了 `CountDownLatch` 。具体场景是下面这样的:
|
||||
|
||||
我们要读取处理 6 个文件,这 6 个任务都是没有执行顺序依赖的任务,但是我们需要返回给用户的时候将这几个文件的处理的结果进行统计整理。
|
||||
|
||||
为此我们定义了一个线程池和 count 为 6 的`CountDownLatch`对象 。使用线程池处理读取任务,每一个线程处理完之后就将 count-1,调用`CountDownLatch`对象的 `await()`方法,直到所有文件读取完之后,才会接着执行后面的逻辑。
|
||||
|
||||
伪代码是下面这样的:
|
||||
|
||||
```java
|
||||
public class CountDownLatchExample1 {
|
||||
// 处理文件的数量
|
||||
private static final int threadCount = 6;
|
||||
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
// 创建一个具有固定线程数量的线程池对象(推荐使用构造方法创建)
|
||||
ExecutorService threadPool = Executors.newFixedThreadPool(10);
|
||||
final CountDownLatch countDownLatch = new CountDownLatch(threadCount);
|
||||
for (int i = 0; i < threadCount; i++) {
|
||||
final int threadnum = i;
|
||||
threadPool.execute(() -> {
|
||||
try {
|
||||
//处理文件的业务操作
|
||||
......
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
} finally {
|
||||
//表示一个文件已经被完成
|
||||
countDownLatch.countDown();
|
||||
}
|
||||
|
||||
});
|
||||
}
|
||||
countDownLatch.await();
|
||||
threadPool.shutdown();
|
||||
System.out.println("finish");
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
**有没有可以改进的地方呢?**
|
||||
|
||||
可以使用 `CompletableFuture` 类来改进!Java8 的 `CompletableFuture` 提供了很多对多线程友好的方法,使用它可以很方便地为我们编写多线程程序,什么异步、串行、并行或者等待所有线程执行完任务什么的都非常方便。
|
||||
|
||||
```java
|
||||
CompletableFuture<Void> task1 =
|
||||
CompletableFuture.supplyAsync(()->{
|
||||
//自定义业务操作
|
||||
});
|
||||
......
|
||||
CompletableFuture<Void> task6 =
|
||||
CompletableFuture.supplyAsync(()->{
|
||||
//自定义业务操作
|
||||
});
|
||||
......
|
||||
CompletableFuture<Void> headerFuture=CompletableFuture.allOf(task1,.....,task6);
|
||||
|
||||
try {
|
||||
headerFuture.join();
|
||||
} catch (Exception ex) {
|
||||
......
|
||||
}
|
||||
System.out.println("all done. ");
|
||||
```
|
||||
|
||||
上面的代码还可以接续优化,当任务过多的时候,把每一个 task 都列出来不太现实,可以考虑通过循环来添加任务。
|
||||
|
||||
```java
|
||||
//文件夹位置
|
||||
List<String> filePaths = Arrays.asList(...)
|
||||
// 异步处理所有文件
|
||||
List<CompletableFuture<String>> fileFutures = filePaths.stream()
|
||||
.map(filePath -> doSomeThing(filePath))
|
||||
.collect(Collectors.toList());
|
||||
// 将他们合并起来
|
||||
CompletableFuture<Void> allFutures = CompletableFuture.allOf(
|
||||
fileFutures.toArray(new CompletableFuture[fileFutures.size()])
|
||||
);
|
||||
|
||||
```
|
||||
|
||||
## 7 Reference
|
||||
|
||||
- 《深入理解 Java 虚拟机》
|
||||
- 《实战 Java 高并发程序设计》
|
||||
- 《Java并发编程的艺术》
|
||||
- 《Java 并发编程的艺术》
|
||||
- http://www.cnblogs.com/waterystone/p/4920797.html
|
||||
- https://www.cnblogs.com/chengxiao/archive/2017/07/24/7141160.html
|
||||
- <https://www.journaldev.com/1076/java-threadlocal-example>
|
||||
@ -922,8 +1112,8 @@ tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true
|
||||
|
||||
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
|
||||
|
||||
**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"面试突击"** 即可免费领取!
|
||||
**《Java 面试突击》:** 由本文档衍生的专为面试而生的《Java 面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"面试突击"** 即可免费领取!
|
||||
|
||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
**Java 工程师必备学习资源:** 一些 Java 工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
|
||||

|
||||
|
||||
@ -1,5 +1,4 @@
|
||||
点击关注[公众号](#公众号 "公众号")及时获取笔主最新更新文章,并可免费领取本文档配套的《Java 面试突击》以及 Java 工程师必备学习资源。
|
||||
|
||||
<!-- TOC -->
|
||||
|
||||
- [Java 并发基础常见面试题总结](#java-并发基础常见面试题总结)
|
||||
- [1. 什么是线程和进程?](#1-什么是线程和进程)
|
||||
@ -22,6 +21,7 @@
|
||||
- [10. 为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?](#10-为什么我们调用-start-方法时会执行-run-方法为什么我们不能直接调用-run-方法)
|
||||
- [公众号](#公众号)
|
||||
|
||||
<!-- /TOC -->
|
||||
|
||||
# Java 并发基础常见面试题总结
|
||||
|
||||
@ -84,7 +84,7 @@ public class MultiThread {
|
||||
|
||||
从上图可以看出:一个进程中可以有多个线程,多个线程共享进程的**堆**和**方法区 (JDK1.8 之后的元空间)**资源,但是每个线程有自己的**程序计数器**、**虚拟机栈** 和 **本地方法栈**。
|
||||
|
||||
**总结:** 线程 是 进程 划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。线程执行开销小,但不利于资源的管理和保护;而进程正相反
|
||||
**总结:** **线程是进程划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。线程执行开销小,但不利于资源的管理和保护;而进程正相反。**
|
||||
|
||||
下面是该知识点的扩展内容!
|
||||
|
||||
@ -110,7 +110,7 @@ public class MultiThread {
|
||||
|
||||
### 2.4. 一句话简单了解堆和方法区
|
||||
|
||||
堆和方法区是所有线程共享的资源,其中堆是进程中最大的一块内存,主要用于存放新创建的对象 (所有对象都在这里分配内存),方法区主要用于存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
|
||||
堆和方法区是所有线程共享的资源,其中堆是进程中最大的一块内存,主要用于存放新创建的对象 (几乎所有对象都在这里分配内存),方法区主要用于存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
|
||||
|
||||
## 3. 说说并发与并行的区别?
|
||||
|
||||
@ -131,7 +131,7 @@ public class MultiThread {
|
||||
|
||||
## 5. 使用多线程可能带来什么问题?
|
||||
|
||||
并发编程的目的就是为了能提高程序的执行效率提高程序运行速度,但是并发编程并不总是能提高程序运行速度的,而且并发编程可能会遇到很多问题,比如:内存泄漏、上下文切换、死锁还有受限于硬件和软件的资源闲置问题。
|
||||
并发编程的目的就是为了能提高程序的执行效率提高程序运行速度,但是并发编程并不总是能提高程序运行速度的,而且并发编程可能会遇到很多问题,比如:内存泄漏、死锁、线程不安全等等。
|
||||
|
||||
## 6. 说说线程的生命周期和状态?
|
||||
|
||||
@ -143,9 +143,11 @@ Java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种
|
||||
|
||||
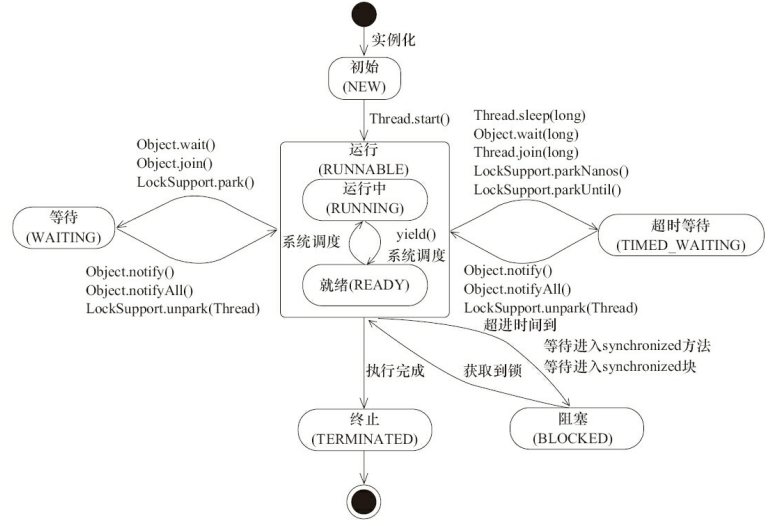
|
||||
|
||||
> 订正(来自[issue736](https://github.com/Snailclimb/JavaGuide/issues/736)):原图中 wait到 runnable状态的转换中,`join`实际上是`Thread`类的方法,但这里写成了`Object`。
|
||||
|
||||
由上图可以看出:线程创建之后它将处于 **NEW(新建)** 状态,调用 `start()` 方法后开始运行,线程这时候处于 **READY(可运行)** 状态。可运行状态的线程获得了 CPU 时间片(timeslice)后就处于 **RUNNING(运行)** 状态。
|
||||
|
||||
> 操作系统隐藏 Java 虚拟机(JVM)中的 RUNNABLE 和 RUNNING 状态,它只能看到 RUNNABLE 状态(图源:[HowToDoInJava](https://howtodoinjava.com/ "HowToDoInJava"):[Java Thread Life Cycle and Thread States](https://howtodoinjava.com/java/multi-threading/java-thread-life-cycle-and-thread-states/ "Java Thread Life Cycle and Thread States")),所以 Java 系统一般将这两个状态统称为 **RUNNABLE(运行中)** 状态 。
|
||||
> 操作系统隐藏 Java 虚拟机(JVM)中的 READY 和 RUNNING 状态,它只能看到 RUNNABLE 状态(图源:[HowToDoInJava](https://howtodoinjava.com/ "HowToDoInJava"):[Java Thread Life Cycle and Thread States](https://howtodoinjava.com/java/multi-threading/java-thread-life-cycle-and-thread-states/ "Java Thread Life Cycle and Thread States")),所以 Java 系统一般将这两个状态统称为 **RUNNABLE(运行中)** 状态 。
|
||||
|
||||

|
||||
|
||||
@ -165,7 +167,7 @@ Linux 相比与其他操作系统(包括其他类 Unix 系统)有很多的
|
||||
|
||||
### 8.1. 认识线程死锁
|
||||
|
||||
多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。
|
||||
线程死锁描述的是这样一种情况:多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。
|
||||
|
||||
如下图所示,线程 A 持有资源 2,线程 B 持有资源 1,他们同时都想申请对方的资源,所以这两个线程就会互相等待而进入死锁状态。
|
||||
|
||||
@ -232,23 +234,12 @@ Thread[线程 2,5,main]waiting get resource1
|
||||
|
||||
### 8.2. 如何避免线程死锁?
|
||||
|
||||
我们只要破坏产生死锁的四个条件中的其中一个就可以了。
|
||||
我上面说了产生死锁的四个必要条件,为了避免死锁,我们只要破坏产生死锁的四个条件中的其中一个就可以了。现在我们来挨个分析一下:
|
||||
|
||||
**破坏互斥条件**
|
||||
|
||||
这个条件我们没有办法破坏,因为我们用锁本来就是想让他们互斥的(临界资源需要互斥访问)。
|
||||
|
||||
**破坏请求与保持条件**
|
||||
|
||||
一次性申请所有的资源。
|
||||
|
||||
**破坏不剥夺条件**
|
||||
|
||||
占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
|
||||
|
||||
**破坏循环等待条件**
|
||||
|
||||
靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
|
||||
1. **破坏互斥条件** :这个条件我们没有办法破坏,因为我们用锁本来就是想让他们互斥的(临界资源需要互斥访问)。
|
||||
2. **破坏请求与保持条件** :一次性申请所有的资源。
|
||||
3. **破坏不剥夺条件** :占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
|
||||
4. **破坏循环等待条件** :靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
|
||||
|
||||
我们对线程 2 的代码修改成下面这样就不会产生死锁了。
|
||||
|
||||
@ -310,3 +301,5 @@ new 一个 Thread,线程进入了新建状态;调用 start() 方法,会启
|
||||
**Java 工程师必备学习资源:** 一些 Java 工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
170
docs/java/Multithread/ThreadLocal(未完成).md
Normal file
@ -0,0 +1,170 @@
|
||||
[ThreadLocal造成OOM内存溢出案例演示与原理分析](https://blog.csdn.net/xlgen157387/article/details/78298840)
|
||||
|
||||
[深入理解 Java 之 ThreadLocal 工作原理](<https://allenwu.itscoder.com/threadlocal-source>)
|
||||
|
||||
## ThreadLocal
|
||||
|
||||
### ThreadLocal简介
|
||||
|
||||
通常情况下,我们创建的变量是可以被任何一个线程访问并修改的。**如果想实现每一个线程都有自己的专属本地变量该如何解决呢?** JDK中提供的`ThreadLocal`类正是为了解决这样的问题。 **`ThreadLocal`类主要解决的就是让每个线程绑定自己的值,可以将`ThreadLocal`类形象的比喻成存放数据的盒子,盒子中可以存储每个线程的私有数据。**
|
||||
|
||||
**如果你创建了一个`ThreadLocal`变量,那么访问这个变量的每个线程都会有这个变量的本地副本,这也是`ThreadLocal`变量名的由来。他们可以使用 `get()` 和 `set()` 方法来获取默认值或将其值更改为当前线程所存的副本的值,从而避免了线程安全问题。**
|
||||
|
||||
再举个简单的例子:
|
||||
|
||||
比如有两个人去宝屋收集宝物,这两个共用一个袋子的话肯定会产生争执,但是给他们两个人每个人分配一个袋子的话就不会出现这样的问题。如果把这两个人比作线程的话,那么ThreadLocal就是用来这两个线程竞争的。
|
||||
|
||||
### ThreadLocal示例
|
||||
|
||||
相信看了上面的解释,大家已经搞懂 ThreadLocal 类是个什么东西了。
|
||||
|
||||
```java
|
||||
import java.text.SimpleDateFormat;
|
||||
import java.util.Random;
|
||||
|
||||
public class ThreadLocalExample implements Runnable{
|
||||
|
||||
// SimpleDateFormat 不是线程安全的,所以每个线程都要有自己独立的副本
|
||||
private static final ThreadLocal<SimpleDateFormat> formatter = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyyMMdd HHmm"));
|
||||
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
ThreadLocalExample obj = new ThreadLocalExample();
|
||||
for(int i=0 ; i<10; i++){
|
||||
Thread t = new Thread(obj, ""+i);
|
||||
Thread.sleep(new Random().nextInt(1000));
|
||||
t.start();
|
||||
}
|
||||
}
|
||||
|
||||
@Override
|
||||
public void run() {
|
||||
System.out.println("Thread Name= "+Thread.currentThread().getName()+" default Formatter = "+formatter.get().toPattern());
|
||||
try {
|
||||
Thread.sleep(new Random().nextInt(1000));
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
//formatter pattern is changed here by thread, but it won't reflect to other threads
|
||||
formatter.set(new SimpleDateFormat());
|
||||
|
||||
System.out.println("Thread Name= "+Thread.currentThread().getName()+" formatter = "+formatter.get().toPattern());
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
Output:
|
||||
|
||||
```
|
||||
Thread Name= 0 default Formatter = yyyyMMdd HHmm
|
||||
Thread Name= 0 formatter = yy-M-d ah:mm
|
||||
Thread Name= 1 default Formatter = yyyyMMdd HHmm
|
||||
Thread Name= 2 default Formatter = yyyyMMdd HHmm
|
||||
Thread Name= 1 formatter = yy-M-d ah:mm
|
||||
Thread Name= 3 default Formatter = yyyyMMdd HHmm
|
||||
Thread Name= 2 formatter = yy-M-d ah:mm
|
||||
Thread Name= 4 default Formatter = yyyyMMdd HHmm
|
||||
Thread Name= 3 formatter = yy-M-d ah:mm
|
||||
Thread Name= 4 formatter = yy-M-d ah:mm
|
||||
Thread Name= 5 default Formatter = yyyyMMdd HHmm
|
||||
Thread Name= 5 formatter = yy-M-d ah:mm
|
||||
Thread Name= 6 default Formatter = yyyyMMdd HHmm
|
||||
Thread Name= 6 formatter = yy-M-d ah:mm
|
||||
Thread Name= 7 default Formatter = yyyyMMdd HHmm
|
||||
Thread Name= 7 formatter = yy-M-d ah:mm
|
||||
Thread Name= 8 default Formatter = yyyyMMdd HHmm
|
||||
Thread Name= 9 default Formatter = yyyyMMdd HHmm
|
||||
Thread Name= 8 formatter = yy-M-d ah:mm
|
||||
Thread Name= 9 formatter = yy-M-d ah:mm
|
||||
```
|
||||
|
||||
从输出中可以看出,Thread-0已经改变了formatter的值,但仍然是thread-2默认格式化程序与初始化值相同,其他线程也一样。
|
||||
|
||||
上面有一段代码用到了创建 `ThreadLocal` 变量的那段代码用到了 Java8 的知识,它等于下面这段代码,如果你写了下面这段代码的话,IDEA会提示你转换为Java8的格式(IDEA真的不错!)。因为ThreadLocal类在Java 8中扩展,使用一个新的方法`withInitial()`,将Supplier功能接口作为参数。
|
||||
|
||||
```java
|
||||
private static final ThreadLocal<SimpleDateFormat> formatter = new ThreadLocal<SimpleDateFormat>(){
|
||||
@Override
|
||||
protected SimpleDateFormat initialValue()
|
||||
{
|
||||
return new SimpleDateFormat("yyyyMMdd HHmm");
|
||||
}
|
||||
};
|
||||
```
|
||||
|
||||
### ThreadLocal原理
|
||||
|
||||
从 `Thread`类源代码入手。
|
||||
|
||||
```java
|
||||
public class Thread implements Runnable {
|
||||
......
|
||||
//与此线程有关的ThreadLocal值。由ThreadLocal类维护
|
||||
ThreadLocal.ThreadLocalMap threadLocals = null;
|
||||
|
||||
//与此线程有关的InheritableThreadLocal值。由InheritableThreadLocal类维护
|
||||
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
|
||||
......
|
||||
}
|
||||
```
|
||||
|
||||
从上面`Thread`类 源代码可以看出`Thread` 类中有一个 `threadLocals` 和 一个 `inheritableThreadLocals` 变量,它们都是 `ThreadLocalMap` 类型的变量,我们可以把 `ThreadLocalMap` 理解为`ThreadLocal` 类实现的定制化的 `HashMap`。默认情况下这两个变量都是null,只有当前线程调用 `ThreadLocal` 类的 `set`或`get`方法时才创建它们,实际上调用这两个方法的时候,我们调用的是`ThreadLocalMap`类对应的 `get()`、`set() `方法。
|
||||
|
||||
`ThreadLocal`类的`set()`方法
|
||||
|
||||
```java
|
||||
public void set(T value) {
|
||||
Thread t = Thread.currentThread();
|
||||
ThreadLocalMap map = getMap(t);
|
||||
if (map != null)
|
||||
map.set(this, value);
|
||||
else
|
||||
createMap(t, value);
|
||||
}
|
||||
ThreadLocalMap getMap(Thread t) {
|
||||
return t.threadLocals;
|
||||
}
|
||||
```
|
||||
|
||||
通过上面这些内容,我们足以通过猜测得出结论:**最终的变量是放在了当前线程的 `ThreadLocalMap` 中,并不是存在 `ThreadLocal` 上,ThreadLocal 可以理解为只是ThreadLocalMap的封装,传递了变量值。**
|
||||
|
||||
**每个Thread中都具备一个ThreadLocalMap,而ThreadLocalMap可以存储以ThreadLocal为key的键值对。** 比如我们在同一个线程中声明了两个 `ThreadLocal` 对象的话,会使用 `Thread`内部都是使用仅有那个`ThreadLocalMap` 存放数据的,`ThreadLocalMap`的 key 就是 `ThreadLocal`对象,value 就是 `ThreadLocal` 对象调用`set`方法设置的值。`ThreadLocal` 是 map结构是为了让每个线程可以关联多个 `ThreadLocal`变量。这也就解释了ThreadLocal声明的变量为什么在每一个线程都有自己的专属本地变量。
|
||||
|
||||
```java
|
||||
public class Thread implements Runnable {
|
||||
......
|
||||
//与此线程有关的ThreadLocal值。由ThreadLocal类维护
|
||||
ThreadLocal.ThreadLocalMap threadLocals = null;
|
||||
|
||||
//与此线程有关的InheritableThreadLocal值。由InheritableThreadLocal类维护
|
||||
ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
|
||||
......
|
||||
}
|
||||
```
|
||||
|
||||
`ThreadLocalMap`是`ThreadLocal`的静态内部类。
|
||||
|
||||
|
||||
|
||||
### ThreadLocal 内存泄露问题
|
||||
|
||||
`ThreadLocalMap` 中使用的 key 为 `ThreadLocal` 的弱引用,而 value 是强引用。所以,如果 `ThreadLocal` 没有被外部强引用的情况下,在垃圾回收的时候会 key 会被清理掉,而 value 不会被清理掉。这样一来,`ThreadLocalMap` 中就会出现key为null的Entry。假如我们不做任何措施的话,value 永远无法被GC 回收,这个时候就可能会产生内存泄露。ThreadLocalMap实现中已经考虑了这种情况,在调用 `set()`、`get()`、`remove()` 方法的时候,会清理掉 key 为 null 的记录。使用完 `ThreadLocal`方法后 最好手动调用`remove()`方法
|
||||
|
||||
```java
|
||||
static class Entry extends WeakReference<ThreadLocal<?>> {
|
||||
/** The value associated with this ThreadLocal. */
|
||||
Object value;
|
||||
|
||||
Entry(ThreadLocal<?> k, Object v) {
|
||||
super(k);
|
||||
value = v;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**弱引用介绍:**
|
||||
|
||||
> 如果一个对象只具有弱引用,那就类似于**可有可无的生活用品**。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它 所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
|
||||
>
|
||||
> 弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。
|
||||
422
docs/java/Multithread/Untitled.md
Normal file
@ -0,0 +1,422 @@
|
||||
## synchronized / Lock
|
||||
|
||||
1. JDK 1.5之前
|
||||
|
||||
,Java通过
|
||||
|
||||
synchronized
|
||||
|
||||
关键字来实现
|
||||
|
||||
锁
|
||||
|
||||
功能
|
||||
|
||||
- synchronized是JVM实现的**内置锁**,锁的获取和释放都是由JVM**隐式**实现的
|
||||
|
||||
2. JDK 1.5
|
||||
|
||||
,并发包中新增了
|
||||
|
||||
Lock接口
|
||||
|
||||
来实现锁功能
|
||||
|
||||
- 提供了与synchronized类似的同步功能,但需要**显式**获取和释放锁
|
||||
|
||||
3. Lock同步锁是基于
|
||||
|
||||
Java
|
||||
|
||||
实现的,而synchronized是基于底层操作系统的
|
||||
|
||||
Mutex Lock
|
||||
|
||||
实现的
|
||||
|
||||
- 每次获取和释放锁都会带来**用户态和内核态的切换**,从而增加系统的**性能开销**
|
||||
- 在锁竞争激烈的情况下,synchronized同步锁的性能很糟糕
|
||||
- 在**JDK 1.5**,在**单线程重复申请锁**的情况下,synchronized锁性能要比Lock的性能**差很多**
|
||||
|
||||
4. **JDK 1.6**,Java对synchronized同步锁做了**充分的优化**,甚至在某些场景下,它的性能已经超越了Lock同步锁
|
||||
|
||||
|
||||
|
||||
## 实现原理
|
||||
|
||||
复制
|
||||
|
||||
```
|
||||
public class SyncTest {
|
||||
public synchronized void method1() {
|
||||
}
|
||||
|
||||
public void method2() {
|
||||
Object o = new Object();
|
||||
synchronized (o) {
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
复制
|
||||
|
||||
```
|
||||
$ javac -encoding UTF-8 SyncTest.java
|
||||
$ javap -v SyncTest
|
||||
```
|
||||
|
||||
### 修饰方法
|
||||
|
||||
复制
|
||||
|
||||
```
|
||||
public synchronized void method1();
|
||||
descriptor: ()V
|
||||
flags: ACC_PUBLIC, ACC_SYNCHRONIZED
|
||||
Code:
|
||||
stack=0, locals=1, args_size=1
|
||||
0: return
|
||||
```
|
||||
|
||||
1. JVM使用**ACC_SYNCHRONIZED**访问标识来区分一个方法是否为**同步方法**
|
||||
|
||||
2. 在方法调用时,会检查方法是否被设置了
|
||||
|
||||
ACC_SYNCHRONIZED
|
||||
|
||||
访问标识
|
||||
|
||||
- 如果是,执行线程会将先尝试**持有Monitor对象**,再执行方法,方法执行完成后,最后**释放Monitor对象**
|
||||
|
||||
### 修饰代码块
|
||||
|
||||
复制
|
||||
|
||||
```
|
||||
public void method2();
|
||||
descriptor: ()V
|
||||
flags: ACC_PUBLIC
|
||||
Code:
|
||||
stack=2, locals=4, args_size=1
|
||||
0: new #2 // class java/lang/Object
|
||||
3: dup
|
||||
4: invokespecial #1 // Method java/lang/Object."<init>":()V
|
||||
7: astore_1
|
||||
8: aload_1
|
||||
9: dup
|
||||
10: astore_2
|
||||
11: monitorenter
|
||||
12: aload_2
|
||||
13: monitorexit
|
||||
14: goto 22
|
||||
17: astore_3
|
||||
18: aload_2
|
||||
19: monitorexit
|
||||
20: aload_3
|
||||
21: athrow
|
||||
22: return
|
||||
```
|
||||
|
||||
1. synchronized修饰同步代码块时,由**monitorenter**和**monitorexit**指令来实现同步
|
||||
2. 进入**monitorenter**指令后,线程将**持有**该**Monitor对象**,进入**monitorexit**指令,线程将**释放**该**Monitor对象**
|
||||
|
||||
### 管程模型
|
||||
|
||||
1. JVM中的**同步**是基于进入和退出**管程**(**Monitor**)对象实现的
|
||||
|
||||
2. **每个Java对象实例都会有一个Monitor**,Monitor可以和Java对象实例一起被创建和销毁
|
||||
|
||||
3. Monitor是由**ObjectMonitor**实现的,对应[ObjectMonitor.hpp](https://github.com/JetBrains/jdk8u_hotspot/blob/master/src/share/vm/runtime/objectMonitor.hpp)
|
||||
|
||||
4. 当多个线程同时访问一段同步代码时,会先被放在**EntryList**中
|
||||
|
||||
5. 当线程获取到Java对象的Monitor时(Monitor是依靠
|
||||
|
||||
底层操作系统
|
||||
|
||||
的
|
||||
|
||||
Mutex Lock
|
||||
|
||||
来实现
|
||||
|
||||
互斥
|
||||
|
||||
的)
|
||||
|
||||
- 线程申请Mutex成功,则持有该Mutex,其它线程将无法获取到该Mutex
|
||||
|
||||
6. 进入
|
||||
|
||||
WaitSet
|
||||
|
||||
- 竞争锁**失败**的线程会进入**WaitSet**
|
||||
- 竞争锁**成功**的线程如果调用**wait**方法,就会**释放当前持有的Mutex**,并且该线程会进入**WaitSet**
|
||||
- 进入**WaitSet**的进程会等待下一次唤醒,然后进入EntryList**重新排队**
|
||||
|
||||
7. 如果当前线程顺利执行完方法,也会释放Mutex
|
||||
|
||||
8. Monitor依赖于**底层操作系统**的实现,存在**用户态**和**内核态之间**的**切换**,所以增加了**性能开销**
|
||||
|
||||
[](https://java-performance-1253868755.cos.ap-guangzhou.myqcloud.com/java-performance-synchronized-monitor.png)
|
||||
|
||||
复制
|
||||
|
||||
```
|
||||
ObjectMonitor() {
|
||||
_header = NULL;
|
||||
_count = 0; // 记录个数
|
||||
_waiters = 0,
|
||||
_recursions = 0;
|
||||
_object = NULL;
|
||||
_owner = NULL; // 持有该Monitor的线程
|
||||
_WaitSet = NULL; // 处于wait状态的线程,会被加入 _WaitSet
|
||||
_WaitSetLock = 0 ;
|
||||
_Responsible = NULL ;
|
||||
_succ = NULL ;
|
||||
_cxq = NULL ;
|
||||
FreeNext = NULL ;
|
||||
_EntryList = NULL ; // 多个线程访问同步块或同步方法,会首先被加入 _EntryList
|
||||
_SpinFreq = 0 ;
|
||||
_SpinClock = 0 ;
|
||||
OwnerIsThread = 0 ;
|
||||
_previous_owner_tid = 0;
|
||||
}
|
||||
```
|
||||
|
||||
## 锁升级优化
|
||||
|
||||
1. 为了提升性能,在**JDK 1.6**引入**偏向锁、轻量级锁、重量级锁**,用来**减少锁竞争带来的上下文切换**
|
||||
2. 借助JDK 1.6新增的**Java对象头**,实现了**锁升级**功能
|
||||
|
||||
### Java对象头
|
||||
|
||||
1. 在**JDK 1.6**的JVM中,对象实例在**堆内存**中被分为三部分:**对象头**、**实例数据**、**对齐填充**
|
||||
2. 对象头的组成部分:**Mark Word**、**指向类的指针**、**数组长度**(可选,数组类型时才有)
|
||||
3. Mark Word记录了**对象**和**锁**有关的信息,在64位的JVM中,Mark Word为**64 bit**
|
||||
4. 锁升级功能主要依赖于Mark Word中**锁标志位**和**是否偏向锁标志位**
|
||||
5. synchronized同步锁的升级优化路径:***偏向锁** -> **轻量级锁** -> **重量级锁***
|
||||
|
||||
[](https://java-performance-1253868755.cos.ap-guangzhou.myqcloud.com/java-performance-synchronized-mark-word.jpg)
|
||||
|
||||
### 偏向锁
|
||||
|
||||
1. 偏向锁主要用来优化**同一线程多次申请同一个锁**的竞争,在某些情况下,大部分时间都是同一个线程竞争锁资源
|
||||
|
||||
2. 偏向锁的作用
|
||||
|
||||
- 当一个线程再次访问同一个同步代码时,该线程只需对该对象头的**Mark Word**中去判断是否有偏向锁指向它
|
||||
- **无需再进入Monitor去竞争对象**(避免用户态和内核态的**切换**)
|
||||
|
||||
3. 当对象被当做同步锁,并有一个线程抢到锁时
|
||||
|
||||
- 锁标志位还是**01**,是否偏向锁标志位设置为**1**,并且记录抢到锁的**线程ID**,进入***偏向锁状态***
|
||||
|
||||
4. 偏向锁
|
||||
|
||||
**不会主动释放锁**
|
||||
|
||||
- 当线程1再次获取锁时,会比较**当前线程的ID**与**锁对象头部的线程ID**是否一致,如果一致,无需CAS来抢占锁
|
||||
|
||||
- 如果不一致,需要查看
|
||||
|
||||
锁对象头部记录的线程
|
||||
|
||||
是否存活
|
||||
|
||||
- 如果**没有存活**,那么锁对象被重置为**无锁**状态(也是一种撤销),然后重新偏向线程2
|
||||
|
||||
- 如果
|
||||
|
||||
存活
|
||||
|
||||
,查找线程1的栈帧信息
|
||||
|
||||
- 如果线程1还是需要继续持有该锁对象,那么暂停线程1(**STW**),**撤销偏向锁**,**升级为轻量级锁**
|
||||
- 如果线程1不再使用该锁对象,那么将该锁对象设为**无锁**状态(也是一种撤销),然后重新偏向线程2
|
||||
|
||||
5. 一旦出现其他线程竞争锁资源时,偏向锁就会被
|
||||
|
||||
撤销
|
||||
|
||||
- 偏向锁的撤销**可能需要**等待**全局安全点**,暂停持有该锁的线程,同时检查该线程**是否还在执行该方法**
|
||||
- 如果还没有执行完,说明此刻有**多个线程**竞争,升级为**轻量级锁**;如果已经执行完毕,唤醒其他线程继续**CAS**抢占
|
||||
|
||||
6. 在
|
||||
|
||||
高并发
|
||||
|
||||
场景下,当
|
||||
|
||||
大量线程
|
||||
|
||||
同时竞争同一个锁资源时,偏向锁会被
|
||||
|
||||
撤销
|
||||
|
||||
,发生
|
||||
|
||||
STW
|
||||
|
||||
,加大了
|
||||
|
||||
性能开销
|
||||
|
||||
- 默认配置
|
||||
|
||||
- `-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=4000`
|
||||
- 默认开启偏向锁,并且**延迟生效**,因为JVM刚启动时竞争非常激烈
|
||||
|
||||
- 关闭偏向锁
|
||||
|
||||
- `-XX:-UseBiasedLocking`
|
||||
|
||||
- 直接
|
||||
|
||||
设置为重量级锁
|
||||
|
||||
- `-XX:+UseHeavyMonitors`
|
||||
|
||||
红线流程部分:偏向锁的**获取**和**撤销**
|
||||
[](https://java-performance-1253868755.cos.ap-guangzhou.myqcloud.com/java-performance-synchronized-lock-upgrade-1.png)
|
||||
|
||||
### 轻量级锁
|
||||
|
||||
1. 当有另外一个线程竞争锁时,由于该锁处于**偏向锁**状态
|
||||
|
||||
2. 发现对象头Mark Word中的线程ID不是自己的线程ID,该线程就会执行
|
||||
|
||||
CAS
|
||||
|
||||
操作获取锁
|
||||
|
||||
- 如果获取**成功**,直接替换Mark Word中的线程ID为自己的线程ID,该锁会***保持偏向锁状态***
|
||||
- 如果获取**失败**,说明当前锁有一定的竞争,将偏向锁**升级**为轻量级锁
|
||||
|
||||
3. 线程获取轻量级锁时会有两步
|
||||
|
||||
- 先把**锁对象的Mark Word**复制一份到线程的**栈帧**中(**DisplacedMarkWord**),主要为了**保留现场**!!
|
||||
- 然后使用**CAS**,把对象头中的内容替换为**线程栈帧中DisplacedMarkWord的地址**
|
||||
|
||||
4. 场景
|
||||
|
||||
- 在线程1复制对象头Mark Word的同时(CAS之前),线程2也准备获取锁,也复制了对象头Mark Word
|
||||
- 在线程2进行CAS时,发现线程1已经把对象头换了,线程2的CAS失败,线程2会尝试使用**自旋锁**来等待线程1释放锁
|
||||
|
||||
5. 轻量级锁的适用场景:线程**交替执行**同步块,***绝大部分的锁在整个同步周期内都不存在长时间的竞争***
|
||||
|
||||
红线流程部分:升级轻量级锁
|
||||
[](https://java-performance-1253868755.cos.ap-guangzhou.myqcloud.com/java-performance-synchronized-lock-upgrade-2.png)
|
||||
|
||||
### 自旋锁 / 重量级锁
|
||||
|
||||
1. 轻量级锁
|
||||
|
||||
CAS
|
||||
|
||||
抢占失败,线程将会被挂起进入
|
||||
|
||||
阻塞
|
||||
|
||||
状态
|
||||
|
||||
- 如果正在持有锁的线程在**很短的时间**内释放锁资源,那么进入**阻塞**状态的线程被**唤醒**后又要**重新抢占**锁资源
|
||||
|
||||
2. JVM提供了**自旋锁**,可以通过**自旋**的方式**不断尝试获取锁**,从而***避免线程被挂起阻塞***
|
||||
|
||||
3. 从
|
||||
|
||||
JDK 1.7
|
||||
|
||||
开始,
|
||||
|
||||
自旋锁默认启用
|
||||
|
||||
,自旋次数
|
||||
|
||||
不建议设置过大
|
||||
|
||||
(意味着
|
||||
|
||||
长时间占用CPU
|
||||
|
||||
)
|
||||
|
||||
- `-XX:+UseSpinning -XX:PreBlockSpin=10`
|
||||
|
||||
4. 自旋锁重试之后如果依然抢锁失败,同步锁会升级至
|
||||
|
||||
重量级锁
|
||||
|
||||
,锁标志位为
|
||||
|
||||
10
|
||||
|
||||
- 在这个状态下,未抢到锁的线程都会**进入Monitor**,之后会被阻塞在**WaitSet**中
|
||||
|
||||
5. 在
|
||||
|
||||
锁竞争不激烈
|
||||
|
||||
且
|
||||
|
||||
锁占用时间非常短
|
||||
|
||||
的场景下,自旋锁可以提高系统性能
|
||||
|
||||
- 一旦锁竞争激烈或者锁占用的时间过长,自旋锁将会导致大量的线程一直处于**CAS重试状态**,**占用CPU资源**
|
||||
|
||||
6. 在
|
||||
|
||||
高并发
|
||||
|
||||
的场景下,可以通过
|
||||
|
||||
关闭自旋锁
|
||||
|
||||
来优化系统性能
|
||||
|
||||
- ```
|
||||
-XX:-UseSpinning
|
||||
```
|
||||
|
||||
- 关闭自旋锁优化
|
||||
|
||||
- ```
|
||||
-XX:PreBlockSpin
|
||||
```
|
||||
|
||||
- 默认的自旋次数,在**JDK 1.7**后,**由JVM控制**
|
||||
|
||||
[](https://java-performance-1253868755.cos.ap-guangzhou.myqcloud.com/java-performance-synchronized-lock-upgrade-3.png)
|
||||
|
||||
## 小结
|
||||
|
||||
1. JVM在**JDK 1.6**中引入了**分级锁**机制来优化synchronized
|
||||
|
||||
2. 当一个线程获取锁时,首先对象锁成为一个
|
||||
|
||||
偏向锁
|
||||
|
||||
- 这是为了避免在**同一线程重复获取同一把锁**时,**用户态和内核态频繁切换**
|
||||
|
||||
3. 如果有多个线程竞争锁资源,锁将会升级为
|
||||
|
||||
轻量级锁
|
||||
|
||||
- 这适用于在**短时间**内持有锁,且分锁**交替切换**的场景
|
||||
- 轻量级锁还结合了**自旋锁**来**避免线程用户态与内核态的频繁切换**
|
||||
|
||||
4. 如果锁竞争太激烈(自旋锁失败),同步锁会升级为重量级锁
|
||||
|
||||
5. 优化synchronized同步锁的关键:
|
||||
|
||||
减少锁竞争
|
||||
|
||||
- 应该尽量使synchronized同步锁处于**轻量级锁**或**偏向锁**,这样才能提高synchronized同步锁的性能
|
||||
- 常用手段
|
||||
- **减少锁粒度**:降低锁竞争
|
||||
- **减少锁的持有时间**,提高synchronized同步锁在自旋时获取锁资源的成功率,**避免升级为重量级锁**
|
||||
|
||||
6. 在**锁竞争激烈**时,可以考虑**禁用偏向锁**和**禁用自旋锁**
|
||||
305
docs/java/Multithread/best-practice-of-threadpool.md
Normal file
@ -0,0 +1,305 @@
|
||||
# 线程池最佳实践
|
||||
|
||||
这篇文章篇幅虽短,但是绝对是干货。标题稍微有点夸张,嘿嘿,实际都是自己使用线程池的时候总结的一些个人感觉比较重要的点。
|
||||
|
||||
## 线程池知识回顾
|
||||
|
||||
开始这篇文章之前还是简单介绍一嘴线程池,之前写的[《新手也能看懂的线程池学习总结》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485808&idx=1&sn=1013253533d73450cef673aee13267ab&chksm=cea246bbf9d5cfad1c21316340a0ef1609a7457fea4113a1f8d69e8c91e7d9cd6285f5ee1490&token=510053261&lang=zh_CN&scene=21#wechat_redirect)这篇文章介绍的很详细了。
|
||||
|
||||
### 为什么要使用线程池?
|
||||
|
||||
> **池化技术相比大家已经屡见不鲜了,线程池、数据库连接池、Http 连接池等等都是对这个思想的应用。池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。**
|
||||
|
||||
**线程池**提供了一种限制和管理资源(包括执行一个任务)。 每个**线程池**还维护一些基本统计信息,例如已完成任务的数量。
|
||||
|
||||
这里借用《Java 并发编程的艺术》提到的来说一下**使用线程池的好处**:
|
||||
|
||||
- **降低资源消耗**。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
|
||||
- **提高响应速度**。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
|
||||
- **提高线程的可管理性**。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
|
||||
|
||||
### 线程池在实际项目的使用场景
|
||||
|
||||
**线程池一般用于执行多个不相关联的耗时任务,没有多线程的情况下,任务顺序执行,使用了线程池的话可让多个不相关联的任务同时执行。**
|
||||
|
||||
假设我们要执行三个不相关的耗时任务,Guide 画图给大家展示了使用线程池前后的区别。
|
||||
|
||||
注意:**下面三个任务可能做的是同一件事情,也可能是不一样的事情。**
|
||||
|
||||

|
||||
|
||||
### 如何使用线程池?
|
||||
|
||||
一般是通过 `ThreadPoolExecutor` 的构造函数来创建线程池,然后提交任务给线程池执行就可以了。
|
||||
|
||||
`ThreadPoolExecutor`构造函数如下:
|
||||
|
||||
```java
|
||||
/**
|
||||
* 用给定的初始参数创建一个新的ThreadPoolExecutor。
|
||||
*/
|
||||
public ThreadPoolExecutor(int corePoolSize,//线程池的核心线程数量
|
||||
int maximumPoolSize,//线程池的最大线程数
|
||||
long keepAliveTime,//当线程数大于核心线程数时,多余的空闲线程存活的最长时间
|
||||
TimeUnit unit,//时间单位
|
||||
BlockingQueue<Runnable> workQueue,//任务队列,用来储存等待执行任务的队列
|
||||
ThreadFactory threadFactory,//线程工厂,用来创建线程,一般默认即可
|
||||
RejectedExecutionHandler handler//拒绝策略,当提交的任务过多而不能及时处理时,我们可以定制策略来处理任务
|
||||
) {
|
||||
if (corePoolSize < 0 ||
|
||||
maximumPoolSize <= 0 ||
|
||||
maximumPoolSize < corePoolSize ||
|
||||
keepAliveTime < 0)
|
||||
throw new IllegalArgumentException();
|
||||
if (workQueue == null || threadFactory == null || handler == null)
|
||||
throw new NullPointerException();
|
||||
this.corePoolSize = corePoolSize;
|
||||
this.maximumPoolSize = maximumPoolSize;
|
||||
this.workQueue = workQueue;
|
||||
this.keepAliveTime = unit.toNanos(keepAliveTime);
|
||||
this.threadFactory = threadFactory;
|
||||
this.handler = handler;
|
||||
}
|
||||
```
|
||||
|
||||
简单演示一下如何使用线程池,更详细的介绍,请看:[《新手也能看懂的线程池学习总结》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485808&idx=1&sn=1013253533d73450cef673aee13267ab&chksm=cea246bbf9d5cfad1c21316340a0ef1609a7457fea4113a1f8d69e8c91e7d9cd6285f5ee1490&token=510053261&lang=zh_CN&scene=21#wechat_redirect) 。
|
||||
|
||||
```java
|
||||
private static final int CORE_POOL_SIZE = 5;
|
||||
private static final int MAX_POOL_SIZE = 10;
|
||||
private static final int QUEUE_CAPACITY = 100;
|
||||
private static final Long KEEP_ALIVE_TIME = 1L;
|
||||
|
||||
public static void main(String[] args) {
|
||||
|
||||
//使用阿里巴巴推荐的创建线程池的方式
|
||||
//通过ThreadPoolExecutor构造函数自定义参数创建
|
||||
ThreadPoolExecutor executor = new ThreadPoolExecutor(
|
||||
CORE_POOL_SIZE,
|
||||
MAX_POOL_SIZE,
|
||||
KEEP_ALIVE_TIME,
|
||||
TimeUnit.SECONDS,
|
||||
new ArrayBlockingQueue<>(QUEUE_CAPACITY),
|
||||
new ThreadPoolExecutor.CallerRunsPolicy());
|
||||
|
||||
for (int i = 0; i < 10; i++) {
|
||||
executor.execute(() -> {
|
||||
try {
|
||||
Thread.sleep(2000);
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.println("CurrentThread name:" + Thread.currentThread().getName() + "date:" + Instant.now());
|
||||
});
|
||||
}
|
||||
//终止线程池
|
||||
executor.shutdown();
|
||||
try {
|
||||
executor.awaitTermination(5, TimeUnit.SECONDS);
|
||||
} catch (InterruptedException e) {
|
||||
e.printStackTrace();
|
||||
}
|
||||
System.out.println("Finished all threads");
|
||||
}
|
||||
```
|
||||
|
||||
控制台输出:
|
||||
|
||||
```java
|
||||
CurrentThread name:pool-1-thread-5date:2020-06-06T11:45:31.639Z
|
||||
CurrentThread name:pool-1-thread-3date:2020-06-06T11:45:31.639Z
|
||||
CurrentThread name:pool-1-thread-1date:2020-06-06T11:45:31.636Z
|
||||
CurrentThread name:pool-1-thread-4date:2020-06-06T11:45:31.639Z
|
||||
CurrentThread name:pool-1-thread-2date:2020-06-06T11:45:31.639Z
|
||||
CurrentThread name:pool-1-thread-2date:2020-06-06T11:45:33.656Z
|
||||
CurrentThread name:pool-1-thread-4date:2020-06-06T11:45:33.656Z
|
||||
CurrentThread name:pool-1-thread-1date:2020-06-06T11:45:33.656Z
|
||||
CurrentThread name:pool-1-thread-3date:2020-06-06T11:45:33.656Z
|
||||
CurrentThread name:pool-1-thread-5date:2020-06-06T11:45:33.656Z
|
||||
Finished all threads
|
||||
```
|
||||
|
||||
## 线程池最佳实践
|
||||
|
||||
简单总结一下我了解的使用线程池的时候应该注意的东西,网上似乎还没有专门写这方面的文章。
|
||||
|
||||
因为Guide还比较菜,有补充和完善的地方,可以在评论区告知或者在微信上与我交流。
|
||||
|
||||
### 1. 使用 `ThreadPoolExecutor ` 的构造函数声明线程池
|
||||
|
||||
**1. 线程池必须手动通过 `ThreadPoolExecutor ` 的构造函数来声明,避免使用`Executors ` 类的 `newFixedThreadPool` 和 `newCachedThreadPool` ,因为可能会有 OOM 的风险。**
|
||||
|
||||
> Executors 返回线程池对象的弊端如下:
|
||||
>
|
||||
> - **`FixedThreadPool` 和 `SingleThreadExecutor`** : 允许请求的队列长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
|
||||
> - **CachedThreadPool 和 ScheduledThreadPool** : 允许创建的线程数量为 `Integer.MAX_VALUE` ,可能会创建大量线程,从而导致 OOM。
|
||||
|
||||
说白了就是:**使用有界队列,控制线程创建数量。**
|
||||
|
||||
除了避免 OOM 的原因之外,不推荐使用 `Executors `提供的两种快捷的线程池的原因还有:
|
||||
|
||||
1. 实际使用中需要根据自己机器的性能、业务场景来手动配置线程池的参数比如核心线程数、使用的任务队列、饱和策略等等。
|
||||
2. 我们应该显示地给我们的线程池命名,这样有助于我们定位问题。
|
||||
|
||||
### 2.监测线程池运行状态
|
||||
|
||||
你可以通过一些手段来检测线程池的运行状态比如 SpringBoot 中的 Actuator 组件。
|
||||
|
||||
除此之外,我们还可以利用 `ThreadPoolExecutor` 的相关 API做一个简陋的监控。从下图可以看出, `ThreadPoolExecutor`提供了获取线程池当前的线程数和活跃线程数、已经执行完成的任务数、正在排队中的任务数等等。
|
||||
|
||||

|
||||
|
||||
下面是一个简单的 Demo。`printThreadPoolStatus()`会每隔一秒打印出线程池的线程数、活跃线程数、完成的任务数、以及队列中的任务数。
|
||||
|
||||
```java
|
||||
/**
|
||||
* 打印线程池的状态
|
||||
*
|
||||
* @param threadPool 线程池对象
|
||||
*/
|
||||
public static void printThreadPoolStatus(ThreadPoolExecutor threadPool) {
|
||||
ScheduledExecutorService scheduledExecutorService = new ScheduledThreadPoolExecutor(1, createThreadFactory("print-images/thread-pool-status", false));
|
||||
scheduledExecutorService.scheduleAtFixedRate(() -> {
|
||||
log.info("=========================");
|
||||
log.info("ThreadPool Size: [{}]", threadPool.getPoolSize());
|
||||
log.info("Active Threads: {}", threadPool.getActiveCount());
|
||||
log.info("Number of Tasks : {}", threadPool.getCompletedTaskCount());
|
||||
log.info("Number of Tasks in Queue: {}", threadPool.getQueue().size());
|
||||
log.info("=========================");
|
||||
}, 0, 1, TimeUnit.SECONDS);
|
||||
}
|
||||
```
|
||||
|
||||
### 3.建议不同类别的业务用不同的线程池
|
||||
|
||||
很多人在实际项目中都会有类似这样的问题:**我的项目中多个业务需要用到线程池,是为每个线程池都定义一个还是说定义一个公共的线程池呢?**
|
||||
|
||||
一般建议是不同的业务使用不同的线程池,配置线程池的时候根据当前业务的情况对当前线程池进行配置,因为不同的业务的并发以及对资源的使用情况都不同,重心优化系统性能瓶颈相关的业务。
|
||||
|
||||
**我们再来看一个真实的事故案例!** (本案例来源自:[《线程池运用不当的一次线上事故》](https://club.perfma.com/article/646639) ,很精彩的一个案例)
|
||||
|
||||

|
||||
|
||||
上面的代码可能会存在死锁的情况,为什么呢?画个图给大家捋一捋。
|
||||
|
||||
试想这样一种极端情况:
|
||||
|
||||
假如我们线程池的核心线程数为 **n**,父任务(扣费任务)数量为 **n**,父任务下面有两个子任务(扣费任务下的子任务),其中一个已经执行完成,另外一个被放在了任务队列中。由于父任务把线程池核心线程资源用完,所以子任务因为无法获取到线程资源无法正常执行,一直被阻塞在队列中。父任务等待子任务执行完成,而子任务等待父任务释放线程池资源,这也就造成了 **"死锁"**。
|
||||
|
||||

|
||||
|
||||
解决方法也很简单,就是新增加一个用于执行子任务的线程池专门为其服务。
|
||||
|
||||
### 4.别忘记给线程池命名
|
||||
|
||||
初始化线程池的时候需要显示命名(设置线程池名称前缀),有利于定位问题。
|
||||
|
||||
默认情况下创建的线程名字类似 pool-1-thread-n 这样的,没有业务含义,不利于我们定位问题。
|
||||
|
||||
给线程池里的线程命名通常有下面两种方式:
|
||||
|
||||
**1.利用 guava 的 `ThreadFactoryBuilder` **
|
||||
|
||||
```java
|
||||
ThreadFactory threadFactory = new ThreadFactoryBuilder()
|
||||
.setNameFormat(threadNamePrefix + "-%d")
|
||||
.setDaemon(true).build();
|
||||
ExecutorService threadPool = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, TimeUnit.MINUTES, workQueue, threadFactory)
|
||||
```
|
||||
|
||||
**2.自己实现 `ThreadFactor`。**
|
||||
|
||||
```java
|
||||
import java.util.concurrent.Executors;
|
||||
import java.util.concurrent.ThreadFactory;
|
||||
import java.util.concurrent.atomic.AtomicInteger;
|
||||
/**
|
||||
* 线程工厂,它设置线程名称,有利于我们定位问题。
|
||||
*/
|
||||
public final class NamingThreadFactory implements ThreadFactory {
|
||||
|
||||
private final AtomicInteger threadNum = new AtomicInteger();
|
||||
private final ThreadFactory delegate;
|
||||
private final String name;
|
||||
|
||||
/**
|
||||
* 创建一个带名字的线程池生产工厂
|
||||
*/
|
||||
public NamingThreadFactory(ThreadFactory delegate, String name) {
|
||||
this.delegate = delegate;
|
||||
this.name = name; // TODO consider uniquifying this
|
||||
}
|
||||
|
||||
@Override
|
||||
public Thread newThread(Runnable r) {
|
||||
Thread t = delegate.newThread(r);
|
||||
t.setName(name + " [#" + threadNum.incrementAndGet() + "]");
|
||||
return t;
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
### 5.正确配置线程池参数
|
||||
|
||||
说到如何给线程池配置参数,美团的骚操作至今让我难忘(后面会提到)!
|
||||
|
||||
我们先来看一下各种书籍和博客上一般推荐的配置线程池参数的方式,可以作为参考!
|
||||
|
||||
#### 常规操作
|
||||
|
||||
很多人甚至可能都会觉得把线程池配置过大一点比较好!我觉得这明显是有问题的。就拿我们生活中非常常见的一例子来说:**并不是人多就能把事情做好,增加了沟通交流成本。你本来一件事情只需要 3 个人做,你硬是拉来了 6 个人,会提升做事效率嘛?我想并不会。** 线程数量过多的影响也是和我们分配多少人做事情一样,对于多线程这个场景来说主要是增加了**上下文切换**成本。不清楚什么是上下文切换的话,可以看我下面的介绍。
|
||||
|
||||
> 上下文切换:
|
||||
>
|
||||
> 多线程编程中一般线程的个数都大于 CPU 核心的个数,而一个 CPU 核心在任意时刻只能被一个线程使用,为了让这些线程都能得到有效执行,CPU 采取的策略是为每个线程分配时间片并轮转的形式。当一个线程的时间片用完的时候就会重新处于就绪状态让给其他线程使用,这个过程就属于一次上下文切换。概括来说就是:当前任务在执行完 CPU 时间片切换到另一个任务之前会先保存自己的状态,以便下次再切换回这个任务时,可以再加载这个任务的状态。**任务从保存到再加载的过程就是一次上下文切换**。
|
||||
>
|
||||
> 上下文切换通常是计算密集型的。也就是说,它需要相当可观的处理器时间,在每秒几十上百次的切换中,每次切换都需要纳秒量级的时间。所以,上下文切换对系统来说意味着消耗大量的 CPU 时间,事实上,可能是操作系统中时间消耗最大的操作。
|
||||
>
|
||||
> Linux 相比与其他操作系统(包括其他类 Unix 系统)有很多的优点,其中有一项就是,其上下文切换和模式切换的时间消耗非常少。
|
||||
|
||||
**类比于实现世界中的人类通过合作做某件事情,我们可以肯定的一点是线程池大小设置过大或者过小都会有问题,合适的才是最好。**
|
||||
|
||||
**如果我们设置的线程池数量太小的话,如果同一时间有大量任务/请求需要处理,可能会导致大量的请求/任务在任务队列中排队等待执行,甚至会出现任务队列满了之后任务/请求无法处理的情况,或者大量任务堆积在任务队列导致 OOM。这样很明显是有问题的! CPU 根本没有得到充分利用。**
|
||||
|
||||
**但是,如果我们设置线程数量太大,大量线程可能会同时在争取 CPU 资源,这样会导致大量的上下文切换,从而增加线程的执行时间,影响了整体执行效率。**
|
||||
|
||||
有一个简单并且适用面比较广的公式:
|
||||
|
||||
- **CPU 密集型任务(N+1):** 这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1,比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
|
||||
- **I/O 密集型任务(2N):** 这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
|
||||
|
||||
**如何判断是 CPU 密集任务还是 IO 密集任务?**
|
||||
|
||||
CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内存中对大量数据进行排序。但凡涉及到网络读取,文件读取这类都是 IO 密集型,这类任务的特点是 CPU 计算耗费时间相比于等待 IO 操作完成的时间来说很少,大部分时间都花在了等待 IO 操作完成上。
|
||||
|
||||
#### 美团的骚操作
|
||||
|
||||
美团技术团队在[《Java线程池实现原理及其在美团业务中的实践》](https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html)这篇文章中介绍到对线程池参数实现可自定义配置的思路和方法。
|
||||
|
||||
美团技术团队的思路是主要对线程池的核心参数实现自定义可配置。这三个核心参数是:
|
||||
|
||||
- **`corePoolSize` :** 核心线程数线程数定义了最小可以同时运行的线程数量。
|
||||
- **`maximumPoolSize` :** 当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。
|
||||
- **`workQueue`:** 当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,信任就会被存放在队列中。
|
||||
|
||||
**为什么是这三个参数?**
|
||||
|
||||
我在这篇[《新手也能看懂的线程池学习总结》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485808&idx=1&sn=1013253533d73450cef673aee13267ab&chksm=cea246bbf9d5cfad1c21316340a0ef1609a7457fea4113a1f8d69e8c91e7d9cd6285f5ee1490&token=510053261&lang=zh_CN&scene=21#wechat_redirect) 中就说过这三个参数是 `ThreadPoolExecutor` 最重要的参数,它们基本决定了线程池对于任务的处理策略。
|
||||
|
||||
**如何支持参数动态配置?** 且看 `ThreadPoolExecutor` 提供的下面这些方法。
|
||||
|
||||

|
||||
|
||||
格外需要注意的是`corePoolSize`, 程序运行期间的时候,我们调用 `setCorePoolSize() `这个方法的话,线程池会首先判断当前工作线程数是否大于`corePoolSize`,如果大于的话就会回收工作线程。
|
||||
|
||||
另外,你也看到了上面并没有动态指定队列长度的方法,美团的方式是自定义了一个叫做 `ResizableCapacityLinkedBlockIngQueue` 的队列(主要就是把`LinkedBlockingQueue`的capacity 字段的final关键字修饰给去掉了,让它变为可变的)。
|
||||
|
||||
最终实现的可动态修改线程池参数效果如下。👏👏👏
|
||||
|
||||

|
||||
|
||||
还没看够?推荐 why神的[《如何设置线程池参数?美团给出了一个让面试官虎躯一震的回答。》](https://mp.weixin.qq.com/s/9HLuPcoWmTqAeFKa1kj-_A)这篇文章,深度剖析,很不错哦!
|
||||
|
||||
|
||||
|
||||
BIN
docs/java/Multithread/images/ThreadLocal内部类.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 69 KiB |
{kind=link}
|
After Width: | Height: | Size: 155 KiB |