本文是鄙人薛某这位老哥的投稿,虽然面试最后挂了,但是老哥本身还是挺优秀的,而且通过这次面试学到了很多东西,我想这就足够了!加油!不要畏惧面试失败,好好修炼自己,多准备一下,后面一定会找到让自己满意的工作。
+>
+
+## 背景
+
+前段时间家里出了点事,辞职回家待了一段时间,处理完老家的事情后就回到广州这边继续找工作,大概是国庆前几天我去面试了一家叫做Bigo(YY的子公司),面试的职位是面向3-5年的Java开发,最终自己倒在了第三轮的技术面上。虽然有些遗憾和泄气,但想着还是写篇博客来记录一下自己的面试过程好了,也算是对广大程序员同胞们的分享,希望对你们以后的学习和面试能有所帮助。
+
+## 个人情况
+
+先说下LZ的个人情况。
+
+17年毕业,二本,目前位于广州,是一个非常普通的Java开发程序员,算起来有两年多的开发经验。
+
+其实这个阶段有点尴尬,高不成低不就,比初级程序员稍微好点,但也达不到高级的程度。加上现如今IT行业接近饱和,很多岗位都是要求至少3-5年以上开发经验,所以对于两年左右开发经验的需求其实是比较小的,这点在LZ找工作的过程中深有体会。最可悲的是,今年的大环境不好,很多公司不断的在裁员,更别说招人了,残酷的形势对于求职者来说更是雪上加霜,相信很多求职的同学也有所体会。所以,不到万不得已的情况下,建议不要裸辞!
+
+## Bigo面试
+
+面试岗位:Java后台开发
+
+经验要求:3-5年
+
+由于是国庆前去面试Bigo的,到现在也有一个多月的时间了,虽然仍有印象,但也有不少面试题忘了,所以我只能尽量按照自己的回忆来描述面试的过程,不明白之处还请见谅!
+
+### 一面(微信电话面)
+
+bigo的第一面是微信电话面试,本来是想直接电话面,但面试官说需要手写算法题,就改成微信电话面。
+
+- 自我介绍
+- 先了解一下Java基础吧,什么是内存泄漏和内存溢出?(溢出是指创建太多对象导致内存空间不足,泄漏是无用对象没有回收)
+- JVM怎么判断对象是无用对象?(根搜索算法,从GC Root出发,对象没有引用,就判定为无用对象)
+- 根搜索算法中的根节点可以是哪些对象?(类对象,虚拟机栈的对象,常量引用的对象)
+- 重载和重写的区别?(重载发生在同个类,方法名相同,参数列表不同;重写是父子类之间的行为,方法名好参数列表都相同,方法体内的程序不同)
+- 重写有什么限制没有?
+- Java有哪些同步工具?(synchronized和Lock)
+- 这两者有什么区别?
+- ArrayList和LinkedList的区别?(ArrayList基于数组,搜索快,增删元素慢,LinkedList基于链表,增删快,搜索因为要遍历元素所以效率低)
+- 这两种集合哪个比较占内存?(看情况的,ArrayList如果有扩容并且元素没占满数组的话,浪费的内存空间也是比较多的,但一般情况下,LinkedList占用的内存会相对多点,因为每个元素都包含了指向前后节点的指针)
+- 说一下HashMap的底层结构(数组 + 链表,链表过长变成红黑树)
+- HashMap为什么线程不安全,1.7版本之前HashMap有什么问题(扩容时多线程操作可能会导致链表成环的出现,然后调用get方法会死循环)
+- 了解ConcurrentHashMap吗?说一下它为什么能线程安全(用了分段锁)
+- 哪些方法需要锁住整个集合的?(读取size的时候)
+- 看你简历写着你了解RPC啊,那你说下RPC的整个过程?(从客户端发起请求,到socket传输,然后服务端处理消息,以及怎么序列化之类的都大概讲了一下)
+- 服务端获取客户端要调用的接口信息后,怎么找到对应的实现类的?(反射 + 注解吧,这里也不是很懂)
+- dubbo的负载均衡有几种算法?(随机,轮询,最少活跃请求数,一致性hash)
+- 你说的最少活跃数算法是怎么回事?(服务提供者有一个计数器,记录当前同时请求个数,值越小说明该服务器负载越小,路由器会优先选择该服务器)
+- 服务端怎么知道客户端要调用的算法的?(socket传递消息过来的时候会把算法策略传递给服务端)
+- 你用过redis做分布式锁是吧,你们是自己写的工具类吗?(不是,我们用redission做分布式锁)
+- 线程拿到key后是怎么保证不死锁的呢?(给这个key加上一个过期时间)
+- 如果这个过期时间到了,但是业务程序还没处理完,该怎么办?(额......可以在业务逻辑上保证幂等性吧)
+- 那如果多个业务都用到分布式锁的话,每个业务都要保证幂等性了,有没有更好的方法?(额......思考了下暂时没有头绪,面试官就说那先跳过吧。事后我了解到redission本身是有个看门狗的监控线程的,如果检测到key被持有的话就会再次重置过期时间)
+- 你那边有纸和笔吧,写一道算法,用两个栈模拟一个队列的入队和出队。(因为之前复习的时候对这道题有印象,写的时候也比较快,大概是用了五分钟,然后就拍成图片发给了面试官,对方看完后表示没问题就结束了面试。)
+
+第一面问的不算难,问题也都是偏基础之类的,虽然答得不算完美,但过程还是比较顺利的。几天之后,Bigo的hr就邀请我去他们公司参加现场面试。
+
+### 二面
+
+到Bigo公司后,一位hr小姐姐招待我到了一个会议室,等了大概半个小时,一位中年男子走了进来,非常的客气,说不好意思让我等那么久了,并且介绍了自己是技术经理,然后就开始了我们的交谈。
+
+- 依照惯例,让我简单做下自我介绍,这个过程他也在边看我的简历。
+- 说下你最熟悉的项目吧。(我就拿我上家公司最近做的一个电商项目开始介绍,从简单的项目描述,到项目的主要功能,以及我主要负责的功能模块,吧啦吧啦..............)
+- 你对这个项目这么熟悉,那你根据你的理解画一下你的项目架构图,还有说下你具体参与了哪部分。(这个题目还是比较麻烦的,毕竟我当时离职的时间也挺长了,对这个项目的架构也是有些模糊。当然,最后还是硬着头皮还是画了个大概,从前端开始访问,然后通过nginx网关层,最后到具体的服务等等,并且把自己参与的服务模块也标示了出来)
+- 你的项目用到了Spring Cloud GateWay,既然你已经有nginx做网关了,为什么还要用gateWay呢?(nginx是做负载均衡,还有针对客户端的访问做网关用的,gateWay是接入业务层做的网关,而且还整合了熔断器Hystrix)
+- 熔断器Hystrix最主要的作用是什么?(防止服务调用失败导致的服务雪崩,能降级)
+- 你的项目用到了redis,你们的redis是怎么部署的?(额。。。。好像是哨兵模式部署的吧。)
+- 说一下你对哨兵模式的理解?(我对哨兵模式了解的不多,就大概说了下Sentinel监控之类的,还有类似ping命令的心跳机制,以及怎么判断一个master是下线之类。。。。。)
+- 那你们为什么要用哨兵模式呢?怎么不用集群的方式部署呢?一开始get不到他的点,就说哨兵本身就是多实例部署的,他解释了一下,说的是redis-cluster的部署方案。(额......redis的环境搭建有专门的运维人员部署的,应该是优先考虑高可用吧..........开始有点心慌了,因为我也不知道为什么)
+- 哦,那你是觉得集群没有办法实现高可用吗?(不....不是啊,只是觉得哨兵模式可能比较保证主从复制安全性吧........我也不知道自己在说什么)
+- 集群也是能保证高可用的,你知道它又是怎么保证主从一致性的吗?(好吧,这里真的不知道了,只能跳过)
+- 你肯定有微信吧,如果让你来设计微信朋友圈的话,你会怎么设计它的属性成员呢?(嗯......需要有用户表,朋友圈的表,好友表之类的吧)
+- 嗯,好,你也知道微信用户有接近10亿之多,那肯定要涉及到分库分表,如果是你的话,怎么设计分库分表呢?(这个问题考察的点比较大,我答的其实一般,而且这个过程面试官还不断的进行连环炮发问,导致这个话题说了有将近20分钟,限于篇幅,这里就不再详述了)
+- 这边差不多了,最后你写一道算法吧,有一组未排序的整形数组,你设计一个算法,对数组的元素两两配对,然后输出最大的绝对值差和最小的绝对值差的"对数"。(听到这道题,我第一想法就是用HashMap来保存,key是两个元素的绝对值差,value是配对的数量,如果有相同的就加1,没有就赋值为1,然后最后对map做排序,输出最大和最小的value值,写完后面试官说结果虽然是正确的,但是不够效率,因为遍历的时间复杂度成了O(n^2),然后提醒了我往排序这方面想。我灵机一动,可以先对数组做排序,然后首元素与第二个元素做绝对值差,记为num,然后首元素循环和后面的元素做计算,直到绝对值差不等于num位置,这样效率比起O(n^2)快多了。)
+
+面试完后,技术官就问我有什么要问他的,我就针对这个岗位的职责和项目所用的技术栈做了询问,然后就让我先等下,等他去通知三面的技术官。说实话,二面给我的感觉是最舒服的,因为面试官很亲切,面试的过程一直积极的引导我,而且在职业规划方面给了我很多的建议,让我受益匪浅,虽然面试时间有一个半小时,但却丝毫不觉得长,整个面试过程聊得挺舒服的,不过因为时间比较久了,很多问题我也记不清了。
+
+### 三面
+
+二面结束后半个小时,三面的技术面试官就开始进来了,从他的额头发量分布情况就能猜想是个大牛,人狠话不多,坐下后也没让我做自我介绍,直接开问,整个过程我答的也不好,而且面试官的问题表述有些不太清晰,经常需要跟他重复确认清楚。
+
+- 对事务了解吗?说一下事务的隔离级别有哪些(我以比较了解的Spring来说,把Spring的四种事务隔离级别都叙述了一遍)
+
+- 你做过电商,那应该知道下单的时候需要减库存对吧,假设现在有两个服务A和B,分别操作订单和库存表,A保存订单后,调用B减库存的时候失败了,这个时候A也要回滚,这个事务要怎么设计?(B服务的减库存方法不抛异常,由调用方也就是A服务来抛异常)
+
+- 了解过读写分离吗?(额。。。大概了解一点,就是写的时候进主库,读的时候读从库)
+
+- 你说读的时候读从库,现在假设有一张表User做了读写分离,然后有个线程在**一个事务范围内**对User表先做了写的处理,然后又做了读的处理,这时候数据还没同步到从库,怎么保证读的时候能读到最新的数据呢?(听完顿时有点懵圈,一时间答不上来,后来面试官说想办法保证一个事务中读写都是同一个库才行)
+
+- 你的项目里用到了rabbitmq,那你说下mq的消费端是怎么处理的?(就是消费端接收到消息之后,会先把消息存到数据库中,然后再从数据库中定时跑消息)
+
+- 也就是说你的mq是先保存到数据库中,然后业务逻辑就是从mq中读取消息然后再处理的是吧?(是的)
+
+- 那你的消息是唯一的吗?(是的,用了唯一约束)
+
+- 你怎么保证消息一定能被消费?或者说怎么保证一定能存到数据库中?(这里开始慌了,因为mq接入那一块我只是看过部分逻辑,但没有亲自参与,凭着自己对mq的了解就答道,应该是靠rabbitmq的ack确认机制)
+
+- 好,那你整理一下你的消费端的整个处理逻辑流程,然后说说你的ack是在哪里返回的(听到这里我的心凉了一截,mq接入这部分我确实没有参与,硬着头皮按照自己的理解画了一下流程,但其实漏洞百出)
+
+- 按照你这样画的话,如果数据库突然宕机,你的消息该怎么确认已经接收?(额.....那发送消息的时候就存放消息可以吧.........回答的时候心里千万只草泥马路过........行了吧,没玩没了了。)
+
+- 那如果发送端的服务是多台部署呢?你保存消息的时候数据库就一直报唯一性的错误?(好吧,你赢了。。。最后硬是憋出了一句,您说的是,这样设计确实不好。。。。)
+
+- 算了,跳过吧,现在你来设计一个map,然后有两个线程对这个map进行操作,主线程高速增加和删除map的元素,然后有个异步线程定时去删除map中主线程5秒内没有删除的数据,你会怎么设计?
+
+ (这道题我答得并不好,做了下简单的思考就说可以把map的key加上时间戳的标志,遍历的时候发现小于当前时间戳5秒前的元素就进行删除,面试官对这样的回答明显不太满意,说这样遍历会影响效率,ps:对这道题,大佬们如果有什么高见可以在评论区说下!)
+
+......还有其他问题,但我只记住了这么多,就这样吧。
+
+面完最后一道题后,面试官就表示这次面试过程结束了,让我回去等消息。听到这里,我知道基本上算是宣告结果了。回想起来,自己这一轮面试确实表现的很一般,加上时间拖得很长,从当天的2点半一直面试到6点多,精神上也尽显疲态。果然,几天之后,hr微信通知了我,说我第三轮技术面试没有通过,这一次面试以失败告终。
+
+## 总结
+
+以上就是面试的大概过程,不得不说,大厂的面试还是非常有技术水平的,这个过程中我学到了很多,这里分享下个人的一些心得:
+
+1、**基础**!**基础**!**基础**!重要的事情说三遍,无论是什么阶段的程序员,基础都是最重要的。每个公司的面试一定会涉及到基础知识的提问,如果你的基础不扎实,往往第一面就可能被淘汰。
+
+2、**简历需要适当的包装**。老实说,我的简历肯定是经过包装的,这也是我的工作年限不够,但却能获取Bigo面试机会的重要原因,所以适当的包装一下简历很有必要,不过切记一点,就是**不能脱离现实**,比如明明只有两年经验,却硬是写到三年。小厂还可能蒙混过关,但大厂基本很难,因为很多公司会在入职前做背景调查。
+
+3、**要对简历上的技术点很熟悉**。简历包装可以,但一定要对简历上的技术点很熟悉,比如只是简单写过rabbitmq的demo的话,就不要写“熟悉”等字眼,因为很多的面试官会针对一个技能点问的很深入,像连环炮一样的深耕你对这个技能点的理解程度。
+
+4、**简历上的项目要非常熟悉**。一般我们写简历都是需要对自己的项目做一定程序的包装和美化,项目写得好能给简历加很多分。但一定要对项目非常的熟悉,不熟悉的模块最好不要写上去。笔者这次就吃了大亏,我的简历上有个电商项目就写到了用rabbitmq处理下单,虽然稍微了解过那部分下单的处理逻辑,但由于没有亲自参与就没有做深入的了解,面试时在这一块内容上被Bigo三面的面试官逼得最后哑口无言。
+
+5、**提升自己的架构思维**。对于初中级程序员来说,日常的工作就是基本的增删改查,把功能实现就完事了,这种思维不能说不好,只是想更上一层楼的话,业务时间需要提升下自己的架构思维能力,比如说如果让你接手一个项目的话,你会怎么考虑设计这个项目,从整体架构,到引入一些组件,再到设计具体的业务服务,这些都是设计一个项目必须要考虑的环节,对于提升我们的架构思维是一种很好的锻炼,这也是很多大厂面试高级程序员时的重要考察部分。
+
+6、**不要裸辞**。这也是我最朴实的建议了,大环境不好,且行且珍惜吧,唉~~~~
+
+总的来说,这次面试Bigo还是收获颇丰的,虽然有点遗憾,但也没什么后悔的,毕竟自己面试之前也是准备的很充分了,有些题目答得不好说明我还有很多技术盲区,不懂就是不懂,再这么吹也吹不出来。这也算是给我提了个醒,你还嫩着呢,好好修炼内功吧,毕竟菜可是原罪啊。
\ No newline at end of file
diff --git a/docs/essential-content-for-interview/BATJrealInterviewExperience/蚂蚁金服实习生面经总结(已拿口头offer).md b/docs/essential-content-for-interview/BATJrealInterviewExperience/蚂蚁金服实习生面经总结(已拿口头offer).md
index 2e2df23b..e0984325 100644
--- a/docs/essential-content-for-interview/BATJrealInterviewExperience/蚂蚁金服实习生面经总结(已拿口头offer).md
+++ b/docs/essential-content-for-interview/BATJrealInterviewExperience/蚂蚁金服实习生面经总结(已拿口头offer).md
@@ -1,4 +1,4 @@
-本文来自 Anonymous 的投稿 ,JavaGuide 对原文进行了重新排版和一点完善。
+本文来自 Anonymous 的投稿 ,Guide哥 对原文进行了重新排版和一点完善。
diff --git a/docs/essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md b/docs/essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md
index d5156937..06d3ffc9 100644
--- a/docs/essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md
+++ b/docs/essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md
@@ -1,81 +1,101 @@
- 身边的朋友或者公众号的粉丝很多人都向我询问过:“我是双非/三本/专科学校的,我有机会进入大厂吗?”、“非计算机专业的学生能学好吗?”、“如何学习Java?”、“Java学习该学哪些东西?”、“我该如何准备Java面试?”......这些方面的问题。我会根据自己的一点经验对大部分人关心的这些问题进行答疑解惑。现在又刚好赶上考研结束,这篇文章也算是给考研结束准备往Java后端方向发展的朋友们指明一条学习之路。道理懂了如果没有实际行动,那这篇文章对你或许没有任何意义。
+身边的朋友或者公众号的粉丝很多人都向我询问过:“我是双非/三本/专科学校的,我有机会进入大厂吗?”、“非计算机专业的学生能学好吗?”、“如何学习 Java?”、“Java 学习该学哪些东西?”、“我该如何准备 Java 面试?”......这些方面的问题。我会根据自己的一点经验对大部分人关心的这些问题进行答疑解惑。现在又刚好赶上考研结束,这篇文章也算是给考研结束准备往 Java 后端方向发展的朋友们指明一条学习之路。道理懂了如果没有实际行动,那这篇文章对你或许没有任何意义。
+
+
+
+- [Question1:我是双非/三本/专科学校的,我有机会进入大厂吗?](#question1我是双非三本专科学校的我有机会进入大厂吗)
+- [Question2:非计算机专业的学生能学好 Java 后台吗?我能进大厂吗?](#question2非计算机专业的学生能学好-java-后台吗我能进大厂吗)
+- [Question3: 我没有实习经历的话找工作是不是特别艰难?](#question3-我没有实习经历的话找工作是不是特别艰难)
+- [Question4: 我该如何准备面试呢?面试的注意事项有哪些呢?](#question4-我该如何准备面试呢面试的注意事项有哪些呢)
+- [Question5: 我该自学还是报培训班呢?](#question5-我该自学还是报培训班呢)
+- [Question6: 没有项目经历/博客/Github 开源项目怎么办?](#question6-没有项目经历博客github-开源项目怎么办)
+- [Question7: 大厂青睐什么样的人?](#question7-大厂青睐什么样的人)
+
+
### Question1:我是双非/三本/专科学校的,我有机会进入大厂吗?
- 我自己也是非985非211学校的,结合自己的经历以及一些朋友的经历,我觉得让我回答这个问题再好不过。
+我自己也是非 985 非 211 学校的,结合自己的经历以及一些朋友的经历,我觉得让我回答这个问题再好不过。
- 首先,我觉得学校歧视很正常,真的太正常了,如果要抱怨的话,你只能抱怨自己没有进入名校。但是,千万不要动不动说自己学校差,动不动拿自己学校当做自己进不了大厂的借口,学历只是筛选简历的很多标准中的一个而已,如果你够优秀,简历够丰富,你也一样可以和名校同学一起同台竞争。
+首先,我觉得学校歧视很正常,真的太正常了,如果要抱怨的话,你只能抱怨自己没有进入名校。但是,千万不要动不动说自己学校差,动不动拿自己学校当做自己进不了大厂的借口,学历只是筛选简历的很多标准中的一个而已,如果你够优秀,简历够丰富,你也一样可以和名校同学一起同台竞争。
- 企业HR肯定是更喜欢高学历的人,毕竟985、211优秀人才比例肯定比普通学校高很多,HR团队肯定会优先在这些学校里选。这就好比相亲,你是愿意在很多优秀的人中选一个优秀的,还是愿意在很多普通的人中选一个优秀的呢?
-
- 双非本科甚至是二本、三本甚至是专科的同学也有很多进入大厂的,不过比率相比于名校的低很多而已。从大厂招聘的结果上看,高学历人才的数量占据大头,那些成功进入BAT、美团,京东,网易等大厂的双非本科甚至是二本、三本甚至是专科的同学往往是因为具备丰富的项目经历或者在某个含金量比较高的竞赛比如ACM中取得了不错的成绩。**一部分学历不突出但能力出众的面试者能够进入大厂并不是说明学历不重要,而是学历的软肋能够通过其他的优势来弥补。** 所以,如果你的学校不够好而你自己又想去大厂的话,建议你可以从这几点来做:**①尽量在面试前最好有一个可以拿的出手的项目;②有实习条件的话,尽早出去实习,实习经历也会是你的简历的一个亮点(有能力在大厂实习最佳!);③参加一些含金量比较高的比赛,拿不拿得到名次没关系,重在锻炼。**
+企业 HR 肯定是更喜欢高学历的人,毕竟 985、211 优秀人才比例肯定比普通学校高很多,HR 团队肯定会优先在这些学校里选。这就好比相亲,你是愿意在很多优秀的人中选一个优秀的,还是愿意在很多普通的人中选一个优秀的呢?
+双非本科甚至是二本、三本甚至是专科的同学也有很多进入大厂的,不过比率相比于名校的低很多而已。从大厂招聘的结果上看,高学历人才的数量占据大头,那些成功进入 BAT、美团,京东,网易等大厂的双非本科甚至是二本、三本甚至是专科的同学往往是因为具备丰富的项目经历或者在某个含金量比较高的竞赛比如 ACM 中取得了不错的成绩。**一部分学历不突出但能力出众的面试者能够进入大厂并不是说明学历不重要,而是学历的软肋能够通过其他的优势来弥补。** 所以,如果你的学校不够好而你自己又想去大厂的话,建议你可以从这几点来做:**① 尽量在面试前最好有一个可以拿的出手的项目;② 有实习条件的话,尽早出去实习,实习经历也会是你的简历的一个亮点(有能力在大厂实习最佳!);③ 参加一些含金量比较高的比赛,拿不拿得到名次没关系,重在锻炼。**
-### Question2:非计算机专业的学生能学好Java后台吗?我能进大厂吗?
+### Question2:非计算机专业的学生能学好 Java 后台吗?我能进大厂吗?
- 当然可以!现在非科班的程序员很多,很大一部分原因是互联网行业的工资比较高。我们学校外面的培训班里面90%都是非科班,我觉得他们很多人学的都还不错。另外,我的一个朋友本科是机械专业,大一开始自学安卓,技术贼溜,在我看来他比大部分本科是计算机的同学学的还要好。参考Question1的回答,即使你是非科班程序员,如果你想进入大厂的话,你也可以通过自己的其他优势来弥补。
-
- 我觉得我们不应该因为自己的专业给自己划界限或者贴标签,说实话,很多科班的同学可能并不如你,你以为科班的同学就会认真听讲吗?还不是几乎全靠自己课下自学!不过如果你是非科班的话,你想要学好,那么注定就要舍弃自己本专业的一些学习时间,这是无可厚非的。
-
- 建议非科班的同学,首先要打好计算机基础知识基础:①计算机网络、②操作系统、③数据机构与算法,我个人觉得这3个对你最重要。这些东西就像是内功,对你以后的长远发展非常有用。当然,如果你想要进大厂的话,这些知识也是一定会被问到的。另外,“一定学好数据结构与算法!一定学好数据结构与算法!一定学好数据结构与算法!”,重要的东西说3遍。
+当然可以!现在非科班的程序员很多,很大一部分原因是互联网行业的工资比较高。我们学校外面的培训班里面 90%都是非科班,我觉得他们很多人学的都还不错。另外,我的一个朋友本科是机械专业,大一开始自学安卓,技术贼溜,在我看来他比大部分本科是计算机的同学学的还要好。参考 Question1 的回答,即使你是非科班程序员,如果你想进入大厂的话,你也可以通过自己的其他优势来弥补。
+我觉得我们不应该因为自己的专业给自己划界限或者贴标签,说实话,很多科班的同学可能并不如你,你以为科班的同学就会认真听讲吗?还不是几乎全靠自己课下自学!不过如果你是非科班的话,你想要学好,那么注定就要舍弃自己本专业的一些学习时间,这是无可厚非的。
+建议非科班的同学,首先要打好计算机基础知识基础:① 计算机网络、② 操作系统、③ 数据机构与算法,我个人觉得这 3 个对你最重要。这些东西就像是内功,对你以后的长远发展非常有用。当然,如果你想要进大厂的话,这些知识也是一定会被问到的。另外,“一定学好数据结构与算法!一定学好数据结构与算法!一定学好数据结构与算法!”,重要的东西说 3 遍。
### Question3: 我没有实习经历的话找工作是不是特别艰难?
- 没有实习经历没关系,只要你有拿得出手的项目或者大赛经历的话,你依然有可能拿到大厂的 offer 。笔主当时找工作的时候就没有实习经历以及大赛获奖经历,单纯就是凭借自己的项目经验撑起了整个面试。
+没有实习经历没关系,只要你有拿得出手的项目或者大赛经历的话,你依然有可能拿到大厂的 offer 。笔主当时找工作的时候就没有实习经历以及大赛获奖经历,单纯就是凭借自己的项目经验撑起了整个面试。
- 如果你既没有实习经历,又没有拿得出手的项目或者大赛经历的话,我觉得在简历关,除非你有其他特别的亮点,不然,你应该就会被刷。
+如果你既没有实习经历,又没有拿得出手的项目或者大赛经历的话,我觉得在简历关,除非你有其他特别的亮点,不然,你应该就会被刷。
### Question4: 我该如何准备面试呢?面试的注意事项有哪些呢?
-下面是我总结的一些准备面试的Tips以及面试必备的注意事项:
+下面是我总结的一些准备面试的 Tips 以及面试必备的注意事项:
1. **准备一份自己的自我介绍,面试的时候根据面试对象适当进行修改**(突出重点,突出自己的优势在哪里,切忌流水账);
2. **注意随身带上自己的成绩单和简历复印件;** (有的公司在面试前都会让你交一份成绩单和简历当做面试中的参考。)
-3. **如果需要笔试就提前刷一些笔试题,大部分在线笔试的类型是选择题+编程题,有的还会有简答题。**(平时空闲时间多的可以刷一下笔试题目(牛客网上有很多),但是不要只刷面试题,不动手code,程序员不是为了考试而存在的。)另外,注意抓重点,因为题目太多了,但是有很多题目几乎次次遇到,像这样的题目一定要搞定。
+3. **如果需要笔试就提前刷一些笔试题,大部分在线笔试的类型是选择题+编程题,有的还会有简答题。**(平时空闲时间多的可以刷一下笔试题目(牛客网上有很多),但是不要只刷面试题,不动手 code,程序员不是为了考试而存在的。)另外,注意抓重点,因为题目太多了,但是有很多题目几乎次次遇到,像这样的题目一定要搞定。
4. **提前准备技术面试。** 搞清楚自己面试中可能涉及哪些知识点、哪些知识点是重点。面试中哪些问题会被经常问到、自己该如何回答。(强烈不推荐背题,第一:通过背这种方式你能记住多少?能记住多久?第二:背题的方式的学习很难坚持下去!)
5. **面试之前做好定向复习。** 也就是专门针对你要面试的公司来复习。比如你在面试之前可以在网上找找有没有你要面试的公司的面经。
-6. **准备好自己的项目介绍。** 如果有项目的话,技术面试第一步,面试官一般都是让你自己介绍一下你的项目。你可以从下面几个方向来考虑:①对项目整体设计的一个感受(面试官可能会让你画系统的架构图);②在这个项目中你负责了什么、做了什么、担任了什么角色;③ 从这个项目中你学会了那些东西,使用到了那些技术,学会了那些新技术的使用;④项目描述中,最好可以体现自己的综合素质,比如你是如何协调项目组成员协同开发的或者在遇到某一个棘手的问题的时候你是如何解决的又或者说你在这个项目用了什么技术实现了什么功能比如:用 redis 做缓存提高访问速度和并发量、使用消息队列削峰和降流等等。
+6. **准备好自己的项目介绍。** 如果有项目的话,技术面试第一步,面试官一般都是让你自己介绍一下你的项目。你可以从下面几个方向来考虑:① 对项目整体设计的一个感受(面试官可能会让你画系统的架构图);② 在这个项目中你负责了什么、做了什么、担任了什么角色;③ 从这个项目中你学会了那些东西,使用到了那些技术,学会了那些新技术的使用;④ 项目描述中,最好可以体现自己的综合素质,比如你是如何协调项目组成员协同开发的或者在遇到某一个棘手的问题的时候你是如何解决的又或者说你在这个项目用了什么技术实现了什么功能比如:用 redis 做缓存提高访问速度和并发量、使用消息队列削峰和降流等等。
7. **面试之后记得复盘。** 面试遭遇失败是很正常的事情,所以善于总结自己的失败原因才是最重要的。如果失败,不要灰心;如果通过,切勿狂喜。
-
-**一些还算不错的 Java面试/学习相关的仓库,相信对大家准备面试一定有帮助:**[盘点一下Github上开源的Java面试/学习相关的仓库,看完弄懂薪资至少增加10k](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484817&idx=1&sn=12f0c254a240c40c2ccab8314653216b&chksm=fd9853f0caefdae6d191e6bf085d44ab9c73f165e3323aa0362d830e420ccbfad93aa5901021&token=766994974&lang=zh_CN#rd)
+**一些还算不错的 Java 面试/学习相关的仓库,相信对大家准备面试一定有帮助:**[盘点一下 Github 上开源的 Java 面试/学习相关的仓库,看完弄懂薪资至少增加 10k](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484817&idx=1&sn=12f0c254a240c40c2ccab8314653216b&chksm=fd9853f0caefdae6d191e6bf085d44ab9c73f165e3323aa0362d830e420ccbfad93aa5901021&token=766994974&lang=zh_CN#rd)
### Question5: 我该自学还是报培训班呢?
- 我本人更加赞同自学(你要知道去了公司可没人手把手教你了,而且几乎所有的公司都对培训班出生的有偏见。为什么有偏见,你学个东西还要去培训班,说明什么,同等水平下,你的自学能力以及自律能力一定是比不上自学的人的)。但是如果,你连每天在寝室坚持学上8个小时以上都坚持不了,或者总是容易半途而废的话,我还是推荐你去培训班。观望身边同学去培训班的,大多是非计算机专业或者是没有自律能力以及自学能力非常差的人。
+我本人更加赞同自学(你要知道去了公司可没人手把手教你了,而且几乎所有的公司都对培训班出生的有偏见。为什么有偏见,你学个东西还要去培训班,说明什么,同等水平下,你的自学能力以及自律能力一定是比不上自学的人的)。但是如果,你连每天在寝室坚持学上 8 个小时以上都坚持不了,或者总是容易半途而废的话,我还是推荐你去培训班。观望身边同学去培训班的,大多是非计算机专业或者是没有自律能力以及自学能力非常差的人。
- 另外,如果自律能力不行,你也可以通过结伴学习、参加老师的项目等方式来督促自己学习。
+另外,如果自律能力不行,你也可以通过结伴学习、参加老师的项目等方式来督促自己学习。
- 总结:去不去培训班主要还是看自己,如果自己能坚持自学就自学,坚持不下来就去培训班。
+总结:去不去培训班主要还是看自己,如果自己能坚持自学就自学,坚持不下来就去培训班。
-### Question6: 没有项目经历/博客/Github开源项目怎么办?
+### Question6: 没有项目经历/博客/Github 开源项目怎么办?
- 从现在开始做!
+从现在开始做!
- 网上有很多非常不错的项目视频,你就跟着一步一步做,不光要做,还要改进,改善。另外,如果你的老师有相关 Java 后台项目的话,你也可以主动申请参与进来。
+网上有很多非常不错的项目视频,你就跟着一步一步做,不光要做,还要改进,改善。另外,如果你的老师有相关 Java 后台项目的话,你也可以主动申请参与进来。
- 如果有自己的博客,也算是简历上的一个亮点。建议可以在掘金、Segmentfault、CSDN等技术交流社区写博客,当然,你也可以自己搭建一个博客(采用 Hexo+Githu Pages 搭建非常简单)。写一些什么?学习笔记、实战内容、读书笔记等等都可以。
+如果有自己的博客,也算是简历上的一个亮点。建议可以在掘金、Segmentfault、CSDN 等技术交流社区写博客,当然,你也可以自己搭建一个博客(采用 Hexo+Githu Pages 搭建非常简单)。写一些什么?学习笔记、实战内容、读书笔记等等都可以。
- 多用 Github,用好 Github,上传自己不错的项目,写好 readme 文档,在其他技术社区做好宣传。相信你也会收获一个不错的开源项目!
+多用 Github,用好 Github,上传自己不错的项目,写好 readme 文档,在其他技术社区做好宣传。相信你也会收获一个不错的开源项目!
+### Question7: 大厂青睐什么样的人?
-### Question7: 大厂到底青睐什么样的应届生?
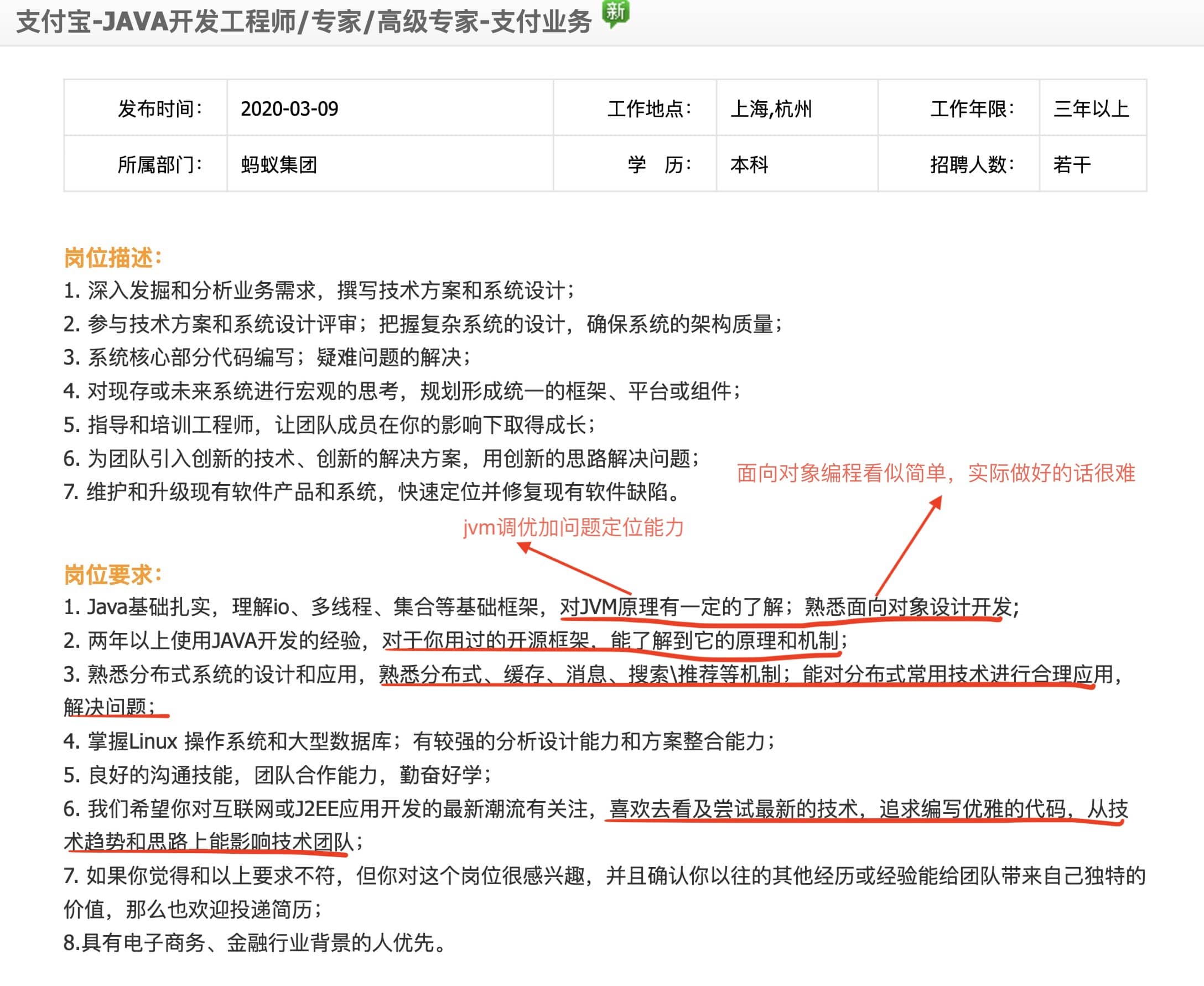
+**先从已经有两年左右开发经验的工程师角度来看:** 我们来看一下阿里官网支付宝 Java 高级开发工程师的招聘要求,从下面的招聘信息可以看出,除去 Java 基础/集合/多线程这些,这些能力格外重要:
- 从阿里、腾讯等大厂招聘官网对于Java后端方向/后端方向的应届实习生的要求,我们大概可以总结归纳出下面这 4 点能给简历增加很多分数:
+1. **底层知识比如 jvm** :不只是懂理论更会实操;
+2. 面**向对象编程能力** :我理解这个不仅包括“面向对象编程”,还有 SOLID 软件设计原则,相关阅读:[《写了这么多年代码,你真的了解 SOLID 吗?》](https://insights.thoughtworks.cn/do-you-really-know-solid/)(我司大佬的一篇文章)
+3. **框架能力** :不只是使用那么简单,更要搞懂原理和机制!搞懂原理和机制的基础是要学会看源码。
+4. **分布式系统开发能力** :缓存、消息队列等等都要掌握,关键是还要能使用这些技术解决实际问题而不是纸上谈兵。
+5. **不错的 sense** :喜欢和尝试新技术、追求编写优雅的代码等等。
-- 参加过竞赛(含金量超高的是ACM);
-- 对数据结构与算法非常熟练;
-- 参与过实际项目(比如学校网站);
-- 参与过某个知名的开源项目或者自己的某个开源项目很不错;
+
- 除了我上面说的这三点,在面试Java工程师的时候,下面几点也提升你的个人竞争力:
+**再从应届生的角度来看:** 我们还是看阿里巴巴的官网相关应届生 Java 工程师招聘岗位的相关要求。
-- 熟悉Python、Shell、Perl等脚本语言;
-- 熟悉 Java 优化,JVM调优;
-- 熟悉 SOA 模式;
-- 熟悉自己所用框架的底层知识比如Spring;
-- 了解分布式一些常见的理论;
-- 具备高并发开发经验;大数据开发经验等等。
+
+结合阿里、腾讯等大厂招聘官网对于 Java 后端方向/后端方向的应届实习生的要求下面几点也提升你的个人竞争力:
+
+1. 参加过竞赛( 含金量超高的是 ACM );
+2. 对数据结构与算法非常熟练;
+3. 参与过实际项目(比如学校网站)
+4. 熟悉 Python、Shell、Perl 其中一门脚本语言;
+5. 熟悉如何优化 Java 代码、有写出质量更高的代码的意识;
+6. 熟悉 SOA 分布式相关的知识尤其是理论知识;
+7. 熟悉自己所用框架的底层知识比如 Spring;
+8. 有高并发开发经验;
+9. 有大数据开发经验等等。
+
+从来到大学之后,我的好多阅历非常深的老师经常就会告诫我们:“ 一定要有一门自己的特长,不管是技术还好还是其他能力 ” 。我觉得这句话真的非常有道理!
+
+刚刚也提到了要有一门特长,所以在这里再强调一点:公司不需要你什么都会,但是在某一方面你一定要有过于常人的优点。换言之就是我们不需要去掌握每一门技术(你也没精力去掌握这么多技术),而是需要去深入研究某一门技术,对于其他技术我们可以简单了解一下。
diff --git a/docs/essential-content-for-interview/PreparingForInterview/interviewPrepare.md b/docs/essential-content-for-interview/PreparingForInterview/interviewPrepare.md
index 1ae36a35..5a091e1c 100644
--- a/docs/essential-content-for-interview/PreparingForInterview/interviewPrepare.md
+++ b/docs/essential-content-for-interview/PreparingForInterview/interviewPrepare.md
@@ -1,11 +1,20 @@
-不论是校招还是社招都避免不了各种面试、笔试,如何去准备这些东西就显得格外重要。不论是笔试还是面试都是有章可循的,我这个“有章可循”说的意思只是说应对技术面试是可以提前准备。 我其实特别不喜欢那种临近考试就提前背啊记啊各种题的行为,非常反对!我觉得这种方法特别极端,而且在稍有一点经验的面试官面前是根本没有用的。建议大家还是一步一个脚印踏踏实实地走。
+不论是笔试还是面试都是有章可循的,但是,一定要不要想着如何去应付面试,糊弄面试官,这样做终究是欺骗自己。这篇文章的目的也主要想让大家知道自己应该从哪些方向去准备面试,有哪些可以提高的方向。
+
+网上已经有很多面经了,但是我认为网上的各种面经仅仅只能作为参考,你的实际面试与之还是有一些区别的。另外如果要在网上看别人的面经的话,建议即要看别人成功的案例也要适当看看别人失败的案例。**看面经没问题,不论是你要找工作还是平时学习,这都是一种比较好地检验自己水平的一种方式。但是,一定不要过分寄希望于各种面经,试着去提高自己的综合能力。**
+
+“ 80% 的 offer 掌握在 20% 的人手 ” 中这句话也不是不无道理的。决定你面试能否成功的因素中实力固然占有很大一部分比例,但是如果你的心态或者说运气不好的话,依然无法拿到满意的 offer。
+
+运气暂且不谈,就拿心态来说,千万不要因为面试失败而气馁或者说怀疑自己的能力,面试失败之后多总结一下失败的原因,后面你就会发现自己会越来越强大。
+
+另外,笔主只是在这里分享一下自己对于 “ 如何备战大厂面试 ” 的一个看法,以下大部分理论/言辞都经过过反复推敲验证,如果有不对的地方或者和你想法不同的地方,请您敬请雅正、不舍赐教。
- [1 如何获取大厂面试机会?](#1-如何获取大厂面试机会)
- [2 面试前的准备](#2--面试前的准备)
- [2.1 准备自己的自我介绍](#21-准备自己的自我介绍)
- - [2.2 关于着装](#22-关于着装)
+ - [2.2 搞清楚技术面可能会问哪些方向的问题](#22-搞清楚技术面可能会问哪些方向的问题)
+ - [2.2 休闲着装即可](#22-休闲着装即可)
- [2.3 随身带上自己的成绩单和简历](#23-随身带上自己的成绩单和简历)
- [2.4 如果需要笔试就提前刷一些笔试题](#24-如果需要笔试就提前刷一些笔试题)
- [2.5 花时间一些逻辑题](#25-花时间一些逻辑题)
@@ -13,6 +22,9 @@
- [2.7 提前准备技术面试](#27-提前准备技术面试)
- [2.7 面试之前做好定向复习](#27-面试之前做好定向复习)
- [3 面试之后复盘](#3-面试之后复盘)
+- [4 如何学习?学会各种框架有必要吗?](#4-如何学习学会各种框架有必要吗)
+ - [4.1 我该如何学习?](#41-我该如何学习)
+ - [4.2 学会各种框架有必要吗?](#42-学会各种框架有必要吗)
@@ -42,13 +54,35 @@
### 2.1 准备自己的自我介绍
-从HR面、技术面到高管面/部门主管面,面试官一般会让你先自我介绍一下,所以好好准备自己的自我介绍真的非常重要。网上一般建议的是准备好两份自我介绍:一份对hr说的,主要讲能突出自己的经历,会的编程技术一语带过;另一份对技术面试官说的,主要讲自己会的技术细节,项目经验,经历那些就一语带过。
+自我介绍一般是你和面试官的第一次面对面正式交流,换位思考一下,假如你是面试官的话,你想听到被你面试的人如何介绍自己呢?一定不是客套地说说自己喜欢编程、平时花了很多时间来学习、自己的兴趣爱好是打球吧?
-我这里简单分享一下我自己的自我介绍的一个简单的模板吧:
+我觉得一个好的自我介绍应该包含这几点要素:
-> 面试官,您好!我叫某某。大学时间我主要利用课外时间学习某某。在校期间参与过一个某某系统的开发,另外,自己学习过程中也写过很多系统比如某某系统。在学习之余,我比较喜欢通过博客整理分享自己所学知识。我现在是某某社区的认证作者,写过某某很不错的文章。另外,我获得过某某奖,我的Github上开源的某个项目已经有多少Star了。
+1. 用简单的话说清楚自己主要的技术栈于擅长的领域;
+2. 把重点放在自己在行的地方以及自己的优势之处;
+3. 重点突出自己的能力比如自己的定位的bug的能力特别厉害;
-### 2.2 关于着装
+从社招和校招两个角度来举例子吧!我下面的两个例子仅供参考,自我介绍并不需要死记硬背,记住要说的要点,面试的时候根据公司的情况临场发挥也是没问题的。另外,网上一般建议的是准备好两份自我介绍:一份对hr说的,主要讲能突出自己的经历,会的编程技术一语带过;另一份对技术面试官说的,主要讲自己会的技术细节和项目经验。
+
+**社招:**
+
+> 面试官,您好!我叫独秀儿。我目前有1年半的工作经验,熟练使用Spring、MyBatis等框架、了解 Java 底层原理比如JVM调优并且有着丰富的分布式开发经验。离开上一家公司是因为我想在技术上得到更多的锻炼。在上一个公司我参与了一个分布式电子交易系统的开发,负责搭建了整个项目的基础架构并且通过分库分表解决了原始数据库以及一些相关表过于庞大的问题,目前这个网站最高支持 10 万人同时访问。工作之余,我利用自己的业余时间写了一个简单的 RPC 框架,这个框架用到了Netty进行网络通信, 目前我已经将这个项目开源,在 Github 上收获了 2k的 Star! 说到业余爱好的话,我比较喜欢通过博客整理分享自己所学知识,现在已经是多个博客平台的认证作者。 生活中我是一个比较积极乐观的人,一般会通过运动打球的方式来放松。我一直都非常想加入贵公司,我觉得贵公司的文化和技术氛围我都非常喜欢,期待能与你共事!
+
+**校招:**
+
+> 面试官,您好!我叫秀儿。大学时间我主要利用课外时间学习了 Java 以及 Spring、MyBatis等框架 。在校期间参与过一个考试系统的开发,这个系统的主要用了 Spring、MyBatis 和 shiro 这三种框架。我在其中主要担任后端开发,主要负责了权限管理功能模块的搭建。另外,我在大学的时候参加过一次软件编程大赛,我和我的团队做的在线订餐系统成功获得了第二名的成绩。我还利用自己的业余时间写了一个简单的 RPC 框架,这个框架用到了Netty进行网络通信, 目前我已经将这个项目开源,在 Github 上收获了 2k的 Star! 说到业余爱好的话,我比较喜欢通过博客整理分享自己所学知识,现在已经是多个博客平台的认证作者。 生活中我是一个比较积极乐观的人,一般会通过运动打球的方式来放松。我一直都非常想加入贵公司,我觉得贵公司的文化和技术氛围我都非常喜欢,期待能与你共事!
+
+### 2.2 搞清楚技术面可能会问哪些方向的问题
+
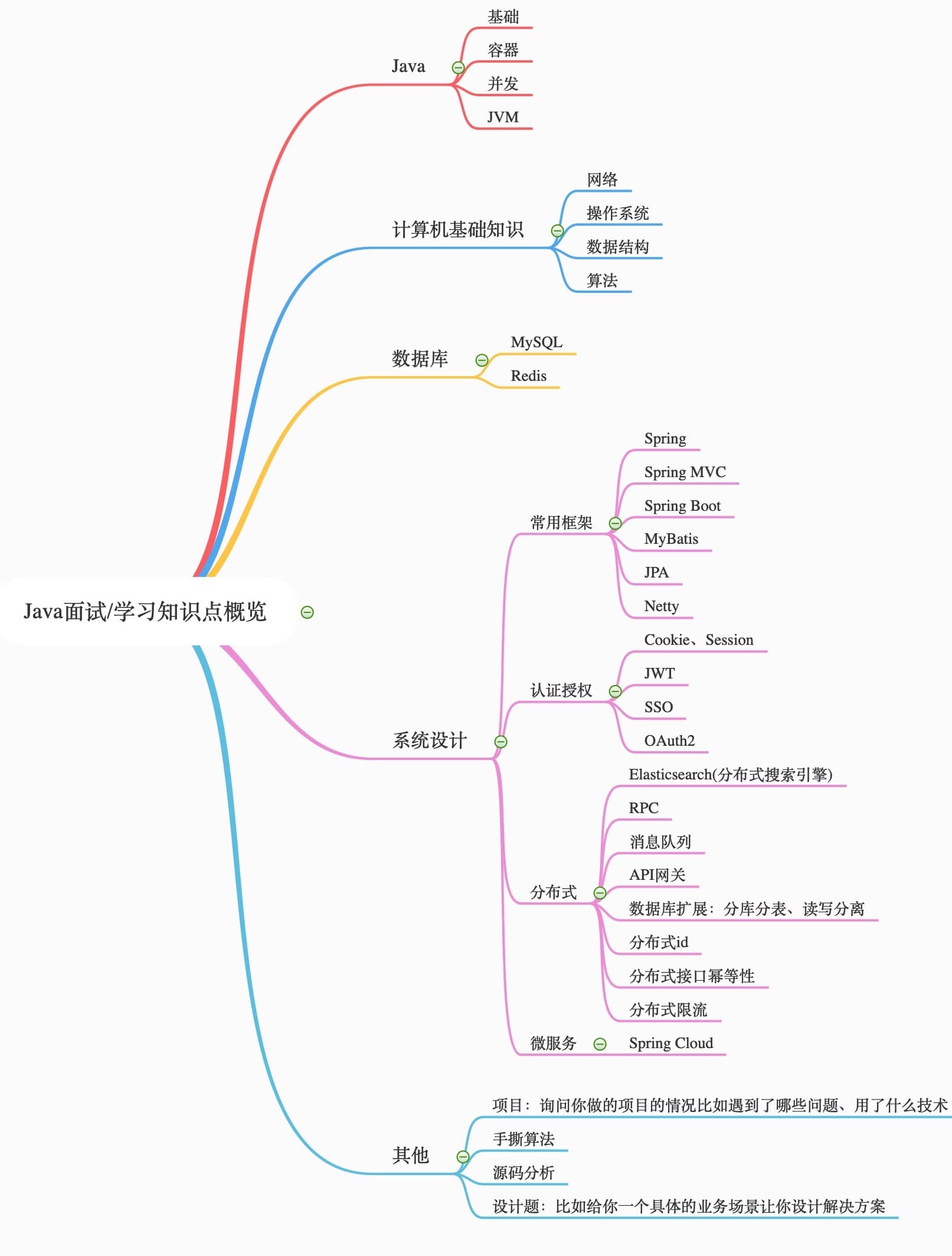
+你准备面试的话首先要搞清技术面可能会被问哪些方向的问题吧!
+
+**我直接用思维导图的形式展示出来吧!这样更加直观形象一点,细化到某个知识点的话这张图没有介绍到,留个悬念,下篇文章会详细介绍。**
+
+
+
+**上面思维导图大概涵盖了技术面试可能会设计的技术,但是你不需要把上面的每一个知识点都搞得很熟悉,要分清主次,对于自己不熟悉的技术不要写在简历上,对于自己简单了解的技术不要说自己熟练掌握!**
+
+### 2.2 休闲着装即可
穿西装、打领带、小皮鞋?NO!NO!NO!这是互联网公司面试又不是去走红毯,所以你只需要穿的简单大方就好,不需要太正式。
@@ -86,3 +120,32 @@
## 3 面试之后复盘
如果失败,不要灰心;如果通过,切勿狂喜。面试和工作实际上是两回事,可能很多面试未通过的人,工作能力比你强的多,反之亦然。我个人觉得面试也像是一场全新的征程,失败和胜利都是平常之事。所以,劝各位不要因为面试失败而灰心、丧失斗志。也不要因为面试通过而沾沾自喜,等待你的将是更美好的未来,继续加油!
+
+## 4 如何学习?学会各种框架有必要吗?
+
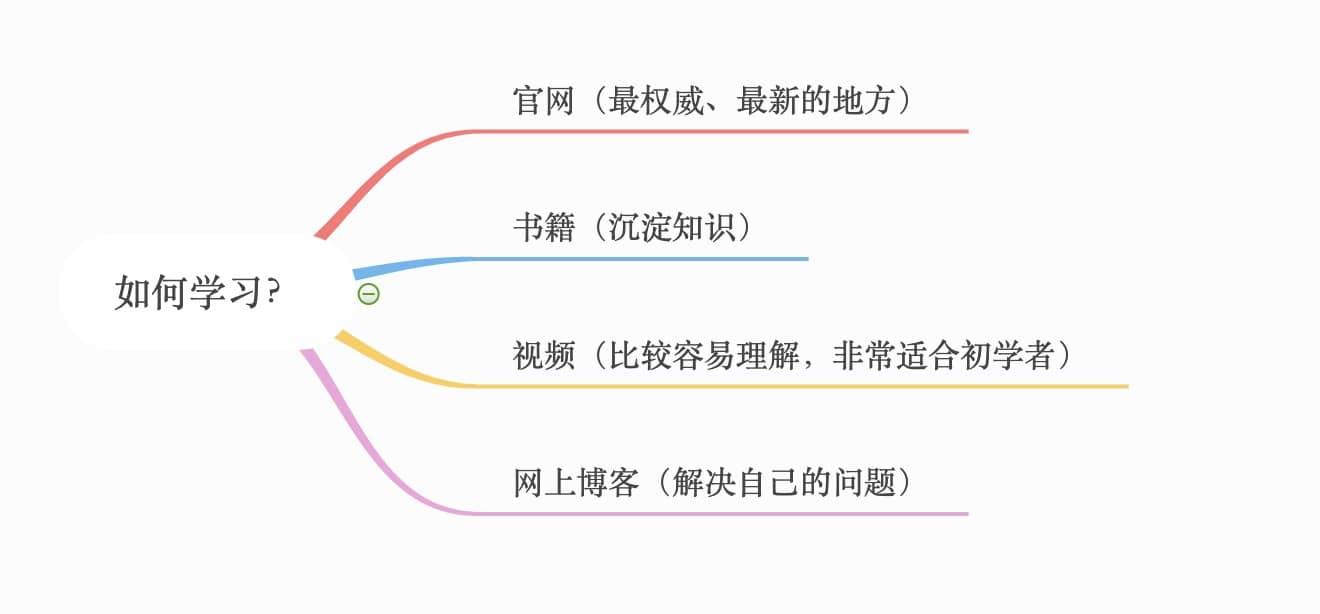
+### 4.1 我该如何学习?
+
+
+
+最最最关键也是对自己最最最重要的就是学习!看看别人分享的面经,看看我写的这篇文章估计你只需要10分钟不到。但这些东西终究是空洞的理论,最主要的还是自己平时的学习!
+
+如何去学呢?我觉得学习每个知识点可以考虑这样去入手:
+
+1. **官网(大概率是英文,不推荐初学者看)**。
+2. **书籍(知识更加系统完全,推荐)**。
+3. **视频(比较容易理解,推荐,特别是初学的时候。慕课网和哔哩哔哩上面有挺多学习视频可以看,只直接在上面搜索关键词就可以了)**。
+4. **网上博客(解决某一知识点的问题的时候可以看看)**。
+
+这里给各位一个建议,**看视频的过程中最好跟着一起练,要做笔记!!!**
+
+**最好可以边看视频边找一本书籍看,看视频没弄懂的知识点一定要尽快解决,如何解决?**
+
+首先百度/Google,通过搜索引擎解决不了的话就找身边的朋友或者认识的一些人。
+
+#### 4.2 学会各种框架有必要吗?
+
+**一定要学会分配自己时间,要学的东西很多,真的很多,搞清楚哪些东西是重点,哪些东西仅仅了解就够了。一定不要把精力都花在了学各种框架上,算法、数据结构还有计算机网络真的很重要!**
+
+另外,**学习的过程中有一个可以参考的文档很重要,非常有助于自己的学习**。我当初弄 JavaGuide: https://github.com/Snailclimb/JavaGuide 的很大一部分目的就是因为这个。**客观来说,相比于博客,JavaGuide 里面的内容因为更多人的参与变得更加准确和完善。**
+
+如果大家觉得这篇文章不错的话,欢迎给我来个三连(评论+转发+在看)!我会在下一篇文章中介绍如何从技术面时的角度准备面试?
\ No newline at end of file
diff --git a/docs/essential-content-for-interview/PreparingForInterview/应届生面试最爱问的几道Java基础问题.md b/docs/essential-content-for-interview/PreparingForInterview/应届生面试最爱问的几道Java基础问题.md
index 2e93113d..42bcb5ed 100644
--- a/docs/essential-content-for-interview/PreparingForInterview/应届生面试最爱问的几道Java基础问题.md
+++ b/docs/essential-content-for-interview/PreparingForInterview/应届生面试最爱问的几道Java基础问题.md
@@ -223,57 +223,42 @@ public class test1 {
- String 中的 equals 方法是被重写过的,因为 object 的 equals 方法是比较的对象的内存地址,而 String 的 equals 方法比较的是对象的值。
- 当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 String 对象。
-## 三 hashCode 与 equals(重要)
+## 三 hashCode() 与 equals()(重要)
-面试官可能会问你:“你重写过 hashcode 和 equals 么,为什么重写 equals 时必须重写 hashCode 方法?”
+面试官可能会问你:“你重写过 `hashcode` 和 `equals `么,为什么重写 `equals` 时必须重写 `hashCode` 方法?”
-### 3.1 hashCode()介绍
+### 3.1 hashCode()介绍
-hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个 int 整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在 JDK 的 Object.java 中,这就意味着 Java 中的任何类都包含有 hashCode() 函数。另外需要注意的是: Object 的 hashcode 方法是本地方法,也就是用 c 语言或 c++ 实现的,该方法通常用来将对象的 内存地址 转换为整数之后返回。
+`hashCode()` 的作用是获取哈希码,也称为散列码;它实际上是返回一个 int 整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。`hashCode() `定义在 JDK 的 `Object` 类中,这就意味着 Java 中的任何类都包含有 `hashCode()` 函数。另外需要注意的是: `Object` 的 hashcode 方法是本地方法,也就是用 c 语言或 c++ 实现的,该方法通常用来将对象的 内存地址 转换为整数之后返回。
```java
- /**
- * Returns a hash code value for the object. This method is
- * supported for the benefit of hash tables such as those provided by
- * {@link java.util.HashMap}.
- *
- * As much as is reasonably practical, the hashCode method defined by
- * class {@code Object} does return distinct integers for distinct
- * objects. (This is typically implemented by converting the internal
- * address of the object into an integer, but this implementation
- * technique is not required by the
- * Java™ programming language.)
- *
- * @return a hash code value for this object.
- * @see java.lang.Object#equals(java.lang.Object)
- * @see java.lang.System#identityHashCode
- */
- public native int hashCode();
+public native int hashCode();
```
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
-### 3.2 为什么要有 hashCode
+### 3.2 为什么要有 hashCode?
-**我们以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode:**
+**我们以“`HashSet` 如何检查重复”为例子来说明为什么要有 hashCode:**
-当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的 Java 启蒙书《Head fist java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
+当你把对象加入 `HashSet` 时,`HashSet` 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,`HashSet` 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,`HashSet` 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的 Java 启蒙书《Head fist java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
-### 3.3 hashCode()与 equals()的相关规定
+### 3.3 为什么重写 `equals` 时必须重写 `hashCode` 方法?
-1. 如果两个对象相等,则 hashcode 一定也是相同的
-2. 两个对象相等,对两个对象分别调用 equals 方法都返回 true
-3. 两个对象有相同的 hashcode 值,它们也不一定是相等的
-4. **因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖**
-5. hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
+如果两个对象相等,则 hashcode 一定也是相同的。两个对象相等,对两个对象分别调用 equals 方法都返回 true。但是,两个对象有相同的 hashcode 值,它们也不一定是相等的 。**因此,equals 方法被覆盖过,则 `hashCode` 方法也必须被覆盖。**
+
+> `hashCode()`的默认行为是对堆上的对象产生独特值。如果没有重写 `hashCode()`,则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
### 3.4 为什么两个对象有相同的 hashcode 值,它们也不一定是相等的?
在这里解释一位小伙伴的问题。以下内容摘自《Head Fisrt Java》。
-因为 hashCode() 所使用的杂凑算法也许刚好会让多个对象传回相同的杂凑值。越糟糕的杂凑算法越容易碰撞,但这也与数据值域分布的特性有关(所谓碰撞也就是指的是不同的对象得到相同的 hashCode)。
+因为 `hashCode()` 所使用的杂凑算法也许刚好会让多个对象传回相同的杂凑值。越糟糕的杂凑算法越容易碰撞,但这也与数据值域分布的特性有关(所谓碰撞也就是指的是不同的对象得到相同的 `hashCode`。
-我们刚刚也提到了 HashSet,如果 HashSet 在对比的时候,同样的 hashcode 有多个对象,它会使用 equals() 来判断是否真的相同。也就是说 hashcode 只是用来缩小查找成本。
+我们刚刚也提到了 `HashSet`,如果 `HashSet` 在对比的时候,同样的 hashcode 有多个对象,它会使用 `equals()` 来判断是否真的相同。也就是说 `hashcode` 只是用来缩小查找成本。
+
+
+更多关于 `hashcode()` 和 `equals()` 的内容可以查看:[Java hashCode() 和 equals()的若干问题解答](https://www.cnblogs.com/skywang12345/p/3324958.html)
## 四 String 和 StringBuffer、StringBuilder 的区别是什么?String 为什么是不可变的?
diff --git a/docs/essential-content-for-interview/PreparingForInterview/程序员的简历之道.md b/docs/essential-content-for-interview/PreparingForInterview/程序员的简历之道.md
index 7feead7d..a746892f 100644
--- a/docs/essential-content-for-interview/PreparingForInterview/程序员的简历之道.md
+++ b/docs/essential-content-for-interview/PreparingForInterview/程序员的简历之道.md
@@ -119,3 +119,4 @@
- 冷熊简历(MarkDown在线简历工具,可在线预览、编辑和生成PDF): list = new ArrayList<>();
+
+list.add(12);
+//这里直接添加会报错
+list.add("a");
+Class clazz = list.getClass();
+Method add = clazz.getDeclaredMethod("add", Object.class);
+//但是通过反射添加,是可以的
+add.invoke(list, "kl");
+
+System.out.println(list)
+```
+
+泛型一般有三种使用方式:泛型类、泛型接口、泛型方法。
+
+**1.泛型类**:
+
+```java
+//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型
+//在实例化泛型类时,必须指定T的具体类型
+public class Generic{
+
+ private T key;
+
+ public Generic(T key) {
+ this.key = key;
+ }
+
+ public T getKey(){
+ return key;
+ }
+}
+```
+
+如何实例化泛型类:
+
+```java
+Generic genericInteger = new Generic(123456);
+```
+
+**2.泛型接口** :
+
+```java
+public interface Generator {
+ public T method();
+}
+```
+
+实现泛型接口,不指定类型:
+
+```java
+class GeneratorImpl implements Generator{
+ @Override
+ public T method() {
+ return null;
+ }
+}
+```
+
+实现泛型接口,指定类型:
+
+```java
+class GeneratorImpl implements Generator{
+ @Override
+ public String method() {
+ return "hello";
+ }
+}
+```
+
+**3.泛型方法** :
+
+```java
+ public static < E > void printArray( E[] inputArray )
+ {
+ for ( E element : inputArray ){
+ System.out.printf( "%s ", element );
+ }
+ System.out.println();
+ }
+```
+
+使用:
+
+```java
+// 创建不同类型数组: Integer, Double 和 Character
+Integer[] intArray = { 1, 2, 3 };
+String[] stringArray = { "Hello", "World" };
+printArray( intArray );
+printArray( stringArray );
+```
+
+**常用的通配符为: T,E,K,V,?**
+
+- ? 表示不确定的 java 类型
+- T (type) 表示具体的一个java类型
+- K V (key value) 分别代表java键值中的Key Value
+- E (element) 代表Element
+
+更多关于Java 泛型中的通配符可以查看这篇文章:[《聊一聊-JAVA 泛型中的通配符 T,E,K,V,?》](https://juejin.im/post/5d5789d26fb9a06ad0056bd9)
+
+#### 1.2.8. ==和equals的区别
+
+**`==`** : 它的作用是判断两个对象的地址是不是相等。即判断两个对象是不是同一个对象。(**基本数据类型==比较的是值,引用数据类型==比较的是内存地址**)
+
+> 因为 Java 只有值传递,所以,对于 == 来说,不管是比较基本数据类型,还是引用数据类型的变量,其本质比较的都是值,只是引用类型变量存的值是对象的地址。
+
+**`equals()`** : 它的作用也是判断两个对象是否相等,它不能用于比较基本数据类型的变量。`equals()`方法存在于`Object`类中,而`Object`类是所有类的直接或间接父类。
+
+`Object`类`equals()`方法:
+
+```java
+public boolean equals(Object obj) {
+ return (this == obj);
+}
+```
+
+`equals()` 方法存在两种使用情况:
+
+- 情况 1:类没有覆盖 `equals()`方法。则通过` equals()`比较该类的两个对象时,等价于通过“==”比较这两个对象。使用的默认是 `Object`类`equals()`方法。
+- 情况 2:类覆盖了 `equals()`方法。一般,我们都覆盖 `equals()`方法来两个对象的内容相等;若它们的内容相等,则返回 true(即,认为这两个对象相等)。
+
+**举个例子:**
+
+```java
+public class test1 {
+ public static void main(String[] args) {
+ String a = new String("ab"); // a 为一个引用
+ String b = new String("ab"); // b为另一个引用,对象的内容一样
+ String aa = "ab"; // 放在常量池中
+ String bb = "ab"; // 从常量池中查找
+ if (aa == bb) // true
+ System.out.println("aa==bb");
+ if (a == b) // false,非同一对象
+ System.out.println("a==b");
+ if (a.equals(b)) // true
+ System.out.println("aEQb");
+ if (42 == 42.0) { // true
+ System.out.println("true");
+ }
+ }
+}
+```
+
+**说明:**
+
+- `String` 中的 `equals` 方法是被重写过的,因为 `Object` 的 `equals` 方法是比较的对象的内存地址,而 `String` 的 `equals` 方法比较的是对象的值。
+- 当创建 `String` 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 `String` 对象。
+
+`String`类`equals()`方法:
+
+```java
+public boolean equals(Object anObject) {
+ if (this == anObject) {
+ return true;
+ }
+ if (anObject instanceof String) {
+ String anotherString = (String)anObject;
+ int n = value.length;
+ if (n == anotherString.value.length) {
+ char v1[] = value;
+ char v2[] = anotherString.value;
+ int i = 0;
+ while (n-- != 0) {
+ if (v1[i] != v2[i])
+ return false;
+ i++;
+ }
+ return true;
+ }
+ }
+ return false;
+}
+```
+
+#### 1.2.9. hashCode()与 equals()
+
+面试官可能会问你:“你重写过 `hashcode` 和 `equals `么,为什么重写 `equals` 时必须重写 `hashCode` 方法?”
+
+**1)hashCode()介绍:**
+
+`hashCode()` 的作用是获取哈希码,也称为散列码;它实际上是返回一个 int 整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。`hashCode() `定义在 JDK 的 `Object` 类中,这就意味着 Java 中的任何类都包含有 `hashCode()` 函数。另外需要注意的是: `Object` 的 hashcode 方法是本地方法,也就是用 c 语言或 c++ 实现的,该方法通常用来将对象的 内存地址 转换为整数之后返回。
+
+```java
+public native int hashCode();
+```
+
+散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
+
+**2)为什么要有 hashCode?**
+
+我们以“`HashSet` 如何检查重复”为例子来说明为什么要有 hashCode?
+
+当你把对象加入 `HashSet` 时,`HashSet` 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,`HashSet` 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 `equals()` 方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,`HashSet` 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的 Java 启蒙书《Head First Java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
+
+**3)为什么重写 `equals` 时必须重写 `hashCode` 方法?**
+
+如果两个对象相等,则 hashcode 一定也是相同的。两个对象相等,对两个对象分别调用 equals 方法都返回 true。但是,两个对象有相同的 hashcode 值,它们也不一定是相等的 。**因此,equals 方法被覆盖过,则 `hashCode` 方法也必须被覆盖。**
+
+> `hashCode()`的默认行为是对堆上的对象产生独特值。如果没有重写 `hashCode()`,则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
+
+**4)为什么两个对象有相同的 hashcode 值,它们也不一定是相等的?**
+
+在这里解释一位小伙伴的问题。以下内容摘自《Head Fisrt Java》。
+
+因为 `hashCode()` 所使用的杂凑算法也许刚好会让多个对象传回相同的杂凑值。越糟糕的杂凑算法越容易碰撞,但这也与数据值域分布的特性有关(所谓碰撞也就是指的是不同的对象得到相同的 `hashCode`。
+
+我们刚刚也提到了 `HashSet`,如果 `HashSet` 在对比的时候,同样的 hashcode 有多个对象,它会使用 `equals()` 来判断是否真的相同。也就是说 `hashcode` 只是用来缩小查找成本。
+
+
+
+
+更多关于 `hashcode()` 和 `equals()` 的内容可以查看:[Java hashCode() 和 equals()的若干问题解答](https://www.cnblogs.com/skywang12345/p/3324958.html)
+
+### 1.3. 基本数据类型
+
+#### 1.3.1. Java中的几种基本数据类型是什么?对应的包装类型是什么?各自占用多少字节呢?
+
+Java**中**有8种基本数据类型,分别为:
+
+1. 6种数字类型 :byte、short、int、long、float、double
+2. 1种字符类型:char
+3. 1种布尔型:boolean。
+
+这八种基本类型都有对应的包装类分别为:Byte、Short、Integer、Long、Float、Double、Character、Boolean
+
+| 基本类型 | 位数 | 字节 | 默认值 |
+| :------- | :--- | :--- | ------- |
+| int | 32 | 4 | 0 |
+| short | 16 | 2 | 0 |
+| long | 64 | 8 | 0L |
+| byte | 8 | 1 | 0 |
+| char | 16 | 2 | 'u0000' |
+| float | 32 | 4 | 0f |
+| double | 64 | 8 | 0d |
+| boolean | 1 | | false |
+
+对于boolean,官方文档未明确定义,它依赖于 JVM 厂商的具体实现。逻辑上理解是占用 1位,但是实际中会考虑计算机高效存储因素。
+
+注意:
+
+1. Java 里使用 long 类型的数据一定要在数值后面加上 **L**,否则将作为整型解析:
+2. `char a = 'h'`char :单引号,`String a = "hello"` :双引号
+
+#### 1.3.2. 自动装箱与拆箱
+
+- **装箱**:将基本类型用它们对应的引用类型包装起来;
+- **拆箱**:将包装类型转换为基本数据类型;
+
+更多内容见:[深入剖析 Java 中的装箱和拆箱](https://www.cnblogs.com/dolphin0520/p/3780005.html)
+
+#### 1.3.3. 8种基本类型的包装类和常量池
+
+**Java 基本类型的包装类的大部分都实现了常量池技术,即 Byte,Short,Integer,Long,Character,Boolean;前面 4 种包装类默认创建了数值[-128,127] 的相应类型的缓存数据,Character创建了数值在[0,127]范围的缓存数据,Boolean 直接返回True Or False。如果超出对应范围仍然会去创建新的对象。** 为啥把缓存设置为[-128,127]区间?([参见issue/461](https://github.com/Snailclimb/JavaGuide/issues/461))性能和资源之间的权衡。
+
+```java
+public static Boolean valueOf(boolean b) {
+ return (b ? TRUE : FALSE);
+}
+```
+
+```java
+private static class CharacterCache {
+ private CharacterCache(){}
+
+ static final Character cache[] = new Character[127 + 1];
+ static {
+ for (int i = 0; i < cache.length; i++)
+ cache[i] = new Character((char)i);
+ }
+}
+```
+
+两种浮点数类型的包装类 Float,Double 并没有实现常量池技术。**
+
+```java
+ Integer i1 = 33;
+ Integer i2 = 33;
+ System.out.println(i1 == i2);// 输出 true
+ Integer i11 = 333;
+ Integer i22 = 333;
+ System.out.println(i11 == i22);// 输出 false
+ Double i3 = 1.2;
+ Double i4 = 1.2;
+ System.out.println(i3 == i4);// 输出 false
+```
+
+**Integer 缓存源代码:**
+
+```java
+/**
+*此方法将始终缓存-128 到 127(包括端点)范围内的值,并可以缓存此范围之外的其他值。
+*/
+ public static Integer valueOf(int i) {
+ if (i >= IntegerCache.low && i <= IntegerCache.high)
+ return IntegerCache.cache[i + (-IntegerCache.low)];
+ return new Integer(i);
+ }
+
+```
+
+**应用场景:**
+1. Integer i1=40;Java 在编译的时候会直接将代码封装成 Integer i1=Integer.valueOf(40);,从而使用常量池中的对象。
+2. Integer i1 = new Integer(40);这种情况下会创建新的对象。
+
+```java
+ Integer i1 = 40;
+ Integer i2 = new Integer(40);
+ System.out.println(i1 == i2);//输出 false
+```
+**Integer 比较更丰富的一个例子:**
+
+```java
+ Integer i1 = 40;
+ Integer i2 = 40;
+ Integer i3 = 0;
+ Integer i4 = new Integer(40);
+ Integer i5 = new Integer(40);
+ Integer i6 = new Integer(0);
+
+ System.out.println("i1=i2 " + (i1 == i2));
+ System.out.println("i1=i2+i3 " + (i1 == i2 + i3));
+ System.out.println("i1=i4 " + (i1 == i4));
+ System.out.println("i4=i5 " + (i4 == i5));
+ System.out.println("i4=i5+i6 " + (i4 == i5 + i6));
+ System.out.println("40=i5+i6 " + (40 == i5 + i6));
+```
+
+结果:
+
+```
+i1=i2 true
+i1=i2+i3 true
+i1=i4 false
+i4=i5 false
+i4=i5+i6 true
+40=i5+i6 true
+```
+
+解释:
+
+语句 i4 == i5 + i6,因为+这个操作符不适用于 Integer 对象,首先 i5 和 i6 进行自动拆箱操作,进行数值相加,即 i4 == 40。然后 Integer 对象无法与数值进行直接比较,所以 i4 自动拆箱转为 int 值 40,最终这条语句转为 40 == 40 进行数值比较。
+
+### 1.4. 方法(函数)
+
+#### 1.4.1. 什么是方法的返回值?返回值在类的方法里的作用是什么?
+
+方法的返回值是指我们获取到的某个方法体中的代码执行后产生的结果!(前提是该方法可能产生结果)。返回值的作用是接收出结果,使得它可以用于其他的操作!
+
+#### 1.4.2. 为什么 Java 中只有值传递?
+
+首先回顾一下在程序设计语言中有关将参数传递给方法(或函数)的一些专业术语。**按值调用(call by value)表示方法接收的是调用者提供的值,而按引用调用(call by reference)表示方法接收的是调用者提供的变量地址。一个方法可以修改传递引用所对应的变量值,而不能修改传递值调用所对应的变量值。** 它用来描述各种程序设计语言(不只是 Java)中方法参数传递方式。
+
+**Java 程序设计语言总是采用按值调用。也就是说,方法得到的是所有参数值的一个拷贝,也就是说,方法不能修改传递给它的任何参数变量的内容。**
+
+**下面通过 3 个例子来给大家说明**
+
+> **example 1**
+
+```java
+public static void main(String[] args) {
+ int num1 = 10;
+ int num2 = 20;
+
+ swap(num1, num2);
+
+ System.out.println("num1 = " + num1);
+ System.out.println("num2 = " + num2);
+}
+
+public static void swap(int a, int b) {
+ int temp = a;
+ a = b;
+ b = temp;
+
+ System.out.println("a = " + a);
+ System.out.println("b = " + b);
+}
+```
+
+**结果:**
+
+```
+a = 20
+b = 10
+num1 = 10
+num2 = 20
+```
+
+**解析:**
+
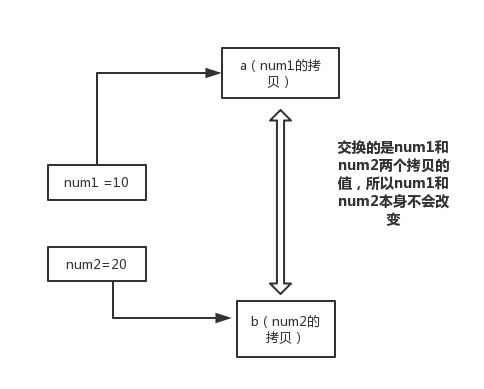
+
+
+在 swap 方法中,a、b 的值进行交换,并不会影响到 num1、num2。因为,a、b 中的值,只是从 num1、num2 的复制过来的。也就是说,a、b 相当于 num1、num2 的副本,副本的内容无论怎么修改,都不会影响到原件本身。
+
+**通过上面例子,我们已经知道了一个方法不能修改一个基本数据类型的参数,而对象引用作为参数就不一样,请看 example2.**
+
+> **example 2**
+
+```java
+ public static void main(String[] args) {
+ int[] arr = { 1, 2, 3, 4, 5 };
+ System.out.println(arr[0]);
+ change(arr);
+ System.out.println(arr[0]);
+ }
+
+ public static void change(int[] array) {
+ // 将数组的第一个元素变为0
+ array[0] = 0;
+ }
+```
+
+**结果:**
+
+```
+1
+0
+```
+
+**解析:**
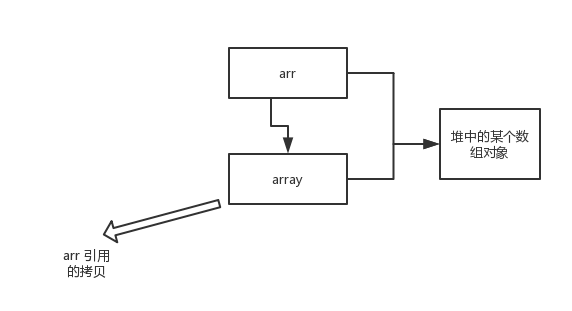
+
+
+
+array 被初始化 arr 的拷贝也就是一个对象的引用,也就是说 array 和 arr 指向的是同一个数组对象。 因此,外部对引用对象的改变会反映到所对应的对象上。
+
+**通过 example2 我们已经看到,实现一个改变对象参数状态的方法并不是一件难事。理由很简单,方法得到的是对象引用的拷贝,对象引用及其他的拷贝同时引用同一个对象。**
+
+**很多程序设计语言(特别是,C++和 Pascal)提供了两种参数传递的方式:值调用和引用调用。有些程序员(甚至本书的作者)认为 Java 程序设计语言对对象采用的是引用调用,实际上,这种理解是不对的。由于这种误解具有一定的普遍性,所以下面给出一个反例来详细地阐述一下这个问题。**
+
+> **example 3**
+
+```java
+public class Test {
+
+ public static void main(String[] args) {
+ // TODO Auto-generated method stub
+ Student s1 = new Student("小张");
+ Student s2 = new Student("小李");
+ Test.swap(s1, s2);
+ System.out.println("s1:" + s1.getName());
+ System.out.println("s2:" + s2.getName());
+ }
+
+ public static void swap(Student x, Student y) {
+ Student temp = x;
+ x = y;
+ y = temp;
+ System.out.println("x:" + x.getName());
+ System.out.println("y:" + y.getName());
+ }
+}
+```
+
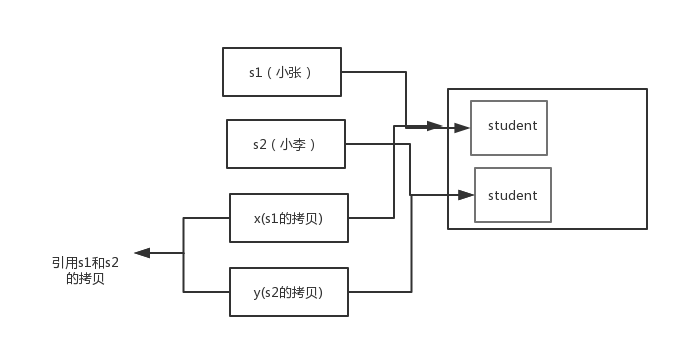
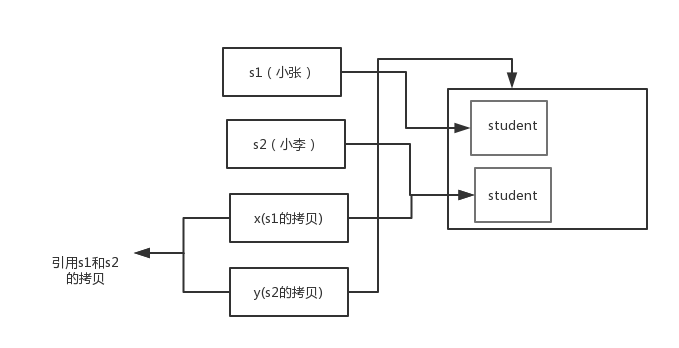
+**结果:**
+
+```
+x:小李
+y:小张
+s1:小张
+s2:小李
+```
+
+**解析:**
+
+交换之前:
+
+
+
+交换之后:
+
+
+
+通过上面两张图可以很清晰的看出: **方法并没有改变存储在变量 s1 和 s2 中的对象引用。swap 方法的参数 x 和 y 被初始化为两个对象引用的拷贝,这个方法交换的是这两个拷贝**
+
+> **总结**
+
+Java 程序设计语言对对象采用的不是引用调用,实际上,对象引用是按
+值传递的。
+
+下面再总结一下 Java 中方法参数的使用情况:
+
+- 一个方法不能修改一个基本数据类型的参数(即数值型或布尔型)。
+- 一个方法可以改变一个对象参数的状态。
+- 一个方法不能让对象参数引用一个新的对象。
+
+**参考:**
+
+《Java 核心技术卷 Ⅰ》基础知识第十版第四章 4.5 小节
+
+#### 1.4.3. 重载和重写的区别
+
+> 重载就是同样的一个方法能够根据输入数据的不同,做出不同的处理
+>
+> 重写就是当子类继承自父类的相同方法,输入数据一样,但要做出有别于父类的响应时,你就要覆盖父类方法
+
+###### 1.4.3.1. 重载
发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同。
-下面是《Java核心技术》对重载这个概念的介绍:
+下面是《Java 核心技术》对重载这个概念的介绍:
-
+
-#### 重写
+**综上:重载就是同一个类中多个同名方法根据不同的传参来执行不同的逻辑处理。**
- 重写是子类对父类的允许访问的方法的实现过程进行重新编写,发生在子类中,方法名、参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类。另外,如果父类方法访问修饰符为 private 则子类就不能重写该方法。**也就是说方法提供的行为改变,而方法的外貌并没有改变。**
+###### 1.4.3.2. 重写
-## 11. Java 面向对象编程三大特性: 封装 继承 多态
+重写发生在运行期,是子类对父类的允许访问的方法的实现过程进行重新编写。
-### 封装
+1. 返回值类型、方法名、参数列表必须相同,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类。
+2. 如果父类方法访问修饰符为 `private/final/static` 则子类就不能重写该方法,但是被 static 修饰的方法能够被再次声明。
+3. 构造方法无法被重写
-封装把一个对象的属性私有化,同时提供一些可以被外界访问的属性的方法,如果属性不想被外界访问,我们大可不必提供方法给外界访问。但是如果一个类没有提供给外界访问的方法,那么这个类也没有什么意义了。
+**综上:重写就是子类对父类方法的重新改造,外部样子不能改变,内部逻辑可以改变**
+
+**暖心的 Guide 哥最后再来个图表总结一下!**
+
+| 区别点 | 重载方法 | 重写方法 |
+| :--------- | :------- | :----------------------------------------------------------- |
+| 发生范围 | 同一个类 | 子类 |
+| 参数列表 | 必须修改 | 一定不能修改 |
+| 返回类型 | 可修改 | 子类方法返回值类型应比父类方法返回值类型更小或相等 |
+| 异常 | 可修改 | 子类方法声明抛出的异常类应比父类方法声明抛出的异常类更小或相等; |
+| 访问修饰符 | 可修改 | 一定不能做更严格的限制(可以降低限制) |
+| 发生阶段 | 编译期 | 运行期 |
-### 继承
-继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通过使用继承我们能够非常方便地复用以前的代码。
+
+**方法的重写要遵循“两同两小一大”**(以下内容摘录自《疯狂 Java 讲义》,[issue#892](https://github.com/Snailclimb/JavaGuide/issues/892) ):
+
+- “两同”即方法名相同、形参列表相同;
+- “两小”指的是子类方法返回值类型应比父类方法返回值类型更小或相等,子类方法声明抛出的异常类应比父类方法声明抛出的异常类更小或相等;
+- “一大”指的是子类方法的访问权限应比父类方法的访问权限更大或相等。
+
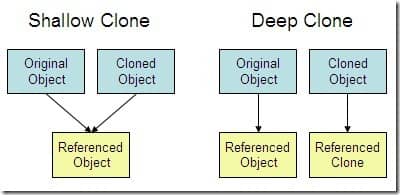
+#### 1.4.4. 深拷贝 vs 浅拷贝
+
+1. **浅拷贝**:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。
+2. **深拷贝**:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。
+
+
+
+#### 1.4.5. 方法的四种类型
+
+1、无参数无返回值的方法
+
+```java
+// 无参数无返回值的方法(如果方法没有返回值,不能不写,必须写void,表示没有返回值)
+public void f1() {
+ System.out.println("无参数无返回值的方法");
+}
+```
+
+2、有参数无返回值的方法
+
+```java
+/**
+* 有参数无返回值的方法
+* 参数列表由零组到多组“参数类型+形参名”组合而成,多组参数之间以英文逗号(,)隔开,形参类型和形参名之间以英文空格隔开
+*/
+public void f2(int a, String b, int c) {
+ System.out.println(a + "-->" + b + "-->" + c);
+}
+```
+
+3、有返回值无参数的方法
+
+```java
+// 有返回值无参数的方法(返回值可以是任意的类型,在函数里面必须有return关键字返回对应的类型)
+public int f3() {
+ System.out.println("有返回值无参数的方法");
+ return 2;
+}
+```
+
+4、有返回值有参数的方法
+
+```java
+// 有返回值有参数的方法
+public int f4(int a, int b) {
+ return a * b;
+}
+```
+
+5、return 在无返回值方法的特殊使用
+
+```java
+// return在无返回值方法的特殊使用
+public void f5(int a) {
+ if (a > 10) {
+ return;//表示结束所在方法 (f5方法)的执行,下方的输出语句不会执行
+ }
+ System.out.println(a);
+}
+```
+
+## 2. Java 面向对象
+
+### 2.1. 类和对象
+
+#### 2.1.1. 面向对象和面向过程的区别
+
+- **面向过程** :**面向过程性能比面向对象高。** 因为类调用时需要实例化,开销比较大,比较消耗资源,所以当性能是最重要的考量因素的时候,比如单片机、嵌入式开发、Linux/Unix 等一般采用面向过程开发。但是,**面向过程没有面向对象易维护、易复用、易扩展。**
+- **面向对象** :**面向对象易维护、易复用、易扩展。** 因为面向对象有封装、继承、多态性的特性,所以可以设计出低耦合的系统,使系统更加灵活、更加易于维护。但是,**面向对象性能比面向过程低**。
+
+参见 issue : [面向过程 :面向过程性能比面向对象高??](https://github.com/Snailclimb/JavaGuide/issues/431)
+
+> 这个并不是根本原因,面向过程也需要分配内存,计算内存偏移量,Java 性能差的主要原因并不是因为它是面向对象语言,而是 Java 是半编译语言,最终的执行代码并不是可以直接被 CPU 执行的二进制机械码。
+>
+> 而面向过程语言大多都是直接编译成机械码在电脑上执行,并且其它一些面向过程的脚本语言性能也并不一定比 Java 好。
+
+#### 2.1.2. 构造器 Constructor 是否可被 override?
+
+Constructor 不能被 override(重写),但是可以 overload(重载),所以你可以看到一个类中有多个构造函数的情况。
+
+#### 2.1.3. 在 Java 中定义一个不做事且没有参数的构造方法的作用
+
+Java 程序在执行子类的构造方法之前,如果没有用 `super()`来调用父类特定的构造方法,则会调用父类中“没有参数的构造方法”。因此,如果父类中只定义了有参数的构造方法,而在子类的构造方法中又没有用 `super()`来调用父类中特定的构造方法,则编译时将发生错误,因为 Java 程序在父类中找不到没有参数的构造方法可供执行。解决办法是在父类里加上一个不做事且没有参数的构造方法。
+
+#### 2.1.4. 成员变量与局部变量的区别有哪些?
+
+1. 从语法形式上看:成员变量是属于类的,而局部变量是在代码块或方法中定义的变量或是方法的参数;成员变量可以被 public,private,static 等修饰符所修饰,而局部变量不能被访问控制修饰符及 static 所修饰;但是,成员变量和局部变量都能被 final 所修饰。
+2. 从变量在内存中的存储方式来看:如果成员变量是使用`static`修饰的,那么这个成员变量是属于类的,如果没有使用`static`修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量则存在于栈内存。
+3. 从变量在内存中的生存时间上看:成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动消失。
+4. 成员变量如果没有被赋初值:则会自动以类型的默认值而赋值(一种情况例外:被 final 修饰的成员变量也必须显式地赋值),而局部变量则不会自动赋值。
+
+#### 2.1.5. 创建一个对象用什么运算符?对象实体与对象引用有何不同?
+
+new 运算符,new 创建对象实例(对象实例在堆内存中),对象引用指向对象实例(对象引用存放在栈内存中)。一个对象引用可以指向 0 个或 1 个对象(一根绳子可以不系气球,也可以系一个气球);一个对象可以有 n 个引用指向它(可以用 n 条绳子系住一个气球)。
+
+#### 2.1.6. 一个类的构造方法的作用是什么? 若一个类没有声明构造方法,该程序能正确执行吗? 为什么?
+
+主要作用是完成对类对象的初始化工作。可以执行。因为一个类即使没有声明构造方法也会有默认的不带参数的构造方法。如果我们自己添加了类的构造方法(无论是否有参),Java 就不会再添加默认的无参数的构造方法了,这时候,就不能直接 new 一个对象而不传递参数了,所以我们一直在不知不觉地使用构造方法,这也是为什么我们在创建对象的时候后面要加一个括号(因为要调用无参的构造方法)。如果我们重载了有参的构造方法,记得都要把无参的构造方法也写出来(无论是否用到),因为这可以帮助我们在创建对象的时候少踩坑。
+
+#### 2.1.7. 构造方法有哪些特性?
+
+1. 名字与类名相同。
+2. 没有返回值,但不能用 void 声明构造函数。
+3. 生成类的对象时自动执行,无需调用。
+
+#### 2.1.8. 在调用子类构造方法之前会先调用父类没有参数的构造方法,其目的是?
+
+帮助子类做初始化工作。
+
+#### 2.1.9. 对象的相等与指向他们的引用相等,两者有什么不同?
+
+对象的相等,比的是内存中存放的内容是否相等。而引用相等,比较的是他们指向的内存地址是否相等。
+
+### 2.2. 面向对象三大特征
+
+#### 2.2.1. 封装
+
+封装是指把一个对象的状态信息(也就是属性)隐藏在对象内部,不允许外部对象直接访问对象的内部信息。但是可以提供一些可以被外界访问的方法来操作属性。就好像我们看不到挂在墙上的空调的内部的零件信息(也就是属性),但是可以通过遥控器(方法)来控制空调。如果属性不想被外界访问,我们大可不必提供方法给外界访问。但是如果一个类没有提供给外界访问的方法,那么这个类也没有什么意义了。就好像如果没有空调遥控器,那么我们就无法操控空凋制冷,空调本身就没有意义了(当然现在还有很多其他方法 ,这里只是为了举例子)。
+
+```java
+public class Student {
+ private int id;//id属性私有化
+ private String name;//name属性私有化
+
+ //获取id的方法
+ public int getId() {
+ return id;
+ }
+
+ //设置id的方法
+ public void setId(int id) {
+ this.id = id;
+ }
+
+ //获取name的方法
+ public String getName() {
+ return name;
+ }
+
+ //设置name的方法
+ public void setName(String name) {
+ this.name = name;
+ }
+}
+```
+
+#### 2.2.2. 继承
+
+不同类型的对象,相互之间经常有一定数量的共同点。例如,小明同学、小红同学、小李同学,都共享学生的特性(班级、学号等)。同时,每一个对象还定义了额外的特性使得他们与众不同。例如小明的数学比较好,小红的性格惹人喜爱;小李的力气比较大。继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通过使用继承,可以快速地创建新的类,可以提高代码的重用,程序的可维护性,节省大量创建新类的时间 ,提高我们的开发效率。
**关于继承如下 3 点请记住:**
@@ -193,124 +966,138 @@ Constructor 不能被 override(重写),但是可以 overload(重载),所
2. 子类可以拥有自己属性和方法,即子类可以对父类进行扩展。
3. 子类可以用自己的方式实现父类的方法。(以后介绍)。
-### 多态
+#### 2.2.3. 多态
-所谓多态就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量到底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。
+多态,顾名思义,表示一个对象具有多种的状态。具体表现为父类的引用指向子类的实例。
-在Java中有两种形式可以实现多态:继承(多个子类对同一方法的重写)和接口(实现接口并覆盖接口中同一方法)。
+**多态的特点:**
-## 12. String StringBuffer 和 StringBuilder 的区别是什么? String 为什么是不可变的?
+- 对象类型和引用类型之间具有继承(类)/实现(接口)的关系;
+- 对象类型不可变,引用类型可变;
+- 方法具有多态性,属性不具有多态性;
+- 引用类型变量发出的方法调用的到底是哪个类中的方法,必须在程序运行期间才能确定;
+- 多态不能调用“只在子类存在但在父类不存在”的方法;
+- 如果子类重写了父类的方法,真正执行的是子类覆盖的方法,如果子类没有覆盖父类的方法,执行的是父类的方法。
-**可变性**
+### 2.3. 修饰符
-简单的来说:String 类中使用 final 关键字修饰字符数组来保存字符串,`private final char value[]`,所以 String 对象是不可变的。而StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类,在 AbstractStringBuilder 中也是使用字符数组保存字符串`char[]value` 但是没有用 final 关键字修饰,所以这两种对象都是可变的。
-
-StringBuilder 与 StringBuffer 的构造方法都是调用父类构造方法也就是 AbstractStringBuilder 实现的,大家可以自行查阅源码。
-
-AbstractStringBuilder.java
-
-```java
-abstract class AbstractStringBuilder implements Appendable, CharSequence {
- char[] value;
- int count;
- AbstractStringBuilder() {
- }
- AbstractStringBuilder(int capacity) {
- value = new char[capacity];
- }
-```
-
-
-**线程安全性**
-
-String 中的对象是不可变的,也就可以理解为常量,线程安全。AbstractStringBuilder 是 StringBuilder 与 StringBuffer 的公共父类,定义了一些字符串的基本操作,如 expandCapacity、append、insert、indexOf 等公共方法。StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。
-
-**性能**
-
-每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 StringBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
-
-**对于三者使用的总结:**
-
-1. 操作少量的数据: 适用String
-2. 单线程操作字符串缓冲区下操作大量数据: 适用StringBuilder
-3. 多线程操作字符串缓冲区下操作大量数据: 适用StringBuffer
-
-## 13. 自动装箱与拆箱
-
-- **装箱**:将基本类型用它们对应的引用类型包装起来;
-- **拆箱**:将包装类型转换为基本数据类型;
-
-## 14. 在一个静态方法内调用一个非静态成员为什么是非法的?
+#### 2.3.1. 在一个静态方法内调用一个非静态成员为什么是非法的?
由于静态方法可以不通过对象进行调用,因此在静态方法里,不能调用其他非静态变量,也不可以访问非静态变量成员。
-## 15. 在 Java 中定义一个不做事且没有参数的构造方法的作用
+#### 2.3.2. 静态方法和实例方法有何不同
-Java 程序在执行子类的构造方法之前,如果没有用 `super() `来调用父类特定的构造方法,则会调用父类中“没有参数的构造方法”。因此,如果父类中只定义了有参数的构造方法,而在子类的构造方法中又没有用 `super() `来调用父类中特定的构造方法,则编译时将发生错误,因为 Java 程序在父类中找不到没有参数的构造方法可供执行。解决办法是在父类里加上一个不做事且没有参数的构造方法。
-
-## 16. import java和javax有什么区别?
-
-刚开始的时候 JavaAPI 所必需的包是 java 开头的包,javax 当时只是扩展 API 包来使用。然而随着时间的推移,javax 逐渐地扩展成为 Java API 的组成部分。但是,将扩展从 javax 包移动到 java 包确实太麻烦了,最终会破坏一堆现有的代码。因此,最终决定 javax 包将成为标准API的一部分。
-
-所以,实际上java和javax没有区别。这都是一个名字。
-
-## 17. 接口和抽象类的区别是什么?
-
-1. 接口的方法默认是 public,所有方法在接口中不能有实现(Java 8 开始接口方法可以有默认实现),而抽象类可以有非抽象的方法。
-2. 接口中除了static、final变量,不能有其他变量,而抽象类中则不一定。
-3. 一个类可以实现多个接口,但只能实现一个抽象类。接口自己本身可以通过extends关键字扩展多个接口。
-4. 接口方法默认修饰符是public,抽象方法可以有public、protected和default这些修饰符(抽象方法就是为了被重写所以不能使用private关键字修饰!)。
-5. 从设计层面来说,抽象是对类的抽象,是一种模板设计,而接口是对行为的抽象,是一种行为的规范。
-
-备注:在JDK8中,接口也可以定义静态方法,可以直接用接口名调用。实现类和实现是不可以调用的。如果同时实现两个接口,接口中定义了一样的默认方法,则必须重写,不然会报错。(详见issue:[https://github.com/Snailclimb/JavaGuide/issues/146](https://github.com/Snailclimb/JavaGuide/issues/146))
-
-## 18. 成员变量与局部变量的区别有哪些?
-
-1. 从语法形式上看:成员变量是属于类的,而局部变量是在方法中定义的变量或是方法的参数;成员变量可以被 public,private,static 等修饰符所修饰,而局部变量不能被访问控制修饰符及 static 所修饰;但是,成员变量和局部变量都能被 final 所修饰。
-2. 从变量在内存中的存储方式来看:如果成员变量是使用`static`修饰的,那么这个成员变量是属于类的,如果没有使用`static`修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量则存在于栈内存。
-3. 从变量在内存中的生存时间上看:成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动消失。
-4. 成员变量如果没有被赋初值:则会自动以类型的默认值而赋值(一种情况例外:被 final 修饰的成员变量也必须显式地赋值),而局部变量则不会自动赋值。
-
-## 19. 创建一个对象用什么运算符?对象实体与对象引用有何不同?
-
-new运算符,new创建对象实例(对象实例在堆内存中),对象引用指向对象实例(对象引用存放在栈内存中)。一个对象引用可以指向0个或1个对象(一根绳子可以不系气球,也可以系一个气球);一个对象可以有n个引用指向它(可以用n条绳子系住一个气球)。
-
-## 20. 什么是方法的返回值?返回值在类的方法里的作用是什么?
-
-方法的返回值是指我们获取到的某个方法体中的代码执行后产生的结果!(前提是该方法可能产生结果)。返回值的作用:接收出结果,使得它可以用于其他的操作!
-
-## 21. 一个类的构造方法的作用是什么? 若一个类没有声明构造方法,该程序能正确执行吗? 为什么?
-
-主要作用是完成对类对象的初始化工作。可以执行。因为一个类即使没有声明构造方法也会有默认的不带参数的构造方法。
-
-## 22. 构造方法有哪些特性?
-
-1. 名字与类名相同。
-2. 没有返回值,但不能用void声明构造函数。
-3. 生成类的对象时自动执行,无需调用。
-
-## 23. 静态方法和实例方法有何不同
-
-1. 在外部调用静态方法时,可以使用"类名.方法名"的方式,也可以使用"对象名.方法名"的方式。而实例方法只有后面这种方式。也就是说,调用静态方法可以无需创建对象。
+1. 在外部调用静态方法时,可以使用"类名.方法名"的方式,也可以使用"对象名.方法名"的方式。而实例方法只有后面这种方式。也就是说,调用静态方法可以无需创建对象。
2. 静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),而不允许访问实例成员变量和实例方法;实例方法则无此限制。
-## 24. 对象的相等与指向他们的引用相等,两者有什么不同?
+#### 2.3.3. 常见关键字总结:static,final,this,super
-对象的相等,比的是内存中存放的内容是否相等。而引用相等,比较的是他们指向的内存地址是否相等。
+详见笔主的这篇文章: https://snailclimb.gitee.io/javaguide/#/docs/java/basic/final,static,this,super
-## 25. 在调用子类构造方法之前会先调用父类没有参数的构造方法,其目的是?
+### 2.4. 接口和抽象类
-帮助子类做初始化工作。
+#### 2.4.1. 接口和抽象类的区别是什么?
-## 26. == 与 equals(重要)
+1. 接口的方法默认是 public,所有方法在接口中不能有实现(Java 8 开始接口方法可以有默认实现),而抽象类可以有非抽象的方法。
+2. 接口中除了 static、final 变量,不能有其他变量,而抽象类中则不一定。
+3. 一个类可以实现多个接口,但只能实现一个抽象类。接口自己本身可以通过 extends 关键字扩展多个接口。
+4. 接口方法默认修饰符是 public,抽象方法可以有 public、protected 和 default 这些修饰符(抽象方法就是为了被重写所以不能使用 private 关键字修饰!)。
+5. 从设计层面来说,抽象是对类的抽象,是一种模板设计,而接口是对行为的抽象,是一种行为的规范。
+
+> 备注:
+>
+> 1. 在 JDK8 中,接口也可以定义静态方法,可以直接用接口名调用。实现类和实现是不可以调用的。如果同时实现两个接口,接口中定义了一样的默认方法,则必须重写,不然会报错。(详见 issue:[https://github.com/Snailclimb/JavaGuide/issues/146](https://github.com/Snailclimb/JavaGuide/issues/146)。
+> 2. jdk9 的接口被允许定义私有方法 。
+
+总结一下 jdk7~jdk9 Java 中接口概念的变化([相关阅读](https://www.geeksforgeeks.org/private-methods-java-9-interfaces/)):
+
+1. 在 jdk 7 或更早版本中,接口里面只能有常量变量和抽象方法。这些接口方法必须由选择实现接口的类实现。
+2. jdk8 的时候接口可以有默认方法和静态方法功能。
+3. Jdk 9 在接口中引入了私有方法和私有静态方法。
+
+### 2.5. 其它重要知识点
+
+#### 2.5.1. String StringBuffer 和 StringBuilder 的区别是什么? String 为什么是不可变的?
+
+简单的来说:`String` 类中使用 final 关键字修饰字符数组来保存字符串,`private final char value[]`,所以` String` 对象是不可变的。
+
+> 补充(来自[issue 675](https://github.com/Snailclimb/JavaGuide/issues/675)):在 Java 9 之后,String 类的实现改用 byte 数组存储字符串 `private final byte[] value`;
+
+而 `StringBuilder` 与 `StringBuffer` 都继承自 `AbstractStringBuilder` 类,在 `AbstractStringBuilder` 中也是使用字符数组保存字符串`char[]value` 但是没有用 `final` 关键字修饰,所以这两种对象都是可变的。
+
+`StringBuilder` 与 `StringBuffer` 的构造方法都是调用父类构造方法也就是`AbstractStringBuilder` 实现的,大家可以自行查阅源码。
+
+`AbstractStringBuilder.java`
+
+```java
+abstract class AbstractStringBuilder implements Appendable, CharSequence {
+ /**
+ * The value is used for character storage.
+ */
+ char[] value;
+
+ /**
+ * The count is the number of characters used.
+ */
+ int count;
+
+ AbstractStringBuilder(int capacity) {
+ value = new char[capacity];
+ }}
+```
+
+**线程安全性**
+
+`String` 中的对象是不可变的,也就可以理解为常量,线程安全。`AbstractStringBuilder` 是 `StringBuilder` 与 `StringBuffer` 的公共父类,定义了一些字符串的基本操作,如 `expandCapacity`、`append`、`insert`、`indexOf` 等公共方法。`StringBuffer` 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。`StringBuilder` 并没有对方法进行加同步锁,所以是非线程安全的。
+
+**性能**
+
+每次对 `String` 类型进行改变的时候,都会生成一个新的 `String` 对象,然后将指针指向新的 `String` 对象。`StringBuffer` 每次都会对 `StringBuffer` 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 `StringBuilder` 相比使用 `StringBuffer` 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
+
+**对于三者使用的总结:**
+
+1. 操作少量的数据: 适用 `String`
+2. 单线程操作字符串缓冲区下操作大量数据: 适用 `StringBuilder`
+3. 多线程操作字符串缓冲区下操作大量数据: 适用 `StringBuffer`
+
+#### 2.5.2. Object 类的常见方法总结
+
+Object 类是一个特殊的类,是所有类的父类。它主要提供了以下 11 个方法:
+
+```java
+
+public final native Class getClass()//native方法,用于返回当前运行时对象的Class对象,使用了final关键字修饰,故不允许子类重写。
+
+public native int hashCode() //native方法,用于返回对象的哈希码,主要使用在哈希表中,比如JDK中的HashMap。
+public boolean equals(Object obj)//用于比较2个对象的内存地址是否相等,String类对该方法进行了重写用户比较字符串的值是否相等。
+
+protected native Object clone() throws CloneNotSupportedException//naitive方法,用于创建并返回当前对象的一份拷贝。一般情况下,对于任何对象 x,表达式 x.clone() != x 为true,x.clone().getClass() == x.getClass() 为true。Object本身没有实现Cloneable接口,所以不重写clone方法并且进行调用的话会发生CloneNotSupportedException异常。
+
+public String toString()//返回类的名字@实例的哈希码的16进制的字符串。建议Object所有的子类都重写这个方法。
+
+public final native void notify()//native方法,并且不能重写。唤醒一个在此对象监视器上等待的线程(监视器相当于就是锁的概念)。如果有多个线程在等待只会任意唤醒一个。
+
+public final native void notifyAll()//native方法,并且不能重写。跟notify一样,唯一的区别就是会唤醒在此对象监视器上等待的所有线程,而不是一个线程。
+
+public final native void wait(long timeout) throws InterruptedException//native方法,并且不能重写。暂停线程的执行。注意:sleep方法没有释放锁,而wait方法释放了锁 。timeout是等待时间。
+
+public final void wait(long timeout, int nanos) throws InterruptedException//多了nanos参数,这个参数表示额外时间(以毫微秒为单位,范围是 0-999999)。 所以超时的时间还需要加上nanos毫秒。
+
+public final void wait() throws InterruptedException//跟之前的2个wait方法一样,只不过该方法一直等待,没有超时时间这个概念
+
+protected void finalize() throws Throwable { }//实例被垃圾回收器回收的时候触发的操作
+
+```
+
+#### 2.5.3. == 与 equals(重要)
**==** : 它的作用是判断两个对象的地址是不是相等。即,判断两个对象是不是同一个对象(基本数据类型==比较的是值,引用数据类型==比较的是内存地址)。
**equals()** : 它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
-- 情况1:类没有覆盖 equals() 方法。则通过 equals() 比较该类的两个对象时,等价于通过“==”比较这两个对象。
-- 情况2:类覆盖了 equals() 方法。一般,我们都覆盖 equals() 方法来比较两个对象的内容是否相等;若它们的内容相等,则返回 true (即,认为这两个对象相等)。
+- 情况 1:类没有覆盖 equals() 方法。则通过 equals() 比较该类的两个对象时,等价于通过“==”比较这两个对象。
+- 情况 2:类覆盖了 equals() 方法。一般,我们都覆盖 equals() 方法来比较两个对象的内容是否相等;若它们的内容相等,则返回 true (即,认为这两个对象相等)。
**举个例子:**
@@ -339,120 +1126,114 @@ public class test1 {
- String 中的 equals 方法是被重写过的,因为 object 的 equals 方法是比较的对象的内存地址,而 String 的 equals 方法比较的是对象的值。
- 当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 String 对象。
-## 27. hashCode 与 equals (重要)
-面试官可能会问你:“你重写过 hashcode 和 equals 么,为什么重写equals时必须重写hashCode方法?”
+#### 2.5.4. hashCode 与 equals (重要)
-### hashCode()介绍
-hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在JDK的Object.java中,这就意味着Java中的任何类都包含有hashCode() 函数。
+面试官可能会问你:“你重写过 hashcode 和 equals 么,为什么重写 equals 时必须重写 hashCode 方法?”
+
+##### 2.5.4.1. hashCode()介绍
+
+hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个 int 整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在 JDK 的 Object.java 中,这就意味着 Java 中的任何类都包含有 hashCode() 函数。
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
-### 为什么要有 hashCode
+##### 2.5.4.2. 为什么要有 hashCode
-**我们先以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode:** 当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 `equals()`方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的Java启蒙书《Head first java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
+**我们先以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode:** 当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与该位置其他已经加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 `equals()`方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的 Java 启蒙书《Head first java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
-通过我们可以看出:`hashCode()` 的作用就是**获取哈希码**,也称为散列码;它实际上是返回一个int整数。这个**哈希码的作用**是确定该对象在哈希表中的索引位置。**`hashCode() `在散列表中才有用,在其它情况下没用**。在散列表中hashCode() 的作用是获取对象的散列码,进而确定该对象在散列表中的位置。
+通过我们可以看出:`hashCode()` 的作用就是**获取哈希码**,也称为散列码;它实际上是返回一个 int 整数。这个**哈希码的作用**是确定该对象在哈希表中的索引位置。**`hashCode()`在散列表中才有用,在其它情况下没用**。在散列表中 hashCode() 的作用是获取对象的散列码,进而确定该对象在散列表中的位置。
-### hashCode()与equals()的相关规定
+##### 2.5.4.3. hashCode()与 equals()的相关规定
-1. 如果两个对象相等,则hashcode一定也是相同的
-2. 两个对象相等,对两个对象分别调用equals方法都返回true
-3. 两个对象有相同的hashcode值,它们也不一定是相等的
+1. 如果两个对象相等,则 hashcode 一定也是相同的
+2. 两个对象相等,对两个对象分别调用 equals 方法都返回 true
+3. 两个对象有相同的 hashcode 值,它们也不一定是相等的
4. **因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖**
5. hashCode() 的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
推荐阅读:[Java hashCode() 和 equals()的若干问题解答](https://www.cnblogs.com/skywang12345/p/3324958.html)
+#### 2.5.5. Java 序列化中如果有些字段不想进行序列化,怎么办?
-## 28. 为什么Java中只有值传递?
+对于不想进行序列化的变量,使用 transient 关键字修饰。
-[为什么Java中只有值传递?](https://juejin.im/post/5e18879e6fb9a02fc63602e2)
+transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。transient 只能修饰变量,不能修饰类和方法。
+
+#### 2.5.6. 获取用键盘输入常用的两种方法
+
+方法 1:通过 Scanner
+
+```java
+Scanner input = new Scanner(System.in);
+String s = input.nextLine();
+input.close();
+```
+
+方法 2:通过 BufferedReader
+
+```java
+BufferedReader input = new BufferedReader(new InputStreamReader(System.in));
+String s = input.readLine();
+```
+
+## 3. Java 核心技术
+
+### 3.1. 集合
+
+#### 3.1.1. Collections 工具类和 Arrays 工具类常见方法总结
+
+详见笔主的这篇文章: https://gitee.com/SnailClimb/JavaGuide/blob/master/docs/java/basic/Arrays,CollectionsCommonMethods.md
+
+### 3.2. 异常
+
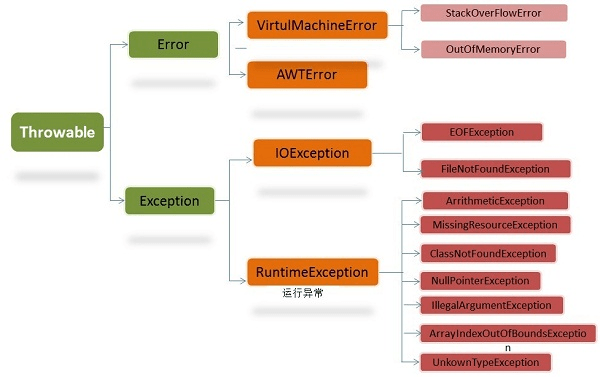
+#### 3.2.1. Java 异常类层次结构图
+
+
-## 29. 简述线程、程序、进程的基本概念。以及他们之间关系是什么?
+图片来自:https://simplesnippets.tech/exception-handling-in-java-part-1/
-**线程**与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享同一块内存空间和一组系统资源,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
-
-**程序**是含有指令和数据的文件,被存储在磁盘或其他的数据存储设备中,也就是说程序是静态的代码。
-
-**进程**是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。简单来说,一个进程就是一个执行中的程序,它在计算机中一个指令接着一个指令地执行着,同时,每个进程还占有某些系统资源如CPU时间,内存空间,文件,输入输出设备的使用权等等。换句话说,当程序在执行时,将会被操作系统载入内存中。
-线程是进程划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。从另一角度来说,进程属于操作系统的范畴,主要是同一段时间内,可以同时执行一个以上的程序,而线程则是在同一程序内几乎同时执行一个以上的程序段。
-
-## 30. 线程有哪些基本状态?
-
-Java 线程在运行的生命周期中的指定时刻只可能处于下面6种不同状态的其中一个状态(图源《Java 并发编程艺术》4.1.4节)。
-
-
-
-线程在生命周期中并不是固定处于某一个状态而是随着代码的执行在不同状态之间切换。Java 线程状态变迁如下图所示(图源《Java 并发编程艺术》4.1.4节):
-
-
+
+图片来自:https://chercher.tech/java-programming/exceptions-java
-由上图可以看出:
+在 Java 中,所有的异常都有一个共同的祖先 java.lang 包中的 **Throwable 类**。Throwable: 有两个重要的子类:**Exception(异常)** 和 **Error(错误)** ,二者都是 Java 异常处理的重要子类,各自都包含大量子类。
-线程创建之后它将处于 **NEW(新建)** 状态,调用 `start()` 方法后开始运行,线程这时候处于 **READY(可运行)** 状态。可运行状态的线程获得了 cpu 时间片(timeslice)后就处于 **RUNNING(运行)** 状态。
+**Error(错误):是程序无法处理的错误**,表示运行应用程序中较严重问题。大多数错误与代码编写者执行的操作无关,而表示代码运行时 JVM(Java 虚拟机)出现的问题。例如,Java 虚拟机运行错误(Virtual MachineError),当 JVM 不再有继续执行操作所需的内存资源时,将出现 OutOfMemoryError。这些异常发生时,Java 虚拟机(JVM)一般会选择线程终止。
-> 操作系统隐藏 Java虚拟机(JVM)中的 READY 和 RUNNING 状态,它只能看到 RUNNABLE 状态(图源:[HowToDoInJava](https://howtodoinjava.com/):[Java Thread Life Cycle and Thread States](https://howtodoinjava.com/java/multi-threading/java-thread-life-cycle-and-thread-states/)),所以 Java 系统一般将这两个状态统称为 **RUNNABLE(运行中)** 状态 。
+这些错误表示故障发生于虚拟机自身、或者发生在虚拟机试图执行应用时,如 Java 虚拟机运行错误(Virtual MachineError)、类定义错误(NoClassDefFoundError)等。这些错误是不可查的,因为它们在应用程序的控制和处理能力之 外,而且绝大多数是程序运行时不允许出现的状况。对于设计合理的应用程序来说,即使确实发生了错误,本质上也不应该试图去处理它所引起的异常状况。在 Java 中,错误通过 Error 的子类描述。
-
-
-当线程执行 `wait()`方法之后,线程进入 **WAITING(等待)**状态。进入等待状态的线程需要依靠其他线程的通知才能够返回到运行状态,而 **TIME_WAITING(超时等待)** 状态相当于在等待状态的基础上增加了超时限制,比如通过 `sleep(long millis)`方法或 `wait(long millis)`方法可以将 Java 线程置于 TIMED WAITING 状态。当超时时间到达后 Java 线程将会返回到 RUNNABLE 状态。当线程调用同步方法时,在没有获取到锁的情况下,线程将会进入到 **BLOCKED(阻塞)** 状态。线程在执行 Runnable 的` run() `方法之后将会进入到 **TERMINATED(终止)** 状态。
-
-## 31 关于 final 关键字的一些总结
-
-final关键字主要用在三个地方:变量、方法、类。
-
-1. 对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。
-2. 当用final修饰一个类时,表明这个类不能被继承。final类中的所有成员方法都会被隐式地指定为final方法。
-3. 使用final方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。在早期的Java实现版本中,会将final方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何性能提升(现在的Java版本已经不需要使用final方法进行这些优化了)。类中所有的private方法都隐式地指定为final。
-
-## 32 Java 中的异常处理
-
-### Java异常类层次结构图
-
-
-
-
-
-在 Java 中,所有的异常都有一个共同的祖先java.lang包中的 **Throwable类**。Throwable: 有两个重要的子类:**Exception(异常)** 和 **Error(错误)** ,二者都是 Java 异常处理的重要子类,各自都包含大量子类。
-
-**Error(错误):是程序无法处理的错误**,表示运行应用程序中较严重问题。大多数错误与代码编写者执行的操作无关,而表示代码运行时 JVM(Java 虚拟机)出现的问题。例如,Java虚拟机运行错误(Virtual MachineError),当 JVM 不再有继续执行操作所需的内存资源时,将出现 OutOfMemoryError。这些异常发生时,Java虚拟机(JVM)一般会选择线程终止。
-
-这些错误表示故障发生于虚拟机自身、或者发生在虚拟机试图执行应用时,如Java虚拟机运行错误(Virtual MachineError)、类定义错误(NoClassDefFoundError)等。这些错误是不可查的,因为它们在应用程序的控制和处理能力之 外,而且绝大多数是程序运行时不允许出现的状况。对于设计合理的应用程序来说,即使确实发生了错误,本质上也不应该试图去处理它所引起的异常状况。在 Java中,错误通过Error的子类描述。
-
-**Exception(异常):是程序本身可以处理的异常**。Exception 类有一个重要的子类 **RuntimeException**。RuntimeException 异常由Java虚拟机抛出。**NullPointerException**(要访问的变量没有引用任何对象时,抛出该异常)、**ArithmeticException**(算术运算异常,一个整数除以0时,抛出该异常)和 **ArrayIndexOutOfBoundsException** (下标越界异常)。
+**Exception(异常):是程序本身可以处理的异常**。Exception 类有一个重要的子类 **RuntimeException**。RuntimeException 异常由 Java 虚拟机抛出。**NullPointerException**(要访问的变量没有引用任何对象时,抛出该异常)、**ArithmeticException**(算术运算异常,一个整数除以 0 时,抛出该异常)和 **ArrayIndexOutOfBoundsException** (下标越界异常)。
**注意:异常和错误的区别:异常能被程序本身处理,错误是无法处理。**
-### Throwable类常用方法
+#### 3.2.2. Throwable 类常用方法
-- **public string getMessage()**:返回异常发生时的简要描述
-- **public string toString()**:返回异常发生时的详细信息
-- **public string getLocalizedMessage()**:返回异常对象的本地化信息。使用Throwable的子类覆盖这个方法,可以生成本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与getMessage()返回的结果相同
-- **public void printStackTrace()**:在控制台上打印Throwable对象封装的异常信息
+- **`public string getMessage()`**:返回异常发生时的简要描述
+- **`public string toString()`**:返回异常发生时的详细信息
+- **`public string getLocalizedMessage()`**:返回异常对象的本地化信息。使用 `Throwable` 的子类覆盖这个方法,可以生成本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与 `getMessage()`返回的结果相同
+- **`public void printStackTrace()`**:在控制台上打印 `Throwable` 对象封装的异常信息
-### 异常处理总结
+#### 3.2.3. try-catch-finally
-- **try 块:** 用于捕获异常。其后可接零个或多个catch块,如果没有catch块,则必须跟一个finally块。
-- **catch 块:** 用于处理try捕获到的异常。
-- **finally 块:** 无论是否捕获或处理异常,finally块里的语句都会被执行。当在try块或catch块中遇到return
-语句时,finally语句块将在方法返回之前被执行。
+- **try 块:** 用于捕获异常。其后可接零个或多个 catch 块,如果没有 catch 块,则必须跟一个 finally 块。
+- **catch 块:** 用于处理 try 捕获到的异常。
+- **finally 块:** 无论是否捕获或处理异常,finally 块里的语句都会被执行。当在 try 块或 catch 块中遇到 return 语句时,finally 语句块将在方法返回之前被执行。
-**在以下4种特殊情况下,finally块不会被执行:**
+**在以下 4 种特殊情况下,finally 块不会被执行:**
-1. 在finally语句块第一行发生了异常。 因为在其他行,finally块还是会得到执行
-2. 在前面的代码中用了System.exit(int)已退出程序。 exit是带参函数 ;若该语句在异常语句之后,finally会执行
+1. 在 finally 语句块第一行发生了异常。 因为在其他行,finally 块还是会得到执行
+2. 在前面的代码中用了 System.exit(int)已退出程序。 exit 是带参函数 ;若该语句在异常语句之后,finally 会执行
3. 程序所在的线程死亡。
-4. 关闭CPU。
+4. 关闭 CPU。
-下面这部分内容来自issue:。
+下面这部分内容来自 issue:。
-**注意:** 当try语句和finally语句中都有return语句时,在方法返回之前,finally语句的内容将被执行,并且finally语句的返回值将会覆盖原始的返回值。如下:
+**注意:** 当 try 语句和 finally 语句中都有 return 语句时,在方法返回之前,finally 语句的内容将被执行,并且 finally 语句的返回值将会覆盖原始的返回值。如下:
```java
+public class Test {
public static int f(int value) {
try {
return value * value;
@@ -462,95 +1243,144 @@ final关键字主要用在三个地方:变量、方法、类。
}
}
}
+}
```
-如果调用 `f(2)`,返回值将是0,因为finally语句的返回值覆盖了try语句块的返回值。
+如果调用 `f(2)`,返回值将是 0,因为 finally 语句的返回值覆盖了 try 语句块的返回值。
-## 33 Java序列化中如果有些字段不想进行序列化,怎么办?
+#### 3.2.4. 使用 `try-with-resources` 来代替`try-catch-finally`
-对于不想进行序列化的变量,使用transient关键字修饰。
+1. **适用范围(资源的定义):** 任何实现 `java.lang.AutoCloseable`或者``java.io.Closeable` 的对象
+2. **关闭资源和final的执行顺序:** 在 `try-with-resources` 语句中,任何 catch 或 finally 块在声明的资源关闭后运行
-transient关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被transient修饰的变量值不会被持久化和恢复。transient只能修饰变量,不能修饰类和方法。
+《Effecitve Java》中明确指出:
-## 34 获取用键盘输入常用的两种方法
+> 面对必须要关闭的资源,我们总是应该优先使用 `try-with-resources` 而不是`try-finally`。随之产生的代码更简短,更清晰,产生的异常对我们也更有用。`try-with-resources`语句让我们更容易编写必须要关闭的资源的代码,若采用`try-finally`则几乎做不到这点。
-方法1:通过 Scanner
+Java 中类似于`InputStream`、`OutputStream` 、`Scanner` 、`PrintWriter`等的资源都需要我们调用`close()`方法来手动关闭,一般情况下我们都是通过`try-catch-finally`语句来实现这个需求,如下:
```java
-Scanner input = new Scanner(System.in);
-String s = input.nextLine();
-input.close();
+ //读取文本文件的内容
+ Scanner scanner = null;
+ try {
+ scanner = new Scanner(new File("D://read.txt"));
+ while (scanner.hasNext()) {
+ System.out.println(scanner.nextLine());
+ }
+ } catch (FileNotFoundException e) {
+ e.printStackTrace();
+ } finally {
+ if (scanner != null) {
+ scanner.close();
+ }
+ }
```
-方法2:通过 BufferedReader
+使用Java 7之后的 `try-with-resources` 语句改造上面的代码:
```java
-BufferedReader input = new BufferedReader(new InputStreamReader(System.in));
-String s = input.readLine();
+try (Scanner scanner = new Scanner(new File("test.txt"))) {
+ while (scanner.hasNext()) {
+ System.out.println(scanner.nextLine());
+ }
+} catch (FileNotFoundException fnfe) {
+ fnfe.printStackTrace();
+}
```
-## 35 Java 中 IO 流
+当然多个资源需要关闭的时候,使用 `try-with-resources` 实现起来也非常简单,如果你还是用`try-catch-finally`可能会带来很多问题。
-### Java 中 IO 流分为几种?
+通过使用分号分隔,可以在`try-with-resources`块中声明多个资源。
- - 按照流的流向分,可以分为输入流和输出流;
- - 按照操作单元划分,可以划分为字节流和字符流;
- - 按照流的角色划分为节点流和处理流。
+```java
+try (BufferedInputStream bin = new BufferedInputStream(new FileInputStream(new File("test.txt")));
+ BufferedOutputStream bout = new BufferedOutputStream(new FileOutputStream(new File("out.txt")))) {
+ int b;
+ while ((b = bin.read()) != -1) {
+ bout.write(b);
+ }
+ }
+ catch (IOException e) {
+ e.printStackTrace();
+ }
+```
-Java Io流共涉及40多个类,这些类看上去很杂乱,但实际上很有规则,而且彼此之间存在非常紧密的联系, Java I0流的40多个类都是从如下4个抽象类基类中派生出来的。
+### 3.3. 多线程
- - InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。
- - OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
+#### 3.3.1. 简述线程、程序、进程的基本概念。以及他们之间关系是什么?
+
+**线程**与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享同一块内存空间和一组系统资源,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
+
+**程序**是含有指令和数据的文件,被存储在磁盘或其他的数据存储设备中,也就是说程序是静态的代码。
+
+**进程**是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。简单来说,一个进程就是一个执行中的程序,它在计算机中一个指令接着一个指令地执行着,同时,每个进程还占有某些系统资源如 CPU 时间,内存空间,文件,输入输出设备的使用权等等。换句话说,当程序在执行时,将会被操作系统载入内存中。
+线程是进程划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。从另一角度来说,进程属于操作系统的范畴,主要是同一段时间内,可以同时执行一个以上的程序,而线程则是在同一程序内几乎同时执行一个以上的程序段。
+
+#### 3.3.2. 线程有哪些基本状态?
+
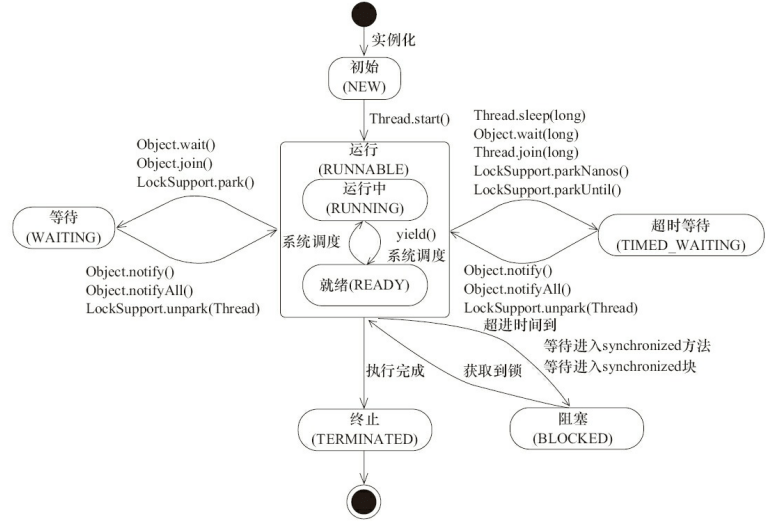
+Java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种不同状态的其中一个状态(图源《Java 并发编程艺术》4.1.4 节)。
+
+
+
+线程在生命周期中并不是固定处于某一个状态而是随着代码的执行在不同状态之间切换。Java 线程状态变迁如下图所示(图源《Java 并发编程艺术》4.1.4 节):
+
+
+
+由上图可以看出:
+
+线程创建之后它将处于 **NEW(新建)** 状态,调用 `start()` 方法后开始运行,线程这时候处于 **READY(可运行)** 状态。可运行状态的线程获得了 cpu 时间片(timeslice)后就处于 **RUNNING(运行)** 状态。
+
+> 操作系统隐藏 Java 虚拟机(JVM)中的 READY 和 RUNNING 状态,它只能看到 RUNNABLE 状态(图源:[HowToDoInJava](https://howtodoinjava.com/):[Java Thread Life Cycle and Thread States](https://howtodoinjava.com/java/multi-threading/java-thread-life-cycle-and-thread-states/)),所以 Java 系统一般将这两个状态统称为 **RUNNABLE(运行中)** 状态 。
+
+
+
+当线程执行 `wait()`方法之后,线程进入 **WAITING(等待)**状态。进入等待状态的线程需要依靠其他线程的通知才能够返回到运行状态,而 **TIME_WAITING(超时等待)** 状态相当于在等待状态的基础上增加了超时限制,比如通过 `sleep(long millis)`方法或 `wait(long millis)`方法可以将 Java 线程置于 TIMED WAITING 状态。当超时时间到达后 Java 线程将会返回到 RUNNABLE 状态。当线程调用同步方法时,在没有获取到锁的情况下,线程将会进入到 **BLOCKED(阻塞)** 状态。线程在执行 Runnable 的`run()`方法之后将会进入到 **TERMINATED(终止)** 状态。
+
+### 3.4. 文件与 I\O 流
+
+#### 3.4.1. Java 中 IO 流分为几种?
+
+- 按照流的流向分,可以分为输入流和输出流;
+- 按照操作单元划分,可以划分为字节流和字符流;
+- 按照流的角色划分为节点流和处理流。
+
+Java Io 流共涉及 40 多个类,这些类看上去很杂乱,但实际上很有规则,而且彼此之间存在非常紧密的联系, Java I0 流的 40 多个类都是从如下 4 个抽象类基类中派生出来的。
+
+- InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。
+- OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
按操作方式分类结构图:
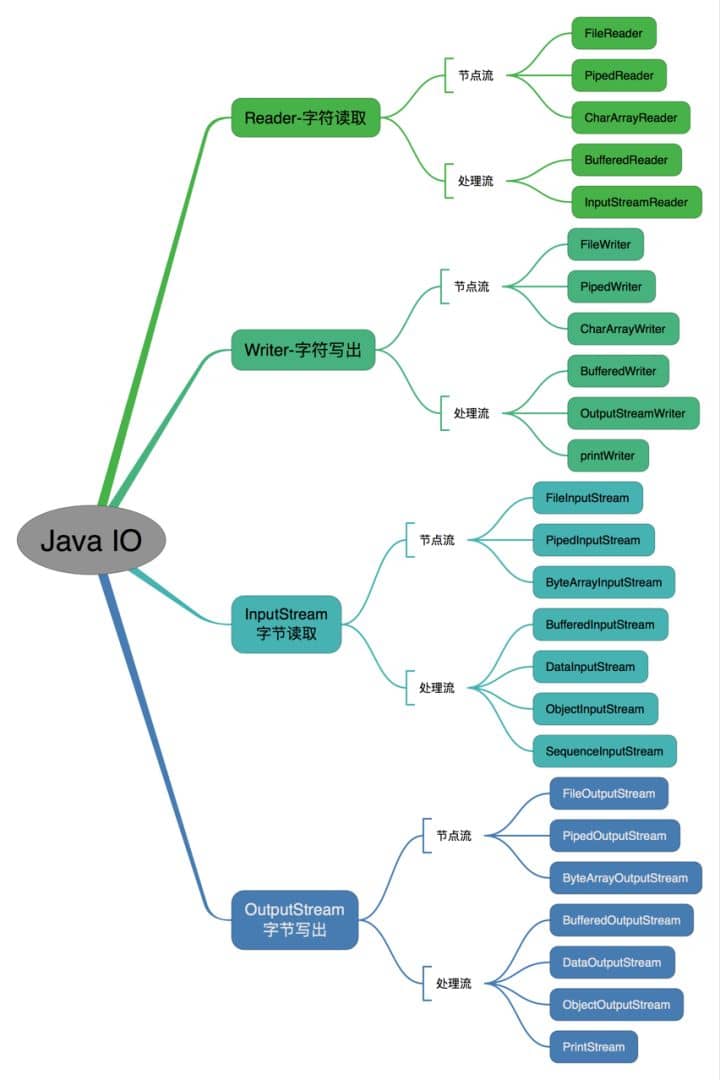
-
按操作对象分类结构图:
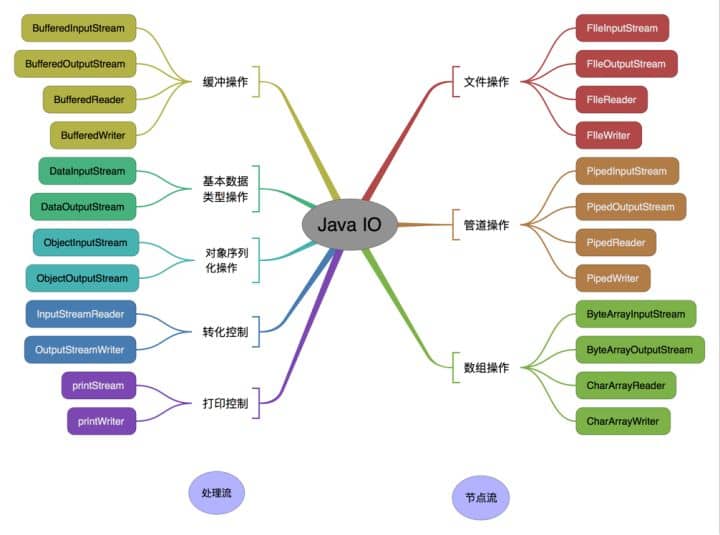
-### 既然有了字节流,为什么还要有字符流?
+##### 3.4.1.1. 既然有了字节流,为什么还要有字符流?
问题本质想问:**不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?**
回答:字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
-### BIO,NIO,AIO 有什么区别?
+##### 3.4.1.2. BIO,NIO,AIO 有什么区别?
-- **BIO (Blocking I/O):** 同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
-- **NIO (New I/O):** NIO是一种同步非阻塞的I/O模型,在Java 1.4 中引入了NIO框架,对应 java.nio 包,提供了 Channel , Selector,Buffer等抽象。NIO中的N可以理解为Non-blocking,不单纯是New。它支持面向缓冲的,基于通道的I/O操作方法。 NIO提供了与传统BIO模型中的 `Socket` 和 `ServerSocket` 相对应的 `SocketChannel` 和 `ServerSocketChannel` 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞I/O来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发
-- **AIO (Asynchronous I/O):** AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的IO模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。AIO 是异步IO的缩写,虽然 NIO 在网络操作中,提供了非阻塞的方法,但是 NIO 的 IO 行为还是同步的。对于 NIO 来说,我们的业务线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操作,IO操作本身是同步的。查阅网上相关资料,我发现就目前来说 AIO 的应用还不是很广泛,Netty 之前也尝试使用过 AIO,不过又放弃了。
+- **BIO (Blocking I/O):** 同步阻塞 I/O 模式,数据的读取写入必须阻塞在一个线程内等待其完成。在活动连接数不是特别高(小于单机 1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
+- **NIO (Non-blocking/New I/O):** NIO 是一种同步非阻塞的 I/O 模型,在 Java 1.4 中引入了 NIO 框架,对应 java.nio 包,提供了 Channel , Selector,Buffer 等抽象。NIO 中的 N 可以理解为 Non-blocking,不单纯是 New。它支持面向缓冲的,基于通道的 I/O 操作方法。 NIO 提供了与传统 BIO 模型中的 `Socket` 和 `ServerSocket` 相对应的 `SocketChannel` 和 `ServerSocketChannel` 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞 I/O 来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发
+- **AIO (Asynchronous I/O):** AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的 IO 模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。AIO 是异步 IO 的缩写,虽然 NIO 在网络操作中,提供了非阻塞的方法,但是 NIO 的 IO 行为还是同步的。对于 NIO 来说,我们的业务线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操作,IO 操作本身是同步的。查阅网上相关资料,我发现就目前来说 AIO 的应用还不是很广泛,Netty 之前也尝试使用过 AIO,不过又放弃了。
-## 36. 常见关键字总结:static,final,this,super
-
-详见笔主的这篇文章:
-
-## 37. Collections 工具类和 Arrays 工具类常见方法总结
-
-详见笔主的这篇文章:
-
-### 38. 深拷贝 vs 浅拷贝
-
-1. **浅拷贝**:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。
-2. **深拷贝**:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。
-
-
-
-## 参考
+## 4. 参考
- https://stackoverflow.com/questions/1906445/what-is-the-difference-between-jdk-and-jre
- https://www.educba.com/oracle-vs-openjdk/
- https://stackoverflow.com/questions/22358071/differences-between-oracle-jdk-and-openjdk?answertab=active#tab-top
-## 公众号
+## 5. 公众号
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
+**《Java 面试突击》:** 由本文档衍生的专为面试而生的《Java 面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java 面试突击"** 即可免费领取!
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
+**Java 工程师必备学习资源:** 一些 Java 工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。

-
diff --git a/docs/java/Java疑难点.md b/docs/java/Java疑难点.md
index 1a10e958..41199449 100644
--- a/docs/java/Java疑难点.md
+++ b/docs/java/Java疑难点.md
@@ -1,23 +1,23 @@
-- [1. 基础](#1-基础)
- - [1.1. 正确使用 equals 方法](#11-正确使用-equals-方法)
- - [1.2. 整型包装类值的比较](#12-整型包装类值的比较)
- - [1.3. BigDecimal](#13-bigdecimal)
- - [1.3.1. BigDecimal 的用处](#131-bigdecimal-的用处)
- - [1.3.2. BigDecimal 的大小比较](#132-bigdecimal-的大小比较)
- - [1.3.3. BigDecimal 保留几位小数](#133-bigdecimal-保留几位小数)
- - [1.3.4. BigDecimal 的使用注意事项](#134-bigdecimal-的使用注意事项)
- - [1.3.5. 总结](#135-总结)
- - [1.4. 基本数据类型与包装数据类型的使用标准](#14-基本数据类型与包装数据类型的使用标准)
-- [2. 集合](#2-集合)
- - [2.1. Arrays.asList()使用指南](#21-arraysaslist使用指南)
- - [2.1.1. 简介](#211-简介)
- - [2.1.2. 《阿里巴巴Java 开发手册》对其的描述](#212-阿里巴巴java-开发手册对其的描述)
- - [2.1.3. 使用时的注意事项总结](#213-使用时的注意事项总结)
- - [2.1.4. 如何正确的将数组转换为ArrayList?](#214-如何正确的将数组转换为arraylist)
- - [2.2. Collection.toArray()方法使用的坑&如何反转数组](#22-collectiontoarray方法使用的坑如何反转数组)
- - [2.3. 不要在 foreach 循环里进行元素的 remove/add 操作](#23-不要在-foreach-循环里进行元素的-removeadd-操作)
+- [1. 基础](#_1-基础)
+ - [1.1. 正确使用 equals 方法](#_11-正确使用-equals-方法)
+ - [1.2. 整型包装类值的比较](#_12-整型包装类值的比较)
+ - [1.3. BigDecimal](#_13-bigdecimal)
+ - [1.3.1. BigDecimal 的用处](#_131-bigdecimal-的用处)
+ - [1.3.2. BigDecimal 的大小比较](#_132-bigdecimal-的大小比较)
+ - [1.3.3. BigDecimal 保留几位小数](#_133-bigdecimal-保留几位小数)
+ - [1.3.4. BigDecimal 的使用注意事项](#_134-bigdecimal-的使用注意事项)
+ - [1.3.5. 总结](#_135-总结)
+ - [1.4. 基本数据类型与包装数据类型的使用标准](#_14-基本数据类型与包装数据类型的使用标准)
+- [2. 集合](#_2-集合)
+ - [2.1. Arrays.asList()使用指南](#_21-arraysaslist使用指南)
+ - [2.1.1. 简介](#_211-简介)
+ - [2.1.2. 《阿里巴巴Java 开发手册》对其的描述](#_212-阿里巴巴java-开发手册对其的描述)
+ - [2.1.3. 使用时的注意事项总结](#_213-使用时的注意事项总结)
+ - [2.1.4. 如何正确的将数组转换为ArrayList?](#_214-如何正确的将数组转换为arraylist)
+ - [2.2. Collection.toArray()方法使用的坑&如何反转数组](#_22-collectiontoarray方法使用的坑如何反转数组)
+ - [2.3. 不要在 foreach 循环里进行元素的 remove/add 操作](#_23-不要在-foreach-循环里进行元素的-removeadd-操作)
@@ -52,9 +52,9 @@ Objects.equals(null,"SnailClimb");// false
我们看一下`java.util.Objects#equals`的源码就知道原因了。
```java
public static boolean equals(Object a, Object b) {
- // 可以避免空指针异常。如果a==null的话此时a.equals(b)就不会得到执行,避免出现空指针异常。
- return (a == b) || (a != null && a.equals(b));
- }
+ // 可以避免空指针异常。如果a==null的话此时a.equals(b)就不会得到执行,避免出现空指针异常。
+ return (a == b) || (a != null && a.equals(b));
+}
```
**注意:**
@@ -104,14 +104,18 @@ System.out.println(a == b);// false
BigDecimal a = new BigDecimal("1.0");
BigDecimal b = new BigDecimal("0.9");
BigDecimal c = new BigDecimal("0.8");
-BigDecimal x = a.subtract(b);// 0.1
-BigDecimal y = b.subtract(c);// 0.1
-System.out.println(x.equals(y));// true
+
+BigDecimal x = a.subtract(b);
+BigDecimal y = b.subtract(c);
+
+System.out.println(x); /* 0.1 */
+System.out.println(y); /* 0.1 */
+System.out.println(Objects.equals(x, y)); /* true */
```
### 1.3.2. BigDecimal 的大小比较
-`a.compareTo(b)` : 返回 -1 表示小于,0 表示 等于, 1表示 大于。
+`a.compareTo(b)` : 返回 -1 表示 `a` 小于 `b`,0 表示 `a` 等于 `b` , 1表示 `a` 大于 `b`。
```java
BigDecimal a = new BigDecimal("1.0");
@@ -167,7 +171,7 @@ Reference:《阿里巴巴Java开发手册》
`Arrays.asList()`在平时开发中还是比较常见的,我们可以使用它将一个数组转换为一个List集合。
```java
-String[] myArray = { "Apple", "Banana", "Orange" };
+String[] myArray = {"Apple", "Banana", "Orange"};
List myList = Arrays.asList(myArray);
//上面两个语句等价于下面一条语句
List myList = Arrays.asList("Apple","Banana", "Orange");
@@ -177,8 +181,9 @@ JDK 源码对于这个方法的说明:
```java
/**
- *返回由指定数组支持的固定大小的列表。此方法作为基于数组和基于集合的API之间的桥梁,与 Collection.toArray()结合使用。返回的List是可序列化并实现RandomAccess接口。
- */
+ *返回由指定数组支持的固定大小的列表。此方法作为基于数组和基于集合的API之间的桥梁,
+ * 与 Collection.toArray()结合使用。返回的List是可序列化并实现RandomAccess接口。
+ */
public static List asList(T... a) {
return new ArrayList<>(a);
}
@@ -197,12 +202,12 @@ public static List asList(T... a) {
`Arrays.asList()`是泛型方法,传入的对象必须是对象数组。
```java
-int[] myArray = { 1, 2, 3 };
+int[] myArray = {1, 2, 3};
List myList = Arrays.asList(myArray);
System.out.println(myList.size());//1
System.out.println(myList.get(0));//数组地址值
System.out.println(myList.get(1));//报错:ArrayIndexOutOfBoundsException
-int [] array=(int[]) myList.get(0);
+int[] array = (int[]) myList.get(0);
System.out.println(array[0]);//1
```
当传入一个原生数据类型数组时,`Arrays.asList()` 的真正得到的参数就不是数组中的元素,而是数组对象本身!此时List 的唯一元素就是这个数组,这也就解释了上面的代码。
@@ -210,7 +215,7 @@ System.out.println(array[0]);//1
我们使用包装类型数组就可以解决这个问题。
```java
-Integer[] myArray = { 1, 2, 3 };
+Integer[] myArray = {1, 2, 3};
```
**使用集合的修改方法:`add()`、`remove()`、`clear()`会抛出异常。**
@@ -296,7 +301,7 @@ static List arrayToList(final T[] array) {
for (final T s : array) {
l.add(s);
}
- return (l);
+ return l;
}
```
@@ -344,6 +349,14 @@ List list = new ArrayList();
CollectionUtils.addAll(list, str);
```
+**6. 使用 Java9 的 `List.of()`方法**
+``` java
+Integer[] array = {1, 2, 3};
+List list = List.of(array);
+System.out.println(list); /* [1, 2, 3] */
+/* 不支持基本数据类型 */
+```
+
## 2.2. Collection.toArray()方法使用的坑&如何反转数组
该方法是一个泛型方法:` T[] toArray(T[] a);` 如果`toArray`方法中没有传递任何参数的话返回的是`Object`类型数组。
@@ -365,6 +378,16 @@ s=list.toArray(new String[0]);//没有指定类型的话会报错
> **fail-fast 机制** :多个线程对 fail-fast 集合进行修改的时,可能会抛出ConcurrentModificationException,单线程下也会出现这种情况,上面已经提到过。
+Java8开始,可以使用`Collection#removeIf()`方法删除满足特定条件的元素,如
+``` java
+List list = new ArrayList<>();
+for (int i = 1; i <= 10; ++i) {
+ list.add(i);
+}
+list.removeIf(filter -> filter % 2 == 0); /* 删除list中的所有偶数 */
+System.out.println(list); /* [1, 3, 5, 7, 9] */
+```
+
`java.util`包下面的所有的集合类都是fail-fast的,而`java.util.concurrent`包下面的所有的类都是fail-safe的。

diff --git a/docs/java/Multithread/AQS.md b/docs/java/Multithread/AQS.md
index ab399087..facba05d 100644
--- a/docs/java/Multithread/AQS.md
+++ b/docs/java/Multithread/AQS.md
@@ -84,7 +84,7 @@ protected final boolean compareAndSetState(int expect, int update) {
- 公平锁:按照线程在队列中的排队顺序,先到者先拿到锁
- 非公平锁:当线程要获取锁时,先通过两次 CAS 操作去抢锁,如果没抢到,当前线程再加入到队列中等待唤醒。
-> 说明:下面这部分关于 `ReentrantLock` 源代码内容节选自:https://www.javadoop.com/post/AbstractQueuedSynchronizer-2,这是一篇很不错文章,推荐阅读。
+> 说明:下面这部分关于 `ReentrantLock` 源代码内容节选自:https://www.javadoop.com/post/AbstractQueuedSynchronizer-2 ,这是一篇很不错文章,推荐阅读。
**下面来看 ReentrantLock 中相关的源代码:**
@@ -238,7 +238,9 @@ tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true
### 3 Semaphore(信号量)-允许多个线程同时访问
-**synchronized 和 ReentrantLock 都是一次只允许一个线程访问某个资源,Semaphore(信号量)可以指定多个线程同时访问某个资源。** 示例代码如下:
+**synchronized 和 ReentrantLock 都是一次只允许一个线程访问某个资源,Semaphore(信号量)可以指定多个线程同时访问某个资源。**
+
+示例代码如下:
```java
/**
@@ -288,9 +290,9 @@ public class SemaphoreExample1 {
当然一次也可以一次拿取和释放多个许可,不过一般没有必要这样做:
```java
- semaphore.acquire(5);// 获取5个许可,所以可运行线程数量为20/5=4
- test(threadnum);
- semaphore.release(5);// 获取5个许可,所以可运行线程数量为20/5=4
+semaphore.acquire(5);// 获取5个许可,所以可运行线程数量为20/5=4
+test(threadnum);
+semaphore.release(5);// 获取5个许可,所以可运行线程数量为20/5=4
```
除了 `acquire`方法之外,另一个比较常用的与之对应的方法是`tryAcquire`方法,该方法如果获取不到许可就立即返回 false。
@@ -314,21 +316,21 @@ Semaphore 有两种模式,公平模式和非公平模式。
**这两个构造方法,都必须提供许可的数量,第二个构造方法可以指定是公平模式还是非公平模式,默认非公平模式。**
-由于篇幅问题,如果对 Semaphore 源码感兴趣的朋友可以看下面这篇文章:
+[issue645补充内容](https://github.com/Snailclimb/JavaGuide/issues/645) :Semaphore与CountDownLatch一样,也是共享锁的一种实现。它默认构造AQS的state为permits。当执行任务的线程数量超出permits,那么多余的线程将会被放入阻塞队列Park,并自旋判断state是否大于0。只有当state大于0的时候,阻塞的线程才能继续执行,此时先前执行任务的线程继续执行release方法,release方法使得state的变量会加1,那么自旋的线程便会判断成功。
+如此,每次只有最多不超过permits数量的线程能自旋成功,便限制了执行任务线程的数量。
-- https://blog.csdn.net/qq_19431333/article/details/70212663
+由于篇幅问题,如果对 Semaphore 源码感兴趣的朋友可以看下这篇文章:https://juejin.im/post/5ae755366fb9a07ab508adc6
### 4 CountDownLatch (倒计时器)
-CountDownLatch 是一个同步工具类,它允许一个或多个线程一直等待,直到其他线程的操作执行完后再执行。在 Java 并发中,countdownlatch 的概念是一个常见的面试题,所以一定要确保你很好的理解了它。
+CountDownLatch允许 count 个线程阻塞在一个地方,直至所有线程的任务都执行完毕。在 Java 并发中,countdownlatch 的概念是一个常见的面试题,所以一定要确保你很好的理解了它。
-#### 4.1 CountDownLatch 的三种典型用法
+CountDownLatch是共享锁的一种实现,它默认构造 AQS 的 state 值为 count。当线程使用countDown方法时,其实使用了`tryReleaseShared`方法以CAS的操作来减少state,直至state为0就代表所有的线程都调用了countDown方法。当调用await方法的时候,如果state不为0,就代表仍然有线程没有调用countDown方法,那么就把已经调用过countDown的线程都放入阻塞队列Park,并自旋CAS判断state == 0,直至最后一个线程调用了countDown,使得state == 0,于是阻塞的线程便判断成功,全部往下执行。
-① 某一线程在开始运行前等待 n 个线程执行完毕。将 CountDownLatch 的计数器初始化为 n :`new CountDownLatch(n)`,每当一个任务线程执行完毕,就将计数器减 1 `countdownlatch.countDown()`,当计数器的值变为 0 时,在`CountDownLatch上 await()` 的线程就会被唤醒。一个典型应用场景就是启动一个服务时,主线程需要等待多个组件加载完毕,之后再继续执行。
+#### 4.1 CountDownLatch 的两种典型用法
-② 实现多个线程开始执行任务的最大并行性。注意是并行性,不是并发,强调的是多个线程在某一时刻同时开始执行。类似于赛跑,将多个线程放到起点,等待发令枪响,然后同时开跑。做法是初始化一个共享的 `CountDownLatch` 对象,将其计数器初始化为 1 :`new CountDownLatch(1)`,多个线程在开始执行任务前首先 `coundownlatch.await()`,当主线程调用 countDown() 时,计数器变为 0,多个线程同时被唤醒。
-
-③ 死锁检测:一个非常方便的使用场景是,你可以使用 n 个线程访问共享资源,在每次测试阶段的线程数目是不同的,并尝试产生死锁。
+1. 某一线程在开始运行前等待 n 个线程执行完毕。将 CountDownLatch 的计数器初始化为 n :`new CountDownLatch(n)`,每当一个任务线程执行完毕,就将计数器减 1 `countdownlatch.countDown()`,当计数器的值变为 0 时,在`CountDownLatch上 await()` 的线程就会被唤醒。一个典型应用场景就是启动一个服务时,主线程需要等待多个组件加载完毕,之后再继续执行。
+2. 实现多个线程开始执行任务的最大并行性。注意是并行性,不是并发,强调的是多个线程在某一时刻同时开始执行。类似于赛跑,将多个线程放到起点,等待发令枪响,然后同时开跑。做法是初始化一个共享的 `CountDownLatch` 对象,将其计数器初始化为 1 :`new CountDownLatch(1)`,多个线程在开始执行任务前首先 `coundownlatch.await()`,当主线程调用 countDown() 时,计数器变为 0,多个线程同时被唤醒。
#### 4.2 CountDownLatch 的使用示例
@@ -377,15 +379,27 @@ public class CountDownLatchExample1 {
上面的代码中,我们定义了请求的数量为 550,当这 550 个请求被处理完成之后,才会执行`System.out.println("finish");`。
-与 CountDownLatch 的第一次交互是主线程等待其他线程。主线程必须在启动其他线程后立即调用 CountDownLatch.await()方法。这样主线程的操作就会在这个方法上阻塞,直到其他线程完成各自的任务。
+与 CountDownLatch 的第一次交互是主线程等待其他线程。主线程必须在启动其他线程后立即调用 `CountDownLatch.await()` 方法。这样主线程的操作就会在这个方法上阻塞,直到其他线程完成各自的任务。
-其他 N 个线程必须引用闭锁对象,因为他们需要通知 CountDownLatch 对象,他们已经完成了各自的任务。这种通知机制是通过 CountDownLatch.countDown()方法来完成的;每调用一次这个方法,在构造函数中初始化的 count 值就减 1。所以当 N 个线程都调 用了这个方法,count 的值等于 0,然后主线程就能通过 await()方法,恢复执行自己的任务。
+其他 N 个线程必须引用闭锁对象,因为他们需要通知 `CountDownLatch` 对象,他们已经完成了各自的任务。这种通知机制是通过 `CountDownLatch.countDown()`方法来完成的;每调用一次这个方法,在构造函数中初始化的 count 值就减 1。所以当 N 个线程都调 用了这个方法,count 的值等于 0,然后主线程就能通过 `await()`方法,恢复执行自己的任务。
+
+再插一嘴:`CountDownLatch` 的 `await()` 方法使用不当很容易产生死锁,比如我们上面代码中的 for 循环改为:
+
+```java
+for (int i = 0; i < threadCount-1; i++) {
+.......
+}
+```
+
+这样就导致 `count` 的值没办法等于 0,然后就会导致一直等待。
+
+如果对CountDownLatch源码感兴趣的朋友,可以查看: [【JUC】JDK1.8源码分析之CountDownLatch(五)](https://www.cnblogs.com/leesf456/p/5406191.html)
#### 4.3 CountDownLatch 的不足
CountDownLatch 是一次性的,计数器的值只能在构造方法中初始化一次,之后没有任何机制再次对其设置值,当 CountDownLatch 使用完毕后,它不能再次被使用。
-#### 4.4 CountDownLatch 相常见面试题:
+#### 4.4 CountDownLatch 相常见面试题
解释一下 CountDownLatch 概念?
@@ -399,6 +413,8 @@ CountDownLatch 类中主要的方法?
CyclicBarrier 和 CountDownLatch 非常类似,它也可以实现线程间的技术等待,但是它的功能比 CountDownLatch 更加复杂和强大。主要应用场景和 CountDownLatch 类似。
+> CountDownLatch的实现是基于AQS的,而CycliBarrier是基于 ReentrantLock(ReentrantLock也属于AQS同步器)和 Condition 的.
+
CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。CyclicBarrier 默认的构造方法是 `CyclicBarrier(int parties)`,其参数表示屏障拦截的线程数量,每个线程调用`await`方法告诉 CyclicBarrier 我已经到达了屏障,然后当前线程被阻塞。
再来看一下它的构造函数:
diff --git a/docs/java/Multithread/Atomic.md b/docs/java/Multithread/Atomic.md
index 627ea3d4..14c5ac5d 100644
--- a/docs/java/Multithread/Atomic.md
+++ b/docs/java/Multithread/Atomic.md
@@ -56,15 +56,61 @@ Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是
**引用类型**
- AtomicReference:引用类型原子类
-- AtomicReferenceFieldUpdater:原子更新引用类型里的字段
-- AtomicMarkableReference :原子更新带有标记位的引用类型
+- AtomicMarkableReference:原子更新带有标记的引用类型。该类将 boolean 标记与引用关联起来,~~也可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。~~
+- AtomicStampedReference :原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
**对象的属性修改类型**
- AtomicIntegerFieldUpdater:原子更新整型字段的更新器
- AtomicLongFieldUpdater:原子更新长整型字段的更新器
-- AtomicStampedReference :原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
-- AtomicMarkableReference:原子更新带有标记的引用类型。该类将 boolean 标记与引用关联起来,也可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
+- AtomicReferenceFieldUpdater:原子更新引用类型里的字段
+
+> 修正: **AtomicMarkableReference 不能解决ABA问题** **[issue#626](https://github.com/Snailclimb/JavaGuide/issues/626)**
+
+```java
+ /**
+
+AtomicMarkableReference是将一个boolean值作是否有更改的标记,本质就是它的版本号只有两个,true和false,
+
+修改的时候在这两个版本号之间来回切换,这样做并不能解决ABA的问题,只是会降低ABA问题发生的几率而已
+
+@author : mazh
+
+@Date : 2020/1/17 14:41
+*/
+
+public class SolveABAByAtomicMarkableReference {
+
+ private static AtomicMarkableReference atomicMarkableReference = new AtomicMarkableReference(100, false);
+
+ public static void main(String[] args) {
+
+ Thread refT1 = new Thread(() -> {
+ try {
+ TimeUnit.SECONDS.sleep(1);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ atomicMarkableReference.compareAndSet(100, 101, atomicMarkableReference.isMarked(), !atomicMarkableReference.isMarked());
+ atomicMarkableReference.compareAndSet(101, 100, atomicMarkableReference.isMarked(), !atomicMarkableReference.isMarked());
+ });
+
+ Thread refT2 = new Thread(() -> {
+ boolean marked = atomicMarkableReference.isMarked();
+ try {
+ TimeUnit.SECONDS.sleep(2);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ boolean c3 = atomicMarkableReference.compareAndSet(100, 101, marked, !marked);
+ System.out.println(c3); // 返回true,实际应该返回false
+ });
+
+ refT1.start();
+ refT2.start();
+ }
+ }
+```
**CAS ABA 问题**
- 描述: 第一个线程取到了变量 x 的值 A,然后巴拉巴拉干别的事,总之就是只拿到了变量 x 的值 A。这段时间内第二个线程也取到了变量 x 的值 A,然后把变量 x 的值改为 B,然后巴拉巴拉干别的事,最后又把变量 x 的值变为 A (相当于还原了)。在这之后第一个线程终于进行了变量 x 的操作,但是此时变量 x 的值还是 A,所以 compareAndSet 操作是成功。
@@ -268,8 +314,8 @@ public final int get(int i) //获取 index=i 位置元素的值
public final int getAndSet(int i, int newValue)//返回 index=i 位置的当前的值,并将其设置为新值:newValue
public final int getAndIncrement(int i)//获取 index=i 位置元素的值,并让该位置的元素自增
public final int getAndDecrement(int i) //获取 index=i 位置元素的值,并让该位置的元素自减
-public final int getAndAdd(int delta) //获取 index=i 位置元素的值,并加上预期的值
-boolean compareAndSet(int expect, int update) //如果输入的数值等于预期值,则以原子方式将 index=i 位置的元素值设置为输入值(update)
+public final int getAndAdd(int i, int delta) //获取 index=i 位置元素的值,并加上预期的值
+boolean compareAndSet(int i, int expect, int update) //如果输入的数值等于预期值,则以原子方式将 index=i 位置的元素值设置为输入值(update)
public final void lazySet(int i, int newValue)//最终 将index=i 位置的元素设置为newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
```
#### 3.2 AtomicIntegerArray 常见方法使用
@@ -306,8 +352,8 @@ public class AtomicIntegerArrayTest {
基本类型原子类只能更新一个变量,如果需要原子更新多个变量,需要使用 引用类型原子类。
- AtomicReference:引用类型原子类
-- AtomicStampedReference:原子更新引用类型里的字段原子类
-- AtomicMarkableReference :原子更新带有标记位的引用类型
+- AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
+- AtomicMarkableReference :原子更新带有标记的引用类型。该类将 boolean 标记与引用关联起来,~~也可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。~~
上面三个类提供的方法几乎相同,所以我们这里以 AtomicReference 为例子来介绍。
@@ -488,7 +534,7 @@ currentValue=true, currentMark=true, wCasResult=true
- AtomicIntegerFieldUpdater:原子更新整形字段的更新器
- AtomicLongFieldUpdater:原子更新长整形字段的更新器
-- AtomicStampedReference :原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
+- AtomicReferenceFieldUpdater :原子更新引用类型里的字段的更新器
要想原子地更新对象的属性需要两步。第一步,因为对象的属性修改类型原子类都是抽象类,所以每次使用都必须使用静态方法 newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。第二步,更新的对象属性必须使用 public volatile 修饰符。
@@ -545,6 +591,10 @@ class User {
23
```
+## Reference
+
+- 《Java并发编程的艺术》
+
## 公众号
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
@@ -553,4 +603,4 @@ class User {
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
-
+
\ No newline at end of file
diff --git a/docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md b/docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md
index 51b21fd0..e5561246 100644
--- a/docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md
+++ b/docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md
@@ -1,65 +1,118 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
+点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java 面试突击》以及 Java 工程师必备学习资源。
-
+
+
+
+
- [Java 并发进阶常见面试题总结](#java-并发进阶常见面试题总结)
- - [1. synchronized 关键字](#1-synchronized-关键字)
- - [1.1. 说一说自己对于 synchronized 关键字的了解](#11-说一说自己对于-synchronized-关键字的了解)
- - [1.2. 说说自己是怎么使用 synchronized 关键字,在项目中用到了吗](#12-说说自己是怎么使用-synchronized-关键字在项目中用到了吗)
- - [1.3. 讲一下 synchronized 关键字的底层原理](#13-讲一下-synchronized-关键字的底层原理)
- - [1.4. 说说 JDK1.6 之后的synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗](#14-说说-jdk16-之后的synchronized-关键字底层做了哪些优化可以详细介绍一下这些优化吗)
- - [1.5. 谈谈 synchronized和ReentrantLock 的区别](#15-谈谈-synchronized和reentrantlock-的区别)
- - [2. volatile关键字](#2-volatile关键字)
- - [2.1. 讲一下Java内存模型](#21-讲一下java内存模型)
- - [2.2. 说说 synchronized 关键字和 volatile 关键字的区别](#22-说说-synchronized-关键字和-volatile-关键字的区别)
- - [3. ThreadLocal](#3-threadlocal)
- - [3.1. ThreadLocal简介](#31-threadlocal简介)
- - [3.2. ThreadLocal示例](#32-threadlocal示例)
- - [3.3. ThreadLocal原理](#33-threadlocal原理)
- - [3.4. ThreadLocal 内存泄露问题](#34-threadlocal-内存泄露问题)
- - [4. 线程池](#4-线程池)
- - [4.1. 为什么要用线程池?](#41-为什么要用线程池)
- - [4.2. 实现Runnable接口和Callable接口的区别](#42-实现runnable接口和callable接口的区别)
- - [4.3. 执行execute()方法和submit()方法的区别是什么呢?](#43-执行execute方法和submit方法的区别是什么呢)
- - [4.4. 如何创建线程池](#44-如何创建线程池)
- - [5. Atomic 原子类](#5-atomic-原子类)
- - [5.1. 介绍一下Atomic 原子类](#51-介绍一下atomic-原子类)
- - [5.2. JUC 包中的原子类是哪4类?](#52-juc-包中的原子类是哪4类)
- - [5.3. 讲讲 AtomicInteger 的使用](#53-讲讲-atomicinteger-的使用)
- - [5.4. 能不能给我简单介绍一下 AtomicInteger 类的原理](#54-能不能给我简单介绍一下-atomicinteger-类的原理)
- - [6. AQS](#6-aqs)
- - [6.1. AQS 介绍](#61-aqs-介绍)
- - [6.2. AQS 原理分析](#62-aqs-原理分析)
- - [6.2.1. AQS 原理概览](#621-aqs-原理概览)
- - [6.2.2. AQS 对资源的共享方式](#622-aqs-对资源的共享方式)
- - [6.2.3. AQS底层使用了模板方法模式](#623-aqs底层使用了模板方法模式)
- - [6.3. AQS 组件总结](#63-aqs-组件总结)
- - [7 Reference](#7-reference)
+ - [1.synchronized 关键字](#1synchronized-关键字)
+ - [1.1.说一说自己对于 synchronized 关键字的了解](#11说一说自己对于-synchronized-关键字的了解)
+ - [1.2. 说说自己是怎么使用 synchronized 关键字](#12-说说自己是怎么使用-synchronized-关键字)
+ - [1.3. 构造方法可以使用 synchronized 关键字修饰么?](#13-构造方法可以使用-synchronized-关键字修饰么)
+ - [1.3. 讲一下 synchronized 关键字的底层原理](#13-讲一下-synchronized-关键字的底层原理)
+ - [1.3.1. synchronized 同步语句块的情况](#131-synchronized-同步语句块的情况)
+ - [1.3.2. `synchronized` 修饰方法的的情况](#132-synchronized-修饰方法的的情况)
+ - [1.3.3.总结](#133总结)
+ - [1.4. 说说 JDK1.6 之后的 synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗](#14-说说-jdk16-之后的-synchronized-关键字底层做了哪些优化可以详细介绍一下这些优化吗)
+ - [1.5. 谈谈 synchronized 和 ReentrantLock 的区别](#15-谈谈-synchronized-和-reentrantlock-的区别)
+ - [1.5.1. 两者都是可重入锁](#151-两者都是可重入锁)
+ - [1.5.2.synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API](#152synchronized-依赖于-jvm-而-reentrantlock-依赖于-api)
+ - [1.5.3.ReentrantLock 比 synchronized 增加了一些高级功能](#153reentrantlock-比-synchronized-增加了一些高级功能)
+ - [2. volatile 关键字](#2-volatile-关键字)
+ - [2.1. CPU 缓存模型](#21-cpu-缓存模型)
+ - [2.2. 讲一下 JMM(Java 内存模型)](#22-讲一下-jmmjava-内存模型)
+ - [2.3. 并发编程的三个重要特性](#23-并发编程的三个重要特性)
+ - [2.4. 说说 synchronized 关键字和 volatile 关键字的区别](#24-说说-synchronized-关键字和-volatile-关键字的区别)
+ - [3. ThreadLocal](#3-threadlocal)
+ - [3.1. ThreadLocal 简介](#31-threadlocal-简介)
+ - [3.2. ThreadLocal 示例](#32-threadlocal-示例)
+ - [3.3. ThreadLocal 原理](#33-threadlocal-原理)
+ - [3.4. ThreadLocal 内存泄露问题](#34-threadlocal-内存泄露问题)
+ - [4. 线程池](#4-线程池)
+ - [4.1. 为什么要用线程池?](#41-为什么要用线程池)
+ - [4.2. 实现 Runnable 接口和 Callable 接口的区别](#42-实现-runnable-接口和-callable-接口的区别)
+ - [4.3. 执行 execute()方法和 submit()方法的区别是什么呢?](#43-执行-execute方法和-submit方法的区别是什么呢)
+ - [4.4. 如何创建线程池](#44-如何创建线程池)
+ - [4.5 ThreadPoolExecutor 类分析](#45-threadpoolexecutor-类分析)
+ - [4.5.1 `ThreadPoolExecutor`构造函数重要参数分析](#451-threadpoolexecutor构造函数重要参数分析)
+ - [4.5.2 `ThreadPoolExecutor` 饱和策略](#452-threadpoolexecutor-饱和策略)
+ - [4.6 一个简单的线程池 Demo](#46-一个简单的线程池-demo)
+ - [4.7 线程池原理分析](#47-线程池原理分析)
+ - [5. Atomic 原子类](#5-atomic-原子类)
+ - [5.1. 介绍一下 Atomic 原子类](#51-介绍一下-atomic-原子类)
+ - [5.2. JUC 包中的原子类是哪 4 类?](#52-juc-包中的原子类是哪-4-类)
+ - [5.3. 讲讲 AtomicInteger 的使用](#53-讲讲-atomicinteger-的使用)
+ - [5.4. 能不能给我简单介绍一下 AtomicInteger 类的原理](#54-能不能给我简单介绍一下-atomicinteger-类的原理)
+ - [6. AQS](#6-aqs)
+ - [6.1. AQS 介绍](#61-aqs-介绍)
+ - [6.2. AQS 原理分析](#62-aqs-原理分析)
+ - [6.2.1. AQS 原理概览](#621-aqs-原理概览)
+ - [6.2.2. AQS 对资源的共享方式](#622-aqs-对资源的共享方式)
+ - [6.2.3. AQS 底层使用了模板方法模式](#623-aqs-底层使用了模板方法模式)
+ - [6.3. AQS 组件总结](#63-aqs-组件总结)
+ - [6.4. 用过 CountDownLatch 么?什么场景下用的?](#64-用过-countdownlatch-么什么场景下用的)
+ - [7 Reference](#7-reference)
+ - [公众号](#公众号)
+
+
-
# Java 并发进阶常见面试题总结
-## 1. synchronized 关键字
+## 1.synchronized 关键字
-### 1.1. 说一说自己对于 synchronized 关键字的了解
+
-synchronized关键字解决的是多个线程之间访问资源的同步性,synchronized关键字可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行。
+### 1.1.说一说自己对于 synchronized 关键字的了解
-另外,在 Java 早期版本中,synchronized属于重量级锁,效率低下,因为监视器锁(monitor)是依赖于底层的操作系统的 Mutex Lock 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高,这也是为什么早期的 synchronized 效率低的原因。庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对synchronized 较大优化,所以现在的 synchronized 锁效率也优化得很不错了。JDK1.6对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
+**`synchronized` 关键字解决的是多个线程之间访问资源的同步性,`synchronized`关键字可以保证被它修饰的方法或者代码块在任意时刻只能有一个线程执行。**
+另外,在 Java 早期版本中,`synchronized` 属于 **重量级锁**,效率低下。
-### 1.2. 说说自己是怎么使用 synchronized 关键字,在项目中用到了吗
+**为什么呢?**
-**synchronized关键字最主要的三种使用方式:**
+因为监视器锁(monitor)是依赖于底层的操作系统的 `Mutex Lock` 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高。
-- **修饰实例方法:** 作用于当前对象实例加锁,进入同步代码前要获得当前对象实例的锁
-- **修饰静态方法:** 也就是给当前类加锁,会作用于类的所有对象实例,因为静态成员不属于任何一个实例对象,是类成员( static 表明这是该类的一个静态资源,不管new了多少个对象,只有一份)。所以如果一个线程A调用一个实例对象的非静态 synchronized 方法,而线程B需要调用这个实例对象所属类的静态 synchronized 方法,是允许的,不会发生互斥现象,**因为访问静态 synchronized 方法占用的锁是当前类的锁,而访问非静态 synchronized 方法占用的锁是当前实例对象锁**。
-- **修饰代码块:** 指定加锁对象,对给定对象加锁,进入同步代码库前要获得给定对象的锁。
+庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对 synchronized 较大优化,所以现在的 synchronized 锁效率也优化得很不错了。JDK1.6 对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
-**总结:** synchronized 关键字加到 static 静态方法和 synchronized(class)代码块上都是是给 Class 类上锁。synchronized 关键字加到实例方法上是给对象实例上锁。尽量不要使用 synchronized(String a) 因为JVM中,字符串常量池具有缓存功能!
+所以,你会发现目前的话,不论是各种开源框架还是 JDK 源码都大量使用了 synchronized 关键字。
-下面我以一个常见的面试题为例讲解一下 synchronized 关键字的具体使用。
+### 1.2. 说说自己是怎么使用 synchronized 关键字
+
+**synchronized 关键字最主要的三种使用方式:**
+
+**1.修饰实例方法:** 作用于当前对象实例加锁,进入同步代码前要获得 **当前对象实例的锁**
+
+```java
+synchronized void method() {
+ //业务代码
+}
+```
+
+**2.修饰静态方法:** 也就是给当前类加锁,会作用于类的所有对象实例 ,进入同步代码前要获得 **当前 class 的锁**。因为静态成员不属于任何一个实例对象,是类成员( _static 表明这是该类的一个静态资源,不管 new 了多少个对象,只有一份_)。所以,如果一个线程 A 调用一个实例对象的非静态 `synchronized` 方法,而线程 B 需要调用这个实例对象所属类的静态 `synchronized` 方法,是允许的,不会发生互斥现象,**因为访问静态 `synchronized` 方法占用的锁是当前类的锁,而访问非静态 `synchronized` 方法占用的锁是当前实例对象锁**。
+
+```java
+synchronized void staic method() {
+ //业务代码
+}
+```
+
+**3.修饰代码块** :指定加锁对象,对给定对象/类加锁。`synchronized(this|object)` 表示进入同步代码库前要获得**给定对象的锁**。`synchronized(类.class)` 表示进入同步代码前要获得 **当前 class 的锁**
+
+```java
+synchronized(this) {
+ //业务代码
+}
+```
+
+**总结:**
+
+- `synchronized` 关键字加到 `static` 静态方法和 `synchronized(class)` 代码块上都是是给 Class 类上锁。
+- `synchronized` 关键字加到实例方法上是给对象实例上锁。
+- 尽量不要使用 `synchronized(String a)` 因为 JVM 中,字符串常量池具有缓存功能!
+
+下面我以一个常见的面试题为例讲解一下 `synchronized` 关键字的具体使用。
面试中面试官经常会说:“单例模式了解吗?来给我手写一下!给我解释一下双重检验锁方式实现单例模式的原理呗!”
@@ -73,7 +126,7 @@ public class Singleton {
private Singleton() {
}
- public static Singleton getUniqueInstance() {
+ public static Singleton getUniqueInstance() {
//先判断对象是否已经实例过,没有实例化过才进入加锁代码
if (uniqueInstance == null) {
//类对象加锁
@@ -87,23 +140,30 @@ public class Singleton {
}
}
```
-另外,需要注意 uniqueInstance 采用 volatile 关键字修饰也是很有必要。
-uniqueInstance 采用 volatile 关键字修饰也是很有必要的, uniqueInstance = new Singleton(); 这段代码其实是分为三步执行:
+另外,需要注意 `uniqueInstance` 采用 `volatile` 关键字修饰也是很有必要。
-1. 为 uniqueInstance 分配内存空间
-2. 初始化 uniqueInstance
-3. 将 uniqueInstance 指向分配的内存地址
+`uniqueInstance` 采用 `volatile` 关键字修饰也是很有必要的, `uniqueInstance = new Singleton();` 这段代码其实是分为三步执行:
-但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 getUniqueInstance() 后发现 uniqueInstance 不为空,因此返回 uniqueInstance,但此时 uniqueInstance 还未被初始化。
+1. 为 `uniqueInstance` 分配内存空间
+2. 初始化 `uniqueInstance`
+3. 将 `uniqueInstance` 指向分配的内存地址
-使用 volatile 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
+但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 `getUniqueInstance`() 后发现 `uniqueInstance` 不为空,因此返回 `uniqueInstance`,但此时 `uniqueInstance` 还未被初始化。
+
+使用 `volatile` 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
+
+### 1.3. 构造方法可以使用 synchronized 关键字修饰么?
+
+先说结论:**构造方法不能使用 synchronized 关键字修饰。**
+
+构造方法本身就属于线程安全的,不存在同步的构造方法一说。
### 1.3. 讲一下 synchronized 关键字的底层原理
**synchronized 关键字底层原理属于 JVM 层面。**
-**① synchronized 同步语句块的情况**
+#### 1.3.1. synchronized 同步语句块的情况
```java
public class SynchronizedDemo {
@@ -116,15 +176,25 @@ public class SynchronizedDemo {
```
-通过 JDK 自带的 javap 命令查看 SynchronizedDemo 类的相关字节码信息:首先切换到类的对应目录执行 `javac SynchronizedDemo.java` 命令生成编译后的 .class 文件,然后执行`javap -c -s -v -l SynchronizedDemo.class`。
+通过 JDK 自带的 `javap` 命令查看 `SynchronizedDemo` 类的相关字节码信息:首先切换到类的对应目录执行 `javac SynchronizedDemo.java` 命令生成编译后的 .class 文件,然后执行`javap -c -s -v -l SynchronizedDemo.class`。

从上面我们可以看出:
-**synchronized 同步语句块的实现使用的是 monitorenter 和 monitorexit 指令,其中 monitorenter 指令指向同步代码块的开始位置,monitorexit 指令则指明同步代码块的结束位置。** 当执行 monitorenter 指令时,线程试图获取锁也就是获取 monitor(monitor对象存在于每个Java对象的对象头中,synchronized 锁便是通过这种方式获取锁的,也是为什么Java中任意对象可以作为锁的原因) 的持有权。当计数器为0则可以成功获取,获取后将锁计数器设为1也就是加1。相应的在执行 monitorexit 指令后,将锁计数器设为0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
+**`synchronized` 同步语句块的实现使用的是 `monitorenter` 和 `monitorexit` 指令,其中 `monitorenter` 指令指向同步代码块的开始位置,`monitorexit` 指令则指明同步代码块的结束位置。**
-**② synchronized 修饰方法的的情况**
+当执行 `monitorenter` 指令时,线程试图获取锁也就是获取 **对象监视器 `monitor`** 的持有权。
+
+> 在 Java 虚拟机(HotSpot)中,Monitor 是基于 C++实现的,由[ObjectMonitor](https://github.com/openjdk-mirror/jdk7u-hotspot/blob/50bdefc3afe944ca74c3093e7448d6b889cd20d1/src/share/vm/runtime/objectMonitor.cpp)实现的。每个对象中都内置了一个 `ObjectMonitor`对象。
+>
+> 另外,**`wait/notify`等方法也依赖于`monitor`对象,这就是为什么只有在同步的块或者方法中才能调用`wait/notify`等方法,否则会抛出`java.lang.IllegalMonitorStateException`的异常的原因。**
+
+在执行`monitorenter`时,会尝试获取对象的锁,如果锁的计数器为 0 则表示锁可以被获取,获取后将锁计数器设为 1 也就是加 1。
+
+在执行 `monitorexit` 指令后,将锁计数器设为 0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
+
+#### 1.3.2. `synchronized` 修饰方法的的情况
```java
public class SynchronizedDemo2 {
@@ -137,78 +207,112 @@ public class SynchronizedDemo2 {
-synchronized 修饰的方法并没有 monitorenter 指令和 monitorexit 指令,取得代之的确实是 ACC_SYNCHRONIZED 标识,该标识指明了该方法是一个同步方法,JVM 通过该 ACC_SYNCHRONIZED 访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。
+`synchronized` 修饰的方法并没有 `monitorenter` 指令和 `monitorexit` 指令,取得代之的确实是 `ACC_SYNCHRONIZED` 标识,该标识指明了该方法是一个同步方法。JVM 通过该 `ACC_SYNCHRONIZED` 访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。
+#### 1.3.3.总结
-### 1.4. 说说 JDK1.6 之后的synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗
+`synchronized` 同步语句块的实现使用的是 `monitorenter` 和 `monitorexit` 指令,其中 `monitorenter` 指令指向同步代码块的开始位置,`monitorexit` 指令则指明同步代码块的结束位置。
+
+`synchronized` 修饰的方法并没有 `monitorenter` 指令和 `monitorexit` 指令,取得代之的确实是 `ACC_SYNCHRONIZED` 标识,该标识指明了该方法是一个同步方法。
+
+**不过两者的本质都是对对象监视器 monitor 的获取。**
+
+### 1.4. 说说 JDK1.6 之后的 synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗
JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术来减少锁操作的开销。
锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
-关于这几种优化的详细信息可以查看笔主的这篇文章:
+关于这几种优化的详细信息可以查看下面这几篇文章:
-### 1.5. 谈谈 synchronized和ReentrantLock 的区别
+- [Java 性能 -- synchronized 锁升级优化](https://blog.csdn.net/qq_34337272/article/details/108498442)
+- [Java6 及以上版本对 synchronized 的优化](https://www.cnblogs.com/wuqinglong/p/9945618.html)
+### 1.5. 谈谈 synchronized 和 ReentrantLock 的区别
-**① 两者都是可重入锁**
+#### 1.5.1. 两者都是可重入锁
-两者都是可重入锁。“可重入锁”概念是:自己可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果不可锁重入的话,就会造成死锁。同一个线程每次获取锁,锁的计数器都自增1,所以要等到锁的计数器下降为0时才能释放锁。
+**“可重入锁”** 指的是自己可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果不可锁重入的话,就会造成死锁。同一个线程每次获取锁,锁的计数器都自增 1,所以要等到锁的计数器下降为 0 时才能释放锁。
-**② synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API**
+#### 1.5.2.synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API
-synchronized 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团队在 JDK1.6 为 synchronized 关键字进行了很多优化,但是这些优化都是在虚拟机层面实现的,并没有直接暴露给我们。ReentrantLock 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock() 方法配合 try/finally 语句块来完成),所以我们可以通过查看它的源代码,来看它是如何实现的。
+`synchronized` 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团队在 JDK1.6 为 `synchronized` 关键字进行了很多优化,但是这些优化都是在虚拟机层面实现的,并没有直接暴露给我们。`ReentrantLock` 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock() 方法配合 try/finally 语句块来完成),所以我们可以通过查看它的源代码,来看它是如何实现的。
-**③ ReentrantLock 比 synchronized 增加了一些高级功能**
+#### 1.5.3.ReentrantLock 比 synchronized 增加了一些高级功能
-相比synchronized,ReentrantLock增加了一些高级功能。主要来说主要有三点:**①等待可中断;②可实现公平锁;③可实现选择性通知(锁可以绑定多个条件)**
+相比`synchronized`,`ReentrantLock`增加了一些高级功能。主要来说主要有三点:
-- **ReentrantLock提供了一种能够中断等待锁的线程的机制**,通过lock.lockInterruptibly()来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。
-- **ReentrantLock可以指定是公平锁还是非公平锁。而synchronized只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。** ReentrantLock默认情况是非公平的,可以通过 ReentrantLock类的`ReentrantLock(boolean fair)`构造方法来制定是否是公平的。
-- synchronized关键字与wait()和notify()/notifyAll()方法相结合可以实现等待/通知机制,ReentrantLock类当然也可以实现,但是需要借助于Condition接口与newCondition() 方法。Condition是JDK1.5之后才有的,它具有很好的灵活性,比如可以实现多路通知功能也就是在一个Lock对象中可以创建多个Condition实例(即对象监视器),**线程对象可以注册在指定的Condition中,从而可以有选择性的进行线程通知,在调度线程上更加灵活。 在使用notify()/notifyAll()方法进行通知时,被通知的线程是由 JVM 选择的,用ReentrantLock类结合Condition实例可以实现“选择性通知”** ,这个功能非常重要,而且是Condition接口默认提供的。而synchronized关键字就相当于整个Lock对象中只有一个Condition实例,所有的线程都注册在它一个身上。如果执行notifyAll()方法的话就会通知所有处于等待状态的线程这样会造成很大的效率问题,而Condition实例的signalAll()方法 只会唤醒注册在该Condition实例中的所有等待线程。
+- **等待可中断** : `ReentrantLock`提供了一种能够中断等待锁的线程的机制,通过 `lock.lockInterruptibly()` 来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。
+- **可实现公平锁** : `ReentrantLock`可以指定是公平锁还是非公平锁。而`synchronized`只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。`ReentrantLock`默认情况是非公平的,可以通过 `ReentrantLock`类的`ReentrantLock(boolean fair)`构造方法来制定是否是公平的。
+- **可实现选择性通知(锁可以绑定多个条件)**: `synchronized`关键字与`wait()`和`notify()`/`notifyAll()`方法相结合可以实现等待/通知机制。`ReentrantLock`类当然也可以实现,但是需要借助于`Condition`接口与`newCondition()`方法。
-如果你想使用上述功能,那么选择ReentrantLock是一个不错的选择。
+> `Condition`是 JDK1.5 之后才有的,它具有很好的灵活性,比如可以实现多路通知功能也就是在一个`Lock`对象中可以创建多个`Condition`实例(即对象监视器),**线程对象可以注册在指定的`Condition`中,从而可以有选择性的进行线程通知,在调度线程上更加灵活。 在使用`notify()/notifyAll()`方法进行通知时,被通知的线程是由 JVM 选择的,用`ReentrantLock`类结合`Condition`实例可以实现“选择性通知”** ,这个功能非常重要,而且是 Condition 接口默认提供的。而`synchronized`关键字就相当于整个 Lock 对象中只有一个`Condition`实例,所有的线程都注册在它一个身上。如果执行`notifyAll()`方法的话就会通知所有处于等待状态的线程这样会造成很大的效率问题,而`Condition`实例的`signalAll()`方法 只会唤醒注册在该`Condition`实例中的所有等待线程。
-**④ 性能已不是选择标准**
+**如果你想使用上述功能,那么选择 ReentrantLock 是一个不错的选择。性能已不是选择标准**
-## 2. volatile关键字
+## 2. volatile 关键字
-### 2.1. 讲一下Java内存模型
+我们先要从 **CPU 缓存模型** 说起!
+### 2.1. CPU 缓存模型
-在 JDK1.2 之前,Java的内存模型实现总是从**主存**(即共享内存)读取变量,是不需要进行特别的注意的。而在当前的 Java 内存模型下,线程可以把变量保存**本地内存**(比如机器的寄存器)中,而不是直接在主存中进行读写。这就可能造成一个线程在主存中修改了一个变量的值,而另外一个线程还继续使用它在寄存器中的变量值的拷贝,造成**数据的不一致**。
+**为什么要弄一个 CPU 高速缓存呢?**
-
+类比我们开发网站后台系统使用的缓存(比如 Redis)是为了解决程序处理速度和访问常规关系型数据库速度不对等的问题。 **CPU 缓存则是为了解决 CPU 处理速度和内存处理速度不对等的问题。**
-要解决这个问题,就需要把变量声明为**volatile**,这就指示 JVM,这个变量是不稳定的,每次使用它都到主存中进行读取。
+我们甚至可以把 **内存可以看作外存的高速缓存**,程序运行的时候我们把外存的数据复制到内存,由于内存的处理速度远远高于外存,这样提高了处理速度。
-说白了, **volatile** 关键字的主要作用就是保证变量的可见性然后还有一个作用是防止指令重排序。
+总结:**CPU Cache 缓存的是内存数据用于解决 CPU 处理速度和内存不匹配的问题,内存缓存的是硬盘数据用于解决硬盘访问速度过慢的问题。**
-
+为了更好地理解,我画了一个简单的 CPU Cache 示意图如下(实际上,现代的 CPU Cache 通常分为三层,分别叫 L1,L2,L3 Cache):
+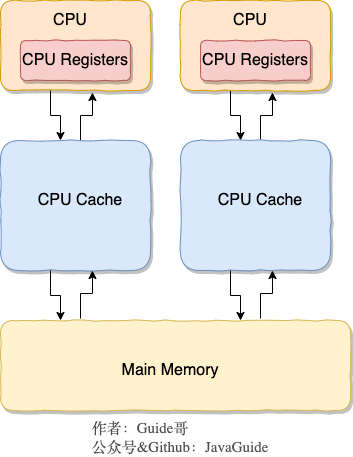
-### 2.2. 说说 synchronized 关键字和 volatile 关键字的区别
+**CPU Cache 的工作方式:**
- synchronized关键字和volatile关键字比较
+先复制一份数据到 CPU Cache 中,当 CPU 需要用到的时候就可以直接从 CPU Cache 中读取数据,当运算完成后,再将运算得到的数据写回 Main Memory 中。但是,这样存在 **内存缓存不一致性的问题** !比如我执行一个 i++操作的话,如果两个线程同时执行的话,假设两个线程从 CPU Cache 中读取的 i=1,两个线程做了 1++运算完之后再写回 Main Memory 之后 i=2,而正确结果应该是 i=3。
-- **volatile关键字**是线程同步的**轻量级实现**,所以**volatile性能肯定比synchronized关键字要好**。但是**volatile关键字只能用于变量而synchronized关键字可以修饰方法以及代码块**。synchronized关键字在JavaSE1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的偏向锁和轻量级锁以及其它各种优化之后执行效率有了显著提升,**实际开发中使用 synchronized 关键字的场景还是更多一些**。
-- **多线程访问volatile关键字不会发生阻塞,而synchronized关键字可能会发生阻塞**
-- **volatile关键字能保证数据的可见性,但不能保证数据的原子性。synchronized关键字两者都能保证。**
-- **volatile关键字主要用于解决变量在多个线程之间的可见性,而 synchronized关键字解决的是多个线程之间访问资源的同步性。**
+**CPU 为了解决内存缓存不一致性问题可以通过制定缓存一致协议或者其他手段来解决。**
+
+### 2.2. 讲一下 JMM(Java 内存模型)
+
+在 JDK1.2 之前,Java 的内存模型实现总是从**主存**(即共享内存)读取变量,是不需要进行特别的注意的。而在当前的 Java 内存模型下,线程可以把变量保存**本地内存**(比如机器的寄存器)中,而不是直接在主存中进行读写。这就可能造成一个线程在主存中修改了一个变量的值,而另外一个线程还继续使用它在寄存器中的变量值的拷贝,造成**数据的不一致**。
+
+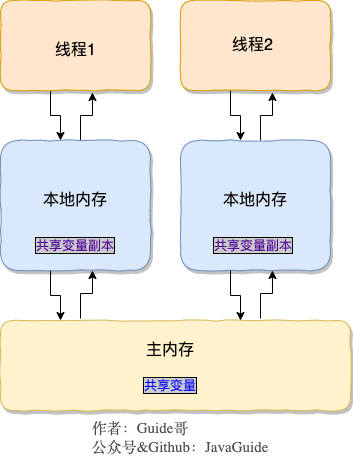
+
+要解决这个问题,就需要把变量声明为**`volatile`**,这就指示 JVM,这个变量是共享且不稳定的,每次使用它都到主存中进行读取。
+
+所以,**`volatile` 关键字 除了防止 JVM 的指令重排 ,还有一个重要的作用就是保证变量的可见性。**
+
+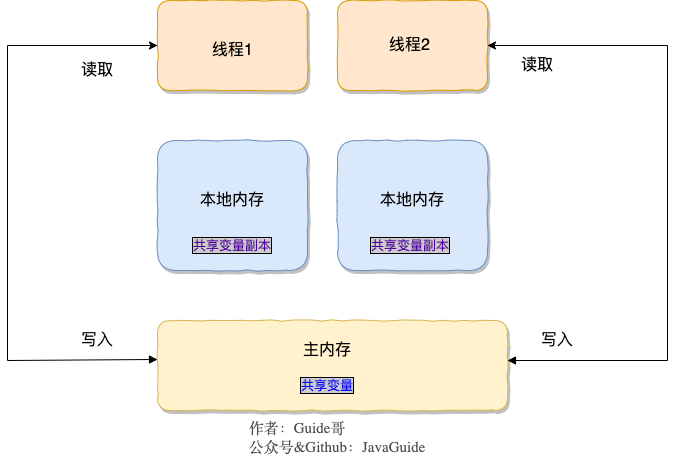
+
+### 2.3. 并发编程的三个重要特性
+
+1. **原子性** : 一个的操作或者多次操作,要么所有的操作全部都得到执行并且不会收到任何因素的干扰而中断,要么所有的操作都执行,要么都不执行。`synchronized` 可以保证代码片段的原子性。
+2. **可见性** :当一个变量对共享变量进行了修改,那么另外的线程都是立即可以看到修改后的最新值。`volatile` 关键字可以保证共享变量的可见性。
+3. **有序性** :代码在执行的过程中的先后顺序,Java 在编译器以及运行期间的优化,代码的执行顺序未必就是编写代码时候的顺序。`volatile` 关键字可以禁止指令进行重排序优化。
+
+### 2.4. 说说 synchronized 关键字和 volatile 关键字的区别
+
+`synchronized` 关键字和 `volatile` 关键字是两个互补的存在,而不是对立的存在!
+
+- **volatile 关键字**是线程同步的**轻量级实现**,所以**volatile 性能肯定比 synchronized 关键字要好**。但是**volatile 关键字只能用于变量而 synchronized 关键字可以修饰方法以及代码块**。
+- **volatile 关键字能保证数据的可见性,但不能保证数据的原子性。synchronized 关键字两者都能保证。**
+- **volatile 关键字主要用于解决变量在多个线程之间的可见性,而 synchronized 关键字解决的是多个线程之间访问资源的同步性。**
## 3. ThreadLocal
-### 3.1. ThreadLocal简介
+### 3.1. ThreadLocal 简介
-通常情况下,我们创建的变量是可以被任何一个线程访问并修改的。**如果想实现每一个线程都有自己的专属本地变量该如何解决呢?** JDK中提供的`ThreadLocal`类正是为了解决这样的问题。 **`ThreadLocal`类主要解决的就是让每个线程绑定自己的值,可以将`ThreadLocal`类形象的比喻成存放数据的盒子,盒子中可以存储每个线程的私有数据。**
+通常情况下,我们创建的变量是可以被任何一个线程访问并修改的。**如果想实现每一个线程都有自己的专属本地变量该如何解决呢?** JDK 中提供的`ThreadLocal`类正是为了解决这样的问题。 **`ThreadLocal`类主要解决的就是让每个线程绑定自己的值,可以将`ThreadLocal`类形象的比喻成存放数据的盒子,盒子中可以存储每个线程的私有数据。**
**如果你创建了一个`ThreadLocal`变量,那么访问这个变量的每个线程都会有这个变量的本地副本,这也是`ThreadLocal`变量名的由来。他们可以使用 `get()` 和 `set()` 方法来获取默认值或将其值更改为当前线程所存的副本的值,从而避免了线程安全问题。**
-再举个简单的例子:
+再举个简单的例子:
-比如有两个人去宝屋收集宝物,这两个共用一个袋子的话肯定会产生争执,但是给他们两个人每个人分配一个袋子的话就不会出现这样的问题。如果把这两个人比作线程的话,那么ThreadLocal就是用来避免这两个线程竞争的。
+比如有两个人去宝屋收集宝物,这两个共用一个袋子的话肯定会产生争执,但是给他们两个人每个人分配一个袋子的话就不会出现这样的问题。如果把这两个人比作线程的话,那么 ThreadLocal 就是用来避免这两个线程竞争的。
-### 3.2. ThreadLocal示例
+### 3.2. ThreadLocal 示例
相信看了上面的解释,大家已经搞懂 ThreadLocal 类是个什么东西了。
@@ -273,9 +377,9 @@ Thread Name= 8 formatter = yy-M-d ah:mm
Thread Name= 9 formatter = yy-M-d ah:mm
```
-从输出中可以看出,Thread-0已经改变了formatter的值,但仍然是thread-2默认格式化程序与初始化值相同,其他线程也一样。
+从输出中可以看出,Thread-0 已经改变了 formatter 的值,但仍然是 thread-2 默认格式化程序与初始化值相同,其他线程也一样。
-上面有一段代码用到了创建 `ThreadLocal` 变量的那段代码用到了 Java8 的知识,它等于下面这段代码,如果你写了下面这段代码的话,IDEA会提示你转换为Java8的格式(IDEA真的不错!)。因为ThreadLocal类在Java 8中扩展,使用一个新的方法`withInitial()`,将Supplier功能接口作为参数。
+上面有一段代码用到了创建 `ThreadLocal` 变量的那段代码用到了 Java8 的知识,它等于下面这段代码,如果你写了下面这段代码的话,IDEA 会提示你转换为 Java8 的格式(IDEA 真的不错!)。因为 ThreadLocal 类在 Java 8 中扩展,使用一个新的方法`withInitial()`,将 Supplier 功能接口作为参数。
```java
private static final ThreadLocal formatter = new ThreadLocal(){
@@ -287,7 +391,7 @@ Thread Name= 9 formatter = yy-M-d ah:mm
};
```
-### 3.3. ThreadLocal原理
+### 3.3. ThreadLocal 原理
从 `Thread`类源代码入手。
@@ -303,7 +407,7 @@ ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
}
```
-从上面`Thread`类 源代码可以看出`Thread` 类中有一个 `threadLocals` 和 一个 `inheritableThreadLocals` 变量,它们都是 `ThreadLocalMap` 类型的变量,我们可以把 `ThreadLocalMap` 理解为`ThreadLocal` 类实现的定制化的 `HashMap`。默认情况下这两个变量都是null,只有当前线程调用 `ThreadLocal` 类的 `set`或`get`方法时才创建它们,实际上调用这两个方法的时候,我们调用的是`ThreadLocalMap`类对应的 `get()`、`set() `方法。
+从上面`Thread`类 源代码可以看出`Thread` 类中有一个 `threadLocals` 和 一个 `inheritableThreadLocals` 变量,它们都是 `ThreadLocalMap` 类型的变量,我们可以把 `ThreadLocalMap` 理解为`ThreadLocal` 类实现的定制化的 `HashMap`。默认情况下这两个变量都是 null,只有当前线程调用 `ThreadLocal` 类的 `set`或`get`方法时才创建它们,实际上调用这两个方法的时候,我们调用的是`ThreadLocalMap`类对应的 `get()`、`set()`方法。
`ThreadLocal`类的`set()`方法
@@ -323,19 +427,25 @@ ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
通过上面这些内容,我们足以通过猜测得出结论:**最终的变量是放在了当前线程的 `ThreadLocalMap` 中,并不是存在 `ThreadLocal` 上,`ThreadLocal` 可以理解为只是`ThreadLocalMap`的封装,传递了变量值。** `ThrealLocal` 类中可以通过`Thread.currentThread()`获取到当前线程对象后,直接通过`getMap(Thread t)`可以访问到该线程的`ThreadLocalMap`对象。
-**每个`Thread`中都具备一个`ThreadLocalMap`,而`ThreadLocalMap`可以存储以`ThreadLocal`为key的键值对。** 比如我们在同一个线程中声明了两个 `ThreadLocal` 对象的话,会使用 `Thread`内部都是使用仅有那个`ThreadLocalMap` 存放数据的,`ThreadLocalMap`的 key 就是 `ThreadLocal`对象,value 就是 `ThreadLocal` 对象调用`set`方法设置的值。
+**每个`Thread`中都具备一个`ThreadLocalMap`,而`ThreadLocalMap`可以存储以`ThreadLocal`为 key ,Object 对象为 value 的键值对。**
-`ThreadLocal` 内部维护的是一个类似 `Map` 的`ThreadLocalMap` 数据结构,`key` 为当前对象的 `Thread` 对象,值为 Object 对象。
+```java
+ThreadLocalMap(ThreadLocal firstKey, Object firstValue) {
+ ......
+}
+```
-
+比如我们在同一个线程中声明了两个 `ThreadLocal` 对象的话,会使用 `Thread`内部都是使用仅有那个`ThreadLocalMap` 存放数据的,`ThreadLocalMap`的 key 就是 `ThreadLocal`对象,value 就是 `ThreadLocal` 对象调用`set`方法设置的值。
+
+
`ThreadLocalMap`是`ThreadLocal`的静态内部类。
-
+
### 3.4. ThreadLocal 内存泄露问题
-`ThreadLocalMap` 中使用的 key 为 `ThreadLocal` 的弱引用,而 value 是强引用。所以,如果 `ThreadLocal` 没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。这样一来,`ThreadLocalMap` 中就会出现key为null的Entry。假如我们不做任何措施的话,value 永远无法被GC 回收,这个时候就可能会产生内存泄露。ThreadLocalMap实现中已经考虑了这种情况,在调用 `set()`、`get()`、`remove()` 方法的时候,会清理掉 key 为 null 的记录。使用完 `ThreadLocal`方法后 最好手动调用`remove()`方法
+`ThreadLocalMap` 中使用的 key 为 `ThreadLocal` 的弱引用,而 value 是强引用。所以,如果 `ThreadLocal` 没有被外部强引用的情况下,在垃圾回收的时候,key 会被清理掉,而 value 不会被清理掉。这样一来,`ThreadLocalMap` 中就会出现 key 为 null 的 Entry。假如我们不做任何措施的话,value 永远无法被 GC 回收,这个时候就可能会产生内存泄露。ThreadLocalMap 实现中已经考虑了这种情况,在调用 `set()`、`get()`、`remove()` 方法的时候,会清理掉 key 为 null 的记录。使用完 `ThreadLocal`方法后 最好手动调用`remove()`方法
```java
static class Entry extends WeakReference> {
@@ -353,7 +463,7 @@ ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
> 如果一个对象只具有弱引用,那就类似于**可有可无的生活用品**。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它 所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
>
-> 弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。
+> 弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java 虚拟机就会把这个弱引用加入到与之关联的引用队列中。
## 4. 线程池
@@ -369,9 +479,9 @@ ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
- **提高响应速度**。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- **提高线程的可管理性**。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
-### 4.2. 实现Runnable接口和Callable接口的区别
+### 4.2. 实现 Runnable 接口和 Callable 接口的区别
-`Runnable`自Java 1.0以来一直存在,但`Callable`仅在Java 1.5中引入,目的就是为了来处理`Runnable`不支持的用例。**`Runnable` 接口**不会返回结果或抛出检查异常,但是**`Callable` 接口**可以。所以,如果任务不需要返回结果或抛出异常推荐使用 **`Runnable` 接口**,这样代码看起来会更加简洁。
+`Runnable`自 Java 1.0 以来一直存在,但`Callable`仅在 Java 1.5 中引入,目的就是为了来处理`Runnable`不支持的用例。**`Runnable` 接口**不会返回结果或抛出检查异常,但是**`Callable` 接口**可以。所以,如果任务不需要返回结果或抛出异常推荐使用 **`Runnable` 接口**,这样代码看起来会更加简洁。
工具类 `Executors` 可以实现 `Runnable` 对象和 `Callable` 对象之间的相互转换。(`Executors.callable(Runnable task`)或 `Executors.callable(Runnable task,Object resule)`)。
@@ -401,7 +511,7 @@ public interface Callable {
}
```
-### 4.3. 执行execute()方法和submit()方法的区别是什么呢?
+### 4.3. 执行 execute()方法和 submit()方法的区别是什么呢?
1. **`execute()`方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功与否;**
2. **`submit()`方法用于提交需要返回值的任务。线程池会返回一个 `Future` 类型的对象,通过这个 `Future` 对象可以判断任务是否执行成功**,并且可以通过 `Future` 的 `get()`方法来获取返回值,`get()`方法会阻塞当前线程直到任务完成,而使用 `get(long timeout,TimeUnit unit)`方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务没有执行完。
@@ -435,23 +545,23 @@ public interface Callable {
### 4.4. 如何创建线程池
-《阿里巴巴Java开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
+《阿里巴巴 Java 开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
> Executors 返回线程池对象的弊端如下:
>
-> - **FixedThreadPool 和 SingleThreadExecutor** : 允许请求的队列长度为 Integer.MAX_VALUE ,可能堆积大量的请求,从而导致OOM。
-> - **CachedThreadPool 和 ScheduledThreadPool** : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致OOM。
+> - **FixedThreadPool 和 SingleThreadExecutor** : 允许请求的队列长度为 Integer.MAX_VALUE ,可能堆积大量的请求,从而导致 OOM。
+> - **CachedThreadPool 和 ScheduledThreadPool** : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致 OOM。
**方式一:通过构造方法实现**

-**方式二:通过Executor 框架的工具类Executors来实现**
-我们可以创建三种类型的ThreadPoolExecutor:
+**方式二:通过 Executor 框架的工具类 Executors 来实现**
+我们可以创建三种类型的 ThreadPoolExecutor:
- **FixedThreadPool** : 该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
- **SingleThreadExecutor:** 方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
- **CachedThreadPool:** 该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
-对应Executors工具类中的方法如图所示:
+对应 Executors 工具类中的方法如图所示:
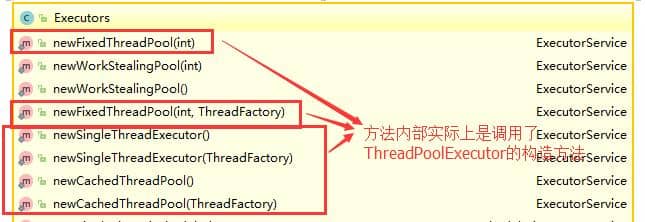
### 4.5 ThreadPoolExecutor 类分析
@@ -509,13 +619,13 @@ public interface Callable {
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任时,`ThreadPoolTaskExecutor` 定义一些策略:
- **`ThreadPoolExecutor.AbortPolicy`**:抛出 `RejectedExecutionException`来拒绝新任务的处理。
-- **`ThreadPoolExecutor.CallerRunsPolicy`**:调用执行自己的线程运行任务。您不会任务请求。但是这种策略会降低对于新任务提交速度,影响程序的整体性能。另外,这个策略喜欢增加队列容量。如果您的应用程序可以承受此延迟并且你不能任务丢弃任何一个任务请求的话,你可以选择这个策略。
+- **`ThreadPoolExecutor.CallerRunsPolicy`**:调用执行自己的线程运行任务,也就是直接在调用`execute`方法的线程中运行(`run`)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。
- **`ThreadPoolExecutor.DiscardPolicy`:** 不处理新任务,直接丢弃掉。
- **`ThreadPoolExecutor.DiscardOldestPolicy`:** 此策略将丢弃最早的未处理的任务请求。
举个例子: Spring 通过 `ThreadPoolTaskExecutor` 或者我们直接通过 `ThreadPoolExecutor` 的构造函数创建线程池的时候,当我们不指定 `RejectedExecutionHandler` 饱和策略的话来配置线程池的时候默认使用的是 `ThreadPoolExecutor.AbortPolicy`。在默认情况下,`ThreadPoolExecutor` 将抛出 `RejectedExecutionException` 来拒绝新来的任务 ,这代表你将丢失对这个任务的处理。 对于可伸缩的应用程序,建议使用 `ThreadPoolExecutor.CallerRunsPolicy`。当最大池被填满时,此策略为我们提供可伸缩队列。(这个直接查看 `ThreadPoolExecutor` 的构造函数源码就可以看出,比较简单的原因,这里就不贴代码了)
-### 4.6 一个简单的线程池Demo:`Runnable`+`ThreadPoolExecutor`
+### 4.6 一个简单的线程池 Demo
为了让大家更清楚上面的面试题中的一些概念,我写了一个简单的线程池 Demo。
@@ -702,20 +812,19 @@ pool-1-thread-1 End. Time = Tue Nov 12 20:59:54 CST 2019
## 5. Atomic 原子类
-### 5.1. 介绍一下Atomic 原子类
+### 5.1. 介绍一下 Atomic 原子类
Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是构成一般物质的最小单位,在化学反应中是不可分割的。在我们这里 Atomic 是指一个操作是不可中断的。即使是在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰。
所以,所谓原子类说简单点就是具有原子/原子操作特征的类。
-
并发包 `java.util.concurrent` 的原子类都存放在`java.util.concurrent.atomic`下,如下图所示。
-### 5.2. JUC 包中的原子类是哪4类?
+### 5.2. JUC 包中的原子类是哪 4 类?
-**基本类型**
+**基本类型**
使用原子的方式更新基本类型
@@ -727,7 +836,6 @@ Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是
使用原子的方式更新数组里的某个元素
-
- AtomicIntegerArray:整形数组原子类
- AtomicLongArray:长整形数组原子类
- AtomicReferenceArray:引用类型数组原子类
@@ -744,10 +852,9 @@ Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是
- AtomicLongFieldUpdater:原子更新长整形字段的更新器
- AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
-
### 5.3. 讲讲 AtomicInteger 的使用
- **AtomicInteger 类常用方法**
+**AtomicInteger 类常用方法**
```java
public final int get() //获取当前的值
@@ -759,9 +866,10 @@ boolean compareAndSet(int expect, int update) //如果输入的数值等于预
public final void lazySet(int newValue)//最终设置为newValue,使用 lazySet 设置之后可能导致其他线程在之后的一小段时间内还是可以读到旧的值。
```
- **AtomicInteger 类的使用示例**
+**AtomicInteger 类的使用示例**
使用 AtomicInteger 之后,不用对 increment() 方法加锁也可以保证线程安全。
+
```java
class AtomicIntegerTest {
private AtomicInteger count = new AtomicInteger();
@@ -769,7 +877,7 @@ class AtomicIntegerTest {
public void increment() {
count.incrementAndGet();
}
-
+
public int getCount() {
return count.get();
}
@@ -800,7 +908,7 @@ AtomicInteger 类的部分源码:
AtomicInteger 类主要利用 CAS (compare and swap) + volatile 和 native 方法来保证原子操作,从而避免 synchronized 的高开销,执行效率大为提升。
-CAS的原理是拿期望的值和原本的一个值作比较,如果相同则更新成新的值。UnSafe 类的 objectFieldOffset() 方法是一个本地方法,这个方法是用来拿到“原来的值”的内存地址,返回值是 valueOffset。另外 value 是一个volatile变量,在内存中可见,因此 JVM 可以保证任何时刻任何线程总能拿到该变量的最新值。
+CAS 的原理是拿期望的值和原本的一个值作比较,如果相同则更新成新的值。UnSafe 类的 objectFieldOffset() 方法是一个本地方法,这个方法是用来拿到“原来的值”的内存地址,返回值是 valueOffset。另外 value 是一个 volatile 变量,在内存中可见,因此 JVM 可以保证任何时刻任何线程总能拿到该变量的最新值。
关于 Atomic 原子类这部分更多内容可以查看我的这篇文章:并发编程面试必备:[JUC 中的 Atomic 原子类总结](https://mp.weixin.qq.com/s/joa-yOiTrYF67bElj8xqvg)
@@ -808,47 +916,46 @@ CAS的原理是拿期望的值和原本的一个值作比较,如果相同则
### 6.1. AQS 介绍
-AQS的全称为(AbstractQueuedSynchronizer),这个类在java.util.concurrent.locks包下面。
+AQS 的全称为(AbstractQueuedSynchronizer),这个类在 java.util.concurrent.locks 包下面。
-AQS是一个用来构建锁和同步器的框架,使用AQS能简单且高效地构造出应用广泛的大量的同步器,比如我们提到的ReentrantLock,Semaphore,其他的诸如ReentrantReadWriteLock,SynchronousQueue,FutureTask等等皆是基于AQS的。当然,我们自己也能利用AQS非常轻松容易地构造出符合我们自己需求的同步器。
+AQS 是一个用来构建锁和同步器的框架,使用 AQS 能简单且高效地构造出应用广泛的大量的同步器,比如我们提到的 ReentrantLock,Semaphore,其他的诸如 ReentrantReadWriteLock,SynchronousQueue,FutureTask 等等皆是基于 AQS 的。当然,我们自己也能利用 AQS 非常轻松容易地构造出符合我们自己需求的同步器。
### 6.2. AQS 原理分析
-AQS 原理这部分参考了部分博客,在5.2节末尾放了链接。
+AQS 原理这部分参考了部分博客,在 5.2 节末尾放了链接。
-> 在面试中被问到并发知识的时候,大多都会被问到“请你说一下自己对于AQS原理的理解”。下面给大家一个示例供大家参加,面试不是背题,大家一定要加入自己的思想,即使加入不了自己的思想也要保证自己能够通俗的讲出来而不是背出来。
+> 在面试中被问到并发知识的时候,大多都会被问到“请你说一下自己对于 AQS 原理的理解”。下面给大家一个示例供大家参加,面试不是背题,大家一定要加入自己的思想,即使加入不了自己的思想也要保证自己能够通俗的讲出来而不是背出来。
-下面大部分内容其实在AQS类注释上已经给出了,不过是英语看着比较吃力一点,感兴趣的话可以看看源码。
+下面大部分内容其实在 AQS 类注释上已经给出了,不过是英语看着比较吃力一点,感兴趣的话可以看看源码。
#### 6.2.1. AQS 原理概览
-**AQS核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制AQS是用CLH队列锁实现的,即将暂时获取不到锁的线程加入到队列中。**
+**AQS 核心思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的工作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占用,那么就需要一套线程阻塞等待以及被唤醒时锁分配的机制,这个机制 AQS 是用 CLH 队列锁实现的,即将暂时获取不到锁的线程加入到队列中。**
-> CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS是将每条请求共享资源的线程封装成一个CLH锁队列的一个结点(Node)来实现锁的分配。
-
-看个AQS(AbstractQueuedSynchronizer)原理图:
+> CLH(Craig,Landin,and Hagersten)队列是一个虚拟的双向队列(虚拟的双向队列即不存在队列实例,仅存在结点之间的关联关系)。AQS 是将每条请求共享资源的线程封装成一个 CLH 锁队列的一个结点(Node)来实现锁的分配。
+看个 AQS(AbstractQueuedSynchronizer)原理图:
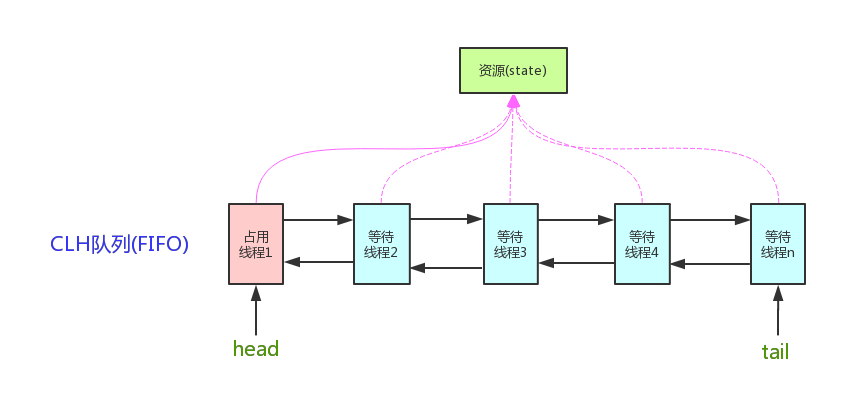
-AQS使用一个int成员变量来表示同步状态,通过内置的FIFO队列来完成获取资源线程的排队工作。AQS使用CAS对该同步状态进行原子操作实现对其值的修改。
+AQS 使用一个 int 成员变量来表示同步状态,通过内置的 FIFO 队列来完成获取资源线程的排队工作。AQS 使用 CAS 对该同步状态进行原子操作实现对其值的修改。
```java
private volatile int state;//共享变量,使用volatile修饰保证线程可见性
```
-状态信息通过protected类型的getState,setState,compareAndSetState进行操作
+状态信息通过 protected 类型的 getState,setState,compareAndSetState 进行操作
```java
//返回同步状态的当前值
-protected final int getState() {
+protected final int getState() {
return state;
}
// 设置同步状态的值
-protected final void setState(int newState) {
+protected final void setState(int newState) {
state = newState;
}
//原子地(CAS操作)将同步状态值设置为给定值update如果当前同步状态的值等于expect(期望值)
@@ -859,27 +966,27 @@ protected final boolean compareAndSetState(int expect, int update) {
#### 6.2.2. AQS 对资源的共享方式
-**AQS定义两种资源共享方式**
+**AQS 定义两种资源共享方式**
-- **Exclusive**(独占):只有一个线程能执行,如ReentrantLock。又可分为公平锁和非公平锁:
- - 公平锁:按照线程在队列中的排队顺序,先到者先拿到锁
- - 非公平锁:当线程要获取锁时,无视队列顺序直接去抢锁,谁抢到就是谁的
-- **Share**(共享):多个线程可同时执行,如Semaphore/CountDownLatch。Semaphore、CountDownLatch、 CyclicBarrier、ReadWriteLock 我们都会在后面讲到。
+- **Exclusive**(独占):只有一个线程能执行,如 ReentrantLock。又可分为公平锁和非公平锁:
+ - 公平锁:按照线程在队列中的排队顺序,先到者先拿到锁
+ - 非公平锁:当线程要获取锁时,无视队列顺序直接去抢锁,谁抢到就是谁的
+- **Share**(共享):多个线程可同时执行,如 Semaphore/CountDownLatch。Semaphore、CountDownLatch、 CyclicBarrier、ReadWriteLock 我们都会在后面讲到。
-ReentrantReadWriteLock 可以看成是组合式,因为ReentrantReadWriteLock也就是读写锁允许多个线程同时对某一资源进行读。
+ReentrantReadWriteLock 可以看成是组合式,因为 ReentrantReadWriteLock 也就是读写锁允许多个线程同时对某一资源进行读。
-不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS已经在顶层实现好了。
+不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS 已经在顶层实现好了。
-#### 6.2.3. AQS底层使用了模板方法模式
+#### 6.2.3. AQS 底层使用了模板方法模式
同步器的设计是基于模板方法模式的,如果需要自定义同步器一般的方式是这样(模板方法模式很经典的一个应用):
-1. 使用者继承AbstractQueuedSynchronizer并重写指定的方法。(这些重写方法很简单,无非是对于共享资源state的获取和释放)
-2. 将AQS组合在自定义同步组件的实现中,并调用其模板方法,而这些模板方法会调用使用者重写的方法。
+1. 使用者继承 AbstractQueuedSynchronizer 并重写指定的方法。(这些重写方法很简单,无非是对于共享资源 state 的获取和释放)
+2. 将 AQS 组合在自定义同步组件的实现中,并调用其模板方法,而这些模板方法会调用使用者重写的方法。
这和我们以往通过实现接口的方式有很大区别,这是模板方法模式很经典的一个运用。
-**AQS使用了模板方法模式,自定义同步器时需要重写下面几个AQS提供的模板方法:**
+**AQS 使用了模板方法模式,自定义同步器时需要重写下面几个 AQS 提供的模板方法:**
```java
isHeldExclusively()//该线程是否正在独占资源。只有用到condition才需要去实现它。
@@ -890,13 +997,13 @@ tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true
```
-默认情况下,每个方法都抛出 `UnsupportedOperationException`。 这些方法的实现必须是内部线程安全的,并且通常应该简短而不是阻塞。AQS类中的其他方法都是final ,所以无法被其他类使用,只有这几个方法可以被其他类使用。
+默认情况下,每个方法都抛出 `UnsupportedOperationException`。 这些方法的实现必须是内部线程安全的,并且通常应该简短而不是阻塞。AQS 类中的其他方法都是 final ,所以无法被其他类使用,只有这几个方法可以被其他类使用。
-以ReentrantLock为例,state初始化为0,表示未锁定状态。A线程lock()时,会调用tryAcquire()独占该锁并将state+1。此后,其他线程再tryAcquire()时就会失败,直到A线程unlock()到state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A线程自己是可以重复获取此锁的(state会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证state是能回到零态的。
+以 ReentrantLock 为例,state 初始化为 0,表示未锁定状态。A 线程 lock()时,会调用 tryAcquire()独占该锁并将 state+1。此后,其他线程再 tryAcquire()时就会失败,直到 A 线程 unlock()到 state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A 线程自己是可以重复获取此锁的(state 会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证 state 是能回到零态的。
-再以CountDownLatch以例,任务分为N个子线程去执行,state也初始化为N(注意N要与线程个数一致)。这N个子线程是并行执行的,每个子线程执行完后countDown()一次,state会CAS(Compare and Swap)减1。等到所有子线程都执行完后(即state=0),会unpark()主调用线程,然后主调用线程就会从await()函数返回,继续后余动作。
+再以 CountDownLatch 以例,任务分为 N 个子线程去执行,state 也初始化为 N(注意 N 要与线程个数一致)。这 N 个子线程是并行执行的,每个子线程执行完后 countDown()一次,state 会 CAS(Compare and Swap)减 1。等到所有子线程都执行完后(即 state=0),会 unpark()主调用线程,然后主调用线程就会从 await()函数返回,继续后余动作。
-一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现`tryAcquire-tryRelease`、`tryAcquireShared-tryReleaseShared`中的一种即可。但AQS也支持自定义同步器同时实现独占和共享两种方式,如`ReentrantReadWriteLock`。
+一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现`tryAcquire-tryRelease`、`tryAcquireShared-tryReleaseShared`中的一种即可。但 AQS 也支持自定义同步器同时实现独占和共享两种方式,如`ReentrantReadWriteLock`。
推荐两篇 AQS 原理和相关源码分析的文章:
@@ -906,14 +1013,97 @@ tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true
### 6.3. AQS 组件总结
- **Semaphore(信号量)-允许多个线程同时访问:** synchronized 和 ReentrantLock 都是一次只允许一个线程访问某个资源,Semaphore(信号量)可以指定多个线程同时访问某个资源。
-- **CountDownLatch (倒计时器):** CountDownLatch是一个同步工具类,用来协调多个线程之间的同步。这个工具通常用来控制线程等待,它可以让某一个线程等待直到倒计时结束,再开始执行。
-- **CyclicBarrier(循环栅栏):** CyclicBarrier 和 CountDownLatch 非常类似,它也可以实现线程间的技术等待,但是它的功能比 CountDownLatch 更加复杂和强大。主要应用场景和 CountDownLatch 类似。CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。CyclicBarrier默认的构造方法是 CyclicBarrier(int parties),其参数表示屏障拦截的线程数量,每个线程调用await()方法告诉 CyclicBarrier 我已经到达了屏障,然后当前线程被阻塞。
+- **CountDownLatch (倒计时器):** CountDownLatch 是一个同步工具类,用来协调多个线程之间的同步。这个工具通常用来控制线程等待,它可以让某一个线程等待直到倒计时结束,再开始执行。
+- **CyclicBarrier(循环栅栏):** CyclicBarrier 和 CountDownLatch 非常类似,它也可以实现线程间的技术等待,但是它的功能比 CountDownLatch 更加复杂和强大。主要应用场景和 CountDownLatch 类似。CyclicBarrier 的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续干活。CyclicBarrier 默认的构造方法是 CyclicBarrier(int parties),其参数表示屏障拦截的线程数量,每个线程调用 await()方法告诉 CyclicBarrier 我已经到达了屏障,然后当前线程被阻塞。
+
+### 6.4. 用过 CountDownLatch 么?什么场景下用的?
+
+`CountDownLatch` 的作用就是 允许 count 个线程阻塞在一个地方,直至所有线程的任务都执行完毕。之前在项目中,有一个使用多线程读取多个文件处理的场景,我用到了 `CountDownLatch` 。具体场景是下面这样的:
+
+我们要读取处理 6 个文件,这 6 个任务都是没有执行顺序依赖的任务,但是我们需要返回给用户的时候将这几个文件的处理的结果进行统计整理。
+
+为此我们定义了一个线程池和 count 为 6 的`CountDownLatch`对象 。使用线程池处理读取任务,每一个线程处理完之后就将 count-1,调用`CountDownLatch`对象的 `await()`方法,直到所有文件读取完之后,才会接着执行后面的逻辑。
+
+伪代码是下面这样的:
+
+```java
+public class CountDownLatchExample1 {
+ // 处理文件的数量
+ private static final int threadCount = 6;
+
+ public static void main(String[] args) throws InterruptedException {
+ // 创建一个具有固定线程数量的线程池对象(推荐使用构造方法创建)
+ ExecutorService threadPool = Executors.newFixedThreadPool(10);
+ final CountDownLatch countDownLatch = new CountDownLatch(threadCount);
+ for (int i = 0; i < threadCount; i++) {
+ final int threadnum = i;
+ threadPool.execute(() -> {
+ try {
+ //处理文件的业务操作
+ ......
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ } finally {
+ //表示一个文件已经被完成
+ countDownLatch.countDown();
+ }
+
+ });
+ }
+ countDownLatch.await();
+ threadPool.shutdown();
+ System.out.println("finish");
+ }
+
+}
+```
+
+**有没有可以改进的地方呢?**
+
+可以使用 `CompletableFuture` 类来改进!Java8 的 `CompletableFuture` 提供了很多对多线程友好的方法,使用它可以很方便地为我们编写多线程程序,什么异步、串行、并行或者等待所有线程执行完任务什么的都非常方便。
+
+```java
+CompletableFuture task1 =
+ CompletableFuture.supplyAsync(()->{
+ //自定义业务操作
+ });
+......
+CompletableFuture task6 =
+ CompletableFuture.supplyAsync(()->{
+ //自定义业务操作
+ });
+......
+ CompletableFuture headerFuture=CompletableFuture.allOf(task1,.....,task6);
+
+ try {
+ headerFuture.join();
+ } catch (Exception ex) {
+ ......
+ }
+System.out.println("all done. ");
+```
+
+上面的代码还可以接续优化,当任务过多的时候,把每一个 task 都列出来不太现实,可以考虑通过循环来添加任务。
+
+```java
+//文件夹位置
+List filePaths = Arrays.asList(...)
+// 异步处理所有文件
+List> fileFutures = filePaths.stream()
+ .map(filePath -> doSomeThing(filePath))
+ .collect(Collectors.toList());
+// 将他们合并起来
+CompletableFuture allFutures = CompletableFuture.allOf(
+ fileFutures.toArray(new CompletableFuture[fileFutures.size()])
+);
+
+```
## 7 Reference
- 《深入理解 Java 虚拟机》
- 《实战 Java 高并发程序设计》
-- 《Java并发编程的艺术》
+- 《Java 并发编程的艺术》
- http://www.cnblogs.com/waterystone/p/4920797.html
- https://www.cnblogs.com/chengxiao/archive/2017/07/24/7141160.html
-
@@ -922,8 +1112,8 @@ tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"面试突击"** 即可免费领取!
+**《Java 面试突击》:** 由本文档衍生的专为面试而生的《Java 面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"面试突击"** 即可免费领取!
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
+**Java 工程师必备学习资源:** 一些 Java 工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。

diff --git a/docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md b/docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md
index ca2518ee..59c14848 100644
--- a/docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md
+++ b/docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md
@@ -1,5 +1,4 @@
-点击关注[公众号](#公众号 "公众号")及时获取笔主最新更新文章,并可免费领取本文档配套的《Java 面试突击》以及 Java 工程师必备学习资源。
-
+
- [Java 并发基础常见面试题总结](#java-并发基础常见面试题总结)
- [1. 什么是线程和进程?](#1-什么是线程和进程)
@@ -22,6 +21,7 @@
- [10. 为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?](#10-为什么我们调用-start-方法时会执行-run-方法为什么我们不能直接调用-run-方法)
- [公众号](#公众号)
+
# Java 并发基础常见面试题总结
@@ -84,7 +84,7 @@ public class MultiThread {
从上图可以看出:一个进程中可以有多个线程,多个线程共享进程的**堆**和**方法区 (JDK1.8 之后的元空间)**资源,但是每个线程有自己的**程序计数器**、**虚拟机栈** 和 **本地方法栈**。
-**总结:** 线程 是 进程 划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。线程执行开销小,但不利于资源的管理和保护;而进程正相反
+**总结:** **线程是进程划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。线程执行开销小,但不利于资源的管理和保护;而进程正相反。**
下面是该知识点的扩展内容!
@@ -110,7 +110,7 @@ public class MultiThread {
### 2.4. 一句话简单了解堆和方法区
-堆和方法区是所有线程共享的资源,其中堆是进程中最大的一块内存,主要用于存放新创建的对象 (所有对象都在这里分配内存),方法区主要用于存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
+堆和方法区是所有线程共享的资源,其中堆是进程中最大的一块内存,主要用于存放新创建的对象 (几乎所有对象都在这里分配内存),方法区主要用于存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
## 3. 说说并发与并行的区别?
@@ -131,7 +131,7 @@ public class MultiThread {
## 5. 使用多线程可能带来什么问题?
-并发编程的目的就是为了能提高程序的执行效率提高程序运行速度,但是并发编程并不总是能提高程序运行速度的,而且并发编程可能会遇到很多问题,比如:内存泄漏、上下文切换、死锁还有受限于硬件和软件的资源闲置问题。
+并发编程的目的就是为了能提高程序的执行效率提高程序运行速度,但是并发编程并不总是能提高程序运行速度的,而且并发编程可能会遇到很多问题,比如:内存泄漏、死锁、线程不安全等等。
## 6. 说说线程的生命周期和状态?
@@ -143,9 +143,11 @@ Java 线程在运行的生命周期中的指定时刻只可能处于下面 6 种
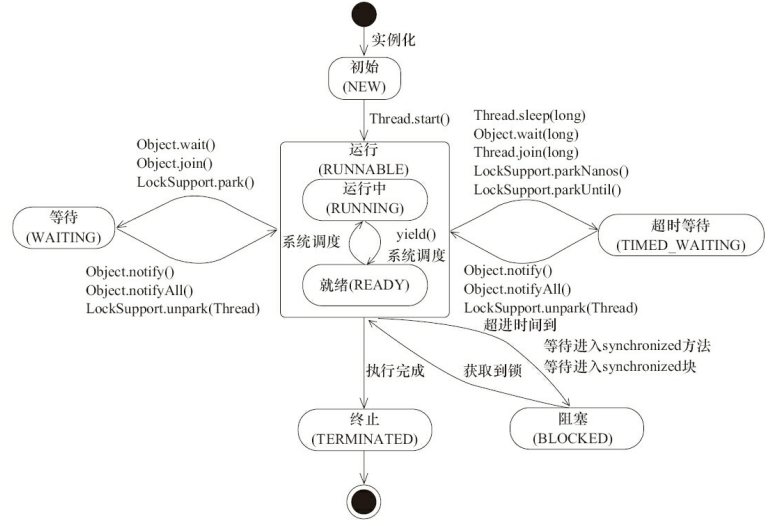
+> 订正(来自[issue736](https://github.com/Snailclimb/JavaGuide/issues/736)):原图中 wait到 runnable状态的转换中,`join`实际上是`Thread`类的方法,但这里写成了`Object`。
+
由上图可以看出:线程创建之后它将处于 **NEW(新建)** 状态,调用 `start()` 方法后开始运行,线程这时候处于 **READY(可运行)** 状态。可运行状态的线程获得了 CPU 时间片(timeslice)后就处于 **RUNNING(运行)** 状态。
-> 操作系统隐藏 Java 虚拟机(JVM)中的 RUNNABLE 和 RUNNING 状态,它只能看到 RUNNABLE 状态(图源:[HowToDoInJava](https://howtodoinjava.com/ "HowToDoInJava"):[Java Thread Life Cycle and Thread States](https://howtodoinjava.com/java/multi-threading/java-thread-life-cycle-and-thread-states/ "Java Thread Life Cycle and Thread States")),所以 Java 系统一般将这两个状态统称为 **RUNNABLE(运行中)** 状态 。
+> 操作系统隐藏 Java 虚拟机(JVM)中的 READY 和 RUNNING 状态,它只能看到 RUNNABLE 状态(图源:[HowToDoInJava](https://howtodoinjava.com/ "HowToDoInJava"):[Java Thread Life Cycle and Thread States](https://howtodoinjava.com/java/multi-threading/java-thread-life-cycle-and-thread-states/ "Java Thread Life Cycle and Thread States")),所以 Java 系统一般将这两个状态统称为 **RUNNABLE(运行中)** 状态 。

@@ -165,7 +167,7 @@ Linux 相比与其他操作系统(包括其他类 Unix 系统)有很多的
### 8.1. 认识线程死锁
-多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。
+线程死锁描述的是这样一种情况:多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。
如下图所示,线程 A 持有资源 2,线程 B 持有资源 1,他们同时都想申请对方的资源,所以这两个线程就会互相等待而进入死锁状态。
@@ -232,23 +234,12 @@ Thread[线程 2,5,main]waiting get resource1
### 8.2. 如何避免线程死锁?
-我们只要破坏产生死锁的四个条件中的其中一个就可以了。
+我上面说了产生死锁的四个必要条件,为了避免死锁,我们只要破坏产生死锁的四个条件中的其中一个就可以了。现在我们来挨个分析一下:
-**破坏互斥条件**
-
-这个条件我们没有办法破坏,因为我们用锁本来就是想让他们互斥的(临界资源需要互斥访问)。
-
-**破坏请求与保持条件**
-
-一次性申请所有的资源。
-
-**破坏不剥夺条件**
-
-占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
-
-**破坏循环等待条件**
-
-靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
+1. **破坏互斥条件** :这个条件我们没有办法破坏,因为我们用锁本来就是想让他们互斥的(临界资源需要互斥访问)。
+2. **破坏请求与保持条件** :一次性申请所有的资源。
+3. **破坏不剥夺条件** :占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
+4. **破坏循环等待条件** :靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
我们对线程 2 的代码修改成下面这样就不会产生死锁了。
@@ -310,3 +301,5 @@ new 一个 Thread,线程进入了新建状态;调用 start() 方法,会启
**Java 工程师必备学习资源:** 一些 Java 工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。

+
+
diff --git a/docs/java/Multithread/ThreadLocal.md b/docs/java/Multithread/ThreadLocal.md
index 06cdbea5..6383ef1d 100644
--- a/docs/java/Multithread/ThreadLocal.md
+++ b/docs/java/Multithread/ThreadLocal.md
@@ -1,170 +1,914 @@
-[ThreadLocal造成OOM内存溢出案例演示与原理分析](https://blog.csdn.net/xlgen157387/article/details/78298840)
+> 本文来自一枝花算不算浪漫投稿, 原文地址:[https://juejin.im/post/5eacc1c75188256d976df748](https://juejin.im/post/5eacc1c75188256d976df748)。
-[深入理解 Java 之 ThreadLocal 工作原理]()
+### 前言
-## ThreadLocal
+
-### ThreadLocal简介
+**全文共10000+字,31张图,这篇文章同样耗费了不少的时间和精力才创作完成,原创不易,请大家点点关注+在看,感谢。**
-通常情况下,我们创建的变量是可以被任何一个线程访问并修改的。**如果想实现每一个线程都有自己的专属本地变量该如何解决呢?** JDK中提供的`ThreadLocal`类正是为了解决这样的问题。 **`ThreadLocal`类主要解决的就是让每个线程绑定自己的值,可以将`ThreadLocal`类形象的比喻成存放数据的盒子,盒子中可以存储每个线程的私有数据。**
+对于`ThreadLocal`,大家的第一反应可能是很简单呀,线程的变量副本,每个线程隔离。那这里有几个问题大家可以思考一下:
-**如果你创建了一个`ThreadLocal`变量,那么访问这个变量的每个线程都会有这个变量的本地副本,这也是`ThreadLocal`变量名的由来。他们可以使用 `get()` 和 `set()` 方法来获取默认值或将其值更改为当前线程所存的副本的值,从而避免了线程安全问题。**
+- `ThreadLocal`的key是**弱引用**,那么在 `ThreadLocal`.get()的时候,发生**GC**之后,key是否为**null**?
+- `ThreadLocal`中`ThreadLocalMap`的**数据结构**?
+- `ThreadLocalMap`的**Hash算法**?
+- `ThreadLocalMap`中**Hash冲突**如何解决?
+- `ThreadLocalMap`的**扩容机制**?
+- `ThreadLocalMap`中**过期key的清理机制**?**探测式清理**和**启发式清理**流程?
+- `ThreadLocalMap.set()`方法实现原理?
+- `ThreadLocalMap.get()`方法实现原理?
+- 项目中`ThreadLocal`使用情况?遇到的坑?
+- ......
-再举个简单的例子:
+上述的一些问题你是否都已经掌握的很清楚了呢?本文将围绕这些问题使用图文方式来剖析`ThreadLocal`的**点点滴滴**。
-比如有两个人去宝屋收集宝物,这两个共用一个袋子的话肯定会产生争执,但是给他们两个人每个人分配一个袋子的话就不会出现这样的问题。如果把这两个人比作线程的话,那么ThreadLocal就是用来这两个线程竞争的。
+### 目录
-### ThreadLocal示例
-相信看了上面的解释,大家已经搞懂 ThreadLocal 类是个什么东西了。
+
+**注明:** 本文源码基于`JDK 1.8`
+
+### `ThreadLocal`代码演示
+
+我们先看下`ThreadLocal`使用示例:
```java
-import java.text.SimpleDateFormat;
-import java.util.Random;
+public class ThreadLocalTest {
+ private List messages = Lists.newArrayList();
-public class ThreadLocalExample implements Runnable{
+ public static final `ThreadLocal` holder = `ThreadLocal`.withInitial(ThreadLocalTest::new);
- // SimpleDateFormat 不是线程安全的,所以每个线程都要有自己独立的副本
- private static final ThreadLocal formatter = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyyMMdd HHmm"));
+ public static void add(String message) {
+ holder.get().messages.add(message);
+ }
- public static void main(String[] args) throws InterruptedException {
- ThreadLocalExample obj = new ThreadLocalExample();
- for(int i=0 ; i<10; i++){
- Thread t = new Thread(obj, ""+i);
- Thread.sleep(new Random().nextInt(1000));
- t.start();
+ public static List clear() {
+ List messages = holder.get().messages;
+ holder.remove();
+
+ System.out.println("size: " + holder.get().messages.size());
+ return messages;
+ }
+
+ public static void main(String[] args) {
+ ThreadLocalTest.add("一枝花算不算浪漫");
+ System.out.println(holder.get().messages);
+ ThreadLocalTest.clear();
+ }
+}
+```
+
+打印结果:
+
+```java
+[一枝花算不算浪漫]
+size: 0
+```
+
+`ThreadLocal`对象可以提供线程局部变量,每个线程`Thread`拥有一份自己的**副本变量**,多个线程互不干扰。
+
+### `ThreadLocal`的数据结构
+
+
+
+
+`Thread`类有一个类型为``ThreadLocal`.`ThreadLocalMap``的实例变量`threadLocals`,也就是说每个线程有一个自己的`ThreadLocalMap`。
+
+`ThreadLocalMap`有自己的独立实现,可以简单地将它的`key`视作`ThreadLocal`,`value`为代码中放入的值(实际上`key`并不是`ThreadLocal`本身,而是它的一个**弱引用**)。
+
+每个线程在往`ThreadLocal`里放值的时候,都会往自己的`ThreadLocalMap`里存,读也是以`ThreadLocal`作为引用,在自己的`map`里找对应的`key`,从而实现了**线程隔离**。
+
+`ThreadLocalMap`有点类似`HashMap`的结构,只是`HashMap`是由**数组+链表**实现的,而`ThreadLocalMap`中并没有**链表**结构。
+
+我们还要注意`Entry`, 它的`key`是``ThreadLocal` k` ,继承自`WeakReference, 也就是我们常说的弱引用类型。
+
+### GC 之后key是否为null?
+
+回应开头的那个问题, `ThreadLocal` 的`key`是弱引用,那么在` `ThreadLocal`.get()`的时候,发生`GC`之后,`key`是否是`null`?
+
+为了搞清楚这个问题,我们需要搞清楚`Java`的**四种引用类型**:
+
+- **强引用**:我们常常new出来的对象就是强引用类型,只要强引用存在,垃圾回收器将永远不会回收被引用的对象,哪怕内存不足的时候
+- **软引用**:使用SoftReference修饰的对象被称为软引用,软引用指向的对象在内存要溢出的时候被回收
+- **弱引用**:使用WeakReference修饰的对象被称为弱引用,只要发生垃圾回收,若这个对象只被弱引用指向,那么就会被回收
+- **虚引用**:虚引用是最弱的引用,在 Java 中使用 PhantomReference 进行定义。虚引用中唯一的作用就是用队列接收对象即将死亡的通知
+
+
+接着再来看下代码,我们使用反射的方式来看看`GC`后`ThreadLocal`中的数据情况:(下面代码来源自:https://blog.csdn.net/thewindkee/article/details/103726942,本地运行演示GC回收场景)
+
+```java
+public class ThreadLocalDemo {
+
+ public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException, InterruptedException {
+ Thread t = new Thread(()->test("abc",false));
+ t.start();
+ t.join();
+ System.out.println("--gc后--");
+ Thread t2 = new Thread(() -> test("def", true));
+ t2.start();
+ t2.join();
+ }
+
+ private static void test(String s,boolean isGC) {
+ try {
+ new `ThreadLocal`<>().set(s);
+ if (isGC) {
+ System.gc();
+ }
+ Thread t = Thread.currentThread();
+ Class clz = t.getClass();
+ Field field = clz.getDeclaredField("threadLocals");
+ field.setAccessible(true);
+ Object `ThreadLocalMap` = field.get(t);
+ Class tlmClass = `ThreadLocalMap`.getClass();
+ Field tableField = tlmClass.getDeclaredField("table");
+ tableField.setAccessible(true);
+ Object[] arr = (Object[]) tableField.get(`ThreadLocalMap`);
+ for (Object o : arr) {
+ if (o != null) {
+ Class entryClass = o.getClass();
+ Field valueField = entryClass.getDeclaredField("value");
+ Field referenceField = entryClass.getSuperclass().getSuperclass().getDeclaredField("referent");
+ valueField.setAccessible(true);
+ referenceField.setAccessible(true);
+ System.out.println(String.format("弱引用key:%s,值:%s", referenceField.get(o), valueField.get(o)));
+ }
+ }
+ } catch (Exception e) {
+ e.printStackTrace();
}
}
+}
+```
+
+结果如下:
+```java
+弱引用key:java.lang.`ThreadLocal`@433619b6,值:abc
+弱引用key:java.lang.`ThreadLocal`@418a15e3,值:java.lang.ref.SoftReference@bf97a12
+--gc后--
+弱引用key:null,值:def
+```
+
+
+
+如图所示,因为这里创建的`ThreadLocal`并没有指向任何值,也就是没有任何引用:
+
+```java
+new ThreadLocal<>().set(s);
+```
+
+所以这里在`GC`之后,`key`就会被回收,我们看到上面`debug`中的`referent=null`, 如果**改动一下代码:**
+
+
+
+这个问题刚开始看,如果没有过多思考,**弱引用**,还有**垃圾回收**,那么肯定会觉得是`null`。
+
+其实是不对的,因为题目说的是在做 ``ThreadLocal`.get()` 操作,证明其实还是有**强引用**存在的,所以 `key` 并不为 `null`,如下图所示,`ThreadLocal`的**强引用**仍然是存在的。
+
+
+
+如果我们的**强引用**不存在的话,那么 `key` 就会被回收,也就是会出现我们 `value` 没被回收,`key` 被回收,导致 `value` 永远存在,出现内存泄漏。
+
+### `ThreadLocal.set()`方法源码详解
+
+
+
+`ThreadLocal`中的`set`方法原理如上图所示,很简单,主要是判断`ThreadLocalMap`是否存在,然后使用`ThreadLocal`中的`set`方法进行数据处理。
+
+代码如下:
+
+```java
+public void set(T value) {
+ Thread t = Thread.currentThread();
+ ThreadLocalMap map = getMap(t);
+ if (map != null)
+ map.set(this, value);
+ else
+ createMap(t, value);
+}
+
+void createMap(Thread t, T firstValue) {
+ t.threadLocals = new `ThreadLocalMap`(this, firstValue);
+}
+```
+
+主要的核心逻辑还是在`ThreadLocalMap`中的,一步步往下看,后面还有更详细的剖析。
+
+### `ThreadLocalMap` Hash算法
+
+既然是`Map`结构,那么`ThreadLocalMap`当然也要实现自己的`hash`算法来解决散列表数组冲突问题。
+
+```java
+int i = key.threadLocalHashCode & (len-1);
+```
+
+`ThreadLocalMap`中`hash`算法很简单,这里`i`就是当前key在散列表中对应的数组下标位置。
+
+这里最关键的就是`threadLocalHashCode`值的计算,`ThreadLocal`中有一个属性为`HASH_INCREMENT = 0x61c88647`
+
+```java
+public class ThreadLocal {
+ private final int threadLocalHashCode = nextHashCode();
+
+ private static AtomicInteger nextHashCode = new AtomicInteger();
+
+ private static final int HASH_INCREMENT = 0x61c88647;
+
+ private static int nextHashCode() {
+ return nextHashCode.getAndAdd(HASH_INCREMENT);
+ }
+
+ static class `ThreadLocalMap` {
+ `ThreadLocalMap`(`ThreadLocal` firstKey, Object firstValue) {
+ table = new Entry[INITIAL_CAPACITY];
+ int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1);
+
+ table[i] = new Entry(firstKey, firstValue);
+ size = 1;
+ setThreshold(INITIAL_CAPACITY);
+ }
+ }
+}
+```
+
+每当创建一个`ThreadLocal`对象,这个``ThreadLocal`.nextHashCode` 这个值就会增长 `0x61c88647` 。
+
+这个值很特殊,它是**斐波那契数** 也叫 **黄金分割数**。`hash`增量为 这个数字,带来的好处就是 `hash` **分布非常均匀**。
+
+我们自己可以尝试下:
+
+
+
+可以看到产生的哈希码分布很均匀,这里不去细纠**斐波那契**具体算法,感兴趣的可以自行查阅相关资料。
+
+### `ThreadLocalMap` Hash冲突
+
+> **注明:** 下面所有示例图中,**绿色块**`Entry`代表**正常数据**,**灰色块**代表`Entry`的`key`值为`null`,**已被垃圾回收**。**白色块**表示`Entry`为`null`。
+
+虽然`ThreadLocalMap`中使用了**黄金分隔数来**作为`hash`计算因子,大大减少了`Hash`冲突的概率,但是仍然会存在冲突。
+
+`HashMap`中解决冲突的方法是在数组上构造一个**链表**结构,冲突的数据挂载到链表上,如果链表长度超过一定数量则会转化成**红黑树**。
+
+而`ThreadLocalMap`中并没有链表结构,所以这里不能适用`HashMap`解决冲突的方式了。
+
+
+
+
+如上图所示,如果我们插入一个`value=27`的数据,通过`hash`计算后应该落入第4个槽位中,而槽位4已经有了`Entry`数据。
+
+此时就会线性向后查找,一直找到`Entry`为`null`的槽位才会停止查找,将当前元素放入此槽位中。当然迭代过程中还有其他的情况,比如遇到了`Entry`不为`null`且`key`值相等的情况,还有`Entry`中的`key`值为`null`的情况等等都会有不同的处理,后面会一一详细讲解。
+
+这里还画了一个`Entry`中的`key`为`null`的数据(**Entry=2的灰色块数据**),因为`key`值是**弱引用**类型,所以会有这种数据存在。在`set`过程中,如果遇到了`key`过期的`Entry`数据,实际上是会进行一轮**探测式清理**操作的,具体操作方式后面会讲到。
+
+### `ThreadLocalMap.set()`详解
+
+#### `ThreadLocalMap.set()`原理图解
+
+看完了`ThreadLocal` **hash算法**后,我们再来看`set`是如何实现的。
+
+往`ThreadLocalMap`中`set`数据(**新增**或者**更新**数据)分为好几种情况,针对不同的情况我们画图来说说明。
+
+**第一种情况:** 通过`hash`计算后的槽位对应的`Entry`数据为空:
+
+
+
+这里直接将数据放到该槽位即可。
+
+**第二种情况:** 槽位数据不为空,`key`值与当前`ThreadLocal`通过`hash`计算获取的`key`值一致:
+
+
+
+这里直接更新该槽位的数据。
+
+**第三种情况:** 槽位数据不为空,往后遍历过程中,在找到`Entry`为`null`的槽位之前,没有遇到`key`过期的`Entry`:
+
+
+
+遍历散列数组,线性往后查找,如果找到`Entry`为`null`的槽位,则将数据放入该槽位中,或者往后遍历过程中,遇到了**key值相等**的数据,直接更新即可。
+
+**第四种情况:** 槽位数据不为空,往后遍历过程中,在找到`Entry`为`null`的槽位之前,遇到`key`过期的`Entry`,如下图,往后遍历过程中,一到了`index=7`的槽位数据`Entry`的`key=null`:
+
+
+
+散列数组下标为7位置对应的`Entry`数据`key`为`null`,表明此数据`key`值已经被垃圾回收掉了,此时就会执行`replaceStaleEntry()`方法,该方法含义是**替换过期数据的逻辑**,以**index=7**位起点开始遍历,进行探测式数据清理工作。
+
+初始化探测式清理过期数据扫描的开始位置:`slotToExpunge = staleSlot = 7`
+
+以当前`staleSlot`开始 向前迭代查找,找其他过期的数据,然后更新过期数据起始扫描下标`slotToExpunge`。`for`循环迭代,直到碰到`Entry`为`null`结束。
+
+如果找到了过期的数据,继续向前迭代,直到遇到`Entry=null`的槽位才停止迭代,如下图所示,**slotToExpunge被更新为0**:
+
+
+
+以当前节点(`index=7`)向前迭代,检测是否有过期的`Entry`数据,如果有则更新`slotToExpunge`值。碰到`null`则结束探测。以上图为例`slotToExpunge`被更新为0。
+
+上面向前迭代的操作是为了更新探测清理过期数据的起始下标`slotToExpunge`的值,这个值在后面会讲解,它是用来判断当前过期槽位`staleSlot`之前是否还有过期元素。
+
+接着开始以`staleSlot`位置(index=7)向后迭代,**如果找到了相同key值的Entry数据:**
+
+
+
+从当前节点`staleSlot`向后查找`key`值相等的`Entry`元素,找到后更新`Entry`的值并交换`staleSlot`元素的位置(`staleSlot`位置为过期元素),更新`Entry`数据,然后开始进行过期`Entry`的清理工作,如下图所示:
+
+
+
+
+**向后遍历过程中,如果没有找到相同key值的Entry数据:**
+
+
+
+从当前节点`staleSlot`向后查找`key`值相等的`Entry`元素,直到`Entry`为`null`则停止寻找。通过上图可知,此时`table`中没有`key`值相同的`Entry`。
+
+创建新的`Entry`,替换`table[stableSlot]`位置:
+
+
+
+替换完成后也是进行过期元素清理工作,清理工作主要是有两个方法:`expungeStaleEntry()`和`cleanSomeSlots()`,具体细节后面会讲到,请继续往后看。
+
+#### `ThreadLocalMap.set()`源码详解
+
+上面已经用图的方式解析了`set()`实现的原理,其实已经很清晰了,我们接着再看下源码:
+
+`java.lang.ThreadLocal`.`ThreadLocalMap.set()`:
+
+```java
+private void set(ThreadLocal key, Object value) {
+ Entry[] tab = table;
+ int len = tab.length;
+ int i = key.threadLocalHashCode & (len-1);
+
+ for (Entry e = tab[i];
+ e != null;
+ e = tab[i = nextIndex(i, len)]) {
+ `ThreadLocal` k = e.get();
+
+ if (k == key) {
+ e.value = value;
+ return;
+ }
+
+ if (k == null) {
+ replaceStaleEntry(key, value, i);
+ return;
+ }
+ }
+
+ tab[i] = new Entry(key, value);
+ int sz = ++size;
+ if (!cleanSomeSlots(i, sz) && sz >= threshold)
+ rehash();
+}
+```
+
+这里会通过`key`来计算在散列表中的对应位置,然后以当前`key`对应的桶的位置向后查找,找到可以使用的桶。
+
+```java
+Entry[] tab = table;
+int len = tab.length;
+int i = key.threadLocalHashCode & (len-1);
+```
+
+什么情况下桶才是可以使用的呢?
+1. `k = key` 说明是替换操作,可以使用
+2. 碰到一个过期的桶,执行替换逻辑,占用过期桶
+3. 查找过程中,碰到桶中`Entry=null`的情况,直接使用
+
+接着就是执行`for`循环遍历,向后查找,我们先看下`nextIndex()`、`prevIndex()`方法实现:
+
+
+
+```java
+private static int nextIndex(int i, int len) {
+ return ((i + 1 < len) ? i + 1 : 0);
+}
+
+private static int prevIndex(int i, int len) {
+ return ((i - 1 >= 0) ? i - 1 : len - 1);
+}
+```
+
+接着看剩下`for`循环中的逻辑:
+1. 遍历当前`key`值对应的桶中`Entry`数据为空,这说明散列数组这里没有数据冲突,跳出`for`循环,直接`set`数据到对应的桶中
+2. 如果`key`值对应的桶中`Entry`数据不为空
+2.1 如果`k = key`,说明当前`set`操作是一个替换操作,做替换逻辑,直接返回
+2.2 如果`key = null`,说明当前桶位置的`Entry`是过期数据,执行`replaceStaleEntry()`方法(核心方法),然后返回
+3. `for`循环执行完毕,继续往下执行说明向后迭代的过程中遇到了`entry`为`null`的情况
+3.1 在`Entry`为`null`的桶中创建一个新的`Entry`对象
+3.2 执行`++size`操作
+4. 调用`cleanSomeSlots()`做一次启发式清理工作,清理散列数组中`Entry`的`key`过期的数据
+4.1 如果清理工作完成后,未清理到任何数据,且`size`超过了阈值(数组长度的2/3),进行`rehash()`操作
+4.2 `rehash()`中会先进行一轮探测式清理,清理过期`key`,清理完成后如果**size >= threshold - threshold / 4**,就会执行真正的扩容逻辑(扩容逻辑往后看)
+
+接着重点看下`replaceStaleEntry()`方法,`replaceStaleEntry()`方法提供替换过期数据的功能,我们可以对应上面**第四种情况**的原理图来再回顾下,具体代码如下:
+
+`java.lang.ThreadLocal.ThreadLocalMap.replaceStaleEntry()`:
+
+```java
+private void replaceStaleEntry(`ThreadLocal` key, Object value,
+ int staleSlot) {
+ Entry[] tab = table;
+ int len = tab.length;
+ Entry e;
+
+ int slotToExpunge = staleSlot;
+ for (int i = prevIndex(staleSlot, len);
+ (e = tab[i]) != null;
+ i = prevIndex(i, len))
+
+ if (e.get() == null)
+ slotToExpunge = i;
+
+ for (int i = nextIndex(staleSlot, len);
+ (e = tab[i]) != null;
+ i = nextIndex(i, len)) {
+
+ `ThreadLocal` k = e.get();
+
+ if (k == key) {
+ e.value = value;
+
+ tab[i] = tab[staleSlot];
+ tab[staleSlot] = e;
+
+ if (slotToExpunge == staleSlot)
+ slotToExpunge = i;
+ cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
+ return;
+ }
+
+ if (k == null && slotToExpunge == staleSlot)
+ slotToExpunge = i;
+ }
+
+ tab[staleSlot].value = null;
+ tab[staleSlot] = new Entry(key, value);
+
+ if (slotToExpunge != staleSlot)
+ cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
+}
+```
+
+`slotToExpunge`表示开始探测式清理过期数据的开始下标,默认从当前的`staleSlot`开始。以当前的`staleSlot`开始,向前迭代查找,找到没有过期的数据,`for`循环一直碰到`Entry`为`null`才会结束。如果向前找到了过期数据,更新探测清理过期数据的开始下标为i,即`slotToExpunge=i`
+
+```java
+for (int i = prevIndex(staleSlot, len);
+ (e = tab[i]) != null;
+ i = prevIndex(i, len)){
+
+ if (e.get() == null){
+ slotToExpunge = i;
+ }
+}
+```
+
+接着开始从`staleSlot`向后查找,也是碰到`Entry`为`null`的桶结束。
+如果迭代过程中,**碰到k == key**,这说明这里是替换逻辑,替换新数据并且交换当前`staleSlot`位置。如果`slotToExpunge == staleSlot`,这说明`replaceStaleEntry()`一开始向前查找过期数据时并未找到过期的`Entry`数据,接着向后查找过程中也未发现过期数据,修改开始探测式清理过期数据的下标为当前循环的index,即`slotToExpunge = i`。最后调用`cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);`进行启发式过期数据清理。
+
+```java
+if (k == key) {
+ e.value = value;
+
+ tab[i] = tab[staleSlot];
+ tab[staleSlot] = e;
+
+ if (slotToExpunge == staleSlot)
+ slotToExpunge = i;
+
+ cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
+ return;
+}
+```
+
+`cleanSomeSlots()`和`expungeStaleEntry()`方法后面都会细讲,这两个是和清理相关的方法,一个是过期`key`相关`Entry`的启发式清理(`Heuristically scan`),另一个是过期`key`相关`Entry`的探测式清理。
+
+**如果k != key**则会接着往下走,`k == null`说明当前遍历的`Entry`是一个过期数据,`slotToExpunge == staleSlot`说明,一开始的向前查找数据并未找到过期的`Entry`。如果条件成立,则更新`slotToExpunge` 为当前位置,这个前提是前驱节点扫描时未发现过期数据。
+
+```java
+if (k == null && slotToExpunge == staleSlot)
+ slotToExpunge = i;
+```
+
+往后迭代的过程中如果没有找到`k == key`的数据,且碰到`Entry`为`null`的数据,则结束当前的迭代操作。此时说明这里是一个添加的逻辑,将新的数据添加到`table[staleSlot]` 对应的`slot`中。
+
+```java
+tab[staleSlot].value = null;
+tab[staleSlot] = new Entry(key, value);
+```
+
+最后判断除了`staleSlot`以外,还发现了其他过期的`slot`数据,就要开启清理数据的逻辑:
+```java
+if (slotToExpunge != staleSlot)
+ cleanSomeSlots(expungeStaleEntry(slotToExpunge), len);
+```
+
+### `ThreadLocalMap`过期key的探测式清理流程
+
+上面我们有提及`ThreadLocalMap`的两种过期`key`数据清理方式:**探测式清理**和**启发式清理**。
+
+我们先讲下探测式清理,也就是`expungeStaleEntry`方法,遍历散列数组,从开始位置向后探测清理过期数据,将过期数据的`Entry`设置为`null`,沿途中碰到未过期的数据则将此数据`rehash`后重新在`table`数组中定位,如果定位的位置已经有了数据,则会将未过期的数据放到最靠近此位置的`Entry=null`的桶中,使`rehash`后的`Entry`数据距离正确的桶的位置更近一些。操作逻辑如下:
+
+
+
+如上图,`set(27)` 经过hash计算后应该落到`index=4`的桶中,由于`index=4`桶已经有了数据,所以往后迭代最终数据放入到`index=7`的桶中,放入后一段时间后`index=5`中的`Entry`数据`key`变为了`null`
+
+
+
+如果再有其他数据`set`到`map`中,就会触发**探测式清理**操作。
+
+如上图,执行**探测式清理**后,`index=5`的数据被清理掉,继续往后迭代,到`index=7`的元素时,经过`rehash`后发现该元素正确的`index=4`,而此位置已经已经有了数据,往后查找离`index=4`最近的`Entry=null`的节点(刚被探测式清理掉的数据:index=5),找到后移动`index= 7`的数据到`index=5`中,此时桶的位置离正确的位置`index=4`更近了。
+
+经过一轮探测式清理后,`key`过期的数据会被清理掉,没过期的数据经过`rehash`重定位后所处的桶位置理论上更接近`i= key.hashCode & (tab.len - 1)`的位置。这种优化会提高整个散列表查询性能。
+
+接着看下`expungeStaleEntry()`具体流程,我们还是以先原理图后源码讲解的方式来一步步梳理:
+
+
+
+我们假设`expungeStaleEntry(3)` 来调用此方法,如上图所示,我们可以看到`ThreadLocalMap`中`table`的数据情况,接着执行清理操作:
+
+
+
+第一步是清空当前`staleSlot`位置的数据,`index=3`位置的`Entry`变成了`null`。然后接着往后探测:
+
+
+
+执行完第二步后,index=4的元素挪到index=3的槽位中。
+
+继续往后迭代检查,碰到正常数据,计算该数据位置是否偏移,如果被偏移,则重新计算`slot`位置,目的是让正常数据尽可能存放在正确位置或离正确位置更近的位置
+
+
+
+在往后迭代的过程中碰到空的槽位,终止探测,这样一轮探测式清理工作就完成了,接着我们继续看看具体**实现源代码**:
+
+```java
+private int expungeStaleEntry(int staleSlot) {
+ Entry[] tab = table;
+ int len = tab.length;
+
+ tab[staleSlot].value = null;
+ tab[staleSlot] = null;
+ size--;
+
+ Entry e;
+ int i;
+ for (i = nextIndex(staleSlot, len);
+ (e = tab[i]) != null;
+ i = nextIndex(i, len)) {
+ `ThreadLocal` k = e.get();
+ if (k == null) {
+ e.value = null;
+ tab[i] = null;
+ size--;
+ } else {
+ int h = k.threadLocalHashCode & (len - 1);
+ if (h != i) {
+ tab[i] = null;
+
+ while (tab[h] != null)
+ h = nextIndex(h, len);
+ tab[h] = e;
+ }
+ }
+ }
+ return i;
+}
+```
+
+这里我们还是以`staleSlot=3` 来做示例说明,首先是将`tab[staleSlot]`槽位的数据清空,然后设置`size--`
+接着以`staleSlot`位置往后迭代,如果遇到`k==null`的过期数据,也是清空该槽位数据,然后`size--`
+
+```java
+ThreadLocal k = e.get();
+
+if (k == null) {
+ e.value = null;
+ tab[i] = null;
+ size--;
+}
+```
+
+如果`key`没有过期,重新计算当前`key`的下标位置是不是当前槽位下标位置,如果不是,那么说明产生了`hash`冲突,此时以新计算出来正确的槽位位置往后迭代,找到最近一个可以存放`entry`的位置。
+
+```java
+int h = k.threadLocalHashCode & (len - 1);
+if (h != i) {
+ tab[i] = null;
+
+ while (tab[h] != null)
+ h = nextIndex(h, len);
+
+ tab[h] = e;
+}
+```
+
+这里是处理正常的产生`Hash`冲突的数据,经过迭代后,有过`Hash`冲突数据的`Entry`位置会更靠近正确位置,这样的话,查询的时候 效率才会更高。
+
+### `ThreadLocalMap`扩容机制
+
+在``ThreadLocalMap.set()`方法的最后,如果执行完启发式清理工作后,未清理到任何数据,且当前散列数组中`Entry`的数量已经达到了列表的扩容阈值`(len*2/3)`,就开始执行`rehash()`逻辑:
+
+```java
+if (!cleanSomeSlots(i, sz) && sz >= threshold)
+ rehash();
+```
+
+接着看下`rehash()`具体实现:
+
+```java
+private void rehash() {
+ expungeStaleEntries();
+
+ if (size >= threshold - threshold / 4)
+ resize();
+}
+
+private void expungeStaleEntries() {
+ Entry[] tab = table;
+ int len = tab.length;
+ for (int j = 0; j < len; j++) {
+ Entry e = tab[j];
+ if (e != null && e.get() == null)
+ expungeStaleEntry(j);
+ }
+}
+```
+
+这里首先是会进行探测式清理工作,从`table`的起始位置往后清理,上面有分析清理的详细流程。清理完成之后,`table`中可能有一些`key`为`null`的`Entry`数据被清理掉,所以此时通过判断`size >= threshold - threshold / 4` 也就是`size >= threshold* 3/4` 来决定是否扩容。
+
+我们还记得上面进行`rehash()`的阈值是`size >= threshold`,所以当面试官套路我们`ThreadLocalMap`扩容机制的时候 我们一定要说清楚这两个步骤:
+
+
+
+接着看看具体的`resize()`方法,为了方便演示,我们以`oldTab.len=8`来举例:
+
+
+
+扩容后的`tab`的大小为`oldLen * 2`,然后遍历老的散列表,重新计算`hash`位置,然后放到新的`tab`数组中,如果出现`hash`冲突则往后寻找最近的`entry`为`null`的槽位,遍历完成之后,`oldTab`中所有的`entry`数据都已经放入到新的`tab`中了。重新计算`tab`下次扩容的**阈值**,具体代码如下:
+
+```java
+private void resize() {
+ Entry[] oldTab = table;
+ int oldLen = oldTab.length;
+ int newLen = oldLen * 2;
+ Entry[] newTab = new Entry[newLen];
+ int count = 0;
+
+ for (int j = 0; j < oldLen; ++j) {
+ Entry e = oldTab[j];
+ if (e != null) {
+ `ThreadLocal` k = e.get();
+ if (k == null) {
+ e.value = null;
+ } else {
+ int h = k.threadLocalHashCode & (newLen - 1);
+ while (newTab[h] != null)
+ h = nextIndex(h, newLen);
+ newTab[h] = e;
+ count++;
+ }
+ }
+ }
+
+ setThreshold(newLen);
+ size = count;
+ table = newTab;
+}
+```
+
+### `ThreadLocalMap.get()`详解
+
+上面已经看完了`set()`方法的源码,其中包括`set`数据、清理数据、优化数据桶的位置等操作,接着看看`get()`操作的原理。
+
+#### `ThreadLocalMap.get()`图解
+
+**第一种情况:** 通过查找`key`值计算出散列表中`slot`位置,然后该`slot`位置中的`Entry.key`和查找的`key`一致,则直接返回:
+
+
+
+**第二种情况:** `slot`位置中的`Entry.key`和要查找的`key`不一致:
+
+
+
+我们以`get(ThreadLocal1)`为例,通过`hash`计算后,正确的`slot`位置应该是4,而`index=4`的槽位已经有了数据,且`key`值不等于``ThreadLocal`1`,所以需要继续往后迭代查找。
+
+迭代到`index=5`的数据时,此时`Entry.key=null`,触发一次探测式数据回收操作,执行`expungeStaleEntry()`方法,执行完后,`index 5,8`的数据都会被回收,而`index 6,7`的数据都会前移,此时继续往后迭代,到`index = 6`的时候即找到了`key`值相等的`Entry`数据,如下图所示:
+
+
+
+#### `ThreadLocalMap.get()`源码详解
+
+`java.lang.ThreadLocal.ThreadLocalMap.getEntry()`:
+
+```java
+private Entry getEntry(`ThreadLocal` key) {
+ int i = key.threadLocalHashCode & (table.length - 1);
+ Entry e = table[i];
+ if (e != null && e.get() == key)
+ return e;
+ else
+ return getEntryAfterMiss(key, i, e);
+}
+
+private Entry getEntryAfterMiss(`ThreadLocal` key, int i, Entry e) {
+ Entry[] tab = table;
+ int len = tab.length;
+
+ while (e != null) {
+ `ThreadLocal` k = e.get();
+ if (k == key)
+ return e;
+ if (k == null)
+ expungeStaleEntry(i);
+ else
+ i = nextIndex(i, len);
+ e = tab[i];
+ }
+ return null;
+}
+```
+
+
+### `ThreadLocalMap`过期key的启发式清理流程
+
+
+上面多次提及到`ThreadLocalMap`过期可以的两种清理方式:**探测式清理(expungeStaleEntry())**、**启发式清理(cleanSomeSlots())**
+
+探测式清理是以当前`Entry` 往后清理,遇到值为`null`则结束清理,属于**线性探测清理**。
+
+而启发式清理被作者定义为:**Heuristically scan some cells looking for stale entries**.
+
+
+
+具体代码如下:
+
+```java
+private boolean cleanSomeSlots(int i, int n) {
+ boolean removed = false;
+ Entry[] tab = table;
+ int len = tab.length;
+ do {
+ i = nextIndex(i, len);
+ Entry e = tab[i];
+ if (e != null && e.get() == null) {
+ n = len;
+ removed = true;
+ i = expungeStaleEntry(i);
+ }
+ } while ( (n >>>= 1) != 0);
+ return removed;
+}
+```
+
+### `InheritableThreadLocal`
+
+我们使用`ThreadLocal`的时候,在异步场景下是无法给子线程共享父线程中创建的线程副本数据的。
+
+为了解决这个问题,JDK中还有一个`InheritableThreadLocal`类,我们来看一个例子:
+
+```java
+public class InheritableThreadLocalDemo {
+ public static void main(String[] args) {
+ ThreadLocal ThreadLocal = new ThreadLocal<>();
+ ThreadLocal inheritableThreadLocal = new InheritableThreadLocal<>();
+ ThreadLocal.set("父类数据:threadLocal");
+ inheritableThreadLocal.set("父类数据:inheritableThreadLocal");
+
+ new Thread(new Runnable() {
+ @Override
+ public void run() {
+ System.out.println("子线程获取父类`ThreadLocal`数据:" + `ThreadLocal`.get());
+ System.out.println("子线程获取父类inheritableThreadLocal数据:" + inheritableThreadLocal.get());
+ }
+ }).start();
+ }
+}
+```
+
+打印结果:
+
+```java
+子线程获取父类`ThreadLocal`数据:null
+子线程获取父类inheritableThreadLocal数据:父类数据:inheritableThreadLocal
+```
+
+实现原理是子线程是通过在父线程中通过调用`new Thread()`方法来创建子线程,`Thread#init`方法在`Thread`的构造方法中被调用。在`init`方法中拷贝父线程数据到子线程中:
+
+```java
+private void init(ThreadGroup g, Runnable target, String name,
+ long stackSize, AccessControlContext acc,
+ boolean inheritThreadLocals) {
+ if (name == null) {
+ throw new NullPointerException("name cannot be null");
+ }
+
+ if (inheritThreadLocals && parent.inheritableThreadLocals != null)
+ this.inheritableThreadLocals =
+ ThreadLocal.createInheritedMap(parent.inheritableThreadLocals);
+ this.stackSize = stackSize;
+ tid = nextThreadID();
+}
+```
+
+但`InheritableThreadLocal`仍然有缺陷,一般我们做异步化处理都是使用的线程池,而`InheritableThreadLocal`是在`new Thread`中的`init()`方法给赋值的,而线程池是线程复用的逻辑,所以这里会存在问题。
+
+当然,有问题出现就会有解决问题的方案,阿里巴巴开源了一个`TransmittableThreadLocal`组件就可以解决这个问题,这里就不再延伸,感兴趣的可自行查阅资料。
+
+### `ThreadLocal`项目中使用实战
+
+#### `ThreadLocal`使用场景
+
+我们现在项目中日志记录用的是`ELK+Logstash`,最后在`Kibana`中进行展示和检索。
+
+现在都是分布式系统统一对外提供服务,项目间调用的关系可以通过traceId来关联,但是不同项目之间如何传递`traceId`呢?
+
+这里我们使用`org.slf4j.MDC`来实现此功能,内部就是通过`ThreadLocal`来实现的,具体实现如下:
+
+当前端发送请求到**服务A**时,**服务A**会生成一个类似`UUID`的`traceId`字符串,将此字符串放入当前线程的`ThreadLocal`中,在调用**服务B**的时候,将`traceId`写入到请求的`Header`中,**服务B**在接收请求时会先判断请求的`Header`中是否有`traceId`,如果存在则写入自己线程的`ThreadLocal`中。
+
+
+
+图中的`requestId`即为我们各个系统链路关联的`traceId`,系统间互相调用,通过这个`requestId`即可找到对应链路,这里还有会有一些其他场景:
+
+
+
+针对于这些场景,我们都可以有相应的解决方案,如下所示
+
+#### Feign远程调用解决方案
+
+**服务发送请求:**
+```java
+@Component
+@Slf4j
+public class FeignInvokeInterceptor implements RequestInterceptor {
+
+ @Override
+ public void apply(RequestTemplate template) {
+ String requestId = MDC.get("requestId");
+ if (StringUtils.isNotBlank(requestId)) {
+ template.header("requestId", requestId);
+ }
+ }
+}
+```
+
+**服务接收请求:**
+```java
+@Slf4j
+@Component
+public class LogInterceptor extends HandlerInterceptorAdapter {
+
+ @Override
+ public void afterCompletion(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2, Exception arg3) {
+ MDC.remove("requestId");
+ }
@Override
- public void run() {
- System.out.println("Thread Name= "+Thread.currentThread().getName()+" default Formatter = "+formatter.get().toPattern());
+ public void postHandle(HttpServletRequest arg0, HttpServletResponse arg1, Object arg2, ModelAndView arg3) {
+ }
+
+ @Override
+ public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
+
+ String requestId = request.getHeader(BaseConstant.REQUEST_ID_KEY);
+ if (StringUtils.isBlank(requestId)) {
+ requestId = UUID.randomUUID().toString().replace("-", "");
+ }
+ MDC.put("requestId", requestId);
+ return true;
+ }
+}
+```
+
+#### 线程池异步调用,requestId传递
+
+因为`MDC`是基于`ThreadLocal`去实现的,异步过程中,子线程并没有办法获取到父线程`ThreadLocal`存储的数据,所以这里可以自定义线程池执行器,修改其中的`run()`方法:
+
+```java
+public class MyThreadPoolTaskExecutor extends ThreadPoolTaskExecutor {
+
+ @Override
+ public void execute(Runnable runnable) {
+ Map context = MDC.getCopyOfContextMap();
+ super.execute(() -> run(runnable, context));
+ }
+
+ @Override
+ private void run(Runnable runnable, Map context) {
+ if (context != null) {
+ MDC.setContextMap(context);
+ }
try {
- Thread.sleep(new Random().nextInt(1000));
- } catch (InterruptedException e) {
- e.printStackTrace();
+ runnable.run();
+ } finally {
+ MDC.remove();
}
- //formatter pattern is changed here by thread, but it won't reflect to other threads
- formatter.set(new SimpleDateFormat());
-
- System.out.println("Thread Name= "+Thread.currentThread().getName()+" formatter = "+formatter.get().toPattern());
}
-
-}
-
-```
-
-Output:
-
-```
-Thread Name= 0 default Formatter = yyyyMMdd HHmm
-Thread Name= 0 formatter = yy-M-d ah:mm
-Thread Name= 1 default Formatter = yyyyMMdd HHmm
-Thread Name= 2 default Formatter = yyyyMMdd HHmm
-Thread Name= 1 formatter = yy-M-d ah:mm
-Thread Name= 3 default Formatter = yyyyMMdd HHmm
-Thread Name= 2 formatter = yy-M-d ah:mm
-Thread Name= 4 default Formatter = yyyyMMdd HHmm
-Thread Name= 3 formatter = yy-M-d ah:mm
-Thread Name= 4 formatter = yy-M-d ah:mm
-Thread Name= 5 default Formatter = yyyyMMdd HHmm
-Thread Name= 5 formatter = yy-M-d ah:mm
-Thread Name= 6 default Formatter = yyyyMMdd HHmm
-Thread Name= 6 formatter = yy-M-d ah:mm
-Thread Name= 7 default Formatter = yyyyMMdd HHmm
-Thread Name= 7 formatter = yy-M-d ah:mm
-Thread Name= 8 default Formatter = yyyyMMdd HHmm
-Thread Name= 9 default Formatter = yyyyMMdd HHmm
-Thread Name= 8 formatter = yy-M-d ah:mm
-Thread Name= 9 formatter = yy-M-d ah:mm
-```
-
-从输出中可以看出,Thread-0已经改变了formatter的值,但仍然是thread-2默认格式化程序与初始化值相同,其他线程也一样。
-
-上面有一段代码用到了创建 `ThreadLocal` 变量的那段代码用到了 Java8 的知识,它等于下面这段代码,如果你写了下面这段代码的话,IDEA会提示你转换为Java8的格式(IDEA真的不错!)。因为ThreadLocal类在Java 8中扩展,使用一个新的方法`withInitial()`,将Supplier功能接口作为参数。
-
-```java
- private static final ThreadLocal formatter = new ThreadLocal(){
- @Override
- protected SimpleDateFormat initialValue()
- {
- return new SimpleDateFormat("yyyyMMdd HHmm");
- }
- };
-```
-
-### ThreadLocal原理
-
-从 `Thread`类源代码入手。
-
-```java
-public class Thread implements Runnable {
- ......
-//与此线程有关的ThreadLocal值。由ThreadLocal类维护
-ThreadLocal.ThreadLocalMap threadLocals = null;
-
-//与此线程有关的InheritableThreadLocal值。由InheritableThreadLocal类维护
-ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
- ......
}
```
-从上面`Thread`类 源代码可以看出`Thread` 类中有一个 `threadLocals` 和 一个 `inheritableThreadLocals` 变量,它们都是 `ThreadLocalMap` 类型的变量,我们可以把 `ThreadLocalMap` 理解为`ThreadLocal` 类实现的定制化的 `HashMap`。默认情况下这两个变量都是null,只有当前线程调用 `ThreadLocal` 类的 `set`或`get`方法时才创建它们,实际上调用这两个方法的时候,我们调用的是`ThreadLocalMap`类对应的 `get()`、`set() `方法。
+#### 使用MQ发送消息给第三方系统
-`ThreadLocal`类的`set()`方法
+在MQ发送的消息体中自定义属性`requestId`,接收方消费消息后,自己解析`requestId`使用即可。
-```java
- public void set(T value) {
- Thread t = Thread.currentThread();
- ThreadLocalMap map = getMap(t);
- if (map != null)
- map.set(this, value);
- else
- createMap(t, value);
- }
- ThreadLocalMap getMap(Thread t) {
- return t.threadLocals;
- }
-```
-通过上面这些内容,我们足以通过猜测得出结论:**最终的变量是放在了当前线程的 `ThreadLocalMap` 中,并不是存在 `ThreadLocal` 上,ThreadLocal 可以理解为只是ThreadLocalMap的封装,传递了变量值。**
-**每个Thread中都具备一个ThreadLocalMap,而ThreadLocalMap可以存储以ThreadLocal为key的键值对。** 比如我们在同一个线程中声明了两个 `ThreadLocal` 对象的话,会使用 `Thread`内部都是使用仅有那个`ThreadLocalMap` 存放数据的,`ThreadLocalMap`的 key 就是 `ThreadLocal`对象,value 就是 `ThreadLocal` 对象调用`set`方法设置的值。`ThreadLocal` 是 map结构是为了让每个线程可以关联多个 `ThreadLocal`变量。这也就解释了ThreadLocal声明的变量为什么在每一个线程都有自己的专属本地变量。
-```java
-public class Thread implements Runnable {
- ......
-//与此线程有关的ThreadLocal值。由ThreadLocal类维护
-ThreadLocal.ThreadLocalMap threadLocals = null;
-//与此线程有关的InheritableThreadLocal值。由InheritableThreadLocal类维护
-ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
- ......
-}
-```
-
-`ThreadLocalMap`是`ThreadLocal`的静态内部类。
-
-
-
-### ThreadLocal 内存泄露问题
-
-`ThreadLocalMap` 中使用的 key 为 `ThreadLocal` 的弱引用,而 value 是强引用。所以,如果 `ThreadLocal` 没有被外部强引用的情况下,在垃圾回收的时候会 key 会被清理掉,而 value 不会被清理掉。这样一来,`ThreadLocalMap` 中就会出现key为null的Entry。假如我们不做任何措施的话,value 永远无法被GC 回收,这个时候就可能会产生内存泄露。ThreadLocalMap实现中已经考虑了这种情况,在调用 `set()`、`get()`、`remove()` 方法的时候,会清理掉 key 为 null 的记录。使用完 `ThreadLocal`方法后 最好手动调用`remove()`方法
-
-```java
- static class Entry extends WeakReference> {
- /** The value associated with this ThreadLocal. */
- Object value;
-
- Entry(ThreadLocal k, Object v) {
- super(k);
- value = v;
- }
- }
-```
-
-**弱引用介绍:**
-
-> 如果一个对象只具有弱引用,那就类似于**可有可无的生活用品**。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它 所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
->
-> 弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。
diff --git a/docs/java/Multithread/ThreadLocal(未完成).md b/docs/java/Multithread/ThreadLocal(未完成).md
new file mode 100644
index 00000000..f69cc1d6
--- /dev/null
+++ b/docs/java/Multithread/ThreadLocal(未完成).md
@@ -0,0 +1,170 @@
+[ThreadLocal造成OOM内存溢出案例演示与原理分析](https://blog.csdn.net/xlgen157387/article/details/78298840)
+
+[深入理解 Java 之 ThreadLocal 工作原理]()
+
+## ThreadLocal
+
+### ThreadLocal简介
+
+通常情况下,我们创建的变量是可以被任何一个线程访问并修改的。**如果想实现每一个线程都有自己的专属本地变量该如何解决呢?** JDK中提供的`ThreadLocal`类正是为了解决这样的问题。 **`ThreadLocal`类主要解决的就是让每个线程绑定自己的值,可以将`ThreadLocal`类形象的比喻成存放数据的盒子,盒子中可以存储每个线程的私有数据。**
+
+**如果你创建了一个`ThreadLocal`变量,那么访问这个变量的每个线程都会有这个变量的本地副本,这也是`ThreadLocal`变量名的由来。他们可以使用 `get()` 和 `set()` 方法来获取默认值或将其值更改为当前线程所存的副本的值,从而避免了线程安全问题。**
+
+再举个简单的例子:
+
+比如有两个人去宝屋收集宝物,这两个共用一个袋子的话肯定会产生争执,但是给他们两个人每个人分配一个袋子的话就不会出现这样的问题。如果把这两个人比作线程的话,那么ThreadLocal就是用来这两个线程竞争的。
+
+### ThreadLocal示例
+
+相信看了上面的解释,大家已经搞懂 ThreadLocal 类是个什么东西了。
+
+```java
+import java.text.SimpleDateFormat;
+import java.util.Random;
+
+public class ThreadLocalExample implements Runnable{
+
+ // SimpleDateFormat 不是线程安全的,所以每个线程都要有自己独立的副本
+ private static final ThreadLocal formatter = ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyyMMdd HHmm"));
+
+ public static void main(String[] args) throws InterruptedException {
+ ThreadLocalExample obj = new ThreadLocalExample();
+ for(int i=0 ; i<10; i++){
+ Thread t = new Thread(obj, ""+i);
+ Thread.sleep(new Random().nextInt(1000));
+ t.start();
+ }
+ }
+
+ @Override
+ public void run() {
+ System.out.println("Thread Name= "+Thread.currentThread().getName()+" default Formatter = "+formatter.get().toPattern());
+ try {
+ Thread.sleep(new Random().nextInt(1000));
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ //formatter pattern is changed here by thread, but it won't reflect to other threads
+ formatter.set(new SimpleDateFormat());
+
+ System.out.println("Thread Name= "+Thread.currentThread().getName()+" formatter = "+formatter.get().toPattern());
+ }
+
+}
+
+```
+
+Output:
+
+```
+Thread Name= 0 default Formatter = yyyyMMdd HHmm
+Thread Name= 0 formatter = yy-M-d ah:mm
+Thread Name= 1 default Formatter = yyyyMMdd HHmm
+Thread Name= 2 default Formatter = yyyyMMdd HHmm
+Thread Name= 1 formatter = yy-M-d ah:mm
+Thread Name= 3 default Formatter = yyyyMMdd HHmm
+Thread Name= 2 formatter = yy-M-d ah:mm
+Thread Name= 4 default Formatter = yyyyMMdd HHmm
+Thread Name= 3 formatter = yy-M-d ah:mm
+Thread Name= 4 formatter = yy-M-d ah:mm
+Thread Name= 5 default Formatter = yyyyMMdd HHmm
+Thread Name= 5 formatter = yy-M-d ah:mm
+Thread Name= 6 default Formatter = yyyyMMdd HHmm
+Thread Name= 6 formatter = yy-M-d ah:mm
+Thread Name= 7 default Formatter = yyyyMMdd HHmm
+Thread Name= 7 formatter = yy-M-d ah:mm
+Thread Name= 8 default Formatter = yyyyMMdd HHmm
+Thread Name= 9 default Formatter = yyyyMMdd HHmm
+Thread Name= 8 formatter = yy-M-d ah:mm
+Thread Name= 9 formatter = yy-M-d ah:mm
+```
+
+从输出中可以看出,Thread-0已经改变了formatter的值,但仍然是thread-2默认格式化程序与初始化值相同,其他线程也一样。
+
+上面有一段代码用到了创建 `ThreadLocal` 变量的那段代码用到了 Java8 的知识,它等于下面这段代码,如果你写了下面这段代码的话,IDEA会提示你转换为Java8的格式(IDEA真的不错!)。因为ThreadLocal类在Java 8中扩展,使用一个新的方法`withInitial()`,将Supplier功能接口作为参数。
+
+```java
+ private static final ThreadLocal formatter = new ThreadLocal(){
+ @Override
+ protected SimpleDateFormat initialValue()
+ {
+ return new SimpleDateFormat("yyyyMMdd HHmm");
+ }
+ };
+```
+
+### ThreadLocal原理
+
+从 `Thread`类源代码入手。
+
+```java
+public class Thread implements Runnable {
+ ......
+//与此线程有关的ThreadLocal值。由ThreadLocal类维护
+ThreadLocal.ThreadLocalMap threadLocals = null;
+
+//与此线程有关的InheritableThreadLocal值。由InheritableThreadLocal类维护
+ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
+ ......
+}
+```
+
+从上面`Thread`类 源代码可以看出`Thread` 类中有一个 `threadLocals` 和 一个 `inheritableThreadLocals` 变量,它们都是 `ThreadLocalMap` 类型的变量,我们可以把 `ThreadLocalMap` 理解为`ThreadLocal` 类实现的定制化的 `HashMap`。默认情况下这两个变量都是null,只有当前线程调用 `ThreadLocal` 类的 `set`或`get`方法时才创建它们,实际上调用这两个方法的时候,我们调用的是`ThreadLocalMap`类对应的 `get()`、`set() `方法。
+
+`ThreadLocal`类的`set()`方法
+
+```java
+ public void set(T value) {
+ Thread t = Thread.currentThread();
+ ThreadLocalMap map = getMap(t);
+ if (map != null)
+ map.set(this, value);
+ else
+ createMap(t, value);
+ }
+ ThreadLocalMap getMap(Thread t) {
+ return t.threadLocals;
+ }
+```
+
+通过上面这些内容,我们足以通过猜测得出结论:**最终的变量是放在了当前线程的 `ThreadLocalMap` 中,并不是存在 `ThreadLocal` 上,ThreadLocal 可以理解为只是ThreadLocalMap的封装,传递了变量值。**
+
+**每个Thread中都具备一个ThreadLocalMap,而ThreadLocalMap可以存储以ThreadLocal为key的键值对。** 比如我们在同一个线程中声明了两个 `ThreadLocal` 对象的话,会使用 `Thread`内部都是使用仅有那个`ThreadLocalMap` 存放数据的,`ThreadLocalMap`的 key 就是 `ThreadLocal`对象,value 就是 `ThreadLocal` 对象调用`set`方法设置的值。`ThreadLocal` 是 map结构是为了让每个线程可以关联多个 `ThreadLocal`变量。这也就解释了ThreadLocal声明的变量为什么在每一个线程都有自己的专属本地变量。
+
+```java
+public class Thread implements Runnable {
+ ......
+//与此线程有关的ThreadLocal值。由ThreadLocal类维护
+ThreadLocal.ThreadLocalMap threadLocals = null;
+
+//与此线程有关的InheritableThreadLocal值。由InheritableThreadLocal类维护
+ThreadLocal.ThreadLocalMap inheritableThreadLocals = null;
+ ......
+}
+```
+
+`ThreadLocalMap`是`ThreadLocal`的静态内部类。
+
+
+
+### ThreadLocal 内存泄露问题
+
+`ThreadLocalMap` 中使用的 key 为 `ThreadLocal` 的弱引用,而 value 是强引用。所以,如果 `ThreadLocal` 没有被外部强引用的情况下,在垃圾回收的时候会 key 会被清理掉,而 value 不会被清理掉。这样一来,`ThreadLocalMap` 中就会出现key为null的Entry。假如我们不做任何措施的话,value 永远无法被GC 回收,这个时候就可能会产生内存泄露。ThreadLocalMap实现中已经考虑了这种情况,在调用 `set()`、`get()`、`remove()` 方法的时候,会清理掉 key 为 null 的记录。使用完 `ThreadLocal`方法后 最好手动调用`remove()`方法
+
+```java
+ static class Entry extends WeakReference> {
+ /** The value associated with this ThreadLocal. */
+ Object value;
+
+ Entry(ThreadLocal k, Object v) {
+ super(k);
+ value = v;
+ }
+ }
+```
+
+**弱引用介绍:**
+
+> 如果一个对象只具有弱引用,那就类似于**可有可无的生活用品**。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它 所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
+>
+> 弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。
diff --git a/docs/java/Multithread/Untitled.md b/docs/java/Multithread/Untitled.md
new file mode 100644
index 00000000..ca7411cb
--- /dev/null
+++ b/docs/java/Multithread/Untitled.md
@@ -0,0 +1,422 @@
+## synchronized / Lock
+
+1. JDK 1.5之前
+
+ ,Java通过
+
+ synchronized
+
+ 关键字来实现
+
+ 锁
+
+ 功能
+
+ - synchronized是JVM实现的**内置锁**,锁的获取和释放都是由JVM**隐式**实现的
+
+2. JDK 1.5
+
+ ,并发包中新增了
+
+ Lock接口
+
+ 来实现锁功能
+
+ - 提供了与synchronized类似的同步功能,但需要**显式**获取和释放锁
+
+3. Lock同步锁是基于
+
+ Java
+
+ 实现的,而synchronized是基于底层操作系统的
+
+ Mutex Lock
+
+ 实现的
+
+ - 每次获取和释放锁都会带来**用户态和内核态的切换**,从而增加系统的**性能开销**
+ - 在锁竞争激烈的情况下,synchronized同步锁的性能很糟糕
+ - 在**JDK 1.5**,在**单线程重复申请锁**的情况下,synchronized锁性能要比Lock的性能**差很多**
+
+4. **JDK 1.6**,Java对synchronized同步锁做了**充分的优化**,甚至在某些场景下,它的性能已经超越了Lock同步锁
+
+
+
+## 实现原理
+
+复制
+
+```
+public class SyncTest {
+ public synchronized void method1() {
+ }
+
+ public void method2() {
+ Object o = new Object();
+ synchronized (o) {
+ }
+ }
+}
+```
+
+复制
+
+```
+$ javac -encoding UTF-8 SyncTest.java
+$ javap -v SyncTest
+```
+
+### 修饰方法
+
+复制
+
+```
+public synchronized void method1();
+ descriptor: ()V
+ flags: ACC_PUBLIC, ACC_SYNCHRONIZED
+ Code:
+ stack=0, locals=1, args_size=1
+ 0: return
+```
+
+1. JVM使用**ACC_SYNCHRONIZED**访问标识来区分一个方法是否为**同步方法**
+
+2. 在方法调用时,会检查方法是否被设置了
+
+ ACC_SYNCHRONIZED
+
+ 访问标识
+
+ - 如果是,执行线程会将先尝试**持有Monitor对象**,再执行方法,方法执行完成后,最后**释放Monitor对象**
+
+### 修饰代码块
+
+复制
+
+```
+public void method2();
+ descriptor: ()V
+ flags: ACC_PUBLIC
+ Code:
+ stack=2, locals=4, args_size=1
+ 0: new #2 // class java/lang/Object
+ 3: dup
+ 4: invokespecial #1 // Method java/lang/Object."":()V
+ 7: astore_1
+ 8: aload_1
+ 9: dup
+ 10: astore_2
+ 11: monitorenter
+ 12: aload_2
+ 13: monitorexit
+ 14: goto 22
+ 17: astore_3
+ 18: aload_2
+ 19: monitorexit
+ 20: aload_3
+ 21: athrow
+ 22: return
+```
+
+1. synchronized修饰同步代码块时,由**monitorenter**和**monitorexit**指令来实现同步
+2. 进入**monitorenter**指令后,线程将**持有**该**Monitor对象**,进入**monitorexit**指令,线程将**释放**该**Monitor对象**
+
+### 管程模型
+
+1. JVM中的**同步**是基于进入和退出**管程**(**Monitor**)对象实现的
+
+2. **每个Java对象实例都会有一个Monitor**,Monitor可以和Java对象实例一起被创建和销毁
+
+3. Monitor是由**ObjectMonitor**实现的,对应[ObjectMonitor.hpp](https://github.com/JetBrains/jdk8u_hotspot/blob/master/src/share/vm/runtime/objectMonitor.hpp)
+
+4. 当多个线程同时访问一段同步代码时,会先被放在**EntryList**中
+
+5. 当线程获取到Java对象的Monitor时(Monitor是依靠
+
+ 底层操作系统
+
+ 的
+
+ Mutex Lock
+
+ 来实现
+
+ 互斥
+
+ 的)
+
+ - 线程申请Mutex成功,则持有该Mutex,其它线程将无法获取到该Mutex
+
+6. 进入
+
+ WaitSet
+
+ - 竞争锁**失败**的线程会进入**WaitSet**
+ - 竞争锁**成功**的线程如果调用**wait**方法,就会**释放当前持有的Mutex**,并且该线程会进入**WaitSet**
+ - 进入**WaitSet**的进程会等待下一次唤醒,然后进入EntryList**重新排队**
+
+7. 如果当前线程顺利执行完方法,也会释放Mutex
+
+8. Monitor依赖于**底层操作系统**的实现,存在**用户态**和**内核态之间**的**切换**,所以增加了**性能开销**
+
+[](https://java-performance-1253868755.cos.ap-guangzhou.myqcloud.com/java-performance-synchronized-monitor.png)
+
+复制
+
+```
+ObjectMonitor() {
+ _header = NULL;
+ _count = 0; // 记录个数
+ _waiters = 0,
+ _recursions = 0;
+ _object = NULL;
+ _owner = NULL; // 持有该Monitor的线程
+ _WaitSet = NULL; // 处于wait状态的线程,会被加入 _WaitSet
+ _WaitSetLock = 0 ;
+ _Responsible = NULL ;
+ _succ = NULL ;
+ _cxq = NULL ;
+ FreeNext = NULL ;
+ _EntryList = NULL ; // 多个线程访问同步块或同步方法,会首先被加入 _EntryList
+ _SpinFreq = 0 ;
+ _SpinClock = 0 ;
+ OwnerIsThread = 0 ;
+ _previous_owner_tid = 0;
+}
+```
+
+## 锁升级优化
+
+1. 为了提升性能,在**JDK 1.6**引入**偏向锁、轻量级锁、重量级锁**,用来**减少锁竞争带来的上下文切换**
+2. 借助JDK 1.6新增的**Java对象头**,实现了**锁升级**功能
+
+### Java对象头
+
+1. 在**JDK 1.6**的JVM中,对象实例在**堆内存**中被分为三部分:**对象头**、**实例数据**、**对齐填充**
+2. 对象头的组成部分:**Mark Word**、**指向类的指针**、**数组长度**(可选,数组类型时才有)
+3. Mark Word记录了**对象**和**锁**有关的信息,在64位的JVM中,Mark Word为**64 bit**
+4. 锁升级功能主要依赖于Mark Word中**锁标志位**和**是否偏向锁标志位**
+5. synchronized同步锁的升级优化路径:***偏向锁** -> **轻量级锁** -> **重量级锁***
+
+[](https://java-performance-1253868755.cos.ap-guangzhou.myqcloud.com/java-performance-synchronized-mark-word.jpg)
+
+### 偏向锁
+
+1. 偏向锁主要用来优化**同一线程多次申请同一个锁**的竞争,在某些情况下,大部分时间都是同一个线程竞争锁资源
+
+2. 偏向锁的作用
+
+ - 当一个线程再次访问同一个同步代码时,该线程只需对该对象头的**Mark Word**中去判断是否有偏向锁指向它
+ - **无需再进入Monitor去竞争对象**(避免用户态和内核态的**切换**)
+
+3. 当对象被当做同步锁,并有一个线程抢到锁时
+
+ - 锁标志位还是**01**,是否偏向锁标志位设置为**1**,并且记录抢到锁的**线程ID**,进入***偏向锁状态***
+
+4. 偏向锁
+
+ **不会主动释放锁**
+
+ - 当线程1再次获取锁时,会比较**当前线程的ID**与**锁对象头部的线程ID**是否一致,如果一致,无需CAS来抢占锁
+
+ - 如果不一致,需要查看
+
+ 锁对象头部记录的线程
+
+ 是否存活
+
+ - 如果**没有存活**,那么锁对象被重置为**无锁**状态(也是一种撤销),然后重新偏向线程2
+
+ - 如果
+
+ 存活
+
+ ,查找线程1的栈帧信息
+
+ - 如果线程1还是需要继续持有该锁对象,那么暂停线程1(**STW**),**撤销偏向锁**,**升级为轻量级锁**
+ - 如果线程1不再使用该锁对象,那么将该锁对象设为**无锁**状态(也是一种撤销),然后重新偏向线程2
+
+5. 一旦出现其他线程竞争锁资源时,偏向锁就会被
+
+ 撤销
+
+ - 偏向锁的撤销**可能需要**等待**全局安全点**,暂停持有该锁的线程,同时检查该线程**是否还在执行该方法**
+ - 如果还没有执行完,说明此刻有**多个线程**竞争,升级为**轻量级锁**;如果已经执行完毕,唤醒其他线程继续**CAS**抢占
+
+6. 在
+
+ 高并发
+
+ 场景下,当
+
+ 大量线程
+
+ 同时竞争同一个锁资源时,偏向锁会被
+
+ 撤销
+
+ ,发生
+
+ STW
+
+ ,加大了
+
+ 性能开销
+
+ - 默认配置
+
+ - `-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=4000`
+ - 默认开启偏向锁,并且**延迟生效**,因为JVM刚启动时竞争非常激烈
+
+ - 关闭偏向锁
+
+ - `-XX:-UseBiasedLocking`
+
+ - 直接
+
+ 设置为重量级锁
+
+ - `-XX:+UseHeavyMonitors`
+
+红线流程部分:偏向锁的**获取**和**撤销**
+[](https://java-performance-1253868755.cos.ap-guangzhou.myqcloud.com/java-performance-synchronized-lock-upgrade-1.png)
+
+### 轻量级锁
+
+1. 当有另外一个线程竞争锁时,由于该锁处于**偏向锁**状态
+
+2. 发现对象头Mark Word中的线程ID不是自己的线程ID,该线程就会执行
+
+ CAS
+
+ 操作获取锁
+
+ - 如果获取**成功**,直接替换Mark Word中的线程ID为自己的线程ID,该锁会***保持偏向锁状态***
+ - 如果获取**失败**,说明当前锁有一定的竞争,将偏向锁**升级**为轻量级锁
+
+3. 线程获取轻量级锁时会有两步
+
+ - 先把**锁对象的Mark Word**复制一份到线程的**栈帧**中(**DisplacedMarkWord**),主要为了**保留现场**!!
+ - 然后使用**CAS**,把对象头中的内容替换为**线程栈帧中DisplacedMarkWord的地址**
+
+4. 场景
+
+ - 在线程1复制对象头Mark Word的同时(CAS之前),线程2也准备获取锁,也复制了对象头Mark Word
+ - 在线程2进行CAS时,发现线程1已经把对象头换了,线程2的CAS失败,线程2会尝试使用**自旋锁**来等待线程1释放锁
+
+5. 轻量级锁的适用场景:线程**交替执行**同步块,***绝大部分的锁在整个同步周期内都不存在长时间的竞争***
+
+红线流程部分:升级轻量级锁
+[](https://java-performance-1253868755.cos.ap-guangzhou.myqcloud.com/java-performance-synchronized-lock-upgrade-2.png)
+
+### 自旋锁 / 重量级锁
+
+1. 轻量级锁
+
+ CAS
+
+ 抢占失败,线程将会被挂起进入
+
+ 阻塞
+
+ 状态
+
+ - 如果正在持有锁的线程在**很短的时间**内释放锁资源,那么进入**阻塞**状态的线程被**唤醒**后又要**重新抢占**锁资源
+
+2. JVM提供了**自旋锁**,可以通过**自旋**的方式**不断尝试获取锁**,从而***避免线程被挂起阻塞***
+
+3. 从
+
+ JDK 1.7
+
+ 开始,
+
+ 自旋锁默认启用
+
+ ,自旋次数
+
+ 不建议设置过大
+
+ (意味着
+
+ 长时间占用CPU
+
+ )
+
+ - `-XX:+UseSpinning -XX:PreBlockSpin=10`
+
+4. 自旋锁重试之后如果依然抢锁失败,同步锁会升级至
+
+ 重量级锁
+
+ ,锁标志位为
+
+ 10
+
+ - 在这个状态下,未抢到锁的线程都会**进入Monitor**,之后会被阻塞在**WaitSet**中
+
+5. 在
+
+ 锁竞争不激烈
+
+ 且
+
+ 锁占用时间非常短
+
+ 的场景下,自旋锁可以提高系统性能
+
+ - 一旦锁竞争激烈或者锁占用的时间过长,自旋锁将会导致大量的线程一直处于**CAS重试状态**,**占用CPU资源**
+
+6. 在
+
+ 高并发
+
+ 的场景下,可以通过
+
+ 关闭自旋锁
+
+ 来优化系统性能
+
+ - ```
+ -XX:-UseSpinning
+ ```
+
+ - 关闭自旋锁优化
+
+ - ```
+ -XX:PreBlockSpin
+ ```
+
+ - 默认的自旋次数,在**JDK 1.7**后,**由JVM控制**
+
+[](https://java-performance-1253868755.cos.ap-guangzhou.myqcloud.com/java-performance-synchronized-lock-upgrade-3.png)
+
+## 小结
+
+1. JVM在**JDK 1.6**中引入了**分级锁**机制来优化synchronized
+
+2. 当一个线程获取锁时,首先对象锁成为一个
+
+ 偏向锁
+
+ - 这是为了避免在**同一线程重复获取同一把锁**时,**用户态和内核态频繁切换**
+
+3. 如果有多个线程竞争锁资源,锁将会升级为
+
+ 轻量级锁
+
+ - 这适用于在**短时间**内持有锁,且分锁**交替切换**的场景
+ - 轻量级锁还结合了**自旋锁**来**避免线程用户态与内核态的频繁切换**
+
+4. 如果锁竞争太激烈(自旋锁失败),同步锁会升级为重量级锁
+
+5. 优化synchronized同步锁的关键:
+
+ 减少锁竞争
+
+ - 应该尽量使synchronized同步锁处于**轻量级锁**或**偏向锁**,这样才能提高synchronized同步锁的性能
+ - 常用手段
+ - **减少锁粒度**:降低锁竞争
+ - **减少锁的持有时间**,提高synchronized同步锁在自旋时获取锁资源的成功率,**避免升级为重量级锁**
+
+6. 在**锁竞争激烈**时,可以考虑**禁用偏向锁**和**禁用自旋锁**
\ No newline at end of file
diff --git a/docs/java/Multithread/best-practice-of-threadpool.md b/docs/java/Multithread/best-practice-of-threadpool.md
new file mode 100644
index 00000000..06b2ccf4
--- /dev/null
+++ b/docs/java/Multithread/best-practice-of-threadpool.md
@@ -0,0 +1,305 @@
+# 线程池最佳实践
+
+这篇文章篇幅虽短,但是绝对是干货。标题稍微有点夸张,嘿嘿,实际都是自己使用线程池的时候总结的一些个人感觉比较重要的点。
+
+## 线程池知识回顾
+
+开始这篇文章之前还是简单介绍一嘴线程池,之前写的[《新手也能看懂的线程池学习总结》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485808&idx=1&sn=1013253533d73450cef673aee13267ab&chksm=cea246bbf9d5cfad1c21316340a0ef1609a7457fea4113a1f8d69e8c91e7d9cd6285f5ee1490&token=510053261&lang=zh_CN&scene=21#wechat_redirect)这篇文章介绍的很详细了。
+
+### 为什么要使用线程池?
+
+> **池化技术相比大家已经屡见不鲜了,线程池、数据库连接池、Http 连接池等等都是对这个思想的应用。池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。**
+
+**线程池**提供了一种限制和管理资源(包括执行一个任务)。 每个**线程池**还维护一些基本统计信息,例如已完成任务的数量。
+
+这里借用《Java 并发编程的艺术》提到的来说一下**使用线程池的好处**:
+
+- **降低资源消耗**。通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
+- **提高响应速度**。当任务到达时,任务可以不需要的等到线程创建就能立即执行。
+- **提高线程的可管理性**。线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
+
+### 线程池在实际项目的使用场景
+
+**线程池一般用于执行多个不相关联的耗时任务,没有多线程的情况下,任务顺序执行,使用了线程池的话可让多个不相关联的任务同时执行。**
+
+假设我们要执行三个不相关的耗时任务,Guide 画图给大家展示了使用线程池前后的区别。
+
+注意:**下面三个任务可能做的是同一件事情,也可能是不一样的事情。**
+
+
+
+### 如何使用线程池?
+
+一般是通过 `ThreadPoolExecutor` 的构造函数来创建线程池,然后提交任务给线程池执行就可以了。
+
+ `ThreadPoolExecutor`构造函数如下:
+
+```java
+ /**
+ * 用给定的初始参数创建一个新的ThreadPoolExecutor。
+ */
+ public ThreadPoolExecutor(int corePoolSize,//线程池的核心线程数量
+ int maximumPoolSize,//线程池的最大线程数
+ long keepAliveTime,//当线程数大于核心线程数时,多余的空闲线程存活的最长时间
+ TimeUnit unit,//时间单位
+ BlockingQueue workQueue,//任务队列,用来储存等待执行任务的队列
+ ThreadFactory threadFactory,//线程工厂,用来创建线程,一般默认即可
+ RejectedExecutionHandler handler//拒绝策略,当提交的任务过多而不能及时处理时,我们可以定制策略来处理任务
+ ) {
+ if (corePoolSize < 0 ||
+ maximumPoolSize <= 0 ||
+ maximumPoolSize < corePoolSize ||
+ keepAliveTime < 0)
+ throw new IllegalArgumentException();
+ if (workQueue == null || threadFactory == null || handler == null)
+ throw new NullPointerException();
+ this.corePoolSize = corePoolSize;
+ this.maximumPoolSize = maximumPoolSize;
+ this.workQueue = workQueue;
+ this.keepAliveTime = unit.toNanos(keepAliveTime);
+ this.threadFactory = threadFactory;
+ this.handler = handler;
+ }
+```
+
+简单演示一下如何使用线程池,更详细的介绍,请看:[《新手也能看懂的线程池学习总结》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485808&idx=1&sn=1013253533d73450cef673aee13267ab&chksm=cea246bbf9d5cfad1c21316340a0ef1609a7457fea4113a1f8d69e8c91e7d9cd6285f5ee1490&token=510053261&lang=zh_CN&scene=21#wechat_redirect) 。
+
+```java
+ private static final int CORE_POOL_SIZE = 5;
+ private static final int MAX_POOL_SIZE = 10;
+ private static final int QUEUE_CAPACITY = 100;
+ private static final Long KEEP_ALIVE_TIME = 1L;
+
+ public static void main(String[] args) {
+
+ //使用阿里巴巴推荐的创建线程池的方式
+ //通过ThreadPoolExecutor构造函数自定义参数创建
+ ThreadPoolExecutor executor = new ThreadPoolExecutor(
+ CORE_POOL_SIZE,
+ MAX_POOL_SIZE,
+ KEEP_ALIVE_TIME,
+ TimeUnit.SECONDS,
+ new ArrayBlockingQueue<>(QUEUE_CAPACITY),
+ new ThreadPoolExecutor.CallerRunsPolicy());
+
+ for (int i = 0; i < 10; i++) {
+ executor.execute(() -> {
+ try {
+ Thread.sleep(2000);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ System.out.println("CurrentThread name:" + Thread.currentThread().getName() + "date:" + Instant.now());
+ });
+ }
+ //终止线程池
+ executor.shutdown();
+ try {
+ executor.awaitTermination(5, TimeUnit.SECONDS);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ System.out.println("Finished all threads");
+ }
+```
+
+控制台输出:
+
+```java
+CurrentThread name:pool-1-thread-5date:2020-06-06T11:45:31.639Z
+CurrentThread name:pool-1-thread-3date:2020-06-06T11:45:31.639Z
+CurrentThread name:pool-1-thread-1date:2020-06-06T11:45:31.636Z
+CurrentThread name:pool-1-thread-4date:2020-06-06T11:45:31.639Z
+CurrentThread name:pool-1-thread-2date:2020-06-06T11:45:31.639Z
+CurrentThread name:pool-1-thread-2date:2020-06-06T11:45:33.656Z
+CurrentThread name:pool-1-thread-4date:2020-06-06T11:45:33.656Z
+CurrentThread name:pool-1-thread-1date:2020-06-06T11:45:33.656Z
+CurrentThread name:pool-1-thread-3date:2020-06-06T11:45:33.656Z
+CurrentThread name:pool-1-thread-5date:2020-06-06T11:45:33.656Z
+Finished all threads
+```
+
+## 线程池最佳实践
+
+简单总结一下我了解的使用线程池的时候应该注意的东西,网上似乎还没有专门写这方面的文章。
+
+因为Guide还比较菜,有补充和完善的地方,可以在评论区告知或者在微信上与我交流。
+
+### 1. 使用 `ThreadPoolExecutor ` 的构造函数声明线程池
+
+**1. 线程池必须手动通过 `ThreadPoolExecutor ` 的构造函数来声明,避免使用`Executors ` 类的 `newFixedThreadPool` 和 `newCachedThreadPool` ,因为可能会有 OOM 的风险。**
+
+> Executors 返回线程池对象的弊端如下:
+>
+> - **`FixedThreadPool` 和 `SingleThreadExecutor`** : 允许请求的队列长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
+> - **CachedThreadPool 和 ScheduledThreadPool** : 允许创建的线程数量为 `Integer.MAX_VALUE` ,可能会创建大量线程,从而导致 OOM。
+
+说白了就是:**使用有界队列,控制线程创建数量。**
+
+除了避免 OOM 的原因之外,不推荐使用 `Executors `提供的两种快捷的线程池的原因还有:
+
+1. 实际使用中需要根据自己机器的性能、业务场景来手动配置线程池的参数比如核心线程数、使用的任务队列、饱和策略等等。
+2. 我们应该显示地给我们的线程池命名,这样有助于我们定位问题。
+
+### 2.监测线程池运行状态
+
+你可以通过一些手段来检测线程池的运行状态比如 SpringBoot 中的 Actuator 组件。
+
+除此之外,我们还可以利用 `ThreadPoolExecutor` 的相关 API做一个简陋的监控。从下图可以看出, `ThreadPoolExecutor`提供了获取线程池当前的线程数和活跃线程数、已经执行完成的任务数、正在排队中的任务数等等。
+
+
+
+下面是一个简单的 Demo。`printThreadPoolStatus()`会每隔一秒打印出线程池的线程数、活跃线程数、完成的任务数、以及队列中的任务数。
+
+```java
+ /**
+ * 打印线程池的状态
+ *
+ * @param threadPool 线程池对象
+ */
+ public static void printThreadPoolStatus(ThreadPoolExecutor threadPool) {
+ ScheduledExecutorService scheduledExecutorService = new ScheduledThreadPoolExecutor(1, createThreadFactory("print-images/thread-pool-status", false));
+ scheduledExecutorService.scheduleAtFixedRate(() -> {
+ log.info("=========================");
+ log.info("ThreadPool Size: [{}]", threadPool.getPoolSize());
+ log.info("Active Threads: {}", threadPool.getActiveCount());
+ log.info("Number of Tasks : {}", threadPool.getCompletedTaskCount());
+ log.info("Number of Tasks in Queue: {}", threadPool.getQueue().size());
+ log.info("=========================");
+ }, 0, 1, TimeUnit.SECONDS);
+ }
+```
+
+### 3.建议不同类别的业务用不同的线程池
+
+很多人在实际项目中都会有类似这样的问题:**我的项目中多个业务需要用到线程池,是为每个线程池都定义一个还是说定义一个公共的线程池呢?**
+
+一般建议是不同的业务使用不同的线程池,配置线程池的时候根据当前业务的情况对当前线程池进行配置,因为不同的业务的并发以及对资源的使用情况都不同,重心优化系统性能瓶颈相关的业务。
+
+**我们再来看一个真实的事故案例!** (本案例来源自:[《线程池运用不当的一次线上事故》](https://club.perfma.com/article/646639) ,很精彩的一个案例)
+
+
+
+上面的代码可能会存在死锁的情况,为什么呢?画个图给大家捋一捋。
+
+试想这样一种极端情况:
+
+假如我们线程池的核心线程数为 **n**,父任务(扣费任务)数量为 **n**,父任务下面有两个子任务(扣费任务下的子任务),其中一个已经执行完成,另外一个被放在了任务队列中。由于父任务把线程池核心线程资源用完,所以子任务因为无法获取到线程资源无法正常执行,一直被阻塞在队列中。父任务等待子任务执行完成,而子任务等待父任务释放线程池资源,这也就造成了 **"死锁"**。
+
+
+
+解决方法也很简单,就是新增加一个用于执行子任务的线程池专门为其服务。
+
+### 4.别忘记给线程池命名
+
+初始化线程池的时候需要显示命名(设置线程池名称前缀),有利于定位问题。
+
+默认情况下创建的线程名字类似 pool-1-thread-n 这样的,没有业务含义,不利于我们定位问题。
+
+给线程池里的线程命名通常有下面两种方式:
+
+**1.利用 guava 的 `ThreadFactoryBuilder` **
+
+```java
+ThreadFactory threadFactory = new ThreadFactoryBuilder()
+ .setNameFormat(threadNamePrefix + "-%d")
+ .setDaemon(true).build();
+ExecutorService threadPool = new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, TimeUnit.MINUTES, workQueue, threadFactory)
+```
+
+**2.自己实现 `ThreadFactor`。**
+
+```java
+import java.util.concurrent.Executors;
+import java.util.concurrent.ThreadFactory;
+import java.util.concurrent.atomic.AtomicInteger;
+/**
+ * 线程工厂,它设置线程名称,有利于我们定位问题。
+ */
+public final class NamingThreadFactory implements ThreadFactory {
+
+ private final AtomicInteger threadNum = new AtomicInteger();
+ private final ThreadFactory delegate;
+ private final String name;
+
+ /**
+ * 创建一个带名字的线程池生产工厂
+ */
+ public NamingThreadFactory(ThreadFactory delegate, String name) {
+ this.delegate = delegate;
+ this.name = name; // TODO consider uniquifying this
+ }
+
+ @Override
+ public Thread newThread(Runnable r) {
+ Thread t = delegate.newThread(r);
+ t.setName(name + " [#" + threadNum.incrementAndGet() + "]");
+ return t;
+ }
+
+}
+```
+
+### 5.正确配置线程池参数
+
+说到如何给线程池配置参数,美团的骚操作至今让我难忘(后面会提到)!
+
+我们先来看一下各种书籍和博客上一般推荐的配置线程池参数的方式,可以作为参考!
+
+#### 常规操作
+
+很多人甚至可能都会觉得把线程池配置过大一点比较好!我觉得这明显是有问题的。就拿我们生活中非常常见的一例子来说:**并不是人多就能把事情做好,增加了沟通交流成本。你本来一件事情只需要 3 个人做,你硬是拉来了 6 个人,会提升做事效率嘛?我想并不会。** 线程数量过多的影响也是和我们分配多少人做事情一样,对于多线程这个场景来说主要是增加了**上下文切换**成本。不清楚什么是上下文切换的话,可以看我下面的介绍。
+
+> 上下文切换:
+>
+> 多线程编程中一般线程的个数都大于 CPU 核心的个数,而一个 CPU 核心在任意时刻只能被一个线程使用,为了让这些线程都能得到有效执行,CPU 采取的策略是为每个线程分配时间片并轮转的形式。当一个线程的时间片用完的时候就会重新处于就绪状态让给其他线程使用,这个过程就属于一次上下文切换。概括来说就是:当前任务在执行完 CPU 时间片切换到另一个任务之前会先保存自己的状态,以便下次再切换回这个任务时,可以再加载这个任务的状态。**任务从保存到再加载的过程就是一次上下文切换**。
+>
+> 上下文切换通常是计算密集型的。也就是说,它需要相当可观的处理器时间,在每秒几十上百次的切换中,每次切换都需要纳秒量级的时间。所以,上下文切换对系统来说意味着消耗大量的 CPU 时间,事实上,可能是操作系统中时间消耗最大的操作。
+>
+> Linux 相比与其他操作系统(包括其他类 Unix 系统)有很多的优点,其中有一项就是,其上下文切换和模式切换的时间消耗非常少。
+
+**类比于实现世界中的人类通过合作做某件事情,我们可以肯定的一点是线程池大小设置过大或者过小都会有问题,合适的才是最好。**
+
+**如果我们设置的线程池数量太小的话,如果同一时间有大量任务/请求需要处理,可能会导致大量的请求/任务在任务队列中排队等待执行,甚至会出现任务队列满了之后任务/请求无法处理的情况,或者大量任务堆积在任务队列导致 OOM。这样很明显是有问题的! CPU 根本没有得到充分利用。**
+
+**但是,如果我们设置线程数量太大,大量线程可能会同时在争取 CPU 资源,这样会导致大量的上下文切换,从而增加线程的执行时间,影响了整体执行效率。**
+
+有一个简单并且适用面比较广的公式:
+
+- **CPU 密集型任务(N+1):** 这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1,比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
+- **I/O 密集型任务(2N):** 这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
+
+**如何判断是 CPU 密集任务还是 IO 密集任务?**
+
+CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内存中对大量数据进行排序。但凡涉及到网络读取,文件读取这类都是 IO 密集型,这类任务的特点是 CPU 计算耗费时间相比于等待 IO 操作完成的时间来说很少,大部分时间都花在了等待 IO 操作完成上。
+
+#### 美团的骚操作
+
+美团技术团队在[《Java线程池实现原理及其在美团业务中的实践》](https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html)这篇文章中介绍到对线程池参数实现可自定义配置的思路和方法。
+
+美团技术团队的思路是主要对线程池的核心参数实现自定义可配置。这三个核心参数是:
+
+- **`corePoolSize` :** 核心线程数线程数定义了最小可以同时运行的线程数量。
+- **`maximumPoolSize` :** 当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。
+- **`workQueue`:** 当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,信任就会被存放在队列中。
+
+**为什么是这三个参数?**
+
+我在这篇[《新手也能看懂的线程池学习总结》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485808&idx=1&sn=1013253533d73450cef673aee13267ab&chksm=cea246bbf9d5cfad1c21316340a0ef1609a7457fea4113a1f8d69e8c91e7d9cd6285f5ee1490&token=510053261&lang=zh_CN&scene=21#wechat_redirect) 中就说过这三个参数是 `ThreadPoolExecutor` 最重要的参数,它们基本决定了线程池对于任务的处理策略。
+
+**如何支持参数动态配置?** 且看 `ThreadPoolExecutor` 提供的下面这些方法。
+
+
+
+格外需要注意的是`corePoolSize`, 程序运行期间的时候,我们调用 `setCorePoolSize() `这个方法的话,线程池会首先判断当前工作线程数是否大于`corePoolSize`,如果大于的话就会回收工作线程。
+
+另外,你也看到了上面并没有动态指定队列长度的方法,美团的方式是自定义了一个叫做 `ResizableCapacityLinkedBlockIngQueue` 的队列(主要就是把`LinkedBlockingQueue`的capacity 字段的final关键字修饰给去掉了,让它变为可变的)。
+
+最终实现的可动态修改线程池参数效果如下。👏👏👏
+
+
+
+还没看够?推荐 why神的[《如何设置线程池参数?美团给出了一个让面试官虎躯一震的回答。》](https://mp.weixin.qq.com/s/9HLuPcoWmTqAeFKa1kj-_A)这篇文章,深度剖析,很不错哦!
+
+
+
diff --git a/docs/java/Multithread/images/ThreadLocal内部类.png b/docs/java/Multithread/images/ThreadLocal内部类.png
new file mode 100644
index 00000000..6997f5ca
Binary files /dev/null and b/docs/java/Multithread/images/ThreadLocal内部类.png differ
diff --git a/docs/java/Multithread/images/interview-questions/synchronized关键字.png b/docs/java/Multithread/images/interview-questions/synchronized关键字.png
new file mode 100644
index 00000000..24ac1a8c
Binary files /dev/null and b/docs/java/Multithread/images/interview-questions/synchronized关键字.png differ
diff --git a/docs/java/Multithread/images/thread-local/1.png b/docs/java/Multithread/images/thread-local/1.png
new file mode 100644
index 00000000..b394e304
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/1.png differ
diff --git a/docs/java/Multithread/images/thread-local/10.png b/docs/java/Multithread/images/thread-local/10.png
new file mode 100644
index 00000000..c9edb13f
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/10.png differ
diff --git a/docs/java/Multithread/images/thread-local/11.png b/docs/java/Multithread/images/thread-local/11.png
new file mode 100644
index 00000000..06d30638
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/11.png differ
diff --git a/docs/java/Multithread/images/thread-local/12.png b/docs/java/Multithread/images/thread-local/12.png
new file mode 100644
index 00000000..bd765217
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/12.png differ
diff --git a/docs/java/Multithread/images/thread-local/13.png b/docs/java/Multithread/images/thread-local/13.png
new file mode 100644
index 00000000..34c8d8c8
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/13.png differ
diff --git a/docs/java/Multithread/images/thread-local/14.png b/docs/java/Multithread/images/thread-local/14.png
new file mode 100644
index 00000000..b1b3abd6
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/14.png differ
diff --git a/docs/java/Multithread/images/thread-local/15.png b/docs/java/Multithread/images/thread-local/15.png
new file mode 100644
index 00000000..25f5cb2b
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/15.png differ
diff --git a/docs/java/Multithread/images/thread-local/16.png b/docs/java/Multithread/images/thread-local/16.png
new file mode 100644
index 00000000..45d0424f
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/16.png differ
diff --git a/docs/java/Multithread/images/thread-local/17.png b/docs/java/Multithread/images/thread-local/17.png
new file mode 100644
index 00000000..3194e4a3
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/17.png differ
diff --git a/docs/java/Multithread/images/thread-local/18.png b/docs/java/Multithread/images/thread-local/18.png
new file mode 100644
index 00000000..2b340b0b
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/18.png differ
diff --git a/docs/java/Multithread/images/thread-local/19.png b/docs/java/Multithread/images/thread-local/19.png
new file mode 100644
index 00000000..4c906279
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/19.png differ
diff --git a/docs/java/Multithread/images/thread-local/2.png b/docs/java/Multithread/images/thread-local/2.png
new file mode 100644
index 00000000..c9af80e1
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/2.png differ
diff --git a/docs/java/Multithread/images/thread-local/20.png b/docs/java/Multithread/images/thread-local/20.png
new file mode 100644
index 00000000..234c32a6
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/20.png differ
diff --git a/docs/java/Multithread/images/thread-local/21.png b/docs/java/Multithread/images/thread-local/21.png
new file mode 100644
index 00000000..1b5a02b9
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/21.png differ
diff --git a/docs/java/Multithread/images/thread-local/22.png b/docs/java/Multithread/images/thread-local/22.png
new file mode 100644
index 00000000..62eeff12
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/22.png differ
diff --git a/docs/java/Multithread/images/thread-local/23.png b/docs/java/Multithread/images/thread-local/23.png
new file mode 100644
index 00000000..0b4a0409
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/23.png differ
diff --git a/docs/java/Multithread/images/thread-local/24.png b/docs/java/Multithread/images/thread-local/24.png
new file mode 100644
index 00000000..ae2fe0df
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/24.png differ
diff --git a/docs/java/Multithread/images/thread-local/25.png b/docs/java/Multithread/images/thread-local/25.png
new file mode 100644
index 00000000..9c66e254
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/25.png differ
diff --git a/docs/java/Multithread/images/thread-local/26.png b/docs/java/Multithread/images/thread-local/26.png
new file mode 100644
index 00000000..ef53f0a9
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/26.png differ
diff --git a/docs/java/Multithread/images/thread-local/27.png b/docs/java/Multithread/images/thread-local/27.png
new file mode 100644
index 00000000..61710050
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/27.png differ
diff --git a/docs/java/Multithread/images/thread-local/28.png b/docs/java/Multithread/images/thread-local/28.png
new file mode 100644
index 00000000..68f67602
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/28.png differ
diff --git a/docs/java/Multithread/images/thread-local/29.png b/docs/java/Multithread/images/thread-local/29.png
new file mode 100644
index 00000000..d662f80b
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/29.png differ
diff --git a/docs/java/Multithread/images/thread-local/3.png b/docs/java/Multithread/images/thread-local/3.png
new file mode 100644
index 00000000..a0b418c0
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/3.png differ
diff --git a/docs/java/Multithread/images/thread-local/30.png b/docs/java/Multithread/images/thread-local/30.png
new file mode 100644
index 00000000..27ec27f7
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/30.png differ
diff --git a/docs/java/Multithread/images/thread-local/31.png b/docs/java/Multithread/images/thread-local/31.png
new file mode 100644
index 00000000..96b83ca1
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/31.png differ
diff --git a/docs/java/Multithread/images/thread-local/4.png b/docs/java/Multithread/images/thread-local/4.png
new file mode 100644
index 00000000..b0278b70
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/4.png differ
diff --git a/docs/java/Multithread/images/thread-local/5.png b/docs/java/Multithread/images/thread-local/5.png
new file mode 100644
index 00000000..81f24a08
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/5.png differ
diff --git a/docs/java/Multithread/images/thread-local/6.png b/docs/java/Multithread/images/thread-local/6.png
new file mode 100644
index 00000000..66dc77c1
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/6.png differ
diff --git a/docs/java/Multithread/images/thread-local/7.png b/docs/java/Multithread/images/thread-local/7.png
new file mode 100644
index 00000000..d13653a0
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/7.png differ
diff --git a/docs/java/Multithread/images/thread-local/8.png b/docs/java/Multithread/images/thread-local/8.png
new file mode 100644
index 00000000..b7e466d8
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/8.png differ
diff --git a/docs/java/Multithread/images/thread-local/9.png b/docs/java/Multithread/images/thread-local/9.png
new file mode 100644
index 00000000..5964fb0c
Binary files /dev/null and b/docs/java/Multithread/images/thread-local/9.png differ
diff --git a/docs/java/Multithread/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png b/docs/java/Multithread/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png
new file mode 100644
index 00000000..62f2c3e3
Binary files /dev/null and b/docs/java/Multithread/images/thread-pool/19a0255a-6ef3-4835-98d1-a839d1983332.png differ
diff --git a/docs/java/Multithread/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png b/docs/java/Multithread/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png
new file mode 100644
index 00000000..1dc7e4b6
Binary files /dev/null and b/docs/java/Multithread/images/thread-pool/1bc44c67-26ba-42ab-bcb8-4e29e6fd99b9.png differ
diff --git a/docs/java/Multithread/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png b/docs/java/Multithread/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png
new file mode 100644
index 00000000..7dc9b398
Binary files /dev/null and b/docs/java/Multithread/images/thread-pool/5b9b814d-722a-4116-b066-43dc80fc1dc4.png differ
diff --git a/docs/java/Multithread/images/thread-pool/7888fb0d-4699-4d3a-8885-405cb5415617.png b/docs/java/Multithread/images/thread-pool/7888fb0d-4699-4d3a-8885-405cb5415617.png
new file mode 100644
index 00000000..a3678a72
Binary files /dev/null and b/docs/java/Multithread/images/thread-pool/7888fb0d-4699-4d3a-8885-405cb5415617.png differ
diff --git a/docs/java/Multithread/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png b/docs/java/Multithread/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png
new file mode 100644
index 00000000..27cdbee3
Binary files /dev/null and b/docs/java/Multithread/images/thread-pool/b6fd95a7-4c9d-4fc6-ad26-890adb3f6c4c.png differ
diff --git a/docs/java/Multithread/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png b/docs/java/Multithread/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png
new file mode 100644
index 00000000..f0a781d6
Binary files /dev/null and b/docs/java/Multithread/images/thread-pool/ddf22709-bff5-45b4-acb7-a3f2e6798608.png differ
diff --git a/docs/java/Multithread/images/threadlocal数据结构.png b/docs/java/Multithread/images/threadlocal数据结构.png
new file mode 100644
index 00000000..a5791ce5
Binary files /dev/null and b/docs/java/Multithread/images/threadlocal数据结构.png differ
diff --git a/docs/java/Multithread/images/多线程学习指南/Java并发编程的艺术.png b/docs/java/Multithread/images/多线程学习指南/Java并发编程的艺术.png
new file mode 100644
index 00000000..ff907c9c
Binary files /dev/null and b/docs/java/Multithread/images/多线程学习指南/Java并发编程的艺术.png differ
diff --git a/docs/java/Multithread/images/多线程学习指南/javaguide-并发.png b/docs/java/Multithread/images/多线程学习指南/javaguide-并发.png
new file mode 100644
index 00000000..862f282f
Binary files /dev/null and b/docs/java/Multithread/images/多线程学习指南/javaguide-并发.png differ
diff --git a/docs/java/Multithread/images/多线程学习指南/java并发编程之美.png b/docs/java/Multithread/images/多线程学习指南/java并发编程之美.png
new file mode 100644
index 00000000..05e3bff5
Binary files /dev/null and b/docs/java/Multithread/images/多线程学习指南/java并发编程之美.png differ
diff --git a/docs/java/Multithread/images/多线程学习指南/实战Java高并发程序设计.png b/docs/java/Multithread/images/多线程学习指南/实战Java高并发程序设计.png
new file mode 100644
index 00000000..ab61bff8
Binary files /dev/null and b/docs/java/Multithread/images/多线程学习指南/实战Java高并发程序设计.png differ
diff --git a/docs/java/Multithread/images/多线程学习指南/深入浅出Java多线程.png b/docs/java/Multithread/images/多线程学习指南/深入浅出Java多线程.png
new file mode 100644
index 00000000..14d1ea85
Binary files /dev/null and b/docs/java/Multithread/images/多线程学习指南/深入浅出Java多线程.png differ
diff --git a/docs/java/Multithread/java线程池学习总结.md b/docs/java/Multithread/java线程池学习总结.md
index bfbe99d4..54f4b650 100644
--- a/docs/java/Multithread/java线程池学习总结.md
+++ b/docs/java/Multithread/java线程池学习总结.md
@@ -1,3 +1,4 @@
+
- [一 使用线程池的好处](#一-使用线程池的好处)
@@ -28,7 +29,7 @@
- [5.2 SingleThreadExecutor 详解](#52-singlethreadexecutor-详解)
- [5.2.1 介绍](#521-介绍)
- [5.2.2 执行任务过程介绍](#522-执行任务过程介绍)
- - [5.2.3 为什么不推荐使用`FixedThreadPool`?](#523-为什么不推荐使用fixedthreadpool)
+ - [5.2.3 为什么不推荐使用`SingleThreadExecutor`?](#523-为什么不推荐使用singlethreadexecutor)
- [5.3 CachedThreadPool 详解](#53-cachedthreadpool-详解)
- [5.3.1 介绍](#531-介绍)
- [5.3.2 执行任务过程介绍](#532-执行任务过程介绍)
@@ -43,6 +44,7 @@
+
## 一 使用线程池的好处
> **池化技术相比大家已经屡见不鲜了,线程池、数据库连接池、Http 连接池等等都是对这个思想的应用。池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。**
@@ -154,7 +156,7 @@ public class ScheduledThreadPoolExecutor
- **`corePoolSize` :** 核心线程数线程数定义了最小可以同时运行的线程数量。
- **`maximumPoolSize` :** 当队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。
-- **`workQueue`:** 当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,信任就会被存放在队列中。
+- **`workQueue`:** 当新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
`ThreadPoolExecutor`其他常见参数:
@@ -163,16 +165,16 @@ public class ScheduledThreadPoolExecutor
3. **`threadFactory`** :executor 创建新线程的时候会用到。
4. **`handler`** :饱和策略。关于饱和策略下面单独介绍一下。
-下面这张图可以加深你对线程池中各个参数的相互关系的理解(图片来源:《Java性能调优实战》):
+下面这张图可以加深你对线程池中各个参数的相互关系的理解(图片来源:《Java 性能调优实战》):

**`ThreadPoolExecutor` 饱和策略定义:**
-如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任时,`ThreadPoolTaskExecutor` 定义一些策略:
+如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,`ThreadPoolTaskExecutor` 定义一些策略:
- **`ThreadPoolExecutor.AbortPolicy`**:抛出 `RejectedExecutionException`来拒绝新任务的处理。
-- **`ThreadPoolExecutor.CallerRunsPolicy`**:调用执行自己的线程运行任务,也就是直接在调用`execute`方法的线程中运行(`run`)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。另外,这个策略喜欢增加队列容量。如果您的应用程序可以承受此延迟并且你不能任务丢弃任何一个任务请求的话,你可以选择这个策略。
+- **`ThreadPoolExecutor.CallerRunsPolicy`**:调用执行自己的线程运行任务,也就是直接在调用`execute`方法的线程中运行(`run`)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。
- **`ThreadPoolExecutor.DiscardPolicy`:** 不处理新任务,直接丢弃掉。
- **`ThreadPoolExecutor.DiscardOldestPolicy`:** 此策略将丢弃最早的未处理的任务请求。
@@ -205,7 +207,7 @@ public class ScheduledThreadPoolExecutor
- **CachedThreadPool**
对应 Executors 工具类中的方法如图所示:
-
+
## 四 (重要)ThreadPoolExecutor 使用示例
@@ -310,32 +312,32 @@ public class ThreadPoolExecutorDemo {
**Output:**
```
-pool-1-thread-2 Start. Time = Tue Nov 12 20:59:44 CST 2019
-pool-1-thread-5 Start. Time = Tue Nov 12 20:59:44 CST 2019
-pool-1-thread-4 Start. Time = Tue Nov 12 20:59:44 CST 2019
-pool-1-thread-1 Start. Time = Tue Nov 12 20:59:44 CST 2019
-pool-1-thread-3 Start. Time = Tue Nov 12 20:59:44 CST 2019
-pool-1-thread-5 End. Time = Tue Nov 12 20:59:49 CST 2019
-pool-1-thread-3 End. Time = Tue Nov 12 20:59:49 CST 2019
-pool-1-thread-2 End. Time = Tue Nov 12 20:59:49 CST 2019
-pool-1-thread-4 End. Time = Tue Nov 12 20:59:49 CST 2019
-pool-1-thread-1 End. Time = Tue Nov 12 20:59:49 CST 2019
-pool-1-thread-2 Start. Time = Tue Nov 12 20:59:49 CST 2019
-pool-1-thread-1 Start. Time = Tue Nov 12 20:59:49 CST 2019
-pool-1-thread-4 Start. Time = Tue Nov 12 20:59:49 CST 2019
-pool-1-thread-3 Start. Time = Tue Nov 12 20:59:49 CST 2019
-pool-1-thread-5 Start. Time = Tue Nov 12 20:59:49 CST 2019
-pool-1-thread-2 End. Time = Tue Nov 12 20:59:54 CST 2019
-pool-1-thread-3 End. Time = Tue Nov 12 20:59:54 CST 2019
-pool-1-thread-4 End. Time = Tue Nov 12 20:59:54 CST 2019
-pool-1-thread-5 End. Time = Tue Nov 12 20:59:54 CST 2019
-pool-1-thread-1 End. Time = Tue Nov 12 20:59:54 CST 2019
+pool-1-thread-3 Start. Time = Sun Apr 12 11:14:37 CST 2020
+pool-1-thread-5 Start. Time = Sun Apr 12 11:14:37 CST 2020
+pool-1-thread-2 Start. Time = Sun Apr 12 11:14:37 CST 2020
+pool-1-thread-1 Start. Time = Sun Apr 12 11:14:37 CST 2020
+pool-1-thread-4 Start. Time = Sun Apr 12 11:14:37 CST 2020
+pool-1-thread-3 End. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-4 End. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-1 End. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-5 End. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-1 Start. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-2 End. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-5 Start. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-4 Start. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-3 Start. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-2 Start. Time = Sun Apr 12 11:14:42 CST 2020
+pool-1-thread-1 End. Time = Sun Apr 12 11:14:47 CST 2020
+pool-1-thread-4 End. Time = Sun Apr 12 11:14:47 CST 2020
+pool-1-thread-5 End. Time = Sun Apr 12 11:14:47 CST 2020
+pool-1-thread-3 End. Time = Sun Apr 12 11:14:47 CST 2020
+pool-1-thread-2 End. Time = Sun Apr 12 11:14:47 CST 2020
```
### 4.2 线程池原理分析
-承接 4.1 节,我们通过代码输出结果可以看出:**线程池每次会同时执行 5 个任务,这 5 个任务执行完之后,剩余的 5 个任务才会被执行。** 大家可以先通过上面讲解的内容,分析一下到底是咋回事?(自己独立思考一会)
+承接 4.1 节,我们通过代码输出结果可以看出:**线程首先会先执行 5 个任务,然后这些任务有任务被执行完的话,就会去拿新的任务执行。** 大家可以先通过上面讲解的内容,分析一下到底是咋回事?(自己独立思考一会)
现在,我们就分析上面的输出内容来简单分析一下线程池原理。
@@ -344,11 +346,11 @@ pool-1-thread-1 End. Time = Tue Nov 12 20:59:54 CST 2019
```java
// 存放线程池的运行状态 (runState) 和线程池内有效线程的数量 (workerCount)
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
-
+
private static int workerCountOf(int c) {
return c & CAPACITY;
}
-
+ //任务队列
private final BlockingQueue workQueue;
public void execute(Runnable command) {
@@ -388,11 +390,120 @@ pool-1-thread-1 End. Time = Tue Nov 12 20:59:54 CST 2019

+
+
+**`addWorker` 这个方法主要用来创建新的工作线程,如果返回true说明创建和启动工作线程成功,否则的话返回的就是false。**
+
+```java
+ // 全局锁,并发操作必备
+ private final ReentrantLock mainLock = new ReentrantLock();
+ // 跟踪线程池的最大大小,只有在持有全局锁mainLock的前提下才能访问此集合
+ private int largestPoolSize;
+ // 工作线程集合,存放线程池中所有的(活跃的)工作线程,只有在持有全局锁mainLock的前提下才能访问此集合
+ private final HashSet workers = new HashSet<>();
+ //获取线程池状态
+ private static int runStateOf(int c) { return c & ~CAPACITY; }
+ //判断线程池的状态是否为 Running
+ private static boolean isRunning(int c) {
+ return c < SHUTDOWN;
+ }
+
+
+ /**
+ * 添加新的工作线程到线程池
+ * @param firstTask 要执行
+ * @param core参数为true的话表示使用线程池的基本大小,为false使用线程池最大大小
+ * @return 添加成功就返回true否则返回false
+ */
+ private boolean addWorker(Runnable firstTask, boolean core) {
+ retry:
+ for (;;) {
+ //这两句用来获取线程池的状态
+ int c = ctl.get();
+ int rs = runStateOf(c);
+
+ // Check if queue empty only if necessary.
+ if (rs >= SHUTDOWN &&
+ ! (rs == SHUTDOWN &&
+ firstTask == null &&
+ ! workQueue.isEmpty()))
+ return false;
+
+ for (;;) {
+ //获取线程池中线程的数量
+ int wc = workerCountOf(c);
+ // core参数为true的话表明队列也满了,线程池大小变为 maximumPoolSize
+ if (wc >= CAPACITY ||
+ wc >= (core ? corePoolSize : maximumPoolSize))
+ return false;
+ //原子操作将workcount的数量加1
+ if (compareAndIncrementWorkerCount(c))
+ break retry;
+ // 如果线程的状态改变了就再次执行上述操作
+ c = ctl.get();
+ if (runStateOf(c) != rs)
+ continue retry;
+ // else CAS failed due to workerCount change; retry inner loop
+ }
+ }
+ // 标记工作线程是否启动成功
+ boolean workerStarted = false;
+ // 标记工作线程是否创建成功
+ boolean workerAdded = false;
+ Worker w = null;
+ try {
+
+ w = new Worker(firstTask);
+ final Thread t = w.thread;
+ if (t != null) {
+ // 加锁
+ final ReentrantLock mainLock = this.mainLock;
+ mainLock.lock();
+ try {
+ //获取线程池状态
+ int rs = runStateOf(ctl.get());
+ //rs < SHUTDOWN 如果线程池状态依然为RUNNING,并且线程的状态是存活的话,就会将工作线程添加到工作线程集合中
+ //(rs=SHUTDOWN && firstTask == null)如果线程池状态小于STOP,也就是RUNNING或者SHUTDOWN状态下,同时传入的任务实例firstTask为null,则需要添加到工作线程集合和启动新的Worker
+ // firstTask == null证明只新建线程而不执行任务
+ if (rs < SHUTDOWN ||
+ (rs == SHUTDOWN && firstTask == null)) {
+ if (t.isAlive()) // precheck that t is startable
+ throw new IllegalThreadStateException();
+ workers.add(w);
+ //更新当前工作线程的最大容量
+ int s = workers.size();
+ if (s > largestPoolSize)
+ largestPoolSize = s;
+ // 工作线程是否启动成功
+ workerAdded = true;
+ }
+ } finally {
+ // 释放锁
+ mainLock.unlock();
+ }
+ //// 如果成功添加工作线程,则调用Worker内部的线程实例t的Thread#start()方法启动真实的线程实例
+ if (workerAdded) {
+ t.start();
+ /// 标记线程启动成功
+ workerStarted = true;
+ }
+ }
+ } finally {
+ // 线程启动失败,需要从工作线程中移除对应的Worker
+ if (! workerStarted)
+ addWorkerFailed(w);
+ }
+ return workerStarted;
+ }
+```
+
+更多关于线程池源码分析的内容推荐这篇文章:《[JUC线程池ThreadPoolExecutor源码分析](http://www.throwable.club/2019/07/15/java-concurrency-thread-pool-executor/)》
+
现在,让我们在回到 4.1 节我们写的 Demo, 现在应该是不是很容易就可以搞懂它的原理了呢?
没搞懂的话,也没关系,可以看看我的分析:
-> 我们在代码中模拟了 10 个任务,我们配置的核心线程数为 5 、等待队列容量为 100 ,所以每次只可能存在 5 个任务同时执行,剩下的 5 个任务会被放到等待队列中去。当前的 5 个任务之行完成后,才会之行剩下的 5 个任务。
+> 我们在代码中模拟了 10 个任务,我们配置的核心线程数为 5 、等待队列容量为 100 ,所以每次只可能存在 5 个任务同时执行,剩下的 5 个任务会被放到等待队列中去。当前的5个任务中如果有任务被执行完了,线程池就会去拿新的任务执行。
### 4.3 几个常见的对比
@@ -650,7 +761,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
1. 如果当前运行的线程数少于 corePoolSize,则创建一个新的线程执行任务;
2. 当前线程池中有一个运行的线程后,将任务加入 `LinkedBlockingQueue`
-3. 线程执行完当前的任务后,会在循环中反复从` LinkedBlockingQueue` 中获取任务来执行;
+3. 线程执行完当前的任务后,会在循环中反复从`LinkedBlockingQueue` 中获取任务来执行;
#### 5.2.3 为什么不推荐使用`SingleThreadExecutor`?
@@ -683,7 +794,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
}
```
-`CachedThreadPool` 的` corePoolSize` 被设置为空(0),`maximumPoolSize `被设置为 Integer.MAX.VALUE,即它是无界的,这也就意味着如果主线程提交任务的速度高于 `maximumPool` 中线程处理任务的速度时,`CachedThreadPool` 会不断创建新的线程。极端情况下,这样会导致耗尽 cpu 和内存资源。
+`CachedThreadPool` 的`corePoolSize` 被设置为空(0),`maximumPoolSize`被设置为 Integer.MAX.VALUE,即它是无界的,这也就意味着如果主线程提交任务的速度高于 `maximumPool` 中线程处理任务的速度时,`CachedThreadPool` 会不断创建新的线程。极端情况下,这样会导致耗尽 cpu 和内存资源。
#### 5.3.2 执行任务过程介绍
@@ -695,13 +806,13 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
1. 首先执行 `SynchronousQueue.offer(Runnable task)` 提交任务到任务队列。如果当前 `maximumPool` 中有闲线程正在执行 `SynchronousQueue.poll(keepAliveTime,TimeUnit.NANOSECONDS)`,那么主线程执行 offer 操作与空闲线程执行的 `poll` 操作配对成功,主线程把任务交给空闲线程执行,`execute()`方法执行完成,否则执行下面的步骤 2;
2. 当初始 `maximumPool` 为空,或者 `maximumPool` 中没有空闲线程时,将没有线程执行 `SynchronousQueue.poll(keepAliveTime,TimeUnit.NANOSECONDS)`。这种情况下,步骤 1 将失败,此时 `CachedThreadPool` 会创建新线程执行任务,execute 方法执行完成;
-#### 5.3.3 为什么不推荐使用`CachedThreadPool`?
+#### 5.3.3 为什么不推荐使用`CachedThreadPool`?
`CachedThreadPool`允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致 OOM。
## 六 ScheduledThreadPoolExecutor 详解
-**`ScheduledThreadPoolExecutor` 主要用来在给定的延迟后运行任务,或者定期执行任务。** 这个在实际项目中基本不会被用到,所以对这部分大家只需要简单了解一下它的思想。关于如何在Spring Boot 中 实现定时任务,可以查看这篇文章[《5分钟搞懂如何在Spring Boot中Schedule Tasks》](https://github.com/Snailclimb/springboot-guide/blob/master/docs/advanced/SpringBoot-ScheduleTasks.md)。
+**`ScheduledThreadPoolExecutor` 主要用来在给定的延迟后运行任务,或者定期执行任务。** 这个在实际项目中基本不会被用到,因为有其他方案选择比如`quartz`。大家只需要简单了解一下它的思想。关于如何在 Spring Boot 中 实现定时任务,可以查看这篇文章[《5 分钟搞懂如何在 Spring Boot 中 Schedule Tasks》](https://github.com/Snailclimb/springboot-guide/blob/master/docs/advanced/SpringBoot-ScheduleTasks.md)。
### 6.1 简介
@@ -726,7 +837,7 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5
1. 当调用 `ScheduledThreadPoolExecutor` 的 **`scheduleAtFixedRate()`** 方法或者**`scheduleWirhFixedDelay()`** 方法时,会向 `ScheduledThreadPoolExecutor` 的 **`DelayQueue`** 添加一个实现了 **`RunnableScheduledFuture`** 接口的 **`ScheduledFutureTask`** 。
2. 线程池中的线程从 `DelayQueue` 中获取 `ScheduledFutureTask`,然后执行任务。
-**`ScheduledThreadPoolExecutor` 为了实现周期性的执行任务,对 `ThreadPoolExecutor `做了如下修改:**
+**`ScheduledThreadPoolExecutor` 为了实现周期性的执行任务,对 `ThreadPoolExecutor`做了如下修改:**
- 使用 **`DelayQueue`** 作为任务队列;
- 获取任务的方不同
@@ -736,38 +847,40 @@ Wed Nov 13 13:40:43 CST 2019::pool-1-thread-5

-1. 线程 1 从 `DelayQueue` 中获取已到期的 `ScheduledFutureTask(DelayQueue.take())`。到期任务是指 `ScheduledFutureTask `的 time 大于等于当前系统的时间;
+1. 线程 1 从 `DelayQueue` 中获取已到期的 `ScheduledFutureTask(DelayQueue.take())`。到期任务是指 `ScheduledFutureTask`的 time 大于等于当前系统的时间;
2. 线程 1 执行这个 `ScheduledFutureTask`;
3. 线程 1 修改 `ScheduledFutureTask` 的 time 变量为下次将要被执行的时间;
4. 线程 1 把这个修改 time 之后的 `ScheduledFutureTask` 放回 `DelayQueue` 中(`DelayQueue.add()`)。
## 七 线程池大小确定
-**线程池数量的确定一直是困扰着程序员的一个难题,大部分程序员在设定线程池大小的时候就是随心而定。我们并没有考虑过这样大小的配置是否会带来什么问题,我自己就是这大部分程序员中的一个代表。**
+**线程池数量的确定一直是困扰着程序员的一个难题,大部分程序员在设定线程池大小的时候就是随心而定。**
-由于笔主对如何确定线程池大小也没有什么实际经验,所以,这部分内容参考了网上很多文章/书籍。
-
-**首先,可以肯定的一点是线程池大小设置过大或者过小都会有问题。合适的才是最好,貌似在 95 % 的场景下都是合适的。**
-
-如果阅读过我的上一篇关于线程池的文章的话,你一定知道:
-
-**如果我们设置的线程池数量太小的话,如果同一时间有大量任务/请求需要处理,可能会导致大量的请求/任务在任务队列中排队等待执行,甚至会出现任务队列满了之后任务/请求无法处理的情况,或者大量任务堆积在任务队列导致 OOM。这样很明显是有问题的! CPU 根本没有得到充分利用。**
-
-**但是,如果我们设置线程数量太大,大量线程可能会同时在争取 CPU 资源,这样会导致大量的上下文切换,从而增加线程的执行时间,影响了整体执行效率。**
+很多人甚至可能都会觉得把线程池配置过大一点比较好!我觉得这明显是有问题的。就拿我们生活中非常常见的一例子来说:**并不是人多就能把事情做好,增加了沟通交流成本。你本来一件事情只需要 3 个人做,你硬是拉来了 6 个人,会提升做事效率嘛?我想并不会。** 线程数量过多的影响也是和我们分配多少人做事情一样,对于多线程这个场景来说主要是增加了**上下文切换**成本。不清楚什么是上下文切换的话,可以看我下面的介绍。
> 上下文切换:
>
> 多线程编程中一般线程的个数都大于 CPU 核心的个数,而一个 CPU 核心在任意时刻只能被一个线程使用,为了让这些线程都能得到有效执行,CPU 采取的策略是为每个线程分配时间片并轮转的形式。当一个线程的时间片用完的时候就会重新处于就绪状态让给其他线程使用,这个过程就属于一次上下文切换。概括来说就是:当前任务在执行完 CPU 时间片切换到另一个任务之前会先保存自己的状态,以便下次再切换回这个任务时,可以再加载这个任务的状态。**任务从保存到再加载的过程就是一次上下文切换**。
>
-> 上下文切换通常是计算密集型的。也就是说,它需要相当可观的处理器时间,在每秒几十上百次的切换中,每次切换都需要纳秒量级的时间。所以,上下文切换对系统来说意味着消耗大量的 CPU 时间,事实上,可能是操作系统中时间消耗最大的操作。
+> 上下文切换通常是计算密集型的。也就是说,它需要相当可观的处理器时间,在每秒几十上百次的切换中,每次切换都需要纳秒量级的时间。所以,上下文切换对系统来说意味着消耗大量的 CPU 时间,事实上,可能是操作系统中时间消耗最大的操作。
>
> Linux 相比与其他操作系统(包括其他类 Unix 系统)有很多的优点,其中有一项就是,其上下文切换和模式切换的时间消耗非常少。
+**类比于实现世界中的人类通过合作做某件事情,我们可以肯定的一点是线程池大小设置过大或者过小都会有问题,合适的才是最好。**
+
+**如果我们设置的线程池数量太小的话,如果同一时间有大量任务/请求需要处理,可能会导致大量的请求/任务在任务队列中排队等待执行,甚至会出现任务队列满了之后任务/请求无法处理的情况,或者大量任务堆积在任务队列导致 OOM。这样很明显是有问题的! CPU 根本没有得到充分利用。**
+
+**但是,如果我们设置线程数量太大,大量线程可能会同时在争取 CPU 资源,这样会导致大量的上下文切换,从而增加线程的执行时间,影响了整体执行效率。**
+
有一个简单并且适用面比较广的公式:
- **CPU 密集型任务(N+1):** 这种任务消耗的主要是 CPU 资源,可以将线程数设置为 N(CPU 核心数)+1,比 CPU 核心数多出来的一个线程是为了防止线程偶发的缺页中断,或者其它原因导致的任务暂停而带来的影响。一旦任务暂停,CPU 就会处于空闲状态,而在这种情况下多出来的一个线程就可以充分利用 CPU 的空闲时间。
- **I/O 密集型任务(2N):** 这种任务应用起来,系统会用大部分的时间来处理 I/O 交互,而线程在处理 I/O 的时间段内不会占用 CPU 来处理,这时就可以将 CPU 交出给其它线程使用。因此在 I/O 密集型任务的应用中,我们可以多配置一些线程,具体的计算方法是 2N。
+**如何判断是 CPU 密集任务还是 IO 密集任务?**
+
+CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内存中对大量数据进行排序。单凡涉及到网络读取,文件读取这类都是 IO 密集型,这类任务的特点是 CPU 计算耗费时间相比于等待 IO 操作完成的时间来说很少,大部分时间都花在了等待 IO 操作完成上。
+
## 八 参考
- 《Java 并发编程的艺术》
diff --git a/docs/java/Multithread/synchronized.md b/docs/java/Multithread/synchronized.md
deleted file mode 100644
index 3c926654..00000000
--- a/docs/java/Multithread/synchronized.md
+++ /dev/null
@@ -1,169 +0,0 @@
-
-
-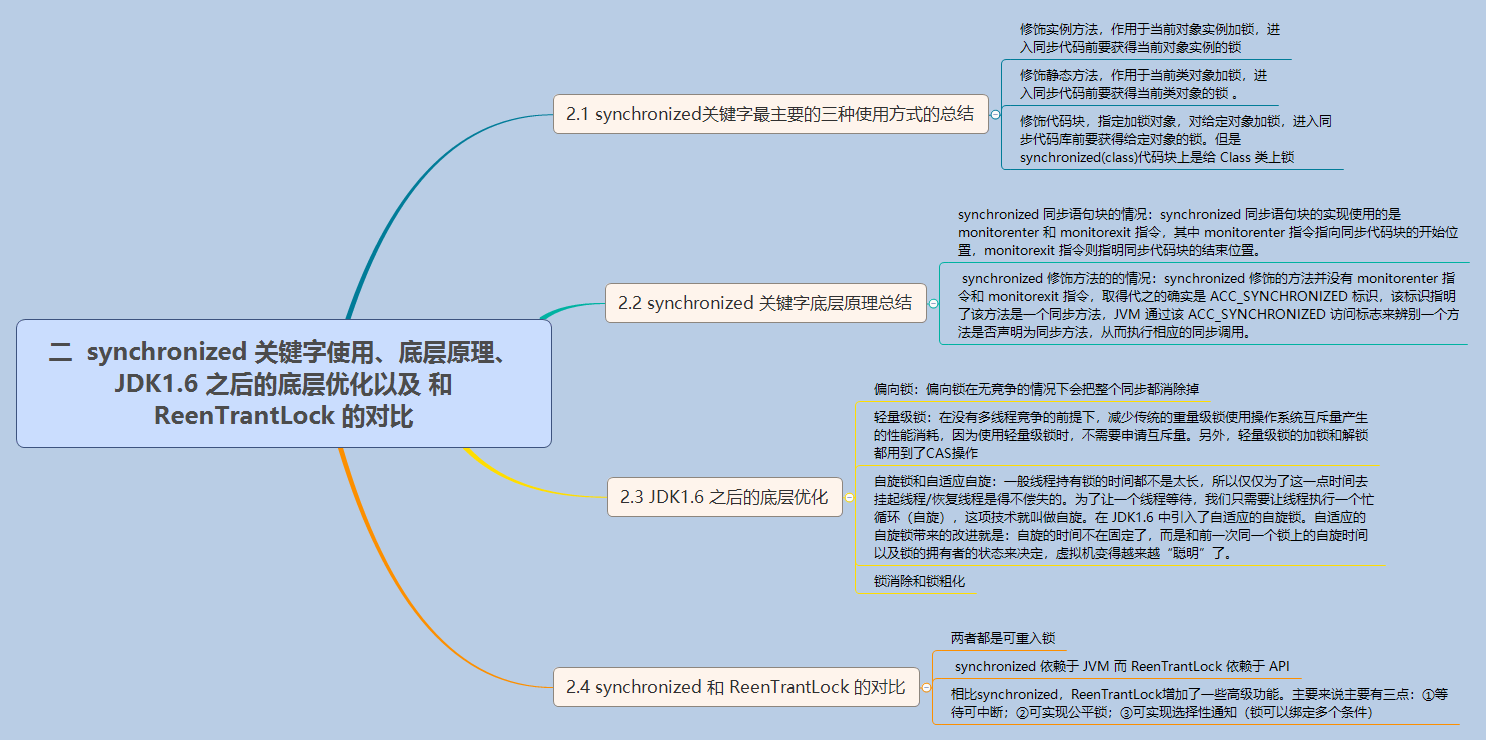
-
-### synchronized关键字最主要的三种使用方式的总结
-
-- **修饰实例方法,作用于当前对象实例加锁,进入同步代码前要获得当前对象实例的锁**
-- **修饰静态方法,作用于当前类对象加锁,进入同步代码前要获得当前类对象的锁** 。也就是给当前类加锁,会作用于类的所有对象实例,因为静态成员不属于任何一个实例对象,是类成员( static 表明这是该类的一个静态资源,不管new了多少个对象,只有一份,所以对该类的所有对象都加了锁)。所以如果一个线程A调用一个实例对象的非静态 synchronized 方法,而线程B需要调用这个实例对象所属类的静态 synchronized 方法,是允许的,不会发生互斥现象,**因为访问静态 synchronized 方法占用的锁是当前类的锁,而访问非静态 synchronized 方法占用的锁是当前实例对象锁**。
-- **修饰代码块,指定加锁对象,对给定对象加锁,进入同步代码块前要获得给定对象的锁。** 和 synchronized 方法一样,synchronized(this)代码块也是锁定当前对象的。synchronized 关键字加到 static 静态方法和 synchronized(class)代码块上都是是给 Class 类上锁。这里再提一下:synchronized关键字加到非 static 静态方法上是给对象实例上锁。另外需要注意的是:尽量不要使用 synchronized(String a) 因为JVM中,字符串常量池具有缓冲功能!
-
-下面我已一个常见的面试题为例讲解一下 synchronized 关键字的具体使用。
-
-面试中面试官经常会说:“单例模式了解吗?来给我手写一下!给我解释一下双重检验锁方式实现单例模式的原理呗!”
-
-
-
-**双重校验锁实现对象单例(线程安全)**
-
-```java
-public class Singleton {
-
- private volatile static Singleton uniqueInstance;
-
- private Singleton() {
- }
-
- public static Singleton getUniqueInstance() {
- //先判断对象是否已经实例过,没有实例化过才进入加锁代码
- if (uniqueInstance == null) {
- //类对象加锁
- synchronized (Singleton.class) {
- if (uniqueInstance == null) {
- uniqueInstance = new Singleton();
- }
- }
- }
- return uniqueInstance;
- }
-}
-```
-另外,需要注意 uniqueInstance 采用 volatile 关键字修饰也是很有必要。
-
-uniqueInstance 采用 volatile 关键字修饰也是很有必要的, uniqueInstance = new Singleton(); 这段代码其实是分为三步执行:
-
-1. 为 uniqueInstance 分配内存空间
-2. 初始化 uniqueInstance
-3. 将 uniqueInstance 指向分配的内存地址
-
-但是由于 JVM 具有指令重排的特性,执行顺序有可能变成 1->3->2。指令重排在单线程环境下不会出现问题,但是在多线程环境下会导致一个线程获得还没有初始化的实例。例如,线程 T1 执行了 1 和 3,此时 T2 调用 getUniqueInstance() 后发现 uniqueInstance 不为空,因此返回 uniqueInstance,但此时 uniqueInstance 还未被初始化。
-
-使用 volatile 可以禁止 JVM 的指令重排,保证在多线程环境下也能正常运行。
-
-
-###synchronized 关键字底层原理总结
-
-
-
-**synchronized 关键字底层原理属于 JVM 层面。**
-
-**① synchronized 同步语句块的情况**
-
-```java
-public class SynchronizedDemo {
- public void method() {
- synchronized (this) {
- System.out.println("synchronized 代码块");
- }
- }
-}
-
-```
-
-通过 JDK 自带的 javap 命令查看 SynchronizedDemo 类的相关字节码信息:首先切换到类的对应目录执行 `javac SynchronizedDemo.java` 命令生成编译后的 .class 文件,然后执行`javap -c -s -v -l SynchronizedDemo.class`。
-
-
-
-从上面我们可以看出:
-
-**synchronized 同步语句块的实现使用的是 monitorenter 和 monitorexit 指令,其中 monitorenter 指令指向同步代码块的开始位置,monitorexit 指令则指明同步代码块的结束位置。** 当执行 monitorenter 指令时,线程试图获取锁也就是获取 monitor(monitor对象存在于每个Java对象的对象头中,synchronized 锁便是通过这种方式获取锁的,也是为什么Java中任意对象可以作为锁的原因) 的持有权.当计数器为0则可以成功获取,获取后将锁计数器设为1也就是加1。相应的在执行 monitorexit 指令后,将锁计数器设为0,表明锁被释放。如果获取对象锁失败,那当前线程就要阻塞等待,直到锁被另外一个线程释放为止。
-
-**② synchronized 修饰方法的的情况**
-
-```java
-public class SynchronizedDemo2 {
- public synchronized void method() {
- System.out.println("synchronized 方法");
- }
-}
-
-```
-
-
-
-synchronized 修饰的方法并没有 monitorenter 指令和 monitorexit 指令,取得代之的确实是 ACC_SYNCHRONIZED 标识,该标识指明了该方法是一个同步方法,JVM 通过该 ACC_SYNCHRONIZED 访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。
-
-
-在 Java 早期版本中,synchronized 属于重量级锁,效率低下,因为监视器锁(monitor)是依赖于底层的操作系统的 Mutex Lock 来实现的,Java 的线程是映射到操作系统的原生线程之上的。如果要挂起或者唤醒一个线程,都需要操作系统帮忙完成,而操作系统实现线程之间的切换时需要从用户态转换到内核态,这个状态之间的转换需要相对比较长的时间,时间成本相对较高,这也是为什么早期的 synchronized 效率低的原因。庆幸的是在 Java 6 之后 Java 官方对从 JVM 层面对synchronized 较大优化,所以现在的 synchronized 锁效率也优化得很不错了。JDK1.6对锁的实现引入了大量的优化,如自旋锁、适应性自旋锁、锁消除、锁粗化、偏向锁、轻量级锁等技术来减少锁操作的开销。
-
-
-### JDK1.6 之后的底层优化
-
-JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术来减少锁操作的开销。
-
-锁主要存在四中状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
-
-**①偏向锁**
-
-**引入偏向锁的目的和引入轻量级锁的目的很像,他们都是为了没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。但是不同是:轻量级锁在无竞争的情况下使用 CAS 操作去代替使用互斥量。而偏向锁在无竞争的情况下会把整个同步都消除掉**。
-
-偏向锁的“偏”就是偏心的偏,它的意思是会偏向于第一个获得它的线程,如果在接下来的执行中,该锁没有被其他线程获取,那么持有偏向锁的线程就不需要进行同步!关于偏向锁的原理可以查看《深入理解Java虚拟机:JVM高级特性与最佳实践》第二版的13章第三节锁优化。
-
-但是对于锁竞争比较激烈的场合,偏向锁就失效了,因为这样场合极有可能每次申请锁的线程都是不相同的,因此这种场合下不应该使用偏向锁,否则会得不偿失,需要注意的是,偏向锁失败后,并不会立即膨胀为重量级锁,而是先升级为轻量级锁。
-
-**② 轻量级锁**
-
-倘若偏向锁失败,虚拟机并不会立即升级为重量级锁,它还会尝试使用一种称为轻量级锁的优化手段(1.6之后加入的)。**轻量级锁不是为了代替重量级锁,它的本意是在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗,因为使用轻量级锁时,不需要申请互斥量。另外,轻量级锁的加锁和解锁都用到了CAS操作。** 关于轻量级锁的加锁和解锁的原理可以查看《深入理解Java虚拟机:JVM高级特性与最佳实践》第二版的13章第三节锁优化。
-
-**轻量级锁能够提升程序同步性能的依据是“对于绝大部分锁,在整个同步周期内都是不存在竞争的”,这是一个经验数据。如果没有竞争,轻量级锁使用 CAS 操作避免了使用互斥操作的开销。但如果存在锁竞争,除了互斥量开销外,还会额外发生CAS操作,因此在有锁竞争的情况下,轻量级锁比传统的重量级锁更慢!如果锁竞争激烈,那么轻量级将很快膨胀为重量级锁!**
-
-**③ 自旋锁和自适应自旋**
-
-轻量级锁失败后,虚拟机为了避免线程真实地在操作系统层面挂起,还会进行一项称为自旋锁的优化手段。
-
-互斥同步对性能最大的影响就是阻塞的实现,因为挂起线程/恢复线程的操作都需要转入内核态中完成(用户态转换到内核态会耗费时间)。
-
-**一般线程持有锁的时间都不是太长,所以仅仅为了这一点时间去挂起线程/恢复线程是得不偿失的。** 所以,虚拟机的开发团队就这样去考虑:“我们能不能让后面来的请求获取锁的线程等待一会而不被挂起呢?看看持有锁的线程是否很快就会释放锁”。**为了让一个线程等待,我们只需要让线程执行一个忙循环(自旋),这项技术就叫做自旋**。
-
-百度百科对自旋锁的解释:
-
-> 何谓自旋锁?它是为实现保护共享资源而提出一种锁机制。其实,自旋锁与互斥锁比较类似,它们都是为了解决对某项资源的互斥使用。无论是互斥锁,还是自旋锁,在任何时刻,最多只能有一个保持者,也就说,在任何时刻最多只能有一个执行单元获得锁。但是两者在调度机制上略有不同。对于互斥锁,如果资源已经被占用,资源申请者只能进入睡眠状态。但是自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁,"自旋"一词就是因此而得名。
-
-自旋锁在 JDK1.6 之前其实就已经引入了,不过是默认关闭的,需要通过`--XX:+UseSpinning`参数来开启。JDK1.6及1.6之后,就改为默认开启的了。需要注意的是:自旋等待不能完全替代阻塞,因为它还是要占用处理器时间。如果锁被占用的时间短,那么效果当然就很好了!反之,相反!自旋等待的时间必须要有限度。如果自旋超过了限定次数任然没有获得锁,就应该挂起线程。**自旋次数的默认值是10次,用户可以修改`--XX:PreBlockSpin`来更改**。
-
-另外,**在 JDK1.6 中引入了自适应的自旋锁。自适应的自旋锁带来的改进就是:自旋的时间不在固定了,而是和前一次同一个锁上的自旋时间以及锁的拥有者的状态来决定,虚拟机变得越来越“聪明”了**。
-
-**④ 锁消除**
-
-锁消除理解起来很简单,它指的就是虚拟机即使编译器在运行时,如果检测到那些共享数据不可能存在竞争,那么就执行锁消除。锁消除可以节省毫无意义的请求锁的时间。
-
-**⑤ 锁粗化**
-
-原则上,我们在编写代码的时候,总是推荐将同步块的作用范围限制得尽量小,——直在共享数据的实际作用域才进行同步,这样是为了使得需要同步的操作数量尽可能变小,如果存在锁竞争,那等待线程也能尽快拿到锁。
-
-大部分情况下,上面的原则都是没有问题的,但是如果一系列的连续操作都对同一个对象反复加锁和解锁,那么会带来很多不必要的性能消耗。
-
-### Synchronized 和 ReenTrantLock 的对比
-
-
-**① 两者都是可重入锁**
-
-两者都是可重入锁。“可重入锁”概念是:自己可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果不可锁重入的话,就会造成死锁。同一个线程每次获取锁,锁的计数器都自增1,所以要等到锁的计数器下降为0时才能释放锁。
-
-**② synchronized 依赖于 JVM 而 ReenTrantLock 依赖于 API**
-
-synchronized 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团队在 JDK1.6 为 synchronized 关键字进行了很多优化,但是这些优化都是在虚拟机层面实现的,并没有直接暴露给我们。ReenTrantLock 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock 方法配合 try/finally 语句块来完成),所以我们可以通过查看它的源代码,来看它是如何实现的。
-
-**③ ReenTrantLock 比 synchronized 增加了一些高级功能**
-
-相比synchronized,ReenTrantLock增加了一些高级功能。主要来说主要有三点:**①等待可中断;②可实现公平锁;③可实现选择性通知(锁可以绑定多个条件)**
-
-- **ReenTrantLock提供了一种能够中断等待锁的线程的机制**,通过lock.lockInterruptibly()来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。
-- **ReenTrantLock可以指定是公平锁还是非公平锁。而synchronized只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。** ReenTrantLock默认情况是非公平的,可以通过 ReenTrantLock类的`ReentrantLock(boolean fair)`构造方法来制定是否是公平的。
-- synchronized关键字与wait()和notify/notifyAll()方法相结合可以实现等待/通知机制,ReentrantLock类当然也可以实现,但是需要借助于Condition接口与newCondition() 方法。Condition是JDK1.5之后才有的,它具有很好的灵活性,比如可以实现多路通知功能也就是在一个Lock对象中可以创建多个Condition实例(即对象监视器),**线程对象可以注册在指定的Condition中,从而可以有选择性的进行线程通知,在调度线程上更加灵活。 在使用notify/notifyAll()方法进行通知时,被通知的线程是由 JVM 选择的,用ReentrantLock类结合Condition实例可以实现“选择性通知”** ,这个功能非常重要,而且是Condition接口默认提供的。而synchronized关键字就相当于整个Lock对象中只有一个Condition实例,所有的线程都注册在它一个身上。如果执行notifyAll()方法的话就会通知所有处于等待状态的线程这样会造成很大的效率问题,而Condition实例的signalAll()方法 只会唤醒注册在该Condition实例中的所有等待线程。
-
-如果你想使用上述功能,那么选择ReenTrantLock是一个不错的选择。
-
-**④ 性能已不是选择标准**
-
-在JDK1.6之前,synchronized 的性能是比 ReenTrantLock 差很多。具体表示为:synchronized 关键字吞吐量随线程数的增加,下降得非常严重。而ReenTrantLock 基本保持一个比较稳定的水平。我觉得这也侧面反映了, synchronized 关键字还有非常大的优化余地。后续的技术发展也证明了这一点,我们上面也讲了在 JDK1.6 之后 JVM 团队对 synchronized 关键字做了很多优化。**JDK1.6 之后,synchronized 和 ReenTrantLock 的性能基本是持平了。所以网上那些说因为性能才选择 ReenTrantLock 的文章都是错的!JDK1.6之后,性能已经不是选择synchronized和ReenTrantLock的影响因素了!而且虚拟机在未来的性能改进中会更偏向于原生的synchronized,所以还是提倡在synchronized能满足你的需求的情况下,优先考虑使用synchronized关键字来进行同步!优化后的synchronized和ReenTrantLock一样,在很多地方都是用到了CAS操作**。
diff --git a/docs/java/Multithread/synchronized在JDK1.6之后的底层优化.md b/docs/java/Multithread/synchronized在JDK1.6之后的底层优化.md
new file mode 100644
index 00000000..d8e454de
--- /dev/null
+++ b/docs/java/Multithread/synchronized在JDK1.6之后的底层优化.md
@@ -0,0 +1,62 @@
+JDK1.6 对锁的实现引入了大量的优化来减少锁操作的开销,如: **偏向锁**、**轻量级锁**、**自旋锁**、**适应性自旋锁**、**锁消除**、**锁粗化** 等等技术。
+
+锁主要存在四中状态,依次是:
+
+1. 无锁状态
+2. 偏向锁状态
+3. 轻量级锁状态
+4. 重量级锁状态
+
+锁🔐会随着竞争的激烈而逐渐升级。
+
+另外,需要注意:**锁可以升级不可降级,即 无锁 -> 偏向锁 -> 轻量级锁 -> 重量级锁是单向的。** 这种策略是为了提高获得锁和释放锁的效率。
+
+### 偏向锁
+
+**引入偏向锁的目的和引入轻量级锁的目的很像,他们都是为了没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗。但是不同是:轻量级锁在无竞争的情况下使用 CAS 操作去代替使用互斥量。而偏向锁在无竞争的情况下会把整个同步都消除掉**。
+
+偏向锁的“偏”就是偏心的偏,它的意思是会偏向于第一个获得它的线程,如果在接下来的执行中,该锁没有被其他线程获取,那么持有偏向锁的线程就不需要进行同步!(关于偏向锁的原理可以查看《深入理解Java虚拟机:JVM高级特性与最佳实践》第二版的13章第三节锁优化。)
+
+#### 偏向锁的加锁
+
+当一个线程访问同步块并获取锁时, 会在锁对象的对象头和栈帧中的锁记录里存储锁偏向的线程ID, 以后该线程进入和退出同步块时不需要进行CAS操作来加锁和解锁, 只需要简单的测试一下锁对象的对象头的MarkWord里是否存储着指向当前线程的偏向锁(线程ID是当前线程), 如果测试成功, 表示线程已经获得了锁; 如果测试失败, 则需要再测试一下MarkWord中偏向锁的标识是否设置成1(表示当前是偏向锁), 如果没有设置, 则使用CAS竞争锁, 如果设置了, 则尝试使用CAS将锁对象的对象头的偏向锁指向当前线程.
+
+#### 偏向锁的撤销
+
+偏向锁使用了一种等到竞争出现才释放锁的机制, 所以当其他线程尝试竞争偏向锁时, 持有偏向锁的线程才会释放锁. 偏向锁的撤销需要等到全局安全点(在这个时间点上没有正在执行的字节码). 首先会暂停持有偏向锁的线程, 然后检查持有偏向锁的线程是否存活, 如果线程不处于活动状态, 则将锁对象的对象头设置为无锁状态; 如果线程仍然活着, 则锁对象的对象头中的MarkWord和栈中的锁记录要么重新偏向于其它线程要么恢复到无锁状态, 最后唤醒暂停的线程(释放偏向锁的线程).
+
+但是对于锁竞争比较激烈的场合,偏向锁就失效了,因为这样场合极有可能每次申请锁的线程都是不相同的,因此这种场合下不应该使用偏向锁,否则会得不偿失,需要注意的是,偏向锁失败后,并不会立即膨胀为重量级锁,而是先升级为轻量级锁。
+
+### 轻量级锁
+
+倘若偏向锁失败,虚拟机并不会立即升级为重量级锁,它还会尝试使用一种称为轻量级锁的优化手段(1.6之后加入的)。**轻量级锁不是为了代替重量级锁,它的本意是在没有多线程竞争的前提下,减少传统的重量级锁使用操作系统互斥量产生的性能消耗,因为使用轻量级锁时,不需要申请互斥量。另外,轻量级锁的加锁和解锁都用到了CAS操作。** 关于轻量级锁的加锁和解锁的原理可以查看《深入理解Java虚拟机:JVM高级特性与最佳实践》第二版的13章第三节锁优化。
+
+**轻量级锁能够提升程序同步性能的依据是“对于绝大部分锁,在整个同步周期内都是不存在竞争的”,这是一个经验数据。如果没有竞争,轻量级锁使用 CAS 操作避免了使用互斥操作的开销。但如果存在锁竞争,除了互斥量开销外,还会额外发生CAS操作,因此在有锁竞争的情况下,轻量级锁比传统的重量级锁更慢!如果锁竞争激烈,那么轻量级将很快膨胀为重量级锁!**
+
+### 自旋锁和自适应自旋
+
+轻量级锁失败后,虚拟机为了避免线程真实地在操作系统层面挂起,还会进行一项称为自旋锁的优化手段。
+
+互斥同步对性能最大的影响就是阻塞的实现,因为挂起线程/恢复线程的操作都需要转入内核态中完成(用户态转换到内核态会耗费时间)。
+
+**一般线程持有锁的时间都不是太长,所以仅仅为了这一点时间去挂起线程/恢复线程是得不偿失的。** 所以,虚拟机的开发团队就这样去考虑:“我们能不能让后面来的请求获取锁的线程等待一会而不被挂起呢?看看持有锁的线程是否很快就会释放锁”。**为了让一个线程等待,我们只需要让线程执行一个忙循环(自旋),这项技术就叫做自旋**。
+
+百度百科对自旋锁的解释:
+
+> 何谓自旋锁?它是为实现保护共享资源而提出一种锁机制。其实,自旋锁与互斥锁比较类似,它们都是为了解决对某项资源的互斥使用。无论是互斥锁,还是自旋锁,在任何时刻,最多只能有一个保持者,也就说,在任何时刻最多只能有一个执行单元获得锁。但是两者在调度机制上略有不同。对于互斥锁,如果资源已经被占用,资源申请者只能进入睡眠状态。但是自旋锁不会引起调用者睡眠,如果自旋锁已经被别的执行单元保持,调用者就一直循环在那里看是否该自旋锁的保持者已经释放了锁,"自旋"一词就是因此而得名。
+
+自旋锁在 JDK1.6 之前其实就已经引入了,不过是默认关闭的,需要通过`--XX:+UseSpinning`参数来开启。JDK1.6及1.6之后,就改为默认开启的了。需要注意的是:自旋等待不能完全替代阻塞,因为它还是要占用处理器时间。如果锁被占用的时间短,那么效果当然就很好了!反之,相反!自旋等待的时间必须要有限度。如果自旋超过了限定次数任然没有获得锁,就应该挂起线程。**自旋次数的默认值是10次,用户可以修改`--XX:PreBlockSpin`来更改**。
+
+另外,**在 JDK1.6 中引入了自适应的自旋锁。自适应的自旋锁带来的改进就是:自旋的时间不在固定了,而是和前一次同一个锁上的自旋时间以及锁的拥有者的状态来决定,虚拟机变得越来越“聪明”了**。
+
+### 锁消除
+
+锁消除理解起来很简单,它指的就是虚拟机即使编译器在运行时,如果检测到那些共享数据不可能存在竞争,那么就执行锁消除。锁消除可以节省毫无意义的请求锁的时间。
+
+### 锁粗化
+
+原则上,我们在编写代码的时候,总是推荐将同步块的作用范围限制得尽量小,——直在共享数据的实际作用域才进行同步,这样是为了使得需要同步的操作数量尽可能变小,如果存在锁竞争,那等待线程也能尽快拿到锁。
+
+大部分情况下,上面的原则都是没有问题的,但是如果一系列的连续操作都对同一个对象反复加锁和解锁,那么会带来很多不必要的性能消耗。
+
+
diff --git a/docs/java/Multithread/创建线程的几种方式总结.md b/docs/java/Multithread/创建线程的几种方式总结.md
new file mode 100644
index 00000000..764a63a4
--- /dev/null
+++ b/docs/java/Multithread/创建线程的几种方式总结.md
@@ -0,0 +1,40 @@
+## 面试官:“创建线程有哪几种常见的方式?”
+
+1. 继承 Thread 类
+2. 实现 Runnable 接口
+3. 使用 Executor 框架
+4. 使用 FutureTask
+
+## 最简单的两种方式
+
+### 1.继承 Thread 类
+
+
+
+
+
+### 2.实现 Runnable 接口
+
+## 比较实用的两种方式
+
+### 3.使用 Executor 框架
+
+Executor 框架是 Java5 之后引进的,在 Java 5 之后,通过 Executor 来启动线程比使用 Thread 的 start 方法更好,除了更易管理,效率更好(用线程池实现,节约开销)外,还有关键的一点:有助于避免 this 逃逸问题。
+
+> 补充:this 逃逸是指在构造函数返回之前其他线程就持有该对象的引用. 调用尚未构造完全的对象的方法可能引发令人疑惑的错误。
+
+Executor 框架不仅包括了线程池的管理,还提供了线程工厂、队列以及拒绝策略等,Executor 框架让并发编程变得更加简单。
+
+为了能搞懂如何使用 Executor 框架创建
+
+### Executor 框架结构(主要由三大部分组成)
+
+#### 1) 任务(`Runnable` /`Callable`)
+
+执行任务需要实现的 **`Runnable` 接口** 或 **`Callable`接口**。**`Runnable` 接口**或 **`Callable` 接口** 实现类都可以被 **`ThreadPoolExecutor`** 或 **`ScheduledThreadPoolExecutor`** 执行。
+
+#### 2) 任务的执行(`Executor`)
+
+如下图所示,包括任务执行机制的核心接口 **`Executor`** ,以及继承自 `Executor` 接口的 **`ExecutorService` 接口。`ThreadPoolExecutor`** 和 **`ScheduledThreadPoolExecutor`** 这两个关键类实现了 **ExecutorService 接口**。
+
+### 4.使用 FutureTask
\ No newline at end of file
diff --git a/docs/java/Multithread/多线程学习指南.md b/docs/java/Multithread/多线程学习指南.md
new file mode 100644
index 00000000..84830521
--- /dev/null
+++ b/docs/java/Multithread/多线程学习指南.md
@@ -0,0 +1,158 @@
+## 前言
+
+这是我的第二篇专门介绍如何去学习某个知识点的文章,在上一篇[《写给 Java 程序员看的算法学习指南!》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486508&idx=1&sn=ce2faafcde166d5412d7166a01fdc1e9&chksm=cea243e7f9d5caf1dbf4d6ccf0438a1731bc0070310bba1ac481d485e4a6756349c20f02a6b1&token=211950660&lang=zh_CN#rd) 的文章中,我推荐了一些关于 **算法学习的书籍以及资源** 。
+
+相比于写技术文章来说,写这种这种类型的文章实际花费的时间可能会稍微少一点。但是,这种学习指南形式的文章,我想对于 Java 初学者甚至是工作几年的 Java 工程师来说应该还是非常有帮助的!
+
+我们都知道多线程应该是大部分 Java 程序员最难啃的一块骨头之一,这部分内容的难度跨度大,难实践,并且市面上的参考资料的质量也层次不齐。
+
+在这篇文章中,我会首先介绍一下 **Java 多线程学习** 中比较重要的一些问题,然后还会推荐一些比较不错的学习资源供大家参考。希望对你们学习多线程相关的知识能有帮助。以下介绍的很多知识点你都可以在这里找到:[https://snailclimb.gitee.io/javaguide/#/?id=并发](https://snailclimb.gitee.io/javaguide/#/?id=并发)
+
+
+
+**另外,我还将本文的内容同步到了 Github 上,点击阅读原文即可直达。如果你觉得有任何需要完善和修改的地方,都可以去 Github 给我提交 Issue 或者 PR(推荐)。**
+
+## 一.Java 多线程知识点总结
+
+### 1.1.多线程基础
+
+1. 什么是线程和进程? 线程与进程的关系,区别及优缺点?
+2. 说说并发与并行的区别?
+3. 为什么要使用多线程呢?
+4. 使用多线程可能带来什么问题?(内存泄漏、死锁、线程不安全等等)
+5. 创建线程有哪几种方式?(a.继承 Thread 类;b.实现 Runnable 接口;c. 使用 Executor 框架;d.使用 FutureTask)
+6. 说说线程的生命周期和状态?
+7. 什么是上下文切换?
+8. 什么是线程死锁?如何避免死锁?
+9. 说说 sleep() 方法和 wait() 方法区别和共同点?
+10. 为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?
+11. ......
+
+### 1.2.多线程知识进阶
+
+#### volatile 关键字
+
+1. Java 内存模型(**JMM**);
+2. 重排序与 happens-before 原则了解吗?
+3. volatile 关键字的作用;
+4. 说说 synchronized 关键字和 volatile 关键字的区别;
+5. ......
+
+#### ThreadLocal
+
+1. 有啥用(解决了什么问题)?怎么用?
+2. 原理了解吗?
+3. 内存泄露问题了解吗?
+
+#### 线程池
+
+1. 为什么要用线程池?
+2. 你会使用线程池吗?
+3. 如何创建线程池比较好? (推荐使用 `ThreadPoolExecutor` 构造函数创建线程池)
+4. `ThreadPoolExecutor` 类的重要参数了解吗?`ThreadPoolExecutor` 饱和策略了解吗?
+5. 线程池原理了解吗?
+6. 几种常见的线程池了解吗?为什么不推荐使用`FixedThreadPool`?
+7. 如何设置线程池的大小?
+8. ......
+
+#### AQS
+
+1. 简介
+2. 原理
+3. AQS 常用组件。
+ - **Semaphore(信号量)**-允许多个线程同时访问
+ - **CountDownLatch (倒计时器)**-CountDownLatch 允许 count 个线程阻塞在一个地方,直至所有线程的任务都执行完毕。
+ - **CyclicBarrier(循环栅栏)**-CyclicBarrier 和 CountDownLatch 非常类似,它也可以实现线程间的技术等待,但是它的功能比 CountDownLatch 更加复杂和强大。主要应用场景和 CountDownLatch 类似。
+ - **ReentrantLock 和 ReentrantReadWriteLock**
+ - ......
+
+#### 锁
+
+锁的常见分类
+
+1. 可重入锁和非可重入锁
+2. 公平锁与非公平锁
+3. 读写锁和排它锁
+
+**synchronized 关键字**
+
+1. 说一说自己对于 synchronized 关键字的了解;
+2. 说说自己是怎么使用 synchronized 关键字,在项目中用到了吗;
+3. 讲一下 synchronized 关键字的底层原理;
+4. 说说 JDK1.6 之后的 synchronized 关键字底层做了哪些优化,可以详细介绍一下这些优化吗;
+5. 谈谈 synchronized 和 ReentrantLock 的区别;
+6. ......
+
+**ReentrantLock 和 ReentrantReadWriteLock**
+
+**ReadWriteLock**
+
+**StampedLock(JDK8)**
+
+#### **Atomic 与 CAS**
+
+**CAS:**
+
+1. 介绍
+2. 原理
+
+**Atomic 原子类:**
+
+1. 介绍一下 Atomic 原子类;
+2. JUC 包中的原子类是哪 4 类?;
+3. 讲讲 AtomicInteger 的使用;
+4. 能不能给我简单介绍一下 AtomicInteger 类的原理。
+5. ......
+
+#### 并发容器
+
+JDK 提供的这些容器大部分在 `java.util.concurrent` 包中。
+
+- **ConcurrentHashMap:** 线程安全的 HashMap
+- **CopyOnWriteArrayList:** 线程安全的 List,在读多写少的场合性能非常好,远远好于 Vector.
+- **ConcurrentLinkedQueue:** 高效的并发队列,使用链表实现。可以看做一个线程安全的 LinkedList,这是一个非阻塞队列。
+- **BlockingQueue:** 这是一个接口,JDK 内部通过链表、数组等方式实现了这个接口。表示阻塞队列,非常适合用于作为数据共享的通道。
+- **ConcurrentSkipListMap:** 跳表的实现。这是一个 Map,使用跳表的数据结构进行快速查找。
+- ......
+
+#### Future 和 CompletableFuture
+
+## 二.书籍推荐
+
+#### 《Java 并发编程之美》
+
+
+
+**我觉得这本书还是非常适合我们用来学习 Java 多线程的。这本书的讲解非常通俗易懂,作者从并发编程基础到实战都是信手拈来。**
+
+另外,这本书的作者加多自身也会经常在网上发布各种技术文章。我觉得这本书也是加多大佬这么多年在多线程领域的沉淀所得的结果吧!他书中的内容基本都是结合代码讲解,非常有说服力!
+
+#### 《实战 Java 高并发程序设计》
+
+
+
+这个是我第二本要推荐的书籍,比较适合作为多线程入门/进阶书籍来看。这本书内容同样是理论结合实战,对于每个知识点的讲解也比较通俗易懂,整体结构也比较清。
+
+#### 《深入浅出 Java 多线程》
+
+
+
+这本书是几位大厂(如阿里)的大佬开源的,Github 地址:[https://github.com/RedSpider1/concurrent](https://github.com/RedSpider1/concurrent)
+
+几位作者为了写好《深入浅出 Java 多线程》这本书阅读了大量的 Java 多线程方面的书籍和博客,然后再加上他们的经验总结、Demo 实例、源码解析,最终才形成了这本书。
+
+这本书的质量也是非常过硬!给作者们点个赞!这本书有统一的排版规则和语言风格、清晰的表达方式和逻辑。并且每篇文章初稿写完后,作者们就会互相审校,合并到主分支时所有成员会再次审校,最后再通篇修订了三遍。
+
+#### 《Java 并发编程的艺术》
+
+
+
+这本书不是很适合作为 Java 多线程入门书籍,需要具备一定的 JVM 基础,有些东西讲的还是挺深入的。另外,就我自己阅读这本书的感觉来说,我觉得这本书的章节规划有点杂乱,但是,具体到某个知识点又很棒!这可能也和这本书由三名作者共同编写完成有关系吧!
+
+**综上:这本书并不是和 Java 多线程入门,你也不需要把这本书的每一章节都看一遍,建议挑选自己想要详细了解的知识点来看。**
+
+## 三.总结
+
+在这篇文章中我主要总结了 Java 多线程方面的知识点,并且推荐了相关的书籍。并发这部分东西实战的话比较难,你可以尝试学会了某个知识点之后然后在自己写过的一些项目上实践。另外,leetcode 有一个练习多线程的类别: [https://leetcode-cn.com/problemset/concurrency](https://leetcode-cn.com/problemset/concurrency) 可以作为参考。
+
+**为了这篇文章的内容更加完善,我还将本文的内容同步到了 Github 上,点击阅读原文即可直达。如果你觉得有任何需要完善和修改的地方,都可以去 Github 给我提交 Issue 或者 PR(推荐)。**
\ No newline at end of file
diff --git a/docs/java/Multithread/并发编程基础知识.md b/docs/java/Multithread/并发编程基础知识.md
deleted file mode 100644
index 68509cdc..00000000
--- a/docs/java/Multithread/并发编程基础知识.md
+++ /dev/null
@@ -1,407 +0,0 @@
-# Java 并发基础知识
-
-Java 并发的基础知识,可能会在笔试中遇到,技术面试中也可能以并发知识环节提问的第一个问题出现。比如面试官可能会问你:“谈谈自己对于进程和线程的理解,两者的区别是什么?”
-
-**本节思维导图:**
-
-## 一 进程和线程
-
-进程和线程的对比这一知识点由于过于基础,所以在面试中很少碰到,但是极有可能会在笔试题中碰到。
-
-常见的提问形式是这样的:**“什么是线程和进程?,请简要描述线程与进程的关系、区别及优缺点? ”**。
-
-### 1.1. 何为进程?
-
-进程是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。
-
-在 Java 中,当我们启动 main 函数时其实就是启动了一个 JVM 的进程,而 main 函数所在的线程就是这个进程中的一个线程,也称主线程。
-
-如下图所示,在 windows 中通过查看任务管理器的方式,我们就可以清楚看到 window 当前运行的进程(.exe 文件的运行)。
-
-
-
-### 1.2 何为线程?
-
-线程与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享进程的**堆**和**方法区**资源,但每个线程有自己的**程序计数器**、**虚拟机栈**和**本地方法栈**,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
-
-Java 程序天生就是多线程程序,我们可以通过 JMX 来看一下一个普通的 Java 程序有哪些线程,代码如下。
-
-```java
-public class MultiThread {
- public static void main(String[] args) {
- // 获取 Java 线程管理 MXBean
- ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
- // 不需要获取同步的 monitor 和 synchronizer 信息,仅获取线程和线程堆栈信息
- ThreadInfo[] threadInfos = threadMXBean.dumpAllThreads(false, false);
- // 遍历线程信息,仅打印线程 ID 和线程名称信息
- for (ThreadInfo threadInfo : threadInfos) {
- System.out.println("[" + threadInfo.getThreadId() + "] " + threadInfo.getThreadName());
- }
- }
-}
-```
-
-上述程序输出如下(输出内容可能不同,不用太纠结下面每个线程的作用,只用知道 main 线程执行 main 方法即可):
-
-```
-[5] Attach Listener //添加事件
-[4] Signal Dispatcher // 分发处理给 JVM 信号的线程
-[3] Finalizer //调用对象 finalize 方法的线程
-[2] Reference Handler //清除 reference 线程
-[1] main //main 线程,程序入口
-```
-
-从上面的输出内容可以看出:**一个 Java 程序的运行是 main 线程和多个其他线程同时运行**。
-
-### 1.3 从 JVM 角度说进程和线程之间的关系(重要)
-
-#### 1.3.1 图解进程和线程的关系
-
-下图是 Java 内存区域,通过下图我们从 JVM 的角度来说一下线程和进程之间的关系。如果你对 Java 内存区域 (运行时数据区) 这部分知识不太了解的话可以阅读一下我的这篇文章:[《可能是把 Java 内存区域讲的最清楚的一篇文章》]()
-
-
-
-
isEmpty = String::isEmpty;
Predicate isNotEmpty = isEmpty.negate();
```
-#### Functions
+#### Function
Function 接口接受一个参数并生成结果。默认方法可用于将多个函数链接在一起(compose, andThen):
@@ -382,7 +382,7 @@ Function backToString = toInteger.andThen(String::valueOf);
backToString.apply("123"); // "123"
```
-#### Suppliers
+#### Supplier
Supplier 接口产生给定泛型类型的结果。 与 Function 接口不同,Supplier 接口不接受参数。
@@ -391,7 +391,7 @@ Supplier personSupplier = Person::new;
personSupplier.get(); // new Person
```
-#### Consumers
+#### Consumer
Consumer 接口表示要对单个输入参数执行的操作。
@@ -400,7 +400,7 @@ Consumer greeter = (p) -> System.out.println("Hello, " + p.firstName);
greeter.accept(new Person("Luke", "Skywalker"));
```
-#### Comparators
+#### Comparator
Comparator 是老Java中的经典接口, Java 8在此之上添加了多种默认方法:
@@ -414,9 +414,9 @@ comparator.compare(p1, p2); // > 0
comparator.reversed().compare(p1, p2); // < 0
```
-## Optionals
+## Optional
-Optionals不是函数式接口,而是用于防止 NullPointerException 的漂亮工具。这是下一节的一个重要概念,让我们快速了解一下Optionals的工作原理。
+Optional不是函数式接口,而是用于防止 NullPointerException 的漂亮工具。这是下一节的一个重要概念,让我们快速了解一下Optional的工作原理。
Optional 是一个简单的容器,其值可能是null或者不是null。在Java 8之前一般某个函数应该返回非空对象但是有时却什么也没有返回,而在Java 8中,你应该返回 Optional 而不是 null。
diff --git a/docs/java/Basis/Arrays,CollectionsCommonMethods.md b/docs/java/basic/Arrays,CollectionsCommonMethods.md
similarity index 100%
rename from docs/java/Basis/Arrays,CollectionsCommonMethods.md
rename to docs/java/basic/Arrays,CollectionsCommonMethods.md
diff --git a/docs/java/Basis/final、static、this、super.md b/docs/java/basic/final,static,this,super.md
similarity index 70%
rename from docs/java/Basis/final、static、this、super.md
rename to docs/java/basic/final,static,this,super.md
index 77e8b094..d9eaf1a8 100644
--- a/docs/java/Basis/final、static、this、super.md
+++ b/docs/java/basic/final,static,this,super.md
@@ -23,13 +23,15 @@
## final 关键字
-**final关键字主要用在三个地方:变量、方法、类。**
+**final关键字,意思是最终的、不可修改的,最见不得变化 ,用来修饰类、方法和变量,具有以下特点:**
-1. **对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。**
+1. **final修饰的类不能被继承,final类中的所有成员方法都会被隐式的指定为final方法;**
-2. **当用final修饰一个类时,表明这个类不能被继承。final类中的所有成员方法都会被隐式地指定为final方法。**
+2. **final修饰的方法不能被重写;**
-3. 使用final方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。在早期的Java实现版本中,会将final方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何性能提升(现在的Java版本已经不需要使用final方法进行这些优化了)。类中所有的private方法都隐式地指定为final。
+3. **final修饰的变量是常量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能让其指向另一个对象。**
+
+说明:使用final方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。在早期的Java实现版本中,会将final方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何性能提升(现在的Java版本已经不需要使用final方法进行这些优化了)。类中所有的private方法都隐式地指定为final。
## static 关键字
@@ -90,7 +92,7 @@ public class Sub extends Super {
**使用 this 和 super 要注意的问题:**
-- 在构造器中使用 `super()` 调用父类中的其他构造方法时,该语句必须处于构造器的首行,否则编译器会报错。另外,this 调用本类中的其他构造方法时,也要放在首行。
+- 在构造器中使用 `super()` 调用父类中的其他构造方法时,该语句必须处于构造器的首行,否则编译器会报错。另外,this 调用本类中的其他构造方法时,也要放在首行。
- this、super不能用在static方法中。
**简单解释一下:**
@@ -121,8 +123,8 @@ public class Sub extends Super {
调用格式:
-- 类名.静态变量名
-- 类名.静态方法名()
+- `类名.静态变量名`
+- `类名.静态方法名()`
如果变量或者方法被 private 则代表该属性或者该方法只能在类的内部被访问而不能在类的外部被访问。
@@ -132,21 +134,21 @@ public class Sub extends Super {
public class StaticBean {
String name;
- 静态变量
+ //静态变量
static int age;
public StaticBean(String name) {
this.name = name;
}
- 静态方法
- static void SayHello() {
- System.out.println(Hello i am java);
+ //静态方法
+ static void sayHello() {
+ System.out.println("Hello i am java");
}
@Override
public String toString() {
- return StaticBean{ +
- name=' + name + ''' + age + age +
- '}';
+ return "StaticBean{"+
+ "name=" + name + ",age=" + age +
+ "}";
}
}
```
@@ -155,14 +157,14 @@ public class StaticBean {
public class StaticDemo {
public static void main(String[] args) {
- StaticBean staticBean = new StaticBean(1);
- StaticBean staticBean2 = new StaticBean(2);
- StaticBean staticBean3 = new StaticBean(3);
- StaticBean staticBean4 = new StaticBean(4);
+ StaticBean staticBean = new StaticBean("1");
+ StaticBean staticBean2 = new StaticBean("2");
+ StaticBean staticBean3 = new StaticBean("3");
+ StaticBean staticBean4 = new StaticBean("4");
StaticBean.age = 33;
- StaticBean{name='1'age33} StaticBean{name='2'age33} StaticBean{name='3'age33} StaticBean{name='4'age33}
- System.out.println(staticBean+ +staticBean2+ +staticBean3+ +staticBean4);
- StaticBean.SayHello();Hello i am java
+ System.out.println(staticBean + " " + staticBean2 + " " + staticBean3 + " " + staticBean4);
+ //StaticBean{name=1,age=33} StaticBean{name=2,age=33} StaticBean{name=3,age=33} StaticBean{name=4,age=33}
+ StaticBean.sayHello();//Hello i am java
}
}
@@ -171,7 +173,7 @@ public class StaticDemo {
### 静态代码块
-静态代码块定义在类中方法外, 静态代码块在非静态代码块之前执行(静态代码块—非静态代码块—构造方法)。 该类不管创建多少对象,静态代码块只执行一次.
+静态代码块定义在类中方法外, 静态代码块在非静态代码块之前执行(静态代码块 —> 非静态代码块 —> 构造方法)。 该类不管创建多少对象,静态代码块只执行一次.
静态代码块的格式是
@@ -202,11 +204,11 @@ Example(静态内部类实现单例模式)
```java
public class Singleton {
- 声明为 private 避免调用默认构造方法创建对象
+ //声明为 private 避免调用默认构造方法创建对象
private Singleton() {
}
- 声明为 private 表明静态内部该类只能在该 Singleton 类中被访问
+ // 声明为 private 表明静态内部该类只能在该 Singleton 类中被访问
private static class SingletonHolder {
private static final Singleton INSTANCE = new Singleton();
}
@@ -230,12 +232,10 @@ public class Singleton {
```java
- Math. --- 将Math中的所有静态资源导入,这时候可以直接使用里面的静态方法,而不用通过类名进行调用
- 如果只想导入单一某个静态方法,只需要将换成对应的方法名即可
+ //将Math中的所有静态资源导入,这时候可以直接使用里面的静态方法,而不用通过类名进行调用
+ //如果只想导入单一某个静态方法,只需要将换成对应的方法名即可
-import static java.lang.Math.;
-
- 换成import static java.lang.Math.max;具有一样的效果
+import static java.lang.Math.*;//换成import static java.lang.Math.max;具有一样的效果
public class Demo {
public static void main(String[] args) {
@@ -264,69 +264,83 @@ class Foo {
}
public static String method1() {
- return An example string that doesn't depend on i (an instance variable);
+ return "An example string that doesn't depend on i (an instance variable)";
}
public int method2() {
- return this.i + 1; Depends on i
+ return this.i + 1; //Depends on i
}
}
```
-你可以像这样调用静态方法:`Foo.method1()`。 如果您尝试使用这种方法调用 method2 将失败。 但这样可行:`Foo bar = new Foo(1);bar.method2();`
+你可以像这样调用静态方法:`Foo.method1()`。 如果您尝试使用这种方法调用 method2 将失败。 但这样可行
+``` java
+Foo bar = new Foo(1);
+bar.method2();
+```
总结:
- 在外部调用静态方法时,可以使用”类名.方法名”的方式,也可以使用”对象名.方法名”的方式。而实例方法只有后面这种方式。也就是说,调用静态方法可以无需创建对象。
- 静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),而不允许访问实例成员变量和实例方法;实例方法则无此限制
-### static{}静态代码块与{}非静态代码块(构造代码块)
+### `static{}`静态代码块与`{}`非静态代码块(构造代码块)
相同点: 都是在JVM加载类时且在构造方法执行之前执行,在类中都可以定义多个,定义多个时按定义的顺序执行,一般在代码块中对一些static变量进行赋值。
-不同点: 静态代码块在非静态代码块之前执行(静态代码块—非静态代码块—构造方法)。静态代码块只在第一次new执行一次,之后不再执行,而非静态代码块在每new一次就执行一次。 非静态代码块可在普通方法中定义(不过作用不大);而静态代码块不行。
+不同点: 静态代码块在非静态代码块之前执行(静态代码块 -> 非静态代码块 -> 构造方法)。静态代码块只在第一次new执行一次,之后不再执行,而非静态代码块在每new一次就执行一次。 非静态代码块可在普通方法中定义(不过作用不大);而静态代码块不行。
+
+> 修正 [issue #677](https://github.com/Snailclimb/JavaGuide/issues/677):静态代码块可能在第一次new的时候执行,但不一定只在第一次new的时候执行。比如通过 `Class.forName("ClassDemo")`创建 Class 对象的时候也会执行。
一般情况下,如果有些代码比如一些项目最常用的变量或对象必须在项目启动的时候就执行的时候,需要使用静态代码块,这种代码是主动执行的。如果我们想要设计不需要创建对象就可以调用类中的方法,例如:Arrays类,Character类,String类等,就需要使用静态方法, 两者的区别是 静态代码块是自动执行的而静态方法是被调用的时候才执行的.
-Example
+Example:
```java
public class Test {
public Test() {
- System.out.print(默认构造方法!--);
+ System.out.print("默认构造方法!--");
}
- 非静态代码块
+ //非静态代码块
{
- System.out.print(非静态代码块!--);
- }
- 静态代码块
- static {
- System.out.print(静态代码块!--);
+ System.out.print("非静态代码块!--");
}
- public static void test() {
- System.out.print(静态方法中的内容! --);
+ //静态代码块
+ static {
+ System.out.print("静态代码块!--");
+ }
+
+ private static void test() {
+ System.out.print("静态方法中的内容! --");
{
- System.out.print(静态方法中的代码块!--);
+ System.out.print("静态方法中的代码块!--");
}
}
- public static void main(String[] args) {
- Test test = new Test();
- Test.test();静态代码块!--静态方法中的内容! --静态方法中的代码块!--
+ public static void main(String[] args) {
+ Test test = new Test();
+ Test.test();//静态代码块!--静态方法中的内容! --静态方法中的代码块!--
}
+}
```
-当执行 `Test.test();` 时输出:
+上述代码输出:
+
+```
+静态代码块!--非静态代码块!--默认构造方法!--静态方法中的内容! --静态方法中的代码块!--
+```
+
+当只执行 `Test.test();` 时输出:
```
静态代码块!--静态方法中的内容! --静态方法中的代码块!--
```
-当执行 `Test test = new Test();` 时输出:
+当只执行 `Test test = new Test();` 时输出:
```
静态代码块!--非静态代码块!--默认构造方法!--
@@ -337,6 +351,6 @@ public class Test {
### 参考
-- httpsblog.csdn.netchen13579867831articledetails78995480
-- httpwww.cnblogs.comchenssyp3388487.html
-- httpwww.cnblogs.comQian123p5713440.html
+- https://blog.csdn.net/chen13579867831/article/details/78995480
+- https://www.cnblogs.com/chenssy/p/3388487.html
+- https://www.cnblogs.com/Qian123/p/5713440.html
diff --git a/docs/java/basic/java-proxy.md b/docs/java/basic/java-proxy.md
new file mode 100644
index 00000000..c35c8b14
--- /dev/null
+++ b/docs/java/basic/java-proxy.md
@@ -0,0 +1,420 @@
+> 本文首更于[《从零开始手把手教你实现一个简单的RPC框架》](https://t.zsxq.com/iIUv7Mn) 。
+
+
+
+
+
+- [1. 代理模式](#1-代理模式)
+- [2. 静态代理](#2-静态代理)
+- [3. 动态代理](#3-动态代理)
+ - [3.1. JDK 动态代理机制](#31-jdk-动态代理机制)
+ - [3.1.1. 介绍](#311-介绍)
+ - [3.1.2. JDK 动态代理类使用步骤](#312-jdk-动态代理类使用步骤)
+ - [3.1.3. 代码示例](#313-代码示例)
+ - [3.2. CGLIB 动态代理机制](#32-cglib-动态代理机制)
+ - [3.2.1. 介绍](#321-介绍)
+ - [3.2.2. CGLIB 动态代理类使用步骤](#322-cglib-动态代理类使用步骤)
+ - [3.2.3. 代码示例](#323-代码示例)
+ - [3.3. JDK 动态代理和 CGLIB 动态代理对比](#33-jdk-动态代理和-cglib-动态代理对比)
+- [4. 静态代理和动态代理的对比](#4-静态代理和动态代理的对比)
+- [5. 总结](#5-总结)
+
+
+
+
+## 1. 代理模式
+
+代理模式是一种比较好的理解的设计模式。简单来说就是 **我们使用代理对象来代替对真实对象(real object)的访问,这样就可以在不修改原目标对象的前提下,提供额外的功能操作,扩展目标对象的功能。**
+
+**代理模式的主要作用是扩展目标对象的功能,比如说在目标对象的某个方法执行前后你可以增加一些自定义的操作。**
+
+举个例子:你的找了一小红来帮你问话,小红就看作是代理我的代理对象,代理的行为(方法)是问话。
+
+
+
+https://medium.com/@mithunsasidharan/understanding-the-proxy-design-pattern-5e63fe38052a
+
+代理模式有静态代理和动态代理两种实现方式,我们 先来看一下静态代理模式的实现。
+
+## 2. 静态代理
+
+**静态代理中,我们对目标对象的每个方法的增强都是手动完成的(_后面会具体演示代码_),非常不灵活(_比如接口一旦新增加方法,目标对象和代理对象都要进行修改_)且麻烦(_需要对每个目标类都单独写一个代理类_)。** 实际应用场景非常非常少,日常开发几乎看不到使用静态代理的场景。
+
+上面我们是从实现和应用角度来说的静态代理,从 JVM 层面来说, **静态代理在编译时就将接口、实现类、代理类这些都变成了一个个实际的 class 文件。**
+
+静态代理实现步骤:
+
+1. 定义一个接口及其实现类;
+2. 创建一个代理类同样实现这个接口
+3. 将目标对象注注入进代理类,然后在代理类的对应方法调用目标类中的对应方法。这样的话,我们就可以通过代理类屏蔽对目标对象的访问,并且可以在目标方法执行前后做一些自己想做的事情。
+
+下面通过代码展示!
+
+**1.定义发送短信的接口**
+
+```java
+public interface SmsService {
+ String send(String message);
+}
+```
+
+**2.实现发送短信的接口**
+
+```java
+public class SmsServiceImpl implements SmsService {
+ public String send(String message) {
+ System.out.println("send message:" + message);
+ return message;
+ }
+}
+```
+
+**3.创建代理类并同样实现发送短信的接口**
+
+```java
+public class SmsProxy implements SmsService {
+
+ private final SmsService smsService;
+
+ public SmsProxy(SmsService smsService) {
+ this.smsService = smsService;
+ }
+
+ @Override
+ public String send(String message) {
+ //调用方法之前,我们可以添加自己的操作
+ System.out.println("before method send()");
+ smsService.send(message);
+ //调用方法之后,我们同样可以添加自己的操作
+ System.out.println("after method send()");
+ return null;
+ }
+}
+```
+
+**4.实际使用**
+
+```java
+public class Main {
+ public static void main(String[] args) {
+ SmsService smsService = new SmsServiceImpl();
+ SmsProxy smsProxy = new SmsProxy(smsService);
+ smsProxy.send("java");
+ }
+}
+```
+
+运行上述代码之后,控制台打印出:
+
+```bash
+before method send()
+send message:java
+after method send()
+```
+
+可以输出结果看出,我们已经增加了 `SmsServiceImpl` 的`send()`方法。
+
+## 3. 动态代理
+
+相比于静态代理来说,动态代理更加灵活。我们不需要针对每个目标类都单独创建一个代理类,并且也不需要我们必须实现接口,我们可以直接代理实现类( _CGLIB 动态代理机制_)。
+
+**从 JVM 角度来说,动态代理是在运行时动态生成类字节码,并加载到 JVM 中的。**
+
+说到动态代理,Spring AOP、RPC 框架应该是两个不得不的提的,它们的实现都依赖了动态代理。
+
+**动态代理在我们日常开发中使用的相对较小,但是在框架中的几乎是必用的一门技术。学会了动态代理之后,对于我们理解和学习各种框架的原理也非常有帮助。**
+
+就 Java 来说,动态代理的实现方式有很多种,比如 **JDK 动态代理**、**CGLIB 动态代理**等等。
+
+[guide-rpc-framework](https://github.com/Snailclimb/guide-rpc-framework) 使用的是 JDK 动态代理,我们先来看看 JDK 动态代理的使用。
+
+另外,虽然 [guide-rpc-framework](https://github.com/Snailclimb/guide-rpc-framework) 没有用到 **CGLIB 动态代理 ,我们这里还是简单介绍一下其使用以及和**JDK 动态代理的对比。
+
+### 3.1. JDK 动态代理机制
+
+#### 3.1.1. 介绍
+
+**在 Java 动态代理机制中 `InvocationHandler` 接口和 `Proxy` 类是核心。**
+
+`Proxy` 类中使用频率最高的方法是:`newProxyInstance()` ,这个方法主要用来生成一个代理对象。
+
+```java
+ public static Object newProxyInstance(ClassLoader loader,
+ Class[] interfaces,
+ InvocationHandler h)
+ throws IllegalArgumentException
+ {
+ ......
+ }
+```
+
+这个方法一共有 3 个参数:
+
+1. **loader** :类加载器,用于加载代理对象。
+2. **interfaces** : 被代理类实现的一些接口;
+3. **h** : 实现了 `InvocationHandler` 接口的对象;
+
+要实现动态代理的话,还必须需要实现`InvocationHandler` 来自定义处理逻辑。 当我们的动态代理对象调用一个方法时候,这个方法的调用就会被转发到实现`InvocationHandler` 接口类的 `invoke` 方法来调用。
+
+```java
+public interface InvocationHandler {
+
+ /**
+ * 当你使用代理对象调用方法的时候实际会调用到这个方法
+ */
+ public Object invoke(Object proxy, Method method, Object[] args)
+ throws Throwable;
+}
+```
+
+`invoke()` 方法有下面三个参数:
+
+1. **proxy** :动态生成的代理类
+2. **method** : 与代理类对象调用的方法相对应
+3. **args** : 当前 method 方法的参数
+
+也就是说:**你通过`Proxy` 类的 `newProxyInstance()` 创建的代理对象在调用方法的时候,实际会调用到实现`InvocationHandler` 接口的类的 `invoke()`方法。** 你可以在 `invoke()` 方法中自定义处理逻辑,比如在方法执行前后做什么事情。
+
+#### 3.1.2. JDK 动态代理类使用步骤
+
+1. 定义一个接口及其实现类;
+2. 自定义 `InvocationHandler` 并重写`invoke`方法,在 `invoke` 方法中我们会调用原生方法(被代理类的方法)并自定义一些处理逻辑;
+3. 通过 `Proxy.newProxyInstance(ClassLoader loader,Class[] interfaces,InvocationHandler h)` 方法创建代理对象;
+
+#### 3.1.3. 代码示例
+
+这样说可能会有点空洞和难以理解,我上个例子,大家感受一下吧!
+
+**1.定义发送短信的接口**
+
+```java
+public interface SmsService {
+ String send(String message);
+}
+```
+
+**2.实现发送短信的接口**
+
+```java
+public class SmsServiceImpl implements SmsService {
+ public String send(String message) {
+ System.out.println("send message:" + message);
+ return message;
+ }
+}
+```
+
+**3.定义一个 JDK 动态代理类**
+
+```java
+import java.lang.reflect.InvocationHandler;
+import java.lang.reflect.InvocationTargetException;
+import java.lang.reflect.Method;
+
+/**
+ * @author shuang.kou
+ * @createTime 2020年05月11日 11:23:00
+ */
+public class DebugInvocationHandler implements InvocationHandler {
+ /**
+ * 代理类中的真实对象
+ */
+ private final Object target;
+
+ public DebugInvocationHandler(Object target) {
+ this.target = target;
+ }
+
+
+ public Object invoke(Object proxy, Method method, Object[] args) throws InvocationTargetException, IllegalAccessException {
+ //调用方法之前,我们可以添加自己的操作
+ System.out.println("before method " + method.getName());
+ Object result = method.invoke(target, args);
+ //调用方法之后,我们同样可以添加自己的操作
+ System.out.println("after method " + method.getName());
+ return result;
+ }
+}
+
+```
+
+`invoke()` 方法: 当我们的动态代理对象调用原生方法的时候,最终实际上调用到的是 `invoke()` 方法,然后 `invoke()` 方法代替我们去调用了被代理对象的原生方法。
+
+**4.获取代理对象的工厂类**
+
+```java
+public class JdkProxyFactory {
+ public static Object getProxy(Object target) {
+ return Proxy.newProxyInstance(
+ target.getClass().getClassLoader(), // 目标类的类加载
+ target.getClass().getInterfaces(), // 代理需要实现的接口,可指定多个
+ new DebugInvocationHandler(target) // 代理对象对应的自定义 InvocationHandler
+ );
+ }
+}
+```
+
+`getProxy()` :主要通过`Proxy.newProxyInstance()`方法获取某个类的代理对象
+
+**5.实际使用**
+
+```java
+SmsService smsService = (SmsService) JdkProxyFactory.getProxy(new SmsServiceImpl());
+smsService.send("java");
+```
+
+运行上述代码之后,控制台打印出:
+
+```
+before method send
+send message:java
+after method send
+```
+
+### 3.2. CGLIB 动态代理机制
+
+#### 3.2.1. 介绍
+
+**JDK 动态代理有一个最致命的问题是其只能代理实现了接口的类。**
+
+**为了解决这个问题,我们可以用 CGLIB 动态代理机制来避免。**
+
+[CGLIB](https://github.com/cglib/cglib)(_Code Generation Library_)是一个基于[ASM](http://www.baeldung.com/java-asm)的字节码生成库,它允许我们在运行时对字节码进行修改和动态生成。CGLIB 通过继承方式实现代理。很多知名的开源框架都使用到了[CGLIB](https://github.com/cglib/cglib), 例如 Spring 中的 AOP 模块中:如果目标对象实现了接口,则默认采用 JDK 动态代理,否则采用 CGLIB 动态代理。
+
+**在 CGLIB 动态代理机制中 `MethodInterceptor` 接口和 `Enhancer` 类是核心。**
+
+你需要自定义 `MethodInterceptor` 并重写 `intercept` 方法,`intercept` 用于拦截增强被代理类的方法。
+
+```java
+public interface MethodInterceptor
+extends Callback{
+ // 拦截被代理类中的方法
+ public Object intercept(Object obj, java.lang.reflect.Method method, Object[] args,
+ MethodProxy proxy) throws Throwable;
+}
+
+```
+
+1. **obj** :被代理的对象(需要增强的对象)
+2. **method** :被拦截的方法(需要增强的方法)
+3. **args** :方法入参
+4. **methodProxy** :用于调用原始方法
+
+你可以通过 `Enhancer`类来动态获取被代理类,当代理类调用方法的时候,实际调用的是 `MethodInterceptor` 中的 `intercept` 方法。
+
+#### 3.2.2. CGLIB 动态代理类使用步骤
+
+1. 定义一个类;
+2. 自定义 `MethodInterceptor` 并重写 `intercept` 方法,`intercept` 用于拦截增强被代理类的方法,和 JDK 动态代理中的 `invoke` 方法类似;
+3. 通过 `Enhancer` 类的 `create()`创建代理类;
+
+#### 3.2.3. 代码示例
+
+不同于 JDK 动态代理不需要额外的依赖。[CGLIB](https://github.com/cglib/cglib)(_Code Generation Library_) 实际是属于一个开源项目,如果你要使用它的话,需要手动添加相关依赖。
+
+```xml
+
+ cglib
+ cglib
+ 3.3.0
+
+```
+
+**1.实现一个使用阿里云发送短信的类**
+
+```java
+package github.javaguide.dynamicProxy.cglibDynamicProxy;
+
+public class AliSmsService {
+ public String send(String message) {
+ System.out.println("send message:" + message);
+ return message;
+ }
+}
+```
+
+**2.自定义 `MethodInterceptor`(方法拦截器)**
+
+```java
+import net.sf.cglib.proxy.MethodInterceptor;
+import net.sf.cglib.proxy.MethodProxy;
+
+import java.lang.reflect.Method;
+
+/**
+ * 自定义MethodInterceptor
+ */
+public class DebugMethodInterceptor implements MethodInterceptor {
+
+
+ /**
+ * @param o 被代理的对象(需要增强的对象)
+ * @param method 被拦截的方法(需要增强的方法)
+ * @param args 方法入参
+ * @param methodProxy 用于调用原始方法
+ */
+ @Override
+ public Object intercept(Object o, Method method, Object[] args, MethodProxy methodProxy) throws Throwable {
+ //调用方法之前,我们可以添加自己的操作
+ System.out.println("before method " + method.getName());
+ Object object = methodProxy.invokeSuper(o, args);
+ //调用方法之后,我们同样可以添加自己的操作
+ System.out.println("after method " + method.getName());
+ return object;
+ }
+
+}
+```
+
+**3.获取代理类**
+
+```java
+import net.sf.cglib.proxy.Enhancer;
+
+public class CglibProxyFactory {
+
+ public static Object getProxy(Class clazz) {
+ // 创建动态代理增强类
+ Enhancer enhancer = new Enhancer();
+ // 设置类加载器
+ enhancer.setClassLoader(clazz.getClassLoader());
+ // 设置被代理类
+ enhancer.setSuperclass(clazz);
+ // 设置方法拦截器
+ enhancer.setCallback(new DebugMethodInterceptor());
+ // 创建代理类
+ return enhancer.create();
+ }
+}
+```
+
+**4.实际使用**
+
+```java
+AliSmsService aliSmsService = (AliSmsService) CglibProxyFactory.getProxy(AliSmsService.class);
+aliSmsService.send("java");
+```
+
+运行上述代码之后,控制台打印出:
+
+```bash
+before method send
+send message:java
+after method send
+```
+
+### 3.3. JDK 动态代理和 CGLIB 动态代理对比
+
+1. **JDK 动态代理只能只能代理实现了接口的类,而 CGLIB 可以代理未实现任何接口的类。** 另外, CGLIB 动态代理是通过生成一个被代理类的子类来拦截被代理类的方法调用,因此不能代理声明为 final 类型的类和方法。
+2. 就二者的效率来说,大部分情况都是 JDK 动态代理更优秀,随着 JDK 版本的升级,这个优势更加明显。
+
+## 4. 静态代理和动态代理的对比
+
+1. **灵活性** :动态代理更加灵活,不需要必须实现接口,可以直接代理实现类,并且可以不需要针对每个目标类都创建一个代理类。另外,静态代理中,接口一旦新增加方法,目标对象和代理对象都要进行修改,这是非常麻烦的!
+2. **JVM 层面** :静态代理在编译时就将接口、实现类、代理类这些都变成了一个个实际的 class 文件。而动态代理是在运行时动态生成类字节码,并加载到 JVM 中的。
+
+## 5. 总结
+
+这篇文章中主要介绍了代理模式的两种实现:静态代理以及动态代理。涵盖了静态代理和动态代理实战、静态代理和动态代理的区别、JDK 动态代理和 Cglib 动态代理区别等内容。
+
+文中涉及到的所有源码,你可以在这里找到:[https://github.com/Snailclimb/guide-rpc-framework-learning/tree/master/src/main/java/github/javaguide/proxy](https://github.com/Snailclimb/guide-rpc-framework-learning/tree/master/src/main/java/github/javaguide/proxy) 。
diff --git a/docs/java/basic/reflection.md b/docs/java/basic/reflection.md
new file mode 100644
index 00000000..ae1cc384
--- /dev/null
+++ b/docs/java/basic/reflection.md
@@ -0,0 +1,148 @@
+### 反射机制介绍
+
+JAVA 反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为 java 语言的反射机制。
+
+### 获取 Class 对象的两种方式
+
+如果我们动态获取到这些信息,我们需要依靠 Class 对象。Class 类对象将一个类的方法、变量等信息告诉运行的程序。Java 提供了三种方式获取 Class 对象:
+
+1.知道具体类的情况下可以使用:
+
+```java
+Class alunbarClass = TargetObject.class;
+```
+
+但是我们一般是不知道具体类的,基本都是通过遍历包下面的类来获取 Class 对象
+
+2.通过 `Class.forName()`传入类的路径获取:
+
+```java
+Class alunbarClass1 = Class.forName("cn.javaguide.TargetObject");
+```
+3.通过对象实例`instance.getClass()`获取:
+```
+Employee e;
+Class alunbarClass2 = e.getClass();
+```
+
+### 代码实例
+
+**简单用代码演示一下反射的一些操作!**
+
+1.创建一个我们要使用反射操作的类 `TargetObject`:
+
+```java
+package cn.javaguide;
+
+public class TargetObject {
+ private String value;
+
+ public TargetObject() {
+ value = "JavaGuide";
+ }
+
+ public void publicMethod(String s) {
+ System.out.println("I love " + s);
+ }
+
+ private void privateMethod() {
+ System.out.println("value is " + value);
+ }
+}
+```
+
+2.使用反射操作这个类的方法以及参数
+
+```java
+package cn.javaguide;
+
+import java.lang.reflect.Field;
+import java.lang.reflect.InvocationTargetException;
+import java.lang.reflect.Method;
+
+public class Main {
+ public static void main(String[] args) throws ClassNotFoundException, NoSuchMethodException, IllegalAccessException, InstantiationException, InvocationTargetException, NoSuchFieldException {
+ /**
+ * 获取TargetObject类的Class对象并且创建TargetObject类实例
+ */
+ Class tagetClass = Class.forName("cn.javaguide.TargetObject");
+ TargetObject targetObject = (TargetObject) tagetClass.newInstance();
+ /**
+ * 获取所有类中所有定义的方法
+ */
+ Method[] methods = tagetClass.getDeclaredMethods();
+ for (Method method : methods) {
+ System.out.println(method.getName());
+ }
+ /**
+ * 获取指定方法并调用
+ */
+ Method publicMethod = tagetClass.getDeclaredMethod("publicMethod",
+ String.class);
+
+ publicMethod.invoke(targetObject, "JavaGuide");
+ /**
+ * 获取指定参数并对参数进行修改
+ */
+ Field field = tagetClass.getDeclaredField("value");
+ //为了对类中的参数进行修改我们取消安全检查
+ field.setAccessible(true);
+ field.set(targetObject, "JavaGuide");
+ /**
+ * 调用 private 方法
+ */
+ Method privateMethod = tagetClass.getDeclaredMethod("privateMethod");
+ //为了调用private方法我们取消安全检查
+ privateMethod.setAccessible(true);
+ privateMethod.invoke(targetObject);
+ }
+}
+
+```
+
+输出内容:
+
+```
+publicMethod
+privateMethod
+I love JavaGuide
+value is JavaGuide
+```
+
+**注意** : 有读者提到上面代码运行会抛出 `ClassNotFoundException` 异常,具体原因是你没有下面把这段代码的包名替换成自己创建的 `TargetObject` 所在的包 。
+
+```java
+Class tagetClass = Class.forName("cn.javaguide.TargetObject");
+```
+
+
+### 静态编译和动态编译
+
+- **静态编译:** 在编译时确定类型,绑定对象
+- **动态编译:** 运行时确定类型,绑定对象
+
+### 反射机制优缺点
+
+- **优点:** 运行期类型的判断,动态加载类,提高代码灵活度。
+- **缺点:** 1,性能瓶颈:反射相当于一系列解释操作,通知 JVM 要做的事情,性能比直接的 java 代码要慢很多。2,安全问题,让我们可以动态操作改变类的属性同时也增加了类的安全隐患。
+
+### 反射的应用场景
+
+**反射是框架设计的灵魂。**
+
+在我们平时的项目开发过程中,基本上很少会直接使用到反射机制,但这不能说明反射机制没有用,实际上有很多设计、开发都与反射机制有关,例如模块化的开发,通过反射去调用对应的字节码;动态代理设计模式也采用了反射机制,还有我们日常使用的 Spring/Hibernate 等框架也大量使用到了反射机制。
+
+举例:
+
+1. 我们在使用 JDBC 连接数据库时使用 `Class.forName()`通过反射加载数据库的驱动程序;
+2. Spring 框架的 IOC(动态加载管理 Bean)创建对象以及 AOP(动态代理)功能都和反射有联系;
+3. 动态配置实例的属性;
+4. ......
+
+**推荐阅读:**
+
+- [Java反射使用总结]( https://zhuanlan.zhihu.com/p/80519709)
+- [Reflection:Java 反射机制的应用场景](https://segmentfault.com/a/1190000010162647?utm_source=tuicool&utm_medium=referral)
+- [Java 基础之—反射(非常重要)](https://blog.csdn.net/sinat_38259539/article/details/71799078)
+
+##
diff --git a/docs/java/Basis/用好Java中的枚举,真的没有那么简单!.md b/docs/java/basic/用好Java中的枚举真的没有那么简单.md
similarity index 93%
rename from docs/java/Basis/用好Java中的枚举,真的没有那么简单!.md
rename to docs/java/basic/用好Java中的枚举真的没有那么简单.md
index 20b02297..bfd347aa 100644
--- a/docs/java/Basis/用好Java中的枚举,真的没有那么简单!.md
+++ b/docs/java/basic/用好Java中的枚举真的没有那么简单.md
@@ -51,10 +51,7 @@ public class Pizza {
}
public boolean isDeliverable() {
- if (getStatus() == PizzaStatus.READY) {
- return true;
- }
- return false;
+ return getStatus() == PizzaStatus.READY;
}
// Methods that set and get the status variable.
@@ -63,9 +60,9 @@ public class Pizza {
## 3.使用 == 比较枚举类型
-由于枚举类型确保JVM中仅存在一个常量实例,因此我们可以安全地使用“ ==”运算符比较两个变量,如上例所示;此外,“ ==”运算符可提供编译时和运行时的安全性。
+由于枚举类型确保JVM中仅存在一个常量实例,因此我们可以安全地使用 `==` 运算符比较两个变量,如上例所示;此外,`==` 运算符可提供编译时和运行时的安全性。
-首先,让我们看一下以下代码段中的运行时安全性,其中“ ==”运算符用于比较状态,并且如果两个值均为null 都不会引发 NullPointerException。相反,如果使用equals方法,将抛出 NullPointerException:
+首先,让我们看一下以下代码段中的运行时安全性,其中 `==` 运算符用于比较状态,并且如果两个值均为null 都不会引发 NullPointerException。相反,如果使用equals方法,将抛出 NullPointerException:
```java
if(testPz.getStatus().equals(Pizza.PizzaStatus.DELIVERED));
@@ -84,9 +81,12 @@ if(testPz.getStatus() == TestColor.GREEN);
```java
public int getDeliveryTimeInDays() {
switch (status) {
- case ORDERED: return 5;
- case READY: return 2;
- case DELIVERED: return 0;
+ case ORDERED:
+ return 5;
+ case READY:
+ return 2;
+ case DELIVERED:
+ return 0;
}
return 0;
}
@@ -257,22 +257,17 @@ EnumMap map;
让我们快速看一个真实的示例,该示例演示如何在实践中使用它:
```java
-public static EnumMap>
- groupPizzaByStatus(List pizzaList) {
- EnumMap> pzByStatus =
- new EnumMap>(PizzaStatus.class);
-
- for (Pizza pz : pizzaList) {
- PizzaStatus status = pz.getStatus();
- if (pzByStatus.containsKey(status)) {
- pzByStatus.get(status).add(pz);
- } else {
- List newPzList = new ArrayList();
- newPzList.add(pz);
- pzByStatus.put(status, newPzList);
- }
+Iterator iterator = pizzaList.iterator();
+while (iterator.hasNext()) {
+ Pizza pz = iterator.next();
+ PizzaStatus status = pz.getStatus();
+ if (pzByStatus.containsKey(status)) {
+ pzByStatus.get(status).add(pz);
+ } else {
+ List newPzList = new ArrayList<>();
+ newPzList.add(pz);
+ pzByStatus.put(status, newPzList);
}
- return pzByStatus;
}
```
diff --git a/docs/java/collection/ArrayList-Grow.md b/docs/java/collection/ArrayList-Grow.md
index ab56b802..2449190f 100644
--- a/docs/java/collection/ArrayList-Grow.md
+++ b/docs/java/collection/ArrayList-Grow.md
@@ -74,6 +74,9 @@
return true;
}
```
+
+> **注意** :JDK11 移除了 `ensureCapacityInternal()` 和 `ensureExplicitCapacity()` 方法
+
### 2. 再来看看 `ensureCapacityInternal()` 方法
可以看到 `add` 方法 首先调用了`ensureCapacityInternal(size + 1)`
@@ -145,7 +148,7 @@
}
```
-**int newCapacity = oldCapacity + (oldCapacity >> 1),所以 ArrayList 每次扩容之后容量都会变为原来的 1.5 倍!(JDK1.6版本以后)** JDk1.6版本时,扩容之后容量为 1.5 倍+1!详情请参考源码
+**int newCapacity = oldCapacity + (oldCapacity >> 1),所以 ArrayList 每次扩容之后容量都会变为原来的 1.5 倍左右(oldCapacity为偶数就是1.5倍,否则是1.5倍左右)!** 奇偶不同,比如 :10+10/2 = 15, 33+33/2=49。如果是奇数的话会丢掉小数.
> ">>"(移位运算符):>>1 右移一位相当于除2,右移n位相当于除以 2 的 n 次方。这里 oldCapacity 明显右移了1位所以相当于oldCapacity /2。对于大数据的2进制运算,位移运算符比那些普通运算符的运算要快很多,因为程序仅仅移动一下而已,不去计算,这样提高了效率,节省了资源
@@ -223,7 +226,7 @@ public class ArraycopyTest {
System.arraycopy(a, 2, a, 3, 3);
a[2]=99;
for (int i = 0; i < a.length; i++) {
- System.out.println(a[i]);
+ System.out.print(a[i] + " ");
}
}
diff --git a/docs/java/collection/ArrayList.md b/docs/java/collection/ArrayList.md
index f6578a7a..43e81ba6 100644
--- a/docs/java/collection/ArrayList.md
+++ b/docs/java/collection/ArrayList.md
@@ -68,23 +68,25 @@ public class ArrayList extends AbstractList
private int size;
/**
- * 带初始容量参数的构造函数。(用户自己指定容量)
+ * 带初始容量参数的构造函数(用户可以在创建ArrayList对象时自己指定集合的初始大小)
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
- //创建initialCapacity大小的数组
+ //如果传入的参数大于0,创建initialCapacity大小的数组
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
- //创建空数组
+ //如果传入的参数等于0,创建空数组
this.elementData = EMPTY_ELEMENTDATA;
} else {
+ //其他情况,抛出异常
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
/**
- *默认构造函数,DEFAULTCAPACITY_EMPTY_ELEMENTDATA 为0.初始化为10,也就是说初始其实是空数组 当添加第一个元素的时候数组容量才变成10
+ *默认无参构造函数
+ *DEFAULTCAPACITY_EMPTY_ELEMENTDATA 为0.初始化为10,也就是说初始其实是空数组 当添加第一个元素的时候数组容量才变成10
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
@@ -94,16 +96,16 @@ public class ArrayList extends AbstractList
* 构造一个包含指定集合的元素的列表,按照它们由集合的迭代器返回的顺序。
*/
public ArrayList(Collection c) {
- //
+ //将指定集合转换为数组
elementData = c.toArray();
- //如果指定集合元素个数不为0
+ //如果elementData数组的长度不为0
if ((size = elementData.length) != 0) {
- // c.toArray 可能返回的不是Object类型的数组所以加上下面的语句用于判断,
- //这里用到了反射里面的getClass()方法
+ // 如果elementData不是Object类型数据(c.toArray可能返回的不是Object类型的数组所以加上下面的语句用于判断)
if (elementData.getClass() != Object[].class)
+ //将原来不是Object类型的elementData数组的内容,赋值给新的Object类型的elementData数组
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
- // 用空数组代替
+ // 其他情况,用空数组代替
this.elementData = EMPTY_ELEMENTDATA;
}
}
@@ -127,13 +129,14 @@ public class ArrayList extends AbstractList
* @param minCapacity 所需的最小容量
*/
public void ensureCapacity(int minCapacity) {
+ //如果是true,minExpand的值为0,如果是false,minExpand的值为10
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
// any size if not default element table
? 0
// larger than default for default empty table. It's already
// supposed to be at default size.
: DEFAULT_CAPACITY;
-
+ //如果最小容量大于已有的最大容量
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
@@ -141,7 +144,7 @@ public class ArrayList extends AbstractList
//得到最小扩容量
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
- // 获取默认的容量和传入参数的较大值
+ // 获取“默认的容量”和“传入参数”两者之间的最大值
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
diff --git a/docs/java/collection/ConcurrentHashMap.md b/docs/java/collection/ConcurrentHashMap.md
new file mode 100644
index 00000000..3dd590ff
--- /dev/null
+++ b/docs/java/collection/ConcurrentHashMap.md
@@ -0,0 +1,584 @@
+> 本文来自公众号:末读代码的投稿,原文地址:https://mp.weixin.qq.com/s/AHWzboztt53ZfFZmsSnMSw 。
+
+上一篇文章介绍了 HashMap 源码,反响不错,也有很多同学发表了自己的观点,这次又来了,这次是 `ConcurrentHashMap ` 了,作为线程安全的HashMap ,它的使用频率也是很高。那么它的存储结构和实现原理是怎么样的呢?
+
+## 1. ConcurrentHashMap 1.7
+
+### 1. 存储结构
+
+
+
+Java 7 中 ConcurrentHashMap 的存储结构如上图,ConcurrnetHashMap 由很多个 Segment 组合,而每一个 Segment 是一个类似于 HashMap 的结构,所以每一个 HashMap 的内部可以进行扩容。但是 Segment 的个数一旦**初始化就不能改变**,默认 Segment 的个数是 16 个,你也可以认为 ConcurrentHashMap 默认支持最多 16 个线程并发。
+
+### 2. 初始化
+
+通过 ConcurrentHashMap 的无参构造探寻 ConcurrentHashMap 的初始化流程。
+
+```java
+ /**
+ * Creates a new, empty map with a default initial capacity (16),
+ * load factor (0.75) and concurrencyLevel (16).
+ */
+ public ConcurrentHashMap() {
+ this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR, DEFAULT_CONCURRENCY_LEVEL);
+ }
+```
+
+无参构造中调用了有参构造,传入了三个参数的默认值,他们的值是。
+
+```java
+ /**
+ * 默认初始化容量
+ */
+ static final int DEFAULT_INITIAL_CAPACITY = 16;
+
+ /**
+ * 默认负载因子
+ */
+ static final float DEFAULT_LOAD_FACTOR = 0.75f;
+
+ /**
+ * 默认并发级别
+ */
+ static final int DEFAULT_CONCURRENCY_LEVEL = 16;
+```
+
+接着看下这个有参构造函数的内部实现逻辑。
+
+```java
+@SuppressWarnings("unchecked")
+public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLevel) {
+ // 参数校验
+ if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
+ throw new IllegalArgumentException();
+ // 校验并发级别大小,大于 1<<16,重置为 65536
+ if (concurrencyLevel > MAX_SEGMENTS)
+ concurrencyLevel = MAX_SEGMENTS;
+ // Find power-of-two sizes best matching arguments
+ // 2的多少次方
+ int sshift = 0;
+ int ssize = 1;
+ // 这个循环可以找到 concurrencyLevel 之上最近的 2的次方值
+ while (ssize < concurrencyLevel) {
+ ++sshift;
+ ssize <<= 1;
+ }
+ // 记录段偏移量
+ this.segmentShift = 32 - sshift;
+ // 记录段掩码
+ this.segmentMask = ssize - 1;
+ // 设置容量
+ if (initialCapacity > MAXIMUM_CAPACITY)
+ initialCapacity = MAXIMUM_CAPACITY;
+ // c = 容量 / ssize ,默认 16 / 16 = 1,这里是计算每个 Segment 中的类似于 HashMap 的容量
+ int c = initialCapacity / ssize;
+ if (c * ssize < initialCapacity)
+ ++c;
+ int cap = MIN_SEGMENT_TABLE_CAPACITY;
+ //Segment 中的类似于 HashMap 的容量至少是2或者2的倍数
+ while (cap < c)
+ cap <<= 1;
+ // create segments and segments[0]
+ // 创建 Segment 数组,设置 segments[0]
+ Segment s0 = new Segment(loadFactor, (int)(cap * loadFactor),
+ (HashEntry[])new HashEntry[cap]);
+ Segment[] ss = (Segment[])new Segment[ssize];
+ UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
+ this.segments = ss;
+}
+```
+
+总结一下在 Java 7 中 ConcurrnetHashMap 的初始化逻辑。
+
+1. 必要参数校验。
+2. 校验并发级别 concurrencyLevel 大小,如果大于最大值,重置为最大值。无惨构造**默认值是 16.**
+3. 寻找并发级别 concurrencyLevel 之上最近的 **2 的幂次方**值,作为初始化容量大小,**默认是 16**。
+4. 记录 segmentShift 偏移量,这个值为【容量 = 2 的N次方】中的 N,在后面 Put 时计算位置时会用到。**默认是 32 - sshift = 28**.
+5. 记录 segmentMask,默认是 ssize - 1 = 16 -1 = 15.
+6. **初始化 segments[0]**,**默认大小为 2**,**负载因子 0.75**,**扩容阀值是 2*0.75=1.5**,插入第二个值时才会进行扩容。
+
+### 3. put
+
+接着上面的初始化参数继续查看 put 方法源码。
+
+```java
+/**
+ * Maps the specified key to the specified value in this table.
+ * Neither the key nor the value can be null.
+ *
+ * The value can be retrieved by calling the get method
+ * with a key that is equal to the original key.
+ *
+ * @param key key with which the specified value is to be associated
+ * @param value value to be associated with the specified key
+ * @return the previous value associated with key , or
+ * null if there was no mapping for key
+ * @throws NullPointerException if the specified key or value is null
+ */
+public V put(K key, V value) {
+ Segment s;
+ if (value == null)
+ throw new NullPointerException();
+ int hash = hash(key);
+ // hash 值无符号右移 28位(初始化时获得),然后与 segmentMask=15 做与运算
+ // 其实也就是把高4位与segmentMask(1111)做与运算
+ int j = (hash >>> segmentShift) & segmentMask;
+ if ((s = (Segment)UNSAFE.getObject // nonvolatile; recheck
+ (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
+ // 如果查找到的 Segment 为空,初始化
+ s = ensureSegment(j);
+ return s.put(key, hash, value, false);
+}
+
+/**
+ * Returns the segment for the given index, creating it and
+ * recording in segment table (via CAS) if not already present.
+ *
+ * @param k the index
+ * @return the segment
+ */
+@SuppressWarnings("unchecked")
+private Segment ensureSegment(int k) {
+ final Segment[] ss = this.segments;
+ long u = (k << SSHIFT) + SBASE; // raw offset
+ Segment seg;
+ // 判断 u 位置的 Segment 是否为null
+ if ((seg = (Segment)UNSAFE.getObjectVolatile(ss, u)) == null) {
+ Segment proto = ss[0]; // use segment 0 as prototype
+ // 获取0号 segment 里的 HashEntry 初始化长度
+ int cap = proto.table.length;
+ // 获取0号 segment 里的 hash 表里的扩容负载因子,所有的 segment 的 loadFactor 是相同的
+ float lf = proto.loadFactor;
+ // 计算扩容阀值
+ int threshold = (int)(cap * lf);
+ // 创建一个 cap 容量的 HashEntry 数组
+ HashEntry[] tab = (HashEntry[])new HashEntry[cap];
+ if ((seg = (Segment)UNSAFE.getObjectVolatile(ss, u)) == null) { // recheck
+ // 再次检查 u 位置的 Segment 是否为null,因为这时可能有其他线程进行了操作
+ Segment s = new Segment(lf, threshold, tab);
+ // 自旋检查 u 位置的 Segment 是否为null
+ while ((seg = (Segment)UNSAFE.getObjectVolatile(ss, u))
+ == null) {
+ // 使用CAS 赋值,只会成功一次
+ if (UNSAFE.compareAndSwapObject(ss, u, null, seg = s))
+ break;
+ }
+ }
+ }
+ return seg;
+}
+```
+
+上面的源码分析了 ConcurrentHashMap 在 put 一个数据时的处理流程,下面梳理下具体流程。
+
+1. 计算要 put 的 key 的位置,获取指定位置的 Segment。
+
+2. 如果指定位置的 Segment 为空,则初始化这个 Segment.
+
+ **初始化 Segment 流程:**
+
+ 1. 检查计算得到的位置的 Segment 是否为null.
+ 2. 为 null 继续初始化,使用 Segment[0] 的容量和负载因子创建一个 HashEntry 数组。
+ 3. 再次检查计算得到的指定位置的 Segment 是否为null.
+ 4. 使用创建的 HashEntry 数组初始化这个 Segment.
+ 5. 自旋判断计算得到的指定位置的 Segment 是否为null,使用 CAS 在这个位置赋值为 Segment.
+
+3. Segment.put 插入 key,value 值。
+
+上面探究了获取 Segment 段和初始化 Segment 段的操作。最后一行的 Segment 的 put 方法还没有查看,继续分析。
+
+```java
+final V put(K key, int hash, V value, boolean onlyIfAbsent) {
+ // 获取 ReentrantLock 独占锁,获取不到,scanAndLockForPut 获取。
+ HashEntry node = tryLock() ? null : scanAndLockForPut(key, hash, value);
+ V oldValue;
+ try {
+ HashEntry[] tab = table;
+ // 计算要put的数据位置
+ int index = (tab.length - 1) & hash;
+ // CAS 获取 index 坐标的值
+ HashEntry first = entryAt(tab, index);
+ for (HashEntry e = first;;) {
+ if (e != null) {
+ // 检查是否 key 已经存在,如果存在,则遍历链表寻找位置,找到后替换 value
+ K k;
+ if ((k = e.key) == key ||
+ (e.hash == hash && key.equals(k))) {
+ oldValue = e.value;
+ if (!onlyIfAbsent) {
+ e.value = value;
+ ++modCount;
+ }
+ break;
+ }
+ e = e.next;
+ }
+ else {
+ // first 有值没说明 index 位置已经有值了,有冲突,链表头插法。
+ if (node != null)
+ node.setNext(first);
+ else
+ node = new HashEntry(hash, key, value, first);
+ int c = count + 1;
+ // 容量大于扩容阀值,小于最大容量,进行扩容
+ if (c > threshold && tab.length < MAXIMUM_CAPACITY)
+ rehash(node);
+ else
+ // index 位置赋值 node,node 可能是一个元素,也可能是一个链表的表头
+ setEntryAt(tab, index, node);
+ ++modCount;
+ count = c;
+ oldValue = null;
+ break;
+ }
+ }
+ } finally {
+ unlock();
+ }
+ return oldValue;
+}
+```
+
+由于 Segment 继承了 ReentrantLock,所以 Segment 内部可以很方便的获取锁,put 流程就用到了这个功能。
+
+1. tryLock() 获取锁,获取不到使用 **`scanAndLockForPut`** 方法继续获取。
+
+2. 计算 put 的数据要放入的 index 位置,然后获取这个位置上的 HashEntry 。
+
+3. 遍历 put 新元素,为什么要遍历?因为这里获取的 HashEntry 可能是一个空元素,也可能是链表已存在,所以要区别对待。
+
+ 如果这个位置上的 **HashEntry 不存在**:
+
+ 1. 如果当前容量大于扩容阀值,小于最大容量,**进行扩容**。
+ 2. 直接头插法插入。
+
+ 如果这个位置上的 **HashEntry 存在**:
+
+ 1. 判断链表当前元素 Key 和 hash 值是否和要 put 的 key 和 hash 值一致。一致则替换值
+ 2. 不一致,获取链表下一个节点,直到发现相同进行值替换,或者链表表里完毕没有相同的。
+ 1. 如果当前容量大于扩容阀值,小于最大容量,**进行扩容**。
+ 2. 直接链表头插法插入。
+
+4. 如果要插入的位置之前已经存在,替换后返回旧值,否则返回 null.
+
+这里面的第一步中的 scanAndLockForPut 操作这里没有介绍,这个方法做的操作就是不断的自旋 `tryLock()` 获取锁。当自旋次数大于指定次数时,使用 `lock()` 阻塞获取锁。在自旋时顺表获取下 hash 位置的 HashEntry。
+
+```java
+private HashEntry scanAndLockForPut(K key, int hash, V value) {
+ HashEntry first = entryForHash(this, hash);
+ HashEntry e = first;
+ HashEntry node = null;
+ int retries = -1; // negative while locating node
+ // 自旋获取锁
+ while (!tryLock()) {
+ HashEntry f; // to recheck first below
+ if (retries < 0) {
+ if (e == null) {
+ if (node == null) // speculatively create node
+ node = new HashEntry(hash, key, value, null);
+ retries = 0;
+ }
+ else if (key.equals(e.key))
+ retries = 0;
+ else
+ e = e.next;
+ }
+ else if (++retries > MAX_SCAN_RETRIES) {
+ // 自旋达到指定次数后,阻塞等到只到获取到锁
+ lock();
+ break;
+ }
+ else if ((retries & 1) == 0 &&
+ (f = entryForHash(this, hash)) != first) {
+ e = first = f; // re-traverse if entry changed
+ retries = -1;
+ }
+ }
+ return node;
+}
+
+```
+
+### 4. 扩容 rehash
+
+ConcurrentHashMap 的扩容只会扩容到原来的两倍。老数组里的数据移动到新的数组时,位置要么不变,要么变为 index+ oldSize,参数里的 node 会在扩容之后使用链表**头插法**插入到指定位置。
+
+```java
+private void rehash(HashEntry node) {
+ HashEntry[] oldTable = table;
+ // 老容量
+ int oldCapacity = oldTable.length;
+ // 新容量,扩大两倍
+ int newCapacity = oldCapacity << 1;
+ // 新的扩容阀值
+ threshold = (int)(newCapacity * loadFactor);
+ // 创建新的数组
+ HashEntry[] newTable = (HashEntry[]) new HashEntry[newCapacity];
+ // 新的掩码,默认2扩容后是4,-1是3,二进制就是11。
+ int sizeMask = newCapacity - 1;
+ for (int i = 0; i < oldCapacity ; i++) {
+ // 遍历老数组
+ HashEntry e = oldTable[i];
+ if (e != null) {
+ HashEntry next = e.next;
+ // 计算新的位置,新的位置只可能是不便或者是老的位置+老的容量。
+ int idx = e.hash & sizeMask;
+ if (next == null) // Single node on list
+ // 如果当前位置还不是链表,只是一个元素,直接赋值
+ newTable[idx] = e;
+ else { // Reuse consecutive sequence at same slot
+ // 如果是链表了
+ HashEntry lastRun = e;
+ int lastIdx = idx;
+ // 新的位置只可能是不便或者是老的位置+老的容量。
+ // 遍历结束后,lastRun 后面的元素位置都是相同的
+ for (HashEntry last = next; last != null; last = last.next) {
+ int k = last.hash & sizeMask;
+ if (k != lastIdx) {
+ lastIdx = k;
+ lastRun = last;
+ }
+ }
+ // ,lastRun 后面的元素位置都是相同的,直接作为链表赋值到新位置。
+ newTable[lastIdx] = lastRun;
+ // Clone remaining nodes
+ for (HashEntry p = e; p != lastRun; p = p.next) {
+ // 遍历剩余元素,头插法到指定 k 位置。
+ V v = p.value;
+ int h = p.hash;
+ int k = h & sizeMask;
+ HashEntry n = newTable[k];
+ newTable[k] = new HashEntry(h, p.key, v, n);
+ }
+ }
+ }
+ }
+ // 头插法插入新的节点
+ int nodeIndex = node.hash & sizeMask; // add the new node
+ node.setNext(newTable[nodeIndex]);
+ newTable[nodeIndex] = node;
+ table = newTable;
+}
+```
+
+有些同学可能会对最后的两个 for 循环有疑惑,这里第一个 for 是为了寻找这样一个节点,这个节点后面的所有 next 节点的新位置都是相同的。然后把这个作为一个链表赋值到新位置。第二个 for 循环是为了把剩余的元素通过头插法插入到指定位置链表。这样实现的原因可能是基于概率统计,有深入研究的同学可以发表下意见。
+
+### 5. get
+
+到这里就很简单了,get 方法只需要两步即可。
+
+1. 计算得到 key 的存放位置。
+2. 遍历指定位置查找相同 key 的 value 值。
+
+```java
+public V get(Object key) {
+ Segment s; // manually integrate access methods to reduce overhead
+ HashEntry[] tab;
+ int h = hash(key);
+ long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
+ // 计算得到 key 的存放位置
+ if ((s = (Segment)UNSAFE.getObjectVolatile(segments, u)) != null &&
+ (tab = s.table) != null) {
+ for (HashEntry e = (HashEntry) UNSAFE.getObjectVolatile
+ (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
+ e != null; e = e.next) {
+ // 如果是链表,遍历查找到相同 key 的 value。
+ K k;
+ if ((k = e.key) == key || (e.hash == h && key.equals(k)))
+ return e.value;
+ }
+ }
+ return null;
+}
+```
+
+## 2. ConcurrentHashMap 1.8
+
+### 1. 存储结构
+
+
+
+可以发现 Java8 的 ConcurrentHashMap 相对于 Java7 来说变化比较大,不再是之前的 **Segment 数组 + HashEntry 数组 + 链表**,而是 **Node 数组 + 链表 / 红黑树**。当冲突链表达到一定长度时,链表会转换成红黑树。
+
+### 2. 初始化 initTable
+
+```java
+/**
+ * Initializes table, using the size recorded in sizeCtl.
+ */
+private final Node[] initTable() {
+ Node[] tab; int sc;
+ while ((tab = table) == null || tab.length == 0) {
+ // 如果 sizeCtl < 0 ,说明另外的线程执行CAS 成功,正在进行初始化。
+ if ((sc = sizeCtl) < 0)
+ // 让出 CPU 使用权
+ Thread.yield(); // lost initialization race; just spin
+ else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
+ try {
+ if ((tab = table) == null || tab.length == 0) {
+ int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
+ @SuppressWarnings("unchecked")
+ Node[] nt = (Node[])new Node[n];
+ table = tab = nt;
+ sc = n - (n >>> 2);
+ }
+ } finally {
+ sizeCtl = sc;
+ }
+ break;
+ }
+ }
+ return tab;
+}
+```
+
+从源码中可以发现 ConcurrentHashMap 的初始化是通过**自旋和 CAS** 操作完成的。里面需要注意的是变量 `sizeCtl` ,它的值决定着当前的初始化状态。
+
+1. -1 说明正在初始化
+2. -N 说明有N-1个线程正在进行扩容
+3. 表示 table 初始化大小,如果 table 没有初始化
+4. 表示 table 容量,如果 table 已经初始化。
+
+### 3. put
+
+直接过一遍 put 源码。
+
+```java
+public V put(K key, V value) {
+ return putVal(key, value, false);
+}
+
+/** Implementation for put and putIfAbsent */
+final V putVal(K key, V value, boolean onlyIfAbsent) {
+ // key 和 value 不能为空
+ if (key == null || value == null) throw new NullPointerException();
+ int hash = spread(key.hashCode());
+ int binCount = 0;
+ for (Node[] tab = table;;) {
+ // f = 目标位置元素
+ Node f; int n, i, fh;// fh 后面存放目标位置的元素 hash 值
+ if (tab == null || (n = tab.length) == 0)
+ // 数组桶为空,初始化数组桶(自旋+CAS)
+ tab = initTable();
+ else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
+ // 桶内为空,CAS 放入,不加锁,成功了就直接 break 跳出
+ if (casTabAt(tab, i, null,new Node(hash, key, value, null)))
+ break; // no lock when adding to empty bin
+ }
+ else if ((fh = f.hash) == MOVED)
+ tab = helpTransfer(tab, f);
+ else {
+ V oldVal = null;
+ // 使用 synchronized 加锁加入节点
+ synchronized (f) {
+ if (tabAt(tab, i) == f) {
+ // 说明是链表
+ if (fh >= 0) {
+ binCount = 1;
+ // 循环加入新的或者覆盖节点
+ for (Node e = f;; ++binCount) {
+ K ek;
+ if (e.hash == hash &&
+ ((ek = e.key) == key ||
+ (ek != null && key.equals(ek)))) {
+ oldVal = e.val;
+ if (!onlyIfAbsent)
+ e.val = value;
+ break;
+ }
+ Node pred = e;
+ if ((e = e.next) == null) {
+ pred.next = new Node(hash, key,
+ value, null);
+ break;
+ }
+ }
+ }
+ else if (f instanceof TreeBin) {
+ // 红黑树
+ Node p;
+ binCount = 2;
+ if ((p = ((TreeBin)f).putTreeVal(hash, key,
+ value)) != null) {
+ oldVal = p.val;
+ if (!onlyIfAbsent)
+ p.val = value;
+ }
+ }
+ }
+ }
+ if (binCount != 0) {
+ if (binCount >= TREEIFY_THRESHOLD)
+ treeifyBin(tab, i);
+ if (oldVal != null)
+ return oldVal;
+ break;
+ }
+ }
+ }
+ addCount(1L, binCount);
+ return null;
+}
+```
+
+1. 根据 key 计算出 hashcode 。
+
+2. 判断是否需要进行初始化。
+
+3. 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
+
+4. 如果当前位置的 `hashcode == MOVED == -1`,则需要进行扩容。
+
+5. 如果都不满足,则利用 synchronized 锁写入数据。
+
+6. 如果数量大于 `TREEIFY_THRESHOLD` 则要转换为红黑树。
+
+### 4. get
+
+get 流程比较简单,直接过一遍源码。
+
+```java
+public V get(Object key) {
+ Node[] tab; Node e, p; int n, eh; K ek;
+ // key 所在的 hash 位置
+ int h = spread(key.hashCode());
+ if ((tab = table) != null && (n = tab.length) > 0 &&
+ (e = tabAt(tab, (n - 1) & h)) != null) {
+ // 如果指定位置元素存在,头结点hash值相同
+ if ((eh = e.hash) == h) {
+ if ((ek = e.key) == key || (ek != null && key.equals(ek)))
+ // key hash 值相等,key值相同,直接返回元素 value
+ return e.val;
+ }
+ else if (eh < 0)
+ // 头结点hash值小于0,说明正在扩容或者是红黑树,find查找
+ return (p = e.find(h, key)) != null ? p.val : null;
+ while ((e = e.next) != null) {
+ // 是链表,遍历查找
+ if (e.hash == h &&
+ ((ek = e.key) == key || (ek != null && key.equals(ek))))
+ return e.val;
+ }
+ }
+ return null;
+}
+```
+
+总结一下 get 过程:
+
+1. 根据 hash 值计算位置。
+2. 查找到指定位置,如果头节点就是要找的,直接返回它的 value.
+3. 如果头节点 hash 值小于 0 ,说明正在扩容或者是红黑树,查找之。
+4. 如果是链表,遍历查找之。
+
+总结:
+
+总的来说 ConcruuentHashMap 在 Java8 中相对于 Java7 来说变化还是挺大的,
+
+## 3. 总结
+
+Java7 中 ConcruuentHashMap 使用的分段锁,也就是每一个 Segment 上同时只有一个线程可以操作,每一个 Segment 都是一个类似 HashMap 数组的结构,它可以扩容,它的冲突会转化为链表。但是 Segment 的个数一但初始化就不能改变。
+
+Java8 中的 ConcruuentHashMap 使用的 Synchronized 锁加 CAS 的机制。结构也由 Java7 中的 **Segment 数组 + HashEntry 数组 + 链表** 进化成了 **Node 数组 + 链表 / 红黑树**,Node 是类似于一个 HashEntry 的结构。它的冲突再达到一定大小时会转化成红黑树,在冲突小于一定数量时又退回链表。
+
+有些同学可能对 Synchronized 的性能存在疑问,其实 Synchronized 锁自从引入锁升级策略后,性能不再是问题,有兴趣的同学可以自己了解下 Synchronized 的**锁升级**。
\ No newline at end of file
diff --git a/docs/java/collection/HashMap.md b/docs/java/collection/HashMap.md
index c850cd57..c29d9223 100644
--- a/docs/java/collection/HashMap.md
+++ b/docs/java/collection/HashMap.md
@@ -512,7 +512,8 @@ public class HashMapDemo {
}
/**
- * 另外一种不常用的遍历方式
+ * 如果既要遍历key又要value,那么建议这种方式,因为如果先获取keySet然后再执行map.get(key),map内部会执行两次遍历。
+ * 一次是在获取keySet的时候,一次是在遍历所有key的时候。
*/
// 当我调用put(key,value)方法的时候,首先会把key和value封装到
// Entry这个静态内部类对象中,把Entry对象再添加到数组中,所以我们想获取
diff --git a/docs/java/collection/Java集合框架常见面试题.md b/docs/java/collection/Java集合框架常见面试题.md
index c5280d53..71e89ac8 100644
--- a/docs/java/collection/Java集合框架常见面试题.md
+++ b/docs/java/collection/Java集合框架常见面试题.md
@@ -1,59 +1,198 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
-- [剖析面试最常见问题之Java集合框架](#剖析面试最常见问题之java集合框架)
- - [说说List,Set,Map三者的区别?](#说说listsetmap三者的区别)
- - [Arraylist 与 LinkedList 区别?](#arraylist-与-linkedlist-区别)
- - [补充内容:RandomAccess接口](#补充内容randomaccess接口)
- - [补充内容:双向链表和双向循环链表](#补充内容双向链表和双向循环链表)
- - [ArrayList 与 Vector 区别呢?为什么要用Arraylist取代Vector呢?](#arraylist-与-vector-区别呢为什么要用arraylist取代vector呢)
- - [说一说 ArrayList 的扩容机制吧](#说一说-arraylist-的扩容机制吧)
- - [HashMap 和 Hashtable 的区别](#hashmap-和-hashtable-的区别)
- - [HashMap 和 HashSet区别](#hashmap-和-hashset区别)
- - [HashSet如何检查重复](#hashset如何检查重复)
- - [HashMap的底层实现](#hashmap的底层实现)
- - [JDK1.8之前](#jdk18之前)
- - [JDK1.8之后](#jdk18之后)
- - [HashMap 的长度为什么是2的幂次方](#hashmap-的长度为什么是2的幂次方)
- - [HashMap 多线程操作导致死循环问题](#hashmap-多线程操作导致死循环问题)
- - [ConcurrentHashMap 和 Hashtable 的区别](#concurrenthashmap-和-hashtable-的区别)
- - [ConcurrentHashMap线程安全的具体实现方式/底层具体实现](#concurrenthashmap线程安全的具体实现方式底层具体实现)
- - [JDK1.7(上面有示意图)](#jdk17上面有示意图)
- - [JDK1.8 (上面有示意图)](#jdk18-上面有示意图)
- - [comparable 和 Comparator的区别](#comparable-和-comparator的区别)
- - [Comparator定制排序](#comparator定制排序)
- - [重写compareTo方法实现按年龄来排序](#重写compareto方法实现按年龄来排序)
- - [集合框架底层数据结构总结](#集合框架底层数据结构总结)
- - [Collection](#collection)
- - [1. List](#1-list)
- - [2. Set](#2-set)
- - [Map](#map)
- - [如何选用集合?](#如何选用集合)
+- [1. 剖析面试最常见问题之 Java 集合框架](#1-剖析面试最常见问题之-java-集合框架)
+ - [1.1. 集合概述](#11-集合概述)
+ - [1.1.1. Java 集合概览](#111-java-集合概览)
+ - [1.1.2. 说说 List,Set,Map 三者的区别?](#112-说说-listsetmap-三者的区别)
+ - [1.1.3. 集合框架底层数据结构总结](#113-集合框架底层数据结构总结)
+ - [1.1.3.1. List](#1131-list)
+ - [1.1.3.2. Set](#1132-set)
+ - [1.1.3.3. Map](#1133-map)
+ - [1.1.4. 如何选用集合?](#114-如何选用集合)
+ - [1.1.5. 为什么要使用集合?](#115-为什么要使用集合)
+ - [1.1.6. Iterator 迭代器](#116-iterator-迭代器)
+ - [1.1.6.1. 迭代器 Iterator 是什么?](#1161-迭代器-iterator-是什么)
+ - [1.1.6.2. 迭代器 Iterator 有啥用?](#1162-迭代器-iterator-有啥用)
+ - [1.1.6.3. 如何使用?](#1163-如何使用)
+ - [1.1.7. 有哪些集合是线程不安全的?怎么解决呢?](#117-有哪些集合是线程不安全的怎么解决呢)
+ - [1.2. Collection 子接口之 List](#12-collection-子接口之-list)
+ - [1.2.1. Arraylist 和 Vector 的区别?](#121-arraylist-和-vector-的区别)
+ - [1.2.2. Arraylist 与 LinkedList 区别?](#122-arraylist-与-linkedlist-区别)
+ - [1.2.2.1. 补充内容:双向链表和双向循环链表](#1221-补充内容双向链表和双向循环链表)
+ - [1.2.2.2. 补充内容:RandomAccess 接口](#1222-补充内容randomaccess-接口)
+ - [1.2.3. 说一说 ArrayList 的扩容机制吧](#123-说一说-arraylist-的扩容机制吧)
+ - [1.3. Collection 子接口之 Set](#13-collection-子接口之-set)
+ - [1.3.1. comparable 和 Comparator 的区别](#131-comparable-和-comparator-的区别)
+ - [1.3.1.1. Comparator 定制排序](#1311-comparator-定制排序)
+ - [1.3.1.2. 重写 compareTo 方法实现按年龄来排序](#1312-重写-compareto-方法实现按年龄来排序)
+ - [1.3.2. 无序性和不可重复性的含义是什么](#132-无序性和不可重复性的含义是什么)
+ - [1.3.3. 比较 HashSet、LinkedHashSet 和 TreeSet 三者的异同](#133-比较-hashsetlinkedhashset-和-treeset-三者的异同)
+ - [1.4. Map 接口](#14-map-接口)
+ - [1.4.1. HashMap 和 Hashtable 的区别](#141-hashmap-和-hashtable-的区别)
+ - [1.4.2. HashMap 和 HashSet 区别](#142-hashmap-和-hashset-区别)
+ - [1.4.3. HashMap 和 TreeMap 区别](#143-hashmap-和-treemap-区别)
+ - [1.4.4. HashSet 如何检查重复](#144-hashset-如何检查重复)
+ - [1.4.5. HashMap 的底层实现](#145-hashmap-的底层实现)
+ - [1.4.5.1. JDK1.8 之前](#1451-jdk18-之前)
+ - [1.4.5.2. JDK1.8 之后](#1452-jdk18-之后)
+ - [1.4.6. HashMap 的长度为什么是 2 的幂次方](#146-hashmap-的长度为什么是-2-的幂次方)
+ - [1.4.7. HashMap 多线程操作导致死循环问题](#147-hashmap-多线程操作导致死循环问题)
+ - [1.4.8. HashMap 有哪几种常见的遍历方式?](#148-hashmap-有哪几种常见的遍历方式)
+ - [1.4.9. ConcurrentHashMap 和 Hashtable 的区别](#149-concurrenthashmap-和-hashtable-的区别)
+ - [1.4.10. ConcurrentHashMap 线程安全的具体实现方式/底层具体实现](#1410-concurrenthashmap-线程安全的具体实现方式底层具体实现)
+ - [1.4.10.1. JDK1.7(上面有示意图)](#14101-jdk17上面有示意图)
+ - [1.4.10.2. JDK1.8 (上面有示意图)](#14102-jdk18-上面有示意图)
+ - [1.5. Collections 工具类](#15-collections-工具类)
+ - [1.5.1. 排序操作](#151-排序操作)
+ - [1.5.2. 查找,替换操作](#152-查找替换操作)
+ - [1.5.3. 同步控制](#153-同步控制)
+ - [1.6. 其他重要问题](#16-其他重要问题)
+ - [1.6.1. 什么是快速失败(fail-fast)?](#161-什么是快速失败fail-fast)
+ - [1.6.2. 什么是安全失败(fail-safe)呢?](#162-什么是安全失败fail-safe呢)
+ - [1.6.3. Arrays.asList()避坑指南](#163-arraysaslist避坑指南)
+ - [1.6.3.1. 简介](#1631-简介)
+ - [1.6.3.2. 《阿里巴巴 Java 开发手册》对其的描述](#1632-阿里巴巴-java-开发手册对其的描述)
+ - [1.6.3.3. 使用时的注意事项总结](#1633-使用时的注意事项总结)
-# 剖析面试最常见问题之Java集合框架
-## 说说List,Set,Map三者的区别?
+# 1. 剖析面试最常见问题之 Java 集合框架
-- **List(对付顺序的好帮手):** List接口存储一组不唯一(可以有多个元素引用相同的对象),有序的对象
-- **Set(注重独一无二的性质):** 不允许重复的集合。不会有多个元素引用相同的对象。
-- **Map(用Key来搜索的专家):** 使用键值对存储。Map会维护与Key有关联的值。两个Key可以引用相同的对象,但Key不能重复,典型的Key是String类型,但也可以是任何对象。
+## 1.1. 集合概述
-## Arraylist 与 LinkedList 区别?
+### 1.1.1. Java 集合概览
-- **1. 是否保证线程安全:** `ArrayList` 和 `LinkedList` 都是不同步的,也就是不保证线程安全;
+从下图可以看出,在 Java 中除了以 `Map` 结尾的类之外, 其他类都实现了 `Collection` 接口。
-- **2. 底层数据结构:** `Arraylist` 底层使用的是 **`Object` 数组**;`LinkedList` 底层使用的是 **双向链表** 数据结构(JDK1.6之前为循环链表,JDK1.7取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!)
+并且,以 `Map` 结尾的类都实现了 `Map` 接口。
-- **3. 插入和删除是否受元素位置的影响:** ① **`ArrayList` 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。** 比如:执行`add(E e) `方法的时候, `ArrayList` 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element) `)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② **`LinkedList` 采用链表存储,所以对于`add(�E e)`方法的插入,删除元素时间复杂度不受元素位置的影响,近似 O(1),如果是要在指定位置`i`插入和删除元素的话(`(add(int index, E element)`) 时间复杂度近似为`o(n))`因为需要先移动到指定位置再插入。**
+
-- **4. 是否支持快速随机访问:** `LinkedList` 不支持高效的随机元素访问,而 `ArrayList` 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index) `方法)。
+### 1.1.2. 说说 List,Set,Map 三者的区别?
-- **5. 内存空间占用:** ArrayList的空 间浪费主要体现在在list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
+- `List`(对付顺序的好帮手): 存储的元素是有序的、可重复的。
+- `Set`(注重独一无二的性质): 存储的元素是无序的、不可重复的。
+- `Map`(用 Key 来搜索的专家): 使用键值对(kye-value)存储,类似于数学上的函数 y=f(x),“x”代表 key,"y"代表 value,Key 是无序的、不可重复的,value 是无序的、可重复的,每个键最多映射到一个值。
-### **补充内容:RandomAccess接口**
+### 1.1.3. 集合框架底层数据结构总结
+
+先来看一下 `Collection` 接口下面的集合。
+
+#### 1.1.3.1. List
+
+- `Arraylist`: `Object[]`数组
+- `Vector`:`Object[]`数组
+- `LinkedList`: 双向链表(JDK1.6 之前为循环链表,JDK1.7 取消了循环)
+
+#### 1.1.3.2. Set
+
+- `HashSet`(无序,唯一): 基于 `HashMap` 实现的,底层采用 `HashMap` 来保存元素
+- `LinkedHashSet`:`LinkedHashSet` 是 `HashSet` 的子类,并且其内部是通过 `LinkedHashMap` 来实现的。有点类似于我们之前说的 `LinkedHashMap` 其内部是基于 `HashMap` 实现一样,不过还是有一点点区别的
+- `TreeSet`(有序,唯一): 红黑树(自平衡的排序二叉树)
+
+再来看看 `Map` 接口下面的集合。
+
+#### 1.1.3.3. Map
+
+- `HashMap`: JDK1.8 之前 HashMap 由数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间
+- `LinkedHashMap`: `LinkedHashMap` 继承自 `HashMap`,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,`LinkedHashMap` 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。详细可以查看:[《LinkedHashMap 源码详细分析(JDK1.8)》](https://www.imooc.com/article/22931)
+- `Hashtable`: 数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的
+- `TreeMap`: 红黑树(自平衡的排序二叉树)
+
+### 1.1.4. 如何选用集合?
+
+主要根据集合的特点来选用,比如我们需要根据键值获取到元素值时就选用 `Map` 接口下的集合,需要排序时选择 `TreeMap`,不需要排序时就选择 `HashMap`,需要保证线程安全就选用 `ConcurrentHashMap`。
+
+当我们只需要存放元素值时,就选择实现`Collection` 接口的集合,需要保证元素唯一时选择实现 `Set` 接口的集合比如 `TreeSet` 或 `HashSet`,不需要就选择实现 `List` 接口的比如 `ArrayList` 或 `LinkedList`,然后再根据实现这些接口的集合的特点来选用。
+
+### 1.1.5. 为什么要使用集合?
+
+当我们需要保存一组类型相同的数据的时候,我们应该是用一个容器来保存,这个容器就是数组,但是,使用数组存储对象具有一定的弊端,
+因为我们在实际开发中,存储的数据的类型是多种多样的,于是,就出现了“集合”,集合同样也是用来存储多个数据的。
+
+数组的缺点是一旦声明之后,长度就不可变了;同时,声明数组时的数据类型也决定了该数组存储的数据的类型;而且,数组存储的数据是有序的、可重复的,特点单一。
+但是集合提高了数据存储的灵活性,Java 集合不仅可以用来存储不同类型不同数量的对象,还可以保存具有映射关系的数据
+
+### 1.1.6. Iterator 迭代器
+
+#### 1.1.6.1. 迭代器 Iterator 是什么?
+
+```java
+public interface Iterator {
+ //集合中是否还有元素
+ boolean hasNext();
+ //获得集合中的下一个元素
+ E next();
+ ......
+}
+```
+
+`Iterator` 对象称为迭代器(设计模式的一种),迭代器可以对集合进行遍历,但每一个集合内部的数据结构可能是不尽相同的,所以每一个集合存和取都很可能是不一样的,虽然我们可以人为地在每一个类中定义 `hasNext()` 和 `next()` 方法,但这样做会让整个集合体系过于臃肿。于是就有了迭代器。
+
+迭代器是将这样的方法抽取出接口,然后在每个类的内部,定义自己迭代方式,这样做就规定了整个集合体系的遍历方式都是 `hasNext()`和`next()`方法,使用者不用管怎么实现的,会用即可。迭代器的定义为:提供一种方法访问一个容器对象中各个元素,而又不需要暴露该对象的内部细节。
+
+#### 1.1.6.2. 迭代器 Iterator 有啥用?
+
+`Iterator` 主要是用来遍历集合用的,它的特点是更加安全,因为它可以确保,在当前遍历的集合元素被更改的时候,就会抛出 `ConcurrentModificationException` 异常。
+
+#### 1.1.6.3. 如何使用?
+
+我们通过使用迭代器来遍历 `HashMap`,演示一下 迭代器 Iterator 的使用。
+
+```java
+
+Map map = new HashMap();
+map.put(1, "Java");
+map.put(2, "C++");
+map.put(3, "PHP");
+Iterator> iterator = map.entrySet().iterator();
+while (iterator.hasNext()) {
+ Map.Entry entry = iterator.next();
+ System.out.println(entry.getKey() + entry.getValue());
+}
+```
+
+### 1.1.7. 有哪些集合是线程不安全的?怎么解决呢?
+
+我们常用的 `Arraylist` ,`LinkedList`,`Hashmap`,`HashSet`,`TreeSet`,`TreeMap`,`PriorityQueue` 都不是线程安全的。解决办法很简单,可以使用线程安全的集合来代替。
+
+如果你要使用线程安全的集合的话, `java.util.concurrent` 包中提供了很多并发容器供你使用:
+
+1. `ConcurrentHashMap`: 可以看作是线程安全的 `HashMap`
+2. `CopyOnWriteArrayList`:可以看作是线程安全的 `ArrayList`,在读多写少的场合性能非常好,远远好于 `Vector`.
+3. `ConcurrentLinkedQueue`:高效的并发队列,使用链表实现。可以看做一个线程安全的 `LinkedList`,这是一个非阻塞队列。
+4. `BlockingQueue`: 这是一个接口,JDK 内部通过链表、数组等方式实现了这个接口。表示阻塞队列,非常适合用于作为数据共享的通道。
+5. `ConcurrentSkipListMap` :跳表的实现。这是一个`Map`,使用跳表的数据结构进行快速查找。
+
+## 1.2. Collection 子接口之 List
+
+### 1.2.1. Arraylist 和 Vector 的区别?
+
+1. ArrayList 是 List 的主要实现类,底层使用 Object[ ]存储,适用于频繁的查找工作,线程不安全 ;
+2. Vector 是 List 的古老实现类,底层使用 Object[ ]存储,线程安全的。
+
+### 1.2.2. Arraylist 与 LinkedList 区别?
+
+1. **是否保证线程安全:** `ArrayList` 和 `LinkedList` 都是不同步的,也就是不保证线程安全;
+2. **底层数据结构:** `Arraylist` 底层使用的是 **`Object` 数组**;`LinkedList` 底层使用的是 **双向链表** 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!)
+3. **插入和删除是否受元素位置的影响:** ① **`ArrayList` 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。** 比如:执行`add(E e)`方法的时候, `ArrayList` 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element)`)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② **`LinkedList` 采用链表存储,所以对于`add(E e)`方法的插入,删除元素时间复杂度不受元素位置的影响,近似 O(1),如果是要在指定位置`i`插入和删除元素的话(`(add(int index, E element)`) 时间复杂度近似为`o(n))`因为需要先移动到指定位置再插入。**
+4. **是否支持快速随机访问:** `LinkedList` 不支持高效的随机元素访问,而 `ArrayList` 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index)`方法)。
+5. **内存空间占用:** ArrayList 的空 间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
+
+#### 1.2.2.1. 补充内容:双向链表和双向循环链表
+
+**双向链表:** 包含两个指针,一个 prev 指向前一个节点,一个 next 指向后一个节点。
+
+> 另外推荐一篇把双向链表讲清楚的文章:[https://juejin.im/post/5b5d1a9af265da0f47352f14](https://juejin.im/post/5b5d1a9af265da0f47352f14)
+
+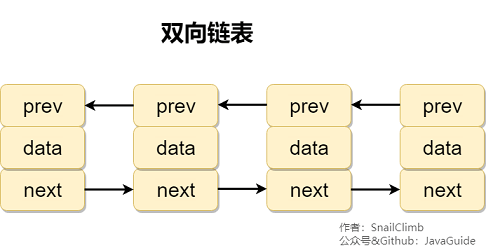
+
+**双向循环链表:** 最后一个节点的 next 指向 head,而 head 的 prev 指向最后一个节点,构成一个环。
+
+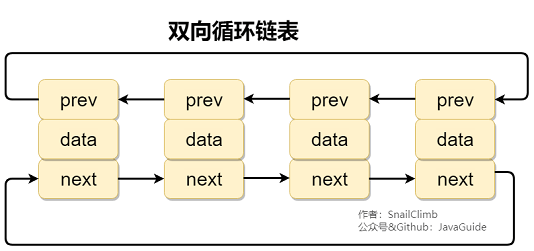
+
+#### 1.2.2.2. 补充内容:RandomAccess 接口
```java
public interface RandomAccess {
@@ -62,7 +201,7 @@ public interface RandomAccess {
查看源码我们发现实际上 `RandomAccess` 接口中什么都没有定义。所以,在我看来 `RandomAccess` 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
-在 `binarySearch(`)方法中,它要判断传入的list 是否 `RamdomAccess` 的实例,如果是,调用`indexedBinarySearch()`方法,如果不是,那么调用`iteratorBinarySearch()`方法
+在 `binarySearch()` 方法中,它要判断传入的 list 是否 `RamdomAccess` 的实例,如果是,调用`indexedBinarySearch()`方法,如果不是,那么调用`iteratorBinarySearch()`方法
```java
public static
@@ -74,228 +213,22 @@ public interface RandomAccess {
}
```
-`ArrayList` 实现了 `RandomAccess` 接口, 而 `LinkedList` 没有实现。为什么呢?我觉得还是和底层数据结构有关!`ArrayList` 底层是数组,而 `LinkedList` 底层是链表。数组天然支持随机访问,时间复杂度为 O(1),所以称为快速随机访问。链表需要遍历到特定位置才能访问特定位置的元素,时间复杂度为 O(n),所以不支持快速随机访问。,`ArrayList` 实现了 `RandomAccess` 接口,就表明了他具有快速随机访问功能。 `RandomAccess` 接口只是标识,并不是说 `ArrayList` 实现 `RandomAccess` 接口才具有快速随机访问功能的!
+`ArrayList` 实现了 `RandomAccess` 接口, 而 `LinkedList` 没有实现。为什么呢?我觉得还是和底层数据结构有关!`ArrayList` 底层是数组,而 `LinkedList` 底层是链表。数组天然支持随机访问,时间复杂度为 O(1),所以称为快速随机访问。链表需要遍历到特定位置才能访问特定位置的元素,时间复杂度为 O(n),所以不支持快速随机访问。,`ArrayList` 实现了 `RandomAccess` 接口,就表明了他具有快速随机访问功能。 `RandomAccess` 接口只是标识,并不是说 `ArrayList` 实现 `RandomAccess` 接口才具有快速随机访问功能的!
-**下面再总结一下 list 的遍历方式选择:**
+### 1.2.3. 说一说 ArrayList 的扩容机制吧
-- 实现了 `RandomAccess` 接口的list,优先选择普通 for 循环 ,其次 foreach,
-- 未实现 `RandomAccess`接口的list,优先选择iterator遍历(foreach遍历底层也是通过iterator实现的,),大size的数据,千万不要使用普通for循环
+详见笔主的这篇文章:[通过源码一步一步分析 ArrayList 扩容机制](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/ArrayList-Grow.md)
-### 补充内容:双向链表和双向循环链表
+## 1.3. Collection 子接口之 Set
-**双向链表:** 包含两个指针,一个prev指向前一个节点,一个next指向后一个节点。
+### 1.3.1. comparable 和 Comparator 的区别
-
+- `comparable` 接口实际上是出自`java.lang`包 它有一个 `compareTo(Object obj)`方法用来排序
+- `comparator`接口实际上是出自 java.util 包它有一个`compare(Object obj1, Object obj2)`方法用来排序
-**双向循环链表:** 最后一个节点的 next 指向head,而 head 的prev指向最后一个节点,构成一个环。
+一般我们需要对一个集合使用自定义排序时,我们就要重写`compareTo()`方法或`compare()`方法,当我们需要对某一个集合实现两种排序方式,比如一个 song 对象中的歌名和歌手名分别采用一种排序方法的话,我们可以重写`compareTo()`方法和使用自制的`Comparator`方法或者以两个 Comparator 来实现歌名排序和歌星名排序,第二种代表我们只能使用两个参数版的 `Collections.sort()`.
-
-
-## ArrayList 与 Vector 区别呢?为什么要用Arraylist取代Vector呢?
-
-`Vector`类的所有方法都是同步的。可以由两个线程安全地访问一个Vector对象、但是一个线程访问Vector的话代码要在同步操作上耗费大量的时间。
-
-`Arraylist`不是同步的,所以在不需要保证线程安全时建议使用Arraylist。
-
-## 说一说 ArrayList 的扩容机制吧
-
-详见笔主的这篇文章:[通过源码一步一步分析ArrayList 扩容机制](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/ArrayList-Grow.md)
-
-## HashMap 和 Hashtable 的区别
-
-1. **线程是否安全:** HashMap 是非线程安全的,HashTable 是线程安全的;HashTable 内部的方法基本都经过`synchronized` 修饰。(如果你要保证线程安全的话就使用 ConcurrentHashMap 吧!);
-2. **效率:** 因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;
-3. **对Null key 和Null value的支持:** HashMap 中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null。。但是在 HashTable 中 put 进的键值只要有一个 null,直接抛出 NullPointerException。
-4. **初始容量大小和每次扩充容量大小的不同 :** ①创建时如果不指定容量初始值,Hashtable 默认的初始大小为11,之后每次扩充,容量变为原来的2n+1。HashMap 默认的初始化大小为16。之后每次扩充,容量变为原来的2倍。②创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为2的幂次方大小(HashMap 中的`tableSizeFor()`方法保证,下面给出了源代码)。也就是说 HashMap 总是使用2的幂作为哈希表的大小,后面会介绍到为什么是2的幂次方。
-5. **底层数据结构:** JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
-
-**HashMap 中带有初始容量的构造函数:**
-
-```java
- public HashMap(int initialCapacity, float loadFactor) {
- if (initialCapacity < 0)
- throw new IllegalArgumentException("Illegal initial capacity: " +
- initialCapacity);
- if (initialCapacity > MAXIMUM_CAPACITY)
- initialCapacity = MAXIMUM_CAPACITY;
- if (loadFactor <= 0 || Float.isNaN(loadFactor))
- throw new IllegalArgumentException("Illegal load factor: " +
- loadFactor);
- this.loadFactor = loadFactor;
- this.threshold = tableSizeFor(initialCapacity);
- }
- public HashMap(int initialCapacity) {
- this(initialCapacity, DEFAULT_LOAD_FACTOR);
- }
-```
-
-下面这个方法保证了 HashMap 总是使用2的幂作为哈希表的大小。
-
-```java
- /**
- * Returns a power of two size for the given target capacity.
- */
- static final int tableSizeFor(int cap) {
- int n = cap - 1;
- n |= n >>> 1;
- n |= n >>> 2;
- n |= n >>> 4;
- n |= n >>> 8;
- n |= n >>> 16;
- return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
- }
-```
-
-## HashMap 和 HashSet区别
-
-如果你看过 `HashSet` 源码的话就应该知道:HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码非常非常少,因为除了 `clone() `、`writeObject()`、`readObject()`是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法。
-
-| HashMap | HashSet |
-| :------------------------------: | :----------------------------------------------------------: |
-| 实现了Map接口 | 实现Set接口 |
-| 存储键值对 | 仅存储对象 |
-| 调用 `put()`向map中添加元素 | 调用 `add()`方法向Set中添加元素 |
-| HashMap使用键(Key)计算Hashcode | HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性, |
-
-## HashSet如何检查重复
-
-当你把对象加入`HashSet`时,HashSet会先计算对象的`hashcode`值来判断对象加入的位置,同时也会与其他加入的对象的hashcode值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调用`equals()`方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让加入操作成功。(摘自我的Java启蒙书《Head fist java》第二版)
-
-**hashCode()与equals()的相关规定:**
-
-1. 如果两个对象相等,则hashcode一定也是相同的
-2. 两个对象相等,对两个equals方法返回true
-3. 两个对象有相同的hashcode值,它们也不一定是相等的
-4. 综上,equals方法被覆盖过,则hashCode方法也必须被覆盖
-5. hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写hashCode(),则该class的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
-
-**==与equals的区别**
-
-1. ==是判断两个变量或实例是不是指向同一个内存空间 equals是判断两个变量或实例所指向的内存空间的值是不是相同
-2. ==是指对内存地址进行比较 equals()是对字符串的内容进行比较
-3. ==指引用是否相同 equals()指的是值是否相同
-
-## HashMap的底层实现
-
-### JDK1.8之前
-
-JDK1.8 之前 `HashMap` 底层是 **数组和链表** 结合在一起使用也就是 **链表散列**。**HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。**
-
-**所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。**
-
-**JDK 1.8 HashMap 的 hash 方法源码:**
-
-JDK 1.8 的 hash方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
-
-```java
- static final int hash(Object key) {
- int h;
- // key.hashCode():返回散列值也就是hashcode
- // ^ :按位异或
- // >>>:无符号右移,忽略符号位,空位都以0补齐
- return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
- }
-```
-
-对比一下 JDK1.7的 HashMap 的 hash 方法源码.
-
-```java
-static int hash(int h) {
- // This function ensures that hashCodes that differ only by
- // constant multiples at each bit position have a bounded
- // number of collisions (approximately 8 at default load factor).
-
- h ^= (h >>> 20) ^ (h >>> 12);
- return h ^ (h >>> 7) ^ (h >>> 4);
-}
-```
-
-相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
-
-所谓 **“拉链法”** 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
-
-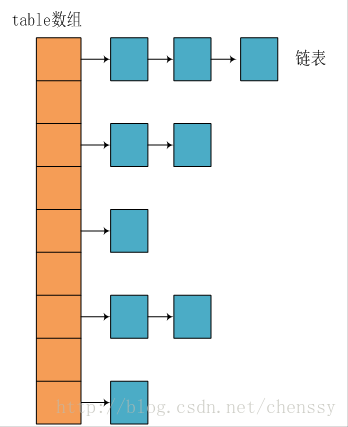
-
-### JDK1.8之后
-
-相比于之前的版本, JDK1.8之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
-
-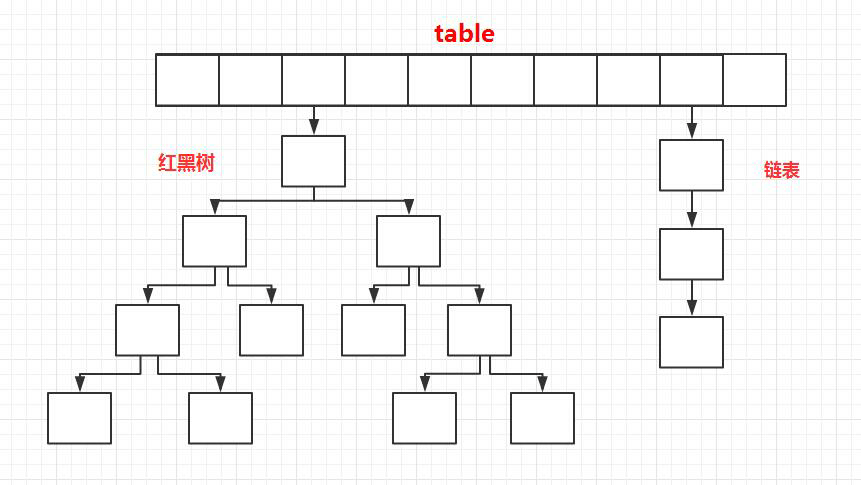
-
-> TreeMap、TreeSet以及JDK1.8之后的HashMap底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
-
-**推荐阅读:**
-
-- 《Java 8系列之重新认识HashMap》 :
-
-## HashMap 的长度为什么是2的幂次方
-
-为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648到2147483647,前后加起来大概40亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ `(n - 1) & hash`”。(n代表数组长度)。这也就解释了 HashMap 的长度为什么是2的幂次方。
-
-**这个算法应该如何设计呢?**
-
-我们首先可能会想到采用%取余的操作来实现。但是,重点来了:**“取余(%)操作中如果除数是2的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是2的 n 次方;)。”** 并且 **采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是2的幂次方。**
-
-## HashMap 多线程操作导致死循环问题
-
-主要原因在于 并发下的Rehash 会造成元素之间会形成一个循环链表。不过,jdk 1.8 后解决了这个问题,但是还是不建议在多线程下使用 HashMap,因为多线程下使用 HashMap 还是会存在其他问题比如数据丢失。并发环境下推荐使用 ConcurrentHashMap 。
-
-详情请查看:
-
-## ConcurrentHashMap 和 Hashtable 的区别
-
-ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
-
-- **底层数据结构:** JDK1.7的 ConcurrentHashMap 底层采用 **分段的数组+链表** 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 **数组+链表** 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
-- **实现线程安全的方式(重要):** ① **在JDK1.7的时候,ConcurrentHashMap(分段锁)** 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 **到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6以后 对 synchronized锁做了很多优化)** 整个看起来就像是优化过且线程安全的 HashMap,虽然在JDK1.8中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② **Hashtable(同一把锁)** :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
-
-**两者的对比图:**
-
-图片来源:
-
-**HashTable:**
-
-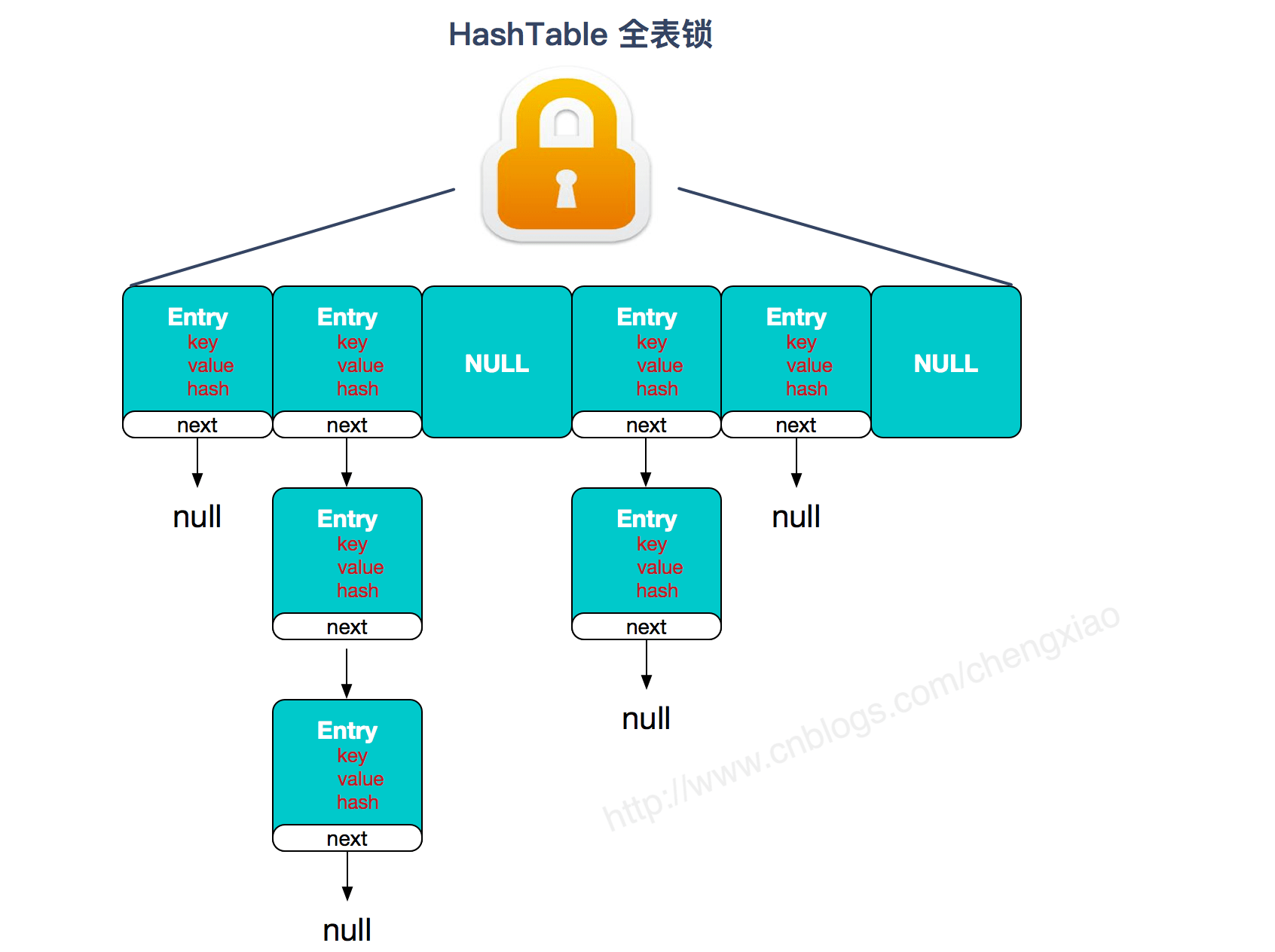
-
-**JDK1.7的ConcurrentHashMap:**
-
-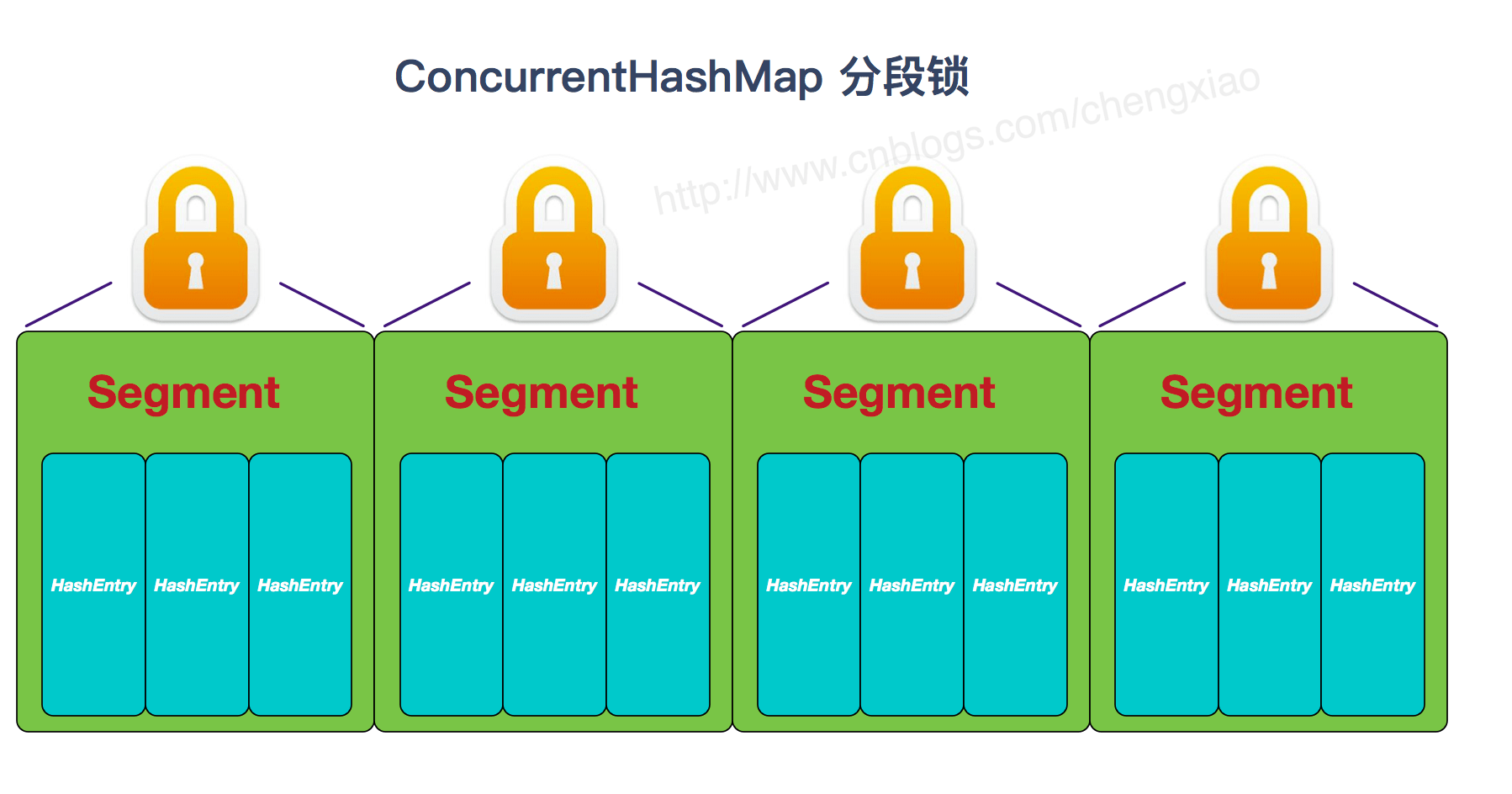
-
-**JDK1.8的ConcurrentHashMap(TreeBin: 红黑二叉树节点 Node: 链表节点):**
-
-
-
-## ConcurrentHashMap线程安全的具体实现方式/底层具体实现
-
-### JDK1.7(上面有示意图)
-
-首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
-
-**ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成**。
-
-Segment 实现了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。HashEntry 用于存储键值对数据。
-
-```java
-static class Segment extends ReentrantLock implements Serializable {
-}
-```
-
-一个 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构和HashMap类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个HashEntry数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment的锁。
-
-### JDK1.8 (上面有示意图)
-
-ConcurrentHashMap取消了Segment分段锁,采用CAS和synchronized来保证并发安全。数据结构跟HashMap1.8的结构类似,数组+链表/红黑二叉树。Java 8在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为O(N))转换为红黑树(寻址时间复杂度为O(log(N)))
-
-synchronized只锁定当前链表或红黑二叉树的首节点,这样只要hash不冲突,就不会产生并发,效率又提升N倍。
-
-## comparable 和 Comparator的区别
-
-- comparable接口实际上是出自java.lang包 它有一个 `compareTo(Object obj)`方法用来排序
-- comparator接口实际上是出自 java.util 包它有一个`compare(Object obj1, Object obj2)`方法用来排序
-
-一般我们需要对一个集合使用自定义排序时,我们就要重写`compareTo()`方法或`compare()`方法,当我们需要对某一个集合实现两种排序方式,比如一个song对象中的歌名和歌手名分别采用一种排序方法的话,我们可以重写`compareTo()`方法和使用自制的Comparator方法或者以两个Comparator来实现歌名排序和歌星名排序,第二种代表我们只能使用两个参数版的 `Collections.sort()`.
-
-### Comparator定制排序
+#### 1.3.1.1. Comparator 定制排序
```java
ArrayList arrayList = new ArrayList();
@@ -343,13 +276,12 @@ Collections.sort(arrayList):
[7, 4, 3, 3, -1, -5, -7, -9]
```
-### 重写compareTo方法实现按年龄来排序
+#### 1.3.1.2. 重写 compareTo 方法实现按年龄来排序
```java
// person对象没有实现Comparable接口,所以必须实现,这样才不会出错,才可以使treemap中的数据按顺序排列
// 前面一个例子的String类已经默认实现了Comparable接口,详细可以查看String类的API文档,另外其他
// 像Integer类等都已经实现了Comparable接口,所以不需要另外实现了
-
public class Person implements Comparable {
private String name;
private int age;
@@ -377,17 +309,17 @@ public class Person implements Comparable {
}
/**
- * TODO重写compareTo方法实现按年龄来排序
+ * T重写compareTo方法实现按年龄来排序
*/
@Override
public int compareTo(Person o) {
- // TODO Auto-generated method stub
if (this.age > o.getAge()) {
return 1;
- } else if (this.age < o.getAge()) {
+ }
+ if (this.age < o.getAge()) {
return -1;
}
- return age;
+ return 0;
}
}
@@ -418,39 +350,497 @@ Output:
30-张三
```
-## 集合框架底层数据结构总结
+### 1.3.2. 无序性和不可重复性的含义是什么
-### Collection
+1、什么是无序性?无序性不等于随机性 ,无序性是指存储的数据在底层数组中并非按照数组索引的顺序添加 ,而是根据数据的哈希值决定的。
-#### 1. List
+2、什么是不可重复性?不可重复性是指添加的元素按照 equals()判断时 ,返回 false,需要同时重写 equals()方法和 HashCode()方法。
-- **Arraylist:** Object数组
-- **Vector:** Object数组
-- **LinkedList:** 双向链表(JDK1.6之前为循环链表,JDK1.7取消了循环)
+### 1.3.3. 比较 HashSet、LinkedHashSet 和 TreeSet 三者的异同
-#### 2. Set
+HashSet 是 Set 接口的主要实现类 ,HashSet 的底层是 HashMap,线程不安全的,可以存储 null 值;
-- **HashSet(无序,唯一):** 基于 HashMap 实现的,底层采用 HashMap 来保存元素
-- **LinkedHashSet:** LinkedHashSet 继承于 HashSet,并且其内部是通过 LinkedHashMap 来实现的。有点类似于我们之前说的LinkedHashMap 其内部是基于 HashMap 实现一样,不过还是有一点点区别的
-- **TreeSet(有序,唯一):** 红黑树(自平衡的排序二叉树)
+LinkedHashSet 是 HashSet 的子类,能够按照添加的顺序遍历;
-### Map
+TreeSet 底层使用红黑树,能够按照添加元素的顺序进行遍历,排序的方式有自然排序和定制排序。
-- **HashMap:** JDK1.8之前HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间
-- **LinkedHashMap:** LinkedHashMap 继承自 HashMap,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,LinkedHashMap 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。详细可以查看:[《LinkedHashMap 源码详细分析(JDK1.8)》](https://www.imooc.com/article/22931)
-- **Hashtable:** 数组+链表组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的
-- **TreeMap:** 红黑树(自平衡的排序二叉树)
+## 1.4. Map 接口
-## 如何选用集合?
+### 1.4.1. HashMap 和 Hashtable 的区别
-主要根据集合的特点来选用,比如我们需要根据键值获取到元素值时就选用Map接口下的集合,需要排序时选择TreeMap,不需要排序时就选择HashMap,需要保证线程安全就选用ConcurrentHashMap.当我们只需要存放元素值时,就选择实现Collection接口的集合,需要保证元素唯一时选择实现Set接口的集合比如TreeSet或HashSet,不需要就选择实现List接口的比如ArrayList或LinkedList,然后再根据实现这些接口的集合的特点来选用。
+1. **线程是否安全:** HashMap 是非线程安全的,HashTable 是线程安全的,因为 HashTable 内部的方法基本都经过`synchronized` 修饰。(如果你要保证线程安全的话就使用 ConcurrentHashMap 吧!);
+2. **效率:** 因为线程安全的问题,HashMap 要比 HashTable 效率高一点。另外,HashTable 基本被淘汰,不要在代码中使用它;
+3. **对 Null key 和 Null value 的支持:** HashMap 可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个;HashTable 不允许有 null 键和 null 值,否则会抛出 NullPointerException。
+4. **初始容量大小和每次扩充容量大小的不同 :** ① 创建时如果不指定容量初始值,Hashtable 默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1。HashMap 默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。② 创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为 2 的幂次方大小(HashMap 中的`tableSizeFor()`方法保证,下面给出了源代码)。也就是说 HashMap 总是使用 2 的幂作为哈希表的大小,后面会介绍到为什么是 2 的幂次方。
+5. **底层数据结构:** JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
-## 公众号
+**HashMap 中带有初始容量的构造函数:**
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+```java
+ public HashMap(int initialCapacity, float loadFactor) {
+ if (initialCapacity < 0)
+ throw new IllegalArgumentException("Illegal initial capacity: " +
+ initialCapacity);
+ if (initialCapacity > MAXIMUM_CAPACITY)
+ initialCapacity = MAXIMUM_CAPACITY;
+ if (loadFactor <= 0 || Float.isNaN(loadFactor))
+ throw new IllegalArgumentException("Illegal load factor: " +
+ loadFactor);
+ this.loadFactor = loadFactor;
+ this.threshold = tableSizeFor(initialCapacity);
+ }
+ public HashMap(int initialCapacity) {
+ this(initialCapacity, DEFAULT_LOAD_FACTOR);
+ }
+```
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
+下面这个方法保证了 HashMap 总是使用 2 的幂作为哈希表的大小。
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
+```java
+ /**
+ * Returns a power of two size for the given target capacity.
+ */
+ static final int tableSizeFor(int cap) {
+ int n = cap - 1;
+ n |= n >>> 1;
+ n |= n >>> 2;
+ n |= n >>> 4;
+ n |= n >>> 8;
+ n |= n >>> 16;
+ return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
+ }
+```
-
+### 1.4.2. HashMap 和 HashSet 区别
+
+如果你看过 `HashSet` 源码的话就应该知道:HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码非常非常少,因为除了 `clone()`、`writeObject()`、`readObject()`是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法。
+
+| HashMap | HashSet |
+| :--------------------------------: | :----------------------------------------------------------: |
+| 实现了 Map 接口 | 实现 Set 接口 |
+| 存储键值对 | 仅存储对象 |
+| 调用 `put()`向 map 中添加元素 | 调用 `add()`方法向 Set 中添加元素 |
+| HashMap 使用键(Key)计算 Hashcode | HashSet 使用成员对象来计算 hashcode 值,对于两个对象来说 hashcode 可能相同,所以 equals()方法用来判断对象的相等性, |
+
+### 1.4.3. HashMap 和 TreeMap 区别
+
+`TreeMap` 和`HashMap` 都继承自`AbstractMap` ,但是需要注意的是`TreeMap`它还实现了`NavigableMap`接口和`SortedMap` 接口。
+
+
+
+实现 `NavigableMap` 接口让 `TreeMap` 有了对集合内元素的搜索的能力。
+
+实现`SortMap`接口让 `TreeMap` 有了对集合中的元素根据键排序的能力。默认是按 key 的升序排序,不过我们也可以指定排序的比较器。示例代码如下:
+
+```java
+/**
+ * @author shuang.kou
+ * @createTime 2020年06月15日 17:02:00
+ */
+public class Person {
+ private Integer age;
+
+ public Person(Integer age) {
+ this.age = age;
+ }
+
+ public Integer getAge() {
+ return age;
+ }
+
+
+ public static void main(String[] args) {
+ TreeMap treeMap = new TreeMap<>(new Comparator() {
+ @Override
+ public int compare(Person person1, Person person2) {
+ int num = person1.getAge() - person2.getAge();
+ return Integer.compare(num, 0);
+ }
+ });
+ treeMap.put(new Person(3), "person1");
+ treeMap.put(new Person(18), "person2");
+ treeMap.put(new Person(35), "person3");
+ treeMap.put(new Person(16), "person4");
+ treeMap.entrySet().stream().forEach(personStringEntry -> {
+ System.out.println(personStringEntry.getValue());
+ });
+ }
+}
+```
+
+输出:
+
+```
+person1
+person4
+person2
+person3
+```
+
+可以看出,`TreeMap` 中的元素已经是按照 `Person` 的 age 字段的升序来排列了。
+
+上面,我们是通过传入匿名内部类的方式实现的,你可以将代码替换成 Lambda 表达式实现的方式:
+
+```java
+TreeMap treeMap = new TreeMap<>((person1, person2) -> {
+ int num = person1.getAge() - person2.getAge();
+ return Integer.compare(num, 0);
+});
+```
+
+**综上,相比于`HashMap`来说 `TreeMap` 主要多了对集合中的元素根据键排序的能力以及对集合内元素的搜索的能力。**
+
+### 1.4.4. HashSet 如何检查重复
+
+当你把对象加入`HashSet`时,HashSet 会先计算对象的`hashcode`值来判断对象加入的位置,同时也会与其他加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用`equals()`方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让加入操作成功。(摘自我的 Java 启蒙书《Head fist java》第二版)
+
+**hashCode()与 equals()的相关规定:**
+
+1. 如果两个对象相等,则 hashcode 一定也是相同的
+2. 两个对象相等,对两个 equals 方法返回 true
+3. 两个对象有相同的 hashcode 值,它们也不一定是相等的
+4. 综上,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖
+5. hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)。
+
+**==与 equals 的区别**
+
+对于基本类型来说,== 比较的是值是否相等;
+
+对于引用类型来说,== 比较的是两个引用是否指向同一个对象地址(两者在内存中存放的地址(堆内存地址)是否指向同一个地方);
+
+对于引用类型(包括包装类型)来说,equals 如果没有被重写,对比它们的地址是否相等;如果 equals()方法被重写(例如 String),则比较的是地址里的内容。
+
+### 1.4.5. HashMap 的底层实现
+
+#### 1.4.5.1. JDK1.8 之前
+
+JDK1.8 之前 `HashMap` 底层是 **数组和链表** 结合在一起使用也就是 **链表散列**。**HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 (n - 1) & hash 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。**
+
+**所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。**
+
+**JDK 1.8 HashMap 的 hash 方法源码:**
+
+JDK 1.8 的 hash 方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
+
+```java
+ static final int hash(Object key) {
+ int h;
+ // key.hashCode():返回散列值也就是hashcode
+ // ^ :按位异或
+ // >>>:无符号右移,忽略符号位,空位都以0补齐
+ return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
+ }
+```
+
+对比一下 JDK1.7 的 HashMap 的 hash 方法源码.
+
+```java
+static int hash(int h) {
+ // This function ensures that hashCodes that differ only by
+ // constant multiples at each bit position have a bounded
+ // number of collisions (approximately 8 at default load factor).
+
+ h ^= (h >>> 20) ^ (h >>> 12);
+ return h ^ (h >>> 7) ^ (h >>> 4);
+}
+```
+
+相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
+
+所谓 **“拉链法”** 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
+
+
+
+#### 1.4.5.2. JDK1.8 之后
+
+相比于之前的版本, JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。
+
+
+
+> TreeMap、TreeSet 以及 JDK1.8 之后的 HashMap 底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
+
+### 1.4.6. HashMap 的长度为什么是 2 的幂次方
+
+为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648 到 2147483647,前后加起来大概 40 亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个 40 亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ `(n - 1) & hash`”。(n 代表数组长度)。这也就解释了 HashMap 的长度为什么是 2 的幂次方。
+
+**这个算法应该如何设计呢?**
+
+我们首先可能会想到采用%取余的操作来实现。但是,重点来了:**“取余(%)操作中如果除数是 2 的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是 2 的 n 次方;)。”** 并且 **采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是 2 的幂次方。**
+
+### 1.4.7. HashMap 多线程操作导致死循环问题
+
+主要原因在于并发下的 Rehash 会造成元素之间会形成一个循环链表。不过,jdk 1.8 后解决了这个问题,但是还是不建议在多线程下使用 HashMap,因为多线程下使用 HashMap 还是会存在其他问题比如数据丢失。并发环境下推荐使用 ConcurrentHashMap 。
+
+详情请查看:
+
+### 1.4.8. HashMap 有哪几种常见的遍历方式?
+
+[HashMap 的 7 种遍历方式与性能分析!](https://mp.weixin.qq.com/s/Zz6mofCtmYpABDL1ap04ow)
+
+### 1.4.9. ConcurrentHashMap 和 Hashtable 的区别
+
+ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
+
+- **底层数据结构:** JDK1.7 的 ConcurrentHashMap 底层采用 **分段的数组+链表** 实现,JDK1.8 采用的数据结构跟 HashMap1.8 的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 **数组+链表** 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
+- **实现线程安全的方式(重要):** ① **在 JDK1.7 的时候,ConcurrentHashMap(分段锁)** 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 **到了 JDK1.8 的时候已经摒弃了 Segment 的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6 以后 对 synchronized 锁做了很多优化)** 整个看起来就像是优化过且线程安全的 HashMap,虽然在 JDK1.8 中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② **Hashtable(同一把锁)** :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
+
+**两者的对比图:**
+
+**HashTable:**
+
+
+
+http://www.cnblogs.com/chengxiao/p/6842045.html>
+
+**JDK1.7 的 ConcurrentHashMap:**
+
+
+
+http://www.cnblogs.com/chengxiao/p/6842045.html>
+
+**JDK1.8 的 ConcurrentHashMap:**
+
+
+
+JDK1.8 的 `ConcurrentHashMap` 不在是 **Segment 数组 + HashEntry 数组 + 链表**,而是 **Node 数组 + 链表 / 红黑树**。不过,Node 只能用于链表的情况,红黑树的情况需要使用 **`TreeNode`**。当冲突链表达到一定长度时,链表会转换成红黑树。
+
+### 1.4.10. ConcurrentHashMap 线程安全的具体实现方式/底层具体实现
+
+#### 1.4.10.1. JDK1.7(上面有示意图)
+
+首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
+
+**ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成**。
+
+Segment 实现了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。HashEntry 用于存储键值对数据。
+
+```java
+static class Segment extends ReentrantLock implements Serializable {
+}
+```
+
+一个 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构和 HashMap 类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 的锁。
+
+#### 1.4.10.2. JDK1.8 (上面有示意图)
+
+ConcurrentHashMap 取消了 Segment 分段锁,采用 CAS 和 synchronized 来保证并发安全。数据结构跟 HashMap1.8 的结构类似,数组+链表/红黑二叉树。Java 8 在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为 O(N))转换为红黑树(寻址时间复杂度为 O(log(N)))
+
+synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,效率又提升 N 倍。
+
+## 1.5. Collections 工具类
+
+Collections 工具类常用方法:
+
+1. 排序
+2. 查找,替换操作
+3. 同步控制(不推荐,需要线程安全的集合类型时请考虑使用 JUC 包下的并发集合)
+
+### 1.5.1. 排序操作
+
+```java
+void reverse(List list)//反转
+void shuffle(List list)//随机排序
+void sort(List list)//按自然排序的升序排序
+void sort(List list, Comparator c)//定制排序,由Comparator控制排序逻辑
+void swap(List list, int i , int j)//交换两个索引位置的元素
+void rotate(List list, int distance)//旋转。当distance为正数时,将list后distance个元素整体移到前面。当distance为负数时,将 list的前distance个元素整体移到后面
+```
+
+### 1.5.2. 查找,替换操作
+
+```java
+int binarySearch(List list, Object key)//对List进行二分查找,返回索引,注意List必须是有序的
+int max(Collection coll)//根据元素的自然顺序,返回最大的元素。 类比int min(Collection coll)
+int max(Collection coll, Comparator c)//根据定制排序,返回最大元素,排序规则由Comparatator类控制。类比int min(Collection coll, Comparator c)
+void fill(List list, Object obj)//用指定的元素代替指定list中的所有元素。
+int frequency(Collection c, Object o)//统计元素出现次数
+int indexOfSubList(List list, List target)//统计target在list中第一次出现的索引,找不到则返回-1,类比int lastIndexOfSubList(List source, list target).
+boolean replaceAll(List list, Object oldVal, Object newVal), 用新元素替换旧元素
+```
+
+### 1.5.3. 同步控制
+
+`Collections` 提供了多个`synchronizedXxx()`方法·,该方法可以将指定集合包装成线程同步的集合,从而解决多线程并发访问集合时的线程安全问题。
+
+我们知道 `HashSet`,`TreeSet`,`ArrayList`,`LinkedList`,`HashMap`,`TreeMap` 都是线程不安全的。`Collections` 提供了多个静态方法可以把他们包装成线程同步的集合。
+
+**最好不要用下面这些方法,效率非常低,需要线程安全的集合类型时请考虑使用 JUC 包下的并发集合。**
+
+方法如下:
+
+```java
+synchronizedCollection(Collection c) //返回指定 collection 支持的同步(线程安全的)collection。
+synchronizedList(List list)//返回指定列表支持的同步(线程安全的)List。
+synchronizedMap(Map m) //返回由指定映射支持的同步(线程安全的)Map。
+synchronizedSet(Set s) //返回指定 set 支持的同步(线程安全的)set。
+```
+
+## 1.6. 其他重要问题
+
+### 1.6.1. 什么是快速失败(fail-fast)?
+
+**快速失败(fail-fast)** 是 Java 集合的一种错误检测机制。**在使用迭代器对集合进行遍历的时候,我们在多线程下操作非安全失败(fail-safe)的集合类可能就会触发 fail-fast 机制,导致抛出 `ConcurrentModificationException` 异常。 另外,在单线程下,如果在遍历过程中对集合对象的内容进行了修改的话也会触发 fail-fast 机制。**
+
+> 注:增强 for 循环也是借助迭代器进行遍历。
+
+举个例子:多线程下,如果线程 1 正在对集合进行遍历,此时线程 2 对集合进行修改(增加、删除、修改),或者线程 1 在遍历过程中对集合进行修改,都会导致线程 1 抛出 `ConcurrentModificationException` 异常。
+
+**为什么呢?**
+
+每当迭代器使用 `hashNext()`/`next()`遍历下一个元素之前,都会检测 `modCount` 变量是否为 `expectedModCount` 值,是的话就返回遍历;否则抛出异常,终止遍历。
+
+如果我们在集合被遍历期间对其进行修改的话,就会改变 `modCount` 的值,进而导致 `modCount != expectedModCount` ,进而抛出 `ConcurrentModificationException` 异常。
+
+> 注:通过 `Iterator` 的方法修改集合的话会修改到 `expectedModCount` 的值,所以不会抛出异常。
+
+```java
+final void checkForComodification() {
+ if (modCount != expectedModCount)
+ throw new ConcurrentModificationException();
+}
+```
+
+好吧!相信大家已经搞懂了快速失败(fail-fast)机制以及它的原理。
+
+我们再来趁热打铁,看一个阿里巴巴手册相关的规定:
+
+
+
+有了前面讲的基础,我们应该知道:使用 `Iterator` 提供的 `remove` 方法,可以修改到 `expectedModCount` 的值。所以,才不会再抛出`ConcurrentModificationException` 异常。
+
+### 1.6.2. 什么是安全失败(fail-safe)呢?
+
+明白了快速失败(fail-fast)之后,安全失败(fail-safe)我们就很好理解了。
+
+采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。所以,在遍历过程中对原集合所作的修改并不能被迭代器检测到,故不会抛 `ConcurrentModificationException` 异常。
+
+### 1.6.3. Arrays.asList()避坑指南
+
+最近使用`Arrays.asList()`遇到了一些坑,然后在网上看到这篇文章:[Java Array to List Examples](http://javadevnotes.com/java-array-to-list-examples) 感觉挺不错的,但是还不是特别全面。所以,自己对于这块小知识点进行了简单的总结。
+
+#### 1.6.3.1. 简介
+
+`Arrays.asList()`在平时开发中还是比较常见的,我们可以使用它将一个数组转换为一个 List 集合。
+
+```java
+String[] myArray = { "Apple", "Banana", "Orange" };
+List myList = Arrays.asList(myArray);
+//上面两个语句等价于下面一条语句
+List myList = Arrays.asList("Apple","Banana", "Orange");
+```
+
+JDK 源码对于这个方法的说明:
+
+```java
+/**
+ *返回由指定数组支持的固定大小的列表。此方法作为基于数组和基于集合的API之间的桥梁,与 Collection.toArray()结合使用。返回的List是可序列化并实现RandomAccess接口。
+ */
+public static List asList(T... a) {
+ return new ArrayList<>(a);
+}
+```
+
+#### 1.6.3.2. 《阿里巴巴 Java 开发手册》对其的描述
+
+`Arrays.asList()`将数组转换为集合后,底层其实还是数组,《阿里巴巴 Java 开发手册》对于这个方法有如下描述:
+
+![阿里巴巴Java开发手-Arrays.asList()方法]()
+
+#### 1.6.3.3. 使用时的注意事项总结
+
+**传递的数组必须是对象数组,而不是基本类型。**
+
+`Arrays.asList()`是泛型方法,传入的对象必须是对象数组。
+
+```java
+int[] myArray = { 1, 2, 3 };
+List myList = Arrays.asList(myArray);
+System.out.println(myList.size());//1
+System.out.println(myList.get(0));//数组地址值
+System.out.println(myList.get(1));//报错:ArrayIndexOutOfBoundsException
+int [] array=(int[]) myList.get(0);
+System.out.println(array[0]);//1
+```
+
+当传入一个原生数据类型数组时,`Arrays.asList()` 的真正得到的参数就不是数组中的元素,而是数组对象本身!此时 List 的唯一元素就是这个数组,这也就解释了上面的代码。
+
+我们使用包装类型数组就可以解决这个问题。
+
+```java
+Integer[] myArray = { 1, 2, 3 };
+```
+
+**使用集合的修改方法:`add()`、`remove()`、`clear()`会抛出异常。**
+
+```java
+List myList = Arrays.asList(1, 2, 3);
+myList.add(4);//运行时报错:UnsupportedOperationException
+myList.remove(1);//运行时报错:UnsupportedOperationException
+myList.clear();//运行时报错:UnsupportedOperationException
+```
+
+`Arrays.asList()` 方法返回的并不是 `java.util.ArrayList` ,而是 `java.util.Arrays` 的一个内部类,这个内部类并没有实现集合的修改方法或者说并没有重写这些方法。
+
+```java
+List myList = Arrays.asList(1, 2, 3);
+System.out.println(myList.getClass());//class java.util.Arrays$ArrayList
+```
+
+下图是`java.util.Arrays$ArrayList`的简易源码,我们可以看到这个类重写的方法有哪些。
+
+```java
+ private static class ArrayList extends AbstractList
+ implements RandomAccess, java.io.Serializable
+ {
+ ...
+
+ @Override
+ public E get(int index) {
+ ...
+ }
+
+ @Override
+ public E set(int index, E element) {
+ ...
+ }
+
+ @Override
+ public int indexOf(Object o) {
+ ...
+ }
+
+ @Override
+ public boolean contains(Object o) {
+ ...
+ }
+
+ @Override
+ public void forEach(Consumer action) {
+ ...
+ }
+
+ @Override
+ public void replaceAll(UnaryOperator operator) {
+ ...
+ }
+
+ @Override
+ public void sort(Comparator c) {
+ ...
+ }
+ }
+```
+
+我们再看一下`java.util.AbstractList`的`remove()`方法,这样我们就明白为啥会抛出`UnsupportedOperationException`。
+
+```java
+public E remove(int index) {
+ throw new UnsupportedOperationException();
+}
+```
+
+
+
+**《Java面试突击》:** Java 程序员面试必备的《Java面试突击》V3.0 PDF 版本扫码关注下面的公众号,在后台回复 **"面试突击"** 即可免费领取!
+
+
\ No newline at end of file
diff --git a/docs/java/collection/images/77c95eb733284dbd8ce4e85c9cb6b042.png b/docs/java/collection/images/77c95eb733284dbd8ce4e85c9cb6b042.png
new file mode 100644
index 00000000..54180092
Binary files /dev/null and b/docs/java/collection/images/77c95eb733284dbd8ce4e85c9cb6b042.png differ
diff --git a/docs/java/collection/images/Java-Collections.jpeg b/docs/java/collection/images/Java-Collections.jpeg
new file mode 100644
index 00000000..cf9071ff
Binary files /dev/null and b/docs/java/collection/images/Java-Collections.jpeg differ
diff --git a/docs/java/collection/images/TreeMap继承结构.png b/docs/java/collection/images/TreeMap继承结构.png
new file mode 100644
index 00000000..553e41b8
Binary files /dev/null and b/docs/java/collection/images/TreeMap继承结构.png differ
diff --git a/docs/java/collection/images/ad28e3ba-e419-4724-869c-73879e604da1.png b/docs/java/collection/images/ad28e3ba-e419-4724-869c-73879e604da1.png
new file mode 100644
index 00000000..1c05ebaa
Binary files /dev/null and b/docs/java/collection/images/ad28e3ba-e419-4724-869c-73879e604da1.png differ
diff --git a/docs/java/collection/images/image-20200405151029416.png b/docs/java/collection/images/image-20200405151029416.png
new file mode 100644
index 00000000..26ea14ca
Binary files /dev/null and b/docs/java/collection/images/image-20200405151029416.png differ
diff --git a/docs/java/collection/images/java8_concurrenthashmap.png b/docs/java/collection/images/java8_concurrenthashmap.png
new file mode 100644
index 00000000..a090c7cc
Binary files /dev/null and b/docs/java/collection/images/java8_concurrenthashmap.png differ
diff --git a/docs/java/collection/images/jdk1.8之前的内部结构-HashMap.png b/docs/java/collection/images/jdk1.8之前的内部结构-HashMap.png
new file mode 100644
index 00000000..54180092
Binary files /dev/null and b/docs/java/collection/images/jdk1.8之前的内部结构-HashMap.png differ
diff --git a/docs/java/collection/images/jdk1.8之后的内部结构-HashMap.png b/docs/java/collection/images/jdk1.8之后的内部结构-HashMap.png
new file mode 100644
index 00000000..7c95e738
Binary files /dev/null and b/docs/java/collection/images/jdk1.8之后的内部结构-HashMap.png differ
diff --git a/docs/java/images/Java异常类层次结构图.png b/docs/java/images/Java异常类层次结构图.png
new file mode 100644
index 00000000..595dc8af
Binary files /dev/null and b/docs/java/images/Java异常类层次结构图.png differ
diff --git a/docs/java/images/Java异常类层次结构图2.png b/docs/java/images/Java异常类层次结构图2.png
new file mode 100644
index 00000000..fd2a910d
Binary files /dev/null and b/docs/java/images/Java异常类层次结构图2.png differ
diff --git a/docs/java/images/image-20200405151029416.png b/docs/java/images/image-20200405151029416.png
new file mode 100644
index 00000000..26ea14ca
Binary files /dev/null and b/docs/java/images/image-20200405151029416.png differ
diff --git a/docs/java/images/performance-tuning/java-performance1.png b/docs/java/images/performance-tuning/java-performance1.png
new file mode 100644
index 00000000..0975d265
Binary files /dev/null and b/docs/java/images/performance-tuning/java-performance1.png differ
diff --git a/docs/java/images/performance-tuning/java-performance2.png b/docs/java/images/performance-tuning/java-performance2.png
new file mode 100644
index 00000000..76bbc0a8
Binary files /dev/null and b/docs/java/images/performance-tuning/java-performance2.png differ
diff --git a/docs/java/images/performance-tuning/java-performance3.png b/docs/java/images/performance-tuning/java-performance3.png
new file mode 100644
index 00000000..150e5ce5
Binary files /dev/null and b/docs/java/images/performance-tuning/java-performance3.png differ
diff --git a/docs/java/images/performance-tuning/java-performance4.png b/docs/java/images/performance-tuning/java-performance4.png
new file mode 100644
index 00000000..e3bf7450
Binary files /dev/null and b/docs/java/images/performance-tuning/java-performance4.png differ
diff --git a/docs/java/images/performance-tuning/java-performance5.png b/docs/java/images/performance-tuning/java-performance5.png
new file mode 100644
index 00000000..c6b44840
Binary files /dev/null and b/docs/java/images/performance-tuning/java-performance5.png differ
diff --git a/docs/java/images/performance-tuning/java-performance6.png b/docs/java/images/performance-tuning/java-performance6.png
new file mode 100644
index 00000000..b1e182ed
Binary files /dev/null and b/docs/java/images/performance-tuning/java-performance6.png differ
diff --git a/docs/java/images/performance-tuning/java-performance7.png b/docs/java/images/performance-tuning/java-performance7.png
new file mode 100644
index 00000000..0796e30d
Binary files /dev/null and b/docs/java/images/performance-tuning/java-performance7.png differ
diff --git a/docs/java/images/performance-tuning/java-performance8.png b/docs/java/images/performance-tuning/java-performance8.png
new file mode 100644
index 00000000..75172dfa
Binary files /dev/null and b/docs/java/images/performance-tuning/java-performance8.png differ
diff --git a/docs/java/java-naming-conventions.md b/docs/java/java-naming-conventions.md
new file mode 100644
index 00000000..d205f5f5
--- /dev/null
+++ b/docs/java/java-naming-conventions.md
@@ -0,0 +1,416 @@
+> 原文链接:https://www.cnblogs.com/liqiangchn/p/12000361.html
+
+简洁清爽的代码风格应该是大多数工程师所期待的。在工作中笔者常常因为起名字而纠结,夸张点可以说是编程5分钟,命名两小时!究竟为什么命名成为了工作中的拦路虎。
+
+每个公司都有不同的标准,目的是为了保持统一,减少沟通成本,提升团队研发效能。所以本文中是笔者结合阿里巴巴开发规范,以及工作中的见闻针对Java领域相关命名进行整理和总结,仅供参考。
+
+## 一,Java中的命名规范
+
+好的命名能体现出代码的特征,含义或者是用途,让阅读者可以根据名称的含义快速厘清程序的脉络。不同语言中采用的命名形式大相径庭,Java中常用到的命名形式共有三种,既首字母大写的UpperCamelCase,首字母小写的lowerCamelCase以及全部大写的并用下划线分割单词的UPPER_CAMEL_UNSER_SCORE。通常约定,**类一般采用大驼峰命名,方法和局部变量使用小驼峰命名,而大写下划线命名通常是常量和枚举中使用。**
+
+| 类型 | 约束 | 例 |
+| :----: | :----------------------------------------------------------: | :--------------------------------------------: |
+| 项目名 | 全部小写,多个单词用中划线分隔‘-’ | spring-cloud |
+| 包名 | 全部小写 | com.alibaba.fastjson |
+| 类名 | 单词首字母大写 | Feature, ParserConfig,DefaultFieldDeserializer |
+| 变量名 | 首字母小写,多个单词组成时,除首个单词,其他单词首字母都要大写 | password, userName |
+| 常量名 | 全部大写,多个单词,用'_'分隔 | CACHE_EXPIRED_TIME |
+| 方法 | 同变量 | read(), readObject(), getById() |
+
+## 二,包命名
+
+**包名**统一使用**小写**,**点分隔符**之间有且仅有一个自然语义的英文单词或者多个单词自然连接到一块(如 springframework,deepspace不需要使用任何分割)。包名统一使用单数形式,如果类命有复数含义,则可以使用复数形式。
+
+包名的构成可以分为以下几四部分【前缀】 【发起者名】【项目名】【模块名】。常见的前缀可以分为以下几种:
+
+| 前缀名 | 例 | 含义 |
+| :-------------: | :----------------------------: | :----------------------------------------------------------: |
+| indi(或onem ) | indi.发起者名.项目名.模块名.…… | 个体项目,指个人发起,但非自己独自完成的项目,可公开或私有项目,copyright主要属于发起者。 |
+| pers | pers.个人名.项目名.模块名.…… | 个人项目,指个人发起,独自完成,可分享的项目,copyright主要属于个人 |
+| priv | priv.个人名.项目名.模块名.…… | 私有项目,指个人发起,独自完成,非公开的私人使用的项目,copyright属于个人。 |
+| team | team.团队名.项目名.模块名.…… | 团队项目,指由团队发起,并由该团队开发的项目,copyright属于该团队所有 |
+| 顶级域名 | com.公司名.项目名.模块名.…… | 公司项目,copyright由项目发起的公司所有 |
+
+## 三,类命名
+
+**类名使用大驼峰命名形式**,类命通常时**名词或名词短语**,接口名除了用名词和名词短语以外,还可以使用形容词或形容词短语,如Cloneable,Callable等,表示实现该接口的类有某种功能或能力。对于测试类则以它要测试的类开头,以Test结尾,如HashMapTest。
+
+对于一些特殊特有名词缩写也可以使用全大写命名,比如XMLHttpRequest,不过笔者认为缩写三个字母以内都大写,超过三个字母则按照要给单词算。这个没有标准如阿里巴巴中fastjson用JSONObject作为类命,而google则使用JsonObjectRequest命名,对于这种特殊的缩写,原则是统一就好。
+
+| 属性 | 约束 | 例 |
+| -------------- | ----------------------------------------- | ------------------------------------------------------------ |
+| 抽象类 | Abstract 或者 Base 开头 | BaseUserService |
+| 枚举类 | Enum 作为后缀 | GenderEnum |
+| 工具类 | Utils作为后缀 | StringUtils |
+| 异常类 | Exception结尾 | RuntimeException |
+| 接口实现类 | 接口名+ Impl | UserServiceImpl |
+| 领域模型相关 | /DO/DTO/VO/DAO | 正例:UserDAO 反例: UserDo, UserDao |
+| 设计模式相关类 | Builder,Factory等 | 当使用到设计模式时,需要使用对应的设计模式作为后缀,如ThreadFactory |
+| 处理特定功能的 | Handler,Predicate, Validator | 表示处理器,校验器,断言,这些类工厂还有配套的方法名如handle,predicate,validate |
+| 测试类 | Test结尾 | UserServiceTest, 表示用来测试UserService类的 |
+| MVC分层 | Controller,Service,ServiceImpl,DAO后缀 | UserManageController,UserManageDAO |
+
+## 四,方法
+
+**方法命名采用小驼峰的形式**,首字小写,往后的每个单词首字母都要大写。 和类名不同的是,方法命名一般为**动词或动词短语**,与参数或参数名共同组成动宾短语,即动词 + 名词。一个好的函数名一般能通过名字直接获知该函数实现什么样的功能。
+
+### 4.1 返回真伪值的方法
+
+注:Prefix-前缀,Suffix-后缀,Alone-单独使用
+
+| 位置 | 单词 | 意义 | 例 |
+| ------ | ------ | ------------------------------------------------------------ | ------------- |
+| Prefix | is | 对象是否符合期待的状态 | isValid |
+| Prefix | can | 对象**能否执行**所期待的动作 | canRemove |
+| Prefix | should | 调用方执行某个命令或方法是**好还是不好**,**应不应该**,或者说**推荐还是不推荐** | shouldMigrate |
+| Prefix | has | 对象**是否持有**所期待的数据和属性 | hasObservers |
+| Prefix | needs | 调用方**是否需要**执行某个命令或方法 | needsMigrate |
+
+### 4.2 用来检查的方法
+
+| 单词 | 意义 | 例 |
+| -------- | ---------------------------------------------------- | -------------- |
+| ensure | 检查是否为期待的状态,不是则抛出异常或返回error code | ensureCapacity |
+| validate | 检查是否为正确的状态,不是则抛出异常或返回error code | validateInputs |
+
+### 4.3 按需求才执行的方法
+
+| 位置 | 单词 | 意义 | 例 |
+| ------ | --------- | ----------------------------------------- | ---------------------- |
+| Suffix | IfNeeded | 需要的时候执行,不需要的时候什么都不做 | drawIfNeeded |
+| Prefix | might | 同上 | mightCreate |
+| Prefix | try | 尝试执行,失败时抛出异常或是返回errorcode | tryCreate |
+| Suffix | OrDefault | 尝试执行,失败时返回默认值 | getOrDefault |
+| Suffix | OrElse | 尝试执行、失败时返回实际参数中指定的值 | getOrElse |
+| Prefix | force | 强制尝试执行。error抛出异常或是返回值 | forceCreate, forceStop |
+
+### 4.4 异步相关方法
+
+| 位置 | 单词 | 意义 | 例 |
+| --------------- | ------------ | -------------------------------------------- | --------------------- |
+| Prefix | blocking | 线程阻塞方法 | blockingGetUser |
+| Suffix | InBackground | 执行在后台的线程 | doInBackground |
+| Suffix | Async | 异步方法 | sendAsync |
+| Suffix | Sync | 对应已有异步方法的同步方法 | sendSync |
+| Prefix or Alone | schedule | Job和Task放入队列 | schedule, scheduleJob |
+| Prefix or Alone | post | 同上 | postJob |
+| Prefix or Alone | execute | 执行异步方法(注:我一般拿这个做同步方法名) | execute, executeTask |
+| Prefix or Alone | start | 同上 | start, startJob |
+| Prefix or Alone | cancel | 停止异步方法 | cancel, cancelJob |
+| Prefix or Alone | stop | 同上 | stop, stopJob |
+
+### 4.5 回调方法
+
+| 位置 | 单词 | 意义 | 例 |
+| ------ | ------ | -------------------------- | ------------ |
+| Prefix | on | 事件发生时执行 | onCompleted |
+| Prefix | before | 事件发生前执行 | beforeUpdate |
+| Prefix | pre | 同上 | preUpdate |
+| Prefix | will | 同上 | willUpdate |
+| Prefix | after | 事件发生后执行 | afterUpdate |
+| Prefix | post | 同上 | postUpdate |
+| Prefix | did | 同上 | didUpdate |
+| Prefix | should | 确认事件是否可以发生时执行 | shouldUpdate |
+
+### 4.6 操作对象生命周期的方法
+
+| 单词 | 意义 | 例 |
+| ---------- | ------------------------------ | --------------- |
+| initialize | 初始化。也可作为延迟初始化使用 | initialize |
+| pause | 暂停 | onPause ,pause |
+| stop | 停止 | onStop,stop |
+| abandon | 销毁的替代 | abandon |
+| destroy | 同上 | destroy |
+| dispose | 同上 | dispose |
+
+### 4.7 与集合操作相关的方法
+
+| 单词 | 意义 | 例 |
+| -------- | ---------------------------- | ---------- |
+| contains | 是否持有与指定对象相同的对象 | contains |
+| add | 添加 | addJob |
+| append | 添加 | appendJob |
+| insert | 插入到下标n | insertJob |
+| put | 添加与key对应的元素 | putJob |
+| remove | 移除元素 | removeJob |
+| enqueue | 添加到队列的最末位 | enqueueJob |
+| dequeue | 从队列中头部取出并移除 | dequeueJob |
+| push | 添加到栈头 | pushJob |
+| pop | 从栈头取出并移除 | popJob |
+| peek | 从栈头取出但不移除 | peekJob |
+| find | 寻找符合条件的某物 | findById |
+
+### 4.8 与数据相关的方法
+
+| 单词 | 意义 | 例 |
+| ------ | -------------------------------------- | ------------- |
+| create | 新创建 | createAccount |
+| new | 新创建 | newAccount |
+| from | 从既有的某物新建,或是从其他的数据新建 | fromConfig |
+| to | 转换 | toString |
+| update | 更新既有某物 | updateAccount |
+| load | 读取 | loadAccount |
+| fetch | 远程读取 | fetchAccount |
+| delete | 删除 | deleteAccount |
+| remove | 删除 | removeAccount |
+| save | 保存 | saveAccount |
+| store | 保存 | storeAccount |
+| commit | 保存 | commitChange |
+| apply | 保存或应用 | applyChange |
+| clear | 清除数据或是恢复到初始状态 | clearAll |
+| reset | 清除数据或是恢复到初始状态 | resetAll |
+
+### 4.9 成对出现的动词
+
+| 单词 | 意义 |
+| -------------- | ----------------- |
+| get获取 | set 设置 |
+| add 增加 | remove 删除 |
+| create 创建 | destory 移除 |
+| start 启动 | stop 停止 |
+| open 打开 | close 关闭 |
+| read 读取 | write 写入 |
+| load 载入 | save 保存 |
+| create 创建 | destroy 销毁 |
+| begin 开始 | end 结束 |
+| backup 备份 | restore 恢复 |
+| import 导入 | export 导出 |
+| split 分割 | merge 合并 |
+| inject 注入 | extract 提取 |
+| attach 附着 | detach 脱离 |
+| bind 绑定 | separate 分离 |
+| view 查看 | browse 浏览 |
+| edit 编辑 | modify 修改 |
+| select 选取 | mark 标记 |
+| copy 复制 | paste 粘贴 |
+| undo 撤销 | redo 重做 |
+| insert 插入 | delete 移除 |
+| add 加入 | append 添加 |
+| clean 清理 | clear 清除 |
+| index 索引 | sort 排序 |
+| find 查找 | search 搜索 |
+| increase 增加 | decrease 减少 |
+| play 播放 | pause 暂停 |
+| launch 启动 | run 运行 |
+| compile 编译 | execute 执行 |
+| debug 调试 | trace 跟踪 |
+| observe 观察 | listen 监听 |
+| build 构建 | publish 发布 |
+| input 输入 | output 输出 |
+| encode 编码 | decode 解码 |
+| encrypt 加密 | decrypt 解密 |
+| compress 压缩 | decompress 解压缩 |
+| pack 打包 | unpack 解包 |
+| parse 解析 | emit 生成 |
+| connect 连接 | disconnect 断开 |
+| send 发送 | receive 接收 |
+| download 下载 | upload 上传 |
+| refresh 刷新 | synchronize 同步 |
+| update 更新 | revert 复原 |
+| lock 锁定 | unlock 解锁 |
+| check out 签出 | check in 签入 |
+| submit 提交 | commit 交付 |
+| push 推 | pull 拉 |
+| expand 展开 | collapse 折叠 |
+| begin 起始 | end 结束 |
+| start 开始 | finish 完成 |
+| enter 进入 | exit 退出 |
+| abort 放弃 | quit 离开 |
+| obsolete 废弃 | depreciate 废旧 |
+| collect 收集 | aggregate 聚集 |
+
+## 五,变量&常量命名
+
+### 5.1 变量命名
+
+变量是指在程序运行中可以改变其值的量,包括成员变量和局部变量。变量名由多单词组成时,第一个单词的首字母小写,其后单词的首字母大写,俗称骆驼式命名法(也称驼峰命名法),如 computedValues,index、变量命名时,尽量简短且能清楚的表达变量的作用,命名体现具体的业务含义即可。
+
+变量名不应以下划线或美元符号开头,尽管这在语法上是允许的。变量名应简短且富于描述。变量名的选用应该易于记忆,即,能够指出其用途。尽量避免单个字符的变量名,除非是一次性的临时变量。pojo中的布尔变量,都不要加is(数据库中的布尔字段全都要加 is_ 前缀)。
+
+### 5.2 常量命名
+
+常量命名CONSTANT_CASE,一般采用全部大写(作为方法参数时除外),单词间用下划线分割。那么什么是常量呢?
+
+常量是在作用域内保持不变的值,一般使用final进行修饰。一般分为三种,全局常量(public static final修饰),类内常量(private static final 修饰)以及局部常量(方法内,或者参数中的常量),局部常量比较特殊,通常采用小驼峰命名即可。
+
+```java
+/**
+ * 一个demo
+ *
+ * @author Jann Lee
+ * @date 2019-12-07 00:25
+ **/
+public class HelloWorld {
+
+ /**
+ * 局部常量(正例)
+ */
+ public static final long USER_MESSAGE_CACHE_EXPIRE_TIME = 3600;
+
+ /**
+ * 局部常量(反例,命名不清晰)
+ */
+ public static final long MESSAGE_CACHE_TIME = 3600;
+
+ /**
+ * 全局常量
+ */
+ private static final String ERROR_MESSAGE = " error message";
+
+ /**
+ * 成员变量
+ */
+ private int currentUserId;
+
+ /**
+ * 控制台打印 {@code message} 信息
+ *
+ * @param message 消息体,局部常量
+ */
+ public void sayHello(final String message){
+ System.out.println("Hello world!");
+ }
+
+}
+```
+
+常量一般都有自己的业务含义,**不要害怕长度过长而进行省略或者缩写**。如,用户消息缓存过期时间的表示,那种方式更佳清晰,交给你来评判。
+
+## 通用命名规则[#](https://www.cnblogs.com/liqiangchn/p/12000361.html#450918152)
+
+1. 尽量不要使用拼音;杜绝拼音和英文混用。对于一些通用的表示或者难以用英文描述的可以采用拼音,一旦采用拼音就坚决不能和英文混用。
+ 正例: BeiJing, HangZhou
+ 反例: validateCanShu
+2. 命名过程中尽量不要出现特殊的字符,常量除外。
+3. 尽量不要和jdk或者框架中已存在的类重名,也不能使用java中的关键字命名。
+4. 妙用介词,如for(可以用同音的4代替), to(可用同音的2代替), from, with,of等。
+ 如类名采用User4RedisDO,方法名getUserInfoFromRedis,convertJson2Map等。
+
+## 六,代码注解
+
+### 6.1 注解的原则
+
+好的命名增加代码阅读性,代码的命名往往有严格的限制。而注解不同,程序员往往可以自由发挥,单并不意味着可以为所欲为之胡作非为。优雅的注解通常要满足三要素。
+
+1. Nothing is strange
+ 没有注解的代码对于阅读者非常不友好,哪怕代码写的在清除,阅读者至少从心理上会有抵触,更何况代码中往往有许多复杂的逻辑,所以一定要写注解,不仅要记录代码的逻辑,还有说清楚修改的逻辑。
+2. Less is more
+ 从代码维护角度来讲,代码中的注解一定是精华中的精华。合理清晰的命名能让代码易于理解,对于逻辑简单且命名规范,能够清楚表达代码功能的代码不需要注解。滥用注解会增加额外的负担,更何况大部分都是废话。
+
+```java
+// 根据id获取信息【废话注解】
+getMessageById(id)
+```
+
+1. Advance with the time
+ 注解应该随着代码的变动而改变,注解表达的信息要与代码中完全一致。通常情况下修改代码后一定要修改注解。
+
+### 6.2 注解格式
+
+注解大体上可以分为两种,一种是javadoc注解,另一种是简单注解。javadoc注解可以生成JavaAPI为外部用户提供有效的支持javadoc注解通常在使用IDEA,或者Eclipse等开发工具时都可以自动生成,也支持自定义的注解模板,仅需要对对应的字段进行解释。参与同一项目开发的同学,尽量设置成相同的注解模板。
+
+#### a. 包注解
+
+包注解在工作中往往比较特殊,通过包注解可以快速知悉当前包下代码是用来实现哪些功能,强烈建议工作中加上,尤其是对于一些比较复杂的包,包注解一般在包的根目录下,名称统一为package-info.java。
+
+```java
+/**
+ * 落地也质量检测
+ * 1. 用来解决什么问题
+ * 对广告主投放的广告落地页进行性能检测,模拟不同的系统,如Android,IOS等; 模拟不同的网络:2G,3G,4G,wifi等
+ *
+ * 2. 如何实现
+ * 基于chrome浏览器,用chromedriver驱动浏览器,设置对应的网络,OS参数,获取到浏览器返回结果。
+ *
+ * 注意: 网络环境配置信息{@link cn.mycookies.landingpagecheck.meta.NetWorkSpeedEnum}目前使用是常规速度,可以根据实际情况进行调整
+ *
+ * @author cruder
+ * @time 2019/12/7 20:3 下午
+ */
+package cn.mycookies.landingpagecheck;
+```
+
+#### b. 类注接
+
+javadoc注解中,每个类都必须有注解。
+
+```java
+/**
+* Copyright (C), 2019-2020, Jann balabala...
+*
+* 类的介绍:这是一个用来做什么事情的类,有哪些功能,用到的技术.....
+*
+* @author 类创建者姓名 保持对齐
+* @date 创建日期 保持对齐
+* @version 版本号 保持对齐
+*/
+```
+
+#### c. 属性注解
+
+在每个属性前面必须加上属性注释,通常有以下两种形式,至于怎么选择,你高兴就好,不过一个项目中要保持统一。
+
+```java
+/** 提示信息 */
+private String userName;
+/**
+ * 密码
+ */
+private String password;
+```
+
+#### d. 方法注释
+
+在每个方法前面必须加上方法注释,对于方法中的每个参数,以及返回值都要有说明。
+
+```java
+/**
+ * 方法的详细说明,能干嘛,怎么实现的,注意事项...
+ *
+ * @param xxx 参数1的使用说明, 能否为null
+ * @return 返回结果的说明, 不同情况下会返回怎样的结果
+ * @throws 异常类型 注明从此类方法中抛出异常的说明
+ */
+```
+
+#### e. 构造方法注释
+
+在每个构造方法前面必须加上注释,注释模板如下:
+
+```java
+ /**
+ * 构造方法的详细说明
+ *
+ * @param xxx 参数1的使用说明, 能否为null
+ * @throws 异常类型 注明从此类方法中抛出异常的说明
+ */
+```
+
+而简单注解往往是需要工程师字节定义,在使用注解时应该注意以下几点:
+
+1. 枚举类的各个属性值都要使用注解,枚举可以理解为是常量,通常不会发生改变,通常会被在多个地方引用,对枚举的修改和添加属性通常会带来很大的影响。
+2. 保持排版整洁,不要使用行尾注释;双斜杠和星号之后要用1个空格分隔。
+
+```java
+id = 1;// 反例:不要使用行尾注释
+//反例:换行符与注释之间没有缩进
+int age = 18;
+// 正例:姓名
+String name;
+/**
+ * 1. 多行注释
+ *
+ * 2. 对于不同的逻辑说明,可以用空行分隔
+ */
+```
+
+## 总结
+
+无论是命名和注解,他们的目的都是为了让代码和工程师进行对话,增强代码的可读性,可维护性。优秀的代码往往能够见名知意,注解往往是对命名的补充和完善。命名太南了!
+
+参考文献:
+
+- 《码出高效》
+- https://www.cnblogs.com/wangcp-2014/p/10215620.html
+- https://qiita.com/KeithYokoma/items/2193cf79ba76563e3db6
+- https://google.github.io/styleguide/javaguide.html#s2.1-file-name
\ No newline at end of file
diff --git a/docs/java/Java程序设计题.md b/docs/java/java-programming-problem/Java程序设计题.md
similarity index 77%
rename from docs/java/Java程序设计题.md
rename to docs/java/java-programming-problem/Java程序设计题.md
index 46c9c169..112c1bff 100644
--- a/docs/java/Java程序设计题.md
+++ b/docs/java/java-programming-problem/Java程序设计题.md
@@ -1,6 +1,12 @@
-## 泛型的实际应用
+
-### 实现最小值函数
+- [0.0.1. 泛型的实际应用:实现最小值函数](#001-%e6%b3%9b%e5%9e%8b%e7%9a%84%e5%ae%9e%e9%99%85%e5%ba%94%e7%94%a8%e5%ae%9e%e7%8e%b0%e6%9c%80%e5%b0%8f%e5%80%bc%e5%87%bd%e6%95%b0)
+- [0.0.2. 使用数组实现栈](#002-%e4%bd%bf%e7%94%a8%e6%95%b0%e7%bb%84%e5%ae%9e%e7%8e%b0%e6%a0%88)
+- [0.0.3. 实现线程安全的 LRU 缓存](#003-%e5%ae%9e%e7%8e%b0%e7%ba%bf%e7%a8%8b%e5%ae%89%e5%85%a8%e7%9a%84-lru-%e7%bc%93%e5%ad%98)
+
+
+
+### 0.0.1. 泛型的实际应用:实现最小值函数
自己设计一个泛型的获取数组最小值的函数.并且这个方法只能接受Number的子类并且实现了Comparable接口。
@@ -23,10 +29,7 @@ int minInteger = min(new Integer[]{1, 2, 3});//result:1
double minDouble = min(new Double[]{1.2, 2.2, -1d});//result:-1d
String typeError = min(new String[]{"1","3"});//报错
```
-
-## 数据结构
-
-### 使用数组实现栈
+### 0.0.2. 使用数组实现栈
**自己实现一个栈,要求这个栈具有`push()`、`pop()`(返回栈顶元素并出栈)、`peek()` (返回栈顶元素不出栈)、`isEmpty()`、`size()`这些基本的方法。**
@@ -39,14 +42,14 @@ public class MyStack {
private int count;//栈中元素数量
private static final int GROW_FACTOR = 2;
- //TODO:不带初始容量的构造方法。默认容量为8
+ //不带初始容量的构造方法。默认容量为8
public MyStack() {
this.capacity = 8;
this.storage=new int[8];
this.count = 0;
}
- //TODO:带初始容量的构造方法
+ //带初始容量的构造方法
public MyStack(int initialCapacity) {
if (initialCapacity < 1)
throw new IllegalArgumentException("Capacity too small.");
@@ -56,7 +59,7 @@ public class MyStack {
this.count = 0;
}
- //TODO:入栈
+ //入栈
public void push(int value) {
if (count == capacity) {
ensureCapacity();
@@ -64,23 +67,22 @@ public class MyStack {
storage[count++] = value;
}
- //TODO:确保容量大小
+ //确保容量大小
private void ensureCapacity() {
int newCapacity = capacity * GROW_FACTOR;
storage = Arrays.copyOf(storage, newCapacity);
capacity = newCapacity;
}
- //TODO:返回栈顶元素并出栈
+ //返回栈顶元素并出栈
private int pop() {
- count--;
- if (count == -1)
+ if (count == 0)
throw new IllegalArgumentException("Stack is empty.");
-
+ count--;
return storage[count];
}
- //TODO:返回栈顶元素不出栈
+ //返回栈顶元素不出栈
private int peek() {
if (count == 0){
throw new IllegalArgumentException("Stack is empty.");
@@ -89,12 +91,12 @@ public class MyStack {
}
}
- //TODO:判断栈是否为空
+ //判断栈是否为空
private boolean isEmpty() {
return count == 0;
}
- //TODO:返回栈中元素的个数
+ //返回栈中元素的个数
private int size() {
return count;
}
@@ -122,4 +124,7 @@ for (int i = 0; i < 8; i++) {
}
System.out.println(myStack.isEmpty());//true
myStack.pop();//报错:java.lang.IllegalArgumentException: Stack is empty.
-```
\ No newline at end of file
+```
+
+
+
diff --git a/docs/java/java-programming-problem/a-thread-safe-implementation-of-lru-cache.md b/docs/java/java-programming-problem/a-thread-safe-implementation-of-lru-cache.md
new file mode 100644
index 00000000..7c367e11
--- /dev/null
+++ b/docs/java/java-programming-problem/a-thread-safe-implementation-of-lru-cache.md
@@ -0,0 +1,441 @@
+
+
+- [1. LRU 缓存介绍](#1-lru-%e7%bc%93%e5%ad%98%e4%bb%8b%e7%bb%8d)
+- [2. ConcurrentLinkedQueue简单介绍](#2-concurrentlinkedqueue%e7%ae%80%e5%8d%95%e4%bb%8b%e7%bb%8d)
+- [3. ReadWriteLock简单介绍](#3-readwritelock%e7%ae%80%e5%8d%95%e4%bb%8b%e7%bb%8d)
+- [4. ScheduledExecutorService 简单介绍](#4-scheduledexecutorservice-%e7%ae%80%e5%8d%95%e4%bb%8b%e7%bb%8d)
+- [5. 徒手撸一个线程安全的 LRU 缓存](#5-%e5%be%92%e6%89%8b%e6%92%b8%e4%b8%80%e4%b8%aa%e7%ba%bf%e7%a8%8b%e5%ae%89%e5%85%a8%e7%9a%84-lru-%e7%bc%93%e5%ad%98)
+ - [5.1. 实现方法](#51-%e5%ae%9e%e7%8e%b0%e6%96%b9%e6%b3%95)
+ - [5.2. 原理](#52-%e5%8e%9f%e7%90%86)
+ - [5.3. put方法具体流程分析](#53-put%e6%96%b9%e6%b3%95%e5%85%b7%e4%bd%93%e6%b5%81%e7%a8%8b%e5%88%86%e6%9e%90)
+ - [5.4. 源码](#54-%e6%ba%90%e7%a0%81)
+- [6. 实现一个线程安全并且带有过期时间的 LRU 缓存](#6-%e5%ae%9e%e7%8e%b0%e4%b8%80%e4%b8%aa%e7%ba%bf%e7%a8%8b%e5%ae%89%e5%85%a8%e5%b9%b6%e4%b8%94%e5%b8%a6%e6%9c%89%e8%bf%87%e6%9c%9f%e6%97%b6%e9%97%b4%e7%9a%84-lru-%e7%bc%93%e5%ad%98)
+
+
+
+最近被读者问到“不用LinkedHashMap的话,如何实现一个线程安全的 LRU 缓存?网上的代码太杂太乱,Guide哥哥能不能帮忙写一个?”。
+
+*划重点,手写一个 LRU 缓存在面试中还是挺常见的!*
+
+很多人就会问了:“网上已经有这么多现成的缓存了!为什么面试官还要我们自己实现一个呢?” 。咳咳咳,当然是为了面试需要。哈哈!开个玩笑,我个人觉得更多地是为了学习吧!今天Guide哥教大家:
+
+1. 实现一个线程安全的 LRU 缓存
+2. 实现一个线程安全并且带有过期时间的 LRU 缓存
+
+考虑到了线程安全性我们使用了 `ConcurrentHashMap` 、`ConcurrentLinkedQueue` 这两个线程安全的集合。另外,还用到 `ReadWriteLock`(读写锁)。为了实现带有过期时间的缓存,我们用到了 `ScheduledExecutorService`来做定时任务执行。
+
+如果有任何不对或者需要完善的地方,请帮忙指出!
+
+### 1. LRU 缓存介绍
+
+**LRU (Least Recently Used,最近最少使用)是一种缓存淘汰策略。**
+
+LRU缓存指的是当缓存大小已达到最大分配容量的时候,如果再要去缓存新的对象数据的话,就需要将缓存中最近访问最少的对象删除掉以便给新来的数据腾出空间。
+
+### 2. ConcurrentLinkedQueue简单介绍
+
+**ConcurrentLinkedQueue是一个基于单向链表的无界无锁线程安全的队列,适合在高并发环境下使用,效率比较高。** 我们在使用的时候,可以就把它理解为我们经常接触的数据结构——队列,不过是增加了多线程下的安全性保证罢了。**和普通队列一样,它也是按照先进先出(FIFO)的规则对接点进行排序。** 另外,队列元素中不可以放置null元素。
+
+`ConcurrentLinkedQueue` 整个继承关系如下图所示:
+
+
+
+`ConcurrentLinkedQueue中`最主要的两个方法是:`offer(value)`和`poll()`,分别实现队列的两个重要的操作:入队和出队(`offer(value)`等价于 `add(value)`)。
+
+我们添加一个元素到队列的时候,它会添加到队列的尾部,当我们获取一个元素时,它会返回队列头部的元素。
+
+
+
+利用`ConcurrentLinkedQueue`队列先进先出的特性,每当我们 `put`/`get`(缓存被使用)元素的时候,我们就将这个元素存放在队列尾部,这样就能保证队列头部的元素是最近最少使用的。
+
+### 3. ReadWriteLock简单介绍
+
+`ReadWriteLock` 是一个接口,位于`java.util.concurrent.locks`包下,里面只有两个方法分别返回读锁和写锁:
+
+```java
+public interface ReadWriteLock {
+ /**
+ * 返回读锁
+ */
+ Lock readLock();
+
+ /**
+ * 返回写锁
+ */
+ Lock writeLock();
+}
+```
+
+`ReentrantReadWriteLock` 是`ReadWriteLock`接口的具体实现类。
+
+**读写锁还是比较适合缓存这种读多写少的场景。读写锁可以保证多个线程和同时读取,但是只有一个线程可以写入。**
+
+读写锁的特点是:写锁和写锁互斥,读锁和写锁互斥,读锁之间不互斥。也就说:同一时刻只能有一个线程写,但是可以有多个线程
+读。读写之间是互斥的,两者不能同时发生(当进行写操作时,同一时刻其他线程的读操作会被阻塞;当进行读操作时,同一时刻所有线程的写操作会被阻塞)。
+
+另外,**同一个线程持有写锁时是可以申请读锁,但是持有读锁的情况下不可以申请写锁。**
+
+### 4. ScheduledExecutorService 简单介绍
+
+`ScheduledExecutorService` 是一个接口,`ScheduledThreadPoolExecutor` 是其主要实现类。
+
+
+
+**`ScheduledThreadPoolExecutor` 主要用来在给定的延迟后运行任务,或者定期执行任务。** 这个在实际项目用到的比较少,因为有其他方案选择比如`quartz`。但是,在一些需求比较简单的场景下还是非常有用的!
+
+**`ScheduledThreadPoolExecutor` 使用的任务队列 `DelayQueue` 封装了一个 `PriorityQueue`,`PriorityQueue` 会对队列中的任务进行排序,执行所需时间短的放在前面先被执行,如果执行所需时间相同则先提交的任务将被先执行。**
+
+### 5. 徒手撸一个线程安全的 LRU 缓存
+
+#### 5.1. 实现方法
+
+ `ConcurrentHashMap` + `ConcurrentLinkedQueue` +`ReadWriteLock`
+
+#### 5.2. 原理
+
+`ConcurrentHashMap` 是线程安全的Map,我们可以利用它缓存 key,value形式的数据。`ConcurrentLinkedQueue`是一个线程安全的基于链表的队列(先进先出),我们可以用它来维护 key 。每当我们put/get(缓存被使用)元素的时候,我们就将这个元素对应的 key 存放在队列尾部,这样就能保证队列头部的元素是最近最少使用的。当我们的缓存容量不够的时候,我们直接移除队列头部对应的key以及这个key对应的缓存即可!
+
+另外,我们用到了`ReadWriteLock`(读写锁)来保证线程安全。
+
+#### 5.3. put方法具体流程分析
+
+为了方便大家理解,我将代码中比较重要的 `put(key,value)`方法的原理图画了出来,如下图所示:
+
+
+
+
+
+#### 5.4. 源码
+
+```java
+/**
+ * @author shuang.kou
+ *
+ * 使用 ConcurrentHashMap+ConcurrentLinkedQueue+ReadWriteLock实现线程安全的 LRU 缓存
+ * 这里只是为了学习使用,本地缓存推荐使用 Guava 自带的,使用 Spring 的话,推荐使用Spring Cache
+ */
+public class MyLruCache {
+
+ /**
+ * 缓存的最大容量
+ */
+ private final int maxCapacity;
+
+ private ConcurrentHashMap cacheMap;
+ private ConcurrentLinkedQueue keys;
+ /**
+ * 读写锁
+ */
+ private ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
+ private Lock writeLock = readWriteLock.writeLock();
+ private Lock readLock = readWriteLock.readLock();
+
+ public MyLruCache(int maxCapacity) {
+ if (maxCapacity < 0) {
+ throw new IllegalArgumentException("Illegal max capacity: " + maxCapacity);
+ }
+ this.maxCapacity = maxCapacity;
+ cacheMap = new ConcurrentHashMap<>(maxCapacity);
+ keys = new ConcurrentLinkedQueue<>();
+ }
+
+ public V put(K key, V value) {
+ // 加写锁
+ writeLock.lock();
+ try {
+ //1.key是否存在于当前缓存
+ if (cacheMap.containsKey(key)) {
+ moveToTailOfQueue(key);
+ cacheMap.put(key, value);
+ return value;
+ }
+ //2.是否超出缓存容量,超出的话就移除队列头部的元素以及其对应的缓存
+ if (cacheMap.size() == maxCapacity) {
+ System.out.println("maxCapacity of cache reached");
+ removeOldestKey();
+ }
+ //3.key不存在于当前缓存。将key添加到队列的尾部并且缓存key及其对应的元素
+ keys.add(key);
+ cacheMap.put(key, value);
+ return value;
+ } finally {
+ writeLock.unlock();
+ }
+ }
+
+ public V get(K key) {
+ //加读锁
+ readLock.lock();
+ try {
+ //key是否存在于当前缓存
+ if (cacheMap.containsKey(key)) {
+ // 存在的话就将key移动到队列的尾部
+ moveToTailOfQueue(key);
+ return cacheMap.get(key);
+ }
+ //不存在于当前缓存中就返回Null
+ return null;
+ } finally {
+ readLock.unlock();
+ }
+ }
+
+ public V remove(K key) {
+ writeLock.lock();
+ try {
+ //key是否存在于当前缓存
+ if (cacheMap.containsKey(key)) {
+ // 存在移除队列和Map中对应的Key
+ keys.remove(key);
+ return cacheMap.remove(key);
+ }
+ //不存在于当前缓存中就返回Null
+ return null;
+ } finally {
+ writeLock.unlock();
+ }
+ }
+
+ /**
+ * 将元素添加到队列的尾部(put/get的时候执行)
+ */
+ private void moveToTailOfQueue(K key) {
+ keys.remove(key);
+ keys.add(key);
+ }
+
+ /**
+ * 移除队列头部的元素以及其对应的缓存 (缓存容量已满的时候执行)
+ */
+ private void removeOldestKey() {
+ K oldestKey = keys.poll();
+ if (oldestKey != null) {
+ cacheMap.remove(oldestKey);
+ }
+ }
+
+ public int size() {
+ return cacheMap.size();
+ }
+
+}
+```
+
+**非并发环境测试:**
+
+```java
+MyLruCache myLruCache = new MyLruCache<>(3);
+myLruCache.put(1, "Java");
+System.out.println(myLruCache.get(1));// Java
+myLruCache.remove(1);
+System.out.println(myLruCache.get(1));// null
+myLruCache.put(2, "C++");
+myLruCache.put(3, "Python");
+System.out.println(myLruCache.get(2));//C++
+myLruCache.put(4, "C");
+myLruCache.put(5, "PHP");
+System.out.println(myLruCache.get(2));// C++
+```
+
+**并发环境测试:**
+
+我们初始化了一个固定容量为 10 的线程池和count为10的`CountDownLatch`。我们将1000000次操作分10次添加到线程池,然后我们等待线程池执行完成这10次操作。
+
+
+```java
+int threadNum = 10;
+int batchSize = 100000;
+//init cache
+MyLruCache myLruCache = new MyLruCache<>(batchSize * 10);
+//init thread pool with 10 threads
+ExecutorService fixedThreadPool = Executors.newFixedThreadPool(threadNum);
+//init CountDownLatch with 10 count
+CountDownLatch latch = new CountDownLatch(threadNum);
+AtomicInteger atomicInteger = new AtomicInteger(0);
+long startTime = System.currentTimeMillis();
+for (int t = 0; t < threadNum; t++) {
+ fixedThreadPool.submit(() -> {
+ for (int i = 0; i < batchSize; i++) {
+ int value = atomicInteger.incrementAndGet();
+ myLruCache.put("id" + value, value);
+ }
+ latch.countDown();
+ });
+}
+//wait for 10 threads to complete the task
+latch.await();
+fixedThreadPool.shutdown();
+System.out.println("Cache size:" + myLruCache.size());//Cache size:1000000
+long endTime = System.currentTimeMillis();
+long duration = endTime - startTime;
+System.out.println(String.format("Time cost:%dms", duration));//Time cost:511ms
+```
+
+### 6. 实现一个线程安全并且带有过期时间的 LRU 缓存
+
+实际上就是在我们上面时间的LRU缓存的基础上加上一个定时任务去删除缓存,单纯利用 JDK 提供的类,我们实现定时任务的方式有很多种:
+
+1. `Timer` :不被推荐,多线程会存在问题。
+2. `ScheduledExecutorService` :定时器线程池,可以用来替代 `Timer`
+3. `DelayQueue` :延时队列
+4. `quartz` :一个很火的开源任务调度框架,很多其他框架都是基于 `quartz` 开发的,比如当当网的`elastic-job `就是基于`quartz`二次开发之后的分布式调度解决方案
+5. ......
+
+最终我们选择了 `ScheduledExecutorService`,主要原因是它易用(基于`DelayQueue`做了很多封装)并且基本能满足我们的大部分需求。
+
+我们在我们上面实现的线程安全的 LRU 缓存基础上,简单稍作修改即可!我们增加了一个方法:
+
+```java
+private void removeAfterExpireTime(K key, long expireTime) {
+ scheduledExecutorService.schedule(() -> {
+ //过期后清除该键值对
+ cacheMap.remove(key);
+ keys.remove(key);
+ }, expireTime, TimeUnit.MILLISECONDS);
+}
+```
+我们put元素的时候,如果通过这个方法就能直接设置过期时间。
+
+
+**完整源码如下:**
+
+```java
+/**
+ * @author shuang.kou
+ *
+ * 使用 ConcurrentHashMap+ConcurrentLinkedQueue+ReadWriteLock+ScheduledExecutorService实现线程安全的 LRU 缓存
+ * 这里只是为了学习使用,本地缓存推荐使用 Guava 自带的,使用 Spring 的话,推荐使用Spring Cache
+ */
+public class MyLruCacheWithExpireTime {
+
+ /**
+ * 缓存的最大容量
+ */
+ private final int maxCapacity;
+
+ private ConcurrentHashMap cacheMap;
+ private ConcurrentLinkedQueue keys;
+ /**
+ * 读写锁
+ */
+ private ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
+ private Lock writeLock = readWriteLock.writeLock();
+ private Lock readLock = readWriteLock.readLock();
+
+ private ScheduledExecutorService scheduledExecutorService;
+
+ public MyLruCacheWithExpireTime(int maxCapacity) {
+ if (maxCapacity < 0) {
+ throw new IllegalArgumentException("Illegal max capacity: " + maxCapacity);
+ }
+ this.maxCapacity = maxCapacity;
+ cacheMap = new ConcurrentHashMap<>(maxCapacity);
+ keys = new ConcurrentLinkedQueue<>();
+ scheduledExecutorService = Executors.newScheduledThreadPool(3);
+ }
+
+ public V put(K key, V value, long expireTime) {
+ // 加写锁
+ writeLock.lock();
+ try {
+ //1.key是否存在于当前缓存
+ if (cacheMap.containsKey(key)) {
+ moveToTailOfQueue(key);
+ cacheMap.put(key, value);
+ return value;
+ }
+ //2.是否超出缓存容量,超出的话就移除队列头部的元素以及其对应的缓存
+ if (cacheMap.size() == maxCapacity) {
+ System.out.println("maxCapacity of cache reached");
+ removeOldestKey();
+ }
+ //3.key不存在于当前缓存。将key添加到队列的尾部并且缓存key及其对应的元素
+ keys.add(key);
+ cacheMap.put(key, value);
+ if (expireTime > 0) {
+ removeAfterExpireTime(key, expireTime);
+ }
+ return value;
+ } finally {
+ writeLock.unlock();
+ }
+ }
+
+ public V get(K key) {
+ //加读锁
+ readLock.lock();
+ try {
+ //key是否存在于当前缓存
+ if (cacheMap.containsKey(key)) {
+ // 存在的话就将key移动到队列的尾部
+ moveToTailOfQueue(key);
+ return cacheMap.get(key);
+ }
+ //不存在于当前缓存中就返回Null
+ return null;
+ } finally {
+ readLock.unlock();
+ }
+ }
+
+ public V remove(K key) {
+ writeLock.lock();
+ try {
+ //key是否存在于当前缓存
+ if (cacheMap.containsKey(key)) {
+ // 存在移除队列和Map中对应的Key
+ keys.remove(key);
+ return cacheMap.remove(key);
+ }
+ //不存在于当前缓存中就返回Null
+ return null;
+ } finally {
+ writeLock.unlock();
+ }
+ }
+
+ /**
+ * 将元素添加到队列的尾部(put/get的时候执行)
+ */
+ private void moveToTailOfQueue(K key) {
+ keys.remove(key);
+ keys.add(key);
+ }
+
+ /**
+ * 移除队列头部的元素以及其对应的缓存 (缓存容量已满的时候执行)
+ */
+ private void removeOldestKey() {
+ K oldestKey = keys.poll();
+ if (oldestKey != null) {
+ cacheMap.remove(oldestKey);
+ }
+ }
+
+ private void removeAfterExpireTime(K key, long expireTime) {
+ scheduledExecutorService.schedule(() -> {
+ //过期后清除该键值对
+ cacheMap.remove(key);
+ keys.remove(key);
+ }, expireTime, TimeUnit.MILLISECONDS);
+ }
+
+ public int size() {
+ return cacheMap.size();
+ }
+
+}
+
+```
+
+**测试效果:**
+
+```java
+MyLruCacheWithExpireTime myLruCache = new MyLruCacheWithExpireTime<>(3);
+myLruCache.put(1,"Java",3000);
+myLruCache.put(2,"C++",3000);
+myLruCache.put(3,"Python",1500);
+System.out.println(myLruCache.size());//3
+Thread.sleep(2000);
+System.out.println(myLruCache.size());//2
+```
diff --git a/docs/java/jdk-new-features/images/fc66979f-7974-40e8-88ae-6dbff15ac9ef.png b/docs/java/jdk-new-features/images/fc66979f-7974-40e8-88ae-6dbff15ac9ef.png
new file mode 100644
index 00000000..7529c73f
Binary files /dev/null and b/docs/java/jdk-new-features/images/fc66979f-7974-40e8-88ae-6dbff15ac9ef.png differ
diff --git a/docs/java/jdk-new-features/new-features-from-jdk8-to-jdk14.md b/docs/java/jdk-new-features/new-features-from-jdk8-to-jdk14.md
new file mode 100644
index 00000000..5b193cd5
--- /dev/null
+++ b/docs/java/jdk-new-features/new-features-from-jdk8-to-jdk14.md
@@ -0,0 +1,441 @@
+大家好,我是Guide哥!这篇文章来自读者的投稿,经过了两次较大的改动,两周的完善终于完成。Java 8新特性见这里:[Java8新特性最佳指南](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247484744&idx=1&sn=9db31dca13d327678845054af75efb74&chksm=cea24a83f9d5c3956f4feb9956b068624ab2fdd6c4a75fe52d5df5dca356a016577301399548&token=1082669959&lang=zh_CN&scene=21#wechat_redirect) 。
+
+*Guide 哥:别人家的特性都用了几年了,我 Java 才出来,哈哈!真实!*
+
+## Java9
+
+发布于 2017 年 9 月 21 日 。作为 Java8 之后 3 年半才发布的新版本,Java 9 带 来了很多重大的变化其中最重要的改动是 Java 平台模块系统的引入,其他还有诸如集合、Stream 流
+
+### Java 平台模块系统
+
+Java 平台模块系统,也就是 Project Jigsaw,把模块化开发实践引入到了 Java 平台中。在引入了模块系统之后,JDK 被重新组织成 94 个模块。Java 应用可以通过新增的 jlink 工具,创建出只包含所依赖的 JDK 模块的自定义运行时镜像。这样可以极大的减少 Java 运行时环境的大小。
+
+Java 9 模块的重要特征是在其工件(artifact)的根目录中包含了一个描述模块的 module-info.class 文 件。 工件的格式可以是传统的 JAR 文件或是 Java 9 新增的 JMOD 文件。
+
+### Jshell
+
+jshell 是 Java 9 新增的一个实用工具。为 Java 提供了类似于 Python 的实时命令行交互工具。
+
+在 Jshell 中可以直接输入表达式并查看其执行结果
+
+### 集合、Stream 和 Optional
+
+- 增加 了 `List.of()`、`Set.of()`、`Map.of()` 和 `Map.ofEntries()`等工厂方法来创建不可变集合,比如`List.of("Java", "C++");`、`Map.of("Java", 1, "C++", 2)`;(这部分内容有点参考 Guava 的味道)
+- `Stream` 中增加了新的方法 `ofNullable`、`dropWhile`、`takeWhile` 和 `iterate` 方法。`Collectors` 中增加了新的方法 `filtering` 和 `flatMapping`
+- `Optional` 类中新增了 `ifPresentOrElse`、`or` 和 `stream` 等方法
+
+### 进程 API
+
+Java 9 增加了 `ProcessHandle` 接口,可以对原生进程进行管理,尤其适合于管理长时间运行的进程
+
+### 平台日志 API 和服务
+
+Java 9 允许为 JDK 和应用配置同样的日志实现。新增了 `System.LoggerFinder` 用来管理 JDK 使 用的日志记录器实现。JVM 在运行时只有一个系统范围的 `LoggerFinder` 实例。
+
+我们可以通过添加自己的 `System.LoggerFinder` 实现来让 JDK 和应用使用 SLF4J 等其他日志记录框架。
+
+### 反应式流 ( Reactive Streams )
+
+- 在 Java9 中的 `java.util.concurrent.Flow` 类中新增了反应式流规范的核心接口
+- Flow 中包含了 `Flow.Publisher`、`Flow.Subscriber`、`Flow.Subscription` 和 `Flow.Processor` 等 4 个核心接口。Java 9 还提供了`SubmissionPublisher` 作为`Flow.Publisher` 的一个实现。
+
+### 变量句柄
+
+- 变量句柄是一个变量或一组变量的引用,包括静态域,非静态域,数组元素和堆外数据结构中的组成部分等
+- 变量句柄的含义类似于已有的方法句柄`MethodHandle`
+- 由 Java 类`java.lang.invoke.VarHandle` 来表示,可以使用类 `java.lang.invoke.MethodHandles.Lookup` 中的静态工厂方法来创建 `VarHandle` 对 象
+
+### 改进方法句柄(Method Handle)
+
+- 方法句柄从 Java7 开始引入,Java9 在类`java.lang.invoke.MethodHandles` 中新增了更多的静态方法来创建不同类型的方法句柄
+
+### 其它新特性
+
+- **接口私有方法** :Java 9 允许在接口中使用私有方法
+- **try-with-resources 增强** :在 try-with-resources 语句中可以使用 effectively-final 变量(什么是 effectively-final 变量,见这篇文章 [http://ilkinulas.github.io/programming/java/2016/03/27/effectively-final-java.html](http://ilkinulas.github.io/programming/java/2016/03/27/effectively-final-java.html))
+- **类 `CompletableFuture` 中增加了几个新的方法(`completeAsync` ,`orTimeout` 等)**
+- **Nashorn 引擎的增强** :Nashorn 从 Java8 开始引入的 JavaScript 引擎,Java9 对 Nashorn 做了些增强,实现了一些 ES6 的新特性
+- **I/O 流的新特性** :增加了新的方法来读取和复制 InputStream 中包含的数据
+- **改进应用的安全性能** :Java 9 新增了 4 个 SHA- 3 哈希算法,SHA3-224、SHA3-256、SHA3-384 和 S HA3-512
+- ......
+
+## Java10
+
+发布于 2018 年 3 月 20 日,最知名的特性应该是 var 关键字(局部变量类型推断)的引入了,其他还有垃圾收集器改善、GC 改进、性能提升、线程管控等一批新特性
+
+### var 关键字
+
+- **介绍** :提供了 var 关键字声明局部变量:`var list = new ArrayList(); // ArrayList`
+- **局限性** :只能用于带有构造器的**局部变量**和 for 循环中
+
+_Guide 哥:实际上 Lombok 早就体用了一个类似的关键字,使用它可以简化代码,但是可能会降低程序的易读性、可维护性。一般情况下,我个人都不太推荐使用。_
+
+### 不可变集合
+
+**list,set,map 提供了静态方法`copyOf()`返回入参集合的一个不可变拷贝(以下为 JDK 的源码)**
+
+```java
+static List copyOf(Collection coll) {
+ return ImmutableCollections.listCopy(coll);
+}
+```
+
+**`java.util.stream.Collectors`中新增了静态方法,用于将流中的元素收集为不可变的集合**
+
+### Optional
+
+- 新增了`orElseThrow()`方法来在没有值时抛出异常
+
+### 并行全垃圾回收器 G1
+
+从 Java9 开始 G1 就了默认的垃圾回收器,G1 是以一种低延时的垃圾回收器来设计的,旨在避免进行 Full GC,但是 Java9 的 G1 的 FullGC 依然是使用单线程去完成标记清除算法,这可能会导致垃圾回收期在无法回收内存的时候触发 Full GC。
+
+为了最大限度地减少 Full GC 造成的应用停顿的影响,从 Java10 开始,G1 的 FullGC 改为并行的标记清除算法,同时会使用与年轻代回收和混合回收相同的并行工作线程数量,从而减少了 Full GC 的发生,以带来更好的性能提升、更大的吞吐量。
+
+### 应用程序类数据共享
+
+在 Java 5 中就已经引入了类数据共享机制 (Class Data Sharing,简称 CDS),允许将一组类预处理为共享归档文件,以便在运行时能够进行内存映射以减少 Java 程序的启动时间,当多个 Java 虚拟机(JVM)共享相同的归档文件时,还可以减少动态内存的占用量,同时减少多个虚拟机在同一个物理或虚拟的机器上运行时的资源占用
+
+Java 10 在现有的 CDS 功能基础上再次拓展,以允许应用类放置在共享存档中。CDS 特性在原来的 bootstrap 类基础之上,扩展加入了应用类的 CDS (Application Class-Data Sharing) 支持。其原理为:在启动时记录加载类的过程,写入到文本文件中,再次启动时直接读取此启动文本并加载。设想如果应用环境没有大的变化,启动速度就会得到提升
+
+### 其他特性
+
+- **线程-局部管控**:Java 10 中线程管控引入 JVM 安全点的概念,将允许在不运行全局 JVM 安全点的情况下实现线程回调,由线程本身或者 JVM 线程来执行,同时保持线程处于阻塞状态,这种方式使得停止单个线程变成可能,而不是只能启用或停止所有线程
+
+- **备用存储装置上的堆分配**:Java 10 中将使得 JVM 能够使用适用于不同类型的存储机制的堆,在可选内存设备上进行堆内存分配
+- **统一的垃圾回收接口**:Java 10 中,hotspot/gc 代码实现方面,引入一个干净的 GC 接口,改进不同 GC 源代码的隔离性,多个 GC 之间共享的实现细节代码应该存在于辅助类中。统一垃圾回收接口的主要原因是:让垃圾回收器(GC)这部分代码更加整洁,便于新人上手开发,便于后续排查相关问题。
+
+## Java11
+
+Java11 于 2018 年 9 月 25 日正式发布,这是很重要的一个版本!Java 11 和 2017 年 9 月份发布的 Java 9 以及 2018 年 3 月份发布的 Java 10 相比,其最大的区别就是:在长期支持(Long-Term-Support)方面,**Oracle 表示会对 Java 11 提供大力支持,这一支持将会持续至 2026 年 9 月。这是据 Java 8 以后支持的首个长期版本。**
+
+
+
+### 字符串加强
+
+Java 11 增加了一系列的字符串处理方法,如以下所示。
+
+_Guide 哥:说白点就是多了层封装,JDK 开发组的人没少看市面上常见的工具类框架啊!_
+
+```java
+//判断字符串是否为空
+" ".isBlank();//true
+//去除字符串首尾空格
+" Java ".strip();// "Java"
+//去除字符串首部空格
+" Java ".stripLeading(); // "Java "
+//去除字符串尾部空格
+" Java ".stripTrailing(); // " Java"
+//重复字符串多少次
+"Java".repeat(3); // "JavaJavaJava"
+
+//返回由行终止符分隔的字符串集合。
+"A\nB\nC".lines().count(); // 3
+"A\nB\nC".lines().collect(Collectors.toList());
+```
+
+### ZGC:可伸缩低延迟垃圾收集器
+
+**ZGC 即 Z Garbage Collector**,是一个可伸缩的、低延迟的垃圾收集器。
+
+ZGC 主要为了满足如下目标进行设计:
+
+- GC 停顿时间不超过 10ms
+- 即能处理几百 MB 的小堆,也能处理几个 TB 的大堆
+- 应用吞吐能力不会下降超过 15%(与 G1 回收算法相比)
+- 方便在此基础上引入新的 GC 特性和利用 colord
+- 针以及 Load barriers 优化奠定基础
+- 当前只支持 Linux/x64 位平台
+
+ZGC 目前 **处在实验阶段**,只支持 Linux/x64 平台
+
+### 标准 HTTP Client 升级
+
+Java 11 对 Java 9 中引入并在 Java 10 中进行了更新的 Http Client API 进行了标准化,在前两个版本中进行孵化的同时,Http Client 几乎被完全重写,并且现在完全支持异步非阻塞。
+
+并且,Java11 中,Http Client 的包名由 `jdk.incubator.http` 改为`java.net.http`,该 API 通过 `CompleteableFuture` 提供非阻塞请求和响应语义。
+
+使用起来也很简单,如下:
+
+```java
+var request = HttpRequest.newBuilder()
+
+ .uri(URI.create("https://javastack.cn"))
+
+ .GET()
+
+ .build();
+
+var client = HttpClient.newHttpClient();
+
+// 同步
+
+HttpResponse response = client.send(request, HttpResponse.BodyHandlers.ofString());
+
+System.out.println(response.body());
+
+// 异步
+
+client.sendAsync(request, HttpResponse.BodyHandlers.ofString())
+
+ .thenApply(HttpResponse::body)
+
+ .thenAccept(System.out::println);
+
+
+```
+
+### 简化启动单个源代码文件的方法
+
+- 增强了 Java 启动器,使其能够运行单一文件的 Java 源代码。此功能允许使用 Java 解释器直接执行 Java 源代码。源代码在内存中编译,然后由解释器执行。唯一的约束在于所有相关的类必须定义在同一个 Java 文件中
+- 对于 Java 初学者并希望尝试简单程序的人特别有用,并且能和 jshell 一起使用
+- 一定能程度上增强了使用 Java 来写脚本程序的能力
+
+### 用于 Lambda 参数的局部变量语法
+
+- 从 Java 10 开始,便引入了局部变量类型推断这一关键特性。类型推断允许使用关键字 var 作为局部变量的类型而不是实际类型,编译器根据分配给变量的值推断出类型
+- Java 10 中对 var 关键字存在几个限制
+ - 只能用于局部变量上
+ - 声明时必须初始化
+ - 不能用作方法参数
+ - 不能在 Lambda 表达式中使用
+- Java11 开始允许开发者在 Lambda 表达式中使用 var 进行参数声明
+
+### 其他特性
+
+- 新的垃圾回收器 Epsilon,一个完全消极的 GC 实现,分配有限的内存资源,最大限度的降低内存占用和内存吞吐延迟时间
+- 低开销的 Heap Profiling:Java 11 中提供一种低开销的 Java 堆分配采样方法,能够得到堆分配的 Java 对象信息,并且能够通过 JVMTI 访问堆信息
+- TLS1.3 协议:Java 11 中包含了传输层安全性(TLS)1.3 规范(RFC 8446)的实现,替换了之前版本中包含的 TLS,包括 TLS 1.2,同时还改进了其他 TLS 功能,例如 OCSP 装订扩展(RFC 6066,RFC 6961),以及会话散列和扩展主密钥扩展(RFC 7627),在安全性和性能方面也做了很多提升
+- 飞行记录器:飞行记录器之前是商业版 JDK 的一项分析工具,但在 Java 11 中,其代码被包含到公开代码库中,这样所有人都能使用该功能了
+
+## Java12
+
+### 增强 Switch
+
+- 传统的 switch 语法存在容易漏写 break 的问题,而且从代码整洁性层面来看,多个 break 本质也是一种重复
+
+- Java12 提供了 swtich 表达式,使用类似 lambda 语法条件匹配成功后的执行块,不需要多写 break
+
+- 作为预览特性加入,需要在`javac`编译和`java`运行时增加参数`--enable-preview`
+
+ ```java
+ switch (day) {
+ case MONDAY, FRIDAY, SUNDAY -> System.out.println(6);
+ case TUESDAY -> System.out.println(7);
+ case THURSDAY, SATURDAY -> System.out.println(8);
+ case WEDNESDAY -> System.out.println(9);
+ }
+ ```
+
+### 数字格式化工具类
+
+- `NumberFormat` 新增了对复杂的数字进行格式化的支持
+
+ ```java
+ NumberFormat fmt = NumberFormat.getCompactNumberInstance(Locale.US, NumberFormat.Style.SHORT);
+ String result = fmt.format(1000);
+ System.out.println(result); // 输出为 1K,计算工资是多少K更方便了。。。
+ ```
+
+### Shenandoah GC
+
+- Redhat 主导开发的 Pauseless GC 实现,主要目标是 99.9% 的暂停小于 10ms,暂停与堆大小无关等
+- 和 Java11 开源的 ZGC 相比(需要升级到 JDK11 才能使用),Shenandoah GC 有稳定的 JDK8u 版本,在 Java8 占据主要市场份额的今天有更大的可落地性
+
+### G1 收集器提升
+
+- **Java12 为默认的垃圾收集器 G1 带来了两项更新:**
+ - 可中止的混合收集集合:JEP344 的实现,为了达到用户提供的停顿时间目标,JEP 344 通过把要被回收的区域集(混合收集集合)拆分为强制和可选部分,使 G1 垃圾回收器能中止垃圾回收过程。 G1 可以中止可选部分的回收以达到停顿时间目标
+ - 及时返回未使用的已分配内存:JEP346 的实现,增强 G1 GC,以便在空闲时自动将 Java 堆内存返回给操作系统
+
+## Java13
+
+### 引入 yield 关键字到 Switch 中
+
+- `Switch` 表达式中就多了一个关键字用于跳出 `Switch` 块的关键字 `yield`,主要用于返回一个值
+
+- `yield`和 `return` 的区别在于:`return` 会直接跳出当前循环或者方法,而 `yield` 只会跳出当前 `Switch` 块,同时在使用 `yield` 时,需要有 `default` 条件
+
+ ```java
+ private static String descLanguage(String name) {
+ return switch (name) {
+ case "Java": yield "object-oriented, platform independent and secured";
+ case "Ruby": yield "a programmer's best friend";
+ default: yield name +" is a good language";
+ };
+ }
+ ```
+
+### 文本块
+
+- 解决 Java 定义多行字符串时只能通过换行转义或者换行连接符来变通支持的问题,引入**三重双引号**来定义多行文本
+
+- 两个`"""`中间的任何内容都会被解释为字符串的一部分,包括换行符
+
+ ```java
+ String json ="{\n" +
+ " \"name\":\"mkyong\",\n" +
+ " \"age\":38\n" +
+ "}\n"; // 未支持文本块之前
+ ```
+
+ ```java
+
+ String json = """
+ {
+ "name":"mkyong",
+ "age":38
+ }
+ """;
+ ```
+
+### 增强 ZGC 释放未使用内存
+
+- 在 Java 11 中是实验性的引入的 ZGC 在实际的使用中存在未能主动将未使用的内存释放给操作系统的问题
+- ZGC 堆由一组称为 ZPages 的堆区域组成。在 GC 周期中清空 ZPages 区域时,它们将被释放并返回到页面缓存 **ZPageCache** 中,此缓存中的 ZPages 按最近最少使用(LRU)的顺序,并按照大小进行组织
+- 在 Java 13 中,ZGC 将向操作系统返回被标识为长时间未使用的页面,这样它们将可以被其他进程重用
+
+### SocketAPI 重构
+
+- Java 13 为 Socket API 带来了新的底层实现方法,并且在 Java 13 中是默认使用新的 Socket 实现,使其易于发现并在排除问题同时增加可维护性
+
+### 动态应用程序类-数据共享
+
+- Java 13 中对 Java 10 中引入的 应用程序类数据共享进行了进一步的简化、改进和扩展,即:**允许在 Java 应用程序执行结束时动态进行类归档**,具体能够被归档的类包括:所有已被加载,但不属于默认基层 CDS 的应用程序类和引用类库中的类
+
+## Java14
+
+### record 关键字
+
+- 简化数据类的定义方式,使用 record 代替 class 定义的类,只需要声明属性,就可以在获得属性的访问方法,以及 toString,hashCode,equals 方法
+
+- 类似于使用 Class 定义类,同时使用了 lomobok 插件,并打上了`@Getter,@ToString,@EqualsAndHashCode`注解
+
+- 作为预览特性引入
+
+ ```java
+ /**
+ * 这个类具有两个特征
+ * 1. 所有成员属性都是final
+ * 2. 全部方法由构造方法,和两个成员属性访问器组成(共三个)
+ * 那么这种类就很适合使用record来声明
+ */
+ final class Rectangle implements Shape {
+ final double length;
+ final double width;
+
+ public Rectangle(double length, double width) {
+ this.length = length;
+ this.width = width;
+ }
+
+ double length() { return length; }
+ double width() { return width; }
+ }
+ /**
+ * 1. 使用record声明的类会自动拥有上面类中的三个方法
+ * 2. 在这基础上还附赠了equals(),hashCode()方法以及toString()方法
+ * 3. toString方法中包括所有成员属性的字符串表示形式及其名称
+ */
+ record Rectangle(float length, float width) { }
+ ```
+
+### 空指针异常精准提示
+
+- 通过 JVM 参数中添加`-XX:+ShowCodeDetailsInExceptionMessages`,可以在空指针异常中获取更为详细的调用信息,更快的定位和解决问题
+
+ ```java
+ a.b.c.i = 99; // 假设这段代码会发生空指针
+ ```
+
+ ```java
+ Exception in thread "main" java.lang.NullPointerException:
+ Cannot read field 'c' because 'a.b' is null.
+ at Prog.main(Prog.java:5) // 增加参数后提示的异常中很明确的告知了哪里为空导致
+ ```
+
+### switch 的增强终于转正
+
+- JDK12 引入的 switch(预览特性)在 JDK14 变为正式版本,不需要增加参数来启用,直接在 JDK14 中就能使用
+- 主要是用`->`来替代以前的`:`+`break`;另外就是提供了 yield 来在 block 中返回值
+
+_Before Java 14_
+
+```java
+switch (day) {
+ case MONDAY:
+ case FRIDAY:
+ case SUNDAY:
+ System.out.println(6);
+ break;
+ case TUESDAY:
+ System.out.println(7);
+ break;
+ case THURSDAY:
+ case SATURDAY:
+ System.out.println(8);
+ break;
+ case WEDNESDAY:
+ System.out.println(9);
+ break;
+}
+```
+
+_Java 14 enhancements_
+
+```java
+switch (day) {
+ case MONDAY, FRIDAY, SUNDAY -> System.out.println(6);
+ case TUESDAY -> System.out.println(7);
+ case THURSDAY, SATURDAY -> System.out.println(8);
+ case WEDNESDAY -> System.out.println(9);
+}
+```
+
+### instanceof 增强
+
+- instanceof 主要在**类型强转前探测对象的具体类型**,然后执行具体的强转
+
+- 新版的 instanceof 可以在判断的是否属于具体的类型同时完成转换
+
+```java
+Object obj = "我是字符串";
+if(obj instanceof String str){
+ System.out.println(str);
+}
+```
+
+### 其他特性
+
+- 从 Java11 引入的 ZGC 作为继 G1 过后的下一代 GC 算法,从支持 Linux 平台到 Java14 开始支持 MacOS 和 Window(个人感觉是终于可以在日常开发工具中先体验下 ZGC 的效果了,虽然其实 G1 也够用)
+- 移除了 CMS 垃圾收集器(功成而退)
+- 新增了 jpackage 工具,标配将应用打成 jar 包外,还支持不同平台的特性包,比如 linux 下的`deb`和`rpm`,window 平台下的`msi`和`exe`
+
+## 总结
+
+### 关于预览特性
+
+- 先贴一段 oracle 官网原文:`This is a preview feature, which is a feature whose design, specification, and implementation are complete, but is not permanent, which means that the feature may exist in a different form or not at all in future JDK releases. To compile and run code that contains preview features, you must specify additional command-line options.`
+- 这是一个预览功能,该功能的设计,规格和实现是完整的,但不是永久性的,这意味着该功能可能以其他形式存在或在将来的 JDK 版本中根本不存在。 要编译和运行包含预览功能的代码,必须指定其他命令行选项。
+- 就以`switch`的增强为例子,从 Java12 中推出,到 Java13 中将继续增强,直到 Java14 才正式转正进入 JDK 可以放心使用,不用考虑后续 JDK 版本对其的改动或修改
+- 一方面可以看出 JDK 作为标准平台在增加新特性的严谨态度,另一方面个人认为是对于预览特性应该采取审慎使用的态度。特性的设计和实现容易,但是其实际价值依然需要在使用中去验证
+
+### JVM 虚拟机优化
+
+- 每次 Java 版本的发布都伴随着对 JVM 虚拟机的优化,包括对现有垃圾回收算法的改进,引入新的垃圾回收算法,移除老旧的不再适用于今天的垃圾回收算法等
+- 整体优化的方向是**高效,低时延的垃圾回收表现**
+- 对于日常的应用开发者可能比较关注新的语法特性,但是从一个公司角度来说,在考虑是否升级 Java 平台时更加考虑的是**JVM 运行时的提升**
+
+## 参考信息
+
+- IBM Developer Java9
+- Java 10 新特性介绍
+- IBM Devloper Java11
+- Java 11 – Features and Comparison:
+- Oracle Java13 ReleaseNote
+- New Java13 Features
+- Java13 新特性概述
+- Oracle Java14 record
+- java14-features
\ No newline at end of file
diff --git a/docs/java/jvm/GC调优参数.md b/docs/java/jvm/GC调优参数.md
index b9475b08..31dd48b7 100644
--- a/docs/java/jvm/GC调优参数.md
+++ b/docs/java/jvm/GC调优参数.md
@@ -1,19 +1,24 @@
> 原文地址: https://juejin.im/post/5c94a123f265da610916081f。
-## JVM 配置常用参数
+## JVM 配置常用参数
-1. 堆参数;
-2. 回收器参数;
-3. 项目中常用配置;
-4. 常用组合;
+1. Java内存区域常见配置参数概览
+2. 堆参数;
+3. 回收器参数;
+4. 项目中常用配置;
+5. 常用组合;
+
+### Java内存区域常见配置参数概览
+
+
### 堆参数
-
+![堆参数][1]
### 回收器参数
-
+![垃圾回收器参数][2]
如上表所示,目前**主要有串行、并行和并发三种**,对于大内存的应用而言,串行的性能太低,因此使用到的主要是并行和并发两种。并行和并发 GC 的策略通过 `UseParallelGC `和` UseConcMarkSweepGC` 来指定,还有一些细节的配置参数用来配置策略的执行方式。例如:`XX:ParallelGCThreads`, `XX:CMSInitiatingOccupancyFraction` 等。 通常:Young 区对象回收只可选择并行(耗时间),Old 区选择并发(耗 CPU)。
@@ -21,11 +26,11 @@
> 备注:在Java8中永久代的参数`-XX:PermSize` 和`-XX:MaxPermSize`已经失效。
-
+![项目中垃圾回收器常用配置][3]
### 常用组合
-
+![垃圾回收器常用组合][4]
## 常用 GC 调优策略
@@ -55,4 +60,9 @@
**策略5:**注意: 如果满足下面的指标,**则一般不需要进行 GC 优化:**
-> MinorGC 执行时间不到50ms; Minor GC 执行不频繁,约10秒一次; Full GC 执行时间不到1s; Full GC 执行频率不算频繁,不低于10分钟1次。
\ No newline at end of file
+> MinorGC 执行时间不到50ms; Minor GC 执行不频繁,约10秒一次; Full GC 执行时间不到1s; Full GC 执行频率不算频繁,不低于10分钟1次。
+
+[1]: ./../../../media/pictures/jvm/java_jvm_heap_parameters.png
+[2]: ./../../../media/pictures/jvm/java_jvm_garbage_collector_parameters.png
+[3]: ./../../../media/pictures/jvm/java_jvm_suggest_parameters.png
+[4]: ./../../../media/pictures/jvm/java_jvm_compose_garbage_collector.png
\ No newline at end of file
diff --git a/docs/java/jvm/JDK监控和故障处理工具总结.md b/docs/java/jvm/JDK监控和故障处理工具总结.md
index 8a8ec160..d5cb29de 100644
--- a/docs/java/jvm/JDK监控和故障处理工具总结.md
+++ b/docs/java/jvm/JDK监控和故障处理工具总结.md
@@ -83,9 +83,9 @@ jstat - [-t] [-h] [ []]
- `jstat -gccapacity vmid` :显示各个代的容量及使用情况;
- `jstat -gcnew vmid` :显示新生代信息;
- `jstat -gcnewcapcacity vmid` :显示新生代大小与使用情况;
-- `jstat -gcold vmid` :显示老年代和永久代的信息;
+- `jstat -gcold vmid` :显示老年代和永久代的行为统计,从jdk1.8开始,该选项仅表示老年代,因为永久代被移除了;
- `jstat -gcoldcapacity vmid` :显示老年代的大小;
-- `jstat -gcpermcapacity vmid` :显示永久代大小;
+- `jstat -gcpermcapacity vmid` :显示永久代大小,从jdk1.8开始,该选项不存在了,因为永久代被移除了;
- `jstat -gcutil vmid` :显示垃圾收集信息;
另外,加上 `-t`参数可以在输出信息上加一个 Timestamp 列,显示程序的运行时间。
@@ -264,7 +264,7 @@ JConsole 是基于 JMX 的可视化监视、管理工具。可以很方便的监
#### 连接 Jconsole
-
+
如果需要使用 JConsole 连接远程进程,可以在远程 Java 程序启动时加上下面这些参数:
@@ -283,7 +283,7 @@ JConsole 是基于 JMX 的可视化监视、管理工具。可以很方便的监
#### 查看 Java 程序概况
-
+
#### 内存监控
@@ -294,7 +294,7 @@ JConsole 可以显示当前内存的详细信息。不仅包括堆内存/非堆
> - **新生代 GC(Minor GC)**:指发生新生代的的垃圾收集动作,Minor GC 非常频繁,回收速度一般也比较快。
> - **老年代 GC(Major GC/Full GC)**:指发生在老年代的 GC,出现了 Major GC 经常会伴随至少一次的 Minor GC(并非绝对),Major GC 的速度一般会比 Minor GC 的慢 10 倍以上。
-
+
#### 线程监控
@@ -302,7 +302,7 @@ JConsole 可以显示当前内存的详细信息。不仅包括堆内存/非堆
最下面有一个"检测死锁 (D)"按钮,点击这个按钮可以自动为你找到发生死锁的线程以及它们的详细信息 。
-
+
### Visual VM:多合一故障处理工具
diff --git a/docs/java/jvm/JVM垃圾回收.md b/docs/java/jvm/JVM垃圾回收.md
index bc05d82d..95363151 100644
--- a/docs/java/jvm/JVM垃圾回收.md
+++ b/docs/java/jvm/JVM垃圾回收.md
@@ -54,7 +54,7 @@
### 本文导火索
-
+
当需要排查各种内存溢出问题、当垃圾收集成为系统达到更高并发的瓶颈时,我们就需要对这些“自动化”的技术实施必要的监控和调节。
@@ -66,14 +66,38 @@ Java 堆是垃圾收集器管理的主要区域,因此也被称作**GC 堆(G
**堆空间的基本结构:**
-
-
-
-
-
-
-
:
-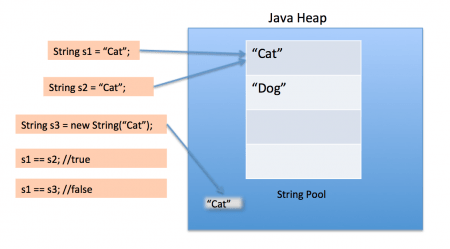
+
**String 类型的常量池比较特殊。它的主要使用方法有两种:**
@@ -362,7 +368,7 @@ System.out.println(str2==str3);//false
System.out.println(str3 == str5);//true
System.out.println(str4 == str5);//false
```
-
+
尽量避免多个字符串拼接,因为这样会重新创建对象。如果需要改变字符串的话,可以使用 StringBuilder 或者 StringBuffer。
### 4.2 String s1 = new String("abc");这句话创建了几个字符串对象?
diff --git a/docs/java/jvm/jvm 知识点汇总.md b/docs/java/jvm/jvm 知识点汇总.md
index 4529e858..7a835ecc 100644
--- a/docs/java/jvm/jvm 知识点汇总.md
+++ b/docs/java/jvm/jvm 知识点汇总.md
@@ -1,4 +1,3 @@
-
无论什么级别的Java从业者,JVM都是进阶时必须迈过的坎。不管是工作还是面试中,JVM都是必考题。如果不懂JVM的话,薪酬会非常吃亏(近70%的面试者挂在JVM上了)。
@@ -10,4 +9,4 @@
掌握JVM,是深入Java技术栈的必经之路。
-
+
\ No newline at end of file
diff --git a/docs/java/jvm/pictures/HsJXU8S4oVtCTM7.png b/docs/java/jvm/pictures/HsJXU8S4oVtCTM7.png
new file mode 100644
index 00000000..52f4b008
Binary files /dev/null and b/docs/java/jvm/pictures/HsJXU8S4oVtCTM7.png differ
diff --git a/docs/java/jvm/pictures/java内存区域/2019-3Java运行时数据区域JDK1.8.png b/docs/java/jvm/pictures/java内存区域/2019-3Java运行时数据区域JDK1.8.png
new file mode 100644
index 00000000..c5088be5
Binary files /dev/null and b/docs/java/jvm/pictures/java内存区域/2019-3Java运行时数据区域JDK1.8.png differ
diff --git a/docs/java/jvm/pictures/java内存区域/2019-3String-Pool-Java1-450x249.png b/docs/java/jvm/pictures/java内存区域/2019-3String-Pool-Java1-450x249.png
new file mode 100644
index 00000000..b6e24178
Binary files /dev/null and b/docs/java/jvm/pictures/java内存区域/2019-3String-Pool-Java1-450x249.png differ
diff --git a/docs/java/jvm/pictures/java内存区域/JVM堆内存结构-JDK7.png b/docs/java/jvm/pictures/java内存区域/JVM堆内存结构-JDK7.png
new file mode 100644
index 00000000..3e90da89
Binary files /dev/null and b/docs/java/jvm/pictures/java内存区域/JVM堆内存结构-JDK7.png differ
diff --git a/docs/java/jvm/pictures/java内存区域/JVM堆内存结构-jdk8.png b/docs/java/jvm/pictures/java内存区域/JVM堆内存结构-jdk8.png
new file mode 100644
index 00000000..829aede4
Binary files /dev/null and b/docs/java/jvm/pictures/java内存区域/JVM堆内存结构-jdk8.png differ
diff --git a/docs/java/jvm/pictures/java内存区域/JVM运行时数据区域.png b/docs/java/jvm/pictures/java内存区域/JVM运行时数据区域.png
new file mode 100644
index 00000000..bf52c66e
Binary files /dev/null and b/docs/java/jvm/pictures/java内存区域/JVM运行时数据区域.png differ
diff --git a/docs/java/jvm/pictures/java内存区域/Java创建对象的过程.png b/docs/java/jvm/pictures/java内存区域/Java创建对象的过程.png
new file mode 100644
index 00000000..7c4a79f1
Binary files /dev/null and b/docs/java/jvm/pictures/java内存区域/Java创建对象的过程.png differ
diff --git a/docs/java/jvm/pictures/java内存区域/内存分配的两种方式.png b/docs/java/jvm/pictures/java内存区域/内存分配的两种方式.png
new file mode 100644
index 00000000..1d0081b1
Binary files /dev/null and b/docs/java/jvm/pictures/java内存区域/内存分配的两种方式.png differ
diff --git a/docs/java/jvm/pictures/java内存区域/字符串拼接-常量池2.png b/docs/java/jvm/pictures/java内存区域/字符串拼接-常量池2.png
new file mode 100644
index 00000000..b680fb60
Binary files /dev/null and b/docs/java/jvm/pictures/java内存区域/字符串拼接-常量池2.png differ
diff --git a/docs/java/jvm/pictures/java内存区域/对象的访问定位-直接指针.png b/docs/java/jvm/pictures/java内存区域/对象的访问定位-直接指针.png
new file mode 100644
index 00000000..145bd405
Binary files /dev/null and b/docs/java/jvm/pictures/java内存区域/对象的访问定位-直接指针.png differ
diff --git a/docs/java/jvm/pictures/jdk监控和故障处理工具总结/1JConsole连接.png b/docs/java/jvm/pictures/jdk监控和故障处理工具总结/1JConsole连接.png
new file mode 100644
index 00000000..ae1e6106
Binary files /dev/null and b/docs/java/jvm/pictures/jdk监控和故障处理工具总结/1JConsole连接.png differ
diff --git a/docs/java/jvm/pictures/jdk监控和故障处理工具总结/2查看Java程序概况.png b/docs/java/jvm/pictures/jdk监控和故障处理工具总结/2查看Java程序概况.png
new file mode 100644
index 00000000..3a997022
Binary files /dev/null and b/docs/java/jvm/pictures/jdk监控和故障处理工具总结/2查看Java程序概况.png differ
diff --git a/docs/java/jvm/pictures/jdk监控和故障处理工具总结/3内存监控.png b/docs/java/jvm/pictures/jdk监控和故障处理工具总结/3内存监控.png
new file mode 100644
index 00000000..56d98052
Binary files /dev/null and b/docs/java/jvm/pictures/jdk监控和故障处理工具总结/3内存监控.png differ
diff --git a/docs/java/jvm/pictures/jdk监控和故障处理工具总结/4线程监控.png b/docs/java/jvm/pictures/jdk监控和故障处理工具总结/4线程监控.png
new file mode 100644
index 00000000..2ad324bd
Binary files /dev/null and b/docs/java/jvm/pictures/jdk监控和故障处理工具总结/4线程监控.png differ
diff --git a/docs/java/jvm/pictures/jvm垃圾回收/01d330d8-2710-4fad-a91c-7bbbfaaefc0e.png b/docs/java/jvm/pictures/jvm垃圾回收/01d330d8-2710-4fad-a91c-7bbbfaaefc0e.png
new file mode 100644
index 00000000..7934357e
Binary files /dev/null and b/docs/java/jvm/pictures/jvm垃圾回收/01d330d8-2710-4fad-a91c-7bbbfaaefc0e.png differ
diff --git a/docs/java/jvm/pictures/jvm垃圾回收/10317146.png b/docs/java/jvm/pictures/jvm垃圾回收/10317146.png
new file mode 100644
index 00000000..a77222ba
Binary files /dev/null and b/docs/java/jvm/pictures/jvm垃圾回收/10317146.png differ
diff --git a/docs/java/jvm/pictures/jvm垃圾回收/11034259.png b/docs/java/jvm/pictures/jvm垃圾回收/11034259.png
new file mode 100644
index 00000000..092dc12e
Binary files /dev/null and b/docs/java/jvm/pictures/jvm垃圾回收/11034259.png differ
diff --git a/docs/java/jvm/pictures/jvm垃圾回收/22018368.png b/docs/java/jvm/pictures/jvm垃圾回收/22018368.png
new file mode 100644
index 00000000..c79c76f3
Binary files /dev/null and b/docs/java/jvm/pictures/jvm垃圾回收/22018368.png differ
diff --git a/docs/java/jvm/pictures/jvm垃圾回收/22018368213213.png b/docs/java/jvm/pictures/jvm垃圾回收/22018368213213.png
new file mode 100644
index 00000000..c79c76f3
Binary files /dev/null and b/docs/java/jvm/pictures/jvm垃圾回收/22018368213213.png differ
diff --git a/docs/java/jvm/pictures/jvm垃圾回收/25178350.png b/docs/java/jvm/pictures/jvm垃圾回收/25178350.png
new file mode 100644
index 00000000..cc307027
Binary files /dev/null and b/docs/java/jvm/pictures/jvm垃圾回收/25178350.png differ
diff --git a/docs/java/jvm/pictures/jvm垃圾回收/29176325.png b/docs/java/jvm/pictures/jvm垃圾回收/29176325.png
new file mode 100644
index 00000000..a6d2199e
Binary files /dev/null and b/docs/java/jvm/pictures/jvm垃圾回收/29176325.png differ
diff --git a/docs/java/jvm/pictures/jvm垃圾回收/46873026.png b/docs/java/jvm/pictures/jvm垃圾回收/46873026.png
new file mode 100644
index 00000000..2145dce9
Binary files /dev/null and b/docs/java/jvm/pictures/jvm垃圾回收/46873026.png differ
diff --git a/docs/java/jvm/pictures/jvm垃圾回收/72762049.png b/docs/java/jvm/pictures/jvm垃圾回收/72762049.png
new file mode 100644
index 00000000..f326103f
Binary files /dev/null and b/docs/java/jvm/pictures/jvm垃圾回收/72762049.png differ
diff --git a/docs/java/jvm/pictures/jvm垃圾回收/82825079.png b/docs/java/jvm/pictures/jvm垃圾回收/82825079.png
new file mode 100644
index 00000000..3ed3bd82
Binary files /dev/null and b/docs/java/jvm/pictures/jvm垃圾回收/82825079.png differ
diff --git a/docs/java/jvm/pictures/jvm垃圾回收/90984624.png b/docs/java/jvm/pictures/jvm垃圾回收/90984624.png
new file mode 100644
index 00000000..6909a605
Binary files /dev/null and b/docs/java/jvm/pictures/jvm垃圾回收/90984624.png differ
diff --git a/docs/java/jvm/pictures/jvm垃圾回收/94057049.png b/docs/java/jvm/pictures/jvm垃圾回收/94057049.png
new file mode 100644
index 00000000..86d43ee6
Binary files /dev/null and b/docs/java/jvm/pictures/jvm垃圾回收/94057049.png differ
diff --git a/docs/java/jvm/pictures/jvm垃圾回收/CMS收集器.png b/docs/java/jvm/pictures/jvm垃圾回收/CMS收集器.png
new file mode 100644
index 00000000..3ed3bd82
Binary files /dev/null and b/docs/java/jvm/pictures/jvm垃圾回收/CMS收集器.png differ
diff --git a/docs/java/jvm/pictures/jvm垃圾回收/parllel-scavenge收集器.png b/docs/java/jvm/pictures/jvm垃圾回收/parllel-scavenge收集器.png
new file mode 100644
index 00000000..c79c76f3
Binary files /dev/null and b/docs/java/jvm/pictures/jvm垃圾回收/parllel-scavenge收集器.png differ
diff --git a/docs/java/jvm/pictures/jvm垃圾回收/垃圾收集器.png b/docs/java/jvm/pictures/jvm垃圾回收/垃圾收集器.png
new file mode 100644
index 00000000..888f879d
Binary files /dev/null and b/docs/java/jvm/pictures/jvm垃圾回收/垃圾收集器.png differ
diff --git a/docs/java/jvm/pictures/jvm垃圾回收/垃圾收集算法.png b/docs/java/jvm/pictures/jvm垃圾回收/垃圾收集算法.png
new file mode 100644
index 00000000..0a4973bd
Binary files /dev/null and b/docs/java/jvm/pictures/jvm垃圾回收/垃圾收集算法.png differ
diff --git a/docs/java/jvm/pictures/jvm垃圾回收/堆内存.png b/docs/java/jvm/pictures/jvm垃圾回收/堆内存.png
new file mode 100644
index 00000000..14815710
Binary files /dev/null and b/docs/java/jvm/pictures/jvm垃圾回收/堆内存.png differ
diff --git a/docs/java/jvm/pictures/jvm垃圾回收/标记-清除算法.jpeg b/docs/java/jvm/pictures/jvm垃圾回收/标记-清除算法.jpeg
new file mode 100644
index 00000000..c4cdc750
Binary files /dev/null and b/docs/java/jvm/pictures/jvm垃圾回收/标记-清除算法.jpeg differ
diff --git a/docs/java/jvm/pictures/内存区域常见配置参数.png b/docs/java/jvm/pictures/内存区域常见配置参数.png
new file mode 100644
index 00000000..7199d806
Binary files /dev/null and b/docs/java/jvm/pictures/内存区域常见配置参数.png differ
diff --git a/docs/java/jvm/类加载器.md b/docs/java/jvm/类加载器.md
index 00a89047..1d0a826f 100644
--- a/docs/java/jvm/类加载器.md
+++ b/docs/java/jvm/类加载器.md
@@ -118,7 +118,11 @@ protected Class loadClass(String name, boolean resolve)
### 如果我们不想用双亲委派模型怎么办?
-为了避免双亲委托机制,我们可以自己定义一个类加载器,然后重写 `loadClass()` 即可。
+~~为了避免双亲委托机制,我们可以自己定义一个类加载器,然后重写 `loadClass()` 即可。~~
+
+完善修正([issue871](https://github.com/Snailclimb/JavaGuide/issues/871):类加载器一问的补充说明):
+
+ **自定义加载器的话,需要继承 `ClassLoader` 。如果我们不想打破双亲委派模型,就重写 `ClassLoader` 类中的 `findClass()` 方法即可,无法被父类加载器加载的类最终会通过这个方法被加载。但是,如果想打破双亲委派模型则需要重写 `loadClass()` 方法**
## 自定义类加载器
diff --git a/docs/java/jvm/类加载过程.md b/docs/java/jvm/类加载过程.md
index 895ba43f..9330c581 100644
--- a/docs/java/jvm/类加载过程.md
+++ b/docs/java/jvm/类加载过程.md
@@ -1,27 +1,37 @@
点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
-
-- [类加载过程](#类加载过程)
- - [加载](#加载)
- - [验证](#验证)
- - [准备](#准备)
- - [解析](#解析)
- - [初始化](#初始化)
-
-
-
> 公众号JavaGuide 后台回复关键字“1”,免费获取JavaGuide配套的Java工程师必备学习资源(文末有公众号二维码)。
-# 类加载过程
+
+
+- [类的生命周期](#类的生命周期)
+ - [类加载过程](#类加载过程)
+ - [加载](#加载)
+ - [验证](#验证)
+ - [准备](#准备)
+ - [解析](#解析)
+ - [初始化](#初始化)
+ - [卸载](#卸载)
+ - [公众号](#公众号)
+
+
+
+# 类的生命周期
+
+一个类的完整生命周期如下:
+
+
+
+
+## 类加载过程
Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚拟机是如何加载这些 Class 文件呢?
系统加载 Class 类型的文件主要三步:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。
-
+
-## 加载
+### 加载
类加载过程的第一步,主要完成下面3件事情:
@@ -37,11 +47,11 @@ Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚
加载阶段和连接阶段的部分内容是交叉进行的,加载阶段尚未结束,连接阶段可能就已经开始了。
-## 验证
+### 验证

-## 准备
+### 准备
**准备阶段是正式为类变量分配内存并设置类变量初始值的阶段**,这些内存都将在方法区中分配。对于该阶段有以下几点需要注意:
@@ -52,7 +62,7 @@ Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚
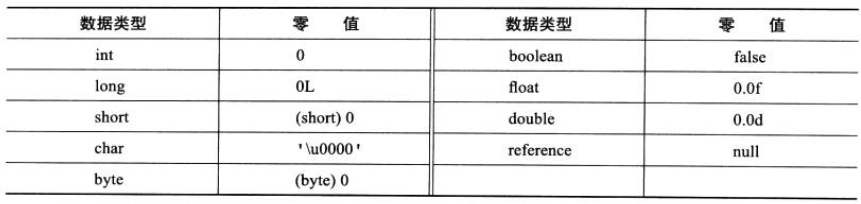
-## 解析
+### 解析
解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用限定符7类符号引用进行。
@@ -60,19 +70,41 @@ Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚
综上,解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程,也就是得到类或者字段、方法在内存中的指针或者偏移量。
-## 初始化
+### 初始化
初始化是类加载的最后一步,也是真正执行类中定义的 Java 程序代码(字节码),初始化阶段是执行类构造器 ` ()`方法的过程。
对于`()` 方法的调用,虚拟机会自己确保其在多线程环境中的安全性。因为 `()` 方法是带锁线程安全,所以在多线程环境下进行类初始化的话可能会引起死锁,并且这种死锁很难被发现。
-对于初始化阶段,虚拟机严格规范了有且只有5种情况下,必须对类进行初始化:
+对于初始化阶段,虚拟机严格规范了有且只有5种情况下,必须对类进行初始化(只有主动去使用类才会初始化类):
1. 当遇到 new 、 getstatic、putstatic或invokestatic 这4条直接码指令时,比如 new 一个类,读取一个静态字段(未被 final 修饰)、或调用一个类的静态方法时。
-2. 使用 `java.lang.reflect` 包的方法对类进行反射调用时 ,如果类没初始化,需要触发其初始化。
+ - 当jvm执行new指令时会初始化类。即当程序创建一个类的实例对象。
+ - 当jvm执行getstatic指令时会初始化类。即程序访问类的静态变量(不是静态常量,常量会被加载到运行时常量池)。
+ - 当jvm执行putstatic指令时会初始化类。即程序给类的静态变量赋值。
+ - 当jvm执行invokestatic指令时会初始化类。即程序调用类的静态方法。
+2. 使用 `java.lang.reflect` 包的方法对类进行反射调用时如Class.forname("..."),newInstance()等等。 ,如果类没初始化,需要触发其初始化。
3. 初始化一个类,如果其父类还未初始化,则先触发该父类的初始化。
4. 当虚拟机启动时,用户需要定义一个要执行的主类 (包含 main 方法的那个类),虚拟机会先初始化这个类。
-5. 当使用 JDK1.7 的动态动态语言时,如果一个 MethodHandle 实例的最后解析结构为 REF_getStatic、REF_putStatic、REF_invokeStatic、的方法句柄,并且这个句柄没有初始化,则需要先触发器初始化。
+5. MethodHandle和VarHandle可以看作是轻量级的反射调用机制,而要想使用这2个调用,
+ 就必须先使用findStaticVarHandle来初始化要调用的类。
+6. **「补充,来自[issue745](https://github.com/Snailclimb/JavaGuide/issues/745)」** 当一个接口中定义了JDK8新加入的默认方法(被default关键字修饰的接口方法)时,如果有这个接口的实现类发生了初始化,那该接口要在其之前被初始化。
+
+## 卸载
+
+> 卸载这部分内容来自 [issue#662](https://github.com/Snailclimb/JavaGuide/issues/662)由 **[guang19](https://github.com/guang19)** 补充完善。
+
+卸载类即该类的Class对象被GC。
+
+卸载类需要满足3个要求:
+
+1. 该类的所有的实例对象都已被GC,也就是说堆不存在该类的实例对象。
+2. 该类没有在其他任何地方被引用
+3. 该类的类加载器的实例已被GC
+
+所以,在JVM生命周期类,由jvm自带的类加载器加载的类是不会被卸载的。但是由我们自定义的类加载器加载的类是可能被卸载的。
+
+只要想通一点就好了,jdk自带的BootstrapClassLoader,PlatformClassLoader,AppClassLoader负责加载jdk提供的类,所以它们(类加载器的实例)肯定不会被回收。而我们自定义的类加载器的实例是可以被回收的,所以使用我们自定义加载器加载的类是可以被卸载掉的。
**参考**
@@ -89,3 +121,4 @@ Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚
**Java工程师必备学习资源:** 一些Java工程师常用学习资源[公众号](#公众号)后台回复关键字 **“1”** 即可免费无套路获取。

+
diff --git a/docs/java/jvm/类文件结构.md b/docs/java/jvm/类文件结构.md
index 6cdc3120..d766aa80 100644
--- a/docs/java/jvm/类文件结构.md
+++ b/docs/java/jvm/类文件结构.md
@@ -46,7 +46,7 @@ ClassFile {
u2 interfaces_count;//接口
u2 interfaces[interfaces_count];//一个类可以实现多个接口
u2 fields_count;//Class 文件的字段属性
- field_info fields[fields_count];//一个类会可以有个字段
+ field_info fields[fields_count];//一个类会可以有多个字段
u2 methods_count;//Class 文件的方法数量
method_info methods[methods_count];//一个类可以有个多个方法
u2 attributes_count;//此类的属性表中的属性数
@@ -144,12 +144,12 @@ public class Employee {
u2 this_class;//当前类
u2 super_class;//父类
u2 interfaces_count;//接口
- u2 interfaces[interfaces_count];//一个雷可以实现多个接口
+ u2 interfaces[interfaces_count];//一个类可以实现多个接口
```
**类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名,由于 Java 语言的单继承,所以父类索引只有一个,除了 `java.lang.Object` 之外,所有的 java 类都有父类,因此除了 `java.lang.Object` 外,所有 Java 类的父类索引都不为 0。**
-**接口索引集合用来描述这个类实现了那些接口,这些被实现的接口将按`implents`(如果这个类本身是接口的话则是`extends`) 后的接口顺序从左到右排列在接口索引集合中。**
+**接口索引集合用来描述这个类实现了那些接口,这些被实现的接口将按 `implements` (如果这个类本身是接口的话则是`extends`) 后的接口顺序从左到右排列在接口索引集合中。**
### 2.6 字段表集合
diff --git a/docs/java/手把手教你定位常见Java性能问题.md b/docs/java/手把手教你定位常见Java性能问题.md
new file mode 100644
index 00000000..980eeefb
--- /dev/null
+++ b/docs/java/手把手教你定位常见Java性能问题.md
@@ -0,0 +1,404 @@
+## 手把手教你定位常见Java性能问题
+
+## 概述
+
+性能优化一向是后端服务优化的重点,但是线上性能故障问题不是经常出现,或者受限于业务产品,根本就没办法出现性能问题,包括笔者自己遇到的性能问题也不多,所以为了提前储备知识,当出现问题的时候不会手忙脚乱,我们本篇文章来模拟下常见的几个Java性能故障,来学习怎么去分析和定位。
+
+## 预备知识
+
+既然是定位问题,肯定是需要借助工具,我们先了解下需要哪些工具可以帮忙定位问题。
+
+ **top命令**
+
+`top`命令使我们最常用的Linux命令之一,它可以实时的显示当前正在执行的进程的CPU使用率,内存使用率等系统信息。`top -Hp pid` 可以查看线程的系统资源使用情况。
+
+ **vmstat命令**
+
+vmstat是一个指定周期和采集次数的虚拟内存检测工具,可以统计内存,CPU,swap的使用情况,它还有一个重要的常用功能,用来观察进程的上下文切换。字段说明如下:
+
+- r: 运行队列中进程数量(当数量大于CPU核数表示有阻塞的线程)
+- b: 等待IO的进程数量
+- swpd: 使用虚拟内存大小
+- free: 空闲物理内存大小
+- buff: 用作缓冲的内存大小(内存和硬盘的缓冲区)
+- cache: 用作缓存的内存大小(CPU和内存之间的缓冲区)
+- si: 每秒从交换区写到内存的大小,由磁盘调入内存
+- so: 每秒写入交换区的内存大小,由内存调入磁盘
+- bi: 每秒读取的块数
+- bo: 每秒写入的块数
+- in: 每秒中断数,包括时钟中断。
+- cs: 每秒上下文切换数。
+- us: 用户进程执行时间百分比(user time)
+- sy: 内核系统进程执行时间百分比(system time)
+- wa: IO等待时间百分比
+- id: 空闲时间百分比
+
+ **pidstat命令**
+
+pidstat 是 Sysstat 中的一个组件,也是一款功能强大的性能监测工具,`top` 和 `vmstat` 两个命令都是监测进程的内存、CPU 以及 I/O 使用情况,而 pidstat 命令可以检测到线程级别的。`pidstat`命令线程切换字段说明如下:
+
+- UID :被监控任务的真实用户ID。
+
+- TGID :线程组ID。
+
+- TID:线程ID。
+
+- cswch/s:主动切换上下文次数,这里是因为资源阻塞而切换线程,比如锁等待等情况。
+
+- nvcswch/s:被动切换上下文次数,这里指CPU调度切换了线程。
+
+ **jstack命令**
+
+jstack是JDK工具命令,它是一种线程堆栈分析工具,最常用的功能就是使用 `jstack pid` 命令查看线程的堆栈信息,也经常用来排除死锁情况。
+
+**jstat 命令**
+
+它可以检测Java程序运行的实时情况,包括堆内存信息和垃圾回收信息,我们常常用来查看程序垃圾回收情况。常用的命令是`jstat -gc pid`。信息字段说明如下:
+
+- S0C:年轻代中 To Survivor 的容量(单位 KB);
+
+- S1C:年轻代中 From Survivor 的容量(单位 KB);
+
+- S0U:年轻代中 To Survivor 目前已使用空间(单位 KB);
+
+- S1U:年轻代中 From Survivor 目前已使用空间(单位 KB);
+
+- EC:年轻代中 Eden 的容量(单位 KB);
+
+- EU:年轻代中 Eden 目前已使用空间(单位 KB);
+
+- OC:老年代的容量(单位 KB);
+
+- OU:老年代目前已使用空间(单位 KB);
+
+- MC:元空间的容量(单位 KB);
+
+- MU:元空间目前已使用空间(单位 KB);
+
+- YGC:从应用程序启动到采样时年轻代中 gc 次数;
+
+- YGCT:从应用程序启动到采样时年轻代中 gc 所用时间 (s);
+
+- FGC:从应用程序启动到采样时 老年代(Full Gc)gc 次数;
+
+- FGCT:从应用程序启动到采样时 老年代代(Full Gc)gc 所用时间 (s);
+
+- GCT:从应用程序启动到采样时 gc 用的总时间 (s)。
+
+
+
+ **jmap命令**
+
+jmap也是JDK工具命令,他可以查看堆内存的初始化信息以及堆内存的使用情况,还可以生成dump文件来进行详细分析。查看堆内存情况命令`jmap -heap pid`。
+
+ **mat内存工具**
+
+MAT(Memory Analyzer Tool)工具是eclipse的一个插件(MAT也可以单独使用),它分析大内存的dump文件时,可以非常直观的看到各个对象在堆空间中所占用的内存大小、类实例数量、对象引用关系、利用OQL对象查询,以及可以很方便的找出对象GC Roots的相关信息。
+
+**idea中也有这么一个插件,就是JProfiler**。
+
+相关阅读:
+
+1. 《性能诊断利器 JProfiler 快速入门和最佳实践》:[https://segmentfault.com/a/1190000017795841](https://segmentfault.com/a/1190000017795841)
+
+## 模拟环境准备
+
+基础环境jdk1.8,采用SpringBoot框架来写几个接口来触发模拟场景,首先是模拟CPU占满情况
+
+## CPU占满
+
+模拟CPU占满还是比较简单,直接写一个死循环计算消耗CPU即可。
+
+````java
+ /**
+ * 模拟CPU占满
+ */
+ @GetMapping("/cpu/loop")
+ public void testCPULoop() throws InterruptedException {
+ System.out.println("请求cpu死循环");
+ Thread.currentThread().setName("loop-thread-cpu");
+ int num = 0;
+ while (true) {
+ num++;
+ if (num == Integer.MAX_VALUE) {
+ System.out.println("reset");
+ }
+ num = 0;
+ }
+
+ }
+````
+
+请求接口地址测试`curl localhost:8080/cpu/loop`,发现CPU立马飙升到100%
+
+
+
+通过执行`top -Hp 32805` 查看Java线程情况
+
+
+
+执行 `printf '%x' 32826` 获取16进制的线程id,用于`dump`信息查询,结果为 `803a`。最后我们执行`jstack 32805 |grep -A 20 803a `来查看下详细的`dump`信息。
+
+
+
+这里`dump`信息直接定位出了问题方法以及代码行,这就定位出了CPU占满的问题。
+
+## 内存泄露
+
+模拟内存泄漏借助了ThreadLocal对象来完成,ThreadLocal是一个线程私有变量,可以绑定到线程上,在整个线程的生命周期都会存在,但是由于ThreadLocal的特殊性,ThreadLocal是基于ThreadLocalMap实现的,ThreadLocalMap的Entry继承WeakReference,而Entry的Key是WeakReference的封装,换句话说Key就是弱引用,弱引用在下次GC之后就会被回收,如果ThreadLocal在set之后不进行后续的操作,因为GC会把Key清除掉,但是Value由于线程还在存活,所以Value一直不会被回收,最后就会发生内存泄漏。
+
+````Java
+/**
+ * 模拟内存泄漏
+ */
+ @GetMapping(value = "/memory/leak")
+ public String leak() {
+ System.out.println("模拟内存泄漏");
+ ThreadLocal localVariable = new ThreadLocal();
+ localVariable.set(new Byte[4096 * 1024]);// 为线程添加变量
+ return "ok";
+ }
+````
+
+我们给启动加上堆内存大小限制,同时设置内存溢出的时候输出堆栈快照并输出日志。
+
+`java -jar -Xms500m -Xmx500m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/heapdump.hprof -XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Xloggc:/tmp/heaplog.log analysis-demo-0.0.1-SNAPSHOT.jar`
+
+启动成功后我们循环执行100次,`for i in {1..500}; do curl localhost:8080/memory/leak;done`,还没执行完毕,系统已经返回500错误了。查看系统日志出现了如下异常:
+
+```
+java.lang.OutOfMemoryError: Java heap space
+```
+
+我们用`jstat -gc pid` 命令来看看程序的GC情况。
+
+
+
+很明显,内存溢出了,堆内存经过45次 Full Gc 之后都没释放出可用内存,这说明当前堆内存中的对象都是存活的,有GC Roots引用,无法回收。那是什么原因导致内存溢出呢?是不是我只要加大内存就行了呢?如果是普通的内存溢出也许扩大内存就行了,但是如果是内存泄漏的话,扩大的内存不一会就会被占满,所以我们还需要确定是不是内存泄漏。我们之前保存了堆 Dump 文件,这个时候借助我们的MAT工具来分析下。导入工具选择`Leak Suspects Report`,工具直接就会给你列出问题报告。
+
+
+
+这里已经列出了可疑的4个内存泄漏问题,我们点击其中一个查看详情。
+
+
+
+这里已经指出了内存被线程占用了接近50M的内存,占用的对象就是ThreadLocal。如果想详细的通过手动去分析的话,可以点击`Histogram`,查看最大的对象占用是谁,然后再分析它的引用关系,即可确定是谁导致的内存溢出。
+
+
+
+上图发现占用内存最大的对象是一个Byte数组,我们看看它到底被那个GC Root引用导致没有被回收。按照上图红框操作指引,结果如下图:
+
+
+
+我们发现Byte数组是被线程对象引用的,图中也标明,Byte数组对像的GC Root是线程,所以它是不会被回收的,展开详细信息查看,我们发现最终的内存占用对象是被ThreadLocal对象占据了。这也和MAT工具自动帮我们分析的结果一致。
+
+## 死锁
+
+死锁会导致耗尽线程资源,占用内存,表现就是内存占用升高,CPU不一定会飙升(看场景决定),如果是直接new线程,会导致JVM内存被耗尽,报无法创建线程的错误,这也是体现了使用线程池的好处。
+
+```java
+ ExecutorService service = new ThreadPoolExecutor(4, 10,
+ 0, TimeUnit.SECONDS, new LinkedBlockingQueue(1024),
+ Executors.defaultThreadFactory(),
+ new ThreadPoolExecutor.AbortPolicy());
+ /**
+ * 模拟死锁
+ */
+ @GetMapping("/cpu/test")
+ public String testCPU() throws InterruptedException {
+ System.out.println("请求cpu");
+ Object lock1 = new Object();
+ Object lock2 = new Object();
+ service.submit(new DeadLockThread(lock1, lock2), "deadLookThread-" + new Random().nextInt());
+ service.submit(new DeadLockThread(lock2, lock1), "deadLookThread-" + new Random().nextInt());
+ return "ok";
+ }
+
+public class DeadLockThread implements Runnable {
+ private Object lock1;
+ private Object lock2;
+
+ public DeadLockThread1(Object lock1, Object lock2) {
+ this.lock1 = lock1;
+ this.lock2 = lock2;
+ }
+
+ @Override
+ public void run() {
+ synchronized (lock2) {
+ System.out.println(Thread.currentThread().getName()+"get lock2 and wait lock1");
+ try {
+ TimeUnit.MILLISECONDS.sleep(2000);
+ } catch (InterruptedException e) {
+ e.printStackTrace();
+ }
+ synchronized (lock1) {
+ System.out.println(Thread.currentThread().getName()+"get lock1 and lock2 ");
+ }
+ }
+ }
+}
+```
+
+我们循环请求接口2000次,发现不一会系统就出现了日志错误,线程池和队列都满了,由于我选择的当队列满了就拒绝的策略,所以系统直接抛出异常。
+
+```
+java.util.concurrent.RejectedExecutionException: Task java.util.concurrent.FutureTask@2760298 rejected from java.util.concurrent.ThreadPoolExecutor@7ea7cd51[Running, pool size = 10, active threads = 10, queued tasks = 1024, completed tasks = 846]
+```
+
+通过`ps -ef|grep java`命令找出 Java 进程 pid,执行`jstack pid` 即可出现java线程堆栈信息,这里发现了5个死锁,我们只列出其中一个,很明显线程`pool-1-thread-2`锁住了`0x00000000f8387d88`等待`0x00000000f8387d98`锁,线程`pool-1-thread-1`锁住了`0x00000000f8387d98`等待锁`0x00000000f8387d88`,这就产生了死锁。
+
+```JAVA
+Java stack information for the threads listed above:
+===================================================
+"pool-1-thread-2":
+ at top.luozhou.analysisdemo.controller.DeadLockThread2.run(DeadLockThread.java:30)
+ - waiting to lock <0x00000000f8387d98> (a java.lang.Object)
+ - locked <0x00000000f8387d88> (a java.lang.Object)
+ at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
+ at java.util.concurrent.FutureTask.run(FutureTask.java:266)
+ at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
+ at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
+ at java.lang.Thread.run(Thread.java:748)
+"pool-1-thread-1":
+ at top.luozhou.analysisdemo.controller.DeadLockThread1.run(DeadLockThread.java:30)
+ - waiting to lock <0x00000000f8387d88> (a java.lang.Object)
+ - locked <0x00000000f8387d98> (a java.lang.Object)
+ at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
+ at java.util.concurrent.FutureTask.run(FutureTask.java:266)
+ at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
+ at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
+ at java.lang.Thread.run(Thread.java:748)
+
+ Found 5 deadlocks.
+```
+
+## 线程频繁切换
+
+上下文切换会导致将大量CPU时间浪费在寄存器、内核栈以及虚拟内存的保存和恢复上,导致系统整体性能下降。当你发现系统的性能出现明显的下降时候,需要考虑是否发生了大量的线程上下文切换。
+
+```java
+ @GetMapping(value = "/thread/swap")
+ public String theadSwap(int num) {
+ System.out.println("模拟线程切换");
+ for (int i = 0; i < num; i++) {
+ new Thread(new ThreadSwap1(new AtomicInteger(0)),"thread-swap"+i).start();
+ }
+ return "ok";
+ }
+public class ThreadSwap1 implements Runnable {
+ private AtomicInteger integer;
+
+ public ThreadSwap1(AtomicInteger integer) {
+ this.integer = integer;
+ }
+
+ @Override
+ public void run() {
+ while (true) {
+ integer.addAndGet(1);
+ Thread.yield(); //让出CPU资源
+ }
+ }
+}
+```
+
+这里我创建多个线程去执行基础的原子+1操作,然后让出 CPU 资源,理论上 CPU 就会去调度别的线程,我们请求接口创建100个线程看看效果如何,`curl localhost:8080/thread/swap?num=100`。接口请求成功后,我们执行`vmstat 1 10,表示每1秒打印一次,打印10次,线程切换采集结果如下:
+
+```
+procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
+ r b swpd free buff cache si so bi bo in cs us sy id wa st
+101 0 128000 878384 908 468684 0 0 0 0 4071 8110498 14 86 0 0 0
+100 0 128000 878384 908 468684 0 0 0 0 4065 8312463 15 85 0 0 0
+100 0 128000 878384 908 468684 0 0 0 0 4107 8207718 14 87 0 0 0
+100 0 128000 878384 908 468684 0 0 0 0 4083 8410174 14 86 0 0 0
+100 0 128000 878384 908 468684 0 0 0 0 4083 8264377 14 86 0 0 0
+100 0 128000 878384 908 468688 0 0 0 108 4182 8346826 14 86 0 0 0
+```
+
+
+
+这里我们关注4个指标,`r`,`cs`,`us`,`sy`。
+
+**r=100**,说明等待的进程数量是100,线程有阻塞。
+
+**cs=800多万**,说明每秒上下文切换了800多万次,这个数字相当大了。
+
+**us=14**,说明用户态占用了14%的CPU时间片去处理逻辑。
+
+**sy=86**,说明内核态占用了86%的CPU,这里明显就是做上下文切换工作了。
+
+我们通过`top`命令以及`top -Hp pid`查看进程和线程CPU情况,发现Java线程CPU占满了,但是线程CPU使用情况很平均,没有某一个线程把CPU吃满的情况。
+
+```
+PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
+ 87093 root 20 0 4194788 299056 13252 S 399.7 16.1 65:34.67 java
+```
+
+```
+ PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
+ 87189 root 20 0 4194788 299056 13252 R 4.7 16.1 0:41.11 java
+ 87129 root 20 0 4194788 299056 13252 R 4.3 16.1 0:41.14 java
+ 87130 root 20 0 4194788 299056 13252 R 4.3 16.1 0:40.51 java
+ 87133 root 20 0 4194788 299056 13252 R 4.3 16.1 0:40.59 java
+ 87134 root 20 0 4194788 299056 13252 R 4.3 16.1 0:40.95 java
+```
+
+结合上面用户态CPU只使用了14%,内核态CPU占用了86%,可以基本判断是Java程序线程上下文切换导致性能问题。
+
+我们使用`pidstat`命令来看看Java进程内部的线程切换数据,执行`pidstat -p 87093 -w 1 10 `,采集数据如下:
+
+```
+11:04:30 PM UID TGID TID cswch/s nvcswch/s Command
+11:04:30 PM 0 - 87128 0.00 16.07 |__java
+11:04:30 PM 0 - 87129 0.00 15.60 |__java
+11:04:30 PM 0 - 87130 0.00 15.54 |__java
+11:04:30 PM 0 - 87131 0.00 15.60 |__java
+11:04:30 PM 0 - 87132 0.00 15.43 |__java
+11:04:30 PM 0 - 87133 0.00 16.02 |__java
+11:04:30 PM 0 - 87134 0.00 15.66 |__java
+11:04:30 PM 0 - 87135 0.00 15.23 |__java
+11:04:30 PM 0 - 87136 0.00 15.33 |__java
+11:04:30 PM 0 - 87137 0.00 16.04 |__java
+```
+
+根据上面采集的信息,我们知道Java的线程每秒切换15次左右,正常情况下,应该是个位数或者小数。结合这些信息我们可以断定Java线程开启过多,导致频繁上下文切换,从而影响了整体性能。
+
+**为什么系统的上下文切换是每秒800多万,而 Java 进程中的某一个线程切换才15次左右?**
+
+系统上下文切换分为三种情况:
+
+1、多任务:在多任务环境中,一个进程被切换出CPU,运行另外一个进程,这里会发生上下文切换。
+
+2、中断处理:发生中断时,硬件会切换上下文。在vmstat命令中是`in`
+
+3、用户和内核模式切换:当操作系统中需要在用户模式和内核模式之间进行转换时,需要进行上下文切换,比如进行系统函数调用。
+
+Linux 为每个 CPU 维护了一个就绪队列,将活跃进程按照优先级和等待 CPU 的时间排序,然后选择最需要 CPU 的进程,也就是优先级最高和等待 CPU 时间最长的进程来运行。也就是vmstat命令中的`r`。
+
+那么,进程在什么时候才会被调度到 CPU 上运行呢?
+
+- 进程执行完终止了,它之前使用的 CPU 会释放出来,这时再从就绪队列中拿一个新的进程来运行
+- 为了保证所有进程可以得到公平调度,CPU 时间被划分为一段段的时间片,这些时间片被轮流分配给各个进程。当某个进程时间片耗尽了就会被系统挂起,切换到其它等待 CPU 的进程运行。
+- 进程在系统资源不足时,要等待资源满足后才可以运行,这时进程也会被挂起,并由系统调度其它进程运行。
+- 当进程通过睡眠函数 sleep 主动挂起时,也会重新调度。
+- 当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
+- 发生硬件中断时,CPU 上的进程会被中断挂起,转而执行内核中的中断服务程序。
+
+结合我们之前的内容分析,阻塞的就绪队列是100左右,而我们的CPU只有4核,这部分原因造成的上下文切换就可能会相当高,再加上中断次数是4000左右和系统的函数调用等,整个系统的上下文切换到800万也不足为奇了。Java内部的线程切换才15次,是因为线程使用`Thread.yield()`来让出CPU资源,但是CPU有可能继续调度该线程,这个时候线程之间并没有切换,这也是为什么内部的某个线程切换次数并不是非常大的原因。
+
+## 总结
+
+本文模拟了常见的性能问题场景,分析了如何定位CPU100%、内存泄漏、死锁、线程频繁切换问题。分析问题我们需要做好两件事,第一,掌握基本的原理,第二,借助好工具。本文也列举了分析问题的常用工具和命令,希望对你解决问题有所帮助。当然真正的线上环境可能十分复杂,并没有模拟的环境那么简单,但是原理是一样的,问题的表现也是类似的,我们重点抓住原理,活学活用,相信复杂的线上问题也可以顺利解决。
+
+## 参考
+
+1、https://linux.die.net/man/1/pidstat
+
+2、https://linux.die.net/man/8/vmstat
+
+3、https://help.eclipse.org/2020-03/index.jsp?topic=/org.eclipse.mat.ui.help/welcome.html
+
+4、https://www.linuxblogs.cn/articles/18120200.html
+
+5、https://www.tutorialspoint.com/what-is-context-switching-in-operating-system
\ No newline at end of file
diff --git a/docs/javaguide面试突击版.md b/docs/javaguide面试突击版.md
new file mode 100644
index 00000000..f1576d75
--- /dev/null
+++ b/docs/javaguide面试突击版.md
@@ -0,0 +1,55 @@
+今天(2020-03-07)终于把PDF版本的《JavaGuide面试突击版》搞定!废话不多说,直接上成品:
+
+
+
+### 如何获取
+
+公众号后台回复:“面试突击”即可。
+
+
+
+### 关于《JavaGuide面试突击版》
+
+JavaGuide 目前已经 70k+ Star ,目前已经是所有 Java 类别项目中 Star 数量第二的开源项目了。Star虽然很多,但是价值远远比不上 Dubbo 这些开源项目,希望以后可以多出现一些这样的国产开源项目。国产开源项目!加油!奥利给!
+
+随着越来越多的人参与完善这个项目,这个专注 “Java知识总结+面试指南 ” 项目的知识体系和内容的不断完善。JavaGuide 目前包括下面这两部分内容:
+
+1. **Java 核心知识总结**;
+2. **面试方向**:面试题、面试经验、备战面试系列文章以及面试真实体验系列文章
+
+内容的庞大让JavaGuide 显的有一点臃肿。所以,我决定将专门为 Java 面试所写的文章以及来自读者投稿的文章整理成 **《JavaGuide面试突击版》** 系列,同时也为了更加方便大家阅读查阅。起这个名字也犹豫了很久,大家如果有更好的名字的话也可以向我建议。暂时的定位是将其作为 PDF 电子书,并不会像 JavaGuide 提供在线阅读版本。我之前也免费分享过PDF 版本的《Java面试突击》,期间一共更新了 3 个版本,但是由于后面难以同步和订正所以就没有再更新。**《JavaGuide面试突击版》** pdf 版由于我工作流程的转变可以有效避免这个问题。
+
+另外,这段时间,向我提这个建议的读者也不是一个两个,我自己当然也有这个感觉。只是自己一直没有抽出时间去做罢了!毕竟这算是一个比较耗费时间的工程。加油!奥利给!
+
+这件事情具体耗费时间的地方是内容的排版优化(为了方便导出PDF生成目录),导出 PDF 我是通过 Typora 来做的。
+
+### 如何学习本项目
+
+提供了非常详细的目录,建议可以从头看是看一遍,如果基础不错的话也可以挑自己需要的章节查看。看的过程中自己要多思考,碰到不懂的地方,自己记得要勤搜索,需要记忆的地方也不要吝啬自己的脑子。
+
+### 关于更新
+
+**《JavaGuide面试突击版》** 预计一个月左右会有一次内容更新和完善,大家在我的公众号 **JavaGuide** 后台回复**“面试突击”** 即可获取最新版!另外,为了保证自己的辛勤劳动不被恶意盗版滥用,所以我添加了水印并且在一些内容注明版权,希望大家理解。
+
+### 如何贡献
+
+大家阅读过程中如果遇到错误的地方可以通过微信与我交流(ps:加过我微信的就不要重复添加了,这是另外一个账号,前一个已经满了)。
+
+
+
+希望大家给我提反馈的时候可以按照如下格式:
+
+> 我觉得2.3节Java基础的 2.3.1 这部分的描述有问题,应该这样描述:~巴拉巴拉~ 会更好!具体可以参考Oracle 官方文档,地址:~~~~。
+
+为了提高准确性已经不必要的时间花费,希望大家尽量确保自己想法的准确性。
+
+### 如何赞赏
+
+如果觉得本文档对你有帮助的话,欢迎加入我的知识星球。创建星球的目的主要是为了提高知识沉淀,微信群的弊端相比大家都了解。星球没有免费的原因是了设立门槛,提高进入读者的质量。我会在星球回答大家的问题,更新更多的大厂面试干货!
+
+
+
+我的知识星球的价格应该是我了解的圈子里面最低的,也就1顿饭钱吧!毕竟关注我的大部分还是学生,我打心底里希望自己分享的东西能对大家有帮助。
+
+4,互联网按工作方式可划分为边缘部分和核心部分。主机在网络的边缘部分,其作用是进行信息处理。由大量网络和连接这些网络的路由器组成核心部分,其作用是提供连通性和交换。
5,计算机通信是计算机中进程(即运行着的程序)之间的通信。计算机网络采用的通信方式是客户-服务器方式(C/S方式)和对等连接方式(P2P方式)。
-
+
6,客户和服务器都是指通信中所涉及的应用进程。客户是服务请求方,服务器是服务提供方。
-
+
7,按照作用范围的不同,计算机网络分为广域网WAN,城域网MAN,局域网LAN,个人区域网PAN。
8,计算机网络最常用的性能指标是:速率,带宽,吞吐量,时延(发送时延,处理时延,排队时延),时延带宽积,往返时间和信道利用率。
-
+
9,网络协议即协议,是为进行网络中的数据交换而建立的规则。计算机网络的各层以及其协议集合,称为网络的体系结构。
-
+
10,五层体系结构由应用层,运输层,网络层(网际层),数据链路层,物理层组成。运输层最主要的协议是TCP和UDP协议,网络层最重要的协议是IP协议。
## 二物理层
@@ -165,7 +164,7 @@
一种用于数据链路层实现中继,连接两个或多个局域网的网络互连设备。
#### 交换机(switch ):
广义的来说,交换机指的是一种通信系统中完成信息交换的设备。这里工作在数据链路层的交换机指的是交换式集线器,其实质是一个多接口的网桥
-
+
### (2),重要知识点总结
@@ -295,7 +294,7 @@
10,TCP用主机的IP地址加上主机上的端口号作为TCP连接的端点。这样的端点就叫做套接字(socket)或插口。套接字用(IP地址:端口号)来表示。每一条TCP连接唯一被通信两端的两个端点所确定。
11,停止等待协议是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
-
+
12,为了提高传输效率,发送方可以不使用低效率的停止等待协议,而是采用流水线传输。流水线传输就是发送方可连续发送多个分组,不必每发完一个分组就停下来等待对方确认。这样可使信道上一直有数据不间断的在传送。这种传输方式可以明显提高信道利用率。
13,停止等待协议中超时重传是指只要超过一段时间仍然没有收到确认,就重传前面发送过的分组(认为刚才发送过的分组丢失了)。因此每发送完一个分组需要设置一个超时计时器,其重转时间应比数据在分组传输的平均往返时间更长一些。这种自动重传方式常称为自动重传请求ARQ。另外在停止等待协议中若收到重复分组,就丢弃该分组,但同时还要发送确认。连续ARQ协议可提高信道利用率。发送维持一个发送窗口,凡位于发送窗口内的分组可连续发送出去,而不需要等待对方确认。接收方一般采用累积确认,对按序到达的最后一个分组发送确认,表明到这个分组位置的所有分组都已经正确收到了。
@@ -335,7 +334,7 @@
FTP 是File TransferProtocol(文件传输协议)的英文简称,而中文简称为“文传协议”。用于Internet上的控制文件的双向传输。同时,它也是一个应用程序(Application)。
基于不同的操作系统有不同的FTP应用程序,而所有这些应用程序都遵守同一种协议以传输文件。在FTP的使用当中,用户经常遇到两个概念:"下载"(Download)和"上传"(Upload)。
"下载"文件就是从远程主机拷贝文件至自己的计算机上;"上传"文件就是将文件从自己的计算机中拷贝至远程主机上。用Internet语言来说,用户可通过客户机程序向(从)远程主机上传(下载)文件。
-
+
#### 简单文件传输协议(TFTP):
TFTP(Trivial File Transfer Protocol,简单文件传输协议)是TCP/IP协议族中的一个用来在客户机与服务器之间进行简单文件传输的协议,提供不复杂、开销不大的文件传输服务。端口号为69。
@@ -364,7 +363,7 @@
代理服务器(Proxy Server)是一种网络实体,它又称为万维网高速缓存。
代理服务器把最近的一些请求和响应暂存在本地磁盘中。当新请求到达时,若代理服务器发现这个请求与暂时存放的的请求相同,就返回暂存的响应,而不需要按URL的地址再次去互联网访问该资源。
代理服务器可在客户端或服务器工作,也可以在中间系统工作。
-
+
#### http请求头:
http请求头,HTTP客户程序(例如浏览器),向服务器发送请求的时候必须指明请求类型(一般是GET或者POST)。如有必要,客户程序还可以选择发送其他的请求头。
- Accept:浏览器可接受的MIME类型。
diff --git a/docs/network/计算机网络.md b/docs/network/计算机网络.md
index 8ea49e02..1cfe2695 100644
--- a/docs/network/计算机网络.md
+++ b/docs/network/计算机网络.md
@@ -1,39 +1,3 @@
-
-
-- [一 OSI与TCP/IP各层的结构与功能,都有哪些协议?](#一-osi与tcpip各层的结构与功能都有哪些协议)
- - [1.1 应用层](#11-应用层)
- - [1.2 运输层](#12-运输层)
- - [1.3 网络层](#13-网络层)
- - [1.4 数据链路层](#14-数据链路层)
- - [1.5 物理层](#15-物理层)
- - [1.6 总结一下](#16-总结一下)
-- [二 TCP 三次握手和四次挥手(面试常客)](#二-tcp-三次握手和四次挥手面试常客)
- - [2.1 TCP 三次握手漫画图解](#21-tcp-三次握手漫画图解)
- - [2.2 为什么要三次握手](#22-为什么要三次握手)
- - [2.3 为什么要传回 SYN](#23-为什么要传回-syn)
- - [2.4 传了 SYN,为啥还要传 ACK](#24-传了-syn为啥还要传-ack)
- - [2.5 为什么要四次挥手](#25-为什么要四次挥手)
-- [三 TCP,UDP 协议的区别](#三-tcpudp-协议的区别)
-- [四 TCP 协议如何保证可靠传输](#四-tcp-协议如何保证可靠传输)
- - [4.1 ARQ协议](#41-arq协议)
- - [停止等待ARQ协议](#停止等待arq协议)
- - [连续ARQ协议](#连续arq协议)
- - [4.2 滑动窗口和流量控制](#42-滑动窗口和流量控制)
- - [4.3 拥塞控制](#43-拥塞控制)
-- [五 在浏览器中输入url地址 ->> 显示主页的过程(面试常客)](#五--在浏览器中输入url地址---显示主页的过程面试常客)
-- [六 状态码](#六-状态码)
-- [七 各种协议与HTTP协议之间的关系](#七-各种协议与http协议之间的关系)
-- [八 HTTP长连接,短连接](#八--http长连接短连接)
-- [九 HTTP是不保存状态的协议,如何保存用户状态?](#九-http是不保存状态的协议如何保存用户状态)
-- [十 Cookie的作用是什么?和Session有什么区别?](#十-cookie的作用是什么和session有什么区别)
-- [十一 HTTP 1.0和HTTP 1.1的主要区别是什么?](#十一-http-10和http-11的主要区别是什么)
-- [十二 URI和URL的区别是什么?](#十二-uri和url的区别是什么)
-- [十三 HTTP 和 HTTPS 的区别?](#十三-http-和-https-的区别)
-- [建议](#建议)
-- [参考](#参考)
-
-
-
## 一 OSI与TCP/IP各层的结构与功能,都有哪些协议?
学习计算机网络时我们一般采用折中的办法,也就是中和 OSI 和 TCP/IP 的优点,采用一种只有五层协议的体系结构,这样既简洁又能将概念阐述清楚。
@@ -90,7 +54,7 @@
### 1.6 总结一下
-上面我们对计算机网络的五层体系结构有了初步的了解,下面附送一张七层体系结构图总结一下。图片来源:https://blog.csdn.net/yaopeng_2005/article/details/7064869
+上面我们对计算机网络的五层体系结构有了初步的了解,下面附送一张七层体系结构图总结一下(图片来源于网络)。

@@ -122,15 +86,13 @@
所以三次握手就能确认双发收发功能都正常,缺一不可。
-### 2.3 为什么要传回 SYN
-接收端传回发送端所发送的 SYN 是为了告诉发送端,我接收到的信息确实就是你所发送的信号了。
+### 2.3 第2次握手传回了ACK,为什么还要传回SYN?
-> SYN 是 TCP/IP 建立连接时使用的握手信号。在客户机和服务器之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务器使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement[汉译:确认字符 ,在数据通信传输中,接收站发给发送站的一种传输控制字符。它表示确认发来的数据已经接受无误。 ])消息响应。这样在客户机和服务器之间才能建立起可靠的TCP连接,数据才可以在客户机和服务器之间传递。
+接收端传回发送端所发送的ACK是为了告诉客户端,我接收到的信息确实就是你所发送的信号了,这表明从客户端到服务端的通信是正常的。而回传SYN则是为了建立并确认从服务端到客户端的通信。”
+> SYN 同步序列编号(Synchronize Sequence Numbers) 是 TCP/IP 建立连接时使用的握手信号。在客户机和服务器之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务器使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement)消息响应。这样在客户机和服务器之间才能建立起可靠的 TCP 连接,数据才可以在客户机和服务器之间传递。
-### 2.4 传了 SYN,为啥还要传 ACK
-
-双方通信无误必须是两者互相发送信息都无误。传了 SYN,证明发送方到接收方的通道没有问题,但是接收方到发送方的通道还需要 ACK 信号来进行验证。
+### 2.5 为什么要四次挥手
@@ -141,8 +103,6 @@
- 服务器-关闭与客户端的连接,发送一个FIN给客户端
- 客户端-发回 ACK 报文确认,并将确认序号设置为收到序号加1
-### 2.5 为什么要四次挥手
-
任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了TCP连接。
举个例子:A 和 B 打电话,通话即将结束后,A 说“我没啥要说的了”,B回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话,于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”,A 回答“知道了”,这样通话才算结束。
@@ -222,12 +182,14 @@ TCP的拥塞控制采用了四种算法,即 **慢开始** 、 **拥塞避免**
百度好像最喜欢问这个问题。
-> 打开一个网页,整个过程会使用哪些协议
+> 打开一个网页,整个过程会使用哪些协议?
图解(图片来源:《图解HTTP》):
-c 数目:在发送指定数目的包后停止。
+
+-i 秒数:设定间隔几秒送一个网络封包给一台机器,预设值是一秒送一次。
+
+-I 网络界面:使用指定的网络界面送出数据包。
+
+-l 前置载入:设置在送出要求信息之前,先行发出的数据包。
+
+-p 范本样式:设置填满数据包的范本样式。
+
+-s 字节数:指定发送的数据字节数,预设值是56,加上8字节的ICMP头,一共是64ICMP数据字节。
+
+-t 存活数值:设置存活数值TTL的大小。
+
+> ping -b 192.168.120.1 --ping网关
+>
+> ping -c 10 192.168.120.206 --ping指定次数
+>
+> ping -c 10 -i 0.5 192.168.120.206 --时间间隔和次数限制的ping
+
+#### netstat
+
+netstat命令是一个监控TCP/IP网络的非常有用的工具,它可以显示路由表、实际的网络连接以及每一个网络接口设备的状态信息。
+
+netstat [选项]
+
+```
+-a或--all:显示所有连线中的Socket;
+-a (all) 显示所有选项,默认不显示LISTEN相关。
+-t (tcp) 仅显示tcp相关选项。
+-u (udp) 仅显示udp相关选项。
+-n 拒绝显示别名,能显示数字的全部转化成数字。
+-l 仅列出有在 Listen (监听) 的服务状态。
+-p 显示建立相关链接的程序名
+-r 显示路由信息,路由表
+-e 显示扩展信息,例如uid等
+-s 按各个协议进行统计
+-c 每隔一个固定时间,执行该netstat命令。
+```
+
+常用命令:
+
+列出所有端口情况
+
+```
+netstat -a # 列出所有端口
+netstat -at # 列出所有TCP端口
+netstat -au # 列出所有UDP端口
+```
+
+列出所有处于监听状态的 Sockets
+
+```
+netstat -l # 只显示监听端口
+netstat -lt # 显示监听TCP端口
+netstat -lu # 显示监听UDP端口
+netstat -lx # 显示监听UNIX端口
+```
+
+显示每个协议的统计信息
+
+```
+netstat -s # 显示所有端口的统计信息
+netstat -st # 显示所有TCP的统计信息
+netstat -su # 显示所有UDP的统计信息
+```
+
+显示 PID 和进程名称
+
+```
+netstat -p
+```
+
+显示网络统计信息
+
+```
+netstat -s
+```
+
+统计机器中网络连接各个状态个数
+
+```
+netstat` `-an | ``awk` `'/^tcp/ {++S[$NF]} END {for (a in S) print a,S[a]} '
+```
+
+**补充netstat网络状态详解:**
+
+一个正常的TCP连接,都会有三个阶段:1、TCP三次握手;2、数据传送;3、TCP四次挥手
+
+
+
+现代处理器使用的是一种称为 **虚拟寻址(Virtual Addressing)** 的寻址方式。**使用虚拟寻址,CPU 需要将虚拟地址翻译成物理地址,这样才能访问到真实的物理内存。** 实际上完成虚拟地址转换为物理地址转换的硬件是 CPU 中含有一个被称为 **内存管理单元(Memory Management Unit, MMU)** 的硬件。如下图所示:
+
+
+
+**为什么要有虚拟地址空间呢?**
+
+先从没有虚拟地址空间的时候说起吧!没有虚拟地址空间的时候,**程序都是直接访问和操作的都是物理内存** 。但是这样有什么问题呢?
+
+1. 用户程序可以访问任意内存,寻址内存的每个字节,这样就很容易(有意或者无意)破坏操作系统,造成操作系统崩溃。
+2. 想要同时运行多个程序特别困难,比如你想同时运行一个微信和一个 QQ 音乐都不行。为什么呢?举个简单的例子:微信在运行的时候给内存地址 1xxx 赋值后,QQ 音乐也同样给内存地址 1xxx 赋值,那么 QQ 音乐对内存的赋值就会覆盖微信之前所赋的值,这就造成了微信这个程序就会崩溃。
+
+**总结来说:如果直接把物理地址暴露出来的话会带来严重问题,比如可能对操作系统造成伤害以及给同时运行多个程序造成困难。**
+
+通过虚拟地址访问内存有以下优势:
+
+- 程序可以使用一系列相邻的虚拟地址来访问物理内存中不相邻的大内存缓冲区。
+- 程序可以使用一系列虚拟地址来访问大于可用物理内存的内存缓冲区。当物理内存的供应量变小时,内存管理器会将物理内存页(通常大小为 4 KB)保存到磁盘文件。数据或代码页会根据需要在物理内存与磁盘之间移动。
+- 不同进程使用的虚拟地址彼此隔离。一个进程中的代码无法更改正在由另一进程或操作系统使用的物理内存。
+
+## 四 虚拟内存
+
+### 4.1 什么是虚拟内存(Virtual Memory)?
+
+👨💻**面试官** :再问你一个常识性的问题!**什么是虚拟内存(Virtual Memory)?**
+
+🙋 **我** :这个在我们平时使用电脑特别是 Windows 系统的时候太常见了。很多时候我们使用点开了很多占内存的软件,这些软件占用的内存可能已经远远超出了我们电脑本身具有的物理内存。**为什么可以这样呢?** 正是因为 **虚拟内存** 的存在,通过 **虚拟内存** 可以让程序可以拥有超过系统物理内存大小的可用内存空间。另外,**虚拟内存为每个进程提供了一个一致的、私有的地址空间,它让每个进程产生了一种自己在独享主存的错觉(每个进程拥有一片连续完整的内存空间)**。这样会更加有效地管理内存并减少出错。
+
+**虚拟内存**是计算机系统内存管理的一种技术,我们可以手动设置自己电脑的虚拟内存。不要单纯认为虚拟内存只是“使用硬盘空间来扩展内存“的技术。**虚拟内存的重要意义是它定义了一个连续的虚拟地址空间**,并且 **把内存扩展到硬盘空间**。推荐阅读:[《虚拟内存的那点事儿》](https://juejin.im/post/59f8691b51882534af254317)
+
+维基百科中有几句话是这样介绍虚拟内存的。
+
+> **虚拟内存** 使得应用程序认为它拥有连续的可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。与没有使用虚拟内存技术的系统相比,使用这种技术的系统使得大型程序的编写变得更容易,对真正的物理内存(例如 RAM)的使用也更有效率。目前,大多数操作系统都使用了虚拟内存,如 Windows 家族的“虚拟内存”;Linux 的“交换空间”等。From:
+
+### 4.2 局部性原理
+
+👨💻**面试官** :要想更好地理解虚拟内存技术,必须要知道计算机中著名的**局部性原理**。另外,局部性原理既适用于程序结构,也适用于数据结构,是非常重要的一个概念。
+
+🙋 **我** :局部性原理是虚拟内存技术的基础,正是因为程序运行具有局部性原理,才可以只装入部分程序到内存就开始运行。
+
+> 以下内容摘自《计算机操作系统教程》 第 4 章存储器管理。
+
+早在 1968 年的时候,就有人指出我们的程序在执行的时候往往呈现局部性规律,也就是说在某个较短的时间段内,程序执行局限于某一小部分,程序访问的存储空间也局限于某个区域。
+
+局部性原理表现在以下两个方面:
+
+1. **时间局部性** :如果程序中的某条指令一旦执行,不久以后该指令可能再次执行;如果某数据被访问过,不久以后该数据可能再次被访问。产生时间局部性的典型原因,是由于在程序中存在着大量的循环操作。
+2. **空间局部性** :一旦程序访问了某个存储单元,在不久之后,其附近的存储单元也将被访问,即程序在一段时间内所访问的地址,可能集中在一定的范围之内,这是因为指令通常是顺序存放、顺序执行的,数据也一般是以向量、数组、表等形式簇聚存储的。
+
+时间局部性是通过将近来使用的指令和数据保存到高速缓存存储器中,并使用高速缓存的层次结构实现。空间局部性通常是使用较大的高速缓存,并将预取机制集成到高速缓存控制逻辑中实现。虚拟内存技术实际上就是建立了 “内存一外存”的两级存储器的结构,利用局部性原理实现髙速缓存。
+
+### 4.3 虚拟存储器
+
+👨💻**面试官** :都说了虚拟内存了。你再讲讲**虚拟存储器**把!
+
+🙋 **我** :
+
+> 这部分内容来自:[王道考研操作系统知识点整理](https://wizardforcel.gitbooks.io/wangdaokaoyan-os/content/13.html)。
+
+基于局部性原理,在程序装入时,可以将程序的一部分装入内存,而将其他部分留在外存,就可以启动程序执行。由于外存往往比内存大很多,所以我们运行的软件的内存大小实际上是可以比计算机系统实际的内存大小大的。在程序执行过程中,当所访问的信息不在内存时,由操作系统将所需要的部分调入内存,然后继续执行程序。另一方面,操作系统将内存中暂时不使用的内容换到外存上,从而腾出空间存放将要调入内存的信息。这样,计算机好像为用户提供了一个比实际内存大的多的存储器——**虚拟存储器**。
+
+实际上,我觉得虚拟内存同样是一种时间换空间的策略,你用 CPU 的计算时间,页的调入调出花费的时间,换来了一个虚拟的更大的空间来支持程序的运行。不得不感叹,程序世界几乎不是时间换空间就是空间换时间。
+
+### 4.4 虚拟内存的技术实现
+
+👨💻**面试官** :**虚拟内存技术的实现呢?**
+
+🙋 **我** :**虚拟内存的实现需要建立在离散分配的内存管理方式的基础上。** 虚拟内存的实现有以下三种方式:
+
+1. **请求分页存储管理** :建立在分页管理之上,为了支持虚拟存储器功能而增加了请求调页功能和页面置换功能。请求分页是目前最常用的一种实现虚拟存储器的方法。请求分页存储管理系统中,在作业开始运行之前,仅装入当前要执行的部分段即可运行。假如在作业运行的过程中发现要访问的页面不在内存,则由处理器通知操作系统按照对应的页面置换算法将相应的页面调入到主存,同时操作系统也可以将暂时不用的页面置换到外存中。
+2. **请求分段存储管理** :建立在分段存储管理之上,增加了请求调段功能、分段置换功能。请求分段储存管理方式就如同请求分页储存管理方式一样,在作业开始运行之前,仅装入当前要执行的部分段即可运行;在执行过程中,可使用请求调入中断动态装入要访问但又不在内存的程序段;当内存空间已满,而又需要装入新的段时,根据置换功能适当调出某个段,以便腾出空间而装入新的段。
+3. **请求段页式存储管理**
+
+**这里多说一下?很多人容易搞混请求分页与分页存储管理,两者有何不同呢?**
+
+请求分页存储管理建立在分页管理之上。他们的根本区别是是否将程序全部所需的全部地址空间都装入主存,这也是请求分页存储管理可以提供虚拟内存的原因,我们在上面已经分析过了。
+
+它们之间的根本区别在于是否将一作业的全部地址空间同时装入主存。请求分页存储管理不要求将作业全部地址空间同时装入主存。基于这一点,请求分页存储管理可以提供虚存,而分页存储管理却不能提供虚存。
+
+不管是上面那种实现方式,我们一般都需要:
+
+1. 一定容量的内存和外存:在载入程序的时候,只需要将程序的一部分装入内存,而将其他部分留在外存,然后程序就可以执行了;
+2. **缺页中断**:如果**需执行的指令或访问的数据尚未在内存**(称为缺页或缺段),则由处理器通知操作系统将相应的页面或段**调入到内存**,然后继续执行程序;
+3. **虚拟地址空间** :逻辑地址到物理地址的变换。
+
+### 4.5 页面置换算法
+
+👨💻**面试官** :虚拟内存管理很重要的一个概念就是页面置换算法。那你说一下 **页面置换算法的作用?常见的页面置换算法有哪些?**
+
+🙋 **我** :
+
+> 这个题目经常作为笔试题出现,网上已经给出了很不错的回答,我这里只是总结整理了一下。
+
+地址映射过程中,若在页面中发现所要访问的页面不在内存中,则发生缺页中断 。
+
+> **缺页中断** 就是要访问的**页**不在主存,需要操作系统将其调入主存后再进行访问。 在这个时候,被内存映射的文件实际上成了一个分页交换文件。
+
+当发生缺页中断时,如果当前内存中并没有空闲的页面,操作系统就必须在内存选择一个页面将其移出内存,以便为即将调入的页面让出空间。用来选择淘汰哪一页的规则叫做页面置换算法,我们可以把页面置换算法看成是淘汰页面的规则。
+
+- **OPT 页面置换算法(最佳页面置换算法)** :最佳(Optimal, OPT)置换算法所选择的被淘汰页面将是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。但由于人们目前无法预知进程在内存下的若千页面中哪个是未来最长时间内不再被访问的,因而该算法无法实现。一般作为衡量其他置换算法的方法。
+- **FIFO(First In First Out) 页面置换算法(先进先出页面置换算法)** : 总是淘汰最先进入内存的页面,即选择在内存中驻留时间最久的页面进行淘汰。
+- **LRU (Least Currently Used)页面置换算法(最近最久未使用页面置换算法)** :LRU算法赋予每个页面一个访问字段,用来记录一个页面自上次被访问以来所经历的时间 T,当须淘汰一个页面时,选择现有页面中其 T 值最大的,即最近最久未使用的页面予以淘汰。
+- **LFU (Least Frequently Used)页面置换算法(最少使用页面置换算法)** : 该置换算法选择在之前时期使用最少的页面作为淘汰页。
+
+## Reference
+
+- 《计算机操作系统—汤小丹》第四版
+- [《深入理解计算机系统》](https://book.douban.com/subject/1230413/)
+- [https://zh.wikipedia.org/wiki/输入输出内存管理单元](https://zh.wikipedia.org/wiki/输入输出内存管理单元)
+- [https://baike.baidu.com/item/快表/19781679](https://baike.baidu.com/item/快表/19781679)
+- https://www.jianshu.com/p/1d47ed0b46d5
+-
+-
+- 王道考研操作系统知识点整理: https://wizardforcel.gitbooks.io/wangdaokaoyan-os/content/13.html
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/docs/operating-system/images/Linux-Logo.png b/docs/operating-system/images/Linux-Logo.png
new file mode 100644
index 00000000..40e75aaa
Binary files /dev/null and b/docs/operating-system/images/Linux-Logo.png differ
diff --git a/docs/operating-system/images/Linux之父.png b/docs/operating-system/images/Linux之父.png
new file mode 100644
index 00000000..33145373
Binary files /dev/null and b/docs/operating-system/images/Linux之父.png differ
diff --git a/docs/operating-system/images/Linux权限命令.png b/docs/operating-system/images/Linux权限命令.png
new file mode 100644
index 00000000..f59b2e63
Binary files /dev/null and b/docs/operating-system/images/Linux权限命令.png differ
diff --git a/docs/operating-system/images/Linux权限解读.png b/docs/operating-system/images/Linux权限解读.png
new file mode 100644
index 00000000..1292c125
Binary files /dev/null and b/docs/operating-system/images/Linux权限解读.png differ
diff --git a/docs/operating-system/images/Linux目录树.png b/docs/operating-system/images/Linux目录树.png
new file mode 100644
index 00000000..beef4203
Binary files /dev/null and b/docs/operating-system/images/Linux目录树.png differ
diff --git a/docs/operating-system/images/linux.png b/docs/operating-system/images/linux.png
new file mode 100644
index 00000000..20ead246
Binary files /dev/null and b/docs/operating-system/images/linux.png differ
diff --git a/docs/operating-system/images/macos.png b/docs/operating-system/images/macos.png
new file mode 100644
index 00000000..33294577
Binary files /dev/null and b/docs/operating-system/images/macos.png differ
diff --git a/docs/operating-system/images/unix.png b/docs/operating-system/images/unix.png
new file mode 100644
index 00000000..0afabcd8
Binary files /dev/null and b/docs/operating-system/images/unix.png differ
diff --git a/docs/operating-system/images/windows.png b/docs/operating-system/images/windows.png
new file mode 100644
index 00000000..c2687dc7
Binary files /dev/null and b/docs/operating-system/images/windows.png differ
diff --git a/docs/operating-system/images/修改文件权限.png b/docs/operating-system/images/修改文件权限.png
new file mode 100644
index 00000000..de940941
Binary files /dev/null and b/docs/operating-system/images/修改文件权限.png differ
diff --git a/docs/operating-system/images/文件inode信息.png b/docs/operating-system/images/文件inode信息.png
new file mode 100644
index 00000000..b47551e8
Binary files /dev/null and b/docs/operating-system/images/文件inode信息.png differ
diff --git a/docs/operating-system/images/用户态与内核态.png b/docs/operating-system/images/用户态与内核态.png
new file mode 100644
index 00000000..aa0dafc2
Binary files /dev/null and b/docs/operating-system/images/用户态与内核态.png differ
diff --git a/docs/operating-system/linux.md b/docs/operating-system/linux.md
new file mode 100644
index 00000000..7f318ccc
--- /dev/null
+++ b/docs/operating-system/linux.md
@@ -0,0 +1,455 @@
+点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java 面试突击》以及 Java 工程师必备学习资源。
+
+
+
+
+
+
+- [1. 从认识操作系统开始](#1-从认识操作系统开始)
+ - [1.1. 操作系统简介](#11-操作系统简介)
+ - [1.2. 操作系统简单分类](#12-操作系统简单分类)
+ - [1.2.1. Windows](#121-windows)
+ - [1.2.2. Unix](#122-unix)
+ - [1.2.3. Linux](#123-linux)
+ - [1.2.4. Mac OS](#124-mac-os)
+ - [1.3. 操作系统的内核(Kernel)](#13-操作系统的内核kernel)
+ - [1.4. 中央处理器(CPU,Central Processing Unit)](#14-中央处理器cpucentral-processing-unit)
+ - [1.5. CPU vs Kernel(内核)](#15-cpu-vs-kernel内核)
+ - [1.6. 系统调用](#16-系统调用)
+- [2. 初探 Linux](#2-初探-linux)
+ - [2.1. Linux 简介](#21-linux-简介)
+ - [2.2. Linux 诞生](#22-linux-诞生)
+ - [2.3. 常见 Linux 发行版本有哪些?](#23-常见-linux-发行版本有哪些)
+- [3. Linux 文件系统概览](#3-linux-文件系统概览)
+ - [3.1. Linux 文件系统简介](#31-linux-文件系统简介)
+ - [3.2. inode 介绍](#32-inode-介绍)
+ - [3.3. Linux 文件类型](#33-linux-文件类型)
+ - [3.4. Linux 目录树](#34-linux-目录树)
+- [4. Linux 基本命令](#4-linux-基本命令)
+ - [4.1. 目录切换命令](#41-目录切换命令)
+ - [4.2. 目录的操作命令(增删改查)](#42-目录的操作命令增删改查)
+ - [4.3. 文件的操作命令(增删改查)](#43-文件的操作命令增删改查)
+ - [4.4. 压缩文件的操作命令](#44-压缩文件的操作命令)
+ - [4.5. Linux 的权限命令](#45-linux-的权限命令)
+ - [4.6. Linux 用户管理](#46-linux-用户管理)
+ - [4.7. Linux 系统用户组的管理](#47-linux-系统用户组的管理)
+ - [4.8. 其他常用命令](#48-其他常用命令)
+- [5. 公众号](#5-公众号)
+
+
+
+
+今天这篇文章中简单介绍一下一个 Java 程序员必知的 Linux 的一些概念以及常见命令。
+
+_如果文章有任何需要改善和完善的地方,欢迎在评论区指出,共同进步!笔芯!_
+
+## 1. 从认识操作系统开始
+
+
+
+正式开始 Linux 之前,简单花一点点篇幅科普一下操作系统相关的内容。
+
+### 1.1. 操作系统简介
+
+我通过以下四点介绍什么是操作系统:
+
+1. **操作系统(Operating System,简称 OS)是管理计算机硬件与软件资源的程序,是计算机的基石。**
+2. **操作系统本质上是一个运行在计算机上的软件程序 ,用于管理计算机硬件和软件资源。** 举例:运行在你电脑上的所有应用程序都通过操作系统来调用系统内存以及磁盘等等硬件。
+3. **操作系统存在屏蔽了硬件层的复杂性。** 操作系统就像是硬件使用的负责人,统筹着各种相关事项。
+4. **操作系统的内核(Kernel)是操作系统的核心部分,它负责系统的内存管理,硬件设备的管理,文件系统的管理以及应用程序的管理**。
+
+> 内核(Kernel)在后文中会提到。
+
+
+
+### 1.2. 操作系统简单分类
+
+#### 1.2.1. Windows
+
+目前最流行的个人桌面操作系统 ,不做多的介绍,大家都清楚。界面简单易操作,软件生态非常好。
+
+_玩玩电脑游戏还是必须要有 Windows 的,所以我现在是一台 Windows 用于玩游戏,一台 Mac 用于平时日常开发和学习使用。_
+
+
+
+#### 1.2.2. Unix
+
+最早的多用户、多任务操作系统 。后面崛起的 Linux 在很多方面都参考了 Unix。
+
+目前这款操作系统已经逐渐逐渐退出操作系统的舞台。
+
+
+
+#### 1.2.3. Linux
+
+**Linux 是一套免费使用、开源的类 Unix 操作系统。** Linux 存在着许多不同的发行版本,但它们都使用了 **Linux 内核** 。
+
+> 严格来讲,Linux 这个词本身只表示 Linux 内核,在 GNU/Linux 系统中,Linux 实际就是 Linux 内核,而该系统的其余部分主要是由 GNU 工程编写和提供的程序组成。单独的 Linux 内核并不能成为一个可以正常工作的操作系统。
+>
+> **很多人更倾向使用 “GNU/Linux” 一词来表达人们通常所说的 “Linux”。**
+
+
+
+#### 1.2.4. Mac OS
+
+苹果自家的操作系统,编程体验和 Linux 相当,但是界面、软件生态以及用户体验各方面都要比 Linux 操作系统更好。
+
+
+
+### 1.3. 操作系统的内核(Kernel)
+
+我们先来看看维基百科对于内核的解释,我觉得总结的非常好!
+
+> **内核**(英语:Kernel,又称核心)在计算机科学中是一个用来管理软件发出的数据 I/O(输入与输出)要求的电脑程序,将这些要求转译为数据处理的指令并交由中央处理器(CPU)及电脑中其他电子组件进行处理,是现代操作系统中最基本的部分。它是为众多应用程序提供对计算机硬件的安全访问的一部分软件,这种访问是有限的,并由内核决定一个程序在什么时候对某部分硬件操作多长时间。 **直接对硬件操作是非常复杂的。所以内核通常提供一种硬件抽象的方法,来完成这些操作。有了这个,通过进程间通信机制及系统调用,应用进程可间接控制所需的硬件资源(特别是处理器及 IO 设备)。**
+>
+> 早期计算机系统的设计中,还没有操作系统的内核这个概念。随着计算机系统的发展,操作系统内核的概念才渐渐明晰起来了!
+
+简单概括两点:
+
+1. **操作系统的内核(Kernel)是操作系统的核心部分,它负责系统的内存管理,硬件设备的管理,文件系统的管理以及应用程序的管理。**
+2. **操作系统的内核是连接应用程序和硬件的桥梁,决定着操作系统的性能和稳定性。**
+
+### 1.4. 中央处理器(CPU,Central Processing Unit)
+
+关于 CPU 简单概括三点:
+
+1. **CPU 是一台计算机的运算核心(Core)+控制核心( Control Unit),可以称得上是计算机的大脑。**
+2. **CPU 主要包括两个部分:控制器+运算器。**
+3. **CPU 的根本任务就是执行指令,对计算机来说最终都是一串由“0”和“1”组成的序列。**
+
+### 1.5. CPU vs Kernel(内核)
+
+很多人容易无法区分操作系统的内核(Kernel)和中央处理器(CPU),你可以简单从下面两点来区别:
+
+1. 操作系统的内核(Kernel)属于操作系统层面,而 CPU 属于硬件。
+2. CPU 主要提供运算,处理各种指令的能力。内核(Kernel)主要负责系统管理比如内存管理,它屏蔽了对硬件的操作。
+
+下图清晰说明了应用程序、内核、CPU 这三者的关系。
+
+
+
+### 1.6. 系统调用
+
+介绍系统调用之前,我们先来了解一下用户态和系统态。
+
+根据进程访问资源的特点,我们可以把进程在系统上的运行分为两个级别:
+
+1. **用户态(user mode)** : 用户态运行的进程或可以直接读取用户程序的数据。
+2. **系统态(kernel mode)**: 可以简单的理解系统态运行的进程或程序几乎可以访问计算机的任何资源,不受限制。
+
+**说了用户态和系统态之后,那么什么是系统调用呢?**
+
+我们运行的程序基本都是运行在用户态,如果我们调用操作系统提供的系统态级别的子功能咋办呢?那就需要系统调用了!
+
+也就是说在我们运行的用户程序中,凡是与系统态级别的资源有关的操作(如文件管理、进程控制、内存管理等),都必须通过系统调用方式向操作系统提出服务请求,并由操作系统代为完成。
+
+这些系统调用按功能大致可分为如下几类:
+
+- **设备管理** :完成设备的请求或释放,以及设备启动等功能。
+- **文件管理** :完成文件的读、写、创建及删除等功能。
+- **进程控制** :完成进程的创建、撤销、阻塞及唤醒等功能。
+- **进程通信** :完成进程之间的消息传递或信号传递等功能。
+- **内存管理** :完成内存的分配、回收以及获取作业占用内存区大小及地址等功能。
+
+我在网上找了一个图,通过这个图可以很清晰的说明用户程序、系统调用、内核和硬件之间的关系。(_太难了~木有自己画_)
+
+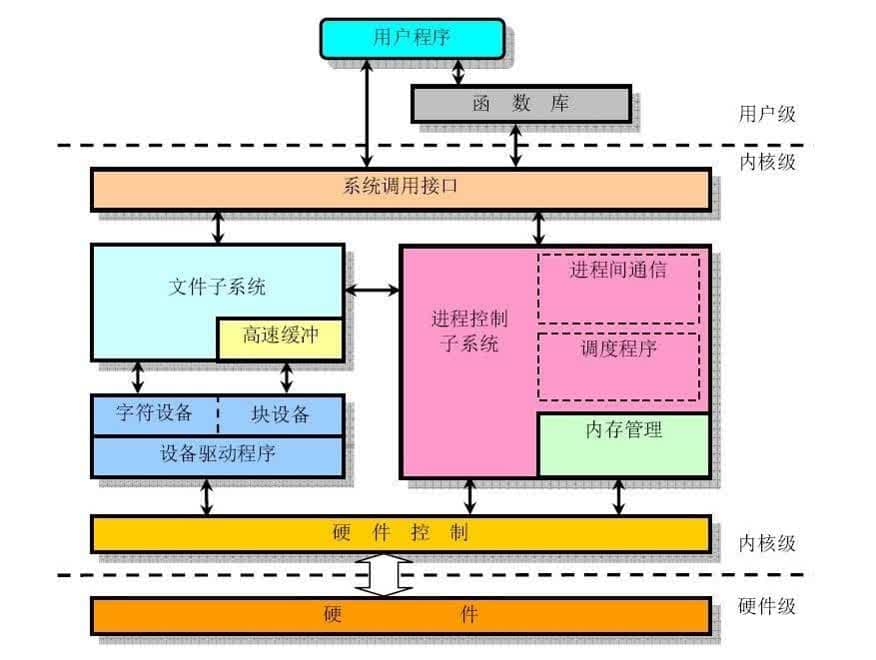
+
+## 2. 初探 Linux
+
+### 2.1. Linux 简介
+
+我们上面已经简单了 Linux,这里只强调三点。
+
+- **类 Unix 系统** : Linux 是一种自由、开放源码的类似 Unix 的操作系统
+- **Linux 本质是指 Linux 内核** : 严格来讲,Linux 这个词本身只表示 Linux 内核,单独的 Linux 内核并不能成为一个可以正常工作的操作系统。所以,就有了各种 Linux 发行版。
+- **Linux 之父** : 一个编程领域的传奇式人物,真大佬!我辈崇拜敬仰之楷模。他是 **Linux 内核** 的最早作者,随后发起了这个开源项目,担任 Linux 内核的首要架构师。他还发起了 Git 这个开源项目,并为主要的开发者。
+
+
+
+### 2.2. Linux 诞生
+
+1989 年,Linus Torvalds 进入芬兰陆军新地区旅,服 11 个月的国家义务兵役,军衔为少尉,主要服务于计算机部门,任务是弹道计算。服役期间,购买了安德鲁·斯图尔特·塔能鲍姆所著的教科书及 minix 源代码,开始研究操作系统。1990 年,他退伍后回到大学,开始接触 Unix。
+
+> **Minix** 是一个迷你版本的类 Unix 操作系统,由塔能鲍姆教授为了教学之用而创作,采用微核心设计。它启发了 Linux 内核的创作。
+
+1991 年,Linus Torvalds 开源了 Linux 内核。Linux 以一只可爱的企鹅作为标志,象征着敢作敢为、热爱生活。
+
+
+
+### 2.3. 常见 Linux 发行版本有哪些?
+
+Linus Torvalds 开源的只是 Linux 内核,我们上面也提到了操作系统内核的作用。一些组织或厂商将 Linux 内核与各种软件和文档包装起来,并提供系统安装界面和系统配置、设定与管理工具,就构成了 Linux 的发行版本。
+
+> 内核主要负责系统的内存管理,硬件设备的管理,文件系统的管理以及应用程序的管理。
+
+Linux 的发行版本可以大体分为两类:
+
+- 商业公司维护的发行版本,以著名的 Red Hat 为代表,比较典型的有 CentOS 。
+- 社区组织维护的发行版本,以 Debian 为代表,比较典型的有 Ubuntu、Debian。
+
+对于初学者学习 Linux ,推荐选择 CentOS 。
+
+## 3. Linux 文件系统概览
+
+### 3.1. Linux 文件系统简介
+
+**在 Linux 操作系统中,所有被操作系统管理的资源,例如网络接口卡、磁盘驱动器、打印机、输入输出设备、普通文件或是目录都被看作是一个文件。** 也就是说在 Linux 系统中有一个重要的概念:**一切都是文件**。
+
+其实这是 UNIX 哲学的一个体现,在 UNIX 系统中,把一切资源都看作是文件,Linux 的文件系统也是借鉴 UNIX 文件系统而来。
+
+### 3.2. inode 介绍
+
+**inode 是 linux/unix 文件系统的基础。那么,inode 是什么?有什么作用呢?**
+
+硬盘的最小存储单位是扇区(Sector),块(block)由多个扇区组成。文件数据存储在块中。块的最常见的大小是 4kb,约为 8 个连续的扇区组成(每个扇区存储 512 字节)。一个文件可能会占用多个 block,但是一个块只能存放一个文件。
+
+虽然,我们将文件存储在了块(block)中,但是我们还需要一个空间来存储文件的 **元信息 metadata** :如某个文件被分成几块、每一块在的地址、文件拥有者,创建时间,权限,大小等。这种 **存储文件元信息的区域就叫 inode**,译为索引节点:**i(index)+node**。 每个文件都有一个 inode,存储文件的元信息。
+
+可以使用 `stat` 命令可以查看文件的 inode 信息。每个 inode 都有一个号码,Linux/Unix 操作系统不使用文件名来区分文件,而是使用 inode 号码区分不同的文件。
+
+简单来说:inode 就是用来维护某个文件被分成几块、每一块在的地址、文件拥有者,创建时间,权限,大小等信息。
+
+简单总结一下:
+
+- **inode** :记录文件的属性信息,可以使用 stat 命令查看 inode 信息。
+- **block** :实际文件的内容,如果一个文件大于一个块时候,那么将占用多个 block,但是一个块只能存放一个文件。(因为数据是由 inode 指向的,如果有两个文件的数据存放在同一个块中,就会乱套了)
+
+
+
+### 3.3. Linux 文件类型
+
+Linux 支持很多文件类型,其中非常重要的文件类型有: **普通文件**,**目录文件**,**链接文件**,**设备文件**,**管道文件**,**Socket 套接字文件**等。
+
+- **普通文件(-)** : 用于存储信息和数据, Linux 用户可以根据访问权限对普通文件进行查看、更改和删除。比如:图片、声音、PDF、text、视频、源代码等等。
+- **目录文件(d,directory file)** :目录也是文件的一种,用于表示和管理系统中的文件,目录文件中包含一些文件名和子目录名。打开目录事实上就是打开目录文件。
+- **符号链接文件(l,symbolic link)** :保留了指向文件的地址而不是文件本身。
+- **字符设备(c,char)** :用来访问字符设备比如硬盘。
+- **设备文件(b,block)** : 用来访问块设备比如硬盘、软盘。
+- **管道文件(p,pipe)** : 一种特殊类型的文件,用于进程之间的通信。
+- **套接字(s,socket)** :用于进程间的网络通信,也可以用于本机之间的非网络通信。
+
+### 3.4. Linux 目录树
+
+所有可操作的计算机资源都存在于目录树这个结构中,对计算资源的访问,可以看做是对这棵目录树的访问。
+
+**Linux 的目录结构如下:**
+
+Linux 文件系统的结构层次鲜明,就像一棵倒立的树,最顶层是其根目录:
+
+
+**常见目录说明:**
+
+- **/bin:** 存放二进制可执行文件(ls、cat、mkdir 等),常用命令一般都在这里;
+- **/etc:** 存放系统管理和配置文件;
+- **/home:** 存放所有用户文件的根目录,是用户主目录的基点,比如用户 user 的主目录就是/home/user,可以用~user 表示;
+- **/usr :** 用于存放系统应用程序;
+- **/opt:** 额外安装的可选应用程序包所放置的位置。一般情况下,我们可以把 tomcat 等都安装到这里;
+- **/proc:** 虚拟文件系统目录,是系统内存的映射。可直接访问这个目录来获取系统信息;
+- **/root:** 超级用户(系统管理员)的主目录(特权阶级^o^);
+- **/sbin:** 存放二进制可执行文件,只有 root 才能访问。这里存放的是系统管理员使用的系统级别的管理命令和程序。如 ifconfig 等;
+- **/dev:** 用于存放设备文件;
+- **/mnt:** 系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统;
+- **/boot:** 存放用于系统引导时使用的各种文件;
+- **/lib :** 存放着和系统运行相关的库文件 ;
+- **/tmp:** 用于存放各种临时文件,是公用的临时文件存储点;
+- **/var:** 用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件(系统启动日志等。)等;
+- **/lost+found:** 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows 下叫什么.chk)就在这里。
+
+## 4. Linux 基本命令
+
+下面只是给出了一些比较常用的命令。推荐一个 Linux 命令快查网站,非常不错,大家如果遗忘某些命令或者对某些命令不理解都可以在这里得到解决。
+
+Linux 命令大全:[http://man.linuxde.net/](http://man.linuxde.net/)
+
+### 4.1. 目录切换命令
+
+- **`cd usr`:** 切换到该目录下 usr 目录
+- **`cd ..(或cd../)`:** 切换到上一层目录
+- **`cd /`:** 切换到系统根目录
+- **`cd ~`:** 切换到用户主目录
+- **`cd -`:** 切换到上一个操作所在目录
+
+### 4.2. 目录的操作命令(增删改查)
+
+- **`mkdir 目录名称`:** 增加目录。
+- **`ls/ll`**(ll 是 ls -l 的别名,ll 命令可以看到该目录下的所有目录和文件的详细信息):查看目录信息。
+- **`find 目录 参数`:** 寻找目录(查)。示例:① 列出当前目录及子目录下所有文件和文件夹: `find .`;② 在`/home`目录下查找以.txt 结尾的文件名:`find /home -name "*.txt"` ,忽略大小写: `find /home -iname "*.txt"` ;③ 当前目录及子目录下查找所有以.txt 和.pdf 结尾的文件:`find . \( -name "*.txt" -o -name "*.pdf" \)`或`find . -name "*.txt" -o -name "*.pdf"`。
+- **`mv 目录名称 新目录名称`:** 修改目录的名称(改)。注意:mv 的语法不仅可以对目录进行重命名而且也可以对各种文件,压缩包等进行 重命名的操作。mv 命令用来对文件或目录重新命名,或者将文件从一个目录移到另一个目录中。后面会介绍到 mv 命令的另一个用法。
+- **`mv 目录名称 目录的新位置`:** 移动目录的位置---剪切(改)。注意:mv 语法不仅可以对目录进行剪切操作,对文件和压缩包等都可执行剪切操作。另外 mv 与 cp 的结果不同,mv 好像文件“搬家”,文件个数并未增加。而 cp 对文件进行复制,文件个数增加了。
+- **`cp -r 目录名称 目录拷贝的目标位置`:** 拷贝目录(改),-r 代表递归拷贝 。注意:cp 命令不仅可以拷贝目录还可以拷贝文件,压缩包等,拷贝文件和压缩包时不 用写-r 递归。
+- **`rm [-rf] 目录` :** 删除目录(删)。注意:rm 不仅可以删除目录,也可以删除其他文件或压缩包,为了增强大家的记忆, 无论删除任何目录或文件,都直接使用`rm -rf` 目录/文件/压缩包。
+
+### 4.3. 文件的操作命令(增删改查)
+
+- **`touch 文件名称`:** 文件的创建(增)。
+- **`cat/more/less/tail 文件名称`** :文件的查看(查) 。命令 `tail -f 文件` 可以对某个文件进行动态监控,例如 tomcat 的日志文件, 会随着程序的运行,日志会变化,可以使用 `tail -f catalina-2016-11-11.log` 监控 文 件的变化 。
+- **`vim 文件`:** 修改文件的内容(改)。vim 编辑器是 Linux 中的强大组件,是 vi 编辑器的加强版,vim 编辑器的命令和快捷方式有很多,但此处不一一阐述,大家也无需研究的很透彻,使用 vim 编辑修改文件的方式基本会使用就可以了。在实际开发中,使用 vim 编辑器主要作用就是修改配置文件,下面是一般步骤: `vim 文件------>进入文件----->命令模式------>按i进入编辑模式----->编辑文件 ------->按Esc进入底行模式----->输入:wq/q!` (输入 wq 代表写入内容并退出,即保存;输入 q!代表强制退出不保存)。
+- **`rm -rf 文件`:** 删除文件(删)。
+
+### 4.4. 压缩文件的操作命令
+
+**1)打包并压缩文件:**
+
+Linux 中的打包文件一般是以.tar 结尾的,压缩的命令一般是以.gz 结尾的。而一般情况下打包和压缩是一起进行的,打包并压缩后的文件的后缀名一般.tar.gz。
+命令:`tar -zcvf 打包压缩后的文件名 要打包压缩的文件` ,其中:
+
+- z:调用 gzip 压缩命令进行压缩
+- c:打包文件
+- v:显示运行过程
+- f:指定文件名
+
+比如:假如 test 目录下有三个文件分别是:aaa.txt bbb.txt ccc.txt,如果我们要打包 test 目录并指定压缩后的压缩包名称为 test.tar.gz 可以使用命令:**`tar -zcvf test.tar.gz aaa.txt bbb.txt ccc.txt` 或 `tar -zcvf test.tar.gz /test/`**
+
+**2)解压压缩包:**
+
+命令:`tar [-xvf] 压缩文件``
+
+其中:x:代表解压
+
+示例:
+
+- 将 /test 下的 test.tar.gz 解压到当前目录下可以使用命令:**`tar -xvf test.tar.gz`**
+- 将 /test 下的 test.tar.gz 解压到根目录/usr 下:**`tar -xvf test.tar.gz -C /usr`**(- C 代表指定解压的位置)
+
+### 4.5. Linux 的权限命令
+
+操作系统中每个文件都拥有特定的权限、所属用户和所属组。权限是操作系统用来限制资源访问的机制,在 Linux 中权限一般分为读(readable)、写(writable)和执行(excutable),分为三组。分别对应文件的属主(owner),属组(group)和其他用户(other),通过这样的机制来限制哪些用户、哪些组可以对特定的文件进行什么样的操作。
+
+通过 **`ls -l`** 命令我们可以 查看某个目录下的文件或目录的权限
+
+示例:在随意某个目录下`ls -l`
+
+
+
+第一列的内容的信息解释如下:
+
+
+
+> 下面将详细讲解文件的类型、Linux 中权限以及文件有所有者、所在组、其它组具体是什么?
+
+**文件的类型:**
+
+- d: 代表目录
+- -: 代表文件
+- l: 代表软链接(可以认为是 window 中的快捷方式)
+
+**Linux 中权限分为以下几种:**
+
+- r:代表权限是可读,r 也可以用数字 4 表示
+- w:代表权限是可写,w 也可以用数字 2 表示
+- x:代表权限是可执行,x 也可以用数字 1 表示
+
+**文件和目录权限的区别:**
+
+对文件和目录而言,读写执行表示不同的意义。
+
+对于文件:
+
+| 权限名称 | 可执行操作 |
+| :------- | --------------------------: |
+| r | 可以使用 cat 查看文件的内容 |
+| w | 可以修改文件的内容 |
+| x | 可以将其运行为二进制文件 |
+
+对于目录:
+
+| 权限名称 | 可执行操作 |
+| :------- | -----------------------: |
+| r | 可以查看目录下列表 |
+| w | 可以创建和删除目录下文件 |
+| x | 可以使用 cd 进入目录 |
+
+需要注意的是: **超级用户可以无视普通用户的权限,即使文件目录权限是 000,依旧可以访问。**
+
+**在 linux 中的每个用户必须属于一个组,不能独立于组外。在 linux 中每个文件有所有者、所在组、其它组的概念。**
+
+- **所有者(u)** :一般为文件的创建者,谁创建了该文件,就天然的成为该文件的所有者,用 `ls ‐ahl` 命令可以看到文件的所有者 也可以使用 chown 用户名 文件名来修改文件的所有者 。
+- **文件所在组(g)** :当某个用户创建了一个文件后,这个文件的所在组就是该用户所在的组用 `ls ‐ahl`命令可以看到文件的所有组也可以使用 chgrp 组名 文件名来修改文件所在的组。
+- **其它组(o)** :除开文件的所有者和所在组的用户外,系统的其它用户都是文件的其它组。
+
+> 我们再来看看如何修改文件/目录的权限。
+
+**修改文件/目录的权限的命令:`chmod`**
+
+示例:修改/test 下的 aaa.txt 的权限为文件所有者有全部权限,文件所有者所在的组有读写权限,其他用户只有读的权限。
+
+**`chmod u=rwx,g=rw,o=r aaa.txt`** 或者 **`chmod 764 aaa.txt`**
+
+
+
+**补充一个比较常用的东西:**
+
+假如我们装了一个 zookeeper,我们每次开机到要求其自动启动该怎么办?
+
+1. 新建一个脚本 zookeeper
+2. 为新建的脚本 zookeeper 添加可执行权限,命令是:`chmod +x zookeeper`
+3. 把 zookeeper 这个脚本添加到开机启动项里面,命令是:`chkconfig --add zookeeper`
+4. 如果想看看是否添加成功,命令是:`chkconfig --list`
+
+### 4.6. Linux 用户管理
+
+Linux 系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以这个账号的身份进入系统。
+
+用户的账号一方面可以帮助系统管理员对使用系统的用户进行跟踪,并控制他们对系统资源的访问;另一方面也可以帮助用户组织文件,并为用户提供安全性保护。
+
+**Linux 用户管理相关命令:**
+
+- `useradd 选项 用户名`:添加用户账号
+- `userdel 选项 用户名`:删除用户帐号
+- `usermod 选项 用户名`:修改帐号
+- `passwd 用户名`:更改或创建用户的密码
+- `passwd -S 用户名` :显示用户账号密码信息
+- `passwd -d 用户名`: 清除用户密码
+
+`useradd` 命令用于 Linux 中创建的新的系统用户。`useradd`可用来建立用户帐号。帐号建好之后,再用`passwd`设定帐号的密码.而可用`userdel`删除帐号。使用`useradd`指令所建立的帐号,实际上是保存在 `/etc/passwd`文本文件中。
+
+`passwd`命令用于设置用户的认证信息,包括用户密码、密码过期时间等。系统管理者则能用它管理系统用户的密码。只有管理者可以指定用户名称,一般用户只能变更自己的密码。
+
+### 4.7. Linux 系统用户组的管理
+
+每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。不同 Linux 系统对用户组的规定有所不同,如 Linux 下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建。
+
+用户组的管理涉及用户组的添加、删除和修改。组的增加、删除和修改实际上就是对`/etc/group`文件的更新。
+
+**Linux 系统用户组的管理相关命令:**
+
+- `groupadd 选项 用户组` :增加一个新的用户组
+- `groupdel 用户组`:要删除一个已有的用户组
+- `groupmod 选项 用户组` : 修改用户组的属性
+
+### 4.8. 其他常用命令
+
+- **`pwd`:** 显示当前所在位置
+
+- `sudo + 其他命令`:以系统管理者的身份执行指令,也就是说,经由 sudo 所执行的指令就好像是 root 亲自执行。
+
+- **`grep 要搜索的字符串 要搜索的文件 --color`:** 搜索命令,--color 代表高亮显示
+
+- **`ps -ef`/`ps -aux`:** 这两个命令都是查看当前系统正在运行进程,两者的区别是展示格式不同。如果想要查看特定的进程可以使用这样的格式:**`ps aux|grep redis`** (查看包括 redis 字符串的进程),也可使用 `pgrep redis -a`。
+
+ 注意:如果直接用 ps((Process Status))命令,会显示所有进程的状态,通常结合 grep 命令查看某进程的状态。
+
+- **`kill -9 进程的pid`:** 杀死进程(-9 表示强制终止。)
+
+ 先用 ps 查找进程,然后用 kill 杀掉
+
+- **网络通信命令:**
+ - 查看当前系统的网卡信息:ifconfig
+ - 查看与某台机器的连接情况:ping
+ - 查看当前系统的端口使用:netstat -an
+- **net-tools 和 iproute2 :**
+ `net-tools`起源于 BSD 的 TCP/IP 工具箱,后来成为老版本 LinuxLinux 中配置网络功能的工具。但自 2001 年起,Linux 社区已经对其停止维护。同时,一些 Linux 发行版比如 Arch Linux 和 CentOS/RHEL 7 则已经完全抛弃了 net-tools,只支持`iproute2`。linux ip 命令类似于 ifconfig,但功能更强大,旨在替代它。更多详情请阅读[如何在 Linux 中使用 IP 命令和示例](https://linoxide.com/linux-command/use-ip-command-linux)
+- **`shutdown`:** `shutdown -h now`: 指定现在立即关机;`shutdown +5 "System will shutdown after 5 minutes"`:指定 5 分钟后关机,同时送出警告信息给登入用户。
+
+- **`reboot`:** **`reboot`:** 重开机。**`reboot -w`:** 做个重开机的模拟(只有纪录并不会真的重开机)。
+
+## 5. 公众号
+
+如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
+
+**《Java 面试突击》:** 由本文档衍生的专为面试而生的《Java 面试突击》V3.0 PDF 版本[公众号](#公众号)后台回复 **"Java 面试突击"** 即可免费领取!
+
+**Java 工程师必备学习资源:** 一些 Java 工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
+
+
diff --git a/docs/operating-system/后端程序员必备的Linux基础知识.md b/docs/operating-system/后端程序员必备的Linux基础知识.md
deleted file mode 100644
index 3af99b4e..00000000
--- a/docs/operating-system/后端程序员必备的Linux基础知识.md
+++ /dev/null
@@ -1,372 +0,0 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
-
-
-- [一 从认识操作系统开始](#一-从认识操作系统开始)
- - [1.1 操作系统简介](#11-操作系统简介)
- - [1.2 操作系统简单分类](#12-操作系统简单分类)
-- [二 初探Linux](#二-初探linux)
- - [2.1 Linux简介](#21-linux简介)
- - [2.2 Linux诞生简介](#22-linux诞生简介)
- - [2.3 Linux的分类](#23-linux的分类)
-- [三 Linux文件系统概览](#三-linux文件系统概览)
- - [3.1 Linux文件系统简介](#31-linux文件系统简介)
- - [3.2 文件类型与目录结构](#32-文件类型与目录结构)
-- [四 Linux基本命令](#四-linux基本命令)
- - [4.1 目录切换命令](#41-目录切换命令)
- - [4.2 目录的操作命令(增删改查)](#42-目录的操作命令增删改查)
- - [4.3 文件的操作命令(增删改查)](#43-文件的操作命令增删改查)
- - [4.4 压缩文件的操作命令](#44-压缩文件的操作命令)
- - [4.5 Linux的权限命令](#45-linux的权限命令)
- - [4.6 Linux 用户管理](#46-linux-用户管理)
- - [4.7 Linux系统用户组的管理](#47-linux系统用户组的管理)
- - [4.8 其他常用命令](#48-其他常用命令)
-
-
-
-推荐一个Github开源的Linux学习指南(Java工程师向):
-
-> 学习Linux之前,我们先来简单的认识一下操作系统。
-
-## 一 从认识操作系统开始
-
-### 1.1 操作系统简介
-
-我通过以下四点介绍什么是操作系统:
-
-- **操作系统(Operation System,简称OS)是管理计算机硬件与软件资源的程序,是计算机系统的内核与基石;**
-- **操作系统本质上是运行在计算机上的软件程序 ;**
-- **为用户提供一个与系统交互的操作界面 ;**
-- **操作系统分内核与外壳(我们可以把外壳理解成围绕着内核的应用程序,而内核就是能操作硬件的程序)。**
-
-
-### 1.2 操作系统简单分类
-
-1. **Windows:** 目前最流行的个人桌面操作系统 ,不做多的介绍,大家都清楚。
-2. **Unix:** 最早的多用户、多任务操作系统 .按照操作系统的分类,属于分时操作系统。Unix 大多被用在服务器、工作站,现在也有用在个人计算机上。它在创建互联网、计算机网络或客户端/服务器模型方面发挥着非常重要的作用。
-
-3. **Linux:** Linux是一套免费使用和自由传播的类Unix操作系统.Linux存在着许多不同的Linux版本,但它们都使用了 **Linux内核** 。Linux可安装在各种计算机硬件设备中,比如手机、平板电脑、路由器、视频游戏控制台、台式计算机、大型机和超级计算机。严格来讲,Linux这个词本身只表示Linux内核,但实际上人们已经习惯了用Linux来形容整个基于Linux内核,并且使用GNU 工程各种工具和数据库的操作系统。
-
-
-
-
-## 二 初探Linux
-
-### 2.1 Linux简介
-
-我们上面已经介绍到了Linux,我们这里只强调三点。
-- **类Unix系统:** Linux是一种自由、开放源码的类似Unix的操作系统
-- **Linux内核:** 严格来说,Linux这个词本身只表示Linux内核
-- **Linux之父:** 一个编程领域的传奇式人物。他是Linux内核的最早作者,随后发起了这个开源项目,担任Linux内核的首要架构师与项目协调者,是当今世界最著名的电脑程序员、黑客之一。他还发起了Git这个开源项目,并为主要的开发者。
-
-
-
-### 2.2 Linux诞生简介
-
-- 1991年,芬兰的业余计算机爱好者Linus Torvalds编写了一款类似Minix的系统(基于微内核架构的类Unix操作系统)被ftp管理员命名为Linux 加入到自由软件基金的GNU计划中;
-- Linux以一只可爱的企鹅作为标志,象征着敢作敢为、热爱生活。
-
-
-### 2.3 Linux的分类
-
-**Linux根据原生程度,分为两种:**
-
-1. **内核版本:** Linux不是一个操作系统,严格来讲,Linux只是一个操作系统中的内核。内核是什么?内核建立了计算机软件与硬件之间通讯的平台,内核提供系统服务,比如文件管理、虚拟内存、设备I/O等;
-2. **发行版本:** 一些组织或公司在内核版基础上进行二次开发而重新发行的版本。Linux发行版本有很多种(ubuntu和CentOS用的都很多,初学建议选择CentOS),如下图所示:
-
-
-
-## 三 Linux文件系统概览
-
-### 3.1 Linux文件系统简介
-
-**在Linux操作系统中,所有被操作系统管理的资源,例如网络接口卡、磁盘驱动器、打印机、输入输出设备、普通文件或是目录都被看作是一个文件。**
-
-也就是说在LINUX系统中有一个重要的概念:**一切都是文件**。其实这是UNIX哲学的一个体现,而Linux是重写UNIX而来,所以这个概念也就传承了下来。在UNIX系统中,把一切资源都看作是文件,包括硬件设备。UNIX系统把每个硬件都看成是一个文件,通常称为设备文件,这样用户就可以用读写文件的方式实现对硬件的访问。
-
-
-### 3.2 文件类型与目录结构
-
-**Linux支持5种文件类型 :**
-
-
-**Linux的目录结构如下:**
-
-Linux文件系统的结构层次鲜明,就像一棵倒立的树,最顶层是其根目录:
-
-
-**常见目录说明:**
-
-- **/bin:** 存放二进制可执行文件(ls、cat、mkdir等),常用命令一般都在这里;
-- **/etc:** 存放系统管理和配置文件;
-- **/home:** 存放所有用户文件的根目录,是用户主目录的基点,比如用户user的主目录就是/home/user,可以用~user表示;
-- **/usr :** 用于存放系统应用程序;
-- **/opt:** 额外安装的可选应用程序包所放置的位置。一般情况下,我们可以把tomcat等都安装到这里;
-- **/proc:** 虚拟文件系统目录,是系统内存的映射。可直接访问这个目录来获取系统信息;
-- **/root:** 超级用户(系统管理员)的主目录(特权阶级^o^);
-- **/sbin:** 存放二进制可执行文件,只有root才能访问。这里存放的是系统管理员使用的系统级别的管理命令和程序。如ifconfig等;
-- **/dev:** 用于存放设备文件;
-- **/mnt:** 系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统;
-- **/boot:** 存放用于系统引导时使用的各种文件;
-- **/lib :** 存放着和系统运行相关的库文件 ;
-- **/tmp:** 用于存放各种临时文件,是公用的临时文件存储点;
-- **/var:** 用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件(系统启动日志等。)等;
-- **/lost+found:** 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows下叫什么.chk)就在这里。
-
-
-## 四 Linux基本命令
-
-下面只是给出了一些比较常用的命令。推荐一个Linux命令快查网站,非常不错,大家如果遗忘某些命令或者对某些命令不理解都可以在这里得到解决。
-
-Linux命令大全:[http://man.linuxde.net/](http://man.linuxde.net/)
-### 4.1 目录切换命令
-
-- **`cd usr`:** 切换到该目录下usr目录
-- **`cd ..(或cd../)`:** 切换到上一层目录
-- **`cd /`:** 切换到系统根目录
-- **`cd ~`:** 切换到用户主目录
-- **`cd -`:** 切换到上一个操作所在目录
-
-### 4.2 目录的操作命令(增删改查)
-
-1. **`mkdir 目录名称`:** 增加目录
-2. **`ls或者ll`**(ll是ls -l的别名,ll命令可以看到该目录下的所有目录和文件的详细信息):查看目录信息
-3. **`find 目录 参数`:** 寻找目录(查)
-
- 示例:
-
- - 列出当前目录及子目录下所有文件和文件夹: `find .`
- - 在`/home`目录下查找以.txt结尾的文件名:`find /home -name "*.txt"`
- - 同上,但忽略大小写: `find /home -iname "*.txt"`
- - 当前目录及子目录下查找所有以.txt和.pdf结尾的文件:`find . \( -name "*.txt" -o -name "*.pdf" \)`或`find . -name "*.txt" -o -name "*.pdf" `
-
-4. **`mv 目录名称 新目录名称`:** 修改目录的名称(改)
-
- 注意:mv的语法不仅可以对目录进行重命名而且也可以对各种文件,压缩包等进行 重命名的操作。mv命令用来对文件或目录重新命名,或者将文件从一个目录移到另一个目录中。后面会介绍到mv命令的另一个用法。
-5. **`mv 目录名称 目录的新位置`:** 移动目录的位置---剪切(改)
-
- 注意:mv语法不仅可以对目录进行剪切操作,对文件和压缩包等都可执行剪切操作。另外mv与cp的结果不同,mv好像文件“搬家”,文件个数并未增加。而cp对文件进行复制,文件个数增加了。
-6. **`cp -r 目录名称 目录拷贝的目标位置`:** 拷贝目录(改),-r代表递归拷贝
-
- 注意:cp命令不仅可以拷贝目录还可以拷贝文件,压缩包等,拷贝文件和压缩包时不 用写-r递归
-7. **`rm [-rf] 目录`:** 删除目录(删)
-
- 注意:rm不仅可以删除目录,也可以删除其他文件或压缩包,为了增强大家的记忆, 无论删除任何目录或文件,都直接使用`rm -rf` 目录/文件/压缩包
-
-
-### 4.3 文件的操作命令(增删改查)
-
-1. **`touch 文件名称`:** 文件的创建(增)
-2. **`cat/more/less/tail 文件名称`** 文件的查看(查)
- - **`cat`:** 查看显示文件内容
- - **`more`:** 可以显示百分比,回车可以向下一行, 空格可以向下一页,q可以退出查看
- - **`less`:** 可以使用键盘上的PgUp和PgDn向上 和向下翻页,q结束查看
- - **`tail-10` :** 查看文件的后10行,Ctrl+C结束
-
- 注意:命令 tail -f 文件 可以对某个文件进行动态监控,例如tomcat的日志文件, 会随着程序的运行,日志会变化,可以使用tail -f catalina-2016-11-11.log 监控 文 件的变化
-3. **`vim 文件`:** 修改文件的内容(改)
-
- vim编辑器是Linux中的强大组件,是vi编辑器的加强版,vim编辑器的命令和快捷方式有很多,但此处不一一阐述,大家也无需研究的很透彻,使用vim编辑修改文件的方式基本会使用就可以了。
-
- **在实际开发中,使用vim编辑器主要作用就是修改配置文件,下面是一般步骤:**
-
- vim 文件------>进入文件----->命令模式------>按i进入编辑模式----->编辑文件 ------->按Esc进入底行模式----->输入:wq/q! (输入wq代表写入内容并退出,即保存;输入q!代表强制退出不保存。)
-4. **`rm -rf 文件`:** 删除文件(删)
-
- 同目录删除:熟记 `rm -rf` 文件 即可
-
-### 4.4 压缩文件的操作命令
-
-**1)打包并压缩文件:**
-
-Linux中的打包文件一般是以.tar结尾的,压缩的命令一般是以.gz结尾的。
-
-而一般情况下打包和压缩是一起进行的,打包并压缩后的文件的后缀名一般.tar.gz。
-命令:**`tar -zcvf 打包压缩后的文件名 要打包压缩的文件`**
-其中:
-
- z:调用gzip压缩命令进行压缩
-
- c:打包文件
-
- v:显示运行过程
-
- f:指定文件名
-
-比如:假如test目录下有三个文件分别是:aaa.txt bbb.txt ccc.txt,如果我们要打包test目录并指定压缩后的压缩包名称为test.tar.gz可以使用命令:**`tar -zcvf test.tar.gz aaa.txt bbb.txt ccc.txt`或:`tar -zcvf test.tar.gz /test/`**
-
-
-**2)解压压缩包:**
-
-命令:tar [-xvf] 压缩文件
-
-其中:x:代表解压
-
-示例:
-
-1 将/test下的test.tar.gz解压到当前目录下可以使用命令:**`tar -xvf test.tar.gz`**
-
-2 将/test下的test.tar.gz解压到根目录/usr下:**`tar -xvf test.tar.gz -C /usr`**(- C代表指定解压的位置)
-
-
-### 4.5 Linux的权限命令
-
- 操作系统中每个文件都拥有特定的权限、所属用户和所属组。权限是操作系统用来限制资源访问的机制,在Linux中权限一般分为读(readable)、写(writable)和执行(excutable),分为三组。分别对应文件的属主(owner),属组(group)和其他用户(other),通过这样的机制来限制哪些用户、哪些组可以对特定的文件进行什么样的操作。通过 **`ls -l`** 命令我们可以 查看某个目录下的文件或目录的权限
-
-示例:在随意某个目录下`ls -l`
-
-
-
-第一列的内容的信息解释如下:
-
-
-
-> 下面将详细讲解文件的类型、Linux中权限以及文件有所有者、所在组、其它组具体是什么?
-
-
-**文件的类型:**
-
-- d: 代表目录
-- -: 代表文件
-- l: 代表软链接(可以认为是window中的快捷方式)
-
-
-**Linux中权限分为以下几种:**
-
-- r:代表权限是可读,r也可以用数字4表示
-- w:代表权限是可写,w也可以用数字2表示
-- x:代表权限是可执行,x也可以用数字1表示
-
-**文件和目录权限的区别:**
-
- 对文件和目录而言,读写执行表示不同的意义。
-
- 对于文件:
-
-| 权限名称 | 可执行操作 |
-| :-------- | --------:|
-| r | 可以使用cat查看文件的内容 |
-|w | 可以修改文件的内容 |
-| x | 可以将其运行为二进制文件 |
-
- 对于目录:
-
-| 权限名称 | 可执行操作 |
-| :-------- | --------:|
-| r | 可以查看目录下列表 |
-|w | 可以创建和删除目录下文件 |
-| x | 可以使用cd进入目录 |
-
-
-**需要注意的是超级用户可以无视普通用户的权限,即使文件目录权限是000,依旧可以访问。**
-**在linux中的每个用户必须属于一个组,不能独立于组外。在linux中每个文件有所有者、所在组、其它组的概念。**
-
-- **所有者**
-
- 一般为文件的创建者,谁创建了该文件,就天然的成为该文件的所有者,用ls ‐ahl命令可以看到文件的所有者 也可以使用chown 用户名 文件名来修改文件的所有者 。
-- **文件所在组**
-
- 当某个用户创建了一个文件后,这个文件的所在组就是该用户所在的组 用ls ‐ahl命令可以看到文件的所有组 也可以使用chgrp 组名 文件名来修改文件所在的组。
-- **其它组**
-
- 除开文件的所有者和所在组的用户外,系统的其它用户都是文件的其它组
-
-> 我们再来看看如何修改文件/目录的权限。
-
-**修改文件/目录的权限的命令:`chmod`**
-
-示例:修改/test下的aaa.txt的权限为属主有全部权限,属主所在的组有读写权限,
-其他用户只有读的权限
-
-**`chmod u=rwx,g=rw,o=r aaa.txt`**
-
-
-
-上述示例还可以使用数字表示:
-
-chmod 764 aaa.txt
-
-
-**补充一个比较常用的东西:**
-
-假如我们装了一个zookeeper,我们每次开机到要求其自动启动该怎么办?
-
-1. 新建一个脚本zookeeper
-2. 为新建的脚本zookeeper添加可执行权限,命令是:`chmod +x zookeeper`
-3. 把zookeeper这个脚本添加到开机启动项里面,命令是:` chkconfig --add zookeeper`
-4. 如果想看看是否添加成功,命令是:`chkconfig --list`
-
-
-### 4.6 Linux 用户管理
-
-Linux系统是一个多用户多任务的分时操作系统,任何一个要使用系统资源的用户,都必须首先向系统管理员申请一个账号,然后以这个账号的身份进入系统。
-
-用户的账号一方面可以帮助系统管理员对使用系统的用户进行跟踪,并控制他们对系统资源的访问;另一方面也可以帮助用户组织文件,并为用户提供安全性保护。
-
-**Linux用户管理相关命令:**
-- `useradd 选项 用户名`:添加用户账号
-- `userdel 选项 用户名`:删除用户帐号
-- `usermod 选项 用户名`:修改帐号
-- `passwd 用户名`:更改或创建用户的密码
-- `passwd -S 用户名` :显示用户账号密码信息
-- `passwd -d 用户名`: 清除用户密码
-
-useradd命令用于Linux中创建的新的系统用户。useradd可用来建立用户帐号。帐号建好之后,再用passwd设定帐号的密码.而可用userdel删除帐号。使用useradd指令所建立的帐号,实际上是保存在/etc/passwd文本文件中。
-
-passwd命令用于设置用户的认证信息,包括用户密码、密码过期时间等。系统管理者则能用它管理系统用户的密码。只有管理者可以指定用户名称,一般用户只能变更自己的密码。
-
-
-### 4.7 Linux系统用户组的管理
-
-每个用户都有一个用户组,系统可以对一个用户组中的所有用户进行集中管理。不同Linux 系统对用户组的规定有所不同,如Linux下的用户属于与它同名的用户组,这个用户组在创建用户时同时创建。
-
-用户组的管理涉及用户组的添加、删除和修改。组的增加、删除和修改实际上就是对/etc/group文件的更新。
-
-**Linux系统用户组的管理相关命令:**
-- `groupadd 选项 用户组` :增加一个新的用户组
-- `groupdel 用户组`:要删除一个已有的用户组
-- `groupmod 选项 用户组` : 修改用户组的属性
-
-
-### 4.8 其他常用命令
-
-- **`pwd`:** 显示当前所在位置
-
-- `sudo + 其他命令`:以系统管理者的身份执行指令,也就是说,经由 sudo 所执行的指令就好像是 root 亲自执行。
-
-- **`grep 要搜索的字符串 要搜索的文件 --color`:** 搜索命令,--color代表高亮显示
-
-- **`ps -ef`/`ps -aux`:** 这两个命令都是查看当前系统正在运行进程,两者的区别是展示格式不同。如果想要查看特定的进程可以使用这样的格式:**`ps aux|grep redis`** (查看包括redis字符串的进程),也可使用 `pgrep redis -a`。
-
- 注意:如果直接用ps((Process Status))命令,会显示所有进程的状态,通常结合grep命令查看某进程的状态。
-
-- **`kill -9 进程的pid`:** 杀死进程(-9 表示强制终止。)
-
- 先用ps查找进程,然后用kill杀掉
-
-- **网络通信命令:**
- - 查看当前系统的网卡信息:ifconfig
- - 查看与某台机器的连接情况:ping
- - 查看当前系统的端口使用:netstat -an
-
-- **net-tools 和 iproute2 :**
- `net-tools`起源于BSD的TCP/IP工具箱,后来成为老版本Linux内核中配置网络功能的工具。但自2001年起,Linux社区已经对其停止维护。同时,一些Linux发行版比如Arch Linux和CentOS/RHEL 7则已经完全抛弃了net-tools,只支持`iproute2`。linux ip命令类似于ifconfig,但功能更强大,旨在替代它。更多详情请阅读[如何在Linux中使用IP命令和示例](https://linoxide.com/linux-command/use-ip-command-linux)
-
-- **`shutdown`:** `shutdown -h now`: 指定现在立即关机;`shutdown +5 "System will shutdown after 5 minutes"`:指定5分钟后关机,同时送出警告信息给登入用户。
-
-- **`reboot`:** **`reboot`:** 重开机。**`reboot -w`:** 做个重开机的模拟(只有纪录并不会真的重开机)。
-
-## 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
-
-
-
-
-
-
-
diff --git a/docs/operating-system/完全使用GNU_Linux学习.md b/docs/operating-system/完全使用GNU_Linux学习.md
new file mode 100644
index 00000000..d9e171da
--- /dev/null
+++ b/docs/operating-system/完全使用GNU_Linux学习.md
@@ -0,0 +1,252 @@
+
+
+ * [完全使用GNU/Linux学习](#完全使用gnulinux学习)
+ * [为什么要写这篇文章?](#为什么要写这篇文章)
+ * [为什么我要从Windows切换到Linux?](#为什么我要从windows切换到linux)
+ * [Linux作为日常使用的缺点](#linux作为日常使用的缺点)
+ * [硬件驱动问题](#硬件驱动问题)
+ * [软件问题](#软件问题)
+ * [你真的需要完全使用Linux吗?](#你真的需要完全使用linux吗)
+ * [结尾](#结尾)
+ * [我使用Debian/Ubuntu时遇到的问题](#我使用debianubuntu时遇到的问题)
+ * [IDEA编辑Markdown预渲染问题](#idea编辑markdown预渲染问题)
+ * [wifi适配器找不到](#wifi适配器找不到)
+ * [XMind安装](#xmind安装)
+ * [Fcitx候选框的定位问题](#fcitx候选框的定位问题)
+
+
+
+# 完全使用GNU/Linux学习
+
+喔,看到这个标题千万不要以为我要写和王垠前辈一样的内容啊,嘿嘿。不过在这里还是献上王垠前辈的那篇文章的链接吧:[完全用Linux工作](https://www.douban.com/group/topic/12121637/)。
+
+## 为什么要写这篇文章?
+
+首先介绍本篇文章产出的时间,现在是2020/04/06。在三,四天之前,我其实并没有写这篇文章的打算,但是这三,四天以来,我一直在忙活从Ubuntu18换到Debian10 Buster的事情,没有时间写代码,手确实有些痒了。你可能想象不到,我这个之前一直使用Ubuntu的人,只是切换到Debian就花这么长时间,你可能以为我是在劝退各位同学,其实不是的,我只是想表达:我对Linux并不熟悉,这其中一部分原因是我使用的是对用户较为友好的发行版Ubuntu,另一部分原因是我仍然没有那么大的动力去学习Linux,即使它一直作为我的日常使用。
+
+这篇文章并不是吹嘘或贬低Windows和Linux系统,而是想记录一下我一直以来使用Linux作为日常学习的心得,以及这几天再度折腾Debian以来的感触。
+
+
+
+## 为什么我要从Windows切换到Linux?
+
+Windows是商业软件,这使它具备易用的性质。Linux是自由软件,这使得它拥有开源的性质。
+
+易用软件通常带来的是对用户的友好度,以致于Windows发展至今,被许许多多的普通用户所采用。自由软件通常带来的是其社区的发展,所以你现在可以在网上看到许多如 ask ubuntu 这样的论坛。
+
+我非常赞同《完全用Linux工作》中的一个观点: **UNIX 不是计算机专家的专利。**
+
+我对这句话的理解就是:即使你学习或工作的方向不是计算机,但你仍然可以去学习Unix/Linux,如果你是计算机方向的同学,那么,你就更应该去学习Unix/Linux了。
+
+但这只是我从Win切换到Linux的一部分原因,另一个很重要的原因是我受够了Windows的 “易用性”。这里的易用性并不是说我排斥Windows的人性化,而是因为人性化给我带来了很多学习上的困难。举个很简单的栗子:你在学习一项技术的时候,无论是否有面试造火箭的需要,你是否都会好奇想了解其原理和实现,即使你可能知道它很复杂。
+
+**为什么你会好奇一个事物的源头?**
+
+我个人认为的答案是:有趣的事情就在眼前,为什么不去了解它呢?
+
+而Windows只是有趣,但它并不在“眼前”。
+
+我个人的体验哈,不知道有没有同学和我一样的经历,在很多时候,你的Windows可能会出现一些莫名奇妙的问题,但你却不知道如何解决它,你只能求助搜索引擎,当你解决完问题后,你不会想要去了解为什么会发生这种问题,因为Windows太庞大了。
+
+就比如: 我现在安装了Git,使用起来没有任何问题。但等到过一段时间后,Git莫名奇妙的不能使用了,明明你啥都没干。更甚之,有一些流氓问题或流氓软件不能被解决和被屏蔽。
+
+问题出现了,总得要解决吧,所以此时你开始在互联网上查询相关问题的解决方法,如果你的运气好,那么有人可能遇到过和你出现相同的问题,你也因此可能会得到答案。不过一般的答案只是教你怎么解决的,如打开注册表,添加或删除某个key,你不会想要知道为什么做,因为对于初学者来说,当你看到注册表那么多的内容时,你只想着不出错就行了,哪还有心思去学习这玩意啊。如果你的运气不好,且并没有更换系统的打算,那么你可能会将就着使用,但此时,你的心里可能已经衍生了对Windows的厌烦情绪。
+
+我对流氓软件的定义是:当你想让一个软件如你的想法停止运行或停止弹出广告的时候,这个软件不能或不能做的很好的达到你的要求时,这就是一个流氓软件。你也许会说,每个人都有不同的要求,软件怎么可能达到每个人的标准呢?但我指的是停止和停止弹出广告等这样最基本的诉求,如果一个软件连最基本的诉求都实现不了,又何必再使用它呢?
+
+综上所述,我从Window切换到Linux的最主要的原因有:**学习和自由。**
+
+是的,你不得不承认Linux是你学习计算机的非常好的环境,与C/C++天然的集成,比你在Windows上冷冰冰的安装一个IDE就开始敲起代码来,显得多了那么一点感觉。
+
+还有一点,可能有的同学和我一样,刚接触Linux的时候,是在Windows上安装一个虚拟机环境或使用Docker来进行学习。不可否认,这确实是在Windows上学习Linux的主要途径了,但是你有没有感觉到,你在采取这种方式学习的时候,对Linux始终有种陌生感,似乎我只是在为了学习而学习。
+
+产生这种想法的主要原因就是你没有融入到Linux环境之中,当你融入到Linux环境之中时,你不再只是需要学习那些操作命令,你会不可避免的遇到某个你从来没有接触过的问题,这个问题不是你在Windows上“丢失图标”的那种烦人问题,而可能是令你有些害怕的因为Nvidia的驱动而黑屏的问题。你也会在互联网上查询为什么会出现这种问题,但你得到的并不是“修改注册表”这种答案,而是会学习到:为什么Nvidia在Linux上会出现这种问题?我怎么做才能解决驱动问题?其他驱动是否也有类似Nvidia这种问题? 当你解决问题后,你的电脑开始正常工作了,你便开始使用它作为你的日常使用...
+
+关于使用Linux学习的原因的最后一点是我认为自己不够慎独,不够克制。当我使用Windows的时候,并不能完全克制住自己接触那些新鲜游戏的念头,我玩起游戏来,通常会连续很长时间,可能是一天-_-。不过我并不是说Linux上没有游戏,相反,Linux是对很多游戏的支持是很好的,你可以玩到很多游戏,但你是否会因为使用Linux对游戏不再那么执着,至少我是如此了。这一点可以归结为“使用Linux对戒游戏有帮助吧” ,哈哈。
+
+再谈谈自由:
+
+我对自由的理解是:软件在你的掌控之中,你可以了解它的每一部分,你可以去到你想到达的地方,不受任何限制,这只取决于你愿不愿意。
+
+来看看基本的Linux目录吧:
+
+
+
+这些目录你可能有很多都不认识,但没关系,因为这就是Linux系统(大部分)所有的目录了,你稍微了解下,就知道这些目录里放的是什么文件了。
+
+这也是我个人的体验而已,总之,Linux的自由是一种开源精神,比我描述的可大的多。至于Windows,我到现在连C盘的目录放了些什么都不太熟悉,但我并不是在贬低Windows,因为这就是Windows易用性的代价,相应的,Linux作为自由软件,它也有很多缺点。
+
+
+
+## Linux作为日常使用的缺点
+
+### 硬件驱动问题
+
+硬件驱动问题一般是在安装Linux时会出现的问题,根据个人电脑配置的不同,你的电脑的硬件驱动可能与要安装的Linux发行版不兼容,导致系统出现相应的问题。我这几天对驱动问题最深刻的体会就明白了为啥Linus大神会吐槽: “Nvidia Fuck You”。很多驱动厂商对Linux系统是闭源的,你可以下载这些厂商的驱动,但是能不能用,或者用起来有什么毛病都得你自己买单。
+
+随着Linux开始在普通用户中变得流行起来,我相信今后Linux的生态会发展的越来越好,且现在很多Linux发行版对各种硬件的兼容性也越来越好,就以我之前使用的Ubuntu18来说,Nvidia,Wifi,蓝牙等驱动使用都是没啥问题的。我现在使用的Debian10 Buster对Nvidia的支持可能还不是那么好,使用起来总有一些小毛病,不过无伤大雅,其实没毛病我还有点不适应,不是说Debian是Ubuntu的爸爸吗,哈哈。
+
+
+
+### 软件问题
+
+不得不承认的一点是Linux的软件生态确实没有Windows那么丰富,你在考虑切换系统之前,必须先调查清楚Linux上是否有你必需的软件,你所需的软件是否支持跨平台或者是否有可替代的应用。我个人对软件要求较为简单,大部分都是生产力工具,其他的应用如娱乐软件之类的都可以使用网页版作为替代。如果你在Linux系统上想尝试游戏的话,我认为也是OK的,因为我也尝试过Linux Dota2 ,体验非常好(不是广告-_-)。不过大多数国内游戏厂商对Linux的支持都是很差的,所以如果过不了这道坎,也不要切换系统了。
+
+软件问题其实可以分为2部分看待,一部分就是刚刚介绍过的生态问题,另一部分就是当你在使用某些软件的时候,总会出现某些小Bug。
+
+就以Fcitx来说,Fcitx是一款通用的Linux输入法框架,被称为小企鹅输入法,很多输入法都是在Fcitx之上开发的,如搜狗,Googlepinyin,Sunpinyin等。使用过Fcitx的同学可能会遇到这种问题:当你在使用Fcitx在某些软件上打字时,候选框并不会跟随你光标的位置,而是总会固定在某一个位置,并且你无法改变,这个问题是我目前见过的最大Bug。不过这个Bug只在部分软件上有,在Chrome,Typora上都没有这个问题,这让我怀疑是软件的国际化问题,而非Fcitx问题。
+
+所以第二个部分总结起来就是某些软件可能会出现某些未知的Bug,你得寻求解决的办法,或者忍耐使用,使用Linux也是得牺牲一些代价的。
+
+
+
+## 你真的需要完全使用Linux吗?
+
+说到这里,其实我想借用知乎某位前辈的话来表达一下我的真实想法: “**Linux最好的地方在与开放自由,最大的毛病也是在这里。普通人没有能力去选择,也没有时间做选择。透明就一定好么?也有很多人喜欢被安排啊!**“ ([知乎 - 汉卿](https://www.zhihu.com/question/309704636))
+
+就像我开头说过的: “我对Linux并不熟悉,这其中一部分原因是我使用的是对用户较为友好的发行版Ubuntu,另一部分原因是我仍然没有那么大的动力去学习Linux,即使它一直作为我的日常使用。”
+
+我完全使用Linux是为了学习和自由,我确实在Linux上感受到了自由,且学到了很多东西,但我却一直沉溺在这种使用Linux带来的满足感之中,并不能真正理解Linux给我们带来的到底是什么。
+
+这次从Ubuntu切换到Debian的原因是我想尝试换个新的环境,但是当我花了3,4天后,我明白了:我只是呆在一个地方久了,想换个新地方而已,但老地方不一定坏,因为我都没怎么了解过这个老地方,就像当初我从Windows换到Linux那样,我都没有深入的了解过Windows就换了,那一段时间我还抱怨Windows的各种缺点,现在看来,非常可笑。
+
+
+
+#### 结尾
+
+一文把想说的话几乎都给说了,个人文笔有限,且本文主观意识太强,如果觉得本文不符合您的胃口,就当看个笑话吧。
+
+
+---
+
+## 我使用Debian/Ubuntu时遇到的问题
+
+**以下内容是我在Debian10 Buster下遇到的问题以及相关解决办法,
+使用Ubuntu和Debian其他版本的同学也可借鉴。**
+
+PS:欢迎各位同学在此处写下你遇到的问题和解决办法。
+
+### IDEA编辑Markdown预渲染问题
+这个问题花了我很长时间。
+
+当我安装IDEA后,使用它编辑markdown文件的时候,就出现了如下图所示的情况:
+
+
+
+你可以看到右边渲染的画面明显有问题。刚开始的时候我一度怀疑是IDEA版本的问题,
+于是我又安装IDEA其他版本,但也没有任何作用,这时我怀疑是显卡的原因:
+
+
+
+可以看到使用的是Intel的核显,于是当我查询相关资料,使用脚本将核显换为了独显,这里没留截图,当你换到独显后,
+图形会显示独显的配置,使用nvidia-smi命令可以查看独显使用状态。
+于是我满怀期待的打开IDEA,但还是无济于事。当我以为真的是Debian的Bug的时候,
+我又发现Bumblebee可以管理显卡,何不一试?于是我安装Bumblebee后,使用optirun命令启动IDEA,没想到啊,
+还真是可以:
+
+
+
+我真的就很奇怪,同样是使用了独显,为什么optirun启动就可以正常显示。
+于是我后来又查询optirun是否开启了gpu加速,但很可惜,我并没有得到相关答案,不过这让我确定了这个问题出现在
+显卡上。如果有知道原因的同学,敬请告之,感激不尽。
+
+
+### wifi适配器找不到
+我猜(不确定)这个问题应该发生在大多数使用联想笔记本的同学的电脑上,不止Debian,且Ubuntu也有这个问题。
+当安装完系统后,我们打开设置会发现wifi一栏显示 “wifi适配器找不到” 此类的错误信息。
+这个问题的大概原因是:无线网络适配器被阻塞了,需要手动将电脑上的wifi开关打开,而在我的笔记本上并wifi开关,
+所以可以猜测是联想网络驱动的问题。
+可以使用 rfkill list all命令查询你的wlan是否被阻塞了,没有此命令的同学可以使用
+
+````text
+sudo apt-get install rfkill
+````
+
+安装,当wlan显示Hard blocked: true , 就证明你的无线驱动被阻塞了。
+解决办法是将阻塞无限驱动的那个模块从内核中移除掉,直接在 /etc/modprobe.d
+目录下编辑 blacklist.conf文件,其内容为:
+
+````text
+blacklist ideapad_laptop
+````
+
+文件名不一定要与我的一致,但是要以.conf结尾。
+你可以将modprobe.d目录下的文件理解为黑名单文件,
+当Linux启动时就不会加载conf文件指定的模块,
+这里的 ideapad_laptop 就是我们需要移除的那个无线模块。
+
+**后遗症:
+当我们移除 ideapad_laptop 模块后,以后开机的时候,有时会出现
+蓝牙适配器找不到的情况,之前在Ubuntu上却并未发现这种问题,
+看来Debian在驱动方面没有Ubuntu做的好,不过这也是可以理解的,
+而且大多数时候还是可以正常使用的-_-。**
+
+
+### XMind安装
+XMind是使用Java编写的,依赖于Openjdk8。所以在Linux上使用XMind,
+首先需要有Openjdk8的环境。
+其次启动的时候需要编写Shell脚本来启动(不是唯一办法,但却是非常简单的办法),没想到吧,我也没想到,
+这也是我趟过很多坑才玩出来的。
+
+首先我们需要准备一张XMind的软件启动图片:XMind.png,
+这个我已经放到[目录](https://github.com/guang19/framework-learning/tree/dev/img/linux)
+下了,需要的同学请自取。
+
+其次我们进入XMind_amd64目录下,32位系统的同学进入XMind_i386目录,
+我们创建并编辑 start.sh 脚本,其内容为:
+
+````text
+#!/bin/bash
+cd /home/guang19/SDK/xmind/XMind_amd64 (这个路径为你的XMind脚本的路径)
+./XMind
+````
+
+这个脚本的内容很简单吧,当启动脚本的时候,进入目录,直接启动XMind。
+
+脚本写完后需要让它能够被执行,使用
+
+````text
+chmod +x start.sh
+````
+
+命令让start.sh可以被执行。
+
+此时你可以尝试执行 ./start.sh 命令来启动XMind,启动成功的话,
+就已经完成了99%了,如果启动不成功,可以再检测下前面的步骤是否有误。
+
+如果以后你只想用Shell启动XMind的话,那么到此也就为止了,连上面所说的图片都不需要了。
+如果你想更方便的启动的话,那么就需要创建桌面文件启动。
+在Debian/Ubuntu下,你所看到的桌面文件,都存储在 /usr/share/applications
+目录下面(也有的在.local/share/applications目录下),这个目录下文件全是以.desktop结尾。
+我们现在就需要在这个目录下创建xmind.desktop文件(名字可以不叫xmind)。
+
+其内容为:
+
+````text
+[Desktop Entry]
+Encoding=UTF-8
+Name=XMind
+Type=Application
+Exec=sh /home/guang19/SDK/xmind/XMind_amd64/start.sh
+Icon=/home/guang19/SDK/xmind/XMind.png
+````
+
+我们暂时只需要理解Icon和Exec属性。
+Icon就是你在桌面上看到的应用的图标,把Icon的路径改为你XMind.png的路径就行了。
+再看Exec属性,当我们在桌面上点击XMind的图标的时候,就会执行Exec对应的命令或脚本,
+我们把Exec改为start.sh文件的路径就行了,别掉了sh命令,因为start.sh是脚本,
+需要sh命令启动。
+
+以上步骤完成,保存desktop文件后,你就可以在桌面上看到XMind应用了。
+
+
+### Fcitx候选框的定位问题
+这个问题贴一张我处境的截图就明白了:
+
+
+
+可以看到我的光标定位在第207行,但是我输入法的候选框停留在IDEA的左下角。
+为什么我要说停留在IDEA的左下角?因为就目前我的使用而言,这个问题只在IDEA下存在,
+不仅是Debian,Ubuntu也存在这种问题,我个人认为这应该是IDEA的问题,
+查到的相关文章大部分都是说Swing的问题,看来这个问题还真是比较困难了。
+如果有同学知道解决办法,还请不吝分享,非常感谢。
\ No newline at end of file
diff --git a/docs/questions/java-big-data.md b/docs/questions/java-big-data.md
index 2ede8233..6bea7d6f 100644
--- a/docs/questions/java-big-data.md
+++ b/docs/questions/java-big-data.md
@@ -1,9 +1,3 @@
-写这篇文章主要是为了回答球友的一个提问,提问如下:
-
-科学理财,年盈利率过万
+```
+
+上面也提到过,进行Session 认证的时候,我们一般使用 Cookie 来存储 SessionId,当我们登陆后后端生成一个SessionId放在Cookie中返回给客户端,服务端通过Redis或者其他存储工具记录保存着这个Sessionid,客户端登录以后每次请求都会带上这个SessionId,服务端通过这个SessionId来标示你这个人。如果别人通过 cookie拿到了 SessionId 后就可以代替你的身份访问系统了。
+
+ Session 认证中 Cookie 中的 SessionId是由浏览器发送到服务端的,借助这个特性,攻击者就可以通过让用户误点攻击链接,达到攻击效果。
+
+但是,我们使用 token 的话就不会存在这个问题,在我们登录成功获得 token 之后,一般会选择存放在 local storage 中。然后我们在前端通过某些方式会给每个发到后端的请求加上这个 token,这样就不会出现 CSRF 漏洞的问题。因为,即使有个你点击了非法链接发送了请求到服务端,这个非法请求是不会携带 token 的,所以这个请求将是非法的。
+
+需要注意的是不论是 Cookie 还是 token 都无法避免跨站脚本攻击(Cross Site Scripting)XSS。
+
+> 跨站脚本攻击(Cross Site Scripting)缩写为 CSS 但这会与层叠样式表(Cascading Style Sheets,CSS)的缩写混淆。因此,有人将跨站脚本攻击缩写为XSS。
+
+XSS中攻击者会用各种方式将恶意代码注入到其他用户的页面中。就可以通过脚本盗用信息比如cookie。
+
+推荐阅读:
+
+1. [如何防止CSRF攻击?—美团技术团队](https://tech.meituan.com/2018/10/11/fe-security-csrf.html)
+
+## 6. 什么是 Token?什么是 JWT?如何基于Token进行身份验证?
我们在上一个问题中探讨了使用 Session 来鉴别用户的身份,并且给出了几个 Spring Session 的案例分享。 我们知道 Session 信息需要保存一份在服务器端。这种方式会带来一些麻烦,比如需要我们保证保存 Session 信息服务器的可用性、不适合移动端(依赖Cookie)等等。
@@ -117,7 +167,7 @@ JWT 由 3 部分构成:
在基于 Token 进行身份验证的的应用程序中,服务器通过`Payload`、`Header`和一个密钥(`secret`)创建令牌(`Token`)并将 `Token` 发送给客户端,客户端将 `Token` 保存在 Cookie 或者 localStorage 里面,以后客户端发出的所有请求都会携带这个令牌。你可以把它放在 Cookie 里面自动发送,但是这样不能跨域,所以更好的做法是放在 HTTP Header 的 Authorization字段中:` Authorization: Bearer Token`。
-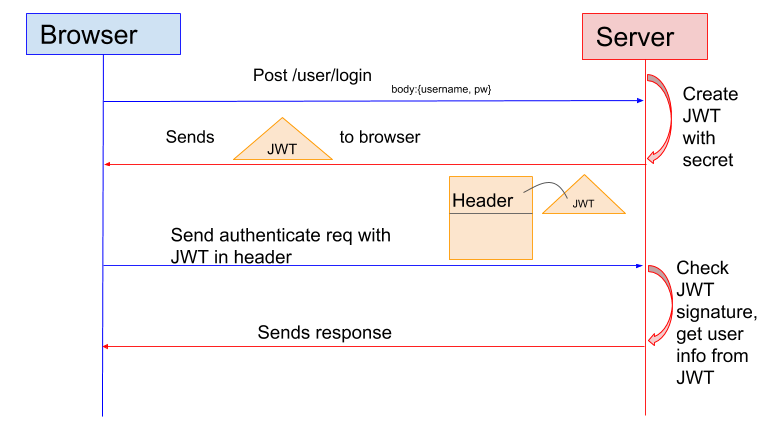
+
1. 用户向服务器发送用户名和密码用于登陆系统。
2. 身份验证服务响应并返回了签名的 JWT,上面包含了用户是谁的内容。
@@ -132,7 +182,7 @@ JWT 由 3 部分构成:
- [JSON Web Token 入门教程](https://www.ruanyifeng.com/blog/2018/07/json_web_token-tutorial.html)
- [彻底理解Cookie,Session,Token](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485603&idx=1&sn=c8d324f44d6102e7b44554733da10bb7&chksm=cea24768f9d5ce7efe7291ddabce02b68db34073c7e7d9a7dc9a7f01c5a80cebe33ac75248df&token=844918801&lang=zh_CN#rd)
-## 5 什么是OAuth 2.0?
+## 7 什么是OAuth 2.0?
OAuth 是一个行业的标准授权协议,主要用来授权第三方应用获取有限的权限。而 OAuth 2.0是对 OAuth 1.0 的完全重新设计,OAuth 2.0更快,更容易实现,OAuth 1.0 已经被废弃。详情请见:[rfc6749](https://tools.ietf.org/html/rfc6749)。
@@ -140,6 +190,12 @@ OAuth 是一个行业的标准授权协议,主要用来授权第三方应用
OAuth 2.0 比较常用的场景就是第三方登录,当你的网站接入了第三方登录的时候一般就是使用的 OAuth 2.0 协议。
+另外,现在OAuth 2.0也常见于支付场景(微信支付、支付宝支付)和开发平台(微信开放平台、阿里开放平台等等)。
+
+微信支付账户相关参数:
+
+),然后将消息append到batch中.如果有batch满了则唤醒Sender 线程。队列的操作是加锁执行,所以batch内消息时有序的。后续的Sender操作当前方法异步操作。
-
-
-
-
-**3.Sender把消息有序发到 broker(tp replia leader)**
-**3.1 确定tp relica leader 所在的broker**
-
-Kafka中 每台broker都保存了kafka集群的metadata信息,metadata信息里包括了每个topic的所有partition的信息: leader, leader_epoch, controller_epoch, isr, replicas等;Kafka客户端从任一broker都可以获取到需要的metadata信息;sender线程通过metadata信息可以知道tp leader的brokerId
-producer也保存了metada信息,同时根据metadata更新策略(定期更新metadata.max.age.ms、失效检测,强制更新:检查到metadata失效以后,调用metadata.requestUpdate()强制更新
-
-```
-public class PartitionInfo {
- private final String topic; private final int partition;
- private final Node leader; private final Node[] replicas;
- private final Node[] inSyncReplicas; private final Node[] offlineReplicas;
-}
-```
-
-**3.2 幂等性发送**
-
-为实现Producer的幂等性,Kafka引入了Producer ID(即PID)和Sequence Number。对于每个PID,该Producer发送消息的每个都对应一个单调递增的Sequence Number。同样,Broker端也会为每个维护一个序号,并且每Commit一条消息时将其对应序号递增。对于接收的每条消息,如果其序号比Broker维护的序号)大一,则Broker会接受它,否则将其丢弃:
-
-如果消息序号比Broker维护的序号差值比一大,说明中间有数据尚未写入,即乱序,此时Broker拒绝该消息,Producer抛出InvalidSequenceNumber
-如果消息序号小于等于Broker维护的序号,说明该消息已被保存,即为重复消息,Broker直接丢弃该消息,Producer抛出DuplicateSequenceNumber
-Sender发送失败后会重试,这样可以保证每个消息都被发送到broker
-
-**4. Sender处理broker发来的produce response**
-一旦broker处理完Sender的produce请求,就会发送produce response给Sender,此时producer将执行我们为send()设置的回调函数。至此producer的send执行完毕。
-
-## 吞吐性&&延时:
-
-buffer.memory:buffer设置大了有助于提升吞吐性,但是batch太大会增大延迟,可搭配linger_ms参数使用
-linger_ms:如果batch太大,或者producer qps不高,batch添加的会很慢,我们可以强制在linger_ms时间后发送batch数据
-ack:producer收到多少broker的答复才算真的发送成功
-0表示producer无需等待leader的确认(吞吐最高、数据可靠性最差)
-1代表需要leader确认写入它的本地log并立即确认
--1/all 代表所有的ISR都完成后确认(吞吐最低、数据可靠性最高)
-
-## Sender线程和长连接
-
-每初始化一个producer实例,都会初始化一个Sender实例,新增到broker的长连接。
-代码角度:每初始化一次KafkaProducer,都赋一个空的client
-
-```
-public KafkaProducer(final Map configs) {
- this(configs, null, null, null, null, null, Time.SYSTEM);
-}
-```
-
-
-
-终端查看TCP连接数:
-lsof -p portNum -np | grep TCP
-
-# Consumer设计原理
-
-## poll消息
-
-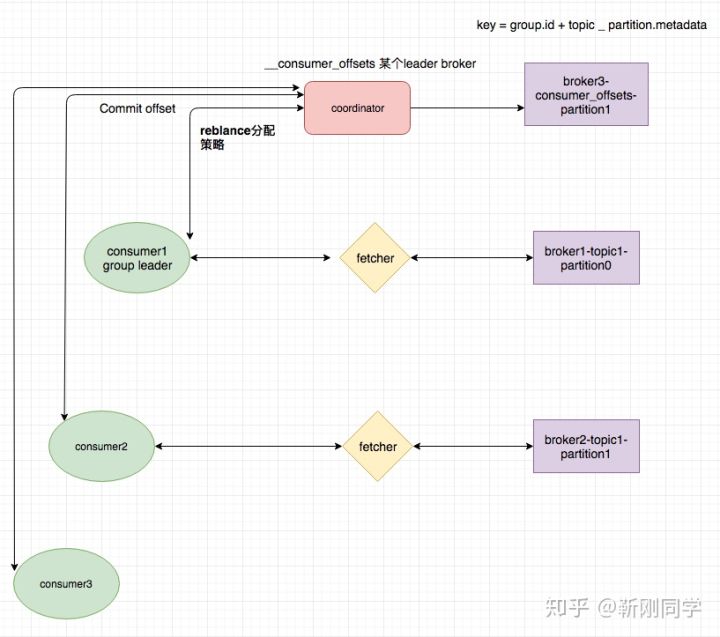
-
-- 消费者通过fetch线程拉消息(单线程)
-- 消费者通过心跳线程来与broker发送心跳。超时会认为挂掉
-- 每个consumer
- group在broker上都有一个coordnator来管理,消费者加入和退出,以及消费消息的位移都由coordnator处理。
-
-## 位移管理
-
-consumer的消息位移代表了当前group对topic-partition的消费进度,consumer宕机重启后可以继续从该offset开始消费。
-在kafka0.8之前,位移信息存放在zookeeper上,由于zookeeper不适合高并发的读写,新版本Kafka把位移信息当成消息,发往__consumers_offsets 这个topic所在的broker,__consumers_offsets默认有50个分区。
-消息的key 是groupId+topic_partition,value 是offset.
-
-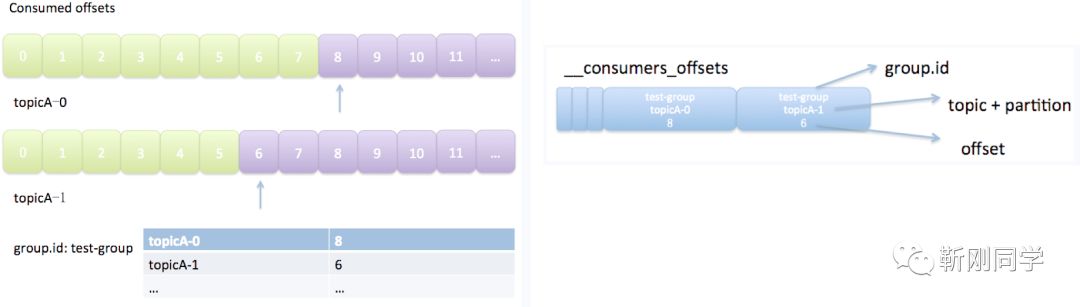
-
-
-
-## Kafka Group 状态
-
-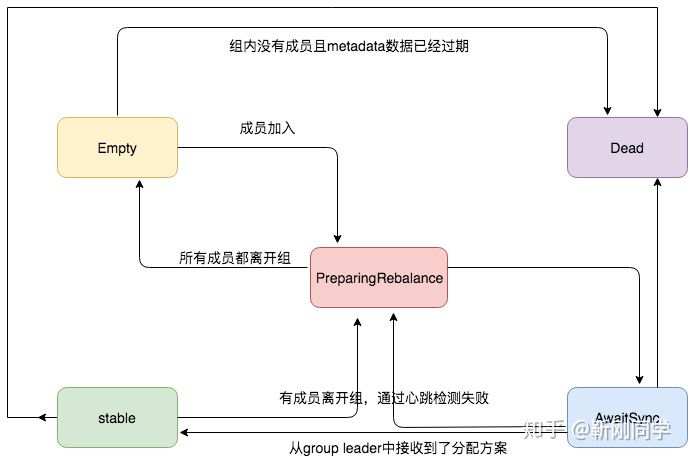
-
-- Empty:初始状态,Group 没有任何成员,如果所有的 offsets 都过期的话就会变成 Dead
-- PreparingRebalance:Group 正在准备进行 Rebalance
-- AwaitingSync:Group 正在等待来 group leader 的 分配方案
-- Stable:稳定的状态(Group is stable);
-- Dead:Group 内已经没有成员,并且它的 Metadata 已经被移除
-
-## 重平衡reblance
-
-当一些原因导致consumer对partition消费不再均匀时,kafka会自动执行reblance,使得consumer对partition的消费再次平衡。
-什么时候发生rebalance?:
-
-- 组订阅topic数变更
-- topic partition数变更
-- consumer成员变更
-- consumer 加入群组或者离开群组的时候
-- consumer被检测为崩溃的时候
-
-## reblance过程
-
-举例1 consumer被检测为崩溃引起的reblance
-比如心跳线程在timeout时间内没和broker发送心跳,此时coordnator认为该group应该进行reblance。接下来其他consumer发来fetch请求后,coordnator将回复他们进行reblance通知。当consumer成员收到请求后,只有leader会根据分配策略进行分配,然后把各自的分配结果返回给coordnator。这个时候只有consumer leader返回的是实质数据,其他返回的都为空。收到分配方法后,consumer将会把分配策略同步给各consumer
-
-举例2 consumer加入引起的reblance
-
-使用join协议,表示有consumer 要加入到group中
-使用sync 协议,根据分配规则进行分配
-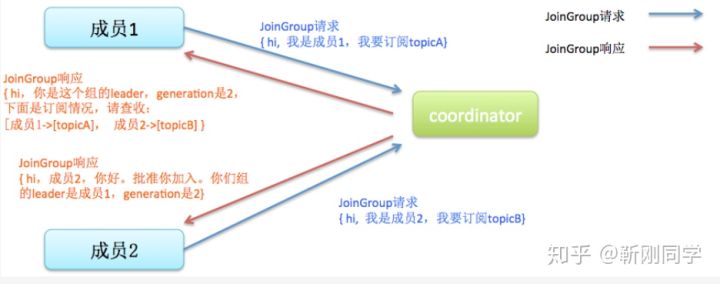
-
-(上图图片摘自网络)
-
-## 引申:以上reblance机制存在的问题
-
-在大型系统中,一个topic可能对应数百个consumer实例。这些consumer陆续加入到一个空消费组将导致多次的rebalance;此外consumer 实例启动的时间不可控,很有可能超出coordinator确定的rebalance timeout(即max.poll.interval.ms),将会再次触发rebalance,而每次rebalance的代价又相当地大,因为很多状态都需要在rebalance前被持久化,而在rebalance后被重新初始化。
-
-## 新版本改进
-
-**通过延迟进入PreparingRebalance状态减少reblance次数**
-
-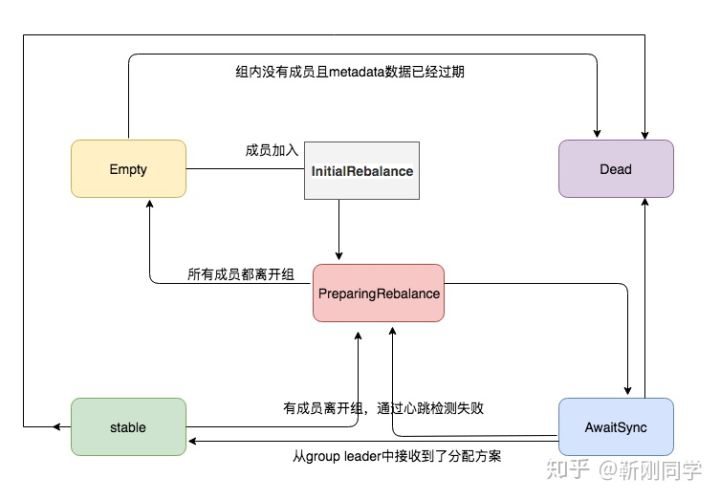
-
-新版本新增了group.initial.rebalance.delay.ms参数。空消费组接受到成员加入请求时,不立即转化到PreparingRebalance状态来开启reblance。当时间超过group.initial.rebalance.delay.ms后,再把group状态改为PreparingRebalance(开启reblance)。实现机制是在coordinator底层新增一个group状态:InitialReblance。假设此时有多个consumer陆续启动,那么group状态先转化为InitialReblance,待group.initial.rebalance.delay.ms时间后,再转换为PreparingRebalance(开启reblance)
-
-
-
-# Broker设计原理
-
-Broker 是Kafka 集群中的节点。负责处理生产者发送过来的消息,消费者消费的请求。以及集群节点的管理等。由于涉及内容较多,先简单介绍,后续专门抽出一篇文章分享
-
-## broker zk注册
-
-
-
-## broker消息存储
-
-Kafka的消息以二进制的方式紧凑地存储,节省了很大空间
-此外消息存在ByteBuffer而不是堆,这样broker进程挂掉时,数据不会丢失,同时避免了gc问题
-通过零拷贝和顺序寻址,让消息存储和读取速度都非常快
-处理fetch请求的时候通过zero-copy 加快速度
-
-## broker状态数据
-
-broker设计中,每台机器都保存了相同的状态数据。主要包括以下:
-
-controller所在的broker ID,即保存了当前集群中controller是哪台broker
-集群中所有broker的信息:比如每台broker的ID、机架信息以及配置的若干组连接信息
-集群中所有节点的信息:严格来说,它和上一个有些重复,不过此项是按照broker ID和***类型进行分组的。对于超大集群来说,使用这一项缓存可以快速地定位和查找给定节点信息,而无需遍历上一项中的内容,算是一个优化吧
-集群中所有分区的信息:所谓分区信息指的是分区的leader、ISR和AR信息以及当前处于offline状态的副本集合。这部分数据按照topic-partitionID进行分组,可以快速地查找到每个分区的当前状态。(注:AR表示assigned replicas,即创建topic时为该分区分配的副本集合)
-
-## broker负载均衡
-
-**分区数量负载**:各台broker的partition数量应该均匀
-partition Replica分配算法如下:
-
-将所有Broker(假设共n个Broker)和待分配的Partition排序
-将第i个Partition分配到第(i mod n)个Broker上
-将第i个Partition的第j个Replica分配到第((i + j) mod n)个Broker上
-
-**容量大小负载:**每台broker的硬盘占用大小应该均匀
-在kafka1.1之前,Kafka能够保证各台broker上partition数量均匀,但由于每个partition内的消息数不同,可能存在不同硬盘之间内存占用差异大的情况。在Kafka1.1中增加了副本跨路径迁移功能kafka-reassign-partitions.sh,我们可以结合它和监控系统,实现自动化的负载均衡
-
-# Kafka高可用
-
-在介绍kafka高可用之前先介绍几个概念
-
-同步复制:要求所有能工作的Follower都复制完,这条消息才会被认为commit,这种复制方式极大的影响了吞吐率
-异步复制:Follower异步的从Leader pull数据,data只要被Leader写入log认为已经commit,这种情况下如果Follower落后于Leader的比较多,如果Leader突然宕机,会丢失数据
-
-## Isr
-
-Kafka结合同步复制和异步复制,使用ISR(与Partition Leader保持同步的Replica列表)的方式在确保数据不丢失和吞吐率之间做了平衡。Producer只需把消息发送到Partition Leader,Leader将消息写入本地Log。Follower则从Leader pull数据。Follower在收到该消息向Leader发送ACK。一旦Leader收到了ISR中所有Replica的ACK,该消息就被认为已经commit了,Leader将增加HW并且向Producer发送ACK。这样如果leader挂了,只要Isr中有一个replica存活,就不会丢数据。
-
-## Isr动态更新
-
-Leader会跟踪ISR,如果ISR中一个Follower宕机,或者落后太多,Leader将把它从ISR中移除。这里所描述的“落后太多”指Follower复制的消息落后于Leader后的条数超过预定值(replica.lag.max.messages)或者Follower超过一定时间(replica.lag.time.max.ms)未向Leader发送fetch请求。
-
-broker Nodes In Zookeeper
-/brokers/topics/[topic]/partitions/[partition]/state 保存了topic-partition的leader和Isr等信息
-
-
-
-## Controller负责broker故障检查&&故障转移(fail/recover)
-
-1. Controller在Zookeeper上注册Watch,一旦有Broker宕机,其在Zookeeper对应的znode会自动被删除,Zookeeper会触发
- Controller注册的watch,Controller读取最新的Broker信息
-2. Controller确定set_p,该集合包含了宕机的所有Broker上的所有Partition
-3. 对set_p中的每一个Partition,选举出新的leader、Isr,并更新结果。
-
-3.1 从/brokers/topics/[topic]/partitions/[partition]/state读取该Partition当前的ISR
-
-3.2 决定该Partition的新Leader和Isr。如果当前ISR中有至少一个Replica还幸存,则选择其中一个作为新Leader,新的ISR则包含当前ISR中所有幸存的Replica。否则选择该Partition中任意一个幸存的Replica作为新的Leader以及ISR(该场景下可能会有潜在的数据丢失)
-
-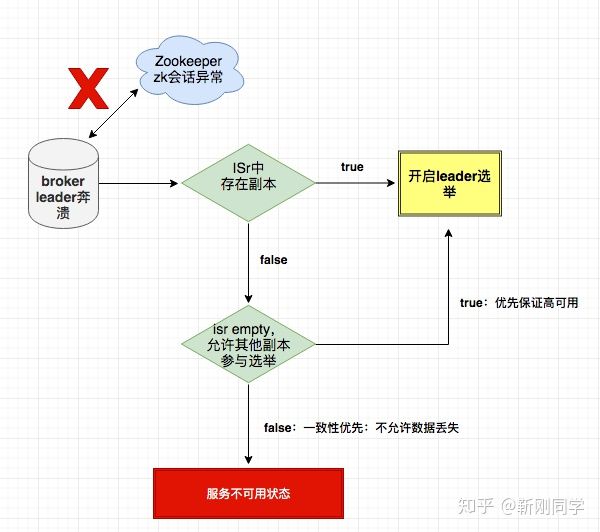
-3.3 更新Leader、ISR、leader_epoch、controller_epoch:写入/brokers/topics/[topic]/partitions/[partition]/state
-
-4. 直接通过RPC向set_p相关的Broker发送LeaderAndISRRequest命令。Controller可以在一个RPC操作中发送多个命令从而提高效率。
-
-## Controller挂掉
-
-每个 broker 都会在 zookeeper 的临时节点 "/controller" 注册 watcher,当 controller 宕机时 "/controller" 会消失,触发broker的watch,每个 broker 都尝试创建新的 controller path,只有一个竞选成功并当选为 controller。
-
-# 使用Kafka如何保证幂等性
-
-不丢消息
-
-首先kafka保证了对已提交消息的at least保证
-Sender有重试机制
-producer业务方在使用producer发送消息时,注册回调函数。在onError方法中重发消息
-consumer 拉取到消息后,处理完毕再commit,保证commit的消息一定被处理完毕
-
-不重复
-
-consumer拉取到消息先保存,commit成功后删除缓存数据
-
-# Kafka高性能
-
-partition提升了并发
-zero-copy
-顺序写入
-消息聚集batch
-页缓存
-业务方对 Kafka producer的优化
-
-增大producer数量
-ack配置
-batch
diff --git a/docs/system-design/data-communication/dubbo.md b/docs/system-design/data-communication/dubbo.md
index f2e0ac48..f5dfbfb4 100644
--- a/docs/system-design/data-communication/dubbo.md
+++ b/docs/system-design/data-communication/dubbo.md
@@ -44,7 +44,7 @@ Dubbo 是由阿里开源,后来加入了 Apache 。正式由于 Dubbo 的出
**什么是 RPC?**
-RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。比如两个不同的服务 A、B 部署在两台不同的机器上,那么服务 A 如果想要调用服务 B 中的某个方法该怎么办呢?使用 HTTP请求 当然可以,但是可能会比较慢而且一些优化做的并不好。 RPC 的出现就是为了解决这个问题。
+RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。比如两个不同的服务 A、B 部署在两台不同的机器上,那么服务 A 如果想要调用服务 B 中的某个方法该怎么办呢?使用 HTTP请求当然可以,但是可能会比较麻烦。 RPC 的出现就是为了让你调用远程方法像调用本地方法一样简单。
**RPC原理是什么?**
@@ -179,7 +179,7 @@ Dubbo 的诞生和 SOA 分布式架构的流行有着莫大的关系。SOA 面
#### 3.2.1 Random LoadBalance(默认,基于权重的随机负载均衡机制)
-
+
- **随机,按权重设置随机概率。**
- 在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。
diff --git a/docs/system-design/data-communication/kafka-inverview.md b/docs/system-design/data-communication/kafka-inverview.md
new file mode 100644
index 00000000..42ef9746
--- /dev/null
+++ b/docs/system-design/data-communication/kafka-inverview.md
@@ -0,0 +1,210 @@
+------
+
+
+
+## Kafka面试题总结
+
+### Kafka 是什么?主要应用场景有哪些?
+
+Kafka 是一个分布式流式处理平台。这到底是什么意思呢?
+
+流平台具有三个关键功能:
+
+1. **消息队列**:发布和订阅消息流,这个功能类似于消息队列,这也是 Kafka 也被归类为消息队列的原因。
+2. **容错的持久方式存储记录消息流**: Kafka 会把消息持久化到磁盘,有效避免了消息丢失的风险·。
+3. **流式处理平台:** 在消息发布的时候进行处理,Kafka 提供了一个完整的流式处理类库。
+
+Kafka 主要有两大应用场景:
+
+1. **消息队列** :建立实时流数据管道,以可靠地在系统或应用程序之间获取数据。
+2. **数据处理:** 构建实时的流数据处理程序来转换或处理数据流。
+
+### 和其他消息队列相比,Kafka的优势在哪里?
+
+我们现在经常提到 Kafka 的时候就已经默认它是一个非常优秀的消息队列了,我们也会经常拿它给 RocketMQ、RabbitMQ 对比。我觉得 Kafka 相比其他消息队列主要的优势如下:
+
+1. **极致的性能** :基于 Scala 和 Java 语言开发,设计中大量使用了批量处理和异步的思想,最高可以每秒处理千万级别的消息。
+2. **生态系统兼容性无可匹敌** :Kafka 与周边生态系统的兼容性是最好的没有之一,尤其在大数据和流计算领域。
+
+实际上在早期的时候 Kafka 并不是一个合格的消息队列,早期的 Kafka 在消息队列领域就像是一个衣衫褴褛的孩子一样,功能不完备并且有一些小问题比如丢失消息、不保证消息可靠性等等。当然,这也和 LinkedIn 最早开发 Kafka 用于处理海量的日志有很大关系,哈哈哈,人家本来最开始就不是为了作为消息队列滴,谁知道后面误打误撞在消息队列领域占据了一席之地。
+
+随着后续的发展,这些短板都被 Kafka 逐步修复完善。所以,**Kafka 作为消息队列不可靠这个说法已经过时!**
+
+### 队列模型了解吗?Kafka 的消息模型知道吗?
+
+> 题外话:早期的 JMS 和 AMQP 属于消息服务领域权威组织所做的相关的标准,我在 [JavaGuide](https://github.com/Snailclimb/JavaGuide)的 [《消息队列其实很简单》](https://github.com/Snailclimb/JavaGuide#%E6%95%B0%E6%8D%AE%E9%80%9A%E4%BF%A1%E4%B8%AD%E9%97%B4%E4%BB%B6)这篇文章中介绍过。但是,这些标准的进化跟不上消息队列的演进速度,这些标准实际上已经属于废弃状态。所以,可能存在的情况是:不同的消息队列都有自己的一套消息模型。
+
+#### 队列模型:早期的消息模型
+
+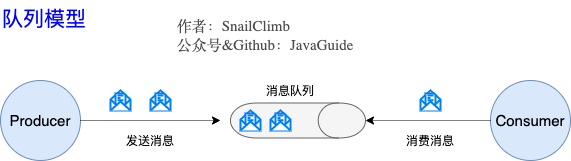
+
+**使用队列(Queue)作为消息通信载体,满足生产者与消费者模式,一条消息只能被一个消费者使用,未被消费的消息在队列中保留直到被消费或超时。** 比如:我们生产者发送 100 条消息的话,两个消费者来消费一般情况下两个消费者会按照消息发送的顺序各自消费一半(也就是你一个我一个的消费。)
+
+**队列模型存在的问题:**
+
+假如我们存在这样一种情况:我们需要将生产者产生的消息分发给多个消费者,并且每个消费者都能接收到完成的消息内容。
+
+这种情况,队列模型就不好解决了。很多比较杠精的人就说:我们可以为每个消费者创建一个单独的队列,让生产者发送多份。这是一种非常愚蠢的做法,浪费资源不说,还违背了使用消息队列的目的。
+
+#### 发布-订阅模型:Kafka 消息模型
+
+发布-订阅模型主要是为了解决队列模型存在的问题。
+
+
+
+发布订阅模型(Pub-Sub) 使用**主题(Topic)** 作为消息通信载体,类似于**广播模式**;发布者发布一条消息,该消息通过主题传递给所有的订阅者,**在一条消息广播之后才订阅的用户则是收不到该条消息的**。
+
+**在发布 - 订阅模型中,如果只有一个订阅者,那它和队列模型就基本是一样的了。所以说,发布 - 订阅模型在功能层面上是可以兼容队列模型的。**
+
+**Kafka 采用的就是发布 - 订阅模型。**
+
+> **RocketMQ 的消息模型和 Kafka 基本是完全一样的。唯一的区别是 Kafka 中没有队列这个概念,与之对应的是 Partition(分区)。**
+
+### 什么是Producer、Consumer、Broker、Topic、Partition?
+
+Kafka 将生产者发布的消息发送到 **Topic(主题)** 中,需要这些消息的消费者可以订阅这些 **Topic(主题)**,如下图所示:
+
+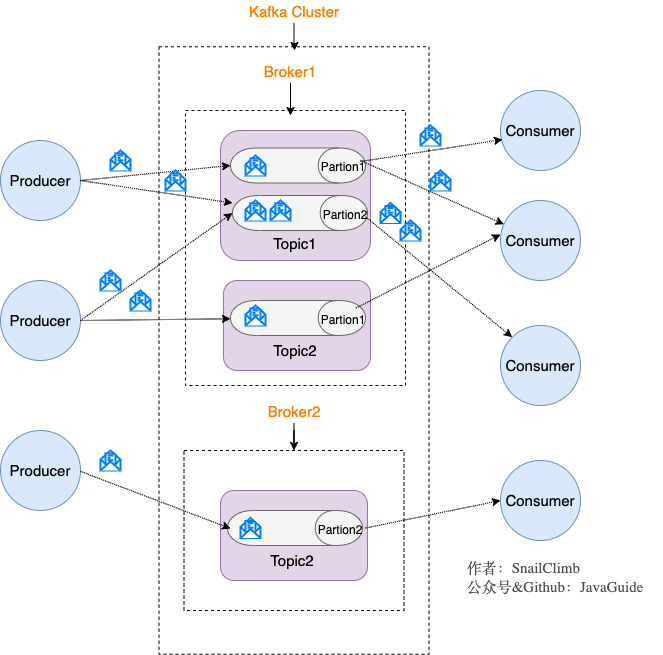
+
+上面这张图也为我们引出了,Kafka 比较重要的几个概念:
+
+1. **Producer(生产者)** : 产生消息的一方。
+2. **Consumer(消费者)** : 消费消息的一方。
+3. **Broker(代理)** : 可以看作是一个独立的 Kafka 实例。多个 Kafka Broker 组成一个 Kafka Cluster。
+
+同时,你一定也注意到每个 Broker 中又包含了 Topic 以及 Partition 这两个重要的概念:
+
+- **Topic(主题)** : Producer 将消息发送到特定的主题,Consumer 通过订阅特定的 Topic(主题) 来消费消息。
+- **Partition(分区)** : Partition 属于 Topic 的一部分。一个 Topic 可以有多个 Partition ,并且同一 Topic 下的 Partition 可以分布在不同的 Broker 上,这也就表明一个 Topic 可以横跨多个 Broker 。这正如我上面所画的图一样。
+
+> 划重点:**Kafka 中的 Partition(分区) 实际上可以对应成为消息队列中的队列。这样是不是更好理解一点?**
+
+### Kafka 的多副本机制了解吗?带来了什么好处?
+
+还有一点我觉得比较重要的是 Kafka 为分区(Partition)引入了多副本(Replica)机制。分区(Partition)中的多个副本之间会有一个叫做 leader 的家伙,其他副本称为 follower。我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。
+
+> 生产者和消费者只与 leader 副本交互。你可以理解为其他副本只是 leader 副本的拷贝,它们的存在只是为了保证消息存储的安全性。当 leader 副本发生故障时会从 follower 中选举出一个 leader,但是 follower 中如果有和 leader 同步程度达不到要求的参加不了 leader 的竞选。
+
+**Kafka 的多分区(Partition)以及多副本(Replica)机制有什么好处呢?**
+
+1. Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力(负载均衡)。
+2. Partition 可以指定对应的 Replica 数, 这也极大地提高了消息存储的安全性, 提高了容灾能力,不过也相应的增加了所需要的存储空间。
+
+### Zookeeper 在 Kafka 中的作用知道吗?
+
+> **要想搞懂 zookeeper 在 Kafka 中的作用 一定要自己搭建一个 Kafka 环境然后自己进 zookeeper 去看一下有哪些文件夹和 Kafka 有关,每个节点又保存了什么信息。** 一定不要光看不实践,这样学来的也终会忘记!这部分内容参考和借鉴了这篇文章:https://www.jianshu.com/p/a036405f989c 。
+
+
+
+下图就是我的本地 Zookeeper ,它成功和我本地的 Kafka 关联上(以下文件夹结构借助 idea 插件 Zookeeper tool 实现)。
+
+ sendResult = kafkaTemplate.send(topic, o).get();
+if (sendResult.getRecordMetadata() != null) {
+ logger.info("生产者成功发送消息到" + sendResult.getProducerRecord().topic() + "-> " + sendRe
+ sult.getProducerRecord().value().toString());
+}
+```
+
+但是一般不推荐这么做!可以采用为其添加回调函数的形式,示例代码如下:
+
+````java
+ ListenableFuture> future = kafkaTemplate.send(topic, o);
+ future.addCallback(result -> logger.info("生产者成功发送消息到topic:{} partition:{}的消息", result.getRecordMetadata().topic(), result.getRecordMetadata().partition()),
+ ex -> logger.error("生产者发送消失败,原因:{}", ex.getMessage()));
+````
+
+如果消息发送失败的话,我们检查失败的原因之后重新发送即可!
+
+**另外这里推荐为 Producer 的`retries `(重试次数)设置一个比较合理的值,一般是 3 ,但是为了保证消息不丢失的话一般会设置比较大一点。设置完成之后,当出现网络问题之后能够自动重试消息发送,避免消息丢失。另外,建议还要设置重试间隔,因为间隔太小的话重试的效果就不明显了,网络波动一次你3次一下子就重试完了**
+
+#### 消费者丢失消息的情况
+
+我们知道消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。偏移量(offset)表示 Consumer 当前消费到的 Partition(分区)的所在的位置。Kafka 通过偏移量(offset)可以保证消息在分区内的顺序性。
+
+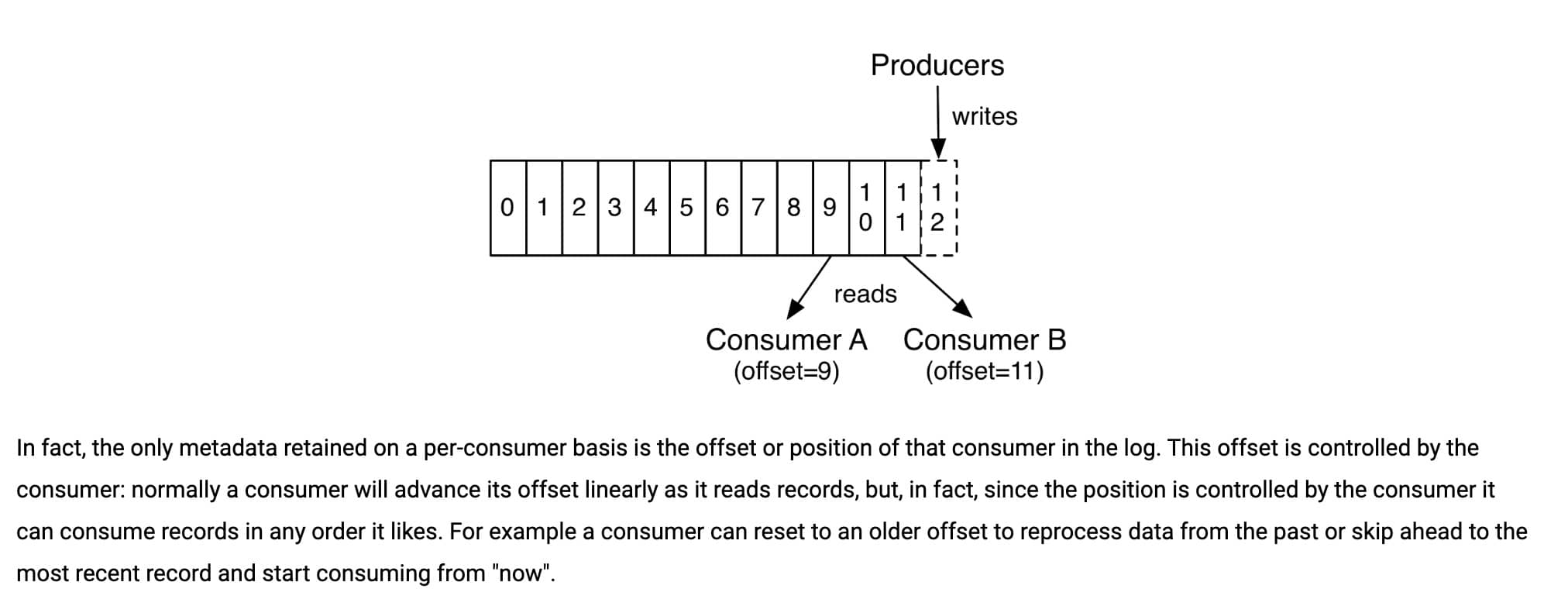
+
+当消费者拉取到了分区的某个消息之后,消费者会自动提交了 offset。自动提交的话会有一个问题,试想一下,当消费者刚拿到这个消息准备进行真正消费的时候,突然挂掉了,消息实际上并没有被消费,但是 offset 却被自动提交了。
+
+**解决办法也比较粗暴,我们手动关闭闭自动提交 offset,每次在真正消费完消息之后之后再自己手动提交 offset 。** 但是,细心的朋友一定会发现,这样会带来消息被重新消费的问题。比如你刚刚消费完消息之后,还没提交 offset,结果自己挂掉了,那么这个消息理论上就会被消费两次。
+
+#### Kafka 弄丢了消息
+
+ 我们知道 Kafka 为分区(Partition)引入了多副本(Replica)机制。分区(Partition)中的多个副本之间会有一个叫做 leader 的家伙,其他副本称为 follower。我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。生产者和消费者只与 leader 副本交互。你可以理解为其他副本只是 leader 副本的拷贝,它们的存在只是为了保证消息存储的安全性。
+
+**试想一种情况:假如 leader 副本所在的 broker 突然挂掉,那么就要从 follower 副本重新选出一个 leader ,但是 leader 的数据还有一些没有被 follower 副本的同步的话,就会造成消息丢失。**
+
+**设置 acks = all**
+
+解决办法就是我们设置 **acks = all**。acks 是 Kafka 生产者(Producer) 很重要的一个参数。
+
+acks 的默认值即为1,代表我们的消息被leader副本接收之后就算被成功发送。当我们配置 **acks = all** 代表则所有副本都要接收到该消息之后该消息才算真正成功被发送。
+
+**设置 replication.factor >= 3**
+
+为了保证 leader 副本能有 follower 副本能同步消息,我们一般会为 topic 设置 **replication.factor >= 3**。这样就可以保证每个 分区(partition) 至少有 3 个副本。虽然造成了数据冗余,但是带来了数据的安全性。
+
+**设置 min.insync.replicas > 1**
+
+一般情况下我们还需要设置 **min.insync.replicas> 1** ,这样配置代表消息至少要被写入到 2 个副本才算是被成功发送。**min.insync.replicas** 的默认值为 1 ,在实际生产中应尽量避免默认值 1。
+
+但是,为了保证整个 Kafka 服务的高可用性,你需要确保 **replication.factor > min.insync.replicas** 。为什么呢?设想一下假如两者相等的话,只要是有一个副本挂掉,整个分区就无法正常工作了。这明显违反高可用性!一般推荐设置成 **replication.factor = min.insync.replicas + 1**。
+
+**设置 unclean.leader.election.enable = false**
+
+> **Kafka 0.11.0.0版本开始 unclean.leader.election.enable 参数的默认值由原来的true 改为false**
+
+我们最开始也说了我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。多个 follower 副本之间的消息同步情况不一样,当我们配置了 **unclean.leader.election.enable = false** 的话,当 leader 副本发生故障时就不会从 follower 副本中和 leader 同步程度达不到要求的副本中选择出 leader ,这样降低了消息丢失的可能性。
+
+### Kafka 如何保证消息不重复消费
+
+代办...
+
+### Reference
+
+- Kafka 官方文档: https://kafka.apache.org/documentation/
+- 极客时间—《Kafka核心技术与实战》第11节:无消息丢失配置怎么实现?
diff --git a/docs/system-design/data-communication/message-queue.md b/docs/system-design/data-communication/message-queue.md
index 3f99c07c..a0db7269 100644
--- a/docs/system-design/data-communication/message-queue.md
+++ b/docs/system-design/data-communication/message-queue.md
@@ -20,47 +20,52 @@
# 消息队列其实很简单
- “RabbitMQ?”“Kafka?”“RocketMQ?”...在日常学习与开发过程中,我们常常听到消息队列这个关键词。我也在我的多篇文章中提到了这个概念。可能你是熟练使用消息队列的老手,又或者你是不懂消息队列的新手,不论你了不了解消息队列,本文都将带你搞懂消息队列的一些基本理论。如果你是老手,你可能从本文学到你之前不曾注意的一些关于消息队列的重要概念,如果你是新手,相信本文将是你打开消息队列大门的一板砖。
+“RabbitMQ?”“Kafka?”“RocketMQ?”...在日常学习与开发过程中,我们常常听到消息队列这个关键词。我也在我的多篇文章中提到了这个概念。可能你是熟练使用消息队列的老手,又或者你是不懂消息队列的新手,不论你了不了解消息队列,本文都将带你搞懂消息队列的一些基本理论。如果你是老手,你可能从本文学到你之前不曾注意的一些关于消息队列的重要概念,如果你是新手,相信本文将是你打开消息队列大门的一板砖。
## 一 什么是消息队列
- 我们可以把消息队列比作是一个存放消息的容器,当我们需要使用消息的时候可以取出消息供自己使用。消息队列是分布式系统中重要的组件,使用消息队列主要是为了通过异步处理提高系统性能和削峰、降低系统耦合性。目前使用较多的消息队列有ActiveMQ,RabbitMQ,Kafka,RocketMQ,我们后面会一一对比这些消息队列。
+我们可以把消息队列比作是一个存放消息的容器,当我们需要使用消息的时候可以取出消息供自己使用。消息队列是分布式系统中重要的组件,使用消息队列主要是为了通过异步处理提高系统性能和削峰、降低系统耦合性。目前使用较多的消息队列有ActiveMQ,RabbitMQ,Kafka,RocketMQ,我们后面会一一对比这些消息队列。
- 另外,我们知道队列 Queue 是一种先进先出的数据结构,所以消费消息时也是按照顺序来消费的。比如生产者发送消息1,2,3...对于消费者就会按照1,2,3...的顺序来消费。但是偶尔也会出现消息被消费的顺序不对的情况,比如某个消息消费失败又或者一个 queue 多个consumer 也会导致消息被消费的顺序不对,我们一定要保证消息被消费的顺序正确。
+另外,我们知道队列 Queue 是一种先进先出的数据结构,所以消费消息时也是按照顺序来消费的。比如生产者发送消息1,2,3...对于消费者就会按照1,2,3...的顺序来消费。但是偶尔也会出现消息被消费的顺序不对的情况,比如某个消息消费失败又或者一个 queue 多个consumer 也会导致消息被消费的顺序不对,我们一定要保证消息被消费的顺序正确。
- 除了上面说的消息消费顺序的问题,使用消息队列,我们还要考虑如何保证消息不被重复消费?如何保证消息的可靠性传输(如何处理消息丢失的问题)?......等等问题。所以说使用消息队列也不是十全十美的,使用它也会让系统可用性降低、复杂度提高,另外需要我们保障一致性等问题。
+除了上面说的消息消费顺序的问题,使用消息队列,我们还要考虑如何保证消息不被重复消费?如何保证消息的可靠性传输(如何处理消息丢失的问题)?......等等问题。所以说使用消息队列也不是十全十美的,使用它也会让系统可用性降低、复杂度提高,另外需要我们保障一致性等问题。
## 二 为什么要用消息队列
- 我觉得使用消息队列主要有两点好处:1.通过异步处理提高系统性能(削峰、减少响应所需时间);2.降低系统耦合性。如果在面试的时候你被面试官问到这个问题的话,一般情况是你在你的简历上涉及到消息队列这方面的内容,这个时候推荐你结合你自己的项目来回答。
+我觉得使用消息队列主要有两点好处:
+
+1. 通过异步处理提高系统性能(削峰、减少响应所需时间)
+2. 降低系统耦合性。
+
+如果在面试的时候你被面试官问到这个问题的话,一般情况是你在你的简历上涉及到消息队列这方面的内容,这个时候推荐你结合你自己的项目来回答。
- 《大型网站技术架构》第四章和第七章均有提到消息队列对应用性能及扩展性的提升。
+《大型网站技术架构》第四章和第七章均有提到消息队列对应用性能及扩展性的提升。
### (1) 通过异步处理提高系统性能(削峰、减少响应所需时间)
- 如上图,**在不使用消息队列服务器的时候,用户的请求数据直接写入数据库,在高并发的情况下数据库压力剧增,使得响应速度变慢。但是在使用消息队列之后,用户的请求数据发送给消息队列之后立即 返回,再由消息队列的消费者进程从消息队列中获取数据,异步写入数据库。由于消息队列服务器处理速度快于数据库(消息队列也比数据库有更好的伸缩性),因此响应速度得到大幅改善。**
+如上图,**在不使用消息队列服务器的时候,用户的请求数据直接写入数据库,在高并发的情况下数据库压力剧增,使得响应速度变慢。但是在使用消息队列之后,用户的请求数据发送给消息队列之后立即返回,再由消息队列的消费者进程从消息队列中获取数据,异步写入数据库。由于消息队列服务器处理速度快于数据库(消息队列也比数据库有更好的伸缩性),因此响应速度得到大幅改善。**
- 通过以上分析我们可以得出**消息队列具有很好的削峰作用的功能**——即**通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。** 举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
+通过以上分析我们可以得出**消息队列具有很好的削峰作用的功能**——即**通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。** 举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:

- 因为**用户请求数据写入消息队列之后就立即返回给用户了,但是请求数据在后续的业务校验、写数据库等操作中可能失败**。因此使用消息队列进行异步处理之后,需要**适当修改业务流程进行配合**,比如**用户在提交订单之后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功**,以免交易纠纷。这就类似我们平时手机订火车票和电影票。
+因为**用户请求数据写入消息队列之后就立即返回给用户了,但是请求数据在后续的业务校验、写数据库等操作中可能失败**。因此使用消息队列进行异步处理之后,需要**适当修改业务流程进行配合**,比如**用户在提交订单之后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功**,以免交易纠纷。这就类似我们平时手机订火车票和电影票。
### (2) 降低系统耦合性
- 使用消息队列还可以降低系统耦合性。我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。还是直接上图吧:
+使用消息队列还可以降低系统耦合性。我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。还是直接上图吧:
- 生产者(客户端)发送消息到消息队列中去,接受者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合, 这显然也提高了系统的扩展性。
+生产者(客户端)发送消息到消息队列中去,接受者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合, 这显然也提高了系统的扩展性。
- **消息队列使利用发布-订阅模式工作,消息发送者(生产者)发布消息,一个或多个消息接受者(消费者)订阅消息。** 从上图可以看到**消息发送者(生产者)和消息接受者(消费者)之间没有直接耦合**,消息发送者将消息发送至分布式消息队列即结束对消息的处理,消息接受者从分布式消息队列获取该消息后进行后续处理,并不需要知道该消息从何而来。**对新增业务,只要对该类消息感兴趣,即可订阅该消息,对原有系统和业务没有任何影响,从而实现网站业务的可扩展性设计**。
+**消息队列使利用发布-订阅模式工作,消息发送者(生产者)发布消息,一个或多个消息接受者(消费者)订阅消息。** 从上图可以看到**消息发送者(生产者)和消息接受者(消费者)之间没有直接耦合**,消息发送者将消息发送至分布式消息队列即结束对消息的处理,消息接受者从分布式消息队列获取该消息后进行后续处理,并不需要知道该消息从何而来。**对新增业务,只要对该类消息感兴趣,即可订阅该消息,对原有系统和业务没有任何影响,从而实现网站业务的可扩展性设计**。
- 消息接受者对消息进行过滤、处理、包装后,构造成一个新的消息类型,将消息继续发送出去,等待其他消息接受者订阅该消息。因此基于事件(消息对象)驱动的业务架构可以是一系列流程。
+消息接受者对消息进行过滤、处理、包装后,构造成一个新的消息类型,将消息继续发送出去,等待其他消息接受者订阅该消息。因此基于事件(消息对象)驱动的业务架构可以是一系列流程。
- **另外为了避免消息队列服务器宕机造成消息丢失,会将成功发送到消息队列的消息存储在消息生产者服务器上,等消息真正被消费者服务器处理后才删除消息。在消息队列服务器宕机后,生产者服务器会选择分布式消息队列服务器集群中的其他服务器发布消息。**
+**另外为了避免消息队列服务器宕机造成消息丢失,会将成功发送到消息队列的消息存储在消息生产者服务器上,等消息真正被消费者服务器处理后才删除消息。在消息队列服务器宕机后,生产者服务器会选择分布式消息队列服务器集群中的其他服务器发布消息。**
**备注:** 不要认为消息队列只能利用发布-订阅模式工作,只不过在解耦这个特定业务环境下是使用发布-订阅模式的。**除了发布-订阅模式,还有点对点订阅模式(一个消息只有一个消费者),我们比较常用的是发布-订阅模式。** 另外,这两种消息模型是 JMS 提供的,AMQP 协议还提供了 5 种消息模型。
@@ -76,7 +81,7 @@
#### 4.1.1 JMS 简介
- JMS(JAVA Message Service,java消息服务)是java的消息服务,JMS的客户端之间可以通过JMS服务进行异步的消息传输。**JMS(JAVA Message Service,Java消息服务)API是一个消息服务的标准或者说是规范**,允许应用程序组件基于JavaEE平台创建、发送、接收和读取消息。它使分布式通信耦合度更低,消息服务更加可靠以及异步性。
+JMS(JAVA Message Service,java消息服务)是java的消息服务,JMS的客户端之间可以通过JMS服务进行异步的消息传输。**JMS(JAVA Message Service,Java消息服务)API是一个消息服务的标准或者说是规范**,允许应用程序组件基于JavaEE平台创建、发送、接收和读取消息。它使分布式通信耦合度更低,消息服务更加可靠以及异步性。
**ActiveMQ 就是基于 JMS 规范实现的。**
@@ -98,7 +103,7 @@
#### 4.1.3 JMS 五种不同的消息正文格式
- JMS定义了五种不同的消息正文格式,以及调用的消息类型,允许你发送并接收以一些不同形式的数据,提供现有消息格式的一些级别的兼容性。
+JMS定义了五种不同的消息正文格式,以及调用的消息类型,允许你发送并接收以一些不同形式的数据,提供现有消息格式的一些级别的兼容性。
- StreamMessage -- Java原始值的数据流
- MapMessage--一套名称-值对
@@ -109,12 +114,10 @@
### 4.2 AMQP
- AMQP,即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准 **高级消息队列协议**(二进制应用层协议),是应用层协议的一个开放标准,为面向消息的中间件设计,兼容 JMS。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件同产品,不同的开发语言等条件的限制。
+AMQP,即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准 **高级消息队列协议**(二进制应用层协议),是应用层协议的一个开放标准,为面向消息的中间件设计,兼容 JMS。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件同产品,不同的开发语言等条件的限制。
**RabbitMQ 就是基于 AMQP 协议实现的。**
-
-
### 4.3 JMS vs AMQP
@@ -151,7 +154,7 @@
- ActiveMQ 的社区算是比较成熟,但是较目前来说,ActiveMQ 的性能比较差,而且版本迭代很慢,不推荐使用。
- RabbitMQ 在吞吐量方面虽然稍逊于 Kafka 和 RocketMQ ,但是由于它基于 erlang 开发,所以并发能力很强,性能极其好,延时很低,达到微秒级。但是也因为 RabbitMQ 基于 erlang 开发,所以国内很少有公司有实力做erlang源码级别的研究和定制。如果业务场景对并发量要求不是太高(十万级、百万级),那这四种消息队列中,RabbitMQ 一定是你的首选。如果是大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的,绝对没问题,社区活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范。
- RocketMQ 阿里出品,Java 系开源项目,源代码我们可以直接阅读,然后可以定制自己公司的MQ,并且 RocketMQ 有阿里巴巴的实际业务场景的实战考验。RocketMQ 社区活跃度相对较为一般,不过也还可以,文档相对来说简单一些,然后接口这块不是按照标准 JMS 规范走的有些系统要迁移需要修改大量代码。还有就是阿里出台的技术,你得做好这个技术万一被抛弃,社区黄掉的风险,那如果你们公司有技术实力我觉得用RocketMQ 挺好的
-- kafka 的特点其实很明显,就是仅仅提供较少的核心功能,但是提供超高的吞吐量,ms 级的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展。同时 kafka 最好是支撑较少的 topic 数量即可,保证其超高吞吐量。kafka 唯一的一点劣势是有可能消息重复消费,那么对数据准确性会造成极其轻微的影响,在大数据领域中以及日志采集中,这点轻微影响可以忽略这个特性天然适合大数据实时计算以及日志收集。
+- Kafka 的特点其实很明显,就是仅仅提供较少的核心功能,但是提供超高的吞吐量,ms 级的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展。同时 kafka 最好是支撑较少的 topic 数量即可,保证其超高吞吐量。kafka 唯一的一点劣势是有可能消息重复消费,那么对数据准确性会造成极其轻微的影响,在大数据领域中以及日志采集中,这点轻微影响可以忽略这个特性天然适合大数据实时计算以及日志收集。
参考:《Java工程师面试突击第1季-中华石杉老师》
diff --git a/docs/system-design/data-communication/rabbitmq.md b/docs/system-design/data-communication/rabbitmq.md
index 28407cce..79f24fdc 100644
--- a/docs/system-design/data-communication/rabbitmq.md
+++ b/docs/system-design/data-communication/rabbitmq.md
@@ -253,7 +253,7 @@ wget https://www.rabbitmq.com/releases/rabbitmq-server/v3.6.8/rabbitmq-server-3.
```
或者直接在官网下载
-https://www.rabbitmq.com/install-rpm.html[enter link description here](https://www.rabbitmq.com/install-rpm.html)
+[https://www.rabbitmq.com/install-rpm.html](https://www.rabbitmq.com/install-rpm.html)
**2. 安装rpm**
diff --git a/docs/system-design/data-communication/summary.md b/docs/system-design/data-communication/summary.md
deleted file mode 100644
index 209df6b6..00000000
--- a/docs/system-design/data-communication/summary.md
+++ /dev/null
@@ -1,100 +0,0 @@
-> ## RPC
-
-**RPC(Remote Procedure Call)—远程过程调用** ,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发分布式程序就像开发本地程序一样简单。
-
-**RPC采用客户端(服务调用方)/服务器端(服务提供方)模式,** 都运行在自己的JVM中。客户端只需要引入要使用的接口,接口的实现和运行都在服务器端。RPC主要依赖的技术包括序列化、反序列化和数据传输协议,这是一种定义与实现相分离的设计。
-
-**目前Java使用比较多的RPC方案主要有RMI(JDK自带)、Hessian、Dubbo以及Thrift等。**
-
-**注意: RPC主要指内部服务之间的调用,RESTful也可以用于内部服务之间的调用,但其主要用途还在于外部系统提供服务,因此没有将其包含在本知识点内。**
-
-### 常见RPC框架:
-
-- **RMI(JDK自带):** JDK自带的RPC
-
- 详细内容可以参考:[从懵逼到恍然大悟之Java中RMI的使用](https://blog.csdn.net/lmy86263/article/details/72594760)
-
-- **Dubbo:** Dubbo是 阿里巴巴公司开源的一个高性能优秀的服务框架,使得应用可通过高性能的 RPC 实现服务的输出和输入功能,可以和 Spring框架无缝集成。
-
- 详细内容可以参考:
-
- - [ 高性能优秀的服务框架-dubbo介绍](https://blog.csdn.net/qq_34337272/article/details/79862899)
-
- - [Dubbo是什么?能做什么?](https://blog.csdn.net/houshaolin/article/details/76408399)
-
-
-- **Hessian:** Hessian是一个轻量级的remotingonhttp工具,使用简单的方法提供了RMI的功能。 相比WebService,Hessian更简单、快捷。采用的是二进制RPC协议,因为采用的是二进制协议,所以它很适合于发送二进制数据。
-
- 详细内容可以参考: [Hessian的使用以及理解](https://blog.csdn.net/sunwei_pyw/article/details/74002351)
-
-- **Thrift:** Apache Thrift是Facebook开源的跨语言的RPC通信框架,目前已经捐献给Apache基金会管理,由于其跨语言特性和出色的性能,在很多互联网公司得到应用,有能力的公司甚至会基于thrift研发一套分布式服务框架,增加诸如服务注册、服务发现等功能。
-
-
- 详细内容可以参考: [【Java】分布式RPC通信框架Apache Thrift 使用总结](https://www.cnblogs.com/zeze/p/8628585.html)
-
-### 如何进行选择:
-
-- **是否允许代码侵入:** 即需要依赖相应的代码生成器生成代码,比如Thrift。
-- **是否需要长连接获取高性能:** 如果对于性能需求较高的haul,那么可以果断选择基于TCP的Thrift、Dubbo。
-- **是否需要跨越网段、跨越防火墙:** 这种情况一般选择基于HTTP协议的Hessian和Thrift的HTTP Transport。
-
-此外,Google推出的基于HTTP2.0的gRPC框架也开始得到应用,其序列化协议基于Protobuf,网络框架使用的是Netty4,但是其需要生成代码,可扩展性也比较差。
-
-> ## 消息中间件
-
-**消息中间件,也可以叫做中央消息队列或者是消息队列(区别于本地消息队列,本地消息队列指的是JVM内的队列实现)**,是一种独立的队列系统,消息中间件经常用来解决内部服务之间的 **异步调用问题** 。请求服务方把请求队列放到队列中即可返回,然后等待服务提供方去队列中获取请求进行处理,之后通过回调等机制把结果返回给请求服务方。
-
-异步调用只是消息中间件一个非常常见的应用场景。此外,常用的消息队列应用场景还有如下几个:
-- **解耦 :** 一个业务的非核心流程需要依赖其他系统,但结果并不重要,有通知即可。
-- **最终一致性 :** 指的是两个系统的状态保持一致,可以有一定的延迟,只要最终达到一致性即可。经常用在解决分布式事务上。
-- **广播 :** 消息队列最基本的功能。生产者只负责生产消息,订阅者接收消息。
-- **错峰和流控**
-
-
-具体可以参考:
-
-[《消息队列深入解析》](https://blog.csdn.net/qq_34337272/article/details/80029918)
-
-当前使用较多的消息队列有ActiveMQ(性能差,不推荐使用)、RabbitMQ、RocketMQ、Kafka等等,我们之前提到的redis数据库也可以实现消息队列,不过不推荐,redis本身设计就不是用来做消息队列的。
-
-- **ActiveMQ:** ActiveMQ是Apache出品,最流行的,能力强劲的开源消息总线。ActiveMQ是一个完全支持JMS1.1和J2EE 1.4规范的JMSProvider实现,尽管JMS规范出台已经是很久的事情了,但是JMS在当今的J2EE应用中间仍然扮演着特殊的地位。
-
- 具体可以参考:
-
- [《消息队列ActiveMQ的使用详解》](https://blog.csdn.net/qq_34337272/article/details/80031702)
-
-- **RabbitMQ:** RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。RabbitMQ 最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性、扩展性、高可用性等方面表现不俗
- > AMQP :Advanced Message Queue,高级消息队列协议。它是应用层协议的一个开放标准,为面向消息的中间件设计,基于此协议的客户端与消息中间件可传递消息,并不受产品、开发语言等条件的限制。
-
-
- 具体可以参考:
-
- [《消息队列之 RabbitMQ》](https://www.jianshu.com/p/79ca08116d57)
-
-- **RocketMQ:**
-
- 具体可以参考:
-
- [《RocketMQ 实战之快速入门》](https://www.jianshu.com/p/824066d70da8)
-
- [《十分钟入门RocketMQ》](http://jm.taobao.org/2017/01/12/rocketmq-quick-start-in-10-minutes/) (阿里中间件团队博客)
-
-
-- **Kafka**:Kafka是一个分布式的、可分区的、可复制的、基于发布/订阅的消息系统(现在官方的描述是“一个分布式流平台”),Kafka主要用于大数据领域,当然在分布式系统中也有应用。目前市面上流行的消息队列RocketMQ就是阿里借鉴Kafka的原理、用Java开发而得。
-
- 具体可以参考:
-
- [《Kafka应用场景》](http://book.51cto.com/art/201801/565244.htm)
-
- [《初谈Kafka》](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484106&idx=1&sn=aa1999895d009d91eb3692a3e6429d18&chksm=fd9854abcaefddbd1101ca5dc2c7c783d7171320d6300d9b2d8e68b7ef8abd2b02ea03e03600#rd)
-
-**推荐阅读:**
-
-[《Kafka、RabbitMQ、RocketMQ等消息中间件的对比 —— 消息发送性能和区别》](https://mp.weixin.qq.com/s?__biz=MzU5OTMyODAyNg==&mid=2247484721&idx=1&sn=11e4e29886e581dd328311d308ccc068&chksm=feb7d144c9c058529465b02a4e26a25ef76b60be8984ace9e4a0f5d3d98ca52e014ecb73b061&scene=21#wechat_redirect)
-
-
-
-
-
-
-
diff --git a/docs/system-design/framework/ZooKeeper.md b/docs/system-design/framework/ZooKeeper.md
deleted file mode 100644
index 4b10ca0c..00000000
--- a/docs/system-design/framework/ZooKeeper.md
+++ /dev/null
@@ -1,185 +0,0 @@
-
-## 前言
-
-相信大家对 ZooKeeper 应该不算陌生。但是你真的了解 ZooKeeper 是个什么东西吗?如果别人/面试官让你给他讲讲 ZooKeeper 是个什么东西,你能回答到什么地步呢?
-
-我本人曾经使用过 ZooKeeper 作为 Dubbo 的注册中心,另外在搭建 solr 集群的时候,我使用到了 ZooKeeper 作为 solr 集群的管理工具。前几天,总结项目经验的时候,我突然问自己 ZooKeeper 到底是个什么东西?想了半天,脑海中只是简单的能浮现出几句话:“①Zookeeper 可以被用作注册中心。 ②Zookeeper 是 Hadoop 生态系统的一员;③构建 Zookeeper 集群的时候,使用的服务器最好是奇数台。” 可见,我对于 Zookeeper 的理解仅仅是停留在了表面。
-
-所以,**通过本文,希望带大家稍微详细的了解一下 ZooKeeper 。如果没有学过 ZooKeeper ,那么本文将会是你进入 ZooKeeper 大门的垫脚砖。如果你已经接触过 ZooKeeper ,那么本文将带你回顾一下 ZooKeeper 的一些基础概念。**
-
-最后,**本文只涉及 ZooKeeper 的一些概念,并不涉及 ZooKeeper 的使用以及 ZooKeeper 集群的搭建。** 网上有介绍 ZooKeeper 的使用以及搭建 ZooKeeper 集群的文章,大家有需要可以自行查阅。
-
-## 一 什么是 ZooKeeper
-
-### ZooKeeper 的由来
-
-**下面这段内容摘自《从Paxos到Zookeeper 》第四章第一节的某段内容,推荐大家阅读以下:**
-
-> Zookeeper最早起源于雅虎研究院的一个研究小组。在当时,研究人员发现,在雅虎内部很多大型系统基本都需要依赖一个类似的系统来进行分布式协调,但是这些系统往往都存在分布式单点问题。所以,**雅虎的开发人员就试图开发一个通用的无单点问题的分布式协调框架,以便让开发人员将精力集中在处理业务逻辑上。**
->
->关于“ZooKeeper”这个项目的名字,其实也有一段趣闻。在立项初期,考虑到之前内部很多项目都是使用动物的名字来命名的(例如著名的Pig项目),雅虎的工程师希望给这个项目也取一个动物的名字。时任研究院的首席科学家RaghuRamakrishnan开玩笑地说:“在这样下去,我们这儿就变成动物园了!”此话一出,大家纷纷表示就叫动物园管理员吧一一一因为各个以动物命名的分布式组件放在一起,**雅虎的整个分布式系统看上去就像一个大型的动物园了,而Zookeeper正好要用来进行分布式环境的协调一一于是,Zookeeper的名字也就由此诞生了。**
-
-
-### 1.1 ZooKeeper 概览
-
-ZooKeeper 是一个开源的分布式协调服务,ZooKeeper框架最初是在“Yahoo!"上构建的,用于以简单而稳健的方式访问他们的应用程序。 后来,Apache ZooKeeper成为Hadoop,HBase和其他分布式框架使用的有组织服务的标准。 例如,Apache HBase使用ZooKeeper跟踪分布式数据的状态。**ZooKeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。**
-
-> **原语:** 操作系统或计算机网络用语范畴。是由若干条指令组成的,用于完成一定功能的一个过程。具有不可分割性·即原语的执行必须是连续的,在执行过程中不允许被中断。
-
-**ZooKeeper 是一个典型的分布式数据一致性解决方案,分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。**
-
-**Zookeeper 一个最常用的使用场景就是用于担任服务生产者和服务消费者的注册中心(提供发布订阅服务)。** 服务生产者将自己提供的服务注册到Zookeeper中心,服务的消费者在进行服务调用的时候先到Zookeeper中查找服务,获取到服务生产者的详细信息之后,再去调用服务生产者的内容与数据。如下图所示,在 Dubbo架构中 Zookeeper 就担任了注册中心这一角色。
-
-
-
-### 1.2 结合个人使用情况的讲一下 ZooKeeper
-
-在我自己做过的项目中,主要使用到了 ZooKeeper 作为 Dubbo 的注册中心(Dubbo 官方推荐使用 ZooKeeper注册中心)。另外在搭建 solr 集群的时候,我使用 ZooKeeper 作为 solr 集群的管理工具。这时,ZooKeeper 主要提供下面几个功能:1、集群管理:容错、负载均衡。2、配置文件的集中管理3、集群的入口。
-
-
-我个人觉得在使用 ZooKeeper 的时候,最好是使用 集群版的 ZooKeeper 而不是单机版的。官网给出的架构图就描述的是一个集群版的 ZooKeeper 。通常 3 台服务器就可以构成一个 ZooKeeper 集群了。
-
-**为什么最好使用奇数台服务器构成 ZooKeeper 集群?**
-
-所谓的zookeeper容错是指,当宕掉几个zookeeper服务器之后,剩下的个数必须大于宕掉的个数的话整个zookeeper才依然可用。假如我们的集群中有n台zookeeper服务器,那么也就是剩下的服务数必须大于n/2。先说一下结论,2n和2n-1的容忍度是一样的,都是n-1,大家可以先自己仔细想一想,这应该是一个很简单的数学问题了。
-比如假如我们有3台,那么最大允许宕掉1台zookeeper服务器,如果我们有4台的的时候也同样只允许宕掉1台。
-假如我们有5台,那么最大允许宕掉2台zookeeper服务器,如果我们有6台的的时候也同样只允许宕掉2台。
-
-综上,何必增加那一个不必要的zookeeper呢?
-
-## 二 关于 ZooKeeper 的一些重要概念
-
-### 2.1 重要概念总结
-
-- **ZooKeeper 本身就是一个分布式程序(只要半数以上节点存活,ZooKeeper 就能正常服务)。**
-- **为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么 ZooKeeper 本身仍然是可用的。**
-- **ZooKeeper 将数据保存在内存中,这也就保证了 高吞吐量和低延迟**(但是内存限制了能够存储的容量不太大,此限制也是保持znode中存储的数据量较小的进一步原因)。
-- **ZooKeeper 是高性能的。 在“读”多于“写”的应用程序中尤其地高性能,因为“写”会导致所有的服务器间同步状态。**(“读”多于“写”是协调服务的典型场景。)
-- **ZooKeeper有临时节点的概念。 当创建临时节点的客户端会话一直保持活动,瞬时节点就一直存在。而当会话终结时,瞬时节点被删除。持久节点是指一旦这个ZNode被创建了,除非主动进行ZNode的移除操作,否则这个ZNode将一直保存在Zookeeper上。**
-- ZooKeeper 底层其实只提供了两个功能:①管理(存储、读取)用户程序提交的数据;②为用户程序提供数据节点监听服务。
-
-**下面关于会话(Session)、 Znode、版本、Watcher、ACL概念的总结都在《从Paxos到Zookeeper 》第四章第一节以及第七章第八节有提到,感兴趣的可以看看!**
-
-### 2.2 会话(Session)
-
-Session 指的是 ZooKeeper 服务器与客户端会话。**在 ZooKeeper 中,一个客户端连接是指客户端和服务器之间的一个 TCP 长连接**。客户端启动的时候,首先会与服务器建立一个 TCP 连接,从第一次连接建立开始,客户端会话的生命周期也开始了。**通过这个连接,客户端能够通过心跳检测与服务器保持有效的会话,也能够向Zookeeper服务器发送请求并接受响应,同时还能够通过该连接接收来自服务器的Watch事件通知。** Session的`sessionTimeout`值用来设置一个客户端会话的超时时间。当由于服务器压力太大、网络故障或是客户端主动断开连接等各种原因导致客户端连接断开时,**只要在`sessionTimeout`规定的时间内能够重新连接上集群中任意一台服务器,那么之前创建的会话仍然有效。**
-
-**在为客户端创建会话之前,服务端首先会为每个客户端都分配一个sessionID。由于 sessionID 是 Zookeeper 会话的一个重要标识,许多与会话相关的运行机制都是基于这个 sessionID 的,因此,无论是哪台服务器为客户端分配的 sessionID,都务必保证全局唯一。**
-
-### 2.3 Znode
-
-**在谈到分布式的时候,我们通常说的“节点"是指组成集群的每一台机器。然而,在Zookeeper中,“节点"分为两类,第一类同样是指构成集群的机器,我们称之为机器节点;第二类则是指数据模型中的数据单元,我们称之为数据节点一一ZNode。**
-
-Zookeeper将所有数据存储在内存中,数据模型是一棵树(Znode Tree),由斜杠(/)的进行分割的路径,就是一个Znode,例如/foo/path1。每个上都会保存自己的数据内容,同时还会保存一系列属性信息。
-
-**在Zookeeper中,node可以分为持久节点和临时节点两类。所谓持久节点是指一旦这个ZNode被创建了,除非主动进行ZNode的移除操作,否则这个ZNode将一直保存在Zookeeper上。而临时节点就不一样了,它的生命周期和客户端会话绑定,一旦客户端会话失效,那么这个客户端创建的所有临时节点都会被移除。** 另外,ZooKeeper还允许用户为每个节点添加一个特殊的属性:**SEQUENTIAL**.一旦节点被标记上这个属性,那么在这个节点被创建的时候,Zookeeper会自动在其节点名后面追加上一个整型数字,这个整型数字是一个由父节点维护的自增数字。
-
-### 2.4 版本
-
-在前面我们已经提到,Zookeeper 的每个 ZNode 上都会存储数据,对应于每个ZNode,Zookeeper 都会为其维护一个叫作 **Stat** 的数据结构,Stat 中记录了这个 ZNode 的三个数据版本,分别是version(当前ZNode的版本)、cversion(当前ZNode子节点的版本)和 aversion(当前ZNode的ACL版本)。
-
-
-### 2.5 Watcher
-
-**Watcher(事件监听器),是Zookeeper中的一个很重要的特性。Zookeeper允许用户在指定节点上注册一些Watcher,并且在一些特定事件触发的时候,ZooKeeper服务端会将事件通知到感兴趣的客户端上去,该机制是Zookeeper实现分布式协调服务的重要特性。**
-
-### 2.6 ACL
-
-Zookeeper采用ACL(AccessControlLists)策略来进行权限控制,类似于 UNIX 文件系统的权限控制。Zookeeper 定义了如下5种权限。
-
-
-
-其中尤其需要注意的是,CREATE和DELETE这两种权限都是针对子节点的权限控制。
-
-## 三 ZooKeeper 特点
-
-- **顺序一致性:** 从同一客户端发起的事务请求,最终将会严格地按照顺序被应用到 ZooKeeper 中去。
-- **原子性:** 所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,也就是说,要么整个集群中所有的机器都成功应用了某一个事务,要么都没有应用。
-- **单一系统映像 :** 无论客户端连到哪一个 ZooKeeper 服务器上,其看到的服务端数据模型都是一致的。
-- **可靠性:** 一旦一次更改请求被应用,更改的结果就会被持久化,直到被下一次更改覆盖。
-
-## 四 ZooKeeper 设计目标
-
-### 4.1 简单的数据模型
-
-ZooKeeper 允许分布式进程通过共享的层次结构命名空间进行相互协调,这与标准文件系统类似。 名称空间由 ZooKeeper 中的数据寄存器组成 - 称为znode,这些类似于文件和目录。 与为存储设计的典型文件系统不同,ZooKeeper数据保存在内存中,这意味着ZooKeeper可以实现高吞吐量和低延迟。
-
-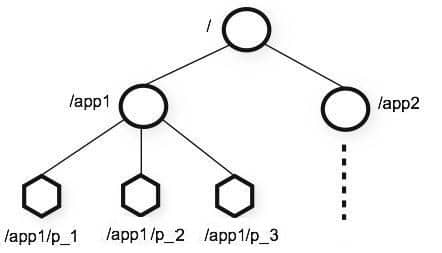
-
-### 4.2 可构建集群
-
-**为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么zookeeper本身仍然是可用的。** 客户端在使用 ZooKeeper 时,需要知道集群机器列表,通过与集群中的某一台机器建立 TCP 连接来使用服务,客户端使用这个TCP链接来发送请求、获取结果、获取监听事件以及发送心跳包。如果这个连接异常断开了,客户端可以连接到另外的机器上。
-
-**ZooKeeper 官方提供的架构图:**
-
-
-
-上图中每一个Server代表一个安装Zookeeper服务的服务器。组成 ZooKeeper 服务的服务器都会在内存中维护当前的服务器状态,并且每台服务器之间都互相保持着通信。集群间通过 Zab 协议(Zookeeper Atomic Broadcast)来保持数据的一致性。
-
-### 4.3 顺序访问
-
-**对于来自客户端的每个更新请求,ZooKeeper 都会分配一个全局唯一的递增编号,这个编号反应了所有事务操作的先后顺序,应用程序可以使用 ZooKeeper 这个特性来实现更高层次的同步原语。** **这个编号也叫做时间戳——zxid(Zookeeper Transaction Id)**
-
-### 4.4 高性能
-
-**ZooKeeper 是高性能的。 在“读”多于“写”的应用程序中尤其地高性能,因为“写”会导致所有的服务器间同步状态。(“读”多于“写”是协调服务的典型场景。)**
-
-## 五 ZooKeeper 集群角色介绍
-
-**最典型集群模式: Master/Slave 模式(主备模式)**。在这种模式中,通常 Master服务器作为主服务器提供写服务,其他的 Slave 服务器从服务器通过异步复制的方式获取 Master 服务器最新的数据提供读服务。
-
-但是,**在 ZooKeeper 中没有选择传统的 Master/Slave 概念,而是引入了Leader、Follower 和 Observer 三种角色**。如下图所示
-
-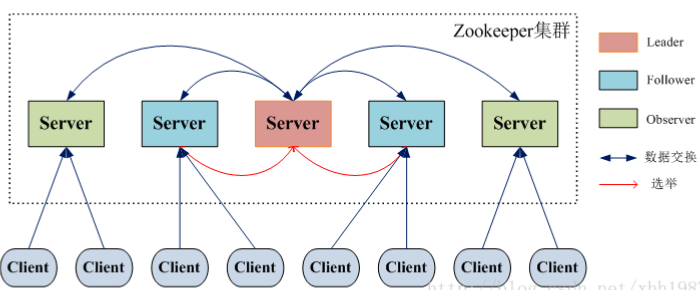
-
- **ZooKeeper 集群中的所有机器通过一个 Leader 选举过程来选定一台称为 “Leader” 的机器,Leader 既可以为客户端提供写服务又能提供读服务。除了 Leader 外,Follower 和 Observer 都只能提供读服务。Follower 和 Observer 唯一的区别在于 Observer 机器不参与 Leader 的选举过程,也不参与写操作的“过半写成功”策略,因此 Observer 机器可以在不影响写性能的情况下提升集群的读性能。**
-
-
-
-**当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进人恢复模式并选举产生新的Leader服务器。这个过程大致是这样的:**
-
-1. Leader election(选举阶段):节点在一开始都处于选举阶段,只要有一个节点得到超半数节点的票数,它就可以当选准 leader。
-2. Discovery(发现阶段):在这个阶段,followers 跟准 leader 进行通信,同步 followers 最近接收的事务提议。
-3. Synchronization(同步阶段):同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后
-准 leader 才会成为真正的 leader。
-4. Broadcast(广播阶段)
-到了这个阶段,Zookeeper 集群才能正式对外提供事务服务,并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
-
-## 六 ZooKeeper &ZAB 协议&Paxos算法
-
-### 6.1 ZAB 协议&Paxos算法
-
-Paxos 算法应该可以说是 ZooKeeper 的灵魂了。但是,ZooKeeper 并没有完全采用 Paxos算法 ,而是使用 ZAB 协议作为其保证数据一致性的核心算法。另外,在ZooKeeper的官方文档中也指出,ZAB协议并不像 Paxos 算法那样,是一种通用的分布式一致性算法,它是一种特别为Zookeeper设计的崩溃可恢复的原子消息广播算法。
-
-### 6.2 ZAB 协议介绍
-
-**ZAB(ZooKeeper Atomic Broadcast 原子广播) 协议是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议。 在 ZooKeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。**
-
-### 6.3 ZAB 协议两种基本的模式:崩溃恢复和消息广播
-
-ZAB协议包括两种基本的模式,分别是 **崩溃恢复和消息广播**。当整个服务框架在启动过程中,或是当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进人恢复模式并选举产生新的Leader服务器。当选举产生了新的 Leader 服务器,同时集群中已经有过半的机器与该Leader服务器完成了状态同步之后,ZAB协议就会退出恢复模式。其中,**所谓的状态同步是指数据同步,用来保证集群中存在过半的机器能够和Leader服务器的数据状态保持一致**。
-
-**当集群中已经有过半的Follower服务器完成了和Leader服务器的状态同步,那么整个服务框架就可以进人消息广播模式了。** 当一台同样遵守ZAB协议的服务器启动后加人到集群中时,如果此时集群中已经存在一个Leader服务器在负责进行消息广播,那么新加人的服务器就会自觉地进人数据恢复模式:找到Leader所在的服务器,并与其进行数据同步,然后一起参与到消息广播流程中去。正如上文介绍中所说的,ZooKeeper设计成只允许唯一的一个Leader服务器来进行事务请求的处理。Leader服务器在接收到客户端的事务请求后,会生成对应的事务提案并发起一轮广播协议;而如果集群中的其他机器接收到客户端的事务请求,那么这些非Leader服务器会首先将这个事务请求转发给Leader服务器。
-
-关于 **ZAB 协议&Paxos算法** 需要讲和理解的东西太多了,说实话,笔主到现在不太清楚这俩兄弟的具体原理和实现过程。推荐阅读下面两篇文章:
-
-- [图解 Paxos 一致性协议](http://codemacro.com/2014/10/15/explain-poxos/)
-- [Zookeeper ZAB 协议分析](https://dbaplus.cn/news-141-1875-1.html)
-
-关于如何使用 zookeeper 实现分布式锁,可以查看下面这篇文章:
-
--
-[10分钟看懂!基于Zookeeper的分布式锁](https://blog.csdn.net/qiangcuo6087/article/details/79067136)
-
-## 六 总结
-
-通过阅读本文,想必大家已从 **①ZooKeeper的由来。** -> **②ZooKeeper 到底是什么 。**-> **③ ZooKeeper 的一些重要概念**(会话(Session)、 Znode、版本、Watcher、ACL)-> **④ZooKeeper 的特点。** -> **⑤ZooKeeper 的设计目标。**-> **⑥ ZooKeeper 集群角色介绍** (Leader、Follower 和 Observer 三种角色)-> **⑦ZooKeeper &ZAB 协议&Paxos算法。** 这七点了解了 ZooKeeper 。
-
-## 参考
-
-- 《从Paxos到Zookeeper 》
-- https://cwiki.apache.org/confluence/display/ZOOKEEPER/ProjectDescription
-- https://cwiki.apache.org/confluence/display/ZOOKEEPER/Index
-- https://www.cnblogs.com/raphael5200/p/5285583.html
-- https://zhuanlan.zhihu.com/p/30024403
-
diff --git a/docs/system-design/framework/ZooKeeper数据模型和常见命令.md b/docs/system-design/framework/ZooKeeper数据模型和常见命令.md
deleted file mode 100644
index eceaf229..00000000
--- a/docs/system-design/framework/ZooKeeper数据模型和常见命令.md
+++ /dev/null
@@ -1,200 +0,0 @@
-
-
-- [ZooKeeper 数据模型](#zookeeper-数据模型)
-- [ZNode\(数据节点\)的结构](#znode数据节点的结构)
-- [测试 ZooKeeper 中的常见操作](#测试-zookeeper-中的常见操作)
- - [连接 ZooKeeper 服务](#连接-zookeeper-服务)
- - [查看常用命令\(help 命令\)](#查看常用命令help-命令)
- - [创建节点\(create 命令\)](#创建节点create-命令)
- - [更新节点数据内容\(set 命令\)](#更新节点数据内容set-命令)
- - [获取节点的数据\(get 命令\)](#获取节点的数据get-命令)
- - [查看某个目录下的子节点\(ls 命令\)](#查看某个目录下的子节点ls-命令)
- - [查看节点状态\(stat 命令\)](#查看节点状态stat-命令)
- - [查看节点信息和状态\(ls2 命令\)](#查看节点信息和状态ls2-命令)
- - [删除节点\(delete 命令\)](#删除节点delete-命令)
-- [参考](#参考)
-
-
-
-> 看本文之前如果你没有安装 ZooKeeper 的话,可以参考这篇文章:[《使用 SpringBoot+Dubbo 搭建一个简单分布式服务》](https://github.com/Snailclimb/springboot-integration-examples/blob/master/md/springboot-dubbo.md) 的 “开始实战 1 :zookeeper 环境安装搭建” 这部分进行安装(Centos7.4 环境下)。如果你想对 ZooKeeper 有一个整体了解的话,可以参考这篇文章:[《可能是把 ZooKeeper 概念讲的最清楚的一篇文章》](https://github.com/Snailclimb/JavaGuide/blob/master/%E4%B8%BB%E6%B5%81%E6%A1%86%E6%9E%B6/ZooKeeper.md)
-
-### ZooKeeper 数据模型
-
-ZNode(数据节点)是 ZooKeeper 中数据的最小单元,每个ZNode上都可以保存数据,同时还是可以有子节点(这就像树结构一样,如下图所示)。可以看出,节点路径标识方式和Unix文件
-系统路径非常相似,都是由一系列使用斜杠"/"进行分割的路径表示,开发人员可以向这个节点中写人数据,也可以在节点下面创建子节点。这些操作我们后面都会介绍到。
-
-
-提到 ZooKeeper 数据模型,还有一个不得不得提的东西就是 **事务 ID** 。事务的ACID(Atomic:原子性;Consistency:一致性;Isolation:隔离性;Durability:持久性)四大特性我在这里就不多说了,相信大家也已经挺腻了。
-
-在Zookeeper中,事务是指能够改变 ZooKeeper 服务器状态的操作,我们也称之为事务操作或更新操作,一般包括数据节点创建与删除、数据节点内容更新和客户端会话创建与失效等操作。**对于每一个事务请求,ZooKeeper 都会为其分配一个全局唯一的事务ID,用 ZXID 来表示**,通常是一个64位的数字。每一个ZXID对应一次更新操作,**从这些 ZXID 中可以间接地识别出Zookeeper处理这些更新操作请求的全局顺序**。
-
-### ZNode(数据节点)的结构
-
-每个 ZNode 由2部分组成:
-
-- stat:状态信息
-- data:数据内容
-
-如下所示,我通过 get 命令来获取 根目录下的 dubbo 节点的内容。(get 命令在下面会介绍到)
-
-```shell
-[zk: 127.0.0.1:2181(CONNECTED) 6] get /dubbo
-# 该数据节点关联的数据内容为空
-null
-# 下面是该数据节点的一些状态信息,其实就是 Stat 对象的格式化输出
-cZxid = 0x2
-ctime = Tue Nov 27 11:05:34 CST 2018
-mZxid = 0x2
-mtime = Tue Nov 27 11:05:34 CST 2018
-pZxid = 0x3
-cversion = 1
-dataVersion = 0
-aclVersion = 0
-ephemeralOwner = 0x0
-dataLength = 0
-numChildren = 1
-
-```
-这些状态信息其实就是 Stat 对象的格式化输出。Stat 类中包含了一个数据节点的所有状态信息的字段,包括事务ID、版本信息和子节点个数等,如下图所示(图源:《从Paxos到Zookeeper 分布式一致性原理与实践》,下面会介绍通过 stat 命令查看数据节点的状态)。
-
-**Stat 类:**
-
-
-
-关于数据节点的状态信息说明(也就是对Stat 类中的各字段进行说明),可以参考下图(图源:《从Paxos到Zookeeper 分布式一致性原理与实践》)。
-
-
-
-### 测试 ZooKeeper 中的常见操作
-
-
-#### 连接 ZooKeeper 服务
-
-进入安装 ZooKeeper文件夹的 bin 目录下执行下面的命令连接 ZooKeeper 服务(Linux环境下)(连接之前首选要确定你的 ZooKeeper 服务已经启动成功)。
-
-```shell
-./zkCli.sh -server 127.0.0.1:2181
-```
-
-
-从上图可以看出控制台打印出了很多信息,包括我们的主机名称、JDK 版本、操作系统等等。如果你成功看到这些信息,说明你成功连接到 ZooKeeper 服务。
-
-#### 查看常用命令(help 命令)
-
-help 命令查看 zookeeper 常用命令
-
-
-
-#### 创建节点(create 命令)
-
-通过 create 命令在根目录创建了node1节点,与它关联的字符串是"node1"
-
-```shell
-[zk: 127.0.0.1:2181(CONNECTED) 34] create /node1 “node1”
-```
-通过 create 命令在根目录创建了node1节点,与它关联的内容是数字 123
-
-```shell
-[zk: 127.0.0.1:2181(CONNECTED) 1] create /node1/node1.1 123
-Created /node1/node1.1
-```
-
-#### 更新节点数据内容(set 命令)
-
-```shell
-[zk: 127.0.0.1:2181(CONNECTED) 11] set /node1 "set node1"
-```
-
-#### 获取节点的数据(get 命令)
-
-get 命令可以获取指定节点的数据内容和节点的状态,可以看出我们通过set 命令已经将节点数据内容改为 "set node1"。
-
-```shell
-set node1
-cZxid = 0x47
-ctime = Sun Jan 20 10:22:59 CST 2019
-mZxid = 0x4b
-mtime = Sun Jan 20 10:41:10 CST 2019
-pZxid = 0x4a
-cversion = 1
-dataVersion = 1
-aclVersion = 0
-ephemeralOwner = 0x0
-dataLength = 9
-numChildren = 1
-
-```
-
-#### 查看某个目录下的子节点(ls 命令)
-
-通过 ls 命令查看根目录下的节点
-
-```shell
-[zk: 127.0.0.1:2181(CONNECTED) 37] ls /
-[dubbo, zookeeper, node1]
-```
-通过 ls 命令查看 node1 目录下的节点
-
-```shell
-[zk: 127.0.0.1:2181(CONNECTED) 5] ls /node1
-[node1.1]
-```
-zookeeper 中的 ls 命令和 linux 命令中的 ls 类似, 这个命令将列出绝对路径path下的所有子节点信息(列出1级,并不递归)
-
-#### 查看节点状态(stat 命令)
-
-通过 stat 命令查看节点状态
-
-```shell
-[zk: 127.0.0.1:2181(CONNECTED) 10] stat /node1
-cZxid = 0x47
-ctime = Sun Jan 20 10:22:59 CST 2019
-mZxid = 0x47
-mtime = Sun Jan 20 10:22:59 CST 2019
-pZxid = 0x4a
-cversion = 1
-dataVersion = 0
-aclVersion = 0
-ephemeralOwner = 0x0
-dataLength = 11
-numChildren = 1
-```
-上面显示的一些信息比如cversion、aclVersion、numChildren等等,我在上面 “ZNode(数据节点)的结构” 这部分已经介绍到。
-
-#### 查看节点信息和状态(ls2 命令)
-
-
-ls2 命令更像是 ls 命令和 stat 命令的结合。ls2 命令返回的信息包括2部分:子节点列表 + 当前节点的stat信息。
-
-```shell
-[zk: 127.0.0.1:2181(CONNECTED) 7] ls2 /node1
-[node1.1]
-cZxid = 0x47
-ctime = Sun Jan 20 10:22:59 CST 2019
-mZxid = 0x47
-mtime = Sun Jan 20 10:22:59 CST 2019
-pZxid = 0x4a
-cversion = 1
-dataVersion = 0
-aclVersion = 0
-ephemeralOwner = 0x0
-dataLength = 11
-numChildren = 1
-
-```
-
-#### 删除节点(delete 命令)
-
-这个命令很简单,但是需要注意的一点是如果你要删除某一个节点,那么这个节点必须无子节点才行。
-
-```shell
-[zk: 127.0.0.1:2181(CONNECTED) 3] delete /node1/node1.1
-```
-
-在后面我会介绍到 Java 客户端 API的使用以及开源 Zookeeper 客户端 ZkClient 和 Curator 的使用。
-
-
-### 参考
-
-- 《从Paxos到Zookeeper 分布式一致性原理与实践》
-
diff --git a/docs/system-design/framework/spring/Spring-Design-Patterns.md b/docs/system-design/framework/spring/Spring-Design-Patterns.md
index 968937f1..b37e318b 100644
--- a/docs/system-design/framework/spring/Spring-Design-Patterns.md
+++ b/docs/system-design/framework/spring/Spring-Design-Patterns.md
@@ -30,7 +30,7 @@ Design Patterns(设计模式) 表示面向对象软件开发中最好的计算
## 控制反转(IoC)和依赖注入(DI)
-**IoC(Inversion of Control,控制翻转)** 是Spring 中一个非常非常重要的概念,它不是什么技术,而是一种解耦的设计思想。它的主要目的是借助于“第三方”(Spring 中的 IOC 容器) 实现具有依赖关系的对象之间的解耦(IOC容易管理对象,你只管使用即可),从而降低代码之间的耦合度。**IOC 是一个原则,而不是一个模式,以下模式(但不限于)实现了IoC原则。**
+**IoC(Inversion of Control,控制反转)** 是Spring 中一个非常非常重要的概念,它不是什么技术,而是一种解耦的设计思想。它的主要目的是借助于“第三方”(Spring 中的 IOC 容器) 实现具有依赖关系的对象之间的解耦(IOC容器管理对象,你只管使用即可),从而降低代码之间的耦合度。**IOC 是一个原则,而不是一个模式,以下模式(但不限于)实现了IoC原则。**
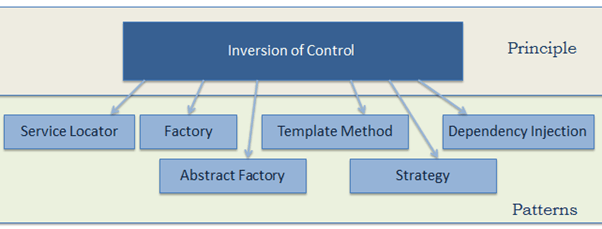
@@ -38,7 +38,7 @@ Design Patterns(设计模式) 表示面向对象软件开发中最好的计算
在实际项目中一个 Service 类如果有几百甚至上千个类作为它的底层,我们需要实例化这个 Service,你可能要每次都要搞清这个 Service 所有底层类的构造函数,这可能会把人逼疯。如果利用 IOC 的话,你只需要配置好,然后在需要的地方引用就行了,这大大增加了项目的可维护性且降低了开发难度。关于Spring IOC 的理解,推荐看这一下知乎的一个回答: ,非常不错。
-**控制翻转怎么理解呢?** 举个例子:"对象a 依赖了对象 b,当对象 a 需要使用 对象 b的时候必须自己去创建。但是当系统引入了 IOC 容器后, 对象a 和对象 b 之前就失去了直接的联系。这个时候,当对象 a 需要使用 对象 b的时候, 我们可以指定 IOC 容器去创建一个对象b注入到对象 a 中"。 对象 a 获得依赖对象 b 的过程,由主动行为变为了被动行为,控制权翻转,这就是控制反转名字的由来。
+**控制反转怎么理解呢?** 举个例子:"对象a 依赖了对象 b,当对象 a 需要使用 对象 b的时候必须自己去创建。但是当系统引入了 IOC 容器后, 对象a 和对象 b 之前就失去了直接的联系。这个时候,当对象 a 需要使用 对象 b的时候, 我们可以指定 IOC 容器去创建一个对象b注入到对象 a 中"。 对象 a 获得依赖对象 b 的过程,由主动行为变为了被动行为,控制权反转,这就是控制反转名字的由来。
**DI(Dependecy Inject,依赖注入)是实现控制反转的一种设计模式,依赖注入就是将实例变量传入到一个对象中去。**
@@ -212,7 +212,7 @@ Spring 中默认存在以下事件,他们都是对 `ApplicationContextEvent`
#### 事件监听者角色
-`ApplicationListener` 充当了事件监听者角色,它是一个接口,里面只定义了一个 `onApplicationEvent()`方法来处理`ApplicationEvent`。`ApplicationListener`接口类源码如下,可以看出接口定义看出接口中的事件只要实现了 `ApplicationEvent`就可以了。所以,在 Spring中我们只要实现 `ApplicationListener` 接口实现 `onApplicationEvent()` 方法即可完成监听事件
+`ApplicationListener` 充当了事件监听者角色,它是一个接口,里面只定义了一个 `onApplicationEvent()`方法来处理`ApplicationEvent`。`ApplicationListener`接口类源码如下,可以看出接口定义看出接口中的事件只要实现了 `ApplicationEvent`就可以了。所以,在 Spring中我们只要实现 `ApplicationListener` 接口的 `onApplicationEvent()` 方法即可完成监听事件
```java
package org.springframework.context;
diff --git a/docs/system-design/framework/spring/Spring.md b/docs/system-design/framework/spring/Spring.md
index 52f195a3..18efadcc 100644
--- a/docs/system-design/framework/spring/Spring.md
+++ b/docs/system-design/framework/spring/Spring.md
@@ -52,13 +52,11 @@ AOP思想的实现一般都是基于 **代理模式** ,在JAVA中一般采用J
### IOC
-Spring IOC的初始化过程:
-
-
- [[Spring框架]Spring IOC的原理及详解。](https://www.cnblogs.com/wang-meng/p/5597490.html)
-
- [Spring IOC核心源码学习](https://yikun.github.io/2015/05/29/Spring-IOC核心源码学习/) :比较简短,推荐阅读。
- [Spring IOC 容器源码分析](https://javadoop.com/post/spring-ioc) :强烈推荐,内容详尽,而且便于阅读。
+- [Bean初始化过程](https://www.qzztf.com/2019/08/21/Bean%E5%88%9D%E5%A7%8B%E5%8C%96/#Bean-%E5%AE%9E%E4%BE%8B%E5%8C%96)
+
## Spring事务管理
diff --git a/docs/system-design/framework/spring/SpringBean.md b/docs/system-design/framework/spring/SpringBean.md
index 4e8279e7..3291e7fa 100644
--- a/docs/system-design/framework/spring/SpringBean.md
+++ b/docs/system-design/framework/spring/SpringBean.md
@@ -177,7 +177,7 @@ public class GiraffeService {
```
-需要注意的是自定义的init-method和post-method方法可以抛异常但是不能有参数。
+需要注意的是自定义的init-method和destroy-method方法可以抛异常但是不能有参数。
这种方式比较推荐,因为可以自己创建方法,无需将Bean的实现直接依赖于spring的框架。
@@ -303,7 +303,7 @@ public class CustomerBeanPostProcessor implements BeanPostProcessor {
- 如果涉及到一些属性值 利用set方法设置一些属性值。
- 如果Bean实现了BeanNameAware接口,调用setBeanName()方法,传入Bean的名字。
- 如果Bean实现了BeanClassLoaderAware接口,调用setBeanClassLoader()方法,传入ClassLoader对象的实例。
-- 如果Bean实现了BeanFactoryAware接口,调用setBeanClassLoader()方法,传入ClassLoader对象的实例。
+- 如果Bean实现了BeanFactoryAware接口,调用setBeanFactory()方法,传入BeanFactory对象的实例。
- 与上面的类似,如果实现了其他*Aware接口,就调用相应的方法。
- 如果有和加载这个Bean的Spring容器相关的BeanPostProcessor对象,执行postProcessBeforeInitialization()方法
- 如果Bean实现了InitializingBean接口,执行afterPropertiesSet()方法。
diff --git a/docs/system-design/framework/spring/SpringInterviewQuestions.md b/docs/system-design/framework/spring/SpringInterviewQuestions.md
index ff49cbbc..401b8255 100644
--- a/docs/system-design/framework/spring/SpringInterviewQuestions.md
+++ b/docs/system-design/framework/spring/SpringInterviewQuestions.md
@@ -54,7 +54,7 @@ Spring 官网列出的 Spring 的 6 个特征:
Reference:
-- https://dzone.com/articles/spring-framework-restcontroller-vs-controller(图片来源)
+- https://dzone.com/articles/spring-framework-restcontroller-vs-controller (图片来源)
- https://javarevisited.blogspot.com/2017/08/difference-between-restcontroller-and-controller-annotations-spring-mvc-rest.html?m=1
## 4. Spring IOC & AOP
@@ -63,7 +63,7 @@ Reference:
#### IoC
-IoC(Inverse of Control:控制反转)是一种**设计思想**,就是 **将原本在程序中手动创建对象的控制权,交由Spring框架来管理。** IoC 在其他语言中也有应用,并非 Spirng 特有。 **IoC 容器是 Spring 用来实现 IoC 的载体, IoC 容器实际上就是个Map(key,value),Map 中存放的是各种对象。**
+IoC(Inverse of Control:控制反转)是一种**设计思想**,就是 **将原本在程序中手动创建对象的控制权,交由Spring框架来管理。** IoC 在其他语言中也有应用,并非 Spring 特有。 **IoC 容器是 Spring 用来实现 IoC 的载体, IoC 容器实际上就是个Map(key,value),Map 中存放的是各种对象。**
将对象之间的相互依赖关系交给 IoC 容器来管理,并由 IoC 容器完成对象的注入。这样可以很大程度上简化应用的开发,把应用从复杂的依赖关系中解放出来。 **IoC 容器就像是一个工厂一样,当我们需要创建一个对象的时候,只需要配置好配置文件/注解即可,完全不用考虑对象是如何被创建出来的。** 在实际项目中一个 Service 类可能有几百甚至上千个类作为它的底层,假如我们需要实例化这个 Service,你可能要每次都要搞清这个 Service 所有底层类的构造函数,这可能会把人逼疯。如果利用 IoC 的话,你只需要配置好,然后在需要的地方引用就行了,这大大增加了项目的可维护性且降低了开发难度。
@@ -170,7 +170,7 @@ public OneService getService(status) {
- `@Component` :通用的注解,可标注任意类为 `Spring` 组件。如果一个Bean不知道属于哪个层,可以使用`@Component` 注解标注。
- `@Repository` : 对应持久层即 Dao 层,主要用于数据库相关操作。
- `@Service` : 对应服务层,主要涉及一些复杂的逻辑,需要用到 Dao层。
-- `@Controller` : 对应 Spring MVC 控制层,主要用户接受用户请求并调用 Service 层返回数据给前端页面。
+- `@Controller` : 对应 Spring MVC 控制层,主要用于接受用户请求并调用 Service 层返回数据给前端页面。
### 5.5 Spring 中的 bean 生命周期?
@@ -203,7 +203,7 @@ public OneService getService(status) {
谈到这个问题,我们不得不提提之前 Model1 和 Model2 这两个没有 Spring MVC 的时代。
-- **Model1 时代** : 很多学 Java 后端比较晚的朋友可能并没有接触过 Model1 模式下的 JavaWeb 应用开发。在 Model1 模式下,整个 Web 应用几乎全部用 JSP 页面组成,只用少量的 JavaBean 来处理数据库连接、访问等操作。这个模式下 JSP 即是控制层又是表现层。显而易见,这种模式存在很多问题。比如①将控制逻辑和表现逻辑混杂在一起,导致代码重用率极低;②前端和后端相互依赖,难以进行测试并且开发效率极低;
+- **Model1 时代** : 很多学 Java 后端比较晚的朋友可能并没有接触过 Model1 模式下的 JavaWeb 应用开发。在 Model1 模式下,整个 Web 应用几乎全部用 JSP 页面组成,只用少量的 JavaBean 来处理数据库连接、访问等操作。这个模式下 JSP 既是控制层又是表现层。显而易见,这种模式存在很多问题。比如①将控制逻辑和表现逻辑混杂在一起,导致代码重用率极低;②前端和后端相互依赖,难以进行测试并且开发效率极低;
- **Model2 时代** :学过 Servlet 并做过相关 Demo 的朋友应该了解“Java Bean(Model)+ JSP(View,)+Servlet(Controller) ”这种开发模式,这就是早期的 JavaWeb MVC 开发模式。Model:系统涉及的数据,也就是 dao 和 bean。View:展示模型中的数据,只是用来展示。Controller:处理用户请求都发送给 ,返回数据给 JSP 并展示给用户。
Model2 模式下还存在很多问题,Model2的抽象和封装程度还远远不够,使用Model2进行开发时不可避免地会重复造轮子,这就大大降低了程序的可维护性和复用性。于是很多JavaWeb开发相关的 MVC 框架应运而生比如Struts2,但是 Struts2 比较笨重。随着 Spring 轻量级开发框架的流行,Spring 生态圈出现了 Spring MVC 框架, Spring MVC 是当前最优秀的 MVC 框架。相比于 Struts2 , Spring MVC 使用更加简单和方便,开发效率更高,并且 Spring MVC 运行速度更快。
@@ -226,7 +226,7 @@ MVC 是一种设计模式,Spring MVC 是一款很优秀的 MVC 框架。Spring M
1. 客户端(浏览器)发送请求,直接请求到 `DispatcherServlet`。
2. `DispatcherServlet` 根据请求信息调用 `HandlerMapping`,解析请求对应的 `Handler`。
3. 解析到对应的 `Handler`(也就是我们平常说的 `Controller` 控制器)后,开始由 `HandlerAdapter` 适配器处理。
-4. `HandlerAdapter` 会根据 `Handler `来调用真正的处理器开处理请求,并处理相应的业务逻辑。
+4. `HandlerAdapter` 会根据 `Handler `来调用真正的处理器来处理请求,并处理相应的业务逻辑。
5. 处理器处理完业务后,会返回一个 `ModelAndView` 对象,`Model` 是返回的数据对象,`View` 是个逻辑上的 `View`。
6. `ViewResolver` 会根据逻辑 `View` 查找实际的 `View`。
7. `DispaterServlet` 把返回的 `Model` 传给 `View`(视图渲染)。
diff --git a/docs/system-design/framework/spring/SpringMVC-Principle.md b/docs/system-design/framework/spring/SpringMVC-Principle.md
index 0efcd3f9..0a2cc5f4 100644
--- a/docs/system-design/framework/spring/SpringMVC-Principle.md
+++ b/docs/system-design/framework/spring/SpringMVC-Principle.md
@@ -46,7 +46,7 @@ SpringMVC 框架是以请求为驱动,围绕 Servlet 设计,将请求发给
**简单来说:**
-客户端发送请求-> 前端控制器 DispatcherServlet 接受客户端请求 -> 找到处理器映射 HandlerMapping 解析请求对应的 Handler-> HandlerAdapter 会根据 Handler 来调用真正的处理器开处理请求,并处理相应的业务逻辑 -> 处理器返回一个模型视图 ModelAndView -> 视图解析器进行解析 -> 返回一个视图对象->前端控制器 DispatcherServlet 渲染数据(Moder)->将得到视图对象返回给用户
+客户端发送请求-> 前端控制器 DispatcherServlet 接受客户端请求 -> 找到处理器映射 HandlerMapping 解析请求对应的 Handler-> HandlerAdapter 会根据 Handler 来调用真正的处理器来处理请求,并处理相应的业务逻辑 -> 处理器返回一个模型视图 ModelAndView -> 视图解析器进行解析 -> 返回一个视图对象->前端控制器 DispatcherServlet 渲染数据(Model)->将得到视图对象返回给用户
diff --git a/docs/system-design/framework/spring/images/spring-transaction/a616b84d-9eea-4ad1-b4fc-461ff05e951d.png b/docs/system-design/framework/spring/images/spring-transaction/a616b84d-9eea-4ad1-b4fc-461ff05e951d.png
new file mode 100644
index 00000000..f99c106a
Binary files /dev/null and b/docs/system-design/framework/spring/images/spring-transaction/a616b84d-9eea-4ad1-b4fc-461ff05e951d.png differ
diff --git a/docs/system-design/framework/spring/images/spring-transaction/ae964c2c-7289-441c-bddd-511161f51ee1.png b/docs/system-design/framework/spring/images/spring-transaction/ae964c2c-7289-441c-bddd-511161f51ee1.png
new file mode 100644
index 00000000..c50b8748
Binary files /dev/null and b/docs/system-design/framework/spring/images/spring-transaction/ae964c2c-7289-441c-bddd-511161f51ee1.png differ
diff --git a/docs/system-design/framework/spring/images/spring-transaction/bda7231b-ab05-4e23-95ee-89ac90ac7fcf.png b/docs/system-design/framework/spring/images/spring-transaction/bda7231b-ab05-4e23-95ee-89ac90ac7fcf.png
new file mode 100644
index 00000000..4232f8b9
Binary files /dev/null and b/docs/system-design/framework/spring/images/spring-transaction/bda7231b-ab05-4e23-95ee-89ac90ac7fcf.png differ
diff --git a/docs/system-design/framework/spring/images/spring-transaction/ed279f05-f5ad-443e-84e9-513a9e777139.png b/docs/system-design/framework/spring/images/spring-transaction/ed279f05-f5ad-443e-84e9-513a9e777139.png
new file mode 100644
index 00000000..d868e051
Binary files /dev/null and b/docs/system-design/framework/spring/images/spring-transaction/ed279f05-f5ad-443e-84e9-513a9e777139.png differ
diff --git a/docs/system-design/framework/spring/images/spring-transaction/f6c6f0aa-0f26-49e1-84b3-7f838c7379d1.png b/docs/system-design/framework/spring/images/spring-transaction/f6c6f0aa-0f26-49e1-84b3-7f838c7379d1.png
new file mode 100644
index 00000000..d6b83731
Binary files /dev/null and b/docs/system-design/framework/spring/images/spring-transaction/f6c6f0aa-0f26-49e1-84b3-7f838c7379d1.png differ
diff --git a/docs/system-design/framework/spring/spring-annotations.md b/docs/system-design/framework/spring/spring-annotations.md
new file mode 100644
index 00000000..610c0908
--- /dev/null
+++ b/docs/system-design/framework/spring/spring-annotations.md
@@ -0,0 +1,1009 @@
+
+### 文章目录
+
+
+- [文章目录](#%e6%96%87%e7%ab%a0%e7%9b%ae%e5%bd%95)
+- [0.前言](#0%e5%89%8d%e8%a8%80)
+- [1. `@SpringBootApplication`](#1-springbootapplication)
+- [2. Spring Bean 相关](#2-spring-bean-%e7%9b%b8%e5%85%b3)
+ - [2.1. `@Autowired`](#21-autowired)
+ - [2.2. `@Component`,`@Repository`,`@Service`, `@Controller`](#22-componentrepositoryservice-controller)
+ - [2.3. `@RestController`](#23-restcontroller)
+ - [2.4. `@Scope`](#24-scope)
+ - [2.5. `@Configuration`](#25-configuration)
+- [3. 处理常见的 HTTP 请求类型](#3-%e5%a4%84%e7%90%86%e5%b8%b8%e8%a7%81%e7%9a%84-http-%e8%af%b7%e6%b1%82%e7%b1%bb%e5%9e%8b)
+ - [3.1. GET 请求](#31-get-%e8%af%b7%e6%b1%82)
+ - [3.2. POST 请求](#32-post-%e8%af%b7%e6%b1%82)
+ - [3.3. PUT 请求](#33-put-%e8%af%b7%e6%b1%82)
+ - [3.4. **DELETE 请求**](#34-delete-%e8%af%b7%e6%b1%82)
+ - [3.5. **PATCH 请求**](#35-patch-%e8%af%b7%e6%b1%82)
+- [4. 前后端传值](#4-%e5%89%8d%e5%90%8e%e7%ab%af%e4%bc%a0%e5%80%bc)
+ - [4.1. `@PathVariable` 和 `@RequestParam`](#41-pathvariable-%e5%92%8c-requestparam)
+ - [4.2. `@RequestBody`](#42-requestbody)
+- [5. 读取配置信息](#5-%e8%af%bb%e5%8f%96%e9%85%8d%e7%bd%ae%e4%bf%a1%e6%81%af)
+ - [5.1. `@value`(常用)](#51-value%e5%b8%b8%e7%94%a8)
+ - [5.2. `@ConfigurationProperties`(常用)](#52-configurationproperties%e5%b8%b8%e7%94%a8)
+ - [5.3. `PropertySource`(不常用)](#53-propertysource%e4%b8%8d%e5%b8%b8%e7%94%a8)
+- [6. 参数校验](#6-%e5%8f%82%e6%95%b0%e6%a0%a1%e9%aa%8c)
+ - [6.1. 一些常用的字段验证的注解](#61-%e4%b8%80%e4%ba%9b%e5%b8%b8%e7%94%a8%e7%9a%84%e5%ad%97%e6%ae%b5%e9%aa%8c%e8%af%81%e7%9a%84%e6%b3%a8%e8%a7%a3)
+ - [6.2. 验证请求体(RequestBody)](#62-%e9%aa%8c%e8%af%81%e8%af%b7%e6%b1%82%e4%bd%93requestbody)
+ - [6.3. 验证请求参数(Path Variables 和 Request Parameters)](#63-%e9%aa%8c%e8%af%81%e8%af%b7%e6%b1%82%e5%8f%82%e6%95%b0path-variables-%e5%92%8c-request-parameters)
+- [7. 全局处理 Controller 层异常](#7-%e5%85%a8%e5%b1%80%e5%a4%84%e7%90%86-controller-%e5%b1%82%e5%bc%82%e5%b8%b8)
+- [8. JPA 相关](#8-jpa-%e7%9b%b8%e5%85%b3)
+ - [8.1. 创建表](#81-%e5%88%9b%e5%bb%ba%e8%a1%a8)
+ - [8.2. 创建主键](#82-%e5%88%9b%e5%bb%ba%e4%b8%bb%e9%94%ae)
+ - [8.3. 设置字段类型](#83-%e8%ae%be%e7%bd%ae%e5%ad%97%e6%ae%b5%e7%b1%bb%e5%9e%8b)
+ - [8.4. 指定不持久化特定字段](#84-%e6%8c%87%e5%ae%9a%e4%b8%8d%e6%8c%81%e4%b9%85%e5%8c%96%e7%89%b9%e5%ae%9a%e5%ad%97%e6%ae%b5)
+ - [8.5. 声明大字段](#85-%e5%a3%b0%e6%98%8e%e5%a4%a7%e5%ad%97%e6%ae%b5)
+ - [8.6. 创建枚举类型的字段](#86-%e5%88%9b%e5%bb%ba%e6%9e%9a%e4%b8%be%e7%b1%bb%e5%9e%8b%e7%9a%84%e5%ad%97%e6%ae%b5)
+ - [8.7. 增加审计功能](#87-%e5%a2%9e%e5%8a%a0%e5%ae%a1%e8%ae%a1%e5%8a%9f%e8%83%bd)
+ - [8.8. 删除/修改数据](#88-%e5%88%a0%e9%99%a4%e4%bf%ae%e6%94%b9%e6%95%b0%e6%8d%ae)
+ - [8.9. 关联关系](#89-%e5%85%b3%e8%81%94%e5%85%b3%e7%b3%bb)
+- [9. 事务 `@Transactional`](#9-%e4%ba%8b%e5%8a%a1-transactional)
+- [10. json 数据处理](#10-json-%e6%95%b0%e6%8d%ae%e5%a4%84%e7%90%86)
+ - [10.1. 过滤 json 数据](#101-%e8%bf%87%e6%bb%a4-json-%e6%95%b0%e6%8d%ae)
+ - [10.2. 格式化 json 数据](#102-%e6%a0%bc%e5%bc%8f%e5%8c%96-json-%e6%95%b0%e6%8d%ae)
+ - [10.3. 扁平化对象](#103-%e6%89%81%e5%b9%b3%e5%8c%96%e5%af%b9%e8%b1%a1)
+- [11. 测试相关](#11-%e6%b5%8b%e8%af%95%e7%9b%b8%e5%85%b3)
+
+
+### 0.前言
+
+_大家好,我是 Guide 哥!这是我的 221 篇优质原创文章。如需转载,请在文首注明地址,蟹蟹!_
+
+本文已经收录进我的 75K Star 的 Java 开源项目 JavaGuide:[https://github.com/Snailclimb/JavaGuide](https://github.com/Snailclimb/JavaGuide)。
+
+可以毫不夸张地说,这篇文章介绍的 Spring/SpringBoot 常用注解基本已经涵盖你工作中遇到的大部分常用的场景。对于每一个注解我都说了具体用法,掌握搞懂,使用 SpringBoot 来开发项目基本没啥大问题了!
+
+**为什么要写这篇文章?**
+
+最近看到网上有一篇关于 SpringBoot 常用注解的文章被转载的比较多,我看了文章内容之后属实觉得质量有点低,并且有点会误导没有太多实际使用经验的人(这些人又占据了大多数)。所以,自己索性花了大概 两天时间简单总结一下了。
+
+**因为我个人的能力和精力有限,如果有任何不对或者需要完善的地方,请帮忙指出!Guide 哥感激不尽!**
+
+### 1. `@SpringBootApplication`
+
+这里先单独拎出`@SpringBootApplication` 注解说一下,虽然我们一般不会主动去使用它。
+
+_Guide 哥:这个注解是 Spring Boot 项目的基石,创建 SpringBoot 项目之后会默认在主类加上。_
+
+```java
+@SpringBootApplication
+public class SpringSecurityJwtGuideApplication {
+ public static void main(java.lang.String[] args) {
+ SpringApplication.run(SpringSecurityJwtGuideApplication.class, args);
+ }
+}
+```
+
+我们可以把 `@SpringBootApplication`看作是 `@Configuration`、`@EnableAutoConfiguration`、`@ComponentScan` 注解的集合。
+
+```java
+package org.springframework.boot.autoconfigure;
+@Target(ElementType.TYPE)
+@Retention(RetentionPolicy.RUNTIME)
+@Documented
+@Inherited
+@SpringBootConfiguration
+@EnableAutoConfiguration
+@ComponentScan(excludeFilters = {
+ @Filter(type = FilterType.CUSTOM, classes = TypeExcludeFilter.class),
+ @Filter(type = FilterType.CUSTOM, classes = AutoConfigurationExcludeFilter.class) })
+public @interface SpringBootApplication {
+ ......
+}
+
+package org.springframework.boot;
+@Target(ElementType.TYPE)
+@Retention(RetentionPolicy.RUNTIME)
+@Documented
+@Configuration
+public @interface SpringBootConfiguration {
+
+}
+```
+
+根据 SpringBoot 官网,这三个注解的作用分别是:
+
+- `@EnableAutoConfiguration`:启用 SpringBoot 的自动配置机制
+- `@ComponentScan`: 扫描被`@Component` (`@Service`,`@Controller`)注解的 bean,注解默认会扫描该类所在的包下所有的类。
+- `@Configuration`:允许在 Spring 上下文中注册额外的 bean 或导入其他配置类
+
+### 2. Spring Bean 相关
+
+#### 2.1. `@Autowired`
+
+自动导入对象到类中,被注入进的类同样要被 Spring 容器管理比如:Service 类注入到 Controller 类中。
+
+```java
+@Service
+public class UserService {
+ ......
+}
+
+@RestController
+@RequestMapping("/users")
+public class UserController {
+ @Autowired
+ private UserService userService;
+ ......
+}
+```
+
+#### 2.2. `@Component`,`@Repository`,`@Service`, `@Controller`
+
+我们一般使用 `@Autowired` 注解让 Spring 容器帮我们自动装配 bean。要想把类标识成可用于 `@Autowired` 注解自动装配的 bean 的类,可以采用以下注解实现:
+
+- `@Component` :通用的注解,可标注任意类为 `Spring` 组件。如果一个 Bean 不知道属于哪个层,可以使用`@Component` 注解标注。
+- `@Repository` : 对应持久层即 Dao 层,主要用于数据库相关操作。
+- `@Service` : 对应服务层,主要涉及一些复杂的逻辑,需要用到 Dao 层。
+- `@Controller` : 对应 Spring MVC 控制层,主要用于接受用户请求并调用 Service 层返回数据给前端页面。
+
+#### 2.3. `@RestController`
+
+`@RestController`注解是`@Controller和`@`ResponseBody`的合集,表示这是个控制器 bean,并且是将函数的返回值直 接填入 HTTP 响应体中,是 REST 风格的控制器。
+
+_Guide 哥:现在都是前后端分离,说实话我已经很久没有用过`@Controller`。如果你的项目太老了的话,就当我没说。_
+
+单独使用 `@Controller` 不加 `@ResponseBody`的话一般使用在要返回一个视图的情况,这种情况属于比较传统的 Spring MVC 的应用,对应于前后端不分离的情况。`@Controller` +`@ResponseBody` 返回 JSON 或 XML 形式数据
+
+关于`@RestController` 和 `@Controller`的对比,请看这篇文章:[@RestController vs @Controller](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485544&idx=1&sn=3cc95b88979e28fe3bfe539eb421c6d8&chksm=cea247a3f9d5ceb5e324ff4b8697adc3e828ecf71a3468445e70221cce768d1e722085359907&token=1725092312&lang=zh_CN#rd)。
+
+#### 2.4. `@Scope`
+
+声明 Spring Bean 的作用域,使用方法:
+
+```java
+@Bean
+@Scope("singleton")
+public Person personSingleton() {
+ return new Person();
+}
+```
+
+**四种常见的 Spring Bean 的作用域:**
+
+- singleton : 唯一 bean 实例,Spring 中的 bean 默认都是单例的。
+- prototype : 每次请求都会创建一个新的 bean 实例。
+- request : 每一次 HTTP 请求都会产生一个新的 bean,该 bean 仅在当前 HTTP request 内有效。
+- session : 每一次 HTTP 请求都会产生一个新的 bean,该 bean 仅在当前 HTTP session 内有效。
+
+#### 2.5. `@Configuration`
+
+一般用来声明配置类,可以使用 `@Component`注解替代,不过使用`@Configuration`注解声明配置类更加语义化。
+
+```java
+@Configuration
+public class AppConfig {
+ @Bean
+ public TransferService transferService() {
+ return new TransferServiceImpl();
+ }
+
+}
+```
+
+### 3. 处理常见的 HTTP 请求类型
+
+**5 种常见的请求类型:**
+
+- **GET** :请求从服务器获取特定资源。举个例子:`GET /users`(获取所有学生)
+- **POST** :在服务器上创建一个新的资源。举个例子:`POST /users`(创建学生)
+- **PUT** :更新服务器上的资源(客户端提供更新后的整个资源)。举个例子:`PUT /users/12`(更新编号为 12 的学生)
+- **DELETE** :从服务器删除特定的资源。举个例子:`DELETE /users/12`(删除编号为 12 的学生)
+- **PATCH** :更新服务器上的资源(客户端提供更改的属性,可以看做作是部分更新),使用的比较少,这里就不举例子了。
+
+#### 3.1. GET 请求
+
+`@GetMapping("users")` 等价于`@RequestMapping(value="/users",method=RequestMethod.GET)`
+
+```java
+@GetMapping("/users")
+public ResponseEntity> getAllUsers() {
+ return userRepository.findAll();
+}
+```
+
+#### 3.2. POST 请求
+
+`@PostMapping("users")` 等价于`@RequestMapping(value="/users",method=RequestMethod.POST)`
+
+关于`@RequestBody`注解的使用,在下面的“前后端传值”这块会讲到。
+
+```java
+@PostMapping("/users")
+public ResponseEntity
 -
-
-
- +
+  +
+  +
+  -
-
 +
+
+
+  @@ -461,12 +502,12 @@ Markdown 格式参考:[Github Markdown格式](https://guides.github.com/featur
@@ -461,12 +502,12 @@ Markdown 格式参考:[Github Markdown格式](https://guides.github.com/featur
 -### 公众号
+## 公众号
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
+**《Java 面试突击》:** 由本文档衍生的专为面试而生的《Java 面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java 面试突击"** 即可免费领取!
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
+**Java 工程师必备学习资源:** 一些 Java 工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
-
+
\ No newline at end of file
diff --git a/_coverpage.md b/_coverpage.md
index 9e45fbab..7310181a 100644
--- a/_coverpage.md
+++ b/_coverpage.md
@@ -1,13 +1,12 @@
-### 公众号
+## 公众号
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
+**《Java 面试突击》:** 由本文档衍生的专为面试而生的《Java 面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java 面试突击"** 即可免费领取!
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
+**Java 工程师必备学习资源:** 一些 Java 工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
-
+
\ No newline at end of file
diff --git a/_coverpage.md b/_coverpage.md
index 9e45fbab..7310181a 100644
--- a/_coverpage.md
+++ b/_coverpage.md
@@ -1,13 +1,12 @@
 +
+ +
+**[我的第一本算法书](https://book.douban.com/subject/30357170/) (豆瓣评分 7.1,0.2K+人评价)**
+
+一本不那么“专业”的算法书籍。和下面两本推荐的算法书籍都是比较通俗易懂,“不那么深入”的算法书籍。我个人非常推荐,配图和讲解都非常不错!
+
+
+
+**[我的第一本算法书](https://book.douban.com/subject/30357170/) (豆瓣评分 7.1,0.2K+人评价)**
+
+一本不那么“专业”的算法书籍。和下面两本推荐的算法书籍都是比较通俗易懂,“不那么深入”的算法书籍。我个人非常推荐,配图和讲解都非常不错!
+
+ +
+**[《算法图解》](https://book.douban.com/subject/26979890/)(豆瓣评分 8.4,1.5K+人评价)**
+
+入门类型的书籍,读起来比较浅显易懂,非常适合没有算法基础或者说算法没学好的小伙伴用来入门。示例丰富,图文并茂,以让人容易理解的方式阐释了算法.读起来比较快,内容不枯燥!
+
+
+
+**[啊哈!算法](https://book.douban.com/subject/25894685/) (豆瓣评分 7.7,0.5K+人评价)**
+
+和《算法图解》类似的算法趣味入门书籍。
+
+### 经典
+
+
+
+**[《算法图解》](https://book.douban.com/subject/26979890/)(豆瓣评分 8.4,1.5K+人评价)**
+
+入门类型的书籍,读起来比较浅显易懂,非常适合没有算法基础或者说算法没学好的小伙伴用来入门。示例丰富,图文并茂,以让人容易理解的方式阐释了算法.读起来比较快,内容不枯燥!
+
+
+
+**[啊哈!算法](https://book.douban.com/subject/25894685/) (豆瓣评分 7.7,0.5K+人评价)**
+
+和《算法图解》类似的算法趣味入门书籍。
+
+### 经典
+
+ +
+**[《算法 第四版》](https://book.douban.com/subject/10432347/)(豆瓣评分 9.3,0.4K+人评价)**
+
+我在大二的时候被我们的一个老师强烈安利过!自己也在当时购买了一本放在宿舍,到离开大学的时候自己大概看了一半多一点。因为内容实在太多了!另外,这本书还提供了详细的Java代码,非常适合学习 Java 的朋友来看,可以说是 Java 程序员的必备书籍之一了。
+
+再来介绍一下这本书籍吧!这本书籍算的上是算法领域经典的参考书,全面介绍了关于算法和数据结构的必备知识,并特别针对排序、搜索、图处理和字符串处理进行了论述。
+
+> **下面这些书籍都是经典中的经典,但是阅读起来难度也比较大,不做太多阐述,神书就完事了!推荐先看 《算法》,然后再选下面的书籍进行进一步阅读。不需要都看,找一本好好看或者找某本书的某一个章节知识点好好看。**
+
+
+
+**[《算法 第四版》](https://book.douban.com/subject/10432347/)(豆瓣评分 9.3,0.4K+人评价)**
+
+我在大二的时候被我们的一个老师强烈安利过!自己也在当时购买了一本放在宿舍,到离开大学的时候自己大概看了一半多一点。因为内容实在太多了!另外,这本书还提供了详细的Java代码,非常适合学习 Java 的朋友来看,可以说是 Java 程序员的必备书籍之一了。
+
+再来介绍一下这本书籍吧!这本书籍算的上是算法领域经典的参考书,全面介绍了关于算法和数据结构的必备知识,并特别针对排序、搜索、图处理和字符串处理进行了论述。
+
+> **下面这些书籍都是经典中的经典,但是阅读起来难度也比较大,不做太多阐述,神书就完事了!推荐先看 《算法》,然后再选下面的书籍进行进一步阅读。不需要都看,找一本好好看或者找某本书的某一个章节知识点好好看。**
+
+ +
+**[编程珠玑](https://book.douban.com/subject/3227098/)(豆瓣评分 9.1,2K+人评价)**
+
+经典名著,被无数读者强烈推荐的书籍,几乎是顶级程序员必看的书籍之一了。这本书的作者也非常厉害,Java之父 James Gosling 就是他的学生。
+
+很多人都说这本书不是教你具体的算法,而是教你一种编程的思考方式。这种思考方式不仅仅在编程领域适用,在其他同样适用。
+
+
+
+
+
+**[编程珠玑](https://book.douban.com/subject/3227098/)(豆瓣评分 9.1,2K+人评价)**
+
+经典名著,被无数读者强烈推荐的书籍,几乎是顶级程序员必看的书籍之一了。这本书的作者也非常厉害,Java之父 James Gosling 就是他的学生。
+
+很多人都说这本书不是教你具体的算法,而是教你一种编程的思考方式。这种思考方式不仅仅在编程领域适用,在其他同样适用。
+
+
+
+ +
+**[《算法设计手册》](https://book.douban.com/subject/4048566/)(豆瓣评分9.1 , 45人评价)**
+
+被 [Teach Yourself Computer Science](https://teachyourselfcs.com/) 强烈推荐的一本算法书籍。
+
+
+
+**[《算法设计手册》](https://book.douban.com/subject/4048566/)(豆瓣评分9.1 , 45人评价)**
+
+被 [Teach Yourself Computer Science](https://teachyourselfcs.com/) 强烈推荐的一本算法书籍。
+
+ +
+**[《算法导论》](https://book.douban.com/subject/20432061/) (豆瓣评分 9.2,0.4K+人评价)**
+
+
+
+**[《计算机程序设计艺术(第1卷)》](https://book.douban.com/subject/1130500/)(豆瓣评分 9.4,0.4K+人评价)**
+
+### 面试
+
+
+
+**[《剑指Offer》](https://book.douban.com/subject/6966465/)(豆瓣评分 8.3,0.7K+人评价)**
+
+这本面试宝典上面涵盖了很多经典的算法面试题,如果你要准备大厂面试的话一定不要错过这本书。
+
+《剑指Offer》 对应的算法编程题部分的开源项目解析:[CodingInterviews](https://github.com/gatieme/CodingInterviews)
+
+
+
+
+
+
+
+**[《算法导论》](https://book.douban.com/subject/20432061/) (豆瓣评分 9.2,0.4K+人评价)**
+
+
+
+**[《计算机程序设计艺术(第1卷)》](https://book.douban.com/subject/1130500/)(豆瓣评分 9.4,0.4K+人评价)**
+
+### 面试
+
+
+
+**[《剑指Offer》](https://book.douban.com/subject/6966465/)(豆瓣评分 8.3,0.7K+人评价)**
+
+这本面试宝典上面涵盖了很多经典的算法面试题,如果你要准备大厂面试的话一定不要错过这本书。
+
+《剑指Offer》 对应的算法编程题部分的开源项目解析:[CodingInterviews](https://github.com/gatieme/CodingInterviews)
+
+
+
+
+
+ +
+**[程序员代码面试指南:IT名企算法与数据结构题目最优解(第2版)](https://book.douban.com/subject/30422021/) (豆瓣评分 8.7,0.2K+人评价)**
+
+题目相比于《剑指 offer》 来说要难很多,题目涵盖面相比于《剑指 offer》也更加全面。全书一共有将近300道真实出现过的经典代码面试题。
+
+
+
+
+
+**[程序员代码面试指南:IT名企算法与数据结构题目最优解(第2版)](https://book.douban.com/subject/30422021/) (豆瓣评分 8.7,0.2K+人评价)**
+
+题目相比于《剑指 offer》 来说要难很多,题目涵盖面相比于《剑指 offer》也更加全面。全书一共有将近300道真实出现过的经典代码面试题。
+
+
+
+ +
+
+
+**[编程之美](https://book.douban.com/subject/3004255/)(豆瓣评分 8.4,3K+人评价)**
+
+这本书收集了约60道算法和程序设计题目,这些题目大部分在近年的笔试、面试中出现过,或者是被微软员工热烈讨论过。作者试图从书中各种有趣的问题出发,引导读者发现问题,分析问题,解决问题,寻找更优的解法。
+
+## 网站推荐
+
我比较推荐大家可以刷一下 Leetcode ,我自己平时没事也会刷一下,我觉得刷 Leetcode 不仅是为了能让你更从容地面对面试中的手撕算法问题,更可以提高你的编程思维能力、解决问题的能力以及你对某门编程语言 API 的熟练度。当然牛客网也有一些算法题,我下面也整理了一些。
-## LeetCode
+### [LeetCode](https://leetcode-cn.com/)
-- [LeetCode(中国)官网](https://leetcode-cn.com/)
+[如何高效地使用 LeetCode](https://leetcode-cn.com/articles/%E5%A6%82%E4%BD%95%E9%AB%98%E6%95%88%E5%9C%B0%E4%BD%BF%E7%94%A8-leetcode/)
-- [如何高效地使用 LeetCode](https://leetcode-cn.com/articles/%E5%A6%82%E4%BD%95%E9%AB%98%E6%95%88%E5%9C%B0%E4%BD%BF%E7%94%A8-leetcode/)
+- [《程序员代码面试指南》](https://leetcode-cn.com/problemset/lcci/)
+- [《剑指offer》](https://leetcode-cn.com/problemset/lcof/)
-## 牛客网
+### [牛客网](https://www.nowcoder.com)
+
+**[在线编程](https://www.nowcoder.com/activity/oj):**
+
+- [《剑指offer》](https://www.nowcoder.com/ta/coding-interviews)
+- [《程序员代码面试指南》](https://www.nowcoder.com/ta/programmer-code-interview-guide)
+- [2019 校招真题](https://www.nowcoder.com/ta/2019test)
+- [大一大二编程入门训练](https://www.nowcoder.com/ta/beginner-programmers)
+- .......
+
+**[大厂编程面试真题](https://www.nowcoder.com/contestRoom?filter=0&orderByHotValue=3&target=content&categories=-1&mutiTagIds=2491&page=1)**
+
-- [牛客网官网](https://www.nowcoder.com)
-- [剑指offer编程题](https://www.nowcoder.com/ta/coding-interviews)
-- [2017校招真题](https://www.nowcoder.com/ta/2017test)
-- [华为机试题](https://www.nowcoder.com/ta/huawei)
-
-## 公司真题
-
-- [ 网易2018校园招聘编程题真题集合](https://www.nowcoder.com/test/6910869/summary)
-- [ 网易2018校招内推编程题集合](https://www.nowcoder.com/test/6291726/summary)
-- [2017年校招全国统一模拟笔试(第五场)编程题集合](https://www.nowcoder.com/test/5986669/summary)
-- [2017年校招全国统一模拟笔试(第四场)编程题集合](https://www.nowcoder.com/test/5507925/summary)
-- [2017年校招全国统一模拟笔试(第三场)编程题集合](https://www.nowcoder.com/test/5217106/summary)
-- [2017年校招全国统一模拟笔试(第二场)编程题集合](https://www.nowcoder.com/test/4546329/summary)
-- [ 2017年校招全国统一模拟笔试(第一场)编程题集合](https://www.nowcoder.com/test/4236887/summary)
-- [百度2017春招笔试真题编程题集合](https://www.nowcoder.com/test/4998655/summary)
-- [网易2017春招笔试真题编程题集合](https://www.nowcoder.com/test/4575457/summary)
-- [网易2017秋招编程题集合](https://www.nowcoder.com/test/2811407/summary)
-- [网易有道2017内推编程题](https://www.nowcoder.com/test/2385858/summary)
-- [ 滴滴出行2017秋招笔试真题-编程题汇总](https://www.nowcoder.com/test/3701760/summary)
-- [腾讯2017暑期实习生编程题](https://www.nowcoder.com/test/1725829/summary)
-- [今日头条2017客户端工程师实习生笔试题](https://www.nowcoder.com/test/1649301/summary)
-- [今日头条2017后端工程师实习生笔试题](https://www.nowcoder.com/test/1649268/summary)
diff --git a/docs/database/MySQL Index.md b/docs/database/MySQL Index.md
index b25589fc..8003a69f 100644
--- a/docs/database/MySQL Index.md
+++ b/docs/database/MySQL Index.md
@@ -1,13 +1,86 @@
+## 为什么要使用索引?
-# 思维导图-索引篇
+1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
+2. 可以大大加快 数据的检索速度(大大减少的检索的数据量), 这也是创建索引的最主要的原因。
+3. 帮助服务器避免排序和临时表。
+4. 将随机IO变为顺序IO
+5. 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
-> 系列思维导图源文件(数据库+架构)以及思维导图制作软件—XMind8 破解安装,公众号后台回复:**“思维导图”** 免费领取!(下面的图片不是很清楚,原图非常清晰,另外提供给大家源文件也是为了大家根据自己需要进行修改)
+## 索引这么多优点,为什么不对表中的每一个列创建一个索引呢?
-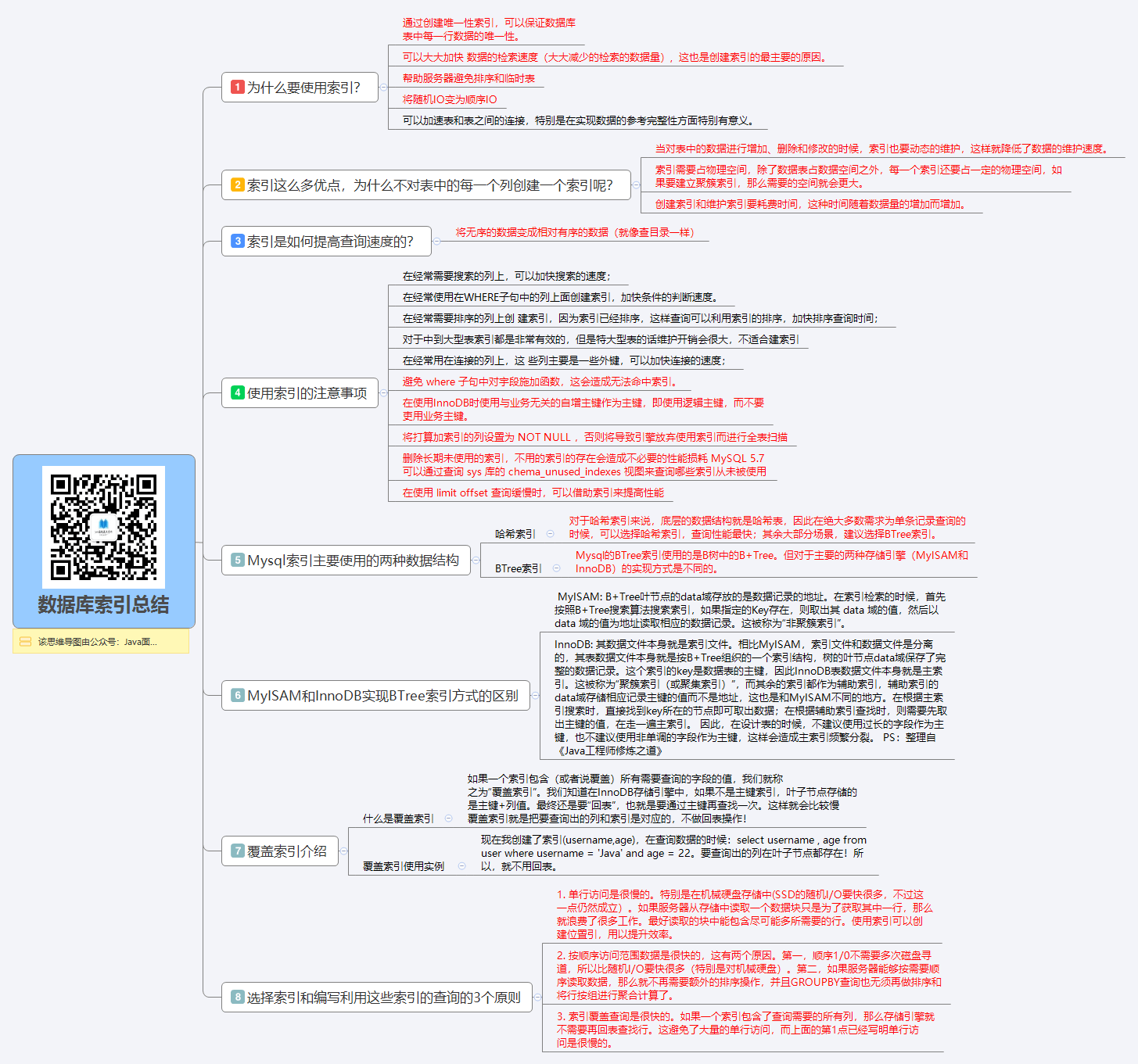
+1. 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
+2. 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
+3. 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
-> **下面是我补充的一些内容**
+## 使用索引的注意事项?
-# 为什么索引能提高查询速度
+1. 在经常需要搜索的列上,可以加快搜索的速度;
+
+2. 在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
+
+3. 在经常需要排序的列上创 建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
+
+4. 对于中到大型表索引都是非常有效的,但是特大型表的话维护开销会很大,不适合建索引
+
+5. 在经常用在连接的列上,这 些列主要是一些外键,可以加快连接的速度;
+
+6. 避免 where 子句中对字段施加函数,这会造成无法命中索引。
+
+7. 在使用InnoDB时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键。
+
+8. ~~将打算加索引的列设置为 NOT NULL ,否则将导致引擎放弃使用索引而进行全表扫描。~~
+
+ 订正,来自[issue758](https://github.com/Snailclimb/JavaGuide/issues/758) 。**将某一列设置为default null,where 是可以走索引,另外索引列是否设置 null 是不影响性能的。** 但是,还是不建议列上允许为空。最好限制not null,因为null需要更多的存储空间并且null值无法参与某些运算。
+
+ 《高性能MySQL》第四章如是说:And, in case you’re wondering, allowing NULL values in the index really doesn’t impact performance 。NULL 值的索引查找流程参考:https://juejin.im/post/5d5defc2518825591523a1db ,相关阅读:[MySQL中IS NULL、IS NOT NULL、!=不能用索引?胡扯!](https://juejin.im/post/5d5defc2518825591523a1db) 。
+
+9. 删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 chema_unused_indexes 视图来查询哪些索引从未被使用
+
+10. 在使用 limit offset 查询缓慢时,可以借助索引来提高性能
+
+## Mysql索引主要使用的两种数据结构
+
+### 哈希索引
+
+对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引。
+
+### BTree索引
+
+## MyISAM和InnoDB实现BTree索引方式的区别
+
+### MyISAM
+
+B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
+
+### InnoDB
+
+其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”,而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,在走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。 PS:整理自《Java工程师修炼之道》
+
+## 覆盖索引介绍
+
+### 什么是覆盖索引
+
+如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。我们知道InnoDB存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
+
+### 覆盖索引使用实例
+
+现在我创建了索引(username,age),我们执行下面的 sql 语句
+
+```sql
+select username , age from user where username = 'Java' and age = 22
+```
+
+在查询数据的时候:要查询出的列在叶子节点都存在!所以,就不用回表。
+
+## 选择索引和编写利用这些索引的查询的3个原则
+
+1. 单行访问是很慢的。特别是在机械硬盘存储中(SSD的随机I/O要快很多,不过这一点仍然成立)。如果服务器从存储中读取一个数据块只是为了获取其中一行,那么就浪费了很多工作。最好读取的块中能包含尽可能多所需要的行。使用索引可以创建位置引,用以提升效率。
+2. 按顺序访问范围数据是很快的,这有两个原因。第一,顺序 I/O 不需要多次磁盘寻道,所以比随机I/O要快很多(特别是对机械硬盘)。第二,如果服务器能够按需要顺序读取数据,那么就不再需要额外的排序操作,并且GROUPBY查询也无须再做排序和将行按组进行聚合计算了。
+3. 索引覆盖查询是很快的。如果一个索引包含了查询需要的所有列,那么存储引擎就
+ 不需要再回表查找行。这避免了大量的单行访问,而上面的第1点已经写明单行访
+ 问是很慢的。
+
+## 为什么索引能提高查询速度
> 以下内容整理自:
> 地址: https://juejin.im/post/5b55b842f265da0f9e589e79
@@ -48,7 +121,7 @@ MySQL的基本存储结构是页(记录都存在页里边):
其实底层结构就是B+树,B+树作为树的一种实现,能够让我们很快地查找出对应的记录。
-# 关于索引其他重要的内容补充
+## 关于索引其他重要的内容补充
> 以下内容整理自:《Java工程师修炼之道》
@@ -61,7 +134,7 @@ MySQL中的索引可以以一定顺序引用多列,这种索引叫作联合索
select * from user where name=xx and city=xx ; //可以命中索引
select * from user where name=xx ; // 可以命中索引
select * from user where city=xx ; // 无法命中索引
-```
+```
这里需要注意的是,查询的时候如果两个条件都用上了,但是顺序不同,如 `city= xx and name =xx`,那么现在的查询引擎会自动优化为匹配联合索引的顺序,这样是能够命中索引的。
由于最左前缀原则,在创建联合索引时,索引字段的顺序需要考虑字段值去重之后的个数,较多的放前面。ORDER BY子句也遵循此规则。
@@ -84,19 +157,19 @@ ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
```
ALTER TABLE `table_name` ADD UNIQUE ( `column` )
```
-
+
3.添加INDEX(普通索引)
```
ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
```
-
+
4.添加FULLTEXT(全文索引)
```
ALTER TABLE `table_name` ADD FULLTEXT ( `column`)
```
-
+
5.添加多列索引
```
@@ -104,7 +177,7 @@ ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3`
```
-# 参考
+## 参考
- 《Java工程师修炼之道》
- 《MySQL高性能书籍_第3版》
diff --git a/docs/database/MySQL.md b/docs/database/MySQL.md
index 64dfad2f..ed841e87 100644
--- a/docs/database/MySQL.md
+++ b/docs/database/MySQL.md
@@ -98,7 +98,7 @@ MyISAM是MySQL的默认数据库引擎(5.5版之前)。虽然性能极佳,
**两者的对比:**
1. **是否支持行级锁** : MyISAM 只有表级锁(table-level locking),而InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
-2. **是否支持事务和崩溃后的安全恢复: MyISAM** 强调的是性能,每次查询具有原子性,其执行速度比InnoDB类型更快,但是不提供事务支持。但是**InnoDB** 提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
+2. **是否支持事务和崩溃后的安全恢复: MyISAM** 强调的是性能,每次查询具有原子性,其执行速度比InnoDB类型更快,但是不提供事务支持。但是**InnoDB** 提供事务支持,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
3. **是否支持外键:** MyISAM不支持,而InnoDB支持。
4. **是否支持MVCC** :仅 InnoDB 支持。应对高并发事务, MVCC比单纯的加锁更高效;MVCC只在 `READ COMMITTED` 和 `REPEATABLE READ` 两个隔离级别下工作;MVCC可以使用 乐观(optimistic)锁 和 悲观(pessimistic)锁来实现;各数据库中MVCC实现并不统一。推荐阅读:[MySQL-InnoDB-MVCC多版本并发控制](https://segmentfault.com/a/1190000012650596)
5. ......
@@ -148,7 +148,7 @@ set global query_cache_size=600000;
缓存建立之后,MySQL的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
-**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启缓存查询要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十MB比较合适。此外,**还可以通过sql_cache和sql_no_cache来控制某个查询语句是否需要缓存:**
+**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启查询缓存要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十MB比较合适。此外,**还可以通过sql_cache和sql_no_cache来控制某个查询语句是否需要缓存:**
```sql
select sql_no_cache count(*) from usr;
```
@@ -164,7 +164,7 @@ select sql_no_cache count(*) from usr;
1. **原子性(Atomicity):** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
-2. **一致性(Consistency):** 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
+2. **一致性(Consistency):** 执行事务后,数据库从一个正确的状态变化到另一个正确的状态;
3. **隔离性(Isolation):** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
4. **持久性(Durability):** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
@@ -199,7 +199,7 @@ select sql_no_cache count(*) from usr;
| REPEATABLE-READ | × | × | √ |
| SERIALIZABLE | × | × | × |
-MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看
+MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;`
```sql
mysql> SELECT @@tx_isolation;
@@ -288,9 +288,9 @@ InnoDB 存储引擎在 **分布式事务** 的情况下一般会用到 **SERIALI
### 解释一下什么是池化设计思想。什么是数据库连接池?为什么需要数据库连接池?
-池话设计应该不是一个新名词。我们常见的如java线程池、jdbc连接池、redis连接池等就是这类设计的代表实现。这种设计会初始预设资源,解决的问题就是抵消每次获取资源的消耗,如创建线程的开销,获取远程连接的开销等。就好比你去食堂打饭,打饭的大妈会先把饭盛好几份放那里,你来了就直接拿着饭盒加菜即可,不用再临时又盛饭又打菜,效率就高了。除了初始化资源,池化设计还包括如下这些特征:池子的初始值、池子的活跃值、池子的最大值等,这些特征可以直接映射到java线程池和数据库连接池的成员属性中。——这篇文章对[池化设计思想](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485679&idx=1&sn=57dbca8c9ad49e1f3968ecff04a4f735&chksm=cea24724f9d5ce3212292fac291234a760c99c0960b5430d714269efe33554730b5f71208582&token=1141994790&lang=zh_CN#rd)介绍的还不错,直接复制过来,避免重复造轮子了。
+池化设计应该不是一个新名词。我们常见的如java线程池、jdbc连接池、redis连接池等就是这类设计的代表实现。这种设计会初始预设资源,解决的问题就是抵消每次获取资源的消耗,如创建线程的开销,获取远程连接的开销等。就好比你去食堂打饭,打饭的大妈会先把饭盛好几份放那里,你来了就直接拿着饭盒加菜即可,不用再临时又盛饭又打菜,效率就高了。除了初始化资源,池化设计还包括如下这些特征:池子的初始值、池子的活跃值、池子的最大值等,这些特征可以直接映射到java线程池和数据库连接池的成员属性中。这篇文章对[池化设计思想](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485679&idx=1&sn=57dbca8c9ad49e1f3968ecff04a4f735&chksm=cea24724f9d5ce3212292fac291234a760c99c0960b5430d714269efe33554730b5f71208582&token=1141994790&lang=zh_CN#rd)介绍的还不错,直接复制过来,避免重复造轮子了。
-数据库连接本质就是一个 socket 的连接。数据库服务端还要维护一些缓存和用户权限信息之类的 所以占用了一些内存。我们可以把数据库连接池是看做是维护的数据库连接的缓存,以便将来需要对数据库的请求时可以重用这些连接。为每个用户打开和维护数据库连接,尤其是对动态数据库驱动的网站应用程序的请求,既昂贵又浪费资源。**在连接池中,创建连接后,将其放置在池中,并再次使用它,因此不必建立新的连接。如果使用了所有连接,则会建立一个新连接并将其添加到池中。**连接池还减少了用户必须等待建立与数据库的连接的时间。
+数据库连接本质就是一个 socket 的连接。数据库服务端还要维护一些缓存和用户权限信息之类的 所以占用了一些内存。我们可以把数据库连接池是看做是维护的数据库连接的缓存,以便将来需要对数据库的请求时可以重用这些连接。为每个用户打开和维护数据库连接,尤其是对动态数据库驱动的网站应用程序的请求,既昂贵又浪费资源。**在连接池中,创建连接后,将其放置在池中,并再次使用它,因此不必建立新的连接。如果使用了所有连接,则会建立一个新连接并将其添加到池中**。 连接池还减少了用户必须等待建立与数据库的连接的时间。
### 分库分表之后,id 主键如何处理?
diff --git a/docs/database/MySQL高性能优化规范建议.md b/docs/database/MySQL高性能优化规范建议.md
index f079ad77..60f17583 100644
--- a/docs/database/MySQL高性能优化规范建议.md
+++ b/docs/database/MySQL高性能优化规范建议.md
@@ -35,7 +35,7 @@
- [2. 避免数据类型的隐式转换](#2-避免数据类型的隐式转换)
- [3. 充分利用表上已经存在的索引](#3-充分利用表上已经存在的索引)
- [4. 数据库设计时,应该要对以后扩展进行考虑](#4-数据库设计时应该要对以后扩展进行考虑)
- - [5. 程序连接不同的数据库使用不同的账号,进制跨库查询](#5-程序连接不同的数据库使用不同的账号进制跨库查询)
+ - [5. 程序连接不同的数据库使用不同的账号,禁止跨库查询](#5-程序连接不同的数据库使用不同的账号禁止跨库查询)
- [6. 禁止使用 SELECT * 必须使用 SELECT <字段列表> 查询](#6-禁止使用-select--必须使用-select-字段列表-查询)
- [7. 禁止使用不含字段列表的 INSERT 语句](#7-禁止使用不含字段列表的-insert-语句)
- [8. 避免使用子查询,可以把子查询优化为 join 操作](#8-避免使用子查询可以把子查询优化为-join-操作)
@@ -76,6 +76,8 @@ Innodb 支持事务,支持行级锁,更好的恢复性,高并发下性能
兼容性更好,统一字符集可以避免由于字符集转换产生的乱码,不同的字符集进行比较前需要进行转换会造成索引失效,如果数据库中有存储 emoji 表情的需要,字符集需要采用 utf8mb4 字符集。
+参考文章:[MySQL 字符集不一致导致索引失效的一个真实案例](https://blog.csdn.net/horses/article/details/107243447)
+
### 3. 所有表和字段都需要添加注释
使用 comment 从句添加表和列的备注,从一开始就进行数据字典的维护
diff --git a/docs/database/Redis/Redis.md b/docs/database/Redis/Redis.md
deleted file mode 100644
index a17c7f04..00000000
--- a/docs/database/Redis/Redis.md
+++ /dev/null
@@ -1,370 +0,0 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
-
-
-- [redis 简介](#redis-简介)
-- [为什么要用 redis/为什么要用缓存](#为什么要用-redis为什么要用缓存)
-- [为什么要用 redis 而不用 map/guava 做缓存?](#为什么要用-redis-而不用-mapguava-做缓存)
-- [redis 和 memcached 的区别](#redis-和-memcached-的区别)
-- [redis 常见数据结构以及使用场景分析](#redis-常见数据结构以及使用场景分析)
- - [1.String](#1string)
- - [2.Hash](#2hash)
- - [3.List](#3list)
- - [4.Set](#4set)
- - [5.Sorted Set](#5sorted-set)
-- [redis 设置过期时间](#redis-设置过期时间)
-- [redis 内存淘汰机制(MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据?)](#redis-内存淘汰机制mysql里有2000w数据redis中只存20w的数据如何保证redis中的数据都是热点数据)
-- [redis 持久化机制(怎么保证 redis 挂掉之后再重启数据可以进行恢复)](#redis-持久化机制怎么保证-redis-挂掉之后再重启数据可以进行恢复)
-- [redis 事务](#redis-事务)
-- [缓存雪崩和缓存穿透问题解决方案](#缓存雪崩和缓存穿透问题解决方案)
-- [如何解决 Redis 的并发竞争 Key 问题](#如何解决-redis-的并发竞争-key-问题)
-- [如何保证缓存与数据库双写时的数据一致性?](#如何保证缓存与数据库双写时的数据一致性)
-
-
-
-### redis 简介
-
-简单来说 redis 就是一个数据库,不过与传统数据库不同的是 redis 的数据是存在内存中的,所以读写速度非常快,因此 redis 被广泛应用于缓存方向。另外,redis 也经常用来做分布式锁。redis 提供了多种数据类型来支持不同的业务场景。除此之外,redis 支持事务 、持久化、LUA脚本、LRU驱动事件、多种集群方案。
-
-### 为什么要用 redis/为什么要用缓存
-
-主要从“高性能”和“高并发”这两点来看待这个问题。
-
-**高性能:**
-
-假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
-
-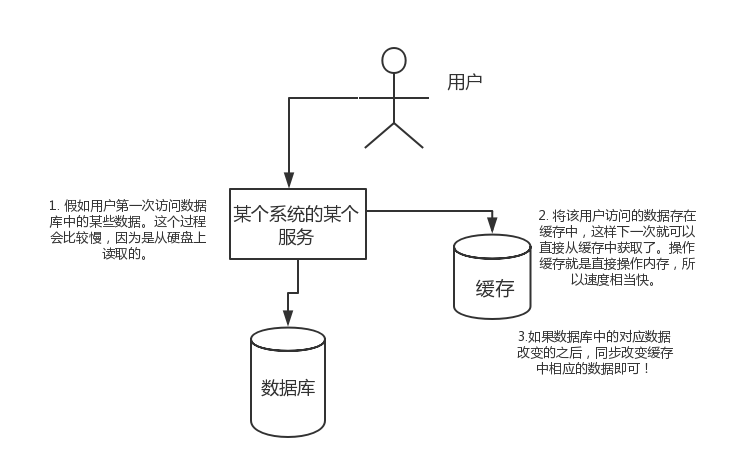
-
-
-**高并发:**
-
-直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
-
-
-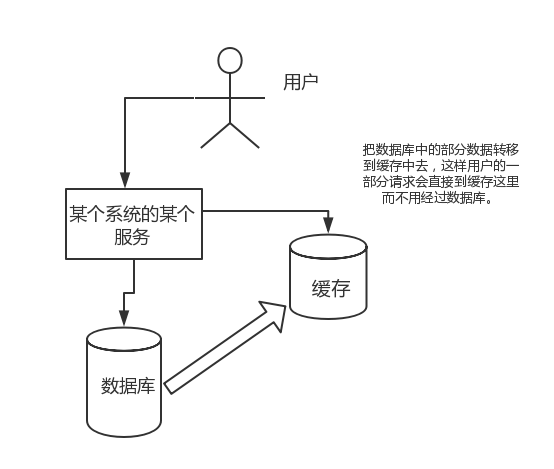
-
-
-### 为什么要用 redis 而不用 map/guava 做缓存?
-
-
->下面的内容来自 segmentfault 一位网友的提问,地址:https://segmentfault.com/q/1010000009106416
-
-缓存分为本地缓存和分布式缓存。以 Java 为例,使用自带的 map 或者 guava 实现的是本地缓存,最主要的特点是轻量以及快速,生命周期随着 jvm 的销毁而结束,并且在多实例的情况下,每个实例都需要各自保存一份缓存,缓存不具有一致性。
-
-使用 redis 或 memcached 之类的称为分布式缓存,在多实例的情况下,各实例共用一份缓存数据,缓存具有一致性。缺点是需要保持 redis 或 memcached服务的高可用,整个程序架构上较为复杂。
-
-### redis 的线程模型
-
-> 参考地址:https://www.javazhiyin.com/22943.html
-
-redis 内部使用文件事件处理器 `file event handler`,这个文件事件处理器是单线程的,所以 redis 才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 socket,根据 socket 上的事件来选择对应的事件处理器进行处理。
-
-文件事件处理器的结构包含 4 个部分:
-
-- 多个 socket
-- IO 多路复用程序
-- 文件事件分派器
-- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
-
-多个 socket 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 socket,会将 socket 产生的事件放入队列中排队,事件分派器每次从队列中取出一个事件,把该事件交给对应的事件处理器进行处理。
-
-
-### redis 和 memcached 的区别
-
-对于 redis 和 memcached 我总结了下面四点。现在公司一般都是用 redis 来实现缓存,而且 redis 自身也越来越强大了!
-
-1. **redis支持更丰富的数据类型(支持更复杂的应用场景)**:Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。memcache支持简单的数据类型,String。
-2. **Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而Memecache把数据全部存在内存之中。**
-3. **集群模式**:memcached没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 redis 目前是原生支持 cluster 模式的.
-4. **Memcached是多线程,非阻塞IO复用的网络模型;Redis使用单线程的多路 IO 复用模型。**
-
-
-> 来自网络上的一张图,这里分享给大家!
-
-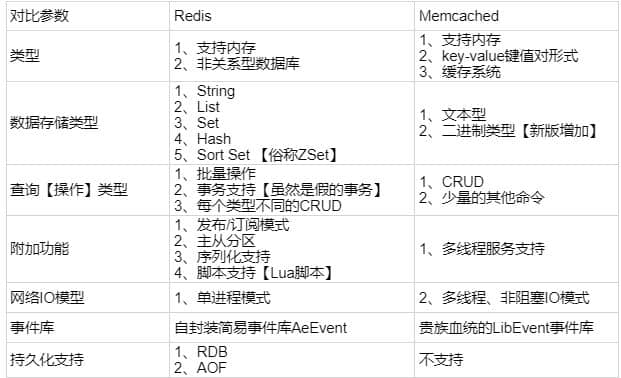
-
-
-### redis 常见数据结构以及使用场景分析
-
-#### 1.String
-
-> **常用命令:** set,get,decr,incr,mget 等。
-
-
-String数据结构是简单的key-value类型,value其实不仅可以是String,也可以是数字。
-常规key-value缓存应用;
-常规计数:微博数,粉丝数等。
-
-#### 2.Hash
-> **常用命令:** hget,hset,hgetall 等。
-
-hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象,后续操作的时候,你可以直接仅仅修改这个对象中的某个字段的值。 比如我们可以 hash 数据结构来存储用户信息,商品信息等等。比如下面我就用 hash 类型存放了我本人的一些信息:
-
-```
-key=JavaUser293847
-value={
- “id”: 1,
- “name”: “SnailClimb”,
- “age”: 22,
- “location”: “Wuhan, Hubei”
-}
-
-```
-
-
-#### 3.List
-> **常用命令:** lpush,rpush,lpop,rpop,lrange等
-
-list 就是链表,Redis list 的应用场景非常多,也是Redis最重要的数据结构之一,比如微博的关注列表,粉丝列表,消息列表等功能都可以用Redis的 list 结构来实现。
-
-Redis list 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。
-
-另外可以通过 lrange 命令,就是从某个元素开始读取多少个元素,可以基于 list 实现分页查询,这个很棒的一个功能,基于 redis 实现简单的高性能分页,可以做类似微博那种下拉不断分页的东西(一页一页的往下走),性能高。
-
-#### 4.Set
-
-> **常用命令:**
-sadd,spop,smembers,sunion 等
-
-set 对外提供的功能与list类似是一个列表的功能,特殊之处在于 set 是可以自动排重的。
-
-当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。可以基于 set 轻易实现交集、并集、差集的操作。
-
-比如:在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程,具体命令如下:
-
-```
-sinterstore key1 key2 key3 将交集存在key1内
-```
-
-#### 5.Sorted Set
-> **常用命令:** zadd,zrange,zrem,zcard等
-
-
-和set相比,sorted set增加了一个权重参数score,使得集合中的元素能够按score进行有序排列。
-
-**举例:** 在直播系统中,实时排行信息包含直播间在线用户列表,各种礼物排行榜,弹幕消息(可以理解为按消息维度的消息排行榜)等信息,适合使用 Redis 中的 Sorted Set 结构进行存储。
-
-
-### redis 设置过期时间
-
-Redis中有个设置时间过期的功能,即对存储在 redis 数据库中的值可以设置一个过期时间。作为一个缓存数据库,这是非常实用的。如我们一般项目中的 token 或者一些登录信息,尤其是短信验证码都是有时间限制的,按照传统的数据库处理方式,一般都是自己判断过期,这样无疑会严重影响项目性能。
-
-我们 set key 的时候,都可以给一个 expire time,就是过期时间,通过过期时间我们可以指定这个 key 可以存活的时间。
-
-如果假设你设置了一批 key 只能存活1个小时,那么接下来1小时后,redis是怎么对这批key进行删除的?
-
-**定期删除+惰性删除。**
-
-通过名字大概就能猜出这两个删除方式的意思了。
-
-- **定期删除**:redis默认是每隔 100ms 就**随机抽取**一些设置了过期时间的key,检查其是否过期,如果过期就删除。注意这里是随机抽取的。为什么要随机呢?你想一想假如 redis 存了几十万个 key ,每隔100ms就遍历所有的设置过期时间的 key 的话,就会给 CPU 带来很大的负载!
-- **惰性删除** :定期删除可能会导致很多过期 key 到了时间并没有被删除掉。所以就有了惰性删除。假如你的过期 key,靠定期删除没有被删除掉,还停留在内存里,除非你的系统去查一下那个 key,才会被redis给删除掉。这就是所谓的惰性删除,也是够懒的哈!
-
-
-但是仅仅通过设置过期时间还是有问题的。我们想一下:如果定期删除漏掉了很多过期 key,然后你也没及时去查,也就没走惰性删除,此时会怎么样?如果大量过期key堆积在内存里,导致redis内存块耗尽了。怎么解决这个问题呢? **redis 内存淘汰机制。**
-
-### redis 内存淘汰机制(MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据?)
-
-redis 配置文件 redis.conf 中有相关注释,我这里就不贴了,大家可以自行查阅或者通过这个网址查看: [http://download.redis.io/redis-stable/redis.conf](http://download.redis.io/redis-stable/redis.conf)
-
-**redis 提供 6种数据淘汰策略:**
-
-1. **volatile-lru**:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
-2. **volatile-ttl**:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
-3. **volatile-random**:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
-4. **allkeys-lru**:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
-5. **allkeys-random**:从数据集(server.db[i].dict)中任意选择数据淘汰
-6. **no-eviction**:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
-
-4.0版本后增加以下两种:
-
-7. **volatile-lfu**:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
-8. **allkeys-lfu**:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的key
-
-**备注: 关于 redis 设置过期时间以及内存淘汰机制,我这里只是简单的总结一下,后面会专门写一篇文章来总结!**
-
-
-### redis 持久化机制(怎么保证 redis 挂掉之后再重启数据可以进行恢复)
-
-很多时候我们需要持久化数据也就是将内存中的数据写入到硬盘里面,大部分原因是为了之后重用数据(比如重启机器、机器故障之后恢复数据),或者是为了防止系统故障而将数据备份到一个远程位置。
-
-Redis不同于Memcached的很重一点就是,Redis支持持久化,而且支持两种不同的持久化操作。**Redis的一种持久化方式叫快照(snapshotting,RDB),另一种方式是只追加文件(append-only file,AOF)**。这两种方法各有千秋,下面我会详细这两种持久化方法是什么,怎么用,如何选择适合自己的持久化方法。
-
-**快照(snapshotting)持久化(RDB)**
-
-Redis可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本。Redis创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis主从结构,主要用来提高Redis性能),还可以将快照留在原地以便重启服务器的时候使用。
-
-快照持久化是Redis默认采用的持久化方式,在redis.conf配置文件中默认有此下配置:
-
-```conf
-
-save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
-
-save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
-
-save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
-```
-
-**AOF(append-only file)持久化**
-
-与快照持久化相比,AOF持久化 的实时性更好,因此已成为主流的持久化方案。默认情况下Redis没有开启AOF(append only file)方式的持久化,可以通过appendonly参数开启:
-
-```conf
-appendonly yes
-```
-
-开启AOF持久化后每执行一条会更改Redis中的数据的命令,Redis就会将该命令写入硬盘中的AOF文件。AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的,默认的文件名是appendonly.aof。
-
-在Redis的配置文件中存在三种不同的 AOF 持久化方式,它们分别是:
-
-```conf
-appendfsync always #每次有数据修改发生时都会写入AOF文件,这样会严重降低Redis的速度
-appendfsync everysec #每秒钟同步一次,显示地将多个写命令同步到硬盘
-appendfsync no #让操作系统决定何时进行同步
-```
-
-为了兼顾数据和写入性能,用户可以考虑 appendfsync everysec选项 ,让Redis每秒同步一次AOF文件,Redis性能几乎没受到任何影响。而且这样即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis还会优雅的放慢自己的速度以便适应硬盘的最大写入速度。
-
-**Redis 4.0 对于持久化机制的优化**
-
-Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 `aof-use-rdb-preamble` 开启)。
-
-如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
-
-**补充内容:AOF 重写**
-
-AOF重写可以产生一个新的AOF文件,这个新的AOF文件和原有的AOF文件所保存的数据库状态一样,但体积更小。
-
-AOF重写是一个有歧义的名字,该功能是通过读取数据库中的键值对来实现的,程序无须对现有AOF文件进行任何读入、分析或者写入操作。
-
-在执行 BGREWRITEAOF 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子进程创建新AOF文件期间,记录服务器执行的所有写命令。当子进程完成创建新AOF文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新AOF文件的末尾,使得新旧两个AOF文件所保存的数据库状态一致。最后,服务器用新的AOF文件替换旧的AOF文件,以此来完成AOF文件重写操作
-
-**更多内容可以查看我的这篇文章:**
-
-- [Redis持久化](Redis持久化.md)
-
-
-### redis 事务
-
-Redis 通过 MULTI、EXEC、WATCH 等命令来实现事务(transaction)功能。事务提供了一种将多个命令请求打包,然后一次性、按顺序地执行多个命令的机制,并且在事务执行期间,服务器不会中断事务而改去执行其他客户端的命令请求,它会将事务中的所有命令都执行完毕,然后才去处理其他客户端的命令请求。
-
-在传统的关系式数据库中,常常用 ACID 性质来检验事务功能的可靠性和安全性。在 Redis 中,事务总是具有原子性(Atomicity)、一致性(Consistency)和隔离性(Isolation),并且当 Redis 运行在某种特定的持久化模式下时,事务也具有持久性(Durability)。
-
-补充内容:
-
-> 1. redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚。(来自[issue:关于Redis事务不是原子性问题](https://github.com/Snailclimb/JavaGuide/issues/452) )
-
-### 缓存雪崩和缓存穿透问题解决方案
-
-#### **缓存雪崩**
-
-**什么是缓存雪崩?**
-
-简介:缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
-
-**有哪些解决办法?**
-
-(中华石杉老师在他的视频中提到过,视频地址在最后一个问题中有提到):
-
-- 事前:尽量保证整个 redis 集群的高可用性,发现机器宕机尽快补上。选择合适的内存淘汰策略。
-- 事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL崩掉
-- 事后:利用 redis 持久化机制保存的数据尽快恢复缓存
-
-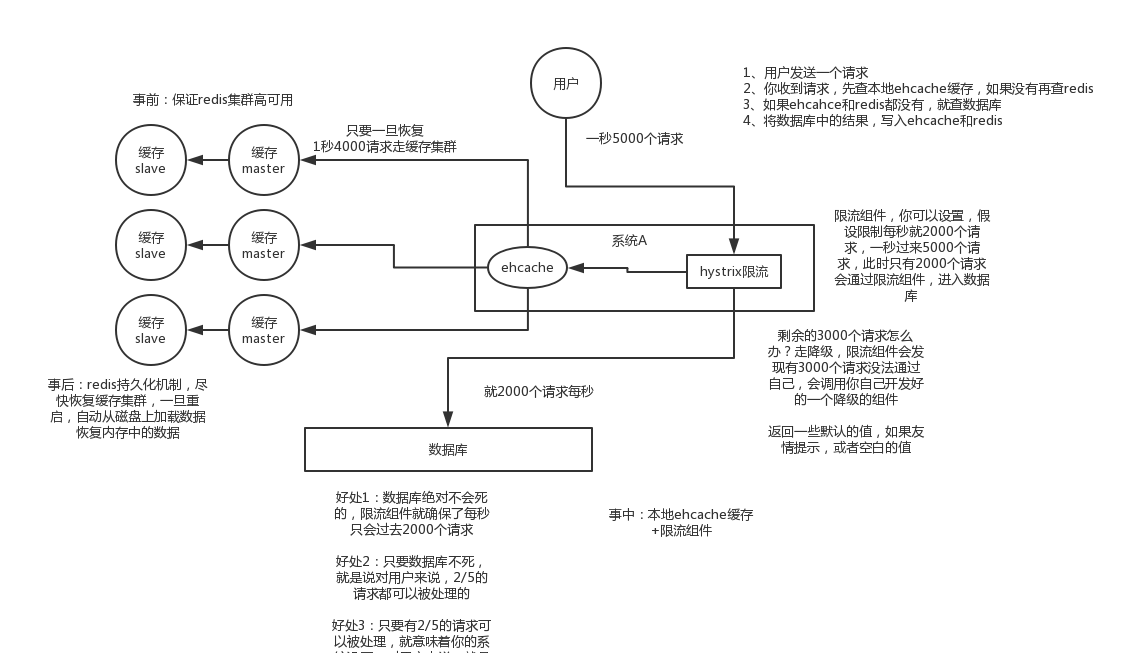
-
-#### **缓存穿透**
-
-**什么是缓存穿透?**
-
-缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。下面用图片展示一下(这两张图片不是我画的,为了省事直接在网上找的,这里说明一下):
-
-**正常缓存处理流程:**
-
-
+
+
+
+**[编程之美](https://book.douban.com/subject/3004255/)(豆瓣评分 8.4,3K+人评价)**
+
+这本书收集了约60道算法和程序设计题目,这些题目大部分在近年的笔试、面试中出现过,或者是被微软员工热烈讨论过。作者试图从书中各种有趣的问题出发,引导读者发现问题,分析问题,解决问题,寻找更优的解法。
+
+## 网站推荐
+
我比较推荐大家可以刷一下 Leetcode ,我自己平时没事也会刷一下,我觉得刷 Leetcode 不仅是为了能让你更从容地面对面试中的手撕算法问题,更可以提高你的编程思维能力、解决问题的能力以及你对某门编程语言 API 的熟练度。当然牛客网也有一些算法题,我下面也整理了一些。
-## LeetCode
+### [LeetCode](https://leetcode-cn.com/)
-- [LeetCode(中国)官网](https://leetcode-cn.com/)
+[如何高效地使用 LeetCode](https://leetcode-cn.com/articles/%E5%A6%82%E4%BD%95%E9%AB%98%E6%95%88%E5%9C%B0%E4%BD%BF%E7%94%A8-leetcode/)
-- [如何高效地使用 LeetCode](https://leetcode-cn.com/articles/%E5%A6%82%E4%BD%95%E9%AB%98%E6%95%88%E5%9C%B0%E4%BD%BF%E7%94%A8-leetcode/)
+- [《程序员代码面试指南》](https://leetcode-cn.com/problemset/lcci/)
+- [《剑指offer》](https://leetcode-cn.com/problemset/lcof/)
-## 牛客网
+### [牛客网](https://www.nowcoder.com)
+
+**[在线编程](https://www.nowcoder.com/activity/oj):**
+
+- [《剑指offer》](https://www.nowcoder.com/ta/coding-interviews)
+- [《程序员代码面试指南》](https://www.nowcoder.com/ta/programmer-code-interview-guide)
+- [2019 校招真题](https://www.nowcoder.com/ta/2019test)
+- [大一大二编程入门训练](https://www.nowcoder.com/ta/beginner-programmers)
+- .......
+
+**[大厂编程面试真题](https://www.nowcoder.com/contestRoom?filter=0&orderByHotValue=3&target=content&categories=-1&mutiTagIds=2491&page=1)**
+
-- [牛客网官网](https://www.nowcoder.com)
-- [剑指offer编程题](https://www.nowcoder.com/ta/coding-interviews)
-- [2017校招真题](https://www.nowcoder.com/ta/2017test)
-- [华为机试题](https://www.nowcoder.com/ta/huawei)
-
-## 公司真题
-
-- [ 网易2018校园招聘编程题真题集合](https://www.nowcoder.com/test/6910869/summary)
-- [ 网易2018校招内推编程题集合](https://www.nowcoder.com/test/6291726/summary)
-- [2017年校招全国统一模拟笔试(第五场)编程题集合](https://www.nowcoder.com/test/5986669/summary)
-- [2017年校招全国统一模拟笔试(第四场)编程题集合](https://www.nowcoder.com/test/5507925/summary)
-- [2017年校招全国统一模拟笔试(第三场)编程题集合](https://www.nowcoder.com/test/5217106/summary)
-- [2017年校招全国统一模拟笔试(第二场)编程题集合](https://www.nowcoder.com/test/4546329/summary)
-- [ 2017年校招全国统一模拟笔试(第一场)编程题集合](https://www.nowcoder.com/test/4236887/summary)
-- [百度2017春招笔试真题编程题集合](https://www.nowcoder.com/test/4998655/summary)
-- [网易2017春招笔试真题编程题集合](https://www.nowcoder.com/test/4575457/summary)
-- [网易2017秋招编程题集合](https://www.nowcoder.com/test/2811407/summary)
-- [网易有道2017内推编程题](https://www.nowcoder.com/test/2385858/summary)
-- [ 滴滴出行2017秋招笔试真题-编程题汇总](https://www.nowcoder.com/test/3701760/summary)
-- [腾讯2017暑期实习生编程题](https://www.nowcoder.com/test/1725829/summary)
-- [今日头条2017客户端工程师实习生笔试题](https://www.nowcoder.com/test/1649301/summary)
-- [今日头条2017后端工程师实习生笔试题](https://www.nowcoder.com/test/1649268/summary)
diff --git a/docs/database/MySQL Index.md b/docs/database/MySQL Index.md
index b25589fc..8003a69f 100644
--- a/docs/database/MySQL Index.md
+++ b/docs/database/MySQL Index.md
@@ -1,13 +1,86 @@
+## 为什么要使用索引?
-# 思维导图-索引篇
+1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
+2. 可以大大加快 数据的检索速度(大大减少的检索的数据量), 这也是创建索引的最主要的原因。
+3. 帮助服务器避免排序和临时表。
+4. 将随机IO变为顺序IO
+5. 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
-> 系列思维导图源文件(数据库+架构)以及思维导图制作软件—XMind8 破解安装,公众号后台回复:**“思维导图”** 免费领取!(下面的图片不是很清楚,原图非常清晰,另外提供给大家源文件也是为了大家根据自己需要进行修改)
+## 索引这么多优点,为什么不对表中的每一个列创建一个索引呢?
-
+1. 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
+2. 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
+3. 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
-> **下面是我补充的一些内容**
+## 使用索引的注意事项?
-# 为什么索引能提高查询速度
+1. 在经常需要搜索的列上,可以加快搜索的速度;
+
+2. 在经常使用在WHERE子句中的列上面创建索引,加快条件的判断速度。
+
+3. 在经常需要排序的列上创 建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间;
+
+4. 对于中到大型表索引都是非常有效的,但是特大型表的话维护开销会很大,不适合建索引
+
+5. 在经常用在连接的列上,这 些列主要是一些外键,可以加快连接的速度;
+
+6. 避免 where 子句中对字段施加函数,这会造成无法命中索引。
+
+7. 在使用InnoDB时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键。
+
+8. ~~将打算加索引的列设置为 NOT NULL ,否则将导致引擎放弃使用索引而进行全表扫描。~~
+
+ 订正,来自[issue758](https://github.com/Snailclimb/JavaGuide/issues/758) 。**将某一列设置为default null,where 是可以走索引,另外索引列是否设置 null 是不影响性能的。** 但是,还是不建议列上允许为空。最好限制not null,因为null需要更多的存储空间并且null值无法参与某些运算。
+
+ 《高性能MySQL》第四章如是说:And, in case you’re wondering, allowing NULL values in the index really doesn’t impact performance 。NULL 值的索引查找流程参考:https://juejin.im/post/5d5defc2518825591523a1db ,相关阅读:[MySQL中IS NULL、IS NOT NULL、!=不能用索引?胡扯!](https://juejin.im/post/5d5defc2518825591523a1db) 。
+
+9. 删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 chema_unused_indexes 视图来查询哪些索引从未被使用
+
+10. 在使用 limit offset 查询缓慢时,可以借助索引来提高性能
+
+## Mysql索引主要使用的两种数据结构
+
+### 哈希索引
+
+对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引。
+
+### BTree索引
+
+## MyISAM和InnoDB实现BTree索引方式的区别
+
+### MyISAM
+
+B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
+
+### InnoDB
+
+其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”,而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,在走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。 PS:整理自《Java工程师修炼之道》
+
+## 覆盖索引介绍
+
+### 什么是覆盖索引
+
+如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。我们知道InnoDB存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
+
+### 覆盖索引使用实例
+
+现在我创建了索引(username,age),我们执行下面的 sql 语句
+
+```sql
+select username , age from user where username = 'Java' and age = 22
+```
+
+在查询数据的时候:要查询出的列在叶子节点都存在!所以,就不用回表。
+
+## 选择索引和编写利用这些索引的查询的3个原则
+
+1. 单行访问是很慢的。特别是在机械硬盘存储中(SSD的随机I/O要快很多,不过这一点仍然成立)。如果服务器从存储中读取一个数据块只是为了获取其中一行,那么就浪费了很多工作。最好读取的块中能包含尽可能多所需要的行。使用索引可以创建位置引,用以提升效率。
+2. 按顺序访问范围数据是很快的,这有两个原因。第一,顺序 I/O 不需要多次磁盘寻道,所以比随机I/O要快很多(特别是对机械硬盘)。第二,如果服务器能够按需要顺序读取数据,那么就不再需要额外的排序操作,并且GROUPBY查询也无须再做排序和将行按组进行聚合计算了。
+3. 索引覆盖查询是很快的。如果一个索引包含了查询需要的所有列,那么存储引擎就
+ 不需要再回表查找行。这避免了大量的单行访问,而上面的第1点已经写明单行访
+ 问是很慢的。
+
+## 为什么索引能提高查询速度
> 以下内容整理自:
> 地址: https://juejin.im/post/5b55b842f265da0f9e589e79
@@ -48,7 +121,7 @@ MySQL的基本存储结构是页(记录都存在页里边):
其实底层结构就是B+树,B+树作为树的一种实现,能够让我们很快地查找出对应的记录。
-# 关于索引其他重要的内容补充
+## 关于索引其他重要的内容补充
> 以下内容整理自:《Java工程师修炼之道》
@@ -61,7 +134,7 @@ MySQL中的索引可以以一定顺序引用多列,这种索引叫作联合索
select * from user where name=xx and city=xx ; //可以命中索引
select * from user where name=xx ; // 可以命中索引
select * from user where city=xx ; // 无法命中索引
-```
+```
这里需要注意的是,查询的时候如果两个条件都用上了,但是顺序不同,如 `city= xx and name =xx`,那么现在的查询引擎会自动优化为匹配联合索引的顺序,这样是能够命中索引的。
由于最左前缀原则,在创建联合索引时,索引字段的顺序需要考虑字段值去重之后的个数,较多的放前面。ORDER BY子句也遵循此规则。
@@ -84,19 +157,19 @@ ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
```
ALTER TABLE `table_name` ADD UNIQUE ( `column` )
```
-
+
3.添加INDEX(普通索引)
```
ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
```
-
+
4.添加FULLTEXT(全文索引)
```
ALTER TABLE `table_name` ADD FULLTEXT ( `column`)
```
-
+
5.添加多列索引
```
@@ -104,7 +177,7 @@ ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3`
```
-# 参考
+## 参考
- 《Java工程师修炼之道》
- 《MySQL高性能书籍_第3版》
diff --git a/docs/database/MySQL.md b/docs/database/MySQL.md
index 64dfad2f..ed841e87 100644
--- a/docs/database/MySQL.md
+++ b/docs/database/MySQL.md
@@ -98,7 +98,7 @@ MyISAM是MySQL的默认数据库引擎(5.5版之前)。虽然性能极佳,
**两者的对比:**
1. **是否支持行级锁** : MyISAM 只有表级锁(table-level locking),而InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
-2. **是否支持事务和崩溃后的安全恢复: MyISAM** 强调的是性能,每次查询具有原子性,其执行速度比InnoDB类型更快,但是不提供事务支持。但是**InnoDB** 提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
+2. **是否支持事务和崩溃后的安全恢复: MyISAM** 强调的是性能,每次查询具有原子性,其执行速度比InnoDB类型更快,但是不提供事务支持。但是**InnoDB** 提供事务支持,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
3. **是否支持外键:** MyISAM不支持,而InnoDB支持。
4. **是否支持MVCC** :仅 InnoDB 支持。应对高并发事务, MVCC比单纯的加锁更高效;MVCC只在 `READ COMMITTED` 和 `REPEATABLE READ` 两个隔离级别下工作;MVCC可以使用 乐观(optimistic)锁 和 悲观(pessimistic)锁来实现;各数据库中MVCC实现并不统一。推荐阅读:[MySQL-InnoDB-MVCC多版本并发控制](https://segmentfault.com/a/1190000012650596)
5. ......
@@ -148,7 +148,7 @@ set global query_cache_size=600000;
缓存建立之后,MySQL的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
-**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启缓存查询要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十MB比较合适。此外,**还可以通过sql_cache和sql_no_cache来控制某个查询语句是否需要缓存:**
+**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启查询缓存要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十MB比较合适。此外,**还可以通过sql_cache和sql_no_cache来控制某个查询语句是否需要缓存:**
```sql
select sql_no_cache count(*) from usr;
```
@@ -164,7 +164,7 @@ select sql_no_cache count(*) from usr;

1. **原子性(Atomicity):** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
-2. **一致性(Consistency):** 执行事务前后,数据保持一致,多个事务对同一个数据读取的结果是相同的;
+2. **一致性(Consistency):** 执行事务后,数据库从一个正确的状态变化到另一个正确的状态;
3. **隔离性(Isolation):** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
4. **持久性(Durability):** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
@@ -199,7 +199,7 @@ select sql_no_cache count(*) from usr;
| REPEATABLE-READ | × | × | √ |
| SERIALIZABLE | × | × | × |
-MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看
+MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;`
```sql
mysql> SELECT @@tx_isolation;
@@ -288,9 +288,9 @@ InnoDB 存储引擎在 **分布式事务** 的情况下一般会用到 **SERIALI
### 解释一下什么是池化设计思想。什么是数据库连接池?为什么需要数据库连接池?
-池话设计应该不是一个新名词。我们常见的如java线程池、jdbc连接池、redis连接池等就是这类设计的代表实现。这种设计会初始预设资源,解决的问题就是抵消每次获取资源的消耗,如创建线程的开销,获取远程连接的开销等。就好比你去食堂打饭,打饭的大妈会先把饭盛好几份放那里,你来了就直接拿着饭盒加菜即可,不用再临时又盛饭又打菜,效率就高了。除了初始化资源,池化设计还包括如下这些特征:池子的初始值、池子的活跃值、池子的最大值等,这些特征可以直接映射到java线程池和数据库连接池的成员属性中。——这篇文章对[池化设计思想](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485679&idx=1&sn=57dbca8c9ad49e1f3968ecff04a4f735&chksm=cea24724f9d5ce3212292fac291234a760c99c0960b5430d714269efe33554730b5f71208582&token=1141994790&lang=zh_CN#rd)介绍的还不错,直接复制过来,避免重复造轮子了。
+池化设计应该不是一个新名词。我们常见的如java线程池、jdbc连接池、redis连接池等就是这类设计的代表实现。这种设计会初始预设资源,解决的问题就是抵消每次获取资源的消耗,如创建线程的开销,获取远程连接的开销等。就好比你去食堂打饭,打饭的大妈会先把饭盛好几份放那里,你来了就直接拿着饭盒加菜即可,不用再临时又盛饭又打菜,效率就高了。除了初始化资源,池化设计还包括如下这些特征:池子的初始值、池子的活跃值、池子的最大值等,这些特征可以直接映射到java线程池和数据库连接池的成员属性中。这篇文章对[池化设计思想](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485679&idx=1&sn=57dbca8c9ad49e1f3968ecff04a4f735&chksm=cea24724f9d5ce3212292fac291234a760c99c0960b5430d714269efe33554730b5f71208582&token=1141994790&lang=zh_CN#rd)介绍的还不错,直接复制过来,避免重复造轮子了。
-数据库连接本质就是一个 socket 的连接。数据库服务端还要维护一些缓存和用户权限信息之类的 所以占用了一些内存。我们可以把数据库连接池是看做是维护的数据库连接的缓存,以便将来需要对数据库的请求时可以重用这些连接。为每个用户打开和维护数据库连接,尤其是对动态数据库驱动的网站应用程序的请求,既昂贵又浪费资源。**在连接池中,创建连接后,将其放置在池中,并再次使用它,因此不必建立新的连接。如果使用了所有连接,则会建立一个新连接并将其添加到池中。**连接池还减少了用户必须等待建立与数据库的连接的时间。
+数据库连接本质就是一个 socket 的连接。数据库服务端还要维护一些缓存和用户权限信息之类的 所以占用了一些内存。我们可以把数据库连接池是看做是维护的数据库连接的缓存,以便将来需要对数据库的请求时可以重用这些连接。为每个用户打开和维护数据库连接,尤其是对动态数据库驱动的网站应用程序的请求,既昂贵又浪费资源。**在连接池中,创建连接后,将其放置在池中,并再次使用它,因此不必建立新的连接。如果使用了所有连接,则会建立一个新连接并将其添加到池中**。 连接池还减少了用户必须等待建立与数据库的连接的时间。
### 分库分表之后,id 主键如何处理?
diff --git a/docs/database/MySQL高性能优化规范建议.md b/docs/database/MySQL高性能优化规范建议.md
index f079ad77..60f17583 100644
--- a/docs/database/MySQL高性能优化规范建议.md
+++ b/docs/database/MySQL高性能优化规范建议.md
@@ -35,7 +35,7 @@
- [2. 避免数据类型的隐式转换](#2-避免数据类型的隐式转换)
- [3. 充分利用表上已经存在的索引](#3-充分利用表上已经存在的索引)
- [4. 数据库设计时,应该要对以后扩展进行考虑](#4-数据库设计时应该要对以后扩展进行考虑)
- - [5. 程序连接不同的数据库使用不同的账号,进制跨库查询](#5-程序连接不同的数据库使用不同的账号进制跨库查询)
+ - [5. 程序连接不同的数据库使用不同的账号,禁止跨库查询](#5-程序连接不同的数据库使用不同的账号禁止跨库查询)
- [6. 禁止使用 SELECT * 必须使用 SELECT <字段列表> 查询](#6-禁止使用-select--必须使用-select-字段列表-查询)
- [7. 禁止使用不含字段列表的 INSERT 语句](#7-禁止使用不含字段列表的-insert-语句)
- [8. 避免使用子查询,可以把子查询优化为 join 操作](#8-避免使用子查询可以把子查询优化为-join-操作)
@@ -76,6 +76,8 @@ Innodb 支持事务,支持行级锁,更好的恢复性,高并发下性能
兼容性更好,统一字符集可以避免由于字符集转换产生的乱码,不同的字符集进行比较前需要进行转换会造成索引失效,如果数据库中有存储 emoji 表情的需要,字符集需要采用 utf8mb4 字符集。
+参考文章:[MySQL 字符集不一致导致索引失效的一个真实案例](https://blog.csdn.net/horses/article/details/107243447)
+
### 3. 所有表和字段都需要添加注释
使用 comment 从句添加表和列的备注,从一开始就进行数据字典的维护
diff --git a/docs/database/Redis/Redis.md b/docs/database/Redis/Redis.md
deleted file mode 100644
index a17c7f04..00000000
--- a/docs/database/Redis/Redis.md
+++ /dev/null
@@ -1,370 +0,0 @@
-点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
-
-
-- [redis 简介](#redis-简介)
-- [为什么要用 redis/为什么要用缓存](#为什么要用-redis为什么要用缓存)
-- [为什么要用 redis 而不用 map/guava 做缓存?](#为什么要用-redis-而不用-mapguava-做缓存)
-- [redis 和 memcached 的区别](#redis-和-memcached-的区别)
-- [redis 常见数据结构以及使用场景分析](#redis-常见数据结构以及使用场景分析)
- - [1.String](#1string)
- - [2.Hash](#2hash)
- - [3.List](#3list)
- - [4.Set](#4set)
- - [5.Sorted Set](#5sorted-set)
-- [redis 设置过期时间](#redis-设置过期时间)
-- [redis 内存淘汰机制(MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据?)](#redis-内存淘汰机制mysql里有2000w数据redis中只存20w的数据如何保证redis中的数据都是热点数据)
-- [redis 持久化机制(怎么保证 redis 挂掉之后再重启数据可以进行恢复)](#redis-持久化机制怎么保证-redis-挂掉之后再重启数据可以进行恢复)
-- [redis 事务](#redis-事务)
-- [缓存雪崩和缓存穿透问题解决方案](#缓存雪崩和缓存穿透问题解决方案)
-- [如何解决 Redis 的并发竞争 Key 问题](#如何解决-redis-的并发竞争-key-问题)
-- [如何保证缓存与数据库双写时的数据一致性?](#如何保证缓存与数据库双写时的数据一致性)
-
-
-
-### redis 简介
-
-简单来说 redis 就是一个数据库,不过与传统数据库不同的是 redis 的数据是存在内存中的,所以读写速度非常快,因此 redis 被广泛应用于缓存方向。另外,redis 也经常用来做分布式锁。redis 提供了多种数据类型来支持不同的业务场景。除此之外,redis 支持事务 、持久化、LUA脚本、LRU驱动事件、多种集群方案。
-
-### 为什么要用 redis/为什么要用缓存
-
-主要从“高性能”和“高并发”这两点来看待这个问题。
-
-**高性能:**
-
-假如用户第一次访问数据库中的某些数据。这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。如果数据库中的对应数据改变的之后,同步改变缓存中相应的数据即可!
-
-
-
-
-**高并发:**
-
-直接操作缓存能够承受的请求是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。
-
-
-
-
-
-### 为什么要用 redis 而不用 map/guava 做缓存?
-
-
->下面的内容来自 segmentfault 一位网友的提问,地址:https://segmentfault.com/q/1010000009106416
-
-缓存分为本地缓存和分布式缓存。以 Java 为例,使用自带的 map 或者 guava 实现的是本地缓存,最主要的特点是轻量以及快速,生命周期随着 jvm 的销毁而结束,并且在多实例的情况下,每个实例都需要各自保存一份缓存,缓存不具有一致性。
-
-使用 redis 或 memcached 之类的称为分布式缓存,在多实例的情况下,各实例共用一份缓存数据,缓存具有一致性。缺点是需要保持 redis 或 memcached服务的高可用,整个程序架构上较为复杂。
-
-### redis 的线程模型
-
-> 参考地址:https://www.javazhiyin.com/22943.html
-
-redis 内部使用文件事件处理器 `file event handler`,这个文件事件处理器是单线程的,所以 redis 才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 socket,根据 socket 上的事件来选择对应的事件处理器进行处理。
-
-文件事件处理器的结构包含 4 个部分:
-
-- 多个 socket
-- IO 多路复用程序
-- 文件事件分派器
-- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
-
-多个 socket 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 socket,会将 socket 产生的事件放入队列中排队,事件分派器每次从队列中取出一个事件,把该事件交给对应的事件处理器进行处理。
-
-
-### redis 和 memcached 的区别
-
-对于 redis 和 memcached 我总结了下面四点。现在公司一般都是用 redis 来实现缓存,而且 redis 自身也越来越强大了!
-
-1. **redis支持更丰富的数据类型(支持更复杂的应用场景)**:Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。memcache支持简单的数据类型,String。
-2. **Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而Memecache把数据全部存在内存之中。**
-3. **集群模式**:memcached没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 redis 目前是原生支持 cluster 模式的.
-4. **Memcached是多线程,非阻塞IO复用的网络模型;Redis使用单线程的多路 IO 复用模型。**
-
-
-> 来自网络上的一张图,这里分享给大家!
-
-
-
-
-### redis 常见数据结构以及使用场景分析
-
-#### 1.String
-
-> **常用命令:** set,get,decr,incr,mget 等。
-
-
-String数据结构是简单的key-value类型,value其实不仅可以是String,也可以是数字。
-常规key-value缓存应用;
-常规计数:微博数,粉丝数等。
-
-#### 2.Hash
-> **常用命令:** hget,hset,hgetall 等。
-
-hash 是一个 string 类型的 field 和 value 的映射表,hash 特别适合用于存储对象,后续操作的时候,你可以直接仅仅修改这个对象中的某个字段的值。 比如我们可以 hash 数据结构来存储用户信息,商品信息等等。比如下面我就用 hash 类型存放了我本人的一些信息:
-
-```
-key=JavaUser293847
-value={
- “id”: 1,
- “name”: “SnailClimb”,
- “age”: 22,
- “location”: “Wuhan, Hubei”
-}
-
-```
-
-
-#### 3.List
-> **常用命令:** lpush,rpush,lpop,rpop,lrange等
-
-list 就是链表,Redis list 的应用场景非常多,也是Redis最重要的数据结构之一,比如微博的关注列表,粉丝列表,消息列表等功能都可以用Redis的 list 结构来实现。
-
-Redis list 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。
-
-另外可以通过 lrange 命令,就是从某个元素开始读取多少个元素,可以基于 list 实现分页查询,这个很棒的一个功能,基于 redis 实现简单的高性能分页,可以做类似微博那种下拉不断分页的东西(一页一页的往下走),性能高。
-
-#### 4.Set
-
-> **常用命令:**
-sadd,spop,smembers,sunion 等
-
-set 对外提供的功能与list类似是一个列表的功能,特殊之处在于 set 是可以自动排重的。
-
-当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。可以基于 set 轻易实现交集、并集、差集的操作。
-
-比如:在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程,具体命令如下:
-
-```
-sinterstore key1 key2 key3 将交集存在key1内
-```
-
-#### 5.Sorted Set
-> **常用命令:** zadd,zrange,zrem,zcard等
-
-
-和set相比,sorted set增加了一个权重参数score,使得集合中的元素能够按score进行有序排列。
-
-**举例:** 在直播系统中,实时排行信息包含直播间在线用户列表,各种礼物排行榜,弹幕消息(可以理解为按消息维度的消息排行榜)等信息,适合使用 Redis 中的 Sorted Set 结构进行存储。
-
-
-### redis 设置过期时间
-
-Redis中有个设置时间过期的功能,即对存储在 redis 数据库中的值可以设置一个过期时间。作为一个缓存数据库,这是非常实用的。如我们一般项目中的 token 或者一些登录信息,尤其是短信验证码都是有时间限制的,按照传统的数据库处理方式,一般都是自己判断过期,这样无疑会严重影响项目性能。
-
-我们 set key 的时候,都可以给一个 expire time,就是过期时间,通过过期时间我们可以指定这个 key 可以存活的时间。
-
-如果假设你设置了一批 key 只能存活1个小时,那么接下来1小时后,redis是怎么对这批key进行删除的?
-
-**定期删除+惰性删除。**
-
-通过名字大概就能猜出这两个删除方式的意思了。
-
-- **定期删除**:redis默认是每隔 100ms 就**随机抽取**一些设置了过期时间的key,检查其是否过期,如果过期就删除。注意这里是随机抽取的。为什么要随机呢?你想一想假如 redis 存了几十万个 key ,每隔100ms就遍历所有的设置过期时间的 key 的话,就会给 CPU 带来很大的负载!
-- **惰性删除** :定期删除可能会导致很多过期 key 到了时间并没有被删除掉。所以就有了惰性删除。假如你的过期 key,靠定期删除没有被删除掉,还停留在内存里,除非你的系统去查一下那个 key,才会被redis给删除掉。这就是所谓的惰性删除,也是够懒的哈!
-
-
-但是仅仅通过设置过期时间还是有问题的。我们想一下:如果定期删除漏掉了很多过期 key,然后你也没及时去查,也就没走惰性删除,此时会怎么样?如果大量过期key堆积在内存里,导致redis内存块耗尽了。怎么解决这个问题呢? **redis 内存淘汰机制。**
-
-### redis 内存淘汰机制(MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据?)
-
-redis 配置文件 redis.conf 中有相关注释,我这里就不贴了,大家可以自行查阅或者通过这个网址查看: [http://download.redis.io/redis-stable/redis.conf](http://download.redis.io/redis-stable/redis.conf)
-
-**redis 提供 6种数据淘汰策略:**
-
-1. **volatile-lru**:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
-2. **volatile-ttl**:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
-3. **volatile-random**:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
-4. **allkeys-lru**:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的)
-5. **allkeys-random**:从数据集(server.db[i].dict)中任意选择数据淘汰
-6. **no-eviction**:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
-
-4.0版本后增加以下两种:
-
-7. **volatile-lfu**:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
-8. **allkeys-lfu**:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的key
-
-**备注: 关于 redis 设置过期时间以及内存淘汰机制,我这里只是简单的总结一下,后面会专门写一篇文章来总结!**
-
-
-### redis 持久化机制(怎么保证 redis 挂掉之后再重启数据可以进行恢复)
-
-很多时候我们需要持久化数据也就是将内存中的数据写入到硬盘里面,大部分原因是为了之后重用数据(比如重启机器、机器故障之后恢复数据),或者是为了防止系统故障而将数据备份到一个远程位置。
-
-Redis不同于Memcached的很重一点就是,Redis支持持久化,而且支持两种不同的持久化操作。**Redis的一种持久化方式叫快照(snapshotting,RDB),另一种方式是只追加文件(append-only file,AOF)**。这两种方法各有千秋,下面我会详细这两种持久化方法是什么,怎么用,如何选择适合自己的持久化方法。
-
-**快照(snapshotting)持久化(RDB)**
-
-Redis可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本。Redis创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis主从结构,主要用来提高Redis性能),还可以将快照留在原地以便重启服务器的时候使用。
-
-快照持久化是Redis默认采用的持久化方式,在redis.conf配置文件中默认有此下配置:
-
-```conf
-
-save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
-
-save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
-
-save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
-```
-
-**AOF(append-only file)持久化**
-
-与快照持久化相比,AOF持久化 的实时性更好,因此已成为主流的持久化方案。默认情况下Redis没有开启AOF(append only file)方式的持久化,可以通过appendonly参数开启:
-
-```conf
-appendonly yes
-```
-
-开启AOF持久化后每执行一条会更改Redis中的数据的命令,Redis就会将该命令写入硬盘中的AOF文件。AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的,默认的文件名是appendonly.aof。
-
-在Redis的配置文件中存在三种不同的 AOF 持久化方式,它们分别是:
-
-```conf
-appendfsync always #每次有数据修改发生时都会写入AOF文件,这样会严重降低Redis的速度
-appendfsync everysec #每秒钟同步一次,显示地将多个写命令同步到硬盘
-appendfsync no #让操作系统决定何时进行同步
-```
-
-为了兼顾数据和写入性能,用户可以考虑 appendfsync everysec选项 ,让Redis每秒同步一次AOF文件,Redis性能几乎没受到任何影响。而且这样即使出现系统崩溃,用户最多只会丢失一秒之内产生的数据。当硬盘忙于执行写入操作的时候,Redis还会优雅的放慢自己的速度以便适应硬盘的最大写入速度。
-
-**Redis 4.0 对于持久化机制的优化**
-
-Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 `aof-use-rdb-preamble` 开启)。
-
-如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
-
-**补充内容:AOF 重写**
-
-AOF重写可以产生一个新的AOF文件,这个新的AOF文件和原有的AOF文件所保存的数据库状态一样,但体积更小。
-
-AOF重写是一个有歧义的名字,该功能是通过读取数据库中的键值对来实现的,程序无须对现有AOF文件进行任何读入、分析或者写入操作。
-
-在执行 BGREWRITEAOF 命令时,Redis 服务器会维护一个 AOF 重写缓冲区,该缓冲区会在子进程创建新AOF文件期间,记录服务器执行的所有写命令。当子进程完成创建新AOF文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新AOF文件的末尾,使得新旧两个AOF文件所保存的数据库状态一致。最后,服务器用新的AOF文件替换旧的AOF文件,以此来完成AOF文件重写操作
-
-**更多内容可以查看我的这篇文章:**
-
-- [Redis持久化](Redis持久化.md)
-
-
-### redis 事务
-
-Redis 通过 MULTI、EXEC、WATCH 等命令来实现事务(transaction)功能。事务提供了一种将多个命令请求打包,然后一次性、按顺序地执行多个命令的机制,并且在事务执行期间,服务器不会中断事务而改去执行其他客户端的命令请求,它会将事务中的所有命令都执行完毕,然后才去处理其他客户端的命令请求。
-
-在传统的关系式数据库中,常常用 ACID 性质来检验事务功能的可靠性和安全性。在 Redis 中,事务总是具有原子性(Atomicity)、一致性(Consistency)和隔离性(Isolation),并且当 Redis 运行在某种特定的持久化模式下时,事务也具有持久性(Durability)。
-
-补充内容:
-
-> 1. redis同一个事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚。(来自[issue:关于Redis事务不是原子性问题](https://github.com/Snailclimb/JavaGuide/issues/452) )
-
-### 缓存雪崩和缓存穿透问题解决方案
-
-#### **缓存雪崩**
-
-**什么是缓存雪崩?**
-
-简介:缓存同一时间大面积的失效,所以,后面的请求都会落到数据库上,造成数据库短时间内承受大量请求而崩掉。
-
-**有哪些解决办法?**
-
-(中华石杉老师在他的视频中提到过,视频地址在最后一个问题中有提到):
-
-- 事前:尽量保证整个 redis 集群的高可用性,发现机器宕机尽快补上。选择合适的内存淘汰策略。
-- 事中:本地ehcache缓存 + hystrix限流&降级,避免MySQL崩掉
-- 事后:利用 redis 持久化机制保存的数据尽快恢复缓存
-
-
-
-#### **缓存穿透**
-
-**什么是缓存穿透?**
-
-缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。下面用图片展示一下(这两张图片不是我画的,为了省事直接在网上找的,这里说明一下):
-
-**正常缓存处理流程:**
-
- -
-**缓存穿透情况处理流程:**
-
-
-
-**缓存穿透情况处理流程:**
-
-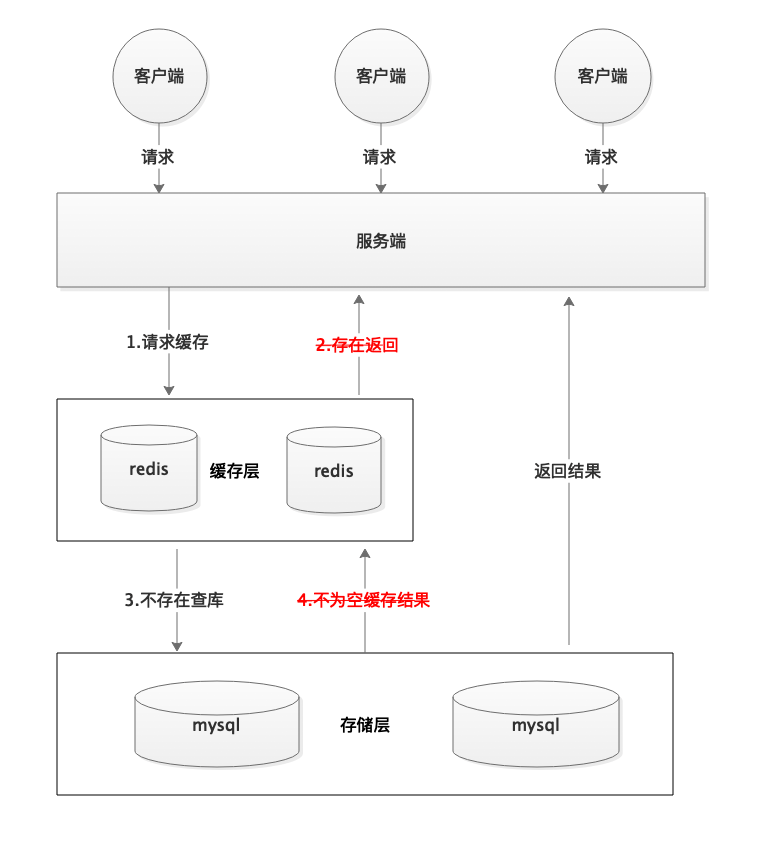 -
-一般MySQL 默认的最大连接数在 150 左右,这个可以通过 `show variables like '%max_connections%'; `命令来查看。最大连接数一个还只是一个指标,cpu,内存,磁盘,网络等无力条件都是其运行指标,这些指标都会限制其并发能力!所以,一般 3000 个并发请求就能打死大部分数据库了。
-
-**有哪些解决办法?**
-
-最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
-
-**1)缓存无效 key** : 如果缓存和数据库都查不到某个 key 的数据就写一个到 redis 中去并设置过期时间,具体命令如下:`SET key value EX 10086`。这种方式可以解决请求的 key 变化不频繁的情况,如果黑客恶意攻击,每次构建不同的请求key,会导致 redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。
-
-另外,这里多说一嘴,一般情况下我们是这样设计 key 的: `表名:列名:主键名:主键值`。
-
- 如果用 Java 代码展示的话,差不多是下面这样的:
-
-```java
-public Object getObjectInclNullById(Integer id) {
- // 从缓存中获取数据
- Object cacheValue = cache.get(id);
- // 缓存为空
- if (cacheValue == null) {
- // 从数据库中获取
- Object storageValue = storage.get(key);
- // 缓存空对象
- cache.set(key, storageValue);
- // 如果存储数据为空,需要设置一个过期时间(300秒)
- if (storageValue == null) {
- // 必须设置过期时间,否则有被攻击的风险
- cache.expire(key, 60 * 5);
- }
- return storageValue;
- }
- return cacheValue;
-}
-```
-
-**2)布隆过滤器:**布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在与海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。具体是这样做的:把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,我会先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。总结一下就是下面这张图(这张图片不是我画的,为了省事直接在网上找的):
-
-
-
-一般MySQL 默认的最大连接数在 150 左右,这个可以通过 `show variables like '%max_connections%'; `命令来查看。最大连接数一个还只是一个指标,cpu,内存,磁盘,网络等无力条件都是其运行指标,这些指标都会限制其并发能力!所以,一般 3000 个并发请求就能打死大部分数据库了。
-
-**有哪些解决办法?**
-
-最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
-
-**1)缓存无效 key** : 如果缓存和数据库都查不到某个 key 的数据就写一个到 redis 中去并设置过期时间,具体命令如下:`SET key value EX 10086`。这种方式可以解决请求的 key 变化不频繁的情况,如果黑客恶意攻击,每次构建不同的请求key,会导致 redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。
-
-另外,这里多说一嘴,一般情况下我们是这样设计 key 的: `表名:列名:主键名:主键值`。
-
- 如果用 Java 代码展示的话,差不多是下面这样的:
-
-```java
-public Object getObjectInclNullById(Integer id) {
- // 从缓存中获取数据
- Object cacheValue = cache.get(id);
- // 缓存为空
- if (cacheValue == null) {
- // 从数据库中获取
- Object storageValue = storage.get(key);
- // 缓存空对象
- cache.set(key, storageValue);
- // 如果存储数据为空,需要设置一个过期时间(300秒)
- if (storageValue == null) {
- // 必须设置过期时间,否则有被攻击的风险
- cache.expire(key, 60 * 5);
- }
- return storageValue;
- }
- return cacheValue;
-}
-```
-
-**2)布隆过滤器:**布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在与海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。具体是这样做的:把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,我会先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。总结一下就是下面这张图(这张图片不是我画的,为了省事直接在网上找的):
-
-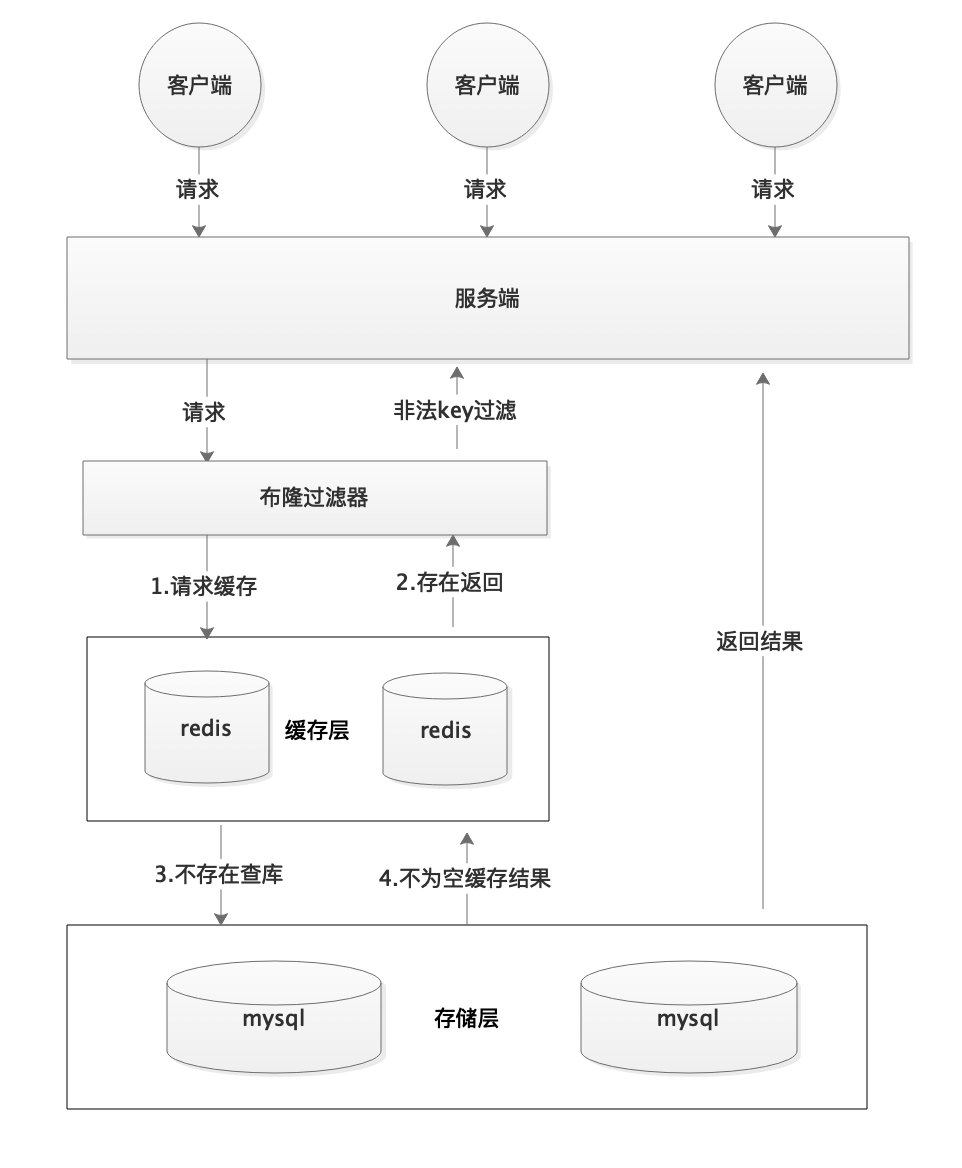 -
-更多关于布隆过滤器的内容可以看我的这篇原创:[《不了解布隆过滤器?一文给你整的明明白白!》](https://github.com/Snailclimb/JavaGuide/blob/master/docs/dataStructures-algorithms/data-structure/bloom-filter.md) ,强烈推荐,个人感觉网上应该找不到总结的这么明明白白的文章了。
-
-### 如何解决 Redis 的并发竞争 Key 问题
-
-所谓 Redis 的并发竞争 Key 的问题也就是多个系统同时对一个 key 进行操作,但是最后执行的顺序和我们期望的顺序不同,这样也就导致了结果的不同!
-
-推荐一种方案:分布式锁(zookeeper 和 redis 都可以实现分布式锁)。(如果不存在 Redis 的并发竞争 Key 问题,不要使用分布式锁,这样会影响性能)
-
-基于zookeeper临时有序节点可以实现的分布式锁。大致思想为:每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。完成业务流程后,删除对应的子节点释放锁。
-
-在实践中,当然是从以可靠性为主。所以首推Zookeeper。
-
-参考:
-
-- https://www.jianshu.com/p/8bddd381de06
-
-### 如何保证缓存与数据库双写时的数据一致性?
-
-> 一般情况下我们都是这样使用缓存的:先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。这种方式很明显会存在缓存和数据库的数据不一致的情况。
-
-你只要用缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题?
-
-一般来说,就是如果你的系统不是严格要求缓存+数据库必须一致性的话,缓存可以稍微的跟数据库偶尔有不一致的情况,最好不要做这个方案,读请求和写请求串行化,串到一个内存队列里去,这样就可以保证一定不会出现不一致的情况
-
-串行化之后,就会导致系统的吞吐量会大幅度的降低,用比正常情况下多几倍的机器去支撑线上的一个请求。
-
-更多内容可以查看:https://github.com/doocs/advanced-java/blob/master/docs/high-concurrency/redis-consistence.md
-
-**参考:** Java工程师面试突击第1季(可能是史上最好的Java面试突击课程)-中华石杉老师!公众号后台回复关键字“1”即可获取该视频内容。
-
-### 参考
-
-- 《Redis开发与运维》
-- Redis 命令总结:http://redisdoc.com/string/set.html
-
-## 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
-
-
diff --git a/docs/database/Redis/Redis持久化.md b/docs/database/Redis/Redis持久化.md
index fbad9555..0408c276 100644
--- a/docs/database/Redis/Redis持久化.md
+++ b/docs/database/Redis/Redis持久化.md
@@ -1,5 +1,4 @@
-
非常感谢《redis实战》真本书,本文大多内容也参考了书中的内容。非常推荐大家看一下《redis实战》这本书,感觉书中的很多理论性东西还是很不错的。
为什么本文的名字要加上春夏秋冬又一春,哈哈 ,这是一部韩国的电影,我感觉电影不错,所以就用在文章名字上了,没有什么特别的含义,然后下面的有些配图也是电影相关镜头。
@@ -10,12 +9,10 @@
Redis不同于Memcached的很重一点就是,**Redis支持持久化**,而且支持两种不同的持久化操作。Redis的一种持久化方式叫**快照(snapshotting,RDB)**,另一种方式是**只追加文件(append-only file,AOF)**.这两种方法各有千秋,下面我会详细这两种持久化方法是什么,怎么用,如何选择适合自己的持久化方法。
-
## 快照(snapshotting)持久化
Redis可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本。Redis创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis主从结构,主要用来提高Redis性能),还可以将快照留在原地以便重启服务器的时候使用。
-

**快照持久化是Redis默认采用的持久化方式**,在redis.conf配置文件中默认有此下配置:
@@ -46,6 +43,7 @@ save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生
## **AOF(append-only file)持久化**
与快照持久化相比,AOF持久化 的实时性更好,因此已成为主流的持久化方案。默认情况下Redis没有开启AOF(append only file)方式的持久化,可以通过appendonly参数开启:
+
```
appendonly yes
```
diff --git a/docs/database/Redis/images/redis-all/redis-list.drawio b/docs/database/Redis/images/redis-all/redis-list.drawio
new file mode 100644
index 00000000..afa76715
--- /dev/null
+++ b/docs/database/Redis/images/redis-all/redis-list.drawio
@@ -0,0 +1 @@
+
-
-更多关于布隆过滤器的内容可以看我的这篇原创:[《不了解布隆过滤器?一文给你整的明明白白!》](https://github.com/Snailclimb/JavaGuide/blob/master/docs/dataStructures-algorithms/data-structure/bloom-filter.md) ,强烈推荐,个人感觉网上应该找不到总结的这么明明白白的文章了。
-
-### 如何解决 Redis 的并发竞争 Key 问题
-
-所谓 Redis 的并发竞争 Key 的问题也就是多个系统同时对一个 key 进行操作,但是最后执行的顺序和我们期望的顺序不同,这样也就导致了结果的不同!
-
-推荐一种方案:分布式锁(zookeeper 和 redis 都可以实现分布式锁)。(如果不存在 Redis 的并发竞争 Key 问题,不要使用分布式锁,这样会影响性能)
-
-基于zookeeper临时有序节点可以实现的分布式锁。大致思想为:每个客户端对某个方法加锁时,在zookeeper上的与该方法对应的指定节点的目录下,生成一个唯一的瞬时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。完成业务流程后,删除对应的子节点释放锁。
-
-在实践中,当然是从以可靠性为主。所以首推Zookeeper。
-
-参考:
-
-- https://www.jianshu.com/p/8bddd381de06
-
-### 如何保证缓存与数据库双写时的数据一致性?
-
-> 一般情况下我们都是这样使用缓存的:先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。这种方式很明显会存在缓存和数据库的数据不一致的情况。
-
-你只要用缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题?
-
-一般来说,就是如果你的系统不是严格要求缓存+数据库必须一致性的话,缓存可以稍微的跟数据库偶尔有不一致的情况,最好不要做这个方案,读请求和写请求串行化,串到一个内存队列里去,这样就可以保证一定不会出现不一致的情况
-
-串行化之后,就会导致系统的吞吐量会大幅度的降低,用比正常情况下多几倍的机器去支撑线上的一个请求。
-
-更多内容可以查看:https://github.com/doocs/advanced-java/blob/master/docs/high-concurrency/redis-consistence.md
-
-**参考:** Java工程师面试突击第1季(可能是史上最好的Java面试突击课程)-中华石杉老师!公众号后台回复关键字“1”即可获取该视频内容。
-
-### 参考
-
-- 《Redis开发与运维》
-- Redis 命令总结:http://redisdoc.com/string/set.html
-
-## 公众号
-
-如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
-
-**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
-
-**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
-
-
diff --git a/docs/database/Redis/Redis持久化.md b/docs/database/Redis/Redis持久化.md
index fbad9555..0408c276 100644
--- a/docs/database/Redis/Redis持久化.md
+++ b/docs/database/Redis/Redis持久化.md
@@ -1,5 +1,4 @@
-
非常感谢《redis实战》真本书,本文大多内容也参考了书中的内容。非常推荐大家看一下《redis实战》这本书,感觉书中的很多理论性东西还是很不错的。
为什么本文的名字要加上春夏秋冬又一春,哈哈 ,这是一部韩国的电影,我感觉电影不错,所以就用在文章名字上了,没有什么特别的含义,然后下面的有些配图也是电影相关镜头。
@@ -10,12 +9,10 @@
Redis不同于Memcached的很重一点就是,**Redis支持持久化**,而且支持两种不同的持久化操作。Redis的一种持久化方式叫**快照(snapshotting,RDB)**,另一种方式是**只追加文件(append-only file,AOF)**.这两种方法各有千秋,下面我会详细这两种持久化方法是什么,怎么用,如何选择适合自己的持久化方法。
-
## 快照(snapshotting)持久化
Redis可以通过创建快照来获得存储在内存里面的数据在某个时间点上的副本。Redis创建快照之后,可以对快照进行备份,可以将快照复制到其他服务器从而创建具有相同数据的服务器副本(Redis主从结构,主要用来提高Redis性能),还可以将快照留在原地以便重启服务器的时候使用。
-

**快照持久化是Redis默认采用的持久化方式**,在redis.conf配置文件中默认有此下配置:
@@ -46,6 +43,7 @@ save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生
## **AOF(append-only file)持久化**
与快照持久化相比,AOF持久化 的实时性更好,因此已成为主流的持久化方案。默认情况下Redis没有开启AOF(append only file)方式的持久化,可以通过appendonly参数开启:
+
```
appendonly yes
```
diff --git a/docs/database/Redis/images/redis-all/redis-list.drawio b/docs/database/Redis/images/redis-all/redis-list.drawio
new file mode 100644
index 00000000..afa76715
--- /dev/null
+++ b/docs/database/Redis/images/redis-all/redis-list.drawio
@@ -0,0 +1 @@
+ +
+每种方式都有各自的优势,根据实际场景才是王道。下面再对这三种方式做一个简单的对比,以供大家实际开发中选择正确的存放时间的数据类型:
+
+
+
+每种方式都有各自的优势,根据实际场景才是王道。下面再对这三种方式做一个简单的对比,以供大家实际开发中选择正确的存放时间的数据类型:
+
+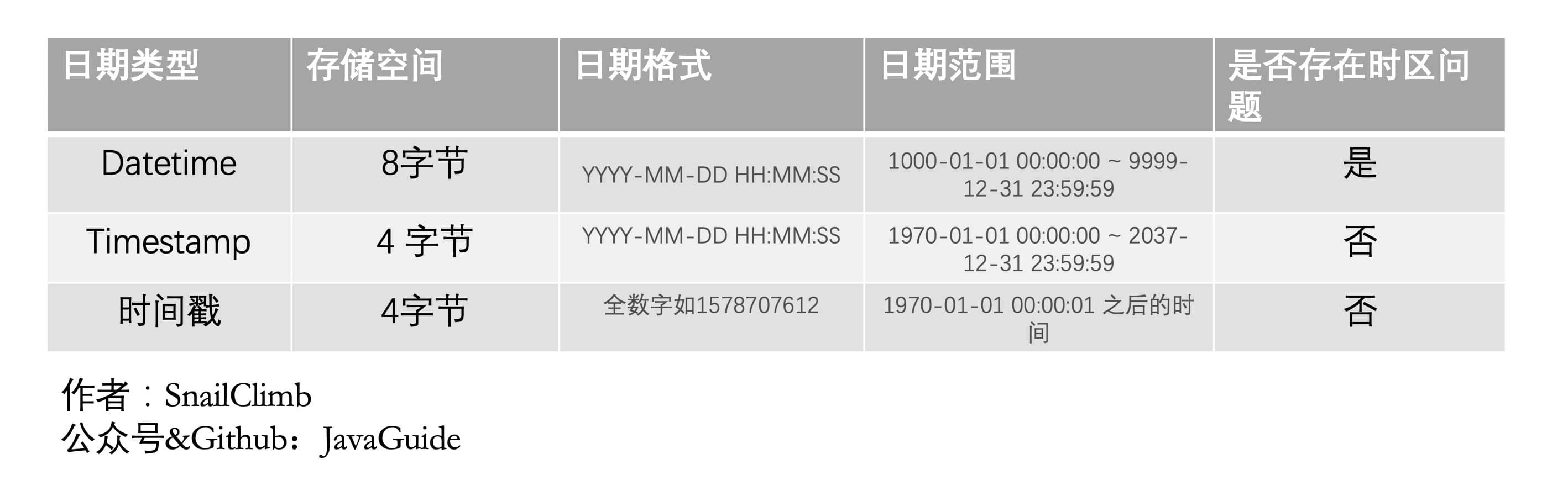 +
+如果还有什么问题欢迎给我留言!如果文章有什么问题的话,也劳烦指出,Guide 哥感激不尽!
+
+后面的文章我会介绍:
+
+- [ ] Java8 对日期的支持以及为啥不能用 SimpleDateFormat。
+- [ ] SpringBoot 中如何实际使用(JPA 为例)
\ No newline at end of file
diff --git a/docs/database/数据库索引.md b/docs/database/数据库索引.md
new file mode 100644
index 00000000..568ba833
--- /dev/null
+++ b/docs/database/数据库索引.md
@@ -0,0 +1,225 @@
+## 什么是索引?
+**索引是一种用于快速查询和检索数据的数据结构。常见的索引结构有: B树, B+树和Hash。**
+
+索引的作用就相当于目录的作用。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
+
+## 为什么要用索引?索引的优缺点分析
+
+### 索引的优点
+**可以大大加快 数据的检索速度(大大减少的检索的数据量), 这也是创建索引的最主要的原因。毕竟大部分系统的读请求总是大于写请求的。 ** 另外,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
+
+### 索引的缺点
+1. **创建索引和维护索引需要耗费许多时间**:当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低SQL执行效率。
+2. **占用物理存储空间** :索引需要使用物理文件存储,也会耗费一定空间。
+
+## B树和B+树区别
+
+* B树的所有节点既存放 键(key) 也存放 数据(data);而B+树只有叶子节点存放 key 和 data,其他内节点只存放key。
+* B树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
+* B树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而B+树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
+
+
+
+## Hash索引和 B+树索引优劣分析
+
+**Hash索引定位快**
+
+Hash索引指的就是Hash表,最大的优点就是能够在很短的时间内,根据Hash函数定位到数据所在的位置,这是B+树所不能比的。
+
+**Hash冲突问题**
+
+知道HashMap或HashTable的同学,相信都知道它们最大的缺点就是Hash冲突了。不过对于数据库来说这还不算最大的缺点。
+
+**Hash索引不支持顺序和范围查询(Hash索引不支持顺序和范围查询是它最大的缺点。**
+
+试想一种情况:
+
+````text
+SELECT * FROM tb1 WHERE id < 500;
+````
+
+B+树是有序的,在这种范围查询中,优势非常大,直接遍历比500小的叶子节点就够了。而Hash索引是根据hash算法来定位的,难不成还要把 1 - 499的数据,每个都进行一次hash计算来定位吗?这就是Hash最大的缺点了。
+
+---
+
+## 索引类型
+
+### 主键索引(Primary Key)
+**数据表的主键列使用的就是主键索引。**
+
+**一张数据表有只能有一个主键,并且主键不能为null,不能重复。**
+
+**在mysql的InnoDB的表中,当没有显示的指定表的主键时,InnoDB会自动先检查表中是否有唯一索引的字段,如果有,则选择该字段为默认的主键,否则InnoDB将会自动创建一个6Byte的自增主键。**
+
+### 二级索引(辅助索引)
+**二级索引又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。**
+
+唯一索引,普通索引,前缀索引等索引属于二级索引。
+
+**PS:不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,也可以自行搜索。**
+
+1. **唯一索引(Unique Key)** :唯一索引也是一种约束。**唯一索引的属性列不能出现重复的数据,但是允许数据为NULL,一张表允许创建多个唯一索引。**建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
+2. **普通索引(Index)** :**普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和NULL。**
+3. **前缀索引(Prefix)** :前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,
+ 因为只取前几个字符。
+4. **全文索引(Full Text)** :全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6之前只有MYISAM引擎支持全文索引,5.6之后InnoDB也支持了全文索引。
+
+二级索引:
+.png)
+
+## 聚集索引与非聚集索引
+
+### 聚集索引
+**聚集索引即索引结构和数据一起存放的索引。主键索引属于聚集索引。**
+
+在 Mysql 中,InnoDB引擎的表的 `.ibd`文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
+
+#### 聚集索引的优点
+聚集索引的查询速度非常的快,因为整个B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。
+
+#### 聚集索引的缺点
+1. **依赖于有序的数据** :因为B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或UUID这种又长又难比较的数据,插入或查找的速度肯定比较慢。
+2. **更新代价大** : 如果对索引列的数据被修改时,那么对应的索引也将会被修改,
+ 而且况聚集索引的叶子节点还存放着数据,修改代价肯定是较大的,
+ 所以对于主键索引来说,主键一般都是不可被修改的。
+
+### 非聚集索引
+
+**非聚集索引即索引结构和数据分开存放的索引。**
+
+**二级索引属于非聚集索引。**
+
+>MYISAM引擎的表的.MYI文件包含了表的索引,
+>该表的索引(B+树)的每个叶子非叶子节点存储索引,
+>叶子节点存储索引和索引对应数据的指针,指向.MYD文件的数据。
+>
+**非聚集索引的叶子节点并不一定存放数据的指针,
+因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。**
+
+#### 非聚集索引的优点
+**更新代价比聚集索引要小** 。非聚集索引的更新代价就没有聚集索引那么大了,非聚集索引的叶子节点是不存放数据的
+
+#### 非聚集索引的缺点
+1. 跟聚集索引一样,非聚集索引也依赖于有序的数据
+2. **可能会二次查询(回表)** :这应该是非聚集索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
+
+这是Mysql的表的文件截图:
+
+
+
+聚集索引和非聚集索引:
+
+
+
+### 非聚集索引一定回表查询吗(覆盖索引)?
+**非聚集索引不一定回表查询。**
+
+>试想一种情况,用户准备使用SQL查询用户名,而用户名字段正好建立了索引。
+
+````text
+ SELECT name FROM table WHERE username='guang19';
+````
+
+>那么这个索引的key本身就是name,查到对应的name直接返回就行了,无需回表查询。
+
+**即使是MYISAM也是这样,虽然MYISAM的主键索引确实需要回表,
+因为它的主键索引的叶子节点存放的是指针。但是如果SQL查的就是主键呢?**
+
+```text
+SELECT id FROM table WHERE id=1;
+```
+
+主键索引本身的key就是主键,查到返回就行了。这种情况就称之为覆盖索引了。
+
+## 覆盖索引
+
+如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。我们知道在InnoDB存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
+
+**覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了,
+而无需回表查询。**
+
+>如主键索引,如果一条SQL需要查询主键,那么正好根据主键索引就可以查到主键。
+>
+>再如普通索引,如果一条SQL需要查询name,name字段正好有索引,
+>那么直接根据这个索引就可以查到数据,也无需回表。
+
+覆盖索引:
+
+
+---
+
+## 索引创建原则
+
+### 单列索引
+单列索引即由一列属性组成的索引。
+
+### 联合索引(多列索引)
+联合索引即由多列属性组成索引。
+
+### 最左前缀原则
+
+假设创建的联合索引由三个字段组成:
+
+```text
+ALTER TABLE table ADD INDEX index_name (num,name,age)
+```
+
+那么当查询的条件有为:num / (num AND name) / (num AND name AND age)时,索引才生效。所以在创建联合索引时,尽量把查询最频繁的那个字段作为最左(第一个)字段。查询的时候也尽量以这个字段为第一条件。
+
+> 但可能由于版本原因(我的mysql版本为8.0.x),我创建的联合索引,相当于在联合索引的每个字段上都创建了相同的索引:
+
+.png)
+
+无论是否符合最左前缀原则,每个字段的索引都生效:
+
+
+
+## 索引创建注意点
+
+### 最左前缀原则
+
+虽然我目前的Mysql版本较高,好像不遵守最左前缀原则,索引也会生效。
+但是我们仍应遵守最左前缀原则,以免版本更迭带来的麻烦。
+
+### 选择合适的字段
+
+#### 1.不为NULL的字段
+
+索引字段的数据应该尽量不为NULL,因为对于数据为NULL的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为NULL,建议使用0,1,true,false这样语义较为清晰的短值或短字符作为替代。
+
+#### 2.被频繁查询的字段
+
+我们创建索引的字段应该是查询操作非常频繁的字段。
+
+#### 3.被作为条件查询的字段
+
+被作为WHERE条件查询的字段,应该被考虑建立索引。
+
+#### 4.被经常频繁用于连接的字段
+
+经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
+
+### 不合适创建索引的字段
+
+#### 1.被频繁更新的字段应该慎重建立索引
+
+虽然索引能带来查询上的效率,但是维护索引的成本也是不小的。
+如果一个字段不被经常查询,反而被经常修改,那么就更不应该在这种字段上建立索引了。
+
+#### 2.不被经常查询的字段没有必要建立索引
+
+#### 3.尽可能的考虑建立联合索引而不是单列索引
+
+因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗B+树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
+
+#### 4.注意避免冗余索引
+
+冗余索引指的是索引的功能相同,能够命中 就肯定能命中 ,那么 就是冗余索引如(name,city )和(name )这两个索引就是冗余索引,能够命中后者的查询肯定是能够命中前者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
+
+#### 5.考虑在字符串类型的字段上使用前缀索引代替普通索引
+
+前缀索引仅限于字符串类型,较普通索引会占用更小的空间,所以可以考虑使用前缀索引带替普通索引。
+
+### 使用索引一定能提高查询性能吗?
+
+大多数情况下,索引查询都是比全表扫描要快的。但是如果数据库的数据量不大,那么使用索引也不一定能够带来很大提升。
\ No newline at end of file
diff --git a/docs/database/阿里巴巴开发手册数据库部分的一些最佳实践.md b/docs/database/阿里巴巴开发手册数据库部分的一些最佳实践.md
index 7eb84001..abd9331d 100644
--- a/docs/database/阿里巴巴开发手册数据库部分的一些最佳实践.md
+++ b/docs/database/阿里巴巴开发手册数据库部分的一些最佳实践.md
@@ -21,7 +21,7 @@
> 1. **增加了复杂性:** a.每次做DELETE 或者UPDATE都必须考虑外键约束,会导致开发的时候很痛苦,测试数据极为不方便;b.外键的主从关系是定的,假如那天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
> 2. **增加了额外工作**: 数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗资源;(个人觉得这个不是不用外键的原因,因为即使你不使用外键,你在应用层面也还是要保证的。所以,我觉得这个影响可以忽略不计。)
> 3. 外键还会因为需要请求对其他表内部加锁而容易出现死锁情况;
-> 4. **对分不分表不友好** :因为分库分表下外键是无法生效的。
+> 4. **对分库分表不友好** :因为分库分表下外键是无法生效的。
> 5. ......
我个人觉得上面这种回答不是特别的全面,只是说了外键存在的一个常见的问题。实际上,我们知道外键也是有很多好处的,比如:
diff --git a/docs/essential-content-for-interview/BATJrealInterviewExperience/2020-zijietiaodong.md b/docs/essential-content-for-interview/BATJrealInterviewExperience/2020-zijietiaodong.md
new file mode 100644
index 00000000..0e63008b
--- /dev/null
+++ b/docs/essential-content-for-interview/BATJrealInterviewExperience/2020-zijietiaodong.md
@@ -0,0 +1,61 @@
+
+
+> 本文来自读者 Boyn 投稿!恭喜这位粉丝拿到了含金量极高的字节跳动实习 offer!赞!
+
+## 基本条件
+
+本人是底层 211 本科,现在大三,无科研经历,但是有一些项目经历,在国内监控行业某头部企业做过一段时间的实习。想着投一下字节,可以积累一下面试经验和为春招做准备.投了简历之后,过了一段时间,HR 就打电话跟我约时间,在年后进行远程面。
+
+说明一下,我投的是北京 office。
+
+## 一面
+
+面试官很和蔼,由于疫情的原因,大家都在家里面进行远程面试
+
+开头没有自我介绍,直接开始问项目了,问了比如
+
+- 常用的 Web 组件有哪些(回答了自己经常用到的 SpringBoot,Redis,Mysql 等等,字节这边基本没有用 Java 的后台,所以感觉面试官不大会问 Spring,Java 这些东西,反倒是对数据库和中间件比较感兴趣)
+- Kafka 相关,如何保证不会重复消费,Kafka 消费组结构等等(这个只是凭着感觉和面试官说了,因为 Kafka 自己确实准备得不充分,但是心态稳住了)
+- **Mysql 索引,B+树(必考嗷同学们)**
+
+还有一些项目中的细节,这些因人而异,就不放上来了,提示一点就是要在项目中介绍一些亮眼的地方,比如用了什么牛逼的数据结构,架构上有什么特点,并发量大小还有怎么去 hold 住并发量
+
+后面就是算法题了,一共做了两道
+
+1. 判断平衡二叉树(这道题总体来说并不难,但是面试官在中间穿插了垃圾回收的知识,这就很难受了,具体的就是大家要判断一下对象在什么时候会回收,可达性分析什么时候对这个对象来说是不可达的,还有在递归函数中内存如何变化,这个是让我们来对这个函数进行执行过程的建模,只看栈帧大小变化的话,应该有是两个峰值,中间会有抖动的情况)
+2. 二分查找法的变种题,给定`target`和一个升序的数组,寻找下一个比数组大的数.这道题也不难,靠大家对二分查找法的熟悉程度,当然,这边还有一个优化的点,可以看看[我的博客](https://boyn.top/2019/11/09/%E7%AE%97%E6%B3%95%E4%B8%8E%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE%E6%B3%95/)找找灵感
+
+完成了之后,面试官让我等一会有二面,大概 10 分钟左右吧,休息了一会就继续了
+
+## 二面
+
+二面一上来就是先让我自我介绍,当然还是同样的套路,同样的香脆
+
+然后问了我一些关于 Redis 的问题,比如 **zset 的实现(跳表,这个高频)** ,键的过期策略,持久化等等,这些在大多数 Redis 的介绍中都可以找到,就不细说了
+
+还有一些数据结构的问题,比如说问了哈希表是什么,给面试官详细说了一下`java.util.HashMap`是怎么实现(当然里面就穿插着红黑树了,多看看红黑树是有什么特点之类的)的,包括说为什么要用链地址法来避免冲突,探测法有哪些,链地址法和探测法的优劣对比
+
+后面还跟我讨论了很久的项目,所以说大家的项目一定要做好,要有亮点的地方,在这里跟面试官讨论了很多项目优化的地方,还有什么不足,还有什么地方可以新增功能等等,同样不细说了
+
+一边讨论的时候劈里啪啦敲了很多,应该是对个人的面试评价一类的
+
+后面就是字节的传统艺能手撕算法了,一共做了三道
+
+- 一二道是连在一起的.给定一个规则`S_0 = {1} S_1={1,2,1} S_2 = {1,2,1,3,1,2,1} S_n = {S_n-1 , n + 1, S_n-1}`.第一个问题是他们的个数有什么关系(1 3 7 15... 2 的 n 次方-1,用位运算解决).第二个问题是给定数组个数下标 n 和索引 k,让我们求出 S_n(k)所指的数,假如`S_2(2) = 1`,我在做的时候没有什么好的思路,如果有的话大家可以分享一下
+- 第三道是下一个排列:[https://leetcode-cn.com/problems/next-permutation](https://leetcode-cn.com/problems/next-permutation) 的题型,不过做了一些修改,数组大小`10000
+
+如果还有什么问题欢迎给我留言!如果文章有什么问题的话,也劳烦指出,Guide 哥感激不尽!
+
+后面的文章我会介绍:
+
+- [ ] Java8 对日期的支持以及为啥不能用 SimpleDateFormat。
+- [ ] SpringBoot 中如何实际使用(JPA 为例)
\ No newline at end of file
diff --git a/docs/database/数据库索引.md b/docs/database/数据库索引.md
new file mode 100644
index 00000000..568ba833
--- /dev/null
+++ b/docs/database/数据库索引.md
@@ -0,0 +1,225 @@
+## 什么是索引?
+**索引是一种用于快速查询和检索数据的数据结构。常见的索引结构有: B树, B+树和Hash。**
+
+索引的作用就相当于目录的作用。打个比方: 我们在查字典的时候,如果没有目录,那我们就只能一页一页的去找我们需要查的那个字,速度很慢。如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
+
+## 为什么要用索引?索引的优缺点分析
+
+### 索引的优点
+**可以大大加快 数据的检索速度(大大减少的检索的数据量), 这也是创建索引的最主要的原因。毕竟大部分系统的读请求总是大于写请求的。 ** 另外,通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
+
+### 索引的缺点
+1. **创建索引和维护索引需要耗费许多时间**:当对表中的数据进行增删改的时候,如果数据有索引,那么索引也需要动态的修改,会降低SQL执行效率。
+2. **占用物理存储空间** :索引需要使用物理文件存储,也会耗费一定空间。
+
+## B树和B+树区别
+
+* B树的所有节点既存放 键(key) 也存放 数据(data);而B+树只有叶子节点存放 key 和 data,其他内节点只存放key。
+* B树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
+* B树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而B+树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
+
+
+
+## Hash索引和 B+树索引优劣分析
+
+**Hash索引定位快**
+
+Hash索引指的就是Hash表,最大的优点就是能够在很短的时间内,根据Hash函数定位到数据所在的位置,这是B+树所不能比的。
+
+**Hash冲突问题**
+
+知道HashMap或HashTable的同学,相信都知道它们最大的缺点就是Hash冲突了。不过对于数据库来说这还不算最大的缺点。
+
+**Hash索引不支持顺序和范围查询(Hash索引不支持顺序和范围查询是它最大的缺点。**
+
+试想一种情况:
+
+````text
+SELECT * FROM tb1 WHERE id < 500;
+````
+
+B+树是有序的,在这种范围查询中,优势非常大,直接遍历比500小的叶子节点就够了。而Hash索引是根据hash算法来定位的,难不成还要把 1 - 499的数据,每个都进行一次hash计算来定位吗?这就是Hash最大的缺点了。
+
+---
+
+## 索引类型
+
+### 主键索引(Primary Key)
+**数据表的主键列使用的就是主键索引。**
+
+**一张数据表有只能有一个主键,并且主键不能为null,不能重复。**
+
+**在mysql的InnoDB的表中,当没有显示的指定表的主键时,InnoDB会自动先检查表中是否有唯一索引的字段,如果有,则选择该字段为默认的主键,否则InnoDB将会自动创建一个6Byte的自增主键。**
+
+### 二级索引(辅助索引)
+**二级索引又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。**
+
+唯一索引,普通索引,前缀索引等索引属于二级索引。
+
+**PS:不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,也可以自行搜索。**
+
+1. **唯一索引(Unique Key)** :唯一索引也是一种约束。**唯一索引的属性列不能出现重复的数据,但是允许数据为NULL,一张表允许创建多个唯一索引。**建立唯一索引的目的大部分时候都是为了该属性列的数据的唯一性,而不是为了查询效率。
+2. **普通索引(Index)** :**普通索引的唯一作用就是为了快速查询数据,一张表允许创建多个普通索引,并允许数据重复和NULL。**
+3. **前缀索引(Prefix)** :前缀索引只适用于字符串类型的数据。前缀索引是对文本的前几个字符创建索引,相比普通索引建立的数据更小,
+ 因为只取前几个字符。
+4. **全文索引(Full Text)** :全文索引主要是为了检索大文本数据中的关键字的信息,是目前搜索引擎数据库使用的一种技术。Mysql5.6之前只有MYISAM引擎支持全文索引,5.6之后InnoDB也支持了全文索引。
+
+二级索引:
+.png)
+
+## 聚集索引与非聚集索引
+
+### 聚集索引
+**聚集索引即索引结构和数据一起存放的索引。主键索引属于聚集索引。**
+
+在 Mysql 中,InnoDB引擎的表的 `.ibd`文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
+
+#### 聚集索引的优点
+聚集索引的查询速度非常的快,因为整个B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。
+
+#### 聚集索引的缺点
+1. **依赖于有序的数据** :因为B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或UUID这种又长又难比较的数据,插入或查找的速度肯定比较慢。
+2. **更新代价大** : 如果对索引列的数据被修改时,那么对应的索引也将会被修改,
+ 而且况聚集索引的叶子节点还存放着数据,修改代价肯定是较大的,
+ 所以对于主键索引来说,主键一般都是不可被修改的。
+
+### 非聚集索引
+
+**非聚集索引即索引结构和数据分开存放的索引。**
+
+**二级索引属于非聚集索引。**
+
+>MYISAM引擎的表的.MYI文件包含了表的索引,
+>该表的索引(B+树)的每个叶子非叶子节点存储索引,
+>叶子节点存储索引和索引对应数据的指针,指向.MYD文件的数据。
+>
+**非聚集索引的叶子节点并不一定存放数据的指针,
+因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。**
+
+#### 非聚集索引的优点
+**更新代价比聚集索引要小** 。非聚集索引的更新代价就没有聚集索引那么大了,非聚集索引的叶子节点是不存放数据的
+
+#### 非聚集索引的缺点
+1. 跟聚集索引一样,非聚集索引也依赖于有序的数据
+2. **可能会二次查询(回表)** :这应该是非聚集索引最大的缺点了。 当查到索引对应的指针或主键后,可能还需要根据指针或主键再到数据文件或表中查询。
+
+这是Mysql的表的文件截图:
+
+
+
+聚集索引和非聚集索引:
+
+
+
+### 非聚集索引一定回表查询吗(覆盖索引)?
+**非聚集索引不一定回表查询。**
+
+>试想一种情况,用户准备使用SQL查询用户名,而用户名字段正好建立了索引。
+
+````text
+ SELECT name FROM table WHERE username='guang19';
+````
+
+>那么这个索引的key本身就是name,查到对应的name直接返回就行了,无需回表查询。
+
+**即使是MYISAM也是这样,虽然MYISAM的主键索引确实需要回表,
+因为它的主键索引的叶子节点存放的是指针。但是如果SQL查的就是主键呢?**
+
+```text
+SELECT id FROM table WHERE id=1;
+```
+
+主键索引本身的key就是主键,查到返回就行了。这种情况就称之为覆盖索引了。
+
+## 覆盖索引
+
+如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。我们知道在InnoDB存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
+
+**覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了,
+而无需回表查询。**
+
+>如主键索引,如果一条SQL需要查询主键,那么正好根据主键索引就可以查到主键。
+>
+>再如普通索引,如果一条SQL需要查询name,name字段正好有索引,
+>那么直接根据这个索引就可以查到数据,也无需回表。
+
+覆盖索引:
+
+
+---
+
+## 索引创建原则
+
+### 单列索引
+单列索引即由一列属性组成的索引。
+
+### 联合索引(多列索引)
+联合索引即由多列属性组成索引。
+
+### 最左前缀原则
+
+假设创建的联合索引由三个字段组成:
+
+```text
+ALTER TABLE table ADD INDEX index_name (num,name,age)
+```
+
+那么当查询的条件有为:num / (num AND name) / (num AND name AND age)时,索引才生效。所以在创建联合索引时,尽量把查询最频繁的那个字段作为最左(第一个)字段。查询的时候也尽量以这个字段为第一条件。
+
+> 但可能由于版本原因(我的mysql版本为8.0.x),我创建的联合索引,相当于在联合索引的每个字段上都创建了相同的索引:
+
+.png)
+
+无论是否符合最左前缀原则,每个字段的索引都生效:
+
+
+
+## 索引创建注意点
+
+### 最左前缀原则
+
+虽然我目前的Mysql版本较高,好像不遵守最左前缀原则,索引也会生效。
+但是我们仍应遵守最左前缀原则,以免版本更迭带来的麻烦。
+
+### 选择合适的字段
+
+#### 1.不为NULL的字段
+
+索引字段的数据应该尽量不为NULL,因为对于数据为NULL的字段,数据库较难优化。如果字段频繁被查询,但又避免不了为NULL,建议使用0,1,true,false这样语义较为清晰的短值或短字符作为替代。
+
+#### 2.被频繁查询的字段
+
+我们创建索引的字段应该是查询操作非常频繁的字段。
+
+#### 3.被作为条件查询的字段
+
+被作为WHERE条件查询的字段,应该被考虑建立索引。
+
+#### 4.被经常频繁用于连接的字段
+
+经常用于连接的字段可能是一些外键列,对于外键列并不一定要建立外键,只是说该列涉及到表与表的关系。对于频繁被连接查询的字段,可以考虑建立索引,提高多表连接查询的效率。
+
+### 不合适创建索引的字段
+
+#### 1.被频繁更新的字段应该慎重建立索引
+
+虽然索引能带来查询上的效率,但是维护索引的成本也是不小的。
+如果一个字段不被经常查询,反而被经常修改,那么就更不应该在这种字段上建立索引了。
+
+#### 2.不被经常查询的字段没有必要建立索引
+
+#### 3.尽可能的考虑建立联合索引而不是单列索引
+
+因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗B+树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
+
+#### 4.注意避免冗余索引
+
+冗余索引指的是索引的功能相同,能够命中 就肯定能命中 ,那么 就是冗余索引如(name,city )和(name )这两个索引就是冗余索引,能够命中后者的查询肯定是能够命中前者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
+
+#### 5.考虑在字符串类型的字段上使用前缀索引代替普通索引
+
+前缀索引仅限于字符串类型,较普通索引会占用更小的空间,所以可以考虑使用前缀索引带替普通索引。
+
+### 使用索引一定能提高查询性能吗?
+
+大多数情况下,索引查询都是比全表扫描要快的。但是如果数据库的数据量不大,那么使用索引也不一定能够带来很大提升。
\ No newline at end of file
diff --git a/docs/database/阿里巴巴开发手册数据库部分的一些最佳实践.md b/docs/database/阿里巴巴开发手册数据库部分的一些最佳实践.md
index 7eb84001..abd9331d 100644
--- a/docs/database/阿里巴巴开发手册数据库部分的一些最佳实践.md
+++ b/docs/database/阿里巴巴开发手册数据库部分的一些最佳实践.md
@@ -21,7 +21,7 @@
> 1. **增加了复杂性:** a.每次做DELETE 或者UPDATE都必须考虑外键约束,会导致开发的时候很痛苦,测试数据极为不方便;b.外键的主从关系是定的,假如那天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
> 2. **增加了额外工作**: 数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗资源;(个人觉得这个不是不用外键的原因,因为即使你不使用外键,你在应用层面也还是要保证的。所以,我觉得这个影响可以忽略不计。)
> 3. 外键还会因为需要请求对其他表内部加锁而容易出现死锁情况;
-> 4. **对分不分表不友好** :因为分库分表下外键是无法生效的。
+> 4. **对分库分表不友好** :因为分库分表下外键是无法生效的。
> 5. ......
我个人觉得上面这种回答不是特别的全面,只是说了外键存在的一个常见的问题。实际上,我们知道外键也是有很多好处的,比如:
diff --git a/docs/essential-content-for-interview/BATJrealInterviewExperience/2020-zijietiaodong.md b/docs/essential-content-for-interview/BATJrealInterviewExperience/2020-zijietiaodong.md
new file mode 100644
index 00000000..0e63008b
--- /dev/null
+++ b/docs/essential-content-for-interview/BATJrealInterviewExperience/2020-zijietiaodong.md
@@ -0,0 +1,61 @@
+
+
+> 本文来自读者 Boyn 投稿!恭喜这位粉丝拿到了含金量极高的字节跳动实习 offer!赞!
+
+## 基本条件
+
+本人是底层 211 本科,现在大三,无科研经历,但是有一些项目经历,在国内监控行业某头部企业做过一段时间的实习。想着投一下字节,可以积累一下面试经验和为春招做准备.投了简历之后,过了一段时间,HR 就打电话跟我约时间,在年后进行远程面。
+
+说明一下,我投的是北京 office。
+
+## 一面
+
+面试官很和蔼,由于疫情的原因,大家都在家里面进行远程面试
+
+开头没有自我介绍,直接开始问项目了,问了比如
+
+- 常用的 Web 组件有哪些(回答了自己经常用到的 SpringBoot,Redis,Mysql 等等,字节这边基本没有用 Java 的后台,所以感觉面试官不大会问 Spring,Java 这些东西,反倒是对数据库和中间件比较感兴趣)
+- Kafka 相关,如何保证不会重复消费,Kafka 消费组结构等等(这个只是凭着感觉和面试官说了,因为 Kafka 自己确实准备得不充分,但是心态稳住了)
+- **Mysql 索引,B+树(必考嗷同学们)**
+
+还有一些项目中的细节,这些因人而异,就不放上来了,提示一点就是要在项目中介绍一些亮眼的地方,比如用了什么牛逼的数据结构,架构上有什么特点,并发量大小还有怎么去 hold 住并发量
+
+后面就是算法题了,一共做了两道
+
+1. 判断平衡二叉树(这道题总体来说并不难,但是面试官在中间穿插了垃圾回收的知识,这就很难受了,具体的就是大家要判断一下对象在什么时候会回收,可达性分析什么时候对这个对象来说是不可达的,还有在递归函数中内存如何变化,这个是让我们来对这个函数进行执行过程的建模,只看栈帧大小变化的话,应该有是两个峰值,中间会有抖动的情况)
+2. 二分查找法的变种题,给定`target`和一个升序的数组,寻找下一个比数组大的数.这道题也不难,靠大家对二分查找法的熟悉程度,当然,这边还有一个优化的点,可以看看[我的博客](https://boyn.top/2019/11/09/%E7%AE%97%E6%B3%95%E4%B8%8E%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE%E6%B3%95/)找找灵感
+
+完成了之后,面试官让我等一会有二面,大概 10 分钟左右吧,休息了一会就继续了
+
+## 二面
+
+二面一上来就是先让我自我介绍,当然还是同样的套路,同样的香脆
+
+然后问了我一些关于 Redis 的问题,比如 **zset 的实现(跳表,这个高频)** ,键的过期策略,持久化等等,这些在大多数 Redis 的介绍中都可以找到,就不细说了
+
+还有一些数据结构的问题,比如说问了哈希表是什么,给面试官详细说了一下`java.util.HashMap`是怎么实现(当然里面就穿插着红黑树了,多看看红黑树是有什么特点之类的)的,包括说为什么要用链地址法来避免冲突,探测法有哪些,链地址法和探测法的优劣对比
+
+后面还跟我讨论了很久的项目,所以说大家的项目一定要做好,要有亮点的地方,在这里跟面试官讨论了很多项目优化的地方,还有什么不足,还有什么地方可以新增功能等等,同样不细说了
+
+一边讨论的时候劈里啪啦敲了很多,应该是对个人的面试评价一类的
+
+后面就是字节的传统艺能手撕算法了,一共做了三道
+
+- 一二道是连在一起的.给定一个规则`S_0 = {1} S_1={1,2,1} S_2 = {1,2,1,3,1,2,1} S_n = {S_n-1 , n + 1, S_n-1}`.第一个问题是他们的个数有什么关系(1 3 7 15... 2 的 n 次方-1,用位运算解决).第二个问题是给定数组个数下标 n 和索引 k,让我们求出 S_n(k)所指的数,假如`S_2(2) = 1`,我在做的时候没有什么好的思路,如果有的话大家可以分享一下
+- 第三道是下一个排列:[https://leetcode-cn.com/problems/next-permutation](https://leetcode-cn.com/problems/next-permutation) 的题型,不过做了一些修改,数组大小`10000 -
-