mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
布隆过滤器
This commit is contained in:
parent
80a25217c5
commit
5bda607f04
@ -0,0 +1,51 @@
|
||||
最近,当我在做一个项目的时候需要过滤掉重复的 URL ,为了完成这个任务,我学到了一种称为 Bloom Filter (布隆过滤器)的东西,然后我学会了它并写下了这个博客。
|
||||
|
||||
下面我们将分为几个方面来介绍布隆过滤器:
|
||||
|
||||
1. 什么是布隆过滤器?
|
||||
2. 布隆过滤器的原理介绍。
|
||||
3. 布隆过滤器使用场景。
|
||||
4. 通过 Java 编程手动实现布隆过滤器。
|
||||
5. 利用Google开源的guava中自带的布隆过滤器。
|
||||
6. 总结。
|
||||
|
||||
### 1.什么是布隆过滤器?
|
||||
|
||||
首先,我们需要了解布隆过滤器的概念。
|
||||
|
||||
布隆过滤器(Bloom Filter)是一个叫做 Bloom 的老哥于1970年提出的。我们可以把它看作由二进制向量(或者说位数组)和一系列随机映射函数(哈希函数)两部分组成的数据结构。相比于我们平时常用的的 List、Map 、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。并且理论情况下添加到集合中的元素越多,误报的可能性就越大。
|
||||
|
||||

|
||||
|
||||
位数组中的每个元素都只占用 1 bit ,并且每个元素只能是 0 或者 1。这样申请一个 100w 个元素的位数组只占用 1000000 / 8 = 125000 B = 15625 byte ≈ 15.3kb 的空间。
|
||||
|
||||
总结:**一个名叫 Bloom 的人提出了一种来检索元素是否在给定大集合中的数据结构,这种数据结构是高效且性能很好的,但缺点是具有一定的错误识别率和删除难度。并且,理论情况下,添加到集合中的元素越多,误报的可能性就越大。**
|
||||
|
||||
### 2.布隆过滤器的原理介绍。
|
||||
|
||||
**当一个元素加入布隆过滤器中的时候,会进行如下操作:**
|
||||
|
||||
1. 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
|
||||
2. 根据得到的哈希值,在位数组中把对应下标的值置为 1。
|
||||
|
||||
**当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:**
|
||||
|
||||
1. 对给定元素再次进行相同的哈希计算;
|
||||
2. 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
|
||||
|
||||
举个简单的例子:
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
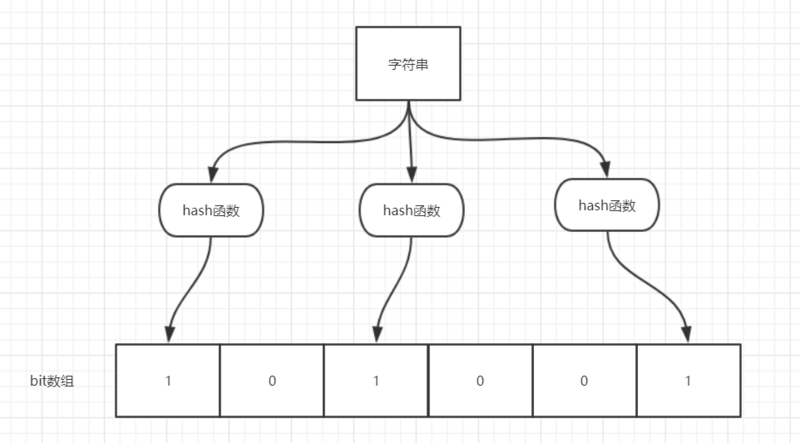
如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后在对应的位数组的下表的元素设置为 1(当位数组初始化时 ,所有位置均为0)。当第二次存储相同字符串时,因为先前的对应位置已设置为1,所以很容易知道此值已经存在(去重非常方便)。
|
||||
|
||||
如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
|
||||
|
||||
存在的问题是:**不同的字符串可能哈希出来的位置相同,这种情况我们可以适当增加位数组大小或者调整我们的哈希函数。**
|
||||
|
||||
### 3.布隆过滤器使用场景
|
||||
|
||||
1. 判断给定数据是否存在:比如判断 防止缓存穿透
|
||||
2. 去重:比如爬给定网址的时候对已经爬取过的 URL 去重。
|
||||
Loading…
x
Reference in New Issue
Block a user