mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-14 05:21:42 +08:00
Compare commits
5 Commits
f0d2864bca
...
78fee25ee8
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
78fee25ee8 | ||
|
|
cafb410791 | ||
|
|
f68e7944cb | ||
|
|
9b20bb29f6 | ||
|
|
ddd5139e8e |
@ -38,7 +38,7 @@ icon: "lock"
|
||||
|
||||
### 如何基于 Redis 实现一个最简易的分布式锁?
|
||||
|
||||
不论是实现锁还是分布式锁,核心都在于“互斥”。
|
||||
不论是本地锁还是分布式锁,核心都在于“互斥”。
|
||||
|
||||
在 Redis 中, `SETNX` 命令是可以帮助我们实现互斥。`SETNX` 即 **SET** if **N**ot e**X**ists (对应 Java 中的 `setIfAbsent` 方法),如果 key 不存在的话,才会设置 key 的值。如果 key 已经存在, `SETNX` 啥也不做。
|
||||
|
||||
@ -56,7 +56,7 @@ icon: "lock"
|
||||
(integer) 1
|
||||
```
|
||||
|
||||
为了误删到其他的锁,这里我们建议使用 Lua 脚本通过 key 对应的 value(唯一值)来判断。
|
||||
为了防止误删到其他的锁,这里我们建议使用 Lua 脚本通过 key 对应的 value(唯一值)来判断。
|
||||
|
||||
选用 Lua 脚本是为了保证解锁操作的原子性。因为 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,从而保证了锁释放操作的原子性。
|
||||
|
||||
|
||||
@ -29,7 +29,7 @@ tag:
|
||||
1. **客户端(服务消费端)** :调用远程方法的一端。
|
||||
1. **客户端 Stub(桩)** : 这其实就是一代理类。代理类主要做的事情很简单,就是把你调用方法、类、方法参数等信息传递到服务端。
|
||||
1. **网络传输** : 网络传输就是你要把你调用的方法的信息比如说参数啊这些东西传输到服务端,然后服务端执行完之后再把返回结果通过网络传输给你传输回来。网络传输的实现方式有很多种比如最近基本的 Socket或者性能以及封装更加优秀的 Netty(推荐)。
|
||||
1. **服务端 Stub(桩)** :这个桩就不是代理类了。我觉得理解为桩实际不太好,大家注意一下就好。这里的服务端 Stub 实际指的就是接收到客户端执行方法的请求后,去指定对应的方法然后返回结果给客户端的类。
|
||||
1. **服务端 Stub(桩)** :这个桩就不是代理类了。我觉得理解为桩实际不太好,大家注意一下就好。这里的服务端 Stub 实际指的就是接收到客户端执行方法的请求后,去执行对应的方法然后返回结果给客户端的类。
|
||||
1. **服务端(服务提供端)** :提供远程方法的一端。
|
||||
|
||||
具体原理图如下,后面我会串起来将整个RPC的过程给大家说一下。
|
||||
|
||||
@ -143,7 +143,7 @@ Demo 级别的,一般就是你本地启动了玩玩儿的?,没人生产用
|
||||
|
||||
## 如何解决消息挤压问题?
|
||||
|
||||
**临时紧急扩容**。先修复 consumer 的问题,确保其恢复消费速度,然后将现有 cnosumer 都停掉。新建一个 topic,partition 是原来的 10 倍,临时建立好原先 10 倍的 queue 数量。然后写一个临时的分发数据的 consumer 程序,这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的 10 倍数量的 queue。接着临时征用 10 倍的机器来部署 consumer,每一批 consumer 消费一个临时 queue 的数据。这种做法相当于是临时将 queue 资源和 consumer 资源扩大 10 倍,以正常的 10 倍速度来消费数据。等快速消费完积压数据之后,得恢复原先部署的架构,重新用原先的 consumer 机器来消费消息。
|
||||
**临时紧急扩容**。先修复 consumer 的问题,确保其恢复消费速度,然后将现有 consumer 都停掉。新建一个 topic,partition 是原来的 10 倍,临时建立好原先 10 倍的 queue 数量。然后写一个临时的分发数据的 consumer 程序,这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的 10 倍数量的 queue。接着临时征用 10 倍的机器来部署 consumer,每一批 consumer 消费一个临时 queue 的数据。这种做法相当于是临时将 queue 资源和 consumer 资源扩大 10 倍,以正常的 10 倍速度来消费数据。等快速消费完积压数据之后,得恢复原先部署的架构,重新用原先的 consumer 机器来消费消息。
|
||||
|
||||
## 如何解决消息队列的延时以及过期失效问题?
|
||||
|
||||
|
||||
@ -58,7 +58,7 @@ class Class<T> {
|
||||
}
|
||||
```
|
||||
|
||||
简单来说,**类加载器的主要作用就是加载 Java 类的字节码( `.class` 文件)到 JVM 中(在内存中生成一个代表该类的 `Class` 对象)。** 字节码可以是 Java 源程序(`.java`文件)经过 javac 编译得来,也可以是通过工具动态生成或者通过网络下载得来。
|
||||
简单来说,**类加载器的主要作用就是加载 Java 类的字节码( `.class` 文件)到 JVM 中(在内存中生成一个代表该类的 `Class` 对象)。** 字节码可以是 Java 源程序(`.java`文件)经过 `javac` 编译得来,也可以是通过工具动态生成或者通过网络下载得来。
|
||||
|
||||
其实除了加载类之外,类加载器还可以加载 Java 应用所需的资源如文本、图像、配置文件、视频等等文件资源。本文只讨论其核心功能:加载类。
|
||||
|
||||
@ -92,7 +92,7 @@ JVM 中内置了三个重要的 `ClassLoader`:
|
||||
|
||||
> 🌈 拓展一下:
|
||||
>
|
||||
> - **`rt.jar`** : rt 代表“RunTime”,``rt.jar`是Java基础类库,包含Java doc里面看到的所有的类的类文件。也就是说,我们常用内置库 java.xxx.* 都在里面,比如`java.util._`、`java.io._`、`java.nio._`、`java.lang._`、`java.sql._`、`java.math._`。
|
||||
> - **`rt.jar`** : rt 代表“RunTime”,`rt.jar`是Java基础类库,包含Java doc里面看到的所有的类的类文件。也就是说,我们常用内置库 `java.xxx.* `都在里面,比如`java.util.*`、`java.io.*`、`java.nio.*`、`java.lang.*`、`java.sql.*`、`java.math.*`。
|
||||
> - Java 9 引入了模块系统,并且略微更改了上述的类加载器。扩展类加载器被改名为平台类加载器(platform class loader)。Java SE 中除了少数几个关键模块,比如说 `java.base` 是由启动类加载器加载之外,其他的模块均由平台类加载器所加载。
|
||||
|
||||
除了这三种类加载器之外,用户还可以加入自定义的类加载器来进行拓展,以满足自己的特殊需求。就比如说,我们可以对 Java 类的字节码( `.class` 文件)进行加密,加载时再利用自定义的类加载器对其解密。
|
||||
@ -178,6 +178,8 @@ public class PrintClassLoaderTree {
|
||||
|
||||
### 双亲委派模型介绍
|
||||
|
||||
类加载器有很多种,当我们想要加载一个类的时候,具体是哪个类加载器加载呢?这就需要提到双亲委派模型了。
|
||||
|
||||
根据官网介绍:
|
||||
|
||||
> The ClassLoader class uses a delegation model to search for classes and resources. Each instance of ClassLoader has an associated parent class loader. When requested to find a class or resource, a ClassLoader instance will delegate the search for the class or resource to its parent class loader before attempting to find the class or resource itself. The virtual machine's built-in class loader, called the "bootstrap class loader", does not itself have a parent but may serve as the parent of a ClassLoader instance.
|
||||
@ -197,6 +199,8 @@ public class PrintClassLoaderTree {
|
||||
|
||||
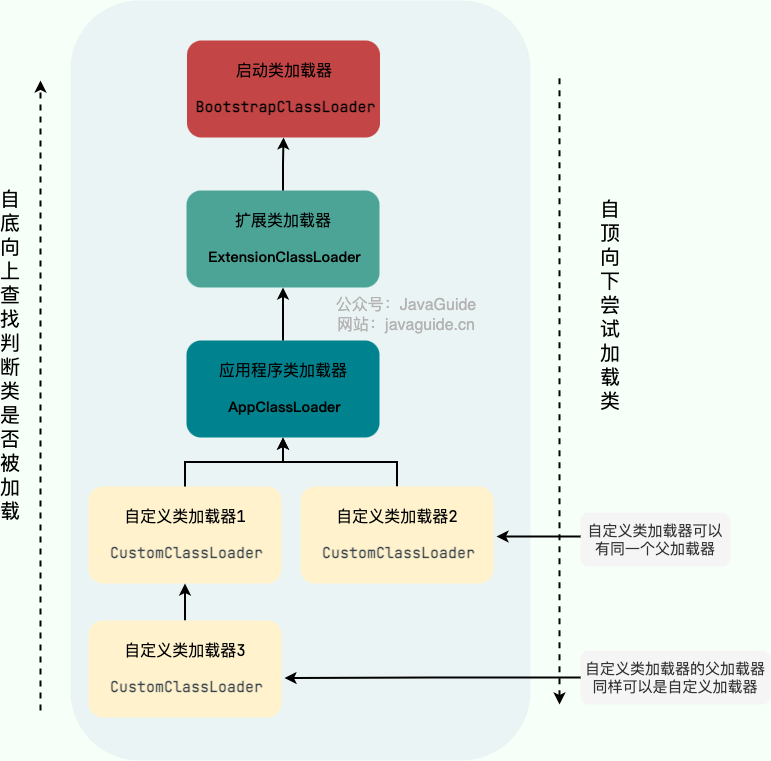
|
||||
|
||||
注意⚠️:双亲委派模型并不是一种强制性的约束,只是 JDK 官方推荐的一种方式。如果我们因为某些特殊需求想要打破双亲委派模型,也是可以的,后文会介绍具体的方法。
|
||||
|
||||
其实这个双亲翻译的容易让别人误解,我们一般理解的双亲都是父母,这里的双亲更多地表达的是“父母这一辈”的人而已,并不是说真的有一个 `MotherClassLoader` 和一个`FatherClassLoader` 。个人觉得翻译成单亲委派模型更好一些,不过,国内既然翻译成了双亲委派模型并流传了,按照这个来也没问题,不要被误解了就好。
|
||||
|
||||
另外,类加载器之间的父子关系一般不是以继承的关系来实现的,而是通常使用组合关系来复用父加载器的代码。
|
||||
@ -286,6 +290,10 @@ protected Class<?> loadClass(String name, boolean resolve)
|
||||
|
||||
**🐛 修正(参见:[issue871](https://github.com/Snailclimb/JavaGuide/issues/871) )** :自定义加载器的话,需要继承 `ClassLoader` 。如果我们不想打破双亲委派模型,就重写 `ClassLoader` 类中的 `findClass()` 方法即可,无法被父类加载器加载的类最终会通过这个方法被加载。但是,如果想打破双亲委派模型则需要重写 `loadClass()` 方法。
|
||||
|
||||
为什么是重写 `loadClass()` 方法打破双亲委派模型呢?双亲委派模型的执行流程已经解释了:
|
||||
|
||||
> 类加载器在进行类加载的时候,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成(调用父加载器 `loadClass()`方法来加载类)。
|
||||
|
||||
我们比较熟悉的 Tomcat 服务器为了能够优先加载 Web 应用目录下的类,然后再加载其他目录下的类,就自定义了类加载器 `WebAppClassLoader` 来打破双亲委托机制。这也是 Tomcat 下 Web 应用之间的类实现隔离的具体原理。
|
||||
|
||||
Tomcat 的类加载器的层次结构如下:
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user