mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
Compare commits
7 Commits
b9c2db4209
...
1dbb8cf3c3
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
1dbb8cf3c3 | ||
|
|
02ec4e4150 | ||
|
|
b5cd6d3fe4 | ||
|
|
700401e20a | ||
|
|
f7abbcc539 | ||
|
|
7c6e03dd21 | ||
|
|
0682a55265 |
@ -321,8 +321,12 @@ LRU 算法是实际使用中应用的比较多,也被认为是最接近 OPT
|
||||
|
||||
在段页式机制下,地址翻译的过程分为两个步骤:
|
||||
|
||||
1. 段式地址映射:段式转换将虚拟地址(段选择符+段内偏移)转换为线性地址(通过段基址+偏移计算)。
|
||||
2. 页式地址映射:页式转换将线性地址拆分为页号+页内偏移,通过页表映射到物理地址。
|
||||
1. **段式地址映射(虚拟地址 → 线性地址):**
|
||||
- 虚拟地址 = 段选择符(段号)+ 段内偏移。
|
||||
- 根据段号查段表,找到段基址,加上段内偏移得到线性地址。
|
||||
2. **页式地址映射(线性地址 → 物理地址):**
|
||||
- 线性地址 = 页号 + 页内偏移。
|
||||
- 根据页号查页表,找到物理页框号,加上页内偏移得到物理地址。
|
||||
|
||||
### 局部性原理
|
||||
|
||||
|
||||
@ -17,7 +17,7 @@ tag:
|
||||
|
||||
索引的作用就相当于书的目录。打个比方:我们在查字典的时候,如果没有目录,那我们就只能一页一页地去找我们需要查的那个字,速度很慢;如果有目录了,我们只需要先去目录里查找字的位置,然后直接翻到那一页就行了。
|
||||
|
||||
索引底层数据结构存在很多种类型,常见的索引结构有:B 树、 B+ 树 和 Hash、红黑树。在 MySQL 中,无论是 Innodb 还是 MyISAM,都使用了 B+ 树作为索引结构。
|
||||
索引底层数据结构存在很多种类型,常见的索引结构有:B树、 B+树 和 Hash、红黑树。在 MySQL 中,无论是 Innodb 还是 MyISAM,都使用了 B+树作为索引结构。
|
||||
|
||||
## 索引的优缺点
|
||||
|
||||
@ -112,20 +112,20 @@ AVL 树采用了旋转操作来保持平衡。主要有四种旋转操作:LL
|
||||
|
||||
**红黑树的应用还是比较广泛的,TreeMap、TreeSet 以及 JDK1.8 的 HashMap 底层都用到了红黑树。对于数据在内存中的这种情况来说,红黑树的表现是非常优异的。**
|
||||
|
||||
### B 树& B+ 树
|
||||
### B树& B+树
|
||||
|
||||
B 树也称 B- 树,全称为 **多路平衡查找树**,B+ 树是 B 树的一种变体。B 树和 B+ 树中的 B 是 `Balanced`(平衡)的意思。
|
||||
B树也称 B-树,全称为 **多路平衡查找树**,B+树是 B树的一种变体。B树和 B+树中的 B 是 `Balanced`(平衡)的意思。
|
||||
|
||||
目前大部分数据库系统及文件系统都采用 B-Tree 或其变种 B+Tree 作为索引结构。
|
||||
|
||||
**B 树& B+ 树两者有何异同呢?**
|
||||
**B树& B+树两者有何异同呢?**
|
||||
|
||||
- B 树的所有节点既存放键(key)也存放数据(data),而 B+ 树只有叶子节点存放 key 和 data,其他内节点只存放 key。
|
||||
- B 树的叶子节点都是独立的;B+ 树的叶子节点有一条引用链指向与它相邻的叶子节点。
|
||||
- B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而 B+ 树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
|
||||
- 在 B 树中进行范围查询时,首先找到要查找的下限,然后对 B 树进行中序遍历,直到找到查找的上限;而 B+ 树的范围查询,只需要对链表进行遍历即可。
|
||||
- B树的所有节点既存放键(key)也存放数据(data),而 B+树只有叶子节点存放 key 和 data,其他内节点只存放 key。
|
||||
- B树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
|
||||
- B树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而 B+树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
|
||||
- 在 B树中进行范围查询时,首先找到要查找的下限,然后对 B树进行中序遍历,直到找到查找的上限;而 B+树的范围查询,只需要对链表进行遍历即可。
|
||||
|
||||
综上,B+ 树与 B 树相比,具备更少的 IO 次数、更稳定的查询效率和更适于范围查询这些优势。
|
||||
综上,B+树与 B树相比,具备更少的 IO 次数、更稳定的查询效率和更适于范围查询这些优势。
|
||||
|
||||
在 MySQL 中,MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是,两者的实现方式不太一样。(下面的内容整理自《Java 工程师修炼之道》)
|
||||
|
||||
@ -198,18 +198,18 @@ PS:不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
|
||||
|
||||
聚簇索引(Clustered Index)即索引结构和数据一起存放的索引,并不是一种单独的索引类型。InnoDB 中的主键索引就属于聚簇索引。
|
||||
|
||||
在 MySQL 中,InnoDB 引擎的表的 `.ibd`文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+ 树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
|
||||
在 MySQL 中,InnoDB 引擎的表的 `.ibd`文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
|
||||
|
||||
#### 聚簇索引的优缺点
|
||||
|
||||
**优点**:
|
||||
|
||||
- **查询速度非常快**:聚簇索引的查询速度非常的快,因为整个 B+ 树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。相比于非聚簇索引, 聚簇索引少了一次读取数据的 IO 操作。
|
||||
- **查询速度非常快**:聚簇索引的查询速度非常的快,因为整个 B+树本身就是一颗多叉平衡树,叶子节点也都是有序的,定位到索引的节点,就相当于定位到了数据。相比于非聚簇索引, 聚簇索引少了一次读取数据的 IO 操作。
|
||||
- **对排序查找和范围查找优化**:聚簇索引对于主键的排序查找和范围查找速度非常快。
|
||||
|
||||
**缺点**:
|
||||
|
||||
- **依赖于有序的数据**:因为 B+ 树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
|
||||
- **依赖于有序的数据**:因为 B+树是多路平衡树,如果索引的数据不是有序的,那么就需要在插入时排序,如果数据是整型还好,否则类似于字符串或 UUID 这种又长又难比较的数据,插入或查找的速度肯定比较慢。
|
||||
- **更新代价大**:如果对索引列的数据被修改时,那么对应的索引也将会被修改,而且聚簇索引的叶子节点还存放着数据,修改代价肯定是较大的,所以对于主键索引来说,主键一般都是不可被修改的。
|
||||
|
||||
### 非聚簇索引(非聚集索引)
|
||||
@ -478,7 +478,7 @@ MySQL 可以简单分为 Server 层和存储引擎层这两层。Server 层处
|
||||
|
||||
### 尽可能的考虑建立联合索引而不是单列索引
|
||||
|
||||
因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗 B+ 树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
|
||||
因为索引是需要占用磁盘空间的,可以简单理解为每个索引都对应着一颗 B+树。如果一个表的字段过多,索引过多,那么当这个表的数据达到一个体量后,索引占用的空间也是很多的,且修改索引时,耗费的时间也是较多的。如果是联合索引,多个字段在一个索引上,那么将会节约很大磁盘空间,且修改数据的操作效率也会提升。
|
||||
|
||||
### 注意避免冗余索引
|
||||
|
||||
|
||||
@ -9,7 +9,7 @@ tag:
|
||||
|
||||
在我看来,造成这个问题的原因是我们在学习 Redis 的时候,可能只是简单写了一些 Demo,并没有去关注缓存的读写策略,或者说压根不知道这回事。
|
||||
|
||||
但是,搞懂 3 种常见的缓存读写策略对于实际工作中使用缓存以及面试中被问到缓存都是非常有帮助的!
|
||||
但是,搞懂 3 种常见的缓存读写策略,对于实际工作中使用缓存以及面试中被问到缓存都是非常有帮助的!
|
||||
|
||||
**下面介绍到的三种模式各有优劣,不存在最佳模式,根据具体的业务场景选择适合自己的缓存读写模式。**
|
||||
|
||||
@ -23,17 +23,17 @@ Cache Aside Pattern 中服务端需要同时维系 db 和 cache,并且是以 d
|
||||
|
||||
**写**:
|
||||
|
||||
- 先更新 db
|
||||
- 然后直接删除 cache 。
|
||||
- 先更新 db;
|
||||
- 然后直接删除 cache。
|
||||
|
||||
简单画了一张图帮助大家理解写的步骤。
|
||||
|
||||

|
||||
|
||||
**读** :
|
||||
**读**:
|
||||
|
||||
- 从 cache 中读取数据,读取到就直接返回
|
||||
- cache 中读取不到的话,就从 db 中读取数据返回
|
||||
- 从 cache 中读取数据,读取到就直接返回;
|
||||
- cache 中读取不到的话,就从 db 中读取数据返回;
|
||||
- 再把数据放到 cache 中。
|
||||
|
||||
简单画了一张图帮助大家理解读的步骤。
|
||||
@ -42,9 +42,9 @@ Cache Aside Pattern 中服务端需要同时维系 db 和 cache,并且是以 d
|
||||
|
||||
你仅仅了解了上面这些内容的话是远远不够的,我们还要搞懂其中的原理。
|
||||
|
||||
比如说面试官很可能会追问:“**在写数据的过程中,可以先删除 cache ,后更新 db 么?**”
|
||||
比如说面试官很可能会追问:“**在写数据的过程中,可以先删除 cache,后更新 db 么?**”
|
||||
|
||||
**答案:** 那肯定是不行的!因为这样可能会造成 **数据库(db)和缓存(Cache)数据不一致**的问题。
|
||||
**答案**:那肯定是不行的!因为这样可能会造成 **数据库(db)和缓存(Cache)数据不一致** 的问题。
|
||||
|
||||
举例:请求 1 先写数据 A,请求 2 随后读数据 A 的话,就很有可能产生数据不一致性的问题。
|
||||
|
||||
@ -54,7 +54,7 @@ Cache Aside Pattern 中服务端需要同时维系 db 和 cache,并且是以 d
|
||||
|
||||
当你这样回答之后,面试官可能会紧接着就追问:“**在写数据的过程中,先更新 db,后删除 cache 就没有问题了么?**”
|
||||
|
||||
**答案:** 理论上来说还是可能会出现数据不一致性的问题,不过概率非常小,因为缓存的写入速度是比数据库的写入速度快很多。
|
||||
**答案**:理论上来说还是可能会出现数据不一致性的问题,不过概率非常小,因为缓存的写入速度是比数据库的写入速度快很多。
|
||||
|
||||
举例:请求 1 先读数据 A,请求 2 随后写数据 A,并且数据 A 在请求 1 请求之前不在缓存中的话,也有可能产生数据不一致性的问题。
|
||||
|
||||
@ -64,11 +64,11 @@ Cache Aside Pattern 中服务端需要同时维系 db 和 cache,并且是以 d
|
||||
|
||||
现在我们再来分析一下 **Cache Aside Pattern 的缺陷**。
|
||||
|
||||
**缺陷 1:首次请求数据一定不在 cache 的问题**
|
||||
**缺陷 1:首次请求数据一定不在 cache 的问题。**
|
||||
|
||||
解决办法:可以将热点数据可以提前放入 cache 中。
|
||||
|
||||
**缺陷 2:写操作比较频繁的话导致 cache 中的数据会被频繁被删除,这样会影响缓存命中率 。**
|
||||
**缺陷 2:写操作比较频繁的话导致 cache 中的数据会被频繁被删除,这样会影响缓存命中率。**
|
||||
|
||||
解决办法:
|
||||
|
||||
@ -81,7 +81,7 @@ Read/Write Through Pattern 中服务端把 cache 视为主要数据存储,从
|
||||
|
||||
这种缓存读写策略小伙伴们应该也发现了在平时在开发过程中非常少见。抛去性能方面的影响,大概率是因为我们经常使用的分布式缓存 Redis 并没有提供 cache 将数据写入 db 的功能。
|
||||
|
||||
**写(Write Through):**
|
||||
**写(Write Through)**:
|
||||
|
||||
- 先查 cache,cache 中不存在,直接更新 db。
|
||||
- cache 中存在,则先更新 cache,然后 cache 服务自己更新 db(**同步更新 cache 和 db**)。
|
||||
@ -90,9 +90,9 @@ Read/Write Through Pattern 中服务端把 cache 视为主要数据存储,从
|
||||
|
||||
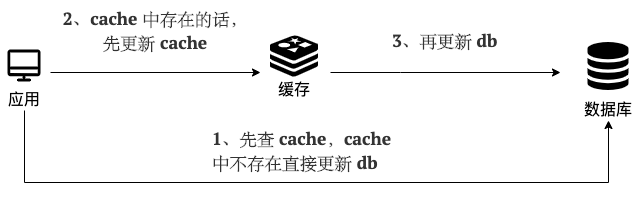
|
||||
|
||||
**读(Read Through):**
|
||||
**读(Read Through)**:
|
||||
|
||||
- 从 cache 中读取数据,读取到就直接返回 。
|
||||
- 从 cache 中读取数据,读取到就直接返回。
|
||||
- 读取不到的话,先从 db 加载,写入到 cache 后返回响应。
|
||||
|
||||
简单画了一张图帮助大家理解读的步骤。
|
||||
|
||||
@ -5,13 +5,13 @@ tag:
|
||||
- Redis
|
||||
---
|
||||
|
||||
> 本文整理完善自:<https://mp.weixin.qq.com/s/0Nqfq_eQrUb12QH6eBbHXA> ,作者:阿 Q 说代码
|
||||
> 本文整理完善自:<https://mp.weixin.qq.com/s/0Nqfq_eQrUb12QH6eBbHXA>,作者:阿 Q 说代码
|
||||
|
||||
这篇文章会详细总结一下可能导致 Redis 阻塞的情况,这些情况也是影响 Redis 性能的关键因素,使用 Redis 的时候应该格外注意!
|
||||
|
||||
## O(n) 命令
|
||||
|
||||
Redis 中的大部分命令都是 O(1)时间复杂度,但也有少部分 O(n) 时间复杂度的命令,例如:
|
||||
Redis 中的大部分命令都是 O(1) 时间复杂度,但也有少部分 O(n) 时间复杂度的命令,例如:
|
||||
|
||||
- `KEYS *`:会返回所有符合规则的 key。
|
||||
- `HGETALL`:会返回一个 Hash 中所有的键值对。
|
||||
@ -22,18 +22,18 @@ Redis 中的大部分命令都是 O(1)时间复杂度,但也有少部分 O(n)
|
||||
|
||||
由于这些命令时间复杂度是 O(n),有时候也会全表扫描,随着 n 的增大,执行耗时也会越长,从而导致客户端阻塞。不过, 这些命令并不是一定不能使用,但是需要明确 N 的值。另外,有遍历的需求可以使用 `HSCAN`、`SSCAN`、`ZSCAN` 代替。
|
||||
|
||||
除了这些 O(n)时间复杂度的命令可能会导致阻塞之外, 还有一些时间复杂度可能在 O(N) 以上的命令,例如:
|
||||
除了这些 O(n) 时间复杂度的命令可能会导致阻塞之外,还有一些时间复杂度可能在 O(N) 以上的命令,例如:
|
||||
|
||||
- `ZRANGE`/`ZREVRANGE`:返回指定 Sorted Set 中指定排名范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 为返回的元素数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
|
||||
- `ZREMRANGEBYRANK`/`ZREMRANGEBYSCORE`:移除 Sorted Set 中指定排名范围/指定 score 范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 被删除元素的数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
|
||||
- `ZRANGE`/`ZREVRANGE`:返回指定 Sorted Set 中指定排名范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量,m 为返回的元素数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
|
||||
- `ZREMRANGEBYRANK`/`ZREMRANGEBYSCORE`:移除 Sorted Set 中指定排名范围/指定 score 范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量,m 被删除元素的数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
|
||||
- ……
|
||||
|
||||
## SAVE 创建 RDB 快照
|
||||
|
||||
Redis 提供了两个命令来生成 RDB 快照文件:
|
||||
|
||||
- `save` : 同步保存操作,会阻塞 Redis 主线程;
|
||||
- `bgsave` : fork 出一个子进程,子进程执行,不会阻塞 Redis 主线程,默认选项。
|
||||
- `save`:同步保存操作,会阻塞 Redis 主线程;
|
||||
- `bgsave`:fork 出一个子进程,子进程执行保存操作,不会阻塞 Redis 主线程,默认选项。
|
||||
|
||||
默认情况下,Redis 默认配置会使用 `bgsave` 命令。如果手动使用 `save` 命令生成 RDB 快照文件的话,就会阻塞主线程。
|
||||
|
||||
@ -59,13 +59,13 @@ Redis AOF 持久化机制是在执行完命令之后再记录日志,这和关
|
||||
|
||||
开启 AOF 持久化后每执行一条会更改 Redis 中的数据的命令,Redis 就会将该命令写入到 AOF 缓冲区 `server.aof_buf` 中,然后再根据 `appendfsync` 配置来决定何时将其同步到硬盘中的 AOF 文件。
|
||||
|
||||
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( `fsync`策略),它们分别是:
|
||||
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式(`fsync`策略),它们分别是:
|
||||
|
||||
1. `appendfsync always`:主线程调用 `write` 执行写操作后,后台线程( `aof_fsync` 线程)立即会调用 `fsync` 函数同步 AOF 文件(刷盘),`fsync` 完成后线程返回,这样会严重降低 Redis 的性能(`write` + `fsync`)。
|
||||
2. `appendfsync everysec`:主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)
|
||||
3. `appendfsync no`:主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。
|
||||
1. `appendfsync always`:主线程调用 `write` 执行写操作后,后台线程(`aof_fsync` 线程)立即会调用 `fsync` 函数同步 AOF 文件(刷盘),`fsync` 完成后线程返回,这样会严重降低 Redis 的性能(`write`+`fsync`)。
|
||||
2. `appendfsync everysec`:主线程调用 `write` 执行写操作后立即返回,由后台线程(`aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)
|
||||
3. `appendfsync no`:主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write` 但不 `fsync`,`fsync` 的时机由操作系统决定)。
|
||||
|
||||
当后台线程( `aof_fsync` 线程)调用 `fsync` 函数同步 AOF 文件时,需要等待,直到写入完成。当磁盘压力太大的时候,会导致 `fsync` 操作发生阻塞,主线程调用 `write` 函数时也会被阻塞。`fsync` 完成后,主线程执行 `write` 才能成功返回。
|
||||
当后台线程(`aof_fsync` 线程)调用 `fsync` 函数同步 AOF 文件时,需要等待,直到写入完成。当磁盘压力太大的时候,会导致 `fsync` 操作发生阻塞,主线程调用 `write` 函数时也会被阻塞。`fsync` 完成后,主线程执行 `write` 才能成功返回。
|
||||
|
||||
关于 AOF 工作流程的详细介绍可以查看:[Redis 持久化机制详解](./redis-persistence.md),有助于理解 AOF 刷盘阻塞。
|
||||
|
||||
@ -75,7 +75,7 @@ Redis AOF 持久化机制是在执行完命令之后再记录日志,这和关
|
||||
2. 当子线程完成创建新 AOF 文件的工作之后,服务器会将重写缓冲区中的所有内容追加到新 AOF 文件的末尾,使得新的 AOF 文件保存的数据库状态与现有的数据库状态一致。
|
||||
3. 最后,服务器用新的 AOF 文件替换旧的 AOF 文件,以此来完成 AOF 文件重写操作。
|
||||
|
||||
阻塞就是出现在第 2 步的过程中,将缓冲区中新数据写到新文件的过程中会产生**阻塞**。
|
||||
阻塞就是出现在第 2 步的过程中,将缓冲区中新数据写到新文件的过程中会产生 **阻塞**。
|
||||
|
||||
相关阅读:[Redis AOF 重写阻塞问题分析](https://cloud.tencent.com/developer/article/1633077)。
|
||||
|
||||
@ -83,7 +83,7 @@ Redis AOF 持久化机制是在执行完命令之后再记录日志,这和关
|
||||
|
||||
如果一个 key 对应的 value 所占用的内存比较大,那这个 key 就可以看作是 bigkey。具体多大才算大呢?有一个不是特别精确的参考标准:
|
||||
|
||||
- string 类型的 value 超过 1MB
|
||||
- string 类型的 value 超过 1MB;
|
||||
- 复合类型(列表、哈希、集合、有序集合等)的 value 包含的元素超过 5000 个(对于复合类型的 value 来说,不一定包含的元素越多,占用的内存就越多)。
|
||||
|
||||
大 key 造成的阻塞问题如下:
|
||||
@ -94,20 +94,20 @@ Redis AOF 持久化机制是在执行完命令之后再记录日志,这和关
|
||||
|
||||
### 查找大 key
|
||||
|
||||
当我们在使用 Redis 自带的 `--bigkeys` 参数查找大 key 时,最好选择在从节点上执行该命令,因为主节点上执行时,会**阻塞**主节点。
|
||||
当我们在使用 Redis 自带的 `--bigkeys` 参数查找大 key 时,最好选择在从节点上执行该命令,因为主节点上执行时,会 **阻塞** 主节点。
|
||||
|
||||
- 我们还可以使用 SCAN 命令来查找大 key;
|
||||
|
||||
- 通过分析 RDB 文件来找出 big key,这种方案的前提是 Redis 采用的是 RDB 持久化。网上有现成的工具:
|
||||
|
||||
- - redis-rdb-tools:Python 语言写的用来分析 Redis 的 RDB 快照文件用的工具
|
||||
- redis-rdb-tools:Python 语言写的用来分析 Redis 的 RDB 快照文件用的工具;
|
||||
- rdb_bigkeys:Go 语言写的用来分析 Redis 的 RDB 快照文件用的工具,性能更好。
|
||||
|
||||
### 删除大 key
|
||||
|
||||
删除操作的本质是要释放键值对占用的内存空间。
|
||||
|
||||
释放内存只是第一步,为了更加高效地管理内存空间,在应用程序释放内存时,**操作系统需要把释放掉的内存块插入一个空闲内存块的链表**,以便后续进行管理和再分配。这个过程本身需要一定时间,而且会**阻塞**当前释放内存的应用程序。
|
||||
释放内存只是第一步,为了更加高效地管理内存空间,在应用程序释放内存时,**操作系统需要把释放掉的内存块插入一个空闲内存块的链表**,以便后续进行管理和再分配。这个过程本身需要一定时间,而且会 **阻塞** 当前释放内存的应用程序。
|
||||
|
||||
所以,如果一下子释放了大量内存,空闲内存块链表操作时间就会增加,相应地就会造成 Redis 主线程的阻塞,如果主线程发生了阻塞,其他所有请求可能都会超时,超时越来越多,会造成 Redis 连接耗尽,产生各种异常。
|
||||
|
||||
@ -156,19 +156,19 @@ Swap: 0kB
|
||||
|
||||
预防内存交换的方法:
|
||||
|
||||
- 保证机器充足的可用内存
|
||||
- 确保所有 Redis 实例设置最大可用内存(maxmemory),防止极端情况 Redis 内存不可控的增长
|
||||
- 降低系统使用 swap 优先级,如`echo 10 > /proc/sys/vm/swappiness`
|
||||
- 保证机器充足的可用内存;
|
||||
- 确保所有 Redis 实例设置最大可用内存(maxmemory),防止极端情况 Redis 内存不可控的增长;
|
||||
- 降低系统使用 swap 优先级,如 `echo 10 > /proc/sys/vm/swappiness`。
|
||||
|
||||
## CPU 竞争
|
||||
|
||||
Redis 是典型的 CPU 密集型应用,不建议和其他多核 CPU 密集型服务部署在一起。当其他进程过度消耗 CPU 时,将严重影响 Redis 的吞吐量。
|
||||
|
||||
可以通过`redis-cli --stat`获取当前 Redis 使用情况。通过`top`命令获取进程对 CPU 的利用率等信息 通过`info commandstats`统计信息分析出命令不合理开销时间,查看是否是因为高算法复杂度或者过度的内存优化问题。
|
||||
可以通过 `redis-cli --stat` 获取当前 Redis 使用情况。通过 `top` 命令获取进程对 CPU 的利用率等信息 通过 `info commandstats` 统计信息分析出命令不合理开销时间,查看是否是因为高算法复杂度或者过度的内存优化问题。
|
||||
|
||||
## 网络问题
|
||||
|
||||
连接拒绝、网络延迟,网卡软中断等网络问题也可能会导致 Redis 阻塞。
|
||||
连接拒绝、网络延迟、网卡软中断等网络问题也可能会导致 Redis 阻塞。
|
||||
|
||||
## 参考
|
||||
|
||||
|
||||
@ -14,7 +14,7 @@ head:
|
||||
|
||||
Redis 共有 5 种基本数据类型:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
|
||||
|
||||
这 5 种数据类型是直接提供给用户使用的,是数据的保存形式,其底层实现主要依赖这 8 种数据结构:简单动态字符串(SDS)、LinkedList(双向链表)、Dict(哈希表/字典)、SkipList(跳跃表)、Intset(整数集合)、ZipList(压缩列表)、QuickList(快速列表)。
|
||||
这 5 种数据类型是直接提供给用户使用的,是数据的保存形式,其底层实现主要依赖这 8 种数据结构:SDS(简单动态字符串)、LinkedList(双向链表)、Dict(哈希表/字典)、SkipList(跳跃表)、Intset(整数集合)、ZipList(压缩列表)、QuickList(快速列表)。
|
||||
|
||||
Redis 5 种基本数据类型对应的底层数据结构实现如下表所示:
|
||||
|
||||
@ -22,7 +22,7 @@ Redis 5 种基本数据类型对应的底层数据结构实现如下表所示:
|
||||
| :----- | :--------------------------- | :------------ | :----------- | :---------------- |
|
||||
| SDS | LinkedList/ZipList/QuickList | Dict、ZipList | Dict、Intset | ZipList、SkipList |
|
||||
|
||||
Redis 3.2 之前,List 底层实现是 LinkedList 或者 ZipList。 Redis 3.2 之后,引入了 LinkedList 和 ZipList 的结合 QuickList,List 的底层实现变为 QuickList。从 Redis 7.0 开始, ZipList 被 ListPack 取代。
|
||||
Redis 3.2 之前,List 底层实现是 LinkedList 或者 ZipList。Redis 3.2 之后,引入了 LinkedList 和 ZipList 的结合 QuickList,List 的底层实现变为 QuickList。从 Redis 7.0 开始,ZipList 被 ListPack 取代。
|
||||
|
||||
你可以在 Redis 官网上找到 Redis 数据类型/结构非常详细的介绍:
|
||||
|
||||
@ -43,7 +43,7 @@ String 是一种二进制安全的数据类型,可以用来存储任何类型
|
||||
|
||||
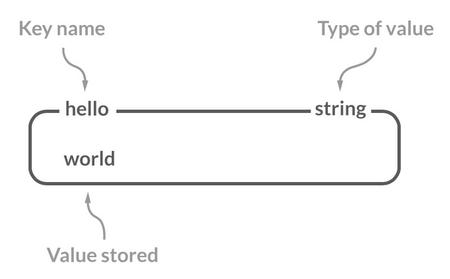
|
||||
|
||||
虽然 Redis 是用 C 语言写的,但是 Redis 并没有使用 C 的字符串表示,而是自己构建了一种 **简单动态字符串**(Simple Dynamic String,**SDS**)。相比于 C 的原生字符串,Redis 的 SDS 不光可以保存文本数据还可以保存二进制数据,并且获取字符串长度复杂度为 O(1)(C 字符串为 O(N)),除此之外,Redis 的 SDS API 是安全的,不会造成缓冲区溢出。
|
||||
虽然 Redis 是用 C 语言写的,但是 Redis 并没有使用 C 的字符串表示,而是自己构建了一种 **简单动态字符串**(Simple Dynamic String,**SDS**)。相比于 C 的原生字符串,Redis 的 SDS 不光可以保存文本数据还可以保存二进制数据,并且获取字符串长度复杂度为 O(1)(C 字符串为 O(N)),除此之外,Redis 的 SDS API 是安全的,不会造成缓冲区溢出。
|
||||
|
||||
### 常用命令
|
||||
|
||||
@ -61,7 +61,7 @@ String 是一种二进制安全的数据类型,可以用来存储任何类型
|
||||
| DEL key(通用) | 删除指定的 key |
|
||||
| EXPIRE key seconds(通用) | 给指定 key 设置过期时间 |
|
||||
|
||||
更多 Redis String 命令以及详细使用指南,请查看 Redis 官网对应的介绍:<https://redis.io/commands/?group=string> 。
|
||||
更多 Redis String 命令以及详细使用指南,请查看 Redis 官网对应的介绍:<https://redis.io/commands/?group=string>。
|
||||
|
||||
**基本操作**:
|
||||
|
||||
@ -90,7 +90,7 @@ OK
|
||||
2) "value2"
|
||||
```
|
||||
|
||||
**计数器(字符串的内容为整数的时候可以使用):**
|
||||
**计数器(字符串的内容为整数的时候可以使用)**:
|
||||
|
||||
```bash
|
||||
> SET number 1
|
||||
@ -120,13 +120,13 @@ OK
|
||||
|
||||
**需要存储常规数据的场景**
|
||||
|
||||
- 举例:缓存 Session、Token、图片地址、序列化后的对象(相比较于 Hash 存储更节省内存)。
|
||||
- 举例:缓存 Session、Token、图片地址、序列化后的对象(相比较于 Hash 存储更节省内存)。
|
||||
- 相关命令:`SET`、`GET`。
|
||||
|
||||
**需要计数的场景**
|
||||
|
||||
- 举例:用户单位时间的请求数(简单限流可以用到)、页面单位时间的访问数。
|
||||
- 相关命令:`SET`、`GET`、 `INCR`、`DECR` 。
|
||||
- 相关命令:`SET`、`GET`、`INCR`、`DECR`。
|
||||
|
||||
**分布式锁**
|
||||
|
||||
@ -136,27 +136,27 @@ OK
|
||||
|
||||
### 介绍
|
||||
|
||||
Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据结构 :数组、链表、栈、队列](https://javaguide.cn/cs-basics/data-structure/linear-data-structure.html) 这篇文章中详细介绍了链表这种数据结构,我这里就不多做介绍了。
|
||||
Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据结构 :数组、链表、栈、队列](https://javaguide.cn/cs-basics/data-structure/linear-data-structure.html) 这篇文章中详细介绍了链表这种数据结构,这里就不多做介绍了。
|
||||
|
||||
许多高级编程语言都内置了链表的实现比如 Java 中的 `LinkedList`,但是 C 语言并没有实现链表,所以 Redis 实现了自己的链表数据结构。Redis 的 List 的实现为一个 **双向链表**,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。
|
||||
许多高级编程语言都内置了链表的实现,比如 Java 中的 `LinkedList`,但是 C 语言并没有实现链表,所以 Redis 实现了自己的链表数据结构。Redis 的 List 的实现为一个 **双向链表**,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。
|
||||
|
||||
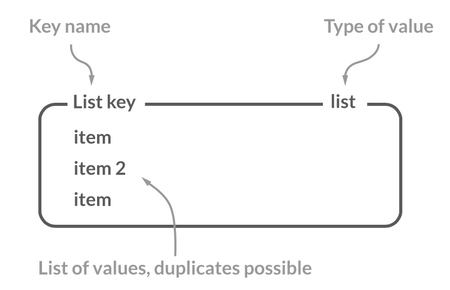
|
||||
|
||||
### 常用命令
|
||||
|
||||
| 命令 | 介绍 |
|
||||
| --------------------------- | ------------------------------------------ |
|
||||
| RPUSH key value1 value2 ... | 在指定列表的尾部(右边)添加一个或多个元素 |
|
||||
| LPUSH key value1 value2 ... | 在指定列表的头部(左边)添加一个或多个元素 |
|
||||
| LSET key index value | 将指定列表索引 index 位置的值设置为 value |
|
||||
| LPOP key | 移除并获取指定列表的第一个元素(最左边) |
|
||||
| RPOP key | 移除并获取指定列表的最后一个元素(最右边) |
|
||||
| LLEN key | 获取列表元素数量 |
|
||||
| LRANGE key start end | 获取列表 start 和 end 之间 的元素 |
|
||||
| 命令 | 介绍 |
|
||||
| --------------------------- |-----------------------------|
|
||||
| RPUSH key value1 value2 ... | 在指定列表的尾部(右边)添加一个或多个元素 |
|
||||
| LPUSH key value1 value2 ... | 在指定列表的头部(左边)添加一个或多个元素 |
|
||||
| LSET key index value | 将指定列表索引 index 位置的值设置为 value |
|
||||
| LPOP key | 移除并获取指定列表的第一个元素(最左边) |
|
||||
| RPOP key | 移除并获取指定列表的最后一个元素(最右边) |
|
||||
| LLEN key | 获取列表元素数量 |
|
||||
| LRANGE key start end | 获取列表 start 和 end 之间 的元素 |
|
||||
|
||||
更多 Redis List 命令以及详细使用指南,请查看 Redis 官网对应的介绍:<https://redis.io/commands/?group=list> 。
|
||||
更多 Redis List 命令以及详细使用指南,请查看 Redis 官网对应的介绍:<https://redis.io/commands/?group=list>。
|
||||
|
||||
**通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`实现队列**:
|
||||
**通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP` 实现队列**:
|
||||
|
||||
```bash
|
||||
> RPUSH myList value1
|
||||
@ -173,7 +173,7 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
|
||||
2) "value3"
|
||||
```
|
||||
|
||||
**通过 `RPUSH/RPOP`或者`LPUSH/LPOP` 实现栈**:
|
||||
**通过 `RPUSH/RPOP` 或者 `LPUSH/LPOP` 实现栈**:
|
||||
|
||||
```bash
|
||||
> RPUSH myList2 value1 value2 value3
|
||||
@ -182,7 +182,7 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
|
||||
"value3"
|
||||
```
|
||||
|
||||
我专门画了一个图方便大家理解 `RPUSH` , `LPOP` , `lpush` , `RPOP` 命令:
|
||||
我专门画了一个图方便大家理解 `RPUSH`、`LPOP`、`lpush`、`RPOP` 命令:
|
||||
|
||||

|
||||
|
||||
@ -220,7 +220,7 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
|
||||
|
||||
`List` 可以用来做消息队列,只是功能过于简单且存在很多缺陷,不建议这样做。
|
||||
|
||||
相对来说,Redis 5.0 新增加的一个数据结构 `Stream` 更适合做消息队列一些,只是功能依然非常简陋。和专业的消息队列相比,还是有很多欠缺的地方比如消息丢失和堆积问题不好解决。
|
||||
相对来说,Redis 5.0 新增加的一个数据结构 `Stream` 更适合做消息队列一些,只是功能依然非常简陋。和专业的消息队列相比,还是有很多欠缺的地方,比如消息丢失和堆积问题不好解决。
|
||||
|
||||
## Hash(哈希)
|
||||
|
||||
@ -228,26 +228,26 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
|
||||
|
||||
Redis 中的 Hash 是一个 String 类型的 field-value(键值对) 的映射表,特别适合用于存储对象,后续操作的时候,你可以直接修改这个对象中的某些字段的值。
|
||||
|
||||
Hash 类似于 JDK1.8 前的 `HashMap`,内部实现也差不多(数组 + 链表)。不过,Redis 的 Hash 做了更多优化。
|
||||
Hash 类似于 JDK1.8 前的 `HashMap`,内部实现也差不多(数组+链表)。不过,Redis 的 Hash 做了更多优化。
|
||||
|
||||
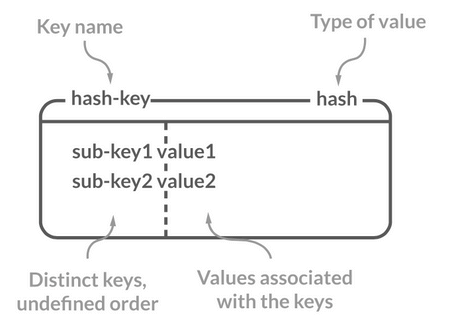
|
||||
|
||||
### 常用命令
|
||||
|
||||
| 命令 | 介绍 |
|
||||
| ----------------------------------------- | -------------------------------------------------------- |
|
||||
| HSET key field value | 设置指定哈希表中指定字段的值 |
|
||||
| HSETNX key field value | 只有指定字段不存在时设置指定字段的值 |
|
||||
| HMSET key field1 value1 field2 value2 ... | 同时将一个或多个 field-value (域-值)对设置到指定哈希表中 |
|
||||
| HGET key field | 获取指定哈希表中指定字段的值 |
|
||||
| HMGET key field1 field2 ... | 获取指定哈希表中一个或者多个指定字段的值 |
|
||||
| HGETALL key | 获取指定哈希表中所有的键值对 |
|
||||
| HEXISTS key field | 查看指定哈希表中指定的字段是否存在 |
|
||||
| HDEL key field1 field2 ... | 删除一个或多个哈希表字段 |
|
||||
| HLEN key | 获取指定哈希表中字段的数量 |
|
||||
| HINCRBY key field increment | 对指定哈希中的指定字段做运算操作(正数为加,负数为减) |
|
||||
| 命令 | 介绍 |
|
||||
| ----------------------------------------- |-------------------------------------|
|
||||
| HSET key field value | 设置指定哈希表中指定字段的值 |
|
||||
| HSETNX key field value | 只有指定字段不存在时设置指定字段的值 |
|
||||
| HMSET key field1 value1 field2 value2 ... | 同时将一个或多个 field-value(域-值)对设置到指定哈希表中 |
|
||||
| HGET key field | 获取指定哈希表中指定字段的值 |
|
||||
| HMGET key field1 field2 ... | 获取指定哈希表中一个或者多个指定字段的值 |
|
||||
| HGETALL key | 获取指定哈希表中所有的键值对 |
|
||||
| HEXISTS key field | 查看指定哈希表中指定的字段是否存在 |
|
||||
| HDEL key field1 field2 ... | 删除一个或多个哈希表字段 |
|
||||
| HLEN key | 获取指定哈希表中字段的数量 |
|
||||
| HINCRBY key field increment | 对指定哈希中的指定字段做运算操作(正数为加,负数为减) |
|
||||
|
||||
更多 Redis Hash 命令以及详细使用指南,请查看 Redis 官网对应的介绍:<https://redis.io/commands/?group=hash> 。
|
||||
更多 Redis Hash 命令以及详细使用指南,请查看 Redis 官网对应的介绍:<https://redis.io/commands/?group=hash>。
|
||||
|
||||
**模拟对象数据存储**:
|
||||
|
||||
@ -279,13 +279,13 @@ OK
|
||||
**对象数据存储场景**
|
||||
|
||||
- 举例:用户信息、商品信息、文章信息、购物车信息。
|
||||
- 相关命令:`HSET` (设置单个字段的值)、`HMSET`(设置多个字段的值)、`HGET`(获取单个字段的值)、`HMGET`(获取多个字段的值)。
|
||||
- 相关命令:`HSET`(设置单个字段的值)、`HMSET`(设置多个字段的值)、`HGET`(获取单个字段的值)、`HMGET`(获取多个字段的值)。
|
||||
|
||||
## Set(集合)
|
||||
|
||||
### 介绍
|
||||
|
||||
Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 `HashSet` 。当你需要存储一个列表数据,又不希望出现重复数据时,Set 是一个很好的选择,并且 Set 提供了判断某个元素是否在一个 Set 集合内的重要接口,这个也是 List 所不能提供的。
|
||||
Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 `HashSet`。当你需要存储一个列表数据,又不希望出现重复数据时,Set 是一个很好的选择,并且 Set 提供了判断某个元素是否在一个 Set 集合内的重要接口,这个也是 List 所不能提供的。
|
||||
|
||||
你可以基于 Set 轻易实现交集、并集、差集的操作,比如你可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。这样的话,Set 可以非常方便的实现如共同关注、共同粉丝、共同喜好等功能。这个过程也就是求交集的过程。
|
||||
|
||||
@ -308,7 +308,7 @@ Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺
|
||||
| SPOP key count | 随机移除并获取指定集合中一个或多个元素 |
|
||||
| SRANDMEMBER key count | 随机获取指定集合中指定数量的元素 |
|
||||
|
||||
更多 Redis Set 命令以及详细使用指南,请查看 Redis 官网对应的介绍:<https://redis.io/commands/?group=set> 。
|
||||
更多 Redis Set 命令以及详细使用指南,请查看 Redis 官网对应的介绍:<https://redis.io/commands/?group=set>。
|
||||
|
||||
**基本操作**:
|
||||
|
||||
@ -328,8 +328,8 @@ Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺
|
||||
(integer) 2
|
||||
```
|
||||
|
||||
- `mySet` : `value1`、`value2` 。
|
||||
- `mySet2`:`value2`、`value3` 。
|
||||
- `mySet`:`value1`、`value2`。
|
||||
- `mySet2`:`value2`、`value3`。
|
||||
|
||||
**求交集**:
|
||||
|
||||
@ -360,15 +360,15 @@ Redis 中的 Set 类型是一种无序集合,集合中的元素没有先后顺
|
||||
|
||||
**需要存放的数据不能重复的场景**
|
||||
|
||||
- 举例:网站 UV 统计(数据量巨大的场景还是 `HyperLogLog`更适合一些)、文章点赞、动态点赞等场景。
|
||||
- 相关命令:`SCARD`(获取集合数量) 。
|
||||
- 举例:网站 UV 统计(数据量巨大的场景还是 `HyperLogLog` 更适合一些)、文章点赞、动态点赞等场景。
|
||||
- 相关命令:`SCARD`(获取集合数量)。
|
||||
|
||||
|
||||
|
||||
**需要获取多个数据源交集、并集和差集的场景**
|
||||
|
||||
- 举例:共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集)、订阅号推荐(差集+交集) 等场景。
|
||||
- 相关命令:`SINTER`(交集)、`SINTERSTORE` (交集)、`SUNION` (并集)、`SUNIONSTORE`(并集)、`SDIFF`(差集)、`SDIFFSTORE` (差集)。
|
||||
- 举例:共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集)、订阅号推荐(差集+交集)等场景。
|
||||
- 相关命令:`SINTER`(交集)、`SINTERSTORE`(交集)、`SUNION`(并集)、`SUNIONSTORE`(并集)、`SDIFF`(差集)、`SDIFFSTORE`(差集)。
|
||||
|
||||
|
||||
|
||||
@ -387,19 +387,19 @@ Sorted Set 类似于 Set,但和 Set 相比,Sorted Set 增加了一个权重
|
||||
|
||||
### 常用命令
|
||||
|
||||
| 命令 | 介绍 |
|
||||
| --------------------------------------------- | ------------------------------------------------------------------------------------------------------------- |
|
||||
| ZADD key score1 member1 score2 member2 ... | 向指定有序集合添加一个或多个元素 |
|
||||
| ZCARD KEY | 获取指定有序集合的元素数量 |
|
||||
| ZSCORE key member | 获取指定有序集合中指定元素的 score 值 |
|
||||
| 命令 | 介绍 |
|
||||
| --------------------------------------------- |-------------------------------------------------------------------------|
|
||||
| ZADD key score1 member1 score2 member2 ... | 向指定有序集合添加一个或多个元素 |
|
||||
| ZCARD KEY | 获取指定有序集合的元素数量 |
|
||||
| ZSCORE key member | 获取指定有序集合中指定元素的 score 值 |
|
||||
| ZINTERSTORE destination numkeys key1 key2 ... | 将给定所有有序集合的交集存储在 destination 中,对相同元素对应的 score 值进行 SUM 聚合操作,numkeys 为集合数量 |
|
||||
| ZUNIONSTORE destination numkeys key1 key2 ... | 求并集,其它和 ZINTERSTORE 类似 |
|
||||
| ZDIFFSTORE destination numkeys key1 key2 ... | 求差集,其它和 ZINTERSTORE 类似 |
|
||||
| ZRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score 从低到高) |
|
||||
| ZREVRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score 从高到底) |
|
||||
| ZREVRANK key member | 获取指定有序集合中指定元素的排名(score 从大到小排序) |
|
||||
| ZUNIONSTORE destination numkeys key1 key2 ... | 求并集,其它和 ZINTERSTORE 类似 |
|
||||
| ZDIFFSTORE destination numkeys key1 key2 ... | 求差集,其它和 ZINTERSTORE 类似 |
|
||||
| ZRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score 从低到高) |
|
||||
| ZREVRANGE key start end | 获取指定有序集合 start 和 end 之间的元素(score 从高到底) |
|
||||
| ZREVRANK key member | 获取指定有序集合中指定元素的排名(score 从大到小排序) |
|
||||
|
||||
更多 Redis Sorted Set 命令以及详细使用指南,请查看 Redis 官网对应的介绍:<https://redis.io/commands/?group=sorted-set> 。
|
||||
更多 Redis Sorted Set 命令以及详细使用指南,请查看 Redis 官网对应的介绍:<https://redis.io/commands/?group=sorted-set>。
|
||||
|
||||
**基本操作**:
|
||||
|
||||
@ -421,8 +421,8 @@ Sorted Set 类似于 Set,但和 Set 相比,Sorted Set 增加了一个权重
|
||||
|
||||
```
|
||||
|
||||
- `myZset` : `value1`(2.0)、`value2`(1.0) 。
|
||||
- `myZset2`:`value2` (4.0)、`value3`(3.0) 。
|
||||
- `myZset`:`value1`(2.0)、`value2`(1.0)。
|
||||
- `myZset2`:`value2`(4.0)、`value3`(3.0)。
|
||||
|
||||
**获取指定元素的排名**:
|
||||
|
||||
@ -469,8 +469,8 @@ value1
|
||||
|
||||
**需要随机获取数据源中的元素根据某个权重进行排序的场景**
|
||||
|
||||
- 举例:各种排行榜比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
|
||||
- 相关命令:`ZRANGE` (从小到大排序)、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
|
||||
- 举例:各种排行榜,比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
|
||||
- 相关命令:`ZRANGE`(从小到大排序)、`ZREVRANGE`(从大到小排序)、`ZREVRANK`(指定元素排名)。
|
||||
|
||||

|
||||
|
||||
@ -478,26 +478,26 @@ value1
|
||||
|
||||
|
||||
|
||||
**需要存储的数据有优先级或者重要程度的场景** 比如优先级任务队列。
|
||||
**需要存储的数据有优先级或者重要程度的场景**
|
||||
|
||||
- 举例:优先级任务队列。
|
||||
- 相关命令:`ZRANGE` (从小到大排序)、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
|
||||
- 相关命令:`ZRANGE`(从小到大排序)、`ZREVRANGE`(从大到小排序)、`ZREVRANK`(指定元素排名)。
|
||||
|
||||
## 总结
|
||||
|
||||
| 数据类型 | 说明 |
|
||||
| -------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| 数据类型 | 说明 |
|
||||
| -------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| String | 一种二进制安全的数据类型,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。 |
|
||||
| List | Redis 的 List 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。 |
|
||||
| Hash | 一个 String 类型的 field-value(键值对) 的映射表,特别适合用于存储对象,后续操作的时候,你可以直接修改这个对象中的某些字段的值。 |
|
||||
| Set | 无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 `HashSet` 。 |
|
||||
| Set | 无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 `HashSet`。 |
|
||||
| Zset | 和 Set 相比,Sorted Set 增加了一个权重参数 `score`,使得集合中的元素能够按 `score` 进行有序排列,还可以通过 `score` 的范围来获取元素的列表。有点像是 Java 中 `HashMap` 和 `TreeSet` 的结合体。 |
|
||||
|
||||
## 参考
|
||||
|
||||
- Redis Data Structures:<https://redis.com/redis-enterprise/data-structures/> 。
|
||||
- Redis Commands:<https://redis.io/commands/> 。
|
||||
- Redis Data types tutorial:<https://redis.io/docs/manual/data-types/data-types-tutorial/> 。
|
||||
- Redis 存储对象信息是用 Hash 还是 String : <https://segmentfault.com/a/1190000040032006>
|
||||
- Redis Data Structures:<https://redis.com/redis-enterprise/data-structures/>。
|
||||
- Redis Commands:<https://redis.io/commands/>。
|
||||
- Redis Data types tutorial:<https://redis.io/docs/manual/data-types/data-types-tutorial/>。
|
||||
- Redis 存储对象信息是用 Hash 还是 String:<https://segmentfault.com/a/1190000040032006>。
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
||||
@ -24,7 +24,7 @@ head:
|
||||
>
|
||||
> Bitmap 不是 Redis 中的实际数据类型,而是在 String 类型上定义的一组面向位的操作,将其视为位向量。由于字符串是二进制安全的块,且最大长度为 512 MB,它们适合用于设置最多 2^32 个不同的位。
|
||||
|
||||
Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。
|
||||
Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap,只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。
|
||||
|
||||
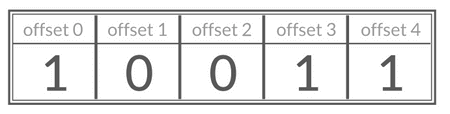
你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。
|
||||
|
||||
@ -32,12 +32,12 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
|
||||
|
||||
### 常用命令
|
||||
|
||||
| 命令 | 介绍 |
|
||||
| ------------------------------------- | ---------------------------------------------------------------- |
|
||||
| SETBIT key offset value | 设置指定 offset 位置的值 |
|
||||
| GETBIT key offset | 获取指定 offset 位置的值 |
|
||||
| BITCOUNT key start end | 获取 start 和 end 之间值为 1 的元素个数 |
|
||||
| BITOP operation destkey key1 key2 ... | 对一个或多个 Bitmap 进行运算,可用运算符有 AND, OR, XOR 以及 NOT |
|
||||
| 命令 | 介绍 |
|
||||
| ------------------------------------- |---------------------------------------------|
|
||||
| SETBIT key offset value | 设置指定 offset 位置的值 |
|
||||
| GETBIT key offset | 获取指定 offset 位置的值 |
|
||||
| BITCOUNT key start end | 获取 start 和 end 之间值为 1 的元素个数 |
|
||||
| BITOP operation destkey key1 key2 ... | 对一个或多个 Bitmap 进行运算,可用运算符有 AND、OR、XOR 以及 NOT |
|
||||
|
||||
**Bitmap 基本操作演示**:
|
||||
|
||||
@ -69,9 +69,9 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
|
||||
|
||||
### 介绍
|
||||
|
||||
HyperLogLog 是一种有名的基数计数概率算法 ,基于 LogLog Counting(LLC)优化改进得来,并不是 Redis 特有的,Redis 只是实现了这个算法并提供了一些开箱即用的 API。
|
||||
HyperLogLog 是一种有名的基数计数概率算法,基于 LogLog Counting(LLC)优化改进得来,并不是 Redis 特有的,Redis 只是实现了这个算法并提供了一些开箱即用的 API。
|
||||
|
||||
Redis 提供的 HyperLogLog 占用空间非常非常小,只需要 12k 的空间就能存储接近`2^64`个不同元素。这是真的厉害,这就是数学的魅力么!并且,Redis 对 HyperLogLog 的存储结构做了优化,采用两种方式计数:
|
||||
Redis 提供的 HyperLogLog 占用空间非常非常小,只需要 12k 的空间就能存储接近 `2^64` 个不同元素。这是真的厉害,这就是数学的魅力么!并且,Redis 对 HyperLogLog 的存储结构做了优化,采用两种方式计数:
|
||||
|
||||
- **稀疏矩阵**:计数较少的时候,占用空间很小。
|
||||
- **稠密矩阵**:计数达到某个阈值的时候,占用 12k 的空间。
|
||||
@ -80,15 +80,15 @@ Redis 官方文档中有对应的详细说明:
|
||||
|
||||

|
||||
|
||||
基数计数概率算法为了节省内存并不会直接存储元数据,而是通过一定的概率统计方法预估基数值(集合中包含元素的个数)。因此, HyperLogLog 的计数结果并不是一个精确值,存在一定的误差(标准误差为 `0.81%` )。
|
||||
基数计数概率算法为了节省内存并不会直接存储元数据,而是通过一定的概率统计方法预估基数值(集合中包含元素的个数)。因此,HyperLogLog 的计数结果并不是一个精确值,存在一定的误差(标准误差为 `0.81%`)。
|
||||
|
||||
|
||||
|
||||
HyperLogLog 的使用非常简单,但原理非常复杂。HyperLogLog 的原理以及在 Redis 中的实现可以看这篇文章:[HyperLogLog 算法的原理讲解以及 Redis 是如何应用它的](https://juejin.cn/post/6844903785744056333) 。
|
||||
HyperLogLog 的使用非常简单,但原理非常复杂。HyperLogLog 的原理以及在 Redis 中的实现可以看这篇文章:[HyperLogLog 算法的原理讲解以及 Redis 是如何应用它的](https://juejin.cn/post/6844903785744056333)。
|
||||
|
||||
再推荐一个可以帮助理解 HyperLogLog 原理的工具:[Sketch of the Day: HyperLogLog — Cornerstone of a Big Data Infrastructure](http://content.research.neustar.biz/blog/hll.html) 。
|
||||
再推荐一个可以帮助理解 HyperLogLog 原理的工具:[Sketch of the Day: HyperLogLog — Cornerstone of a Big Data Infrastructure](http://content.research.neustar.biz/blog/hll.html)。
|
||||
|
||||
除了 HyperLogLog 之外,Redis 还提供了其他的概率数据结构,对应的官方文档地址:<https://redis.io/docs/data-types/probabilistic/> 。
|
||||
除了 HyperLogLog 之外,Redis 还提供了其他的概率数据结构,对应的官方文档地址:<https://redis.io/docs/data-types/probabilistic/>。
|
||||
|
||||
### 常用命令
|
||||
|
||||
@ -126,7 +126,7 @@ HyperLogLog 相关的命令非常少,最常用的也就 3 个。
|
||||
**数量巨大(百万、千万级别以上)的计数场景**
|
||||
|
||||
- 举例:热门网站每日/每周/每月访问 ip 数统计、热门帖子 uv 统计。
|
||||
- 相关命令:`PFADD`、`PFCOUNT` 。
|
||||
- 相关命令:`PFADD`、`PFCOUNT`。
|
||||
|
||||
## Geospatial (地理位置)
|
||||
|
||||
@ -140,13 +140,13 @@ Geospatial index(地理空间索引,简称 GEO) 主要用于存储地理
|
||||
|
||||
### 常用命令
|
||||
|
||||
| 命令 | 介绍 |
|
||||
| ------------------------------------------------ | ---------------------------------------------------------------------------------------------------- |
|
||||
| GEOADD key longitude1 latitude1 member1 ... | 添加一个或多个元素对应的经纬度信息到 GEO 中 |
|
||||
| GEOPOS key member1 member2 ... | 返回给定元素的经纬度信息 |
|
||||
| GEODIST key member1 member2 M/KM/FT/MI | 返回两个给定元素之间的距离 |
|
||||
| GEORADIUS key longitude latitude radius distance | 获取指定位置附近 distance 范围内的其他元素,支持 ASC(由近到远)、DESC(由远到近)、Count(数量) 等参数 |
|
||||
| GEORADIUSBYMEMBER key member radius distance | 类似于 GEORADIUS 命令,只是参照的中心点是 GEO 中的元素 |
|
||||
| 命令 | 介绍 |
|
||||
| ------------------------------------------------ |-----------------------------------------------------------------|
|
||||
| GEOADD key longitude1 latitude1 member1 ... | 添加一个或多个元素对应的经纬度信息到 GEO 中 |
|
||||
| GEOPOS key member1 member2 ... | 返回给定元素的经纬度信息 |
|
||||
| GEODIST key member1 member2 M/KM/FT/MI | 返回两个给定元素之间的距离 |
|
||||
| GEORADIUS key longitude latitude radius distance | 获取指定位置附近 distance 范围内的其他元素,支持 ASC(由近到远)、DESC(由远到近)、Count(数量)等参数 |
|
||||
| GEORADIUSBYMEMBER key member radius distance | 类似于 GEORADIUS 命令,只是参照的中心点是 GEO 中的元素 |
|
||||
|
||||
**基本操作**:
|
||||
|
||||
@ -160,9 +160,9 @@ Geospatial index(地理空间索引,简称 GEO) 主要用于存储地理
|
||||
1.4018
|
||||
```
|
||||
|
||||
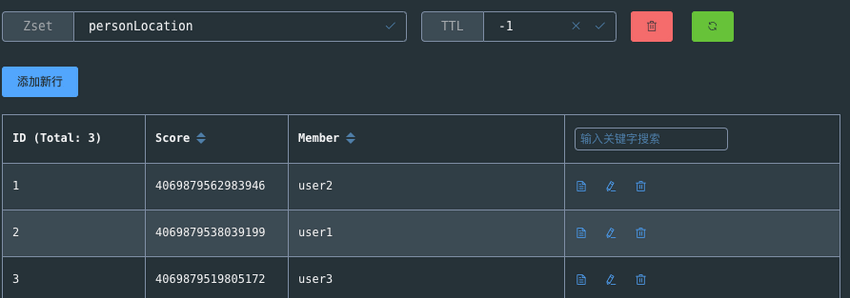
通过 Redis 可视化工具查看 `personLocation` ,果不其然,底层就是 Sorted Set。
|
||||
通过 Redis 可视化工具查看 `personLocation`,果不其然,底层就是 Sorted Set。
|
||||
|
||||
GEO 中存储的地理位置信息的经纬度数据通过 GeoHash 算法转换成了一个整数,这个整数作为 Sorted Set 的 score(权重参数)使用。
|
||||
GEO 中存储的地理位置信息的经纬度数据通过 GeoHash 算法转换成了一个整数,这个整数作为 Sorted Set 的 score(权重参数)使用。
|
||||
|
||||
|
||||
|
||||
@ -186,11 +186,11 @@ user1
|
||||
user2
|
||||
```
|
||||
|
||||
`GEORADIUS` 命令的底层原理解析可以看看阿里的这篇文章:[Redis 到底是怎么实现“附近的人”这个功能的呢?](https://juejin.cn/post/6844903966061363207) 。
|
||||
`GEORADIUS` 命令的底层原理解析可以看看阿里的这篇文章:[Redis 到底是怎么实现“附近的人”这个功能的呢?](https://juejin.cn/post/6844903966061363207)。
|
||||
|
||||
**移除元素**:
|
||||
|
||||
GEO 底层是 Sorted Set ,你可以对 GEO 使用 Sorted Set 相关的命令。
|
||||
GEO 底层是 Sorted Set,你可以对 GEO 使用 Sorted Set 相关的命令。
|
||||
|
||||
```bash
|
||||
> ZREM personLocation user1
|
||||
@ -211,16 +211,16 @@ user2
|
||||
|
||||
## 总结
|
||||
|
||||
| 数据类型 | 说明 |
|
||||
| ---------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Bitmap | 你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。通过 Bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。 |
|
||||
| HyperLogLog | Redis 提供的 HyperLogLog 占用空间非常非常小,只需要 12k 的空间就能存储接近`2^64`个不同元素。不过,HyperLogLog 的计数结果并不是一个精确值,存在一定的误差(标准误差为 `0.81%` )。 |
|
||||
| Geospatial index | Geospatial index(地理空间索引,简称 GEO) 主要用于存储地理位置信息,基于 Sorted Set 实现。 |
|
||||
| 数据类型 | 说明 |
|
||||
| ---------------- |---------------------------------------------------------------------------------------------------------------------------------------------------------------|
|
||||
| Bitmap | 你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。通过 Bitmap,只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。 |
|
||||
| HyperLogLog | Redis 提供的 HyperLogLog 占用空间非常非常小,只需要 12k 的空间就能存储接近 `2^64` 个不同元素。不过,HyperLogLog 的计数结果并不是一个精确值,存在一定的误差(标准误差为 `0.81%`)。 |
|
||||
| Geospatial index | Geospatial index(地理空间索引,简称 GEO)主要用于存储地理位置信息,基于 Sorted Set 实现。 |
|
||||
|
||||
## 参考
|
||||
|
||||
- Redis Data Structures:<https://redis.com/redis-enterprise/data-structures/> 。
|
||||
- 《Redis 深度历险:核心原理与应用实践》1.6 四两拨千斤——HyperLogLog
|
||||
- 布隆过滤器,位图,HyperLogLog:<https://hogwartsrico.github.io/2020/06/08/BloomFilter-HyperLogLog-BitMap/index.html>
|
||||
- Redis Data Structures:<https://redis.com/redis-enterprise/data-structures/>。
|
||||
- 《Redis 深度历险:核心原理与应用实践》1.6 四两拨千斤——HyperLogLog。
|
||||
- 布隆过滤器、位图、HyperLogLog:<https://hogwartsrico.github.io/2020/06/08/BloomFilter-HyperLogLog-BitMap/index.html>。
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
||||
@ -7,8 +7,8 @@ tag:
|
||||
|
||||
基于 Redis 实现延时任务的功能无非就下面两种方案:
|
||||
|
||||
1. Redis 过期事件监听
|
||||
2. Redisson 内置的延时队列
|
||||
1. Redis 过期事件监听;
|
||||
2. Redisson 内置的延时队列。
|
||||
|
||||
面试的时候,你可以先说自己考虑了这两种方案,但最后发现 Redis 过期事件监听这种方案存在很多问题,因此你最终选择了 Redisson 内置的 DelayedQueue 这种方案。
|
||||
|
||||
@ -18,28 +18,28 @@ tag:
|
||||
|
||||
### Redis 过期事件监听实现延时任务功能的原理?
|
||||
|
||||
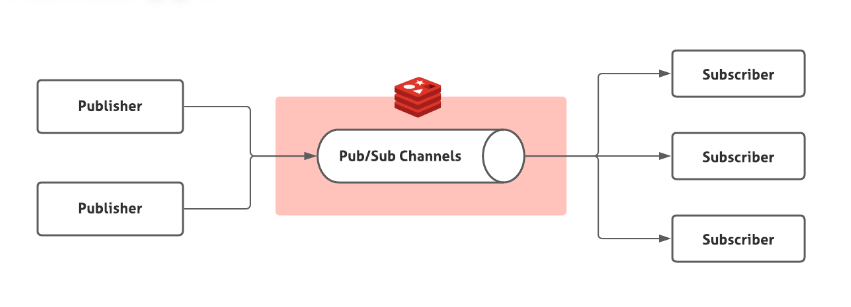
Redis 2.0 引入了发布订阅 (pub/sub) 功能。在 pub/sub 中,引入了一个叫做 **channel(频道)** 的概念,有点类似于消息队列中的 **topic(主题)**。
|
||||
Redis 2.0 引入了发布订阅(pub/sub)功能。在 pub/sub 中,引入了一个叫做 **channel(频道)** 的概念,有点类似于消息队列中的 **topic(主题)**。
|
||||
|
||||
pub/sub 涉及发布者(publisher)和订阅者(subscriber,也叫消费者)两个角色:
|
||||
|
||||
- 发布者通过 `PUBLISH` 投递消息给指定 channel。
|
||||
- 订阅者通过`SUBSCRIBE`订阅它关心的 channel。并且,订阅者可以订阅一个或者多个 channel。
|
||||
- 订阅者通过 `SUBSCRIBE` 订阅它关心的 channel。并且,订阅者可以订阅一个或者多个 channel。
|
||||
|
||||
|
||||
|
||||
在 pub/sub 模式下,生产者需要指定消息发送到哪个 channel 中,而消费者则订阅对应的 channel 以获取消息。
|
||||
|
||||
Redis 中有很多默认的 channel,这些 channel 是由 Redis 本身向它们发送消息的,而不是我们自己编写的代码。其中,`__keyevent@0__:expired` 就是一个默认的 channel,负责监听 key 的过期事件。也就是说,当一个 key 过期之后,Redis 会发布一个 key 过期的事件到`__keyevent@<db>__:expired`这个 channel 中。
|
||||
Redis 中有很多默认的 channel,这些 channel 是由 Redis 本身向它们发送消息的,而不是我们自己编写的代码。其中,`__keyevent@0__:expired` 就是一个默认的 channel,负责监听 key 的过期事件。也就是说,当一个 key 过期之后,Redis 会发布一个 key 过期的事件到 `__keyevent@<db>__:expired` 这个 channel 中。
|
||||
|
||||
我们只需要监听这个 channel,就可以拿到过期的 key 的消息,进而实现了延时任务功能。
|
||||
|
||||
这个功能被 Redis 官方称为 **keyspace notifications** ,作用是实时监控 Redis 键和值的变化。
|
||||
这个功能被 Redis 官方称为 **keyspace notifications**,作用是实时监控 Redis 键和值的变化。
|
||||
|
||||
### Redis 过期事件监听实现延时任务功能有什么缺陷?
|
||||
|
||||
**1、时效性差**
|
||||
|
||||
官方文档的一段介绍解释了时效性差的原因,地址:<https://redis.io/docs/manual/keyspace-notifications/#timing-of-expired-events> 。
|
||||
官方文档的一段介绍解释了时效性差的原因,地址:<https://redis.io/docs/manual/keyspace-notifications/#timing-of-expired-events>。
|
||||
|
||||

|
||||
|
||||
@ -50,7 +50,7 @@ Redis 中有很多默认的 channel,这些 channel 是由 Redis 本身向它
|
||||
1. **惰性删除**:只会在取出 key 的时候才对数据进行过期检查。这样对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
|
||||
2. **定期删除**:每隔一段时间抽取一批 key 执行删除过期 key 操作。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
|
||||
|
||||
定期删除对内存更加友好,惰性删除对 CPU 更加友好。两者各有千秋,所以 Redis 采用的是 **定期删除+惰性/懒汉式删除** 。
|
||||
定期删除对内存更加友好,惰性删除对 CPU 更加友好。两者各有千秋,所以 Redis 采用的是 **定期删除+惰性/懒汉式删除**。
|
||||
|
||||
因此,就会存在我设置了 key 的过期时间,但到了指定时间 key 还未被删除,进而没有发布过期事件的情况。
|
||||
|
||||
|
||||
@ -25,7 +25,7 @@ Redis 内存碎片产生比较常见的 2 个原因:
|
||||
|
||||
> To store user keys, Redis allocates at most as much memory as the `maxmemory` setting enables (however there are small extra allocations possible).
|
||||
|
||||
Redis 使用 `zmalloc` 方法(Redis 自己实现的内存分配方法)进行内存分配的时候,除了要分配 `size` 大小的内存之外,还会多分配 `PREFIX_SIZE` 大小的内存。
|
||||
Redis 使用 `zmalloc` 方法(Redis 自己实现的内存分配方法)进行内存分配的时候,除了要分配 `size` 大小的内存之外,还会多分配 `PREFIX_SIZE` 大小的内存。
|
||||
|
||||
`zmalloc` 方法源码如下(源码地址:<https://github.com/antirez/redis-tools/blob/master/zmalloc.c):>
|
||||
|
||||
@ -45,7 +45,7 @@ void *zmalloc(size_t size) {
|
||||
}
|
||||
```
|
||||
|
||||
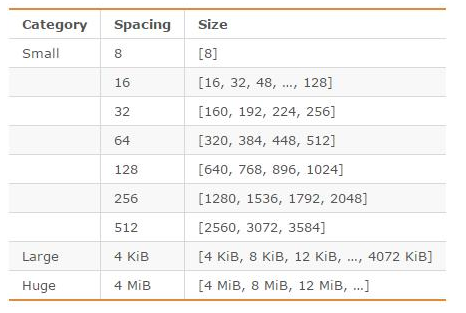
另外,Redis 可以使用多种内存分配器来分配内存( libc、jemalloc、tcmalloc),默认使用 [jemalloc](https://github.com/jemalloc/jemalloc),而 jemalloc 按照一系列固定的大小(8 字节、16 字节、32 字节……)来分配内存的。jemalloc 划分的内存单元如下图所示:
|
||||
另外,Redis 可以使用多种内存分配器来分配内存(libc、jemalloc、tcmalloc),默认使用 [jemalloc](https://github.com/jemalloc/jemalloc),而 jemalloc 按照一系列固定的大小(8 字节、16 字节、32 字节……)来分配内存的。jemalloc 划分的内存单元如下图所示:
|
||||
|
||||
|
||||
|
||||
@ -55,27 +55,27 @@ void *zmalloc(size_t size) {
|
||||
|
||||
当 Redis 中的某个数据删除时,Redis 通常不会轻易释放内存给操作系统。
|
||||
|
||||
这个在 Redis 官方文档中也有对应的原话:
|
||||
这个在 Redis 官方文档中也有对应的原话:
|
||||
|
||||

|
||||
|
||||
文档地址:<https://redis.io/topics/memory-optimization> 。
|
||||
文档地址:<https://redis.io/topics/memory-optimization>。
|
||||
|
||||
## 如何查看 Redis 内存碎片的信息?
|
||||
|
||||
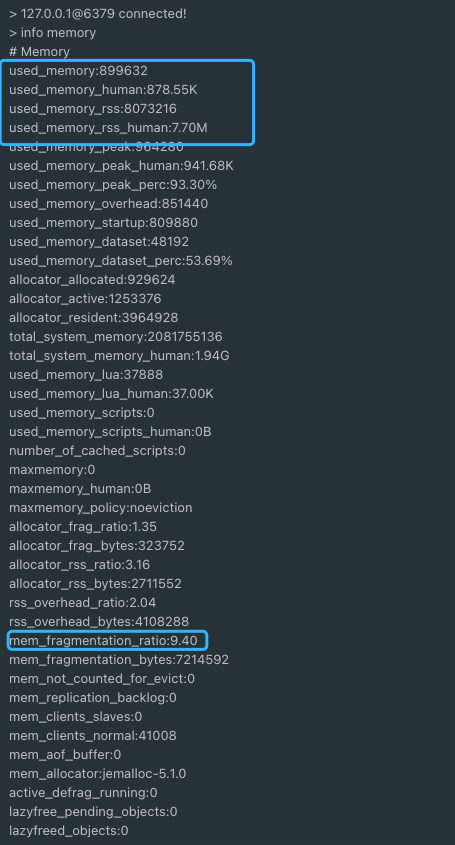
使用 `info memory` 命令即可查看 Redis 内存相关的信息。下图中每个参数具体的含义,Redis 官方文档有详细的介绍:<https://redis.io/commands/INFO> 。
|
||||
使用 `info memory` 命令即可查看 Redis 内存相关的信息。下图中每个参数具体的含义,Redis 官方文档有详细的介绍:<https://redis.io/commands/INFO>。
|
||||
|
||||
|
||||
|
||||
Redis 内存碎片率的计算公式:`mem_fragmentation_ratio` (内存碎片率)= `used_memory_rss` (操作系统实际分配给 Redis 的物理内存空间大小)/ `used_memory`(Redis 内存分配器为了存储数据实际申请使用的内存空间大小)
|
||||
Redis 内存碎片率的计算公式:`mem_fragmentation_ratio`(内存碎片率)=`used_memory_rss`(操作系统实际分配给 Redis 的物理内存空间大小)/`used_memory`(Redis 内存分配器为了存储数据实际申请使用的内存空间大小)。
|
||||
|
||||
也就是说,`mem_fragmentation_ratio` (内存碎片率)的值越大代表内存碎片率越严重。
|
||||
也就是说,`mem_fragmentation_ratio`(内存碎片率)的值越大,代表内存碎片率越严重。
|
||||
|
||||
一定不要误认为`used_memory_rss` 减去 `used_memory`值就是内存碎片的大小!!!这不仅包括内存碎片,还包括其他进程开销,以及共享库、堆栈等的开销。
|
||||
一定不要误认为 `used_memory_rss` 减去 `used_memory` 值就是内存碎片的大小!!!这不仅包括内存碎片,还包括其他进程开销,以及共享库、堆栈等的开销。
|
||||
|
||||
很多小伙伴可能要问了:“多大的内存碎片率才是需要清理呢?”。
|
||||
|
||||
通常情况下,我们认为 `mem_fragmentation_ratio > 1.5` 的话才需要清理内存碎片。 `mem_fragmentation_ratio > 1.5` 意味着你使用 Redis 存储实际大小 2G 的数据需要使用大于 3G 的内存。
|
||||
通常情况下,我们认为 `mem_fragmentation_ratio > 1.5` 的话才需要清理内存碎片。`mem_fragmentation_ratio > 1.5` 意味着你使用 Redis 存储实际大小 2G 的数据需要使用大于 3G 的内存。
|
||||
|
||||
如果想要快速查看内存碎片率的话,你还可以通过下面这个命令:
|
||||
|
||||
@ -83,7 +83,7 @@ Redis 内存碎片率的计算公式:`mem_fragmentation_ratio` (内存碎片
|
||||
> redis-cli -p 6379 info | grep mem_fragmentation_ratio
|
||||
```
|
||||
|
||||
另外,内存碎片率可能存在小于 1 的情况。这种情况我在日常使用中还没有遇到过,感兴趣的小伙伴可以看看这篇文章 [故障分析 | Redis 内存碎片率太低该怎么办?- 爱可生开源社区](https://mp.weixin.qq.com/s/drlDvp7bfq5jt2M5pTqJCw) 。
|
||||
另外,内存碎片率可能存在小于 1 的情况。这种情况我在日常使用中还没有遇到过,感兴趣的小伙伴可以看看这篇文章 [故障分析 | Redis 内存碎片率太低该怎么办?- 爱可生开源社区](https://mp.weixin.qq.com/s/drlDvp7bfq5jt2M5pTqJCw)。
|
||||
|
||||
## 如何清理 Redis 内存碎片?
|
||||
|
||||
|
||||
@ -12,15 +12,15 @@ head:
|
||||
content: Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而且支持 3 种持久化方式:快照(snapshotting,RDB)、只追加文件(append-only file, AOF)、RDB 和 AOF 的混合持久化(Redis 4.0 新增)。
|
||||
---
|
||||
|
||||
使用缓存的时候,我们经常需要对内存中的数据进行持久化也就是将内存中的数据写入到硬盘中。大部分原因是为了之后重用数据(比如重启机器、机器故障之后恢复数据),或者是为了做数据同步(比如 Redis 集群的主从节点通过 RDB 文件同步数据)。
|
||||
使用缓存的时候,我们经常需要对内存中的数据进行持久化,也就是将内存中的数据写入到硬盘中。大部分原因是为了之后重用数据(比如重启机器、机器故障之后恢复数据),或者是为了做数据同步(比如 Redis 集群的主从节点通过 RDB 文件同步数据)。
|
||||
|
||||
Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而且支持 3 种持久化方式:
|
||||
Redis 不同于 Memcached 的很重要一点就是,Redis 支持持久化,而且支持 3 种持久化方式:
|
||||
|
||||
- 快照(snapshotting,RDB)
|
||||
- 只追加文件(append-only file, AOF)
|
||||
- RDB 和 AOF 的混合持久化(Redis 4.0 新增)
|
||||
- 快照(snapshotting,RDB);
|
||||
- 只追加文件(append-only file, AOF);
|
||||
- RDB 和 AOF 的混合持久化(Redis 4.0 新增)。
|
||||
|
||||
官方文档地址:<https://redis.io/topics/persistence> 。
|
||||
官方文档地址:<https://redis.io/topics/persistence>。
|
||||
|
||||

|
||||
|
||||
@ -45,7 +45,7 @@ save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生
|
||||
Redis 提供了两个命令来生成 RDB 快照文件:
|
||||
|
||||
- `save` : 同步保存操作,会阻塞 Redis 主线程;
|
||||
- `bgsave` : fork 出一个子进程,子进程执行,不会阻塞 Redis 主线程,默认选项。
|
||||
- `bgsave` : fork 出一个子进程,子进程执行保存操作,不会阻塞 Redis 主线程,默认选项。
|
||||
|
||||
> 这里说 Redis 主线程而不是主进程的主要是因为 Redis 启动之后主要是通过单线程的方式完成主要的工作。如果你想将其描述为 Redis 主进程,也没毛病。
|
||||
|
||||
@ -59,7 +59,7 @@ Redis 提供了两个命令来生成 RDB 快照文件:
|
||||
appendonly yes
|
||||
```
|
||||
|
||||
开启 AOF 持久化后每执行一条会更改 Redis 中的数据的命令,Redis 就会将该命令写入到 AOF 缓冲区 `server.aof_buf` 中,然后再写入到 AOF 文件中(此时还在系统内核缓存区未同步到磁盘),最后再根据持久化方式( `fsync`策略)的配置来决定何时将系统内核缓存区的数据同步到硬盘中的。
|
||||
开启 AOF 持久化后,每执行一条会更改 Redis 中的数据的命令,Redis 就会将该命令写入到 AOF 缓冲区 `server.aof_buf` 中,然后再写入到 AOF 文件中(此时还在系统内核缓存区未同步到磁盘),最后再根据持久化方式(`fsync`策略)的配置来决定何时将系统内核缓存区的数据同步到硬盘中。
|
||||
|
||||
只有同步到磁盘中才算持久化保存了,否则依然存在数据丢失的风险,比如说:系统内核缓存区的数据还未同步,磁盘机器就宕机了,那这部分数据就算丢失了。
|
||||
|
||||
@ -70,17 +70,17 @@ AOF 文件的保存位置和 RDB 文件的位置相同,都是通过 `dir` 参
|
||||
AOF 持久化功能的实现可以简单分为 5 步:
|
||||
|
||||
1. **命令追加(append)**:所有的写命令会追加到 AOF 缓冲区中。
|
||||
2. **文件写入(write)**:将 AOF 缓冲区的数据写入到 AOF 文件中。这一步需要调用`write`函数(系统调用),`write`将数据写入到了系统内核缓冲区之后直接返回了(延迟写)。注意!!!此时并没有同步到磁盘。
|
||||
3. **文件同步(fsync)**:AOF 缓冲区根据对应的持久化方式( `fsync` 策略)向硬盘做同步操作。这一步需要调用 `fsync` 函数(系统调用), `fsync` 针对单个文件操作,对其进行强制硬盘同步,`fsync` 将阻塞直到写入磁盘完成后返回,保证了数据持久化。
|
||||
2. **文件写入(write)**:将 AOF 缓冲区的数据写入到 AOF 文件中。这一步需要调用 `write` 函数(系统调用),`write` 将数据写入到了系统内核缓冲区之后直接返回了(延迟写)。注意!!!此时并没有同步到磁盘。
|
||||
3. **文件同步(fsync)**:AOF 缓冲区根据对应的持久化方式(`fsync` 策略)向硬盘做同步操作。这一步需要调用 `fsync` 函数(系统调用),`fsync` 针对单个文件操作,对其进行强制硬盘同步,`fsync` 将阻塞直到写入磁盘完成后返回,保证了数据持久化。
|
||||
4. **文件重写(rewrite)**:随着 AOF 文件越来越大,需要定期对 AOF 文件进行重写,达到压缩的目的。
|
||||
5. **重启加载(load)**:当 Redis 重启时,可以加载 AOF 文件进行数据恢复。
|
||||
|
||||
> Linux 系统直接提供了一些函数用于对文件和设备进行访问和控制,这些函数被称为 **系统调用(syscall)**。
|
||||
|
||||
这里对上面提到的一些 Linux 系统调用再做一遍解释:
|
||||
这里对上面提到的一些 Linux 系统调用再作一遍解释:
|
||||
|
||||
- `write`:写入系统内核缓冲区之后直接返回(仅仅是写到缓冲区),不会立即同步到硬盘。虽然提高了效率,但也带来了数据丢失的风险。同步硬盘操作通常依赖于系统调度机制,Linux 内核通常为 30s 同步一次,具体值取决于写出的数据量和 I/O 缓冲区的状态。
|
||||
- `fsync`:`fsync`用于强制刷新系统内核缓冲区(同步到到磁盘),确保写磁盘操作结束才会返回。
|
||||
- `fsync`:`fsync` 用于强制刷新系统内核缓冲区(同步到到磁盘),确保写磁盘操作结束才会返回。
|
||||
|
||||
AOF 工作流程图如下:
|
||||
|
||||
@ -88,11 +88,11 @@ AOF 工作流程图如下:
|
||||
|
||||
### AOF 持久化方式有哪些?
|
||||
|
||||
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( `fsync`策略),它们分别是:
|
||||
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式(`fsync`策略),它们分别是:
|
||||
|
||||
1. `appendfsync always`:主线程调用 `write` 执行写操作后,后台线程( `aof_fsync` 线程)立即会调用 `fsync` 函数同步 AOF 文件(刷盘),`fsync` 完成后线程返回,这样会严重降低 Redis 的性能(`write` + `fsync`)。
|
||||
2. `appendfsync everysec`:主线程调用 `write` 执行写操作后立即返回,由后台线程( `aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync`间隔为 1 秒)
|
||||
3. `appendfsync no`:主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write`但不`fsync`,`fsync` 的时机由操作系统决定)。
|
||||
1. `appendfsync always`:主线程调用 `write` 执行写操作后,后台线程(`aof_fsync` 线程)立即会调用 `fsync` 函数同步 AOF 文件(刷盘),`fsync` 完成后线程返回,这样会严重降低 Redis 的性能(`write`+`fsync`)。
|
||||
2. `appendfsync everysec`:主线程调用 `write` 执行写操作后立即返回,由后台线程(`aof_fsync` 线程)每秒钟调用 `fsync` 函数(系统调用)同步一次 AOF 文件(`write`+`fsync`,`fsync` 间隔为 1 秒)
|
||||
3. `appendfsync no`:主线程调用 `write` 执行写操作后立即返回,让操作系统决定何时进行同步,Linux 下一般为 30 秒一次(`write` 但不 `fsync`,`fsync` 的时机由操作系统决定)。
|
||||
|
||||
可以看出:**这 3 种持久化方式的主要区别在于 `fsync` 同步 AOF 文件的时机(刷盘)**。
|
||||
|
||||
@ -104,7 +104,7 @@ AOF 工作流程图如下:
|
||||
- INCR:表示增量 AOF 文件,它一般会在 AOFRW 开始执行时被创建,该文件可能存在多个。
|
||||
- HISTORY:表示历史 AOF 文件,它由 BASE 和 INCR AOF 变化而来,每次 AOFRW 成功完成时,本次 AOFRW 之前对应的 BASE 和 INCR AOF 都将变为 HISTORY,HISTORY 类型的 AOF 会被 Redis 自动删除。
|
||||
|
||||
Multi Part AOF 不是重点,了解即可,详细介绍可以看看阿里开发者的[Redis 7.0 Multi Part AOF 的设计和实现](https://zhuanlan.zhihu.com/p/467217082) 这篇文章。
|
||||
Multi Part AOF 不是重点,了解即可,详细介绍可以看看阿里开发者的 [Redis 7.0 Multi Part AOF 的设计和实现](https://zhuanlan.zhihu.com/p/467217082) 这篇文章。
|
||||
|
||||
**相关 issue**:[Redis 的 AOF 方式 #783](https://github.com/Snailclimb/JavaGuide/issues/783)。
|
||||
|
||||
@ -143,17 +143,17 @@ AOF 文件重写期间,Redis 还会维护一个 **AOF 重写缓冲区**,该
|
||||
|
||||
Redis 7.0 版本之前,如果在重写期间有写入命令,AOF 可能会使用大量内存,重写期间到达的所有写入命令都会写入磁盘两次。
|
||||
|
||||
Redis 7.0 版本之后,AOF 重写机制得到了优化改进。下面这段内容摘自阿里开发者的[从 Redis7.0 发布看 Redis 的过去与未来](https://mp.weixin.qq.com/s/RnoPPL7jiFSKkx3G4p57Pg) 这篇文章。
|
||||
Redis 7.0 版本之后,AOF 重写机制得到了优化改进。下面这段内容摘自阿里开发者的 [从 Redis7.0 发布看 Redis 的过去与未来](https://mp.weixin.qq.com/s/RnoPPL7jiFSKkx3G4p57Pg) 这篇文章。
|
||||
|
||||
> AOF 重写期间的增量数据如何处理一直是个问题,在过去写期间的增量数据需要在内存中保留,写结束后再把这部分增量数据写入新的 AOF 文件中以保证数据完整性。可以看出来 AOF 写会额外消耗内存和磁盘 IO,这也是 Redis AOF 写的痛点,虽然之前也进行过多次改进但是资源消耗的本质问题一直没有解决。
|
||||
> AOF 重写期间的增量数据如何处理一直是个问题,在过去写期间的增量数据需要在内存中保留,写结束后再把这部分增量数据写入新的 AOF 文件中以保证数据完整性。可以看出来 AOF 写会额外消耗内存和磁盘 IO,这也是 Redis AOF 写的痛点,虽然之前也进行过多次改进,但是资源消耗的本质问题一直没有解决。
|
||||
>
|
||||
> 阿里云的 Redis 企业版在最初也遇到了这个问题,在内部经过多次迭代开发,实现了 Multi-part AOF 机制来解决,同时也贡献给了社区并随此次 7.0 发布。具体方法是采用 base(全量数据)+inc(增量数据)独立文件存储的方式,彻底解决内存和 IO 资源的浪费,同时也支持对历史 AOF 文件的保存管理,结合 AOF 文件中的时间信息还可以实现 PITR 按时间点恢复(阿里云企业版 Tair 已支持),这进一步增强了 Redis 的数据可靠性,满足用户数据回档等需求。
|
||||
> 阿里云的 Redis 企业版在最初也遇到了这个问题,不过在经过内部多次迭代开发后,阿里云实现了 Multi-part AOF 机制来解决该问题,同时也将其贡献给了社区并随此次 7.0 发布。具体方法是采用 base(全量数据)+inc(增量数据)独立文件存储的方式,彻底解决内存和 IO 资源的浪费,同时也支持对历史 AOF 文件的保存管理,结合 AOF 文件中的时间信息还可以实现 PITR 按时间点恢复(阿里云企业版 Tair 已支持),这进一步增强了 Redis 的数据可靠性,满足用户数据回档等需求。
|
||||
|
||||
**相关 issue**:[Redis AOF 重写描述不准确 #1439](https://github.com/Snailclimb/JavaGuide/issues/1439)。
|
||||
|
||||
### AOF 校验机制了解吗?
|
||||
|
||||
AOF 校验机制是 Redis 在启动时对 AOF 文件进行检查,以判断文件是否完整,是否有损坏或者丢失的数据。这个机制的原理其实非常简单,就是通过使用一种叫做 **校验和(checksum)** 的数字来验证 AOF 文件。这个校验和是通过对整个 AOF 文件内容进行 CRC64 算法计算得出的数字。如果文件内容发生了变化,那么校验和也会随之改变。因此,Redis 在启动时会比较计算出的校验和与文件末尾保存的校验和(计算的时候会把最后一行保存校验和的内容给忽略点),从而判断 AOF 文件是否完整。如果发现文件有问题,Redis 就会拒绝启动并提供相应的错误信息。AOF 校验机制十分简单有效,可以提高 Redis 数据的可靠性。
|
||||
AOF 校验机制是 Redis 在启动时对 AOF 文件进行检查,以判断文件是否完整,是否有损坏或者丢失的数据。这个机制的原理其实非常简单,就是通过使用一种叫做 **校验和(checksum)** 的数字来验证 AOF 文件。这个校验和是通过对整个 AOF 文件内容进行 CRC64 算法计算得出的数字。如果文件内容发生了变化,那么校验和也会随之改变。因此,Redis 在启动时会比较计算出的校验和与文件末尾保存的校验和(计算的时候会把最后一行保存校验和的内容给忽略掉),从而判断 AOF 文件是否完整。如果发现文件有问题,Redis 就会拒绝启动并提供相应的错误信息。AOF 校验机制十分简单有效,可以提高 Redis 数据的可靠性。
|
||||
|
||||
类似地,RDB 文件也有类似的校验机制来保证 RDB 文件的正确性,这里就不重复进行介绍了。
|
||||
|
||||
@ -161,26 +161,26 @@ AOF 校验机制是 Redis 在启动时对 AOF 文件进行检查,以判断文
|
||||
|
||||
由于 RDB 和 AOF 各有优势,于是,Redis 4.0 开始支持 RDB 和 AOF 的混合持久化(默认关闭,可以通过配置项 `aof-use-rdb-preamble` 开启)。
|
||||
|
||||
如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的, AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
|
||||
如果把混合持久化打开,AOF 重写的时候就直接把 RDB 的内容写到 AOF 文件开头。这样做的好处是可以结合 RDB 和 AOF 的优点, 快速加载同时避免丢失过多的数据。当然缺点也是有的,AOF 里面的 RDB 部分是压缩格式不再是 AOF 格式,可读性较差。
|
||||
|
||||
官方文档地址:<https://redis.io/topics/persistence>
|
||||
官方文档地址:<https://redis.io/topics/persistence>。
|
||||
|
||||

|
||||
|
||||
## 如何选择 RDB 和 AOF?
|
||||
|
||||
关于 RDB 和 AOF 的优缺点,官网上面也给了比较详细的说明[Redis persistence](https://redis.io/docs/manual/persistence/),这里结合自己的理解简单总结一下。
|
||||
关于 RDB 和 AOF 的优缺点,官网上面也给了比较详细的说明 [Redis persistence](https://redis.io/docs/manual/persistence/),这里结合自己的理解简单总结一下。
|
||||
|
||||
**RDB 比 AOF 优秀的地方**:
|
||||
|
||||
- RDB 文件存储的内容是经过压缩的二进制数据, 保存着某个时间点的数据集,文件很小,适合做数据的备份,灾难恢复。AOF 文件存储的是每一次写命令,类似于 MySQL 的 binlog 日志,通常会比 RDB 文件大很多。当 AOF 变得太大时,Redis 能够在后台自动重写 AOF。新的 AOF 文件和原有的 AOF 文件所保存的数据库状态一样,但体积更小。不过, Redis 7.0 版本之前,如果在重写期间有写入命令,AOF 可能会使用大量内存,重写期间到达的所有写入命令都会写入磁盘两次。
|
||||
- RDB 文件存储的内容是经过压缩的二进制数据,保存着某个时间点的数据集,文件很小,适合做数据的备份,用于灾难恢复。AOF 文件存储的是每一次写命令,类似于 MySQL 的 binlog 日志,通常会比 RDB 文件大很多。当 AOF 变得太大时,Redis 能够在后台自动重写 AOF。新的 AOF 文件和原有的 AOF 文件所保存的数据库状态一样,但体积更小。不过,Redis 7.0 版本之前,如果在重写期间有写入命令,AOF 可能会使用大量内存,重写期间到达的所有写入命令都会写入磁盘两次。
|
||||
- 使用 RDB 文件恢复数据,直接解析还原数据即可,不需要一条一条地执行命令,速度非常快。而 AOF 则需要依次执行每个写命令,速度非常慢。也就是说,与 AOF 相比,恢复大数据集的时候,RDB 速度更快。
|
||||
|
||||
**AOF 比 RDB 优秀的地方**:
|
||||
|
||||
- RDB 的数据安全性不如 AOF,没有办法实时或者秒级持久化数据。生成 RDB 文件的过程是比较繁重的, 虽然 BGSAVE 子进程写入 RDB 文件的工作不会阻塞主线程,但会对机器的 CPU 资源和内存资源产生影响,严重的情况下甚至会直接把 Redis 服务干宕机。AOF 支持秒级数据丢失(取决 fsync 策略,如果是 everysec,最多丢失 1 秒的数据),仅仅是追加命令到 AOF 文件,操作轻量。
|
||||
- RDB 文件是以特定的二进制格式保存的,并且在 Redis 版本演进中有多个版本的 RDB,所以存在老版本的 Redis 服务不兼容新版本的 RDB 格式的问题。
|
||||
- AOF 以一种易于理解和解析的格式包含所有操作的日志。你可以轻松地导出 AOF 文件进行分析,你也可以直接操作 AOF 文件来解决一些问题。比如,如果执行`FLUSHALL`命令意外地刷新了所有内容后,只要 AOF 文件没有被重写,删除最新命令并重启即可恢复之前的状态。
|
||||
- AOF 以一种易于理解和解析的格式包含所有操作的日志。你可以轻松地导出 AOF 文件进行分析,你也可以直接操作 AOF 文件来解决一些问题。比如,如果执行 `FLUSHALL` 命令意外地刷新了所有内容后,只要 AOF 文件没有被重写,删除最新命令并重启即可恢复之前的状态。
|
||||
|
||||
**综上**:
|
||||
|
||||
|
||||
@ -455,13 +455,13 @@ Redis 中有一个叫做 `Sorted Set`(有序集合)的数据类型经常被
|
||||
|
||||

|
||||
|
||||
### Redis 的有序集合底层为什么要用跳表,而不用平衡树、红黑树或者 B+ 树?
|
||||
### Redis 的有序集合底层为什么要用跳表,而不用平衡树、红黑树或者 B+树?
|
||||
|
||||
这道面试题很多大厂比较喜欢问,难度还是有点大的。
|
||||
|
||||
- 平衡树 vs 跳表:平衡树的插入、删除和查询的时间复杂度和跳表一样都是 **O(log n)**。对于范围查询来说,平衡树也可以通过中序遍历的方式达到和跳表一样的效果。但是它的每一次插入或者删除操作都需要保证整颗树左右节点的绝对平衡,只要不平衡就要通过旋转操作来保持平衡,这个过程是比较耗时的。跳表诞生的初衷就是为了克服平衡树的一些缺点。跳表使用概率平衡而不是严格强制的平衡,因此,跳表中的插入和删除算法比平衡树的等效算法简单得多,速度也快得多。
|
||||
- 红黑树 vs 跳表:相比较于红黑树来说,跳表的实现也更简单一些,不需要通过旋转和染色(红黑变换)来保证黑平衡。并且,按照区间来查找数据这个操作,红黑树的效率没有跳表高。
|
||||
- B+ 树 vs 跳表:B+ 树更适合作为数据库和文件系统中常用的索引结构之一,它的核心思想是通过可能少的 IO 定位到尽可能多的索引来获得查询数据。对于 Redis 这种内存数据库来说,它对这些并不感冒,因为 Redis 作为内存数据库它不可能存储大量的数据,所以对于索引不需要通过 B+ 树这种方式进行维护,只需按照概率进行随机维护即可,节约内存。而且使用跳表实现 zset 时相较前者来说更简单一些,在进行插入时只需通过索引将数据插入到链表中合适的位置再随机维护一定高度的索引即可,也不需要像 B+ 树那样插入时发现失衡时还需要对节点分裂与合并。
|
||||
- B+树 vs 跳表:B+树更适合作为数据库和文件系统中常用的索引结构之一,它的核心思想是通过可能少的 IO 定位到尽可能多的索引来获得查询数据。对于 Redis 这种内存数据库来说,它对这些并不感冒,因为 Redis 作为内存数据库它不可能存储大量的数据,所以对于索引不需要通过 B+树这种方式进行维护,只需按照概率进行随机维护即可,节约内存。而且使用跳表实现 zset 时相较前者来说更简单一些,在进行插入时只需通过索引将数据插入到链表中合适的位置再随机维护一定高度的索引即可,也不需要像 B+树那样插入时发现失衡时还需要对节点分裂与合并。
|
||||
|
||||
另外,我还单独写了一篇文章从有序集合的基本使用到跳表的源码分析和实现,让你会对 Redis 的有序集合底层实现的跳表有着更深刻的理解和掌握:[Redis 为什么用跳表实现有序集合](./redis-skiplist.md)。
|
||||
|
||||
|
||||
@ -703,7 +703,7 @@ Bloom Filter 会使用一个较大的 bit 数组来保存所有的数据,数
|
||||
|
||||
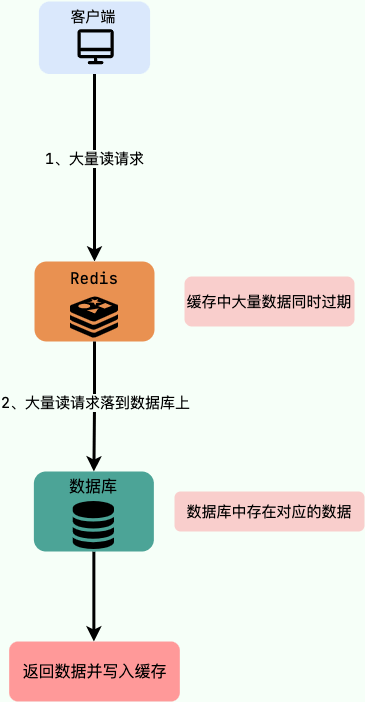
|
||||
|
||||
举个例子:数据库中的大量数据在同一时间过期,这个时候突然有大量的请求需要访问这些过期的数据。这就导致大量的请求直接落到数据库上,对数据库造成了巨大的压力。
|
||||
举个例子:缓存中的大量数据在同一时间过期,这个时候突然有大量的请求需要访问这些过期的数据。这就导致大量的请求直接落到数据库上,对数据库造成了巨大的压力。
|
||||
|
||||
#### 有哪些解决办法?
|
||||
|
||||
@ -779,7 +779,7 @@ Cache Aside Pattern 中遇到写请求是这样的:更新数据库,然后直
|
||||
1. 使用连接池:避免频繁创建关闭客户端连接。
|
||||
2. 尽量不使用 O(n) 指令,使用 O(n) 命令时要关注 n 的数量:像 `KEYS *`、`HGETALL`、`LRANGE`、`SMEMBERS`、`SINTER`/`SUNION`/`SDIFF` 等 O(n) 命令并非不能使用,但是需要明确 n 的值。另外,有遍历的需求可以使用 `HSCAN`、`SSCAN`、`ZSCAN` 代替。
|
||||
3. 使用批量操作减少网络传输:原生批量操作命令(比如 `MGET`、`MSET` 等等)、pipeline、Lua 脚本。
|
||||
4. 尽量不适用 Redis 事务:Redis 事务实现的功能比较鸡肋,可以使用 Lua 脚本代替。
|
||||
4. 尽量不使用 Redis 事务:Redis 事务实现的功能比较鸡肋,可以使用 Lua 脚本代替。
|
||||
5. 禁止长时间开启 monitor:对性能影响比较大。
|
||||
6. 控制 key 的生命周期:避免 Redis 中存放了太多不经常被访问的数据。
|
||||
7. ……
|
||||
|
||||
@ -17,9 +17,9 @@ tag:
|
||||
|
||||
## 跳表在 Redis 中的运用
|
||||
|
||||
这里我们需要先了解一下 Redis 用到跳表的数据结构有序集合的使用,Redis 有个比较常用的数据结构叫**有序集合(sorted set,简称 zset)**,正如其名它是一个可以保证有序且元素唯一的集合,所以它经常用于排行榜等需要进行统计排列的场景。
|
||||
这里我们需要先了解一下 Redis 用到跳表的数据结构有序集合的使用,Redis 有个比较常用的数据结构叫**有序集合(sorted set,简称 zset)**,正如其名它是一个可以保证有序且元素唯一的集合,所以它经常用于排行榜等需要进行统计排列的场景。
|
||||
|
||||
这里我们通过命令行的形式演示一下排行榜的实现,可以看到笔者分别输入 3 名用户:**xiaoming**、**xiaohong**、**xiaowang**,它们的**score**分别是 60、80、60,最终按照成绩升级降序排列。
|
||||
这里我们通过命令行的形式演示一下排行榜的实现,可以看到笔者分别输入 3 名用户:**xiaoming**、**xiaohong**、**xiaowang**,它们的 **score** 分别是 60、80、60,最终按照成绩升级降序排列。
|
||||
|
||||
```bash
|
||||
|
||||
@ -40,7 +40,7 @@ tag:
|
||||
6) "60"
|
||||
```
|
||||
|
||||
此时我们通过 `object` 指令查看 zset 的数据结构,可以看到当前有序集合存储的还是**ziplist(压缩列表)**。
|
||||
此时我们通过 `object` 指令查看 zset 的数据结构,可以看到当前有序集合存储的还是 **ziplist(压缩列表)**。
|
||||
|
||||
```bash
|
||||
127.0.0.1:6379> object encoding rankList
|
||||
@ -54,7 +54,7 @@ zset-max-ziplist-value 64
|
||||
zset-max-ziplist-entries 128
|
||||
```
|
||||
|
||||
一旦有序集合中的某个元素超出这两个其中的一个阈值它就会转为 **skiplist**(实际是 dict+skiplist,还会借用字典来提高获取指定元素的效率)。
|
||||
一旦有序集合中的某个元素超出这两个其中的一个阈值,它就会转为 **skiplist**(实际是 dict+skiplist,还会借用字典来提高获取指定元素的效率)。
|
||||
|
||||
我们不妨在添加一个大于 64 字节的元素,可以看到有序集合的底层存储转为 skiplist。
|
||||
|
||||
@ -72,13 +72,13 @@ zset-max-ziplist-entries 128
|
||||
- 当有序集合对象同时满足以下两个条件时,使用 ziplist:
|
||||
1. ZSet 保存的键值对数量少于 128 个;
|
||||
2. 每个元素的长度小于 64 字节。
|
||||
- 如果不满足上述两个条件,那么使用 skiplist 。
|
||||
- 如果不满足上述两个条件,那么使用 skiplist。
|
||||
|
||||
## 手写一个跳表
|
||||
|
||||
为了更好的回答上述问题以及更好的理解和掌握跳表,这里可以通过手写一个简单的跳表的形式来帮助读者理解跳表这个数据结构。
|
||||
|
||||
我们都知道有序链表在添加、查询、删除的平均时间复杂都都是 **O(n)** 即线性增长,所以一旦节点数量达到一定体量后其性能表现就会非常差劲。而跳表我们完全可以理解为在原始链表基础上,建立多级索引,通过多级索引检索定位将增删改查的时间复杂度变为 **O(log n)** 。
|
||||
我们都知道有序链表在添加、查询、删除的平均时间复杂都都是 **O(n)** 即线性增长,所以一旦节点数量达到一定体量后其性能表现就会非常差劲。而跳表我们完全可以理解为在原始链表基础上,建立多级索引,通过多级索引检索定位将增删改查的时间复杂度变为 **O(log n)**。
|
||||
|
||||
可能这里说的有些抽象,我们举个例子,以下图跳表为例,其原始链表存储按序存储 1-10,有 2 级索引,每级索引的索引个数都是基于下层元素个数的一半。
|
||||
|
||||
@ -90,11 +90,11 @@ zset-max-ziplist-entries 128
|
||||
2. 查看 4 的后继节点,是 8 的 2 级索引,这个值大于 6,说明 2 级索引后续的索引都是大于 6 的,没有再往后搜寻的必要,我们索引向下查找。
|
||||
3. 来到 4 的 1 级索引,比对其后继节点为 6,查找结束。
|
||||
|
||||
相较于原始有序链表需要 6 次,我们的跳表通过建立多级索引,我们只需两次就直接定位到了目标元素,其查寻的复杂度被直接优化为**O(log n)**。
|
||||
相较于原始有序链表需要 6 次,我们的跳表通过建立多级索引,我们只需两次就直接定位到了目标元素,其查寻的复杂度被直接优化为 **O(log n)**。
|
||||
|
||||

|
||||
|
||||
对应的添加也是一个道理,假如我们需要在这个有序集合中添加一个元素 7,那么我们就需要通过跳表找到**小于元素 7 的最大值**,也就是下图元素 6 的位置,将其插入到元素 6 的后面,让元素 6 的索引指向新插入的节点 7,其工作流程如下:
|
||||
对应的添加也是一个道理,假如我们需要在这个有序集合中添加一个元素 7,那么我们就需要通过跳表找到 **小于元素 7 的最大值**,也就是下图元素 6 的位置,将其插入到元素 6 的后面,让元素 6 的索引指向新插入的节点 7,其工作流程如下:
|
||||
|
||||
1. 从 2 级索引开始定位到了元素 4 的索引。
|
||||
2. 查看索引 4 的后继索引为 8,索引向下推进。
|
||||
@ -138,21 +138,21 @@ r=n/2^k
|
||||
=> h=log2^n -1
|
||||
```
|
||||
|
||||
而 Redis 又是内存数据库,我们假设元素最大个数是**65536**,我们把**65536**代入上述公式可知最大高度为 16。所以我们建议添加一个元素后为其建立的索引高度不超过 16。
|
||||
而 Redis 又是内存数据库,我们假设元素最大个数是 **65536**,我们把 **65536** 代入上述公式可知最大高度为 16。所以我们建议添加一个元素后为其建立的索引高度不超过 16。
|
||||
|
||||
因为我们要求尽可能保证每一个上级索引都是下级索引的一半,在实现高度生成算法时,我们可以这样设计:
|
||||
|
||||
1. 跳表的高度计算从原始链表开始,即默认情况下插入的元素的高度为 1,代表没有索引,只有元素节点。
|
||||
2. 设计一个为插入元素生成节点索引高度 level 的方法。
|
||||
3. 进行一次随机运算,随机数值范围为 0-1 之间。
|
||||
4. 如果随机数大于 0.5 则为当前元素添加一级索引,自此我们保证生成一级索引的概率为 **50%** ,这也就保证了 1 级索引理想情况下只有一半的元素会生成索引。
|
||||
5. 同理后续每次随机算法得到的值大于 0.5 时,我们的索引高度就加 1,这样就可以保证节点生成的 2 级索引概率为 **25%** ,3 级索引为 **12.5%** ……
|
||||
4. 如果随机数大于 0.5 则为当前元素添加一级索引,自此我们保证生成一级索引的概率为 **50%**,这也就保证了 1 级索引理想情况下只有一半的元素会生成索引。
|
||||
5. 同理后续每次随机算法得到的值大于 0.5 时,我们的索引高度就加 1,这样就可以保证节点生成的 2 级索引概率为 **25%**,3 级索引为 **12.5%**……
|
||||
|
||||
我们回过头,上述插入 7 之后,我们通过随机算法得到 2,即要为其建立 1 级索引:
|
||||
|
||||

|
||||
|
||||
最后我们再来说说删除,假设我们这里要删除元素 10,我们必须定位到当前跳表**各层**元素小于 10 的最大值,索引执行步骤为:
|
||||
最后我们再来说说删除,假设我们这里要删除元素 10,我们必须定位到当前跳表 **各层** 元素小于 10 的最大值,索引执行步骤为:
|
||||
|
||||
1. 2 级索引 4 的后继节点为 8,指针推进。
|
||||
2. 索引 8 无后继节点,该层无要删除的元素,指针直接向下。
|
||||
@ -164,19 +164,19 @@ r=n/2^k
|
||||
|
||||
### 模板定义
|
||||
|
||||
有了整体的思路之后,我们可以开始实现一个跳表了,首先定义一下跳表中的节点**Node**,从上文的演示中可以看出每一个**Node**它都包含以下几个元素:
|
||||
有了整体的思路之后,我们可以开始实现一个跳表了,首先定义一下跳表中的节点 **Node**,从上文的演示中可以看出每一个 **Node** 都包含以下几个元素:
|
||||
|
||||
1. 存储的**value**值。
|
||||
1. 存储的 **value** 值。
|
||||
2. 后继节点的地址。
|
||||
3. 多级索引。
|
||||
|
||||
为了更方便统一管理**Node**后继节点地址和多级索引指向的元素地址,笔者在**Node**中设置了一个**forwards**数组,用于记录原始链表节点的后继节点和多级索引的后继节点指向。
|
||||
为了更方便统一管理 **Node** 后继节点地址和多级索引指向的元素地址,笔者在 **Node** 中设置了一个 **forwards** 数组,用于记录原始链表节点的后继节点和多级索引的后继节点指向。
|
||||
|
||||
以下图为例,我们**forwards**数组长度为 5,其中**索引 0**记录的是原始链表节点的后继节点地址,而其余自底向上表示从 1 级索引到 4 级索引的后继节点指向。
|
||||
以下图为例,我们 **forwards** 数组长度为 5,其中 **索引 0** 记录的是原始链表节点的后继节点地址,而其余自底向上表示从 1 级索引到 4 级索引的后继节点指向。
|
||||
|
||||
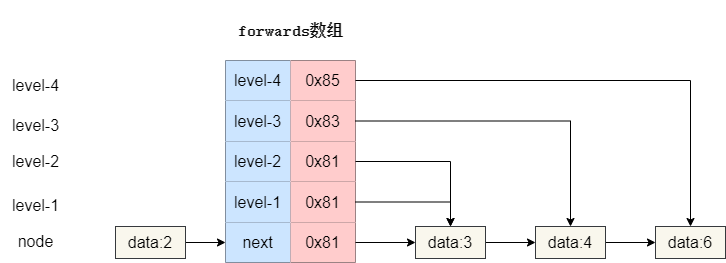
|
||||
|
||||
于是我们的就有了这样一个代码定义,可以看出笔者对于数组的长度设置为固定的 16**(上文的推算最大高度建议是 16)**,默认**data**为-1,节点最大高度**maxLevel**初始化为 1,注意这个**maxLevel**的值代表原始链表加上索引的总高度。
|
||||
于是我们的就有了这样一个代码定义,可以看出笔者对于数组的长度设置为固定的 16 **(上文的推算最大高度建议是 16)**,默认 **data** 为 -1,节点最大高度 **maxLevel** 初始化为 1,注意这个 **maxLevel** 的值代表原始链表加上索引的总高度。
|
||||
|
||||
```java
|
||||
/**
|
||||
@ -194,18 +194,18 @@ class Node {
|
||||
|
||||
### 元素添加
|
||||
|
||||
定义好节点之后,我们先实现以下元素的添加,添加元素时首先自然是设置**data**这一步我们直接根据将传入的**value**设置到**data**上即可。
|
||||
定义好节点之后,我们先实现以下元素的添加,添加元素时首先自然是设置 **data**,这一步我们直接根据将传入的 **value** 设置到 **data** 上即可。
|
||||
|
||||
然后就是高度**maxLevel**的设置 ,我们在上文也已经给出了思路,默认高度为 1,即只有一个原始链表节点,通过随机算法每次大于 0.5 索引高度加 1,由此我们得出高度计算的算法`randomLevel()`:
|
||||
然后就是高度 **maxLevel** 的设置 ,我们在上文也已经给出了思路,默认高度为 1,即只有一个原始链表节点,通过随机算法每次大于 0.5 索引高度加 1,由此我们得出高度计算的算法 `randomLevel()`:
|
||||
|
||||
```java
|
||||
/**
|
||||
* 理论来讲,一级索引中元素个数应该占原始数据的 50%,二级索引中元素个数占 25%,三级索引12.5% ,一直到最顶层。
|
||||
* 理论来讲,一级索引中元素个数应该占原始数据的 50%,二级索引中元素个数占 25%,三级索引12.5%,一直到最顶层。
|
||||
* 因为这里每一层的晋升概率是 50%。对于每一个新插入的节点,都需要调用 randomLevel 生成一个合理的层数。
|
||||
* 该 randomLevel 方法会随机生成 1~MAX_LEVEL 之间的数,且 :
|
||||
* 该 randomLevel 方法会随机生成 1~MAX_LEVEL 之间的数,且:
|
||||
* 50%的概率返回 1
|
||||
* 25%的概率返回 2
|
||||
* 12.5%的概率返回 3 ...
|
||||
* 12.5%的概率返回 3......
|
||||
* @return
|
||||
*/
|
||||
private int randomLevel() {
|
||||
@ -217,13 +217,13 @@ private int randomLevel() {
|
||||
}
|
||||
```
|
||||
|
||||
然后再设置当前要插入的**Node**和**Node**索引的后继节点地址,这一步稍微复杂一点,我们假设当前节点的高度为 4,即 1 个节点加 3 个索引,所以我们创建一个长度为 4 的数组**maxOfMinArr** ,遍历各级索引节点中小于当前**value**的最大值。
|
||||
然后再设置当前要插入的 **Node** 和 **Node** 索引的后继节点地址,这一步稍微复杂一点,我们假设当前节点的高度为 4,即 1 个节点加 3 个索引,所以我们创建一个长度为 4 的数组 **maxOfMinArr**,遍历各级索引节点中小于当前 **value** 的最大值。
|
||||
|
||||
假设我们要插入的**value**为 5,我们的数组查找结果当前节点的前驱节点和 1 级索引、2 级索引的前驱节点都为 4,三级索引为空。
|
||||
假设我们要插入的 **value** 为 5,我们的数组查找结果当前节点的前驱节点和 1 级索引、2 级索引的前驱节点都为 4,三级索引为空。
|
||||
|
||||
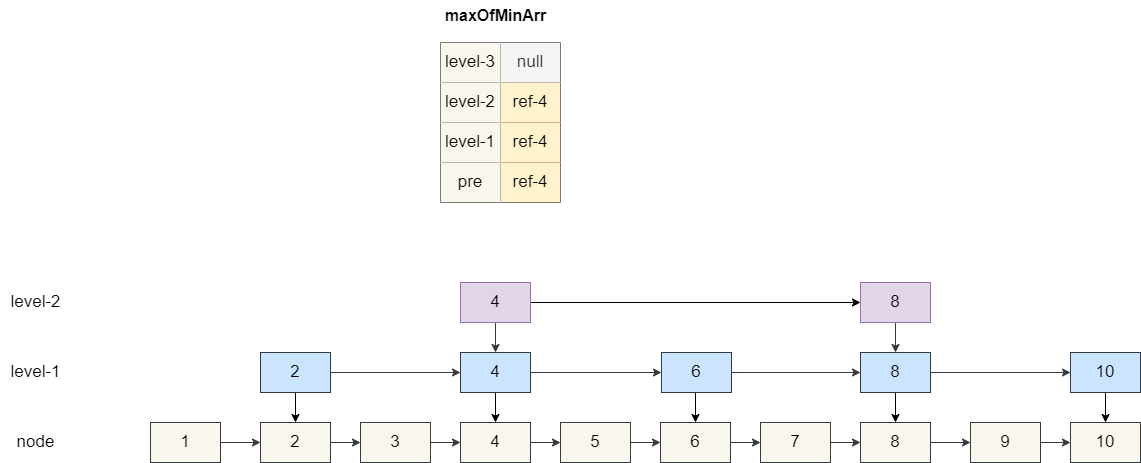
|
||||
|
||||
然后我们基于这个数组**maxOfMinArr** 定位到各级的后继节点,让插入的元素 5 指向这些后继节点,而**maxOfMinArr**指向 5,结果如下图:
|
||||
然后我们基于这个数组 **maxOfMinArr** 定位到各级的后继节点,让插入的元素 5 指向这些后继节点,而 **maxOfMinArr** 指向 5,结果如下图:
|
||||
|
||||
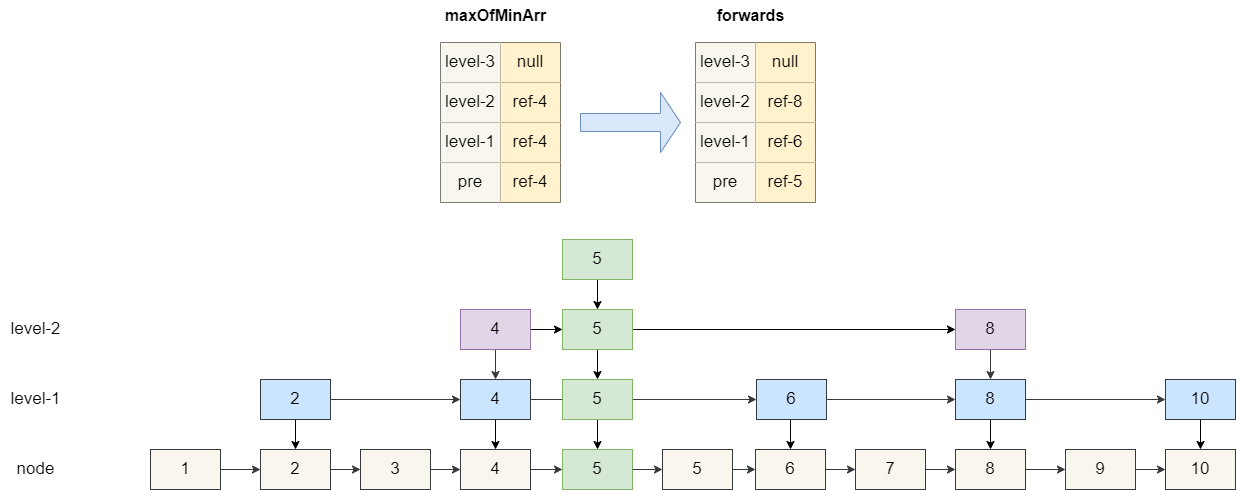
|
||||
|
||||
@ -361,7 +361,7 @@ public void delete(int value) {
|
||||
|
||||
### 完整代码以及测试
|
||||
|
||||
完整代码如下,读者可自行参阅:
|
||||
完整代码如下,读者可自行参阅:
|
||||
|
||||
```java
|
||||
public class SkipList {
|
||||
@ -374,7 +374,7 @@ public class SkipList {
|
||||
/**
|
||||
* 每个节点添加一层索引高度的概率为二分之一
|
||||
*/
|
||||
private static final float PROB = 0.5 f;
|
||||
private static final float PROB = 0.5f;
|
||||
|
||||
/**
|
||||
* 默认情况下的高度为1,即只有自己一个节点
|
||||
@ -602,7 +602,7 @@ Node{data=23, maxLevel=1}
|
||||
**Redis 跳表的特点**:
|
||||
|
||||
1. 采用**双向链表**,不同于上面的示例,存在一个回退指针。主要用于简化操作,例如删除某个元素时,还需要找到该元素的前驱节点,使用回退指针会非常方便。
|
||||
2. `score` 值可以重复,如果 `score` 值一样,则按照 ele(节点存储的值,为 sds)字典排序
|
||||
2. `score` 值可以重复,如果 `score` 值一样,则按照 ele(节点存储的值,为 sds)字典排序。
|
||||
3. Redis 跳跃表默认允许最大的层数是 32,被源码中 `ZSKIPLIST_MAXLEVEL` 定义。
|
||||
|
||||
## 和其余三种数据结构的比较
|
||||
@ -611,13 +611,13 @@ Node{data=23, maxLevel=1}
|
||||
|
||||
### 平衡树 vs 跳表
|
||||
|
||||
先来说说它和平衡树的比较,平衡树我们又会称之为 **AVL 树**,是一个严格的平衡二叉树,平衡条件必须满足(所有节点的左右子树高度差不超过 1,即平衡因子为范围为 `[-1,1]`)。平衡树的插入、删除和查询的时间复杂度和跳表一样都是 **O(log n)** 。
|
||||
先来说说它和平衡树的比较,平衡树我们又会称之为 **AVL 树**,是一个严格的平衡二叉树,平衡条件必须满足(所有节点的左右子树高度差不超过 1,即平衡因子为范围为 `[-1,1]`)。平衡树的插入、删除和查询的时间复杂度和跳表一样都是 **O(log n)**。
|
||||
|
||||
对于范围查询来说,它也可以通过中序遍历的方式达到和跳表一样的效果。但是它的每一次插入或者删除操作都需要保证整颗树左右节点的绝对平衡,只要不平衡就要通过旋转操作来保持平衡,这个过程是比较耗时的。
|
||||
|
||||
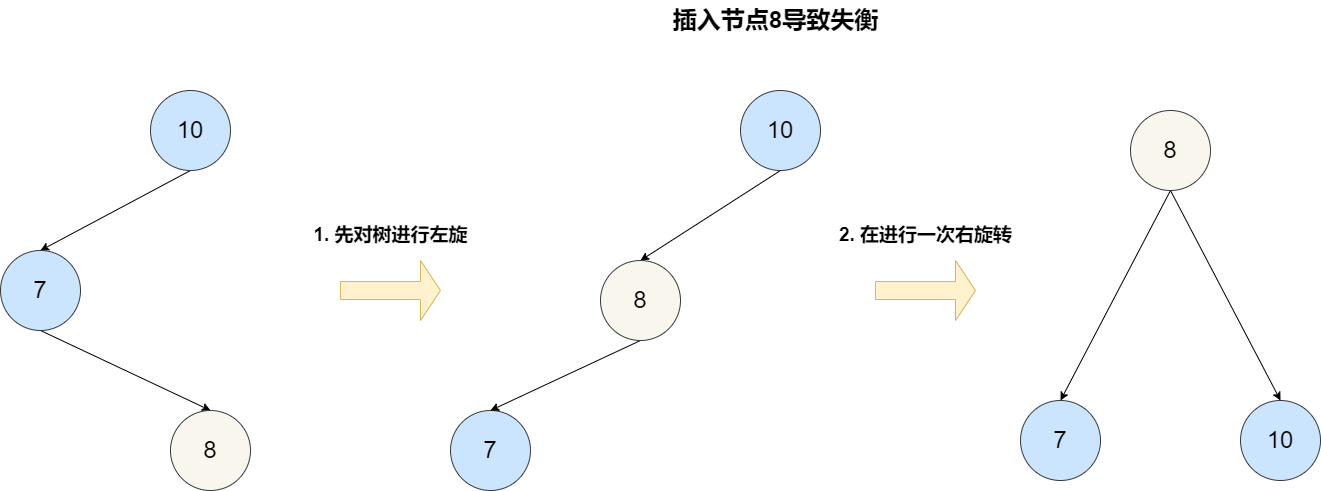
|
||||
|
||||
跳表诞生的初衷就是为了克服平衡树的一些缺点,跳表的发明者在论文[《Skip lists: a probabilistic alternative to balanced trees》](https://15721.courses.cs.cmu.edu/spring2018/papers/08-oltpindexes1/pugh-skiplists-cacm1990.pdf)中有详细提到:
|
||||
跳表诞生的初衷就是为了克服平衡树的一些缺点,跳表的发明者在论文 [《Skip lists: a probabilistic alternative to balanced trees》](https://15721.courses.cs.cmu.edu/spring2018/papers/08-oltpindexes1/pugh-skiplists-cacm1990.pdf) 中有详细提到:
|
||||
|
||||

|
||||
|
||||
@ -680,9 +680,9 @@ private Node add(Node node, K key, V value) {
|
||||
|
||||
### 红黑树 vs 跳表
|
||||
|
||||
红黑树(Red Black Tree)也是一种自平衡二叉查找树,它的查询性能略微逊色于 AVL 树,但插入和删除效率更高。红黑树的插入、删除和查询的时间复杂度和跳表一样都是 **O(log n)** 。
|
||||
红黑树(Red Black Tree)也是一种自平衡二叉查找树,它的查询性能略微逊色于 AVL 树,但插入和删除效率更高。红黑树的插入、删除和查询的时间复杂度和跳表一样都是 **O(log n)**。
|
||||
|
||||
红黑树是一个**黑平衡树**,即从任意节点到另外一个叶子叶子节点,它所经过的黑节点是一样的。当对它进行插入操作时,需要通过旋转和染色(红黑变换)来保证黑平衡。不过,相较于 AVL 树为了维持平衡的开销要小一些。关于红黑树的详细介绍,可以查看这篇文章:[红黑树](https://javaguide.cn/cs-basics/data-structure/red-black-tree.html)。
|
||||
红黑树是一个 **黑平衡树**,即从任意节点到另外一个叶子叶子节点,它所经过的黑节点是一样的。当对它进行插入操作时,需要通过旋转和染色(红黑变换)来保证黑平衡。不过,相较于 AVL 树为了维持平衡的开销要小一些。关于红黑树的详细介绍,可以查看这篇文章:[红黑树](https://javaguide.cn/cs-basics/data-structure/red-black-tree.html)。
|
||||
|
||||
相比较于红黑树来说,跳表的实现也更简单一些。并且,按照区间来查找数据这个操作,红黑树的效率没有跳表高。
|
||||
|
||||
|
||||
@ -11,7 +11,7 @@ tag:
|
||||
|
||||
Java 阻塞队列的历史可以追溯到 JDK1.5 版本,当时 Java 平台增加了 `java.util.concurrent`,即我们常说的 JUC 包,其中包含了各种并发流程控制工具、并发容器、原子类等。这其中自然也包含了我们这篇文章所讨论的阻塞队列。
|
||||
|
||||
为了解决高并发场景下多线程之间数据共享的问题,JDK1.5 版本中出现了 `ArrayBlockingQueue` 和 `LinkedBlockingQueue`,它们是带有生产者-消费者模式实现的并发容器。其中,`ArrayBlockingQueue` 是有界队列,即添加的元素达到上限之后,再次添加就会被阻塞或者抛出异常。而 `LinkedBlockingQueue` 则由链表构成的队列,正是因为链表的特性,所以 `LinkedBlockingQueue` 在添加元素上并不会向 `ArrayBlockingQueue` 那样有着较多的约束,所以 `LinkedBlockingQueue` 设置队列是否有界是可选的(注意这里的无界并不是指可以添加任务数量的元素,而是说队列的大小默认为 `Integer.MAX_VALUE`,近乎于无限大)。
|
||||
为了解决高并发场景下多线程之间数据共享的问题,JDK1.5 版本中出现了 `ArrayBlockingQueue` 和 `LinkedBlockingQueue`,它们是带有生产者-消费者模式实现的并发容器。其中,`ArrayBlockingQueue` 是有界队列,即添加的元素达到上限之后,再次添加就会被阻塞或者抛出异常。而 `LinkedBlockingQueue` 则由链表构成的队列,正是因为链表的特性,所以 `LinkedBlockingQueue` 在添加元素上并不会向 `ArrayBlockingQueue` 那样有着较多的约束,所以 `LinkedBlockingQueue` 设置队列是否有界是可选的(注意这里的无界并不是指可以添加任意数量的元素,而是说队列的大小默认为 `Integer.MAX_VALUE`,近乎于无限大)。
|
||||
|
||||
随着 Java 的不断发展,JDK 后续的几个版本又对阻塞队列进行了不少的更新和完善:
|
||||
|
||||
|
||||
@ -341,7 +341,7 @@ Final Reference: Daisy, Final Mark: true
|
||||
- `AtomicLongFieldUpdater`:原子更新长整形字段的更新器
|
||||
- `AtomicReferenceFieldUpdater`:原子更新引用类型里的字段的更新器
|
||||
|
||||
要想原子地更新对象的属性需要两步。第一步,因为对象的属性修改类型原子类都是抽象类,所以每次使用都必须使用静态方法 newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。第二步,更新的对象属性必须使用 public volatile 修饰符。
|
||||
要想原子地更新对象的属性需要两步。第一步,因为对象的属性修改类型原子类都是抽象类,所以每次使用都必须使用静态方法 newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。第二步,更新的对象属性必须使用 volatile int 修饰符。
|
||||
|
||||
上面三个类提供的方法几乎相同,所以我们这里以 `AtomicIntegerFieldUpdater`为例子来介绍。
|
||||
|
||||
@ -351,8 +351,8 @@ Final Reference: Daisy, Final Mark: true
|
||||
// Person 类
|
||||
class Person {
|
||||
private String name;
|
||||
// 要使用 AtomicIntegerFieldUpdater,字段必须是 public volatile
|
||||
private volatile int age;
|
||||
// 要使用 AtomicIntegerFieldUpdater,字段必须是 volatile int
|
||||
volatile int age;
|
||||
//省略getter/setter和toString
|
||||
}
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user