mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
Compare commits
12 Commits
b5f8894c70
...
37a51a0e6f
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
37a51a0e6f | ||
|
|
ef7c74c2ce | ||
|
|
bb5e4cd5e7 | ||
|
|
d4e2ffb06f | ||
|
|
88a179d767 | ||
|
|
e93ce70adc | ||
|
|
3af7abfcd9 | ||
|
|
ae32d743c5 | ||
|
|
04ebec50b5 | ||
|
|
4db584bc3e | ||
|
|
f20a7a03bb | ||
|
|
dc0593be9b |
11
README.md
11
README.md
@ -373,18 +373,17 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8](https://docs.oracle.
|
||||
|
||||
## 高性能
|
||||
|
||||
### 数据库读写分离&分库分表
|
||||
### 数据库优化
|
||||
|
||||
[数据库读写分离和分库分表常见知识点&面试题总结](./docs/high-performance/read-and-write-separation-and-library-subtable.md)
|
||||
- [数据库读写分离和分库分表](./docs/high-performance/read-and-write-separation-and-library-subtable.md)
|
||||
- [数据冷热分离](./docs/high-performance/data-cold-hot-separation.md)
|
||||
- [常见 SQL 优化手段总结](./docs/high-performance/sql-optimization.md)
|
||||
- [深度分页介绍及优化建议](./docs/high-performance/deep-pagination-optimization.md)
|
||||
|
||||
### 负载均衡
|
||||
|
||||
[负载均衡常见知识点&面试题总结](./docs/high-performance/load-balancing.md)
|
||||
|
||||
### SQL 优化
|
||||
|
||||
[常见 SQL 优化手段总结](./docs/high-performance/sql-optimization.md)
|
||||
|
||||
### CDN
|
||||
|
||||
[CDN(内容分发网络)常见知识点&面试题总结](./docs/high-performance/cdn.md)
|
||||
|
||||
@ -4,7 +4,7 @@ import theme from "./theme.js";
|
||||
export default defineUserConfig({
|
||||
dest: "./dist",
|
||||
|
||||
title: "JavaGuide(Java面试+学习指南)",
|
||||
title: "JavaGuide",
|
||||
description:
|
||||
"「Java学习指北 + Java面试指南」一份涵盖大部分 Java 程序员所需要掌握的核心知识。准备 Java 面试,复习 Java 知识点,首选 JavaGuide! ",
|
||||
lang: "zh-CN",
|
||||
@ -30,6 +30,14 @@ export default defineUserConfig({
|
||||
"Java基础, 多线程, JVM, 虚拟机, 数据库, MySQL, Spring, Redis, MyBatis, 系统设计, 分布式, RPC, 高可用, 高并发",
|
||||
},
|
||||
],
|
||||
[
|
||||
"meta",
|
||||
{
|
||||
name: "description",
|
||||
content:
|
||||
"「Java学习 + 面试指南」一份涵盖大部分 Java 程序员所需要掌握的核心知识。准备 Java 面试,首选 JavaGuide!",
|
||||
},
|
||||
],
|
||||
["meta", { name: "apple-mobile-web-app-capable", content: "yes" }],
|
||||
// 添加百度统计
|
||||
[
|
||||
|
||||
@ -184,13 +184,14 @@ export default sidebar({
|
||||
children: [
|
||||
"other-network-questions",
|
||||
"other-network-questions2",
|
||||
"computer-network-xiexiren-summary",
|
||||
// "computer-network-xiexiren-summary",
|
||||
{
|
||||
text: "重要知识点",
|
||||
icon: "star",
|
||||
collapsible: true,
|
||||
children: [
|
||||
"osi-and-tcp-ip-model",
|
||||
"the-whole-process-of-accessing-web-pages",
|
||||
"application-layer-protocol",
|
||||
"http-vs-https",
|
||||
"http1.0-vs-http1.1",
|
||||
@ -424,7 +425,7 @@ export default sidebar({
|
||||
collapsible: true,
|
||||
children: [
|
||||
{
|
||||
text: "基础",
|
||||
text: "基础知识",
|
||||
prefix: "basis/",
|
||||
icon: "basic",
|
||||
collapsible: true,
|
||||
@ -440,7 +441,7 @@ export default sidebar({
|
||||
],
|
||||
},
|
||||
{
|
||||
text: "安全",
|
||||
text: "认证授权",
|
||||
prefix: "security/",
|
||||
icon: "security-fill",
|
||||
collapsible: true,
|
||||
@ -450,6 +451,14 @@ export default sidebar({
|
||||
"advantages-and-disadvantages-of-jwt",
|
||||
"sso-intro",
|
||||
"design-of-authority-system",
|
||||
],
|
||||
},
|
||||
{
|
||||
text: "数据安全",
|
||||
prefix: "security/",
|
||||
icon: "security-fill",
|
||||
collapsible: true,
|
||||
children: [
|
||||
"encryption-algorithms",
|
||||
"sentive-words-filter",
|
||||
"data-desensitization",
|
||||
@ -541,7 +550,9 @@ export default sidebar({
|
||||
icon: "mysql",
|
||||
children: [
|
||||
"read-and-write-separation-and-library-subtable",
|
||||
"data-cold-hot-separation",
|
||||
"sql-optimization",
|
||||
"deep-pagination-optimization",
|
||||
],
|
||||
},
|
||||
{
|
||||
|
||||
@ -12,7 +12,7 @@ export default hopeTheme({
|
||||
logo: "/logo.png",
|
||||
favicon: "/favicon.ico",
|
||||
|
||||
iconAssets: "//at.alicdn.com/t/c/font_2922463_kweia6fbo9.css",
|
||||
iconAssets: "//at.alicdn.com/t/c/font_2922463_o9q9dxmps9.css",
|
||||
|
||||
author: {
|
||||
name: "Guide",
|
||||
@ -53,10 +53,12 @@ export default hopeTheme({
|
||||
plugins: {
|
||||
components: {
|
||||
rootComponents: {
|
||||
// https://plugin-components.vuejs.press/zh/guide/utilities/notice.html#%E7%94%A8%E6%B3%95
|
||||
notice: [
|
||||
{
|
||||
path: "/",
|
||||
title: "Java学习路线最新版",
|
||||
showOnce: true,
|
||||
content:
|
||||
"花了一个月零碎的时间,我根据当下 Java 后端求职和招聘的最新要求,对之前写的 Java 后端学习路线进行了全面的优化和改进。这可能是你所见过的最用心、最全面的 Java 后端学习路线,共 4w+ 字。",
|
||||
actions: [
|
||||
|
||||
@ -14,14 +14,20 @@ Elasticsearch 在 Apache Lucene 的基础上开发而成,学习 ES 之前,
|
||||
|
||||
## Elasticsearch
|
||||
|
||||
极客时间的[《Elasticsearch 核心技术与实战》](http://gk.link/a/10bcT "《Elasticsearch 核心技术与实战》")这门课程基于 Elasticsearch 7.1 版本讲解,还算比较新。并且,作者是 eBay 资深技术专家,有 20 年的行业经验,课程质量有保障!
|
||||
**[《一本书讲透 Elasticsearch:原理、进阶与工程实践》](https://book.douban.com/subject/36716996/)**
|
||||
|
||||

|
||||
|
||||
基于 8.x 版本编写,目前全网最新的 Elasticsearch 讲解书籍。内容覆盖 Elastic 官方认证的核心知识点,源自真实项目案例和企业级问题解答。
|
||||
|
||||
**[《Elasticsearch 核心技术与实战》](http://gk.link/a/10bcT "《Elasticsearch 核心技术与实战》")**
|
||||
|
||||
极客时间的这门课程基于 Elasticsearch 7.1 版本讲解,还算比较新。并且,作者是 eBay 资深技术专家,有 20 年的行业经验,课程质量有保障!
|
||||
|
||||

|
||||
|
||||
如果你想看书的话,可以考虑一下 **[《Elasticsearch 实战》](https://book.douban.com/subject/30380439/)** 这本书。不过,需要说明的是,这本书中的 Elasticsearch 版本比较老,你可以将其作为一个参考书籍来看,有一些原理性的东西可以在上面找找答案。
|
||||
|
||||

|
||||
|
||||
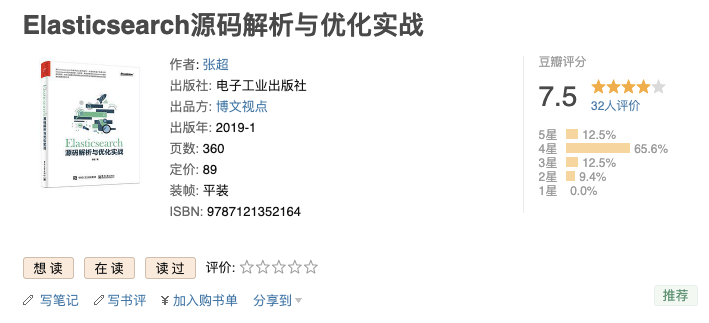
如果你想进一步深入研究 Elasticsearch 原理的话,可以看看张超老师的 **[《Elasticsearch 源码解析与优化实战》](https://book.douban.com/subject/30386800/)** 这本书。这是市面上唯一一本写 Elasticsearch 源码的书。
|
||||
**[《Elasticsearch 源码解析与优化实战》](https://book.douban.com/subject/30386800/)**
|
||||
|
||||
|
||||
|
||||
如果你想进一步深入研究 Elasticsearch 原理的话,可以看看张超老师的这本书。这是市面上唯一一本写 Elasticsearch 源码的书。
|
||||
|
||||
@ -78,7 +78,7 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
|
||||
|
||||

|
||||
|
||||
- **TCP(Transmisson Control Protocol,传输控制协议 )**:提供 **面向连接** 的,**可靠** 的数据传输服务。
|
||||
- **TCP(Transmission Control Protocol,传输控制协议 )**:提供 **面向连接** 的,**可靠** 的数据传输服务。
|
||||
- **UDP(User Datagram Protocol,用户数据协议)**:提供 **无连接** 的,**尽最大努力** 的数据传输服务(不保证数据传输的可靠性),简单高效。
|
||||
|
||||
### 网络层(Network layer)
|
||||
|
||||
@ -104,25 +104,17 @@ tag:
|
||||
|
||||
> 类似的问题:打开一个网页,整个过程会使用哪些协议?
|
||||
|
||||
图解(图片来源:《图解 HTTP》):
|
||||
总体来说分为以下几个步骤:
|
||||
|
||||
<img src="https://oss.javaguide.cn/github/javaguide/url%E8%BE%93%E5%85%A5%E5%88%B0%E5%B1%95%E7%A4%BA%E5%87%BA%E6%9D%A5%E7%9A%84%E8%BF%87%E7%A8%8B.jpg" style="zoom:50%" />
|
||||
1. 在浏览器中输入指定网页的 URL。
|
||||
2. 浏览器通过 DNS 协议,获取域名对应的 IP 地址。
|
||||
3. 浏览器根据 IP 地址和端口号,向目标服务器发起一个 TCP 连接请求。
|
||||
4. 浏览器在 TCP 连接上,向服务器发送一个 HTTP 请求报文,请求获取网页的内容。
|
||||
5. 服务器收到 HTTP 请求报文后,处理请求,并返回 HTTP 响应报文给浏览器。
|
||||
6. 浏览器收到 HTTP 响应报文后,解析响应体中的 HTML 代码,渲染网页的结构和样式,同时根据 HTML 中的其他资源的 URL(如图片、CSS、JS 等),再次发起 HTTP 请求,获取这些资源的内容,直到网页完全加载显示。
|
||||
7. 浏览器在不需要和服务器通信时,可以主动关闭 TCP 连接,或者等待服务器的关闭请求。
|
||||
|
||||
> 上图有一个错误,请注意,是 OSPF 不是 OPSF。 OSPF(Open Shortest Path First,ospf)开放最短路径优先协议, 是由 Internet 工程任务组开发的路由选择协议
|
||||
|
||||
总体来说分为以下几个过程:
|
||||
|
||||
1. DNS 解析
|
||||
2. TCP 连接
|
||||
3. 发送 HTTP 请求
|
||||
4. 服务器处理请求并返回 HTTP 报文
|
||||
5. 浏览器解析渲染页面
|
||||
6. 连接结束
|
||||
|
||||
具体可以参考下面这两篇文章:
|
||||
|
||||
- [从输入 URL 到页面加载发生了什么?](https://segmentfault.com/a/1190000006879700)
|
||||
- [浏览器从输入网址到页面展示的过程](https://cloud.tencent.com/developer/article/1879758)
|
||||
详细介绍可以查看这篇文章:[访问网页的全过程(知识串联)](./the-whole-process-of-accessing-web-pages.md)(强烈推荐)。
|
||||
|
||||
### HTTP 状态码有哪些?
|
||||
|
||||
@ -303,6 +295,24 @@ WebSocket 的工作过程可以分为以下几个步骤:
|
||||
|
||||
另外,建立 WebSocket 连接之后,通过心跳机制来保持 WebSocket 连接的稳定性和活跃性。
|
||||
|
||||
### SSE 与 WebSocket 有什么区别?
|
||||
|
||||
> 摘自[Web 实时消息推送详解](https://javaguide.cn/system-design/web-real-time-message-push.html)。
|
||||
|
||||
SSE 与 WebSocket 作用相似,都可以建立服务端与浏览器之间的通信,实现服务端向客户端推送消息,但还是有些许不同:
|
||||
|
||||
- SSE 是基于 HTTP 协议的,它们不需要特殊的协议或服务器实现即可工作;WebSocket 需单独服务器来处理协议。
|
||||
- SSE 单向通信,只能由服务端向客户端单向通信;WebSocket 全双工通信,即通信的双方可以同时发送和接受信息。
|
||||
- SSE 实现简单开发成本低,无需引入其他组件;WebSocket 传输数据需做二次解析,开发门槛高一些。
|
||||
- SSE 默认支持断线重连;WebSocket 则需要自己实现。
|
||||
- SSE 只能传送文本消息,二进制数据需要经过编码后传送;WebSocket 默认支持传送二进制数据。
|
||||
|
||||
**SSE 与 WebSocket 该如何选择?**
|
||||
|
||||
SSE 好像一直不被大家所熟知,一部分原因是出现了 WebSocket,这个提供了更丰富的协议来执行双向、全双工通信。对于游戏、即时通信以及需要双向近乎实时更新的场景,拥有双向通道更具吸引力。
|
||||
|
||||
但是,在某些情况下,不需要从客户端发送数据。而你只需要一些服务器操作的更新。比如:站内信、未读消息数、状态更新、股票行情、监控数量等场景,SEE 不管是从实现的难易和成本上都更加有优势。此外,SSE 具有 WebSocket 在设计上缺乏的多种功能,例如:自动重新连接、事件 ID 和发送任意事件的能力。
|
||||
|
||||
## PING
|
||||
|
||||
### PING 命令的作用是什么?
|
||||
|
||||
@ -0,0 +1,78 @@
|
||||
---
|
||||
title: 访问网页的全过程(知识串联)
|
||||
category: 计算机基础
|
||||
tag:
|
||||
- 计算机网络
|
||||
---
|
||||
|
||||
开发岗中总是会考很多计算机网络的知识点,但如果让面试官只靠一道题,便涵盖最多的计网知识点,那可能就是 **网页浏览的全过程** 了。本篇文章将带大家从头到尾过一遍这道被考烂的面试题,必会!!!
|
||||
|
||||
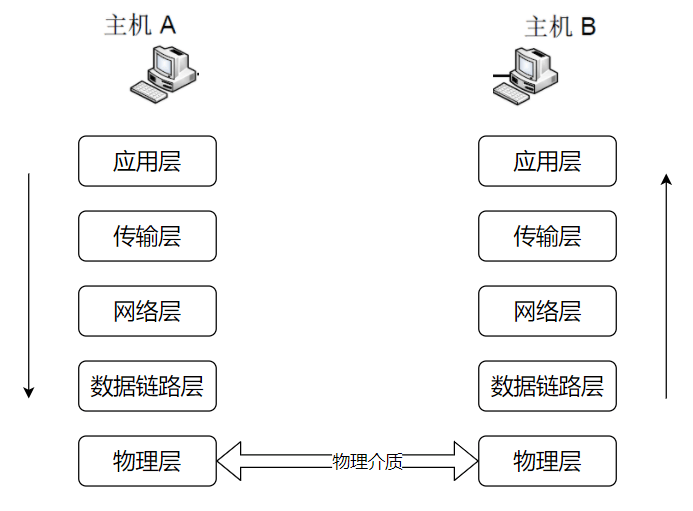
总的来说,网络通信模型可以用下图来表示,也就是大家只要熟记网络结构五层模型,按照这个体系,很多知识点都能顺出来了。访问网页的过程也是如此。
|
||||
|
||||
|
||||
|
||||
开始之前,我们先简单过一遍完整流程:
|
||||
|
||||
1. 在浏览器中输入指定网页的 URL。
|
||||
2. 浏览器通过 DNS 协议,获取域名对应的 IP 地址。
|
||||
3. 浏览器根据 IP 地址和端口号,向目标服务器发起一个 TCP 连接请求。
|
||||
4. 浏览器在 TCP 连接上,向服务器发送一个 HTTP 请求报文,请求获取网页的内容。
|
||||
5. 服务器收到 HTTP 请求报文后,处理请求,并返回 HTTP 响应报文给浏览器。
|
||||
6. 浏览器收到 HTTP 响应报文后,解析响应体中的 HTML 代码,渲染网页的结构和样式,同时根据 HTML 中的其他资源的 URL(如图片、CSS、JS 等),再次发起 HTTP 请求,获取这些资源的内容,直到网页完全加载显示。
|
||||
7. 浏览器在不需要和服务器通信时,可以主动关闭 TCP 连接,或者等待服务器的关闭请求。
|
||||
|
||||
## 应用层
|
||||
|
||||
一切的开始——打开浏览器,在地址栏输入 URL,回车确认。那么,什么是 URL?访问 URL 有什么用?
|
||||
|
||||
### URL
|
||||
|
||||
URL(Uniform Resource Locators),即统一资源定位器。网络上的所有资源都靠 URL 来定位,每一个文件就对应着一个 URL,就像是路径地址。理论上,文件资源和 URL 一一对应。实际上也有例外,比如某些 URL 指向的文件已经被重定位到另一个位置,这样就有多个 URL 指向同一个文件。
|
||||
|
||||
### URL 的组成结构
|
||||
|
||||

|
||||
|
||||
1. 协议。URL 的前缀通常表示了该网址采用了何种应用层协议,通常有两种——HTTP 和 HTTPS。当然也有一些不太常见的前缀头,比如文件传输时用到的`ftp:`。
|
||||
2. 域名。域名便是访问网址的通用名,这里也有可能是网址的 IP 地址,域名可以理解为 IP 地址的可读版本,毕竟绝大部分人都不会选择记住一个网址的 IP 地址。
|
||||
3. 端口。如果指明了访问网址的端口的话,端口会紧跟在域名后面,并用一个冒号隔开。
|
||||
4. 资源路径。域名(端口)后紧跟的就是资源路径,从第一个`/`开始,表示从服务器上根目录开始进行索引到的文件路径,上图中要访问的文件就是服务器根目录下`/path/to/myfile.html`。早先的设计是该文件通常物理存储于服务器主机上,但现在随着网络技术的进步,该文件不一定会物理存储在服务器主机上,有可能存放在云上,而文件路径也有可能是虚拟的(遵循某种规则)。
|
||||
5. 参数。参数是浏览器在向服务器提交请求时,在 URL 中附带的参数。服务器解析请求时,会提取这些参数。参数采用键值对的形式`key=value`,每一个键值对使用`&`隔开。参数的具体含义和请求操作的具体方法有关。
|
||||
6. 锚点。锚点顾名思义,是在要访问的页面上的一个锚。要访问的页面大部分都多于一页,如果指定了锚点,那么在客户端显示该网页是就会定位到锚点处,相当于一个小书签。值得一提的是,在 URL 中,锚点以`#`开头,并且**不会**作为请求的一部分发送给服务端。
|
||||
|
||||
### DNS
|
||||
|
||||
键入了 URL 之后,第一个重头戏登场——DNS 服务器解析。DNS(Domain Name System)域名系统,要解决的是 **域名和 IP 地址的映射问题** 。毕竟,域名只是一个网址便于记住的名字,而网址真正存在的地址其实是 IP 地址。
|
||||
|
||||
传送门:[DNS 域名系统详解(应用层)](https://javaguide.cn/cs-basics/network/dns.html)
|
||||
|
||||
### HTTP/HTTPS
|
||||
|
||||
利用 DNS 拿到了目标主机的 IP 地址之后,浏览器便可以向目标 IP 地址发送 HTTP 报文,请求需要的资源了。在这里,根据目标网站的不同,请求报文可能是 HTTP 协议或安全性增强的 HTTPS 协议。
|
||||
|
||||
传送门:
|
||||
|
||||
- [HTTP vs HTTPS(应用层)](https://javaguide.cn/cs-basics/network/http-vs-https.html)
|
||||
- [HTTP 1.0 vs HTTP 1.1(应用层)](https://javaguide.cn/cs-basics/network/http1.0-vs-http1.1.html)
|
||||
|
||||
## 传输层
|
||||
|
||||
由于 HTTP 协议是基于 TCP 协议的,在应用层的数据封装好以后,要交给传输层,经 TCP 协议继续封装。
|
||||
|
||||
TCP 协议保证了数据传输的可靠性,是数据包传输的主力协议。
|
||||
|
||||
传送门:
|
||||
|
||||
- [TCP 三次握手和四次挥手(传输层)](https://javaguide.cn/cs-basics/network/tcp-connection-and-disconnection.html)
|
||||
- [TCP 传输可靠性保障(传输层)](https://javaguide.cn/cs-basics/network/tcp-reliability-guarantee.html)
|
||||
|
||||
## 网络层
|
||||
|
||||
终于,来到网络层,此时我们的主机不再是和另一台主机进行交互了,而是在和中间系统进行交互。也就是说,应用层和传输层都是端到端的协议,而网络层及以下都是中间件的协议了。
|
||||
|
||||
**网络层的的核心功能——转发与路由**,必会!!!如果面试官问到了网络层,而你恰好又什么都不会的话,最最起码要说出这五个字——**转发与路由**。
|
||||
|
||||
- 转发:将分组从路由器的输入端口转移到合适的输出端口。
|
||||
- 路由:确定分组从源到目的经过的路径。
|
||||
|
||||
所以到目前为止,我们的数据包经过了应用层、传输层的封装,来到了网络层,终于开始准备在物理层面传输了,第一个要解决的问题就是——**往哪里传输?或者说,要把数据包发到哪个路由器上?**这便是 BGP 协议要解决的问题。
|
||||
@ -237,7 +237,7 @@ Linux 中的打包文件一般是以 `.tar` 结尾的,压缩的命令一般是
|
||||
|
||||
### 文件权限
|
||||
|
||||
操作系统中每个文件都拥有特定的权限、所属用户和所属组。权限是操作系统用来限制资源访问的机制,在 Linux 中权限一般分为读(readable)、写(writable)和执行(excutable),分为三组。分别对应文件的属主(owner),属组(group)和其他用户(other),通过这样的机制来限制哪些用户、哪些组可以对特定的文件进行什么样的操作。
|
||||
操作系统中每个文件都拥有特定的权限、所属用户和所属组。权限是操作系统用来限制资源访问的机制,在 Linux 中权限一般分为读(readable)、写(writable)和执行(executable),分为三组。分别对应文件的属主(owner),属组(group)和其他用户(other),通过这样的机制来限制哪些用户、哪些组可以对特定的文件进行什么样的操作。
|
||||
|
||||
通过 **`ls -l`** 命令我们可以 查看某个目录下的文件或目录的权限
|
||||
|
||||
|
||||
@ -385,7 +385,7 @@ c. WHERE 子句
|
||||
-- 运算符:
|
||||
=, <=>, <>, !=, <=, <, >=, >, !, &&, ||,
|
||||
in (not) null, (not) like, (not) in, (not) between and, is (not), and, or, not, xor
|
||||
is/is not 加上ture/false/unknown,检验某个值的真假
|
||||
is/is not 加上true/false/unknown,检验某个值的真假
|
||||
<=>与<>功能相同,<=>可用于null比较
|
||||
d. GROUP BY 子句, 分组子句
|
||||
GROUP BY 字段/别名 [排序方式]
|
||||
@ -792,7 +792,7 @@ default();
|
||||
CREATE FUNCTION function_name (参数列表) RETURNS 返回值类型
|
||||
函数体
|
||||
- 函数名,应该合法的标识符,并且不应该与已有的关键字冲突。
|
||||
- 一个函数应该属于某个数据库,可以使用db_name.funciton_name的形式执行当前函数所属数据库,否则为当前数据库。
|
||||
- 一个函数应该属于某个数据库,可以使用db_name.function_name的形式执行当前函数所属数据库,否则为当前数据库。
|
||||
- 参数部分,由"参数名"和"参数类型"组成。多个参数用逗号隔开。
|
||||
- 函数体由多条可用的mysql语句,流程控制,变量声明等语句构成。
|
||||
- 多条语句应该使用 begin...end 语句块包含。
|
||||
|
||||
@ -213,7 +213,7 @@ InnoDB 是按照主键索引的顺序来组织表的
|
||||
|
||||
**覆盖索引的好处:**
|
||||
|
||||
- **避免 InnoDB 表进行索引的二次查询:** InnoDB 是以聚集索引的顺序来存储的,对于 InnoDB 来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询 ,减少了 IO 操作,提升了查询效率。
|
||||
- **避免 InnoDB 表进行索引的二次查询,也就是回表操作:** InnoDB 是以聚集索引的顺序来存储的,对于 InnoDB 来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询(回表),减少了 IO 操作,提升了查询效率。
|
||||
- **可以把随机 IO 变成顺序 IO 加快查询效率:** 由于覆盖索引是按键值的顺序存储的,对于 IO 密集型的范围查找来说,对比随机从磁盘读取每一行的数据 IO 要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的 IO 转变成索引查找的顺序 IO。
|
||||
|
||||
---
|
||||
|
||||
@ -811,6 +811,24 @@ mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
|
||||
|
||||
读写分离和分库分表相关的问题比较多,于是,我单独写了一篇文章来介绍:[读写分离和分库分表详解](../../high-performance/read-and-write-separation-and-library-subtable.md)。
|
||||
|
||||
### 深度分页如何优化?
|
||||
|
||||
[深度分页介绍及优化建议](../../high-performance/deep-pagination-optimization.md)
|
||||
|
||||
### 数据冷热分离如何做?
|
||||
|
||||
[数据冷热分离详解](../../high-performance/data-cold-hot-separation.md)
|
||||
|
||||
### 常见的数据库优化方法有哪些?
|
||||
|
||||
- [索引优化](./mysql-index.md)
|
||||
- [读写分离和分库分表](../../high-performance/read-and-write-separation-and-library-subtable.md)
|
||||
- [数据冷热分离](../../high-performance/data-cold-hot-separation.md)
|
||||
- [SQL 优化](../../high-performance/sql-optimization.md)
|
||||
- [深度分页优化](../../high-performance/deep-pagination-optimization.md)
|
||||
- 适当冗余数据
|
||||
- 使用更高的硬件配置
|
||||
|
||||
## MySQL 学习资料推荐
|
||||
|
||||
[**书籍推荐**](../../books/database.md#mysql) 。
|
||||
|
||||
@ -164,7 +164,7 @@ Redis 从 4.0 版本开始,支持通过 Module 来扩展其功能以满足特
|
||||
|
||||
不过,通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`这样的方式存在性能问题,我们需要不断轮询去调用 `RPOP` 或 `LPOP` 来消费消息。当 List 为空时,大部分的轮询的请求都是无效请求,这种方式大量浪费了系统资源。
|
||||
|
||||
因此,Redis 还提供了 `BLPOP`、`BRPOP` 这种阻塞式读取的命令(带 B-Bloking 的都是阻塞式),并且还支持一个超时参数。如果 List 为空,Redis 服务端不会立刻返回结果,它会等待 List 中有新数据后在返回或者是等待最多一个超时时间后返回空。如果将超时时间设置为 0 时,即可无限等待,直到弹出消息
|
||||
因此,Redis 还提供了 `BLPOP`、`BRPOP` 这种阻塞式读取的命令(带 B-Blocking 的都是阻塞式),并且还支持一个超时参数。如果 List 为空,Redis 服务端不会立刻返回结果,它会等待 List 中有新数据后在返回或者是等待最多一个超时时间后返回空。如果将超时时间设置为 0 时,即可无限等待,直到弹出消息
|
||||
|
||||
```bash
|
||||
# 超时时间为 10s
|
||||
|
||||
@ -671,6 +671,10 @@ _为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理
|
||||
|
||||
更多关于布隆过滤器的内容可以看我的这篇原创:[《不了解布隆过滤器?一文给你整的明明白白!》](https://javaguide.cn/cs-basics/data-structure/bloom-filter/) ,强烈推荐,个人感觉网上应该找不到总结的这么明明白白的文章了。
|
||||
|
||||
**3)接口限流**
|
||||
|
||||
根据用户或者 IP 对接口进行限流,对于异常频繁的访问行为,还可以采取黑名单机制,例如将异常 IP 列入黑名单。
|
||||
|
||||
### 缓存击穿
|
||||
|
||||
#### 什么是缓存击穿?
|
||||
@ -683,9 +687,9 @@ _为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理
|
||||
|
||||
#### 有哪些解决办法?
|
||||
|
||||
- 设置热点数据永不过期或者过期时间比较长。
|
||||
- 针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。
|
||||
- 请求数据库写数据到缓存之前,先获取互斥锁,保证只有一个请求会落到数据库上,减少数据库的压力。
|
||||
1. 设置热点数据永不过期或者过期时间比较长。
|
||||
2. 针对热点数据提前预热,将其存入缓存中并设置合理的过期时间比如秒杀场景下的数据在秒杀结束之前不过期。
|
||||
3. 请求数据库写数据到缓存之前,先获取互斥锁,保证只有一个请求会落到数据库上,减少数据库的压力。
|
||||
|
||||
#### 缓存穿透和缓存击穿有什么区别?
|
||||
|
||||
@ -713,12 +717,20 @@ _为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理
|
||||
|
||||
1. 采用 Redis 集群,避免单机出现问题整个缓存服务都没办法使用。
|
||||
2. 限流,避免同时处理大量的请求。
|
||||
3. 多级缓存,例如本地缓存+Redis 缓存的组合,当 Redis 缓存出现问题时,还可以从本地缓存中获取到部分数据。
|
||||
|
||||
**针对热点缓存失效的情况:**
|
||||
|
||||
1. 设置不同的失效时间比如随机设置缓存的失效时间。
|
||||
2. 缓存永不失效(不太推荐,实用性太差)。
|
||||
3. 设置二级缓存。
|
||||
3. 缓存预热,也就是在程序启动后或运行过程中,主动将热点数据加载到缓存中。
|
||||
|
||||
**缓存预热如何实现?**
|
||||
|
||||
常见的缓存预热方式有两种:
|
||||
|
||||
1. 使用定时任务,比如 xxl-job,来定时触发缓存预热的逻辑,将数据库中的热点数据查询出来并存入缓存中。
|
||||
2. 使用消息队列,比如 Kafka,来异步地进行缓存预热,将数据库中的热点数据的主键或者 ID 发送到消息队列中,然后由缓存服务消费消息队列中的数据,根据主键或者 ID 查询数据库并更新缓存。
|
||||
|
||||
#### 缓存雪崩和缓存击穿有什么区别?
|
||||
|
||||
|
||||
@ -858,7 +858,7 @@ ORDER BY level_cnt DESC
|
||||
|
||||
**解释**:“试卷”有 3 人共练习 3 次试卷 9001,1 人作答 3 次 9002;“刷题”有 3 人刷 5 次 8001,有 2 人刷 2 次 8002
|
||||
|
||||
**思路**:这题的难点和易错点在于`UNOIN`和`ORDER BY` 同时使用的问题
|
||||
**思路**:这题的难点和易错点在于`UNION`和`ORDER BY` 同时使用的问题
|
||||
|
||||
有以下几种情况:使用`union`和多个`order by`不加括号,报错!
|
||||
|
||||
|
||||
@ -1127,7 +1127,7 @@ MySQL 不允许在触发器中使用 CALL 语句 ,也就是不能调用存储
|
||||
|
||||
> 注意:在 MySQL 中,分号 `;` 是语句结束的标识符,遇到分号表示该段语句已经结束,MySQL 可以开始执行了。因此,解释器遇到触发器执行动作中的分号后就开始执行,然后会报错,因为没有找到和 BEGIN 匹配的 END。
|
||||
>
|
||||
> 这时就会用到 `DELIMITER` 命令(DELIMITER 是定界符,分隔符的意思)。它是一条命令,不需要语句结束标识,语法为:`DELIMITER new_delemiter`。`new_delemiter` 可以设为 1 个或多个长度的符号,默认的是分号 `;`,我们可以把它修改为其他符号,如 `$` - `DELIMITER $` 。在这之后的语句,以分号结束,解释器不会有什么反应,只有遇到了 `$`,才认为是语句结束。注意,使用完之后,我们还应该记得把它给修改回来。
|
||||
> 这时就会用到 `DELIMITER` 命令(DELIMITER 是定界符,分隔符的意思)。它是一条命令,不需要语句结束标识,语法为:`DELIMITER new_delimiter`。`new_delimiter` 可以设为 1 个或多个长度的符号,默认的是分号 `;`,我们可以把它修改为其他符号,如 `$` - `DELIMITER $` 。在这之后的语句,以分号结束,解释器不会有什么反应,只有遇到了 `$`,才认为是语句结束。注意,使用完之后,我们还应该记得把它给修改回来。
|
||||
|
||||
在 MySQL 5.7.2 版之前,可以为每个表定义最多六个触发器。
|
||||
|
||||
|
||||
@ -265,7 +265,7 @@ ZAB 协议包括两种基本的模式,分别是
|
||||
关于 **ZAB 协议&Paxos 算法** 需要讲和理解的东西太多了,具体可以看下面这几篇文章:
|
||||
|
||||
- [Paxos 算法详解](https://javaguide.cn/distributed-system/protocol/paxos-algorithm.html)
|
||||
- [Zookeeper ZAB 协议分析](https://dbaplus.cn/news-141-1875-1.html)
|
||||
- [ZooKeeper 与 Zab 协议 · Analyze](https://wingsxdu.com/posts/database/zookeeper/)
|
||||
- [Raft 算法详解](https://javaguide.cn/distributed-system/protocol/raft-algorithm.html)
|
||||
|
||||
## 总结
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
title: 降级&熔断详解(付费)
|
||||
category: 高可用
|
||||
icon: circuit
|
||||
---
|
||||
|
||||
**降级&熔断** 相关的面试题为我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)中。
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
title: 高可用系统设计指南
|
||||
category: 高可用
|
||||
icon: design
|
||||
---
|
||||
|
||||
## 什么是高可用?可用性的判断标准是啥?
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
title: 服务限流详解
|
||||
category: 高可用
|
||||
icon: limit_rate
|
||||
---
|
||||
|
||||
针对软件系统来说,限流就是对请求的速率进行限制,避免瞬时的大量请求击垮软件系统。毕竟,软件系统的处理能力是有限的。如果说超过了其处理能力的范围,软件系统可能直接就挂掉了。
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
title: 性能测试入门
|
||||
category: 高可用
|
||||
icon: et-performance
|
||||
---
|
||||
|
||||
性能测试一般情况下都是由测试这个职位去做的,那还需要我们开发学这个干嘛呢?了解性能测试的指标、分类以及工具等知识有助于我们更好地去写出性能更好的程序,另外作为开发这个角色,如果你会性能测试的话,相信也会为你的履历加分不少。
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
title: 冗余设计详解
|
||||
category: 高可用
|
||||
icon: cluster
|
||||
---
|
||||
|
||||
冗余设计是保证系统和数据高可用的最常的手段。
|
||||
|
||||
@ -1,6 +1,7 @@
|
||||
---
|
||||
title: 超时&重试详解
|
||||
category: 高可用
|
||||
icon: retry
|
||||
---
|
||||
|
||||
由于网络问题、系统或者服务内部的 Bug、服务器宕机、操作系统崩溃等问题的不确定性,我们的系统或者服务永远不可能保证时刻都是可用的状态。
|
||||
@ -65,7 +66,7 @@ category: 高可用
|
||||
|
||||
重试的次数通常建议设为 3 次。大部分情况下,我们还是更建议使用梯度间隔重试策略,比如说我们要重试 3 次的话,第 1 次请求失败后,等待 1 秒再进行重试,第 2 次请求失败后,等待 2 秒再进行重试,第 3 次请求失败后,等待 3 秒再进行重试。
|
||||
|
||||
### 重试幂等
|
||||
### 什么是重试幂等?
|
||||
|
||||
超时和重试机制在实际项目中使用的话,需要注意保证同一个请求没有被多次执行。
|
||||
|
||||
@ -73,6 +74,10 @@ category: 高可用
|
||||
|
||||
举个例子:用户支付购买某个课程,结果用户支付的请求由于重试的问题导致用户购买同一门课程支付了两次。对于这种情况,我们在执行用户购买课程的请求的时候需要判断一下用户是否已经购买过。这样的话,就不会因为重试的问题导致重复购买了。
|
||||
|
||||
### Java 中如何实现重试?
|
||||
|
||||
如果要手动编写代码实现重试逻辑的话,可以通过循环(例如 while 或 for 循环)或者递归实现。不过,一般不建议自己动手实现,有很多第三方开源库提供了更完善的重试机制实现,例如 Spring Retry、Resilience4j、Guava Retrying。
|
||||
|
||||
## 参考
|
||||
|
||||
- 微服务之间调用超时的设置治理:<https://www.infoq.cn/article/eyrslar53l6hjm5yjgyx>
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
---
|
||||
title: CDN常见问题总结
|
||||
title: CDN工作原理详解
|
||||
category: 高性能
|
||||
head:
|
||||
- - meta
|
||||
|
||||
68
docs/high-performance/data-cold-hot-separation.md
Normal file
68
docs/high-performance/data-cold-hot-separation.md
Normal file
@ -0,0 +1,68 @@
|
||||
---
|
||||
title: 数据冷热分离详解
|
||||
category: 高性能
|
||||
head:
|
||||
- - meta
|
||||
- name: keywords
|
||||
content: 数据冷热分离,冷数据迁移,冷数据存储
|
||||
- - meta
|
||||
- name: description
|
||||
content: 数据冷热分离是指根据数据的访问频率和业务重要性,将数据分为冷数据和热数据,冷数据一般存储在存储在低成本、低性能的介质中,热数据高性能存储介质中。
|
||||
---
|
||||
|
||||
## 什么是数据冷热分离?
|
||||
|
||||
数据冷热分离是指根据数据的访问频率和业务重要性,将数据分为冷数据和热数据,冷数据一般存储在存储在低成本、低性能的介质中,热数据高性能存储介质中。
|
||||
|
||||
### 冷数据和热数据
|
||||
|
||||
热数据是指经常被访问和修改且需要快速访问的数据,冷数据是指不经常访问,对当前项目价值较低,但需要长期保存的数据。
|
||||
|
||||
冷热数据到底如何区分呢?有两个常见的区分方法:
|
||||
|
||||
1. **时间维度区分**:按照数据的创建时间、更新时间、过期时间等,将一定时间段内的数据视为热数据,超过该时间段的数据视为冷数据。例如,订单系统可以将 1 年后的订单数据作为冷数据,1 年内的订单数据作为热数据。这种方法适用于数据的访问频率和时间有较强的相关性的场景。
|
||||
2. **访问评率区分**:将高频访问的数据视为热数据,低频访问的数据视为冷数据。例如,内容系统可以将浏览量非常低的文章作为冷数据,浏览量较高的文章作为热数据。这种方法需要记录数据的访问频率,成本较高,适合访问频率和数据本身有较强的相关性的场景。
|
||||
|
||||
几年前的数据并不一定都是热数据,例如一些优质文章发表几年后依然有很多人访问,大部分普通用户新发表的文章却基本没什么人访问。
|
||||
|
||||
这两种区分冷热数据的方法各有优劣,实际项目中,可以将两者结合使用。
|
||||
|
||||
### 冷热分离的思想
|
||||
|
||||
冷热分离的思想非常简单,就是对数据进行分类,然后分开存储。冷热分离的思想可以应用到很多领域和场景中,而不仅仅是数据存储,例如:
|
||||
|
||||
- 邮件系统中,可以将近期的比较重要的邮件放在收件箱,将比较久远的不太重要的邮件存入归档。
|
||||
- 日常生活中,可以将常用的物品放在显眼的位置,不常用的物品放入储藏室或者阁楼。
|
||||
- 图书馆中,可以将最受欢迎和最常借阅的图书单独放在一个显眼的区域,将较少借阅的书籍放在不起眼的位置。
|
||||
- ……
|
||||
|
||||
### 数据冷热分离的优缺点
|
||||
|
||||
- 优点:热数据的查询性能得到优化(用户的绝大部分操作体验会更好)、节约成本(可以冷热数据的不同存储需求,选择对应的数据库类型和硬件配置,比如将热数据放在 SSD 上,将冷数据放在 HDD 上)
|
||||
- 缺点:系统复杂性和风险增加(需要分离冷热数据,数据错误的风险增加)、统计效率低(统计的时候可能需要用到冷库的数据)。
|
||||
|
||||
## 冷数据如何迁移?
|
||||
|
||||
冷数据迁移方案:
|
||||
|
||||
1. 业务层代码实现:当有对数据进行写操作时,触发冷热分离的逻辑,判断数据是冷数据还是热数据,冷数据就入冷库,热数据就入热库。这种方案会影响性能且冷热数据的判断逻辑不太好确定,还需要修改业务层代码,因此一般不会使用。
|
||||
2. 任务调度:可以利用 xxl-job 或者其他分布式任务调度平台定时去扫描数据库,找出满足冷数据条件的数据,然后批量地将其复制到冷库中,并从热库中删除。这种方法修改的代码非常少,非常适合按照时间区分冷热数据的场景。
|
||||
3. 监听数据库的变更日志 binlog :将满足冷数据条件的数据从 binlog 中提取出来,然后复制到冷库中,并从热库中删除。这种方法可以不用修改代码,但不适合按照时间维度区分冷热数据的场景。
|
||||
|
||||
如果你的公司有 DBA 的话,也可以让 DBA 进行冷数据的人工迁移,一次迁移完成冷数据到冷库。然后,再搭配上面介绍的方案实现后续冷数据的迁移工作。
|
||||
|
||||
## 冷数据如何存储?
|
||||
|
||||
冷数据的存储要求主要是容量大,成本低,可靠性高,访问速度可以适当牺牲。
|
||||
|
||||
冷数据存储方案:
|
||||
|
||||
- 中小厂:直接使用 MySQL/PostgreSQL 即可(不改变数据库选型和项目当前使用的数据库保持一致),比如新增一张表来存储某个业务的冷数据或者使用单独的冷库来存放冷数据(涉及跨库查询,增加了系统复杂性和维护难度)
|
||||
- 大厂:Hbase(常用)、RocksDB、Doris、Cassandra
|
||||
|
||||
如果公司成本预算足的话,也可以直接上 TiDB 这种分布式关系型数据库,直接一步到位。TiDB 6.0 正式支持数据冷热存储分离,可以降低 SSD 使用成本。使用 TiDB 6.0 的数据放置功能,可以在同一个集群实现海量数据的冷热存储,将新的热数据存入 SSD,历史冷数据存入 HDD。
|
||||
|
||||
## 案例分享
|
||||
|
||||
- [如何快速优化几千万数据量的订单表 - 程序员济癫 - 2023](https://www.cnblogs.com/fulongyuanjushi/p/17910420.html)
|
||||
- [海量数据冷热分离方案与实践 - 字节跳动技术团队 - 2022](https://mp.weixin.qq.com/s/ZKRkZP6rLHuTE1wvnqmAPQ)
|
||||
99
docs/high-performance/deep-pagination-optimization.md
Normal file
99
docs/high-performance/deep-pagination-optimization.md
Normal file
@ -0,0 +1,99 @@
|
||||
---
|
||||
title: 深度分页介绍及优化建议
|
||||
category: 高性能
|
||||
head:
|
||||
- - meta
|
||||
- name: keywords
|
||||
content: 深度分页
|
||||
- - meta
|
||||
- name: description
|
||||
content: 查询偏移量过大的场景我们称为深度分页,这会导致查询性能较低。深度分页可以采用范围查询、子查询、INNER JOIN 延迟关联、覆盖索引等方法进行优化。
|
||||
---
|
||||
|
||||
## 深度分页介绍
|
||||
|
||||
查询偏移量过大的场景我们称为深度分页,这会导致查询性能较低,例如:
|
||||
|
||||
```sql
|
||||
# MySQL 在无法利用索引的情况下跳过1000000条记录后,再获取10条记录
|
||||
SELECT * FROM t_order ORDER BY id LIMIT 1000000, 10
|
||||
```
|
||||
|
||||
## 深度分页优化建议
|
||||
|
||||
这里以 MySQL 数据库为例介绍一下如何优化深度分页。
|
||||
|
||||
### 范围查询
|
||||
|
||||
当可以保证 ID 的连续性时,根据 ID 范围进行分页是比较好的解决方案:
|
||||
|
||||
```sql
|
||||
# 查询指定 ID 范围的数据
|
||||
SELECT * FROM t_order WHERE id > 100000 AND id <= 100010 ORDER BY id
|
||||
# 也可以通过记录上次查询结果的最后一条记录的ID进行下一页的查询:
|
||||
SELECT * FROM t_order WHERE id > 100000 LIMIT 10
|
||||
```
|
||||
|
||||
这种优化方式限制比较大,且一般项目的 ID 也没办法保证完全连续。
|
||||
|
||||
### 子查询
|
||||
|
||||
我们先查询出 limit 第一个参数对应的主键值,再根据这个主键值再去过滤并 limit,这样效率会更快一些。
|
||||
|
||||
阿里巴巴《Java 开发手册》中也有对应的描述:
|
||||
|
||||
> 利用延迟关联或者子查询优化超多分页场景。
|
||||
>
|
||||
> 
|
||||
|
||||
```sql
|
||||
# 通过子查询来获取 id 的起始值,把 limit 1000000 的条件转移到子查询
|
||||
SELECT * FROM t_order WHERE id >= (SELECT id FROM t_order limit 1000000, 1) LIMIT 10;
|
||||
```
|
||||
|
||||
不过,子查询的结果会产生一张新表,会影响性能,应该尽量避免大量使用子查询。并且,这种方法只适用于 ID 是正序的。在复杂分页场景,往往需要通过过滤条件,筛选到符合条件的 ID,此时的 ID 是离散且不连续的。
|
||||
|
||||
当然,我们也可以利用子查询先去获取目标分页的 ID 集合,然后再根据 ID 集合获取内容,但这种写法非常繁琐,不如使用 INNER JOIN 延迟关联。
|
||||
|
||||
### 延迟关联
|
||||
|
||||
延迟关联的优化思路,跟子查询的优化思路其实是一样的:都是把条件转移到主键索引树,减少回表的次数。不同点是,延迟关联使用了 INNER JOIN(内连接) 包含子查询。
|
||||
|
||||
```sql
|
||||
SELECT t1.* FROM t_order t1
|
||||
INNER JOIN (SELECT id FROM t_order limit 1000000, 10) t2
|
||||
ON t1.id = t2.id
|
||||
LIMIT 10;
|
||||
```
|
||||
|
||||
除了使用 INNER JOIN 之外,还可以使用逗号连接子查询。
|
||||
|
||||
```sql
|
||||
SELECT t1.* FROM t_order t1,
|
||||
(SELECT id FROM t_order limit 1000000, 10) t2
|
||||
WHERE t1.id = t2.id;
|
||||
```
|
||||
|
||||
### 覆盖索引
|
||||
|
||||
索引中已经包含了所有需要获取的字段的查询方式称为覆盖索引。
|
||||
|
||||
**覆盖索引的好处:**
|
||||
|
||||
- **避免 InnoDB 表进行索引的二次查询,也就是回表操作:** InnoDB 是以聚集索引的顺序来存储的,对于 InnoDB 来说,二级索引在叶子节点中所保存的是行的主键信息,如果是用二级索引查询数据的话,在查找到相应的键值后,还要通过主键进行二次查询才能获取我们真实所需要的数据。而在覆盖索引中,二级索引的键值中可以获取所有的数据,避免了对主键的二次查询(回表),减少了 IO 操作,提升了查询效率。
|
||||
- **可以把随机 IO 变成顺序 IO 加快查询效率:** 由于覆盖索引是按键值的顺序存储的,对于 IO 密集型的范围查找来说,对比随机从磁盘读取每一行的数据 IO 要少的多,因此利用覆盖索引在访问时也可以把磁盘的随机读取的 IO 转变成索引查找的顺序 IO。
|
||||
|
||||
```sql
|
||||
# 如果只需要查询 id, code, type 这三列,可建立 code 和 type 的覆盖索引
|
||||
SELECT id, code, type FROM t_order
|
||||
ORDER BY code
|
||||
LIMIT 1000000, 10;
|
||||
```
|
||||
|
||||
不过,当查询的结果集占表的总行数的很大一部分时,可能就不会走索引了,自动转换为全表扫描。当然了,也可以通过 `FORCE INDEX` 来强制查询优化器走索引,但这种提升效果一般不明显。
|
||||
|
||||
## 参考
|
||||
|
||||
- 聊聊如何解决 MySQL 深分页问题 - 捡田螺的小男孩:<https://juejin.cn/post/7012016858379321358>
|
||||
- 数据库深分页介绍及优化方案 - 京东零售技术:<https://mp.weixin.qq.com/s/ZEwGKvRCyvAgGlmeseAS7g>
|
||||
- MySQL 深分页优化 - 得物技术:<https://juejin.cn/post/6985478936683610149>
|
||||
@ -1,5 +1,5 @@
|
||||
---
|
||||
title: 负载均衡常见问题总结
|
||||
title: 负载均衡原理及算法详解
|
||||
category: 高性能
|
||||
head:
|
||||
- - meta
|
||||
|
||||
@ -925,7 +925,7 @@ emmm,是不是有一点复杂 🤣,看英文图片和英文文档的时候
|
||||
2. 消息队列的作用(异步,解耦,削峰)
|
||||
3. 消息队列带来的一系列问题(消息堆积、重复消费、顺序消费、分布式事务等等)
|
||||
4. 消息队列的两种消息模型——队列和主题模式
|
||||
5. 分析了 `RocketMQ` 的技术架构(`NameServer`、`Broker`、`Producer`、`Comsumer`)
|
||||
5. 分析了 `RocketMQ` 的技术架构(`NameServer`、`Broker`、`Producer`、`Consumer`)
|
||||
6. 结合 `RocketMQ` 回答了消息队列副作用的解决方案
|
||||
7. 介绍了 `RocketMQ` 的存储机制和刷盘策略。
|
||||
|
||||
|
||||
@ -1,5 +1,5 @@
|
||||
---
|
||||
title: 读写分离和分库分表常见问题总结
|
||||
title: 读写分离和分库分表详解
|
||||
category: 高性能
|
||||
head:
|
||||
- - meta
|
||||
|
||||
21
docs/home.md
21
docs/home.md
@ -13,16 +13,6 @@ title: JavaGuide(Java学习&面试指南)
|
||||
|
||||
:::
|
||||
|
||||
<div align="center">
|
||||
|
||||

|
||||
|
||||
[GitHub](https://github.com/Snailclimb/JavaGuide) | [Gitee](https://gitee.com/SnailClimb/JavaGuide)
|
||||
|
||||
</div>
|
||||
|
||||
[](./about-the-author/zhishixingqiu-two-years.md)
|
||||
|
||||
## Java
|
||||
|
||||
### 基础
|
||||
@ -369,18 +359,17 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8](https://docs.oracle.
|
||||
|
||||
## 高性能
|
||||
|
||||
### 数据库读写分离&分库分表
|
||||
### 数据库优化
|
||||
|
||||
[数据库读写分离和分库分表常见知识点&面试题总结](./high-performance/read-and-write-separation-and-library-subtable.md)
|
||||
- [数据库读写分离和分库分表](./high-performance/read-and-write-separation-and-library-subtable.md)
|
||||
- [数据冷热分离](./high-performance/data-cold-hot-separation.md)
|
||||
- [常见 SQL 优化手段总结](./high-performance/sql-optimization.md)
|
||||
- [深度分页介绍及优化建议](./high-performance/deep-pagination-optimization.md)
|
||||
|
||||
### 负载均衡
|
||||
|
||||
[负载均衡常见知识点&面试题总结](./high-performance/load-balancing.md)
|
||||
|
||||
### SQL 优化
|
||||
|
||||
[常见 SQL 优化手段总结](./high-performance/sql-optimization.md)
|
||||
|
||||
### CDN
|
||||
|
||||
[CDN(内容分发网络)常见知识点&面试题总结](./high-performance/cdn.md)
|
||||
|
||||
@ -215,7 +215,7 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
newCapacity = minCapacity;
|
||||
//再检查新容量是否超出了ArrayList所定义的最大容量,
|
||||
//若超出了,则调用hugeCapacity()来比较minCapacity和 MAX_ARRAY_SIZE,
|
||||
//如果minCapacity大于MAX_ARRAY_SIZE,则新容量则为Interger.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE。
|
||||
//如果minCapacity大于MAX_ARRAY_SIZE,则新容量则为Integer.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE。
|
||||
if (newCapacity - MAX_ARRAY_SIZE > 0)
|
||||
newCapacity = hugeCapacity(minCapacity);
|
||||
// minCapacity is usually close to size, so this is a win:
|
||||
|
||||
@ -439,10 +439,10 @@ private final Node<K,V>[] initTable() {
|
||||
}
|
||||
```
|
||||
|
||||
从源码中可以发现 `ConcurrentHashMap` 的初始化是通过**自旋和 CAS** 操作完成的。里面需要注意的是变量 `sizeCtl` ,它的值决定着当前的初始化状态。
|
||||
从源码中可以发现 `ConcurrentHashMap` 的初始化是通过**自旋和 CAS** 操作完成的。里面需要注意的是变量 `sizeCtl` (sizeControl 的缩写),它的值决定着当前的初始化状态。
|
||||
|
||||
1. -1 说明正在初始化
|
||||
2. -N 说明有 N-1 个线程正在进行扩容
|
||||
1. -1 说明正在初始化,其他线程需要自旋等待
|
||||
2. -N 说明 table 正在进行扩容,高 16 位表示扩容的标识戳,低 16 位减 1 为正在进行扩容的线程数
|
||||
3. 0 表示 table 初始化大小,如果 table 没有初始化
|
||||
4. \>0 表示 table 扩容的阈值,如果 table 已经初始化。
|
||||
|
||||
|
||||
@ -473,7 +473,7 @@ public interface BlockingQueue<E> extends Queue<E> {
|
||||
Java 中常用的阻塞队列实现类有以下几种:
|
||||
|
||||
1. `ArrayBlockingQueue`:使用数组实现的有界阻塞队列。在创建时需要指定容量大小,并支持公平和非公平两种方式的锁访问机制。
|
||||
2. `LinkedBlockingQueue`:使用单向链表实现的可选有界阻塞队列。在创建时可以指定容量大小,如果不指定则默认为`Integer.MAX_VALUE`。和`ArrayBlockingQueue`类似, 它也支持公平和非公平的锁访问机制。
|
||||
2. `LinkedBlockingQueue`:使用单向链表实现的可选有界阻塞队列。在创建时可以指定容量大小,如果不指定则默认为`Integer.MAX_VALUE`。和`ArrayBlockingQueue`不同的是, 它仅支持非公平的锁访问机制。
|
||||
3. `PriorityBlockingQueue`:支持优先级排序的无界阻塞队列。元素必须实现`Comparable`接口或者在构造函数中传入`Comparator`对象,并且不能插入 null 元素。
|
||||
4. `SynchronousQueue`:同步队列,是一种不存储元素的阻塞队列。每个插入操作都必须等待对应的删除操作,反之删除操作也必须等待插入操作。因此,`SynchronousQueue`通常用于线程之间的直接传递数据。
|
||||
5. `DelayQueue`:延迟队列,其中的元素只有到了其指定的延迟时间,才能够从队列中出队。
|
||||
|
||||
@ -623,7 +623,7 @@ public ReentrantReadWriteLock(boolean fair) {
|
||||
|
||||
### StampedLock 是什么?
|
||||
|
||||
`StampedLock` 是 JDK 1.8 引入的性能更好的读写锁,不可重入且不支持条件变量 `Conditon`。
|
||||
`StampedLock` 是 JDK 1.8 引入的性能更好的读写锁,不可重入且不支持条件变量 `Condition`。
|
||||
|
||||
不同于一般的 `Lock` 类,`StampedLock` 并不是直接实现 `Lock`或 `ReadWriteLock`接口,而是基于 **CLH 锁** 独立实现的(AQS 也是基于这玩意)。
|
||||
|
||||
@ -678,7 +678,7 @@ public long tryOptimisticRead() {
|
||||
|
||||
和 `ReentrantReadWriteLock` 一样,`StampedLock` 同样适合读多写少的业务场景,可以作为 `ReentrantReadWriteLock`的替代品,性能更好。
|
||||
|
||||
不过,需要注意的是`StampedLock`不可重入,不支持条件变量 `Conditon`,对中断操作支持也不友好(使用不当容易导致 CPU 飙升)。如果你需要用到 `ReentrantLock` 的一些高级性能,就不太建议使用 `StampedLock` 了。
|
||||
不过,需要注意的是`StampedLock`不可重入,不支持条件变量 `Condition`,对中断操作支持也不友好(使用不当容易导致 CPU 飙升)。如果你需要用到 `ReentrantLock` 的一些高级性能,就不太建议使用 `StampedLock` 了。
|
||||
|
||||
另外,`StampedLock` 性能虽好,但使用起来相对比较麻烦,一旦使用不当,就会出现生产问题。强烈建议你在使用`StampedLock` 之前,看看 [StampedLock 官方文档中的案例](https://docs.oracle.com/javase/8/docs/api/java/util/concurrent/locks/StampedLock.html)。
|
||||
|
||||
|
||||
@ -319,7 +319,7 @@ public ScheduledThreadPoolExecutor(int corePoolSize) {
|
||||
|
||||
### 线程池的饱和策略有哪些?
|
||||
|
||||
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,`ThreadPoolTaskExecutor` 定义一些策略:
|
||||
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,`ThreadPoolExecutor` 定义一些策略:
|
||||
|
||||
- **`ThreadPoolExecutor.AbortPolicy`:** 抛出 `RejectedExecutionException`来拒绝新任务的处理。
|
||||
- **`ThreadPoolExecutor.CallerRunsPolicy`:** 调用执行自己的线程运行任务,也就是直接在调用`execute`方法的线程中运行(`run`)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。
|
||||
@ -381,33 +381,30 @@ ExecutorService threadPool = new ThreadPoolExecutor(corePoolSize, maximumPoolSiz
|
||||
**2、自己实现 `ThreadFactory`。**
|
||||
|
||||
```java
|
||||
import java.util.concurrent.Executors;
|
||||
import java.util.concurrent.ThreadFactory;
|
||||
import java.util.concurrent.atomic.AtomicInteger;
|
||||
|
||||
/**
|
||||
* 线程工厂,它设置线程名称,有利于我们定位问题。
|
||||
*/
|
||||
public final class NamingThreadFactory implements ThreadFactory {
|
||||
|
||||
private final AtomicInteger threadNum = new AtomicInteger();
|
||||
private final ThreadFactory delegate;
|
||||
private final String name;
|
||||
|
||||
/**
|
||||
* 创建一个带名字的线程池生产工厂
|
||||
*/
|
||||
public NamingThreadFactory(ThreadFactory delegate, String name) {
|
||||
this.delegate = delegate;
|
||||
this.name = name; // TODO consider uniquifying this
|
||||
public NamingThreadFactory(String name) {
|
||||
this.name = name;
|
||||
}
|
||||
|
||||
@Override
|
||||
public Thread newThread(Runnable r) {
|
||||
Thread t = delegate.newThread(r);
|
||||
Thread t = new Thread(r);
|
||||
t.setName(name + " [#" + threadNum.incrementAndGet() + "]");
|
||||
return t;
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
@ -133,7 +133,7 @@ public class ScheduledThreadPoolExecutor
|
||||
|
||||
**`ThreadPoolExecutor` 饱和策略定义:**
|
||||
|
||||
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,`ThreadPoolTaskExecutor` 定义一些策略:
|
||||
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,`ThreadPoolExecutor` 定义一些策略:
|
||||
|
||||
- `ThreadPoolExecutor.AbortPolicy`:抛出 `RejectedExecutionException`来拒绝新任务的处理。
|
||||
- `ThreadPoolExecutor.CallerRunsPolicy`:调用执行自己的线程运行任务,也就是直接在调用`execute`方法的线程中运行(`run`)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。
|
||||
|
||||
@ -598,7 +598,7 @@ private void cancelAcquire(Node node) {
|
||||
compareAndSetNext(pred, predNext, null);
|
||||
} else {
|
||||
int ws;
|
||||
// 如果当前节点不是head的后继节点,1:判断当前节点前驱节点的是否为SIGNAL,2:如果不是,则把前驱节点设置为SINGAL看是否成功
|
||||
// 如果当前节点不是head的后继节点,1:判断当前节点前驱节点的是否为SIGNAL,2:如果不是,则把前驱节点设置为SIGNAL看是否成功
|
||||
// 如果1和2中有一个为true,再判断当前节点的线程是否为null
|
||||
// 如果上述条件都满足,把当前节点的前驱节点的后继指针指向当前节点的后继节点
|
||||
if (pred != head && ((ws = pred.waitStatus) == Node.SIGNAL || (ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) && pred.thread != null) {
|
||||
|
||||
@ -367,7 +367,7 @@ private void loadFileIntoMemory(File xmlFile) throws IOException {
|
||||
FileInputStream fis = new FileInputStream(xmlFile);
|
||||
// 创建 FileChannel 对象
|
||||
FileChannel fc = fis.getChannel();
|
||||
// FileChannle.map() 将文件映射到直接内存并返回 MappedByteBuffer 对象
|
||||
// FileChannel.map() 将文件映射到直接内存并返回 MappedByteBuffer 对象
|
||||
MappedByteBuffer mmb = fc.map(FileChannel.MapMode.READ_ONLY, 0, fc.size());
|
||||
xmlFileBuffer = new byte[(int)fc.size()];
|
||||
mmb.get(xmlFileBuffer);
|
||||
|
||||
@ -119,7 +119,7 @@ JDK 1.8 之前永久代还没被彻底移除的时候通常通过下面这些参
|
||||
|
||||
```c
|
||||
void MetaspaceGC::initialize() {
|
||||
// Set the high-water mark to MaxMetapaceSize during VM initializaton since
|
||||
// Set the high-water mark to MaxMetapaceSize during VM initialization since
|
||||
// we can't do a GC during initialization.
|
||||
_capacity_until_GC = MaxMetaspaceSize;
|
||||
}
|
||||
|
||||
@ -127,7 +127,7 @@ Java 堆是垃圾收集器管理的主要区域,因此也被称作 **GC 堆(
|
||||
|
||||
大部分情况,对象都会首先在 Eden 区域分配,在一次新生代垃圾回收后,如果对象还存活,则会进入 S0 或者 S1,并且对象的年龄还会加 1(Eden 区->Survivor 区后对象的初始年龄变为 1),当它的年龄增加到一定程度(默认为 15 岁),就会被晋升到老年代中。对象晋升到老年代的年龄阈值,可以通过参数 `-XX:MaxTenuringThreshold` 来设置。
|
||||
|
||||
> **🐛 修正(参见:[issue552](https://github.com/Snailclimb/JavaGuide/issues/552))**:“Hotspot 遍历所有对象时,按照年龄从小到大对其所占用的大小进行累积,当累积的某个年龄大小超过了 survivor 区的一半时,取这个年龄和 MaxTenuringThreshold 中更小的一个值,作为新的晋升年龄阈值”。
|
||||
> **🐛 修正(参见:[issue552](https://github.com/Snailclimb/JavaGuide/issues/552))**:“Hotspot 遍历所有对象时,按照年龄从小到大对其所占用的大小进行累加,当累加到某个年龄时,所累加的大小超过了 Survivor 区的一半,则取这个年龄和 `MaxTenuringThreshold` 中更小的一个值,作为新的晋升年龄阈值”。
|
||||
>
|
||||
> **动态年龄计算的代码如下**
|
||||
>
|
||||
@ -260,7 +260,7 @@ JDK1.4 中新加入的 **NIO(Non-Blocking I/O,也被称为 New I/O)**,
|
||||
|
||||
类似的概念还有 **堆外内存** 。在一些文章中将直接内存等价于堆外内存,个人觉得不是特别准确。
|
||||
|
||||
堆外内存就是把内存对象分配在堆(新生代+老年代+永久代)以外的内存,这些内存直接受操作系统管理(而不是虚拟机),这样做的结果就是能够在一定程度上减少垃圾回收对应用程序造成的影响。
|
||||
堆外内存就是把内存对象分配在堆外的内存,这些内存直接受操作系统管理(而不是虚拟机),这样做的结果就是能够在一定程度上减少垃圾回收对应用程序造成的影响。
|
||||
|
||||
## HotSpot 虚拟机对象探秘
|
||||
|
||||
|
||||
@ -16,8 +16,6 @@ footer: |-
|
||||
<a href="https://beian.miit.gov.cn/" target="_blank">鄂ICP备2020015769号-1</a> | 主题: <a href="https://vuepress-theme-hope.github.io/v2/" target="_blank">VuePress Theme Hope</a>
|
||||
---
|
||||
|
||||
[](./about-the-author/zhishixingqiu-two-years.md)
|
||||
|
||||
## 关于网站
|
||||
|
||||
JavaGuide 已经持续维护 5 年多了,累计提交了 **5000+** commit ,共有 **440** 多位朋友参与维护。真心希望能够把这个项目做好,真正能够帮助到有需要的朋友!
|
||||
|
||||
@ -168,7 +168,7 @@ public ResponseEntity<List<User>> getAllUsers() {
|
||||
```java
|
||||
@PostMapping("/users")
|
||||
public ResponseEntity<User> createUser(@Valid @RequestBody UserCreateRequest userCreateRequest) {
|
||||
return userRespository.save(userCreateRequest);
|
||||
return userRepository.save(userCreateRequest);
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
@ -207,7 +207,7 @@ public OneService getService(status) {
|
||||
|
||||
Spring 内置的 `@Autowired` 以及 JDK 内置的 `@Resource` 和 `@Inject` 都可以用于注入 Bean。
|
||||
|
||||
| Annotaion | Package | Source |
|
||||
| Annotation | Package | Source |
|
||||
| ------------ | ---------------------------------- | ------------ |
|
||||
| `@Autowired` | `org.springframework.bean.factory` | Spring 2.5+ |
|
||||
| `@Resource` | `javax.annotation` | Java JSR-250 |
|
||||
|
||||
@ -77,14 +77,14 @@ byte[] result = messageDigest.digest();
|
||||
// 将哈希值转换为十六进制字符串
|
||||
String hexString = new HexBinaryAdapter().marshal(result);
|
||||
System.out.println("Original String: " + originalString);
|
||||
System.out.println("SHA-256 Hash: " + hexString.toLowerCase());
|
||||
System.out.println("MD5 Hash: " + hexString.toLowerCase());
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
```bash
|
||||
Original String: Java学习 + 面试指南:javaguide.cn
|
||||
SHA-256 Hash: fb246796f5b1b60d4d0268c817c608fa
|
||||
MD5 Hash: fb246796f5b1b60d4d0268c817c608fa
|
||||
```
|
||||
|
||||
### SHA
|
||||
|
||||
@ -32,9 +32,9 @@ tag:
|
||||
|
||||
可以看出, **Trie 树的核心原理其实很简单,就是通过公共前缀来提高字符串匹配效率。**
|
||||
|
||||
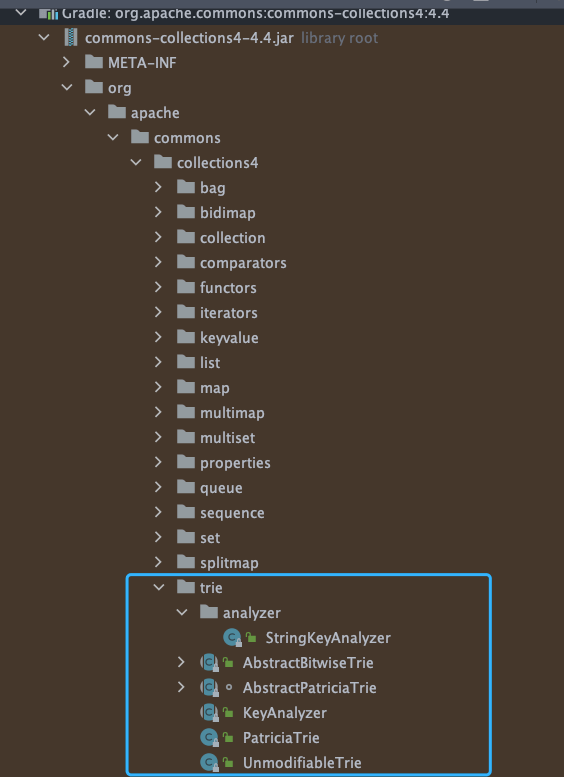
[Apache Commons Collecions](https://mvnrepository.com/artifact/org.apache.commons/commons-collections4) 这个库中就有 Trie 树实现:
|
||||
[Apache Commons Collections](https://mvnrepository.com/artifact/org.apache.commons/commons-collections4) 这个库中就有 Trie 树实现:
|
||||
|
||||
|
||||

|
||||
|
||||
```java
|
||||
Trie<String, String> trie = new PatriciaTrie<>();
|
||||
|
||||
@ -30,11 +30,11 @@
|
||||
"nano-staged": "0.8.0",
|
||||
"nodejs-jieba": "0.1.2",
|
||||
"prettier": "3.1.1",
|
||||
"vue": "3.4.1",
|
||||
"vue": "^3.4.13",
|
||||
"vuepress": "2.0.0-rc.0",
|
||||
"vuepress-plugin-copyright2": "2.0.0-rc.10",
|
||||
"vuepress-plugin-feed2": "2.0.0-rc.10",
|
||||
"vuepress-theme-hope": "2.0.0-rc.10"
|
||||
"vuepress-plugin-copyright2": "2.0.0-rc.11",
|
||||
"vuepress-plugin-feed2": "2.0.0-rc.11",
|
||||
"vuepress-theme-hope": "2.0.0-rc.11"
|
||||
},
|
||||
"devDependencies": {
|
||||
"vuepress-plugin-components": "2.0.0-rc.11"
|
||||
|
||||
4971
pnpm-lock.yaml
generated
4971
pnpm-lock.yaml
generated
File diff suppressed because it is too large
Load Diff
Loading…
x
Reference in New Issue
Block a user