mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-10 00:41:37 +08:00
Compare commits
No commits in common. "ada9064ed2b79d12410e96e851f7dc5d489749e3" and "e778f21f6fad092d048b9e2dce6cbd8fc00ad526" have entirely different histories.
ada9064ed2
...
e778f21f6f
@ -357,7 +357,7 @@ public static int[] merge(int[] arr_1, int[] arr_2) {
|
||||
|
||||
### 算法步骤
|
||||
|
||||
快速排序使用[分治法](https://zh.wikipedia.org/wiki/分治法)(Divide and conquer)策略来把一个序列分为较小和较大的 2 个子序列,然后递归地排序两个子序列。具体算法描述如下:
|
||||
快速排序使用[分治法](https://zh.wikipedia.org/wiki/分治法)(Divide and conquer)策略来把一个序列分为较小和较大的 2 个子序列,然后递回地排序两个子序列。具体算法描述如下:
|
||||
|
||||
1. 从序列中**随机**挑出一个元素,做为 “基准”(`pivot`);
|
||||
2. 重新排列序列,将所有比基准值小的元素摆放在基准前面,所有比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个操作结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作;
|
||||
@ -738,4 +738,4 @@ public static int[] radixSort(int[] arr) {
|
||||
- <https://en.wikipedia.org/wiki/Sorting_algorithm>
|
||||
- <https://sort.hust.cc/>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
@ -1,22 +1,22 @@
|
||||
---
|
||||
title: Redis 5 种基本数据类型详解
|
||||
title: Redis 5 种基本数据结构详解
|
||||
category: 数据库
|
||||
tag:
|
||||
- Redis
|
||||
head:
|
||||
- - meta
|
||||
- name: keywords
|
||||
content: Redis常见数据类型
|
||||
content: Redis常见数据结构
|
||||
- - meta
|
||||
- name: description
|
||||
content: Redis基础数据类型总结:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)
|
||||
content: Redis基础数据结构总结:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)
|
||||
---
|
||||
|
||||
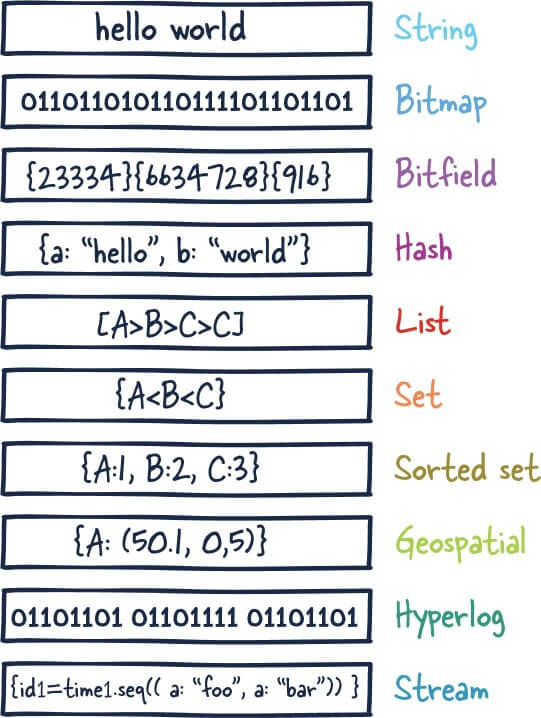
Redis 共有 5 种基本数据类型:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
|
||||
Redis 共有 5 种基本数据结构:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
|
||||
|
||||
这 5 种数据类型是直接提供给用户使用的,是数据的保存形式,其底层实现主要依赖这 8 种数据结构:简单动态字符串(SDS)、LinkedList(双向链表)、Dict(哈希表/字典)、SkipList(跳跃表)、Intset(整数集合)、ZipList(压缩列表)、QuickList(快速列表)。
|
||||
这 5 种数据结构是直接提供给用户使用的,是数据的保存形式,其底层实现主要依赖这 8 种数据结构:简单动态字符串(SDS)、LinkedList(双向链表)、Dict(哈希表/字典)、SkipList(跳跃表)、Intset(整数集合)、ZipList(压缩列表)、QuickList(快速列表)。
|
||||
|
||||
Redis 5种基本数据类型对应的底层数据结构实现如下表所示:
|
||||
Redis 基本数据结构的底层数据结构实现如下:
|
||||
|
||||
| String | List | Hash | Set | Zset |
|
||||
| :----- | :--------------------------- | :------------ | :----------- | :---------------- |
|
||||
@ -24,7 +24,7 @@ Redis 5种基本数据类型对应的底层数据结构实现如下表所示:
|
||||
|
||||
Redis 3.2 之前,List 底层实现是 LinkedList 或者 ZipList。 Redis 3.2 之后,引入了 LinkedList 和 ZipList 的结合 QuickList,List 的底层实现变为 QuickList。从 Redis 7.0 开始, ZipList 被 ListPack 取代。
|
||||
|
||||
你可以在 Redis 官网上找到 Redis 数据类型/结构非常详细的介绍:
|
||||
你可以在 Redis 官网上找到 Redis 数据结构非常详细的介绍:
|
||||
|
||||
- [Redis Data Structures](https://redis.com/redis-enterprise/data-structures/)
|
||||
- [Redis Data types tutorial](https://redis.io/docs/manual/data-types/data-types-tutorial/)
|
||||
@ -37,9 +37,9 @@ Redis 3.2 之前,List 底层实现是 LinkedList 或者 ZipList。 Redis 3.2
|
||||
|
||||
### 介绍
|
||||
|
||||
String 是 Redis 中最简单同时也是最常用的一个数据类型。
|
||||
String 是 Redis 中最简单同时也是最常用的一个数据结构。
|
||||
|
||||
String 是一种二进制安全的数据类型,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。
|
||||
String 是一种二进制安全的数据结构,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。
|
||||
|
||||
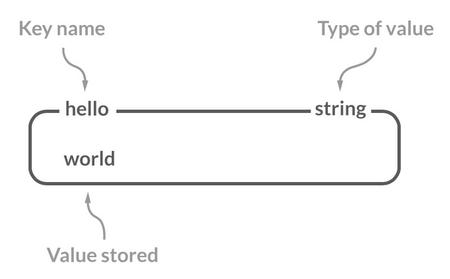
|
||||
|
||||
@ -120,7 +120,7 @@ OK
|
||||
|
||||
**需要存储常规数据的场景**
|
||||
|
||||
- 举例:缓存 Session、Token、图片地址、序列化后的对象(相比较于 Hash 存储更节省内存)。
|
||||
- 举例:缓存 session、token、图片地址、序列化后的对象(相比较于 Hash 存储更节省内存)。
|
||||
- 相关命令:`SET`、`GET`。
|
||||
|
||||
**需要计数的场景**
|
||||
@ -218,7 +218,7 @@ Redis 中的 List 其实就是链表数据结构的实现。我在 [线性数据
|
||||
|
||||
**消息队列**
|
||||
|
||||
`List` 可以用来做消息队列,只是功能过于简单且存在很多缺陷,不建议这样做。
|
||||
Redis List 数据结构可以用来做消息队列,只是功能过于简单且存在很多缺陷,不建议这样做。
|
||||
|
||||
相对来说,Redis 5.0 新增加的一个数据结构 `Stream` 更适合做消息队列一些,只是功能依然非常简陋。和专业的消息队列相比,还是有很多欠缺的地方比如消息丢失和堆积问题不好解决。
|
||||
|
||||
@ -487,7 +487,7 @@ value1
|
||||
|
||||
| 数据类型 | 说明 |
|
||||
| -------------------------------- | ------------------------------------------------- |
|
||||
| String | 一种二进制安全的数据类型,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。 |
|
||||
| String | 一种二进制安全的数据结构,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。 |
|
||||
| List | Redis 的 List 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。 |
|
||||
| Hash | 一个 String 类型的 field-value(键值对) 的映射表,特别适合用于存储对象,后续操作的时候,你可以直接修改这个对象中的某些字段的值。 |
|
||||
| Set | 无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 `HashSet` 。 |
|
||||
|
||||
@ -1,29 +1,23 @@
|
||||
---
|
||||
title: Redis 3 种特殊数据类型详解
|
||||
title: Redis 3 种特殊数据结构详解
|
||||
category: 数据库
|
||||
tag:
|
||||
- Redis
|
||||
head:
|
||||
- - meta
|
||||
- name: keywords
|
||||
content: Redis常见数据类型
|
||||
content: Redis常见数据结构
|
||||
- - meta
|
||||
- name: description
|
||||
content: Redis特殊数据类型总结:HyperLogLogs(基数统计)、Bitmap (位存储)、Geospatial (地理位置)。
|
||||
content: Redis特殊数据结构总结:HyperLogLogs(基数统计)、Bitmap (位存储)、Geospatial (地理位置)。
|
||||
---
|
||||
|
||||
除了 5 种基本的数据类型之外,Redis 还支持 3 种特殊的数据类型:Bitmap、HyperLogLog、GEO。
|
||||
除了 5 种基本的数据结构之外,Redis 还支持 3 种特殊的数据结构:Bitmap、HyperLogLog、GEO。
|
||||
|
||||
## Bitmap (位图)
|
||||
## Bitmap
|
||||
|
||||
### 介绍
|
||||
|
||||
根据官网介绍:
|
||||
|
||||
> Bitmaps are not an actual data type, but a set of bit-oriented operations defined on the String type which is treated like a bit vector. Since strings are binary safe blobs and their maximum length is 512 MB, they are suitable to set up to 2^32 different bits.
|
||||
>
|
||||
> Bitmap 不是 Redis 中的实际数据类型,而是在 String 类型上定义的一组面向位的操作,将其视为位向量。由于字符串是二进制安全的块,且最大长度为 512 MB,它们适合用于设置最多 2^32 个不同的位。
|
||||
|
||||
Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。
|
||||
|
||||
你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。
|
||||
@ -65,7 +59,7 @@ Bitmap 存储的是连续的二进制数字(0 和 1),通过 Bitmap, 只需
|
||||
- 举例:用户签到情况、活跃用户情况、用户行为统计(比如是否点赞过某个视频)。
|
||||
- 相关命令:`SETBIT`、`GETBIT`、`BITCOUNT`、`BITOP`。
|
||||
|
||||
## HyperLogLog(基数统计)
|
||||
## HyperLogLog
|
||||
|
||||
### 介绍
|
||||
|
||||
@ -88,8 +82,6 @@ HyperLogLog 的使用非常简单,但原理非常复杂。HyperLogLog 的原
|
||||
|
||||
再推荐一个可以帮助理解 HyperLogLog 原理的工具:[Sketch of the Day: HyperLogLog — Cornerstone of a Big Data Infrastructure](http://content.research.neustar.biz/blog/hll.html) 。
|
||||
|
||||
除了 HyperLogLog 之外,Redis 还提供了其他的概率数据结构,对应的官方文档地址:<https://redis.io/docs/data-types/probabilistic/> 。
|
||||
|
||||
### 常用命令
|
||||
|
||||
HyperLogLog 相关的命令非常少,最常用的也就 3 个。
|
||||
@ -128,7 +120,7 @@ HyperLogLog 相关的命令非常少,最常用的也就 3 个。
|
||||
- 举例:热门网站每日/每周/每月访问 ip 数统计、热门帖子 uv 统计、
|
||||
- 相关命令:`PFADD`、`PFCOUNT` 。
|
||||
|
||||
## Geospatial (地理位置)
|
||||
## Geospatial index
|
||||
|
||||
### 介绍
|
||||
|
||||
|
||||
@ -18,12 +18,10 @@ head:
|
||||
|
||||
### 什么是 Redis?
|
||||
|
||||
[Redis](https://redis.io/) (**RE**mote **DI**ctionary **S**erver)是一个基于 C 语言开发的开源 NoSQL 数据库(BSD 许可)。与传统数据库不同的是,Redis 的数据是保存在内存中的(内存数据库,支持持久化),因此读写速度非常快,被广泛应用于分布式缓存方向。并且,Redis 存储的是 KV 键值对数据。
|
||||
[Redis](https://redis.io/) 是一个基于 C 语言开发的开源数据库(BSD 许可),与传统数据库不同的是 Redis 的数据是存在内存中的(内存数据库),读写速度非常快,被广泛应用于缓存方向。并且,Redis 存储的是 KV 键值对数据。
|
||||
|
||||
为了满足不同的业务场景,Redis 内置了多种数据类型实现(比如 String、Hash、Sorted Set、Bitmap、HyperLogLog、GEO)。并且,Redis 还支持事务、持久化、Lua 脚本、多种开箱即用的集群方案(Redis Sentinel、Redis Cluster)。
|
||||
|
||||
|
||||
|
||||
Redis 没有外部依赖,Linux 和 OS X 是 Redis 开发和测试最多的两个操作系统,官方推荐生产环境使用 Linux 部署 Redis。
|
||||
|
||||
个人学习的话,你可以自己本机安装 Redis 或者通过 Redis 官网提供的[在线 Redis 环境](https://try.redis.io/)(少部分命令无法使用)来实际体验 Redis。
|
||||
@ -38,9 +36,9 @@ Redis 内部做了非常多的性能优化,比较重要的有下面 3 点:
|
||||
|
||||
1. Redis 基于内存,内存的访问速度是磁盘的上千倍;
|
||||
2. Redis 基于 Reactor 模式设计开发了一套高效的事件处理模型,主要是单线程事件循环和 IO 多路复用(Redis 线程模式后面会详细介绍到);
|
||||
3. Redis 内置了多种优化过后的数据类型/结构实现,性能非常高。
|
||||
3. Redis 内置了多种优化过后的数据结构实现,性能非常高。
|
||||
|
||||
> 下面这张图片总结的挺不错的,分享一下,出自 [Why is Redis so fast?](https://twitter.com/alexxubyte/status/1498703822528544770) 。
|
||||
下面这张图片总结的挺不错的,分享一下,出自 [Why is Redis so fast?](https://twitter.com/alexxubyte/status/1498703822528544770) 。
|
||||
|
||||

|
||||
|
||||
@ -107,10 +105,10 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
|
||||
|
||||
- **分布式锁**:通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html) 。
|
||||
- **限流**:一般是通过 Redis + Lua 脚本的方式来实现限流。相关阅读:[《我司用了 6 年的 Redis 分布式限流器,可以说是非常厉害了!》](https://mp.weixin.qq.com/s/kyFAWH3mVNJvurQDt4vchA)。
|
||||
- **消息队列**:Redis 自带的 List 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 Stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
|
||||
- **延时队列**:Redisson 内置了延时队列(基于 Sorted Set 实现的)。
|
||||
- **分布式 Session** :利用 String 或者 Hash 数据类型保存 Session 数据,所有的服务器都可以访问。
|
||||
- **复杂业务场景**:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 Bitmap 统计活跃用户、通过 Sorted Set 维护排行榜。
|
||||
- **消息队列**:Redis 自带的 list 数据结构可以作为一个简单的队列使用。Redis 5.0 中增加的 stream 类型的数据结构更加适合用来做消息队列。它比较类似于 Kafka,有主题和消费组的概念,支持消息持久化以及 ACK 机制。
|
||||
- **延时队列**:Redisson 内置了延时队列(基于 sorted set 实现的)。
|
||||
- **分布式 Session** :利用 string 或者 hash 保存 Session 数据,所有的服务器都可以访问。
|
||||
- **复杂业务场景**:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 bitmap 统计活跃用户、通过 sorted set 维护排行榜。
|
||||
- ......
|
||||
|
||||
### 如何基于 Redis 实现分布式锁?
|
||||
@ -121,7 +119,7 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
|
||||
|
||||
> 实际项目中也没见谁使用 Redis 来做消息队列,对于这部分知识点大家了解就好了。
|
||||
|
||||
先说结论:**可以是可以,但不建议使用 Redis 来做消息队列。和专业的消息队列相比,还是有很多欠缺的地方。**
|
||||
先说结论:可以是可以,但不建议使用 Redis 来做消息队列。和专业的消息队列相比,还是有很多欠缺的地方。
|
||||
|
||||
**Redis 2.0 之前,如果想要使用 Redis 来做消息队列的话,只能通过 List 来实现。**
|
||||
|
||||
@ -180,34 +178,30 @@ pub/sub 既能单播又能广播,还支持 channel 的简单正则匹配。不
|
||||
|
||||
相关阅读:[Redis 消息队列发展历程 - 阿里开发者 - 2022](https://mp.weixin.qq.com/s/gCUT5TcCQRAxYkTJfTRjJw)。
|
||||
|
||||
## Redis 数据类型
|
||||
## Redis 数据结构
|
||||
|
||||
关于 Redis 5 种基础数据类型和 3 种特殊数据类型的详细介绍请看下面这两篇文章以及 [Redis 官方文档](https://redis.io/docs/data-types/) :
|
||||
> 关于 Redis 5 种基础数据结构和 3 种特殊数据结构的详细介绍请看下面这两篇文章:
|
||||
>
|
||||
> - [Redis 5 种基本数据结构详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)
|
||||
> - [Redis 3 种特殊数据结构详解](https://javaguide.cn/database/redis/redis-data-structures-02.html)
|
||||
|
||||
- [Redis 5 种基本数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)
|
||||
- [Redis 3 种特殊数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-02.html)
|
||||
### Redis 常用的数据结构有哪些?
|
||||
|
||||
### Redis 常用的数据类型有哪些?
|
||||
|
||||
Redis 中比较常见的数据类型有下面这些:
|
||||
|
||||
- **5 种基础数据类型**:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
|
||||
- **3 种特殊数据类型**:HyperLogLog(基数统计)、Bitmap (位图)、Geospatial (地理位置)。
|
||||
|
||||
除了上面提到的之外,还有一些其他的比如 [Bloom filter(布隆过滤器)](https://javaguide.cn/cs-basics/data-structure/bloom-filter.html)、Bitfield(位域)。
|
||||
- **5 种基础数据结构**:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
|
||||
- **3 种特殊数据结构**:HyperLogLogs(基数统计)、Bitmap (位存储)、Geospatial (地理位置)。
|
||||
|
||||
### String 的应用场景有哪些?
|
||||
|
||||
String 是 Redis 中最简单同时也是最常用的一个数据类型。它是一种二进制安全的数据类型,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。
|
||||
String 是 Redis 中最简单同时也是最常用的一个数据结构。String 是一种二进制安全的数据结构,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。
|
||||
|
||||
String 的常见应用场景如下:
|
||||
|
||||
- 常规数据(比如 Session、Token、序列化后的对象、图片的路径)的缓存;
|
||||
- 常规数据(比如 session、token、序列化后的对象、图片的路径)的缓存;
|
||||
- 计数比如用户单位时间的请求数(简单限流可以用到)、页面单位时间的访问数;
|
||||
- 分布式锁(利用 `SETNX key value` 命令可以实现一个最简易的分布式锁);
|
||||
- ......
|
||||
|
||||
关于 String 的详细介绍请看这篇文章:[Redis 5 种基本数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)。
|
||||
关于 String 的详细介绍请看这篇文章:[Redis 5 种基本数据结构详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)。
|
||||
|
||||
### String 还是 Hash 存储对象数据更好呢?
|
||||
|
||||
@ -259,13 +253,13 @@ struct __attribute__ ((__packed__)) sdshdr64 {
|
||||
|
||||
通过源码可以看出,SDS 共有五种实现方式 SDS_TYPE_5(并未用到)、SDS_TYPE_8、SDS_TYPE_16、SDS_TYPE_32、SDS_TYPE_64,其中只有后四种实际用到。Redis 会根据初始化的长度决定使用哪种类型,从而减少内存的使用。
|
||||
|
||||
| 类型 | 字节 | 位 |
|
||||
| -------- | ---- | ---- |
|
||||
| sdshdr5 | < 1 | <8 |
|
||||
| sdshdr8 | 1 | 8 |
|
||||
| sdshdr16 | 2 | 16 |
|
||||
| sdshdr32 | 4 | 32 |
|
||||
| sdshdr64 | 8 | 64 |
|
||||
| 类型 | 字节 | 位 |
|
||||
| -------- | ---- | --- |
|
||||
| sdshdr5 | < 1 | <8 |
|
||||
| sdshdr8 | 1 | 8 |
|
||||
| sdshdr16 | 2 | 16 |
|
||||
| sdshdr32 | 4 | 32 |
|
||||
| sdshdr64 | 8 | 64 |
|
||||
|
||||
对于后四种实现都包含了下面这 4 个属性:
|
||||
|
||||
@ -314,7 +308,7 @@ struct sdshdr {
|
||||
|
||||
### 使用 Redis 实现一个排行榜怎么做?
|
||||
|
||||
Redis 中有一个叫做 `Sorted Set ` 的数据类型经常被用在各种排行榜的场景,比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
|
||||
Redis 中有一个叫做 `sorted set` 的数据结构经常被用在各种排行榜的场景,比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
|
||||
|
||||
相关的一些 Redis 命令: `ZRANGE` (从小到大排序)、 `ZREVRANGE` (从大到小排序)、`ZREVRANK` (指定元素排名)。
|
||||
|
||||
@ -328,7 +322,7 @@ Redis 中有一个叫做 `Sorted Set ` 的数据类型经常被用在各种排
|
||||
|
||||
Redis 中 `Set` 是一种无序集合,集合中的元素没有先后顺序但都唯一,有点类似于 Java 中的 `HashSet` 。
|
||||
|
||||
`Set` 的常见应用场景如下:
|
||||
Set 的常见应用场景如下:
|
||||
|
||||
- 存放的数据不能重复的场景:网站 UV 统计(数据量巨大的场景还是 `HyperLogLog`更适合一些)、文章点赞、动态点赞等等。
|
||||
- 需要获取多个数据源交集、并集和差集的场景:共同好友(交集)、共同粉丝(交集)、共同关注(交集)、好友推荐(差集)、音乐推荐(差集)、订阅号推荐(差集+交集) 等等。
|
||||
@ -336,7 +330,7 @@ Redis 中 `Set` 是一种无序集合,集合中的元素没有先后顺序但
|
||||
|
||||
### 使用 Set 实现抽奖系统怎么做?
|
||||
|
||||
如果想要使用 `Set` 实现一个简单的抽奖系统的话,直接使用下面这几个命令就可以了:
|
||||
如果想要使用 Set 实现一个简单的抽奖系统的话,直接使用下面这几个命令就可以了:
|
||||
|
||||
- `SADD key member1 member2 ...`:向指定集合添加一个或多个元素。
|
||||
- `SPOP key count`:随机移除并获取指定集合中一个或多个元素,适合不允许重复中奖的场景。
|
||||
@ -544,7 +538,7 @@ OK
|
||||
|
||||
**过期时间除了有助于缓解内存的消耗,还有什么其他用么?**
|
||||
|
||||
很多时候,我们的业务场景就是需要某个数据只在某一时间段内存在,比如我们的短信验证码可能只在 1 分钟内有效,用户登录的 Token 可能只在 1 天内有效。
|
||||
很多时候,我们的业务场景就是需要某个数据只在某一时间段内存在,比如我们的短信验证码可能只在 1 分钟内有效,用户登录的 token 可能只在 1 天内有效。
|
||||
|
||||
如果使用传统的数据库来处理的话,一般都是自己判断过期,这样更麻烦并且性能要差很多。
|
||||
|
||||
|
||||
@ -352,7 +352,7 @@ bigkey 的常见处理以及优化办法如下(这些方法可以配合起来
|
||||
|
||||
#### 什么是 hotkey?
|
||||
|
||||
如果一个 key 的访问次数比较多且明显多于其他 key 的话,那这个 key 就可以看作是 **hotkey(热 Key)**。例如在 Redis 实例的每秒处理请求达到 5000 次,而其中某个 key 的每秒访问量就高达 2000 次,那这个 key 就可以看作是 hotkey。
|
||||
简单来说,如果一个 key 的访问次数比较多且明显多于其他 key 的话,那这个 key 就可以看作是 hotkey。例如在 Redis 实例的每秒处理请求达到 5000 次,而其中某个 key 的每秒访问量就高达 2000 次,那这个 key 就可以看作是 hotkey。
|
||||
|
||||
hotkey 出现的原因主要是某个热点数据访问量暴增,如重大的热搜事件、参与秒杀的商品。
|
||||
|
||||
|
||||
@ -81,11 +81,11 @@ MySQL binlog(binary log 即二进制日志文件) 主要记录了 MySQL 数据
|
||||
|
||||
读写分离对于提升数据库的并发非常有效,但是,同时也会引来一个问题:主库和从库的数据存在延迟,比如你写完主库之后,主库的数据同步到从库是需要时间的,这个时间差就导致了主库和从库的数据不一致性问题。这也就是我们经常说的 **主从同步延迟** 。
|
||||
|
||||
如果我们的业务场景无法容忍主从同步延迟的话,应该如何避免呢(注意:我这里说的是避免而不是减少延迟)?
|
||||
如果我们的业务场景无法容忍主从同步延迟的话,应该如何避免呢?
|
||||
|
||||
这里提供两种我知道的方案(能力有限,欢迎补充),你可以根据自己的业务场景参考一下。
|
||||
|
||||
#### 强制将读请求路由到主库处理
|
||||
**1.强制将读请求路由到主库处理。**
|
||||
|
||||
既然你从库的数据过期了,那我就直接从主库读取嘛!这种方案虽然会增加主库的压力,但是,实现起来比较简单,也是我了解到的使用最多的一种方式。
|
||||
|
||||
@ -99,21 +99,17 @@ hintManager.setMasterRouteOnly();
|
||||
|
||||
对于这种方案,你可以将那些必须获取最新数据的读请求都交给主库处理。
|
||||
|
||||
#### 延迟读取
|
||||
**2.延迟读取。**
|
||||
|
||||
还有一些朋友肯定会想既然主从同步存在延迟,那我就在延迟之后读取啊,比如主从同步延迟 0.5s,那我就 1s 之后再读取数据。这样多方便啊!方便是方便,但是也很扯淡。
|
||||
|
||||
不过,如果你是这样设计业务流程就会好很多:对于一些对数据比较敏感的场景,你可以在完成写请求之后,避免立即进行请求操作。比如你支付成功之后,跳转到一个支付成功的页面,当你点击返回之后才返回自己的账户。
|
||||
|
||||
#### 总结
|
||||
|
||||
关于如何避免主从延迟,我们这里介绍了两种方案。实际上,延迟读取这种方案没办法完全避免主从延迟,只能说可以减少出现延迟的概率而已,实际项目中一般不会使用。
|
||||
|
||||
总的来说,要想不出现延迟问题,一般还是要强制将那些必须获取最新数据的读请求都交给主库处理。如果你的项目的大部分业务场景对数据准确性要求不是那么高的话,这种方案还是可以选择的。
|
||||
另外,[《MySQL 实战 45 讲》](https://time.geekbang.org/column/intro/100020801?code=ieY8HeRSlDsFbuRtggbBQGxdTh-1jMASqEIeqzHAKrI%3D)这个专栏中的[《读写分离有哪些坑?》](https://time.geekbang.org/column/article/77636)这篇文章还介绍了很多其他比较实际的解决办法,感兴趣的小伙伴可以自行研究一下。
|
||||
|
||||
### 什么情况下会出现主从延迟?如何尽量减少延迟?
|
||||
|
||||
我们在上面的内容中也提到了主从延迟以及避免主从延迟的方法,这里我们再来详细分析一下主从延迟出现的原因以及应该如何尽量减少主从延迟。
|
||||
我们在上面的内容中也提到了主从延迟以及解决办法,这里我们再来详细分析一下主从延迟出现的原因以及应该如何尽量减少延迟。
|
||||
|
||||
要搞懂什么情况下会出现主从延迟,我们需要先搞懂什么是主从延迟。
|
||||
|
||||
@ -140,12 +136,10 @@ MySQL 主从同步延时是指从库的数据落后于主库的数据,这种
|
||||
3. **大事务**:运行时间比较长,长时间未提交的事务就可以称为大事务。由于大事务执行时间长,并且从库上的大事务会比主库上的大事务花费更多的时间和资源,因此非常容易造成主从延迟。解决办法是避免大批量修改数据,尽量分批进行。类似的情况还有执行时间较长的慢 SQL ,实际项目遇到慢 SQL 应该进行优化。
|
||||
4. **从库太多**:主库需要将 binlog 同步到所有的从库,如果从库数量太多,会增加同步的时间和开销(也就是 T2-T1 的值会比较大,但这里是因为主库同步压力大导致的)。解决方案是减少从库的数量,或者将从库分为不同的层级,让上层的从库再同步给下层的从库,减少主库的压力。
|
||||
5. **网络延迟**:如果主从之间的网络传输速度慢,或者出现丢包、抖动等问题,那么就会影响 binlog 的传输效率,导致从库延迟。解决方法是优化网络环境,比如提升带宽、降低延迟、增加稳定性等。
|
||||
6. **单线程复制**:MySQL5.5 及之前,只支持单线程复制。为了优化复制性能,MySQL 5.6 引入了 **多线程复制**,MySQL 5.7 还进一步完善了多线程复制。
|
||||
7. **复制模式**:MySQL 默认的复制是异步的,必然会存在延迟问题。全同步复制不存在延迟问题,但性能太差了。半同步复制是一种折中方案,相对于异步复制,半同步复制提高了数据的安全性,减少了主从延迟(还是有一定程度的延迟)。MySQL 5.5 开始,MySQL 以插件的形式支持 **semi-sync 半同步复制**。并且,MySQL 5.7 引入了 **增强半同步复制** 。
|
||||
6. **单线程复制**:MySQL5.5 及之前,只支持单线程复制。为了优化复制性能,MySQL 5.6 引入了多线程复制,MySQL 5.7 还进一步完善了多线程复制。
|
||||
7. **复制模式**:MySQL 默认的复制是异步的,必然会存在延迟问题。全同步复制不存在延迟问题,但性能太差了。半同步复制是一种折中方案,相对于异步复制,半同步复制提高了数据的安全性,减少了主从延迟(还是有一定程度的延迟)。MySQL 5.5 开始,MySQL 以插件的形式支持 semi-sync 半同步复制。并且,MySQL 5.7 引入了增强半同步复制
|
||||
8. ......
|
||||
|
||||
[《MySQL 实战 45 讲》](https://time.geekbang.org/column/intro/100020801?code=ieY8HeRSlDsFbuRtggbBQGxdTh-1jMASqEIeqzHAKrI%3D)这个专栏中的[读写分离有哪些坑?](https://time.geekbang.org/column/article/77636)这篇文章也有对主从延迟解决方案这一话题进行探讨,感兴趣的可以阅读学习一下。
|
||||
|
||||
## 分库分表
|
||||
|
||||
读写分离主要应对的是数据库读并发,没有解决数据库存储问题。试想一下:**如果 MySQL 一张表的数据量过大怎么办?**
|
||||
|
||||
@ -351,7 +351,7 @@ public class BigDecimalUtil {
|
||||
}
|
||||
```
|
||||
|
||||
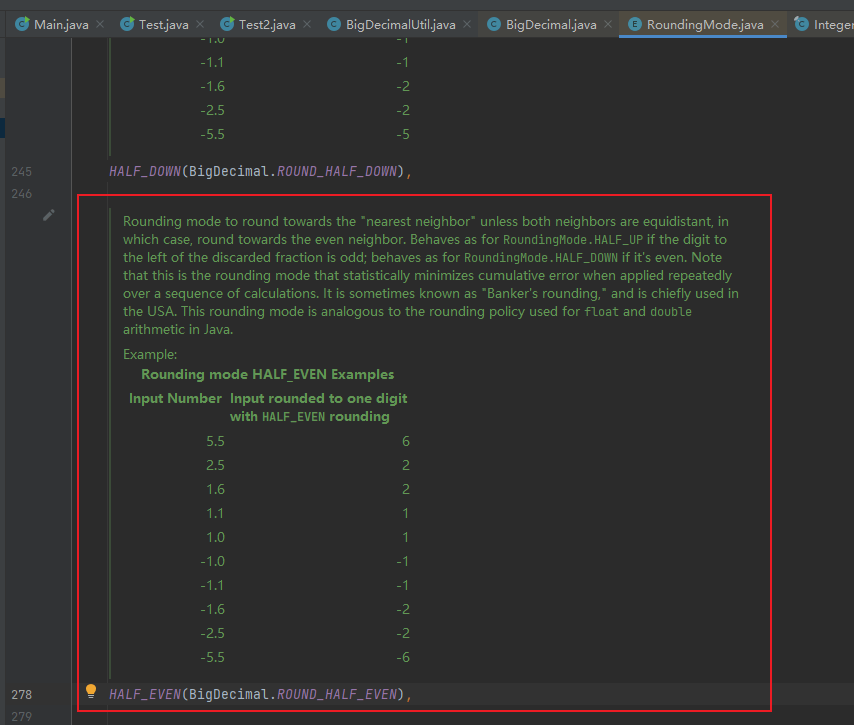
相关 issue:[建议对保留规则设置为 RoundingMode.HALF_EVEN,即四舍六入五成双]([#2129](https://github.com/Snailclimb/JavaGuide/issues/2129)) 。
|
||||
相关 issue:[建议对保留规则设置为 RoundingMode.HALF_EVEN,即四舍六入五成双]([#1122](https://github.com/Snailclimb/JavaGuide/issues/1122)) 。
|
||||
|
||||
|
||||
|
||||
@ -361,4 +361,4 @@ public class BigDecimalUtil {
|
||||
|
||||
不过,Java 提供了`BigDecimal` 来操作浮点数。`BigDecimal` 的实现利用到了 `BigInteger` (用来操作大整数), 所不同的是 `BigDecimal` 加入了小数位的概念。
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
@ -348,7 +348,7 @@ public static class CallerRunsPolicy implements RejectedExecutionHandler {
|
||||
|
||||
不同的线程池会选用不同的阻塞队列,我们可以结合内置线程池来分析。
|
||||
|
||||
- 容量为 `Integer.MAX_VALUE` 的 `LinkedBlockingQueue`(无界队列):`FixedThreadPool` 和 `SingleThreadExector` 。由于队列永远不会被放满,因此`FixedThreadPool`最多只能创建核心线程数的线程,`SingleThreadExector`只能创建一个线程。
|
||||
- 容量为 `Integer.MAX_VALUE` 的 `LinkedBlockingQueue`(无界队列):`FixedThreadPool` 和 `SingleThreadExector` 。由于队列永远不会被放满,因此`FixedThreadPool`最多只能创建核心线程数的线程。
|
||||
- `SynchronousQueue`(同步队列):`CachedThreadPool` 。`SynchronousQueue` 没有容量,不存储元素,目的是保证对于提交的任务,如果有空闲线程,则使用空闲线程来处理;否则新建一个线程来处理任务。也就是说,`CachedThreadPool` 的最大线程数是 `Integer.MAX_VALUE` ,可以理解为线程数是可以无限扩展的,可能会创建大量线程,从而导致 OOM。
|
||||
- `DelayedWorkQueue`(延迟阻塞队列):`ScheduledThreadPool` 和 `SingleThreadScheduledExecutor` 。`DelayedWorkQueue` 的内部元素并不是按照放入的时间排序,而是会按照延迟的时间长短对任务进行排序,内部采用的是“堆”的数据结构,可以保证每次出队的任务都是当前队列中执行时间最靠前的。`DelayedWorkQueue` 添加元素满了之后会自动扩容原来容量的 1/2,即永远不会阻塞,最大扩容可达 `Integer.MAX_VALUE`,所以最多只能创建核心线程数的线程。
|
||||
|
||||
@ -494,7 +494,7 @@ CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内
|
||||
|
||||
|
||||
|
||||
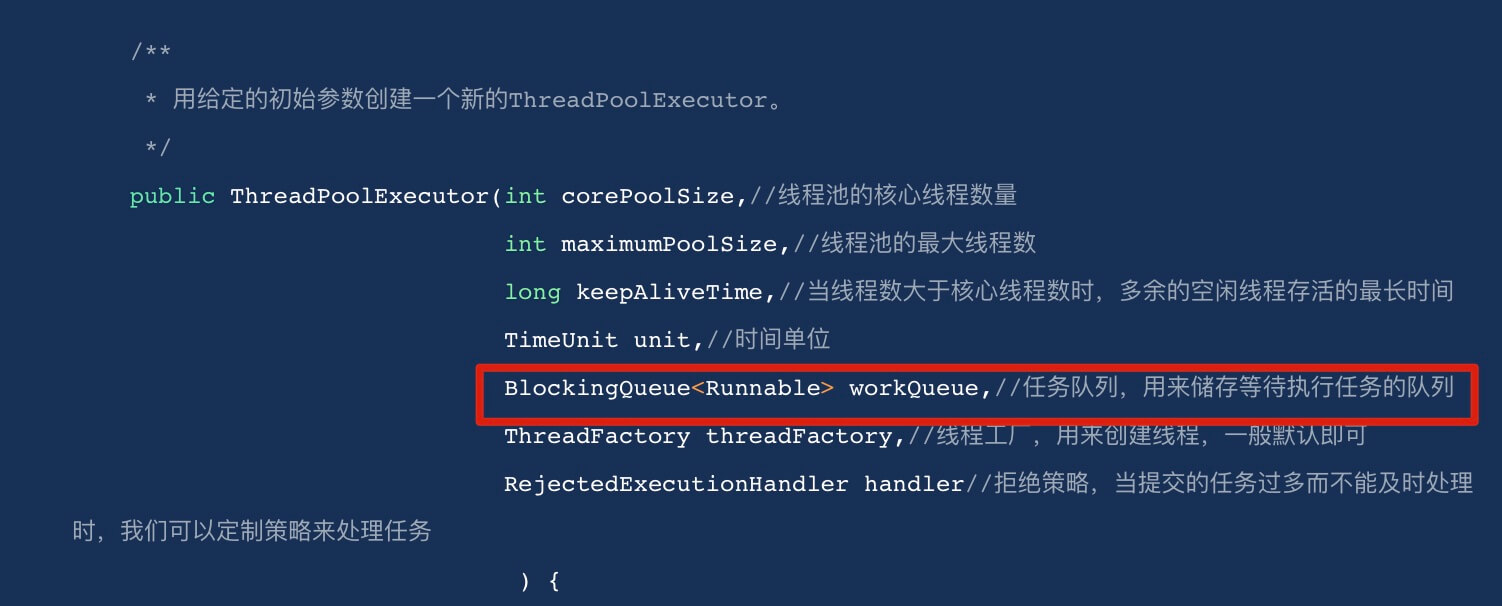
`PriorityBlockingQueue` 是一个支持优先级的无界阻塞队列,可以看作是线程安全的 `PriorityQueue`,两者底层都是使用小顶堆形式的二叉堆,即值最小的元素优先出队。不过,`PriorityQueue` 不支持阻塞操作。
|
||||
`PriorityBlockingQueue` 是一个支持优先级的无界阻塞队列,可以看作是线程安全的`PriorityQueue`,两者底层都是使用小顶堆形式的二叉堆,即值最小的元素优先出队。不过,`PriorityQueue` 不支持阻塞操作并且是有界的。
|
||||
|
||||
要想让 `PriorityBlockingQueue` 实现对任务的排序,传入其中的任务必须是具备排序能力的,方式有两种:
|
||||
|
||||
@ -505,7 +505,7 @@ CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内
|
||||
|
||||
- `PriorityBlockingQueue` 是无界的,可能堆积大量的请求,从而导致 OOM。
|
||||
- 可能会导致饥饿问题,即低优先级的任务长时间得不到执行。
|
||||
- 由于需要对队列中的元素进行排序操作以及保证线程安全(并发控制采用的是可重入锁 `ReentrantLock`),因此会降低性能。
|
||||
- 由于需要对队列中的元素进行排序操作,因此会降低性能。
|
||||
|
||||
对于 OOM 这个问题的解决比较简单粗暴,就是继承`PriorityBlockingQueue` 并重写一下 `offer` 方法(入队)的逻辑,当插入的元素数量超过指定值就返回 false 。
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user