mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-07-28 12:22:17 +08:00
Compare commits
9 Commits
a44dd32df7
...
6a8ac9ec27
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
6a8ac9ec27 | ||
|
|
58696c742b | ||
|
|
ab283c76aa | ||
|
|
b1572cc89b | ||
|
|
f580245cf8 | ||
|
|
107337c8b7 | ||
|
|
a43c620c60 | ||
|
|
538a0cb037 | ||
|
|
9145feec50 |
@ -18,20 +18,18 @@ head:
|
||||
# MySQL 在无法利用索引的情况下跳过1000000条记录后,再获取10条记录
|
||||
SELECT * FROM t_order ORDER BY id LIMIT 1000000, 10
|
||||
```
|
||||
|
||||
## 深度分页问题的原因
|
||||
**全表扫描**:当OFFSET值较大时,MySQL可能会选择执行全表扫描而不是使用索引。
|
||||

|
||||

|
||||
|
||||
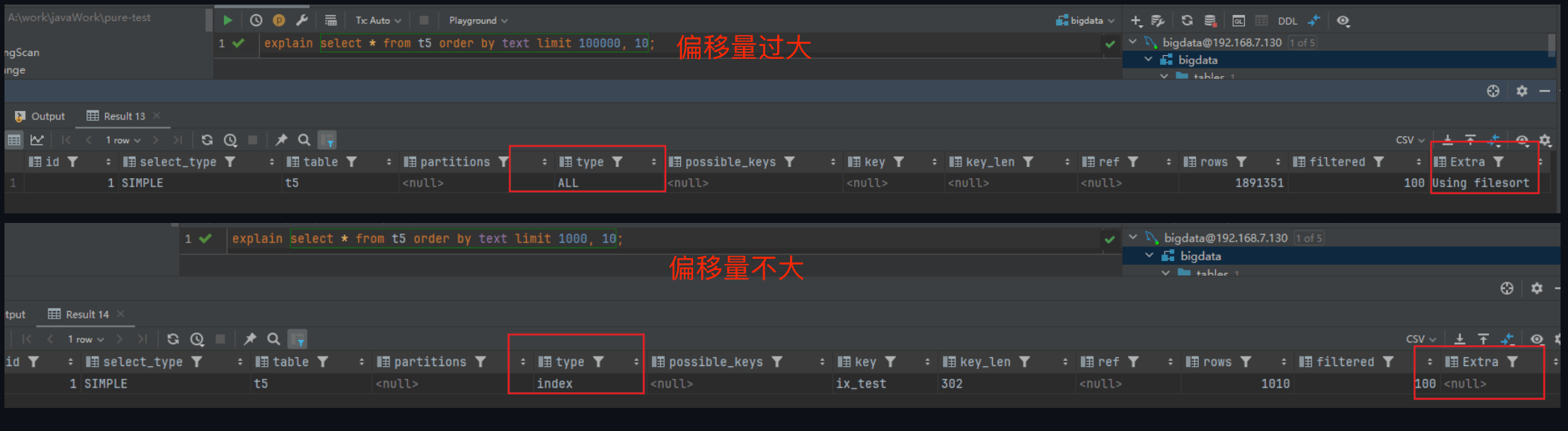
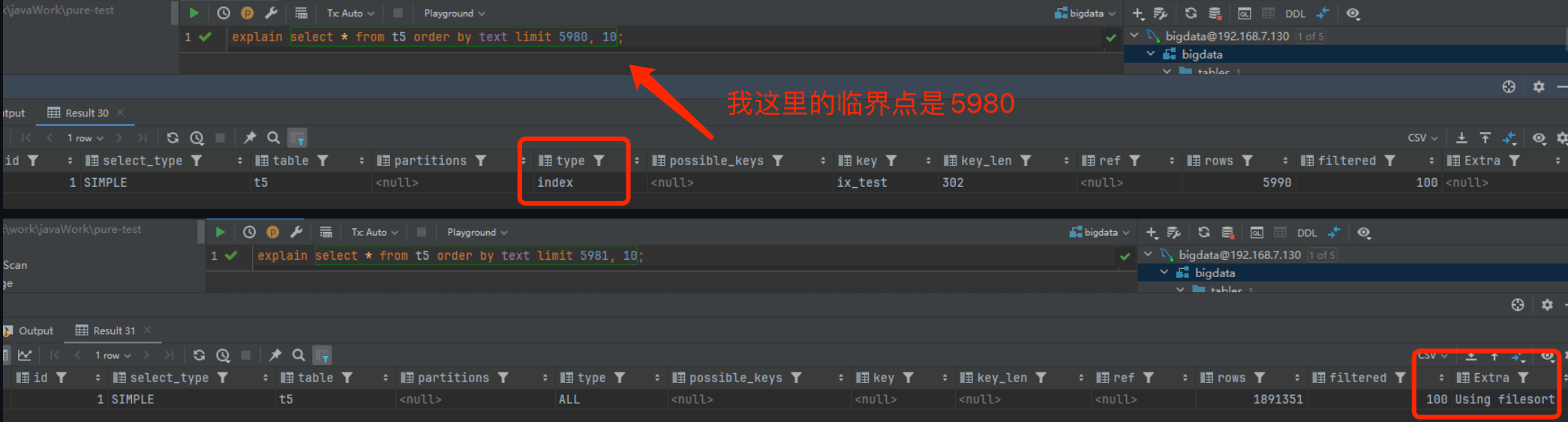
具体的临界点每个机器不一样,我的机器上是5980,为什么产生呢?
|
||||

|
||||

|
||||
MySQL数据库的查询优化器是采用了基于代价的,而查询代价的估算是基于CPU代价和IO代价。
|
||||
如果MySQL在查询代价估算中,认为全表扫描方式比走索引扫描的方式效率更高的话,就会放弃索引,直接全表扫描。
|
||||
这就是为什么在大分页的SQL查询中,明明给该字段加了索引,但是MySQL却走了全表扫描的原因。
|
||||
当查询偏移量过大时,MySQL 的查询优化器可能会选择全表扫描而不是利用索引来优化查询。这是因为扫描索引和跳过大量记录可能比直接全表扫描更耗费资源。
|
||||
|
||||
|
||||
|
||||
不同机器上这个查询偏移量过大的临界点可能不同,取决于多个因素,包括硬件配置(如 CPU 性能、磁盘速度)、表的大小、索引的类型和统计信息等。
|
||||
|
||||
|
||||
|
||||
MySQL 的查询优化器采用基于成本的策略来选择最优的查询执行计划。它会根据 CPU 和 I/O 的成本来决定是否使用索引扫描或全表扫描。如果优化器认为全表扫描的成本更低,它就会放弃使用索引。不过,即使偏移量很大,如果查询中使用了覆盖索引(covering index),MySQL 仍然可能会使用索引,避免回表操作。
|
||||
|
||||
## 深度分页优化建议
|
||||
|
||||
|
||||
@ -116,7 +116,7 @@ public class TargetObject {
|
||||
}
|
||||
```
|
||||
|
||||
2. 使用反射操作这个类的方法以及参数
|
||||
2. 使用反射操作这个类的方法以及属性
|
||||
|
||||
```java
|
||||
package cn.javaguide;
|
||||
|
||||
@ -258,7 +258,7 @@ public V get(Object key) {
|
||||
```java
|
||||
void afterNodeAccess(Node < K, V > e) { // move node to last
|
||||
LinkedHashMap.Entry < K, V > last;
|
||||
//如果accessOrder 且当前节点不未链表尾节点
|
||||
//如果accessOrder 且当前节点不为链表尾节点
|
||||
if (accessOrder && (last = tail) != e) {
|
||||
|
||||
//获取当前节点、以及前驱节点和后继节点
|
||||
|
||||
@ -561,7 +561,7 @@ public final class NamingThreadFactory implements ThreadFactory {
|
||||
>
|
||||
> Linux 相比与其他操作系统(包括其他类 Unix 系统)有很多的优点,其中有一项就是,其上下文切换和模式切换的时间消耗非常少。
|
||||
|
||||
类比于实现世界中的人类通过合作做某件事情,我们可以肯定的一点是线程池大小设置过大或者过小都会有问题,合适的才是最好。
|
||||
类比于现实世界中的人类通过合作做某件事情,我们可以肯定的一点是线程池大小设置过大或者过小都会有问题,合适的才是最好。
|
||||
|
||||
- 如果我们设置的线程池数量太小的话,如果同一时间有大量任务/请求需要处理,可能会导致大量的请求/任务在任务队列中排队等待执行,甚至会出现任务队列满了之后任务/请求无法处理的情况,或者大量任务堆积在任务队列导致 OOM。这样很明显是有问题的,CPU 根本没有得到充分利用。
|
||||
- 如果我们设置线程数量太大,大量线程可能会同时在争取 CPU 资源,这样会导致大量的上下文切换,从而增加线程的执行时间,影响了整体执行效率。
|
||||
|
||||
@ -136,7 +136,7 @@ public final class NamingThreadFactory implements ThreadFactory {
|
||||
>
|
||||
> Linux 相比与其他操作系统(包括其他类 Unix 系统)有很多的优点,其中有一项就是,其上下文切换和模式切换的时间消耗非常少。
|
||||
|
||||
类比于实现世界中的人类通过合作做某件事情,我们可以肯定的一点是线程池大小设置过大或者过小都会有问题,合适的才是最好。
|
||||
类比于现实世界中的人类通过合作做某件事情,我们可以肯定的一点是线程池大小设置过大或者过小都会有问题,合适的才是最好。
|
||||
|
||||
- 如果我们设置的线程池数量太小的话,如果同一时间有大量任务/请求需要处理,可能会导致大量的请求/任务在任务队列中排队等待执行,甚至会出现任务队列满了之后任务/请求无法处理的情况,或者大量任务堆积在任务队列导致 OOM。这样很明显是有问题的,CPU 根本没有得到充分利用。
|
||||
- 如果我们设置线程数量太大,大量线程可能会同时在争取 CPU 资源,这样会导致大量的上下文切换,从而增加线程的执行时间,影响了整体执行效率。
|
||||
|
||||
@ -83,7 +83,7 @@ tag:
|
||||
2. 从概念上讲,类变量所使用的内存都应当在 **方法区** 中进行分配。不过有一点需要注意的是:JDK 7 之前,HotSpot 使用永久代来实现方法区的时候,实现是完全符合这种逻辑概念的。 而在 JDK 7 及之后,HotSpot 已经把原本放在永久代的字符串常量池、静态变量等移动到堆中,这个时候类变量则会随着 Class 对象一起存放在 Java 堆中。相关阅读:[《深入理解 Java 虚拟机(第 3 版)》勘误#75](https://github.com/fenixsoft/jvm_book/issues/75 "《深入理解Java虚拟机(第3版)》勘误#75")
|
||||
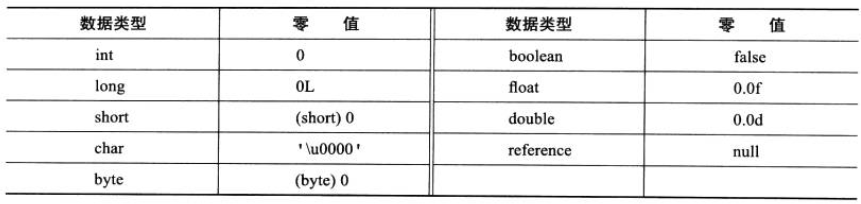
3. 这里所设置的初始值"通常情况"下是数据类型默认的零值(如 0、0L、null、false 等),比如我们定义了`public static int value=111` ,那么 value 变量在准备阶段的初始值就是 0 而不是 111(初始化阶段才会赋值)。特殊情况:比如给 value 变量加上了 final 关键字`public static final int value=111` ,那么准备阶段 value 的值就被赋值为 111。
|
||||
|
||||
**基本数据类型的零值**:(图片来自《深入理解 Java 虚拟机》第 3 版 7.33 )
|
||||
**基本数据类型的零值**:(图片来自《深入理解 Java 虚拟机》第 3 版 7.3.3 )
|
||||
|
||||
|
||||
|
||||
@ -91,7 +91,7 @@ tag:
|
||||
|
||||
**解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。** 解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用限定符 7 类符号引用进行。
|
||||
|
||||
《深入理解 Java 虚拟机》7.34 节第三版对符号引用和直接引用的解释如下:
|
||||
《深入理解 Java 虚拟机》7.3.4 节第三版对符号引用和直接引用的解释如下:
|
||||
|
||||

|
||||
|
||||
|
||||
@ -346,7 +346,6 @@ Spring 框架中用到了哪些设计模式?
|
||||
|
||||
- 《Spring 技术内幕》
|
||||
- <https://blog.eduonix.com/java-programming-2/learn-design-patterns-used-spring-framework/>
|
||||
- <http://blog.yeamin.top/2018/03/27/单例模式-Spring%20单例实现原理分析/>
|
||||
- <https://www.tutorialsteacher.com/ioc/inversion-of-control>
|
||||
- <https://design-patterns.readthedocs.io/zh_CN/latest/behavioral_patterns/observer.html>
|
||||
- <https://juejin.im/post/5a8eb261f265da4e9e307230>
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user