mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
Compare commits
14 Commits
9d11263c6e
...
0032d1deb2
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
0032d1deb2 | ||
|
|
6c4e416f01 | ||
|
|
d3bcbd60b2 | ||
|
|
7980d03265 | ||
|
|
6f3f2c90fe | ||
|
|
c901f230c6 | ||
|
|
db72d110ff | ||
|
|
237ec3bec3 | ||
|
|
297e782068 | ||
|
|
8745a28fa1 | ||
|
|
187a7367e4 | ||
|
|
b1867d3f44 | ||
|
|
dbdd3aaedd | ||
|
|
79f741803c |
14
README.md
14
README.md
@ -313,15 +313,13 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8](https://docs.oracle.
|
||||
- [JWT 优缺点分析以及常见问题解决方案](./docs/system-design/security/advantages-and-disadvantages-of-jwt.md)
|
||||
- [SSO 单点登录详解](./docs/system-design/security/sso-intro.md)
|
||||
- [权限系统设计详解](./docs/system-design/security/design-of-authority-system.md)
|
||||
|
||||
#### 数据安全
|
||||
|
||||
- [常见加密算法总结](./docs/system-design/security/encryption-algorithms.md)
|
||||
|
||||
#### 数据脱敏
|
||||
|
||||
数据脱敏说的就是我们根据特定的规则对敏感信息数据进行变形,比如我们把手机号、身份证号某些位数使用 \* 来代替。
|
||||
|
||||
#### 敏感词过滤
|
||||
|
||||
[敏感词过滤方案总结](./docs/system-design/security/sentive-words-filter.md)
|
||||
- [敏感词过滤方案总结](./docs/system-design/security/sentive-words-filter.md)
|
||||
- [数据脱敏方案总结](./docs/system-design/security/data-desensitization.md)
|
||||
- [为什么前后端都要做数据校验](./docs/system-design/security/data-validation.md)
|
||||
|
||||
### 定时任务
|
||||
|
||||
|
||||
@ -469,6 +469,7 @@ export default sidebar({
|
||||
"encryption-algorithms",
|
||||
"sentive-words-filter",
|
||||
"data-desensitization",
|
||||
"data-validation",
|
||||
],
|
||||
},
|
||||
"system-design-questions",
|
||||
|
||||
@ -73,9 +73,21 @@ tag:
|
||||
|
||||
🐛 修正(参见 [issue#1915](https://github.com/Snailclimb/JavaGuide/issues/1915)):
|
||||
|
||||
HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 **基于 UDP 的 QUIC 协议** 。
|
||||
HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 **基于 UDP 的 QUIC 协议** :
|
||||
|
||||
此变化解决了 HTTP/2.0 中存在的队头阻塞问题。队头阻塞是指在 HTTP/2.0 中,多个 HTTP 请求和响应共享一个 TCP 连接,如果其中一个请求或响应因为网络拥塞或丢包而被阻塞,那么后续的请求或响应也无法发送,导致整个连接的效率降低。这是由于 HTTP/2.0 在单个 TCP 连接上使用了多路复用,受到 TCP 拥塞控制的影响,少量的丢包就可能导致整个 TCP 连接上的所有流被阻塞。HTTP/3.0 在一定程度上解决了队头阻塞问题,一个连接建立多个不同的数据流,这些数据流之间独立互不影响,某个数据流发生丢包了,其数据流不受影响(本质上是多路复用+轮询)。
|
||||
- **HTTP/1.x 和 HTTP/2.0**:这两个版本的 HTTP 协议都明确建立在 TCP 之上。TCP 提供了可靠的、面向连接的传输,确保数据按序、无差错地到达,这对于网页内容的正确展示非常重要。发送 HTTP 请求前,需要先通过 TCP 的三次握手建立连接。
|
||||
- **HTTP/3.0**:这是一个重大的改变。HTTP/3 弃用了 TCP,转而使用 QUIC 协议,而 QUIC 是构建在 UDP 之上的。
|
||||
|
||||

|
||||
|
||||
**为什么 HTTP/3 要做这个改变呢?主要有两大原因:**
|
||||
|
||||
1. 解决队头阻塞 (Head-of-Line Blocking,简写:HOL blocking) 问题。
|
||||
2. 减少连接建立的延迟。
|
||||
|
||||
下面我们来详细介绍这两大优化。
|
||||
|
||||
在 HTTP/2 中,虽然可以在一个 TCP 连接上并发传输多个请求/响应流(多路复用),但 TCP 本身的特性(保证有序、可靠)意味着如果其中一个流的某个 TCP 报文丢失或延迟,整个 TCP 连接都会被阻塞,等待该报文重传。这会导致所有在这个 TCP 连接上的 HTTP/2 流都受到影响,即使其他流的数据包已经到达。**QUIC (运行在 UDP 上) 解决了这个问题**。QUIC 内部实现了自己的多路复用和流控制机制。不同的 HTTP 请求/响应流在 QUIC 层面是真正独立的。如果一个流的数据包丢失,它只会阻塞该流,而不会影响同一 QUIC 连接上的其他流(本质上是多路复用+轮询),大大提高了并发传输的效率。
|
||||
|
||||
除了解决队头阻塞问题,HTTP/3.0 还可以减少握手过程的延迟。在 HTTP/2.0 中,如果要建立一个安全的 HTTPS 连接,需要经过 TCP 三次握手和 TLS 握手:
|
||||
|
||||
@ -89,25 +101,40 @@ HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 **
|
||||
- <https://zh.wikipedia.org/zh/HTTP/3>
|
||||
- <https://datatracker.ietf.org/doc/rfc9114/>
|
||||
|
||||
### 使用 TCP 的协议有哪些?使用 UDP 的协议有哪些?
|
||||
### 你知道哪些基于 TCP/UDP 的协议?
|
||||
|
||||
**运行于 TCP 协议之上的协议**:
|
||||
TCP (传输控制协议) 和 UDP (用户数据报协议) 是互联网传输层的两大核心协议,它们为各种应用层协议提供了基础的通信服务。以下是一些常见的、分别构建在 TCP 和 UDP 之上的应用层协议:
|
||||
|
||||
1. **HTTP 协议(HTTP/3.0 之前)**:超文本传输协议(HTTP,HyperText Transfer Protocol)是一种用于传输超文本和多媒体内容的协议,主要是为 Web 浏览器与 Web 服务器之间的通信而设计的。当我们使用浏览器浏览网页的时候,我们网页就是通过 HTTP 请求进行加载的。
|
||||
2. **HTTPS 协议**:更安全的超文本传输协议(HTTPS,Hypertext Transfer Protocol Secure),身披 SSL 外衣的 HTTP 协议
|
||||
3. **FTP 协议**:文件传输协议 FTP(File Transfer Protocol)是一种用于在计算机之间传输文件的协议,可以屏蔽操作系统和文件存储方式。注意 ⚠️:FTP 是一种不安全的协议,因为它在传输过程中不会对数据进行加密。建议在传输敏感数据时使用更安全的协议,如 SFTP。
|
||||
4. **SMTP 协议**:简单邮件传输协议(SMTP,Simple Mail Transfer Protocol)的缩写,是一种用于发送电子邮件的协议。注意 ⚠️:SMTP 协议只负责邮件的发送,而不是接收。要从邮件服务器接收邮件,需要使用 POP3 或 IMAP 协议。
|
||||
5. **POP3/IMAP 协议**:两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
|
||||
6. **Telnet 协议**:用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
|
||||
7. **SSH 协议** : SSH( Secure Shell)是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。利用 SSH 协议可以有效防止远程管理过程中的信息泄露问题。SSH 建立在可靠的传输协议 TCP 之上。
|
||||
8. ……
|
||||
**运行于 TCP 协议之上的协议 (强调可靠、有序传输):**
|
||||
|
||||
**运行于 UDP 协议之上的协议**:
|
||||
| 中文全称 (缩写) | 英文全称 | 主要用途 | 说明与特性 |
|
||||
| -------------------------- | ---------------------------------- | ---------------------------- | --------------------------------------------------------------------------------------------------------------------------- |
|
||||
| 超文本传输协议 (HTTP) | HyperText Transfer Protocol | 传输网页、超文本、多媒体内容 | **HTTP/1.x 和 HTTP/2 基于 TCP**。早期版本不加密,是 Web 通信的基础。 |
|
||||
| 安全超文本传输协议 (HTTPS) | HyperText Transfer Protocol Secure | 加密的网页传输 | 在 HTTP 和 TCP 之间增加了 SSL/TLS 加密层,确保数据传输的机密性和完整性。 |
|
||||
| 文件传输协议 (FTP) | File Transfer Protocol | 文件传输 | 传统的 FTP **明文传输**,不安全。推荐使用其安全版本 **SFTP (SSH File Transfer Protocol)** 或 **FTPS (FTP over SSL/TLS)** 。 |
|
||||
| 简单邮件传输协议 (SMTP) | Simple Mail Transfer Protocol | **发送**电子邮件 | 负责将邮件从客户端发送到服务器,或在邮件服务器之间传递。可通过 **STARTTLS** 升级到加密传输。 |
|
||||
| 邮局协议第 3 版 (POP3) | Post Office Protocol version 3 | **接收**电子邮件 | 通常将邮件从服务器**下载到本地设备后删除服务器副本** (可配置保留)。**POP3S** 是其 SSL/TLS 加密版本。 |
|
||||
| 互联网消息访问协议 (IMAP) | Internet Message Access Protocol | **接收和管理**电子邮件 | 邮件保留在服务器,支持多设备同步邮件状态、文件夹管理、在线搜索等。**IMAPS** 是其 SSL/TLS 加密版本。现代邮件服务首选。 |
|
||||
| 远程终端协议 (Telnet) | Teletype Network | 远程终端登录 | **明文传输**所有数据 (包括密码),安全性极差,基本已被 SSH 完全替代。 |
|
||||
| 安全外壳协议 (SSH) | Secure Shell | 安全远程管理、加密数据传输 | 提供了加密的远程登录和命令执行,以及安全的文件传输 (SFTP) 等功能,是 Telnet 的安全替代品。 |
|
||||
|
||||
1. **HTTP 协议(HTTP/3.0 )**: HTTP/3.0 弃用 TCP,改用基于 UDP 的 QUIC 协议 。
|
||||
2. **DHCP 协议**:动态主机配置协议,动态配置 IP 地址
|
||||
3. **DNS**:域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。 我们可以将其理解为专为互联网设计的电话薄。实际上,DNS 同时支持 UDP 和 TCP 协议。
|
||||
4. ……
|
||||
**运行于 UDP 协议之上的协议 (强调快速、低开销传输):**
|
||||
|
||||
| 中文全称 (缩写) | 英文全称 | 主要用途 | 说明与特性 |
|
||||
| ----------------------- | ------------------------------------- | -------------------------- | ------------------------------------------------------------------------------------------------------------ |
|
||||
| 超文本传输协议 (HTTP/3) | HyperText Transfer Protocol version 3 | 新一代网页传输 | 基于 **QUIC** 协议 (QUIC 本身构建于 UDP 之上),旨在减少延迟、解决 TCP 队头阻塞问题,支持 0-RTT 连接建立。 |
|
||||
| 动态主机配置协议 (DHCP) | Dynamic Host Configuration Protocol | 动态分配 IP 地址及网络配置 | 客户端从服务器自动获取 IP 地址、子网掩码、网关、DNS 服务器等信息。 |
|
||||
| 域名系统 (DNS) | Domain Name System | 域名到 IP 地址的解析 | **通常使用 UDP** 进行快速查询。当响应数据包过大或进行区域传送 (AXFR) 时,会**切换到 TCP** 以保证数据完整性。 |
|
||||
| 实时传输协议 (RTP) | Real-time Transport Protocol | 实时音视频数据流传输 | 常用于 VoIP、视频会议、直播等。追求低延迟,允许少量丢包。通常与 RTCP 配合使用。 |
|
||||
| RTP 控制协议 (RTCP) | RTP Control Protocol | RTP 流的质量监控和控制信息 | 配合 RTP 工作,提供丢包、延迟、抖动等统计信息,辅助流量控制和拥塞管理。 |
|
||||
| 简单文件传输协议 (TFTP) | Trivial File Transfer Protocol | 简化的文件传输 | 功能简单,常用于局域网内无盘工作站启动、网络设备固件升级等小文件传输场景。 |
|
||||
| 简单网络管理协议 (SNMP) | Simple Network Management Protocol | 网络设备的监控与管理 | 允许网络管理员查询和修改网络设备的状态信息。 |
|
||||
| 网络时间协议 (NTP) | Network Time Protocol | 同步计算机时钟 | 用于在网络中的计算机之间同步时间,确保时间的一致性。 |
|
||||
|
||||
**总结一下:**
|
||||
|
||||
- **TCP** 更适合那些对数据**可靠性、完整性和顺序性**要求高的应用,如网页浏览 (HTTP/HTTPS)、文件传输 (FTP/SFTP)、邮件收发 (SMTP/POP3/IMAP)。
|
||||
- **UDP** 则更适用于那些对**实时性要求高、能容忍少量数据丢失**的应用,如域名解析 (DNS)、实时音视频 (RTP)、在线游戏、网络管理 (SNMP) 等。
|
||||
|
||||
### TCP 三次握手和四次挥手(非常重要)
|
||||
|
||||
|
||||
@ -187,6 +187,37 @@ TIMESTAMP 只需要使用 4 个字节的存储空间,但是 DATETIME 需要耗
|
||||
|
||||
MySQL 中没有专门的布尔类型,而是用 TINYINT(1) 类型来表示布尔值。TINYINT(1) 类型可以存储 0 或 1,分别对应 false 或 true。
|
||||
|
||||
### 手机号存储用 INT 还是 VARCHAR?
|
||||
|
||||
存储手机号,**强烈推荐使用 VARCHAR 类型**,而不是 INT 或 BIGINT。主要原因如下:
|
||||
|
||||
1. **格式兼容性与完整性:**
|
||||
- 手机号可能包含前导零(如某些地区的固话区号)、国家代码前缀('+'),甚至可能带有分隔符('-' 或空格)。INT 或 BIGINT 这种数字类型会自动丢失这些重要的格式信息(比如前导零会被去掉,'+' 和 '-' 无法存储)。
|
||||
- VARCHAR 可以原样存储各种格式的号码,无论是国内的 11 位手机号,还是带有国家代码的国际号码,都能完美兼容。
|
||||
2. **非算术性:**手机号虽然看起来是数字,但我们从不对它进行数学运算(比如求和、平均值)。它本质上是一个标识符,更像是一个字符串。用 VARCHAR 更符合其数据性质。
|
||||
3. **查询灵活性:**
|
||||
- 业务中常常需要根据号段(前缀)进行查询,例如查找所有 "138" 开头的用户。使用 VARCHAR 类型配合 `LIKE '138%'` 这样的 SQL 查询既直观又高效。
|
||||
- 如果使用数字类型,进行类似的前缀匹配通常需要复杂的函数转换(如 CAST 或 SUBSTRING),或者使用范围查询(如 `WHERE phone >= 13800000000 AND phone < 13900000000`),这不仅写法繁琐,而且可能无法有效利用索引,导致性能下降。
|
||||
4. **加密存储的要求(非常关键):**
|
||||
- 出于数据安全和隐私合规的要求,手机号这类敏感个人信息通常必须加密存储在数据库中。
|
||||
- 加密后的数据(密文)是一长串字符串(通常由字母、数字、符号组成,或经过 Base64/Hex 编码),INT 或 BIGINT 类型根本无法存储这种密文。只有 VARCHAR、TEXT 或 BLOB 等类型可以。
|
||||
|
||||
**关于 VARCHAR 长度的选择:**
|
||||
|
||||
- **如果不加密存储(强烈不推荐!):** 考虑到国际号码和可能的格式符,VARCHAR(20) 到 VARCHAR(32) 通常是一个比较安全的范围,足以覆盖全球绝大多数手机号格式。VARCHAR(15) 可能对某些带国家码和格式符的号码来说不够用。
|
||||
- **如果进行加密存储(推荐的标准做法):** 长度必须根据所选加密算法产生的密文最大长度,以及可能的编码方式(如 Base64 会使长度增加约 1/3)来精确计算和设定。通常会需要更长的 VARCHAR 长度,例如 VARCHAR(128), VARCHAR(256) 甚至更长。
|
||||
|
||||
最后,来一张表格总结一下:
|
||||
|
||||
| 对比维度 | VARCHAR 类型(推荐) | INT/BIGINT 类型(不推荐) | 说明/备注 |
|
||||
| ---------------- | --------------------------------- | ---------------------------- | --------------------------------------------------------------------------- |
|
||||
| **格式兼容性** | ✔ 能存前导零、"+"、"-"、空格等 | ✘ 自动丢失前导零,不能存符号 | VARCHAR 能原样存储各种手机号格式,INT/BIGINT 只支持单纯数字,且前导零会消失 |
|
||||
| **完整性** | ✔ 不丢失任何格式信息 | ✘ 丢失格式信息 | 例如 "013800012345" 存进 INT 会变成 13800012345,"+" 也无法存储 |
|
||||
| **非算术性** | ✔ 适合存储“标识符” | ✘ 只适合做数值运算 | 手机号本质是字符串标识符,不做数学运算,VARCHAR 更贴合实际用途 |
|
||||
| **查询灵活性** | ✔ 支持 `LIKE '138%'` 等 | ✘ 查询前缀不方便或性能差 | 使用 VARCHAR 可高效按号段/前缀查询,数字类型需转为字符串或其他复杂处理 |
|
||||
| **加密存储支持** | ✔ 可存储加密密文(字母、符号等) | ✘ 无法存储密文 | 加密手机号后密文是字符串/二进制,只有 VARCHAR、TEXT、BLOB 等能兼容 |
|
||||
| **长度设置建议** | 15~20(未加密),加密视情况而定 | 无意义 | 不加密时 VARCHAR(15~20) 通用,加密后长度取决于算法和编码方式 |
|
||||
|
||||
## MySQL 基础架构
|
||||
|
||||
> 建议配合 [SQL 语句在 MySQL 中的执行过程](./how-sql-executed-in-mysql.md) 这篇文章来理解 MySQL 基础架构。另外,“一个 SQL 语句在 MySQL 中的执行流程”也是面试中比较常问的一个问题。
|
||||
@ -864,7 +895,7 @@ MySQL 性能优化是一个系统性工程,涉及多个方面,在面试中
|
||||
|
||||
- **读写分离:** 将读操作和写操作分离到不同的数据库实例,提升数据库的并发处理能力。
|
||||
- **分库分表:** 将数据分散到多个数据库实例或数据表中,降低单表数据量,提升查询效率。但要权衡其带来的复杂性和维护成本,谨慎使用。
|
||||
- **数据冷热分离**:根据数据的访问频率和业务重要性,将数据分为冷数据和热数据,冷数据一般存储在存储在低成本、低性能的介质中,热数据高性能存储介质中。
|
||||
- **数据冷热分离**:根据数据的访问频率和业务重要性,将数据分为冷数据和热数据,冷数据一般存储在低成本、低性能的介质中,热数据存储在高性能存储介质中。
|
||||
- **缓存机制:** 使用 Redis 等缓存中间件,将热点数据缓存到内存中,减轻数据库压力。这个非常常用,提升效果非常明显,性价比极高!
|
||||
|
||||
**4. 其他优化手段**
|
||||
|
||||
@ -283,33 +283,39 @@ public void add(int value) {
|
||||
|
||||
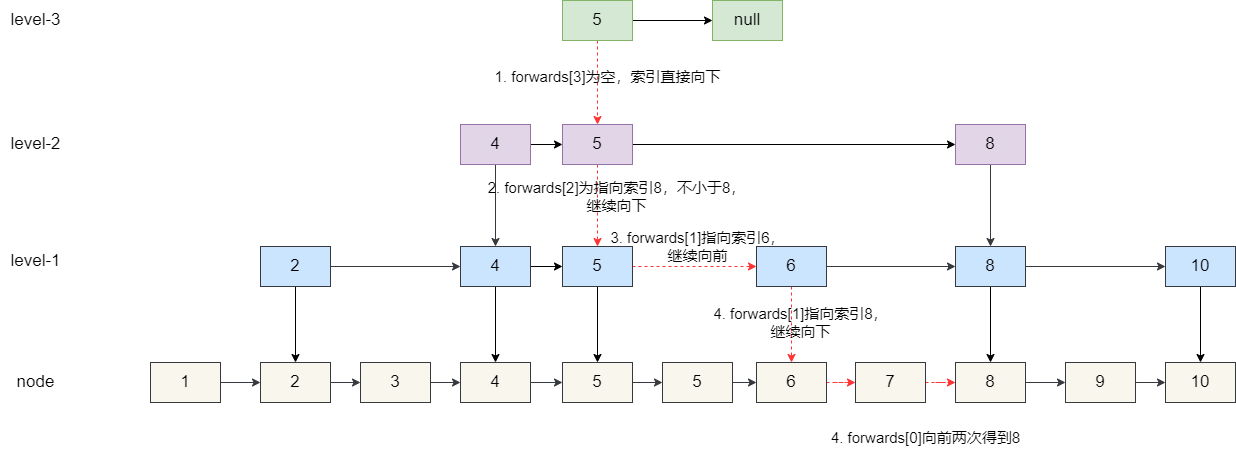
查询逻辑比较简单,从跳表最高级的索引开始定位找到小于要查的 value 的最大值,以下图为例,我们希望查找到节点 8:
|
||||
|
||||
1. 跳表的 3 级索引首先找找到 5 的索引,5 的 3 级索引 **forwards[3]** 指向空,索引直接向下。
|
||||
2. 来到 5 的 2 级索引,其后继 **forwards[2]** 指向 8,继续向下。
|
||||
3. 5 的 1 级索引 **forwards[1]** 指向索引 6,继续向前。
|
||||
4. 索引 6 的 **forwards[1]** 指向索引 8,继续向下。
|
||||
5. 我们在原始节点向前找到节点 7。
|
||||
6. 节点 7 后续就是节点 8,继续向前为节点 8,无法继续向下,结束搜寻。
|
||||
7. 判断 7 的前驱,等于 8,查找结束。
|
||||
|
||||
|
||||
|
||||
- **从最高层级开始 (3 级索引)** :查找指针 `p` 从头节点开始。在 3 级索引上,`p` 的后继 `forwards[2]`(假设最高 3 层,索引从 0 开始)指向节点 `5`。由于 `5 < 8`,指针 `p` 向右移动到节点 `5`。节点 `5` 在 3 级索引上的后继 `forwards[2]` 为 `null`(或指向一个大于 `8` 的节点,图中未画出)。当前层级向右查找结束,指针 `p` 保持在节点 `5`,**向下移动到 2 级索引**。
|
||||
- **在 2 级索引**:当前指针 `p` 为节点 `5`。`p` 的后继 `forwards[1]` 指向节点 `8`。由于 `8` 不小于 `8`(即 `8 < 8` 为 `false`),当前层级向右查找结束(`p` 不会移动到节点 `8`)。指针 `p` 保持在节点 `5`,**向下移动到 1 级索引**。
|
||||
- **在 1 级索引** :当前指针 `p` 为节点 `5`。`p` 的后继 `forwards[0]` 指向最底层的节点 `5`。由于 `5 < 8`,指针 `p` 向右移动到最底层的节点 `5`。此时,当前指针 `p` 为最底层的节点 `5`。其后继 `forwards[0]` 指向最底层的节点 `6`。由于 `6 < 8`,指针 `p` 向右移动到最底层的节点 `6`。当前指针 `p` 为最底层的节点 `6`。其后继 `forwards[0]` 指向最底层的节点 `7`。由于 `7 < 8`,指针 `p` 向右移动到最底层的节点 `7`。当前指针 `p` 为最底层的节点 `7`。其后继 `forwards[0]` 指向最底层的节点 `8`。由于 `8` 不小于 `8`(即 `8 < 8` 为 `false`),当前层级向右查找结束。此时,已经遍历完所有层级,`for` 循环结束。
|
||||
- **最终定位与检查** :经过所有层级的查找,指针 `p` 最终停留在最底层(0 级索引)的节点 `7`。这个节点是整个跳表中值小于目标值 `8` 的那个最大的节点。检查节点 `7` 的**后继节点**(即 `p.forwards[0]`):`p.forwards[0]` 指向节点 `8`。判断 `p.forwards[0].data`(即节点 `8` 的值)是否等于目标值 `8`。条件满足(`8 == 8`),**查找成功,找到节点 `8`**。
|
||||
|
||||
所以我们的代码实现也很上述步骤差不多,从最高级索引开始向前查找,如果不为空且小于要查找的值,则继续向前搜寻,遇到不小于的节点则继续向下,如此往复,直到得到当前跳表中小于查找值的最大节点,查看其前驱是否等于要查找的值:
|
||||
|
||||
```java
|
||||
public Node get(int value) {
|
||||
Node p = h;
|
||||
//找到小于value的最大值
|
||||
Node p = h; // 从头节点开始
|
||||
|
||||
// 从最高层级索引开始,逐层向下
|
||||
for (int i = levelCount - 1; i >= 0; i--) {
|
||||
// 在当前层级向右查找,直到 p.forwards[i] 为 null
|
||||
// 或者 p.forwards[i].data 大于等于目标值 value
|
||||
while (p.forwards[i] != null && p.forwards[i].data < value) {
|
||||
p = p.forwards[i];
|
||||
p = p.forwards[i]; // 向右移动
|
||||
}
|
||||
}
|
||||
//如果p的前驱节点等于value则直接返回
|
||||
if (p.forwards[0] != null && p.forwards[0].data == value) {
|
||||
return p.forwards[0];
|
||||
// 此时 p.forwards[i] 为 null,或者 p.forwards[i].data >= value
|
||||
// 或者 p 是当前层级中小于 value 的最大节点(如果存在这样的节点)
|
||||
}
|
||||
|
||||
return null;
|
||||
// 经过所有层级的查找,p 现在是原始链表(0级索引)中
|
||||
// 小于目标值 value 的最大节点(或者头节点,如果所有元素都大于等于 value)
|
||||
|
||||
// 检查 p 在原始链表中的下一个节点是否是目标值
|
||||
if (p.forwards[0] != null && p.forwards[0].data == value) {
|
||||
return p.forwards[0]; // 找到了,返回该节点
|
||||
}
|
||||
|
||||
return null; // 未找到
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
@ -101,7 +101,7 @@ RocketMQ、 Kafka、Pulsar、QMQ 都提供了事务相关的功能。事务允
|
||||
|
||||
### 延时/定时处理
|
||||
|
||||
消息发送后不会立即被消费,而是指定一个时间,到时间后再消费。大部分消息队列,例如 RocketMQ、RabbitMQ、Pulsar、Kafka,都支持定时/延时消息。
|
||||
消息发送后不会立即被消费,而是指定一个时间,到时间后再消费。大部分消息队列,例如 RocketMQ、RabbitMQ、Pulsar,都支持定时/延时消息。
|
||||
|
||||
|
||||
|
||||
|
||||
14
docs/home.md
14
docs/home.md
@ -299,15 +299,13 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8](https://docs.oracle.
|
||||
- [JWT 优缺点分析以及常见问题解决方案](./system-design/security/advantages-and-disadvantages-of-jwt.md)
|
||||
- [SSO 单点登录详解](./system-design/security/sso-intro.md)
|
||||
- [权限系统设计详解](./system-design/security/design-of-authority-system.md)
|
||||
|
||||
#### 数据安全
|
||||
|
||||
- [常见加密算法总结](./system-design/security/encryption-algorithms.md)
|
||||
|
||||
#### 数据脱敏
|
||||
|
||||
数据脱敏说的就是我们根据特定的规则对敏感信息数据进行变形,比如我们把手机号、身份证号某些位数使用 \* 来代替。
|
||||
|
||||
#### 敏感词过滤
|
||||
|
||||
[敏感词过滤方案总结](./system-design/security/sentive-words-filter.md)
|
||||
- [敏感词过滤方案总结](./system-design/security/sentive-words-filter.md)
|
||||
- [数据脱敏方案总结](./system-design/security/data-desensitization.md)
|
||||
- [为什么前后端都要做数据校验](./system-design/security/data-validation.md)
|
||||
|
||||
### 定时任务
|
||||
|
||||
|
||||
@ -332,7 +332,7 @@ static final int hash(Object key) {
|
||||
- **位字段管理**:例如存储和操作多个布尔值。
|
||||
- **哈希算法和加密解密**:通过移位和与、或等操作来混淆数据。
|
||||
- **数据压缩**:例如霍夫曼编码通过移位运算符可以快速处理和操作二进制数据,以生成紧凑的压缩格式。
|
||||
- **数据校验**:例如 CRC(循环冗余校验)通过移位和多项式除法生成和校验数据完整性。。
|
||||
- **数据校验**:例如 CRC(循环冗余校验)通过移位和多项式除法生成和校验数据完整性。
|
||||
- **内存对齐**:通过移位操作,可以轻松计算和调整数据的对齐地址。
|
||||
|
||||
掌握最基本的移位运算符知识还是很有必要的,这不光可以帮助我们在代码中使用,还可以帮助我们理解源码中涉及到移位运算符的代码。
|
||||
|
||||
@ -516,11 +516,94 @@ private void increment(int x){
|
||||
1 2 3 4 5 6 7 8 9
|
||||
```
|
||||
|
||||
在上面的例子中,使用两个线程去修改`int`型属性`a`的值,并且只有在`a`的值等于传入的参数`x`减一时,才会将`a`的值变为`x`,也就是实现对`a`的加一的操作。流程如下所示:
|
||||
如果你把上面这段代码贴到 IDE 中运行,会发现并不能得到目标输出结果。有朋友已经在 Github 上指出了这个问题:[issue#2650](https://github.com/Snailclimb/JavaGuide/issues/2650)。下面是修正后的代码:
|
||||
|
||||
```java
|
||||
private volatile int a = 0; // 共享变量,初始值为 0
|
||||
private static final Unsafe unsafe;
|
||||
private static final long fieldOffset;
|
||||
|
||||
static {
|
||||
try {
|
||||
// 获取 Unsafe 实例
|
||||
Field theUnsafe = Unsafe.class.getDeclaredField("theUnsafe");
|
||||
theUnsafe.setAccessible(true);
|
||||
unsafe = (Unsafe) theUnsafe.get(null);
|
||||
// 获取 a 字段的内存偏移量
|
||||
fieldOffset = unsafe.objectFieldOffset(CasTest.class.getDeclaredField("a"));
|
||||
} catch (Exception e) {
|
||||
throw new RuntimeException("Failed to initialize Unsafe or field offset", e);
|
||||
}
|
||||
}
|
||||
|
||||
public static void main(String[] args) {
|
||||
CasTest casTest = new CasTest();
|
||||
|
||||
Thread t1 = new Thread(() -> {
|
||||
for (int i = 1; i <= 4; i++) {
|
||||
casTest.incrementAndPrint(i);
|
||||
}
|
||||
});
|
||||
|
||||
Thread t2 = new Thread(() -> {
|
||||
for (int i = 5; i <= 9; i++) {
|
||||
casTest.incrementAndPrint(i);
|
||||
}
|
||||
});
|
||||
|
||||
t1.start();
|
||||
t2.start();
|
||||
|
||||
// 等待线程结束,以便观察完整输出 (可选,用于演示)
|
||||
try {
|
||||
t1.join();
|
||||
t2.join();
|
||||
} catch (InterruptedException e) {
|
||||
Thread.currentThread().interrupt();
|
||||
}
|
||||
}
|
||||
|
||||
// 将递增和打印操作封装在一个原子性更强的方法内
|
||||
private void incrementAndPrint(int targetValue) {
|
||||
while (true) {
|
||||
int currentValue = a; // 读取当前 a 的值
|
||||
// 只有当 a 的当前值等于目标值的前一个值时,才尝试更新
|
||||
if (currentValue == targetValue - 1) {
|
||||
if (unsafe.compareAndSwapInt(this, fieldOffset, currentValue, targetValue)) {
|
||||
// CAS 成功,说明成功将 a 更新为 targetValue
|
||||
System.out.print(targetValue + " ");
|
||||
break; // 成功更新并打印后退出循环
|
||||
}
|
||||
// 如果 CAS 失败,意味着在读取 currentValue 和执行 CAS 之间,a 的值被其他线程修改了,
|
||||
// 此时 currentValue 已经不是 a 的最新值,需要重新读取并重试。
|
||||
}
|
||||
// 如果 currentValue != targetValue - 1,说明还没轮到当前线程更新,
|
||||
// 或者已经被其他线程更新超过了,让出CPU给其他线程机会。
|
||||
// 对于严格顺序递增的场景,如果 current > targetValue - 1,可能意味着逻辑错误或死循环,
|
||||
// 但在此示例中,我们期望线程能按顺序执行。
|
||||
Thread.yield(); // 提示CPU调度器可以切换线程,减少无效自旋
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
在上述例子中,我们创建了两个线程,它们都尝试修改共享变量 a。每个线程在调用 `incrementAndPrint(targetValue)` 方法时:
|
||||
|
||||
1. 会先读取 a 的当前值 `currentValue`。
|
||||
2. 检查 `currentValue` 是否等于 `targetValue - 1` (即期望的前一个值)。
|
||||
3. 如果条件满足,则调用`unsafe.compareAndSwapInt()` 尝试将 `a` 从 `currentValue` 更新到 `targetValue`。
|
||||
4. 如果 CAS 操作成功(返回 true),则打印 `targetValue` 并退出循环。
|
||||
5. 如果 CAS 操作失败,或者 `currentValue` 不满足条件,则当前线程会继续循环(自旋),并通过 `Thread.yield()` 尝试让出 CPU,直到成功更新并打印或者条件满足。
|
||||
|
||||
这种机制确保了每个数字(从 1 到 9)只会被成功设置并打印一次,并且是按顺序进行的。
|
||||
|
||||

|
||||
|
||||
需要注意的是,在调用`compareAndSwapInt`方法后,会直接返回`true`或`false`的修改结果,因此需要我们在代码中手动添加自旋的逻辑。在`AtomicInteger`类的设计中,也是采用了将`compareAndSwapInt`的结果作为循环条件,直至修改成功才退出死循环的方式来实现的原子性的自增操作。
|
||||
需要注意的是:
|
||||
|
||||
1. **自旋逻辑:** `compareAndSwapInt` 方法本身只执行一次比较和交换操作,并立即返回结果。因此,为了确保操作最终成功(在值符合预期的情况下),我们需要在代码中显式地实现自旋逻辑(如 `while(true)` 循环),不断尝试直到 CAS 操作成功。
|
||||
2. **`AtomicInteger` 的实现:** JDK 中的 `java.util.concurrent.atomic.AtomicInteger` 类内部正是利用了类似的 CAS 操作和自旋逻辑来实现其原子性的 `getAndIncrement()`, `compareAndSet()` 等方法。直接使用 `AtomicInteger` 通常是更安全、更推荐的做法,因为它封装了底层的复杂性。
|
||||
3. **ABA 问题:** CAS 操作本身存在 ABA 问题(一个值从 A 变为 B,再变回 A,CAS 检查时会认为值没有变过)。在某些场景下,如果值的变化历史很重要,可能需要使用 `AtomicStampedReference` 来解决。但在本例的简单递增场景中,ABA 问题通常不构成影响。
|
||||
4. **CPU 消耗:** 长时间的自旋会消耗 CPU 资源。在竞争激烈或条件长时间不满足的情况下,可以考虑加入更复杂的退避策略(如 `Thread.sleep()` 或 `LockSupport.parkNanos()`)来优化。
|
||||
|
||||
### 线程调度
|
||||
|
||||
|
||||
@ -134,6 +134,7 @@ public static <T> T requireNonNull(T obj) {
|
||||
return obj;
|
||||
}
|
||||
```
|
||||
> `Collectors`也提供了无需mergeFunction的`toMap()`方法,但此时若出现key冲突,则会抛出`duplicateKeyException`异常,因此强烈建议使用`toMap()`方法必填mergeFunction。
|
||||
|
||||
## 集合遍历
|
||||
|
||||
|
||||
203
docs/system-design/security/data-validation.md
Normal file
203
docs/system-design/security/data-validation.md
Normal file
@ -0,0 +1,203 @@
|
||||
---
|
||||
title: 为什么前后端都要做数据校验
|
||||
category: 系统设计
|
||||
tag:
|
||||
- 安全
|
||||
---
|
||||
|
||||
> 相关面试题:
|
||||
>
|
||||
> - 前端做了校验,后端还还需要做校验吗?
|
||||
> - 前端已经做了数据校验,为什么后端还需要再做一遍同样(甚至更严格)的校验呢?
|
||||
> - 前端/后端需要对哪些内容进行校验?
|
||||
|
||||
咱们平时做 Web 开发,不管是写前端页面还是后端接口,都离不开跟数据打交道。那怎么保证这些传来传去的数据是靠谱的、安全的呢?这就得靠**数据校验**了。而且,这活儿,前端得干,后端**更得干**,还得加上**权限校验**这道重要的“锁”,缺一不可!
|
||||
|
||||
为啥这么说?你想啊,前端校验主要是为了用户体验和挡掉一些明显的“瞎填”数据,但懂点技术的人绕过前端校验简直不要太轻松(比如直接用 Postman 之类的工具发请求)。所以,**后端校验才是咱们系统安全和数据准确性的最后一道,也是最硬核的防线**。它得确保进到系统里的数据不仅格式对,还得符合业务规矩,最重要的是,执行这个操作的人得有**权限**!
|
||||
|
||||
|
||||
|
||||
## 前端校验
|
||||
|
||||
前端校验就像个贴心的门卫,主要目的是在用户填数据的时候,就赶紧告诉他哪儿不对,让他改,省得提交了半天,结果后端说不行,还得重来。这样做的好处显而易见:
|
||||
|
||||
1. **用户体验好:** 输入时就有提示,错了马上知道,改起来方便,用户感觉流畅不闹心。
|
||||
2. **减轻后端压力:** 把一些明显格式错误、必填项没填的数据在前端就拦下来,减少了发往后端的无效请求,省了服务器资源和网络流量。需要注意的是,后端同样还是要校验,只是加上前端校验可以减少很多无效请求。
|
||||
|
||||
那前端一般都得校验点啥呢?
|
||||
|
||||
- **必填项校验:** 最基本的,该填的地儿可不能空着。
|
||||
- **格式校验:** 比如邮箱得像个邮箱样儿 (xxx@xx.com),手机号得是 11 位数字等。正则表达式这时候就派上用场了。
|
||||
- **重复输入校验:** 确保两次输入的内容一致,例如注册时的“确认密码”字段。
|
||||
- **范围/长度校验:** 年龄不能是负数吧?密码长度得在 6 到 20 位之间吧?这种都得看着。
|
||||
- **合法性/业务校验:** 比如用户名是不是已经被注册了?选的商品还有没有库存?这得根据具体业务来,需要配合后端来做。
|
||||
- **文件上传校验:**限制文件类型(如仅支持 `.jpg`、`.png` 格式)和文件大小。
|
||||
- **安全性校验:** 防范像 XSS(跨站脚本攻击)这种坏心思,对用户输入的东西做点处理,别让人家写的脚本在咱们页面上跑起来。
|
||||
- ...等等,根据业务需求来。
|
||||
|
||||
总之,前端校验的核心是 **引导用户正确输入** 和 **提升交互体验**。
|
||||
|
||||
## 后端校验
|
||||
|
||||
前端校验只是第一道防线,虽然提升了用户体验,但毕竟可以被绕过,真正起决定性作用的是后端校验。后端需要对所有前端传来的数据都抱着“可能有问题”的态度,进行全面审查。后端校验不仅要覆盖前端的基本检查(如格式、范围、长度等),还需要更严格、更深入的验证,确保系统的安全性和数据的一致性。以下是后端校验的重点内容:
|
||||
|
||||
1. **完整性校验:** 接口文档中明确要求的字段必须存在,例如 `userId` 和 `orderId`。如果缺失任何必需字段,后端应立即返回错误,拒绝处理请求。
|
||||
2. **合法性/存在性校验:** 验证传入的数据是否真实有效。例如,传过来的 `productId` 是否存在于数据库中?`couponId` 是否已经过期或被使用?这通常需要通过查库或调用其他服务来确认。
|
||||
3. **一致性校验:** 针对涉及多个数据对象的操作,验证它们是否符合业务逻辑。例如,更新订单状态前,需要确保订单的当前状态允许修改,不能直接从“未支付”跳到“已完成”。一致性校验是保证数据流转正确性的关键。
|
||||
4. **安全性校验:** 后端必须防范各种恶意攻击,包括但不限于 XSS、SQL 注入等。所有外部输入都应进行严格的过滤和验证,例如使用参数化查询防止 SQL 注入,或对返回的 HTML 数据进行转义,避免跨站脚本攻击。
|
||||
5. ...基本上,前端能做的校验,后端为了安全都得再来一遍。
|
||||
|
||||
在 Java 后端,每次都手写 if-else 来做这些基础校验太累了。好在 Java 社区给我们提供了 **Bean Validation** 这套标准规范。它允许我们用**注解**的方式,直接在 JavaBean(比如我们的 DTO 对象)的属性上声明校验规则,非常方便。
|
||||
|
||||
- **JSR 303 (1.0):** 打下了基础,引入了 `@NotNull`, `@Size`, `@Min`, `@Max` 这些老朋友。
|
||||
- **JSR 349 (1.1):** 增加了对方法参数和返回值的校验,还有分组校验等增强。
|
||||
- **JSR 380 (2.0):** 拥抱 Java 8,支持了新的日期时间 API,还加了 `@NotEmpty`, `@NotBlank`, `@Email` 等更实用的注解。
|
||||
|
||||
早期的 Spring Boot (大概 2.3.x 之前): spring-boot-starter-web 里自带了 `hibernate-validator`,你啥都不用加。
|
||||
|
||||
Spring Boot 2.3.x 及之后: 为了更灵活,校验相关的依赖被单独拎出来了。你需要手动添加 `spring-boot-starter-validation` 依赖:
|
||||
|
||||
```xml
|
||||
<dependency>
|
||||
<groupId>org.springframework.boot</groupId>
|
||||
<artifactId>spring-boot-starter-validation</artifactId>
|
||||
</dependency>
|
||||
```
|
||||
|
||||
Bean Validation 规范及其实现(如 Hibernate Validator)提供了丰富的注解,用于声明式地定义校验规则。以下是一些常用的注解及其说明:
|
||||
|
||||
- `@NotNull`: 检查被注解的元素(任意类型)不能为 `null`。
|
||||
- `@NotEmpty`: 检查被注解的元素(如 `CharSequence`、`Collection`、`Map`、`Array`)不能为 `null` 且其大小/长度不能为 0。注意:对于字符串,`@NotEmpty` 允许包含空白字符的字符串,如 `" "`。
|
||||
- `@NotBlank`: 检查被注解的 `CharSequence`(如 `String`)不能为 `null`,并且去除首尾空格后的长度必须大于 0。(即,不能为空白字符串)。
|
||||
- `@Null`: 检查被注解的元素必须为 `null`。
|
||||
- `@AssertTrue` / `@AssertFalse`: 检查被注解的 `boolean` 或 `Boolean` 类型元素必须为 `true` / `false`。
|
||||
- `@Min(value)` / `@Max(value)`: 检查被注解的数字类型(或其字符串表示)的值必须大于等于 / 小于等于指定的 `value`。适用于整数类型(`byte`、`short`、`int`、`long`、`BigInteger` 等)。
|
||||
- `@DecimalMin(value)` / `@DecimalMax(value)`: 功能类似 `@Min` / `@Max`,但适用于包含小数的数字类型(`BigDecimal`、`BigInteger`、`CharSequence`、`byte`、`short`、`int`、`long`及其包装类)。 `value` 必须是数字的字符串表示。
|
||||
- `@Size(min=, max=)`: 检查被注解的元素(如 `CharSequence`、`Collection`、`Map`、`Array`)的大小/长度必须在指定的 `min` 和 `max` 范围之内(包含边界)。
|
||||
- `@Digits(integer=, fraction=)`: 检查被注解的数字类型(或其字符串表示)的值,其整数部分的位数必须 ≤ `integer`,小数部分的位数必须 ≤ `fraction`。
|
||||
- `@Pattern(regexp=, flags=)`: 检查被注解的 `CharSequence`(如 `String`)是否匹配指定的正则表达式 (`regexp`)。`flags` 可以指定匹配模式(如不区分大小写)。
|
||||
- `@Email`: 检查被注解的 `CharSequence`(如 `String`)是否符合 Email 格式(内置了一个相对宽松的正则表达式)。
|
||||
- `@Past` / `@Future`: 检查被注解的日期或时间类型(`java.util.Date`、`java.util.Calendar`、JSR 310 `java.time` 包下的类型)是否在当前时间之前 / 之后。
|
||||
- `@PastOrPresent` / `@FutureOrPresent`: 类似 `@Past` / `@Future`,但允许等于当前时间。
|
||||
- ......
|
||||
|
||||
当 Controller 方法使用 `@RequestBody` 注解来接收请求体并将其绑定到一个对象时,可以在该参数前添加 `@Valid` 注解来触发对该对象的校验。如果验证失败,它将抛出`MethodArgumentNotValidException`。
|
||||
|
||||
```java
|
||||
@Data
|
||||
@AllArgsConstructor
|
||||
@NoArgsConstructor
|
||||
public class Person {
|
||||
@NotNull(message = "classId 不能为空")
|
||||
private String classId;
|
||||
|
||||
@Size(max = 33)
|
||||
@NotNull(message = "name 不能为空")
|
||||
private String name;
|
||||
|
||||
@Pattern(regexp = "((^Man$|^Woman$|^UGM$))", message = "sex 值不在可选范围")
|
||||
@NotNull(message = "sex 不能为空")
|
||||
private String sex;
|
||||
|
||||
@Email(message = "email 格式不正确")
|
||||
@NotNull(message = "email 不能为空")
|
||||
private String email;
|
||||
}
|
||||
|
||||
|
||||
@RestController
|
||||
@RequestMapping("/api")
|
||||
public class PersonController {
|
||||
@PostMapping("/person")
|
||||
public ResponseEntity<Person> getPerson(@RequestBody @Valid Person person) {
|
||||
return ResponseEntity.ok().body(person);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
对于直接映射到方法参数的简单类型数据(如路径变量 `@PathVariable` 或请求参数 `@RequestParam`),校验方式略有不同:
|
||||
|
||||
1. **在 Controller 类上添加 `@Validated` 注解**:这个注解是 Spring 提供的(非 JSR 标准),它使得 Spring 能够处理方法级别的参数校验注解。**这是必需步骤。**
|
||||
2. **将校验注解直接放在方法参数上**:将 `@Min`, `@Max`, `@Size`, `@Pattern` 等校验注解直接应用于对应的 `@PathVariable` 或 `@RequestParam` 参数。
|
||||
|
||||
一定一定不要忘记在类上加上 `@Validated` 注解了,这个参数可以告诉 Spring 去校验方法参数。
|
||||
|
||||
```java
|
||||
@RestController
|
||||
@RequestMapping("/api")
|
||||
@Validated // 关键步骤 1: 必须在类上添加 @Validated
|
||||
public class PersonController {
|
||||
|
||||
@GetMapping("/person/{id}")
|
||||
public ResponseEntity<Integer> getPersonByID(
|
||||
@PathVariable("id")
|
||||
@Max(value = 5, message = "ID 不能超过 5") // 关键步骤 2: 校验注解直接放在参数上
|
||||
Integer id
|
||||
) {
|
||||
// 如果传入的 id > 5,Spring 会在进入方法体前抛出 ConstraintViolationException 异常。
|
||||
// 全局异常处理器同样需要处理此异常。
|
||||
return ResponseEntity.ok().body(id);
|
||||
}
|
||||
|
||||
@GetMapping("/person")
|
||||
public ResponseEntity<String> findPersonByName(
|
||||
@RequestParam("name")
|
||||
@NotBlank(message = "姓名不能为空") // 同样适用于 @RequestParam
|
||||
@Size(max = 10, message = "姓名长度不能超过 10")
|
||||
String name
|
||||
) {
|
||||
return ResponseEntity.ok().body("Found person: " + name);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Bean Validation 主要解决的是**数据格式、语法层面**的校验。但光有这个还不够。
|
||||
|
||||
## 权限校验
|
||||
|
||||
数据格式都验过了,没问题。但是,**这个操作,当前登录的这个用户,他有权做吗?** 这就是**权限校验**要解决的问题。比如:
|
||||
|
||||
- 普通用户能修改别人的订单吗?(不行)
|
||||
- 游客能访问管理员后台接口吗?(不行)
|
||||
- 游客能管理其他用户的信息吗?(不行)
|
||||
- VIP 用户能使用专属的优惠券吗?(可以)
|
||||
- ......
|
||||
|
||||
权限校验发生在**数据校验之后**,它关心的是“**谁 (Who)** 能对 **什么资源 (What)** 执行 **什么操作 (Action)**”。
|
||||
|
||||
**为啥权限校验这么重要?**
|
||||
|
||||
- **安全基石:** 防止未经授权的访问和操作,保护用户数据和系统安全。
|
||||
- **业务隔离:** 确保不同角色(管理员、普通用户、VIP 用户等)只能访问和操作其权限范围内的功能。
|
||||
- **合规要求:** 很多行业法规对数据访问权限有严格要求。
|
||||
|
||||
目前 Java 后端主流的方式是使用成熟的安全框架来实现权限校验,而不是自己手写(容易出错且难以维护)。
|
||||
|
||||
1. **Spring Security (业界标准,推荐):** 基于过滤器链(Filter Chain)拦截请求,进行认证(Authentication - 你是谁?)和授权(Authorization - 你能干啥?)。Spring Security 功能强大、社区活跃、与 Spring 生态无缝集成。不过,配置相对复杂,学习曲线较陡峭。
|
||||
2. **Apache Shiro:** 另一个流行的安全框架,相对 Spring Security 更轻量级,API 更直观易懂。同样提供认证、授权、会话管理、加密等功能。对于不熟悉 Spring 或觉得 Spring Security 太重的项目,是一个不错的选择。
|
||||
3. **Sa-Token:** 国产的轻量级 Java 权限认证框架。支持认证授权、单点登录、踢人下线、自动续签等功能。相比于 Spring Security 和 Shiro 来说,Sa-Token 内置的开箱即用的功能更多,使用也更简单。
|
||||
4. **手动检查 (不推荐用于复杂场景):** 在 Service 层或 Controller 层代码里,手动获取当前用户信息(例如从 SecurityContextHolder 或 Session 中),然后 if-else 判断用户角色或权限。权限逻辑与业务逻辑耦合、代码重复、难以维护、容易遗漏。只适用于非常简单的权限场景。
|
||||
|
||||
**权限模型简介:**
|
||||
|
||||
- **RBAC (Role-Based Access Control):** 基于角色的访问控制。给用户分配角色,给角色分配权限。用户拥有其所有角色的权限总和。这是最常见的模型。
|
||||
- **ABAC (Attribute-Based Access Control):** 基于属性的访问控制。决策基于用户属性、资源属性、操作属性和环境属性。更灵活但也更复杂。
|
||||
|
||||
一般情况下,绝大部分系统都使用的是 RBAC 权限模型或者其简化版本。用一个图来描述如下:
|
||||
|
||||

|
||||
|
||||
关于权限系统设计的详细介绍,可以看这篇文章:[权限系统设计详解](https://javaguide.cn/system-design/security/design-of-authority-system.html)。
|
||||
|
||||
## 总结
|
||||
|
||||
总而言之,要想构建一个安全、稳定、用户体验好的 Web 应用,前后端数据校验和后端权限校验这三道关卡,都得设好,而且各有侧重:
|
||||
|
||||
- **前端数据校验:** 提升用户体验,减少无效请求,是第一道“友好”的防线。
|
||||
- **后端数据校验:** 保证数据格式正确、符合业务规则,是防止“脏数据”入库的“技术”防线。 Bean Validation 允许我们用注解的方式,直接在 JavaBean(比如我们的 DTO 对象)的属性上声明校验规则,非常方便。
|
||||
- **后端权限校验:** 确保“对的人”做“对的事”,是防止越权操作的“安全”防线。Spring Security、Shiro、Sa-Token 等框架可以帮助我们实现权限校验。
|
||||
|
||||
## 参考
|
||||
|
||||
- 为什么前后端都需要进行数据校验?: <https://juejin.cn/post/7306045519099658240>
|
||||
- 权限系统设计详解:<https://javaguide.cn/system-design/security/design-of-authority-system.html>
|
||||
Loading…
x
Reference in New Issue
Block a user