mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
Compare commits
6 Commits
7c6e03dd21
...
45ac7d1095
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
45ac7d1095 | ||
|
|
428c0e76df | ||
|
|
02ec4e4150 | ||
|
|
b5cd6d3fe4 | ||
|
|
700401e20a | ||
|
|
f7abbcc539 |
@ -363,7 +363,7 @@ MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较
|
||||
|
||||
**SHA**
|
||||
|
||||
安全散列算法。**SHA** 包括**SHA-1**、**SHA-2**和**SHA-3**三个版本。该算法的基本思想是:接收一段明文数据,通过不可逆的方式将其转换为固定长度的密文。简单来说,SHA将输入数据(即预映射或消息)转化为固定长度、较短的输出值,称为散列值(或信息摘要、信息认证码)。SHA-1已被证明不够安全,因此逐渐被SHA-2取代,而SHA-3则作为SHA系列的最新版本,采用不同的结构(Keccak算法)提供更高的安全性和灵活性。
|
||||
安全散列算法。**SHA** 包括**SHA-1**、**SHA-2**和**SHA-3**三个版本。该算法的基本思想是:接收一段明文数据,通过不可逆的方式将其转换为固定长度的密文。简单来说,SHA 将输入数据(即预映射或消息)转化为固定长度、较短的输出值,称为散列值(或信息摘要、信息认证码)。SHA-1 已被证明不够安全,因此逐渐被 SHA-2 取代,而 SHA-3 则作为 SHA 系列的最新版本,采用不同的结构(Keccak 算法)提供更高的安全性和灵活性。
|
||||
|
||||
**SM3**
|
||||
|
||||
|
||||
@ -355,6 +355,8 @@ Linux 系统是一个多用户多任务的分时操作系统,任何一个要
|
||||
- `ifconfig` 或 `ip`:用于查看系统的网络接口信息,包括网络接口的 IP 地址、MAC 地址、状态等。
|
||||
- `netstat [选项]`:用于查看系统的网络连接状态和网络统计信息,可以查看当前的网络连接情况、监听端口、网络协议等。
|
||||
- `ss [选项]`:比 `netstat` 更好用,提供了更快速、更详细的网络连接信息。
|
||||
- `nload`:`sar` 和 `nload` 都可以监控网络流量,但`sar` 的输出是文本形式的数据,不够直观。`nload` 则是一个专门用于实时监控网络流量的工具,提供图形化的终端界面,更加直观。不过,`nload` 不保存历史数据,所以它不适合用于长期趋势分析。并且,系统并没有默认安装它,需要手动安装。
|
||||
- `sudo hostnamectl set-hostname 新主机名`:更改主机名,并且重启后依然有效。`sudo hostname 新主机名`也可以更改主机名。不过需要注意的是,使用 `hostname` 命令直接更改主机名只是临时生效,系统重启后会恢复为原来的主机名。
|
||||
|
||||
### 其他
|
||||
|
||||
|
||||
@ -153,9 +153,27 @@ Redis 7.0 版本之后,AOF 重写机制得到了优化改进。下面这段内
|
||||
|
||||
### AOF 校验机制了解吗?
|
||||
|
||||
AOF 校验机制是 Redis 在启动时对 AOF 文件进行检查,以判断文件是否完整,是否有损坏或者丢失的数据。这个机制的原理其实非常简单,就是通过使用一种叫做 **校验和(checksum)** 的数字来验证 AOF 文件。这个校验和是通过对整个 AOF 文件内容进行 CRC64 算法计算得出的数字。如果文件内容发生了变化,那么校验和也会随之改变。因此,Redis 在启动时会比较计算出的校验和与文件末尾保存的校验和(计算的时候会把最后一行保存校验和的内容给忽略点),从而判断 AOF 文件是否完整。如果发现文件有问题,Redis 就会拒绝启动并提供相应的错误信息。AOF 校验机制十分简单有效,可以提高 Redis 数据的可靠性。
|
||||
纯 AOF 模式下,Redis 不会对整个 AOF 文件使用校验和(如 CRC64),而是通过逐条解析文件中的命令来验证文件的有效性。如果解析过程中发现语法错误(如命令不完整、格式错误),Redis 会终止加载并报错,从而避免错误数据载入内存。
|
||||
|
||||
类似地,RDB 文件也有类似的校验机制来保证 RDB 文件的正确性,这里就不重复进行介绍了。
|
||||
在 **混合持久化模式**(Redis 4.0 引入)下,AOF 文件由两部分组成:
|
||||
|
||||
- **RDB 快照部分**:文件以固定的 `REDIS` 字符开头,存储某一时刻的内存数据快照,并在快照数据末尾附带一个 CRC64 校验和(位于 RDB 数据块尾部、AOF 增量部分之前)。
|
||||
- **AOF 增量部分**:紧随 RDB 快照部分之后,记录 RDB 快照生成后的增量写命令。这部分增量命令以 Redis 协议格式逐条记录,无整体或全局校验和。
|
||||
|
||||
RDB 文件结构的核心部分如下:
|
||||
|
||||
| **字段** | **解释** |
|
||||
| ----------------- | ---------------------------------------------- |
|
||||
| `"REDIS"` | 固定以该字符串开始 |
|
||||
| `RDB_VERSION` | RDB 文件的版本号 |
|
||||
| `DB_NUM` | Redis 数据库编号,指明数据需要存放到哪个数据库 |
|
||||
| `KEY_VALUE_PAIRS` | Redis 中具体键值对的存储 |
|
||||
| `EOF` | RDB 文件结束标志 |
|
||||
| `CHECK_SUM` | 8 字节确保 RDB 完整性的校验和 |
|
||||
|
||||
Redis 启动并加载 AOF 文件时,首先会校验文件开头 RDB 快照部分的数据完整性,即计算该部分数据的 CRC64 校验和,并与紧随 RDB 数据之后、AOF 增量部分之前存储的 CRC64 校验和值进行比较。如果 CRC64 校验和不匹配,Redis 将拒绝启动并报告错误。
|
||||
|
||||
RDB 部分校验通过后,Redis 随后逐条解析 AOF 部分的增量命令。如果解析过程中出现错误(如不完整的命令或格式错误),Redis 会停止继续加载后续命令,并报告错误,但此时 Redis 已经成功加载了 RDB 快照部分的数据。
|
||||
|
||||
## Redis 4.0 对于持久化机制做了什么优化?
|
||||
|
||||
|
||||
@ -87,7 +87,7 @@ PS:篇幅问题,我这并没有对上面提到的分布式缓存选型做详
|
||||
|
||||
**区别**:
|
||||
|
||||
1. **数据类型**:Redis 支持更丰富的数据类型(支持更复杂的应用场景)。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list、set、zset、hash 等数据结构的存储;而Memcached 只支持最简单的 k/v 数据类型。
|
||||
1. **数据类型**:Redis 支持更丰富的数据类型(支持更复杂的应用场景)。Redis 不仅仅支持简单的 k/v 类型的数据,同时还提供 list、set、zset、hash 等数据结构的存储;而 Memcached 只支持最简单的 k/v 数据类型。
|
||||
2. **数据持久化**:Redis 支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用;而 Memcached 把数据全部存在内存之中。也就是说,Redis 有灾难恢复机制,而 Memcached 没有。
|
||||
3. **集群模式支持**:Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;而 Redis 自 3.0 版本起是原生支持集群模式的。
|
||||
4. **线程模型**:Memcached 是多线程、非阻塞 IO 复用的网络模型;而 Redis 使用单线程的多路 IO 复用模型(Redis 6.0 针对网络数据的读写引入了多线程)。
|
||||
|
||||
@ -703,7 +703,7 @@ Bloom Filter 会使用一个较大的 bit 数组来保存所有的数据,数
|
||||
|
||||
|
||||
|
||||
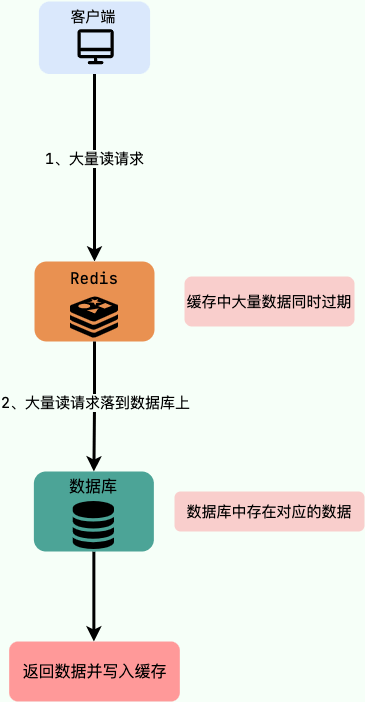
举个例子:数据库中的大量数据在同一时间过期,这个时候突然有大量的请求需要访问这些过期的数据。这就导致大量的请求直接落到数据库上,对数据库造成了巨大的压力。
|
||||
举个例子:缓存中的大量数据在同一时间过期,这个时候突然有大量的请求需要访问这些过期的数据。这就导致大量的请求直接落到数据库上,对数据库造成了巨大的压力。
|
||||
|
||||
#### 有哪些解决办法?
|
||||
|
||||
|
||||
@ -341,7 +341,7 @@ Final Reference: Daisy, Final Mark: true
|
||||
- `AtomicLongFieldUpdater`:原子更新长整形字段的更新器
|
||||
- `AtomicReferenceFieldUpdater`:原子更新引用类型里的字段的更新器
|
||||
|
||||
要想原子地更新对象的属性需要两步。第一步,因为对象的属性修改类型原子类都是抽象类,所以每次使用都必须使用静态方法 newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。第二步,更新的对象属性必须使用 public volatile 修饰符。
|
||||
要想原子地更新对象的属性需要两步。第一步,因为对象的属性修改类型原子类都是抽象类,所以每次使用都必须使用静态方法 newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。第二步,更新的对象属性必须使用 volatile int 修饰符。
|
||||
|
||||
上面三个类提供的方法几乎相同,所以我们这里以 `AtomicIntegerFieldUpdater`为例子来介绍。
|
||||
|
||||
@ -351,8 +351,8 @@ Final Reference: Daisy, Final Mark: true
|
||||
// Person 类
|
||||
class Person {
|
||||
private String name;
|
||||
// 要使用 AtomicIntegerFieldUpdater,字段必须是 public volatile
|
||||
private volatile int age;
|
||||
// 要使用 AtomicIntegerFieldUpdater,字段必须是 volatile int
|
||||
volatile int age;
|
||||
//省略getter/setter和toString
|
||||
}
|
||||
|
||||
|
||||
@ -883,7 +883,7 @@ public FutureTask(Runnable runnable, V result) {
|
||||
|
||||
`FutureTask`相当于对`Callable` 进行了封装,管理着任务执行的情况,存储了 `Callable` 的 `call` 方法的任务执行结果。
|
||||
|
||||
关于更多 `Future` 的源码细节,可以肝这篇万字解析,写的很清楚:[Java是如何实现Future模式的?万字详解!](https://juejin.cn/post/6844904199625375757)。
|
||||
关于更多 `Future` 的源码细节,可以肝这篇万字解析,写的很清楚:[Java 是如何实现 Future 模式的?万字详解!](https://juejin.cn/post/6844904199625375757)。
|
||||
|
||||
### CompletableFuture 类有什么用?
|
||||
|
||||
|
||||
@ -253,7 +253,7 @@ public class ReferenceCountingGc {
|
||||
|
||||
JDK1.2 之前,Java 中引用的定义很传统:如果 reference 类型的数据存储的数值代表的是另一块内存的起始地址,就称这块内存代表一个引用。
|
||||
|
||||
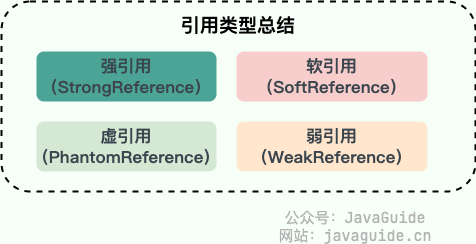
JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引用、软引用、弱引用、虚引用四种(引用强度逐渐减弱),强引用就是 Java 中普通的对象,而软引用、弱引用、虚引用在JDK中定义的类分别是 `SoftReference`、`WeakReference`、`PhantomReference`。
|
||||
JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引用、软引用、弱引用、虚引用四种(引用强度逐渐减弱),强引用就是 Java 中普通的对象,而软引用、弱引用、虚引用在 JDK 中定义的类分别是 `SoftReference`、`WeakReference`、`PhantomReference`。
|
||||
|
||||
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user