mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
Compare commits
10 Commits
71be32559b
...
ff1db4debb
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
ff1db4debb | ||
|
|
a1d352a3fe | ||
|
|
86f959b9cf | ||
|
|
791fe95f29 | ||
|
|
22f13d0429 | ||
|
|
62a6a45d05 | ||
|
|
588f3818fd | ||
|
|
be55c433c0 | ||
|
|
16275c8271 | ||
|
|
e54ce07e8c |
@ -72,7 +72,7 @@ DNS 报文分为查询和回答报文,两种形式的报文结构相同。
|
||||
|
||||
## DNS 记录
|
||||
|
||||
DNS 服务器在响应查询时,需要查询自己的数据库,数据库中的条目被称为**资源记录(Resource Record,RR)**。RR 提供了主机名到 IP 地址的映射。RR 是一个包含了`Name`, `Value`, `Type`, `TTL`四个字段的四元组。
|
||||
DNS 服务器在响应查询时,需要查询自己的数据库,数据库中的条目被称为 **资源记录(Resource Record,RR)** 。RR 提供了主机名到 IP 地址的映射。RR 是一个包含了`Name`, `Value`, `Type`, `TTL`四个字段的四元组。
|
||||
|
||||
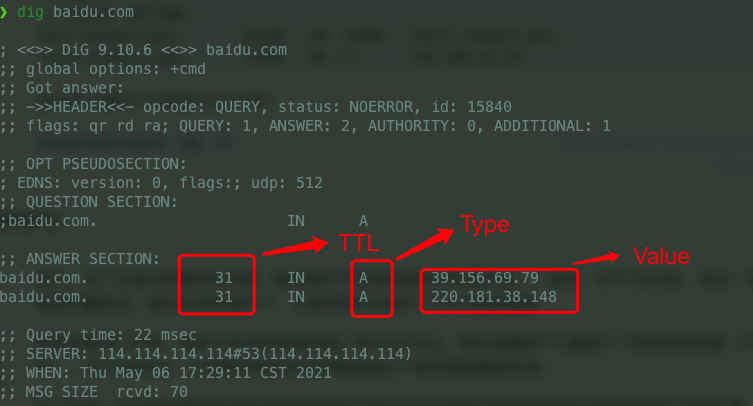
|
||||
|
||||
|
||||
@ -9,7 +9,7 @@ tag:
|
||||
|
||||
## 什么是 ZooKeeper
|
||||
|
||||
`ZooKeeper` 由 `Yahoo` 开发,后来捐赠给了 `Apache` ,现已成为 `Apache` 顶级项目。`ZooKeeper` 是一个开源的分布式应用程序协调服务器,其为分布式系统提供一致性服务。其一致性是通过基于 `Paxos` 算法的 `ZAB` 协议完成的。其主要功能包括:配置维护、分布式同步、集群管理、分布式事务等。
|
||||
`ZooKeeper` 由 `Yahoo` 开发,后来捐赠给了 `Apache` ,现已成为 `Apache` 顶级项目。`ZooKeeper` 是一个开源的分布式应用程序协调服务器,其为分布式系统提供一致性服务。其一致性是通过基于 `Paxos` 算法的 `ZAB` 协议完成的。其主要功能包括:配置维护、分布式同步、集群管理等。
|
||||
|
||||
简单来说, `ZooKeeper` 是一个 **分布式协调服务框架** 。分布式?协调服务?这啥玩意?🤔🤔
|
||||
|
||||
|
||||
@ -239,7 +239,7 @@ Resilience4j 不仅提供限流,还提供了熔断、负载保护、自动重
|
||||
|
||||
分布式限流常见的方案:
|
||||
|
||||
- **借助中间件架限流**:可以借助 Sentinel 或者使用 Redis 来自己实现对应的限流逻辑。
|
||||
- **借助中间件限流**:可以借助 Sentinel 或者使用 Redis 来自己实现对应的限流逻辑。
|
||||
- **网关层限流**:比较常用的一种方案,直接在网关层把限流给安排上了。不过,通常网关层限流通常也需要借助到中间件/框架。就比如 Spring Cloud Gateway 的分布式限流实现`RedisRateLimiter`就是基于 Redis+Lua 来实现的,再比如 Spring Cloud Gateway 还可以整合 Sentinel 来做限流。
|
||||
|
||||
如果你要基于 Redis 来手动实现限流逻辑的话,建议配合 Lua 脚本来做。
|
||||
|
||||
@ -989,7 +989,7 @@ public class SuperSuperMan extends SuperMan {
|
||||
|
||||
### 什么是可变长参数?
|
||||
|
||||
从 Java5 开始,Java 支持定义可变长参数,所谓可变长参数就是允许在调用方法时传入不定长度的参数。就比如下面的这个 `printVariable` 方法就可以接受 0 个或者多个参数。
|
||||
从 Java5 开始,Java 支持定义可变长参数,所谓可变长参数就是允许在调用方法时传入不定长度的参数。就比如下面这个方法就可以接受 0 个或者多个参数。
|
||||
|
||||
```java
|
||||
public static void method1(String... args) {
|
||||
|
||||
@ -328,7 +328,7 @@ private void rehash(HashEntry<K,V> node) {
|
||||
HashEntry<K,V> e = oldTable[i];
|
||||
if (e != null) {
|
||||
HashEntry<K,V> next = e.next;
|
||||
// 计算新的位置,新的位置只可能是不便或者是老的位置+老的容量。
|
||||
// 计算新的位置,新的位置只可能是不变或者是老的位置+老的容量。
|
||||
int idx = e.hash & sizeMask;
|
||||
if (next == null) // Single node on list
|
||||
// 如果当前位置还不是链表,只是一个元素,直接赋值
|
||||
@ -337,7 +337,7 @@ private void rehash(HashEntry<K,V> node) {
|
||||
// 如果是链表了
|
||||
HashEntry<K,V> lastRun = e;
|
||||
int lastIdx = idx;
|
||||
// 新的位置只可能是不便或者是老的位置+老的容量。
|
||||
// 新的位置只可能是不变或者是老的位置+老的容量。
|
||||
// 遍历结束后,lastRun 后面的元素位置都是相同的
|
||||
for (HashEntry<K,V> last = next; last != null; last = last.next) {
|
||||
int k = last.hash & sizeMask;
|
||||
|
||||
@ -228,7 +228,7 @@ new 一个 `Thread`,线程进入了新建状态。调用 `start()`方法,会
|
||||
再深入到计算机底层来探讨:
|
||||
|
||||
- **单核时代**:在单核时代多线程主要是为了提高单进程利用 CPU 和 IO 系统的效率。 假设只运行了一个 Java 进程的情况,当我们请求 IO 的时候,如果 Java 进程中只有一个线程,此线程被 IO 阻塞则整个进程被阻塞。CPU 和 IO 设备只有一个在运行,那么可以简单地说系统整体效率只有 50%。当使用多线程的时候,一个线程被 IO 阻塞,其他线程还可以继续使用 CPU。从而提高了 Java 进程利用系统资源的整体效率。
|
||||
- **多核时代**: 多核时代多线程主要是为了提高进程利用多核 CPU 的能力。举个例子:假如我们要计算一个复杂的任务,我们只用一个线程的话,不论系统有几个 CPU 核心,都只会有一个 CPU 核心被利用到。而创建多个线程,这些线程可以被映射到底层多个 CPU 上执行,在任务中的多个线程没有资源竞争的情况下,任务执行的效率会有显著性的提高,约等于(单核时执行时间/CPU 核心数)。
|
||||
- **多核时代**: 多核时代多线程主要是为了提高进程利用多核 CPU 的能力。举个例子:假如我们要计算一个复杂的任务,我们只用一个线程的话,不论系统有几个 CPU 核心,都只会有一个 CPU 核心被利用到。而创建多个线程,这些线程可以被映射到底层多个 CPU 核心上执行,在任务中的多个线程没有资源竞争的情况下,任务执行的效率会有显著性的提高,约等于(单核时执行时间/CPU 核心数)。
|
||||
|
||||
### 使用多线程可能带来什么问题?
|
||||
|
||||
|
||||
@ -507,6 +507,19 @@ new RejectedExecutionHandler() {
|
||||
3. 如果向任务队列投放任务失败(任务队列已经满了),但是当前运行的线程数是小于最大线程数的,就新建一个线程来执行任务。
|
||||
4. 如果当前运行的线程数已经等同于最大线程数了,新建线程将会使当前运行的线程超出最大线程数,那么当前任务会被拒绝,拒绝策略会调用`RejectedExecutionHandler.rejectedExecution()`方法。
|
||||
|
||||
### 线程池中线程异常后,销毁还是复用?
|
||||
|
||||
先说结论,需要分两种情况:
|
||||
|
||||
- **使用`execute()`提交任务**:当任务通过`execute()`提交到线程池并在执行过程中抛出异常时,如果这个异常没有在任务内被捕获,那么该异常会导致当前线程终止,并且异常会被打印到控制台或日志文件中。线程池会检测到这种线程终止,并创建一个新线程来替换它,从而保持配置的线程数不变。
|
||||
- **使用`submit()`提交任务**:对于通过`submit()`提交的任务,如果在任务执行中发生异常,这个异常不会直接打印出来。相反,异常会被封装在由`submit()`返回的`Future`对象中。当调用`Future.get()`方法时,可以捕获到一个`ExecutionException`。在这种情况下,线程不会因为异常而终止,它会继续存在于线程池中,准备执行后续的任务。
|
||||
|
||||
简单来说:使用`execute()`时,未捕获异常导致线程终止,线程池创建新线程替代;使用`submit()`时,异常被封装在`Future`中,线程继续复用。
|
||||
|
||||
这种设计允许`submit()`提供更灵活的错误处理机制,因为它允许调用者决定如何处理异常,而`execute()`则适用于那些不需要关注执行结果的场景。
|
||||
|
||||
具体的源码分析可以参考这篇:[线程池中线程异常后:销毁还是复用? - 京东技术](https://mp.weixin.qq.com/s/9ODjdUU-EwQFF5PrnzOGfw)。
|
||||
|
||||
### 如何给线程池命名?
|
||||
|
||||
初始化线程池的时候需要显示命名(设置线程池名称前缀),有利于定位问题。
|
||||
|
||||
@ -113,7 +113,7 @@ JUnit 几乎是默认选择,但是其不支持 Mock,因此我们还需要选
|
||||
|
||||
究竟是选择 Mockito 还是 Spock 呢?我这里做了一些简单的对比分析:
|
||||
|
||||
- Spock 没办法 Mock 静态方法和私有方法 ,Mockito 3.4.0 以后,支持静态方法的 Mock,具体可以看这个 issue:<https://github.com/mockito/mockito/issues/1013,具体教程可以看这篇文章:https://www.baeldung.com/mockito-mock-static-methods。>
|
||||
- Spock 没办法 Mock 静态方法和私有方法 ,Mockito 3.4.0 以后,支持静态方法的 Mock,具体可以看这个 issue:<https://github.com/mockito/mockito/issues/1013>,具体教程可以看这篇文章:<https://www.baeldung.com/mockito-mock-static-methods。>
|
||||
- Spock 基于 Groovy,写出来的测试代码更清晰易读,比较规范(自带 given-when-then 的常用测试结构规范)。Mockito 没有具体的结构规范,需要项目组自己约定一个或者遵守比较好的测试代码实践。通常来说,同样的测试用例,Spock 的代码要更简洁。
|
||||
- Mockito 使用的人群更广泛,稳定可靠。并且,Mockito 是 SpringBoot Test 默认集成的 Mock 工具。
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user