mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
Compare commits
4 Commits
557d658b7d
...
f2b24072b5
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
f2b24072b5 | ||
|
|
2d6445071e | ||
|
|
7c6fcbaab7 | ||
|
|
5fe494a0ca |
@ -8,13 +8,11 @@ icon: "distributed-network"
|
||||
|
||||

|
||||
|
||||
**[《深入理解分布式系统》](https://book.douban.com/subject/35794814/)** 是今年 3 月份刚出的一本分布式中文原创书籍,主要讲的是分布式领域的基本概念、常见挑战以及共识算法。
|
||||
**[《深入理解分布式系统》](https://book.douban.com/subject/35794814/)** 是 2022 年出版的一本分布式中文原创书籍,主要讲的是分布式领域的基本概念、常见挑战以及共识算法。
|
||||
|
||||
作者用了大量篇幅来介绍分布式领域中非常重要的共识算法,并且还会基于 Go 语言带着你从零实现了一个共识算法的鼻祖 Paxos 算法。
|
||||
|
||||
实话说,我还没有开始看这本书。但是!这本书的作者的博客上的分布式相关的文章我几乎每一篇都认真看过。
|
||||
|
||||
作者从 2019 年开始构思《深入理解分布式系统》,2020 年开始动笔,花了接近两年的时间才最终交稿。
|
||||
实话说,我还没有开始看这本书。但是!这本书的作者的博客上的分布式相关的文章我几乎每一篇都认真看过。作者从 2019 年开始构思《深入理解分布式系统》,2020 年开始动笔,花了接近两年的时间才最终交稿。
|
||||
|
||||

|
||||
|
||||
@ -32,15 +30,13 @@ icon: "distributed-network"
|
||||
|
||||
书中介绍的大部分概念你可能之前都听过,但是在看了书中的内容之后,你可能会豁然开朗:“哇塞!原来是这样的啊!这不是某技术的原理么?”。
|
||||
|
||||
这本书我之前专门写过知乎回答介绍和推荐,没看过的朋友可以看看:[有哪些你看了以后大呼过瘾的编程书?](https://www.zhihu.com/question/50408698/answer/2278198495) 。
|
||||
|
||||
另外,如果你在阅读这本书的时候感觉难度比较大,很多地方读不懂的话,我这里推荐一下《深入理解分布式系统》作者写的[《DDIA 逐章精读》小册](https://ddia.qtmuniao.com)。
|
||||
这本书我之前专门写过知乎回答介绍和推荐,没看过的朋友可以看看:[有哪些你看了以后大呼过瘾的编程书?](https://www.zhihu.com/question/50408698/answer/2278198495) 。另外,如果你在阅读这本书的时候感觉难度比较大,很多地方读不懂的话,我这里推荐一下《深入理解分布式系统》作者写的[《DDIA 逐章精读》小册](https://ddia.qtmuniao.com)。
|
||||
|
||||
## 《深入理解分布式事务》
|
||||
|
||||

|
||||
|
||||
**[《深入理解分布式事务》](https://book.douban.com/subject/35626925/)** 这本书是的其中一位作者是 Apache ShenYu(incubating)网关创始人、Hmily、RainCat、Myth 等分布式事务框架的创始人。
|
||||
**[《深入理解分布式事务》](https://book.douban.com/subject/35626925/)** 这本书的其中一位作者是 Apache ShenYu(incubating)网关创始人、Hmily、RainCat、Myth 等分布式事务框架的创始人。
|
||||
|
||||
学习分布式事务的时候,可以参考一下这本书。虽有一些小错误以及逻辑不通顺的地方,但对于各种分布式事务解决方案的介绍,总体来说还是不错的。
|
||||
|
||||
@ -50,11 +46,19 @@ icon: "distributed-network"
|
||||
|
||||
**[《从 Paxos 到 Zookeeper》](https://book.douban.com/subject/26292004/)** 是一本带你入门分布式理论的好书。这本书主要介绍几种典型的分布式一致性协议,以及解决分布式一致性问题的思路,其中重点讲解了 Paxos 和 ZAB 协议。
|
||||
|
||||
PS:Zookeeper 现在用的不多,可以不用重点学习,但 Paxos 和 ZAB 协议还是非常值得深入研究的。
|
||||
|
||||
## 《深入理解分布式共识算法》
|
||||
|
||||

|
||||
|
||||
**[《深入理解分布式共识算法》](https://book.douban.com/subject/36335459/)** 详细剖析了 Paxos、Raft、Zab 等主流分布式共识算法的核心原理和实现细节。如果你想要了解分布式共识算法的话,不妨参考一下这本书的总结。
|
||||
|
||||
## 《微服务架构设计模式》
|
||||
|
||||

|
||||
|
||||
**[《微服务架构设计模式》](https://book.douban.com/subject/33425123/)** 的作者 Chris Richardson 被评为世界十大软件架构师之一、微服务架构先驱。这本书主要讲的是如何开发和部署生产级别的微服务架构应用,示例代码使用 Java 语言和 Spring 框架。
|
||||
**[《微服务架构设计模式》](https://book.douban.com/subject/33425123/)** 的作者 Chris Richardson 被评为世界十大软件架构师之一、微服务架构先驱。这本书汇集了 44 个经过实践验证的架构设计模式,这些模式用来解决诸如服务拆分、事务管理、查询和跨服务通信等难题。书中的内容不仅理论扎实,还通过丰富的 Java 代码示例,引导读者一步步掌握开发和部署生产级别的微服务架构应用。
|
||||
|
||||
## 《凤凰架构》
|
||||
|
||||
@ -75,16 +79,6 @@ icon: "distributed-network"
|
||||
- [周志明老师的又一神书!发现宝藏!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247505254&idx=1&sn=04faf3093d6002354f06fffbfc2954e0&chksm=cea19aadf9d613bbba7ed0e02ccc4a9ef3a30f4d83530e7ad319c2cc69cd1770e43d1d470046&scene=178&cur_album_id=1646812382221926401#rd)
|
||||
- [Java 领域的又一神书!周志明老师 YYDS!](https://mp.weixin.qq.com/s/9nbzfZGAWM9_qIMp1r6uUQ)
|
||||
|
||||
## 《架构解密》
|
||||
|
||||

|
||||
|
||||
[《架构解密》](https://book.douban.com/subject/35093373/)这本书和我渊源颇深,在大三的时候,我曾经在图书馆借阅过这本书的第一版,大概了花了不到一周就看完了。
|
||||
|
||||
这本书的第二版在 2020 年就已经出来了,总共也才 15 个评价,算得上是一本非常小众的技术书籍了。
|
||||
|
||||
书籍质量怎么说呢,各个知识点介绍的都比较泛,匆忙结束,一共 9 章,总共 331 页。如果你只是想初步了解一些分布式相关的概念的话,可以看看这本书,快速概览一波分布式相关的技术。
|
||||
|
||||
## 其他
|
||||
|
||||
- [《分布式系统 : 概念与设计》](https://book.douban.com/subject/21624776/):偏教材类型,内容全而无趣,可作为参考书籍;
|
||||
|
||||
@ -15,10 +15,14 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
|
||||
|
||||
### 2xx Success(成功状态码)
|
||||
|
||||
- **200 OK**:请求被成功处理。比如我们发送一个查询用户数据的 HTTP 请求到服务端,服务端正确返回了用户数据。这个是我们平时最常见的一个 HTTP 状态码。
|
||||
- **201 Created**:请求被成功处理并且在服务端创建了一个新的资源。比如我们通过 POST 请求创建一个新的用户。
|
||||
- **202 Accepted**:服务端已经接收到了请求,但是还未处理。
|
||||
- **204 No Content**:服务端已经成功处理了请求,但是没有返回任何内容。
|
||||
- **200 OK**:请求被成功处理。例如,发送一个查询用户数据的 HTTP 请求到服务端,服务端正确返回了用户数据。这个是我们平时最常见的一个 HTTP 状态码。
|
||||
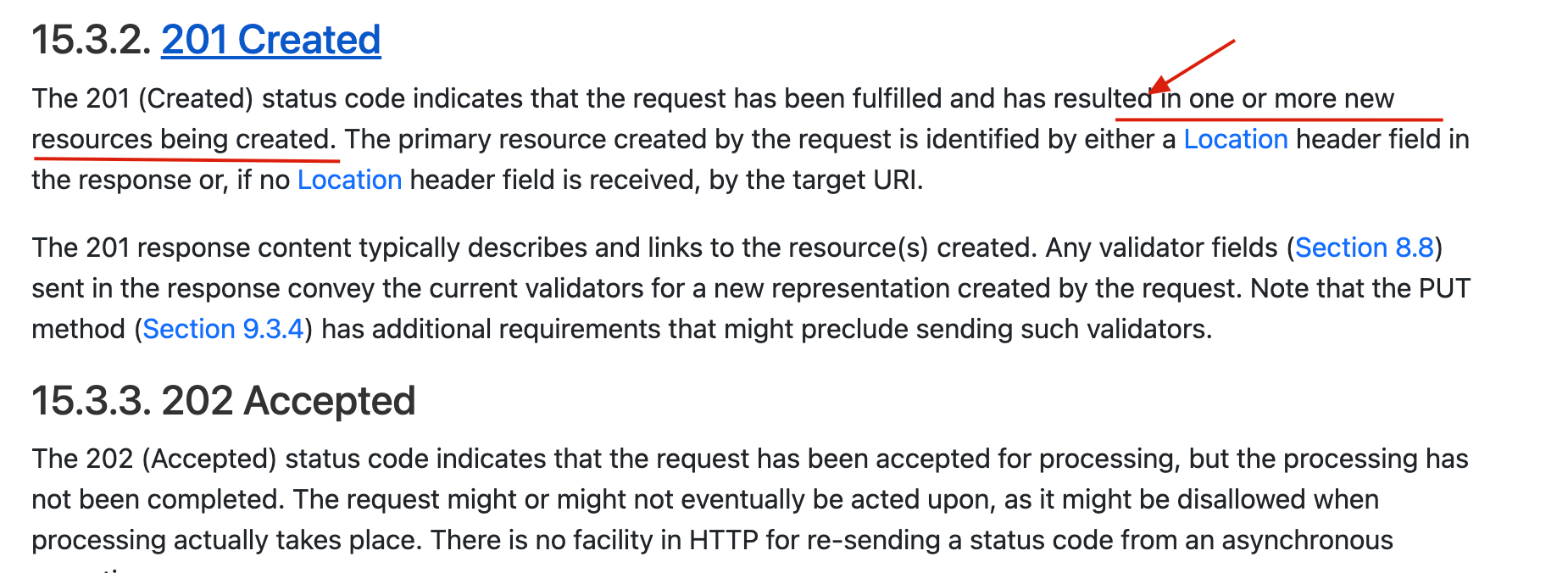
- **201 Created**:请求被成功处理并且在服务端创建了~~一个新的资源~~。例如,通过 POST 请求创建一个新的用户。
|
||||
- **202 Accepted**:服务端已经接收到了请求,但是还未处理。例如,发送一个需要服务端花费较长时间处理的请求(如报告生成、Excel 导出),服务端接收了请求但尚未处理完毕。
|
||||
- **204 No Content**:服务端已经成功处理了请求,但是没有返回任何内容。例如,发送请求删除一个用户,服务器成功处理了删除操作但没有返回任何内容。
|
||||
|
||||
🐛 修正(参见:[issue#2458](https://github.com/Snailclimb/JavaGuide/issues/2458)):201 Created 状态码更准确点来说是创建一个或多个新的资源,可以参考:<https://httpwg.org/specs/rfc9110.html#status.201>。
|
||||
|
||||
|
||||
|
||||
这里格外提一下 204 状态码,平时学习/工作中见到的次数并不多。
|
||||
|
||||
|
||||
@ -70,9 +70,70 @@ Host: example1.org
|
||||
|
||||
HTTP/1.1 引入了范围请求(range request)机制,以避免带宽的浪费。当客户端想请求一个文件的一部分,或者需要继续下载一个已经下载了部分但被终止的文件,HTTP/1.1 可以在请求中加入`Range`头部,以请求(并只能请求字节型数据)数据的一部分。服务器端可以忽略`Range`头部,也可以返回若干`Range`响应。
|
||||
|
||||
如果一个响应包含部分数据的话,那么将带有`206 (Partial Content)`状态码。该状态码的意义在于避免了 HTTP/1.0 代理缓存错误地把该响应认为是一个完整的数据响应,从而把他当作为一个请求的响应缓存。
|
||||
`206 (Partial Content)` 状态码的主要作用是确保客户端和代理服务器能正确识别部分内容响应,避免将其误认为完整资源并错误地缓存。这对于正确处理范围请求和缓存管理非常重要。
|
||||
|
||||
在范围响应中,`Content-Range`头部标志指示出了该数据块的偏移量和数据块的长度。
|
||||
一个典型的 HTTP/1.1 范围请求示例:
|
||||
|
||||
```bash
|
||||
# 获取一个文件的前 1024 个字节
|
||||
GET /z4d4kWk.jpg HTTP/1.1
|
||||
Host: i.imgur.com
|
||||
Range: bytes=0-1023
|
||||
```
|
||||
|
||||
`206 Partial Content` 响应:
|
||||
|
||||
```bash
|
||||
|
||||
HTTP/1.1 206 Partial Content
|
||||
Content-Range: bytes 0-1023/146515
|
||||
Content-Length: 1024
|
||||
…
|
||||
(二进制内容)
|
||||
```
|
||||
|
||||
简单解释一下 HTTP 范围响应头部中的字段:
|
||||
|
||||
- **`Content-Range` 头部**:指示返回数据在整个资源中的位置,包括起始和结束字节以及资源的总长度。例如,`Content-Range: bytes 0-1023/146515` 表示服务器端返回了第 0 到 1023 字节的数据(共 1024 字节),而整个资源的总长度是 146,515 字节。
|
||||
- **`Content-Length` 头部**:指示此次响应中实际传输的字节数。例如,`Content-Length: 1024` 表示服务器端传输了 1024 字节的数据。
|
||||
|
||||
`Range` 请求头不仅可以请求单个字节范围,还可以一次性请求多个范围。这种方式被称为“多重范围请求”(multiple range requests)。
|
||||
|
||||
客户端想要获取资源的第 0 到 499 字节以及第 1000 到 1499 字节:
|
||||
|
||||
```bash
|
||||
GET /path/to/resource HTTP/1.1
|
||||
Host: example.com
|
||||
Range: bytes=0-499,1000-1499
|
||||
```
|
||||
|
||||
服务器端返回多个字节范围,每个范围的内容以分隔符分开:
|
||||
|
||||
```bash
|
||||
HTTP/1.1 206 Partial Content
|
||||
Content-Type: multipart/byteranges; boundary=3d6b6a416f9b5
|
||||
Content-Length: 376
|
||||
|
||||
--3d6b6a416f9b5
|
||||
Content-Type: application/octet-stream
|
||||
Content-Range: bytes 0-99/2000
|
||||
|
||||
(第 0 到 99 字节的数据块)
|
||||
|
||||
--3d6b6a416f9b5
|
||||
Content-Type: application/octet-stream
|
||||
Content-Range: bytes 500-599/2000
|
||||
|
||||
(第 500 到 599 字节的数据块)
|
||||
|
||||
--3d6b6a416f9b5
|
||||
Content-Type: application/octet-stream
|
||||
Content-Range: bytes 1000-1099/2000
|
||||
|
||||
(第 1000 到 1099 字节的数据块)
|
||||
|
||||
--3d6b6a416f9b5--
|
||||
```
|
||||
|
||||
### 状态码 100
|
||||
|
||||
|
||||
@ -69,7 +69,7 @@ mysql> explain SELECT * FROM dept_emp WHERE emp_no IN (SELECT emp_no FROM dept_e
|
||||
|
||||
### id
|
||||
|
||||
SELECT 标识符,是查询中 SELECT 的序号,用来标识整个查询中 SELELCT 语句的顺序。
|
||||
`SELECT` 标识符,用于标识每个 `SELECT` 语句的执行顺序。
|
||||
|
||||
id 如果相同,从上往下依次执行。id 不同,id 值越大,执行优先级越高,如果行引用其他行的并集结果,则该值可以为 NULL。
|
||||
|
||||
@ -94,7 +94,9 @@ id 如果相同,从上往下依次执行。id 不同,id 值越大,执行
|
||||
|
||||
### type(重要)
|
||||
|
||||
查询执行的类型,描述了查询是如何执行的。所有值的顺序从最优到最差排序为:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
|
||||
查询执行的类型,描述了查询是如何执行的。所有值的顺序从最优到最差排序为:
|
||||
|
||||
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
|
||||
|
||||
常见的几种类型具体含义如下:
|
||||
|
||||
|
||||
@ -47,13 +47,22 @@ Redis 内部做了非常多的性能优化,比较重要的有下面 3 点:
|
||||
|
||||
那既然都这么快了,为什么不直接用 Redis 当主数据库呢?主要是因为内存成本太高且 Redis 提供的数据持久化仍然有数据丢失的风险。
|
||||
|
||||
### 分布式缓存常见的技术选型方案有哪些?
|
||||
### 除了 Redis,你还知道其他分布式缓存方案吗?
|
||||
|
||||
如果面试中被问到这个问题的话,面试官主要想看看:
|
||||
|
||||
1. 你在选择 Redis 作为分布式缓存方案时,是否是经过严谨的调研和思考,还是只是因为 Redis 是当前的“热门”技术。
|
||||
2. 你在分布式缓存方向的技术广度。
|
||||
|
||||
如果你了解其他方案,并且能解释为什么最终选择了 Redis(更进一步!),这会对你面试表现加分不少!
|
||||
|
||||
下面简单聊聊常见的分布式缓存技术选型。
|
||||
|
||||
分布式缓存的话,比较老牌同时也是使用的比较多的还是 **Memcached** 和 **Redis**。不过,现在基本没有看过还有项目使用 **Memcached** 来做缓存,都是直接用 **Redis**。
|
||||
|
||||
Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来,随着 Redis 的发展,大家慢慢都转而使用更加强大的 Redis 了。
|
||||
|
||||
有一些大厂也开源了类似于 Redis 的分布式高性能 KV 存储数据库,例如,腾讯开源的 [Tendis](https://github.com/Tencent/Tendis) 。Tendis 基于知名开源项目 [RocksDB](https://github.com/facebook/rocksdb) 作为存储引擎 ,100% 兼容 Redis 协议和 Redis4.0 所有数据模型。关于 Redis 和 Tendis 的对比,腾讯官方曾经发过一篇文章:[Redis vs Tendis:冷热混合存储版架构揭秘](https://mp.weixin.qq.com/s/MeYkfOIdnU6LYlsGb24KjQ) ,可以简单参考一下。
|
||||
有一些大厂也开源了类似于 Redis 的分布式高性能 KV 存储数据库,例如,腾讯开源的 [**Tendis**](https://github.com/Tencent/Tendis) 。Tendis 基于知名开源项目 [RocksDB](https://github.com/facebook/rocksdb) 作为存储引擎 ,100% 兼容 Redis 协议和 Redis4.0 所有数据模型。关于 Redis 和 Tendis 的对比,腾讯官方曾经发过一篇文章:[Redis vs Tendis:冷热混合存储版架构揭秘](https://mp.weixin.qq.com/s/MeYkfOIdnU6LYlsGb24KjQ) ,可以简单参考一下。
|
||||
|
||||
不过,从 Tendis 这个项目的 Github 提交记录可以看出,Tendis 开源版几乎已经没有被维护更新了,加上其关注度并不高,使用的公司也比较少。因此,不建议你使用 Tendis 来实现分布式缓存。
|
||||
|
||||
@ -62,7 +71,9 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
|
||||
- [Dragonfly](https://github.com/dragonflydb/dragonfly):一种针对现代应用程序负荷需求而构建的内存数据库,完全兼容 Redis 和 Memcached 的 API,迁移时无需修改任何代码,号称全世界最快的内存数据库。
|
||||
- [KeyDB](https://github.com/Snapchat/KeyDB): Redis 的一个高性能分支,专注于多线程、内存效率和高吞吐量。
|
||||
|
||||
不过,个人还是建议分布式缓存首选 Redis ,毕竟经过这么多年的生考验,生态也这么优秀,资料也很全面。
|
||||
不过,个人还是建议分布式缓存首选 Redis ,毕竟经过这么多年的生考验,生态也这么优秀,资料也很全面!
|
||||
|
||||
PS:篇幅问题,我这并没有对上面提到的分布式缓存选型做详细介绍和对比,感兴趣的话,可以自行研究一下。
|
||||
|
||||
### 说一下 Redis 和 Memcached 的区别和共同点
|
||||
|
||||
@ -314,10 +325,17 @@ String 的常见应用场景如下:
|
||||
|
||||
### String 还是 Hash 存储对象数据更好呢?
|
||||
|
||||
- String 存储的是序列化后的对象数据,存放的是整个对象。Hash 是对对象的每个字段单独存储,可以获取部分字段的信息,也可以修改或者添加部分字段,节省网络流量。如果对象中某些字段需要经常变动或者经常需要单独查询对象中的个别字段信息,Hash 就非常适合。
|
||||
- String 存储相对来说更加节省内存,缓存相同数量的对象数据,String 消耗的内存约是 Hash 的一半。并且,存储具有多层嵌套的对象时也方便很多。如果系统对性能和资源消耗非常敏感的话,String 就非常适合。
|
||||
简单对比一下二者:
|
||||
|
||||
在绝大部分情况,我们建议使用 String 来存储对象数据即可!
|
||||
- **对象存储方式**:String 存储的是序列化后的对象数据,存放的是整个对象,操作简单直接。Hash 是对对象的每个字段单独存储,可以获取部分字段的信息,也可以修改或者添加部分字段,节省网络流量。如果对象中某些字段需要经常变动或者经常需要单独查询对象中的个别字段信息,Hash 就非常适合。
|
||||
- **内存消耗**:Hash 通常比 String 更节省内存,特别是在字段较多且字段长度较短时。Redis 对小型 Hash 进行优化(如使用 ziplist 存储),进一步降低内存占用。
|
||||
- **复杂对象存储**:String 在处理多层嵌套或复杂结构的对象时更方便,因为无需处理每个字段的独立存储和操作。
|
||||
- **性能**:String 的操作通常具有 O(1) 的时间复杂度,因为它存储的是整个对象,操作简单直接,整体读写的性能较好。Hash 由于需要处理多个字段的增删改查操作,在字段较多且经常变动的情况下,可能会带来额外的性能开销。
|
||||
|
||||
总结:
|
||||
|
||||
- 在绝大多数情况下,**String** 更适合存储对象数据,尤其是当对象结构简单且整体读写是主要操作时。
|
||||
- 如果你需要频繁操作对象的部分字段或节省内存,**Hash** 可能是更好的选择。
|
||||
|
||||
### String 的底层实现是什么?
|
||||
|
||||
|
||||
@ -423,8 +423,6 @@ CAS 经常会用到自旋操作来进行重试,也就是不成功就一直循
|
||||
|
||||
#### 只能保证一个共享变量的原子操作
|
||||
|
||||
CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效。但是从 JDK 1.5 开始,提供了`AtomicReference`类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作.所以我们可以使用锁或者利用`AtomicReference`类把多个共享变量合并成一个共享变量来操作。
|
||||
|
||||
CAS 操作仅能对单个共享变量有效。当需要操作多个共享变量时,CAS 就显得无能为力。不过,从 JDK 1.5 开始,Java 提供了`AtomicReference`类,这使得我们能够保证引用对象之间的原子性。通过将多个变量封装在一个对象中,我们可以使用`AtomicReference`来执行 CAS 操作。
|
||||
|
||||
除了 `AtomicReference` 这种方式之外,还可以利用加锁来保证。
|
||||
|
||||
@ -28,6 +28,7 @@ icon: project
|
||||
- [paicoding](https://github.com/itwanger/paicoding):一款好用又强大的开源社区,基于 Spring Boot 系列主流技术栈,附详细的教程。
|
||||
- [forest](https://github.com/rymcu/forest):下一代的知识社区系统,可以自定义专题和作品集。后端基于 SpringBoot + Shrio + MyBatis + JWT + Redis,前端基于 Vue + NuxtJS + Element-UI。
|
||||
- [community](https://github.com/codedrinker/community):开源论坛、问答系统,现有功能提问、回复、通知、最新、最热、消除零回复功能。功能持续更新中…… 技术栈 Spring、Spring Boot、MyBatis、MySQL/H2、Bootstrap。
|
||||
- [OneBlog](https://gitee.com/yadong.zhang/DBlog):简洁美观、功能强大并且自适应的博客系统,支持广告位、SEO、实时通讯等功能。
|
||||
- [VBlog](https://github.com/lenve/VBlog):V 部落,Vue+SpringBoot 实现的多用户博客管理平台!
|
||||
- [My-Blog](https://github.com/ZHENFENG13/My-Blog): SpringBoot + Mybatis + Thymeleaf 等技术实现的 Java 博客系统,页面美观、功能齐全、部署简单及完善的代码,一定会给使用者无与伦比的体验。
|
||||
|
||||
|
||||
@ -279,6 +279,78 @@ private SmsService smsService;
|
||||
- 当一个接口存在多个实现类的情况下,`@Autowired` 和`@Resource`都需要通过名称才能正确匹配到对应的 Bean。`Autowired` 可以通过 `@Qualifier` 注解来显式指定名称,`@Resource`可以通过 `name` 属性来显式指定名称。
|
||||
- `@Autowired` 支持在构造函数、方法、字段和参数上使用。`@Resource` 主要用于字段和方法上的注入,不支持在构造函数或参数上使用。
|
||||
|
||||
### 注入 Bean 的方式有哪些?
|
||||
|
||||
依赖注入 (Dependency Injection, DI) 的常见方式:
|
||||
|
||||
1. 构造函数注入:通过类的构造函数来注入依赖项。
|
||||
1. Setter 注入:通过类的 Setter 方法来注入依赖项。
|
||||
1. Field(字段) 注入:直接在类的字段上使用注解(如 `@Autowired` 或 `@Resource`)来注入依赖项。
|
||||
|
||||
构造函数注入示例:
|
||||
|
||||
```java
|
||||
@Service
|
||||
public class UserService {
|
||||
|
||||
private final UserRepository userRepository;
|
||||
|
||||
public UserService(UserRepository userRepository) {
|
||||
this.userRepository = userRepository;
|
||||
}
|
||||
|
||||
//...
|
||||
}
|
||||
```
|
||||
|
||||
Setter 注入示例:
|
||||
|
||||
```java
|
||||
@Service
|
||||
public class UserService {
|
||||
|
||||
private UserRepository userRepository;
|
||||
|
||||
// 在 Spring 4.3 及以后的版本,特定情况下 @Autowired 可以省略不写
|
||||
@Autowired
|
||||
public void setUserRepository(UserRepository userRepository) {
|
||||
this.userRepository = userRepository;
|
||||
}
|
||||
|
||||
//...
|
||||
}
|
||||
```
|
||||
|
||||
Field 注入示例:
|
||||
|
||||
```java
|
||||
@Service
|
||||
public class UserService {
|
||||
|
||||
@Autowired
|
||||
private UserRepository userRepository;
|
||||
|
||||
//...
|
||||
}
|
||||
```
|
||||
|
||||
### 构造函数注入还是 Setter 注入?
|
||||
|
||||
Spring 官方有对这个问题的回答:<https://docs.spring.io/spring-framework/reference/core/beans/dependencies/factory-collaborators.html#beans-setter-injection>。
|
||||
|
||||
我这里主要提取总结完善一下 Spring 官方的建议。
|
||||
|
||||
**Spring 官方推荐构造函数注入**,这种注入方式的优势如下:
|
||||
|
||||
1. 依赖完整性:确保所有必需依赖在对象创建时就被注入,避免了空指针异常的风险。
|
||||
2. 不可变性:有助于创建不可变对象,提高了线程安全性。
|
||||
3. 初始化保证:组件在使用前已完全初始化,减少了潜在的错误。
|
||||
4. 测试便利性:在单元测试中,可以直接通过构造函数传入模拟的依赖项,而不必依赖 Spring 容器进行注入。
|
||||
|
||||
构造函数注入适合处理**必需的依赖项**,而 **Setter 注入** 则更适合**可选的依赖项**,这些依赖项可以有默认值或在对象生命周期中动态设置。虽然 `@Autowired` 可以用于 Setter 方法来处理必需的依赖项,但构造函数注入仍然是更好的选择。
|
||||
|
||||
在某些情况下(例如第三方类不提供 Setter 方法),构造函数注入可能是**唯一的选择**。
|
||||
|
||||
### Bean 的作用域有哪些?
|
||||
|
||||
Spring 中 Bean 的作用域通常有下面几种:
|
||||
@ -316,12 +388,68 @@ Spring 框架中的 Bean 是否线程安全,取决于其作用域和状态。
|
||||
|
||||
prototype 作用域下,每次获取都会创建一个新的 bean 实例,不存在资源竞争问题,所以不存在线程安全问题。singleton 作用域下,IoC 容器中只有唯一的 bean 实例,可能会存在资源竞争问题(取决于 Bean 是否有状态)。如果这个 bean 是有状态的话,那就存在线程安全问题(有状态 Bean 是指包含可变的成员变量的对象)。
|
||||
|
||||
有状态 Bean 示例:
|
||||
|
||||
```java
|
||||
// 定义了一个购物车类,其中包含一个保存用户的购物车里商品的 List
|
||||
@Component
|
||||
public class ShoppingCart {
|
||||
private List<String> items = new ArrayList<>();
|
||||
|
||||
public void addItem(String item) {
|
||||
items.add(item);
|
||||
}
|
||||
|
||||
public List<String> getItems() {
|
||||
return items;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
不过,大部分 Bean 实际都是无状态(没有定义可变的成员变量)的(比如 Dao、Service),这种情况下, Bean 是线程安全的。
|
||||
|
||||
对于有状态单例 Bean 的线程安全问题,常见的有两种解决办法:
|
||||
无状态 Bean 示例:
|
||||
|
||||
1. 在 Bean 中尽量避免定义可变的成员变量。
|
||||
2. 在类中定义一个 `ThreadLocal` 成员变量,将需要的可变成员变量保存在 `ThreadLocal` 中(推荐的一种方式)。
|
||||
```java
|
||||
// 定义了一个用户服务,它仅包含业务逻辑而不保存任何状态。
|
||||
@Component
|
||||
public class UserService {
|
||||
|
||||
public User findUserById(Long id) {
|
||||
//...
|
||||
}
|
||||
//...
|
||||
}
|
||||
```
|
||||
|
||||
对于有状态单例 Bean 的线程安全问题,常见的三种解决办法是:
|
||||
|
||||
1. **避免可变成员变量**: 尽量设计 Bean 为无状态。
|
||||
2. **使用`ThreadLocal`**: 将可变成员变量保存在 `ThreadLocal` 中,确保线程独立。
|
||||
3. **使用同步机制**: 利用 `synchronized` 或 `ReentrantLock` 来进行同步控制,确保线程安全。
|
||||
|
||||
这里以 `ThreadLocal`为例,演示一下`ThreadLocal` 保存用户登录信息的场景:
|
||||
|
||||
```java
|
||||
public class UserThreadLocal {
|
||||
|
||||
private UserThreadLocal() {}
|
||||
|
||||
private static final ThreadLocal<SysUser> LOCAL = ThreadLocal.withInitial(() -> null);
|
||||
|
||||
public static void put(SysUser sysUser) {
|
||||
LOCAL.set(sysUser);
|
||||
}
|
||||
|
||||
public static SysUser get() {
|
||||
return LOCAL.get();
|
||||
}
|
||||
|
||||
public static void remove() {
|
||||
LOCAL.remove();
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Bean 的生命周期了解么?
|
||||
|
||||
@ -746,7 +874,7 @@ class B {
|
||||
|
||||
`@Lazy` 用来标识类是否需要懒加载/延迟加载,可以作用在类上、方法上、构造器上、方法参数上、成员变量中。
|
||||
|
||||
Spring Boot 2.2 新增了全局懒加载属性,开启后全局 bean 被设置为懒加载,需要时再去创建。
|
||||
Spring Boot 2.2 新增了**全局懒加载属性**,开启后全局 bean 被设置为懒加载,需要时再去创建。
|
||||
|
||||
配置文件配置全局懒加载:
|
||||
|
||||
@ -773,11 +901,12 @@ springApplication.run(args);
|
||||
- 由于在 A 上标注了 `@Lazy` 注解,因此 Spring 会去创建一个 B 的代理对象,将这个代理对象注入到 A 中的 B 属性;
|
||||
- 之后开始执行 B 的实例化、初始化,在注入 B 中的 A 属性时,此时 A 已经创建完毕了,就可以将 A 给注入进去。
|
||||
|
||||
通过 `@Lazy` 就解决了循环依赖的注入, 关键点就在于对 A 中的属性 B 进行注入时,注入的是 B 的代理对象,因此不会循环依赖。
|
||||
从上面的加载流程可以看出: `@Lazy` 解决循环依赖的关键点在于代理对象的使用。
|
||||
|
||||
之前说的发生循环依赖是因为在对 A 中的属性 B 进行注入时,注入的是 B 对象,此时又会去初始化 B 对象,发现 B 又依赖了 A,因此才导致的循环依赖。
|
||||
- **没有 `@Lazy` 的情况下**:在 Spring 容器初始化 `A` 时会立即尝试创建 `B`,而在创建 `B` 的过程中又会尝试创建 `A`,最终导致循环依赖(即无限递归,最终抛出异常)。
|
||||
- **使用 `@Lazy` 的情况下**:Spring 不会立即创建 `B`,而是会注入一个 `B` 的代理对象。由于此时 `B` 仍未被真正初始化,`A` 的初始化可以顺利完成。等到 `A` 实例实际调用 `B` 的方法时,代理对象才会触发 `B` 的真正初始化。
|
||||
|
||||
一般是不建议使用循环依赖的,但是如果项目比较复杂,可以使用 `@Lazy` 解决一部分循环依赖的问题。
|
||||
`@Lazy` 能够在一定程度上打破循环依赖链,允许 Spring 容器顺利地完成 Bean 的创建和注入。但这并不是一个根本性的解决方案,尤其是在构造函数注入、复杂的多级依赖等场景中,`@Lazy` 无法有效地解决问题。因此,最佳实践仍然是尽量避免设计上的循环依赖。
|
||||
|
||||
### SpringBoot 允许循环依赖发生么?
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user