mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
Compare commits
17 Commits
555fc17e29
...
4b5985b082
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
4b5985b082 | ||
|
|
82c6a052ea | ||
|
|
272035e9c4 | ||
|
|
ece137ec9f | ||
|
|
674d5332d7 | ||
|
|
e9e47ef80e | ||
|
|
c1db361434 | ||
|
|
3427bd3301 | ||
|
|
4e52d41e18 | ||
|
|
d1eadea67b | ||
|
|
955c82756d | ||
|
|
313a696e2d | ||
|
|
a02a05743f | ||
|
|
1b6635a066 | ||
|
|
3d038ada54 | ||
|
|
85d95d3ae5 | ||
|
|
b91315052e |
@ -402,7 +402,7 @@ Thread[线程 2,5,main]waiting get resource1
|
|||||||
|
|
||||||
上面提到的 **破坏** 死锁产生的四个必要条件之一就可以成功 **预防系统发生死锁** ,但是会导致 **低效的进程运行** 和 **资源使用率** 。而死锁的避免相反,它的角度是允许系统中**同时存在四个必要条件** ,只要掌握并发进程中与每个进程有关的资源动态申请情况,做出 **明智和合理的选择** ,仍然可以避免死锁,因为四大条件仅仅是产生死锁的必要条件。
|
上面提到的 **破坏** 死锁产生的四个必要条件之一就可以成功 **预防系统发生死锁** ,但是会导致 **低效的进程运行** 和 **资源使用率** 。而死锁的避免相反,它的角度是允许系统中**同时存在四个必要条件** ,只要掌握并发进程中与每个进程有关的资源动态申请情况,做出 **明智和合理的选择** ,仍然可以避免死锁,因为四大条件仅仅是产生死锁的必要条件。
|
||||||
|
|
||||||
我们将系统的状态分为 **安全状态** 和 **不安全状态** ,每当在未申请者分配资源前先测试系统状态,若把系统资源分配给申请者会产生死锁,则拒绝分配,否则接受申请,并为它分配资源。
|
我们将系统的状态分为 **安全状态** 和 **不安全状态** ,每当在为申请者分配资源前先测试系统状态,若把系统资源分配给申请者会产生死锁,则拒绝分配,否则接受申请,并为它分配资源。
|
||||||
|
|
||||||
> 如果操作系统能够保证所有的进程在有限的时间内得到需要的全部资源,则称系统处于安全状态,否则说系统是不安全的。很显然,系统处于安全状态则不会发生死锁,系统若处于不安全状态则可能发生死锁。
|
> 如果操作系统能够保证所有的进程在有限的时间内得到需要的全部资源,则称系统处于安全状态,否则说系统是不安全的。很显然,系统处于安全状态则不会发生死锁,系统若处于不安全状态则可能发生死锁。
|
||||||
|
|
||||||
|
|||||||
@ -112,7 +112,7 @@ InnoDB 将 redo log 刷到磁盘上有几种情况:
|
|||||||
|
|
||||||
|

|
||||||
|
|
||||||
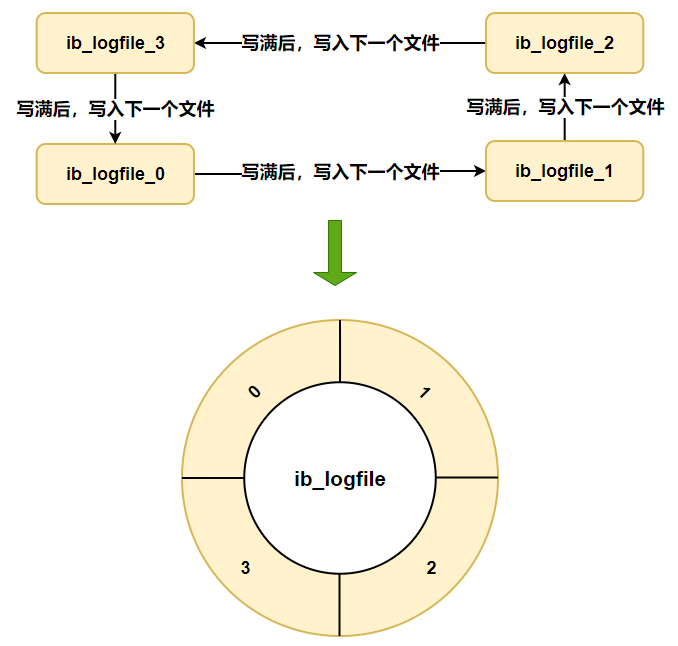
在个**日志文件组**中还有两个重要的属性,分别是 `write pos、checkpoint`
|
在这个**日志文件组**中还有两个重要的属性,分别是 `write pos、checkpoint`
|
||||||
|
|
||||||
- **write pos** 是当前记录的位置,一边写一边后移
|
- **write pos** 是当前记录的位置,一边写一边后移
|
||||||
- **checkpoint** 是当前要擦除的位置,也是往后推移
|
- **checkpoint** 是当前要擦除的位置,也是往后推移
|
||||||
|
|||||||
@ -30,7 +30,7 @@ category: 分布式
|
|||||||
|
|
||||||
悲观锁总是假设最坏的情况,认为共享资源每次被访问的时候就会出现问题(比如共享数据被修改),所以每次在获取资源操作的时候都会上锁,这样其他线程想拿到这个资源就会阻塞直到锁被上一个持有者释放。也就是说,**共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程**。
|
悲观锁总是假设最坏的情况,认为共享资源每次被访问的时候就会出现问题(比如共享数据被修改),所以每次在获取资源操作的时候都会上锁,这样其他线程想拿到这个资源就会阻塞直到锁被上一个持有者释放。也就是说,**共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程**。
|
||||||
|
|
||||||
对于单机多线程来说,在 Java 中,我们通常使用 `ReetrantLock` 类、`synchronized` 关键字这类 JDK 自带的 **本地锁** 来控制一个 JVM 进程内的多个线程对本地共享资源的访问。
|
对于单机多线程来说,在 Java 中,我们通常使用 `ReentrantLock` 类、`synchronized` 关键字这类 JDK 自带的 **本地锁** 来控制一个 JVM 进程内的多个线程对本地共享资源的访问。
|
||||||
|
|
||||||
下面是我对本地锁画的一张示意图。
|
下面是我对本地锁画的一张示意图。
|
||||||
|
|
||||||
|
|||||||
@ -88,6 +88,8 @@ JRE(Java Runtime Environment) 是 Java 运行时环境。它是运行已编
|
|||||||
|
|
||||||
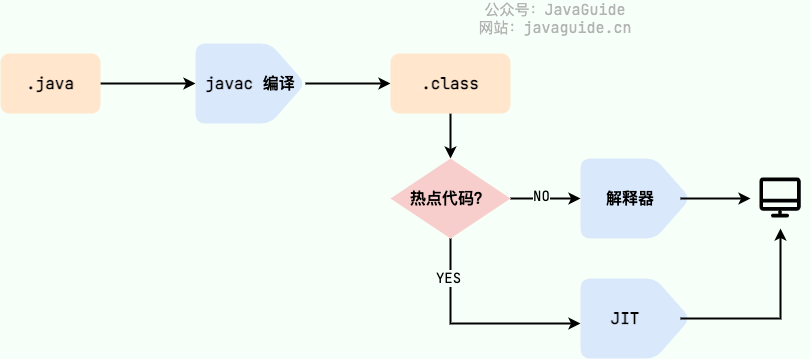
我们需要格外注意的是 `.class->机器码` 这一步。在这一步 JVM 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的(也就是所谓的热点代码),所以后面引进了 **JIT(Just in Time Compilation)** 编译器,而 JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 **Java 是编译与解释共存的语言** 。
|
我们需要格外注意的是 `.class->机器码` 这一步。在这一步 JVM 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的(也就是所谓的热点代码),所以后面引进了 **JIT(Just in Time Compilation)** 编译器,而 JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 **Java 是编译与解释共存的语言** 。
|
||||||
|
|
||||||
|
> 🌈 拓展:[有关JIT的实现细节: JVM C1、C2编译器](https://mp.weixin.qq.com/s/4haTyXUmh8m-dBQaEzwDJw)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
> HotSpot 采用了惰性评估(Lazy Evaluation)的做法,根据二八定律,消耗大部分系统资源的只有那一小部分的代码(热点代码),而这也就是 JIT 所需要编译的部分。JVM 会根据代码每次被执行的情况收集信息并相应地做出一些优化,因此执行的次数越多,它的速度就越快。
|
> HotSpot 采用了惰性评估(Lazy Evaluation)的做法,根据二八定律,消耗大部分系统资源的只有那一小部分的代码(热点代码),而这也就是 JIT 所需要编译的部分。JVM 会根据代码每次被执行的情况收集信息并相应地做出一些优化,因此执行的次数越多,它的速度就越快。
|
||||||
|
|||||||
@ -235,7 +235,7 @@ public interface RandomAccess {
|
|||||||
|
|
||||||
查看源码我们发现实际上 `RandomAccess` 接口中什么都没有定义。所以,在我看来 `RandomAccess` 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
|
查看源码我们发现实际上 `RandomAccess` 接口中什么都没有定义。所以,在我看来 `RandomAccess` 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
|
||||||
|
|
||||||
在 `binarySearch()` 方法中,它要判断传入的 list 是否 `RandomAccess` 的实例,如果是,调用`indexedBinarySearch()`方法,如果不是,那么调用`iteratorBinarySearch()`方法
|
在 `binarySearch()` 方法中,它要判断传入的 list 是否 `RandomAccess` 的实例,如果是,调用`indexedBinarySearch()`方法,如果不是,那么调用`iteratorBinarySearch()`方法
|
||||||
|
|
||||||
```java
|
```java
|
||||||
public static <T>
|
public static <T>
|
||||||
|
|||||||
@ -446,7 +446,7 @@ CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内
|
|||||||
>
|
>
|
||||||
> IO 密集型任务下,几乎全是线程等待时间,从理论上来说,你就可以将线程数设置为 2N(按道理来说,WT/ST 的结果应该比较大,这里选择 2N 的原因应该是为了避免创建过多线程吧)。
|
> IO 密集型任务下,几乎全是线程等待时间,从理论上来说,你就可以将线程数设置为 2N(按道理来说,WT/ST 的结果应该比较大,这里选择 2N 的原因应该是为了避免创建过多线程吧)。
|
||||||
|
|
||||||
公示也只是参考,具体还是要根据项目实际线上运行情况来动态调整。我在后面介绍的美团的线程池参数动态配置这种方案就非常不错,很实用!
|
公式也只是参考,具体还是要根据项目实际线上运行情况来动态调整。我在后面介绍的美团的线程池参数动态配置这种方案就非常不错,很实用!
|
||||||
|
|
||||||
### 如何动态修改线程池的参数?
|
### 如何动态修改线程池的参数?
|
||||||
|
|
||||||
@ -466,7 +466,7 @@ CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
格外需要注意的是`corePoolSize`, 程序运行期间的时候,我们调用 `setCorePoolSize()`这个方法的话,线程池会首先判断当前工作线程数是否大于`corePoolSize`,如果大于的话就会回收工作线程。
|
格外需要注意的是`corePoolSize`, 程序运行期间的时候,我们调用 `setCorePoolSize()`这个方法的话,线程池会首先判断当前工作线程数是否大于`corePoolSize`,如果大于的话就会回收工作线程。
|
||||||
|
|
||||||
另外,你也看到了上面并没有动态指定队列长度的方法,美团的方式是自定义了一个叫做 `ResizableCapacityLinkedBlockIngQueue` 的队列(主要就是把`LinkedBlockingQueue`的 capacity 字段的 final 关键字修饰给去掉了,让它变为可变的)。
|
另外,你也看到了上面并没有动态指定队列长度的方法,美团的方式是自定义了一个叫做 `ResizableCapacityLinkedBlockIngQueue` 的队列(主要就是把`LinkedBlockingQueue`的 capacity 字段的 final 关键字修饰给去掉了,让它变为可变的)。
|
||||||
|
|
||||||
|
|||||||
@ -627,7 +627,7 @@ public class MapAndFlatMapExample {
|
|||||||
.collect(Collectors.toList());
|
.collect(Collectors.toList());
|
||||||
|
|
||||||
System.out.println("Using map:");
|
System.out.println("Using map:");
|
||||||
System.out.println(mapResult);
|
mapResult.forEach(arrays-> System.out.println(Arrays.toString(arrays)));
|
||||||
|
|
||||||
List<String> flatMapResult = listOfArrays.stream()
|
List<String> flatMapResult = listOfArrays.stream()
|
||||||
.flatMap(array -> Arrays.stream(array).map(String::toUpperCase))
|
.flatMap(array -> Arrays.stream(array).map(String::toUpperCase))
|
||||||
|
|||||||
@ -206,7 +206,7 @@ Spring 中默认存在以下事件,他们都是对 `ApplicationContextEvent`
|
|||||||
|
|
||||||
#### 事件监听者角色
|
#### 事件监听者角色
|
||||||
|
|
||||||
`ApplicationListener` 充当了事件监听者角色,它是一个接口,里面只定义了一个 `onApplicationEvent()`方法来处理`ApplicationEvent`。`ApplicationListener`接口类源码如下,可以看出接口定义看出接口中的事件只要实现了 `ApplicationEvent`就可以了。所以,在 Spring 中我们只要实现 `ApplicationListener` 接口的 `onApplicationEvent()` 方法即可完成监听事件
|
`ApplicationListener` 充当了事件监听者角色,它是一个接口,里面只定义了一个 `onApplicationEvent()`方法来处理`ApplicationEvent`。`ApplicationListener`接口类源码如下,可以看出接口定义看出接口中的事件只要实现了 `ApplicationEvent`就可以了。所以,在 Spring 中我们只要实现 `ApplicationListener` 接口的 `onApplicationEvent()` 方法即可完成监听事件
|
||||||
|
|
||||||
```java
|
```java
|
||||||
package org.springframework.context;
|
package org.springframework.context;
|
||||||
@ -233,7 +233,7 @@ public interface ApplicationEventPublisher {
|
|||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
`ApplicationEventPublisher` 接口的`publishEvent()`这个方法在`AbstractApplicationContext`类中被实现,阅读这个方法的实现,你会发现实际上事件真正是通过`ApplicationEventMulticaster`来广播出去的。具体内容过多,就不在这里分析了,后面可能会单独写一篇文章提到。
|
`ApplicationEventPublisher` 接口的`publishEvent()`这个方法在`AbstractApplicationContext`类中被实现,阅读这个方法的实现,你会发现实际上事件真正是通过`ApplicationEventMulticaster`来广播出去的。具体内容过多,就不在这里分析了,后面可能会单独写一篇文章提到。
|
||||||
|
|
||||||
### Spring 的事件流程总结
|
### Spring 的事件流程总结
|
||||||
|
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user