mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
Compare commits
16 Commits
3865282503
...
b93f1384d0
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
b93f1384d0 | ||
|
|
10b1ad2703 | ||
|
|
2a6783d0e4 | ||
|
|
25de0a492c | ||
|
|
94b25a66be | ||
|
|
2aad0b550b | ||
|
|
c999ee734f | ||
|
|
a7e4d059c4 | ||
|
|
171d364d83 | ||
|
|
7331a09220 | ||
|
|
1a54147c50 | ||
|
|
45f7d62695 | ||
|
|
9edc188827 | ||
|
|
8741faddd3 | ||
|
|
c96739f6fa | ||
|
|
a57a7ae0e8 |
@ -363,7 +363,7 @@ MD5 可以用来生成一个 128 位的消息摘要,它是目前应用比较
|
||||
|
||||
**SHA**
|
||||
|
||||
安全散列算法。**SHA** 分为 **SHA1** 和 **SH2** 两个版本。该算法的思想是接收一段明文,然后以一种不可逆的方式将它转换成一段(通常更小)密文,也可以简单的理解为取一串输入码(称为预映射或信息),并把它们转化为长度较短、位数固定的输出序列即散列值(也称为信息摘要或信息认证代码)的过程。
|
||||
安全散列算法。**SHA** 包括**SHA-1**、**SHA-2**和**SHA-3**三个版本。该算法的基本思想是:接收一段明文数据,通过不可逆的方式将其转换为固定长度的密文。简单来说,SHA将输入数据(即预映射或消息)转化为固定长度、较短的输出值,称为散列值(或信息摘要、信息认证码)。SHA-1已被证明不够安全,因此逐渐被SHA-2取代,而SHA-3则作为SHA系列的最新版本,采用不同的结构(Keccak算法)提供更高的安全性和灵活性。
|
||||
|
||||
**SM3**
|
||||
|
||||
|
||||
@ -151,7 +151,7 @@ _玩玩电脑游戏还是必须要有 Windows 的,所以我现在是一台 Win
|
||||
|
||||
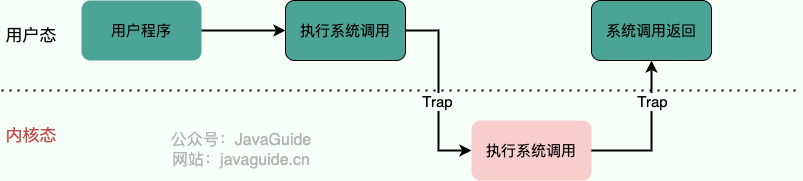
1. 用户态的程序发起系统调用,因为系统调用中涉及一些特权指令(只能由操作系统内核态执行的指令),用户态程序权限不足,因此会中断执行,也就是 Trap(Trap 是一种中断)。
|
||||
2. 发生中断后,当前 CPU 执行的程序会中断,跳转到中断处理程序。内核程序开始执行,也就是开始处理系统调用。
|
||||
3. 内核处理完成后,主动触发 Trap,这样会再次发生中断,切换回用户态工作。
|
||||
3. 当系统调用处理完成后,操作系统使用特权指令(如 `iret`、`sysret` 或 `eret`)切换回用户态,恢复用户态的上下文,继续执行用户程序。
|
||||
|
||||
|
||||
|
||||
|
||||
@ -165,12 +165,21 @@ TIMESTAMP 只需要使用 4 个字节的存储空间,但是 DATETIME 需要耗
|
||||
|
||||
### NULL 和 '' 的区别是什么?
|
||||
|
||||
`NULL` 跟 `''`(空字符串)是两个完全不一样的值,区别如下:
|
||||
`NULL` 和 `''` (空字符串) 是两个完全不同的值,它们分别表示不同的含义,并在数据库中有着不同的行为。`NULL` 代表缺失或未知的数据,而 `''` 表示一个已知存在的空字符串。它们的主要区别如下:
|
||||
|
||||
- `NULL` 代表一个不确定的值,就算是两个 `NULL`,它俩也不一定相等。例如,`SELECT NULL=NULL`的结果为 false,但是在我们使用`DISTINCT`,`GROUP BY`,`ORDER BY`时,`NULL`又被认为是相等的。
|
||||
- `''`的长度是 0,是不占用空间的,而`NULL` 是需要占用空间的。
|
||||
- `NULL` 会影响聚合函数的结果。例如,`SUM`、`AVG`、`MIN`、`MAX` 等聚合函数会忽略 `NULL` 值。 `COUNT` 的处理方式取决于参数的类型。如果参数是 `*`(`COUNT(*)`),则会统计所有的记录数,包括 `NULL` 值;如果参数是某个字段名(`COUNT(列名)`),则会忽略 `NULL` 值,只统计非空值的个数。
|
||||
- 查询 `NULL` 值时,必须使用 `IS NULL` 或 `IS NOT NULLl` 来判断,而不能使用 =、!=、 <、> 之类的比较运算符。而`''`是可以使用这些比较运算符的。
|
||||
1. **含义**:
|
||||
- `NULL` 代表一个不确定的值,它不等于任何值,包括它自身。因此,`SELECT NULL = NULL` 的结果是 `NULL`,而不是 `true` 或 `false`。 `NULL` 意味着缺失或未知的信息。虽然 `NULL` 不等于任何值,但在某些操作中,数据库系统会将 `NULL` 值视为相同的类别进行处理,例如:`DISTINCT`,`GROUP BY`,`ORDER BY`。需要注意的是,这些操作将 `NULL` 值视为相同的类别进行处理,并不意味着 `NULL` 值之间是相等的。 它们只是在特定操作中被特殊处理,以保证结果的正确性和一致性。 这种处理方式是为了方便数据操作,而不是改变了 `NULL` 的语义。
|
||||
- `''` 表示一个空字符串,它是一个已知的值。
|
||||
2. **存储空间**:
|
||||
- `NULL` 的存储空间占用取决于数据库的实现,通常需要一些空间来标记该值为空。
|
||||
- `''` 的存储空间占用通常较小,因为它只存储一个空字符串的标志,不需要存储实际的字符。
|
||||
3. **比较运算**:
|
||||
- 任何值与 `NULL` 进行比较(例如 `=`, `!=`, `>`, `<` 等)的结果都是 `NULL`,表示结果不确定。要判断一个值是否为 `NULL`,必须使用 `IS NULL` 或 `IS NOT NULL`。
|
||||
- `''` 可以像其他字符串一样进行比较运算。例如,`'' = ''` 的结果是 `true`。
|
||||
4. **聚合函数**:
|
||||
- 大多数聚合函数(例如 `SUM`, `AVG`, `MIN`, `MAX`)会忽略 `NULL` 值。
|
||||
- `COUNT(*)` 会统计所有行数,包括包含 `NULL` 值的行。`COUNT(列名)` 会统计指定列中非 `NULL` 值的行数。
|
||||
- 空字符串 `''` 会被聚合函数计算在内。例如,`SUM` 会将其视为 0,`MIN` 和 `MAX` 会将其视为一个空字符串。
|
||||
|
||||
看了上面的介绍之后,相信你对另外一个高频面试题:“为什么 MySQL 不建议使用 `NULL` 作为列默认值?”也有了答案。
|
||||
|
||||
|
||||
@ -217,7 +217,7 @@ catch (IOException e) {
|
||||
|
||||
- 不要把异常定义为静态变量,因为这样会导致异常栈信息错乱。每次手动抛出异常,我们都需要手动 new 一个异常对象抛出。
|
||||
- 抛出的异常信息一定要有意义。
|
||||
- 建议抛出更加具体的异常比如字符串转换为数字格式错误的时候应该抛出`NumberFormatException`而不是其父类`IllegalArgumentException`。
|
||||
- 建议抛出更加具体的异常,比如字符串转换为数字格式错误的时候应该抛出`NumberFormatException`而不是其父类`IllegalArgumentException`。
|
||||
- 避免重复记录日志:如果在捕获异常的地方已经记录了足够的信息(包括异常类型、错误信息和堆栈跟踪等),那么在业务代码中再次抛出这个异常时,就不应该再次记录相同的错误信息。重复记录日志会使得日志文件膨胀,并且可能会掩盖问题的实际原因,使得问题更难以追踪和解决。
|
||||
- ……
|
||||
|
||||
|
||||
@ -220,7 +220,7 @@ new 一个 `Thread`,线程进入了新建状态。调用 `start()`方法,会
|
||||
|
||||
先从总体上来说:
|
||||
|
||||
- **从计算机底层来说:** 线程可以比作是轻量级的进程,是程序执行的最小单位,线程间的切换和调度的成本远远小于进程。另外,多核 CPU 时代意味着多个线程可以同时运行,这减少了线程上下文切换的开销。
|
||||
- **从计算机底层来说:** 线程可以比作是轻量级的进程,是程序执行的最小单位,线程间的切换和调度的成本远远小于进程。另外,多核 CPU 时代意味着多个线程可以同时运行,这减少了线程上下文切换的开销。
|
||||
- **从当代互联网发展趋势来说:** 现在的系统动不动就要求百万级甚至千万级的并发量,而多线程并发编程正是开发高并发系统的基础,利用好多线程机制可以大大提高系统整体的并发能力以及性能。
|
||||
|
||||
再深入到计算机底层来探讨:
|
||||
@ -265,7 +265,7 @@ Java 使用的线程调度是抢占式的。也就是说,JVM 本身不负责
|
||||
|
||||
## ⭐️死锁
|
||||
|
||||
### 什么是线程死锁?
|
||||
### 什么是线程死锁?
|
||||
|
||||
线程死锁描述的是这样一种情况:多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。
|
||||
|
||||
@ -323,14 +323,14 @@ Thread[线程 1,5,main]waiting get resource2
|
||||
Thread[线程 2,5,main]waiting get resource1
|
||||
```
|
||||
|
||||
线程 A 通过 `synchronized (resource1)` 获得 `resource1` 的监视器锁,然后通过`Thread.sleep(1000);`让线程 A 休眠 1s 为的是让线程 B 得到执行然后获取到 resource2 的监视器锁。线程 A 和线程 B 休眠结束了都开始企图请求获取对方的资源,然后这两个线程就会陷入互相等待的状态,这也就产生了死锁。
|
||||
线程 A 通过 `synchronized (resource1)` 获得 `resource1` 的监视器锁,然后通过 `Thread.sleep(1000);` 让线程 A 休眠 1s,为的是让线程 B 得到执行然后获取到 resource2 的监视器锁。线程 A 和线程 B 休眠结束了都开始企图请求获取对方的资源,然后这两个线程就会陷入互相等待的状态,这也就产生了死锁。
|
||||
|
||||
上面的例子符合产生死锁的四个必要条件:
|
||||
|
||||
1. 互斥条件:该资源任意一个时刻只由一个线程占用。
|
||||
2. 请求与保持条件:一个线程因请求资源而阻塞时,对已获得的资源保持不放。
|
||||
3. 不剥夺条件:线程已获得的资源在未使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
|
||||
4. 循环等待条件:若干线程之间形成一种头尾相接的循环等待资源关系。
|
||||
1. **互斥条件**:该资源任意一个时刻只由一个线程占用。
|
||||
2. **请求与保持条件**:一个线程因请求资源而阻塞时,对已获得的资源保持不放。
|
||||
3. **不剥夺条件**:线程已获得的资源在未使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
|
||||
4. **循环等待条件**:若干线程之间形成一种头尾相接的循环等待资源关系。
|
||||
|
||||
### 如何检测死锁?
|
||||
|
||||
|
||||
@ -58,7 +58,7 @@ class Class<T> {
|
||||
}
|
||||
```
|
||||
|
||||
简单来说,**类加载器的主要作用就是加载 Java 类的字节码( `.class` 文件)到 JVM 中(在内存中生成一个代表该类的 `Class` 对象)。** 字节码可以是 Java 源程序(`.java`文件)经过 `javac` 编译得来,也可以是通过工具动态生成或者通过网络下载得来。
|
||||
简单来说,**类加载器的主要作用就是动态加载 Java 类的字节码( `.class` 文件)到 JVM 中(在内存中生成一个代表该类的 `Class` 对象)。** 字节码可以是 Java 源程序(`.java`文件)经过 `javac` 编译得来,也可以是通过工具动态生成或者通过网络下载得来。
|
||||
|
||||
其实除了加载类之外,类加载器还可以加载 Java 应用所需的资源如文本、图像、配置文件、视频等等文件资源。本文只讨论其核心功能:加载类。
|
||||
|
||||
|
||||
@ -253,29 +253,58 @@ public class ReferenceCountingGc {
|
||||
|
||||
JDK1.2 之前,Java 中引用的定义很传统:如果 reference 类型的数据存储的数值代表的是另一块内存的起始地址,就称这块内存代表一个引用。
|
||||
|
||||
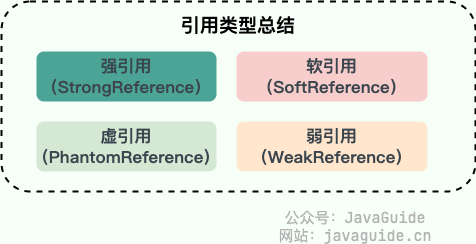
JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引用、软引用、弱引用、虚引用四种(引用强度逐渐减弱)
|
||||
JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引用、软引用、弱引用、虚引用四种(引用强度逐渐减弱),强引用就是 Java 中普通的对象,而软引用、弱引用、虚引用在JDK中定义的类分别是 `SoftReference`、`WeakReference`、`PhantomReference`。
|
||||
|
||||
|
||||
|
||||
**1.强引用(StrongReference)**
|
||||
|
||||
以前我们使用的大部分引用实际上都是强引用,这是使用最普遍的引用。如果一个对象具有强引用,那就类似于**必不可少的生活用品**,垃圾回收器绝不会回收它。当内存空间不足,Java 虚拟机宁愿抛出 OutOfMemoryError 错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足问题。
|
||||
强引用实际上就是程序代码中普遍存在的引用赋值,这是使用最普遍的引用,其代码如下
|
||||
|
||||
```java
|
||||
String strongReference = new String("abc");
|
||||
```
|
||||
|
||||
如果一个对象具有强引用,那就类似于**必不可少的生活用品**,垃圾回收器绝不会回收它。当内存空间不足,Java 虚拟机宁愿抛出 OutOfMemoryError 错误,使程序异常终止,也不会靠随意回收具有强引用的对象来解决内存不足问题。
|
||||
|
||||
**2.软引用(SoftReference)**
|
||||
|
||||
如果一个对象只具有软引用,那就类似于**可有可无的生活用品**。如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存。
|
||||
如果一个对象只具有软引用,那就类似于**可有可无的生活用品**。软引用代码如下
|
||||
|
||||
```java
|
||||
// 软引用
|
||||
String str = new String("abc");
|
||||
SoftReference<String> softReference = new SoftReference<String>(str);
|
||||
```
|
||||
|
||||
如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。软引用可用来实现内存敏感的高速缓存。
|
||||
|
||||
软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收,JAVA 虚拟机就会把这个软引用加入到与之关联的引用队列中。
|
||||
|
||||
**3.弱引用(WeakReference)**
|
||||
|
||||
如果一个对象只具有弱引用,那就类似于**可有可无的生活用品**。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
|
||||
如果一个对象只具有弱引用,那就类似于**可有可无的生活用品**。弱引用代码如下:
|
||||
|
||||
```java
|
||||
String str = new String("abc");
|
||||
WeakReference<String> weakReference = new WeakReference<>(str);
|
||||
str = null; //str变成软引用,可以被收集
|
||||
```
|
||||
|
||||
弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。
|
||||
|
||||
弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java 虚拟机就会把这个弱引用加入到与之关联的引用队列中。
|
||||
|
||||
**4.虚引用(PhantomReference)**
|
||||
|
||||
"虚引用"顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收。
|
||||
"虚引用"顾名思义,就是形同虚设,与其他几种引用都不同,虚引用并不会决定对象的生命周期。如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收。虚引用代码如下:
|
||||
|
||||
```java
|
||||
String str = new String("abc");
|
||||
ReferenceQueue queue = new ReferenceQueue();
|
||||
// 创建虚引用,要求必须与一个引用队列关联
|
||||
PhantomReference pr = new PhantomReference(str, queue);
|
||||
```
|
||||
|
||||
**虚引用主要用来跟踪对象被垃圾回收的活动**。
|
||||
|
||||
|
||||
@ -95,9 +95,7 @@ public class InterfaceNewImpl implements InterfaceNew , InterfaceNew1{
|
||||
|
||||
在 java 8 中专门有一个包放函数式接口`java.util.function`,该包下的所有接口都有 `@FunctionalInterface` 注解,提供函数式编程。
|
||||
|
||||
在其他包中也有函数式接口,其中一些没有`@FunctionalInterface` 注解,但是只要符合函数式接口的定义就是函数式接口,与是否有
|
||||
|
||||
`@FunctionalInterface`注解无关,注解只是在编译时起到强制规范定义的作用。其在 Lambda 表达式中有广泛的应用。
|
||||
在其他包中也有函数式接口,其中一些没有`@FunctionalInterface` 注解,但是只要符合函数式接口的定义就是函数式接口,与是否有`@FunctionalInterface`注解无关,注解只是在编译时起到强制规范定义的作用。其在 Lambda 表达式中有广泛的应用。
|
||||
|
||||
## Lambda 表达式
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user