mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-05 20:31:37 +08:00
Compare commits
3 Commits
294fe56b60
...
8bfc294b6f
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
8bfc294b6f | ||
|
|
f21d432a49 | ||
|
|
f5478e47cb |
@ -39,7 +39,7 @@ _如果文章有任何需要改善和完善的地方,欢迎在评论区指出
|
||||
|
||||
ZooKeeper 是一个开源的**分布式协调服务**,它的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
|
||||
|
||||
> **原语:** 操作系统或计算机网络用语范畴。是由若干条指令组成的,用于完成一定功能的一个过程。具有不可分割性·即原语的执行必须是连续的,在执行过程中不允许被中断。
|
||||
> **原语:** 操作系统或计算机网络用语范畴。是由若干条指令组成的,用于完成一定功能的一个过程。具有不可分割性,即原语的执行必须是连续的,在执行过程中不允许被中断。
|
||||
|
||||
ZooKeeper 为我们提供了高可用、高性能、稳定的分布式数据一致性解决方案,通常被用于实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。这些功能的实现主要依赖于 ZooKeeper 提供的 **数据存储+事件监听** 功能(后文会详细介绍到) 。
|
||||
|
||||
@ -57,6 +57,7 @@ ZooKeeper 将数据保存在内存中,性能是不错的。 在“读”多于
|
||||
- **原子性:** 所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,也就是说,要么整个集群中所有的机器都成功应用了某一个事务,要么都没有应用。
|
||||
- **单一系统映像:** 无论客户端连到哪一个 ZooKeeper 服务器上,其看到的服务端数据模型都是一致的。
|
||||
- **可靠性:** 一旦一次更改请求被应用,更改的结果就会被持久化,直到被下一次更改覆盖。
|
||||
- **实时性:** 每个客户端的系统视图都是最新的。
|
||||
|
||||
### ZooKeeper 应用场景
|
||||
|
||||
@ -76,9 +77,9 @@ _破音:拿出小本本,下面的内容非常重要哦!_
|
||||
|
||||
### Data model(数据模型)
|
||||
|
||||
ZooKeeper 数据模型采用层次化的多叉树形结构,每个节点上都可以存储数据,这些数据可以是数字、字符串或者是二级制序列。并且。每个节点还可以拥有 N 个子节点,最上层是根节点以“/”来代表。每个数据节点在 ZooKeeper 中被称为 **znode**,它是 ZooKeeper 中数据的最小单元。并且,每个 znode 都一个唯一的路径标识。
|
||||
ZooKeeper 数据模型采用层次化的多叉树形结构,每个节点上都可以存储数据,这些数据可以是数字、字符串或者是二级制序列。并且。每个节点还可以拥有 N 个子节点,最上层是根节点以“/”来代表。每个数据节点在 ZooKeeper 中被称为 **znode**,它是 ZooKeeper 中数据的最小单元。并且,每个 znode 都有一个唯一的路径标识。
|
||||
|
||||
强调一句:**ZooKeeper 主要是用来协调服务的,而不是用来存储业务数据的,所以不要放比较大的数据在 znode 上,ZooKeeper 给出的上限是每个结点的数据大小最大是 1M。**
|
||||
强调一句:**ZooKeeper 主要是用来协调服务的,而不是用来存储业务数据的,所以不要放比较大的数据在 znode 上,ZooKeeper 给出的每个节点的数据大小上限是 1M 。**
|
||||
|
||||
从下图可以更直观地看出:ZooKeeper 节点路径标识方式和 Unix 文件系统路径非常相似,都是由一系列使用斜杠"/"进行分割的路径表示,开发人员可以向这个节点中写入数据,也可以在节点下面创建子节点。这些操作我们后面都会介绍到。
|
||||
|
||||
@ -91,7 +92,7 @@ ZooKeeper 数据模型采用层次化的多叉树形结构,每个节点上都
|
||||
我们通常是将 znode 分为 4 大类:
|
||||
|
||||
- **持久(PERSISTENT)节点**:一旦创建就一直存在即使 ZooKeeper 集群宕机,直到将其删除。
|
||||
- **临时(EPHEMERAL)节点**:临时节点的生命周期是与 **客户端会话(session)** 绑定的,**会话消失则节点消失** 。并且,**临时节点只能做叶子节点** ,不能创建子节点。
|
||||
- **临时(EPHEMERAL)节点**:临时节点的生命周期是与 **客户端会话(session)** 绑定的,**会话消失则节点消失**。并且,**临时节点只能做叶子节点** ,不能创建子节点。
|
||||
- **持久顺序(PERSISTENT_SEQUENTIAL)节点**:除了具有持久(PERSISTENT)节点的特性之外, 子节点的名称还具有顺序性。比如 `/node1/app0000000001`、`/node1/app0000000002` 。
|
||||
- **临时顺序(EPHEMERAL_SEQUENTIAL)节点**:除了具备临时(EPHEMERAL)节点的特性之外,子节点的名称还具有顺序性
|
||||
|
||||
@ -215,8 +216,8 @@ ZooKeeper 集群中的所有机器通过一个 **Leader 选举过程** 来选定
|
||||
|
||||
1. **Leader election(选举阶段)**:节点在一开始都处于选举阶段,只要有一个节点得到超半数节点的票数,它就可以当选准 leader。
|
||||
2. **Discovery(发现阶段)**:在这个阶段,followers 跟准 leader 进行通信,同步 followers 最近接收的事务提议。
|
||||
3. **Synchronization(同步阶段)** :同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后准 leader 才会成为真正的 leader。
|
||||
4. **Broadcast(广播阶段)** :到了这个阶段,ZooKeeper 集群才能正式对外提供事务服务,并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
|
||||
3. **Synchronization(同步阶段)**:同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后准 leader 才会成为真正的 leader。
|
||||
4. **Broadcast(广播阶段)**:到了这个阶段,ZooKeeper 集群才能正式对外提供事务服务,并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
|
||||
|
||||
ZooKeeper 集群中的服务器状态有下面几种:
|
||||
|
||||
|
||||
@ -299,6 +299,24 @@ tag:
|
||||
|
||||
总的来说,我们可以完全 **利用 临时节点、节点状态 和 `watcher` 来实现选主的功能**,临时节点主要用来选举,节点状态和`watcher` 可以用来判断 `master` 的活性和进行重新选举。
|
||||
|
||||
### 数据发布/订阅
|
||||
|
||||
还记得 Zookeeper 的 `Watcher` 机制吗? Zookeeper 通过这种推拉相结合的方式实现客户端与服务端的交互:客户端向服务端注册节点,一旦相应节点的数据变更,服务端就会向“监听”该节点的客户端发送 `Watcher` 事件通知,客户端接收到通知后需要 **主动** 到服务端获取最新的数据。基于这种方式,Zookeeper 实现了 **数据发布/订阅** 功能。
|
||||
|
||||
一个典型的应用场景为 **全局配置信息的集中管理**。 客户端在启动时会主动到 Zookeeper 服务端获取配置信息,同时 **在指定节点注册一个** `Watcher` **监听**。当配置信息发生变更,服务端通知所有订阅的客户端重新获取配置信息,实现配置信息的实时更新。
|
||||
|
||||
上面所提到的全局配置信息通常包括机器列表信息、运行时的开关配置、数据库配置信息等。需要注意的是,这类全局配置信息通常具备以下特性:
|
||||
|
||||
- 数据量较小
|
||||
- 数据内容在运行时动态变化
|
||||
- 集群中机器共享一致配置
|
||||
|
||||
### 负载均衡
|
||||
|
||||
可以通过 Zookeeper 的 **临时节点** 实现负载均衡。回顾一下临时节点的特性:当创建节点的客户端与服务端之间断开连接,即客户端会话(session)消失时,对应节点也会自动消失。因此,我们可以使用临时节点来维护 Server 的地址列表,从而保证请求不会被分配到已停机的服务上。
|
||||
|
||||
具体地,我们需要在集群的每一个 Server 中都使用 Zookeeper 客户端连接 Zookeeper 服务端,同时用 Server **自身的地址信息**在服务端指定目录下创建临时节点。当客户端请求调用集群服务时,首先通过 Zookeeper 获取该目录下的节点列表 (即所有可用的 Server),随后根据不同的负载均衡策略将请求转发到某一具体的 Server。
|
||||
|
||||
### 分布式锁
|
||||
|
||||
分布式锁的实现方式有很多种,比如 `Redis`、数据库、`zookeeper` 等。个人认为 `zookeeper` 在实现分布式锁这方面是非常非常简单的。
|
||||
|
||||
@ -25,9 +25,9 @@ category: 高可用
|
||||
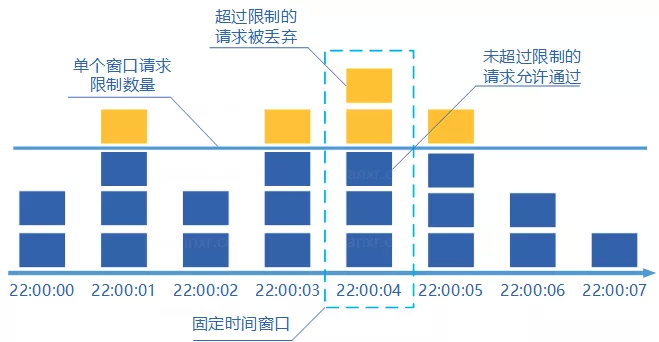
- 1 分钟之内每处理一个请求之后就将 `counter+1` ,当 `counter=33` 之后(也就是说在这 1 分钟内接口已经被访问 33 次的话),后续的请求就会被全部拒绝。
|
||||
- 等到 1 分钟结束后,将 `counter` 重置 0,重新开始计数。
|
||||
|
||||
**这种限流算法无法保证限流速率,因而无法保证突然激增的流量。**
|
||||
这种限流算法限流不够平滑。例如,我们限制某个接口每分钟只能访问 30 次,假设前 30 秒就有 30 个请求到达的话,那后续 30 秒将无法处理请求,这是不可取的,用户体验极差!
|
||||
|
||||
就比如说我们限制某个接口 1 分钟只能访问 1000 次,该接口的 QPS 为 500,前 55s 这个接口 1 个请求没有接收,后 1s 突然接收了 1000 个请求。然后,在当前场景下,这 1000 个请求在 1s 内是没办法被处理的,系统直接就被瞬时的大量请求给击垮了。
|
||||
除此之外,这种限流算法无法保证限流速率,因而无法应对突然激增的流量。例如,我们限制某个接口 1 分钟只能访问 1000 次,该接口的 QPS 为 500,前 55s 这个接口 1 个请求没有接收,后 1s 突然接收了 1000 个请求。然后,在当前场景下,这 1000 个请求在 1s 内是没办法被处理的,系统直接就被瞬时的大量请求给击垮了。
|
||||
|
||||
|
||||
|
||||
@ -43,6 +43,8 @@ category: 高可用
|
||||
|
||||
|
||||
|
||||
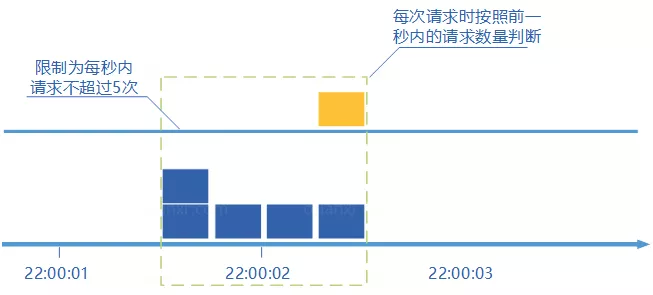
滑动窗口计数器算法可以应对突然激增的流量,但依然存在限流不够平滑的问题。
|
||||
|
||||
### 漏桶算法
|
||||
|
||||
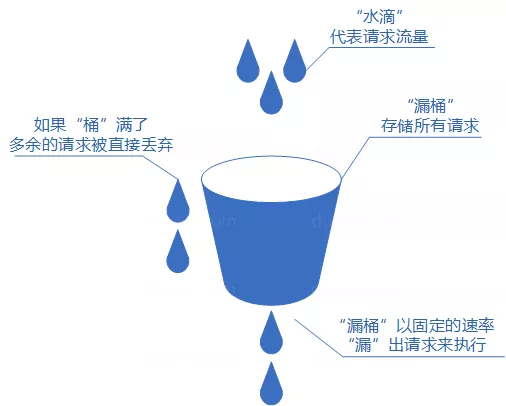
我们可以把发请求的动作比作成注水到桶中,我们处理请求的过程可以比喻为漏桶漏水。我们往桶中以任意速率流入水,以一定速率流出水。当水超过桶流量则丢弃,因为桶容量是不变的,保证了整体的速率。
|
||||
@ -51,12 +53,20 @@ category: 高可用
|
||||
|
||||
|
||||
|
||||
漏桶算法可以控制限流速率,避免网络拥塞和系统过载。不过,漏桶算法无法应对突然激增的流量,因为只能以固定的速率处理请求,对系统资源利用不够友好。
|
||||
|
||||
实际业务场景中,基本不会使用漏桶算法。
|
||||
|
||||
### 令牌桶算法
|
||||
|
||||
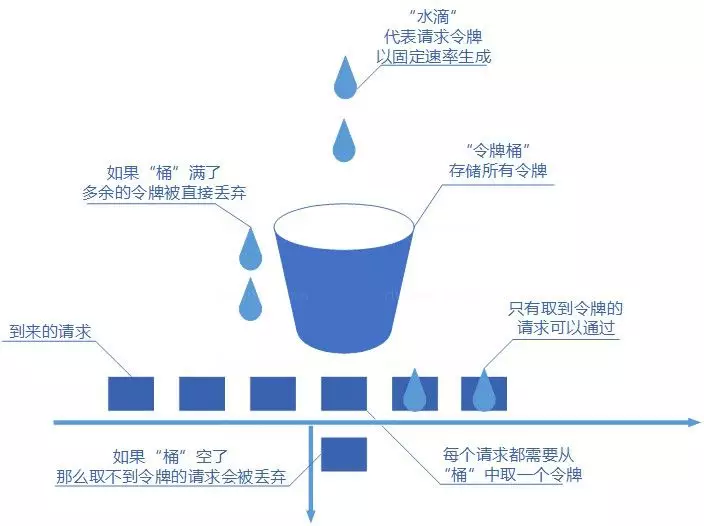
令牌桶算法也比较简单。和漏桶算法算法一样,我们的主角还是桶(这限流算法和桶过不去啊)。不过现在桶里装的是令牌了,请求在被处理之前需要拿到一个令牌,请求处理完毕之后将这个令牌丢弃(删除)。我们根据限流大小,按照一定的速率往桶里添加令牌。如果桶装满了,就不能继续往里面继续添加令牌了。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
令牌桶算法可以限制平均速率和应对突然激增的流量,还可以动态调整生成令牌的速率。不过,如果令牌产生速率和桶的容量设置不合理,可能会出现问题比如大量的请求被丢弃、系统过载。
|
||||
|
||||
## 单机限流怎么做?
|
||||
|
||||
单机限流针对的是单体架构应用。
|
||||
@ -204,10 +214,39 @@ Resilience4j 不仅提供限流,还提供了熔断、负载保护、自动重
|
||||
|
||||

|
||||
|
||||
另外,如果不想自己写 Lua 脚本的话,也可以直接利用 Redisson 中的 `RRateLimiter` 来实现分布式限流,其底层实现就是基于 Lua 代码。
|
||||
|
||||
Redisson 是一个开源的 Java 语言 Redis 客户端,提供了很多开箱即用的功能,比如 Java 中常用的数据结构实现、分布式锁、延迟队列等等。并且,Redisson 还支持 Redis 单机、Redis Sentinel、Redis Cluster 等多种部署架构。
|
||||
|
||||
`RRateLimiter` 的使用方式非常简单。我们首先需要获取一个`RRateLimiter`对象,直接通过 Redisson 客户端获取即可。然后,设置限流规则就好。
|
||||
|
||||
```java
|
||||
// 创建一个 Redisson 客户端实例
|
||||
RedissonClient redissonClient = Redisson.create();
|
||||
// 获取一个名为 "javaguide.limiter" 的限流器对象
|
||||
RRateLimiter rateLimiter = redissonClient.getRateLimiter("javaguide.limiter");
|
||||
// 尝试设置限流器的速率为每小时 100 次
|
||||
// RateType 有两种,OVERALL是全局限流,ER_CLIENT是单Client限流(可以认为就是单机限流)
|
||||
rateLimiter.trySetRate(RateType.OVERALL, 100, 1, RateIntervalUnit.HOURS);
|
||||
```
|
||||
|
||||
接下来我们调用`acquire()`方法或`tryAcquire()`方法即可获取许可。
|
||||
|
||||
```java
|
||||
// 获取一个许可,如果超过限流器的速率则会等待
|
||||
// acquire()是同步方法,对应的异步方法:acquireAsync()
|
||||
rateLimiter.acquire(1);
|
||||
// 尝试在 5 秒内获取一个许可,如果成功则返回 true,否则返回 false
|
||||
// tryAcquire()是同步方法,对应的异步方法:tryAcquireAsync()
|
||||
boolean res = rateLimiter.tryAcquire(1, 5, TimeUnit.SECONDS);
|
||||
```
|
||||
|
||||
## 相关阅读
|
||||
|
||||
- 服务治理之轻量级熔断框架 Resilience4j:<https://xie.infoq.cn/article/14786e571c1a4143ad1ef8f19>
|
||||
- 超详细的 Guava RateLimiter 限流原理解析:<https://cloud.tencent.com/developer/article/1408819>
|
||||
- 实战 Spring Cloud Gateway 之限流篇 👍:<https://www.aneasystone.com/archives/2020/08/spring-cloud-gateway-current-limiting.html>
|
||||
- 详解 Redisson 分布式限流的实现原理:<https://juejin.cn/post/7199882882138898489>
|
||||
- 一文详解 Java 限流接口实现 - 阿里云开发者:<https://mp.weixin.qq.com/s/A5VYjstIDeVvizNK2HkrTQ>
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user