mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
Compare commits
5 Commits
2243803aed
...
219cea0d3d
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
219cea0d3d | ||
|
|
7ff2ff030b | ||
|
|
6a77dadd95 | ||
|
|
3710aec7af | ||
|
|
5fa50dc5a6 |
@ -1095,13 +1095,14 @@ WHERE b.prod_id = 'BR01'
|
||||
|
||||
```sql
|
||||
# 写法 1:子查询
|
||||
SELECT o.cust_id AS cust_id, tb.total_ordered AS total_ordered
|
||||
FROM (SELECT order_num, Sum(item_price * quantity) AS total_ordered
|
||||
SELECT o.cust_id, SUM(tb.total_ordered) AS `total_ordered`
|
||||
FROM (SELECT order_num, SUM(item_price * quantity) AS total_ordered
|
||||
FROM OrderItems
|
||||
GROUP BY order_num) AS tb,
|
||||
Orders o
|
||||
WHERE tb.order_num = o.order_num
|
||||
ORDER BY total_ordered DESC
|
||||
GROUP BY o.cust_id
|
||||
ORDER BY total_ordered DESC;
|
||||
|
||||
# 写法 2:连接表
|
||||
SELECT b.cust_id, Sum(a.quantity * a.item_price) AS total_ordered
|
||||
@ -1111,6 +1112,8 @@ GROUP BY cust_id
|
||||
ORDER BY total_ordered DESC
|
||||
```
|
||||
|
||||
关于写法一详细介绍可以参考: [issue#2402:写法 1 存在的错误以及修改方法](https://github.com/Snailclimb/JavaGuide/issues/2402)。
|
||||
|
||||
### 从 Products 表中检索所有的产品名称以及对应的销售总数
|
||||
|
||||
`Products` 表中检索所有的产品名称:`prod_name`、产品 id:`prod_id`
|
||||
@ -1653,12 +1656,12 @@ ORDER BY prod_name
|
||||
注意:`vend_id` 列会显示在多个表中,因此在每次引用它时都需要完全限定它。
|
||||
|
||||
```sql
|
||||
SELECT vend_id, COUNT(prod_id) AS prod_id
|
||||
FROM Vendors
|
||||
LEFT JOIN Products
|
||||
SELECT v.vend_id, COUNT(prod_id) AS prod_id
|
||||
FROM Vendors v
|
||||
LEFT JOIN Products p
|
||||
USING(vend_id)
|
||||
GROUP BY vend_id
|
||||
ORDER BY vend_id
|
||||
GROUP BY v.vend_id
|
||||
ORDER BY v.vend_id
|
||||
```
|
||||
|
||||
## 组合查询
|
||||
|
||||
@ -8,15 +8,15 @@ icon: et-performance
|
||||
|
||||
这篇文章是我会结合自己的实际经历以及在测试这里取的经所得,除此之外,我还借鉴了一些优秀书籍,希望对你有帮助。
|
||||
|
||||
## 一 不同角色看网站性能
|
||||
## 不同角色看网站性能
|
||||
|
||||
### 1.1 用户
|
||||
### 用户
|
||||
|
||||
当用户打开一个网站的时候,最关注的是什么?当然是网站响应速度的快慢。比如我们点击了淘宝的主页,淘宝需要多久将首页的内容呈现在我的面前,我点击了提交订单按钮需要多久返回结果等等。
|
||||
|
||||
所以,用户在体验我们系统的时候往往根据你的响应速度的快慢来评判你的网站的性能。
|
||||
|
||||
### 1.2 开发人员
|
||||
### 开发人员
|
||||
|
||||
用户与开发人员都关注速度,这个速度实际上就是我们的系统**处理用户请求的速度**。
|
||||
|
||||
@ -31,7 +31,7 @@ icon: et-performance
|
||||
7. 项目使用的 Redis 缓存多大?服务器性能如何?用的是机械硬盘还是固态硬盘?
|
||||
8. ……
|
||||
|
||||
### 1.3 测试人员
|
||||
### 测试人员
|
||||
|
||||
测试人员一般会根据性能测试工具来测试,然后一般会做出一个表格。这个表格可能会涵盖下面这些重要的内容:
|
||||
|
||||
@ -40,63 +40,87 @@ icon: et-performance
|
||||
3. 吞吐量;
|
||||
4. ……
|
||||
|
||||
### 1.4 运维人员
|
||||
### 运维人员
|
||||
|
||||
运维人员会倾向于根据基础设施和资源的利用率来判断网站的性能,比如我们的服务器资源使用是否合理、数据库资源是否存在滥用的情况、当然,这是传统的运维人员,现在 Devops 火起来后,单纯干运维的很少了。我们这里暂且还保留有这个角色。
|
||||
|
||||
## 二 性能测试需要注意的点
|
||||
## 性能测试需要注意的点
|
||||
|
||||
几乎没有文章在讲性能测试的时候提到这个问题,大家都会讲如何去性能测试,有哪些性能测试指标这些东西。
|
||||
|
||||
### 2.1 了解系统的业务场景
|
||||
### 了解系统的业务场景
|
||||
|
||||
**性能测试之前更需要你了解当前的系统的业务场景。** 对系统业务了解的不够深刻,我们很容易犯测试方向偏执的错误,从而导致我们忽略了对系统某些更需要性能测试的地方进行测试。比如我们的系统可以为用户提供发送邮件的功能,用户配置成功邮箱后只需输入相应的邮箱之后就能发送,系统每天大概能处理上万次发邮件的请求。很多人看到这个可能就直接开始使用相关工具测试邮箱发送接口,但是,发送邮件这个场景可能不是当前系统的性能瓶颈,这么多人用我们的系统发邮件, 还可能有很多人一起发邮件,单单这个场景就这么人用,那用户管理可能才是性能瓶颈吧!
|
||||
|
||||
### 2.2 历史数据非常有用
|
||||
### 历史数据非常有用
|
||||
|
||||
当前系统所留下的历史数据非常重要,一般情况下,我们可以通过相应的些历史数据初步判定这个系统哪些接口调用的比较多、哪些 service 承受的压力最大,这样的话,我们就可以针对这些地方进行更细致的性能测试与分析。
|
||||
当前系统所留下的历史数据非常重要,一般情况下,我们可以通过相应的些历史数据初步判定这个系统哪些接口调用的比较多、哪些服务承受的压力最大,这样的话,我们就可以针对这些地方进行更细致的性能测试与分析。
|
||||
|
||||
另外,这些地方也就像这个系统的一个短板一样,优化好了这些地方会为我们的系统带来质的提升。
|
||||
|
||||
### 三 性能测试的指标
|
||||
## 常见性能指标
|
||||
|
||||
### 3.1 响应时间
|
||||
### 响应时间
|
||||
|
||||
**响应时间就是用户发出请求到用户收到系统处理结果所需要的时间。** 重要吗?实在太重要!
|
||||
**响应时间 RT(Response-time)就是用户发出请求到用户收到系统处理结果所需要的时间。**
|
||||
|
||||
比较出名的 2-5-8 原则是这样描述的:通常来说,2 到 5 秒,页面体验会比较好,5 到 8 秒还可以接受,8 秒以上基本就很难接受了。另外,据统计当网站慢一秒就会流失十分之一的客户。
|
||||
RT 是一个非常重要且直观的指标,RT 数值大小直接反应了系统处理用户请求速度的快慢。
|
||||
|
||||
但是,在某些场景下我们也并不需要太看重 2-5-8 原则 ,比如我觉得系统导出导入大数据量这种就不需要,系统生成系统报告这种也不需要。
|
||||
### 并发数
|
||||
|
||||
### 3.2 并发数
|
||||
**并发数可以简单理解为系统能够同时供多少人访问使用也就是说系统同时能处理的请求数量。**
|
||||
|
||||
**并发数是系统能同时处理请求的数目即同时提交请求的用户数目。**
|
||||
并发数反应了系统的负载能力。
|
||||
|
||||
不得不说,高并发是现在后端架构中非常非常火热的一个词了,这个与当前的互联网环境以及中国整体的互联网用户量都有很大关系。一般情况下,你的系统并发量越大,说明你的产品做的就越大。但是,并不是每个系统都需要达到像淘宝、12306 这种亿级并发量的。
|
||||
### QPS 和 TPS
|
||||
|
||||
### 3.3 吞吐量
|
||||
|
||||
吞吐量指的是系统单位时间内系统处理的请求数量。衡量吞吐量有几个重要的参数:QPS(TPS)、并发数、响应时间。
|
||||
|
||||
1. QPS(Query Per Second):服务器每秒可以执行的查询次数;
|
||||
2. TPS(Transaction Per Second):服务器每秒处理的事务数(这里的一个事务可以理解为客户发出请求到收到服务器的过程);
|
||||
3. 并发数;系统能同时处理请求的数目即同时提交请求的用户数目。
|
||||
4. 响应时间:一般取多次请求的平均响应时间
|
||||
|
||||
理清他们的概念,就很容易搞清楚他们之间的关系了。
|
||||
|
||||
- **QPS(TPS)** = 并发数/平均响应时间
|
||||
- **并发数** = QPS\*平均响应时间
|
||||
- **QPS(Query Per Second)** :服务器每秒可以执行的查询次数;
|
||||
- **TPS(Transaction Per Second)** :服务器每秒处理的事务数(这里的一个事务可以理解为客户发出请求到收到服务器的过程);
|
||||
|
||||
书中是这样描述 QPS 和 TPS 的区别的。
|
||||
|
||||
> QPS vs TPS:QPS 基本类似于 TPS,但是不同的是,对于一个页面的一次访问,形成一个 TPS;但一次页面请求,可能产生多次对服务器的请求,服务器对这些请求,就可计入“QPS”之中。如,访问一个页面会请求服务器 2 次,一次访问,产生一个“T”,产生 2 个“Q”。
|
||||
|
||||
### 3.4 性能计数器
|
||||
### 吞吐量
|
||||
|
||||
**性能计数器是描述服务器或者操作系统的一些数据指标如内存使用、CPU 使用、磁盘与网络 I/O 等情况。**
|
||||
**吞吐量指的是系统单位时间内系统处理的请求数量。**
|
||||
|
||||
### 四 几种常见的性能测试
|
||||
一个系统的吞吐量与请求对系统的资源消耗等紧密关联。请求对系统资源消耗越多,系统吞吐能力越低,反之则越高。
|
||||
|
||||
TPS、QPS 都是吞吐量的常用量化指标。
|
||||
|
||||
- **QPS(TPS)** = 并发数/平均响应时间(RT)
|
||||
- **并发数** = QPS \* 平均响应时间(RT)
|
||||
|
||||
## 系统活跃度指标
|
||||
|
||||
### PV(Page View)
|
||||
|
||||
访问量, 即页面浏览量或点击量,衡量网站用户访问的网页数量;在一定统计周期内用户每打开或刷新一个页面就记录 1 次,多次打开或刷新同一页面则浏览量累计。UV 从网页打开的数量/刷新的次数的角度来统计的。
|
||||
|
||||
### UV(Unique Visitor)
|
||||
|
||||
独立访客,统计 1 天内访问某站点的用户数。1 天内相同访客多次访问网站,只计算为 1 个独立访客。UV 是从用户个体的角度来统计的。
|
||||
|
||||
### DAU(Daily Active User)
|
||||
|
||||
日活跃用户数量。
|
||||
|
||||
### MAU(monthly active users)
|
||||
|
||||
月活跃用户人数。
|
||||
|
||||
举例:某网站 DAU 为 1200w, 用户日均使用时长 1 小时,RT 为 0.5s,求并发量和 QPS。
|
||||
|
||||
平均并发量 = DAU(1200w)\* 日均使用时长(1 小时,3600 秒) /一天的秒数(86400)=1200w/24 = 50w
|
||||
|
||||
真实并发量(考虑到某些时间段使用人数比较少) = DAU(1200w)\* 日均使用时长(1 小时,3600 秒) /一天的秒数-访问量比较小的时间段假设为 8 小时(57600)=1200w/16 = 75w
|
||||
|
||||
峰值并发量 = 平均并发量 \* 6 = 300w
|
||||
|
||||
QPS = 真实并发量/RT = 75W/0.5=150w/s
|
||||
|
||||
## 性能测试分类
|
||||
|
||||
### 性能测试
|
||||
|
||||
@ -118,25 +142,27 @@ icon: et-performance
|
||||
|
||||
模拟真实场景,给系统一定压力,看看业务是否能稳定运行。
|
||||
|
||||
## 五 常用性能测试工具
|
||||
## 常用性能测试工具
|
||||
|
||||
这里就不多扩展了,有时间的话会单独拎一个熟悉的说一下。
|
||||
### 后端常用
|
||||
|
||||
### 5.1 后端常用
|
||||
既然系统设计涉及到系统性能方面的问题,那在面试的时候,面试官就很可能会问:**你是如何进行性能测试的?**
|
||||
|
||||
没记错的话,除了 LoadRunner 其他几款性能测试工具都是开源免费的。
|
||||
推荐 4 个比较常用的性能测试工具:
|
||||
|
||||
1. Jmeter:Apache JMeter 是 JAVA 开发的性能测试工具。
|
||||
2. LoadRunner:一款商业的性能测试工具。
|
||||
3. Galtling:一款基于 Scala 开发的高性能服务器性能测试工具。
|
||||
4. ab:全称为 Apache Bench 。Apache 旗下的一款测试工具,非常实用。
|
||||
1. **Jmeter** :Apache JMeter 是 JAVA 开发的性能测试工具。
|
||||
2. **LoadRunner**:一款商业的性能测试工具。
|
||||
3. **Galtling** :一款基于 Scala 开发的高性能服务器性能测试工具。
|
||||
4. **ab** :全称为 Apache Bench 。Apache 旗下的一款测试工具,非常实用。
|
||||
|
||||
### 5.2 前端常用
|
||||
没记错的话,除了 **LoadRunner** 其他几款性能测试工具都是开源免费的。
|
||||
|
||||
1. Fiddler:抓包工具,它可以修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是 Web 调试的利器。
|
||||
2. HttpWatch: 可用于录制 HTTP 请求信息的工具。
|
||||
### 前端常用
|
||||
|
||||
## 六 常见的性能优化策略
|
||||
1. **Fiddler**:抓包工具,它可以修改请求的数据,甚至可以修改服务器返回的数据,功能非常强大,是 Web 调试的利器。
|
||||
2. **HttpWatch**: 可用于录制 HTTP 请求信息的工具。
|
||||
|
||||
## 常见的性能优化策略
|
||||
|
||||
性能优化之前我们需要对请求经历的各个环节进行分析,排查出可能出现性能瓶颈的地方,定位问题。
|
||||
|
||||
|
||||
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 48 KiB |
{kind=link}
Binary file not shown.
|
Before Width: | Height: | Size: 23 KiB |
@ -23,9 +23,9 @@ tag:
|
||||
|
||||
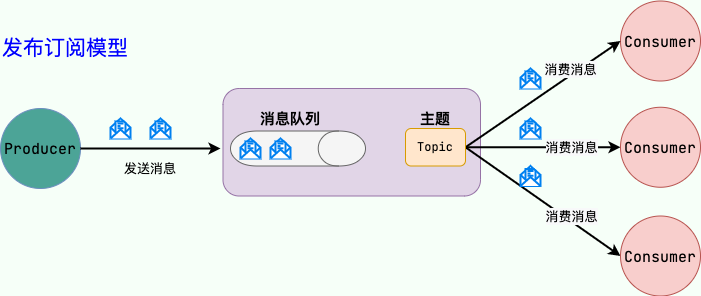
参与消息传递的双方称为 **生产者** 和 **消费者** ,生产者负责发送消息,消费者负责处理消息。
|
||||
|
||||

|
||||
|
||||
|
||||
我们知道操作系统中的进程通信的一种很重要的方式就是消息队列。我们这里提到的消息队列稍微有点区别,更多指的是各个服务以及系统内部各个组件/模块之前的通信,属于一种 **中间件** 。
|
||||
操作系统中的进程通信的一种很重要的方式就是消息队列。我们这里提到的消息队列稍微有点区别,更多指的是各个服务以及系统内部各个组件/模块之前的通信,属于一种 **中间件** 。
|
||||
|
||||
维基百科是这样介绍中间件的:
|
||||
|
||||
@ -43,7 +43,7 @@ tag:
|
||||
|
||||
通常来说,使用消息队列主要能为我们的系统带来下面三点好处:
|
||||
|
||||
1. 通过异步处理提高系统性能(减少响应所需时间)
|
||||
1. 异步处理
|
||||
2. 削峰/限流
|
||||
3. 降低系统耦合性
|
||||
|
||||
@ -51,11 +51,11 @@ tag:
|
||||
|
||||
如果在面试的时候你被面试官问到这个问题的话,一般情况是你在你的简历上涉及到消息队列这方面的内容,这个时候推荐你结合你自己的项目来回答。
|
||||
|
||||
### 通过异步处理提高系统性能(减少响应时间)
|
||||
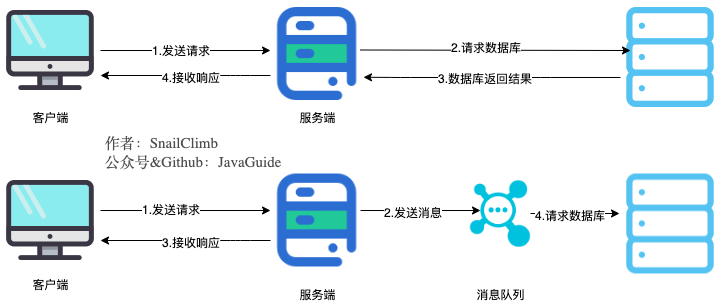
### 异步处理
|
||||
|
||||
|
||||
|
||||
将用户的请求数据存储到消息队列之后就立即返回结果。随后,系统再对消息进行消费。
|
||||
将用户请求中包含的耗时操作,通过消息队列实现异步处理,将对应的消息发送到消息队列之后就立即返回结果,减少响应时间,提高用户体验。随后,系统再对消息进行消费。
|
||||
|
||||
因为用户请求数据写入消息队列之后就立即返回给用户了,但是请求数据在后续的业务校验、写数据库等操作中可能失败。因此,**使用消息队列进行异步处理之后,需要适当修改业务流程进行配合**,比如用户在提交订单之后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功,以免交易纠纷。这就类似我们平时手机订火车票和电影票。
|
||||
|
||||
@ -69,11 +69,11 @@ tag:
|
||||
|
||||
### 降低系统耦合性
|
||||
|
||||
使用消息队列还可以降低系统耦合性。我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。还是直接上图吧:
|
||||
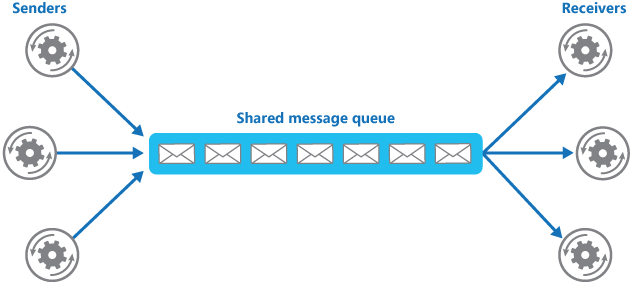
使用消息队列还可以降低系统耦合性。如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。
|
||||
|
||||
|
||||
生产者(客户端)发送消息到消息队列中去,消费者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合,这显然也提高了系统的扩展性。
|
||||
|
||||
生产者(客户端)发送消息到消息队列中去,接受者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合,这显然也提高了系统的扩展性。
|
||||

|
||||
|
||||
**消息队列使用发布-订阅模式工作,消息发送者(生产者)发布消息,一个或多个消息接受者(消费者)订阅消息。** 从上图可以看到**消息发送者(生产者)和消息接受者(消费者)之间没有直接耦合**,消息发送者将消息发送至分布式消息队列即结束对消息的处理,消息接受者从分布式消息队列获取该消息后进行后续处理,并不需要知道该消息从何而来。**对新增业务,只要对该类消息感兴趣,即可订阅该消息,对原有系统和业务没有任何影响,从而实现网站业务的可扩展性设计**。
|
||||
|
||||
@ -87,7 +87,7 @@ tag:
|
||||
|
||||
### 实现分布式事务
|
||||
|
||||
我们知道分布式事务的解决方案之一就是 MQ 事务。
|
||||
分布式事务的解决方案之一就是 MQ 事务。
|
||||
|
||||
RocketMQ、 Kafka、Pulsar、QMQ 都提供了事务相关的功能。事务允许事件流应用将消费,处理,生产消息整个过程定义为一个原子操作。
|
||||
|
||||
@ -103,6 +103,14 @@ RocketMQ、 Kafka、Pulsar、QMQ 都提供了事务相关的功能。事务允
|
||||
|
||||
消息发送后不会立即被消费,而是指定一个时间,到时间后再消费。大部分消息队列,例如 RocketMQ、RabbitMQ、Pulsar、Kafka,都支持定时/延时消息。
|
||||
|
||||
|
||||
|
||||
### 即时通讯
|
||||
|
||||
MQTT(消息队列遥测传输协议)是一种轻量级的通讯协议,采用发布/订阅模式,非常适合于物联网(IoT)等需要在低带宽、高延迟或不可靠网络环境下工作的应用。它支持即时消息传递,即使在网络条件较差的情况下也能保持通信的稳定性。
|
||||
|
||||
RabbitMQ 内置了 MQTT 插件用于实现 MQTT 功能(默认不启用,需要手动开启)。
|
||||
|
||||
### 数据流处理
|
||||
|
||||
针对分布式系统产生的海量数据流,如业务日志、监控数据、用户行为等,消息队列可以实时或批量收集这些数据,并将其导入到大数据处理引擎中,实现高效的数据流管理和处理。
|
||||
@ -133,13 +141,13 @@ JMS 定义了五种不同的消息正文格式以及调用的消息类型,允
|
||||
|
||||
#### 点到点(P2P)模型
|
||||
|
||||

|
||||
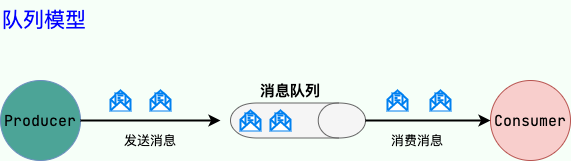
|
||||
|
||||
使用**队列(Queue)**作为消息通信载体;满足**生产者与消费者模式**,一条消息只能被一个消费者使用,未被消费的消息在队列中保留直到被消费或超时。比如:我们生产者发送 100 条消息的话,两个消费者来消费一般情况下两个消费者会按照消息发送的顺序各自消费一半(也就是你一个我一个的消费。)
|
||||
|
||||
#### 发布/订阅(Pub/Sub)模型
|
||||
|
||||

|
||||

|
||||
|
||||
发布订阅模型(Pub/Sub) 使用**主题(Topic)**作为消息通信载体,类似于**广播模式**;发布者发布一条消息,该消息通过主题传递给所有的订阅者。
|
||||
|
||||
|
||||
@ -285,11 +285,11 @@ final void treeifyBin(Node<K,V>[] tab, int hash) {
|
||||
|
||||
### HashMap 的长度为什么是 2 的幂次方
|
||||
|
||||
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648 到 2147483647,前后加起来大概 40 亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个 40 亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ `(n - 1) & hash`”。(n 代表数组长度)。这也就解释了 HashMap 的长度为什么是 2 的幂次方。
|
||||
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648 到 2147483647,前后加起来大概 40 亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个 40 亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。
|
||||
|
||||
**这个算法应该如何设计呢?**
|
||||
|
||||
我们首先可能会想到采用%取余的操作来实现。但是,重点来了:**“取余(%)操作中如果除数是 2 的幂次则等价于与其除数减一的与(&)操作(也就是说 hash%length==hash&(length-1)的前提是 length 是 2 的 n 次方;)。”** 并且 **采用二进制位操作 &,相对于%能够提高运算效率,这就解释了 HashMap 的长度为什么是 2 的幂次方。**
|
||||
我们首先可能会想到采用 % 取余的操作来实现。但是,重点来了:“**取余(%)操作中如果除数是 2 的幂次则等价于与其除数减一的与(&)操作**(也就是说 hash%length==hash&(length-1)的前提是 length 是 2 的 n 次方;)。” 并且 **采用二进制位操作 & 相对于 % 能够提高运算效率**,这就解释了 HashMap 的长度为什么是 2 的幂次方。
|
||||
|
||||
### HashMap 多线程操作导致死循环问题
|
||||
|
||||
|
||||
@ -317,6 +317,15 @@ public ScheduledThreadPoolExecutor(int corePoolSize) {
|
||||
|
||||
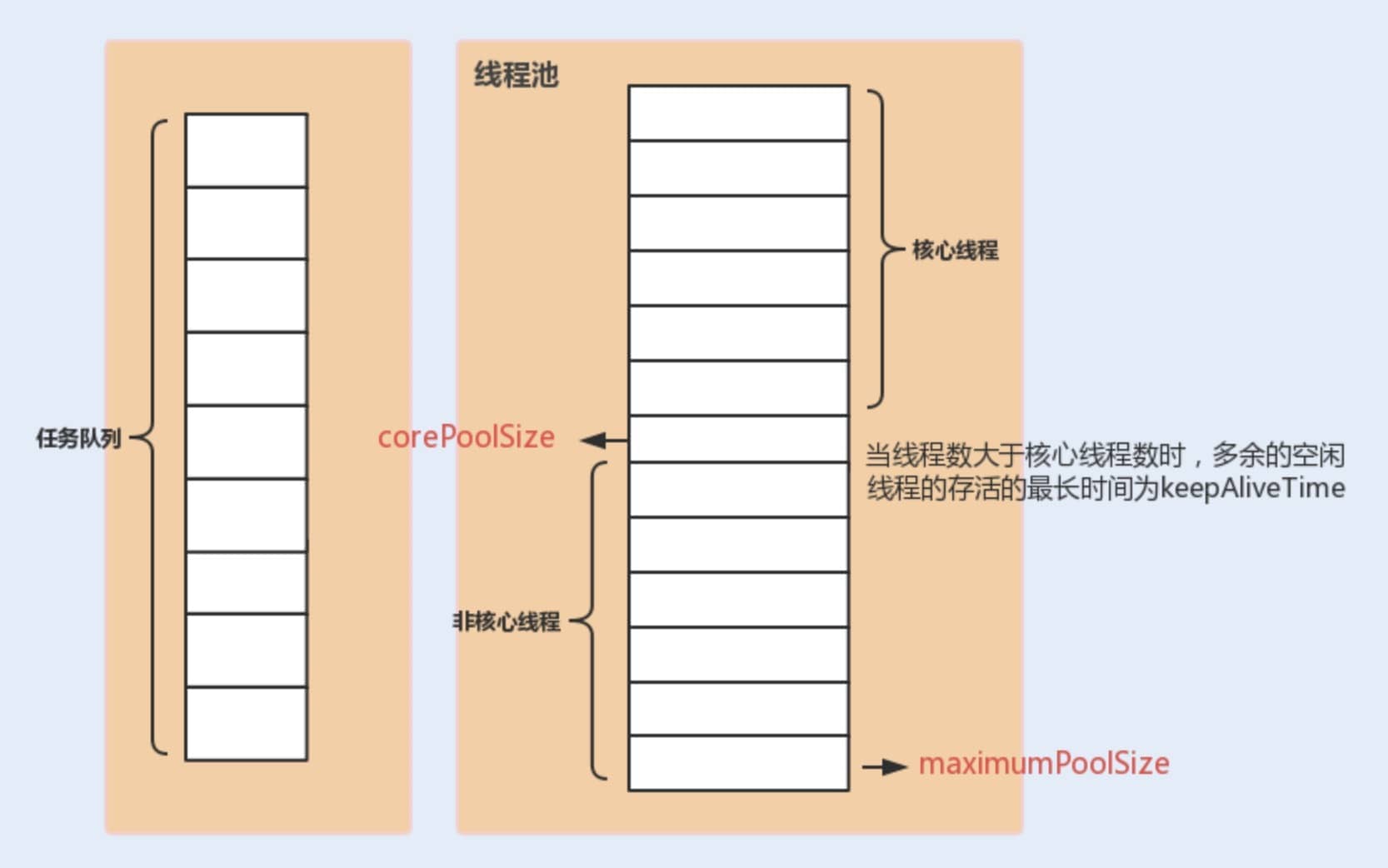
|
||||
|
||||
### 线程池的核心线程会被回收吗?
|
||||
|
||||
`ThreadPoolExecutor` 默认不会回收核心线程,即使它们已经空闲了。这是为了减少创建线程的开销,因为核心线程通常是要长期保持活跃的。但是,如果线程池是被用于周期性使用的场景,且频率不高(周期之间有明显的空闲时间),可以考虑将 `allowCoreThreadTimeOut(boolean value)` 方法的参数设置为 `true`,这样就会回收空闲(时间间隔由 `keepAliveTime` 指定)的核心线程了。
|
||||
|
||||
```java
|
||||
ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor(4, 6, 6, TimeUnit.SECONDS, new SynchronousQueue<>());
|
||||
threadPoolExecutor.allowCoreThreadTimeOut(true);
|
||||
```
|
||||
|
||||
### 线程池的拒绝策略有哪些?
|
||||
|
||||
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,`ThreadPoolExecutor` 定义一些策略:
|
||||
@ -518,6 +527,13 @@ new RejectedExecutionHandler() {
|
||||
3. 如果向任务队列投放任务失败(任务队列已经满了),但是当前运行的线程数是小于最大线程数的,就新建一个线程来执行任务。
|
||||
4. 如果当前运行的线程数已经等同于最大线程数了,新建线程将会使当前运行的线程超出最大线程数,那么当前任务会被拒绝,拒绝策略会调用`RejectedExecutionHandler.rejectedExecution()`方法。
|
||||
|
||||
再提一个有意思的小问题:**线程池在提交任务前,可以提前创建线程吗?**
|
||||
|
||||
答案是可以的!`ThreadPoolExecutor` 提供了两个方法帮助我们在提交任务之前,完成核心线程的创建,从而实现线程池预热的效果:
|
||||
|
||||
- `prestartCoreThread()`:启动一个线程,等待任务,如果已达到核心线程数,这个方法返回 false,否则返回 true;
|
||||
- `prestartAllCoreThreads()`:启动所有的核心线程,并返回启动成功的核心线程数。
|
||||
|
||||
### 线程池中线程异常后,销毁还是复用?
|
||||
|
||||
先说结论,需要分两种情况:
|
||||
@ -1151,6 +1167,7 @@ public int await() throws InterruptedException, BrokenBarrierException {
|
||||
|
||||
- 《深入理解 Java 虚拟机》
|
||||
- 《实战 Java 高并发程序设计》
|
||||
- Java 线程池的实现原理及其在业务中的最佳实践:阿里云开发者:<https://mp.weixin.qq.com/s/icrrxEsbABBvEU0Gym7D5Q>
|
||||
- 带你了解下 SynchronousQueue(并发队列专题):<https://juejin.cn/post/7031196740128768037>
|
||||
- 阻塞队列 — DelayedWorkQueue 源码分析:<https://zhuanlan.zhihu.com/p/310621485>
|
||||
- Java 多线程(三)——FutureTask/CompletableFuture:<https://www.cnblogs.com/iwehdio/p/14285282.html>
|
||||
|
||||
@ -71,6 +71,7 @@ icon: "xitongsheji"
|
||||
|
||||
- [MyBatis-Plus](https://github.com/baomidou/mybatis-plus) : [MyBatis](http://www.mybatis.org/mybatis-3/) 增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
|
||||
- [MyBatis-Flex](https://gitee.com/mybatis-flex/mybatis-flex):一个优雅的 MyBatis 增强框架,无其他任何第三方依赖,支持 CRUD、分页查询、多表查询、批量操作。
|
||||
- [jOOQ](https://github.com/jOOQ/jOOQ):用 Java 编写 SQL 的最佳方式。
|
||||
- [Redisson](https://github.com/redisson/redisson "redisson"):Redis 基础上的一个 Java 驻内存数据网格(In-Memory Data Grid),支持超过 30 个对象和服务:`Set`,`SortedSet`, `Map`, `List`, `Queue`, `Deque` ……,并且提供了多种分布式锁的实现。更多介绍请看:[《Redisson 项目介绍》](https://github.com/redisson/redisson/wiki/Redisson%E9%A1%B9%E7%9B%AE%E4%BB%8B%E7%BB%8D "Redisson项目介绍")。
|
||||
|
||||
### 数据同步
|
||||
|
||||
@ -9,11 +9,6 @@ icon: codelibrary-fill
|
||||
- [lombok](https://github.com/rzwitserloot/lombok) :使用 Lombok 我们可以简化我们的 Java 代码,比如使用它之后我们通过注释就可以实现 getter/setter、equals 等方法。
|
||||
- [guava](https://github.com/google/guava "guava"):Guava 是一组核心库,其中包括新的集合类型(例如 multimap 和 multiset),不可变集合,图形库以及用于并发、I / O、哈希、原始类型、字符串等的实用程序!
|
||||
- [hutool](https://github.com/looly/hutool "hutool") : Hutool 是一个 Java 工具包,也只是一个工具包,它帮助我们简化每一行代码,减少每一个方法,让 Java 语言也可以“甜甜的”。
|
||||
- [p3c](https://github.com/alibaba/p3c "p3c"):Alibaba Java Coding Guidelines pmd implements and IDE plugin。Eclipse 和 IDEA 上都有该插件,推荐使用!
|
||||
- [sonarqube](https://github.com/SonarSource/sonarqube "sonarqube"):SonarQube 支持所有开发人员编写更干净,更安全的代码。
|
||||
- [checkstyle](https://github.com/checkstyle/checkstyle "checkstyle") :Checkstyle 是一种开发工具,可帮助程序员编写符合编码标准的 Java 代码。它使检查 Java 代码的过程自动化,从而使人们不必执行这项无聊(但很重要)的任务。这使其成为想要实施编码标准的项目的理想选择。
|
||||
- [pmd](https://github.com/pmd/pmd "pmd") : 可扩展的多语言静态代码分析器。
|
||||
- [spotbugs](https://github.com/spotbugs/spotbugs "spotbugs") :SpotBugs 是 FindBugs 的继任者。静态分析工具,用于查找 Java 代码中的错误。
|
||||
|
||||
## 问题排查和性能优化
|
||||
|
||||
|
||||
@ -4,6 +4,15 @@ category: 开源项目
|
||||
icon: tool
|
||||
---
|
||||
|
||||
## 代码质量
|
||||
|
||||
- [SonarQube](https://github.com/SonarSource/sonarqube "sonarqube"):静态代码检查工具,,帮助检查代码缺陷,可以快速的定位代码中潜在的或者明显的错误,改善代码质量,提高开发速度。
|
||||
- [Spotless](https://github.com/diffplug/spotless):Spotless 是支持多种语言的代码格式化工具,支持 Maven 和 Gradle 以 Plugin 的形式构建。
|
||||
- [CheckStyle](https://github.com/checkstyle/checkstyle "checkstyle") : 类似于 Spotless,可帮助程序员编写符合编码标准的 Java 代码。
|
||||
- [PMD](https://github.com/pmd/pmd "pmd") : 可扩展的多语言静态代码分析器。
|
||||
- [SpotBugs](https://github.com/spotbugs/spotbugs "spotbugs") : FindBugs 的继任者。静态分析工具,用于查找 Java 代码中的错误。
|
||||
- [P3C](https://github.com/alibaba/p3c "p3c"):Alibaba Java Coding Guidelines pmd implements and IDE plugin。Eclipse 和 IDEA 上都有该插件。
|
||||
|
||||
## 项目构建
|
||||
|
||||
- [Maven](https://maven.apache.org/):一个软件项目管理和理解工具。基于项目对象模型 (Project Object Model,POM) 的概念,Maven 可以从一条中心信息管理项目的构建、报告和文档。详细介绍:[Maven 核心概念总结](https://javaguide.cn/tools/maven/maven-core-concepts.html)。
|
||||
|
||||
@ -20,7 +20,7 @@ footer: |-
|
||||
|
||||
JavaGuide 已经持续维护 5 年多了,累计提交了 **5000+** commit ,共有 **440** 多位朋友参与维护。真心希望能够把这个项目做好,真正能够帮助到有需要的朋友!
|
||||
|
||||
如果觉得 JavaGuide 的内容对你有帮助的话,还请点个免费的 Star(绝不强制点 Star,你觉得内容不错再点赞就好),这是对我最大的鼓励,感谢各位一起同行,共勉!传送门:[GitHub](https://github.com/Snailclimb/JavaGuide) | [Gitee](https://gitee.com/SnailClimb/JavaGuide)。
|
||||
如果觉得 JavaGuide 的内容对你有帮助的话,还请点个免费的 Star(绝不强制点 Star,觉得内容不错有收货再点赞就好),这是对我最大的鼓励,感谢各位一路同行,共勉!传送门:[GitHub](https://github.com/Snailclimb/JavaGuide) | [Gitee](https://gitee.com/SnailClimb/JavaGuide)。
|
||||
|
||||
- [项目介绍](./javaguide/intro.md)
|
||||
- [贡献指南](./javaguide/contribution-guideline.md)
|
||||
|
||||
@ -186,9 +186,21 @@ mysql/mysql-server Optimized MySQL Server Docker images. Create
|
||||
|
||||
上面涉及到了一些 Docker 的基本命令,后面会详细介绍大。
|
||||
|
||||
---
|
||||
### Build Ship and Run
|
||||
|
||||
## 常见命令
|
||||
Docker 的概念基本上已经讲完,我们再来谈谈:Build, Ship, and Run。
|
||||
|
||||
如果你搜索 Docker 官网,会发现如下的字样:**“Docker - Build, Ship, and Run Any App, Anywhere”**。那么 Build, Ship, and Run 到底是在干什么呢?
|
||||
|
||||
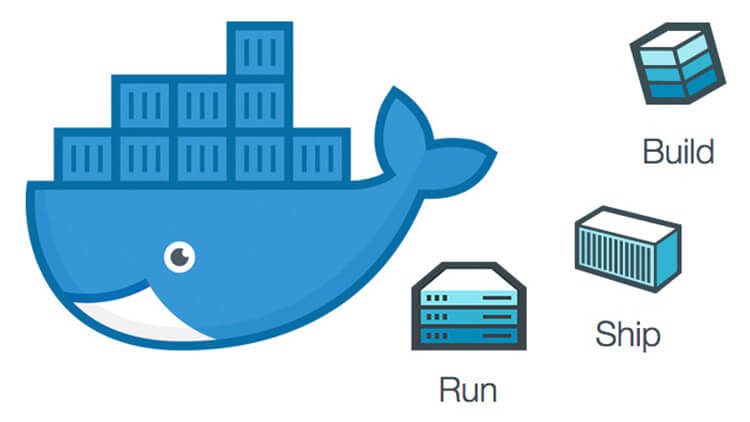
|
||||
|
||||
- **Build(构建镜像)**:镜像就像是集装箱包括文件以及运行环境等等资源。
|
||||
- **Ship(运输镜像)**:主机和仓库间运输,这里的仓库就像是超级码头一样。
|
||||
- **Run (运行镜像)**:运行的镜像就是一个容器,容器就是运行程序的地方。
|
||||
|
||||
Docker 运行过程也就是去仓库把镜像拉到本地,然后用一条命令把镜像运行起来变成容器。所以,我们也常常将 Docker 称为码头工人或码头装卸工,这和 Docker 的中文翻译搬运工人如出一辙。
|
||||
|
||||
## Docker 常见命令
|
||||
|
||||
### 基本命令
|
||||
|
||||
@ -262,20 +274,6 @@ docker push harbor.example.com/ubuntu:18.04
|
||||
|
||||
镜像推送之前,要确保本地已经构建好需要推送的 Docker 镜像。另外,务必先登录到对应的镜像仓库。
|
||||
|
||||
## Build Ship and Run
|
||||
|
||||
Docker 的概念以及常见命令基本上已经讲完,我们再来谈谈:Build, Ship, and Run。
|
||||
|
||||
如果你搜索 Docker 官网,会发现如下的字样:**“Docker - Build, Ship, and Run Any App, Anywhere”**。那么 Build, Ship, and Run 到底是在干什么呢?
|
||||
|
||||

|
||||
|
||||
- **Build(构建镜像)**:镜像就像是集装箱包括文件以及运行环境等等资源。
|
||||
- **Ship(运输镜像)**:主机和仓库间运输,这里的仓库就像是超级码头一样。
|
||||
- **Run (运行镜像)**:运行的镜像就是一个容器,容器就是运行程序的地方。
|
||||
|
||||
Docker 运行过程也就是去仓库把镜像拉到本地,然后用一条命令把镜像运行起来变成容器。所以,我们也常常将 Docker 称为码头工人或码头装卸工,这和 Docker 的中文翻译搬运工人如出一辙。
|
||||
|
||||
## Docker 数据管理
|
||||
|
||||
在容器中管理数据主要有两种方式:
|
||||
@ -307,6 +305,144 @@ docker volume rm my-vol
|
||||
|
||||
还可以通过 `--mount` 标记将宿主机上的文件或目录挂载到容器中,这使得容器可以直接访问宿主机的文件系统。Docker 挂载主机目录的默认权限是读写,用户也可以通过增加 `readonly` 指定为只读。
|
||||
|
||||
## Docker Compose
|
||||
|
||||
### 什么是 Docker Compose?有什么用?
|
||||
|
||||
Docker Compose 是 Docker 官方编排(Orchestration)项目之一,基于 Python 编写,负责实现对 Docker 容器集群的快速编排。通过 Docker Compose,开发者可以使用 YAML 文件来配置应用的所有服务,然后只需一个简单的命令即可创建和启动所有服务。
|
||||
|
||||
Docker Compose 是开源项目,地址:<https://github.com/docker/compose>。
|
||||
|
||||
Docker Compose 的核心功能:
|
||||
|
||||
- **多容器管理**:允许用户在一个 YAML 文件中定义和管理多个容器。
|
||||
- **服务编排**:配置容器间的网络和依赖关系。
|
||||
- **一键部署**:通过简单的命令,如`docker-compose up`和`docker-compose down`,可以轻松地启动和停止整个应用程序。
|
||||
|
||||
Docker Compose 简化了多容器应用程序的开发、测试和部署过程,提高了开发团队的生产力,同时降低了应用程序的部署复杂度和管理成本。
|
||||
|
||||
### Docker Compose 文件基本结构
|
||||
|
||||
Docker Compose 文件是 Docker Compose 工具的核心,用于定义和配置多容器 Docker 应用。这个文件通常命名为 `docker-compose.yml`,采用 YAML(YAML Ain't Markup Language)格式编写。
|
||||
|
||||
Docker Compose 文件基本结构如下:
|
||||
|
||||
- **版本(version):** 指定 Compose 文件格式的版本。版本决定了可用的配置选项。
|
||||
- **服务(services):** 定义了应用中的每个容器(服务)。每个服务可以使用不同的镜像、环境设置和依赖关系。
|
||||
- **镜像(image):** 从指定的镜像中启动容器,可以是存储仓库、标签以及镜像 ID。
|
||||
- **命令(command):** 可选,覆盖容器启动后默认执行的命令。在启动服务时运行特定的命令或脚本,常用于启动应用程序、执行初始化脚本等。
|
||||
- **端口(ports):** 可选,映射容器和宿主机的端口。
|
||||
- **依赖(depends_on):** 依赖配置的选项,意思是如果服务启动是如果有依赖于其他服务的,先启动被依赖的服务,启动完成后在启动该服务。
|
||||
- **环境变量(environment):** 可选,设置服务运行所需的环境变量。
|
||||
- **重启(restart):** 可选,控制容器的重启策略。在容器退出时,根据指定的策略自动重启容器。
|
||||
- **服务卷(volumes):** 可选,定义服务使用的卷,用于数据持久化或在容器之间共享数据。
|
||||
- **构建(build):** 指定构建镜像的 dockerfile 的上下文路径,或者详细配置对象。
|
||||
- **网络(networks):** 定义了容器间的网络连接。
|
||||
- **卷(volumes):** 用于数据持久化和共享的数据卷定义。常用于数据库存储、配置文件、日志等数据的持久化。
|
||||
|
||||
```yaml
|
||||
version: "3.8" # 定义版本, 表示当前使用的 docker-compose 语法的版本
|
||||
services: # 服务,可以存在多个
|
||||
servicename1: # 服务名字,它也是内部 bridge 网络可以使用的 DNS name,如果不是集群模式相当于 docker run 的时候指定的一个名称,
|
||||
#集群(Swarm)模式是多个容器的逻辑抽象
|
||||
image: # 镜像的名字
|
||||
command: # 可选,如果设置,则会覆盖默认镜像里的 CMD 命令
|
||||
environment: # 可选,等价于 docker container run 里的 --env 选项设置环境变量
|
||||
volumes: # 可选,等价于 docker container run 里的 -v 选项 绑定数据卷
|
||||
networks: # 可选,等价于 docker container run 里的 --network 选项指定网络
|
||||
ports: # 可选,等价于 docker container run 里的 -p 选项指定端口映射
|
||||
restart: # 可选,控制容器的重启策略
|
||||
build: #构建目录
|
||||
depends_on: #服务依赖配置
|
||||
servicename2:
|
||||
image:
|
||||
command:
|
||||
networks:
|
||||
ports:
|
||||
servicename3:
|
||||
#...
|
||||
volumes: # 可选,需要创建的数据卷,类似 docker volume create
|
||||
db_data:
|
||||
networks: # 可选,等价于 docker network create
|
||||
```
|
||||
|
||||
### Docker Compose 常见命令
|
||||
|
||||
#### 启动
|
||||
|
||||
`docker-compose up`会根据 `docker-compose.yml` 文件中定义的服务来创建和启动容器,并将它们连接到默认的网络中。
|
||||
|
||||
```bash
|
||||
# 在当前目录下寻找 docker-compose.yml 文件,并根据其中定义的服务启动应用程序
|
||||
docker-compose up
|
||||
# 后台启动
|
||||
docker-compose up -d
|
||||
# 强制重新创建所有容器,即使它们已经存在
|
||||
docker-compose up --force-recreate
|
||||
# 重新构建镜像
|
||||
docker-compose up --build
|
||||
# 指定要启动的服务名称,而不是启动所有服务
|
||||
# 可以同时指定多个服务,用空格分隔。
|
||||
docker-compose up service_name
|
||||
```
|
||||
|
||||
另外,如果 Compose 文件名称不是 `docker-compose.yml` 也没问题,可以通过 `-f` 参数指定。
|
||||
|
||||
```bash
|
||||
docker-compose -f docker-compose.prod.yml up
|
||||
```
|
||||
|
||||
#### 暂停
|
||||
|
||||
`docker-compose down`用于停止并移除通过 `docker-compose up` 启动的容器和网络。
|
||||
|
||||
```bash
|
||||
# 在当前目录下寻找 docker-compose.yml 文件
|
||||
# 根据其中定义移除启动的所有容器,网络和卷。
|
||||
docker-compose down
|
||||
# 停止容器但不移除
|
||||
docker-compose down --stop
|
||||
# 指定要停止和移除的特定服务,而不是停止和移除所有服务
|
||||
# 可以同时指定多个服务,用空格分隔。
|
||||
docker-compose down service_name
|
||||
```
|
||||
|
||||
同样地,如果 Compose 文件名称不是 `docker-compose.yml` 也没问题,可以通过 `-f` 参数指定。
|
||||
|
||||
```bash
|
||||
docker-compose -f docker-compose.prod.yml down
|
||||
```
|
||||
|
||||
#### 查看
|
||||
|
||||
`docker-compose ps`用于查看通过 `docker-compose up` 启动的所有容器的状态信息。
|
||||
|
||||
```bash
|
||||
# 查看所有容器的状态信息
|
||||
docker-compose ps
|
||||
# 只显示服务名称
|
||||
docker-compose ps --services
|
||||
# 查看指定服务的容器
|
||||
docker-compose ps service_name
|
||||
```
|
||||
|
||||
#### 其他
|
||||
|
||||
| 命令 | 介绍 |
|
||||
| ------------------------ | ---------------------- |
|
||||
| `docker-compose version` | 查看版本 |
|
||||
| `docker-compose images` | 列出所有容器使用的镜像 |
|
||||
| `docker-compose kill` | 强制停止服务的容器 |
|
||||
| `docker-compose exec` | 在容器中执行命令 |
|
||||
| `docker-compose logs` | 查看日志 |
|
||||
| `docker-compose pause` | 暂停服务 |
|
||||
| `docker-compose unpause` | 恢复服务 |
|
||||
| `docker-compose push` | 推送服务镜像 |
|
||||
| `docker-compose start` | 启动当前停止的某个容器 |
|
||||
| `docker-compose stop` | 停止当前运行的某个容器 |
|
||||
| `docker-compose rm` | 删除服务停止的容器 |
|
||||
| `docker-compose top` | 查看进程 |
|
||||
|
||||
## Docker 底层原理
|
||||
|
||||
首先,Docker 是基于轻量级虚拟化技术的软件,那什么是虚拟化技术呢?
|
||||
@ -345,6 +481,7 @@ LXC 技术主要是借助 Linux 内核中提供的 CGroup 功能和 namespace
|
||||
|
||||
## 参考
|
||||
|
||||
- [Docker Compose:从零基础到实战应用的全面指南](https://juejin.cn/post/7306756690727747610)
|
||||
- [Linux Namespace 和 Cgroup](https://segmentfault.com/a/1190000009732550 "Linux Namespace和Cgroup")
|
||||
- [LXC vs Docker: Why Docker is Better](https://www.upguard.com/articles/docker-vs-lxc "LXC vs Docker: Why Docker is Better")
|
||||
- [CGroup 介绍、应用实例及原理描述](https://www.ibm.com/developerworks/cn/linux/1506_cgroup/index.html "CGroup 介绍、应用实例及原理描述")
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user