mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-05 20:31:37 +08:00
Compare commits
4 Commits
1962dbd0ea
...
cd267ee70c
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
cd267ee70c | ||
|
|
09a832b5f6 | ||
|
|
7df1cf17e6 | ||
|
|
b8c5c74047 |
@ -120,6 +120,7 @@ export default sidebar({
|
||||
"atomic-classes",
|
||||
"threadlocal",
|
||||
"completablefuture-intro",
|
||||
"virtual-thread",
|
||||
],
|
||||
},
|
||||
],
|
||||
|
||||
@ -29,7 +29,7 @@ tag:
|
||||
|
||||
IP 欺骗技术就是**伪造**某台主机的 IP 地址的技术。通过 IP 地址的伪装使得某台主机能够**伪装**另外的一台主机,而这台主机往往具有某种特权或者被另外的主机所信任。
|
||||
|
||||
假设现在有一个合法用户 **(1.1.1.1)** 已经同服务器建立正常的连接,攻击者构造攻击的 TCP 数据,伪装自己的 IP 为 **1.1.1.1**,并向服务器发送一个带有 RSI 位的 TCP 数据段。服务器接收到这样的数据后,认为从 **1.1.1.1** 发送的连接有错误,就会清空缓冲区中建立好的连接。
|
||||
假设现在有一个合法用户 **(1.1.1.1)** 已经同服务器建立正常的连接,攻击者构造攻击的 TCP 数据,伪装自己的 IP 为 **1.1.1.1**,并向服务器发送一个带有 RST 位的 TCP 数据段。服务器接收到这样的数据后,认为从 **1.1.1.1** 发送的连接有错误,就会清空缓冲区中建立好的连接。
|
||||
|
||||
这时,如果合法用户 **1.1.1.1** 再发送合法数据,服务器就已经没有这样的连接了,该用户就必须从新开始建立连接。攻击时,伪造大量的 IP 地址,向目标发送 RST 数据,使服务器不对合法用户服务。虽然 IP 地址欺骗攻击有着相当难度,但我们应该清醒地意识到,这种攻击非常广泛,入侵往往从这种攻击开始。
|
||||
|
||||
|
||||
@ -39,29 +39,30 @@ Java 集合框架如下图所示:
|
||||
|
||||
#### List
|
||||
|
||||
- `ArrayList`:`Object[]` 数组
|
||||
- `Vector`:`Object[]` 数组
|
||||
- `LinkedList`:双向链表(JDK1.6 之前为循环链表,JDK1.7 取消了循环)
|
||||
- `ArrayList`:`Object[]` 数组。详细可以查看:[ArrayList 源码分析](./arraylist-source-code.md)。
|
||||
- `Vector`:`Object[]` 数组。
|
||||
- `LinkedList`:双向链表(JDK1.6 之前为循环链表,JDK1.7 取消了循环)。详细可以查看:[LinkedList 源码分析](./linkedlist-source-code.md)。
|
||||
|
||||
#### Set
|
||||
|
||||
- `HashSet`(无序,唯一): 基于 `HashMap` 实现的,底层采用 `HashMap` 来保存元素
|
||||
- `LinkedHashSet`: `LinkedHashSet` 是 `HashSet` 的子类,并且其内部是通过 `LinkedHashMap` 来实现的。有点类似于我们之前说的 `LinkedHashMap` 其内部是基于 `HashMap` 实现一样,不过还是有一点点区别的
|
||||
- `TreeSet`(有序,唯一): 红黑树(自平衡的排序二叉树)
|
||||
- `HashSet`(无序,唯一): 基于 `HashMap` 实现的,底层采用 `HashMap` 来保存元素。
|
||||
- `LinkedHashSet`: `LinkedHashSet` 是 `HashSet` 的子类,并且其内部是通过 `LinkedHashMap` 来实现的。
|
||||
- `TreeSet`(有序,唯一): 红黑树(自平衡的排序二叉树)。
|
||||
|
||||
#### Queue
|
||||
|
||||
- `PriorityQueue`: `Object[]` 数组来实现二叉堆
|
||||
- `ArrayQueue`: `Object[]` 数组 + 双指针
|
||||
- `PriorityQueue`: `Object[]` 数组来实现小顶堆。详细可以查看:[PriorityQueue 源码分析](./priorityqueue-source-code.md)。
|
||||
- `DelayQueue`:`PriorityQueue`。详细可以查看:[DelayQueue 源码分析](./delayqueue-source-code.md)。
|
||||
- `ArrayDeque`: 可扩容动态双向数组。
|
||||
|
||||
再来看看 `Map` 接口下面的集合。
|
||||
|
||||
#### Map
|
||||
|
||||
- `HashMap`:JDK1.8 之前 `HashMap` 由数组+链表组成的,数组是 `HashMap` 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间
|
||||
- `LinkedHashMap`:`LinkedHashMap` 继承自 `HashMap`,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,`LinkedHashMap` 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。详细可以查看:[《LinkedHashMap 源码详细分析(JDK1.8)》](https://www.imooc.com/article/22931)
|
||||
- `Hashtable`:数组+链表组成的,数组是 `Hashtable` 的主体,链表则是主要为了解决哈希冲突而存在的
|
||||
- `TreeMap`:红黑树(自平衡的排序二叉树)
|
||||
- `HashMap`:JDK1.8 之前 `HashMap` 由数组+链表组成的,数组是 `HashMap` 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树)时,将链表转化为红黑树,以减少搜索时间。详细可以查看:[HashMap 源码分析](./hashmap-source-code.md)。
|
||||
- `LinkedHashMap`:`LinkedHashMap` 继承自 `HashMap`,所以它的底层仍然是基于拉链式散列结构即由数组和链表或红黑树组成。另外,`LinkedHashMap` 在上面结构的基础上,增加了一条双向链表,使得上面的结构可以保持键值对的插入顺序。同时通过对链表进行相应的操作,实现了访问顺序相关逻辑。详细可以查看:[LinkedHashMap 源码分析](./linkedhashmap-source-code.md)
|
||||
- `Hashtable`:数组+链表组成的,数组是 `Hashtable` 的主体,链表则是主要为了解决哈希冲突而存在的。
|
||||
- `TreeMap`:红黑树(自平衡的排序二叉树)。
|
||||
|
||||
### 如何选用集合?
|
||||
|
||||
|
||||
@ -82,7 +82,7 @@ JDK 1.2 之前,Java 线程是基于绿色线程(Green Threads)实现的,
|
||||
|
||||
在 Windows 和 Linux 等主流操作系统中,Java 线程采用的是一对一的线程模型,也就是一个 Java 线程对应一个系统内核线程。Solaris 系统是一个特例(Solaris 系统本身就支持多对多的线程模型),HotSpot VM 在 Solaris 上支持多对多和一对一。具体可以参考 R 大的回答: [JVM 中的线程模型是用户级的么?](https://www.zhihu.com/question/23096638/answer/29617153)。
|
||||
|
||||
虚拟线程在 JDK 21 顺利转正,关于虚拟线程、平台线程(也就是我们前面提到的 Java 线程)和内核线程三者的关系可以阅读我写的这篇文章:[Java 20 新特性概览](../new-features/java20.md)。
|
||||
虚拟线程在 JDK 21 顺利转正,关于虚拟线程、平台线程(也就是我们上面提到的 Java 线程)和内核线程三者的关系可以阅读我写的这篇文章:[Java 20 新特性概览](../new-features/java20.md)。
|
||||
|
||||
## 请简要描述线程与进程的关系,区别及优缺点?
|
||||
|
||||
|
||||
@ -193,7 +193,7 @@ static class Entry extends WeakReference<ThreadLocal<?>> {
|
||||
|
||||
### 为什么要用线程池?
|
||||
|
||||
池化技术想必大家已经屡见不鲜了,线程池、数据库连接池、Http 连接池等等都是对这个思想的应用。池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。
|
||||
池化技术想必大家已经屡见不鲜了,线程池、数据库连接池、HTTP 连接池等等都是对这个思想的应用。池化技术的思想主要是为了减少每次获取资源的消耗,提高对资源的利用率。
|
||||
|
||||
**线程池**提供了一种限制和管理资源(包括执行一个任务)的方式。 每个**线程池**还维护一些基本统计信息,例如已完成任务的数量。
|
||||
|
||||
@ -348,7 +348,7 @@ public static class CallerRunsPolicy implements RejectedExecutionHandler {
|
||||
|
||||
不同的线程池会选用不同的阻塞队列,我们可以结合内置线程池来分析。
|
||||
|
||||
- 容量为 `Integer.MAX_VALUE` 的 `LinkedBlockingQueue`(无界队列):`FixedThreadPool` 和 `SingleThreadExector` 。由于队列永远不会被放满,因此`FixedThreadPool`最多只能创建核心线程数的线程,`SingleThreadExector`只能创建一个线程。
|
||||
- 容量为 `Integer.MAX_VALUE` 的 `LinkedBlockingQueue`(无界队列):`FixedThreadPool` 和 `SingleThreadExector` 。`FixedThreadPool`最多只能创建核心线程数的线程(核心线程数和最大线程数相等),`SingleThreadExector`只能创建一个线程(核心线程数和最大线程数都是 1),二者的任务队列永远不会被放满。
|
||||
- `SynchronousQueue`(同步队列):`CachedThreadPool` 。`SynchronousQueue` 没有容量,不存储元素,目的是保证对于提交的任务,如果有空闲线程,则使用空闲线程来处理;否则新建一个线程来处理任务。也就是说,`CachedThreadPool` 的最大线程数是 `Integer.MAX_VALUE` ,可以理解为线程数是可以无限扩展的,可能会创建大量线程,从而导致 OOM。
|
||||
- `DelayedWorkQueue`(延迟阻塞队列):`ScheduledThreadPool` 和 `SingleThreadScheduledExecutor` 。`DelayedWorkQueue` 的内部元素并不是按照放入的时间排序,而是会按照延迟的时间长短对任务进行排序,内部采用的是“堆”的数据结构,可以保证每次出队的任务都是当前队列中执行时间最靠前的。`DelayedWorkQueue` 添加元素满了之后会自动扩容原来容量的 1/2,即永远不会阻塞,最大扩容可达 `Integer.MAX_VALUE`,所以最多只能创建核心线程数的线程。
|
||||
|
||||
@ -974,6 +974,12 @@ public int await() throws InterruptedException, BrokenBarrierException {
|
||||
}
|
||||
```
|
||||
|
||||
## 虚拟线程
|
||||
|
||||
虚拟线程在 Java 21 正式发布,这是一项重量级的更新。
|
||||
|
||||
虽然目前面试中问的不多,但还是建议大家去简单了解一下,具体可以阅读这篇文章:[虚拟线程极简入门](./virtual-thread.md) 。重点搞清楚虚拟线程和平台线程的关系以及虚拟线程的优势即可。
|
||||
|
||||
## 参考
|
||||
|
||||
- 《深入理解 Java 虚拟机》
|
||||
|
||||
@ -209,7 +209,7 @@ public ScheduledThreadPoolExecutor(int corePoolSize) {
|
||||
|
||||
不同的线程池会选用不同的阻塞队列,我们可以结合内置线程池来分析。
|
||||
|
||||
- 容量为 `Integer.MAX_VALUE` 的 `LinkedBlockingQueue`(无界队列):`FixedThreadPool` 和 `SingleThreadExector` 。由于队列永远不会被放满,因此`FixedThreadPool`最多只能创建核心线程数的线程。
|
||||
- 容量为 `Integer.MAX_VALUE` 的 `LinkedBlockingQueue`(无界队列):`FixedThreadPool` 和 `SingleThreadExector` 。`FixedThreadPool`最多只能创建核心线程数的线程(核心线程数和最大线程数相等),`SingleThreadExector`只能创建一个线程(核心线程数和最大线程数都是 1),二者的任务队列永远不会被放满。
|
||||
- `SynchronousQueue`(同步队列):`CachedThreadPool` 。`SynchronousQueue` 没有容量,不存储元素,目的是保证对于提交的任务,如果有空闲线程,则使用空闲线程来处理;否则新建一个线程来处理任务。也就是说,`CachedThreadPool` 的最大线程数是 `Integer.MAX_VALUE` ,可以理解为线程数是可以无限扩展的,可能会创建大量线程,从而导致 OOM。
|
||||
- `DelayedWorkQueue`(延迟阻塞队列):`ScheduledThreadPool` 和 `SingleThreadScheduledExecutor` 。`DelayedWorkQueue` 的内部元素并不是按照放入的时间排序,而是会按照延迟的时间长短对任务进行排序,内部采用的是“堆”的数据结构,可以保证每次出队的任务都是当前队列中执行时间最靠前的。`DelayedWorkQueue` 添加元素满了之后会自动扩容原来容量的 1/2,即永远不会阻塞,最大扩容可达 `Integer.MAX_VALUE`,所以最多只能创建核心线程数的线程。
|
||||
|
||||
|
||||
230
docs/java/concurrent/virtual-thread.md
Normal file
230
docs/java/concurrent/virtual-thread.md
Normal file
@ -0,0 +1,230 @@
|
||||
---
|
||||
title: 虚拟线程极简入门
|
||||
category: Java
|
||||
tag:
|
||||
- Java并发
|
||||
---
|
||||
|
||||
> 本文部分内容来自 [Lorin](https://github.com/Lorin-github) 的[PR](https://github.com/Snailclimb/JavaGuide/pull/2190)。
|
||||
|
||||
虚拟线程在 Java 21 正式发布,这是一项重量级的更新。
|
||||
|
||||
## 什么是虚拟线程?
|
||||
|
||||
虚拟线程(Virtual Thread)是 JDK 而不是 OS 实现的轻量级线程(Lightweight Process,LWP),由 JVM 调度。许多虚拟线程共享同一个操作系统线程,虚拟线程的数量可以远大于操作系统线程的数量。
|
||||
|
||||
## 虚拟线程和平台线程有什么关系?
|
||||
|
||||
在引入虚拟线程之前,`java.lang.Thread` 包已经支持所谓的平台线程(Platform Thread),也就是没有虚拟线程之前,我们一直使用的线程。JVM 调度程序通过平台线程(载体线程)来管理虚拟线程,一个平台线程可以在不同的时间执行不同的虚拟线程(多个虚拟线程挂载在一个平台线程上),当虚拟线程被阻塞或等待时,平台线程可以切换到执行另一个虚拟线程。
|
||||
|
||||
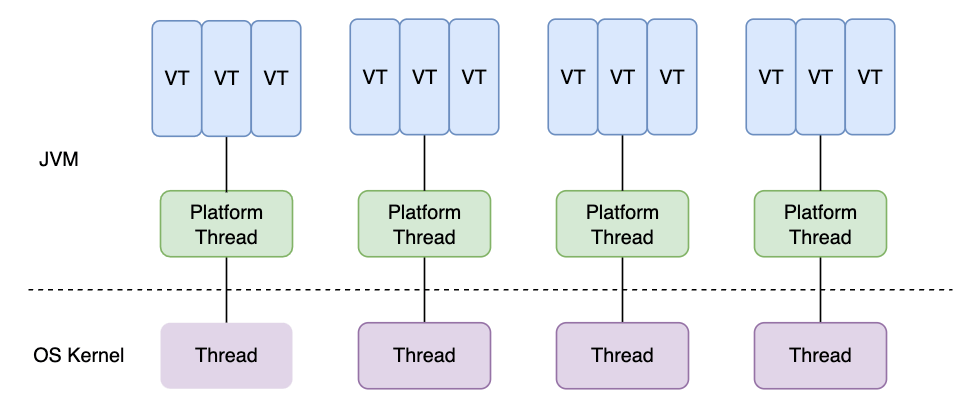
虚拟线程、平台线程和系统内核线程的关系图如下所示(图源:[How to Use Java 19 Virtual Threads](https://medium.com/javarevisited/how-to-use-java-19-virtual-threads-c16a32bad5f7)):
|
||||
|
||||
|
||||
|
||||
关于平台线程和系统内核线程的对应关系多提一点:在 Windows 和 Linux 等主流操作系统中,Java 线程采用的是一对一的线程模型,也就是一个平台线程对应一个系统内核线程。Solaris 系统是一个特例,HotSpot VM 在 Solaris 上支持多对多和一对一。具体可以参考 R 大的回答: [JVM 中的线程模型是用户级的么?](https://www.zhihu.com/question/23096638/answer/29617153)。
|
||||
|
||||
## 虚拟线程有什么优点和缺点?
|
||||
|
||||
### 优点
|
||||
- 非常轻量级:可以在单个线程中创建成百上千个虚拟线程而不会导致过多的线程创建和上下文切换。
|
||||
- 简化异步编程: 虚拟线程可以简化异步编程,使代码更易于理解和维护。它可以将异步代码编写得更像同步代码,避免了回调地狱(Callback Hell)。
|
||||
- 减少资源开销: 相比于操作系统线程,虚拟线程的资源开销更小。本质上是提高了线程的执行效率,从而减少线程资源的创建和上下文切换。
|
||||
|
||||
### 缺点
|
||||
- 不适用于计算密集型任务: 虚拟线程适用于 I/O 密集型任务,但不适用于计算密集型任务,因为密集型计算始终需要 CPU 资源作为支持。
|
||||
- 依赖于语言或库的支持: 协程需要编程语言或库提供支持。不是所有编程语言都原生支持协程。比如 Java 实现的虚拟线程。
|
||||
|
||||
## 四种创建虚拟线程的方法
|
||||
|
||||
Java 21 已经正式支持虚拟线程,大家可以在官网下载使用,在使用上官方为了降低使用门槛,尽量复用原有的 `Thread` 类,让大家可以更加平滑的使用。
|
||||
|
||||
官方提供了以下四种方式创建虚拟线程:
|
||||
|
||||
1. 使用 `Thread.startVirtualThread()` 创建
|
||||
2. 使用 `Thread.ofVirtual()` 创建
|
||||
3. 使用 `ThreadFactory` 创建
|
||||
|
||||
|
||||
#### 使用 Thread.startVirtualThread()创建
|
||||
|
||||
```java
|
||||
public class VirtualThreadTest {
|
||||
public static void main(String[] args) {
|
||||
CustomThread customThread = new CustomThread();
|
||||
Thread.startVirtualThread(customThread);
|
||||
}
|
||||
}
|
||||
|
||||
static class CustomThread implements Runnable {
|
||||
@Override
|
||||
public void run() {
|
||||
System.out.println("CustomThread run");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 使用 Thread.ofVirtual()创建
|
||||
|
||||
```java
|
||||
public class VirtualThreadTest {
|
||||
public static void main(String[] args) {
|
||||
CustomThread customThread = new CustomThread();
|
||||
// 创建不启动
|
||||
Thread unStarted = Thread.ofVirtual().unstarted(customThread);
|
||||
unStarted.start();
|
||||
// 创建直接启动
|
||||
Thread.ofVirtual().start(customThread);
|
||||
}
|
||||
}
|
||||
static class CustomThread implements Runnable {
|
||||
@Override
|
||||
public void run() {
|
||||
System.out.println("CustomThread run");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 使用 ThreadFactory 创建
|
||||
|
||||
```java
|
||||
public class VirtualThreadTest {
|
||||
public static void main(String[] args) {
|
||||
CustomThread customThread = new CustomThread();
|
||||
ThreadFactory factory = Thread.ofVirtual().factory();
|
||||
Thread thread = factory.newThread(customThread);
|
||||
thread.start();
|
||||
}
|
||||
}
|
||||
|
||||
static class CustomThread implements Runnable {
|
||||
@Override
|
||||
public void run() {
|
||||
System.out.println("CustomThread run");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
#### 使用 Executors.newVirtualThreadPerTaskExecutor()创建
|
||||
|
||||
```java
|
||||
public class VirtualThreadTest {
|
||||
public static void main(String[] args) {
|
||||
CustomThread customThread = new CustomThread();
|
||||
ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor();
|
||||
executor.submit(customThread);
|
||||
}
|
||||
}
|
||||
static class CustomThread implements Runnable {
|
||||
@Override
|
||||
public void run() {
|
||||
System.out.println("CustomThread run");
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 虚拟线程和平台线程性能对比
|
||||
通过多线程和虚拟线程的方式处理相同的任务,对比创建的系统线程数和处理耗时。
|
||||
|
||||
**说明**:统计创建的系统线程中部分为后台线程(比如 GC 线程),两种场景下都一样,所以并不影响对比。
|
||||
|
||||
**测试代码**:
|
||||
|
||||
```java
|
||||
public class VirtualThreadTest {
|
||||
static List<Integer> list = new ArrayList<>();
|
||||
public static void main(String[] args) {
|
||||
// 开启线程 统计平台线程数
|
||||
ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(1);
|
||||
scheduledExecutorService.scheduleAtFixedRate(() -> {
|
||||
ThreadMXBean threadBean = ManagementFactory.getThreadMXBean();
|
||||
ThreadInfo[] threadInfo = threadBean.dumpAllThreads(false, false);
|
||||
updateMaxThreadNum(threadInfo.length);
|
||||
}, 10, 10, TimeUnit.MILLISECONDS);
|
||||
|
||||
long start = System.currentTimeMillis();
|
||||
// 虚拟线程
|
||||
ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor();
|
||||
// 使用平台线程
|
||||
// ExecutorService executor = Executors.newFixedThreadPool(200);
|
||||
for (int i = 0; i < 10000; i++) {
|
||||
executor.submit(() -> {
|
||||
try {
|
||||
// 线程睡眠 0.5 s,模拟业务处理
|
||||
TimeUnit.MILLISECONDS.sleep(500);
|
||||
} catch (InterruptedException ignored) {
|
||||
}
|
||||
});
|
||||
}
|
||||
executor.close();
|
||||
System.out.println("max:" + list.get(0) + " platform thread/os thread");
|
||||
System.out.printf("totalMillis:%dms\n", System.currentTimeMillis() - start);
|
||||
|
||||
|
||||
}
|
||||
// 更新创建的平台最大线程数
|
||||
private static void updateMaxThreadNum(int num) {
|
||||
if (list.isEmpty()) {
|
||||
list.add(num);
|
||||
} else {
|
||||
Integer integer = list.get(0);
|
||||
if (num > integer) {
|
||||
list.add(0, num);
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**请求数 10000 单请求耗时 1s**:
|
||||
|
||||
```plain
|
||||
// Virtual Thread
|
||||
max:22 platform thread/os thread
|
||||
totalMillis:1806ms
|
||||
|
||||
// Platform Thread 线程数200
|
||||
max:209 platform thread/os thread
|
||||
totalMillis:50578ms
|
||||
|
||||
// Platform Thread 线程数500
|
||||
max:509 platform thread/os thread
|
||||
totalMillis:20254ms
|
||||
|
||||
// Platform Thread 线程数1000
|
||||
max:1009 platform thread/os thread
|
||||
totalMillis:10214ms
|
||||
|
||||
// Platform Thread 线程数2000
|
||||
max:2009 platform thread/os thread
|
||||
totalMillis:5358ms
|
||||
```
|
||||
|
||||
**请求数 10000 单请求耗时 0.5s**:
|
||||
|
||||
```plain
|
||||
// Virtual Thread
|
||||
max:22 platform thread/os thread
|
||||
totalMillis:1316ms
|
||||
|
||||
// Platform Thread 线程数200
|
||||
max:209 platform thread/os thread
|
||||
totalMillis:25619ms
|
||||
|
||||
// Platform Thread 线程数500
|
||||
max:509 platform thread/os thread
|
||||
totalMillis:10277ms
|
||||
|
||||
// Platform Thread 线程数1000
|
||||
max:1009 platform thread/os thread
|
||||
totalMillis:5197ms
|
||||
|
||||
// Platform Thread 线程数2000
|
||||
max:2009 platform thread/os thread
|
||||
totalMillis:2865ms
|
||||
```
|
||||
|
||||
- 可以看到在密集 IO 的场景下,需要创建大量的平台线程异步处理才能达到虚拟线程的处理速度。
|
||||
- 因此,在密集 IO 的场景,虚拟线程可以大幅提高线程的执行效率,减少线程资源的创建以及上下文切换。
|
||||
- 吐槽:虽然虚拟线程我很想用,但是我 Java8 有机会升级到 Java21 吗?呜呜
|
||||
|
||||
**注意**:有段时间 JDK 一直致力于 Reactor 响应式编程来提高 Java 性能,但响应式编程难以理解、调试、使用,最终又回到了同步编程,最终虚拟线程诞生。
|
||||
@ -254,7 +254,6 @@ executorService.submit(() -> {
|
||||
// your code here
|
||||
});
|
||||
|
||||
//
|
||||
class CustomThread implements Runnable {
|
||||
@Override
|
||||
public void run() {
|
||||
|
||||
@ -7,9 +7,11 @@ icon: project
|
||||
## 快速开发平台
|
||||
|
||||
- [Snowy](https://gitee.com/xiaonuobase/snowy):国内首个国密前后端分离快速开发平台,定位不是深度封装的框架,也不是无代码平台,更不是某个领域的产品。详细介绍:[5.1k!这是我见过最强的前后端分离快速开发脚手架!!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247534316&idx=1&sn=69938397674fc33ecda43c8c9d0a4039&chksm=cea10927f9d68031bc862485c6be984ade5af233d4d871d498c38f22164a84314678c0c67cd7&token=1464380539&lang=zh_CN#rd)。
|
||||
- [eladmin](https://github.com/elunez/eladmin) : 前后端分离的后台管理系统,项目采用分模块开发方式, 权限控制采用 RBAC,支持数据字典与数据权限管理,支持一键生成前后端代码,支持动态路由。
|
||||
- [RuoYi](https://gitee.com/y_project/RuoYi):RuoYi 一款基于基于 SpringBoot 的权限管理系统 易读易懂、界面简洁美观,直接运行即可用 。
|
||||
- [AgileBoot-Back-End](https://github.com/valarchie/AgileBoot-Back-End):基于 Ruoyi 做了大量重构优化的基础快速开发框架。
|
||||
- [RuoYi-Vue-Pro](https://github.com/YunaiV/ruoyi-vue-pro):RuoYi-Vue 全新 Pro 版本,优化重构所有功能。
|
||||
- [pig](https://gitee.com/log4j/pig "pig"):(gitee)基于 Spring Boot 2.2、 Spring Cloud Hoxton & Alibaba、 OAuth2 的 RBAC 权限管理系统。
|
||||
- [Guns](https://gitee.com/stylefeng/guns):现代化的 Java 应用开发基础框架。
|
||||
- [JeecgBoot](https://github.com/zhangdaiscott/jeecg-boot):一款基于代码生成器的 J2EE 低代码快速开发平台,支持生成前后端分离架构的项目。
|
||||
- [Erupt](https://gitee.com/erupt/erupt) : 低代码全栈类框架,它使用 Java 注解 动态生成页面以及增、删、改、查、权限控制等后台功能。
|
||||
@ -66,11 +68,8 @@ icon: project
|
||||
|
||||
权限管理系统在企业级的项目中一般都是非常重要的,如果你需求去实际了解一个不错的权限系统是如何设计的话,推荐你可以参考下面这些开源项目。
|
||||
|
||||
- [Spring-Cloud-Admin](https://github.com/wxiaoqi/Spring-Cloud-Admin "Spring-Cloud-Admin"):Cloud-Admin 是国内首个基于 Spring Cloud 微服务化开发平台,具有统一授权、认证后台管理系统,其中包含具备用户管理、资源权限管理、网关 API 管理等多个模块,支持多业务系统并行开发,可以作为后端服务的开发脚手架。代码简洁,架构清晰,适合学习和直接项目中使用。核心技术采用 Spring Boot2 以及 Spring Cloud Gateway 相关核心组件,前端采用 vue-element-admin 组件。
|
||||
- [pig](https://gitee.com/log4j/pig "pig"):(gitee)基于 Spring Boot 2.2、 Spring Cloud Hoxton & Alibaba、 OAuth2 的 RBAC 权限管理系统。
|
||||
- [FEBS-Shiro](https://github.com/wuyouzhuguli/FEBS-Shiro "FEBS-Shiro"):Spring Boot 2.1.3,Shiro1.4.0 & Layui 2.5.4 权限管理系统。
|
||||
- [eladmin](https://github.com/elunez/eladmin) : 项目基于 Spring Boot 2.1.0、 Jpa、 Spring Security、redis、Vue 的前后端分离的后台管理系统,项目采用分模块开发方式, 权限控制采用 RBAC,支持数据字典与数据权限管理,支持一键生成前后端代码,支持动态路由。
|
||||
- [SpringBoot-Shiro-Vue](https://github.com/Heeexy/SpringBoot-Shiro-Vue):提供一套基于 Spring Boot-Shiro-Vue 的权限管理思路.前后端都加以控制,做到按钮/接口级别的权限。
|
||||
- [SpringBoot-Shiro-Vue](https://github.com/Heeexy/SpringBoot-Shiro-Vue):基于 Spring Boot-Shiro-Vue 的权限管理思路,前后端都加以控制,可以做到按钮/接口级别的权限。
|
||||
- [renren-security](https://gitee.com/renrenio/renren-security):一套灵活的权限控制系统,可控制到页面或按钮,满足绝大部分的权限需求
|
||||
|
||||
## 造轮子
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user