mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-07-28 12:22:17 +08:00
Compare commits
8 Commits
0bb301e441
...
5036625207
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
5036625207 | ||
|
|
dc8e5a3c21 | ||
|
|
9d7d0d66f3 | ||
|
|
7812cd6aa3 | ||
|
|
8abb2f7c41 | ||
|
|
be73d849d4 | ||
|
|
f3e1ed6873 | ||
|
|
a746734c79 |
@ -110,7 +110,7 @@ tag:
|
||||
|
||||
### 顺序存储
|
||||
|
||||
顺序存储就是利用数组进行存储,数组中的每一个位置仅存储节点的 data,不存储左右子节点的指针,子节点的索引通过数组下标完成。根结点的序号为 1,对于每个节点 Node,假设它存储在数组中下标为 i 的位置,那么它的左子节点就存储在 2 _ i 的位置,它的右子节点存储在下标为 2 _ i+1 的位置。
|
||||
顺序存储就是利用数组进行存储,数组中的每一个位置仅存储节点的 data,不存储左右子节点的指针,子节点的索引通过数组下标完成。根结点的序号为 1,对于每个节点 Node,假设它存储在数组中下标为 i 的位置,那么它的左子节点就存储在 2i 的位置,它的右子节点存储在下标为 2i+1 的位置。
|
||||
|
||||
一棵完全二叉树的数组顺序存储如下图所示:
|
||||
|
||||
@ -181,4 +181,4 @@ public void postOrder(TreeNode root){
|
||||
postOrder(root.right);
|
||||
system.out.println(root.data);
|
||||
}
|
||||
```
|
||||
```
|
||||
|
||||
@ -5,7 +5,7 @@ tag:
|
||||
- MySQL
|
||||
---
|
||||
|
||||
|
||||
> 感谢**[WT-AHA](https://github.com/WT-AHA)** 对本人的完善,相关 PR:https://github.com/Snailclimb/JavaGuide/pull/1648 。
|
||||
|
||||
## 何为索引?有什么作用?
|
||||
|
||||
@ -31,7 +31,7 @@ tag:
|
||||
|
||||
## 索引的底层数据结构
|
||||
|
||||
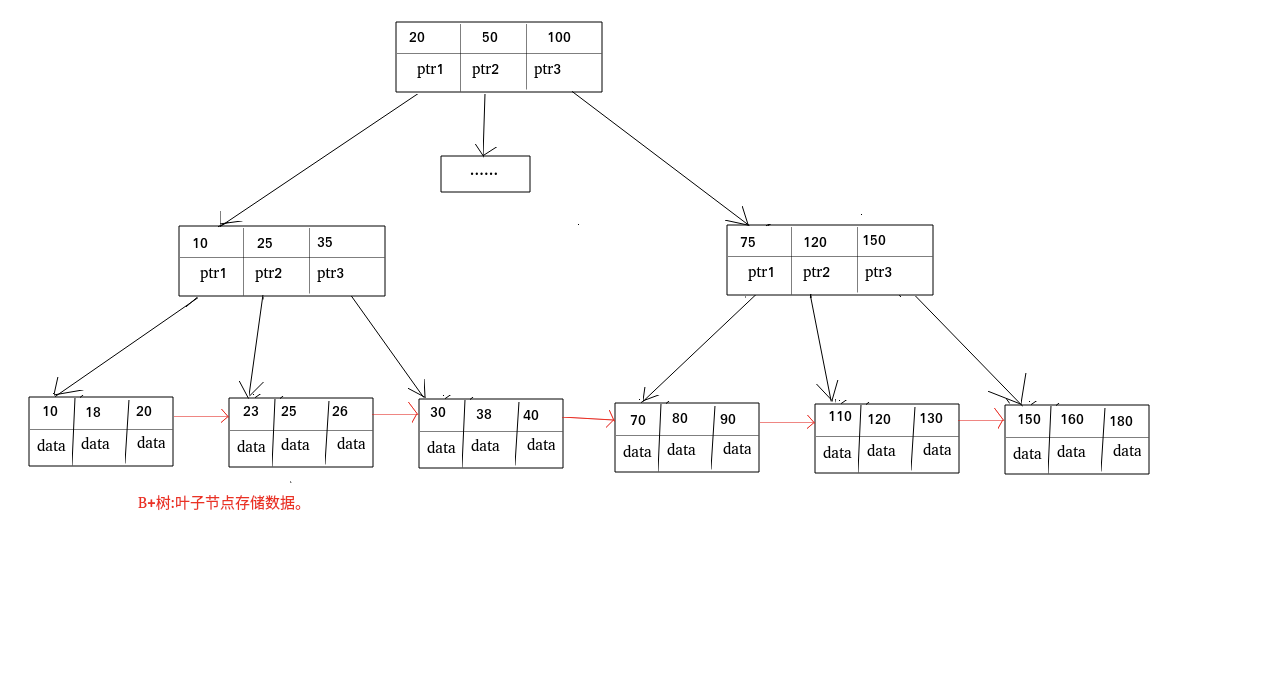
### Hash表 & B+树
|
||||
### Hash表
|
||||
|
||||
哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。
|
||||
|
||||
@ -76,8 +76,6 @@ B 树也称 B-树,全称为 **多路平衡查找树** ,B+ 树是 B 树的一
|
||||
- B 树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
|
||||
- B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而 B+树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
|
||||
|
||||
|
||||
|
||||
在 MySQL 中,MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是,两者的实现方式不太一样。(下面的内容整理自《Java 工程师修炼之道》)
|
||||
|
||||
MyISAM 引擎中,B+Tree 叶节点的 data 域存放的是数据记录的地址。在索引检索的时候,首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
|
||||
@ -94,6 +92,8 @@ InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索
|
||||
|
||||
在 MySQL 的 InnoDB 的表中,当没有显示的指定表的主键时,InnoDB 会自动先检查表中是否有唯一索引且不允许存在null值的字段,如果有,则选择该字段为默认的主键,否则 InnoDB 将会自动创建一个 6Byte 的自增主键。
|
||||
|
||||

|
||||
|
||||
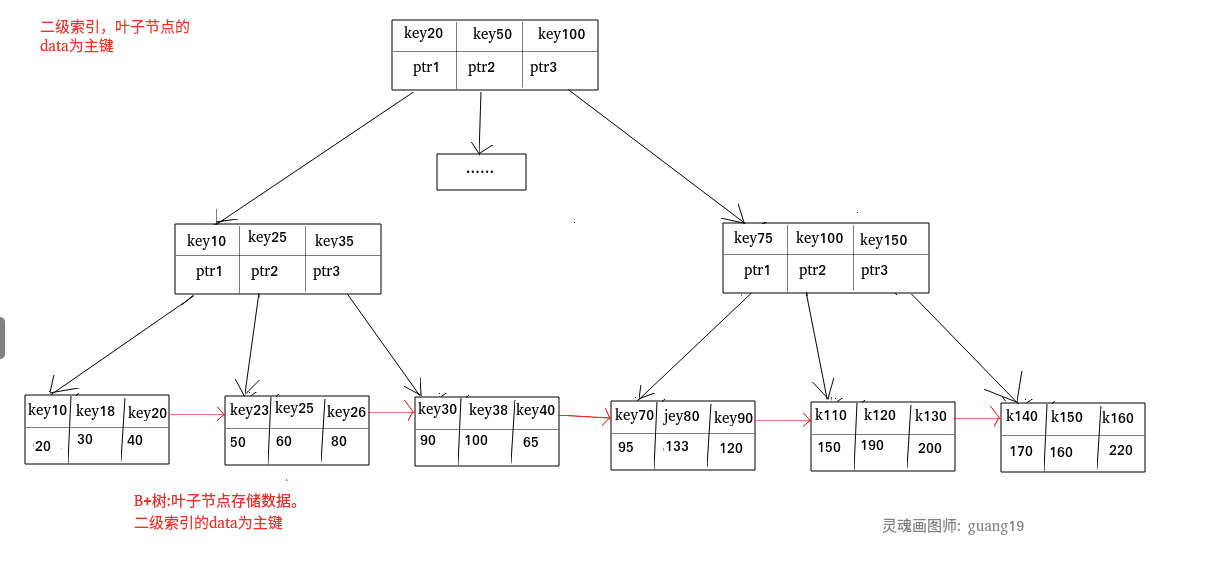
### 二级索引(辅助索引)
|
||||
|
||||
**二级索引又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。**
|
||||
@ -110,7 +110,7 @@ InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索
|
||||
|
||||
二级索引:
|
||||
|
||||
|
||||

|
||||
|
||||
## 聚集索引与非聚集索引
|
||||
|
||||
@ -190,6 +190,20 @@ SELECT id FROM table WHERE id=1;
|
||||
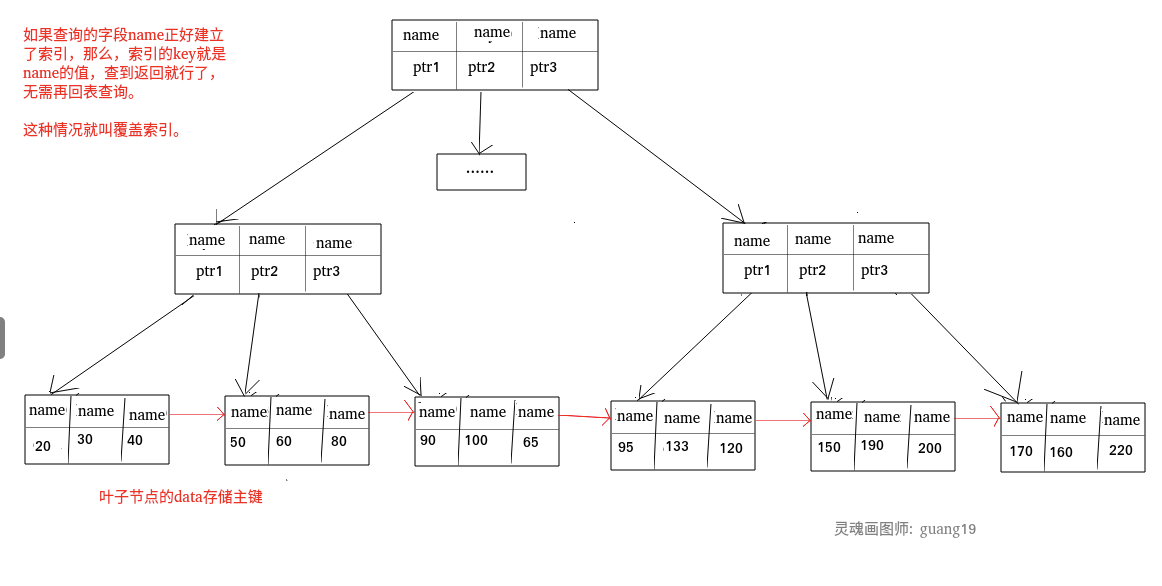
覆盖索引:
|
||||
|
||||
|
||||
## 联合索引
|
||||
|
||||
使用表中的多个字段创建索引,就是 **联合索引**,也叫 **组合索引** 或 **复合索引**。
|
||||
|
||||
## 最左前缀匹配原则
|
||||
|
||||
最左前缀匹配原则指的是,在使用联合索引时,**MySQL** 会根据联合索引中的字段顺序,从左到右依次到查询条件中去匹配,如果查询条件中存在与联合索引中最左侧字段相匹配的字段,则就会使用该字段过滤一批数据,直至联合索引中全部字段匹配完成,或者在执行过程中遇到范围查询,如 **`>`**、**`<`**、**`between`** 和 **`以%开头的like查询`** 等条件,才会停止匹配。
|
||||
|
||||
所以,我们在使用联合索引时,可以将区分度高的字段放在最左边,这也可以过滤更多数据。
|
||||
|
||||
## 索引下推
|
||||
|
||||
索引下推是 **MySQL 5.6** 版本中提供的一项索引优化功能,可以在非聚簇索引遍历过程中,对索引中包含的字段先做判断,过滤掉不符合条件的记录,减少回表次数。
|
||||
|
||||
## 创建索引的注意事项
|
||||
|
||||
**1.选择合适的字段创建索引:**
|
||||
|
||||
@ -54,7 +54,7 @@ tag:
|
||||
|
||||
----
|
||||
|
||||
| 隔离级别 | 脏读 | 不可重复读 | 幻影读 |
|
||||
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|
||||
| :---: | :---: | :---:| :---: |
|
||||
| READ-UNCOMMITTED | √ | √ | √ |
|
||||
| READ-COMMITTED | × | √ | √ |
|
||||
@ -127,17 +127,26 @@ SET [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL [READ UNCOMMITTED|READ COMMITTE
|
||||
<div align="center">
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-33-2可重复读.jpg"/>
|
||||
</div>
|
||||
#### 幻读
|
||||
|
||||
#### 防止幻读(可重复读)
|
||||
##### 演示幻读出现的情况
|
||||
|
||||
<div align="center">
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-33防止幻读(使用可重复读).jpg"/>
|
||||
</div>
|
||||

|
||||
|
||||
一个事务对数据库进行操作,这种操作的范围是数据库的全部行,然后第二个事务也在对这个数据库操作,这种操作可以是插入一行记录或删除一行记录,那么第一个是事务就会觉得自己出现了幻觉,怎么还有没有处理的记录呢? 或者 怎么多处理了一行记录呢?
|
||||
sql 脚本1 在第一次查询工资为 500 的记录时只有一条,sql 脚本 2 插入了一条工资为 500 的记录,提交之后;sql 脚本 1 在同一个事务中再次使用当前读查询发现出现了两条工资为 500 的记录这种就是幻读。
|
||||
|
||||
幻读和不可重复读有些相似之处 ,但是不可重复读的重点是修改,幻读的重点在于新增或者删除。
|
||||
|
||||
##### 解决幻读的方法
|
||||
|
||||
解决幻读的方式有很多,但是它们的核心思想就是一个事务在操作某张表数据的时候,另外一个事务不允许新增或者删除这张表中的数据了。解决幻读的方式主要有以下几种:
|
||||
|
||||
1. 将事务隔离级别调整为 `SERIALIZABLE`
|
||||
2. 在可重复读的事务级别下,给事务操作的这张表添加表锁
|
||||
3. 在可重复读的事务级别下,给事务操作的这张表添加 `Next-Key Locks`
|
||||
|
||||
> 说明:`Next-Key Locks` 相当于 行锁 + 间隙锁
|
||||
|
||||
### 参考
|
||||
|
||||
- 《MySQL技术内幕:InnoDB存储引擎》
|
||||
|
||||
@ -20,6 +20,8 @@ category: 开源项目
|
||||
## ZooKeeper 可视化管理
|
||||
|
||||
- **[PrettyZoo](https://github.com/vran-dev/PrettyZoo)** : 一个基于 Apache Curator 和 JavaFX 实现的 ZooKeeper 图形化管理客户端,颜值非常高,支持 Mac / Windows / Linux 。你可以使用 PrettyZoo 来实现对 ZooKeeper 的可视化增删改查。
|
||||
- **[zktools](https://zktools.readthedocs.io/en/latest/#installing)** : 一个低延迟的 ZooKeeper 图形化管理客户端,颜值非常高,支持 Mac / Windows / Linux 。你可以使用 zktools 来实现对 ZooKeeper 的可视化增删改查。
|
||||
|
||||
|
||||
## Markdown
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user