mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
Compare commits
13 Commits
0428e1dba7
...
555fc17e29
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
555fc17e29 | ||
|
|
76ae23e3f9 | ||
|
|
36c2c3c47e | ||
|
|
c3de9404d6 | ||
|
|
554f7a8b3d | ||
|
|
4637706b18 | ||
|
|
036445495d | ||
|
|
74ccdbcdab | ||
|
|
e5f34711dd | ||
|
|
0fd8d59cbb | ||
|
|
aecb6e442a | ||
|
|
4723458cab | ||
|
|
b33d501202 |
@ -136,7 +136,7 @@ Swap 对于 Redis 来说是非常致命的,Redis 保证高性能的一个重
|
|||||||
1、查询 Redis 进程号
|
1、查询 Redis 进程号
|
||||||
|
|
||||||
```bash
|
```bash
|
||||||
reids-cli -p 6383 info server | grep process_id
|
redis-cli -p 6383 info server | grep process_id
|
||||||
process_id: 4476
|
process_id: 4476
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -164,7 +164,7 @@ Swap: 0kB
|
|||||||
|
|
||||||
Redis 是典型的 CPU 密集型应用,不建议和其他多核 CPU 密集型服务部署在一起。当其他进程过度消耗 CPU 时,将严重影响 Redis 的吞吐量。
|
Redis 是典型的 CPU 密集型应用,不建议和其他多核 CPU 密集型服务部署在一起。当其他进程过度消耗 CPU 时,将严重影响 Redis 的吞吐量。
|
||||||
|
|
||||||
可以通过`reids-cli --stat`获取当前 Redis 使用情况。通过`top`命令获取进程对 CPU 的利用率等信息 通过`info commandstats`统计信息分析出命令不合理开销时间,查看是否是因为高算法复杂度或者过度的内存优化问题。
|
可以通过`redis-cli --stat`获取当前 Redis 使用情况。通过`top`命令获取进程对 CPU 的利用率等信息 通过`info commandstats`统计信息分析出命令不合理开销时间,查看是否是因为高算法复杂度或者过度的内存优化问题。
|
||||||
|
|
||||||
## 网络问题
|
## 网络问题
|
||||||
|
|
||||||
|
|||||||
@ -272,29 +272,32 @@ ZAB 协议包括两种基本的模式,分别是
|
|||||||
- [ZooKeeper 与 Zab 协议 · Analyze](https://wingsxdu.com/posts/database/zookeeper/)
|
- [ZooKeeper 与 Zab 协议 · Analyze](https://wingsxdu.com/posts/database/zookeeper/)
|
||||||
- [Raft 算法详解](https://javaguide.cn/distributed-system/protocol/raft-algorithm.html)
|
- [Raft 算法详解](https://javaguide.cn/distributed-system/protocol/raft-algorithm.html)
|
||||||
|
|
||||||
## ZooKeeper VS Etcd
|
## ZooKeeper VS ETCD
|
||||||
|
|
||||||
[Etcd](https://etcd.io/) 是一种强一致性的分布式键值存储,它提供了一种可靠的方式来存储需要由分布式系统或机器集群访问的数据。Etcd 内部采用 [Raft 算法](https://javaguide.cn/distributed-system/protocol/raft-algorithm.html)作为一致性算法,基于 Go 语言实现。
|
[ETCD](https://etcd.io/) 是一种强一致性的分布式键值存储,它提供了一种可靠的方式来存储需要由分布式系统或机器集群访问的数据。ETCD 内部采用 [Raft 算法](https://javaguide.cn/distributed-system/protocol/raft-algorithm.html)作为一致性算法,基于 Go 语言实现。
|
||||||
|
|
||||||
与 ZooKeeper 类似,Etcd 也可用于数据发布/订阅、负载均衡、命名服务、分布式协调/通知、分布式锁等场景。那二者如何选择呢?
|
与 ZooKeeper 类似,ETCD 也可用于数据发布/订阅、负载均衡、命名服务、分布式协调/通知、分布式锁等场景。那二者如何选择呢?
|
||||||
|
|
||||||
得物技术的[浅析如何基于 ZooKeeper 实现高可用架构](https://mp.weixin.qq.com/s/pBI3rjv5NdS1124Z7HQ-JA)这篇文章给出了如下的对比表格,可以作为参考:
|
得物技术的[浅析如何基于 ZooKeeper 实现高可用架构](https://mp.weixin.qq.com/s/pBI3rjv5NdS1124Z7HQ-JA)这篇文章给出了如下的对比表格(我进一步做了优化),可以作为参考:
|
||||||
|
|
||||||
| | ZooKeeper | Etcd |
|
| | ZooKeeper | ETCD |
|
||||||
| -------------- | --------------------------------------------------------------------- | ------------------------------------------------------ |
|
| ---------------- | --------------------------------------------------------------------- | ------------------------------------------------------ |
|
||||||
| **语言** | Java | Go |
|
| **语言** | Java | Go |
|
||||||
| **协议** | TCP | Grpc |
|
| **协议** | TCP | Grpc |
|
||||||
| **接口调用** | 必须要使用自己的 client 进行调用 | 可通过 HTTP 传输,即可通过 CURL 等命令实现调用 |
|
| **接口调用** | 必须要使用自己的 client 进行调用 | 可通过 HTTP 传输,即可通过 CURL 等命令实现调用 |
|
||||||
| **一致性算法** | Zab 协议 | Raft 算法 |
|
| **一致性算法** | Zab 协议 | Raft 算法 |
|
||||||
| **Watch 功能** | 较局限,一次性触发器 | 一次 Watch 可以监听所有的事件 |
|
| **Watcher 机制** | 较局限,一次性触发器 | 一次 Watch 可以监听所有的事件 |
|
||||||
| **数据模型** | 基于目录的层次模式 | 参考了 zk 的数据模型,是个扁平的 kv 模型 |
|
| **数据模型** | 基于目录的层次模式 | 参考了 zk 的数据模型,是个扁平的 kv 模型 |
|
||||||
| **存储** | kv 存储,使用的是 ConcurrentHashMap,内存存储,一般不建议存储较多数据 | kv 存储,使用 bbolt 存储引擎,可以处理几个 GB 的数据。 |
|
| **存储** | kv 存储,使用的是 ConcurrentHashMap,内存存储,一般不建议存储较多数据 | kv 存储,使用 bbolt 存储引擎,可以处理几个 GB 的数据。 |
|
||||||
| **支持 MVCC** | 不支持 | 支持,通过两个 B+ Tree 进行版本控制 |
|
| **MVCC** | 不支持 | 支持,通过两个 B+ Tree 进行版本控制 |
|
||||||
| **权限校验** | 实现的 ACL | 实现了 RBAC |
|
| **全局 Session** | 存在缺陷 | 实现更灵活,避免了安全性问题 |
|
||||||
|
| **权限校验** | ACL | RBAC |
|
||||||
| **事务能力** | 提供了简易的事务能力 | 只提供了版本号的检查能力 |
|
| **事务能力** | 提供了简易的事务能力 | 只提供了版本号的检查能力 |
|
||||||
| 部署维护 | 复杂 | 简单 |
|
| **部署维护** | 复杂 | 简单 |
|
||||||
|
|
||||||
实际选用哪个要根据实际业务场景和需求来定,Etcd 相对来说更适合云原生领域,并且提供了更稳定的高负载稳定读写能力以及更高的可用性。
|
ZooKeeper 在存储性能、全局 Session、Watcher 机制等方面存在一定局限性,越来越多的开源项目在替换 ZooKeeper 为 Raft 实现或其它分布式协调服务,例如:[Kafka Needs No Keeper - Removing ZooKeeper Dependency (confluent.io)](https://www.confluent.io/blog/removing-zookeeper-dependency-in-kafka/)、[Moving Toward a ZooKeeper-Less Apache Pulsar (streamnative.io)](https://streamnative.io/blog/moving-toward-zookeeper-less-apache-pulsar)。
|
||||||
|
|
||||||
|
ETCD 相对来说更优秀一些,提供了更稳定的高负载读写能力,对 ZooKeeper 暴露的许多问题进行了改进优化。并且,ETCD 基本能够覆盖 ZooKeeper 的所有应用场景,实现对其的替代。
|
||||||
|
|
||||||
## 总结
|
## 总结
|
||||||
|
|
||||||
@ -308,5 +311,6 @@ ZAB 协议包括两种基本的模式,分别是
|
|||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
- 《从 Paxos 到 ZooKeeper 分布式一致性原理与实践》
|
- 《从 Paxos 到 ZooKeeper 分布式一致性原理与实践》
|
||||||
|
- 谈谈 ZooKeeper 的局限性:<https://wingsxdu.com/posts/database/zookeeper-limitations/>
|
||||||
|
|
||||||
<!-- @include: @article-footer.snippet.md -->
|
<!-- @include: @article-footer.snippet.md -->
|
||||||
|
|||||||
@ -81,7 +81,7 @@ Gossip 设计了两种可能的消息传播模式:**反熵(Anti-Entropy)**
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
在我们实际应用场景中,一般不会采用随机的节点进行反熵,而是需要可以的设计一个闭环。这样的话,我们能够在一个确定的时间范围内实现各个节点数据的最终一致性,而不是基于随机的概率。像 InfluxDB 就是这样来实现反熵的。
|
在我们实际应用场景中,一般不会采用随机的节点进行反熵,而是可以设计成一个闭环。这样的话,我们能够在一个确定的时间范围内实现各个节点数据的最终一致性,而不是基于随机的概率。像 InfluxDB 就是这样来实现反熵的。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|||||||
{kind=link}
|
Before Width: | Height: | Size: 204 KiB After Width: | Height: | Size: 204 KiB |
@ -67,7 +67,7 @@ Basic Paxos 中存在 3 个重要的角色:
|
|||||||
|
|
||||||
## Multi Paxos 思想
|
## Multi Paxos 思想
|
||||||
|
|
||||||
Basic Paxos 算法的仅能就单个值达成共识,为了能够对一系列的值达成共识,我们需要用到 Basic Paxos 思想。
|
Basic Paxos 算法的仅能就单个值达成共识,为了能够对一系列的值达成共识,我们需要用到 Multi Paxos 思想。
|
||||||
|
|
||||||
⚠️**注意**:Multi-Paxos 只是一种思想,这种思想的核心就是通过多个 Basic Paxos 实例就一系列值达成共识。也就是说,Basic Paxos 是 Multi-Paxos 思想的核心,Multi-Paxos 就是多执行几次 Basic Paxos。
|
⚠️**注意**:Multi-Paxos 只是一种思想,这种思想的核心就是通过多个 Basic Paxos 实例就一系列值达成共识。也就是说,Basic Paxos 是 Multi-Paxos 思想的核心,Multi-Paxos 就是多执行几次 Basic Paxos。
|
||||||
|
|
||||||
|
|||||||
@ -112,7 +112,7 @@ Leader 收到客户端请求后,会生成一个 entry,包含`<index,term,cmd
|
|||||||
|
|
||||||
如果 Follower 接受该 entry,则会将 entry 添加到自己的日志后面,同时返回给 Leader 同意。
|
如果 Follower 接受该 entry,则会将 entry 添加到自己的日志后面,同时返回给 Leader 同意。
|
||||||
|
|
||||||
如果 Leader 收到了多数的成功响应,Leader 会将这个 entry 应用到自己的状态机中,之后可以成为这个 entry 是 committed 的,并且向客户端返回执行结果。
|
如果 Leader 收到了多数的成功响应,Leader 会将这个 entry 应用到自己的状态机中,之后可以称这个 entry 是 committed 的,并且向客户端返回执行结果。
|
||||||
|
|
||||||
raft 保证以下两个性质:
|
raft 保证以下两个性质:
|
||||||
|
|
||||||
|
|||||||
@ -218,7 +218,7 @@ catch (IOException e) {
|
|||||||
- 不要把异常定义为静态变量,因为这样会导致异常栈信息错乱。每次手动抛出异常,我们都需要手动 new 一个异常对象抛出。
|
- 不要把异常定义为静态变量,因为这样会导致异常栈信息错乱。每次手动抛出异常,我们都需要手动 new 一个异常对象抛出。
|
||||||
- 抛出的异常信息一定要有意义。
|
- 抛出的异常信息一定要有意义。
|
||||||
- 建议抛出更加具体的异常比如字符串转换为数字格式错误的时候应该抛出`NumberFormatException`而不是其父类`IllegalArgumentException`。
|
- 建议抛出更加具体的异常比如字符串转换为数字格式错误的时候应该抛出`NumberFormatException`而不是其父类`IllegalArgumentException`。
|
||||||
- 使用日志打印异常之后就不要再抛出异常了(两者不要同时存在一段代码逻辑中)。
|
- 避免重复记录日志:如果在捕获异常的地方已经记录了足够的信息(包括异常类型、错误信息和堆栈跟踪等),那么在业务代码中再次抛出这个异常时,就不应该再次记录相同的错误信息。重复记录日志会使得日志文件膨胀,并且可能会掩盖问题的实际原因,使得问题更难以追踪和解决。
|
||||||
- ……
|
- ……
|
||||||
|
|
||||||
## 泛型
|
## 泛型
|
||||||
|
|||||||
@ -96,7 +96,7 @@ public class Singleton {
|
|||||||
* @author Guide哥
|
* @author Guide哥
|
||||||
* @date 2022/08/03 13:40
|
* @date 2022/08/03 13:40
|
||||||
**/
|
**/
|
||||||
public class VolatoleAtomicityDemo {
|
public class VolatileAtomicityDemo {
|
||||||
public volatile static int inc = 0;
|
public volatile static int inc = 0;
|
||||||
|
|
||||||
public void increase() {
|
public void increase() {
|
||||||
@ -105,11 +105,11 @@ public class VolatoleAtomicityDemo {
|
|||||||
|
|
||||||
public static void main(String[] args) throws InterruptedException {
|
public static void main(String[] args) throws InterruptedException {
|
||||||
ExecutorService threadPool = Executors.newFixedThreadPool(5);
|
ExecutorService threadPool = Executors.newFixedThreadPool(5);
|
||||||
VolatoleAtomicityDemo volatoleAtomicityDemo = new VolatoleAtomicityDemo();
|
VolatileAtomicityDemo volatileAtomicityDemo = new VolatileAtomicityDemo();
|
||||||
for (int i = 0; i < 5; i++) {
|
for (int i = 0; i < 5; i++) {
|
||||||
threadPool.execute(() -> {
|
threadPool.execute(() -> {
|
||||||
for (int j = 0; j < 500; j++) {
|
for (int j = 0; j < 500; j++) {
|
||||||
volatoleAtomicityDemo.increase();
|
volatileAtomicityDemo.increase();
|
||||||
}
|
}
|
||||||
});
|
});
|
||||||
}
|
}
|
||||||
|
|||||||
@ -204,7 +204,7 @@ channel.read(buffer);
|
|||||||
|
|
||||||
### Selector(选择器)
|
### Selector(选择器)
|
||||||
|
|
||||||
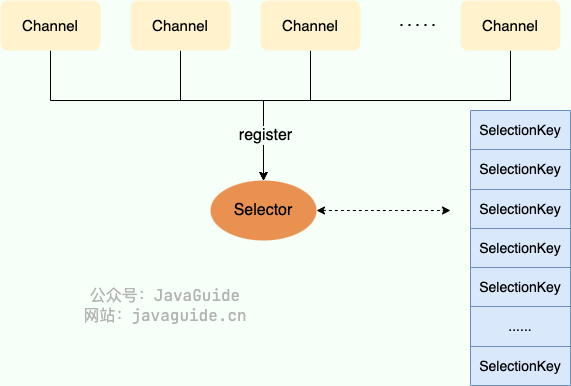
Selector(选择器) 是 NIO 中的一个关键组件,它允许一个线程处理多个 Channel。Selector 是基于事件驱动的 I/O 多路复用模型,主要运作原理是:通过 Selector 注册通道的事件,Selector 会不断地轮询注册在其上的 Channel。当事件发生时,比如:某个 Channel 上面有新的 TCP 连接接入、读和写事件,这个 Channel 就处于就绪状态,会被 Selector 轮询出来。Selector 会将相关的 Channel 加入到就绪集合中。通过 SelectionKey 可以获取就绪 Channel 的集合,然后对这些就绪的 Channel 进行响应的 I/O 操作。
|
Selector(选择器) 是 NIO 中的一个关键组件,它允许一个线程处理多个 Channel。Selector 是基于事件驱动的 I/O 多路复用模型,主要运作原理是:通过 Selector 注册通道的事件,Selector 会不断地轮询注册在其上的 Channel。当事件发生时,比如:某个 Channel 上面有新的 TCP 连接接入、读和写事件,这个 Channel 就处于就绪状态,会被 Selector 轮询出来。Selector 会将相关的 Channel 加入到就绪集合中。通过 SelectionKey 可以获取就绪 Channel 的集合,然后对这些就绪的 Channel 进行相应的 I/O 操作。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|||||||
@ -130,7 +130,7 @@ public class HuToolDesensitizationTest {
|
|||||||
|
|
||||||
现在有了数据脱敏工具类,如果前端需要显示数据数据的地方比较多,我们不可能在每个地方都调用一个工具类,这样就显得代码太冗余了,那我们如何通过注解的方式优雅的完成数据脱敏呢?
|
现在有了数据脱敏工具类,如果前端需要显示数据数据的地方比较多,我们不可能在每个地方都调用一个工具类,这样就显得代码太冗余了,那我们如何通过注解的方式优雅的完成数据脱敏呢?
|
||||||
|
|
||||||
如果项目是基于 Spring Boot 的 web 项目,则可以利用 Spring Boot 自带的 jackson 自定义序列化实现。它的实现原来其实就是在 json 进行序列化渲染给前端时,进行脱敏。
|
如果项目是基于 Spring Boot 的 web 项目,则可以利用 Spring Boot 自带的 jackson 自定义序列化实现。它的实现原理其实就是在 json 进行序列化渲染给前端时,进行脱敏。
|
||||||
|
|
||||||
**第一步:脱敏策略的枚举。**
|
**第一步:脱敏策略的枚举。**
|
||||||
|
|
||||||
|
|||||||
@ -16,7 +16,7 @@ tag:
|
|||||||
|
|
||||||
## 哈希算法
|
## 哈希算法
|
||||||
|
|
||||||
哈希算法也叫哈希算法、散列函数或摘要算法,它的作用是对任意长度的数据生成一个固定长度的唯一标识,也叫哈希值、散列值或消息摘要(后文统称为哈希值)。
|
哈希算法也叫散列函数或摘要算法,它的作用是对任意长度的数据生成一个固定长度的唯一标识,也叫哈希值、散列值或消息摘要(后文统称为哈希值)。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|||||||
@ -13,7 +13,7 @@ tag:
|
|||||||
|
|
||||||
### Trie 树
|
### Trie 树
|
||||||
|
|
||||||
**Trie 树** 也称为字典树、单词查找树,哈系树的一种变种,通常被用于字符串匹配,用来解决在一组字符串集合中快速查找某个字符串的问题。像浏览器搜索的关键词提示就可以基于 Trie 树来做的。
|
**Trie 树** 也称为字典树、单词查找树,哈希树的一种变种,通常被用于字符串匹配,用来解决在一组字符串集合中快速查找某个字符串的问题。像浏览器搜索的关键词提示就可以基于 Trie 树来做的。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user