mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-14 05:21:42 +08:00
Compare commits
4 Commits
026eb7e7e7
...
c48a51a3b1
| Author | SHA1 | Date | |
|---|---|---|---|
|
|
c48a51a3b1 | ||
|
|
d75c49f4a5 | ||
|
|
37e91ad9ce | ||
|
|
b9a3f99312 |
@ -207,6 +207,7 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
|
||||
- [InnoDB 存储引擎对 MVCC 的实现](./docs/database/mysql/innodb-implementation-of-mvcc.md)
|
||||
- [SQL 语句在 MySQL 中的执行过程](./docs/database/mysql/how-sql-executed-in-mysql.md)
|
||||
- [MySQL执行计划分析](./docs/database/mysql/mysql-query-execution-plan.md)
|
||||
- [MySQL自增主键一定是连续的吗](./docs/database/mysql/mysql-auto-increment-primary-key-continuous.md)
|
||||
- [MySQL 时间类型数据存储建议](./docs/database/mysql/some-thoughts-on-database-storage-time.md)
|
||||
- [MySQL 隐式转换造成索引失效](./docs/database/mysql/index-invalidation-caused-by-implicit-conversion.md)
|
||||
|
||||
@ -232,7 +233,7 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
|
||||
|
||||
## 搜索引擎
|
||||
|
||||
用于提高搜索效率,功能和浏览器搜索引擎类似。比较常见的搜索引擎是 Elasticsearch(推荐) 和 Solr。
|
||||
[Elasticsearch常见面试题总结(付费)](./docs/database/elasticsearch/elasticsearch-questions-01.md)
|
||||
|
||||

|
||||
|
||||
@ -242,6 +243,10 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
|
||||
|
||||
[Maven 核心概念总结](./docs/tools/maven/maven-core-concepts.md)
|
||||
|
||||
### Gradle
|
||||
|
||||
[Gradle 核心概念总结](./docs/tools/gradle/gradle-core-concepts.md)(可选,目前国内还是使用 Maven 普遍一些)
|
||||
|
||||
### Docker
|
||||
|
||||
* [Docker 核心概念总结](./docs/tools/docker/docker-intro.md)
|
||||
|
||||
@ -253,6 +253,7 @@ export const sidebarConfig = sidebar({
|
||||
"innodb-implementation-of-mvcc",
|
||||
"how-sql-executed-in-mysql",
|
||||
"mysql-query-execution-plan",
|
||||
"mysql-auto-increment-primary-key-continuous",
|
||||
"some-thoughts-on-database-storage-time",
|
||||
"index-invalidation-caused-by-implicit-conversion",
|
||||
],
|
||||
@ -307,6 +308,12 @@ export const sidebarConfig = sidebar({
|
||||
prefix: "maven/",
|
||||
children: ["maven-core-concepts"],
|
||||
},
|
||||
{
|
||||
text: "Gradle",
|
||||
icon: "gradle",
|
||||
prefix: "gradle/",
|
||||
children: ["gradle-core-concepts"],
|
||||
},
|
||||
{
|
||||
text: "Git",
|
||||
icon: "git",
|
||||
|
||||
@ -11,7 +11,7 @@ export const themeConfig = hopeTheme({
|
||||
},
|
||||
repo: "https://github.com/Snailclimb/JavaGuide",
|
||||
docsDir: "docs",
|
||||
iconAssets: "//at.alicdn.com/t/c/font_2922463_rmfowz6l95f.css",
|
||||
iconAssets: "//at.alicdn.com/t/c/font_2922463_st01t0e9sr.css",
|
||||
navbar: navbarConfig,
|
||||
sidebar: sidebarConfig,
|
||||
pageInfo: [
|
||||
|
||||
@ -9,29 +9,70 @@ tag:
|
||||
|
||||
## 什么是数据库, 数据库管理系统, 数据库系统, 数据库管理员?
|
||||
|
||||
* **数据库** : 数据库(DataBase 简称 DB)就是信息的集合或者说数据库是由数据库管理系统管理的数据的集合。
|
||||
* **数据库管理系统** : 数据库管理系统(Database Management System 简称 DBMS)是一种操纵和管理数据库的大型软件,通常用于建立、使用和维护数据库。
|
||||
* **数据库系统** : 数据库系统(Data Base System,简称 DBS)通常由软件、数据库和数据管理员(DBA)组成。
|
||||
* **数据库管理员** : 数据库管理员(Database Administrator, 简称 DBA)负责全面管理和控制数据库系统。
|
||||
|
||||
数据库系统基本构成如下图所示:
|
||||
|
||||
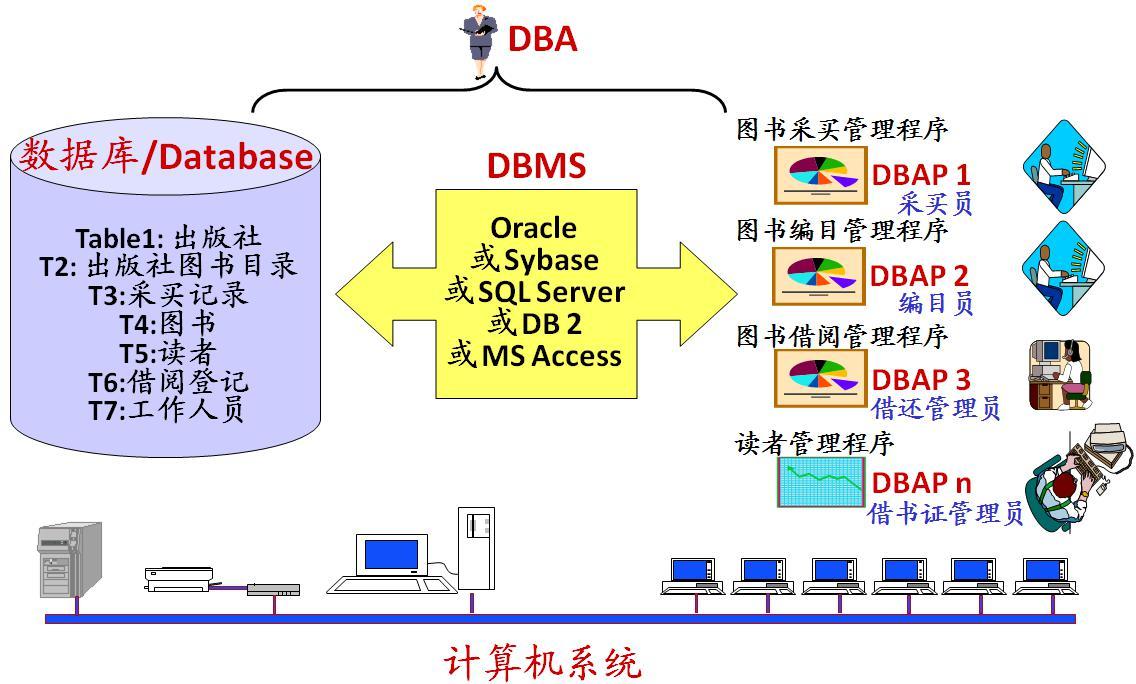
|
||||
- **数据库** : 数据库(DataBase 简称 DB)就是信息的集合或者说数据库是由数据库管理系统管理的数据的集合。
|
||||
- **数据库管理系统** : 数据库管理系统(Database Management System 简称 DBMS)是一种操纵和管理数据库的大型软件,通常用于建立、使用和维护数据库。
|
||||
- **数据库系统** : 数据库系统(Data Base System,简称 DBS)通常由软件、数据库和数据管理员(DBA)组成。
|
||||
- **数据库管理员** : 数据库管理员(Database Administrator, 简称 DBA)负责全面管理和控制数据库系统。
|
||||
|
||||
## 什么是元组, 码, 候选码, 主码, 外码, 主属性, 非主属性?
|
||||
|
||||
* **元组** : 元组(tuple)是关系数据库中的基本概念,关系是一张表,表中的每行(即数据库中的每条记录)就是一个元组,每列就是一个属性。 在二维表里,元组也称为行。
|
||||
* **码** :码就是能唯一标识实体的属性,对应表中的列。
|
||||
* **候选码** : 若关系中的某一属性或属性组的值能唯一的标识一个元组,而其任何、子集都不能再标识,则称该属性组为候选码。例如:在学生实体中,“学号”是能唯一的区分学生实体的,同时又假设“姓名”、“班级”的属性组合足以区分学生实体,那么{学号}和{姓名,班级}都是候选码。
|
||||
* **主码** : 主码也叫主键。主码是从候选码中选出来的。 一个实体集中只能有一个主码,但可以有多个候选码。
|
||||
* **外码** : 外码也叫外键。如果一个关系中的一个属性是另外一个关系中的主码则这个属性为外码。
|
||||
* **主属性** : 候选码中出现过的属性称为主属性。比如关系 工人(工号,身份证号,姓名,性别,部门). 显然工号和身份证号都能够唯一标示这个关系,所以都是候选码。工号、身份证号这两个属性就是主属性。如果主码是一个属性组,那么属性组中的属性都是主属性。
|
||||
* **非主属性:** 不包含在任何一个候选码中的属性称为非主属性。比如在关系——学生(学号,姓名,年龄,性别,班级)中,主码是“学号”,那么其他的“姓名”、“年龄”、“性别”、“班级”就都可以称为非主属性。
|
||||
- **元组** : 元组(tuple)是关系数据库中的基本概念,关系是一张表,表中的每行(即数据库中的每条记录)就是一个元组,每列就是一个属性。 在二维表里,元组也称为行。
|
||||
- **码** :码就是能唯一标识实体的属性,对应表中的列。
|
||||
- **候选码** : 若关系中的某一属性或属性组的值能唯一的标识一个元组,而其任何、子集都不能再标识,则称该属性组为候选码。例如:在学生实体中,“学号”是能唯一的区分学生实体的,同时又假设“姓名”、“班级”的属性组合足以区分学生实体,那么{学号}和{姓名,班级}都是候选码。
|
||||
- **主码** : 主码也叫主键。主码是从候选码中选出来的。 一个实体集中只能有一个主码,但可以有多个候选码。
|
||||
- **外码** : 外码也叫外键。如果一个关系中的一个属性是另外一个关系中的主码则这个属性为外码。
|
||||
- **主属性** : 候选码中出现过的属性称为主属性。比如关系 工人(工号,身份证号,姓名,性别,部门). 显然工号和身份证号都能够唯一标示这个关系,所以都是候选码。工号、身份证号这两个属性就是主属性。如果主码是一个属性组,那么属性组中的属性都是主属性。
|
||||
- **非主属性:** 不包含在任何一个候选码中的属性称为非主属性。比如在关系——学生(学号,姓名,年龄,性别,班级)中,主码是“学号”,那么其他的“姓名”、“年龄”、“性别”、“班级”就都可以称为非主属性。
|
||||
|
||||
## 什么是 ER 图?
|
||||
|
||||
我们做一个项目的时候一定要试着画 ER 图来捋清数据库设计,这个也是面试官问你项目的时候经常会被问到的。
|
||||
|
||||
**ER 图** 全称是 Entity Relationship Diagram(实体联系图),提供了表示实体类型、属性和联系的方法。
|
||||
|
||||
ER 图由下面 3 个要素组成:
|
||||
|
||||
- **实体** :通常是现实世界的业务对象,当然使用一些逻辑对象也可以。比如对于一个校园管理系统,会涉及学生、教师、课程、班级等等实体。在 ER 图中,实体使用矩形框表示。
|
||||
- **属性** :即某个实体拥有的属性,属性用来描述组成实体的要素,对于产品设计来说可以理解为字段。在 ER 图中,属性使用椭圆形表示。
|
||||
- **联系** :即实体与实体之间的关系,这个关系不仅有业务关联关系,还能通过数字表示实体之间的数量对照关系。例如,一个班级会有多个学生就是一种实体间的联系。
|
||||
|
||||
下图是一个学生选课的 ER 图,每个学生可以选若干门课程,同一门课程也可以被若干人选择,所以它们之间的关系是多对多(M: N)。另外,还有其他两种实体之间的关系是:1 对 1(1:1)、1 对多(1: N)。
|
||||
|
||||
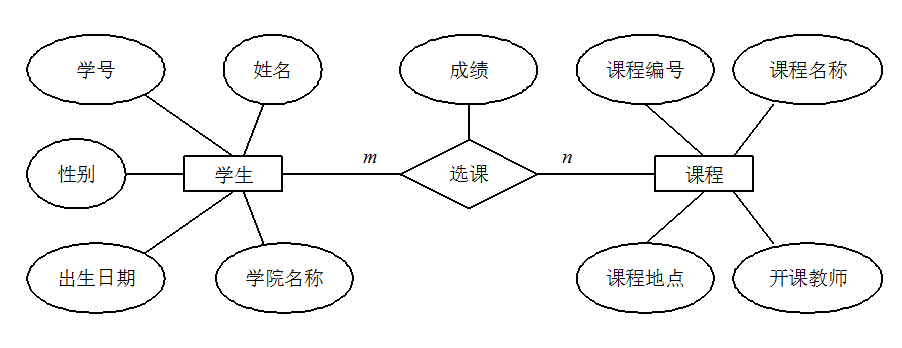
|
||||
|
||||
## 数据库范式了解吗?
|
||||
|
||||
数据库范式有 3 种:
|
||||
|
||||
- 1NF(第一范式):属性不可再分。
|
||||
- 2NF(第二范式):1NF 的基础之上,消除了非主属性对于码的部分函数依赖。
|
||||
- 3NF(第三范式):3NF 在 2NF 的基础之上,消除了非主属性对于码的传递函数依赖 。
|
||||
|
||||
### 1NF(第一范式)
|
||||
|
||||
属性(对应于表中的字段)不能再被分割,也就是这个字段只能是一个值,不能再分为多个其他的字段了。**1NF 是所有关系型数据库的最基本要求** ,也就是说关系型数据库中创建的表一定满足第一范式。
|
||||
|
||||
### 2NF(第二范式)
|
||||
|
||||
2NF 在 1NF 的基础之上,消除了非主属性对于码的部分函数依赖。如下图所示,展示了第一范式到第二范式的过渡。第二范式在第一范式的基础上增加了一个列,这个列称为主键,非主属性都依赖于主键。
|
||||
|
||||
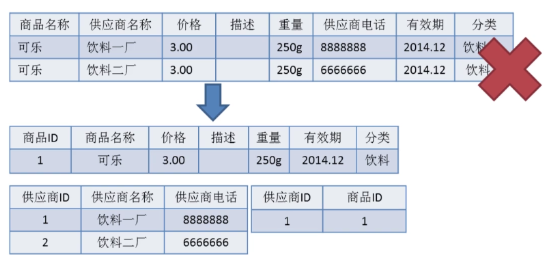
|
||||
|
||||
一些重要的概念:
|
||||
|
||||
- **函数依赖(functional dependency)** :若在一张表中,在属性(或属性组)X 的值确定的情况下,必定能确定属性 Y 的值,那么就可以说 Y 函数依赖于 X,写作 X → Y。
|
||||
- **部分函数依赖(partial functional dependency)** :如果 X→Y,并且存在 X 的一个真子集 X0,使得 X0→Y,则称 Y 对 X 部分函数依赖。比如学生基本信息表 R 中(学号,身份证号,姓名)当然学号属性取值是唯一的,在 R 关系中,(学号,身份证号)->(姓名),(学号)->(姓名),(身份证号)->(姓名);所以姓名部分函数依赖与(学号,身份证号);
|
||||
- **完全函数依赖(Full functional dependency)** :在一个关系中,若某个非主属性数据项依赖于全部关键字称之为完全函数依赖。比如学生基本信息表 R(学号,班级,姓名)假设不同的班级学号有相同的,班级内学号不能相同,在 R 关系中,(学号,班级)->(姓名),但是(学号)->(姓名)不成立,(班级)->(姓名)不成立,所以姓名完全函数依赖与(学号,班级);
|
||||
- **传递函数依赖** : 在关系模式 R(U)中,设 X,Y,Z 是 U 的不同的属性子集,如果 X 确定 Y、Y 确定 Z,且有 X 不包含 Y,Y 不确定 X,(X∪Y)∩Z=空集合,则称 Z 传递函数依赖(transitive functional dependency) 于 X。传递函数依赖会导致数据冗余和异常。传递函数依赖的 Y 和 Z 子集往往同属于某一个事物,因此可将其合并放到一个表中。比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖。。
|
||||
|
||||
### 3NF(第三范式)
|
||||
|
||||
3NF 在 2NF 的基础之上,消除了非主属性对于码的传递函数依赖 。符合 3NF 要求的数据库设计,**基本**上解决了数据冗余过大,插入异常,修改异常,删除异常的问题。比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖,所以该表的设计,不符合 3NF 的要求。
|
||||
|
||||
## 主键和外键有什么区别?
|
||||
|
||||
* **主键(主码)** :主键用于唯一标识一个元组,不能有重复,不允许为空。一个表只能有一个主键。
|
||||
* **外键(外码)** :外键用来和其他表建立联系用,外键是另一表的主键,外键是可以有重复的,可以是空值。一个表可以有多个外键。
|
||||
- **主键(主码)** :主键用于唯一标识一个元组,不能有重复,不允许为空。一个表只能有一个主键。
|
||||
- **外键(外码)** :外键用来和其他表建立联系用,外键是另一表的主键,外键是可以有重复的,可以是空值。一个表可以有多个外键。
|
||||
|
||||
## 为什么不推荐使用外键与级联?
|
||||
|
||||
@ -43,10 +84,10 @@ tag:
|
||||
|
||||
为什么不要用外键呢?大部分人可能会这样回答:
|
||||
|
||||
> 1. **增加了复杂性:** a. 每次做DELETE 或者UPDATE都必须考虑外键约束,会导致开发的时候很痛苦, 测试数据极为不方便; b. 外键的主从关系是定的,假如那天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
|
||||
> 2. **增加了额外工作**: 数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗资源;(个人觉得这个不是不用外键的原因,因为即使你不使用外键,你在应用层面也还是要保证的。所以,我觉得这个影响可以忽略不计。)
|
||||
> 4. **对分库分表不友好** :因为分库分表下外键是无法生效的。
|
||||
> 5. ......
|
||||
1. **增加了复杂性:** a. 每次做 DELETE 或者 UPDATE 都必须考虑外键约束,会导致开发的时候很痛苦, 测试数据极为不方便; b. 外键的主从关系是定的,假如那天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
|
||||
2. **增加了额外工作**: 数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗资源;(个人觉得这个不是不用外键的原因,因为即使你不使用外键,你在应用层面也还是要保证的。所以,我觉得这个影响可以忽略不计。)
|
||||
3. **对分库分表不友好** :因为分库分表下外键是无法生效的。
|
||||
4. ......
|
||||
|
||||
我个人觉得上面这种回答不是特别的全面,只是说了外键存在的一个常见的问题。实际上,我们知道外键也是有很多好处的,比如:
|
||||
|
||||
@ -56,50 +97,6 @@ tag:
|
||||
|
||||
所以说,不要一股脑的就抛弃了外键这个概念,既然它存在就有它存在的道理,如果系统不涉及分库分表,并发量不是很高的情况还是可以考虑使用外键的。
|
||||
|
||||
|
||||
## 什么是 ER 图?
|
||||
|
||||
> 我们做一个项目的时候一定要试着画 ER 图来捋清数据库设计,这个也是面试官问你项目的时候经常会被问道的。
|
||||
|
||||
**E-R 图** 也称实体-联系图(Entity Relationship Diagram),提供了表示实体类型、属性和联系的方法,用来描述现实世界的概念模型。 它是描述现实世界关系概念模型的有效方法。 是表示概念关系模型的一种方式。
|
||||
|
||||
下图是一个学生选课的 ER 图,每个学生可以选若干门课程,同一门课程也可以被若干人选择,所以它们之间的关系是多对多(M: N)。另外,还有其他两种关系是:1 对 1(1:1)、1 对多(1: N)。
|
||||
|
||||
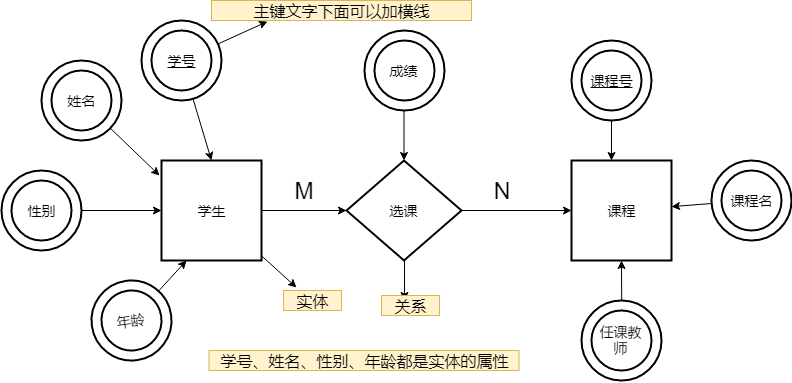
|
||||
|
||||
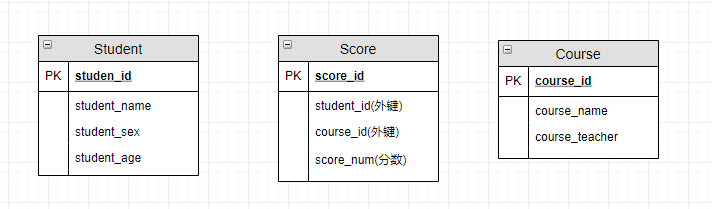
我们试着将上面的 ER 图转换成数据库实际的关系模型(实际设计中,我们通常会将任课教师也作为一个实体来处理):
|
||||
|
||||
|
||||
|
||||
## 数据库范式了解吗?
|
||||
|
||||
**1NF(第一范式)**
|
||||
|
||||
属性(对应于表中的字段)不能再被分割,也就是这个字段只能是一个值,不能再分为多个其他的字段了。**1NF 是所有关系型数据库的最基本要求** ,也就是说关系型数据库中创建的表一定满足第一范式。
|
||||
|
||||
**2NF(第二范式)**
|
||||
|
||||
2NF 在 1NF 的基础之上,消除了非主属性对于码的部分函数依赖。如下图所示,展示了第一范式到第二范式的过渡。第二范式在第一范式的基础上增加了一个列,这个列称为主键,非主属性都依赖于主键。
|
||||
|
||||

|
||||
|
||||
一些重要的概念:
|
||||
|
||||
* **函数依赖(functional dependency)** :若在一张表中,在属性(或属性组)X 的值确定的情况下,必定能确定属性 Y 的值,那么就可以说 Y 函数依赖于 X,写作 X → Y。
|
||||
* **部分函数依赖(partial functional dependency)** :如果 X→Y,并且存在 X 的一个真子集 X0,使得 X0→Y,则称 Y 对 X 部分函数依赖。比如学生基本信息表 R 中(学号,身份证号,姓名)当然学号属性取值是唯一的,在 R 关系中,(学号,身份证号)->(姓名),(学号)->(姓名),(身份证号)->(姓名);所以姓名部分函数依赖与(学号,身份证号);
|
||||
* **完全函数依赖(Full functional dependency)** :在一个关系中,若某个非主属性数据项依赖于全部关键字称之为完全函数依赖。比如学生基本信息表 R(学号,班级,姓名)假设不同的班级学号有相同的,班级内学号不能相同,在 R 关系中,(学号,班级)->(姓名),但是(学号)->(姓名)不成立,(班级)->(姓名)不成立,所以姓名完全函数依赖与(学号,班级);
|
||||
* **传递函数依赖** : 在关系模式 R(U)中,设 X,Y,Z 是 U 的不同的属性子集,如果 X 确定 Y、Y 确定 Z,且有 X 不包含 Y,Y 不确定 X,(X∪Y)∩Z=空集合,则称 Z 传递函数依赖(transitive functional dependency) 于 X。传递函数依赖会导致数据冗余和异常。传递函数依赖的 Y 和 Z 子集往往同属于某一个事物,因此可将其合并放到一个表中。比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖。。
|
||||
|
||||
**3NF(第三范式)**
|
||||
|
||||
3NF 在 2NF 的基础之上,消除了非主属性对于码的传递函数依赖 。符合 3NF 要求的数据库设计,**基本**上解决了数据冗余过大,插入异常,修改异常,删除异常的问题。比如在关系 R(学号 , 姓名, 系名,系主任)中,学号 → 系名,系名 → 系主任,所以存在非主属性系主任对于学号的传递函数依赖,所以该表的设计,不符合 3NF 的要求。
|
||||
|
||||
**总结**
|
||||
|
||||
* 1NF:属性不可再分。
|
||||
* 2NF:1NF 的基础之上,消除了非主属性对于码的部分函数依赖。
|
||||
* 3NF:3NF 在 2NF 的基础之上,消除了非主属性对于码的传递函数依赖 。
|
||||
|
||||
## 什么是存储过程?
|
||||
|
||||
我们可以把存储过程看成是一些 SQL 语句的集合,中间加了点逻辑控制语句。存储过程在业务比较复杂的时候是非常实用的,比如很多时候我们完成一个操作可能需要写一大串 SQL 语句,这时候我们就可以写有一个存储过程,这样也方便了我们下一次的调用。存储过程一旦调试完成通过后就能稳定运行,另外,使用存储过程比单纯 SQL 语句执行要快,因为存储过程是预编译过的。
|
||||
@ -114,33 +111,32 @@ tag:
|
||||
|
||||
### 用法不同
|
||||
|
||||
* drop(丢弃数据): `drop table 表名` ,直接将表都删除掉,在删除表的时候使用。
|
||||
* truncate (清空数据) : `truncate table 表名` ,只删除表中的数据,再插入数据的时候自增长 id 又从 1 开始,在清空表中数据的时候使用。
|
||||
* delete(删除数据) : `delete from 表名 where 列名=值`,删除某一行的数据,如果不加 where 子句和`truncate table 表名`作用类似。
|
||||
- `drop`(丢弃数据): `drop table 表名` ,直接将表都删除掉,在删除表的时候使用。
|
||||
- `truncate` (清空数据) : `truncate table 表名` ,只删除表中的数据,再插入数据的时候自增长 id 又从 1 开始,在清空表中数据的时候使用。
|
||||
- `delete`(删除数据) : `delete from 表名 where 列名=值`,删除某一行的数据,如果不加 `where` 子句和`truncate table 表名`作用类似。
|
||||
|
||||
truncate 和不带 where 子句的 delete、以及 drop 都会删除表内的数据,但是 **truncate 和 delete 只删除数据不删除表的结构(定义),执行 drop 语句,此表的结构也会删除,也就是执行 drop 之后对应的表不复存在。**
|
||||
`truncate` 和不带 where``子句的 `delete`、以及 `drop` 都会删除表内的数据,但是 **`truncate` 和 `delete` 只删除数据不删除表的结构(定义),执行 `drop` 语句,此表的结构也会删除,也就是执行 `drop` 之后对应的表不复存在。**
|
||||
|
||||
### 属于不同的数据库语言
|
||||
|
||||
truncate 和 drop 属于 DDL(数据定义语言)语句,操作立即生效,原数据不放到 rollback segment 中,不能回滚,操作不触发 trigger。而 delete 语句是 DML (数据库操作语言)语句,这个操作会放到 rollback segement 中,事务提交之后才生效。
|
||||
`truncate` 和 `drop` 属于 DDL(数据定义语言)语句,操作立即生效,原数据不放到 rollback segment 中,不能回滚,操作不触发 trigger。而 `delete` 语句是 DML (数据库操作语言)语句,这个操作会放到 rollback segement 中,事务提交之后才生效。
|
||||
|
||||
**DML 语句和 DDL 语句区别:**
|
||||
|
||||
* DML 是数据库操作语言(Data Manipulation Language)的缩写,是指对数据库中表记录的操作,主要包括表记录的插入(insert)、更新(update)、删除(delete)和查询(select),是开发人员日常使用最频繁的操作。
|
||||
* DDL (Data Definition Language)是数据定义语言的缩写,简单来说,就是对数据库内部的对象进行创建、删除、修改的操作语言。它和 DML 语言的最大区别是 DML 只是对表内部数据的操作,而不涉及到表的定义、结构的修改,更不会涉及到其他对象。DDL 语句更多的被数据库管理员(DBA)所使用,一般的开发人员很少使用。
|
||||
- DML 是数据库操作语言(Data Manipulation Language)的缩写,是指对数据库中表记录的操作,主要包括表记录的插入、更新、删除和查询,是开发人员日常使用最频繁的操作。
|
||||
- DDL (Data Definition Language)是数据定义语言的缩写,简单来说,就是对数据库内部的对象进行创建、删除、修改的操作语言。它和 DML 语言的最大区别是 DML 只是对表内部数据的操作,而不涉及到表的定义、结构的修改,更不会涉及到其他对象。DDL 语句更多的被数据库管理员(DBA)所使用,一般的开发人员很少使用。
|
||||
|
||||
> 由于`select`不会对表进行破坏,所以有的地方也会把`select`单独区分开叫做数据库查询语言DQL(Data Query Language)
|
||||
另外,由于`select`不会对表进行破坏,所以有的地方也会把`select`单独区分开叫做数据库查询语言 DQL(Data Query Language)。
|
||||
|
||||
### 执行速度不同
|
||||
|
||||
一般来说:drop > truncate > delete(这个我没有设计测试过)。
|
||||
> `delete`命令执行的时候会产生数据库的`binlog`日志,而日志记录是需要消耗时间的,但是也有个好处方便数据回滚恢复。
|
||||
>
|
||||
> `truncate`命令执行的时候不会产生数据库日志,因此比`delete`要快。除此之外,还会把表的自增值重置和索引恢复到初始大小等。
|
||||
>
|
||||
> `drop`命令会把表占用的空间全部释放掉。
|
||||
>
|
||||
> Tips:你应该更多地关注在使用场景上,而不是执行效率。
|
||||
一般来说:`drop` > `truncate` > `delete`(这个我没有设计测试过)。
|
||||
|
||||
- `delete`命令执行的时候会产生数据库的`binlog`日志,而日志记录是需要消耗时间的,但是也有个好处方便数据回滚恢复。
|
||||
- `truncate`命令执行的时候不会产生数据库日志,因此比`delete`要快。除此之外,还会把表的自增值重置和索引恢复到初始大小等。
|
||||
- `drop`命令会把表占用的空间全部释放掉。
|
||||
|
||||
Tips:你应该更多地关注在使用场景上,而不是执行效率。
|
||||
|
||||
## 数据库设计通常分为哪几步?
|
||||
|
||||
@ -153,6 +149,6 @@ truncate 和 drop 属于 DDL(数据定义语言)语句,操作立即生效,
|
||||
|
||||
## 参考
|
||||
|
||||
* <https://blog.csdn.net/rl529014/article/details/48391465>
|
||||
* <https://www.zhihu.com/question/24696366/answer/29189700>
|
||||
* <https://blog.csdn.net/bieleyang/article/details/77149954>
|
||||
- <https://blog.csdn.net/rl529014/article/details/48391465>
|
||||
- <https://www.zhihu.com/question/24696366/answer/29189700>
|
||||
- <https://blog.csdn.net/bieleyang/article/details/77149954>
|
||||
|
||||
@ -0,0 +1,219 @@
|
||||
---
|
||||
title: MySQL自增主键一定是连续的吗
|
||||
category: 数据库
|
||||
tag:
|
||||
- MySQL
|
||||
- 大厂面试
|
||||
---
|
||||
|
||||
> 作者:飞天小牛肉
|
||||
>
|
||||
> 原文:https://mp.weixin.qq.com/s/qci10h9rJx_COZbHV3aygQ
|
||||
|
||||
众所周知,自增主键可以让聚集索引尽量地保持递增顺序插入,避免了随机查询,从而提高了查询效率。
|
||||
|
||||
但实际上,MySQL 的自增主键并不能保证一定是连续递增的。
|
||||
|
||||
下面举个例子来看下,如下所示创建一张表:
|
||||
|
||||

|
||||
|
||||
## 自增值保存在哪里?
|
||||
|
||||
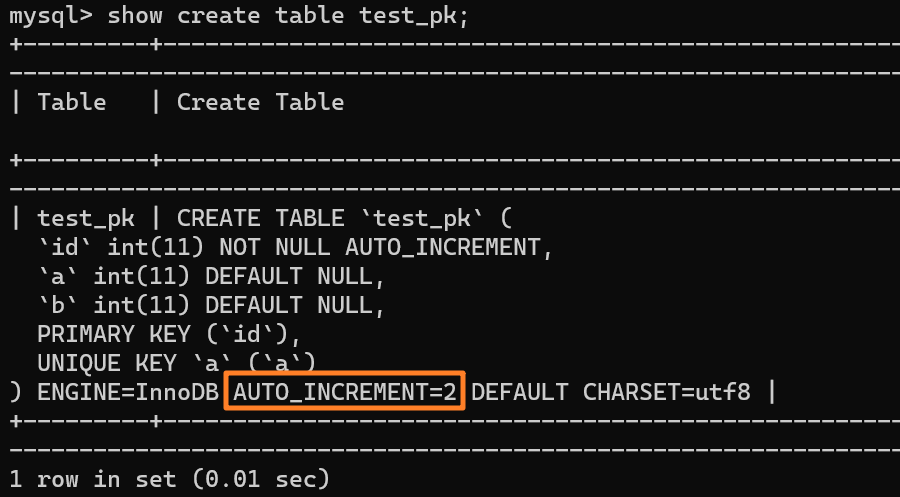
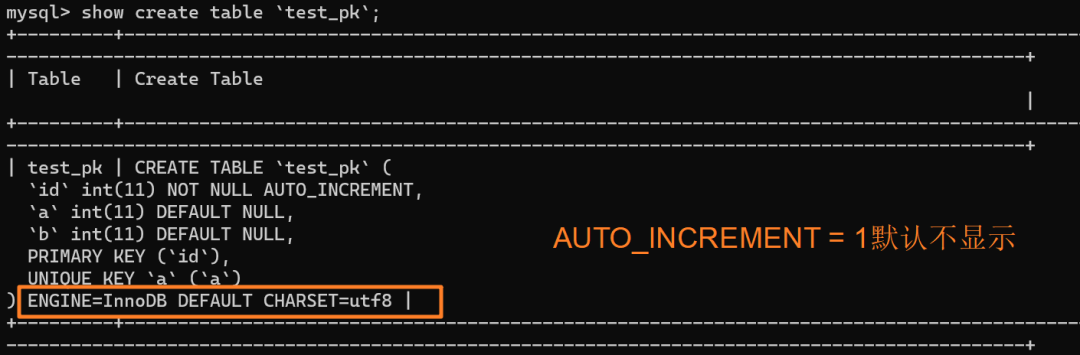
使用 `insert into test_pk values(null, 1, 1)` 插入一行数据,再执行 `show create table` 命令来看一下表的结构定义:
|
||||
|
||||
|
||||
|
||||
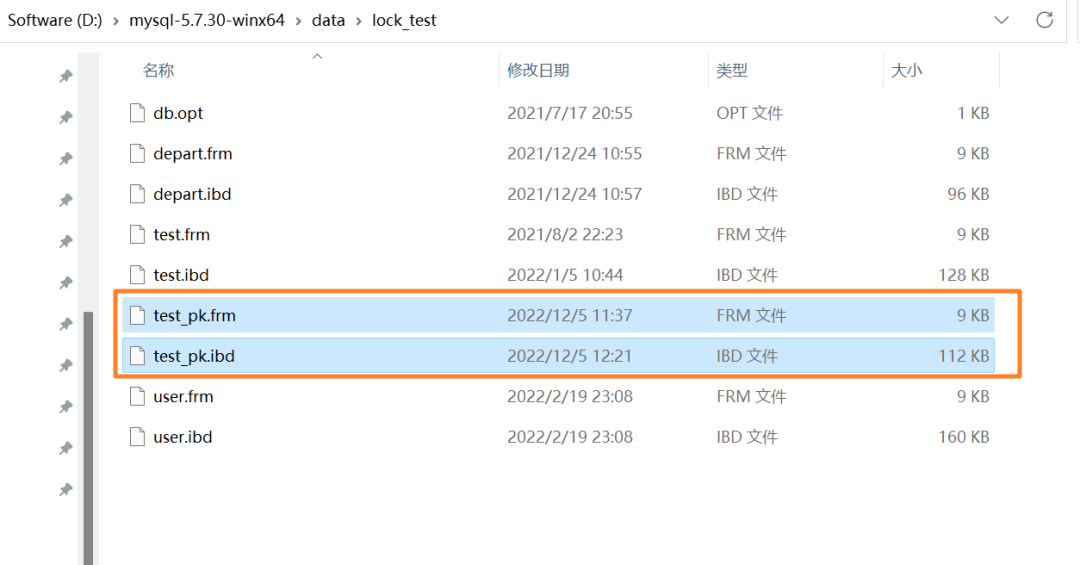
上述表的结构定义存放在后缀名为 `.frm` 的本地文件中,在 MySQL 安装目录下的 data 文件夹下可以找到这个 `.frm` 文件:
|
||||
|
||||
|
||||
|
||||
从上述表结构可以看到,表定义里面出现了一个 `AUTO_INCREMENT=2`,表示下一次插入数据时,如果需要自动生成自增值,会生成 id = 2。
|
||||
|
||||
但需要注意的是,自增值并不会保存在这个表结构也就是 `.frm` 文件中,不同的引擎对于自增值的保存策略不同:
|
||||
|
||||
1)MyISAM 引擎的自增值保存在数据文件中
|
||||
|
||||
2)InnoDB 引擎的自增值,其实是保存在了内存里,并没有持久化。第一次打开表的时候,都会去找自增值的最大值 `max(id)`,然后将 `max(id)+1` 作为这个表当前的自增值。
|
||||
|
||||
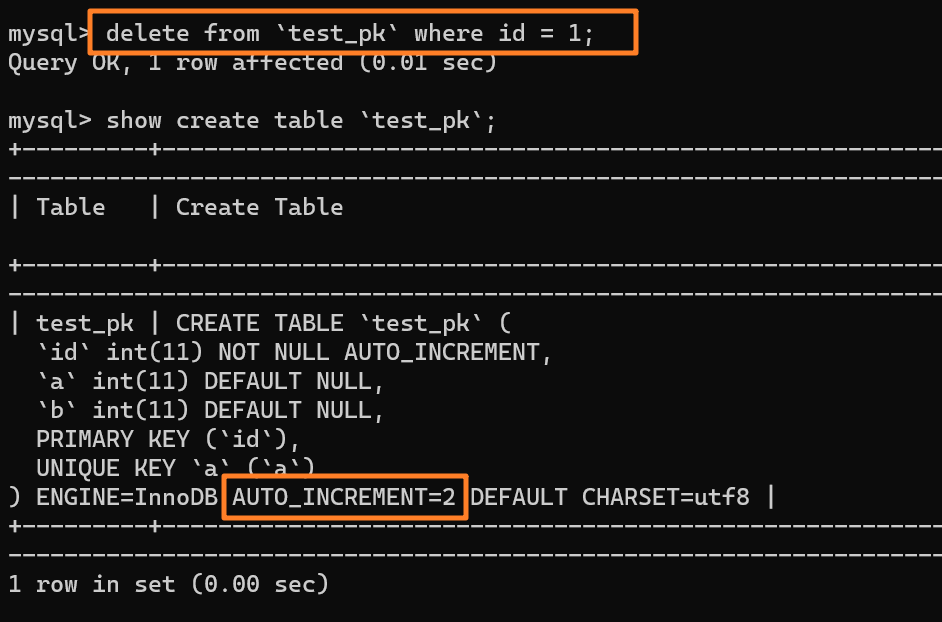
举个例子:我们现在表里当前数据行里最大的 id 是 1,AUTO_INCREMENT=2,对吧。这时候,我们删除 id=1 的行,AUTO_INCREMENT 还是 2。
|
||||
|
||||
|
||||
|
||||
但如果马上重启 MySQL 实例,重启后这个表的 AUTO_INCREMENT 就会变成 1。也就是说,MySQL 重启可能会修改一个表的 AUTO_INCREMENT 的值。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
以上,是在我本地 MySQL 5.x 版本的实验,实际上,**到了 MySQL 8.0 版本后,自增值的变更记录被放在了 redo log 中,提供了自增值持久化的能力** ,也就是实现了“如果发生重启,表的自增值可以根据 redo log 恢复为 MySQL 重启前的值”
|
||||
|
||||
也就是说对于上面这个例子来说,重启实例后这个表的 AUTO_INCREMENT 仍然是 2。
|
||||
|
||||
理解了 MySQL 自增值到底保存在哪里以后,我们再来看看自增值的修改机制,并以此引出第一种自增值不连续的场景。
|
||||
|
||||
## 自增值不连续的场景
|
||||
|
||||
### 自增值不连续场景 1
|
||||
|
||||
在 MySQL 里面,如果字段 id 被定义为 AUTO_INCREMENT,在插入一行数据的时候,自增值的行为如下:
|
||||
|
||||
- 如果插入数据时 id 字段指定为 0、null 或未指定值,那么就把这个表当前的 AUTO_INCREMENT 值填到自增字段;
|
||||
- 如果插入数据时 id 字段指定了具体的值,就直接使用语句里指定的值。
|
||||
|
||||
根据要插入的值和当前自增值的大小关系,自增值的变更结果也会有所不同。假设某次要插入的值是 `insert_num`,当前的自增值是 `autoIncrement_num`:
|
||||
|
||||
- 如果 `insert_num < autoIncrement_num`,那么这个表的自增值不变
|
||||
- 如果 `insert_num >= autoIncrement_num`,就需要把当前自增值修改为新的自增值
|
||||
|
||||
也就是说,如果插入的 id 是 100,当前的自增值是 90,`insert_num >= autoIncrement_num`,那么自增值就会被修改为新的自增值即 101
|
||||
|
||||
一定是这样吗?
|
||||
|
||||
非也~
|
||||
|
||||
了解过分布式 id 的小伙伴一定知道,为了避免两个库生成的主键发生冲突,我们可以让一个库的自增 id 都是奇数,另一个库的自增 id 都是偶数
|
||||
|
||||
这个奇数偶数其实是通过 `auto_increment_offset` 和 `auto_increment_increment` 这两个参数来决定的,这俩分别用来表示自增的初始值和步长,默认值都是 1。
|
||||
|
||||
所以,上面的例子中生成新的自增值的步骤实际是这样的:从 `auto_increment_offset` 开始,以 `auto_increment_increment` 为步长,持续叠加,直到找到第一个大于 100 的值,作为新的自增值。
|
||||
|
||||
所以,这种情况下,自增值可能会是 102,103 等等之类的,就会导致不连续的主键 id。
|
||||
|
||||
更遗憾的是,即使在自增初始值和步长这两个参数都设置为 1 的时候,自增主键 id 也不一定能保证主键是连续的
|
||||
|
||||
### 自增值不连续场景 2
|
||||
|
||||
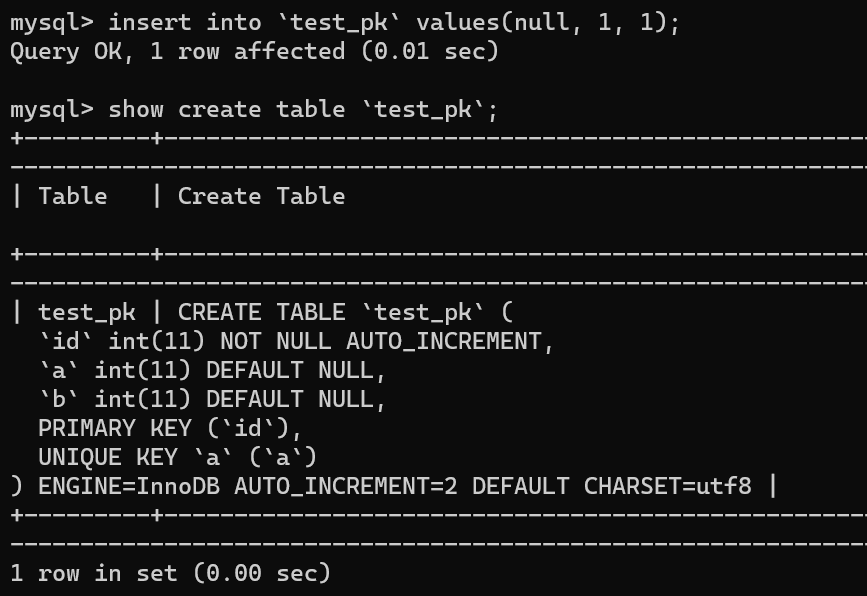
举个例子,我们现在往表里插入一条 (null,1,1) 的记录,生成的主键是 1,AUTO_INCREMENT= 2,对吧
|
||||
|
||||
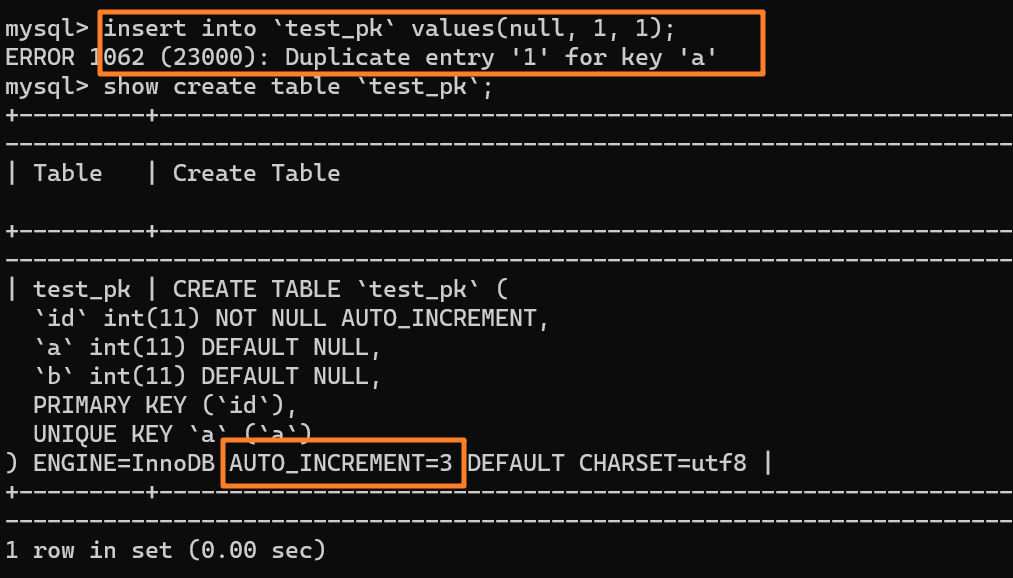
|
||||
|
||||
这时我再执行一条插入 `(null,1,1)` 的命令,很显然会报错 `Duplicate entry`,因为我们设置了一个唯一索引字段 `a`:
|
||||
|
||||
|
||||
|
||||
但是,你会惊奇的发现,虽然插入失败了,但自增值仍然从 2 增加到了 3!
|
||||
|
||||
这是为啥?
|
||||
|
||||
我们来分析下这个 insert 语句的执行流程:
|
||||
|
||||
1. 执行器调用 InnoDB 引擎接口准备插入一行记录 (null,1,1);
|
||||
2. InnoDB 发现用户没有指定自增 id 的值,则获取表 `test_pk` 当前的自增值 2;
|
||||
3. 将传入的记录改成 (2,1,1);
|
||||
4. 将表的自增值改成 3;
|
||||
5. 继续执行插入数据操作,由于已经存在 a=1 的记录,所以报 Duplicate key error,语句返回
|
||||
|
||||
可以看到,自增值修改的这个操作,是在真正执行插入数据的操作之前。
|
||||
|
||||
这个语句真正执行的时候,因为碰到唯一键 a 冲突,所以 id = 2 这一行并没有插入成功,但也没有将自增值再改回去。所以,在这之后,再插入新的数据行时,拿到的自增 id 就是 3。也就是说,出现了自增主键不连续的情况。
|
||||
|
||||
至此,我们已经罗列了两种自增主键不连续的情况:
|
||||
|
||||
1. 自增初始值和自增步长设置不为 1
|
||||
2. 唯一键冲突
|
||||
|
||||
除此之外,事务回滚也会导致这种情况
|
||||
|
||||
### 自增值不连续场景 3
|
||||
|
||||
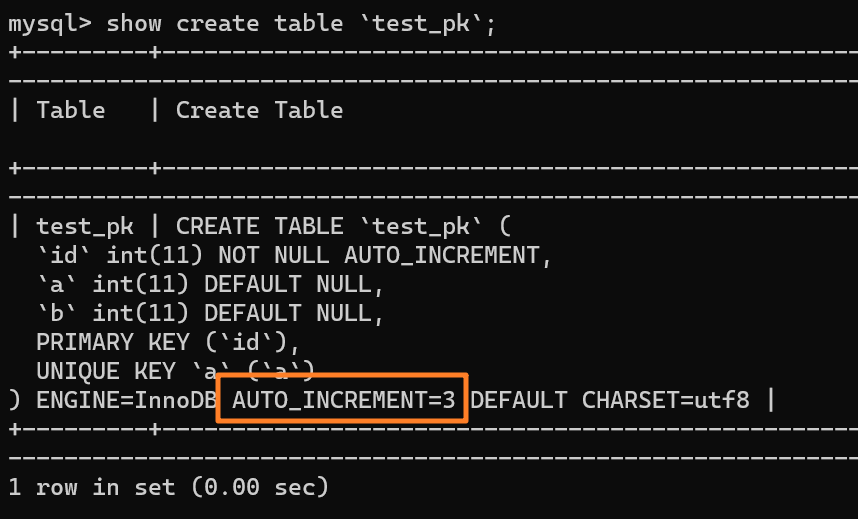
我们现在表里有一行 `(1,1,1)` 的记录,AUTO_INCREMENT = 3:
|
||||
|
||||
|
||||
|
||||
我们先插入一行数据 `(null, 2, 2)`,也就是 (3, 2, 2) 嘛,并且 AUTO_INCREMENT 变为 4:
|
||||
|
||||
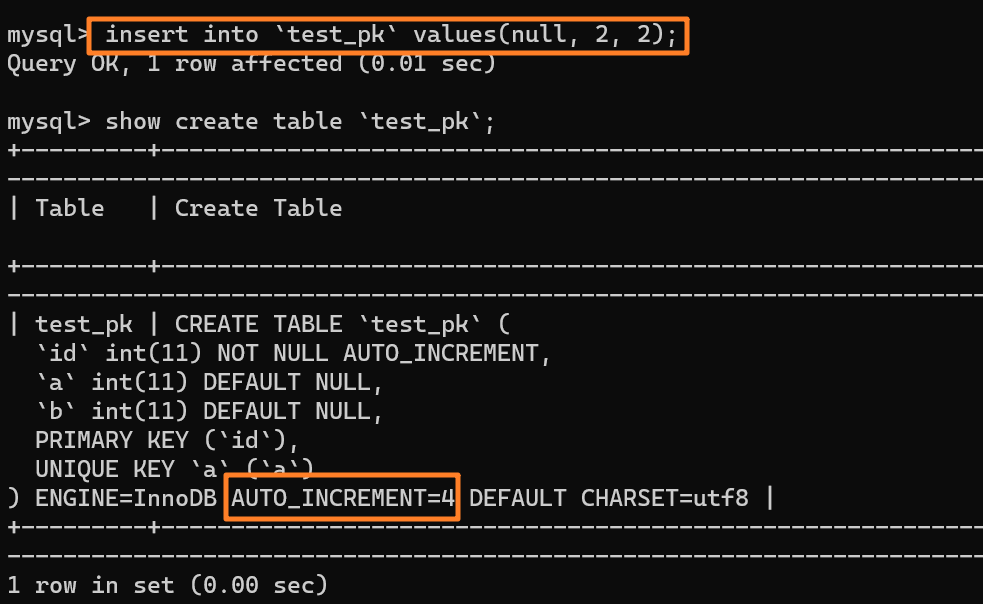
|
||||
|
||||
再去执行这样一段 SQL:
|
||||
|
||||
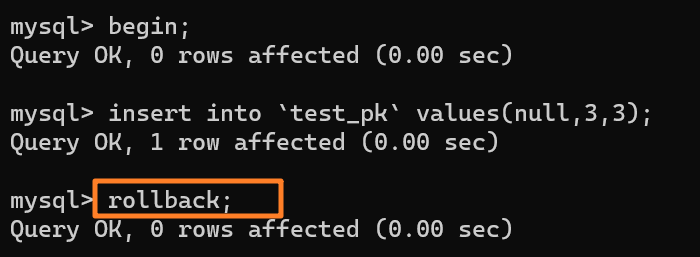
|
||||
|
||||
虽然我们插入了一条 (null, 3, 3) 记录,但是使用 rollback 进行回滚了,所以数据库中是没有这条记录的:
|
||||
|
||||
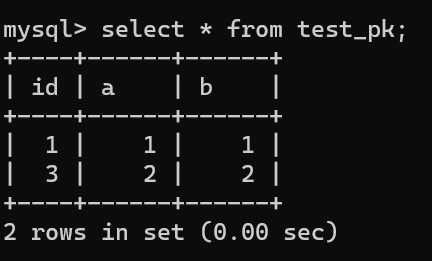
|
||||
|
||||
在这种事务回滚的情况下,自增值并没有同样发生回滚!如下图所示,自增值仍然固执地从 4 增加到了 5:
|
||||
|
||||
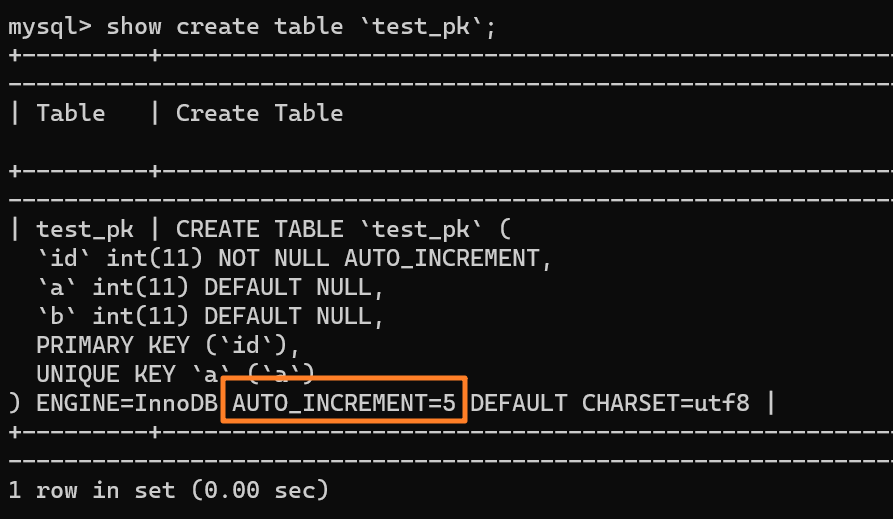
|
||||
|
||||
所以这时候我们再去插入一条数据(null, 3, 3)的时候,主键 id 就会被自动赋为 `5` 了:
|
||||
|
||||
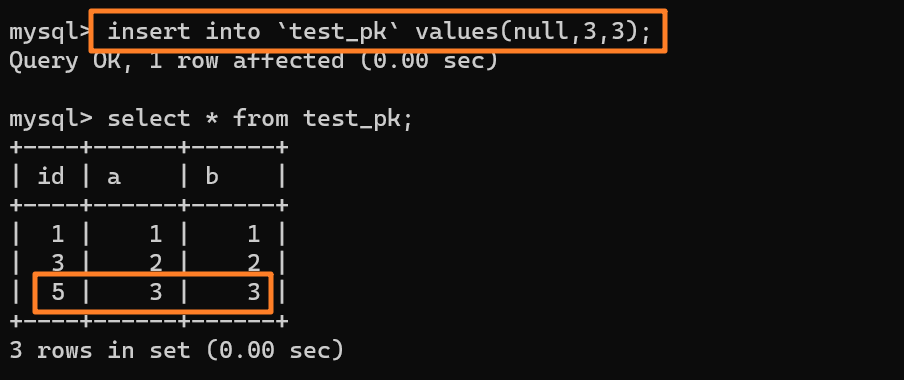
|
||||
|
||||
那么,为什么在出现唯一键冲突或者回滚的时候,MySQL 没有把表的自增值改回去呢?回退回去的话不就不会发生自增 id 不连续了吗?
|
||||
|
||||
事实上,这么做的主要原因是为了提高性能。
|
||||
|
||||
我们直接用反证法来验证:假设 MySQL 在事务回滚的时候会把自增值改回去,会发生什么?
|
||||
|
||||
现在有两个并行执行的事务 A 和 B,在申请自增值的时候,为了避免两个事务申请到相同的自增 id,肯定要加锁,然后顺序申请,对吧。
|
||||
|
||||
1. 假设事务 A 申请到了 id = 1, 事务 B 申请到 id=2,那么这时候表 t 的自增值是3,之后继续执行。
|
||||
2. 事务 B 正确提交了,但事务 A 出现了唯一键冲突,也就是 id = 1 的那行记录插入失败了,那如果允许事务 A 把自增 id 回退,也就是把表的当前自增值改回 1,那么就会出现这样的情况:表里面已经有 id = 2 的行,而当前的自增 id 值是 1。
|
||||
3. 接下来,继续执行的其他事务就会申请到 id=2。这时,就会出现插入语句报错“主键冲突”。
|
||||
|
||||
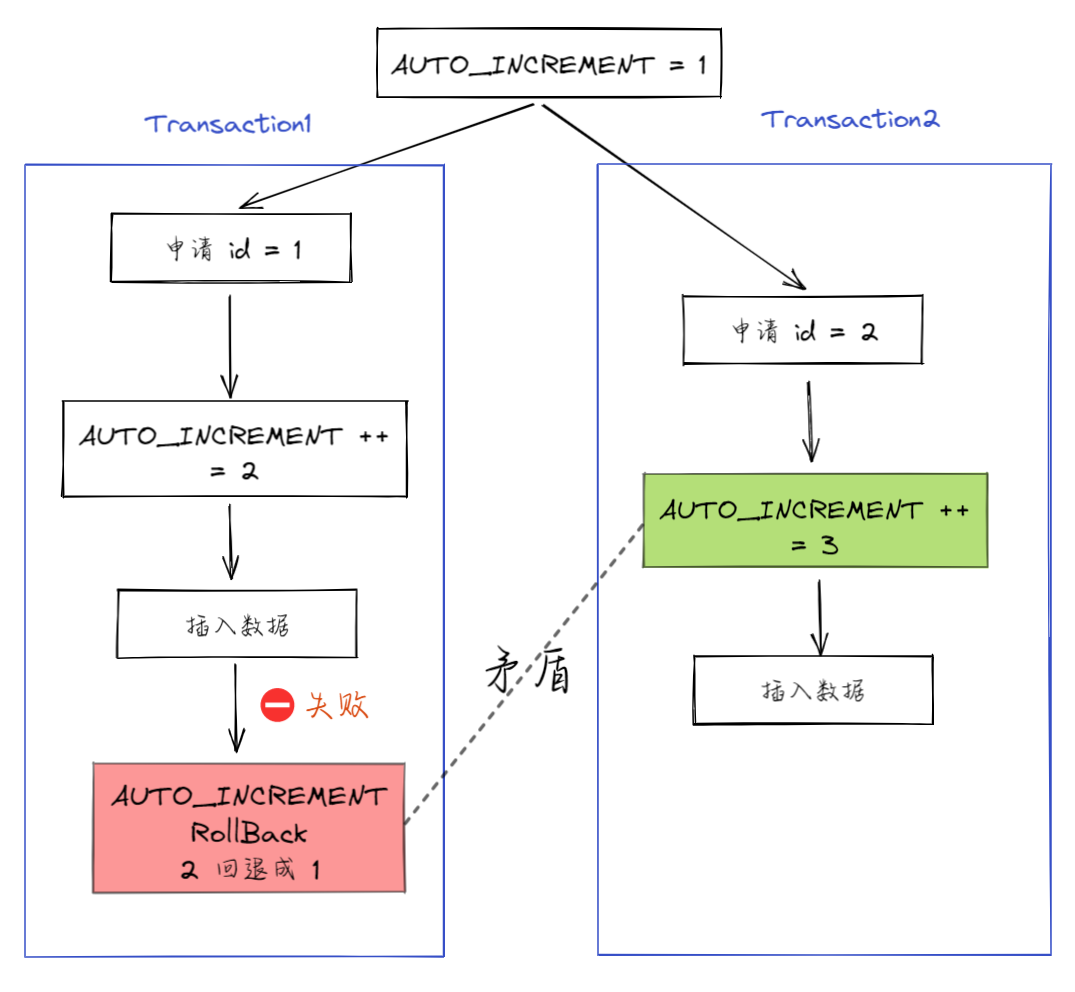
|
||||
|
||||
而为了解决这个主键冲突,有两种方法:
|
||||
|
||||
1. 每次申请 id 之前,先判断表里面是否已经存在这个 id,如果存在,就跳过这个 id
|
||||
2. 把自增 id 的锁范围扩大,必须等到一个事务执行完成并提交,下一个事务才能再申请自增 id
|
||||
|
||||
很显然,上述两个方法的成本都比较高,会导致性能问题。而究其原因呢,是我们假设的这个 “允许自增 id 回退”。
|
||||
|
||||
因此,InnoDB 放弃了这个设计,语句执行失败也不回退自增 id。也正是因为这样,所以才只保证了自增 id 是递增的,但不保证是连续的。
|
||||
|
||||
综上,已经分析了三种自增值不连续的场景,还有第四种场景:批量插入数据。
|
||||
|
||||
### 自增值不连续场景 4
|
||||
|
||||
对于批量插入数据的语句,MySQL 有一个批量申请自增 id 的策略:
|
||||
|
||||
1. 语句执行过程中,第一次申请自增 id,会分配 1 个;
|
||||
2. 1 个用完以后,这个语句第二次申请自增 id,会分配 2 个;
|
||||
3. 2 个用完以后,还是这个语句,第三次申请自增 id,会分配 4 个;
|
||||
4. 依此类推,同一个语句去申请自增 id,每次申请到的自增 id 个数都是上一次的两倍。
|
||||
|
||||
注意,这里说的批量插入数据,不是在普通的 insert 语句里面包含多个 value 值!!!,因为这类语句在申请自增 id 的时候,是可以精确计算出需要多少个 id 的,然后一次性申请,申请完成后锁就可以释放了。
|
||||
|
||||
而对于 `insert … select`、replace … select 和 load data 这种类型的语句来说,MySQL 并不知道到底需要申请多少 id,所以就采用了这种批量申请的策略,毕竟一个一个申请的话实在太慢了。
|
||||
|
||||
举个例子,假设我们现在这个表有下面这些数据:
|
||||
|
||||
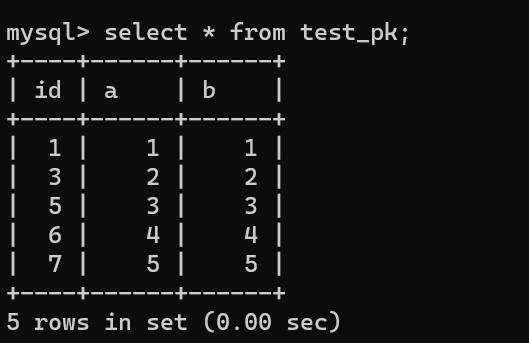
|
||||
|
||||
我们创建一个和当前表 `test_pk` 有相同结构定义的表 `test_pk2`:
|
||||
|
||||
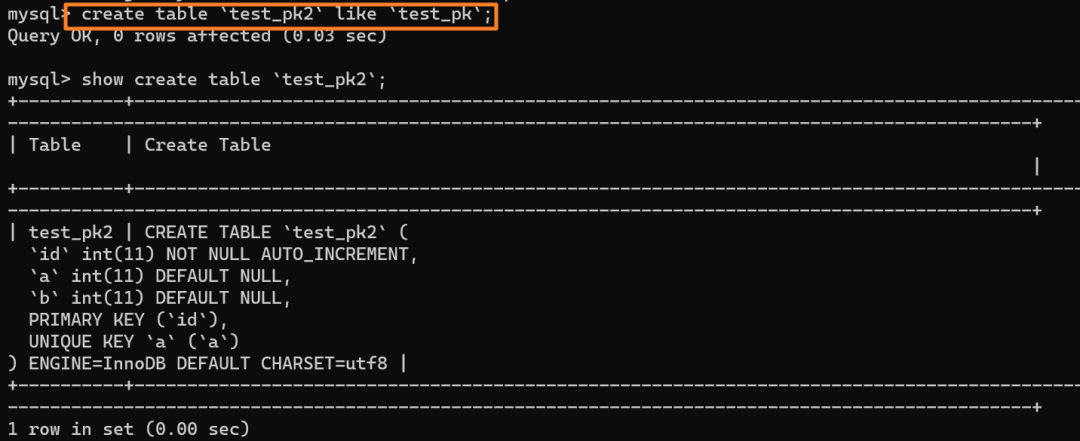
|
||||
|
||||
然后使用 `insert...select` 往 `teset_pk2` 表中批量插入数据:
|
||||
|
||||

|
||||
|
||||
可以看到,成功导入了数据。
|
||||
|
||||
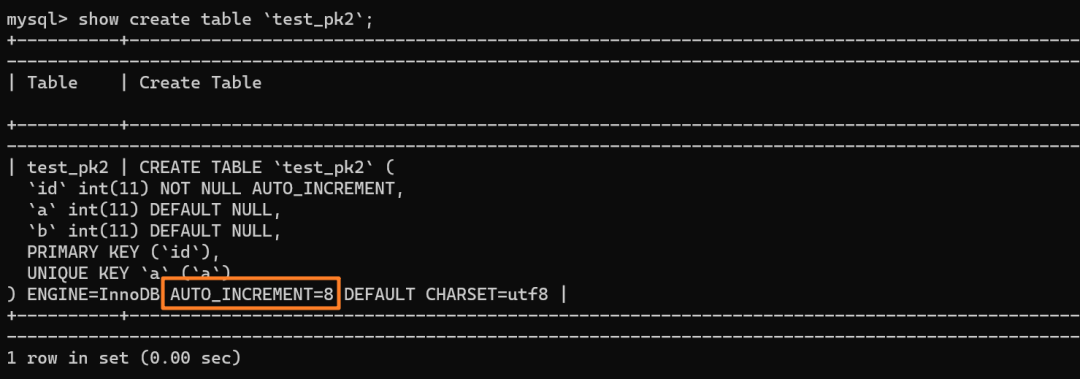
再来看下 `test_pk2` 的自增值是多少:
|
||||
|
||||
|
||||
|
||||
如上分析,是 8 而不是 6
|
||||
|
||||
具体来说,insert…select 实际上往表中插入了 5 行数据 (1 1)(2 2)(3 3)(4 4)(5 5)。但是,这五行数据是分三次申请的自增 id,结合批量申请策略,每次申请到的自增 id 个数都是上一次的两倍,所以:
|
||||
|
||||
- 第一次申请到了一个 id:id=1
|
||||
- 第二次被分配了两个 id:id=2 和 id=3
|
||||
- 第三次被分配到了 4 个 id:id=4、id = 5、id = 6、id=7
|
||||
|
||||
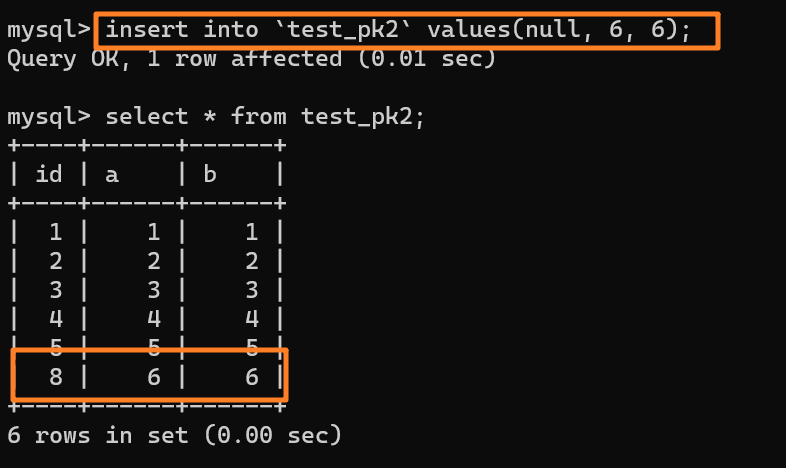
由于这条语句实际只用上了 5 个 id,所以 id=6 和 id=7 就被浪费掉了。之后,再执行 `insert into test_pk2 values(null,6,6)`,实际上插入的数据就是(8,6,6):
|
||||
|
||||
|
||||
|
||||
## 小结
|
||||
|
||||
本文总结下自增值不连续的 4 个场景:
|
||||
|
||||
1. 自增初始值和自增步长设置不为 1
|
||||
2. 唯一键冲突
|
||||
3. 事务回滚
|
||||
4. 批量插入(如 `insert...select` 语句)
|
||||
@ -17,7 +17,7 @@ head:
|
||||
|
||||
### 什么是关系型数据库?
|
||||
|
||||
顾名思义,关系型数据库就是一种建立在关系模型的基础上的数据库。关系模型表明了数据库中所存储的数据之间的联系(一对一、一对多、多对多)。
|
||||
顾名思义,关系型数据库(RDBMS,Relational Database Management System)就是一种建立在关系模型的基础上的数据库。关系模型表明了数据库中所存储的数据之间的联系(一对一、一对多、多对多)。
|
||||
|
||||
关系型数据库中,我们的数据都被存放在了各种表中(比如用户表),表中的每一行就存放着一条数据(比如一个用户的信息)。
|
||||
|
||||
@ -29,6 +29,22 @@ head:
|
||||
|
||||
MySQL、PostgreSQL、Oracle、SQL Server、SQLite(微信本地的聊天记录的存储就是用的 SQLite) ......。
|
||||
|
||||
### 什么是 SQL?
|
||||
|
||||
SQL 是一种结构化查询语言(Structured Query Language),专门用来与数据库打交道,目的是提供一种从数据库中读写数据的简单有效的方法。
|
||||
|
||||
几乎所有的主流关系数据库都支持 SQL ,适用性非常强。并且,一些非关系型数据库也兼容 SQL 或者使用的是类似于 SQL 的查询语言。
|
||||
|
||||
SQL 可以帮助我们:
|
||||
|
||||
- 新建数据库、数据表、字段;
|
||||
- 在数据库中增加,删除,修改,查询数据;
|
||||
- 新建视图、函数、存储过程;
|
||||
- 对数据库中的数据进行简单的数据分析;
|
||||
- 搭配 Hive,Spark SQL 做大数据;
|
||||
- 搭配 SQLFlow 做机器学习;
|
||||
- ......
|
||||
|
||||
### 什么是 MySQL?
|
||||
|
||||

|
||||
|
||||
@ -208,6 +208,7 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
|
||||
- [InnoDB 存储引擎对 MVCC 的实现](./database/mysql/innodb-implementation-of-mvcc.md)
|
||||
- [SQL 语句在 MySQL 中的执行过程](./database/mysql/how-sql-executed-in-mysql.md)
|
||||
- [MySQL执行计划分析](./database/mysql/mysql-query-execution-plan.md)
|
||||
- [MySQL自增主键一定是连续的吗](./database/mysql/mysql-auto-increment-primary-key-continuous.md)
|
||||
- [MySQL 时间类型数据存储建议](./database/mysql/some-thoughts-on-database-storage-time.md)
|
||||
- [MySQL 隐式转换造成索引失效](./database/mysql/index-invalidation-caused-by-implicit-conversion.md)
|
||||
|
||||
@ -233,7 +234,7 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
|
||||
|
||||
## 搜索引擎
|
||||
|
||||
用于提高搜索效率,功能和浏览器搜索引擎类似。比较常见的搜索引擎是 Elasticsearch(推荐) 和 Solr。
|
||||
[Elasticsearch常见面试题总结(付费)](./database/elasticsearch/elasticsearch-questions-01.md)
|
||||
|
||||

|
||||
|
||||
@ -243,6 +244,10 @@ JVM 这部分内容主要参考 [JVM 虚拟机规范-Java8 ](https://docs.oracle
|
||||
|
||||
[Maven 核心概念总结](./tools/maven/maven-core-concepts.md)
|
||||
|
||||
### Gradle
|
||||
|
||||
[Gradle 核心概念总结](./tools/gradle/gradle-core-concepts.md)(可选,目前国内还是使用 Maven 普遍一些)
|
||||
|
||||
### Docker
|
||||
|
||||
* [Docker 核心概念总结](./tools/docker/docker-intro.md)
|
||||
|
||||
@ -263,7 +263,7 @@ Java 中有三种移位运算符:
|
||||
|
||||
当 int 类型左移/右移位数大于等于 32 位操作时,会先求余(%)后再进行左移/右移操作。也就是说左移/右移 32 位相当于不进行移位操作(32%32=0),左移/右移 42 位相当于左移/右移 10 位(42%32=10)。当 long 类型进行左移/右移操作时,由于 long 对应的二进制是 64 位,因此求余操作的基数也变成了 64。
|
||||
|
||||
也就是说:`x<<42`等同于`x<<10`,`x>>42`等同于`x>>10`,``x >>>42`等同于`i4 >>> 10`。
|
||||
也就是说:`x<<42`等同于`x<<10`,`x>>42`等同于`x>>10`,`x >>>42`等同于`x >>> 10`。
|
||||
|
||||
**左移运算符代码示例** :
|
||||
|
||||
|
||||
304
docs/tools/gradle/gradle-core-concepts.md
Normal file
304
docs/tools/gradle/gradle-core-concepts.md
Normal file
@ -0,0 +1,304 @@
|
||||
---
|
||||
title: Gradle 核心概念总结
|
||||
category: 开发工具
|
||||
head:
|
||||
- - meta
|
||||
- name: keywords
|
||||
content: Gradle,Groovy,Gradle Wrapper,Gradle 包装器,Gradle 插件
|
||||
- - meta
|
||||
- name: description
|
||||
content: Gradle 就是一个运行在 JVM 上的自动化的项目构建工具,用来帮助我们自动构建项目。
|
||||
---
|
||||
|
||||
> 这部分内容主要根据 Gradle 官方文档整理,做了对应的删减,主要保留比较重要的部分,不涉及实战,主要是一些重要概念的介绍。
|
||||
|
||||
Gradle 这部分内容属于可选内容,可以根据自身需求决定是否学习,目前国内还是使用 Maven 普遍一些。
|
||||
|
||||
## Gradle 介绍
|
||||
|
||||
Gradle 官方文档是这样介绍的 Gradle 的:
|
||||
|
||||
> Gradle is an open-source [build automation](https://en.wikipedia.org/wiki/Build_automation) tool flexible enough to build almost any type of software. Gradle makes few assumptions about what you’re trying to build or how to build it. This makes Gradle particularly flexible.
|
||||
>
|
||||
> Gradle 是一个开源的构建自动化工具,它足够灵活,可以构建几乎任何类型的软件。Gradle 对你要构建什么或者如何构建它做了很少的假设。这使得 Gradle 特别灵活。
|
||||
|
||||
简单来说,Gradle 就是一个运行在 JVM 上的自动化的项目构建工具,用来帮助我们自动构建项目。
|
||||
|
||||
对于开发者来说,Gradle 的主要作用主要有 3 个:
|
||||
|
||||
1. **项目构建** :提供标准的、跨平台的自动化项目构建方式。
|
||||
2. **依赖管理** :方便快捷的管理项目依赖的资源(jar 包),避免资源间的版本冲突问题。
|
||||
3. **统一开发结构** :提供标准的、统一的项目结构。
|
||||
|
||||
Gradle 构建脚本是使用 Groovy 或 Kotlin 语言编写的,表达能力非常强,也足够灵活。
|
||||
|
||||
## Groovy 介绍
|
||||
|
||||
Gradle 是运行在 JVM 上的一个程序,它可以使用 Groovy 来编写构建脚本。
|
||||
|
||||
Groovy 是运行在 JVM 上的脚本语言,是基于 Java 扩展的动态语言,它的语法和 Java 非常的相似,可以使用 Java 的类库。Groovy 可以用于面向对象编程,也可以用作纯粹的脚本语言。在语言的设计上它吸纳了 Java 、Python、Ruby 和 Smalltalk 语言的优秀特性,比如动态类型转换、闭包和元编程支持。
|
||||
|
||||
我们可以用学习 Java 的方式去学习 Groovy ,学习成本相对来说还是比较低的,即使开发过程中忘记 Groovy 语法,也可以用 Java 语法继续编码。
|
||||
|
||||
基于 JVM 的语言有很多种比如 Groovy,Kotlin,Java,Scala,他们最终都会编译生成 Java 字节码文件并在 JVM 上运行。
|
||||
|
||||
## Gradle 优势
|
||||
|
||||
Gradle 是新一代的构建系统,具有高效和灵活等诸多优势,广泛用于 Java 开发。不仅 Android 将其作为官方构建系统, 越来越多的 Java 项目比如 Spring Boot 也慢慢迁移到 Gradle。
|
||||
|
||||
- 在灵活性上,Gradle 支持基于 Groovy 语言编写脚本,侧重于构建过程的灵活性,适合于构建复杂度较高的项目,可以完成非常复杂的构建。
|
||||
- 在粒度性上,Gradle 构建的粒度细化到了每一个 task 之中。并且它所有的 Task 源码都是开源的,在我们掌握了这一整套打包流程后,我们就可以通过去修改它的 Task 去动态改变其执行流程。
|
||||
- 在扩展性上,Gradle 支持插件机制,所以我们可以复用这些插件,就如同复用库一样简单方便。
|
||||
|
||||
## Gradle Wrapper 介绍
|
||||
|
||||
Gradle 官方文档是这样介绍的 Gradle Wrapper 的:
|
||||
|
||||
> The recommended way to execute any Gradle build is with the help of the Gradle Wrapper (in short just “Wrapper”). The Wrapper is a script that invokes a declared version of Gradle, downloading it beforehand if necessary. As a result, developers can get up and running with a Gradle project quickly without having to follow manual installation processes saving your company time and money.
|
||||
>
|
||||
> 执行 Gradle 构建的推荐方法是借助 Gradle Wrapper(简而言之就是“Wrapper”)。Wrapper 它是一个脚本,调用了已经声明的 Gradle 版本,如果需要的话,可以预先下载它。因此,开发人员可以快速启动并运行 Gradle 项目,而不必遵循手动安装过程,从而为公司节省时间和金钱。
|
||||
|
||||
我们可以称 Gradle Wrapper 为 Gradle 包装器,它将 Gradle 再次包装,让所有的 Gradle 构建方法在 Gradle 包装器的帮助下运行。
|
||||
|
||||
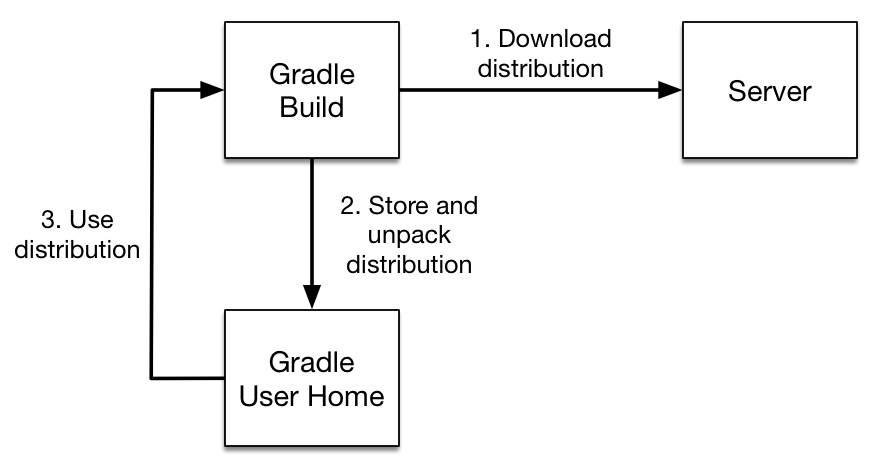
Gradle Wrapper 的工作流程图如下(图源[Gradle Wrapper 官方文档介绍](https://docs.gradle.org/current/userguide/gradle_wrapper.html)):
|
||||
|
||||
|
||||
|
||||
整个流程主要分为下面 3 步:
|
||||
|
||||
1. 首先当我们刚创建的时候,如果指定的版本没有被下载,就先会去 Gradle 的服务器中下载对应版本的压缩包;
|
||||
2. 下载完成后需要先进行解压缩并且执行批处理文件;
|
||||
3. 后续项目每次构建都会重用这个解压过的 Gradle 版本。
|
||||
|
||||
Gradle Wrapper 会给我们带来下面这些好处:
|
||||
|
||||
1. 在给定的 Gradle 版本上标准化项目,从而实现更可靠和健壮的构建。
|
||||
2. 可以让我们的电脑中不安装 Gradle 环境也可以运行 Gradle 项目。
|
||||
3. 为不同的用户和执行环境(例如 IDE 或持续集成服务器)提供新的 Gradle 版本就像更改 Wrapper 定义一样简单。
|
||||
|
||||
### 生成 Gradle Wrapper
|
||||
|
||||
如果想要生成 Gradle Wrapper 的话,需要本地配置好 Gradle 环境变量。Gradle 中已经内置了内置了 Wrapper Task,在项目根目录执行执行`gradle wrapper`命令即可帮助我们生成 Gradle Wrapper。
|
||||
|
||||
执行命令 `gradle wrapper` 命令时可以指定一些参数来控制 wrapper 的生成。具体有如下两个配置参数:
|
||||
|
||||
- `--gradle-version` 用于指定使用的 Gradle 的版本
|
||||
- `--gradle-distribution-url` 用于指定下载 Gradle 版本的 URL,该值的规则是 `http://services.gradle.org/distributions/gradle-${gradleVersion}-bin.zip`
|
||||
|
||||
执行`gradle wrapper`命令之后,Gradle Wrapper 就生成完成了,项目根目录中生成如下文件:
|
||||
|
||||
```
|
||||
├── gradle
|
||||
│ └── wrapper
|
||||
│ ├── gradle-wrapper.jar
|
||||
│ └── gradle-wrapper.properties
|
||||
├── gradlew
|
||||
└── gradlew.bat
|
||||
```
|
||||
|
||||
每个文件的含义如下:
|
||||
|
||||
- `gradle-wrapper.jar`:包含了 Gradle 运行时的逻辑代码。
|
||||
- `gradle-wrapper.properties` : 定义了 Gradle 的版本号和 Gradle 运行时的行为属性。
|
||||
- `gradlew`:Linux 平台下,用于执行 Gralde 命令的包装器脚本。
|
||||
- `gradlew.bat`:Windows 平台下,用于执行 Gralde 命令的包装器脚本。
|
||||
|
||||
`gradle-wrapper.properties` 文件的内容如下:
|
||||
|
||||
```properties
|
||||
distributionBase=GRADLE_USER_HOME
|
||||
distributionPath=wrapper/dists
|
||||
distributionUrl=https\://services.gradle.org/distributions/gradle-6.0.1-bin.zip
|
||||
zipStoreBase=GRADLE_USER_HOME
|
||||
zipStorePath=wrapper/dists
|
||||
```
|
||||
|
||||
- `distributionBase`: Gradle 解包后存储的父目录。
|
||||
- `distributionPath`: `distributionBase`指定目录的子目录。`distributionBase+distributionPath`就是 Gradle 解包后的存放的具体目录。
|
||||
- `distributionUrl`: Gradle 指定版本的压缩包下载地址。
|
||||
- `zipStoreBase`: Gradle 压缩包下载后存储父目录。
|
||||
- `zipStorePath`: `zipStoreBase`指定目录的子目录。`zipStoreBase+zipStorePath`就是 Gradle 压缩包的存放位置。
|
||||
|
||||
### 更新 Gradle Wrapper
|
||||
|
||||
更新 Gradle Wrapper 有 2 种方式:
|
||||
|
||||
1. 接修改`distributionUrl`字段,然后执行 Gradle 命令。
|
||||
2. 执行 gradlew 命令`gradlew wrapper –-gradle-version [version]`。
|
||||
|
||||
下面的命令会将 Gradle 版本升级为 7.6。
|
||||
|
||||
```shell
|
||||
$ gradlew wrapper --gradle-version 7.6
|
||||
```
|
||||
|
||||
`gradle-wrapper.properties` 文件中的 `distributionUrl` 属性也发生了改变。
|
||||
|
||||
```properties
|
||||
distributionUrl=https\://services.gradle.org/distributions/gradle-7.6-all.zip
|
||||
```
|
||||
|
||||
### 自定义 Gradle Wrapper
|
||||
|
||||
Gradle 已经内置了 Wrapper Task,因此构建 Gradle Wrapper 会生成 Gradle Wrapper 的属性文件,这个属性文件可以通过自定义 Wrapper Task 来设置。比如我们想要修改要下载的 Gralde 版本为 7.6,可以这么设置:
|
||||
|
||||
```javascript
|
||||
task wrapper(type: Wrapper) {
|
||||
gradleVersion = '7.6'
|
||||
}
|
||||
```
|
||||
|
||||
也可以设置 Gradle 发行版压缩包的下载地址和 Gradle 解包后的本地存储路径等配置。
|
||||
|
||||
```groovy
|
||||
task wrapper(type: Wrapper) {
|
||||
gradleVersion = '7.6'
|
||||
distributionUrl = '../../gradle-7.6-bin.zip'
|
||||
distributionPath=wrapper/dists
|
||||
}
|
||||
```
|
||||
|
||||
`distributionUrl` 属性可以设置为本地的项目目录,你也可以设置为网络地址。
|
||||
|
||||
## Gradle 任务
|
||||
|
||||
在 Gradle 中,任务(Task)是构建执行的单个工作单元。
|
||||
|
||||
Gradle 的构建是基于 Task 进行的,当你运行项目的时候,实际就是在执行了一系列的 Task 比如编译 Java 源码的 Task、生成 jar 文件的 Task。
|
||||
|
||||
Task 的声明方式如下(还有其他几种声明方式):
|
||||
|
||||
```groovy
|
||||
// 声明一个名字为 helloTask 的 Task
|
||||
task helloTask{
|
||||
doLast{
|
||||
println "Hello"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
创建一个 Task 后,可以根据需要给 Task 添加不同的 Action,上面的“doLast”就是给队列尾增加一个 Action。
|
||||
|
||||
```groovy
|
||||
//在Action 队列头部添加Action
|
||||
Task doFirst(Action<? super Task> action);
|
||||
Task doFirst(Closure action);
|
||||
|
||||
//在Action 队列尾部添加Action
|
||||
Task doLast(Action<? super Task> action);
|
||||
Task doLast(Closure action);
|
||||
|
||||
//删除所有的Action
|
||||
Task deleteAllActions();
|
||||
```
|
||||
|
||||
一个 Task 中可以有多个 Acton,从队列头部开始向队列尾部执行 Acton。
|
||||
|
||||
Action 代表的是一个个函数、方法,每个 Task 都是一堆 Action 按序组成的执行图。
|
||||
|
||||
Task 声明依赖的关键字是`dependsOn`,支持声明一个或多个依赖:
|
||||
|
||||
```groovy
|
||||
task first {
|
||||
doLast {
|
||||
println "+++++first+++++"
|
||||
}
|
||||
}
|
||||
task second {
|
||||
doLast {
|
||||
println "+++++second+++++"
|
||||
}
|
||||
}
|
||||
|
||||
// 指定多个 task 依赖
|
||||
task print(dependsOn :[second,first]) {
|
||||
doLast {
|
||||
logger.quiet "指定多个task依赖"
|
||||
}
|
||||
}
|
||||
|
||||
// 指定一个 task 依赖
|
||||
task third(dependsOn : print) {
|
||||
doLast {
|
||||
println '+++++third+++++'
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
执行 Task 之前,会先执行它的依赖 Task。
|
||||
|
||||
我们还可以设置默认 Task,脚本中我们不调用默认 Task ,也会执行。
|
||||
|
||||
```groovy
|
||||
defaultTasks 'clean', 'run'
|
||||
|
||||
task clean {
|
||||
doLast {
|
||||
println 'Default Cleaning!'
|
||||
}
|
||||
}
|
||||
|
||||
task run {
|
||||
doLast {
|
||||
println 'Default Running!'
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Gradle 本身也内置了很多 Task 比如 copy(复制文件)、delete(删除文件)。
|
||||
|
||||
```groovy
|
||||
task deleteFile(type: Delete) {
|
||||
delete "C:\\Users\\guide\\Desktop\\test"
|
||||
}
|
||||
```
|
||||
|
||||
## Gradle 插件
|
||||
|
||||
Gradle 提供的是一套核心的构建机制,而 Gradle 插件则是运行在这套机制上的一些具体构建逻辑,其本质上和 `.gradle` 文件是相同。你可以将 Gradle 插件看作是封装了一系列 Task 并执行的工具。
|
||||
|
||||
Gradle 插件主要分为两类:
|
||||
|
||||
- 脚本插件: 脚本插件就是一个普通的脚本文件,它可以被导入都其他构建脚本中。
|
||||
- 二进制插件 / 对象插件:在一个单独的插件模块中定义,其他模块通过 Plugin ID 应用插件。因为这种方式发布和复用更加友好,我们一般接触到的 Gradle 插件都是指二进制插件的形式。
|
||||
|
||||
虽然 Gradle 插件与 .gradle 文件本质上没有区别,`.gradle` 文件也能实现 Gradle 插件类似的功能。但是,Gradle 插件使用了独立模块封装构建逻辑,无论是从开发开始使用来看,Gradle 插件的整体体验都更友好。
|
||||
|
||||
- **逻辑复用:** 将相同的逻辑提供给多个相似项目复用,减少重复维护类似逻辑开销。当然 .gradle 文件也能做到逻辑复用,但 Gradle 插件的封装性更好;
|
||||
- **组件发布:** 可以将插件发布到 Maven 仓库进行管理,其他项目可以使用插件 ID 依赖。当然 .gradle 文件也可以放到一个远程路径被其他项目引用;
|
||||
- **构建配置:** Gradle 插件可以声明插件扩展来暴露可配置的属性,提供定制化能力。当然 .gradle 文件也可以做到,但实现会麻烦些。
|
||||
|
||||
## Gradle 构建生命周期
|
||||
|
||||
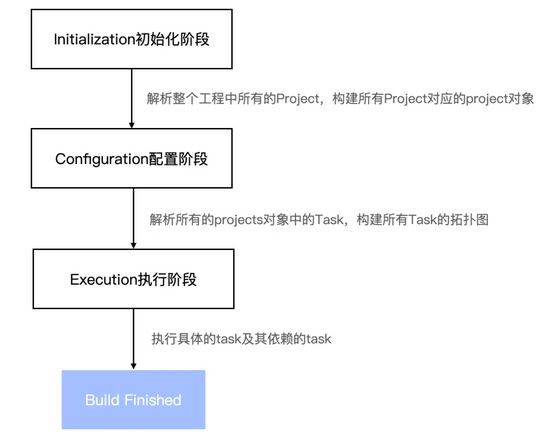
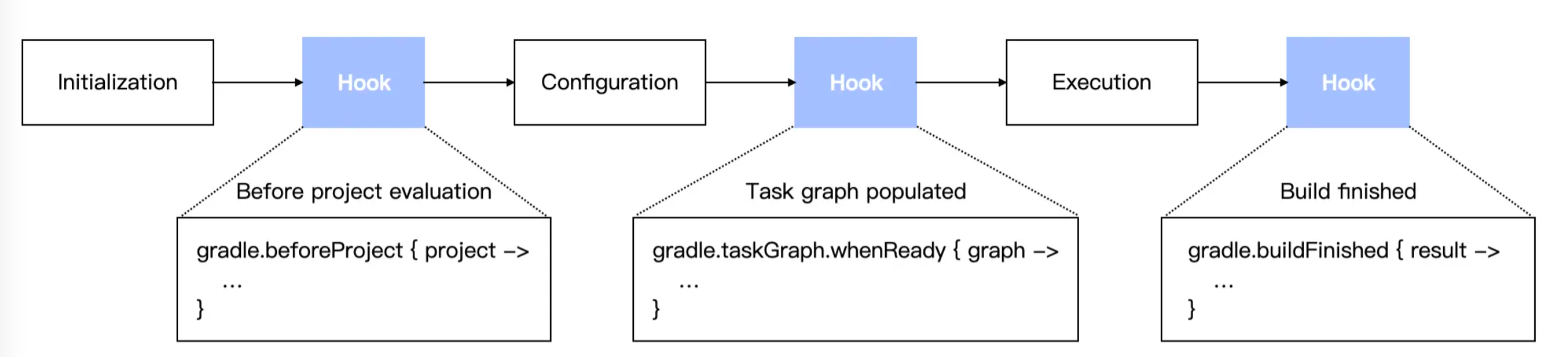
Gradle 构建的生命周期有三个阶段:**初始化阶段,配置阶段**和**运行阶段**。
|
||||
|
||||
|
||||
|
||||
在初始化阶段与配置阶段之间、配置阶段结束之后、执行阶段结束之后,我们都可以加一些定制化的 Hook。
|
||||
|
||||
|
||||
|
||||
### 初始化阶段
|
||||
|
||||
Gradle 支持单项目和多项目构建。在初始化阶段,Gradle 确定哪些项目将参与构建,并为每个项目创建一个 [Project 实例](https://docs.gradle.org/current/dsl/org.gradle.api.Project.html) 。本质上也就是执行 `settings.gradle` 脚本,从而读取整个项目中有多少个 Project 实例。
|
||||
|
||||
### 配置阶段
|
||||
|
||||
在配置阶段,Gradle 会解析每个工程的 `build.gradle` 文件,创建要执行的任务子集和确定各种任务之间的关系,以供执行阶段按照顺序执行,并对任务的做一些初始化配置。
|
||||
|
||||
每个 `build.gradle` 对应一个 Project 对象,配置阶段执行的代码包括 `build.gradle` 中的各种语句、闭包以及 Task 中的配置语句。
|
||||
|
||||
在配置阶段结束后,Gradle 会根据 Task 的依赖关系会创建一个 **有向无环图** 。
|
||||
|
||||
### 运行阶段
|
||||
|
||||
在运行阶段,Gradle 根据配置阶段创建和配置的要执行的任务子集,执行任务。
|
||||
|
||||
## 参考
|
||||
|
||||
- Gradle 官方文档:https://docs.gradle.org/current/userguide/userguide.html
|
||||
- Gradle 入门教程:https://www.imooc.com/wiki/gradlebase
|
||||
- Groovy 快速入门看这篇就够了:https://cloud.tencent.com/developer/article/1358357
|
||||
- 【Gradle】Gradle 的生命周期详解:https://juejin.cn/post/7067719629874921508
|
||||
- 手把手带你自定义 Gradle 插件 —— Gradle 系列(2):https://www.cnblogs.com/pengxurui/p/16281537.html
|
||||
- Gradle 爬坑指南 -- 理解 Plugin、Task、构建流程:https://juejin.cn/post/6889090530593112077
|
||||
Loading…
x
Reference in New Issue
Block a user