mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
修正多个单词/专业术语/专业名词错误
This commit is contained in:
parent
fa0fd5b2b3
commit
fb826b64f1
@ -38,7 +38,7 @@ icon: "java"
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
Java 8 算是一个里程碑式的版本,现在一般企业还是用 Java 8 比较多。掌握 Java 8 的一些新特性比如 Lambda、Strean API 还是挺有必要的。这块的话,我推荐 **[《Java 8 实战》](https://book.douban.com/subject/26772632/)** 这本书。
|
Java 8 算是一个里程碑式的版本,现在一般企业还是用 Java 8 比较多。掌握 Java 8 的一些新特性比如 Lambda、Stream API 还是挺有必要的。这块的话,我推荐 **[《Java 8 实战》](https://book.douban.com/subject/26772632/)** 这本书。
|
||||||
|
|
||||||
## Java 并发
|
## Java 并发
|
||||||
|
|
||||||
|
|||||||
@ -61,7 +61,7 @@ A 首先发送 **SYN**(Synchronization)消息给 B,要求 B 做好接收
|
|||||||
- 向 A 确认已做好接收数据的准备,
|
- 向 A 确认已做好接收数据的准备,
|
||||||
- 同时要求 A 也做好接收数据的准备,此时 B 已向 A 确认好接收状态,并等待 A 的确认,连接处于**半开状态(Half-Open)**,顾名思义只开了一半;A 收到后再次发送 **ACK** (Acknowledgement) 消息给 B,向 B 确认也做好了接收数据的准备,至此三次握手完成,「**连接**」就建立了,
|
- 同时要求 A 也做好接收数据的准备,此时 B 已向 A 确认好接收状态,并等待 A 的确认,连接处于**半开状态(Half-Open)**,顾名思义只开了一半;A 收到后再次发送 **ACK** (Acknowledgement) 消息给 B,向 B 确认也做好了接收数据的准备,至此三次握手完成,「**连接**」就建立了,
|
||||||
|
|
||||||
大家注意到没有,最关键的一点在于双方是否都按对方的要求进入了**可以接收消息**的状态。而这个状态的确认主要是双方将要使用的**消息序号(**SquenceNum),**TCP** 为保证消息按发送顺序抵达接收方的上层应用,需要用**消息序号**来标记消息的发送先后顺序的。
|
大家注意到没有,最关键的一点在于双方是否都按对方的要求进入了**可以接收消息**的状态。而这个状态的确认主要是双方将要使用的**消息序号(**SequenceNum),**TCP** 为保证消息按发送顺序抵达接收方的上层应用,需要用**消息序号**来标记消息的发送先后顺序的。
|
||||||
|
|
||||||
**TCP**是「**双工**」(Duplex)连接,同时支持双向通信,也就是双方同时可向对方发送消息,其中 **SYN** 和 **SYN-ACK** 消息开启了 A→B 的单向通信通道(B 获知了 A 的消息序号);**SYN-ACK** 和 **ACK** 消息开启了 B→A 单向通信通道(A 获知了 B 的消息序号)。
|
**TCP**是「**双工**」(Duplex)连接,同时支持双向通信,也就是双方同时可向对方发送消息,其中 **SYN** 和 **SYN-ACK** 消息开启了 A→B 的单向通信通道(B 获知了 A 的消息序号);**SYN-ACK** 和 **ACK** 消息开启了 B→A 单向通信通道(A 获知了 B 的消息序号)。
|
||||||
|
|
||||||
|
|||||||
@ -91,7 +91,7 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
|
|||||||
|
|
||||||
这里强调指出,网络层中的“网络”二字已经不是我们通常谈到的具体网络,而是指计算机网络体系结构模型中第三层的名称。
|
这里强调指出,网络层中的“网络”二字已经不是我们通常谈到的具体网络,而是指计算机网络体系结构模型中第三层的名称。
|
||||||
|
|
||||||
互联网是由大量的异构(heterogeneous)网络通过路由器(router)相互连接起来的。互联网使用的网络层协议是无连接的网际协议(Internet Prococol)和许多路由选择协议,因此互联网的网络层也叫做 **网际层** 或 **IP 层**。
|
互联网是由大量的异构(heterogeneous)网络通过路由器(router)相互连接起来的。互联网使用的网络层协议是无连接的网际协议(Internet Protocol)和许多路由选择协议,因此互联网的网络层也叫做 **网际层** 或 **IP 层**。
|
||||||
|
|
||||||
**网络层常见协议** :
|
**网络层常见协议** :
|
||||||
|
|
||||||
|
|||||||
@ -81,7 +81,7 @@ tag:
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
- **TCP(Transmisson Control Protocol,传输控制协议 )**:提供 **面向连接** 的,**可靠** 的数据传输服务。
|
- **TCP(Transmission Control Protocol,传输控制协议 )**:提供 **面向连接** 的,**可靠** 的数据传输服务。
|
||||||
- **UDP(User Datagram Protocol,用户数据协议)**:提供 **无连接** 的,**尽最大努力** 的数据传输服务(不保证数据传输的可靠性),简单高效。
|
- **UDP(User Datagram Protocol,用户数据协议)**:提供 **无连接** 的,**尽最大努力** 的数据传输服务(不保证数据传输的可靠性),简单高效。
|
||||||
|
|
||||||
#### 网络层有哪些常见的协议?
|
#### 网络层有哪些常见的协议?
|
||||||
|
|||||||
@ -339,7 +339,7 @@ Linux 系统是一个多用户多任务的分时操作系统,任何一个要
|
|||||||
- `top [选项]`:用于实时查看系统的 CPU 使用率、内存使用率、进程信息等。
|
- `top [选项]`:用于实时查看系统的 CPU 使用率、内存使用率、进程信息等。
|
||||||
- `htop [选项]`:类似于 `top`,但提供了更加交互式和友好的界面,可让用户交互式操作,支持颜色主题,可横向或纵向滚动浏览进程列表,并支持鼠标操作。
|
- `htop [选项]`:类似于 `top`,但提供了更加交互式和友好的界面,可让用户交互式操作,支持颜色主题,可横向或纵向滚动浏览进程列表,并支持鼠标操作。
|
||||||
- `uptime [选项]`:用于查看系统总共运行了多长时间、系统的平均负载等信息。
|
- `uptime [选项]`:用于查看系统总共运行了多长时间、系统的平均负载等信息。
|
||||||
- `vmstat [间隔时间] [重复次数]` :vmstat (Viryual Memor Statics) 的含义为显示虚拟内存状态,但是它可以报告关于进程、内存、I/O等系统整体运行状态。
|
- `vmstat [间隔时间] [重复次数]` :vmstat (Virtual Memory Statistics) 的含义为显示虚拟内存状态,但是它可以报告关于进程、内存、I/O等系统整体运行状态。
|
||||||
- `free [选项]`:用于查看系统的内存使用情况,包括已用内存、可用内存、缓冲区和缓存等。
|
- `free [选项]`:用于查看系统的内存使用情况,包括已用内存、可用内存、缓冲区和缓存等。
|
||||||
- `df [选项] [文件系统]`:用于查看系统的磁盘空间使用情况,包括磁盘空间的总量、已使用量和可用量等,可以指定文件系统上。例如:`df -a`,查看全部文件系统。
|
- `df [选项] [文件系统]`:用于查看系统的磁盘空间使用情况,包括磁盘空间的总量、已使用量和可用量等,可以指定文件系统上。例如:`df -a`,查看全部文件系统。
|
||||||
- `du [选项] [文件]`:用于查看指定目录或文件的磁盘空间使用情况,可以指定不同的选项来控制输出格式和单位。
|
- `du [选项] [文件]`:用于查看指定目录或文件的磁盘空间使用情况,可以指定不同的选项来控制输出格式和单位。
|
||||||
|
|||||||
@ -264,8 +264,8 @@ TLB 的设计思想非常简单,但命中率往往非常高,效果很好。
|
|||||||
|
|
||||||
常见的页缺失有下面这两种:
|
常见的页缺失有下面这两种:
|
||||||
|
|
||||||
- **硬性页缺失(Hard Page Fault)** :物理内存中没有对应的物理页。于是,Page Fault Hander 会指示 CPU 从已经打开的磁盘文件中读取相应的内容到物理内存,而后交由 MMU 建立相应的虚拟页和物理页的映射关系。
|
- **硬性页缺失(Hard Page Fault)** :物理内存中没有对应的物理页。于是,Page Fault Handler 会指示 CPU 从已经打开的磁盘文件中读取相应的内容到物理内存,而后交由 MMU 建立相应的虚拟页和物理页的映射关系。
|
||||||
- **软性页缺失(Soft Page Fault)**:物理内存中有对应的物理页,但虚拟页还未和物理页建立映射。于是,Page Fault Hander 会指示 MMU 建立相应的虚拟页和物理页的映射关系。
|
- **软性页缺失(Soft Page Fault)**:物理内存中有对应的物理页,但虚拟页还未和物理页建立映射。于是,Page Fault Handler 会指示 MMU 建立相应的虚拟页和物理页的映射关系。
|
||||||
|
|
||||||
发生上面这两种缺页错误的时候,应用程序访问的是有效的物理内存,只是出现了物理页缺失或者虚拟页和物理页的映射关系未建立的问题。如果应用程序访问的是无效的物理内存的话,还会出现 **无效缺页错误(Invalid Page Fault)** 。
|
发生上面这两种缺页错误的时候,应用程序访问的是有效的物理内存,只是出现了物理页缺失或者虚拟页和物理页的映射关系未建立的问题。如果应用程序访问的是无效的物理内存的话,还会出现 **无效缺页错误(Invalid Page Fault)** 。
|
||||||
|
|
||||||
|
|||||||
@ -119,7 +119,7 @@ ER 图由下面 3 个要素组成:
|
|||||||
|
|
||||||
### 属于不同的数据库语言
|
### 属于不同的数据库语言
|
||||||
|
|
||||||
`truncate` 和 `drop` 属于 DDL(数据定义语言)语句,操作立即生效,原数据不放到 rollback segment 中,不能回滚,操作不触发 trigger。而 `delete` 语句是 DML (数据库操作语言)语句,这个操作会放到 rollback segement 中,事务提交之后才生效。
|
`truncate` 和 `drop` 属于 DDL(数据定义语言)语句,操作立即生效,原数据不放到 rollback segment 中,不能回滚,操作不触发 trigger。而 `delete` 语句是 DML (数据库操作语言)语句,这个操作会放到 rollback segment 中,事务提交之后才生效。
|
||||||
|
|
||||||
**DML 语句和 DDL 语句区别:**
|
**DML 语句和 DDL 语句区别:**
|
||||||
|
|
||||||
|
|||||||
@ -35,7 +35,7 @@ MongoDB 的存储结构区别于传统的关系型数据库,主要由如下三
|
|||||||
| 列(Col) | 字段(Field) |
|
| 列(Col) | 字段(Field) |
|
||||||
| 主键(Primary Key) | 对象 ID(Objectid) |
|
| 主键(Primary Key) | 对象 ID(Objectid) |
|
||||||
| 索引(Index) | 索引(Index) |
|
| 索引(Index) | 索引(Index) |
|
||||||
| 嵌套表(Embeded Table) | 嵌入式文档(Embeded Document) |
|
| 嵌套表(Embedded Table) | 嵌入式文档(Embedded Document) |
|
||||||
| 数组(Array) | 数组(Array) |
|
| 数组(Array) | 数组(Array) |
|
||||||
|
|
||||||
#### 文档
|
#### 文档
|
||||||
|
|||||||
@ -201,7 +201,7 @@ MongoDB 的分片集群由如下三个部分组成(下图来源于[官方文
|
|||||||
- **查询带分片** 查询时建议带上分片,使用分片键进行条件查询时,mongos 可以直接定位到具体分片,否则 mongos 需要将查询分发到所有分片,再等待响应返回。
|
- **查询带分片** 查询时建议带上分片,使用分片键进行条件查询时,mongos 可以直接定位到具体分片,否则 mongos 需要将查询分发到所有分片,再等待响应返回。
|
||||||
- **避免单调递增或递减** 单调递增的 sharding key,数据文件挪动小,但写入会集中,导致最后一篇的数据量持续增大,不断发生迁移,递减同理。
|
- **避免单调递增或递减** 单调递增的 sharding key,数据文件挪动小,但写入会集中,导致最后一篇的数据量持续增大,不断发生迁移,递减同理。
|
||||||
|
|
||||||
综上,在选择片键时要考虑以上4个条件,尽可能满足更多的条件,才能降低 MoveChuncks 对性能的影响,从而获得最优的性能体验。
|
综上,在选择片键时要考虑以上4个条件,尽可能满足更多的条件,才能降低 MoveChunks 对性能的影响,从而获得最优的性能体验。
|
||||||
|
|
||||||
#### 分片策略有哪些?
|
#### 分片策略有哪些?
|
||||||
|
|
||||||
|
|||||||
@ -67,7 +67,7 @@ hintManager.setMasterRouteOnly();
|
|||||||
|
|
||||||
我们可以在应用和数据中间加了一个代理层。应用程序所有的数据请求都交给代理层处理,代理层负责分离读写请求,将它们路由到对应的数据库中。
|
我们可以在应用和数据中间加了一个代理层。应用程序所有的数据请求都交给代理层处理,代理层负责分离读写请求,将它们路由到对应的数据库中。
|
||||||
|
|
||||||
提供类似功能的中间件有 **MySQL Router**(官方)、**Atlas**(基于 MySQL Proxy)、**Maxscale**、**MyCat**。
|
提供类似功能的中间件有 **MySQL Router**(官方)、**Atlas**(基于 MySQL Proxy)、**MaxScale**、**MyCat**。
|
||||||
|
|
||||||
**2.组件方式**
|
**2.组件方式**
|
||||||
|
|
||||||
|
|||||||
@ -114,7 +114,7 @@ tag:
|
|||||||
|
|
||||||
## 18、手动修改生产环境数据库
|
## 18、手动修改生产环境数据库
|
||||||
|
|
||||||
直连生产环境数据库修改数据,更有 UPDATE / DELETE SQL 忘写 WEHRE 条件的情况,产生数据事故。
|
直连生产环境数据库修改数据,更有 UPDATE / DELETE SQL 忘写 WHERE 条件的情况,产生数据事故。
|
||||||
|
|
||||||
修改生产环境数据库一定要谨慎再谨慎,建议操作前先找同事 review 代码再操作。
|
修改生产环境数据库一定要谨慎再谨慎,建议操作前先找同事 review 代码再操作。
|
||||||
|
|
||||||
|
|||||||
@ -106,7 +106,7 @@ tag:
|
|||||||
2. 如果前端提交成功,后端无法接受数据,这时候你将如何排查问题;
|
2. 如果前端提交成功,后端无法接受数据,这时候你将如何排查问题;
|
||||||
3. 描述一下 HTTP 基本报文结构;
|
3. 描述一下 HTTP 基本报文结构;
|
||||||
4. 如果服务器返回 Cookie,存储在响应内容里面 head 头的字段叫做什么;
|
4. 如果服务器返回 Cookie,存储在响应内容里面 head 头的字段叫做什么;
|
||||||
5. 当服务端返回 Transer-Encoding:chunked 代表什么含义
|
5. 当服务端返回 Transfer-Encoding:chunked 代表什么含义
|
||||||
6. 是否了解分段加载并描述下其技术流程。
|
6. 是否了解分段加载并描述下其技术流程。
|
||||||
|
|
||||||
当然,面向不同的技术,对应的技术深度自然也不一样。
|
当然,面向不同的技术,对应的技术深度自然也不一样。
|
||||||
|
|||||||
@ -45,7 +45,7 @@ Java 中最常用的语法糖主要有泛型、变长参数、条件编译、自
|
|||||||
|
|
||||||
前面提到过,从 Java 7 开始,Java 语言中的语法糖在逐渐丰富,其中一个比较重要的就是 Java 7 中`switch`开始支持`String`。
|
前面提到过,从 Java 7 开始,Java 语言中的语法糖在逐渐丰富,其中一个比较重要的就是 Java 7 中`switch`开始支持`String`。
|
||||||
|
|
||||||
在开始之前先科普下,Java 中的`switch`自身原本就支持基本类型。比如`int`、`char`等。对于`int`类型,直接进行数值的比较。对于`char`类型则是比较其 ascii 码。所以,对于编译器来说,`switch`中其实只能使用整型,任何类型的比较都要转换成整型。比如`byte`。`short`,`char`(ackii 码是整型)以及`int`。
|
在开始之前先科普下,Java 中的`switch`自身原本就支持基本类型。比如`int`、`char`等。对于`int`类型,直接进行数值的比较。对于`char`类型则是比较其 ascii 码。所以,对于编译器来说,`switch`中其实只能使用整型,任何类型的比较都要转换成整型。比如`byte`。`short`,`char`(ascii 码是整型)以及`int`。
|
||||||
|
|
||||||
那么接下来看下`switch`对`String`得支持,有以下代码:
|
那么接下来看下`switch`对`String`得支持,有以下代码:
|
||||||
|
|
||||||
@ -651,7 +651,7 @@ public static transient void main(String args[])
|
|||||||
|
|
||||||
### Lambda 表达式
|
### Lambda 表达式
|
||||||
|
|
||||||
关于 lambda 表达式,有人可能会有质疑,因为网上有人说他并不是语法糖。其实我想纠正下这个说法。**Labmda 表达式不是匿名内部类的语法糖,但是他也是一个语法糖。实现方式其实是依赖了几个 JVM 底层提供的 lambda 相关 api。**
|
关于 lambda 表达式,有人可能会有质疑,因为网上有人说他并不是语法糖。其实我想纠正下这个说法。**Lambda 表达式不是匿名内部类的语法糖,但是他也是一个语法糖。实现方式其实是依赖了几个 JVM 底层提供的 lambda 相关 api。**
|
||||||
|
|
||||||
先来看一个简单的 lambda 表达式。遍历一个 list:
|
先来看一个简单的 lambda 表达式。遍历一个 list:
|
||||||
|
|
||||||
|
|||||||
@ -668,7 +668,7 @@ public class ArrayList<E> extends AbstractList<E>
|
|||||||
我们来仔细分析一下:
|
我们来仔细分析一下:
|
||||||
|
|
||||||
- 当我们要 add 进第 1 个元素到 ArrayList 时,elementData.length 为 0 (因为还是一个空的 list),因为执行了 `ensureCapacityInternal()` 方法 ,所以 minCapacity 此时为 10。此时,`minCapacity - elementData.length > 0`成立,所以会进入 `grow(minCapacity)` 方法。
|
- 当我们要 add 进第 1 个元素到 ArrayList 时,elementData.length 为 0 (因为还是一个空的 list),因为执行了 `ensureCapacityInternal()` 方法 ,所以 minCapacity 此时为 10。此时,`minCapacity - elementData.length > 0`成立,所以会进入 `grow(minCapacity)` 方法。
|
||||||
- 当 add 第 2 个元素时,minCapacity 为 2,此时 e lementData.length(容量)在添加第一个元素后扩容成 10 了。此时,`minCapacity - elementData.length > 0` 不成立,所以不会进入 (执行)`grow(minCapacity)` 方法。
|
- 当 add 第 2 个元素时,minCapacity 为 2,此时 elementData.length(容量)在添加第一个元素后扩容成 10 了。此时,`minCapacity - elementData.length > 0` 不成立,所以不会进入 (执行)`grow(minCapacity)` 方法。
|
||||||
- 添加第 3、4···到第 10 个元素时,依然不会执行 grow 方法,数组容量都为 10。
|
- 添加第 3、4···到第 10 个元素时,依然不会执行 grow 方法,数组容量都为 10。
|
||||||
|
|
||||||
直到添加第 11 个元素,minCapacity(为 11)比 elementData.length(为 10)要大。进入 grow 方法进行扩容。
|
直到添加第 11 个元素,minCapacity(为 11)比 elementData.length(为 10)要大。进入 grow 方法进行扩容。
|
||||||
|
|||||||
@ -96,7 +96,7 @@ public ConcurrentHashMap(int initialCapacity,float loadFactor, int concurrencyLe
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
总结一下在 Java 7 中 ConcurrnetHashMap 的初始化逻辑。
|
总结一下在 Java 7 中 ConcurrentHashMap 的初始化逻辑。
|
||||||
|
|
||||||
1. 必要参数校验。
|
1. 必要参数校验。
|
||||||
2. 校验并发级别 `concurrencyLevel` 大小,如果大于最大值,重置为最大值。无参构造**默认值是 16.**
|
2. 校验并发级别 `concurrencyLevel` 大小,如果大于最大值,重置为最大值。无参构造**默认值是 16.**
|
||||||
|
|||||||
@ -99,7 +99,7 @@ IO 流中的装饰器模式应用的例子实在是太多了,不需要特意
|
|||||||
|
|
||||||
**适配器(Adapter Pattern)模式** 主要用于接口互不兼容的类的协调工作,你可以将其联想到我们日常经常使用的电源适配器。
|
**适配器(Adapter Pattern)模式** 主要用于接口互不兼容的类的协调工作,你可以将其联想到我们日常经常使用的电源适配器。
|
||||||
|
|
||||||
适配器模式中存在被适配的对象或者类称为 **适配者(Adaptee)** ,作用于适配者的对象或者类称为**适配器(Adapter)** 。适配器分为对象适配器和类适配器。类适配器使用继承关系来实现,对象适配器使用组合关系来实现。
|
适配器模式中存在被适配的对象或者类称为 **适配者(Adapter)** ,作用于适配者的对象或者类称为**适配器(Adapter)** 。适配器分为对象适配器和类适配器。类适配器使用继承关系来实现,对象适配器使用组合关系来实现。
|
||||||
|
|
||||||
IO 流中的字符流和字节流的接口不同,它们之间可以协调工作就是基于适配器模式来做的,更准确点来说是对象适配器。通过适配器,我们可以将字节流对象适配成一个字符流对象,这样我们可以直接通过字节流对象来读取或者写入字符数据。
|
IO 流中的字符流和字节流的接口不同,它们之间可以协调工作就是基于适配器模式来做的,更准确点来说是对象适配器。通过适配器,我们可以将字节流对象适配成一个字符流对象,这样我们可以直接通过字节流对象来读取或者写入字符数据。
|
||||||
|
|
||||||
|
|||||||
@ -94,8 +94,8 @@ ClassFile {
|
|||||||
|
|
||||||
常量池中每一项常量都是一个表,这 14 种表有一个共同的特点:**开始的第一位是一个 u1 类型的标志位 -tag 来标识常量的类型,代表当前这个常量属于哪种常量类型.**
|
常量池中每一项常量都是一个表,这 14 种表有一个共同的特点:**开始的第一位是一个 u1 类型的标志位 -tag 来标识常量的类型,代表当前这个常量属于哪种常量类型.**
|
||||||
|
|
||||||
| 类型 | 标志(tag) | 描述 |
|
| 类型 | 标志(tag) | 描述 |
|
||||||
| :------------------------------: | :---------: | :--------------------: |
|
|:--------------------------------:| :---------: | :--------------------: |
|
||||||
| CONSTANT_utf8_info | 1 | UTF-8 编码的字符串 |
|
| CONSTANT_utf8_info | 1 | UTF-8 编码的字符串 |
|
||||||
| CONSTANT_Integer_info | 3 | 整形字面量 |
|
| CONSTANT_Integer_info | 3 | 整形字面量 |
|
||||||
| CONSTANT_Float_info | 4 | 浮点型字面量 |
|
| CONSTANT_Float_info | 4 | 浮点型字面量 |
|
||||||
@ -103,11 +103,11 @@ ClassFile {
|
|||||||
| CONSTANT_Double_info | 6 | 双精度浮点型字面量 |
|
| CONSTANT_Double_info | 6 | 双精度浮点型字面量 |
|
||||||
| CONSTANT_Class_info | 7 | 类或接口的符号引用 |
|
| CONSTANT_Class_info | 7 | 类或接口的符号引用 |
|
||||||
| CONSTANT_String_info | 8 | 字符串类型字面量 |
|
| CONSTANT_String_info | 8 | 字符串类型字面量 |
|
||||||
| CONSTANT_Fieldref_info | 9 | 字段的符号引用 |
|
| CONSTANT_FieldRef_info | 9 | 字段的符号引用 |
|
||||||
| CONSTANT_Methodref_info | 10 | 类中方法的符号引用 |
|
| CONSTANT_MethodRef_info | 10 | 类中方法的符号引用 |
|
||||||
| CONSTANT_InterfaceMethodref_info | 11 | 接口中方法的符号引用 |
|
| CONSTANT_InterfaceMethodRef_info | 11 | 接口中方法的符号引用 |
|
||||||
| CONSTANT_NameAndType_info | 12 | 字段或方法的符号引用 |
|
| CONSTANT_NameAndType_info | 12 | 字段或方法的符号引用 |
|
||||||
| CONSTANT_MothodType_info | 16 | 标志方法类型 |
|
| CONSTANT_MethodType_info | 16 | 标志方法类型 |
|
||||||
| CONSTANT_MethodHandle_info | 15 | 表示方法句柄 |
|
| CONSTANT_MethodHandle_info | 15 | 表示方法句柄 |
|
||||||
| CONSTANT_InvokeDynamic_info | 18 | 表示一个动态方法调用点 |
|
| CONSTANT_InvokeDynamic_info | 18 | 表示一个动态方法调用点 |
|
||||||
|
|
||||||
|
|||||||
@ -290,7 +290,7 @@ JConsole 可以显示当前内存的详细信息。不仅包括堆内存/非堆
|
|||||||
|
|
||||||
### Visual VM:多合一故障处理工具
|
### Visual VM:多合一故障处理工具
|
||||||
|
|
||||||
VisualVM 提供在 Java 虚拟机 (Java Virutal Machine, JVM) 上运行的 Java 应用程序的详细信息。在 VisualVM 的图形用户界面中,您可以方便、快捷地查看多个 Java 应用程序的相关信息。Visual VM 官网:<https://visualvm.github.io/> 。Visual VM 中文文档:<https://visualvm.github.io/documentation.html>。
|
VisualVM 提供在 Java 虚拟机 (Java Virtual Machine, JVM) 上运行的 Java 应用程序的详细信息。在 VisualVM 的图形用户界面中,您可以方便、快捷地查看多个 Java 应用程序的相关信息。Visual VM 官网:<https://visualvm.github.io/> 。Visual VM 中文文档:<https://visualvm.github.io/documentation.html>。
|
||||||
|
|
||||||
下面这段话摘自《深入理解 Java 虚拟机》。
|
下面这段话摘自《深入理解 Java 虚拟机》。
|
||||||
|
|
||||||
|
|||||||
@ -41,7 +41,7 @@ tag:
|
|||||||
|
|
||||||
根据[Oracle 官方文档](https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/sizing.html),在堆总可用内存配置完成之后,第二大影响因素是为 `Young Generation` 在堆内存所占的比例。默认情况下,YG 的最小大小为 1310 _MB_,最大大小为*无限制*。
|
根据[Oracle 官方文档](https://docs.oracle.com/javase/8/docs/technotes/guides/vm/gctuning/sizing.html),在堆总可用内存配置完成之后,第二大影响因素是为 `Young Generation` 在堆内存所占的比例。默认情况下,YG 的最小大小为 1310 _MB_,最大大小为*无限制*。
|
||||||
|
|
||||||
一共有两种指定 新生代内存(Young Ceneration)大小的方法:
|
一共有两种指定 新生代内存(Young Generation)大小的方法:
|
||||||
|
|
||||||
**1.通过`-XX:NewSize`和`-XX:MaxNewSize`指定**
|
**1.通过`-XX:NewSize`和`-XX:MaxNewSize`指定**
|
||||||
|
|
||||||
@ -226,7 +226,7 @@ JVM 具有四种类型的 GC 实现:
|
|||||||
- [JVM 内存配置最佳实践 - 阿里云官方文档 - 2022](https://help.aliyun.com/document_detail/383255.html)
|
- [JVM 内存配置最佳实践 - 阿里云官方文档 - 2022](https://help.aliyun.com/document_detail/383255.html)
|
||||||
- [求你了,GC 日志打印别再瞎配置了 - 思否 - 2022](https://segmentfault.com/a/1190000039806436)
|
- [求你了,GC 日志打印别再瞎配置了 - 思否 - 2022](https://segmentfault.com/a/1190000039806436)
|
||||||
- [一次大量 JVM Native 内存泄露的排查分析(64M 问题) - 掘金 - 2022](https://juejin.cn/post/7078624931826794503)
|
- [一次大量 JVM Native 内存泄露的排查分析(64M 问题) - 掘金 - 2022](https://juejin.cn/post/7078624931826794503)
|
||||||
- [一次线上 JVM 调优实践,FullGC40 次/天到 10 天一次的优化过程 - HeadpDump - 2021](https://heapdump.cn/article/1859160)
|
- [一次线上 JVM 调优实践,FullGC40 次/天到 10 天一次的优化过程 - HeapDump - 2021](https://heapdump.cn/article/1859160)
|
||||||
- [听说 JVM 性能优化很难?今天我小试了一把! - 陈树义 - 2021](https://shuyi.tech/archives/have-a-try-in-jvm-combat)
|
- [听说 JVM 性能优化很难?今天我小试了一把! - 陈树义 - 2021](https://shuyi.tech/archives/have-a-try-in-jvm-combat)
|
||||||
- [你们要的线上 GC 问题案例来啦 - 编了个程 - 2021](https://mp.weixin.qq.com/s/df1uxHWUXzhErxW1sZ6OvQ)
|
- [你们要的线上 GC 问题案例来啦 - 编了个程 - 2021](https://mp.weixin.qq.com/s/df1uxHWUXzhErxW1sZ6OvQ)
|
||||||
- [Java 中 9 种常见的 CMS GC 问题分析与解决 - 美团技术团队 - 2020](https://tech.meituan.com/2020/11/12/java-9-cms-gc.html)
|
- [Java 中 9 种常见的 CMS GC 问题分析与解决 - 美团技术团队 - 2020](https://tech.meituan.com/2020/11/12/java-9-cms-gc.html)
|
||||||
|
|||||||
@ -139,7 +139,7 @@ public class Outer {
|
|||||||
- **JEP 389:外部链接器 API(孵化) :** 该孵化器 API 提供了静态类型、纯 Java 访问原生代码的特性,该 API 将大大简化绑定原生库的原本复杂且容易出错的过程。Java 1.1 就已通过 Java 原生接口(JNI)支持了原生方法调用,但并不好用。Java 开发人员应该能够为特定任务绑定特定的原生库。它还提供了外来函数支持,而无需任何中间的 JNI 粘合代码。
|
- **JEP 389:外部链接器 API(孵化) :** 该孵化器 API 提供了静态类型、纯 Java 访问原生代码的特性,该 API 将大大简化绑定原生库的原本复杂且容易出错的过程。Java 1.1 就已通过 Java 原生接口(JNI)支持了原生方法调用,但并不好用。Java 开发人员应该能够为特定任务绑定特定的原生库。它还提供了外来函数支持,而无需任何中间的 JNI 粘合代码。
|
||||||
- **JEP 357:从 Mercurial 迁移到 Git** :在此之前,OpenJDK 源代码是使用版本管理工具 Mercurial 进行管理,现在迁移到了 Git。
|
- **JEP 357:从 Mercurial 迁移到 Git** :在此之前,OpenJDK 源代码是使用版本管理工具 Mercurial 进行管理,现在迁移到了 Git。
|
||||||
- **JEP 369:迁移到 GitHub**:和 JEP 357 从 Mercurial 迁移到 Git 的改变一致,在把版本管理迁移到 Git 之后,选择了在 GitHub 上托管 OpenJDK 社区的 Git 仓库。不过只对 JDK 11 以及更高版本 JDK 进行了迁移。
|
- **JEP 369:迁移到 GitHub**:和 JEP 357 从 Mercurial 迁移到 Git 的改变一致,在把版本管理迁移到 Git 之后,选择了在 GitHub 上托管 OpenJDK 社区的 Git 仓库。不过只对 JDK 11 以及更高版本 JDK 进行了迁移。
|
||||||
- **JEP 386:移植 Alpine Linux** :Apine Linux 是一个独立的、非商业的 Linux 发行版,它十分的小,一个容器需要不超过 8MB 的空间,最小安装到磁盘只需要大约 130MB 存储空间,并且十分的简单,同时兼顾了安全性。此提案将 JDK 移植到了 Apline Linux,由于 Apline Linux 是基于 musl lib 的轻量级 Linux 发行版,因此其他 x64 和 AArch64 架构上使用 musl lib 的 Linux 发行版也适用。
|
- **JEP 386:移植 Alpine Linux** :Alpine Linux 是一个独立的、非商业的 Linux 发行版,它十分的小,一个容器需要不超过 8MB 的空间,最小安装到磁盘只需要大约 130MB 存储空间,并且十分的简单,同时兼顾了安全性。此提案将 JDK 移植到了 Apline Linux,由于 Apline Linux 是基于 musl lib 的轻量级 Linux 发行版,因此其他 x64 和 AArch64 架构上使用 musl lib 的 Linux 发行版也适用。
|
||||||
- **JEP 388:Windows/AArch64 移植** :这些 JEP 的重点不是移植工作本身,而是将它们集成到 JDK 主线存储库中;JEP 386 将 JDK 移植到 Alpine Linux 和其他使用 musl 作为 x64 上主要 C 库的发行版上。此外,JEP 388 将 JDK 移植到 Windows AArch64(ARM64)。
|
- **JEP 388:Windows/AArch64 移植** :这些 JEP 的重点不是移植工作本身,而是将它们集成到 JDK 主线存储库中;JEP 386 将 JDK 移植到 Alpine Linux 和其他使用 musl 作为 x64 上主要 C 库的发行版上。此外,JEP 388 将 JDK 移植到 Windows AArch64(ARM64)。
|
||||||
|
|
||||||
## 参考文献
|
## 参考文献
|
||||||
|
|||||||
@ -27,7 +27,7 @@ tag:
|
|||||||
|
|
||||||
**控制反转怎么理解呢?** 举个例子:"对象 a 依赖了对象 b,当对象 a 需要使用 对象 b 的时候必须自己去创建。但是当系统引入了 IOC 容器后, 对象 a 和对象 b 之前就失去了直接的联系。这个时候,当对象 a 需要使用 对象 b 的时候, 我们可以指定 IOC 容器去创建一个对象 b 注入到对象 a 中"。 对象 a 获得依赖对象 b 的过程,由主动行为变为了被动行为,控制权反转,这就是控制反转名字的由来。
|
**控制反转怎么理解呢?** 举个例子:"对象 a 依赖了对象 b,当对象 a 需要使用 对象 b 的时候必须自己去创建。但是当系统引入了 IOC 容器后, 对象 a 和对象 b 之前就失去了直接的联系。这个时候,当对象 a 需要使用 对象 b 的时候, 我们可以指定 IOC 容器去创建一个对象 b 注入到对象 a 中"。 对象 a 获得依赖对象 b 的过程,由主动行为变为了被动行为,控制权反转,这就是控制反转名字的由来。
|
||||||
|
|
||||||
**DI(Dependecy Inject,依赖注入)是实现控制反转的一种设计模式,依赖注入就是将实例变量传入到一个对象中去。**
|
**DI(Dependency Inject,依赖注入)是实现控制反转的一种设计模式,依赖注入就是将实例变量传入到一个对象中去。**
|
||||||
|
|
||||||
## 工厂设计模式
|
## 工厂设计模式
|
||||||
|
|
||||||
|
|||||||
@ -74,7 +74,7 @@ setInterval(() => {
|
|||||||
|
|
||||||
长轮询其实原理跟轮询差不多,都是采用轮询的方式。不过,如果服务端的数据没有发生变更,会 一直 hold 住请求,直到服务端的数据发生变化,或者等待一定时间超时才会返回。返回后,客户端又会立即再次发起下一次长轮询。
|
长轮询其实原理跟轮询差不多,都是采用轮询的方式。不过,如果服务端的数据没有发生变更,会 一直 hold 住请求,直到服务端的数据发生变化,或者等待一定时间超时才会返回。返回后,客户端又会立即再次发起下一次长轮询。
|
||||||
|
|
||||||
这次我使用 Apollo 配置中心实现长轮询的方式,应用了一个类`DeferredResult`,它是在 Servelet3.0 后经过 Spring 封装提供的一种异步请求机制,直意就是延迟结果。
|
这次我使用 Apollo 配置中心实现长轮询的方式,应用了一个类`DeferredResult`,它是在 Servlet3.0 后经过 Spring 封装提供的一种异步请求机制,直意就是延迟结果。
|
||||||
|
|
||||||
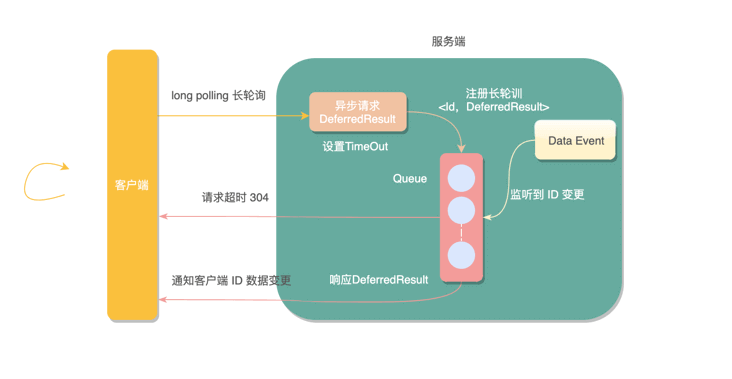
|

|
||||||
|
|
||||||
|
|||||||
@ -173,7 +173,7 @@ Docker 设计时,就充分利用 **Union FS** 的技术,将其设计为**分
|
|||||||
|
|
||||||
- **OFFICIAL Image** :代表镜像为 Docker 官方提供和维护,相对来说稳定性和安全性较高。
|
- **OFFICIAL Image** :代表镜像为 Docker 官方提供和维护,相对来说稳定性和安全性较高。
|
||||||
- **Stars** :和点赞差不多的意思,类似 GitHub 的 Star。
|
- **Stars** :和点赞差不多的意思,类似 GitHub 的 Star。
|
||||||
- **Dowloads** :代表镜像被拉取的次数,基本上能够表示镜像被使用的频度。
|
- **Downloads** :代表镜像被拉取的次数,基本上能够表示镜像被使用的频度。
|
||||||
|
|
||||||
当然,除了直接通过 Docker Hub 网站搜索镜像这种方式外,我们还可以通过 `docker search` 这个命令搜索 Docker Hub 中的镜像,搜索的结果是一致的。
|
当然,除了直接通过 Docker Hub 网站搜索镜像这种方式外,我们还可以通过 `docker search` 这个命令搜索 Docker Hub 中的镜像,搜索的结果是一致的。
|
||||||
|
|
||||||
|
|||||||
@ -34,7 +34,7 @@ head:
|
|||||||
|
|
||||||
项目中依赖的第三方库以及插件可统称为构件。每一个构件都可以使用 Maven 坐标唯一标识,坐标元素包括:
|
项目中依赖的第三方库以及插件可统称为构件。每一个构件都可以使用 Maven 坐标唯一标识,坐标元素包括:
|
||||||
|
|
||||||
- **goupId**(必须): 定义了当前 Maven 项目隶属的组织或公司。groupId 一般分为多段,通常情况下,第一段为域,第二段为公司名称。域又分为 org、com、cn 等,其中 org 为非营利组织,com 为商业组织,cn 表示中国。以 apache 开源社区的 tomcat 项目为例,这个项目的 groupId 是 org.apache,它的域是 org(因为 tomcat 是非营利项目),公司名称是 apache,artifactId 是 tomcat。
|
- **groupId**(必须): 定义了当前 Maven 项目隶属的组织或公司。groupId 一般分为多段,通常情况下,第一段为域,第二段为公司名称。域又分为 org、com、cn 等,其中 org 为非营利组织,com 为商业组织,cn 表示中国。以 apache 开源社区的 tomcat 项目为例,这个项目的 groupId 是 org.apache,它的域是 org(因为 tomcat 是非营利项目),公司名称是 apache,artifactId 是 tomcat。
|
||||||
- **artifactId**(必须):定义了当前 Maven 项目的名称,项目的唯一的标识符,对应项目根目录的名称。
|
- **artifactId**(必须):定义了当前 Maven 项目的名称,项目的唯一的标识符,对应项目根目录的名称。
|
||||||
- **version**(必须): 定义了 Maven 项目当前所处版本。
|
- **version**(必须): 定义了 Maven 项目当前所处版本。
|
||||||
- **packaging**(可选):定义了 Maven 项目的打包方式(比如 jar,war...),默认使用 jar。
|
- **packaging**(可选):定义了 Maven 项目的打包方式(比如 jar,war...),默认使用 jar。
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user