mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
Merge remote-tracking branch 'origin/main'
This commit is contained in:
commit
f9d5fc8c79
@ -83,7 +83,7 @@
|
||||
1. **线程池** :[Java 线程池详解](./docs/java/concurrent/java-thread-pool-summary.md)、[Java 线程池最佳实践](./docs/java/concurrent/java-thread-pool-best-practices.md)
|
||||
2. [ThreadLocal 关键字解析](docs/java/concurrent/threadlocal.md)
|
||||
3. [Java 并发容器总结](docs/java/concurrent/java-concurrent-collections.md)
|
||||
4. [Atomic 原子类总结](docs/java/concurrent/atomic原子类总结.md)
|
||||
4. [Atomic 原子类总结](docs/java/concurrent/atomic-classes.md)
|
||||
5. [AQS 原理以及 AQS 同步组件总结](docs/java/concurrent/aqs原理以及aqs同步组件总结.md)
|
||||
6. [CompletableFuture入门](docs/java/concurrent/completablefuture-intro.md)
|
||||
|
||||
|
||||
@ -249,7 +249,7 @@ module.exports = config({
|
||||
"数据库基础知识",
|
||||
"字符集",
|
||||
{
|
||||
title: "MySQL", prefix: "mysql/",
|
||||
title: "MySQL", prefix: "mysql/", icon: "mysql",
|
||||
children: [
|
||||
"mysql知识点&面试题总结",
|
||||
"a-thousand-lines-of-mysql-study-notes",
|
||||
@ -260,7 +260,7 @@ module.exports = config({
|
||||
],
|
||||
},
|
||||
{
|
||||
title: "Redis", prefix: "redis/",
|
||||
title: "Redis", prefix: "redis/", icon: "redis",
|
||||
children: ["redis-questions-01", "3-commonly-used-cache-read-and-write-strategies"],
|
||||
},
|
||||
],
|
||||
@ -321,7 +321,7 @@ module.exports = config({
|
||||
children: [
|
||||
"读写分离&分库分表", "负载均衡",
|
||||
{
|
||||
title: "消息队列", prefix: "message-queue/",
|
||||
title: "消息队列", prefix: "message-queue/", icon: "MQ",
|
||||
children: ["message-queue", "kafka知识点&面试题总结", "rocketmq-intro", "rocketmq-questions", "rabbitmq-intro"],
|
||||
},
|
||||
],
|
||||
|
||||
@ -1,2 +1,2 @@
|
||||
// import icon
|
||||
@import '//at.alicdn.com/t/font_2922463_m6dpqhk3xfh.css'
|
||||
@import '//at.alicdn.com/t/font_2922463_j457c9usui.css'
|
||||
@ -74,8 +74,6 @@ tag:
|
||||
|
||||
🙋 **我:** 好的! 下图是 Java 内存区域,我们从 JVM 的角度来说一下线程和进程之间的关系吧!
|
||||
|
||||
> 如果你对 Java 内存区域 (运行时数据区) 这部分知识不太了解的话可以阅读一下这篇文章:[《可能是把 Java 内存区域讲的最清楚的一篇文章》](https://snailclimb.gitee.io/javaguide/#/docs/java/jvm/Java内存区域)
|
||||
|
||||
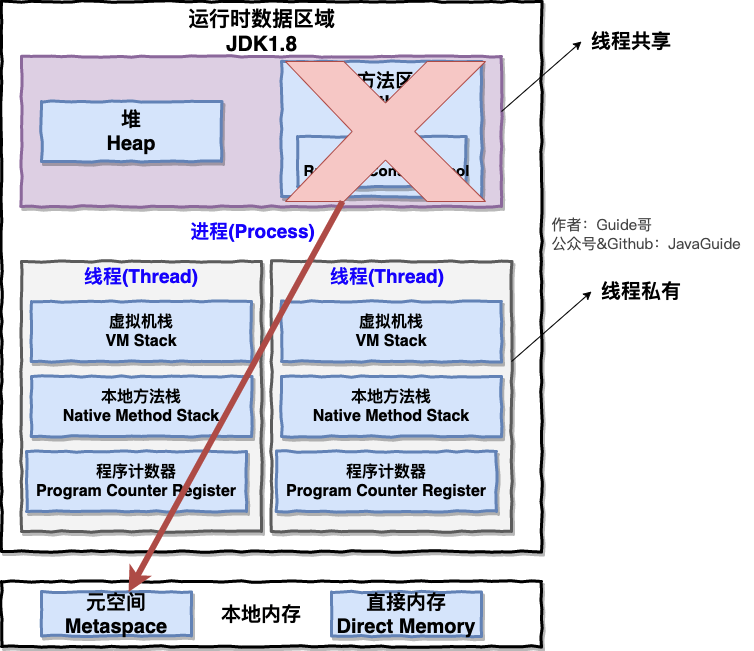
|
||||
|
||||
从上图可以看出:一个进程中可以有多个线程,多个线程共享进程的**堆**和**方法区 (JDK1.8 之后的元空间)**资源,但是每个线程有自己的**程序计数器**、**虚拟机栈** 和 **本地方法栈**。
|
||||
|
||||
@ -84,7 +84,7 @@ B 树也称 B-树,全称为 **多路平衡查找树** ,B+ 树是 B 树的一
|
||||
|
||||
MyISAM 引擎中,B+Tree 叶节点的 data 域存放的是数据记录的地址。在索引检索的时候,首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
|
||||
|
||||
InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”,而其余的索引都作为辅助索引,辅助索引的 data 域存储相应记录主键的值而不是地址,这也是和 MyISAM 不同的地方。在根据主索引搜索时,直接找到 key 所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,在走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
|
||||
InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按 B+Tree 组织的一个索引结构,树的叶节点 data 域保存了完整的数据记录。这个索引的 key 是数据表的主键,因此 InnoDB 表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”,而其余的索引都作为辅助索引,辅助索引的 data 域存储相应记录主键的值而不是地址,这也是和 MyISAM 不同的地方。在根据主索引搜索时,直接找到 key 所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。 因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。
|
||||
|
||||
## 索引类型
|
||||
|
||||
@ -263,4 +263,4 @@ ALTER TABLE `table_name` ADD FULLTEXT ( `column`)
|
||||
|
||||
```sql
|
||||
ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
|
||||
```
|
||||
```
|
||||
|
||||
@ -276,7 +276,7 @@ mysql> SELECT @@tx_isolation;
|
||||
|
||||
~~这里需要注意的是:与 SQL 标准不同的地方在于 InnoDB 存储引擎在 **REPEATABLE-READ(可重读)** 事务隔离级别下使用的是 Next-Key Lock 锁算法,因此可以避免幻读的产生,这与其他数据库系统(如 SQL Server)是不同的。所以说 InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)** 已经可以完全保证事务的隔离性要求,即达到了 SQL 标准的 **SERIALIZABLE(可串行化)** 隔离级别。~~
|
||||
|
||||
🐛 问题更正:**MySQL InnoDB 的 REPEATABLE-READ(可重读)并不保证避免幻读,需要应用使用加锁读来保证。而这个加锁度使用到的机制就是 Next-Key Locks。**
|
||||
🐛 问题更正:**MySQL InnoDB 的 REPEATABLE-READ(可重读)并不保证避免幻读,需要应用使用加锁读来保证。而这个加锁读使用到的机制就是 Next-Key Locks。**
|
||||
|
||||
因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 **READ-COMMITTED(读取提交内容)** ,但是你要知道的是 InnoDB 存储引擎默认使用 **REPEATABLE-READ(可重读)** 并不会有任何性能损失。
|
||||
|
||||
|
||||
@ -74,7 +74,7 @@ mysql> SELECT @@tx_isolation;
|
||||
|
||||
~~这里需要注意的是:与 SQL 标准不同的地方在于 InnoDB 存储引擎在 **REPEATABLE-READ(可重读)** 事务隔离级别下使用的是 Next-Key Lock 锁算法,因此可以避免幻读的产生,这与其他数据库系统(如 SQL Server)是不同的。所以说 InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)** 已经可以完全保证事务的隔离性要求,即达到了 SQL 标准的 **SERIALIZABLE(可串行化)** 隔离级别。~~
|
||||
|
||||
🐛 问题更正:**MySQL InnoDB 的 REPEATABLE-READ(可重读)并不保证避免幻读,需要应用使用加锁读来保证。而这个加锁度使用到的机制就是 Next-Key Locks。**
|
||||
🐛 问题更正:**MySQL InnoDB 的 REPEATABLE-READ(可重读)并不保证避免幻读,需要应用使用加锁读来保证。而这个加锁读使用到的机制就是 Next-Key Locks。**
|
||||
|
||||
因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 **READ-COMMITTED(读取提交内容)** ,但是你要知道的是 InnoDB 存储引擎默认使用 **REPEATABLE-READ(可重读)** 并不会有任何性能损失。
|
||||
|
||||
|
||||
@ -577,7 +577,7 @@ AOF 文件的保存位置和 RDB 文件的位置相同,都是通过 dir 参数
|
||||
|
||||
```conf
|
||||
appendfsync always #每次有数据修改发生时都会写入AOF文件,这样会严重降低Redis的速度
|
||||
appendfsync everysec #每秒钟同步一次,显示地将多个写命令同步到硬盘
|
||||
appendfsync everysec #每秒钟同步一次,显式地将多个写命令同步到硬盘
|
||||
appendfsync no #让操作系统决定何时进行同步
|
||||
```
|
||||
|
||||
|
||||
@ -174,7 +174,7 @@ Watcher(事件监听器),是 ZooKeeper 中的一个很重要的特性。Zo
|
||||
|
||||

|
||||
|
||||
_破音:非常有用的一个特性,都能出小本本记好了,后面用到 ZooKeeper 基本离不开 Watcher(事件监听器)机制。_
|
||||
_破音:非常有用的一个特性,都拿出小本本记好了,后面用到 ZooKeeper 基本离不开 Watcher(事件监听器)机制。_
|
||||
|
||||
### 3.6. 会话(Session)
|
||||
|
||||
|
||||
@ -71,7 +71,7 @@
|
||||
|
||||
Dubbo 目前已经有接近 34.4 k 的 Star 。
|
||||
|
||||
在 **2020 年度 OSC 中国开源项目** 评选活动中,Dubbo 位列开发框架和基础组件类项目的第7名。想比几年前来说,热度和排名有所下降。
|
||||
在 **2020 年度 OSC 中国开源项目** 评选活动中,Dubbo 位列开发框架和基础组件类项目的第7名。相比几年前来说,热度和排名有所下降。
|
||||
|
||||

|
||||
|
||||
|
||||
@ -21,7 +21,7 @@ tag:
|
||||
|
||||
解决方案大致可以理解成:先在所有的将军中选出一个大将军,用来做出所有的决定。
|
||||
|
||||
举例如下:假如现在一共有 3 个将军 A,B 和 C,每个讲解都有一个随机时间的倒计时器,倒计时一结束,这个将军就把自己当成大将军候选人,然后派信使传递选举投票的信息给将军 B 和 C,如果将军 B 和 C 还没有把自己当作候选人(自己的倒计时还没有结束),并且没有把选举票投给其他人,它们就会把票投给将军 A,信使回到将军 A 时,将军 A 知道自己收到了足够的票数,成为大将军。在有了大将军之后,是否需要进攻就由大将军 A 决定,然后再去派信使通知另外两个将军,自己已经成为了大将军。如果一段时间还没收到将军 B 和 C 的回复(信使可能会被暗示),那就再重派一个信使,直到收到回复。
|
||||
举例如下:假如现在一共有 3 个将军 A,B 和 C,每个将军都有一个随机时间的倒计时器,倒计时一结束,这个将军就把自己当成大将军候选人,然后派信使传递选举投票的信息给将军 B 和 C,如果将军 B 和 C 还没有把自己当作候选人(自己的倒计时还没有结束),并且没有把选举票投给其他人,它们就会把票投给将军 A,信使回到将军 A 时,将军 A 知道自己收到了足够的票数,成为大将军。在有了大将军之后,是否需要进攻就由大将军 A 决定,然后再去派信使通知另外两个将军,自己已经成为了大将军。如果一段时间还没收到将军 B 和 C 的回复(信使可能会被暗示),那就再重派一个信使,直到收到回复。
|
||||
|
||||
### 1.2 共识算法
|
||||
|
||||
|
||||
@ -36,9 +36,11 @@ new 运算符,new 创建对象实例(对象实例在堆内存中),对象
|
||||
- 对象的相等一般比较的是内存中存放的内容是否相等。
|
||||
- 引用相等一般比较的是他们指向的内存地址是否相等。
|
||||
|
||||
### 一个类的构造方法的作用是什么? 若一个类没有声明构造方法,该程序能正确执行吗?
|
||||
### 一个类的构造方法的作用是什么?
|
||||
|
||||
构造方法主要作用是完成对类对象的初始化工作。
|
||||
构造方法是一种特殊的方法,主要作用是完成对象的初始化工作。
|
||||
|
||||
### 如果一个类没有声明构造方法,该程序能正确执行吗?
|
||||
|
||||
如果一个类没有声明构造方法,也可以执行!因为一个类即使没有声明构造方法也会有默认的不带参数的构造方法。如果我们自己添加了类的构造方法(无论是否有参),Java 就不会再添加默认的无参数的构造方法了,这时候,就不能直接 new 一个对象而不传递参数了,所以我们一直在不知不觉地使用构造方法,这也是为什么我们在创建对象的时候后面要加一个括号(因为要调用无参的构造方法)。如果我们重载了有参的构造方法,记得都要把无参的构造方法也写出来(无论是否用到),因为这可以帮助我们在创建对象的时候少踩坑。
|
||||
|
||||
|
||||
@ -392,7 +392,7 @@ pool-1-thread-2 End. Time = Sun Apr 12 11:14:47 CST 2020
|
||||
return false;
|
||||
|
||||
for (;;) {
|
||||
//获取线程池中线程的数量
|
||||
//获取线程池中工作的线程的数量
|
||||
int wc = workerCountOf(c);
|
||||
// core参数为true的话表明队列也满了,线程池大小变为 maximumPoolSize
|
||||
if (wc >= CAPACITY ||
|
||||
|
||||
@ -314,7 +314,7 @@ JVM的参数非常之多,这里只列举比较重要的几个,通过各种
|
||||
|------|------------|------------|------|
|
||||
| -Xms | 初始堆大小 | 物理内存的1/64(<1GB) |默认(MinHeapFreeRatio参数可以调整)空余堆内存小于40%时,JVM就会增大堆直到-Xmx的最大限制.
|
||||
| -Xmx | 最大堆大小 | 物理内存的1/4(<1GB) | 默认(MaxHeapFreeRatio参数可以调整)空余堆内存大于70%时,JVM会减少堆直到 -Xms的最小限制
|
||||
| -Xmn | 年轻代大小(1.4or lator) | |注意:此处的大小是(eden+ 2 survivor space).与jmap -heap中显示的New gen是不同的。整个堆大小=年轻代大小 + 老年代大小 + 持久代(永久代)大小.增大年轻代后,将会减小年老代大小.此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8
|
||||
| -Xmn | 年轻代大小(1.4or later) | |注意:此处的大小是(eden+ 2 survivor space).与jmap -heap中显示的New gen是不同的。整个堆大小=年轻代大小 + 老年代大小 + 持久代(永久代)大小.增大年轻代后,将会减小年老代大小.此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8
|
||||
| -XX:NewSize | 设置年轻代大小(for 1.3/1.4) | |
|
||||
| -XX:MaxNewSize | 年轻代最大值(for 1.3/1.4) | |
|
||||
| -XX:PermSize | 设置持久代(perm gen)初始值 | 物理内存的1/64 |
|
||||
|
||||
@ -506,7 +506,7 @@ mysql> SELECT @@tx_isolation;
|
||||
|
||||
~~这里需要注意的是:与 SQL 标准不同的地方在于 InnoDB 存储引擎在 **REPEATABLE-READ(可重读)** 事务隔离级别下使用的是Next-Key Lock 锁算法,因此可以避免幻读的产生,这与其他数据库系统(如 SQL Server)是不同的。所以说InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)** 已经可以完全保证事务的隔离性要求,即达到了 SQL标准的 **SERIALIZABLE(可串行化)** 隔离级别。~~
|
||||
|
||||
🐛问题更正:**MySQL InnoDB的REPEATABLE-READ(可重读)并不保证避免幻读,需要应用使用加锁读来保证。而这个加锁度使用到的机制就是 Next-Key Locks。**
|
||||
🐛问题更正:**MySQL InnoDB的REPEATABLE-READ(可重读)并不保证避免幻读,需要应用使用加锁读来保证。而这个加锁读使用到的机制就是 Next-Key Locks。**
|
||||
|
||||
因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 **READ-COMMITTED(读取提交内容)** ,但是你要知道的是InnoDB 存储引擎默认使用 **REPEAaTABLE-READ(可重读)** 并不会有任何性能损失。
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user