mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
[docs update]完善redis内存管理
This commit is contained in:
parent
b6cdf6dd3a
commit
f852aaf6e1
@ -665,7 +665,7 @@ OK
|
|||||||
|
|
||||||
Redis 通过一个叫做过期字典(可以看作是 hash 表)来保存数据过期的时间。过期字典的键指向 Redis 数据库中的某个 key(键),过期字典的值是一个 long long 类型的整数,这个整数保存了 key 所指向的数据库键的过期时间(毫秒精度的 UNIX 时间戳)。
|
Redis 通过一个叫做过期字典(可以看作是 hash 表)来保存数据过期的时间。过期字典的键指向 Redis 数据库中的某个 key(键),过期字典的值是一个 long long 类型的整数,这个整数保存了 key 所指向的数据库键的过期时间(毫秒精度的 UNIX 时间戳)。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
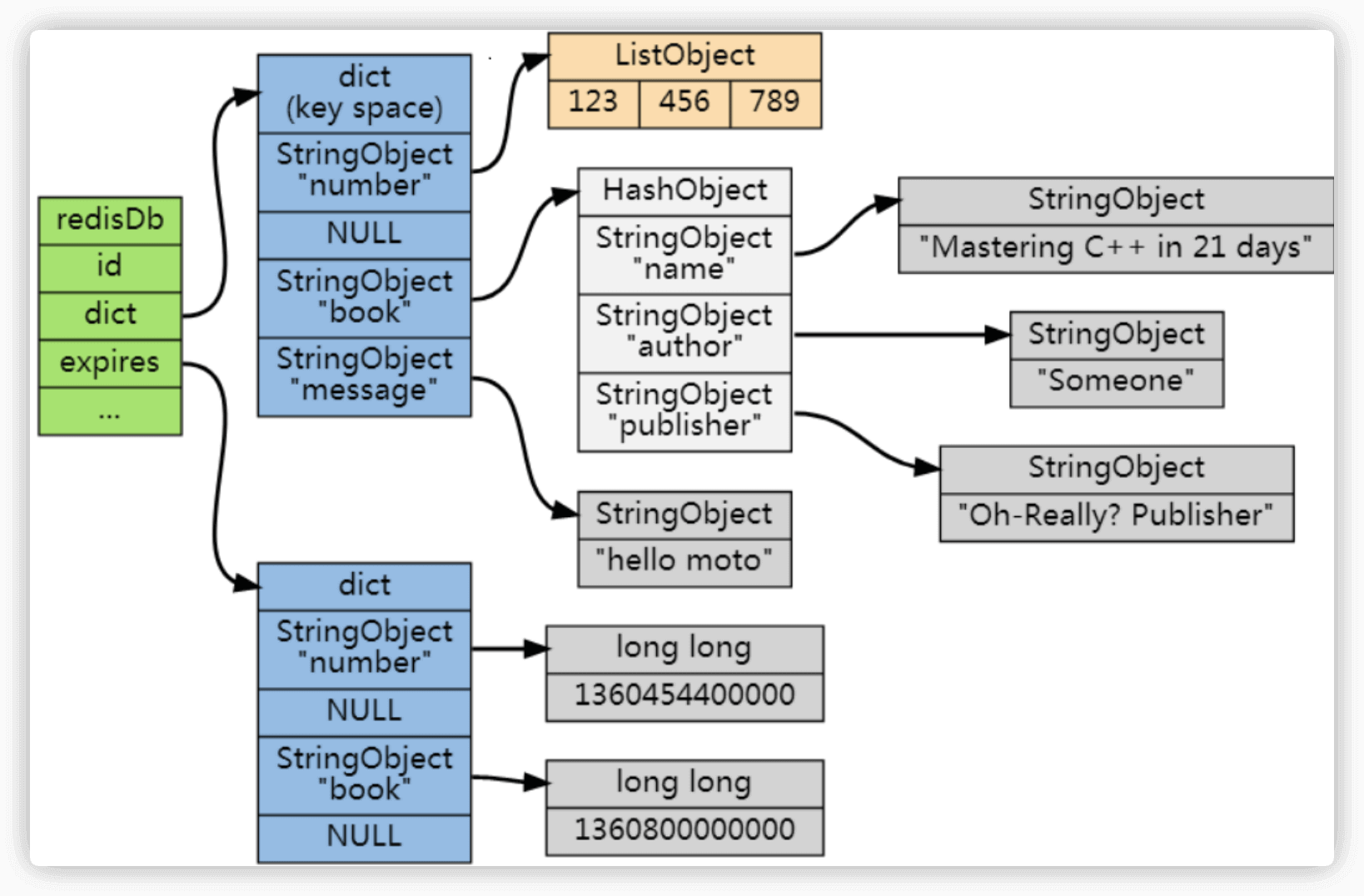
过期字典是存储在 redisDb 这个结构里的:
|
过期字典是存储在 redisDb 这个结构里的:
|
||||||
|
|
||||||
@ -679,38 +679,151 @@ typedef struct redisDb {
|
|||||||
} redisDb;
|
} redisDb;
|
||||||
```
|
```
|
||||||
|
|
||||||
### 过期的数据的删除策略了解么?
|
在查询一个 key 的时候,Redis 首先检查该 key 是否存在于过期字典中(时间复杂度为 O(1)),如果不在就直接返回,在的话需要判断一下这个 key 是否过期,过期直接删除 key 然后返回 null。
|
||||||
|
|
||||||
|
### Redis 过期 key 删除策略了解么?
|
||||||
|
|
||||||
如果假设你设置了一批 key 只能存活 1 分钟,那么 1 分钟后,Redis 是怎么对这批 key 进行删除的呢?
|
如果假设你设置了一批 key 只能存活 1 分钟,那么 1 分钟后,Redis 是怎么对这批 key 进行删除的呢?
|
||||||
|
|
||||||
常用的过期数据的删除策略就两个(重要!自己造缓存轮子的时候需要格外考虑的东西):
|
常用的过期数据的删除策略就下面这几种(重要!自己造缓存轮子的时候需要格外考虑的东西):
|
||||||
|
|
||||||
1. **惰性删除**:只会在取出 key 的时候才对数据进行过期检查。这样对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
|
1. **惰性删除**:只会在取出/查询 key 的时候才对数据进行过期检查。这种方式对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
|
||||||
2. **定期删除**:每隔一段时间抽取一批 key 执行删除过期 key 操作。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
|
2. **定期删除**:周期性地随机从设置了过期时间的 key 中抽查一批,然后逐个检查这些 key 是否过期,过期就删除 key。相比于惰性删除,定期删除对内存更友好,对 CPU 不太友好。
|
||||||
|
3. **延迟队列**:把设置过期时间的 key 放到一个延迟队列里,到期之后就删除 key。这种方式可以保证每个过期 key 都能被删除,但维护延迟队列太麻烦,队列本身也要占用资源。
|
||||||
|
4. **定时删除**:每个设置了过期时间的 key 都会在设置的时间到达时立即被删除。这种方法可以确保内存中不会有过期的键,但是它对 CPU 的压力最大,因为它需要为每个键都设置一个定时器。
|
||||||
|
|
||||||
定期删除对内存更加友好,惰性删除对 CPU 更加友好。两者各有千秋,所以 Redis 采用的是 **定期删除+惰性/懒汉式删除** 。
|
**Redis 采用的那种删除策略呢?**
|
||||||
|
|
||||||
但是,仅仅通过给 key 设置过期时间还是有问题的。因为还是可能存在定期删除和惰性删除漏掉了很多过期 key 的情况。这样就导致大量过期 key 堆积在内存里,然后就 Out of memory 了。
|
Redis 采用的是 **定期删除+惰性/懒汉式删除** 结合的策略,这也是大部分缓存框架的选择。定期删除对内存更加友好,惰性删除对 CPU 更加友好。两者各有千秋,结合起来使用既能兼顾 CPU 友好,又能兼顾内存友好。
|
||||||
|
|
||||||
怎么解决这个问题呢?答案就是:**Redis 内存淘汰机制。**
|
下面是我们详细介绍一下 Redis 中的定期删除具体是如何做的。
|
||||||
|
|
||||||
### Redis 内存淘汰机制了解么?
|
Redis 的定期删除过程是随机的(周期性地随机从设置了过期时间的 key 中抽查一批),所以并不保证所有过期键都会被立即删除。这也就解释了为什么有的 key 过期了,并没有被删除。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
|
||||||
|
|
||||||
|
另外,定期删除还会受到执行时间和过期 key 的比例的影响:
|
||||||
|
|
||||||
|
- 执行时间已经超过了阈值,那么就中断这一次定期删除循环,以避免使用过多的 CPU 时间。
|
||||||
|
- 如果这一批过期的 key 比例超过一个比例,就会重复执行此删除流程,以更积极地清理过期 key。相应地,如果过期的 key 比例低于这个比例,就会中断这一次定期删除循环,避免做过多的工作而获得很少的内存回收。
|
||||||
|
|
||||||
|
Redis 7.2 版本的执行时间阈值是 **25ms**,过期 key 比例设定值是 **10%**。
|
||||||
|
|
||||||
|
```java
|
||||||
|
#define ACTIVE_EXPIRE_CYCLE_FAST_DURATION 1000 /* Microseconds. */
|
||||||
|
#define ACTIVE_EXPIRE_CYCLE_SLOW_TIME_PERC 25 /* Max % of CPU to use. */
|
||||||
|
#define ACTIVE_EXPIRE_CYCLE_ACCEPTABLE_STALE 10 /* % of stale keys after which
|
||||||
|
we do extra efforts. */
|
||||||
|
```
|
||||||
|
|
||||||
|
**每次随机抽查数量是多少?**
|
||||||
|
|
||||||
|
`expire.c`中定义了每次随机抽查的数量,Redis 7.2 版本为 20 ,也就是说每次会随机选择 20 个设置了过期时间的 key 判断是否过期。
|
||||||
|
|
||||||
|
```c
|
||||||
|
#define ACTIVE_EXPIRE_CYCLE_KEYS_PER_LOOP 20 /* Keys for each DB loop. */
|
||||||
|
```
|
||||||
|
|
||||||
|
**如何控制定期删除的执行频率?**
|
||||||
|
|
||||||
|
在 Redis 中,定期删除的频率是由 **hz** 参数控制的。hz 默认为 10,代表每秒执行 10 次,也就是每秒钟进行 10 次尝试来查找并删除过期的 key。
|
||||||
|
|
||||||
|
hz 的取值范围为 1~500。增大 hz 参数的值会提升定期删除的频率。如果你想要更频繁地执行定期删除任务,可以适当增加 hz 的值,但这会加 CPU 的使用率。根据 Redis 官方建议,hz 的值不建议超过 100,对于大部分用户使用默认的 10 就足够了。
|
||||||
|
|
||||||
|
下面是 hz 参数的官方注释,我翻译了其中的重要信息(Redis 7.2 版本)。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
类似的参数还有一个 **dynamic-hz**,这个参数开启之后 Redis 就会在 hz 的基础上动态计算一个值。Redis 提供并默认启用了使用自适应 hz 值的能力,
|
||||||
|
|
||||||
|
这两个参数都在 Redis 配置文件 `redis.conf`中:
|
||||||
|
|
||||||
|
```properties
|
||||||
|
# 默认为 10
|
||||||
|
hz 10
|
||||||
|
# 默认开启
|
||||||
|
dynamic-hz yes
|
||||||
|
```
|
||||||
|
|
||||||
|
多提一嘴,除了定期删除过期 key 这个定期任务之外,还有一些其他定期任务例如关闭超时的客户端连接、更新统计信息,这些定期任务的执行频率也是通过 hz 参数决定。
|
||||||
|
|
||||||
|
**为什么定期删除不是把所有过期 key 都删除呢?**
|
||||||
|
|
||||||
|
这样会对性能造成太大的影响。如果我们 key 数量非常庞大的话,挨个遍历检查是非常耗时的,会严重影响性能。Redis 设计这种策略的目的是为了平衡内存和性能。
|
||||||
|
|
||||||
|
**为什么 key 过期之后不立马把它删掉呢?这样不是会浪费很多内存空间吗?**
|
||||||
|
|
||||||
|
因为不太好办到,或者说这种删除方式的成本太高了。假如我们使用延迟队列作为删除策略,这样存在下面这些问题:
|
||||||
|
|
||||||
|
1. 队列本身的开销可能很大:key 多的情况下,一个延迟队列可能无法容纳。
|
||||||
|
2. 维护延迟队列太麻烦:修改 key 的过期时间就需要调整期在延迟队列中的位置,并且,还需要引入并发控制。
|
||||||
|
|
||||||
|
### 大量 key 集中过期怎么办?
|
||||||
|
|
||||||
|
如果存在大量 key 集中过期的问题,可能会使 Redis 的请求延迟变高。可以采用下面的可选方案来应对:
|
||||||
|
|
||||||
|
1. 尽量避免 key 集中过期,在设置键的过期时间时尽量随机一点。
|
||||||
|
2. 对过期的 key 开启 lazyfree 机制(修改 `redis.conf` 中的 `lazyfree-lazy-expire`参数即可),这样会在后台异步删除过期的 key,不会阻塞主线程的运行。
|
||||||
|
|
||||||
|
### Redis 内存淘汰策略了解么?
|
||||||
|
|
||||||
> 相关问题:MySQL 里有 2000w 数据,Redis 中只存 20w 的数据,如何保证 Redis 中的数据都是热点数据?
|
> 相关问题:MySQL 里有 2000w 数据,Redis 中只存 20w 的数据,如何保证 Redis 中的数据都是热点数据?
|
||||||
|
|
||||||
Redis 提供 6 种数据淘汰策略:
|
Redis 的内存淘汰策略只有在运行内存达到了配置的最大内存阈值时才会触发,这个阈值是通过`redis.conf`的`maxmemory`参数来定义的。64 位操作系统下,`maxmemory` 默认为 0 ,表示不限制内存大小。32 位操作系统下,默认的最大内存值是 3GB。
|
||||||
|
|
||||||
|
你可以使用命令 `config get maxmemory` 来查看 `maxmemory`的值。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
> config get maxmemory
|
||||||
|
maxmemory
|
||||||
|
0
|
||||||
|
```
|
||||||
|
|
||||||
|
Redis 提供了 6 种内存淘汰策略:
|
||||||
|
|
||||||
1. **volatile-lru(least recently used)**:从已设置过期时间的数据集(`server.db[i].expires`)中挑选最近最少使用的数据淘汰。
|
1. **volatile-lru(least recently used)**:从已设置过期时间的数据集(`server.db[i].expires`)中挑选最近最少使用的数据淘汰。
|
||||||
2. **volatile-ttl**:从已设置过期时间的数据集(`server.db[i].expires`)中挑选将要过期的数据淘汰。
|
2. **volatile-ttl**:从已设置过期时间的数据集(`server.db[i].expires`)中挑选将要过期的数据淘汰。
|
||||||
3. **volatile-random**:从已设置过期时间的数据集(`server.db[i].expires`)中任意选择数据淘汰。
|
3. **volatile-random**:从已设置过期时间的数据集(`server.db[i].expires`)中任意选择数据淘汰。
|
||||||
4. **allkeys-lru(least recently used)**:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的 key(这个是最常用的)。
|
4. **allkeys-lru(least recently used)**:从数据集(`server.db[i].dict`)中移除最近最少使用的数据淘汰。
|
||||||
5. **allkeys-random**:从数据集(`server.db[i].dict`)中任意选择数据淘汰。
|
5. **allkeys-random**:从数据集(`server.db[i].dict`)中任意选择数据淘汰。
|
||||||
6. **no-eviction**:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
|
6. **no-eviction**(默认内存淘汰策略):禁止驱逐数据,当内存不足以容纳新写入数据时,新写入操作会报错。
|
||||||
|
|
||||||
4.0 版本后增加以下两种:
|
4.0 版本后增加以下两种:
|
||||||
|
|
||||||
7. **volatile-lfu(least frequently used)**:从已设置过期时间的数据集(`server.db[i].expires`)中挑选最不经常使用的数据淘汰。
|
7. **volatile-lfu(least frequently used)**:从已设置过期时间的数据集(`server.db[i].expires`)中挑选最不经常使用的数据淘汰。
|
||||||
8. **allkeys-lfu(least frequently used)**:当内存不足以容纳新写入数据时,在键空间中,移除最不经常使用的 key。
|
8. **allkeys-lfu(least frequently used)**:从数据集(`server.db[i].dict`)中移除最不经常使用的数据淘汰。
|
||||||
|
|
||||||
|
`allkeys-xxx` 表示从所有的键值中淘汰数据,而 `volatile-xxx` 表示从设置了过期时间的键值中淘汰数据。
|
||||||
|
|
||||||
|
`config.c`中定义了内存淘汰策略的枚举数组:
|
||||||
|
|
||||||
|
```c
|
||||||
|
configEnum maxmemory_policy_enum[] = {
|
||||||
|
{"volatile-lru", MAXMEMORY_VOLATILE_LRU},
|
||||||
|
{"volatile-lfu", MAXMEMORY_VOLATILE_LFU},
|
||||||
|
{"volatile-random",MAXMEMORY_VOLATILE_RANDOM},
|
||||||
|
{"volatile-ttl",MAXMEMORY_VOLATILE_TTL},
|
||||||
|
{"allkeys-lru",MAXMEMORY_ALLKEYS_LRU},
|
||||||
|
{"allkeys-lfu",MAXMEMORY_ALLKEYS_LFU},
|
||||||
|
{"allkeys-random",MAXMEMORY_ALLKEYS_RANDOM},
|
||||||
|
{"noeviction",MAXMEMORY_NO_EVICTION},
|
||||||
|
{NULL, 0}
|
||||||
|
};
|
||||||
|
```
|
||||||
|
|
||||||
|
你可以使用 `config get maxmemory-policy` 命令来查看当前 Redis 的内存淘汰策略。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
> config get maxmemory-policy
|
||||||
|
maxmemory-policy
|
||||||
|
noeviction
|
||||||
|
```
|
||||||
|
|
||||||
|
可以通过`config set maxmemory-policy 内存淘汰策略` 命令修改内存淘汰策略,立即生效,但这种方式重启 Redis 之后就失效了。修改 `redis.conf` 中的 `maxmemory-policy` 参数不会因为重启而失效,不过,需要重启之后修改才能生效。
|
||||||
|
|
||||||
|
```properties
|
||||||
|
maxmemory-policy noeviction
|
||||||
|
```
|
||||||
|
|
||||||
|
关于淘汰策略的详细说明可以参考 Redis 官方文档:<https://redis.io/docs/reference/eviction/>。
|
||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
|
|||||||
@ -75,8 +75,8 @@ String message = STR."Greetings \{name}!";
|
|||||||
Java 目前支持三种模板处理器:
|
Java 目前支持三种模板处理器:
|
||||||
|
|
||||||
- STR:自动执行字符串插值,即将模板中的每个嵌入式表达式替换为其值(转换为字符串)。
|
- STR:自动执行字符串插值,即将模板中的每个嵌入式表达式替换为其值(转换为字符串)。
|
||||||
- FMT:和 STR 类似,但是它还可以接受格式说明符,这些格式说明符出现在嵌入式表达式的左边,用来控制输出的样式
|
- FMT:和 STR 类似,但是它还可以接受格式说明符,这些格式说明符出现在嵌入式表达式的左边,用来控制输出的样式。
|
||||||
- RAW:不会像 STR 和 FMT 模板处理器那样自动处理字符串模板,而是返回一个 `StringTemplate` 对象,这个对象包含了模板中的文本和表达式的信息
|
- RAW:不会像 STR 和 FMT 模板处理器那样自动处理字符串模板,而是返回一个 `StringTemplate` 对象,这个对象包含了模板中的文本和表达式的信息。
|
||||||
|
|
||||||
```java
|
```java
|
||||||
String name = "Lokesh";
|
String name = "Lokesh";
|
||||||
@ -92,7 +92,7 @@ StringTemplate st = RAW."Greetings \{name}.";
|
|||||||
String message = STR.process(st);
|
String message = STR.process(st);
|
||||||
```
|
```
|
||||||
|
|
||||||
除了 JDK 自带的三种模板处理器外,你还可以实现 `StringTemplate.Processor` 接口来创建自己的模板处理器。
|
除了 JDK 自带的三种模板处理器外,你还可以实现 `StringTemplate.Processor` 接口来创建自己的模板处理器,只需要继承 `StringTemplate.Processor`接口,然后实现 `process` 方法即可。
|
||||||
|
|
||||||
我们可以使用局部变量、静态/非静态字段甚至方法作为嵌入表达式:
|
我们可以使用局部变量、静态/非静态字段甚至方法作为嵌入表达式:
|
||||||
|
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user