diff --git a/README.md b/README.md
index 2055a367..23756eb7 100644
--- a/README.md
+++ b/README.md
@@ -21,6 +21,13 @@
 +
+Sponsor
+
+
+ +
+
+
+
+
推荐使用 https://snailclimb.top/JavaGuide/ 在线阅读(访问速度慢的话,请使用 https://snailclimb.gitee.io/javaguide ),在线阅读内容本仓库同步一致。这种方式阅读的优势在于:有侧边栏阅读体验更好,Gitee pages 的访问速度相对来说也比较快。
## 目录
@@ -142,7 +149,8 @@
### MySQL
-* **[MySQL 学习与面试](docs/database/MySQL.md)**
+* **[【推荐】MySQL/数据库 知识点总结](docs/database/MySQL.md)**
+* **[阿里巴巴开发手册数据库部分的一些最佳实践](docs/database/阿里巴巴开发手册数据库部分的一些最佳实践.md)**
* **[一千行MySQL学习笔记](docs/database/一千行MySQL命令.md)**
* [MySQL高性能优化规范建议](docs/database/MySQL高性能优化规范建议.md)
* [数据库索引总结](docs/database/MySQL%20Index.md)
@@ -209,6 +217,7 @@
* **[【备战面试4】Github上开源的Java面试/学习相关的仓库推荐](docs/essential-content-for-interview/PreparingForInterview/JavaInterviewLibrary.md)**
* **[【备战面试5】如果面试官问你“你有什么问题问我吗?”时,你该如何回答](docs/essential-content-for-interview/PreparingForInterview/如果面试官问你"你有什么问题问我吗?"时,你该如何回答.md)**
* **[【备战面试6】美团面试常见问题总结(附详解答案)](docs/essential-content-for-interview/PreparingForInterview/美团面试常见问题总结.md)**
+* **[【备战面试7】一些刁难的面试问题总结](https://xiaozhuanlan.com/topic/9056431872)**
### 常见面试题总结
diff --git a/docs/data/spring-boot-practical-projects.md b/docs/data/spring-boot-practical-projects.md
index 09c545b1..046af88a 100644
--- a/docs/data/spring-boot-practical-projects.md
+++ b/docs/data/spring-boot-practical-projects.md
@@ -1,3 +1,5 @@
+最近经常被读者问到有没有 Spring Boot 实战项目可以学习,于是,我就去 Github 上找了 10 个我觉得还不错的实战项目。对于这些实战项目,有部分是比较适合 Spring Boot 刚入门的朋友学习的,还有一部分可能要求你对 Spring Boot 相关技术比较熟悉。需要的朋友可以根据个人实际情况进行选择。如果你对 Spring Boot 不太熟悉的话,可以看我最近开源的 springboot-guide:https://github.com/Snailclimb/springboot-guide 入门(还在持续更新中)。
+
### mall
- **Github地址**: [https://github.com/macrozheng/mall](https://github.com/macrozheng/mall)
@@ -32,4 +34,33 @@
- **Github地址**:[https://github.com/YunaiV/onemall](https://github.com/YunaiV/onemall)
- **star**: 1.2k
-- **介绍**: mall 商城,基于微服务的思想,构建在 B2C 电商场景下的项目实战。核心技术栈,是 Spring Boot + Dubbo 。未来,会重构成 Spring Cloud Alibaba 。
\ No newline at end of file
+- **介绍**: mall 商城,基于微服务的思想,构建在 B2C 电商场景下的项目实战。核心技术栈,是 Spring Boot + Dubbo 。未来,会重构成 Spring Cloud Alibaba 。
+
+### Guns
+
+- **Github地址**:[https://github.com/stylefeng/Guns](https://github.com/stylefeng/Guns)
+- **star**: 2.3k
+- **介绍**: Guns基于SpringBoot 2,致力于做更简洁的后台管理系统,完美整合springmvc + shiro + mybatis-plus + beetl!Guns项目代码简洁,注释丰富,上手容易,同时Guns包含许多基础模块(用户管理,角色管理,部门管理,字典管理等10个模块),可以直接作为一个后台管理系统的脚手架!
+
+### SpringCloud
+
+- **Github地址**:[https://github.com/YunaiV/onemall](https://github.com/YunaiV/onemall)
+- **star**: 1.2k
+- **介绍**: mall 商城,基于微服务的思想,构建在 B2C 电商场景下的项目实战。核心技术栈,是 Spring Boot + Dubbo 。未来,会重构成 Spring Cloud Alibaba 。
+
+### SpringBoot-Shiro-Vue
+
+- **Github地址**:[https://github.com/Heeexy/SpringBoot-Shiro-Vue](https://github.com/Heeexy/SpringBoot-Shiro-Vue)
+- **star**: 1.8k
+- **介绍**: 提供一套基于Spring Boot-Shiro-Vue的权限管理思路.前后端都加以控制,做到按钮/接口级别的权限。
+
+### newbee-mall
+
+最近开源的一个商城项目。
+
+- **Github地址**:[https://github.com/newbee-ltd/newbee-mall](https://github.com/newbee-ltd/newbee-mall)
+- **star**: 50
+- **介绍**: newbee-mall 项目是一套电商系统,包括 newbee-mall 商城系统及 newbee-mall-admin 商城后台管理系统,基于 Spring Boot 2.X 及相关技术栈开发。 前台商城系统包含首页门户、商品分类、新品上线、首页轮播、商品推荐、商品搜索、商品展示、购物车、订单结算、订单流程、个人订单管理、会员中心、帮助中心等模块。 后台管理系统包含数据面板、轮播图管理、商品管理、订单管理、会员管理、分类管理、设置等模块。
+
+
+
diff --git a/docs/database/MySQL.md b/docs/database/MySQL.md
index 144607da..64dfad2f 100644
--- a/docs/database/MySQL.md
+++ b/docs/database/MySQL.md
@@ -1,7 +1,5 @@
点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
-
-
- [书籍推荐](#书籍推荐)
- [文字教程推荐](#文字教程推荐)
- [视频教程推荐](#视频教程推荐)
@@ -288,6 +286,25 @@ InnoDB 存储引擎在 **分布式事务** 的情况下一般会用到 **SERIALI
详细内容可以参考: MySQL大表优化方案: [https://segmentfault.com/a/1190000006158186](https://segmentfault.com/a/1190000006158186)
+### 解释一下什么是池化设计思想。什么是数据库连接池?为什么需要数据库连接池?
+
+池话设计应该不是一个新名词。我们常见的如java线程池、jdbc连接池、redis连接池等就是这类设计的代表实现。这种设计会初始预设资源,解决的问题就是抵消每次获取资源的消耗,如创建线程的开销,获取远程连接的开销等。就好比你去食堂打饭,打饭的大妈会先把饭盛好几份放那里,你来了就直接拿着饭盒加菜即可,不用再临时又盛饭又打菜,效率就高了。除了初始化资源,池化设计还包括如下这些特征:池子的初始值、池子的活跃值、池子的最大值等,这些特征可以直接映射到java线程池和数据库连接池的成员属性中。——这篇文章对[池化设计思想](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485679&idx=1&sn=57dbca8c9ad49e1f3968ecff04a4f735&chksm=cea24724f9d5ce3212292fac291234a760c99c0960b5430d714269efe33554730b5f71208582&token=1141994790&lang=zh_CN#rd)介绍的还不错,直接复制过来,避免重复造轮子了。
+
+数据库连接本质就是一个 socket 的连接。数据库服务端还要维护一些缓存和用户权限信息之类的 所以占用了一些内存。我们可以把数据库连接池是看做是维护的数据库连接的缓存,以便将来需要对数据库的请求时可以重用这些连接。为每个用户打开和维护数据库连接,尤其是对动态数据库驱动的网站应用程序的请求,既昂贵又浪费资源。**在连接池中,创建连接后,将其放置在池中,并再次使用它,因此不必建立新的连接。如果使用了所有连接,则会建立一个新连接并将其添加到池中。**连接池还减少了用户必须等待建立与数据库的连接的时间。
+
+### 分库分表之后,id 主键如何处理?
+
+因为要是分成多个表之后,每个表都是从 1 开始累加,这样是不对的,我们需要一个全局唯一的 id 来支持。
+
+生成全局 id 有下面这几种方式:
+
+- **UUID**:不适合作为主键,因为太长了,并且无序不可读,查询效率低。比较适合用于生成唯一的名字的标示比如文件的名字。
+- **数据库自增 id** : 两台数据库分别设置不同步长,生成不重复ID的策略来实现高可用。这种方式生成的 id 有序,但是需要独立部署数据库实例,成本高,还会有性能瓶颈。
+- **利用 redis 生成 id :** 性能比较好,灵活方便,不依赖于数据库。但是,引入了新的组件造成系统更加复杂,可用性降低,编码更加复杂,增加了系统成本。
+- **Twitter的snowflake算法** :Github 地址:https://github.com/twitter-archive/snowflake。
+- **美团的[Leaf](https://tech.meituan.com/2017/04/21/mt-leaf.html)分布式ID生成系统** :Leaf 是美团开源的分布式ID生成器,能保证全局唯一性、趋势递增、单调递增、信息安全,里面也提到了几种分布式方案的对比,但也需要依赖关系数据库、Zookeeper等中间件。感觉还不错。美团技术团队的一篇文章:https://tech.meituan.com/2017/04/21/mt-leaf.html 。
+- ......
+
### 一条SQL语句在MySQL中如何执行的
[一条SQL语句在MySQL中如何执行的]()
diff --git a/docs/database/阿里巴巴开发手册数据库部分的一些最佳实践.md b/docs/database/阿里巴巴开发手册数据库部分的一些最佳实践.md
new file mode 100644
index 00000000..7eb84001
--- /dev/null
+++ b/docs/database/阿里巴巴开发手册数据库部分的一些最佳实践.md
@@ -0,0 +1,41 @@
+# 阿里巴巴Java开发手册数据库部分的一些最佳实践总结
+
+## 模糊查询
+
+对于模糊查询阿里巴巴开发手册这样说到:
+
+> 【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
+>
+> 说明:索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
+
+## 外键和级联
+
+对于外键和级联,阿里巴巴开发手册这样说到:
+
+>【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
+>
+>说明:以学生和成绩的关系为例,学生表中的 student_id 是主键,那么成绩表中的 student_id 则为外键。如果更新学生表中的 student_id,同时触发成绩表中的 student_id 更新,即为级联更新。外键与级联更新适用于单机低并发,不适合分布式、高并发集群;级联更新是强阻塞,存在数据库更新风暴的风 险;外键影响数据库的插入速度
+
+为什么不要用外键呢?大部分人可能会这样回答:
+
+> 1. **增加了复杂性:** a.每次做DELETE 或者UPDATE都必须考虑外键约束,会导致开发的时候很痛苦,测试数据极为不方便;b.外键的主从关系是定的,假如那天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
+> 2. **增加了额外工作**: 数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗资源;(个人觉得这个不是不用外键的原因,因为即使你不使用外键,你在应用层面也还是要保证的。所以,我觉得这个影响可以忽略不计。)
+> 3. 外键还会因为需要请求对其他表内部加锁而容易出现死锁情况;
+> 4. **对分不分表不友好** :因为分库分表下外键是无法生效的。
+> 5. ......
+
+我个人觉得上面这种回答不是特别的全面,只是说了外键存在的一个常见的问题。实际上,我们知道外键也是有很多好处的,比如:
+
+1. 保证了数据库数据的一致性和完整性;
+2. 级联操作方便,减轻了程序代码量;
+3. ......
+
+所以说,不要一股脑的就抛弃了外键这个概念,既然它存在就有它存在的道理,如果系统不涉及分不分表,并发量不是很高的情况还是可以考虑使用外键的。
+
+我个人是不太喜欢外键约束,比较喜欢在应用层去进行相关操作。
+
+## 关于@Transactional注解
+
+对于`@Transactional`事务注解,阿里巴巴开发手册这样说到:
+
+>【参考】@Transactional事务不要滥用。事务会影响数据库的QPS,另外使用事务的地方需要考虑各方面的回滚方案,包括缓存回滚、搜索引擎回滚、消息补偿、统计修正等。
diff --git a/docs/java/Java基础知识.md b/docs/java/Java基础知识.md
index 1dfe750c..08191f60 100644
--- a/docs/java/Java基础知识.md
+++ b/docs/java/Java基础知识.md
@@ -3,8 +3,6 @@
- [1. 面向对象和面向过程的区别](#1-面向对象和面向过程的区别)
- - [面向过程](#面向过程)
- - [面向对象](#面向对象)
- [2. Java 语言有哪些特点?](#2-java-语言有哪些特点)
- [3. 关于 JVM JDK 和 JRE 最详细通俗的解答](#3-关于-jvm-jdk-和-jre-最详细通俗的解答)
- [JVM](#jvm)
@@ -49,8 +47,9 @@
- [异常处理总结](#异常处理总结)
- [33 Java序列化中如果有些字段不想进行序列化,怎么办?](#33-java序列化中如果有些字段不想进行序列化怎么办)
- [34 获取用键盘输入常用的两种方法](#34-获取用键盘输入常用的两种方法)
-- [35 Java 中 IO 流分为几种?BIO,NIO,AIO 有什么区别?](#35-java-中-io-流分为几种bionioaio-有什么区别)
- - [java 中 IO 流分为几种?](#java-中-io-流分为几种)
+- [35 Java 中 IO 流](#35-java-中-io-流)
+ - [Java 中 IO 流分为几种?](#java-中-io-流分为几种)
+ - [既然有了字节流,为什么还要有字符流?](#既然有了字节流为什么还要有字符流)
- [BIO,NIO,AIO 有什么区别?](#bionioaio-有什么区别)
- [36. 常见关键字总结:static,final,this,super](#36-常见关键字总结staticfinalthissuper)
- [37. Collections 工具类和 Arrays 工具类常见方法总结](#37-collections-工具类和-arrays-工具类常见方法总结)
@@ -478,9 +477,9 @@ BufferedReader input = new BufferedReader(new InputStreamReader(System.in));
String s = input.readLine();
```
-## 35 Java 中 IO 流分为几种?BIO,NIO,AIO 有什么区别?
+## 35 Java 中 IO 流
-### java 中 IO 流分为几种?
+### Java 中 IO 流分为几种?
- 按照流的流向分,可以分为输入流和输出流;
- 按照操作单元划分,可以划分为字节流和字符流;
@@ -500,6 +499,12 @@ Java Io流共涉及40多个类,这些类看上去很杂乱,但实际上很
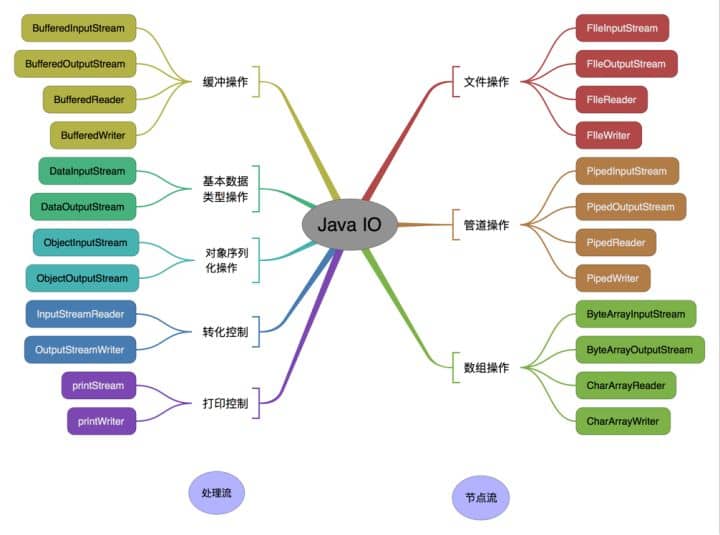
+### 既然有了字节流,为什么还要有字符流?
+
+问题本质想问:**不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?**
+
+回答:字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
+
### BIO,NIO,AIO 有什么区别?
- **BIO (Blocking I/O):** 同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
@@ -529,3 +534,4 @@ Java Io流共涉及40多个类,这些类看上去很杂乱,但实际上很
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。

+
diff --git a/docs/java/collection/Java集合框架常见面试题.md b/docs/java/collection/Java集合框架常见面试题.md
index a920af8b..db10324f 100644
--- a/docs/java/collection/Java集合框架常见面试题.md
+++ b/docs/java/collection/Java集合框架常见面试题.md
@@ -47,7 +47,7 @@
- **2. 底层数据结构:** `Arraylist` 底层使用的是 **`Object` 数组**;`LinkedList` 底层使用的是 **双向链表** 数据结构(JDK1.6之前为循环链表,JDK1.7取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!)
-- **3. 插入和删除是否受元素位置的影响:** ① **`ArrayList` 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。** 比如:执行`add(E e) `方法的时候, `ArrayList` 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element) `)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② **`LinkedList` 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1)而数组为近似 O(n)。**
+- **3. 插入和删除是否受元素位置的影响:** ① **`ArrayList` 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。** 比如:执行`add(E e) `方法的时候, `ArrayList` 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element) `)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② **`LinkedList` 采用链表存储,所以对于`add(�E e)`方法的插入,删除元素时间复杂度不受元素位置的影响,近似 O(1),如果是要在指定位置`i`插入和删除元素的话(`(add(int index, E element)`) 时间复杂度应为`o(n))`因为需要新创立一个新的链表,复制前i-1个元素并在第i位加入新的元素,最后附上n-i个元素。**
- **4. 是否支持快速随机访问:** `LinkedList` 不支持高效的随机元素访问,而 `ArrayList` 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index) `方法)。
diff --git a/docs/system-design/data-communication/dubbo.md b/docs/system-design/data-communication/dubbo.md
index 17a08d88..f2e0ac48 100644
--- a/docs/system-design/data-communication/dubbo.md
+++ b/docs/system-design/data-communication/dubbo.md
@@ -251,7 +251,7 @@ HelloService helloService;
zookeeper宕机与dubbo直连的情况在面试中可能会被经常问到,所以要引起重视。
-在实际生产中,假如zookeeper注册中心宕掉,一段时间内服务消费方还是能够调用提供方的服务的,实际上它使用的本地缓存进行通讯,这只是dubbo健壮性的一种提现。
+在实际生产中,假如zookeeper注册中心宕掉,一段时间内服务消费方还是能够调用提供方的服务的,实际上它使用的本地缓存进行通讯,这只是dubbo健壮性的一种体现。
**dubbo的健壮性表现:**
diff --git a/media/pictures/kafaka/前言.md b/media/pictures/kafaka/前言.md
new file mode 100644
index 00000000..24d6e370
--- /dev/null
+++ b/media/pictures/kafaka/前言.md
@@ -0,0 +1,202 @@
+# 前言
+
+谈到java的线程池最熟悉的莫过于ExecutorService接口了,jdk1.5新增的java.util.concurrent包下的这个api,大大的简化了多线程代码的开发。而不论你用FixedThreadPool还是CachedThreadPool其背后实现都是ThreadPoolExecutor。ThreadPoolExecutor是一个典型的缓存池化设计的产物,因为池子有大小,当池子体积不够承载时,就涉及到拒绝策略。JDK中已经预设了4种线程池拒绝策略,下面结合场景详细聊聊这些策略的使用场景,以及我们还能扩展哪些拒绝策略。
+
+# 池化设计思想
+
+池话设计应该不是一个新名词。我们常见的如java线程池、jdbc连接池、redis连接池等就是这类设计的代表实现。这种设计会初始预设资源,解决的问题就是抵消每次获取资源的消耗,如创建线程的开销,获取远程连接的开销等。就好比你去食堂打饭,打饭的大妈会先把饭盛好几份放那里,你来了就直接拿着饭盒加菜即可,不用再临时又盛饭又打菜,效率就高了。除了初始化资源,池化设计还包括如下这些特征:池子的初始值、池子的活跃值、池子的最大值等,这些特征可以直接映射到java线程池和数据库连接池的成员属性中。
+
+# 线程池触发拒绝策略的时机
+
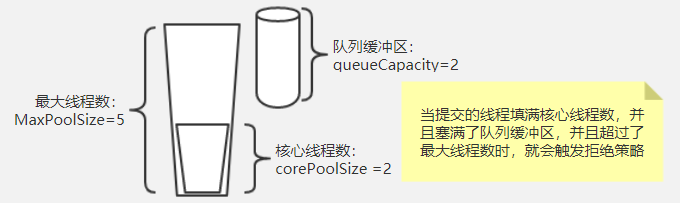
+和数据源连接池不一样,线程池除了初始大小和池子最大值,还多了一个阻塞队列来缓冲。数据源连接池一般请求的连接数超过连接池的最大值的时候就会触发拒绝策略,策略一般是阻塞等待设置的时间或者直接抛异常。而线程池的触发时机如下图:
+
+
+
+如图,想要了解线程池什么时候触发拒绝粗略,需要明确上面三个参数的具体含义,是这三个参数总体协调的结果,而不是简单的超过最大线程数就会触发线程拒绝粗略,当提交的任务数大于corePoolSize时,会优先放到队列缓冲区,只有填满了缓冲区后,才会判断当前运行的任务是否大于maxPoolSize,小于时会新建线程处理。大于时就触发了拒绝策略,总结就是:当前提交任务数大于(maxPoolSize + queueCapacity)时就会触发线程池的拒绝策略了。
+
+# JDK内置4种线程池拒绝策略
+
+# 拒绝策略接口定义
+
+在分析JDK自带的线程池拒绝策略前,先看下JDK定义的 拒绝策略接口,如下:
+
+```java
+public interface RejectedExecutionHandler {
+ void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
+}
+```
+
+接口定义很明确,当触发拒绝策略时,线程池会调用你设置的具体的策略,将当前提交的任务以及线程池实例本身传递给你处理,具体作何处理,不同场景会有不同的考虑,下面看JDK为我们内置了哪些实现:
+
+# CallerRunsPolicy(调用者运行策略)
+
+```java
+ public static class CallerRunsPolicy implements RejectedExecutionHandler {
+
+ public CallerRunsPolicy() { }
+
+ public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
+ if (!e.isShutdown()) {
+ r.run();
+ }
+ }
+ }
+```
+
+功能:当触发拒绝策略时,只要线程池没有关闭,就由提交任务的当前线程处理。
+
+使用场景:一般在不允许失败的、对性能要求不高、并发量较小的场景下使用,因为线程池一般情况下不会关闭,也就是提交的任务一定会被运行,但是由于是调用者线程自己执行的,当多次提交任务时,就会阻塞后续任务执行,性能和效率自然就慢了。
+
+# AbortPolicy(中止策略)
+
+```java
+ public static class AbortPolicy implements RejectedExecutionHandler {
+
+ public AbortPolicy() { }
+
+ public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
+ throw new RejectedExecutionException("Task " + r.toString() +
+ " rejected from " +
+ e.toString());
+ }
+ }
+```
+
+功能:当触发拒绝策略时,直接抛出拒绝执行的异常,中止策略的意思也就是打断当前执行流程
+
+使用场景:这个就没有特殊的场景了,但是一点要正确处理抛出的异常。ThreadPoolExecutor中默认的策略就是AbortPolicy,ExecutorService接口的系列ThreadPoolExecutor因为都没有显示的设置拒绝策略,所以默认的都是这个。但是请注意,ExecutorService中的线程池实例队列都是无界的,也就是说把内存撑爆了都不会触发拒绝策略。当自己自定义线程池实例时,使用这个策略一定要处理好触发策略时抛的异常,因为他会打断当前的执行流程。
+
+# DiscardPolicy(丢弃策略)
+
+```java
+ public static class DiscardPolicy implements RejectedExecutionHandler {
+
+ public DiscardPolicy() { }
+
+ public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
+ }
+ }
+```
+
+功能:如果线程池未关闭,就弹出队列头部的元素,然后尝试执行
+
+使用场景:这个策略还是会丢弃任务,丢弃时也是毫无声息,但是特点是丢弃的是老的未执行的任务,而且是待执行优先级较高的任务。基于这个特性,我能想到的场景就是,发布消息,和修改消息,当消息发布出去后,还未执行,此时更新的消息又来了,这个时候未执行的消息的版本比现在提交的消息版本要低就可以被丢弃了。因为队列中还有可能存在消息版本更低的消息会排队执行,所以在真正处理消息的时候一定要做好消息的版本比较
+
+# 第三方实现的拒绝策略
+
+# dubbo中的线程拒绝策略
+
+```java
+public class AbortPolicyWithReport extends ThreadPoolExecutor.AbortPolicy {
+
+ protected static final Logger logger = LoggerFactory.getLogger(AbortPolicyWithReport.class);
+
+ private final String threadName;
+
+ private final URL url;
+
+ private static volatile long lastPrintTime = 0;
+
+ private static Semaphore guard = new Semaphore(1);
+
+ public AbortPolicyWithReport(String threadName, URL url) {
+ this.threadName = threadName;
+ this.url = url;
+ }
+
+ @Override
+ public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
+ String msg = String.format("Thread pool is EXHAUSTED!" +
+ " Thread Name: %s, Pool Size: %d (active: %d, core: %d, max: %d, largest: %d), Task: %d (completed: %d)," +
+ " Executor status:(isShutdown:%s, isTerminated:%s, isTerminating:%s), in %s://%s:%d!",
+ threadName, e.getPoolSize(), e.getActiveCount(), e.getCorePoolSize(), e.getMaximumPoolSize(), e.getLargestPoolSize(),
+ e.getTaskCount(), e.getCompletedTaskCount(), e.isShutdown(), e.isTerminated(), e.isTerminating(),
+ url.getProtocol(), url.getIp(), url.getPort());
+ logger.warn(msg);
+ dumpJStack();
+ throw new RejectedExecutionException(msg);
+ }
+
+ private void dumpJStack() {
+ //省略实现
+ }
+}
+```
+
+可以看到,当dubbo的工作线程触发了线程拒绝后,主要做了三个事情,原则就是尽量让使用者清楚触发线程拒绝策略的真实原因
+
+- 输出了一条警告级别的日志,日志内容为线程池的详细设置参数,以及线程池当前的状态,还有当前拒绝任务的一些详细信息。可以说,这条日志,使用dubbo的有过生产运维经验的或多或少是见过的,这个日志简直就是日志打印的典范,其他的日志打印的典范还有spring。得益于这么详细的日志,可以很容易定位到问题所在
+- 输出当前线程堆栈详情,这个太有用了,当你通过上面的日志信息还不能定位问题时,案发现场的dump线程上下文信息就是你发现问题的救命稻草。
+- 继续抛出拒绝执行异常,使本次任务失败,这个继承了JDK默认拒绝策略的特性
+
+# Netty中的线程池拒绝策略
+
+```java
+ private static final class NewThreadRunsPolicy implements RejectedExecutionHandler {
+ NewThreadRunsPolicy() {
+ super();
+ }
+
+ public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
+ try {
+ final Thread t = new Thread(r, "Temporary task executor");
+ t.start();
+ } catch (Throwable e) {
+ throw new RejectedExecutionException(
+ "Failed to start a new thread", e);
+ }
+ }
+ }
+```
+
+Netty中的实现很像JDK中的CallerRunsPolicy,舍不得丢弃任务。不同的是,CallerRunsPolicy是直接在调用者线程执行的任务。而 Netty是新建了一个线程来处理的。所以,Netty的实现相较于调用者执行策略的使用面就可以扩展到支持高效率高性能的场景了。但是也要注意一点,Netty的实现里,在创建线程时未做任何的判断约束,也就是说只要系统还有资源就会创建新的线程来处理,直到new不出新的线程了,才会抛创建线程失败的异常
+
+# ActiveMq中的线程池拒绝策略
+
+```java
+new RejectedExecutionHandler() {
+ @Override
+ public void rejectedExecution(final Runnable r, final ThreadPoolExecutor executor) {
+ try {
+ executor.getQueue().offer(r, 60, TimeUnit.SECONDS);
+ } catch (InterruptedException e) {
+ throw new RejectedExecutionException("Interrupted waiting for BrokerService.worker");
+ }
+
+ throw new RejectedExecutionException("Timed Out while attempting to enqueue Task.");
+ }
+ });
+```
+
+ActiveMq中的策略属于最大努力执行任务型,当触发拒绝策略时,在尝试一分钟的时间重新将任务塞进任务队列,当一分钟超时还没成功时,就抛出异常
+
+# pinpoint中的线程池拒绝策略
+
+```java
+public class RejectedExecutionHandlerChain implements RejectedExecutionHandler {
+ private final RejectedExecutionHandler[] handlerChain;
+
+ public static RejectedExecutionHandler build(List chain) {
+ Objects.requireNonNull(chain, "handlerChain must not be null");
+ RejectedExecutionHandler[] handlerChain = chain.toArray(new RejectedExecutionHandler[0]);
+ return new RejectedExecutionHandlerChain(handlerChain);
+ }
+
+ private RejectedExecutionHandlerChain(RejectedExecutionHandler[] handlerChain) {
+ this.handlerChain = Objects.requireNonNull(handlerChain, "handlerChain must not be null");
+ }
+
+ @Override
+ public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
+ for (RejectedExecutionHandler rejectedExecutionHandler : handlerChain) {
+ rejectedExecutionHandler.rejectedExecution(r, executor);
+ }
+ }
+}
+```
+
+pinpoint的拒绝策略实现很有特点,和其他的实现都不同。他定义了一个拒绝策略链,包装了一个拒绝策略列表,当触发拒绝策略时,会将策略链中的rejectedExecution依次执行一遍
+
+# 结语
+
+前文从线程池设计思想,以及线程池触发拒绝策略的时机引出java线程池拒绝策略接口的定义。并辅以JDK内置4种以及四个第三方开源软件的拒绝策略定义描述了线程池拒绝策略实现的各种思路和使用场景。希望阅读此文后能让你对java线程池拒绝策略有更加深刻的认识,能够根据不同的使用场景更加灵活的应用。
\ No newline at end of file
diff --git a/media/sponsor/WechatIMG143.jpeg b/media/sponsor/WechatIMG143.jpeg
new file mode 100644
index 00000000..5e1b53b4
Binary files /dev/null and b/media/sponsor/WechatIMG143.jpeg differ
diff --git a/面试又载在jvm上了.md b/面试又载在jvm上了.md
new file mode 100644
index 00000000..e797775a
--- /dev/null
+++ b/面试又载在jvm上了.md
@@ -0,0 +1,13 @@
+
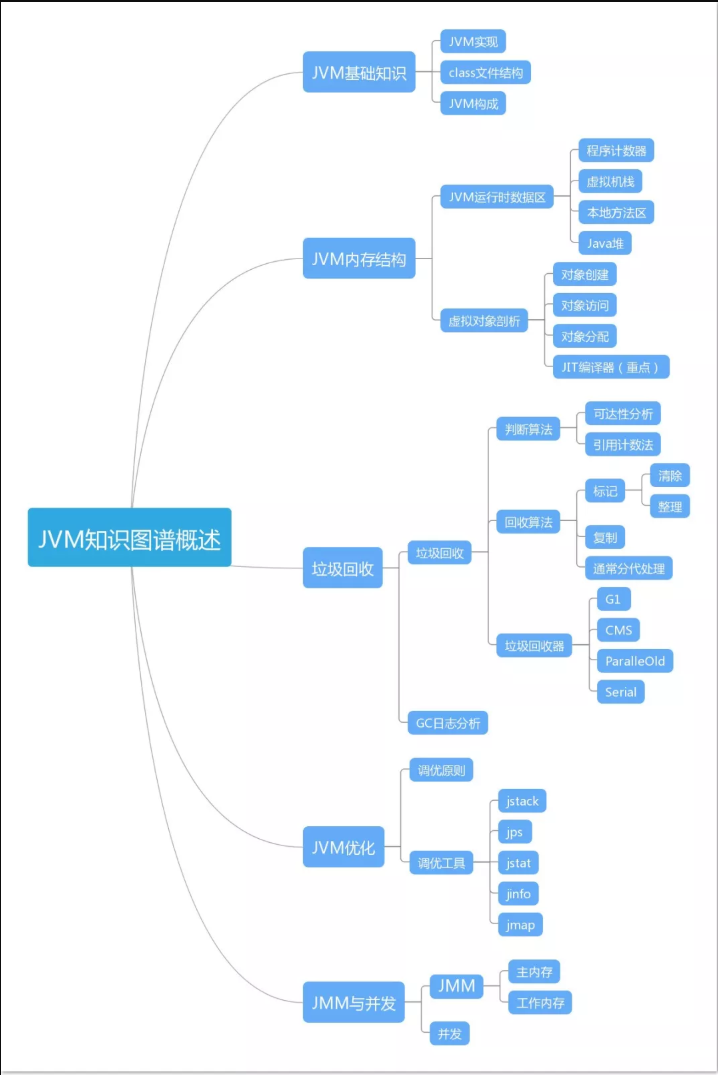
+无论什么级别的Java从业者,JVM都是进阶时必须迈过的坎。不管是工作还是面试中,JVM都是必考题。如果不懂JVM的话,薪酬会非常吃亏(近70%的面试者挂在JVM上了)。
+
+
+掌握了JVM机制,就等于学会了深层次解决问题的方法。对于Java开发者而言,只有熟悉底层虚拟机的运行机制,才能通过JVM日志深入到字节码的层次去分析排查问题,发现隐性的系统缺陷,进而提升系统性能。
+
+
+一些技术人员开发工具用得很熟练,触及JVM问题时却是模棱两可,甚至连内存模型和内存区域,HotSpot和JVM规范,都混淆不清。工作很长时间,在生产时还在用缺省参数来直接启动,以致系统运行时出现性能、稳定性等问题时束手无措,不知该如何追踪排查。久而久之,这对自己的职业成长是极为不利的。
+
+
+掌握JVM,是深入Java技术栈的必经之路。
+
+