mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
[docs fix]Markdown 格式规范
This commit is contained in:
parent
7ea0b68011
commit
e96ea425d3
@ -46,10 +46,8 @@ tag:
|
||||
还没完成的:
|
||||
|
||||
1. Kafka 高级特性比如工作流程、Kafka 为什么快等等的分析;
|
||||
|
||||
2. 源码阅读分析;
|
||||
|
||||
3. ......
|
||||
3. ……
|
||||
|
||||
**所以,我觉得技术的积累和沉淀很大程度在乎工作之外的时间(大佬和一些本身就特别厉害的除外)。**
|
||||
|
||||
|
||||
@ -372,7 +372,7 @@ tag:
|
||||
6. 管理自己的身材,没事去跑跑步,别当油腻男。
|
||||
7. 别太看重绩点。我觉得绩点对于找工作还有考研实际的作用都可以忽略不计,不过不挂科还是比较重要的。但是,绩点确实在奖学金评选和保研名额选取上占有最大的分量。
|
||||
8. 别太功利性。做事情以及学习知识都不要奢求它能立马带给你什么,坚持和功利往往是成反比的。
|
||||
9. ......
|
||||
9. ……
|
||||
|
||||
## 后记
|
||||
|
||||
|
||||
@ -36,7 +36,7 @@ star: 2
|
||||
6. 海量 Java 优质面试资源分享。
|
||||
7. 打卡活动,读书交流,学习交流,让学习不再孤单,报团取暖。
|
||||
8. 不定期福利:节日抽奖、送书送课、球友线下聚会等等。
|
||||
9. ......
|
||||
9. ……
|
||||
|
||||
其中的任何一项服务单独拎出来价值都远超星球门票了。
|
||||
|
||||
|
||||
@ -243,7 +243,7 @@ O'Reilly 家族书,性能调优的入门书,我个人觉得性能调优是
|
||||
|
||||

|
||||
|
||||
事务与锁、分布式(CAP、分布式事务......)、高并发、高可用 《软件架构设计:大型网站技术架构与业务架构融合之道》 这本书都有介绍到。
|
||||
事务与锁、分布式(CAP、分布式事务……)、高并发、高可用 《软件架构设计:大型网站技术架构与业务架构融合之道》 这本书都有介绍到。
|
||||
|
||||
## 面试
|
||||
|
||||
|
||||
@ -15,7 +15,7 @@ tag:
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
```plain
|
||||
输入:(2 -> 4 -> 3) + (5 -> 6 -> 4)
|
||||
输出:7 -> 0 -> 8
|
||||
原因:342 + 465 = 807
|
||||
@ -153,7 +153,7 @@ public class Solution {
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
```plain
|
||||
5
|
||||
4
|
||||
3
|
||||
@ -225,7 +225,7 @@ public class Solution {
|
||||
|
||||
**示例:**
|
||||
|
||||
```
|
||||
```plain
|
||||
给定一个链表: 1->2->3->4->5, 和 n = 2.
|
||||
|
||||
当删除了倒数第二个节点后,链表变为 1->2->3->5.
|
||||
|
||||
@ -81,14 +81,14 @@ str.toString().replace(" ","%20");
|
||||
|
||||
示例 1:
|
||||
|
||||
```
|
||||
```plain
|
||||
输入: ["flower","flow","flight"]
|
||||
输出: "fl"
|
||||
```
|
||||
|
||||
示例 2:
|
||||
|
||||
```
|
||||
```plain
|
||||
输入: ["dog","racecar","car"]
|
||||
输出: ""
|
||||
解释: 输入不存在公共前缀。
|
||||
@ -163,7 +163,7 @@ public class Main {
|
||||
|
||||
示例 1:
|
||||
|
||||
```
|
||||
```plain
|
||||
输入:
|
||||
"abccccdd"
|
||||
|
||||
@ -210,14 +210,14 @@ class Solution {
|
||||
|
||||
示例 1:
|
||||
|
||||
```
|
||||
```plain
|
||||
输入: "A man, a plan, a canal: Panama"
|
||||
输出: true
|
||||
```
|
||||
|
||||
示例 2:
|
||||
|
||||
```
|
||||
```plain
|
||||
输入: "race a car"
|
||||
输出: false
|
||||
```
|
||||
@ -254,7 +254,7 @@ class Solution {
|
||||
|
||||
示例 1:
|
||||
|
||||
```
|
||||
```plain
|
||||
输入: "babad"
|
||||
输出: "bab"
|
||||
注意: "aba"也是一个有效答案。
|
||||
@ -262,7 +262,7 @@ class Solution {
|
||||
|
||||
示例 2:
|
||||
|
||||
```
|
||||
```plain
|
||||
输入: "cbbd"
|
||||
输出: "bb"
|
||||
```
|
||||
@ -307,7 +307,7 @@ class Solution {
|
||||
|
||||
示例 1:
|
||||
|
||||
```
|
||||
```plain
|
||||
输入:
|
||||
"bbbab"
|
||||
输出:
|
||||
@ -318,7 +318,7 @@ class Solution {
|
||||
|
||||
示例 2:
|
||||
|
||||
```
|
||||
```plain
|
||||
输入:
|
||||
"cbbd"
|
||||
输出:
|
||||
@ -367,7 +367,7 @@ class Solution {
|
||||
|
||||
> 例如: "()()()"的深度是 1,"((()))"的深度是 3。牛牛现在给你一个合法的括号序列,需要你计算出其深度。
|
||||
|
||||
```
|
||||
```plain
|
||||
输入描述:
|
||||
输入包括一个合法的括号序列s,s长度length(2 ≤ length ≤ 50),序列中只包含'('和')'。
|
||||
|
||||
@ -377,7 +377,7 @@ class Solution {
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
```plain
|
||||
输入:
|
||||
(())
|
||||
输出:
|
||||
|
||||
@ -74,7 +74,7 @@ public int Fibonacci(int n) {
|
||||
|
||||
**所以这道题其实就是斐波那契数列的问题。**
|
||||
|
||||
代码只需要在上一题的代码稍做修改即可。和上一题唯一不同的就是这一题的初始元素变为 1 2 3 5 8.....而上一题为 1 1 2 3 5 .......。另外这一题也可以用递归做,但是递归效率太低,所以我这里只给出了迭代方式的代码。
|
||||
代码只需要在上一题的代码稍做修改即可。和上一题唯一不同的就是这一题的初始元素变为 1 2 3 5 8……而上一题为 1 1 2 3 5 ……。另外这一题也可以用递归做,但是递归效率太低,所以我这里只给出了迭代方式的代码。
|
||||
|
||||
**示例代码:**
|
||||
|
||||
@ -110,7 +110,7 @@ int jumpFloor(int number) {
|
||||
假设 n>=2,第一步有 n 种跳法:跳 1 级、跳 2 级、到跳 n 级
|
||||
跳 1 级,剩下 n-1 级,则剩下跳法是 f(n-1)
|
||||
跳 2 级,剩下 n-2 级,则剩下跳法是 f(n-2)
|
||||
......
|
||||
……
|
||||
跳 n-1 级,剩下 1 级,则剩下跳法是 f(1)
|
||||
跳 n 级,剩下 0 级,则剩下跳法是 f(0)
|
||||
所以在 n>=2 的情况下:
|
||||
@ -647,7 +647,7 @@ https://www.nowcoder.com/questionTerminal/d77d11405cc7470d82554cb392585106
|
||||
|
||||
此时栈顶 5=5,出栈 5,弹出序列向后一位,此时为 3,,辅助栈里面是 1,2,3
|
||||
|
||||
….
|
||||
…….
|
||||
依次执行,最后辅助栈为空。如果不为空说明弹出序列不是该栈的弹出顺序。
|
||||
|
||||
**考察内容:**
|
||||
|
||||
@ -171,7 +171,7 @@ System.out.println(filter.contains(value2));
|
||||
|
||||
Output:
|
||||
|
||||
```
|
||||
```plain
|
||||
false
|
||||
false
|
||||
true
|
||||
@ -250,7 +250,7 @@ Redis v4.0 之后有了 Module(模块/插件) 功能,Redis Modules 让 Red
|
||||
|
||||
- redis-lua-scaling-bloom-filter(lua 脚本实现):https://github.com/erikdubbelboer/redis-lua-scaling-bloom-filter
|
||||
- pyreBloom(Python 中的快速 Redis 布隆过滤器):https://github.com/seomoz/pyreBloom
|
||||
- ......
|
||||
- ……
|
||||
|
||||
RedisBloom 提供了多种语言的客户端支持,包括:Python、Java、JavaScript 和 PHP。
|
||||
|
||||
|
||||
@ -326,6 +326,6 @@ myStack.pop();//报错:java.lang.IllegalArgumentException: Stack is empty.
|
||||
- Linux 内核进程队列(按优先级排队)
|
||||
- 现实生活中的派对,播放器上的播放列表;
|
||||
- 消息队列
|
||||
- 等等......
|
||||
- 等等……
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
@ -86,7 +86,7 @@ DNS 服务器在响应查询时,需要查询自己的数据库,数据库中
|
||||
|
||||
`CNAME`记录总是指向另一则域名,而非 IP 地址。假设有下述 DNS zone:
|
||||
|
||||
```
|
||||
```plain
|
||||
NAME TYPE VALUE
|
||||
--------------------------------------------------
|
||||
bar.example.com. CNAME foo.example.com.
|
||||
|
||||
@ -57,7 +57,7 @@ HTTP/1.1 的缓存机制在 HTTP/1.0 的基础上,大大增加了灵活性和
|
||||
|
||||
因此,HTTP/1.1 在请求头中加入了`Host`字段。加入`Host`字段的报文头部将会是:
|
||||
|
||||
```
|
||||
```plain
|
||||
GET /home.html HTTP/1.1
|
||||
Host: example1.org
|
||||
```
|
||||
|
||||
@ -132,7 +132,7 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
|
||||
- SSH(Secure Shell Protocol,安全的网络传输协议)
|
||||
- RTP(Real-time Transport Protocol,实时传输协议)
|
||||
- DNS(Domain Name System,域名管理系统)
|
||||
- ......
|
||||
- ……
|
||||
|
||||
**传输层协议** :
|
||||
|
||||
@ -154,7 +154,7 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
|
||||
- OSPF(Open Shortest Path First,开放式最短路径优先)
|
||||
- RIP(Routing Information Protocol,路由信息协议)
|
||||
- BGP(Border Gateway Protocol,边界网关协议)
|
||||
- ......
|
||||
- ……
|
||||
|
||||
**网络接口层** :
|
||||
|
||||
@ -163,7 +163,7 @@ OSI 七层模型虽然失败了,但是却提供了很多不错的理论基础
|
||||
- CSMA/CD 协议
|
||||
- MAC 协议
|
||||
- 以太网技术
|
||||
- ......
|
||||
- ……
|
||||
|
||||
## 网络分层的原因
|
||||
|
||||
|
||||
@ -18,7 +18,7 @@ tag:
|
||||
5. **传输形式**:TCP 是面向字节流的,UDP 是面向报文的。
|
||||
6. **首部开销**:TCP 首部开销(20 ~ 60 字节)比 UDP 首部开销(8 字节)要大。
|
||||
7. **是否提供广播或多播服务**:TCP 只支持点对点通信,UDP 支持一对一、一对多、多对一、多对多;
|
||||
8. ......
|
||||
8. ……
|
||||
|
||||
我把上面总结的内容通过表格形式展示出来了!确定不点个赞嘛?
|
||||
|
||||
@ -70,13 +70,13 @@ HTTP/3.0 之前是基于 TCP 协议的,而 HTTP/3.0 将弃用 TCP,改用 **
|
||||
5. **POP3/IMAP 协议**:两者都是负责邮件接收的协议。IMAP 协议是比 POP3 更新的协议,它在功能和性能上都更加强大。IMAP 支持邮件搜索、标记、分类、归档等高级功能,而且可以在多个设备之间同步邮件状态。几乎所有现代电子邮件客户端和服务器都支持 IMAP。
|
||||
6. **Telnet 协议**:用于通过一个终端登陆到其他服务器。Telnet 协议的最大缺点之一是所有数据(包括用户名和密码)均以明文形式发送,这有潜在的安全风险。这就是为什么如今很少使用 Telnet,而是使用一种称为 SSH 的非常安全的网络传输协议的主要原因。
|
||||
7. **SSH 协议** : SSH( Secure Shell)是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。利用 SSH 协议可以有效防止远程管理过程中的信息泄露问题。SSH 建立在可靠的传输协议 TCP 之上。
|
||||
8. ......
|
||||
8. ……
|
||||
|
||||
**运行于 UDP 协议之上的协议**:
|
||||
|
||||
1. **DHCP 协议**:动态主机配置协议,动态配置 IP 地址
|
||||
2. **DNS**:**域名系统(DNS,Domain Name System)将人类可读的域名 (例如,www.baidu.com) 转换为机器可读的 IP 地址 (例如,220.181.38.148)。** 我们可以将其理解为专为互联网设计的电话薄。实际上 DNS 同时支持 UDP 和 TCP 协议。
|
||||
3. ......
|
||||
3. ……
|
||||
|
||||
### TCP 三次握手和四次挥手(非常重要)
|
||||
|
||||
@ -138,7 +138,7 @@ IP 地址过滤是一种简单的网络安全措施,实际应用中一般会
|
||||
- **对标头结构进行了改进**:IPv6 标头结构相较于 IPv4 更加简化和高效,减少了处理开销,提高了网络性能。
|
||||
- **可选的扩展头**:允许在 IPv6 标头中添加不同的扩展头(Extension Headers),用于实现不同类型的功能和选项。
|
||||
- **ICMPv6(Internet Control Message Protocol for IPv6)**:IPv6 中的 ICMPv6 相较于 IPv4 中的 ICMP 有了一些改进,如邻居发现、路径 MTU 发现等功能的改进,从而提升了网络的可靠性和性能。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
### NAT 的作用是什么?
|
||||
|
||||
|
||||
@ -220,7 +220,7 @@ PCB 主要包含下面几部分的内容:
|
||||
- 进程对资源的需求情况,包括 CPU 时间、内存空间、I/O 设备等等。
|
||||
- 进程打开的文件信息,包括文件描述符、文件类型、打开模式等等。
|
||||
- 处理机的状态信息(由处理机的各种寄存器中的内容组成的),包括通用寄存器、指令计数器、程序状态字 PSW、用户栈指针。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
### 进程有哪几种状态?
|
||||
|
||||
@ -303,7 +303,7 @@ ps -A -ostat,ppid,pid,cmd |grep -e '^[Zz]'
|
||||
1. **互斥**:资源必须处于非共享模式,即一次只有一个进程可以使用。如果另一进程申请该资源,那么必须等待直到该资源被释放为止。
|
||||
2. **占有并等待**:一个进程至少应该占有一个资源,并等待另一资源,而该资源被其他进程所占有。
|
||||
3. **非抢占**:资源不能被抢占。只能在持有资源的进程完成任务后,该资源才会被释放。
|
||||
4. **循环等待**:有一组等待进程 `{P0, P1,..., Pn}`, `P0` 等待的资源被 `P1` 占有,`P1` 等待的资源被 `P2` 占有,......,`Pn-1` 等待的资源被 `Pn` 占有,`Pn` 等待的资源被 `P0` 占有。
|
||||
4. **循环等待**:有一组等待进程 `{P0, P1,..., Pn}`, `P0` 等待的资源被 `P1` 占有,`P1` 等待的资源被 `P2` 占有,……,`Pn-1` 等待的资源被 `Pn` 占有,`Pn` 等待的资源被 `P0` 占有。
|
||||
|
||||
**注意 ⚠️**:这四个条件是产生死锁的 **必要条件** ,也就是说只要系统发生死锁,这些条件必然成立,而只要上述条件之一不满足,就不会发生死锁。
|
||||
|
||||
|
||||
@ -26,7 +26,7 @@ head:
|
||||
- **内存映射**:将一个文件直接映射到进程的进程空间中,这样可以通过内存指针用读写内存的办法直接存取文件内容,速度更快。
|
||||
- **内存优化**:通过调整内存分配策略和回收算法来优化内存使用效率。
|
||||
- **内存安全**:保证进程之间使用内存互不干扰,避免一些恶意程序通过修改内存来破坏系统的安全性。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
### 什么是内存碎片?
|
||||
|
||||
@ -98,7 +98,7 @@ head:
|
||||
1. 用户程序可以访问任意物理内存,可能会不小心操作到系统运行必需的内存,进而造成操作系统崩溃,严重影响系统的安全。
|
||||
2. 同时运行多个程序容易崩溃。比如你想同时运行一个微信和一个 QQ 音乐,微信在运行的时候给内存地址 1xxx 赋值后,QQ 音乐也同样给内存地址 1xxx 赋值,那么 QQ 音乐对内存的赋值就会覆盖微信之前所赋的值,这就可能会造成微信这个程序会崩溃。
|
||||
3. 程序运行过程中使用的所有数据或指令都要载入物理内存,根据局部性原理,其中很大一部分可能都不会用到,白白占用了宝贵的物理内存资源。
|
||||
4. ......
|
||||
4. ……
|
||||
|
||||
#### 什么是虚拟地址和物理地址?
|
||||
|
||||
|
||||
@ -123,7 +123,7 @@ echo $hello
|
||||
|
||||
输出内容:
|
||||
|
||||
```
|
||||
```plain
|
||||
Hello, I am $name!
|
||||
```
|
||||
|
||||
@ -138,7 +138,7 @@ echo $hello
|
||||
|
||||
输出内容:
|
||||
|
||||
```
|
||||
```plain
|
||||
Hello, I am SnailClimb!
|
||||
```
|
||||
|
||||
@ -177,7 +177,7 @@ expr length "$name";
|
||||
|
||||
输出结果:
|
||||
|
||||
```
|
||||
```plain
|
||||
10
|
||||
10
|
||||
```
|
||||
@ -295,7 +295,7 @@ fi
|
||||
|
||||
输出结果:
|
||||
|
||||
```
|
||||
```plain
|
||||
B
|
||||
```
|
||||
|
||||
@ -338,7 +338,7 @@ fi
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
```plain
|
||||
a 不等于 b
|
||||
```
|
||||
|
||||
@ -371,7 +371,7 @@ fi
|
||||
|
||||
输出结果:
|
||||
|
||||
```
|
||||
```plain
|
||||
a 小于 b
|
||||
```
|
||||
|
||||
@ -439,7 +439,7 @@ done
|
||||
|
||||
输出内容:
|
||||
|
||||
```
|
||||
```plain
|
||||
按下 <CTRL-D> 退出
|
||||
输入你最喜欢的电影: 变形金刚
|
||||
是的!变形金刚 是一个好电影
|
||||
@ -470,7 +470,7 @@ echo "-----函数执行完毕-----"
|
||||
|
||||
输出结果:
|
||||
|
||||
```
|
||||
```plain
|
||||
-----函数开始执行-----
|
||||
这是我的第一个 shell 函数!
|
||||
-----函数执行完毕-----
|
||||
@ -496,7 +496,7 @@ echo "输入的两个数字之和为 $?"
|
||||
|
||||
输出结果:
|
||||
|
||||
```
|
||||
```plain
|
||||
输入第一个数字:
|
||||
1
|
||||
输入第二个数字:
|
||||
@ -523,7 +523,7 @@ funWithParam 1 2 3 4 5 6 7 8 9 34 73
|
||||
|
||||
输出结果:
|
||||
|
||||
```
|
||||
```plain
|
||||
第一个参数为 1 !
|
||||
第二个参数为 2 !
|
||||
第十个参数为 10 !
|
||||
|
||||
@ -89,13 +89,13 @@ ER 图由下面 3 个要素组成:
|
||||
1. **增加了复杂性:** a. 每次做 DELETE 或者 UPDATE 都必须考虑外键约束,会导致开发的时候很痛苦, 测试数据极为不方便; b. 外键的主从关系是定的,假如那天需求有变化,数据库中的这个字段根本不需要和其他表有关联的话就会增加很多麻烦。
|
||||
2. **增加了额外工作**:数据库需要增加维护外键的工作,比如当我们做一些涉及外键字段的增,删,更新操作之后,需要触发相关操作去检查,保证数据的的一致性和正确性,这样会不得不消耗资源;(个人觉得这个不是不用外键的原因,因为即使你不使用外键,你在应用层面也还是要保证的。所以,我觉得这个影响可以忽略不计。)
|
||||
3. **对分库分表不友好**:因为分库分表下外键是无法生效的。
|
||||
4. ......
|
||||
4. ……
|
||||
|
||||
我个人觉得上面这种回答不是特别的全面,只是说了外键存在的一个常见的问题。实际上,我们知道外键也是有很多好处的,比如:
|
||||
|
||||
1. 保证了数据库数据的一致性和完整性;
|
||||
2. 级联操作方便,减轻了程序代码量;
|
||||
3. ......
|
||||
3. ……
|
||||
|
||||
所以说,不要一股脑的就抛弃了外键这个概念,既然它存在就有它存在的道理,如果系统不涉及分库分表,并发量不是很高的情况还是可以考虑使用外键的。
|
||||
|
||||
|
||||
@ -21,7 +21,7 @@ MySQL 字符编码集中有两套 UTF-8 编码实现:**`utf8`** 和 **`utf8mb4
|
||||
|
||||
## 有哪些常见的字符集?
|
||||
|
||||
常见的字符集有 ASCII、GB2312、GBK、UTF-8......。
|
||||
常见的字符集有 ASCII、GB2312、GBK、UTF-8……。
|
||||
|
||||
不同的字符集的主要区别在于:
|
||||
|
||||
@ -308,7 +308,7 @@ VALUES
|
||||
|
||||
报错信息如下:
|
||||
|
||||
```
|
||||
```plain
|
||||
Incorrect string value: '\xF0\x9F\x98\x98\xF0\x9F...' for column 'name' at row 1
|
||||
```
|
||||
|
||||
|
||||
@ -116,7 +116,7 @@ MongoDB 预留了几个特殊的数据库。
|
||||
- 随着项目的发展,使用类 JSON 格式(BSON)保存数据是否满足项目需求?MongoDB 中的记录就是一个 BSON 文档,它是由键值对组成的数据结构,类似于 JSON 对象,是 MongoDB 中的基本数据单元。
|
||||
- 是否需要大数据量的存储?是否需要快速水平扩展?MongoDB 支持分片集群,可以很方便地添加更多的节点(实例),让集群存储更多的数据,具备更强的性能。
|
||||
- 是否需要更多类型索引来满足更多应用场景?MongoDB 支持多种类型的索引,包括单字段索引、复合索引、多键索引、哈希索引、文本索引、 地理位置索引等,每种类型的索引有不同的使用场合。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
## MongoDB 存储引擎
|
||||
|
||||
@ -143,7 +143,7 @@ MongoDB 预留了几个特殊的数据库。
|
||||
|
||||
上面也说了,自 MongoDB 3.2 以后,默认的存储引擎为 WiredTiger 存储引擎。在 WiredTiger 引擎官网上,我们发现 WiredTiger 使用的是 B+ 树作为其存储结构:
|
||||
|
||||
```
|
||||
```plain
|
||||
WiredTiger maintains a table's data in memory using a data structure called a B-Tree ( B+ Tree to be specific), referring to the nodes of a B-Tree as pages. Internal pages carry only keys. The leaf pages store both keys and values.
|
||||
```
|
||||
|
||||
|
||||
@ -26,7 +26,7 @@ tag:
|
||||
- **地理位置索引:** 基于经纬度的索引,适合 2D 和 3D 的位置查询。
|
||||
- **唯一索引**:确保索引字段不会存储重复值。如果集合已经存在了违反索引的唯一约束的文档,则后台创建唯一索引会失败。
|
||||
- **TTL 索引**:TTL 索引提供了一个过期机制,允许为每一个文档设置一个过期时间,当一个文档达到预设的过期时间之后就会被删除。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
### 复合索引中字段的顺序有影响吗?
|
||||
|
||||
|
||||
@ -86,12 +86,7 @@ select * from tb_student A where A.age='18' and A.name=' 张三 ';
|
||||
|
||||
- 先检查该语句是否有权限,如果没有权限,直接返回错误信息,如果有权限,在 MySQL8.0 版本以前,会先查询缓存,以这条 SQL 语句为 key 在内存中查询是否有结果,如果有直接缓存,如果没有,执行下一步。
|
||||
- 通过分析器进行词法分析,提取 SQL 语句的关键元素,比如提取上面这个语句是查询 select,提取需要查询的表名为 tb_student,需要查询所有的列,查询条件是这个表的 id='1'。然后判断这个 SQL 语句是否有语法错误,比如关键词是否正确等等,如果检查没问题就执行下一步。
|
||||
- 接下来就是优化器进行确定执行方案,上面的 SQL 语句,可以有两种执行方案:
|
||||
|
||||
a.先查询学生表中姓名为“张三”的学生,然后判断是否年龄是 18。
|
||||
b.先找出学生中年龄 18 岁的学生,然后再查询姓名为“张三”的学生。
|
||||
|
||||
那么优化器根据自己的优化算法进行选择执行效率最好的一个方案(优化器认为,有时候不一定最好)。那么确认了执行计划后就准备开始执行了。
|
||||
- 接下来就是优化器进行确定执行方案,上面的 SQL 语句,可以有两种执行方案:a.先查询学生表中姓名为“张三”的学生,然后判断是否年龄是 18。b.先找出学生中年龄 18 岁的学生,然后再查询姓名为“张三”的学生。那么优化器根据自己的优化算法进行选择执行效率最好的一个方案(优化器认为,有时候不一定最好)。那么确认了执行计划后就准备开始执行了。
|
||||
|
||||
- 进行权限校验,如果没有权限就会返回错误信息,如果有权限就会调用数据库引擎接口,返回引擎的执行结果。
|
||||
|
||||
@ -99,7 +94,7 @@ select * from tb_student A where A.age='18' and A.name=' 张三 ';
|
||||
|
||||
以上就是一条查询 SQL 的执行流程,那么接下来我们看看一条更新语句如何执行的呢?SQL 语句如下:
|
||||
|
||||
```
|
||||
```plain
|
||||
update tb_student A set A.age='19' where A.name=' 张三 ';
|
||||
```
|
||||
|
||||
|
||||
@ -177,7 +177,7 @@ tag:
|
||||
|
||||
注意,这里说的批量插入数据,不是在普通的 insert 语句里面包含多个 value 值!!!,因为这类语句在申请自增 id 的时候,是可以精确计算出需要多少个 id 的,然后一次性申请,申请完成后锁就可以释放了。
|
||||
|
||||
而对于 `insert … select`、replace … select 和 load data 这种类型的语句来说,MySQL 并不知道到底需要申请多少 id,所以就采用了这种批量申请的策略,毕竟一个一个申请的话实在太慢了。
|
||||
而对于 `insert … select`、replace …… select 和 load data 这种类型的语句来说,MySQL 并不知道到底需要申请多少 id,所以就采用了这种批量申请的策略,毕竟一个一个申请的话实在太慢了。
|
||||
|
||||
举个例子,假设我们现在这个表有下面这些数据:
|
||||
|
||||
@ -199,7 +199,7 @@ tag:
|
||||
|
||||
如上分析,是 8 而不是 6
|
||||
|
||||
具体来说,insert…select 实际上往表中插入了 5 行数据 (1 1)(2 2)(3 3)(4 4)(5 5)。但是,这五行数据是分三次申请的自增 id,结合批量申请策略,每次申请到的自增 id 个数都是上一次的两倍,所以:
|
||||
具体来说,insert……select 实际上往表中插入了 5 行数据 (1 1)(2 2)(3 3)(4 4)(5 5)。但是,这五行数据是分三次申请的自增 id,结合批量申请策略,每次申请到的自增 id 个数都是上一次的两倍,所以:
|
||||
|
||||
- 第一次申请到了一个 id:id=1
|
||||
- 第二次被分配了两个 id:id=2 和 id=3
|
||||
|
||||
@ -156,7 +156,7 @@ MySQL830 mysql:8.0.32
|
||||
|
||||
现在我们来看一下启动日志:
|
||||
|
||||
```
|
||||
```plain
|
||||
2023-08-03T02:05:11.720357Z 0 [Warning] [MY-013907] [InnoDB] Deprecated configuration parameters innodb_log_file_size and/or innodb_log_files_in_group have been used to compute innodb_redo_log_capacity=671088640. Please use innodb_redo_log_capacity instead.
|
||||
```
|
||||
|
||||
|
||||
@ -128,7 +128,7 @@ set global query_cache_size=600000;
|
||||
- 缓存建立之后,MySQL 的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
|
||||
- MySQL 缓存在分库分表环境下是不起作用的。
|
||||
- 不缓存使用 `SQL_NO_CACHE` 的查询。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
查询缓存 `SELECT` 选项示例:
|
||||
|
||||
|
||||
@ -29,7 +29,7 @@ head:
|
||||
|
||||
**有哪些常见的关系型数据库呢?**
|
||||
|
||||
MySQL、PostgreSQL、Oracle、SQL Server、SQLite(微信本地的聊天记录的存储就是用的 SQLite) ......。
|
||||
MySQL、PostgreSQL、Oracle、SQL Server、SQLite(微信本地的聊天记录的存储就是用的 SQLite) ……。
|
||||
|
||||
### 什么是 SQL?
|
||||
|
||||
@ -45,7 +45,7 @@ SQL 可以帮助我们:
|
||||
- 对数据库中的数据进行简单的数据分析;
|
||||
- 搭配 Hive,Spark SQL 做大数据;
|
||||
- 搭配 SQLFlow 做机器学习;
|
||||
- ......
|
||||
- ……
|
||||
|
||||
### 什么是 MySQL?
|
||||
|
||||
@ -150,7 +150,7 @@ BLOB 类型主要用于存储二进制大对象,例如图片、音视频等文
|
||||
- 不能直接创建索引,需要指定前缀长度。
|
||||
- 可能会消耗大量的网络和 IO 带宽。
|
||||
- 可能导致表上的 DML 操作变慢。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
### DATETIME 和 TIMESTAMP 的区别是什么?
|
||||
|
||||
@ -390,7 +390,7 @@ MySQL 日志常见的面试题有:
|
||||
- 页修改之后为什么不直接刷盘呢?
|
||||
- binlog 和 redolog 有什么区别?
|
||||
- undo log 如何保证事务的原子性?
|
||||
- ......
|
||||
- ……
|
||||
|
||||
上诉问题的答案可以在[《Java 面试指北》(付费)](../../zhuanlan/java-mian-shi-zhi-bei.md) 的 **「技术面试题篇」** 中找到。
|
||||
|
||||
@ -405,7 +405,7 @@ MySQL 日志常见的面试题有:
|
||||
- 数据库中途突然因为某些原因挂掉了。
|
||||
- 客户端突然因为网络原因连接不上数据库了。
|
||||
- 并发访问数据库时,多个线程同时写入数据库,覆盖了彼此的更改。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
上面的任何一个问题都可能会导致数据的不一致性。为了保证数据的一致性,系统必须能够处理这些问题。事务就是我们抽象出来简化这些问题的首选机制。事务的概念起源于数据库,目前,已经成为一个比较广泛的概念。
|
||||
|
||||
|
||||
@ -55,7 +55,7 @@ select date_time,time_stamp from time_zone_test;
|
||||
|
||||
结果:
|
||||
|
||||
```
|
||||
```plain
|
||||
+---------------------+---------------------+
|
||||
| date_time | time_stamp |
|
||||
+---------------------+---------------------+
|
||||
@ -73,7 +73,7 @@ set time_zone='+8:00';
|
||||
|
||||
再次查看数据:
|
||||
|
||||
```
|
||||
```plain
|
||||
+---------------------+---------------------+
|
||||
| date_time | time_stamp |
|
||||
+---------------------+---------------------+
|
||||
|
||||
@ -18,7 +18,7 @@ Redis 中的大部分命令都是 O(1)时间复杂度,但也有少部分 O(n)
|
||||
- `LRANGE`:会返回 List 中指定范围内的元素。
|
||||
- `SMEMBERS`:返回 Set 中的所有元素。
|
||||
- `SINTER`/`SUNION`/`SDIFF`:计算多个 Set 的交集/并集/差集。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
由于这些命令时间复杂度是 O(n),有时候也会全表扫描,随着 n 的增大,执行耗时也会越长,从而导致客户端阻塞。不过, 这些命令并不是一定不能使用,但是需要明确 N 的值。另外,有遍历的需求可以使用 `HSCAN`、`SSCAN`、`ZSCAN` 代替。
|
||||
|
||||
@ -26,7 +26,7 @@ Redis 中的大部分命令都是 O(1)时间复杂度,但也有少部分 O(n)
|
||||
|
||||
- `ZRANGE`/`ZREVRANGE`:返回指定 Sorted Set 中指定排名范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 为返回的元素数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
|
||||
- `ZREMRANGEBYRANK`/`ZREMRANGEBYSCORE`:移除 Sorted Set 中指定排名范围/指定 score 范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 被删除元素的数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
## SAVE 创建 RDB 快照
|
||||
|
||||
|
||||
@ -52,7 +52,7 @@ String 是一种二进制安全的数据类型,可以用来存储任何类型
|
||||
| SET key value | 设置指定 key 的值 |
|
||||
| SETNX key value | 只有在 key 不存在时设置 key 的值 |
|
||||
| GET key | 获取指定 key 的值 |
|
||||
| MSET key1 value1 key2 value2 … | 设置一个或多个指定 key 的值 |
|
||||
| MSET key1 value1 key2 value2 …… | 设置一个或多个指定 key 的值 |
|
||||
| MGET key1 key2 ... | 获取一个或多个指定 key 的值 |
|
||||
| STRLEN key | 返回 key 所储存的字符串值的长度 |
|
||||
| INCR key | 将 key 中储存的数字值增一 |
|
||||
|
||||
@ -45,7 +45,7 @@ void *zmalloc(size_t size) {
|
||||
}
|
||||
```
|
||||
|
||||
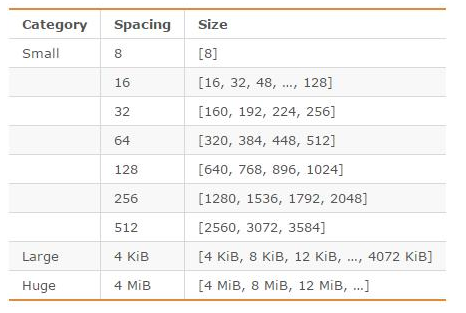
另外,Redis 可以使用多种内存分配器来分配内存( libc、jemalloc、tcmalloc),默认使用 [jemalloc](https://github.com/jemalloc/jemalloc),而 jemalloc 按照一系列固定的大小(8 字节、16 字节、32 字节......)来分配内存的。jemalloc 划分的内存单元如下图所示:
|
||||
另外,Redis 可以使用多种内存分配器来分配内存( libc、jemalloc、tcmalloc),默认使用 [jemalloc](https://github.com/jemalloc/jemalloc),而 jemalloc 按照一系列固定的大小(8 字节、16 字节、32 字节……)来分配内存的。jemalloc 划分的内存单元如下图所示:
|
||||
|
||||
|
||||
|
||||
|
||||
@ -111,7 +111,7 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
|
||||
- **延时队列**:Redisson 内置了延时队列(基于 Sorted Set 实现的)。
|
||||
- **分布式 Session** :利用 String 或者 Hash 数据类型保存 Session 数据,所有的服务器都可以访问。
|
||||
- **复杂业务场景**:通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 Bitmap 统计活跃用户、通过 Sorted Set 维护排行榜。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
### 如何基于 Redis 实现分布式锁?
|
||||
|
||||
@ -205,7 +205,7 @@ String 的常见应用场景如下:
|
||||
- 常规数据(比如 Session、Token、序列化后的对象、图片的路径)的缓存;
|
||||
- 计数比如用户单位时间的请求数(简单限流可以用到)、页面单位时间的访问数;
|
||||
- 分布式锁(利用 `SETNX key value` 命令可以实现一个最简易的分布式锁);
|
||||
- ......
|
||||
- ……
|
||||
|
||||
关于 String 的详细介绍请看这篇文章:[Redis 5 种基本数据类型详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)。
|
||||
|
||||
|
||||
@ -215,7 +215,7 @@ Redis 中有一些原生支持批量操作的命令,比如:
|
||||
- `MGET`(获取一个或多个指定 key 的值)、`MSET`(设置一个或多个指定 key 的值)、
|
||||
- `HMGET`(获取指定哈希表中一个或者多个指定字段的值)、`HMSET`(同时将一个或多个 field-value 对设置到指定哈希表中)、
|
||||
- `SADD`(向指定集合添加一个或多个元素)
|
||||
- ......
|
||||
- ……
|
||||
|
||||
不过,在 Redis 官方提供的分片集群解决方案 Redis Cluster 下,使用这些原生批量操作命令可能会存在一些小问题需要解决。就比如说 `MGET` 无法保证所有的 key 都在同一个 **hash slot**(哈希槽)上,`MGET`可能还是需要多次网络传输,原子操作也无法保证了。不过,相较于非批量操作,还是可以节省不少网络传输次数。
|
||||
|
||||
@ -478,7 +478,7 @@ Redis 中的大部分命令都是 O(1)时间复杂度,但也有少部分 O(n)
|
||||
- `LRANGE`:会返回 List 中指定范围内的元素。
|
||||
- `SMEMBERS`:返回 Set 中的所有元素。
|
||||
- `SINTER`/`SUNION`/`SDIFF`:计算多个 Set 的交集/并集/差集。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
由于这些命令时间复杂度是 O(n),有时候也会全表扫描,随着 n 的增大,执行耗时也会越长。不过, 这些命令并不是一定不能使用,但是需要明确 N 的值。另外,有遍历的需求可以使用 `HSCAN`、`SSCAN`、`ZSCAN` 代替。
|
||||
|
||||
@ -486,7 +486,7 @@ Redis 中的大部分命令都是 O(1)时间复杂度,但也有少部分 O(n)
|
||||
|
||||
- `ZRANGE`/`ZREVRANGE`:返回指定 Sorted Set 中指定排名范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 为返回的元素数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
|
||||
- `ZREMRANGEBYRANK`/`ZREMRANGEBYSCORE`:移除 Sorted Set 中指定排名范围/指定 score 范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 被删除元素的数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
#### 如何找到慢查询命令?
|
||||
|
||||
@ -742,7 +742,7 @@ Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删
|
||||
4. 尽量不适用 Redis 事务:Redis 事务实现的功能比较鸡肋,可以使用 Lua 脚本代替。
|
||||
5. 禁止长时间开启 monitor:对性能影响比较大。
|
||||
6. 控制 key 的生命周期:避免 Redis 中存放了太多不经常被访问的数据。
|
||||
7. ......
|
||||
7. ……
|
||||
|
||||
相关文章推荐:[阿里云 Redis 开发规范](https://developer.aliyun.com/article/531067) 。
|
||||
|
||||
|
||||
@ -137,7 +137,7 @@ SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `bi
|
||||
|
||||
结果:
|
||||
|
||||
```
|
||||
```plain
|
||||
id current_max_id step version biz_type
|
||||
1 0 100 0 101
|
||||
```
|
||||
@ -151,7 +151,7 @@ SELECT `current_max_id`, `step`,`version` FROM `sequence_id_generator` where `bi
|
||||
|
||||
结果:
|
||||
|
||||
```
|
||||
```plain
|
||||
id current_max_id step version biz_type
|
||||
1 100 100 1 101
|
||||
```
|
||||
|
||||
@ -47,7 +47,7 @@ Redis Cluster 的节点之间会相互发送多种 Gossip 消息:
|
||||
- **MEET**:在 Redis Cluster 中的某个 Redis 节点上执行 `CLUSTER MEET ip port` 命令,可以向指定的 Redis 节点发送一条 MEET 信息,用于将其添加进 Redis Cluster 成为新的 Redis 节点。
|
||||
- **PING/PONG**:Redis Cluster 中的节点都会定时地向其他节点发送 PING 消息,来交换各个节点状态信息,检查各个节点状态,包括在线状态、疑似下线状态 PFAIL 和已下线状态 FAIL。
|
||||
- **FAIL**:Redis Cluster 中的节点 A 发现 B 节点 PFAIL ,并且在下线报告的有效期限内集群中半数以上的节点将 B 节点标记为 PFAIL,节点 A 就会向集群广播一条 FAIL 消息,通知其他节点将故障节点 B 标记为 FAIL 。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
下图就是主从架构的 Redis Cluster 的示意图,图中的虚线代表的就是各个节点之间使用 Gossip 进行通信 ,实线表示主从复制。
|
||||
|
||||
|
||||
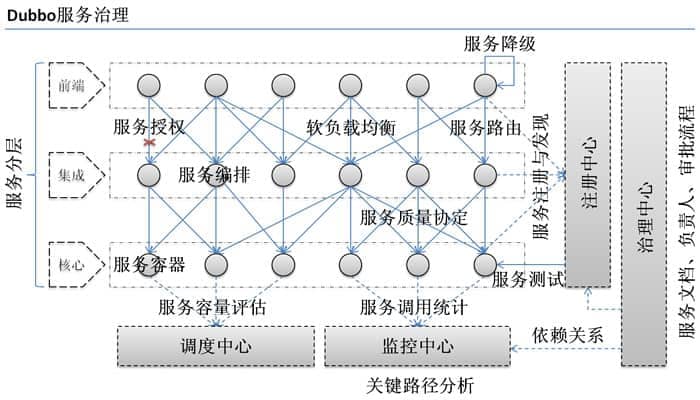
@ -56,7 +56,7 @@ Dubbo 是由阿里开源,后来加入了 Apache 。正是由于 Dubbo 的出
|
||||
1. **负载均衡**:同一个服务部署在不同的机器时该调用哪一台机器上的服务。
|
||||
2. **服务调用链路生成**:随着系统的发展,服务越来越多,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。Dubbo 可以为我们解决服务之间互相是如何调用的。
|
||||
3. **服务访问压力以及时长统计、资源调度和治理**:基于访问压力实时管理集群容量,提高集群利用率。
|
||||
4. ......
|
||||
4. ……
|
||||
|
||||
|
||||
|
||||
@ -171,7 +171,7 @@ src
|
||||
|
||||
`org.apache.dubbo.rpc.cluster.LoadBalance`
|
||||
|
||||
```
|
||||
```plain
|
||||
xxx=com.xxx.XxxLoadBalance
|
||||
```
|
||||
|
||||
|
||||
@ -19,7 +19,7 @@ category: 高可用
|
||||
4. 代码中的坏味道导致内存泄漏或者其他问题导致程序挂掉。
|
||||
5. 网站架构某个重要的角色比如 Nginx 或者数据库突然不可用。
|
||||
6. 自然灾害或者人为破坏。
|
||||
7. ......
|
||||
7. ……
|
||||
|
||||
## 有哪些提高系统可用性的方法?
|
||||
|
||||
@ -65,6 +65,6 @@ category: 高可用
|
||||
- **注意备份,必要时候回滚。**
|
||||
- **灰度发布:** 将服务器集群分成若干部分,每天只发布一部分机器,观察运行稳定没有故障,第二天继续发布一部分机器,持续几天才把整个集群全部发布完毕,期间如果发现问题,只需要回滚已发布的一部分服务器即可
|
||||
- **定期检查/更换硬件:** 如果不是购买的云服务的话,定期还是需要对硬件进行一波检查的,对于一些需要更换或者升级的硬件,要及时更换或者升级。
|
||||
- .....
|
||||
- ……
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
@ -28,7 +28,7 @@ category: 高可用
|
||||
5. 系统用到的算法是否还需要优化?
|
||||
6. 系统是否存在内存泄露的问题?
|
||||
7. 项目使用的 Redis 缓存多大?服务器性能如何?用的是机械硬盘还是固态硬盘?
|
||||
8. ......
|
||||
8. ……
|
||||
|
||||
### 1.3 测试人员
|
||||
|
||||
@ -37,7 +37,7 @@ category: 高可用
|
||||
1. 响应时间;
|
||||
2. 请求成功率;
|
||||
3. 吞吐量;
|
||||
4. ......
|
||||
4. ……
|
||||
|
||||
### 1.4 运维人员
|
||||
|
||||
@ -146,6 +146,6 @@ category: 高可用
|
||||
3. 系统是否存在死锁的地方?
|
||||
4. 系统是否存在内存泄漏?(Java 的自动回收内存虽然很方便,但是,有时候代码写的不好真的会造成内存泄漏)
|
||||
5. 数据库索引使用是否合理?
|
||||
6. ......
|
||||
6. ……
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
@ -104,7 +104,7 @@ CDN 服务提供商几乎都提供了这种比较基础的防盗链机制。
|
||||
|
||||
时间戳防盗链 URL 示例:
|
||||
|
||||
```
|
||||
```plain
|
||||
http://cdn.wangsu.com/4/123.mp3? wsSecret=79aead3bd7b5db4adeffb93a010298b5&wsTime=1601026312
|
||||
```
|
||||
|
||||
|
||||
@ -76,7 +76,7 @@ Disruptor 真的很快,关于它为什么这么快这个问题,会在后文
|
||||
- **SOFATracer**:SOFATracer 是蚂蚁金服开源的分布式应用链路追踪工具,它基于 Disruptor 来实现异步日志。
|
||||
- **Storm** : Storm 是一个开源的分布式实时计算系统,它基于 Disruptor 来实现工作进程内发生的消息传递(同一 Storm 节点上的线程间,无需网络通信)。
|
||||
- **HBase**:HBase 是一个分布式列存储数据库系统,它基于 Disruptor 来提高写并发性能。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
## Disruptor 核心概念有哪些?
|
||||
|
||||
|
||||
@ -112,7 +112,7 @@ ZooKeeper 主要为 Kafka 提供元数据的管理的功能。
|
||||
1. **Broker 注册**:在 Zookeeper 上会有一个专门**用来进行 Broker 服务器列表记录**的节点。每个 Broker 在启动时,都会到 Zookeeper 上进行注册,即到 `/brokers/ids` 下创建属于自己的节点。每个 Broker 就会将自己的 IP 地址和端口等信息记录到该节点中去
|
||||
2. **Topic 注册**:在 Kafka 中,同一个**Topic 的消息会被分成多个分区**并将其分布在多个 Broker 上,**这些分区信息及与 Broker 的对应关系**也都是由 Zookeeper 在维护。比如我创建了一个名字为 my-topic 的主题并且它有两个分区,对应到 zookeeper 中会创建这些文件夹:`/brokers/topics/my-topic/Partitions/0`、`/brokers/topics/my-topic/Partitions/1`
|
||||
3. **负载均衡**:上面也说过了 Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力。 对于同一个 Topic 的不同 Partition,Kafka 会尽力将这些 Partition 分布到不同的 Broker 服务器上。当生产者产生消息后也会尽量投递到不同 Broker 的 Partition 里面。当 Consumer 消费的时候,Zookeeper 可以根据当前的 Partition 数量以及 Consumer 数量来实现动态负载均衡。
|
||||
4. ......
|
||||
4. ……
|
||||
|
||||
### 使用 Kafka 能否不引入 Zookeeper?
|
||||
|
||||
|
||||
@ -142,7 +142,7 @@ MySQL 主从同步延时是指从库的数据落后于主库的数据,这种
|
||||
5. **网络延迟**:如果主从之间的网络传输速度慢,或者出现丢包、抖动等问题,那么就会影响 binlog 的传输效率,导致从库延迟。解决方法是优化网络环境,比如提升带宽、降低延迟、增加稳定性等。
|
||||
6. **单线程复制**:MySQL5.5 及之前,只支持单线程复制。为了优化复制性能,MySQL 5.6 引入了 **多线程复制**,MySQL 5.7 还进一步完善了多线程复制。
|
||||
7. **复制模式**:MySQL 默认的复制是异步的,必然会存在延迟问题。全同步复制不存在延迟问题,但性能太差了。半同步复制是一种折中方案,相对于异步复制,半同步复制提高了数据的安全性,减少了主从延迟(还是有一定程度的延迟)。MySQL 5.5 开始,MySQL 以插件的形式支持 **semi-sync 半同步复制**。并且,MySQL 5.7 引入了 **增强半同步复制** 。
|
||||
8. ......
|
||||
8. ……
|
||||
|
||||
[《MySQL 实战 45 讲》](https://time.geekbang.org/column/intro/100020801?code=ieY8HeRSlDsFbuRtggbBQGxdTh-1jMASqEIeqzHAKrI%3D)这个专栏中的[读写分离有哪些坑?](https://time.geekbang.org/column/article/77636)这篇文章也有对主从延迟解决方案这一话题进行探讨,感兴趣的可以阅读学习一下。
|
||||
|
||||
@ -202,7 +202,7 @@ MySQL 主从同步延时是指从库的数据落后于主库的数据,这种
|
||||
- **范围分片**:按照特性的范围区间(比如时间区间、ID 区间)来分配数据,比如 将 `id` 为 `1~299999` 的记录分到第一个库, `300000~599999` 的分到第二个库。范围分片适合需要经常进行范围查找的场景,不太适合随机读写的场景(数据未被分散,容易出现热点数据的问题)。
|
||||
- **地理位置分片**:很多 NewSQL 数据库都支持地理位置分片算法,也就是根据地理位置(如城市、地域)来分配数据。
|
||||
- **融合算法**:灵活组合多种分片算法,比如将哈希分片和范围分片组合。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
### 分库分表会带来什么问题呢?
|
||||
|
||||
@ -214,7 +214,7 @@ MySQL 主从同步延时是指从库的数据落后于主库的数据,这种
|
||||
- **事务问题**:同一个数据库中的表分布在了不同的数据库中,如果单个操作涉及到多个数据库,那么数据库自带的事务就无法满足我们的要求了。这个时候,我们就需要引入分布式事务了。关于分布式事务常见解决方案总结,网站上也有对应的总结:<https://javaguide.cn/distributed-system/distributed-transaction.html> 。
|
||||
- **分布式 ID**:分库之后, 数据遍布在不同服务器上的数据库,数据库的自增主键已经没办法满足生成的主键唯一了。我们如何为不同的数据节点生成全局唯一主键呢?这个时候,我们就需要为我们的系统引入分布式 ID 了。关于分布式 ID 的详细介绍&实现方案总结,网站上也有对应的总结:<https://javaguide.cn/distributed-system/distributed-id.html> 。
|
||||
- **跨库聚合查询问题**:分库分表会导致常规聚合查询操作,如 group by,order by 等变得异常复杂。这是因为这些操作需要在多个分片上进行数据汇总和排序,而不是在单个数据库上进行。为了实现这些操作,需要编写复杂的业务代码,或者使用中间件来协调分片间的通信和数据传输。这样会增加开发和维护的成本,以及影响查询的性能和可扩展性。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
另外,引入分库分表之后,一般需要 DBA 的参与,同时还需要更多的数据库服务器,这些都属于成本。
|
||||
|
||||
|
||||
@ -60,9 +60,9 @@ tag:
|
||||
|
||||
第一次投了钉钉,没想到因为行测做的不好,在简历筛选给拒绝了。
|
||||
|
||||
第二次阿里妈妈的后端面试,一面电话面试,我感觉面的还可以,最后题目也做出来了。最后反问阶段问对我的面试有什么建议,面试官说投阿里最好还是 Java 的… 然后电话结束后就给我拒了…
|
||||
第二次阿里妈妈的后端面试,一面电话面试,我感觉面的还可以,最后题目也做出来了。最后反问阶段问对我的面试有什么建议,面试官说投阿里最好还是 Java 的…… 然后电话结束后就给我拒了……
|
||||
|
||||
当时真的心态有点崩,问了这个晚上 7 点半的面试,一直看书晚上都没吃…
|
||||
当时真的心态有点崩,问了这个晚上 7 点半的面试,一直看书晚上都没吃……
|
||||
|
||||
所以春招和阿里就无缘了。
|
||||
|
||||
@ -82,7 +82,7 @@ tag:
|
||||
|
||||
#### 字节飞书
|
||||
|
||||
第一次一面就凉了,原因应该是笔试题目结果不对…
|
||||
第一次一面就凉了,原因应该是笔试题目结果不对……
|
||||
|
||||
第二次一面在 4 月底了,很顺利。二面在五一劳动节后,面试官还让学姐告诉我让我多看看智能指针,面试的时候让我手写 shared_ptr,我之前看了一些实现,但是没有自己写过,导致代码考虑的不够完善,leader 就一直提醒我要怎么改怎么改。
|
||||
|
||||
@ -96,7 +96,7 @@ tag:
|
||||
|
||||
## 入职字节实习
|
||||
|
||||
入职字节之前我本来觉得这个岗位可能是我面试的最适合我的了,因为我主 c++,而且飞书用 c++应该挺深的。来之后就觉得我可能不太喜欢做客户端相关,感觉好复杂…也许服务端好一些,现在我仍然不能确定。
|
||||
入职字节之前我本来觉得这个岗位可能是我面试的最适合我的了,因为我主 c++,而且飞书用 c++应该挺深的。来之后就觉得我可能不太喜欢做客户端相关,感觉好复杂……也许服务端好一些,现在我仍然不能确定。
|
||||
|
||||
字节的实习福利在这些公司中应该算是比较好的,小问题是工位比较窄,还是工作强度比其他的互联网公司大一些。字节食堂免费而且挺不错的。字节办公大厦很多,我所在的办公地点比较小。
|
||||
|
||||
|
||||
@ -69,7 +69,7 @@ tag:
|
||||
- [MySQL 实战 45 讲](https://time.geekbang.org/column/intro/100020801):前 27 讲多看几遍基本可以秒杀面试中遇到的 MySQL 问题了。
|
||||
- [Redis 核心技术与实战](https://time.geekbang.org/column/intro/100056701):讲解了大量的 Redis 在生产上的使用场景,和《Redis 设计与实现》配合着看,也可以秒杀面试中遇到的 Redis 问题了。
|
||||
- [JavaGuide](https://javaguide.cn/books/):「Java 学习+面试指南」一份涵盖大部分 Java 程序员所需要掌握的核心知识。
|
||||
- [《Java 面试指北》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247519384&idx=1&sn=bc7e71af75350b755f04ca4178395b1a&chksm=cea1c353f9d64a458f797696d4144b4d6e58639371a4612b8e4d106d83a66d2289e7b2cd7431&token=660789642&lang=zh_CN&scene=21#wechat_redirect):这是一份教你如何更高效地准备面试的小册,涵盖常见八股文(系统设计、常见框架、分布式、高并发 ......)、优质面经等内容。
|
||||
- [《Java 面试指北》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247519384&idx=1&sn=bc7e71af75350b755f04ca4178395b1a&chksm=cea1c353f9d64a458f797696d4144b4d6e58639371a4612b8e4d106d83a66d2289e7b2cd7431&token=660789642&lang=zh_CN&scene=21#wechat_redirect):这是一份教你如何更高效地准备面试的小册,涵盖常见八股文(系统设计、常见框架、分布式、高并发 ……)、优质面经等内容。
|
||||
|
||||
## 找工作
|
||||
|
||||
|
||||
@ -76,7 +76,7 @@ tag:
|
||||
- 明确的知道业务架构或技术方案选型以及决策逻辑
|
||||
- 深入掌握项目中涉及的组件以及框架
|
||||
- 熟悉项目中的疑难杂症或长期遗留 bug 的解决方案
|
||||
- ......
|
||||
- ……
|
||||
|
||||
## 专业知识考查
|
||||
|
||||
|
||||
@ -64,7 +64,7 @@ tag:
|
||||
还听到一些内部的说法:
|
||||
|
||||
- 没股票,没 TUP,年终奖少,只有工资可能比我司高一点点而已;
|
||||
- 不能借针对 HW 的消费贷,也不能买公司提供的优惠保险…
|
||||
- 不能借针对 HW 的消费贷,也不能买公司提供的优惠保险……
|
||||
|
||||
### 那,到底要不要去华为 OD?
|
||||
|
||||
|
||||
@ -16,7 +16,7 @@ tag:
|
||||
> - 想舔就舔,不想舔也没必要酸别人,Respect Greatness。
|
||||
> - 时刻准备着,技术在手就没什么可怕的,哪天干得不爽了直接跳槽。
|
||||
> - 平时积极总结沉淀,多跟别人交流,形成方法论。
|
||||
> - ......
|
||||
> - ……
|
||||
>
|
||||
> **原文地址**:https://www.nowcoder.com/discuss/351805
|
||||
|
||||
|
||||
@ -15,7 +15,7 @@ tag:
|
||||
|
||||
一年一度的金三银四跳槽大戏即将落幕,相信很多跳槽的小伙伴们已经找到了心仪的工作,即将或已经有了新的开始。
|
||||
|
||||
相信有过跳槽经验的小伙伴们都知道,每到一个新的公司面临的可能都是新的业务、新的技术、新的团队......这些可能会打破你原来工作思维、编码习惯、合作方式......
|
||||
相信有过跳槽经验的小伙伴们都知道,每到一个新的公司面临的可能都是新的业务、新的技术、新的团队……这些可能会打破你原来工作思维、编码习惯、合作方式……
|
||||
|
||||
而于公司而言,又不能给你几个月的时间去慢慢的熟悉。这个时候,如何快速进入工作状态,尽快发挥自己的价值是非常重要的。
|
||||
|
||||
@ -47,7 +47,7 @@ tag:
|
||||
|
||||
我认为测试绝对是一个人快速了解团队业务的方式。通过测试我们可以走一走自己团队所负责项目的整体流程,如果遇到自己走不下去或想不通的地方及时去问,在这个过程中我们自然而然的就可以快速的了解到核心的业务流程。
|
||||
|
||||
在了解业务的过程中,我们应该注意的是不要让自己过多的去追求细节,我们的目的是先能够整体了解业务流程,我们面向哪些用户,提供了哪些服务......
|
||||
在了解业务的过程中,我们应该注意的是不要让自己过多的去追求细节,我们的目的是先能够整体了解业务流程,我们面向哪些用户,提供了哪些服务……
|
||||
|
||||
## 技术
|
||||
|
||||
@ -57,13 +57,13 @@ tag:
|
||||
|
||||
接下来,我们就是要了解技术了,但也不是一上来就去翻源代码。 **应该按照从宏观到细节,由外而内逐步地对系统进行分析。**
|
||||
|
||||
首先,我们应该简单的了解一下 **自己团队/项目的所用到的技术栈** ,Java 还是.NET、亦或是多种语言并存,项目是前后端分离还是服务端全包,使用的数据库是 MySQL 还是 PostgreSQL......,这样我们可能会对所用到的技术和框架,以及自己所负责的内容有一定的预期,这一点有的人可能在面试的时候就会简单了解过。
|
||||
首先,我们应该简单的了解一下 **自己团队/项目的所用到的技术栈** ,Java 还是.NET、亦或是多种语言并存,项目是前后端分离还是服务端全包,使用的数据库是 MySQL 还是 PostgreSQL……,这样我们可能会对所用到的技术和框架,以及自己所负责的内容有一定的预期,这一点有的人可能在面试的时候就会简单了解过。
|
||||
|
||||
下一步,我们应该了解的是 **系统的宏观业务架构** 。自己的团队主要负责哪些系统,每个系统又主要包含哪些模块,又与哪些外部系统进行交互......对于这些,最好可以通过流程图或者思维导图等方式整理出来。
|
||||
下一步,我们应该了解的是 **系统的宏观业务架构** 。自己的团队主要负责哪些系统,每个系统又主要包含哪些模块,又与哪些外部系统进行交互……对于这些,最好可以通过流程图或者思维导图等方式整理出来。
|
||||
|
||||
然后,我们要做的是看一下 **自己的团队提供了哪些对外的接口或者服务** 。每个接口和服务所提供功能是什么。这一点我们可以继续去测试自己的系统,这个时候我们要看一看主要流程中主要包含了哪些页面,每个页面又调用了后端的哪些接口,每个后端接口又对应着哪个代码仓库。(如果是单纯做后端服务的,可以看一下我们提供了哪些服务,又有哪些上游服务,每个上游服务调用自己团队的哪些服务......),同样我们应该用画图的形式整理出来。
|
||||
然后,我们要做的是看一下 **自己的团队提供了哪些对外的接口或者服务** 。每个接口和服务所提供功能是什么。这一点我们可以继续去测试自己的系统,这个时候我们要看一看主要流程中主要包含了哪些页面,每个页面又调用了后端的哪些接口,每个后端接口又对应着哪个代码仓库。(如果是单纯做后端服务的,可以看一下我们提供了哪些服务,又有哪些上游服务,每个上游服务调用自己团队的哪些服务……),同样我们应该用画图的形式整理出来。
|
||||
|
||||
接着,我们要了解一下 **自己的系统或服务又依赖了哪些外部服务** ,也就是说需要哪些外部系统的支持,这些服务也许是团队之外、公司之外,也可能是其他公司提供的。这个时候我们可以简单的进入代码看一下与外部系统的交互是怎么做的,包括通讯框架(REST、RPC)、通讯协议......
|
||||
接着,我们要了解一下 **自己的系统或服务又依赖了哪些外部服务** ,也就是说需要哪些外部系统的支持,这些服务也许是团队之外、公司之外,也可能是其他公司提供的。这个时候我们可以简单的进入代码看一下与外部系统的交互是怎么做的,包括通讯框架(REST、RPC)、通讯协议……
|
||||
|
||||
到了代码层面,我们首先应该了解每个模块代码的层次结构,一个模块分了多少层,每个层次的职责是什么,了解了这个就对系统的整个设计有了初步的概念,紧接着就是代码的目录结构、配置文件的位置。
|
||||
|
||||
@ -75,13 +75,13 @@ tag:
|
||||
|
||||
上面我们提到,新入职一家公司,第一阶段的目标是有跟着团队做项目的能力,接下来我们要了解的就是项目是如何运作的。
|
||||
|
||||
我们应该把握从需求设计到代码编写入库最终到发布上线的整个过程中的一些关键点。例如项目采用敏捷还是瀑布的模式,一个迭代周期是多长,需求的来源以及展现形式,有没有需求评审,代码的编写规范是什么,编写完成后如何构建,如何入库,有没有提交规范,如何交付测试,发布前的准备是什么,发布工具如何使用......
|
||||
我们应该把握从需求设计到代码编写入库最终到发布上线的整个过程中的一些关键点。例如项目采用敏捷还是瀑布的模式,一个迭代周期是多长,需求的来源以及展现形式,有没有需求评审,代码的编写规范是什么,编写完成后如何构建,如何入库,有没有提交规范,如何交付测试,发布前的准备是什么,发布工具如何使用……
|
||||
|
||||
关于项目我们只需要观察同事,或者自己亲身经历一个迭代的开发,就能够大概了解清楚。
|
||||
|
||||
在了解项目运作的同时,我们还应该去了解团队,同样我们应该先从外部开始,我们对接了哪些外部团队,比如需求从哪里来,是否对接公司外部的团队,提供服务的上游团队有哪些,依赖的下游团队有哪些,团队之间如何沟通,常用的沟通方式是什么.......
|
||||
在了解项目运作的同时,我们还应该去了解团队,同样我们应该先从外部开始,我们对接了哪些外部团队,比如需求从哪里来,是否对接公司外部的团队,提供服务的上游团队有哪些,依赖的下游团队有哪些,团队之间如何沟通,常用的沟通方式是什么……
|
||||
|
||||
接下来则是团队内部,团队中有哪些角色,每个人的职责是什么,这样遇到问题我们也可以清楚的找到对应的同事寻求帮助。是否有一些定期的活动与会议,例如每日站会、周例会,是否有一些约定俗成的规矩,是否有一些内部评审,分享机制......
|
||||
接下来则是团队内部,团队中有哪些角色,每个人的职责是什么,这样遇到问题我们也可以清楚的找到对应的同事寻求帮助。是否有一些定期的活动与会议,例如每日站会、周例会,是否有一些约定俗成的规矩,是否有一些内部评审,分享机制……
|
||||
|
||||
## 总结
|
||||
|
||||
|
||||
@ -198,8 +198,10 @@ JVM 内存会划分为堆内存和非堆内存,堆内存中也会划分为**
|
||||
|
||||
堆内存中存放的是对象,垃圾收集就是收集这些对象然后交给 GC 算法进行回收。非堆内存其实我们已经说过了,就是方法区。在 1.8 中已经移除永久代,替代品是一个元空间(MetaSpace),最大区别是 metaSpace 是不存在于 JVM 中的,它使用的是本地内存。并有两个参数
|
||||
|
||||
```plain
|
||||
MetaspaceSize:初始化元空间大小,控制发生GC
|
||||
MaxMetaspaceSize:限制元空间大小上限,防止占用过多物理内存。
|
||||
```
|
||||
|
||||
移除的原因可以大致了解一下:融合 HotSpot JVM 和 JRockit VM 而做出的改变,因为 JRockit 是没有永久代的,不过这也间接性地解决了永久代的 OOM 问题。
|
||||
|
||||
@ -328,7 +330,9 @@ System.out.println("total mem=" + Runtime.getRuntime().totalMemory() / 1024.0 /
|
||||
|
||||
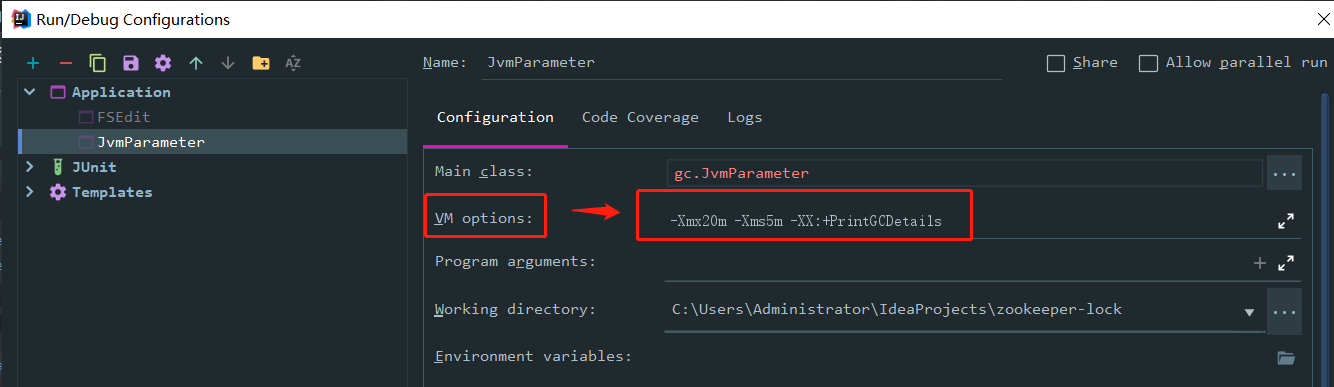
设置一个 VM options 的参数
|
||||
|
||||
```
|
||||
-Xmx20m -Xms5m -XX:+PrintGCDetails
|
||||
```
|
||||
|
||||
|
||||
|
||||
@ -381,21 +385,26 @@ System.out.println("total mem=" + Runtime.getRuntime().totalMemory() / 1024.0 /
|
||||
|
||||
### 4.2 调整新生代和老年代的比值
|
||||
|
||||
```
|
||||
-XX:NewRatio --- 新生代(eden+2\*Survivor)和老年代(不包含永久区)的比值
|
||||
|
||||
例如:-XX:NewRatio=4,表示新生代:老年代=1:4,即新生代占整个堆的 1/5。在 Xms=Xmx 并且设置了 Xmn 的情况下,该参数不需要进行设置。
|
||||
```
|
||||
|
||||
### 4.3 调整 Survivor 区和 Eden 区的比值
|
||||
|
||||
```
|
||||
-XX:SurvivorRatio(幸存代)--- 设置两个 Survivor 区和 eden 的比值
|
||||
|
||||
例如:8,表示两个 Survivor:eden=2:8,即一个 Survivor 占年轻代的 1/10
|
||||
```
|
||||
|
||||
### 4.4 设置年轻代和老年代的大小
|
||||
|
||||
```
|
||||
-XX:NewSize --- 设置年轻代大小
|
||||
|
||||
-XX:MaxNewSize --- 设置年轻代最大值
|
||||
```
|
||||
|
||||
可以通过设置不同参数来测试不同的情况,反正最优解当然就是官方的 Eden 和 Survivor 的占比为 8:1:1,然后在刚刚介绍这些参数的时候都已经附带了一些说明,感兴趣的也可以看看。反正最大堆内存和最小堆内存如果数值不同会导致多次的 gc,需要注意。
|
||||
|
||||
@ -405,13 +414,17 @@ System.out.println("total mem=" + Runtime.getRuntime().totalMemory() / 1024.0 /
|
||||
|
||||
在 OOM 时,记得 Dump 出堆,确保可以排查现场问题,通过下面命令你可以输出一个.dump 文件,这个文件可以使用 VisualVM 或者 Java 自带的 Java VisualVM 工具。
|
||||
|
||||
```
|
||||
-Xmx20m -Xms5m -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=你要输出的日志路径
|
||||
```
|
||||
|
||||
一般我们也可以通过编写脚本的方式来让 OOM 出现时给我们报个信,可以通过发送邮件或者重启程序等来解决。
|
||||
|
||||
### 4.6 永久区的设置
|
||||
|
||||
```
|
||||
-XX:PermSize -XX:MaxPermSize
|
||||
```
|
||||
|
||||
初始空间(默认为物理内存的 1/64)和最大空间(默认为物理内存的 1/4)。也就是说,jvm 启动时,永久区一开始就占用了 PermSize 大小的空间,如果空间还不够,可以继续扩展,但是不能超过 MaxPermSize,否则会 OOM。
|
||||
|
||||
@ -427,8 +440,10 @@ JDK5.0 以后每个线程堆栈大小为 1M,以前每个线程堆栈大小为
|
||||
|
||||
#### 4.7.2 设置线程栈的大小
|
||||
|
||||
```
|
||||
-XXThreadStackSize:
|
||||
设置线程栈的大小(0 means use default stack size)
|
||||
```
|
||||
|
||||
这些参数都是可以通过自己编写程序去简单测试的,这里碍于篇幅问题就不再提供 demo 了
|
||||
|
||||
@ -438,60 +453,78 @@ JDK5.0 以后每个线程堆栈大小为 1M,以前每个线程堆栈大小为
|
||||
|
||||
#### 4.8.1 设置内存页的大小
|
||||
|
||||
```
|
||||
-XXThreadStackSize:
|
||||
设置内存页的大小,不可设置过大,会影响Perm的大小
|
||||
```
|
||||
|
||||
#### 4.8.2 设置原始类型的快速优化
|
||||
|
||||
```
|
||||
-XX:+UseFastAccessorMethods:
|
||||
设置原始类型的快速优化
|
||||
```
|
||||
|
||||
#### 4.8.3 设置关闭手动 GC
|
||||
|
||||
```
|
||||
-XX:+DisableExplicitGC:
|
||||
设置关闭System.gc()(这个参数需要严格的测试)
|
||||
```
|
||||
|
||||
#### 4.8.4 设置垃圾最大年龄
|
||||
|
||||
```
|
||||
-XX:MaxTenuringThreshold
|
||||
设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代.
|
||||
对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,
|
||||
则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,
|
||||
增加在年轻代即被回收的概率。该参数只有在串行GC时才有效.
|
||||
设置垃圾最大年龄。如果设置为0的话,则年轻代对象不经过Survivor区,直接进入年老代.对于年老代比较多的应用,可以提高效率。如果将此值设置为一个较大值,则年轻代对象会在Survivor区进行多次复制,这样可以增加对象再年轻代的存活时间,加在年轻代即被回收的概率。该参数只有在串行GC时才有效.
|
||||
```
|
||||
|
||||
#### 4.8.5 加快编译速度
|
||||
|
||||
```
|
||||
-XX:+AggressiveOpts
|
||||
|
||||
加快编译速度
|
||||
```
|
||||
|
||||
#### 4.8.6 改善锁机制性能
|
||||
|
||||
```
|
||||
-XX:+UseBiasedLocking
|
||||
```
|
||||
|
||||
#### 4.8.7 禁用垃圾回收
|
||||
|
||||
```
|
||||
-Xnoclassgc
|
||||
```
|
||||
|
||||
#### 4.8.8 设置堆空间存活时间
|
||||
|
||||
```
|
||||
-XX:SoftRefLRUPolicyMSPerMB
|
||||
设置每兆堆空闲空间中SoftReference的存活时间,默认值是1s。
|
||||
```
|
||||
|
||||
#### 4.8.9 设置对象直接分配在老年代
|
||||
|
||||
```
|
||||
-XX:PretenureSizeThreshold
|
||||
设置对象超过多大时直接在老年代分配,默认值是0。
|
||||
```
|
||||
|
||||
#### 4.8.10 设置 TLAB 占 eden 区的比例
|
||||
|
||||
```
|
||||
-XX:TLABWasteTargetPercent
|
||||
设置TLAB占eden区的百分比,默认值是1% 。
|
||||
```
|
||||
|
||||
#### 4.8.11 设置是否优先 YGC
|
||||
|
||||
```
|
||||
-XX:+CollectGen0First
|
||||
设置FullGC时是否先YGC,默认值是false。
|
||||
```
|
||||
|
||||
## finally
|
||||
|
||||
|
||||
@ -40,7 +40,7 @@ JavaGuide 这个项目诞生一年左右就有出版社的老师联系我了,
|
||||
- 开源版本更容易维护和修改,也能让更多人更方便地参与到项目的建设中,这也是我最初做这个项目的初衷。
|
||||
- 我觉得出书是一件神圣的事情,自认能力还不够。
|
||||
- 个人精力有限,不光有本职工作,还弄了一个[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)赚点外快,还要维护完善 JavaGuide。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
这几年一直在默默完善,真心希望 JavaGuide 越来越好,帮助到更多朋友!也欢迎大家参与进来!
|
||||
|
||||
|
||||
@ -18,7 +18,7 @@ icon: star
|
||||
|
||||
而且, **面试中有水平的面试官都是根据你的项目经历来顺带着问一些技术八股文** 。
|
||||
|
||||
举个例子:你的项目用到了消息队列,那面试官可能就会问你:为什么使用消息队列?项目中什么模块用到了消息队列?如何保证消息不丢失?如何保证消息的顺序性?(结合你使用的具体的消息队列来准备)......。
|
||||
举个例子:你的项目用到了消息队列,那面试官可能就会问你:为什么使用消息队列?项目中什么模块用到了消息队列?如何保证消息不丢失?如何保证消息的顺序性?(结合你使用的具体的消息队列来准备)……。
|
||||
|
||||
**一定要记住你的主要目标是理解和记关键词,而不是像背课文一样一字一句地记下来!**
|
||||
|
||||
|
||||
@ -58,7 +58,7 @@ icon: "xitongsheji"
|
||||
|
||||
- [MyBatis-Plus](https://github.com/baomidou/mybatis-plus) : [MyBatis](http://www.mybatis.org/mybatis-3/) 增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
|
||||
- [MyBatis-Flex](https://gitee.com/mybatis-flex/mybatis-flex):一个优雅的 MyBatis 增强框架,无其他任何第三方依赖,支持 CRUD、分页查询、多表查询、批量操作。
|
||||
- [Redisson](https://github.com/redisson/redisson "redisson"):Redis 基础上的一个 Java 驻内存数据网格(In-Memory Data Grid),支持超过 30 个对象和服务:`Set`,`SortedSet`, `Map`, `List`, `Queue`, `Deque` ......,并且提供了多种分布式锁的实现。更多介绍请看:[《Redisson 项目介绍》](https://github.com/redisson/redisson/wiki/Redisson%E9%A1%B9%E7%9B%AE%E4%BB%8B%E7%BB%8D "Redisson项目介绍")。
|
||||
- [Redisson](https://github.com/redisson/redisson "redisson"):Redis 基础上的一个 Java 驻内存数据网格(In-Memory Data Grid),支持超过 30 个对象和服务:`Set`,`SortedSet`, `Map`, `List`, `Queue`, `Deque` ……,并且提供了多种分布式锁的实现。更多介绍请看:[《Redisson 项目介绍》](https://github.com/redisson/redisson/wiki/Redisson%E9%A1%B9%E7%9B%AE%E4%BB%8B%E7%BB%8D "Redisson项目介绍")。
|
||||
|
||||
### 数据同步
|
||||
|
||||
|
||||
@ -57,4 +57,4 @@ icon: codelibrary-fill
|
||||
|
||||
- [oshi](https://github.com/oshi/oshi "oshi"):一款为 Java 语言提供的基于 JNA 的(本机)操作系统和硬件信息库。
|
||||
- [ip2region](https://github.com/lionsoul2014/ip2region) :最自由的 ip 地址查询库,ip 到地区的映射库,提供 Binary,B 树和纯内存三种查询算法,妈妈再也不用担心我的 ip 地址定位。
|
||||
- [agrona](https://github.com/real-logic/agrona):Java 高性能数据结构(`Buffers`、`Lists`、`Maps`、`Scalable Timer Wheel`......)和实用方法。
|
||||
- [agrona](https://github.com/real-logic/agrona):Java 高性能数据结构(`Buffers`、`Lists`、`Maps`、`Scalable Timer Wheel`……)和实用方法。
|
||||
|
||||
@ -25,7 +25,7 @@ category: 代码质量
|
||||
|
||||
1. 你通过某电商网站搜索某某商品,电商网站的前端就调用了后端提供了搜索商品相关的 API。
|
||||
2. 你使用 JDK 开发 Java 程序,想要读取用户的输入的话,你就需要使用 JDK 提供的 IO 相关的 API。
|
||||
3. ......
|
||||
3. ……
|
||||
|
||||
你可以把 API 理解为程序与程序之间通信的桥梁,其本质就是一个函数而已。另外,API 的使用也不是没有章法的,它的规则由(比如数据输入和输出的格式)API 提供方制定。
|
||||
|
||||
@ -37,7 +37,7 @@ category: 代码质量
|
||||
|
||||
举个例子,如果我给你下面两个 API 你是不是立马能知道它们是干什么用的!这就是 RESTful API 的强大之处!
|
||||
|
||||
```
|
||||
```plain
|
||||
GET /classes:列出所有班级
|
||||
POST /classes:新建一个班级
|
||||
```
|
||||
@ -87,7 +87,7 @@ POST /classes:新建一个班级
|
||||
|
||||
Talk is cheap!来举个实际的例子来说明一下吧!现在有这样一个 API 提供班级(class)的信息,还包括班级中的学生和教师的信息,则它的路径应该设计成下面这样。
|
||||
|
||||
```
|
||||
```plain
|
||||
GET /classes:列出所有班级
|
||||
POST /classes:新建一个班级
|
||||
GET /classes/{classId}:获取某个指定班级的信息
|
||||
@ -101,7 +101,7 @@ DELETE /classes/{classId}/teachers/{ID}:删除某个指定班级下的指定
|
||||
|
||||
反例:
|
||||
|
||||
```
|
||||
```plain
|
||||
/getAllclasses
|
||||
/createNewclass
|
||||
/deleteAllActiveclasses
|
||||
@ -113,13 +113,13 @@ DELETE /classes/{classId}/teachers/{ID}:删除某个指定班级下的指定
|
||||
|
||||
如果我们在查询的时候需要添加特定条件的话,建议使用 url 参数的形式。比如我们要查询 state 状态为 active 并且 name 为 guidegege 的班级:
|
||||
|
||||
```
|
||||
```plain
|
||||
GET /classes?state=active&name=guidegege
|
||||
```
|
||||
|
||||
比如我们要实现分页查询:
|
||||
|
||||
```
|
||||
```plain
|
||||
GET /classes?page=1&size=10 //指定第1页,每页10个数据
|
||||
```
|
||||
|
||||
|
||||
@ -242,7 +242,7 @@ Codelf 提供了在线网站版本,网址:[https://unbug.github.io/codelf/](
|
||||
|
||||
好的命名对于其他人(包括你自己)理解你的代码有着很大的帮助!你的代码越容易被理解,可维护性就越强,侧面也就说明你的代码设计的也就越好!
|
||||
|
||||
在日常编码过程中,我们需要谨记常见命名规范比如类名需要使用大驼峰命名法、不要使用拼音,更不要使用中文......。
|
||||
在日常编码过程中,我们需要谨记常见命名规范比如类名需要使用大驼峰命名法、不要使用拼音,更不要使用中文……。
|
||||
|
||||
另外,国人开发的一个叫做 Codelf 的网站被很多人称为“变量命名神器”,当你为命名而头疼的时候,你可以去参考一下上面提供的一些命名示例。
|
||||
|
||||
|
||||
@ -42,7 +42,7 @@ category: 代码质量
|
||||
2. **避免代码腐化**:通过重构干掉坏味道代码;
|
||||
3. **加深对代码的理解**:重构代码的过程会加深你对某部分代码的理解;
|
||||
4. **发现潜在 bug**:是这样的,很多潜在的 bug ,都是我们在重构的过程中发现的;
|
||||
5. ......
|
||||
5. ……
|
||||
|
||||
看了上面介绍的关于重构带来的好处之后,你会发现重构的最终目标是 **提高软件开发速度和质量** 。
|
||||
|
||||
@ -122,7 +122,7 @@ Code Review 可以非常有效提高代码的整体质量,它会帮助我们
|
||||
- 学习了某个设计模式/工程实践之后,不顾项目实际情况,刻意使用在项目上(避免货物崇拜编程);
|
||||
- 项目进展比较急的时候,重构项目调用的某个 API 的底层代码(重构之后对项目调用这个 API 并没有带来什么价值);
|
||||
- 重写比重构更容易更省事;
|
||||
- ......
|
||||
- ……
|
||||
|
||||
### 遵循方法
|
||||
|
||||
|
||||
@ -27,7 +27,7 @@ category: 代码质量
|
||||
|
||||
每个开发者都会经历重构,重构后把代码改坏了的情况并不少见,很可能你只是修改了一个很简单的方法就导致系统出现了一个比较严重的错误。
|
||||
|
||||
如果有了单元测试的话,就不会存在这个隐患了。写完一个类,把单元测试写了,确保这个类逻辑正确;写第二个类,单元测试.....写 100 个类,道理一样,每个类做到第一点“保证逻辑正确性”,100 个类拼在一起肯定不出问题。你大可以放心一边重构,一边运行 APP;而不是整体重构完,提心吊胆地 run。
|
||||
如果有了单元测试的话,就不会存在这个隐患了。写完一个类,把单元测试写了,确保这个类逻辑正确;写第二个类,单元测试……写 100 个类,道理一样,每个类做到第一点“保证逻辑正确性”,100 个类拼在一起肯定不出问题。你大可以放心一边重构,一边运行 APP;而不是整体重构完,提心吊胆地 run。
|
||||
|
||||
### 提高代码质量
|
||||
|
||||
@ -41,7 +41,7 @@ category: 代码质量
|
||||
|
||||
### 快速定位 bug
|
||||
|
||||
如果程序有 bug,我们运行一次全部单元测试,找到不通过的测试,可以很快地定位对应的执行代码。修复代码后,运行对应的单元测试;如还不通过,继续修改,运行测试.....直到**测试通过**。
|
||||
如果程序有 bug,我们运行一次全部单元测试,找到不通过的测试,可以很快地定位对应的执行代码。修复代码后,运行对应的单元测试;如还不通过,继续修改,运行测试……直到**测试通过**。
|
||||
|
||||
### 持续集成依赖单元测试
|
||||
|
||||
@ -57,7 +57,7 @@ category: 代码质量
|
||||
|
||||
### 大牛都写单元测试
|
||||
|
||||
国外很多家喻户晓的开源项目,都有大量单元测试。例如,[retrofit](https://link.jianshu.com?t=https://github.com/square/retrofit/tree/master/retrofit/src/test/java/retrofit2)、[okhttp](https://link.jianshu.com?t=https://github.com/square/okhttp/tree/master/okhttp-tests/src/test/java/okhttp3)、[butterknife](https://link.jianshu.com?t=https://github.com/JakeWharton/butterknife/tree/master/butterknife-compiler/src/test/java/butterknife).... 国外大牛都写单元测试,我们也写吧!
|
||||
国外很多家喻户晓的开源项目,都有大量单元测试。例如,[retrofit](https://link.jianshu.com?t=https://github.com/square/retrofit/tree/master/retrofit/src/test/java/retrofit2)、[okhttp](https://link.jianshu.com?t=https://github.com/square/okhttp/tree/master/okhttp-tests/src/test/java/okhttp3)、[butterknife](https://link.jianshu.com?t=https://github.com/JakeWharton/butterknife/tree/master/butterknife-compiler/src/test/java/butterknife)…… 国外大牛都写单元测试,我们也写吧!
|
||||
|
||||
很多读者都有这种想法,一开始满腔热血。当真要对自己项目单元测试时,便困难重重,很大原因是项目对单元测试不友好。最后只能对一些不痛不痒的工具类做单元测试,久而久之,当初美好愿望也不了了之。
|
||||
|
||||
@ -67,7 +67,7 @@ category: 代码质量
|
||||
|
||||
### 心虚
|
||||
|
||||
笔者也是个不太相信自己代码的人,总觉得哪里会突然冒出莫名其妙的 bug,也怕别人不小心改了自己的代码(被害妄想症),新版本上线提心吊胆......花点时间写单元测试,有事没事跑一下测试,确保原逻辑没问题,至少能睡安稳一点。
|
||||
笔者也是个不太相信自己代码的人,总觉得哪里会突然冒出莫名其妙的 bug,也怕别人不小心改了自己的代码(被害妄想症),新版本上线提心吊胆……花点时间写单元测试,有事没事跑一下测试,确保原逻辑没问题,至少能睡安稳一点。
|
||||
|
||||
## TDD 测试驱动开发
|
||||
|
||||
|
||||
@ -194,7 +194,7 @@ public CommonResponse<Object> method1() {
|
||||
- 权限控制:利用 AOP 在目标方法执行前判断用户是否具备所需要的权限,如果具备,就执行目标方法,否则就不执行。例如,SpringSecurity 利用`@PreAuthorize` 注解一行代码即可自定义权限校验。
|
||||
- 接口限流:利用 AOP 在目标方法执行前通过具体的限流算法和实现对请求进行限流处理。
|
||||
- 缓存管理:利用 AOP 在目标方法执行前后进行缓存的读取和更新。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
### AOP 实现方式有哪些?
|
||||
|
||||
|
||||
@ -235,7 +235,7 @@ AutoConfigurationEntry getAutoConfigurationEntry(AutoConfigurationMetadata autoC
|
||||
|
||||
获取需要自动装配的所有配置类,读取`META-INF/spring.factories`
|
||||
|
||||
```
|
||||
```plain
|
||||
spring-boot/spring-boot-project/spring-boot-autoconfigure/src/main/resources/META-INF/spring.factories
|
||||
```
|
||||
|
||||
|
||||
@ -390,7 +390,7 @@ SpringBoot 项目的 spring-boot-starter-web 依赖中已经有 hibernate-valida
|
||||
- `@Digits(integer, fraction)`被注释的元素必须是一个数字,其值必须在可接受的范围内
|
||||
- `@Past`被注释的元素必须是一个过去的日期
|
||||
- `@Future` 被注释的元素必须是一个将来的日期
|
||||
- ......
|
||||
- ……
|
||||
|
||||
#### 6.2. 验证请求体(RequestBody)
|
||||
|
||||
|
||||
@ -340,7 +340,7 @@ Spring 框架中用到了哪些设计模式?
|
||||
- **包装器设计模式** : 我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
|
||||
- **观察者模式:** Spring 事件驱动模型就是观察者模式很经典的一个应用。
|
||||
- **适配器模式** :Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配`Controller`。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
## 参考
|
||||
|
||||
|
||||
@ -547,7 +547,7 @@ public class GlobalExceptionHandler {
|
||||
- **包装器设计模式** : 我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。
|
||||
- **观察者模式:** Spring 事件驱动模型就是观察者模式很经典的一个应用。
|
||||
- **适配器模式** : Spring AOP 的增强或通知(Advice)使用到了适配器模式、spring MVC 中也是用到了适配器模式适配`Controller`。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
## Spring 事务
|
||||
|
||||
|
||||
@ -705,7 +705,7 @@ private void method1() {
|
||||
- 正确的设置 `@Transactional` 的 `rollbackFor` 和 `propagation` 属性,否则事务可能会回滚失败;
|
||||
- 被 `@Transactional` 注解的方法所在的类必须被 Spring 管理,否则不生效;
|
||||
- 底层使用的数据库必须支持事务机制,否则不生效;
|
||||
- ......
|
||||
- ……
|
||||
|
||||
## 参考
|
||||
|
||||
|
||||
@ -20,7 +20,7 @@ head:
|
||||
3. 某媒体聚合平台,每 10 分钟动态抓取某某网站的数据为自己所用。
|
||||
4. 某博客平台,支持定时发送文章。
|
||||
5. 某基金平台,每晚定时计算用户当日收益情况并推送给用户最新的数据。
|
||||
6. ......
|
||||
6. ……
|
||||
|
||||
这些场景往往都要求我们在某个特定的时间去做某个事情,也就是定时或者延时去做某个事情。
|
||||
|
||||
|
||||
@ -100,7 +100,7 @@ public class XSSFilter implements Filter {
|
||||
- 用户的帐户被封禁/删除;
|
||||
- 用户被服务端强制注销;
|
||||
- 用户被踢下线;
|
||||
- ......
|
||||
- ……
|
||||
|
||||
这个问题不存在于 Session 认证方式中,因为在 Session 认证方式中,遇到这种情况的话服务端删除对应的 Session 记录即可。但是,使用 JWT 认证的方式就不好解决了。我们也说过了,JWT 一旦派发出去,如果后端不增加其他逻辑的话,它在失效之前都是有效的。
|
||||
|
||||
|
||||
@ -70,7 +70,7 @@ RBAC 即基于角色的权限访问控制(Role-Based Access Control)。这
|
||||
1. 我们在 `Cookie` 中保存已经登录过的用户信息,下次访问网站的时候页面可以自动帮你登录的一些基本信息给填了。除此之外,`Cookie` 还能保存用户首选项,主题和其他设置信息。
|
||||
2. 使用 `Cookie` 保存 `SessionId` 或者 `Token` ,向后端发送请求的时候带上 `Cookie`,这样后端就能取到 `Session` 或者 `Token` 了。这样就能记录用户当前的状态了,因为 HTTP 协议是无状态的。
|
||||
3. `Cookie` 还可以用来记录和分析用户行为。举个简单的例子你在网上购物的时候,因为 HTTP 协议是没有状态的,如果服务器想要获取你在某个页面的停留状态或者看了哪些商品,一种常用的实现方式就是将这些信息存放在 `Cookie`
|
||||
4. ......
|
||||
4. ……
|
||||
|
||||
## 如何在项目中使用 Cookie 呢?
|
||||
|
||||
|
||||
@ -32,7 +32,7 @@ tag:
|
||||
- 重排:将原始数据中的某些字符或字段的顺序打乱。例如,将身份证号码的随机位交错互换。
|
||||
- 加噪:在数据中注入一些误差或者噪音,达到对数据脱敏的效果。例如,在敏感数据中添加一些随机生成的字符。
|
||||
- 加密(常用):使用加密算法将敏感数据转换为密文。例如,将银行卡号用 MD5 或 SHA-256 等哈希函数进行散列。常见加密算法总结可以参考这篇文章:<https://javaguide.cn/system-design/security/encryption-algorithms.html> 。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
## 常用脱敏工具
|
||||
|
||||
|
||||
@ -12,7 +12,7 @@ tag:
|
||||
1. 保存在数据库中的密码需要加盐之后使用哈希算法(比如 BCrypt)进行加密。
|
||||
2. 保存在数据库中的银行卡号、身份号这类敏感数据需要使用对称加密算法(比如 AES)保存。
|
||||
3. 网络传输的敏感数据比如银行卡号、身份号需要用 HTTPS + 非对称加密算法(如 RSA)来保证传输数据的安全性。
|
||||
4. ......
|
||||
4. ……
|
||||
|
||||
## 哈希算法
|
||||
|
||||
@ -38,7 +38,7 @@ tag:
|
||||
- SHA(Secure Hash Algorithm,安全哈希算法):比如 SHA-1、SHA-256。
|
||||
- MAC(Message Authentication Code,消息认证码算法):比如 HMAC(Hash Message Authentication Code)。
|
||||
- 其他:国密算法(SM3)、密码哈希算法(Bcrypt)。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
国密算法常见的如 SM2、SM3、SM4,其中 SM2 为非对称加密算法,SM4 为对称加密算法,SM3 为哈希算法(安全性及效率和 SHA-256 相当,但更适合国内的应用环境)。
|
||||
|
||||
|
||||
@ -37,7 +37,7 @@ JWT 通常是这样的:`xxxxx.yyyyy.zzzzz`。
|
||||
|
||||
示例:
|
||||
|
||||
```
|
||||
```plain
|
||||
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.
|
||||
eyJzdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIiwiaWF0IjoxNTE2MjM5MDIyfQ.
|
||||
SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
|
||||
@ -116,7 +116,7 @@ Signature 部分是对前两部分的签名,作用是防止 JWT(主要是 pa
|
||||
|
||||
签名的计算公式如下:
|
||||
|
||||
```
|
||||
```plain
|
||||
HMACSHA256(
|
||||
base64UrlEncode(header) + "." +
|
||||
base64UrlEncode(payload),
|
||||
@ -163,6 +163,6 @@ HMACSHA256(
|
||||
4. 一定不要将隐私信息存放在 Payload 当中。
|
||||
5. 密钥一定保管好,一定不要泄露出去。JWT 安全的核心在于签名,签名安全的核心在密钥。
|
||||
6. Payload 要加入 `exp` (JWT 的过期时间),永久有效的 JWT 不合理。并且,JWT 的过期时间不易过长。
|
||||
7. ......
|
||||
7. ……
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
@ -83,7 +83,7 @@ System.out.println(matchStrList2);
|
||||
|
||||
输出:
|
||||
|
||||
```
|
||||
```plain
|
||||
大
|
||||
[大, 憨憨]
|
||||
[大, 大憨憨]
|
||||
|
||||
@ -121,7 +121,7 @@ Git 有三种状态,你的文件可能处于其中之一:
|
||||
|
||||
一个好的 Git 提交消息如下:
|
||||
|
||||
```
|
||||
```plain
|
||||
标题行:用这一行来描述和解释你的这次提交
|
||||
|
||||
主体部分可以是很少的几行,来加入更多的细节来解释提交,最好是能给出一些相关的背景或者解释这个提交能修复和解决什么问题。
|
||||
|
||||
@ -127,7 +127,7 @@ Github 前段时间推出的 Codespaces 可以提供类似 VS Code 的在线 IDE
|
||||
2. Githunb Topics 按照类别/话题将一些项目进行了分类汇总。比如 [Data visualization](https://github.com/topics/data-visualization) 汇总了数据可视化相关的一些开源项目,[Awesome Lists](https://github.com/topics/awesome) 汇总了 Awesome 系列的仓库;
|
||||
3. 通过 Github Trending 我们可以看到最近比较热门的一些开源项目,我们可以按照语言类型以及时间维度对项目进行筛选;
|
||||
4. Github Collections 类似一个收藏夹集合。比如 [Teaching materials for computational social science](https://github.com/collections/teaching-computational-social-science) 这个收藏夹就汇总了计算机课程相关的开源资源,[Learn to Code](https://github.com/collections/learn-to-code) 这个收藏夹就汇总了对你学习编程有帮助的一些仓库;
|
||||
5. ......
|
||||
5. ……
|
||||
|
||||

|
||||
|
||||
|
||||
@ -87,7 +87,7 @@ Gradle Wrapper 会给我们带来下面这些好处:
|
||||
|
||||
执行`gradle wrapper`命令之后,Gradle Wrapper 就生成完成了,项目根目录中生成如下文件:
|
||||
|
||||
```
|
||||
```plain
|
||||
├── gradle
|
||||
│ └── wrapper
|
||||
│ ├── gradle-wrapper.jar
|
||||
|
||||
@ -194,7 +194,7 @@ jobs:
|
||||
- maven-checkstyle-plugin:强制执行编码标准和最佳实践。
|
||||
- jacoco-maven-plugin: 单测覆盖率。
|
||||
- sonar-maven-plugin:分析代码质量。
|
||||
- ......
|
||||
- ……
|
||||
|
||||
jacoco-maven-plugin 使用示例:
|
||||
|
||||
|
||||
@ -139,7 +139,7 @@ Maven 的依赖范围如下:
|
||||
|
||||
举个例子,项目存在下面这样的依赖关系:
|
||||
|
||||
```
|
||||
```plain
|
||||
依赖链路一:A -> B -> C -> X(1.0)
|
||||
依赖链路二:A -> D -> X(2.0)
|
||||
```
|
||||
@ -152,7 +152,7 @@ Maven 在遇到这种问题的时候,会遵循 **路径最短优先** 和 **
|
||||
|
||||
**路径最短优先**
|
||||
|
||||
```
|
||||
```plain
|
||||
依赖链路一:A -> B -> C -> X(1.0) // dist = 3
|
||||
依赖链路二:A -> D -> X(2.0) // dist = 2
|
||||
```
|
||||
@ -161,7 +161,7 @@ Maven 在遇到这种问题的时候,会遵循 **路径最短优先** 和 **
|
||||
|
||||
不过,你也可以发现。路径最短优先原则并不是通用的,像下面这种路径长度相等的情况就不能单单通过其解决了:
|
||||
|
||||
```
|
||||
```plain
|
||||
依赖链路一:A -> B -> X(1.0) // dist = 2
|
||||
依赖链路二:A -> D -> X(2.0) // dist = 2
|
||||
```
|
||||
@ -190,7 +190,7 @@ Maven 在遇到这种问题的时候,会遵循 **路径最短优先** 和 **
|
||||
|
||||
举个例子,当前项目存在下面这样的依赖关系:
|
||||
|
||||
```
|
||||
```plain
|
||||
依赖链路一:A -> B -> C -> X(1.5) // dist = 3
|
||||
依赖链路二:A -> D -> X(1.0) // dist = 2
|
||||
```
|
||||
@ -221,7 +221,7 @@ Maven 在遇到这种问题的时候,会遵循 **路径最短优先** 和 **
|
||||
|
||||
还是上面的例子:
|
||||
|
||||
```
|
||||
```plain
|
||||
依赖链路一:A -> B -> C -> X(1.5) // dist = 3
|
||||
依赖链路二:A -> D -> X(1.0) // dist = 2
|
||||
```
|
||||
|
||||
@ -15,7 +15,7 @@ star: 5
|
||||
**《Java 面试指北》** 是我的[知识星球](../about-the-author/zhishixingqiu-two-years.md)的一个内部小册,和 [JavaGuide 开源版](https://javaguide.cn/)的内容互补。相比于开源版本来说,《Java 面试指北》添加了下面这些内容(不仅仅是这些内容):
|
||||
|
||||
- 15+ 篇文章手把手教你如何准备面试,40+ 准备面试过程中的常见问题详细解读,让你更高效地准备 Java 面试。
|
||||
- 更全面的八股文面试题(系统设计、场景题、常见框架、分布式&微服务、高并发 ......)。
|
||||
- 更全面的八股文面试题(系统设计、场景题、常见框架、分布式&微服务、高并发 ……)。
|
||||
- 优质面经精选(相比于牛客网或者其他网站的面经,《Java 面试指北》中整理的面经质量更高,并且,我会提供优质的参考资料)。
|
||||
- 技术面试题自测(高效准备技术八股文的技巧之一在于多多自测,查漏补缺)。
|
||||
- 练级攻略(有助于个人成长的经验分享)。
|
||||
|
||||
@ -9,7 +9,7 @@ category: 知识星球
|
||||
- **[《后端面试高频系统设计&场景题》](./back-end-interview-high-frequency-system-design-and-scenario-questions.md)** : 包含了常见的系统设计案例比如短链系统、秒杀系统以及高频的场景题比如海量数据去重、第三方授权登录。
|
||||
- **[《手写 RPC 框架》](./java-mian-shi-zhi-bei.md)** : 从零开始基于 Netty+Kyro+Zookeeper 实现一个简易的 RPC 框架。
|
||||
- **[《Java 必读源码系列》](./source-code-reading.md)**:目前已经整理了 Dubbo 2.6.x、Netty 4.x、SpringBoot 2.1 等框架/中间件的源码
|
||||
- ......
|
||||
- ……
|
||||
|
||||
欢迎准备 Java 面试以及学习 Java 的同学加入我的[知识星球](../about-the-author/zhishixingqiu-two-years.md),干货非常多!收费虽然是白菜价,但星球里的内容比你参加几万的培训班质量还要高。
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user