mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-05 20:31:37 +08:00
Merge pull request #2070 from paigeman/paigeman-patch-1
feat: 补充有关于MySQL字符集的一些内容
This commit is contained in:
commit
e35101ac05
@ -34,7 +34,7 @@ ER 图由下面 3 个要素组成:
|
||||
|
||||
- **实体**:通常是现实世界的业务对象,当然使用一些逻辑对象也可以。比如对于一个校园管理系统,会涉及学生、教师、课程、班级等等实体。在 ER 图中,实体使用矩形框表示。
|
||||
- **属性**:即某个实体拥有的属性,属性用来描述组成实体的要素,对于产品设计来说可以理解为字段。在 ER 图中,属性使用椭圆形表示。
|
||||
- **联系**:即实体与实体之间的关系,这个关系不仅有业务关联关系,还能通过数字表示实体之间的数量对照关系。例如,一个班级会有多个学生就是一种实体间的联系。
|
||||
- **联系**:即实体与实体之间的关系,在 ER 图中用菱形表示,这个关系不仅有业务关联关系,还能通过数字表示实体之间的数量对照关系。例如,一个班级会有多个学生就是一种实体间的联系。
|
||||
|
||||
下图是一个学生选课的 ER 图,每个学生可以选若干门课程,同一门课程也可以被若干人选择,所以它们之间的关系是多对多(M: N)。另外,还有其他两种实体之间的关系是:1 对 1(1:1)、1 对多(1: N)。
|
||||
|
||||
@ -130,7 +130,7 @@ ER 图由下面 3 个要素组成:
|
||||
|
||||
### 执行速度不同
|
||||
|
||||
一般来说:`drop` > `truncate` > `delete`(这个我没有设计测试过)。
|
||||
一般来说:`drop` > `truncate` > `delete`(这个我没有实际测试过)。
|
||||
|
||||
- `delete`命令执行的时候会产生数据库的`binlog`日志,而日志记录是需要消耗时间的,但是也有个好处方便数据回滚恢复。
|
||||
- `truncate`命令执行的时候不会产生数据库日志,因此比`delete`要快。除此之外,还会把表的自增值重置和索引恢复到初始大小等。
|
||||
|
||||
@ -94,7 +94,7 @@ UTF-8 可以根据不同的符号自动选择编码的长短,像英文字符
|
||||
|
||||
UTF-32 的规则最简单,不过缺陷也比较明显,对于英文字母这类字符消耗的空间是 UTF-8 的 4 倍之多。
|
||||
|
||||
**UTF-8** 是目前使用最广的一种字符编码,。
|
||||
**UTF-8** 是目前使用最广的一种字符编码。
|
||||
|
||||
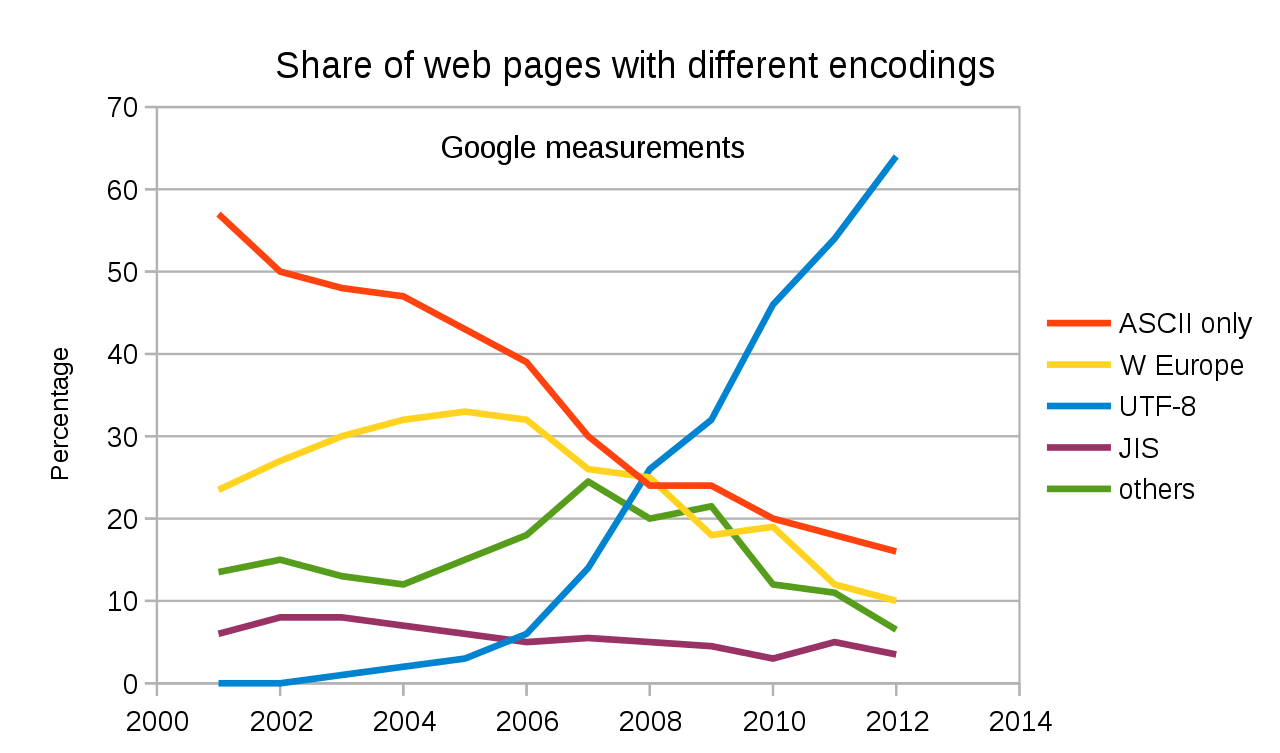
|
||||
|
||||
@ -102,10 +102,165 @@ UTF-32 的规则最简单,不过缺陷也比较明显,对于英文字母这
|
||||
|
||||
MySQL 支持很多种字符编码的方式,比如 UTF-8、GB2312、GBK、BIG5。
|
||||
|
||||
你可以通过 `SHOW CHARSET` 命令来查看。
|
||||
### 查看支持的字符集
|
||||
|
||||
你可以通过 `SHOW CHARSET` 命令来查看,支持like和where子句。
|
||||
|
||||
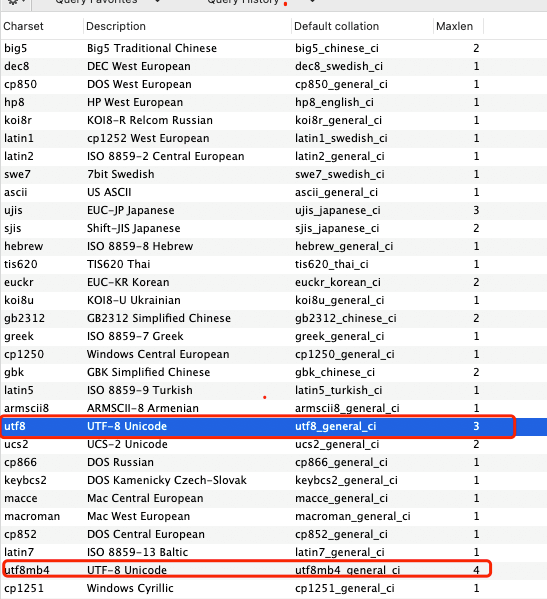
|
||||
|
||||
### 默认字符集
|
||||
|
||||
在MySQL5.7中,默认字符集是 `latin1` ;在MySQL8.0中,默认字符集是 `utf8mb4`
|
||||
|
||||
### 字符集的层次级别
|
||||
|
||||
MySQL中的字符集有以下的层次级别:
|
||||
|
||||
- `server`
|
||||
- `database`
|
||||
- `table`
|
||||
- `column`
|
||||
|
||||
它们的优先级可以简单的认为是从上往下依次增大,也即 `column` 的优先级会大于 `table` 等其余层次的
|
||||
|
||||
#### server
|
||||
|
||||
不同版本的MySQL其 `server` 级别的字符集默认值不同,在MySQL5.7中,其默认值是 `latin1` ;在MySQL8.0中,其默认值是 `utf8mb4` 。
|
||||
|
||||
当然也可以通过在启动 `mysqld` 时指定 `--character-set-server` 来设置 `server` 级别的字符集。或者如果你是通过源码构建的方式启动的MySQL,你可以在 `cmake` 命令中指定选项:
|
||||
|
||||
```sh
|
||||
cmake . -DDEFAULT_CHARSET=latin1
|
||||
```
|
||||
|
||||
此外,你也可以在运行时改变 ` character_set_server` 的值,从而达到修改 `server` 级别的字符集的目的。
|
||||
|
||||
`server` 级别的字符集可以在我们使用 `create database` 语句未指定字符集时被用作默认值,同时它还可能会对连接字符集产生影响,这个可以查看 **[`MySQL Connector/J 8.0` 文档](https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-reference-charsets.html)**。
|
||||
|
||||
#### database
|
||||
|
||||
`database` 级别的字符集是我们在创建数据库和修改数据库时指定的:
|
||||
|
||||
```sql
|
||||
CREATE DATABASE db_name
|
||||
[[DEFAULT] CHARACTER SET charset_name]
|
||||
[[DEFAULT] COLLATE collation_name]
|
||||
|
||||
ALTER DATABASE db_name
|
||||
[[DEFAULT] CHARACTER SET charset_name]
|
||||
[[DEFAULT] COLLATE collation_name]
|
||||
```
|
||||
|
||||
如前面所说,如果在执行上述语句时未指定字符集,那么MySQL将会使用 `server` 级别的字符集。这里关于字符集是如何选择的,还有一些比较细致的规则,建议自己翻阅MySQL文档。
|
||||
|
||||
可以通过下面的方式查看某个数据库的字符集:
|
||||
|
||||
```sql
|
||||
USE db_name;
|
||||
SELECT @@character_set_database, @@collation_database;
|
||||
```
|
||||
|
||||
```sql
|
||||
SELECT DEFAULT_CHARACTER_SET_NAME, DEFAULT_COLLATION_NAME
|
||||
FROM INFORMATION_SCHEMA.SCHEMATA WHERE SCHEMA_NAME = 'db_name';
|
||||
```
|
||||
|
||||
#### table
|
||||
|
||||
`table` 级别的字符集是在创建表和修改表时指定的:
|
||||
|
||||
```sql
|
||||
CREATE TABLE tbl_name (column_list)
|
||||
[[DEFAULT] CHARACTER SET charset_name]
|
||||
[COLLATE collation_name]]
|
||||
|
||||
ALTER TABLE tbl_name
|
||||
[[DEFAULT] CHARACTER SET charset_name]
|
||||
[COLLATE collation_name]
|
||||
```
|
||||
|
||||
如果在创建表和修改表时未指定字符集,那么将会使用 `database` 级别的字符集。这里关于字符集是如何选择的,还有一些比较细致的规则,建议自己翻阅MySQL文档。
|
||||
|
||||
#### column
|
||||
|
||||
`column` 级别的字符集同样是在创建表和修改表时指定的,只不过它是定义在列中。下面是个例子:
|
||||
|
||||
```sql
|
||||
CREATE TABLE t1
|
||||
(
|
||||
col1 VARCHAR(5)
|
||||
CHARACTER SET latin1
|
||||
COLLATE latin1_german1_ci
|
||||
);
|
||||
```
|
||||
|
||||
如果未指定列级别的字符集,那么将会使用表级别的字符集。这里关于字符集是如何选择的,还有一些比较细致的规则,建议自己翻阅MySQL文档。
|
||||
|
||||
### 连接字符集
|
||||
|
||||
前面说到了字符集的层次级别,它们是和存储相关的。而连接字符集涉及的是和MySQL服务器的通信。
|
||||
|
||||
连接字符集与下面这几个变量息息相关:
|
||||
|
||||
- `character_set_client` (描述了客户端发送给服务器的SQL语句使用的是什么字符集)
|
||||
- `character_set_connection` (描述了服务器接收到SQL语句时使用什么字符集进行翻译)
|
||||
- `character_set_results` (描述了服务器返回给客户端的结果使用的是什么字符集)
|
||||
|
||||
它们的值可以通过下面的SQL语句查询:
|
||||
|
||||
```sql
|
||||
SELECT * FROM performance_schema.session_variables
|
||||
WHERE VARIABLE_NAME IN (
|
||||
'character_set_client', 'character_set_connection',
|
||||
'character_set_results', 'collation_connection'
|
||||
) ORDER BY VARIABLE_NAME;
|
||||
```
|
||||
|
||||
```sql
|
||||
SHOW SESSION VARIABLES LIKE 'character\_set\_%';
|
||||
```
|
||||
|
||||
如果要想修改前面提到的几个变量的值,有以下方式:
|
||||
|
||||
- 修改配置文件
|
||||
|
||||
比如加上:
|
||||
|
||||
```
|
||||
[mysql]
|
||||
# 只针对MySQL客户端程序
|
||||
default-character-set=utf8mb4
|
||||
```
|
||||
|
||||
- 使用SQL语句
|
||||
|
||||
比如:
|
||||
|
||||
```sql
|
||||
set names utf8mb4
|
||||
# 或者一个个进行修改
|
||||
# SET character_set_client = utf8mb4;
|
||||
# SET character_set_results = utf8mb4;
|
||||
# SET collation_connection = utf8mb4;
|
||||
```
|
||||
|
||||
### jdbc对连接字符集的影响
|
||||
|
||||
不知道你们有没有碰到过存储emoji表情正常,但是使用类似Navicat之类的软件的进行查询的时候,发现emoji表情变成了问号的情况。这个问题很有可能就是jdbc驱动引起的。
|
||||
|
||||
根据前面的内容,我们知道连接字符集也是会影响我们存储的数据的,而jdbc驱动会影响连接字符集。
|
||||
|
||||
`mysql-connector-java` (jdbc驱动)主要通过这几个属性影响连接字符集:
|
||||
|
||||
- `characterEncoding`
|
||||
- `characterSetResults`
|
||||
|
||||
以 `DataGrip 2023.1.2` 来说,在它配置数据源的高级对话框中,可以看到 `characterSetResults` 的默认值是 `utf8` ,在使用 `mysql-connector-java 8.0.25` 时,连接字符集最后会被设置成 `utf8mb3` 。那么这种情况下emoji表情就会被显示为问号,并且当前版本驱动还不支持把 `characterSetResults` 设置为 `utf8mb4` ,不过换成 `mysql-connector-java driver 8.0.29` 却是允许的。
|
||||
|
||||
具体可以看一下StackOverflow的 **[这个回答](https://stackoverflow.com/questions/54815419/datagrip-mysql-stores-emojis-correctly-but-displays-them-as/76625399#76625399)**。
|
||||
|
||||
### UTF-8使用
|
||||
|
||||
通常情况下,我们建议使用 UTF-8 作为默认的字符编码方式。
|
||||
|
||||
不过,这里有一个小坑。
|
||||
@ -127,10 +282,10 @@ MySQL 字符编码集中有两套 UTF-8 编码实现:
|
||||
|
||||
```sql
|
||||
CREATE TABLE `user` (
|
||||
`id` varchar(66) CHARACTER SET utf8mb4 NOT NULL,
|
||||
`name` varchar(33) CHARACTER SET utf8mb4 NOT NULL,
|
||||
`phone` varchar(33) CHARACTER SET utf8mb4 DEFAULT NULL,
|
||||
`password` varchar(100) CHARACTER SET utf8mb4 DEFAULT NULL
|
||||
`id` varchar(66) CHARACTER SET utf8mb3 NOT NULL,
|
||||
`name` varchar(33) CHARACTER SET utf8mb3 NOT NULL,
|
||||
`phone` varchar(33) CHARACTER SET utf8mb3 DEFAULT NULL,
|
||||
`password` varchar(100) CHARACTER SET utf8mb3 DEFAULT NULL
|
||||
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
|
||||
```
|
||||
|
||||
@ -157,3 +312,6 @@ Incorrect string value: '\xF0\x9F\x98\x98\xF0\x9F...' for column 'name' at row 1
|
||||
- GB2312-维基百科:<https://zh.wikipedia.org/wiki/GB_2312>
|
||||
- UTF-8-维基百科:<https://zh.wikipedia.org/wiki/UTF-8>
|
||||
- GB18030-维基百科: <https://zh.wikipedia.org/wiki/GB_18030>
|
||||
- MySQL8文档:<https://dev.mysql.com/doc/refman/8.0/en/charset.html>
|
||||
- MySQL5.7文档:<https://dev.mysql.com/doc/refman/5.7/en/charset.html>
|
||||
- MySQL Connector/J文档:<https://dev.mysql.com/doc/connector-j/8.0/en/connector-j-reference-charsets.html>
|
||||
|
||||
@ -210,7 +210,7 @@ JVM 具有四种类型的 GC 实现:
|
||||
- `-server` : 启用“ Server Hotspot VM”; 此参数默认用于 64 位 JVM
|
||||
- `-XX:+UseStringDeduplication` : _Java 8u20_ 引入了这个 JVM 参数,通过创建太多相同 String 的实例来减少不必要的内存使用; 这通过将重复 String 值减少为单个全局 `char []` 数组来优化堆内存。
|
||||
- `-XX:+UseLWPSynchronization`: 设置基于 LWP (轻量级进程)的同步策略,而不是基于线程的同步。
|
||||
- ``-XX:LargePageSizeInBytes `: 设置用于 Java 堆的较大页面大小; 它采用 GB/MB/KB 的参数; 页面大小越大,我们可以更好地利用虚拟内存硬件资源; 然而,这可能会导致 PermGen 的空间大小更大,这反过来又会迫使 Java 堆空间的大小减小。
|
||||
- `-XX:LargePageSizeInBytes`: 设置用于 Java 堆的较大页面大小; 它采用 GB/MB/KB 的参数; 页面大小越大,我们可以更好地利用虚拟内存硬件资源; 然而,这可能会导致 PermGen 的空间大小更大,这反过来又会迫使 Java 堆空间的大小减小。
|
||||
- `-XX:MaxHeapFreeRatio` : 设置 GC 后, 堆空闲的最大百分比,以避免收缩。
|
||||
- `-XX:SurvivorRatio` : eden/survivor 空间的比例, 例如`-XX:SurvivorRatio=6` 设置每个 survivor 和 eden 之间的比例为 1:6。
|
||||
- `-XX:+UseLargePages` : 如果系统支持,则使用大页面内存; 请注意,如果使用这个 JVM 参数,OpenJDK 7 可能会崩溃。
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user