mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
[docs update]内容完善
This commit is contained in:
parent
a89d33f02d
commit
e29ad07899
@ -88,7 +88,7 @@ SELECT * FROM tb1 WHERE id < 500;
|
|||||||
|
|
||||||
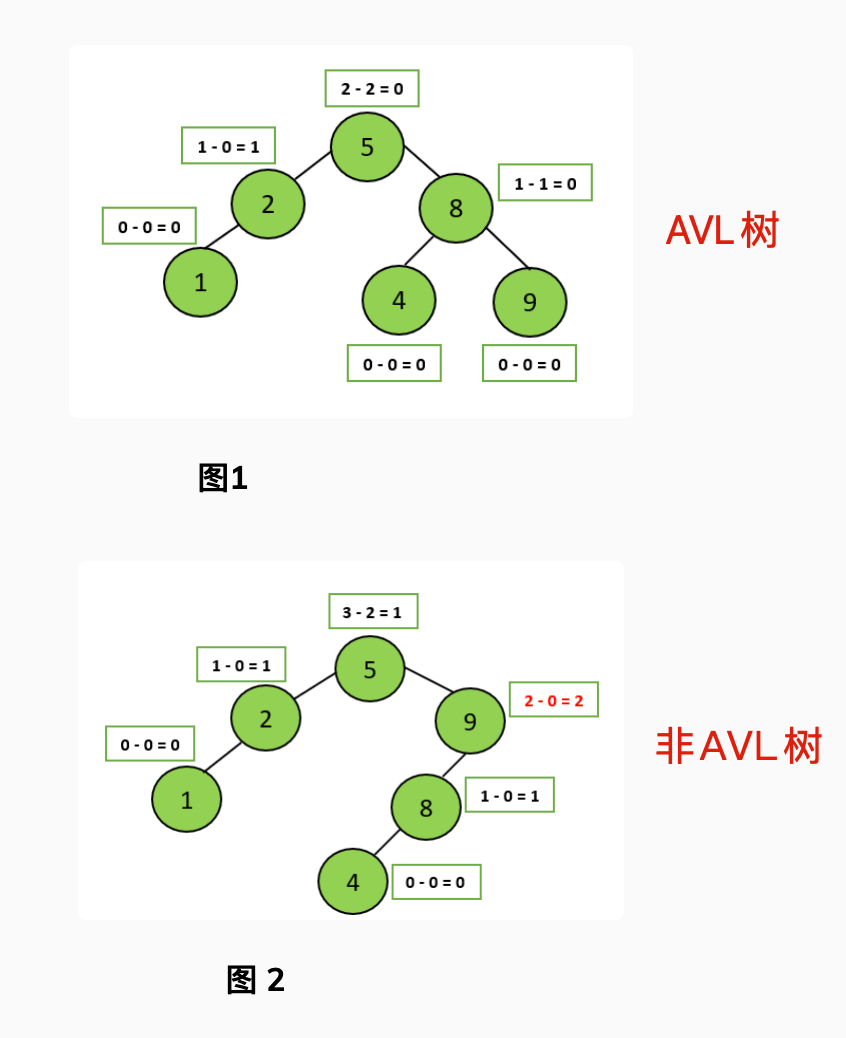
AVL 树是计算机科学中最早被发明的自平衡二叉查找树,它的名称来自于发明者 G.M. Adelson-Velsky 和 E.M. Landis 的名字缩写。AVL 树的特点是保证任何节点的左右子树高度之差不超过 1,因此也被称为高度平衡二叉树,它的查找、插入和删除在平均和最坏情况下的时间复杂度都是 O(logn)。
|
AVL 树是计算机科学中最早被发明的自平衡二叉查找树,它的名称来自于发明者 G.M. Adelson-Velsky 和 E.M. Landis 的名字缩写。AVL 树的特点是保证任何节点的左右子树高度之差不超过 1,因此也被称为高度平衡二叉树,它的查找、插入和删除在平均和最坏情况下的时间复杂度都是 O(logn)。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
AVL 树采用了旋转操作来保持平衡。主要有四种旋转操作:LL 旋转、RR 旋转、LR 旋转和 RL 旋转。其中 LL 旋转和 RR 旋转分别用于处理左左和右右失衡,而 LR 旋转和 RL 旋转则用于处理左右和右左失衡。
|
AVL 树采用了旋转操作来保持平衡。主要有四种旋转操作:LL 旋转、RR 旋转、LR 旋转和 RL 旋转。其中 LL 旋转和 RR 旋转分别用于处理左左和右右失衡,而 LR 旋转和 RL 旋转则用于处理左右和右左失衡。
|
||||||
|
|
||||||
|
|||||||
@ -341,15 +341,13 @@ InnoDB 使用缓冲池(Buffer Pool)缓存数据页和索引页,MyISAM 使
|
|||||||
|
|
||||||
### MyISAM 和 InnoDB 如何选择?
|
### MyISAM 和 InnoDB 如何选择?
|
||||||
|
|
||||||
大多数时候我们使用的都是 InnoDB 存储引擎,在某些读密集的情况下,使用 MyISAM 也是合适的。不过,前提是你的项目不介意 MyISAM 不支持事务、崩溃恢复等缺点(可是~我们一般都会介意啊!)。
|
大多数时候我们使用的都是 InnoDB 存储引擎,在某些读密集的情况下,使用 MyISAM 也是合适的。不过,前提是你的项目不介意 MyISAM 不支持事务、崩溃恢复等缺点(可是~我们一般都会介意啊)。
|
||||||
|
|
||||||
《MySQL 高性能》上面有一句话这样写到:
|
《MySQL 高性能》上面有一句话这样写到:
|
||||||
|
|
||||||
> 不要轻易相信“MyISAM 比 InnoDB 快”之类的经验之谈,这个结论往往不是绝对的。在很多我们已知场景中,InnoDB 的速度都可以让 MyISAM 望尘莫及,尤其是用到了聚簇索引,或者需要访问的数据都可以放入内存的应用。
|
> 不要轻易相信“MyISAM 比 InnoDB 快”之类的经验之谈,这个结论往往不是绝对的。在很多我们已知场景中,InnoDB 的速度都可以让 MyISAM 望尘莫及,尤其是用到了聚簇索引,或者需要访问的数据都可以放入内存的应用。
|
||||||
|
|
||||||
一般情况下我们选择 InnoDB 都是没有问题的,但是某些情况下你并不在乎可扩展能力和并发能力,也不需要事务支持,也不在乎崩溃后的安全恢复问题的话,选择 MyISAM 也是一个不错的选择。但是一般情况下,我们都是需要考虑到这些问题的。
|
因此,对于咱们日常开发的业务系统来说,你几乎找不到什么理由使用 MyISAM 了,老老实实用默认的 InnoDB 就可以了!
|
||||||
|
|
||||||
因此,对于咱们日常开发的业务系统来说,你几乎找不到什么理由再使用 MyISAM 作为自己的 MySQL 数据库的存储引擎。
|
|
||||||
|
|
||||||
## MySQL 索引
|
## MySQL 索引
|
||||||
|
|
||||||
|
|||||||
@ -23,7 +23,7 @@ head:
|
|||||||
1. **时间维度区分**:按照数据的创建时间、更新时间、过期时间等,将一定时间段内的数据视为热数据,超过该时间段的数据视为冷数据。例如,订单系统可以将 1 年前的订单数据作为冷数据,1 年内的订单数据作为热数据。这种方法适用于数据的访问频率和时间有较强的相关性的场景。
|
1. **时间维度区分**:按照数据的创建时间、更新时间、过期时间等,将一定时间段内的数据视为热数据,超过该时间段的数据视为冷数据。例如,订单系统可以将 1 年前的订单数据作为冷数据,1 年内的订单数据作为热数据。这种方法适用于数据的访问频率和时间有较强的相关性的场景。
|
||||||
2. **访问频率区分**:将高频访问的数据视为热数据,低频访问的数据视为冷数据。例如,内容系统可以将浏览量非常低的文章作为冷数据,浏览量较高的文章作为热数据。这种方法需要记录数据的访问频率,成本较高,适合访问频率和数据本身有较强的相关性的场景。
|
2. **访问频率区分**:将高频访问的数据视为热数据,低频访问的数据视为冷数据。例如,内容系统可以将浏览量非常低的文章作为冷数据,浏览量较高的文章作为热数据。这种方法需要记录数据的访问频率,成本较高,适合访问频率和数据本身有较强的相关性的场景。
|
||||||
|
|
||||||
几年前的数据并不一定都是热数据,例如一些优质文章发表几年后依然有很多人访问,大部分普通用户新发表的文章却基本没什么人访问。
|
几年前的数据并不一定都是冷数据,例如一些优质文章发表几年后依然有很多人访问,大部分普通用户新发表的文章却基本没什么人访问。
|
||||||
|
|
||||||
这两种区分冷热数据的方法各有优劣,实际项目中,可以将两者结合使用。
|
这两种区分冷热数据的方法各有优劣,实际项目中,可以将两者结合使用。
|
||||||
|
|
||||||
|
|||||||
@ -305,8 +305,11 @@ public class ArrayList<E> extends AbstractList<E>
|
|||||||
|
|
||||||
/**
|
/**
|
||||||
* 以正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。
|
* 以正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。
|
||||||
* 返回的数组将是“安全的”,因为该列表不保留对它的引用。 (换句话说,这个方法必须分配一个新的数组)。
|
* 返回的数组将是“安全的”,因为该列表不保留对它的引用。
|
||||||
* 因此,调用者可以自由地修改返回的数组。 此方法充当基于阵列和基于集合的API之间的桥梁。
|
* (换句话说,这个方法必须分配一个新的数组)。
|
||||||
|
* 因此,调用者可以自由地修改返回的数组结构。
|
||||||
|
* 注意:如果元素是引用类型,修改元素的内容会影响到原列表中的对象。
|
||||||
|
* 此方法充当基于数组和基于集合的API之间的桥梁。
|
||||||
*/
|
*/
|
||||||
public Object[] toArray() {
|
public Object[] toArray() {
|
||||||
return Arrays.copyOf(elementData, size);
|
return Arrays.copyOf(elementData, size);
|
||||||
|
|||||||
@ -125,9 +125,8 @@ icon: "xitongsheji"
|
|||||||
- [Quartz](https://github.com/quartz-scheduler/quartz):一个很火的开源任务调度框架,Java 定时任务领域的老大哥或者说参考标准, 很多其他任务调度框架都是基于 `quartz` 开发的,比如当当网的`elastic-job`就是基于`quartz`二次开发之后的分布式调度解决方案
|
- [Quartz](https://github.com/quartz-scheduler/quartz):一个很火的开源任务调度框架,Java 定时任务领域的老大哥或者说参考标准, 很多其他任务调度框架都是基于 `quartz` 开发的,比如当当网的`elastic-job`就是基于`quartz`二次开发之后的分布式调度解决方案
|
||||||
- [XXL-JOB](https://github.com/xuxueli/xxl-job) :XXL-JOB 是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
|
- [XXL-JOB](https://github.com/xuxueli/xxl-job) :XXL-JOB 是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
|
||||||
- [Elastic-Job](http://elasticjob.io/index_zh.html):Elastic-Job 是当当网开源的一个基于 Quartz 和 Zookeeper 的分布式调度解决方案,由两个相互独立的子项目 Elastic-Job-Lite 和 Elastic-Job-Cloud 组成,一般我们只要使用 Elastic-Job-Lite 就好。
|
- [Elastic-Job](http://elasticjob.io/index_zh.html):Elastic-Job 是当当网开源的一个基于 Quartz 和 Zookeeper 的分布式调度解决方案,由两个相互独立的子项目 Elastic-Job-Lite 和 Elastic-Job-Cloud 组成,一般我们只要使用 Elastic-Job-Lite 就好。
|
||||||
- [EasyScheduler](https://github.com/analysys/EasyScheduler "EasyScheduler") (已经更名为 DolphinScheduler,已经成为 Apache 孵化器项目):Easy Scheduler 是一个分布式工作流任务调度系统,主要解决“复杂任务依赖但无法直接监控任务健康状态”的问题。Easy Scheduler 以 DAG 方式组装任务,可以实时监控任务的运行状态。同时,它支持重试,重新运行等操作... 。
|
- [EasyScheduler](https://github.com/analysys/EasyScheduler "EasyScheduler") (已经更名为 DolphinScheduler,已经成为 Apache 孵化器项目):分布式易扩展的可视化工作流任务调度平台,主要解决“复杂任务依赖但无法直接监控任务健康状态”的问题。
|
||||||
- [PowerJob](https://gitee.com/KFCFans/PowerJob):新一代分布式任务调度与计算框架,支持 CRON、API、固定频率、固定延迟等调度策略,提供工作流来编排任务解决依赖关系,使用简单,功能强大,文档齐全,欢迎各位接入使用!<http://www.powerjob.tech/> 。
|
- [PowerJob](https://gitee.com/KFCFans/PowerJob):新一代分布式任务调度与计算框架,支持 CRON、API、固定频率、固定延迟等调度策略,提供工作流来编排任务解决依赖关系,使用简单,功能强大,文档齐全,欢迎各位接入使用!<http://www.powerjob.tech/> 。
|
||||||
- [DolphinScheduler](https://github.com/apache/dolphinscheduler):分布式易扩展的可视化工作流任务调度平台。
|
|
||||||
|
|
||||||
## 分布式
|
## 分布式
|
||||||
|
|
||||||
|
|||||||
@ -18,7 +18,7 @@ footer: |-
|
|||||||
|
|
||||||
## 关于网站
|
## 关于网站
|
||||||
|
|
||||||
JavaGuide 已经持续维护 5 年多了,累计提交了 **5000+** commit ,共有 **440** 多位朋友参与维护。真心希望能够把这个项目做好,真正能够帮助到有需要的朋友!
|
JavaGuide 已经持续维护 6 年多了,累计提交了 **5500+** commit ,共有 **520+** 多位贡献者共同参与维护和完善。真心希望能够把这个项目做好,真正能够帮助到有需要的朋友!
|
||||||
|
|
||||||
如果觉得 JavaGuide 的内容对你有帮助的话,还请点个免费的 Star(绝不强制点 Star,觉得内容不错有收货再点赞就好),这是对我最大的鼓励,感谢各位一路同行,共勉!传送门:[GitHub](https://github.com/Snailclimb/JavaGuide) | [Gitee](https://gitee.com/SnailClimb/JavaGuide)。
|
如果觉得 JavaGuide 的内容对你有帮助的话,还请点个免费的 Star(绝不强制点 Star,觉得内容不错有收货再点赞就好),这是对我最大的鼓励,感谢各位一路同行,共勉!传送门:[GitHub](https://github.com/Snailclimb/JavaGuide) | [Gitee](https://gitee.com/SnailClimb/JavaGuide)。
|
||||||
|
|
||||||
|
|||||||
@ -368,38 +368,43 @@ FastJSON 实现数据脱敏的方式主要有两种:
|
|||||||
- 基于注解 `@JSONField` 实现:需要自定义一个用于脱敏的序列化的类,然后在需要脱敏的字段上通过 `@JSONField` 中的 `serializeUsing` 指定为我们自定义的序列化类型即可。
|
- 基于注解 `@JSONField` 实现:需要自定义一个用于脱敏的序列化的类,然后在需要脱敏的字段上通过 `@JSONField` 中的 `serializeUsing` 指定为我们自定义的序列化类型即可。
|
||||||
- 基于序列化过滤器:需要实现 `ValueFilter` 接口,重写 `process` 方法完成自定义脱敏,然后在 JSON 转换时使用自定义的转换策略。具体实现可参考这篇文章: <https://juejin.cn/post/7067916686141161479>。
|
- 基于序列化过滤器:需要实现 `ValueFilter` 接口,重写 `process` 方法完成自定义脱敏,然后在 JSON 转换时使用自定义的转换策略。具体实现可参考这篇文章: <https://juejin.cn/post/7067916686141161479>。
|
||||||
|
|
||||||
### Mybatis-mate
|
### Mybatis-Mate
|
||||||
|
|
||||||
MybatisPlus 也提供了数据脱敏模块 mybatis-mate。mybatis-mate 为 MybatisPlus 企业级模块,使用之前需要配置授权码(付费),旨在更敏捷优雅处理数据。
|
先介绍一下 MyBatis、MyBatis-Plus 和 Mybatis-Mate 这三者的关系:
|
||||||
|
|
||||||
配置内容如下所示:
|
- MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。
|
||||||
|
- MyBatis-Plus 是一个 MyBatis 的增强工具,能够极大地简化持久层的开发工作。
|
||||||
|
- Mybatis-Mate 是为 MyBatis-Plus 提供的企业级模块,旨在更敏捷优雅处理数据。不过,使用之前需要配置授权码(付费)。
|
||||||
|
|
||||||
```yaml
|
Mybatis-Mate 支持敏感词脱敏,内置手机号、邮箱、银行卡号等 9 种常用脱敏规则。
|
||||||
# Mybatis Mate 配置
|
|
||||||
mybatis-mate:
|
```java
|
||||||
cert:
|
@FieldSensitive("testStrategy")
|
||||||
grant: jxftsdfggggx
|
private String username;
|
||||||
license: GKXP9r4MCJhGID/DTGigcBcLmZjb1YZGjE4GXaAoxbtGsPC20sxpEtiUr2F7Nb1ANTUekvF6Syo6DzraA4M4oacwoLVTglzfvaEfadfsd232485eLJK1QsskrSJmreMnEaNh9lsV7Lpbxy9JeGCeM0HPEbRvq8Y+8dUt5bQYLklsa3ZIBexir+4XykZY15uqn1pYIp4pEK0+aINTa57xjJNoWuBIqm7BdFIb4l1TAcPYMTsMXhF5hfMmKD2h391HxWTshJ6jbt4YqdKD167AgeoM+B+DE1jxlLjcpskY+kFs9piOS7RCcmKBBUOgX2BD/JxhR2gQ==
|
|
||||||
|
@Configuration
|
||||||
|
public class SensitiveStrategyConfig {
|
||||||
|
|
||||||
|
/**
|
||||||
|
* 注入脱敏策略
|
||||||
|
*/
|
||||||
|
@Bean
|
||||||
|
public ISensitiveStrategy sensitiveStrategy() {
|
||||||
|
// 自定义 testStrategy 类型脱敏处理
|
||||||
|
return new SensitiveStrategy().addStrategy("testStrategy", t -> t + "***test***");
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// 跳过脱密处理,用于编辑场景
|
||||||
|
RequestDataTransfer.skipSensitive();
|
||||||
```
|
```
|
||||||
|
|
||||||
具体实现可参考 baomidou 提供的如下代码:<https://gitee.com/baomidou/mybatis-mate-examples> 。
|
|
||||||
|
|
||||||
### MyBatis-Flex
|
### MyBatis-Flex
|
||||||
|
|
||||||
类似于 MybatisPlus,MyBatis-Flex 也是一个 MyBatis 增强框架。MyBatis-Flex 同样提供了数据脱敏功能,并且是可以免费使用的。
|
类似于 MybatisPlus,MyBatis-Flex 也是一个 MyBatis 增强框架。MyBatis-Flex 同样提供了数据脱敏功能,并且是可以免费使用的。
|
||||||
|
|
||||||
MyBatis-Flex 提供了 `@ColumnMask()` 注解,以及内置的 9 种脱敏规则,开箱即用:
|
MyBatis-Flex 提供了 `@ColumnMask()` 注解,以及内置的 9 种脱敏规则,开箱即用:
|
||||||
|
|
||||||
- 用户名脱敏
|
|
||||||
- 手机号脱敏
|
|
||||||
- 固定电话脱敏
|
|
||||||
- 身份证号脱敏
|
|
||||||
- 车牌号脱敏
|
|
||||||
- 地址脱敏
|
|
||||||
- 邮件脱敏
|
|
||||||
- 密码脱敏
|
|
||||||
- 银行卡号脱敏
|
|
||||||
|
|
||||||
```java
|
```java
|
||||||
/**
|
/**
|
||||||
* 内置的数据脱敏方式
|
* 内置的数据脱敏方式
|
||||||
@ -465,14 +470,57 @@ public class Account {
|
|||||||
|
|
||||||
如果这些内置的脱敏规则不满足你的要求的话,你还可以自定义脱敏规则。
|
如果这些内置的脱敏规则不满足你的要求的话,你还可以自定义脱敏规则。
|
||||||
|
|
||||||
|
1、通过 `MaskManager` 注册新的脱敏规则:
|
||||||
|
|
||||||
|
```java
|
||||||
|
MaskManager.registerMaskProcessor("自定义规则名称"
|
||||||
|
, data -> {
|
||||||
|
return data;
|
||||||
|
})
|
||||||
|
```
|
||||||
|
|
||||||
|
2、使用自定义的脱敏规则
|
||||||
|
|
||||||
|
```java
|
||||||
|
@Table("tb_account")
|
||||||
|
public class Account {
|
||||||
|
|
||||||
|
@Id(keyType = KeyType.Auto)
|
||||||
|
private Long id;
|
||||||
|
|
||||||
|
@ColumnMask("自定义规则名称")
|
||||||
|
private String userName;
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
并且,对于需要跳过脱密处理的场景,例如进入编辑页面编辑用户数据,MyBatis-Flex 也提供了对应的支持:
|
||||||
|
|
||||||
|
1. **`MaskManager#execWithoutMask`**(推荐):该方法使用了模版方法设计模式,保障跳过脱敏处理并执行相关逻辑后自动恢复脱敏处理。
|
||||||
|
2. **`MaskManager#skipMask`**:跳过脱敏处理。
|
||||||
|
3. **`MaskManager#restoreMask`**:恢复脱敏处理,确保后续的操作继续使用脱敏逻辑。
|
||||||
|
|
||||||
|
`MaskManager#execWithoutMask`方法实现如下:
|
||||||
|
|
||||||
|
```java
|
||||||
|
public static <T> T execWithoutMask(Supplier<T> supplier) {
|
||||||
|
try {
|
||||||
|
skipMask();
|
||||||
|
return supplier.get();
|
||||||
|
} finally {
|
||||||
|
restoreMask();
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
`MaskManager` 的`skipMask`和`restoreMask`方法一般配套使用,推荐`try{...}finally{...}`模式。
|
||||||
|
|
||||||
## 总结
|
## 总结
|
||||||
|
|
||||||
本文主要介绍了数据脱敏的相关内容,首先介绍了数据脱敏的概念,在此基础上介绍了常用的数据脱敏规则;随后介绍了本文的重点 Hutool 工具及其使用方法,在此基础上进行了实操,分别演示了使用 DesensitizedUtil 工具类、配合 Jackson 通过注解的方式完成数据脱敏;最后,介绍了一些常见的数据脱敏方法,并附上了对应的教程链接供大家参考,本文内容如有不当之处,还请大家批评指正。
|
这篇文章主要介绍了:
|
||||||
|
|
||||||
## 推荐阅读
|
- 数据脱敏的定义:数据脱敏是指对某些敏感信息通过脱敏规则进行数据的变形,实现敏感隐私数据的可靠保护。
|
||||||
|
- 常用的脱敏规则:替换、删除、重排、加噪和加密。
|
||||||
- [Spring Boot 日志、配置文件、接口数据如何脱敏?老鸟们都是这样玩的!](https://mp.weixin.qq.com/s/59osrnjyPJ7BV070x6ABwQ)
|
- 常用的脱敏工具:Hutool、Apache ShardingSphere、FastJSON、Mybatis-Mate 和 MyBatis-Flex。
|
||||||
- [大厂也在用的 6 种数据脱敏方案,严防泄露数据的“内鬼”](https://mp.weixin.qq.com/s/_Dgekk1AJsIx0TTlnH6kUA)
|
|
||||||
|
|
||||||
## 参考
|
## 参考
|
||||||
|
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user