mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
commit
dab0f571b7
@ -54,7 +54,7 @@
|
||||
|
||||
```
|
||||
|
||||
细心的同学一定会发现 :**以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为10。** 下面在我们分析 ArrayList 扩容时会降到这一点内容!
|
||||
细心的同学一定会发现 :**以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为10。** 下面在我们分析 ArrayList 扩容时会讲到这一点内容!
|
||||
|
||||
## 二 一步一步分析 ArrayList 扩容机制
|
||||
|
||||
@ -308,7 +308,7 @@ ArrayList 源码中有一个 `ensureCapacity` 方法不知道大家注意到没
|
||||
|
||||
```
|
||||
|
||||
**最好在 add 大量元素之前用 `ensureCapacity` 方法,以减少增量从新分配的次数**
|
||||
**最好在 add 大量元素之前用 `ensureCapacity` 方法,以减少增量重新分配的次数**
|
||||
|
||||
我们通过下面的代码实际测试以下这个方法的效果:
|
||||
|
||||
@ -344,4 +344,4 @@ public class EnsureCapacityTest {
|
||||
|
||||
```
|
||||
|
||||
通过运行结果,我们可以很明显的看出向 ArrayList 添加大量元素之前最好先使用`ensureCapacity` 方法,以减少增量从新分配的次数
|
||||
通过运行结果,我们可以很明显的看出向 ArrayList 添加大量元素之前最好先使用`ensureCapacity` 方法,以减少增量重新分配的次数
|
||||
|
||||
@ -1,4 +1,3 @@
|
||||
|
||||
<!-- MarkdownTOC -->
|
||||
|
||||
- [ArrayList简介](#arraylist简介)
|
||||
@ -19,15 +18,15 @@
|
||||
它继承于 **AbstractList**,实现了 **List**, **RandomAccess**, **Cloneable**, **java.io.Serializable** 这些接口。
|
||||
|
||||
在我们学数据结构的时候就知道了线性表的顺序存储,插入删除元素的时间复杂度为**O(n)**,求表长以及增加元素,取第 i 元素的时间复杂度为**O(1)**
|
||||
|
||||
|
||||
ArrayList 继承了AbstractList,实现了List。它是一个数组队列,提供了相关的添加、删除、修改、遍历等功能。
|
||||
|
||||
|
||||
ArrayList 实现了**RandomAccess 接口**,即提供了随机访问功能。RandomAccess 是 Java 中用来被 List 实现,为 List 提供**快速访问功能**的。在 ArrayList 中,我们即可以通过元素的序号快速获取元素对象,这就是快速随机访问。
|
||||
|
||||
|
||||
ArrayList 实现了**Cloneable 接口**,即覆盖了函数 clone(),**能被克隆**。
|
||||
|
||||
|
||||
ArrayList 实现**java.io.Serializable 接口**,这意味着ArrayList**支持序列化**,**能通过序列化去传输**。
|
||||
|
||||
|
||||
和 Vector 不同,**ArrayList 中的操作不是线程安全的**!所以,建议在单线程中才使用 ArrayList,而在多线程中可以选择 Vector 或者 CopyOnWriteArrayList。
|
||||
### ArrayList核心源码
|
||||
|
||||
@ -85,7 +84,7 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
}
|
||||
|
||||
/**
|
||||
*默认构造函数,其默认初始容量为10
|
||||
*默认构造函数,DEFAULTCAPACITY_EMPTY_ELEMENTDATA 为0.初始化为10,也就是说初始其实是空数组 当添加第一个元素的时候数组容量才变成10
|
||||
*/
|
||||
public ArrayList() {
|
||||
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
|
||||
@ -177,7 +176,7 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
newCapacity = minCapacity;
|
||||
//再检查新容量是否超出了ArrayList所定义的最大容量,
|
||||
//若超出了,则调用hugeCapacity()来比较minCapacity和 MAX_ARRAY_SIZE,
|
||||
//如果minCapacity大于最大容量,则新容量则为ArrayList定义的最大容量,否则,新容量大小则为 minCapacity。
|
||||
//如果minCapacity大于MAX_ARRAY_SIZE,则新容量则为Interger.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE。
|
||||
if (newCapacity - MAX_ARRAY_SIZE > 0)
|
||||
newCapacity = hugeCapacity(minCapacity);
|
||||
// minCapacity is usually close to size, so this is a win:
|
||||
@ -631,7 +630,7 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
newCapacity = minCapacity;
|
||||
//再检查新容量是否超出了ArrayList所定义的最大容量,
|
||||
//若超出了,则调用hugeCapacity()来比较minCapacity和 MAX_ARRAY_SIZE,
|
||||
//如果minCapacity大于最大容量,则新容量则为ArrayList定义的最大容量,否则,新容量大小则为 minCapacity。
|
||||
//如果minCapacity大于MAX_ARRAY_SIZE,则新容量则为Interger.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE。
|
||||
if (newCapacity - MAX_ARRAY_SIZE > 0)
|
||||
newCapacity = hugeCapacity(minCapacity);
|
||||
// minCapacity is usually close to size, so this is a win:
|
||||
@ -653,14 +652,14 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
|
||||
3. .java 中的**size()方法**是针对泛型集合说的,如果想看这个泛型有多少个元素,就调用此方法来查看!
|
||||
|
||||
|
||||
|
||||
#### 内部类
|
||||
```java
|
||||
(1)private class Itr implements Iterator<E>
|
||||
(2)private class ListItr extends Itr implements ListIterator<E>
|
||||
(3)private class SubList extends AbstractList<E> implements RandomAccess
|
||||
(4)static final class ArrayListSpliterator<E> implements Spliterator<E>
|
||||
```
|
||||
```
|
||||
ArrayList有四个内部类,其中的**Itr是实现了Iterator接口**,同时重写了里面的**hasNext()**,**next()**,**remove()**等方法;其中的**ListItr**继承**Itr**,实现了**ListIterator接口**,同时重写了**hasPrevious()**,**nextIndex()**,**previousIndex()**,**previous()**,**set(E e)**,**add(E e)**等方法,所以这也可以看出了**Iterator和ListIterator的区别:**ListIterator在Iterator的基础上增加了添加对象,修改对象,逆向遍历等方法,这些是Iterator不能实现的。
|
||||
### <font face="楷体" id="6"> ArrayList经典Demo</font>
|
||||
|
||||
|
||||
347
Java相关/BIO,NIO,AIO summary.md
Normal file
347
Java相关/BIO,NIO,AIO summary.md
Normal file
@ -0,0 +1,347 @@
|
||||
熟练掌握 BIO,NIO,AIO 的基本概念以及一些常见问题是你准备面试的过程中不可或缺的一部分,另外这些知识点也是你学习 Netty 的基础。
|
||||
|
||||
<!-- MarkdownTOC -->
|
||||
|
||||
- [BIO,NIO,AIO 总结](#bionioaio-总结)
|
||||
- [1. BIO \(Blocking I/O\)](#1-bio-blocking-io)
|
||||
- [1.1 传统 BIO](#11-传统-bio)
|
||||
- [1.2 伪异步 IO](#12-伪异步-io)
|
||||
- [1.3 代码示例](#13-代码示例)
|
||||
- [1.4 总结](#14-总结)
|
||||
- [2. NIO \(New I/O\)](#2-nio-new-io)
|
||||
- [2.1 NIO 简介](#21-nio-简介)
|
||||
- [2.2 NIO的特性/NIO与IO区别](#22-nio的特性nio与io区别)
|
||||
- [1)Non-blocking IO(非阻塞IO)](#1non-blocking-io(非阻塞io))
|
||||
- [2)Buffer\(缓冲区\)](#2buffer缓冲区)
|
||||
- [3)Channel \(通道\)](#3channel-通道)
|
||||
- [4)Selectors\(选择器\)](#4selectors选择器)
|
||||
- [2.3 NIO 读数据和写数据方式](#23-nio-读数据和写数据方式)
|
||||
- [2.4 NIO核心组件简单介绍](#24-nio核心组件简单介绍)
|
||||
- [2.5 代码示例](#25-代码示例)
|
||||
- [3. AIO \(Asynchronous I/O\)](#3-aio-asynchronous-io)
|
||||
- [参考](#参考)
|
||||
|
||||
<!-- /MarkdownTOC -->
|
||||
|
||||
|
||||
# BIO,NIO,AIO 总结
|
||||
|
||||
Java 中的 BIO、NIO和 AIO 理解为是 Java 语言对操作系统的各种 IO 模型的封装。程序员在使用这些 API 的时候,不需要关心操作系统层面的知识,也不需要根据不同操作系统编写不同的代码。只需要使用Java的API就可以了。
|
||||
|
||||
在讲 BIO,NIO,AIO 之前先来回顾一下这样几个概念:同步与异步,阻塞与非阻塞。
|
||||
|
||||
**同步与异步**
|
||||
|
||||
- **同步:** 同步就是发起一个调用后,被调用者未处理完请求之前,调用不返回。
|
||||
- **异步:** 异步就是发起一个调用后,立刻得到被调用者的回应表示已接收到请求,但是被调用者并没有返回结果,此时我们可以处理其他的请求,被调用者通常依靠事件,回调等机制来通知调用者其返回结果。
|
||||
|
||||
同步和异步的区别最大在于异步的话调用者不需要等待处理结果,被调用者会通过回调等机制来通知调用者其返回结果。
|
||||
|
||||
**阻塞和非阻塞**
|
||||
|
||||
- **阻塞:** 阻塞就是发起一个请求,调用者一直等待请求结果返回,也就是当前线程会被挂起,无法从事其他任务,只有当条件就绪才能继续。
|
||||
- **非阻塞:** 非阻塞就是发起一个请求,调用者不用一直等着结果返回,可以先去干其他事情。
|
||||
|
||||
举个生活中简单的例子,你妈妈让你烧水,小时候你比较笨啊,在哪里傻等着水开(**同步阻塞**)。等你稍微再长大一点,你知道每次烧水的空隙可以去干点其他事,然后只需要时不时来看看水开了没有(**同步非阻塞**)。后来,你们家用上了水开了会发出声音的壶,这样你就只需要听到响声后就知道水开了,在这期间你可以随便干自己的事情,你需要去倒水了(**异步非阻塞**)。
|
||||
|
||||
|
||||
## 1. BIO (Blocking I/O)
|
||||
|
||||
同步阻塞I/O模式,数据的读取写入必须阻塞在一个线程内等待其完成。
|
||||
|
||||
### 1.1 传统 BIO
|
||||
|
||||
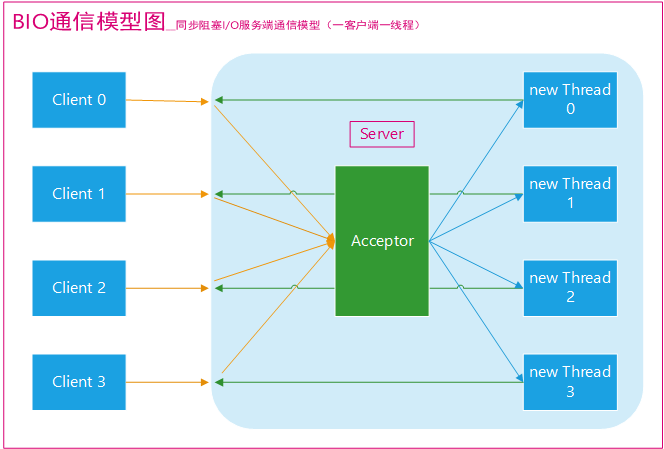
BIO通信(一请求一应答)模型图如下(图源网络,原出处不明):
|
||||
|
||||
|
||||
|
||||
采用 **BIO 通信模型** 的服务端,通常由一个独立的 Acceptor 线程负责监听客户端的连接。我们一般通过在`while(true)` 循环中服务端会调用 `accept()` 方法等待接收客户端的连接的方式监听请求,请求一旦接收到一个连接请求,就可以建立通信套接字在这个通信套接字上进行读写操作,此时不能再接收其他客户端连接请求,只能等待同当前连接的客户端的操作执行完成, 不过可以通过多线程来支持多个客户端的连接,如上图所示。
|
||||
|
||||
如果要让 **BIO 通信模型** 能够同时处理多个客户端请求,就必须使用多线程(主要原因是`socket.accept()`、`socket.read()`、`socket.write()` 涉及的三个主要函数都是同步阻塞的),也就是说它在接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理,处理完成之后,通过输出流返回应答给客户端,线程销毁。这就是典型的 **一请求一应答通信模型** 。我们可以设想一下如果这个连接不做任何事情的话就会造成不必要的线程开销,不过可以通过 **线程池机制** 改善,线程池还可以让线程的创建和回收成本相对较低。使用`FixedThreadPool` 可以有效的控制了线程的最大数量,保证了系统有限的资源的控制,实现了N(客户端请求数量):M(处理客户端请求的线程数量)的伪异步I/O模型(N 可以远远大于 M),下面一节"伪异步 BIO"中会详细介绍到。
|
||||
|
||||
**我们再设想一下当客户端并发访问量增加后这种模型会出现什么问题?**
|
||||
|
||||
在 Java 虚拟机中,线程是宝贵的资源,线程的创建和销毁成本很高,除此之外,线程的切换成本也是很高的。尤其在 Linux 这样的操作系统中,线程本质上就是一个进程,创建和销毁线程都是重量级的系统函数。如果并发访问量增加会导致线程数急剧膨胀可能会导致线程堆栈溢出、创建新线程失败等问题,最终导致进程宕机或者僵死,不能对外提供服务。
|
||||
|
||||
### 1.2 伪异步 IO
|
||||
|
||||
为了解决同步阻塞I/O面临的一个链路需要一个线程处理的问题,后来有人对它的线程模型进行了优化一一一后端通过一个线程池来处理多个客户端的请求接入,形成客户端个数M:线程池最大线程数N的比例关系,其中M可以远远大于N.通过线程池可以灵活地调配线程资源,设置线程的最大值,防止由于海量并发接入导致线程耗尽。
|
||||
|
||||
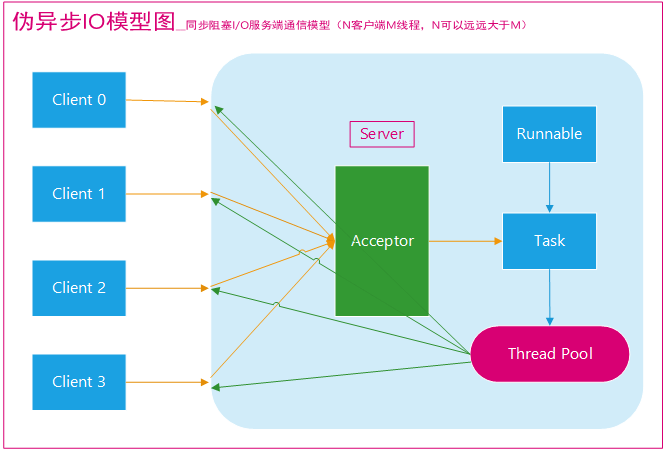
伪异步IO模型图(图源网络,原出处不明):
|
||||
|
||||
|
||||
|
||||
采用线程池和任务队列可以实现一种叫做伪异步的 I/O 通信框架,它的模型图如上图所示。当有新的客户端接入时,将客户端的 Socket 封装成一个Task(该任务实现java.lang.Runnable接口)投递到后端的线程池中进行处理,JDK 的线程池维护一个消息队列和 N 个活跃线程,对消息队列中的任务进行处理。由于线程池可以设置消息队列的大小和最大线程数,因此,它的资源占用是可控的,无论多少个客户端并发访问,都不会导致资源的耗尽和宕机。
|
||||
|
||||
伪异步I/O通信框架采用了线程池实现,因此避免了为每个请求都创建一个独立线程造成的线程资源耗尽问题。不过因为它的底层任然是同步阻塞的BIO模型,因此无法从根本上解决问题。
|
||||
|
||||
### 1.3 代码示例
|
||||
|
||||
下面代码中演示了BIO通信(一请求一应答)模型。我们会在客户端创建多个线程依次连接服务端并向其发送"当前时间+:hello world",服务端会为每个客户端线程创建一个线程来处理。代码示例出自闪电侠的博客,原地址如下:
|
||||
|
||||
[https://www.jianshu.com/p/a4e03835921a](https://www.jianshu.com/p/a4e03835921a)
|
||||
|
||||
**客户端**
|
||||
|
||||
```java
|
||||
/**
|
||||
*
|
||||
* @author 闪电侠
|
||||
* @date 2018年10月14日
|
||||
* @Description:客户端
|
||||
*/
|
||||
public class IOClient {
|
||||
|
||||
public static void main(String[] args) {
|
||||
// TODO 创建多个线程,模拟多个客户端连接服务端
|
||||
new Thread(() -> {
|
||||
try {
|
||||
Socket socket = new Socket("127.0.0.1", 3333);
|
||||
while (true) {
|
||||
try {
|
||||
socket.getOutputStream().write((new Date() + ": hello world").getBytes());
|
||||
Thread.sleep(2000);
|
||||
} catch (Exception e) {
|
||||
}
|
||||
}
|
||||
} catch (IOException e) {
|
||||
}
|
||||
}).start();
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
**服务端**
|
||||
|
||||
```java
|
||||
/**
|
||||
* @author 闪电侠
|
||||
* @date 2018年10月14日
|
||||
* @Description: 服务端
|
||||
*/
|
||||
public class IOServer {
|
||||
|
||||
public static void main(String[] args) throws IOException {
|
||||
// TODO 服务端处理客户端连接请求
|
||||
ServerSocket serverSocket = new ServerSocket(3333);
|
||||
|
||||
// 接收到客户端连接请求之后为每个客户端创建一个新的线程进行链路处理
|
||||
new Thread(() -> {
|
||||
while (true) {
|
||||
try {
|
||||
// 阻塞方法获取新的连接
|
||||
Socket socket = serverSocket.accept();
|
||||
|
||||
// 每一个新的连接都创建一个线程,负责读取数据
|
||||
new Thread(() -> {
|
||||
try {
|
||||
int len;
|
||||
byte[] data = new byte[1024];
|
||||
InputStream inputStream = socket.getInputStream();
|
||||
// 按字节流方式读取数据
|
||||
while ((len = inputStream.read(data)) != -1) {
|
||||
System.out.println(new String(data, 0, len));
|
||||
}
|
||||
} catch (IOException e) {
|
||||
}
|
||||
}).start();
|
||||
|
||||
} catch (IOException e) {
|
||||
}
|
||||
|
||||
}
|
||||
}).start();
|
||||
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
### 1.4 总结
|
||||
|
||||
在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的 I/O 并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。但是,当面对十万甚至百万级连接的时候,传统的 BIO 模型是无能为力的。因此,我们需要一种更高效的 I/O 处理模型来应对更高的并发量。
|
||||
|
||||
|
||||
|
||||
## 2. NIO (New I/O)
|
||||
|
||||
### 2.1 NIO 简介
|
||||
|
||||
NIO是一种同步非阻塞的I/O模型,在Java 1.4 中引入了NIO框架,对应 java.nio 包,提供了 Channel , Selector,Buffer等抽象。
|
||||
|
||||
NIO中的N可以理解为Non-blocking,不单纯是New。它支持面向缓冲的,基于通道的I/O操作方法。 NIO提供了与传统BIO模型中的 `Socket` 和 `ServerSocket` 相对应的 `SocketChannel` 和 `ServerSocketChannel` 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞两种模式。阻塞模式使用就像传统中的支持一样,比较简单,但是性能和可靠性都不好;非阻塞模式正好与之相反。对于低负载、低并发的应用程序,可以使用同步阻塞I/O来提升开发速率和更好的维护性;对于高负载、高并发的(网络)应用,应使用 NIO 的非阻塞模式来开发。
|
||||
|
||||
### 2.2 NIO的特性/NIO与IO区别
|
||||
|
||||
如果是在面试中回答这个问题,我觉得首先肯定要从 NIO 流是非阻塞 IO 而 IO 流是阻塞 IO 说起。然后,可以从 NIO 的3个核心组件/特性为 NIO 带来的一些改进来分析。如果,你把这些都回答上了我觉得你对于 NIO 就有了更为深入一点的认识,面试官问到你这个问题,你也能很轻松的回答上来了。
|
||||
|
||||
#### 1)Non-blocking IO(非阻塞IO)
|
||||
|
||||
**IO流是阻塞的,NIO流是不阻塞的。**
|
||||
|
||||
Java NIO使我们可以进行非阻塞IO操作。比如说,单线程中从通道读取数据到buffer,同时可以继续做别的事情,当数据读取到buffer中后,线程再继续处理数据。写数据也是一样的。另外,非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。
|
||||
|
||||
Java IO的各种流是阻塞的。这意味着,当一个线程调用 `read()` 或 `write()` 时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了
|
||||
|
||||
#### 2)Buffer(缓冲区)
|
||||
|
||||
**IO 面向流(Stream oriented),而 NIO 面向缓冲区(Buffer oriented)。**
|
||||
|
||||
Buffer是一个对象,它包含一些要写入或者要读出的数据。在NIO类库中加入Buffer对象,体现了新库与原I/O的一个重要区别。在面向流的I/O中·可以将数据直接写入或者将数据直接读到 Stream 对象中。虽然 Stream 中也有 Buffer 开头的扩展类,但只是流的包装类,还是从流读到缓冲区,而 NIO 却是直接读到 Buffer 中进行操作。
|
||||
|
||||
在NIO厍中,所有数据都是用缓冲区处理的。在读取数据时,它是直接读到缓冲区中的; 在写入数据时,写入到缓冲区中。任何时候访问NIO中的数据,都是通过缓冲区进行操作。
|
||||
|
||||
最常用的缓冲区是 ByteBuffer,一个 ByteBuffer 提供了一组功能用于操作 byte 数组。除了ByteBuffer,还有其他的一些缓冲区,事实上,每一种Java基本类型(除了Boolean类型)都对应有一种缓冲区。
|
||||
|
||||
#### 3)Channel (通道)
|
||||
|
||||
NIO 通过Channel(通道) 进行读写。
|
||||
|
||||
通道是双向的,可读也可写,而流的读写是单向的。无论读写,通道只能和Buffer交互。因为 Buffer,通道可以异步地读写。
|
||||
|
||||
#### 4)Selectors(选择器)
|
||||
|
||||
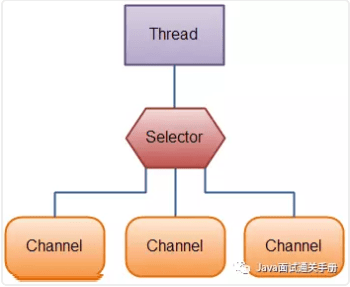
NIO有选择器,而IO没有。
|
||||
|
||||
选择器用于使用单个线程处理多个通道。因此,它需要较少的线程来处理这些通道。线程之间的切换对于操作系统来说是昂贵的。 因此,为了提高系统效率选择器是有用的。
|
||||
|
||||
|
||||
|
||||
### 2.3 NIO 读数据和写数据方式
|
||||
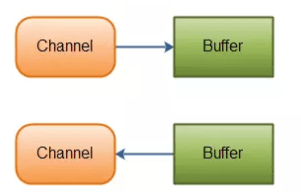
通常来说NIO中的所有IO都是从 Channel(通道) 开始的。
|
||||
|
||||
- 从通道进行数据读取 :创建一个缓冲区,然后请求通道读取数据。
|
||||
- 从通道进行数据写入 :创建一个缓冲区,填充数据,并要求通道写入数据。
|
||||
|
||||
数据读取和写入操作图示:
|
||||
|
||||
|
||||
|
||||
|
||||
### 2.4 NIO核心组件简单介绍
|
||||
|
||||
NIO 包含下面几个核心的组件:
|
||||
|
||||
- Channel(通道)
|
||||
- Buffer(缓冲区)
|
||||
- Selector(选择器)
|
||||
|
||||
整个NIO体系包含的类远远不止这三个,只能说这三个是NIO体系的“核心API”。我们上面已经对这三个概念进行了基本的阐述,这里就不多做解释了。
|
||||
|
||||
### 2.5 代码示例
|
||||
|
||||
代码示例出自闪电侠的博客,原地址如下:
|
||||
|
||||
[https://www.jianshu.com/p/a4e03835921a](https://www.jianshu.com/p/a4e03835921a)
|
||||
|
||||
客户端 IOClient.java 的代码不变,我们对服务端使用 NIO 进行改造。以下代码较多而且逻辑比较复杂,大家看看就好。
|
||||
|
||||
```java
|
||||
/**
|
||||
*
|
||||
* @author 闪电侠
|
||||
* @date 2019年2月21日
|
||||
* @Description: NIO 改造后的服务端
|
||||
*/
|
||||
public class NIOServer {
|
||||
public static void main(String[] args) throws IOException {
|
||||
// 1. serverSelector负责轮询是否有新的连接,服务端监测到新的连接之后,不再创建一个新的线程,
|
||||
// 而是直接将新连接绑定到clientSelector上,这样就不用 IO 模型中 1w 个 while 循环在死等
|
||||
Selector serverSelector = Selector.open();
|
||||
// 2. clientSelector负责轮询连接是否有数据可读
|
||||
Selector clientSelector = Selector.open();
|
||||
|
||||
new Thread(() -> {
|
||||
try {
|
||||
// 对应IO编程中服务端启动
|
||||
ServerSocketChannel listenerChannel = ServerSocketChannel.open();
|
||||
listenerChannel.socket().bind(new InetSocketAddress(3333));
|
||||
listenerChannel.configureBlocking(false);
|
||||
listenerChannel.register(serverSelector, SelectionKey.OP_ACCEPT);
|
||||
|
||||
while (true) {
|
||||
// 监测是否有新的连接,这里的1指的是阻塞的时间为 1ms
|
||||
if (serverSelector.select(1) > 0) {
|
||||
Set<SelectionKey> set = serverSelector.selectedKeys();
|
||||
Iterator<SelectionKey> keyIterator = set.iterator();
|
||||
|
||||
while (keyIterator.hasNext()) {
|
||||
SelectionKey key = keyIterator.next();
|
||||
|
||||
if (key.isAcceptable()) {
|
||||
try {
|
||||
// (1)
|
||||
// 每来一个新连接,不需要创建一个线程,而是直接注册到clientSelector
|
||||
SocketChannel clientChannel = ((ServerSocketChannel) key.channel()).accept();
|
||||
clientChannel.configureBlocking(false);
|
||||
clientChannel.register(clientSelector, SelectionKey.OP_READ);
|
||||
} finally {
|
||||
keyIterator.remove();
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
}
|
||||
} catch (IOException ignored) {
|
||||
}
|
||||
}).start();
|
||||
new Thread(() -> {
|
||||
try {
|
||||
while (true) {
|
||||
// (2) 批量轮询是否有哪些连接有数据可读,这里的1指的是阻塞的时间为 1ms
|
||||
if (clientSelector.select(1) > 0) {
|
||||
Set<SelectionKey> set = clientSelector.selectedKeys();
|
||||
Iterator<SelectionKey> keyIterator = set.iterator();
|
||||
|
||||
while (keyIterator.hasNext()) {
|
||||
SelectionKey key = keyIterator.next();
|
||||
|
||||
if (key.isReadable()) {
|
||||
try {
|
||||
SocketChannel clientChannel = (SocketChannel) key.channel();
|
||||
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
|
||||
// (3) 面向 Buffer
|
||||
clientChannel.read(byteBuffer);
|
||||
byteBuffer.flip();
|
||||
System.out.println(
|
||||
Charset.defaultCharset().newDecoder().decode(byteBuffer).toString());
|
||||
} finally {
|
||||
keyIterator.remove();
|
||||
key.interestOps(SelectionKey.OP_READ);
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
}
|
||||
}
|
||||
} catch (IOException ignored) {
|
||||
}
|
||||
}).start();
|
||||
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
为什么大家都不愿意用 JDK 原生 NIO 进行开发呢?从上面的代码中大家都可以看出来,是真的难用!除了编程复杂、编程模型难之外,它还有以下让人诟病的问题:
|
||||
|
||||
- JDK 的 NIO 底层由 epoll 实现,该实现饱受诟病的空轮询 bug 会导致 cpu 飙升 100%
|
||||
- 项目庞大之后,自行实现的 NIO 很容易出现各类 bug,维护成本较高,上面这一坨代码我都不能保证没有 bug
|
||||
|
||||
Netty 的出现很大程度上改善了 JDK 原生 NIO 所存在的一些让人难以忍受的问题。
|
||||
|
||||
### 3. AIO (Asynchronous I/O)
|
||||
|
||||
AIO 也就是 NIO 2。在 Java 7 中引入了 NIO 的改进版 NIO 2,它是异步非阻塞的IO模型。异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
|
||||
|
||||
AIO 是异步IO的缩写,虽然 NIO 在网络操作中,提供了非阻塞的方法,但是 NIO 的 IO 行为还是同步的。对于 NIO 来说,我们的业务线程是在 IO 操作准备好时,得到通知,接着就由这个线程自行进行 IO 操作,IO操作本身是同步的。(除了 AIO 其他的 IO 类型都是同步的,这一点可以从底层IO线程模型解释,推荐一篇文章:[《漫话:如何给女朋友解释什么是Linux的五种IO模型?》](https://mp.weixin.qq.com/s?__biz=Mzg3MjA4MTExMw==&mid=2247484746&idx=1&sn=c0a7f9129d780786cabfcac0a8aa6bb7&source=41#wechat_redirect) )
|
||||
|
||||
查阅网上相关资料,我发现就目前来说 AIO 的应用还不是很广泛,Netty 之前也尝试使用过 AIO,不过又放弃了。
|
||||
|
||||
## 参考
|
||||
|
||||
- 《Netty 权威指南》第二版
|
||||
- https://zhuanlan.zhihu.com/p/23488863 (美团技术团队)
|
||||
@ -90,15 +90,17 @@ public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneabl
|
||||
transient int modCount;
|
||||
// 临界值 当实际大小(容量*填充因子)超过临界值时,会进行扩容
|
||||
int threshold;
|
||||
// 填充因子
|
||||
// 加载因子
|
||||
final float loadFactor;
|
||||
}
|
||||
```
|
||||
- **loadFactor加载因子**
|
||||
|
||||
loadFactor加载因子是控制数组存放数据的疏密程度,loadFactor越趋近于1,那么 数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,load Factor越小,也就是趋近于0,
|
||||
loadFactor加载因子是控制数组存放数据的疏密程度,loadFactor越趋近于1,那么 数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,loadFactor越小,也就是趋近于0,数组中存放的数据(entry)也就越少,也就越稀疏。
|
||||
|
||||
**loadFactor太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor的默认值为0.75f是官方给出的一个比较好的临界值**。
|
||||
**loadFactor太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor的默认值为0.75f是官方给出的一个比较好的临界值**。
|
||||
|
||||
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
|
||||
|
||||
- **threshold**
|
||||
|
||||
@ -171,23 +173,23 @@ static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
|
||||

|
||||
```java
|
||||
// 默认构造函数。
|
||||
public More ...HashMap() {
|
||||
public HashMap() {
|
||||
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted
|
||||
}
|
||||
|
||||
// 包含另一个“Map”的构造函数
|
||||
public More ...HashMap(Map<? extends K, ? extends V> m) {
|
||||
public HashMap(Map<? extends K, ? extends V> m) {
|
||||
this.loadFactor = DEFAULT_LOAD_FACTOR;
|
||||
putMapEntries(m, false);//下面会分析到这个方法
|
||||
}
|
||||
|
||||
// 指定“容量大小”的构造函数
|
||||
public More ...HashMap(int initialCapacity) {
|
||||
public HashMap(int initialCapacity) {
|
||||
this(initialCapacity, DEFAULT_LOAD_FACTOR);
|
||||
}
|
||||
|
||||
// 指定“容量大小”和“加载因子”的构造函数
|
||||
public More ...HashMap(int initialCapacity, float loadFactor) {
|
||||
public HashMap(int initialCapacity, float loadFactor) {
|
||||
if (initialCapacity < 0)
|
||||
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
|
||||
if (initialCapacity > MAXIMUM_CAPACITY)
|
||||
@ -399,7 +401,7 @@ final Node<K,V>[] resize() {
|
||||
else if (oldThr > 0) // initial capacity was placed in threshold
|
||||
newCap = oldThr;
|
||||
else {
|
||||
signifies using defaults
|
||||
// signifies using defaults
|
||||
newCap = DEFAULT_INITIAL_CAPACITY;
|
||||
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
|
||||
}
|
||||
|
||||
@ -67,13 +67,13 @@ Servlet接口定义了5个方法,其中**前三个方法与Servlet生命周期
|
||||
|
||||
## get和post请求的区别
|
||||
|
||||
> 网上也有文章说:get和post请求实际上是没有区别,大家可以自行查询相关文章!我下面给出的只是一种常见的答案。
|
||||
> 网上也有文章说:get和post请求实际上是没有区别,大家可以自行查询相关文章(参考文章:[https://www.cnblogs.com/logsharing/p/8448446.html](https://www.cnblogs.com/logsharing/p/8448446.html),知乎对应的问题链接:[get和post区别?](https://www.zhihu.com/question/28586791))!我下面给出的只是一种常见的答案。
|
||||
|
||||
①get请求用来从服务器上获得资源,而post是用来向服务器提交数据;
|
||||
|
||||
②get将表单中数据按照name=value的形式,添加到action 所指向的URL 后面,并且两者使用"?"连接,而各个变量之间使用"&"连接;post是将表单中的数据放在HTTP协议的请求头或消息体中,传递到action所指向URL;
|
||||
|
||||
③get传输的数据要受到URL长度限制(1024字节即256个字符);而post可以传输大量的数据,上传文件通常要使用post方式;
|
||||
③get传输的数据要受到URL长度限制(最大长度是 2048 个字符);而post可以传输大量的数据,上传文件通常要使用post方式;
|
||||
|
||||
④使用get时参数会显示在地址栏上,如果这些数据不是敏感数据,那么可以使用get;对于敏感数据还是应用使用post;
|
||||
|
||||
@ -98,7 +98,7 @@ Form标签里的method的属性为get时调用doGet(),为post时调用doPost()
|
||||
```java
|
||||
request.getRequestDispatcher("login_success.jsp").forward(request, response);
|
||||
```
|
||||
**重定向(Redirect)** 是利用服务器返回的状态吗来实现的。客户端浏览器请求服务器的时候,服务器会返回一个状态码。服务器通过HttpServletRequestResponse的setStatus(int status)方法设置状态码。如果服务器返回301或者302,则浏览器会到新的网址重新请求该资源。
|
||||
**重定向(Redirect)** 是利用服务器返回的状态码来实现的。客户端浏览器请求服务器的时候,服务器会返回一个状态码。服务器通过 `HttpServletResponse` 的 `setStatus(int status)` 方法设置状态码。如果服务器返回301或者302,则浏览器会到新的网址重新请求该资源。
|
||||
|
||||
1. **从地址栏显示来说**
|
||||
|
||||
@ -123,9 +123,9 @@ redirect:低.
|
||||
## 自动刷新(Refresh)
|
||||
自动刷新不仅可以实现一段时间之后自动跳转到另一个页面,还可以实现一段时间之后自动刷新本页面。Servlet中通过HttpServletResponse对象设置Header属性实现自动刷新例如:
|
||||
```java
|
||||
Response.setHeader("Refresh","1000;URL=http://localhost:8080/servlet/example.htm");
|
||||
Response.setHeader("Refresh","5;URL=http://localhost:8080/servlet/example.htm");
|
||||
```
|
||||
其中1000为时间,单位为毫秒。URL指定就是要跳转的页面(如果设置自己的路径,就会实现没过一秒自动刷新本页面一次)
|
||||
其中5为时间,单位为秒。URL指定就是要跳转的页面(如果设置自己的路径,就会实现每过5秒自动刷新本页面一次)
|
||||
|
||||
|
||||
## Servlet与线程安全
|
||||
|
||||
@ -1,55 +1,60 @@
|
||||
|
||||
|
||||
<!-- MarkdownTOC -->
|
||||
|
||||
- [1. 面向对象和面向过程的区别](#1-面向对象和面向过程的区别)
|
||||
- [面向过程](#面向过程)
|
||||
- [面向对象](#面向对象)
|
||||
- [2. Java 语言有哪些特点](#2-java-语言有哪些特点)
|
||||
- [3. 什么是 JDK 什么是 JRE 什么是 JVM 三者之间的联系与区别](#3-什么是-jdk-什么是-jre-什么是-jvm-三者之间的联系与区别)
|
||||
- [4. 什么是字节码 采用字节码的最大好处是什么](#4-什么是字节码-采用字节码的最大好处是什么)
|
||||
- [先看下 java 中的编译器和解释器:](#先看下-java-中的编译器和解释器)
|
||||
- [采用字节码的好处:](#采用字节码的好处)
|
||||
- [3. 关于 JVM JDK 和 JRE 最详细通俗的解答](#3-关于-jvm-jdk-和-jre-最详细通俗的解答)
|
||||
- [JVM](#jvm)
|
||||
- [JDK 和 JRE](#jdk-和-jre)
|
||||
- [4. Oracle JDK 和 OpenJDK 的对比](#4-oracle-jdk-和-openjdk-的对比)
|
||||
- [5. Java和C++的区别](#5-java和c的区别)
|
||||
- [6. 什么是 Java 程序的主类 应用程序和小程序的主类有何不同](#6-什么是-java-程序的主类-应用程序和小程序的主类有何不同)
|
||||
- [7. Java 应用程序与小程序之间有那些差别](#7-java-应用程序与小程序之间有那些差别)
|
||||
- [8. 字符型常量和字符串常量的区别](#8-字符型常量和字符串常量的区别)
|
||||
- [9. 构造器 Constructor 是否可被 override](#9-构造器-constructor-是否可被-override)
|
||||
- [10. 重载和重写的区别](#10-重载和重写的区别)
|
||||
- [11. Java 面向对象编程三大特性:封装、继承、多态](#11-java-面向对象编程三大特性封装继承多态)
|
||||
- [11. Java 面向对象编程三大特性: 封装 继承 多态](#11-java-面向对象编程三大特性-封装-继承-多态)
|
||||
- [封装](#封装)
|
||||
- [继承](#继承)
|
||||
- [多态](#多态)
|
||||
- [12. String 和 StringBuffer、StringBuilder 的区别是什么 String 为什么是不可变的](#12-string-和-stringbuffer、stringbuilder-的区别是什么-string-为什么是不可变的)
|
||||
- [13. 自动装箱与拆箱](#13-自动装箱与拆箱)
|
||||
- [12. String StringBuffer 和 StringBuilder 的区别是什么 String 为什么是不可变的](#12-string-stringbuffer-和-stringbuilder-的区别是什么-string-为什么是不可变的)
|
||||
- [13. 自动装箱与拆箱](#13-自动装箱与拆箱)
|
||||
- [14. 在一个静态方法内调用一个非静态成员为什么是非法的](#14-在一个静态方法内调用一个非静态成员为什么是非法的)
|
||||
- [15. 在 Java 中定义一个不做事且没有参数的构造方法的作用](#15-在-java-中定义一个不做事且没有参数的构造方法的作用)
|
||||
- [16. import java和javax有什么区别](#16-import-java和javax有什么区别)
|
||||
- [17. 接口和抽象类的区别是什么](#17-接口和抽象类的区别是什么)
|
||||
- [18. 成员变量与局部变量的区别有那些](#18-成员变量与局部变量的区别有那些)
|
||||
- [19. 创建一个对象用什么运算符?对象实体与对象引用有何不同?](#19-创建一个对象用什么运算符对象实体与对象引用有何不同)
|
||||
- [20. 什么是方法的返回值?返回值在类的方法里的作用是什么?](#20-什么是方法的返回值返回值在类的方法里的作用是什么)
|
||||
- [21. 一个类的构造方法的作用是什么 若一个类没有声明构造方法,该程序能正确执行吗 为什么](#21-一个类的构造方法的作用是什么-若一个类没有声明构造方法,该程序能正确执行吗-为什么)
|
||||
- [19. 创建一个对象用什么运算符?对象实体与对象引用有何不同?](#19-创建一个对象用什么运算符对象实体与对象引用有何不同)
|
||||
- [20. 什么是方法的返回值?返回值在类的方法里的作用是什么?](#20-什么是方法的返回值返回值在类的方法里的作用是什么)
|
||||
- [21. 一个类的构造方法的作用是什么 若一个类没有声明构造方法,该程序能正确执行吗 ?为什么?](#21-一个类的构造方法的作用是什么-若一个类没有声明构造方法该程序能正确执行吗-为什么)
|
||||
- [22. 构造方法有哪些特性](#22-构造方法有哪些特性)
|
||||
- [23. 静态方法和实例方法有何不同](#23-静态方法和实例方法有何不同)
|
||||
- [24. 对象的相等与指向他们的引用相等,两者有什么不同?](#24-对象的相等与指向他们的引用相等,两者有什么不同)
|
||||
- [25. 在调用子类构造方法之前会先调用父类没有参数的构造方法,其目的是?](#25-在调用子类构造方法之前会先调用父类没有参数的构造方法其目的是)
|
||||
- [24. 对象的相等与指向他们的引用相等,两者有什么不同?](#24-对象的相等与指向他们的引用相等两者有什么不同)
|
||||
- [25. 在调用子类构造方法之前会先调用父类没有参数的构造方法,其目的是?](#25-在调用子类构造方法之前会先调用父类没有参数的构造方法其目的是)
|
||||
- [26. == 与 equals\(重要\)](#26--与-equals重要)
|
||||
- [27. hashCode 与 equals(重要)](#27-hashcode-与-equals(重要))
|
||||
- [27. hashCode 与 equals \(重要\)](#27-hashcode-与-equals-重要)
|
||||
- [hashCode()介绍](#hashcode()介绍)
|
||||
- [为什么要有 hashCode](#为什么要有-hashcode)
|
||||
- [hashCode()与equals()的相关规定](#hashcode()与equals()的相关规定)
|
||||
- [28. 为什么Java中只有值传递](#28-为什么java中只有值传递)
|
||||
- [29. 简述线程,程序、进程的基本概念。以及他们之间关系是什么](#29-简述线程,程序、进程的基本概念。以及他们之间关系是什么)
|
||||
- [30. 线程有哪些基本状态?这些状态是如何定义的?](#30-线程有哪些基本状态?这些状态是如何定义的)
|
||||
- [29. 简述线程,程序、进程的基本概念。以及他们之间关系是什么](#29-简述线程程序进程的基本概念以及他们之间关系是什么)
|
||||
- [30. 线程有哪些基本状态?](#30-线程有哪些基本状态)
|
||||
- [31 关于 final 关键字的一些总结](#31-关于-final-关键字的一些总结)
|
||||
- [32 Java 中的异常处理](#32-java-中的异常处理)
|
||||
- [Java异常类层次结构图](#java异常类层次结构图)
|
||||
- [Trowable类常用方法](#trowable类常用方法)
|
||||
- [Throwable类常用方法](#throwable类常用方法)
|
||||
- [异常处理总结](#异常处理总结)
|
||||
- [33 Java序列话中如果有些字段不想进行序列化 怎么办](#33-java序列话中如果有些字段不想进行序列化-怎么办)
|
||||
- [Java基础学习书籍推荐](#java基础学习书籍推荐)
|
||||
- [33 Java序列化中如果有些字段不想进行序列化 怎么办](#33-java序列化中如果有些字段不想进行序列化-怎么办)
|
||||
- [34 获取用键盘输入常用的的两种方法](#34-获取用键盘输入常用的的两种方法)
|
||||
- [参考](#参考)
|
||||
|
||||
<!-- /MarkdownTOC -->
|
||||
|
||||
|
||||
|
||||
## 1. 面向对象和面向过程的区别
|
||||
|
||||
### 面向过程
|
||||
@ -75,39 +80,52 @@
|
||||
7. 支持网络编程并且很方便( Java 语言诞生本身就是为简化网络编程设计的,因此 Java 语言不仅支持网络编程而且很方便);
|
||||
8. 编译与解释并存;
|
||||
|
||||
## 3. 什么是 JDK 什么是 JRE 什么是 JVM 三者之间的联系与区别
|
||||
## 3. 关于 JVM JDK 和 JRE 最详细通俗的解答
|
||||
|
||||
这几个是Java中很基本很基本的东西,但是我相信一定还有很多人搞不清楚!为什么呢?因为我们大多数时候在使用现成的编译工具以及环境的时候,并没有去考虑这些东西。
|
||||
### JVM
|
||||
|
||||
**JDK:** 顾名思义它是给开发者提供的开发工具箱,是给程序开发者用的。它除了包括完整的JRE(Java Runtime Environment),Java运行环境,还包含了其他供开发者使用的工具包。
|
||||
Java虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。
|
||||
|
||||
**JRE:** 普通用户而只需要安装 JRE(Java Runtime Environment)来运行 Java 程序。而程序开发者必须安装JDK来编译、调试程序。
|
||||
**什么是字节码?采用字节码的好处是什么?**
|
||||
|
||||
**JVM:** 当我们运行一个程序时,JVM 负责将字节码转换为特定机器代码,JVM 提供了内存管理/垃圾回收和安全机制等。这种独立于硬件和操作系统,正是 java 程序可以一次编写多处执行的原因。
|
||||
> 在 Java 中,JVM可以理解的代码就叫做`字节码`(即扩展名为 `.class` 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不专对一种特定的机器,因此,Java程序无须重新编译便可在多种不同的计算机上运行。
|
||||
|
||||
**区别与联系:**
|
||||
**Java 程序从源代码到运行一般有下面3步:**
|
||||
|
||||
1. JDK 用于开发,JRE 用于运行java程序 ;
|
||||
2. JDK 和 JRE 中都包含 JVM ;
|
||||
3. JVM 是 java 编程语言的核心并且具有平台独立性。
|
||||

|
||||
|
||||
## 4. 什么是字节码 采用字节码的最大好处是什么
|
||||
我们需要格外注意的是 .class->机器码 这一步。在这一步 jvm 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的,也就是所谓的热点代码,所以后面引进了 JIT 编译器,JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 Java 是编译与解释共存的语言。
|
||||
|
||||
### 先看下 java 中的编译器和解释器:
|
||||
> HotSpot采用了惰性评估(Lazy Evaluation)的做法,根据二八定律,消耗大部分系统资源的只有那一小部分的代码(热点代码),而这也就是JIT所需要编译的部分。JVM会根据代码每次被执行的情况收集信息并相应地做出一些优化,因此执行的次数越多,它的速度就越快。JDK 9引入了一种新的编译模式AOT(Ahead of Time Compilation),它是直接将字节码编译成机器码,这样就避免了JIT预热等各方面的开销。JDK支持分层编译和AOT协作使用。但是 ,AOT 编译器的编译质量是肯定比不上 JIT 编译器的。
|
||||
|
||||
Java 中引入了虚拟机的概念,即在机器和编译程序之间加入了一层抽象的虚拟的机器。这台虚拟的机器在任何平台上都提供给编译程序一个的共同的接口。
|
||||
总结:Java虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。字节码和不同系统的 JVM 实现是 Java 语言“一次编译,随处可以运行”的关键所在。
|
||||
|
||||
编译程序只需要面向虚拟机,生成虚拟机能够理解的代码,然后由解释器来将虚拟机代码转换为特定系统的机器码执行。在 Java 中,这种供虚拟机理解的代码叫做`字节码`(即扩展名为 `.class` 的文件),它不面向任何特定的处理器,只面向虚拟机。
|
||||
### JDK 和 JRE
|
||||
|
||||
每一种平台的解释器是不同的,但是实现的虚拟机是相同的。Java 源程序经过编译器编译后变成字节码,字节码由虚拟机解释执行,虚拟机将每一条要执行的字节码送给解释器,解释器将其翻译成特定机器上的机器码,然后在特定的机器上运行。这也就是解释了 Java 的编译与解释并存的特点。
|
||||
JDK是Java Development Kit,它是功能齐全的Java SDK。它拥有JRE所拥有的一切,还有编译器(javac)和工具(如javadoc和jdb)。它能够创建和编译程序。
|
||||
|
||||
Java 源代码---->编译器---->jvm 可执行的 Java 字节码(即虚拟指令)---->jvm---->jvm 中解释器----->机器可执行的二进制机器码---->程序运行。
|
||||
JRE 是 Java运行时环境。它是运行已编译 Java 程序所需的所有内容的集合,包括 Java虚拟机(JVM),Java类库,java命令和其他的一些基础构件。但是,它不能用于创建新程序。
|
||||
|
||||
### 采用字节码的好处:
|
||||
如果你只是为了运行一下 Java 程序的话,那么你只需要安装 JRE 就可以了。如果你需要进行一些 Java 编程方面的工作,那么你就需要安装JDK了。但是,这不是绝对的。有时,即使您不打算在计算机上进行任何Java开发,仍然需要安装JDK。例如,如果要使用JSP部署Web应用程序,那么从技术上讲,您只是在应用程序服务器中运行Java程序。那你为什么需要JDK呢?因为应用程序服务器会将 JSP 转换为 Java servlet,并且需要使用 JDK 来编译 servlet。
|
||||
|
||||
**Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不专对一种特定的机器,因此,Java程序无须重新编译便可在多种不同的计算机上运行。**
|
||||
## 4. Oracle JDK 和 OpenJDK 的对比
|
||||
|
||||
> 解释性语言:解释型语言,是在运行的时候将程序翻译成机器语言。解释型语言的程序不需要在运行前编译,在运行程序的时候才翻译,专门的解释器负责在每个语句执行的时候解释程序代码。这样解释型语言每执行一次就要翻译一次,效率比较低。——百度百科
|
||||
可能在看这个问题之前很多人和我一样并没有接触和使用过 OpenJDK 。那么Oracle和OpenJDK之间是否存在重大差异?下面通过我通过我收集到一些资料对你解答这个被很多人忽视的问题。
|
||||
|
||||
对于Java 7,没什么关键的地方。OpenJDK项目主要基于Sun捐赠的HotSpot源代码。此外,OpenJDK被选为Java 7的参考实现,由Oracle工程师维护。关于JVM,JDK,JRE和OpenJDK之间的区别,Oracle博客帖子在2012年有一个更详细的答案:
|
||||
|
||||
> 问:OpenJDK存储库中的源代码与用于构建Oracle JDK的代码之间有什么区别?
|
||||
>
|
||||
> 答:非常接近 - 我们的Oracle JDK版本构建过程基于OpenJDK 7构建,只添加了几个部分,例如部署代码,其中包括Oracle的Java插件和Java WebStart的实现,以及一些封闭的源代码派对组件,如图形光栅化器,一些开源的第三方组件,如Rhino,以及一些零碎的东西,如附加文档或第三方字体。展望未来,我们的目的是开源Oracle JDK的所有部分,除了我们考虑商业功能的部分。
|
||||
|
||||
总结:
|
||||
|
||||
1. Oracle JDK版本将每三年发布一次,而OpenJDK版本每三个月发布一次;
|
||||
2. OpenJDK 是一个参考模型并且是完全开源的,而Oracle JDK是OpenJDK的一个实现,并不是完全开源的;
|
||||
3. Oracle JDK 比 OpenJDK 更稳定。OpenJDK和Oracle JDK的代码几乎相同,但Oracle JDK有更多的类和一些错误修复。因此,如果您想开发企业/商业软件,我建议您选择Oracle JDK,因为它经过了彻底的测试和稳定。某些情况下,有些人提到在使用OpenJDK 可能会遇到了许多应用程序崩溃的问题,但是,只需切换到Oracle JDK就可以解决问题;
|
||||
4. 在响应性和JVM性能方面,Oracle JDK与OpenJDK相比提供了更好的性能;
|
||||
5. Oracle JDK不会为即将发布的版本提供长期支持,用户每次都必须通过更新到最新版本获得支持来获取最新版本;
|
||||
6. Oracle JDK根据二进制代码许可协议获得许可,而OpenJDK根据GPL v2许可获得许可。
|
||||
|
||||
## 5. Java和C++的区别
|
||||
|
||||
@ -146,7 +164,7 @@ Java 中引入了虚拟机的概念,即在机器和编译程序之间加入了
|
||||
|
||||
**重写:** 发生在父子类中,方法名、参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类;如果父类方法访问修饰符为 private 则子类就不能重写该方法。
|
||||
|
||||
## 11. Java 面向对象编程三大特性:封装、继承、多态
|
||||
## 11. Java 面向对象编程三大特性: 封装 继承 多态
|
||||
|
||||
### 封装
|
||||
|
||||
@ -164,11 +182,11 @@ Java 中引入了虚拟机的概念,即在机器和编译程序之间加入了
|
||||
|
||||
### 多态
|
||||
|
||||
所谓多态就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量倒底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。
|
||||
所谓多态就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量到底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。
|
||||
|
||||
在Java中有两种形式可以实现多态:继承(多个子类对同一方法的重写)和接口(实现接口并覆盖接口中同一方法)。
|
||||
|
||||
## 12. String 和 StringBuffer、StringBuilder 的区别是什么 String 为什么是不可变的
|
||||
## 12. String StringBuffer 和 StringBuilder 的区别是什么 String 为什么是不可变的
|
||||
|
||||
**可变性**
|
||||
|
||||
@ -198,14 +216,14 @@ String 中的对象是不可变的,也就可以理解为常量,线程安全
|
||||
|
||||
**性能**
|
||||
|
||||
每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 StirngBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
|
||||
每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 StringBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
|
||||
|
||||
**对于三者使用的总结:**
|
||||
1. 操作少量的数据 = String
|
||||
2. 单线程操作字符串缓冲区下操作大量数据 = StringBuilder
|
||||
3. 多线程操作字符串缓冲区下操作大量数据 = StringBuffer
|
||||
|
||||
## 13. 自动装箱与拆箱
|
||||
## 13. 自动装箱与拆箱
|
||||
**装箱**:将基本类型用它们对应的引用类型包装起来;
|
||||
|
||||
**拆箱**:将包装类型转换为基本数据类型;
|
||||
@ -223,7 +241,7 @@ String 中的对象是不可变的,也就可以理解为常量,线程安全
|
||||
|
||||
所以,实际上java和javax没有区别。这都是一个名字。
|
||||
|
||||
## 17. 接口和抽象类的区别是什么
|
||||
## 17. 接口和抽象类的区别是什么
|
||||
|
||||
1. 接口的方法默认是 public,所有方法在接口中不能有实现(Java 8 开始接口方法可以有默认实现),抽象类可以有非抽象的方法
|
||||
2. 接口中的实例变量默认是 final 类型的,而抽象类中则不一定
|
||||
@ -231,22 +249,24 @@ String 中的对象是不可变的,也就可以理解为常量,线程安全
|
||||
4. 一个类实现接口的话要实现接口的所有方法,而抽象类不一定
|
||||
5. 接口不能用 new 实例化,但可以声明,但是必须引用一个实现该接口的对象 从设计层面来说,抽象是对类的抽象,是一种模板设计,接口是行为的抽象,是一种行为的规范。
|
||||
|
||||
## 18. 成员变量与局部变量的区别有那些
|
||||
备注:在JDK8中,接口也可以定义静态方法,可以直接用接口名调用。实现类和实现是不可以调用的。如果同时实现两个接口,接口中定义了一样的默认方法,必须重写,不然会报错。(详见issue:[https://github.com/Snailclimb/JavaGuide/issues/146](https://github.com/Snailclimb/JavaGuide/issues/146))
|
||||
|
||||
## 18. 成员变量与局部变量的区别有那些
|
||||
|
||||
1. 从语法形式上,看成员变量是属于类的,而局部变量是在方法中定义的变量或是方法的参数;成员变量可以被 public,private,static 等修饰符所修饰,而局部变量不能被访问控制修饰符及 static 所修饰;但是,成员变量和局部变量都能被 final 所修饰;
|
||||
2. 从变量在内存中的存储方式来看,成员变量是对象的一部分,而对象存在于堆内存,局部变量存在于栈内存
|
||||
3. 从变量在内存中的生存时间上看,成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动消失。
|
||||
4. 成员变量如果没有被赋初值,则会自动以类型的默认值而赋值(一种情况例外被 final 修饰但没有被 static 修饰的成员变量必须显示地赋值);而局部变量则不会自动赋值。
|
||||
2. 从变量在内存中的存储方式来看:如果成员变量是使用`static`修饰的,那么这个成员变量是属于类的,如果没有使用使用`static`修饰,这个成员变量是属于实例的。而对象存在于堆内存,局部变量存在于栈内存
|
||||
3. 从变量在内存中的生存时间上看:成员变量是对象的一部分,它随着对象的创建而存在,而局部变量随着方法的调用而自动消失。
|
||||
4. 成员变量如果没有被赋初值:则会自动以类型的默认值而赋值(一种情况例外被 final 修饰的成员变量也必须显示地赋值);而局部变量则不会自动赋值。
|
||||
|
||||
## 19. 创建一个对象用什么运算符?对象实体与对象引用有何不同?
|
||||
## 19. 创建一个对象用什么运算符?对象实体与对象引用有何不同?
|
||||
|
||||
new运算符,new创建对象实例(对象实例在堆内存中),对象引用指向对象实例(对象引用存放在栈内存中)。一个对象引用可以指向0个或1个对象(一根绳子可以不系气球,也可以系一个气球);一个对象可以有n个引用指向它(可以用n条绳子系住一个气球)。
|
||||
|
||||
## 20. 什么是方法的返回值?返回值在类的方法里的作用是什么?
|
||||
## 20. 什么是方法的返回值?返回值在类的方法里的作用是什么?
|
||||
|
||||
方法的返回值是指我们获取到的某个方法体中的代码执行后产生的结果!(前提是该方法可能产生结果)。返回值的作用:接收出结果,使得它可以用于其他的操作!
|
||||
|
||||
## 21. 一个类的构造方法的作用是什么 若一个类没有声明构造方法,该程序能正确执行吗 为什么
|
||||
## 21. 一个类的构造方法的作用是什么 若一个类没有声明构造方法,该程序能正确执行吗 ?为什么?
|
||||
|
||||
主要作用是完成对类对象的初始化工作。可以执行。因为一个类即使没有声明构造方法也会有默认的不带参数的构造方法。
|
||||
|
||||
@ -262,15 +282,15 @@ new运算符,new创建对象实例(对象实例在堆内存中),对象
|
||||
|
||||
2. 静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),而不允许访问实例成员变量和实例方法;实例方法则无此限制.
|
||||
|
||||
## 24. 对象的相等与指向他们的引用相等,两者有什么不同?
|
||||
## 24. 对象的相等与指向他们的引用相等,两者有什么不同?
|
||||
|
||||
对象的相等,比的是内存中存放的内容是否相等。而引用相等,比较的是他们指向的内存地址是否相等。
|
||||
|
||||
## 25. 在调用子类构造方法之前会先调用父类没有参数的构造方法,其目的是?
|
||||
## 25. 在调用子类构造方法之前会先调用父类没有参数的构造方法,其目的是?
|
||||
|
||||
帮助子类做初始化工作。
|
||||
|
||||
## 26. == 与 equals(重要)
|
||||
## 26. == 与 equals(重要)
|
||||
|
||||
**==** : 它的作用是判断两个对象的地址是不是相等。即,判断两个对象是不是同一个对象。(基本数据类型==比较的是值,引用数据类型==比较的是内存地址)
|
||||
|
||||
@ -307,7 +327,7 @@ public class test1 {
|
||||
|
||||
|
||||
|
||||
## 27. hashCode 与 equals(重要)
|
||||
## 27. hashCode 与 equals (重要)
|
||||
|
||||
面试官可能会问你:“你重写过 hashcode 和 equals 么,为什么重写equals时必须重写hashCode方法?”
|
||||
|
||||
@ -321,7 +341,7 @@ hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返
|
||||
|
||||
**我们以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode:**
|
||||
|
||||
当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的Java启蒙书《Head fist java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
|
||||
当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的Java启蒙书《Head first java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
|
||||
|
||||
|
||||
|
||||
@ -339,7 +359,7 @@ hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返
|
||||
[为什么Java中只有值传递?](https://github.com/Snailclimb/Java-Guide/blob/master/%E9%9D%A2%E8%AF%95%E5%BF%85%E5%A4%87/%E6%9C%80%E6%9C%80%E6%9C%80%E5%B8%B8%E8%A7%81%E7%9A%84Java%E9%9D%A2%E8%AF%95%E9%A2%98%E6%80%BB%E7%BB%93/%E7%AC%AC%E4%B8%80%E5%91%A8%EF%BC%882018-8-7%EF%BC%89.md)
|
||||
|
||||
|
||||
## 29. 简述线程,程序、进程的基本概念。以及他们之间关系是什么
|
||||
## 29. 简述线程,程序,进程的基本概念.以及他们之间关系是什么?
|
||||
|
||||
**线程**与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享同一块内存空间和一组系统资源,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
|
||||
|
||||
@ -348,34 +368,17 @@ hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返
|
||||
**进程**是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。简单来说,一个进程就是一个执行中的程序,它在计算机中一个指令接着一个指令地执行着,同时,每个进程还占有某些系统资源如CPU时间,内存空间,文件,文件,输入输出设备的使用权等等。换句话说,当程序在执行时,将会被操作系统载入内存中。
|
||||
线程是进程划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。从另一角度来说,进程属于操作系统的范畴,主要是同一段时间内,可以同时执行一个以上的程序,而线程则是在同一程序内几乎同时执行一个以上的程序段。
|
||||
|
||||
## 30. 线程有哪些基本状态?这些状态是如何定义的?
|
||||
## 30. 线程有哪些基本状态?
|
||||
|
||||
1. **新建(new)**:新创建了一个线程对象。
|
||||
2. **可运行(runnable)**:线程对象创建后,其他线程(比如main线程)调用了该对象的start()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获 取cpu的使用权。
|
||||
3. **运行(running)**:可运行状态(runnable)的线程获得了cpu时间片(timeslice),执行程序代码。
|
||||
4. **阻塞(block)**:阻塞状态是指线程因为某种原因放弃了cpu使用权,也即让出了cpu timeslice,暂时停止运行。直到线程进入可运行(runnable)状态,才有 机会再次获得cpu timeslice转到运行(running)状态。阻塞的情况分三种:
|
||||
(一). 等待阻塞:运行(running)的线程执行o.wait()方法,JVM会把该线程放 入等待队列(waitting queue)中。
|
||||
(二). 同步阻塞:运行(running)的线程在获取对象的同步锁时,若该同步锁 被别的线程占用,则JVM会把该线程放入锁池(lock pool)中。
|
||||
(三). 其他阻塞: 运行(running)的线程执行Thread.sleep(long ms)或t.join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。当sleep()状态超时join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入可运行(runnable)状态。
|
||||
5. **死亡(dead)**:线程run()、main()方法执行结束,或者因异常退出了run()方法,则该线程结束生命周期。死亡的线程不可再次复生。
|
||||
参考《Java 并发编程艺术》4.1.4节。
|
||||
|
||||

|
||||
Java 线程在运行的生命周期中的指定时刻只可能处于下面6种不同状态的其中一个状态。
|
||||
|
||||
备注: 可以用早起坐地铁来比喻这个过程:
|
||||

|
||||
|
||||
还没起床:sleeping
|
||||
线程在生命周期中并不是固定处于某一个状态而是随着代码的执行在不同状态之间切换。Java 线程状态变迁如下图所示:
|
||||
|
||||
起床收拾好了,随时可以坐地铁出发:Runnable
|
||||
|
||||
等地铁来:Waiting
|
||||
|
||||
地铁来了,但要排队上地铁:I/O阻塞
|
||||
|
||||
上了地铁,发现暂时没座位:synchronized阻塞
|
||||
|
||||
地铁上找到座位:Running
|
||||
|
||||
到达目的地:Dead
|
||||
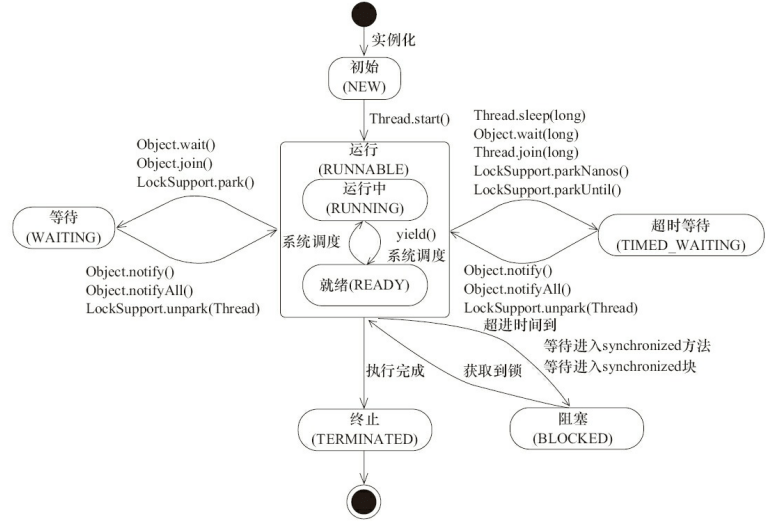
|
||||
|
||||
## 31 关于 final 关键字的一些总结
|
||||
|
||||
@ -383,7 +386,7 @@ final关键字主要用在三个地方:变量、方法、类。
|
||||
|
||||
1. 对于一个final变量,如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改;如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。
|
||||
2. 当用final修饰一个类时,表明这个类不能被继承。final类中的所有成员方法都会被隐式地指定为final方法。
|
||||
3. 使用final方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。在早期的Java实现版本中,会将final方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何性能提升(现在的Java版本已经不需要使用final方法进行这些优化了)。类中所有的private方法都隐式地指定为fianl。
|
||||
3. 使用final方法的原因有两个。第一个原因是把方法锁定,以防任何继承类修改它的含义;第二个原因是效率。在早期的Java实现版本中,会将final方法转为内嵌调用。但是如果方法过于庞大,可能看不到内嵌调用带来的任何性能提升(现在的Java版本已经不需要使用final方法进行这些优化了)。类中所有的private方法都隐式地指定为final。
|
||||
|
||||
## 32 Java 中的异常处理
|
||||
|
||||
@ -391,7 +394,7 @@ final关键字主要用在三个地方:变量、方法、类。
|
||||
|
||||
|
||||
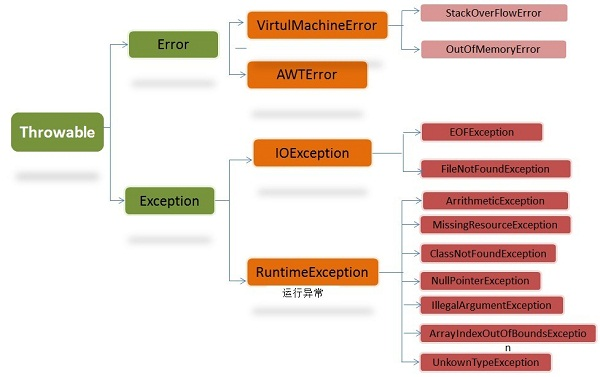
在 Java 中,所有的异常都有一个共同的祖先java.lang包中的 **Throwable类**。Throwable: 有两个重要的子类:**Exception(异常)** 和 **Error(错误)** ,二者都是 Java 异常处理的重要子类,各自都包含大量子类。
|
||||
|
||||
|
||||
**Error(错误):是程序无法处理的错误**,表示运行应用程序中较严重问题。大多数错误与代码编写者执行的操作无关,而表示代码运行时 JVM(Java 虚拟机)出现的问题。例如,Java虚拟机运行错误(Virtual MachineError),当 JVM 不再有继续执行操作所需的内存资源时,将出现 OutOfMemoryError。这些异常发生时,Java虚拟机(JVM)一般会选择线程终止。
|
||||
|
||||
这些错误表示故障发生于虚拟机自身、或者发生在虚拟机试图执行应用时,如Java虚拟机运行错误(Virtual MachineError)、类定义错误(NoClassDefFoundError)等。这些错误是不可查的,因为它们在应用程序的控制和处理能力之 外,而且绝大多数是程序运行时不允许出现的状况。对于设计合理的应用程序来说,即使确实发生了错误,本质上也不应该试图去处理它所引起的异常状况。在 Java中,错误通过Error的子类描述。
|
||||
@ -420,7 +423,7 @@ final关键字主要用在三个地方:变量、方法、类。
|
||||
3. 程序所在的线程死亡。
|
||||
4. 关闭CPU。
|
||||
|
||||
## 33 Java序列话中如果有些字段不想进行序列化 怎么办
|
||||
## 33 Java序列化中如果有些字段不想进行序列化 怎么办
|
||||
|
||||
对于不想进行序列化的变量,使用transient关键字修饰。
|
||||
|
||||
@ -443,16 +446,8 @@ BufferedReader input = new BufferedReader(new InputStreamReader(System.in));
|
||||
String s = input.readLine();
|
||||
```
|
||||
|
||||
## 参考
|
||||
|
||||
# Java基础学习书籍推荐
|
||||
|
||||
**《Head First Java.第二版》:**
|
||||
可以说是我的 Java 启蒙书籍了,特别适合新手读当然也适合我们用来温故Java知识点。
|
||||
|
||||
**《Java核心技术卷1+卷2》:**
|
||||
很棒的两本书,建议有点 Java 基础之后再读,介绍的还是比较深入的,非常推荐。
|
||||
|
||||
**《Java编程思想(第4版)》:**
|
||||
这本书要常读,初学者可以快速概览,中等程序员可以深入看看 Java,老鸟还可以用之回顾 Java 的体系。这本书之所以厉害,因为它在无形中整合了设计模式,这本书之所以难读,也恰恰在于他对设计模式的整合是无形的。
|
||||
|
||||
|
||||
- https://stackoverflow.com/questions/1906445/what-is-the-difference-between-jdk-and-jre
|
||||
- https://www.educba.com/oracle-vs-openjdk/
|
||||
- https://stackoverflow.com/questions/22358071/differences-between-oracle-jdk-and-openjdk?answertab=active#tab-top
|
||||
|
||||
@ -1,10 +1,33 @@
|
||||
|
||||
> 常见问题:AQS 原理?;CountDownLatch和CyclicBarrier了解吗,两者的区别是什么?用过Semaphore吗?
|
||||
**目录:**
|
||||
<!-- MarkdownTOC -->
|
||||
|
||||
- [1 AQS 简单介绍](#1-aqs-简单介绍)
|
||||
- [2 AQS 原理](#2-aqs-原理)
|
||||
- [2.1 AQS 原理概览](#21-aqs-原理概览)
|
||||
- [2.2 AQS 对资源的共享方式](#22-aqs-对资源的共享方式)
|
||||
- [2.3 AQS底层使用了模板方法模式](#23-aqs底层使用了模板方法模式)
|
||||
- [3 Semaphore\(信号量\)-允许多个线程同时访问](#3-semaphore信号量-允许多个线程同时访问)
|
||||
- [4 CountDownLatch (倒计时器)](#4-countdownlatch-倒计时器)
|
||||
- [4.1 CountDownLatch 的三种典型用法](#41-countdownlatch-的三种典型用法)
|
||||
- [4.2 CountDownLatch 的使用示例](#42-countdownlatch-的使用示例)
|
||||
- [4.3 CountDownLatch 的不足](#43-countdownlatch-的不足)
|
||||
- [4.4 CountDownLatch相常见面试题:](#44-countdownlatch相常见面试题)
|
||||
- [5 CyclicBarrier\(循环栅栏\)](#5-cyclicbarrier循环栅栏)
|
||||
- [5.1 CyclicBarrier 的应用场景](#51-cyclicbarrier-的应用场景)
|
||||
- [5.2 CyclicBarrier 的使用示例](#52-cyclicbarrier-的使用示例)
|
||||
- [5.3 CyclicBarrier和CountDownLatch的区别](#53-cyclicbarrier和countdownlatch的区别)
|
||||
- [6 ReentrantLock 和 ReentrantReadWriteLock](#6-reentrantlock-和-reentrantreadwritelock)
|
||||
|
||||
<!-- /MarkdownTOC -->
|
||||
|
||||
> 常见问题:AQS原理?;CountDownLatch和CyclicBarrier了解吗,两者的区别是什么?用过Semaphore吗?
|
||||
|
||||
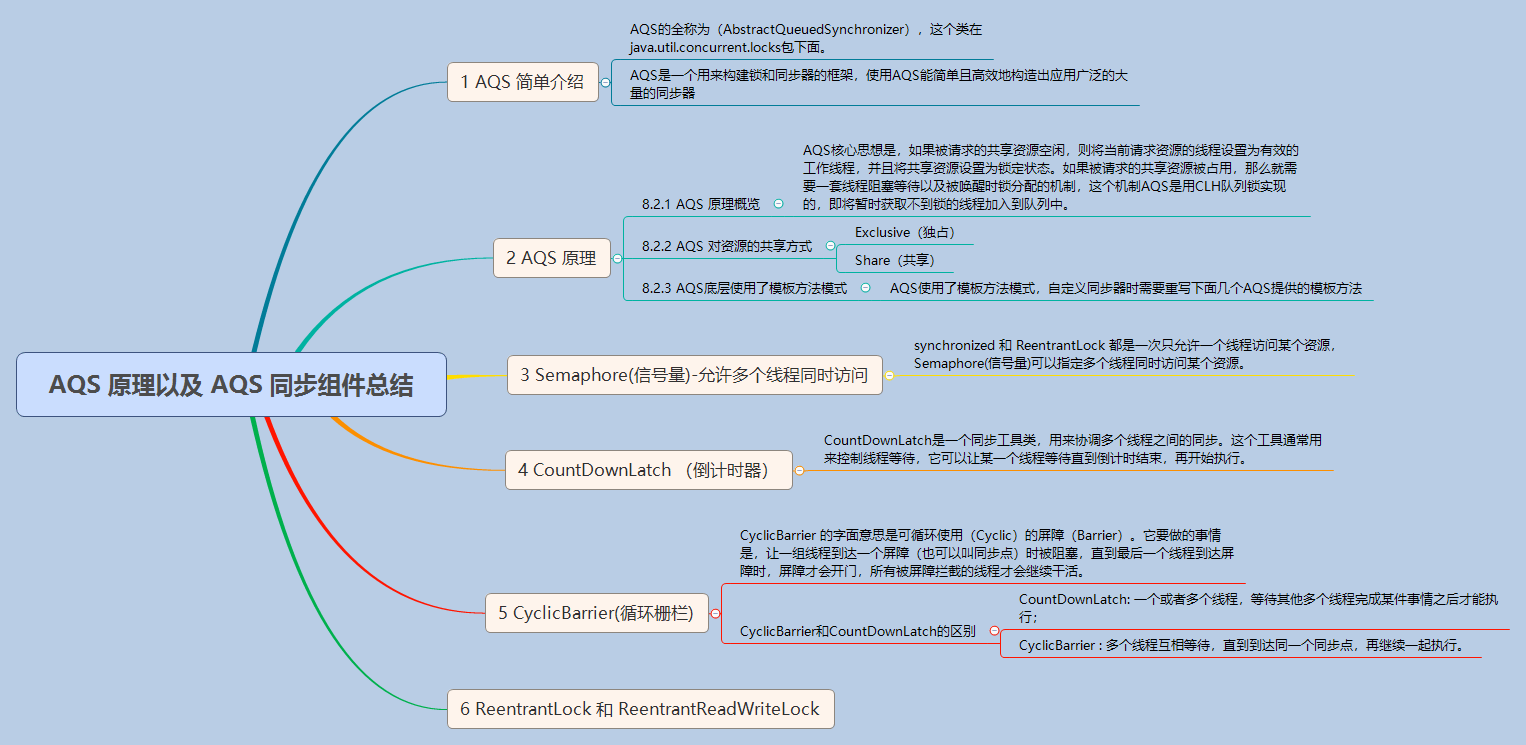
**本节思维导图:**
|
||||
|
||||
|
||||
|
||||
|
||||
### 1 AQS 简单介绍
|
||||
AQS的全称为(AbstractQueuedSynchronizer),这个类在java.util.concurrent.locks包下面。
|
||||
|
||||
@ -35,7 +58,7 @@ AQS使用一个int成员变量来表示同步状态,通过内置的FIFO队列
|
||||
private volatile int state;//共享变量,使用volatile修饰保证线程可见性
|
||||
```
|
||||
|
||||
状态信息通过procted类型的getState,setState,compareAndSetState进行操作
|
||||
状态信息通过protected类型的getState,setState,compareAndSetState进行操作
|
||||
|
||||
```java
|
||||
|
||||
@ -115,38 +138,38 @@ tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true
|
||||
* @Description: 需要一次性拿一个许可的情况
|
||||
*/
|
||||
public class SemaphoreExample1 {
|
||||
// 请求的数量
|
||||
private static final int threadCount = 550;
|
||||
// 请求的数量
|
||||
private static final int threadCount = 550;
|
||||
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
// 创建一个具有固定线程数量的线程池对象(如果这里线程池的线程数量给太少的话你会发现执行的很慢)
|
||||
ExecutorService threadPool = Executors.newFixedThreadPool(300);
|
||||
// 一次只能允许执行的线程数量。
|
||||
final Semaphore semaphore = new Semaphore(20);
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
// 创建一个具有固定线程数量的线程池对象(如果这里线程池的线程数量给太少的话你会发现执行的很慢)
|
||||
ExecutorService threadPool = Executors.newFixedThreadPool(300);
|
||||
// 一次只能允许执行的线程数量。
|
||||
final Semaphore semaphore = new Semaphore(20);
|
||||
|
||||
for (int i = 0; i < threadCount; i++) {
|
||||
final int threadnum = i;
|
||||
threadPool.execute(() -> {// Lambda 表达式的运用
|
||||
try {
|
||||
semaphore.acquire();// 获取一个许可,所以可运行线程数量为20/1=20
|
||||
test(threadnum);
|
||||
semaphore.release();// 释放一个许可
|
||||
} catch (InterruptedException e) {
|
||||
// TODO Auto-generated catch block
|
||||
e.printStackTrace();
|
||||
}
|
||||
for (int i = 0; i < threadCount; i++) {
|
||||
final int threadnum = i;
|
||||
threadPool.execute(() -> {// Lambda 表达式的运用
|
||||
try {
|
||||
semaphore.acquire();// 获取一个许可,所以可运行线程数量为20/1=20
|
||||
test(threadnum);
|
||||
semaphore.release();// 释放一个许可
|
||||
} catch (InterruptedException e) {
|
||||
// TODO Auto-generated catch block
|
||||
e.printStackTrace();
|
||||
}
|
||||
|
||||
});
|
||||
}
|
||||
threadPool.shutdown();
|
||||
System.out.println("finish");
|
||||
}
|
||||
});
|
||||
}
|
||||
threadPool.shutdown();
|
||||
System.out.println("finish");
|
||||
}
|
||||
|
||||
public static void test(int threadnum) throws InterruptedException {
|
||||
Thread.sleep(1000);// 模拟请求的耗时操作
|
||||
System.out.println("threadnum:" + threadnum);
|
||||
Thread.sleep(1000);// 模拟请求的耗时操作
|
||||
}
|
||||
public static void test(int threadnum) throws InterruptedException {
|
||||
Thread.sleep(1000);// 模拟请求的耗时操作
|
||||
System.out.println("threadnum:" + threadnum);
|
||||
Thread.sleep(1000);// 模拟请求的耗时操作
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
@ -155,9 +178,9 @@ public class SemaphoreExample1 {
|
||||
当然一次也可以一次拿取和释放多个许可,不过一般没有必要这样做:
|
||||
|
||||
```java
|
||||
semaphore.acquire(5);// 获取5个许可,所以可运行线程数量为20/5=4
|
||||
test(threadnum);
|
||||
semaphore.release(5);// 获取5个许可,所以可运行线程数量为20/5=4
|
||||
semaphore.acquire(5);// 获取5个许可,所以可运行线程数量为20/5=4
|
||||
test(threadnum);
|
||||
semaphore.release(5);// 获取5个许可,所以可运行线程数量为20/5=4
|
||||
```
|
||||
|
||||
除了 `acquire`方法之外,另一个比较常用的与之对应的方法是`tryAcquire`方法,该方法如果获取不到许可就立即返回false。
|
||||
@ -187,14 +210,16 @@ Semaphore 有两种模式,公平模式和非公平模式。
|
||||
|
||||
### 4 CountDownLatch (倒计时器)
|
||||
|
||||
CountDownLatch是一个同步工具类,用来协调多个线程之间的同步。这个工具通常用来控制线程等待,它可以让某一个线程等待直到倒计时结束,再开始执行。
|
||||
CountDownLatch是一个同步工具类,它允许一个或多个线程一直等待,直到其他线程的操作执行完后再执行。在Java并发中,countdownlatch的概念是一个常见的面试题,所以一定要确保你很好的理解了它。
|
||||
|
||||
#### 4.1 CountDownLatch 的两种典型用法
|
||||
#### 4.1 CountDownLatch 的三种典型用法
|
||||
|
||||
①某一线程在开始运行前等待n个线程执行完毕。将 CountDownLatch 的计数器初始化为n :`new CountDownLatch(n) `,每当一个任务线程执行完毕,就将计数器减1 `countdownlatch.countDown()`,当计数器的值变为0时,在`CountDownLatch上 await()` 的线程就会被唤醒。一个典型应用场景就是启动一个服务时,主线程需要等待多个组件加载完毕,之后再继续执行。
|
||||
|
||||
②实现多个线程开始执行任务的最大并行性。注意是并行性,不是并发,强调的是多个线程在某一时刻同时开始执行。类似于赛跑,将多个线程放到起点,等待发令枪响,然后同时开跑。做法是初始化一个共享的 `CountDownLatch` 对象,将其计数器初始化为 1 :`new CountDownLatch(1) `,多个线程在开始执行任务前首先 `coundownlatch.await()`,当主线程调用 countDown() 时,计数器变为0,多个线程同时被唤醒。
|
||||
|
||||
③死锁检测:一个非常方便的使用场景是,你可以使用n个线程访问共享资源,在每次测试阶段的线程数目是不同的,并尝试产生死锁。
|
||||
|
||||
#### 4.2 CountDownLatch 的使用示例
|
||||
|
||||
```java
|
||||
@ -205,46 +230,60 @@ CountDownLatch是一个同步工具类,用来协调多个线程之间的同步
|
||||
* @Description: CountDownLatch 使用方法示例
|
||||
*/
|
||||
public class CountDownLatchExample1 {
|
||||
// 请求的数量
|
||||
private static final int threadCount = 550;
|
||||
// 请求的数量
|
||||
private static final int threadCount = 550;
|
||||
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
// 创建一个具有固定线程数量的线程池对象(如果这里线程池的线程数量给太少的话你会发现执行的很慢)
|
||||
ExecutorService threadPool = Executors.newFixedThreadPool(300);
|
||||
final CountDownLatch countDownLatch = new CountDownLatch(threadCount);
|
||||
for (int i = 0; i < threadCount; i++) {
|
||||
final int threadnum = i;
|
||||
threadPool.execute(() -> {// Lambda 表达式的运用
|
||||
try {
|
||||
test(threadnum);
|
||||
} catch (InterruptedException e) {
|
||||
// TODO Auto-generated catch block
|
||||
e.printStackTrace();
|
||||
} finally {
|
||||
countDownLatch.countDown();// 表示一个请求已经被完成
|
||||
}
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
// 创建一个具有固定线程数量的线程池对象(如果这里线程池的线程数量给太少的话你会发现执行的很慢)
|
||||
ExecutorService threadPool = Executors.newFixedThreadPool(300);
|
||||
final CountDownLatch countDownLatch = new CountDownLatch(threadCount);
|
||||
for (int i = 0; i < threadCount; i++) {
|
||||
final int threadnum = i;
|
||||
threadPool.execute(() -> {// Lambda 表达式的运用
|
||||
try {
|
||||
test(threadnum);
|
||||
} catch (InterruptedException e) {
|
||||
// TODO Auto-generated catch block
|
||||
e.printStackTrace();
|
||||
} finally {
|
||||
countDownLatch.countDown();// 表示一个请求已经被完成
|
||||
}
|
||||
|
||||
});
|
||||
}
|
||||
countDownLatch.await();
|
||||
threadPool.shutdown();
|
||||
System.out.println("finish");
|
||||
}
|
||||
});
|
||||
}
|
||||
countDownLatch.await();
|
||||
threadPool.shutdown();
|
||||
System.out.println("finish");
|
||||
}
|
||||
|
||||
public static void test(int threadnum) throws InterruptedException {
|
||||
Thread.sleep(1000);// 模拟请求的耗时操作
|
||||
System.out.println("threadnum:" + threadnum);
|
||||
Thread.sleep(1000);// 模拟请求的耗时操作
|
||||
}
|
||||
public static void test(int threadnum) throws InterruptedException {
|
||||
Thread.sleep(1000);// 模拟请求的耗时操作
|
||||
System.out.println("threadnum:" + threadnum);
|
||||
Thread.sleep(1000);// 模拟请求的耗时操作
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
上面的代码中,我们定义了请求的数量为550,当这550个请求被处理完成之后,才会执行`System.out.println("finish");`。
|
||||
|
||||
与CountDownLatch的第一次交互是主线程等待其他线程。主线程必须在启动其他线程后立即调用CountDownLatch.await()方法。这样主线程的操作就会在这个方法上阻塞,直到其他线程完成各自的任务。
|
||||
|
||||
其他N个线程必须引用闭锁对象,因为他们需要通知CountDownLatch对象,他们已经完成了各自的任务。这种通知机制是通过 CountDownLatch.countDown()方法来完成的;每调用一次这个方法,在构造函数中初始化的count值就减1。所以当N个线程都调 用了这个方法,count的值等于0,然后主线程就能通过await()方法,恢复执行自己的任务。
|
||||
|
||||
#### 4.3 CountDownLatch 的不足
|
||||
|
||||
CountDownLatch是一次性的,计数器的值只能在构造方法中初始化一次,之后没有任何机制再次对其设置值,当CountDownLatch使用完毕后,它不能再次被使用。
|
||||
|
||||
#### 4.4 CountDownLatch相常见面试题:
|
||||
|
||||
解释一下CountDownLatch概念?
|
||||
|
||||
CountDownLatch 和CyclicBarrier的不同之处?
|
||||
|
||||
给出一些CountDownLatch使用的例子?
|
||||
|
||||
CountDownLatch 类中主要的方法?
|
||||
|
||||
### 5 CyclicBarrier(循环栅栏)
|
||||
|
||||
CyclicBarrier 和 CountDownLatch 非常类似,它也可以实现线程间的技术等待,但是它的功能比 CountDownLatch 更加复杂和强大。主要应用场景和 CountDownLatch 类似。
|
||||
@ -267,42 +306,42 @@ CyclicBarrier 可以用于多线程计算数据,最后合并计算结果的应
|
||||
* @Description: 测试 CyclicBarrier 类中带参数的 await() 方法
|
||||
*/
|
||||
public class CyclicBarrierExample2 {
|
||||
// 请求的数量
|
||||
private static final int threadCount = 550;
|
||||
// 需要同步的线程数量
|
||||
private static final CyclicBarrier cyclicBarrier = new CyclicBarrier(5);
|
||||
// 请求的数量
|
||||
private static final int threadCount = 550;
|
||||
// 需要同步的线程数量
|
||||
private static final CyclicBarrier cyclicBarrier = new CyclicBarrier(5);
|
||||
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
// 创建线程池
|
||||
ExecutorService threadPool = Executors.newFixedThreadPool(10);
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
// 创建线程池
|
||||
ExecutorService threadPool = Executors.newFixedThreadPool(10);
|
||||
|
||||
for (int i = 0; i < threadCount; i++) {
|
||||
final int threadNum = i;
|
||||
Thread.sleep(1000);
|
||||
threadPool.execute(() -> {
|
||||
try {
|
||||
test(threadNum);
|
||||
} catch (InterruptedException e) {
|
||||
// TODO Auto-generated catch block
|
||||
e.printStackTrace();
|
||||
} catch (BrokenBarrierException e) {
|
||||
// TODO Auto-generated catch block
|
||||
e.printStackTrace();
|
||||
}
|
||||
});
|
||||
}
|
||||
threadPool.shutdown();
|
||||
}
|
||||
for (int i = 0; i < threadCount; i++) {
|
||||
final int threadNum = i;
|
||||
Thread.sleep(1000);
|
||||
threadPool.execute(() -> {
|
||||
try {
|
||||
test(threadNum);
|
||||
} catch (InterruptedException e) {
|
||||
// TODO Auto-generated catch block
|
||||
e.printStackTrace();
|
||||
} catch (BrokenBarrierException e) {
|
||||
// TODO Auto-generated catch block
|
||||
e.printStackTrace();
|
||||
}
|
||||
});
|
||||
}
|
||||
threadPool.shutdown();
|
||||
}
|
||||
|
||||
public static void test(int threadnum) throws InterruptedException, BrokenBarrierException {
|
||||
System.out.println("threadnum:" + threadnum + "is ready");
|
||||
try {
|
||||
cyclicBarrier.await(2000, TimeUnit.MILLISECONDS);
|
||||
} catch (Exception e) {
|
||||
System.out.println("-----CyclicBarrierException------");
|
||||
}
|
||||
System.out.println("threadnum:" + threadnum + "is finish");
|
||||
}
|
||||
public static void test(int threadnum) throws InterruptedException, BrokenBarrierException {
|
||||
System.out.println("threadnum:" + threadnum + "is ready");
|
||||
try {
|
||||
cyclicBarrier.await(2000, TimeUnit.MILLISECONDS);
|
||||
} catch (Exception e) {
|
||||
System.out.println("-----CyclicBarrierException------");
|
||||
}
|
||||
System.out.println("threadnum:" + threadnum + "is finish");
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
@ -344,40 +383,40 @@ threadnum:6is finish
|
||||
* @Description: 新建 CyclicBarrier 的时候指定一个 Runnable
|
||||
*/
|
||||
public class CyclicBarrierExample3 {
|
||||
// 请求的数量
|
||||
private static final int threadCount = 550;
|
||||
// 需要同步的线程数量
|
||||
private static final CyclicBarrier cyclicBarrier = new CyclicBarrier(5, () -> {
|
||||
System.out.println("------当线程数达到之后,优先执行------");
|
||||
});
|
||||
// 请求的数量
|
||||
private static final int threadCount = 550;
|
||||
// 需要同步的线程数量
|
||||
private static final CyclicBarrier cyclicBarrier = new CyclicBarrier(5, () -> {
|
||||
System.out.println("------当线程数达到之后,优先执行------");
|
||||
});
|
||||
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
// 创建线程池
|
||||
ExecutorService threadPool = Executors.newFixedThreadPool(10);
|
||||
public static void main(String[] args) throws InterruptedException {
|
||||
// 创建线程池
|
||||
ExecutorService threadPool = Executors.newFixedThreadPool(10);
|
||||
|
||||
for (int i = 0; i < threadCount; i++) {
|
||||
final int threadNum = i;
|
||||
Thread.sleep(1000);
|
||||
threadPool.execute(() -> {
|
||||
try {
|
||||
test(threadNum);
|
||||
} catch (InterruptedException e) {
|
||||
// TODO Auto-generated catch block
|
||||
e.printStackTrace();
|
||||
} catch (BrokenBarrierException e) {
|
||||
// TODO Auto-generated catch block
|
||||
e.printStackTrace();
|
||||
}
|
||||
});
|
||||
}
|
||||
threadPool.shutdown();
|
||||
}
|
||||
for (int i = 0; i < threadCount; i++) {
|
||||
final int threadNum = i;
|
||||
Thread.sleep(1000);
|
||||
threadPool.execute(() -> {
|
||||
try {
|
||||
test(threadNum);
|
||||
} catch (InterruptedException e) {
|
||||
// TODO Auto-generated catch block
|
||||
e.printStackTrace();
|
||||
} catch (BrokenBarrierException e) {
|
||||
// TODO Auto-generated catch block
|
||||
e.printStackTrace();
|
||||
}
|
||||
});
|
||||
}
|
||||
threadPool.shutdown();
|
||||
}
|
||||
|
||||
public static void test(int threadnum) throws InterruptedException, BrokenBarrierException {
|
||||
System.out.println("threadnum:" + threadnum + "is ready");
|
||||
cyclicBarrier.await();
|
||||
System.out.println("threadnum:" + threadnum + "is finish");
|
||||
}
|
||||
public static void test(int threadnum) throws InterruptedException, BrokenBarrierException {
|
||||
System.out.println("threadnum:" + threadnum + "is ready");
|
||||
cyclicBarrier.await();
|
||||
System.out.println("threadnum:" + threadnum + "is finish");
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
@ -433,4 +472,4 @@ ReentrantLock 和 synchronized 的区别在上面已经讲过了这里就不多
|
||||
|
||||
由于篇幅问题,关于 ReentrantLock 和 ReentrantReadWriteLock 详细内容可以查看我的这篇原创文章。
|
||||
|
||||
- [ReentrantLock 和 ReentrantReadWriteLock](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247483745&idx=2&sn=6778ee954a19816310df54ef9a3c2f8a&chksm=fd985700caefde16b9970f5e093b0c140d3121fb3a8458b11871e5e9723c5fd1b5a961fd2228&token=1829606453&lang=zh_CN#rd)
|
||||
- [ReentrantLock 和 ReentrantReadWriteLock](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247483745&idx=2&sn=6778ee954a19816310df54ef9a3c2f8a&chksm=fd985700caefde16b9970f5e093b0c140d3121fb3a8458b11871e5e9723c5fd1b5a961fd2228&token=1829606453&lang=zh_CN#rd)
|
||||
|
||||
@ -20,7 +20,7 @@ synchronized关键字解决的是多个线程之间访问资源的同步性,sy
|
||||
|
||||
下面我已一个常见的面试题为例讲解一下 synchronized 关键字的具体使用。
|
||||
|
||||
面试中面试官经常会说:“单例模式了解吗?来给我手写一下!给我解释一下双重检验锁方式实现单利模式的原理呗!”
|
||||
面试中面试官经常会说:“单例模式了解吗?来给我手写一下!给我解释一下双重检验锁方式实现单例模式的原理呗!”
|
||||
|
||||
|
||||
|
||||
@ -105,7 +105,7 @@ synchronized 修饰的方法并没有 monitorenter 指令和 monitorexit 指令
|
||||
|
||||
JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、自旋锁、适应性自旋锁、锁消除、锁粗化等技术来减少锁操作的开销。
|
||||
|
||||
锁主要存在四中状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
|
||||
锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
|
||||
|
||||
关于这几种优化的详细信息可以查看:[synchronized 关键字使用、底层原理、JDK1.6 之后的底层优化以及 和ReenTrantLock 的对比](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484539&idx=1&sn=3500cdcd5188bdc253fb19a1bfa805e6&chksm=fd98521acaefdb0c5167247a1fa903a1a53bb4e050b558da574f894f9feda5378ec9d0fa1ac7&token=1604028915&lang=zh_CN#rd)
|
||||
|
||||
@ -187,7 +187,7 @@ synchronized 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团
|
||||
|
||||
### 3.4 如何创建线程池
|
||||
|
||||
《阿里巴巴Java开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险**
|
||||
《阿里巴巴Java开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
|
||||
|
||||
> Executors 返回线程池对象的弊端如下:
|
||||
>
|
||||
@ -426,4 +426,4 @@ tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true
|
||||
- 《实战 Java 高并发程序设计》
|
||||
- 《Java并发编程的艺术》
|
||||
- http://www.cnblogs.com/waterystone/p/4920797.html
|
||||
- https://www.cnblogs.com/chengxiao/archive/2017/07/24/7141160.html
|
||||
- https://www.cnblogs.com/chengxiao/archive/2017/07/24/7141160.html
|
||||
|
||||
223
Java相关/Multithread/并发容器总结.md
Normal file
223
Java相关/Multithread/并发容器总结.md
Normal file
@ -0,0 +1,223 @@
|
||||
|
||||
<!-- MarkdownTOC -->
|
||||
|
||||
- [一 JDK 提供的并发容器总结](#一-jdk-提供的并发容器总结)
|
||||
- [二 ConcurrentHashMap](#二-concurrenthashmap)
|
||||
- [三 CopyOnWriteArrayList](#三-copyonwritearraylist)
|
||||
- [3.1 CopyOnWriteArrayList 简介](#31-copyonwritearraylist-简介)
|
||||
- [3.2 CopyOnWriteArrayList 是如何做到的?](#32-copyonwritearraylist-是如何做到的?)
|
||||
- [3.3 CopyOnWriteArrayList 读取和写入源码简单分析](#33-copyonwritearraylist-读取和写入源码简单分析)
|
||||
- [3.3.1 CopyOnWriteArrayList 读取操作的实现](#331-copyonwritearraylist-读取操作的实现)
|
||||
- [3.3.2 CopyOnWriteArrayList 写入操作的实现](#332-copyonwritearraylist-写入操作的实现)
|
||||
- [四 ConcurrentLinkedQueue](#四-concurrentlinkedqueue)
|
||||
- [五 BlockingQueue](#五-blockingqueue)
|
||||
- [5.1 BlockingQueue 简单介绍](#51-blockingqueue-简单介绍)
|
||||
- [5.2 ArrayBlockingQueue](#52-arrayblockingqueue)
|
||||
- [5.3 LinkedBlockingQueue](#53-linkedblockingqueue)
|
||||
- [5.4 PriorityBlockingQueue](#54-priorityblockingqueue)
|
||||
- [六 ConcurrentSkipListMap](#六-concurrentskiplistmap)
|
||||
- [七 参考](#七-参考)
|
||||
|
||||
<!-- /MarkdownTOC -->
|
||||
|
||||
## 一 JDK 提供的并发容器总结
|
||||
|
||||
JDK提供的这些容器大部分在 `java.util.concurrent` 包中。
|
||||
|
||||
|
||||
- **ConcurrentHashMap:** 线程安全的HashMap
|
||||
- **CopyOnWriteArrayList:** 线程安全的List,在读多写少的场合性能非常好,远远好于Vector.
|
||||
- **ConcurrentLinkedQueue:**高效的并发队列,使用链表实现。可以看做一个线程安全的 LinkedList,这是一个非阻塞队列。
|
||||
- **BlockingQueue:** 这是一个接口,JDK内部通过链表、数组等方式实现了这个接口。表示阻塞队列,非常适合用于作为数据共享的通道。
|
||||
- **ConcurrentSkipListMap:** 跳表的实现。这是一个Map,使用跳表的数据结构进行快速查找。
|
||||
|
||||
## 二 ConcurrentHashMap
|
||||
|
||||
我们知道 HashMap 不是线程安全的,在并发场景下如果要保证一种可行的方式是使用 `Collections.synchronizedMap()` 方法来包装我们的 HashMap。但这是通过使用一个全局的锁来同步不同线程间的并发访问,因此会带来不可忽视的性能问题。
|
||||
|
||||
所以就有了 HashMap 的线程安全版本—— ConcurrentHashMap 的诞生。在ConcurrentHashMap中,无论是读操作还是写操作都能保证很高的性能:在进行读操作时(几乎)不需要加锁,而在写操作时通过锁分段技术只对所操作的段加锁而不影响客户端对其它段的访问。
|
||||
|
||||
关于 ConcurrentHashMap 相关问题,我在 [《这几道Java集合框架面试题几乎必问》](https://github.com/Snailclimb/JavaGuide/blob/master/Java%E7%9B%B8%E5%85%B3/%E8%BF%99%E5%87%A0%E9%81%93Java%E9%9B%86%E5%90%88%E6%A1%86%E6%9E%B6%E9%9D%A2%E8%AF%95%E9%A2%98%E5%87%A0%E4%B9%8E%E5%BF%85%E9%97%AE.md) 这篇文章中已经提到过。下面梳理一下关于 ConcurrentHashMap 比较重要的问题:
|
||||
|
||||
- [ConcurrentHashMap 和 Hashtable 的区别](https://github.com/Snailclimb/JavaGuide/blob/master/Java%E7%9B%B8%E5%85%B3/%E8%BF%99%E5%87%A0%E9%81%93Java%E9%9B%86%E5%90%88%E6%A1%86%E6%9E%B6%E9%9D%A2%E8%AF%95%E9%A2%98%E5%87%A0%E4%B9%8E%E5%BF%85%E9%97%AE.md#concurrenthashmap-%E5%92%8C-hashtable-%E7%9A%84%E5%8C%BA%E5%88%AB)
|
||||
- [ConcurrentHashMap线程安全的具体实现方式/底层具体实现](https://github.com/Snailclimb/JavaGuide/blob/master/Java%E7%9B%B8%E5%85%B3/%E8%BF%99%E5%87%A0%E9%81%93Java%E9%9B%86%E5%90%88%E6%A1%86%E6%9E%B6%E9%9D%A2%E8%AF%95%E9%A2%98%E5%87%A0%E4%B9%8E%E5%BF%85%E9%97%AE.md#concurrenthashmap%E7%BA%BF%E7%A8%8B%E5%AE%89%E5%85%A8%E7%9A%84%E5%85%B7%E4%BD%93%E5%AE%9E%E7%8E%B0%E6%96%B9%E5%BC%8F%E5%BA%95%E5%B1%82%E5%85%B7%E4%BD%93%E5%AE%9E%E7%8E%B0)
|
||||
|
||||
|
||||
|
||||
## 三 CopyOnWriteArrayList
|
||||
|
||||
### 3.1 CopyOnWriteArrayList 简介
|
||||
|
||||
```java
|
||||
public class CopyOnWriteArrayList<E>
|
||||
extends Object
|
||||
implements List<E>, RandomAccess, Cloneable, Serializable
|
||||
```
|
||||
|
||||
在很多应用场景中,读操作可能会远远大于写操作。由于读操作根本不会修改原有的数据,因此对于每次读取都进行加锁其实是一种资源浪费。我们应该允许多个线程同时访问List的内部数据,毕竟读取操作是安全的。
|
||||
|
||||
这和我们之前在多线程章节讲过 `ReentrantReadWriteLock` 读写锁的思想非常类似,也就是读读共享、写写互斥、读写互斥、写读互斥。JDK中提供了 `CopyOnWriteArrayList` 类比相比于在读写锁的思想又更进一步。为了将读取的性能发挥到极致,`CopyOnWriteArrayList` 读取是完全不用加锁的,并且更厉害的是:写入也不会阻塞读取操作。只有写入和写入之间需要进行同步等待。这样一来,读操作的性能就会大幅度提升。**那它是怎么做的呢?**
|
||||
|
||||
### 3.2 CopyOnWriteArrayList 是如何做到的?
|
||||
|
||||
`CopyOnWriteArrayList` 类的所有可变操作(add,set等等)都是通过创建底层数组的新副本来实现的。当 List 需要被修改的时候,我并不修改原有内容,而是对原有数据进行一次复制,将修改的内容写入副本。写完之后,再将修改完的副本替换原来的数据,这样就可以保证写操作不会影响读操作了。
|
||||
|
||||
从 `CopyOnWriteArrayList` 的名字就能看出`CopyOnWriteArrayList` 是满足`CopyOnWrite` 的ArrayList,所谓`CopyOnWrite` 也就是说:在计算机,如果你想要对一块内存进行修改时,我们不在原有内存块中进行写操作,而是将内存拷贝一份,在新的内存中进行写操作,写完之后呢,就将指向原来内存指针指向新的内存,原来的内存就可以被回收掉了。
|
||||
|
||||
### 3.3 CopyOnWriteArrayList 读取和写入源码简单分析
|
||||
|
||||
#### 3.3.1 CopyOnWriteArrayList 读取操作的实现
|
||||
|
||||
读取操作没有任何同步控制和锁操作,理由就是内部数组 array 不会发生修改,只会被另外一个 array 替换,因此可以保证数据安全。
|
||||
|
||||
```java
|
||||
/** The array, accessed only via getArray/setArray. */
|
||||
private transient volatile Object[] array;
|
||||
public E get(int index) {
|
||||
return get(getArray(), index);
|
||||
}
|
||||
@SuppressWarnings("unchecked")
|
||||
private E get(Object[] a, int index) {
|
||||
return (E) a[index];
|
||||
}
|
||||
final Object[] getArray() {
|
||||
return array;
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
#### 3.3.2 CopyOnWriteArrayList 写入操作的实现
|
||||
|
||||
CopyOnWriteArrayList 写入操作 add() 方法在添加集合的时候加了锁,保证了同步,避免了多线程写的时候会 copy 出多个副本出来。
|
||||
|
||||
```java
|
||||
/**
|
||||
* Appends the specified element to the end of this list.
|
||||
*
|
||||
* @param e element to be appended to this list
|
||||
* @return {@code true} (as specified by {@link Collection#add})
|
||||
*/
|
||||
public boolean add(E e) {
|
||||
final ReentrantLock lock = this.lock;
|
||||
lock.lock();//加锁
|
||||
try {
|
||||
Object[] elements = getArray();
|
||||
int len = elements.length;
|
||||
Object[] newElements = Arrays.copyOf(elements, len + 1);//拷贝新数组
|
||||
newElements[len] = e;
|
||||
setArray(newElements);
|
||||
return true;
|
||||
} finally {
|
||||
lock.unlock();//释放锁
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
## 四 ConcurrentLinkedQueue
|
||||
|
||||
Java提供的线程安全的 Queue 可以分为**阻塞队列**和**非阻塞队列**,其中阻塞队列的典型例子是 BlockingQueue,非阻塞队列的典型例子是ConcurrentLinkedQueue,在实际应用中要根据实际需要选用阻塞队列或者非阻塞队列。 **阻塞队列可以通过加锁来实现,非阻塞队列可以通过 CAS 操作实现。**
|
||||
|
||||
从名字可以看出,`ConcurrentLinkedQueue`这个队列使用链表作为其数据结构.ConcurrentLinkedQueue 应该算是在高并发环境中性能最好的队列了。它之所有能有很好的性能,是因为其内部复杂的实现。
|
||||
|
||||
ConcurrentLinkedQueue 内部代码我们就不分析了,大家知道ConcurrentLinkedQueue 主要使用 CAS 非阻塞算法来实现线程安全就好了。
|
||||
|
||||
ConcurrentLinkedQueue 适合在对性能要求相对较高,同时对队列的读写存在多个线程同时进行的场景,即如果对队列加锁的成本较高则适合使用无锁的ConcurrentLinkedQueue来替代。
|
||||
|
||||
## 五 BlockingQueue
|
||||
|
||||
### 5.1 BlockingQueue 简单介绍
|
||||
|
||||
上面我们己经提到了 ConcurrentLinkedQueue 作为高性能的非阻塞队列。下面我们要讲到的是阻塞队列——BlockingQueue。阻塞队列(BlockingQueue)被广泛使用在“生产者-消费者”问题中,其原因是BlockingQueue提供了可阻塞的插入和移除的方法。当队列容器已满,生产者线程会被阻塞,直到队列未满;当队列容器为空时,消费者线程会被阻塞,直至队列非空时为止。
|
||||
|
||||
BlockingQueue 是一个接口,继承自 Queue,所以其实现类也可以作为 Queue 的实现来使用,而 Queue 又继承自 Collection 接口。下面是 BlockingQueue 的相关实现类:
|
||||
|
||||
|
||||
|
||||
**下面主要介绍一下:ArrayBlockingQueue、LinkedBlockingQueue、PriorityBlockingQueue,这三个 BlockingQueue 的实现类。**
|
||||
|
||||
### 5.2 ArrayBlockingQueue
|
||||
|
||||
**ArrayBlockingQueue** 是 BlockingQueue 接口的有界队列实现类,底层采用**数组**来实现。ArrayBlockingQueue一旦创建,容量不能改变。其并发控制采用可重入锁来控制,不管是插入操作还是读取操作,都需要获取到锁才能进行操作。当队列容量满时,尝试将元素放入队列将导致操作阻塞;尝试从一个空队列中取一个元素也会同样阻塞。
|
||||
|
||||
ArrayBlockingQueue 默认情况下不能保证线程访问队列的公平性,所谓公平性是指严格按照线程等待的绝对时间顺序,即最先等待的线程能够最先访问到 ArrayBlockingQueue。而非公平性则是指访问 ArrayBlockingQueue 的顺序不是遵守严格的时间顺序,有可能存在,当 ArrayBlockingQueue 可以被访问时,长时间阻塞的线程依然无法访问到 ArrayBlockingQueue。如果保证公平性,通常会降低吞吐量。如果需要获得公平性的 ArrayBlockingQueue,可采用如下代码:
|
||||
|
||||
```java
|
||||
private static ArrayBlockingQueue<Integer> blockingQueue = new ArrayBlockingQueue<Integer>(10,true);
|
||||
```
|
||||
|
||||
### 5.3 LinkedBlockingQueue
|
||||
|
||||
**LinkedBlockingQueue** 底层基于**单向链表**实现的阻塞队列,可以当做无界队列也可以当做有界队列来使用,同样满足FIFO的特性,与ArrayBlockingQueue 相比起来具有更高的吞吐量,为了防止 LinkedBlockingQueue 容量迅速增,损耗大量内存。通常在创建LinkedBlockingQueue 对象时,会指定其大小,如果未指定,容量等于Integer.MAX_VALUE。
|
||||
|
||||
**相关构造方法:**
|
||||
|
||||
```java
|
||||
/**
|
||||
*某种意义上的无界队列
|
||||
* Creates a {@code LinkedBlockingQueue} with a capacity of
|
||||
* {@link Integer#MAX_VALUE}.
|
||||
*/
|
||||
public LinkedBlockingQueue() {
|
||||
this(Integer.MAX_VALUE);
|
||||
}
|
||||
|
||||
/**
|
||||
*有界队列
|
||||
* Creates a {@code LinkedBlockingQueue} with the given (fixed) capacity.
|
||||
*
|
||||
* @param capacity the capacity of this queue
|
||||
* @throws IllegalArgumentException if {@code capacity} is not greater
|
||||
* than zero
|
||||
*/
|
||||
public LinkedBlockingQueue(int capacity) {
|
||||
if (capacity <= 0) throw new IllegalArgumentException();
|
||||
this.capacity = capacity;
|
||||
last = head = new Node<E>(null);
|
||||
}
|
||||
```
|
||||
|
||||
### 5.4 PriorityBlockingQueue
|
||||
|
||||
**PriorityBlockingQueue** 是一个支持优先级的无界阻塞队列。默认情况下元素采用自然顺序进行排序,也可以通过自定义类实现 `compareTo()` 方法来指定元素排序规则,或者初始化时通过构造器参数 `Comparator` 来指定排序规则。
|
||||
|
||||
PriorityBlockingQueue 并发控制采用的是 **ReentrantLock**,队列为无界队列(ArrayBlockingQueue 是有界队列,LinkedBlockingQueue 也可以通过在构造函数中传入 capacity 指定队列最大的容量,但是 PriorityBlockingQueue 只能指定初始的队列大小,后面插入元素的时候,**如果空间不够的话会自动扩容**)。
|
||||
|
||||
简单地说,它就是 PriorityQueue 的线程安全版本。不可以插入 null 值,同时,插入队列的对象必须是可比较大小的(comparable),否则报 ClassCastException 异常。它的插入操作 put 方法不会 block,因为它是无界队列(take 方法在队列为空的时候会阻塞)。
|
||||
|
||||
**推荐文章:**
|
||||
|
||||
《解读 Java 并发队列 BlockingQueue》
|
||||
|
||||
[https://javadoop.com/post/java-concurrent-queue](https://javadoop.com/post/java-concurrent-queue)
|
||||
|
||||
## 六 ConcurrentSkipListMap
|
||||
|
||||
下面这部分内容参考了极客时间专栏[《数据结构与算法之美》](https://time.geekbang.org/column/intro/126?code=zl3GYeAsRI4rEJIBNu5B/km7LSZsPDlGWQEpAYw5Vu0=&utm_term=SPoster)以及《实战Java高并发程序设计》。
|
||||
|
||||
**为了引出ConcurrentSkipListMap,先带着大家简单理解一下跳表。**
|
||||
|
||||
对于一个单链表,即使链表是有序的,如果我们想要在其中查找某个数据,也只能从头到尾遍历链表,这样效率自然就会很低,跳表就不一样了。跳表是一种可以用来快速查找的数据结构,有点类似于平衡树。它们都可以对元素进行快速的查找。但一个重要的区别是:对平衡树的插入和删除往往很可能导致平衡树进行一次全局的调整。而对跳表的插入和删除只需要对整个数据结构的局部进行操作即可。这样带来的好处是:在高并发的情况下,你会需要一个全局锁来保证整个平衡树的线程安全。而对于跳表,你只需要部分锁即可。这样,在高并发环境下,你就可以拥有更好的性能。而就查询的性能而言,跳表的时间复杂度也是 **O(logn)** 所以在并发数据结构中,JDK 使用跳表来实现一个 Map。
|
||||
|
||||
跳表的本质是同时维护了多个链表,并且链表是分层的,
|
||||
|
||||
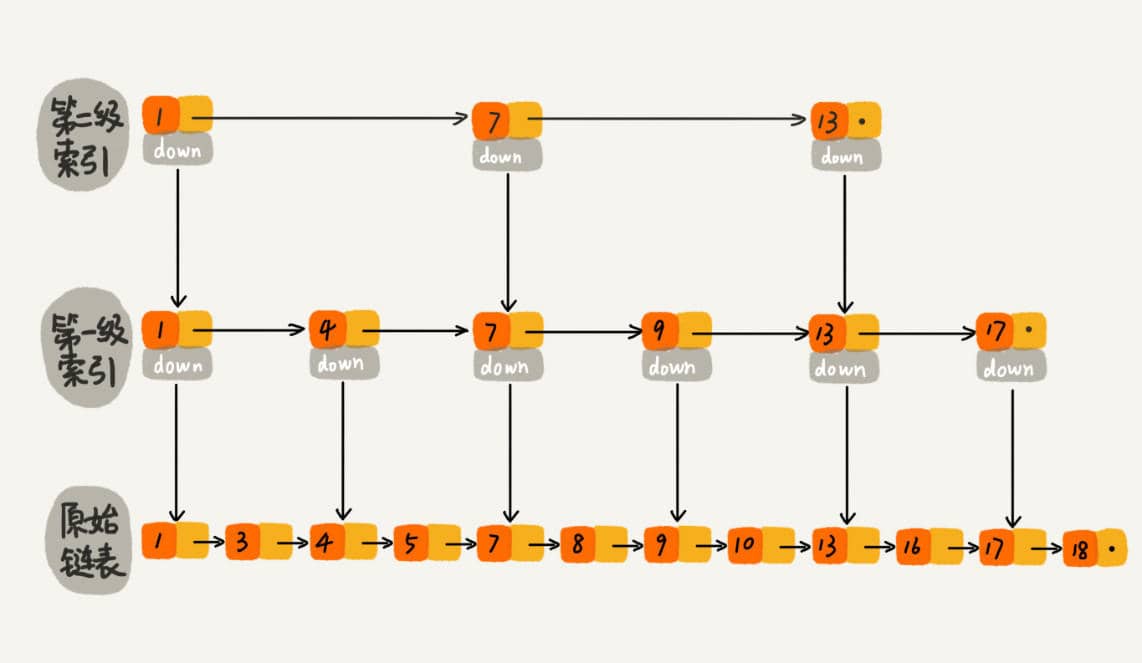
|
||||
|
||||
最低层的链表维护了跳表内所有的元素,每上面一层链表都是下面一层的子集。
|
||||
|
||||
跳表内的所有链表的元素都是排序的。查找时,可以从顶级链表开始找。一旦发现被查找的元素大于当前链表中的取值,就会转入下一层链表继续找。这也就是说在查找过程中,搜索是跳跃式的。如上图所示,在跳表中查找元素18。
|
||||
|
||||
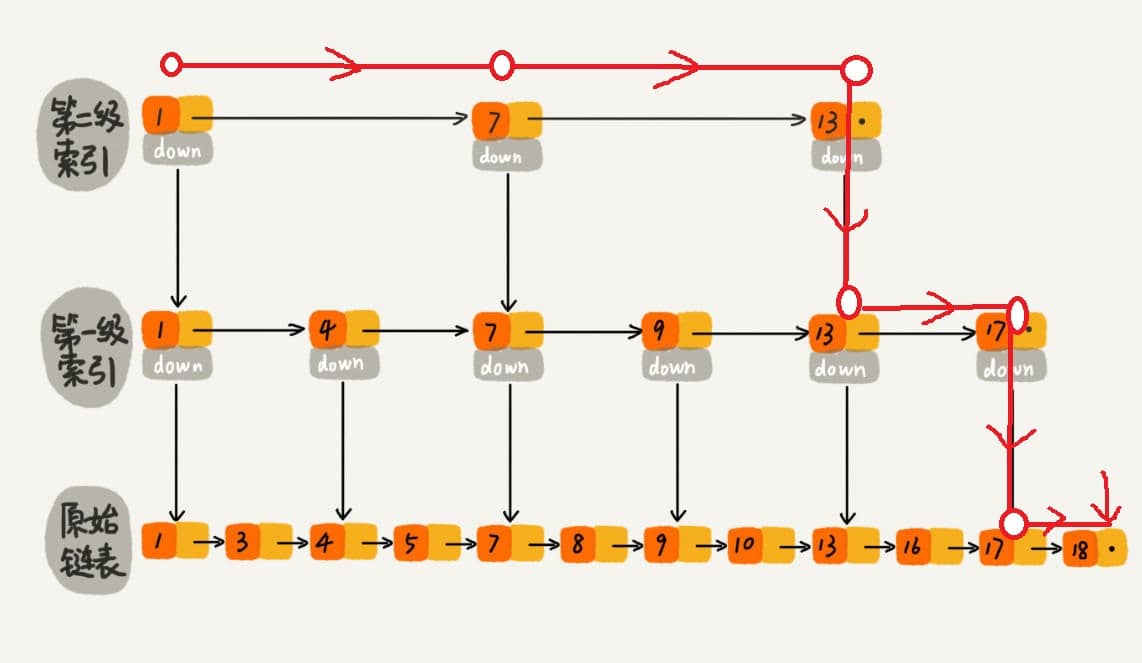
|
||||
|
||||
查找18 的时候原来需要遍历 18 次,现在只需要 7 次即可。针对链表长度比较大的时候,构建索引查找效率的提升就会非常明显。
|
||||
|
||||
从上面很容易看出,**跳表是一种利用空间换时间的算法。**
|
||||
|
||||
使用跳表实现Map 和使用哈希算法实现Map的另外一个不同之处是:哈希并不会保存元素的顺序,而跳表内所有的元素都是排序的。因此在对跳表进行遍历时,你会得到一个有序的结果。所以,如果你的应用需要有序性,那么跳表就是你不二的选择。JDK 中实现这一数据结构的类是ConcurrentSkipListMap。
|
||||
|
||||
|
||||
|
||||
## 七 参考
|
||||
|
||||
- 《实战Java高并发程序设计》
|
||||
- https://javadoop.com/post/java-concurrent-queue
|
||||
- https://juejin.im/post/5aeebd02518825672f19c546
|
||||
@ -23,7 +23,7 @@
|
||||
- 类名.静态变量名
|
||||
- 类名.静态方法名()
|
||||
|
||||
如果变量或者方法被 private 则代表该属性或者该方法只能在类的内部被访问而不能在类的外部被方法。
|
||||
如果变量或者方法被 private 则代表该属性或者该方法只能在类的内部被访问而不能在类的外部被访问。
|
||||
|
||||
测试方法:
|
||||
|
||||
|
||||
@ -65,5 +65,5 @@
|
||||
|
||||
### Java多线程学习(八)线程池与Executor 框架
|
||||
|
||||

|
||||

|
||||
|
||||
|
||||
@ -65,7 +65,7 @@ public class GCTest {
|
||||
添加的参数:`-XX:+PrintGCDetails`
|
||||
|
||||
|
||||
运行结果:
|
||||
运行结果(红色字体描述有误,应该是对应于JDK1.7的永久代):
|
||||
|
||||
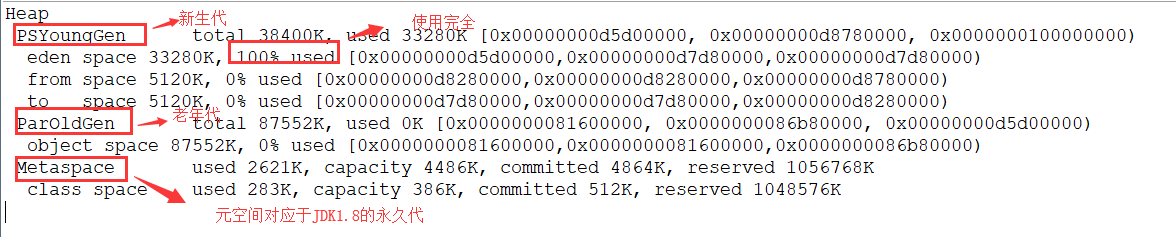
|
||||
|
||||
@ -236,7 +236,7 @@ JDK1.2以后,Java对引用的概念进行了扩充,将引用分为强引用
|
||||
|
||||
### 3.4 分代收集算法
|
||||
|
||||
当前虚拟机的垃圾手机都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将java堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
|
||||
当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将java堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
|
||||
|
||||
**比如在新生代中,每次收集都会有大量对象死去,所以可以选择复制算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。**
|
||||
|
||||
|
||||
@ -97,7 +97,7 @@
|
||||
- **职责链模式:**
|
||||
|
||||
[Java设计模式之责任链模式、职责链模式](https://blog.csdn.net/jason0539/article/details/45091639)
|
||||
|
||||
|
||||
[责任链模式实现的三种方式](https://www.cnblogs.com/lizo/p/7503862.html)
|
||||
|
||||
- **命令模式:**
|
||||
@ -108,9 +108,19 @@
|
||||
- **迭代器模式:**
|
||||
- **中介者模式:**
|
||||
- **备忘录模式:**
|
||||
- **观察者模式:**
|
||||
- **观察者模式:**
|
||||
|
||||
观察者模式也是非常常用的设计模式,下面这个博客简单介绍了观察者模式的简单定义、解决了一个什么问题,用一个气象站和气象看板的例子去描述一对多的关系中观察者模式的应用,并且还介绍了jdk内置的观察者模式接口。
|
||||
|
||||
[Java设计模式之观察者模式](https://zhanglijun1217.github.io/blog/2018/12/24/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F%E2%80%94%E2%80%94%E8%A7%82%E5%AF%9F%E8%80%85%E6%A8%A1%E5%BC%8F-md/)
|
||||
|
||||
- **状态模式:**
|
||||
- **策略模式:**
|
||||
|
||||
策略模式作为设计原则中开闭原则最典型的体现,也是经常使用的。下面这篇博客介绍了策略模式一般的组成部分和概念,并用了一个小demo去说明了策略模式的应用。
|
||||
|
||||
[java设计模式之策略模式](https://blog.csdn.net/zlj1217/article/details/81230077)
|
||||
|
||||
- **模板方法模式:**
|
||||
- **访问者模式:**
|
||||
|
||||
|
||||
@ -1,26 +1,38 @@
|
||||
> 本文是“最最最常见Java面试题总结”系列第三周的文章。
|
||||
> 主要内容:
|
||||
> 1. Arraylist 与 LinkedList 异同
|
||||
> 2. ArrayList 与 Vector 区别
|
||||
> 3. HashMap的底层实现
|
||||
> 4. HashMap 和 Hashtable 的区别
|
||||
> 5. HashMap 的长度为什么是2的幂次方
|
||||
> 6. HashMap 多线程操作导致死循环问题
|
||||
> 7. HashSet 和 HashMap 区别
|
||||
> 8. ConcurrentHashMap 和 Hashtable 的区别
|
||||
> 9. ConcurrentHashMap线程安全的具体实现方式/底层具体实现
|
||||
> 10. 集合框架底层数据结构总结
|
||||
|
||||
|
||||
<!-- MarkdownTOC -->
|
||||
|
||||
- [Arraylist 与 LinkedList 异同](#arraylist-与-linkedlist-异同)
|
||||
- [补充:数据结构基础之双向链表](#补充:数据结构基础之双向链表)
|
||||
- [ArrayList 与 Vector 区别](#arraylist-与-vector-区别)
|
||||
- [HashMap的底层实现](#hashmap的底层实现)
|
||||
- [JDK1.8之前](#jdk18之前)
|
||||
- [JDK1.8之后](#jdk18之后)
|
||||
- [HashMap 和 Hashtable 的区别](#hashmap-和-hashtable-的区别)
|
||||
- [HashMap 的长度为什么是2的幂次方](#hashmap-的长度为什么是2的幂次方)
|
||||
- [HashMap 多线程操作导致死循环问题](#hashmap-多线程操作导致死循环问题)
|
||||
- [HashSet 和 HashMap 区别](#hashset-和-hashmap-区别)
|
||||
- [ConcurrentHashMap 和 Hashtable 的区别](#concurrenthashmap-和-hashtable-的区别)
|
||||
- [ConcurrentHashMap线程安全的具体实现方式/底层具体实现](#concurrenthashmap线程安全的具体实现方式底层具体实现)
|
||||
- [JDK1.7(上面有示意图)](#jdk17(上面有示意图))
|
||||
- [JDK1.8 (上面有示意图)](#jdk18-(上面有示意图))
|
||||
- [集合框架底层数据结构总结](#集合框架底层数据结构总结)
|
||||
- [Collection](#collection)
|
||||
- [1. List](#1-list)
|
||||
- [2. Set](#2-set)
|
||||
- [Map](#map)
|
||||
- [推荐阅读:](#推荐阅读:)
|
||||
|
||||
<!-- /MarkdownTOC -->
|
||||
|
||||
## Arraylist 与 LinkedList 异同
|
||||
|
||||
- **1. 是否保证线程安全:** ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
|
||||
- **2. 底层数据结构:** Arraylist 底层使用的是Object数组;LinkedList 底层使用的是双向链表数据结构(注意双向链表和双向循环链表的区别:);
|
||||
- **2. 底层数据结构:** Arraylist 底层使用的是Object数组;LinkedList 底层使用的是双向链表数据结构(JDK1.6之前为循环链表,JDK1.7取消了循环。注意双向链表和双向循环链表的区别:); 详细可阅读[JDK1.7-LinkedList循环链表优化](https://www.cnblogs.com/xingele0917/p/3696593.html)
|
||||
- **3. 插入和删除是否受元素位置的影响:** ① **ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。** 比如:执行`add(E e) `方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element) `)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② **LinkedList 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1)而数组为近似 O(n)。**
|
||||
- **4. 是否支持快速随机访问:** LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index) `方法)。
|
||||
- **5. 内存空间占用:** ArrayList的空 间浪费主要体现在在list列表的结尾会预留一定的容量空间,而LinkedList的空间花费则体现在它的每一个元素都需要消耗比ArrayList更多的空间(因为要存放直接后继和直接前驱以及数据)。
|
||||
|
||||
-**6. 发
|
||||
**补充内容:RandomAccess接口**
|
||||
|
||||
```java
|
||||
@ -42,13 +54,13 @@ public interface RandomAccess {
|
||||
}
|
||||
|
||||
```
|
||||
ArraysList 实现了 RandomAccess 接口, 而 LinkedList 没有实现。为什么呢?我觉得还是和底层数据结构有关!ArraysList 底层是数组,而 LinkedList 底层是链表。数组天然支持随机访问,时间复杂度为 O(1),所以称为快速随机访问。链表需要遍历到特定位置才能访问特定位置的元素,时间复杂度为 O(n),所以不支持快速随机访问。,ArraysList 实现了 RandomAccess 接口,就表明了他具有快速随机访问功能。 RandomAccess 接口只是标识,并不是说 ArraysList 实现 RandomAccess 接口才具有快速随机访问功能的!
|
||||
ArrayList 实现了 RandomAccess 接口, 而 LinkedList 没有实现。为什么呢?我觉得还是和底层数据结构有关!ArrayList 底层是数组,而 LinkedList 底层是链表。数组天然支持随机访问,时间复杂度为 O(1),所以称为快速随机访问。链表需要遍历到特定位置才能访问特定位置的元素,时间复杂度为 O(n),所以不支持快速随机访问。,ArrayList 实现了 RandomAccess 接口,就表明了他具有快速随机访问功能。 RandomAccess 接口只是标识,并不是说 ArrayList 实现 RandomAccess 接口才具有快速随机访问功能的!
|
||||
|
||||
|
||||
**下面再总结一下 list 的遍历方式选择:**
|
||||
|
||||
- 实现了RadmoAcces接口的list,优先选择普通for循环 ,其次foreach,
|
||||
- 未实现RadmoAcces接口的ist, 优先选择iterator遍历(foreach遍历底层也是通过iterator实现的),大size的数据,千万不要使用普通for循环
|
||||
- 实现了RandomAccess接口的list,优先选择普通for循环 ,其次foreach,
|
||||
- 未实现RandomAccess接口的ist, 优先选择iterator遍历(foreach遍历底层也是通过iterator实现的),大size的数据,千万不要使用普通for循环
|
||||
|
||||
|
||||
### 补充:数据结构基础之双向链表
|
||||
@ -166,7 +178,7 @@ static int hash(int h) {
|
||||
|
||||
## HashMap 的长度为什么是2的幂次方
|
||||
|
||||
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648到2147483648,前后加起来大概40亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ `(n - 1) & hash` ”。(n代表数组长度)。这也就解释了 HashMap 的长度为什么是2的幂次方。
|
||||
为了能让 HashMap 存取高效,尽量较少碰撞,也就是要尽量把数据分配均匀。我们上面也讲到了过了,Hash 值的范围值-2147483648到2147483647,前后加起来大概40亿的映射空间,只要哈希函数映射得比较均匀松散,一般应用是很难出现碰撞的。但问题是一个40亿长度的数组,内存是放不下的。所以这个散列值是不能直接拿来用的。用之前还要先做对数组的长度取模运算,得到的余数才能用来要存放的位置也就是对应的数组下标。这个数组下标的计算方法是“ `(n - 1) & hash` ”。(n代表数组长度)。这也就解释了 HashMap 的长度为什么是2的幂次方。
|
||||
|
||||
**这个算法应该如何设计呢?**
|
||||
|
||||
@ -205,7 +217,7 @@ static int hash(int h) {
|
||||
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
|
||||
|
||||
- **底层数据结构:** JDK1.7的 ConcurrentHashMap 底层采用 **分段的数组+链表** 实现,JDK1.8 采用的数据结构跟HashMap1.8的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 **数组+链表** 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
|
||||
- **实现线程安全的方式(重要):** ① **在JDK1.7的时候,ConcurrentHashMap(分段锁)** 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。(默认分配16个Segment,比Hashtable效率提高16倍。) **到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6以后 对 synchronized锁做了很多优化)** 整个看起来就像是优化过且线程安全的 HashMap,虽然在JDK1.8中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② **Hashtable(同一把锁)** :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
|
||||
- **实现线程安全的方式(重要):** ① **在JDK1.7的时候,ConcurrentHashMap(分段锁)** 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 **到了 JDK1.8 的时候已经摒弃了Segment的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6以后 对 synchronized锁做了很多优化)** 整个看起来就像是优化过且线程安全的 HashMap,虽然在JDK1.8中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② **Hashtable(同一把锁)** :使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
|
||||
|
||||
**两者的对比图:**
|
||||
|
||||
@ -251,7 +263,8 @@ synchronized只锁定当前链表或红黑二叉树的首节点,这样只要ha
|
||||
#### 1. List
|
||||
- **Arraylist:** Object数组
|
||||
- **Vector:** Object数组
|
||||
- **LinkedList:** 双向循环链表
|
||||
- **LinkedList:** 双向链表(JDK1.6之前为循环链表,JDK1.7取消了循环)
|
||||
详细可阅读[JDK1.7-LinkedList循环链表优化](https://www.cnblogs.com/xingele0917/p/3696593.html)
|
||||
|
||||
#### 2. Set
|
||||
- **HashSet(无序,唯一):** 基于 HashMap 实现的,底层采用 HashMap 来保存元素
|
||||
|
||||
284
README.md
284
README.md
@ -1,177 +1,241 @@
|
||||
[月底最后一波知识福利(建议微信断打开)](https://mp.weixin.qq.com/s/jNwhlHvR2EB_f4z0hy1rfA)。我整理了一份面试相关资源(视频+PDF文档) 如果大家需要的话可以点击此链接[添加我的微信](#最后) (记得备注来自Github),成功通过好友请求之后回复“面试”免费领取!
|
||||
<div align="center">
|
||||
|
||||
为了优化大家的阅读体验,我重新进行了排版,并且增加了较为详细的目录供大家参考!如果有老哥对操作系统比较重要的知识总结过的话,欢迎找我哦!
|
||||
一些常用资源[公众号](#公众号)后台回复关键字“1”即可免费无套路获取。
|
||||
|
||||
【限时福利,最后一天】极客时间[《Java 并发编程面试必备》](#Java并发编程专栏)专栏限时特惠,购买之后的小伙伴加 [我的微信](#我的微信) 报上自己的极客时间大名可以找我会把24元返现退给大家,减轻各位学习成本。
|
||||
|
||||
<div align="center">
|
||||
<img src="http://my-blog-to-use.oss-cn-beijing.aliyuncs.com/18-11-16/49833984.jpg" width=""/>
|
||||
</br>
|
||||
|
||||
[](//shang.qq.com/wpa/qunwpa?idkey=f128b25264f43170c2721e0789b24b180fc482113b6f256928b6198ae07fe5d4)
|
||||
[](//shang.qq.com/wpa/qunwpa?idkey=10aee68bd241e739e59a8dfb0d4b33690bd3a4b5af0d09142cbdae2cb8c3966a)
|
||||
</br>
|
||||
微信交流群添加 [我的微信](#我的微信) 后回复关键字“加群”即可入群。
|
||||
|
||||
</div>
|
||||
|
||||
仓库新增了【备战春招/秋招系列】,希望可以为马上面临春招或者以后需要面试的小老哥助力!目前更新了美团常见面试题以及一些面试必备内容。下面是腾讯云双11做的活动,还剩9天,秒杀的服务器很便宜哦!
|
||||
> 腾讯云热门云产品1折起,送13000元续费/升级大礼包:https://cloud.tencent.com/redirect.php?redirect=1034&cps_key=2b96dd3b35e69197e2f3dfb779a6139b&from=console
|
||||
>
|
||||
> 腾讯云新用户大额代金券:https://cloud.tencent.com/redirect.php?redirect=1025&cps_key=2b96dd3b35e69197e2f3dfb779a6139b&from=console
|
||||
|
||||
|
||||
| Ⅰ | Ⅱ | Ⅲ | Ⅳ | Ⅴ | Ⅵ | Ⅶ | Ⅷ | Ⅸ | Ⅹ |
|
||||
| :--------: | :----------: | :-----------: | :---------: | :---------: | :---------:| :---------: | :-------: | :-------:| :----:|
|
||||
| [Java](#coffee-Java) | [数据结构与算法](#open_file_folder-数据结构与算法)|[计算机网络与数据通信](#computer-计算机网络与数据通信) | [操作系统](#iphone-操作系统)| [主流框架](#pencil2-主流框架)| [数据存储](#floppy_disk-数据存储)|[架构](#punch-架构)| [面试必备](#musical_note-面试必备)| [其他](#art-其他)| [说明](#envelope-该开源文档一些说明)|
|
||||
## 目录
|
||||
|
||||
- [:coffee: Java](#coffee-java)
|
||||
- [Java/J2EE 基础](#javaj2ee-基础)
|
||||
- [Java 集合框架](#java-集合框架)
|
||||
- [Java 多线程](#java-多线程)
|
||||
- [Java BIO,NIO,AIO](#java-bionioaio)
|
||||
- [Java 虚拟机 jvm](#java-虚拟机-jvm)
|
||||
- [:open_file_folder: 数据结构与算法](#open_file_folder-数据结构与算法)
|
||||
- [数据结构](#数据结构)
|
||||
- [算法](#算法)
|
||||
- [:computer: 计算机网络与数据通信](#computer-计算机网络与数据通信)
|
||||
- [网络相关](#网络相关)
|
||||
- [数据通信\(RESTful,RPC,消息队列\)总结](#数据通信restfulrpc消息队列总结)
|
||||
- [:iphone: 操作系统](#iphone-操作系统)
|
||||
- [Linux相关](#linux相关)
|
||||
- [:pencil2: 主流框架/软件](#pencil2-主流框架软件)
|
||||
- [Spring](#spring)
|
||||
- [ZooKeeper](#zookeeper)
|
||||
- [:floppy_disk: 数据存储](#floppy_disk-数据存储)
|
||||
- [MySQL](#mysql)
|
||||
- [Redis](#redis)
|
||||
- [:punch: 架构](#punch-架构)
|
||||
- [:musical_note: 面试必备](#musical_note-面试必备)
|
||||
- [备战春招/秋招系列](#备战春招秋招系列)
|
||||
- [最最最常见的Java面试题总结](#最最最常见的java面试题总结)
|
||||
- [Java学习/面试开源仓库推荐](#java学习面试开源仓库推荐)
|
||||
- [:art: 闲谈](#art-闲谈)
|
||||
- [:envelope: 说明](#envelope-说明)
|
||||
|
||||
## 待办
|
||||
|
||||
- [ ] Java 8 新特性总结
|
||||
- [x] BIO,NIO,AIO 总结
|
||||
- [ ] Netty 总结
|
||||
- [ ] 数据结构总结重构
|
||||
|
||||
|
||||
## :coffee: Java
|
||||
- ### Java/J2EE 基础
|
||||
- [Java 基础知识回顾](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/Java基础知识.md)
|
||||
- [J2EE 基础知识回顾](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/J2EE基础知识.md)
|
||||
- [static、final、this、super关键字总结](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/final、static、this、super.md)
|
||||
- [static 关键字详解](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/static.md)
|
||||
|
||||
- ### Java 集合框架
|
||||
- [这几道Java集合框架面试题几乎必问](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/这几道Java集合框架面试题几乎必问.md)
|
||||
- [Java 集合框架常见面试题总结](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/Java集合框架常见面试题总结.md)
|
||||
- [ArrayList 源码学习](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/ArrayList.md)
|
||||
- [【面试必备】透过源码角度一步一步带你分析 ArrayList 扩容机制](https://github.com/Snailclimb/JavaGuide/blob/master/Java相关/ArrayList-Grow.md)
|
||||
- [LinkedList 源码学习](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/LinkedList.md)
|
||||
- [HashMap(JDK1.8)源码学习](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/HashMap.md)
|
||||
|
||||
- ### Java 多线程
|
||||
- [多线程系列文章](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/多线程系列.md)
|
||||
- [并发编程面试必备:synchronized 关键字使用、底层原理、JDK1.6 之后的底层优化以及 和ReenTrantLock 的对比](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/synchronized.md)
|
||||
- [并发编程面试必备:乐观锁与悲观锁](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/面试必备之乐观锁与悲观锁.md)
|
||||
- [并发编程面试必备:JUC 中的 Atomic 原子类总结](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/Multithread/Atomic.md)
|
||||
- [并发编程面试必备:AQS 原理以及 AQS 同步组件总结](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/Multithread/AQS.md)
|
||||
- [BATJ都爱问的多线程面试题](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/Multithread/BATJ都爱问的多线程面试题.md)
|
||||
- ### Java IO 与 NIO
|
||||
- [Java IO 与 NIO系列文章](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/Java%20IO与NIO.md)
|
||||
|
||||
- ### Java虚拟机(jvm)
|
||||
- [可能是把Java内存区域讲的最清楚的一篇文章](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/可能是把Java内存区域讲的最清楚的一篇文章.md)
|
||||
- [搞定JVM垃圾回收就是这么简单](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/搞定JVM垃圾回收就是这么简单.md)
|
||||
- [Java虚拟机(jvm)学习与面试](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/Java虚拟机(jvm).md)
|
||||
- ### 设计模式
|
||||
- [设计模式系列文章](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/设计模式.md)
|
||||
### Java/J2EE 基础
|
||||
|
||||
* [Java 基础知识回顾](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/Java基础知识.md)
|
||||
* [J2EE 基础知识回顾](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/J2EE基础知识.md)
|
||||
* [static、final、this、super关键字总结](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/final、static、this、super.md)
|
||||
* [static 关键字详解](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/static.md)
|
||||
|
||||
### Java 集合框架
|
||||
|
||||
* [这几道Java集合框架面试题几乎必问](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/这几道Java集合框架面试题几乎必问.md)
|
||||
* [Java 集合框架常见面试题总结](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/Java集合框架常见面试题总结.md)
|
||||
* [ArrayList 源码学习](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/ArrayList.md)
|
||||
* [【面试必备】透过源码角度一步一步带你分析 ArrayList 扩容机制](https://github.com/Snailclimb/JavaGuide/blob/master/Java相关/ArrayList-Grow.md)
|
||||
* [LinkedList 源码学习](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/LinkedList.md)
|
||||
* [HashMap(JDK1.8)源码学习](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/HashMap.md)
|
||||
|
||||
### Java 多线程
|
||||
* [多线程系列文章](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/多线程系列.md)
|
||||
* [并发编程面试必备:synchronized 关键字使用、底层原理、JDK1.6 之后的底层优化以及 和ReenTrantLock 的对比](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/synchronized.md)
|
||||
* [并发编程面试必备:乐观锁与悲观锁](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/面试必备之乐观锁与悲观锁.md)
|
||||
* [并发编程面试必备:JUC 中的 Atomic 原子类总结](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/Multithread/Atomic.md)
|
||||
* [并发编程面试必备:AQS 原理以及 AQS 同步组件总结](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/Multithread/AQS.md)
|
||||
* [BATJ都爱问的多线程面试题](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/Multithread/BATJ都爱问的多线程面试题.md)
|
||||
* [并发容器总结](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/Multithread/并发容器总结.md)
|
||||
|
||||
### Java 虚拟机 jvm
|
||||
|
||||
* [可能是把Java内存区域讲的最清楚的一篇文章](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/可能是把Java内存区域讲的最清楚的一篇文章.md)
|
||||
* [搞定JVM垃圾回收就是这么简单](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/搞定JVM垃圾回收就是这么简单.md)
|
||||
* [《深入理解Java虚拟机》第2版学习笔记](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/Java虚拟机(jvm).md)
|
||||
|
||||
|
||||
### Java BIO,NIO,AIO
|
||||
|
||||
* [BIO,NIO,AIO 总结 ](https://github.com/Snailclimb/JavaGuide/blob/master/Java%E7%9B%B8%E5%85%B3/BIO%2CNIO%2CAIO%20summary.md)
|
||||
* [Java IO 与 NIO系列文章](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/Java%20IO与NIO.md)
|
||||
|
||||
### 设计模式
|
||||
|
||||
* [设计模式系列文章](https://github.com/Snailclimb/Java_Guide/blob/master/Java相关/设计模式.md)
|
||||
|
||||
## :open_file_folder: 数据结构与算法
|
||||
|
||||
- ### 数据结构
|
||||
- [数据结构知识学习与面试](https://github.com/Snailclimb/Java_Guide/blob/master/数据结构与算法/数据结构.md)
|
||||
### 数据结构
|
||||
|
||||
* [数据结构知识学习与面试](https://github.com/Snailclimb/Java_Guide/blob/master/数据结构与算法/数据结构.md)
|
||||
|
||||
- ### 算法
|
||||
### 算法
|
||||
|
||||
- [算法学习与面试](https://github.com/Snailclimb/Java_Guide/blob/master/数据结构与算法/算法.md)
|
||||
- [常见安全算法(MD5、SHA1、Base64等等)总结](https://github.com/Snailclimb/Java_Guide/blob/master/数据结构与算法/常见安全算法(MD5、SHA1、Base64等等)总结.md)
|
||||
- [算法总结——几道常见的子符串算法题 ](https://github.com/Snailclimb/Java_Guide/blob/master/数据结构与算法/搞定BAT面试——几道常见的子符串算法题.md)
|
||||
- [算法总结——几道常见的链表算法题 ](https://github.com/Snailclimb/Java_Guide/blob/master/数据结构与算法/Leetcode-LinkList1.md)
|
||||
* [算法学习与面试](https://github.com/Snailclimb/Java_Guide/blob/master/数据结构与算法/算法.md)
|
||||
* [常见安全算法(MD5、SHA1、Base64等等)总结](https://github.com/Snailclimb/Java_Guide/blob/master/数据结构与算法/常见安全算法(MD5、SHA1、Base64等等)总结.md)
|
||||
* [算法总结——几道常见的子符串算法题 ](https://github.com/Snailclimb/Java_Guide/blob/master/数据结构与算法/搞定BAT面试——几道常见的子符串算法题.md)
|
||||
* [算法总结——几道常见的链表算法题 ](https://github.com/Snailclimb/Java_Guide/blob/master/数据结构与算法/Leetcode-LinkList1.md)
|
||||
|
||||
## :computer: 计算机网络与数据通信
|
||||
- ### 网络相关
|
||||
- [计算机网络常见面试题](https://github.com/Snailclimb/Java_Guide/blob/master/计算机网络与数据通信/计算机网络.md)
|
||||
- [计算机网络基础知识总结](https://github.com/Snailclimb/Java_Guide/blob/master/计算机网络与数据通信/干货:计算机网络知识总结.md)
|
||||
|
||||
- ### 数据通信(RESTful、RPC、消息队列)
|
||||
- [数据通信(RESTful、RPC、消息队列)相关知识点总结](https://github.com/Snailclimb/Java-Guide/blob/master/计算机网络与数据通信/数据通信(RESTful、RPC、消息队列).md)
|
||||
|
||||
|
||||
### 网络相关
|
||||
|
||||
* [计算机网络常见面试题](https://github.com/Snailclimb/Java_Guide/blob/master/计算机网络与数据通信/计算机网络.md)
|
||||
* [计算机网络基础知识总结](https://github.com/Snailclimb/Java_Guide/blob/master/计算机网络与数据通信/干货:计算机网络知识总结.md)
|
||||
* [HTTPS中的TLS](https://github.com/Snailclimb/Java_Guide/blob/master/计算机网络与数据通信/HTTPS中的TLS.md)
|
||||
|
||||
### 数据通信(RESTful,RPC,消息队列)总结
|
||||
|
||||
* [数据通信(RESTful、RPC、消息队列)相关知识点总结](https://github.com/Snailclimb/Java-Guide/blob/master/计算机网络与数据通信/数据通信(RESTful、RPC、消息队列).md)
|
||||
* [Dubbo 总结:关于 Dubbo 的重要知识点](https://github.com/Snailclimb/Java-Guide/blob/master/计算机网络与数据通信/dubbo.md)
|
||||
* [消息队列总结:新手也能看懂,消息队列其实很简单](https://github.com/Snailclimb/Java-Guide/blob/master/计算机网络与数据通信/message-queue.md)
|
||||
* [一文搞懂 RabbitMQ 的重要概念以及安装](https://github.com/Snailclimb/Java-Guide/blob/master/计算机网络与数据通信/rabbitmq.md)
|
||||
|
||||
## :iphone: 操作系统
|
||||
|
||||
- ### Linux相关
|
||||
- [后端程序员必备的 Linux 基础知识](https://github.com/Snailclimb/Java-Guide/blob/master/操作系统/后端程序员必备的Linux基础知识.md)
|
||||
### Linux相关
|
||||
|
||||
* [后端程序员必备的 Linux 基础知识](https://github.com/Snailclimb/Java-Guide/blob/master/操作系统/后端程序员必备的Linux基础知识.md)
|
||||
* [Shell 编程入门](https://github.com/Snailclimb/Java-Guide/blob/master/操作系统/Shell.md)
|
||||
## :pencil2: 主流框架/软件
|
||||
|
||||
- ### Spring
|
||||
- [Spring 学习与面试](https://github.com/Snailclimb/Java_Guide/blob/master/主流框架/Spring学习与面试.md)
|
||||
- [Spring中bean的作用域与生命周期](https://github.com/Snailclimb/Java_Guide/blob/master/主流框架/SpringBean.md)
|
||||
- [SpringMVC 工作原理详解](https://github.com/Snailclimb/JavaGuide/blob/master/主流框架/SpringMVC%20%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86%E8%AF%A6%E8%A7%A3.md)
|
||||
- ### ZooKeeper
|
||||
- [可能是把 ZooKeeper 概念讲的最清楚的一篇文章](https://github.com/Snailclimb/Java_Guide/blob/master/主流框架/ZooKeeper.md)
|
||||
### Spring
|
||||
|
||||
* [Spring 学习与面试](https://github.com/Snailclimb/Java_Guide/blob/master/主流框架/Spring学习与面试.md)
|
||||
* [Spring中bean的作用域与生命周期](https://github.com/Snailclimb/Java_Guide/blob/master/主流框架/SpringBean.md)
|
||||
* [SpringMVC 工作原理详解](https://github.com/Snailclimb/JavaGuide/blob/master/主流框架/SpringMVC%20%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86%E8%AF%A6%E8%A7%A3.md)
|
||||
|
||||
### ZooKeeper
|
||||
|
||||
* [可能是把 ZooKeeper 概念讲的最清楚的一篇文章](https://github.com/Snailclimb/Java_Guide/blob/master/主流框架/ZooKeeper.md)
|
||||
* [ZooKeeper 数据模型和常见命令了解一下,速度收藏!](https://github.com/Snailclimb/Java_Guide/blob/master/主流框架/ZooKeeper数据模型和常见命令.md)
|
||||
|
||||
## :floppy_disk: 数据存储
|
||||
- ### MySQL
|
||||
- [MySQL 学习与面试](https://github.com/Snailclimb/Java_Guide/blob/master/数据存储/MySQL.md)
|
||||
- [【思维导图-索引篇】搞定数据库索引就是这么简单](https://github.com/Snailclimb/Java_Guide/blob/master/数据存储/MySQL%20Index.md)
|
||||
- ### Redis
|
||||
- [Redis 总结](https://github.com/Snailclimb/Java_Guide/blob/master/数据存储/Redis/Redis.md)
|
||||
- [Redlock分布式锁](https://github.com/Snailclimb/Java_Guide/blob/master/数据存储/Redis/Redlock分布式锁.md)
|
||||
- [如何做可靠的分布式锁,Redlock真的可行么](https://github.com/Snailclimb/Java_Guide/blob/master/数据存储/Redis/如何做可靠的分布式锁,Redlock真的可行么.md)\
|
||||
|
||||
### MySQL
|
||||
|
||||
* [MySQL 学习与面试](https://github.com/Snailclimb/Java_Guide/blob/master/数据存储/MySQL.md)
|
||||
* [【思维导图-索引篇】搞定数据库索引就是这么简单](https://github.com/Snailclimb/Java_Guide/blob/master/数据存储/MySQL%20Index.md)
|
||||
|
||||
### Redis
|
||||
|
||||
* [Redis 总结](https://github.com/Snailclimb/Java_Guide/blob/master/数据存储/Redis/Redis.md)
|
||||
* [Redlock分布式锁](https://github.com/Snailclimb/Java_Guide/blob/master/数据存储/Redis/Redlock分布式锁.md)
|
||||
* [如何做可靠的分布式锁,Redlock真的可行么](https://github.com/Snailclimb/Java_Guide/blob/master/数据存储/Redis/如何做可靠的分布式锁,Redlock真的可行么.md)
|
||||
|
||||
## :punch: 架构
|
||||
- ### 分布式相关
|
||||
- [分布式学习与面试](https://github.com/Snailclimb/Java_Guide/blob/master/架构/分布式.md)
|
||||
|
||||
* [一文读懂分布式应该学什么](https://github.com/Snailclimb/Java_Guide/blob/master/架构/分布式.md)
|
||||
* [8 张图读懂大型网站技术架构](https://github.com/Snailclimb/JavaGuide/blob/master/架构/8%20张图读懂大型网站技术架构.md)
|
||||
* [【面试精选】关于大型网站系统架构你不得不懂的10个问题](https://github.com/Snailclimb/JavaGuide/blob/master/架构/【面试精选】关于大型网站系统架构你不得不懂的10个问题.md)
|
||||
|
||||
## :musical_note: 面试必备
|
||||
|
||||
- ### 备战春招/秋招系列
|
||||
### 备战春招/秋招系列
|
||||
|
||||
- [【备战春招/秋招系列1】程序员的简历就该这样写](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/程序员的简历之道.md)
|
||||
- [手把手教你用Markdown写一份高质量的简历](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/手把手教你用Markdown写一份高质量的简历.md)
|
||||
- [【备战春招/秋招系列2】初出茅庐的程序员该如何准备面试?](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/interviewPrepare.md)
|
||||
- [【备战春招/秋招系列3】Java程序员必备书单](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/books.md)
|
||||
- [ 【备战春招/秋招系列4】美团面经总结基础篇 (附详解答案)](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/美团-基础篇.md)
|
||||
- [ 【备战春招/秋招系列5】美团面经总结进阶篇 (附详解答案)](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/美团-进阶篇.md)
|
||||
- [ 【备战春招/秋招系列5】美团面经总结终结篇篇 (附详解答案)](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/美团-终结篇.md)
|
||||
* [【备战春招/秋招系列1】程序员的简历就该这样写](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/程序员的简历之道.md)
|
||||
* [手把手教你用Markdown写一份高质量的简历](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/手把手教你用Markdown写一份高质量的简历.md)
|
||||
* [【备战春招/秋招系列2】初出茅庐的程序员该如何准备面试?](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/interviewPrepare.md)
|
||||
* [【备战春招/秋招系列3】Java程序员必备书单](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/books.md)
|
||||
* [ 【备战春招/秋招系列4】美团面经总结基础篇 (附详解答案)](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/美团-基础篇.md)
|
||||
* [ 【备战春招/秋招系列5】美团面经总结进阶篇 (附详解答案)](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/美团-进阶篇.md)
|
||||
* [ 【备战春招/秋招系列5】美团面经总结终结篇篇 (附详解答案)](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/美团-终结篇.md)
|
||||
|
||||
- ### 最最最常见的Java面试题总结
|
||||
这里会分享一些出现频率极其极其高的面试题,初定周更一篇,什么时候更完什么时候停止。
|
||||
### 最最最常见的Java面试题总结
|
||||
|
||||
- [第一周(2018-8-7)](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/最最最常见的Java面试题总结/第一周(2018-8-7).md) (为什么 Java 中只有值传递、==与equals、 hashCode与equals)
|
||||
- [第二周(2018-8-13)](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/最最最常见的Java面试题总结/第二周(2018-8-13).md)(String和StringBuffer、StringBuilder的区别是什么?String为什么是不可变的?、什么是反射机制?反射机制的应用场景有哪些?......)
|
||||
- [第三周(2018-08-22)](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/这几道Java集合框架面试题几乎必问.md) (Arraylist 与 LinkedList 异同、ArrayList 与 Vector 区别、HashMap的底层实现、HashMap 和 Hashtable 的区别、HashMap 的长度为什么是2的幂次方、HashSet 和 HashMap 区别、ConcurrentHashMap 和 Hashtable 的区别、ConcurrentHashMap线程安全的具体实现方式/底层具体实现、集合框架底层数据结构总结)
|
||||
- [第四周(2018-8-30).md](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/最最最常见的Java面试题总结/第四周(2018-8-30).md) (主要内容是几道面试常问的多线程基础题。)
|
||||
这里会分享一些出现频率极其极其高的面试题,初定周更一篇,什么时候更完什么时候停止。
|
||||
|
||||
* [第一周(2018-8-7)](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/最最最常见的Java面试题总结/第一周(2018-8-7).md) (为什么 Java 中只有值传递、==与equals、 hashCode与equals)
|
||||
* [第二周(2018-8-13)](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/最最最常见的Java面试题总结/第二周(2018-8-13).md)(String和StringBuffer、StringBuilder的区别是什么?String为什么是不可变的?、什么是反射机制?反射机制的应用场景有哪些?......)
|
||||
* [第三周(2018-08-22)](https://github.com/Snailclimb/Java-Guide/blob/master/Java相关/这几道Java集合框架面试题几乎必问.md) (Arraylist 与 LinkedList 异同、ArrayList 与 Vector 区别、HashMap的底层实现、HashMap 和 Hashtable 的区别、HashMap 的长度为什么是2的幂次方、HashSet 和 HashMap 区别、ConcurrentHashMap 和 Hashtable 的区别、ConcurrentHashMap线程安全的具体实现方式/底层具体实现、集合框架底层数据结构总结)
|
||||
* [第四周(2018-8-30).md](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/最最最常见的Java面试题总结/第四周(2018-8-30).md) (主要内容是几道面试常问的多线程基础题。)
|
||||
|
||||
### Java学习/面试开源仓库推荐
|
||||
|
||||
* [盘点一下Github上开源的Java面试/学习相关的仓库,看完弄懂薪资至少增加10k](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/JavaInterviewGithub.md)
|
||||
|
||||
## :art: 其他
|
||||
## :art: 闲谈
|
||||
|
||||
|
||||
- ### 技术方向选择
|
||||
- [选择技术方向都要考虑哪些因素](https://github.com/Snailclimb/Java-Guide/blob/master/其他/选择技术方向都要考虑哪些因素.md)
|
||||
|
||||
- ### 2018 年秋招简单回顾
|
||||
- [结束了我短暂的秋招,说点自己的感受](https://github.com/Snailclimb/JavaGuide/blob/master/%E5%85%B6%E4%BB%96/2018%20%E7%A7%8B%E6%8B%9B.md)
|
||||
|
||||
* [选择技术方向都要考虑哪些因素](https://github.com/Snailclimb/Java-Guide/blob/master/其他/选择技术方向都要考虑哪些因素.md)
|
||||
* [结束了我短暂的秋招,说点自己的感受](https://github.com/Snailclimb/JavaGuide/blob/master/%E5%85%B6%E4%BB%96/2018%20%E7%A7%8B%E6%8B%9B.md)
|
||||
* [这7个问题,可能大部分Java程序员都比较关心吧!](https://github.com/Snailclimb/JavaGuide/blob/master/%E9%9D%A2%E8%AF%95%E5%BF%85%E5%A4%87/java%20programmer%20need%20know.md)
|
||||
* [【2018总结】即使平凡,也要热爱自己的生活](https://github.com/Snailclimb/JavaGuide/blob/master/%E5%85%B6%E4%BB%96/2018%20summary.md)
|
||||
|
||||
***
|
||||
|
||||
> # :envelope: 该开源文档一些说明
|
||||
## :envelope: 说明
|
||||
|
||||
## 介绍
|
||||
### 项目介绍
|
||||
|
||||
该文档主要是笔主在学习 Java 的过程中的一些学习笔记,但是为了能够涉及到大部分后端学习所需的技术知识点我也会偶尔引用一些别人的优秀文章的链接。文档大部分内容都是笔者参考书籍以及自己的原创。少部分面试题回答参考了其他人已有答案,上面都已注明。
|
||||
|
||||
该文档涉及的主要内容包括: Java、 数据结构与算法、计算机网络与数据通信、 操作系统、主流框架、数据存储、架构、面试必备知识点等等。相信不论你是前端还是后端都能在这份文档中收获到东西。
|
||||
|
||||
## 关于转载
|
||||
### 关于转载
|
||||
|
||||
**如果需要引用到本仓库的一些东西,必须注明转载地址!!!毕竟大多都是手敲的,或者引用的是我的原创文章,希望大家尊重一下作者的劳动**:smiley::smiley::smiley:!
|
||||
|
||||
## 如何对该开源文档进行贡献
|
||||
### 如何对该开源文档进行贡献
|
||||
|
||||
1. 笔记内容大多是手敲,所以难免会有笔误,你可以帮我找错别字。
|
||||
2. 很多知识点我可能没有涉及到,所以你可以对其他知识点进行补充。
|
||||
3. 现有的知识点难免存在不完善或者错误,所以你可以对已有知识点的修改/补充。
|
||||
|
||||
## 为什么要做这个开源文档?
|
||||
### 为什么要做这个开源文档?
|
||||
|
||||
在我们学习Java的时候,很多人会面临我不知道继续学什么或者面试会问什么的尴尬情况(我本人之前就很迷茫:smile:)。所以,我决定通过这个开源平台来帮助一些有需要的人,通过下面的内容,你会掌握系统的Java学习以及面试的相关知识。本来是想通过Gitbook的形式来制作的,后来想了想觉得可能有点大题小做 :grin: 。另外,我自己一个人的力量毕竟有限,希望各位有想法的朋友可以提issue。开源的最大目的是,让更多人参与进来,这样文档的正确性才能得以保障!
|
||||
|
||||
## 最后
|
||||
### 最后
|
||||
|
||||
本人会利用业余时间一直更新下去,目前还有很多地方不完善,一些知识点我会原创总结,还有一些知识点如果说网上有比较好的文章了,我会把这些文章加入进去。您也可以关注我的微信公众号:“Java面试通关手册”,我会在这里分享一些自己的原创文章。 另外该文档格式参考:[Github Markdown格式](https://guides.github.com/features/mastering-markdown/),表情素材来自:[EMOJI CHEAT SHEET](https://www.webpagefx.com/tools/emoji-cheat-sheet/)。如果大家需要与我交流,可以扫描下方二维码添加我的微信:
|
||||
|
||||

|
||||
### 我的微信
|
||||
|
||||
## 推荐一下阿里云服务
|
||||

|
||||
|
||||
> 阿里云技术有保障,在云服务技术上远远领先于国内其他云服务提供商。大家或者公司如果需要用到云服务器的话,推荐阿里云服务器,下面是阿里云目前正在做的一些活动,错过这波,后续可能多花很多钱:
|
||||
### Java并发编程专栏
|
||||
|
||||
1. [全民云计算:ECS云服务器2折起,1核1G仅需293元/年](https://promotion.aliyun.com/ntms/act/qwbk.html?userCode=hf47liqn)
|
||||
2. [高性能企业级性能云服务器限时2折起,2核4G仅需720元/年](https://promotion.aliyun.com/ntms/act/enterprise-discount.html?userCode=hf47liqn)
|
||||
3. [拉1人拼团,立享云服务器¥234/年](https://promotion.aliyun.com/ntms/act/vmpt/aliyun-group/home.html?spm=5176.8849694.home.4.27a24b70kENhtV&userCode=hf47liqn)
|
||||
4. [最高¥1888云产品通用代金券](https://promotion.aliyun.com/ntms/yunparter/invite.html?userCode=hf47liqn)
|
||||
5. [阿里云建站服务](https://promotion.aliyun.com/ntms/act/jianzhanquan.html?userCode=hf47liqn)(企业官网、电商网站,多种可供选择模板,代金券免费领取)
|
||||
微信扫描下方二维码,购买之后我会将自己得到的24元返现都还给你,减轻各位的学习成本!
|
||||
|
||||

|
||||
|
||||
### 公众号
|
||||
|
||||
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。我是 ThoughtWorks 准入职Java工程师。专注Java知识分享!开源 Java 学习指南——JavaGuide(12k+ Star)的作者。公众号多篇文章被各大技术社区转载。公众号后台回复关键字“1”可以领取一份我精选的Java资源哦!可以扫描下方二维码或者通过微信的搜一搜搜索ID:“Java_Guide”即可。
|
||||
|
||||
|
||||
**你若盛开,清风自来。 欢迎关注我的微信公众号:“Java面试通关手册”,一个有温度的微信公众号。公众号多篇优质文章被各大社区转载,公众号后台回复关键字“1”你可能看到想要的东西哦!:**
|
||||
|
||||
|
||||

|
||||

|
||||
|
||||
@ -23,6 +23,8 @@
|
||||
|
||||
**Spring中的bean默认都是单例的,这些单例Bean在多线程程序下如何保证线程安全呢?** 例如对于Web应用来说,Web容器对于每个用户请求都创建一个单独的Sevlet线程来处理请求,引入Spring框架之后,每个Action都是单例的,那么对于Spring托管的单例Service Bean,如何保证其安全呢? **Spring的单例是基于BeanFactory也就是Spring容器的,单例Bean在此容器内只有一个,Java的单例是基于 JVM,每个 JVM 内只有一个实例。**
|
||||
|
||||
在大多数情况下。单例 bean 是很理想的方案。不过,有时候你可能会发现你所使用的类是易变的,它们会保持一些状态,因此重用是不安全的。在这种情况下,将 class 声明为单例的就不是那么明智了。因为对象会被污染,稍后重用的时候会出现意想不到的问题。所以 Spring 定义了多种作用域的bean。
|
||||
|
||||
# 一 bean的作用域
|
||||
|
||||
创建一个bean定义,其实质是用该bean定义对应的类来创建真正实例的“配方”。把bean定义看成一个配方很有意义,它与class很类似,只根据一张“处方”就可以创建多个实例。不仅可以控制注入到对象中的各种依赖和配置值,还可以控制该对象的作用域。这样可以灵活选择所建对象的作用域,而不必在Java Class级定义作用域。Spring Framework支持五种作用域,分别阐述如下表。
|
||||
@ -65,7 +67,7 @@ public class ServiceImpl{
|
||||
|
||||
### 3. request——每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP request内有效
|
||||
|
||||
**request只适用于Web程序,每一次 HTTP 请求都会产生一个新的bean,同时该bean仅在当前HTTP request内有效,当请求结束后,该对象的生命周期即告结束。** 在 XML 中将 bean 定义成 prototype ,可以这样配置:
|
||||
**request只适用于Web程序,每一次 HTTP 请求都会产生一个新的bean,同时该bean仅在当前HTTP request内有效,当请求结束后,该对象的生命周期即告结束。** 在 XML 中将 bean 定义成 request ,可以这样配置:
|
||||
|
||||
```java
|
||||
<bean id="loginAction" class=cn.csdn.LoginAction" scope="request"/>
|
||||
|
||||
@ -116,7 +116,7 @@ Spring IOC的初始化过程:
|
||||
|
||||
> ## Spring源码阅读
|
||||
|
||||
阅读源码不仅可以加深我们对Spring设计思想的理解,提高自己的编码水品,还可以让自己字面试中如鱼得水。下面的是Github上的一个开源的Spring源码阅读,大家有时间可以看一下,当然你如果有时间也可以自己慢慢研究源码。
|
||||
阅读源码不仅可以加深我们对Spring设计思想的理解,提高自己的编码水品,还可以让自己在面试中如鱼得水。下面的是Github上的一个开源的Spring源码阅读,大家有时间可以看一下,当然你如果有时间也可以自己慢慢研究源码。
|
||||
|
||||
### [Spring源码阅读](https://github.com/seaswalker/Spring)
|
||||
- [spring-core](https://github.com/seaswalker/Spring/blob/master/note/Spring.md)
|
||||
|
||||
@ -28,7 +28,7 @@ ZooKeeper 是一个开源的分布式协调服务,ZooKeeper框架最初是在
|
||||
|
||||
**ZooKeeper 是一个典型的分布式数据一致性解决方案,分布式应用程序可以基于 ZooKeeper 实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。**
|
||||
|
||||
**Zookeeper 一个最常用的使用场景就是用于担任服务生产者和服务消费者的注册中心。** 服务生产者将自己提供的服务注册到Zookeeper中心,服务的消费者在进行服务调用的时候先到Zookeeper中查找服务,获取到服务生产者的详细信息之后,再去调用服务生产者的内容与数据。如下图所示,在 Dubbo架构中 Zookeeper 就担任了注册中心这一角色。
|
||||
**Zookeeper 一个最常用的使用场景就是用于担任服务生产者和服务消费者的注册中心(提供发布订阅服务)。** 服务生产者将自己提供的服务注册到Zookeeper中心,服务的消费者在进行服务调用的时候先到Zookeeper中查找服务,获取到服务生产者的详细信息之后,再去调用服务生产者的内容与数据。如下图所示,在 Dubbo架构中 Zookeeper 就担任了注册中心这一角色。
|
||||
|
||||
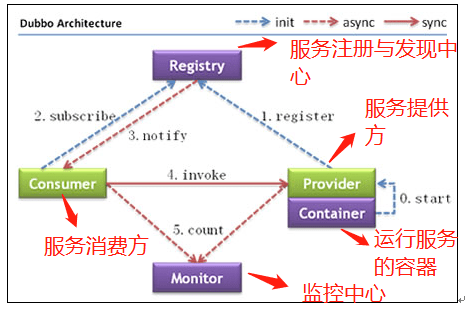
|
||||
|
||||
@ -58,7 +58,7 @@ ZooKeeper 是一个开源的分布式协调服务,ZooKeeper框架最初是在
|
||||
- **ZooKeeper 将数据保存在内存中,这也就保证了 高吞吐量和低延迟**(但是内存限制了能够存储的容量不太大,此限制也是保持znode中存储的数据量较小的进一步原因)。
|
||||
- **ZooKeeper 是高性能的。 在“读”多于“写”的应用程序中尤其地高性能,因为“写”会导致所有的服务器间同步状态。**(“读”多于“写”是协调服务的典型场景。)
|
||||
- **ZooKeeper有临时节点的概念。 当创建临时节点的客户端会话一直保持活动,瞬时节点就一直存在。而当会话终结时,瞬时节点被删除。持久节点是指一旦这个ZNode被创建了,除非主动进行ZNode的移除操作,否则这个ZNode将一直保存在Zookeeper上。**
|
||||
- ZooKeeper 底层其实只提供了两个功能:①管理(存储、读取)用户程序提交的数据;②为用户程序提交数据节点监听服务。
|
||||
- ZooKeeper 底层其实只提供了两个功能:①管理(存储、读取)用户程序提交的数据;②为用户程序提供数据节点监听服务。
|
||||
|
||||
**下面关于会话(Session)、 Znode、版本、Watcher、ACL概念的总结都在《从Paxos到Zookeeper 》第四章第一节以及第七章第八节有提到,感兴趣的可以看看!**
|
||||
|
||||
@ -74,11 +74,11 @@ Session 指的是 ZooKeeper 服务器与客户端会话。**在 ZooKeeper 中
|
||||
|
||||
Zookeeper将所有数据存储在内存中,数据模型是一棵树(Znode Tree),由斜杠(/)的进行分割的路径,就是一个Znode,例如/foo/path1。每个上都会保存自己的数据内容,同时还会保存一系列属性信息。
|
||||
|
||||
**在Zookeeper中,node可以分为持久节点和临时节点两类。所谓持久节点是指一旦这个ZNode被创建了,除非主动进行ZNode的移除操作,否则这个ZNode将一直保存在Zookeeper上。而临时节点就不一样了,它的生命周期和客户端会话绑定,一旦客户端会话失效,那么这个客户端创建的所有临时节点都会被移除。**另外,ZooKeeper还允许用户为每个节点添加一个特殊的属性:**SEQUENTIAL**.一旦节点被标记上这个属性,那么在这个节点被创建的时候,Zookeeper会自动在其节点名后面追加上一个整型数字,这个整型数字是一个由父节点维护的自增数字。
|
||||
**在Zookeeper中,node可以分为持久节点和临时节点两类。所谓持久节点是指一旦这个ZNode被创建了,除非主动进行ZNode的移除操作,否则这个ZNode将一直保存在Zookeeper上。而临时节点就不一样了,它的生命周期和客户端会话绑定,一旦客户端会话失效,那么这个客户端创建的所有临时节点都会被移除。** 另外,ZooKeeper还允许用户为每个节点添加一个特殊的属性:**SEQUENTIAL**.一旦节点被标记上这个属性,那么在这个节点被创建的时候,Zookeeper会自动在其节点名后面追加上一个整型数字,这个整型数字是一个由父节点维护的自增数字。
|
||||
|
||||
### 2.4 版本
|
||||
|
||||
在前面我们已经提到,Zookeeper 的每个 ZNode 上都会存储数据,对应于每个ZNode,Zookeeper 都会为其维护一个叫作 **Stat** 的数据结构,Stat中记录了这个 ZNode 的三个数据版本,分别是version(当前ZNode的版本)、cversion(当前ZNode子节点的版本)和 cversion(当前ZNode的ACL版本)。
|
||||
在前面我们已经提到,Zookeeper 的每个 ZNode 上都会存储数据,对应于每个ZNode,Zookeeper 都会为其维护一个叫作 **Stat** 的数据结构,Stat 中记录了这个 ZNode 的三个数据版本,分别是version(当前ZNode的版本)、cversion(当前ZNode子节点的版本)和 aversion(当前ZNode的ACL版本)。
|
||||
|
||||
|
||||
### 2.5 Watcher
|
||||
|
||||
202
主流框架/ZooKeeper数据模型和常见命令.md
Normal file
202
主流框架/ZooKeeper数据模型和常见命令.md
Normal file
@ -0,0 +1,202 @@
|
||||
<!-- MarkdownTOC -->
|
||||
|
||||
- [ZooKeeper 数据模型](#zookeeper-数据模型)
|
||||
- [ZNode\(数据节点\)的结构](#znode数据节点的结构)
|
||||
- [测试 ZooKeeper 中的常见操作](#测试-zookeeper-中的常见操作)
|
||||
- [连接 ZooKeeper 服务](#连接-zookeeper-服务)
|
||||
- [查看常用命令\(help 命令\)](#查看常用命令help-命令)
|
||||
- [创建节点\(create 命令\)](#创建节点create-命令)
|
||||
- [更新节点数据内容\(set 命令\)](#更新节点数据内容set-命令)
|
||||
- [获取节点的数据\(get 命令\)](#获取节点的数据get-命令)
|
||||
- [查看某个目录下的子节点\(ls 命令\)](#查看某个目录下的子节点ls-命令)
|
||||
- [查看节点状态\(stat 命令\)](#查看节点状态stat-命令)
|
||||
- [查看节点信息和状态\(ls2 命令\)](#查看节点信息和状态ls2-命令)
|
||||
- [删除节点\(delete 命令\)](#删除节点delete-命令)
|
||||
- [参考](#参考)
|
||||
|
||||
<!-- /MarkdownTOC -->
|
||||
|
||||
> 看本文之前如果你没有安装 ZooKeeper 的话,可以参考这篇文章:[《使用 SpringBoot+Dubbo 搭建一个简单分布式服务》](https://github.com/Snailclimb/springboot-integration-examples/blob/master/md/springboot-dubbo.md) 的 “开始实战 1 :zookeeper 环境安装搭建” 这部分进行安装(Centos7.4 环境下)。如果你想对 ZooKeeper 有一个整体了解的话,可以参考这篇文章:[《可能是把 ZooKeeper 概念讲的最清楚的一篇文章》](https://github.com/Snailclimb/JavaGuide/blob/master/%E4%B8%BB%E6%B5%81%E6%A1%86%E6%9E%B6/ZooKeeper.md)
|
||||
|
||||
### ZooKeeper 数据模型
|
||||
|
||||
ZNode(数据节点)是 ZooKeeper 中数据的最小单元,每个ZNode上都可以保存数据,同时还是可以有子节点(这就像树结构一样,如下图所示)。可以看出,节点路径标识方式和Unix文件
|
||||
系统路径非常相似,都是由一系列使用斜杠"/"进行分割的路径表示,开发人员可以向这个节点中写人数据,也可以在节点下面创建子节点。这些操作我们后面都会介绍到。
|
||||

|
||||
|
||||
提到 ZooKeeper 数据模型,还有一个不得不得提的东西就是 **事务 ID** 。事务的ACID(Atomic:原子性;Consistency:一致性;Isolation:隔离性;Durability:持久性)四大特性我在这里就不多说了,相信大家也已经挺腻了。
|
||||
|
||||
在Zookeeper中,事务是指能够改变 ZooKeeper 服务器状态的操作,我们也称之为事务操作或更新操作,一般包括数据节点创建与删除、数据节点内容更新和客户端会话创建与失效等操作。对于每一个事务请求,**ZooKeeper 都会为其分配一个全局唯一的事务ID,用 ZXID 来表示**,通常是一个64位的数字。每一个ZXID对应一次更新操作,**从这些 ZXID 中可以间接地识别出Zookeeper处理这些更新操作请求的全局顺序**。
|
||||
|
||||
|
||||
|
||||
### ZNode(数据节点)的结构
|
||||
|
||||
每个 ZNode 由2部分组成:
|
||||
|
||||
- stat:状态信息
|
||||
- data:数据内容
|
||||
|
||||
如下所示,我通过 get 命令来获取 根目录下的 dubbo 节点的内容。(get 命令在下面会介绍到)
|
||||
|
||||
```shell
|
||||
[zk: 127.0.0.1:2181(CONNECTED) 6] get /dubbo
|
||||
# 该数据节点关联的数据内容为空
|
||||
null
|
||||
# 下面是该数据节点的一些状态信息,其实就是 Stat 对象的格式化输出
|
||||
cZxid = 0x2
|
||||
ctime = Tue Nov 27 11:05:34 CST 2018
|
||||
mZxid = 0x2
|
||||
mtime = Tue Nov 27 11:05:34 CST 2018
|
||||
pZxid = 0x3
|
||||
cversion = 1
|
||||
dataVersion = 0
|
||||
aclVersion = 0
|
||||
ephemeralOwner = 0x0
|
||||
dataLength = 0
|
||||
numChildren = 1
|
||||
|
||||
```
|
||||
这些状态信息其实就是 Stat 对象的格式化输出。Stat 类中包含了一个数据节点的所有状态信息的字段,包括事务ID、版本信息和子节点个数等,如下图所示(图源:《从Paxos到Zookeeper 分布式一致性原理与实践》,下面会介绍通过 stat 命令查看数据节点的状态)。
|
||||
|
||||
**Stat 类:**
|
||||
|
||||

|
||||
|
||||
关于数据节点的状态信息说明(也就是对Stat 类中的各字段进行说明),可以参考下图(图源:《从Paxos到Zookeeper 分布式一致性原理与实践》)。
|
||||
|
||||

|
||||
|
||||
### 测试 ZooKeeper 中的常见操作
|
||||
|
||||
|
||||
#### 连接 ZooKeeper 服务
|
||||
|
||||
进入安装 ZooKeeper文件夹的 bin 目录下执行下面的命令连接 ZooKeeper 服务(Linux环境下)(连接之前首选要确定你的 ZooKeeper 服务已经启动成功)。
|
||||
|
||||
```shell
|
||||
./zkCli.sh -server 127.0.0.1:2181
|
||||
```
|
||||

|
||||
|
||||
从上图可以看出控制台打印出了很多信息,包括我们的主机名称、JDK 版本、操作系统等等。如果你成功看到这些信息,说明你成功连接到 ZooKeeper 服务。
|
||||
|
||||
#### 查看常用命令(help 命令)
|
||||
|
||||
help 命令查看 zookeeper 常用命令
|
||||
|
||||

|
||||
|
||||
#### 创建节点(create 命令)
|
||||
|
||||
通过 create 命令在根目录创建了node1节点,与它关联的字符串是"node1"
|
||||
|
||||
```shell
|
||||
[zk: 127.0.0.1:2181(CONNECTED) 34] create /node1 “node1”
|
||||
```
|
||||
通过 create 命令在根目录创建了node1节点,与它关联的内容是数字 123
|
||||
|
||||
```shell
|
||||
[zk: 127.0.0.1:2181(CONNECTED) 1] create /node1/node1.1 123
|
||||
Created /node1/node1.1
|
||||
```
|
||||
|
||||
#### 更新节点数据内容(set 命令)
|
||||
|
||||
```shell
|
||||
[zk: 127.0.0.1:2181(CONNECTED) 11] set /node1 "set node1"
|
||||
```
|
||||
|
||||
#### 获取节点的数据(get 命令)
|
||||
|
||||
get 命令可以获取指定节点的数据内容和节点的状态,可以看出我们通过set 命令已经将节点数据内容改为 "set node1"。
|
||||
|
||||
```shell
|
||||
set node1
|
||||
cZxid = 0x47
|
||||
ctime = Sun Jan 20 10:22:59 CST 2019
|
||||
mZxid = 0x4b
|
||||
mtime = Sun Jan 20 10:41:10 CST 2019
|
||||
pZxid = 0x4a
|
||||
cversion = 1
|
||||
dataVersion = 1
|
||||
aclVersion = 0
|
||||
ephemeralOwner = 0x0
|
||||
dataLength = 9
|
||||
numChildren = 1
|
||||
|
||||
```
|
||||
|
||||
#### 查看某个目录下的子节点(ls 命令)
|
||||
|
||||
通过 ls 命令查看根目录下的节点
|
||||
|
||||
```shell
|
||||
[zk: 127.0.0.1:2181(CONNECTED) 37] ls /
|
||||
[dubbo, zookeeper, node1]
|
||||
```
|
||||
通过 ls 命令查看 node1 目录下的节点
|
||||
|
||||
```shell
|
||||
[zk: 127.0.0.1:2181(CONNECTED) 5] ls /node1
|
||||
[node1.1]
|
||||
```
|
||||
zookeeper 中的 ls 命令和 linux 命令中的 ls 类似, 这个命令将列出绝对路径path下的所有子节点信息(列出1级,并不递归)
|
||||
|
||||
#### 查看节点状态(stat 命令)
|
||||
|
||||
通过 stat 命令查看节点状态
|
||||
|
||||
```shell
|
||||
[zk: 127.0.0.1:2181(CONNECTED) 10] stat /node1
|
||||
cZxid = 0x47
|
||||
ctime = Sun Jan 20 10:22:59 CST 2019
|
||||
mZxid = 0x47
|
||||
mtime = Sun Jan 20 10:22:59 CST 2019
|
||||
pZxid = 0x4a
|
||||
cversion = 1
|
||||
dataVersion = 0
|
||||
aclVersion = 0
|
||||
ephemeralOwner = 0x0
|
||||
dataLength = 11
|
||||
numChildren = 1
|
||||
```
|
||||
上面显示的一些信息比如cversion、aclVersion、numChildren等等,我在上面 “ZNode(数据节点)的结构” 这部分已经介绍到。
|
||||
|
||||
#### 查看节点信息和状态(ls2 命令)
|
||||
|
||||
|
||||
ls2 命令更像是 ls 命令和 stat 命令的结合。ls2 命令返回的信息包括2部分:子节点列表 + 当前节点的stat信息。
|
||||
|
||||
```shell
|
||||
[zk: 127.0.0.1:2181(CONNECTED) 7] ls2 /node1
|
||||
[node1.1]
|
||||
cZxid = 0x47
|
||||
ctime = Sun Jan 20 10:22:59 CST 2019
|
||||
mZxid = 0x47
|
||||
mtime = Sun Jan 20 10:22:59 CST 2019
|
||||
pZxid = 0x4a
|
||||
cversion = 1
|
||||
dataVersion = 0
|
||||
aclVersion = 0
|
||||
ephemeralOwner = 0x0
|
||||
dataLength = 11
|
||||
numChildren = 1
|
||||
|
||||
```
|
||||
|
||||
#### 删除节点(delete 命令)
|
||||
|
||||
这个命令很简单,但是需要注意的一点是如果你要删除某一个节点,那么这个节点必须无子节点才行。
|
||||
|
||||
```shell
|
||||
[zk: 127.0.0.1:2181(CONNECTED) 3] delete /node1/node1.1
|
||||
```
|
||||
|
||||
在后面我会介绍到 Java 客户端 API的使用以及开源 Zookeeper 客户端 ZkClient 和 Curator 的使用。
|
||||
|
||||
|
||||
### 参考
|
||||
|
||||
- 《从Paxos到Zookeeper 分布式一致性原理与实践》
|
||||
|
||||
174
其他/2018 summary.md
Normal file
174
其他/2018 summary.md
Normal file
@ -0,0 +1,174 @@
|
||||
# 【2018总结】即使平凡,也要热爱自己的生活
|
||||
|
||||
2018 年于我而讲,虽然平凡,但是自己就是在这平凡的一年也收货了很多东西。不光是自己学到的知识,我觉得 2018 年最大的幸运有三:其一是自己拥有了一份爱情,一份甜蜜的初恋,我真的很幸运遇到我现在的女朋友,愿以后的日子都能有她;其一是在 2018 年,我拥有了一份自己还算满意的 offer,马上就要毕业了,自己也要正式进去社会了;其一是自己在 2018 年的实现了自己的经济独立,这是一件让我很高兴的事情,我觉得大在学生时代实现经济独立还算是一件很不错的事情,花了这么多年父母的辛苦钱,自己也终于能替他们分担一点了。2018 年,感恩父母,感恩老师,感恩朋友,感恩遇到的每个善良的人,同时感恩2018年那个还算努力的自己。2019 继续加油!
|
||||
|
||||
## 一份甜蜜的初恋(分手)
|
||||
|
||||
先说说爱情。我和我的女朋友在一起已经半年多了,准确的来说截止到今天也就是 2018-12-30 号已经 190 天了。
|
||||
|
||||

|
||||
|
||||
我俩是异地,我在荆州,她在三亚。相见一面不管是时间上还是经济上对于还是学生的我们来说都甚是不易。见过很多人议论异地恋的种种不好,但是,于我而言,一份好的感情是值得被等待的。“待每一天如初恋,互相尊重彼此生活,共同努力,等老了就退隐山林养老......”,这应该是我和她之间最好的承诺了。
|
||||
|
||||
## 还算不错的学习收获
|
||||
|
||||
再来说说学习。这一年还算是让人满意,虽然我也不知道这一年自己到底学到了什么。如果你要问我这一年在学习上做的最满意的事情是什么,我还真不好回答,下面就从下面几个维度来简单谈一谈。
|
||||
|
||||
### 开源
|
||||
|
||||
这一年自己在Github上还是挺活跃的,提交了很多的代码和文档,同时也收获了很多的star、follower、pr、issue以及fork。
|
||||
|
||||

|
||||
|
||||

|
||||
|
||||
开源的Java学习/面试指南—JavaGuide 某种程度上让我挺满意的,3月份开源 ,到现在的18k+ star 也算是可以用厚积薄发来形容了。但是,JavaGuide 也有很多让我不满意的,在2019年以及以后我也会继续完善。JavaGuide 地址:[https://github.com/Snailclimb/JavaGuide](https://github.com/Snailclimb/JavaGuide)
|
||||
|
||||

|
||||
|
||||
### 技术博客
|
||||
|
||||
我更新的博客主要都是关于Java方面的,也更新了几篇Python的,有一篇Python的文章竟然在我的CSDN上面阅读霸榜。
|
||||

|
||||
|
||||
在这一年,我更新了挺多技术文章,这里就不一一列举了,我贴一下自己觉得不错的文章吧!
|
||||
|
||||
#### 最常见面试题系列
|
||||
|
||||
- [最最最常见的Java面试题总结——第一周](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484252&idx=1&sn=cb160d67fc1c0a95babc464b703df5e7&chksm=fd98553dcaefdc2b18f934957dd950aeaf04e90136099fa2817fffbd1e1df452b581e1caee17&token=1398134989&lang=zh_CN#rd)
|
||||
- [最最最常见的Java面试题总结——第二周](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484282&idx=1&sn=7f986dc3263b6ca0f9e182145fdd40a1&chksm=fd98551bcaefdc0d5aff9577692881dc79765a339ce97e55958e23e1956aa7092dfac44b68f1&token=1398134989&lang=zh_CN#rd)
|
||||
- [这几道Java集合框架面试题在面试中几乎必问](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484308&idx=1&sn=e3607919aed604be629617f867f46844&chksm=fd9855f5caefdce3f1ee72cb33b9b3bf9899fa2b64bbb92f1e820c0ef3985245b1f7dfc05358&token=1398134989&lang=zh_CN#rd)
|
||||
- [如果不会这几道多线程基础题,请自觉面壁!](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484337&idx=1&sn=d5e953d4b2da7ed37a7f843bfb437ed8&chksm=fd9855d0caefdcc65cb2e5cc0c69d27f785fc41477bcf55fff2cdff3268b0b078eb1a5107726&token=1398134989&lang=zh_CN#rd)
|
||||
- [值得立马保存的 synchronized 关键字总结](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484355&idx=1&sn=6da29974b6dd1a4aa0d032f44d5fa8de&chksm=fd9855a2caefdcb4c370814baafd4baca27dfccaf609c9edf82370637ba4856176ab143a375e&token=1398134989&lang=zh_CN#rd)
|
||||
- [【面试必备】源码角度一步一步分析 ArrayList 扩容机制](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484400&idx=1&sn=1b6155015fedfc9f78fabecc18da7b18&chksm=fd985591caefdc870cb018d27f92e1908b6c6e22816a77ead03c4e44b2f53caec00871172b1f&token=1398134989&lang=zh_CN#rd)
|
||||
- [Synchronized 关键字使用、底层原理、JDK1.6 之后的底层优化以及 和ReenTrantLock 的对比](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484539&idx=1&sn=3500cdcd5188bdc253fb19a1bfa805e6&chksm=fd98521acaefdb0c5167247a1fa903a1a53bb4e050b558da574f894f9feda5378ec9d0fa1ac7&token=1398134989&lang=zh_CN#rd)
|
||||
|
||||
#### Github
|
||||
|
||||
- [近几个月Github上最热门的Java项目一览](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484188&idx=1&sn=40037de4844f62316465bbe4e910c69c&chksm=fd98557dcaefdc6bedcaeb275aae7c340d46cf6ab0dc96e49c51982f9c53d6a44de283efc9a8&token=1398134989&lang=zh_CN#rd)
|
||||
- [推荐10个Java方向最热门的开源项目(8月)](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484333&idx=1&sn=8c97b029692877a537d55175a8c82977&chksm=fd9855cccaefdcdaffe0558ba5e8dca415495935b0ad1181e6b148b08e1c86ce5d841e9df901&token=1398134989&lang=zh_CN#rd)
|
||||
- [Github上 Star 数相加超过 7w+ 的三个面试相关的仓库推荐](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484644&idx=1&sn=5016caaf97e498b76de2189e3f55e9dc&chksm=fd985285caefdb93f4e3c7545d30edac6ad31b99f1fcc4503350101f0b20bba9a9705ed7d124&token=1398134989&lang=zh_CN#rd)
|
||||
- [11月 Github Trending 榜最热门的 10 个 Java 项目](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484730&idx=1&sn=86e35dfea1478221b6d14a263e88ac89&chksm=fd98535bcaefda4d4f03bf0cd2e0a8fd9f44b1a2b118457a0c8b3de2ff8a1f4c4b7cd083f40e&token=1398134989&lang=zh_CN#rd)
|
||||
- [盘点一下Github上开源的Java面试/学习相关的仓库,看完弄懂薪资至少增加10k](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484817&idx=1&sn=12f0c254a240c40c2ccab8314653216b&chksm=fd9853f0caefdae6d191e6bf085d44ab9c73f165e3323aa0362d830e420ccbfad93aa5901021&token=1398134989&lang=zh_CN#rd)
|
||||
|
||||
|
||||
#### 备战面试系列
|
||||
|
||||
- [可能是一份最适合你的后端面试指南(部分内容前端同样适用)](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484529&idx=1&sn=9c7a3d6ad124affcadc19b0ff49bf68a&chksm=fd985210caefdb0615a9643fa698cb6267e89562730423841d942cde17ec9c1280dfc3a2b933&token=1398134989&lang=zh_CN#rd)
|
||||
- [【备战春招/秋招系列1】程序员的简历就该这样写](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484573&idx=1&sn=8c5965d4a3710d405d8e8cc10c7b0ce5&chksm=fd9852fccaefdbea8dfe0bc40188b7579f1cddb1e8905dc981669a3f21d2a04cadceafa9023f&token=1990180468&lang=zh_CN#rd)
|
||||
- [【备战春招/秋招系列2】初出茅庐的程序员该如何准备面试?](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484578&idx=1&sn=eea72d80a2325257f00aaed21d5b226f&chksm=fd9852c3caefdbd52dd8a537cc723ed1509314401b3a669a253ef5bc0360b6fddef48b9c2e94&token=1990180468&lang=zh_CN#rd)
|
||||
- [【备战春招/秋招系列3】Java程序员必备书单](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484592&idx=1&sn=6d9731ce7401be49e97c1af6ed384ecc&chksm=fd9852d1caefdbc720a361ae65a8ad9d53cfb4800b15a7c68cbdc630b313215c6c52e0934ec2&token=1990180468&lang=zh_CN#rd)
|
||||
- [【备战春招/秋招系列】美团面经总结基础篇 (附详解答案)](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484601&idx=1&sn=4907b7fef0856791c565d49d788ba8cc&chksm=fd9852d8caefdbce88e51c0a10a4ec77c97f382fd2af4a840ea47cffc828bfd0f993f50d5f0d&token=1895808268&lang=zh_CN#rd)
|
||||
- [【备战春招/秋招系列】美团面经总结进阶篇 (附详解答案)](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484625&idx=1&sn=9c4fa1f7d4291a5fbd7daa44bac2b012&chksm=fd9852b0caefdba6edcf9a827aa4a17ddc97bf6ad2e5ee6f7e1aa1b443b54444d05d2b76732b&token=1895808268&lang=zh_CN#rd)
|
||||
- [【备战春招/秋招系列】美团Java面经总结终结篇 (附详解答案)](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484668&idx=1&sn=9d4631588393075d9c453f307410f0cd&chksm=fd98529dcaefdb8b5497d1f161834af6917c33ea3d305eb41872e522707fa94218769ca60101&token=1398134989&lang=zh_CN#rd)
|
||||
- [GitHub 上四万 Star 大佬的求职回忆](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484739&idx=1&sn=25cf5b36090f69299150663bdccfeec2&chksm=fd985322caefda34df0734efa607114704d1937f083aee2230b797d1f5aa04f7d13bf2f81dc5&token=1398134989&lang=zh_CN#rd)(非原创)
|
||||
|
||||
|
||||
#### 并发编程面试必备
|
||||
|
||||
- [并发编程面试必备:synchronized 关键字使用、底层原理、JDK1.6 之后的底层优化以及 和ReenTrantLock 的对比](http://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484539&idx=1&sn=3500cdcd5188bdc253fb19a1bfa805e6&chksm=fd98521acaefdb0c5167247a1fa903a1a53bb4e050b558da574f894f9feda5378ec9d0fa1ac7&scene=21#wechat_redirect)
|
||||
- [并发编程面试必备:JUC 中的 Atomic 原子类总结](http://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484553&idx=1&sn=aca9fa19f723206eff7e33a10973a887&chksm=fd9852e8caefdbfe7180c34f83bbb422a1a0bef1ed44b1e84f56924244ea3fd2da720f25c6dd#rd)
|
||||
- [并发编程面试必备:AQS 原理以及 AQS 同步组件总结](http://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484559&idx=1&sn=28dae85c38c4c500201c39234d25d731&chksm=fd9852eecaefdbf80cc54a25204e7c7d81170ce659acf92b7fa4151799ca3d0d7df2225d4ff1#rd)
|
||||
- [并发编程面试必备:BATJ都爱问的多线程面试题](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484564&idx=1&sn=d8467fdc5c1b3883e9b99485f7b0fb9a&chksm=fd9852f5caefdbe364d1c438865cff84acd8f40c1c9e2f9f5c8fef673b30f905b4c5f5255368&token=1398134989&lang=zh_CN#rd)
|
||||
|
||||
#### 虚拟机
|
||||
|
||||
- [可能是把Java内存区域讲的最清楚的一篇文章](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484303&idx=1&sn=af0fd436cef755463f59ee4dd0720cbd&chksm=fd9855eecaefdcf8d94ac581cfda4e16c8a730bda60c3b50bc55c124b92f23b6217f7f8e58d5&token=1398134989&lang=zh_CN#rd)
|
||||
- [搞定 JVM 垃圾回收就是这么简单](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484328&idx=1&sn=214f5e18a6afa096eb552fd8627e0cea&chksm=fd9855c9caefdcdf70c746c74d31f65bbb109eedaea0cfe311a1e10af666047df59ff04c873b&token=1398134989&lang=zh_CN#rd)
|
||||
|
||||
#### Spring Boot
|
||||
|
||||
- [超详细,新手都能看懂 !使用SpringBoot+Dubbo 搭建一个简单的分布式服务](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484706&idx=1&sn=d413fc17023482f67ca17cb6756b9ff8&chksm=fd985343caefda555969568fdf4734536e0a1745f9de337d434a7dbd04e893bd2d75f3641aab&token=1398134989&lang=zh_CN#rd)
|
||||
- [基于 SpringBoot2.0+优雅整合 SpringBoot+Mybatis](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484730&idx=2&sn=9be4636dd9a416b46f9029df68fad232&chksm=fd98535bcaefda4dccf14a286a24fcd2b3d4ab0d0e4d89dfbc955df99d2b06a1e17392b3c10b&token=1398134989&lang=zh_CN#rd)
|
||||
- [新手也能实现,基于SpirngBoot2.0+ 的 SpringBoot+Mybatis 多数据源配置](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484737&idx=1&sn=e39693d845f022d689437ee58948ef6a&chksm=fd985320caefda36d5ab8abd52f5516c11cc5d1104608695bcea5909602b28dc40c132d6d46c&token=1398134989&lang=zh_CN#rd)
|
||||
- [SpringBoot 整合 阿里云OSS 存储服务,快来免费搭建一个自己的图床](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484745&idx=1&sn=dbeec694916d204605929244d48a6b1c&chksm=fd985328caefda3e793170d81433c7c0b7dc1c4a4ae99395cce23b1d1a239482fd5bf1d89bc6&token=1398134989&lang=zh_CN#rd)
|
||||
|
||||
#### 成长
|
||||
|
||||
- [结束了我短暂的秋招,说点自己的感受](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484516&idx=1&sn=4e2320613e76dd73a130c63beebbc3ca&chksm=fd985205caefdb13b4b611ed3c604d95314d28d567ec0c3b44585b89a7dc3142bcd52bc2d4cb&token=1398134989&lang=zh_CN#rd)
|
||||
- [保研之路:从双非到南大](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484477&idx=1&sn=3b597e2431611aacca2b5d671a309d85&chksm=fd98525ccaefdb4a7e3742b5958244d453efe26f61f42f9f108190a0c18313f083189f10944e&token=1398134989&lang=zh_CN#rd)(非原创)
|
||||
- [【周日闲谈】最近想说的几件小事](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484650&idx=1&sn=e97ea1eeebdb5def58bae1949bec9448&chksm=fd98528bcaefdb9d76ac62fd10544f058b1fee4a40ffd06ab9312b7eb3a62f86d67ea653b88a&token=1398134989&lang=zh_CN#rd)
|
||||
- [这7个问题,可能大部分Java程序员都比较关心吧!](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484836&idx=1&sn=a6ada99c9506af01dc3bb472f66c57be&chksm=fd9853c5caefdad3034dbed00cf04412ea990fc05b6168720e6828ae6c90c9a885793acd7a14&token=1398134989&lang=zh_CN#rd)
|
||||
|
||||
#### Docker
|
||||
|
||||
- [可能是把Docker的概念讲的最清楚的一篇文章](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484127&idx=1&sn=70ee95619ec761da884c4f9af3e83194&chksm=fd9854becaefdda81a02bf6cf9bd07a2fc879efa7cefc79691a0d319b501d8572e8bad981d87&token=1398134989&lang=zh_CN#rd)
|
||||
|
||||
#### Linux
|
||||
|
||||
- [后端程序员必备的Linux基础知识](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484157&idx=1&sn=8b47e623e83fb3666bce7c680e4649b8&chksm=fd98549ccaefdd8ad815f3d8eaca86cc7e7245b4f8de1d23897af3017f5fdb3f152734c40f5e&token=1398134989&lang=zh_CN#rd)
|
||||
- [快速入门大厂后端面试必备的 Shell 编程](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484696&idx=1&sn=d3c1ba5abc10c10ff844cae2109a2628&chksm=fd985379caefda6faff8e050b7dfa1e92fbfe2912e44150cb4ae349aea807836166355062970&token=1398134989&lang=zh_CN#rd)
|
||||
|
||||
#### ZooKeeper
|
||||
|
||||
- [可能是全网把 ZooKeeper 概念讲的最清楚的一篇文章](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484379&idx=1&sn=036f5d3defa8a6979afb77acc82a9517&chksm=fd9855bacaefdcacc1462f781b634e5599f2ee9e806bd24297dae4af0e4196a70ca6bbd8c354&token=1398134989&lang=zh_CN#rd)
|
||||
|
||||
#### Redis
|
||||
|
||||
- [redis 总结——重构版](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484450&idx=1&sn=7ee03fa67aecd05c5becd2a8259d3631&chksm=fd985243caefdb554ebab9149e750ac0c819074c57bd208f2d7f097fbc461ed58223e71c05f1&token=1398134989&lang=zh_CN#rd)
|
||||
- [史上最全Redis高可用技术解决方案大全](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484478&idx=1&sn=a1250d9b8025cd7cb6fc6a58238ab51e&chksm=fd98525fcaefdb499a027df0138c98d4b02d828f27bd6144a4d40a1c088d340c29dd53d4a026&token=1398134989&lang=zh_CN#rd)(非原创)
|
||||
|
||||
#### 计算机网络
|
||||
|
||||
- [搞定计算机网络面试,看这篇就够了(补充版)](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484289&idx=1&sn=6b556843c60aac9a17b0e7c2e3cd6bca&chksm=fd9855e0caefdcf6af4123b719448c81d90c5442d4052ae01a4698047e226c0c18c14b2cc54a&token=1398134989&lang=zh_CN#rd)
|
||||
|
||||
#### 数据库
|
||||
|
||||
- [【思维导图-索引篇】搞定数据库索引就是这么简单](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484486&idx=1&sn=215450f11e042bca8a58eac9f4a97686&chksm=fd985227caefdb3117b8375f150676f5824aa20d1ebfdbcfb93ff06e23e26efbafae6cf6b48e&token=1398134989&lang=zh_CN#rd)
|
||||
|
||||
#### 消息队列
|
||||
|
||||
- [新手也能看懂,消息队列其实很简单](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484789&idx=1&sn=ba972f0aac39e9a28b29ddf92fc15c18&chksm=fd985314caefda0278235427d43846b6374ff32f4149352dec063287cbf9733b888acbb79923&token=1398134989&lang=zh_CN#rd)
|
||||
- [一文搞懂 RabbitMQ 的重要概念以及安装](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484796&idx=1&sn=bc56fecb634732669cfe7db8d1820ded&chksm=fd98531dcaefda0b07b8a9c13429ef225d36a6e287c96c53d7aa3dfd65c62ccd60d13b22ebbf&token=1398134989&lang=zh_CN#rd)
|
||||
|
||||
### 读书
|
||||
|
||||
推荐一下 2018 年看过的书籍,小部分可能2017年也看过一些。
|
||||
|
||||
#### 已看完
|
||||
|
||||
- [《图解HTTP》](https://book.douban.com/subject/25863515/)(推荐,豆瓣评分 8.1 , 1.6K+人评价): 讲漫画一样的讲HTTP,很有意思,不会觉得枯燥,大概也涵盖也HTTP常见的知识点。因为篇幅问题,内容可能不太全面。不过,如果不是专门做网络方向研究的小伙伴想研究HTTP相关知识的话,读这本书的话应该来说就差不多了。
|
||||
- [《大话数据结构》](https://book.douban.com/subject/6424904/)(推荐,豆瓣评分 7.9 , 1K+人评价):入门类型的书籍,读起来比较浅显易懂,适合没有数据结构基础或者说数据结构没学好的小伙伴用来入门数据结构。
|
||||
- [《算法图解》](https://book.douban.com/subject/26979890/)(推荐,豆瓣评分 8.4,0.6K+人评价):入门类型的书籍,读起来比较浅显易懂,适合没有算法基础或者说算法没学好的小伙伴用来入门。示例丰富,图文并茂,以让人容易理解的方式阐释了算法.读起来比较快,内容不枯燥!
|
||||
- [《Java并发编程的艺术》](https://book.douban.com/subject/26591326/)(推荐,豆瓣评分 7.2,0.2K+人评价): 这本书不是很适合作为Java并发入门书籍,需要具备一定的JVM基础。我感觉有些东西讲的还是挺深入的,推荐阅读。
|
||||
- [《实战Java高并发程序设计》](https://book.douban.com/subject/26663605/)(推荐):豆瓣评分 8.3 ,书的质量没的说,推荐大家好好看一下。
|
||||
- [《深入理解Java虚拟机(第2版)周志明》](https://book.douban.com/subject/24722612/)(推荐,豆瓣评分 8.9,1.0K+人评价):建议多刷几遍,书中的所有知识点可以通过JAVA运行时区域和JAVA的内存模型与线程两个大模块罗列完全。
|
||||
- [《Netty实战》](https://book.douban.com/subject/27038538/)(推荐,豆瓣评分 7.8,92人评价):内容很细,如果想学Netty的话,推荐阅读这本书!
|
||||
- [《从Paxos到Zookeeper》](https://book.douban.com/subject/26292004/)(推荐,豆瓣评分 7.8,0.3K人评价):简要介绍几种典型的分布式一致性协议,以及解决分布式一致性问题的思路,其中重点讲解了Paxos和ZAB协议。同时,本书深入介绍了分布式一致性问题的工业解决方案——ZooKeeper,并着重向读者展示这一分布式协调框架的使用方法、内部实现及运维技巧,旨在帮助读者全面了解ZooKeeper,并更好地使用和运维ZooKeeper。
|
||||
- [《Redis实战》](https://book.douban.com/subject/26612779/):如果你想了解Redis的一些概念性知识的话,这本书真的非常不错。
|
||||
- [《Redis设计与实现》](https://book.douban.com/subject/25900156/)(推荐,豆瓣评分 8.5,0.5K+人评价)
|
||||
- [《大型网站技术架构:核心原理与案例分析+李智慧》](https://book.douban.com/subject/25723064/)(推荐):这本书我读过,基本不需要你有什么基础啊~读起来特别轻松,但是却可以学到很多东西,非常推荐了。另外我写过这本书的思维导图,关注我的微信公众号:“Java面试通关手册”回复“大型网站技术架构”即可领取思维导图。
|
||||
|
||||
|
||||
#### 未看完
|
||||
|
||||
|
||||
- [《鸟哥的Linux私房菜》](https://book.douban.com/subject/4889838/)(推荐,,豆瓣评分 9.1,0.3K+人评价):本书是最具知名度的Linux入门书《鸟哥的Linux私房菜基础学习篇》的最新版,全面而详细地介绍了Linux操作系统。全书分为5个部分:第一部分着重说明Linux的起源及功能,如何规划和安装Linux主机;第二部分介绍Linux的文件系统、文件、目录与磁盘的管理;第三部分介绍文字模式接口 shell和管理系统的好帮手shell脚本,另外还介绍了文字编辑器vi和vim的使用方法;第四部分介绍了对于系统安全非常重要的Linux账号的管理,以及主机系统与程序的管理,如查看进程、任务分配和作业管理;第五部分介绍了系统管理员(root)的管理事项,如了解系统运行状况、系统服务,针对登录文件进行解析,对系统进行备份以及核心的管理等。
|
||||
- [《亿级流量网站架构核心技术》](https://book.douban.com/subject/26999243/)(推荐):一书总结并梳理了亿级流量网站高可用和高并发原则,通过实例详细介绍了如何落地这些原则。本书分为四部分:概述、高可用原则、高并发原则、案例实战。从负载均衡、限流、降级、隔离、超时与重试、回滚机制、压测与预案、缓存、池化、异步化、扩容、队列等多方面详细介绍了亿级流量网站的架构核心技术,让读者看后能快速运用到实践项目中。
|
||||
- [《重构_改善既有代码的设计》](https://book.douban.com/subject/4262627/)(推荐):豆瓣 9.1 分,重构书籍的开山鼻祖。
|
||||
- [《深入剖析Tomcat》](https://book.douban.com/subject/10426640/)(推荐,豆瓣评分 8.4,0.2K+人评价):本书深入剖析Tomcat 4和Tomcat 5中的每个组件,并揭示其内部工作原理。通过学习本书,你将可以自行开发Tomcat组件,或者扩展已有的组件。 读完这本书,基本可以摆脱背诵面试题的尴尬。
|
||||
- [《高性能MySQL》](https://book.douban.com/subject/23008813/)(推荐,豆瓣评分 9.3,0.4K+人评价):mysql 领域的经典之作,拥有广泛的影响力。不但适合数据库管理员(dba)阅读,也适合开发人员参考学习。不管是数据库新手还是专家,相信都能从本书有所收获。
|
||||
- [深入理解Nginx(第2版)](https://book.douban.com/subject/26745255/):作者讲的非常细致,注释都写的都很工整,对于 Nginx 的开发人员非常有帮助。优点是细致,缺点是过于细致,到处都是代码片段,缺少一些抽象。
|
||||
- [《RabbitMQ实战指南》](https://book.douban.com/subject/27591386/):《RabbitMQ实战指南》从消息中间件的概念和RabbitMQ的历史切入,主要阐述RabbitMQ的安装、使用、配置、管理、运维、原理、扩展等方面的细节。如果你想浅尝RabbitMQ的使用,这本书是你最好的选择;如果你想深入RabbitMQ的原理,这本书也是你最好的选择;总之,如果你想玩转RabbitMQ,这本书一定是最值得看的书之一
|
||||
- [《Spring Cloud微服务实战》](https://book.douban.com/subject/27025912/):从时下流行的微服务架构概念出发,详细介绍了Spring Cloud针对微服务架构中几大核心要素的解决方案和基础组件。对于各个组件的介绍,《Spring Cloud微服务实战》主要以示例与源码结合的方式来帮助读者更好地理解这些组件的使用方法以及运行原理。同时,在介绍的过程中,还包含了作者在实践中所遇到的一些问题和解决思路,可供读者在实践中作为参考。
|
||||
- [《第一本Docker书》](https://book.douban.com/subject/26780404/):Docker入门书籍!
|
||||
- [《Effective java 》](https://book.douban.com/subject/3360807/)(推荐,豆瓣评分 9.0,1.4K+人评价):本书介绍了在Java编程中78条极具实用价值的经验规则,这些经验规则涵盖了大多数开发人员每天所面临的问题的解决方案。通过对Java平台设计专家所使用的技术的全面描述,揭示了应该做什么,不应该做什么才能产生清晰、健壮和高效的代码。本书中的每条规则都以简短、独立的小文章形式出现,并通过例子代码加以进一步说明。本书内容全面,结构清晰,讲解详细。可作为技术人员的参考用书。
|
||||
- [《算法 第四版》](https://book.douban.com/subject/10432347/)(推荐,豆瓣评分 9.3,0.4K+人评价):Java语言描述,算法领域经典的参考书,全面介绍了关于算法和数据结构的必备知识,并特别针对排序、搜索、图处理和字符串处理进行了论述。书的内容非常多,可以说是Java程序员的必备书籍之一了。
|
||||
|
||||
## 一些个人愚见
|
||||
|
||||
### 关于读书
|
||||
|
||||
不知道大家收藏栏是不是和我一样收藏了很多文章,但是有多少篇是你真真认真看的呢?或者那几篇你认真看之后,经过一个月之后还记得这篇文章的大概内容。现在这个社会真是一个信息爆炸的社会,我个人真的深有感触,就在刚刚我还取消关注了好多微信公众号,很多公众号给我推的文章都有好几十篇了,但是我一篇都没有看,所以索性取消关注,省个位置。我个人觉得遇到好的文章,我们不光要读,而且要记录下来。就拿我本人来说,我平时喜欢用 OneNote 来记录学习笔记以及其他我感觉重要的事情比如重要人的生日啦这些。每当遇到自己喜欢的文章的时候,我都先会把文章的地址保存到我分好类的笔记本上,我会先进行第一遍阅读,第一遍我会读的很仔细,如果晦涩难懂的话我会先快速把总体看一遍,然后在细细品读。一般第二遍的时候我就会在笔记本上记录这篇文章的一些要点,以便我日后看到这些要点可以快速回忆起整篇文章的内容。如果某篇文章的知识点太过庞大的话,我会去选择采用思维导图的方式展示要点。看视频一样,看教学视频的话,如果觉得老师讲的不错,我们不妨记录下来,Onenote 或者有道云笔记都行,记录大概,够我们日后回忆就好。
|
||||
|
||||
### 关于学习
|
||||
|
||||
做事不要有功利性,我最早在掘金写文章,其实也只是为了记录自己的学习,没想到会有人喜欢自己的文章,另外我课外学的很多东西,我自己也不清楚以后工作会不会用到,反正我自己感觉即然自己感兴趣,那么就去学吧。我相信,很多东西可能暂时带给你不了带多实质性的帮助,但是总有一天它会对你有帮助。如果感到迷茫的话,就做好眼前的事(拿我们班主任的话说,如果你感到迷茫,你就学好现在的专业知识就好了),我觉得没毛病。
|
||||
|
||||
### 关于个人
|
||||
|
||||
在生活中一定要保持谦虚,保持谦虚,保持谦虚,时刻都要有反省的准备,你要记住学无止境,永远不要满足现在的现状。另外,就是一定要掌控好自己的时间,多留点时间给父母亲人,以及那些自己在乎的人。如果对别人很在乎的话,不要去装作不在乎,因为这样真的不是太好,虽然我之前也会这样,很多时候撰写的消息,最后没发出去。
|
||||
|
||||
## 最后分享一句话
|
||||
|
||||
分享给大家,我笔记本里一直保存的杨绛老先生的一句话:“我们曾如此渴望命运的波澜,到最后才发现:人生最曼妙的风景,竟是内心的淡定与从容……我们曾如此期盼外界的认可,到最后才知道:世界是自己的,与他人毫无关系!”。
|
||||
@ -75,7 +75,10 @@
|
||||
- :thumbsup: [《重构_改善既有代码的设计》](https://book.douban.com/subject/4262627/)
|
||||
|
||||
豆瓣 9.1 分,重构书籍的开山鼻祖。
|
||||
> ### linux操作系统相关
|
||||
- :thumbsup:[<<unix环境编程>>](https://book.douban.com/subject/25900403/) :thumbsup: [<<unix网络编程>>](https://book.douban.com/subject/1500149/)
|
||||
|
||||
对于理解linux操作系统原理非常有用,同时可以打好个人的基本功力,面试中很多公司也会问到linux知识。
|
||||
> ### 课外书籍
|
||||
|
||||
《技术奇点》 :thumbsup:《追风筝的人》 :thumbsup:《穆斯林的葬礼》 :thumbsup:《三体》 《人工智能——李开复》
|
||||
|
||||
557
操作系统/Shell.md
Normal file
557
操作系统/Shell.md
Normal file
@ -0,0 +1,557 @@
|
||||
|
||||
<!-- MarkdownTOC -->
|
||||
|
||||
- [Shell 编程入门](#shell-编程入门)
|
||||
- [走进 Shell 编程的大门](#走进-shell-编程的大门)
|
||||
- [为什么要学Shell?](#为什么要学shell)
|
||||
- [什么是 Shell?](#什么是-shell)
|
||||
- [Shell 编程的 Hello World](#shell-编程的-hello-world)
|
||||
- [Shell 变量](#shell-变量)
|
||||
- [Shell 编程中的变量介绍](#shell-编程中的变量介绍)
|
||||
- [Shell 字符串入门](#shell-字符串入门)
|
||||
- [Shell 字符串常见操作](#shell-字符串常见操作)
|
||||
- [Shell 数组](#shell-数组)
|
||||
- [Shell 基本运算符](#shell-基本运算符)
|
||||
- [算数运算符](#算数运算符)
|
||||
- [关系运算符](#关系运算符)
|
||||
- [逻辑运算符](#逻辑运算符)
|
||||
- [布尔运算符](#布尔运算符)
|
||||
- [字符串运算符](#字符串运算符)
|
||||
- [文件相关运算符](#文件相关运算符)
|
||||
- [shell流程控制](#shell流程控制)
|
||||
- [if 条件语句](#if-条件语句)
|
||||
- [for 循环语句](#for-循环语句)
|
||||
- [while 语句](#while-语句)
|
||||
- [shell 函数](#shell-函数)
|
||||
- [不带参数没有返回值的函数](#不带参数没有返回值的函数)
|
||||
- [有返回值的函数](#有返回值的函数)
|
||||
- [带参数的函数](#带参数的函数)
|
||||
|
||||
<!-- /MarkdownTOC -->
|
||||
|
||||
# Shell 编程入门
|
||||
|
||||
## 走进 Shell 编程的大门
|
||||
|
||||
### 为什么要学Shell?
|
||||
|
||||
学一个东西,我们大部分情况都是往实用性方向着想。从工作角度来讲,学习 Shell 是为了提高我们自己工作效率,提高产出,让我们在更少的时间完成更多的事情。
|
||||
|
||||
很多人会说 Shell 编程属于运维方面的知识了,应该是运维人员来做,我们做后端开发的没必要学。我觉得这种说法大错特错,相比于专门做Linux运维的人员来说,我们对 Shell 编程掌握程度的要求要比他们低,但是shell编程也是我们必须要掌握的!
|
||||
|
||||
目前Linux系统下最流行的运维自动化语言就是Shell和Python了。
|
||||
|
||||
两者之间,Shell几乎是IT企业必须使用的运维自动化编程语言,特别是在运维工作中的服务监控、业务快速部署、服务启动停止、数据备份及处理、日志分析等环节里,shell是不可缺的。Python 更适合处理复杂的业务逻辑,以及开发复杂的运维软件工具,实现通过web访问等。Shell是一个命令解释器,解释执行用户所输入的命令和程序。一输入命令,就立即回应的交互的对话方式。
|
||||
|
||||
另外,了解 shell 编程也是大部分互联网公司招聘后端开发人员的要求。下图是我截取的一些知名互联网公司对于 Shell 编程的要求。
|
||||
|
||||
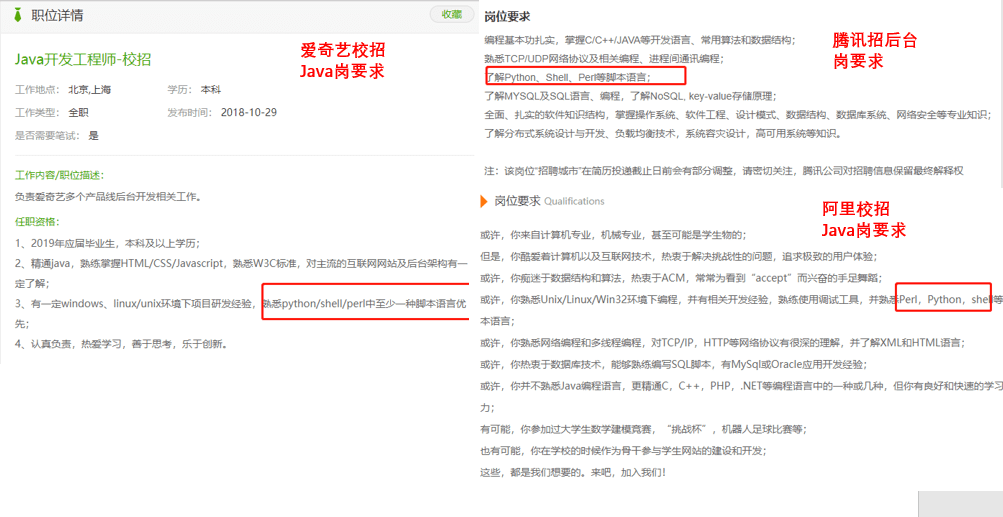
|
||||
|
||||
### 什么是 Shell?
|
||||
|
||||
简单来说“Shell编程就是对一堆Linux命令的逻辑化处理”。
|
||||
|
||||
|
||||
W3Cschool 上的一篇文章是这样介绍 Shell的,如下图所示。
|
||||
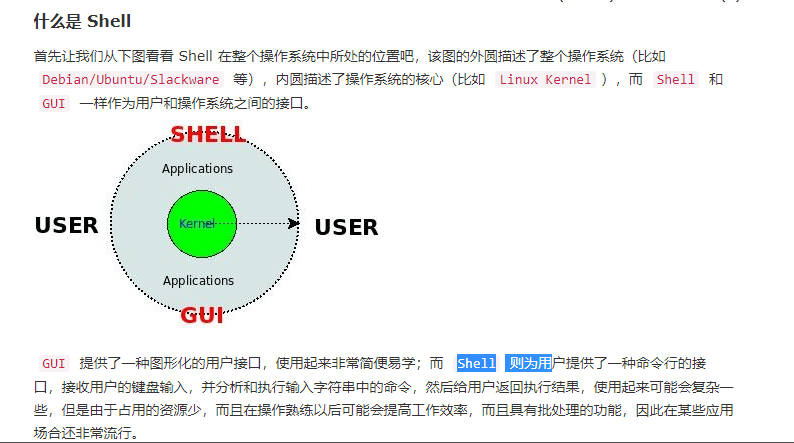
|
||||
|
||||
|
||||
### Shell 编程的 Hello World
|
||||
|
||||
学习任何一门编程语言第一件事就是输出HelloWord了!下面我会从新建文件到shell代码编写来说下Shell 编程如何输出Hello World。
|
||||
|
||||
|
||||
(1)新建一个文件 helloworld.sh :`touch helloworld.sh`,扩展名为 sh(sh代表Shell)(扩展名并不影响脚本执行,见名知意就好,如果你用 php 写 shell 脚本,扩展名就用 php 好了)
|
||||
|
||||
(2) 使脚本具有执行权限:`chmod +x helloworld.sh`
|
||||
|
||||
(3) 使用 vim 命令修改helloworld.sh文件:`vim helloworld.sh`(vim 文件------>进入文件----->命令模式------>按i进入编辑模式----->编辑文件 ------->按Esc进入底行模式----->输入:wq/q! (输入wq代表写入内容并退出,即保存;输入q!代表强制退出不保存。))
|
||||
|
||||
helloworld.sh 内容如下:
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
#第一个shell小程序,echo 是linux中的输出命令。
|
||||
echo "helloworld!"
|
||||
```
|
||||
|
||||
shell中 # 符号表示注释。**shell 的第一行比较特殊,一般都会以#!开始来指定使用的 shell 类型。在linux中,除了bash shell以外,还有很多版本的shell, 例如zsh、dash等等...不过bash shell还是我们使用最多的。**
|
||||
|
||||
|
||||
(4) 运行脚本:`./helloworld.sh` 。(注意,一定要写成 `./helloworld.sh` ,而不是 `helloworld.sh` ,运行其它二进制的程序也一样,直接写 `helloworld.sh` ,linux 系统会去 PATH 里寻找有没有叫 test.sh 的,而只有 /bin, /sbin, /usr/bin,/usr/sbin 等在 PATH 里,你的当前目录通常不在 PATH 里,所以写成 `helloworld.sh` 是会找不到命令的,要用`./helloworld.sh` 告诉系统说,就在当前目录找。)
|
||||
|
||||

|
||||
|
||||
|
||||
## Shell 变量
|
||||
|
||||
### Shell 编程中的变量介绍
|
||||
|
||||
|
||||
**Shell编程中一般分为三种变量:**
|
||||
|
||||
1. **我们自己定义的变量(自定义变量):** 仅在当前 Shell 实例中有效,其他 Shell 启动的程序不能访问局部变量。
|
||||
2. **Linux已定义的环境变量**(环境变量, 例如:$PATH, $HOME 等..., 这类变量我们可以直接使用),使用 `env` 命令可以查看所有的环境变量,而set命令既可以查看环境变量也可以查看自定义变量。
|
||||
3. **Shell变量** :Shell变量是由 Shell 程序设置的特殊变量。Shell 变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了 Shell 的正常运行
|
||||
|
||||
**常用的环境变量:**
|
||||
> PATH 决定了shell将到哪些目录中寻找命令或程序
|
||||
HOME 当前用户主目录
|
||||
HISTSIZE 历史记录数
|
||||
LOGNAME 当前用户的登录名
|
||||
HOSTNAME 指主机的名称
|
||||
SHELL 当前用户Shell类型
|
||||
LANGUGE 语言相关的环境变量,多语言可以修改此环境变量
|
||||
MAIL 当前用户的邮件存放目录
|
||||
PS1 基本提示符,对于root用户是#,对于普通用户是$
|
||||
|
||||
**使用 Linux 已定义的环境变量:**
|
||||
|
||||
比如我们要看当前用户目录可以使用:`echo $HOME`命令;如果我们要看当前用户Shell类型 可以使用`echo $SHELL`命令。可以看出,使用方法非常简单。
|
||||
|
||||
**使用自己定义的变量:**
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
#自定义变量hello
|
||||
hello="hello world"
|
||||
echo $hello
|
||||
echo "helloworld!"
|
||||
```
|
||||

|
||||
|
||||
|
||||
**Shell 编程中的变量名的命名的注意事项:**
|
||||
|
||||
|
||||
- 命名只能使用英文字母,数字和下划线,首个字符不能以数字开头,但是可以使用下划线(_)开头。
|
||||
- 中间不能有空格,可以使用下划线(_)。
|
||||
- 不能使用标点符号。
|
||||
- 不能使用bash里的关键字(可用help命令查看保留关键字)。
|
||||
|
||||
|
||||
### Shell 字符串入门
|
||||
|
||||
字符串是shell编程中最常用最有用的数据类型(除了数字和字符串,也没啥其它类型好用了),字符串可以用单引号,也可以用双引号。这点和Java中有所不同。
|
||||
|
||||
**单引号字符串:**
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
name='SnailClimb'
|
||||
hello='Hello, I am '$name'!'
|
||||
echo $hello
|
||||
```
|
||||
输出内容:
|
||||
|
||||
```
|
||||
Hello, I am SnailClimb!
|
||||
```
|
||||
|
||||
**双引号字符串:**
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
name='SnailClimb'
|
||||
hello="Hello, I am "$name"!"
|
||||
echo $hello
|
||||
```
|
||||
|
||||
输出内容:
|
||||
|
||||
```
|
||||
Hello, I am SnailClimb!
|
||||
```
|
||||
|
||||
|
||||
### Shell 字符串常见操作
|
||||
|
||||
**拼接字符串:**
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
name="SnailClimb"
|
||||
# 使用双引号拼接
|
||||
greeting="hello, "$name" !"
|
||||
greeting_1="hello, ${name} !"
|
||||
echo $greeting $greeting_1
|
||||
# 使用单引号拼接
|
||||
greeting_2='hello, '$name' !'
|
||||
greeting_3='hello, ${name} !'
|
||||
echo $greeting_2 $greeting_3
|
||||
```
|
||||
|
||||
输出结果:
|
||||
|
||||

|
||||
|
||||
|
||||
**获取字符串长度:**
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
#获取字符串长度
|
||||
name="SnailClimb"
|
||||
# 第一种方式
|
||||
echo ${#name} #输出 10
|
||||
# 第二种方式
|
||||
expr length "$name";
|
||||
```
|
||||
|
||||
输出结果:
|
||||
```
|
||||
10
|
||||
10
|
||||
```
|
||||
|
||||
使用 expr 命令时,表达式中的运算符左右必须包含空格,如果不包含空格,将会输出表达式本身:
|
||||
|
||||
```shell
|
||||
expr 5+6 // 直接输出 5+6
|
||||
expr 5 + 6 // 输出 11
|
||||
```
|
||||
对于某些运算符,还需要我们使用符号"\"进行转义,否则就会提示语法错误。
|
||||
|
||||
```shell
|
||||
expr 5 * 6 // 输出错误
|
||||
expr 5 \* 6 // 输出30
|
||||
```
|
||||
|
||||
**截取子字符串:**
|
||||
|
||||
简单的字符串截取:
|
||||
|
||||
|
||||
```shell
|
||||
#从字符串第 1 个字符开始往后截取 10 个字符
|
||||
str="SnailClimb is a great man"
|
||||
echo ${str:0:10} #输出:SnailClimb
|
||||
```
|
||||
|
||||
根据表达式截取:
|
||||
|
||||
```shell
|
||||
#!bin/bash
|
||||
#author:amau
|
||||
|
||||
var="http://www.runoob.com/linux/linux-shell-variable.html"
|
||||
|
||||
s1=${var%%t*}#h
|
||||
s2=${var%t*}#http://www.runoob.com/linux/linux-shell-variable.h
|
||||
s3=${var%%.*}#http://www
|
||||
s4=${var#*/}#/www.runoob.com/linux/linux-shell-variable.html
|
||||
s5=${var##*/}#linux-shell-variable.html
|
||||
```
|
||||
|
||||
### Shell 数组
|
||||
|
||||
bash支持一维数组(不支持多维数组),并且没有限定数组的大小。我下面给了大家一个关于数组操作的 Shell 代码示例,通过该示例大家可以知道如何创建数组、获取数组长度、获取/删除特定位置的数组元素、删除整个数组以及遍历数组。
|
||||
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
array=(1 2 3 4 5);
|
||||
# 获取数组长度
|
||||
length=${#array[@]}
|
||||
# 或者
|
||||
length2=${#array[*]}
|
||||
#输出数组长度
|
||||
echo $length #输出:5
|
||||
echo $length2 #输出:5
|
||||
# 输出数组第三个元素
|
||||
echo ${array[2]} #输出:3
|
||||
unset array[1]# 删除下表为1的元素也就是删除第二个元素
|
||||
for i in ${array[@]};do echo $i ;done # 遍历数组,输出: 1 3 4 5
|
||||
unset arr_number; # 删除数组中的所有元素
|
||||
for i in ${array[@]};do echo $i ;done # 遍历数组,数组元素为空,没有任何输出内容
|
||||
```
|
||||
|
||||
|
||||
## Shell 基本运算符
|
||||
|
||||
> 说明:图片来自《菜鸟教程》
|
||||
|
||||
Shell 编程支持下面几种运算符
|
||||
|
||||
- 算数运算符
|
||||
- 关系运算符
|
||||
- 布尔运算符
|
||||
- 字符串运算符
|
||||
- 文件测试运算符
|
||||
|
||||
### 算数运算符
|
||||
|
||||
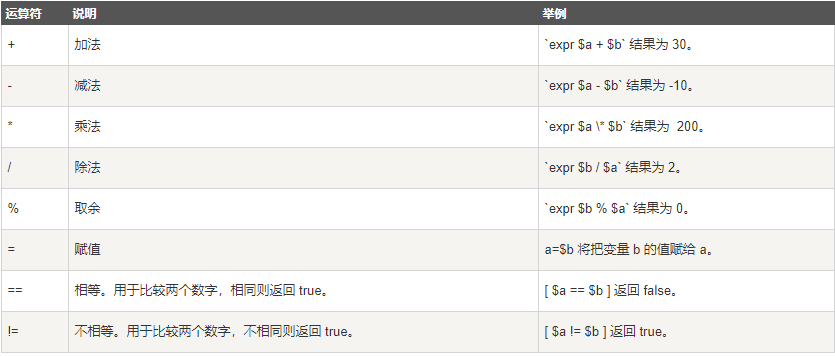
|
||||
|
||||
我以加法运算符做一个简单的示例:
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
a=3;b=3;
|
||||
val=`expr $a + $b`
|
||||
#输出:Total value : 6
|
||||
echo "Total value : $val
|
||||
```
|
||||
|
||||
|
||||
### 关系运算符
|
||||
|
||||
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
|
||||
|
||||
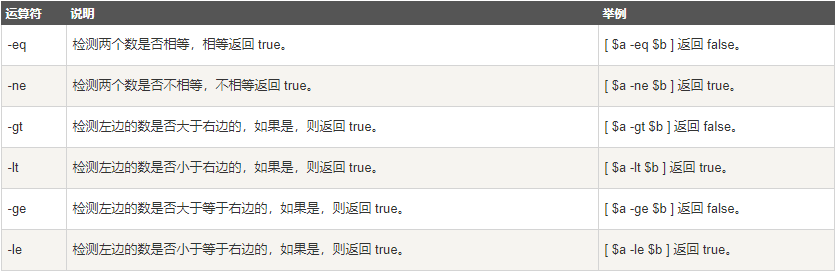
|
||||
|
||||
通过一个简单的示例演示关系运算符的使用,下面shell程序的作用是当score=100的时候输出A否则输出B。
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
score=90;
|
||||
maxscore=100;
|
||||
if [ $score -eq $maxscore ]
|
||||
then
|
||||
echo "A"
|
||||
else
|
||||
echo "B"
|
||||
fi
|
||||
```
|
||||
|
||||
输出结果:
|
||||
|
||||
```
|
||||
B
|
||||
```
|
||||
|
||||
### 逻辑运算符
|
||||
|
||||

|
||||
|
||||
示例:
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
a=$(( 1 && 0))
|
||||
# 输出:0;逻辑与运算只有相与的两边都是1,与的结果才是1;否则与的结果是0
|
||||
echo $a;
|
||||
```
|
||||
|
||||
### 布尔运算符
|
||||
|
||||
|
||||

|
||||
|
||||
这里就不做演示了,应该挺简单的。
|
||||
|
||||
### 字符串运算符
|
||||
|
||||
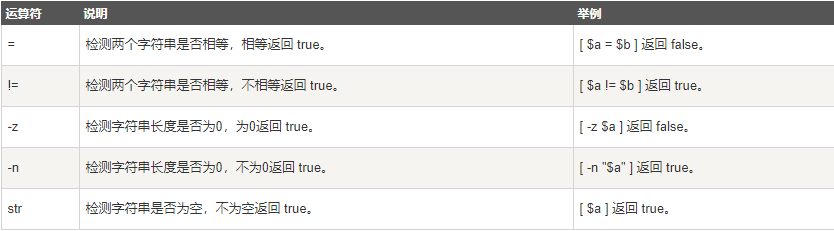
|
||||
|
||||
简单示例:
|
||||
|
||||
```shell
|
||||
|
||||
#!/bin/bash
|
||||
a="abc";
|
||||
b="efg";
|
||||
if [ $a = $b ]
|
||||
then
|
||||
echo "a 等于 b"
|
||||
else
|
||||
echo "a 不等于 b"
|
||||
fi
|
||||
```
|
||||
输出:
|
||||
|
||||
```
|
||||
a 不等于 b
|
||||
```
|
||||
|
||||
### 文件相关运算符
|
||||
|
||||
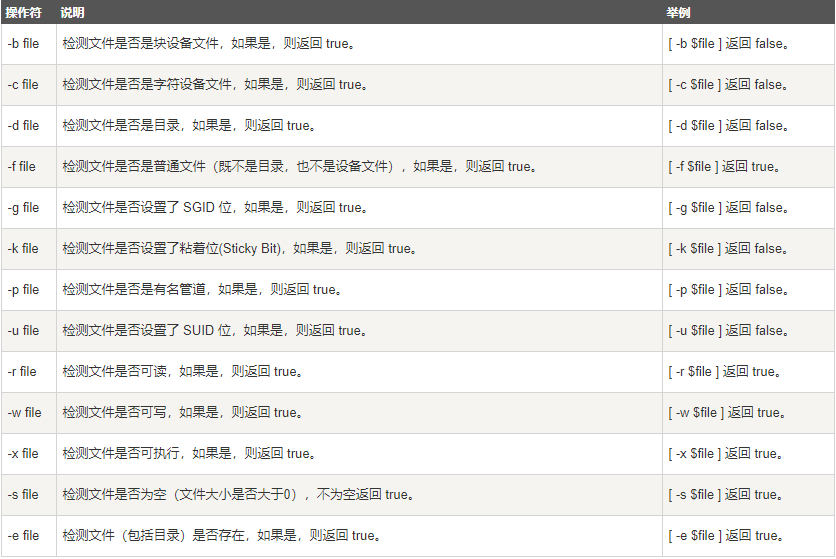
|
||||
|
||||
使用方式很简单,比如我们定义好了一个文件路径`file="/usr/learnshell/test.sh"` 如果我们想判断这个文件是否可读,可以这样`if [ -r $file ]` 如果想判断这个文件是否可写,可以这样`-w $file`,是不是很简单。
|
||||
|
||||
## shell流程控制
|
||||
|
||||
### if 条件语句
|
||||
|
||||
简单的 if else-if else 的条件语句示例
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
a=3;
|
||||
b=9;
|
||||
if [ $a = $b ]
|
||||
then
|
||||
echo "a 等于 b"
|
||||
elif [ $a > $b ]
|
||||
then
|
||||
echo "a 大于 b"
|
||||
else
|
||||
echo "a 小于 b"
|
||||
fi
|
||||
```
|
||||
|
||||
输出结果:
|
||||
|
||||
```
|
||||
a 大于 b
|
||||
```
|
||||
|
||||
相信大家通过上面的示例就已经掌握了 shell 编程中的 if 条件语句。不过,还要提到的一点是,不同于我们常见的 Java 以及 PHP 中的 if 条件语句,shell if 条件语句中不能包含空语句也就是什么都不做的语句。
|
||||
|
||||
### for 循环语句
|
||||
|
||||
通过下面三个简单的示例认识 for 循环语句最基本的使用,实际上 for 循环语句的功能比下面你看到的示例展现的要大得多。
|
||||
|
||||
**输出当前列表中的数据:**
|
||||
|
||||
```shell
|
||||
for loop in 1 2 3 4 5
|
||||
do
|
||||
echo "The value is: $loop"
|
||||
done
|
||||
```
|
||||
|
||||
**产生 10 个随机数:**
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
for i in {0..9};
|
||||
do
|
||||
echo $RANDOM;
|
||||
done
|
||||
```
|
||||
|
||||
**输出1到5:**
|
||||
|
||||
通常情况下 shell 变量调用需要加 $,但是 for 的 (()) 中不需要,下面来看一个例子:
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
for((i=1;i<=5;i++));do
|
||||
echo $i;
|
||||
done;
|
||||
```
|
||||
|
||||
|
||||
### while 语句
|
||||
|
||||
**基本的 while 循环语句:**
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
int=1
|
||||
while(( $int<=5 ))
|
||||
do
|
||||
echo $int
|
||||
let "int++"
|
||||
done
|
||||
```
|
||||
|
||||
**while循环可用于读取键盘信息:**
|
||||
|
||||
```shell
|
||||
echo '按下 <CTRL-D> 退出'
|
||||
echo -n '输入你最喜欢的电影: '
|
||||
while read FILM
|
||||
do
|
||||
echo "是的!$FILM 是一个好电影"
|
||||
done
|
||||
```
|
||||
|
||||
输出内容:
|
||||
|
||||
```
|
||||
按下 <CTRL-D> 退出
|
||||
输入你最喜欢的电影: 变形金刚
|
||||
是的!变形金刚 是一个好电影
|
||||
```
|
||||
|
||||
**无线循环:**
|
||||
|
||||
```shell
|
||||
while true
|
||||
do
|
||||
command
|
||||
done
|
||||
```
|
||||
|
||||
## shell 函数
|
||||
|
||||
### 不带参数没有返回值的函数
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
function(){
|
||||
echo "这是我的第一个 shell 函数!"
|
||||
}
|
||||
function
|
||||
```
|
||||
|
||||
输出结果:
|
||||
|
||||
```
|
||||
这是我的第一个 shell 函数!
|
||||
```
|
||||
|
||||
|
||||
### 有返回值的函数
|
||||
|
||||
**输入两个数字之后相加并返回结果:**
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
funWithReturn(){
|
||||
echo "输入第一个数字: "
|
||||
read aNum
|
||||
echo "输入第二个数字: "
|
||||
read anotherNum
|
||||
echo "两个数字分别为 $aNum 和 $anotherNum !"
|
||||
return $(($aNum+$anotherNum))
|
||||
}
|
||||
funWithReturn
|
||||
echo "输入的两个数字之和为 $?"
|
||||
```
|
||||
|
||||
输出结果:
|
||||
|
||||
```
|
||||
输入第一个数字:
|
||||
1
|
||||
输入第二个数字:
|
||||
2
|
||||
两个数字分别为 1 和 2 !
|
||||
输入的两个数字之和为 3
|
||||
```
|
||||
|
||||
### 带参数的函数
|
||||
|
||||
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
funWithParam(){
|
||||
echo "第一个参数为 $1 !"
|
||||
echo "第二个参数为 $2 !"
|
||||
echo "第十个参数为 $10 !"
|
||||
echo "第十个参数为 ${10} !"
|
||||
echo "第十一个参数为 ${11} !"
|
||||
echo "参数总数有 $# 个!"
|
||||
echo "作为一个字符串输出所有参数 $* !"
|
||||
}
|
||||
funWithParam 1 2 3 4 5 6 7 8 9 34 73
|
||||
|
||||
```
|
||||
|
||||
输出结果:
|
||||
|
||||
```
|
||||
第一个参数为 1 !
|
||||
第二个参数为 2 !
|
||||
第十个参数为 10 !
|
||||
第十个参数为 34 !
|
||||
第十一个参数为 73 !
|
||||
参数总数有 11 个!
|
||||
作为一个字符串输出所有参数 1 2 3 4 5 6 7 8 9 34 73 !
|
||||
|
||||
```
|
||||
@ -1,8 +1,31 @@
|
||||
<!-- MarkdownTOC -->
|
||||
|
||||
- [一 从认识操作系统开始](#一-从认识操作系统开始)
|
||||
- [1.1 操作系统简介](#11-操作系统简介)
|
||||
- [1.2 操作系统简单分类](#12-操作系统简单分类)
|
||||
- [二 初探Linux](#二-初探linux)
|
||||
- [2.1 Linux简介](#21-linux简介)
|
||||
- [2.2 Linux诞生简介](#22-linux诞生简介)
|
||||
- [2.3 Linux的分类](#23-linux的分类)
|
||||
- [三 Linux文件系统概览](#三-linux文件系统概览)
|
||||
- [3.1 Linux文件系统简介](#31-linux文件系统简介)
|
||||
- [3.2 文件类型与目录结构](#32-文件类型与目录结构)
|
||||
- [四 Linux基本命令](#四-linux基本命令)
|
||||
- [4.1 目录切换命令](#41-目录切换命令)
|
||||
- [4.2 目录的操作命令(增删改查)](#42-目录的操作命令增删改查)
|
||||
- [4.3 文件的操作命令(增删改查)](#43-文件的操作命令增删改查)
|
||||
- [4.4 压缩文件的操作命令](#44-压缩文件的操作命令)
|
||||
- [4.5 Linux的权限命令](#45-linux的权限命令)
|
||||
- [4.6 Linux 用户管理](#46-linux-用户管理)
|
||||
- [4.7 Linux系统用户组的管理](#47-linux系统用户组的管理)
|
||||
- [4.8 其他常用命令](#48-其他常用命令)
|
||||
|
||||
<!-- /MarkdownTOC -->
|
||||
|
||||
> 学习Linux之前,我们先来简单的认识一下操作系统。
|
||||
|
||||
## 一 从认识操作系统开始
|
||||
### 1.1 操作系统简介
|
||||
### 1.1 操作系统简介
|
||||
|
||||
我通过以下四点介绍什么操作系统:
|
||||
|
||||
@ -12,7 +35,7 @@
|
||||
- **操作系统分内核与外壳(我们可以把外壳理解成围绕着内核的应用程序,而内核就是能操作硬件的程序)。**
|
||||
|
||||

|
||||
### 1.2 操作系统简单分类
|
||||
### 1.2 操作系统简单分类
|
||||
|
||||
1. **Windows:** 目前最流行的个人桌面操作系统 ,不做多的介绍,大家都清楚。
|
||||
2. **Unix:** 最早的多用户、多任务操作系统 .按照操作系统的分类,属于分时操作系统。Unix 大多被用在服务器、工作站,现在也有用在个人计算机上。它在创建互联网、计算机网络或客户端/服务器模型方面发挥着非常重要的作用。
|
||||
@ -22,7 +45,7 @@
|
||||

|
||||
|
||||
|
||||
## 二 初探Linux
|
||||
## 二 初探Linux
|
||||
|
||||
### 2.1 Linux简介
|
||||
|
||||
@ -33,7 +56,7 @@
|
||||
|
||||

|
||||
|
||||
### 2.2 Linux诞生简介
|
||||
### 2.2 Linux诞生简介
|
||||
|
||||
- 1991年,芬兰的业余计算机爱好者Linus Torvalds编写了一款类似Minix的系统(基于微内核架构的类Unix操作系统)被ftp管理员命名为Linux 加入到自由软件基金的GNU计划中;
|
||||
- Linux以一只可爱的企鹅作为标志,象征着敢作敢为、热爱生活。
|
||||
@ -48,7 +71,7 @@
|
||||

|
||||
|
||||
|
||||
## 三 Linux文件系统概览
|
||||
## 三 Linux文件系统概览
|
||||
|
||||
### 3.1 Linux文件系统简介
|
||||
|
||||
@ -75,34 +98,34 @@ Linux文件系统的结构层次鲜明,就像一棵倒立的树,最顶层是
|
||||
- **/usr :** 用于存放系统应用程序;
|
||||
- **/opt:** 额外安装的可选应用程序包所放置的位置。一般情况下,我们可以把tomcat等都安装到这里;
|
||||
- **/proc:** 虚拟文件系统目录,是系统内存的映射。可直接访问这个目录来获取系统信息;
|
||||
- **/root:** 超级用户(系统管理员)的主目录(特权阶级^o^);
|
||||
- **/sbin:** 存放二进制可执行文件,只有root才能访问。这里存放的是系统管理员使用的系统级别的管理命令和程序。如ifconfig等;
|
||||
- **/dev:** 用于存放设备文件;
|
||||
- **/mnt:** 系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统;
|
||||
- **/boot:** 存放用于系统引导时使用的各种文件;
|
||||
- **/root:** 超级用户(系统管理员)的主目录(特权阶级^o^);
|
||||
- **/sbin:** 存放二进制可执行文件,只有root才能访问。这里存放的是系统管理员使用的系统级别的管理命令和程序。如ifconfig等;
|
||||
- **/dev:** 用于存放设备文件;
|
||||
- **/mnt:** 系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统;
|
||||
- **/boot:** 存放用于系统引导时使用的各种文件;
|
||||
- **/lib :** 存放着和系统运行相关的库文件 ;
|
||||
- **/tmp:** 用于存放各种临时文件,是公用的临时文件存储点;
|
||||
- **/var:** 用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件(系统启动日志等。)等;
|
||||
- **/lost+found:** 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows下叫什么.chk)就在这里。
|
||||
- **/tmp:** 用于存放各种临时文件,是公用的临时文件存储点;
|
||||
- **/var:** 用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件(系统启动日志等。)等;
|
||||
- **/lost+found:** 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows下叫什么.chk)就在这里。
|
||||
|
||||
|
||||
## 四 Linux基本命令
|
||||
## 四 Linux基本命令
|
||||
|
||||
下面只是给出了一些比较常用的命令。推荐一个Linux命令快查网站,非常不错,大家如果遗忘某些命令或者对某些命令不理解都可以在这里得到解决。
|
||||
|
||||
Linux命令大全:[http://man.linuxde.net/](http://man.linuxde.net/)
|
||||
### 4.1 目录切换命令
|
||||
|
||||
- **`cd usr`:** 切换到该目录下usr目录
|
||||
- **`cd ..(或cd../)`:** 切换到上一层目录
|
||||
- **`cd /`:** 切换到系统根目录
|
||||
- **`cd ~`:** 切换到用户主目录
|
||||
- **`cd -`:** 切换到上一个所在目录
|
||||
- **`cd usr`:** 切换到该目录下usr目录
|
||||
- **`cd ..(或cd../)`:** 切换到上一层目录
|
||||
- **`cd /`:** 切换到系统根目录
|
||||
- **`cd ~`:** 切换到用户主目录
|
||||
- **`cd -`:** 切换到上一个操作所在目录
|
||||
|
||||
### 4.2 目录的操作命令(增删改查)
|
||||
### 4.2 目录的操作命令(增删改查)
|
||||
|
||||
1. **`mkdir 目录名称`:** 增加目录
|
||||
2. **`ls或者ll`**(ll是ls -l的缩写,ll命令以看到该目录下的所有目录和文件的详细信息):查看目录信息
|
||||
2. **`ls或者ll`**(ll是ls -l的别名,ll命令可以看到该目录下的所有目录和文件的详细信息):查看目录信息
|
||||
3. **`find 目录 参数`:** 寻找目录(查)
|
||||
|
||||
示例:
|
||||
@ -114,35 +137,35 @@ Linux命令大全:[http://man.linuxde.net/](http://man.linuxde.net/)
|
||||
|
||||
4. **`mv 目录名称 新目录名称`:** 修改目录的名称(改)
|
||||
|
||||
注意:mv的语法不仅可以对目录进行重命名而且也可以对各种文件,压缩包等进行 重命名的操作。mv命令用来对文件或目录重新命名,或者将文件从一个目录移到另一个目录中。后面会介绍到mv命令的另一个用法。
|
||||
注意:mv的语法不仅可以对目录进行重命名而且也可以对各种文件,压缩包等进行 重命名的操作。mv命令用来对文件或目录重新命名,或者将文件从一个目录移到另一个目录中。后面会介绍到mv命令的另一个用法。
|
||||
5. **`mv 目录名称 目录的新位置`:** 移动目录的位置---剪切(改)
|
||||
|
||||
注意:mv语法不仅可以对目录进行剪切操作,对文件和压缩包等都可执行剪切操作。另外mv与cp的结果不同,mv好像文件“搬家”,文件个数并未增加。而cp对文件进行复制,文件个数增加了。
|
||||
6. **`cp -r 目录名称 目录拷贝的目标位置`:** 拷贝目录(改),-r代表递归拷贝
|
||||
|
||||
注意:cp命令不仅可以拷贝目录还可以拷贝文件,压缩包等,拷贝文件和压缩包时不 用写-r递归
|
||||
注意:cp命令不仅可以拷贝目录还可以拷贝文件,压缩包等,拷贝文件和压缩包时不 用写-r递归
|
||||
7. **`rm [-rf] 目录`:** 删除目录(删)
|
||||
|
||||
注意:rm不仅可以删除目录,也可以删除其他文件或压缩包,为了增强大家的记忆, 无论删除任何目录或文件,都直接使用`rm -rf` 目录/文件/压缩包
|
||||
注意:rm不仅可以删除目录,也可以删除其他文件或压缩包,为了增强大家的记忆, 无论删除任何目录或文件,都直接使用`rm -rf` 目录/文件/压缩包
|
||||
|
||||
|
||||
### 4.3 文件的操作命令(增删改查)
|
||||
### 4.3 文件的操作命令(增删改查)
|
||||
|
||||
1. **`touch 文件名称`:** 文件的创建(增)
|
||||
2. **`cat/more/less/tail 文件名称`** 文件的查看(查)
|
||||
- **`cat`:** 只能显示最后一屏内容
|
||||
- **`more`:** 可以显示百分比,回车可以向下一行, 空格可以向下一页,q可以退出查看
|
||||
- **`less`:** 可以使用键盘上的PgUp和PgDn向上 和向下翻页,q结束查看
|
||||
- **`cat`:** 查看显示文件内容
|
||||
- **`more`:** 可以显示百分比,回车可以向下一行, 空格可以向下一页,q可以退出查看
|
||||
- **`less`:** 可以使用键盘上的PgUp和PgDn向上 和向下翻页,q结束查看
|
||||
- **`tail-10` :** 查看文件的后10行,Ctrl+C结束
|
||||
|
||||
注意:命令 tail -f 文件 可以对某个文件进行动态监控,例如tomcat的日志文件, 会随着程序的运行,日志会变化,可以使用tail -f catalina-2016-11-11.log 监控 文 件的变化
|
||||
注意:命令 tail -f 文件 可以对某个文件进行动态监控,例如tomcat的日志文件, 会随着程序的运行,日志会变化,可以使用tail -f catalina-2016-11-11.log 监控 文 件的变化
|
||||
3. **`vim 文件`:** 修改文件的内容(改)
|
||||
|
||||
vim编辑器是Linux中的强大组件,是vi编辑器的加强版,vim编辑器的命令和快捷方式有很多,但此处不一一阐述,大家也无需研究的很透彻,使用vim编辑修改文件的方式基本会使用就可以了。
|
||||
|
||||
**在实际开发中,使用vim编辑器主要作用就是修改配置文件,下面是一般步骤:**
|
||||
|
||||
vim 文件------>进入文件----->命令模式------>按i进入编辑模式----->编辑文件 ------->按Esc进入底行模式----->输入:wq/q! (输入wq代表写入内容并退出,即保存;输入q!代表强制退出不保存。)
|
||||
vim 文件------>进入文件----->命令模式------>按i进入编辑模式----->编辑文件 ------->按Esc进入底行模式----->输入:wq/q! (输入wq代表写入内容并退出,即保存;输入q!代表强制退出不保存。)
|
||||
4. **`rm -rf 文件`:** 删除文件(删)
|
||||
|
||||
同目录删除:熟记 `rm -rf` 文件 即可
|
||||
@ -183,7 +206,7 @@ Linux中的打包文件一般是以.tar结尾的,压缩的命令一般是以.g
|
||||
|
||||
### 4.5 Linux的权限命令
|
||||
|
||||
操作系统中每个文件都拥有特定的权限、所属用户和所属组。权限是操作系统用来限制资源访问的机制,在Linux中权限一般分为读(readable)、写(writable)和执行(excutable),分为三组。分别对应文件的属主(owner),属组(group)和其他用户(other),通过这样的机制来限制哪些用户、哪些组可以对特定的文件进行什么样的操作。通过 **`ls -l`** 命令我们可以 查看某个目录下的文件或目录的权限
|
||||
操作系统中每个文件都拥有特定的权限、所属用户和所属组。权限是操作系统用来限制资源访问的机制,在Linux中权限一般分为读(readable)、写(writable)和执行(excutable),分为三组。分别对应文件的属主(owner),属组(group)和其他用户(other),通过这样的机制来限制哪些用户、哪些组可以对特定的文件进行什么样的操作。通过 **`ls -l`** 命令我们可以 查看某个目录下的文件或目录的权限
|
||||
|
||||
示例:在随意某个目录下`ls -l`
|
||||
|
||||
@ -200,7 +223,7 @@ Linux中的打包文件一般是以.tar结尾的,压缩的命令一般是以.g
|
||||
|
||||
- d: 代表目录
|
||||
- -: 代表文件
|
||||
- l: 代表链接(可以认为是window中的快捷方式)
|
||||
- l: 代表软链接(可以认为是window中的快捷方式)
|
||||
|
||||
|
||||
**Linux中权限分为以下几种:**
|
||||
@ -230,7 +253,7 @@ Linux中的打包文件一般是以.tar结尾的,压缩的命令一般是以.g
|
||||
| x | 可以使用cd进入目录 |
|
||||
|
||||
|
||||
|
||||
**需要注意的是超级用户可以无视普通用户的权限,即使文件目录权限是000,依旧可以访问。**
|
||||
**在linux中的每个用户必须属于一个组,不能独立于组外。在linux中每个文件有所有者、所在组、其它组的概念。**
|
||||
|
||||
- **所有者**
|
||||
@ -304,7 +327,7 @@ passwd命令用于设置用户的认证信息,包括用户密码、密码过
|
||||
|
||||
- **`pwd`:** 显示当前所在位置
|
||||
- **`grep 要搜索的字符串 要搜索的文件 --color`:** 搜索命令,--color代表高亮显示
|
||||
- **`ps -ef`/`ps aux`:** 这两个命令都是查看当前系统正在运行进程,两者的区别是展示格式不同。如果想要查看特定的进程可以使用这样的格式:**`ps aux|grep redis`** (查看包括redis字符串的进程)
|
||||
- **`ps -ef`/`ps -aux`:** 这两个命令都是查看当前系统正在运行进程,两者的区别是展示格式不同。如果想要查看特定的进程可以使用这样的格式:**`ps aux|grep redis`** (查看包括redis字符串的进程),也可使用 `pgrep redis -a`。
|
||||
|
||||
注意:如果直接用ps((Process Status))命令,会显示所有进程的状态,通常结合grep命令查看某进程的状态。
|
||||
- **`kill -9 进程的pid`:** 杀死进程(-9 表示强制终止。)
|
||||
@ -314,6 +337,8 @@ passwd命令用于设置用户的认证信息,包括用户密码、密码过
|
||||
- 查看当前系统的网卡信息:ifconfig
|
||||
- 查看与某台机器的连接情况:ping
|
||||
- 查看当前系统的端口使用:netstat -an
|
||||
- **net-tools 和 iproute2 :**
|
||||
`net-tools`起源于BSD的TCP/IP工具箱,后来成为老版本Linux内核中配置网络功能的工具。但自2001年起,Linux社区已经对其停止维护。同时,一些Linux发行版比如Arch Linux和CentOS/RHEL 7则已经完全抛弃了net-tools,只支持`iproute2`。linux ip命令类似于ifconfig,但功能更强大,旨在替代它。更多详情请阅读[如何在Linux中使用IP命令和示例](https://linoxide.com/linux-command/use-ip-command-linux)
|
||||
- **`shutdown`:** `shutdown -h now`: 指定现在立即关机;`shutdown +5 "System will shutdown after 5 minutes"`:指定5分钟后关机,同时送出警告信息给登入用户。
|
||||
- **`reboot`:** **`reboot`:** 重开机。**`reboot -w`:** 做个重开机的模拟(只有纪录并不会真的重开机)。
|
||||
|
||||
|
||||
@ -47,7 +47,7 @@ Java面试通关手册(Java学习指南,欢迎Star,会一直完善下去
|
||||
|
||||
**MyISAM:** B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
|
||||
|
||||
**InnoDB:** 其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”。而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。**在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,在走一遍主索引。** **因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。** PS:整理自《Java工程师修炼之道》
|
||||
**InnoDB:** 其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”。而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。**在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。** **因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。** PS:整理自《Java工程师修炼之道》
|
||||
|
||||
详细内容可以参考:
|
||||
|
||||
@ -87,20 +87,20 @@ Java面试通关手册(Java学习指南,欢迎Star,会一直完善下去
|
||||

|
||||
|
||||
1. **原子性:** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
|
||||
2. **一致性:** 执行事务前后,数据保持一致;
|
||||
3. **隔离性:** 并发访问数据库时,一个用户的事物不被其他事物所干扰,各并发事务之间数据库是独立的;
|
||||
4. **持久性:** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库 发生故障也不应该对其有任何影响。
|
||||
2. **一致性:** 执行事务前后,数据库从一个一致性状态转换到另一个一致性状态。
|
||||
3. **隔离性:** 并发访问数据库时,一个用户的事物不被其他事务所干扰,各并发事务之间数据库是独立的;
|
||||
4. **持久性:** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库 发生故障也不应该对其有任何影响。
|
||||
|
||||
**为了达到上述事务特性,数据库定义了几种不同的事务隔离级别:**
|
||||
|
||||
- **READ_UNCOMMITTED(未授权读取):** 最低的隔离级别,允许读取尚未提交的数据变更,**可能会导致脏读、幻读或不可重复读**
|
||||
- **READ_COMMITTED(授权读取):** 允许读取并发事务已经提交的数据,**可以阻止脏读,但是幻读或不可重复读仍有可能发生**
|
||||
- **REPEATABLE_READ(可重复读):** 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,**可以阻止脏读和不可重复读,但幻读仍有可能发生。**
|
||||
- **READ_UNCOMMITTED(未提交读):** 最低的隔离级别,允许读取尚未提交的数据变更,**可能会导致脏读、幻读或不可重复读**
|
||||
- **READ_COMMITTED(提交读):** 允许读取并发事务已经提交的数据,**可以阻止脏读,但是幻读或不可重复读仍有可能发生**
|
||||
- **REPEATABLE_READ(可重复读):** 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,**可以阻止脏读和不可重复读,但幻读仍有可能发生。**
|
||||
- **SERIALIZABLE(串行):** 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,**该级别可以防止脏读、不可重复读以及幻读**。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
|
||||
|
||||
这里需要注意的是:**Mysql 默认采用的 REPEATABLE_READ隔离级别 Oracle 默认采用的 READ_COMMITTED隔离级别.**
|
||||
|
||||
事务隔离机制的实现基于锁机制和并发调度。其中并发调度使用的是MVVC(多版本并发控制),通过保存修改的旧版本信息来支持并发一致性读和回滚等特性。
|
||||
事务隔离机制的实现基于锁机制和并发调度。其中并发调度使用的是MVCC(多版本并发控制),通过行的创建时间和行的过期时间来支持并发一致性读和回滚等特性。
|
||||
|
||||
详细内容可以参考: [可能是最漂亮的Spring事务管理详解](https://blog.csdn.net/qq_34337272/article/details/80394121)
|
||||
|
||||
@ -136,8 +136,7 @@ Java面试通关手册(Java学习指南,欢迎Star,会一直完善下去
|
||||
|
||||
1. **限定数据的范围:** 务必禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内。;
|
||||
2. **读/写分离:** 经典的数据库拆分方案,主库负责写,从库负责读;
|
||||
3. **缓存:** 使用MySQL的缓存,另外对重量级、更新少的数据可以考虑使用应用级别的缓存;
|
||||
4. **垂直分区:**
|
||||
3 . **垂直分区:**
|
||||
|
||||
**根据数据库里面数据表的相关性进行拆分。** 例如,用户表中既有用户的登录信息又有用户的基本信息,可以将用户表拆分成两个单独的表,甚至放到单独的库做分库。
|
||||
|
||||
@ -148,7 +147,7 @@ Java面试通关手册(Java学习指南,欢迎Star,会一直完善下去
|
||||
|
||||
**垂直拆分的缺点:** 主键会出现冗余,需要管理冗余列,并会引起Join操作,可以通过在应用层进行Join来解决。此外,垂直分区会让事务变得更加复杂;
|
||||
|
||||
5. **水平分区:**
|
||||
4. **水平分区:**
|
||||
|
||||
|
||||
**保持数据表结构不变,通过某种策略存储数据分片。这样每一片数据分散到不同的表或者库中,达到了分布式的目的。 水平拆分可以支撑非常大的数据量。**
|
||||
@ -157,7 +156,7 @@ Java面试通关手册(Java学习指南,欢迎Star,会一直完善下去
|
||||
|
||||

|
||||
|
||||
水品拆分可以支持非常大的数据量。需要注意的一点是:分表仅仅是解决了单一表数据过大的问题,但由于表的数据还是在同一台机器上,其实对于提升MySQL并发能力没有什么意义,所以 **水品拆分最好分库** 。
|
||||
水平拆分可以支持非常大的数据量。需要注意的一点是:分表仅仅是解决了单一表数据过大的问题,但由于表的数据还是在同一台机器上,其实对于提升MySQL并发能力没有什么意义,所以 **水平拆分最好分库** 。
|
||||
|
||||
水平拆分能够 **支持非常大的数据量存储,应用端改造也少**,但 **分片事务难以解决** ,跨界点Join性能较差,逻辑复杂。《Java工程师修炼之道》的作者推荐 **尽量不要对数据进行分片,因为拆分会带来逻辑、部署、运维的各种复杂度** ,一般的数据表在优化得当的情况下支撑千万以下的数据量是没有太大问题的。如果实在要分片,尽量选择客户端分片架构,这样可以减少一次和中间件的网络I/O。
|
||||
|
||||
|
||||
@ -162,7 +162,7 @@ redis 配置文件 redis.conf 中有相关注释,我这里就不贴了,大
|
||||
3. **volatile-random**:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
|
||||
4. **allkeys-lru**:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key(这个是最常用的).
|
||||
5. **allkeys-random**:从数据集(server.db[i].dict)中任意选择数据淘汰
|
||||
6. **no-enviction**:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
|
||||
6. **no-eviction**:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
|
||||
|
||||
|
||||
**备注: 关于 redis 设置过期时间以及内存淘汰机制,我这里只是简单的总结一下,后面会专门写一篇文章来总结!**
|
||||
|
||||
@ -167,7 +167,7 @@ Set 继承于 Collection 接口,是一个不允许出现重复元素,并且
|
||||
B-树(或B树)是一种平衡的多路查找(又称排序)树,在文件系统中有所应用。主要用作文件的索引。其中的B就表示平衡(Balance)
|
||||
1. B+ 树的叶子节点链表结构相比于 B- 树便于扫库,和范围检索。
|
||||
2. B+树支持range-query(区间查询)非常方便,而B树不支持。这是数据库选用B+树的最主要原因。
|
||||
3. B*树 是B+树的变体,B*树分配新结点的概率比B+树要低,空间使用率更高;
|
||||
3. B\*树 是B+树的变体,B\*树分配新结点的概率比B+树要低,空间使用率更高;
|
||||
* ### 8 LSM 树
|
||||
|
||||
[[HBase] LSM树 VS B+树](https://blog.csdn.net/dbanote/article/details/8897599)
|
||||
@ -179,4 +179,12 @@ Set 继承于 Collection 接口,是一个不允许出现重复元素,并且
|
||||
[LSM树由来、设计思想以及应用到HBase的索引](http://www.cnblogs.com/yanghuahui/p/3483754.html)
|
||||
|
||||
|
||||
## 图
|
||||
|
||||
|
||||
|
||||
|
||||
## BFS及DFS
|
||||
|
||||
- [《使用BFS及DFS遍历树和图的思路及实现》](https://blog.csdn.net/Gene1994/article/details/85097507)
|
||||
|
||||
|
||||
47
架构/8 张图读懂大型网站技术架构.md
Normal file
47
架构/8 张图读懂大型网站技术架构.md
Normal file
@ -0,0 +1,47 @@
|
||||
> 本文是作者读 《大型网站技术架构》所做的思维导图,在这里分享给各位,公众号(JavaGuide)后台回复:“架构”。即可获得下面图片的源文件以及思维导图源文件!
|
||||
|
||||
<!-- MarkdownTOC -->
|
||||
|
||||
- [1. 大型网站架构演化](#1-大型网站架构演化)
|
||||
- [2. 大型架构模式](#2-大型架构模式)
|
||||
- [3. 大型网站核心架构要素](#3-大型网站核心架构要素)
|
||||
- [4. 瞬时响应:网站的高性能架构](#4-瞬时响应网站的高性能架构)
|
||||
- [5. 万无一失:网站的高可用架构](#5-万无一失网站的高可用架构)
|
||||
- [6. 永无止境:网站的伸缩性架构](#6-永无止境网站的伸缩性架构)
|
||||
- [7. 随机应变:网站的可扩展性架构](#7-随机应变网站的可扩展性架构)
|
||||
- [8. 固若金汤:网站的安全机构](#8-固若金汤网站的安全机构)
|
||||
|
||||
<!-- /MarkdownTOC -->
|
||||
|
||||
|
||||
### 1. 大型网站架构演化
|
||||
|
||||
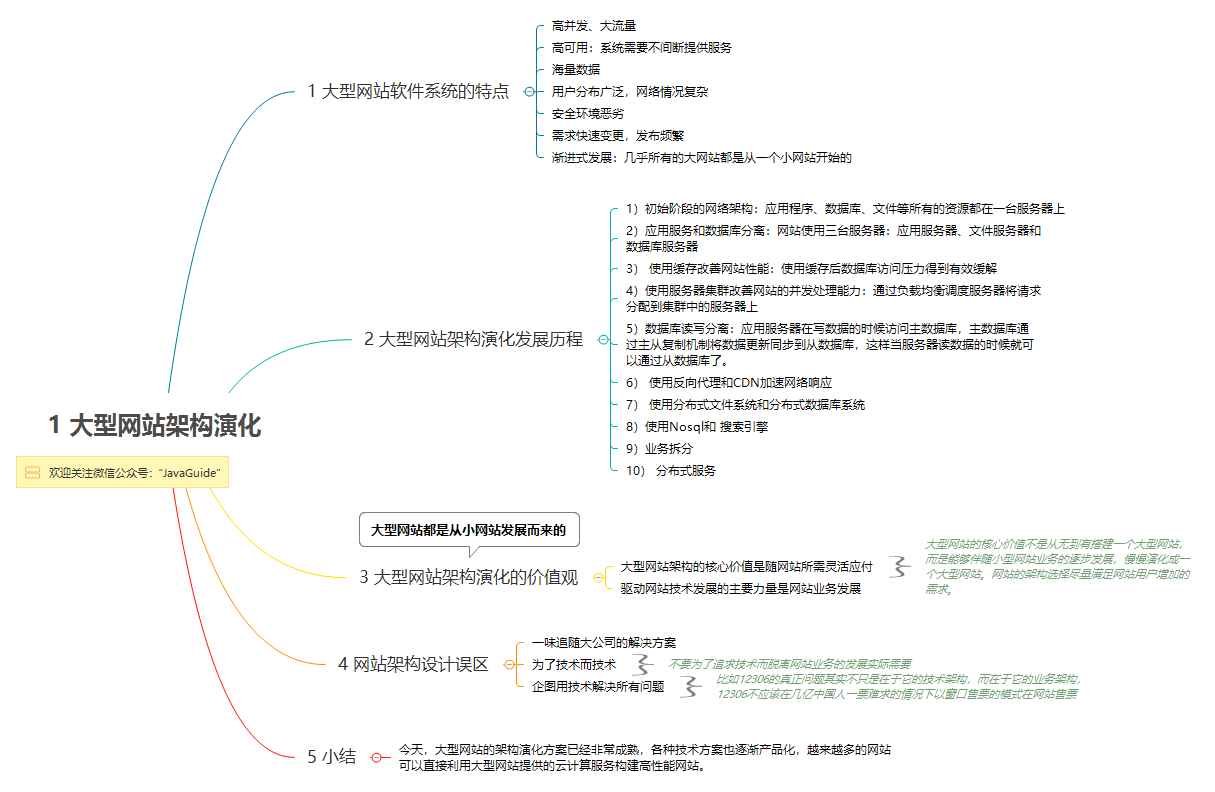
|
||||
|
||||
### 2. 大型架构模式
|
||||
|
||||

|
||||
|
||||
### 3. 大型网站核心架构要素
|
||||
|
||||
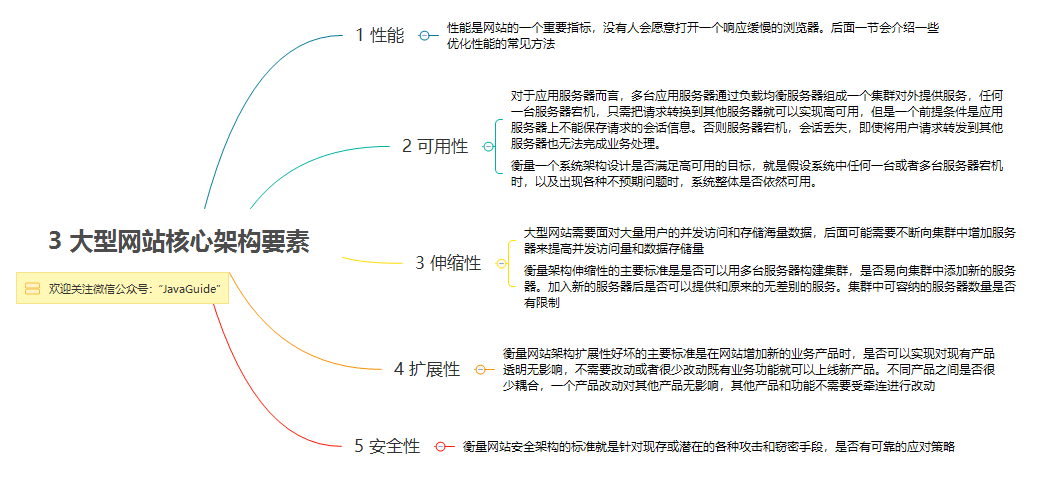
|
||||
|
||||
### 4. 瞬时响应:网站的高性能架构
|
||||
|
||||
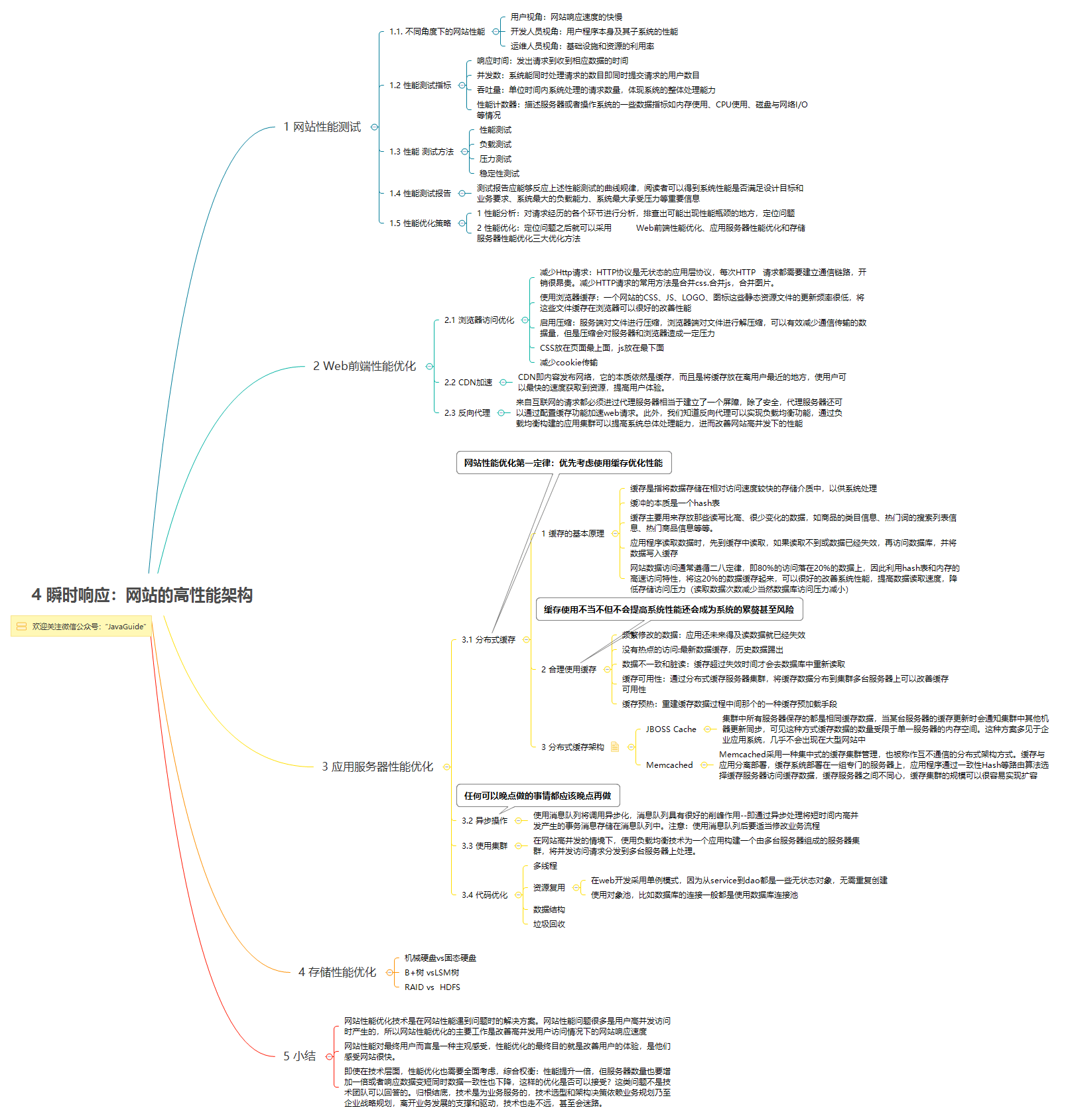
|
||||
|
||||
### 5. 万无一失:网站的高可用架构
|
||||
|
||||
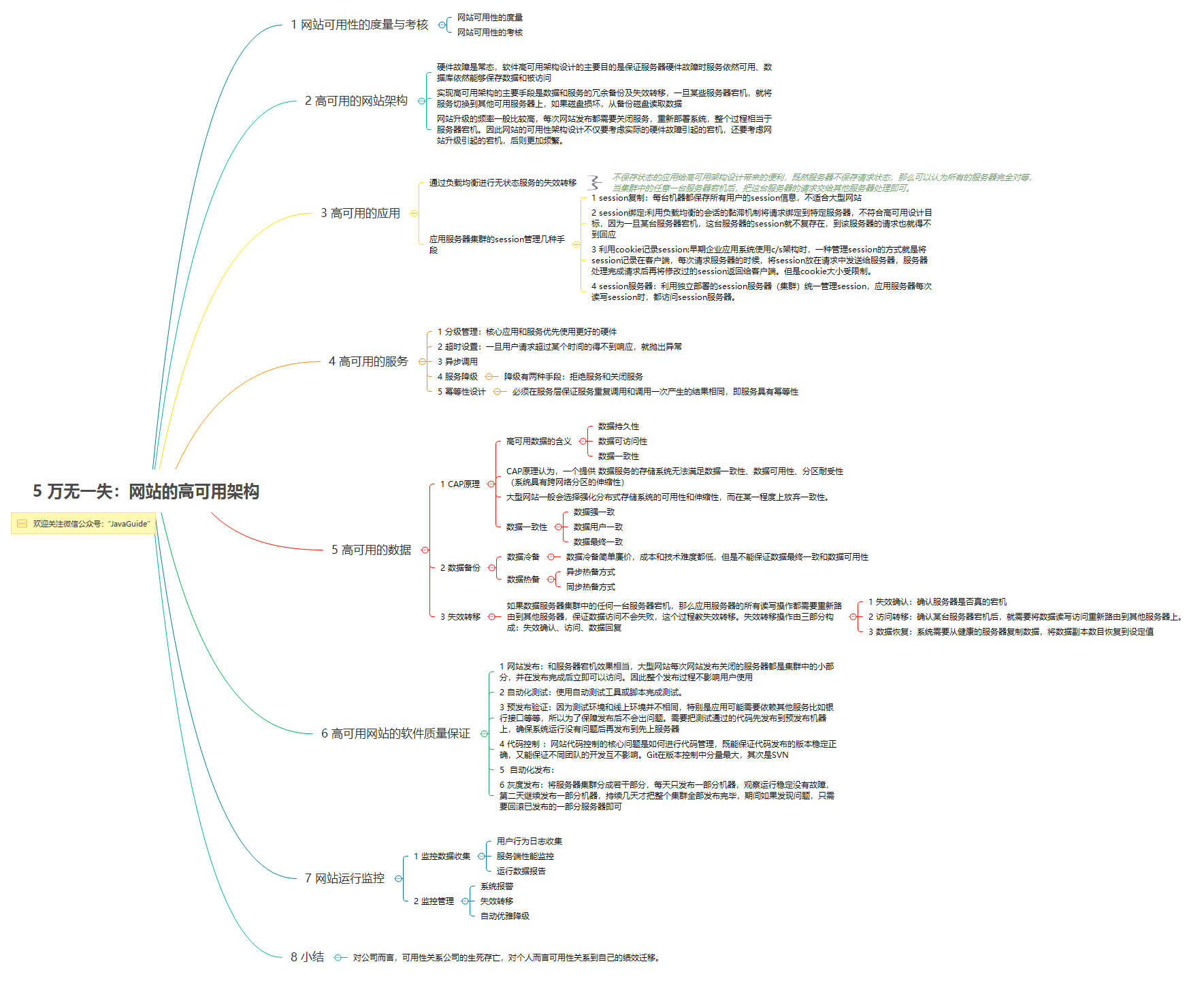
|
||||
|
||||
### 6. 永无止境:网站的伸缩性架构
|
||||
|
||||
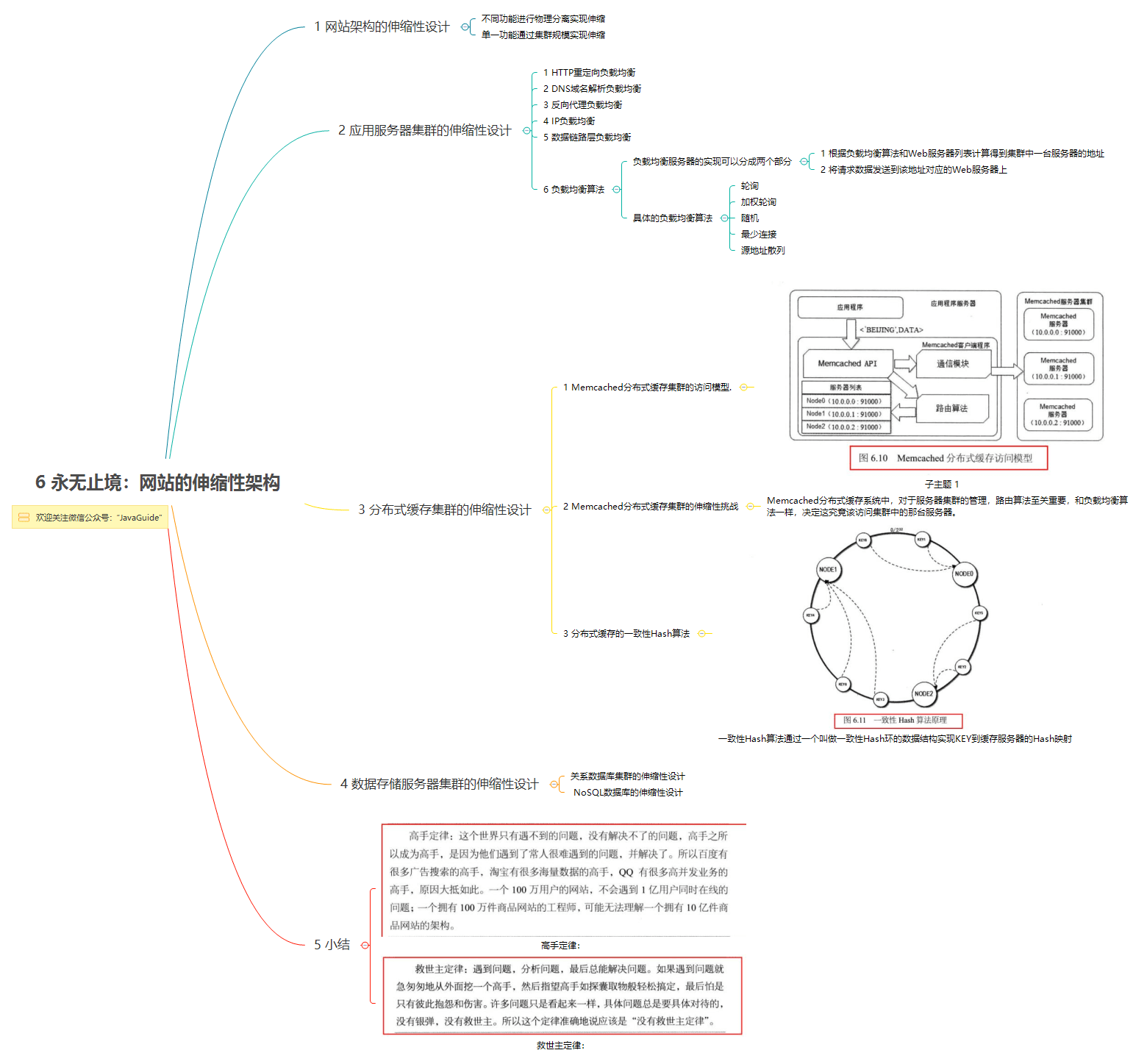
|
||||
|
||||
### 7. 随机应变:网站的可扩展性架构
|
||||
|
||||
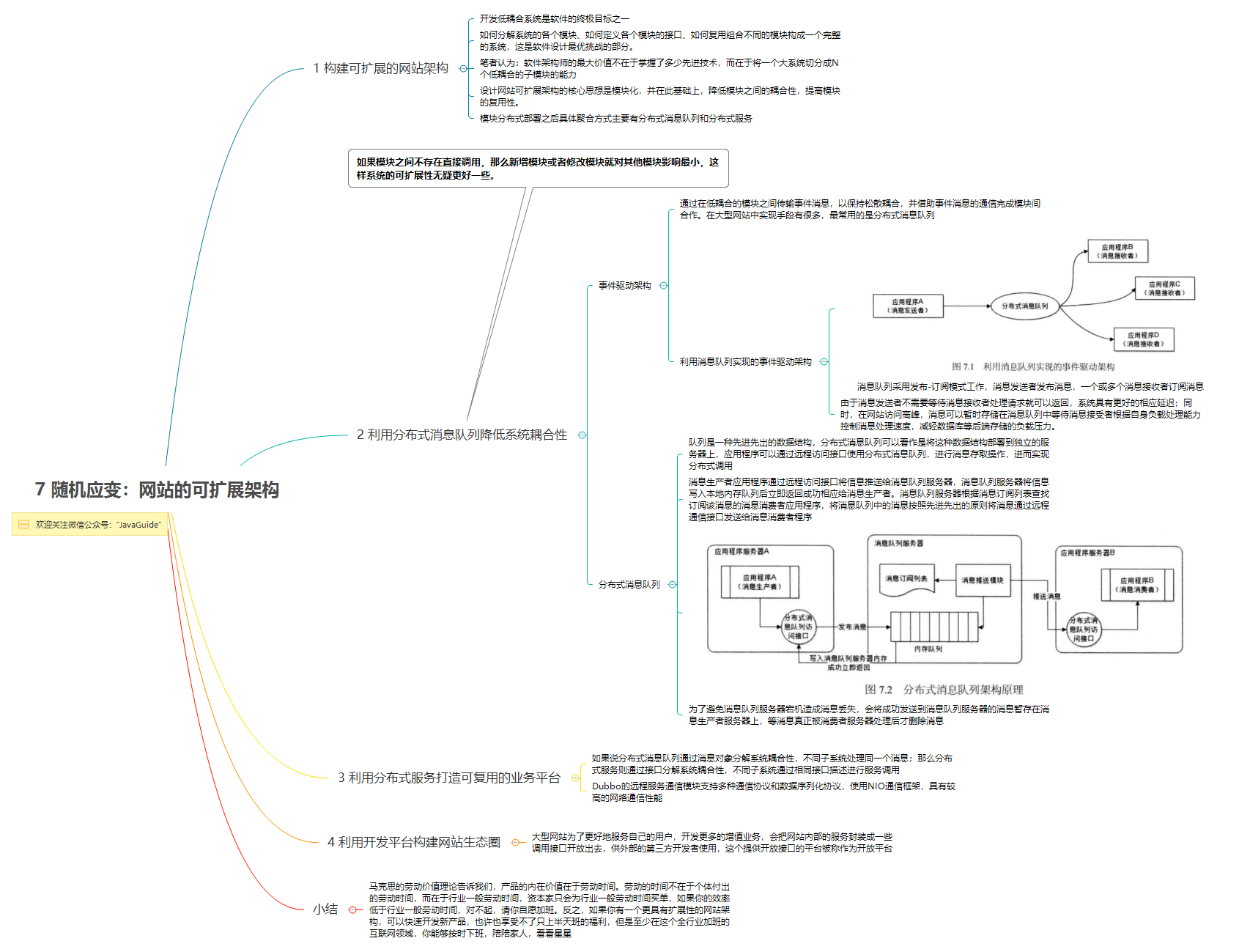
|
||||
|
||||
### 8. 固若金汤:网站的安全机构
|
||||
|
||||
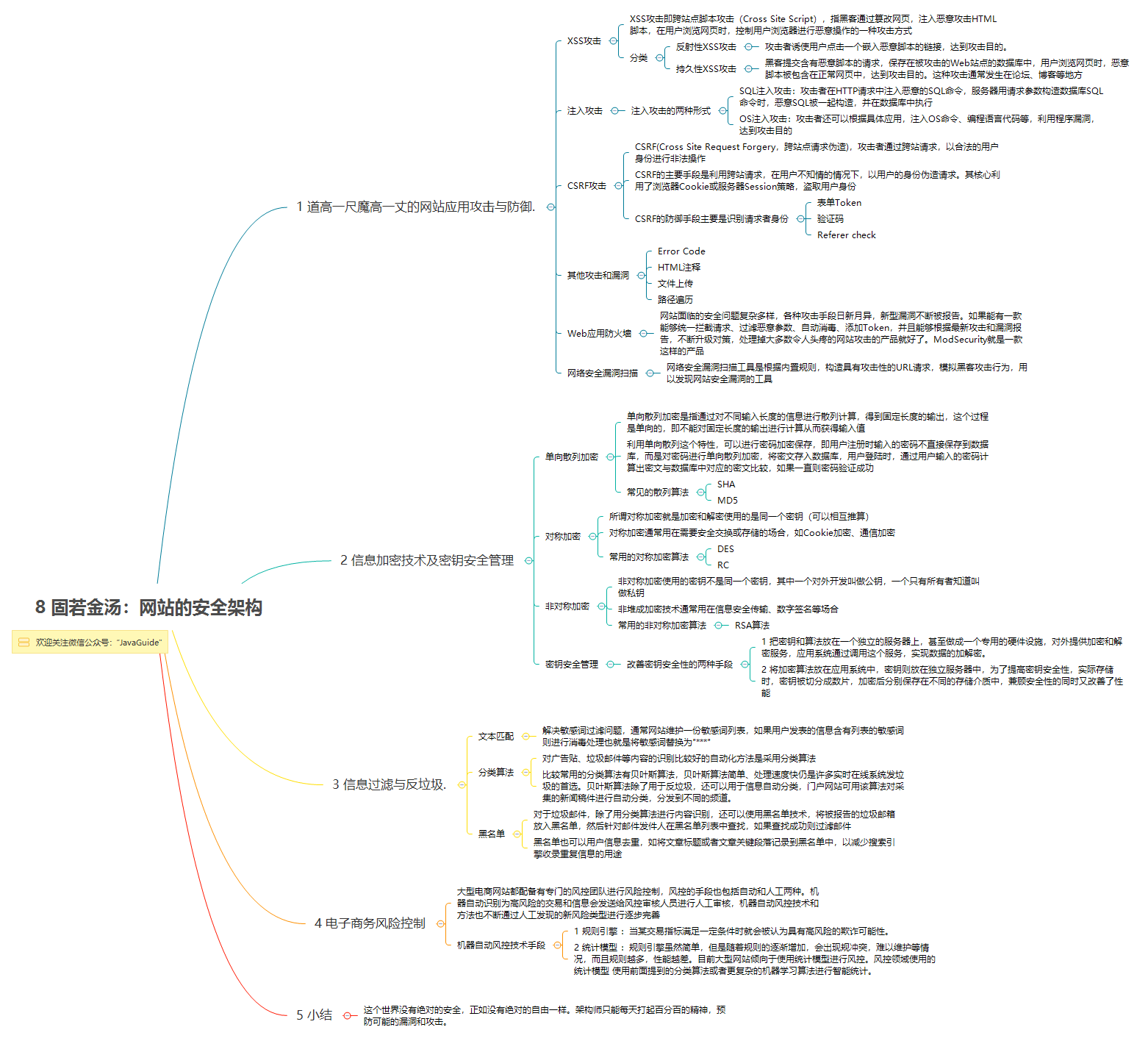
|
||||
190
架构/【面试精选】关于大型网站系统架构你不得不懂的10个问题.md
Normal file
190
架构/【面试精选】关于大型网站系统架构你不得不懂的10个问题.md
Normal file
@ -0,0 +1,190 @@
|
||||
下面这些问题都是一线大厂的真实面试问题,不论是对你面试还是说拓宽知识面都很有帮助。之前发过一篇[8 张图读懂大型网站技术架构](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484416&idx=1&sn=6ced00d65491ef8fd33151bdfa8895c9&chksm=fd985261caefdb779412974a6a7207c93d0c2da5b28489afb74acd2fee28505daebbadb018ff&token=177958022&lang=zh_CN#rd) 可以作为不太了解大型网站系统技术架构朋友的入门文章。
|
||||
|
||||
<!-- MarkdownTOC -->
|
||||
|
||||
- [1. 你使用过哪些组件或者方法来提升网站性能,可用性以及并发量](#1-你使用过哪些组件或者方法来提升网站性能可用性以及并发量)
|
||||
- [2. 设计高可用系统的常用手段](#2-设计高可用系统的常用手段)
|
||||
- [3. 现代互联网应用系统通常具有哪些特点?](#3-现代互联网应用系统通常具有哪些特点)
|
||||
- [4. 谈谈你对微服务领域的了解和认识](#4-谈谈你对微服务领域的了解和认识)
|
||||
- [5. 谈谈你对 Dubbo 和 Spring Cloud 的认识\(两者关系\)](#5-谈谈你对-dubbo-和-spring-cloud-的认识两者关系)
|
||||
- [6. 性能测试了解吗?说说你知道的性能测试工具?](#6-性能测试了解吗说说你知道的性能测试工具)
|
||||
- [7. 对于一个单体应用系统,随着产品使用的用户越来越多,网站的流量会增加,最终单台服务器无法处理那么大的流量怎么办?](#7-对于一个单体应用系统随着产品使用的用户越来越多网站的流量会增加最终单台服务器无法处理那么大的流量怎么办)
|
||||
- [8. 大表优化的常见手段](#8-大表优化的常见手段)
|
||||
- [9. 在系统中使用消息队列能带来什么好处?](#9-在系统中使用消息队列能带来什么好处)
|
||||
- [1) 通过异步处理提高系统性能](#1-通过异步处理提高系统性能)
|
||||
- [2) 降低系统耦合性](#2-降低系统耦合性)
|
||||
- [10. 说说自己对 CAP 定理,BASE 理论的了解](#10-说说自己对-cap-定理base-理论的了解)
|
||||
- [CAP 定理](#cap-定理)
|
||||
- [BASE 理论](#base-理论)
|
||||
- [参考](#参考)
|
||||
|
||||
<!-- /MarkdownTOC -->
|
||||
|
||||
|
||||
### 1. 你使用过哪些组件或者方法来提升网站性能,可用性以及并发量
|
||||
|
||||
1. **提高硬件能力、增加系统服务器**。(当服务器增加到某个程度的时候系统所能提供的并发访问量几乎不变,所以不能根本解决问题)
|
||||
2. **使用缓存**(本地缓存:本地可以使用JDK自带的 Map、Guava Cache.分布式缓存:Redis、Memcache.本地缓存不适用于提高系统并发量,一般是用处用在程序中。比如Spring是如何实现单例的呢?大家如果看过源码的话,应该知道,Spiring把已经初始过的变量放在一个Map中,下次再要使用这个变量的时候,先判断Map中有没有,这也就是系统中常见的单例模式的实现。)
|
||||
3. **消息队列** (解耦+削峰+异步)
|
||||
4. **采用分布式开发** (不同的服务部署在不同的机器节点上,并且一个服务也可以部署在多台机器上,然后利用 Nginx 负载均衡访问。这样就解决了单点部署(All In)的缺点,大大提高的系统并发量)
|
||||
5. **数据库分库(读写分离)、分表(水平分表、垂直分表)**
|
||||
6. **采用集群** (多台机器提供相同的服务)
|
||||
7. **CDN 加速** (将一些静态资源比如图片、视频等等缓存到离用户最近的网络节点)
|
||||
8. **浏览器缓存**
|
||||
9. **使用合适的连接池**(数据库连接池、线程池等等)
|
||||
10. **适当使用多线程进行开发。**
|
||||
|
||||
|
||||
### 2. 设计高可用系统的常用手段
|
||||
|
||||
1. **降级:** 服务降级是当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行。降级往往会指定不同的级别,面临不同的异常等级执行不同的处理。根据服务方式:可以拒接服务,可以延迟服务,也有时候可以随机服务。根据服务范围:可以砍掉某个功能,也可以砍掉某些模块。总之服务降级需要根据不同的业务需求采用不同的降级策略。主要的目的就是服务虽然有损但是总比没有好;
|
||||
2. **限流:** 防止恶意请求流量、恶意攻击,或者防止流量超出系统峰值;
|
||||
3. **缓存:** 避免大量请求直接落到数据库,将数据库击垮;
|
||||
4. **超时和重试机制:** 避免请求堆积造成雪崩;
|
||||
5. **回滚机制:** 快速修复错误版本。
|
||||
|
||||
|
||||
### 3. 现代互联网应用系统通常具有哪些特点?
|
||||
|
||||
1. 高并发,大流量;
|
||||
2. 高可用:系统7×24小时不间断服务;
|
||||
3. 海量数据:需要存储、管理海量数据,需要使用大量服务器;
|
||||
4. 用户分布广泛,网络情况复杂:许多大型互联网都是为全球用户提供服务的,用户分布范围广,各地网络情况千差万别;
|
||||
5. 安全环境恶劣:由于互联网的开放性,使得互联网更容易受到攻击,大型网站几乎每天都会被黑客攻击;
|
||||
6. 需求快速变更,发布频繁:和传统软件的版本发布频率不同,互联网产品为快速适应市场,满足用户需求,其产品发布频率是极高的;
|
||||
7. 渐进式发展:与传统软件产品或企业应用系统一开始就规划好全部的功能和非功能需求不同,几乎所有的大型互联网网站都是从一个小网站开始,渐进地发展起来。
|
||||
|
||||
### 4. 谈谈你对微服务领域的了解和认识
|
||||
|
||||
现在大公司都在用并且未来的趋势都是 Spring Cloud,而阿里开源的 Spring Cloud Alibaba 也是 Spring Cloud 规范的实现 。
|
||||
|
||||
我们通常把 Spring Cloud 理解为一系列开源组件的集合,但是 Spring Cloud并不是等同于 Spring Cloud Netflix 的 Ribbon、Feign、Eureka(停止更新)、Hystrix 这一套组件,而是抽象了一套通用的开发模式。它的目的是通过抽象出这套通用的模式,让开发者更快更好地开发业务。但是这套开发模式运行时的实际载体,还是依赖于 RPC、网关、服务发现、配置管理、限流熔断、分布式链路跟踪等组件的具体实现。
|
||||
|
||||
Spring Cloud Alibaba 是官方认证的新一套 Spring Cloud 规范的实现,Spring Cloud Alibaba 是一套国产开源产品集合,后续还会有中文 reference 和一些原理分析文章,所以,这对于国内的开发者是非常棒的一件事。阿里的这一举动势必会推动国内微服务技术的发展,因为在没有 Spring Cloud Alibaba 之前,我们的第一选择是 Spring Cloud Netflix,但是它们的文档都是英文的,出问题后排查也比较困难, 在国内并不是有特别多的人精通。Spring Cloud Alibaba 由阿里开源组件和阿里云产品组件两部分组成,其致力于提供微服务一站式解决方案,方便开发者通过 Spring Cloud 编程模型轻松开发微服务应用。
|
||||
|
||||
另外,Apache Dubbo Ecosystem 是围绕 Apache Dubbo 打造的微服务生态,是经过生产验证的微服务的最佳实践组合。在阿里巴巴的微服务解决方案中,Dubbo、Nacos 和 Sentinel,以及后续将开源的微服务组件,都是 Dubbo EcoSystem 的一部分。阿里后续也会将 Dubbo EcoSystem 集成到 Spring Cloud 的生态中。
|
||||
|
||||
### 5. 谈谈你对 Dubbo 和 Spring Cloud 的认识(两者关系)
|
||||
|
||||
具体可以看公众号-阿里巴巴中间件的这篇文章:[独家解读:Dubbo Ecosystem - 从微服务框架到微服务生态](https://mp.weixin.qq.com/s/iNVctXw7tUGHhnF0hV84ww)
|
||||
|
||||
Dubbo 与 Spring Cloud 并不是竞争关系,Dubbo 作为成熟的 RPC 框架,其易用性、扩展性和健壮性已得到业界的认可。未来 Dubbo 将会作为 Spring Cloud Alibaba 的 RPC 组件,并与 Spring Cloud 原生的 Feign 以及 RestTemplate 进行无缝整合,实现“零”成本迁移。
|
||||
|
||||
在阿里巴巴的微服务解决方案中,Dubbo、Nacos 和 Sentinel,以及后续将开源的微服务组件,都是 Dubbo EcoSystem 的一部分。我们后续也会将 Dubbo EcoSystem 集成到 Spring Cloud 的生态中。
|
||||
|
||||
### 6. 性能测试了解吗?说说你知道的性能测试工具?
|
||||
|
||||
性能测试指通过自动化的测试工具模拟多种正常、峰值以及异常负载条件来对系统的各项性能指标进行测试。性能测试是总称,通常细分为:
|
||||
|
||||
1. **基准测试:** 在给系统施加较低压力时,查看系统的运行状况并记录相关数做为基础参考
|
||||
2. **负载测试:**是指对系统不断地增加压力或增加一定压力下的持续时间,直到系统的某项或多项性能指标达到安全临界值,例如某种资源已经达到饱和状态等 。此时继续加压,系统处理能力会下降。
|
||||
3. **压力测试:** 超过安全负载情况下,不断施加压力(增加并发请求),直到系统崩溃或无法处理任何请求,依此获得系统最大压力承受能力。
|
||||
4. **稳定性测试:** 被测试系统在特定硬件、软件、网络环境下,加载一定业务压力(模拟生产环境不同时间点、不均匀请求,呈波浪特性)运行一段较长时间,以此检测系统是否稳定。
|
||||
|
||||
后端程序员或者测试平常比较常用的测试工具是 JMeter(官网:[https://jmeter.apache.org/](https://jmeter.apache.org/))。Apache JMeter 是一款基于Java的压力测试工具(100%纯Java应用程序),旨在加载测试功能行为和测量性能。它最初被设计用于 Web 应用测试但后来扩展到其他测试领域。
|
||||
|
||||
### 7. 对于一个单体应用系统,随着产品使用的用户越来越多,网站的流量会增加,最终单台服务器无法处理那么大的流量怎么办?
|
||||
|
||||
这个时候就要考虑扩容了。《亿级流量网站架构核心技术》这本书上面介绍到我们可以考虑下面几步来解决这个问题:
|
||||
|
||||
- 第一步,可以考虑简单的扩容来解决问题。比如增加系统的服务器,提高硬件能力等等。
|
||||
- 第二步,如果简单扩容搞不定,就需要水平拆分和垂直拆分数据/应用来提升系统的伸缩性,即通过扩容提升系统负载能力。
|
||||
- 第三步,如果通过水平拆分/垂直拆分还是搞不定,那就需要根据现有系统特性,架构层面进行重构甚至是重新设计,即推倒重来。
|
||||
|
||||
对于系统设计,理想的情况下应支持线性扩容和弹性扩容,即在系统瓶颈时,只需要增加机器就可以解决系统瓶颈,如降低延迟提升吞吐量,从而实现扩容需求。
|
||||
|
||||
如果你想扩容,则支持水平/垂直伸缩是前提。在进行拆分时,一定要清楚知道自己的目的是什么,拆分后带来的问题如何解决,拆分后如果没有得到任何收益就不要为了
|
||||
拆而拆,即不要过度拆分,要适合自己的业务。
|
||||
|
||||
### 8. 大表优化的常见手段
|
||||
|
||||
当MySQL单表记录数过大时,数据库的CRUD性能会明显下降,一些常见的优化措施如下:
|
||||
|
||||
1. **限定数据的范围:** 务必禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内。;
|
||||
2. **读/写分离:** 经典的数据库拆分方案,主库负责写,从库负责读;
|
||||
3. **垂直分区:** **根据数据库里面数据表的相关性进行拆分。** 例如,用户表中既有用户的登录信息又有用户的基本信息,可以将用户表拆分成两个单独的表,甚至放到单独的库做分库。**简单来说垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表。** 如下图所示,这样来说大家应该就更容易理解了。**垂直拆分的优点:** 可以使得行数据变小,在查询时减少读取的Block数,减少I/O次数。此外,垂直分区可以简化表的结构,易于维护。**垂直拆分的缺点:** 主键会出现冗余,需要管理冗余列,并会引起Join操作,可以通过在应用层进行Join来解决。此外,垂直分区会让事务变得更加复杂;
|
||||
4. **水平分区:** **保持数据表结构不变,通过某种策略存储数据分片。这样每一片数据分散到不同的表或者库中,达到了分布式的目的。 水平拆分可以支撑非常大的数据量。** 水平拆分是指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放。举个例子:我们可以将用户信息表拆分成多个用户信息表,这样就可以避免单一表数据量过大对性能造成影响。水平拆分可以支持非常大的数据量。需要注意的一点是:分表仅仅是解决了单一表数据过大的问题,但由于表的数据还是在同一台机器上,其实对于提升MySQL并发能力没有什么意义,所以 **水平拆分最好分库** 。水平拆分能够 **支持非常大的数据量存储,应用端改造也少**,但 **分片事务难以解决** ,跨界点Join性能较差,逻辑复杂。《Java工程师修炼之道》的作者推荐 **尽量不要对数据进行分片,因为拆分会带来逻辑、部署、运维的各种复杂度** ,一般的数据表在优化得当的情况下支撑千万以下的数据量是没有太大问题的。如果实在要分片,尽量选择客户端分片架构,这样可以减少一次和中间件的网络I/O。
|
||||
|
||||
**下面补充一下数据库分片的两种常见方案:**
|
||||
|
||||
- **客户端代理:** **分片逻辑在应用端,封装在jar包中,通过修改或者封装JDBC层来实现。** 当当网的 **Sharding-JDBC** 、阿里的TDDL是两种比较常用的实现。
|
||||
- **中间件代理:** **在应用和数据中间加了一个代理层。分片逻辑统一维护在中间件服务中。** 我们现在谈的 **Mycat** 、360的Atlas、网易的DDB等等都是这种架构的实现。
|
||||
|
||||
### 9. 在系统中使用消息队列能带来什么好处?
|
||||
|
||||
**《大型网站技术架构》第四章和第七章均有提到消息队列对应用性能及扩展性的提升。**
|
||||
|
||||
#### 1) 通过异步处理提高系统性能
|
||||

|
||||
如上图,**在不使用消息队列服务器的时候,用户的请求数据直接写入数据库,在高并发的情况下数据库压力剧增,使得响应速度变慢。但是在使用消息队列之后,用户的请求数据发送给消息队列之后立即 返回,再由消息队列的消费者进程从消息队列中获取数据,异步写入数据库。由于消息队列服务器处理速度快于数据库(消息队列也比数据库有更好的伸缩性),因此响应速度得到大幅改善。**
|
||||
|
||||
通过以上分析我们可以得出**消息队列具有很好的削峰作用的功能**——即**通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。** 举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
|
||||

|
||||
因为**用户请求数据写入消息队列之后就立即返回给用户了,但是请求数据在后续的业务校验、写数据库等操作中可能失败**。因此使用消息队列进行异步处理之后,需要**适当修改业务流程进行配合**,比如**用户在提交订单之后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功**,以免交易纠纷。这就类似我们平时手机订火车票和电影票。
|
||||
|
||||
### 2) 降低系统耦合性
|
||||
我们知道模块分布式部署以后聚合方式通常有两种:1.**分布式消息队列**和2.**分布式服务**。
|
||||
|
||||
> **先来简单说一下分布式服务:**
|
||||
|
||||
目前使用比较多的用来构建**SOA(Service Oriented Architecture面向服务体系结构)**的**分布式服务框架**是阿里巴巴开源的**Dubbo**.如果想深入了解Dubbo的可以看我写的关于Dubbo的这一篇文章:**《高性能优秀的服务框架-dubbo介绍》**:[https://juejin.im/post/5acadeb1f265da2375072f9c](https://juejin.im/post/5acadeb1f265da2375072f9c)
|
||||
|
||||
> **再来谈我们的分布式消息队列:**
|
||||
|
||||
我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。
|
||||
|
||||
我们最常见的**事件驱动架构**类似生产者消费者模式,在大型网站中通常用利用消息队列实现事件驱动结构。如下图所示:
|
||||

|
||||
**消息队列使利用发布-订阅模式工作,消息发送者(生产者)发布消息,一个或多个消息接受者(消费者)订阅消息。** 从上图可以看到**消息发送者(生产者)和消息接受者(消费者)之间没有直接耦合**,消息发送者将消息发送至分布式消息队列即结束对消息的处理,消息接受者从分布式消息队列获取该消息后进行后续处理,并不需要知道该消息从何而来。**对新增业务,只要对该类消息感兴趣,即可订阅该消息,对原有系统和业务没有任何影响,从而实现网站业务的可扩展性设计**。
|
||||
|
||||
消息接受者对消息进行过滤、处理、包装后,构造成一个新的消息类型,将消息继续发送出去,等待其他消息接受者订阅该消息。因此基于事件(消息对象)驱动的业务架构可以是一系列流程。
|
||||
|
||||
**另外为了避免消息队列服务器宕机造成消息丢失,会将成功发送到消息队列的消息存储在消息生产者服务器上,等消息真正被消费者服务器处理后才删除消息。在消息队列服务器宕机后,生产者服务器会选择分布式消息队列服务器集群中的其他服务器发布消息。**
|
||||
|
||||
**备注:** 不要认为消息队列只能利用发布-订阅模式工作,只不过在解耦这个特定业务环境下是使用发布-订阅模式的,**比如在我们的ActiveMQ消息队列中还有点对点工作模式**,具体的会在后面的文章给大家详细介绍,这一篇文章主要还是让大家对消息队列有一个更透彻的了解。
|
||||
|
||||
> 这个问题一般会在上一个问题问完之后,紧接着被问到。“使用消息队列会带来什么问题?”这个问题要引起重视,一般我们都会考虑使用消息队列会带来的好处而忽略它带来的问题!
|
||||
|
||||
### 10. 说说自己对 CAP 定理,BASE 理论的了解
|
||||
|
||||
#### CAP 定理
|
||||
|
||||

|
||||
在理论计算机科学中,CAP定理(CAP theorem),又被称作布鲁尔定理(Brewer's theorem),它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
|
||||
|
||||
- **一致性(Consistence)** :所有节点访问同一份最新的数据副本
|
||||
- **可用性(Availability)**:每次请求都能获取到非错的响应——但是不保证获取的数据为最新数据
|
||||
- **分区容错性(Partition tolerance)** : 分布式系统在遇到某节点或网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。
|
||||
|
||||
CAP仅适用于原子读写的NOSQL场景中,并不适合数据库系统。现在的分布式系统具有更多特性比如扩展性、可用性等等,在进行系统设计和开发时,我们不应该仅仅局限在CAP问题上。
|
||||
|
||||
**注意:不是所谓的3选2(不要被网上大多数文章误导了):**
|
||||
|
||||
大部分人解释这一定律时,常常简单的表述为:“一致性、可用性、分区容忍性三者你只能同时达到其中两个,不可能同时达到”。实际上这是一个非常具有误导性质的说法,而且在CAP理论诞生12年之后,CAP之父也在2012年重写了之前的论文。
|
||||
|
||||
**当发生网络分区的时候,如果我们要继续服务,那么强一致性和可用性只能2选1。也就是说当网络分区之后P是前提,决定了P之后才有C和A的选择。也就是说分区容错性(Partition tolerance)我们是必须要实现的。**
|
||||
|
||||
我在网上找了很多文章想看一下有没有文章提到这个不是所谓的3选2,用百度半天没找到了一篇,用谷歌搜索找到一篇比较不错的,如果想深入学习一下CAP就看这篇文章把,我这里就不多BB了:**《分布式系统之CAP理论》 :** [http://www.cnblogs.com/hxsyl/p/4381980.html](http://www.cnblogs.com/hxsyl/p/4381980.html)
|
||||
|
||||
|
||||
#### BASE 理论
|
||||
|
||||
**BASE** 是 **Basically Available(基本可用)** 、**Soft-state(软状态)** 和 **Eventually Consistent(最终一致性)** 三个短语的缩写。BASE理论是对CAP中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于CAP定理逐步演化而来的,它大大降低了我们对系统的要求。
|
||||
|
||||
**BASE理论的核心思想:** 即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。也就是牺牲数据的一致性来满足系统的高可用性,系统中一部分数据不可用或者不一致时,仍需要保持系统整体“主要可用”。
|
||||
|
||||
|
||||
**BASE理论三要素:**
|
||||
|
||||

|
||||
|
||||
1. **基本可用:** 基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性。但是,这绝不等价于系统不可用。 比如: **①响应时间上的损失**:正常情况下,一个在线搜索引擎需要在0.5秒之内返回给用户相应的查询结果,但由于出现故障,查询结果的响应时间增加了1~2秒;**②系统功能上的损失**:正常情况下,在一个电子商务网站上进行购物的时候,消费者几乎能够顺利完成每一笔订单,但是在一些节日大促购物高峰的时候,由于消费者的购物行为激增,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面;
|
||||
2. **软状态:** 软状态指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时;
|
||||
3. **最终一致性:** 最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
|
||||
|
||||
### 参考
|
||||
|
||||
- 《大型网站技术架构》
|
||||
- 《亿级流量网站架构核心技术》
|
||||
- 《Java工程师修炼之道》
|
||||
- https://www.cnblogs.com/puresoul/p/5456855.html
|
||||
137
计算机网络与数据通信/HTTPS中的TLS.md
Normal file
137
计算机网络与数据通信/HTTPS中的TLS.md
Normal file
@ -0,0 +1,137 @@
|
||||
<!-- TOC -->
|
||||
|
||||
- [1. SSL 与 TLS](#1-ssl-%E4%B8%8E-tls)
|
||||
- [2. 从网络协议的角度理解 HTTPS](#2-%E4%BB%8E%E7%BD%91%E7%BB%9C%E5%8D%8F%E8%AE%AE%E7%9A%84%E8%A7%92%E5%BA%A6%E7%90%86%E8%A7%A3-https)
|
||||
- [3. 从密码学的角度理解 HTTPS](#3-%E4%BB%8E%E5%AF%86%E7%A0%81%E5%AD%A6%E7%9A%84%E8%A7%92%E5%BA%A6%E7%90%86%E8%A7%A3-https)
|
||||
- [3.1. TLS 工作流程](#31-tls-%E5%B7%A5%E4%BD%9C%E6%B5%81%E7%A8%8B)
|
||||
- [3.2. 密码基础](#32-%E5%AF%86%E7%A0%81%E5%9F%BA%E7%A1%80)
|
||||
- [3.2.1. 伪随机数生成器](#321-%E4%BC%AA%E9%9A%8F%E6%9C%BA%E6%95%B0%E7%94%9F%E6%88%90%E5%99%A8)
|
||||
- [3.2.2. 消息认证码](#322-%E6%B6%88%E6%81%AF%E8%AE%A4%E8%AF%81%E7%A0%81)
|
||||
- [3.2.3. 数字签名](#323-%E6%95%B0%E5%AD%97%E7%AD%BE%E5%90%8D)
|
||||
- [3.2.4. 公钥密码](#324-%E5%85%AC%E9%92%A5%E5%AF%86%E7%A0%81)
|
||||
- [3.2.5. 证书](#325-%E8%AF%81%E4%B9%A6)
|
||||
- [3.2.6. 密码小结](#326-%E5%AF%86%E7%A0%81%E5%B0%8F%E7%BB%93)
|
||||
- [3.3. TLS 使用的密码技术](#33-tls-%E4%BD%BF%E7%94%A8%E7%9A%84%E5%AF%86%E7%A0%81%E6%8A%80%E6%9C%AF)
|
||||
- [3.4. TLS 总结](#34-tls-%E6%80%BB%E7%BB%93)
|
||||
- [4. RSA 简单示例](#4-rsa-%E7%AE%80%E5%8D%95%E7%A4%BA%E4%BE%8B)
|
||||
- [5. 参考](#5-%E5%8F%82%E8%80%83)
|
||||
|
||||
<!-- TOC -->
|
||||
|
||||
# 1. SSL 与 TLS
|
||||
|
||||
SSL:(Secure Socket Layer) 安全套接层,于 1994 年由网景公司设计,并于 1995 年发布了 3.0 版本
|
||||
TLS:(Transport Layer Security)传输层安全性协议,是 IETF 在 SSL3.0 的基础上设计的协议
|
||||
以下全部使用 TLS 来表示
|
||||
|
||||
# 2. 从网络协议的角度理解 HTTPS
|
||||
|
||||
![此图并不准确][1]
|
||||
HTTP:HyperText Transfer Protocol 超文本传输协议
|
||||
HTTPS:Hypertext Transfer Protocol Secure 超文本传输安全协议
|
||||
TLS:位于 HTTP 和 TCP 之间的协议,其内部有 TLS握手协议、TLS记录协议
|
||||
HTTPS 经由 HTTP 进行通信,但利用 TLS 来保证安全,即 HTTPS = HTTP + TLS
|
||||
|
||||
# 3. 从密码学的角度理解 HTTPS
|
||||
|
||||
HTTPS 使用 TLS 保证安全,这里的“安全”分两部分,一是传输内容加密、二是服务端的身份认证
|
||||
|
||||
## 3.1. TLS 工作流程
|
||||
|
||||
![此图并不准确][2]
|
||||
此为服务端单向认证,还有客户端/服务端双向认证,流程类似,只不过客户端也有自己的证书,并发送给服务器进行验证
|
||||
|
||||
## 3.2. 密码基础
|
||||
|
||||
### 3.2.1. 伪随机数生成器
|
||||
|
||||
为什么叫伪随机数,因为没有真正意义上的随机数,具体可以参考 Random/TheadLocalRandom
|
||||
它的主要作用在于生成对称密码的秘钥、用于公钥密码生成秘钥对
|
||||
|
||||
### 3.2.2. 消息认证码
|
||||
|
||||
消息认证码主要用于验证消息的完整性与消息的认证,其中消息的认证指“消息来自正确的发送者”
|
||||
|
||||
>消息认证码用于验证和认证,而不是加密
|
||||
|
||||
![消息认证码过程][3]
|
||||
|
||||
1. 发送者与接收者事先共享秘钥
|
||||
2. 发送者根据发送消息计算 MAC 值
|
||||
3. 发送者发送消息和 MAC 值
|
||||
4. 接收者根据接收到的消息计算 MAC 值
|
||||
5. 接收者根据自己计算的 MAC 值与收到的 MAC 对比
|
||||
6. 如果对比成功,说明消息完整,并来自与正确的发送者
|
||||
|
||||
### 3.2.3. 数字签名
|
||||
|
||||
消息认证码的缺点在于**无法防止否认**,因为共享秘钥被 client、server 两端拥有,server 可以伪造 client 发送给自己的消息(自己给自己发送消息),为了解决这个问题,我们需要它们有各自的秘钥不被第二个知晓(这样也解决了共享秘钥的配送问题)
|
||||
|
||||
![数字签名过程][4]
|
||||
|
||||
>数字签名和消息认证码都**不是为了加密**
|
||||
>可以将单向散列函数获取散列值的过程理解为使用 md5 摘要算法获取摘要的过程
|
||||
|
||||
使用自己的私钥对自己所认可的消息生成一个该消息专属的签名,这就是数字签名,表明我承认该消息来自自己
|
||||
注意:**私钥用于加签,公钥用于解签,每个人都可以解签,查看消息的归属人**
|
||||
|
||||
### 3.2.4. 公钥密码
|
||||
|
||||
公钥密码也叫非对称密码,由公钥和私钥组成,它是最开始是为了解决秘钥的配送传输安全问题,即,我们不配送私钥,只配送公钥,私钥由本人保管
|
||||
它与数字签名相反,公钥密码的私钥用于解密、公钥用于加密,每个人都可以用别人的公钥加密,但只有对应的私钥才能解开密文
|
||||
client:明文 + 公钥 = 密文
|
||||
server:密文 + 私钥 = 明文
|
||||
注意:**公钥用于加密,私钥用于解密,只有私钥的归属者,才能查看消息的真正内容**
|
||||
|
||||
### 3.2.5. 证书
|
||||
|
||||
证书:全称公钥证书(Public-Key Certificate, PKC),里面保存着归属者的基本信息,以及证书过期时间、归属者的公钥,并由认证机构(Certification Authority, **CA**)施加数字签名,表明,某个认证机构认定该公钥的确属于此人
|
||||
|
||||
>想象这个场景:你想在支付宝页面交易,你需要支付宝的公钥进行加密通信,于是你从百度上搜索关键字“支付宝公钥”,你获得了支什宝的公钥,这个时候,支什宝通过中间人攻击,让你访问到了他们支什宝的页面,最后你在这个支什宝页面完美的使用了支什宝的公钥完成了与支什宝的交易
|
||||
>![证书过程][5]
|
||||
|
||||
在上面的场景中,你可以理解支付宝证书就是由支付宝的公钥、和给支付宝颁发证书的企业的数字签名组成
|
||||
任何人都可以给自己或别人的公钥添加自己的数字签名,表明:我拿我的尊严担保,我的公钥/别人的公钥是真的,至于信不信那是另一回事了
|
||||
|
||||
### 3.2.6. 密码小结
|
||||
|
||||
| 密码 | 作用 | 组成 |
|
||||
| :-- | :-- | :-- |
|
||||
| 消息认证码 | 确认消息的完整、并对消息的来源认证 | 共享秘钥+消息的散列值 |
|
||||
| 数字签名 | 对消息的散列值签名 | 公钥+私钥+消息的散列值 |
|
||||
| 公钥密码 | 解决秘钥的配送问题 | 公钥+私钥+消息 |
|
||||
| 证书 | 解决公钥的归属问题 | 公钥密码中的公钥+数字签名 |
|
||||
|
||||
## 3.3. TLS 使用的密码技术
|
||||
|
||||
1. 伪随机数生成器:秘钥生成随机性,更难被猜测
|
||||
2. 对称密码:对称密码使用的秘钥就是由伪随机数生成,相较于非对称密码,效率更高
|
||||
3. 消息认证码:保证消息信息的完整性、以及验证消息信息的来源
|
||||
4. 公钥密码:证书技术使用的就是公钥密码
|
||||
5. 数字签名:验证证书的签名,确定由真实的某个 CA 颁发
|
||||
6. 证书:解决公钥的真实归属问题,降低中间人攻击概率
|
||||
|
||||
## 3.4. TLS 总结
|
||||
|
||||
TLS 是一系列密码工具的框架,作为框架,它也是非常的灵活,体现在每个工具套件它都可以替换,即:客户端与服务端之间协商密码套件,从而更难的被攻破,例如使用不同方式的对称密码,或者公钥密码、数字签名生成方式、单向散列函数技术的替换等
|
||||
|
||||
# 4. RSA 简单示例
|
||||
|
||||
RSA 是一种公钥密码算法,我们简单的走一遍它的加密解密过程
|
||||
加密算法:密文 = (明文^E) mod N,其中公钥为{E,N},即”求明文的E次方的对 N 的余数“
|
||||
解密算法:明文 = (密文^D) mod N,其中秘钥为{D,N},即”求密文的D次方的对 N 的余数“
|
||||
例:我们已知公钥为{5,323},私钥为{29,323},明文为300,请写出加密和解密的过程:
|
||||
>加密:密文 = 123 ^ 5 mod 323 = 225
|
||||
>解密:明文 = 225 ^ 29 mod 323 = [[(225 ^ 5) mod 323] * [(225 ^ 5) mod 323] * [(225 ^ 5) mod 323] * [(225 ^ 5) mod 323] * [(225 ^ 5) mod 323] * [(225 ^ 4) mod 323]] mod 323 = (4 * 4 * 4 * 4 * 4 * 290) mod 323 = 123
|
||||
|
||||
# 5. 参考
|
||||
|
||||
1. SSL加密发生在哪里:<https://security.stackexchange.com/questions/19681/where-does-ssl-encryption-take-place>
|
||||
2. TLS工作流程:<https://blog.csdn.net/ustccw/article/details/76691248>
|
||||
3. 《图解密码技术》:<https://book.douban.com/subject/26822106/> 豆瓣评分 9.5
|
||||
|
||||
[1]: https://leran2deeplearnjavawebtech.oss-cn-beijing.aliyuncs.com/somephoto/%E4%B8%83%E5%B1%82.png
|
||||
[2]: https://leran2deeplearnjavawebtech.oss-cn-beijing.aliyuncs.com/somephoto/tls%E6%B5%81%E7%A8%8B.png
|
||||
[3]: https://leran2deeplearnjavawebtech.oss-cn-beijing.aliyuncs.com/somephoto/%E6%B6%88%E6%81%AF%E8%AE%A4%E8%AF%81%E7%A0%81%E8%BF%87%E7%A8%8B.png
|
||||
[4]: https://leran2deeplearnjavawebtech.oss-cn-beijing.aliyuncs.com/somephoto/%E6%95%B0%E5%AD%97%E7%AD%BE%E5%90%8D%E8%BF%87%E7%A8%8B.png
|
||||
[5]: https://leran2deeplearnjavawebtech.oss-cn-beijing.aliyuncs.com/somephoto/dns%E4%B8%AD%E9%97%B4%E4%BA%BA%E6%94%BB%E5%87%BB.png
|
||||
282
计算机网络与数据通信/dubbo.md
Normal file
282
计算机网络与数据通信/dubbo.md
Normal file
@ -0,0 +1,282 @@
|
||||
本文是作者根据官方文档以及自己平时的使用情况,对 Dubbo 所做的一个总结。如果不懂 Dubbo 的使用的话,可以参考我的这篇文章[《超详细,新手都能看懂 !使用SpringBoot+Dubbo 搭建一个简单的分布式服务》](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484706&idx=1&sn=d413fc17023482f67ca17cb6756b9ff8&chksm=fd985343caefda555969568fdf4734536e0a1745f9de337d434a7dbd04e893bd2d75f3641aab&token=1902169190&lang=zh_CN#rd)
|
||||
|
||||
Dubbo 官网:http://dubbo.apache.org/zh-cn/index.html
|
||||
|
||||
Dubbo 中文文档: http://dubbo.apache.org/zh-cn/index.html
|
||||
|
||||
<!-- MarkdownTOC -->
|
||||
|
||||
- [一 重要的概念](#一-重要的概念)
|
||||
- [1.1 什么是 Dubbo?](#11-什么是-dubbo)
|
||||
- [1.2 什么是 RPC?RPC原理是什么?](#12-什么是-rpcrpc原理是什么)
|
||||
- [1.3 为什么要用 Dubbo?](#13-为什么要用-dubbo)
|
||||
- [1.4 什么是分布式?](#14-什么是分布式)
|
||||
- [1.5 为什么要分布式?](#15-为什么要分布式)
|
||||
- [二 Dubbo 的架构](#二-dubbo-的架构)
|
||||
- [2.1 Dubbo 的架构图解](#21-dubbo-的架构图解)
|
||||
- [2.2 Dubbo 工作原理](#22-dubbo-工作原理)
|
||||
- [三 Dubbo 的负载均衡策略](#三-dubbo-的负载均衡策略)
|
||||
- [3.1 先来解释一下什么是负载均衡](#31-先来解释一下什么是负载均衡)
|
||||
- [3.2 再来看看 Dubbo 提供的负载均衡策略](#32-再来看看-dubbo-提供的负载均衡策略)
|
||||
- [3.2.1 Random LoadBalance\(默认,基于权重的随机负载均衡机制\)](#321-random-loadbalance默认基于权重的随机负载均衡机制)
|
||||
- [3.2.2 RoundRobin LoadBalance\(不推荐,基于权重的轮询负载均衡机制\)](#322-roundrobin-loadbalance不推荐基于权重的轮询负载均衡机制)
|
||||
- [3.2.3 LeastActive LoadBalance](#323-leastactive-loadbalance)
|
||||
- [3.2.4 ConsistentHash LoadBalance](#324-consistenthash-loadbalance)
|
||||
- [3.3 配置方式](#33-配置方式)
|
||||
- [四 zookeeper宕机与dubbo直连的情况](#四-zookeeper宕机与dubbo直连的情况)
|
||||
|
||||
<!-- /MarkdownTOC -->
|
||||
|
||||
|
||||
## 一 重要的概念
|
||||
|
||||
### 1.1 什么是 Dubbo?
|
||||
|
||||
Apache Dubbo (incubating) |ˈdʌbəʊ| 是一款高性能、轻量级的开源Java RPC 框架,它提供了三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。简单来说 Dubbo 是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案。
|
||||
|
||||
Dubbo 目前已经有接近 23k 的 Star ,Dubbo的Github 地址:[https://github.com/apache/incubator-dubbo](https://github.com/apache/incubator-dubbo) 。 另外,在开源中国举行的2018年度最受欢迎中国开源软件这个活动的评选中,Dubbo 更是凭借其超高人气仅次于 vue.js 和 ECharts 获得第三名的好成绩。
|
||||
|
||||
Dubbo 是由阿里开源,后来加入了 Apache 。正式由于 Dubbo 的出现,才使得越来越多的公司开始使用以及接受分布式架构。
|
||||
|
||||
**我们上面说了 Dubbo 实际上是 RPC 框架,那么什么是 RPC呢?**
|
||||
|
||||
### 1.2 什么是 RPC?RPC原理是什么?
|
||||
|
||||
**什么是 RPC?**
|
||||
|
||||
RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。比如两个不同的服务A,B部署在两台不同的机器上,那么服务 A 如果想要调用服务 B 中的某个方法该怎么办呢?使用 HTTP请求 当然可以,但是可能会比较慢而且一些优化做的并不好。 RPC 的出现就是为了解决这个问题。
|
||||
|
||||
**RPC原理是什么?**
|
||||
|
||||
我这里这是简单的提一下。详细内容可以查看下面这篇文章:
|
||||
|
||||
[http://www.importnew.com/22003.html](http://www.importnew.com/22003.html)
|
||||
|
||||
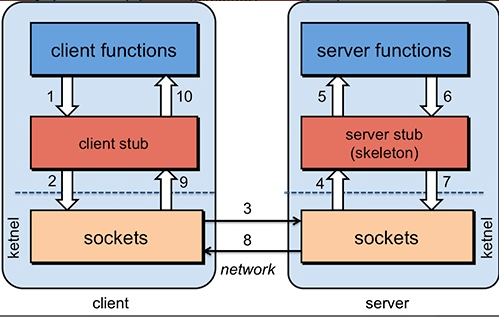
|
||||
|
||||
|
||||
1. 服务消费方(client)调用以本地调用方式调用服务;
|
||||
2. client stub接收到调用后负责将方法、参数等组装成能够进行网络传输的消息体;
|
||||
3. client stub找到服务地址,并将消息发送到服务端;
|
||||
4. server stub收到消息后进行解码;
|
||||
5. server stub根据解码结果调用本地的服务;
|
||||
6. 本地服务执行并将结果返回给server stub;
|
||||
7. server stub将返回结果打包成消息并发送至消费方;
|
||||
8. client stub接收到消息,并进行解码;
|
||||
9. 服务消费方得到最终结果。
|
||||
|
||||
下面再贴一个网上的时序图:
|
||||
|
||||
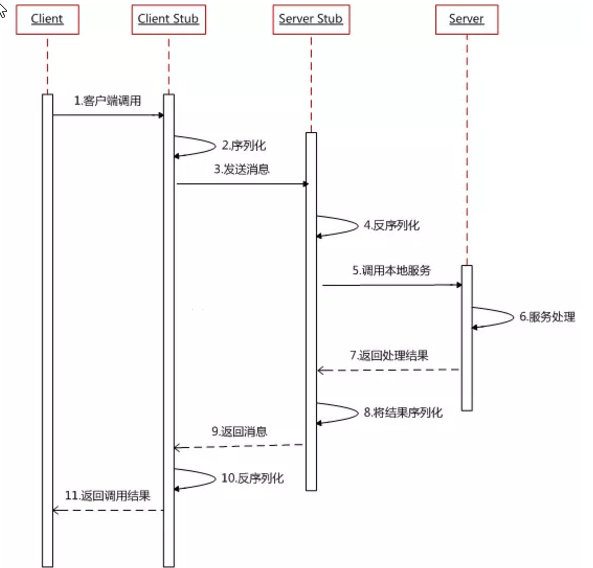
|
||||
|
||||
**说了这么多,我们为什么要用 Dubbo 呢?**
|
||||
|
||||
### 1.3 为什么要用 Dubbo?
|
||||
|
||||
Dubbo 的诞生和 SOA 分布式架构的流行有着莫大的关系。SOA 面向服务的架构(Service Oriented Architecture),也就是把工程按照业务逻辑拆分成服务层、表现层两个工程。服务层中包含业务逻辑,只需要对外提供服务即可。表现层只需要处理和页面的交互,业务逻辑都是调用服务层的服务来实现。SOA架构中有两个主要角色:服务提供者(Provider)和服务使用者(Consumer)。
|
||||
|
||||
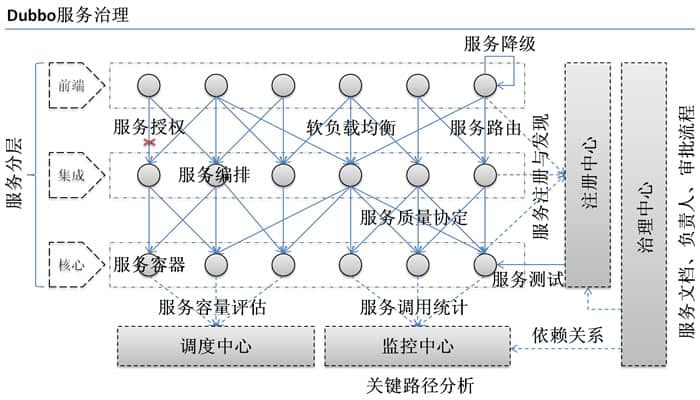
|
||||
|
||||
**如果你要开发分布式程序,你也可以直接基于 HTTP 接口进行通信,但是为什么要用 Dubbo呢?**
|
||||
|
||||
我觉得主要可以从 Dubbo 提供的下面四点特性来说为什么要用 Dubbo:
|
||||
|
||||
1. **负载均衡**——同一个服务部署在不同的机器时该调用那一台机器上的服务
|
||||
2. **服务调用链路生成**——随着系统的发展,服务越来越多,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。Dubbo 可以为我们解决服务之间互相是如何调用的。
|
||||
3. **服务访问压力以及时长统计、资源调度和治理**——基于访问压力实时管理集群容量,提高集群利用率。
|
||||
4. **服务降级**——某个服务挂掉之后调用备用服务
|
||||
|
||||
另外,Dubbo 除了能够应用在分布式系统中,也可以应用在现在比较火的微服务系统中。不过,由于 Spring Cloud 在微服务中应用更加广泛,所以,我觉得一般我们提 Dubbo 的话,大部分是分布式系统的情况。
|
||||
|
||||
**我们刚刚提到了分布式这个概念,下面再给大家介绍一下什么是分布式?为什么要分布式?**
|
||||
|
||||
### 1.4 什么是分布式?
|
||||
|
||||
分布式或者说 SOA 分布式重要的就是面向服务,说简单的分布式就是我们把整个系统拆分成不同的服务然后将这些服务放在不同的服务器上减轻单体服务的压力提高并发量和性能。比如电商系统可以简单地拆分成订单系统、商品系统、登录系统等等,拆分之后的每个服务可以部署在不同的机器上,如果某一个服务的访问量比较大的话也可以将这个服务同时部署在多台机器上。
|
||||
|
||||
### 1.5 为什么要分布式?
|
||||
|
||||
从开发角度来讲单体应用的代码都集中在一起,而分布式系统的代码根据业务被拆分。所以,每个团队可以负责一个服务的开发,这样提升了开发效率。另外,代码根据业务拆分之后更加便于维护和扩展。
|
||||
|
||||
另外,我觉得将系统拆分成分布式之后不光便于系统扩展和维护,更能提高整个系统的性能。你想一想嘛?把整个系统拆分成不同的服务/系统,然后每个服务/系统 单独部署在一台服务器上,是不是很大程度上提高了系统性能呢?
|
||||
|
||||
## 二 Dubbo 的架构
|
||||
|
||||
### 2.1 Dubbo 的架构图解
|
||||
|
||||
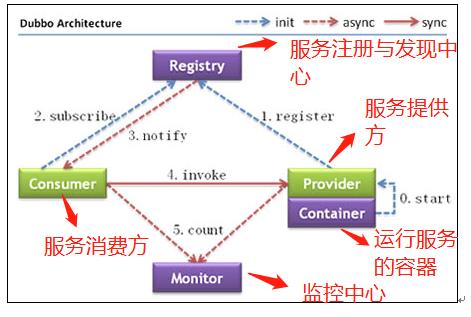
|
||||
|
||||
**上述节点简单说明:**
|
||||
|
||||
- **Provider:** 暴露服务的服务提供方
|
||||
- **Consumer:** 调用远程服务的服务消费方
|
||||
- **Registry:** 服务注册与发现的注册中心
|
||||
- **Monitor:** 统计服务的调用次数和调用时间的监控中心
|
||||
- **Container:** 服务运行容器
|
||||
|
||||
**调用关系说明:**
|
||||
|
||||
1. 服务容器负责启动,加载,运行服务提供者。
|
||||
2. 服务提供者在启动时,向注册中心注册自己提供的服务。
|
||||
3. 服务消费者在启动时,向注册中心订阅自己所需的服务。
|
||||
4. 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
|
||||
5. 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
|
||||
6. 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
|
||||
|
||||
**重要知识点总结:**
|
||||
|
||||
- **注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小**
|
||||
- **监控中心负责统计各服务调用次数,调用时间等,统计先在内存汇总后每分钟一次发送到监控中心服务器,并以报表展示**
|
||||
- **注册中心,服务提供者,服务消费者三者之间均为长连接,监控中心除外**
|
||||
- **注册中心通过长连接感知服务提供者的存在,服务提供者宕机,注册中心将立即推送事件通知消费者**
|
||||
- **注册中心和监控中心全部宕机,不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表**
|
||||
- **注册中心和监控中心都是可选的,服务消费者可以直连服务提供者**
|
||||
- **服务提供者无状态,任意一台宕掉后,不影响使用**
|
||||
- **服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复**
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
### 2.2 Dubbo 工作原理
|
||||
|
||||
|
||||
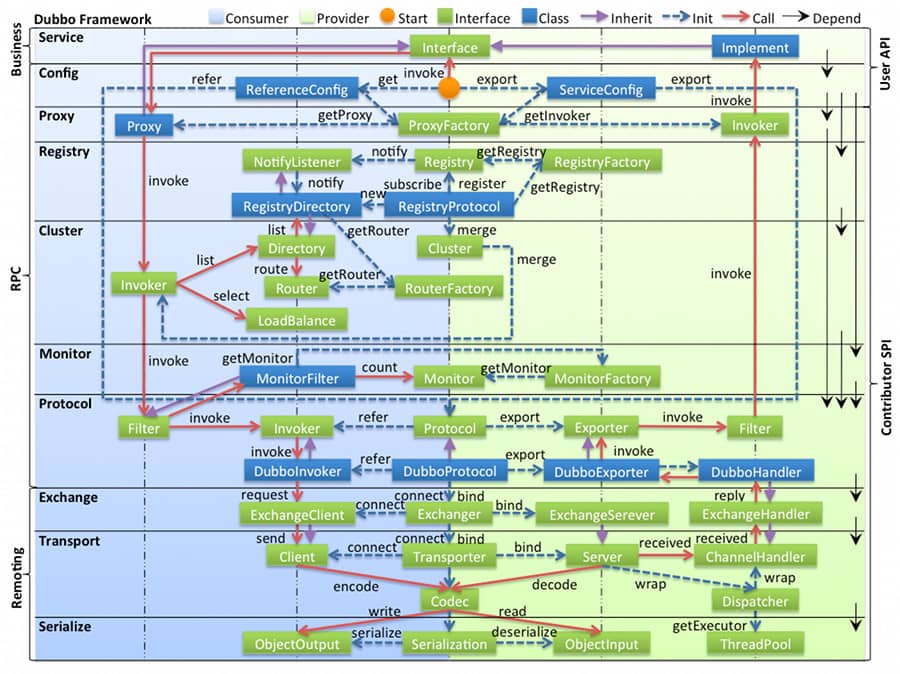
|
||||
|
||||
图中从下至上分为十层,各层均为单向依赖,右边的黑色箭头代表层之间的依赖关系,每一层都可以剥离上层被复用,其中,Service 和 Config 层为 API,其它各层均为 SPI。
|
||||
|
||||
**各层说明**:
|
||||
|
||||
- 第一层:**service层**,接口层,给服务提供者和消费者来实现的
|
||||
- 第二层:**config层**,配置层,主要是对dubbo进行各种配置的
|
||||
- 第三层:**proxy层**,服务接口透明代理,生成服务的客户端 Stub 和服务器端 Skeleton
|
||||
- 第四层:**registry层**,服务注册层,负责服务的注册与发现
|
||||
- 第五层:**cluster层**,集群层,封装多个服务提供者的路由以及负载均衡,将多个实例组合成一个服务
|
||||
- 第六层:**monitor层**,监控层,对rpc接口的调用次数和调用时间进行监控
|
||||
- 第七层:**protocol层**,远程调用层,封装rpc调用
|
||||
- 第八层:**exchange层**,信息交换层,封装请求响应模式,同步转异步
|
||||
- 第九层:**transport层**,网络传输层,抽象mina和netty为统一接口
|
||||
- 第十层:**serialize层**,数据序列化层。网络传输需要。
|
||||
|
||||
|
||||
## 三 Dubbo 的负载均衡策略
|
||||
|
||||
### 3.1 先来解释一下什么是负载均衡
|
||||
|
||||
**先来个官方的解释。**
|
||||
|
||||
> 维基百科对负载均衡的定义:负载均衡改善了跨多个计算资源(例如计算机,计算机集群,网络链接,中央处理单元或磁盘驱动的的工作负载分布。负载平衡旨在优化资源使用,最大化吞吐量,最小化响应时间,并避免任何单个资源的过载。使用具有负载平衡而不是单个组件的多个组件可以通过冗余提高可靠性和可用性。负载平衡通常涉及专用软件或硬件
|
||||
|
||||
**上面讲的大家可能不太好理解,再用通俗的话给大家说一下。**
|
||||
|
||||
比如我们的系统中的某个服务的访问量特别大,我们将这个服务部署在了多台服务器上,当客户端发起请求的时候,多台服务器都可以处理这个请求。那么,如何正确选择处理该请求的服务器就很关键。假如,你就要一台服务器来处理该服务的请求,那该服务部署在多台服务器的意义就不复存在了。负载均衡就是为了避免单个服务器响应同一请求,容易造成服务器宕机、崩溃等问题,我们从负载均衡的这四个字就能明显感受到它的意义。
|
||||
|
||||
### 3.2 再来看看 Dubbo 提供的负载均衡策略
|
||||
|
||||
在集群负载均衡时,Dubbo 提供了多种均衡策略,默认为 `random` 随机调用。可以自行扩展负载均衡策略,参见:[负载均衡扩展](https://dubbo.gitbooks.io/dubbo-dev-book/content/impls/load-balance.html)。
|
||||
|
||||
备注:下面的图片来自于:尚硅谷2018Dubbo 视频。
|
||||
|
||||
|
||||
#### 3.2.1 Random LoadBalance(默认,基于权重的随机负载均衡机制)
|
||||
|
||||
- **随机,按权重设置随机概率。**
|
||||
- 在一个截面上碰撞的概率高,但调用量越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重。
|
||||
|
||||
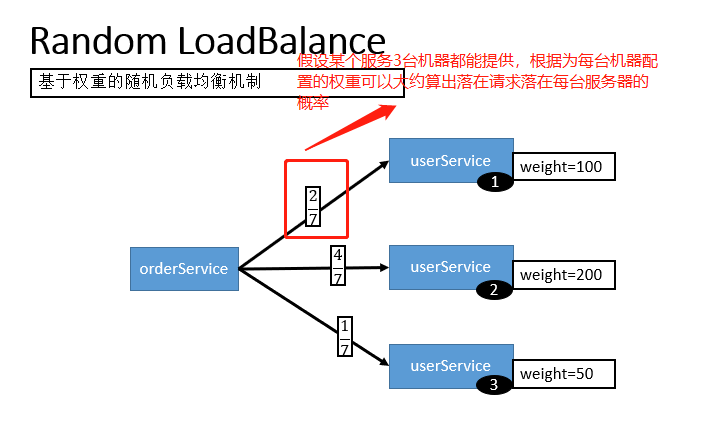
|
||||
|
||||
|
||||
|
||||
#### 3.2.2 RoundRobin LoadBalance(不推荐,基于权重的轮询负载均衡机制)
|
||||
|
||||
- 轮循,按公约后的权重设置轮循比率。
|
||||
- 存在慢的提供者累积请求的问题,比如:第二台机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上。
|
||||
|
||||
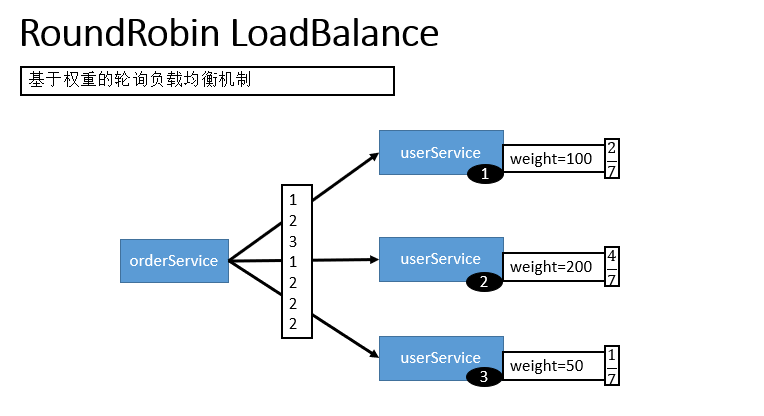
|
||||
|
||||
#### 3.2.3 LeastActive LoadBalance
|
||||
|
||||
- 最少活跃调用数,相同活跃数的随机,活跃数指调用前后计数差。
|
||||
- 使慢的提供者收到更少请求,因为越慢的提供者的调用前后计数差会越大。
|
||||
|
||||
#### 3.2.4 ConsistentHash LoadBalance
|
||||
|
||||
- **一致性 Hash,相同参数的请求总是发到同一提供者。(如果你需要的不是随机负载均衡,是要一类请求都到一个节点,那就走这个一致性hash策略。)**
|
||||
- 当某一台提供者挂时,原本发往该提供者的请求,基于虚拟节点,平摊到其它提供者,不会引起剧烈变动。
|
||||
- 算法参见:http://en.wikipedia.org/wiki/Consistent_hashing
|
||||
- 缺省只对第一个参数 Hash,如果要修改,请配置 `<dubbo:parameter key="hash.arguments" value="0,1" />`
|
||||
- 缺省用 160 份虚拟节点,如果要修改,请配置 `<dubbo:parameter key="hash.nodes" value="320" />`
|
||||
|
||||
### 3.3 配置方式
|
||||
|
||||
**xml 配置方式**
|
||||
|
||||
服务端服务级别
|
||||
|
||||
```java
|
||||
<dubbo:service interface="..." loadbalance="roundrobin" />
|
||||
```
|
||||
客户端服务级别
|
||||
|
||||
```java
|
||||
<dubbo:reference interface="..." loadbalance="roundrobin" />
|
||||
```
|
||||
|
||||
服务端方法级别
|
||||
|
||||
```java
|
||||
<dubbo:service interface="...">
|
||||
<dubbo:method name="..." loadbalance="roundrobin"/>
|
||||
</dubbo:service>
|
||||
```
|
||||
|
||||
客户端方法级别
|
||||
|
||||
```java
|
||||
<dubbo:reference interface="...">
|
||||
<dubbo:method name="..." loadbalance="roundrobin"/>
|
||||
</dubbo:reference>
|
||||
```
|
||||
|
||||
**注解配置方式:**
|
||||
|
||||
消费方基于基于注解的服务级别配置方式:
|
||||
|
||||
```java
|
||||
@Reference(loadbalance = "roundrobin")
|
||||
HelloService helloService;
|
||||
```
|
||||
|
||||
## 四 zookeeper宕机与dubbo直连的情况
|
||||
|
||||
zookeeper宕机与dubbo直连的情况在面试中可能会被经常问到,所以要引起重视。
|
||||
|
||||
在实际生产中,假如zookeeper注册中心宕掉,一段时间内服务消费方还是能够调用提供方的服务的,实际上它使用的本地缓存进行通讯,这只是dubbo健壮性的一种提现。
|
||||
|
||||
**dubbo的健壮性表现:**
|
||||
|
||||
1. 监控中心宕掉不影响使用,只是丢失部分采样数据
|
||||
2. 数据库宕掉后,注册中心仍能通过缓存提供服务列表查询,但不能注册新服务
|
||||
3. 注册中心对等集群,任意一台宕掉后,将自动切换到另一台
|
||||
4. 注册中心全部宕掉后,服务提供者和服务消费者仍能通过本地缓存通讯
|
||||
5. 服务提供者无状态,任意一台宕掉后,不影响使用
|
||||
5. 服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复
|
||||
|
||||
我们前面提到过:注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小。所以,我们可以完全可以绕过注册中心——采用 **dubbo 直连** ,即在服务消费方配置服务提供方的位置信息。
|
||||
|
||||
|
||||
**xml配置方式:**
|
||||
|
||||
```xml
|
||||
<dubbo:reference id="userService" interface="com.zang.gmall.service.UserService" url="dubbo://localhost:20880" />
|
||||
```
|
||||
|
||||
**注解方式:**
|
||||
|
||||
```java
|
||||
@Reference(url = "127.0.0.1:20880")
|
||||
HelloService helloService;
|
||||
```
|
||||
|
||||
|
||||
|
||||
152
计算机网络与数据通信/message-queue.md
Normal file
152
计算机网络与数据通信/message-queue.md
Normal file
@ -0,0 +1,152 @@
|
||||
<!-- MarkdownTOC -->
|
||||
|
||||
- [消息队列其实很简单](#消息队列其实很简单)
|
||||
- [一 什么是消息队列](#一-什么是消息队列)
|
||||
- [二 为什么要用消息队列](#二-为什么要用消息队列)
|
||||
- [\(1\) 通过异步处理提高系统性能(削峰、减少响应所需时间)](#1-通过异步处理提高系统性能削峰减少响应所需时间)
|
||||
- [\(2\) 降低系统耦合性](#2-降低系统耦合性)
|
||||
- [三 使用消息队列带来的一些问题](#三-使用消息队列带来的一些问题)
|
||||
- [四 JMS VS AMQP](#四-jms-vs-amqp)
|
||||
- [4.1 JMS](#41-jms)
|
||||
- [4.1.1 JMS 简介](#411-jms-简介)
|
||||
- [4.1.2 JMS两种消息模型](#412-jms两种消息模型)
|
||||
- [4.1.3 JMS 五种不同的消息正文格式](#413-jms-五种不同的消息正文格式)
|
||||
- [4.2 AMQP](#42-amqp)
|
||||
- [4.3 JMS vs AMQP](#43-jms-vs-amqp)
|
||||
- [五 常见的消息队列对比](#五-常见的消息队列对比)
|
||||
|
||||
<!-- /MarkdownTOC -->
|
||||
|
||||
|
||||
# 消息队列其实很简单
|
||||
|
||||
“RabbitMQ?”“Kafka?”“RocketMQ?”...在日常学习与开发过程中,我们常常听到消息队列这个关键词。我也在我的多篇文章中提到了这个概念。可能你是熟练使用消息队列的老手,又或者你是不懂消息队列的新手,不论你了不了解消息队列,本文都将带你搞懂消息队列的一些基本理论。如果你是老手,你可能从本文学到你之前不曾注意的一些关于消息队列的重要概念,如果你是新手,相信本文将是你打开消息队列大门的一板砖。
|
||||
|
||||
## 一 什么是消息队列
|
||||
|
||||
我们可以把消息队列比作是一个存放消息的容器,当我们需要使用消息的时候可以取出消息供自己使用。消息队列是分布式系统中重要的组件,使用消息队列主要是为了通过异步处理提高系统性能和削峰、降低系统耦合性。目前使用较多的消息队列有ActiveMQ,RabbitMQ,Kafka,RocketMQ,我们后面会一一对比这些消息队列。
|
||||
|
||||
另外,我们知道队列 Queue 是一种先进先出的数据结构,所以消费消息时也是按照顺序来消费的。比如生产者发送消息1,2,3...对于消费者就会按照1,2,3...的顺序来消费。但是偶尔也会出现消息被消费的顺序不对的情况,比如某个消息消费失败又或者一个 queue 多个consumer 也会导致消息被消费的顺序不对,我们一定要保证消息被消费的顺序正确。
|
||||
|
||||
除了上面说的消息消费顺序的问题,使用消息队列,我们还要考虑如何保证消息不被重复消费?如何保证消息的可靠性传输(如何处理消息丢失的问题)?......等等问题。所以说使用消息队列也不是十全十美的,使用它也会让系统可用性降低、复杂度提高,另外需要我们保障一致性等问题。
|
||||
|
||||
## 二 为什么要用消息队列
|
||||
|
||||
我觉得使用消息队列主要有两点好处:1.通过异步处理提高系统性能(削峰、减少响应所需时间);2.降低系统耦合性。如果在面试的时候你被面试官问到这个问题的话,一般情况是你在你的简历上涉及到消息队列这方面的内容,这个时候推荐你结合你自己的项目来回答。
|
||||
|
||||
|
||||
《大型网站技术架构》第四章和第七章均有提到消息队列对应用性能及扩展性的提升。
|
||||
|
||||
### (1) 通过异步处理提高系统性能(削峰、减少响应所需时间)
|
||||
|
||||

|
||||
如上图,**在不使用消息队列服务器的时候,用户的请求数据直接写入数据库,在高并发的情况下数据库压力剧增,使得响应速度变慢。但是在使用消息队列之后,用户的请求数据发送给消息队列之后立即 返回,再由消息队列的消费者进程从消息队列中获取数据,异步写入数据库。由于消息队列服务器处理速度快于数据库(消息队列也比数据库有更好的伸缩性),因此响应速度得到大幅改善。**
|
||||
|
||||
通过以上分析我们可以得出**消息队列具有很好的削峰作用的功能**——即**通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。** 举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
|
||||

|
||||
|
||||
因为**用户请求数据写入消息队列之后就立即返回给用户了,但是请求数据在后续的业务校验、写数据库等操作中可能失败**。因此使用消息队列进行异步处理之后,需要**适当修改业务流程进行配合**,比如**用户在提交订单之后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功**,以免交易纠纷。这就类似我们平时手机订火车票和电影票。
|
||||
|
||||
### (2) 降低系统耦合性
|
||||
|
||||
我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。
|
||||
|
||||
我们最常见的**事件驱动架构**类似生产者消费者模式,在大型网站中通常用利用消息队列实现事件驱动结构。如下图所示:
|
||||
|
||||

|
||||
|
||||
**消息队列使利用发布-订阅模式工作,消息发送者(生产者)发布消息,一个或多个消息接受者(消费者)订阅消息。** 从上图可以看到**消息发送者(生产者)和消息接受者(消费者)之间没有直接耦合**,消息发送者将消息发送至分布式消息队列即结束对消息的处理,消息接受者从分布式消息队列获取该消息后进行后续处理,并不需要知道该消息从何而来。**对新增业务,只要对该类消息感兴趣,即可订阅该消息,对原有系统和业务没有任何影响,从而实现网站业务的可扩展性设计**。
|
||||
|
||||
消息接受者对消息进行过滤、处理、包装后,构造成一个新的消息类型,将消息继续发送出去,等待其他消息接受者订阅该消息。因此基于事件(消息对象)驱动的业务架构可以是一系列流程。
|
||||
|
||||
**另外为了避免消息队列服务器宕机造成消息丢失,会将成功发送到消息队列的消息存储在消息生产者服务器上,等消息真正被消费者服务器处理后才删除消息。在消息队列服务器宕机后,生产者服务器会选择分布式消息队列服务器集群中的其他服务器发布消息。**
|
||||
|
||||
**备注:** 不要认为消息队列只能利用发布-订阅模式工作,只不过在解耦这个特定业务环境下是使用发布-订阅模式的。**除了发布-订阅模式,还有点对点订阅模式(一个消息只有一个消费者),我们比较常用的是发布-订阅模式。** 另外,这两种消息模型是 JMS 提供的,AMQP 协议还提供了 5 种消息模型。
|
||||
|
||||
## 三 使用消息队列带来的一些问题
|
||||
|
||||
- **系统可用性降低:** 系统可用性在某种程度上降低,为什么这样说呢?在加入MQ之前,你不用考虑消息丢失或者说MQ挂掉等等的情况,但是,引入MQ之后你就需要去考虑了!
|
||||
- **系统复杂性提高:** 加入MQ之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
|
||||
- **一致性问题:** 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
|
||||
|
||||
## 四 JMS VS AMQP
|
||||
|
||||
### 4.1 JMS
|
||||
|
||||
#### 4.1.1 JMS 简介
|
||||
|
||||
JMS(JAVA Message Service,java消息服务)是java的消息服务,JMS的客户端之间可以通过JMS服务进行异步的消息传输。**JMS(JAVA Message Service,Java消息服务)API是一个消息服务的标准或者说是规范**,允许应用程序组件基于JavaEE平台创建、发送、接收和读取消息。它使分布式通信耦合度更低,消息服务更加可靠以及异步性。
|
||||
|
||||
**ActiveMQ 就是基于 JMS 规范实现的。**
|
||||
|
||||
#### 4.1.2 JMS两种消息模型
|
||||
|
||||
①点到点(P2P)模型
|
||||
|
||||

|
||||
使用**队列(Queue)**作为消息通信载体;满足**生产者与消费者模式**,一条消息只能被一个消费者使用,未被消费的消息在队列中保留直到被消费或超时。比如:我们生产者发送100条消息的话,两个消费者来消费一般情况下两个消费者会按照消息发送的顺序各自消费一半(也就是你一个我一个的消费。)
|
||||
|
||||
② 发布/订阅(Pub/Sub)模型
|
||||
|
||||

|
||||
发布订阅模型(Pub/Sub) 使用**主题(Topic)**作为消息通信载体,类似于**广播模式**;发布者发布一条消息,该消息通过主题传递给所有的订阅者,**在一条消息广播之后才订阅的用户则是收不到该条消息的**。
|
||||
|
||||
#### 4.1.3 JMS 五种不同的消息正文格式
|
||||
|
||||
JMS定义了五种不同的消息正文格式,以及调用的消息类型,允许你发送并接收以一些不同形式的数据,提供现有消息格式的一些级别的兼容性。
|
||||
|
||||
- StreamMessage -- Java原始值的数据流
|
||||
- MapMessage--一套名称-值对
|
||||
- TextMessage--一个字符串对象
|
||||
- ObjectMessage--一个序列化的 Java对象
|
||||
- BytesMessage--一个字节的数据流
|
||||
|
||||
|
||||
### 4.2 AMQP
|
||||
|
||||
AMQP,即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准 **高级消息队列协议**(二进制应用层协议),是应用层协议的一个开放标准,为面向消息的中间件设计,兼容 JMS。基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件同产品,不同的开发语言等条件的限制。
|
||||
|
||||
**RabbitMQ 就是基于 AMQP 协议实现的。**
|
||||
|
||||
|
||||
|
||||
### 4.3 JMS vs AMQP
|
||||
|
||||
|
||||
|对比方向| JMS | AMQP |
|
||||
| :-------- | --------:| :--: |
|
||||
| 定义| Java API | 协议 |
|
||||
| 跨语言 | 否 | 是 |
|
||||
| 跨平台 | 否 | 是 |
|
||||
| 支持消息类型 | 提供两种消息模型:①Peer-2-Peer;②Pub/sub| 提供了五种消息模型:①direct exchange;②fanout exchange;③topic change;④headers exchange;⑤system exchange。本质来讲,后四种和JMS的pub/sub模型没有太大差别,仅是在路由机制上做了更详细的划分;|
|
||||
|支持消息类型| 支持多种消息类型 ,我们在上面提到过| byte[](二进制)|
|
||||
|
||||
**总结:**
|
||||
|
||||
- AMQP 为消息定义了线路层(wire-level protocol)的协议,而JMS所定义的是API规范。在 Java 体系中,多个client均可以通过JMS进行交互,不需要应用修改代码,但是其对跨平台的支持较差。而AMQP天然具有跨平台、跨语言特性。
|
||||
- JMS 支持TextMessage、MapMessage 等复杂的消息类型;而 AMQP 仅支持 byte[] 消息类型(复杂的类型可序列化后发送)。
|
||||
- 由于Exchange 提供的路由算法,AMQP可以提供多样化的路由方式来传递消息到消息队列,而 JMS 仅支持 队列 和 主题/订阅 方式两种。
|
||||
|
||||
|
||||
## 五 常见的消息队列对比
|
||||
|
||||
|
||||
|
||||
对比方向 |概要
|
||||
-------- | ---
|
||||
吞吐量| 万级的 ActiveMQ 和 RabbitMQ 的吞吐量(ActiveMQ 的性能最差)要比 十万级甚至是百万级的 RocketMQ 和 Kafka 低一个数量级。
|
||||
可用性| 都可以实现高可用。ActiveMQ 和 RabbitMQ 都是基于主从架构实现高可用性。RocketMQ 基于分布式架构。 kafka 也是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用
|
||||
时效性| RabbitMQ 基于erlang开发,所以并发能力很强,性能极其好,延时很低,达到微秒级。其他三个都是 ms 级。
|
||||
功能支持| 除了 Kafka,其他三个功能都较为完备。 Kafka 功能较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准
|
||||
消息丢失| ActiveMQ 和 RabbitMQ 丢失的可能性非常低, RocketMQ 和 Kafka 理论上不会丢失。
|
||||
|
||||
|
||||
**总结:**
|
||||
|
||||
- ActiveMQ 的社区算是比较成熟,但是较目前来说,ActiveMQ 的性能比较差,而且版本迭代很慢,不推荐使用。
|
||||
- RabbitMQ 在吞吐量方面虽然稍逊于 Kafka 和 RocketMQ ,但是由于它基于 erlang 开发,所以并发能力很强,性能极其好,延时很低,达到微秒级。但是也因为 RabbitMQ 基于 erlang 开发,所以国内很少有公司有实力做erlang源码级别的研究和定制。如果业务场景对并发量要求不是太高(十万级、百万级),那这四种消息队列中,RabbitMQ 一定是你的首选。如果是大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的,绝对没问题,社区活跃度很高,绝对不会黄,何况几乎是全世界这个领域的事实性规范。
|
||||
- RocketMQ 阿里出品,Java 系开源项目,源代码我们可以直接阅读,然后可以定制自己公司的MQ,并且 RocketMQ 有阿里巴巴的实际业务场景的实战考验。RocketMQ 社区活跃度相对较为一般,不过也还可以,文档相对来说简单一些,然后接口这块不是按照标准 JMS 规范走的有些系统要迁移需要修改大量代码。还有就是阿里出台的技术,你得做好这个技术万一被抛弃,社区黄掉的风险,那如果你们公司有技术实力我觉得用RocketMQ 挺好的
|
||||
- kafka 的特点其实很明显,就是仅仅提供较少的核心功能,但是提供超高的吞吐量,ms 级的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展。同时 kafka 最好是支撑较少的 topic 数量即可,保证其超高吞吐量。kafka 唯一的一点劣势是有可能消息重复消费,那么对数据准确性会造成极其轻微的影响,在大数据领域中以及日志采集中,这点轻微影响可以忽略这个特性天然适合大数据实时计算以及日志收集。
|
||||
|
||||
|
||||
参考:《Java工程师面试突击第1季-中华石杉老师》
|
||||
320
计算机网络与数据通信/rabbitmq.md
Normal file
320
计算机网络与数据通信/rabbitmq.md
Normal file
@ -0,0 +1,320 @@
|
||||
<!-- TOC -->
|
||||
|
||||
- [一文搞懂 RabbitMQ 的重要概念以及安装](#一文搞懂-rabbitmq-的重要概念以及安装)
|
||||
- [一 RabbitMQ 介绍](#一-rabbitmq-介绍)
|
||||
- [1.1 RabbitMQ 简介](#11-rabbitmq-简介)
|
||||
- [1.2 RabbitMQ 核心概念](#12-rabbitmq-核心概念)
|
||||
- [1.2.1 Producer(生产者) 和 Consumer(消费者)](#121-producer生产者-和-consumer消费者)
|
||||
- [1.2.2 Exchange(交换器)](#122-exchange交换器)
|
||||
- [1.2.3 Queue(消息队列)](#123-queue消息队列)
|
||||
- [1.2.4 Broker(消息中间件的服务节点)](#124-broker消息中间件的服务节点)
|
||||
- [1.2.5 Exchange Types(交换器类型)](#125-exchange-types交换器类型)
|
||||
- [① fanout](#①-fanout)
|
||||
- [② direct](#②-direct)
|
||||
- [③ topic](#③-topic)
|
||||
- [④ headers(不推荐)](#④-headers不推荐)
|
||||
- [二 安装 RabbitMq](#二-安装-rabbitmq)
|
||||
- [2.1 安装 erlang](#21-安装-erlang)
|
||||
- [2.2 安装 RabbitMQ](#22-安装-rabbitmq)
|
||||
|
||||
<!-- /TOC -->
|
||||
|
||||
# 一文搞懂 RabbitMQ 的重要概念以及安装
|
||||
|
||||
## 一 RabbitMQ 介绍
|
||||
|
||||
这部分参考了 《RabbitMQ实战指南》这本书的第 1 章和第 2 章。
|
||||
|
||||
### 1.1 RabbitMQ 简介
|
||||
|
||||
RabbitMQ 是采用 Erlang 语言实现 AMQP(Advanced Message Queuing Protocol,高级消息队列协议)的消息中间件,它最初起源于金融系统,用于在分布式系统中存储转发消息。
|
||||
|
||||
RabbitMQ 发展到今天,被越来越多的人认可,这和它在易用性、扩展性、可靠性和高可用性等方面的卓著表现是分不开的。RabbitMQ 的具体特点可以概括为以下几点:
|
||||
|
||||
- **可靠性:** RabbitMQ使用一些机制来保证消息的可靠性,如持久化、传输确认及发布确认等。
|
||||
- **灵活的路由:** 在消息进入队列之前,通过交换器来路由消息。对于典型的路由功能,RabbitMQ 己经提供了一些内置的交换器来实现。针对更复杂的路由功能,可以将多个交换器绑定在一起,也可以通过插件机制来实现自己的交换器。这个后面会在我们将 RabbitMQ 核心概念的时候详细介绍到。
|
||||
- **扩展性:** 多个RabbitMQ节点可以组成一个集群,也可以根据实际业务情况动态地扩展集群中节点。
|
||||
- **高可用性:** 队列可以在集群中的机器上设置镜像,使得在部分节点出现问题的情况下队列仍然可用。
|
||||
- **支持多种协议:** RabbitMQ 除了原生支持 AMQP 协议,还支持 STOMP、MQTT 等多种消息中间件协议。
|
||||
- **多语言客户端:** RabbitMQ几乎支持所有常用语言,比如 Java、Python、Ruby、PHP、C#、JavaScript等。
|
||||
- **易用的管理界面:** RabbitMQ提供了一个易用的用户界面,使得用户可以监控和管理消息、集群中的节点等。在安装 RabbitMQ 的时候会介绍到,安装好 RabbitMQ 就自带管理界面。
|
||||
- **插件机制:** RabbitMQ 提供了许多插件,以实现从多方面进行扩展,当然也可以编写自己的插件。感觉这个有点类似 Dubbo 的 SPI机制。
|
||||
|
||||
### 1.2 RabbitMQ 核心概念
|
||||
|
||||
RabbitMQ 整体上是一个生产者与消费者模型,主要负责接收、存储和转发消息。可以把消息传递的过程想象成:当你将一个包裹送到邮局,邮局会暂存并最终将邮件通过邮递员送到收件人的手上,RabbitMQ就好比由邮局、邮箱和邮递员组成的一个系统。从计算机术语层面来说,RabbitMQ 模型更像是一种交换机模型。
|
||||
|
||||
下面再来看看图1—— RabbitMQ 的整体模型架构。
|
||||
|
||||
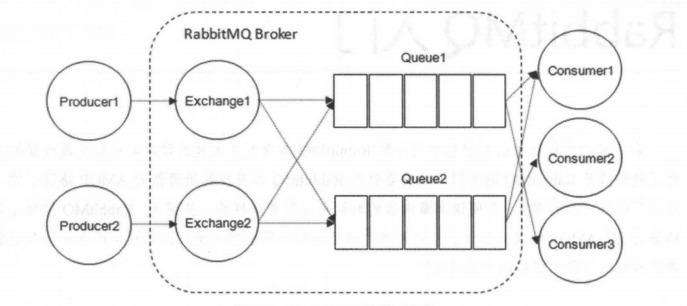
|
||||
|
||||
下面我会一一介绍上图中的一些概念。
|
||||
|
||||
#### 1.2.1 Producer(生产者) 和 Consumer(消费者)
|
||||
|
||||
- **Producer(生产者)** :生产消息的一方(邮件投递者)
|
||||
- **Consumer(消费者)** :消费消息的一方(邮件收件人)
|
||||
|
||||
消息一般由 2 部分组成:**消息头**(或者说是标签 Label)和 **消息体**。消息体也可以称为 payLoad ,消息体是不透明的,而消息头则由一系列的可选属性组成,这些属性包括 routing-key(路由键)、priority(相对于其他消息的优先权)、delivery-mode(指出该消息可能需要持久性存储)等。生产者把消息交由 RabbitMQ 后,RabbitMQ 会根据消息头把消息发送给感兴趣的 Consumer(消费者)。
|
||||
|
||||
#### 1.2.2 Exchange(交换器)
|
||||
|
||||
在 RabbitMQ 中,消息并不是直接被投递到 **Queue(消息队列)** 中的,中间还必须经过 **Exchange(交换器)** 这一层,**Exchange(交换器)** 会把我们的消息分配到对应的 **Queue(消息队列)** 中。
|
||||
|
||||
**Exchange(交换器)** 用来接收生产者发送的消息并将这些消息路由给服务器中的队列中,如果路由不到,或许会返回给 **Producer(生产者)** ,或许会被直接丢弃掉 。这里可以将RabbitMQ中的交换器看作一个简单的实体。
|
||||
|
||||
**RabbitMQ 的 Exchange(交换器) 有4种类型,不同的类型对应着不同的路由策略**:**direct(默认)**,**fanout**, **topic**, 和 **headers**,不同类型的Exchange转发消息的策略有所区别。这个会在介绍 **Exchange Types(交换器类型)** 的时候介绍到。
|
||||
|
||||
Exchange(交换器) 示意图如下:
|
||||
|
||||
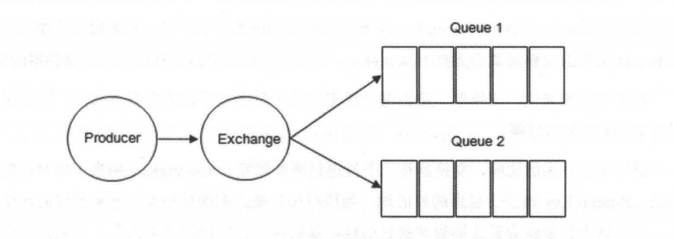
|
||||
|
||||
生产者将消息发给交换器的时候,一般会指定一个 **RoutingKey(路由键)**,用来指定这个消息的路由规则,而这个 **RoutingKey 需要与交换器类型和绑定键(BindingKey)联合使用才能最终生效**。
|
||||
|
||||
RabbitMQ 中通过 **Binding(绑定)** 将 **Exchange(交换器)** 与 **Queue(消息队列)** 关联起来,在绑定的时候一般会指定一个 **BindingKey(绑定建)** ,这样 RabbitMQ 就知道如何正确将消息路由到队列了,如下图所示。一个绑定就是基于路由键将交换器和消息队列连接起来的路由规则,所以可以将交换器理解成一个由绑定构成的路由表。Exchange 和 Queue 的绑定可以是多对多的关系。
|
||||
|
||||
Binding(绑定) 示意图:
|
||||
|
||||
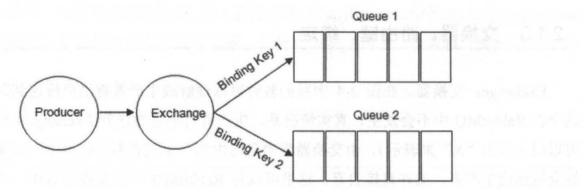
|
||||
|
||||
生产者将消息发送给交换器时,需要一个RoutingKey,当 BindingKey 和 RoutingKey 相匹配时,消息会被路由到对应的队列中。在绑定多个队列到同一个交换器的时候,这些绑定允许使用相同的 BindingKey。BindingKey 并不是在所有的情况下都生效,它依赖于交换器类型,比如fanout类型的交换器就会无视,而是将消息路由到所有绑定到该交换器的队列中。
|
||||
|
||||
#### 1.2.3 Queue(消息队列)
|
||||
|
||||
**Queue(消息队列)** 用来保存消息直到发送给消费者。它是消息的容器,也是消息的终点。一个消息可投入一个或多个队列。消息一直在队列里面,等待消费者连接到这个队列将其取走。
|
||||
|
||||
**RabbitMQ** 中消息只能存储在 **队列** 中,这一点和 **Kafka** 这种消息中间件相反。Kafka 将消息存储在 **topic(主题)** 这个逻辑层面,而相对应的队列逻辑只是topic实际存储文件中的位移标识。 RabbitMQ 的生产者生产消息并最终投递到队列中,消费者可以从队列中获取消息并消费。
|
||||
|
||||
**多个消费者可以订阅同一个队列**,这时队列中的消息会被平均分摊(Round-Robin,即轮询)给多个消费者进行处理,而不是每个消费者都收到所有的消息并处理,这样避免的消息被重复消费。
|
||||
|
||||
**RabbitMQ** 不支持队列层面的广播消费,如果有广播消费的需求,需要在其上进行二次开发,这样会很麻烦,不建议这样做。
|
||||
|
||||
#### 1.2.4 Broker(消息中间件的服务节点)
|
||||
|
||||
对于 RabbitMQ 来说,一个 RabbitMQ Broker 可以简单地看作一个 RabbitMQ 服务节点,或者RabbitMQ服务实例。大多数情况下也可以将一个 RabbitMQ Broker 看作一台 RabbitMQ 服务器。
|
||||
|
||||
下图展示了生产者将消息存入 RabbitMQ Broker,以及消费者从Broker中消费数据的整个流程。
|
||||
|
||||
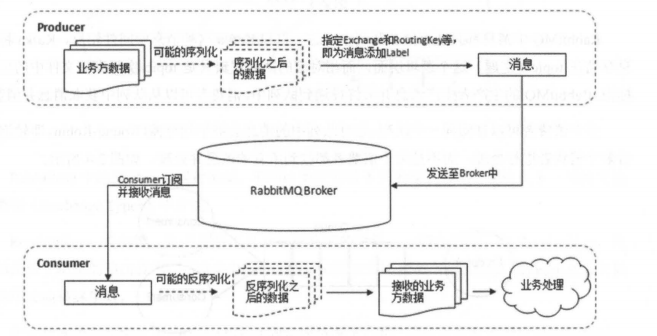
|
||||
|
||||
这样图1中的一些关于 RabbitMQ 的基本概念我们就介绍完毕了,下面再来介绍一下 **Exchange Types(交换器类型)** 。
|
||||
|
||||
#### 1.2.5 Exchange Types(交换器类型)
|
||||
|
||||
RabbitMQ 常用的 Exchange Type 有 **fanout**、**direct**、**topic**、**headers** 这四种(AMQP规范里还提到两种 Exchange Type,分别为 system 与 自定义,这里不予以描述)。
|
||||
|
||||
##### ① fanout
|
||||
|
||||
fanout 类型的Exchange路由规则非常简单,它会把所有发送到该Exchange的消息路由到所有与它绑定的Queue中,不需要做任何判断操作,所以 fanout 类型是所有的交换机类型里面速度最快的。fanout 类型常用来广播消息。
|
||||
|
||||
##### ② direct
|
||||
|
||||
direct 类型的Exchange路由规则也很简单,它会把消息路由到那些 Bindingkey 与 RoutingKey 完全匹配的 Queue 中。
|
||||
|
||||
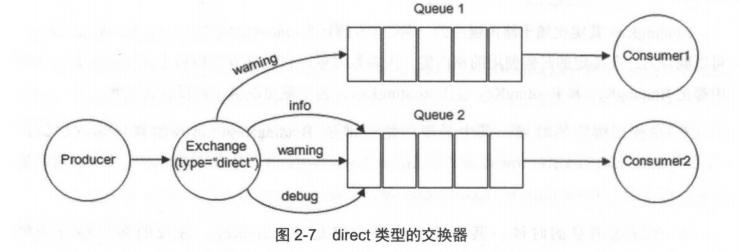
|
||||
|
||||
以上图为例,如果发送消息的时候设置路由键为“warning”,那么消息会路由到 Queue1 和 Queue2。如果在发送消息的时候设置路由键为"Info”或者"debug”,消息只会路由到Queue2。如果以其他的路由键发送消息,则消息不会路由到这两个队列中。
|
||||
|
||||
direct 类型常用在处理有优先级的任务,根据任务的优先级把消息发送到对应的队列,这样可以指派更多的资源去处理高优先级的队列。
|
||||
|
||||
##### ③ topic
|
||||
|
||||
前面讲到direct类型的交换器路由规则是完全匹配 BindingKey 和 RoutingKey ,但是这种严格的匹配方式在很多情况下不能满足实际业务的需求。topic类型的交换器在匹配规则上进行了扩展,它与 direct 类型的交换器相似,也是将消息路由到 BindingKey 和 RoutingKey 相匹配的队列中,但这里的匹配规则有些不同,它约定:
|
||||
|
||||
- RoutingKey 为一个点号“.”分隔的字符串(被点号“.”分隔开的每一段独立的字符串称为一个单词),如 “com.rabbitmq.client”、“java.util.concurrent”、“com.hidden.client”;
|
||||
- BindingKey 和 RoutingKey 一样也是点号“.”分隔的字符串;
|
||||
- BindingKey 中可以存在两种特殊字符串“*”和“#”,用于做模糊匹配,其中“#”用于匹配一个单词,“#”用于匹配多规格单词(可以是零个)。
|
||||
|
||||
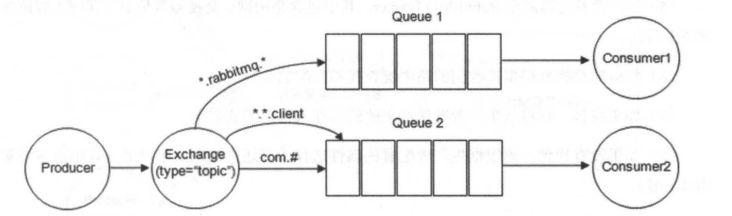
|
||||
|
||||
以上图为例:
|
||||
|
||||
- 路由键为 “com.rabbitmq.client” 的消息会同时路由到 Queuel 和 Queue2;
|
||||
- 路由键为 “com.hidden.client” 的消息只会路由到 Queue2 中;
|
||||
- 路由键为 “com.hidden.demo” 的消息只会路由到 Queue2 中;
|
||||
- 路由键为 “java.rabbitmq.demo” 的消息只会路由到Queuel中;
|
||||
- 路由键为 “java.util.concurrent” 的消息将会被丢弃或者返回给生产者(需要设置 mandatory 参数),因为它没有匹配任何路由键。
|
||||
|
||||
##### ④ headers(不推荐)
|
||||
|
||||
headers 类型的交换器不依赖于路由键的匹配规则来路由消息,而是根据发送的消息内容中的 headers 属性进行匹配。在绑定队列和交换器时制定一组键值对,当发送消息到交换器时,RabbitMQ会获取到该消息的 headers(也是一个键值对的形式)'对比其中的键值对是否完全匹配队列和交换器绑定时指定的键值对,如果完全匹配则消息会路由到该队列,否则不会路由到该队列。headers 类型的交换器性能会很差,而且也不实用,基本上不会看到它的存在。
|
||||
|
||||
## 二 安装 RabbitMq
|
||||
|
||||
通过 Docker 安装非常方便,只需要几条命令就好了,我这里是只说一下常规安装方法。
|
||||
|
||||
前面提到了 RabbitMQ 是由 Erlang语言编写的,也正因如此,在安装RabbitMQ 之前需要安装 Erlang。
|
||||
|
||||
### 2.1 安装 erlang
|
||||
|
||||
**1 下载 erlang 安装包**
|
||||
|
||||
在官网下载然后上传到 Linux 上或者直接使用下面的命令下载对应的版本。
|
||||
|
||||
```shell
|
||||
[root@SnailClimb local]#wget http://erlang.org/download/otp_src_19.3.tar.gz
|
||||
```
|
||||
|
||||
erlang 官网下载:[http://www.erlang.org/downloads](http://www.erlang.org/downloads)
|
||||
|
||||
**2 解压 erlang 安装包**
|
||||
|
||||
```shell
|
||||
[root@SnailClimb local]#tar -xvzf otp_src_19.3.tar.gz
|
||||
```
|
||||
|
||||
**3 删除 erlang 安装包**
|
||||
|
||||
```shell
|
||||
[root@SnailClimb local]#rm -rf otp_src_19.3.tar.gz
|
||||
```
|
||||
|
||||
**4 安装 erlang 的依赖工具**
|
||||
|
||||
```shell
|
||||
[root@SnailClimb local]#yum -y install make gcc gcc-c++ kernel-devel m4 ncurses-devel openssl-devel unixODBC-devel
|
||||
```
|
||||
|
||||
**5 进入erlang 安装包解压文件对 erlang 进行安装环境的配置**
|
||||
|
||||
新建一个文件夹
|
||||
|
||||
```shell
|
||||
[root@SnailClimb local]# mkdir erlang
|
||||
```
|
||||
|
||||
对 erlang 进行安装环境的配置
|
||||
|
||||
```shell
|
||||
[root@SnailClimb otp_src_19.3]#
|
||||
./configure --prefix=/usr/local/erlang --without-javac
|
||||
```
|
||||
|
||||
**6 编译安装**
|
||||
|
||||
```shell
|
||||
[root@SnailClimb otp_src_19.3]#
|
||||
make && make install
|
||||
```
|
||||
|
||||
**7 验证一下 erlang 是否安装成功了**
|
||||
|
||||
```shell
|
||||
[root@SnailClimb otp_src_19.3]# ./bin/erl
|
||||
```
|
||||
运行下面的语句输出“hello world”
|
||||
|
||||
```erlang
|
||||
io:format("hello world~n", []).
|
||||
```
|
||||

|
||||
|
||||
大功告成,我们的 erlang 已经安装完成。
|
||||
|
||||
**8 配置 erlang 环境变量**
|
||||
|
||||
```shell
|
||||
[root@SnailClimb etc]# vim profile
|
||||
```
|
||||
|
||||
追加下列环境变量到文件末尾
|
||||
|
||||
```shell
|
||||
#erlang
|
||||
ERL_HOME=/usr/local/erlang
|
||||
PATH=$ERL_HOME/bin:$PATH
|
||||
export ERL_HOME PATH
|
||||
```
|
||||
|
||||
运行下列命令使配置文件`profile`生效
|
||||
|
||||
```shell
|
||||
[root@SnailClimb etc]# source /etc/profile
|
||||
```
|
||||
|
||||
输入 erl 查看 erlang 环境变量是否配置正确
|
||||
|
||||
```shell
|
||||
[root@SnailClimb etc]# erl
|
||||
```
|
||||
|
||||

|
||||
|
||||
### 2.2 安装 RabbitMQ
|
||||
|
||||
**1. 下载rpm**
|
||||
|
||||
```shell
|
||||
wget https://www.rabbitmq.com/releases/rabbitmq-server/v3.6.8/rabbitmq-server-3.6.8-1.el7.noarch.rpm
|
||||
```
|
||||
或者直接在官网下载
|
||||
|
||||
https://www.rabbitmq.com/install-rpm.html[enter link description here](https://www.rabbitmq.com/install-rpm.html)
|
||||
|
||||
**2. 安装rpm**
|
||||
|
||||
```shell
|
||||
rpm --import https://www.rabbitmq.com/rabbitmq-release-signing-key.asc
|
||||
```
|
||||
紧接着执行:
|
||||
|
||||
```shell
|
||||
yum install rabbitmq-server-3.6.8-1.el7.noarch.rpm
|
||||
```
|
||||
中途需要你输入"y"才能继续安装。
|
||||
|
||||
**3 开启 web 管理插件**
|
||||
|
||||
```shell
|
||||
rabbitmq-plugins enable rabbitmq_management
|
||||
```
|
||||
|
||||
**4 设置开机启动**
|
||||
|
||||
```shell
|
||||
chkconfig rabbitmq-server on
|
||||
```
|
||||
|
||||
**4. 启动服务**
|
||||
|
||||
```shell
|
||||
service rabbitmq-server start
|
||||
```
|
||||
|
||||
**5. 查看服务状态**
|
||||
|
||||
```shell
|
||||
service rabbitmq-server status
|
||||
```
|
||||
|
||||
**6. 访问 RabbitMQ 控制台**
|
||||
|
||||
浏览器访问:http://你的ip地址:15672/
|
||||
|
||||
默认用户名和密码: guest/guest;但是需要注意的是:guestuest用户只是被容许从localhost访问。官网文档描述如下:
|
||||
|
||||
```shell
|
||||
“guest” user can only connect via localhost
|
||||
```
|
||||
|
||||
**解决远程访问 RabbitMQ 远程访问密码错误**
|
||||
|
||||
新建用户并授权
|
||||
|
||||
```shell
|
||||
[root@SnailClimb rabbitmq]# rabbitmqctl add_user root root
|
||||
Creating user "root" ...
|
||||
[root@SnailClimb rabbitmq]# rabbitmqctl set_user_tags root administrator
|
||||
|
||||
Setting tags for user "root" to [administrator] ...
|
||||
[root@SnailClimb rabbitmq]#
|
||||
[root@SnailClimb rabbitmq]# rabbitmqctl set_permissions -p / root ".*" ".*" ".*"
|
||||
Setting permissions for user "root" in vhost "/" ...
|
||||
|
||||
```
|
||||
|
||||
再次访问:http://你的ip地址:15672/ ,输入用户名和密码:root root
|
||||
|
||||
|
||||
|
||||
|
||||
@ -55,7 +55,7 @@
|
||||
|
||||
[《消息队列深入解析》](https://blog.csdn.net/qq_34337272/article/details/80029918)
|
||||
|
||||
当前使用较多的消息队列有ActiveMQ(性能差,不推荐使用)、RabbitMQ、RocketMQ、Kafka等等,我们之前提高的redis数据库也可以实现消息队列,不过不推荐,redis本身设计就不是用来做消息队列的。
|
||||
当前使用较多的消息队列有ActiveMQ(性能差,不推荐使用)、RabbitMQ、RocketMQ、Kafka等等,我们之前提到的redis数据库也可以实现消息队列,不过不推荐,redis本身设计就不是用来做消息队列的。
|
||||
|
||||
- **ActiveMQ:** ActiveMQ是Apache出品,最流行的,能力强劲的开源消息总线。ActiveMQ是一个完全支持JMS1.1和J2EE 1.4规范的JMSProvider实现,尽管JMS规范出台已经是很久的事情了,但是JMS在当今的J2EE应用中间仍然扮演着特殊的地位。
|
||||
|
||||
@ -80,7 +80,7 @@
|
||||
[《十分钟入门RocketMQ》](http://jm.taobao.org/2017/01/12/rocketmq-quick-start-in-10-minutes/) (阿里中间件团队博客)
|
||||
|
||||
|
||||
- **Kafka**:Kafka是一个分布式的、可分区的、可复制的、基于发布/订阅的消息系统,Kafka主要用于大数据领域,当然在分布式系统中也有应用。目前市面上流行的消息队列RocketMQ就是阿里借鉴Kafka的原理、用Java开发而得。
|
||||
- **Kafka**:Kafka是一个分布式的、可分区的、可复制的、基于发布/订阅的消息系统(现在官方的描述是“一个分布式流平台”),Kafka主要用于大数据领域,当然在分布式系统中也有应用。目前市面上流行的消息队列RocketMQ就是阿里借鉴Kafka的原理、用Java开发而得。
|
||||
|
||||
具体可以参考:
|
||||
|
||||
|
||||
78
面试必备/JavaInterviewGithub.md
Normal file
78
面试必备/JavaInterviewGithub.md
Normal file
@ -0,0 +1,78 @@
|
||||
最近浏览 Github ,收藏了一些还算不错的 Java面试/学习相关的仓库,分享给大家,希望对你有帮助。我暂且按照目前的 Star 数量来排序。
|
||||
|
||||
本文由 SnailClimb 整理,如需转载请联系作者。
|
||||
|
||||
### 1. interviews
|
||||
|
||||
- Github地址: [https://github.com/kdn251/interviews/blob/master/README-zh-cn.md](https://github.com/kdn251/interviews/blob/master/README-zh-cn.md)
|
||||
- star: 31k
|
||||
- 介绍: 软件工程技术面试个人指南。
|
||||
- 概览:
|
||||
|
||||
|
||||
|
||||
### 2. JCSprout
|
||||
|
||||
- Github地址:[https://github.com/crossoverJie/JCSprout](https://github.com/crossoverJie/JCSprout)
|
||||
- star: 17.7k
|
||||
- 介绍: Java Core Sprout:处于萌芽阶段的 Java 核心知识库。
|
||||
- 概览:
|
||||
|
||||

|
||||
|
||||
### 3. JavaGuide
|
||||
|
||||
- Github地址: [https://github.com/Snailclimb/JavaGuide](https://github.com/Snailclimb/JavaGuide)
|
||||
- star: 17.4k
|
||||
- 介绍: 【Java学习+面试指南】 一份涵盖大部分Java程序员所需要掌握的核心知识。
|
||||
- 概览:
|
||||
|
||||

|
||||
|
||||
### 4. technology-talk
|
||||
|
||||
- Github地址: [https://github.com/aalansehaiyang/technology-talk](https://github.com/aalansehaiyang/technology-talk)
|
||||
- star: 4.2k
|
||||
- 介绍: 汇总java生态圈常用技术框架、开源中间件,系统架构、项目管理、经典架构案例、数据库、常用三方库、线上运维等知识。
|
||||
|
||||
### 5. fullstack-tutorial
|
||||
|
||||
- Github地址: [https://github.com/frank-lam/fullstack-tutorial](https://github.com/frank-lam/fullstack-tutorial)
|
||||
- star: 2.8k
|
||||
- 介绍: Full Stack Developer Tutorial,后台技术栈/全栈开发/架构师之路,秋招/春招/校招/面试。 from zero to hero。
|
||||
- 概览:
|
||||
|
||||

|
||||
|
||||
### 6. java-bible
|
||||
|
||||
- Github地址:[https://github.com/biezhi/java-bible](https://github.com/biezhi/java-bible)
|
||||
- star: 1.9k
|
||||
- 介绍: 这里记录了一些技术摘要,部分文章来自网络,本项目的目的力求分享精品技术干货,以Java为主。
|
||||
- 概览:
|
||||
|
||||

|
||||
|
||||
### 7. EasyJob
|
||||
|
||||
- Github地址:[https://github.com/it-interview/EasyJob](https://github.com/it-interview/EasyJob)
|
||||
- star: 1.9k
|
||||
- 介绍: 互联网求职面试题、知识点和面经整理。
|
||||
|
||||
### 8. advanced-java
|
||||
|
||||
- Github地址:[https://github.com/doocs/advanced-java](https://github.com/doocs/advanced-java)
|
||||
- star: 1k
|
||||
- 介绍: 互联网 Java 工程师进阶知识完全扫盲
|
||||
|
||||
### 9. 3y
|
||||
|
||||
- Github地址:[https://github.com/ZhongFuCheng3y/3y](https://github.com/ZhongFuCheng3y/3y)
|
||||
- star: 0.4 k
|
||||
- 介绍: Java 知识整合。
|
||||
|
||||
除了这九个仓库,再推荐几个不错的学习方向的仓库给大家。
|
||||
|
||||
1. Star 数高达 4w+的 CS 笔记-CS-Notes:[https://github.com/CyC2018/CS-Notes](https://github.com/CyC2018/CS-Notes)
|
||||
2. 后端(尤其是Java)程序员的 Linux 学习仓库-Linux-Tutorial:[https://github.com/judasn/Linux-Tutorial](https://github.com/judasn/Linux-Tutorial)( Star:4.6k)
|
||||
3. 两个算法相关的仓库,刷 Leetcode 的小伙伴必备:①awesome-java-leetcode:[https://github.com/Blankj/awesome-java-leetcode](https://github.com/Blankj/awesome-java-leetcode);②LintCode:[https://github.com/awangdev/LintCode](https://github.com/awangdev/LintCode)
|
||||
81
面试必备/java programmer need know.md
Normal file
81
面试必备/java programmer need know.md
Normal file
@ -0,0 +1,81 @@
|
||||
身边的朋友或者公众号的粉丝很多人都向我询问过:“我是双非/三本/专科学校的,我有机会进入大厂吗?”、“非计算机专业的学生能学好吗?”、“如何学习Java?”、“Java学习该学那些东西?”、“我该如何准备Java面试?”......这些方面的问题。我会根据自己的一点经验对大部分人关心的这些问题进行答疑解惑。现在又刚好赶上考研结束,这篇文章也算是给考研结束准备往Java后端方向发展的朋友们指名一条学习之路。道理懂了如果没有实际行动,那这篇文章对你或许没有任何意义。
|
||||
|
||||
### Question1:我是双非/三本/专科学校的,我有机会进入大厂吗?
|
||||
|
||||
我自己也是非985非211学校的,结合自己的经历以及一些朋友的经历,我觉得让我回答这个问题再好不过。
|
||||
|
||||
首先,我觉得学校歧视很正常,真的太正常了,如果要抱怨的话,你只能抱怨自己没有进入名校。但是,千万不要动不动说自己学校差,动不动拿自己学校当做自己进不了大厂的借口,学历只是筛选简历的很多标准中的一个而已,如果你够优秀,简历够丰富,你也一样可以和名校同学一起同台竞争。
|
||||
|
||||
企业HR肯定是更喜欢高学历的人,毕竟985,211优秀人才比例肯定比普通学校高很多,HR团队肯定会优先在这些学校里选。这就好比相亲,你是愿意在很多优秀的人中选一个优秀的,还是愿意在很多普通的人中选一个优秀的呢?
|
||||
|
||||
双非本科甚至是二本、三本甚至是专科的同学也有很多进入大厂的,不过比率相比于名校的低很多而已。从大厂招聘的结果上看,高学历人才的数量占据大头,那些成功进入BAT、美团,京东,网易等大厂的双非本科甚至是二本、三本甚至是专科的同学往往是因为具备丰富的项目经历或者在某个含金量比较高的竞赛比如ACM中取得了不错的成绩。**一部分学历不突出但能力出众的面试者能够进入大厂并不是说明学历不重要,而是学历的软肋能够通过其他的优势来弥补。** 所以,如果你的学校不够好而你自己又想去大厂的话,建议你可以从这几点来做:**①尽量在面试前最好有一个可以拿的出手的项目;②有实习条件的话,尽早出去实习,实习经历也会是你的简历的一个亮点(有能力在大厂实习最佳!);③参加一些含金量比较高的比赛,拿不拿得到名次没关系,重在锻炼。**
|
||||
|
||||
|
||||
### Question2:非计算机专业的学生能学好Java后台吗?我能进大厂吗?
|
||||
|
||||
当然可以!现在非科班的程序员很多,很大一部分原因是互联网行业的工资比较高。我们学校外面的培训班里面90%都是非科班,我觉得他们很多人学的都还不错。另外,我的一个朋友本科是机械专业,大一开始自学安卓,技术贼溜,在我看来他比大部分本科是计算机的同学学的还要好。参考Question1的回答,即使你是非科班程序员,如果你想进入大厂的话,你也可以通过自己的其他优势来弥补。
|
||||
|
||||
我觉得我们不应该因为自己的专业给自己划界限或者贴标签,说实话,很多科班的同学可能并不如你,你以为科班的同学就会认真听讲吗?还不是几乎全靠自己课下自学!不过如果你是非科班的话,你想要学好,那么注定就要舍弃自己本专业的一些学习时间,这是无可厚非的。
|
||||
|
||||
建议非科班的同学,首先要打好计算机基础知识基础:①计算机网络、②操作系统、③数据机构与算法,我个人觉得这3个对你最重要。这些东西就像是内功,对你以后的长远发展非常有用。当然,如果你想要进大厂的话,这些知识也是一定会被问到的。另外,“一定学好数据机构与算法!一定学好数据机构与算法!一定学好数据机构与算法!”,重要的东西说3遍。
|
||||
|
||||
|
||||
|
||||
### Question3: 我没有实习经历的话找工作是不是特别艰难?
|
||||
|
||||
没有实习经历没关系,只要你有拿得出手的项目或者大赛经历的话,你依然有可能拿到大厂的 offer 。笔主当时找工作的时候就没有实习经历以及大赛获奖经历,单纯就是凭借自己的项目经验撑起了整个面试。
|
||||
|
||||
如果你既没有实习经历,又没有拿得出手的项目或者大赛经历的话,我觉得在简历关,除非你有其他特别的亮点,不然,你应该就会被刷。
|
||||
|
||||
### Question4: 我该如何准备面试呢?面试的注意事项有哪些呢?
|
||||
|
||||
下面是我总结的一些准备面试的Tips以及面试必备的注意事项:
|
||||
|
||||
1. **准备一份自己的自我介绍,面试的时候根据面试对象适当进行修改**(突出重点,突出自己的优势在哪里,切忌流水账);
|
||||
2. **注意随身带上自己的成绩单和简历复印件;** (有的公司在面试前都会让你交一份成绩单和简历当做面试中的参考。)
|
||||
3. **如果需要笔试就提前刷一些笔试题,大部分在线笔试的类型是选择题+编程题,有的还会有简答题。**(平时空闲时间多的可以刷一下笔试题目(牛客网上有很多),但是不要只刷面试题,不动手code,程序员不是为了考试而存在的。)另外,注意抓重点,因为题目太多了,但是有很多题目几乎次次遇到,像这样的题目一定要搞定。
|
||||
4. **提前准备技术面试。** 搞清楚自己面试中可能涉及哪些知识点、那些知识点是重点。面试中哪些问题会被经常问到、自己改如何回答。(强烈不推荐背题,第一:通过背这种方式你能记住多少?能记住多久?第二:背题的方式的学习很难坚持下去!)
|
||||
5. **面试之前做好定向复习。** 也就是专门针对你要面试的公司来复习。比如你在面试之前可以在网上找找有没有你要面试的公司的面经。
|
||||
6. **准备好自己的项目介绍。** 如果有项目的话,技术面试第一步,面试官一般都是让你自己介绍一下你的项目。你可以从下面几个方向来考虑:①对项目整体设计的一个感受(面试官可能会让你画系统的架构图;②在这个项目中你负责了什么、做了什么、担任了什么角色;③ 从这个项目中你学会了那些东西,使用到了那些技术,学会了那些新技术的使用;④项目描述中,最好可以体现自己的综合素质,比如你是如何协调项目组成员协同开发的或者在遇到某一个棘手的问题的时候你是如何解决的又或者说你在这个项目用了什么技术实现了什么功能比如:用redis做缓存提高访问速度和并发量、使用消息队列削峰和降流等等。
|
||||
7. **面试之后记得复盘。** 面试遭遇失败是很正常的事情,所以善于总结自己的失败原因才是最重要的。如果失败,不要灰心;如果通过,切勿狂喜。
|
||||
|
||||
|
||||
**一些还算不错的 Java面试/学习相关的仓库,相信对大家准备面试一定有帮助:**[盘点一下Github上开源的Java面试/学习相关的仓库,看完弄懂薪资至少增加10k](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484817&idx=1&sn=12f0c254a240c40c2ccab8314653216b&chksm=fd9853f0caefdae6d191e6bf085d44ab9c73f165e3323aa0362d830e420ccbfad93aa5901021&token=766994974&lang=zh_CN#rd)
|
||||
|
||||
### Question5: 我该自学还是报培训班呢?
|
||||
|
||||
我本人更加赞同自学(你要知道去了公司可没人手把手教你了,而且几乎所有的公司都对培训班出生的有偏见。为什么有偏见,你学个东西还要去培训班,说明什么,同等水平下,你的自学能力以及自律能力一定是比不上自学的人的)。但是如果,你连每天在寝室坚持学上8个小时以上都坚持不了,或者总是容易半途而废的话,我还是推荐你去培训班。观望身边同学去培训班的,大多是非计算机专业或者是没有自律能力以及自学能力非常差的人。
|
||||
|
||||
另外,如果自律能力不行,你也可以通过结伴学习、参加老师的项目等方式来督促自己学习。
|
||||
|
||||
总结:去不去培训班主要还是看自己,如果自己能坚持自学就自学,坚持不下来就去培训班。
|
||||
|
||||
### Question6: 没有项目经历/博客/Github开源项目怎么办?
|
||||
|
||||
从现在开始做!
|
||||
|
||||
网上有很多非常不错的项目视频,你就跟着一步一步做,不光要做,还要改进,改善。另外,如果你的老师有相关 Java 后台项目的话,你也可以主动申请参与进来。
|
||||
|
||||
如果有自己的博客,也算是简历上的一个亮点。建议可以在掘金、Segmentfault、CSDN等技术交流社区写博客,当然,你也可以自己搭建一个博客(采用 Hexo+Githu Pages 搭建非常简单)。写一些什么?学习笔记、实战内容、读书笔记等等都可以。
|
||||
|
||||
多用 Github,用好 Github,上传自己不错的项目,写好 readme 文档,在其他技术社区做好宣传。相信你也会收获一个不错的开源项目!
|
||||
|
||||
|
||||
### Question7: 大厂到底青睐什么样的应届生?
|
||||
|
||||
从阿里、腾讯等大厂招聘官网对于Java后端方向/后端方向的应届实习生的要求,我们大概可以总结归纳出下面这 4 点能给简历增加很多分数:
|
||||
|
||||
- 参加过竞赛(含金量超高的是ACM);
|
||||
- 对数据结构与算法非常熟练;
|
||||
- 参与过实际项目(比如学校网站);
|
||||
- 参与过某个知名的开源项目或者自己的某个开源项目很不错;
|
||||
|
||||
除了我上面说的这三点,在面试Java工程师的时候,下面几点也提升你的个人竞争力:
|
||||
|
||||
- 熟悉Python、Shell、Perl等脚本语言;
|
||||
- 熟悉 Java 优化,JVM调优;
|
||||
- 熟悉 SOA 模式;
|
||||
- 熟悉自己所用框架的底层知识比如Spring;
|
||||
- 了解分布式一些常见的理论;
|
||||
- 具备高并发开发经验;大数据开发经验等等。
|
||||
|
||||
@ -173,6 +173,8 @@ Java语言通过字节码的方式,在一定程度上解决了传统解释型
|
||||
4. 一个类实现接口的话要实现接口的所有方法,而抽象类不一定
|
||||
5. 接口不能用new实例化,但可以声明,但是必须引用一个实现该接口的对象 从设计层面来说,抽象是对类的抽象,是一种模板设计,接口是行为的抽象,是一种行为的规范。
|
||||
|
||||
注意:Java8 后接口可以有默认实现( default )。
|
||||
|
||||
### 成员变量与局部变量的区别有那些?
|
||||
|
||||
1. 从语法形式上,看成员变量是属于类的,而局部变量是在方法中定义的变量或是方法的参数;成员变量可以被public,private,static等修饰符所修饰,而局部变量不能被访问控制修饰符及static所修饰;但是,成员变量和局部变量都能被final所修饰;
|
||||
|
||||
@ -194,7 +194,7 @@ HTTP响应报文主要由状态行、响应头部、响应正文3部分组成
|
||||
|
||||
**说一下使用索引的注意事项**
|
||||
|
||||
1. 避免 where 子句中对宇段施加函数,这会造成无法命中索引。
|
||||
1. 避免 where 子句中对字段施加函数,这会造成无法命中索引。
|
||||
2. 在使用InnoDB时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键。
|
||||
3. 将打算加索引的列设置为 NOT NULL ,否则将导致引擎放弃使用索引而进行全表扫描
|
||||
4. 删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 chema_unused_indexes 视图来查询哪些索引从未被使用
|
||||
@ -226,7 +226,7 @@ HTTP响应报文主要由状态行、响应头部、响应正文3部分组成
|
||||
4. **消息队列(message queue)**:消息队列是由消息组成的链表,存放在内核中 并由消息队列标识符标识。消息队列克服了信号传递信息少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。消息队列与管道通信相比,其优势是对每个消息指定特定的消息类型,接收的时候不需要按照队列次序,而是可以根据自定义条件接收特定类型的消息。
|
||||
5. **信号(signal)**:信号是一种比较复杂的通信方式,用于通知接收进程某一事件已经发生。
|
||||
6. **共享内存(shared memory)**:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问,共享内存是最快的IPC方式,它是针对其他进程间的通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量配合使用,来实现进程间的同步和通信。
|
||||
7. **套接字(socket)**:套接口也是一种进程间的通信机制,与其他通信机制不同的是它可以用于不同及其间的进程通信。
|
||||
7. **套接字(socket)**:socket,即套接字是一种通信机制,凭借这种机制,客户/服务器(即要进行通信的进程)系统的开发工作既可以在本地单机上进行,也可以跨网络进行。也就是说它可以让不在同一台计算机但通过网络连接计算机上的进程进行通信。也因为这样,套接字明确地将客户端和服务器区分开来。
|
||||
|
||||
**线程间的几种通信方式知道不?**
|
||||
|
||||
@ -341,7 +341,7 @@ TransactionDefinition 接口中定义了五个表示隔离级别的常量:
|
||||
|
||||

|
||||
|
||||
客户端发送请求-> 前端控制器 DispatcherServlet 接受客户端请求 -> 找到处理器映射 HandlerMapping 解析请求对应的 Handler-> HandlerAdapter 会根据 Handler 来调用真正的处理器开处理请求,并处理相应的业务逻辑 -> 处理器返回一个模型视图 ModelAndView -> 视图解析器进行解析 -> 返回一个视图对象->前端控制器 DispatcherServlet 渲染数据(Moder)->将得到视图对象返回给用户
|
||||
客户端发送请求-> 前端控制器 DispatcherServlet 接受客户端请求 -> 找到处理器映射 HandlerMapping 解析请求对应的 Handler-> HandlerAdapter 会根据 Handler 来调用真正的处理器开处理请求,并处理相应的业务逻辑 -> 处理器返回一个模型视图 ModelAndView -> 视图解析器进行解析 -> 返回一个视图对象->前端控制器 DispatcherServlet 渲染数据(Model)->将得到视图对象返回给用户
|
||||
|
||||
关于 SpringMVC 原理更多内容可以查看我的这篇文章:[SpringMVC 工作原理详解](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484496&idx=1&sn=5472ffa687fe4a05f8900d8ee6726de4&chksm=fd985231caefdb27fc75b44ecf76b6f43e4617e0b01b3c040f8b8fab32e51dfa5118eed1d6ad&token=1990180468&lang=zh_CN#rd)
|
||||
|
||||
|
||||
@ -232,10 +232,10 @@ synchronized 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团
|
||||
|
||||
#### Java 主要提供了下面4种线程池
|
||||
|
||||
- **FixedThreadPool** : 该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
|
||||
- **FixedThreadPool:** 该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
|
||||
- **SingleThreadExecutor:** 方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
|
||||
- **CachedThreadPool:** 该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
|
||||
- **ScheduledThreadPoolExecutor:**主要用来在给定的延迟后运行任务,或者定期执行任务。ScheduledThreadPoolExecutor又分为:ScheduledThreadPoolExecutor(包含多个线程)和SingleThreadScheduledExecutor (只包含一个线程)两种。
|
||||
- **ScheduledThreadPoolExecutor:** 主要用来在给定的延迟后运行任务,或者定期执行任务。ScheduledThreadPoolExecutor又分为:ScheduledThreadPoolExecutor(包含多个线程)和SingleThreadScheduledExecutor (只包含一个线程)两种。
|
||||
|
||||
#### 各种线程池的适用场景介绍
|
||||
|
||||
@ -350,4 +350,4 @@ Nginx 有以下5个优点:
|
||||
- Nginx 二进制可执行文件:由各模块源码编译出一个文件
|
||||
- Nginx.conf 配置文件:控制Nginx 行为
|
||||
- acess.log 访问日志: 记录每一条HTTP请求信息
|
||||
- error.log 错误日志:定位问题
|
||||
- error.log 错误日志:定位问题
|
||||
|
||||
@ -80,7 +80,7 @@
|
||||
|
||||
### 1.2 那么使用消息队列会带来什么问题?考虑过这个问题吗?
|
||||
|
||||
- **系统可用性降低:**系统可用性在某种程度上降低,为什么这样说呢?在加入MQ之前,你不用考虑消息丢失或者说MQ挂掉等等的情况,但是,引入MQ之后你就需要去考虑了!
|
||||
- **系统可用性降低:** 系统可用性在某种程度上降低,为什么这样说呢?在加入MQ之前,你不用考虑消息丢失或者说MQ挂掉等等的情况,但是,引入MQ之后你就需要去考虑了!
|
||||
- **系统复杂性提高:** 加入MQ之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
|
||||
- **一致性问题:** 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
|
||||
|
||||
@ -169,14 +169,14 @@ ArraysList 实现了 RandomAccess 接口, 而 LinkedList 没有实现。为什
|
||||
|
||||
**下面再总结一下 list 的遍历方式选择:**
|
||||
|
||||
- 实现了RadmoAcces接口的list,优先选择普通for循环 ,其次foreach,
|
||||
- 未实现RadmoAcces接口的ist, 优先选择iterator遍历(foreach遍历底层也是通过iterator实现的),大size的数据,千万不要使用普通for循环
|
||||
- 实现了RandomAccess接口的list,优先选择普通for循环 ,其次foreach,
|
||||
- 未实现RandomAccess接口的ist, 优先选择iterator遍历(foreach遍历底层也是通过iterator实现的),大size的数据,千万不要使用普通for循环
|
||||
|
||||
> Java 中的集合这类问题几乎是面试必问的,问到这类问题的时候,HashMap 又是几乎必问的问题,所以大家一定要引起重视!
|
||||
|
||||
### 3.2 HashMap的底层实现
|
||||
|
||||
####① JDK1.8之前
|
||||
#### ① JDK1.8之前
|
||||
|
||||
JDK1.8 之前 HashMap 底层是 **数组和链表** 结合在一起使用也就是 **链表散列**。**HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 `(n - 1) & hash` 判断当前元素存放的位置(这里的 n 指的时数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。**
|
||||
|
||||
@ -217,7 +217,7 @@ static int hash(int h) {
|
||||

|
||||
|
||||
|
||||
###② JDK1.8之后
|
||||
#### ② JDK1.8之后
|
||||
|
||||
相比于之前的版本, JDK1.8之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user