mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
commit
c1b54d9fee
@ -202,13 +202,13 @@ NIO 通过Channel(通道) 进行读写。
|
|||||||
|
|
||||||
通道是双向的,可读也可写,而流的读写是单向的。无论读写,通道只能和Buffer交互。因为 Buffer,通道可以异步地读写。
|
通道是双向的,可读也可写,而流的读写是单向的。无论读写,通道只能和Buffer交互。因为 Buffer,通道可以异步地读写。
|
||||||
|
|
||||||
#### 4)Selectors(选择器)
|
#### 4)Selector (选择器)
|
||||||
|
|
||||||
NIO有选择器,而IO没有。
|
NIO有选择器,而IO没有。
|
||||||
|
|
||||||
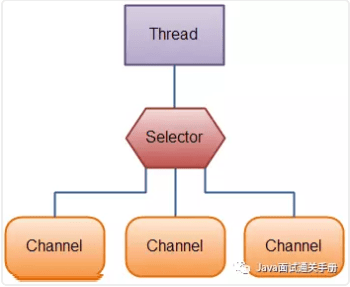
选择器用于使用单个线程处理多个通道。因此,它需要较少的线程来处理这些通道。线程之间的切换对于操作系统来说是昂贵的。 因此,为了提高系统效率选择器是有用的。
|
选择器用于使用单个线程处理多个通道。因此,它需要较少的线程来处理这些通道。线程之间的切换对于操作系统来说是昂贵的。 因此,为了提高系统效率选择器是有用的。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
### 2.3 NIO 读数据和写数据方式
|
### 2.3 NIO 读数据和写数据方式
|
||||||
通常来说NIO中的所有IO都是从 Channel(通道) 开始的。
|
通常来说NIO中的所有IO都是从 Channel(通道) 开始的。
|
||||||
@ -273,8 +273,7 @@ public class NIOServer {
|
|||||||
|
|
||||||
if (key.isAcceptable()) {
|
if (key.isAcceptable()) {
|
||||||
try {
|
try {
|
||||||
// (1)
|
// (1) 每来一个新连接,不需要创建一个线程,而是直接注册到clientSelector
|
||||||
// 每来一个新连接,不需要创建一个线程,而是直接注册到clientSelector
|
|
||||||
SocketChannel clientChannel = ((ServerSocketChannel) key.channel()).accept();
|
SocketChannel clientChannel = ((ServerSocketChannel) key.channel()).accept();
|
||||||
clientChannel.configureBlocking(false);
|
clientChannel.configureBlocking(false);
|
||||||
clientChannel.register(clientSelector, SelectionKey.OP_READ);
|
clientChannel.register(clientSelector, SelectionKey.OP_READ);
|
||||||
|
|||||||
@ -267,7 +267,7 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引
|
|||||||
<img src="http://my-blog-to-use.oss-cn-beijing.aliyuncs.com/18-8-27/90984624.jpg" alt="公众号" width="500px">
|
<img src="http://my-blog-to-use.oss-cn-beijing.aliyuncs.com/18-8-27/90984624.jpg" alt="公众号" width="500px">
|
||||||
|
|
||||||
### 3.3 标记-整理算法
|
### 3.3 标记-整理算法
|
||||||
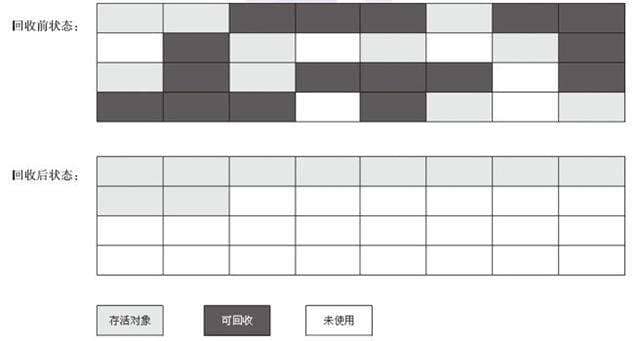
根据老年代的特点特出的一种标记算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一端移动,然后直接清理掉端边界以外的内存。
|
根据老年代的特点提出的一种标记算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一端移动,然后直接清理掉端边界以外的内存。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
@ -330,7 +330,7 @@ Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它
|
|||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
**Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。** Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解的话,手工优化存在的话可以选择把内存管理优化交给虚拟机去完成也是一个不错的选择。
|
**Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。** Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解的话,手工优化存在困难的话可以选择把内存管理优化交给虚拟机去完成也是一个不错的选择。
|
||||||
|
|
||||||
**新生代采用复制算法,老年代采用标记-整理算法。**
|
**新生代采用复制算法,老年代采用标记-整理算法。**
|
||||||

|

|
||||||
@ -344,7 +344,7 @@ Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它
|
|||||||
|
|
||||||
### 4.6 CMS 收集器
|
### 4.6 CMS 收集器
|
||||||
|
|
||||||
**CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它而非常符合在注重用户体验的应用上使用。**
|
**CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它非常符合在注重用户体验的应用上使用。**
|
||||||
|
|
||||||
**CMS(Concurrent Mark Sweep)收集器是 HotSpot 虚拟机第一款真正意义上的并发收集器,它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作。**
|
**CMS(Concurrent Mark Sweep)收集器是 HotSpot 虚拟机第一款真正意义上的并发收集器,它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作。**
|
||||||
|
|
||||||
|
|||||||
@ -197,7 +197,7 @@ JDK 1.8 的时候,方法区(HotSpot 的永久代)被彻底移除了(JDK1
|
|||||||
|
|
||||||
JDK1.4 中新加入的 **NIO(New Input/Output) 类**,引入了一种基于**通道(Channel)** 与**缓存区(Buffer)** 的 I/O 方式,它可以直接使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样就能在一些场景中显著提高性能,因为**避免了在 Java 堆和 Native 堆之间来回复制数据**。
|
JDK1.4 中新加入的 **NIO(New Input/Output) 类**,引入了一种基于**通道(Channel)** 与**缓存区(Buffer)** 的 I/O 方式,它可以直接使用 Native 函数库直接分配堆外内存,然后通过一个存储在 Java 堆中的 DirectByteBuffer 对象作为这块内存的引用进行操作。这样就能在一些场景中显著提高性能,因为**避免了在 Java 堆和 Native 堆之间来回复制数据**。
|
||||||
|
|
||||||
本机直接内存的分配不会收到 Java 堆的限制,但是,既然是内存就会受到本机总内存大小以及处理器寻址空间的限制。
|
本机直接内存的分配不会受到 Java 堆的限制,但是,既然是内存就会受到本机总内存大小以及处理器寻址空间的限制。
|
||||||
|
|
||||||
|
|
||||||
## 三 HotSpot 虚拟机对象探秘
|
## 三 HotSpot 虚拟机对象探秘
|
||||||
@ -253,7 +253,7 @@ JDK1.4 中新加入的 **NIO(New Input/Output) 类**,引入了一种基于**
|
|||||||
**对齐填充部分不是必然存在的,也没有什么特别的含义,仅仅起占位作用。** 因为 Hotspot 虚拟机的自动内存管理系统要求对象起始地址必须是 8 字节的整数倍,换句话说就是对象的大小必须是 8 字节的整数倍。而对象头部分正好是 8 字节的倍数(1 倍或 2 倍),因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。
|
**对齐填充部分不是必然存在的,也没有什么特别的含义,仅仅起占位作用。** 因为 Hotspot 虚拟机的自动内存管理系统要求对象起始地址必须是 8 字节的整数倍,换句话说就是对象的大小必须是 8 字节的整数倍。而对象头部分正好是 8 字节的倍数(1 倍或 2 倍),因此,当对象实例数据部分没有对齐时,就需要通过对齐填充来补全。
|
||||||
|
|
||||||
### 3.3 对象的访问定位
|
### 3.3 对象的访问定位
|
||||||
建立对象就是为了使用对象,我们的 Java 程序通过栈上的 reference 数据来操作堆上的具体对象。对象的访问方式有虚拟机实现而定,目前主流的访问方式有**①使用句柄**和**②直接指针**两种:
|
建立对象就是为了使用对象,我们的 Java 程序通过栈上的 reference 数据来操作堆上的具体对象。对象的访问方式由虚拟机实现而定,目前主流的访问方式有**①使用句柄**和**②直接指针**两种:
|
||||||
|
|
||||||
1. **句柄:** 如果使用句柄的话,那么 Java 堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息;
|
1. **句柄:** 如果使用句柄的话,那么 Java 堆中将会划分出一块内存来作为句柄池,reference 中存储的就是对象的句柄地址,而句柄中包含了对象实例数据与类型数据各自的具体地址信息;
|
||||||
|
|
||||||
@ -322,7 +322,7 @@ System.out.println(str2==str3);//false
|
|||||||
尽量避免多个字符串拼接,因为这样会重新创建对象。如果需要改变字符串的话,可以使用 StringBuilder 或者 StringBuffer。
|
尽量避免多个字符串拼接,因为这样会重新创建对象。如果需要改变字符串的话,可以使用 StringBuilder 或者 StringBuffer。
|
||||||
### 4.2 String s1 = new String("abc");这句话创建了几个字符串对象?
|
### 4.2 String s1 = new String("abc");这句话创建了几个字符串对象?
|
||||||
|
|
||||||
**将创建 1 或 2 个字符串。如果池中已存在字符串文字“abc”,则池中只会创建一个字符串“s1”。如果池中没有字符串文字“abc”,那么它将首先在池中创建,然后在堆空间中创建,因此将创建总共 2 个字符串对象。**
|
**将创建 1 或 2 个字符串。如果池中已存在字符串常量“abc”,则只会在堆空间创建一个字符串常量“abc”。如果池中没有字符串常量“abc”,那么它将首先在池中创建,然后在堆空间中创建,因此将创建总共 2 个字符串对象。**
|
||||||
|
|
||||||
**验证:**
|
**验证:**
|
||||||
|
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user