Merge branch 'master' of https://github.com/shahainloong/JavaGuide
2
.gitignore
vendored
@ -32,3 +32,5 @@ dataSources/
|
|||||||
|
|
||||||
### OS ###
|
### OS ###
|
||||||
.DS_Store
|
.DS_Store
|
||||||
|
.Ds_Store´
|
||||||
|
/node_modules
|
||||||
|
|||||||
236
HomePage.md
@ -1,236 +0,0 @@
|
|||||||
点击订阅[Java面试进阶指南](https://xiaozhuanlan.com/javainterview?rel=javaguide)(专为Java面试方向准备)。[为什么要弄这个专栏?](https://shimo.im/./9BJjNsNg7S4dCnz3/)
|
|
||||||
|
|
||||||
<h1 align="center">Java 学习/面试指南</h1>
|
|
||||||
<p align="center">
|
|
||||||
<a href="https://github.com/Snailclimb/JavaGuide" target="_blank">
|
|
||||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-3/logo - 副本.png" width=""/>
|
|
||||||
</a>
|
|
||||||
|
|
||||||
## 目录
|
|
||||||
|
|
||||||
- [Java](#java)
|
|
||||||
- [基础](#基础)
|
|
||||||
- [容器](#容器)
|
|
||||||
- [并发](#并发)
|
|
||||||
- [JVM](#jvm)
|
|
||||||
- [I/O](#io)
|
|
||||||
- [Java 8](#java-8)
|
|
||||||
- [编程规范](#编程规范)
|
|
||||||
- [网络](#网络)
|
|
||||||
- [操作系统](#操作系统)
|
|
||||||
- [Linux相关](#linux相关)
|
|
||||||
- [数据结构与算法](#数据结构与算法)
|
|
||||||
- [数据结构](#数据结构)
|
|
||||||
- [算法](#算法)
|
|
||||||
- [数据库](#数据库)
|
|
||||||
- [MySQL](#mysql)
|
|
||||||
- [Redis](#redis)
|
|
||||||
- [系统设计](#系统设计)
|
|
||||||
- [设计模式(工厂模式、单例模式 ... )](#设计模式)
|
|
||||||
- [常用框架(Spring、Zookeeper ... )](#常用框架)
|
|
||||||
- [数据通信(消息队列、Dubbo ... )](#数据通信)
|
|
||||||
- [网站架构](#网站架构)
|
|
||||||
- [面试指南](#面试指南)
|
|
||||||
- [备战面试](#备战面试)
|
|
||||||
- [常见面试题总结](#常见面试题总结)
|
|
||||||
- [面经](#面经)
|
|
||||||
- [工具](#工具)
|
|
||||||
- [Git](#git)
|
|
||||||
- [Docker](#Docker)
|
|
||||||
- [资料](#资料)
|
|
||||||
- [书单](#书单)
|
|
||||||
- [Github榜单](#Github榜单)
|
|
||||||
- [待办](#待办)
|
|
||||||
- [说明](#说明)
|
|
||||||
|
|
||||||
## Java
|
|
||||||
|
|
||||||
### 基础
|
|
||||||
|
|
||||||
* [Java 基础知识回顾](java/Java基础知识.md)
|
|
||||||
* [Java 基础知识疑难点总结](java/Java疑难点.md)
|
|
||||||
* [J2EE 基础知识回顾](java/J2EE基础知识.md)
|
|
||||||
|
|
||||||
### 容器
|
|
||||||
|
|
||||||
* [Java容器常见面试题/知识点总结](java/collection/Java集合框架常见面试题.md)
|
|
||||||
* [ArrayList 源码学习](java/collection/ArrayList.md)
|
|
||||||
* [LinkedList 源码学习](java/collection/LinkedList.md)
|
|
||||||
* [HashMap(JDK1.8)源码学习](java/collection/HashMap.md)
|
|
||||||
|
|
||||||
### 并发
|
|
||||||
|
|
||||||
* [Java 并发基础常见面试题总结](java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md)
|
|
||||||
* [Java 并发进阶常见面试题总结](java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md)
|
|
||||||
* [并发容器总结](java/Multithread/并发容器总结.md)
|
|
||||||
* [乐观锁与悲观锁](essential-content-for-interview/面试必备之乐观锁与悲观锁.md)
|
|
||||||
* [JUC 中的 Atomic 原子类总结](java/Multithread/Atomic.md)
|
|
||||||
* [AQS 原理以及 AQS 同步组件总结](java/Multithread/AQS.md)
|
|
||||||
|
|
||||||
### JVM
|
|
||||||
* [一 Java内存区域](java/jvm/Java内存区域.md)
|
|
||||||
* [二 JVM垃圾回收](java/jvm/JVM垃圾回收.md)
|
|
||||||
* [三 JDK 监控和故障处理工具](java/jvm/JDK监控和故障处理工具总结.md)
|
|
||||||
* [四 类文件结构](java/jvm/类文件结构.md)
|
|
||||||
* [五 类加载过程](java/jvm/类加载过程.md)
|
|
||||||
* [六 类加载器](java/jvm/类加载器.md)
|
|
||||||
|
|
||||||
### I/O
|
|
||||||
|
|
||||||
* [BIO,NIO,AIO 总结 ](java/BIO-NIO-AIO.md)
|
|
||||||
* [Java IO 与 NIO系列文章](java/Java%20IO与NIO.md)
|
|
||||||
|
|
||||||
### Java 8
|
|
||||||
|
|
||||||
* [Java 8 新特性总结](java/What's%20New%20in%20JDK8/Java8Tutorial.md)
|
|
||||||
* [Java 8 学习资源推荐](java/What's%20New%20in%20JDK8/Java8教程推荐.md)
|
|
||||||
|
|
||||||
### 编程规范
|
|
||||||
|
|
||||||
- [Java 编程规范](java/Java编程规范.md)
|
|
||||||
|
|
||||||
## 网络
|
|
||||||
|
|
||||||
* [计算机网络常见面试题](network/计算机网络.md)
|
|
||||||
* [计算机网络基础知识总结](network/干货:计算机网络知识总结.md)
|
|
||||||
* [HTTPS中的TLS](network/HTTPS中的TLS.md)
|
|
||||||
|
|
||||||
## 操作系统
|
|
||||||
|
|
||||||
### Linux相关
|
|
||||||
|
|
||||||
* [后端程序员必备的 Linux 基础知识](operating-system/后端程序员必备的Linux基础知识.md)
|
|
||||||
* [Shell 编程入门](operating-system/Shell.md)
|
|
||||||
|
|
||||||
## 数据结构与算法
|
|
||||||
|
|
||||||
### 数据结构
|
|
||||||
|
|
||||||
- [数据结构知识学习与面试](dataStructures-algorithms/数据结构.md)
|
|
||||||
|
|
||||||
### 算法
|
|
||||||
|
|
||||||
- [算法学习资源推荐](dataStructures-algorithms/算法学习资源推荐.md)
|
|
||||||
- [几道常见的字符串算法题总结 ](dataStructures-algorithms/几道常见的子符串算法题.md)
|
|
||||||
- [几道常见的链表算法题总结 ](dataStructures-algorithms/几道常见的链表算法题.md)
|
|
||||||
- [剑指offer部分编程题](dataStructures-algorithms/剑指offer部分编程题.md)
|
|
||||||
- [公司真题](dataStructures-algorithms/公司真题.md)
|
|
||||||
- [回溯算法经典案例之N皇后问题](dataStructures-algorithms/Backtracking-NQueens.md)
|
|
||||||
|
|
||||||
## 数据库
|
|
||||||
|
|
||||||
### MySQL
|
|
||||||
|
|
||||||
* [MySQL 学习与面试](database/MySQL.md)
|
|
||||||
* [一千行MySQL学习笔记](database/一千行MySQL命令.md)
|
|
||||||
* [MySQL高性能优化规范建议](database/MySQL高性能优化规范建议.md)
|
|
||||||
* [数据库索引总结](database/MySQL%20Index.md)
|
|
||||||
* [事务隔离级别(图文详解)](database/事务隔离级别(图文详解).md)
|
|
||||||
* [一条SQL语句在MySQL中如何执行的](database/一条sql语句在mysql中如何执行的.md)
|
|
||||||
|
|
||||||
### Redis
|
|
||||||
|
|
||||||
* [Redis 总结](database/Redis/Redis.md)
|
|
||||||
* [Redlock分布式锁](database/Redis/Redlock分布式锁.md)
|
|
||||||
* [如何做可靠的分布式锁,Redlock真的可行么](database/Redis/如何做可靠的分布式锁,Redlock真的可行么.md)
|
|
||||||
|
|
||||||
## 系统设计
|
|
||||||
|
|
||||||
### 设计模式
|
|
||||||
|
|
||||||
- [设计模式系列文章](system-design/设计模式.md)
|
|
||||||
|
|
||||||
### 常用框架
|
|
||||||
|
|
||||||
#### Spring
|
|
||||||
|
|
||||||
- [Spring 学习与面试](system-design/framework/spring/Spring.md)
|
|
||||||
- [Spring 常见问题总结](system-design/framework/spring/SpringInterviewQuestions.md)
|
|
||||||
- [Spring中bean的作用域与生命周期](system-design/framework/spring/SpringBean.md)
|
|
||||||
- [SpringMVC 工作原理详解](system-design/framework/spring/SpringMVC-Principle.md)
|
|
||||||
- [Spring中都用到了那些设计模式?](system-design/framework/spring/Spring-Design-Patterns.md)
|
|
||||||
|
|
||||||
#### ZooKeeper
|
|
||||||
|
|
||||||
- [ZooKeeper 相关概念总结](system-design/framework/ZooKeeper.md)
|
|
||||||
- [ZooKeeper 数据模型和常见命令](system-design/framework/ZooKeeper数据模型和常见命令.md)
|
|
||||||
|
|
||||||
### 数据通信
|
|
||||||
|
|
||||||
- [数据通信(RESTful、RPC、消息队列)相关知识点总结](system-design/data-communication/summary.md)
|
|
||||||
- [Dubbo 总结:关于 Dubbo 的重要知识点](system-design/data-communication/dubbo.md)
|
|
||||||
- [消息队列总结](system-design/data-communication/message-queue.md)
|
|
||||||
- [RabbitMQ 入门](system-design/data-communication/rabbitmq.md)
|
|
||||||
- [RocketMQ的几个简单问题与答案](system-design/data-communication/RocketMQ-Questions.md)
|
|
||||||
|
|
||||||
### 网站架构
|
|
||||||
|
|
||||||
- [一文读懂分布式应该学什么](system-design/website-architecture/分布式.md)
|
|
||||||
- [8 张图读懂大型网站技术架构](system-design/website-architecture/8%20张图读懂大型网站技术架构.md)
|
|
||||||
- [【面试精选】关于大型网站系统架构你不得不懂的10个问题](system-design/website-architecture/【面试精选】关于大型网站系统架构你不得不懂的10个问题.md)
|
|
||||||
|
|
||||||
## 面试指南
|
|
||||||
|
|
||||||
### 备战面试
|
|
||||||
|
|
||||||
* [【备战面试1】程序员的简历就该这样写](essential-content-for-interview/PreparingForInterview/程序员的简历之道.md)
|
|
||||||
* [【备战面试2】初出茅庐的程序员该如何准备面试?](essential-content-for-interview/PreparingForInterview/interviewPrepare.md)
|
|
||||||
* [【备战面试3】7个大部分程序员在面试前很关心的问题](essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md)
|
|
||||||
* [【备战面试4】Github上开源的Java面试/学习相关的仓库推荐](essential-content-for-interview/PreparingForInterview/JavaInterviewLibrary.md)
|
|
||||||
* [【备战面试5】如果面试官问你“你有什么问题问我吗?”时,你该如何回答](essential-content-for-interview/PreparingForInterview/如果面试官问你“你有什么问题问我吗?”时,你该如何回答.md)
|
|
||||||
* [【备战面试6】美团面试常见问题总结(附详解答案)](essential-content-for-interview/PreparingForInterview/美团面试常见问题总结.md)
|
|
||||||
|
|
||||||
### 常见面试题总结
|
|
||||||
|
|
||||||
* [第一周(2018-8-7)](essential-content-for-interview/MostCommonJavaInterviewQuestions/第一周(2018-8-7).md) (为什么 Java 中只有值传递、==与equals、 hashCode与equals)
|
|
||||||
* [第二周(2018-8-13)](essential-content-for-interview/MostCommonJavaInterviewQuestions/第二周(2018-8-13).md)(String和StringBuffer、StringBuilder的区别是什么?String为什么是不可变的?、什么是反射机制?反射机制的应用场景有哪些?......)
|
|
||||||
* [第三周(2018-08-22)](java/collection/Java集合框架常见面试题.md) (Arraylist 与 LinkedList 异同、ArrayList 与 Vector 区别、HashMap的底层实现、HashMap 和 Hashtable 的区别、HashMap 的长度为什么是2的幂次方、HashSet 和 HashMap 区别、ConcurrentHashMap 和 Hashtable 的区别、ConcurrentHashMap线程安全的具体实现方式/底层具体实现、集合框架底层数据结构总结)
|
|
||||||
* [第四周(2018-8-30).md](essential-content-for-interview/MostCommonJavaInterviewQuestions/第四周(2018-8-30).md) (主要内容是几道面试常问的多线程基础题。)
|
|
||||||
|
|
||||||
### 面经
|
|
||||||
|
|
||||||
- [5面阿里,终获offer(2018年秋招)](essential-content-for-interview/BATJrealInterviewExperience/5面阿里,终获offer.md)
|
|
||||||
- [蚂蚁金服2019实习生面经总结(已拿口头offer)](essential-content-for-interview/BATJrealInterviewExperience/蚂蚁金服实习生面经总结(已拿口头offer).md)
|
|
||||||
- [2019年蚂蚁金服、头条、拼多多的面试总结](essential-content-for-interview/BATJrealInterviewExperience/2019alipay-pinduoduo-toutiao.md)
|
|
||||||
|
|
||||||
## 工具
|
|
||||||
|
|
||||||
### Git
|
|
||||||
|
|
||||||
* [Git入门](tools/Git.md)
|
|
||||||
|
|
||||||
### Docker
|
|
||||||
|
|
||||||
* [Docker 入门](tools/Docker.md)
|
|
||||||
* [一文搞懂 Docker 镜像的常用操作!](tools/Docker-Image.md)
|
|
||||||
|
|
||||||
## 资料
|
|
||||||
|
|
||||||
### 书单
|
|
||||||
|
|
||||||
- [Java程序员必备书单](data/java-recommended-books.md)
|
|
||||||
|
|
||||||
### Github榜单
|
|
||||||
|
|
||||||
- [Java 项目月榜单](github-trending/JavaGithubTrending.md)
|
|
||||||
|
|
||||||
***
|
|
||||||
|
|
||||||
## 待办
|
|
||||||
|
|
||||||
- [x] [Java 8 新特性总结](./java/What's%20New%20in%20JDK8/Java8Tutorial.md)
|
|
||||||
- [x] [Java 8 新特性详解](./java/What's%20New%20in%20JDK8/Java8教程推荐.md)
|
|
||||||
- [ ] Java 多线程类别知识重构(---正在进行中---)
|
|
||||||
- [x] [BIO,NIO,AIO 总结 ](./java/BIO-NIO-AIO.md)
|
|
||||||
- [ ] Netty 总结(---正在进行中---)
|
|
||||||
- [ ] 数据结构总结重构(---正在进行中---)
|
|
||||||
|
|
||||||
## 公众号
|
|
||||||
|
|
||||||
- 如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
|
|
||||||
- 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本公众号后台回复 **"Java面试突击"** 即可免费领取!
|
|
||||||
- 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
|
||||||
|
|
||||||
<p align="center">
|
|
||||||
<img src="https://user-gold-cdn.xitu.io/2018/11/28/167598cd2e17b8ec?w=258&h=258&f=jpeg&s=27334" width=""/>
|
|
||||||
</p>
|
|
||||||
168
README.md
@ -1,16 +1,11 @@
|
|||||||
👍推荐 [在线阅读](https://snailclimb.gitee.io/javaguide) (Github 访问速度比较慢可能会导致部分图片无法刷新出来)
|
👍推荐 [在线阅读](https://snailclimb.gitee.io/javaguide) (Github 访问速度比较慢可能会导致部分图片无法刷新出来)
|
||||||
|
|
||||||
👍推荐 [图解Java+操作系统+HTTP+计算机网络的 PDF 资料](#优质原创PDF资源)
|
书单已经被移动到[awesome-cs](https://github.com/CodingDocs/awesome-cs) 这个仓库。
|
||||||
|
|
||||||
👍推荐 [一个纯粹的 Java 交流社区:简历修改、提问、原创面试小册、手写RPC框架......](https://sourl.cn/U7rukQ)
|
> 1. **介绍**:关于 JavaGuide 的相关介绍请看:[关于 JavaGuide 的一些说明](https://www.yuque.com/snailclimb/dr6cvl/mr44yt) 。
|
||||||
|
> 2. **PDF版本** : [《JavaGuide 面试突击版》PDF 版本](#公众号) 。[图解计算机基础 PDF 版](#优质原创PDF资源)。
|
||||||
## 一些闲话:
|
> 3. **知识星球** : 简历指导/Java学习/面试指导/面试小册。欢迎加入[我的知识星球](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=100015911&idx=1&sn=2e8a0f5acb749ecbcbb417aa8a4e18cc&chksm=4ea1b0ec79d639fae37df1b86f196e8ce397accfd1dd2004bcadb66b4df5f582d90ae0d62448#rd) 。星球内部更新的[《Java面试进阶指北 打造个人的技术竞争力》](https://www.yuque.com/docs/share/f37fc804-bfe6-4b0d-b373-9c462188fec7)这个小册的质量很高,专为面试打造。
|
||||||
|
> 4. **面试专版** :准备面试的小伙伴可以考虑面试专版:[《Java 面试进阶指南》](https://xiaozhuanlan.com/javainterview?rel=javaguide)
|
||||||
> 1. **介绍**:关于 JavaGuide 的相关介绍请看:[关于 JavaGuide 的一些说明](https://www.yuque.com/snailclimb/dr6cvl/mr44yt) 。PDF 版本请看:[完结撒花!JavaGuide 面试突击版来啦!](./docs/javaguide面试突击版.md) 。
|
|
||||||
> 2. **PDF版本** : [《JavaGuide 面试突击版》PDF 版本](#公众号) 。
|
|
||||||
> 3. **面试专版** :准备面试的小伙伴可以考虑面试专版:[《Java 面试进阶指南》](https://xiaozhuanlan.com/javainterview?rel=javaguide) ,
|
|
||||||
> 4. **知识星球** : 简历指导/Java学习/面试指导/offer选择。欢迎加入[我的知识星球](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247497451&idx=1&sn=ea566dd64662ff8d5260f079c11c2268&chksm=cea1b920f9d630367eb80666da7b599bb610b9d61c6f956add1ee0a607ddcd61372931808877&token=804689790&lang=zh_CN#rd) 。
|
|
||||||
> 5. **联系我** :如要进群或者请教问题,请[联系我](#联系我) (备注来自 Github。请直入问题,工作时间不回复)。
|
|
||||||
> 6. **转载须知** :以下所有文章如非文首说明皆为我(Guide哥)的原创,转载在文首注明出处,如发现恶意抄袭/搬运,会动用法律武器维护自己的权益。让我们一起维护一个良好的技术创作环境!⛽️
|
> 6. **转载须知** :以下所有文章如非文首说明皆为我(Guide哥)的原创,转载在文首注明出处,如发现恶意抄袭/搬运,会动用法律武器维护自己的权益。让我们一起维护一个良好的技术创作环境!⛽️
|
||||||
|
|
||||||
<p align="center">
|
<p align="center">
|
||||||
@ -34,78 +29,13 @@
|
|||||||
<tbody>
|
<tbody>
|
||||||
<tr>
|
<tr>
|
||||||
<td align="center" valign="middle">
|
<td align="center" valign="middle">
|
||||||
<a href="https://sourl.cn/U7rukQ">
|
<a href="https://t.1yb.co/iskv">
|
||||||
<img src="./media/sponsor/知识星球.png" style="margin: 0 auto;width:450px" /></a>
|
<img src="./media/sponsor/知识星球.png" style="margin: 0 auto;width:850px" /></a>
|
||||||
</td>
|
</td>
|
||||||
</tr>
|
</tr>
|
||||||
</tbody>
|
</tbody>
|
||||||
</table>
|
</table>
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
<!-- @import "[TOC]" {cmd="toc" depthFrom=1 depthTo=6 orderedList=false} -->
|
|
||||||
|
|
||||||
<!-- code_chunk_output -->
|
|
||||||
|
|
||||||
- [Java](#java)
|
|
||||||
- [基础](#基础)
|
|
||||||
- [容器](#容器)
|
|
||||||
- [并发](#并发)
|
|
||||||
- [JVM (必看 :+1:)](#jvm-必看-1)
|
|
||||||
- [新特性](#新特性)
|
|
||||||
- [网络](#网络)
|
|
||||||
- [操作系统](#操作系统)
|
|
||||||
- [数据结构与算法](#数据结构与算法)
|
|
||||||
- [数据结构](#数据结构)
|
|
||||||
- [算法](#算法)
|
|
||||||
- [数据库](#数据库)
|
|
||||||
- [MySQL](#mysql)
|
|
||||||
- [Redis](#redis)
|
|
||||||
- [系统设计](#系统设计)
|
|
||||||
- [编码之道(必看 :+1:)](#编码之道必看-1)
|
|
||||||
- [常用框架](#常用框架)
|
|
||||||
- [Spring/SpringBoot](#springspringboot)
|
|
||||||
- [MyBatis](#mybatis)
|
|
||||||
- [Netty (必看 :+1:)](#netty-必看-1)
|
|
||||||
- [ZooKeeper](#zookeeper)
|
|
||||||
- [认证授权](#认证授权)
|
|
||||||
- [JWT](#jwt)
|
|
||||||
- [SSO(单点登录)](#sso单点登录)
|
|
||||||
- [分布式](#分布式)
|
|
||||||
- [CAP 理论](#cap-理论)
|
|
||||||
- [BASE 理论](#base-理论)
|
|
||||||
- [Paxos 算法和 Raft 算法](#paxos-算法和-raft-算法)
|
|
||||||
- [搜索引擎](#搜索引擎)
|
|
||||||
- [RPC](#rpc)
|
|
||||||
- [API 网关](#api-网关)
|
|
||||||
- [分布式 id](#分布式-id)
|
|
||||||
- [微服务](#微服务)
|
|
||||||
- [高并发](#高并发)
|
|
||||||
- [消息队列](#消息队列)
|
|
||||||
- [读写分离](#读写分离)
|
|
||||||
- [分库分表](#分库分表)
|
|
||||||
- [负载均衡](#负载均衡)
|
|
||||||
- [高可用](#高可用)
|
|
||||||
- [限流](#限流)
|
|
||||||
- [降级](#降级)
|
|
||||||
- [熔断](#熔断)
|
|
||||||
- [排队](#排队)
|
|
||||||
- [大型网站架构](#大型网站架构)
|
|
||||||
- [工具](#工具)
|
|
||||||
- [面试指南](#面试指南)
|
|
||||||
- [Java 学习常见问题汇总](#java-学习常见问题汇总)
|
|
||||||
- [书单](#书单)
|
|
||||||
- [其他](#其他)
|
|
||||||
- [待办](#待办)
|
|
||||||
- [联系我](#联系我)
|
|
||||||
- [捐赠支持](#捐赠支持)
|
|
||||||
- [Contributor](#贡献者)
|
|
||||||
- [公众号](#公众号)
|
|
||||||
|
|
||||||
<!-- /code_chunk_output -->
|
|
||||||
|
|
||||||
|
|
||||||
## Java
|
## Java
|
||||||
|
|
||||||
### 基础
|
### 基础
|
||||||
@ -119,13 +49,13 @@
|
|||||||
|
|
||||||
1. [枚举](docs/java/basis/用好Java中的枚举真的没有那么简单.md) (很重要的一个数据结构,用好枚举真的没有那么简单!)
|
1. [枚举](docs/java/basis/用好Java中的枚举真的没有那么简单.md) (很重要的一个数据结构,用好枚举真的没有那么简单!)
|
||||||
2. [Java 常见关键字总结:final、static、this、super!](docs/java/basis/Java常见关键字总结.md)
|
2. [Java 常见关键字总结:final、static、this、super!](docs/java/basis/Java常见关键字总结.md)
|
||||||
3. [什么是反射机制?反射机制的应用场景有哪些?](docs/java/basis/反射机制.md)
|
3. [什么是反射机制?反射机制的应用场景有哪些?](docs/java/basis/反射机制.md)
|
||||||
4. [代理模式详解:静态代理+JDK/CGLIB 动态代理实战](docs/java/basis/代理模式详解.md)
|
4. [代理模式详解:静态代理+JDK/CGLIB 动态代理实战](docs/java/basis/代理模式详解.md)
|
||||||
5. [BIO,NIO,AIO 总结 ](docs/java/basis/BIO,NIO,AIO总结.md)
|
5. [常见的 IO 模型有哪些?Java 中的 BIO、NIO、AIO 有啥区别?](https://www.cnblogs.com/javaguide/p/io.html)
|
||||||
|
|
||||||
### 容器
|
### 容器
|
||||||
|
|
||||||
1. **[Java 容器常见面试题/知识点总结](docs/java/collection/Java集合框架常见面试题.md)** (必看 :+1:)
|
1. **[Java 容器常见问题总结](docs/java/collection/Java集合框架常见面试题.md)** (必看 :+1:)
|
||||||
2. **源码分析** :[ArrayList 源码+扩容机制分析](docs/java/collection/ArrayList源码+扩容机制分析.md) 、[LinkedList 源码](docs/java/collection/LinkedList源码分析.md) 、[HashMap(JDK1.8)源码+底层数据结构分析](<docs/java/collection/HashMap(JDK1.8)源码+底层数据结构分析.md>) 、[ConcurrentHashMap 源码+底层数据结构分析](docs/java/collection/ConcurrentHashMap源码+底层数据结构分析.md)
|
2. **源码分析** :[ArrayList 源码+扩容机制分析](docs/java/collection/ArrayList源码+扩容机制分析.md) 、[LinkedList 源码](docs/java/collection/LinkedList源码分析.md) 、[HashMap(JDK1.8)源码+底层数据结构分析](<docs/java/collection/HashMap(JDK1.8)源码+底层数据结构分析.md>) 、[ConcurrentHashMap 源码+底层数据结构分析](docs/java/collection/ConcurrentHashMap源码+底层数据结构分析.md)
|
||||||
|
|
||||||
### 并发
|
### 并发
|
||||||
@ -140,7 +70,6 @@
|
|||||||
**重要知识点详解:**
|
**重要知识点详解:**
|
||||||
|
|
||||||
2. **线程池**:[Java 线程池学习总结](./docs/java/multi-thread/java线程池学习总结.md)、[拿来即用的线程池最佳实践](./docs/java/multi-thread/拿来即用的线程池最佳实践.md)
|
2. **线程池**:[Java 线程池学习总结](./docs/java/multi-thread/java线程池学习总结.md)、[拿来即用的线程池最佳实践](./docs/java/multi-thread/拿来即用的线程池最佳实践.md)
|
||||||
3. [乐观锁与悲观锁](docs/essential-content-for-interview/面试必备之乐观锁与悲观锁.md)
|
|
||||||
4. [ ThreadLocal 关键字解析](docs/java/multi-thread/万字详解ThreadLocal关键字.md)
|
4. [ ThreadLocal 关键字解析](docs/java/multi-thread/万字详解ThreadLocal关键字.md)
|
||||||
5. [并发容器总结](docs/java/multi-thread/并发容器总结.md)
|
5. [并发容器总结](docs/java/multi-thread/并发容器总结.md)
|
||||||
6. [JUC 中的 Atomic 原子类总结](docs/java/multi-thread/Atomic原子类总结.md)
|
6. [JUC 中的 Atomic 原子类总结](docs/java/multi-thread/Atomic原子类总结.md)
|
||||||
@ -155,12 +84,11 @@
|
|||||||
5. **[类加载过程](docs/java/jvm/类加载过程.md)**
|
5. **[类加载过程](docs/java/jvm/类加载过程.md)**
|
||||||
6. [类加载器](docs/java/jvm/类加载器.md)
|
6. [类加载器](docs/java/jvm/类加载器.md)
|
||||||
7. **[【待完成】最重要的 JVM 参数指南(翻译完善了一半)](docs/java/jvm/最重要的JVM参数指南.md)**
|
7. **[【待完成】最重要的 JVM 参数指南(翻译完善了一半)](docs/java/jvm/最重要的JVM参数指南.md)**
|
||||||
8. [JVM 配置常用参数和常用 GC 调优策略](docs/java/jvm/GC调优参数.md)
|
|
||||||
9. **[【加餐】大白话带你认识 JVM](docs/java/jvm/[加餐]大白话带你认识JVM.md)**
|
9. **[【加餐】大白话带你认识 JVM](docs/java/jvm/[加餐]大白话带你认识JVM.md)**
|
||||||
|
|
||||||
### 新特性
|
### 新特性
|
||||||
|
|
||||||
1. **Java 8** :[Java 8 新特性总结](docs/java/new-features/Java8新特性总结.md)、[Java 8 学习资源推荐](docs/java/new-features/Java8教程推荐.md)、[Java8 forEach 指南](docs/java/new-features/Java8foreach指南.md)
|
1. **Java 8** :[Java 8 新特性总结](docs/java/new-features/Java8新特性总结.md)、[Java8常用新特性总结](docs/java/new-features/java8-common-new-features.md) 、[Java 8 学习资源推荐](docs/java/new-features/Java8教程推荐.md)、[Java8 forEach 指南](docs/java/new-features/Java8foreach指南.md)
|
||||||
2. **Java9~Java14** : [一文带你看遍 JDK9~14 的重要新特性!](./docs/java/new-features/一文带你看遍JDK9到14的重要新特性.md)
|
2. **Java9~Java14** : [一文带你看遍 JDK9~14 的重要新特性!](./docs/java/new-features/一文带你看遍JDK9到14的重要新特性.md)
|
||||||
|
|
||||||
## 网络
|
## 网络
|
||||||
@ -202,9 +130,9 @@
|
|||||||
|
|
||||||
**总结:**
|
**总结:**
|
||||||
|
|
||||||
1. **[【推荐】MySQL/数据库 知识点总结](docs/database/MySQL.md)**
|
1. **[MySQL知识点总结](docs/database/MySQL.md)** (必看 :+1:)
|
||||||
2. **[阿里巴巴开发手册数据库部分的一些最佳实践](docs/database/阿里巴巴开发手册数据库部分的一些最佳实践.md)**
|
2. [阿里巴巴开发手册数据库部分的一些最佳实践](docs/database/阿里巴巴开发手册数据库部分的一些最佳实践.md)
|
||||||
3. **[一千行 MySQL 学习笔记](docs/database/一千行MySQL命令.md)**
|
3. [一千行 MySQL 学习笔记](docs/database/一千行MySQL命令.md)
|
||||||
4. [MySQL 高性能优化规范建议](docs/database/MySQL高性能优化规范建议.md)
|
4. [MySQL 高性能优化规范建议](docs/database/MySQL高性能优化规范建议.md)
|
||||||
|
|
||||||
**重要知识点:**
|
**重要知识点:**
|
||||||
@ -212,7 +140,7 @@
|
|||||||
1. [数据库索引总结 1](docs/database/MySQL%20Index.md)、[数据库索引总结 2](docs/database/数据库索引.md)
|
1. [数据库索引总结 1](docs/database/MySQL%20Index.md)、[数据库索引总结 2](docs/database/数据库索引.md)
|
||||||
2. [事务隔离级别(图文详解)](<docs/database/事务隔离级别(图文详解).md>)
|
2. [事务隔离级别(图文详解)](<docs/database/事务隔离级别(图文详解).md>)
|
||||||
3. [一条 SQL 语句在 MySQL 中如何执行的](docs/database/一条sql语句在mysql中如何执行的.md)
|
3. [一条 SQL 语句在 MySQL 中如何执行的](docs/database/一条sql语句在mysql中如何执行的.md)
|
||||||
4. **[关于数据库中如何存储时间的一点思考](docs/database/关于数据库存储时间的一点思考.md)**
|
4. [关于数据库中如何存储时间的一点思考](docs/database/关于数据库存储时间的一点思考.md)
|
||||||
|
|
||||||
### Redis
|
### Redis
|
||||||
|
|
||||||
@ -236,14 +164,14 @@
|
|||||||
**知识点/面试题:**
|
**知识点/面试题:**
|
||||||
|
|
||||||
1. **[Spring 常见问题总结](docs/system-design/framework/spring/Spring常见问题总结.md)**
|
1. **[Spring 常见问题总结](docs/system-design/framework/spring/Spring常见问题总结.md)**
|
||||||
2. **[SpringBoot 指南/常见面试题总结](https://github.com/Snailclimb/springboot-guide)**
|
2. **[SpringBoot 入门指南](https://github.com/Snailclimb/springboot-guide)**
|
||||||
|
3. **[面试常问:“讲述一下 SpringBoot 自动装配原理?”](https://www.cnblogs.com/javaguide/p/springboot-auto-config.html)**
|
||||||
|
|
||||||
**重要知识点详解:**
|
**重要知识点详解:**
|
||||||
|
|
||||||
1. **[Spring/Spring Boot 常用注解总结!安排!](./docs/system-design/framework/spring/SpringBoot+Spring常用注解总结.md)**
|
1. **[Spring/Spring Boot 常用注解总结!安排!](./docs/system-design/framework/spring/SpringBoot+Spring常用注解总结.md)**
|
||||||
2. **[Spring 事务总结](docs/system-design/framework/spring/Spring事务总结.md)**
|
2. **[Spring 事务总结](docs/system-design/framework/spring/Spring事务总结.md)**
|
||||||
3. [Spring 中都用到了那些设计模式?](docs/system-design/framework/spring/Spring-Design-Patterns.md)
|
3. [Spring 中都用到了那些设计模式?](docs/system-design/framework/spring/Spring-Design-Patterns.md)
|
||||||
4. [面试常问:“讲述一下 SpringBoot 自动装配原理?”](https://www.cnblogs.com/javaguide/p/springboot-auto-config.html)
|
|
||||||
|
|
||||||
#### MyBatis
|
#### MyBatis
|
||||||
|
|
||||||
@ -262,18 +190,24 @@
|
|||||||
2. [【进阶】ZooKeeper 相关概念总结](docs/system-design/distributed-system/zookeeper/zookeeper-plus.md)
|
2. [【进阶】ZooKeeper 相关概念总结](docs/system-design/distributed-system/zookeeper/zookeeper-plus.md)
|
||||||
3. [【实战】ZooKeeper 实战](docs/system-design/distributed-system/zookeeper/zookeeper-in-action.md)
|
3. [【实战】ZooKeeper 实战](docs/system-design/distributed-system/zookeeper/zookeeper-in-action.md)
|
||||||
|
|
||||||
### 认证授权
|
### 安全
|
||||||
|
|
||||||
|
#### 认证授权
|
||||||
|
|
||||||
**[《认证授权基础》](docs/system-design/authority-certification/basis-of-authority-certification.md)** 这篇文章中我会介绍认证授权常见概念: **Authentication**,**Authorization** 以及 **Cookie**、**Session**、Token、**OAuth 2**、**SSO** 。如果你不清楚这些概念的话,建议好好阅读一下这篇文章。
|
**[《认证授权基础》](docs/system-design/authority-certification/basis-of-authority-certification.md)** 这篇文章中我会介绍认证授权常见概念: **Authentication**,**Authorization** 以及 **Cookie**、**Session**、Token、**OAuth 2**、**SSO** 。如果你不清楚这些概念的话,建议好好阅读一下这篇文章。
|
||||||
|
|
||||||
#### JWT
|
- **JWT** :JWT(JSON Web Token)是一种身份认证的方式,JWT 本质上就一段签名的 JSON 格式的数据。由于它是带有签名的,因此接收者便可以验证它的真实性。相关阅读:
|
||||||
|
- [JWT 优缺点分析以及常见问题解决方案](docs/system-design/authority-certification/JWT优缺点分析以及常见问题解决方案.md)
|
||||||
|
- [适合初学者入门 Spring Security With JWT 的 Demo](https://github.com/Snailclimb/spring-security-jwt-guide)
|
||||||
|
|
||||||
1. [JWT 优缺点分析以及常见问题解决方案](docs/system-design/authority-certification/JWT优缺点分析以及常见问题解决方案.md)
|
- **SSO(单点登录)** :**SSO(Single Sign On)** 即单点登录说的是用户登陆多个子系统的其中一个就有权访问与其相关的其他系统。举个例子我们在登陆了京东金融之后,我们同时也成功登陆京东的京东超市、京东家电等子系统。相关阅读:[**SSO 单点登录看这篇就够了!**](docs/system-design/authority-certification/SSO单点登录看这一篇就够了.md)
|
||||||
2. [适合初学者入门 Spring Security With JWT 的 Demo](https://github.com/Snailclimb/spring-security-jwt-guide)
|
|
||||||
|
|
||||||
#### SSO(单点登录)
|
#### 数据脱敏
|
||||||
|
|
||||||
**SSO(Single Sign On)** 即单点登录说的是用户登陆多个子系统的其中一个就有权访问与其相关的其他系统。举个例子我们在登陆了京东金融之后,我们同时也成功登陆京东的京东超市、京东家电等子系统。相关阅读:**[SSO 单点登录看这篇就够了!](docs/system-design/authority-certification/SSO单点登录看这一篇就够了.md)**
|
数据脱敏说的就是我们根据特定的规则对敏感信息数据进行变形,比如我们把手机号、身份证号某些位数使用 * 来代替。相关阅读:
|
||||||
|
|
||||||
|
- [大厂也在用的 6种 数据脱敏方案,严防泄露数据的 “内鬼”](https://www.cnblogs.com/chengxy-nds/p/14107671.html)
|
||||||
|
- [【进阶之路】基于ShardingSphere的线上业务数据脱敏解决方案](https://juejin.cn/post/6906074730437836813)
|
||||||
|
|
||||||
### 分布式
|
### 分布式
|
||||||
|
|
||||||
@ -291,7 +225,7 @@ CAP 也就是 Consistency(一致性)、Availability(可用性)、Partiti
|
|||||||
|
|
||||||
#### Paxos 算法和 Raft 算法
|
#### Paxos 算法和 Raft 算法
|
||||||
|
|
||||||
**Paxos 算法**诞生于 1900 年,这是一种解决分布式系统一致性的经典算法 。但是,由于 Paxos 算法非常难以理解和实现,不断有人尝试简化这一算法。到了2013 年才诞生了一个比 Paxos 算法更易理解和实现的分布式一致性算法—**Raft 算法**。
|
**Paxos 算法**诞生于 1990 年,这是一种解决分布式系统一致性的经典算法 。但是,由于 Paxos 算法非常难以理解和实现,不断有人尝试简化这一算法。到了2013 年才诞生了一个比 Paxos 算法更易理解和实现的分布式一致性算法—**Raft 算法**。
|
||||||
|
|
||||||
#### 搜索引擎
|
#### 搜索引擎
|
||||||
|
|
||||||
@ -301,9 +235,10 @@ CAP 也就是 Consistency(一致性)、Availability(可用性)、Partiti
|
|||||||
|
|
||||||
RPC 让调用远程服务调用像调用本地方法那样简单。
|
RPC 让调用远程服务调用像调用本地方法那样简单。
|
||||||
|
|
||||||
1. [Dubbo 总结:关于 Dubbo 的重要知识点](docs/system-design/distributed-system/rpc/关于Dubbo的重要知识点.md)
|
Dubbo 是一款国产的 RPC 框架,由阿里开源。相关阅读:
|
||||||
2. [服务之间的调用为啥不直接用 HTTP 而用 RPC?](docs/system-design/distributed-system/rpc/服务之间的调用为啥不直接用HTTP而用RPC.md)
|
|
||||||
3. [一款基于 Netty+Kyro+Zookeeper 实现的自定义 RPC 框架](https://github.com/Snailclimb/guide-rpc-framework)
|
- [Dubbo 常见问题总结](docs/system-design/distributed-system/rpc/Dubbo.md)
|
||||||
|
- [服务之间的调用为啥不直接用 HTTP 而用 RPC?](docs/system-design/distributed-system/rpc/服务之间的调用为啥不直接用HTTP而用RPC.md)
|
||||||
|
|
||||||
#### API 网关
|
#### API 网关
|
||||||
|
|
||||||
@ -331,23 +266,23 @@ RPC 让调用远程服务调用像调用本地方法那样简单。
|
|||||||
|
|
||||||
#### 消息队列
|
#### 消息队列
|
||||||
|
|
||||||
消息队列在分布式系统中主要是为了解耦和削峰。相关阅读: **[消息队列总结](docs/system-design/distributed-system/message-queue/message-queue.md)** 。
|
消息队列在分布式系统中主要是为了解耦和削峰。相关阅读: [消息队列常见问题总结](docs/system-design/distributed-system/message-queue/message-queue.md)。
|
||||||
|
|
||||||
1. **RabbitMQ** : [RabbitMQ 入门](docs/system-design/distributed-system/message-queue/RabbitMQ入门看这一篇就够了.md)
|
1. **RabbitMQ** : [RabbitMQ 入门](docs/system-design/distributed-system/message-queue/RabbitMQ入门看这一篇就够了.md)
|
||||||
2. **RocketMQ** : [RocketMQ 入门](docs/system-design/distributed-system/message-queue/RocketMQ.md)、[RocketMQ 的几个简单问题与答案](docs/system-design/distributed-system/message-queue/RocketMQ-Questions.md)
|
2. **RocketMQ** : [RocketMQ 入门](docs/system-design/distributed-system/message-queue/RocketMQ.md)、[RocketMQ 的几个简单问题与答案](docs/system-design/distributed-system/message-queue/RocketMQ-Questions.md)
|
||||||
3. **Kafka** :[Kafka 常见面试题总结](docs/system-design/distributed-system/message-queue/Kafka常见面试题总结.md)
|
3. **Kafka** :[Kafka 常见问题总结](docs/system-design/distributed-system/message-queue/Kafka常见面试题总结.md)
|
||||||
|
|
||||||
#### 读写分离
|
#### 读写分离&分库分表
|
||||||
|
|
||||||
读写分离主要是为了将数据库的读和写操作分不到不同的数据库节点上。主服务器负责写,从服务器负责读。另外,一主一从或者一主多从都可以。
|
读写分离主要是为了将数据库的读和写操作分不到不同的数据库节点上。主服务器负责写,从服务器负责读。另外,一主一从或者一主多从都可以。
|
||||||
|
|
||||||
**读写分离可以大幅提高读性能,小幅提高写的性能。因此,读写分离更适合单机并发读请求比较多的场景。**
|
读写分离可以大幅提高读性能,小幅提高写的性能。因此,读写分离更适合单机并发读请求比较多的场景。
|
||||||
|
|
||||||
#### 分库分表
|
分库分表是为了解决由于库、表数据量过大,而导致数据库性能持续下降的问题。
|
||||||
|
|
||||||
**分库分表是为了解决由于库、表数据量过大,而导致数据库性能持续下降的问题。** 常见的分库分表工具有:`sharding-jdbc`(当当)、`TSharding`(蘑菇街)、`MyCAT`(基于 Cobar)、`Cobar`(阿里巴巴)...。
|
常见的分库分表工具有:`sharding-jdbc`(当当)、`TSharding`(蘑菇街)、`MyCAT`(基于 Cobar)、`Cobar`(阿里巴巴)...。 推荐使用 `sharding-jdbc`。 因为,`sharding-jdbc` 是一款轻量级 `Java` 框架,以 `jar` 包形式提供服务,不要我们做额外的运维工作,并且兼容性也很好。
|
||||||
|
|
||||||
**推荐使用 `sharding-jdbc`** 。 因为,`sharding-jdbc` 是一款轻量级 `Java` 框架,以 `jar` 包形式提供服务,不要我们做额外的运维工作,并且兼容性也很好。
|
相关阅读: [读写分离&分库分表常见问题总结](docs/system-design/读写分离&分库分表.md)
|
||||||
|
|
||||||
#### 负载均衡
|
#### 负载均衡
|
||||||
|
|
||||||
@ -406,21 +341,9 @@ RPC 让调用远程服务调用像调用本地方法那样简单。
|
|||||||
|
|
||||||
1. **Java** :[JAD 反编译](docs/java/JAD反编译tricks.md)、[手把手教你定位常见 Java 性能问题](./docs/java/手把手教你定位常见Java性能问题.md)
|
1. **Java** :[JAD 反编译](docs/java/JAD反编译tricks.md)、[手把手教你定位常见 Java 性能问题](./docs/java/手把手教你定位常见Java性能问题.md)
|
||||||
2. **Git** :[Git 入门](docs/tools/Git.md)
|
2. **Git** :[Git 入门](docs/tools/Git.md)
|
||||||
3. **Github** : [我使用Github 5 年总结了这些骚操作](docs/tools/Github技巧.md)
|
3. **Github** : [Github小技巧](docs/tools/Github技巧.md)
|
||||||
4. **Docker** : [Docker 基本概念解读](docs/tools/Docker.md) 、[一文搞懂 Docker 镜像的常用操作!](docs/tools/Docker-Image.md)
|
4. **Docker** : [Docker 基本概念解读](docs/tools/Docker.md) 、[一文搞懂 Docker 镜像的常用操作!](docs/tools/Docker-Image.md)
|
||||||
|
|
||||||
## 面试指南
|
|
||||||
|
|
||||||
> 这部分很多内容比如大厂面经、真实面经分析被移除,详见[完结撒花!JavaGuide 面试突击版来啦!](./docs/javaguide面试突击版.md)。
|
|
||||||
|
|
||||||
1. **[【备战面试 1】程序员的简历就该这样写](docs/essential-content-for-interview/PreparingForInterview/程序员的简历之道.md)**
|
|
||||||
2. **[【备战面试 2】初出茅庐的程序员该如何准备面试?](docs/essential-content-for-interview/PreparingForInterview/interviewPrepare.md)**
|
|
||||||
3. **[【备战面试 3】7 个大部分程序员在面试前很关心的问题](docs/essential-content-for-interview/PreparingForInterview/JavaProgrammerNeedKnow.md)**
|
|
||||||
4. **[【备战面试 4】Github 上开源的 Java 面试/学习相关的仓库推荐](docs/essential-content-for-interview/PreparingForInterview/JavaInterviewLibrary.md)**
|
|
||||||
5. **[【备战面试 5】如果面试官问你“你有什么问题问我吗?”时,你该如何回答](docs/essential-content-for-interview/PreparingForInterview/面试官-你有什么问题要问我.md)**
|
|
||||||
6. [【备战面试 6】应届生面试最爱问的几道 Java 基础问题](docs/essential-content-for-interview/PreparingForInterview/应届生面试最爱问的几道Java基础问题.md)
|
|
||||||
7. **[【备战面试 6】美团面试常见问题总结(附详解答案)](docs/essential-content-for-interview/PreparingForInterview/美团面试常见问题总结.md)**
|
|
||||||
|
|
||||||
## Java 学习常见问题汇总
|
## Java 学习常见问题汇总
|
||||||
|
|
||||||
1. [Java 学习路线和方法推荐](docs/questions/java-learning-path-and-methods.md)
|
1. [Java 学习路线和方法推荐](docs/questions/java-learning-path-and-methods.md)
|
||||||
@ -428,10 +351,6 @@ RPC 让调用远程服务调用像调用本地方法那样简单。
|
|||||||
3. [新手学习 Java,有哪些 Java 相关的博客,专栏,和技术学习网站推荐?](docs/questions/java-learning-website-blog.md)
|
3. [新手学习 Java,有哪些 Java 相关的博客,专栏,和技术学习网站推荐?](docs/questions/java-learning-website-blog.md)
|
||||||
4. [Java 还是大数据,你需要了解这些东西!](docs/questions/java-big-data.md)
|
4. [Java 还是大数据,你需要了解这些东西!](docs/questions/java-big-data.md)
|
||||||
|
|
||||||
## 书单
|
|
||||||
|
|
||||||
1. [「基础篇」Java 书单](./docs/books/java基础篇.md)
|
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
## 其他
|
## 其他
|
||||||
@ -444,7 +363,6 @@ RPC 让调用远程服务调用像调用本地方法那样简单。
|
|||||||
|
|
||||||
### 待办
|
### 待办
|
||||||
|
|
||||||
- [x] Netty 总结
|
|
||||||
- [ ] 数据结构总结重构
|
- [ ] 数据结构总结重构
|
||||||
|
|
||||||
### 优质原创PDF资源
|
### 优质原创PDF资源
|
||||||
@ -469,7 +387,7 @@ RPC 让调用远程服务调用像调用本地方法那样简单。
|
|||||||
|
|
||||||
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号“**JavaGuide**”。
|
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号“**JavaGuide**”。
|
||||||
|
|
||||||
**《Java 面试突击》:** 由本文档衍生的专为面试而生的《Java 面试突击》V3.0 PDF 版本[公众号](#公众号)后台回复 **"面试突击"** 即可免费领取!
|
**《Java 面试突击》:** 由本文档衍生的专为面试而生的《Java 面试突击》V3.0 PDF 版本[公众号](#公众号)后台回复 **"面试突击"** 即可领取!
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|||||||
2
code/java/ThreadPoolExecutorDemo/.idea/.gitignore
generated
vendored
@ -1,2 +0,0 @@
|
|||||||
# Default ignored files
|
|
||||||
/workspace.xml
|
|
||||||
@ -1,16 +0,0 @@
|
|||||||
<?xml version="1.0" encoding="UTF-8"?>
|
|
||||||
<project version="4">
|
|
||||||
<component name="CheckStyle-IDEA">
|
|
||||||
<option name="configuration">
|
|
||||||
<map>
|
|
||||||
<entry key="checkstyle-version" value="8.25" />
|
|
||||||
<entry key="copy-libs" value="false" />
|
|
||||||
<entry key="location-0" value="BUNDLED:(bundled):Sun Checks" />
|
|
||||||
<entry key="location-1" value="BUNDLED:(bundled):Google Checks" />
|
|
||||||
<entry key="scan-before-checkin" value="false" />
|
|
||||||
<entry key="scanscope" value="JavaOnly" />
|
|
||||||
<entry key="suppress-errors" value="false" />
|
|
||||||
</map>
|
|
||||||
</option>
|
|
||||||
</component>
|
|
||||||
</project>
|
|
||||||
@ -1,36 +0,0 @@
|
|||||||
<component name="InspectionProjectProfileManager">
|
|
||||||
<profile version="1.0">
|
|
||||||
<option name="myName" value="Project Default" />
|
|
||||||
<inspection_tool class="JavaDoc" enabled="true" level="WARNING" enabled_by_default="true">
|
|
||||||
<option name="TOP_LEVEL_CLASS_OPTIONS">
|
|
||||||
<value>
|
|
||||||
<option name="ACCESS_JAVADOC_REQUIRED_FOR" value="none" />
|
|
||||||
<option name="REQUIRED_TAGS" value="" />
|
|
||||||
</value>
|
|
||||||
</option>
|
|
||||||
<option name="INNER_CLASS_OPTIONS">
|
|
||||||
<value>
|
|
||||||
<option name="ACCESS_JAVADOC_REQUIRED_FOR" value="none" />
|
|
||||||
<option name="REQUIRED_TAGS" value="" />
|
|
||||||
</value>
|
|
||||||
</option>
|
|
||||||
<option name="METHOD_OPTIONS">
|
|
||||||
<value>
|
|
||||||
<option name="ACCESS_JAVADOC_REQUIRED_FOR" value="none" />
|
|
||||||
<option name="REQUIRED_TAGS" value="@return@param@throws or @exception" />
|
|
||||||
</value>
|
|
||||||
</option>
|
|
||||||
<option name="FIELD_OPTIONS">
|
|
||||||
<value>
|
|
||||||
<option name="ACCESS_JAVADOC_REQUIRED_FOR" value="none" />
|
|
||||||
<option name="REQUIRED_TAGS" value="" />
|
|
||||||
</value>
|
|
||||||
</option>
|
|
||||||
<option name="IGNORE_DEPRECATED" value="false" />
|
|
||||||
<option name="IGNORE_JAVADOC_PERIOD" value="true" />
|
|
||||||
<option name="IGNORE_DUPLICATED_THROWS" value="false" />
|
|
||||||
<option name="IGNORE_POINT_TO_ITSELF" value="false" />
|
|
||||||
<option name="myAdditionalJavadocTags" value="date" />
|
|
||||||
</inspection_tool>
|
|
||||||
</profile>
|
|
||||||
</component>
|
|
||||||
6
code/java/ThreadPoolExecutorDemo/.idea/misc.xml
generated
@ -1,6 +0,0 @@
|
|||||||
<?xml version="1.0" encoding="UTF-8"?>
|
|
||||||
<project version="4">
|
|
||||||
<component name="ProjectRootManager" version="2" languageLevel="JDK_1_8" default="true" project-jdk-name="1.8" project-jdk-type="JavaSDK">
|
|
||||||
<output url="file://$PROJECT_DIR$/out" />
|
|
||||||
</component>
|
|
||||||
</project>
|
|
||||||
@ -1,8 +0,0 @@
|
|||||||
<?xml version="1.0" encoding="UTF-8"?>
|
|
||||||
<project version="4">
|
|
||||||
<component name="ProjectModuleManager">
|
|
||||||
<modules>
|
|
||||||
<module fileurl="file://$PROJECT_DIR$/ThreadPoolExecutorDemo.iml" filepath="$PROJECT_DIR$/ThreadPoolExecutorDemo.iml" />
|
|
||||||
</modules>
|
|
||||||
</component>
|
|
||||||
</project>
|
|
||||||
124
code/java/ThreadPoolExecutorDemo/.idea/uiDesigner.xml
generated
@ -1,124 +0,0 @@
|
|||||||
<?xml version="1.0" encoding="UTF-8"?>
|
|
||||||
<project version="4">
|
|
||||||
<component name="Palette2">
|
|
||||||
<group name="Swing">
|
|
||||||
<item class="com.intellij.uiDesigner.HSpacer" tooltip-text="Horizontal Spacer" icon="/com/intellij/uiDesigner/icons/hspacer.png" removable="false" auto-create-binding="false" can-attach-label="false">
|
|
||||||
<default-constraints vsize-policy="1" hsize-policy="6" anchor="0" fill="1" />
|
|
||||||
</item>
|
|
||||||
<item class="com.intellij.uiDesigner.VSpacer" tooltip-text="Vertical Spacer" icon="/com/intellij/uiDesigner/icons/vspacer.png" removable="false" auto-create-binding="false" can-attach-label="false">
|
|
||||||
<default-constraints vsize-policy="6" hsize-policy="1" anchor="0" fill="2" />
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JPanel" icon="/com/intellij/uiDesigner/icons/panel.png" removable="false" auto-create-binding="false" can-attach-label="false">
|
|
||||||
<default-constraints vsize-policy="3" hsize-policy="3" anchor="0" fill="3" />
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JScrollPane" icon="/com/intellij/uiDesigner/icons/scrollPane.png" removable="false" auto-create-binding="false" can-attach-label="true">
|
|
||||||
<default-constraints vsize-policy="7" hsize-policy="7" anchor="0" fill="3" />
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JButton" icon="/com/intellij/uiDesigner/icons/button.png" removable="false" auto-create-binding="true" can-attach-label="false">
|
|
||||||
<default-constraints vsize-policy="0" hsize-policy="3" anchor="0" fill="1" />
|
|
||||||
<initial-values>
|
|
||||||
<property name="text" value="Button" />
|
|
||||||
</initial-values>
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JRadioButton" icon="/com/intellij/uiDesigner/icons/radioButton.png" removable="false" auto-create-binding="true" can-attach-label="false">
|
|
||||||
<default-constraints vsize-policy="0" hsize-policy="3" anchor="8" fill="0" />
|
|
||||||
<initial-values>
|
|
||||||
<property name="text" value="RadioButton" />
|
|
||||||
</initial-values>
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JCheckBox" icon="/com/intellij/uiDesigner/icons/checkBox.png" removable="false" auto-create-binding="true" can-attach-label="false">
|
|
||||||
<default-constraints vsize-policy="0" hsize-policy="3" anchor="8" fill="0" />
|
|
||||||
<initial-values>
|
|
||||||
<property name="text" value="CheckBox" />
|
|
||||||
</initial-values>
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JLabel" icon="/com/intellij/uiDesigner/icons/label.png" removable="false" auto-create-binding="false" can-attach-label="false">
|
|
||||||
<default-constraints vsize-policy="0" hsize-policy="0" anchor="8" fill="0" />
|
|
||||||
<initial-values>
|
|
||||||
<property name="text" value="Label" />
|
|
||||||
</initial-values>
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JTextField" icon="/com/intellij/uiDesigner/icons/textField.png" removable="false" auto-create-binding="true" can-attach-label="true">
|
|
||||||
<default-constraints vsize-policy="0" hsize-policy="6" anchor="8" fill="1">
|
|
||||||
<preferred-size width="150" height="-1" />
|
|
||||||
</default-constraints>
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JPasswordField" icon="/com/intellij/uiDesigner/icons/passwordField.png" removable="false" auto-create-binding="true" can-attach-label="true">
|
|
||||||
<default-constraints vsize-policy="0" hsize-policy="6" anchor="8" fill="1">
|
|
||||||
<preferred-size width="150" height="-1" />
|
|
||||||
</default-constraints>
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JFormattedTextField" icon="/com/intellij/uiDesigner/icons/formattedTextField.png" removable="false" auto-create-binding="true" can-attach-label="true">
|
|
||||||
<default-constraints vsize-policy="0" hsize-policy="6" anchor="8" fill="1">
|
|
||||||
<preferred-size width="150" height="-1" />
|
|
||||||
</default-constraints>
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JTextArea" icon="/com/intellij/uiDesigner/icons/textArea.png" removable="false" auto-create-binding="true" can-attach-label="true">
|
|
||||||
<default-constraints vsize-policy="6" hsize-policy="6" anchor="0" fill="3">
|
|
||||||
<preferred-size width="150" height="50" />
|
|
||||||
</default-constraints>
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JTextPane" icon="/com/intellij/uiDesigner/icons/textPane.png" removable="false" auto-create-binding="true" can-attach-label="true">
|
|
||||||
<default-constraints vsize-policy="6" hsize-policy="6" anchor="0" fill="3">
|
|
||||||
<preferred-size width="150" height="50" />
|
|
||||||
</default-constraints>
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JEditorPane" icon="/com/intellij/uiDesigner/icons/editorPane.png" removable="false" auto-create-binding="true" can-attach-label="true">
|
|
||||||
<default-constraints vsize-policy="6" hsize-policy="6" anchor="0" fill="3">
|
|
||||||
<preferred-size width="150" height="50" />
|
|
||||||
</default-constraints>
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JComboBox" icon="/com/intellij/uiDesigner/icons/comboBox.png" removable="false" auto-create-binding="true" can-attach-label="true">
|
|
||||||
<default-constraints vsize-policy="0" hsize-policy="2" anchor="8" fill="1" />
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JTable" icon="/com/intellij/uiDesigner/icons/table.png" removable="false" auto-create-binding="true" can-attach-label="false">
|
|
||||||
<default-constraints vsize-policy="6" hsize-policy="6" anchor="0" fill="3">
|
|
||||||
<preferred-size width="150" height="50" />
|
|
||||||
</default-constraints>
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JList" icon="/com/intellij/uiDesigner/icons/list.png" removable="false" auto-create-binding="true" can-attach-label="false">
|
|
||||||
<default-constraints vsize-policy="6" hsize-policy="2" anchor="0" fill="3">
|
|
||||||
<preferred-size width="150" height="50" />
|
|
||||||
</default-constraints>
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JTree" icon="/com/intellij/uiDesigner/icons/tree.png" removable="false" auto-create-binding="true" can-attach-label="false">
|
|
||||||
<default-constraints vsize-policy="6" hsize-policy="6" anchor="0" fill="3">
|
|
||||||
<preferred-size width="150" height="50" />
|
|
||||||
</default-constraints>
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JTabbedPane" icon="/com/intellij/uiDesigner/icons/tabbedPane.png" removable="false" auto-create-binding="true" can-attach-label="false">
|
|
||||||
<default-constraints vsize-policy="3" hsize-policy="3" anchor="0" fill="3">
|
|
||||||
<preferred-size width="200" height="200" />
|
|
||||||
</default-constraints>
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JSplitPane" icon="/com/intellij/uiDesigner/icons/splitPane.png" removable="false" auto-create-binding="false" can-attach-label="false">
|
|
||||||
<default-constraints vsize-policy="3" hsize-policy="3" anchor="0" fill="3">
|
|
||||||
<preferred-size width="200" height="200" />
|
|
||||||
</default-constraints>
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JSpinner" icon="/com/intellij/uiDesigner/icons/spinner.png" removable="false" auto-create-binding="true" can-attach-label="true">
|
|
||||||
<default-constraints vsize-policy="0" hsize-policy="6" anchor="8" fill="1" />
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JSlider" icon="/com/intellij/uiDesigner/icons/slider.png" removable="false" auto-create-binding="true" can-attach-label="false">
|
|
||||||
<default-constraints vsize-policy="0" hsize-policy="6" anchor="8" fill="1" />
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JSeparator" icon="/com/intellij/uiDesigner/icons/separator.png" removable="false" auto-create-binding="false" can-attach-label="false">
|
|
||||||
<default-constraints vsize-policy="6" hsize-policy="6" anchor="0" fill="3" />
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JProgressBar" icon="/com/intellij/uiDesigner/icons/progressbar.png" removable="false" auto-create-binding="true" can-attach-label="false">
|
|
||||||
<default-constraints vsize-policy="0" hsize-policy="6" anchor="0" fill="1" />
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JToolBar" icon="/com/intellij/uiDesigner/icons/toolbar.png" removable="false" auto-create-binding="false" can-attach-label="false">
|
|
||||||
<default-constraints vsize-policy="0" hsize-policy="6" anchor="0" fill="1">
|
|
||||||
<preferred-size width="-1" height="20" />
|
|
||||||
</default-constraints>
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JToolBar$Separator" icon="/com/intellij/uiDesigner/icons/toolbarSeparator.png" removable="false" auto-create-binding="false" can-attach-label="false">
|
|
||||||
<default-constraints vsize-policy="0" hsize-policy="0" anchor="0" fill="1" />
|
|
||||||
</item>
|
|
||||||
<item class="javax.swing.JScrollBar" icon="/com/intellij/uiDesigner/icons/scrollbar.png" removable="false" auto-create-binding="true" can-attach-label="false">
|
|
||||||
<default-constraints vsize-policy="6" hsize-policy="0" anchor="0" fill="2" />
|
|
||||||
</item>
|
|
||||||
</group>
|
|
||||||
</component>
|
|
||||||
</project>
|
|
||||||
6
code/java/ThreadPoolExecutorDemo/.idea/vcs.xml
generated
@ -1,6 +0,0 @@
|
|||||||
<?xml version="1.0" encoding="UTF-8"?>
|
|
||||||
<project version="4">
|
|
||||||
<component name="VcsDirectoryMappings">
|
|
||||||
<mapping directory="$PROJECT_DIR$/../../.." vcs="Git" />
|
|
||||||
</component>
|
|
||||||
</project>
|
|
||||||
@ -1,11 +0,0 @@
|
|||||||
<?xml version="1.0" encoding="UTF-8"?>
|
|
||||||
<module type="JAVA_MODULE" version="4">
|
|
||||||
<component name="NewModuleRootManager" inherit-compiler-output="true">
|
|
||||||
<exclude-output />
|
|
||||||
<content url="file://$MODULE_DIR$">
|
|
||||||
<sourceFolder url="file://$MODULE_DIR$/src" isTestSource="false" />
|
|
||||||
</content>
|
|
||||||
<orderEntry type="inheritedJdk" />
|
|
||||||
<orderEntry type="sourceFolder" forTests="false" />
|
|
||||||
</component>
|
|
||||||
</module>
|
|
||||||
@ -1,49 +0,0 @@
|
|||||||
package callable;
|
|
||||||
|
|
||||||
import java.util.ArrayList;
|
|
||||||
import java.util.Date;
|
|
||||||
import java.util.List;
|
|
||||||
import java.util.concurrent.ArrayBlockingQueue;
|
|
||||||
import java.util.concurrent.Callable;
|
|
||||||
import java.util.concurrent.ExecutionException;
|
|
||||||
import java.util.concurrent.Future;
|
|
||||||
import java.util.concurrent.ThreadPoolExecutor;
|
|
||||||
import java.util.concurrent.TimeUnit;
|
|
||||||
|
|
||||||
import static common.ThreadPoolConstants.CORE_POOL_SIZE;
|
|
||||||
import static common.ThreadPoolConstants.KEEP_ALIVE_TIME;
|
|
||||||
import static common.ThreadPoolConstants.MAX_POOL_SIZE;
|
|
||||||
import static common.ThreadPoolConstants.QUEUE_CAPACITY;
|
|
||||||
|
|
||||||
public class CallableDemo {
|
|
||||||
public static void main(String[] args) {
|
|
||||||
//使用阿里巴巴推荐的创建线程池的方式
|
|
||||||
//通过ThreadPoolExecutor构造函数自定义参数创建
|
|
||||||
ThreadPoolExecutor executor = new ThreadPoolExecutor(
|
|
||||||
CORE_POOL_SIZE,
|
|
||||||
MAX_POOL_SIZE,
|
|
||||||
KEEP_ALIVE_TIME,
|
|
||||||
TimeUnit.SECONDS,
|
|
||||||
new ArrayBlockingQueue<>(QUEUE_CAPACITY),
|
|
||||||
new ThreadPoolExecutor.CallerRunsPolicy());
|
|
||||||
|
|
||||||
List<Future<String>> futureList = new ArrayList<>();
|
|
||||||
Callable<String> callable = new MyCallable();
|
|
||||||
for (int i = 0; i < 10; i++) {
|
|
||||||
//提交任务到线程池
|
|
||||||
Future<String> future = executor.submit(callable);
|
|
||||||
//将返回值 future 添加到 list,我们可以通过 future 获得 执行 Callable 得到的返回值
|
|
||||||
futureList.add(future);
|
|
||||||
}
|
|
||||||
for (Future<String> fut : futureList) {
|
|
||||||
try {
|
|
||||||
System.out.println(new Date() + "::" + fut.get());
|
|
||||||
} catch (InterruptedException | ExecutionException e) {
|
|
||||||
e.printStackTrace();
|
|
||||||
}
|
|
||||||
}
|
|
||||||
//关闭线程池
|
|
||||||
executor.shutdown();
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
@ -1,13 +0,0 @@
|
|||||||
package callable;
|
|
||||||
|
|
||||||
import java.util.concurrent.Callable;
|
|
||||||
|
|
||||||
public class MyCallable implements Callable<String> {
|
|
||||||
|
|
||||||
@Override
|
|
||||||
public String call() throws Exception {
|
|
||||||
Thread.sleep(1000);
|
|
||||||
//返回执行当前 Callable 的线程名字
|
|
||||||
return Thread.currentThread().getName();
|
|
||||||
}
|
|
||||||
}
|
|
||||||
@ -1,11 +0,0 @@
|
|||||||
package common;
|
|
||||||
|
|
||||||
public class ThreadPoolConstants {
|
|
||||||
public static final int CORE_POOL_SIZE = 5;
|
|
||||||
public static final int MAX_POOL_SIZE = 10;
|
|
||||||
public static final int QUEUE_CAPACITY = 100;
|
|
||||||
public static final Long KEEP_ALIVE_TIME = 1L;
|
|
||||||
private ThreadPoolConstants(){
|
|
||||||
|
|
||||||
}
|
|
||||||
}
|
|
||||||
@ -1,36 +0,0 @@
|
|||||||
package threadPoolExecutor;
|
|
||||||
|
|
||||||
import java.util.Date;
|
|
||||||
|
|
||||||
/**
|
|
||||||
* 这是一个简单的Runnable类,需要大约5秒钟来执行其任务。
|
|
||||||
* @author shuang.kou
|
|
||||||
*/
|
|
||||||
public class MyRunnable implements Runnable {
|
|
||||||
|
|
||||||
private String command;
|
|
||||||
|
|
||||||
public MyRunnable(String s) {
|
|
||||||
this.command = s;
|
|
||||||
}
|
|
||||||
|
|
||||||
@Override
|
|
||||||
public void run() {
|
|
||||||
System.out.println(Thread.currentThread().getName() + " Start. Time = " + new Date());
|
|
||||||
processCommand();
|
|
||||||
System.out.println(Thread.currentThread().getName() + " End. Time = " + new Date());
|
|
||||||
}
|
|
||||||
|
|
||||||
private void processCommand() {
|
|
||||||
try {
|
|
||||||
Thread.sleep(5000);
|
|
||||||
} catch (InterruptedException e) {
|
|
||||||
e.printStackTrace();
|
|
||||||
}
|
|
||||||
}
|
|
||||||
|
|
||||||
@Override
|
|
||||||
public String toString() {
|
|
||||||
return this.command;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
@ -1,39 +0,0 @@
|
|||||||
package threadPoolExecutor;
|
|
||||||
|
|
||||||
import java.util.concurrent.ArrayBlockingQueue;
|
|
||||||
import java.util.concurrent.ThreadPoolExecutor;
|
|
||||||
import java.util.concurrent.TimeUnit;
|
|
||||||
|
|
||||||
import static common.ThreadPoolConstants.CORE_POOL_SIZE;
|
|
||||||
import static common.ThreadPoolConstants.KEEP_ALIVE_TIME;
|
|
||||||
import static common.ThreadPoolConstants.MAX_POOL_SIZE;
|
|
||||||
import static common.ThreadPoolConstants.QUEUE_CAPACITY;
|
|
||||||
|
|
||||||
|
|
||||||
public class ThreadPoolExecutorDemo {
|
|
||||||
|
|
||||||
public static void main(String[] args) {
|
|
||||||
|
|
||||||
//使用阿里巴巴推荐的创建线程池的方式
|
|
||||||
//通过ThreadPoolExecutor构造函数自定义参数创建
|
|
||||||
ThreadPoolExecutor executor = new ThreadPoolExecutor(
|
|
||||||
CORE_POOL_SIZE,
|
|
||||||
MAX_POOL_SIZE,
|
|
||||||
KEEP_ALIVE_TIME,
|
|
||||||
TimeUnit.SECONDS,
|
|
||||||
new ArrayBlockingQueue<>(QUEUE_CAPACITY),
|
|
||||||
new ThreadPoolExecutor.CallerRunsPolicy());
|
|
||||||
|
|
||||||
for (int i = 0; i < 10; i++) {
|
|
||||||
//创建WorkerThread对象(WorkerThread类实现了Runnable 接口)
|
|
||||||
Runnable worker = new MyRunnable("" + i);
|
|
||||||
//执行Runnable
|
|
||||||
executor.execute(worker);
|
|
||||||
}
|
|
||||||
//终止线程池
|
|
||||||
executor.shutdown();
|
|
||||||
while (!executor.isTerminated()) {
|
|
||||||
}
|
|
||||||
System.out.println("Finished all threads");
|
|
||||||
}
|
|
||||||
}
|
|
||||||
{kind=link}
|
Before Width: | Height: | Size: 107 KiB |
{kind=link}
|
Before Width: | Height: | Size: 96 KiB |
{kind=link}
|
Before Width: | Height: | Size: 102 KiB |
{kind=link}
|
Before Width: | Height: | Size: 116 KiB |
{kind=link}
|
Before Width: | Height: | Size: 93 KiB |
{kind=link}
|
Before Width: | Height: | Size: 336 KiB |
{kind=link}
|
Before Width: | Height: | Size: 140 KiB |
{kind=link}
|
Before Width: | Height: | Size: 140 KiB |
{kind=link}
|
Before Width: | Height: | Size: 166 KiB |
{kind=link}
|
Before Width: | Height: | Size: 554 KiB |
{kind=link}
|
Before Width: | Height: | Size: 382 KiB |
{kind=link}
|
Before Width: | Height: | Size: 145 KiB |
{kind=link}
|
Before Width: | Height: | Size: 128 KiB |
{kind=link}
|
Before Width: | Height: | Size: 210 KiB |
{kind=link}
|
Before Width: | Height: | Size: 36 KiB |
{kind=link}
|
Before Width: | Height: | Size: 76 KiB |
{kind=link}
|
Before Width: | Height: | Size: 64 KiB |
{kind=link}
|
Before Width: | Height: | Size: 341 KiB |
{kind=link}
|
Before Width: | Height: | Size: 85 KiB |
{kind=link}
|
Before Width: | Height: | Size: 161 KiB |
{kind=link}
|
Before Width: | Height: | Size: 142 KiB |
{kind=link}
|
Before Width: | Height: | Size: 27 KiB |
{kind=link}
|
Before Width: | Height: | Size: 13 KiB |
{kind=link}
|
Before Width: | Height: | Size: 15 KiB |
{kind=link}
|
Before Width: | Height: | Size: 14 KiB |
@ -1,184 +0,0 @@
|
|||||||
**目录:**
|
|
||||||
|
|
||||||
<!-- TOC -->
|
|
||||||
|
|
||||||
- [Java](#java)
|
|
||||||
- [基础](#基础)
|
|
||||||
- [并发](#并发)
|
|
||||||
- [JVM](#jvm)
|
|
||||||
- [Java8 新特性](#java8-新特性)
|
|
||||||
- [代码优化](#代码优化)
|
|
||||||
- [面试](#面试)
|
|
||||||
- [网络](#网络)
|
|
||||||
- [操作系统](#操作系统)
|
|
||||||
- [数据结构](#数据结构)
|
|
||||||
- [算法](#算法)
|
|
||||||
- [入门](#入门)
|
|
||||||
- [经典](#经典)
|
|
||||||
- [面试](#面试-1)
|
|
||||||
- [数据库](#数据库)
|
|
||||||
- [系统设计](#系统设计)
|
|
||||||
- [设计模式](#设计模式)
|
|
||||||
- [常用框架](#常用框架)
|
|
||||||
- [Spring/SpringBoot](#springspringboot)
|
|
||||||
- [Netty](#netty)
|
|
||||||
- [分布式](#分布式)
|
|
||||||
- [网站架构](#网站架构)
|
|
||||||
- [底层](#底层)
|
|
||||||
- [软件设计之道](#软件设计之道)
|
|
||||||
- [其他](#其他)
|
|
||||||
|
|
||||||
<!-- /TOC -->
|
|
||||||
|
|
||||||
## Java
|
|
||||||
|
|
||||||
### 基础
|
|
||||||
|
|
||||||
- **[《Head First Java》](https://book.douban.com/subject/2000732/)** : 可以说是我的 Java 启蒙书籍了,我个人觉得还是很适合稍微有一点点经验的新手来阅读的当然也适合我们用来温故 Java 知识点。*ps:刚入门编程,最好的方式还是通过看视频来学习。*
|
|
||||||
- **[《Java 核心技术卷 1+卷 2》](https://book.douban.com/subject/25762168/)**: 很棒的两本书,建议有点 Java 基础之后再读,介绍的还是比较深入的,非常推荐。这两本书我一般也会用来巩固知识点或者当做工具书参考,是两本适合放在自己身边的好书。
|
|
||||||
- **[《Java 编程思想 (第 4 版)》](https://book.douban.com/subject/2130190/)**(推荐,豆瓣评分 9.1,3.2K+人评价):大部分人称之为Java领域的圣经,但我不推荐初学者阅读,有点劝退的味道。稍微有点基础后阅读更好。
|
|
||||||
- **[《JAVA 网络编程 第 4 版》](https://book.douban.com/subject/26259017/)**: 可以系统的学习一下网络的一些概念以及网络编程在 Java 中的使用。
|
|
||||||
- **[《Java性能权威指南》](https://book.douban.com/subject/26740520/)**:O'Reilly 家族书,性能调优的入门书,我个人觉得性能调优是每个 Java 从业者必备知识,这本书的缺点就是太老了,但是这本书可以作为一个实战书,尤其是 JVM 调优!不适合初学者。前置书籍:《深入理解 Java 虚拟机》
|
|
||||||
|
|
||||||
### 并发
|
|
||||||
|
|
||||||
- **[《Java 并发编程之美》](<https://book.douban.com/subject/30351286/>)** :**我觉得这本书还是非常适合我们用来学习 Java 多线程的。这本书的讲解非常通俗易懂,作者从并发编程基础到实战都是信手拈来。** 另外,这本书的作者加多自身也会经常在网上发布各种技术文章。我觉得这本书也是加多大佬这么多年在多线程领域的沉淀所得的结果吧!他书中的内容基本都是结合代码讲解,非常有说服力!
|
|
||||||
- **[《实战 Java 高并发程序设计》](https://book.douban.com/subject/26663605/)**: 这个是我第二本要推荐的书籍,比较适合作为多线程入门/进阶书籍来看。这本书内容同样是理论结合实战,对于每个知识点的讲解也比较通俗易懂,整体结构也比较清。
|
|
||||||
- **[《深入浅出 Java 多线程》](https://github.com/RedSpider1/concurrent)**:这本书是几位大厂(如阿里)的大佬开源的,Github 地址:[https://github.com/RedSpider1/concurrent](https://github.com/RedSpider1/concurrent)几位作者为了写好《深入浅出 Java 多线程》这本书阅读了大量的 Java 多线程方面的书籍和博客,然后再加上他们的经验总结、Demo 实例、源码解析,最终才形成了这本书。这本书的质量也是非常过硬!给作者们点个赞!这本书有统一的排版规则和语言风格、清晰的表达方式和逻辑。并且每篇文章初稿写完后,作者们就会互相审校,合并到主分支时所有成员会再次审校,最后再通篇修订了三遍。
|
|
||||||
- **《Java 并发编程的艺术》** :这本书不是很适合作为 Java 多线程入门书籍,需要具备一定的 JVM 基础,有些东西讲的还是挺深入的。另外,就我自己阅读这本书的感觉来说,我觉得这本书的章节规划有点杂乱,但是,具体到某个知识点又很棒!这可能也和这本书由三名作者共同编写完成有关系吧!
|
|
||||||
- ......
|
|
||||||
|
|
||||||
### JVM
|
|
||||||
|
|
||||||
- **[《深入理解 Java 虚拟机(第 3 版)》](https://book.douban.com/subject/24722612/))**:必读!必读!必读!神书,建议多刷几篇。里面不光有丰富地JVM理论知识,还有JVM实战案例!必读!
|
|
||||||
- **[《实战 JAVA 虚拟机》](https://book.douban.com/subject/26354292/)**:作为入门的了解 Java 虚拟机的知识还是不错的。
|
|
||||||
|
|
||||||
### Java8 新特性
|
|
||||||
|
|
||||||
- **[《Java 8 实战》](https://book.douban.com/subject/26772632/)**:面向 Java 8 的技能升级,包括 Lambdas、流和函数式编程特性。实战系列的一贯风格让自己快速上手应用起来。Java 8 支持的 Lambda 是精简表达在语法上提供的支持。Java 8 提供了 Stream,学习和使用可以建立流式编程的认知。
|
|
||||||
- **[《Java 8 编程参考官方教程》](https://book.douban.com/subject/26556574/)**:建议当做工具书来用!哪里不会翻哪里!
|
|
||||||
|
|
||||||
### 代码优化
|
|
||||||
|
|
||||||
- **[《重构_改善既有代码的设计》](https://book.douban.com/subject/4262627/)**:豆瓣 9.1 分,重构书籍的开山鼻祖。
|
|
||||||
- **[《Effective java 》](https://book.douban.com/subject/3360807/)**:本书介绍了在 Java 编程中很多极具实用价值的经验规则,这些经验规则涵盖了大多数开发人员每天所面临的问题的解决方案。这篇文章能够非常实际地帮助你写出更加清晰、健壮和高效的代码。本书中的每条规则都以简短、独立的小文章形式出现,并通过例子代码加以进一步说明。
|
|
||||||
- **[《代码整洁之道》](https://book.douban.com/subject/5442024/)**:虽然是用 Java 语言作为例子,全篇都是在阐述 Java 面向对象的思想,但是其中大部分内容其它语言也能应用到。
|
|
||||||
- **阿里巴巴 Java 开发手册** :[https://github.com/alibaba/p3c](https://github.com/alibaba/p3c)
|
|
||||||
- **Google Java 编程风格指南:** <http://www.hawstein.com/posts/google-java-style.html>
|
|
||||||
|
|
||||||
### 面试
|
|
||||||
|
|
||||||
1. **[《JavaGuide面试突击版》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486324&idx=1&sn=e8b690ddaedabc486bd399310105aad3&chksm=cea244bff9d5cda9a627fa65235be09e7b089e92cf49c0eb0ceb35b39bbed86c1fab0125f5af&token=1745528586&lang=zh_CN&scene=21#wechat_redirect)** :我的75k+ star的开源项目 [JavaGuide ](https://github.com/Snailclimb/JavaGuide) 转为面试浓缩而成的版本,不光提供了PDF版本(我的公众号JavaGuide后台回复:“面试突击”即可获取),在线阅读版本:[https://snailclimb.gitee.io/javaguide-interview/](https://snailclimb.gitee.io/javaguide-interview/)。
|
|
||||||
2. **[《Offer来了:Java面试核心知识点精讲》](https://book.douban.com/subject/34872163/)** : 这本书基本概括了Java程序员面试必备知识点,可以拿来准备Java面试或者夯实基础。不过,我还是更推荐我的 [JavaGuide](https://github.com/Snailclimb/JavaGuide) 和 **[《JavaGuide面试突击版》](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486324&idx=1&sn=e8b690ddaedabc486bd399310105aad3&chksm=cea244bff9d5cda9a627fa65235be09e7b089e92cf49c0eb0ceb35b39bbed86c1fab0125f5af&token=1745528586&lang=zh_CN&scene=21#wechat_redirect)** ,两者配合起来学习,真香!
|
|
||||||
|
|
||||||
## 网络
|
|
||||||
|
|
||||||
- **[《图解 HTTP》](https://book.douban.com/subject/25863515/)**: 讲漫画一样的讲 HTTP,很有意思,不会觉得枯燥,大概也涵盖也 HTTP 常见的知识点。因为篇幅问题,内容可能不太全面。不过,如果不是专门做网络方向研究的小伙伴想研究 HTTP 相关知识的话,读这本书的话应该来说就差不多了。
|
|
||||||
- **[《HTTP 权威指南》](https://book.douban.com/subject/10746113/)**:如果要全面了解 HTTP 非此书不可!
|
|
||||||
|
|
||||||
## 操作系统
|
|
||||||
|
|
||||||
- **[《鸟哥的 Linux 私房菜》](https://book.douban.com/subject/4889838/)**:本书是最具知名度的 Linux 入门书《鸟哥的 Linux 私房菜基础学习篇》的最新版,全面而详细地介绍了 Linux 操作系统。
|
|
||||||
|
|
||||||
## 数据结构
|
|
||||||
|
|
||||||
- **[《大话数据结构》](https://book.douban.com/subject/6424904/)**:入门类型的书籍,读起来比较浅显易懂,适合没有数据结构基础或者说数据结构没学好的小伙伴用来入门数据结构。
|
|
||||||
|
|
||||||
## 算法
|
|
||||||
|
|
||||||
### 入门
|
|
||||||
|
|
||||||
- **[《我的第一本算法书》](https://book.douban.com/subject/30357170/) (豆瓣评分 7.1,0.2K+人评价)** 一本不那么“专业”的算法书籍。和下面两本推荐的算法书籍都是比较通俗易懂,“不那么深入”的算法书籍。我个人非常推荐,配图和讲解都非常不错!
|
|
||||||
- **[《算法图解》](https://book.douban.com/subject/26979890/)(豆瓣评分 8.4,1.5K+人评价)** :入门类型的书籍,读起来比较浅显易懂,非常适合没有算法基础或者说算法没学好的小伙伴用来入门。示例丰富,图文并茂,以让人容易理解的方式阐释了算法.读起来比较快,内容不枯燥!
|
|
||||||
- **[《啊哈!算法》](https://book.douban.com/subject/25894685/) (豆瓣评分 7.7,0.5K+人评价)** :和《算法图解》类似的算法趣味入门书籍。
|
|
||||||
|
|
||||||
### 经典
|
|
||||||
|
|
||||||
> 下面这些书籍都是经典中的经典,但是阅读起来难度也比较大,不做太多阐述,神书就完事了!推荐先看 《算法》,然后再选下面的书籍进行进一步阅读。不需要都看,找一本好好看或者找某本书的某一个章节知识点好好看。
|
|
||||||
|
|
||||||
- **[《算法 第四版》](https://book.douban.com/subject/10432347/)(豆瓣评分 9.3,0.4K+人评价):** 我在大二的时候被我们的一个老师强烈安利过!自己也在当时购买了一本放在宿舍,到离开大学的时候自己大概看了一半多一点。因为内容实在太多了!另外,这本书还提供了详细的Java代码,非常适合学习 Java 的朋友来看,可以说是 Java 程序员的必备书籍之一了。再来介绍一下这本书籍吧!这本书籍算的上是算法领域经典的参考书,全面介绍了关于算法和数据结构的必备知识,并特别针对排序、搜索、图处理和字符串处理进行了论述。
|
|
||||||
- **[编程珠玑](https://book.douban.com/subject/3227098/)(豆瓣评分 9.1,2K+人评价)** :经典名著,被无数读者强烈推荐的书籍,几乎是顶级程序员必看的书籍之一了。这本书的作者也非常厉害,Java之父 James Gosling 就是他的学生。很多人都说这本书不是教你具体的算法,而是教你一种编程的思考方式。这种思考方式不仅仅在编程领域适用,在其他同样适用。
|
|
||||||
- **[《算法设计手册》](https://book.douban.com/subject/4048566/)(豆瓣评分9.1 , 45人评价)** :被 [Teach Yourself Computer Science](https://teachyourselfcs.com/) 强烈推荐的一本算法书籍。
|
|
||||||
- **[《算法导论》](https://book.douban.com/subject/20432061/) (豆瓣评分 9.2,0.4K+人评价)**
|
|
||||||
- **[《计算机程序设计艺术(第1卷)》](https://book.douban.com/subject/1130500/)(豆瓣评分 9.4,0.4K+人评价)**
|
|
||||||
|
|
||||||
### 面试
|
|
||||||
|
|
||||||
1. **[《剑指Offer》](https://book.douban.com/subject/6966465/)(豆瓣评分 8.3,0.7K+人评价)**这本面试宝典上面涵盖了很多经典的算法面试题,如果你要准备大厂面试的话一定不要错过这本书。《剑指Offer》 对应的算法编程题部分的开源项目解析:[CodingInterviews](https://github.com/gatieme/CodingInterviews)
|
|
||||||
2. **[程序员代码面试指南:IT名企算法与数据结构题目最优解(第2版)](https://book.douban.com/subject/30422021/) (豆瓣评分 8.7,0.2K+人评价)** :题目相比于《剑指 offer》 来说要难很多,题目涵盖面相比于《剑指 offer》也更加全面。全书一共有将近300道真实出现过的经典代码面试题。
|
|
||||||
3. **[编程之美](https://book.douban.com/subject/3004255/)(豆瓣评分 8.4,3K+人评价)**:这本书收集了约60道算法和程序设计题目,这些题目大部分在近年的笔试、面试中出现过,或者是被微软员工热烈讨论过。作者试图从书中各种有趣的问题出发,引导读者发现问题,分析问题,解决问题,寻找更优的解法。
|
|
||||||
|
|
||||||
## 数据库
|
|
||||||
|
|
||||||
**MySQL:**
|
|
||||||
|
|
||||||
- **[《高性能 MySQL》](https://book.douban.com/subject/23008813/)**:这本书不用多说了把!MySQL 领域的经典之作,拥有广泛的影响力。不但适合数据库管理员(dba)阅读,也适合开发人员参考学习。不管是数据库新手还是专家,相信都能从本书有所收获。如果你的时间不够的话,第5章关于索引的内容和第6章关于查询的内容是必读的!
|
|
||||||
- [《MySQL 技术内幕-InnoDB 存储引擎》](<https://book.douban.com/subject/24708143/>)(推荐,豆瓣评分 8.7):了解 InnoDB 存储引擎底层原理必备的一本书,比较深入。
|
|
||||||
|
|
||||||
**Redis:**
|
|
||||||
|
|
||||||
- **[《Redis 实战》](https://book.douban.com/subject/26612779/)**:如果你想了解 Redis 的一些概念性知识的话,这本书真的非常不错。
|
|
||||||
- **[《Redis 设计与实现》](https://book.douban.com/subject/25900156/)**:也还行吧!
|
|
||||||
|
|
||||||
## 系统设计
|
|
||||||
|
|
||||||
### 设计模式
|
|
||||||
|
|
||||||
- **[《设计模式 : 可复用面向对象软件的基础》](https://book.douban.com/subject/1052241/)** :设计模式的经典!
|
|
||||||
- **[《Head First 设计模式(中文版)》](https://book.douban.com/subject/2243615/)** :相当赞的一本设计模式入门书籍。用实际的编程案例讲解算法设计中会遇到的各种问题和需求变更(对的,连需求变更都考虑到了!),并以此逐步推导出良好的设计模式解决办法。
|
|
||||||
- **[《大话设计模式》](https://book.douban.com/subject/2334288/)** :本书通篇都是以情景对话的形式,用多个小故事或编程示例来组织讲解GOF(即《设计模式 : 可复用面向对象软件的基础》这本书)),但是不像《设计模式 : 可复用面向对象软件的基础》难懂。但是设计模式只看书是不够的,还是需要在实际项目中运用,在实战中体会。
|
|
||||||
|
|
||||||
### 常用框架
|
|
||||||
|
|
||||||
#### Spring/SpringBoot
|
|
||||||
|
|
||||||
- **[《Spring 实战(第 4 版)》](https://book.douban.com/subject/26767354/)** :不建议当做入门书籍读,入门的话可以找点国人的书或者视频看。这本定位就相当于是关于 Spring 的新华字典,只有一些基本概念的介绍和示例,涵盖了 Spring 的各个方面,但都不够深入。就像作者在最后一页写的那样:“学习 Spring,这才刚刚开始”。
|
|
||||||
- **《[Spring源码深度解析 第2版](https://book.douban.com/subject/30452948/)》** :读Spring源码必备的一本书籍。市面上关于Spring源码分析的书籍太少了。
|
|
||||||
- **[《Spring 5高级编程(第5版)》](https://book.douban.com/subject/30452637/)** :推荐阅读,对于Spring5的新特性介绍的很好!不过内容比较多,可以作为工具书参考。
|
|
||||||
- **[《精通Spring4.x企业应用开发实战》](https://read.douban.com/ebook/58113975/?dcs=subject-rec&dcm=douban&dct=26767354)** :通过实战讲解,比较适合作为Spring入门书籍来看。
|
|
||||||
- **[《Spring入门经典》](https://book.douban.com/subject/26652876/)** :适合入门,也有很多示例!
|
|
||||||
- **[《Spring Boot实战派》](https://book.douban.com/subject/34894533/)** :这本书使用的Spring Boot 2.0+的版本,还算比较新。整本书采用“知识点+实例”的形式编写。本书通过“58个基于知识的实例+2个综合性的项目”,深入地讲解Spring Boot的技术原理、知识点和具体应用;把晦涩难懂的理论用实例展现出来,使得读者对知识的理解变得非常容易,同时也立即学会如何使用它。说实话,我还是比较推荐这本书的。
|
|
||||||
- **[《Spring Boot编程思想(核心篇)》](https://book.douban.com/subject/33390560/)** :SpringBoot深入书,不适合初学者。书尤其的厚,这本书的缺点是书的很多知识点的讲解过于啰嗦和拖沓,优点是书中对SpringBoot内部原理讲解很清楚。
|
|
||||||
|
|
||||||
#### Netty
|
|
||||||
|
|
||||||
- **[《Netty进阶之路:跟着案例学Netty》](https://book.douban.com/subject/30381214/)** : 这本书的优点是有不少实际的案例的讲解,通过案例来学习是很不错的!
|
|
||||||
- **[《Netty 4.x 用户指南》](https://waylau.gitbooks.io/netty-4-user-guide/content/)** :《Netty 4.x 用户指南》中文翻译(包含了官方文档以及其他文章)。
|
|
||||||
- **[《Netty 入门与实战:仿写微信 IM 即时通讯系统》](https://juejin.im/book/5b4bc28bf265da0f60130116?referrer=59fbb2daf265da4319559f3a)** :基于 Netty 框架实现 IM 核心系统,带你深入学习 Netty 网络编程核心知识
|
|
||||||
- **[《Netty 实战》](https://book.douban.com/subject/27038538/)** :可以作为工具书参考!
|
|
||||||
|
|
||||||
### 分布式
|
|
||||||
|
|
||||||
- **[《从 Paxos 到 Zookeeper》](https://book.douban.com/subject/26292004/)**:简要介绍几种典型的分布式一致性协议,以及解决分布式一致性问题的思路,其中重点讲解了 Paxos 和 ZAB 协议。同时,本书深入介绍了分布式一致性问题的工业解决方案——ZooKeeper,并着重向读者展示这一分布式协调框架的使用方法、内部实现及运维技巧,旨在帮助读者全面了解 ZooKeeper,并更好地使用和运维 ZooKeeper。
|
|
||||||
- **[《RabbitMQ 实战指南》](https://book.douban.com/subject/27591386/)**:《RabbitMQ 实战指南》从消息中间件的概念和 RabbitMQ 的历史切入,主要阐述 RabbitMQ 的安装、使用、配置、管理、运维、原理、扩展等方面的细节。如果你想浅尝 RabbitMQ 的使用,这本书是你最好的选择;如果你想深入 RabbitMQ 的原理,这本书也是你最好的选择;总之,如果你想玩转 RabbitMQ,这本书一定是最值得看的书之一
|
|
||||||
- **[《Spring Cloud 微服务实战》](https://book.douban.com/subject/27025912/)**:从时下流行的微服务架构概念出发,详细介绍了 Spring Cloud 针对微服务架构中几大核心要素的解决方案和基础组件。对于各个组件的介绍,《Spring Cloud 微服务实战》主要以示例与源码结合的方式来帮助读者更好地理解这些组件的使用方法以及运行原理。同时,在介绍的过程中,还包含了作者在实践中所遇到的一些问题和解决思路,可供读者在实践中作为参考。
|
|
||||||
|
|
||||||
### 网站架构
|
|
||||||
|
|
||||||
- **[《大型网站技术架构:核心原理与案例分析+李智慧》](https://book.douban.com/subject/25723064/)**:这本书我读过,基本不需要你有什么基础啊~读起来特别轻松,但是却可以学到很多东西,非常推荐了。另外我写过这本书的思维导图,关注我的微信公众号:“Java 面试通关手册”回复“大型网站技术架构”即可领取思维导图。
|
|
||||||
- **[《亿级流量网站架构核心技术》](https://book.douban.com/subject/26999243/)**:一书总结并梳理了亿级流量网站高可用和高并发原则,通过实例详细介绍了如何落地这些原则。本书分为四部分:概述、高可用原则、高并发原则、案例实战。从负载均衡、限流、降级、隔离、超时与重试、回滚机制、压测与预案、缓存、池化、异步化、扩容、队列等多方面详细介绍了亿级流量网站的架构核心技术,让读者看后能快速运用到实践项目中。
|
|
||||||
- **[《从零开始学架构(李运华)》](https://book.douban.com/subject/30335935/)** : 这本书对应的有一个极客时间的专栏—《从零开始学架构》,里面的很多内容都是这个专栏里面的,两者买其一就可以了。我看了很小一部分,内容挺全面的,是一本真正在讲如何做架构的书籍。
|
|
||||||
- **[《架构修炼之道——亿级网关、平台开放、分布式、微服务、容错等核心技术修炼实践》](https://book.douban.com/subject/33389549/)** :非常喜欢的一本书,对一些知识点比如消息队列、API网管讲解的很好,通俗易懂。
|
|
||||||
|
|
||||||
### 底层
|
|
||||||
|
|
||||||
- **[《深入剖析 Tomcat》](https://book.douban.com/subject/10426640/)**:本书深入剖析 Tomcat 4 和 Tomcat 5 中的每个组件,并揭示其内部工作原理。通过学习本书,你将可以自行开发 Tomcat 组件,或者扩展已有的组件。 读完这本书,基本可以摆脱背诵面试题的尴尬。
|
|
||||||
- **[《深入理解 Nginx(第 2 版)》](https://book.douban.com/subject/26745255/)**:作者讲的非常细致,注释都写的都很工整,对于 Nginx 的开发人员非常有帮助。优点是细致,缺点是过于细致,到处都是代码片段,缺少一些抽象。
|
|
||||||
|
|
||||||
## 软件设计之道
|
|
||||||
|
|
||||||
- **[《人月神话》](https://book.douban.com/subject/1102259/)** : 非常值得阅读的一本书籍。看书名感觉的第一眼感觉不像是技术类的书籍。这本书对于现代软件尤其是复杂软件的开发的规范化有深刻的意义。
|
|
||||||
- **《领域驱动设计:软件核心复杂性应对之道》** : 这本领域驱动设计方面的经典之作一直被各种推荐,但是我还来及读。
|
|
||||||
|
|
||||||
## 其他
|
|
||||||
|
|
||||||
- **[《黑客与画家》](https://read.douban.com/ebook/387525/?dcs=subject-rec&dcm=douban&dct=2243615)**:这本书是硅谷创业之父,Y Combinator 创始人 Paul Graham 的文集。之所以叫这个名字,是因为作者认为黑客(并非负面的那个意思)与画家有着极大的相似性,他们都是在创造,而不是完成某个任务。
|
|
||||||
|
|
||||||
- **[《图解密码技术》](https://book.douban.com/subject/26265544/)**:本书以**图配文**的形式,第一部分讲述了密码技术的历史沿革、对称密码、分组密码模式(包括ECB、CBC、CFB、OFB、CTR)、公钥、混合密码系统。第二部分重点介绍了认证方面的内容,涉及单向散列函数、消息认证码、数字签名、证书等。第三部分讲述了密钥、随机数、PGP、SSL/TLS 以及密码技术在现实生活中的应用。关键字:JWT 前置知识、区块链密码技术前置知识。属于密码知识入门书籍。、
|
|
||||||
- 《程序开发心理学》 、《程序员修炼之道,从小工道专家》、 《高效程序员的45个习惯,敏捷开发修炼之道》 、《高效能程序员的修炼》 、《软技能,代码之外的生存之道》 、《程序员的职业素养》 、《程序员的思维修炼》
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
@ -1,246 +0,0 @@
|
|||||||
|
|
||||||
|
|
||||||
这篇文章推荐了大部分我所读过的优秀书籍,虽然部分可能没看完。答应我,一定要看到最后,看完之后应该不会再纠结要看什么书了。走起!!!
|
|
||||||
|
|
||||||
*这篇文章未涵盖计算机基础比如算法和数据结构、数据库、分布式、微服务方面的书籍,这个留在下一篇文章推荐。*
|
|
||||||
|
|
||||||
## Java
|
|
||||||
|
|
||||||
### 基础
|
|
||||||
|
|
||||||
#### 《Head First Java》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
*Guide的 Java 启蒙书籍了。因为是我学习Java看的第一本书,所以,我对其有不一样的情感。*
|
|
||||||
|
|
||||||
*ps:我是当时学完了 C语言之后才开始学习 Java 的,刚开始看这本书感觉很轻松有趣,可以说是我学习编程初期最喜欢的一本书了。*
|
|
||||||
|
|
||||||
有些人说这本书不适合编程新手阅读?(问号脸) 我个人觉得还是很适合稍微有一点点经验的新手来阅读的,当然也适合我们用来温故 Java 知识点。
|
|
||||||
|
|
||||||
> ps:刚入门编程,最好的方式还是通过看视频来学习。
|
|
||||||
|
|
||||||
#### 《Java 核心技术卷 1+卷 2》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
*Guide拿来当做工具书的两本Java领域的好书!我当时在大学的时候就买了两本放在寝室,没事的时候就翻翻。*
|
|
||||||
|
|
||||||
建议有点 Java 基础之后再读,介绍的还是比较深入和全面的,非常推荐。
|
|
||||||
|
|
||||||
这两本书的内容很多,全看的话比较费时间,我一般也会用来巩固知识点或者当做工具书参考,是两本适合放在自己身边的好书。
|
|
||||||
|
|
||||||
#### 《Java 编程思想 (第 4 版)》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
*这本书Guide第一次看的时候还觉得有点枯燥,那时候还在上大二,看了 1/3就没看下去了。*
|
|
||||||
|
|
||||||
大部分人称之为Java领域的圣经(*感觉有点过了~~~*),但我不推荐初学者阅读,有点劝退的味道。稍微有点基础后阅读更好。
|
|
||||||
|
|
||||||
这本书到现在我也才看了一半左右,内容确实也比较多,而且稍微有点枯燥,但是比较权威。我一般也是拿来当做工具书参考。
|
|
||||||
|
|
||||||
#### 《Java性能权威指南》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
*希望能有更多这Java性能优化方面的好书!*
|
|
||||||
|
|
||||||
O'Reilly 家族书,性能调优的入门书,我个人觉得性能调优是每个 Java 从业者必备知识。
|
|
||||||
|
|
||||||
这本书介绍的实战内容很不错,尤其是 JVM 调优,缺点也比较明显,就是内容稍微有点老。市面上这种书很少。这本书不适合初学者,建议对 Java 语言已经比价掌握了再看。另外,阅读之前,最好先看看周志明大佬的《深入理解 Java 虚拟机》。
|
|
||||||
|
|
||||||
### 并发
|
|
||||||
|
|
||||||
#### 《Java 并发编程之美》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
*这本书还是非常适合我们用来学习 Java 多线程的。这本书的讲解非常通俗易懂,作者从并发编程基础到实战都是信手拈来。*
|
|
||||||
|
|
||||||
另外,这本书的作者加多自身也会经常在网上发布各种技术文章。这本书也是加多大佬这么多年在多线程领域的沉淀所得的结果吧!他书中的内容基本都是结合代码讲解,非常有说服力!
|
|
||||||
|
|
||||||
#### 《实战 Java 高并发程序设计》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
这个是我第二本要推荐的书籍,比较适合作为多线程入门/进阶书籍来看。这本书内容同样是理论结合实战,对于每个知识点的讲解也比较通俗易懂,整体结构也比较清。
|
|
||||||
|
|
||||||
#### 《深入浅出 Java 多线程》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
这本书是几位大厂(如阿里)的大佬开源的,Github 地址:[https://github.com/RedSpider1/concurrent](https://github.com/RedSpider1/concurrent)
|
|
||||||
|
|
||||||
几位作者为了写好《深入浅出 Java 多线程》这本书阅读了大量的 Java 多线程方面的书籍和博客,然后再加上他们的经验总结、Demo 实例、源码解析,最终才形成了这本书。
|
|
||||||
|
|
||||||
这本书的质量也是非常过硬!给作者们点个赞!这本书有统一的排版规则和语言风格、清晰的表达方式和逻辑。并且每篇文章初稿写完后,作者们就会互相审校,合并到主分支时所有成员会再次审校,最后再通篇修订了三遍。
|
|
||||||
|
|
||||||
### JVM
|
|
||||||
|
|
||||||
JVM 这里就先只推荐一本书籍和一个关于 JVM 参数调优的免费教程(你假笨大佬将的)。
|
|
||||||
|
|
||||||
#### 《深入理解Java虚拟机(第3版)》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
*希望国内能有更多这样的优质书籍出现!加油!💪*
|
|
||||||
|
|
||||||
这本书就一句话形容:**国产书籍中的战斗机,实实在在的优秀!**
|
|
||||||
|
|
||||||
这本书的第三版去年年底已经出来了,新增了很多实在的内容比如ZGC等新一代GC的原理剖析。目前豆瓣上是 9.6 的高分,🐂不🐂我就不多说了!
|
|
||||||
|
|
||||||
不论是你面试还是你想要在 Java 领域学习的更深,你都离不开这本书籍。这本书不光要看,你还要多看几遍,都是干货,里面很多实战内容自己还最好实践一篇。
|
|
||||||
|
|
||||||
这里额外推荐一个你假笨大佬的[《JVM 参数【Memory篇】》](https://club.perfma.com/course/438755/list)教程,很厉害了!
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 面试
|
|
||||||
|
|
||||||
#### 《JavaGuide面试突击版》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
*谁看谁说好!哈哈!*
|
|
||||||
|
|
||||||
Guide自己开源的,涵盖了Java后端方面的大部分知识点比如 集合、JVM、多线程还有数据库MySQL等内容。
|
|
||||||
|
|
||||||
在我的公众号后台回复 :“**面试突击**”即可免费获取。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### Java 8
|
|
||||||
|
|
||||||
#### 《Java 8实战》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
*还没用上 Java 8 的可以反思一下了,还没用过 Lambda 也可以反思一下了。*
|
|
||||||
|
|
||||||
现在大部分公司至少都用到了 Java 8 , Java 8算是一个里程碑式的版本,提供了很多有用的新特性比如 Lambda、流式处理等等。
|
|
||||||
|
|
||||||
这本书是学习 Java 8 新特性很好的选择,它内容包括 Lambda、流和函数式编程等Java8新特性。实战系列的一贯风格让自己快速上手应用起来。
|
|
||||||
|
|
||||||
## 软件质量
|
|
||||||
|
|
||||||
### 代码质量
|
|
||||||
|
|
||||||
#### 《重构_改善既有代码的设计》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
*程序员必看!*
|
|
||||||
|
|
||||||
世界顶级、国宝级别的 Martin Fowler 的书籍,可以说是软件开发领域最经典的基本书之一。目前已经出了第二版,我也在不久前买了第二版。
|
|
||||||
|
|
||||||
这本书我觉是每一个程序员都必须要看,并且需要看很多次的!
|
|
||||||
|
|
||||||
#### 《Effective java 》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
*程序员必看!*
|
|
||||||
|
|
||||||
又是一本 Java 领域国宝级别的书,非常经典。这本书主要介绍了在 Java 编程中很多极具实用价值的经验规则,这些经验规则涵盖了大多数开发人员每天所面临的问题的解决方案。这篇文章能够非常实际地帮助你写出更加清晰、健壮和高效的代码。本书中的每条规则都以简短、独立的小文章形式出现,并通过例子代码加以进一步说明。
|
|
||||||
|
|
||||||
#### 《代码整洁之道》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
*程序员必看!*
|
|
||||||
|
|
||||||
每个程序员都必须要看看的一本书籍,书中很多实际可体会的例子,可以教你写出更优质代码。
|
|
||||||
|
|
||||||
最后再推荐两个相关的文档:
|
|
||||||
|
|
||||||
- **阿里巴巴 Java 开发手册** :[https://github.com/alibaba/p3c](https://github.com/alibaba/p3c)
|
|
||||||
- **Google Java 编程风格指南:** <http://www.hawstein.com/posts/google-java-style.html>
|
|
||||||
|
|
||||||
### 软件设计之道
|
|
||||||
|
|
||||||
#### 《人月神话》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
*主要描述了软件开发的基本定律:一个需要10天才能干完的活,不可能让10个人在1天干完!*
|
|
||||||
|
|
||||||
非常值得阅读的一本书籍。看书名感觉的第一眼感觉不像是技术类的书籍。这本书对于现代软件尤其是复杂软件的开发的规范化有深刻的意义。
|
|
||||||
|
|
||||||
#### 《领域驱动设计:软件核心复杂性应对之道》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
这本领域驱动设计方面的经典之作一直被各种推荐,但是我还来及读。
|
|
||||||
|
|
||||||
## 常用框架
|
|
||||||
|
|
||||||
### Spring/SpringBoot
|
|
||||||
|
|
||||||
#### 《Spring 实战(第 5 版)》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
*比较一般!*
|
|
||||||
|
|
||||||
不建议当做入门书籍读,入门的话可以找点国人的书或者视频看。这本定位就相当于是关于 Spring 的一个概览,只有一些基本概念的介绍和示例,涵盖了 Spring 的各个方面,但都不够深入。就像作者在最后一页写的那样:“学习 Spring,这才刚刚开始”。
|
|
||||||
|
|
||||||
#### 《Spring 5高级编程(第5版)》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
*工具人!*
|
|
||||||
|
|
||||||
对于Spring5的新特性介绍的比较详细,也说不上好。另外,感觉全书翻译的有一点蹩脚的味道,还有一点枯燥。全书的内容比较多,我一般拿来当做工具书参考。
|
|
||||||
|
|
||||||
#### 《Spring Boot编程思想(核心篇)》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
*稍微有点啰嗦,但是原理介绍的比较清楚。*
|
|
||||||
|
|
||||||
SpringBoot 解析,不适合初学者。我是去年入手的,现在就看了几章,后面没看下去。书很厚,感觉很多很多知识点的讲解过于啰嗦和拖沓,不过,这本书对于SpringBoot内部原理讲解的还是很清楚。
|
|
||||||
|
|
||||||
#### 《Spring Boot实战》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
比较一般的一本书,可以简单拿来看一下。
|
|
||||||
|
|
||||||
#### 《Spring Boot实战派》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
这本书使用的Spring Boot 2.0+的版本,还算比较新。整本书采用“知识点+实例”的形式编写。
|
|
||||||
|
|
||||||
另外,这本书的干货很多,作者在注意实战的过程中还不忘记对于一些重要的基础知识的讲解。
|
|
||||||
|
|
||||||
如果你要学习 Spring Boot 的话,我还是比较推荐这本书的。
|
|
||||||
|
|
||||||
### Netty
|
|
||||||
|
|
||||||
#### 《Netty实战》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
*Guide学习Netty看的就是这本书籍,RPC框架乞丐版 Guide已经写完,Netty系列也在路上了!*
|
|
||||||
|
|
||||||
这本书可以用来入门 Netty ,内容从BIO聊到了 NIO、之后才详细介绍为什么有 Netty 、Netty 为什么好用以及Netty重要的知识点讲解。
|
|
||||||
|
|
||||||
这本书基本把 Netty 一些重要的知识点都介绍到了,而且基本都是通过实战的形式讲解。
|
|
||||||
|
|
||||||
#### 《Netty进阶之路:跟着案例学Netty》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
*深入Netty必看!*
|
|
||||||
|
|
||||||
内容都是关于使用 Netty 的实践案例比如内存泄露这些东西。如果你觉得你的 Netty 已经完全入门了,并且你想要对Netty掌握的更深的话,推荐你看一下这本书。
|
|
||||||
|
|
||||||
#### 《Netty 入门与实战:仿写微信 IM 即时通讯系统》
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
*质量很高的一个小册!*
|
|
||||||
|
|
||||||
通过一个基于 Netty 框架实现 IM 核心系统为引子,带你学习Netty。整个小册的质量还是很高的,即使你没有 Netty 使用经验也能看懂。
|
|
||||||
@ -72,8 +72,8 @@
|
|||||||
|
|
||||||
### 2.3. 应用场景
|
### 2.3. 应用场景
|
||||||
|
|
||||||
- 如果需要支持随机访问的话,链表没办法做到。如
|
- 如果需要支持随机访问的话,链表没办法做到。
|
||||||
- 果需要存储的数据元素的个数不确定,并且需要经常添加和删除数据的话,使用链表比较合适。
|
- 如果需要存储的数据元素的个数不确定,并且需要经常添加和删除数据的话,使用链表比较合适。
|
||||||
- 如果需要存储的数据元素的个数确定,并且不需要经常添加和删除数据的话,使用数组比较合适。
|
- 如果需要存储的数据元素的个数确定,并且不需要经常添加和删除数据的话,使用数组比较合适。
|
||||||
|
|
||||||
### 2.4. 数组 vs 链表
|
### 2.4. 数组 vs 链表
|
||||||
|
|||||||
@ -34,7 +34,7 @@
|
|||||||
|
|
||||||
《高性能MySQL》第四章如是说:And, in case you’re wondering, allowing NULL values in the index really doesn’t impact performance 。NULL 值的索引查找流程参考:https://juejin.im/post/5d5defc2518825591523a1db ,相关阅读:[MySQL中IS NULL、IS NOT NULL、!=不能用索引?胡扯!](https://juejin.im/post/5d5defc2518825591523a1db) 。
|
《高性能MySQL》第四章如是说:And, in case you’re wondering, allowing NULL values in the index really doesn’t impact performance 。NULL 值的索引查找流程参考:https://juejin.im/post/5d5defc2518825591523a1db ,相关阅读:[MySQL中IS NULL、IS NOT NULL、!=不能用索引?胡扯!](https://juejin.im/post/5d5defc2518825591523a1db) 。
|
||||||
|
|
||||||
9. 删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 chema_unused_indexes 视图来查询哪些索引从未被使用
|
9. 删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 schema_unused_indexes 视图来查询哪些索引从未被使用
|
||||||
|
|
||||||
10. 在使用 limit offset 查询缓慢时,可以借助索引来提高性能
|
10. 在使用 limit offset 查询缓慢时,可以借助索引来提高性能
|
||||||
|
|
||||||
@ -141,7 +141,7 @@ select * from user where city=xx ; // 无法命中索引
|
|||||||
|
|
||||||
### 注意避免冗余索引
|
### 注意避免冗余索引
|
||||||
|
|
||||||
冗余索引指的是索引的功能相同,能够命中 就肯定能命中 ,那么 就是冗余索引如(name,city )和(name )这两个索引就是冗余索引,能够命中后者的查询肯定是能够命中前者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
|
冗余索引指的是索引的功能相同,能够命中索引(a, b)就肯定能命中索引(a) ,那么索引(a)就是冗余索引。如(name,city )和(name )这两个索引就是冗余索引,能够命中前者的查询肯定是能够命中后者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
|
||||||
|
|
||||||
MySQL 5.7 版本后,可以通过查询 sys 库的 `schema_redundant_indexes` 表来查看冗余索引
|
MySQL 5.7 版本后,可以通过查询 sys 库的 `schema_redundant_indexes` 表来查看冗余索引
|
||||||
|
|
||||||
|
|||||||
@ -1,69 +1,32 @@
|
|||||||
点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
|
## MySQL 基础
|
||||||
|
|
||||||
- [书籍推荐](#书籍推荐)
|
### 关系型数据库介绍
|
||||||
- [文字教程推荐](#文字教程推荐)
|
|
||||||
- [视频教程推荐](#视频教程推荐)
|
|
||||||
- [常见问题总结](#常见问题总结)
|
|
||||||
- [什么是MySQL?](#什么是mysql)
|
|
||||||
- [存储引擎](#存储引擎)
|
|
||||||
- [一些常用命令](#一些常用命令)
|
|
||||||
- [MyISAM和InnoDB区别](#myisam和innodb区别)
|
|
||||||
- [字符集及校对规则](#字符集及校对规则)
|
|
||||||
- [索引](#索引)
|
|
||||||
- [查询缓存的使用](#查询缓存的使用)
|
|
||||||
- [什么是事务?](#什么是事务)
|
|
||||||
- [事物的四大特性(ACID)](#事物的四大特性acid)
|
|
||||||
- [并发事务带来哪些问题?](#并发事务带来哪些问题)
|
|
||||||
- [事务隔离级别有哪些?MySQL的默认隔离级别是?](#事务隔离级别有哪些mysql的默认隔离级别是)
|
|
||||||
- [锁机制与InnoDB锁算法](#锁机制与innodb锁算法)
|
|
||||||
- [大表优化](#大表优化)
|
|
||||||
- [1. 限定数据的范围](#1-限定数据的范围)
|
|
||||||
- [2. 读/写分离](#2-读写分离)
|
|
||||||
- [3. 垂直分区](#3-垂直分区)
|
|
||||||
- [4. 水平分区](#4-水平分区)
|
|
||||||
- [一条SQL语句在MySQL中如何执行的](#一条sql语句在mysql中如何执行的)
|
|
||||||
- [MySQL高性能优化规范建议](#mysql高性能优化规范建议)
|
|
||||||
- [一条SQL语句执行得很慢的原因有哪些?](#一条sql语句执行得很慢的原因有哪些)
|
|
||||||
|
|
||||||
<!-- /TOC -->
|
顾名思义,关系型数据库就是一种建立在关系模型的基础上的数据库。关系模型表明了数据库中所存储的数据之间的联系(一对一、一对多、多对多)。
|
||||||
|
|
||||||
## 书籍推荐
|
关系型数据库中,我们的数据都被存放在了各种表中(比如用户表),表中的每一列就存放着一条数据(比如一个用户的信息)。
|
||||||
|
|
||||||
- 《SQL基础教程(第2版)》 (入门级)
|
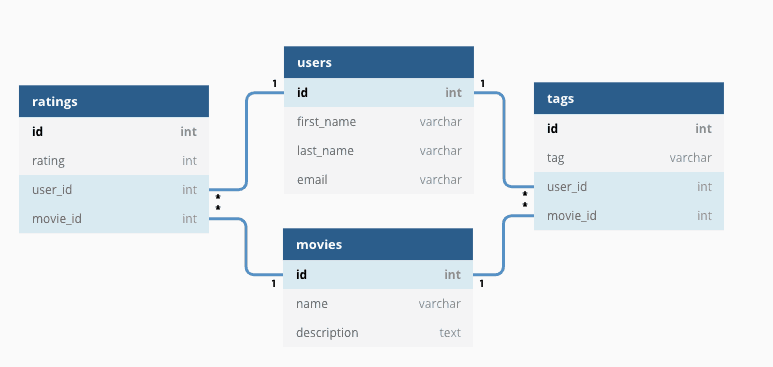
|
||||||
- 《高性能MySQL : 第3版》 (进阶)
|
|
||||||
|
|
||||||
## 文字教程推荐
|
大部分关系型数据库都使用 SQL 来操作数据库中的数据。并且,大部分关系型数据库都支持事务的四大特性(ACID)。
|
||||||
|
|
||||||
- [SQL Tutorial](https://www.w3schools.com/sql/default.asp) (SQL语句学习,英文)、[SQL Tutorial](https://www.w3school.com.cn/sql/index.asp)(SQL语句学习,中文)、[SQL语句在线练习](https://www.w3schools.com/sql/exercise.asp) (非常不错)
|
**有哪些常见的关系型数据库呢?**
|
||||||
- [Github-MySQL入门教程(MySQL tutorial book)](https://github.com/jaywcjlove/mysql-tutorial) (从零开始学习MySQL,主要是面向MySQL数据库管理系统初学者)
|
|
||||||
- [官方教程](https://dev.mysql.com/doc/refman/5.7/)
|
|
||||||
- [MySQL 教程(菜鸟教程)](http://www.runoob.com/MySQL/MySQL-tutorial.html)
|
|
||||||
|
|
||||||
## 相关资源推荐
|
MySQL、PostgreSQL、Oracle、SQL Server、SQLite(微信本地的聊天记录的存储就是用的 SQLite) ......。
|
||||||
|
|
||||||
- [中国5级行政区域mysql库](https://github.com/kakuilan/china_area_mysql)
|
### MySQL 介绍
|
||||||
|
|
||||||
## 视频教程推荐
|

|
||||||
|
|
||||||
**基础入门:** [与MySQL的零距离接触-慕课网](https://www.imooc.com/learn/122)
|
**MySQL 是一种关系型数据库,主要用于持久化存储我们的系统中的一些数据比如用户信息。**
|
||||||
|
|
||||||
**MySQL开发技巧:** [MySQL开发技巧(一)](https://www.imooc.com/learn/398) [MySQL开发技巧(二)](https://www.imooc.com/learn/427) [MySQL开发技巧(三)](https://www.imooc.com/learn/449)
|
由于 MySQL 是开源免费并且比较成熟的数据库,因此,MySQL 被大量使用在各种系统中。任何人都可以在 GPL(General Public License) 的许可下下载并根据个性化的需要对其进行修改。MySQL 的默认端口号是**3306**。
|
||||||
|
|
||||||
**MySQL5.7新特性及相关优化技巧:** [MySQL5.7版本新特性](https://www.imooc.com/learn/533) [性能优化之MySQL优化](https://www.imooc.com/learn/194)
|
## 存储引擎
|
||||||
|
|
||||||
[MySQL集群(PXC)入门](https://www.imooc.com/learn/993) [MyCAT入门及应用](https://www.imooc.com/learn/951)
|
### 存储引擎相关的命令
|
||||||
|
|
||||||
## 常见问题总结
|
**查看 MySQL 提供的所有存储引擎**
|
||||||
|
|
||||||
### 什么是MySQL?
|
|
||||||
|
|
||||||
MySQL 是一种关系型数据库,在Java企业级开发中非常常用,因为 MySQL 是开源免费的,并且方便扩展。阿里巴巴数据库系统也大量用到了 MySQL,因此它的稳定性是有保障的。MySQL是开放源代码的,因此任何人都可以在 GPL(General Public License) 的许可下下载并根据个性化的需要对其进行修改。MySQL的默认端口号是**3306**。
|
|
||||||
|
|
||||||
### 存储引擎
|
|
||||||
|
|
||||||
#### 一些常用命令
|
|
||||||
|
|
||||||
**查看MySQL提供的所有存储引擎**
|
|
||||||
|
|
||||||
```sql
|
```sql
|
||||||
mysql> show engines;
|
mysql> show engines;
|
||||||
@ -71,9 +34,9 @@ mysql> show engines;
|
|||||||
|
|
||||||
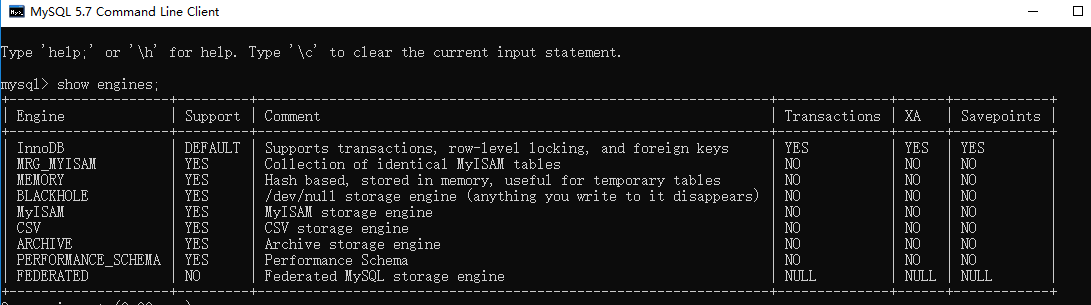
|

|
||||||
|
|
||||||
从上图我们可以查看出 MySQL 当前默认的存储引擎是InnoDB,并且在5.7版本所有的存储引擎中只有 InnoDB 是事务性存储引擎,也就是说只有 InnoDB 支持事务。
|
从上图我们可以查看出 MySQL 当前默认的存储引擎是 InnoDB,并且在 5.7 版本所有的存储引擎中只有 InnoDB 是事务性存储引擎,也就是说只有 InnoDB 支持事务。
|
||||||
|
|
||||||
**查看MySQL当前默认的存储引擎**
|
**查看 MySQL 当前默认的存储引擎**
|
||||||
|
|
||||||
我们也可以通过下面的命令查看默认的存储引擎。
|
我们也可以通过下面的命令查看默认的存储引擎。
|
||||||
|
|
||||||
@ -89,91 +52,181 @@ show table status like "table_name" ;
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
#### MyISAM和InnoDB区别
|
### MyISAM 和 InnoDB 的区别
|
||||||
|
|
||||||
MyISAM是MySQL的默认数据库引擎(5.5版之前)。虽然性能极佳,而且提供了大量的特性,包括全文索引、压缩、空间函数等,但MyISAM不支持事务和行级锁,而且最大的缺陷就是崩溃后无法安全恢复。不过,5.5版本之后,MySQL引入了InnoDB(事务性数据库引擎),MySQL 5.5版本后默认的存储引擎为InnoDB。
|

|
||||||
|
|
||||||
大多数时候我们使用的都是 InnoDB 存储引擎,但是在某些情况下使用 MyISAM 也是合适的比如读密集的情况下。(如果你不介意 MyISAM 崩溃恢复问题的话)。
|
MySQL 5.5 之前,MyISAM 引擎是 MySQL 的默认存储引擎,可谓是风光一时。
|
||||||
|
|
||||||
**两者的对比:**
|
虽然,MyISAM 的性能还行,各种特性也还不错(比如全文索引、压缩、空间函数等)。但是,MyISAM 不支持事务和行级锁,而且最大的缺陷就是崩溃后无法安全恢复。
|
||||||
|
|
||||||
1. **是否支持行级锁** : MyISAM 只有表级锁(table-level locking),而InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
|
5.5 版本之后,MySQL 引入了 InnoDB(事务性数据库引擎),MySQL 5.5 版本后默认的存储引擎为 InnoDB。小伙子,一定要记好这个 InnoDB ,你每次使用 MySQL 数据库都是用的这个存储引擎吧?
|
||||||
2. **是否支持事务和崩溃后的安全恢复: MyISAM** 强调的是性能,每次查询具有原子性,其执行速度比InnoDB类型更快,但是不提供事务支持。但是**InnoDB** 提供事务支持,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
|
|
||||||
3. **是否支持外键:** MyISAM不支持,而InnoDB支持。
|
|
||||||
4. **是否支持MVCC** :仅 InnoDB 支持。应对高并发事务, MVCC比单纯的加锁更高效;MVCC只在 `READ COMMITTED` 和 `REPEATABLE READ` 两个隔离级别下工作;MVCC可以使用 乐观(optimistic)锁 和 悲观(pessimistic)锁来实现;各数据库中MVCC实现并不统一。推荐阅读:[MySQL-InnoDB-MVCC多版本并发控制](https://segmentfault.com/a/1190000012650596)
|
|
||||||
5. ......
|
|
||||||
|
|
||||||
《MySQL高性能》上面有一句话这样写到:
|
言归正传!咱们下面还是来简单对比一下两者:
|
||||||
|
|
||||||
> 不要轻易相信“MyISAM比InnoDB快”之类的经验之谈,这个结论往往不是绝对的。在很多我们已知场景中,InnoDB的速度都可以让MyISAM望尘莫及,尤其是用到了聚簇索引,或者需要访问的数据都可以放入内存的应用。
|
**1.是否支持行级锁**
|
||||||
|
|
||||||
一般情况下我们选择 InnoDB 都是没有问题的,但是某些情况下你并不在乎可扩展能力和并发能力,也不需要事务支持,也不在乎崩溃后的安全恢复问题的话,选择MyISAM也是一个不错的选择。但是一般情况下,我们都是需要考虑到这些问题的。
|
MyISAM 只有表级锁(table-level locking),而 InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁。
|
||||||
|
|
||||||
### 字符集及校对规则
|
也就说,MyISAM 一锁就是锁住了整张表,这在并发写的情况下是多么滴憨憨啊!这也是为什么 InnoDB 在并发写的时候,性能更牛皮了!
|
||||||
|
|
||||||
字符集指的是一种从二进制编码到某类字符符号的映射。校对规则则是指某种字符集下的排序规则。MySQL中每一种字符集都会对应一系列的校对规则。
|
**2.是否支持事务**
|
||||||
|
|
||||||
MySQL采用的是类似继承的方式指定字符集的默认值,每个数据库以及每张数据表都有自己的默认值,他们逐层继承。比如:某个库中所有表的默认字符集将是该数据库所指定的字符集(这些表在没有指定字符集的情况下,才会采用默认字符集) PS:整理自《Java工程师修炼之道》
|
MyISAM 不提供事务支持。
|
||||||
|
|
||||||
详细内容可以参考: [MySQL字符集及校对规则的理解](https://www.cnblogs.com/geaozhang/p/6724393.html#MySQLyuzifuji)
|
InnoDB 提供事务支持,具有提交(commit)和回滚(rollback)事务的能力。
|
||||||
|
|
||||||
### 索引
|
**3.是否支持外键**
|
||||||
|
|
||||||
MySQL索引使用的数据结构主要有**BTree索引** 和 **哈希索引** 。对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择BTree索引。
|
MyISAM 不支持,而 InnoDB 支持。
|
||||||
|
|
||||||
MySQL的BTree索引使用的是B树中的B+Tree,但对于主要的两种存储引擎的实现方式是不同的。
|
🌈 拓展一下:
|
||||||
|
|
||||||
- **MyISAM:** B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
|
一般我们也是不建议在数据库层面使用外键的,应用层面可以解决。不过,这样会对数据的一致性造成威胁。具体要不要使用外键还是要根据你的项目来决定。
|
||||||
- **InnoDB:** 其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件是分离的,其表数据文件本身就是按B+Tree组织的一个索引结构,树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。这被称为“聚簇索引(或聚集索引)”。而其余的索引都作为辅助索引,辅助索引的data域存储相应记录主键的值而不是地址,这也是和MyISAM不同的地方。**在根据主索引搜索时,直接找到key所在的节点即可取出数据;在根据辅助索引查找时,则需要先取出主键的值,再走一遍主索引。** **因此,在设计表的时候,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样会造成主索引频繁分裂。** PS:整理自《Java工程师修炼之道》
|
|
||||||
|
|
||||||
**更多关于索引的内容可以查看文档首页MySQL目录下关于索引的详细总结。**
|
**4.是否支持数据库异常崩溃后的安全恢复**
|
||||||
|
|
||||||
### 查询缓存的使用
|
MyISAM 不支持,而 InnoDB 支持。
|
||||||
|
|
||||||
> 执行查询语句的时候,会先查询缓存。不过,MySQL 8.0 版本后移除,因为这个功能不太实用
|
使用 InnoDB 的数据库在异常崩溃后,数据库重新启动的时候会保证数据库恢复到崩溃前的状态。这个恢复的过程依赖于 `redo log` 。
|
||||||
|
|
||||||
|
🌈 拓展一下:
|
||||||
|
|
||||||
|
- MySQL InnoDB 引擎使用 **redo log(重做日志)** 保证事务的**持久性**,使用 **undo log(回滚日志)** 来保证事务的**原子性**。
|
||||||
|
- MySQL InnoDB 引擎通过 **锁机制**、**MVCC** 等手段来保证事务的隔离性( 默认支持的隔离级别是 **`REPEATABLE-READ`** )。
|
||||||
|
- 保证了事务的持久性、原子性、隔离性之后,一致性才能得到保障。
|
||||||
|
|
||||||
|
**5.是否支持 MVCC**
|
||||||
|
|
||||||
|
MyISAM 不支持,而 InnoDB 支持。
|
||||||
|
|
||||||
|
讲真,这个对比有点废话,毕竟 MyISAM 连行级锁都不支持。
|
||||||
|
|
||||||
|
MVCC 可以看作是行级锁的一个升级,可以有效减少加锁操作,提供性能。
|
||||||
|
|
||||||
|
### 关于 MyISAM 和 InnoDB 的选择问题
|
||||||
|
|
||||||
|
大多数时候我们使用的都是 InnoDB 存储引擎,在某些读密集的情况下,使用 MyISAM 也是合适的。不过,前提是你的项目不介意 MyISAM 不支持事务、崩溃恢复等缺点(可是~我们一般都会介意啊!)。
|
||||||
|
|
||||||
|
《MySQL 高性能》上面有一句话这样写到:
|
||||||
|
|
||||||
|
> 不要轻易相信“MyISAM 比 InnoDB 快”之类的经验之谈,这个结论往往不是绝对的。在很多我们已知场景中,InnoDB 的速度都可以让 MyISAM 望尘莫及,尤其是用到了聚簇索引,或者需要访问的数据都可以放入内存的应用。
|
||||||
|
|
||||||
|
一般情况下我们选择 InnoDB 都是没有问题的,但是某些情况下你并不在乎可扩展能力和并发能力,也不需要事务支持,也不在乎崩溃后的安全恢复问题的话,选择 MyISAM 也是一个不错的选择。但是一般情况下,我们都是需要考虑到这些问题的。
|
||||||
|
|
||||||
|
因此,对于咱们日常开发的业务系统来说,你几乎找不到什么理由再使用 MyISAM 作为自己的 MySQL 数据库的存储引擎。
|
||||||
|
|
||||||
|
## 锁机制与 InnoDB 锁算法
|
||||||
|
|
||||||
|
**MyISAM 和 InnoDB 存储引擎使用的锁:**
|
||||||
|
|
||||||
|
- MyISAM 采用表级锁(table-level locking)。
|
||||||
|
- InnoDB 支持行级锁(row-level locking)和表级锁,默认为行级锁
|
||||||
|
|
||||||
|
**表级锁和行级锁对比:**
|
||||||
|
|
||||||
|
- **表级锁:** MySQL 中锁定 **粒度最大** 的一种锁,对当前操作的整张表加锁,实现简单,资源消耗也比较少,加锁快,不会出现死锁。其锁定粒度最大,触发锁冲突的概率最高,并发度最低,MyISAM 和 InnoDB 引擎都支持表级锁。
|
||||||
|
- **行级锁:** MySQL 中锁定 **粒度最小** 的一种锁,只针对当前操作的行进行加锁。 行级锁能大大减少数据库操作的冲突。其加锁粒度最小,并发度高,但加锁的开销也最大,加锁慢,会出现死锁。
|
||||||
|
|
||||||
|
**InnoDB 存储引擎的锁的算法有三种:**
|
||||||
|
|
||||||
|
- Record lock:单个行记录上的锁
|
||||||
|
- Gap lock:间隙锁,锁定一个范围,不包括记录本身
|
||||||
|
- Next-key lock:record+gap 锁定一个范围,包含记录本身
|
||||||
|
|
||||||
|
## 查询缓存
|
||||||
|
|
||||||
|
执行查询语句的时候,会先查询缓存。不过,MySQL 8.0 版本后移除,因为这个功能不太实用
|
||||||
|
|
||||||
|
`my.cnf` 加入以下配置,重启 MySQL 开启查询缓存
|
||||||
|
|
||||||
my.cnf加入以下配置,重启MySQL开启查询缓存
|
|
||||||
```properties
|
```properties
|
||||||
query_cache_type=1
|
query_cache_type=1
|
||||||
query_cache_size=600000
|
query_cache_size=600000
|
||||||
```
|
```
|
||||||
|
|
||||||
MySQL执行以下命令也可以开启查询缓存
|
MySQL 执行以下命令也可以开启查询缓存
|
||||||
|
|
||||||
```properties
|
```properties
|
||||||
set global query_cache_type=1;
|
set global query_cache_type=1;
|
||||||
set global query_cache_size=600000;
|
set global query_cache_size=600000;
|
||||||
```
|
```
|
||||||
如上,**开启查询缓存后在同样的查询条件以及数据情况下,会直接在缓存中返回结果**。这里的查询条件包括查询本身、当前要查询的数据库、客户端协议版本号等一些可能影响结果的信息。因此任何两个查询在任何字符上的不同都会导致缓存不命中。此外,如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、MySQL库中的系统表,其查询结果也不会被缓存。
|
|
||||||
|
|
||||||
缓存建立之后,MySQL的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
|
如上,**开启查询缓存后在同样的查询条件以及数据情况下,会直接在缓存中返回结果**。这里的查询条件包括查询本身、当前要查询的数据库、客户端协议版本号等一些可能影响结果的信息。因此任何两个查询在任何字符上的不同都会导致缓存不命中。此外,如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、MySQL 库中的系统表,其查询结果也不会被缓存。
|
||||||
|
|
||||||
|
缓存建立之后,MySQL 的查询缓存系统会跟踪查询中涉及的每张表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。
|
||||||
|
|
||||||
|
**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启查询缓存要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十 MB 比较合适。此外,**还可以通过 sql_cache 和 sql_no_cache 来控制某个查询语句是否需要缓存:**
|
||||||
|
|
||||||
**缓存虽然能够提升数据库的查询性能,但是缓存同时也带来了额外的开销,每次查询后都要做一次缓存操作,失效后还要销毁。** 因此,开启查询缓存要谨慎,尤其对于写密集的应用来说更是如此。如果开启,要注意合理控制缓存空间大小,一般来说其大小设置为几十MB比较合适。此外,**还可以通过sql_cache和sql_no_cache来控制某个查询语句是否需要缓存:**
|
|
||||||
```sql
|
```sql
|
||||||
select sql_no_cache count(*) from usr;
|
select sql_no_cache count(*) from usr;
|
||||||
```
|
```
|
||||||
|
|
||||||
### 什么是事务?
|
## 事务
|
||||||
|
|
||||||
**事务是逻辑上的一组操作,要么都执行,要么都不执行。**
|
### 何为事务?
|
||||||
|
|
||||||
事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账1000元,这个转账会涉及到两个关键操作就是:将小明的余额减少1000元,将小红的余额增加1000元。万一在这两个操作之间突然出现错误比如银行系统崩溃,导致小明余额减少而小红的余额没有增加,这样就不对了。事务就是保证这两个关键操作要么都成功,要么都要失败。
|
一言蔽之,**事务是逻辑上的一组操作,要么都执行,要么都不执行。**
|
||||||
|
|
||||||
### 事务的四大特性(ACID)
|
**可以简单举一个例子不?**
|
||||||
|
|
||||||
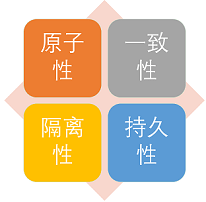
|
事务最经典也经常被拿出来说例子就是转账了。假如小明要给小红转账 1000 元,这个转账会涉及到两个关键操作就是:
|
||||||
|
|
||||||
1. **原子性(Atomicity):** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
|
1. 将小明的余额减少 1000 元
|
||||||
2. **一致性(Consistency):** 执行事务后,数据库从一个正确的状态变化到另一个正确的状态;
|
2. 将小红的余额增加 1000 元。
|
||||||
3. **隔离性(Isolation):** 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
|
|
||||||
4. **持久性(Durability):** 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
|
事务会把这两个操作就可以看成逻辑上的一个整体,这个整体包含的操作要么都成功,要么都要失败。
|
||||||
|
|
||||||
|
这样就不会出现小明余额减少而小红的余额却并没有增加的情况。
|
||||||
|
|
||||||
|
### 何为数据库事务?
|
||||||
|
|
||||||
|
数据库事务在我们日常开发中接触的最多了。如果你的项目属于单体架构的话,你接触到的往往就是数据库事务了。
|
||||||
|
|
||||||
|
平时,我们在谈论事务的时候,如果没有特指**分布式事务**,往往指的就是**数据库事务**。
|
||||||
|
|
||||||
|
**那数据库事务有什么作用呢?**
|
||||||
|
|
||||||
|
简单来说:数据库事务可以保证多个对数据库的操作(也就是 SQL 语句)构成一个逻辑上的整体。构成这个逻辑上的整体的这些数据库操作遵循:**要么全部执行成功,要么全部不执行** 。
|
||||||
|
|
||||||
|
```sql
|
||||||
|
# 开启一个事务
|
||||||
|
START TRANSACTION;
|
||||||
|
# 多条 SQL 语句
|
||||||
|
SQL1,SQL2...
|
||||||
|
## 提交事务
|
||||||
|
COMMIT;
|
||||||
|
```
|
||||||
|
|
||||||
|
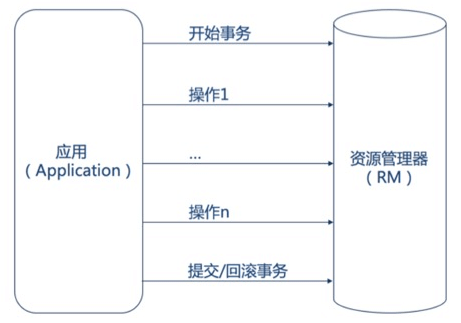
|
||||||
|
|
||||||
|
另外,关系型数据库(例如:`MySQL`、`SQL Server`、`Oracle` 等)事务都有 **ACID** 特性:
|
||||||
|
|
||||||
|
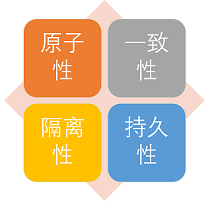
|
||||||
|
|
||||||
|
### 何为 ACID 特性呢?
|
||||||
|
|
||||||
|
1. **原子性**(`Atomicity`) : 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
|
||||||
|
2. **一致性**(`Consistency`): 执行事务前后,数据保持一致,例如转账业务中,无论事务是否成功,转账者和收款人的总额应该是不变的;
|
||||||
|
3. **隔离性**(`Isolation`): 并发访问数据库时,一个用户的事务不被其他事务所干扰,各并发事务之间数据库是独立的;
|
||||||
|
4. **持久性**(`Durabilily`): 一个事务被提交之后。它对数据库中数据的改变是持久的,即使数据库发生故障也不应该对其有任何影响。
|
||||||
|
|
||||||
|
**数据事务的实现原理呢?**
|
||||||
|
|
||||||
|
我们这里以 MySQL 的 InnoDB 引擎为例来简单说一下。
|
||||||
|
|
||||||
|
MySQL InnoDB 引擎使用 **redo log(重做日志)** 保证事务的**持久性**,使用 **undo log(回滚日志)** 来保证事务的**原子性**。
|
||||||
|
|
||||||
|
MySQL InnoDB 引擎通过 **锁机制**、**MVCC** 等手段来保证事务的隔离性( 默认支持的隔离级别是 **`REPEATABLE-READ`** )。
|
||||||
|
|
||||||
|
保证了事务的持久性、原子性、隔离性之后,一致性才能得到保障。
|
||||||
|
|
||||||
### 并发事务带来哪些问题?
|
### 并发事务带来哪些问题?
|
||||||
|
|
||||||
在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对同一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题。
|
在典型的应用程序中,多个事务并发运行,经常会操作相同的数据来完成各自的任务(多个用户对同一数据进行操作)。并发虽然是必须的,但可能会导致以下的问题。
|
||||||
|
|
||||||
- **脏读(Dirty read):** 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
|
- **脏读(Dirty read):** 当一个事务正在访问数据并且对数据进行了修改,而这种修改还没有提交到数据库中,这时另外一个事务也访问了这个数据,然后使用了这个数据。因为这个数据是还没有提交的数据,那么另外一个事务读到的这个数据是“脏数据”,依据“脏数据”所做的操作可能是不正确的。
|
||||||
- **丢失修改(Lost to modify):** 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务1读取某表中的数据A=20,事务2也读取A=20,事务1修改A=A-1,事务2也修改A=A-1,最终结果A=19,事务1的修改被丢失。
|
- **丢失修改(Lost to modify):** 指在一个事务读取一个数据时,另外一个事务也访问了该数据,那么在第一个事务中修改了这个数据后,第二个事务也修改了这个数据。这样第一个事务内的修改结果就被丢失,因此称为丢失修改。 例如:事务 1 读取某表中的数据 A=20,事务 2 也读取 A=20,事务 1 修改 A=A-1,事务 2 也修改 A=A-1,最终结果 A=19,事务 1 的修改被丢失。
|
||||||
- **不可重复读(Unrepeatableread):** 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
|
- **不可重复读(Unrepeatableread):** 指在一个事务内多次读同一数据。在这个事务还没有结束时,另一个事务也访问该数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改导致第一个事务两次读取的数据可能不太一样。这就发生了在一个事务内两次读到的数据是不一样的情况,因此称为不可重复读。
|
||||||
- **幻读(Phantom read):** 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
|
- **幻读(Phantom read):** 幻读与不可重复读类似。它发生在一个事务(T1)读取了几行数据,接着另一个并发事务(T2)插入了一些数据时。在随后的查询中,第一个事务(T1)就会发现多了一些原本不存在的记录,就好像发生了幻觉一样,所以称为幻读。
|
||||||
|
|
||||||
@ -181,23 +234,25 @@ select sql_no_cache count(*) from usr;
|
|||||||
|
|
||||||
不可重复读的重点是修改比如多次读取一条记录发现其中某些列的值被修改,幻读的重点在于新增或者删除比如多次读取一条记录发现记录增多或减少了。
|
不可重复读的重点是修改比如多次读取一条记录发现其中某些列的值被修改,幻读的重点在于新增或者删除比如多次读取一条记录发现记录增多或减少了。
|
||||||
|
|
||||||
### 事务隔离级别有哪些?MySQL的默认隔离级别是?
|
### 事务隔离级别有哪些?
|
||||||
|
|
||||||
**SQL 标准定义了四个隔离级别:**
|
SQL 标准定义了四个隔离级别:
|
||||||
|
|
||||||
- **READ-UNCOMMITTED(读取未提交):** 最低的隔离级别,允许读取尚未提交的数据变更,**可能会导致脏读、幻读或不可重复读**。
|
- **READ-UNCOMMITTED(读取未提交):** 最低的隔离级别,允许读取尚未提交的数据变更,**可能会导致脏读、幻读或不可重复读**。
|
||||||
- **READ-COMMITTED(读取已提交):** 允许读取并发事务已经提交的数据,**可以阻止脏读,但是幻读或不可重复读仍有可能发生**。
|
- **READ-COMMITTED(读取已提交):** 允许读取并发事务已经提交的数据,**可以阻止脏读,但是幻读或不可重复读仍有可能发生**。
|
||||||
- **REPEATABLE-READ(可重复读):** 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,**可以阻止脏读和不可重复读,但幻读仍有可能发生**。
|
- **REPEATABLE-READ(可重复读):** 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,**可以阻止脏读和不可重复读,但幻读仍有可能发生**。
|
||||||
- **SERIALIZABLE(可串行化):** 最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,**该级别可以防止脏读、不可重复读以及幻读**。
|
- **SERIALIZABLE(可串行化):** 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,**该级别可以防止脏读、不可重复读以及幻读**。
|
||||||
|
|
||||||
------
|
---
|
||||||
|
|
||||||
| 隔离级别 | 脏读 | 不可重复读 | 幻影读 |
|
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|
||||||
| :--------------: | :--: | :--------: | :----: |
|
| :--------------: | :--: | :--------: | :--: |
|
||||||
| READ-UNCOMMITTED | √ | √ | √ |
|
| READ-UNCOMMITTED | √ | √ | √ |
|
||||||
| READ-COMMITTED | × | √ | √ |
|
| READ-COMMITTED | × | √ | √ |
|
||||||
| REPEATABLE-READ | × | × | √ |
|
| REPEATABLE-READ | × | × | √ |
|
||||||
| SERIALIZABLE | × | × | × |
|
| SERIALIZABLE | × | × | × |
|
||||||
|
|
||||||
|
### MySQL 的默认隔离级别是什么?
|
||||||
|
|
||||||
MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;`
|
MySQL InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)**。我们可以通过`SELECT @@tx_isolation;`命令来查看,MySQL 8.0 该命令改为`SELECT @@transaction_isolation;`
|
||||||
|
|
||||||
@ -210,119 +265,20 @@ mysql> SELECT @@tx_isolation;
|
|||||||
+-----------------+
|
+-----------------+
|
||||||
```
|
```
|
||||||
|
|
||||||
这里需要注意的是:与 SQL 标准不同的地方在于 InnoDB 存储引擎在 **REPEATABLE-READ(可重读)**
|
~~这里需要注意的是:与 SQL 标准不同的地方在于 InnoDB 存储引擎在 **REPEATABLE-READ(可重读)** 事务隔离级别下使用的是 Next-Key Lock 锁算法,因此可以避免幻读的产生,这与其他数据库系统(如 SQL Server)是不同的。所以说 InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)** 已经可以完全保证事务的隔离性要求,即达到了 SQL 标准的 **SERIALIZABLE(可串行化)** 隔离级别。~~
|
||||||
事务隔离级别下使用的是Next-Key Lock 锁算法,因此可以避免幻读的产生,这与其他数据库系统(如 SQL Server)
|
|
||||||
是不同的。所以说InnoDB 存储引擎的默认支持的隔离级别是 **REPEATABLE-READ(可重读)** 已经可以完全保证事务的隔离性要求,即达到了
|
🐛 问题更正:**MySQL InnoDB 的 REPEATABLE-READ(可重读)并不保证避免幻读,需要应用使用加锁读来保证。而这个加锁度使用到的机制就是 Next-Key Locks。**
|
||||||
SQL标准的 **SERIALIZABLE(可串行化)** 隔离级别。因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 **READ-COMMITTED(读取提交内容)** ,但是你要知道的是InnoDB 存储引擎默认使用 **REPEAaTABLE-READ(可重读)** 并不会有任何性能损失。
|
|
||||||
|
因为隔离级别越低,事务请求的锁越少,所以大部分数据库系统的隔离级别都是 **READ-COMMITTED(读取提交内容)** ,但是你要知道的是 InnoDB 存储引擎默认使用 **REPEAaTABLE-READ(可重读)** 并不会有任何性能损失。
|
||||||
|
|
||||||
InnoDB 存储引擎在 **分布式事务** 的情况下一般会用到 **SERIALIZABLE(可串行化)** 隔离级别。
|
InnoDB 存储引擎在 **分布式事务** 的情况下一般会用到 **SERIALIZABLE(可串行化)** 隔离级别。
|
||||||
|
|
||||||
### 锁机制与InnoDB锁算法
|
🌈 拓展一下(以下内容摘自《MySQL 技术内幕:InnoDB 存储引擎(第 2 版)》7.7 章):
|
||||||
|
|
||||||
**MyISAM和InnoDB存储引擎使用的锁:**
|
> InnoDB 存储引擎提供了对 XA 事务的支持,并通过 XA 事务来支持分布式事务的实现。分布式事务指的是允许多个独立的事务资源(transactional resources)参与到一个全局的事务中。事务资源通常是关系型数据库系统,但也可以是其他类型的资源。全局事务要求在其中的所有参与的事务要么都提交,要么都回滚,这对于事务原有的 ACID 要求又有了提高。另外,在使用分布式事务时,InnoDB 存储引擎的事务隔离级别必须设置为 SERIALIZABLE。
|
||||||
|
|
||||||
- MyISAM采用表级锁(table-level locking)。
|
## 参考
|
||||||
- InnoDB支持行级锁(row-level locking)和表级锁,默认为行级锁
|
|
||||||
|
|
||||||
**表级锁和行级锁对比:**
|
- 《高性能 MySQL》
|
||||||
|
|
||||||
- **表级锁:** MySQL中锁定 **粒度最大** 的一种锁,对当前操作的整张表加锁,实现简单,资源消耗也比较少,加锁快,不会出现死锁。其锁定粒度最大,触发锁冲突的概率最高,并发度最低,MyISAM和 InnoDB引擎都支持表级锁。
|
- https://www.omnisci.com/technical-glossary/relational-database
|
||||||
- **行级锁:** MySQL中锁定 **粒度最小** 的一种锁,只针对当前操作的行进行加锁。 行级锁能大大减少数据库操作的冲突。其加锁粒度最小,并发度高,但加锁的开销也最大,加锁慢,会出现死锁。
|
|
||||||
|
|
||||||
详细内容可以参考: MySQL锁机制简单了解一下:[https://blog.csdn.net/qq_34337272/article/details/80611486](https://blog.csdn.net/qq_34337272/article/details/80611486)
|
|
||||||
|
|
||||||
**InnoDB存储引擎的锁的算法有三种:**
|
|
||||||
|
|
||||||
- Record lock:单个行记录上的锁
|
|
||||||
- Gap lock:间隙锁,锁定一个范围,不包括记录本身
|
|
||||||
- Next-key lock:record+gap 锁定一个范围,包含记录本身
|
|
||||||
|
|
||||||
**相关知识点:**
|
|
||||||
|
|
||||||
1. innodb对于行的查询使用next-key lock
|
|
||||||
2. Next-locking keying为了解决Phantom Problem幻读问题
|
|
||||||
3. 当查询的索引含有唯一属性时,将next-key lock降级为record key
|
|
||||||
4. Gap锁设计的目的是为了阻止多个事务将记录插入到同一范围内,而这会导致幻读问题的产生
|
|
||||||
5. 有两种方式显式关闭gap锁:(除了外键约束和唯一性检查外,其余情况仅使用record lock) A. 将事务隔离级别设置为RC B. 将参数innodb_locks_unsafe_for_binlog设置为1
|
|
||||||
|
|
||||||
### 大表优化
|
|
||||||
|
|
||||||
当MySQL单表记录数过大时,数据库的CRUD性能会明显下降,一些常见的优化措施如下:
|
|
||||||
|
|
||||||
#### 1. 限定数据的范围
|
|
||||||
|
|
||||||
务必禁止不带任何限制数据范围条件的查询语句。比如:我们当用户在查询订单历史的时候,我们可以控制在一个月的范围内;
|
|
||||||
|
|
||||||
#### 2. 读/写分离
|
|
||||||
|
|
||||||
经典的数据库拆分方案,主库负责写,从库负责读;
|
|
||||||
|
|
||||||
#### 3. 垂直分区
|
|
||||||
|
|
||||||
**根据数据库里面数据表的相关性进行拆分。** 例如,用户表中既有用户的登录信息又有用户的基本信息,可以将用户表拆分成两个单独的表,甚至放到单独的库做分库。
|
|
||||||
|
|
||||||
**简单来说垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表。** 如下图所示,这样来说大家应该就更容易理解了。
|
|
||||||
|
|
||||||
|
|
||||||
- **垂直拆分的优点:** 可以使得列数据变小,在查询时减少读取的Block数,减少I/O次数。此外,垂直分区可以简化表的结构,易于维护。
|
|
||||||
- **垂直拆分的缺点:** 主键会出现冗余,需要管理冗余列,并会引起Join操作,可以通过在应用层进行Join来解决。此外,垂直分区会让事务变得更加复杂;
|
|
||||||
|
|
||||||
#### 4. 水平分区
|
|
||||||
|
|
||||||
**保持数据表结构不变,通过某种策略存储数据分片。这样每一片数据分散到不同的表或者库中,达到了分布式的目的。 水平拆分可以支撑非常大的数据量。**
|
|
||||||
|
|
||||||
水平拆分是指数据表行的拆分,表的行数超过200万行时,就会变慢,这时可以把一张的表的数据拆成多张表来存放。举个例子:我们可以将用户信息表拆分成多个用户信息表,这样就可以避免单一表数据量过大对性能造成影响。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
水平拆分可以支持非常大的数据量。需要注意的一点是:分表仅仅是解决了单一表数据过大的问题,但由于表的数据还是在同一台机器上,其实对于提升MySQL并发能力没有什么意义,所以 **水平拆分最好分库** 。
|
|
||||||
|
|
||||||
水平拆分能够 **支持非常大的数据量存储,应用端改造也少**,但 **分片事务难以解决** ,跨节点Join性能较差,逻辑复杂。《Java工程师修炼之道》的作者推荐 **尽量不要对数据进行分片,因为拆分会带来逻辑、部署、运维的各种复杂度** ,一般的数据表在优化得当的情况下支撑千万以下的数据量是没有太大问题的。如果实在要分片,尽量选择客户端分片架构,这样可以减少一次和中间件的网络I/O。
|
|
||||||
|
|
||||||
**下面补充一下数据库分片的两种常见方案:**
|
|
||||||
|
|
||||||
- **客户端代理:** **分片逻辑在应用端,封装在jar包中,通过修改或者封装JDBC层来实现。** 当当网的 **Sharding-JDBC** 、阿里的TDDL是两种比较常用的实现。
|
|
||||||
- **中间件代理:** **在应用和数据中间加了一个代理层。分片逻辑统一维护在中间件服务中。** 我们现在谈的 **Mycat** 、360的Atlas、网易的DDB等等都是这种架构的实现。
|
|
||||||
|
|
||||||
详细内容可以参考: MySQL大表优化方案: [https://segmentfault.com/a/1190000006158186](https://segmentfault.com/a/1190000006158186)
|
|
||||||
|
|
||||||
### 解释一下什么是池化设计思想。什么是数据库连接池?为什么需要数据库连接池?
|
|
||||||
|
|
||||||
池化设计应该不是一个新名词。我们常见的如java线程池、jdbc连接池、redis连接池等就是这类设计的代表实现。这种设计会初始预设资源,解决的问题就是抵消每次获取资源的消耗,如创建线程的开销,获取远程连接的开销等。就好比你去食堂打饭,打饭的大妈会先把饭盛好几份放那里,你来了就直接拿着饭盒加菜即可,不用再临时又盛饭又打菜,效率就高了。除了初始化资源,池化设计还包括如下这些特征:池子的初始值、池子的活跃值、池子的最大值等,这些特征可以直接映射到java线程池和数据库连接池的成员属性中。这篇文章对[池化设计思想](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485679&idx=1&sn=57dbca8c9ad49e1f3968ecff04a4f735&chksm=cea24724f9d5ce3212292fac291234a760c99c0960b5430d714269efe33554730b5f71208582&token=1141994790&lang=zh_CN#rd)介绍的还不错,直接复制过来,避免重复造轮子了。
|
|
||||||
|
|
||||||
数据库连接本质就是一个 socket 的连接。数据库服务端还要维护一些缓存和用户权限信息之类的 所以占用了一些内存。我们可以把数据库连接池是看做是维护的数据库连接的缓存,以便将来需要对数据库的请求时可以重用这些连接。为每个用户打开和维护数据库连接,尤其是对动态数据库驱动的网站应用程序的请求,既昂贵又浪费资源。**在连接池中,创建连接后,将其放置在池中,并再次使用它,因此不必建立新的连接。如果使用了所有连接,则会建立一个新连接并将其添加到池中**。 连接池还减少了用户必须等待建立与数据库的连接的时间。
|
|
||||||
|
|
||||||
### 分库分表之后,id 主键如何处理?
|
|
||||||
|
|
||||||
因为要是分成多个表之后,每个表都是从 1 开始累加,这样是不对的,我们需要一个全局唯一的 id 来支持。
|
|
||||||
|
|
||||||
生成全局 id 有下面这几种方式:
|
|
||||||
|
|
||||||
- **UUID**:不适合作为主键,因为太长了,并且无序不可读,查询效率低。比较适合用于生成唯一的名字的标示比如文件的名字。
|
|
||||||
- **数据库自增 id** : 两台数据库分别设置不同步长,生成不重复ID的策略来实现高可用。这种方式生成的 id 有序,但是需要独立部署数据库实例,成本高,还会有性能瓶颈。
|
|
||||||
- **利用 redis 生成 id :** 性能比较好,灵活方便,不依赖于数据库。但是,引入了新的组件造成系统更加复杂,可用性降低,编码更加复杂,增加了系统成本。
|
|
||||||
- **Twitter的snowflake算法** :Github 地址:https://github.com/twitter-archive/snowflake。
|
|
||||||
- **美团的[Leaf](https://tech.meituan.com/2017/04/21/mt-leaf.html)分布式ID生成系统** :Leaf 是美团开源的分布式ID生成器,能保证全局唯一性、趋势递增、单调递增、信息安全,里面也提到了几种分布式方案的对比,但也需要依赖关系数据库、Zookeeper等中间件。感觉还不错。美团技术团队的一篇文章:https://tech.meituan.com/2017/04/21/mt-leaf.html 。
|
|
||||||
- ......
|
|
||||||
|
|
||||||
### 一条SQL语句在MySQL中如何执行的
|
|
||||||
|
|
||||||
[一条SQL语句在MySQL中如何执行的](<https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485097&idx=1&sn=84c89da477b1338bdf3e9fcd65514ac1&chksm=cea24962f9d5c074d8d3ff1ab04ee8f0d6486e3d015cfd783503685986485c11738ccb542ba7&token=79317275&lang=zh_CN#rd>)
|
|
||||||
|
|
||||||
### MySQL高性能优化规范建议
|
|
||||||
|
|
||||||
[MySQL高性能优化规范建议](<https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485117&idx=1&sn=92361755b7c3de488b415ec4c5f46d73&chksm=cea24976f9d5c060babe50c3747616cce63df5d50947903a262704988143c2eeb4069ae45420&token=79317275&lang=zh_CN#rd>)
|
|
||||||
|
|
||||||
### 一条SQL语句执行得很慢的原因有哪些?
|
|
||||||
|
|
||||||
[腾讯面试:一条SQL语句执行得很慢的原因有哪些?---不看后悔系列](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485185&idx=1&sn=66ef08b4ab6af5757792223a83fc0d45&chksm=cea248caf9d5c1dc72ec8a281ec16aa3ec3e8066dbb252e27362438a26c33fbe842b0e0adf47&token=79317275&lang=zh_CN#rd)
|
|
||||||
|
|
||||||
## 公众号
|
|
||||||
|
|
||||||
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
|
|
||||||
|
|
||||||
**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取!
|
|
||||||
|
|
||||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
|
||||||
|
|
||||||

|
|
||||||
@ -80,7 +80,7 @@ Read/Write Through Pattern 中服务端把 cache 视为主要数据存储,从
|
|||||||
|
|
||||||
简单画了一张图帮助大家理解写的步骤。
|
简单画了一张图帮助大家理解写的步骤。
|
||||||
|
|
||||||
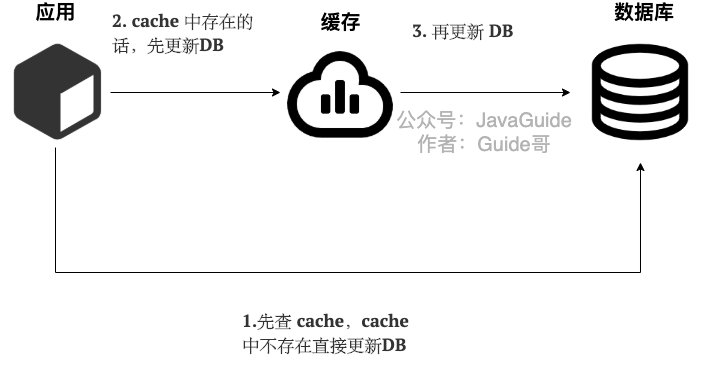
|

|
||||||
|
|
||||||
**读(Read Through):**
|
**读(Read Through):**
|
||||||
|
|
||||||
|
|||||||
{kind=link}
|
Before Width: | Height: | Size: 62 KiB After Width: | Height: | Size: 62 KiB |
@ -16,11 +16,12 @@
|
|||||||
- [6.3. hash](#63-hash)
|
- [6.3. hash](#63-hash)
|
||||||
- [6.4. set](#64-set)
|
- [6.4. set](#64-set)
|
||||||
- [6.5. sorted set](#65-sorted-set)
|
- [6.5. sorted set](#65-sorted-set)
|
||||||
|
- [6.6 bitmap](#66-bitmap)
|
||||||
- [7. Redis 单线程模型详解](#7-redis-单线程模型详解)
|
- [7. Redis 单线程模型详解](#7-redis-单线程模型详解)
|
||||||
- [8. Redis 没有使用多线程?为什么不使用多线程?](#8-redis-没有使用多线程为什么不使用多线程)
|
- [8. Redis 没有使用多线程?为什么不使用多线程?](#8-redis-没有使用多线程为什么不使用多线程)
|
||||||
- [9. Redis6.0 之后为何引入了多线程?](#9-redis60-之后为何引入了多线程)
|
- [9. Redis6.0 之后为何引入了多线程?](#9-redis60-之后为何引入了多线程)
|
||||||
- [10. Redis 给缓存数据设置过期时间有啥用?](#10-redis-给缓存数据设置过期时间有啥用)
|
- [10. Redis 给缓存数据设置过期时间有啥用?](#10-redis-给缓存数据设置过期时间有啥用)
|
||||||
- [11. Redis是如何判断数据是否过期的呢?](#11-redis是如何判断数据是否过期的呢)
|
- [11. Redis 是如何判断数据是否过期的呢?](#11-redis-是如何判断数据是否过期的呢)
|
||||||
- [12. 过期的数据的删除策略了解么?](#12-过期的数据的删除策略了解么)
|
- [12. 过期的数据的删除策略了解么?](#12-过期的数据的删除策略了解么)
|
||||||
- [13. Redis 内存淘汰机制了解么?](#13-redis-内存淘汰机制了解么)
|
- [13. Redis 内存淘汰机制了解么?](#13-redis-内存淘汰机制了解么)
|
||||||
- [14. Redis 持久化机制(怎么保证 Redis 挂掉之后再重启数据可以进行恢复)](#14-redis-持久化机制怎么保证-redis-挂掉之后再重启数据可以进行恢复)
|
- [14. Redis 持久化机制(怎么保证 Redis 挂掉之后再重启数据可以进行恢复)](#14-redis-持久化机制怎么保证-redis-挂掉之后再重启数据可以进行恢复)
|
||||||
@ -32,13 +33,14 @@
|
|||||||
- [17. 缓存雪崩](#17-缓存雪崩)
|
- [17. 缓存雪崩](#17-缓存雪崩)
|
||||||
- [17.1. 什么是缓存雪崩?](#171-什么是缓存雪崩)
|
- [17.1. 什么是缓存雪崩?](#171-什么是缓存雪崩)
|
||||||
- [17.2. 有哪些解决办法?](#172-有哪些解决办法)
|
- [17.2. 有哪些解决办法?](#172-有哪些解决办法)
|
||||||
- [18. 如何保证缓存与数据库双写时的数据一致性?](#18-如何保证缓存与数据库双写时的数据一致性)
|
- [18. 如何保证缓存和数据库数据的一致性?](#18-如何保证缓存和数据库数据的一致性)
|
||||||
- [19. 参考](#19-参考)
|
- [19. 参考](#19-参考)
|
||||||
- [20. 公众号](#20-公众号)
|
- [20. 公众号](#20-公众号)
|
||||||
|
|
||||||
<!-- /code_chunk_output -->
|
<!-- /code_chunk_output -->
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 1. 简单介绍一下 Redis 呗!
|
### 1. 简单介绍一下 Redis 呗!
|
||||||
|
|
||||||
简单来说 **Redis 就是一个使用 C 语言开发的数据库**,不过与传统数据库不同的是 **Redis 的数据是存在内存中的** ,也就是它是内存数据库,所以读写速度非常快,因此 Redis 被广泛应用于缓存方向。
|
简单来说 **Redis 就是一个使用 C 语言开发的数据库**,不过与传统数据库不同的是 **Redis 的数据是存在内存中的** ,也就是它是内存数据库,所以读写速度非常快,因此 Redis 被广泛应用于缓存方向。
|
||||||
@ -74,7 +76,7 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
|
|||||||
5. **Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 目前是原生支持 cluster 模式的.**
|
5. **Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据;但是 Redis 目前是原生支持 cluster 模式的.**
|
||||||
6. **Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型。** (Redis 6.0 引入了多线程 IO )
|
6. **Memcached 是多线程,非阻塞 IO 复用的网络模型;Redis 使用单线程的多路 IO 复用模型。** (Redis 6.0 引入了多线程 IO )
|
||||||
7. **Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。**
|
7. **Redis 支持发布订阅模型、Lua 脚本、事务等功能,而 Memcached 不支持。并且,Redis 支持更多的编程语言。**
|
||||||
8. **Memcached过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除。**
|
8. **Memcached 过期数据的删除策略只用了惰性删除,而 Redis 同时使用了惰性删除与定期删除。**
|
||||||
|
|
||||||
相信看了上面的对比之后,我们已经没有什么理由可以选择使用 Memcached 来作为自己项目的分布式缓存了。
|
相信看了上面的对比之后,我们已经没有什么理由可以选择使用 Memcached 来作为自己项目的分布式缓存了。
|
||||||
|
|
||||||
@ -133,7 +135,7 @@ _简单,来说使用缓存主要是为了提升用户体验以及应对更多
|
|||||||
|
|
||||||
**普通字符串的基本操作:**
|
**普通字符串的基本操作:**
|
||||||
|
|
||||||
``` bash
|
```bash
|
||||||
127.0.0.1:6379> set key value #设置 key-value 类型的值
|
127.0.0.1:6379> set key value #设置 key-value 类型的值
|
||||||
OK
|
OK
|
||||||
127.0.0.1:6379> get key # 根据 key 获得对应的 value
|
127.0.0.1:6379> get key # 根据 key 获得对应的 value
|
||||||
@ -150,7 +152,7 @@ OK
|
|||||||
|
|
||||||
**批量设置** :
|
**批量设置** :
|
||||||
|
|
||||||
``` bash
|
```bash
|
||||||
127.0.0.1:6379> mset key1 value1 key2 value2 # 批量设置 key-value 类型的值
|
127.0.0.1:6379> mset key1 value1 key2 value2 # 批量设置 key-value 类型的值
|
||||||
OK
|
OK
|
||||||
127.0.0.1:6379> mget key1 key2 # 批量获取多个 key 对应的 value
|
127.0.0.1:6379> mget key1 key2 # 批量获取多个 key 对应的 value
|
||||||
@ -160,7 +162,7 @@ OK
|
|||||||
|
|
||||||
**计数器(字符串的内容为整数的时候可以使用):**
|
**计数器(字符串的内容为整数的时候可以使用):**
|
||||||
|
|
||||||
``` bash
|
```bash
|
||||||
|
|
||||||
127.0.0.1:6379> set number 1
|
127.0.0.1:6379> set number 1
|
||||||
OK
|
OK
|
||||||
@ -176,7 +178,7 @@ OK
|
|||||||
|
|
||||||
**过期**:
|
**过期**:
|
||||||
|
|
||||||
``` bash
|
```bash
|
||||||
127.0.0.1:6379> expire key 60 # 数据在 60s 后过期
|
127.0.0.1:6379> expire key 60 # 数据在 60s 后过期
|
||||||
(integer) 1
|
(integer) 1
|
||||||
127.0.0.1:6379> setex key 60 value # 数据在 60s 后过期 (setex:[set] + [ex]pire)
|
127.0.0.1:6379> setex key 60 value # 数据在 60s 后过期 (setex:[set] + [ex]pire)
|
||||||
@ -195,7 +197,7 @@ OK
|
|||||||
|
|
||||||
**通过 `rpush/lpop` 实现队列:**
|
**通过 `rpush/lpop` 实现队列:**
|
||||||
|
|
||||||
``` bash
|
```bash
|
||||||
127.0.0.1:6379> rpush myList value1 # 向 list 的头部(右边)添加元素
|
127.0.0.1:6379> rpush myList value1 # 向 list 的头部(右边)添加元素
|
||||||
(integer) 1
|
(integer) 1
|
||||||
127.0.0.1:6379> rpush myList value2 value3 # 向list的头部(最右边)添加多个元素
|
127.0.0.1:6379> rpush myList value2 value3 # 向list的头部(最右边)添加多个元素
|
||||||
@ -212,7 +214,7 @@ OK
|
|||||||
|
|
||||||
**通过 `rpush/rpop` 实现栈:**
|
**通过 `rpush/rpop` 实现栈:**
|
||||||
|
|
||||||
``` bash
|
```bash
|
||||||
127.0.0.1:6379> rpush myList2 value1 value2 value3
|
127.0.0.1:6379> rpush myList2 value1 value2 value3
|
||||||
(integer) 3
|
(integer) 3
|
||||||
127.0.0.1:6379> rpop myList2 # 将 list的头部(最右边)元素取出
|
127.0.0.1:6379> rpop myList2 # 将 list的头部(最右边)元素取出
|
||||||
@ -225,7 +227,7 @@ OK
|
|||||||
|
|
||||||
**通过 `lrange` 查看对应下标范围的列表元素:**
|
**通过 `lrange` 查看对应下标范围的列表元素:**
|
||||||
|
|
||||||
``` bash
|
```bash
|
||||||
127.0.0.1:6379> rpush myList value1 value2 value3
|
127.0.0.1:6379> rpush myList value1 value2 value3
|
||||||
(integer) 3
|
(integer) 3
|
||||||
127.0.0.1:6379> lrange myList 0 1 # 查看对应下标的list列表, 0 为 start,1为 end
|
127.0.0.1:6379> lrange myList 0 1 # 查看对应下标的list列表, 0 为 start,1为 end
|
||||||
@ -241,7 +243,7 @@ OK
|
|||||||
|
|
||||||
**通过 `llen` 查看链表长度:**
|
**通过 `llen` 查看链表长度:**
|
||||||
|
|
||||||
``` bash
|
```bash
|
||||||
127.0.0.1:6379> llen myList
|
127.0.0.1:6379> llen myList
|
||||||
(integer) 3
|
(integer) 3
|
||||||
```
|
```
|
||||||
@ -254,7 +256,7 @@ OK
|
|||||||
|
|
||||||
下面我们简单看看它的使用!
|
下面我们简单看看它的使用!
|
||||||
|
|
||||||
``` bash
|
```bash
|
||||||
127.0.0.1:6379> hset userInfoKey name "guide" description "dev" age "24"
|
127.0.0.1:6379> hset userInfoKey name "guide" description "dev" age "24"
|
||||||
OK
|
OK
|
||||||
127.0.0.1:6379> hexists userInfoKey name # 查看 key 对应的 value中指定的字段是否存在。
|
127.0.0.1:6379> hexists userInfoKey name # 查看 key 对应的 value中指定的字段是否存在。
|
||||||
@ -291,7 +293,7 @@ OK
|
|||||||
|
|
||||||
下面我们简单看看它的使用!
|
下面我们简单看看它的使用!
|
||||||
|
|
||||||
``` bash
|
```bash
|
||||||
127.0.0.1:6379> sadd mySet value1 value2 # 添加元素进去
|
127.0.0.1:6379> sadd mySet value1 value2 # 添加元素进去
|
||||||
(integer) 2
|
(integer) 2
|
||||||
127.0.0.1:6379> sadd mySet value1 # 不允许有重复元素
|
127.0.0.1:6379> sadd mySet value1 # 不允许有重复元素
|
||||||
@ -317,7 +319,7 @@ OK
|
|||||||
2. **常用命令:** `zadd,zcard,zscore,zrange,zrevrange,zrem` 等。
|
2. **常用命令:** `zadd,zcard,zscore,zrange,zrevrange,zrem` 等。
|
||||||
3. **应用场景:** 需要对数据根据某个权重进行排序的场景。比如在直播系统中,实时排行信息包含直播间在线用户列表,各种礼物排行榜,弹幕消息(可以理解为按消息维度的消息排行榜)等信息。
|
3. **应用场景:** 需要对数据根据某个权重进行排序的场景。比如在直播系统中,实时排行信息包含直播间在线用户列表,各种礼物排行榜,弹幕消息(可以理解为按消息维度的消息排行榜)等信息。
|
||||||
|
|
||||||
``` bash
|
```bash
|
||||||
127.0.0.1:6379> zadd myZset 3.0 value1 # 添加元素到 sorted set 中 3.0 为权重
|
127.0.0.1:6379> zadd myZset 3.0 value1 # 添加元素到 sorted set 中 3.0 为权重
|
||||||
(integer) 1
|
(integer) 1
|
||||||
127.0.0.1:6379> zadd myZset 2.0 value2 1.0 value3 # 一次添加多个元素
|
127.0.0.1:6379> zadd myZset 2.0 value2 1.0 value3 # 一次添加多个元素
|
||||||
@ -338,6 +340,86 @@ OK
|
|||||||
2) "value2"
|
2) "value2"
|
||||||
```
|
```
|
||||||
|
|
||||||
|
#### 6.6 bitmap
|
||||||
|
|
||||||
|
1. **介绍 :** bitmap 存储的是连续的二进制数字(0 和 1),通过 bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 bitmap 本身会极大的节省储存空间。
|
||||||
|
2. **常用命令:** `setbit` 、`getbit` 、`bitcount`、`bitop`
|
||||||
|
3. **应用场景:** 适合需要保存状态信息(比如是否签到、是否登录...)并需要进一步对这些信息进行分析的场景。比如用户签到情况、活跃用户情况、用户行为统计(比如是否点赞过某个视频)。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# SETBIT 会返回之前位的值(默认是 0)这里会生成 7 个位
|
||||||
|
127.0.0.1:6379> setbit mykey 7 1
|
||||||
|
(integer) 0
|
||||||
|
127.0.0.1:6379> setbit mykey 7 0
|
||||||
|
(integer) 1
|
||||||
|
127.0.0.1:6379> getbit mykey 7
|
||||||
|
(integer) 0
|
||||||
|
127.0.0.1:6379> setbit mykey 6 1
|
||||||
|
(integer) 0
|
||||||
|
127.0.0.1:6379> setbit mykey 8 1
|
||||||
|
(integer) 0
|
||||||
|
# 通过 bitcount 统计被被设置为 1 的位的数量。
|
||||||
|
127.0.0.1:6379> bitcount mykey
|
||||||
|
(integer) 2
|
||||||
|
```
|
||||||
|
|
||||||
|
针对上面提到的一些场景,这里进行进一步说明。
|
||||||
|
|
||||||
|
**使用场景一:用户行为分析**
|
||||||
|
很多网站为了分析你的喜好,需要研究你点赞过的内容。
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 记录你喜欢过 001 号小姐姐
|
||||||
|
127.0.0.1:6379> setbit beauty_girl_001 uid 1
|
||||||
|
```
|
||||||
|
|
||||||
|
**使用场景二:统计活跃用户**
|
||||||
|
|
||||||
|
使用时间作为 key,然后用户 ID 为 offset,如果当日活跃过就设置为 1
|
||||||
|
|
||||||
|
那么我该如果计算某几天/月/年的活跃用户呢(暂且约定,统计时间内只有有一天在线就称为活跃),有请下一个 redis 的命令
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 对一个或多个保存二进制位的字符串 key 进行位元操作,并将结果保存到 destkey 上。
|
||||||
|
# BITOP 命令支持 AND 、 OR 、 NOT 、 XOR 这四种操作中的任意一种参数
|
||||||
|
BITOP operation destkey key [key ...]
|
||||||
|
```
|
||||||
|
|
||||||
|
初始化数据:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
127.0.0.1:6379> setbit 20210308 1 1
|
||||||
|
(integer) 0
|
||||||
|
127.0.0.1:6379> setbit 20210308 2 1
|
||||||
|
(integer) 0
|
||||||
|
127.0.0.1:6379> setbit 20210309 1 1
|
||||||
|
(integer) 0
|
||||||
|
```
|
||||||
|
|
||||||
|
统计 20210308~20210309 总活跃用户数: 1
|
||||||
|
|
||||||
|
```bash
|
||||||
|
127.0.0.1:6379> bitop and desk1 20210308 20210309
|
||||||
|
(integer) 1
|
||||||
|
127.0.0.1:6379> bitcount desk1
|
||||||
|
(integer) 1
|
||||||
|
```
|
||||||
|
|
||||||
|
统计 20210308~20210309 在线活跃用户数: 2
|
||||||
|
|
||||||
|
```bash
|
||||||
|
127.0.0.1:6379> bitop or desk2 20210308 20210309
|
||||||
|
(integer) 1
|
||||||
|
127.0.0.1:6379> bitcount desk2
|
||||||
|
(integer) 2
|
||||||
|
```
|
||||||
|
|
||||||
|
**使用场景三:用户在线状态**
|
||||||
|
|
||||||
|
对于获取或者统计用户在线状态,使用 bitmap 是一个节约空间效率又高的一种方法。
|
||||||
|
|
||||||
|
只需要一个 key,然后用户 ID 为 offset,如果在线就设置为 1,不在线就设置为 0。
|
||||||
|
|
||||||
### 7. Redis 单线程模型详解
|
### 7. Redis 单线程模型详解
|
||||||
|
|
||||||
**Redis 基于 Reactor 模式来设计开发了自己的一套高效的事件处理模型** (Netty 的线程模型也基于 Reactor 模式,Reactor 模式不愧是高性能 IO 的基石),这套事件处理模型对应的是 Redis 中的文件事件处理器(file event handler)。由于文件事件处理器(file event handler)是单线程方式运行的,所以我们一般都说 Redis 是单线程模型。
|
**Redis 基于 Reactor 模式来设计开发了自己的一套高效的事件处理模型** (Netty 的线程模型也基于 Reactor 模式,Reactor 模式不愧是高性能 IO 的基石),这套事件处理模型对应的是 Redis 中的文件事件处理器(file event handler)。由于文件事件处理器(file event handler)是单线程方式运行的,所以我们一般都说 Redis 是单线程模型。
|
||||||
@ -362,10 +444,10 @@ Redis 通过**IO 多路复用程序** 来监听来自客户端的大量连接(
|
|||||||
|
|
||||||
可以看出,文件事件处理器(file event handler)主要是包含 4 个部分:
|
可以看出,文件事件处理器(file event handler)主要是包含 4 个部分:
|
||||||
|
|
||||||
* 多个 socket(客户端连接)
|
- 多个 socket(客户端连接)
|
||||||
* IO 多路复用程序(支持多个客户端连接的关键)
|
- IO 多路复用程序(支持多个客户端连接的关键)
|
||||||
* 文件事件分派器(将 socket 关联到相应的事件处理器)
|
- 文件事件分派器(将 socket 关联到相应的事件处理器)
|
||||||
* 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
|
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@ -397,13 +479,13 @@ Redis 通过**IO 多路复用程序** 来监听来自客户端的大量连接(
|
|||||||
|
|
||||||
Redis6.0 的多线程默认是禁用的,只使用主线程。如需开启需要修改 redis 配置文件 `redis.conf` :
|
Redis6.0 的多线程默认是禁用的,只使用主线程。如需开启需要修改 redis 配置文件 `redis.conf` :
|
||||||
|
|
||||||
``` bash
|
```bash
|
||||||
io-threads-do-reads yes
|
io-threads-do-reads yes
|
||||||
```
|
```
|
||||||
|
|
||||||
开启多线程后,还需要设置线程数,否则是不生效的。同样需要修改 redis 配置文件 `redis.conf` :
|
开启多线程后,还需要设置线程数,否则是不生效的。同样需要修改 redis 配置文件 `redis.conf` :
|
||||||
|
|
||||||
``` bash
|
```bash
|
||||||
io-threads 4 #官网建议4核的机器建议设置为2或3个线程,8核的建议设置为6个线程
|
io-threads 4 #官网建议4核的机器建议设置为2或3个线程,8核的建议设置为6个线程
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -416,11 +498,11 @@ io-threads 4 #官网建议4核的机器建议设置为2或3个线程,8核的
|
|||||||
|
|
||||||
一般情况下,我们设置保存的缓存数据的时候都会设置一个过期时间。为什么呢?
|
一般情况下,我们设置保存的缓存数据的时候都会设置一个过期时间。为什么呢?
|
||||||
|
|
||||||
因为内存是有限的,如果缓存中的所有数据都是一直保存的话,分分钟直接Out of memory。
|
因为内存是有限的,如果缓存中的所有数据都是一直保存的话,分分钟直接 Out of memory。
|
||||||
|
|
||||||
Redis 自带了给缓存数据设置过期时间的功能,比如:
|
Redis 自带了给缓存数据设置过期时间的功能,比如:
|
||||||
|
|
||||||
``` bash
|
```bash
|
||||||
127.0.0.1:6379> exp key 60 # 数据在 60s 后过期
|
127.0.0.1:6379> exp key 60 # 数据在 60s 后过期
|
||||||
(integer) 1
|
(integer) 1
|
||||||
127.0.0.1:6379> setex key 60 value # 数据在 60s 后过期 (setex:[set] + [ex]pire)
|
127.0.0.1:6379> setex key 60 value # 数据在 60s 后过期 (setex:[set] + [ex]pire)
|
||||||
@ -429,23 +511,23 @@ OK
|
|||||||
(integer) 56
|
(integer) 56
|
||||||
```
|
```
|
||||||
|
|
||||||
注意:**Redis中除了字符串类型有自己独有设置过期时间的命令 `setex` 外,其他方法都需要依靠 `expire` 命令来设置过期时间 。另外, `persist` 命令可以移除一个键的过期时间: **
|
注意:**Redis 中除了字符串类型有自己独有设置过期时间的命令 `setex` 外,其他方法都需要依靠 `expire` 命令来设置过期时间 。另外, `persist` 命令可以移除一个键的过期时间: **
|
||||||
|
|
||||||
**过期时间除了有助于缓解内存的消耗,还有什么其他用么?**
|
**过期时间除了有助于缓解内存的消耗,还有什么其他用么?**
|
||||||
|
|
||||||
很多时候,我们的业务场景就是需要某个数据只在某一时间段内存在,比如我们的短信验证码可能只在1分钟内有效,用户登录的 token 可能只在 1 天内有效。
|
很多时候,我们的业务场景就是需要某个数据只在某一时间段内存在,比如我们的短信验证码可能只在 1 分钟内有效,用户登录的 token 可能只在 1 天内有效。
|
||||||
|
|
||||||
如果使用传统的数据库来处理的话,一般都是自己判断过期,这样更麻烦并且性能要差很多。
|
如果使用传统的数据库来处理的话,一般都是自己判断过期,这样更麻烦并且性能要差很多。
|
||||||
|
|
||||||
### 11. Redis是如何判断数据是否过期的呢?
|
### 11. Redis 是如何判断数据是否过期的呢?
|
||||||
|
|
||||||
Redis 通过一个叫做过期字典(可以看作是hash表)来保存数据过期的时间。过期字典的键指向Redis数据库中的某个key(键),过期字典的值是一个long long类型的整数,这个整数保存了key所指向的数据库键的过期时间(毫秒精度的UNIX时间戳)。
|
Redis 通过一个叫做过期字典(可以看作是 hash 表)来保存数据过期的时间。过期字典的键指向 Redis 数据库中的某个 key(键),过期字典的值是一个 long long 类型的整数,这个整数保存了 key 所指向的数据库键的过期时间(毫秒精度的 UNIX 时间戳)。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
过期字典是存储在redisDb这个结构里的:
|
过期字典是存储在 redisDb 这个结构里的:
|
||||||
|
|
||||||
``` c
|
```c
|
||||||
typedef struct redisDb {
|
typedef struct redisDb {
|
||||||
...
|
...
|
||||||
|
|
||||||
@ -461,12 +543,12 @@ typedef struct redisDb {
|
|||||||
|
|
||||||
常用的过期数据的删除策略就两个(重要!自己造缓存轮子的时候需要格外考虑的东西):
|
常用的过期数据的删除策略就两个(重要!自己造缓存轮子的时候需要格外考虑的东西):
|
||||||
|
|
||||||
1. **惰性删除** :只会在取出key的时候才对数据进行过期检查。这样对CPU最友好,但是可能会造成太多过期 key 没有被删除。
|
1. **惰性删除** :只会在取出 key 的时候才对数据进行过期检查。这样对 CPU 最友好,但是可能会造成太多过期 key 没有被删除。
|
||||||
2. **定期删除** : 每隔一段时间抽取一批 key 执行删除过期key操作。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对CPU时间的影响。
|
2. **定期删除** : 每隔一段时间抽取一批 key 执行删除过期 key 操作。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
|
||||||
|
|
||||||
定期删除对内存更加友好,惰性删除对CPU更加友好。两者各有千秋,所以Redis 采用的是 **定期删除+惰性/懒汉式删除** 。
|
定期删除对内存更加友好,惰性删除对 CPU 更加友好。两者各有千秋,所以 Redis 采用的是 **定期删除+惰性/懒汉式删除** 。
|
||||||
|
|
||||||
但是,仅仅通过给 key 设置过期时间还是有问题的。因为还是可能存在定期删除和惰性删除漏掉了很多过期 key 的情况。这样就导致大量过期 key 堆积在内存里,然后就Out of memory了。
|
但是,仅仅通过给 key 设置过期时间还是有问题的。因为还是可能存在定期删除和惰性删除漏掉了很多过期 key 的情况。这样就导致大量过期 key 堆积在内存里,然后就 Out of memory 了。
|
||||||
|
|
||||||
怎么解决这个问题呢?答案就是: **Redis 内存淘汰机制。**
|
怎么解决这个问题呢?答案就是: **Redis 内存淘汰机制。**
|
||||||
|
|
||||||
@ -500,7 +582,7 @@ Redis 可以通过创建快照来获得存储在内存里面的数据在某个
|
|||||||
|
|
||||||
快照持久化是 Redis 默认采用的持久化方式,在 Redis.conf 配置文件中默认有此下配置:
|
快照持久化是 Redis 默认采用的持久化方式,在 Redis.conf 配置文件中默认有此下配置:
|
||||||
|
|
||||||
``` conf
|
```conf
|
||||||
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
|
save 900 1 #在900秒(15分钟)之后,如果至少有1个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
|
||||||
|
|
||||||
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
|
save 300 10 #在300秒(5分钟)之后,如果至少有10个key发生变化,Redis就会自动触发BGSAVE命令创建快照。
|
||||||
@ -512,7 +594,7 @@ save 60 10000 #在60秒(1分钟)之后,如果至少有10000个key发生
|
|||||||
|
|
||||||
与快照持久化相比,AOF 持久化 的实时性更好,因此已成为主流的持久化方案。默认情况下 Redis 没有开启 AOF(append only file)方式的持久化,可以通过 appendonly 参数开启:
|
与快照持久化相比,AOF 持久化 的实时性更好,因此已成为主流的持久化方案。默认情况下 Redis 没有开启 AOF(append only file)方式的持久化,可以通过 appendonly 参数开启:
|
||||||
|
|
||||||
``` conf
|
```conf
|
||||||
appendonly yes
|
appendonly yes
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -520,7 +602,7 @@ appendonly yes
|
|||||||
|
|
||||||
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式,它们分别是:
|
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式,它们分别是:
|
||||||
|
|
||||||
``` conf
|
```conf
|
||||||
appendfsync always #每次有数据修改发生时都会写入AOF文件,这样会严重降低Redis的速度
|
appendfsync always #每次有数据修改发生时都会写入AOF文件,这样会严重降低Redis的速度
|
||||||
appendfsync everysec #每秒钟同步一次,显示地将多个写命令同步到硬盘
|
appendfsync everysec #每秒钟同步一次,显示地将多个写命令同步到硬盘
|
||||||
appendfsync no #让操作系统决定何时进行同步
|
appendfsync no #让操作系统决定何时进行同步
|
||||||
@ -546,9 +628,9 @@ AOF 重写是一个有歧义的名字,该功能是通过读取数据库中的
|
|||||||
|
|
||||||
### 15. Redis 事务
|
### 15. Redis 事务
|
||||||
|
|
||||||
Redis 可以通过 **MULTI,EXEC,DISCARD 和 WATCH** 等命令来实现事务(transaction)功能。
|
Redis 可以通过 **MULTI,EXEC,DISCARD 和 WATCH** 等命令来实现事务(transaction)功能。
|
||||||
|
|
||||||
``` bash
|
```bash
|
||||||
> MULTI
|
> MULTI
|
||||||
OK
|
OK
|
||||||
> INCR foo
|
> INCR foo
|
||||||
@ -560,9 +642,9 @@ QUEUED
|
|||||||
2) (integer) 1
|
2) (integer) 1
|
||||||
```
|
```
|
||||||
|
|
||||||
使用 [MULTI](https://redis.io/commands/multi)命令后可以输入多个命令。Redis不会立即执行这些命令,而是将它们放到队列,当调用了[EXEC](https://redis.io/commands/exec)命令将执行所有命令。
|
使用 [MULTI](https://redis.io/commands/multi)命令后可以输入多个命令。Redis 不会立即执行这些命令,而是将它们放到队列,当调用了[EXEC](https://redis.io/commands/exec)命令将执行所有命令。
|
||||||
|
|
||||||
Redis官网相关介绍 [https://redis.io/topics/transactions](https://redis.io/topics/transactions) 如下:
|
Redis 官网相关介绍 [https://redis.io/topics/transactions](https://redis.io/topics/transactions) 如下:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@ -575,13 +657,13 @@ Redis官网相关介绍 [https://redis.io/topics/transactions](https://redis.io/
|
|||||||
|
|
||||||
**Redis 是不支持 roll back 的,因而不满足原子性的(而且不满足持久性)。**
|
**Redis 是不支持 roll back 的,因而不满足原子性的(而且不满足持久性)。**
|
||||||
|
|
||||||
Redis官网也解释了自己为啥不支持回滚。简单来说就是Redis开发者们觉得没必要支持回滚,这样更简单便捷并且性能更好。Redis开发者觉得即使命令执行错误也应该在开发过程中就被发现而不是生产过程中。
|
Redis 官网也解释了自己为啥不支持回滚。简单来说就是 Redis 开发者们觉得没必要支持回滚,这样更简单便捷并且性能更好。Redis 开发者觉得即使命令执行错误也应该在开发过程中就被发现而不是生产过程中。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
你可以将Redis中的事务就理解为 :**Redis事务提供了一种将多个命令请求打包的功能。然后,再按顺序执行打包的所有命令,并且不会被中途打断。**
|
你可以将 Redis 中的事务就理解为 :**Redis 事务提供了一种将多个命令请求打包的功能。然后,再按顺序执行打包的所有命令,并且不会被中途打断。**
|
||||||
|
|
||||||
**相关issue** :[issue452: 关于 Redis 事务不满足原子性的问题](https://github.com/Snailclimb/JavaGuide/issues/452) ,推荐阅读:[https://zhuanlan.zhihu.com/p/43897838](https://zhuanlan.zhihu.com/p/43897838) 。
|
**相关 issue** :[issue452: 关于 Redis 事务不满足原子性的问题](https://github.com/Snailclimb/JavaGuide/issues/452) ,推荐阅读:[https://zhuanlan.zhihu.com/p/43897838](https://zhuanlan.zhihu.com/p/43897838) 。
|
||||||
|
|
||||||
### 16. 缓存穿透
|
### 16. 缓存穿透
|
||||||
|
|
||||||
@ -607,7 +689,7 @@ Redis官网也解释了自己为啥不支持回滚。简单来说就是Redis开
|
|||||||
|
|
||||||
如果用 Java 代码展示的话,差不多是下面这样的:
|
如果用 Java 代码展示的话,差不多是下面这样的:
|
||||||
|
|
||||||
``` java
|
```java
|
||||||
public Object getObjectInclNullById(Integer id) {
|
public Object getObjectInclNullById(Integer id) {
|
||||||
// 从缓存中获取数据
|
// 从缓存中获取数据
|
||||||
Object cacheValue = cache.get(id);
|
Object cacheValue = cache.get(id);
|
||||||
@ -684,24 +766,24 @@ _为什么会出现误判的情况呢? 我们还要从布隆过滤器的原理
|
|||||||
|
|
||||||
### 18. 如何保证缓存和数据库数据的一致性?
|
### 18. 如何保证缓存和数据库数据的一致性?
|
||||||
|
|
||||||
细说的话可以扯很多,但是我觉得其实没太大必要(小声BB:很多解决方案我也没太弄明白)。我个人觉得引入缓存之后,如果为了短时间的不一致性问题,选择让系统设计变得更加复杂的话,完全没必要。
|
细说的话可以扯很多,但是我觉得其实没太大必要(小声 BB:很多解决方案我也没太弄明白)。我个人觉得引入缓存之后,如果为了短时间的不一致性问题,选择让系统设计变得更加复杂的话,完全没必要。
|
||||||
|
|
||||||
下面单独对 **Cache Aside Pattern(旁路缓存模式)** 来聊聊。
|
下面单独对 **Cache Aside Pattern(旁路缓存模式)** 来聊聊。
|
||||||
|
|
||||||
Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删除 cache 。
|
Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删除 cache 。
|
||||||
|
|
||||||
如果更新数据库成功,而删除缓存这一步失败的情况的话,简单说两个解决方案:
|
如果更新数据库成功,而删除缓存这一步失败的情况的话,简单说两个解决方案:
|
||||||
|
|
||||||
1. **缓存失效时间变短(不推荐,治标不治本)** :我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
|
1. **缓存失效时间变短(不推荐,治标不治本)** :我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
|
||||||
2. **增加cache更新重试机制(常用)**: 如果 cache 服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。如果多次重试还是失败的话,我们可以把当前更新失败的 key 存入队列中,等缓存服务可用之后,再将 缓存中对应的 key 删除即可。
|
2. **增加 cache 更新重试机制(常用)**: 如果 cache 服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。如果多次重试还是失败的话,我们可以把当前更新失败的 key 存入队列中,等缓存服务可用之后,再将 缓存中对应的 key 删除即可。
|
||||||
|
|
||||||
### 19. 参考
|
### 19. 参考
|
||||||
|
|
||||||
* 《Redis 开发与运维》
|
- 《Redis 开发与运维》
|
||||||
* 《Redis 设计与实现》
|
- 《Redis 设计与实现》
|
||||||
* Redis 命令总结:http://Redisdoc.com/string/set.html
|
- Redis 命令总结:http://Redisdoc.com/string/set.html
|
||||||
* 通俗易懂的 Redis 数据结构基础教程:[https://juejin.im/post/5b53ee7e5188251aaa2d2e16](https://juejin.im/post/5b53ee7e5188251aaa2d2e16)
|
- 通俗易懂的 Redis 数据结构基础教程:[https://juejin.im/post/5b53ee7e5188251aaa2d2e16](https://juejin.im/post/5b53ee7e5188251aaa2d2e16)
|
||||||
* WHY Redis choose single thread (vs multi threads): [https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153](https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153)
|
- WHY Redis choose single thread (vs multi threads): [https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153](https://medium.com/@jychen7/sharing-redis-single-thread-vs-multi-threads-5870bd44d153)
|
||||||
|
|
||||||
### 20. 公众号
|
### 20. 公众号
|
||||||
|
|
||||||
|
|||||||
@ -179,13 +179,6 @@ ALTER TABLE table ADD INDEX index_name (num,name,age)
|
|||||||
|
|
||||||
那么当查询的条件有为:num / (num AND name) / (num AND name AND age)时,索引才生效。所以在创建联合索引时,尽量把查询最频繁的那个字段作为最左(第一个)字段。查询的时候也尽量以这个字段为第一条件。
|
那么当查询的条件有为:num / (num AND name) / (num AND name AND age)时,索引才生效。所以在创建联合索引时,尽量把查询最频繁的那个字段作为最左(第一个)字段。查询的时候也尽量以这个字段为第一条件。
|
||||||
|
|
||||||
> 但可能由于版本原因(我的 mysql 版本为 8.0.x),我创建的联合索引,相当于在联合索引的每个字段上都创建了相同的索引:
|
|
||||||
|
|
||||||
.png>)
|
|
||||||
|
|
||||||
无论是否符合最左前缀原则,每个字段的索引都生效:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
## 索引创建注意点
|
## 索引创建注意点
|
||||||
|
|
||||||
@ -227,7 +220,8 @@ ALTER TABLE table ADD INDEX index_name (num,name,age)
|
|||||||
|
|
||||||
#### 4.注意避免冗余索引
|
#### 4.注意避免冗余索引
|
||||||
|
|
||||||
冗余索引指的是索引的功能相同,能够命中 就肯定能命中 ,那么 就是冗余索引如(name,city )和(name )这两个索引就是冗余索引,能够命中后者的查询肯定是能够命中前者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
|
冗余索引指的是索引的功能相同,能够命中索引(a, b)就肯定能命中索引(a) ,那么索引(a)就是冗余索引。如(name,city )和(name )这两个索引就是冗余索引,能够命中前者的查询肯定是能够命中后者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
|
||||||
|
|
||||||
|
|
||||||
#### 5.考虑在字符串类型的字段上使用前缀索引代替普通索引
|
#### 5.考虑在字符串类型的字段上使用前缀索引代替普通索引
|
||||||
|
|
||||||
|
|||||||
@ -1,294 +0,0 @@
|
|||||||
作者: rhwayfun,原文地址:https://mp.weixin.qq.com/s/msYty4vjjC0PvrwasRH5Bw ,JavaGuide 已经获得作者授权并对原文进行了重新排版。
|
|
||||||
<!-- TOC -->
|
|
||||||
|
|
||||||
- [写在2019年后的蚂蚁、头条、拼多多的面试总结](#写在2019年后的蚂蚁头条拼多多的面试总结)
|
|
||||||
- [准备过程](#准备过程)
|
|
||||||
- [蚂蚁金服](#蚂蚁金服)
|
|
||||||
- [一面](#一面)
|
|
||||||
- [二面](#二面)
|
|
||||||
- [三面](#三面)
|
|
||||||
- [四面](#四面)
|
|
||||||
- [五面](#五面)
|
|
||||||
- [小结](#小结)
|
|
||||||
- [拼多多](#拼多多)
|
|
||||||
- [面试前](#面试前)
|
|
||||||
- [一面](#一面-1)
|
|
||||||
- [二面](#二面-1)
|
|
||||||
- [三面](#三面-1)
|
|
||||||
- [小结](#小结-1)
|
|
||||||
- [字节跳动](#字节跳动)
|
|
||||||
- [面试前](#面试前-1)
|
|
||||||
- [一面](#一面-2)
|
|
||||||
- [二面](#二面-2)
|
|
||||||
- [小结](#小结-2)
|
|
||||||
- [总结](#总结)
|
|
||||||
|
|
||||||
<!-- /TOC -->
|
|
||||||
|
|
||||||
# 2019年蚂蚁金服、头条、拼多多的面试总结
|
|
||||||
|
|
||||||
文章有点长,请耐心看完,绝对有收获!不想听我BB直接进入面试分享:
|
|
||||||
|
|
||||||
- 准备过程
|
|
||||||
- 蚂蚁金服面试分享
|
|
||||||
- 拼多多面试分享
|
|
||||||
- 字节跳动面试分享
|
|
||||||
- 总结
|
|
||||||
|
|
||||||
说起来开始进行面试是年前倒数第二周,上午9点,我还在去公司的公交上,突然收到蚂蚁的面试电话,其实算不上真正的面试。面试官只是和我聊了下他们在做的事情(主要是做双十一这里大促的稳定性保障,偏中间件吧),说的很详细,然后和我沟通了下是否有兴趣,我表示有兴趣,后面就收到正式面试的通知,最后没选择去蚂蚁表示抱歉。
|
|
||||||
|
|
||||||
当时我自己也准备出去看看机会,顺便看看自己的实力。当时我其实挺纠结的,一方面现在部门也正需要我,还是可以有一番作为的,另一方面觉得近一年来进步缓慢,没有以前飞速进步的成就感了,而且业务和技术偏于稳定,加上自己也属于那种比较懒散的人,骨子里还是希望能够突破现状,持续在技术上有所精进。
|
|
||||||
|
|
||||||
在开始正式的总结之前,还是希望各位同仁能否听我继续发泄一会,抱拳!
|
|
||||||
|
|
||||||
我翻开自己2018年初立的flag,觉得甚是惭愧。其中就有一条是保持一周写一篇博客,奈何中间因为各种原因没能坚持下去。细细想来,主要是自己没能真正静下来心认真投入到技术的研究和学习,那么为什么会这样?说白了还是因为没有确定目标或者目标不明确,没有目标或者目标不明确都可能导致行动的失败。
|
|
||||||
|
|
||||||
那么问题来了,目标是啥?就我而言,短期目标是深入研究某一项技术,比如最近在研究mysql,那么深入研究一定要动手实践并且有所产出,这就够了么?还需要我们能够举一反三,结合实际开发场景想一想日常开发要注意什么,这中间有没有什么坑?可以看出,要进步真的不是一件简单的事,这种反人类的行为需要我们克服自我的弱点,逐渐形成习惯。真正牛逼的人,从不觉得认真学习是一件多么难的事,因为这已经形成了他的习惯,就喝早上起床刷牙洗脸那么自然简单。
|
|
||||||
|
|
||||||
扯了那么多,开始进入正题,先后进行了蚂蚁、拼多多和字节跳动的面试。
|
|
||||||
|
|
||||||
## 准备过程
|
|
||||||
|
|
||||||
先说说我自己的情况,我2016先在蚂蚁实习了将近三个月,然后去了我现在的老东家,2.5年工作经验,可以说毕业后就一直老老实实在老东家打怪升级,虽说有蚂蚁的实习经历,但是因为时间太短,还是有点虚的。所以面试官看到我简历第一个问题绝对是这样的。
|
|
||||||
|
|
||||||
“哇,你在蚂蚁待过,不错啊”,面试官笑嘻嘻地问到。“是的,还好”,我说。“为啥才三个月?”,面试官脸色一沉问到。“哗啦啦解释一通。。。”,我解释道。“哦,原来如此,那我们开始面试吧”,面试官一本正经说到。
|
|
||||||
|
|
||||||
尼玛,早知道不写蚂蚁的实习经历了,后面仔细一想,当初写上蚂蚁不就给简历加点料嘛。
|
|
||||||
|
|
||||||
言归正传,准备过程其实很早开始了(当然这不是说我工作时老想着跳槽,因为我明白现在的老东家并不是终点,我还需要不断提升),具体可追溯到从蚂蚁离职的时候,当时出来也面了很多公司,没啥大公司,面了大概5家公司,都拿到offer了。
|
|
||||||
|
|
||||||
工作之余常常会去额外研究自己感兴趣的技术以及工作用到的技术,力求把原理搞明白,并且会自己实践一把。此外,买了N多书,基本有时间就会去看,补补基础,什么操作系统、数据结构与算法、MySQL、JDK之类的源码,基本都好好温习了(文末会列一下自己看过的书和一些好的资料)。**我深知基础就像“木桶效应”的短板,决定了能装多少水。**
|
|
||||||
|
|
||||||
此外,在正式决定看机会之前,我给自己列了一个提纲,主要包括Java要掌握的核心要点,有不懂的就查资料搞懂。我给自己定位还是Java工程师,所以Java体系是一定要做到心中有数的,很多东西没有常年的积累面试的时候很容易露馅,学习要对得起自己,不要骗人。
|
|
||||||
|
|
||||||
剩下的就是找平台和内推了,除了蚂蚁,头条和拼多多都是找人内推的,感谢蚂蚁面试官对我的欣赏,以后说不定会去蚂蚁咯😄。
|
|
||||||
|
|
||||||
平台:脉脉、GitHub、v2
|
|
||||||
|
|
||||||
## 蚂蚁金服
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
- 一面
|
|
||||||
- 二面
|
|
||||||
- 三面
|
|
||||||
- 四面
|
|
||||||
- 五面
|
|
||||||
- 小结
|
|
||||||
|
|
||||||
### 一面
|
|
||||||
|
|
||||||
一面就做了一道算法题,要求两小时内完成,给了长度为N的有重复元素的数组,要求输出第10大的数。典型的TopK问题,快排算法搞定。
|
|
||||||
|
|
||||||
算法题要注意的是合法性校验、边界条件以及异常的处理。另外,如果要写测试用例,一定要保证测试覆盖场景尽可能全。加上平时刷刷算法题,这种考核应该没问题的。
|
|
||||||
|
|
||||||
### 二面
|
|
||||||
|
|
||||||
- 自我介绍下呗
|
|
||||||
- 开源项目贡献过代码么?(Dubbo提过一个打印accesslog的bug算么)
|
|
||||||
- 目前在部门做什么,业务简单介绍下,内部有哪些系统,作用和交互过程说下
|
|
||||||
- Dubbo踩过哪些坑,分别是怎么解决的?(说了异常处理时业务异常捕获的问题,自定义了一个异常拦截器)
|
|
||||||
- 开始进入正题,说下你对线程安全的理解(多线程访问同一个对象,如果不需要考虑额外的同步,调用对象的行为就可以获得正确的结果就是线程安全)
|
|
||||||
- 事务有哪些特性?(ACID)
|
|
||||||
- 怎么理解原子性?(同一个事务下,多个操作要么成功要么失败,不存在部分成功或者部分失败的情况)
|
|
||||||
- 乐观锁和悲观锁的区别?(悲观锁假定会发生冲突,访问的时候都要先获得锁,保证同一个时刻只有线程获得锁,读读也会阻塞;乐观锁假设不会发生冲突,只有在提交操作的时候检查是否有冲突)这两种锁在Java和MySQL分别是怎么实现的?(Java乐观锁通过CAS实现,悲观锁通过synchronize实现。mysql乐观锁通过MVCC,也就是版本实现,悲观锁可以通过select... for update加上排它锁)
|
|
||||||
- HashMap为什么不是线程安全的?(多线程操作无并发控制,顺便说了在扩容的时候多线程访问时会造成死锁,会形成一个环,不过扩容时多线程操作形成环的问题再JDK1.8已经解决,但多线程下使用HashMap还会有一些其他问题比如数据丢失,所以多线程下不应该使用HashMap,而应该使用ConcurrentHashMap)怎么让HashMap变得线程安全?(Collections的synchronize方法包装一个线程安全的Map,或者直接用ConcurrentHashMap)两者的区别是什么?(前者直接在put和get方法加了synchronize同步,后者采用了分段锁以及CAS支持更高的并发)
|
|
||||||
- jdk1.8对ConcurrentHashMap做了哪些优化?(插入的时候如果数组元素使用了红黑树,取消了分段锁设计,synchronize替代了Lock锁)为什么这样优化?(避免冲突严重时链表多长,提高查询效率,时间复杂度从O(N)提高到O(logN))
|
|
||||||
- redis主从机制了解么?怎么实现的?
|
|
||||||
- 有过GC调优的经历么?(有点虚,答得不是很好)
|
|
||||||
- 有什么想问的么?
|
|
||||||
|
|
||||||
### 三面
|
|
||||||
|
|
||||||
- 简单自我介绍下
|
|
||||||
- 监控系统怎么做的,分为哪些模块,模块之间怎么交互的?用的什么数据库?(MySQL)使用什么存储引擎,为什么使用InnnoDB?(支持事务、聚簇索引、MVCC)
|
|
||||||
- 订单表有做拆分么,怎么拆的?(垂直拆分和水平拆分)
|
|
||||||
- 水平拆分后查询过程描述下
|
|
||||||
- 如果落到某个分片的数据很大怎么办?(按照某种规则,比如哈希取模、range,将单张表拆分为多张表)
|
|
||||||
- 哈希取模会有什么问题么?(有的,数据分布不均,扩容缩容相对复杂 )
|
|
||||||
- 分库分表后怎么解决读写压力?(一主多从、多主多从)
|
|
||||||
- 拆分后主键怎么保证惟一?(UUID、Snowflake算法)
|
|
||||||
- Snowflake生成的ID是全局递增唯一么?(不是,只是全局唯一,单机递增)
|
|
||||||
- 怎么实现全局递增的唯一ID?(讲了TDDL的一次取一批ID,然后再本地慢慢分配的做法)
|
|
||||||
- Mysql的索引结构说下(说了B+树,B+树可以对叶子结点顺序查找,因为叶子结点存放了数据结点且有序)
|
|
||||||
- 主键索引和普通索引的区别(主键索引的叶子结点存放了整行记录,普通索引的叶子结点存放了主键ID,查询的时候需要做一次回表查询)一定要回表查询么?(不一定,当查询的字段刚好是索引的字段或者索引的一部分,就可以不用回表,这也是索引覆盖的原理)
|
|
||||||
- 你们系统目前的瓶颈在哪里?
|
|
||||||
- 你打算怎么优化?简要说下你的优化思路
|
|
||||||
- 有什么想问我么?
|
|
||||||
|
|
||||||
### 四面
|
|
||||||
|
|
||||||
- 介绍下自己
|
|
||||||
- 为什么要做逆向?
|
|
||||||
- 怎么理解微服务?
|
|
||||||
- 服务治理怎么实现的?(说了限流、压测、监控等模块的实现)
|
|
||||||
- 这个不是中间件做的事么,为什么你们部门做?(当时没有单独的中间件团队,微服务刚搞不久,需要进行监控和性能优化)
|
|
||||||
- 说说Spring的生命周期吧
|
|
||||||
- 说说GC的过程(说了young gc和full gc的触发条件和回收过程以及对象创建的过程)
|
|
||||||
- CMS GC有什么问题?(并发清除算法,浮动垃圾,短暂停顿)
|
|
||||||
- 怎么避免产生浮动垃圾?(记得有个VM参数设置可以让扫描新生代之前进行一次young gc,但是因为gc是虚拟机自动调度的,所以不保证一定执行。但是还有参数可以让虚拟机强制执行一次young gc)
|
|
||||||
- 强制young gc会有什么问题?(STW停顿时间变长)
|
|
||||||
- 知道G1么?(了解一点 )
|
|
||||||
- 回收过程是怎么样的?(young gc、并发阶段、混合阶段、full gc,说了Remember Set)
|
|
||||||
- 你提到的Remember Set底层是怎么实现的?
|
|
||||||
- 有什么想问的么?
|
|
||||||
|
|
||||||
### 五面
|
|
||||||
|
|
||||||
五面是HRBP面的,和我提前预约了时间,主要聊了之前在蚂蚁的实习经历、部门在做的事情、职业发展、福利待遇等。阿里面试官确实是具有一票否决权的,很看重你的价值观是否match,一般都比较喜欢皮实的候选人。HR面一定要诚实,不要说谎,只要你说谎HR都会去证实,直接cut了。
|
|
||||||
|
|
||||||
- 之前蚂蚁实习三个月怎么不留下来?
|
|
||||||
- 实习的时候主管是谁?
|
|
||||||
- 实习做了哪些事情?(尼玛这种也问?)
|
|
||||||
- 你对技术怎么看?平时使用什么技术栈?(阿里HR真的是既当爹又当妈,😂)
|
|
||||||
- 最近有在研究什么东西么
|
|
||||||
- 你对SRE怎么看
|
|
||||||
- 对待遇有什么预期么
|
|
||||||
|
|
||||||
最后HR还对我说目前稳定性保障部挺缺人的,希望我尽快回复。
|
|
||||||
|
|
||||||
### 小结
|
|
||||||
|
|
||||||
蚂蚁面试比较重视基础,所以Java那些基本功一定要扎实。蚂蚁的工作环境还是挺赞的,因为我面的是稳定性保障部门,还有许多单独的小组,什么三年1班,很有青春的感觉。面试官基本水平都比较高,基本都P7以上,除了基础还问了不少架构设计方面的问题,收获还是挺大的。
|
|
||||||
|
|
||||||
## 拼多多
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
- 面试前
|
|
||||||
- 一面
|
|
||||||
- 二面
|
|
||||||
- 三面
|
|
||||||
- 小结
|
|
||||||
|
|
||||||
### 面试前
|
|
||||||
|
|
||||||
面完蚂蚁后,早就听闻拼多多这个独角兽,决定也去面一把。首先我在脉脉找了一个拼多多的HR,加了微信聊了下,发了简历便开始我的拼多多面试之旅。这里要非常感谢拼多多HR小姐姐,从面试内推到offer确认一直都在帮我,人真的很nice。
|
|
||||||
|
|
||||||
### 一面
|
|
||||||
|
|
||||||
- 为啥蚂蚁只待了三个月?没转正?(转正了,解释了一通。。。)
|
|
||||||
- Java中的HashMap、TreeMap解释下?(TreeMap红黑树,有序,HashMap无序,数组+链表)
|
|
||||||
- TreeMap查询写入的时间复杂度多少?(O(logN))
|
|
||||||
- HashMap多线程有什么问题?(线程安全,死锁)怎么解决?( jdk1.8用了synchronize + CAS,扩容的时候通过CAS检查是否有修改,是则重试)重试会有什么问题么?(CAS(Compare And Swap)是比较和交换,不会导致线程阻塞,但是因为重试是通过自旋实现的,所以仍然会占用CPU时间,还有ABA的问题)怎么解决?(超时,限定自旋的次数,ABA可以通过原理变量AtomicStampedReference解决,原理利用版本号进行比较)超过重试次数如果仍然失败怎么办?(synchronize互斥锁)
|
|
||||||
- CAS和synchronize有什么区别?都用synchronize不行么?(CAS是乐观锁,不需要阻塞,硬件级别实现的原子性;synchronize会阻塞,JVM级别实现的原子性。使用场景不同,线程冲突严重时CAS会造成CPU压力过大,导致吞吐量下降,synchronize的原理是先自旋然后阻塞,线程冲突严重仍然有较高的吞吐量,因为线程都被阻塞了,不会占用CPU
|
|
||||||
)
|
|
||||||
- 如果要保证线程安全怎么办?(ConcurrentHashMap)
|
|
||||||
- ConcurrentHashMap怎么实现线程安全的?(分段锁)
|
|
||||||
- get需要加锁么,为什么?(不用,volatile关键字)
|
|
||||||
- volatile的作用是什么?(保证内存可见性)
|
|
||||||
- 底层怎么实现的?(说了主内存和工作内存,读写内存屏障,happen-before,并在纸上画了线程交互图)
|
|
||||||
- 在多核CPU下,可见性怎么保证?(思考了一会,总线嗅探技术)
|
|
||||||
- 聊项目,系统之间是怎么交互的?
|
|
||||||
- 系统并发多少,怎么优化?
|
|
||||||
- 给我一张纸,画了一个九方格,都填了数字,给一个M*N矩阵,从1开始逆时针打印这M*N个数,要求时间复杂度尽可能低(内心OS:之前貌似碰到过这题,最优解是怎么实现来着)思考中。。。
|
|
||||||
- 可以先说下你的思路(想起来了,说了什么时候要变换方向的条件,向右、向下、向左、向上,依此循环)
|
|
||||||
- 有什么想问我的?
|
|
||||||
|
|
||||||
### 二面
|
|
||||||
|
|
||||||
- 自我介绍下
|
|
||||||
- 手上还有其他offer么?(拿了蚂蚁的offer)
|
|
||||||
- 部门组织结构是怎样的?(这轮不是技术面么,不过还是老老实实说了)
|
|
||||||
- 系统有哪些模块,每个模块用了哪些技术,数据怎么流转的?(面试官有点秃顶,一看级别就很高)给了我一张纸,我在上面简单画了下系统之间的流转情况
|
|
||||||
- 链路追踪的信息是怎么传递的?(RpcContext的attachment,说了Span的结构:parentSpanId + curSpanId)
|
|
||||||
- SpanId怎么保证唯一性?(UUID,说了下内部的定制改动)
|
|
||||||
- RpcContext是在什么维度传递的?(线程)
|
|
||||||
- Dubbo的远程调用怎么实现的?(讲了读取配置、拼装url、创建Invoker、服务导出、服务注册以及消费者通过动态代理、filter、获取Invoker列表、负载均衡等过程(哗啦啦讲了10多分钟),我可以喝口水么)
|
|
||||||
- Spring的单例是怎么实现的?(单例注册表)
|
|
||||||
- 为什么要单独实现一个服务治理框架?(说了下内部刚搞微服务不久,主要对服务进行一些监控和性能优化)
|
|
||||||
- 谁主导的?内部还在使用么?
|
|
||||||
- 逆向有想过怎么做成通用么?
|
|
||||||
- 有什么想问的么?
|
|
||||||
|
|
||||||
### 三面
|
|
||||||
|
|
||||||
二面老大面完后就直接HR面了,主要问了些职业发展、是否有其他offer、以及入职意向等问题,顺便说了下公司的福利待遇等,都比较常规啦。不过要说的是手上有其他offer或者大厂经历会有一定加分。
|
|
||||||
|
|
||||||
### 小结
|
|
||||||
|
|
||||||
拼多多的面试流程就简单许多,毕竟是一个成立三年多的公司。面试难度中规中矩,只要基础扎实应该不是问题。但不得不说工作强度很大,开始面试前HR就提前和我确认能否接受这样强度的工作,想来的老铁还是要做好准备
|
|
||||||
|
|
||||||
## 字节跳动
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
- 面试前
|
|
||||||
- 一面
|
|
||||||
- 二面
|
|
||||||
- 小结
|
|
||||||
|
|
||||||
### 面试前
|
|
||||||
|
|
||||||
头条的面试是三家里最专业的,每次面试前有专门的HR和你约时间,确定OK后再进行面试。每次都是通过视频面试,因为都是之前都是电话面或现场面,所以视频面试还是有点不自然。也有人觉得视频面试体验很赞,当然萝卜青菜各有所爱。最坑的二面的时候对方面试官的网络老是掉线,最后很冤枉的挂了(当然有一些点答得不好也是原因之一)。所以还是有点遗憾的。
|
|
||||||
|
|
||||||
### 一面
|
|
||||||
|
|
||||||
- 先自我介绍下
|
|
||||||
- 聊项目,逆向系统是什么意思
|
|
||||||
- 聊项目,逆向系统用了哪些技术
|
|
||||||
- 线程池的线程数怎么确定?
|
|
||||||
- 如果是IO操作为主怎么确定?
|
|
||||||
- 如果计算型操作又怎么确定?
|
|
||||||
- Redis熟悉么,了解哪些数据结构?(说了zset) zset底层怎么实现的?(跳表)
|
|
||||||
- 跳表的查询过程是怎么样的,查询和插入的时间复杂度?(说了先从第一层查找,不满足就下沉到第二层找,因为每一层都是有序的,写入和插入的时间复杂度都是O(logN))
|
|
||||||
- 红黑树了解么,时间复杂度?(说了是N叉平衡树,O(logN))
|
|
||||||
- 既然两个数据结构时间复杂度都是O(logN),zset为什么不用红黑树(跳表实现简单,踩坑成本低,红黑树每次插入都要通过旋转以维持平衡,实现复杂)
|
|
||||||
- 点了点头,说下Dubbo的原理?(说了服务注册与发布以及消费者调用的过程)踩过什么坑没有?(说了dubbo异常处理的和打印accesslog的问题)
|
|
||||||
- CAS了解么?(说了CAS的实现)还了解其他同步机制么?(说了synchronize以及两者的区别,一个乐观锁,一个悲观锁)
|
|
||||||
- 那我们做一道题吧,数组A,2*n个元素,n个奇数、n个偶数,设计一个算法,使得数组奇数下标位置放置的都是奇数,偶数下标位置放置的都是偶数
|
|
||||||
- 先说下你的思路(从0下标开始遍历,如果是奇数下标判断该元素是否奇数,是则跳过,否则从该位置寻找下一个奇数)
|
|
||||||
- 下一个奇数?怎么找?(有点懵逼,思考中。。)
|
|
||||||
- 有思路么?(仍然是先遍历一次数组,并对下标进行判断,如果下标属性和该位置元素不匹配从当前下标的下一个遍历数组元素,然后替换)
|
|
||||||
- 你这样时间复杂度有点高,如果要求O(N)要怎么做(思考一会,答道“定义两个指针,分别从下标0和1开始遍历,遇见奇数位是是偶数和偶数位是奇数就停下,交换内容”)
|
|
||||||
- 时间差不多了,先到这吧。你有什么想问我的?
|
|
||||||
|
|
||||||
### 二面
|
|
||||||
|
|
||||||
- 面试官和蔼很多,你先介绍下自己吧
|
|
||||||
- 你对服务治理怎么理解的?
|
|
||||||
- 项目中的限流怎么实现的?(Guava ratelimiter,令牌桶算法)
|
|
||||||
- 具体怎么实现的?(要点是固定速率且令牌数有限)
|
|
||||||
- 如果突然很多线程同时请求令牌,有什么问题?(导致很多请求积压,线程阻塞)
|
|
||||||
- 怎么解决呢?(可以把积压的请求放到消息队列,然后异步处理)
|
|
||||||
- 如果不用消息队列怎么解决?(说了RateLimiter预消费的策略)
|
|
||||||
- 分布式追踪的上下文是怎么存储和传递的?(ThreadLocal + spanId,当前节点的spanId作为下个节点的父spanId)
|
|
||||||
- Dubbo的RpcContext是怎么传递的?(ThreadLocal)主线程的ThreadLocal怎么传递到线程池?(说了先在主线程通过ThreadLocal的get方法拿到上下文信息,在线程池创建新的ThreadLocal并把之前获取的上下文信息设置到ThreadLocal中。这里要注意的线程池创建的ThreadLocal要在finally中手动remove,不然会有内存泄漏的问题)
|
|
||||||
- 你说的内存泄漏具体是怎么产生的?(说了ThreadLocal的结构,主要分两种场景:主线程仍然对ThreadLocal有引用和主线程不存在对ThreadLocal的引用。第一种场景因为主线程仍然在运行,所以还是有对ThreadLocal的引用,那么ThreadLocal变量的引用和value是不会被回收的。第二种场景虽然主线程不存在对ThreadLocal的引用,且该引用是弱引用,所以会在gc的时候被回收,但是对用的value不是弱引用,不会被内存回收,仍然会造成内存泄漏)
|
|
||||||
- 线程池的线程是不是必须手动remove才可以回收value?(是的,因为线程池的核心线程是一直存在的,如果不清理,那么核心线程的threadLocals变量会一直持有ThreadLocal变量)
|
|
||||||
- 那你说的内存泄漏是指主线程还是线程池?(主线程 )
|
|
||||||
- 可是主线程不是都退出了,引用的对象不应该会主动回收么?(面试官和内存泄漏杠上了),沉默了一会。。。
|
|
||||||
- 那你说下SpringMVC不同用户登录的信息怎么保证线程安全的?(刚才解释的有点懵逼,一下没反应过来,居然回答成锁了。大脑有点晕了,此时已经一个小时过去了,感觉情况不妙。。。)
|
|
||||||
- 这个直接用ThreadLocal不就可以么,你见过SpringMVC有锁实现的代码么?(有点晕菜。。。)
|
|
||||||
- 我们聊聊mysql吧,说下索引结构(说了B+树)
|
|
||||||
- 为什么使用B+树?( 说了查询效率高,O(logN),可以充分利用磁盘预读的特性,多叉树,深度小,叶子结点有序且存储数据)
|
|
||||||
- 什么是索引覆盖?(忘记了。。。 )
|
|
||||||
- Java为什么要设计双亲委派模型?
|
|
||||||
- 什么时候需要自定义类加载器?
|
|
||||||
- 我们做一道题吧,手写一个对象池
|
|
||||||
- 有什么想问我的么?(感觉我很多点都没答好,是不是挂了(结果真的是) )
|
|
||||||
|
|
||||||
### 小结
|
|
||||||
|
|
||||||
头条的面试确实很专业,每次面试官会提前给你发一个视频链接,然后准点开始面试,而且考察的点都比较全。
|
|
||||||
|
|
||||||
面试官都有一个特点,会抓住一个值得深入的点或者你没说清楚的点深入下去直到你把这个点讲清楚,不然面试官会觉得你并没有真正理解。二面面试官给了我一点建议,研究技术的时候一定要去研究产生的背景,弄明白在什么场景解决什么特定的问题,其实很多技术内部都是相通的。很诚恳,还是很感谢这位面试官大大。
|
|
||||||
|
|
||||||
## 总结
|
|
||||||
|
|
||||||
从年前开始面试到头条面完大概一个多月的时间,真的有点身心俱疲的感觉。最后拿到了拼多多、蚂蚁的offer,还是蛮幸运的。头条的面试对我帮助很大,再次感谢面试官对我的诚恳建议,以及拼多多的HR对我的啰嗦的问题详细解答。
|
|
||||||
|
|
||||||
这里要说的是面试前要做好两件事:简历和自我介绍,简历要好好回顾下自己做的一些项目,然后挑几个亮点项目。自我介绍基本每轮面试都有,所以最好提前自己练习下,想好要讲哪些东西,分别怎么讲。此外,简历提到的技术一定是自己深入研究过的,没有深入研究也最好找点资料预热下,不打无准备的仗。
|
|
||||||
|
|
||||||
**这些年看过的书**:
|
|
||||||
|
|
||||||
《Effective Java》、《现代操作系统》、《TCP/IP详解:卷一》、《代码整洁之道》、《重构》、《Java程序性能优化》、《Spring实战》、《Zookeeper》、《高性能MySQL》、《亿级网站架构核心技术》、《可伸缩服务架构》、《Java编程思想》
|
|
||||||
|
|
||||||
说实话这些书很多只看了一部分,我通常会带着问题看书,不然看着看着就睡着了,简直是催眠良药😅。
|
|
||||||
|
|
||||||
|
|
||||||
最后,附一张自己面试前准备的脑图:
|
|
||||||
|
|
||||||
链接:https://pan.baidu.com/s/1o2l1tuRakBEP0InKEh4Hzw 密码:300d
|
|
||||||
|
|
||||||
全文完。
|
|
||||||
@ -1,61 +0,0 @@
|
|||||||
|
|
||||||
|
|
||||||
> 本文来自读者 Boyn 投稿!恭喜这位粉丝拿到了含金量极高的字节跳动实习 offer!赞!
|
|
||||||
|
|
||||||
## 基本条件
|
|
||||||
|
|
||||||
本人是底层 211 本科,现在大三,无科研经历,但是有一些项目经历,在国内监控行业某头部企业做过一段时间的实习。想着投一下字节,可以积累一下面试经验和为春招做准备.投了简历之后,过了一段时间,HR 就打电话跟我约时间,在年后进行远程面。
|
|
||||||
|
|
||||||
说明一下,我投的是北京 office。
|
|
||||||
|
|
||||||
## 一面
|
|
||||||
|
|
||||||
面试官很和蔼,由于疫情的原因,大家都在家里面进行远程面试
|
|
||||||
|
|
||||||
开头没有自我介绍,直接开始问项目了,问了比如
|
|
||||||
|
|
||||||
- 常用的 Web 组件有哪些(回答了自己经常用到的 SpringBoot,Redis,Mysql 等等,字节这边基本没有用 Java 的后台,所以感觉面试官不大会问 Spring,Java 这些东西,反倒是对数据库和中间件比较感兴趣)
|
|
||||||
- Kafka 相关,如何保证不会重复消费,Kafka 消费组结构等等(这个只是凭着感觉和面试官说了,因为 Kafka 自己确实准备得不充分,但是心态稳住了)
|
|
||||||
- **Mysql 索引,B+树(必考嗷同学们)**
|
|
||||||
|
|
||||||
还有一些项目中的细节,这些因人而异,就不放上来了,提示一点就是要在项目中介绍一些亮眼的地方,比如用了什么牛逼的数据结构,架构上有什么特点,并发量大小还有怎么去 hold 住并发量
|
|
||||||
|
|
||||||
后面就是算法题了,一共做了两道
|
|
||||||
|
|
||||||
1. 判断平衡二叉树(这道题总体来说并不难,但是面试官在中间穿插了垃圾回收的知识,这就很难受了,具体的就是大家要判断一下对象在什么时候会回收,可达性分析什么时候对这个对象来说是不可达的,还有在递归函数中内存如何变化,这个是让我们来对这个函数进行执行过程的建模,只看栈帧大小变化的话,应该有是两个峰值,中间会有抖动的情况)
|
|
||||||
2. 二分查找法的变种题,给定`target`和一个升序的数组,寻找下一个比数组大的数.这道题也不难,靠大家对二分查找法的熟悉程度,当然,这边还有一个优化的点,可以看看[我的博客](https://boyn.top/2019/11/09/%E7%AE%97%E6%B3%95%E4%B8%8E%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3%E4%BA%8C%E5%88%86%E6%9F%A5%E6%89%BE%E6%B3%95/)找找灵感
|
|
||||||
|
|
||||||
完成了之后,面试官让我等一会有二面,大概 10 分钟左右吧,休息了一会就继续了
|
|
||||||
|
|
||||||
## 二面
|
|
||||||
|
|
||||||
二面一上来就是先让我自我介绍,当然还是同样的套路,同样的香脆
|
|
||||||
|
|
||||||
然后问了我一些关于 Redis 的问题,比如 **zset 的实现(跳表,这个高频)** ,键的过期策略,持久化等等,这些在大多数 Redis 的介绍中都可以找到,就不细说了
|
|
||||||
|
|
||||||
还有一些数据结构的问题,比如说问了哈希表是什么,给面试官详细说了一下`java.util.HashMap`是怎么实现(当然里面就穿插着红黑树了,多看看红黑树是有什么特点之类的)的,包括说为什么要用链地址法来避免冲突,探测法有哪些,链地址法和探测法的优劣对比
|
|
||||||
|
|
||||||
后面还跟我讨论了很久的项目,所以说大家的项目一定要做好,要有亮点的地方,在这里跟面试官讨论了很多项目优化的地方,还有什么不足,还有什么地方可以新增功能等等,同样不细说了
|
|
||||||
|
|
||||||
一边讨论的时候劈里啪啦敲了很多,应该是对个人的面试评价一类的
|
|
||||||
|
|
||||||
后面就是字节的传统艺能手撕算法了,一共做了三道
|
|
||||||
|
|
||||||
- 一二道是连在一起的.给定一个规则`S_0 = {1} S_1={1,2,1} S_2 = {1,2,1,3,1,2,1} S_n = {S_n-1 , n + 1, S_n-1}`.第一个问题是他们的个数有什么关系(1 3 7 15... 2 的 n 次方-1,用位运算解决).第二个问题是给定数组个数下标 n 和索引 k,让我们求出 S_n(k)所指的数,假如`S_2(2) = 1`,我在做的时候没有什么好的思路,如果有的话大家可以分享一下
|
|
||||||
- 第三道是下一个排列:[https://leetcode-cn.com/problems/next-permutation](https://leetcode-cn.com/problems/next-permutation) 的题型,不过做了一些修改,数组大小`10000<n<100000`,不能用暴力法,还有数字是在 1-9 之间会有重复
|
|
||||||
|
|
||||||
## hr 面
|
|
||||||
|
|
||||||
一些偏职业规划的话题了,实习时间,项目经历,实习经历这些。
|
|
||||||
|
|
||||||
## 总结
|
|
||||||
|
|
||||||
基础很重要!这次准备到的 Redis,Mysql,JVM 原理等等都有问到了,(网络这一块没问,但是也是要好好准备的,对于后台来说,网络知识不仅仅是面试,还是以后工作的知识基础).当然自己也有准备不足的地方,比如 Kafka 等中间件,只会用不会原理是万万不行的.并且这些基础知识不能只靠背,面试官还会融合在项目里面进行串问
|
|
||||||
|
|
||||||
问到了不会的不要慌,因为面试官是在试探你的技术深度,有可能会针对某一个问题,问到你不会为止,所以你出现不会的问题是很正常的,心态把控住就行.
|
|
||||||
|
|
||||||
无论是做题,还是回答问题的时候,牢记你不是在考试,而是在交流,和面试官有互动和沟通是很重要的,你说的一些疏漏的地方,如果你及时跟面试官反馈,还是可以补救一下的
|
|
||||||
|
|
||||||
最重要的一点字节的面试就是算法一定要牢固,每一轮都会有手撕算法的,这个不用想,LeetCode+剑指 Offer 走起来就对了,心态很重要,算法题不一定都是你会的,要有一定的心理准备,遇到难题可以先冷静分析一波.而且写出`Bug free`的代码也是很重要的,我前面的几题算法因为在牛客网上进行面试,所以要运行出来.
|
|
||||||
|
|
||||||
最后祝大家在春招取得好的 Offer,_奥力给_!
|
|
||||||
@ -1,96 +0,0 @@
|
|||||||
> 作者:ppxyn。本文来自读者投稿,同时也欢迎各位投稿,**对于不错的原创文章我根据你的选择给予现金(50-200)、付费专栏或者任选书籍进行奖励!所以,快提 pr 或者邮件的方式(邮件地址在主页)给我投稿吧!** 当然,我觉得奖励是次要的,最重要的是你可以从自己整理知识点的过程中学习到很多知识。
|
|
||||||
|
|
||||||
**目录**
|
|
||||||
|
|
||||||
<!-- MarkdownTOC -->
|
|
||||||
|
|
||||||
- [前言](#前言)
|
|
||||||
- [一面\(技术面\)](#一面技术面)
|
|
||||||
- [二面\(技术面\)](#二面技术面)
|
|
||||||
- [三面\(技术面\)](#三面技术面)
|
|
||||||
- [四面\(半个技术面\)](#四面半个技术面)
|
|
||||||
- [五面\(HR面\)](#五面hr面)
|
|
||||||
- [总结](#总结)
|
|
||||||
|
|
||||||
<!-- /MarkdownTOC -->
|
|
||||||
|
|
||||||
### 前言
|
|
||||||
|
|
||||||
在接触 Java 之前我接触的比较多的是硬件方面,用的比较多的语言就是C和C++。到了大三我才正式选择 Java 方向,到目前为止使用Java到现在大概有一年多的时间,所以Java算不上很好。刚开始投递的时候,实习刚辞职,也没准备笔试面试,很多东西都忘记了。所以,刚开始我并没有直接就投递阿里,毕竟心里还是有一点点小害怕的。于是,我就先投递了几个不算大的公司来练手,就是想着刷刷经验而已或者说是练练手(ps:还是挺对不起那些公司的)。面了一个月其他公司后,我找了我实验室的学长内推我,后面就有了这5次面试。
|
|
||||||
|
|
||||||
下面简单的说一下我的这5次面试:4次技术面+1次HR面,希望我的经历能对你有所帮助。
|
|
||||||
|
|
||||||
### 一面(技术面)
|
|
||||||
|
|
||||||
1. 自我介绍(主要讲自己会的技术细节,项目经验,经历那些就一语带过,后面面试官会问你的)。
|
|
||||||
2. 聊聊项目(就是一个很普通的分布式商城,自己做了一些改进),让我画了整个项目的架构图,然后针对项目抛了一系列的提高性能的问题,还问了我做项目的过程中遇到了那些问题,如何解决的,差不读就这些吧。
|
|
||||||
3. 可能是我前面说了我会数据库优化,然后面试官就开始问索引、事务隔离级别、悲观锁和乐观锁、索引、ACID、MVVC这些问题。
|
|
||||||
4. 浏览器输入URL发生了什么? TCP和UDP区别? TCP如何保证传输可靠性?
|
|
||||||
5. 讲下跳表怎么实现的?哈夫曼编码是怎么回事?非递归且不用额外空间(不用栈),如何遍历二叉树
|
|
||||||
6. 后面又问了很多JVM方面的问题,比如Java内存模型、常见的垃圾回收器、双亲委派模型这些
|
|
||||||
7. 你有什么问题要问吗?
|
|
||||||
|
|
||||||
### 二面(技术面)
|
|
||||||
|
|
||||||
1. 自我介绍(主要讲自己会的技术细节,项目经验,经历那些就一语带过,后面面试官会问你的)。
|
|
||||||
2. 操作系统的内存管理机制
|
|
||||||
3. 进程和线程的区别
|
|
||||||
4. 说下你对线程安全的理解
|
|
||||||
5. volatile 有什么作用 ,sychronized和lock有什么区别
|
|
||||||
6. ReentrantLock实现原理
|
|
||||||
7. 用过CountDownLatch么?什么场景下用的?
|
|
||||||
8. AQS底层原理。
|
|
||||||
9. 造成死锁的原因有哪些,如何预防?
|
|
||||||
10. 加锁会带来哪些性能问题。如何解决?
|
|
||||||
11. HashMap、ConcurrentHashMap源码。HashMap是线程安全的吗?Hashtable呢?ConcurrentHashMap有了解吗?
|
|
||||||
12. 是否可以实习?
|
|
||||||
13. 你有什么问题要问吗?
|
|
||||||
|
|
||||||
### 三面(技术面)
|
|
||||||
|
|
||||||
1. 有没有参加过 ACM 或者他竞赛,有没有拿过什么奖?( 我说我没参加过ACM,本科参加过数学建模竞赛,名次并不好,没拿过什么奖。面试官好像有点失望,然后我又赶紧补充说我和老师一起做过一个项目,目前已经投入使用。面试官还比较感兴趣,后面又和他聊了一下这个项目。)
|
|
||||||
2. 研究生期间,做过什么项目,发过论文吗?有什么成果吗?
|
|
||||||
3. 你觉得你有什么优点和缺点?你觉得你相比于那些比你更优秀的人欠缺什么?
|
|
||||||
4. 有读过什么源码吗?(我说我读过 Java 集合框架和 Netty 的,面试官说 Java 集合前几面一定问的差不多,就不问了,然后就问我 Netty的,我当时很慌啊!)
|
|
||||||
5. 介绍一下自己对 Netty 的认识,为什么要用。说说业务中,Netty 的使用场景。什么是TCP 粘包/拆包,解决办法。Netty线程模型。Dubbo 在使用 Netty 作为网络通讯时候是如何避免粘包与半包问题?讲讲Netty的零拷贝?巴拉巴拉问了好多,我记得有好几个我都没回答上来,心里想着凉凉了啊。
|
|
||||||
6. 用到了那些开源技术、在开源领域做过贡献吗?
|
|
||||||
7. 常见的排序算法及其复杂度,现场写了快排。
|
|
||||||
8. 红黑树,B树的一些问题。
|
|
||||||
9. 讲讲算法及数据结构在实习项目中的用处。
|
|
||||||
10. 自己的未来规划(就简单描述了一下自己未来的设想啊,说的还挺诚恳,面试官好像还挺满意的)
|
|
||||||
11. 你有什么问题要问吗?
|
|
||||||
|
|
||||||
### 四面(半个技术面)
|
|
||||||
|
|
||||||
三面面完当天,晚上9点接到面试电话,感觉像是部门或者项目主管。 这个和之前的面试不大相同,感觉面试官主要考察的是你解决问题的能力、学习能力和团队协作能力。
|
|
||||||
|
|
||||||
1. 让我讲一个自己觉得最不错的项目。然后就巴拉巴拉的聊,我记得主要是问了项目是如何进行协作的、遇到问题是如何解决的、与他人发生冲突是如何解决的这些。感觉聊了挺久。
|
|
||||||
2. 出现 OOM 后你会怎么排查问题?
|
|
||||||
3. 自己平时是如何学习新技术的?除了 Java 还回去了解其他技术吗?
|
|
||||||
4. 上一段实习经历的收获。
|
|
||||||
5. NginX如何做负载均衡、常见的负载均衡算法有哪些、一致性哈希的一致性是什么意思、一致性哈希是如何做哈希的
|
|
||||||
6. 你有什么问题问我吗?
|
|
||||||
7. 还有一些其他的,想不起来了,感觉这一面不是偏向技术来问。
|
|
||||||
|
|
||||||
## 五面(HR面)
|
|
||||||
|
|
||||||
1. 自我介绍(主要讲能突出自己的经历,会的编程技术一语带过)。
|
|
||||||
2. 你觉得你有什么优点和缺点?如何克服这些缺点?
|
|
||||||
3. 说一件大学里你自己比较有成就感的一件事情,为此付出了那些努力。
|
|
||||||
4. 你前面跟其他面试官讲过一些你做的项目吧?可以给我讲讲吗?你要考虑到我不是一个做技术的人,怎么让我也听得懂。项目中有什么问题,你怎么解决的?你最大的收获是什么?
|
|
||||||
5. 你目前有面试过其他公司吗?如果让你选,这些公司和阿里,你选哪个?(送分题,回答不好可能送命)
|
|
||||||
6. 你期望的工作地点是哪里?
|
|
||||||
7. 你有什么问题吗?
|
|
||||||
|
|
||||||
### 总结
|
|
||||||
|
|
||||||
1. 可以看出面试官问我的很多问题都是比较常见的问题,所以记得一定要提前准备,还要深入准备,不要回答的太皮毛。很多时候一个问题可能会牵扯出很多问题,遇到不会的问题不要慌,冷静分析,如果你真的回答不上来,也不要担心自己是不是就要挂了,很可能这个问题本身就比较难。
|
|
||||||
2. 表达能力和沟通能力太重要了,一定要提前练一下,我自身就是一个不太会说话的人,所以,面试前我对于自我介绍、项目介绍和一些常见问题都在脑子里练了好久,确保面试的时候能够很清晰和简洁的说出来。
|
|
||||||
3. 等待面试的过程和面试的过程真的好熬人,那段时间我压力也比较大,好在我私下找到学长聊了很多,心情也好了很多。
|
|
||||||
4. 面试之后及时总结,面的好的话,不要得意,尽快准备下一场面试吧!
|
|
||||||
|
|
||||||
我觉得我还算是比较幸运的,最后也祝大家都能获得心仪的Offer。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
@ -1,125 +0,0 @@
|
|||||||
> 本文是鄙人薛某这位老哥的投稿,虽然面试最后挂了,但是老哥本身还是挺优秀的,而且通过这次面试学到了很多东西,我想这就足够了!加油!不要畏惧面试失败,好好修炼自己,多准备一下,后面一定会找到让自己满意的工作。
|
|
||||||
>
|
|
||||||
|
|
||||||
## 背景
|
|
||||||
|
|
||||||
前段时间家里出了点事,辞职回家待了一段时间,处理完老家的事情后就回到广州这边继续找工作,大概是国庆前几天我去面试了一家叫做Bigo(YY的子公司),面试的职位是面向3-5年的Java开发,最终自己倒在了第三轮的技术面上。虽然有些遗憾和泄气,但想着还是写篇博客来记录一下自己的面试过程好了,也算是对广大程序员同胞们的分享,希望对你们以后的学习和面试能有所帮助。
|
|
||||||
|
|
||||||
## 个人情况
|
|
||||||
|
|
||||||
先说下LZ的个人情况。
|
|
||||||
|
|
||||||
17年毕业,二本,目前位于广州,是一个非常普通的Java开发程序员,算起来有两年多的开发经验。
|
|
||||||
|
|
||||||
其实这个阶段有点尴尬,高不成低不就,比初级程序员稍微好点,但也达不到高级的程度。加上现如今IT行业接近饱和,很多岗位都是要求至少3-5年以上开发经验,所以对于两年左右开发经验的需求其实是比较小的,这点在LZ找工作的过程中深有体会。最可悲的是,今年的大环境不好,很多公司不断的在裁员,更别说招人了,残酷的形势对于求职者来说更是雪上加霜,相信很多求职的同学也有所体会。所以,不到万不得已的情况下,建议不要裸辞!
|
|
||||||
|
|
||||||
## Bigo面试
|
|
||||||
|
|
||||||
面试岗位:Java后台开发
|
|
||||||
|
|
||||||
经验要求:3-5年
|
|
||||||
|
|
||||||
由于是国庆前去面试Bigo的,到现在也有一个多月的时间了,虽然仍有印象,但也有不少面试题忘了,所以我只能尽量按照自己的回忆来描述面试的过程,不明白之处还请见谅!
|
|
||||||
|
|
||||||
### 一面(微信电话面)
|
|
||||||
|
|
||||||
bigo的第一面是微信电话面试,本来是想直接电话面,但面试官说需要手写算法题,就改成微信电话面。
|
|
||||||
|
|
||||||
- 自我介绍
|
|
||||||
- 先了解一下Java基础吧,什么是内存泄漏和内存溢出?(溢出是指创建太多对象导致内存空间不足,泄漏是无用对象没有回收)
|
|
||||||
- JVM怎么判断对象是无用对象?(根搜索算法,从GC Root出发,对象没有引用,就判定为无用对象)
|
|
||||||
- 根搜索算法中的根节点可以是哪些对象?(类对象,虚拟机栈的对象,常量引用的对象)
|
|
||||||
- 重载和重写的区别?(重载发生在同个类,方法名相同,参数列表不同;重写是父子类之间的行为,方法名好参数列表都相同,方法体内的程序不同)
|
|
||||||
- 重写有什么限制没有?
|
|
||||||
- Java有哪些同步工具?(synchronized和Lock)
|
|
||||||
- 这两者有什么区别?
|
|
||||||
- ArrayList和LinkedList的区别?(ArrayList基于数组,搜索快,增删元素慢,LinkedList基于链表,增删快,搜索因为要遍历元素所以效率低)
|
|
||||||
- 这两种集合哪个比较占内存?(看情况的,ArrayList如果有扩容并且元素没占满数组的话,浪费的内存空间也是比较多的,但一般情况下,LinkedList占用的内存会相对多点,因为每个元素都包含了指向前后节点的指针)
|
|
||||||
- 说一下HashMap的底层结构(数组 + 链表,链表过长变成红黑树)
|
|
||||||
- HashMap为什么线程不安全,1.7版本之前HashMap有什么问题(扩容时多线程操作可能会导致链表成环的出现,然后调用get方法会死循环)
|
|
||||||
- 了解ConcurrentHashMap吗?说一下它为什么能线程安全(用了分段锁)
|
|
||||||
- 哪些方法需要锁住整个集合的?(读取size的时候)
|
|
||||||
- 看你简历写着你了解RPC啊,那你说下RPC的整个过程?(从客户端发起请求,到socket传输,然后服务端处理消息,以及怎么序列化之类的都大概讲了一下)
|
|
||||||
- 服务端获取客户端要调用的接口信息后,怎么找到对应的实现类的?(反射 + 注解吧,这里也不是很懂)
|
|
||||||
- dubbo的负载均衡有几种算法?(随机,轮询,最少活跃请求数,一致性hash)
|
|
||||||
- 你说的最少活跃数算法是怎么回事?(服务提供者有一个计数器,记录当前同时请求个数,值越小说明该服务器负载越小,路由器会优先选择该服务器)
|
|
||||||
- 服务端怎么知道客户端要调用的算法的?(socket传递消息过来的时候会把算法策略传递给服务端)
|
|
||||||
- 你用过redis做分布式锁是吧,你们是自己写的工具类吗?(不是,我们用redission做分布式锁)
|
|
||||||
- 线程拿到key后是怎么保证不死锁的呢?(给这个key加上一个过期时间)
|
|
||||||
- 如果这个过期时间到了,但是业务程序还没处理完,该怎么办?(额......可以在业务逻辑上保证幂等性吧)
|
|
||||||
- 那如果多个业务都用到分布式锁的话,每个业务都要保证幂等性了,有没有更好的方法?(额......思考了下暂时没有头绪,面试官就说那先跳过吧。事后我了解到redission本身是有个看门狗的监控线程的,如果检测到key被持有的话就会再次重置过期时间)
|
|
||||||
- 你那边有纸和笔吧,写一道算法,用两个栈模拟一个队列的入队和出队。(因为之前复习的时候对这道题有印象,写的时候也比较快,大概是用了五分钟,然后就拍成图片发给了面试官,对方看完后表示没问题就结束了面试。)
|
|
||||||
|
|
||||||
第一面问的不算难,问题也都是偏基础之类的,虽然答得不算完美,但过程还是比较顺利的。几天之后,Bigo的hr就邀请我去他们公司参加现场面试。
|
|
||||||
|
|
||||||
### 二面
|
|
||||||
|
|
||||||
到Bigo公司后,一位hr小姐姐招待我到了一个会议室,等了大概半个小时,一位中年男子走了进来,非常的客气,说不好意思让我等那么久了,并且介绍了自己是技术经理,然后就开始了我们的交谈。
|
|
||||||
|
|
||||||
- 依照惯例,让我简单做下自我介绍,这个过程他也在边看我的简历。
|
|
||||||
- 说下你最熟悉的项目吧。(我就拿我上家公司最近做的一个电商项目开始介绍,从简单的项目描述,到项目的主要功能,以及我主要负责的功能模块,吧啦吧啦..............)
|
|
||||||
- 你对这个项目这么熟悉,那你根据你的理解画一下你的项目架构图,还有说下你具体参与了哪部分。(这个题目还是比较麻烦的,毕竟我当时离职的时间也挺长了,对这个项目的架构也是有些模糊。当然,最后还是硬着头皮还是画了个大概,从前端开始访问,然后通过nginx网关层,最后到具体的服务等等,并且把自己参与的服务模块也标示了出来)
|
|
||||||
- 你的项目用到了Spring Cloud GateWay,既然你已经有nginx做网关了,为什么还要用gateWay呢?(nginx是做负载均衡,还有针对客户端的访问做网关用的,gateWay是接入业务层做的网关,而且还整合了熔断器Hystrix)
|
|
||||||
- 熔断器Hystrix最主要的作用是什么?(防止服务调用失败导致的服务雪崩,能降级)
|
|
||||||
- 你的项目用到了redis,你们的redis是怎么部署的?(额。。。。好像是哨兵模式部署的吧。)
|
|
||||||
- 说一下你对哨兵模式的理解?(我对哨兵模式了解的不多,就大概说了下Sentinel监控之类的,还有类似ping命令的心跳机制,以及怎么判断一个master是下线之类。。。。。)
|
|
||||||
- 那你们为什么要用哨兵模式呢?怎么不用集群的方式部署呢?一开始get不到他的点,就说哨兵本身就是多实例部署的,他解释了一下,说的是redis-cluster的部署方案。(额......redis的环境搭建有专门的运维人员部署的,应该是优先考虑高可用吧..........开始有点心慌了,因为我也不知道为什么)
|
|
||||||
- 哦,那你是觉得集群没有办法实现高可用吗?(不....不是啊,只是觉得哨兵模式可能比较保证主从复制安全性吧........我也不知道自己在说什么)
|
|
||||||
- 集群也是能保证高可用的,你知道它又是怎么保证主从一致性的吗?(好吧,这里真的不知道了,只能跳过)
|
|
||||||
- 你肯定有微信吧,如果让你来设计微信朋友圈的话,你会怎么设计它的属性成员呢?(嗯......需要有用户表,朋友圈的表,好友表之类的吧)
|
|
||||||
- 嗯,好,你也知道微信用户有接近10亿之多,那肯定要涉及到分库分表,如果是你的话,怎么设计分库分表呢?(这个问题考察的点比较大,我答的其实一般,而且这个过程面试官还不断的进行连环炮发问,导致这个话题说了有将近20分钟,限于篇幅,这里就不再详述了)
|
|
||||||
- 这边差不多了,最后你写一道算法吧,有一组未排序的整形数组,你设计一个算法,对数组的元素两两配对,然后输出最大的绝对值差和最小的绝对值差的"对数"。(听到这道题,我第一想法就是用HashMap来保存,key是两个元素的绝对值差,value是配对的数量,如果有相同的就加1,没有就赋值为1,然后最后对map做排序,输出最大和最小的value值,写完后面试官说结果虽然是正确的,但是不够效率,因为遍历的时间复杂度成了O(n^2),然后提醒了我往排序这方面想。我灵机一动,可以先对数组做排序,然后首元素与第二个元素做绝对值差,记为num,然后首元素循环和后面的元素做计算,直到绝对值差不等于num位置,这样效率比起O(n^2)快多了。)
|
|
||||||
|
|
||||||
面试完后,技术官就问我有什么要问他的,我就针对这个岗位的职责和项目所用的技术栈做了询问,然后就让我先等下,等他去通知三面的技术官。说实话,二面给我的感觉是最舒服的,因为面试官很亲切,面试的过程一直积极的引导我,而且在职业规划方面给了我很多的建议,让我受益匪浅,虽然面试时间有一个半小时,但却丝毫不觉得长,整个面试过程聊得挺舒服的,不过因为时间比较久了,很多问题我也记不清了。
|
|
||||||
|
|
||||||
### 三面
|
|
||||||
|
|
||||||
二面结束后半个小时,三面的技术面试官就开始进来了,从他的额头发量分布情况就能猜想是个大牛,人狠话不多,坐下后也没让我做自我介绍,直接开问,整个过程我答的也不好,而且面试官的问题表述有些不太清晰,经常需要跟他重复确认清楚。
|
|
||||||
|
|
||||||
- 对事务了解吗?说一下事务的隔离级别有哪些(我以比较了解的Spring来说,把Spring的四种事务隔离级别都叙述了一遍)
|
|
||||||
|
|
||||||
- 你做过电商,那应该知道下单的时候需要减库存对吧,假设现在有两个服务A和B,分别操作订单和库存表,A保存订单后,调用B减库存的时候失败了,这个时候A也要回滚,这个事务要怎么设计?(B服务的减库存方法不抛异常,由调用方也就是A服务来抛异常)
|
|
||||||
|
|
||||||
- 了解过读写分离吗?(额。。。大概了解一点,就是写的时候进主库,读的时候读从库)
|
|
||||||
|
|
||||||
- 你说读的时候读从库,现在假设有一张表User做了读写分离,然后有个线程在**一个事务范围内**对User表先做了写的处理,然后又做了读的处理,这时候数据还没同步到从库,怎么保证读的时候能读到最新的数据呢?(听完顿时有点懵圈,一时间答不上来,后来面试官说想办法保证一个事务中读写都是同一个库才行)
|
|
||||||
|
|
||||||
- 你的项目里用到了rabbitmq,那你说下mq的消费端是怎么处理的?(就是消费端接收到消息之后,会先把消息存到数据库中,然后再从数据库中定时跑消息)
|
|
||||||
|
|
||||||
- 也就是说你的mq是先保存到数据库中,然后业务逻辑就是从mq中读取消息然后再处理的是吧?(是的)
|
|
||||||
|
|
||||||
- 那你的消息是唯一的吗?(是的,用了唯一约束)
|
|
||||||
|
|
||||||
- 你怎么保证消息一定能被消费?或者说怎么保证一定能存到数据库中?(这里开始慌了,因为mq接入那一块我只是看过部分逻辑,但没有亲自参与,凭着自己对mq的了解就答道,应该是靠rabbitmq的ack确认机制)
|
|
||||||
|
|
||||||
- 好,那你整理一下你的消费端的整个处理逻辑流程,然后说说你的ack是在哪里返回的(听到这里我的心凉了一截,mq接入这部分我确实没有参与,硬着头皮按照自己的理解画了一下流程,但其实漏洞百出)
|
|
||||||
|
|
||||||
- 按照你这样画的话,如果数据库突然宕机,你的消息该怎么确认已经接收?(额.....那发送消息的时候就存放消息可以吧.........回答的时候心里千万只草泥马路过........行了吧,没玩没了了。)
|
|
||||||
|
|
||||||
- 那如果发送端的服务是多台部署呢?你保存消息的时候数据库就一直报唯一性的错误?(好吧,你赢了。。。最后硬是憋出了一句,您说的是,这样设计确实不好。。。。)
|
|
||||||
|
|
||||||
- 算了,跳过吧,现在你来设计一个map,然后有两个线程对这个map进行操作,主线程高速增加和删除map的元素,然后有个异步线程定时去删除map中主线程5秒内没有删除的数据,你会怎么设计?
|
|
||||||
|
|
||||||
(这道题我答得并不好,做了下简单的思考就说可以把map的key加上时间戳的标志,遍历的时候发现小于当前时间戳5秒前的元素就进行删除,面试官对这样的回答明显不太满意,说这样遍历会影响效率,ps:对这道题,大佬们如果有什么高见可以在评论区说下!)
|
|
||||||
|
|
||||||
......还有其他问题,但我只记住了这么多,就这样吧。
|
|
||||||
|
|
||||||
面完最后一道题后,面试官就表示这次面试过程结束了,让我回去等消息。听到这里,我知道基本上算是宣告结果了。回想起来,自己这一轮面试确实表现的很一般,加上时间拖得很长,从当天的2点半一直面试到6点多,精神上也尽显疲态。果然,几天之后,hr微信通知了我,说我第三轮技术面试没有通过,这一次面试以失败告终。
|
|
||||||
|
|
||||||
## 总结
|
|
||||||
|
|
||||||
以上就是面试的大概过程,不得不说,大厂的面试还是非常有技术水平的,这个过程中我学到了很多,这里分享下个人的一些心得:
|
|
||||||
|
|
||||||
1、**基础**!**基础**!**基础**!重要的事情说三遍,无论是什么阶段的程序员,基础都是最重要的。每个公司的面试一定会涉及到基础知识的提问,如果你的基础不扎实,往往第一面就可能被淘汰。
|
|
||||||
|
|
||||||
2、**简历需要适当的包装**。老实说,我的简历肯定是经过包装的,这也是我的工作年限不够,但却能获取Bigo面试机会的重要原因,所以适当的包装一下简历很有必要,不过切记一点,就是**不能脱离现实**,比如明明只有两年经验,却硬是写到三年。小厂还可能蒙混过关,但大厂基本很难,因为很多公司会在入职前做背景调查。
|
|
||||||
|
|
||||||
3、**要对简历上的技术点很熟悉**。简历包装可以,但一定要对简历上的技术点很熟悉,比如只是简单写过rabbitmq的demo的话,就不要写“熟悉”等字眼,因为很多的面试官会针对一个技能点问的很深入,像连环炮一样的深耕你对这个技能点的理解程度。
|
|
||||||
|
|
||||||
4、**简历上的项目要非常熟悉**。一般我们写简历都是需要对自己的项目做一定程序的包装和美化,项目写得好能给简历加很多分。但一定要对项目非常的熟悉,不熟悉的模块最好不要写上去。笔者这次就吃了大亏,我的简历上有个电商项目就写到了用rabbitmq处理下单,虽然稍微了解过那部分下单的处理逻辑,但由于没有亲自参与就没有做深入的了解,面试时在这一块内容上被Bigo三面的面试官逼得最后哑口无言。
|
|
||||||
|
|
||||||
5、**提升自己的架构思维**。对于初中级程序员来说,日常的工作就是基本的增删改查,把功能实现就完事了,这种思维不能说不好,只是想更上一层楼的话,业务时间需要提升下自己的架构思维能力,比如说如果让你接手一个项目的话,你会怎么考虑设计这个项目,从整体架构,到引入一些组件,再到设计具体的业务服务,这些都是设计一个项目必须要考虑的环节,对于提升我们的架构思维是一种很好的锻炼,这也是很多大厂面试高级程序员时的重要考察部分。
|
|
||||||
|
|
||||||
6、**不要裸辞**。这也是我最朴实的建议了,大环境不好,且行且珍惜吧,唉~~~~
|
|
||||||
|
|
||||||
总的来说,这次面试Bigo还是收获颇丰的,虽然有点遗憾,但也没什么后悔的,毕竟自己面试之前也是准备的很充分了,有些题目答得不好说明我还有很多技术盲区,不懂就是不懂,再这么吹也吹不出来。这也算是给我提了个醒,你还嫩着呢,好好修炼内功吧,毕竟菜可是原罪啊。
|
|
||||||
@ -1,251 +0,0 @@
|
|||||||
本文来自 Anonymous 的投稿 ,Guide哥 对原文进行了重新排版和一点完善。
|
|
||||||
|
|
||||||
<!-- TOC -->
|
|
||||||
|
|
||||||
- [一面 (37 分钟左右)](#一面-37-分钟左右)
|
|
||||||
- [二面 (33 分钟左右)](#二面-33-分钟左右)
|
|
||||||
- [三面 (46 分钟)](#三面-46-分钟)
|
|
||||||
- [HR 面](#hr-面)
|
|
||||||
|
|
||||||
<!-- /TOC -->
|
|
||||||
|
|
||||||
### 一面 (37 分钟左右)
|
|
||||||
|
|
||||||
一面是上海的小哥打来的,3.12 号中午确认的内推,下午就打来约时间了,也是唯一一个约时间的面试官。约的晚上八点。紧张的一比,人生第一次面试就献给了阿里。
|
|
||||||
|
|
||||||
幸运的是一面的小哥特温柔。好像是个海归?口语中夹杂着英文。废话不多说,上干货:
|
|
||||||
|
|
||||||
**面试官:** 先自我介绍下吧!
|
|
||||||
|
|
||||||
**我:** 巴拉巴拉...。
|
|
||||||
|
|
||||||
> 关于自我介绍:从 HR 面、技术面到高管面/部门主管面,面试官一般会让你先自我介绍一下,所以好好准备自己的自我介绍真的非常重要。网上一般建议的是准备好两份自我介绍:一份对 HR 说的,主要讲能突出自己的经历,会的编程技术一语带过;另一份对技术面试官说的,主要讲自己会的技术细节,项目经验,经历那些就一语带过。
|
|
||||||
|
|
||||||
**面试官:** 我看你简历上写你做了个秒杀系统?我们就从这个项目开始吧,先介绍下你的项目。
|
|
||||||
|
|
||||||
> 关于项目介绍:如果有项目的话,技术面试第一步,面试官一般都是让你自己介绍一下你的项目。你可以从下面几个方向来考虑:
|
|
||||||
>
|
|
||||||
> 1. 对项目整体设计的一个感受(面试官可能会让你画系统的架构图)
|
|
||||||
> 2. 在这个项目中你负责了什么、做了什么、担任了什么角色
|
|
||||||
> 3. 从这个项目中你学会了那些东西,使用到了那些技术,学会了那些新技术的使用
|
|
||||||
> 4. 另外项目描述中,最好可以体现自己的综合素质,比如你是如何协调项目组成员协同开发的或者在遇到某一个棘手的问题的时候你是如何解决的又或者说你在这个项目用了什么技术实现了什么功能比如:用 redis 做缓存提高访问速度和并发量、使用消息队列削峰和降流等等。
|
|
||||||
|
|
||||||
**我:** 我说了我是如何考虑它的需求(秒杀地址隐藏,记录订单,减库存),一开始简单的用 synchronized 锁住方法,出现了问题,后来乐观锁改进,又有瓶颈,再上缓存,出现了缓存雪崩,于是缓存预热,错开缓存失效时间。最后,发现先记录订单再减库存会减少行级锁等待时间。
|
|
||||||
|
|
||||||
> 一面面试官很耐心地听,并给了我一些指导,问了我乐观锁是怎么实现的,我说是基于 sql 语句,在减库存操作的 where 条件里加剩余库存数>0,他说这应该不算是一种乐观锁,应该先查库存,在减库存的时候判断当前库存是否与读到的库存一样(可这样不是多一次查询操作吗?不是很理解,不过我没有反驳,只是说理解您的意思。事实证明千万别怼面试官,即使你觉得他说的不对)
|
|
||||||
|
|
||||||
**面试官:** 我缓存雪崩什么情况下会发生?如何避免?
|
|
||||||
|
|
||||||
**我:** 当多个商品缓存同时失效时会雪崩,导致大量查询数据库。还有就是秒杀刚开始的时候缓存里没有数据。解决方案:缓存预热,错开缓存失效时间
|
|
||||||
|
|
||||||
**面试官:** 问我更新数据库的同时为什么不马上更新缓存,而是删除缓存?
|
|
||||||
|
|
||||||
**我:** 因为考虑到更新数据库后更新缓存可能会因为多线程下导致写入脏数据(比如线程 A 先更新数据库成功,接下来要取更新缓存,接着线程 B 更新数据库,但 B 又更新了缓存,接着 B 的时间片用完了,线程 A 更新了缓存)
|
|
||||||
|
|
||||||
逼逼了将近 30 分钟,面试官居然用周杰伦的语气对我说:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
我突然受宠若惊,连忙说谢谢,也正是因为第一次面试得到了面试官的肯定,才让我信心大增,二三面稳定发挥。
|
|
||||||
|
|
||||||
**面试官又曰:** 我看你还懂数据库是吧,答:略懂略懂。。。那我问个简单的吧!
|
|
||||||
|
|
||||||
**我:** 因为这个问题太简单了,所以我忘记它是什么了。
|
|
||||||
|
|
||||||
**面试官:** 你还会啥数据库知识?
|
|
||||||
|
|
||||||
**我:** 我一听,问的这么随意的吗。。。都让我选题了,我就说我了解索引,慢查询优化,巴拉巴拉
|
|
||||||
|
|
||||||
**面试官:** 等等,你说索引是吧,那你能说下索引的存储数据结构吗?
|
|
||||||
|
|
||||||
**我:** 我心想这简单啊,我就说 B+树,还说了为什么用 B+树
|
|
||||||
|
|
||||||
**面试官:** 你简历上写的这个 J.U.C 包是什么啊?(他居然不知道 JUC)
|
|
||||||
|
|
||||||
**我:** 就是 java 多线程的那个包啊。。。
|
|
||||||
|
|
||||||
**面试官:** 那你都了解里面的哪些东西呢?
|
|
||||||
|
|
||||||
**我:** 哈哈哈!这可是我的强项,从 ConcurrentHashMap,ConcurrentLinkedQueue 说到 CountDownLatch,CyclicBarrier,又说到线程池,分别说了底层实现和项目中的应用。
|
|
||||||
|
|
||||||
**面试官:** 我觉得差不多了,那我再问个与技术无关的问题哈,虽然这个问题可能不应该我问,就是你是如何考虑你的项目架构的呢?
|
|
||||||
|
|
||||||
**我:** 先用最简单的方式实现它,再去发掘系统的问题和瓶颈,于是查资料改进架构。。。
|
|
||||||
|
|
||||||
**面试官:** 好,那我给你介绍下我这边的情况吧
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**总结:** 一面可能是简历面吧,问的比较简单,我在讲项目中说出了我做项目时的学习历程和思考,赢得了面试官的好感,感觉他应该给我的评价很好。
|
|
||||||
|
|
||||||
### 二面 (33 分钟左右)
|
|
||||||
|
|
||||||
然而开心了没一会,内推人问我面的怎么样啊?看我流程已经到大大 boss 那了。我一听二面不是主管吗???怎么直接跳了一面。于是瞬间慌了,赶紧(下床)学习准备二面。
|
|
||||||
|
|
||||||
隔了一天,3.14 的早上 10:56 分,杭州的大大 boss 给我打来了电话,卧槽我当时在上毛概课,万恶的毛概课每节课都点名,我还在最后一排不敢跑出去。于是接起电话来怂怂地说不好意思我在上课,晚上可以面试吗?大大 boss 看来很忙啊,跟我说晚上没时间啊,再说吧!
|
|
||||||
|
|
||||||
于是又隔了一天,3.16 中午我收到了北京的电话,当时心里小失望,我的大大 boss 呢???接起电话来,就是一番狂轰乱炸。。。
|
|
||||||
|
|
||||||
第一步还是先自我介绍,这个就不多说了,提前准备好要说的重点就没问题!
|
|
||||||
|
|
||||||
**面试官:** 我们还是从你的项目开始吧,说说你的秒杀系统。
|
|
||||||
|
|
||||||
**我:** 一面时的套路。。。我考虑到秒杀地址在开始前不应暴露给用户。。。
|
|
||||||
|
|
||||||
**面试官:** 等下啊,为什么要这样呢?暴露给用户会怎么样?
|
|
||||||
|
|
||||||
**我:** 用户提前知道秒杀地址就可以写脚本来抢购了,这样不公平
|
|
||||||
|
|
||||||
**面试官:** 那比如说啊,我现在是个黑客,我在秒杀开始时写好了脚本,运行一万个线程获取秒杀地址,这样是不是也不公平呢?
|
|
||||||
|
|
||||||
**我:** 我考虑到了这方面,于是我自己写了个 LRU 缓存(划重点,这么多好用的缓存我为啥不用偏要自己写?就是为了让面试官上钩问我是怎么写的,这样我就可以逼逼准备好的内容了!),用这个缓存存储请求的 ip 和用户名,一个 ip 和用户名只能同时透过 3 个请求。
|
|
||||||
|
|
||||||
**面试官:** 那我可不可以创建一个 ip 代理池和很多用户来抢购呢?假设我有很多手机号的账户。
|
|
||||||
|
|
||||||
**我:** 这就是在为难我胖虎啊,我说这种情况跟真实用户操作太像了。。。我没法区别,不过我觉得可以通过地理位置信息或者机器学习算法来做吧。。。
|
|
||||||
|
|
||||||
**面试官:** 好的这个问题就到这吧,你接着说
|
|
||||||
|
|
||||||
**我:** 我把生成订单和减库存两条 sql 语句放在一个事务里,都操作成功了则认为秒杀成功。
|
|
||||||
|
|
||||||
**面试官:** 等等,你这个订单表和商品库存表是在一个数据库的吧,那如果在不同的数据库中呢?
|
|
||||||
|
|
||||||
**我:** 这面试官好变态啊,我只是个本科生?!?!我觉得应该要用分布式锁来实现吧。。。
|
|
||||||
|
|
||||||
**面试官:** 有没有更轻量级的做法?
|
|
||||||
|
|
||||||
**我:** 不知道了。后来查资料发现可以用消息队列来实现。使用消息队列主要能带来两个好处:(1) 通过异步处理提高系统性能(削峰、减少响应所需时间);(2) 降低系统耦合性。关于消息队列的更多内容可以查看这篇文章:<https://snailclimb.gitee.io/javaguide/#/./system-design/data-communication/message-queue>
|
|
||||||
|
|
||||||
后来发现消息队列作用好大,于是现在在学手写一个消息队列。
|
|
||||||
|
|
||||||
**面试官:** 好的你接着说项目吧。
|
|
||||||
|
|
||||||
**我:** 我考虑到了缓存雪崩问题,于是。。。
|
|
||||||
|
|
||||||
**面试官:** 等等,你有没有考虑到一种情况,假如说你的缓存刚刚失效,大量流量就来查缓存,你的数据库会不会炸?
|
|
||||||
|
|
||||||
**我:** 我不知道数据库会不会炸,反正我快炸了。当时说没考虑这么高的并发量,后来发现也是可以用消息队列来解决,对流量削峰填谷。
|
|
||||||
|
|
||||||
**面试官:** 好项目聊(怼)完了,我们来说说别的,操作系统了解吧,你能说说 NIO 吗?
|
|
||||||
|
|
||||||
**我:** NIO 是。。。
|
|
||||||
|
|
||||||
**面试官:** 那你知道 NIO 的系统调用有哪些吗,具体是怎么实现的?
|
|
||||||
|
|
||||||
**我:** 当时复习 NIO 的时候就知道是咋回事,不知道咋实现。最近在补这方面的知识,可见 NIO 还是很重要的!
|
|
||||||
|
|
||||||
**面试官:** 说说进程切换时操作系统都会发生什么?
|
|
||||||
|
|
||||||
**我:** 不如杀了我,我最讨厌操作系统了。简单说了下,可能不对,需要答案自行百度。
|
|
||||||
|
|
||||||
**面试官:** 说说线程池?
|
|
||||||
|
|
||||||
**答:** 卧槽这我熟啊,把 Java 并发编程的艺术里讲的都说出来了,说了得有十分钟,自夸一波,毕竟这本书我看了五遍😂
|
|
||||||
|
|
||||||
**面试官:** 好问问计网吧如果设计一个聊天系统,应该用 TCP 还是 UDP?为什么
|
|
||||||
|
|
||||||
**我:** 当然是 TCP!原因如下:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**面试官:** 好的,你有什么要问我的吗?
|
|
||||||
|
|
||||||
**我:** 我还有下一次面试吗?
|
|
||||||
|
|
||||||
**面试官:** 应该。应该有的,一周内吧。还告诉我居然转正前要实习三个月?wtf,一个大三满课的本科生让我如何在八月底前实习三个月?
|
|
||||||
|
|
||||||
**我:** 面试官再见
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 三面 (46 分钟)
|
|
||||||
|
|
||||||
3.18 号,三面来了,这次又是那个大大 boss!
|
|
||||||
|
|
||||||
第一步还是先自我介绍,这个就不多说了,提前准备好要说的重点就没问题!
|
|
||||||
|
|
||||||
**面试官:** 聊聊你的项目?
|
|
||||||
|
|
||||||
**我:** 经过二面的教训,我迅速学习了一下分布式的理论知识,并应用到了我的项目(吹牛逼)中。
|
|
||||||
|
|
||||||
**面试官:** 看你用到了 Spring 的事务机制,你能说下 Spring 的事务传播吗?
|
|
||||||
|
|
||||||
**我:** 完了这个问题好像没准备,虽然之前刷知乎看到过。。。我就只说出来一条,面试官说其实这个有很多机制的,比如事务嵌套,内事务回滚外事务回滚都会有不同情况,你可以回去看看。
|
|
||||||
|
|
||||||
**面试官:** 说说你的分布式事务解决方案?
|
|
||||||
|
|
||||||
**我:** 我叭叭的照着资料查到的解决方案说了一通,面试官怎么好像没大听懂???
|
|
||||||
|
|
||||||
> 阿里巴巴之前开源了一个分布式 Fescar(一种易于使用,高性能,基于 Java 的开源分布式事务解决方案),后来,Ant Financial 加入 Fescar,使其成为一个更加中立和开放的分布式交易社区,Fescar 重命名为 Seata。Github 地址:<https://github.com/seata/seata>
|
|
||||||
|
|
||||||
**面试官:** 好,我们聊聊其他项目,说说你这个 MapReduce 项目?MapReduce 原理了解过吗?
|
|
||||||
|
|
||||||
**我:** 我叭叭地说了一通,面试官好像觉得这个项目太简单了。要不是没项目,我会把我的实验写上吗???
|
|
||||||
|
|
||||||
**面试官:** 你这个手写 BP 神经网络是干了啥?
|
|
||||||
|
|
||||||
**我:** 这是我选修机器学习课程时的一个作业,我又对它进行了扩展。
|
|
||||||
|
|
||||||
**面试官:** 你能说说为什么调整权值时要沿着梯度下降的方向?
|
|
||||||
|
|
||||||
**我:** 老大,你太厉害了,怎么什么都懂。我压根没准备这个项目。。。没想到会问,做过去好几个月了,加上当时一紧张就忘了,后来想起来大概是....。
|
|
||||||
|
|
||||||
**面试官:** 好我们问问基础知识吧,说说什么叫 xisuo?
|
|
||||||
|
|
||||||
**我:**???xisuo,您说什么,不好意思我没听清。(这面试官有点口音。。。)就是 xisuo 啊!xisuo 你不知道吗?。。。尴尬了十几秒后我终于意识到,他在说死锁!!!
|
|
||||||
|
|
||||||
**面试官:** 假如 A 账户给 B 账户转钱,会发生 xisuo 吗?能具体说说吗?
|
|
||||||
|
|
||||||
**我:** 当时答的不好,后来发现面试官又是想问分布式,具体答案参考这个:<https://blog.csdn.net/taylorchan2016/article/details/51039362>
|
|
||||||
|
|
||||||
**面试官:** 为什么不考研?
|
|
||||||
|
|
||||||
**我:** 不喜欢学术氛围,巴拉巴拉。
|
|
||||||
|
|
||||||
**面试官:** 你有什么问题吗?
|
|
||||||
|
|
||||||
**我:** 我还有下一面吗。。。面试官说让我等,一周内答复。
|
|
||||||
|
|
||||||
------
|
|
||||||
|
|
||||||
等了十天,一度以为我凉了,内推人说我流程到 HR 了,让我等着吧可能 HR 太忙了,3.28 号 HR 打来了电话,当时在教室,我直接飞了出去。
|
|
||||||
|
|
||||||
### HR 面
|
|
||||||
|
|
||||||
**面试官:** 你好啊,先自我介绍下吧
|
|
||||||
|
|
||||||
**我:** 巴拉巴拉....HR 面的技术面试和技术面的还是有所区别的!
|
|
||||||
|
|
||||||
面试官人特别好,一听就是很会说话的小姐姐!说我这里给你悄悄透露下,你的评级是 A 哦!
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
接下来就是几个经典 HR 面挂人的问题,什么难给我来什么,我看别人的 HR 面怎么都是聊聊天。。。
|
|
||||||
|
|
||||||
**面试官:** 你为什么选择支付宝呢,你怎么看待支付宝?
|
|
||||||
|
|
||||||
**我:** 我从个人情怀,公司理念,环境氛围,市场价值,趋势导向分析了一波(说白了就是疯狂夸支付宝,不过说实话我说的那些一点都没撒谎,阿里确实做到了。比如我举了个雷军和格力打赌 5 年 2000 亿销售额,大部分企业家关注的是利益,而马云更关注的是真的为人类为世界做一些事情,利益不是第一位的。)
|
|
||||||
|
|
||||||
**面试官:** 明白了解,那你的优点我们都很明了了,你能说说你的缺点吗?
|
|
||||||
|
|
||||||
> 缺点肯定不能是目标岗位需要的关键能力!!!
|
|
||||||
>
|
|
||||||
> 总之,记住一点,面试官问你这个问题的话,你可以说一些不影响你这个职位工作需要的一些缺点。比如你面试后端工程师,面试官问你的缺点是什么的话,你可以这样说:自己比较内向,平时不太爱与人交流,但是考虑到以后可能要和客户沟通,自己正在努力改。
|
|
||||||
|
|
||||||
**我:** 据说这是 HR 面最难的一个问题。。。我当时翻了好几天的知乎才找到一个合适的,也符合我的答案:我有时候会表现的不太自信,比如阿里的内推二月份就开始了,其实我当时已经复习了很久了,但是老是觉得自己还不行,不敢投简历,于是又把书看了一遍才投的,当时也是舍友怂恿一波才投的,面了之后发现其实自己也没有很差。(划重点,一定要把自己的缺点圆回来)。
|
|
||||||
|
|
||||||
**面试官:** HR 好像不太满意我的答案,继续问我还有缺点吗?
|
|
||||||
|
|
||||||
**我:** 我说比较容易紧张吧,举了自己大一面实验室因为紧张没进去的例子,后来不断调整心态,现在已经好很多了。
|
|
||||||
|
|
||||||
接下来又是个好难的问题。
|
|
||||||
|
|
||||||
**面试官:** BAT 都给你 offer 了,你怎么选?
|
|
||||||
|
|
||||||
其实我当时好想说,BT 是什么?不好意思我只知道阿里。
|
|
||||||
|
|
||||||
**我 :** 哈哈哈哈开玩笑,就说了阿里的文化,支付宝给我们带来很多便利,想加入支付宝为人类做贡献!
|
|
||||||
|
|
||||||
最后 HR 问了我实习时间,现在大几之类的问题,说肯定会给我发 offer 的,让我等着就好了,希望过两天能收到好的结果。
|
|
||||||
|
|
||||||

|
|
||||||
@ -1,89 +0,0 @@
|
|||||||
昨天我整理了公众号历史所有和面试相关的我觉得还不错的文章:[整理了一些有助于你拿Offer的文章](<https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485434&idx=1&sn=f6bdf19d2594bf719e149e48d1384340&chksm=cea24831f9d5c1278617d347238f65f0481f36291675f05fabb382b69ea0ff3adae7ee6e6524&token=1452779379&lang=zh_CN#rd>) 。今天分享一下最近逛Github看到了一些我觉得对于Java面试以及学习有帮助的仓库,这些仓库涉及Java核心知识点整理、Java常见面试题、算法、基础知识点比如网络和操作系统等等。
|
|
||||||
|
|
||||||
## 知识点相关
|
|
||||||
|
|
||||||
### 1.JavaGuide
|
|
||||||
|
|
||||||
- Github地址: [https://github.com/Snailclimb/JavaGuide](https://github.com/Snailclimb/JavaGuide)
|
|
||||||
- star: 64.0k
|
|
||||||
- 介绍: 【Java学习+面试指南】 一份涵盖大部分Java程序员所需要掌握的核心知识。
|
|
||||||
|
|
||||||
### 2.CS-Notes
|
|
||||||
|
|
||||||
- Github 地址:<https://github.com/CyC2018/CS-Notes>
|
|
||||||
- Star: 68.3k
|
|
||||||
- 介绍: 技术面试必备基础知识、Leetcode 题解、后端面试、Java 面试、春招、秋招、操作系统、计算机网络、系统设计。
|
|
||||||
|
|
||||||
### 3. advanced-java
|
|
||||||
|
|
||||||
- Github地址:[https://github.com/doocs/advanced-java](https://github.com/doocs/advanced-java)
|
|
||||||
- star: 23.4k
|
|
||||||
- 介绍: 互联网 Java 工程师进阶知识完全扫盲:涵盖高并发、分布式、高可用、微服务等领域知识,后端同学必看,前端同学也可学习。
|
|
||||||
|
|
||||||
### 4.JCSprout
|
|
||||||
|
|
||||||
- Github地址:[https://github.com/crossoverJie/JCSprout](https://github.com/crossoverJie/JCSprout)
|
|
||||||
- star: 21.2k
|
|
||||||
- 介绍: Java Core Sprout:处于萌芽阶段的 Java 核心知识库。
|
|
||||||
|
|
||||||
### 5.toBeTopJavaer
|
|
||||||
|
|
||||||
- Github地址:[https://github.com/hollischuang/toBeTopJavaer](https://github.com/hollischuang/toBeTopJavaer)
|
|
||||||
- star: 4.0 k
|
|
||||||
- 介绍: Java工程师成神之路。
|
|
||||||
|
|
||||||
### 6.architect-awesome
|
|
||||||
|
|
||||||
- Github地址:[https://github.com/xingshaocheng/architect-awesome](https://github.com/xingshaocheng/architect-awesome)
|
|
||||||
- star: 34.4 k
|
|
||||||
- 介绍:后端架构师技术图谱。
|
|
||||||
|
|
||||||
### 7.technology-talk
|
|
||||||
|
|
||||||
- Github地址: [https://github.com/aalansehaiyang/technology-talk](https://github.com/aalansehaiyang/technology-talk)
|
|
||||||
- star: 6.1k
|
|
||||||
- 介绍: 汇总java生态圈常用技术框架、开源中间件,系统架构、项目管理、经典架构案例、数据库、常用三方库、线上运维等知识。
|
|
||||||
|
|
||||||
### 8.fullstack-tutorial
|
|
||||||
|
|
||||||
- Github地址: [https://github.com/frank-lam/fullstack-tutorial](https://github.com/frank-lam/fullstack-tutorial)
|
|
||||||
- star: 4.0k
|
|
||||||
- 介绍: fullstack tutorial 2019,后台技术栈/架构师之路/全栈开发社区,春招/秋招/校招/面试。
|
|
||||||
|
|
||||||
### 9.3y
|
|
||||||
|
|
||||||
- Github地址:[https://github.com/ZhongFuCheng3y/3y](https://github.com/ZhongFuCheng3y/3y)
|
|
||||||
- star: 1.9 k
|
|
||||||
- 介绍: Java 知识整合。
|
|
||||||
|
|
||||||
### 10.java-bible
|
|
||||||
|
|
||||||
- Github地址:[https://github.com/biezhi/java-bible](https://github.com/biezhi/java-bible)
|
|
||||||
- star: 2.3k
|
|
||||||
- 介绍: 这里记录了一些技术摘要,部分文章来自网络,本项目的目的力求分享精品技术干货,以Java为主。
|
|
||||||
|
|
||||||
### 11.interviews
|
|
||||||
|
|
||||||
- Github地址: [https://github.com/kdn251/interviews/blob/master/README-zh-cn.md](https://github.com/kdn251/interviews/blob/master/README-zh-cn.md)
|
|
||||||
- star: 35.3k
|
|
||||||
- 介绍: 软件工程技术面试个人指南(国外的一个项目,虽然有翻译版,但是不太推荐,因为很多内容并不适用于国内)。
|
|
||||||
|
|
||||||
## 算法相关
|
|
||||||
|
|
||||||
### 1.LeetCodeAnimation
|
|
||||||
|
|
||||||
- Github 地址: <https://github.com/MisterBooo/LeetCodeAnimation>
|
|
||||||
- Star: 33.4k
|
|
||||||
- 介绍: Demonstrate all the questions on LeetCode in the form of animation.(用动画的形式呈现解LeetCode题目的思路)。
|
|
||||||
|
|
||||||
### 2.awesome-java-leetcode
|
|
||||||
|
|
||||||
- Github地址:[https://github.com/Blankj/awesome-java-leetcode](https://github.com/Blankj/awesome-java-leetcode)
|
|
||||||
- star: 6.1k
|
|
||||||
- 介绍: LeetCode 上 Facebook 的面试题目。
|
|
||||||
|
|
||||||
### 3.leetcode
|
|
||||||
|
|
||||||
- Github地址:[https://github.com/azl397985856/leetcode](https://github.com/azl397985856/leetcode)
|
|
||||||
- star: 12.0k
|
|
||||||
- 介绍: LeetCode Solutions: A Record of My Problem Solving Journey.( leetcode题解,记录自己的leetcode解题之路。)
|
|
||||||
@ -1,101 +0,0 @@
|
|||||||
身边的朋友或者公众号的粉丝很多人都向我询问过:“我是双非/三本/专科学校的,我有机会进入大厂吗?”、“非计算机专业的学生能学好吗?”、“如何学习 Java?”、“Java 学习该学哪些东西?”、“我该如何准备 Java 面试?”......这些方面的问题。我会根据自己的一点经验对大部分人关心的这些问题进行答疑解惑。现在又刚好赶上考研结束,这篇文章也算是给考研结束准备往 Java 后端方向发展的朋友们指明一条学习之路。道理懂了如果没有实际行动,那这篇文章对你或许没有任何意义。
|
|
||||||
|
|
||||||
<!-- TOC -->
|
|
||||||
|
|
||||||
- [Question1:我是双非/三本/专科学校的,我有机会进入大厂吗?](#question1我是双非三本专科学校的我有机会进入大厂吗)
|
|
||||||
- [Question2:非计算机专业的学生能学好 Java 后台吗?我能进大厂吗?](#question2非计算机专业的学生能学好-java-后台吗我能进大厂吗)
|
|
||||||
- [Question3: 我没有实习经历的话找工作是不是特别艰难?](#question3-我没有实习经历的话找工作是不是特别艰难)
|
|
||||||
- [Question4: 我该如何准备面试呢?面试的注意事项有哪些呢?](#question4-我该如何准备面试呢面试的注意事项有哪些呢)
|
|
||||||
- [Question5: 我该自学还是报培训班呢?](#question5-我该自学还是报培训班呢)
|
|
||||||
- [Question6: 没有项目经历/博客/Github 开源项目怎么办?](#question6-没有项目经历博客github-开源项目怎么办)
|
|
||||||
- [Question7: 大厂青睐什么样的人?](#question7-大厂青睐什么样的人)
|
|
||||||
|
|
||||||
<!-- /TOC -->
|
|
||||||
|
|
||||||
### Question1:我是双非/三本/专科学校的,我有机会进入大厂吗?
|
|
||||||
|
|
||||||
我自己也是非 985 非 211 学校的,结合自己的经历以及一些朋友的经历,我觉得让我回答这个问题再好不过。
|
|
||||||
|
|
||||||
首先,我觉得学校歧视很正常,真的太正常了,如果要抱怨的话,你只能抱怨自己没有进入名校。但是,千万不要动不动说自己学校差,动不动拿自己学校当做自己进不了大厂的借口,学历只是筛选简历的很多标准中的一个而已,如果你够优秀,简历够丰富,你也一样可以和名校同学一起同台竞争。
|
|
||||||
|
|
||||||
企业 HR 肯定是更喜欢高学历的人,毕竟 985、211 优秀人才比例肯定比普通学校高很多,HR 团队肯定会优先在这些学校里选。这就好比相亲,你是愿意在很多优秀的人中选一个优秀的,还是愿意在很多普通的人中选一个优秀的呢?
|
|
||||||
|
|
||||||
双非本科甚至是二本、三本甚至是专科的同学也有很多进入大厂的,不过比率相比于名校的低很多而已。从大厂招聘的结果上看,高学历人才的数量占据大头,那些成功进入 BAT、美团,京东,网易等大厂的双非本科甚至是二本、三本甚至是专科的同学往往是因为具备丰富的项目经历或者在某个含金量比较高的竞赛比如 ACM 中取得了不错的成绩。**一部分学历不突出但能力出众的面试者能够进入大厂并不是说明学历不重要,而是学历的软肋能够通过其他的优势来弥补。** 所以,如果你的学校不够好而你自己又想去大厂的话,建议你可以从这几点来做:**① 尽量在面试前最好有一个可以拿的出手的项目;② 有实习条件的话,尽早出去实习,实习经历也会是你的简历的一个亮点(有能力在大厂实习最佳!);③ 参加一些含金量比较高的比赛,拿不拿得到名次没关系,重在锻炼。**
|
|
||||||
|
|
||||||
### Question2:非计算机专业的学生能学好 Java 后台吗?我能进大厂吗?
|
|
||||||
|
|
||||||
当然可以!现在非科班的程序员很多,很大一部分原因是互联网行业的工资比较高。我们学校外面的培训班里面 90%都是非科班,我觉得他们很多人学的都还不错。另外,我的一个朋友本科是机械专业,大一开始自学安卓,技术贼溜,在我看来他比大部分本科是计算机的同学学的还要好。参考 Question1 的回答,即使你是非科班程序员,如果你想进入大厂的话,你也可以通过自己的其他优势来弥补。
|
|
||||||
|
|
||||||
我觉得我们不应该因为自己的专业给自己划界限或者贴标签,说实话,很多科班的同学可能并不如你,你以为科班的同学就会认真听讲吗?还不是几乎全靠自己课下自学!不过如果你是非科班的话,你想要学好,那么注定就要舍弃自己本专业的一些学习时间,这是无可厚非的。
|
|
||||||
|
|
||||||
建议非科班的同学,首先要打好计算机基础知识基础:① 计算机网络、② 操作系统、③ 数据机构与算法,我个人觉得这 3 个对你最重要。这些东西就像是内功,对你以后的长远发展非常有用。当然,如果你想要进大厂的话,这些知识也是一定会被问到的。另外,“一定学好数据结构与算法!一定学好数据结构与算法!一定学好数据结构与算法!”,重要的东西说 3 遍。
|
|
||||||
|
|
||||||
### Question3: 我没有实习经历的话找工作是不是特别艰难?
|
|
||||||
|
|
||||||
没有实习经历没关系,只要你有拿得出手的项目或者大赛经历的话,你依然有可能拿到大厂的 offer 。笔主当时找工作的时候就没有实习经历以及大赛获奖经历,单纯就是凭借自己的项目经验撑起了整个面试。
|
|
||||||
|
|
||||||
如果你既没有实习经历,又没有拿得出手的项目或者大赛经历的话,我觉得在简历关,除非你有其他特别的亮点,不然,你应该就会被刷。
|
|
||||||
|
|
||||||
### Question4: 我该如何准备面试呢?面试的注意事项有哪些呢?
|
|
||||||
|
|
||||||
下面是我总结的一些准备面试的 Tips 以及面试必备的注意事项:
|
|
||||||
|
|
||||||
1. **准备一份自己的自我介绍,面试的时候根据面试对象适当进行修改**(突出重点,突出自己的优势在哪里,切忌流水账);
|
|
||||||
2. **注意随身带上自己的成绩单和简历复印件;** (有的公司在面试前都会让你交一份成绩单和简历当做面试中的参考。)
|
|
||||||
3. **如果需要笔试就提前刷一些笔试题,大部分在线笔试的类型是选择题+编程题,有的还会有简答题。**(平时空闲时间多的可以刷一下笔试题目(牛客网上有很多),但是不要只刷面试题,不动手 code,程序员不是为了考试而存在的。)另外,注意抓重点,因为题目太多了,但是有很多题目几乎次次遇到,像这样的题目一定要搞定。
|
|
||||||
4. **提前准备技术面试。** 搞清楚自己面试中可能涉及哪些知识点、哪些知识点是重点。面试中哪些问题会被经常问到、自己该如何回答。(强烈不推荐背题,第一:通过背这种方式你能记住多少?能记住多久?第二:背题的方式的学习很难坚持下去!)
|
|
||||||
5. **面试之前做好定向复习。** 也就是专门针对你要面试的公司来复习。比如你在面试之前可以在网上找找有没有你要面试的公司的面经。
|
|
||||||
6. **准备好自己的项目介绍。** 如果有项目的话,技术面试第一步,面试官一般都是让你自己介绍一下你的项目。你可以从下面几个方向来考虑:① 对项目整体设计的一个感受(面试官可能会让你画系统的架构图);② 在这个项目中你负责了什么、做了什么、担任了什么角色;③ 从这个项目中你学会了那些东西,使用到了那些技术,学会了那些新技术的使用;④ 项目描述中,最好可以体现自己的综合素质,比如你是如何协调项目组成员协同开发的或者在遇到某一个棘手的问题的时候你是如何解决的又或者说你在这个项目用了什么技术实现了什么功能比如:用 redis 做缓存提高访问速度和并发量、使用消息队列削峰和降流等等。
|
|
||||||
7. **面试之后记得复盘。** 面试遭遇失败是很正常的事情,所以善于总结自己的失败原因才是最重要的。如果失败,不要灰心;如果通过,切勿狂喜。
|
|
||||||
|
|
||||||
**一些还算不错的 Java 面试/学习相关的仓库,相信对大家准备面试一定有帮助:**[盘点一下 Github 上开源的 Java 面试/学习相关的仓库,看完弄懂薪资至少增加 10k](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484817&idx=1&sn=12f0c254a240c40c2ccab8314653216b&chksm=fd9853f0caefdae6d191e6bf085d44ab9c73f165e3323aa0362d830e420ccbfad93aa5901021&token=766994974&lang=zh_CN#rd)
|
|
||||||
|
|
||||||
### Question5: 我该自学还是报培训班呢?
|
|
||||||
|
|
||||||
我本人更加赞同自学(你要知道去了公司可没人手把手教你了,而且几乎所有的公司都对培训班出生的有偏见。为什么有偏见,你学个东西还要去培训班,说明什么,同等水平下,你的自学能力以及自律能力一定是比不上自学的人的)。但是如果,你连每天在寝室坚持学上 8 个小时以上都坚持不了,或者总是容易半途而废的话,我还是推荐你去培训班。观望身边同学去培训班的,大多是非计算机专业或者是没有自律能力以及自学能力非常差的人。
|
|
||||||
|
|
||||||
另外,如果自律能力不行,你也可以通过结伴学习、参加老师的项目等方式来督促自己学习。
|
|
||||||
|
|
||||||
总结:去不去培训班主要还是看自己,如果自己能坚持自学就自学,坚持不下来就去培训班。
|
|
||||||
|
|
||||||
### Question6: 没有项目经历/博客/Github 开源项目怎么办?
|
|
||||||
|
|
||||||
从现在开始做!
|
|
||||||
|
|
||||||
网上有很多非常不错的项目视频,你就跟着一步一步做,不光要做,还要改进,改善。另外,如果你的老师有相关 Java 后台项目的话,你也可以主动申请参与进来。
|
|
||||||
|
|
||||||
如果有自己的博客,也算是简历上的一个亮点。建议可以在掘金、Segmentfault、CSDN 等技术交流社区写博客,当然,你也可以自己搭建一个博客(采用 Hexo+Githu Pages 搭建非常简单)。写一些什么?学习笔记、实战内容、读书笔记等等都可以。
|
|
||||||
|
|
||||||
多用 Github,用好 Github,上传自己不错的项目,写好 readme 文档,在其他技术社区做好宣传。相信你也会收获一个不错的开源项目!
|
|
||||||
|
|
||||||
### Question7: 大厂青睐什么样的人?
|
|
||||||
|
|
||||||
**先从已经有两年左右开发经验的工程师角度来看:** 我们来看一下阿里官网支付宝 Java 高级开发工程师的招聘要求,从下面的招聘信息可以看出,除去 Java 基础/集合/多线程这些,这些能力格外重要:
|
|
||||||
|
|
||||||
1. **底层知识比如 jvm** :不只是懂理论更会实操;
|
|
||||||
2. 面**向对象编程能力** :我理解这个不仅包括“面向对象编程”,还有 SOLID 软件设计原则,相关阅读:[《写了这么多年代码,你真的了解 SOLID 吗?》](https://insights.thoughtworks.cn/do-you-really-know-solid/)(我司大佬的一篇文章)
|
|
||||||
3. **框架能力** :不只是使用那么简单,更要搞懂原理和机制!搞懂原理和机制的基础是要学会看源码。
|
|
||||||
4. **分布式系统开发能力** :缓存、消息队列等等都要掌握,关键是还要能使用这些技术解决实际问题而不是纸上谈兵。
|
|
||||||
5. **不错的 sense** :喜欢和尝试新技术、追求编写优雅的代码等等。
|
|
||||||
|
|
||||||
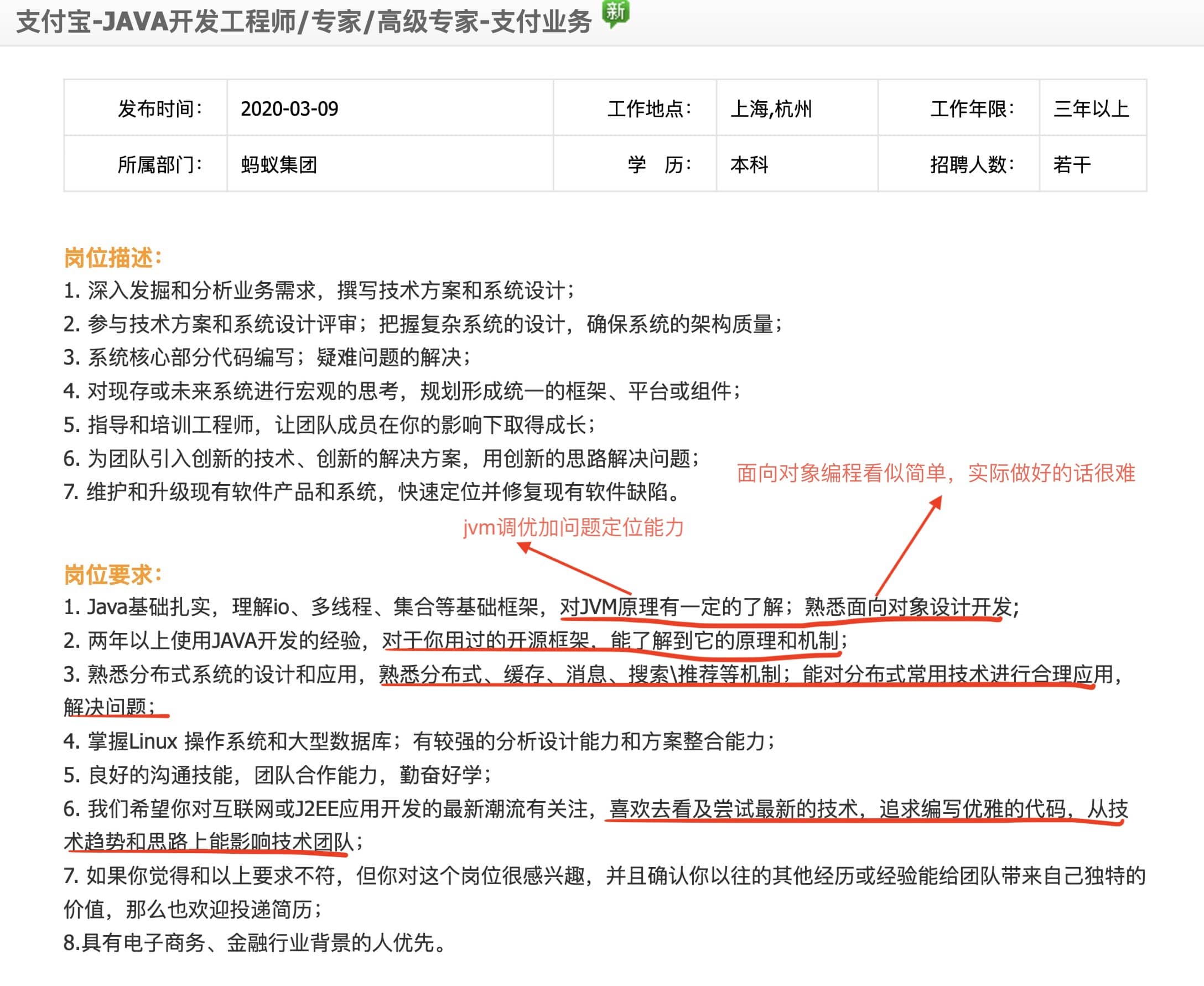
|
|
||||||
|
|
||||||
**再从应届生的角度来看:** 我们还是看阿里巴巴的官网相关应届生 Java 工程师招聘岗位的相关要求。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
结合阿里、腾讯等大厂招聘官网对于 Java 后端方向/后端方向的应届实习生的要求下面几点也提升你的个人竞争力:
|
|
||||||
|
|
||||||
1. 参加过竞赛( 含金量超高的是 ACM );
|
|
||||||
2. 对数据结构与算法非常熟练;
|
|
||||||
3. 参与过实际项目(比如学校网站)
|
|
||||||
4. 熟悉 Python、Shell、Perl 其中一门脚本语言;
|
|
||||||
5. 熟悉如何优化 Java 代码、有写出质量更高的代码的意识;
|
|
||||||
6. 熟悉 SOA 分布式相关的知识尤其是理论知识;
|
|
||||||
7. 熟悉自己所用框架的底层知识比如 Spring;
|
|
||||||
8. 有高并发开发经验;
|
|
||||||
9. 有大数据开发经验等等。
|
|
||||||
|
|
||||||
从来到大学之后,我的好多阅历非常深的老师经常就会告诫我们:“ 一定要有一门自己的特长,不管是技术还好还是其他能力 ” 。我觉得这句话真的非常有道理!
|
|
||||||
|
|
||||||
刚刚也提到了要有一门特长,所以在这里再强调一点:公司不需要你什么都会,但是在某一方面你一定要有过于常人的优点。换言之就是我们不需要去掌握每一门技术(你也没精力去掌握这么多技术),而是需要去深入研究某一门技术,对于其他技术我们可以简单了解一下。
|
|
||||||
@ -1,151 +0,0 @@
|
|||||||
不论是笔试还是面试都是有章可循的,但是,一定要不要想着如何去应付面试,糊弄面试官,这样做终究是欺骗自己。这篇文章的目的也主要想让大家知道自己应该从哪些方向去准备面试,有哪些可以提高的方向。
|
|
||||||
|
|
||||||
网上已经有很多面经了,但是我认为网上的各种面经仅仅只能作为参考,你的实际面试与之还是有一些区别的。另外如果要在网上看别人的面经的话,建议即要看别人成功的案例也要适当看看别人失败的案例。**看面经没问题,不论是你要找工作还是平时学习,这都是一种比较好地检验自己水平的一种方式。但是,一定不要过分寄希望于各种面经,试着去提高自己的综合能力。**
|
|
||||||
|
|
||||||
“ 80% 的 offer 掌握在 20% 的人手 ” 中这句话也不是不无道理的。决定你面试能否成功的因素中实力固然占有很大一部分比例,但是如果你的心态或者说运气不好的话,依然无法拿到满意的 offer。
|
|
||||||
|
|
||||||
运气暂且不谈,就拿心态来说,千万不要因为面试失败而气馁或者说怀疑自己的能力,面试失败之后多总结一下失败的原因,后面你就会发现自己会越来越强大。
|
|
||||||
|
|
||||||
另外,笔主只是在这里分享一下自己对于 “ 如何备战大厂面试 ” 的一个看法,以下大部分理论/言辞都经过过反复推敲验证,如果有不对的地方或者和你想法不同的地方,请您敬请雅正、不舍赐教。
|
|
||||||
|
|
||||||
<!-- TOC -->
|
|
||||||
|
|
||||||
- [1 如何获取大厂面试机会?](#1-如何获取大厂面试机会)
|
|
||||||
- [2 面试前的准备](#2--面试前的准备)
|
|
||||||
- [2.1 准备自己的自我介绍](#21-准备自己的自我介绍)
|
|
||||||
- [2.2 搞清楚技术面可能会问哪些方向的问题](#22-搞清楚技术面可能会问哪些方向的问题)
|
|
||||||
- [2.2 休闲着装即可](#22-休闲着装即可)
|
|
||||||
- [2.3 随身带上自己的成绩单和简历](#23-随身带上自己的成绩单和简历)
|
|
||||||
- [2.4 如果需要笔试就提前刷一些笔试题](#24-如果需要笔试就提前刷一些笔试题)
|
|
||||||
- [2.5 花时间一些逻辑题](#25-花时间一些逻辑题)
|
|
||||||
- [2.6 准备好自己的项目介绍](#26-准备好自己的项目介绍)
|
|
||||||
- [2.7 提前准备技术面试](#27-提前准备技术面试)
|
|
||||||
- [2.7 面试之前做好定向复习](#27-面试之前做好定向复习)
|
|
||||||
- [3 面试之后复盘](#3-面试之后复盘)
|
|
||||||
- [4 如何学习?学会各种框架有必要吗?](#4-如何学习学会各种框架有必要吗)
|
|
||||||
- [4.1 我该如何学习?](#41-我该如何学习)
|
|
||||||
- [4.2 学会各种框架有必要吗?](#42-学会各种框架有必要吗)
|
|
||||||
|
|
||||||
<!-- /TOC -->
|
|
||||||
|
|
||||||
## 1 如何获取大厂面试机会?
|
|
||||||
|
|
||||||
**在讲如何获取大厂面试机会之前,先来给大家科普/对比一下两个校招非常常见的概念——春招和秋招。**
|
|
||||||
|
|
||||||
1. **招聘人数** :秋招多于春招 ;
|
|
||||||
2. **招聘时间** : 秋招一般7月左右开始,大概一直持续到10月底。<font color="red">但是大厂(如BAT)都会早开始早结束,所以一定要把握好时间。</font>春招最佳时间为3月,次佳时间为4月,进入5月基本就不会再有春招了(金三银四)。
|
|
||||||
3. **应聘难度** :秋招略大于春招;
|
|
||||||
4. **招聘公司:** 秋招数量多,而春招数量较少,一般为秋招的补充。
|
|
||||||
|
|
||||||
**综上,一般来说,秋招的含金量明显是高于春招的。**
|
|
||||||
|
|
||||||
**下面我就说一下我自己知道的一些方法,不过应该也涵盖了大部分获取面试机会的方法。**
|
|
||||||
|
|
||||||
1. **关注大厂官网,随时投递简历(走流程的网申);**
|
|
||||||
2. **线下参加宣讲会,直接投递简历;**
|
|
||||||
3. **找到师兄师姐/认识的人,帮忙内推(能够让你避开网申简历筛选,笔试筛选,还是挺不错的,不过也还是需要你的简历够棒);**
|
|
||||||
4. **博客发文被看中/Github优秀开源项目作者,大厂内部人员邀请你面试;**
|
|
||||||
5. **求职类网站投递简历(不是太推荐,适合海投);**
|
|
||||||
|
|
||||||
|
|
||||||
除了这些方法,我也遇到过这样的经历:有些大公司的一些部门可能暂时没招够人,然后如果你的亲戚或者朋友刚好在这个公司,而你正好又在寻求offer,那么面试机会基本上是有了,而且这种面试的难度好像一般还普遍比其他正规面试低很多。
|
|
||||||
|
|
||||||
## 2 面试前的准备
|
|
||||||
|
|
||||||
### 2.1 准备自己的自我介绍
|
|
||||||
|
|
||||||
自我介绍一般是你和面试官的第一次面对面正式交流,换位思考一下,假如你是面试官的话,你想听到被你面试的人如何介绍自己呢?一定不是客套地说说自己喜欢编程、平时花了很多时间来学习、自己的兴趣爱好是打球吧?
|
|
||||||
|
|
||||||
我觉得一个好的自我介绍应该包含这几点要素:
|
|
||||||
|
|
||||||
1. 用简单的话说清楚自己主要的技术栈于擅长的领域;
|
|
||||||
2. 把重点放在自己在行的地方以及自己的优势之处;
|
|
||||||
3. 重点突出自己的能力比如自己的定位的bug的能力特别厉害;
|
|
||||||
|
|
||||||
从社招和校招两个角度来举例子吧!我下面的两个例子仅供参考,自我介绍并不需要死记硬背,记住要说的要点,面试的时候根据公司的情况临场发挥也是没问题的。另外,网上一般建议的是准备好两份自我介绍:一份对hr说的,主要讲能突出自己的经历,会的编程技术一语带过;另一份对技术面试官说的,主要讲自己会的技术细节和项目经验。
|
|
||||||
|
|
||||||
**社招:**
|
|
||||||
|
|
||||||
> 面试官,您好!我叫独秀儿。我目前有1年半的工作经验,熟练使用Spring、MyBatis等框架、了解 Java 底层原理比如JVM调优并且有着丰富的分布式开发经验。离开上一家公司是因为我想在技术上得到更多的锻炼。在上一个公司我参与了一个分布式电子交易系统的开发,负责搭建了整个项目的基础架构并且通过分库分表解决了原始数据库以及一些相关表过于庞大的问题,目前这个网站最高支持 10 万人同时访问。工作之余,我利用自己的业余时间写了一个简单的 RPC 框架,这个框架用到了Netty进行网络通信, 目前我已经将这个项目开源,在 Github 上收获了 2k的 Star! 说到业余爱好的话,我比较喜欢通过博客整理分享自己所学知识,现在已经是多个博客平台的认证作者。 生活中我是一个比较积极乐观的人,一般会通过运动打球的方式来放松。我一直都非常想加入贵公司,我觉得贵公司的文化和技术氛围我都非常喜欢,期待能与你共事!
|
|
||||||
|
|
||||||
**校招:**
|
|
||||||
|
|
||||||
> 面试官,您好!我叫秀儿。大学时间我主要利用课外时间学习了 Java 以及 Spring、MyBatis等框架 。在校期间参与过一个考试系统的开发,这个系统的主要用了 Spring、MyBatis 和 shiro 这三种框架。我在其中主要担任后端开发,主要负责了权限管理功能模块的搭建。另外,我在大学的时候参加过一次软件编程大赛,我和我的团队做的在线订餐系统成功获得了第二名的成绩。我还利用自己的业余时间写了一个简单的 RPC 框架,这个框架用到了Netty进行网络通信, 目前我已经将这个项目开源,在 Github 上收获了 2k的 Star! 说到业余爱好的话,我比较喜欢通过博客整理分享自己所学知识,现在已经是多个博客平台的认证作者。 生活中我是一个比较积极乐观的人,一般会通过运动打球的方式来放松。我一直都非常想加入贵公司,我觉得贵公司的文化和技术氛围我都非常喜欢,期待能与你共事!
|
|
||||||
|
|
||||||
### 2.2 搞清楚技术面可能会问哪些方向的问题
|
|
||||||
|
|
||||||
你准备面试的话首先要搞清技术面可能会被问哪些方向的问题吧!
|
|
||||||
|
|
||||||
**我直接用思维导图的形式展示出来吧!这样更加直观形象一点,细化到某个知识点的话这张图没有介绍到,留个悬念,下篇文章会详细介绍。**
|
|
||||||
|
|
||||||
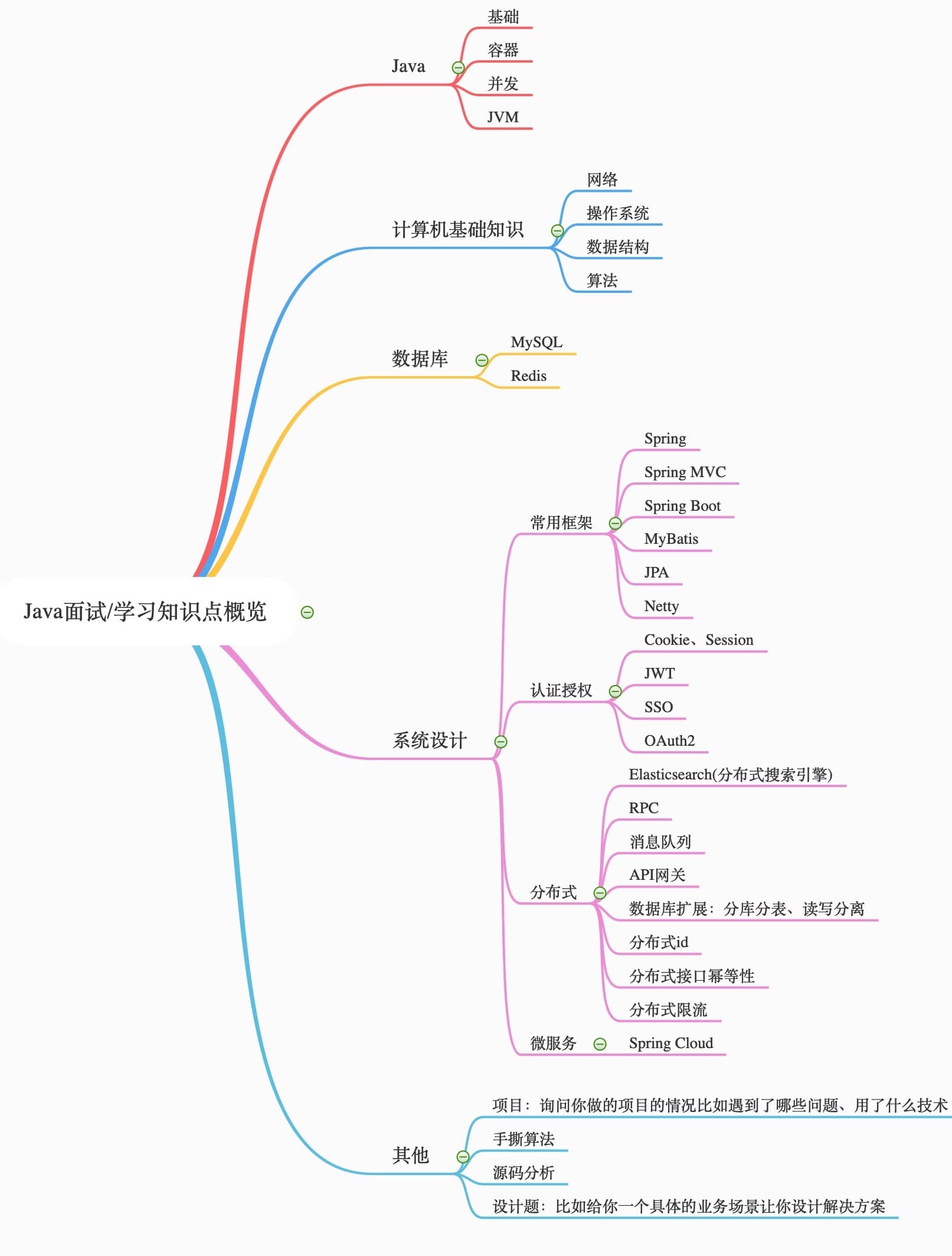
|
|
||||||
|
|
||||||
**上面思维导图大概涵盖了技术面试可能会设计的技术,但是你不需要把上面的每一个知识点都搞得很熟悉,要分清主次,对于自己不熟悉的技术不要写在简历上,对于自己简单了解的技术不要说自己熟练掌握!**
|
|
||||||
|
|
||||||
### 2.2 休闲着装即可
|
|
||||||
|
|
||||||
穿西装、打领带、小皮鞋?NO!NO!NO!这是互联网公司面试又不是去走红毯,所以你只需要穿的简单大方就好,不需要太正式。
|
|
||||||
|
|
||||||
### 2.3 随身带上自己的成绩单和简历
|
|
||||||
|
|
||||||
有的公司在面试前都会让你交一份成绩单和简历当做面试中的参考。
|
|
||||||
|
|
||||||
### 2.4 如果需要笔试就提前刷一些笔试题
|
|
||||||
|
|
||||||
平时空闲时间多的可以刷一下笔试题目(牛客网上有很多)。但是不要只刷面试题,不动手code,程序员不是为了考试而存在的。
|
|
||||||
|
|
||||||
### 2.5 花时间一些逻辑题
|
|
||||||
|
|
||||||
面试中发现有些公司都有逻辑题测试环节,并且都把逻辑笔试成绩作为很重要的一个参考。
|
|
||||||
|
|
||||||
### 2.6 准备好自己的项目介绍
|
|
||||||
|
|
||||||
如果有项目的话,技术面试第一步,面试官一般都是让你自己介绍一下你的项目。你可以从下面几个方向来考虑:
|
|
||||||
|
|
||||||
1. 对项目整体设计的一个感受(面试官可能会让你画系统的架构图)
|
|
||||||
2. 在这个项目中你负责了什么、做了什么、担任了什么角色
|
|
||||||
3. 从这个项目中你学会了那些东西,使用到了那些技术,学会了那些新技术的使用
|
|
||||||
4. 另外项目描述中,最好可以体现自己的综合素质,比如你是如何协调项目组成员协同开发的或者在遇到某一个棘手的问题的时候你是如何解决的又或者说你在这个项目用了什么技术实现了什么功能比如:用redis做缓存提高访问速度和并发量、使用消息队列削峰和降流等等。
|
|
||||||
|
|
||||||
### 2.7 提前准备技术面试
|
|
||||||
|
|
||||||
搞清楚自己面试中可能涉及哪些知识点、哪些知识点是重点。面试中哪些问题会被经常问到、自己该如何回答。(强烈不推荐背题,第一:通过背这种方式你能记住多少?能记住多久?第二:背题的方式的学习很难坚持下去!)
|
|
||||||
|
|
||||||
### 2.7 面试之前做好定向复习
|
|
||||||
|
|
||||||
所谓定向复习就是专门针对你要面试的公司来复习。比如你在面试之前可以在网上找找有没有你要面试的公司的面经。
|
|
||||||
|
|
||||||
举个栗子:在我面试 ThoughtWorks 的前几天我就在网上找了一些关于 ThoughtWorks 的技术面的一些文章。然后知道了 ThoughtWorks 的技术面会让我们在之前做的作业的基础上增加一个或两个功能,所以我提前一天就把我之前做的程序重新重构了一下。然后在技术面的时候,简单的改了几行代码之后写个测试就完事了。如果没有提前准备,我觉得 20 分钟我很大几率会完不成这项任务。
|
|
||||||
|
|
||||||
## 3 面试之后复盘
|
|
||||||
|
|
||||||
如果失败,不要灰心;如果通过,切勿狂喜。面试和工作实际上是两回事,可能很多面试未通过的人,工作能力比你强的多,反之亦然。我个人觉得面试也像是一场全新的征程,失败和胜利都是平常之事。所以,劝各位不要因为面试失败而灰心、丧失斗志。也不要因为面试通过而沾沾自喜,等待你的将是更美好的未来,继续加油!
|
|
||||||
|
|
||||||
## 4 如何学习?学会各种框架有必要吗?
|
|
||||||
|
|
||||||
### 4.1 我该如何学习?
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
最最最关键也是对自己最最最重要的就是学习!看看别人分享的面经,看看我写的这篇文章估计你只需要10分钟不到。但这些东西终究是空洞的理论,最主要的还是自己平时的学习!
|
|
||||||
|
|
||||||
如何去学呢?我觉得学习每个知识点可以考虑这样去入手:
|
|
||||||
|
|
||||||
1. **官网(大概率是英文,不推荐初学者看)**。
|
|
||||||
2. **书籍(知识更加系统完全,推荐)**。
|
|
||||||
3. **视频(比较容易理解,推荐,特别是初学的时候。慕课网和哔哩哔哩上面有挺多学习视频可以看,只直接在上面搜索关键词就可以了)**。
|
|
||||||
4. **网上博客(解决某一知识点的问题的时候可以看看)**。
|
|
||||||
|
|
||||||
这里给各位一个建议,**看视频的过程中最好跟着一起练,要做笔记!!!**
|
|
||||||
|
|
||||||
**最好可以边看视频边找一本书籍看,看视频没弄懂的知识点一定要尽快解决,如何解决?**
|
|
||||||
|
|
||||||
首先百度/Google,通过搜索引擎解决不了的话就找身边的朋友或者认识的一些人。
|
|
||||||
|
|
||||||
#### 4.2 学会各种框架有必要吗?
|
|
||||||
|
|
||||||
**一定要学会分配自己时间,要学的东西很多,真的很多,搞清楚哪些东西是重点,哪些东西仅仅了解就够了。一定不要把精力都花在了学各种框架上,算法、数据结构还有计算机网络真的很重要!**
|
|
||||||
|
|
||||||
另外,**学习的过程中有一个可以参考的文档很重要,非常有助于自己的学习**。我当初弄 JavaGuide: https://github.com/Snailclimb/JavaGuide 的很大一部分目的就是因为这个。**客观来说,相比于博客,JavaGuide 里面的内容因为更多人的参与变得更加准确和完善。**
|
|
||||||
|
|
||||||
如果大家觉得这篇文章不错的话,欢迎给我来个三连(评论+转发+在看)!我会在下一篇文章中介绍如何从技术面时的角度准备面试?
|
|
||||||
@ -1,728 +0,0 @@
|
|||||||
<!-- TOC -->
|
|
||||||
|
|
||||||
- [一 为什么 Java 中只有值传递?](#一-为什么-java-中只有值传递)
|
|
||||||
- [二 ==与 equals(重要)](#二-与-equals重要)
|
|
||||||
- [三 hashCode 与 equals(重要)](#三-hashcode-与-equals重要)
|
|
||||||
- [3.1 hashCode()介绍](#31-hashcode介绍)
|
|
||||||
- [3.2 为什么要有 hashCode](#32-为什么要有-hashcode)
|
|
||||||
- [3.3 hashCode()与 equals()的相关规定](#33-hashcode与-equals的相关规定)
|
|
||||||
- [3.4 为什么两个对象有相同的 hashcode 值,它们也不一定是相等的?](#34-为什么两个对象有相同的-hashcode-值它们也不一定是相等的)
|
|
||||||
- [四 String 和 StringBuffer、StringBuilder 的区别是什么?String 为什么是不可变的?](#四-string-和-stringbufferstringbuilder-的区别是什么string-为什么是不可变的)
|
|
||||||
- [String 为什么是不可变的吗?](#string-为什么是不可变的吗)
|
|
||||||
- [String 真的是不可变的吗?](#string-真的是不可变的吗)
|
|
||||||
- [五 什么是反射机制?反射机制的应用场景有哪些?](#五-什么是反射机制反射机制的应用场景有哪些)
|
|
||||||
- [5.1 反射机制介绍](#51-反射机制介绍)
|
|
||||||
- [5.2 静态编译和动态编译](#52-静态编译和动态编译)
|
|
||||||
- [5.3 反射机制优缺点](#53-反射机制优缺点)
|
|
||||||
- [5.4 反射的应用场景](#54-反射的应用场景)
|
|
||||||
- [六 什么是 JDK?什么是 JRE?什么是 JVM?三者之间的联系与区别](#六-什么是-jdk什么是-jre什么是-jvm三者之间的联系与区别)
|
|
||||||
- [6.1 JVM](#61-jvm)
|
|
||||||
- [6.2 JDK 和 JRE](#62-jdk-和-jre)
|
|
||||||
- [七 什么是字节码?采用字节码的最大好处是什么?](#七-什么是字节码采用字节码的最大好处是什么)
|
|
||||||
- [八 接口和抽象类的区别是什么?](#八-接口和抽象类的区别是什么)
|
|
||||||
- [九 重载和重写的区别](#九-重载和重写的区别)
|
|
||||||
- [重载](#重载)
|
|
||||||
- [重写](#重写)
|
|
||||||
- [十. Java 面向对象编程三大特性: 封装 继承 多态](#十-java-面向对象编程三大特性-封装-继承-多态)
|
|
||||||
- [封装](#封装)
|
|
||||||
- [继承](#继承)
|
|
||||||
- [多态](#多态)
|
|
||||||
- [十一. 什么是线程和进程?](#十一-什么是线程和进程)
|
|
||||||
- [11.1 何为进程?](#111-何为进程)
|
|
||||||
- [11.2 何为线程?](#112-何为线程)
|
|
||||||
- [十二. 请简要描述线程与进程的关系,区别及优缺点?](#十二-请简要描述线程与进程的关系区别及优缺点)
|
|
||||||
- [12.1 图解进程和线程的关系](#121-图解进程和线程的关系)
|
|
||||||
- [12.2 程序计数器为什么是私有的?](#122-程序计数器为什么是私有的)
|
|
||||||
- [12.3 虚拟机栈和本地方法栈为什么是私有的?](#123-虚拟机栈和本地方法栈为什么是私有的)
|
|
||||||
- [12.4 一句话简单了解堆和方法区](#124-一句话简单了解堆和方法区)
|
|
||||||
- [十三. 说说并发与并行的区别?](#十三-说说并发与并行的区别)
|
|
||||||
- [十四. 什么是上下文切换?](#十四-什么是上下文切换)
|
|
||||||
- [十五. 什么是线程死锁?如何避免死锁?](#十五-什么是线程死锁如何避免死锁)
|
|
||||||
- [15.1. 认识线程死锁](#151-认识线程死锁)
|
|
||||||
- [15.2 如何避免线程死锁?](#152-如何避免线程死锁)
|
|
||||||
- [十六. 说说 sleep() 方法和 wait() 方法区别和共同点?](#十六-说说-sleep-方法和-wait-方法区别和共同点)
|
|
||||||
- [十七. 为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?](#十七-为什么我们调用-start-方法时会执行-run-方法为什么我们不能直接调用-run-方法)
|
|
||||||
- [参考](#参考)
|
|
||||||
|
|
||||||
<!-- /TOC -->
|
|
||||||
|
|
||||||
## 一 为什么 Java 中只有值传递?
|
|
||||||
|
|
||||||
首先回顾一下在程序设计语言中有关将参数传递给方法(或函数)的一些专业术语。**按值调用(call by value)表示方法接收的是调用者提供的值,而按引用调用(call by reference)表示方法接收的是调用者提供的变量地址。一个方法可以修改传递引用所对应的变量值,而不能修改传递值调用所对应的变量值。** 它用来描述各种程序设计语言(不只是 Java)中方法参数传递方式。
|
|
||||||
|
|
||||||
**Java 程序设计语言总是采用按值调用。也就是说,方法得到的是所有参数值的一个拷贝,也就是说,方法不能修改传递给它的任何参数变量的内容。**
|
|
||||||
|
|
||||||
**下面通过 3 个例子来给大家说明**
|
|
||||||
|
|
||||||
> **example 1**
|
|
||||||
|
|
||||||
```java
|
|
||||||
public static void main(String[] args) {
|
|
||||||
int num1 = 10;
|
|
||||||
int num2 = 20;
|
|
||||||
|
|
||||||
swap(num1, num2);
|
|
||||||
|
|
||||||
System.out.println("num1 = " + num1);
|
|
||||||
System.out.println("num2 = " + num2);
|
|
||||||
}
|
|
||||||
|
|
||||||
public static void swap(int a, int b) {
|
|
||||||
int temp = a;
|
|
||||||
a = b;
|
|
||||||
b = temp;
|
|
||||||
|
|
||||||
System.out.println("a = " + a);
|
|
||||||
System.out.println("b = " + b);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
**结果:**
|
|
||||||
|
|
||||||
```
|
|
||||||
a = 20
|
|
||||||
b = 10
|
|
||||||
num1 = 10
|
|
||||||
num2 = 20
|
|
||||||
```
|
|
||||||
|
|
||||||
**解析:**
|
|
||||||
|
|
||||||
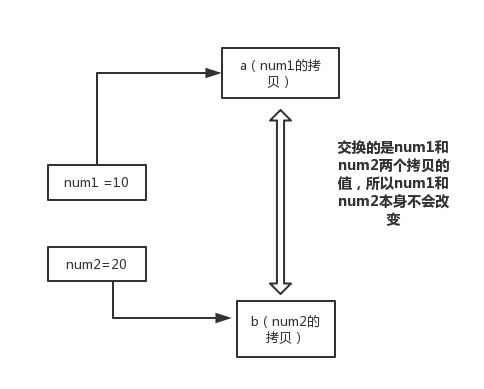
|
|
||||||
|
|
||||||
在 swap 方法中,a、b 的值进行交换,并不会影响到 num1、num2。因为,a、b 中的值,只是从 num1、num2 的复制过来的。也就是说,a、b 相当于 num1、num2 的副本,副本的内容无论怎么修改,都不会影响到原件本身。
|
|
||||||
|
|
||||||
**通过上面例子,我们已经知道了一个方法不能修改一个基本数据类型的参数,而对象引用作为参数就不一样,请看 example2.**
|
|
||||||
|
|
||||||
> **example 2**
|
|
||||||
|
|
||||||
```java
|
|
||||||
public static void main(String[] args) {
|
|
||||||
int[] arr = { 1, 2, 3, 4, 5 };
|
|
||||||
System.out.println(arr[0]);
|
|
||||||
change(arr);
|
|
||||||
System.out.println(arr[0]);
|
|
||||||
}
|
|
||||||
|
|
||||||
public static void change(int[] array) {
|
|
||||||
// 将数组的第一个元素变为0
|
|
||||||
array[0] = 0;
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
**结果:**
|
|
||||||
|
|
||||||
```
|
|
||||||
1
|
|
||||||
0
|
|
||||||
```
|
|
||||||
|
|
||||||
**解析:**
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
array 被初始化 arr 的拷贝也就是一个对象的引用,也就是说 array 和 arr 指向的是同一个数组对象。 因此,外部对引用对象的改变会反映到所对应的对象上。
|
|
||||||
|
|
||||||
**通过 example2 我们已经看到,实现一个改变对象参数状态的方法并不是一件难事。理由很简单,方法得到的是对象引用的拷贝,对象引用及其他的拷贝同时引用同一个对象。**
|
|
||||||
|
|
||||||
**很多程序设计语言(特别是,C++和 Pascal)提供了两种参数传递的方式:值调用和引用调用。有些程序员(甚至本书的作者)认为 Java 程序设计语言对对象采用的是引用调用,实际上,这种理解是不对的。由于这种误解具有一定的普遍性,所以下面给出一个反例来详细地阐述一下这个问题。**
|
|
||||||
|
|
||||||
> **example 3**
|
|
||||||
|
|
||||||
```java
|
|
||||||
public class Test {
|
|
||||||
|
|
||||||
public static void main(String[] args) {
|
|
||||||
// TODO Auto-generated method stub
|
|
||||||
Student s1 = new Student("小张");
|
|
||||||
Student s2 = new Student("小李");
|
|
||||||
Test.swap(s1, s2);
|
|
||||||
System.out.println("s1:" + s1.getName());
|
|
||||||
System.out.println("s2:" + s2.getName());
|
|
||||||
}
|
|
||||||
|
|
||||||
public static void swap(Student x, Student y) {
|
|
||||||
Student temp = x;
|
|
||||||
x = y;
|
|
||||||
y = temp;
|
|
||||||
System.out.println("x:" + x.getName());
|
|
||||||
System.out.println("y:" + y.getName());
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
**结果:**
|
|
||||||
|
|
||||||
```
|
|
||||||
x:小李
|
|
||||||
y:小张
|
|
||||||
s1:小张
|
|
||||||
s2:小李
|
|
||||||
```
|
|
||||||
|
|
||||||
**解析:**
|
|
||||||
|
|
||||||
交换之前:
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
交换之后:
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
通过上面两张图可以很清晰的看出: **方法并没有改变存储在变量 s1 和 s2 中的对象引用。swap 方法的参数 x 和 y 被初始化为两个对象引用的拷贝,这个方法交换的是这两个拷贝**
|
|
||||||
|
|
||||||
> **总结**
|
|
||||||
|
|
||||||
Java 程序设计语言对对象采用的不是引用调用,实际上,对象引用是按
|
|
||||||
值传递的。
|
|
||||||
|
|
||||||
下面再总结一下 Java 中方法参数的使用情况:
|
|
||||||
|
|
||||||
- 一个方法不能修改一个基本数据类型的参数(即数值型或布尔型)。
|
|
||||||
- 一个方法可以改变一个对象参数的状态。
|
|
||||||
- 一个方法不能让对象参数引用一个新的对象。
|
|
||||||
|
|
||||||
**参考:**
|
|
||||||
|
|
||||||
《Java 核心技术卷 Ⅰ》基础知识第十版第四章 4.5 小节
|
|
||||||
|
|
||||||
## 二 ==与 equals(重要)
|
|
||||||
|
|
||||||
**==** : 它的作用是判断两个对象的地址是不是相等。即,判断两个对象是不是同一个对象。(基本数据类型==比较的是值,引用数据类型==比较的是内存地址)
|
|
||||||
|
|
||||||
**equals()** : 它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
|
|
||||||
|
|
||||||
- 情况 1:类没有覆盖 equals()方法。则通过 equals()比较该类的两个对象时,等价于通过“==”比较这两个对象。
|
|
||||||
- 情况 2:类覆盖了 equals()方法。一般,我们都覆盖 equals()方法来两个对象的内容相等;若它们的内容相等,则返回 true(即,认为这两个对象相等)。
|
|
||||||
|
|
||||||
**举个例子:**
|
|
||||||
|
|
||||||
```java
|
|
||||||
public class test1 {
|
|
||||||
public static void main(String[] args) {
|
|
||||||
String a = new String("ab"); // a 为一个引用
|
|
||||||
String b = new String("ab"); // b为另一个引用,对象的内容一样
|
|
||||||
String aa = "ab"; // 放在常量池中
|
|
||||||
String bb = "ab"; // 从常量池中查找
|
|
||||||
if (aa == bb) // true
|
|
||||||
System.out.println("aa==bb");
|
|
||||||
if (a == b) // false,非同一对象
|
|
||||||
System.out.println("a==b");
|
|
||||||
if (a.equals(b)) // true
|
|
||||||
System.out.println("aEQb");
|
|
||||||
if (42 == 42.0) { // true
|
|
||||||
System.out.println("true");
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
**说明:**
|
|
||||||
|
|
||||||
- String 中的 equals 方法是被重写过的,因为 object 的 equals 方法是比较的对象的内存地址,而 String 的 equals 方法比较的是对象的值。
|
|
||||||
- 当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 String 对象。
|
|
||||||
|
|
||||||
## 三 hashCode() 与 equals()(重要)
|
|
||||||
|
|
||||||
面试官可能会问你:“你重写过 `hashcode` 和 `equals `么,为什么重写 `equals` 时必须重写 `hashCode` 方法?”
|
|
||||||
|
|
||||||
### 3.1 hashCode()介绍
|
|
||||||
|
|
||||||
`hashCode()` 的作用是获取哈希码,也称为散列码;它实际上是返回一个 int 整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。`hashCode() `定义在 JDK 的 `Object` 类中,这就意味着 Java 中的任何类都包含有 `hashCode()` 函数。另外需要注意的是: `Object` 的 hashcode 方法是本地方法,也就是用 c 语言或 c++ 实现的,该方法通常用来将对象的 内存地址 转换为整数之后返回。
|
|
||||||
|
|
||||||
```java
|
|
||||||
public native int hashCode();
|
|
||||||
```
|
|
||||||
|
|
||||||
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
|
|
||||||
|
|
||||||
### 3.2 为什么要有 hashCode?
|
|
||||||
|
|
||||||
**我们以“`HashSet` 如何检查重复”为例子来说明为什么要有 hashCode:**
|
|
||||||
|
|
||||||
当你把对象加入 `HashSet` 时,`HashSet` 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,`HashSet` 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,`HashSet` 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的 Java 启蒙书《Head fist java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
|
|
||||||
|
|
||||||
### 3.3 为什么重写 `equals` 时必须重写 `hashCode` 方法?
|
|
||||||
|
|
||||||
如果两个对象相等,则 hashcode 一定也是相同的。两个对象相等,对两个对象分别调用 equals 方法都返回 true。但是,两个对象有相同的 hashcode 值,它们也不一定是相等的 。**因此,equals 方法被覆盖过,则 `hashCode` 方法也必须被覆盖。**
|
|
||||||
|
|
||||||
> `hashCode()`的默认行为是对堆上的对象产生独特值。如果没有重写 `hashCode()`,则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
|
|
||||||
|
|
||||||
### 3.4 为什么两个对象有相同的 hashcode 值,它们也不一定是相等的?
|
|
||||||
|
|
||||||
在这里解释一位小伙伴的问题。以下内容摘自《Head Fisrt Java》。
|
|
||||||
|
|
||||||
因为 `hashCode()` 所使用的杂凑算法也许刚好会让多个对象传回相同的杂凑值。越糟糕的杂凑算法越容易碰撞,但这也与数据值域分布的特性有关(所谓碰撞也就是指的是不同的对象得到相同的 `hashCode`。
|
|
||||||
|
|
||||||
我们刚刚也提到了 `HashSet`,如果 `HashSet` 在对比的时候,同样的 hashcode 有多个对象,它会使用 `equals()` 来判断是否真的相同。也就是说 `hashcode` 只是用来缩小查找成本。
|
|
||||||
|
|
||||||
|
|
||||||
更多关于 `hashcode()` 和 `equals()` 的内容可以查看:[Java hashCode() 和 equals()的若干问题解答](https://www.cnblogs.com/skywang12345/p/3324958.html)
|
|
||||||
|
|
||||||
## 四 String 和 StringBuffer、StringBuilder 的区别是什么?String 为什么是不可变的?
|
|
||||||
|
|
||||||
**可变性**
|
|
||||||
|
|
||||||
简单的来说:String 类中使用 final 关键字修饰字符数组来保存字符串,`private final char value[]`,所以 String 对象是不可变的。而 StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类,在 AbstractStringBuilder 中也是使用字符数组保存字符串`char[]value` 但是没有用 final 关键字修饰,所以这两种对象都是可变的。
|
|
||||||
|
|
||||||
StringBuilder 与 StringBuffer 的构造方法都是调用父类构造方法也就是 AbstractStringBuilder 实现的,大家可以自行查阅源码。
|
|
||||||
|
|
||||||
AbstractStringBuilder.java
|
|
||||||
|
|
||||||
```java
|
|
||||||
abstract class AbstractStringBuilder implements Appendable, CharSequence {
|
|
||||||
char[] value;
|
|
||||||
int count;
|
|
||||||
AbstractStringBuilder() {
|
|
||||||
}
|
|
||||||
AbstractStringBuilder(int capacity) {
|
|
||||||
value = new char[capacity];
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
**线程安全性**
|
|
||||||
|
|
||||||
String 中的对象是不可变的,也就可以理解为常量,线程安全。AbstractStringBuilder 是 StringBuilder 与 StringBuffer 的公共父类,定义了一些字符串的基本操作,如 expandCapacity、append、insert、indexOf 等公共方法。StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。
|
|
||||||
|
|
||||||
**性能**
|
|
||||||
|
|
||||||
每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 StringBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
|
|
||||||
|
|
||||||
**对于三者使用的总结:**
|
|
||||||
|
|
||||||
1. 操作少量的数据: 适用 String
|
|
||||||
2. 单线程操作字符串缓冲区下操作大量数据: 适用 StringBuilder
|
|
||||||
3. 多线程操作字符串缓冲区下操作大量数据: 适用 StringBuffer
|
|
||||||
|
|
||||||
#### String 为什么是不可变的吗?
|
|
||||||
|
|
||||||
简单来说就是 String 类利用了 final 修饰的 char 类型数组存储字符,源码如下图所以:
|
|
||||||
|
|
||||||
```java
|
|
||||||
/** The value is used for character storage. */
|
|
||||||
private final char value[];
|
|
||||||
```
|
|
||||||
|
|
||||||
#### String 真的是不可变的吗?
|
|
||||||
|
|
||||||
我觉得如果别人问这个问题的话,回答不可变就可以了。
|
|
||||||
下面只是给大家看两个有代表性的例子:
|
|
||||||
|
|
||||||
**1) String 不可变但不代表引用不可以变**
|
|
||||||
|
|
||||||
```java
|
|
||||||
String str = "Hello";
|
|
||||||
str = str + " World";
|
|
||||||
System.out.println("str=" + str);
|
|
||||||
```
|
|
||||||
|
|
||||||
结果:
|
|
||||||
|
|
||||||
```
|
|
||||||
str=Hello World
|
|
||||||
```
|
|
||||||
|
|
||||||
解析:
|
|
||||||
|
|
||||||
实际上,原来 String 的内容是不变的,只是 str 由原来指向"Hello"的内存地址转为指向"Hello World"的内存地址而已,也就是说多开辟了一块内存区域给"Hello World"字符串。
|
|
||||||
|
|
||||||
**2) 通过反射是可以修改所谓的“不可变”对象**
|
|
||||||
|
|
||||||
```java
|
|
||||||
// 创建字符串"Hello World", 并赋给引用s
|
|
||||||
String s = "Hello World";
|
|
||||||
|
|
||||||
System.out.println("s = " + s); // Hello World
|
|
||||||
|
|
||||||
// 获取String类中的value字段
|
|
||||||
Field valueFieldOfString = String.class.getDeclaredField("value");
|
|
||||||
|
|
||||||
// 改变value属性的访问权限
|
|
||||||
valueFieldOfString.setAccessible(true);
|
|
||||||
|
|
||||||
// 获取s对象上的value属性的值
|
|
||||||
char[] value = (char[]) valueFieldOfString.get(s);
|
|
||||||
|
|
||||||
// 改变value所引用的数组中的第5个字符
|
|
||||||
value[5] = '_';
|
|
||||||
|
|
||||||
System.out.println("s = " + s); // Hello_World
|
|
||||||
```
|
|
||||||
|
|
||||||
结果:
|
|
||||||
|
|
||||||
```
|
|
||||||
s = Hello World
|
|
||||||
s = Hello_World
|
|
||||||
```
|
|
||||||
|
|
||||||
解析:
|
|
||||||
|
|
||||||
用反射可以访问私有成员, 然后反射出 String 对象中的 value 属性, 进而改变通过获得的 value 引用改变数组的结构。但是一般我们不会这么做,这里只是简单提一下有这个东西。
|
|
||||||
|
|
||||||
## 五 什么是反射机制?反射机制的应用场景有哪些?
|
|
||||||
|
|
||||||
### 5.1 反射机制介绍
|
|
||||||
|
|
||||||
JAVA 反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为 java 语言的反射机制。
|
|
||||||
|
|
||||||
### 5.2 静态编译和动态编译
|
|
||||||
|
|
||||||
- **静态编译:**在编译时确定类型,绑定对象
|
|
||||||
- **动态编译:**运行时确定类型,绑定对象
|
|
||||||
|
|
||||||
### 5.3 反射机制优缺点
|
|
||||||
|
|
||||||
- **优点:** 运行期类型的判断,动态加载类,提高代码灵活度。
|
|
||||||
- **缺点:** 性能瓶颈:反射相当于一系列解释操作,通知 JVM 要做的事情,性能比直接的 java 代码要慢很多。
|
|
||||||
|
|
||||||
### 5.4 反射的应用场景
|
|
||||||
|
|
||||||
**反射是框架设计的灵魂。**
|
|
||||||
|
|
||||||
在我们平时的项目开发过程中,基本上很少会直接使用到反射机制,但这不能说明反射机制没有用,实际上有很多设计、开发都与反射机制有关,例如模块化的开发,通过反射去调用对应的字节码;动态代理设计模式也采用了反射机制,还有我们日常使用的 Spring/Hibernate 等框架也大量使用到了反射机制。
|
|
||||||
|
|
||||||
举例:① 我们在使用 JDBC 连接数据库时使用 `Class.forName()`通过反射加载数据库的驱动程序;②Spring 框架也用到很多反射机制,最经典的就是 xml 的配置模式。Spring 通过 XML 配置模式装载 Bean 的过程:1) 将程序内所有 XML 或 Properties 配置文件加载入内存中;
|
|
||||||
2)Java 类里面解析 xml 或 properties 里面的内容,得到对应实体类的字节码字符串以及相关的属性信息; 3)使用反射机制,根据这个字符串获得某个类的 Class 实例; 4)动态配置实例的属性
|
|
||||||
|
|
||||||
**推荐阅读:**
|
|
||||||
|
|
||||||
- [Reflection:Java 反射机制的应用场景](https://segmentfault.com/a/1190000010162647?utm_source=tuicool&utm_medium=referral "Reflection:Java反射机制的应用场景")
|
|
||||||
- [Java 基础之—反射(非常重要)](https://blog.csdn.net/sinat_38259539/article/details/71799078 "Java基础之—反射(非常重要)")
|
|
||||||
|
|
||||||
## 六 什么是 JDK?什么是 JRE?什么是 JVM?三者之间的联系与区别
|
|
||||||
|
|
||||||
### 6.1 JVM
|
|
||||||
|
|
||||||
Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。
|
|
||||||
|
|
||||||
**什么是字节码?采用字节码的好处是什么?**
|
|
||||||
|
|
||||||
> 在 Java 中,JVM 可以理解的代码就叫做`字节码`(即扩展名为 `.class` 的文件),它不面向任何特定的处理器,只面向虚拟机。Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不针对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同操作系统的计算机上运行。
|
|
||||||
|
|
||||||
**Java 程序从源代码到运行一般有下面 3 步:**
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
我们需要格外注意的是 .class->机器码 这一步。在这一步 JVM 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的(也就是所谓的热点代码),所以后面引进了 JIT 编译器,而 JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 Java 是编译与解释共存的语言。
|
|
||||||
|
|
||||||
> HotSpot 采用了惰性评估(Lazy Evaluation)的做法,根据二八定律,消耗大部分系统资源的只有那一小部分的代码(热点代码),而这也就是 JIT 所需要编译的部分。JVM 会根据代码每次被执行的情况收集信息并相应地做出一些优化,因此执行的次数越多,它的速度就越快。JDK 9 引入了一种新的编译模式 AOT(Ahead of Time Compilation),它是直接将字节码编译成机器码,这样就避免了 JIT 预热等各方面的开销。JDK 支持分层编译和 AOT 协作使用。但是 ,AOT 编译器的编译质量是肯定比不上 JIT 编译器的。
|
|
||||||
|
|
||||||
**总结:**
|
|
||||||
|
|
||||||
Java 虚拟机(JVM)是运行 Java 字节码的虚拟机。JVM 有针对不同系统的特定实现(Windows,Linux,macOS),目的是使用相同的字节码,它们都会给出相同的结果。字节码和不同系统的 JVM 实现是 Java 语言“一次编译,随处可以运行”的关键所在。
|
|
||||||
|
|
||||||
### 6.2 JDK 和 JRE
|
|
||||||
|
|
||||||
JDK 是 Java Development Kit,它是功能齐全的 Java SDK。它拥有 JRE 所拥有的一切,还有编译器(javac)和工具(如 javadoc 和 jdb)。它能够创建和编译程序。
|
|
||||||
|
|
||||||
JRE 是 Java 运行时环境。它是运行已编译 Java 程序所需的所有内容的集合,包括 Java 虚拟机(JVM),Java 类库,java 命令和其他的一些基础构件。但是,它不能用于创建新程序。
|
|
||||||
|
|
||||||
如果你只是为了运行一下 Java 程序的话,那么你只需要安装 JRE 就可以了。如果你需要进行一些 Java 编程方面的工作,那么你就需要安装 JDK 了。但是,这不是绝对的。有时,即使您不打算在计算机上进行任何 Java 开发,仍然需要安装 JDK。例如,如果要使用 JSP 部署 Web 应用程序,那么从技术上讲,您只是在应用程序服务器中运行 Java 程序。那你为什么需要 JDK 呢?因为应用程序服务器会将 JSP 转换为 Java servlet,并且需要使用 JDK 来编译 servlet。
|
|
||||||
|
|
||||||
## 七 什么是字节码?采用字节码的最大好处是什么?
|
|
||||||
|
|
||||||
**先看下 java 中的编译器和解释器:**
|
|
||||||
|
|
||||||
Java 中引入了虚拟机的概念,即在机器和编译程序之间加入了一层抽象的虚拟的机器。这台虚拟的机器在任何平台上都提供给编译程序一个的共同的接口。编译程序只需要面向虚拟机,生成虚拟机能够理解的代码,然后由解释器来将虚拟机代码转换为特定系统的机器码执行。在 Java 中,这种供虚拟机理解的代码叫做`字节码`(即扩展名为`.class`的文件),它不面向任何特定的处理器,只面向虚拟机。每一种平台的解释器是不同的,但是实现的虚拟机是相同的。Java 源程序经过编译器编译后变成字节码,字节码由虚拟机解释执行,虚拟机将每一条要执行的字节码送给解释器,解释器将其翻译成特定机器上的机器码,然后在特定的机器上运行。这也就是解释了 Java 的编译与解释并存的特点。
|
|
||||||
|
|
||||||
Java 源代码---->编译器---->jvm 可执行的 Java 字节码(即虚拟指令)---->jvm---->jvm 中解释器----->机器可执行的二进制机器码---->程序运行。
|
|
||||||
|
|
||||||
**采用字节码的好处:**
|
|
||||||
|
|
||||||
Java 语言通过字节码的方式,在一定程度上解决了传统解释型语言执行效率低的问题,同时又保留了解释型语言可移植的特点。所以 Java 程序运行时比较高效,而且,由于字节码并不专对一种特定的机器,因此,Java 程序无须重新编译便可在多种不同的计算机上运行。
|
|
||||||
|
|
||||||
## 八 接口和抽象类的区别是什么?
|
|
||||||
|
|
||||||
1. 接口的方法默认是 public,所有方法在接口中不能有实现,抽象类可以有非抽象的方法
|
|
||||||
2. 接口中的实例变量默认是 final 类型的,而抽象类中则不一定
|
|
||||||
3. 一个类可以实现多个接口,但最多只能实现一个抽象类
|
|
||||||
4. 一个类实现接口的话要实现接口的所有方法,而抽象类不一定
|
|
||||||
5. 接口不能用 new 实例化,但可以声明,但是必须引用一个实现该接口的对象 从设计层面来说,抽象是对类的抽象,是一种模板设计,接口是行为的抽象,是一种行为的规范。
|
|
||||||
|
|
||||||
注意:Java8 后接口可以有默认实现( default )。
|
|
||||||
|
|
||||||
## 九 重载和重写的区别
|
|
||||||
|
|
||||||
### 重载
|
|
||||||
|
|
||||||
发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同。
|
|
||||||
|
|
||||||
下面是《Java 核心技术》对重载这个概念的介绍:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 重写
|
|
||||||
|
|
||||||
重写是子类对父类的允许访问的方法的实现过程进行重新编写,发生在子类中,方法名、参数列表必须相同,返回值范围小于等于父类,抛出的异常范围小于等于父类,访问修饰符范围大于等于父类。另外,如果父类方法访问修饰符为 private 则子类就不能重写该方法。**也就是说方法提供的行为改变,而方法的外貌并没有改变。**
|
|
||||||
|
|
||||||
## 十. Java 面向对象编程三大特性: 封装 继承 多态
|
|
||||||
|
|
||||||
### 封装
|
|
||||||
|
|
||||||
封装把一个对象的属性私有化,同时提供一些可以被外界访问的属性的方法,如果属性不想被外界访问,我们大可不必提供方法给外界访问。但是如果一个类没有提供给外界访问的方法,那么这个类也没有什么意义了。
|
|
||||||
|
|
||||||
### 继承
|
|
||||||
|
|
||||||
继承是使用已存在的类的定义作为基础建立新类的技术,新类的定义可以增加新的数据或新的功能,也可以用父类的功能,但不能选择性地继承父类。通过使用继承我们能够非常方便地复用以前的代码。
|
|
||||||
|
|
||||||
**关于继承如下 3 点请记住:**
|
|
||||||
|
|
||||||
1. 子类拥有父类对象所有的属性和方法(包括私有属性和私有方法),但是父类中的私有属性和方法子类是无法访问,**只是拥有**。
|
|
||||||
2. 子类可以拥有自己属性和方法,即子类可以对父类进行扩展。
|
|
||||||
3. 子类可以用自己的方式实现父类的方法。(以后介绍)。
|
|
||||||
|
|
||||||
### 多态
|
|
||||||
|
|
||||||
所谓多态就是指程序中定义的引用变量所指向的具体类型和通过该引用变量发出的方法调用在编程时并不确定,而是在程序运行期间才确定,即一个引用变量到底会指向哪个类的实例对象,该引用变量发出的方法调用到底是哪个类中实现的方法,必须在由程序运行期间才能决定。
|
|
||||||
|
|
||||||
在 Java 中有两种形式可以实现多态:继承(多个子类对同一方法的重写)和接口(实现接口并覆盖接口中同一方法)。
|
|
||||||
|
|
||||||
## 十一. 什么是线程和进程?
|
|
||||||
|
|
||||||
### 11.1 何为进程?
|
|
||||||
|
|
||||||
进程是程序的一次执行过程,是系统运行程序的基本单位,因此进程是动态的。系统运行一个程序即是一个进程从创建,运行到消亡的过程。
|
|
||||||
|
|
||||||
在 Java 中,当我们启动 main 函数时其实就是启动了一个 JVM 的进程,而 main 函数所在的线程就是这个进程中的一个线程,也称主线程。
|
|
||||||
|
|
||||||
如下图所示,在 windows 中通过查看任务管理器的方式,我们就可以清楚看到 window 当前运行的进程(.exe 文件的运行)。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 11.2 何为线程?
|
|
||||||
|
|
||||||
线程与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享进程的**堆**和**方法区**资源,但每个线程有自己的**程序计数器**、**虚拟机栈**和**本地方法栈**,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。
|
|
||||||
|
|
||||||
Java 程序天生就是多线程程序,我们可以通过 JMX 来看一下一个普通的 Java 程序有哪些线程,代码如下。
|
|
||||||
|
|
||||||
```java
|
|
||||||
public class MultiThread {
|
|
||||||
public static void main(String[] args) {
|
|
||||||
// 获取 Java 线程管理 MXBean
|
|
||||||
ThreadMXBean threadMXBean = ManagementFactory.getThreadMXBean();
|
|
||||||
// 不需要获取同步的 monitor 和 synchronizer 信息,仅获取线程和线程堆栈信息
|
|
||||||
ThreadInfo[] threadInfos = threadMXBean.dumpAllThreads(false, false);
|
|
||||||
// 遍历线程信息,仅打印线程 ID 和线程名称信息
|
|
||||||
for (ThreadInfo threadInfo : threadInfos) {
|
|
||||||
System.out.println("[" + threadInfo.getThreadId() + "] " + threadInfo.getThreadName());
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
上述程序输出如下(输出内容可能不同,不用太纠结下面每个线程的作用,只用知道 main 线程执行 main 方法即可):
|
|
||||||
|
|
||||||
```
|
|
||||||
[5] Attach Listener //添加事件
|
|
||||||
[4] Signal Dispatcher // 分发处理给 JVM 信号的线程
|
|
||||||
[3] Finalizer //调用对象 finalize 方法的线程
|
|
||||||
[2] Reference Handler //清除 reference 线程
|
|
||||||
[1] main //main 线程,程序入口
|
|
||||||
```
|
|
||||||
|
|
||||||
从上面的输出内容可以看出:**一个 Java 程序的运行是 main 线程和多个其他线程同时运行**。
|
|
||||||
|
|
||||||
## 十二. 请简要描述线程与进程的关系,区别及优缺点?
|
|
||||||
|
|
||||||
**从 JVM 角度说进程和线程之间的关系**
|
|
||||||
|
|
||||||
### 12.1 图解进程和线程的关系
|
|
||||||
|
|
||||||
下图是 Java 内存区域,通过下图我们从 JVM 的角度来说一下线程和进程之间的关系。如果你对 Java 内存区域 (运行时数据区) 这部分知识不太了解的话可以阅读一下这篇文章:[《可能是把 Java 内存区域讲的最清楚的一篇文章》](https://github.com/Snailclimb/JavaGuide/blob/3965c02cc0f294b0bd3580df4868d5e396959e2e/Java%E7%9B%B8%E5%85%B3/%E5%8F%AF%E8%83%BD%E6%98%AF%E6%8A%8AJava%E5%86%85%E5%AD%98%E5%8C%BA%E5%9F%9F%E8%AE%B2%E7%9A%84%E6%9C%80%E6%B8%85%E6%A5%9A%E7%9A%84%E4%B8%80%E7%AF%87%E6%96%87%E7%AB%A0.md "《可能是把 Java 内存区域讲的最清楚的一篇文章》")
|
|
||||||
|
|
||||||
<div align="center">
|
|
||||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-3/JVM运行时数据区域.png" width="600px"/>
|
|
||||||
</div>
|
|
||||||
|
|
||||||
从上图可以看出:一个进程中可以有多个线程,多个线程共享进程的**堆**和**方法区 (JDK1.8 之后的元空间)**资源,但是每个线程有自己的**程序计数器**、**虚拟机栈** 和 **本地方法栈**。
|
|
||||||
|
|
||||||
**总结:** 线程 是 进程 划分成的更小的运行单位。线程和进程最大的不同在于基本上各进程是独立的,而各线程则不一定,因为同一进程中的线程极有可能会相互影响。线程执行开销小,但不利于资源的管理和保护;而进程正相反
|
|
||||||
|
|
||||||
下面是该知识点的扩展内容!
|
|
||||||
|
|
||||||
下面来思考这样一个问题:为什么**程序计数器**、**虚拟机栈**和**本地方法栈**是线程私有的呢?为什么堆和方法区是线程共享的呢?
|
|
||||||
|
|
||||||
### 12.2 程序计数器为什么是私有的?
|
|
||||||
|
|
||||||
程序计数器主要有下面两个作用:
|
|
||||||
|
|
||||||
1. 字节码解释器通过改变程序计数器来依次读取指令,从而实现代码的流程控制,如:顺序执行、选择、循环、异常处理。
|
|
||||||
2. 在多线程的情况下,程序计数器用于记录当前线程执行的位置,从而当线程被切换回来的时候能够知道该线程上次运行到哪儿了。
|
|
||||||
|
|
||||||
需要注意的是,如果执行的是 native 方法,那么程序计数器记录的是 undefined 地址,只有执行的是 Java 代码时程序计数器记录的才是下一条指令的地址。
|
|
||||||
|
|
||||||
所以,程序计数器私有主要是为了**线程切换后能恢复到正确的执行位置**。
|
|
||||||
|
|
||||||
### 12.3 虚拟机栈和本地方法栈为什么是私有的?
|
|
||||||
|
|
||||||
- **虚拟机栈:** 每个 Java 方法在执行的同时会创建一个栈帧用于存储局部变量表、操作数栈、常量池引用等信息。从方法调用直至执行完成的过程,就对应着一个栈帧在 Java 虚拟机栈中入栈和出栈的过程。
|
|
||||||
- **本地方法栈:** 和虚拟机栈所发挥的作用非常相似,区别是: **虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。** 在 HotSpot 虚拟机中和 Java 虚拟机栈合二为一。
|
|
||||||
|
|
||||||
所以,为了**保证线程中的局部变量不被别的线程访问到**,虚拟机栈和本地方法栈是线程私有的。
|
|
||||||
|
|
||||||
### 12.4 一句话简单了解堆和方法区
|
|
||||||
|
|
||||||
堆和方法区是所有线程共享的资源,其中堆是进程中最大的一块内存,主要用于存放新创建的对象 (所有对象都在这里分配内存),方法区主要用于存放已被加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
|
|
||||||
|
|
||||||
## 十三. 说说并发与并行的区别?
|
|
||||||
|
|
||||||
- **并发:** 同一时间段,多个任务都在执行 (单位时间内不一定同时执行);
|
|
||||||
- **并行:** 单位时间内,多个任务同时执行。
|
|
||||||
|
|
||||||
## 十四. 什么是上下文切换?
|
|
||||||
|
|
||||||
多线程编程中一般线程的个数都大于 CPU 核心的个数,而一个 CPU 核心在任意时刻只能被一个线程使用,为了让这些线程都能得到有效执行,CPU 采取的策略是为每个线程分配时间片并轮转的形式。当一个线程的时间片用完的时候就会重新处于就绪状态让给其他线程使用,这个过程就属于一次上下文切换。
|
|
||||||
|
|
||||||
概括来说就是:当前任务在执行完 CPU 时间片切换到另一个任务之前会先保存自己的状态,以便下次再切换回这个任务时,可以再加载这个任务的状态。**任务从保存到再加载的过程就是一次上下文切换**。
|
|
||||||
|
|
||||||
上下文切换通常是计算密集型的。也就是说,它需要相当可观的处理器时间,在每秒几十上百次的切换中,每次切换都需要纳秒量级的时间。所以,上下文切换对系统来说意味着消耗大量的 CPU 时间,事实上,可能是操作系统中时间消耗最大的操作。
|
|
||||||
|
|
||||||
Linux 相比与其他操作系统(包括其他类 Unix 系统)有很多的优点,其中有一项就是,其上下文切换和模式切换的时间消耗非常少。
|
|
||||||
|
|
||||||
## 十五. 什么是线程死锁?如何避免死锁?
|
|
||||||
|
|
||||||
### 15.1. 认识线程死锁
|
|
||||||
|
|
||||||
多个线程同时被阻塞,它们中的一个或者全部都在等待某个资源被释放。由于线程被无限期地阻塞,因此程序不可能正常终止。
|
|
||||||
|
|
||||||
如下图所示,线程 A 持有资源 2,线程 B 持有资源 1,他们同时都想申请对方的资源,所以这两个线程就会互相等待而进入死锁状态。
|
|
||||||
|
|
||||||
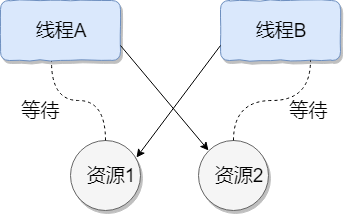
|
|
||||||
|
|
||||||
下面通过一个例子来说明线程死锁,代码模拟了上图的死锁的情况 (代码来源于《并发编程之美》):
|
|
||||||
|
|
||||||
```java
|
|
||||||
public class DeadLockDemo {
|
|
||||||
private static Object resource1 = new Object();//资源 1
|
|
||||||
private static Object resource2 = new Object();//资源 2
|
|
||||||
|
|
||||||
public static void main(String[] args) {
|
|
||||||
new Thread(() -> {
|
|
||||||
synchronized (resource1) {
|
|
||||||
System.out.println(Thread.currentThread() + "get resource1");
|
|
||||||
try {
|
|
||||||
Thread.sleep(1000);
|
|
||||||
} catch (InterruptedException e) {
|
|
||||||
e.printStackTrace();
|
|
||||||
}
|
|
||||||
System.out.println(Thread.currentThread() + "waiting get resource2");
|
|
||||||
synchronized (resource2) {
|
|
||||||
System.out.println(Thread.currentThread() + "get resource2");
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}, "线程 1").start();
|
|
||||||
|
|
||||||
new Thread(() -> {
|
|
||||||
synchronized (resource2) {
|
|
||||||
System.out.println(Thread.currentThread() + "get resource2");
|
|
||||||
try {
|
|
||||||
Thread.sleep(1000);
|
|
||||||
} catch (InterruptedException e) {
|
|
||||||
e.printStackTrace();
|
|
||||||
}
|
|
||||||
System.out.println(Thread.currentThread() + "waiting get resource1");
|
|
||||||
synchronized (resource1) {
|
|
||||||
System.out.println(Thread.currentThread() + "get resource1");
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}, "线程 2").start();
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
Output
|
|
||||||
|
|
||||||
```
|
|
||||||
Thread[线程 1,5,main]get resource1
|
|
||||||
Thread[线程 2,5,main]get resource2
|
|
||||||
Thread[线程 1,5,main]waiting get resource2
|
|
||||||
Thread[线程 2,5,main]waiting get resource1
|
|
||||||
```
|
|
||||||
|
|
||||||
线程 A 通过 synchronized (resource1) 获得 resource1 的监视器锁,然后通过`Thread.sleep(1000);`让线程 A 休眠 1s 为的是让线程 B 得到执行然后获取到 resource2 的监视器锁。线程 A 和线程 B 休眠结束了都开始企图请求获取对方的资源,然后这两个线程就会陷入互相等待的状态,这也就产生了死锁。上面的例子符合产生死锁的四个必要条件。
|
|
||||||
|
|
||||||
学过操作系统的朋友都知道产生死锁必须具备以下四个条件:
|
|
||||||
|
|
||||||
1. 互斥条件:该资源任意一个时刻只由一个线程占用。
|
|
||||||
2. 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
|
|
||||||
3. 不剥夺条件:线程已获得的资源在末使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
|
|
||||||
4. 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
|
|
||||||
|
|
||||||
### 15.2 如何避免线程死锁?
|
|
||||||
|
|
||||||
我们只要破坏产生死锁的四个条件中的其中一个就可以了。
|
|
||||||
|
|
||||||
**破坏互斥条件**
|
|
||||||
|
|
||||||
这个条件我们没有办法破坏,因为我们用锁本来就是想让他们互斥的(临界资源需要互斥访问)。
|
|
||||||
|
|
||||||
**破坏请求与保持条件**
|
|
||||||
|
|
||||||
一次性申请所有的资源。
|
|
||||||
|
|
||||||
**破坏不剥夺条件**
|
|
||||||
|
|
||||||
占用部分资源的线程进一步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
|
|
||||||
|
|
||||||
**破坏循环等待条件**
|
|
||||||
|
|
||||||
靠按序申请资源来预防。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
|
|
||||||
|
|
||||||
我们对线程 2 的代码修改成下面这样就不会产生死锁了。
|
|
||||||
|
|
||||||
```java
|
|
||||||
new Thread(() -> {
|
|
||||||
synchronized (resource1) {
|
|
||||||
System.out.println(Thread.currentThread() + "get resource1");
|
|
||||||
try {
|
|
||||||
Thread.sleep(1000);
|
|
||||||
} catch (InterruptedException e) {
|
|
||||||
e.printStackTrace();
|
|
||||||
}
|
|
||||||
System.out.println(Thread.currentThread() + "waiting get resource2");
|
|
||||||
synchronized (resource2) {
|
|
||||||
System.out.println(Thread.currentThread() + "get resource2");
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}, "线程 2").start();
|
|
||||||
```
|
|
||||||
|
|
||||||
Output
|
|
||||||
|
|
||||||
```
|
|
||||||
Thread[线程 1,5,main]get resource1
|
|
||||||
Thread[线程 1,5,main]waiting get resource2
|
|
||||||
Thread[线程 1,5,main]get resource2
|
|
||||||
Thread[线程 2,5,main]get resource1
|
|
||||||
Thread[线程 2,5,main]waiting get resource2
|
|
||||||
Thread[线程 2,5,main]get resource2
|
|
||||||
|
|
||||||
Process finished with exit code 0
|
|
||||||
```
|
|
||||||
|
|
||||||
我们分析一下上面的代码为什么避免了死锁的发生?
|
|
||||||
|
|
||||||
线程 1 首先获得到 resource1 的监视器锁,这时候线程 2 就获取不到了。然后线程 1 再去获取 resource2 的监视器锁,可以获取到。然后线程 1 释放了对 resource1、resource2 的监视器锁的占用,线程 2 获取到就可以执行了。这样就破坏了破坏循环等待条件,因此避免了死锁。
|
|
||||||
|
|
||||||
## 十六. 说说 sleep() 方法和 wait() 方法区别和共同点?
|
|
||||||
|
|
||||||
- 两者最主要的区别在于:**sleep 方法没有释放锁,而 wait 方法释放了锁** 。
|
|
||||||
- 两者都可以暂停线程的执行。
|
|
||||||
- Wait 通常被用于线程间交互/通信,sleep 通常被用于暂停执行。
|
|
||||||
- wait() 方法被调用后,线程不会自动苏醒,需要别的线程调用同一个对象上的 notify() 或者 notifyAll() 方法。sleep() 方法执行完成后,线程会自动苏醒。或者可以使用 wait(long timeout)超时后线程会自动苏醒。
|
|
||||||
|
|
||||||
## 十七. 为什么我们调用 start() 方法时会执行 run() 方法,为什么我们不能直接调用 run() 方法?
|
|
||||||
|
|
||||||
这是另一个非常经典的 java 多线程面试问题,而且在面试中会经常被问到。很简单,但是很多人都会答不上来!
|
|
||||||
|
|
||||||
new 一个 Thread,线程进入了新建状态;调用 start() 方法,会启动一个线程并使线程进入了就绪状态,当分配到时间片后就可以开始运行了。 start() 会执行线程的相应准备工作,然后自动执行 run() 方法的内容,这是真正的多线程工作。 而直接执行 run() 方法,会把 run 方法当成一个 main 线程下的普通方法去执行,并不会在某个线程中执行它,所以这并不是多线程工作。
|
|
||||||
|
|
||||||
**总结: 调用 start 方法方可启动线程并使线程进入就绪状态,而 run 方法只是 thread 的一个普通方法调用,还是在主线程里执行。**
|
|
||||||
|
|
||||||
## 参考
|
|
||||||
|
|
||||||
- [https://blog.csdn.net/zhzhao999/article/details/53449504](https://blog.csdn.net/zhzhao999/article/details/53449504 "https://blog.csdn.net/zhzhao999/article/details/53449504")
|
|
||||||
- [https://www.cnblogs.com/skywang12345/p/3324958.html](https://www.cnblogs.com/skywang12345/p/3324958.html "https://www.cnblogs.com/skywang12345/p/3324958.html")
|
|
||||||
- [https://www.cnblogs.com/Eason-S/p/5524837.html](https://www.cnblogs.com/Eason-S/p/5524837.html "https://www.cnblogs.com/Eason-S/p/5524837.html")
|
|
||||||
@ -1,122 +0,0 @@
|
|||||||
<!-- TOC -->
|
|
||||||
|
|
||||||
- [程序员简历就该这样写](#程序员简历就该这样写)
|
|
||||||
- [为什么说简历很重要?](#为什么说简历很重要)
|
|
||||||
- [先从面试前来说](#先从面试前来说)
|
|
||||||
- [再从面试中来说](#再从面试中来说)
|
|
||||||
- [下面这几点你必须知道](#下面这几点你必须知道)
|
|
||||||
- [必须了解的两大法则](#必须了解的两大法则)
|
|
||||||
- [STAR法则(Situation Task Action Result)](#star法则situation-task-action-result)
|
|
||||||
- [FAB 法则(Feature Advantage Benefit)](#fab-法则feature-advantage-benefit)
|
|
||||||
- [项目经历怎么写?](#项目经历怎么写)
|
|
||||||
- [专业技能该怎么写?](#专业技能该怎么写)
|
|
||||||
- [排版注意事项](#排版注意事项)
|
|
||||||
- [其他的一些小tips](#其他的一些小tips)
|
|
||||||
- [推荐的工具/网站](#推荐的工具网站)
|
|
||||||
|
|
||||||
<!-- /TOC -->
|
|
||||||
|
|
||||||
# 程序员简历就该这样写
|
|
||||||
|
|
||||||
本篇文章除了教大家用Markdown如何写一份程序员专属的简历,后面还会给大家推荐一些不错的用来写Markdown简历的软件或者网站,以及如何优雅的将Markdown格式转变为PDF格式或者其他格式。
|
|
||||||
|
|
||||||
推荐大家使用Markdown语法写简历,然后再将Markdown格式转换为PDF格式后进行简历投递。
|
|
||||||
|
|
||||||
如果你对Markdown语法不太了解的话,可以花半个小时简单看一下Markdown语法说明: http://www.markdown.cn 。
|
|
||||||
|
|
||||||
## 为什么说简历很重要?
|
|
||||||
|
|
||||||
一份好的简历可以在整个申请面试以及面试过程中起到非常好的作用。 在不夸大自己能力的情况下,写出一份好的简历也是一项很棒的能力。为什么说简历很重要呢?
|
|
||||||
|
|
||||||
### 先从面试前来说
|
|
||||||
|
|
||||||
- 假如你是网申,你的简历必然会经过HR的筛选,一张简历HR可能也就花费10秒钟看一下,然后HR就会决定你这一关是Fail还是Pass。
|
|
||||||
- 假如你是内推,如果你的简历没有什么优势的话,就算是内推你的人再用心,也无能为力。
|
|
||||||
|
|
||||||
另外,就算你通过了筛选,后面的面试中,面试官也会根据你的简历来判断你究竟是否值得他花费很多时间去面试。
|
|
||||||
|
|
||||||
所以,简历就像是我们的一个门面一样,它在很大程度上决定了你能否进入到下一轮的面试中。
|
|
||||||
|
|
||||||
### 再从面试中来说
|
|
||||||
|
|
||||||
我发现大家比较喜欢看面经 ,这点无可厚非,但是大部分面经都没告诉你很多问题都是在特定条件下才问的。举个简单的例子:一般情况下你的简历上注明你会的东西才会被问到(Java、数据结构、网络、算法这些基础是每个人必问的),比如写了你会 redis,那面试官就很大概率会问你 redis 的一些问题。比如:redis的常见数据类型及应用场景、redis是单线程为什么还这么快、 redis 和 memcached 的区别、redis 内存淘汰机制等等。
|
|
||||||
|
|
||||||
所以,首先,你要明确的一点是:**你不会的东西就不要写在简历上**。另外,**你要考虑你该如何才能让你的亮点在简历中凸显出来**,比如:你在某某项目做了什么事情解决了什么问题(只要有项目就一定有要解决的问题)、你的某一个项目里使用了什么技术后整体性能和并发量提升了很多等等。
|
|
||||||
|
|
||||||
面试和工作是两回事,聪明的人会把面试官往自己擅长的领域领,其他人则被面试官牵着鼻子走。虽说面试和工作是两回事,但是你要想要获得自己满意的 offer ,你自身的实力必须要强。
|
|
||||||
|
|
||||||
## 下面这几点你必须知道
|
|
||||||
|
|
||||||
1. 大部分公司的HR都说我们不看重学历(骗你的!),但是如果你的学校不出众的话,很难在一堆简历中脱颖而出,除非你的简历上有特别的亮点,比如:某某大厂的实习经历、获得了某某大赛的奖等等。
|
|
||||||
2. **大部分应届生找工作的硬伤是没有工作经验或实习经历,所以如果你是应届生就不要错过秋招和春招。一旦错过,你后面就极大可能会面临社招,这个时候没有工作经验的你可能就会面临各种碰壁,导致找不到一个好的工作**
|
|
||||||
3. **写在简历上的东西一定要慎重,这是面试官大量提问的地方;**
|
|
||||||
4. **将自己的项目经历完美的展示出来非常重要。**
|
|
||||||
|
|
||||||
## 必须了解的两大法则
|
|
||||||
|
|
||||||
### STAR法则(Situation Task Action Result)
|
|
||||||
|
|
||||||
- **Situation:** 事情是在什么情况下发生;
|
|
||||||
- **Task::** 你是如何明确你的任务的;
|
|
||||||
- **Action:** 针对这样的情况分析,你采用了什么行动方式;
|
|
||||||
- **Result:** 结果怎样,在这样的情况下你学习到了什么。
|
|
||||||
|
|
||||||
简而言之,STAR法则,就是一种讲述自己故事的方式,或者说,是一个清晰、条理的作文模板。不管是什么,合理熟练运用此法则,可以轻松的对面试官描述事物的逻辑方式,表现出自己分析阐述问题的清晰性、条理性和逻辑性。
|
|
||||||
|
|
||||||
### FAB 法则(Feature Advantage Benefit)
|
|
||||||
|
|
||||||
- **Feature:** 是什么;
|
|
||||||
- **Advantage:** 比别人好在哪些地方;
|
|
||||||
- **Benefit:** 如果雇佣你,招聘方会得到什么好处。
|
|
||||||
|
|
||||||
简单来说,这个法则主要是让你的面试官知道你的优势、招了你之后对公司有什么帮助。
|
|
||||||
|
|
||||||
## 项目经历怎么写?
|
|
||||||
|
|
||||||
简历上有一两个项目经历很正常,但是真正能把项目经历很好的展示给面试官的非常少。对于项目经历大家可以考虑从如下几点来写:
|
|
||||||
|
|
||||||
1. 对项目整体设计的一个感受
|
|
||||||
2. 在这个项目中你负责了什么、做了什么、担任了什么角色
|
|
||||||
3. 从这个项目中你学会了那些东西,使用到了那些技术,学会了那些新技术的使用
|
|
||||||
4. 另外项目描述中,最好可以体现自己的综合素质,比如你是如何协调项目组成员协同开发的或者在遇到某一个棘手的问题的时候你是如何解决的又或者说你在这个项目用了什么技术实现了什么功能比如:用redis做缓存提高访问速度和并发量、使用消息队列削峰和降流等等。
|
|
||||||
|
|
||||||
## 专业技能该怎么写?
|
|
||||||
|
|
||||||
先问一下你自己会什么,然后看看你意向的公司需要什么。一般HR可能并不太懂技术,所以他在筛选简历的时候可能就盯着你专业技能的关键词来看。对于公司有要求而你不会的技能,你可以花几天时间学习一下,然后在简历上可以写上自己了解这个技能。比如你可以这样写(下面这部分内容摘自我的简历,大家可以根据自己的情况做一些修改和完善):
|
|
||||||
|
|
||||||
- 计算机网络、数据结构、算法、操作系统等课内基础知识:掌握
|
|
||||||
- Java 基础知识:掌握
|
|
||||||
- JVM 虚拟机(Java内存区域、虚拟机垃圾算法、虚拟垃圾收集器、JVM内存管理):掌握
|
|
||||||
- 高并发、高可用、高性能系统开发:掌握
|
|
||||||
- Struts2、Spring、Hibernate、Ajax、Mybatis、JQuery :掌握
|
|
||||||
- SSH 整合、SSM 整合、 SOA 架构:掌握
|
|
||||||
- Dubbo: 掌握
|
|
||||||
- Zookeeper: 掌握
|
|
||||||
- 常见消息队列: 掌握
|
|
||||||
- Linux:掌握
|
|
||||||
- MySQL常见优化手段:掌握
|
|
||||||
- Spring Boot +Spring Cloud +Docker:了解
|
|
||||||
- Hadoop 生态相关技术中的 HDFS、Storm、MapReduce、Hive、Hbase :了解
|
|
||||||
- Python 基础、一些常见第三方库比如OpenCV、wxpy、wordcloud、matplotlib:熟悉
|
|
||||||
|
|
||||||
## 排版注意事项
|
|
||||||
|
|
||||||
1. 尽量简洁,不要太花里胡哨;
|
|
||||||
2. 一些技术名词不要弄错了大小写比如MySQL不要写成mysql,Java不要写成java。这个在我看来还是比较忌讳的,所以一定要注意这个细节;
|
|
||||||
3. 中文和数字英文之间加上空格的话看起来会舒服一点;
|
|
||||||
|
|
||||||
## 其他的一些小tips
|
|
||||||
|
|
||||||
1. 尽量避免主观表述,少一点语义模糊的形容词,尽量要简洁明了,逻辑结构清晰。
|
|
||||||
2. 如果自己有博客或者个人技术栈点的话,写上去会为你加分很多。
|
|
||||||
3. 如果自己的Github比较活跃的话,写上去也会为你加分很多。
|
|
||||||
4. 注意简历真实性,一定不要写自己不会的东西,或者带有欺骗性的内容
|
|
||||||
5. 项目经历建议以时间倒序排序,另外项目经历不在于多,而在于有亮点。
|
|
||||||
6. 如果内容过多的话,不需要非把内容压缩到一页,保持排版干净整洁就可以了。
|
|
||||||
7. 简历最后最好能加上:“感谢您花时间阅读我的简历,期待能有机会和您共事。”这句话,显的你会很有礼貌。
|
|
||||||
|
|
||||||
## 推荐的工具/网站
|
|
||||||
|
|
||||||
- 冷熊简历(MarkDown在线简历工具,可在线预览、编辑和生成PDF):<http://cv.ftqq.com/>
|
|
||||||
- Typora+[Java程序员简历模板](https://github.com/geekcompany/ResumeSample/blob/master/java.md)
|
|
||||||
- Guide哥自己写的Markdown模板:[https://github.com/Snailclimb/typora-markdown-resume](https://github.com/Snailclimb/typora-markdown-resume)
|
|
||||||
@ -1,925 +0,0 @@
|
|||||||
<!-- TOC -->
|
|
||||||
|
|
||||||
- [一 基础篇](#一-基础篇)
|
|
||||||
- [1. `System.out.println(3|9)`输出什么?](#1-systemoutprintln39输出什么)
|
|
||||||
- [2. 说一下转发(Forward)和重定向(Redirect)的区别](#2-说一下转发forward和重定向redirect的区别)
|
|
||||||
- [3. 在浏览器中输入 url 地址到显示主页的过程,整个过程会使用哪些协议](#3-在浏览器中输入-url-地址到显示主页的过程整个过程会使用哪些协议)
|
|
||||||
- [4. TCP 三次握手和四次挥手](#4-tcp-三次握手和四次挥手)
|
|
||||||
- [为什么要三次握手](#为什么要三次握手)
|
|
||||||
- [为什么要传回 SYN](#为什么要传回-syn)
|
|
||||||
- [传了 SYN,为啥还要传 ACK](#传了-syn为啥还要传-ack)
|
|
||||||
- [为什么要四次挥手](#为什么要四次挥手)
|
|
||||||
- [5. IP 地址与 MAC 地址的区别](#5-ip-地址与-mac-地址的区别)
|
|
||||||
- [6. HTTP 请求,响应报文格式](#6-http-请求响应报文格式)
|
|
||||||
- [7. 为什么要使用索引?索引这么多优点,为什么不对表中的每一个列创建一个索引呢?索引是如何提高查询速度的?说一下使用索引的注意事项?Mysql 索引主要使用的两种数据结构?什么是覆盖索引?](#7-为什么要使用索引索引这么多优点为什么不对表中的每一个列创建一个索引呢索引是如何提高查询速度的说一下使用索引的注意事项mysql-索引主要使用的两种数据结构什么是覆盖索引)
|
|
||||||
- [8. 进程与线程的区别是什么?进程间的几种通信方式说一下?线程间的几种通信方式知道不?](#8-进程与线程的区别是什么进程间的几种通信方式说一下线程间的几种通信方式知道不)
|
|
||||||
- [9. 为什么要用单例模式?手写几种线程安全的单例模式?](#9-为什么要用单例模式手写几种线程安全的单例模式)
|
|
||||||
- [10. 简单介绍一下 bean;知道 Spring 的 bean 的作用域与生命周期吗?](#10-简单介绍一下-bean知道-spring-的-bean-的作用域与生命周期吗)
|
|
||||||
- [11. Spring 中的事务传播行为了解吗?TransactionDefinition 接口中哪五个表示隔离级别的常量?](#11-spring-中的事务传播行为了解吗transactiondefinition-接口中哪五个表示隔离级别的常量)
|
|
||||||
- [事务传播行为](#事务传播行为)
|
|
||||||
- [隔离级别](#隔离级别)
|
|
||||||
- [12. SpringMVC 原理了解吗?](#12-springmvc-原理了解吗)
|
|
||||||
- [13. Spring AOP IOC 实现原理](#13-spring-aop-ioc-实现原理)
|
|
||||||
- [二 进阶篇](#二-进阶篇)
|
|
||||||
- [1 消息队列 MQ 的套路](#1-消息队列-mq-的套路)
|
|
||||||
- [1.1 介绍一下消息队列 MQ 的应用场景/使用消息队列的好处](#11-介绍一下消息队列-mq-的应用场景使用消息队列的好处)
|
|
||||||
- [1)通过异步处理提高系统性能](#1通过异步处理提高系统性能)
|
|
||||||
- [2)降低系统耦合性](#2降低系统耦合性)
|
|
||||||
- [1.2 那么使用消息队列会带来什么问题?考虑过这些问题吗?](#12-那么使用消息队列会带来什么问题考虑过这些问题吗)
|
|
||||||
- [1.3 介绍一下你知道哪几种消息队列,该如何选择呢?](#13-介绍一下你知道哪几种消息队列该如何选择呢)
|
|
||||||
- [1.4 关于消息队列其他一些常见的问题展望](#14-关于消息队列其他一些常见的问题展望)
|
|
||||||
- [2 谈谈 InnoDB 和 MyIsam 两者的区别](#2-谈谈-innodb-和-myisam-两者的区别)
|
|
||||||
- [2.1 两者的对比](#21-两者的对比)
|
|
||||||
- [2.2 关于两者的总结](#22-关于两者的总结)
|
|
||||||
- [3 聊聊 Java 中的集合吧!](#3-聊聊-java-中的集合吧)
|
|
||||||
- [3.1 Arraylist 与 LinkedList 有什么不同?(注意加上从数据结构分析的内容)](#31-arraylist-与-linkedlist-有什么不同注意加上从数据结构分析的内容)
|
|
||||||
- [3.2 HashMap 的底层实现](#32-hashmap-的底层实现)
|
|
||||||
- [1)JDK1.8 之前](#1jdk18-之前)
|
|
||||||
- [2)JDK1.8 之后](#2jdk18-之后)
|
|
||||||
- [3.3 既然谈到了红黑树,你给我手绘一个出来吧,然后简单讲一下自己对于红黑树的理解](#33-既然谈到了红黑树你给我手绘一个出来吧然后简单讲一下自己对于红黑树的理解)
|
|
||||||
- [3.4 红黑树这么优秀,为何不直接使用红黑树得了?](#34-红黑树这么优秀为何不直接使用红黑树得了)
|
|
||||||
- [3.5 HashMap 和 Hashtable 的区别/HashSet 和 HashMap 区别](#35-hashmap-和-hashtable-的区别hashset-和-hashmap-区别)
|
|
||||||
- [三 终结篇](#三-终结篇)
|
|
||||||
- [1. Object 类有哪些方法?](#1-object-类有哪些方法)
|
|
||||||
- [1.1 Object 类的常见方法总结](#11-object-类的常见方法总结)
|
|
||||||
- [1.2 hashCode 与 equals](#12-hashcode-与-equals)
|
|
||||||
- [1.2.1 hashCode()介绍](#121-hashcode介绍)
|
|
||||||
- [1.2.2 为什么要有 hashCode](#122-为什么要有-hashcode)
|
|
||||||
- [1.2.3 hashCode()与 equals()的相关规定](#123-hashcode与-equals的相关规定)
|
|
||||||
- [1.2.4 为什么两个对象有相同的 hashcode 值,它们也不一定是相等的?](#124-为什么两个对象有相同的-hashcode-值它们也不一定是相等的)
|
|
||||||
- [1.3 ==与 equals](#13-与-equals)
|
|
||||||
- [2 ConcurrentHashMap 相关问题](#2-concurrenthashmap-相关问题)
|
|
||||||
- [2.1 ConcurrentHashMap 和 Hashtable 的区别](#21-concurrenthashmap-和-hashtable-的区别)
|
|
||||||
- [2.2 ConcurrentHashMap 线程安全的具体实现方式/底层具体实现](#22-concurrenthashmap-线程安全的具体实现方式底层具体实现)
|
|
||||||
- [JDK1.7(上面有示意图)](#jdk17上面有示意图)
|
|
||||||
- [JDK1.8(上面有示意图)](#jdk18上面有示意图)
|
|
||||||
- [3 谈谈 synchronized 和 ReentrantLock 的区别](#3-谈谈-synchronized-和-reentrantlock-的区别)
|
|
||||||
- [4 线程池了解吗?](#4-线程池了解吗)
|
|
||||||
- [4.1 为什么要用线程池?](#41-为什么要用线程池)
|
|
||||||
- [4.2 Java 提供了哪几种线程池?他们各自的使用场景是什么?](#42-java-提供了哪几种线程池他们各自的使用场景是什么)
|
|
||||||
- [Java 主要提供了下面 4 种线程池](#java-主要提供了下面-4-种线程池)
|
|
||||||
- [各种线程池的适用场景介绍](#各种线程池的适用场景介绍)
|
|
||||||
- [4.3 创建的线程池的方式](#43-创建的线程池的方式)
|
|
||||||
- [5 Nginx](#5-nginx)
|
|
||||||
- [5.1 简单介绍一下 Nginx](#51-简单介绍一下-nginx)
|
|
||||||
- [反向代理](#反向代理)
|
|
||||||
- [负载均衡](#负载均衡)
|
|
||||||
- [动静分离](#动静分离)
|
|
||||||
- [5.2 为什么要用 Nginx?](#52-为什么要用-nginx)
|
|
||||||
- [5.3 Nginx 的四个主要组成部分了解吗?](#53-nginx-的四个主要组成部分了解吗)
|
|
||||||
|
|
||||||
<!-- /TOC -->
|
|
||||||
|
|
||||||
这些问题是 2018 年去美团面试的同学被问到的一些常见的问题,希望对你有帮助!
|
|
||||||
|
|
||||||
# 一 基础篇
|
|
||||||
|
|
||||||
## 1. `System.out.println(3|9)`输出什么?
|
|
||||||
|
|
||||||
正确答案:11。
|
|
||||||
|
|
||||||
**考察知识点:&和&&;|和||**
|
|
||||||
|
|
||||||
**&和&&:**
|
|
||||||
|
|
||||||
共同点:两者都可做逻辑运算符。它们都表示运算符的两边都是 true 时,结果为 true;
|
|
||||||
|
|
||||||
不同点: &也是位运算符。& 表示在运算时两边都会计算,然后再判断;&&表示先运算符号左边的东西,然后判断是否为 true,是 true 就继续运算右边的然后判断并输出,是 false 就停下来直接输出不会再运行后面的东西。
|
|
||||||
|
|
||||||
**|和||:**
|
|
||||||
|
|
||||||
共同点:两者都可做逻辑运算符。它们都表示运算符的两边任意一边为 true,结果为 true,两边都不是 true,结果就为 false;
|
|
||||||
|
|
||||||
不同点:|也是位运算符。| 表示两边都会运算,然后再判断结果;|| 表示先运算符号左边的东西,然后判断是否为 true,是 true 就停下来直接输出不会再运行后面的东西,是 false 就继续运算右边的然后判断并输出。
|
|
||||||
|
|
||||||
**回到本题:**
|
|
||||||
|
|
||||||
3 | 9=0011(二进制) | 1001(二进制)=1011(二进制)=11(十进制)
|
|
||||||
|
|
||||||
## 2. 说一下转发(Forward)和重定向(Redirect)的区别
|
|
||||||
|
|
||||||
**转发是服务器行为,重定向是客户端行为。**
|
|
||||||
|
|
||||||
**转发(Forword)** 通过 RequestDispatcher 对象的`forward(HttpServletRequest request,HttpServletResponse response)`方法实现的。`RequestDispatcher` 可以通过`HttpServletRequest` 的 `getRequestDispatcher()`方法获得。例如下面的代码就是跳转到 login_success.jsp 页面。
|
|
||||||
|
|
||||||
```java
|
|
||||||
request.getRequestDispatcher("login_success.jsp").forward(request, response);
|
|
||||||
```
|
|
||||||
|
|
||||||
**重定向(Redirect)** 是利用服务器返回的状态码来实现的。客户端浏览器请求服务器的时候,服务器会返回一个状态码。服务器通过 HttpServletResponse 的 setStatus(int status)方法设置状态码。如果服务器返回 301 或者 302,则浏览器会到新的网址重新请求该资源。
|
|
||||||
|
|
||||||
1. **从地址栏显示来说**:forward 是服务器请求资源,服务器直接访问目标地址的 URL,把那个 URL 的响应内容读取过来,然后把这些内容再发给浏览器。浏览器根本不知道服务器发送的内容从哪里来的,所以它的地址栏还是原来的地址。redirect 是服务端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址。所以地址栏显示的是新的 URL。
|
|
||||||
2. **从数据共享来说**:forward:转发页面和转发到的页面可以共享 request 里面的数据。redirect:不能共享数据。
|
|
||||||
3. **从运用地方来说**:forward:一般用于用户登陆的时候,根据角色转发到相应的模块。redirect:一般用于用户注销登陆时返回主页面和跳转到其它的网站等。
|
|
||||||
4. **从效率来说**:forward:高。redirect:低。
|
|
||||||
|
|
||||||
## 3. 在浏览器中输入 url 地址到显示主页的过程,整个过程会使用哪些协议
|
|
||||||
|
|
||||||
图片来源:《图解 HTTP》:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
总体来说分为以下几个过程:
|
|
||||||
|
|
||||||
1. DNS 解析
|
|
||||||
2. TCP 连接
|
|
||||||
3. 发送 HTTP 请求
|
|
||||||
4. 服务器处理请求并返回 HTTP 报文
|
|
||||||
5. 浏览器解析渲染页面
|
|
||||||
6. 连接结束
|
|
||||||
|
|
||||||
具体可以参考下面这篇文章:
|
|
||||||
|
|
||||||
- [https://segmentfault.com/a/1190000006879700](https://segmentfault.com/a/1190000006879700 "https://segmentfault.com/a/1190000006879700")
|
|
||||||
|
|
||||||
> 修正 [issue-568](https://github.com/Snailclimb/JavaGuide/issues/568 "issue-568"):上图中 IP 数据包在路由器之间使用的协议为 OPSF 协议错误,应该为 OSPF 协议 。
|
|
||||||
>
|
|
||||||
> IP 数据包在路由器之间传播大致分为 IGP 和 BGP 协议,而 IGP 目前主流为 OSPF 协议,思科,华为和 H3C 等主流厂商都有各自实现并使用;BGP 协议为不同 AS(自治系统号)间路由传输,也分为 I-BGP 和 E-BGP,详细资料请查看《TCP/IP 卷一》
|
|
||||||
|
|
||||||
## 4. TCP 三次握手和四次挥手
|
|
||||||
|
|
||||||
为了准确无误地把数据送达目标处,TCP 协议采用了三次握手策略。
|
|
||||||
|
|
||||||
**漫画图解:**
|
|
||||||
|
|
||||||
图片来源:《图解 HTTP》
|
|
||||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/tcp三次握手.jpg" style="zoom:50%;" />
|
|
||||||
|
|
||||||
**简单示意图:**
|
|
||||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/tcp三次握手2.jpg" style="zoom:50%;" />
|
|
||||||
|
|
||||||
- 客户端–发送带有 SYN 标志的数据包–一次握手–服务端
|
|
||||||
- 服务端–发送带有 SYN/ACK 标志的数据包–二次握手–客户端
|
|
||||||
- 客户端–发送带有带有 ACK 标志的数据包–三次握手–服务端
|
|
||||||
|
|
||||||
#### 为什么要三次握手
|
|
||||||
|
|
||||||
**三次握手的目的是建立可靠的通信信道,说到通讯,简单来说就是数据的发送与接收,而三次握手最主要的目的就是双方确认自己与对方的发送与接收是正常的。**
|
|
||||||
|
|
||||||
第一次握手:Client 什么都不能确认;Server 确认了对方发送正常,自己接收正常。
|
|
||||||
|
|
||||||
第二次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己接收正常,对方发送正常
|
|
||||||
|
|
||||||
第三次握手:Client 确认了:自己发送、接收正常,对方发送、接收正常;Server 确认了:自己发送、接收正常,对方发送、接收正常
|
|
||||||
|
|
||||||
所以三次握手就能确认双发收发功能都正常,缺一不可。
|
|
||||||
|
|
||||||
#### 为什么要传回 SYN
|
|
||||||
|
|
||||||
接收端传回发送端所发送的 SYN 是为了告诉发送端,我接收到的信息确实就是你所发送的信号了。
|
|
||||||
|
|
||||||
> SYN 是 TCP/IP 建立连接时使用的握手信号。在客户机和服务器之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务器使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement[汉译:确认字符 ,在数据通信传输中,接收站发给发送站的一种传输控制字符。它表示确认发来的数据已经接受无误。 ])消息响应。这样在客户机和服务器之间才能建立起可靠的 TCP 连接,数据才可以在客户机和服务器之间传递。
|
|
||||||
|
|
||||||
#### 传了 SYN,为啥还要传 ACK
|
|
||||||
|
|
||||||
双方通信无误必须是两者互相发送信息都无误。传了 SYN,证明发送方(主动关闭方)到接收方(被动关闭方)的通道没有问题,但是接收方到发送方的通道还需要 ACK 信号来进行验证。
|
|
||||||
|
|
||||||
断开一个 TCP 连接则需要“四次挥手”:
|
|
||||||
|
|
||||||
- 客户端-发送一个 FIN,用来关闭客户端到服务器的数据传送
|
|
||||||
- 服务器-收到这个 FIN,它发回一 个 ACK,确认序号为收到的序号加 1 。和 SYN 一样,一个 FIN 将占用一个序号
|
|
||||||
- 服务器-关闭与客户端的连接,发送一个 FIN 给客户端
|
|
||||||
- 客户端-发回 ACK 报文确认,并将确认序号设置为收到序号加 1
|
|
||||||
|
|
||||||
#### 为什么要四次挥手
|
|
||||||
|
|
||||||
任何一方都可以在数据传送结束后发出连接释放的通知,待对方确认后进入半关闭状态。当另一方也没有数据再发送的时候,则发出连接释放通知,对方确认后就完全关闭了 TCP 连接。
|
|
||||||
|
|
||||||
举个例子:A 和 B 打电话,通话即将结束后,A 说“我没啥要说的了”,B 回答“我知道了”,但是 B 可能还会有要说的话,A 不能要求 B 跟着自己的节奏结束通话,于是 B 可能又巴拉巴拉说了一通,最后 B 说“我说完了”,A 回答“知道了”,这样通话才算结束。
|
|
||||||
|
|
||||||
上面讲的比较概括,推荐一篇讲的比较细致的文章:[https://blog.csdn.net/qzcsu/article/details/72861891](https://blog.csdn.net/qzcsu/article/details/72861891 "https://blog.csdn.net/qzcsu/article/details/72861891")
|
|
||||||
|
|
||||||
## 5. IP 地址与 MAC 地址的区别
|
|
||||||
|
|
||||||
参考:[https://blog.csdn.net/guoweimelon/article/details/50858597](https://blog.csdn.net/guoweimelon/article/details/50858597 "https://blog.csdn.net/guoweimelon/article/details/50858597")
|
|
||||||
|
|
||||||
IP 地址是指互联网协议地址(Internet Protocol Address)IP Address 的缩写。IP 地址是 IP 协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。
|
|
||||||
|
|
||||||
MAC 地址又称为物理地址、硬件地址,用来定义网络设备的位置。网卡的物理地址通常是由网卡生产厂家写入网卡的,具有全球唯一性。MAC 地址用于在网络中唯一标示一个网卡,一台电脑会有一或多个网卡,每个网卡都需要有一个唯一的 MAC 地址。
|
|
||||||
|
|
||||||
## 6. HTTP 请求,响应报文格式
|
|
||||||
|
|
||||||
HTTP 请求报文主要由请求行、请求头部、请求正文 3 部分组成
|
|
||||||
|
|
||||||
HTTP 响应报文主要由状态行、响应头部、响应正文 3 部分组成
|
|
||||||
|
|
||||||
详细内容可以参考:[https://blog.csdn.net/a19881029/article/details/14002273](https://blog.csdn.net/a19881029/article/details/14002273 "https://blog.csdn.net/a19881029/article/details/14002273")
|
|
||||||
|
|
||||||
## 7. 为什么要使用索引?索引这么多优点,为什么不对表中的每一个列创建一个索引呢?索引是如何提高查询速度的?说一下使用索引的注意事项?Mysql 索引主要使用的两种数据结构?什么是覆盖索引?
|
|
||||||
|
|
||||||
**为什么要使用索引?**
|
|
||||||
|
|
||||||
1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
|
|
||||||
2. 可以大大加快 数据的检索速度(大大减少的检索的数据量), 这也是创建索引的最主要的原因。
|
|
||||||
3. 帮助服务器避免排序和临时表
|
|
||||||
4. 将随机 IO 变为顺序 IO
|
|
||||||
5. 可以加速表和表之间的连接,特别是在实现数据的参考完整性方面特别有意义。
|
|
||||||
|
|
||||||
**索引这么多优点,为什么不对表中的每一个列创建一个索引呢?**
|
|
||||||
|
|
||||||
1. 当对表中的数据进行增加、删除和修改的时候,索引也要动态的维护,这样就降低了数据的维护速度。
|
|
||||||
2. 索引需要占物理空间,除了数据表占数据空间之外,每一个索引还要占一定的物理空间,如果要建立聚簇索引,那么需要的空间就会更大。
|
|
||||||
3. 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加。
|
|
||||||
|
|
||||||
**索引是如何提高查询速度的?**
|
|
||||||
|
|
||||||
将无序的数据变成相对有序的数据(就像查目录一样)
|
|
||||||
|
|
||||||
**说一下使用索引的注意事项**
|
|
||||||
|
|
||||||
1. 避免 where 子句中对字段施加函数,这会造成无法命中索引。
|
|
||||||
2. 在使用 InnoDB 时使用与业务无关的自增主键作为主键,即使用逻辑主键,而不要使用业务主键。
|
|
||||||
3. 将打算加索引的列建议设置为 NOT NULL ,因为 NULL 比空字符串需要更多的存储空间(不仅仅是索引列,普通的列如果业务允许都建议设置为 NOT NULL)
|
|
||||||
4. 删除长期未使用的索引,不用的索引的存在会造成不必要的性能损耗 MySQL 5.7 可以通过查询 sys 库的 schema_unused_indexes 视图来查询哪些索引从未被使用
|
|
||||||
5. 在使用 limit offset 查询缓慢时,可以借助索引来提高性能
|
|
||||||
|
|
||||||
**Mysql 索引主要使用的哪两种数据结构?**
|
|
||||||
|
|
||||||
- 哈希索引:对于哈希索引来说,底层的数据结构就是哈希表,因此在绝大多数需求为单条记录查询的时候,可以选择哈希索引,查询性能最快;其余大部分场景,建议选择 BTree 索引。
|
|
||||||
- BTree 索引:Mysql 的 BTree 索引使用的是 B 树中的 B+Tree。但对于主要的两种存储引擎(MyISAM 和 InnoDB)的实现方式是不同的。
|
|
||||||
|
|
||||||
更多关于索引的内容可以查看我的这篇文章:[【思维导图-索引篇】搞定数据库索引就是这么简单](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484486&idx=1&sn=215450f11e042bca8a58eac9f4a97686&chksm=fd985227caefdb3117b8375f150676f5824aa20d1ebfdbcfb93ff06e23e26efbafae6cf6b48e&token=1990180468&lang=zh_CN#rd)
|
|
||||||
|
|
||||||
**什么是覆盖索引?**
|
|
||||||
|
|
||||||
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称
|
|
||||||
之为“覆盖索引”。我们知道在 InnoDB 存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次,这样就会比较慢。覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
|
|
||||||
|
|
||||||
## 8. 进程与线程的区别是什么?进程间的几种通信方式说一下?线程间的几种通信方式知道不?
|
|
||||||
|
|
||||||
**进程与线程的区别是什么?**
|
|
||||||
|
|
||||||
线程与进程相似,但线程是一个比进程更小的执行单位。一个进程在其执行的过程中可以产生多个线程。与进程不同的是同类的多个线程共享同一块内存空间和一组系统资源,所以系统在产生一个线程,或是在各个线程之间作切换工作时,负担要比进程小得多,也正因为如此,线程也被称为轻量级进程。另外,也正是因为共享资源,所以线程中执行时一般都要进行同步和互斥。总的来说,进程和线程的主要差别在于它们是不同的操作系统资源管理方式。
|
|
||||||
|
|
||||||
**进程间的几种通信方式说一下?**
|
|
||||||
|
|
||||||
1. **管道(pipe)**:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有血缘关系的进程间使用。进程的血缘关系通常指父子进程关系。管道分为 pipe(无名管道)和 fifo(命名管道)两种,有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间通信。
|
|
||||||
2. **信号量(semophore)**:信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它通常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
|
|
||||||
3. **消息队列(message queue)**:消息队列是由消息组成的链表,存放在内核中 并由消息队列标识符标识。消息队列克服了信号传递信息少,管道只能承载无格式字节流以及缓冲区大小受限等缺点。消息队列与管道通信相比,其优势是对每个消息指定特定的消息类型,接收的时候不需要按照队列次序,而是可以根据自定义条件接收特定类型的消息。
|
|
||||||
4. **信号(signal)**:信号是一种比较复杂的通信方式,用于通知接收进程某一事件已经发生。
|
|
||||||
5. **共享内存(shared memory)**:共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问,共享内存是最快的 IPC 方式,它是针对其他进程间的通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号量配合使用,来实现进程间的同步和通信。
|
|
||||||
6. **套接字(socket)**:socket,即套接字是一种通信机制,凭借这种机制,客户/服务器(即要进行通信的进程)系统的开发工作既可以在本地单机上进行,也可以跨网络进行。也就是说它可以让不在同一台计算机但通过网络连接计算机上的进程进行通信。也因为这样,套接字明确地将客户端和服务器区分开来。
|
|
||||||
|
|
||||||
**线程间的几种通信方式知道不?**
|
|
||||||
|
|
||||||
1、锁机制
|
|
||||||
|
|
||||||
- 互斥锁:提供了以排它方式阻止数据结构被并发修改的方法。
|
|
||||||
- 读写锁:允许多个线程同时读共享数据,而对写操作互斥。
|
|
||||||
- 条件变量:可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
|
|
||||||
|
|
||||||
2、信号量机制:包括无名线程信号量与有名线程信号量
|
|
||||||
|
|
||||||
3、信号机制:类似于进程间的信号处理。
|
|
||||||
|
|
||||||
线程间通信的主要目的是用于线程同步,所以线程没有象进程通信中用于数据交换的通信机制。
|
|
||||||
|
|
||||||
## 9. 为什么要用单例模式?手写几种线程安全的单例模式?
|
|
||||||
|
|
||||||
**简单来说使用单例模式可以带来下面几个好处:**
|
|
||||||
|
|
||||||
- 对于频繁使用的对象,可以省略创建对象所花费的时间,这对于那些重量级对象而言,是非常可观的一笔系统开销;
|
|
||||||
- 由于 new 操作的次数减少,因而对系统内存的使用频率也会降低,这将减轻 GC 压力,缩短 GC 停顿时间。
|
|
||||||
|
|
||||||
**懒汉式(双重检查加锁版本)**
|
|
||||||
|
|
||||||
```java
|
|
||||||
public class Singleton {
|
|
||||||
|
|
||||||
//volatile保证,当uniqueInstance变量被初始化成Singleton实例时,多个线程可以正确处理uniqueInstance变量
|
|
||||||
private volatile static Singleton uniqueInstance;
|
|
||||||
private Singleton() {
|
|
||||||
}
|
|
||||||
public static Singleton getInstance() {
|
|
||||||
//检查实例,如果不存在,就进入同步代码块
|
|
||||||
if (uniqueInstance == null) {
|
|
||||||
//只有第一次才彻底执行这里的代码
|
|
||||||
synchronized(Singleton.class) {
|
|
||||||
//进入同步代码块后,再检查一次,如果仍是null,才创建实例
|
|
||||||
if (uniqueInstance == null) {
|
|
||||||
uniqueInstance = new Singleton();
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
return uniqueInstance;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
**静态内部类方式**
|
|
||||||
|
|
||||||
静态内部实现的单例是懒加载的且线程安全。
|
|
||||||
|
|
||||||
只有通过显式调用 getInstance 方法时,才会显式装载 SingletonHolder 类,从而实例化 instance(只有第一次使用这个单例的实例的时候才加载,同时不会有线程安全问题)。
|
|
||||||
|
|
||||||
```java
|
|
||||||
public class Singleton {
|
|
||||||
private static class SingletonHolder {
|
|
||||||
private static final Singleton INSTANCE = new Singleton();
|
|
||||||
}
|
|
||||||
private Singleton (){}
|
|
||||||
public static final Singleton getInstance() {
|
|
||||||
return SingletonHolder.INSTANCE;
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
## 10. 简单介绍一下 bean;知道 Spring 的 bean 的作用域与生命周期吗?
|
|
||||||
|
|
||||||
在 Spring 中,那些组成应用程序的主体及由 Spring IOC 容器所管理的对象,被称之为 bean。简单地讲,bean 就是由 IOC 容器初始化、装配及管理的对象,除此之外,bean 就与应用程序中的其他对象没有什么区别了。而 bean 的定义以及 bean 相互间的依赖关系将通过配置元数据来描述。
|
|
||||||
|
|
||||||
Spring 中的 bean 默认都是单例的,这些单例 Bean 在多线程程序下如何保证线程安全呢? 例如对于 Web 应用来说,Web 容器对于每个用户请求都创建一个单独的 Sevlet 线程来处理请求,引入 Spring 框架之后,每个 Action 都是单例的,那么对于 Spring 托管的单例 Service Bean,如何保证其安全呢? Spring 的单例是基于 BeanFactory 也就是 Spring 容器的,单例 Bean 在此容器内只有一个,Java 的单例是基于 JVM,每个 JVM 内只有一个实例。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
Spring 的 bean 的生命周期以及更多内容可以查看:[一文轻松搞懂 Spring 中 bean 的作用域与生命周期](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484400&idx=2&sn=7201eb365102fce017f89cb3527fb0bc&chksm=fd985591caefdc872a2fac897288119f94c345e4e12150774f960bf5f816b79e4b9b46be3d7f&token=1990180468&lang=zh_CN#rd)
|
|
||||||
|
|
||||||
## 11. Spring 中的事务传播行为了解吗?TransactionDefinition 接口中哪五个表示隔离级别的常量?
|
|
||||||
|
|
||||||
#### 事务传播行为
|
|
||||||
|
|
||||||
事务传播行为(为了解决业务层方法之间互相调用的事务问题):
|
|
||||||
当事务方法被另一个事务方法调用时,必须指定事务应该如何传播。例如:方法可能继续在现有事务中运行,也可能开启一个新事务,并在自己的事务中运行。在 TransactionDefinition 定义中包括了如下几个表示传播行为的常量:
|
|
||||||
|
|
||||||
**支持当前事务的情况:**
|
|
||||||
|
|
||||||
- TransactionDefinition.PROPAGATION_REQUIRED: 如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。
|
|
||||||
- TransactionDefinition.PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。
|
|
||||||
- TransactionDefinition.PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)
|
|
||||||
|
|
||||||
**不支持当前事务的情况:**
|
|
||||||
|
|
||||||
- TransactionDefinition.PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。
|
|
||||||
- TransactionDefinition.PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。
|
|
||||||
- TransactionDefinition.PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。
|
|
||||||
|
|
||||||
**其他情况:**
|
|
||||||
|
|
||||||
- TransactionDefinition.PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于 TransactionDefinition.PROPAGATION_REQUIRED。
|
|
||||||
|
|
||||||
#### 隔离级别
|
|
||||||
|
|
||||||
TransactionDefinition 接口中定义了五个表示隔离级别的常量:
|
|
||||||
|
|
||||||
- **TransactionDefinition.ISOLATION_DEFAULT:** 使用后端数据库默认的隔离级别,Mysql 默认采用的 REPEATABLE_READ 隔离级别 Oracle 默认采用的 READ_COMMITTED 隔离级别.
|
|
||||||
- **TransactionDefinition.ISOLATION_READ_UNCOMMITTED:** 最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读
|
|
||||||
- **TransactionDefinition.ISOLATION_READ_COMMITTED:** 允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生
|
|
||||||
- **TransactionDefinition.ISOLATION_REPEATABLE_READ:** 对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。
|
|
||||||
- **TransactionDefinition.ISOLATION_SERIALIZABLE:** 最高的隔离级别,完全服从 ACID 的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。
|
|
||||||
|
|
||||||
## 12. SpringMVC 原理了解吗?
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
客户端发送请求-> 前端控制器 DispatcherServlet 接受客户端请求 -> 找到处理器映射 HandlerMapping 解析请求对应的 Handler-> HandlerAdapter 会根据 Handler 来调用真正的处理器处理请求,并处理相应的业务逻辑 -> 处理器返回一个模型视图 ModelAndView -> 视图解析器进行解析 -> 返回一个视图对象->前端控制器 DispatcherServlet 渲染数据(Model)->将得到视图对象返回给用户
|
|
||||||
|
|
||||||
关于 SpringMVC 原理更多内容可以查看我的这篇文章:[SpringMVC 工作原理详解](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484496&idx=1&sn=5472ffa687fe4a05f8900d8ee6726de4&chksm=fd985231caefdb27fc75b44ecf76b6f43e4617e0b01b3c040f8b8fab32e51dfa5118eed1d6ad&token=1990180468&lang=zh_CN#rd)
|
|
||||||
|
|
||||||
## 13. Spring AOP IOC 实现原理
|
|
||||||
|
|
||||||
过了秋招挺长一段时间了,说实话我自己也忘了如何简要概括 Spring AOP IOC 实现原理,就在网上找了一个较为简洁的答案,下面分享给各位。
|
|
||||||
|
|
||||||
**IOC:** 控制反转也叫依赖注入。IOC 利用 java 反射机制,AOP 利用代理模式。IOC 概念看似很抽象,但是很容易理解。说简单点就是将对象交给容器管理,你只需要在 spring 配置文件中配置对应的 bean 以及设置相关的属性,让 spring 容器来生成类的实例对象以及管理对象。在 spring 容器启动的时候,spring 会把你在配置文件中配置的 bean 都初始化好,然后在你需要调用的时候,就把它已经初始化好的那些 bean 分配给你需要调用这些 bean 的类。
|
|
||||||
|
|
||||||
**AOP:** 面向切面编程。(Aspect-Oriented Programming) 。AOP 可以说是对 OOP 的补充和完善。OOP 引入封装、继承和多态性等概念来建立一种对象层次结构,用以模拟公共行为的一个集合。实现 AOP 的技术,主要分为两大类:一是采用动态代理技术,利用截取消息的方式,对该消息进行装饰,以取代原有对象行为的执行;二是采用静态织入的方式,引入特定的语法创建“方面”,从而使得编译器可以在编译期间织入有关“方面”的代码,属于静态代理。
|
|
||||||
|
|
||||||
# 二 进阶篇
|
|
||||||
|
|
||||||
## 1 消息队列 MQ 的套路
|
|
||||||
|
|
||||||
消息队列/消息中间件应该是 Java 程序员必备的一个技能了,如果你之前没接触过消息队列的话,建议先去百度一下某某消息队列入门,然后花 2 个小时就差不多可以学会任何一种消息队列的使用了。如果说仅仅学会使用是万万不够的,在实际生产环境还要考虑消息丢失等等情况。关于消息队列面试相关的问题,推荐大家也可以看一下视频《Java 工程师面试突击第 1 季-中华石杉老师》,如果大家没有资源的话,可以在我的公众号“Java 面试通关手册”后台回复关键字“1”即可!
|
|
||||||
|
|
||||||
### 1.1 介绍一下消息队列 MQ 的应用场景/使用消息队列的好处
|
|
||||||
|
|
||||||
面试官一般会先问你这个问题,预热一下,看你知道消息队列不,一般在第一面的时候面试官可能只会问消息队列 MQ 的应用场景/使用消息队列的好处、使用消息队列会带来什么问题、消息队列的技术选型这几个问题,不会太深究下去,在后面的第二轮/第三轮技术面试中可能会深入问一下。
|
|
||||||
|
|
||||||
**《大型网站技术架构》第四章和第七章均有提到消息队列对应用性能及扩展性的提升。**
|
|
||||||
|
|
||||||
#### 1)通过异步处理提高系统性能
|
|
||||||
|
|
||||||

|
|
||||||
如上图,**在不使用消息队列服务器的时候,用户的请求数据直接写入数据库,在高并发的情况下数据库压力剧增,使得响应速度变慢。但是在使用消息队列之后,用户的请求数据发送给消息队列之后立即 返回,再由消息队列的消费者进程从消息队列中获取数据,异步写入数据库。由于消息队列服务器处理速度快于数据库(消息队列也比数据库有更好的伸缩性),因此响应速度得到大幅改善。**
|
|
||||||
|
|
||||||
通过以上分析我们可以得出**消息队列具有很好的削峰作用的功能**——即**通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。** 举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
|
|
||||||

|
|
||||||
因为**用户请求数据写入消息队列之后就立即返回给用户了,但是请求数据在后续的业务校验、写数据库等操作中可能失败**。因此使用消息队列进行异步处理之后,需要**适当修改业务流程进行配合**,比如**用户在提交订单之后,订单数据写入消息队列,不能立即返回用户订单提交成功,需要在消息队列的订单消费者进程真正处理完该订单之后,甚至出库后,再通过电子邮件或短信通知用户订单成功**,以免交易纠纷。这就类似我们平时手机订火车票和电影票。
|
|
||||||
|
|
||||||
#### 2)降低系统耦合性
|
|
||||||
|
|
||||||
我们知道模块分布式部署以后聚合方式通常有两种:1.**分布式消息队列**和 2.**分布式服务**。
|
|
||||||
|
|
||||||
> **先来简单说一下分布式服务:**
|
|
||||||
|
|
||||||
目前使用比较多的用来构建**SOA(Service Oriented Architecture 面向服务体系结构)**的**分布式服务框架**是阿里巴巴开源的**Dubbo**。如果想深入了解 Dubbo 的可以看我写的关于 Dubbo 的这一篇文章:**《高性能优秀的服务框架-dubbo 介绍》**:[https://juejin.im/post/5acadeb1f265da2375072f9c](https://juejin.im/post/5acadeb1f265da2375072f9c "https://juejin.im/post/5acadeb1f265da2375072f9c")
|
|
||||||
|
|
||||||
> **再来谈我们的分布式消息队列:**
|
|
||||||
|
|
||||||
我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。
|
|
||||||
|
|
||||||
我们最常见的**事件驱动架构**类似生产者消费者模式,在大型网站中通常用利用消息队列实现事件驱动结构。如下图所示:
|
|
||||||
|
|
||||||

|
|
||||||
**消息队列使利用发布-订阅模式工作,消息发送者(生产者)发布消息,一个或多个消息接受者(消费者)订阅消息。** 从上图可以看到**消息发送者(生产者)和消息接受者(消费者)之间没有直接耦合**,消息发送者将消息发送至分布式消息队列即结束对消息的处理,消息接受者从分布式消息队列获取该消息后进行后续处理,并不需要知道该消息从何而来。**对新增业务,只要对该类消息感兴趣,即可订阅该消息,对原有系统和业务没有任何影响,从而实现网站业务的可扩展性设计**。
|
|
||||||
|
|
||||||
消息接受者对消息进行过滤、处理、包装后,构造成一个新的消息类型,将消息继续发送出去,等待其他消息接受者订阅该消息。因此基于事件(消息对象)驱动的业务架构可以是一系列流程。
|
|
||||||
|
|
||||||
**另外为了避免消息队列服务器宕机造成消息丢失,会将成功发送到消息队列的消息存储在消息生产者服务器上,等消息真正被消费者服务器处理后才删除消息。在消息队列服务器宕机后,生产者服务器会选择分布式消息队列服务器集群中的其他服务器发布消息。**
|
|
||||||
|
|
||||||
**备注:** 不要认为消息队列只能利用发布-订阅模式工作,只不过在解耦这个特定业务环境下是使用发布-订阅模式的,**比如在我们的 ActiveMQ 消息队列中还有点对点工作模式**,具体的会在后面的文章给大家详细介绍,这一篇文章主要还是让大家对消息队列有一个更透彻的了解。
|
|
||||||
|
|
||||||
> 这个问题一般会在上一个问题问完之后,紧接着被问到。“使用消息队列会带来什么问题?”这个问题要引起重视,一般我们都会考虑使用消息队列会带来的好处而忽略它带来的问题!
|
|
||||||
|
|
||||||
### 1.2 那么使用消息队列会带来什么问题?考虑过这些问题吗?
|
|
||||||
|
|
||||||
- **系统可用性降低:** 系统可用性在某种程度上降低,为什么这样说呢?在加入 MQ 之前,你不用考虑消息丢失或者说 MQ 挂掉等等的情况,但是,引入 MQ 之后你就需要去考虑了!
|
|
||||||
- **系统复杂性提高:** 加入 MQ 之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
|
|
||||||
- **一致性问题:** 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
|
|
||||||
|
|
||||||
> 了解下面这个问题是为了我们更好的进行技术选型!该部分摘自:《Java 工程师面试突击第 1 季-中华石杉老师》,如果大家没有资源的话,可以在我的公众号“Java 面试通关手册”后台回复关键字“1”即可!
|
|
||||||
|
|
||||||
### 1.3 介绍一下你知道哪几种消息队列,该如何选择呢?
|
|
||||||
|
|
||||||
| 特性 | ActiveMQ | RabbitMQ | RocketMQ | Kafka |
|
|
||||||
| :----------------------- | -----------------------------------------------------------: | -----------------------------------------------------------: | -----------------------------------------------------------: | -----------------------------------------------------------: |
|
|
||||||
| 单机吞吐量 | 万级,吞吐量比 RocketMQ 和 Kafka 要低了一个数量级 | 万级,吞吐量比 RocketMQ 和 Kafka 要低了一个数量级 | 10 万级,RocketMQ 也是可以支撑高吞吐的一种 MQ | 10 万级别,这是 kafka 最大的优点,就是吞吐量高。一般配合大数据类的系统来进行实时数据计算、日志采集等场景 |
|
|
||||||
| topic 数量对吞吐量的影响 | | | topic 可以达到几百,几千个的级别,吞吐量会有较小幅度的下降这是 RocketMQ 的一大优势,在同等机器下,可以支撑大量的 topic | topic 从几十个到几百个的时候,吞吐量会大幅度下降。所以在同等机器下,kafka 尽量保证 topic 数量不要过多。如果要支撑大规模 topic,需要增加更多的机器资源 |
|
|
||||||
| 可用性 | 高,基于主从架构实现高可用性 | 高,基于主从架构实现高可用性 | 非常高,分布式架构 | 非常高,kafka 是分布式的,一个数据多个副本,少数机器宕机,不会丢失数据,不会导致不可用 |
|
|
||||||
| 消息可靠性 | 有较低的概率丢失数据 | | 经过参数优化配置,可以做到 0 丢失 | 经过参数优化配置,消息可以做到 0 丢失 |
|
|
||||||
| 时效性 | ms 级 | 微秒级,这是 rabbitmq 的一大特点,延迟是最低的 | ms 级 | 延迟在 ms 级以内 |
|
|
||||||
| 功能支持 | MQ 领域的功能极其完备 | 基于 erlang 开发,所以并发能力很强,性能极其好,延时很低 | MQ 功能较为完善,还是分布式的,扩展性好 | 功能较为简单,主要支持简单的 MQ 功能,在大数据领域的实时计算以及日志采集被大规模使用,是事实上的标准 |
|
|
||||||
| 优劣势总结 | 非常成熟,功能强大,在业内大量的公司以及项目中都有应用。偶尔会有较低概率丢失消息,而且现在社区以及国内应用都越来越少,官方社区现在对 ActiveMQ 5.x 维护越来越少,几个月才发布一个版本而且确实主要是基于解耦和异步来用的,较少在大规模吞吐的场景中使用 | erlang 语言开发,性能极其好,延时很低;吞吐量到万级,MQ 功能比较完备而且开源提供的管理界面非常棒,用起来很好用。社区相对比较活跃,几乎每个月都发布几个版本分在国内一些互联网公司近几年用 rabbitmq 也比较多一些但是问题也是显而易见的,RabbitMQ 确实吞吐量会低一些,这是因为他做的实现机制比较重。而且 erlang 开发,国内有几个公司有实力做 erlang 源码级别的研究和定制?如果说你没这个实力的话,确实偶尔会有一些问题,你很难去看懂源码,你公司对这个东西的掌控很弱,基本职能依赖于开源社区的快速维护和修复 bug。而且 rabbitmq 集群动态扩展会很麻烦,不过这个我觉得还好。其实主要是 erlang 语言本身带来的问题。很难读源码,很难定制和掌控。 | 接口简单易用,而且毕竟在阿里大规模应用过,有阿里品牌保障。日处理消息上百亿之多,可以做到大规模吞吐,性能也非常好,分布式扩展也很方便,社区维护还可以,可靠性和可用性都是 ok 的,还可以支撑大规模的 topic 数量,支持复杂 MQ 业务场景。而且一个很大的优势在于,阿里出品都是 java 系的,我们可以自己阅读源码,定制自己公司的 MQ,可以掌控。社区活跃度相对较为一般,不过也还可以,文档相对来说简单一些,然后接口这块不是按照标准 JMS 规范走的有些系统要迁移需要修改大量代码。还有就是阿里出台的技术,你得做好这个技术万一被抛弃,社区黄掉的风险,那如果你们公司有技术实力我觉得用 RocketMQ 挺好的 | kafka 的特点其实很明显,就是仅仅提供较少的核心功能,但是提供超高的吞吐量,ms 级的延迟,极高的可用性以及可靠性,而且分布式可以任意扩展。同时 kafka 最好是支撑较少的 topic 数量即可,保证其超高吞吐量。而且 kafka 唯一的一点劣势是有可能消息重复消费,那么对数据准确性会造成极其轻微的影响,在大数据领域中以及日志采集中,这点轻微影响可以忽略这个特性天然适合大数据实时计算以及日志收集。 |
|
|
||||||
|
|
||||||
> 这部分内容,我这里不给出答案,大家可以自行根据自己学习的消息队列查阅相关内容,我可能会在后面的文章中介绍到这部分内容。另外,下面这些问题在视频《Java 工程师面试突击第 1 季-中华石杉老师》中都有提到,如果大家没有资源的话,可以在我的公众号“Java 面试通关手册”后台回复关键字“1”即可!
|
|
||||||
|
|
||||||
### 1.4 关于消息队列其他一些常见的问题展望
|
|
||||||
|
|
||||||
1. 引入消息队列之后如何保证高可用性?
|
|
||||||
2. 如何保证消息不被重复消费呢?
|
|
||||||
3. 如何保证消息的可靠性传输(如何处理消息丢失的问题)?
|
|
||||||
4. 我该怎么保证从消息队列里拿到的数据按顺序执行?
|
|
||||||
5. 如何解决消息队列的延时以及过期失效问题?消息队列满了以后该怎么处理?有几百万消息持续积压几小时,说说怎么解决?
|
|
||||||
6. 如果让你来开发一个消息队列中间件,你会怎么设计架构?
|
|
||||||
|
|
||||||
## 2 谈谈 InnoDB 和 MyIsam 两者的区别
|
|
||||||
|
|
||||||
### 2.1 两者的对比
|
|
||||||
|
|
||||||
1. **count 运算上的区别:** 因为 MyISAM 缓存有表 meta-data(行数等),因此在做 COUNT(\*)时对于一个结构很好的查询是不需要消耗多少资源的。而对于 InnoDB 来说,则没有这种缓存
|
|
||||||
2. **是否支持事务和崩溃后的安全恢复:** MyISAM 强调的是性能,每次查询具有原子性,其执行速度比 InnoDB 类型更快,但是不提供事务支持。但是 InnoDB 提供事务支持,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。
|
|
||||||
3. **是否支持外键:** MyISAM 不支持,而 InnoDB 支持。
|
|
||||||
|
|
||||||
### 2.2 关于两者的总结
|
|
||||||
|
|
||||||
MyISAM 更适合读密集的表,而 InnoDB 更适合写密集的表。 在数据库做主从分离的情况下,经常选择 MyISAM 作为主库的存储引擎。
|
|
||||||
|
|
||||||
一般来说,如果需要事务支持,并且有较高的并发读取频率(MyISAM 的表锁的粒度太大,所以当该表写并发量较高时,要等待的查询就会很多了),InnoDB 是不错的选择。如果你的数据量很大(MyISAM 支持压缩特性可以减少磁盘的空间占用),而且不需要支持事务时,MyISAM 是最好的选择。
|
|
||||||
|
|
||||||
## 3 聊聊 Java 中的集合吧!
|
|
||||||
|
|
||||||
### 3.1 Arraylist 与 LinkedList 有什么不同?(注意加上从数据结构分析的内容)
|
|
||||||
|
|
||||||
- **1. 是否保证线程安全:** ArrayList 和 LinkedList 都是不同步的,也就是不保证线程安全;
|
|
||||||
- **2. 底层数据结构:** Arraylist 底层使用的是 Object 数组;LinkedList 底层使用的是双向链表数据结构(注意双向链表和双向循环链表的区别:);
|
|
||||||
- **3. 插入和删除是否受元素位置的影响:** ① **ArrayList 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。** 比如:执行`add(E e)`方法的时候, ArrayList 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element)`)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② **LinkedList 采用链表存储,所以插入,删除元素时间复杂度不受元素位置的影响,都是近似 O(1) 而数组为近似 O(n) 。**
|
|
||||||
- **4. 是否支持快速随机访问:** LinkedList 不支持高效的随机元素访问,而 ArrayList 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index)`方法)。
|
|
||||||
- **5. 内存空间占用:** ArrayList 的空 间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
|
|
||||||
|
|
||||||
**补充内容:RandomAccess 接口**
|
|
||||||
|
|
||||||
```java
|
|
||||||
public interface RandomAccess {
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
查看源码我们发现实际上 RandomAccess 接口中什么都没有定义。所以,在我看来 RandomAccess 接口不过是一个标识罢了。标识什么? 标识实现这个接口的类具有随机访问功能。
|
|
||||||
|
|
||||||
在 binarySearch() 方法中,它要判断传入的 list 是否 RandomAccess 的实例,如果是,调用 indexedBinarySearch() 方法,如果不是,那么调用 iteratorBinarySearch() 方法
|
|
||||||
|
|
||||||
```java
|
|
||||||
public static <T>
|
|
||||||
int binarySearch(List<? extends Comparable<? super T>> list, T key) {
|
|
||||||
if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
|
|
||||||
return Collections.indexedBinarySearch(list, key);
|
|
||||||
else
|
|
||||||
return Collections.iteratorBinarySearch(list, key);
|
|
||||||
}
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
ArraysList 实现了 RandomAccess 接口, 而 LinkedList 没有实现。为什么呢?我觉得还是和底层数据结构有关!ArraysList 底层是数组,而 LinkedList 底层是链表。数组天然支持随机访问,时间复杂度为 O(1) ,所以称为快速随机访问。链表需要遍历到特定位置才能访问特定位置的元素,时间复杂度为 O(n) ,所以不支持快速随机访问。,ArraysList 实现了 RandomAccess 接口,就表明了他具有快速随机访问功能。 RandomAccess 接口只是标识,并不是说 ArraysList 实现 RandomAccess 接口才具有快速随机访问功能的!
|
|
||||||
|
|
||||||
**下面再总结一下 list 的遍历方式选择:**
|
|
||||||
|
|
||||||
- 实现了 RandomAccess 接口的 list,优先选择普通 for 循环 ,其次 foreach,
|
|
||||||
- 未实现 RandomAccess 接口的 ist, 优先选择 iterator 遍历(foreach 遍历底层也是通过 iterator 实现的),大 size 的数据,千万不要使用普通 for 循环
|
|
||||||
|
|
||||||
> Java 中的集合这类问题几乎是面试必问的,问到这类问题的时候,HashMap 又是几乎必问的问题,所以大家一定要引起重视!
|
|
||||||
|
|
||||||
### 3.2 HashMap 的底层实现
|
|
||||||
|
|
||||||
#### 1)JDK1.8 之前
|
|
||||||
|
|
||||||
JDK1.8 之前 HashMap 底层是 **数组和链表** 结合在一起使用也就是 **链表散列**。**HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 `(n - 1) & hash` 判断当前元素存放的位置(这里的 n 指的时数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。**
|
|
||||||
|
|
||||||
**所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。**
|
|
||||||
|
|
||||||
**JDK 1.8 HashMap 的 hash 方法源码:**
|
|
||||||
|
|
||||||
JDK 1.8 的 hash 方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
|
|
||||||
|
|
||||||
```java
|
|
||||||
static final int hash(Object key) {
|
|
||||||
int h;
|
|
||||||
// key.hashCode():返回散列值也就是hashcode
|
|
||||||
// ^ :按位异或
|
|
||||||
// >>>:无符号右移,忽略符号位,空位都以0补齐
|
|
||||||
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
对比一下 JDK1.7 的 HashMap 的 hash 方法源码.
|
|
||||||
|
|
||||||
```java
|
|
||||||
static int hash(int h) {
|
|
||||||
// This function ensures that hashCodes that differ only by
|
|
||||||
// constant multiples at each bit position have a bounded
|
|
||||||
// number of collisions (approximately 8 at default load factor).
|
|
||||||
|
|
||||||
h ^= (h >>> 20) ^ (h >>> 12);
|
|
||||||
return h ^ (h >>> 7) ^ (h >>> 4);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
相比于 JDK1.8 的 hash 方法 ,JDK 1.7 的 hash 方法的性能会稍差一点点,因为毕竟扰动了 4 次。
|
|
||||||
|
|
||||||
所谓 **“拉链法”** 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。
|
|
||||||
|
|
||||||
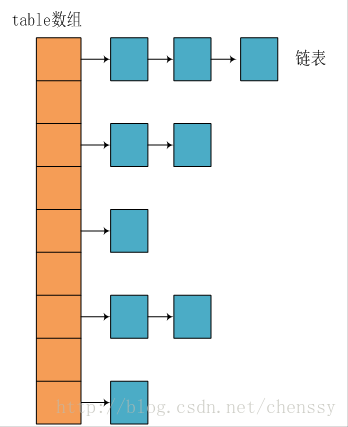
|
|
||||||
|
|
||||||
#### 2)JDK1.8 之后
|
|
||||||
|
|
||||||
相比于之前的版本, JDK1.8 之后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间。
|
|
||||||
|
|
||||||
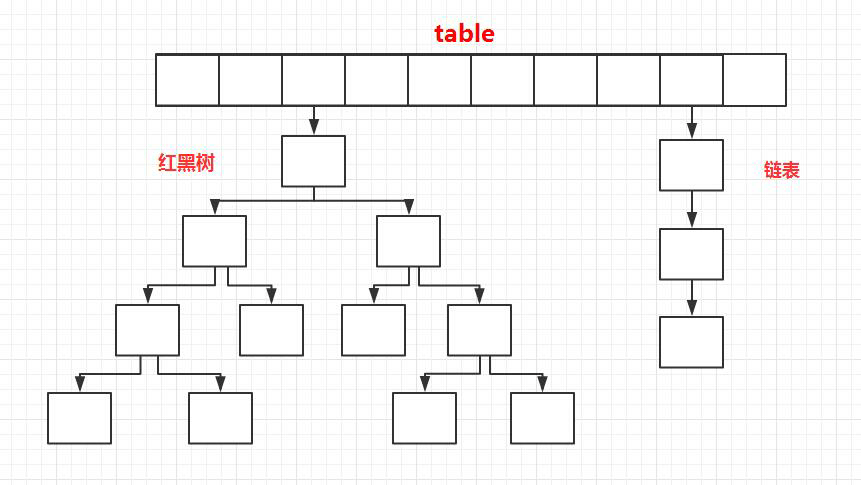
|
|
||||||
|
|
||||||
TreeMap、TreeSet 以及 JDK1.8 之后的 HashMap 底层都用到了红黑树。红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
|
|
||||||
|
|
||||||
> 问完 HashMap 的底层原理之后,面试官可能就会紧接着问你 HashMap 底层数据结构相关的问题!
|
|
||||||
|
|
||||||
### 3.3 既然谈到了红黑树,你给我手绘一个出来吧,然后简单讲一下自己对于红黑树的理解
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**红黑树特点:**
|
|
||||||
|
|
||||||
1. 每个节点非红即黑;
|
|
||||||
2. 根节点总是黑色的;
|
|
||||||
3. 每个叶子节点都是黑色的空节点(NIL 节点);
|
|
||||||
4. 如果节点是红色的,则它的子节点必须是黑色的(反之不一定);
|
|
||||||
5. 从根节点到叶节点或空子节点的每条路径,必须包含相同数目的黑色节点(即相同的黑色高度)
|
|
||||||
|
|
||||||
**红黑树的应用:**
|
|
||||||
|
|
||||||
TreeMap、TreeSet 以及 JDK1.8 之后的 HashMap 底层都用到了红黑树。
|
|
||||||
|
|
||||||
**为什么要用红黑树**
|
|
||||||
|
|
||||||
简单来说红黑树就是为了解决二叉查找树的缺陷,因为二叉查找树在某些情况下会退化成一个线性结构。
|
|
||||||
|
|
||||||
### 3.4 红黑树这么优秀,为何不直接使用红黑树得了?
|
|
||||||
|
|
||||||
说一下自己对于这个问题的看法:我们知道红黑树属于(自)平衡二叉树,但是为了保持“平衡”是需要付出代价的,红黑树在插入新数据后可能需要通过左旋,右旋、变色这些操作来保持平衡,这费事啊。你说说我们引入红黑树就是为了查找数据快,如果链表长度很短的话,根本不需要引入红黑树的,你引入之后还要付出代价维持它的平衡。但是链表过长就不一样了。至于为什么选 8 这个值呢?通过概率统计所得,这个值是综合查询成本和新增元素成本得出的最好的一个值。
|
|
||||||
|
|
||||||
### 3.5 HashMap 和 Hashtable 的区别/HashSet 和 HashMap 区别
|
|
||||||
|
|
||||||
**HashMap 和 Hashtable 的区别**
|
|
||||||
|
|
||||||
1. **线程是否安全:** HashMap 是非线程安全的,Hashtable 是线程安全的;Hashtable 内部的方法基本都经过 `synchronized` 修饰。(如果你要保证线程安全的话就使用 ConcurrentHashMap 吧!);
|
|
||||||
2. **效率:** 因为线程安全的问题,HashMap 要比 Hashtable 效率高一点。另外,Hashtable 基本被淘汰,不要在代码中使用它;
|
|
||||||
3. **对 Null key 和 Null value 的支持:** HashMap 中,null 可以作为键,这样的键只有一个,可以有一个或多个键所对应的值为 null。但是在 Hashtable 中 put 进的键值只要有一个 null,直接抛出 NullPointerException。
|
|
||||||
4. **初始容量大小和每次扩充容量大小的不同 :** ① 创建时如果不指定容量初始值,Hashtable 默认的初始大小为 11,之后每次扩充,容量变为原来的 2n+1。HashMap 默认的初始化大小为 16。之后每次扩充,容量变为原来的 2 倍。② 创建时如果给定了容量初始值,那么 Hashtable 会直接使用你给定的大小,而 HashMap 会将其扩充为 2 的幂次方大小(HashMap 中的`tableSizeFor()`方法保证,下面给出了源代码)。也就是说 HashMap 总是使用 2 的幂作为哈希表的大小,后面会介绍到为什么是 2 的幂次方。
|
|
||||||
5. **底层数据结构:** JDK1.8 以后的 HashMap 在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树,以减少搜索时间。Hashtable 没有这样的机制。
|
|
||||||
|
|
||||||
**HashSet 和 HashMap 区别**
|
|
||||||
|
|
||||||
如果你看过 HashSet 源码的话就应该知道:HashSet 底层就是基于 HashMap 实现的。(HashSet 的源码非常非常少,因为除了 clone() 方法、writeObject()方法、readObject()方法是 HashSet 自己不得不实现之外,其他方法都是直接调用 HashMap 中的方法。)
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
# 三 终结篇
|
|
||||||
|
|
||||||
## 1. Object 类有哪些方法?
|
|
||||||
|
|
||||||
这个问题,面试中经常出现。我觉得不论是出于应付面试还是说更好地掌握 Java 这门编程语言,大家都要掌握!
|
|
||||||
|
|
||||||
### 1.1 Object 类的常见方法总结
|
|
||||||
|
|
||||||
Object 类是一个特殊的类,是所有类的父类。它主要提供了以下 11 个方法:
|
|
||||||
|
|
||||||
```java
|
|
||||||
|
|
||||||
public final native Class<?> getClass()//native方法,用于返回当前运行时对象的Class对象,使用了final关键字修饰,故不允许子类重写。
|
|
||||||
|
|
||||||
public native int hashCode() //native方法,用于返回对象的哈希码,主要使用在哈希表中,比如JDK中的HashMap。
|
|
||||||
public boolean equals(Object obj)//用于比较2个对象的内存地址是否相等,String类对该方法进行了重写用户比较字符串的值是否相等。
|
|
||||||
|
|
||||||
protected native Object clone() throws CloneNotSupportedException//naitive方法,用于创建并返回当前对象的一份拷贝。一般情况下,对于任何对象 x,表达式 x.clone() != x 为true,x.clone().getClass() == x.getClass() 为true。Object本身没有实现Cloneable接口,所以不重写clone方法并且进行调用的话会发生CloneNotSupportedException异常。
|
|
||||||
|
|
||||||
public String toString()//返回类的名字@实例的哈希码的16进制的字符串。建议Object所有的子类都重写这个方法。
|
|
||||||
|
|
||||||
public final native void notify()//native方法,并且不能重写。唤醒一个在此对象监视器上等待的线程(监视器相当于就是锁的概念)。如果有多个线程在等待只会任意唤醒一个。
|
|
||||||
|
|
||||||
public final native void notifyAll()//native方法,并且不能重写。跟notify一样,唯一的区别就是会唤醒在此对象监视器上等待的所有线程,而不是一个线程。
|
|
||||||
|
|
||||||
public final native void wait(long timeout) throws InterruptedException//native方法,并且不能重写。暂停线程的执行。注意:sleep方法没有释放锁,而wait方法释放了锁 。timeout是等待时间。
|
|
||||||
|
|
||||||
public final void wait(long timeout, int nanos) throws InterruptedException//多了nanos参数,这个参数表示额外时间(以毫微秒为单位,范围是 0-999999)。 所以超时的时间还需要加上nanos毫秒。
|
|
||||||
|
|
||||||
public final void wait() throws InterruptedException//跟之前的2个wait方法一样,只不过该方法一直等待,没有超时时间这个概念
|
|
||||||
|
|
||||||
protected void finalize() throws Throwable { }//实例被垃圾回收器回收的时候触发的操作
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
> 问完上面这个问题之后,面试官很可能紧接着就会问你“hashCode 与 equals”相关的问题。
|
|
||||||
|
|
||||||
### 1.2 hashCode 与 equals
|
|
||||||
|
|
||||||
面试官可能会问你:“你重写过 hashcode 和 equals 么,为什么重写 equals 时必须重写 hashCode 方法?”
|
|
||||||
|
|
||||||
#### 1.2.1 hashCode()介绍
|
|
||||||
|
|
||||||
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个 int 整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在 JDK 的 Object.java 中,这就意味着 Java 中的任何类都包含有 hashCode() 函数。另外需要注意的是: Object 的 hashcode 方法是本地方法,也就是用 c 语言或 c++ 实现的,该方法通常用来将对象的 内存地址 转换为整数之后返回。
|
|
||||||
|
|
||||||
```java
|
|
||||||
public native int hashCode();
|
|
||||||
```
|
|
||||||
|
|
||||||
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
|
|
||||||
|
|
||||||
#### 1.2.2 为什么要有 hashCode
|
|
||||||
|
|
||||||
**我们以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode:**
|
|
||||||
|
|
||||||
当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的 Java 启蒙书《Head fist java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
|
|
||||||
|
|
||||||
#### 1.2.3 hashCode()与 equals()的相关规定
|
|
||||||
|
|
||||||
1. 如果两个对象相等,则 hashcode 一定也是相同的
|
|
||||||
2. 两个对象相等,对两个对象分别调用 equals 方法都返回 true
|
|
||||||
3. 两个对象有相同的 hashcode 值,它们也不一定是相等的
|
|
||||||
4. **因此,equals 方法被覆盖过,则 hashCode 方法也必须被覆盖**
|
|
||||||
5. hashCode()的默认行为是对堆上的对象产生独特值。如果没有重写 hashCode(),则该 class 的两个对象无论如何都不会相等(即使这两个对象指向相同的数据)
|
|
||||||
|
|
||||||
#### 1.2.4 为什么两个对象有相同的 hashcode 值,它们也不一定是相等的?
|
|
||||||
|
|
||||||
在这里解释一位小伙伴的问题。以下内容摘自《Head Fisrt Java》。
|
|
||||||
|
|
||||||
因为 hashCode() 所使用的杂凑算法也许刚好会让多个对象传回相同的杂凑值。越糟糕的杂凑算法越容易碰撞,但这也与数据值域分布的特性有关(所谓碰撞也就是指的是不同的对象得到相同的 hashCode)。
|
|
||||||
|
|
||||||
我们刚刚也提到了 HashSet,如果 HashSet 在对比的时候,同样的 hashcode 有多个对象,它会使用 equals() 来判断是否真的相同。也就是说 hashcode 只是用来缩小查找成本。
|
|
||||||
|
|
||||||
> ==与 equals 的对比也是比较常问的基础问题之一!
|
|
||||||
|
|
||||||
### 1.3 ==与 equals
|
|
||||||
|
|
||||||
**==** : 它的作用是判断两个对象的地址是不是相等。即,判断两个对象是不是同一个对象。(基本数据类型==比较的是值,引用数据类型==比较的是内存地址)
|
|
||||||
|
|
||||||
**equals()** : 它的作用也是判断两个对象是否相等。但它一般有两种使用情况:
|
|
||||||
|
|
||||||
- 情况 1:类没有覆盖 equals()方法。则通过 equals()比较该类的两个对象时,等价于通过“==”比较这两个对象。
|
|
||||||
- 情况 2:类覆盖了 equals()方法。一般,我们都覆盖 equals()方法来两个对象的内容相等;若它们的内容相等,则返回 true(即,认为这两个对象相等)。
|
|
||||||
|
|
||||||
**举个例子:**
|
|
||||||
|
|
||||||
```java
|
|
||||||
public class test1 {
|
|
||||||
public static void main(String[] args) {
|
|
||||||
String a = new String("ab"); // a 为一个引用
|
|
||||||
String b = new String("ab"); // b为另一个引用,对象的内容一样
|
|
||||||
String aa = "ab"; // 放在常量池中
|
|
||||||
String bb = "ab"; // 从常量池中查找
|
|
||||||
if (aa == bb) // true
|
|
||||||
System.out.println("aa==bb");
|
|
||||||
if (a == b) // false,非同一对象
|
|
||||||
System.out.println("a==b");
|
|
||||||
if (a.equals(b)) // true
|
|
||||||
System.out.println("aEQb");
|
|
||||||
if (42 == 42.0) { // true
|
|
||||||
System.out.println("true");
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
**说明:**
|
|
||||||
|
|
||||||
- String 中的 equals()方法是被重写过的,因为 Object 的 equals()方法是比较的对象的内存地址,而 String 的 equals()方法比较的是对象的值。
|
|
||||||
- 当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 String 对象。
|
|
||||||
|
|
||||||
> 在[【备战春招/秋招系列 5】美团面经总结进阶篇 (附详解答案)](https://mp.weixin.qq.com/s?__biz=MzU4NDQ4MzU5OA==&mid=2247484625&idx=1&sn=9c4fa1f7d4291a5fbd7daa44bac2b012&chksm=fd9852b0caefdba6edcf9a827aa4a17ddc97bf6ad2e5ee6f7e1aa1b443b54444d05d2b76732b&token=723699735&lang=zh_CN#rd) 这篇文章中,我们已经提到了一下关于 HashMap 在面试中常见的问题:HashMap 的底层实现、简单讲一下自己对于红黑树的理解、红黑树这么优秀,为何不直接使用红黑树得了、HashMap 和 Hashtable 的区别/HashSet 和 HashMap 区别。HashMap 和 ConcurrentHashMap 这俩兄弟在一般只要面试中问到集合相关的问题就一定会被问到,所以各位务必引起重视!
|
|
||||||
|
|
||||||
## 2 ConcurrentHashMap 相关问题
|
|
||||||
|
|
||||||
### 2.1 ConcurrentHashMap 和 Hashtable 的区别
|
|
||||||
|
|
||||||
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式上不同。
|
|
||||||
|
|
||||||
- **底层数据结构:** JDK1.7 的 ConcurrentHashMap 底层采用 **分段的数组+链表** 实现,JDK1.8 采用的数据结构跟 HashMap1.8 的结构一样,数组+链表/红黑二叉树。Hashtable 和 JDK1.8 之前的 HashMap 的底层数据结构类似都是采用 **数组+链表** 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
|
|
||||||
- **实现线程安全的方式(重要):** ① **在 JDK1.7 的时候,ConcurrentHashMap(分段锁)** 对整个桶数组进行了分割分段(Segment),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。(默认分配 16 个 Segment,比 Hashtable 效率提高 16 倍。) **到了 JDK1.8 的时候已经摒弃了 Segment 的概念,而是直接用 Node 数组+链表+红黑树的数据结构来实现,并发控制使用 synchronized 和 CAS 来操作。(JDK1.6 以后 对 synchronized 锁做了很多优化)** 整个看起来就像是优化过且线程安全的 HashMap,虽然在 JDK1.8 中还能看到 Segment 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② **Hashtable(同一把锁)**:使用 synchronized 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
|
|
||||||
|
|
||||||
**两者的对比图:**
|
|
||||||
|
|
||||||
图片来源:http://www.cnblogs.com/chengxiao/p/6842045.html
|
|
||||||
|
|
||||||
Hashtable:
|
|
||||||
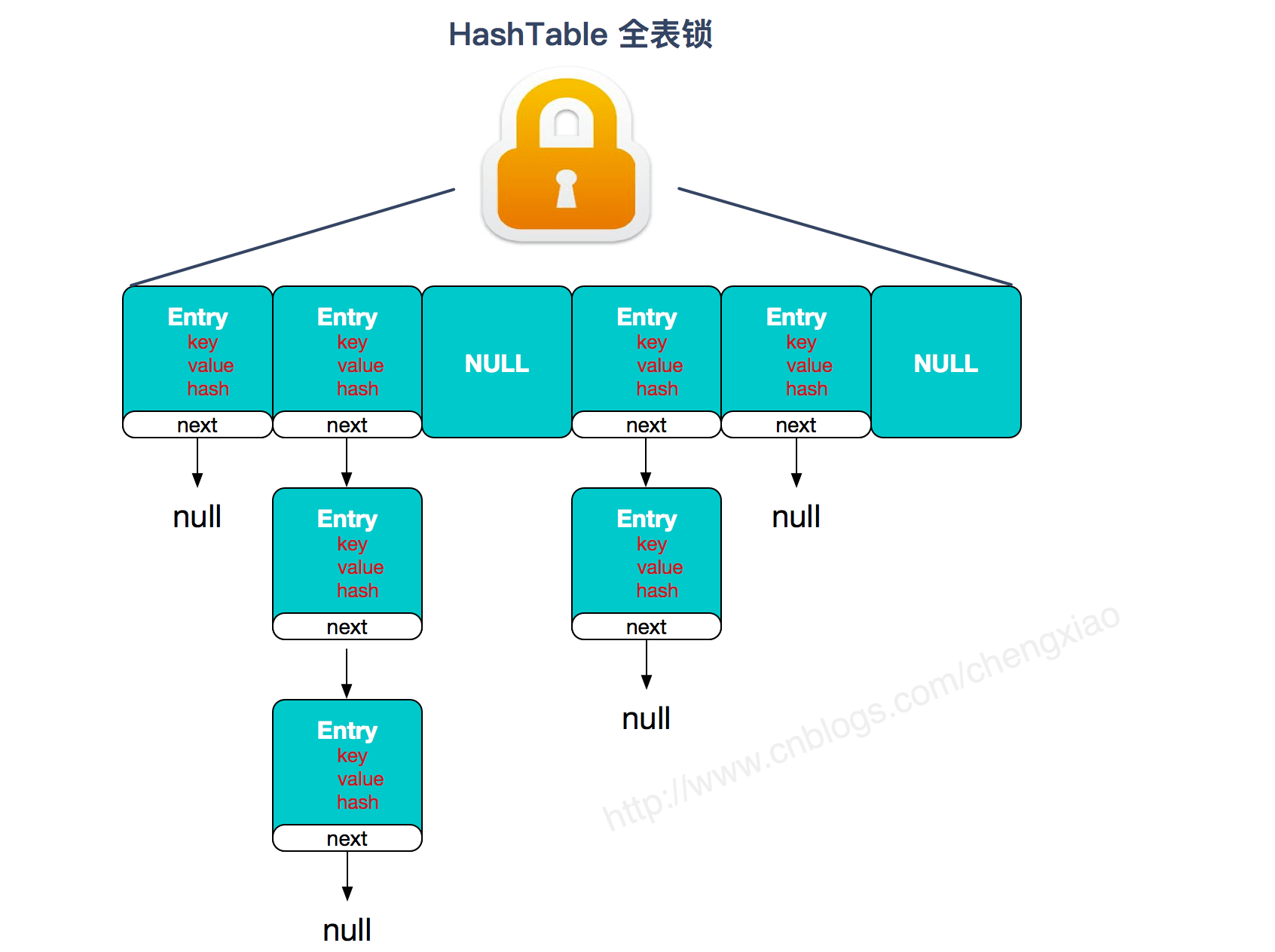
|
|
||||||
|
|
||||||
JDK1.7 的 ConcurrentHashMap:
|
|
||||||
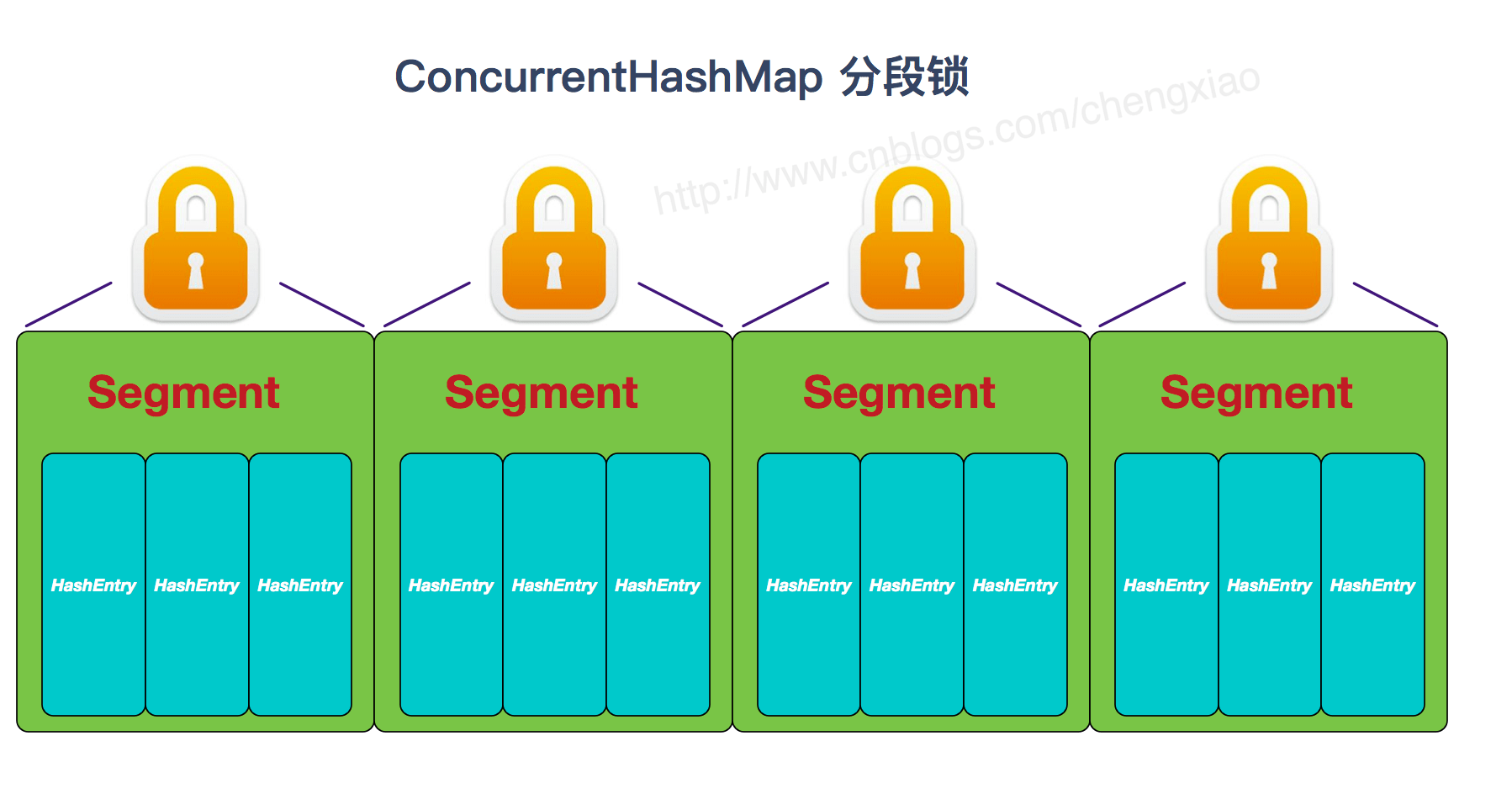
|
|
||||||
JDK1.8 的 ConcurrentHashMap(TreeBin: 红黑二叉树节点
|
|
||||||
Node: 链表节点):
|
|
||||||
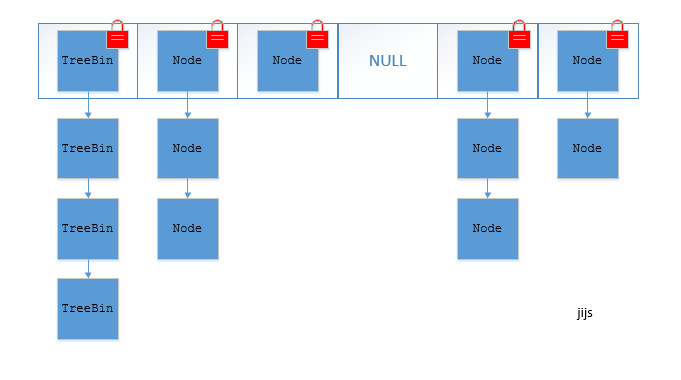
|
|
||||||
|
|
||||||
### 2.2 ConcurrentHashMap 线程安全的具体实现方式/底层具体实现
|
|
||||||
|
|
||||||
#### JDK1.7(上面有示意图)
|
|
||||||
|
|
||||||
首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
|
|
||||||
|
|
||||||
**ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成**。
|
|
||||||
|
|
||||||
Segment 实现了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。HashEntry 用于存储键值对数据。
|
|
||||||
|
|
||||||
```java
|
|
||||||
static class Segment<K,V> extends ReentrantLock implements Serializable {
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
一个 ConcurrentHashMap 里包含一个 Segment 数组。Segment 的结构和 HashMap 类似,是一种数组和链表结构,一个 Segment 包含一个 HashEntry 数组,每个 HashEntry 是一个链表结构的元素,每个 Segment 守护着一个 HashEntry 数组里的元素,当对 HashEntry 数组的数据进行修改时,必须首先获得对应的 Segment 的锁。
|
|
||||||
|
|
||||||
#### JDK1.8(上面有示意图)
|
|
||||||
|
|
||||||
ConcurrentHashMap 取消了 Segment 分段锁,采用 CAS 和 synchronized 来保证并发安全。数据结构跟 HashMap1.8 的结构类似,数组+链表/红黑二叉树。
|
|
||||||
|
|
||||||
synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,效率又提升 N 倍。
|
|
||||||
|
|
||||||
## 3 谈谈 synchronized 和 ReentrantLock 的区别
|
|
||||||
|
|
||||||
**① 两者都是可重入锁**
|
|
||||||
|
|
||||||
两者都是可重入锁。“可重入锁”概念是:自己可以再次获取自己的内部锁。比如一个线程获得了某个对象的锁,此时这个对象锁还没有释放,当其再次想要获取这个对象的锁的时候还是可以获取的,如果不可锁重入的话,就会造成死锁。同一个线程每次获取锁,锁的计数器都自增 1,所以要等到锁的计数器下降为 0 时才能释放锁。
|
|
||||||
|
|
||||||
**② synchronized 依赖于 JVM 而 ReentrantLock 依赖于 API**
|
|
||||||
|
|
||||||
synchronized 是依赖于 JVM 实现的,前面我们也讲到了 虚拟机团队在 JDK1.6 为 synchronized 关键字进行了很多优化,但是这些优化都是在虚拟机层面实现的,并没有直接暴露给我们。ReentrantLock 是 JDK 层面实现的(也就是 API 层面,需要 lock() 和 unlock() 方法配合 try/finally 语句块来完成),所以我们可以通过查看它的源代码,来看它是如何实现的。
|
|
||||||
|
|
||||||
**③ ReentrantLock 比 synchronized 增加了一些高级功能**
|
|
||||||
|
|
||||||
相比 synchronized,ReentrantLock 增加了一些高级功能。主要来说主要有三点:**① 等待可中断;② 可实现公平锁;③ 可实现选择性通知(锁可以绑定多个条件)**
|
|
||||||
|
|
||||||
- **ReentrantLock 提供了一种能够中断等待锁的线程的机制**,通过 lock.lockInterruptibly() 来实现这个机制。也就是说正在等待的线程可以选择放弃等待,改为处理其他事情。
|
|
||||||
- **ReentrantLock 可以指定是公平锁还是非公平锁。而 synchronized 只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。** ReentrantLock 默认情况是非公平的,可以通过 ReentrantLock 类的`ReentrantLock(boolean fair)`构造方法来制定是否是公平的。
|
|
||||||
- synchronized 关键字与 wait()和 notify/notifyAll()方法相结合可以实现等待/通知机制,ReentrantLock 类当然也可以实现,但是需要借助于 Condition 接口与 newCondition() 方法。Condition 是 JDK1.5 之后才有的,它具有很好的灵活性,比如可以实现多路通知功能也就是在一个 Lock 对象中可以创建多个 Condition 实例(即对象监视器),**线程对象可以注册在指定的 Condition 中,从而可以有选择性的进行线程通知,在调度线程上更加灵活。 在使用 notify/notifyAll()方法进行通知时,被通知的线程是由 JVM 选择的,用 ReentrantLock 类结合 Condition 实例可以实现“选择性通知”** ,这个功能非常重要,而且是 Condition 接口默认提供的。而 synchronized 关键字就相当于整个 Lock 对象中只有一个 Condition 实例,所有的线程都注册在它一个身上。如果执行 notifyAll()方法的话就会通知所有处于等待状态的线程这样会造成很大的效率问题,而 Condition 实例的 signalAll()方法 只会唤醒注册在该 Condition 实例中的所有等待线程。
|
|
||||||
|
|
||||||
如果你想使用上述功能,那么选择 ReentrantLock 是一个不错的选择。
|
|
||||||
|
|
||||||
**④ 两者的性能已经相差无几**
|
|
||||||
|
|
||||||
在 JDK1.6 之前,synchronized 的性能是比 ReentrantLock 差很多。具体表示为:synchronized 关键字吞吐量随线程数的增加,下降得非常严重。而 ReentrantLock 基本保持一个比较稳定的水平。我觉得这也侧面反映了, synchronized 关键字还有非常大的优化余地。后续的技术发展也证明了这一点,我们上面也讲了在 JDK1.6 之后 JVM 团队对 synchronized 关键字做了很多优化。JDK1.6 之后,synchronized 和 ReentrantLock 的性能基本是持平了。所以网上那些说因为性能才选择 ReentrantLock 的文章都是错的!JDK1.6 之后,性能已经不是选择 synchronized 和 ReentrantLock 的影响因素了!而且虚拟机在未来的性能改进中会更偏向于原生的 synchronized,所以还是提倡在 synchronized 能满足你的需求的情况下,优先考虑使用 synchronized 关键字来进行同步!优化后的 synchronized 和 ReentrantLock 一样,在很多地方都是用到了 CAS 操作。
|
|
||||||
|
|
||||||
## 4 线程池了解吗?
|
|
||||||
|
|
||||||
### 4.1 为什么要用线程池?
|
|
||||||
|
|
||||||
线程池提供了一种限制和管理资源(包括执行一个任务)。 每个线程池还维护一些基本统计信息,例如已完成任务的数量。
|
|
||||||
|
|
||||||
这里借用《Java 并发编程的艺术》提到的来说一下使用线程池的好处:
|
|
||||||
|
|
||||||
- **降低资源消耗。** 通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
|
|
||||||
- **提高响应速度。** 当任务到达时,任务可以不需要的等到线程创建就能立即执行。
|
|
||||||
- **提高线程的可管理性。** 线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
|
|
||||||
|
|
||||||
### 4.2 Java 提供了哪几种线程池?他们各自的使用场景是什么?
|
|
||||||
|
|
||||||
#### Java 主要提供了下面 4 种线程池
|
|
||||||
|
|
||||||
- **FixedThreadPool:** 该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
|
|
||||||
- **SingleThreadExecutor:** 方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
|
|
||||||
- **CachedThreadPool:** 该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
|
|
||||||
- **ScheduledThreadPoolExecutor:** 主要用来在给定的延迟后运行任务,或者定期执行任务。ScheduledThreadPoolExecutor 又分为:ScheduledThreadPoolExecutor(包含多个线程)和 SingleThreadScheduledExecutor (只包含一个线程)两种。
|
|
||||||
|
|
||||||
#### 各种线程池的适用场景介绍
|
|
||||||
|
|
||||||
- **FixedThreadPool:** 适用于为了满足资源管理需求,而需要限制当前线程数量的应用场景。它适用于负载比较重的服务器;
|
|
||||||
- **SingleThreadExecutor:** 适用于需要保证顺序地执行各个任务并且在任意时间点,不会有多个线程是活动的应用场景;
|
|
||||||
- **CachedThreadPool:** 适用于执行很多的短期异步任务的小程序,或者是负载较轻的服务器;
|
|
||||||
- **ScheduledThreadPoolExecutor:** 适用于需要多个后台执行周期任务,同时为了满足资源管理需求而需要限制后台线程的数量的应用场景;
|
|
||||||
- **SingleThreadScheduledExecutor:** 适用于需要单个后台线程执行周期任务,同时保证顺序地执行各个任务的应用场景。
|
|
||||||
|
|
||||||
### 4.3 创建的线程池的方式
|
|
||||||
|
|
||||||
**(1) 使用 Executors 创建**
|
|
||||||
|
|
||||||
我们上面刚刚提到了 Java 提供的几种线程池,通过 Executors 工具类我们可以很轻松的创建我们上面说的几种线程池。但是实际上我们一般都不是直接使用 Java 提供好的线程池,另外在《阿里巴巴 Java 开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 构造函数 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
|
|
||||||
|
|
||||||
```java
|
|
||||||
Executors 返回线程池对象的弊端如下:
|
|
||||||
|
|
||||||
FixedThreadPool 和 SingleThreadExecutor : 允许请求的队列长度为 Integer.MAX_VALUE,可能堆积大量的请求,从而导致OOM。
|
|
||||||
CachedThreadPool 和 ScheduledThreadPool : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致OOM。
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
**(2) ThreadPoolExecutor 的构造函数创建**
|
|
||||||
|
|
||||||
我们可以自己直接调用 ThreadPoolExecutor 的构造函数来自己创建线程池。在创建的同时,给 BlockQueue 指定容量就可以了。示例如下:
|
|
||||||
|
|
||||||
```java
|
|
||||||
private static ExecutorService executor = new ThreadPoolExecutor(13, 13,
|
|
||||||
60L, TimeUnit.SECONDS,
|
|
||||||
new ArrayBlockingQueue(13));
|
|
||||||
```
|
|
||||||
|
|
||||||
这种情况下,一旦提交的线程数超过当前可用线程数时,就会抛出 java.util.concurrent.RejectedExecutionException,这是因为当前线程池使用的队列是有边界队列,队列已经满了便无法继续处理新的请求。但是异常(Exception)总比发生错误(Error)要好。
|
|
||||||
|
|
||||||
**(3) 使用开源类库**
|
|
||||||
|
|
||||||
Hollis 大佬之前在他的文章中也提到了:“除了自己定义 ThreadPoolExecutor 外。还有其他方法。这个时候第一时间就应该想到开源类库,如 apache 和 guava 等。”他推荐使用 guava 提供的 ThreadFactoryBuilder 来创建线程池。下面是参考他的代码示例:
|
|
||||||
|
|
||||||
```java
|
|
||||||
public class ExecutorsDemo {
|
|
||||||
|
|
||||||
private static ThreadFactory namedThreadFactory = new ThreadFactoryBuilder()
|
|
||||||
.setNameFormat("demo-pool-%d").build();
|
|
||||||
|
|
||||||
private static ExecutorService pool = new ThreadPoolExecutor(5, 200,
|
|
||||||
0L, TimeUnit.MILLISECONDS,
|
|
||||||
new LinkedBlockingQueue<Runnable>(1024), namedThreadFactory, new ThreadPoolExecutor.AbortPolicy());
|
|
||||||
|
|
||||||
public static void main(String[] args) {
|
|
||||||
|
|
||||||
for (int i = 0; i < Integer.MAX_VALUE; i++) {
|
|
||||||
pool.execute(new SubThread());
|
|
||||||
}
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
通过上述方式创建线程时,不仅可以避免 OOM 的问题,还可以自定义线程名称,更加方便的出错的时候溯源。
|
|
||||||
|
|
||||||
## 5 Nginx
|
|
||||||
|
|
||||||
### 5.1 简单介绍一下 Nginx
|
|
||||||
|
|
||||||
Nginx 是一款轻量级的 Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器。 Nginx 主要提供反向代理、负载均衡、动静分离(静态资源服务)等服务。下面我简单地介绍一下这些名词。
|
|
||||||
|
|
||||||
#### 反向代理
|
|
||||||
|
|
||||||
谈到反向代理,就不得不提一下正向代理。无论是正向代理,还是反向代理,说到底,就是代理模式的衍生版本罢了
|
|
||||||
|
|
||||||
- **正向代理:**某些情况下,代理我们用户去访问服务器,需要用户手动的设置代理服务器的 ip 和端口号。正向代理比较常见的一个例子就是 VPN 了。
|
|
||||||
- **反向代理:** 是用来代理服务器的,代理我们要访问的目标服务器。代理服务器接受请求,然后将请求转发给内部网络的服务器,并将从服务器上得到的结果返回给客户端,此时代理服务器对外就表现为一个服务器。
|
|
||||||
|
|
||||||
通过下面两幅图,大家应该更好理解(图源:http://blog.720ui.com/2016/nginx_action_05_proxy/):
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
所以,简单的理解,就是正向代理是为客户端做代理,代替客户端去访问服务器,而反向代理是为服务器做代理,代替服务器接受客户端请求。
|
|
||||||
|
|
||||||
#### 负载均衡
|
|
||||||
|
|
||||||
在高并发情况下需要使用,其原理就是将并发请求分摊到多个服务器执行,减轻每台服务器的压力,多台服务器(集群)共同完成工作任务,从而提高了数据的吞吐量。
|
|
||||||
|
|
||||||
Nginx 支持的 weight 轮询(默认)、ip_hash、fair、url_hash 这四种负载均衡调度算法,感兴趣的可以自行查阅。
|
|
||||||
|
|
||||||
负载均衡相比于反向代理更侧重的是将请求分担到多台服务器上去,所以谈论负载均衡只有在提供某服务的服务器大于两台时才有意义。
|
|
||||||
|
|
||||||
#### 动静分离
|
|
||||||
|
|
||||||
动静分离是让动态网站里的动态网页根据一定规则把不变的资源和经常变的资源区分开来,动静资源做好了拆分以后,我们就可以根据静态资源的特点将其做缓存操作,这就是网站静态化处理的核心思路。
|
|
||||||
|
|
||||||
### 5.2 为什么要用 Nginx?
|
|
||||||
|
|
||||||
> 这部分内容参考极客时间—[Nginx 核心知识 100 讲的内容](https://time.geekbang.org/course/intro/138?code=AycjiiQk6uQRxnVJzBupFkrGkvZlmYELPRsZbWzaAHE= "Nginx核心知识100讲的内容")。
|
|
||||||
|
|
||||||
如果面试官问你这个问题,就一定想看你知道 Nginx 服务器的一些优点吗。
|
|
||||||
|
|
||||||
Nginx 有以下 5 个优点:
|
|
||||||
|
|
||||||
1. 高并发、高性能(这是其他 web 服务器不具有的)
|
|
||||||
2. 可扩展性好(模块化设计,第三方插件生态圈丰富)
|
|
||||||
3. 高可靠性(可以在服务器行持续不间断的运行数年)
|
|
||||||
4. 热部署(这个功能对于 Nginx 来说特别重要,热部署指可以在不停止 Nginx 服务的情况下升级 Nginx)
|
|
||||||
5. BSD 许可证(意味着我们可以将源代码下载下来进行修改然后使用自己的版本)
|
|
||||||
|
|
||||||
### 5.3 Nginx 的四个主要组成部分了解吗?
|
|
||||||
|
|
||||||
> 这部分内容参考极客时间—[Nginx 核心知识 100 讲的内容](https://time.geekbang.org/course/intro/138?code=AycjiiQk6uQRxnVJzBupFkrGkvZlmYELPRsZbWzaAHE= "Nginx核心知识100讲的内容")。
|
|
||||||
|
|
||||||
- Nginx 二进制可执行文件:由各模块源码编译出一个文件
|
|
||||||
- nginx.conf 配置文件:控制 Nginx 行为
|
|
||||||
- acess.log 访问日志: 记录每一条 HTTP 请求信息
|
|
||||||
- error.log 错误日志:定位问题
|
|
||||||
@ -1,64 +0,0 @@
|
|||||||
我还记得当时我去参加面试的时候,几乎每一场面试,特别是HR面和高管面的时候,面试官总是会在结尾问我:“问了你这么多问题了,你有什么问题问我吗?”。这个时候很多人内心就会陷入短暂的纠结中:我该问吗?不问的话面试官会不会对我影响不好?问什么问题?问这个问题会不会让面试官对我的影响不好啊?
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 这个问题对最终面试结果的影响到底大不大?
|
|
||||||
|
|
||||||
就技术面试而言,回答这个问题的时候,只要你不是触碰到你所面试的公司的雷区,那么我觉得这对你能不能拿到最终offer来说影响确实是不大的。我说这些并不代表你就可以直接对面试官说:“我没问题了。”,笔主当时面试的时候确实也说过挺多次“没问题要问了。”,最终也没有导致笔主被pass掉(可能是前面表现比较好,哈哈,自恋一下)。我现在回想起来,觉得自己当时做法其实挺不对的。面试本身就是一个双向选择的过程,你对这个问题的回答也会侧面反映出你对这次面试的上心程度,你的问题是否有价值,也影响了你最终的选择与公司是否选择你。
|
|
||||||
|
|
||||||
面试官在技术面试中主要考察的还是你这样个人到底有没有胜任这个工作的能力以及你是否适合公司未来的发展需要,很多公司还需要你认同它的文化,我觉得你只要不是太笨,应该不会栽在这里。除非你和另外一个人在能力上相同,但是只能在你们两个人中选一个,那么这个问题才对你能不能拿到offer至关重要。有准备总比没准备好,给面试官留一个好的影响总归是没错的。
|
|
||||||
|
|
||||||
但是,就非技术面试来说,我觉得好好回答这个问题对你最终的结果还是比较重要的。
|
|
||||||
|
|
||||||
总的来说不管是技术面试还是非技术面试,如果你想赢得公司的青睐和尊重,我觉得我们都应该重视这个问题。
|
|
||||||
|
|
||||||
### 真诚一点,不要问太 Low 的问题
|
|
||||||
|
|
||||||
回答这个问题很重要的一点就是你没有必要放低自己的姿态问一些很虚或者故意讨好面试官的问题,也不要把自己从面经上学到的东西照搬下来使用。面试官也不是傻子,特别是那种特别有经验的面试官,你是真心诚意的问问题,还是从别处照搬问题来讨好面试官,人家可能一听就听出来了。总的来说,还是要真诚。除此之外,不要问太 Low 的问题,会显得你整个人格局比较小或者说你根本没有准备(侧面反映你对这家公司不上心,既然你不上心,为什么要要你呢)。举例几个比较 Low 的问题,大家看看自己有没有问过其中的问题:
|
|
||||||
|
|
||||||
- 贵公司的主要业务是什么?(面试之前自己不知道提前网上查一下吗?)
|
|
||||||
- 贵公司的男女比例如何?(考虑脱单?记住你是来工作的!)
|
|
||||||
- 贵公司一年搞几次外出旅游?(你是来工作的,这些娱乐活动先别放在心上!)
|
|
||||||
- ......
|
|
||||||
|
|
||||||
### 有哪些有价值的问题值得问?
|
|
||||||
|
|
||||||
针对这个问题。笔主专门找了几个专门做HR工作的小哥哥小姐姐们询问并且查阅了挺多前辈们的回答,然后结合自己的实际经历,我概括了下面几个比较适合问的问题。
|
|
||||||
|
|
||||||
#### 面对HR或者其他Level比较低的面试官时
|
|
||||||
|
|
||||||
1. **能不能谈谈你作为一个公司老员工对公司的感受?** (这个问题比较容易回答,不会让面试官陷入无话可说的尴尬境地。另外,从面试官的回答中你可以加深对这个公司的了解,让你更加清楚这个公司到底是不是你想的那样或者说你是否能适应这个公司的文化。除此之外,这样的问题在某种程度上还可以拉进你与面试官的距离。)
|
|
||||||
2. **能不能问一下,你当时因为什么原因选择加入这家公司的呢或者说这家公司有哪些地方吸引你?有什么地方你觉得还不太好或者可以继续完善吗?** (类似第一个问题,都是问面试官个人对于公司的看法。)
|
|
||||||
3. **我觉得我这次表现的不是太好,你有什么建议或者评价给我吗?**(这个是我常问的。我觉得说自己表现不好只是这个语境需要这样来说,这样可以显的你比较谦虚好学上进。)
|
|
||||||
4. **接下来我会有一段空档期,有什么值得注意或者建议学习的吗?** (体现出你对工作比较上心,自助学习意识比较强。)
|
|
||||||
5. **这个岗位为什么还在招人?** (岗位真实性和价值咨询)
|
|
||||||
6. **大概什么时候能给我回复呢?** (终面的时候,如果面试官没有说的话,可以问一下)
|
|
||||||
7. ......
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 面对部门领导
|
|
||||||
|
|
||||||
1. **部门的主要人员分配以及对应的主要工作能简单介绍一下吗?**
|
|
||||||
2. **未来如果我要加入这个团队,你对我的期望是什么?** (部门领导一般情况下是你的直属上级了,你以后和他打交道的机会应该是最多的。你问这个问题,会让他感觉你是一个对他的部门比较上心,比较有团体意识,并且愿意倾听的候选人。)
|
|
||||||
3. **公司对新入职的员工的培养机制是什么样的呢?** (正规的公司一般都有培养机制,提前问一下是对你自己的负责也会显的你比较上心)
|
|
||||||
4. **以您来看,这个岗位未来在公司内部的发展如何?** (在我看来,问这个问题也是对你自己的负责吧,谁不想发展前景更好的岗位呢?)
|
|
||||||
5. **团队现在面临的最大挑战是什么?** (这样的问题不会暴露你对公司的不了解,并且也能让你对未来工作的挑战或困难有一个提前的预期。)
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
#### 面对Level比较高的(比如总裁,老板)
|
|
||||||
|
|
||||||
1. **贵公司的发展目标和方向是什么?** (看下公司的发展是否满足自己的期望)
|
|
||||||
2. **与同行业的竞争者相比,贵公司的核心竞争优势在什么地方?** (充分了解自己的优势和劣势)
|
|
||||||
3. **公司现在面临的最大挑战是什么?**
|
|
||||||
|
|
||||||
### 来个补充,顺便送个祝福给大家
|
|
||||||
|
|
||||||
薪酬待遇和相关福利问题一般在终面的时候(最好不要在前面几面的时候就问到这个问题),面试官会提出来或者在面试完之后以邮件的形式告知你。一般来说,如果面试官很愿意为你回答问题,对你的问题也比较上心的话,那他肯定是觉得你就是他们要招的人。
|
|
||||||
|
|
||||||
大家在面试的时候,可以根据自己对于公司或者岗位的了解程度,对上面提到的问题进行适当修饰或者修改。上面提到的一些问题只是给没有经验的朋友一个参考,如果你还有其他比较好的问题的话,那当然也更好啦!
|
|
||||||
|
|
||||||
金三银四。过了二月就到了面试高峰期或者说是黄金期。几份惊喜几份愁,愿各位能始终不忘初心!每个人都有每个人的难处。引用一句《阿甘正传》里面的台词:“生活就像一盒巧克力,你永远不知道下一块是什么味道“。
|
|
||||||
|
|
||||||

|
|
||||||
@ -1,222 +0,0 @@
|
|||||||
本文的内容都是根据读者投稿的真实面试经历改编而来,首次尝试这种风格的文章,花了几天晚上才总算写完,希望对你有帮助。
|
|
||||||
|
|
||||||
本文主要涵盖下面的内容:
|
|
||||||
|
|
||||||
1. 分布式商城系统:架构图讲解;
|
|
||||||
2. 消息队列相关:削峰和解耦;
|
|
||||||
3. Redis 相关:缓存穿透问题的解决;
|
|
||||||
4. 一些基础问题:
|
|
||||||
- 网络相关:1.浏览器输入 URL 发生了什么? 2.TCP 和 UDP 区别? 3.TCP 如何保证传输可靠性?
|
|
||||||
- Java 基础:1. 既然有了字节流,为什么还要有字符流? 2.深拷贝 和 浅拷贝有啥区别呢?
|
|
||||||
|
|
||||||
下面是正文!
|
|
||||||
|
|
||||||
面试开始,坐在我前面的就是这次我的面试官吗?这发量看着根本不像程序员啊?我心里正嘀咕着,只听见面试官说:“小伙,下午好,我今天就是你的面试官,咱们开始面试吧!”。
|
|
||||||
|
|
||||||
### 第一面开始
|
|
||||||
|
|
||||||
**面试官:** 我也不用多说了,你先自我介绍一下吧,简历上有的就不要再说了哈。
|
|
||||||
|
|
||||||
**我:** 内心 os:"果然如我所料,就知道会让我先自我介绍一下,还好我看了 [JavaGuide](https://github.com/Snailclimb/JavaGuide "JavaGuide") ,学到了一些套路。套路总结起来就是:**最好准备好两份自我介绍,一份对 hr 说的,主要讲能突出自己的经历,会的编程技术一语带过;另一份对技术面试官说的,主要讲自己会的技术细节,项目经验,经历那些就一语带过。** 所以,我按照这个套路准备了一个还算通用的模板,毕竟我懒嘛!不想多准备一个自我介绍,整个通用的多好!
|
|
||||||
|
|
||||||
> 面试官,您好!我叫小李子。大学时间我主要利用课外时间学习 Java 相关的知识。在校期间参与过一个某某系统的开发,主要负责数据库设计和后端系统开发.,期间解决了什么问题,巴拉巴拉。另外,我自己在学习过程中也参照网上的教程写过一个电商系统的网站,写这个电商网站主要是为了能让自己接触到分布式系统的开发。在学习之余,我比较喜欢通过博客整理分享自己所学知识。我现在已经是某社区的认证作者,写过一系列关于 线程池使用以及源码分析的文章深受好评。另外,我获得过省级编程比赛二等奖,我将这个获奖项目开源到 Github 还收获了 2k 的 Star 呢?
|
|
||||||
|
|
||||||
**面试官:** 你刚刚说参考网上的教程做了一个电商系统?你能画画这个电商系统的架构图吗?
|
|
||||||
|
|
||||||
**我:** 内心 os: "这可难不倒我!早知道写在简历上的项目要重视了,提前都把这个系统的架构图画了好多遍了呢!"
|
|
||||||
|
|
||||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/商城系统-架构图plus.png" style="zoom:50%;" />
|
|
||||||
|
|
||||||
做过分布式电商系统的一定很熟悉上面的架构图(目前比较流行的是微服务架构,但是如果你有分布式开发经验也是非常加分的!)。
|
|
||||||
|
|
||||||
**面试官:** 简单介绍一下你做的这个系统吧!
|
|
||||||
|
|
||||||
**我:** 我一本正经的对着我刚刚画的商城架构图开始了满嘴造火箭的讲起来:
|
|
||||||
|
|
||||||
> 本系统主要分为展示层、服务层和持久层这三层。表现层顾名思义主要就是为了用来展示,比如我们的后台管理系统的页面、商城首页的页面、搜索系统的页面等等,这一层都只是作为展示,并没有提供任何服务。
|
|
||||||
>
|
|
||||||
> 展示层和服务层一般是部署在不同的机器上来提高并发量和扩展性,那么展示层和服务层怎样才能交互呢?在本系统中我们使用 Dubbo 来进行服务治理。Dubbo 是一款高性能、轻量级的开源 Java RPC 框架。Dubbo 在本系统的主要作用就是提供远程 RPC 调用。在本系统中服务层的信息通过 Dubbo 注册给 ZooKeeper,表现层通过 Dubbo 去 ZooKeeper 中获取服务的相关信息。Zookeeper 的作用仅仅是存放提供服务的服务器的地址和一些服务的相关信息,实现 RPC 远程调用功能的还是 Dubbo。如果需要引用到某个服务的时候,我们只需要在配置文件中配置相关信息就可以在代码中直接使用了,就像调用本地方法一样。假如说某个服务的使用量增加时,我们只用为这单个服务增加服务器,而不需要为整个系统添加服务。
|
|
||||||
>
|
|
||||||
> 另外,本系统的数据库使用的是常用的 MySQL,并且用到了数据库中间件 MyCat。另外,本系统还用到 redis 内存数据库来作为缓存来提高系统的反应速度。假如用户第一次访问数据库中的某些数据,这个过程会比较慢,因为是从硬盘上读取的。将该用户访问的数据存在数缓存中,这样下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。
|
|
||||||
>
|
|
||||||
> 系统还用到了 Elasticsearch 来提供搜索功能。使用 Elasticsearch 我们可以非常方便的为我们的商城系统添加必备的搜索功能,并且使用 Elasticsearch 还能提供其它非常实用的功能,并且很容易扩展。
|
|
||||||
|
|
||||||
**面试官:** 我看你的系统里面还用到了消息队列,能说说为什么要用它吗?
|
|
||||||
|
|
||||||
**我:**
|
|
||||||
|
|
||||||
> 使用消息队列主要是为了:
|
|
||||||
>
|
|
||||||
> 1. 减少响应所需时间和削峰。
|
|
||||||
> 2. 降低系统耦合性(解耦/提升系统可扩展性)。
|
|
||||||
|
|
||||||
**面试官:** 你这说的太简单了!能不能稍微详细一点,最好能画图给我解释一下。
|
|
||||||
|
|
||||||
**我:** 内心 os:"都 2019 年了,大部分面试者都能对消息队列的为系统带来的这两个好处倒背如流了,如果你想走的更远就要别别人懂的更深一点!"
|
|
||||||
|
|
||||||
> 当我们不使用消息队列的时候,所有的用户的请求会直接落到服务器,然后通过数据库或者缓存响应。假如在高并发的场景下,如果没有缓存或者数据库承受不了这么大的压力的话,就会造成响应速度缓慢,甚至造成数据库宕机。但是,在使用消息队列之后,用户的请求数据发送给了消息队列之后就可以立即返回,再由消息队列的消费者进程从消息队列中获取数据,异步写入数据库,不过要确保消息不被重复消费还要考虑到消息丢失问题。由于消息队列服务器处理速度快于数据库,因此响应速度得到大幅改善。
|
|
||||||
>
|
|
||||||
> 文字 is too 空洞,直接上图吧!下图展示了使用消息前后系统处理用户请求的对比(ps:我自己都被我画的这个图美到了,如果你也觉得这张图好看的话麻烦来个素质三连!)。
|
|
||||||
>
|
|
||||||
> 
|
|
||||||
>
|
|
||||||
> 通过以上分析我们可以得出**消息队列具有很好的削峰作用的功能**——即**通过异步处理,将短时间高并发产生的事务消息存储在消息队列中,从而削平高峰期的并发事务。** 举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
|
|
||||||
>
|
|
||||||
> 
|
|
||||||
>
|
|
||||||
> 使用消息队列还可以降低系统耦合性。我们知道如果模块之间不存在直接调用,那么新增模块或者修改模块就对其他模块影响较小,这样系统的可扩展性无疑更好一些。还是直接上图吧:
|
|
||||||
>
|
|
||||||
> 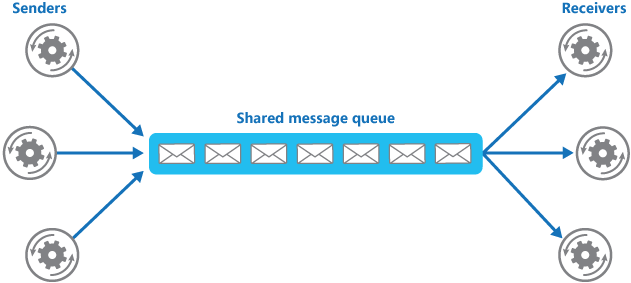
|
|
||||||
>
|
|
||||||
> 生产者(客户端)发送消息到消息队列中去,接受者(服务端)处理消息,需要消费的系统直接去消息队列取消息进行消费即可而不需要和其他系统有耦合, 这显然也提高了系统的扩展性。
|
|
||||||
|
|
||||||
**面试官:** 你觉得它有什么缺点吗?或者说怎么考虑用不用消息队列?
|
|
||||||
|
|
||||||
**我:** 内心 os: "面试官真鸡贼!这不是勾引我上钩么?还好我准备充分。"
|
|
||||||
|
|
||||||
> 我觉得可以从下面几个方面来说:
|
|
||||||
>
|
|
||||||
> 1. **系统可用性降低:** 系统可用性在某种程度上降低,为什么这样说呢?在加入 MQ 之前,你不用考虑消息丢失或者说 MQ 挂掉等等的情况,但是,引入 MQ 之后你就需要去考虑了!
|
|
||||||
> 2. **系统复杂性提高:** 加入 MQ 之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题!
|
|
||||||
> 3. **一致性问题:** 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了!
|
|
||||||
|
|
||||||
**面试官**:做项目的过程中遇到了什么问题吗?解决了吗?如果解决的话是如何解决的呢?
|
|
||||||
|
|
||||||
**我** : 内心 os: "做的过程中好像也没有遇到什么问题啊!怎么办?怎么办?突然想到可以说我在使用 Redis 过程中遇到的问题,毕竟我对 Redis 还算熟悉嘛,**把面试官往这个方向吸引**,准没错。"
|
|
||||||
|
|
||||||
> 我在使用 Redis 对常用数据进行缓冲的过程中出现了缓存穿透问题。然后,我通过谷歌搜索相关的解决方案来解决的。
|
|
||||||
|
|
||||||
**面试官:** 你还知道缓存穿透啊?不错啊!来说说什么是缓存穿透以及你最后的解决办法。
|
|
||||||
|
|
||||||
**我:** 我先来谈谈什么是缓存穿透吧!
|
|
||||||
|
|
||||||
> 缓存穿透说简单点就是大量请求的 key 根本不存在于缓存中,导致请求直接到了数据库上,根本没有经过缓存这一层。举个例子:某个黑客故意制造我们缓存中不存在的 key 发起大量请求,导致大量请求落到数据库。
|
|
||||||
>
|
|
||||||
> 总结一下就是:
|
|
||||||
>
|
|
||||||
> 1. 缓存层不命中。
|
|
||||||
> 2. 存储层不命中,不将空结果写回缓存。
|
|
||||||
> 3. 返回空结果给客户端。
|
|
||||||
>
|
|
||||||
> 一般 MySQL 默认的最大连接数在 150 左右,这个可以通过 `show variables like '%max_connections%';`命令来查看。最大连接数一个还只是一个指标,cpu,内存,磁盘,网络等物理条件都是其运行指标,这些指标都会限制其并发能力!所以,一般 3000 的并发请求就能打死大部分数据库了。
|
|
||||||
|
|
||||||
**面试官:** 小伙子不错啊!还准备问你:“为什么 3000 的并发能把支持最大连接数 4000 数据库压死?”想不到你自己就提前回答了!不错!
|
|
||||||
|
|
||||||
**我:** 别夸了!别夸了!我再来说说我知道的一些解决办法以及我最后采用的方案吧!您帮忙看看有没有问题。
|
|
||||||
|
|
||||||
> 最基本的就是首先做好参数校验,一些不合法的参数请求直接抛出异常信息返回给客户端。比如查询的数据库 id 不能小于 0、传入的邮箱格式不对的时候直接返回错误消息给客户端等等。
|
|
||||||
>
|
|
||||||
> 参数校验通过的情况还是会出现缓存穿透,我们还可以通过以下几个方案来解决这个问题:
|
|
||||||
>
|
|
||||||
> **1)缓存无效 key** : 如果缓存和数据库都查不到某个 key 的数据就写一个到 redis 中去并设置过期时间,具体命令如下:`SET key value EX 10086`。这种方式可以解决请求的 key 变化不频繁的情况,如何黑客恶意攻击,每次构建的不同的请求 key,会导致 redis 中缓存大量无效的 key 。很明显,这种方案并不能从根本上解决此问题。如果非要用这种方式来解决穿透问题的话,尽量将无效的 key 的过期时间设置短一点比如 1 分钟。
|
|
||||||
>
|
|
||||||
> 另外,这里多说一嘴,一般情况下我们是这样设计 key 的: `表名:列名:主键名:主键值`。
|
|
||||||
>
|
|
||||||
> **2)布隆过滤器:** 布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在于海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。
|
|
||||||
|
|
||||||
**面试官:** 不错不错!你还知道布隆过滤器啊!来给我谈一谈。
|
|
||||||
|
|
||||||
**我:** 内心 os:“如果你准备过海量数据处理的面试题,你一定对:“如何确定一个数字是否在于包含大量数字的数字集中(数字集很大,5 亿以上!)?”这个题目很了解了!解决这道题目就要用到布隆过滤器。”
|
|
||||||
|
|
||||||
> 布隆过滤器在针对海量数据去重或者验证数据合法性的时候非常有用。**布隆过滤器的本质实际上是 “位(bit)数组”,也就是说每一个存入布隆过滤器的数据都只占一位。相比于我们平时常用的的 List、Map 、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。**
|
|
||||||
>
|
|
||||||
> **当一个元素加入布隆过滤器中的时候,会进行如下操作:**
|
|
||||||
>
|
|
||||||
> 1. 使用布隆过滤器中的哈希函数对元素值进行计算,得到哈希值(有几个哈希函数得到几个哈希值)。
|
|
||||||
> 2. 根据得到的哈希值,在位数组中把对应下标的值置为 1。
|
|
||||||
>
|
|
||||||
> **当我们需要判断一个元素是否存在于布隆过滤器的时候,会进行如下操作:**
|
|
||||||
>
|
|
||||||
> 1. 对给定元素再次进行相同的哈希计算;
|
|
||||||
> 2. 得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
|
|
||||||
>
|
|
||||||
> 举个简单的例子:
|
|
||||||
>
|
|
||||||
> 
|
|
||||||
>
|
|
||||||
> 如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后在对应的位数组的下表的元素设置为 1(当位数组初始化时 ,所有位置均为 0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便)。
|
|
||||||
>
|
|
||||||
> 如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。
|
|
||||||
>
|
|
||||||
> **不同的字符串可能哈希出来的位置相同,这种情况我们可以适当增加位数组大小或者调整我们的哈希函数。**
|
|
||||||
>
|
|
||||||
> 综上,我们可以得出:**布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。**
|
|
||||||
|
|
||||||
**面试官:** 看来你对布隆过滤器了解的还挺不错的嘛!那你快说说你最后是怎么利用它来解决缓存穿透的。
|
|
||||||
|
|
||||||
**我:** 知道了布隆过滤器的原理就之后就很容易做了。我是利用 Redis 布隆过滤器来做的。我把所有可能存在的请求的值都存放在布隆过滤器中,当用户请求过来,我会先判断用户发来的请求的值是否存在于布隆过滤器中。不存在的话,直接返回请求参数错误信息给客户端,存在的话才会走下面的流程。总结一下就是下面这张图(这张图片不是我画的,为了省事直接在网上找的):
|
|
||||||
|
|
||||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/布隆过滤器-缓存穿透-redis.png" style="zoom:50%;" />
|
|
||||||
|
|
||||||
更多关于布隆过滤器的内容可以看我的这篇原创:[《不了解布隆过滤器?一文给你整的明明白白!》](https://github.com/Snailclimb/JavaGuide/blob/master/docs/dataStructures-algorithms/data-structure/bloom-filter.md "《不了解布隆过滤器?一文给你整的明明白白!》") ,强烈推荐,个人感觉网上应该找不到总结的这么明明白白的文章了。
|
|
||||||
|
|
||||||
**面试官:** 好了好了。项目就暂时问到这里吧!下面有一些比较基础的问题我简单地问一下你。内心 os: 难不成这家伙满口高并发,连最基础的东西都不会吧!
|
|
||||||
|
|
||||||
**我:** 好的好的!没问题!
|
|
||||||
|
|
||||||
**面试官:** 浏览器输入 URL 发生了什么?
|
|
||||||
|
|
||||||
**我:** 内心 os:“很常问的一个问题,建议拿小本本记好了!另外,百度好像最喜欢问这个问题,去百度面试可要提前备好这道题的功课哦!相似问题:打开一个网页,整个过程会使用哪些协议?”。
|
|
||||||
|
|
||||||
> 图解(图片来源:《图解 HTTP》):
|
|
||||||
>
|
|
||||||
> <img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/url输入到展示出来的过程.jpg" style="zoom:50%;" />
|
|
||||||
>
|
|
||||||
> 总体来说分为以下几个过程:
|
|
||||||
>
|
|
||||||
> 1. DNS 解析
|
|
||||||
> 2. TCP 连接
|
|
||||||
> 3. 发送 HTTP 请求
|
|
||||||
> 4. 服务器处理请求并返回 HTTP 报文
|
|
||||||
> 5. 浏览器解析渲染页面
|
|
||||||
> 6. 连接结束
|
|
||||||
>
|
|
||||||
> 具体可以参考下面这篇文章:
|
|
||||||
>
|
|
||||||
> - [https://segmentfault.com/a/1190000006879700](https://segmentfault.com/a/1190000006879700 "https://segmentfault.com/a/1190000006879700")
|
|
||||||
|
|
||||||
**面试官:** TCP 和 UDP 区别?
|
|
||||||
|
|
||||||
**我:**
|
|
||||||
|
|
||||||
> 
|
|
||||||
>
|
|
||||||
> UDP 在传送数据之前不需要先建立连接,远地主机在收到 UDP 报文后,不需要给出任何确认。虽然 UDP 不提供可靠交付,但在某些情况下 UDP 确是一种最有效的工作方式(一般用于即时通信),比如: QQ 语音、 QQ 视频 、直播等等
|
|
||||||
>
|
|
||||||
> TCP 提供面向连接的服务。在传送数据之前必须先建立连接,数据传送结束后要释放连接。 TCP 不提供广播或多播服务。由于 TCP 要提供可靠的,面向连接的传输服务(TCP 的可靠体现在 TCP 在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源),这一难以避免增加了许多开销,如确认,流量控制,计时器以及连接管理等。这不仅使协议数据单元的首部增大很多,还要占用许多处理机资源。TCP 一般用于文件传输、发送和接收邮件、远程登录等场景。
|
|
||||||
|
|
||||||
**面试官:** TCP 如何保证传输可靠性?
|
|
||||||
|
|
||||||
**我:**
|
|
||||||
|
|
||||||
> 1. 应用数据被分割成 TCP 认为最适合发送的数据块。
|
|
||||||
> 2. TCP 给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。
|
|
||||||
> 3. **校验和:** TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。
|
|
||||||
> 4. TCP 的接收端会丢弃重复的数据。
|
|
||||||
> 5. **流量控制:** TCP 连接的每一方都有固定大小的缓冲空间,TCP 的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议。 (TCP 利用滑动窗口实现流量控制)
|
|
||||||
> 6. **拥塞控制:** 当网络拥塞时,减少数据的发送。
|
|
||||||
> 7. **ARQ 协议:** 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。
|
|
||||||
> 8. **超时重传:** 当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。
|
|
||||||
|
|
||||||
**面试官:** 我再来问你一些 Java 基础的问题吧!小伙子。
|
|
||||||
|
|
||||||
**我:** 好的。(内心 os:“你尽管来!”)
|
|
||||||
|
|
||||||
**面试官:** 既然有了字节流,为什么还要有字符流?
|
|
||||||
|
|
||||||
我:内心 os :“问题本质想问:**不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?**”
|
|
||||||
|
|
||||||
> 字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
|
|
||||||
|
|
||||||
**面试官**:深拷贝 和 浅拷贝有啥区别呢?
|
|
||||||
|
|
||||||
**我:**
|
|
||||||
|
|
||||||
> 1. **浅拷贝**:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。
|
|
||||||
> 2. **深拷贝**:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。
|
|
||||||
>
|
|
||||||
> 
|
|
||||||
|
|
||||||
**面试官:** 好的!面试结束。小伙子可以的!回家等通知吧!
|
|
||||||
|
|
||||||
**我:** 好的好的!辛苦您了!
|
|
||||||
@ -1,93 +0,0 @@
|
|||||||
## Markdown 简历模板样式一览
|
|
||||||

|
|
||||||
**可以看到我把联系方式放在第一位,因为公司一般会与你联系,所以把联系方式放在第一位也是为了方便联系考虑。**
|
|
||||||
|
|
||||||
## 为什么要用 Markdown 写简历?
|
|
||||||
|
|
||||||
Markdown 语法简单,易于上手。使用正确的 Markdown 语言写出来的简历不论是在排版还是格式上都比较干净,易于阅读。另外,使用 Markdown 写简历也会给面试官一种你比较专业的感觉。
|
|
||||||
|
|
||||||
除了这些,我觉得使用 Markdown 写简历可以很方便将其与PDF、HTML、PNG格式之间转换。后面我会介绍到转换方法,只需要一条命令你就可以实现 Markdown 到 PDF、HTML 与 PNG之间的无缝切换。
|
|
||||||
|
|
||||||
> 下面的一些内容我在之前的一篇文章中已经提到过,这里再说一遍,最后会分享如何实现Markdown 到 PDF、HTML、PNG格式之间转换。
|
|
||||||
|
|
||||||
## 为什么说简历很重要?
|
|
||||||
|
|
||||||
假如你是网申,你的简历必然会经过HR的筛选,一张简历HR可能也就花费10秒钟看一下,然后HR就会决定你这一关是Fail还是Pass。
|
|
||||||
|
|
||||||
假如你是内推,如果你的简历没有什么优势的话,就算是内推你的人再用心,也无能为力。
|
|
||||||
|
|
||||||
另外,就算你通过了筛选,后面的面试中,面试官也会根据你的简历来判断你究竟是否值得他花费很多时间去面试。
|
|
||||||
|
|
||||||
## 写简历的两大法则
|
|
||||||
|
|
||||||
目前写简历的方式有两种普遍被认可,一种是 STAR, 一种是 FAB。
|
|
||||||
|
|
||||||
**STAR法则(Situation Task Action Result):**
|
|
||||||
|
|
||||||
- **Situation:** 事情是在什么情况下发生;
|
|
||||||
- **Task::** 你是如何明确你的任务的;
|
|
||||||
- **Action:** 针对这样的情况分析,你采用了什么行动方式;
|
|
||||||
- **Result:** 结果怎样,在这样的情况下你学习到了什么。
|
|
||||||
|
|
||||||
**FAB 法则(Feature Advantage Benefit):**
|
|
||||||
|
|
||||||
- **Feature:** 是什么;
|
|
||||||
- **Advantage:** 比别人好在哪些地方;
|
|
||||||
- **Benefit:** 如果雇佣你,招聘方会得到什么好处。
|
|
||||||
|
|
||||||
## 项目经历怎么写?
|
|
||||||
简历上有一两个项目经历很正常,但是真正能把项目经历很好的展示给面试官的非常少。对于项目经历大家可以考虑从如下几点来写:
|
|
||||||
|
|
||||||
1. 对项目整体设计的一个感受
|
|
||||||
2. 在这个项目中你负责了什么、做了什么、担任了什么角色
|
|
||||||
3. 从这个项目中你学会了那些东西,使用到了那些技术,学会了那些新技术的使用
|
|
||||||
4. 另外项目描述中,最好可以体现自己的综合素质,比如你是如何协调项目组成员协同开发的或者在遇到某一个棘手的问题的时候你是如何解决的。
|
|
||||||
|
|
||||||
## 专业技能该怎么写?
|
|
||||||
先问一下你自己会什么,然后看看你意向的公司需要什么。一般HR可能并不太懂技术,所以他在筛选简历的时候可能就盯着你专业技能的关键词来看。对于公司有要求而你不会的技能,你可以花几天时间学习一下,然后在简历上可以写上自己了解这个技能。比如你可以这样写:
|
|
||||||
|
|
||||||
- Dubbo:精通
|
|
||||||
- Spring:精通
|
|
||||||
- Docker:掌握
|
|
||||||
- SOA分布式开发 :掌握
|
|
||||||
- Spring Cloud:了解
|
|
||||||
|
|
||||||
## 简历模板分享
|
|
||||||
|
|
||||||
**开源程序员简历模板**: [https://github.com/geekcompany/ResumeSample](https://github.com/geekcompany/ResumeSample)(包括PHP程序员简历模板、iOS程序员简历模板、Android程序员简历模板、Web前端程序员简历模板、Java程序员简历模板、C/C++程序员简历模板、NodeJS程序员简历模板、架构师简历模板以及通用程序员简历模板)
|
|
||||||
|
|
||||||
**上述简历模板的改进版本:** [https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/简历模板.md](https://github.com/Snailclimb/Java-Guide/blob/master/面试必备/简历模板.md)
|
|
||||||
|
|
||||||
## 其他的一些小tips
|
|
||||||
|
|
||||||
1. 尽量避免主观表述,少一点语义模糊的形容词,尽量要简洁明了,逻辑结构清晰。
|
|
||||||
2. 注意排版(不需要花花绿绿的),尽量使用Markdown语法。
|
|
||||||
3. 如果自己有博客或者个人技术栈点的话,写上去会为你加分很多。
|
|
||||||
4. 如果自己的Github比较活跃的话,写上去也会为你加分很多。
|
|
||||||
5. 注意简历真实性,一定不要写自己不会的东西,或者带有欺骗性的内容
|
|
||||||
6. 项目经历建议以时间倒序排序,另外项目经历不在于多,而在于有亮点。
|
|
||||||
7. 如果内容过多的话,不需要非把内容压缩到一页,保持排版干净整洁就可以了。
|
|
||||||
8. 简历最后最好能加上:“感谢您花时间阅读我的简历,期待能有机会和您共事。”这句话,显的你会很有礼貌。
|
|
||||||
|
|
||||||
|
|
||||||
> 我们刚刚讲了很多关于如何写简历的内容并且分享了一份 Markdown 格式的简历文档。下面我们来看看如何实现 Markdown 到 HTML格式、PNG格式之间转换。
|
|
||||||
## Markdown 到 HTML格式、PNG格式之间转换
|
|
||||||
|
|
||||||
网上很难找到一个比较方便并且效果好的转换方法,最后我是通过 Visual Studio Code 的 Markdown PDF 插件完美解决了这个问题!
|
|
||||||
|
|
||||||
### 安装 Markdown PDF 插件
|
|
||||||
|
|
||||||
**① 打开Visual Studio Code ,按快捷键 F1,选择安装扩展选项**
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
**② 搜索 “Markdown PDF” 插件并安装 ,然后重启**
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 使用方法
|
|
||||||
|
|
||||||
随便打开一份 Markdown 文件 点击F1,然后输入export即可!
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
@ -1,79 +0,0 @@
|
|||||||
# 联系方式
|
|
||||||
|
|
||||||
- 手机:
|
|
||||||
- Email:
|
|
||||||
- 微信:
|
|
||||||
|
|
||||||
# 个人信息
|
|
||||||
|
|
||||||
- 姓名/性别/出生日期
|
|
||||||
- 本科/xxx计算机系xxx专业/英语六级
|
|
||||||
- 技术博客:[http://snailclimb.top/](http://snailclimb.top/)
|
|
||||||
- 荣誉奖励:获得了什么奖(获奖时间)
|
|
||||||
- Github:[https://github.com/Snailclimb ](https://github.com/Snailclimb)
|
|
||||||
- Github Resume: [http://resume.github.io/?Snailclimb](http://resume.github.io/?Snailclimb)
|
|
||||||
- 期望职位:Java 研发程序员/大数据工程师(Java后台开发为首选)
|
|
||||||
- 期望城市:xxx城市
|
|
||||||
|
|
||||||
|
|
||||||
# 项目经历
|
|
||||||
|
|
||||||
## xxx项目
|
|
||||||
|
|
||||||
### 项目描述
|
|
||||||
|
|
||||||
介绍该项目是做什么的、使用到了什么技术以及你对项目整体设计的一个感受
|
|
||||||
|
|
||||||
### 责任描述
|
|
||||||
|
|
||||||
主要可以从下面三点来写:
|
|
||||||
|
|
||||||
1. 在这个项目中你负责了什么、做了什么、担任了什么角色
|
|
||||||
2. 从这个项目中你学会了那些东西,使用到了那些技术,学会了那些新技术的使用
|
|
||||||
3. 另外项目描述中,最好可以体现自己的综合素质,比如你是如何协调项目组成员协同开发的或者在遇到某一个棘手的问题的时候你是如何解决的。
|
|
||||||
|
|
||||||
# 开源项目和技术文章
|
|
||||||
|
|
||||||
## 开源项目
|
|
||||||
|
|
||||||
- [Java-Guide](https://github.com/Snailclimb/Java-Guide) :一份涵盖大部分Java程序员所需要掌握的核心知识。Star:3.9K; Fork:0.9k。
|
|
||||||
|
|
||||||
|
|
||||||
## 技术文章推荐
|
|
||||||
|
|
||||||
- [可能是把Java内存区域讲的最清楚的一篇文章](https://juejin.im/post/5b7d69e4e51d4538ca5730cb)
|
|
||||||
- [搞定JVM垃圾回收就是这么简单](https://juejin.im/post/5b85ea54e51d4538dd08f601)
|
|
||||||
- [前端&后端程序员必备的Linux基础知识](https://juejin.im/post/5b3b19856fb9a04fa42f8c71)
|
|
||||||
- [可能是把Docker的概念讲的最清楚的一篇文章](https://juejin.im/post/5b260ec26fb9a00e8e4b031a)
|
|
||||||
|
|
||||||
|
|
||||||
# 校园经历(可选)
|
|
||||||
|
|
||||||
## 2016-2017
|
|
||||||
|
|
||||||
担任学校社团-致深社副会长,主要负责团队每周活动的组建以及每周例会的主持。
|
|
||||||
|
|
||||||
## 2017-2018
|
|
||||||
担任学校传媒组织:“长江大学在线信息传媒”的副站长以及安卓组成员。主要负责每周例会主持、活动策划以及学校校园通APP的研发工作。
|
|
||||||
|
|
||||||
|
|
||||||
# 技能清单
|
|
||||||
|
|
||||||
以下均为我熟练使用的技能
|
|
||||||
|
|
||||||
- Web开发:PHP/Hack/Node
|
|
||||||
- Web框架:ThinkPHP/Yaf/Yii/Lavarel/LazyPHP
|
|
||||||
- 前端框架:Bootstrap/AngularJS/EmberJS/HTML5/Cocos2dJS/ionic
|
|
||||||
- 前端工具:Bower/Gulp/SaSS/LeSS/PhoneGap
|
|
||||||
- 数据库相关:MySQL/PgSQL/PDO/SQLite
|
|
||||||
- 版本管理、文档和自动化部署工具:Svn/Git/PHPDoc/Phing/Composer
|
|
||||||
- 单元测试:PHPUnit/SimpleTest/Qunit
|
|
||||||
- 云和开放平台:SAE/BAE/AWS/微博开放平台/微信应用开发
|
|
||||||
|
|
||||||
# 自我评价(可选)
|
|
||||||
|
|
||||||
自我发挥。切记不要过度自夸!!!
|
|
||||||
|
|
||||||
|
|
||||||
### 感谢您花时间阅读我的简历,期待能有机会和您共事。
|
|
||||||
|
|
||||||
@ -1,115 +0,0 @@
|
|||||||
点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
|
|
||||||
|
|
||||||
<!-- TOC -->
|
|
||||||
|
|
||||||
- [何谓悲观锁与乐观锁](#何谓悲观锁与乐观锁)
|
|
||||||
- [悲观锁](#悲观锁)
|
|
||||||
- [乐观锁](#乐观锁)
|
|
||||||
- [两种锁的使用场景](#两种锁的使用场景)
|
|
||||||
- [乐观锁常见的两种实现方式](#乐观锁常见的两种实现方式)
|
|
||||||
- [1. 版本号机制](#1-版本号机制)
|
|
||||||
- [2. CAS算法](#2-cas算法)
|
|
||||||
- [乐观锁的缺点](#乐观锁的缺点)
|
|
||||||
- [1 ABA 问题](#1-aba-问题)
|
|
||||||
- [2 循环时间长开销大](#2-循环时间长开销大)
|
|
||||||
- [3 只能保证一个共享变量的原子操作](#3-只能保证一个共享变量的原子操作)
|
|
||||||
- [CAS与synchronized的使用情景](#cas与synchronized的使用情景)
|
|
||||||
|
|
||||||
<!-- /TOC -->
|
|
||||||
|
|
||||||
### 何谓悲观锁与乐观锁
|
|
||||||
|
|
||||||
> 乐观锁对应于生活中乐观的人总是想着事情往好的方向发展,悲观锁对应于生活中悲观的人总是想着事情往坏的方向发展。这两种人各有优缺点,不能不以场景而定说一种人好于另外一种人。
|
|
||||||
|
|
||||||
#### 悲观锁
|
|
||||||
|
|
||||||
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁(**共享资源每次只给一个线程使用,其它线程阻塞,用完后再把资源转让给其它线程**)。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。Java中`synchronized`和`ReentrantLock`等独占锁就是悲观锁思想的实现。
|
|
||||||
|
|
||||||
|
|
||||||
#### 乐观锁
|
|
||||||
|
|
||||||
总是假设最好的情况,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号机制和CAS算法实现。**乐观锁适用于多读的应用类型,这样可以提高吞吐量**,像数据库提供的类似于**write_condition机制**,其实都是提供的乐观锁。在Java中`java.util.concurrent.atomic`包下面的原子变量类就是使用了乐观锁的一种实现方式**CAS**实现的。
|
|
||||||
|
|
||||||
#### 两种锁的使用场景
|
|
||||||
|
|
||||||
从上面对两种锁的介绍,我们知道两种锁各有优缺点,不可认为一种好于另一种,像**乐观锁适用于写比较少的情况下(多读场景)**,即冲突真的很少发生的时候,这样可以省去了锁的开销,加大了系统的整个吞吐量。但如果是多写的情况,一般会经常产生冲突,这就会导致上层应用会不断的进行retry,这样反倒是降低了性能,所以**一般多写的场景下用悲观锁就比较合适。**
|
|
||||||
|
|
||||||
|
|
||||||
### 乐观锁常见的两种实现方式
|
|
||||||
|
|
||||||
> **乐观锁一般会使用版本号机制或CAS算法实现。**
|
|
||||||
|
|
||||||
#### 1. 版本号机制
|
|
||||||
|
|
||||||
一般是在数据表中加上一个数据版本号version字段,表示数据被修改的次数,当数据被修改时,version值会加一。当线程A要更新数据值时,在读取数据的同时也会读取version值,在提交更新时,若刚才读取到的version值为当前数据库中的version值相等时才更新,否则重试更新操作,直到更新成功。
|
|
||||||
|
|
||||||
**举一个简单的例子:**
|
|
||||||
假设数据库中帐户信息表中有一个 version 字段,当前值为 1 ;而当前帐户余额字段( balance )为 $100 。
|
|
||||||
|
|
||||||
1. 操作员 A 此时将其读出( version=1 ),并从其帐户余额中扣除 $50( $100-$50 )。
|
|
||||||
2. 在操作员 A 操作的过程中,操作员B 也读入此用户信息( version=1 ),并从其帐户余额中扣除 $20 ( $100-$20 )。
|
|
||||||
3. 操作员 A 完成了修改工作,将数据版本号( version=1 ),连同帐户扣除后余额( balance=$50 ),提交至数据库更新,此时由于提交数据版本等于数据库记录当前版本,数据被更新,数据库记录 version 更新为 2 。
|
|
||||||
4. 操作员 B 完成了操作,也将版本号( version=1 )试图向数据库提交数据( balance=$80 ),但此时比对数据库记录版本时发现,操作员 B 提交的数据版本号为 1 ,数据库记录当前版本也为 2 ,不满足 “ 提交版本必须等于当前版本才能执行更新 “ 的乐观锁策略,因此,操作员 B 的提交被驳回。
|
|
||||||
|
|
||||||
这样,就避免了操作员 B 用基于 version=1 的旧数据修改的结果覆盖操作员A 的操作结果的可能。
|
|
||||||
|
|
||||||
#### 2. CAS算法
|
|
||||||
|
|
||||||
即**compare and swap(比较与交换)**,是一种有名的**无锁算法**。无锁编程,即不使用锁的情况下实现多线程之间的变量同步,也就是在没有线程被阻塞的情况下实现变量的同步,所以也叫非阻塞同步(Non-blocking Synchronization)。**CAS算法**涉及到三个操作数
|
|
||||||
|
|
||||||
- 需要读写的内存值 V
|
|
||||||
- 进行比较的值 A
|
|
||||||
- 拟写入的新值 B
|
|
||||||
|
|
||||||
当且仅当 V 的值等于 A时,CAS通过原子方式用新值B来更新V的值,否则不会执行任何操作(比较和替换是一个原子操作)。一般情况下是一个**自旋操作**,即**不断的重试**。
|
|
||||||
|
|
||||||
关于自旋锁,大家可以看一下这篇文章,非常不错:[《
|
|
||||||
面试必备之深入理解自旋锁》](https://blog.csdn.net/qq_34337272/article/details/81252853)
|
|
||||||
|
|
||||||
### 乐观锁的缺点
|
|
||||||
|
|
||||||
> ABA 问题是乐观锁一个常见的问题
|
|
||||||
|
|
||||||
#### 1 ABA 问题
|
|
||||||
|
|
||||||
如果一个变量V初次读取的时候是A值,并且在准备赋值的时候检查到它仍然是A值,那我们就能说明它的值没有被其他线程修改过了吗?很明显是不能的,因为在这段时间它的值可能被改为其他值,然后又改回A,那CAS操作就会误认为它从来没有被修改过。这个问题被称为CAS操作的 **"ABA"问题。**
|
|
||||||
|
|
||||||
JDK 1.5 以后的 `AtomicStampedReference 类`就提供了此种能力,其中的 `compareAndSet 方法`就是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
|
|
||||||
|
|
||||||
#### 2 循环时间长开销大
|
|
||||||
**自旋CAS(也就是不成功就一直循环执行直到成功)如果长时间不成功,会给CPU带来非常大的执行开销。** 如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
|
|
||||||
|
|
||||||
#### 3 只能保证一个共享变量的原子操作
|
|
||||||
|
|
||||||
CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效。但是从 JDK 1.5开始,提供了`AtomicReference类`来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作.所以我们可以使用锁或者利用`AtomicReference类`把多个共享变量合并成一个共享变量来操作。
|
|
||||||
|
|
||||||
### CAS与`synchronized`的使用情景
|
|
||||||
|
|
||||||
> **简单的来说CAS适用于写比较少的情况下(多读场景,冲突一般较少),synchronized适用于写比较多的情况下(多写场景,冲突一般较多)**
|
|
||||||
|
|
||||||
1. 对于资源竞争较少(线程冲突较轻)的情况,使用`synchronized`同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
|
|
||||||
2. 对于资源竞争严重(线程冲突严重)的情况,CAS自旋的概率会比较大,从而浪费更多的CPU资源,效率低于synchronized。
|
|
||||||
|
|
||||||
补充: Java并发编程这个领域中`synchronized`关键字一直都是元老级的角色,很久之前很多人都会称它为 **“重量级锁”** 。但是,在JavaSE 1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的 **偏向锁** 和 **轻量级锁** 以及其它**各种优化**之后变得在某些情况下并不是那么重了。`synchronized`的底层实现主要依靠 **Lock-Free** 的队列,基本思路是 **自旋后阻塞**,**竞争切换后继续竞争锁**,**稍微牺牲了公平性,但获得了高吞吐量**。在线程冲突较少的情况下,可以获得和CAS类似的性能;而线程冲突严重的情况下,性能远高于CAS。
|
|
||||||
|
|
||||||
## 公众号
|
|
||||||
|
|
||||||
如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。
|
|
||||||
|
|
||||||
**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"面试突击"** 即可免费领取!
|
|
||||||
|
|
||||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
@ -11,9 +11,8 @@
|
|||||||
- [1.1.2.2. JDK 和 JRE](#1122-jdk-和-jre)
|
- [1.1.2.2. JDK 和 JRE](#1122-jdk-和-jre)
|
||||||
- [1.1.3. Oracle JDK 和 OpenJDK 的对比](#113-oracle-jdk-和-openjdk-的对比)
|
- [1.1.3. Oracle JDK 和 OpenJDK 的对比](#113-oracle-jdk-和-openjdk-的对比)
|
||||||
- [1.1.4. Java 和 C++的区别?](#114-java-和-c的区别)
|
- [1.1.4. Java 和 C++的区别?](#114-java-和-c的区别)
|
||||||
- [1.1.5. 什么是 Java 程序的主类 应用程序和小程序的主类有何不同?](#115-什么是-java-程序的主类-应用程序和小程序的主类有何不同)
|
- [1.1.5. import java 和 javax 有什么区别?](#115-import-java-和-javax-有什么区别)
|
||||||
- [1.1.6. import java 和 javax 有什么区别?](#116-import-java-和-javax-有什么区别)
|
- [1.1.6. 为什么说 Java 语言“编译与解释并存”?](#116-为什么说-java-语言编译与解释并存)
|
||||||
- [1.1.7. 为什么说 Java 语言“编译与解释并存”?](#117-为什么说-java-语言编译与解释并存)
|
|
||||||
- [1.2. Java 语法](#12-java-语法)
|
- [1.2. Java 语法](#12-java-语法)
|
||||||
- [1.2.1. 字符型常量和字符串常量的区别?](#121-字符型常量和字符串常量的区别)
|
- [1.2.1. 字符型常量和字符串常量的区别?](#121-字符型常量和字符串常量的区别)
|
||||||
- [1.2.2. 关于注释?](#122-关于注释)
|
- [1.2.2. 关于注释?](#122-关于注释)
|
||||||
@ -52,19 +51,19 @@
|
|||||||
- [2.3. 修饰符](#23-修饰符)
|
- [2.3. 修饰符](#23-修饰符)
|
||||||
- [2.3.1. 在一个静态方法内调用一个非静态成员为什么是非法的?](#231-在一个静态方法内调用一个非静态成员为什么是非法的)
|
- [2.3.1. 在一个静态方法内调用一个非静态成员为什么是非法的?](#231-在一个静态方法内调用一个非静态成员为什么是非法的)
|
||||||
- [2.3.2. 静态方法和实例方法有何不同](#232-静态方法和实例方法有何不同)
|
- [2.3.2. 静态方法和实例方法有何不同](#232-静态方法和实例方法有何不同)
|
||||||
- [2.5. 其它重要知识点](#25-其它重要知识点)
|
- [2.4. 其它重要知识点](#24-其它重要知识点)
|
||||||
- [2.5.1. String StringBuffer 和 StringBuilder 的区别是什么? String 为什么是不可变的?](#251-string-stringbuffer-和-stringbuilder-的区别是什么-string-为什么是不可变的)
|
- [2.4.1. String StringBuffer 和 StringBuilder 的区别是什么? String 为什么是不可变的?](#241-string-stringbuffer-和-stringbuilder-的区别是什么-string-为什么是不可变的)
|
||||||
- [2.5.2. Object 类的常见方法总结](#252-object-类的常见方法总结)
|
- [2.4.2. Object 类的常见方法总结](#242-object-类的常见方法总结)
|
||||||
- [2.5.3. == 与 equals(重要)](#253-与-equals重要)
|
- [2.4.3. == 与 equals(重要)](#243-与-equals重要)
|
||||||
- [2.5.4. hashCode 与 equals (重要)](#254-hashcode-与-equals-重要)
|
- [2.4.4. hashCode 与 equals (重要)](#244-hashcode-与-equals-重要)
|
||||||
- [2.5.4.1. hashCode()介绍](#2541-hashcode介绍)
|
- [2.4.4.1. hashCode()介绍](#2441-hashcode介绍)
|
||||||
- [2.5.4.2. 为什么要有 hashCode](#2542-为什么要有-hashcode)
|
- [2.4.4.2. 为什么要有 hashCode](#2442-为什么要有-hashcode)
|
||||||
- [2.5.4.3. hashCode()与 equals()的相关规定](#2543-hashcode与-equals的相关规定)
|
- [2.4.4.3. hashCode()与 equals()的相关规定](#2443-hashcode与-equals的相关规定)
|
||||||
- [2.5.5. Java 序列化中如果有些字段不想进行序列化,怎么办?](#255-java-序列化中如果有些字段不想进行序列化怎么办)
|
- [2.4.5. Java 序列化中如果有些字段不想进行序列化,怎么办?](#245-java-序列化中如果有些字段不想进行序列化怎么办)
|
||||||
- [2.5.6. 获取用键盘输入常用的两种方法](#256-获取用键盘输入常用的两种方法)
|
- [2.4.6. 获取用键盘输入常用的两种方法](#246-获取用键盘输入常用的两种方法)
|
||||||
- [3. Java 核心技术](#3-java-核心技术)
|
- [3. Java 核心技术](#3-java-核心技术)
|
||||||
- [3.1. 反射机制](#31-反射机制)
|
- [3.1. 反射机制](#31-反射机制)
|
||||||
- [3.1.1.静态编译和动态编译](#311静态编译和动态编译)
|
- [3.1.1.何为反射?](#311何为反射)
|
||||||
- [3.1.2.反射机制优缺点](#312反射机制优缺点)
|
- [3.1.2.反射机制优缺点](#312反射机制优缺点)
|
||||||
- [3.1.3.反射的应用场景](#313反射的应用场景)
|
- [3.1.3.反射的应用场景](#313反射的应用场景)
|
||||||
- [3.2. 异常](#32-异常)
|
- [3.2. 异常](#32-异常)
|
||||||
@ -273,7 +272,7 @@ Method add = clazz.getDeclaredMethod("add", Object.class);
|
|||||||
//但是通过反射添加,是可以的
|
//但是通过反射添加,是可以的
|
||||||
add.invoke(list, "kl");
|
add.invoke(list, "kl");
|
||||||
|
|
||||||
System.out.println(list)
|
System.out.println(list);
|
||||||
```
|
```
|
||||||
|
|
||||||
泛型一般有三种使用方式:泛型类、泛型接口、泛型方法。
|
泛型一般有三种使用方式:泛型类、泛型接口、泛型方法。
|
||||||
@ -760,7 +759,7 @@ Java 程序设计语言对对象采用的不是引用调用,实际上,对象
|
|||||||
|
|
||||||
**重载:**
|
**重载:**
|
||||||
|
|
||||||
发生在同一个类中,方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同。
|
发生在同一个类中(或者父类和子类之间),方法名必须相同,参数类型不同、个数不同、顺序不同,方法返回值和访问修饰符可以不同。
|
||||||
|
|
||||||
下面是《Java 核心技术》对重载这个概念的介绍:
|
下面是《Java 核心技术》对重载这个概念的介绍:
|
||||||
|
|
||||||
@ -1004,9 +1003,9 @@ public class Student {
|
|||||||
|
|
||||||
2. 静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),而不允许访问实例成员变量和实例方法;实例方法则无此限制。
|
2. 静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),而不允许访问实例成员变量和实例方法;实例方法则无此限制。
|
||||||
|
|
||||||
### 2.5. 其它重要知识点
|
### 2.4. 其它重要知识点
|
||||||
|
|
||||||
#### 2.5.1. String StringBuffer 和 StringBuilder 的区别是什么? String 为什么是不可变的?
|
#### 2.4.1. String StringBuffer 和 StringBuilder 的区别是什么? String 为什么是不可变的?
|
||||||
|
|
||||||
**可变性**
|
**可变性**
|
||||||
|
|
||||||
@ -1051,7 +1050,7 @@ abstract class AbstractStringBuilder implements Appendable, CharSequence {
|
|||||||
2. 单线程操作字符串缓冲区下操作大量数据: 适用 `StringBuilder`
|
2. 单线程操作字符串缓冲区下操作大量数据: 适用 `StringBuilder`
|
||||||
3. 多线程操作字符串缓冲区下操作大量数据: 适用 `StringBuffer`
|
3. 多线程操作字符串缓冲区下操作大量数据: 适用 `StringBuffer`
|
||||||
|
|
||||||
#### 2.5.2. Object 类的常见方法总结
|
#### 2.4.2. Object 类的常见方法总结
|
||||||
|
|
||||||
Object 类是一个特殊的类,是所有类的父类。它主要提供了以下 11 个方法:
|
Object 类是一个特殊的类,是所有类的父类。它主要提供了以下 11 个方法:
|
||||||
|
|
||||||
@ -1080,7 +1079,7 @@ protected void finalize() throws Throwable { }//实例被垃圾回收器回收
|
|||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
#### 2.5.3. == 与 equals(重要)
|
#### 2.4.3. == 与 equals(重要)
|
||||||
|
|
||||||
**==** : 它的作用是判断两个对象的地址是不是相等。即,判断两个对象是不是同一个对象(基本数据类型==比较的是值,引用数据类型==比较的是内存地址)。
|
**==** : 它的作用是判断两个对象的地址是不是相等。即,判断两个对象是不是同一个对象(基本数据类型==比较的是值,引用数据类型==比较的是内存地址)。
|
||||||
|
|
||||||
@ -1116,23 +1115,23 @@ public class test1 {
|
|||||||
- String 中的 equals 方法是被重写过的,因为 object 的 equals 方法是比较的对象的内存地址,而 String 的 equals 方法比较的是对象的值。
|
- String 中的 equals 方法是被重写过的,因为 object 的 equals 方法是比较的对象的内存地址,而 String 的 equals 方法比较的是对象的值。
|
||||||
- 当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 String 对象。
|
- 当创建 String 类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建的值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个 String 对象。
|
||||||
|
|
||||||
#### 2.5.4. hashCode 与 equals (重要)
|
#### 2.4.4. hashCode 与 equals (重要)
|
||||||
|
|
||||||
面试官可能会问你:“你重写过 hashcode 和 equals 么,为什么重写 equals 时必须重写 hashCode 方法?”
|
面试官可能会问你:“你重写过 hashcode 和 equals 么,为什么重写 equals 时必须重写 hashCode 方法?”
|
||||||
|
|
||||||
##### 2.5.4.1. hashCode()介绍
|
##### 2.4.4.1. hashCode()介绍
|
||||||
|
|
||||||
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个 int 整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在 JDK 的 Object.java 中,这就意味着 Java 中的任何类都包含有 hashCode() 函数。
|
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个 int 整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在 JDK 的 Object.java 中,这就意味着 Java 中的任何类都包含有 hashCode() 函数。
|
||||||
|
|
||||||
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
|
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
|
||||||
|
|
||||||
##### 2.5.4.2. 为什么要有 hashCode
|
##### 2.4.4.2. 为什么要有 hashCode
|
||||||
|
|
||||||
**我们先以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode:** 当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与该位置其他已经加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 `equals()`方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的 Java 启蒙书《Head first java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
|
**我们先以“HashSet 如何检查重复”为例子来说明为什么要有 hashCode:** 当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的位置,同时也会与该位置其他已经加入的对象的 hashcode 值作比较,如果没有相符的 hashcode,HashSet 会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调用 `equals()`方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet 就不会让其加入操作成功。如果不同的话,就会重新散列到其他位置。(摘自我的 Java 启蒙书《Head first java》第二版)。这样我们就大大减少了 equals 的次数,相应就大大提高了执行速度。
|
||||||
|
|
||||||
通过我们可以看出:`hashCode()` 的作用就是**获取哈希码**,也称为散列码;它实际上是返回一个 int 整数。这个**哈希码的作用**是确定该对象在哈希表中的索引位置。**`hashCode()`在散列表中才有用,在其它情况下没用**。在散列表中 hashCode() 的作用是获取对象的散列码,进而确定该对象在散列表中的位置。
|
通过我们可以看出:`hashCode()` 的作用就是**获取哈希码**,也称为散列码;它实际上是返回一个 int 整数。这个**哈希码的作用**是确定该对象在哈希表中的索引位置。**`hashCode()`在散列表中才有用,在其它情况下没用**。在散列表中 hashCode() 的作用是获取对象的散列码,进而确定该对象在散列表中的位置。
|
||||||
|
|
||||||
##### 2.5.4.3. hashCode()与 equals()的相关规定
|
##### 2.4.4.3. hashCode()与 equals()的相关规定
|
||||||
|
|
||||||
1. 如果两个对象相等,则 hashcode 一定也是相同的
|
1. 如果两个对象相等,则 hashcode 一定也是相同的
|
||||||
2. 两个对象相等,对两个对象分别调用 equals 方法都返回 true
|
2. 两个对象相等,对两个对象分别调用 equals 方法都返回 true
|
||||||
@ -1142,13 +1141,13 @@ hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返
|
|||||||
|
|
||||||
推荐阅读:[Java hashCode() 和 equals()的若干问题解答](https://www.cnblogs.com/skywang12345/p/3324958.html)
|
推荐阅读:[Java hashCode() 和 equals()的若干问题解答](https://www.cnblogs.com/skywang12345/p/3324958.html)
|
||||||
|
|
||||||
#### 2.5.5. Java 序列化中如果有些字段不想进行序列化,怎么办?
|
#### 2.4.5. Java 序列化中如果有些字段不想进行序列化,怎么办?
|
||||||
|
|
||||||
对于不想进行序列化的变量,使用 transient 关键字修饰。
|
对于不想进行序列化的变量,使用 transient 关键字修饰。
|
||||||
|
|
||||||
transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。transient 只能修饰变量,不能修饰类和方法。
|
transient 关键字的作用是:阻止实例中那些用此关键字修饰的的变量序列化;当对象被反序列化时,被 transient 修饰的变量值不会被持久化和恢复。transient 只能修饰变量,不能修饰类和方法。
|
||||||
|
|
||||||
#### 2.5.6. 获取用键盘输入常用的两种方法
|
#### 2.4.6. 获取用键盘输入常用的两种方法
|
||||||
|
|
||||||
方法 1:通过 Scanner
|
方法 1:通过 Scanner
|
||||||
|
|
||||||
@ -1169,30 +1168,57 @@ String s = input.readLine();
|
|||||||
|
|
||||||
### 3.1. 反射机制
|
### 3.1. 反射机制
|
||||||
|
|
||||||
JAVA 反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为 java 语言的反射机制。
|
#### 3.1.1.何为反射?
|
||||||
|
|
||||||
#### 3.1.1.静态编译和动态编译
|
如果说大家研究过框架的底层原理或者咱们自己写过框架的话,一定对反射这个概念不陌生。
|
||||||
|
|
||||||
- **静态编译:** 在编译时确定类型,绑定对象
|
反射之所以被称为框架的灵魂,主要是因为它赋予了我们在运行时分析类以及执行类中方法的能力。
|
||||||
- **动态编译:** 运行时确定类型,绑定对象
|
|
||||||
|
通过反射你可以获取任意一个类的所有属性和方法,你还可以调用这些方法和属性。
|
||||||
|
|
||||||
#### 3.1.2.反射机制优缺点
|
#### 3.1.2.反射机制优缺点
|
||||||
|
|
||||||
- **优点:** 运行期类型的判断,动态加载类,提高代码灵活度。
|
**优点** : 可以让咱们的代码更加灵活、为各种框架提供开箱即用的功能提供了便利
|
||||||
- **缺点:** 1,性能瓶颈:反射相当于一系列解释操作,通知 JVM 要做的事情,性能比直接的 java 代码要慢很多。2,安全问题,让我们可以动态操作改变类的属性同时也增加了类的安全隐患。
|
|
||||||
|
**缺点** :让我们在运行时有了分析操作类的能力,这同样也增加了安全问题。比如可以无视泛型参数的安全检查(泛型参数的安全检查发生在编译时)。另外,反射的性能也要稍差点,不过,对于框架来说实际是影响不大的。[Java Reflection: Why is it so slow?](https://stackoverflow.com/questions/1392351/java-reflection-why-is-it-so-slow)
|
||||||
|
|
||||||
#### 3.1.3.反射的应用场景
|
#### 3.1.3.反射的应用场景
|
||||||
|
|
||||||
**反射是框架设计的灵魂。**
|
像咱们平时大部分时候都是在写业务代码,很少会接触到直接使用反射机制的场景。
|
||||||
|
|
||||||
在我们平时的项目开发过程中,基本上很少会直接使用到反射机制,但这不能说明反射机制没有用,实际上有很多设计、开发都与反射机制有关,例如模块化的开发,通过反射去调用对应的字节码;动态代理设计模式也采用了反射机制,还有我们日常使用的 Spring/Hibernate 等框架也大量使用到了反射机制。
|
但是,这并不代表反射没有用。相反,正是因为反射,你才能这么轻松地使用各种框架。像 Spring/Spring Boot、MyBatis 等等框架中都大量使用了反射机制。
|
||||||
|
|
||||||
举例:
|
**这些框架中也大量使用了动态代理,而动态代理的实现也依赖反射。**
|
||||||
|
|
||||||
1. 我们在使用 JDBC 连接数据库时使用 `Class.forName()`通过反射加载数据库的驱动程序;
|
比如下面是通过 JDK 实现动态代理的示例代码,其中就使用了反射类 `Method` 来调用指定的方法。
|
||||||
2. Spring 框架的 IOC(动态加载管理 Bean)创建对象以及 AOP(动态代理)功能都和反射有联系;
|
|
||||||
3. 动态配置实例的属性;
|
```java
|
||||||
4. ......
|
public class DebugInvocationHandler implements InvocationHandler {
|
||||||
|
/**
|
||||||
|
* 代理类中的真实对象
|
||||||
|
*/
|
||||||
|
private final Object target;
|
||||||
|
|
||||||
|
public DebugInvocationHandler(Object target) {
|
||||||
|
this.target = target;
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
public Object invoke(Object proxy, Method method, Object[] args) throws InvocationTargetException, IllegalAccessException {
|
||||||
|
System.out.println("before method " + method.getName());
|
||||||
|
Object result = method.invoke(target, args);
|
||||||
|
System.out.println("after method " + method.getName());
|
||||||
|
return result;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
另外,像 Java 中的一大利器 **注解** 的实现也用到了反射。
|
||||||
|
|
||||||
|
为什么你使用 Spring 的时候 ,一个`@Component`注解就声明了一个类为 Spring Bean 呢?为什么你通过一个 `@Value`注解就读取到配置文件中的值呢?究竟是怎么起作用的呢?
|
||||||
|
|
||||||
|
这些都是因为你可以基于反射分析类,然后获取到类/属性/方法/方法的参数上的注解。你获取到注解之后,就可以做进一步的处理。
|
||||||
|
|
||||||
### 3.2. 异常
|
### 3.2. 异常
|
||||||
|
|
||||||
@ -1225,7 +1251,7 @@ Java 代码在编译过程中,如果受检查异常没有被 `catch`/`throw`
|
|||||||
|
|
||||||
Java 代码在编译过程中 ,我们即使不处理不受检查异常也可以正常通过编译。
|
Java 代码在编译过程中 ,我们即使不处理不受检查异常也可以正常通过编译。
|
||||||
|
|
||||||
`RuntimeException` 及其子类都统称为非受检查异常,例如:`NullPointExecrption`、`NumberFormatException`(字符串转换为数字)、`ArrayIndexOutOfBoundsException`(数组越界)、`ClassCastException`(类型转换错误)、`ArithmeticException`(算术错误)等。
|
`RuntimeException` 及其子类都统称为非受检查异常,例如:`NullPointerException`、`NumberFormatException`(字符串转换为数字)、`ArrayIndexOutOfBoundsException`(数组越界)、`ClassCastException`(类型转换错误)、`ArithmeticException`(算术错误)等。
|
||||||
|
|
||||||
#### 3.2.2. Throwable 类常用方法
|
#### 3.2.2. Throwable 类常用方法
|
||||||
|
|
||||||
|
|||||||
@ -233,7 +233,7 @@ public class Singleton {
|
|||||||
|
|
||||||
|
|
||||||
//将Math中的所有静态资源导入,这时候可以直接使用里面的静态方法,而不用通过类名进行调用
|
//将Math中的所有静态资源导入,这时候可以直接使用里面的静态方法,而不用通过类名进行调用
|
||||||
//如果只想导入单一某个静态方法,只需要将换成对应的方法名即可
|
//如果只想导入单一某个静态方法,只需要将*换成对应的方法名即可
|
||||||
|
|
||||||
import static java.lang.Math.*;//换成import static java.lang.Math.max;具有一样的效果
|
import static java.lang.Math.*;//换成import static java.lang.Math.max;具有一样的效果
|
||||||
|
|
||||||
|
|||||||
@ -24,11 +24,11 @@
|
|||||||
|
|
||||||
## 1. 代理模式
|
## 1. 代理模式
|
||||||
|
|
||||||
代理模式是一种比较好的理解的设计模式。简单来说就是 **我们使用代理对象来代替对真实对象(real object)的访问,这样就可以在不修改原目标对象的前提下,提供额外的功能操作,扩展目标对象的功能。**
|
代理模式是一种比较好理解的设计模式。简单来说就是 **我们使用代理对象来代替对真实对象(real object)的访问,这样就可以在不修改原目标对象的前提下,提供额外的功能操作,扩展目标对象的功能。**
|
||||||
|
|
||||||
**代理模式的主要作用是扩展目标对象的功能,比如说在目标对象的某个方法执行前后你可以增加一些自定义的操作。**
|
**代理模式的主要作用是扩展目标对象的功能,比如说在目标对象的某个方法执行前后你可以增加一些自定义的操作。**
|
||||||
|
|
||||||
举个例子:你找了小红来帮你文化,小红就可以看作是代理你的代理对象,代理的行为(方法)是问话。
|
举个例子:你找了小红来帮你问话,小红就可以看作是代理你的代理对象,代理的行为(方法)是问话。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
@ -405,7 +405,7 @@ after method send
|
|||||||
|
|
||||||
### 3.3. JDK 动态代理和 CGLIB 动态代理对比
|
### 3.3. JDK 动态代理和 CGLIB 动态代理对比
|
||||||
|
|
||||||
1. **JDK 动态代理只能只能代理实现了接口的类,而 CGLIB 可以代理未实现任何接口的类。** 另外, CGLIB 动态代理是通过生成一个被代理类的子类来拦截被代理类的方法调用,因此不能代理声明为 final 类型的类和方法。
|
1. **JDK 动态代理只能只能代理实现了接口的类或者直接代理接口,而 CGLIB 可以代理未实现任何接口的类。** 另外, CGLIB 动态代理是通过生成一个被代理类的子类来拦截被代理类的方法调用,因此不能代理声明为 final 类型的类和方法。
|
||||||
2. 就二者的效率来说,大部分情况都是 JDK 动态代理更优秀,随着 JDK 版本的升级,这个优势更加明显。
|
2. 就二者的效率来说,大部分情况都是 JDK 动态代理更优秀,随着 JDK 版本的升级,这个优势更加明显。
|
||||||
|
|
||||||
## 4. 静态代理和动态代理的对比
|
## 4. 静态代理和动态代理的对比
|
||||||
|
|||||||
@ -1,46 +1,95 @@
|
|||||||
### 反射机制介绍
|
## 何为反射?
|
||||||
|
|
||||||
JAVA 反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为 java 语言的反射机制。
|
如果说大家研究过框架的底层原理或者咱们自己写过框架的话,一定对反射这个概念不陌生。
|
||||||
|
|
||||||
|
反射之所以被称为框架的灵魂,主要是因为它赋予了我们在运行时分析类以及执行类中方法的能力。
|
||||||
|
|
||||||
|
通过反射你可以获取任意一个类的所有属性和方法,你还可以调用这些方法和属性。
|
||||||
|
|
||||||
|
## 反射的应用场景了解么?
|
||||||
|
|
||||||
|
像咱们平时大部分时候都是在写业务代码,很少会接触到直接使用反射机制的场景。
|
||||||
|
|
||||||
|
但是,这并不代表反射没有用。相反,正是因为反射,你才能这么轻松地使用各种框架。像 Spring/Spring Boot、MyBatis 等等框架中都大量使用了反射机制。
|
||||||
|
|
||||||
|
**这些框架中也大量使用了动态代理,而动态代理的实现也依赖反射。**
|
||||||
|
|
||||||
|
比如下面是通过 JDK 实现动态代理的示例代码,其中就使用了反射类 `Method` 来调用指定的方法。
|
||||||
|
|
||||||
|
```java
|
||||||
|
public class DebugInvocationHandler implements InvocationHandler {
|
||||||
|
/**
|
||||||
|
* 代理类中的真实对象
|
||||||
|
*/
|
||||||
|
private final Object target;
|
||||||
|
|
||||||
|
public DebugInvocationHandler(Object target) {
|
||||||
|
this.target = target;
|
||||||
|
}
|
||||||
|
|
||||||
|
|
||||||
|
public Object invoke(Object proxy, Method method, Object[] args) throws InvocationTargetException, IllegalAccessException {
|
||||||
|
System.out.println("before method " + method.getName());
|
||||||
|
Object result = method.invoke(target, args);
|
||||||
|
System.out.println("after method " + method.getName());
|
||||||
|
return result;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
另外,像 Java 中的一大利器 **注解** 的实现也用到了反射。
|
||||||
|
|
||||||
|
为什么你使用 Spring 的时候 ,一个`@Component`注解就声明了一个类为 Spring Bean 呢?为什么你通过一个 `@Value`注解就读取到配置文件中的值呢?究竟是怎么起作用的呢?
|
||||||
|
|
||||||
|
这些都是因为你可以基于反射分析类,然后获取到类/属性/方法/方法的参数上的注解。你获取到注解之后,就可以做进一步的处理。
|
||||||
|
|
||||||
|
## 谈谈反射机制的优缺点
|
||||||
|
|
||||||
|
**优点** : 可以让咱们的代码更加灵活、为各种框架提供开箱即用的功能提供了便利
|
||||||
|
|
||||||
|
**缺点** :让我们在运行时有了分析操作类的能力,这同样也增加了安全问题。比如可以无视泛型参数的安全检查(泛型参数的安全检查发生在编译时)。另外,反射的性能也要稍差点,不过,对于框架来说实际是影响不大的。相关阅读:[Java Reflection: Why is it so slow?](https://stackoverflow.com/questions/1392351/java-reflection-why-is-it-so-slow)
|
||||||
|
|
||||||
|
## 反射实战
|
||||||
|
|
||||||
### 获取 Class 对象的四种方式
|
### 获取 Class 对象的四种方式
|
||||||
|
|
||||||
如果我们动态获取到这些信息,我们需要依靠 Class 对象。Class 类对象将一个类的方法、变量等信息告诉运行的程序。Java 提供了四种方式获取 Class 对象:
|
如果我们动态获取到这些信息,我们需要依靠 Class 对象。Class 类对象将一个类的方法、变量等信息告诉运行的程序。Java 提供了四种方式获取 Class 对象:
|
||||||
|
|
||||||
1.知道具体类的情况下可以使用:
|
**1.知道具体类的情况下可以使用:**
|
||||||
|
|
||||||
```java
|
```java
|
||||||
Class alunbarClass = TargetObject.class;
|
Class alunbarClass = TargetObject.class;
|
||||||
```
|
```
|
||||||
|
|
||||||
但是我们一般是不知道具体类的,基本都是通过遍历包下面的类来获取 Class 对象,通过此方式获取Class对象不会进行初始化
|
但是我们一般是不知道具体类的,基本都是通过遍历包下面的类来获取 Class 对象,通过此方式获取 Class 对象不会进行初始化
|
||||||
|
|
||||||
2.通过 `Class.forName()`传入类的路径获取:
|
**2.通过 `Class.forName()`传入类的路径获取:**
|
||||||
|
|
||||||
```java
|
```java
|
||||||
Class alunbarClass1 = Class.forName("cn.javaguide.TargetObject");
|
Class alunbarClass1 = Class.forName("cn.javaguide.TargetObject");
|
||||||
```
|
```
|
||||||
Class.forName(className)方法,内部实际调用的是一个native方法 forName0(className, true, ClassLoader.getClassLoader(caller), caller);
|
|
||||||
|
|
||||||
第2个boolean参数表示类是否需要初始化,Class.forName(className)默认是需要初始化。
|
**3.通过对象实例`instance.getClass()`获取:**
|
||||||
|
|
||||||
一旦初始化,就会触发目标对象的 static块代码执行,static参数也会被再次初始化。
|
|
||||||
|
|
||||||
3.通过对象实例`instance.getClass()`获取:
|
|
||||||
```java
|
```java
|
||||||
Employee e = new Employee();
|
TargetObject o = new TargetObject();
|
||||||
Class alunbarClass2 = e.getClass();
|
Class alunbarClass2 = o.getClass();
|
||||||
```
|
```
|
||||||
4.通过类加载器`xxxClassLoader.loadClass()`传入类路径获取
|
|
||||||
|
**4.通过类加载器`xxxClassLoader.loadClass()`传入类路径获取:**
|
||||||
|
|
||||||
```java
|
```java
|
||||||
class clazz = ClassLoader.LoadClass("cn.javaguide.TargetObject");
|
class clazz = ClassLoader.LoadClass("cn.javaguide.TargetObject");
|
||||||
```
|
```
|
||||||
通过类加载器获取Class对象不会进行初始化,意味着不进行包括初始化等一些列步骤,静态块和静态对象不会得到执行
|
|
||||||
|
|
||||||
### 代码实例
|
通过类加载器获取 Class 对象不会进行初始化,意味着不进行包括初始化等一些列步骤,静态块和静态对象不会得到执行
|
||||||
|
|
||||||
|
### 反射的一些基本操作
|
||||||
|
|
||||||
**简单用代码演示一下反射的一些操作!**
|
**简单用代码演示一下反射的一些操作!**
|
||||||
|
|
||||||
1.创建一个我们要使用反射操作的类 `TargetObject`:
|
1.创建一个我们要使用反射操作的类 `TargetObject`。
|
||||||
|
|
||||||
```java
|
```java
|
||||||
package cn.javaguide;
|
package cn.javaguide;
|
||||||
@ -125,35 +174,3 @@ value is JavaGuide
|
|||||||
```java
|
```java
|
||||||
Class<?> tagetClass = Class.forName("cn.javaguide.TargetObject");
|
Class<?> tagetClass = Class.forName("cn.javaguide.TargetObject");
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
### 静态编译和动态编译
|
|
||||||
|
|
||||||
- **静态编译:** 在编译时确定类型,绑定对象
|
|
||||||
- **动态编译:** 运行时确定类型,绑定对象
|
|
||||||
|
|
||||||
### 反射机制优缺点
|
|
||||||
|
|
||||||
- **优点:** 运行期类型的判断,动态加载类,提高代码灵活度。
|
|
||||||
- **缺点:** 1,性能瓶颈:反射相当于一系列解释操作,通知 JVM 要做的事情,性能比直接的 java 代码要慢很多。2,安全问题,让我们可以动态操作改变类的属性同时也增加了类的安全隐患。
|
|
||||||
|
|
||||||
### 反射的应用场景
|
|
||||||
|
|
||||||
**反射是框架设计的灵魂。**
|
|
||||||
|
|
||||||
在我们平时的项目开发过程中,基本上很少会直接使用到反射机制,但这不能说明反射机制没有用,实际上有很多设计、开发都与反射机制有关,例如模块化的开发,通过反射去调用对应的字节码;动态代理设计模式也采用了反射机制,还有我们日常使用的 Spring/Hibernate 等框架也大量使用到了反射机制。
|
|
||||||
|
|
||||||
举例:
|
|
||||||
|
|
||||||
1. 我们在使用 JDBC 连接数据库时使用 `Class.forName()`通过反射加载数据库的驱动程序;
|
|
||||||
2. Spring 框架的 IOC(动态加载管理 Bean)创建对象以及 AOP(动态代理)功能都和反射有联系;
|
|
||||||
3. 动态配置实例的属性;
|
|
||||||
4. ......
|
|
||||||
|
|
||||||
**推荐阅读:**
|
|
||||||
|
|
||||||
- [Java反射使用总结]( https://zhuanlan.zhihu.com/p/80519709)
|
|
||||||
- [Reflection:Java 反射机制的应用场景](https://segmentfault.com/a/1190000010162647?utm_source=tuicool&utm_medium=referral)
|
|
||||||
- [Java 基础之—反射(非常重要)](https://blog.csdn.net/sinat_38259539/article/details/71799078)
|
|
||||||
|
|
||||||
##
|
|
||||||
|
|||||||
@ -573,12 +573,12 @@ public V get(Object key) {
|
|||||||
|
|
||||||
总结:
|
总结:
|
||||||
|
|
||||||
总的来说 ConcruuentHashMap 在 Java8 中相对于 Java7 来说变化还是挺大的,
|
总的来说 ConcurrentHashMap 在 Java8 中相对于 Java7 来说变化还是挺大的,
|
||||||
|
|
||||||
## 3. 总结
|
## 3. 总结
|
||||||
|
|
||||||
Java7 中 ConcruuentHashMap 使用的分段锁,也就是每一个 Segment 上同时只有一个线程可以操作,每一个 Segment 都是一个类似 HashMap 数组的结构,它可以扩容,它的冲突会转化为链表。但是 Segment 的个数一但初始化就不能改变。
|
Java7 中 ConcurrentHashMap 使用的分段锁,也就是每一个 Segment 上同时只有一个线程可以操作,每一个 Segment 都是一个类似 HashMap 数组的结构,它可以扩容,它的冲突会转化为链表。但是 Segment 的个数一但初始化就不能改变。
|
||||||
|
|
||||||
Java8 中的 ConcruuentHashMap 使用的 Synchronized 锁加 CAS 的机制。结构也由 Java7 中的 **Segment 数组 + HashEntry 数组 + 链表** 进化成了 **Node 数组 + 链表 / 红黑树**,Node 是类似于一个 HashEntry 的结构。它的冲突再达到一定大小时会转化成红黑树,在冲突小于一定数量时又退回链表。
|
Java8 中的 ConcurrentHashMap 使用的 Synchronized 锁加 CAS 的机制。结构也由 Java7 中的 **Segment 数组 + HashEntry 数组 + 链表** 进化成了 **Node 数组 + 链表 / 红黑树**,Node 是类似于一个 HashEntry 的结构。它的冲突再达到一定大小时会转化成红黑树,在冲突小于一定数量时又退回链表。
|
||||||
|
|
||||||
有些同学可能对 Synchronized 的性能存在疑问,其实 Synchronized 锁自从引入锁升级策略后,性能不再是问题,有兴趣的同学可以自己了解下 Synchronized 的**锁升级**。
|
有些同学可能对 Synchronized 的性能存在疑问,其实 Synchronized 锁自从引入锁升级策略后,性能不再是问题,有兴趣的同学可以自己了解下 Synchronized 的**锁升级**。
|
||||||
@ -1,45 +1,60 @@
|
|||||||
<!-- MarkdownTOC -->
|
|
||||||
|
<!-- @import "[TOC]" {cmd="toc" depthFrom=1 depthTo=6 orderedList=false} -->
|
||||||
|
|
||||||
|
<!-- code_chunk_output -->
|
||||||
|
|
||||||
- [HashMap 简介](#hashmap-简介)
|
- [HashMap 简介](#hashmap-简介)
|
||||||
- [底层数据结构分析](#底层数据结构分析)
|
- [底层数据结构分析](#底层数据结构分析)
|
||||||
- [JDK1.8之前](#jdk18之前)
|
- [JDK1.8 之前](#jdk18-之前)
|
||||||
- [JDK1.8之后](#jdk18之后)
|
- [JDK1.8 之后](#jdk18-之后)
|
||||||
- [HashMap源码分析](#hashmap源码分析)
|
- [HashMap 源码分析](#hashmap-源码分析)
|
||||||
- [构造方法](#构造方法)
|
- [构造方法](#构造方法)
|
||||||
- [put方法](#put方法)
|
- [put 方法](#put-方法)
|
||||||
- [get方法](#get方法)
|
- [get 方法](#get-方法)
|
||||||
- [resize方法](#resize方法)
|
- [resize 方法](#resize-方法)
|
||||||
- [HashMap常用方法测试](#hashmap常用方法测试)
|
- [HashMap 常用方法测试](#hashmap-常用方法测试)
|
||||||
|
|
||||||
|
<!-- /code_chunk_output -->
|
||||||
|
|
||||||
<!-- /MarkdownTOC -->
|
|
||||||
|
|
||||||
> 感谢 [changfubai](https://github.com/changfubai) 对本文的改进做出的贡献!
|
> 感谢 [changfubai](https://github.com/changfubai) 对本文的改进做出的贡献!
|
||||||
|
|
||||||
## HashMap 简介
|
## HashMap 简介
|
||||||
HashMap 主要用来存放键值对,它基于哈希表的Map接口实现</font>,是常用的Java集合之一。
|
|
||||||
|
|
||||||
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突).JDK1.8 以后在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为 8)时,将链表转化为红黑树(将链表转换成红黑树前会判断,如果当前数组的长度小于 64,那么会选择先进行数组扩容,而不是转换为红黑树),以减少搜索时间,具体可以参考 `treeifyBin`方法。
|
HashMap 主要用来存放键值对,它基于哈希表的 Map 接口实现,是常用的 Java 集合之一。
|
||||||
|
|
||||||
|
JDK1.8 之前 HashMap 由 数组+链表 组成的,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的(“拉链法”解决冲突)。
|
||||||
|
|
||||||
|
JDK1.8 之后 HashMap 的组成多了红黑树,在满足下面两个条件之后,会执行链表转红黑树操作,以此来加快搜索速度。
|
||||||
|
|
||||||
|
- 链表长度大于阈值(默认为 8)
|
||||||
|
- HashMap 数组长度超过 64
|
||||||
|
|
||||||
## 底层数据结构分析
|
## 底层数据结构分析
|
||||||
### JDK1.8之前
|
|
||||||
JDK1.8 之前 HashMap 底层是 **数组和链表** 结合在一起使用也就是 **链表散列**。**HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 `(n - 1) & hash` 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。**
|
|
||||||
|
|
||||||
**所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。**
|
### JDK1.8 之前
|
||||||
|
|
||||||
|
JDK1.8 之前 HashMap 底层是 **数组和链表** 结合在一起使用也就是 **链表散列**。
|
||||||
|
|
||||||
|
HashMap 通过 key 的 hashCode 经过扰动函数处理过后得到 hash 值,然后通过 `(n - 1) & hash` 判断当前元素存放的位置(这里的 n 指的是数组的长度),如果当前位置存在元素的话,就判断该元素与要存入的元素的 hash 值以及 key 是否相同,如果相同的话,直接覆盖,不相同就通过拉链法解决冲突。
|
||||||
|
|
||||||
|
所谓扰动函数指的就是 HashMap 的 hash 方法。使用 hash 方法也就是扰动函数是为了防止一些实现比较差的 hashCode() 方法 换句话说使用扰动函数之后可以减少碰撞。
|
||||||
|
|
||||||
**JDK 1.8 HashMap 的 hash 方法源码:**
|
**JDK 1.8 HashMap 的 hash 方法源码:**
|
||||||
|
|
||||||
JDK 1.8 的 hash方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
|
JDK 1.8 的 hash 方法 相比于 JDK 1.7 hash 方法更加简化,但是原理不变。
|
||||||
|
|
||||||
```java
|
```java
|
||||||
static final int hash(Object key) {
|
static final int hash(Object key) {
|
||||||
int h;
|
int h;
|
||||||
// key.hashCode():返回散列值也就是hashcode
|
// key.hashCode():返回散列值也就是hashcode
|
||||||
// ^ :按位异或
|
// ^ :按位异或
|
||||||
// >>>:无符号右移,忽略符号位,空位都以0补齐
|
// >>>:无符号右移,忽略符号位,空位都以0补齐
|
||||||
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
|
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
对比一下 JDK1.7的 HashMap 的 hash 方法源码.
|
|
||||||
|
对比一下 JDK1.7 的 HashMap 的 hash 方法源码.
|
||||||
|
|
||||||
```java
|
```java
|
||||||
static int hash(int h) {
|
static int hash(int h) {
|
||||||
@ -58,12 +73,16 @@ static int hash(int h) {
|
|||||||
|
|
||||||
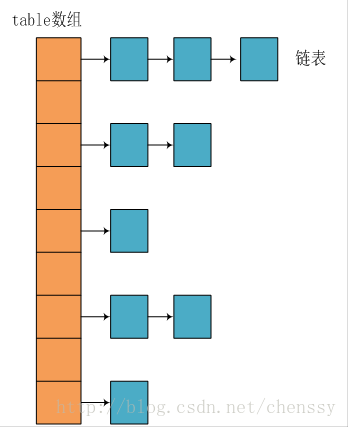
|

|
||||||
|
|
||||||
### JDK1.8之后
|
### JDK1.8 之后
|
||||||
相比于之前的版本,jdk1.8在解决哈希冲突时有了较大的变化,当链表长度大于阈值(默认为8)时,将链表转化为红黑树,以减少搜索时间。
|
|
||||||
|
|
||||||
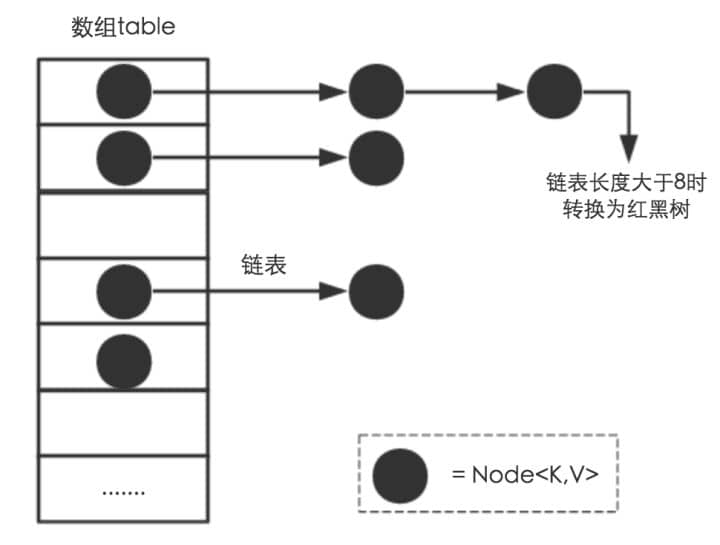
|
相比于之前的版本,JDK1.8 以后在解决哈希冲突时有了较大的变化。
|
||||||
|
|
||||||
|
当链表长度大于阈值(默认为 8)时,会首先调用 `treeifyBin()`方法。这个方法会根据 HashMap 数组来决定是否转换为红黑树。只有当数组长度大于或者等于 64 的情况下,才会执行转换红黑树操作,以减少搜索时间。否则,就是只是执行 `resize()` 方法对数组扩容。相关源码这里就不贴了,重点关注 `treeifyBin()`方法即可!
|
||||||
|
|
||||||
|
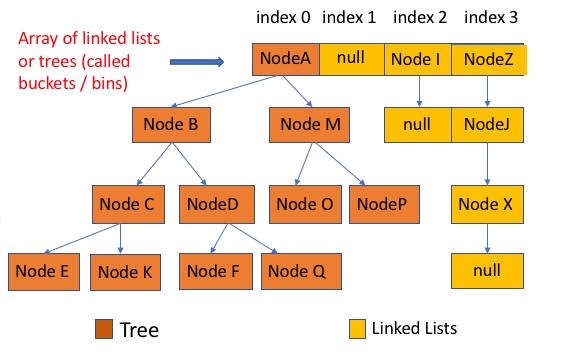
|
||||||
|
|
||||||
**类的属性:**
|
**类的属性:**
|
||||||
|
|
||||||
```java
|
```java
|
||||||
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
|
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
|
||||||
// 序列号
|
// 序列号
|
||||||
@ -94,19 +113,20 @@ public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneabl
|
|||||||
final float loadFactor;
|
final float loadFactor;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
- **loadFactor加载因子**
|
|
||||||
|
|
||||||
loadFactor加载因子是控制数组存放数据的疏密程度,loadFactor越趋近于1,那么 数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,loadFactor越小,也就是趋近于0,数组中存放的数据(entry)也就越少,也就越稀疏。
|
- **loadFactor 加载因子**
|
||||||
|
|
||||||
**loadFactor太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor的默认值为0.75f是官方给出的一个比较好的临界值**。
|
loadFactor 加载因子是控制数组存放数据的疏密程度,loadFactor 越趋近于 1,那么 数组中存放的数据(entry)也就越多,也就越密,也就是会让链表的长度增加,loadFactor 越小,也就是趋近于 0,数组中存放的数据(entry)也就越少,也就越稀疏。
|
||||||
|
|
||||||
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
|
**loadFactor 太大导致查找元素效率低,太小导致数组的利用率低,存放的数据会很分散。loadFactor 的默认值为 0.75f 是官方给出的一个比较好的临界值**。
|
||||||
|
|
||||||
|
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 \* 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
|
||||||
|
|
||||||
- **threshold**
|
- **threshold**
|
||||||
|
|
||||||
**threshold = capacity * loadFactor**,**当Size>=threshold**的时候,那么就要考虑对数组的扩增了,也就是说,这个的意思就是 **衡量数组是否需要扩增的一个标准**。
|
**threshold = capacity \* loadFactor**,**当 Size>=threshold**的时候,那么就要考虑对数组的扩增了,也就是说,这个的意思就是 **衡量数组是否需要扩增的一个标准**。
|
||||||
|
|
||||||
**Node节点类源码:**
|
**Node 节点类源码:**
|
||||||
|
|
||||||
```java
|
```java
|
||||||
// 继承自 Map.Entry<K,V>
|
// 继承自 Map.Entry<K,V>
|
||||||
@ -149,7 +169,9 @@ static class Node<K,V> implements Map.Entry<K,V> {
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
**树节点类源码:**
|
**树节点类源码:**
|
||||||
|
|
||||||
```java
|
```java
|
||||||
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
|
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
|
||||||
TreeNode<K,V> parent; // 父
|
TreeNode<K,V> parent; // 父
|
||||||
@ -168,7 +190,9 @@ static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
|
|||||||
r = p;
|
r = p;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
## HashMap源码分析
|
|
||||||
|
## HashMap 源码分析
|
||||||
|
|
||||||
### 构造方法
|
### 构造方法
|
||||||
|
|
||||||
HashMap 中有四个构造方法,它们分别如下:
|
HashMap 中有四个构造方法,它们分别如下:
|
||||||
@ -203,7 +227,7 @@ HashMap 中有四个构造方法,它们分别如下:
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
**putMapEntries方法:**
|
**putMapEntries 方法:**
|
||||||
|
|
||||||
```java
|
```java
|
||||||
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
|
final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
|
||||||
@ -231,17 +255,22 @@ final void putMapEntries(Map<? extends K, ? extends V> m, boolean evict) {
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
### put方法
|
|
||||||
HashMap只提供了put用于添加元素,putVal方法只是给put方法调用的一个方法,并没有提供给用户使用。
|
|
||||||
|
|
||||||
**对putVal方法添加元素的分析如下:**
|
### put 方法
|
||||||
|
|
||||||
- ①如果定位到的数组位置没有元素 就直接插入。
|
HashMap 只提供了 put 用于添加元素,putVal 方法只是给 put 方法调用的一个方法,并没有提供给用户使用。
|
||||||
- ②如果定位到的数组位置有元素就和要插入的key比较,如果key相同就直接覆盖,如果key不相同,就判断p是否是一个树节点,如果是就调用`e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)`将元素添加进入。如果不是就遍历链表插入(插入的是链表尾部)。
|
|
||||||
|
|
||||||
ps:下图有一个小问题,来自 [issue#608](https://github.com/Snailclimb/JavaGuide/issues/608)指出:直接覆盖之后应该就会 return,不会有后续操作。参考 JDK8 HashMap.java 658 行。
|
**对 putVal 方法添加元素的分析如下:**
|
||||||
|
|
||||||
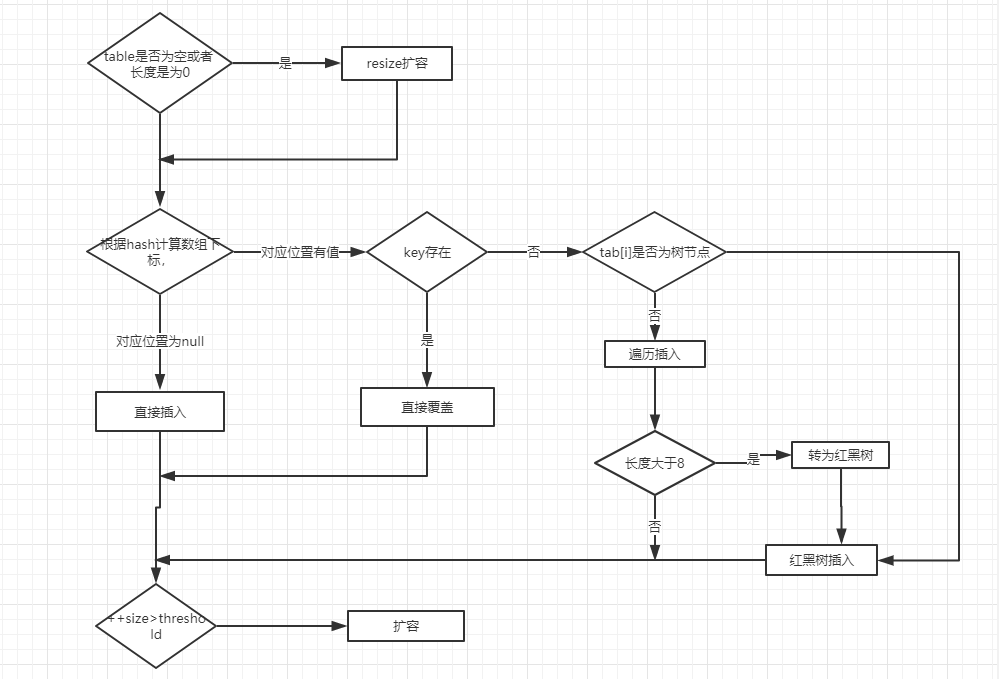
|
1. 如果定位到的数组位置没有元素 就直接插入。
|
||||||
|
2. 如果定位到的数组位置有元素就和要插入的 key 比较,如果 key 相同就直接覆盖,如果 key 不相同,就判断 p 是否是一个树节点,如果是就调用`e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value)`将元素添加进入。如果不是就遍历链表插入(插入的是链表尾部)。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
说明:上图有两个小问题:
|
||||||
|
|
||||||
|
- 直接覆盖之后应该就会 return,不会有后续操作。参考 JDK8 HashMap.java 658 行([issue#608](https://github.com/Snailclimb/JavaGuide/issues/608))。
|
||||||
|
- 当链表长度大于阈值(默认为 8)并且 HashMap 数组长度超过 64 的时候才会执行链表转红黑树的操作,否则就只是对数组扩容。参考 HashMap 的 `treeifyBin()` 方法([issue#1087](https://github.com/Snailclimb/JavaGuide/issues/1087))。
|
||||||
|
|
||||||
```java
|
```java
|
||||||
public V put(K key, V value) {
|
public V put(K key, V value) {
|
||||||
@ -277,7 +306,9 @@ final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
|
|||||||
if ((e = p.next) == null) {
|
if ((e = p.next) == null) {
|
||||||
// 在尾部插入新结点
|
// 在尾部插入新结点
|
||||||
p.next = newNode(hash, key, value, null);
|
p.next = newNode(hash, key, value, null);
|
||||||
// 结点数量达到阈值,转化为红黑树
|
// 结点数量达到阈值(默认为 8 ),执行 treeifyBin 方法
|
||||||
|
// 这个方法会根据 HashMap 数组来决定是否转换为红黑树。
|
||||||
|
// 只有当数组长度大于或者等于 64 的情况下,才会执行转换红黑树操作,以减少搜索时间。否则,就是只是对数组扩容。
|
||||||
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
|
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
|
||||||
treeifyBin(tab, hash);
|
treeifyBin(tab, hash);
|
||||||
// 跳出循环
|
// 跳出循环
|
||||||
@ -317,12 +348,12 @@ final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
**我们再来对比一下 JDK1.7 put方法的代码**
|
**我们再来对比一下 JDK1.7 put 方法的代码**
|
||||||
|
|
||||||
**对于put方法的分析如下:**
|
**对于 put 方法的分析如下:**
|
||||||
|
|
||||||
- ①如果定位到的数组位置没有元素 就直接插入。
|
- ① 如果定位到的数组位置没有元素 就直接插入。
|
||||||
- ②如果定位到的数组位置有元素,遍历以这个元素为头结点的链表,依次和插入的key比较,如果key相同就直接覆盖,不同就采用头插法插入元素。
|
- ② 如果定位到的数组位置有元素,遍历以这个元素为头结点的链表,依次和插入的 key 比较,如果 key 相同就直接覆盖,不同就采用头插法插入元素。
|
||||||
|
|
||||||
```java
|
```java
|
||||||
public V put(K key, V value)
|
public V put(K key, V value)
|
||||||
@ -349,9 +380,8 @@ public V put(K key, V value)
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
|
### get 方法
|
||||||
|
|
||||||
|
|
||||||
### get方法
|
|
||||||
```java
|
```java
|
||||||
public V get(Object key) {
|
public V get(Object key) {
|
||||||
Node<K,V> e;
|
Node<K,V> e;
|
||||||
@ -382,8 +412,11 @@ final Node<K,V> getNode(int hash, Object key) {
|
|||||||
return null;
|
return null;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
### resize方法
|
|
||||||
进行扩容,会伴随着一次重新hash分配,并且会遍历hash表中所有的元素,是非常耗时的。在编写程序中,要尽量避免resize。
|
### resize 方法
|
||||||
|
|
||||||
|
进行扩容,会伴随着一次重新 hash 分配,并且会遍历 hash 表中所有的元素,是非常耗时的。在编写程序中,要尽量避免 resize。
|
||||||
|
|
||||||
```java
|
```java
|
||||||
final Node<K,V>[] resize() {
|
final Node<K,V>[] resize() {
|
||||||
Node<K,V>[] oldTab = table;
|
Node<K,V>[] oldTab = table;
|
||||||
@ -466,7 +499,9 @@ final Node<K,V>[] resize() {
|
|||||||
return newTab;
|
return newTab;
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
## HashMap常用方法测试
|
|
||||||
|
## HashMap 常用方法测试
|
||||||
|
|
||||||
```java
|
```java
|
||||||
package map;
|
package map;
|
||||||
|
|
||||||
|
|||||||
@ -63,7 +63,7 @@
|
|||||||
|
|
||||||
- `List`(对付顺序的好帮手): 存储的元素是有序的、可重复的。
|
- `List`(对付顺序的好帮手): 存储的元素是有序的、可重复的。
|
||||||
- `Set`(注重独一无二的性质): 存储的元素是无序的、不可重复的。
|
- `Set`(注重独一无二的性质): 存储的元素是无序的、不可重复的。
|
||||||
- `Map`(用 Key 来搜索的专家): 使用键值对(kye-value)存储,类似于数学上的函数 y=f(x),“x”代表 key,"y"代表 value,Key 是无序的、不可重复的,value 是无序的、可重复的,每个键最多映射到一个值。
|
- `Map`(用 Key 来搜索的专家): 使用键值对(key-value)存储,类似于数学上的函数 y=f(x),“x”代表 key,"y"代表 value,Key 是无序的、不可重复的,value 是无序的、可重复的,每个键最多映射到一个值。
|
||||||
|
|
||||||
### 1.1.3. 集合框架底层数据结构总结
|
### 1.1.3. 集合框架底层数据结构总结
|
||||||
|
|
||||||
|
|||||||
@ -1,68 +0,0 @@
|
|||||||
> 原文地址: https://juejin.im/post/5c94a123f265da610916081f。
|
|
||||||
|
|
||||||
## JVM 配置常用参数
|
|
||||||
|
|
||||||
1. Java内存区域常见配置参数概览
|
|
||||||
2. 堆参数;
|
|
||||||
3. 回收器参数;
|
|
||||||
4. 项目中常用配置;
|
|
||||||
5. 常用组合;
|
|
||||||
|
|
||||||
### Java内存区域常见配置参数概览
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 堆参数
|
|
||||||
|
|
||||||
![堆参数][1]
|
|
||||||
|
|
||||||
### 回收器参数
|
|
||||||
|
|
||||||
![垃圾回收器参数][2]
|
|
||||||
|
|
||||||
如上表所示,目前**主要有串行、并行和并发三种**,对于大内存的应用而言,串行的性能太低,因此使用到的主要是并行和并发两种。并行和并发 GC 的策略通过 `UseParallelGC `和` UseConcMarkSweepGC` 来指定,还有一些细节的配置参数用来配置策略的执行方式。例如:`XX:ParallelGCThreads`, `XX:CMSInitiatingOccupancyFraction` 等。 通常:Young 区对象回收只可选择并行(耗时间),Old 区选择并发(耗 CPU)。
|
|
||||||
|
|
||||||
### 项目中常用配置
|
|
||||||
|
|
||||||
> 备注:在Java8中永久代的参数`-XX:PermSize` 和`-XX:MaxPermSize`已经失效。
|
|
||||||
|
|
||||||
![项目中垃圾回收器常用配置][3]
|
|
||||||
|
|
||||||
### 常用组合
|
|
||||||
|
|
||||||
![垃圾回收器常用组合][4]
|
|
||||||
|
|
||||||
## 常用 GC 调优策略
|
|
||||||
|
|
||||||
1. GC 调优原则;
|
|
||||||
2. GC 调优目的;
|
|
||||||
3. GC 调优策略;
|
|
||||||
|
|
||||||
### GC 调优原则
|
|
||||||
|
|
||||||
在调优之前,我们需要记住下面的原则:
|
|
||||||
|
|
||||||
> 多数的 Java 应用不需要在服务器上进行 GC 优化; 多数导致 GC 问题的 Java 应用,都不是因为我们参数设置错误,而是代码问题; 在应用上线之前,先考虑将机器的 JVM 参数设置到最优(最适合); 减少创建对象的数量; 减少使用全局变量和大对象; GC 优化是到最后不得已才采用的手段; 在实际使用中,分析 GC 情况优化代码比优化 GC 参数要多得多。
|
|
||||||
|
|
||||||
### GC 调优目的
|
|
||||||
|
|
||||||
将转移到老年代的对象数量降低到最小; 减少 GC 的执行时间。
|
|
||||||
|
|
||||||
### GC 调优策略
|
|
||||||
|
|
||||||
**策略 1:**将新对象预留在新生代,由于 Full GC 的成本远高于 Minor GC,因此尽可能将对象分配在新生代是明智的做法,实际项目中根据 GC 日志分析新生代空间大小分配是否合理,适当通过“-Xmn”命令调节新生代大小,最大限度降低新对象直接进入老年代的情况。
|
|
||||||
|
|
||||||
**策略 2:**大对象进入老年代,虽然大部分情况下,将对象分配在新生代是合理的。但是对于大对象这种做法却值得商榷,大对象如果首次在新生代分配可能会出现空间不足导致很多年龄不够的小对象被分配的老年代,破坏新生代的对象结构,可能会出现频繁的 full gc。因此,对于大对象,可以设置直接进入老年代(当然短命的大对象对于垃圾回收来说简直就是噩梦)。`-XX:PretenureSizeThreshold` 可以设置直接进入老年代的对象大小。
|
|
||||||
|
|
||||||
**策略 3:**合理设置进入老年代对象的年龄,`-XX:MaxTenuringThreshold` 设置对象进入老年代的年龄大小,减少老年代的内存占用,降低 full gc 发生的频率。
|
|
||||||
|
|
||||||
**策略 4:**设置稳定的堆大小,堆大小设置有两个参数:`-Xms` 初始化堆大小,`-Xmx` 最大堆大小。
|
|
||||||
|
|
||||||
**策略5:**注意: 如果满足下面的指标,**则一般不需要进行 GC 优化:**
|
|
||||||
|
|
||||||
> MinorGC 执行时间不到50ms; Minor GC 执行不频繁,约10秒一次; Full GC 执行时间不到1s; Full GC 执行频率不算频繁,不低于10分钟1次。
|
|
||||||
|
|
||||||
[1]: ./../../../media/pictures/jvm/java_jvm_heap_parameters.png
|
|
||||||
[2]: ./../../../media/pictures/jvm/java_jvm_garbage_collector_parameters.png
|
|
||||||
[3]: ./../../../media/pictures/jvm/java_jvm_suggest_parameters.png
|
|
||||||
[4]: ./../../../media/pictures/jvm/java_jvm_compose_garbage_collector.png
|
|
||||||
@ -1,5 +1,3 @@
|
|||||||
|
|
||||||
|
|
||||||
<!-- @import "[TOC]" {cmd="toc" depthFrom=1 depthTo=6 orderedList=false} -->
|
<!-- @import "[TOC]" {cmd="toc" depthFrom=1 depthTo=6 orderedList=false} -->
|
||||||
|
|
||||||
<!-- code_chunk_output -->
|
<!-- code_chunk_output -->
|
||||||
@ -23,7 +21,7 @@
|
|||||||
- [2.6 如何判断一个类是无用的类](#26-如何判断一个类是无用的类)
|
- [2.6 如何判断一个类是无用的类](#26-如何判断一个类是无用的类)
|
||||||
- [3 垃圾收集算法](#3-垃圾收集算法)
|
- [3 垃圾收集算法](#3-垃圾收集算法)
|
||||||
- [3.1 标记-清除算法](#31-标记-清除算法)
|
- [3.1 标记-清除算法](#31-标记-清除算法)
|
||||||
- [3.2 复制算法](#32-复制算法)
|
- [3.2 标记-复制算法](#32-标记-复制算法)
|
||||||
- [3.3 标记-整理算法](#33-标记-整理算法)
|
- [3.3 标记-整理算法](#33-标记-整理算法)
|
||||||
- [3.4 分代收集算法](#34-分代收集算法)
|
- [3.4 分代收集算法](#34-分代收集算法)
|
||||||
- [4 垃圾收集器](#4-垃圾收集器)
|
- [4 垃圾收集器](#4-垃圾收集器)
|
||||||
@ -84,17 +82,20 @@ Java 堆是垃圾收集器管理的主要区域,因此也被称作**GC 堆(G
|
|||||||
>
|
>
|
||||||
> ```c++
|
> ```c++
|
||||||
> uint ageTable::compute_tenuring_threshold(size_t survivor_capacity) {
|
> uint ageTable::compute_tenuring_threshold(size_t survivor_capacity) {
|
||||||
> //survivor_capacity是survivor空间的大小
|
> //survivor_capacity是survivor空间的大小
|
||||||
> size_t desired_survivor_size = (size_t)((((double) survivor_capacity)*TargetSurvivorRatio)/100);
|
> size_t desired_survivor_size = (size_t)((((double)survivor_capacity)*TargetSurvivorRatio)/100);
|
||||||
> size_t total = 0;
|
> size_t total = 0;
|
||||||
> uint age = 1;
|
> uint age = 1;
|
||||||
> while (age < table_size) {
|
> while (age < table_size) {
|
||||||
> total += sizes[age];//sizes数组是每个年龄段对象大小
|
> //sizes数组是每个年龄段对象大小
|
||||||
> if (total > desired_survivor_size) break;
|
> total += sizes[age];
|
||||||
> age++;
|
> if (total > desired_survivor_size) {
|
||||||
> }
|
> break;
|
||||||
> uint result = age < MaxTenuringThreshold ? age : MaxTenuringThreshold;
|
> }
|
||||||
> ...
|
> age++;
|
||||||
|
> }
|
||||||
|
> uint result = age < MaxTenuringThreshold ? age : MaxTenuringThreshold;
|
||||||
|
> ...
|
||||||
> }
|
> }
|
||||||
>
|
>
|
||||||
> ```
|
> ```
|
||||||
@ -181,17 +182,20 @@ public class GCTest {
|
|||||||
>
|
>
|
||||||
> ```c++
|
> ```c++
|
||||||
> uint ageTable::compute_tenuring_threshold(size_t survivor_capacity) {
|
> uint ageTable::compute_tenuring_threshold(size_t survivor_capacity) {
|
||||||
> //survivor_capacity是survivor空间的大小
|
> //survivor_capacity是survivor空间的大小
|
||||||
> size_t desired_survivor_size = (size_t)((((double) survivor_capacity)*TargetSurvivorRatio)/100);
|
> size_t desired_survivor_size = (size_t)((((double)survivor_capacity)*TargetSurvivorRatio)/100);
|
||||||
> size_t total = 0;
|
> size_t total = 0;
|
||||||
> uint age = 1;
|
> uint age = 1;
|
||||||
> while (age < table_size) {
|
> while (age < table_size) {
|
||||||
> total += sizes[age];//sizes数组是每个年龄段对象大小
|
> //sizes数组是每个年龄段对象大小
|
||||||
> if (total > desired_survivor_size) break;
|
> total += sizes[age];
|
||||||
> age++;
|
> if (total > desired_survivor_size) {
|
||||||
> }
|
> break;
|
||||||
> uint result = age < MaxTenuringThreshold ? age : MaxTenuringThreshold;
|
> }
|
||||||
> ...
|
> age++;
|
||||||
|
> }
|
||||||
|
> uint result = age < MaxTenuringThreshold ? age : MaxTenuringThreshold;
|
||||||
|
> ...
|
||||||
> }
|
> }
|
||||||
>
|
>
|
||||||
> ```
|
> ```
|
||||||
@ -225,7 +229,7 @@ public class GCTest {
|
|||||||
|
|
||||||
## 2 对象已经死亡?
|
## 2 对象已经死亡?
|
||||||
|
|
||||||
堆中几乎放着所有的对象实例,对堆垃圾回收前的第一步就是要判断那些对象已经死亡(即不能再被任何途径使用的对象)。
|
堆中几乎放着所有的对象实例,对堆垃圾回收前的第一步就是要判断哪些对象已经死亡(即不能再被任何途径使用的对象)。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@ -262,6 +266,7 @@ public class ReferenceCountingGc {
|
|||||||
- 本地方法栈(Native 方法)中引用的对象
|
- 本地方法栈(Native 方法)中引用的对象
|
||||||
- 方法区中类静态属性引用的对象
|
- 方法区中类静态属性引用的对象
|
||||||
- 方法区中常量引用的对象
|
- 方法区中常量引用的对象
|
||||||
|
- 所有被同步锁持有的对象
|
||||||
|
|
||||||
### 2.3 再谈引用
|
### 2.3 再谈引用
|
||||||
|
|
||||||
@ -342,9 +347,9 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
### 3.2 复制算法
|
### 3.2 标记-复制算法
|
||||||
|
|
||||||
为了解决效率问题,“复制”收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
|
为了解决效率问题,“标记-复制”收集算法出现了。它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@ -358,7 +363,7 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引
|
|||||||
|
|
||||||
当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将 java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
|
当前虚拟机的垃圾收集都采用分代收集算法,这种算法没有什么新的思想,只是根据对象存活周期的不同将内存分为几块。一般将 java 堆分为新生代和老年代,这样我们就可以根据各个年代的特点选择合适的垃圾收集算法。
|
||||||
|
|
||||||
**比如在新生代中,每次收集都会有大量对象死去,所以可以选择复制算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。**
|
**比如在新生代中,每次收集都会有大量对象死去,所以可以选择”标记-复制“算法,只需要付出少量对象的复制成本就可以完成每次垃圾收集。而老年代的对象存活几率是比较高的,而且没有额外的空间对它进行分配担保,所以我们必须选择“标记-清除”或“标记-整理”算法进行垃圾收集。**
|
||||||
|
|
||||||
**延伸面试问题:** HotSpot 为什么要分为新生代和老年代?
|
**延伸面试问题:** HotSpot 为什么要分为新生代和老年代?
|
||||||
|
|
||||||
@ -376,7 +381,7 @@ JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引
|
|||||||
|
|
||||||
Serial(串行)收集器是最基本、历史最悠久的垃圾收集器了。大家看名字就知道这个收集器是一个单线程收集器了。它的 **“单线程”** 的意义不仅仅意味着它只会使用一条垃圾收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集工作的时候必须暂停其他所有的工作线程( **"Stop The World"** ),直到它收集结束。
|
Serial(串行)收集器是最基本、历史最悠久的垃圾收集器了。大家看名字就知道这个收集器是一个单线程收集器了。它的 **“单线程”** 的意义不仅仅意味着它只会使用一条垃圾收集线程去完成垃圾收集工作,更重要的是它在进行垃圾收集工作的时候必须暂停其他所有的工作线程( **"Stop The World"** ),直到它收集结束。
|
||||||
|
|
||||||
**新生代采用复制算法,老年代采用标记-整理算法。**
|
**新生代采用标记-复制算法,老年代采用标记-整理算法。**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@ -388,7 +393,7 @@ Serial(串行)收集器是最基本、历史最悠久的垃圾收集器了
|
|||||||
|
|
||||||
**ParNew 收集器其实就是 Serial 收集器的多线程版本,除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和 Serial 收集器完全一样。**
|
**ParNew 收集器其实就是 Serial 收集器的多线程版本,除了使用多线程进行垃圾收集外,其余行为(控制参数、收集算法、回收策略等等)和 Serial 收集器完全一样。**
|
||||||
|
|
||||||
**新生代采用复制算法,老年代采用标记-整理算法。**
|
**新生代采用标记-复制算法,老年代采用标记-整理算法。**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@ -402,7 +407,7 @@ Serial(串行)收集器是最基本、历史最悠久的垃圾收集器了
|
|||||||
|
|
||||||
### 4.3 Parallel Scavenge 收集器
|
### 4.3 Parallel Scavenge 收集器
|
||||||
|
|
||||||
Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它看上去几乎和 ParNew 都一样。 **那么它有什么特别之处呢?**
|
Parallel Scavenge 收集器也是使用标记-复制算法的多线程收集器,它看上去几乎和 ParNew 都一样。 **那么它有什么特别之处呢?**
|
||||||
|
|
||||||
```
|
```
|
||||||
-XX:+UseParallelGC
|
-XX:+UseParallelGC
|
||||||
@ -417,7 +422,7 @@ Parallel Scavenge 收集器也是使用复制算法的多线程收集器,它
|
|||||||
|
|
||||||
**Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。** Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解,手工优化存在困难的时候,使用 Parallel Scavenge 收集器配合自适应调节策略,把内存管理优化交给虚拟机去完成也是一个不错的选择。
|
**Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)。CMS 等垃圾收集器的关注点更多的是用户线程的停顿时间(提高用户体验)。所谓吞吐量就是 CPU 中用于运行用户代码的时间与 CPU 总消耗时间的比值。** Parallel Scavenge 收集器提供了很多参数供用户找到最合适的停顿时间或最大吞吐量,如果对于收集器运作不太了解,手工优化存在困难的时候,使用 Parallel Scavenge 收集器配合自适应调节策略,把内存管理优化交给虚拟机去完成也是一个不错的选择。
|
||||||
|
|
||||||
**新生代采用复制算法,老年代采用标记-整理算法。**
|
**新生代采用标记-复制算法,老年代采用标记-整理算法。**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@ -471,7 +476,7 @@ JDK1.8 默认使用的是 Parallel Scavenge + Parallel Old,如果指定了-XX:
|
|||||||
|
|
||||||
- **并行与并发**:G1 能充分利用 CPU、多核环境下的硬件优势,使用多个 CPU(CPU 或者 CPU 核心)来缩短 Stop-The-World 停顿时间。部分其他收集器原本需要停顿 Java 线程执行的 GC 动作,G1 收集器仍然可以通过并发的方式让 java 程序继续执行。
|
- **并行与并发**:G1 能充分利用 CPU、多核环境下的硬件优势,使用多个 CPU(CPU 或者 CPU 核心)来缩短 Stop-The-World 停顿时间。部分其他收集器原本需要停顿 Java 线程执行的 GC 动作,G1 收集器仍然可以通过并发的方式让 java 程序继续执行。
|
||||||
- **分代收集**:虽然 G1 可以不需要其他收集器配合就能独立管理整个 GC 堆,但是还是保留了分代的概念。
|
- **分代收集**:虽然 G1 可以不需要其他收集器配合就能独立管理整个 GC 堆,但是还是保留了分代的概念。
|
||||||
- **空间整合**:与 CMS 的“标记--清理”算法不同,G1 从整体来看是基于“标记整理”算法实现的收集器;从局部上来看是基于“复制”算法实现的。
|
- **空间整合**:与 CMS 的“标记-清理”算法不同,G1 从整体来看是基于“标记-整理”算法实现的收集器;从局部上来看是基于“标记-复制”算法实现的。
|
||||||
- **可预测的停顿**:这是 G1 相对于 CMS 的另一个大优势,降低停顿时间是 G1 和 CMS 共同的关注点,但 G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内。
|
- **可预测的停顿**:这是 G1 相对于 CMS 的另一个大优势,降低停顿时间是 G1 和 CMS 共同的关注点,但 G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内。
|
||||||
|
|
||||||
G1 收集器的运作大致分为以下几个步骤:
|
G1 收集器的运作大致分为以下几个步骤:
|
||||||
|
|||||||
@ -64,7 +64,7 @@ Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分成
|
|||||||
|
|
||||||
**JDK 1.8 :**
|
**JDK 1.8 :**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|
||||||
**线程私有的:**
|
**线程私有的:**
|
||||||
@ -102,7 +102,9 @@ Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分成
|
|||||||
**Java 虚拟机栈会出现两种错误:`StackOverFlowError` 和 `OutOfMemoryError`。**
|
**Java 虚拟机栈会出现两种错误:`StackOverFlowError` 和 `OutOfMemoryError`。**
|
||||||
|
|
||||||
- **`StackOverFlowError`:** 若 Java 虚拟机栈的内存大小不允许动态扩展,那么当线程请求栈的深度超过当前 Java 虚拟机栈的最大深度的时候,就抛出 StackOverFlowError 错误。
|
- **`StackOverFlowError`:** 若 Java 虚拟机栈的内存大小不允许动态扩展,那么当线程请求栈的深度超过当前 Java 虚拟机栈的最大深度的时候,就抛出 StackOverFlowError 错误。
|
||||||
- **`OutOfMemoryError`:** 若 Java 虚拟机堆中没有空闲内存,并且垃圾回收器也无法提供更多内存的话。就会抛出 OutOfMemoryError 错误。
|
- **`OutOfMemoryError`:** Java 虚拟机栈的内存大小可以动态扩展, 如果虚拟机在动态扩展栈时无法申请到足够的内存空间,则抛出`OutOfMemoryError`异常异常。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
Java 虚拟机栈也是线程私有的,每个线程都有各自的 Java 虚拟机栈,而且随着线程的创建而创建,随着线程的死亡而死亡。
|
Java 虚拟机栈也是线程私有的,每个线程都有各自的 Java 虚拟机栈,而且随着线程的创建而创建,随着线程的死亡而死亡。
|
||||||
|
|
||||||
|
|||||||
@ -114,9 +114,11 @@ GC将无用对象从内存中卸载
|
|||||||
|
|
||||||
其实这个也是一个隔离的作用,避免了我们的代码影响了JDK的代码,比如我现在要来一个
|
其实这个也是一个隔离的作用,避免了我们的代码影响了JDK的代码,比如我现在要来一个
|
||||||
|
|
||||||
public class String(){
|
```java
|
||||||
public static void main(){sout;}
|
public class String(){
|
||||||
}
|
public static void main(){sout;}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
这种时候,我们的代码肯定会报错,因为在加载的时候其实是找到了rt.jar中的String.class,然后发现这也没有main方法
|
这种时候,我们的代码肯定会报错,因为在加载的时候其实是找到了rt.jar中的String.class,然后发现这也没有main方法
|
||||||
|
|
||||||
@ -143,13 +145,15 @@ GC将无用对象从内存中卸载
|
|||||||
|
|
||||||
它是Java方法执行的内存模型。里面会对局部变量,动态链表,方法出口,栈的操作(入栈和出栈)进行存储,且线程独享。同时如果我们听到局部变量表,那也是在说虚拟机栈
|
它是Java方法执行的内存模型。里面会对局部变量,动态链表,方法出口,栈的操作(入栈和出栈)进行存储,且线程独享。同时如果我们听到局部变量表,那也是在说虚拟机栈
|
||||||
|
|
||||||
public class Person{
|
```java
|
||||||
int a = 1;
|
public class Person{
|
||||||
|
int a = 1;
|
||||||
|
|
||||||
public void doSomething(){
|
public void doSomething(){
|
||||||
int b = 2;
|
int b = 2;
|
||||||
}
|
|
||||||
}
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
#### 3.3.2 虚拟机栈存在的异常
|
#### 3.3.2 虚拟机栈存在的异常
|
||||||
@ -324,9 +328,11 @@ JVM的参数非常之多,这里只列举比较重要的几个,通过各种
|
|||||||
|
|
||||||
我们执行下面的代码
|
我们执行下面的代码
|
||||||
|
|
||||||
System.out.println("Xmx=" + Runtime.getRuntime().maxMemory() / 1024.0 / 1024 + "M"); //系统的最大空间
|
```java
|
||||||
System.out.println("free mem=" + Runtime.getRuntime().freeMemory() / 1024.0 / 1024 + "M"); //系统的空闲空间
|
System.out.println("Xmx=" + Runtime.getRuntime().maxMemory() / 1024.0 / 1024 + "M"); //系统的最大空间
|
||||||
System.out.println("total mem=" + Runtime.getRuntime().totalMemory() / 1024.0 / 1024 + "M"); //当前可用的总空间
|
System.out.println("free mem=" + Runtime.getRuntime().freeMemory() / 1024.0 / 1024 + "M"); //系统的空闲空间
|
||||||
|
System.out.println("total mem=" + Runtime.getRuntime().totalMemory() / 1024.0 / 1024 + "M"); //当前可用的总空间
|
||||||
|
```
|
||||||
|
|
||||||
注意:此处设置的是Java堆大小,也就是新生代大小 + 老年代大小
|
注意:此处设置的是Java堆大小,也就是新生代大小 + 老年代大小
|
||||||
|

|
||||||
@ -346,11 +352,13 @@ JVM的参数非常之多,这里只列举比较重要的几个,通过各种
|
|||||||
|
|
||||||
我们此时创建一个字节数组看看,执行下面的代码
|
我们此时创建一个字节数组看看,执行下面的代码
|
||||||
|
|
||||||
byte[] b = new byte[1 * 1024 * 1024];
|
```java
|
||||||
System.out.println("分配了1M空间给数组");
|
byte[] b = new byte[1 * 1024 * 1024];
|
||||||
System.out.println("Xmx=" + Runtime.getRuntime().maxMemory() / 1024.0 / 1024 + "M"); //系统的最大空间
|
System.out.println("分配了1M空间给数组");
|
||||||
System.out.println("free mem=" + Runtime.getRuntime().freeMemory() / 1024.0 / 1024 + "M"); //系统的空闲空间
|
System.out.println("Xmx=" + Runtime.getRuntime().maxMemory() / 1024.0 / 1024 + "M"); //系统的最大空间
|
||||||
System.out.println("total mem=" + Runtime.getRuntime().totalMemory() / 1024.0 / 1024 + "M");
|
System.out.println("free mem=" + Runtime.getRuntime().freeMemory() / 1024.0 / 1024 + "M"); //系统的空闲空间
|
||||||
|
System.out.println("total mem=" + Runtime.getRuntime().totalMemory() / 1024.0 / 1024 + "M");
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|

|
||||||
@ -370,11 +378,12 @@ JVM的参数非常之多,这里只列举比较重要的几个,通过各种
|
|||||||
|
|
||||||
此时我们再跑一下这个代码
|
此时我们再跑一下这个代码
|
||||||
|
|
||||||
System.gc();
|
```java
|
||||||
System.out.println("Xmx=" + Runtime.getRuntime().maxMemory() / 1024.0 / 1024 + "M"); //系统的最大空间
|
System.gc();
|
||||||
System.out.println("free mem=" + Runtime.getRuntime().freeMemory() / 1024.0 / 1024 + "M"); //系统的空闲空间
|
System.out.println("Xmx=" + Runtime.getRuntime().maxMemory() / 1024.0 / 1024 + "M"); //系统的最大空间
|
||||||
System.out.println("total mem=" + Runtime.getRuntime().totalMemory() / 1024.0 / 1024 + "M"); //当前可用的总空间
|
System.out.println("free mem=" + Runtime.getRuntime().freeMemory() / 1024.0 / 1024 + "M"); //系统的空闲空间
|
||||||
|
System.out.println("total mem=" + Runtime.getRuntime().totalMemory() / 1024.0 / 1024 + "M"); //当前可用的总空间
|
||||||
|
```
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|||||||
{kind=link}
|
Before Width: | Height: | Size: 108 KiB |
BIN
docs/java/jvm/pictures/java内存区域/Java运行时数据区域JDK1.8.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 123 KiB |
BIN
docs/java/jvm/pictures/java内存区域/《深入理解虚拟机》第三版的第2章-虚拟机栈.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 135 KiB |
@ -67,7 +67,7 @@ GC 调优策略中很重要的一条经验总结是这样说的:
|
|||||||
-XX:NewRatio=1
|
-XX:NewRatio=1
|
||||||
```
|
```
|
||||||
|
|
||||||
### 2.3.显示指定永久代/元空间的大小
|
### 2.3.显式指定永久代/元空间的大小
|
||||||
|
|
||||||
**从Java 8开始,如果我们没有指定 Metaspace 的大小,随着更多类的创建,虚拟机会耗尽所有可用的系统内存(永久代并不会出现这种情况)。**
|
**从Java 8开始,如果我们没有指定 Metaspace 的大小,随着更多类的创建,虚拟机会耗尽所有可用的系统内存(永久代并不会出现这种情况)。**
|
||||||
|
|
||||||
@ -80,7 +80,7 @@ JDK 1.8 之前永久代还没被彻底移除的时候通常通过下面这些参
|
|||||||
|
|
||||||
相对而言,垃圾收集行为在这个区域是比较少出现的,但并非数据进入方法区后就“永久存在”了。
|
相对而言,垃圾收集行为在这个区域是比较少出现的,但并非数据进入方法区后就“永久存在”了。
|
||||||
|
|
||||||
**JDK 1.8 的时候,方法区(HotSpot 的永久代)被彻底移除了(JDK1.7 就已经开始了),取而代之是元空间,元空间使用的是直接内存。**
|
**JDK 1.8 的时候,方法区(HotSpot 的永久代)被彻底移除了(JDK1.7 就已经开始了),取而代之是元空间,元空间使用的是本地内存。**
|
||||||
|
|
||||||
下面是一些常用参数:
|
下面是一些常用参数:
|
||||||
|
|
||||||
|
|||||||
@ -16,7 +16,7 @@
|
|||||||
|
|
||||||
## 回顾一下类加载过程
|
## 回顾一下类加载过程
|
||||||
|
|
||||||
类加载过程:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。
|
类加载过程:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。
|
||||||
|
|
||||||
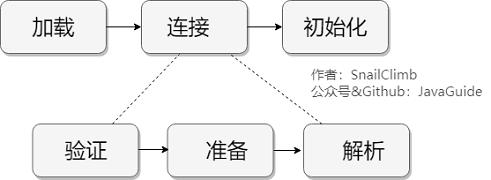
|

|
||||||
|
|
||||||
@ -30,7 +30,7 @@ JVM 中内置了三个重要的 ClassLoader,除了 BootstrapClassLoader 其他
|
|||||||
|
|
||||||
1. **BootstrapClassLoader(启动类加载器)** :最顶层的加载类,由C++实现,负责加载 `%JAVA_HOME%/lib`目录下的jar包和类或者或被 `-Xbootclasspath`参数指定的路径中的所有类。
|
1. **BootstrapClassLoader(启动类加载器)** :最顶层的加载类,由C++实现,负责加载 `%JAVA_HOME%/lib`目录下的jar包和类或者或被 `-Xbootclasspath`参数指定的路径中的所有类。
|
||||||
2. **ExtensionClassLoader(扩展类加载器)** :主要负责加载目录 `%JRE_HOME%/lib/ext` 目录下的jar包和类,或被 `java.ext.dirs` 系统变量所指定的路径下的jar包。
|
2. **ExtensionClassLoader(扩展类加载器)** :主要负责加载目录 `%JRE_HOME%/lib/ext` 目录下的jar包和类,或被 `java.ext.dirs` 系统变量所指定的路径下的jar包。
|
||||||
3. **AppClassLoader(应用程序类加载器)** :面向我们用户的加载器,负责加载当前应用classpath下的所有jar包和类。
|
3. **AppClassLoader(应用程序类加载器)** :面向我们用户的加载器,负责加载当前应用classpath下的所有jar包和类。
|
||||||
|
|
||||||
## 双亲委派模型
|
## 双亲委派模型
|
||||||
|
|
||||||
@ -60,7 +60,7 @@ The Parent of ClassLodarDemo's ClassLoader is sun.misc.Launcher$ExtClassLoader@1
|
|||||||
The GrandParent of ClassLodarDemo's ClassLoader is null
|
The GrandParent of ClassLodarDemo's ClassLoader is null
|
||||||
```
|
```
|
||||||
|
|
||||||
`AppClassLoader`的父类加载器为`ExtClassLoader`
|
`AppClassLoader`的父类加载器为`ExtClassLoader`,
|
||||||
`ExtClassLoader`的父类加载器为null,**null并不代表`ExtClassLoader`没有父类加载器,而是 `BootstrapClassLoader`** 。
|
`ExtClassLoader`的父类加载器为null,**null并不代表`ExtClassLoader`没有父类加载器,而是 `BootstrapClassLoader`** 。
|
||||||
|
|
||||||
其实这个双亲翻译的容易让别人误解,我们一般理解的双亲都是父母,这里的双亲更多地表达的是“父母这一辈”的人而已,并不是说真的有一个 Mother ClassLoader 和一个 Father ClassLoader 。另外,类加载器之间的“父子”关系也不是通过继承来体现的,是由“优先级”来决定。官方API文档对这部分的描述如下:
|
其实这个双亲翻译的容易让别人误解,我们一般理解的双亲都是父母,这里的双亲更多地表达的是“父母这一辈”的人而已,并不是说真的有一个 Mother ClassLoader 和一个 Father ClassLoader 。另外,类加载器之间的“父子”关系也不是通过继承来体现的,是由“优先级”来决定。官方API文档对这部分的描述如下:
|
||||||
|
|||||||
@ -23,7 +23,7 @@
|
|||||||
|
|
||||||
Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚拟机是如何加载这些 Class 文件呢?
|
Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚拟机是如何加载这些 Class 文件呢?
|
||||||
|
|
||||||
系统加载 Class 类型的文件主要三步:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。
|
系统加载 Class 类型的文件主要三步:**加载->连接->初始化**。连接过程又可分为三步:**验证->准备->解析**。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@ -33,7 +33,7 @@ Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚
|
|||||||
|
|
||||||
1. 通过全类名获取定义此类的二进制字节流
|
1. 通过全类名获取定义此类的二进制字节流
|
||||||
2. 将字节流所代表的静态存储结构转换为方法区的运行时数据结构
|
2. 将字节流所代表的静态存储结构转换为方法区的运行时数据结构
|
||||||
3. 在内存中生成一个代表该类的 Class 对象,作为方法区这些数据的访问入口
|
3. 在内存中生成一个代表该类的 Class 对象,作为方法区这些数据的访问入口
|
||||||
|
|
||||||
虚拟机规范上面这3点并不具体,因此是非常灵活的。比如:"通过全类名获取定义此类的二进制字节流" 并没有指明具体从哪里获取、怎样获取。比如:比较常见的就是从 ZIP 包中读取(日后出现的JAR、EAR、WAR格式的基础)、其他文件生成(典型应用就是JSP)等等。
|
虚拟机规范上面这3点并不具体,因此是非常灵活的。比如:"通过全类名获取定义此类的二进制字节流" 并没有指明具体从哪里获取、怎样获取。比如:比较常见的就是从 ZIP 包中读取(日后出现的JAR、EAR、WAR格式的基础)、其他文件生成(典型应用就是JSP)等等。
|
||||||
|
|
||||||
@ -62,7 +62,7 @@ Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚
|
|||||||
|
|
||||||
解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用限定符7类符号引用进行。
|
解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程。解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用限定符7类符号引用进行。
|
||||||
|
|
||||||
符号引用就是一组符号来描述目标,可以是任何字面量。**直接引用**就是直接指向目标的指针、相对偏移量或一个间接定位到目标的句柄。在程序实际运行时,只有符号引用是不够的,举个例子:在程序执行方法时,系统需要明确知道这个方法所在的位置。Java 虚拟机为每个类都准备了一张方法表来存放类中所有的方法。当需要调用一个类的方法的时候,只要知道这个方法在方发表中的偏移量就可以直接调用该方法了。通过解析操作符号引用就可以直接转变为目标方法在类中方法表的位置,从而使得方法可以被调用。
|
符号引用就是一组符号来描述目标,可以是任何字面量。**直接引用**就是直接指向目标的指针、相对偏移量或一个间接定位到目标的句柄。在程序实际运行时,只有符号引用是不够的,举个例子:在程序执行方法时,系统需要明确知道这个方法所在的位置。Java 虚拟机为每个类都准备了一张方法表来存放类中所有的方法。当需要调用一个类的方法的时候,只要知道这个方法在方法表中的偏移量就可以直接调用该方法了。通过解析操作符号引用就可以直接转变为目标方法在类中方法表的位置,从而使得方法可以被调用。
|
||||||
|
|
||||||
综上,解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程,也就是得到类或者字段、方法在内存中的指针或者偏移量。
|
综上,解析阶段是虚拟机将常量池内的符号引用替换为直接引用的过程,也就是得到类或者字段、方法在内存中的指针或者偏移量。
|
||||||
|
|
||||||
@ -70,7 +70,7 @@ Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚
|
|||||||
|
|
||||||
初始化是类加载的最后一步,也是真正执行类中定义的 Java 程序代码(字节码),初始化阶段是执行初始化方法 `<clinit> ()`方法的过程。
|
初始化是类加载的最后一步,也是真正执行类中定义的 Java 程序代码(字节码),初始化阶段是执行初始化方法 `<clinit> ()`方法的过程。
|
||||||
|
|
||||||
对于`<clinit>()` 方法的调用,虚拟机会自己确保其在多线程环境中的安全性。因为 `<clinit>()` 方法是带锁线程安全,所以在多线程环境下进行类初始化的话可能会引起死锁,并且这种死锁很难被发现。
|
对于`<clinit> ()` 方法的调用,虚拟机会自己确保其在多线程环境中的安全性。因为 `<clinit> ()` 方法是带锁线程安全,所以在多线程环境下进行类初始化的话可能会引起死锁,并且这种死锁很难被发现。
|
||||||
|
|
||||||
对于初始化阶段,虚拟机严格规范了有且只有5种情况下,必须对类进行初始化(只有主动去使用类才会初始化类):
|
对于初始化阶段,虚拟机严格规范了有且只有5种情况下,必须对类进行初始化(只有主动去使用类才会初始化类):
|
||||||
|
|
||||||
@ -79,7 +79,7 @@ Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚
|
|||||||
- 当jvm执行getstatic指令时会初始化类。即程序访问类的静态变量(不是静态常量,常量会被加载到运行时常量池)。
|
- 当jvm执行getstatic指令时会初始化类。即程序访问类的静态变量(不是静态常量,常量会被加载到运行时常量池)。
|
||||||
- 当jvm执行putstatic指令时会初始化类。即程序给类的静态变量赋值。
|
- 当jvm执行putstatic指令时会初始化类。即程序给类的静态变量赋值。
|
||||||
- 当jvm执行invokestatic指令时会初始化类。即程序调用类的静态方法。
|
- 当jvm执行invokestatic指令时会初始化类。即程序调用类的静态方法。
|
||||||
2. 使用 `java.lang.reflect` 包的方法对类进行反射调用时如Class.forname("..."),newInstance()等等。 ,如果类没初始化,需要触发其初始化。
|
2. 使用 `java.lang.reflect` 包的方法对类进行反射调用时如Class.forname("..."), newInstance()等等。如果类没初始化,需要触发其初始化。
|
||||||
3. 初始化一个类,如果其父类还未初始化,则先触发该父类的初始化。
|
3. 初始化一个类,如果其父类还未初始化,则先触发该父类的初始化。
|
||||||
4. 当虚拟机启动时,用户需要定义一个要执行的主类 (包含 main 方法的那个类),虚拟机会先初始化这个类。
|
4. 当虚拟机启动时,用户需要定义一个要执行的主类 (包含 main 方法的那个类),虚拟机会先初始化这个类。
|
||||||
5. MethodHandle和VarHandle可以看作是轻量级的反射调用机制,而要想使用这2个调用,
|
5. MethodHandle和VarHandle可以看作是轻量级的反射调用机制,而要想使用这2个调用,
|
||||||
@ -100,7 +100,7 @@ Class 文件需要加载到虚拟机中之后才能运行和使用,那么虚
|
|||||||
|
|
||||||
所以,在JVM生命周期类,由jvm自带的类加载器加载的类是不会被卸载的。但是由我们自定义的类加载器加载的类是可能被卸载的。
|
所以,在JVM生命周期类,由jvm自带的类加载器加载的类是不会被卸载的。但是由我们自定义的类加载器加载的类是可能被卸载的。
|
||||||
|
|
||||||
只要想通一点就好了,jdk自带的BootstrapClassLoader,ExtClassLoader,AppClassLoader负责加载jdk提供的类,所以它们(类加载器的实例)肯定不会被回收。而我们自定义的类加载器的实例是可以被回收的,所以使用我们自定义加载器加载的类是可以被卸载掉的。
|
只要想通一点就好了,jdk自带的BootstrapClassLoader, ExtClassLoader, AppClassLoader负责加载jdk提供的类,所以它们(类加载器的实例)肯定不会被回收。而我们自定义的类加载器的实例是可以被回收的,所以使用我们自定义加载器加载的类是可以被卸载掉的。
|
||||||
|
|
||||||
**参考**
|
**参考**
|
||||||
|
|
||||||
|
|||||||
@ -1,21 +1,23 @@
|
|||||||
点击关注[公众号](#公众号)及时获取笔主最新更新文章,并可免费领取本文档配套的《Java面试突击》以及Java工程师必备学习资源。
|
|
||||||
|
|
||||||
<!-- TOC -->
|
<!-- @import "[TOC]" {cmd="toc" depthFrom=1 depthTo=6 orderedList=false} -->
|
||||||
|
|
||||||
|
<!-- code_chunk_output -->
|
||||||
|
|
||||||
- [类文件结构](#类文件结构)
|
- [类文件结构](#类文件结构)
|
||||||
- [一 概述](#一-概述)
|
- [一 概述](#一-概述)
|
||||||
- [二 Class 文件结构总结](#二-class-文件结构总结)
|
- [二 Class 文件结构总结](#二-class-文件结构总结)
|
||||||
- [2.1 魔数](#21-魔数)
|
- [2.1 魔数(Magic Number)](#21-魔数magic-number)
|
||||||
- [2.2 Class 文件版本](#22-class-文件版本)
|
- [2.2 Class 文件版本号(Minor&Major Version)](#22-class-文件版本号minormajor-version)
|
||||||
- [2.3 常量池](#23-常量池)
|
- [2.3 常量池(Constant Pool)](#23-常量池constant-pool)
|
||||||
- [2.4 访问标志](#24-访问标志)
|
- [2.4 访问标志(Access Flags)](#24-访问标志access-flags)
|
||||||
- [2.5 当前类索引,父类索引与接口索引集合](#25-当前类索引父类索引与接口索引集合)
|
- [2.5 当前类(This Class)、父类(Super Class)、接口(Interfaces)索引集合](#25-当前类this-class-父类super-class-接口interfaces索引集合)
|
||||||
- [2.6 字段表集合](#26-字段表集合)
|
- [2.6 字段表集合(Fields)](#26-字段表集合fields)
|
||||||
- [2.7 方法表集合](#27-方法表集合)
|
- [2.7 方法表集合(Methods)](#27-方法表集合methods)
|
||||||
- [2.8 属性表集合](#28-属性表集合)
|
- [2.8 属性表集合(Attributes)](#28-属性表集合attributes)
|
||||||
- [参考](#参考)
|
- [参考](#参考)
|
||||||
|
|
||||||
|
<!-- /code_chunk_output -->
|
||||||
|
|
||||||
<!-- /TOC -->
|
|
||||||
|
|
||||||
# 类文件结构
|
# 类文件结构
|
||||||
|
|
||||||
@ -27,11 +29,13 @@ Clojure(Lisp 语言的一种方言)、Groovy、Scala 等语言都是运行
|
|||||||
|
|
||||||
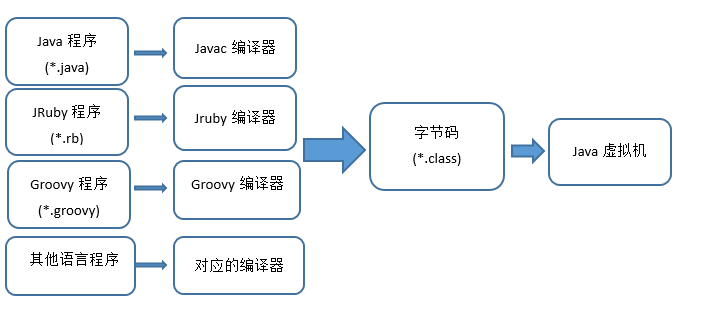
|

|
||||||
|
|
||||||
**可以说`.class`文件是不同的语言在 Java 虚拟机之间的重要桥梁,同时也是支持 Java 跨平台很重要的一个原因。**
|
可以说`.class`文件是不同的语言在 Java 虚拟机之间的重要桥梁,同时也是支持 Java 跨平台很重要的一个原因。
|
||||||
|
|
||||||
## 二 Class 文件结构总结
|
## 二 Class 文件结构总结
|
||||||
|
|
||||||
根据 Java 虚拟机规范,类文件由单个 ClassFile 结构组成:
|
根据 Java 虚拟机规范,Class 文件通过 `ClassFile` 定义,有点类似 C 语言的结构体。
|
||||||
|
|
||||||
|
`ClassFile` 的结构如下:
|
||||||
|
|
||||||
```java
|
```java
|
||||||
ClassFile {
|
ClassFile {
|
||||||
@ -54,41 +58,49 @@ ClassFile {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
|
通过分析 `ClassFile` 的内容,我们便可以知道 class 文件的组成。
|
||||||
|
|
||||||
|
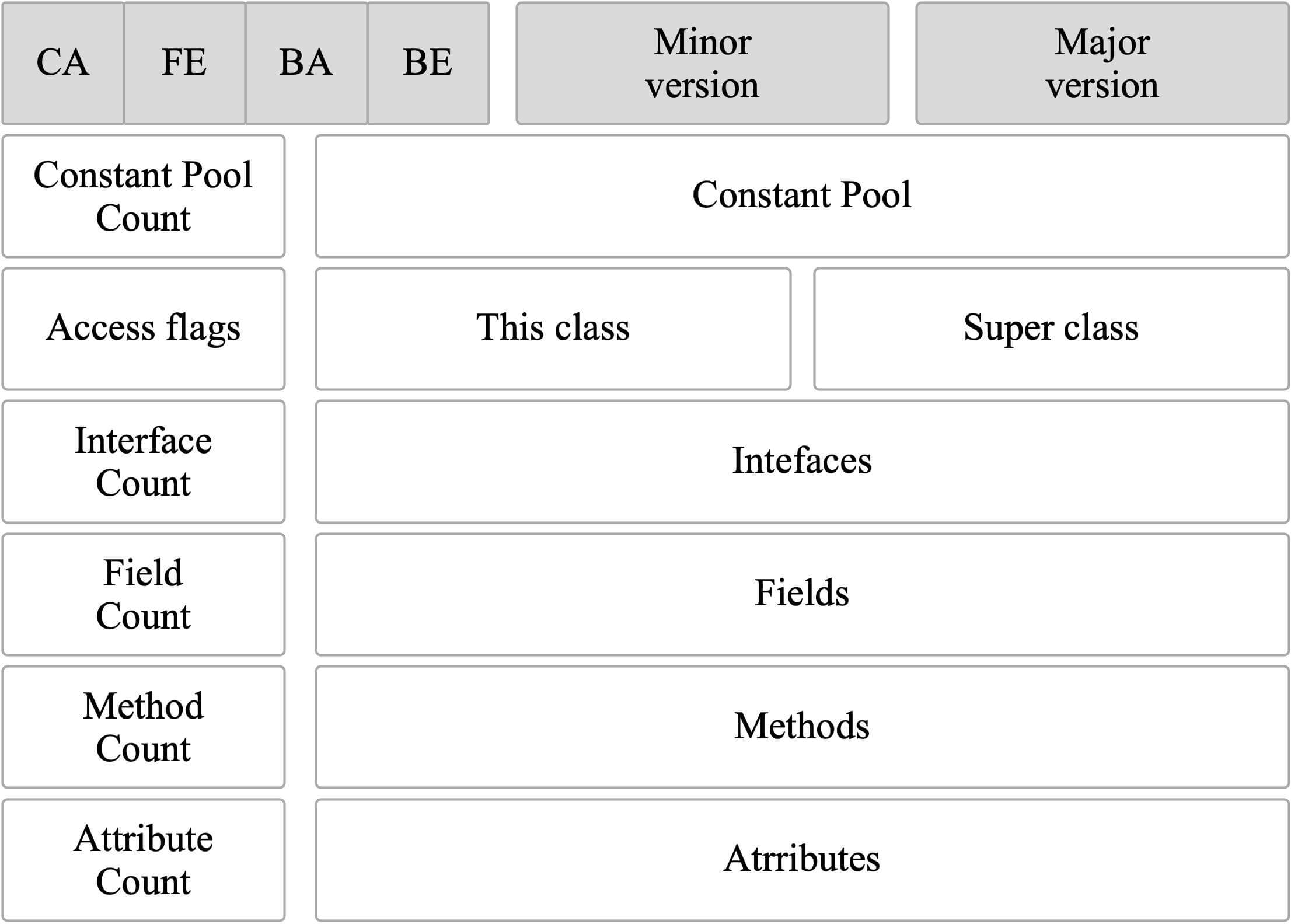
|
||||||
|
|
||||||
|
下面这张图是通过 IDEA 插件 `jclasslib` 查看的,你可以更直观看到 Class 文件结构。
|
||||||
|
|
||||||
|
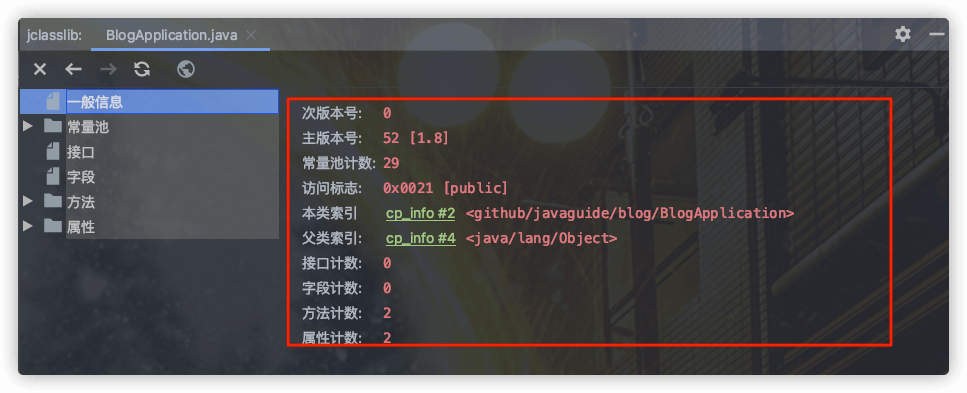
|
||||||
|
|
||||||
|
使用 `jclasslib` 不光可以直观地查看某个类对应的字节码文件,还可以查看类的基本信息、常量池、接口、属性、函数等信息。
|
||||||
|
|
||||||
下面详细介绍一下 Class 文件结构涉及到的一些组件。
|
下面详细介绍一下 Class 文件结构涉及到的一些组件。
|
||||||
|
|
||||||
**Class文件字节码结构组织示意图** (之前在网上保存的,非常不错,原出处不明):
|
### 2.1 魔数(Magic Number)
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 2.1 魔数
|
|
||||||
|
|
||||||
```java
|
```java
|
||||||
u4 magic; //Class 文件的标志
|
u4 magic; //Class 文件的标志
|
||||||
```
|
```
|
||||||
|
|
||||||
每个 Class 文件的头四个字节称为魔数(Magic Number),它的唯一作用是**确定这个文件是否为一个能被虚拟机接收的 Class 文件**。
|
每个 Class 文件的头 4 个字节称为魔数(Magic Number),它的唯一作用是**确定这个文件是否为一个能被虚拟机接收的 Class 文件**。
|
||||||
|
|
||||||
程序设计者很多时候都喜欢用一些特殊的数字表示固定的文件类型或者其它特殊的含义。
|
程序设计者很多时候都喜欢用一些特殊的数字表示固定的文件类型或者其它特殊的含义。
|
||||||
|
|
||||||
### 2.2 Class 文件版本
|
### 2.2 Class 文件版本号(Minor&Major Version)
|
||||||
|
|
||||||
```java
|
```java
|
||||||
u2 minor_version;//Class 的小版本号
|
u2 minor_version;//Class 的小版本号
|
||||||
u2 major_version;//Class 的大版本号
|
u2 major_version;//Class 的大版本号
|
||||||
```
|
```
|
||||||
|
|
||||||
紧接着魔数的四个字节存储的是 Class 文件的版本号:第五和第六是**次版本号**,第七和第八是**主版本号**。
|
紧接着魔数的四个字节存储的是 Class 文件的版本号:第 5 和第 6 位是**次版本号**,第 7 和第 8 位是**主版本号**。
|
||||||
|
|
||||||
|
每当 Java 发布大版本(比如 Java 8,Java9)的时候,主版本号都会加 1。你可以使用 `javap -v` 命令来快速查看 Class 文件的版本号信息。
|
||||||
|
|
||||||
高版本的 Java 虚拟机可以执行低版本编译器生成的 Class 文件,但是低版本的 Java 虚拟机不能执行高版本编译器生成的 Class 文件。所以,我们在实际开发的时候要确保开发的的 JDK 版本和生产环境的 JDK 版本保持一致。
|
高版本的 Java 虚拟机可以执行低版本编译器生成的 Class 文件,但是低版本的 Java 虚拟机不能执行高版本编译器生成的 Class 文件。所以,我们在实际开发的时候要确保开发的的 JDK 版本和生产环境的 JDK 版本保持一致。
|
||||||
|
|
||||||
### 2.3 常量池
|
### 2.3 常量池(Constant Pool)
|
||||||
|
|
||||||
```java
|
```java
|
||||||
u2 constant_pool_count;//常量池的数量
|
u2 constant_pool_count;//常量池的数量
|
||||||
cp_info constant_pool[constant_pool_count-1];//常量池
|
cp_info constant_pool[constant_pool_count-1];//常量池
|
||||||
```
|
```
|
||||||
|
|
||||||
紧接着主次版本号之后的是常量池,常量池的数量是 constant_pool_count-1(**常量池计数器是从1开始计数的,将第0项常量空出来是有特殊考虑的,索引值为0代表“不引用任何一个常量池项”**)。
|
紧接着主次版本号之后的是常量池,常量池的数量是 `constant_pool_count-1`(**常量池计数器是从 1 开始计数的,将第 0 项常量空出来是有特殊考虑的,索引值为 0 代表“不引用任何一个常量池项”**)。
|
||||||
|
|
||||||
常量池主要存放两大常量:字面量和符号引用。字面量比较接近于 Java 语言层面的的常量概念,如文本字符串、声明为 final 的常量值等。而符号引用则属于编译原理方面的概念。包括下面三类常量:
|
常量池主要存放两大常量:字面量和符号引用。字面量比较接近于 Java 语言层面的的常量概念,如文本字符串、声明为 final 的常量值等。而符号引用则属于编译原理方面的概念。包括下面三类常量:
|
||||||
|
|
||||||
@ -96,11 +108,11 @@ ClassFile {
|
|||||||
- 字段的名称和描述符
|
- 字段的名称和描述符
|
||||||
- 方法的名称和描述符
|
- 方法的名称和描述符
|
||||||
|
|
||||||
常量池中每一项常量都是一个表,这14种表有一个共同的特点:**开始的第一位是一个 u1 类型的标志位 -tag 来标识常量的类型,代表当前这个常量属于哪种常量类型.**
|
常量池中每一项常量都是一个表,这 14 种表有一个共同的特点:**开始的第一位是一个 u1 类型的标志位 -tag 来标识常量的类型,代表当前这个常量属于哪种常量类型.**
|
||||||
|
|
||||||
| 类型 | 标志(tag) | 描述 |
|
| 类型 | 标志(tag) | 描述 |
|
||||||
| :------------------------------: | :---------: | :--------------------: |
|
| :------------------------------: | :---------: | :--------------------: |
|
||||||
| CONSTANT_utf8_info | 1 | UTF-8编码的字符串 |
|
| CONSTANT_utf8_info | 1 | UTF-8 编码的字符串 |
|
||||||
| CONSTANT_Integer_info | 3 | 整形字面量 |
|
| CONSTANT_Integer_info | 3 | 整形字面量 |
|
||||||
| CONSTANT_Float_info | 4 | 浮点型字面量 |
|
| CONSTANT_Float_info | 4 | 浮点型字面量 |
|
||||||
| CONSTANT_Long_info | 5 | 长整型字面量 |
|
| CONSTANT_Long_info | 5 | 长整型字面量 |
|
||||||
@ -115,11 +127,11 @@ ClassFile {
|
|||||||
| CONSTANT_MethodHandle_info | 15 | 表示方法句柄 |
|
| CONSTANT_MethodHandle_info | 15 | 表示方法句柄 |
|
||||||
| CONSTANT_InvokeDynamic_info | 18 | 表示一个动态方法调用点 |
|
| CONSTANT_InvokeDynamic_info | 18 | 表示一个动态方法调用点 |
|
||||||
|
|
||||||
`.class` 文件可以通过`javap -v class类名` 指令来看一下其常量池中的信息(`javap -v class类名-> temp.txt` :将结果输出到 temp.txt 文件)。
|
`.class` 文件可以通过`javap -v class类名` 指令来看一下其常量池中的信息(`javap -v class类名-> temp.txt` :将结果输出到 temp.txt 文件)。
|
||||||
|
|
||||||
### 2.4 访问标志
|
### 2.4 访问标志(Access Flags)
|
||||||
|
|
||||||
在常量池结束之后,紧接着的两个字节代表访问标志,这个标志用于识别一些类或者接口层次的访问信息,包括:这个 Class 是类还是接口,是否为 public 或者 abstract 类型,如果是类的话是否声明为 final 等等。
|
在常量池结束之后,紧接着的两个字节代表访问标志,这个标志用于识别一些类或者接口层次的访问信息,包括:这个 Class 是类还是接口,是否为 `public` 或者 `abstract` 类型,如果是类的话是否声明为 `final` 等等。
|
||||||
|
|
||||||
类访问和属性修饰符:
|
类访问和属性修饰符:
|
||||||
|
|
||||||
@ -138,7 +150,7 @@ public class Employee {
|
|||||||
|
|
||||||
|

|
||||||
|
|
||||||
### 2.5 当前类索引,父类索引与接口索引集合
|
### 2.5 当前类(This Class)、父类(Super Class)、接口(Interfaces)索引集合
|
||||||
|
|
||||||
```java
|
```java
|
||||||
u2 this_class;//当前类
|
u2 this_class;//当前类
|
||||||
@ -147,11 +159,11 @@ public class Employee {
|
|||||||
u2 interfaces[interfaces_count];//一个类可以实现多个接口
|
u2 interfaces[interfaces_count];//一个类可以实现多个接口
|
||||||
```
|
```
|
||||||
|
|
||||||
**类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名,由于 Java 语言的单继承,所以父类索引只有一个,除了 `java.lang.Object` 之外,所有的 java 类都有父类,因此除了 `java.lang.Object` 外,所有 Java 类的父类索引都不为 0。**
|
类索引用于确定这个类的全限定名,父类索引用于确定这个类的父类的全限定名,由于 Java 语言的单继承,所以父类索引只有一个,除了 `java.lang.Object` 之外,所有的 java 类都有父类,因此除了 `java.lang.Object` 外,所有 Java 类的父类索引都不为 0。
|
||||||
|
|
||||||
**接口索引集合用来描述这个类实现了那些接口,这些被实现的接口将按 `implements` (如果这个类本身是接口的话则是`extends`) 后的接口顺序从左到右排列在接口索引集合中。**
|
接口索引集合用来描述这个类实现了那些接口,这些被实现的接口将按 `implements` (如果这个类本身是接口的话则是`extends`) 后的接口顺序从左到右排列在接口索引集合中。
|
||||||
|
|
||||||
### 2.6 字段表集合
|
### 2.6 字段表集合(Fields)
|
||||||
|
|
||||||
```java
|
```java
|
||||||
u2 fields_count;//Class 文件的字段的个数
|
u2 fields_count;//Class 文件的字段的个数
|
||||||
@ -164,7 +176,7 @@ public class Employee {
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
- **access_flags:** 字段的作用域(`public` ,`private`,`protected`修饰符),是实例变量还是类变量(`static`修饰符),可否被序列化(transient 修饰符),可变性(final),可见性(volatile 修饰符,是否强制从主内存读写)。
|
- **access_flags:** 字段的作用域(`public` ,`private`,`protected`修饰符),是实例变量还是类变量(`static`修饰符),可否被序列化(transient 修饰符),可变性(final),可见性(volatile 修饰符,是否强制从主内存读写)。
|
||||||
- **name_index:** 对常量池的引用,表示的字段的名称;
|
- **name_index:** 对常量池的引用,表示的字段的名称;
|
||||||
- **descriptor_index:** 对常量池的引用,表示字段和方法的描述符;
|
- **descriptor_index:** 对常量池的引用,表示字段和方法的描述符;
|
||||||
- **attributes_count:** 一个字段还会拥有一些额外的属性,attributes_count 存放属性的个数;
|
- **attributes_count:** 一个字段还会拥有一些额外的属性,attributes_count 存放属性的个数;
|
||||||
@ -176,7 +188,7 @@ public class Employee {
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
### 2.7 方法表集合
|
### 2.7 方法表集合(Methods)
|
||||||
|
|
||||||
```java
|
```java
|
||||||
u2 methods_count;//Class 文件的方法的数量
|
u2 methods_count;//Class 文件的方法的数量
|
||||||
@ -197,7 +209,7 @@ Class 文件存储格式中对方法的描述与对字段的描述几乎采用
|
|||||||
|
|
||||||
注意:因为`volatile`修饰符和`transient`修饰符不可以修饰方法,所以方法表的访问标志中没有这两个对应的标志,但是增加了`synchronized`、`native`、`abstract`等关键字修饰方法,所以也就多了这些关键字对应的标志。
|
注意:因为`volatile`修饰符和`transient`修饰符不可以修饰方法,所以方法表的访问标志中没有这两个对应的标志,但是增加了`synchronized`、`native`、`abstract`等关键字修饰方法,所以也就多了这些关键字对应的标志。
|
||||||
|
|
||||||
### 2.8 属性表集合
|
### 2.8 属性表集合(Attributes)
|
||||||
|
|
||||||
```java
|
```java
|
||||||
u2 attributes_count;//此类的属性表中的属性数
|
u2 attributes_count;//此类的属性表中的属性数
|
||||||
|
|||||||
@ -229,7 +229,7 @@ Thread[线程 2,5,main]waiting get resource1
|
|||||||
|
|
||||||
1. 互斥条件:该资源任意一个时刻只由一个线程占用。
|
1. 互斥条件:该资源任意一个时刻只由一个线程占用。
|
||||||
2. 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
|
2. 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
|
||||||
3. 不剥夺条件:线程已获得的资源在末使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
|
3. 不剥夺条件:线程已获得的资源在未使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
|
||||||
4. 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
|
4. 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
|
||||||
|
|
||||||
### 8.2. 如何避免线程死锁?
|
### 8.2. 如何避免线程死锁?
|
||||||
|
|||||||
@ -93,8 +93,8 @@ synchronized void method() {
|
|||||||
**2.修饰静态方法:** 也就是给当前类加锁,会作用于类的所有对象实例 ,进入同步代码前要获得 **当前 class 的锁**。因为静态成员不属于任何一个实例对象,是类成员( _static 表明这是该类的一个静态资源,不管 new 了多少个对象,只有一份_)。所以,如果一个线程 A 调用一个实例对象的非静态 `synchronized` 方法,而线程 B 需要调用这个实例对象所属类的静态 `synchronized` 方法,是允许的,不会发生互斥现象,**因为访问静态 `synchronized` 方法占用的锁是当前类的锁,而访问非静态 `synchronized` 方法占用的锁是当前实例对象锁**。
|
**2.修饰静态方法:** 也就是给当前类加锁,会作用于类的所有对象实例 ,进入同步代码前要获得 **当前 class 的锁**。因为静态成员不属于任何一个实例对象,是类成员( _static 表明这是该类的一个静态资源,不管 new 了多少个对象,只有一份_)。所以,如果一个线程 A 调用一个实例对象的非静态 `synchronized` 方法,而线程 B 需要调用这个实例对象所属类的静态 `synchronized` 方法,是允许的,不会发生互斥现象,**因为访问静态 `synchronized` 方法占用的锁是当前类的锁,而访问非静态 `synchronized` 方法占用的锁是当前实例对象锁**。
|
||||||
|
|
||||||
```java
|
```java
|
||||||
synchronized void staic method() {
|
synchronized static void method() {
|
||||||
//业务代码
|
//业务代码
|
||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
@ -188,7 +188,7 @@ public class SynchronizedDemo {
|
|||||||
|
|
||||||
> 在 Java 虚拟机(HotSpot)中,Monitor 是基于 C++实现的,由[ObjectMonitor](https://github.com/openjdk-mirror/jdk7u-hotspot/blob/50bdefc3afe944ca74c3093e7448d6b889cd20d1/src/share/vm/runtime/objectMonitor.cpp)实现的。每个对象中都内置了一个 `ObjectMonitor`对象。
|
> 在 Java 虚拟机(HotSpot)中,Monitor 是基于 C++实现的,由[ObjectMonitor](https://github.com/openjdk-mirror/jdk7u-hotspot/blob/50bdefc3afe944ca74c3093e7448d6b889cd20d1/src/share/vm/runtime/objectMonitor.cpp)实现的。每个对象中都内置了一个 `ObjectMonitor`对象。
|
||||||
>
|
>
|
||||||
> 另外,**`wait/notify`等方法也依赖于`monitor`对象,这就是为什么只有在同步的块或者方法中才能调用`wait/notify`等方法,否则会抛出`java.lang.IllegalMonitorStateException`的异常的原因。**
|
> 另外,`wait/notify`等方法也依赖于`monitor`对象,这就是为什么只有在同步的块或者方法中才能调用`wait/notify`等方法,否则会抛出`java.lang.IllegalMonitorStateException`的异常的原因。
|
||||||
|
|
||||||
在执行`monitorenter`时,会尝试获取对象的锁,如果锁的计数器为 0 则表示锁可以被获取,获取后将锁计数器设为 1 也就是加 1。
|
在执行`monitorenter`时,会尝试获取对象的锁,如果锁的计数器为 0 则表示锁可以被获取,获取后将锁计数器设为 1 也就是加 1。
|
||||||
|
|
||||||
@ -223,10 +223,7 @@ JDK1.6 对锁的实现引入了大量的优化,如偏向锁、轻量级锁、
|
|||||||
|
|
||||||
锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
|
锁主要存在四种状态,依次是:无锁状态、偏向锁状态、轻量级锁状态、重量级锁状态,他们会随着竞争的激烈而逐渐升级。注意锁可以升级不可降级,这种策略是为了提高获得锁和释放锁的效率。
|
||||||
|
|
||||||
关于这几种优化的详细信息可以查看下面这几篇文章:
|
关于这几种优化的详细信息可以查看下面这篇文章:[Java6 及以上版本对 synchronized 的优化](https://www.cnblogs.com/wuqinglong/p/9945618.html)
|
||||||
|
|
||||||
- [Java 性能 -- synchronized 锁升级优化](https://blog.csdn.net/qq_34337272/article/details/108498442)
|
|
||||||
- [Java6 及以上版本对 synchronized 的优化](https://www.cnblogs.com/wuqinglong/p/9945618.html)
|
|
||||||
|
|
||||||
### 1.5. 谈谈 synchronized 和 ReentrantLock 的区别
|
### 1.5. 谈谈 synchronized 和 ReentrantLock 的区别
|
||||||
|
|
||||||
|
|||||||
@ -92,7 +92,7 @@ size: 0
|
|||||||
- **虚引用**:虚引用是最弱的引用,在 Java 中使用 PhantomReference 进行定义。虚引用中唯一的作用就是用队列接收对象即将死亡的通知
|
- **虚引用**:虚引用是最弱的引用,在 Java 中使用 PhantomReference 进行定义。虚引用中唯一的作用就是用队列接收对象即将死亡的通知
|
||||||
|
|
||||||
|
|
||||||
接着再来看下代码,我们使用反射的方式来看看`GC`后`ThreadLocal`中的数据情况:(下面代码来源自:https://blog.csdn.net/thewindkee/article/details/103726942,本地运行演示GC回收场景)
|
接着再来看下代码,我们使用反射的方式来看看`GC`后`ThreadLocal`中的数据情况:(下面代码来源自:https://blog.csdn.net/thewindkee/article/details/103726942 本地运行演示GC回收场景)
|
||||||
|
|
||||||
```java
|
```java
|
||||||
public class ThreadLocalDemo {
|
public class ThreadLocalDemo {
|
||||||
|
|||||||
@ -283,7 +283,7 @@ Formula formula = (a) -> sqrt(a * 100);
|
|||||||
|
|
||||||
### 内置函数式接口(Built-in Functional Interfaces)
|
### 内置函数式接口(Built-in Functional Interfaces)
|
||||||
|
|
||||||
JDK 1.8 API包含许多内置函数式接口。 其中一些借口在老版本的 Java 中是比较常见的比如: `Comparator` 或`Runnable`,这些接口都增加了`@FunctionalInterface`注解以便能用在 lambda 表达式上。
|
JDK 1.8 API包含许多内置函数式接口。 其中一些接口在老版本的 Java 中是比较常见的比如: `Comparator` 或`Runnable`,这些接口都增加了`@FunctionalInterface`注解以便能用在 lambda 表达式上。
|
||||||
|
|
||||||
但是 Java 8 API 同样还提供了很多全新的函数式接口来让你的编程工作更加方便,有一些接口是来自 [Google Guava](https://code.google.com/p/guava-libraries/) 库里的,即便你对这些很熟悉了,还是有必要看看这些是如何扩展到lambda上使用的。
|
但是 Java 8 API 同样还提供了很多全新的函数式接口来让你的编程工作更加方便,有一些接口是来自 [Google Guava](https://code.google.com/p/guava-libraries/) 库里的,即便你对这些很熟悉了,还是有必要看看这些是如何扩展到lambda上使用的。
|
||||||
|
|
||||||
|
|||||||
1019
docs/java/new-features/java8-common-new-features.md
Normal file
@ -1,55 +0,0 @@
|
|||||||
今天(2020-03-07)终于把PDF版本的《JavaGuide面试突击版》搞定!废话不多说,直接上成品:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 如何获取
|
|
||||||
|
|
||||||
公众号后台回复:“面试突击”即可。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 关于《JavaGuide面试突击版》
|
|
||||||
|
|
||||||
JavaGuide 目前已经 70k+ Star ,目前已经是所有 Java 类别项目中 Star 数量第二的开源项目了。Star虽然很多,但是价值远远比不上 Dubbo 这些开源项目,希望以后可以多出现一些这样的国产开源项目。国产开源项目!加油!奥利给!
|
|
||||||
|
|
||||||
随着越来越多的人参与完善这个项目,这个专注 “Java知识总结+面试指南 ” 项目的知识体系和内容的不断完善。JavaGuide 目前包括下面这两部分内容:
|
|
||||||
|
|
||||||
1. **Java 核心知识总结**;
|
|
||||||
2. **面试方向**:面试题、面试经验、备战面试系列文章以及面试真实体验系列文章
|
|
||||||
|
|
||||||
内容的庞大让JavaGuide 显的有一点臃肿。所以,我决定将专门为 Java 面试所写的文章以及来自读者投稿的文章整理成 **《JavaGuide面试突击版》** 系列,同时也为了更加方便大家阅读查阅。起这个名字也犹豫了很久,大家如果有更好的名字的话也可以向我建议。暂时的定位是将其作为 PDF 电子书,并不会像 JavaGuide 提供在线阅读版本。我之前也免费分享过PDF 版本的《Java面试突击》,期间一共更新了 3 个版本,但是由于后面难以同步和订正所以就没有再更新。**《JavaGuide面试突击版》** pdf 版由于我工作流程的转变可以有效避免这个问题。
|
|
||||||
|
|
||||||
另外,这段时间,向我提这个建议的读者也不是一个两个,我自己当然也有这个感觉。只是自己一直没有抽出时间去做罢了!毕竟这算是一个比较耗费时间的工程。加油!奥利给!
|
|
||||||
|
|
||||||
这件事情具体耗费时间的地方是内容的排版优化(为了方便导出PDF生成目录),导出 PDF 我是通过 Typora 来做的。
|
|
||||||
|
|
||||||
### 如何学习本项目
|
|
||||||
|
|
||||||
提供了非常详细的目录,建议可以从头看是看一遍,如果基础不错的话也可以挑自己需要的章节查看。看的过程中自己要多思考,碰到不懂的地方,自己记得要勤搜索,需要记忆的地方也不要吝啬自己的脑子。
|
|
||||||
|
|
||||||
### 关于更新
|
|
||||||
|
|
||||||
**《JavaGuide面试突击版》** 预计一个月左右会有一次内容更新和完善,大家在我的公众号 **JavaGuide** 后台回复**“面试突击”** 即可获取最新版!另外,为了保证自己的辛勤劳动不被恶意盗版滥用,所以我添加了水印并且在一些内容注明版权,希望大家理解。
|
|
||||||
|
|
||||||
### 如何贡献
|
|
||||||
|
|
||||||
大家阅读过程中如果遇到错误的地方可以通过微信与我交流(ps:加过我微信的就不要重复添加了,这是另外一个账号,前一个已经满了)。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
希望大家给我提反馈的时候可以按照如下格式:
|
|
||||||
|
|
||||||
> 我觉得2.3节Java基础的 2.3.1 这部分的描述有问题,应该这样描述:~巴拉巴拉~ 会更好!具体可以参考Oracle 官方文档,地址:~~~~。
|
|
||||||
|
|
||||||
为了提高准确性已经不必要的时间花费,希望大家尽量确保自己想法的准确性。
|
|
||||||
|
|
||||||
### 如何赞赏
|
|
||||||
|
|
||||||
如果觉得本文档对你有帮助的话,欢迎加入我的知识星球。创建星球的目的主要是为了提高知识沉淀,微信群的弊端相比大家都了解。星球没有免费的原因是了设立门槛,提高进入读者的质量。我会在星球回答大家的问题,更新更多的大厂面试干货!
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
我的知识星球的价格应该是我了解的圈子里面最低的,也就1顿饭钱吧!毕竟关注我的大部分还是学生,我打心底里希望自己分享的东西能对大家有帮助。
|
|
||||||
|
|
||||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/Screen Shot 2020-03-07 at 7.33.50 PM.jpg" style="zoom:50%;" />
|
|
||||||
|
|
||||||
@ -51,7 +51,7 @@
|
|||||||
|
|
||||||
**物理层(physical layer)的作用是实现相邻计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异,** 使其上面的数据链路层不必考虑网络的具体传输介质是什么。“透明传送比特流”表示经实际电路传送后的比特流没有发生变化,对传送的比特流来说,这个电路好像是看不见的。
|
**物理层(physical layer)的作用是实现相邻计算机节点之间比特流的透明传送,尽可能屏蔽掉具体传输介质和物理设备的差异,** 使其上面的数据链路层不必考虑网络的具体传输介质是什么。“透明传送比特流”表示经实际电路传送后的比特流没有发生变化,对传送的比特流来说,这个电路好像是看不见的。
|
||||||
|
|
||||||
在互联网使用的各种协中最重要和最著名的就是 TCP/IP 两个协议。现在人们经常提到的TCP/IP并不一定单指TCP和IP这两个具体的协议,而往往表示互联网所使用的整个TCP/IP协议族。
|
在互联网使用的各种协议中最重要和最著名的就是 TCP/IP 两个协议。现在人们经常提到的TCP/IP并不一定单指TCP和IP这两个具体的协议,而往往表示互联网所使用的整个TCP/IP协议族。
|
||||||
|
|
||||||
### 1.6 总结一下
|
### 1.6 总结一下
|
||||||
|
|
||||||
@ -133,12 +133,14 @@ TCP 提供面向连接的服务。在传送数据之前必须先建立连接,
|
|||||||
**自动重传请求**(Automatic Repeat-reQuest,ARQ)是OSI模型中数据链路层和传输层的错误纠正协议之一。它通过使用确认和超时这两个机制,在不可靠服务的基础上实现可靠的信息传输。如果发送方在发送后一段时间之内没有收到确认帧,它通常会重新发送。ARQ包括停止等待ARQ协议和连续ARQ协议。
|
**自动重传请求**(Automatic Repeat-reQuest,ARQ)是OSI模型中数据链路层和传输层的错误纠正协议之一。它通过使用确认和超时这两个机制,在不可靠服务的基础上实现可靠的信息传输。如果发送方在发送后一段时间之内没有收到确认帧,它通常会重新发送。ARQ包括停止等待ARQ协议和连续ARQ协议。
|
||||||
|
|
||||||
#### 停止等待ARQ协议
|
#### 停止等待ARQ协议
|
||||||
- 停止等待协议是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认(回复ACK)。如果过了一段时间(超时时间后),还是没有收到 ACK 确认,说明没有发送成功,需要重新发送,直到收到确认后再发下一个分组;
|
停止等待协议是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认(回复ACK)。如果过了一段时间(超时时间后),还是没有收到 ACK 确认,说明没有发送成功,需要重新发送,直到收到确认后再发下一个分组。
|
||||||
- 在停止等待协议中,若接收方收到重复分组,就丢弃该分组,但同时还要发送确认;
|
|
||||||
|
|
||||||
**优点:** 简单
|
在停止等待协议中,若接收方收到重复分组,就丢弃该分组,但同时还要发送确认。
|
||||||
|
|
||||||
**缺点:** 信道利用率低,等待时间长
|
**优缺点:**
|
||||||
|
|
||||||
|
- **优点:** 简单
|
||||||
|
- **缺点:** 信道利用率低,等待时间长
|
||||||
|
|
||||||
**1) 无差错情况:**
|
**1) 无差错情况:**
|
||||||
|
|
||||||
@ -157,9 +159,10 @@ TCP 提供面向连接的服务。在传送数据之前必须先建立连接,
|
|||||||
|
|
||||||
连续 ARQ 协议可提高信道利用率。发送方维持一个发送窗口,凡位于发送窗口内的分组可以连续发送出去,而不需要等待对方确认。接收方一般采用累计确认,对按序到达的最后一个分组发送确认,表明到这个分组为止的所有分组都已经正确收到了。
|
连续 ARQ 协议可提高信道利用率。发送方维持一个发送窗口,凡位于发送窗口内的分组可以连续发送出去,而不需要等待对方确认。接收方一般采用累计确认,对按序到达的最后一个分组发送确认,表明到这个分组为止的所有分组都已经正确收到了。
|
||||||
|
|
||||||
**优点:** 信道利用率高,容易实现,即使确认丢失,也不必重传。
|
**优缺点:**
|
||||||
|
|
||||||
**缺点:** 不能向发送方反映出接收方已经正确收到的所有分组的信息。 比如:发送方发送了 5条 消息,中间第三条丢失(3号),这时接收方只能对前两个发送确认。发送方无法知道后三个分组的下落,而只好把后三个全部重传一次。这也叫 Go-Back-N(回退 N),表示需要退回来重传已经发送过的 N 个消息。
|
- **优点:** 信道利用率高,容易实现,即使确认丢失,也不必重传。
|
||||||
|
- **缺点:** 不能向发送方反映出接收方已经正确收到的所有分组的信息。 比如:发送方发送了 5条 消息,中间第三条丢失(3号),这时接收方只能对前两个发送确认。发送方无法知道后三个分组的下落,而只好把后三个全部重传一次。这也叫 Go-Back-N(回退 N),表示需要退回来重传已经发送过的 N 个消息。
|
||||||
|
|
||||||
### 4.2 滑动窗口和流量控制
|
### 4.2 滑动窗口和流量控制
|
||||||
|
|
||||||
|
|||||||