[refractor]图片迁移
@ -449,7 +449,7 @@ Logo下的小图标是使用[Shields.IO](https://shields.io/) 生成的。
|
|||||||
|
|
||||||
### 联系我
|
### 联系我
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
### Contributor
|
### Contributor
|
||||||
|
|
||||||
@ -514,6 +514,6 @@ Logo下的小图标是使用[Shields.IO](https://shields.io/) 生成的。
|
|||||||
|
|
||||||
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|
||||||
|
|||||||
{kind=link}
|
Before Width: | Height: | Size: 18 KiB After Width: | Height: | Size: 18 KiB |
{kind=link}
|
Before Width: | Height: | Size: 275 KiB After Width: | Height: | Size: 275 KiB |
{kind=link}
|
Before Width: | Height: | Size: 180 KiB After Width: | Height: | Size: 180 KiB |
{kind=link}
|
Before Width: | Height: | Size: 412 KiB After Width: | Height: | Size: 412 KiB |
{kind=link}
|
Before Width: | Height: | Size: 60 KiB After Width: | Height: | Size: 60 KiB |
{kind=link}
|
Before Width: | Height: | Size: 336 KiB After Width: | Height: | Size: 336 KiB |
{kind=link}
|
Before Width: | Height: | Size: 399 KiB After Width: | Height: | Size: 399 KiB |
{kind=link}
|
Before Width: | Height: | Size: 67 KiB After Width: | Height: | Size: 67 KiB |
{kind=link}
|
Before Width: | Height: | Size: 116 KiB After Width: | Height: | Size: 116 KiB |
{kind=link}
|
Before Width: | Height: | Size: 72 KiB After Width: | Height: | Size: 72 KiB |
{kind=link}
|
Before Width: | Height: | Size: 45 KiB After Width: | Height: | Size: 45 KiB |
{kind=link}
|
Before Width: | Height: | Size: 17 KiB After Width: | Height: | Size: 17 KiB |
{kind=link}
|
Before Width: | Height: | Size: 38 KiB After Width: | Height: | Size: 38 KiB |
{kind=link}
|
Before Width: | Height: | Size: 38 KiB After Width: | Height: | Size: 38 KiB |
{kind=link}
|
Before Width: | Height: | Size: 17 KiB After Width: | Height: | Size: 17 KiB |
@ -48,7 +48,7 @@ _先来聊聊本地缓存,这个实际在很多项目中用的蛮多,特别
|
|||||||
|
|
||||||
常见的单体架构图如下,我们使用 **Nginx** 来做**负载均衡**,部署两个相同的服务到服务器,两个服务使用同一个数据库,并且使用的是本地缓存。
|
常见的单体架构图如下,我们使用 **Nginx** 来做**负载均衡**,部署两个相同的服务到服务器,两个服务使用同一个数据库,并且使用的是本地缓存。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
_那本地缓存的方案有哪些呢?且听 Guide 给你来说一说。_
|
_那本地缓存的方案有哪些呢?且听 Guide 给你来说一说。_
|
||||||
|
|
||||||
@ -80,7 +80,7 @@ _我们可以把分布式缓存(Distributed Cache) 看作是一种内存数
|
|||||||
|
|
||||||
如下图所示,就是一个简单的使用分布式缓存的架构图。我们使用 Nginx 来做负载均衡,部署两个相同的服务到服务器,两个服务使用同一个数据库和缓存。
|
如下图所示,就是一个简单的使用分布式缓存的架构图。我们使用 Nginx 来做负载均衡,部署两个相同的服务到服务器,两个服务使用同一个数据库和缓存。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
本地的缓存的优势是低依赖,比较轻量并且通常相比于使用分布式缓存要更加简单。
|
本地的缓存的优势是低依赖,比较轻量并且通常相比于使用分布式缓存要更加简单。
|
||||||
|
|
||||||
@ -136,7 +136,7 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
|
|||||||
|
|
||||||
作为暖男一号,我给大家画了一个草图。
|
作为暖男一号,我给大家画了一个草图。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
简单来说就是:
|
简单来说就是:
|
||||||
|
|
||||||
@ -151,7 +151,7 @@ _简单,来说使用缓存主要是为了提升用户体验以及应对更多
|
|||||||
|
|
||||||
下面我们主要从“高性能”和“高并发”这两点来看待这个问题。
|
下面我们主要从“高性能”和“高并发”这两点来看待这个问题。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
**高性能** :
|
**高性能** :
|
||||||
|
|
||||||
@ -175,7 +175,7 @@ _简单,来说使用缓存主要是为了提升用户体验以及应对更多
|
|||||||
|
|
||||||
你可以自己本机安装 redis 或者通过 redis 官网提供的[在线 redis 环境](https://try.redis.io/)。
|
你可以自己本机安装 redis 或者通过 redis 官网提供的[在线 redis 环境](https://try.redis.io/)。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
#### 8.1. string
|
#### 8.1. string
|
||||||
|
|
||||||
@ -275,7 +275,7 @@ OK
|
|||||||
|
|
||||||
我专门花了一个图方便小伙伴们来理解:
|
我专门花了一个图方便小伙伴们来理解:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
**通过 `lrange` 查看对应下标范围的列表元素:**
|
**通过 `lrange` 查看对应下标范围的列表元素:**
|
||||||
|
|
||||||
@ -421,7 +421,7 @@ Redis 通过**IO 多路复用程序** 来监听来自客户端的大量连接(
|
|||||||
* 文件事件分派器(将 socket 关联到相应的事件处理器)
|
* 文件事件分派器(将 socket 关联到相应的事件处理器)
|
||||||
* 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
|
* 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
<p style="text-align:right; font-size:14px; color:gray">《Redis设计与实现:12章》</p>
|
<p style="text-align:right; font-size:14px; color:gray">《Redis设计与实现:12章》</p>
|
||||||
|
|
||||||
@ -429,7 +429,7 @@ Redis 通过**IO 多路复用程序** 来监听来自客户端的大量连接(
|
|||||||
|
|
||||||
虽然说 Redis 是单线程模型,但是, 实际上,**Redis 在 4.0 之后的版本中就已经加入了对多线程的支持。**
|
虽然说 Redis 是单线程模型,但是, 实际上,**Redis 在 4.0 之后的版本中就已经加入了对多线程的支持。**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
不过,Redis 4.0 增加的多线程主要是针对一些大键值对的删除操作的命令,使用这些命令就会使用主处理之外的其他线程来“异步处理”。
|
不过,Redis 4.0 增加的多线程主要是针对一些大键值对的删除操作的命令,使用这些命令就会使用主处理之外的其他线程来“异步处理”。
|
||||||
|
|
||||||
@ -495,7 +495,7 @@ OK
|
|||||||
|
|
||||||
Redis 通过一个叫做过期字典(可以看作是hash表)来保存数据过期的时间。过期字典的键指向Redis数据库中的某个key(键),过期字典的值是一个long long类型的整数,这个整数保存了key所指向的数据库键的过期时间(毫秒精度的UNIX时间戳)。
|
Redis 通过一个叫做过期字典(可以看作是hash表)来保存数据过期的时间。过期字典的键指向Redis数据库中的某个key(键),过期字典的值是一个long long类型的整数,这个整数保存了key所指向的数据库键的过期时间(毫秒精度的UNIX时间戳)。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
过期字典是存储在redisDb这个结构里的:
|
过期字典是存储在redisDb这个结构里的:
|
||||||
|
|
||||||
@ -622,7 +622,7 @@ QUEUED
|
|||||||
|
|
||||||
Redis官网相关介绍 [https://redis.io/topics/transactions](https://redis.io/topics/transactions) 如下:
|
Redis官网相关介绍 [https://redis.io/topics/transactions](https://redis.io/topics/transactions) 如下:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
但是,Redis 的事务和我们平时理解的关系型数据库的事务不同。我们知道事务具有四大特性: **1. 原子性**,**2. 隔离性**,**3. 持久性**,**4. 一致性**。
|
但是,Redis 的事务和我们平时理解的关系型数据库的事务不同。我们知道事务具有四大特性: **1. 原子性**,**2. 隔离性**,**3. 持久性**,**4. 一致性**。
|
||||||
|
|
||||||
@ -635,7 +635,7 @@ Redis官网相关介绍 [https://redis.io/topics/transactions](https://redis.io/
|
|||||||
|
|
||||||
Redis官网也解释了自己为啥不支持回滚。简单来说就是Redis开发者们觉得没必要支持回滚,这样更简单便捷并且性能更好。Redis开发者觉得即使命令执行错误也应该在开发过程中就被发现而不是生产过程中。
|
Redis官网也解释了自己为啥不支持回滚。简单来说就是Redis开发者们觉得没必要支持回滚,这样更简单便捷并且性能更好。Redis开发者觉得即使命令执行错误也应该在开发过程中就被发现而不是生产过程中。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
你可以将Redis中的事务就理解为 :**Redis事务提供了一种将多个命令请求打包的功能。然后,再按顺序执行打包的所有命令,并且不会被中途打断。**
|
你可以将Redis中的事务就理解为 :**Redis事务提供了一种将多个命令请求打包的功能。然后,再按顺序执行打包的所有命令,并且不会被中途打断。**
|
||||||
|
|
||||||
@ -651,7 +651,7 @@ Redis官网也解释了自己为啥不支持回滚。简单来说就是Redis开
|
|||||||
|
|
||||||
如下图所示,用户的请求最终都要跑到数据库中查询一遍。
|
如下图所示,用户的请求最终都要跑到数据库中查询一遍。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
#### 18.3. 有哪些解决办法?
|
#### 18.3. 有哪些解决办法?
|
||||||
|
|
||||||
@ -694,7 +694,7 @@ public Object getObjectInclNullById(Integer id) {
|
|||||||
|
|
||||||
加入布隆过滤器之后的缓存处理流程图如下。
|
加入布隆过滤器之后的缓存处理流程图如下。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
但是,需要注意的是布隆过滤器可能会存在误判的情况。总结来说就是: **布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。**
|
但是,需要注意的是布隆过滤器可能会存在误判的情况。总结来说就是: **布隆过滤器说某个元素存在,小概率会误判。布隆过滤器说某个元素不在,那么这个元素一定不在。**
|
||||||
|
|
||||||
|
|||||||
@ -2,7 +2,7 @@
|
|||||||
|
|
||||||
### 前言
|
### 前言
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
**全文共10000+字,31张图,这篇文章同样耗费了不少的时间和精力才创作完成,原创不易,请大家点点关注+在看,感谢。**
|
**全文共10000+字,31张图,这篇文章同样耗费了不少的时间和精力才创作完成,原创不易,请大家点点关注+在看,感谢。**
|
||||||
|
|
||||||
@ -68,7 +68,7 @@ size: 0
|
|||||||
|
|
||||||
### `ThreadLocal`的数据结构
|
### `ThreadLocal`的数据结构
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|
||||||
`Thread`类有一个类型为``ThreadLocal`.`ThreadLocalMap``的实例变量`threadLocals`,也就是说每个线程有一个自己的`ThreadLocalMap`。
|
`Thread`类有一个类型为``ThreadLocal`.`ThreadLocalMap``的实例变量`threadLocals`,也就是说每个线程有一个自己的`ThreadLocalMap`。
|
||||||
@ -148,7 +148,7 @@ public class ThreadLocalDemo {
|
|||||||
弱引用key:null,值:def
|
弱引用key:null,值:def
|
||||||
```
|
```
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
如图所示,因为这里创建的`ThreadLocal`并没有指向任何值,也就是没有任何引用:
|
如图所示,因为这里创建的`ThreadLocal`并没有指向任何值,也就是没有任何引用:
|
||||||
|
|
||||||
@ -158,19 +158,19 @@ new ThreadLocal<>().set(s);
|
|||||||
|
|
||||||
所以这里在`GC`之后,`key`就会被回收,我们看到上面`debug`中的`referent=null`, 如果**改动一下代码:**
|
所以这里在`GC`之后,`key`就会被回收,我们看到上面`debug`中的`referent=null`, 如果**改动一下代码:**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
这个问题刚开始看,如果没有过多思考,**弱引用**,还有**垃圾回收**,那么肯定会觉得是`null`。
|
这个问题刚开始看,如果没有过多思考,**弱引用**,还有**垃圾回收**,那么肯定会觉得是`null`。
|
||||||
|
|
||||||
其实是不对的,因为题目说的是在做 ``ThreadLocal`.get()` 操作,证明其实还是有**强引用**存在的,所以 `key` 并不为 `null`,如下图所示,`ThreadLocal`的**强引用**仍然是存在的。
|
其实是不对的,因为题目说的是在做 ``ThreadLocal`.get()` 操作,证明其实还是有**强引用**存在的,所以 `key` 并不为 `null`,如下图所示,`ThreadLocal`的**强引用**仍然是存在的。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
如果我们的**强引用**不存在的话,那么 `key` 就会被回收,也就是会出现我们 `value` 没被回收,`key` 被回收,导致 `value` 永远存在,出现内存泄漏。
|
如果我们的**强引用**不存在的话,那么 `key` 就会被回收,也就是会出现我们 `value` 没被回收,`key` 被回收,导致 `value` 永远存在,出现内存泄漏。
|
||||||
|
|
||||||
### `ThreadLocal.set()`方法源码详解
|
### `ThreadLocal.set()`方法源码详解
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
`ThreadLocal`中的`set`方法原理如上图所示,很简单,主要是判断`ThreadLocalMap`是否存在,然后使用`ThreadLocal`中的`set`方法进行数据处理。
|
`ThreadLocal`中的`set`方法原理如上图所示,很简单,主要是判断`ThreadLocalMap`是否存在,然后使用`ThreadLocal`中的`set`方法进行数据处理。
|
||||||
|
|
||||||
@ -236,7 +236,7 @@ public class ThreadLocal<T> {
|
|||||||
|
|
||||||
我们自己可以尝试下:
|
我们自己可以尝试下:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
可以看到产生的哈希码分布很均匀,这里不去细纠**斐波那契**具体算法,感兴趣的可以自行查阅相关资料。
|
可以看到产生的哈希码分布很均匀,这里不去细纠**斐波那契**具体算法,感兴趣的可以自行查阅相关资料。
|
||||||
|
|
||||||
@ -250,7 +250,7 @@ public class ThreadLocal<T> {
|
|||||||
|
|
||||||
而`ThreadLocalMap`中并没有链表结构,所以这里不能适用`HashMap`解决冲突的方式了。
|
而`ThreadLocalMap`中并没有链表结构,所以这里不能适用`HashMap`解决冲突的方式了。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|
||||||
如上图所示,如果我们插入一个`value=27`的数据,通过`hash`计算后应该落入第4个槽位中,而槽位4已经有了`Entry`数据。
|
如上图所示,如果我们插入一个`value=27`的数据,通过`hash`计算后应该落入第4个槽位中,而槽位4已经有了`Entry`数据。
|
||||||
@ -269,25 +269,25 @@ public class ThreadLocal<T> {
|
|||||||
|
|
||||||
**第一种情况:** 通过`hash`计算后的槽位对应的`Entry`数据为空:
|
**第一种情况:** 通过`hash`计算后的槽位对应的`Entry`数据为空:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
这里直接将数据放到该槽位即可。
|
这里直接将数据放到该槽位即可。
|
||||||
|
|
||||||
**第二种情况:** 槽位数据不为空,`key`值与当前`ThreadLocal`通过`hash`计算获取的`key`值一致:
|
**第二种情况:** 槽位数据不为空,`key`值与当前`ThreadLocal`通过`hash`计算获取的`key`值一致:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
这里直接更新该槽位的数据。
|
这里直接更新该槽位的数据。
|
||||||
|
|
||||||
**第三种情况:** 槽位数据不为空,往后遍历过程中,在找到`Entry`为`null`的槽位之前,没有遇到`key`过期的`Entry`:
|
**第三种情况:** 槽位数据不为空,往后遍历过程中,在找到`Entry`为`null`的槽位之前,没有遇到`key`过期的`Entry`:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
遍历散列数组,线性往后查找,如果找到`Entry`为`null`的槽位,则将数据放入该槽位中,或者往后遍历过程中,遇到了**key值相等**的数据,直接更新即可。
|
遍历散列数组,线性往后查找,如果找到`Entry`为`null`的槽位,则将数据放入该槽位中,或者往后遍历过程中,遇到了**key值相等**的数据,直接更新即可。
|
||||||
|
|
||||||
**第四种情况:** 槽位数据不为空,往后遍历过程中,在找到`Entry`为`null`的槽位之前,遇到`key`过期的`Entry`,如下图,往后遍历过程中,一到了`index=7`的槽位数据`Entry`的`key=null`:
|
**第四种情况:** 槽位数据不为空,往后遍历过程中,在找到`Entry`为`null`的槽位之前,遇到`key`过期的`Entry`,如下图,往后遍历过程中,一到了`index=7`的槽位数据`Entry`的`key=null`:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
散列数组下标为7位置对应的`Entry`数据`key`为`null`,表明此数据`key`值已经被垃圾回收掉了,此时就会执行`replaceStaleEntry()`方法,该方法含义是**替换过期数据的逻辑**,以**index=7**位起点开始遍历,进行探测式数据清理工作。
|
散列数组下标为7位置对应的`Entry`数据`key`为`null`,表明此数据`key`值已经被垃圾回收掉了,此时就会执行`replaceStaleEntry()`方法,该方法含义是**替换过期数据的逻辑**,以**index=7**位起点开始遍历,进行探测式数据清理工作。
|
||||||
|
|
||||||
@ -297,7 +297,7 @@ public class ThreadLocal<T> {
|
|||||||
|
|
||||||
如果找到了过期的数据,继续向前迭代,直到遇到`Entry=null`的槽位才停止迭代,如下图所示,**slotToExpunge被更新为0**:
|
如果找到了过期的数据,继续向前迭代,直到遇到`Entry=null`的槽位才停止迭代,如下图所示,**slotToExpunge被更新为0**:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
以当前节点(`index=7`)向前迭代,检测是否有过期的`Entry`数据,如果有则更新`slotToExpunge`值。碰到`null`则结束探测。以上图为例`slotToExpunge`被更新为0。
|
以当前节点(`index=7`)向前迭代,检测是否有过期的`Entry`数据,如果有则更新`slotToExpunge`值。碰到`null`则结束探测。以上图为例`slotToExpunge`被更新为0。
|
||||||
|
|
||||||
@ -305,7 +305,7 @@ public class ThreadLocal<T> {
|
|||||||
|
|
||||||
接着开始以`staleSlot`位置(index=7)向后迭代,**如果找到了相同key值的Entry数据:**
|
接着开始以`staleSlot`位置(index=7)向后迭代,**如果找到了相同key值的Entry数据:**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
从当前节点`staleSlot`向后查找`key`值相等的`Entry`元素,找到后更新`Entry`的值并交换`staleSlot`元素的位置(`staleSlot`位置为过期元素),更新`Entry`数据,然后开始进行过期`Entry`的清理工作,如下图所示:
|
从当前节点`staleSlot`向后查找`key`值相等的`Entry`元素,找到后更新`Entry`的值并交换`staleSlot`元素的位置(`staleSlot`位置为过期元素),更新`Entry`数据,然后开始进行过期`Entry`的清理工作,如下图所示:
|
||||||
|
|
||||||
@ -314,13 +314,13 @@ public class ThreadLocal<T> {
|
|||||||
|
|
||||||
**向后遍历过程中,如果没有找到相同key值的Entry数据:**
|
**向后遍历过程中,如果没有找到相同key值的Entry数据:**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
从当前节点`staleSlot`向后查找`key`值相等的`Entry`元素,直到`Entry`为`null`则停止寻找。通过上图可知,此时`table`中没有`key`值相同的`Entry`。
|
从当前节点`staleSlot`向后查找`key`值相等的`Entry`元素,直到`Entry`为`null`则停止寻找。通过上图可知,此时`table`中没有`key`值相同的`Entry`。
|
||||||
|
|
||||||
创建新的`Entry`,替换`table[stableSlot]`位置:
|
创建新的`Entry`,替换`table[stableSlot]`位置:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
替换完成后也是进行过期元素清理工作,清理工作主要是有两个方法:`expungeStaleEntry()`和`cleanSomeSlots()`,具体细节后面会讲到,请继续往后看。
|
替换完成后也是进行过期元素清理工作,清理工作主要是有两个方法:`expungeStaleEntry()`和`cleanSomeSlots()`,具体细节后面会讲到,请继续往后看。
|
||||||
|
|
||||||
@ -374,7 +374,7 @@ int i = key.threadLocalHashCode & (len-1);
|
|||||||
|
|
||||||
接着就是执行`for`循环遍历,向后查找,我们先看下`nextIndex()`、`prevIndex()`方法实现:
|
接着就是执行`for`循环遍历,向后查找,我们先看下`nextIndex()`、`prevIndex()`方法实现:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
```java
|
```java
|
||||||
private static int nextIndex(int i, int len) {
|
private static int nextIndex(int i, int len) {
|
||||||
@ -506,11 +506,11 @@ if (slotToExpunge != staleSlot)
|
|||||||
|
|
||||||
我们先讲下探测式清理,也就是`expungeStaleEntry`方法,遍历散列数组,从开始位置向后探测清理过期数据,将过期数据的`Entry`设置为`null`,沿途中碰到未过期的数据则将此数据`rehash`后重新在`table`数组中定位,如果定位的位置已经有了数据,则会将未过期的数据放到最靠近此位置的`Entry=null`的桶中,使`rehash`后的`Entry`数据距离正确的桶的位置更近一些。操作逻辑如下:
|
我们先讲下探测式清理,也就是`expungeStaleEntry`方法,遍历散列数组,从开始位置向后探测清理过期数据,将过期数据的`Entry`设置为`null`,沿途中碰到未过期的数据则将此数据`rehash`后重新在`table`数组中定位,如果定位的位置已经有了数据,则会将未过期的数据放到最靠近此位置的`Entry=null`的桶中,使`rehash`后的`Entry`数据距离正确的桶的位置更近一些。操作逻辑如下:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
如上图,`set(27)` 经过hash计算后应该落到`index=4`的桶中,由于`index=4`桶已经有了数据,所以往后迭代最终数据放入到`index=7`的桶中,放入后一段时间后`index=5`中的`Entry`数据`key`变为了`null`
|
如上图,`set(27)` 经过hash计算后应该落到`index=4`的桶中,由于`index=4`桶已经有了数据,所以往后迭代最终数据放入到`index=7`的桶中,放入后一段时间后`index=5`中的`Entry`数据`key`变为了`null`
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
如果再有其他数据`set`到`map`中,就会触发**探测式清理**操作。
|
如果再有其他数据`set`到`map`中,就会触发**探测式清理**操作。
|
||||||
|
|
||||||
@ -520,21 +520,21 @@ if (slotToExpunge != staleSlot)
|
|||||||
|
|
||||||
接着看下`expungeStaleEntry()`具体流程,我们还是以先原理图后源码讲解的方式来一步步梳理:
|
接着看下`expungeStaleEntry()`具体流程,我们还是以先原理图后源码讲解的方式来一步步梳理:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
我们假设`expungeStaleEntry(3)` 来调用此方法,如上图所示,我们可以看到`ThreadLocalMap`中`table`的数据情况,接着执行清理操作:
|
我们假设`expungeStaleEntry(3)` 来调用此方法,如上图所示,我们可以看到`ThreadLocalMap`中`table`的数据情况,接着执行清理操作:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
第一步是清空当前`staleSlot`位置的数据,`index=3`位置的`Entry`变成了`null`。然后接着往后探测:
|
第一步是清空当前`staleSlot`位置的数据,`index=3`位置的`Entry`变成了`null`。然后接着往后探测:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
执行完第二步后,index=4的元素挪到index=3的槽位中。
|
执行完第二步后,index=4的元素挪到index=3的槽位中。
|
||||||
|
|
||||||
继续往后迭代检查,碰到正常数据,计算该数据位置是否偏移,如果被偏移,则重新计算`slot`位置,目的是让正常数据尽可能存放在正确位置或离正确位置更近的位置
|
继续往后迭代检查,碰到正常数据,计算该数据位置是否偏移,如果被偏移,则重新计算`slot`位置,目的是让正常数据尽可能存放在正确位置或离正确位置更近的位置
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
在往后迭代的过程中碰到空的槽位,终止探测,这样一轮探测式清理工作就完成了,接着我们继续看看具体**实现源代码**:
|
在往后迭代的过程中碰到空的槽位,终止探测,这样一轮探测式清理工作就完成了,接着我们继续看看具体**实现源代码**:
|
||||||
|
|
||||||
@ -635,11 +635,11 @@ private void expungeStaleEntries() {
|
|||||||
|
|
||||||
我们还记得上面进行`rehash()`的阈值是`size >= threshold`,所以当面试官套路我们`ThreadLocalMap`扩容机制的时候 我们一定要说清楚这两个步骤:
|
我们还记得上面进行`rehash()`的阈值是`size >= threshold`,所以当面试官套路我们`ThreadLocalMap`扩容机制的时候 我们一定要说清楚这两个步骤:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
接着看看具体的`resize()`方法,为了方便演示,我们以`oldTab.len=8`来举例:
|
接着看看具体的`resize()`方法,为了方便演示,我们以`oldTab.len=8`来举例:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
扩容后的`tab`的大小为`oldLen * 2`,然后遍历老的散列表,重新计算`hash`位置,然后放到新的`tab`数组中,如果出现`hash`冲突则往后寻找最近的`entry`为`null`的槽位,遍历完成之后,`oldTab`中所有的`entry`数据都已经放入到新的`tab`中了。重新计算`tab`下次扩容的**阈值**,具体代码如下:
|
扩容后的`tab`的大小为`oldLen * 2`,然后遍历老的散列表,重新计算`hash`位置,然后放到新的`tab`数组中,如果出现`hash`冲突则往后寻找最近的`entry`为`null`的槽位,遍历完成之后,`oldTab`中所有的`entry`数据都已经放入到新的`tab`中了。重新计算`tab`下次扩容的**阈值**,具体代码如下:
|
||||||
|
|
||||||
@ -681,17 +681,17 @@ private void resize() {
|
|||||||
|
|
||||||
**第一种情况:** 通过查找`key`值计算出散列表中`slot`位置,然后该`slot`位置中的`Entry.key`和查找的`key`一致,则直接返回:
|
**第一种情况:** 通过查找`key`值计算出散列表中`slot`位置,然后该`slot`位置中的`Entry.key`和查找的`key`一致,则直接返回:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
**第二种情况:** `slot`位置中的`Entry.key`和要查找的`key`不一致:
|
**第二种情况:** `slot`位置中的`Entry.key`和要查找的`key`不一致:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
我们以`get(ThreadLocal1)`为例,通过`hash`计算后,正确的`slot`位置应该是4,而`index=4`的槽位已经有了数据,且`key`值不等于``ThreadLocal`1`,所以需要继续往后迭代查找。
|
我们以`get(ThreadLocal1)`为例,通过`hash`计算后,正确的`slot`位置应该是4,而`index=4`的槽位已经有了数据,且`key`值不等于``ThreadLocal`1`,所以需要继续往后迭代查找。
|
||||||
|
|
||||||
迭代到`index=5`的数据时,此时`Entry.key=null`,触发一次探测式数据回收操作,执行`expungeStaleEntry()`方法,执行完后,`index 5,8`的数据都会被回收,而`index 6,7`的数据都会前移,此时继续往后迭代,到`index = 6`的时候即找到了`key`值相等的`Entry`数据,如下图所示:
|
迭代到`index=5`的数据时,此时`Entry.key=null`,触发一次探测式数据回收操作,执行`expungeStaleEntry()`方法,执行完后,`index 5,8`的数据都会被回收,而`index 6,7`的数据都会前移,此时继续往后迭代,到`index = 6`的时候即找到了`key`值相等的`Entry`数据,如下图所示:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
#### `ThreadLocalMap.get()`源码详解
|
#### `ThreadLocalMap.get()`源码详解
|
||||||
|
|
||||||
@ -735,7 +735,7 @@ private Entry getEntryAfterMiss(`ThreadLocal`<?> key, int i, Entry e) {
|
|||||||
|
|
||||||
而启发式清理被作者定义为:**Heuristically scan some cells looking for stale entries**.
|
而启发式清理被作者定义为:**Heuristically scan some cells looking for stale entries**.
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
具体代码如下:
|
具体代码如下:
|
||||||
|
|
||||||
@ -823,11 +823,11 @@ private void init(ThreadGroup g, Runnable target, String name,
|
|||||||
|
|
||||||
当前端发送请求到**服务A**时,**服务A**会生成一个类似`UUID`的`traceId`字符串,将此字符串放入当前线程的`ThreadLocal`中,在调用**服务B**的时候,将`traceId`写入到请求的`Header`中,**服务B**在接收请求时会先判断请求的`Header`中是否有`traceId`,如果存在则写入自己线程的`ThreadLocal`中。
|
当前端发送请求到**服务A**时,**服务A**会生成一个类似`UUID`的`traceId`字符串,将此字符串放入当前线程的`ThreadLocal`中,在调用**服务B**的时候,将`traceId`写入到请求的`Header`中,**服务B**在接收请求时会先判断请求的`Header`中是否有`traceId`,如果存在则写入自己线程的`ThreadLocal`中。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
图中的`requestId`即为我们各个系统链路关联的`traceId`,系统间互相调用,通过这个`requestId`即可找到对应链路,这里还有会有一些其他场景:
|
图中的`requestId`即为我们各个系统链路关联的`traceId`,系统间互相调用,通过这个`requestId`即可找到对应链路,这里还有会有一些其他场景:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
针对于这些场景,我们都可以有相应的解决方案,如下所示
|
针对于这些场景,我们都可以有相应的解决方案,如下所示
|
||||||
|
|
||||||
|
|||||||
@ -26,7 +26,7 @@
|
|||||||
|
|
||||||
注意:**下面三个任务可能做的是同一件事情,也可能是不一样的事情。**
|
注意:**下面三个任务可能做的是同一件事情,也可能是不一样的事情。**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
### 如何使用线程池?
|
### 如何使用线程池?
|
||||||
|
|
||||||
@ -147,7 +147,7 @@ Finished all threads
|
|||||||
|
|
||||||
除此之外,我们还可以利用 `ThreadPoolExecutor` 的相关 API做一个简陋的监控。从下图可以看出, `ThreadPoolExecutor`提供了获取线程池当前的线程数和活跃线程数、已经执行完成的任务数、正在排队中的任务数等等。
|
除此之外,我们还可以利用 `ThreadPoolExecutor` 的相关 API做一个简陋的监控。从下图可以看出, `ThreadPoolExecutor`提供了获取线程池当前的线程数和活跃线程数、已经执行完成的任务数、正在排队中的任务数等等。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
下面是一个简单的 Demo。`printThreadPoolStatus()`会每隔一秒打印出线程池的线程数、活跃线程数、完成的任务数、以及队列中的任务数。
|
下面是一个简单的 Demo。`printThreadPoolStatus()`会每隔一秒打印出线程池的线程数、活跃线程数、完成的任务数、以及队列中的任务数。
|
||||||
|
|
||||||
@ -158,7 +158,7 @@ Finished all threads
|
|||||||
* @param threadPool 线程池对象
|
* @param threadPool 线程池对象
|
||||||
*/
|
*/
|
||||||
public static void printThreadPoolStatus(ThreadPoolExecutor threadPool) {
|
public static void printThreadPoolStatus(ThreadPoolExecutor threadPool) {
|
||||||
ScheduledExecutorService scheduledExecutorService = new ScheduledThreadPoolExecutor(1, createThreadFactory("print-thread-pool-status", false));
|
ScheduledExecutorService scheduledExecutorService = new ScheduledThreadPoolExecutor(1, createThreadFactory("print-images/thread-pool-status", false));
|
||||||
scheduledExecutorService.scheduleAtFixedRate(() -> {
|
scheduledExecutorService.scheduleAtFixedRate(() -> {
|
||||||
log.info("=========================");
|
log.info("=========================");
|
||||||
log.info("ThreadPool Size: [{}]", threadPool.getPoolSize());
|
log.info("ThreadPool Size: [{}]", threadPool.getPoolSize());
|
||||||
@ -178,7 +178,7 @@ Finished all threads
|
|||||||
|
|
||||||
**我们再来看一个真实的事故案例!** (本案例来源自:[《线程池运用不当的一次线上事故》](https://club.perfma.com/article/646639) ,很精彩的一个案例)
|
**我们再来看一个真实的事故案例!** (本案例来源自:[《线程池运用不当的一次线上事故》](https://club.perfma.com/article/646639) ,很精彩的一个案例)
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
上面的代码可能会存在死锁的情况,为什么呢?画个图给大家捋一捋。
|
上面的代码可能会存在死锁的情况,为什么呢?画个图给大家捋一捋。
|
||||||
|
|
||||||
@ -186,7 +186,7 @@ Finished all threads
|
|||||||
|
|
||||||
假如我们线程池的核心线程数为 **n**,父任务(扣费任务)数量为 **n**,父任务下面有两个子任务(扣费任务下的子任务),其中一个已经执行完成,另外一个被放在了任务队列中。由于父任务把线程池核心线程资源用完,所以子任务因为无法获取到线程资源无法正常执行,一直被阻塞在队列中。父任务等待子任务执行完成,而子任务等待父任务释放线程池资源,这也就造成了 **"死锁"**。
|
假如我们线程池的核心线程数为 **n**,父任务(扣费任务)数量为 **n**,父任务下面有两个子任务(扣费任务下的子任务),其中一个已经执行完成,另外一个被放在了任务队列中。由于父任务把线程池核心线程资源用完,所以子任务因为无法获取到线程资源无法正常执行,一直被阻塞在队列中。父任务等待子任务执行完成,而子任务等待父任务释放线程池资源,这也就造成了 **"死锁"**。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
解决方法也很简单,就是新增加一个用于执行子任务的线程池专门为其服务。
|
解决方法也很简单,就是新增加一个用于执行子任务的线程池专门为其服务。
|
||||||
|
|
||||||
@ -289,7 +289,7 @@ CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内
|
|||||||
|
|
||||||
**如何支持参数动态配置?** 且看 `ThreadPoolExecutor` 提供的下面这些方法。
|
**如何支持参数动态配置?** 且看 `ThreadPoolExecutor` 提供的下面这些方法。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
格外需要注意的是`corePoolSize`, 程序运行期间的时候,我们调用 `setCorePoolSize() `这个方法的话,线程池会首先判断当前工作线程数是否大于`corePoolSize`,如果大于的话就会回收工作线程。
|
格外需要注意的是`corePoolSize`, 程序运行期间的时候,我们调用 `setCorePoolSize() `这个方法的话,线程池会首先判断当前工作线程数是否大于`corePoolSize`,如果大于的话就会回收工作线程。
|
||||||
|
|
||||||
@ -297,7 +297,7 @@ CPU 密集型简单理解就是利用 CPU 计算能力的任务比如你在内
|
|||||||
|
|
||||||
最终实现的可动态修改线程池参数效果如下。👏👏👏
|
最终实现的可动态修改线程池参数效果如下。👏👏👏
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
还没看够?推荐 why神的[《如何设置线程池参数?美团给出了一个让面试官虎躯一震的回答。》](https://mp.weixin.qq.com/s/9HLuPcoWmTqAeFKa1kj-_A)这篇文章,深度剖析,很不错哦!
|
还没看够?推荐 why神的[《如何设置线程池参数?美团给出了一个让面试官虎躯一震的回答。》](https://mp.weixin.qq.com/s/9HLuPcoWmTqAeFKa1kj-_A)这篇文章,深度剖析,很不错哦!
|
||||||
|
|
||||||
|
|||||||
{kind=link}
|
Before Width: | Height: | Size: 212 KiB After Width: | Height: | Size: 212 KiB |
{kind=link}
|
Before Width: | Height: | Size: 32 KiB After Width: | Height: | Size: 32 KiB |
{kind=link}
|
Before Width: | Height: | Size: 40 KiB After Width: | Height: | Size: 40 KiB |
{kind=link}
|
Before Width: | Height: | Size: 74 KiB After Width: | Height: | Size: 74 KiB |
{kind=link}
|
Before Width: | Height: | Size: 98 KiB After Width: | Height: | Size: 98 KiB |
{kind=link}
|
Before Width: | Height: | Size: 93 KiB After Width: | Height: | Size: 93 KiB |
{kind=link}
|
Before Width: | Height: | Size: 72 KiB After Width: | Height: | Size: 72 KiB |
{kind=link}
|
Before Width: | Height: | Size: 60 KiB After Width: | Height: | Size: 60 KiB |
{kind=link}
|
Before Width: | Height: | Size: 31 KiB After Width: | Height: | Size: 31 KiB |
{kind=link}
|
Before Width: | Height: | Size: 72 KiB After Width: | Height: | Size: 72 KiB |
{kind=link}
|
Before Width: | Height: | Size: 94 KiB After Width: | Height: | Size: 94 KiB |
{kind=link}
|
Before Width: | Height: | Size: 35 KiB After Width: | Height: | Size: 35 KiB |
{kind=link}
|
Before Width: | Height: | Size: 49 KiB After Width: | Height: | Size: 49 KiB |
{kind=link}
|
Before Width: | Height: | Size: 29 KiB After Width: | Height: | Size: 29 KiB |
{kind=link}
|
Before Width: | Height: | Size: 93 KiB After Width: | Height: | Size: 93 KiB |
{kind=link}
|
Before Width: | Height: | Size: 32 KiB After Width: | Height: | Size: 32 KiB |
{kind=link}
|
Before Width: | Height: | Size: 75 KiB After Width: | Height: | Size: 75 KiB |
{kind=link}
|
Before Width: | Height: | Size: 69 KiB After Width: | Height: | Size: 69 KiB |
{kind=link}
|
Before Width: | Height: | Size: 54 KiB After Width: | Height: | Size: 54 KiB |
{kind=link}
|
Before Width: | Height: | Size: 68 KiB After Width: | Height: | Size: 68 KiB |
{kind=link}
|
Before Width: | Height: | Size: 90 KiB After Width: | Height: | Size: 90 KiB |
{kind=link}
|
Before Width: | Height: | Size: 88 KiB After Width: | Height: | Size: 88 KiB |
{kind=link}
|
Before Width: | Height: | Size: 135 KiB After Width: | Height: | Size: 135 KiB |
{kind=link}
|
Before Width: | Height: | Size: 64 KiB After Width: | Height: | Size: 64 KiB |
{kind=link}
|
Before Width: | Height: | Size: 29 KiB After Width: | Height: | Size: 29 KiB |
{kind=link}
|
Before Width: | Height: | Size: 129 KiB After Width: | Height: | Size: 129 KiB |
{kind=link}
|
Before Width: | Height: | Size: 25 KiB After Width: | Height: | Size: 25 KiB |
{kind=link}
|
Before Width: | Height: | Size: 50 KiB After Width: | Height: | Size: 50 KiB |
{kind=link}
|
Before Width: | Height: | Size: 65 KiB After Width: | Height: | Size: 65 KiB |
{kind=link}
|
Before Width: | Height: | Size: 111 KiB After Width: | Height: | Size: 111 KiB |
{kind=link}
|
Before Width: | Height: | Size: 46 KiB After Width: | Height: | Size: 46 KiB |
{kind=link}
|
Before Width: | Height: | Size: 162 KiB After Width: | Height: | Size: 162 KiB |
{kind=link}
|
Before Width: | Height: | Size: 27 KiB After Width: | Height: | Size: 27 KiB |
{kind=link}
|
Before Width: | Height: | Size: 399 KiB After Width: | Height: | Size: 399 KiB |
{kind=link}
|
After Width: | Height: | Size: 40 KiB |
{kind=link}
|
Before Width: | Height: | Size: 86 KiB After Width: | Height: | Size: 86 KiB |
{kind=link}
|
Before Width: | Height: | Size: 74 KiB After Width: | Height: | Size: 74 KiB |
BIN
docs/java/Multithread/images/多线程学习指南/Java并发编程的艺术.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 116 KiB |
BIN
docs/java/Multithread/images/多线程学习指南/javaguide-并发.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 128 KiB |
BIN
docs/java/Multithread/images/多线程学习指南/java并发编程之美.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 76 KiB |
BIN
docs/java/Multithread/images/多线程学习指南/实战Java高并发程序设计.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 107 KiB |
BIN
docs/java/Multithread/images/多线程学习指南/深入浅出Java多线程.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 554 KiB |
@ -8,7 +8,7 @@
|
|||||||
|
|
||||||
在这篇文章中,我会首先介绍一下 **Java 多线程学习** 中比较重要的一些问题,然后还会推荐一些比较不错的学习资源供大家参考。希望对你们学习多线程相关的知识能有帮助。以下介绍的很多知识点你都可以在这里找到:[https://snailclimb.gitee.io/javaguide/#/?id=并发](https://snailclimb.gitee.io/javaguide/#/?id=并发)
|
在这篇文章中,我会首先介绍一下 **Java 多线程学习** 中比较重要的一些问题,然后还会推荐一些比较不错的学习资源供大家参考。希望对你们学习多线程相关的知识能有帮助。以下介绍的很多知识点你都可以在这里找到:[https://snailclimb.gitee.io/javaguide/#/?id=并发](https://snailclimb.gitee.io/javaguide/#/?id=并发)
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
**另外,我还将本文的内容同步到了 Github 上,点击阅读原文即可直达。如果你觉得有任何需要完善和修改的地方,都可以去 Github 给我提交 Issue 或者 PR(推荐)。**
|
**另外,我还将本文的内容同步到了 Github 上,点击阅读原文即可直达。如果你觉得有任何需要完善和修改的地方,都可以去 Github 给我提交 Issue 或者 PR(推荐)。**
|
||||||
|
|
||||||
@ -121,7 +121,7 @@ JDK 提供的这些容器大部分在 `java.util.concurrent` 包中。
|
|||||||
|
|
||||||
#### 《Java 并发编程之美》
|
#### 《Java 并发编程之美》
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
**我觉得这本书还是非常适合我们用来学习 Java 多线程的。这本书的讲解非常通俗易懂,作者从并发编程基础到实战都是信手拈来。**
|
**我觉得这本书还是非常适合我们用来学习 Java 多线程的。这本书的讲解非常通俗易懂,作者从并发编程基础到实战都是信手拈来。**
|
||||||
|
|
||||||
@ -129,13 +129,13 @@ JDK 提供的这些容器大部分在 `java.util.concurrent` 包中。
|
|||||||
|
|
||||||
#### 《实战 Java 高并发程序设计》
|
#### 《实战 Java 高并发程序设计》
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
这个是我第二本要推荐的书籍,比较适合作为多线程入门/进阶书籍来看。这本书内容同样是理论结合实战,对于每个知识点的讲解也比较通俗易懂,整体结构也比较清。
|
这个是我第二本要推荐的书籍,比较适合作为多线程入门/进阶书籍来看。这本书内容同样是理论结合实战,对于每个知识点的讲解也比较通俗易懂,整体结构也比较清。
|
||||||
|
|
||||||
#### 《深入浅出 Java 多线程》
|
#### 《深入浅出 Java 多线程》
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
这本书是几位大厂(如阿里)的大佬开源的,Github 地址:[https://github.com/RedSpider1/concurrent](https://github.com/RedSpider1/concurrent)
|
这本书是几位大厂(如阿里)的大佬开源的,Github 地址:[https://github.com/RedSpider1/concurrent](https://github.com/RedSpider1/concurrent)
|
||||||
|
|
||||||
@ -145,7 +145,7 @@ JDK 提供的这些容器大部分在 `java.util.concurrent` 包中。
|
|||||||
|
|
||||||
#### 《Java 并发编程的艺术》
|
#### 《Java 并发编程的艺术》
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
这本书不是很适合作为 Java 多线程入门书籍,需要具备一定的 JVM 基础,有些东西讲的还是挺深入的。另外,就我自己阅读这本书的感觉来说,我觉得这本书的章节规划有点杂乱,但是,具体到某个知识点又很棒!这可能也和这本书由三名作者共同编写完成有关系吧!
|
这本书不是很适合作为 Java 多线程入门书籍,需要具备一定的 JVM 基础,有些东西讲的还是挺深入的。另外,就我自己阅读这本书的感觉来说,我觉得这本书的章节规划有点杂乱,但是,具体到某个知识点又很棒!这可能也和这本书由三名作者共同编写完成有关系吧!
|
||||||
|
|
||||||
|
|||||||
{kind=link}
|
After Width: | Height: | Size: 57 KiB |
@ -109,7 +109,7 @@ Java 10 在现有的 CDS 功能基础上再次拓展,以允许应用类放置
|
|||||||
|
|
||||||
Java11 于 2018 年 9 月 25 日正式发布,这是很重要的一个版本!Java 11 和 2017 年 9 月份发布的 Java 9 以及 2018 年 3 月份发布的 Java 10 相比,其最大的区别就是:在长期支持(Long-Term-Support)方面,**Oracle 表示会对 Java 11 提供大力支持,这一支持将会持续至 2026 年 9 月。这是据 Java 8 以后支持的首个长期版本。**
|
Java11 于 2018 年 9 月 25 日正式发布,这是很重要的一个版本!Java 11 和 2017 年 9 月份发布的 Java 9 以及 2018 年 3 月份发布的 Java 10 相比,其最大的区别就是:在长期支持(Long-Term-Support)方面,**Oracle 表示会对 Java 11 提供大力支持,这一支持将会持续至 2026 年 9 月。这是据 Java 8 以后支持的首个长期版本。**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
### 字符串加强
|
### 字符串加强
|
||||||
|
|
||||||
|
|||||||
@ -10,7 +10,7 @@
|
|||||||
|
|
||||||
### Java内存区域常见配置参数概览
|
### Java内存区域常见配置参数概览
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
### 堆参数
|
### 堆参数
|
||||||
|
|
||||||
|
|||||||
BIN
docs/java/jvm/pictures/内存区域常见配置参数.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 85 KiB |
@ -6,11 +6,11 @@
|
|||||||
|
|
||||||
**认证 (Authentication):** 你是谁。
|
**认证 (Authentication):** 你是谁。
|
||||||
|
|
||||||
<img src="https://imgkr.cn-bj.ufileos.com/96086534-9525-4464-97d6-e6fe94b8263f.png" style="zoom:80%;" />
|
<img src="../pictures/authentication.png" style="zoom:80%;" />
|
||||||
|
|
||||||
**授权 (Authorization):** 你有权限干什么。
|
**授权 (Authorization):** 你有权限干什么。
|
||||||
|
|
||||||
<img src="https://imgkr.cn-bj.ufileos.com/d205bc73-9b3c-421d-ac92-b45a911df098.png" style="zoom:60%;" />
|
<img src="../pictures/authorization.png" style="zoom:60%;" />
|
||||||
|
|
||||||
稍微正式点(啰嗦点)的说法就是:
|
稍微正式点(啰嗦点)的说法就是:
|
||||||
|
|
||||||
@ -21,7 +21,7 @@
|
|||||||
|
|
||||||
## 2. 什么是Cookie ? Cookie的作用是什么?如何在服务端使用 Cookie ?
|
## 2. 什么是Cookie ? Cookie的作用是什么?如何在服务端使用 Cookie ?
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
### 2.1 什么是Cookie ? Cookie的作用是什么?
|
### 2.1 什么是Cookie ? Cookie的作用是什么?
|
||||||
|
|
||||||
@ -90,7 +90,7 @@ public String readAllCookies(HttpServletRequest request) {
|
|||||||
|
|
||||||
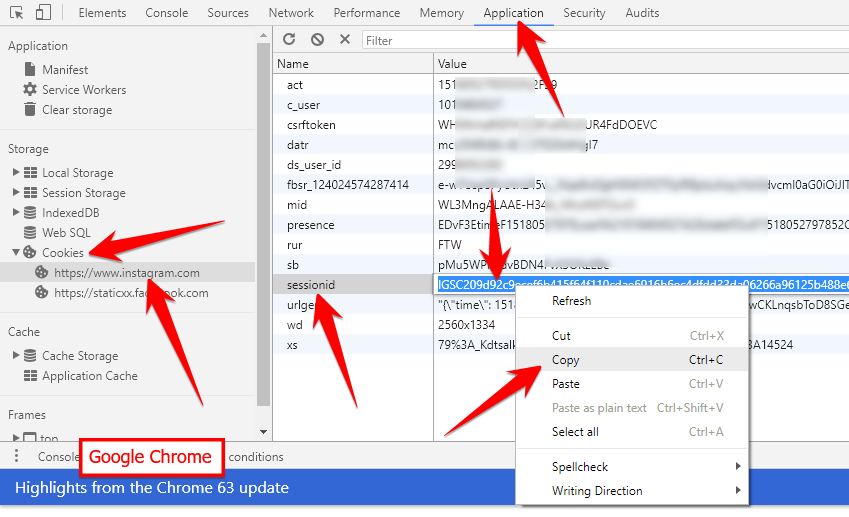
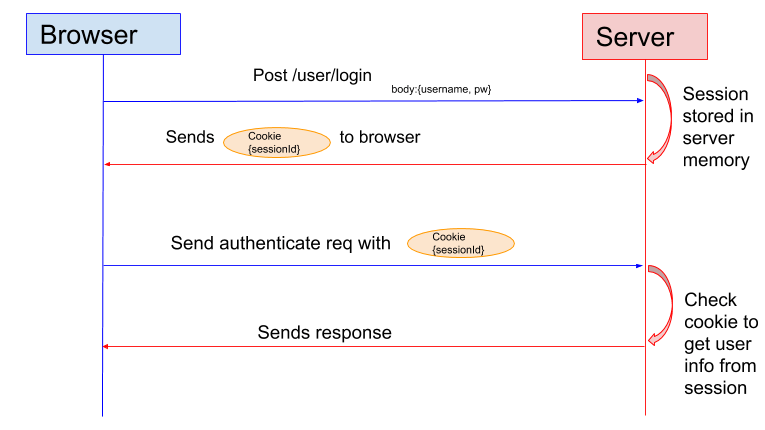
很多时候我们都是通过 SessionID 来实现特定的用户,SessionID 一般会选择存放在 Redis 中。举个例子:用户成功登陆系统,然后返回给客户端具有 SessionID 的 Cookie,当用户向后端发起请求的时候会把 SessionID 带上,这样后端就知道你的身份状态了。关于这种认证方式更详细的过程如下:
|
很多时候我们都是通过 SessionID 来实现特定的用户,SessionID 一般会选择存放在 Redis 中。举个例子:用户成功登陆系统,然后返回给客户端具有 SessionID 的 Cookie,当用户向后端发起请求的时候会把 SessionID 带上,这样后端就知道你的身份状态了。关于这种认证方式更详细的过程如下:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
1. 用户向服务器发送用户名和密码用于登陆系统。
|
1. 用户向服务器发送用户名和密码用于登陆系统。
|
||||||
2. 服务器验证通过后,服务器为用户创建一个 Session,并将 Session信息存储 起来。
|
2. 服务器验证通过后,服务器为用户创建一个 Session,并将 Session信息存储 起来。
|
||||||
@ -105,7 +105,7 @@ public String readAllCookies(HttpServletRequest request) {
|
|||||||
|
|
||||||
花了个图简单总结了一下Session认证涉及的一些东西。
|
花了个图简单总结了一下Session认证涉及的一些东西。
|
||||||
|
|
||||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/session-cookie-intro.jpg" style="zoom:50%;" />
|
<img src="../pictures/session-cookie-intro.png" style="zoom:50%;" />
|
||||||
|
|
||||||
另外,Spring Session提供了一种跨多个应用程序或实例管理用户会话信息的机制。如果想详细了解可以查看下面几篇很不错的文章:
|
另外,Spring Session提供了一种跨多个应用程序或实例管理用户会话信息的机制。如果想详细了解可以查看下面几篇很不错的文章:
|
||||||
|
|
||||||
@ -167,7 +167,7 @@ JWT 由 3 部分构成:
|
|||||||
|
|
||||||
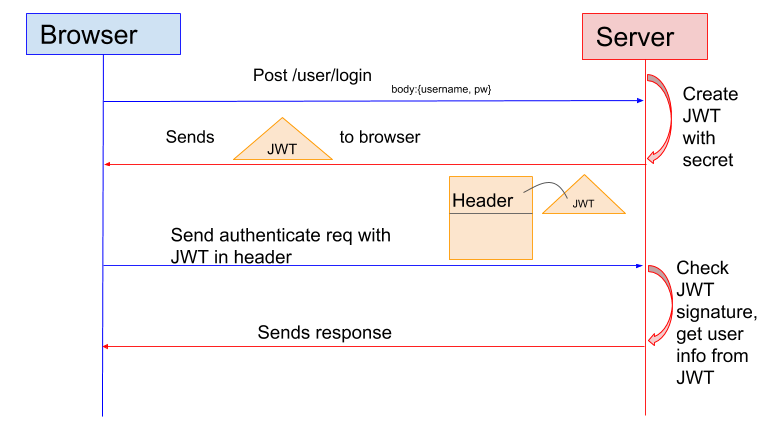
在基于 Token 进行身份验证的的应用程序中,服务器通过`Payload`、`Header`和一个密钥(`secret`)创建令牌(`Token`)并将 `Token` 发送给客户端,客户端将 `Token` 保存在 Cookie 或者 localStorage 里面,以后客户端发出的所有请求都会携带这个令牌。你可以把它放在 Cookie 里面自动发送,但是这样不能跨域,所以更好的做法是放在 HTTP Header 的 Authorization字段中:` Authorization: Bearer Token`。
|
在基于 Token 进行身份验证的的应用程序中,服务器通过`Payload`、`Header`和一个密钥(`secret`)创建令牌(`Token`)并将 `Token` 发送给客户端,客户端将 `Token` 保存在 Cookie 或者 localStorage 里面,以后客户端发出的所有请求都会携带这个令牌。你可以把它放在 Cookie 里面自动发送,但是这样不能跨域,所以更好的做法是放在 HTTP Header 的 Authorization字段中:` Authorization: Bearer Token`。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
1. 用户向服务器发送用户名和密码用于登陆系统。
|
1. 用户向服务器发送用户名和密码用于登陆系统。
|
||||||
2. 身份验证服务响应并返回了签名的 JWT,上面包含了用户是谁的内容。
|
2. 身份验证服务响应并返回了签名的 JWT,上面包含了用户是谁的内容。
|
||||||
@ -194,7 +194,7 @@ OAuth 2.0 比较常用的场景就是第三方登录,当你的网站接入了
|
|||||||
|
|
||||||
微信支付账户相关参数:
|
微信支付账户相关参数:
|
||||||
|
|
||||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/微信支付-fnglfdlgdfj.jpg" style="zoom:50%;" />
|
<img src="../pictures/微信支付-fnglfdlgdfj.png" style="zoom:50%;" />
|
||||||
|
|
||||||
**推荐阅读:**
|
**推荐阅读:**
|
||||||
|
|
||||||
|
|||||||
{kind=link}
|
After Width: | Height: | Size: 78 KiB |
{kind=link}
|
After Width: | Height: | Size: 138 KiB |
{kind=link}
|
After Width: | Height: | Size: 59 KiB |
{kind=link}
|
After Width: | Height: | Size: 262 KiB |
{kind=link}
|
After Width: | Height: | Size: 250 KiB |
@ -316,7 +316,7 @@ public class UserRegisterRequest {
|
|||||||
|
|
||||||
这样我们的后端就可以直接把 json 格式的数据映射到我们的 `UserRegisterRequest` 类上。
|
这样我们的后端就可以直接把 json 格式的数据映射到我们的 `UserRegisterRequest` 类上。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
👉 需要注意的是:**一个请求方法只可以有一个`@RequestBody`,但是可以有多个`@RequestParam`和`@PathVariable`**。 如果你的方法必须要用两个 `@RequestBody`来接受数据的话,大概率是你的数据库设计或者系统设计出问题了!
|
👉 需要注意的是:**一个请求方法只可以有一个`@RequestBody`,但是可以有多个`@RequestParam`和`@PathVariable`**。 如果你的方法必须要用两个 `@RequestBody`来接受数据的话,大概率是你的数据库设计或者系统设计出问题了!
|
||||||
|
|
||||||
@ -410,7 +410,7 @@ class WebSite {
|
|||||||
|
|
||||||
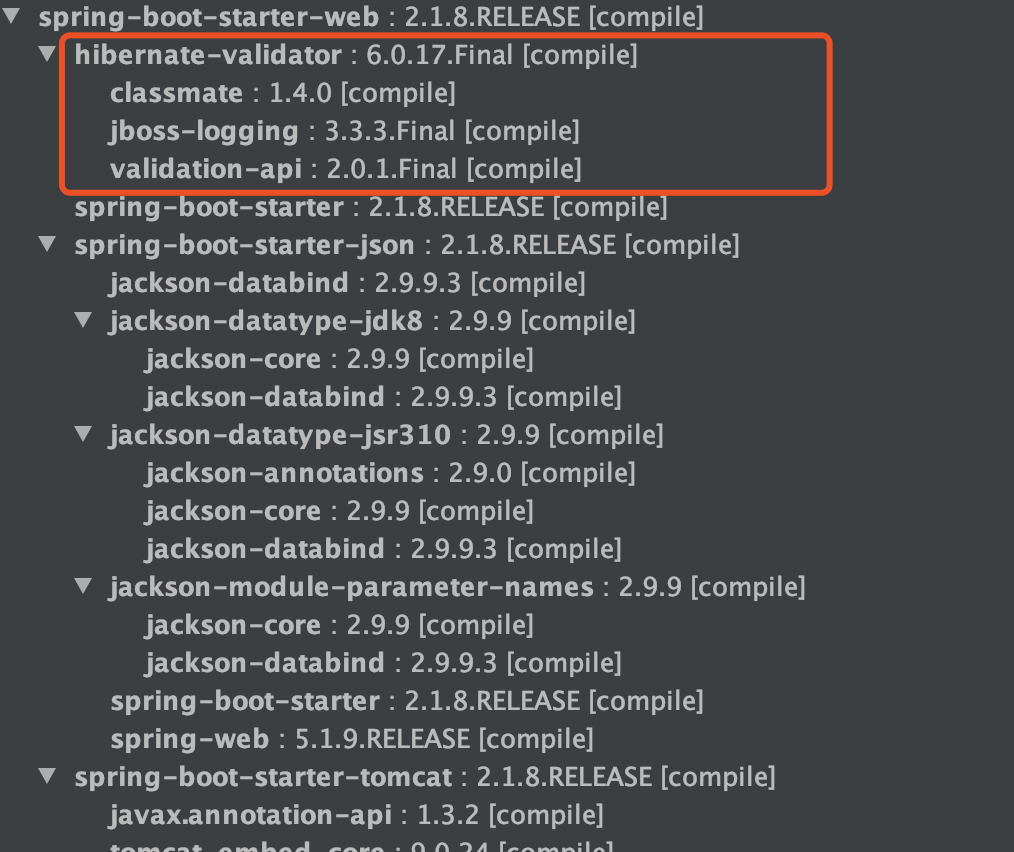
SpringBoot 项目的 spring-boot-starter-web 依赖中已经有 hibernate-validator 包,不需要引用相关依赖。如下图所示(通过 idea 插件—Maven Helper 生成):
|
SpringBoot 项目的 spring-boot-starter-web 依赖中已经有 hibernate-validator 包,不需要引用相关依赖。如下图所示(通过 idea 插件—Maven Helper 生成):
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
非 SpringBoot 项目需要自行引入相关依赖包,这里不多做讲解,具体可以查看我的这篇文章:《[如何在 Spring/Spring Boot 中做参数校验?你需要了解的都在这里!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485783&idx=1&sn=a407f3b75efa17c643407daa7fb2acd6&chksm=cea2469cf9d5cf8afbcd0a8a1c9cc4294d6805b8e01bee6f76bb2884c5bc15478e91459def49&token=292197051&lang=zh_CN#rd)》。
|
非 SpringBoot 项目需要自行引入相关依赖包,这里不多做讲解,具体可以查看我的这篇文章:《[如何在 Spring/Spring Boot 中做参数校验?你需要了解的都在这里!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485783&idx=1&sn=a407f3b75efa17c643407daa7fb2acd6&chksm=cea2469cf9d5cf8afbcd0a8a1c9cc4294d6805b8e01bee6f76bb2884c5bc15478e91459def49&token=292197051&lang=zh_CN#rd)》。
|
||||||
|
|
||||||
|
|||||||
@ -53,7 +53,7 @@ public class OrdersService {
|
|||||||
|
|
||||||
## 2. 事物的特性(ACID)了解么?
|
## 2. 事物的特性(ACID)了解么?
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
- **原子性:** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
|
- **原子性:** 事务是最小的执行单位,不允许分割。事务的原子性确保动作要么全部完成,要么完全不起作用;
|
||||||
- **一致性:** 执行事务前后,数据保持一致;
|
- **一致性:** 执行事务前后,数据保持一致;
|
||||||
@ -153,7 +153,7 @@ Spring 框架中,事务管理相关最重要的 3 个接口如下:
|
|||||||
|
|
||||||
**`PlatformTransactionManager` 接口的具体实现如下:**
|
**`PlatformTransactionManager` 接口的具体实现如下:**
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
`PlatformTransactionManager`接口中定义了三个方法:
|
`PlatformTransactionManager`接口中定义了三个方法:
|
||||||
|
|
||||||
@ -177,7 +177,7 @@ public interface PlatformTransactionManager {
|
|||||||
|
|
||||||
主要是因为要将事务管理行为抽象出来,然后不同的平台去实现它,这样我们可以保证提供给外部的行为不变,方便我们扩展。我前段时间分享过:**“为什么我们要用接口?”**
|
主要是因为要将事务管理行为抽象出来,然后不同的平台去实现它,这样我们可以保证提供给外部的行为不变,方便我们扩展。我前段时间分享过:**“为什么我们要用接口?”**
|
||||||
|
|
||||||
<img src="https://imgkr.cn-bj.ufileos.com/ed279f05-f5ad-443e-84e9-513a9e777139.png" style="zoom:50%;" />
|
<img src="images/spring-transaction/ed279f05-f5ad-443e-84e9-513a9e777139.png" style="zoom:50%;" />
|
||||||
|
|
||||||
#### 3.2.2. TransactionDefinition:事务属性
|
#### 3.2.2. TransactionDefinition:事务属性
|
||||||
|
|
||||||
@ -189,7 +189,7 @@ public interface PlatformTransactionManager {
|
|||||||
|
|
||||||
事务属性包含了 5 个方面:
|
事务属性包含了 5 个方面:
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
`TransactionDefinition` 接口中定义了 5 个方法以及一些表示事务属性的常量比如隔离级别、传播行为等等。
|
`TransactionDefinition` 接口中定义了 5 个方法以及一些表示事务属性的常量比如隔离级别、传播行为等等。
|
||||||
|
|
||||||
@ -544,7 +544,7 @@ public interface TransactionDefinition {
|
|||||||
|
|
||||||
这些规则定义了哪些异常会导致事务回滚而哪些不会。默认情况下,事务只有遇到运行期异常(RuntimeException 的子类)时才会回滚,Error 也会导致事务回滚,但是,在遇到检查型(Checked)异常时不会回滚。
|
这些规则定义了哪些异常会导致事务回滚而哪些不会。默认情况下,事务只有遇到运行期异常(RuntimeException 的子类)时才会回滚,Error 也会导致事务回滚,但是,在遇到检查型(Checked)异常时不会回滚。
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
如果你想要回滚你定义的特定的异常类型的话,可以这样:
|
如果你想要回滚你定义的特定的异常类型的话,可以这样:
|
||||||
|
|
||||||
|
|||||||
{kind=link}
|
After Width: | Height: | Size: 39 KiB |
BIN
docs/system-design/pictures/Token-Based-Authentication.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 38 KiB |
BIN
docs/system-design/pictures/authentication.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 4.5 KiB |
BIN
docs/system-design/pictures/authorization.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 5.7 KiB |
BIN
docs/system-design/pictures/cookie-sessionId.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 93 KiB |
BIN
docs/system-design/pictures/session-cookie-intro.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 86 KiB |
BIN
docs/system-design/pictures/微信支付-fnglfdlgdfj.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 290 KiB |