mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
type: linear-data-structure.md
删除重复的“应用场景” ,添加了一些队列和栈的应用,感觉栈可以对二叉树深度优先遍历,队列可以进行广度优先搜索可以提一下
This commit is contained in:
parent
4b5985b082
commit
b3bcfc6f1b
@ -99,7 +99,7 @@ tag:
|
||||
|
||||
|
||||
|
||||
### 3.2. 栈的常见应用常见应用场景
|
||||
### 3.2. 栈的常见应用场景
|
||||
|
||||
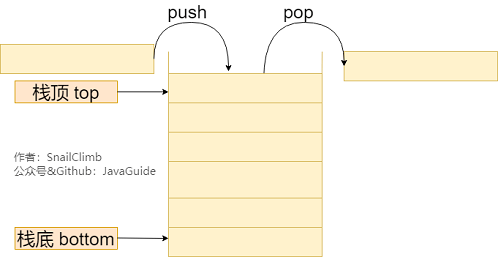
当我们我们要处理的数据只涉及在一端插入和删除数据,并且满足 **后进先出(LIFO, Last In First Out)** 的特性时,我们就可以使用栈这个数据结构。
|
||||
|
||||
@ -154,7 +154,12 @@ public boolean isValid(String s){
|
||||
|
||||
#### 3.2.4. 维护函数调用
|
||||
|
||||
最后一个被调用的函数必须先完成执行,符合栈的 **后进先出(LIFO, Last In First Out)** 特性。
|
||||
最后一个被调用的函数必须先完成执行,符合栈的 **后进先出(LIFO, Last In First Out)** 特性。
|
||||
例如递归函数调用可以通过栈来实现,每次递归调用都会将参数和返回地址压栈。
|
||||
|
||||
#### 3.2.5 深度优先遍历(DFS)
|
||||
|
||||
在深度优先搜索过程中,栈被用来保存搜索路径,以便回溯到上一层。
|
||||
|
||||
### 3.3. 栈的实现
|
||||
|
||||
@ -316,13 +321,14 @@ myStack.pop();//报错:java.lang.IllegalArgumentException: Stack is empty.
|
||||
|
||||
虽然优先队列的底层并非严格的线性结构,但是在我们使用的过程中,我们是感知不到**堆**的,从使用者的眼中优先队列可以被认为是一种线性的数据结构:一种会自动排序的线性队列。
|
||||
|
||||
### 4.3. 常见应用场景
|
||||
### 4.3. 队列的常见应用场景
|
||||
|
||||
当我们需要按照一定顺序来处理数据的时候可以考虑使用队列这个数据结构。
|
||||
|
||||
- **阻塞队列:** 阻塞队列可以看成在队列基础上加了阻塞操作的队列。当队列为空的时候,出队操作阻塞,当队列满的时候,入队操作阻塞。使用阻塞队列我们可以很容易实现“生产者 - 消费者“模型。
|
||||
- **线程池中的请求/任务队列:** 线程池中没有空闲线程时,新的任务请求线程资源时,线程池该如何处理呢?答案是将这些请求放在队列中,当有空闲线程的时候,会循环中反复从队列中获取任务来执行。队列分为无界队列(基于链表)和有界队列(基于数组)。无界队列的特点就是可以一直入列,除非系统资源耗尽,比如:`FixedThreadPool` 使用无界队列 `LinkedBlockingQueue`。但是有界队列就不一样了,当队列满的话后面再有任务/请求就会拒绝,在 Java 中的体现就是会抛出`java.util.concurrent.RejectedExecutionException` 异常。
|
||||
- 栈:双端队列天生便可以实现栈的全部功能(`push`、`pop` 和 `peek`),并且在 Deque 接口中已经实现了相关方法。Stack 类已经和 Vector 一样被遗弃,现在在 Java 中普遍使用双端队列(Deque)来实现栈。
|
||||
- 广度优先搜索(BFS),在图的广度优先搜索过程中,队列被用于存储待访问的节点,保证按照层次顺序遍历图的节点。
|
||||
- Linux 内核进程队列(按优先级排队)
|
||||
- 现实生活中的派对,播放器上的播放列表;
|
||||
- 消息队列
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user