mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-05 20:31:37 +08:00
[docs add]CopyOnWriteArrayList 源码分析
This commit is contained in:
parent
aabba40533
commit
b142e7a739
@ -68,10 +68,11 @@
|
|||||||
|
|
||||||
**源码分析**:
|
**源码分析**:
|
||||||
|
|
||||||
- [ArrayList 源码+扩容机制分析](./docs/java/collection/arraylist-source-code.md)
|
- [ArrayList 核心源码+扩容机制分析](./docs/java/collection/arraylist-source-code.md)
|
||||||
- [LinkedList 源码分析](./docs/java/collection/linkedlist-source-code.md)
|
- [LinkedList 核心源码分析](./docs/java/collection/linkedlist-source-code.md)
|
||||||
- [HashMap(JDK1.8)源码+底层数据结构分析](./docs/java/collection/hashmap-source-code.md)
|
- [HashMap 核心源码+底层数据结构分析](./docs/java/collection/hashmap-source-code.md)
|
||||||
- [ConcurrentHashMap 源码+底层数据结构分析](./docs/java/collection/concurrent-hash-map-source-code.md)
|
- [ConcurrentHashMap 核心源码+底层数据结构分析](./docs/java/collection/concurrent-hash-map-source-code.md)
|
||||||
|
- [CopyOnWriteArrayList 核心源码分析](./docs/java/collection/copyonwritearraylist-source-code.md)
|
||||||
|
|
||||||
### IO
|
### IO
|
||||||
|
|
||||||
|
|||||||
@ -88,6 +88,7 @@ export default sidebar({
|
|||||||
"linkedlist-source-code",
|
"linkedlist-source-code",
|
||||||
"hashmap-source-code",
|
"hashmap-source-code",
|
||||||
"concurrent-hash-map-source-code",
|
"concurrent-hash-map-source-code",
|
||||||
|
"copyonwritearraylist-source-code",
|
||||||
],
|
],
|
||||||
},
|
},
|
||||||
],
|
],
|
||||||
|
|||||||
@ -60,10 +60,11 @@ title: JavaGuide(Java学习&&面试指南)
|
|||||||
|
|
||||||
**源码分析**:
|
**源码分析**:
|
||||||
|
|
||||||
- [ArrayList 源码+扩容机制分析](./java/collection/arraylist-source-code.md)
|
- [ArrayList 核心源码+扩容机制分析](./java/collection/arraylist-source-code.md)
|
||||||
- [LinkedList 源码分析](./java/collection/linkedlist-source-code.md)
|
- [LinkedList 核心源码分析](./java/collection/linkedlist-source-code.md)
|
||||||
- [HashMap(JDK1.8)源码+底层数据结构分析](./java/collection/hashmap-source-code.md)
|
- [HashMap 核心源码+底层数据结构分析](./java/collection/hashmap-source-code.md)
|
||||||
- [ConcurrentHashMap 源码+底层数据结构分析](./java/collection/concurrent-hash-map-source-code.md)
|
- [ConcurrentHashMap 核心源码+底层数据结构分析](./java/collection/concurrent-hash-map-source-code.md)
|
||||||
|
- [CopyOnWriteArrayList 核心源码分析](./java/collection/copyonwritearraylist-source-code.md)
|
||||||
|
|
||||||
### IO
|
### IO
|
||||||
|
|
||||||
|
|||||||
@ -24,6 +24,8 @@ public class ArrayList<E> extends AbstractList<E>
|
|||||||
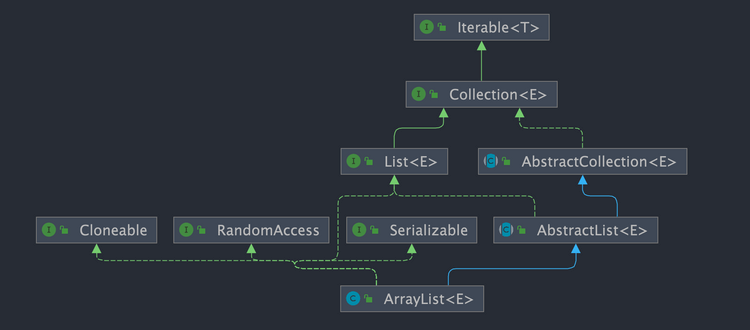
- `Cloneable` :表明它具有拷贝能力,可以进行深拷贝或浅拷贝操作。
|
- `Cloneable` :表明它具有拷贝能力,可以进行深拷贝或浅拷贝操作。
|
||||||
- `Serializable` : 表明它可以进行序列化操作,也就是可以将对象转换为字节流进行持久化存储或网络传输,非常方便。
|
- `Serializable` : 表明它可以进行序列化操作,也就是可以将对象转换为字节流进行持久化存储或网络传输,非常方便。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### ArrayList 和 Vector 的区别?(了解即可)
|
### ArrayList 和 Vector 的区别?(了解即可)
|
||||||
|
|
||||||
- `ArrayList` 是 `List` 的主要实现类,底层使用 `Object[]`存储,适用于频繁的查找工作,线程不安全 。
|
- `ArrayList` 是 `List` 的主要实现类,底层使用 `Object[]`存储,适用于频繁的查找工作,线程不安全 。
|
||||||
|
|||||||
316
docs/java/collection/copyonwritearraylist-source-code.md
Normal file
316
docs/java/collection/copyonwritearraylist-source-code.md
Normal file
@ -0,0 +1,316 @@
|
|||||||
|
---
|
||||||
|
title: CopyOnWriteArrayList 源码分析
|
||||||
|
category: Java
|
||||||
|
tag:
|
||||||
|
- Java集合
|
||||||
|
---
|
||||||
|
|
||||||
|
## CopyOnWriteArrayList 简介
|
||||||
|
|
||||||
|
在 JDK1.5 之前,如果想要使用并发安全的 `List` 只能选择 `Vector`。而 `Vector` 是一种老旧的集合,已经被淘汰。`Vector` 对于增删改查等方法基本都加了 `synchronized`,这种方式虽然能够保证同步,但这相当于对整个 `Vector` 加上了一把大锁,使得每个方法执行的时候都要去获得锁,导致性能非常低下。
|
||||||
|
|
||||||
|
JDK1.5 引入了 `Java.util.concurrent`(JUC)包,其中提供了很多线程安全且并发性能良好的容器,其中唯一的线程安全 `List` 实现就是 `CopyOnWriteArrayList` 。关于`java.util.concurrent` 包下常见并发容器的总结,可以看我写的这篇文章:[Java 常见并发容器总结](https://javaguide.cn/java/concurrent/java-concurrent-collections.html) 。
|
||||||
|
|
||||||
|
### CopyOnWriteArrayList 到底有什么厉害之处?
|
||||||
|
|
||||||
|
对于大部分业务场景来说,读取操作往往是远大于写入操作的。由于读取操作不会对原有数据进行修改,因此,对于每次读取都进行加锁其实是一种资源浪费。相比之下,我们应该允许多个线程同时访问 `List` 的内部数据,毕竟对于读取操作来说是安全的。
|
||||||
|
|
||||||
|
这种思路与 `ReentrantReadWriteLock` 读写锁的设计思想非常类似,即读读不互斥、读写互斥、写写互斥(只有读读不互斥)。`CopyOnWriteArrayList` 更进一步地实现了这一思想。为了将读操作性能发挥到极致,`CopyOnWriteArrayList` 中的读取操作是完全无需加锁的。更加厉害的是,写入操作也不会阻塞读取操作,只有写写才会互斥。这样一来,读操作的性能就可以大幅度提升。
|
||||||
|
|
||||||
|
`CopyOnWriteArrayList` 线程安全的核心在于其采用了 **写时复制(Copy-On-Write)** 的策略,从 `CopyOnWriteArrayList` 的名字就能看出了。
|
||||||
|
|
||||||
|
### Copy-On-Write 的思想是什么?
|
||||||
|
|
||||||
|
`CopyOnWriteArrayList`名字中的“Copy-On-Write”即写时复制,简称 COW。
|
||||||
|
|
||||||
|
下面是维基百科对 Copy-On-Write 的介绍,介绍的挺不错:
|
||||||
|
|
||||||
|
> 写入时复制(英语:Copy-on-write,简称 COW)是一种计算机程序设计领域的优化策略。其核心思想是,如果有多个调用者(callers)同时请求相同资源(如内存或磁盘上的数据存储),他们会共同获取相同的指针指向相同的资源,直到某个调用者试图修改资源的内容时,系统才会真正复制一份专用副本(private copy)给该调用者,而其他调用者所见到的最初的资源仍然保持不变。这过程对其他的调用者都是透明的。此作法主要的优点是如果调用者没有修改该资源,就不会有副本(private copy)被创建,因此多个调用者只是读取操作时可以共享同一份资源。
|
||||||
|
|
||||||
|
这里再以 `CopyOnWriteArrayList`为例介绍:当需要修改( `add`,`set`、`remove` 等操作) `CopyOnWriteArrayList` 的内容时,不会直接修改原数组,而是会先创建底层数组的副本,对副本数组进行修改,修改完之后再将修改后的数组赋值回去,这样就可以保证写操作不会影响读操作了。
|
||||||
|
|
||||||
|
可以看出,写时复制机制非常适合读多写少的并发场景,能够极大地提高系统的并发性能。
|
||||||
|
|
||||||
|
不过,写时复制机制并不是银弹,其依然存在一些缺点,下面列举几点:
|
||||||
|
|
||||||
|
1. 内存占用:每次写操作都需要复制一份原始数据,会占用额外的内存空间,在数据量比较大的情况下,可能会导致内存资源不足。
|
||||||
|
2. 写操作开销:每一次写操作都需要复制一份原始数据,然后再进行修改和替换,所以写操作的开销相对较大,在写入比较频繁的场景下,性能可能会受到影响。
|
||||||
|
3. 数据一致性问题:修改操作不会立即反映到最终结果中,还需要等待复制完成,这可能会导致一定的数据一致性问题。
|
||||||
|
4. ......
|
||||||
|
|
||||||
|
## CopyOnWriteArrayList 源码分析
|
||||||
|
|
||||||
|
这里以 JDK1.8 为例,分析一下 `CopyOnWriteArrayList` 的底层核心源码。
|
||||||
|
|
||||||
|
`CopyOnWriteArrayList` 的类定义如下:
|
||||||
|
|
||||||
|
```java
|
||||||
|
public class CopyOnWriteArrayList<E>
|
||||||
|
extends Object
|
||||||
|
implements List<E>, RandomAccess, Cloneable, Serializable
|
||||||
|
{
|
||||||
|
//...
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
`CopyOnWriteArrayList` 实现了以下接口:
|
||||||
|
|
||||||
|
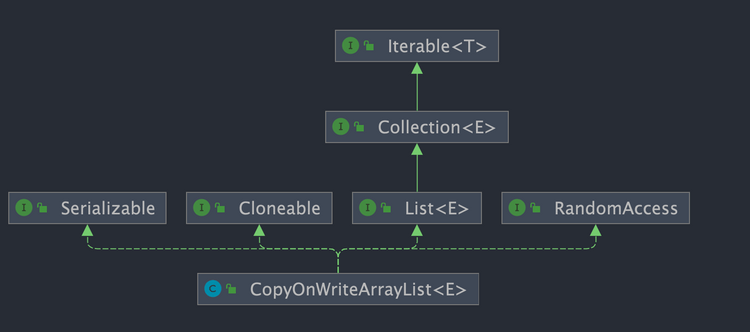
- `List` : 表明它是一个列表,支持添加、删除、查找等操作,并且可以通过下标进行访问。
|
||||||
|
- `RandomAccess` :这是一个标志接口,表明实现这个接口的 `List` 集合是支持 **快速随机访问** 的。
|
||||||
|
- `Cloneable` :表明它具有拷贝能力,可以进行深拷贝或浅拷贝操作。
|
||||||
|
- `Serializable` : 表明它可以进行序列化操作,也就是可以将对象转换为字节流进行持久化存储或网络传输,非常方便。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
### 初始化
|
||||||
|
|
||||||
|
`CopyOnWriteArrayList` 中有一个无参构造函数和两个有参构造函数。
|
||||||
|
|
||||||
|
```java
|
||||||
|
// 创建一个空的 CopyOnWriteArrayList
|
||||||
|
public CopyOnWriteArrayList() {
|
||||||
|
setArray(new Object[0]);
|
||||||
|
}
|
||||||
|
|
||||||
|
// 按照集合的迭代器返回的顺序创建一个包含指定集合元素的 CopyOnWriteArrayList
|
||||||
|
public CopyOnWriteArrayList(Collection<? extends E> c) {
|
||||||
|
Object[] elements;
|
||||||
|
if (c.getClass() == CopyOnWriteArrayList.class)
|
||||||
|
elements = ((CopyOnWriteArrayList<?>)c).getArray();
|
||||||
|
else {
|
||||||
|
elements = c.toArray();
|
||||||
|
// c.toArray might (incorrectly) not return Object[] (see 6260652)
|
||||||
|
if (elements.getClass() != Object[].class)
|
||||||
|
elements = Arrays.copyOf(elements, elements.length, Object[].class);
|
||||||
|
}
|
||||||
|
setArray(elements);
|
||||||
|
}
|
||||||
|
|
||||||
|
// 创建一个包含指定数组的副本的列表
|
||||||
|
public CopyOnWriteArrayList(E[] toCopyIn) {
|
||||||
|
setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class));
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
### 插入元素
|
||||||
|
|
||||||
|
`CopyOnWriteArrayList` 的 `add()`方法有三个版本:
|
||||||
|
|
||||||
|
- `add(E e)`:在 `CopyOnWriteArrayList` 的尾部插入元素。
|
||||||
|
- `add(int index, E element)`:在 `CopyOnWriteArrayList` 的指定位置插入元素。
|
||||||
|
- `addIfAbsent(E e)`:如果指定元素不存在,那么添加该元素。如果成功添加元素则返回 true。
|
||||||
|
|
||||||
|
这里以`add(E e)`为例进行介绍:
|
||||||
|
|
||||||
|
```java
|
||||||
|
// 插入元素到 CopyOnWriteArrayList 的尾部
|
||||||
|
public boolean add(E e) {
|
||||||
|
final ReentrantLock lock = this.lock;
|
||||||
|
// 加锁
|
||||||
|
lock.lock();
|
||||||
|
try {
|
||||||
|
// 获取原来的数组
|
||||||
|
Object[] elements = getArray();
|
||||||
|
// 原来数组的长度
|
||||||
|
int len = elements.length;
|
||||||
|
// 创建一个长度+1的新数组,并将原来数组的元素复制给新数组
|
||||||
|
Object[] newElements = Arrays.copyOf(elements, len + 1);
|
||||||
|
// 元素放在新数组末尾
|
||||||
|
newElements[len] = e;
|
||||||
|
// array指向新数组
|
||||||
|
setArray(newElements);
|
||||||
|
return true;
|
||||||
|
} finally {
|
||||||
|
// 解锁
|
||||||
|
lock.unlock();
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
从上面的源码可以看出:
|
||||||
|
|
||||||
|
- `add`方法内部用到了 `ReentrantLock` 加锁,保证了同步,避免了多线程写的时候会复制出多个副本出来。
|
||||||
|
- `CopyOnWriteArrayList` 通过复制底层数组的方式实现写操作,即先创建一个新的数组来容纳新添加的元素,然后在新数组中进行写操作,最后将新数组赋值给底层数组的引用,替换掉旧的数组。这也就证明了我们前面说的:`CopyOnWriteArrayList` 线程安全的核心在于其采用了 **写时复制(Copy-On-Write)** 的策略。
|
||||||
|
- 每次写操作都需要通过 `Arrays.copyOf` 复制底层数组,时间复杂度是 O(n) 的,且会占用额外的内存空间。因此,`CopyOnWriteArrayList` 适用于读多写少的场景,在写操作不频繁且内存资源充足的情况下,可以提升系统的性能表现。
|
||||||
|
- `CopyOnWriteArrayList` 中并没有类似于 `ArrayList` 的 `grow()` 方法扩容的操作。
|
||||||
|
|
||||||
|
> `Arrays.copyOf` 方法的时间复杂度是 O(n),其中 n 表示需要复制的数组长度。因为这个方法的实现原理是先创建一个新的数组,然后将源数组中的数据复制到新数组中,最后返回新数组。这个方法会复制整个数组,因此其时间复杂度与数组长度成正比,即 O(n)。值得注意的是,由于底层调用了系统级别的拷贝指令,因此在实际应用中这个方法的性能表现比较优秀,但是也需要注意控制复制的数据量,避免出现内存占用过高的情况。
|
||||||
|
|
||||||
|
### 读取元素
|
||||||
|
|
||||||
|
`CopyOnWriteArrayList` 的读取操作是基于内部数组 `array` 并没有发生实际的修改,因此在读取操作时不需要进行同步控制和锁操作,可以保证数据的安全性。这种机制下,多个线程可以同时读取列表中的元素。
|
||||||
|
|
||||||
|
```java
|
||||||
|
// 底层数组,只能通过getArray和setArray方法访问
|
||||||
|
private transient volatile Object[] array;
|
||||||
|
|
||||||
|
public E get(int index) {
|
||||||
|
return get(getArray(), index);
|
||||||
|
}
|
||||||
|
|
||||||
|
final Object[] getArray() {
|
||||||
|
return array;
|
||||||
|
}
|
||||||
|
|
||||||
|
private E get(Object[] a, int index) {
|
||||||
|
return (E) a[index];
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
不过,`get`方法是弱一致性的,在某些情况下可能读到旧的元素值。
|
||||||
|
|
||||||
|
`get(int index)`方法是分两步进行的:
|
||||||
|
|
||||||
|
1. 通过`getArray()`获取当前数组的引用;
|
||||||
|
2. 直接从数组中获取下标为 index 的元素。
|
||||||
|
|
||||||
|
这个过程并没有加锁,所以在并发环境下可能出现如下情况:
|
||||||
|
|
||||||
|
1. 线程 1 调用`get(int index)`方法获取值,内部通过`getArray()`方法获取到了 array 属性值;
|
||||||
|
2. 线程 2 调用`CopyOnWriteArrayList`的`add`、`set`、`remove` 等修改方法时,内部通过`setArray`方法修改了`array`属性的值;
|
||||||
|
3. 线程 1 还是从旧的 `array` 数组中取值。
|
||||||
|
|
||||||
|
### 获取列表中元素的个数
|
||||||
|
|
||||||
|
```java
|
||||||
|
public int size() {
|
||||||
|
return getArray().length;
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
`CopyOnWriteArrayList`中的`array`数组每次复制都刚好能够容纳下所有元素,并不像`ArrayList`那样会预留一定的空间。因此,`CopyOnWriteArrayList`中并没有`size`属性`CopyOnWriteArrayList`的底层数组的长度就是元素个数,因此`size()`方法只要返回数组长度就可以了。
|
||||||
|
|
||||||
|
### 删除元素
|
||||||
|
|
||||||
|
`CopyOnWriteArrayList`删除元素相关的方法一共有 4 个:
|
||||||
|
|
||||||
|
1. `remove(int index)`:移除此列表中指定位置上的元素。将任何后续元素向左移动(从它们的索引中减去 1)。
|
||||||
|
2. `boolean remove(Object o)`:删除此列表中首次出现的指定元素,如果不存在该元素则返回 false。
|
||||||
|
3. `boolean removeAll(Collection<?> c)`:从此列表中删除指定集合中包含的所有元素。
|
||||||
|
4. `void clear()`:移除此列表中的所有元素。
|
||||||
|
|
||||||
|
这里以`remove(int index)`为例进行介绍:
|
||||||
|
|
||||||
|
```java
|
||||||
|
public E remove(int index) {
|
||||||
|
// 获取可重入锁
|
||||||
|
final ReentrantLock lock = this.lock;
|
||||||
|
// 加锁
|
||||||
|
lock.lock();
|
||||||
|
try {
|
||||||
|
//获取当前array数组
|
||||||
|
Object[] elements = getArray();
|
||||||
|
// 获取当前array长度
|
||||||
|
int len = elements.length;
|
||||||
|
//获取指定索引的元素(旧值)
|
||||||
|
E oldValue = get(elements, index);
|
||||||
|
int numMoved = len - index - 1;
|
||||||
|
// 判断删除的是否是最后一个元素
|
||||||
|
if (numMoved == 0)
|
||||||
|
// 如果删除的是最后一个元素,直接复制该元素前的所有元素到新的数组
|
||||||
|
setArray(Arrays.copyOf(elements, len - 1));
|
||||||
|
else {
|
||||||
|
// 分段复制,将index前的元素和index+1后的元素复制到新数组
|
||||||
|
// 新数组长度为旧数组长度-1
|
||||||
|
Object[] newElements = new Object[len - 1];
|
||||||
|
System.arraycopy(elements, 0, newElements, 0, index);
|
||||||
|
System.arraycopy(elements, index + 1, newElements, index,
|
||||||
|
numMoved);
|
||||||
|
//将新数组赋值给array引用
|
||||||
|
setArray(newElements);
|
||||||
|
}
|
||||||
|
return oldValue;
|
||||||
|
} finally {
|
||||||
|
// 解锁
|
||||||
|
lock.unlock();
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
### 判断元素是否存在
|
||||||
|
|
||||||
|
`CopyOnWriteArrayList`提供了两个用于判断指定元素是否在列表中的方法:
|
||||||
|
|
||||||
|
- `contains(Object o)`:判断是否包含指定元素。
|
||||||
|
- `containsAll(Collection<?> c)`:判断是否保证指定集合的全部元素。
|
||||||
|
|
||||||
|
```java
|
||||||
|
// 判断是否包含指定元素
|
||||||
|
public boolean contains(Object o) {
|
||||||
|
//获取当前array数组
|
||||||
|
Object[] elements = getArray();
|
||||||
|
//调用index尝试查找指定元素,如果返回值大于等于0,则返回true,否则返回false
|
||||||
|
return indexOf(o, elements, 0, elements.length) >= 0;
|
||||||
|
}
|
||||||
|
|
||||||
|
// 判断是否保证指定集合的全部元素
|
||||||
|
public boolean containsAll(Collection<?> c) {
|
||||||
|
//获取当前array数组
|
||||||
|
Object[] elements = getArray();
|
||||||
|
//获取数组长度
|
||||||
|
int len = elements.length;
|
||||||
|
//遍历指定集合
|
||||||
|
for (Object e : c) {
|
||||||
|
//循环调用indexOf方法判断,只要有一个没有包含就直接返回false
|
||||||
|
if (indexOf(e, elements, 0, len) < 0)
|
||||||
|
return false;
|
||||||
|
}
|
||||||
|
//最后表示全部包含或者制定集合为空集合,那么返回true
|
||||||
|
return true;
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
## CopyOnWriteArrayList 常用方法测试
|
||||||
|
|
||||||
|
代码:
|
||||||
|
|
||||||
|
```java
|
||||||
|
// 创建一个 CopyOnWriteArrayList 对象
|
||||||
|
CopyOnWriteArrayList<String> list = new CopyOnWriteArrayList<>();
|
||||||
|
|
||||||
|
// 向列表中添加元素
|
||||||
|
list.add("Java");
|
||||||
|
list.add("Python");
|
||||||
|
list.add("C++");
|
||||||
|
System.out.println("初始列表:" + list);
|
||||||
|
|
||||||
|
// 使用 get 方法获取指定位置的元素
|
||||||
|
System.out.println("列表第二个元素为:" + list.get(1));
|
||||||
|
|
||||||
|
// 使用 remove 方法删除指定元素
|
||||||
|
boolean result = list.remove("C++");
|
||||||
|
System.out.println("删除结果:" + result);
|
||||||
|
System.out.println("列表删除元素后为:" + list);
|
||||||
|
|
||||||
|
// 使用 set 方法更新指定位置的元素
|
||||||
|
list.set(1, "Golang");
|
||||||
|
System.out.println("列表更新后为:" + list);
|
||||||
|
|
||||||
|
// 使用 add 方法在指定位置插入元素
|
||||||
|
list.add(0, "PHP");
|
||||||
|
System.out.println("列表插入元素后为:" + list);
|
||||||
|
|
||||||
|
// 使用 size 方法获取列表大小
|
||||||
|
System.out.println("列表大小为:" + list.size());
|
||||||
|
|
||||||
|
// 使用 removeAll 方法删除指定集合中所有出现的元素
|
||||||
|
result = list.removeAll(List.of("Java", "Golang"));
|
||||||
|
System.out.println("批量删除结果:" + result);
|
||||||
|
System.out.println("列表批量删除元素后为:" + list);
|
||||||
|
|
||||||
|
// 使用 clear 方法清空列表中所有元素
|
||||||
|
list.clear();
|
||||||
|
System.out.println("列表清空后为:" + list);
|
||||||
|
```
|
||||||
|
|
||||||
|
输出:
|
||||||
|
|
||||||
|
```
|
||||||
|
列表更新后为:[Java, Golang]
|
||||||
|
列表插入元素后为:[PHP, Java, Golang]
|
||||||
|
列表大小为:3
|
||||||
|
批量删除结果:true
|
||||||
|
列表批量删除元素后为:[PHP]
|
||||||
|
列表清空后为:[]
|
||||||
|
```
|
||||||
|
|
||||||
@ -53,6 +53,8 @@ public class LinkedList<E>
|
|||||||
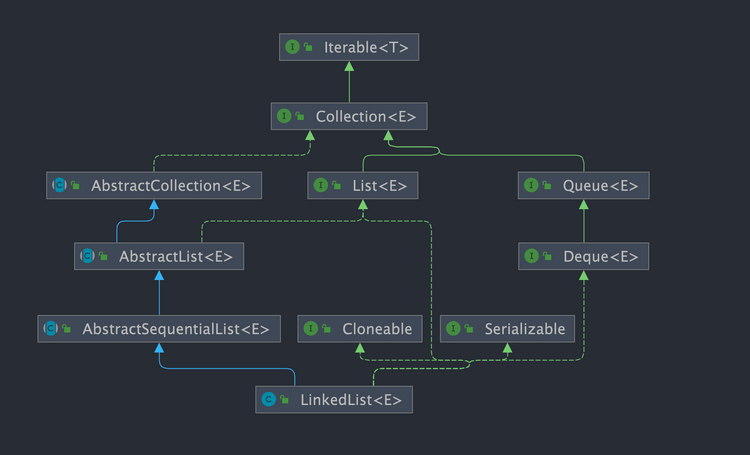
- `Cloneable` :表明它具有拷贝能力,可以进行深拷贝或浅拷贝操作。
|
- `Cloneable` :表明它具有拷贝能力,可以进行深拷贝或浅拷贝操作。
|
||||||
- `Serializable` : 表明它可以进行序列化操作,也就是可以将对象转换为字节流进行持久化存储或网络传输,非常方便。
|
- `Serializable` : 表明它可以进行序列化操作,也就是可以将对象转换为字节流进行持久化存储或网络传输,非常方便。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
`LinkedList` 中的元素是通过 `Node` 定义的:
|
`LinkedList` 中的元素是通过 `Node` 定义的:
|
||||||
|
|
||||||
```java
|
```java
|
||||||
@ -221,12 +223,13 @@ Node<E> node(int index) {
|
|||||||
|
|
||||||
### 删除元素
|
### 删除元素
|
||||||
|
|
||||||
`LinkedList`删除元素相关的方法一共有 4 个:
|
`LinkedList`删除元素相关的方法一共有 5 个:
|
||||||
|
|
||||||
1. `removeFirst()`:删除并返回链表的第一个元素。
|
1. `removeFirst()`:删除并返回链表的第一个元素。
|
||||||
2. `removeLast()`:删除并返回链表的最后一个元素。
|
2. `removeLast()`:删除并返回链表的最后一个元素。
|
||||||
3. `remove(E e)`:删除链表中首次出现的指定元素,如果不存在该元素则返回 false。
|
3. `remove(E e)`:删除链表中首次出现的指定元素,如果不存在该元素则返回 false。
|
||||||
4. `remove(int index)`:删除指定索引处的元素,并返回该元素的值
|
4. `remove(int index)`:删除指定索引处的元素,并返回该元素的值。
|
||||||
|
5. `void clear()`:移除此链表中的所有元素。
|
||||||
|
|
||||||
```java
|
```java
|
||||||
// 删除并返回链表的第一个元素
|
// 删除并返回链表的第一个元素
|
||||||
|
|||||||
@ -23,74 +23,23 @@ JDK 提供的这些容器大部分在 `java.util.concurrent` 包中。
|
|||||||
|
|
||||||
到了 JDK1.8 的时候,`ConcurrentHashMap` 已经摒弃了 `Segment` 的概念,而是直接用 `Node` 数组+链表+红黑树的数据结构来实现,并发控制使用 `synchronized` 和 CAS 来操作。(JDK1.6 以后 `synchronized` 锁做了很多优化) 整个看起来就像是优化过且线程安全的 `HashMap`,虽然在 JDK1.8 中还能看到 `Segment` 的数据结构,但是已经简化了属性,只是为了兼容旧版本。
|
到了 JDK1.8 的时候,`ConcurrentHashMap` 已经摒弃了 `Segment` 的概念,而是直接用 `Node` 数组+链表+红黑树的数据结构来实现,并发控制使用 `synchronized` 和 CAS 来操作。(JDK1.6 以后 `synchronized` 锁做了很多优化) 整个看起来就像是优化过且线程安全的 `HashMap`,虽然在 JDK1.8 中还能看到 `Segment` 的数据结构,但是已经简化了属性,只是为了兼容旧版本。
|
||||||
|
|
||||||
|
关于 `ConcurrentHashMap` 的详细介绍,请看我写的这篇文章:[`ConcurrentHashMap` 源码分析](./../collection/concurrent-hash-map-source-code.md)。
|
||||||
|
|
||||||
## CopyOnWriteArrayList
|
## CopyOnWriteArrayList
|
||||||
|
|
||||||
### CopyOnWriteArrayList 简介
|
在 JDK1.5 之前,如果想要使用并发安全的 `List` 只能选择 `Vector`。而 `Vector` 是一种老旧的集合,已经被淘汰。`Vector` 对于增删改查等方法基本都加了 `synchronized`,这种方式虽然能够保证同步,但这相当于对整个 `Vector` 加上了一把大锁,使得每个方法执行的时候都要去获得锁,导致性能非常低下。
|
||||||
|
|
||||||
```java
|
JDK1.5 引入了 `Java.util.concurrent`(JUC)包,其中提供了很多线程安全且并发性能良好的容器,其中唯一的线程安全 `List` 实现就是 `CopyOnWriteArrayList` 。
|
||||||
public class CopyOnWriteArrayList<E>
|
|
||||||
extends Object
|
|
||||||
implements List<E>, RandomAccess, Cloneable, Serializable
|
|
||||||
```
|
|
||||||
|
|
||||||
在很多应用场景中,读操作可能会远远大于写操作。由于读操作根本不会修改原有的数据,因此对于每次读取都进行加锁其实是一种资源浪费。我们应该允许多个线程同时访问 `List` 的内部数据,毕竟读取操作是安全的。
|
对于大部分业务场景来说,读取操作往往是远大于写入操作的。由于读取操作不会对原有数据进行修改,因此,对于每次读取都进行加锁其实是一种资源浪费。相比之下,我们应该允许多个线程同时访问 `List` 的内部数据,毕竟对于读取操作来说是安全的。
|
||||||
|
|
||||||
这和我们之前提到过的 `ReentrantReadWriteLock` 读写锁的思想非常类似,也就是读读共享、写写互斥、读写互斥、写读互斥。JDK 中提供了 `CopyOnWriteArrayList` 类比相比于在读写锁的思想又更进一步。为了将读取的性能发挥到极致,`CopyOnWriteArrayList` 读取是完全不用加锁的,并且更厉害的是:写入也不会阻塞读取操作。只有写入和写入之间需要进行同步等待。这样一来,读操作的性能就会大幅度提升。**那它是怎么做的呢?**
|
这种思路与 `ReentrantReadWriteLock` 读写锁的设计思想非常类似,即读读不互斥、读写互斥、写写互斥(只有读读不互斥)。`CopyOnWriteArrayList` 更进一步地实现了这一思想。为了将读操作性能发挥到极致,`CopyOnWriteArrayList` 中的读取操作是完全无需加锁的。更加厉害的是,写入操作也不会阻塞读取操作,只有写写才会互斥。这样一来,读操作的性能就可以大幅度提升。
|
||||||
|
|
||||||
### CopyOnWriteArrayList 是如何做到的?
|
`CopyOnWriteArrayList` 线程安全的核心在于其采用了 **写时复制(Copy-On-Write)** 的策略,从 `CopyOnWriteArrayList` 的名字就能看出了。
|
||||||
|
|
||||||
`CopyOnWriteArrayList` 类的所有可变操作(add,set 等等)都是通过创建底层数组的新副本来实现的。当 List 需要被修改的时候,我并不修改原有内容,而是对原有数据进行一次复制,将修改的内容写入副本。写完之后,再将修改完的副本替换原来的数据,这样就可以保证写操作不会影响读操作了。
|
当需要修改( `add`,`set`、`remove` 等操作) `CopyOnWriteArrayList` 的内容时,不会直接修改原数组,而是会先创建底层数组的副本,对副本数组进行修改,修改完之后再将修改后的数组赋值回去,这样就可以保证写操作不会影响读操作了。
|
||||||
|
|
||||||
从 `CopyOnWriteArrayList` 的名字就能看出 `CopyOnWriteArrayList` 是满足 `CopyOnWrite` 的。所谓 `CopyOnWrite` 也就是说:在计算机,如果你想要对一块内存进行修改时,我们不在原有内存块中进行写操作,而是将内存拷贝一份,在新的内存中进行写操作,写完之后呢,就将指向原来内存指针指向新的内存,原来的内存就可以被回收掉了。
|
关于 `CopyOnWriteArrayList` 的详细介绍,请看我写的这篇文章:[`CopyOnWriteArrayList` 源码分析](./../collection/copyonwritearraylist-source-code.md)。
|
||||||
|
|
||||||
### CopyOnWriteArrayList 读取和写入源码简单分析
|
|
||||||
|
|
||||||
#### CopyOnWriteArrayList 读取操作的实现
|
|
||||||
|
|
||||||
读取操作没有任何同步控制和锁操作,理由就是内部数组 `array` 不会发生修改,只会被另外一个 `array` 替换,因此可以保证数据安全。
|
|
||||||
|
|
||||||
```java
|
|
||||||
/** The array, accessed only via getArray/setArray. */
|
|
||||||
private transient volatile Object[] array;
|
|
||||||
public E get(int index) {
|
|
||||||
return get(getArray(), index);
|
|
||||||
}
|
|
||||||
@SuppressWarnings("unchecked")
|
|
||||||
private E get(Object[] a, int index) {
|
|
||||||
return (E) a[index];
|
|
||||||
}
|
|
||||||
final Object[] getArray() {
|
|
||||||
return array;
|
|
||||||
}
|
|
||||||
|
|
||||||
```
|
|
||||||
|
|
||||||
#### CopyOnWriteArrayList 写入操作的实现
|
|
||||||
|
|
||||||
`CopyOnWriteArrayList` 写入操作 `add()`方法在添加集合的时候加了锁,保证了同步,避免了多线程写的时候会 copy 出多个副本出来。
|
|
||||||
|
|
||||||
```java
|
|
||||||
/**
|
|
||||||
* Appends the specified element to the end of this list.
|
|
||||||
*
|
|
||||||
* @param e element to be appended to this list
|
|
||||||
* @return {@code true} (as specified by {@link Collection#add})
|
|
||||||
*/
|
|
||||||
public boolean add(E e) {
|
|
||||||
final ReentrantLock lock = this.lock;
|
|
||||||
lock.lock();//加锁
|
|
||||||
try {
|
|
||||||
Object[] elements = getArray();
|
|
||||||
int len = elements.length;
|
|
||||||
Object[] newElements = Arrays.copyOf(elements, len + 1);//拷贝新数组
|
|
||||||
newElements[len] = e;
|
|
||||||
setArray(newElements);
|
|
||||||
return true;
|
|
||||||
} finally {
|
|
||||||
lock.unlock();//释放锁
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
## ConcurrentLinkedQueue
|
## ConcurrentLinkedQueue
|
||||||
|
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user