mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-05 20:31:37 +08:00
commit
a9bb5b0e50
53
README.md
53
README.md
@ -66,15 +66,18 @@
|
|||||||
- [Spring/SpringBoot](#springspringboot)
|
- [Spring/SpringBoot](#springspringboot)
|
||||||
- [MyBatis](#mybatis)
|
- [MyBatis](#mybatis)
|
||||||
- [Netty (必看 :+1:)](#netty-必看-1)
|
- [Netty (必看 :+1:)](#netty-必看-1)
|
||||||
|
- [ZooKeeper](#zookeeper)
|
||||||
- [认证授权](#认证授权)
|
- [认证授权](#认证授权)
|
||||||
- [JWT](#jwt)
|
- [JWT](#jwt)
|
||||||
- [SSO(单点登录)](#sso单点登录)
|
- [SSO(单点登录)](#sso单点登录)
|
||||||
- [分布式](#分布式)
|
- [分布式](#分布式)
|
||||||
|
- [CAP 理论](#cap-理论)
|
||||||
|
- [BASE 理论](#base-理论)
|
||||||
|
- [Paxos 算法和 Raft 算法](#paxos-算法和-raft-算法)
|
||||||
- [搜索引擎](#搜索引擎)
|
- [搜索引擎](#搜索引擎)
|
||||||
- [RPC](#rpc)
|
- [RPC](#rpc)
|
||||||
- [API 网关](#api-网关)
|
- [API 网关](#api-网关)
|
||||||
- [分布式 id](#分布式-id)
|
- [分布式 id](#分布式-id)
|
||||||
- [ZooKeeper](#zookeeper)
|
|
||||||
- [微服务](#微服务)
|
- [微服务](#微服务)
|
||||||
- [高并发](#高并发)
|
- [高并发](#高并发)
|
||||||
- [消息队列](#消息队列)
|
- [消息队列](#消息队列)
|
||||||
@ -82,8 +85,6 @@
|
|||||||
- [分库分表](#分库分表)
|
- [分库分表](#分库分表)
|
||||||
- [负载均衡](#负载均衡)
|
- [负载均衡](#负载均衡)
|
||||||
- [高可用](#高可用)
|
- [高可用](#高可用)
|
||||||
- [CAP 理论](#cap-理论)
|
|
||||||
- [BASE 理论](#base-理论)
|
|
||||||
- [限流](#限流)
|
- [限流](#限流)
|
||||||
- [降级](#降级)
|
- [降级](#降级)
|
||||||
- [熔断](#熔断)
|
- [熔断](#熔断)
|
||||||
@ -211,7 +212,6 @@
|
|||||||
|
|
||||||
### Redis
|
### Redis
|
||||||
|
|
||||||
1. [关于缓存的一些重要概念(Redis 前置菜)](docs/database/Redis/some-concepts-of-caching.md)
|
|
||||||
2. [Redis 常见问题总结](docs/database/Redis/redis-all.md)
|
2. [Redis 常见问题总结](docs/database/Redis/redis-all.md)
|
||||||
|
|
||||||
## 系统设计
|
## 系统设计
|
||||||
@ -248,6 +248,14 @@
|
|||||||
1. [剖析面试最常见问题之 Netty(上)](https://xiaozhuanlan.com/topic/4028536971)
|
1. [剖析面试最常见问题之 Netty(上)](https://xiaozhuanlan.com/topic/4028536971)
|
||||||
2. [剖析面试最常见问题之 Netty(下)](https://xiaozhuanlan.com/topic/3985146207)
|
2. [剖析面试最常见问题之 Netty(下)](https://xiaozhuanlan.com/topic/3985146207)
|
||||||
|
|
||||||
|
#### ZooKeeper
|
||||||
|
|
||||||
|
> 前两篇文章可能有内容重合部分,推荐都看一遍。
|
||||||
|
|
||||||
|
1. [【入门】ZooKeeper 相关概念总结](docs/system-design/distributed-system/zookeeper/zookeeper-intro.md)
|
||||||
|
2. [【进阶】ZooKeeper 相关概念总结](docs/system-design/distributed-system/zookeeper/zookeeper-plus.md)
|
||||||
|
3. [【实战】ZooKeeper 实战](docs/system-design/distributed-system/zookeeper/zookeeper-in-action.md)
|
||||||
|
|
||||||
### 认证授权
|
### 认证授权
|
||||||
|
|
||||||
**[《认证授权基础》](docs/system-design/authority-certification/basis-of-authority-certification.md)** 这篇文章中我会介绍认证授权常见概念: **Authentication**,**Authorization** 以及 **Cookie**、**Session**、Token、**OAuth 2**、**SSO** 。如果你不清楚这些概念的话,建议好好阅读一下这篇文章。
|
**[《认证授权基础》](docs/system-design/authority-certification/basis-of-authority-certification.md)** 这篇文章中我会介绍认证授权常见概念: **Authentication**,**Authorization** 以及 **Cookie**、**Session**、Token、**OAuth 2**、**SSO** 。如果你不清楚这些概念的话,建议好好阅读一下这篇文章。
|
||||||
@ -263,7 +271,21 @@
|
|||||||
|
|
||||||
### 分布式
|
### 分布式
|
||||||
|
|
||||||
[分布式相关概念入门](docs/system-design/distributed-system/分布式.md)
|
#### CAP 理论
|
||||||
|
|
||||||
|
CAP 也就是 Consistency(一致性)、Availability(可用性)、Partition Tolerance(分区容错性) 这三个单词首字母组合。
|
||||||
|
|
||||||
|
关于 CAP 的详细解读请看:[《CAP理论解读》](docs/system-design/distributed-system/CAP理论.md)。
|
||||||
|
|
||||||
|
#### BASE 理论
|
||||||
|
|
||||||
|
**BASE** 是 **Basically Available(基本可用)** 、**Soft-state(软状态)** 和 **Eventually Consistent(最终一致性)** 三个短语的缩写。BASE 理论是对 CAP 中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于 CAP 定理逐步演化而来的,它大大降低了我们对系统的要求。
|
||||||
|
|
||||||
|
关于 CAP 的详细解读请看:[《BASE理论解读》](docs/system-design/distributed-system/BASE理论.md)。
|
||||||
|
|
||||||
|
#### Paxos 算法和 Raft 算法
|
||||||
|
|
||||||
|
**Paxos 算法**诞生于 1900 年,这是一种解决分布式系统一致性的经典算法 。但是,由于 Paxos 算法非常难以理解和实现,不断有人尝试简化这一算法。到了2013 年才诞生了一个比 Paxos 算法更易理解和实现的分布式一致性算法—**Raft 算法**。
|
||||||
|
|
||||||
#### 搜索引擎
|
#### 搜索引擎
|
||||||
|
|
||||||
@ -275,6 +297,7 @@ RPC 让调用远程服务调用像调用本地方法那样简单。
|
|||||||
|
|
||||||
1. [Dubbo 总结:关于 Dubbo 的重要知识点](docs/system-design/distributed-system/rpc/关于Dubbo的重要知识点.md)
|
1. [Dubbo 总结:关于 Dubbo 的重要知识点](docs/system-design/distributed-system/rpc/关于Dubbo的重要知识点.md)
|
||||||
2. [服务之间的调用为啥不直接用 HTTP 而用 RPC?](docs/system-design/distributed-system/rpc/服务之间的调用为啥不直接用HTTP而用RPC.md)
|
2. [服务之间的调用为啥不直接用 HTTP 而用 RPC?](docs/system-design/distributed-system/rpc/服务之间的调用为啥不直接用HTTP而用RPC.md)
|
||||||
|
3. [一款基于 Netty+Kyro+Zookeeper 实现的自定义 RPC 框架](https://github.com/Snailclimb/guide-rpc-framework)
|
||||||
|
|
||||||
#### API 网关
|
#### API 网关
|
||||||
|
|
||||||
@ -287,13 +310,11 @@ RPC 让调用远程服务调用像调用本地方法那样简单。
|
|||||||
|
|
||||||
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。比如数据量太大之后,往往需要对进行对数据进行分库分表,分库分表后需要有一个唯一 ID 来标识一条数据或消息,数据库的自增 ID 显然不能满足需求。相关阅读:[为什么要分布式 id ?分布式 id 生成方案有哪些?](docs/system-design/micro-service/分布式id生成方案总结.md)
|
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。比如数据量太大之后,往往需要对进行对数据进行分库分表,分库分表后需要有一个唯一 ID 来标识一条数据或消息,数据库的自增 ID 显然不能满足需求。相关阅读:[为什么要分布式 id ?分布式 id 生成方案有哪些?](docs/system-design/micro-service/分布式id生成方案总结.md)
|
||||||
|
|
||||||
#### ZooKeeper
|
#### 分布式事务
|
||||||
|
|
||||||
> 前两篇文章可能有内容重合部分,推荐都看一遍。
|
**分布式事务就是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。**
|
||||||
|
|
||||||
1. [【入门】ZooKeeper 相关概念总结](docs/system-design/distributed-system/zookeeper/zookeeper-intro.md)
|
简单的说,就是一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
|
||||||
2. [【进阶】ZooKeeper 相关概念总结](docs/system-design/distributed-system/zookeeper/zookeeper-plus.md)
|
|
||||||
3. [【实战】ZooKeeper 实战](docs/system-design/distributed-system/zookeeper/zookeeper-in-action.md)
|
|
||||||
|
|
||||||
### 微服务
|
### 微服务
|
||||||
|
|
||||||
@ -338,18 +359,6 @@ RPC 让调用远程服务调用像调用本地方法那样简单。
|
|||||||
|
|
||||||
相关阅读: **《[如何设计一个高可用系统?要考虑哪些地方?](docs/system-design/high-availability/如何设计一个高可用系统要考虑哪些地方.md)》** 。
|
相关阅读: **《[如何设计一个高可用系统?要考虑哪些地方?](docs/system-design/high-availability/如何设计一个高可用系统要考虑哪些地方.md)》** 。
|
||||||
|
|
||||||
#### CAP 理论
|
|
||||||
|
|
||||||
CAP 也就是 Consistency(一致性)、Availability(可用性)、Partition Tolerance(分区容错性) 这三个单词首字母组合。
|
|
||||||
|
|
||||||
关于 CAP 的详细解读请看:[《CAP理论解读》](docs/system-design/high-availability/CAP理论.md)。
|
|
||||||
|
|
||||||
#### BASE 理论
|
|
||||||
|
|
||||||
**BASE** 是 **Basically Available(基本可用)** 、**Soft-state(软状态)** 和 **Eventually Consistent(最终一致性)** 三个短语的缩写。BASE 理论是对 CAP 中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于 CAP 定理逐步演化而来的,它大大降低了我们对系统的要求。
|
|
||||||
|
|
||||||
关于 CAP 的详细解读请看:[《BASE理论解读》](docs/system-design/high-availability/BASE理论.md)。
|
|
||||||
|
|
||||||
#### 限流
|
#### 限流
|
||||||
|
|
||||||
限流是从用户访问压力的角度来考虑如何应对系统故障。
|
限流是从用户访问压力的角度来考虑如何应对系统故障。
|
||||||
|
|||||||
File diff suppressed because one or more lines are too long
BIN
docs/database/Redis/images/缓存读写策略/cache-aside-read.png
Normal file
BIN
docs/database/Redis/images/缓存读写策略/cache-aside-read.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 70 KiB |
File diff suppressed because one or more lines are too long
BIN
docs/database/Redis/images/缓存读写策略/cache-aside-write.png
Normal file
BIN
docs/database/Redis/images/缓存读写策略/cache-aside-write.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 57 KiB |
1
docs/database/Redis/images/缓存读写策略/read-through.drawio
Normal file
1
docs/database/Redis/images/缓存读写策略/read-through.drawio
Normal file
File diff suppressed because one or more lines are too long
BIN
docs/database/Redis/images/缓存读写策略/read-through.png
Normal file
BIN
docs/database/Redis/images/缓存读写策略/read-through.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 55 KiB |
1
docs/database/Redis/images/缓存读写策略/write-through.drawio
Normal file
1
docs/database/Redis/images/缓存读写策略/write-through.drawio
Normal file
File diff suppressed because one or more lines are too long
BIN
docs/database/Redis/images/缓存读写策略/write-through.png
Normal file
BIN
docs/database/Redis/images/缓存读写策略/write-through.png
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 62 KiB |
@ -1,121 +0,0 @@
|
|||||||
|
|
||||||
|
|
||||||
<!-- @import "[TOC]" {cmd="toc" depthFrom=1 depthTo=6 orderedList=false} -->
|
|
||||||
|
|
||||||
<!-- code_chunk_output -->
|
|
||||||
|
|
||||||
- [1. 缓存的基本思想](#1-缓存的基本思想)
|
|
||||||
- [2. 使用缓存为系统带来了什么问题](#2-使用缓存为系统带来了什么问题)
|
|
||||||
- [3. 本地缓存解决方案](#3-本地缓存解决方案)
|
|
||||||
- [4. 为什么要有分布式缓存?/为什么不直接用本地缓存?](#4-为什么要有分布式缓存为什么不直接用本地缓存)
|
|
||||||
- [5. 缓存读写模式/更新策略](#5-缓存读写模式更新策略)
|
|
||||||
- [5.1. Cache Aside Pattern(旁路缓存模式)](#51-cache-aside-pattern旁路缓存模式)
|
|
||||||
- [5.2. Read/Write Through Pattern(读写穿透)](#52-readwrite-through-pattern读写穿透)
|
|
||||||
- [5.3. Write Behind Pattern(异步缓存写入)](#53-write-behind-pattern异步缓存写入)
|
|
||||||
|
|
||||||
<!-- /code_chunk_output -->
|
|
||||||
|
|
||||||
|
|
||||||
### 1. 缓存的基本思想
|
|
||||||
|
|
||||||
很多朋友,只知道缓存可以提高系统性能以及减少请求相应时间,但是,不太清楚缓存的本质思想是什么。
|
|
||||||
|
|
||||||
缓存的基本思想其实很简单,就是我们非常熟悉的空间换时间。不要把缓存想的太高大上,虽然,它的确对系统的性能提升的性价比非常高。
|
|
||||||
|
|
||||||
其实,我们在学习使用缓存的时候,你会发现缓存的思想实际在操作系统或者其他地方都被大量用到。 比如 **CPU Cache 缓存的是内存数据用于解决 CPU 处理速度和内存不匹配的问题,内存缓存的是硬盘数据用于解决硬盘访问速度过慢的问题。** **再比如操作系统在 页表方案 基础之上引入了 快表 来加速虚拟地址到物理地址的转换。我们可以把快表理解为一种特殊的高速缓冲存储器(Cache)。**
|
|
||||||
|
|
||||||
回归到业务系统来说:**我们为了避免用户在请求数据的时候获取速度过于缓慢,所以我们在数据库之上增加了缓存这一层来弥补。**
|
|
||||||
|
|
||||||
当别人再问你,缓存的基本思想的时候,就把上面 👆 这段话告诉他,我觉得会让别人对你刮目相看。
|
|
||||||
|
|
||||||
### 2. 使用缓存为系统带来了什么问题
|
|
||||||
|
|
||||||
**软件系统设计中没有银弹,往往任何技术的引入都像是把双刃剑。** 你使用的方式得当,就能为系统带来很大的收益。否则,只是费了精力不讨好。
|
|
||||||
|
|
||||||
简单来说,为系统引入缓存之后往往会带来下面这些问题:
|
|
||||||
|
|
||||||
_ps:其实我觉得引入本地缓存来做一些简单业务场景的话,实际带来的代价几乎可以忽略,下面 👇 主要是针对分布式缓存来说的。_
|
|
||||||
|
|
||||||
1. **系统复杂性增加** :引入缓存之后,你要维护缓存和数据库的数据一致性、维护热点缓存等等。
|
|
||||||
2. **系统开发成本往往会增加** :引入缓存意味着系统需要一个单独的缓存服务,这是需要花费相应的成本的,并且这个成本还是很贵的,毕竟耗费的是宝贵的内存。但是,如果你只是简单的使用一下本地缓存存储一下简单的数据,并且数据量不大的话,那么就不需要单独去弄一个缓存服务。
|
|
||||||
|
|
||||||
### 3. 本地缓存解决方案
|
|
||||||
|
|
||||||
_先来聊聊本地缓存,这个实际在很多项目中用的蛮多,特别是单体架构的时候。数据量不大,并且没有分布式要求的话,使用本地缓存还是可以的。_
|
|
||||||
|
|
||||||
常见的单体架构图如下,我们使用 **Nginx** 来做**负载均衡**,部署两个相同的服务到服务器,两个服务使用同一个数据库,并且使用的是本地缓存。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
_那本地缓存的方案有哪些呢?且听 Guide 给你来说一说。_
|
|
||||||
|
|
||||||
**一:JDK 自带的 `HashMap` 和 `ConcurrentHashMap` 了。**
|
|
||||||
|
|
||||||
`ConcurrentHashMap` 可以看作是线程安全版本的 `HashMap` ,两者都是存放 key/value 形式的键值对。但是,大部分场景来说不会使用这两者当做缓存,因为只提供了缓存的功能,并没有提供其他诸如过期时间之类的功能。一个稍微完善一点的缓存框架至少要提供:**过期时间**、**淘汰机制**、**命中率统计**这三点。
|
|
||||||
|
|
||||||
**二: `Ehcache` 、 `Guava Cache` 、 `Spring Cache` 这三者是使用的比较多的本地缓存框架。**
|
|
||||||
|
|
||||||
- `Ehcache` 的话相比于其他两者更加重量。不过,相比于 `Guava Cache` 、 `Spring Cache` 来说, `Ehcache` 支持可以嵌入到 hibernate 和 mybatis 作为多级缓存,并且可以将缓存的数据持久化到本地磁盘中、同时也提供了集群方案(比较鸡肋,可忽略)。
|
|
||||||
- `Guava Cache` 和 `Spring Cache` 两者的话比较像。`Guava` 相比于 `Spring Cache` 的话使用的更多一点,它提供了 API 非常方便我们使用,同时也提供了设置缓存有效时间等功能。它的内部实现也比较干净,很多地方都和 `ConcurrentHashMap` 的思想有异曲同工之妙。
|
|
||||||
- 使用 `Spring Cache` 的注解实现缓存的话,代码会看着很干净和优雅,但是很容易出现问题比如缓存穿透、内存溢出。
|
|
||||||
|
|
||||||
**三: 后起之秀 Caffeine。**
|
|
||||||
|
|
||||||
相比于 `Guava` 来说 `Caffeine` 在各个方面比如性能要更加优秀,一般建议使用其来替代 `Guava` 。并且, `Guava` 和 `Caffeine` 的使用方式很像!
|
|
||||||
|
|
||||||
本地缓存固然好,但是缺陷也很明显,比如多个相同服务之间的本地缓存的数据无法共享。
|
|
||||||
|
|
||||||
### 4. 为什么要有分布式缓存?/为什么不直接用本地缓存?
|
|
||||||
|
|
||||||
本地的缓存的优势非常明显:**低依赖**、**轻量**、**简单**、**成本低**。
|
|
||||||
|
|
||||||
但是,本地缓存
|
|
||||||
|
|
||||||
1. **本地缓存对分布式架构支持不友好**,比如同一个相同的服务部署在多台机器上的时候,各个服务之间的缓存是无法共享的,因为本地缓存只在当前机器上有。
|
|
||||||
2. **本地缓存容量受服务部署所在的机器限制明显。** 如果当前系统服务所耗费的内存多,那么本地缓存可用的容量就很少。
|
|
||||||
|
|
||||||
**我们可以把分布式缓存(Distributed Cache) 看作是一种内存数据库的服务,它的最终作用就是提供缓存数据的服务。**
|
|
||||||
|
|
||||||
如下图所示,就是一个简单的使用分布式缓存的架构图。我们使用 Nginx 来做负载均衡,部署两个相同的服务到服务器,两个服务使用同一个数据库和缓存。
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
2.
|
|
||||||
|
|
||||||
使用分布式缓存之后,缓存部署在一台单独的服务器上,即使同一个相同的服务部署在再多机器上,也是使用的同一份缓存。 并且,单独的分布式缓存服务的性能、容量和提供的功能都要更加强大。
|
|
||||||
|
|
||||||
使用分布式缓存的缺点呢,也很显而易见,那就是你需要为分布式缓存引入额外的服务比如 Redis 或 Memcached,你需要单独保证 Redis 或 Memcached 服务的高可用。
|
|
||||||
|
|
||||||
### 5. 缓存读写模式/更新策略
|
|
||||||
|
|
||||||
**下面介绍到的三种模式各有优劣,不存在最佳模式,根据具体的业务场景选择适合自己的缓存读写模式。**
|
|
||||||
|
|
||||||
#### 5.1. Cache Aside Pattern(旁路缓存模式)
|
|
||||||
|
|
||||||
1. 写:更新 DB,然后直接删除 cache 。
|
|
||||||
2. 读:从 cache 中读取数据,读取到就直接返回,读取不到的话,就从 DB 中取数据返回,然后再把数据放到 cache 中。
|
|
||||||
|
|
||||||
Cache Aside Pattern 中服务端需要同时维系 DB 和 cache,并且是以 DB 的结果为准。另外,Cache Aside Pattern 有首次请求数据一定不在 cache 的问题,对于热点数据可以提前放入缓存中。
|
|
||||||
|
|
||||||
**Cache Aside Pattern 是我们平时使用比较多的一个缓存读写模式,比较适合读请求比较多的场景。**
|
|
||||||
|
|
||||||
#### 5.2. Read/Write Through Pattern(读写穿透)
|
|
||||||
|
|
||||||
Read/Write Through 套路是:服务端把 cache 视为主要数据存储,从中读取数据并将数据写入其中。cache 服务负责将此数据读取和写入 DB,从而减轻了应用程序的职责。
|
|
||||||
|
|
||||||
1. 写(Write Through):先查 cache,cache 中不存在,直接更新 DB。 cache 中存在,则先更新 cache,然后 cache 服务自己更新 DB(**同步更新 cache 和 DB**)。
|
|
||||||
2. 读(Read Through): 从 cache 中读取数据,读取到就直接返回 。读取不到的话,先从 DB 加载,写入到 cache 后返回响应。
|
|
||||||
|
|
||||||
Read-Through Pattern 实际只是在 Cache-Aside Pattern 之上进行了封装。在 Cache-Aside Pattern 下,发生读请求的时候,如果 cache 中不存在对应的数据,是由客户端自己负责把数据写入 cache,而 Read Through Pattern 则是 cache 服务自己来写入缓存的,这对客户端是透明的。
|
|
||||||
|
|
||||||
和 Cache Aside Pattern 一样, Read-Through Pattern 也有首次请求数据一定不再 cache 的问题,对于热点数据可以提前放入缓存中。
|
|
||||||
|
|
||||||
#### 5.3. Write Behind Pattern(异步缓存写入)
|
|
||||||
|
|
||||||
Write Behind Pattern 和 Read/Write Through Pattern 很相似,两者都是由 cache 服务来负责 cache 和 DB 的读写。
|
|
||||||
|
|
||||||
但是,两个又有很大的不同:**Read/Write Through 是同步更新 cache 和 DB,而 Write Behind Caching 则是只更新缓存,不直接更新 DB,而是改为异步批量的方式来更新 DB。**
|
|
||||||
|
|
||||||
**Write Behind Pattern 下 DB 的写性能非常高,尤其适合一些数据经常变化的业务场景比如说一篇文章的点赞数量、阅读数量。** 往常一篇文章被点赞 500 次的话,需要重复修改 500 次 DB,但是在 Write Behind Pattern 下可能只需要修改一次 DB 就可以了。
|
|
||||||
|
|
||||||
但是,这种模式同样也给 DB 和 Cache 一致性带来了新的考验,很多时候如果数据还没异步更新到 DB 的话,Cache 服务宕机就 gg 了。
|
|
||||||
@ -106,7 +106,7 @@
|
|||||||
request.getRequestDispatcher("login_success.jsp").forward(request, response);
|
request.getRequestDispatcher("login_success.jsp").forward(request, response);
|
||||||
```
|
```
|
||||||
|
|
||||||
**重定向(Redirect)** 是利用服务器返回的状态码来实现的。客户端浏览器请求服务器的时候,服务器会返回一个状态码。服务器通过 HttpServletRequestResponse 的 setStatus(int status)方法设置状态码。如果服务器返回 301 或者 302,则浏览器会到新的网址重新请求该资源。
|
**重定向(Redirect)** 是利用服务器返回的状态码来实现的。客户端浏览器请求服务器的时候,服务器会返回一个状态码。服务器通过 HttpServletResponse 的 setStatus(int status)方法设置状态码。如果服务器返回 301 或者 302,则浏览器会到新的网址重新请求该资源。
|
||||||
|
|
||||||
1. **从地址栏显示来说**:forward 是服务器请求资源,服务器直接访问目标地址的 URL,把那个 URL 的响应内容读取过来,然后把这些内容再发给浏览器。浏览器根本不知道服务器发送的内容从哪里来的,所以它的地址栏还是原来的地址。redirect 是服务端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址。所以地址栏显示的是新的 URL。
|
1. **从地址栏显示来说**:forward 是服务器请求资源,服务器直接访问目标地址的 URL,把那个 URL 的响应内容读取过来,然后把这些内容再发给浏览器。浏览器根本不知道服务器发送的内容从哪里来的,所以它的地址栏还是原来的地址。redirect 是服务端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址。所以地址栏显示的是新的 URL。
|
||||||
2. **从数据共享来说**:forward:转发页面和转发到的页面可以共享 request 里面的数据。redirect:不能共享数据。
|
2. **从数据共享来说**:forward:转发页面和转发到的页面可以共享 request 里面的数据。redirect:不能共享数据。
|
||||||
|
|||||||
@ -11,10 +11,10 @@
|
|||||||
- [2. NIO \(New I/O\)](#2-nio-new-io)
|
- [2. NIO \(New I/O\)](#2-nio-new-io)
|
||||||
- [2.1 NIO 简介](#21-nio-简介)
|
- [2.1 NIO 简介](#21-nio-简介)
|
||||||
- [2.2 NIO的特性/NIO与IO区别](#22-nio的特性nio与io区别)
|
- [2.2 NIO的特性/NIO与IO区别](#22-nio的特性nio与io区别)
|
||||||
- [1)Non-blocking IO(非阻塞IO)](#1non-blocking-io(非阻塞io))
|
- [1)Non-blocking IO(非阻塞IO)](#1non-blocking-io非阻塞io)
|
||||||
- [2)Buffer\(缓冲区\)](#2buffer缓冲区)
|
- [2)Buffer\(缓冲区\)](#2buffer缓冲区)
|
||||||
- [3)Channel \(通道\)](#3channel-通道)
|
- [3)Channel \(通道\)](#3channel-通道)
|
||||||
- [4)Selectors\(选择器\)](#4selectors选择器)
|
- [4)Selectors\(选择器\)](#4selector-选择器)
|
||||||
- [2.3 NIO 读数据和写数据方式](#23-nio-读数据和写数据方式)
|
- [2.3 NIO 读数据和写数据方式](#23-nio-读数据和写数据方式)
|
||||||
- [2.4 NIO核心组件简单介绍](#24-nio核心组件简单介绍)
|
- [2.4 NIO核心组件简单介绍](#24-nio核心组件简单介绍)
|
||||||
- [2.5 代码示例](#25-代码示例)
|
- [2.5 代码示例](#25-代码示例)
|
||||||
@ -37,7 +37,7 @@
|
|||||||
> 当你同步执行某项任务时,你需要等待其完成才能继续执行其他任务。当你异步执行某些操作时,你可以在完成另一个任务之前继续进行。
|
> 当你同步执行某项任务时,你需要等待其完成才能继续执行其他任务。当你异步执行某些操作时,你可以在完成另一个任务之前继续进行。
|
||||||
|
|
||||||
- **同步** :两个同步任务相互依赖,并且一个任务必须以依赖于另一任务的某种方式执行。 比如在`A->B`事件模型中,你需要先完成 A 才能执行B。 再换句话说,同步调用中被调用者未处理完请求之前,调用不返回,调用者会一直等待结果的返回。
|
- **同步** :两个同步任务相互依赖,并且一个任务必须以依赖于另一任务的某种方式执行。 比如在`A->B`事件模型中,你需要先完成 A 才能执行B。 再换句话说,同步调用中被调用者未处理完请求之前,调用不返回,调用者会一直等待结果的返回。
|
||||||
- **异步**: 两个异步的任务完全独立的,一方的执行不需要等待另外一方的执行。再换句话说,异步调用种一调用就返回结果不需要等待结果返回,当结果返回的时候通过回调函数或者其他方式拿着结果再做相关事情,
|
- **异步**: 两个异步的任务是完全独立的,一方的执行不需要等待另外一方的执行。再换句话说,异步调用中一调用就返回结果不需要等待结果返回,当结果返回的时候通过回调函数或者其他方式拿着结果再做相关事情,
|
||||||
|
|
||||||
**阻塞和非阻塞**
|
**阻塞和非阻塞**
|
||||||
|
|
||||||
|
|||||||
@ -53,8 +53,6 @@
|
|||||||
- [2.3. 修饰符](#23-修饰符)
|
- [2.3. 修饰符](#23-修饰符)
|
||||||
- [2.3.1. 在一个静态方法内调用一个非静态成员为什么是非法的?](#231-在一个静态方法内调用一个非静态成员为什么是非法的)
|
- [2.3.1. 在一个静态方法内调用一个非静态成员为什么是非法的?](#231-在一个静态方法内调用一个非静态成员为什么是非法的)
|
||||||
- [2.3.2. 静态方法和实例方法有何不同](#232-静态方法和实例方法有何不同)
|
- [2.3.2. 静态方法和实例方法有何不同](#232-静态方法和实例方法有何不同)
|
||||||
- [2.4. 接口和抽象类](#24-接口和抽象类)
|
|
||||||
- [2.4.1. 接口和抽象类的区别是什么?](#241-接口和抽象类的区别是什么)
|
|
||||||
- [2.5. 其它重要知识点](#25-其它重要知识点)
|
- [2.5. 其它重要知识点](#25-其它重要知识点)
|
||||||
- [2.5.1. String StringBuffer 和 StringBuilder 的区别是什么? String 为什么是不可变的?](#251-string-stringbuffer-和-stringbuilder-的区别是什么-string-为什么是不可变的)
|
- [2.5.1. String StringBuffer 和 StringBuilder 的区别是什么? String 为什么是不可变的?](#251-string-stringbuffer-和-stringbuilder-的区别是什么-string-为什么是不可变的)
|
||||||
- [2.5.2. Object 类的常见方法总结](#252-object-类的常见方法总结)
|
- [2.5.2. Object 类的常见方法总结](#252-object-类的常见方法总结)
|
||||||
@ -798,7 +796,6 @@ Java 程序设计语言对对象采用的不是引用调用,实际上,对象
|
|||||||
| 发生阶段 | 编译期 | 运行期 |
|
| 发生阶段 | 编译期 | 运行期 |
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
**方法的重写要遵循“两同两小一大”**(以下内容摘录自《疯狂 Java 讲义》,[issue#892](https://github.com/Snailclimb/JavaGuide/issues/892) ):
|
**方法的重写要遵循“两同两小一大”**(以下内容摘录自《疯狂 Java 讲义》,[issue#892](https://github.com/Snailclimb/JavaGuide/issues/892) ):
|
||||||
|
|
||||||
- “两同”即方法名相同、形参列表相同;
|
- “两同”即方法名相同、形参列表相同;
|
||||||
@ -986,27 +983,6 @@ public class Student {
|
|||||||
|
|
||||||
2. 静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),而不允许访问实例成员变量和实例方法;实例方法则无此限制。
|
2. 静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),而不允许访问实例成员变量和实例方法;实例方法则无此限制。
|
||||||
|
|
||||||
### 2.4. 接口和抽象类
|
|
||||||
|
|
||||||
#### 2.4.1. 接口和抽象类的区别是什么?
|
|
||||||
|
|
||||||
1. 接口的方法默认是 public,所有方法在接口中不能有实现(Java 8 开始接口方法可以有默认实现),而抽象类可以有非抽象的方法。
|
|
||||||
2. 接口中除了 static、final 变量,不能有其他变量,而抽象类中则不一定。
|
|
||||||
3. 一个类可以实现多个接口,但只能实现一个抽象类。接口自己本身可以通过 extends 关键字扩展多个接口。
|
|
||||||
4. 接口方法默认修饰符是 public,抽象方法可以有 public、protected 和 default 这些修饰符(抽象方法就是为了被重写所以不能使用 private 关键字修饰!)。
|
|
||||||
5. 从设计层面来说,抽象是对类的抽象,是一种模板设计,而接口是对行为的抽象,是一种行为的规范。
|
|
||||||
|
|
||||||
> 备注:
|
|
||||||
>
|
|
||||||
> 1. 在 JDK8 中,接口也可以定义静态方法,可以直接用接口名调用。实现类和实现是不可以调用的。如果同时实现两个接口,接口中定义了一样的默认方法,则必须重写,不然会报错。(详见 issue:[https://github.com/Snailclimb/JavaGuide/issues/146](https://github.com/Snailclimb/JavaGuide/issues/146)。
|
|
||||||
> 2. jdk9 的接口被允许定义私有方法 。
|
|
||||||
|
|
||||||
总结一下 jdk7~jdk9 Java 中接口概念的变化([相关阅读](https://www.geeksforgeeks.org/private-methods-java-9-interfaces/)):
|
|
||||||
|
|
||||||
1. 在 jdk 7 或更早版本中,接口里面只能有常量变量和抽象方法。这些接口方法必须由选择实现接口的类实现。
|
|
||||||
2. jdk8 的时候接口可以有默认方法和静态方法功能。
|
|
||||||
3. Jdk 9 在接口中引入了私有方法和私有静态方法。
|
|
||||||
|
|
||||||
### 2.5. 其它重要知识点
|
### 2.5. 其它重要知识点
|
||||||
|
|
||||||
#### 2.5.1. String StringBuffer 和 StringBuilder 的区别是什么? String 为什么是不可变的?
|
#### 2.5.1. String StringBuffer 和 StringBuilder 的区别是什么? String 为什么是不可变的?
|
||||||
|
|||||||
@ -10,11 +10,6 @@
|
|||||||
- [1.1.3.3. Map](#1133-map)
|
- [1.1.3.3. Map](#1133-map)
|
||||||
- [1.1.4. 如何选用集合?](#114-如何选用集合)
|
- [1.1.4. 如何选用集合?](#114-如何选用集合)
|
||||||
- [1.1.5. 为什么要使用集合?](#115-为什么要使用集合)
|
- [1.1.5. 为什么要使用集合?](#115-为什么要使用集合)
|
||||||
- [1.1.6. Iterator 迭代器](#116-iterator-迭代器)
|
|
||||||
- [1.1.6.1. 迭代器 Iterator 是什么?](#1161-迭代器-iterator-是什么)
|
|
||||||
- [1.1.6.2. 迭代器 Iterator 有啥用?](#1162-迭代器-iterator-有啥用)
|
|
||||||
- [1.1.6.3. 如何使用?](#1163-如何使用)
|
|
||||||
- [1.1.7. 有哪些集合是线程不安全的?怎么解决呢?](#117-有哪些集合是线程不安全的怎么解决呢)
|
|
||||||
- [1.2. Collection 子接口之 List](#12-collection-子接口之-list)
|
- [1.2. Collection 子接口之 List](#12-collection-子接口之-list)
|
||||||
- [1.2.1. Arraylist 和 Vector 的区别?](#121-arraylist-和-vector-的区别)
|
- [1.2.1. Arraylist 和 Vector 的区别?](#121-arraylist-和-vector-的区别)
|
||||||
- [1.2.2. Arraylist 与 LinkedList 区别?](#122-arraylist-与-linkedlist-区别)
|
- [1.2.2. Arraylist 与 LinkedList 区别?](#122-arraylist-与-linkedlist-区别)
|
||||||
@ -46,13 +41,6 @@
|
|||||||
- [1.5.1. 排序操作](#151-排序操作)
|
- [1.5.1. 排序操作](#151-排序操作)
|
||||||
- [1.5.2. 查找,替换操作](#152-查找替换操作)
|
- [1.5.2. 查找,替换操作](#152-查找替换操作)
|
||||||
- [1.5.3. 同步控制](#153-同步控制)
|
- [1.5.3. 同步控制](#153-同步控制)
|
||||||
- [1.6. 其他重要问题](#16-其他重要问题)
|
|
||||||
- [1.6.1. 什么是快速失败(fail-fast)?](#161-什么是快速失败fail-fast)
|
|
||||||
- [1.6.2. 什么是安全失败(fail-safe)呢?](#162-什么是安全失败fail-safe呢)
|
|
||||||
- [1.6.3. Arrays.asList()避坑指南](#163-arraysaslist避坑指南)
|
|
||||||
- [1.6.3.1. 简介](#1631-简介)
|
|
||||||
- [1.6.3.2. 《阿里巴巴 Java 开发手册》对其的描述](#1632-阿里巴巴-java-开发手册对其的描述)
|
|
||||||
- [1.6.3.3. 使用时的注意事项总结](#1633-使用时的注意事项总结)
|
|
||||||
|
|
||||||
<!-- /TOC -->
|
<!-- /TOC -->
|
||||||
|
|
||||||
@ -112,58 +100,7 @@
|
|||||||
因为我们在实际开发中,存储的数据的类型是多种多样的,于是,就出现了“集合”,集合同样也是用来存储多个数据的。
|
因为我们在实际开发中,存储的数据的类型是多种多样的,于是,就出现了“集合”,集合同样也是用来存储多个数据的。
|
||||||
|
|
||||||
数组的缺点是一旦声明之后,长度就不可变了;同时,声明数组时的数据类型也决定了该数组存储的数据的类型;而且,数组存储的数据是有序的、可重复的,特点单一。
|
数组的缺点是一旦声明之后,长度就不可变了;同时,声明数组时的数据类型也决定了该数组存储的数据的类型;而且,数组存储的数据是有序的、可重复的,特点单一。
|
||||||
但是集合提高了数据存储的灵活性,Java 集合不仅可以用来存储不同类型不同数量的对象,还可以保存具有映射关系的数据
|
但是集合提高了数据存储的灵活性,Java 集合不仅可以用来存储不同类型不同数量的对象,还可以保存具有映射关系的数据。
|
||||||
|
|
||||||
### 1.1.6. Iterator 迭代器
|
|
||||||
|
|
||||||
#### 1.1.6.1. 迭代器 Iterator 是什么?
|
|
||||||
|
|
||||||
```java
|
|
||||||
public interface Iterator<E> {
|
|
||||||
//集合中是否还有元素
|
|
||||||
boolean hasNext();
|
|
||||||
//获得集合中的下一个元素
|
|
||||||
E next();
|
|
||||||
......
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
`Iterator` 对象称为迭代器(设计模式的一种),迭代器可以对集合进行遍历,但每一个集合内部的数据结构可能是不尽相同的,所以每一个集合存和取都很可能是不一样的,虽然我们可以人为地在每一个类中定义 `hasNext()` 和 `next()` 方法,但这样做会让整个集合体系过于臃肿。于是就有了迭代器。
|
|
||||||
|
|
||||||
迭代器是将这样的方法抽取出接口,然后在每个类的内部,定义自己迭代方式,这样做就规定了整个集合体系的遍历方式都是 `hasNext()`和`next()`方法,使用者不用管怎么实现的,会用即可。迭代器的定义为:提供一种方法访问一个容器对象中各个元素,而又不需要暴露该对象的内部细节。
|
|
||||||
|
|
||||||
#### 1.1.6.2. 迭代器 Iterator 有啥用?
|
|
||||||
|
|
||||||
`Iterator` 主要是用来遍历集合用的,它的特点是更加安全,因为它可以确保,在当前遍历的集合元素被更改的时候,就会抛出 `ConcurrentModificationException` 异常。
|
|
||||||
|
|
||||||
#### 1.1.6.3. 如何使用?
|
|
||||||
|
|
||||||
我们通过使用迭代器来遍历 `HashMap`,演示一下 迭代器 Iterator 的使用。
|
|
||||||
|
|
||||||
```java
|
|
||||||
|
|
||||||
Map<Integer, String> map = new HashMap();
|
|
||||||
map.put(1, "Java");
|
|
||||||
map.put(2, "C++");
|
|
||||||
map.put(3, "PHP");
|
|
||||||
Iterator<Map.Entry<Integer, String>> iterator = map.entrySet().iterator();
|
|
||||||
while (iterator.hasNext()) {
|
|
||||||
Map.Entry<Integer, String> entry = iterator.next();
|
|
||||||
System.out.println(entry.getKey() + entry.getValue());
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
### 1.1.7. 有哪些集合是线程不安全的?怎么解决呢?
|
|
||||||
|
|
||||||
我们常用的 `Arraylist` ,`LinkedList`,`Hashmap`,`HashSet`,`TreeSet`,`TreeMap`,`PriorityQueue` 都不是线程安全的。解决办法很简单,可以使用线程安全的集合来代替。
|
|
||||||
|
|
||||||
如果你要使用线程安全的集合的话, `java.util.concurrent` 包中提供了很多并发容器供你使用:
|
|
||||||
|
|
||||||
1. `ConcurrentHashMap`: 可以看作是线程安全的 `HashMap`
|
|
||||||
2. `CopyOnWriteArrayList`:可以看作是线程安全的 `ArrayList`,在读多写少的场合性能非常好,远远好于 `Vector`.
|
|
||||||
3. `ConcurrentLinkedQueue`:高效的并发队列,使用链表实现。可以看做一个线程安全的 `LinkedList`,这是一个非阻塞队列。
|
|
||||||
4. `BlockingQueue`: 这是一个接口,JDK 内部通过链表、数组等方式实现了这个接口。表示阻塞队列,非常适合用于作为数据共享的通道。
|
|
||||||
5. `ConcurrentSkipListMap` :跳表的实现。这是一个`Map`,使用跳表的数据结构进行快速查找。
|
|
||||||
|
|
||||||
## 1.2. Collection 子接口之 List
|
## 1.2. Collection 子接口之 List
|
||||||
|
|
||||||
@ -217,7 +154,7 @@ public interface RandomAccess {
|
|||||||
|
|
||||||
### 1.2.3. 说一说 ArrayList 的扩容机制吧
|
### 1.2.3. 说一说 ArrayList 的扩容机制吧
|
||||||
|
|
||||||
详见笔主的这篇文章:[通过源码一步一步分析 ArrayList 扩容机制](https://github.com/Snailclimb/JavaGuide/blob/master/docs/java/collection/ArrayList-Grow.md)
|
详见笔主的这篇文章:[通过源码一步一步分析 ArrayList 扩容机制](https://snailclimb.gitee.io/javaguide/#/docs/java/collection/ArrayList%E6%BA%90%E7%A0%81+%E6%89%A9%E5%AE%B9%E6%9C%BA%E5%88%B6%E5%88%86%E6%9E%90)
|
||||||
|
|
||||||
## 1.3. Collection 子接口之 Set
|
## 1.3. Collection 子接口之 Set
|
||||||
|
|
||||||
@ -675,170 +612,6 @@ synchronizedMap(Map<K,V> m) //返回由指定映射支持的同步(线程安
|
|||||||
synchronizedSet(Set<T> s) //返回指定 set 支持的同步(线程安全的)set。
|
synchronizedSet(Set<T> s) //返回指定 set 支持的同步(线程安全的)set。
|
||||||
```
|
```
|
||||||
|
|
||||||
## 1.6. 其他重要问题
|
|
||||||
|
|
||||||
### 1.6.1. 什么是快速失败(fail-fast)?
|
|
||||||
|
|
||||||
**快速失败(fail-fast)** 是 Java 集合的一种错误检测机制。**在使用迭代器对集合进行遍历的时候,我们在多线程下操作非安全失败(fail-safe)的集合类可能就会触发 fail-fast 机制,导致抛出 `ConcurrentModificationException` 异常。 另外,在单线程下,如果在遍历过程中对集合对象的内容进行了修改的话也会触发 fail-fast 机制。**
|
|
||||||
|
|
||||||
> 注:增强 for 循环也是借助迭代器进行遍历。
|
|
||||||
|
|
||||||
举个例子:多线程下,如果线程 1 正在对集合进行遍历,此时线程 2 对集合进行修改(增加、删除、修改),或者线程 1 在遍历过程中对集合进行修改,都会导致线程 1 抛出 `ConcurrentModificationException` 异常。
|
|
||||||
|
|
||||||
**为什么呢?**
|
|
||||||
|
|
||||||
每当迭代器使用 `hashNext()`/`next()`遍历下一个元素之前,都会检测 `modCount` 变量是否为 `expectedModCount` 值,是的话就返回遍历;否则抛出异常,终止遍历。
|
|
||||||
|
|
||||||
如果我们在集合被遍历期间对其进行修改的话,就会改变 `modCount` 的值,进而导致 `modCount != expectedModCount` ,进而抛出 `ConcurrentModificationException` 异常。
|
|
||||||
|
|
||||||
> 注:通过 `Iterator` 的方法修改集合的话会修改到 `expectedModCount` 的值,所以不会抛出异常。
|
|
||||||
|
|
||||||
```java
|
|
||||||
final void checkForComodification() {
|
|
||||||
if (modCount != expectedModCount)
|
|
||||||
throw new ConcurrentModificationException();
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
好吧!相信大家已经搞懂了快速失败(fail-fast)机制以及它的原理。
|
|
||||||
|
|
||||||
我们再来趁热打铁,看一个阿里巴巴手册相关的规定:
|
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
有了前面讲的基础,我们应该知道:使用 `Iterator` 提供的 `remove` 方法,可以修改到 `expectedModCount` 的值。所以,才不会再抛出`ConcurrentModificationException` 异常。
|
|
||||||
|
|
||||||
### 1.6.2. 什么是安全失败(fail-safe)呢?
|
|
||||||
|
|
||||||
明白了快速失败(fail-fast)之后,安全失败(fail-safe)我们就很好理解了。
|
|
||||||
|
|
||||||
采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。所以,在遍历过程中对原集合所作的修改并不能被迭代器检测到,故不会抛 `ConcurrentModificationException` 异常。
|
|
||||||
|
|
||||||
### 1.6.3. Arrays.asList()避坑指南
|
|
||||||
|
|
||||||
最近使用`Arrays.asList()`遇到了一些坑,然后在网上看到这篇文章:[Java Array to List Examples](http://javadevnotes.com/java-array-to-list-examples) 感觉挺不错的,但是还不是特别全面。所以,自己对于这块小知识点进行了简单的总结。
|
|
||||||
|
|
||||||
#### 1.6.3.1. 简介
|
|
||||||
|
|
||||||
`Arrays.asList()`在平时开发中还是比较常见的,我们可以使用它将一个数组转换为一个 List 集合。
|
|
||||||
|
|
||||||
```java
|
|
||||||
String[] myArray = { "Apple", "Banana", "Orange" };
|
|
||||||
List<String> myList = Arrays.asList(myArray);
|
|
||||||
//上面两个语句等价于下面一条语句
|
|
||||||
List<String> myList = Arrays.asList("Apple","Banana", "Orange");
|
|
||||||
```
|
|
||||||
|
|
||||||
JDK 源码对于这个方法的说明:
|
|
||||||
|
|
||||||
```java
|
|
||||||
/**
|
|
||||||
*返回由指定数组支持的固定大小的列表。此方法作为基于数组和基于集合的API之间的桥梁,与 Collection.toArray()结合使用。返回的List是可序列化并实现RandomAccess接口。
|
|
||||||
*/
|
|
||||||
public static <T> List<T> asList(T... a) {
|
|
||||||
return new ArrayList<>(a);
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
#### 1.6.3.2. 《阿里巴巴 Java 开发手册》对其的描述
|
|
||||||
|
|
||||||
`Arrays.asList()`将数组转换为集合后,底层其实还是数组,《阿里巴巴 Java 开发手册》对于这个方法有如下描述:
|
|
||||||
|
|
||||||
方法.png>)
|
|
||||||
|
|
||||||
#### 1.6.3.3. 使用时的注意事项总结
|
|
||||||
|
|
||||||
**传递的数组必须是对象数组,而不是基本类型。**
|
|
||||||
|
|
||||||
`Arrays.asList()`是泛型方法,传入的对象必须是对象数组。
|
|
||||||
|
|
||||||
```java
|
|
||||||
int[] myArray = { 1, 2, 3 };
|
|
||||||
List myList = Arrays.asList(myArray);
|
|
||||||
System.out.println(myList.size());//1
|
|
||||||
System.out.println(myList.get(0));//数组地址值
|
|
||||||
System.out.println(myList.get(1));//报错:ArrayIndexOutOfBoundsException
|
|
||||||
int [] array=(int[]) myList.get(0);
|
|
||||||
System.out.println(array[0]);//1
|
|
||||||
```
|
|
||||||
|
|
||||||
当传入一个原生数据类型数组时,`Arrays.asList()` 的真正得到的参数就不是数组中的元素,而是数组对象本身!此时 List 的唯一元素就是这个数组,这也就解释了上面的代码。
|
|
||||||
|
|
||||||
我们使用包装类型数组就可以解决这个问题。
|
|
||||||
|
|
||||||
```java
|
|
||||||
Integer[] myArray = { 1, 2, 3 };
|
|
||||||
```
|
|
||||||
|
|
||||||
**使用集合的修改方法:`add()`、`remove()`、`clear()`会抛出异常。**
|
|
||||||
|
|
||||||
```java
|
|
||||||
List myList = Arrays.asList(1, 2, 3);
|
|
||||||
myList.add(4);//运行时报错:UnsupportedOperationException
|
|
||||||
myList.remove(1);//运行时报错:UnsupportedOperationException
|
|
||||||
myList.clear();//运行时报错:UnsupportedOperationException
|
|
||||||
```
|
|
||||||
|
|
||||||
`Arrays.asList()` 方法返回的并不是 `java.util.ArrayList` ,而是 `java.util.Arrays` 的一个内部类,这个内部类并没有实现集合的修改方法或者说并没有重写这些方法。
|
|
||||||
|
|
||||||
```java
|
|
||||||
List myList = Arrays.asList(1, 2, 3);
|
|
||||||
System.out.println(myList.getClass());//class java.util.Arrays$ArrayList
|
|
||||||
```
|
|
||||||
|
|
||||||
下图是`java.util.Arrays$ArrayList`的简易源码,我们可以看到这个类重写的方法有哪些。
|
|
||||||
|
|
||||||
```java
|
|
||||||
private static class ArrayList<E> extends AbstractList<E>
|
|
||||||
implements RandomAccess, java.io.Serializable
|
|
||||||
{
|
|
||||||
...
|
|
||||||
|
|
||||||
@Override
|
|
||||||
public E get(int index) {
|
|
||||||
...
|
|
||||||
}
|
|
||||||
|
|
||||||
@Override
|
|
||||||
public E set(int index, E element) {
|
|
||||||
...
|
|
||||||
}
|
|
||||||
|
|
||||||
@Override
|
|
||||||
public int indexOf(Object o) {
|
|
||||||
...
|
|
||||||
}
|
|
||||||
|
|
||||||
@Override
|
|
||||||
public boolean contains(Object o) {
|
|
||||||
...
|
|
||||||
}
|
|
||||||
|
|
||||||
@Override
|
|
||||||
public void forEach(Consumer<? super E> action) {
|
|
||||||
...
|
|
||||||
}
|
|
||||||
|
|
||||||
@Override
|
|
||||||
public void replaceAll(UnaryOperator<E> operator) {
|
|
||||||
...
|
|
||||||
}
|
|
||||||
|
|
||||||
@Override
|
|
||||||
public void sort(Comparator<? super E> c) {
|
|
||||||
...
|
|
||||||
}
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
我们再看一下`java.util.AbstractList`的`remove()`方法,这样我们就明白为啥会抛出`UnsupportedOperationException`。
|
|
||||||
|
|
||||||
```java
|
|
||||||
public E remove(int index) {
|
|
||||||
throw new UnsupportedOperationException();
|
|
||||||
}
|
|
||||||
```
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
**《Java面试突击》:** Java 程序员面试必备的《Java面试突击》V3.0 PDF 版本扫码关注下面的公众号,在后台回复 **"面试突击"** 即可免费领取!
|
**《Java面试突击》:** Java 程序员面试必备的《Java面试突击》V3.0 PDF 版本扫码关注下面的公众号,在后台回复 **"面试突击"** 即可免费领取!
|
||||||
|
|||||||
@ -843,14 +843,14 @@ Atomic 翻译成中文是原子的意思。在化学上,我们知道原子是
|
|||||||
**引用类型**
|
**引用类型**
|
||||||
|
|
||||||
- AtomicReference:引用类型原子类
|
- AtomicReference:引用类型原子类
|
||||||
- AtomicStampedReference:原子更新引用类型里的字段原子类
|
- AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
|
||||||
- AtomicMarkableReference :原子更新带有标记位的引用类型
|
- AtomicMarkableReference :原子更新带有标记位的引用类型
|
||||||
|
|
||||||
**对象的属性修改类型**
|
**对象的属性修改类型**
|
||||||
|
|
||||||
- AtomicIntegerFieldUpdater:原子更新整形字段的更新器
|
- AtomicIntegerFieldUpdater:原子更新整形字段的更新器
|
||||||
- AtomicLongFieldUpdater:原子更新长整形字段的更新器
|
- AtomicLongFieldUpdater:原子更新长整形字段的更新器
|
||||||
- AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于解决原子的更新数据和数据的版本号,可以解决使用 CAS 进行原子更新时可能出现的 ABA 问题。
|
- AtomicReferenceFieldUpdater:原子更新引用类型字段的更新器
|
||||||
|
|
||||||
### 5.3. 讲讲 AtomicInteger 的使用
|
### 5.3. 讲讲 AtomicInteger 的使用
|
||||||
|
|
||||||
@ -968,12 +968,12 @@ protected final boolean compareAndSetState(int expect, int update) {
|
|||||||
|
|
||||||
**AQS 定义两种资源共享方式**
|
**AQS 定义两种资源共享方式**
|
||||||
|
|
||||||
- **Exclusive**(独占):只有一个线程能执行,如 ReentrantLock。又可分为公平锁和非公平锁:
|
- **Exclusive**(独占):只有一个线程能执行,如 `ReentrantLock`。又可分为公平锁和非公平锁:
|
||||||
- 公平锁:按照线程在队列中的排队顺序,先到者先拿到锁
|
- 公平锁:按照线程在队列中的排队顺序,先到者先拿到锁
|
||||||
- 非公平锁:当线程要获取锁时,无视队列顺序直接去抢锁,谁抢到就是谁的
|
- 非公平锁:当线程要获取锁时,无视队列顺序直接去抢锁,谁抢到就是谁的
|
||||||
- **Share**(共享):多个线程可同时执行,如 Semaphore/CountDownLatch。Semaphore、CountDownLatch、 CyclicBarrier、ReadWriteLock 我们都会在后面讲到。
|
- **Share**(共享):多个线程可同时执行,如` CountDownLatch`、`Semaphore`、`CountDownLatch`、 `CyclicBarrier`、`ReadWriteLock` 我们都会在后面讲到。
|
||||||
|
|
||||||
ReentrantReadWriteLock 可以看成是组合式,因为 ReentrantReadWriteLock 也就是读写锁允许多个线程同时对某一资源进行读。
|
`ReentrantReadWriteLock` 可以看成是组合式,因为 `ReentrantReadWriteLock` 也就是读写锁允许多个线程同时对某一资源进行读。
|
||||||
|
|
||||||
不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS 已经在顶层实现好了。
|
不同的自定义同步器争用共享资源的方式也不同。自定义同步器在实现时只需要实现共享资源 state 的获取与释放方式即可,至于具体线程等待队列的维护(如获取资源失败入队/唤醒出队等),AQS 已经在顶层实现好了。
|
||||||
|
|
||||||
@ -981,7 +981,7 @@ ReentrantReadWriteLock 可以看成是组合式,因为 ReentrantReadWriteLock
|
|||||||
|
|
||||||
同步器的设计是基于模板方法模式的,如果需要自定义同步器一般的方式是这样(模板方法模式很经典的一个应用):
|
同步器的设计是基于模板方法模式的,如果需要自定义同步器一般的方式是这样(模板方法模式很经典的一个应用):
|
||||||
|
|
||||||
1. 使用者继承 AbstractQueuedSynchronizer 并重写指定的方法。(这些重写方法很简单,无非是对于共享资源 state 的获取和释放)
|
1. 使用者继承 `AbstractQueuedSynchronizer` 并重写指定的方法。(这些重写方法很简单,无非是对于共享资源 state 的获取和释放)
|
||||||
2. 将 AQS 组合在自定义同步组件的实现中,并调用其模板方法,而这些模板方法会调用使用者重写的方法。
|
2. 将 AQS 组合在自定义同步组件的实现中,并调用其模板方法,而这些模板方法会调用使用者重写的方法。
|
||||||
|
|
||||||
这和我们以往通过实现接口的方式有很大区别,这是模板方法模式很经典的一个运用。
|
这和我们以往通过实现接口的方式有很大区别,这是模板方法模式很经典的一个运用。
|
||||||
@ -1001,7 +1001,7 @@ tryReleaseShared(int)//共享方式。尝试释放资源,成功则返回true
|
|||||||
|
|
||||||
以 ReentrantLock 为例,state 初始化为 0,表示未锁定状态。A 线程 lock()时,会调用 tryAcquire()独占该锁并将 state+1。此后,其他线程再 tryAcquire()时就会失败,直到 A 线程 unlock()到 state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A 线程自己是可以重复获取此锁的(state 会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证 state 是能回到零态的。
|
以 ReentrantLock 为例,state 初始化为 0,表示未锁定状态。A 线程 lock()时,会调用 tryAcquire()独占该锁并将 state+1。此后,其他线程再 tryAcquire()时就会失败,直到 A 线程 unlock()到 state=0(即释放锁)为止,其它线程才有机会获取该锁。当然,释放锁之前,A 线程自己是可以重复获取此锁的(state 会累加),这就是可重入的概念。但要注意,获取多少次就要释放多么次,这样才能保证 state 是能回到零态的。
|
||||||
|
|
||||||
再以 CountDownLatch 以例,任务分为 N 个子线程去执行,state 也初始化为 N(注意 N 要与线程个数一致)。这 N 个子线程是并行执行的,每个子线程执行完后 countDown()一次,state 会 CAS(Compare and Swap)减 1。等到所有子线程都执行完后(即 state=0),会 unpark()主调用线程,然后主调用线程就会从 await()函数返回,继续后余动作。
|
再以 `CountDownLatch` 以例,任务分为 N 个子线程去执行,state 也初始化为 N(注意 N 要与线程个数一致)。这 N 个子线程是并行执行的,每个子线程执行完后` countDown()` 一次,state 会 CAS(Compare and Swap)减 1。等到所有子线程都执行完后(即 state=0),会 unpark()主调用线程,然后主调用线程就会从 `await()` 函数返回,继续后余动作。
|
||||||
|
|
||||||
一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现`tryAcquire-tryRelease`、`tryAcquireShared-tryReleaseShared`中的一种即可。但 AQS 也支持自定义同步器同时实现独占和共享两种方式,如`ReentrantReadWriteLock`。
|
一般来说,自定义同步器要么是独占方法,要么是共享方式,他们也只需实现`tryAcquire-tryRelease`、`tryAcquireShared-tryReleaseShared`中的一种即可。但 AQS 也支持自定义同步器同时实现独占和共享两种方式,如`ReentrantReadWriteLock`。
|
||||||
|
|
||||||
|
|||||||
@ -38,7 +38,7 @@
|
|||||||
|
|
||||||
这里强调指出,网络层中的“网络”二字已经不是我们通常谈到的具体网络,而是指计算机网络体系结构模型中第三层的名称.
|
这里强调指出,网络层中的“网络”二字已经不是我们通常谈到的具体网络,而是指计算机网络体系结构模型中第三层的名称.
|
||||||
|
|
||||||
互联网是由大量的异构(heterogeneous)网络通过路由器(router)相互连接起来的。互联网使用的网络层协议是无连接的网际协议(Intert Protocol)和许多路由选择协议,因此互联网的网络层也叫做**网际层**或**IP层**。
|
互联网是由大量的异构(heterogeneous)网络通过路由器(router)相互连接起来的。互联网使用的网络层协议是无连接的网际协议(Internet Protocol)和许多路由选择协议,因此互联网的网络层也叫做**网际层**或**IP层**。
|
||||||
|
|
||||||
### 1.4 数据链路层
|
### 1.4 数据链路层
|
||||||
**数据链路层(data link layer)通常简称为链路层。两台主机之间的数据传输,总是在一段一段的链路上传送的,这就需要使用专门的链路层的协议。** 在两个相邻节点之间传送数据时,**数据链路层将网络层交下来的 IP 数据报组装成帧**,在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息(如同步信息,地址信息,差错控制等)。
|
**数据链路层(data link layer)通常简称为链路层。两台主机之间的数据传输,总是在一段一段的链路上传送的,这就需要使用专门的链路层的协议。** 在两个相邻节点之间传送数据时,**数据链路层将网络层交下来的 IP 数据报组装成帧**,在两个相邻节点间的链路上传送帧。每一帧包括数据和必要的控制信息(如同步信息,地址信息,差错控制等)。
|
||||||
|
|||||||
@ -1,10 +1,16 @@
|
|||||||
## 简介
|
## BASE 理论
|
||||||
|
|
||||||
|
[BASE 理论](https://dl.acm.org/doi/10.1145/1394127.1394128)起源于 2008 年, 由eBay的架构师Dan Pritchett在ACM上发表。
|
||||||
|
|
||||||
|
### 简介
|
||||||
|
|
||||||
**BASE** 是 **Basically Available(基本可用)** 、**Soft-state(软状态)** 和 **Eventually Consistent(最终一致性)** 三个短语的缩写。BASE 理论是对 CAP 中一致性 C 和可用性 A 权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于 CAP 定理逐步演化而来的,它大大降低了我们对系统的要求。
|
**BASE** 是 **Basically Available(基本可用)** 、**Soft-state(软状态)** 和 **Eventually Consistent(最终一致性)** 三个短语的缩写。BASE 理论是对 CAP 中一致性 C 和可用性 A 权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于 CAP 定理逐步演化而来的,它大大降低了我们对系统的要求。
|
||||||
|
|
||||||
## BASE 理论的核心思想
|
### BASE 理论的核心思想
|
||||||
|
|
||||||
即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。也就是牺牲数据的一致性来满足系统的高可用性,系统中一部分数据不可用或者不一致时,仍需要保持系统整体“主要可用”。
|
即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。
|
||||||
|
|
||||||
|
> 也就是牺牲数据的一致性来满足系统的高可用性,系统中一部分数据不可用或者不一致时,仍需要保持系统整体“主要可用”。
|
||||||
|
|
||||||
**BASE 理论本质上是对 CAP 的延伸和补充,更具体地说,是对 CAP 中 AP 方案的一个补充。**
|
**BASE 理论本质上是对 CAP 的延伸和补充,更具体地说,是对 CAP 中 AP 方案的一个补充。**
|
||||||
|
|
||||||
@ -16,11 +22,11 @@ CAP 理论这节我们也说过了:
|
|||||||
|
|
||||||
因此,AP 方案只是在系统发生分区的时候放弃一致性,而不是永远放弃一致性。在分区故障恢复后,系统应该达到最终一致性。这一点其实就是 BASE 理论延伸的地方。
|
因此,AP 方案只是在系统发生分区的时候放弃一致性,而不是永远放弃一致性。在分区故障恢复后,系统应该达到最终一致性。这一点其实就是 BASE 理论延伸的地方。
|
||||||
|
|
||||||
## BASE 理论三要素
|
### BASE 理论三要素
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
### 1. 基本可用
|
#### 1. 基本可用
|
||||||
|
|
||||||
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性。但是,这绝不等价于系统不可用。
|
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性。但是,这绝不等价于系统不可用。
|
||||||
|
|
||||||
@ -29,22 +35,24 @@ CAP 理论这节我们也说过了:
|
|||||||
- **响应时间上的损失**: 正常情况下,处理用户请求需要 0.5s 返回结果,但是由于系统出现故障,处理用户请求的时间变为 3 s。
|
- **响应时间上的损失**: 正常情况下,处理用户请求需要 0.5s 返回结果,但是由于系统出现故障,处理用户请求的时间变为 3 s。
|
||||||
- **系统功能上的损失**:正常情况下,用户可以使用系统的全部功能,但是由于系统访问量突然剧增,系统的部分非核心功能无法使用。
|
- **系统功能上的损失**:正常情况下,用户可以使用系统的全部功能,但是由于系统访问量突然剧增,系统的部分非核心功能无法使用。
|
||||||
|
|
||||||
### 2. 软状态
|
#### 2. 软状态
|
||||||
|
|
||||||
软状态指允许系统中的数据存在中间状态(**CAP 理论中的数据不一致**),并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
|
软状态指允许系统中的数据存在中间状态(**CAP 理论中的数据不一致**),并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时。
|
||||||
|
|
||||||
### 3. 最终一致性
|
#### 3. 最终一致性
|
||||||
|
|
||||||
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
|
最终一致性强调的是系统中所有的数据副本,在经过一段时间的同步后,最终能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
|
||||||
|
|
||||||
> 分布式一致性的 3 种级别:
|
> 分布式一致性的 3 种级别:
|
||||||
>
|
>
|
||||||
> 1. **强一致性** :系统写入了什么,读出来的就是什么。
|
> 1. **强一致性** :系统写入了什么,读出来的就是什么。
|
||||||
|
>
|
||||||
> 2. **弱一致性** :不一定可以读取到最新写入的值,也不保证多少时间之后读取到的数据是最新的,只是会尽量保证某个时刻达到数据一致的状态。
|
> 2. **弱一致性** :不一定可以读取到最新写入的值,也不保证多少时间之后读取到的数据是最新的,只是会尽量保证某个时刻达到数据一致的状态。
|
||||||
|
>
|
||||||
> 3. **最终一致性** :弱一致性的升级版。,系统会保证在一定时间内达到数据一致的状态,
|
> 3. **最终一致性** :弱一致性的升级版。,系统会保证在一定时间内达到数据一致的状态,
|
||||||
>
|
>
|
||||||
> 业界比较推崇是最终一致性级别,但是某些对数据一致要求十分严格的场景比如银行转账还是要保证强一致性。
|
> **业界比较推崇是最终一致性级别,但是某些对数据一致要求十分严格的场景比如银行转账还是要保证强一致性。**
|
||||||
|
|
||||||
## 总结
|
### 总结
|
||||||
|
|
||||||
**ACID 是数据库事务完整性的理论,CAP 是分布式系统设计理论,BASE 是 CAP 理论中 AP 方案的延伸。**
|
**ACID 是数据库事务完整性的理论,CAP 是分布式系统设计理论,BASE 是 CAP 理论中 AP 方案的延伸。**
|
||||||
@ -1,26 +1,44 @@
|
|||||||
|
经历过技术面试的小伙伴想必对这个两个概念已经再熟悉不过了!
|
||||||
|
|
||||||
## 简介
|
Guide哥当年参加面试的时候,不夸张地说,只要问到分布式相关的内容,面试官几乎是必定会问这两个分布式相关的理论。
|
||||||
|
|
||||||
|
并且,这两个理论也可以说是小伙伴们学习分布式相关内容的基础了!
|
||||||
|
|
||||||
|
因此,小伙伴们非常非常有必要将这理论搞懂,并且能够用自己的理解给别人讲出来。
|
||||||
|
|
||||||
|
这篇文章我会站在自己的角度对这两个概念进行解读!
|
||||||
|
|
||||||
|
*个人能力有限。如果文章有任何需要改善和完善的地方,欢迎在评论区指出,共同进步!——爱你们的Guide哥*
|
||||||
|
|
||||||
|
## CAP理论
|
||||||
|
|
||||||
|
[CAP 理论/定理](https://zh.wikipedia.org/wiki/CAP%E5%AE%9A%E7%90%86)起源于 2000年,由加州大学伯克利分校的Eric Brewer教授在分布式计算原理研讨会(PODC)上提出,因此 CAP定理又被称作 **布鲁尔定理(Brewer’s theorem)**
|
||||||
|
|
||||||
|
2年后,麻省理工学院的Seth Gilbert和Nancy Lynch 发表了布鲁尔猜想的证明,CAP理论正式成为分布式领域的定理。
|
||||||
|
|
||||||
|
### 简介
|
||||||
|
|
||||||
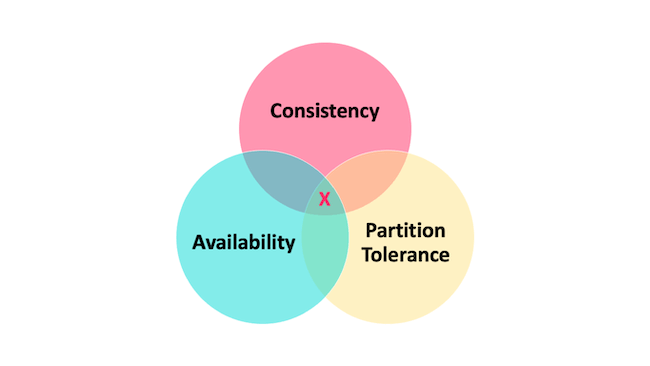
**CAP** 也就是 **Consistency(一致性)**、**Availability(可用性)**、**Partition Tolerance(分区容错性)** 这三个单词首字母组合。
|
**CAP** 也就是 **Consistency(一致性)**、**Availability(可用性)**、**Partition Tolerance(分区容错性)** 这三个单词首字母组合。
|
||||||
|
|
||||||
CAP 理论的提出者布鲁尔在提出 CAP 猜想的时候,并没有详细定义 Consistency、Availability、Partition Tolerance 三个单词的明确定义。
|

|
||||||
|
|
||||||
|
CAP 理论的提出者布鲁尔在提出 CAP 猜想的时候,并没有详细定义 **Consistency**、**Availability**、**Partition Tolerance** 三个单词的明确定义。
|
||||||
|
|
||||||
因此,对于 CAP 的民间解读有很多,一般比较被大家推荐的是下面 👇 这种版本的解。
|
因此,对于 CAP 的民间解读有很多,一般比较被大家推荐的是下面 👇 这种版本的解。
|
||||||
|
|
||||||
在理论计算机科学中,CAP 定理(CAP theorem),又被称作 **布鲁尔定理(Brewer’s theorem)**,它指出对于一个分布式系统来说,当设计读写操作时,只能能同时满足以下三点中的两个:
|
在理论计算机科学中,CAP 定理(CAP theorem)指出对于一个分布式系统来说,当设计读写操作时,只能能同时满足以下三点中的两个:
|
||||||
|
|
||||||
- **一致性(Consistence)** : 所有节点访问同一份最新的数据副本
|
- **一致性(Consistence)** : 所有节点访问同一份最新的数据副本
|
||||||
- **可用性(Availability)**: 非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。
|
- **可用性(Availability)**: 非故障的节点在合理的时间内返回合理的响应(不是错误或者超时的响应)。
|
||||||
- **分区容错性(Partition tolerance)** : 分布式系统出现网络分区的时候,仍然能够对外提供服务。
|
- **分区容错性(Partition tolerance)** : 分布式系统出现网络分区的时候,仍然能够对外提供服务。
|
||||||
|
|
||||||
CAP 仅适用于原子读写的 NOSQL 场景中,并不适合数据库系统。现在的分布式系统具有更多特性比如扩展性、可用性等等,在进行系统设计和开发时,我们不应该仅仅局限在 CAP 问题上。
|
|
||||||
|
|
||||||
**什么是网络分区?**
|
**什么是网络分区?**
|
||||||
|
|
||||||
> 分布式系统中,多个节点之前的网络本来是连通的,但是因为某些故障(比如部分节点网络出了问题)某些节点之间不连通了,整个网络就分成了几块区域,这就叫网络分区。
|
> 分布式系统中,多个节点之前的网络本来是连通的,但是因为某些故障(比如部分节点网络出了问题)某些节点之间不连通了,整个网络就分成了几块区域,这就叫网络分区。
|
||||||
|
|
||||||
## 不是所谓的“3 选 2”
|

|
||||||
|
|
||||||
|
### 不是所谓的“3 选 2”
|
||||||
|
|
||||||
大部分人解释这一定律时,常常简单的表述为:“一致性、可用性、分区容忍性三者你只能同时达到其中两个,不可能同时达到”。实际上这是一个非常具有误导性质的说法,而且在 CAP 理论诞生 12 年之后,CAP 之父也在 2012 年重写了之前的论文。
|
大部分人解释这一定律时,常常简单的表述为:“一致性、可用性、分区容忍性三者你只能同时达到其中两个,不可能同时达到”。实际上这是一个非常具有误导性质的说法,而且在 CAP 理论诞生 12 年之后,CAP 之父也在 2012 年重写了之前的论文。
|
||||||
|
|
||||||
@ -36,7 +54,7 @@ CAP 仅适用于原子读写的 NOSQL 场景中,并不适合数据库系统。
|
|||||||
|
|
||||||
**选择的关键在于当前的业务场景,没有定论,比如对于需要确保强一致性的场景如银行一般会选择保证 CP 。**
|
**选择的关键在于当前的业务场景,没有定论,比如对于需要确保强一致性的场景如银行一般会选择保证 CP 。**
|
||||||
|
|
||||||
## CAP 实际应用案例
|
### CAP 实际应用案例
|
||||||
|
|
||||||
我这里以注册中心来探讨一下 CAP 的实际应用。考虑到很多小伙伴不知道注册中心是干嘛的,这里简单以 Dubbo 为例说一说。
|
我这里以注册中心来探讨一下 CAP 的实际应用。考虑到很多小伙伴不知道注册中心是干嘛的,这里简单以 Dubbo 为例说一说。
|
||||||
|
|
||||||
@ -52,13 +70,17 @@ CAP 仅适用于原子读写的 NOSQL 场景中,并不适合数据库系统。
|
|||||||
2. **Eureka 保证的则是 AP。** Eureka 在设计的时候就是优先保证 A (可用性)。在 Eureka 中不存在什么 Leader 节点,每个节点都是一样的、平等的。因此 Eureka 不会像 ZooKeeper 那样出现选举过程中或者半数以上的机器不可用的时候服务就是不可用的情况。 Eureka 保证即使大部分节点挂掉也不会影响正常提供服务,只要有一个节点是可用的就行了。只不过这个节点上的数据可能并不是最新的。
|
2. **Eureka 保证的则是 AP。** Eureka 在设计的时候就是优先保证 A (可用性)。在 Eureka 中不存在什么 Leader 节点,每个节点都是一样的、平等的。因此 Eureka 不会像 ZooKeeper 那样出现选举过程中或者半数以上的机器不可用的时候服务就是不可用的情况。 Eureka 保证即使大部分节点挂掉也不会影响正常提供服务,只要有一个节点是可用的就行了。只不过这个节点上的数据可能并不是最新的。
|
||||||
3. **Nacos 不仅支持 CP 也支持 AP。**
|
3. **Nacos 不仅支持 CP 也支持 AP。**
|
||||||
|
|
||||||
## 总结
|
### 总结
|
||||||
|
|
||||||
|
在进行分布式系统设计和开发时,我们不应该仅仅局限在 CAP 问题上,还要关注系统的扩展性、可用性等等
|
||||||
|
|
||||||
在系统发生“分区”的情况下,CAP 理论只能满足 CP 或者 AP。要注意的是,这里的前提是系统发生了“分区”
|
在系统发生“分区”的情况下,CAP 理论只能满足 CP 或者 AP。要注意的是,这里的前提是系统发生了“分区”
|
||||||
|
|
||||||
如果系统没有发生“分区”的话,节点间的网络连接通信正常的话,也就不存在 P 了。这个时候,我们就可以同时保证 C 和 A 了。因此,**如果系统发生“分区”,我们要考虑选择 CP 还是 AP。如果系统没有发生“分区”的话,我们要思考如何保证 CA 。**
|
如果系统没有发生“分区”的话,节点间的网络连接通信正常的话,也就不存在 P 了。这个时候,我们就可以同时保证 C 和 A 了。
|
||||||
|
|
||||||
## 推荐阅读
|
总结:**如果系统发生“分区”,我们要考虑选择 CP 还是 AP。如果系统没有发生“分区”的话,我们要思考如何保证 CA 。**
|
||||||
|
|
||||||
|
### 推荐阅读
|
||||||
|
|
||||||
1. [CAP 定理简化](https://medium.com/@ravindraprasad/cap-theorem-simplified-28499a67eab4) (英文,有趣的案例)
|
1. [CAP 定理简化](https://medium.com/@ravindraprasad/cap-theorem-simplified-28499a67eab4) (英文,有趣的案例)
|
||||||
2. [神一样的 CAP 理论被应用在何方](https://juejin.im/post/6844903936718012430) (中文,列举了很多实际的例子)
|
2. [神一样的 CAP 理论被应用在何方](https://juejin.im/post/6844903936718012430) (中文,列举了很多实际的例子)
|
||||||
@ -1,39 +0,0 @@
|
|||||||
### 一 分布式系统的经典基础理论
|
|
||||||
|
|
||||||
[分布式系统的经典基础理论](https://blog.csdn.net/qq_34337272/article/details/80444032)
|
|
||||||
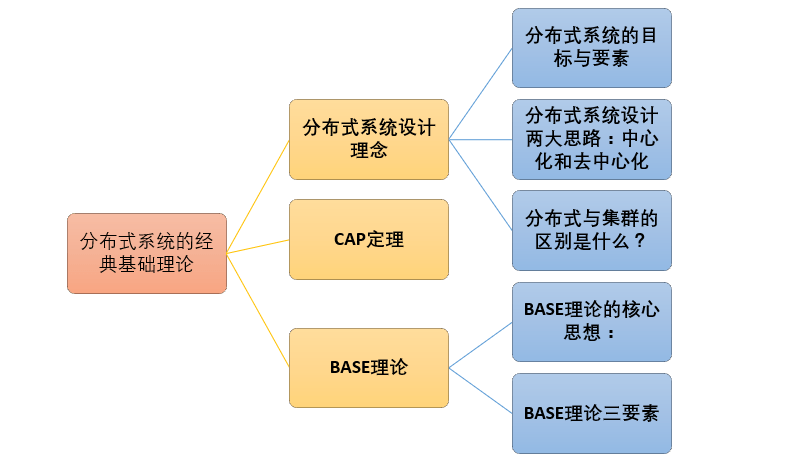
本文主要是简单的介绍了三个常见的概念: **分布式系统设计理念** 、 **CAP定理** 、 **BASE理论** ,关于分布式系统的还有很多很多东西。
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
### 二 分布式事务
|
|
||||||
|
|
||||||
分布式事务就是指事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上。以上是百度百科的解释,简单的说,就是一次大的操作由不同的小操作组成,这些小的操作分布在不同的服务器上,且属于不同的应用,分布式事务需要保证这些小操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
|
|
||||||
- [深入理解分布式事务](http://www.codeceo.com/article/distributed-transaction.html)
|
|
||||||
- [聊聊分布式事务,再说说解决方案](https://www.cnblogs.com/savorboard/p/distributed-system-transaction-consistency.html)
|
|
||||||
|
|
||||||
|
|
||||||
### 三 分布式系统一致性
|
|
||||||
|
|
||||||
[分布式服务化系统一致性的“最佳实干”](https://www.jianshu.com/p/1156151e20c8)
|
|
||||||
|
|
||||||
### 四 一致性协议/算法
|
|
||||||
|
|
||||||
早在1900年就诞生了著名的 **Paxos经典算法** (**Zookeeper就采用了Paxos算法的近亲兄弟Zab算法**),但由于Paxos算法非常难以理解、实现、排错。所以不断有人尝试简化这一算法,直到2013年才有了重大突破:斯坦福的Diego Ongaro、John Ousterhout以易懂性为目标设计了新的一致性算法—— **Raft算法** ,并发布了对应的论文《In Search of an Understandable Consensus Algorithm》,到现在有十多种语言实现的Raft算法框架,较为出名的有以Go语言实现的Etcd,它的功能类似于Zookeeper,但采用了更为主流的Rest接口。
|
|
||||||
|
|
||||||
* [图解 Paxos 一致性协议](https://mp.weixin.qq.com/s?__biz=MzI0NDI0MTgyOA==&mid=2652037784&idx=1&sn=d8c4f31a9cfb49ee91d05bb374e5cdd5&chksm=f2868653c5f10f45fc4a64d15a5f4163c3e66c00ed2ad334fa93edb46671f42db6752001f6c0#rd)
|
|
||||||
* [图解分布式协议-RAFT](http://ifeve.com/raft/)
|
|
||||||
* [Zookeeper ZAB 协议分析](https://dbaplus.cn/news-141-1875-1.html)
|
|
||||||
|
|
||||||
### 五 分布式存储
|
|
||||||
|
|
||||||
**分布式存储系统将数据分散存储在多台独立的设备上**。传统的网络存储系统采用集中的存储服务器存放所有数据,存储服务器成为系统性能的瓶颈,也是可靠性和安全性的焦点,不能满足大规模存储应用的需要。分布式网络存储系统采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。
|
|
||||||
|
|
||||||
* [分布式存储系统概要](http://witchiman.top/2017/05/05/distributed-system/)
|
|
||||||
|
|
||||||
### 六 分布式计算
|
|
||||||
|
|
||||||
**所谓分布式计算是一门计算机科学,它研究如何把一个需要非常巨大的计算能力才能解决的问题分成许多小的部分,然后把这些部分分配给许多计算机进行处理,最后把这些计算结果综合起来得到最终的结果。**
|
|
||||||
分布式网络存储技术是将数据分散的存储于多台独立的机器设备上。分布式网络存储系统采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,不但解决了传统集中式存储系统中单存储服务器的瓶颈问题,还提高了系统的可靠性、可用性和扩展性。
|
|
||||||
|
|
||||||
* [关于分布式计算的一些概念](https://blog.csdn.net/qq_34337272/article/details/80549020)
|
|
||||||
|
|
||||||
@ -51,7 +51,7 @@ public class OrdersService {
|
|||||||
|
|
||||||
另外,数据库事务的 ACID 四大特性是事务的基础,下面简单来了解一下。
|
另外,数据库事务的 ACID 四大特性是事务的基础,下面简单来了解一下。
|
||||||
|
|
||||||
## 2. 事物的特性(ACID)了解么?
|
## 2. 事务的特性(ACID)了解么?
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@ -143,7 +143,7 @@ Spring 框架中,事务管理相关最重要的 3 个接口如下:
|
|||||||
- **`TransactionDefinition`**: 事务定义信息(事务隔离级别、传播行为、超时、只读、回滚规则)。
|
- **`TransactionDefinition`**: 事务定义信息(事务隔离级别、传播行为、超时、只读、回滚规则)。
|
||||||
- **`TransactionStatus`**: 事务运行状态。
|
- **`TransactionStatus`**: 事务运行状态。
|
||||||
|
|
||||||
我们可以把 **`PlatformTransactionManager`** 接口可以被看作是事务上层的管理者,而 **`TransactionDefinition`** 和 **`TransactionStatus`** 这两个接口可以看作是事物的描述。
|
我们可以把 **`PlatformTransactionManager`** 接口可以被看作是事务上层的管理者,而 **`TransactionDefinition`** 和 **`TransactionStatus`** 这两个接口可以看作是事务的描述。
|
||||||
|
|
||||||
**`PlatformTransactionManager`** 会根据 **`TransactionDefinition`** 的定义比如事务超时时间、隔离级别、传播行为等来进行事务管理 ,而 **`TransactionStatus`** 接口则提供了一些方法来获取事务相应的状态比如是否新事务、是否可以回滚等等。
|
**`PlatformTransactionManager`** 会根据 **`TransactionDefinition`** 的定义比如事务超时时间、隔离级别、传播行为等来进行事务管理 ,而 **`TransactionStatus`** 接口则提供了一些方法来获取事务相应的状态比如是否新事务、是否可以回滚等等。
|
||||||
|
|
||||||
@ -238,7 +238,7 @@ public interface TransactionDefinition {
|
|||||||
|
|
||||||
```java
|
```java
|
||||||
public interface TransactionStatus{
|
public interface TransactionStatus{
|
||||||
boolean isNewTransaction(); // 是否是新的事物
|
boolean isNewTransaction(); // 是否是新的事务
|
||||||
boolean hasSavepoint(); // 是否有恢复点
|
boolean hasSavepoint(); // 是否有恢复点
|
||||||
void setRollbackOnly(); // 设置为只回滚
|
void setRollbackOnly(); // 设置为只回滚
|
||||||
boolean isRollbackOnly(); // 是否为只回滚
|
boolean isRollbackOnly(); // 是否为只回滚
|
||||||
|
|||||||
File diff suppressed because one or more lines are too long
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 35 KiB |
Loading…
x
Reference in New Issue
Block a user