mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
[修改]:修改 mysql 索引详解,修改聚集索引与非聚集索引图片,添加联合索引,最左前缀匹配原则,索引下推的概念
This commit is contained in:
parent
45660b1f11
commit
a746734c79
@ -31,7 +31,7 @@ tag:
|
|||||||
|
|
||||||
## 索引的底层数据结构
|
## 索引的底层数据结构
|
||||||
|
|
||||||
### Hash表 & B+树
|
### Hash表
|
||||||
|
|
||||||
哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。
|
哈希表是键值对的集合,通过键(key)即可快速取出对应的值(value),因此哈希表可以快速检索数据(接近 O(1))。
|
||||||
|
|
||||||
@ -76,8 +76,6 @@ B 树也称 B-树,全称为 **多路平衡查找树** ,B+ 树是 B 树的一
|
|||||||
- B 树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
|
- B 树的叶子节点都是独立的;B+树的叶子节点有一条引用链指向与它相邻的叶子节点。
|
||||||
- B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而 B+树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
|
- B 树的检索的过程相当于对范围内的每个节点的关键字做二分查找,可能还没有到达叶子节点,检索就结束了。而 B+树的检索效率就很稳定了,任何查找都是从根节点到叶子节点的过程,叶子节点的顺序检索很明显。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
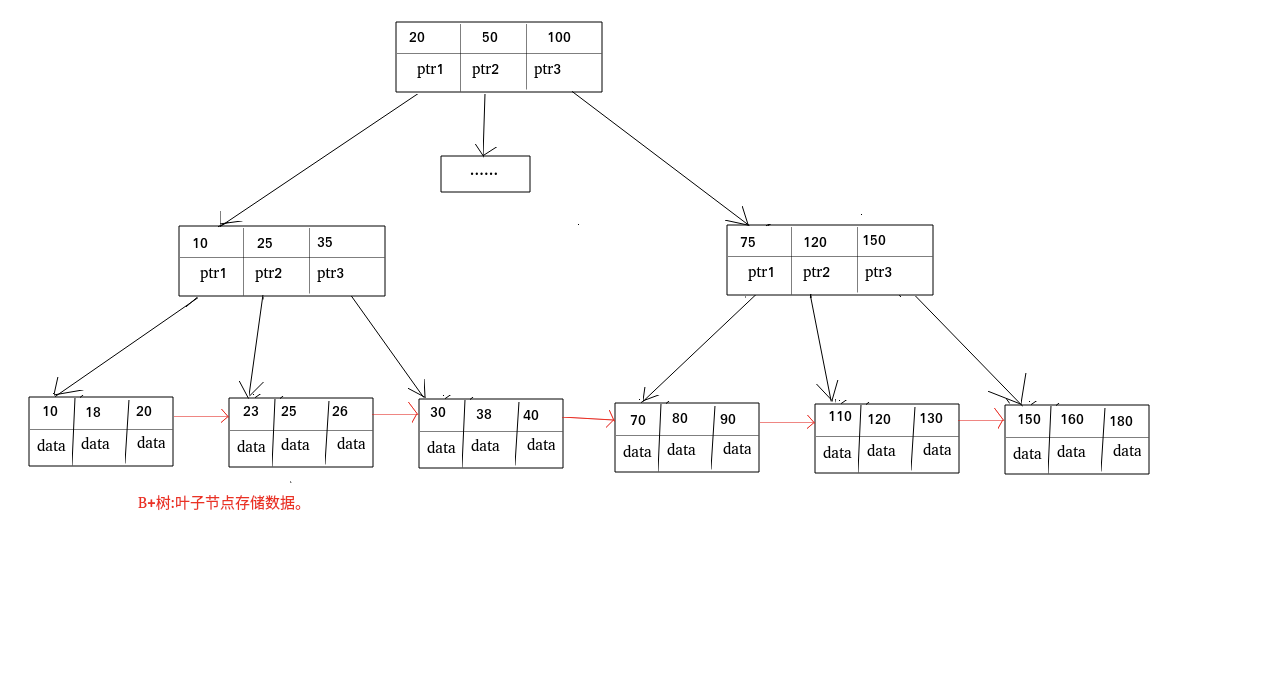
在 MySQL 中,MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是,两者的实现方式不太一样。(下面的内容整理自《Java 工程师修炼之道》)
|
在 MySQL 中,MyISAM 引擎和 InnoDB 引擎都是使用 B+Tree 作为索引结构,但是,两者的实现方式不太一样。(下面的内容整理自《Java 工程师修炼之道》)
|
||||||
|
|
||||||
MyISAM 引擎中,B+Tree 叶节点的 data 域存放的是数据记录的地址。在索引检索的时候,首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
|
MyISAM 引擎中,B+Tree 叶节点的 data 域存放的是数据记录的地址。在索引检索的时候,首先按照 B+Tree 搜索算法搜索索引,如果指定的 Key 存在,则取出其 data 域的值,然后以 data 域的值为地址读取相应的数据记录。这被称为“非聚簇索引”。
|
||||||
@ -94,6 +92,8 @@ InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索
|
|||||||
|
|
||||||
在 MySQL 的 InnoDB 的表中,当没有显示的指定表的主键时,InnoDB 会自动先检查表中是否有唯一索引且不允许存在null值的字段,如果有,则选择该字段为默认的主键,否则 InnoDB 将会自动创建一个 6Byte 的自增主键。
|
在 MySQL 的 InnoDB 的表中,当没有显示的指定表的主键时,InnoDB 会自动先检查表中是否有唯一索引且不允许存在null值的字段,如果有,则选择该字段为默认的主键,否则 InnoDB 将会自动创建一个 6Byte 的自增主键。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
### 二级索引(辅助索引)
|
### 二级索引(辅助索引)
|
||||||
|
|
||||||
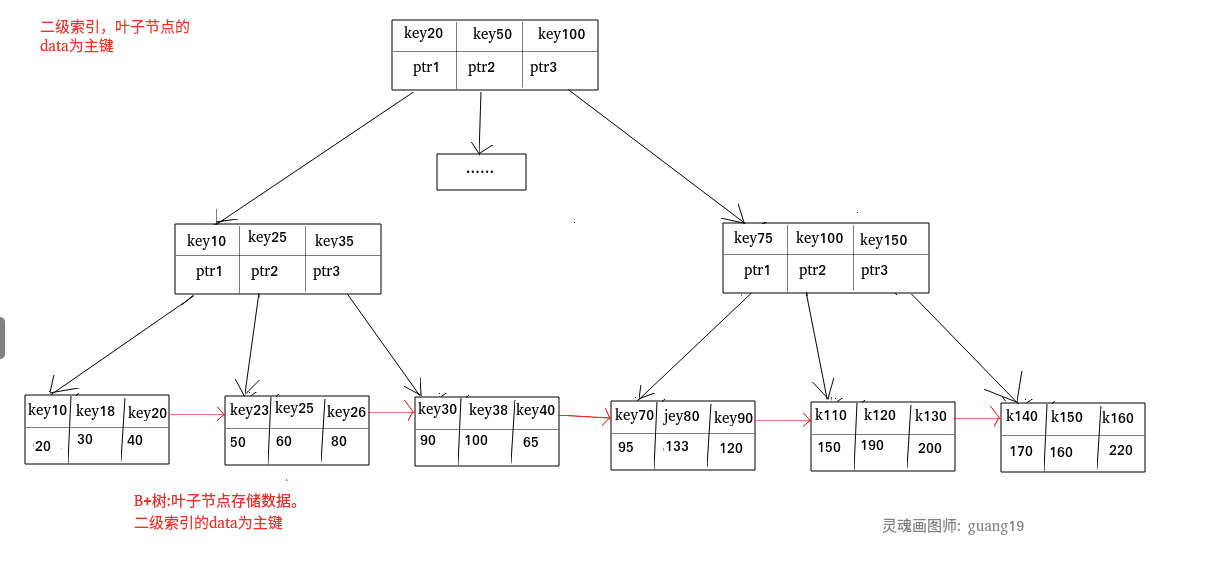
**二级索引又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。**
|
**二级索引又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。**
|
||||||
@ -110,7 +110,7 @@ InnoDB 引擎中,其数据文件本身就是索引文件。相比 MyISAM,索
|
|||||||
|
|
||||||
二级索引:
|
二级索引:
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
## 聚集索引与非聚集索引
|
## 聚集索引与非聚集索引
|
||||||
|
|
||||||
@ -190,6 +190,20 @@ SELECT id FROM table WHERE id=1;
|
|||||||
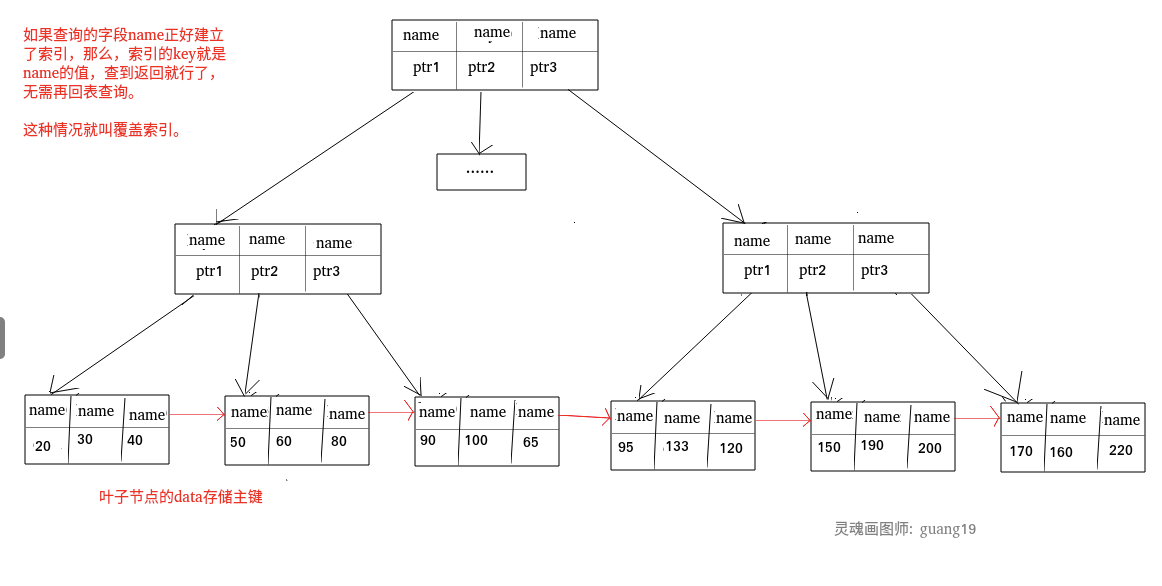
覆盖索引:
|
覆盖索引:
|
||||||
|

|
||||||
|
|
||||||
|
## 联合索引
|
||||||
|
|
||||||
|
使用表中的多个字段创建索引,就是 **联合索引**,也叫 **组合索引** 或 **复合索引**。
|
||||||
|
|
||||||
|
## 最左前缀匹配原则
|
||||||
|
|
||||||
|
最左前缀匹配原则指的是,在使用联合索引时,**MySQL** 会根据联合索引中的字段顺序,从左到右依次到查询条件中去匹配,如果查询条件中存在与联合索引中最左侧字段相匹配的字段,则就会使用该字段过滤一批数据,直至联合索引中全部字段匹配完成,或者在执行过程中遇到范围查询,如 **`>`**、**`<`**、**`between`** 和 **`以%开头的like查询`** 等条件,才会停止匹配。
|
||||||
|
|
||||||
|
所以,我们在使用联合索引时,可以将区分度高的字段放在最左边,这也可以过滤更多数据。
|
||||||
|
|
||||||
|
## 索引下推
|
||||||
|
|
||||||
|
索引下推是 **MySQL 5.6** 版本中提供的一项索引优化功能,可以在非聚簇索引遍历过程中,对索引中包含的字段先做判断,过滤掉不符合条件的记录,减少回表次数。
|
||||||
|
|
||||||
## 创建索引的注意事项
|
## 创建索引的注意事项
|
||||||
|
|
||||||
**1.选择合适的字段创建索引:**
|
**1.选择合适的字段创建索引:**
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user