mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
[docs update] 新增AOF 校验机制和慢查询命令的内容
This commit is contained in:
parent
adbeda68a8
commit
a6ff4563c6
@ -11,9 +11,22 @@ tag:
|
|||||||
|
|
||||||
## O(n) 命令
|
## O(n) 命令
|
||||||
|
|
||||||
使用` O(n)` 命令可能会导致阻塞,例如`keys *`、`hgetall`、`lrange`、`smembers`、`zrange`、`sinter`、`sunion` 命令。这些命令时间复杂度是 O(n),有时候也会全表扫描,随着 n 的增大耗时也会越大从而导致客户端阻塞。
|
Redis 中的大部分命令都是 O(1)时间复杂度,但也有少部分 O(n) 时间复杂度的命令,例如:
|
||||||
|
|
||||||
不过, 这些命令并不是一定不能使用,但是需要明确 N 的值。有遍历的需求可以使用 `hscan`、`sscan`、`zscan` 代替。
|
- `KEYS *`:会返回所有符合规则的 key。
|
||||||
|
- `HGETALL`:会返回一个 Hash 中所有的键值对。
|
||||||
|
- `LRANGE`:会返回 List 中指定范围内的元素。
|
||||||
|
- `SMEMBERS`:返回 Set 中的所有元素。
|
||||||
|
- `SINTER`/`SUNION`/`SDIFF`:计算多个 Set 的交集/并集/差集。
|
||||||
|
- ......
|
||||||
|
|
||||||
|
由于这些命令时间复杂度是 O(n),有时候也会全表扫描,随着 n 的增大,执行耗时也会越长,从而导致客户端阻塞。不过, 这些命令并不是一定不能使用,但是需要明确 N 的值。另外,有遍历的需求可以使用 `HSCAN`、`SSCAN`、`ZSCAN` 代替。
|
||||||
|
|
||||||
|
除了这些 O(n)时间复杂度的命令可能会导致阻塞之外, 还有一些时间复杂度可能在 O(N) 以上的命令,例如:
|
||||||
|
|
||||||
|
- `ZRANGE`/`ZREVRANGE`:返回指定 Sorted Set 中指定排名范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 为返回的元素数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
|
||||||
|
- `ZREMRANGEBYRANK`/`ZREMRANGEBYSCORE`:移除 Sorted Set 中指定排名范围/指定 score 范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 被删除元素的数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
|
||||||
|
- ......
|
||||||
|
|
||||||
## SAVE 创建 RDB 快照
|
## SAVE 创建 RDB 快照
|
||||||
|
|
||||||
|
|||||||
@ -86,7 +86,7 @@ AOF 工作流程图如下:
|
|||||||
|
|
||||||
|

|
||||||
|
|
||||||
### 持久化方式有哪些?
|
### AOF 持久化方式有哪些?
|
||||||
|
|
||||||
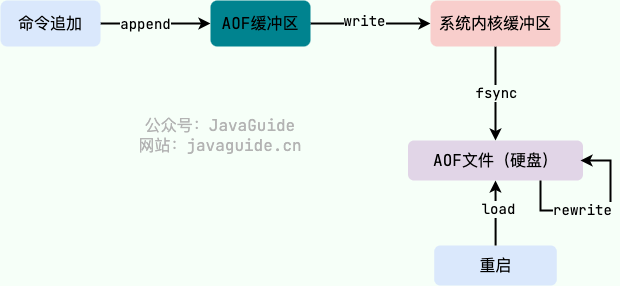
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( `fsync`策略),它们分别是:
|
在 Redis 的配置文件中存在三种不同的 AOF 持久化方式( `fsync`策略),它们分别是:
|
||||||
|
|
||||||
@ -149,7 +149,13 @@ Redis 7.0 版本之后,AOF 重写机制得到了优化改进。下面这段内
|
|||||||
>
|
>
|
||||||
> 阿里云的 Redis 企业版在最初也遇到了这个问题,在内部经过多次迭代开发,实现了 Multi-part AOF 机制来解决,同时也贡献给了社区并随此次 7.0 发布。具体方法是采用 base(全量数据)+inc(增量数据)独立文件存储的方式,彻底解决内存和 IO 资源的浪费,同时也支持对历史 AOF 文件的保存管理,结合 AOF 文件中的时间信息还可以实现 PITR 按时间点恢复(阿里云企业版 Tair 已支持),这进一步增强了 Redis 的数据可靠性,满足用户数据回档等需求。
|
> 阿里云的 Redis 企业版在最初也遇到了这个问题,在内部经过多次迭代开发,实现了 Multi-part AOF 机制来解决,同时也贡献给了社区并随此次 7.0 发布。具体方法是采用 base(全量数据)+inc(增量数据)独立文件存储的方式,彻底解决内存和 IO 资源的浪费,同时也支持对历史 AOF 文件的保存管理,结合 AOF 文件中的时间信息还可以实现 PITR 按时间点恢复(阿里云企业版 Tair 已支持),这进一步增强了 Redis 的数据可靠性,满足用户数据回档等需求。
|
||||||
|
|
||||||
**相关 issue**:[Redis AOF 重写描述不准确 #1439](https://github.com/Snailclimb/JavaGuide/issues/1439)
|
**相关 issue**:[Redis AOF 重写描述不准确 #1439](https://github.com/Snailclimb/JavaGuide/issues/1439)。
|
||||||
|
|
||||||
|
### AOF 校验机制了解吗?
|
||||||
|
|
||||||
|
AOF 校验机制是 Redis 在启动时对 AOF 文件进行检查,以判断文件是否完整,是否有损坏或者丢失的数据。这个机制的原理其实非常简单,就是通过使用一种叫做 **校验和(checksum)** 的数字来验证 AOF 文件。这个校验和是通过对整个 AOF 文件内容进行 CRC64 算法计算得出的数字。如果文件内容发生了变化,那么校验和也会随之改变。因此,Redis 在启动时会比较计算出的校验和与文件末尾保存的校验和(计算的时候会把最后一行保存校验和的内容给忽略点),从而判断 AOF 文件是否完整。如果发现文件有问题,Redis 就会拒绝启动并提供相应的错误信息。AOF 校验机制十分简单有效,可以提高 Redis 数据的可靠性。
|
||||||
|
|
||||||
|
类似地,RDB 文件也有类似的校验机制来保证 RDB 文件的正确性,这里就不重复进行介绍了。
|
||||||
|
|
||||||
## Redis 4.0 对于持久化机制做了什么优化?
|
## Redis 4.0 对于持久化机制做了什么优化?
|
||||||
|
|
||||||
|
|||||||
@ -210,17 +210,17 @@ Redis 从 2.6 版本开始支持执行 Lua 脚本,它的功能和事务非常
|
|||||||
|
|
||||||
Redis 中有一些原生支持批量操作的命令,比如:
|
Redis 中有一些原生支持批量操作的命令,比如:
|
||||||
|
|
||||||
- `mget`(获取一个或多个指定 key 的值)、`mset`(设置一个或多个指定 key 的值)、
|
- `MGET`(获取一个或多个指定 key 的值)、`MSET`(设置一个或多个指定 key 的值)、
|
||||||
- `hmget`(获取指定哈希表中一个或者多个指定字段的值)、`hmset`(同时将一个或多个 field-value 对设置到指定哈希表中)、
|
- `HMGET`(获取指定哈希表中一个或者多个指定字段的值)、`HMSET`(同时将一个或多个 field-value 对设置到指定哈希表中)、
|
||||||
- `sadd`(向指定集合添加一个或多个元素)
|
- `SADD`(向指定集合添加一个或多个元素)
|
||||||
- ......
|
- ......
|
||||||
|
|
||||||
不过,在 Redis 官方提供的分片集群解决方案 Redis Cluster 下,使用这些原生批量操作命令可能会存在一些小问题需要解决。就比如说 `mget` 无法保证所有的 key 都在同一个 **hash slot**(哈希槽)上,`mget`可能还是需要多次网络传输,原子操作也无法保证了。不过,相较于非批量操作,还是可以节省不少网络传输次数。
|
不过,在 Redis 官方提供的分片集群解决方案 Redis Cluster 下,使用这些原生批量操作命令可能会存在一些小问题需要解决。就比如说 `MGET` 无法保证所有的 key 都在同一个 **hash slot**(哈希槽)上,`MGET`可能还是需要多次网络传输,原子操作也无法保证了。不过,相较于非批量操作,还是可以节省不少网络传输次数。
|
||||||
|
|
||||||
整个步骤的简化版如下(通常由 Redis 客户端实现,无需我们自己再手动实现):
|
整个步骤的简化版如下(通常由 Redis 客户端实现,无需我们自己再手动实现):
|
||||||
|
|
||||||
1. 找到 key 对应的所有 hash slot;
|
1. 找到 key 对应的所有 hash slot;
|
||||||
2. 分别向对应的 Redis 节点发起 `mget` 请求获取数据;
|
2. 分别向对应的 Redis 节点发起 `MGET` 请求获取数据;
|
||||||
3. 等待所有请求执行结束,重新组装结果数据,保持跟入参 key 的顺序一致,然后返回结果。
|
3. 等待所有请求执行结束,重新组装结果数据,保持跟入参 key 的顺序一致,然后返回结果。
|
||||||
|
|
||||||
如果想要解决这个多次网络传输的问题,比较常用的办法是自己维护 key 与 slot 的关系。不过这样不太灵活,虽然带来了性能提升,但同样让系统复杂性提升。
|
如果想要解决这个多次网络传输的问题,比较常用的办法是自己维护 key 与 slot 的关系。不过这样不太灵活,虽然带来了性能提升,但同样让系统复杂性提升。
|
||||||
@ -233,7 +233,7 @@ Redis 中有一些原生支持批量操作的命令,比如:
|
|||||||
|
|
||||||
对于不支持批量操作的命令,我们可以利用 **pipeline(流水线)** 将一批 Redis 命令封装成一组,这些 Redis 命令会被一次性提交到 Redis 服务器,只需要一次网络传输。不过,需要注意控制一次批量操作的 **元素个数**(例如 500 以内,实际也和元素字节数有关),避免网络传输的数据量过大。
|
对于不支持批量操作的命令,我们可以利用 **pipeline(流水线)** 将一批 Redis 命令封装成一组,这些 Redis 命令会被一次性提交到 Redis 服务器,只需要一次网络传输。不过,需要注意控制一次批量操作的 **元素个数**(例如 500 以内,实际也和元素字节数有关),避免网络传输的数据量过大。
|
||||||
|
|
||||||
与`mget`、`mset`等原生批量操作命令一样,pipeline 同样在 Redis Cluster 上使用会存在一些小问题。原因类似,无法保证所有的 key 都在同一个 **hash slot**(哈希槽)上。如果想要使用的话,客户端需要自己维护 key 与 slot 的关系。
|
与`MGET`、`MSET`等原生批量操作命令一样,pipeline 同样在 Redis Cluster 上使用会存在一些小问题。原因类似,无法保证所有的 key 都在同一个 **hash slot**(哈希槽)上。如果想要使用的话,客户端需要自己维护 key 与 slot 的关系。
|
||||||
|
|
||||||
原生批量操作命令和 pipeline 的是有区别的,使用的时候需要注意:
|
原生批量操作命令和 pipeline 的是有区别的,使用的时候需要注意:
|
||||||
|
|
||||||
@ -269,7 +269,7 @@ Lua 脚本同样支持批量操作多条命令。一段 Lua 脚本可以视作
|
|||||||
|
|
||||||
定期删除执行过程中,如果突然遇到大量过期 key 的话,客户端请求必须等待定期清理过期 key 任务线程执行完成,因为这个这个定期任务线程是在 Redis 主线程中执行的。这就导致客户端请求没办法被及时处理,响应速度会比较慢。
|
定期删除执行过程中,如果突然遇到大量过期 key 的话,客户端请求必须等待定期清理过期 key 任务线程执行完成,因为这个这个定期任务线程是在 Redis 主线程中执行的。这就导致客户端请求没办法被及时处理,响应速度会比较慢。
|
||||||
|
|
||||||
如何解决呢?下面是两种常见的方法:
|
**如何解决呢?** 下面是两种常见的方法:
|
||||||
|
|
||||||
1. 给 key 设置随机过期时间。
|
1. 给 key 设置随机过期时间。
|
||||||
2. 开启 lazy-free(惰性删除/延迟释放) 。lazy-free 特性是 Redis 4.0 开始引入的,指的是让 Redis 采用异步方式延迟释放 key 使用的内存,将该操作交给单独的子线程处理,避免阻塞主线程。
|
2. 开启 lazy-free(惰性删除/延迟释放) 。lazy-free 特性是 Redis 4.0 开始引入的,指的是让 Redis 采用异步方式延迟释放 key 使用的内存,将该操作交给单独的子线程处理,避免阻塞主线程。
|
||||||
@ -390,17 +390,17 @@ maxmemory-policy volatile-lfu
|
|||||||
maxmemory-policy allkeys-lfu
|
maxmemory-policy allkeys-lfu
|
||||||
```
|
```
|
||||||
|
|
||||||
需要注意的是,`hotkeys` 命令也会增加 Redis 实例的 CPU 和内存消耗(全局扫描),因此需要谨慎使用。
|
需要注意的是,`hotkeys` 参数命令也会增加 Redis 实例的 CPU 和内存消耗(全局扫描),因此需要谨慎使用。
|
||||||
|
|
||||||
**2、使用`monitor` 命令。**
|
**2、使用`MONITOR` 命令。**
|
||||||
|
|
||||||
`monitor` 命令是 Redis 提供的一种实时查看 Redis 的所有操作的方式,可以用于临时监控 Redis 实例的操作情况,包括读写、删除等操作。
|
`MONITOR` 命令是 Redis 提供的一种实时查看 Redis 的所有操作的方式,可以用于临时监控 Redis 实例的操作情况,包括读写、删除等操作。
|
||||||
|
|
||||||
由于该命令对 Redis 性能的影响比较大,因此禁止长时间开启 `monitor`(生产环境中建议谨慎使用该命令)。
|
由于该命令对 Redis 性能的影响比较大,因此禁止长时间开启 `MONITOR`(生产环境中建议谨慎使用该命令)。
|
||||||
|
|
||||||
```java
|
```java
|
||||||
# redis-cli
|
# redis-cli
|
||||||
127.0.0.1:6379> monitor
|
127.0.0.1:6379> MONITOR
|
||||||
OK
|
OK
|
||||||
1683638260.637378 [0 172.17.0.1:61516] "ping"
|
1683638260.637378 [0 172.17.0.1:61516] "ping"
|
||||||
1683638267.144236 [0 172.17.0.1:61518] "smembers" "mySet"
|
1683638267.144236 [0 172.17.0.1:61518] "smembers" "mySet"
|
||||||
@ -413,7 +413,7 @@ OK
|
|||||||
1683638276.327234 [0 172.17.0.1:61518] "smembers" "mySet"
|
1683638276.327234 [0 172.17.0.1:61518] "smembers" "mySet"
|
||||||
```
|
```
|
||||||
|
|
||||||
在发生紧急情况时,我们可以选择在合适的时机短暂执行 monitor 命令并将输出重定向至文件,在关闭 monitor 命令后通过对文件中请求进行归类分析即可找出这段时间中的 hotkey。
|
在发生紧急情况时,我们可以选择在合适的时机短暂执行 `MONITOR` 命令并将输出重定向至文件,在关闭 `MONITOR` 命令后通过对文件中请求进行归类分析即可找出这段时间中的 hotkey。
|
||||||
|
|
||||||
**3、借助开源项目。**
|
**3、借助开源项目。**
|
||||||
|
|
||||||
@ -451,6 +451,104 @@ hotkey 的常见处理以及优化办法如下(这些方法可以配合起来
|
|||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
### 慢查询命令
|
||||||
|
|
||||||
|
#### 为什么会有慢查询命令?
|
||||||
|
|
||||||
|
我们知道一个 Redis 命令的执行可以简化为以下 4 步:
|
||||||
|
|
||||||
|
1. 发送命令
|
||||||
|
2. 命令排队
|
||||||
|
3. 命令执行
|
||||||
|
4. 返回结果
|
||||||
|
|
||||||
|
Redis 慢查询统计的是命令执行这一步骤的耗时,慢查询命令也就是那些命令执行时间较长的命令。
|
||||||
|
|
||||||
|
Redis 为什么会有慢查询命令呢?
|
||||||
|
|
||||||
|
Redis 中的大部分命令都是 O(1)时间复杂度,但也有少部分 O(n) 时间复杂度的命令,例如:
|
||||||
|
|
||||||
|
- `KEYS *`:会返回所有符合规则的 key。
|
||||||
|
- `HGETALL`:会返回一个 Hash 中所有的键值对。
|
||||||
|
- `LRANGE`:会返回 List 中指定范围内的元素。
|
||||||
|
- `SMEMBERS`:返回 Set 中的所有元素。
|
||||||
|
- `SINTER`/`SUNION`/`SDIFF`:计算多个 Set 的交集/并集/差集。
|
||||||
|
- ......
|
||||||
|
|
||||||
|
由于这些命令时间复杂度是 O(n),有时候也会全表扫描,随着 n 的增大,执行耗时也会越长。不过, 这些命令并不是一定不能使用,但是需要明确 N 的值。另外,有遍历的需求可以使用 `HSCAN`、`SSCAN`、`ZSCAN` 代替。
|
||||||
|
|
||||||
|
除了这些 O(n)时间复杂度的命令可能会导致慢查询之外, 还有一些时间复杂度可能在 O(N) 以上的命令,例如:
|
||||||
|
|
||||||
|
- `ZRANGE`/`ZREVRANGE`:返回指定 Sorted Set 中指定排名范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 为返回的元素数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
|
||||||
|
- `ZREMRANGEBYRANK`/`ZREMRANGEBYSCORE`:移除 Sorted Set 中指定排名范围/指定 score 范围内的所有元素。时间复杂度为 O(log(n)+m),n 为所有元素的数量, m 被删除元素的数量,当 m 和 n 相当大时,O(n) 的时间复杂度更小。
|
||||||
|
- ......
|
||||||
|
|
||||||
|
#### 如何找到慢查询命令?
|
||||||
|
|
||||||
|
在 `redis.conf` 文件中,我们可以使用 `slowlog-log-slower-than` 参数设置耗时命令的阈值,并使用 `slowlog-max-len` 参数设置耗时命令的最大记录条数。
|
||||||
|
|
||||||
|
当 Redis 服务器检测到执行时间超过 `slowlog-log-slower-than`阈值的命令时,就会将该命令记录在慢查询日志(slow log) 中,这点和 MySQL 记录慢查询语句类似。当慢查询日志超过设定的最大记录条数之后,Redis 会把最早的执行命令依次舍弃。
|
||||||
|
|
||||||
|
⚠️注意:由于慢查询日志会占用一定内存空间,如果设置最大记录条数过大,可能会导致内存占用过高的问题。
|
||||||
|
|
||||||
|
`slowlog-log-slower-than`和`slowlog-max-len`的默认配置如下(可以自行修改):
|
||||||
|
|
||||||
|
```nginx
|
||||||
|
# The following time is expressed in microseconds, so 1000000 is equivalent
|
||||||
|
# to one second. Note that a negative number disables the slow log, while
|
||||||
|
# a value of zero forces the logging of every command.
|
||||||
|
slowlog-log-slower-than 10000
|
||||||
|
|
||||||
|
# There is no limit to this length. Just be aware that it will consume memory.
|
||||||
|
# You can reclaim memory used by the slow log with SLOWLOG RESET.
|
||||||
|
slowlog-max-len 128
|
||||||
|
```
|
||||||
|
|
||||||
|
除了修改配置文件之外,你也可以直接通过 `CONFIG` 命令直接设置:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 命令执行耗时超过 10000 微妙(即10毫秒)就会被记录
|
||||||
|
CONFIG SET slowlog-log-slower-than 10000
|
||||||
|
# 只保留最近 128 条耗时命令
|
||||||
|
CONFIG SET slowlog-max-len 128
|
||||||
|
```
|
||||||
|
|
||||||
|
获取慢查询日志的内容很简单,直接使用`SLOWLOG GET` 命令即可。
|
||||||
|
|
||||||
|
```java
|
||||||
|
127.0.0.1:6379> SLOWLOG GET #慢日志查询
|
||||||
|
1) 1) (integer) 5
|
||||||
|
2) (integer) 1684326682
|
||||||
|
3) (integer) 12000
|
||||||
|
4) 1) "KEYS"
|
||||||
|
2) "*"
|
||||||
|
5) "172.17.0.1:61152"
|
||||||
|
6) ""
|
||||||
|
// ...
|
||||||
|
```
|
||||||
|
|
||||||
|
慢查询日志中的每个条目都由以下六个值组成:
|
||||||
|
|
||||||
|
1. 唯一渐进的日志标识符。
|
||||||
|
2. 处理记录命令的 Unix 时间戳。
|
||||||
|
3. 执行所需的时间量,以微秒为单位。
|
||||||
|
4. 组成命令参数的数组。
|
||||||
|
5. 客户端 IP 地址和端口。
|
||||||
|
6. 客户端名称。
|
||||||
|
|
||||||
|
`SLOWLOG GET` 命令默认返回最近 10 条的的慢查询命令,你也自己可以指定返回的慢查询命令的数量 `SLOWLOG GET N`。
|
||||||
|
|
||||||
|
下面是其他比较常用的慢查询相关的命令:
|
||||||
|
|
||||||
|
```bash
|
||||||
|
# 返回慢查询命令的数量
|
||||||
|
127.0.0.1:6379> SLOWLOG LEN
|
||||||
|
(integer) 128
|
||||||
|
# 清空慢查询命令
|
||||||
|
127.0.0.1:6379> SLOWLOG RESET
|
||||||
|
OK
|
||||||
|
```
|
||||||
|
|
||||||
### Redis 内存碎片
|
### Redis 内存碎片
|
||||||
|
|
||||||
**相关问题**:
|
**相关问题**:
|
||||||
@ -634,8 +732,8 @@ Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删
|
|||||||
实际使用 Redis 的过程中,我们尽量要准守一些常见的规范,比如:
|
实际使用 Redis 的过程中,我们尽量要准守一些常见的规范,比如:
|
||||||
|
|
||||||
1. 使用连接池:避免频繁创建关闭客户端连接。
|
1. 使用连接池:避免频繁创建关闭客户端连接。
|
||||||
2. 尽量不使用 O(n)指令,使用 O(N)命令时要关注 N 的数量:例如 `hgetall`、`lrange`、`smembers`、`zrange`、`sinter`、`sunion` 命令并非不能使用,但是需要明确 N 的值。有遍历的需求可以使用 `hscan`、`sscan`、`zscan` 代替。
|
2. 尽量不使用 O(n)指令,使用 O(n) 命令时要关注 n 的数量:像 `KEYS *`、`HGETALL`、`LRANGE`、`SMEMBERS`、`SINTER`/`SUNION`/`SDIFF`等 O(n) 命令并非不能使用,但是需要明确 n 的值。另外,有遍历的需求可以使用 `HSCAN`、`SSCAN`、`ZSCAN` 代替。
|
||||||
3. 使用批量操作减少网络传输:原生批量操作命令(比如 `mget`、`mset`等等)、pipeline、Lua 脚本。
|
3. 使用批量操作减少网络传输:原生批量操作命令(比如 `MGET`、`MSET`等等)、pipeline、Lua 脚本。
|
||||||
4. 尽量不适用 Redis 事务:Redis 事务实现的功能比较鸡肋,可以使用 Lua 脚本代替。
|
4. 尽量不适用 Redis 事务:Redis 事务实现的功能比较鸡肋,可以使用 Lua 脚本代替。
|
||||||
5. 禁止长时间开启 monitor:对性能影响比较大。
|
5. 禁止长时间开启 monitor:对性能影响比较大。
|
||||||
6. 控制 key 的生命周期:避免 Redis 中存放了太多不经常被访问的数据。
|
6. 控制 key 的生命周期:避免 Redis 中存放了太多不经常被访问的数据。
|
||||||
|
|||||||
@ -19,7 +19,9 @@ JDK 提供的这些容器大部分在 `java.util.concurrent` 包中。
|
|||||||
|
|
||||||
所以就有了 `HashMap` 的线程安全版本—— `ConcurrentHashMap` 的诞生。
|
所以就有了 `HashMap` 的线程安全版本—— `ConcurrentHashMap` 的诞生。
|
||||||
|
|
||||||
在 `ConcurrentHashMap` 中,无论是读操作还是写操作都能保证很高的性能:在进行读操作时(几乎)不需要加锁,而在写操作时通过锁分段技术只对所操作的段加锁而不影响客户端对其它段的访问。
|
在 JDK1.7 的时候,`ConcurrentHashMap` 对整个桶数组进行了分割分段(`Segment`,分段锁),每一把锁只锁容器其中一部分数据(下面有示意图),多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。
|
||||||
|
|
||||||
|
到了 JDK1.8 的时候,`ConcurrentHashMap` 已经摒弃了 `Segment` 的概念,而是直接用 `Node` 数组+链表+红黑树的数据结构来实现,并发控制使用 `synchronized` 和 CAS 来操作。(JDK1.6 以后 `synchronized` 锁做了很多优化) 整个看起来就像是优化过且线程安全的 `HashMap`,虽然在 JDK1.8 中还能看到 `Segment` 的数据结构,但是已经简化了属性,只是为了兼容旧版本。
|
||||||
|
|
||||||
## CopyOnWriteArrayList
|
## CopyOnWriteArrayList
|
||||||
|
|
||||||
|
|||||||
@ -119,7 +119,7 @@ Spring Boot 只是简化了配置,如果你需要构建 MVC 架构的 Web 程
|
|||||||
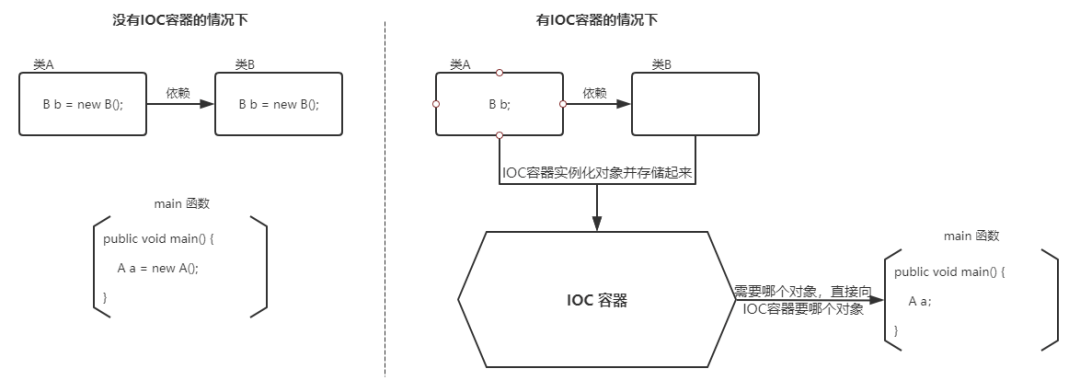
- **控制**:指的是对象创建(实例化、管理)的权力
|
- **控制**:指的是对象创建(实例化、管理)的权力
|
||||||
- **反转**:控制权交给外部环境(Spring 框架、IoC 容器)
|
- **反转**:控制权交给外部环境(Spring 框架、IoC 容器)
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
将对象之间的相互依赖关系交给 IoC 容器来管理,并由 IoC 容器完成对象的注入。这样可以很大程度上简化应用的开发,把应用从复杂的依赖关系中解放出来。 IoC 容器就像是一个工厂一样,当我们需要创建一个对象的时候,只需要配置好配置文件/注解即可,完全不用考虑对象是如何被创建出来的。
|
将对象之间的相互依赖关系交给 IoC 容器来管理,并由 IoC 容器完成对象的注入。这样可以很大程度上简化应用的开发,把应用从复杂的依赖关系中解放出来。 IoC 容器就像是一个工厂一样,当我们需要创建一个对象的时候,只需要配置好配置文件/注解即可,完全不用考虑对象是如何被创建出来的。
|
||||||
|
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user