mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
commit
a0a130f157
@ -78,9 +78,9 @@
|
||||
|
||||
### 2.4. 数组 vs 链表
|
||||
|
||||
- 数据支持随机访问,而链表不支持。
|
||||
- 数组支持随机访问,而链表不支持。
|
||||
- 数组使用的是连续内存空间对 CPU 的缓存机制友好,链表则相反。
|
||||
- 数据的大小固定,而链表则天然支持动态扩容。如果声明的数组过小,需要另外申请一个更大的内存空间存放数组元素,然后将原数组拷贝进去,这个操作是比较耗时的!
|
||||
- 数组的大小固定,而链表则天然支持动态扩容。如果声明的数组过小,需要另外申请一个更大的内存空间存放数组元素,然后将原数组拷贝进去,这个操作是比较耗时的!
|
||||
|
||||
## 3. 栈
|
||||
|
||||
|
||||
@ -510,7 +510,7 @@ ForkJoinPool.commonPool-worker-9>>2
|
||||
>
|
||||
> 正例:使用 JDK8 的 Optional 类来防止 NPE 问题。
|
||||
|
||||
他建议使用 `Optional` 解决 NPE(`java.lang.NumberFormatException`)问题,它就是为 NPE 而生的,其中可以包含空值或非空值。下面我们通过源码逐步揭开 `Optional` 的红盖头。
|
||||
他建议使用 `Optional` 解决 NPE(`java.lang.NullPointerException`)问题,它就是为 NPE 而生的,其中可以包含空值或非空值。下面我们通过源码逐步揭开 `Optional` 的红盖头。
|
||||
|
||||
假设有一个 `Zoo` 类,里面有个属性 `Dog`,需求要获取 `Dog` 的 `age`。
|
||||
|
||||
@ -537,7 +537,7 @@ if(zoo != null){
|
||||
}
|
||||
```
|
||||
|
||||
层层判断对象分空,有人说这种方式很丑陋不优雅,我并不这么认为。反而觉得很整洁,易读,易懂。你们觉得呢?
|
||||
层层判断对象非空,有人说这种方式很丑陋不优雅,我并不这么认为。反而觉得很整洁,易读,易懂。你们觉得呢?
|
||||
|
||||
`Optional` 是这样的实现的:
|
||||
|
||||
|
||||
@ -32,7 +32,7 @@
|
||||
|
||||
### 1.3 网络层
|
||||
|
||||
**在 计算机网络中进行通信的两个计算机之间可能会经过很多个数据链路,也可能还要经过很多通信子网。网络层的任务就是选择合适的网间路由和交换结点, 确保数据及时传送。** 在发送数据时,网络层把运输层产生的报文段或用户数据报封装成分组和包进行传送。在 TCP/IP 体系结构中,由于网络层使用 **IP 协议**,因此分组也叫 **IP 数据报** ,简称 **数据报**。
|
||||
**在计算机网络中进行通信的两个计算机之间可能会经过很多个数据链路,也可能还要经过很多通信子网。网络层的任务就是选择合适的网间路由和交换结点, 确保数据及时传送。** 在发送数据时,网络层把运输层产生的报文段或用户数据报封装成分组和包进行传送。在 TCP/IP 体系结构中,由于网络层使用 **IP 协议**,因此分组也叫 **IP 数据报** ,简称 **数据报**。
|
||||
|
||||
这里要注意:**不要把运输层的“用户数据报 UDP ”和网络层的“ IP 数据报”弄混**。另外,无论是哪一层的数据单元,都可笼统地用“分组”来表示。
|
||||
|
||||
@ -93,62 +93,7 @@
|
||||
|
||||
> SYN 同步序列编号(Synchronize Sequence Numbers) 是 TCP/IP 建立连接时使用的握手信号。在客户机和服务器之间建立正常的 TCP 网络连接时,客户机首先发出一个 SYN 消息,服务器使用 SYN-ACK 应答表示接收到了这个消息,最后客户机再以 ACK(Acknowledgement)消息响应。这样在客户机和服务器之间才能建立起可靠的 TCP 连接,数据才可以在客户机和服务器之间传递。
|
||||
|
||||
#### 2.3.1 三次握手的原因?
|
||||
|
||||
一般来说,这种问题我们可以使用反证法来说明 TCP 为什么要进行三次握手。
|
||||
|
||||
* 如果只有两次握手,我们来看看会发生什么事情。
|
||||
|
||||
正常情况下,TCP 连接建立之后,默认保持长连接。如果只有两次握手,情况就是:
|
||||
|
||||
第一次握手:Client 发送 SYN 请求连接。Client 进入SYN-SENT 状态
|
||||
|
||||
第二次握手:Server 回发 ACK、SYN 报文。确认连接。**Server 由 LISTEN 状态进入 ESTABLISHED 状态**
|
||||
|
||||
到这里,我们看到,Server 只要接收到 SYN 报文 且回发 ACK、SYN 报文后,就建立了连接。
|
||||
|
||||
正常情况下我们这么考虑是没有问题的,但网络环境十分复杂,Client 第一次发送的连接请求报文段可能会在这次连接已经释放(结束)后才到达 Server。显然这是一个已经失效的连接,但由于两次握手机制,Server 认可这个连接请求,所以 Server 会再一次建立连接。
|
||||
|
||||
连接建立之后,由于 Client 已经结束了之前的连接,因此 Server 后面发过来的连接请求,Client是不管的,最终 Server 只能白白维持这次连接(多次重传无效后才发送 RST 报文,断开连接),造成资源的浪费。
|
||||
|
||||
* 有没有必要四次握手呢?
|
||||
|
||||
结论是,没有必要进行四次握手。原因如下:
|
||||
|
||||
1. 有过抓包经验的小伙伴应该直到,**TCP 握手的前两次,TCP 头部的长度一般都是32字节(固定头部:20字节,选项部分:12字节),且数据部分的长度都为0**,这个阶段。TCP 涉及的拥塞控制、流量控制等需要的信息,比如序号(Seq)、窗口信息等都会在前两次握手中交换。
|
||||
2. 使用第三次握手的主要原因就是为了避免 Server 一直等待,浪费资源。
|
||||
|
||||
综上,我们没有必要再添加多一次握手,增加建立连接的成本。
|
||||
|
||||
#### 2.3.2 什么是 SYN 攻击?
|
||||
|
||||
我们重新看一下三次握手的过程:
|
||||
|
||||
第一次握手: Client 向 Server 发送连接请求。
|
||||
|
||||
第二次握手:Server 接收到 Client 的连接请求,向 Client 发送 SYN + ACK 报文。同时 Server 进入 SYN_RCVD 状态。
|
||||
|
||||
第三次握手:Client 返回 ACK 报文以确认收到 Server 的报文,确认通信。
|
||||
|
||||
第二次握手与第三次握手之间, Server 此时开启了新的端口等待 Client 的响应,这个 Server 在等待 Client 响应的状态被称为**半开连接状态**。
|
||||
|
||||
攻击者可以利用半开连接状态对服务器进行攻击,这种攻击称为 SYN 攻击。
|
||||
|
||||
#### 2.3.3 什么是 DDoS 攻击?
|
||||
|
||||
首先,**拒绝服务攻击**(denial-of-service attack,DoS 攻击)也被称为**洪水攻击**,原理就是上面提到的 SYN 攻击。其目的就像它的名字一样,通过 SYN 攻击使目标服务器资源耗尽,让服务器无法正常提供服务,导致用户无法正常访问。
|
||||
|
||||
**分布式拒绝服务攻击**(distributed denial-of-service attack,DDoS 攻击),其概念为攻击者控制两台包括两台以上的电脑向目标发起 DoS攻击。
|
||||
|
||||
网上有一个关于 DDoS 的比喻十分生动:
|
||||
|
||||
我们可以想象大城市堵车的情景,当公路的交通状况很差时,你需要在路上耗费很长的时间,此时公路的交通情况就妨碍了你到达目的地。
|
||||
|
||||
与此相对应,我们把公路看作用户通往服务器的网络通道,公路上的车看作攻击者攻击的服务器的工具,用户此时就是公路上的一辆车。
|
||||
|
||||
如果道路很少车(网络通畅),我们就可以迅速通过这段路(网站快速反应);如果道路很多车,变得很拥挤(网络拥塞),那么我们需要花费比平常更多得时间通过这段路(网站响应时间边长);如果有人制造交通事故导致大塞车(DDoS攻击),那么我们可能无法通过这段路(网站几乎瘫痪)。
|
||||
|
||||
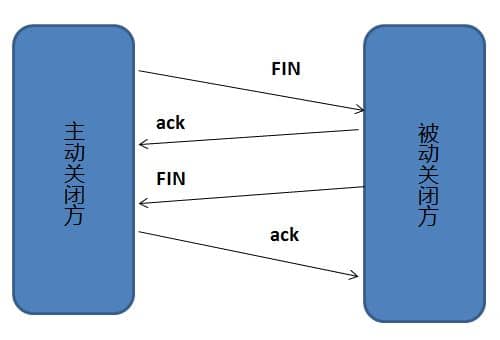
### 2.4 为什么要四次挥手
|
||||
### 2.5 为什么要四次挥手
|
||||
|
||||
|
||||
|
||||
@ -347,3 +292,4 @@ URI的作用像身份证号一样,URL的作用更像家庭住址一样。URL
|
||||
- [https://blog.csdn.net/zixiaomuwu/article/details/60965466](https://blog.csdn.net/zixiaomuwu/article/details/60965466)
|
||||
- [https://blog.csdn.net/turn__back/article/details/73743641](https://blog.csdn.net/turn__back/article/details/73743641)
|
||||
- <https://mp.weixin.qq.com/s/GICbiyJpINrHZ41u_4zT-A?>
|
||||
|
||||
|
||||
@ -51,7 +51,6 @@
|
||||
|
||||
简单来说“Shell编程就是对一堆Linux命令的逻辑化处理”。
|
||||
|
||||
|
||||
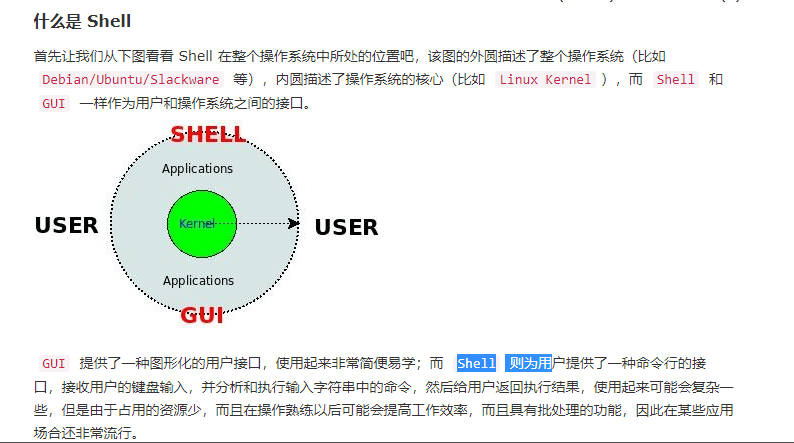
W3Cschool 上的一篇文章是这样介绍 Shell的,如下图所示。
|
||||
|
||||
|
||||
@ -91,7 +90,7 @@ shell中 # 符号表示注释。**shell 的第一行比较特殊,一般都会
|
||||
**Shell编程中一般分为三种变量:**
|
||||
|
||||
1. **我们自己定义的变量(自定义变量):** 仅在当前 Shell 实例中有效,其他 Shell 启动的程序不能访问局部变量。
|
||||
2. **Linux已定义的环境变量**(环境变量, 例如:$PATH, $HOME 等..., 这类变量我们可以直接使用),使用 `env` 命令可以查看所有的环境变量,而set命令既可以查看环境变量也可以查看自定义变量。
|
||||
2. **Linux已定义的环境变量**(环境变量, 例如:`PATH`, `HOME` 等..., 这类变量我们可以直接使用),使用 `env` 命令可以查看所有的环境变量,而set命令既可以查看环境变量也可以查看自定义变量。
|
||||
3. **Shell变量** :Shell变量是由 Shell 程序设置的特殊变量。Shell 变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了 Shell 的正常运行
|
||||
|
||||
**常用的环境变量:**
|
||||
@ -347,7 +346,6 @@ echo $a;
|
||||
简单示例:
|
||||
|
||||
```shell
|
||||
|
||||
#!/bin/bash
|
||||
a="abc";
|
||||
b="efg";
|
||||
@ -530,8 +528,6 @@ echo "输入的两个数字之和为 $?"
|
||||
|
||||
### 带参数的函数
|
||||
|
||||
|
||||
|
||||
```shell
|
||||
#!/bin/bash
|
||||
funWithParam(){
|
||||
@ -544,7 +540,6 @@ funWithParam(){
|
||||
echo "作为一个字符串输出所有参数 $* !"
|
||||
}
|
||||
funWithParam 1 2 3 4 5 6 7 8 9 34 73
|
||||
|
||||
```
|
||||
|
||||
输出结果:
|
||||
@ -557,5 +552,4 @@ funWithParam 1 2 3 4 5 6 7 8 9 34 73
|
||||
第十一个参数为 73 !
|
||||
参数总数有 11 个!
|
||||
作为一个字符串输出所有参数 1 2 3 4 5 6 7 8 9 34 73 !
|
||||
|
||||
```
|
||||
|
||||
@ -8,7 +8,7 @@
|
||||
|
||||
开始本文的内容之前,我们先聊聊为什么要学习操作系统。
|
||||
|
||||
- **从对个人能力方面提升来说** :操作系统中的很多思想、很多经典的算法,你都可以在我们日常开发使用的各种工具或者框架中找到它们的影子。比如说我们开发的系统使用的缓存(比如 Redis)和操作系统的高速缓存就很像。CPU 中的高速缓存有很多种,不过大部分都是为了解决 CPU 处理速度和内存处理速度不对等的问题。我们还可以把内存可以看作外存的高速缓存,程序运行的时候我们把外存的数据复制到内存,由于内存的处理速度远远高于外存,这样提高了处理速度。同样地,我们使用的 Redis 缓存就是为了解决程序处理速度和访问常规关系型数据库速度不对等的问题。高速缓存一般会按照局部性原理(2-8 原则)根据相应的淘汰算法保证缓存中的数据是经常会被访问的。我们平常使用的 Redis 缓存很多时候也会按照 2-8 原则去做,很多淘汰算法都和操作系统中的类似。既说了 2-8 原则,那就不得不提命中率了,这是所有缓存概念都通用的。简单来说也就是你要访问的数据有多少能直接在缓存中直接找到。命中率高的话,一般表明你的缓存设计比较合理,系统处理速度也相对较快。
|
||||
- **从对个人能力方面提升来说** :操作系统中的很多思想、很多经典的算法,你都可以在我们日常开发使用的各种工具或者框架中找到它们的影子。比如说我们开发的系统使用的缓存(比如 Redis)和操作系统的高速缓存就很像。CPU 中的高速缓存有很多种,不过大部分都是为了解决 CPU 处理速度和内存处理速度不对等的问题。我们还可以把内存看作外存的高速缓存,程序运行的时候我们把外存的数据复制到内存,由于内存的处理速度远远高于外存,这样提高了处理速度。同样地,我们使用的 Redis 缓存就是为了解决程序处理速度和访问常规关系型数据库速度不对等的问题。高速缓存一般会按照局部性原理(2-8 原则)根据相应的淘汰算法保证缓存中的数据是经常会被访问的。我们平常使用的 Redis 缓存很多时候也会按照 2-8 原则去做,很多淘汰算法都和操作系统中的类似。既说了 2-8 原则,那就不得不提命中率了,这是所有缓存概念都通用的。简单来说也就是你要访问的数据有多少能直接在缓存中直接找到。命中率高的话,一般表明你的缓存设计比较合理,系统处理速度也相对较快。
|
||||
- **从面试角度来说** :尤其是校招,对于操作系统方面知识的考察是非常非常多的。
|
||||
|
||||
**简单来说,学习操作系统能够提高自己思考的深度以及对技术的理解力,并且,操作系统方面的知识也是面试必备。**
|
||||
|
||||
@ -163,7 +163,7 @@ _玩玩电脑游戏还是必须要有 Windows 的,所以我现在是一台 Win
|
||||
|
||||
- **类 Unix 系统** : Linux 是一种自由、开放源码的类似 Unix 的操作系统
|
||||
- **Linux 本质是指 Linux 内核** : 严格来讲,Linux 这个词本身只表示 Linux 内核,单独的 Linux 内核并不能成为一个可以正常工作的操作系统。所以,就有了各种 Linux 发行版。
|
||||
- **Linux 之父** : 一个编程领域的传奇式人物,真大佬!我辈崇拜敬仰之楷模。他是 **Linux 内核** 的最早作者,随后发起了这个开源项目,担任 Linux 内核的首要架构师。他还发起了 Git 这个开源项目,并为主要的开发者。
|
||||
- **Linux 之父(林纳斯·本纳第克特·托瓦兹 Linus Benedict Torvalds)** : 一个编程领域的传奇式人物,真大佬!我辈崇拜敬仰之楷模。他是 **Linux 内核** 的最早作者,随后发起了这个开源项目,担任 Linux 内核的首要架构师。他还发起了 Git 这个开源项目,并为主要的开发者。
|
||||
|
||||

|
||||
|
||||
@ -303,7 +303,7 @@ Linux 中的打包文件一般是以.tar 结尾的,压缩的命令一般是以
|
||||
|
||||
**2)解压压缩包:**
|
||||
|
||||
命令:`tar [-xvf] 压缩文件``
|
||||
命令:`tar [-xvf] 压缩文件`
|
||||
|
||||
其中:x:代表解压
|
||||
|
||||
|
||||
@ -409,6 +409,8 @@ class WebSite {
|
||||
|
||||
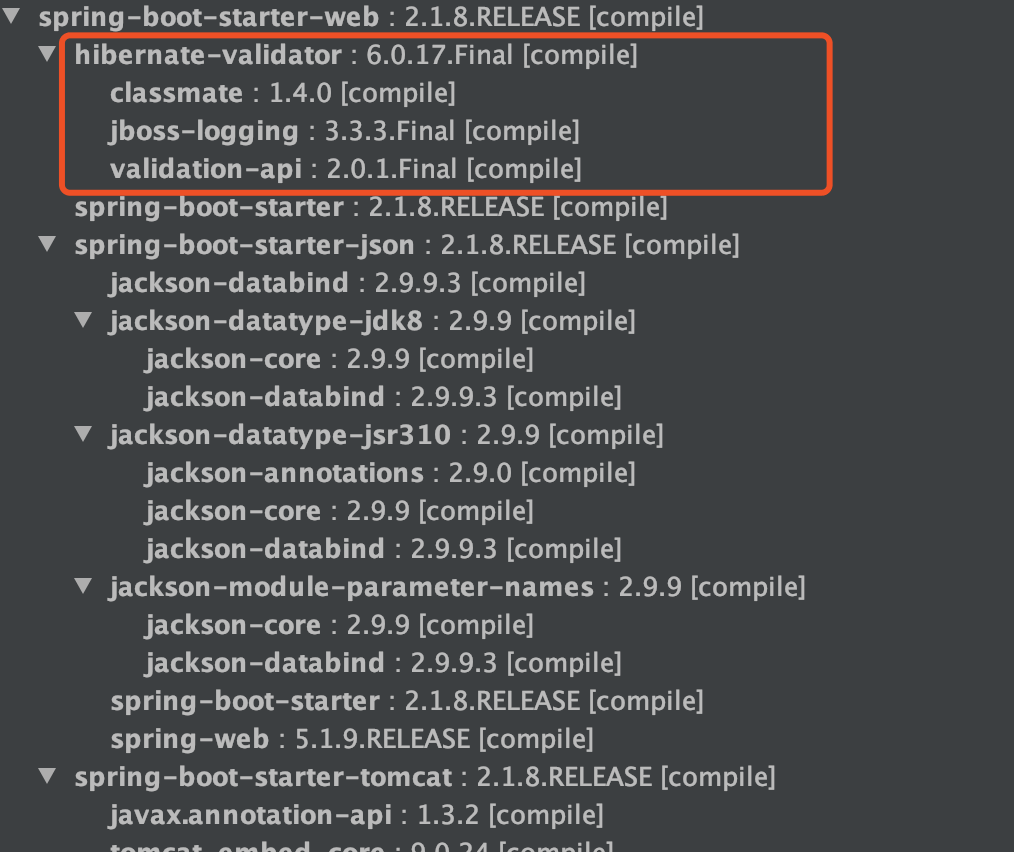
SpringBoot 项目的 spring-boot-starter-web 依赖中已经有 hibernate-validator 包,不需要引用相关依赖。如下图所示(通过 idea 插件—Maven Helper 生成):
|
||||
|
||||
**注**:更新版本的 spring-boot-starter-web 依赖中不再有 hibernate-validator 包(如2.3.11.RELEASE),需要自己引入 `spring-boot-starter-validation` 依赖。
|
||||
|
||||
|
||||
|
||||
非 SpringBoot 项目需要自行引入相关依赖包,这里不多做讲解,具体可以查看我的这篇文章:《[如何在 Spring/Spring Boot 中做参数校验?你需要了解的都在这里!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485783&idx=1&sn=a407f3b75efa17c643407daa7fb2acd6&chksm=cea2469cf9d5cf8afbcd0a8a1c9cc4294d6805b8e01bee6f76bb2884c5bc15478e91459def49&token=292197051&lang=zh_CN#rd)》。
|
||||
|
||||
@ -83,11 +83,11 @@ IoC源码阅读
|
||||
|
||||
AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无关,**却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来**,便于**减少系统的重复代码**,**降低模块间的耦合度**,并**有利于未来的可拓展性和可维护性**。
|
||||
|
||||
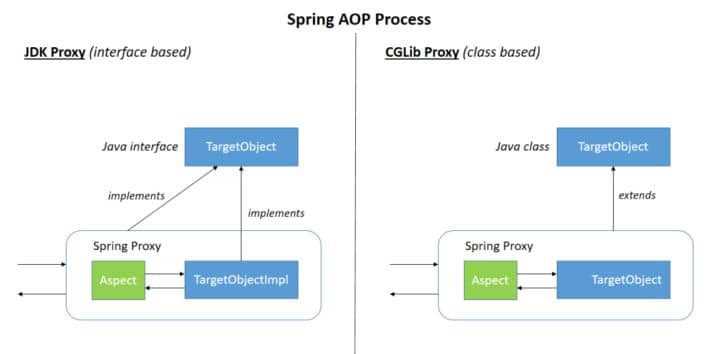
**Spring AOP就是基于动态代理的**,如果要代理的对象,实现了某个接口,那么Spring AOP会使用**JDK Proxy**,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候Spring AOP会使用**Cglib** ,这时候Spring AOP会使用 **Cglib** 生成一个被代理对象的子类来作为代理,如下图所示:
|
||||
**Spring AOP就是基于动态代理的**,如果要代理的对象,实现了某个接口,那么Spring AOP会使用**JDK Proxy**,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候Spring AOP会使用**Cglib**生成一个被代理对象的子类来作为代理,如下图所示:
|
||||
|
||||
|
||||
|
||||
当然你也可以使用 AspectJ ,Spring AOP 已经集成了AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。
|
||||
当然你也可以使用 AspectJ,Spring AOP 已经集成了AspectJ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。
|
||||
|
||||
使用 AOP 之后我们可以把一些通用功能抽象出来,在需要用到的地方直接使用即可,这样大大简化了代码量。我们需要增加新功能时也方便,这样也提高了系统扩展性。日志功能、事务管理等等场景都用到了 AOP 。
|
||||
|
||||
@ -117,7 +117,7 @@ AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无
|
||||
|
||||
常见的有 2 种解决办法:
|
||||
|
||||
2. 在类中定义一个 `ThreadLocal` 成员变量,将需要的可变成员变量保存在 `ThreadLocal` 中(推荐的一种方式)。
|
||||
1. 在类中定义一个 `ThreadLocal` 成员变量,将需要的可变成员变量保存在 `ThreadLocal` 中(推荐的一种方式)。
|
||||
2. 改变 Bean 的作用域为 “prototype”:每次请求都会创建一个新的 bean 实例,自然不会存在线程安全问题。
|
||||
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user