mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
[docs update&fix]修正快排算法&补充WebSocket面试问题&优化Redis慢查询
This commit is contained in:
parent
2e7aa2a8eb
commit
9d11263c6e
@ -367,31 +367,60 @@ public static int[] merge(int[] arr_1, int[] arr_2) {
|
||||
|
||||
### 代码实现
|
||||
|
||||
> 来源:[使用 Java 实现快速排序(详解)](https://segmentfault.com/a/1190000040022056)
|
||||
|
||||
```java
|
||||
public static int partition(int[] array, int low, int high) {
|
||||
int pivot = array[high];
|
||||
int pointer = low;
|
||||
for (int i = low; i < high; i++) {
|
||||
if (array[i] <= pivot) {
|
||||
int temp = array[i];
|
||||
array[i] = array[pointer];
|
||||
array[pointer] = temp;
|
||||
pointer++;
|
||||
import java.util.concurrent.ThreadLocalRandom;
|
||||
|
||||
class Solution {
|
||||
public int[] sortArray(int[] a) {
|
||||
quick(a, 0, a.length - 1);
|
||||
return a;
|
||||
}
|
||||
System.out.println(Arrays.toString(array));
|
||||
|
||||
// 快速排序的核心递归函数
|
||||
void quick(int[] a, int left, int right) {
|
||||
if (left >= right) { // 递归终止条件:区间只有一个或没有元素
|
||||
return;
|
||||
}
|
||||
int temp = array[pointer];
|
||||
array[pointer] = array[high];
|
||||
array[high] = temp;
|
||||
return pointer;
|
||||
}
|
||||
public static void quickSort(int[] array, int low, int high) {
|
||||
if (low < high) {
|
||||
int position = partition(array, low, high);
|
||||
quickSort(array, low, position - 1);
|
||||
quickSort(array, position + 1, high);
|
||||
int p = partition(a, left, right); // 分区操作,返回分区点索引
|
||||
quick(a, left, p - 1); // 对左侧子数组递归排序
|
||||
quick(a, p + 1, right); // 对右侧子数组递归排序
|
||||
}
|
||||
|
||||
// 分区函数:将数组分为两部分,小于基准值的在左,大于基准值的在右
|
||||
int partition(int[] a, int left, int right) {
|
||||
// 随机选择一个基准点,避免最坏情况(如数组接近有序)
|
||||
int idx = ThreadLocalRandom.current().nextInt(right - left + 1) + left;
|
||||
swap(a, left, idx); // 将基准点放在数组的最左端
|
||||
int pv = a[left]; // 基准值
|
||||
int i = left + 1; // 左指针,指向当前需要检查的元素
|
||||
int j = right; // 右指针,从右往左寻找比基准值小的元素
|
||||
|
||||
while (i <= j) {
|
||||
// 左指针向右移动,直到找到一个大于等于基准值的元素
|
||||
while (i <= j && a[i] < pv) {
|
||||
i++;
|
||||
}
|
||||
// 右指针向左移动,直到找到一个小于等于基准值的元素
|
||||
while (i <= j && a[j] > pv) {
|
||||
j--;
|
||||
}
|
||||
// 如果左指针尚未越过右指针,交换两个不符合位置的元素
|
||||
if (i <= j) {
|
||||
swap(a, i, j);
|
||||
i++;
|
||||
j--;
|
||||
}
|
||||
}
|
||||
// 将基准值放到分区点位置,使得基准值左侧小于它,右侧大于它
|
||||
swap(a, j, left);
|
||||
return j;
|
||||
}
|
||||
|
||||
// 交换数组中两个元素的位置
|
||||
void swap(int[] a, int i, int j) {
|
||||
int t = a[i];
|
||||
a[i] = a[j];
|
||||
a[j] = t;
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
@ -336,23 +336,70 @@ WebSocket 的工作过程可以分为以下几个步骤:
|
||||
|
||||
另外,建立 WebSocket 连接之后,通过心跳机制来保持 WebSocket 连接的稳定性和活跃性。
|
||||
|
||||
### WebSocket 与短轮询、长轮询的区别
|
||||
|
||||
这三种方式,都是为了解决“**客户端如何及时获取服务器最新数据,实现实时更新**”的问题。它们的实现方式和效率、实时性差异较大。
|
||||
|
||||
**1.短轮询(Short Polling)**
|
||||
|
||||
- **原理**:客户端每隔固定时间(如 5 秒)发起一次 HTTP 请求,询问服务器是否有新数据。服务器收到请求后立即响应。
|
||||
- **优点**:实现简单,兼容性好,直接用常规 HTTP 请求即可。
|
||||
- **缺点**:
|
||||
- **实时性一般**:消息可能在两次轮询间到达,用户需等到下次请求才知晓。
|
||||
- **资源浪费大**:反复建立/关闭连接,且大多数请求收到的都是“无新消息”,极大增加服务器和网络压力。
|
||||
|
||||
**2.长轮询(Long Polling)**
|
||||
|
||||
- **原理**:客户端发起请求后,若服务器暂时无新数据,则会保持连接,直到有新数据或超时才响应。客户端收到响应后立即发起下一次请求,实现“伪实时”。
|
||||
- **优点**:
|
||||
- **实时性较好**:一旦有新数据可立即推送,无需等待下次定时请求。
|
||||
- **空响应减少**:减少了无效的空响应,提升了效率。
|
||||
- **缺点**:
|
||||
- **服务器资源占用高**:需长时间维护大量连接,消耗服务器线程/连接数。
|
||||
- **资源浪费大**:每次响应后仍需重新建立连接,且依然基于 HTTP 单向请求-响应机制。
|
||||
|
||||
**3. WebSocket**
|
||||
|
||||
- **原理**:客户端与服务器通过一次 HTTP Upgrade 握手后,建立一条持久的 TCP 连接。之后,双方可以随时、主动地发送数据,实现真正的全双工、低延迟通信。
|
||||
- **优点**:
|
||||
- **实时性强**:数据可即时双向收发,延迟极低。
|
||||
- **资源效率高**:连接持续,无需反复建立/关闭,减少资源消耗。
|
||||
- **功能强大**:支持服务端主动推送消息、客户端主动发起通信。
|
||||
- **缺点**:
|
||||
- **使用限制**:需要服务器和客户端都支持 WebSocket 协议。对连接管理有一定要求(如心跳保活、断线重连等)。
|
||||
- **实现麻烦**:实现起来比短轮询和长轮询要更麻烦一些。
|
||||
|
||||

|
||||
|
||||
### SSE 与 WebSocket 有什么区别?
|
||||
|
||||
> 摘自[Web 实时消息推送详解](https://javaguide.cn/system-design/web-real-time-message-push.html)。
|
||||
SSE (Server-Sent Events) 和 WebSocket 都是用来实现服务器向浏览器实时推送消息的技术,让网页内容能自动更新,而不需要用户手动刷新。虽然目标相似,但它们在工作方式和适用场景上有几个关键区别:
|
||||
|
||||
SSE 与 WebSocket 作用相似,都可以建立服务端与浏览器之间的通信,实现服务端向客户端推送消息,但还是有些许不同:
|
||||
1. **通信方式:**
|
||||
- **SSE:** **单向通信**。只有服务器能向客户端(浏览器)发送数据。客户端不能通过同一个连接向服务器发送数据(需要发起新的 HTTP 请求)。
|
||||
- **WebSocket:** **双向通信 (全双工)**。客户端和服务器可以随时互相发送消息,实现真正的实时交互。
|
||||
2. **底层协议:**
|
||||
- **SSE:** 基于**标准的 HTTP/HTTPS 协议**。它本质上是一个“长连接”的 HTTP 请求,服务器保持连接打开并持续发送事件流。不需要特殊的服务器或协议支持,现有的 HTTP 基础设施就能用。
|
||||
- **WebSocket:** 使用**独立的 ws:// 或 wss:// 协议**。它需要通过一个特定的 HTTP "Upgrade" 请求来建立连接,并且服务器需要明确支持 WebSocket 协议来处理连接和消息帧。
|
||||
3. **实现复杂度和成本:**
|
||||
- **SSE:** **实现相对简单**,主要在服务器端处理。浏览器端有标准的 EventSource API,使用方便。开发和维护成本较低。
|
||||
- **WebSocket:** **稍微复杂一些**。需要服务器端专门处理 WebSocket 连接和协议,客户端也需要使用 WebSocket API。如果需要考虑兼容性、心跳、重连等,开发成本会更高。
|
||||
4. **断线重连:**
|
||||
- **SSE:** **浏览器原生支持**。EventSource API 提供了自动断线重连的机制。
|
||||
- **WebSocket:** **需要手动实现**。开发者需要自己编写逻辑来检测断线并进行重连尝试。
|
||||
5. **数据类型:**
|
||||
- **SSE:** **主要设计用来传输文本** (UTF-8 编码)。如果需要传输二进制数据,需要先进行 Base64 等编码转换成文本。
|
||||
- **WebSocket:** **原生支持传输文本和二进制数据**,无需额外编码。
|
||||
|
||||
- SSE 是基于 HTTP 协议的,它们不需要特殊的协议或服务器实现即可工作;WebSocket 需单独服务器来处理协议。
|
||||
- SSE 单向通信,只能由服务端向客户端单向通信;WebSocket 全双工通信,即通信的双方可以同时发送和接受信息。
|
||||
- SSE 实现简单开发成本低,无需引入其他组件;WebSocket 传输数据需做二次解析,开发门槛高一些。
|
||||
- SSE 默认支持断线重连;WebSocket 则需要自己实现。
|
||||
- SSE 只能传送文本消息,二进制数据需要经过编码后传送;WebSocket 默认支持传送二进制数据。
|
||||
为了提供更好的用户体验和利用其简单、高效、基于标准 HTTP 的特性,**Server-Sent Events (SSE) 是目前大型语言模型 API(如 OpenAI、DeepSeek 等)实现流式响应的常用甚至可以说是标准的技木选择**。
|
||||
|
||||
**SSE 与 WebSocket 该如何选择?**
|
||||
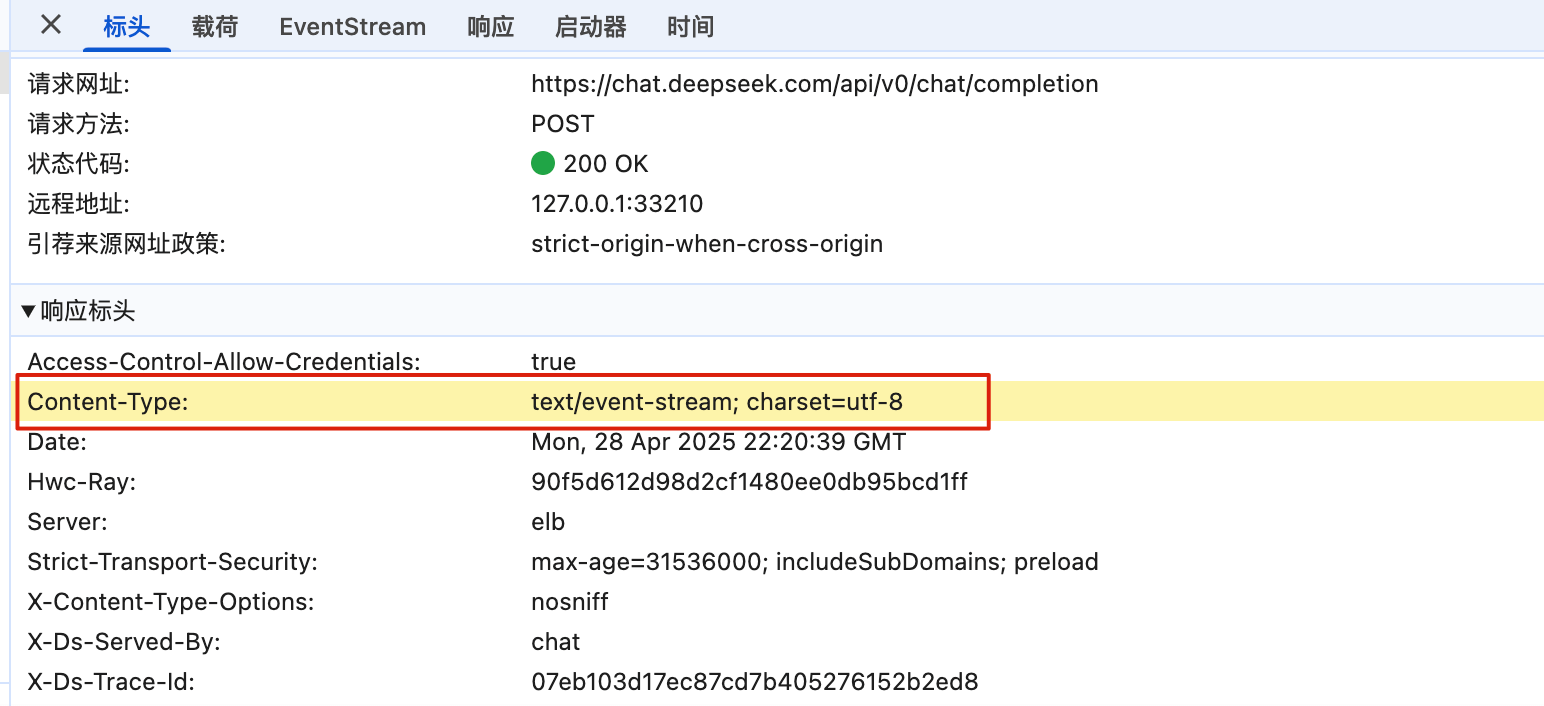
这里以 DeepSeek 为例,我们发送一个请求并打开浏览器控制台验证一下:
|
||||
|
||||
SSE 好像一直不被大家所熟知,一部分原因是出现了 WebSocket,这个提供了更丰富的协议来执行双向、全双工通信。对于游戏、即时通信以及需要双向近乎实时更新的场景,拥有双向通道更具吸引力。
|
||||
|
||||
|
||||
但是,在某些情况下,不需要从客户端发送数据。而你只需要一些服务器操作的更新。比如:站内信、未读消息数、状态更新、股票行情、监控数量等场景,SSE 不管是从实现的难易和成本上都更加有优势。此外,SSE 具有 WebSocket 在设计上缺乏的多种功能,例如:自动重新连接、事件 ID 和发送任意事件的能力。
|
||||
|
||||
|
||||
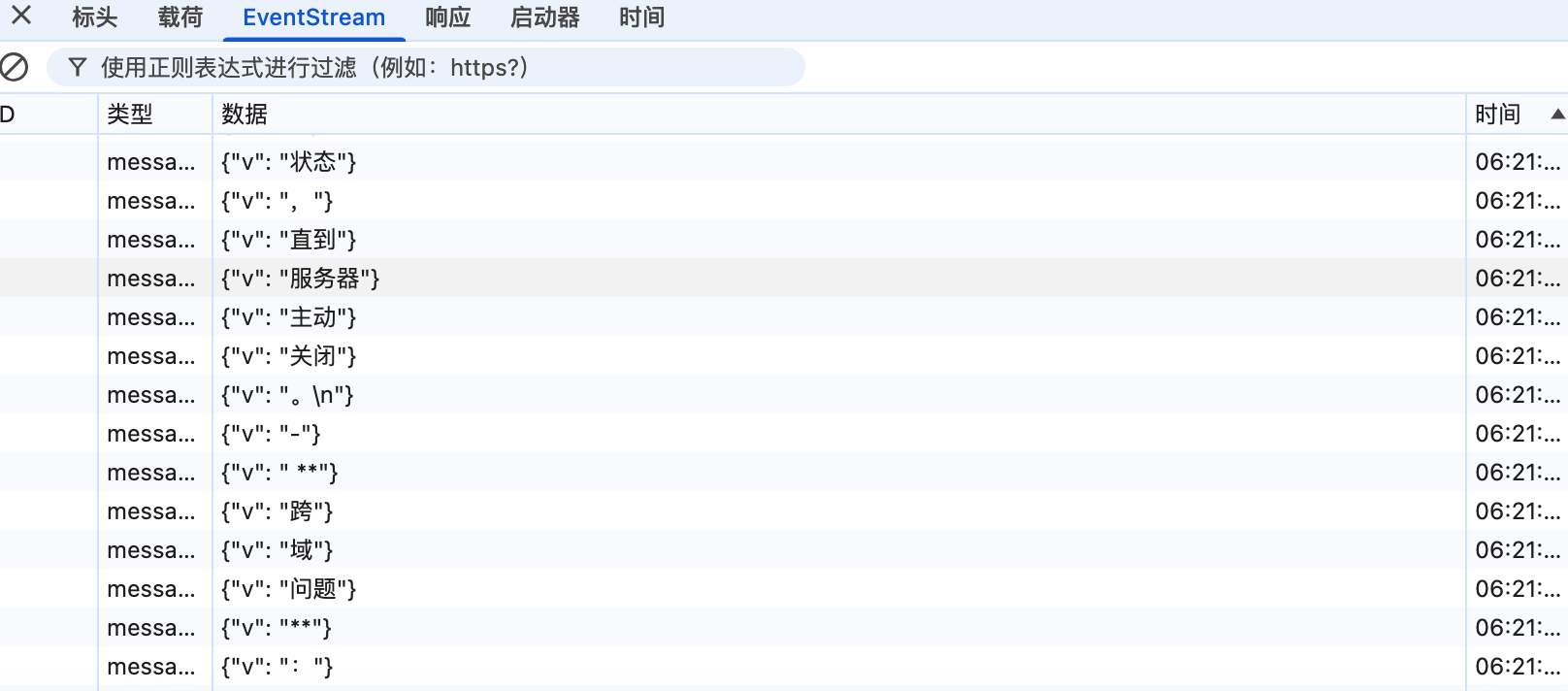
可以看到,响应头应里包含了 `text/event-stream`,说明使用的确实是SSE。并且,响应数据也确实是持续分块传输。
|
||||
|
||||
## PING
|
||||
|
||||
|
||||
@ -525,11 +525,13 @@ Redis 中的大部分命令都是 O(1) 时间复杂度,但也有少部分 O(n)
|
||||
|
||||
#### 如何找到慢查询命令?
|
||||
|
||||
Redis 提供了一个内置的**慢查询日志 (Slow Log)** 功能,专门用来记录执行时间超过指定阈值的命令。这对于排查性能瓶颈、找出导致 Redis 阻塞的“慢”操作非常有帮助,原理和 MySQL 的慢查询日志类似。
|
||||
|
||||
在 `redis.conf` 文件中,我们可以使用 `slowlog-log-slower-than` 参数设置耗时命令的阈值,并使用 `slowlog-max-len` 参数设置耗时命令的最大记录条数。
|
||||
|
||||
当 Redis 服务器检测到执行时间超过 `slowlog-log-slower-than` 阈值的命令时,就会将该命令记录在慢查询日志(slow log)中,这点和 MySQL 记录慢查询语句类似。当慢查询日志超过设定的最大记录条数之后,Redis 会把最早的执行命令依次舍弃。
|
||||
|
||||
⚠️注意:由于慢查询日志会占用一定内存空间,如果设置最大记录条数过大,可能会导致内存占用过高的问题。
|
||||
⚠️ 注意:由于慢查询日志会占用一定内存空间,如果设置最大记录条数过大,可能会导致内存占用过高的问题。
|
||||
|
||||
`slowlog-log-slower-than` 和 `slowlog-max-len` 的默认配置如下(可以自行修改):
|
||||
|
||||
@ -569,12 +571,12 @@ CONFIG SET slowlog-max-len 128
|
||||
|
||||
慢查询日志中的每个条目都由以下六个值组成:
|
||||
|
||||
1. 唯一渐进的日志标识符。
|
||||
2. 处理记录命令的 Unix 时间戳。
|
||||
3. 执行所需的时间量,以微秒为单位。
|
||||
4. 组成命令参数的数组。
|
||||
5. 客户端 IP 地址和端口。
|
||||
6. 客户端名称。
|
||||
1. **唯一 ID**: 日志条目的唯一标识符。
|
||||
2. **时间戳 (Timestamp)**: 命令执行完成时的 Unix 时间戳。
|
||||
3. **耗时 (Duration)**: 命令执行所花费的时间,单位是**微秒**。
|
||||
4. **命令及参数 (Command)**: 执行的具体命令及其参数数组。
|
||||
5. **客户端信息 (Client IP:Port)**: 执行命令的客户端地址和端口。
|
||||
6. **客户端名称 (Client Name)**: 如果客户端设置了名称 (CLIENT SETNAME)。
|
||||
|
||||
`SLOWLOG GET` 命令默认返回最近 10 条的的慢查询命令,你也自己可以指定返回的慢查询命令的数量 `SLOWLOG GET N`。
|
||||
|
||||
@ -731,15 +733,27 @@ Bloom Filter 会使用一个较大的 bit 数组来保存所有的数据,数
|
||||
|
||||
### 如何保证缓存和数据库数据的一致性?
|
||||
|
||||
细说的话可以扯很多,但是我觉得其实没太大必要(小声 BB:很多解决方案我也没太弄明白)。我个人觉得引入缓存之后,如果为了短时间的不一致性问题,选择让系统设计变得更加复杂的话,完全没必要。
|
||||
缓存和数据库一致性是个挺常见的技术挑战。引入缓存主要是为了提升性能、减轻数据库压力,但确实会带来数据不一致的风险。绝对的一致性往往意味着更高的系统复杂度和性能开销,所以实践中我们通常会根据业务场景选择合适的策略,在性能和一致性之间找到一个平衡点。
|
||||
|
||||
下面单独对 **Cache Aside Pattern(旁路缓存模式)** 来聊聊。
|
||||
下面单独对 **Cache Aside Pattern(旁路缓存模式)** 来聊聊。这是非常常用的一种缓存读写策略,它的读写逻辑是这样的:
|
||||
|
||||
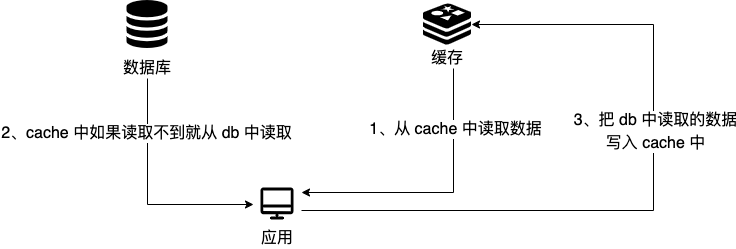
Cache Aside Pattern 中遇到写请求是这样的:更新数据库,然后直接删除缓存。
|
||||
- **读操作**:
|
||||
1. 先尝试从缓存读取数据。
|
||||
2. 如果缓存命中,直接返回数据。
|
||||
3. 如果缓存未命中,从数据库查询数据,将查到的数据放入缓存并返回数据。
|
||||
- **写操作**:
|
||||
1. 先更新数据库。
|
||||
2. 再直接删除缓存中对应的数据。
|
||||
|
||||
图解如下:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
如果更新数据库成功,而删除缓存这一步失败的情况的话,简单说有两个解决方案:
|
||||
|
||||
1. **缓存失效时间变短**(不推荐,治标不治本):我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
|
||||
1. **缓存失效时间(TTL - Time To Live)变短**(不推荐,治标不治本):我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
|
||||
2. **增加缓存更新重试机制**(常用):如果缓存服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。不过,这里更适合引入消息队列实现异步重试,将删除缓存重试的消息投递到消息队列,然后由专门的消费者来重试,直到成功。虽然说多引入了一个消息队列,但其整体带来的收益还是要更高一些。
|
||||
|
||||
相关文章推荐:[缓存和数据库一致性问题,看这篇就够了 - 水滴与银弹](https://mp.weixin.qq.com/s?__biz=MzIyOTYxNDI5OA==&mid=2247487312&idx=1&sn=fa19566f5729d6598155b5c676eee62d&chksm=e8beb8e5dfc931f3e35655da9da0b61c79f2843101c130cf38996446975014f958a6481aacf1&scene=178&cur_album_id=1699766580538032128#rd)。
|
||||
|
||||
@ -321,52 +321,68 @@ printArray( stringArray );
|
||||
|
||||
关于反射的详细解读,请看这篇文章 [Java 反射机制详解](./reflection.md) 。
|
||||
|
||||
### 何谓反射?
|
||||
### 什么是反射?
|
||||
|
||||
如果说大家研究过框架的底层原理或者咱们自己写过框架的话,一定对反射这个概念不陌生。反射之所以被称为框架的灵魂,主要是因为它赋予了我们在运行时分析类以及执行类中方法的能力。通过反射你可以获取任意一个类的所有属性和方法,你还可以调用这些方法和属性。
|
||||
简单来说,Java 反射 (Reflection) 是一种**在程序运行时,动态地获取类的信息并操作类或对象(方法、属性)的能力**。
|
||||
|
||||
### 反射的优缺点?
|
||||
通常情况下,我们写的代码在编译时类型就已经确定了,要调用哪个方法、访问哪个字段都是明确的。但反射允许我们在**运行时**才去探知一个类有哪些方法、哪些属性、它的构造函数是怎样的,甚至可以动态地创建对象、调用方法或修改属性,哪怕这些方法或属性是私有的。
|
||||
|
||||
反射可以让我们的代码更加灵活、为各种框架提供开箱即用的功能提供了便利。
|
||||
正是这种在运行时“反观自身”并进行操作的能力,使得反射成为许多**通用框架和库的基石**。它让代码更加灵活,能够处理在编译时未知的类型。
|
||||
|
||||
不过,反射让我们在运行时有了分析操作类的能力的同时,也增加了安全问题,比如可以无视泛型参数的安全检查(泛型参数的安全检查发生在编译时)。另外,反射的性能也要稍差点,不过,对于框架来说实际是影响不大的。
|
||||
### 反射有什么优缺点?
|
||||
|
||||
**优点:**
|
||||
|
||||
1. **灵活性和动态性**:反射允许程序在运行时动态地加载类、创建对象、调用方法和访问字段。这样可以根据实际需求(如配置文件、用户输入、注解等)动态地适应和扩展程序的行为,显著提高了系统的灵活性和适应性。
|
||||
2. **框架开发的基础**:许多现代 Java 框架(如 Spring、Hibernate、MyBatis)都大量使用反射来实现依赖注入(DI)、面向切面编程(AOP)、对象关系映射(ORM)、注解处理等核心功能。反射是实现这些“魔法”功能不可或缺的基础工具。
|
||||
3. **解耦合和通用性**:通过反射,可以编写更通用、可重用和高度解耦的代码,降低模块之间的依赖。例如,可以通过反射实现通用的对象拷贝、序列化、Bean 工具等。
|
||||
|
||||
**缺点:**
|
||||
|
||||
1. **性能开销**:反射操作通常比直接代码调用要慢。因为涉及到动态类型解析、方法查找以及 JIT 编译器的优化受限等因素。不过,对于大多数框架场景,这种性能损耗通常是可以接受的,或者框架本身会做一些缓存优化。
|
||||
2. **安全性问题**:反射可以绕过 Java 语言的访问控制机制(如访问 `private` 字段和方法),破坏了封装性,可能导致数据泄露或程序被恶意篡改。此外,还可以绕过泛型检查,带来类型安全隐患。
|
||||
3. **代码可读性和维护性**:过度使用反射会使代码变得复杂、难以理解和调试。错误通常在运行时才会暴露,不像编译期错误那样容易发现。
|
||||
|
||||
相关阅读:[Java Reflection: Why is it so slow?](https://stackoverflow.com/questions/1392351/java-reflection-why-is-it-so-slow) 。
|
||||
|
||||
### 反射的应用场景?
|
||||
|
||||
像咱们平时大部分时候都是在写业务代码,很少会接触到直接使用反射机制的场景。但是!这并不代表反射没有用。相反,正是因为反射,你才能这么轻松地使用各种框架。像 Spring/Spring Boot、MyBatis 等等框架中都大量使用了反射机制。
|
||||
我们平时写业务代码可能很少直接跟 Java 的反射(Reflection)打交道。但你可能没意识到,你天天都在享受反射带来的便利!**很多流行的框架,比如 Spring/Spring Boot、MyBatis 等,底层都大量运用了反射机制**,这才让它们能够那么灵活和强大。
|
||||
|
||||
**这些框架中也大量使用了动态代理,而动态代理的实现也依赖反射。**
|
||||
下面简单列举几个最场景的场景帮助大家理解。
|
||||
|
||||
比如下面是通过 JDK 实现动态代理的示例代码,其中就使用了反射类 `Method` 来调用指定的方法。
|
||||
**1.依赖注入与控制反转(IoC)**
|
||||
|
||||
以 Spring/Spring Boot 为代表的 IoC 框架,会在启动时扫描带有特定注解(如 `@Component`, `@Service`, `@Repository`, `@Controller`)的类,利用反射实例化对象(Bean),并通过反射注入依赖(如 `@Autowired`、构造器注入等)。
|
||||
|
||||
**2.注解处理**
|
||||
|
||||
注解本身只是个“标记”,得有人去读这个标记才知道要做什么。反射就是那个“读取器”。框架通过反射检查类、方法、字段上有没有特定的注解,然后根据注解信息执行相应的逻辑。比如,看到 `@Value`,就用反射读取注解内容,去配置文件找对应的值,再用反射把值设置给字段。
|
||||
|
||||
**3.动态代理与 AOP**
|
||||
|
||||
想在调用某个方法前后自动加点料(比如打日志、开事务、做权限检查)?AOP(面向切面编程)就是干这个的,而动态代理是实现 AOP 的常用手段。JDK 自带的动态代理(Proxy 和 InvocationHandler)就离不开反射。代理对象在内部调用真实对象的方法时,就是通过反射的 `Method.invoke` 来完成的。
|
||||
|
||||
```java
|
||||
public class DebugInvocationHandler implements InvocationHandler {
|
||||
/**
|
||||
* 代理类中的真实对象
|
||||
*/
|
||||
private final Object target;
|
||||
private final Object target; // 真实对象
|
||||
|
||||
public DebugInvocationHandler(Object target) {
|
||||
this.target = target;
|
||||
}
|
||||
public DebugInvocationHandler(Object target) { this.target = target; }
|
||||
|
||||
public Object invoke(Object proxy, Method method, Object[] args) throws InvocationTargetException, IllegalAccessException {
|
||||
System.out.println("before method " + method.getName());
|
||||
// proxy: 代理对象, method: 被调用的方法, args: 方法参数
|
||||
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
|
||||
System.out.println("切面逻辑:调用方法 " + method.getName() + " 之前");
|
||||
// 通过反射调用真实对象的同名方法
|
||||
Object result = method.invoke(target, args);
|
||||
System.out.println("after method " + method.getName());
|
||||
System.out.println("切面逻辑:调用方法 " + method.getName() + " 之后");
|
||||
return result;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
另外,像 Java 中的一大利器 **注解** 的实现也用到了反射。
|
||||
**4.对象关系映射(ORM)**
|
||||
|
||||
为什么你使用 Spring 的时候 ,一个`@Component`注解就声明了一个类为 Spring Bean 呢?为什么你通过一个 `@Value`注解就读取到配置文件中的值呢?究竟是怎么起作用的呢?
|
||||
|
||||
这些都是因为你可以基于反射分析类,然后获取到类/属性/方法/方法的参数上的注解。你获取到注解之后,就可以做进一步的处理。
|
||||
像 MyBatis、Hibernate 这种框架,能帮你把数据库查出来的一行行数据,自动变成一个个 Java 对象。它是怎么知道数据库字段对应哪个 Java 属性的?还是靠反射。它通过反射获取 Java 类的属性列表,然后把查询结果按名字或配置对应起来,再用反射调用 setter 或直接修改字段值。反过来,保存对象到数据库时,也是用反射读取属性值来拼 SQL。
|
||||
|
||||
## 注解
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user