[refractor]delete some unused blogs
311
README.md
@ -46,107 +46,45 @@
|
||||
</table>
|
||||
|
||||
|
||||
## 目录
|
||||
|
||||
- [目录](#目录)
|
||||
- [Java](#java)
|
||||
- [基础](#基础)
|
||||
- [容器](#容器)
|
||||
- [并发](#并发)
|
||||
- [JVM](#jvm)
|
||||
- [其他](#其他)
|
||||
- [网络](#网络)
|
||||
- [操作系统](#操作系统)
|
||||
- [Linux](#linux)
|
||||
- [数据结构与算法](#数据结构与算法)
|
||||
- [数据结构](#数据结构)
|
||||
- [算法](#算法)
|
||||
- [数据库](#数据库)
|
||||
- [MySQL](#mysql)
|
||||
- [Redis](#redis)
|
||||
- [系统设计](#系统设计)
|
||||
- [必知](#必知)
|
||||
- [常用框架](#常用框架)
|
||||
- [Spring/SpringBoot](#springspringboot)
|
||||
- [MyBatis](#mybatis)
|
||||
- [Netty](#netty)
|
||||
- [认证授权](#认证授权)
|
||||
- [JWT](#jwt)
|
||||
- [SSO(单点登录)](#sso单点登录)
|
||||
- [分布式](#分布式)
|
||||
- [分布式搜索引擎](#分布式搜索引擎)
|
||||
- [RPC](#rpc)
|
||||
- [消息队列](#消息队列)
|
||||
- [API 网关](#api-网关)
|
||||
- [分布式 id](#分布式id)
|
||||
- [分布式限流](#分布式限流)
|
||||
- [分布式接口幂等性](#分布式接口幂等性)
|
||||
- [ZooKeeper](#zookeeper)
|
||||
- [其他](#其他-1)
|
||||
- [数据库扩展](#数据库扩展)
|
||||
- [大型网站架构](#大型网站架构)
|
||||
- [性能测试](#性能测试)
|
||||
- [高并发](#高并发)
|
||||
- [高可用](#高可用)
|
||||
- [微服务](#微服务)
|
||||
- [Spring Cloud](#spring-cloud)
|
||||
- [必会工具](#必会工具)
|
||||
- [Git](#git)
|
||||
- [Docker](#docker)
|
||||
- [其他](#其他-2)
|
||||
- [面试指南](#面试指南)
|
||||
- [Java 学习常见问题汇总](#java学习常见问题汇总)
|
||||
- [资源](#资源)
|
||||
- [Java 程序员必备书单](#java程序员必备书单)
|
||||
- [实战项目推荐](#实战项目推荐)
|
||||
- [Github](#github)
|
||||
- [待办](#待办)
|
||||
- [说明](#说明)
|
||||
|
||||
## Java
|
||||
|
||||
### 基础
|
||||
|
||||
**基础知识系统总结:**
|
||||
**知识点/面试题:**
|
||||
|
||||
1. **[Java 基础知识](docs/java/Java基础知识.md)**
|
||||
2. **[Java 基础知识疑难点/易错点](docs/java/Java疑难点.md)**
|
||||
3. [【选看】J2EE 基础知识](docs/java/J2EE基础知识.md)
|
||||
1. **[Java 基础知识](docs/java/basis/Java基础知识.md)**
|
||||
2. **[Java 基础知识疑难点/易错点](docs/java/basis/Java基础知识疑难点.md)**
|
||||
|
||||
**重要知识点详解:**
|
||||
|
||||
1. [枚举](docs/java/basic/用好Java中的枚举真的没有那么简单.md) (很重要的一个数据结构,用好枚举真的没有那么简单!)
|
||||
2. [Java 常见关键字总结:final、static、this、super!](docs/java/basic/final,static,this,super.md)
|
||||
3. [什么是反射机制?反射机制的应用场景有哪些?](docs/java/basic/reflection.md)
|
||||
4. [代理模式详解:静态代理+JDK/CGLIB 动态代理实战(动态代理和静态代理的区别?JDK 动态代理 和 CGLIB 动态代理的区别?)](docs/java/basic/java-proxy.md)
|
||||
|
||||
**其他:**
|
||||
|
||||
1. [JAD 反编译](docs/java/JAD反编译tricks.md)
|
||||
2. [手把手教你定位常见 Java 性能问题](./docs/java/手把手教你定位常见Java性能问题.md)
|
||||
1. [枚举](docs/java/basis/用好Java中的枚举真的没有那么简单.md) (很重要的一个数据结构,用好枚举真的没有那么简单!)
|
||||
2. [Java 常见关键字总结:final、static、this、super!](docs/java/basis/Java常见关键字总结:final,static,this,super.md)
|
||||
3. [什么是反射机制?反射机制的应用场景有哪些?](docs/java/basis/什么是反射机制?反射机制的应用场景有哪些?.md)
|
||||
4. [代理模式详解:静态代理+JDK/CGLIB 动态代理实战](docs/java/basis/静态代理+JDK,CGLIB动态代理实战.md)
|
||||
5. [BIO,NIO,AIO 总结 ](docs/java/basis/BIO,NIO,AIO总结.md)
|
||||
|
||||
### 容器
|
||||
|
||||
1. **[Java 容器常见面试题/知识点总结](docs/java/collection/Java集合框架常见面试题.md)**
|
||||
2. 源码分析:[ArrayList 源码](docs/java/collection/ArrayList.md) 、[LinkedList 源码](docs/java/collection/LinkedList.md) 、[HashMap(JDK1.8)源码](docs/java/collection/HashMap.md) 、[ConcurrentHashMap 源码](docs/java/collection/ConcurrentHashMap.md)
|
||||
1. **[Java 容器常见面试题/知识点总结](docs/java/collection/Java集合框架常见面试题.md)(推荐!)**
|
||||
2. **源码分析** :[ArrayList源码+扩容机制分析](docs/java/collection/ArrayList源码+扩容机制分析.md) 、[LinkedList 源码](docs/java/collection/LinkedList源码分析.md) 、[HashMap(JDK1.8)源码+底层数据结构分析](docs/java/collection/HashMap(JDK1.8)源码+底层数据结构分析.md) 、[ConcurrentHashMap 源码+底层数据结构分析](docs/java/collection/ConcurrentHashMap 源码+底层数据结构分析.md)
|
||||
|
||||
### 并发
|
||||
|
||||
**[多线程学习指南](./docs/java/Multithread/多线程学习指南.md)**
|
||||
并发这部分内容非常重要,还是面试中的重点中的重点!但是,学习起来难度较大,因此我写了:**[多线程学习指南](./docs/java/multi-thread/多线程学习指南.md)** 帮助你学习。
|
||||
|
||||
**面试题总结:**
|
||||
**知识点/面试题:**
|
||||
|
||||
1. **[Java 并发基础常见面试题总结](docs/java/Multithread/JavaConcurrencyBasicsCommonInterviewQuestionsSummary.md)**
|
||||
2. **[Java 并发进阶常见面试题总结](docs/java/Multithread/JavaConcurrencyAdvancedCommonInterviewQuestions.md)**
|
||||
1. **[Java 并发基础常见面试题总结](docs/java/multi-thread/2020最新Java并发基础常见面试题总结.md)**
|
||||
2. **[Java 并发进阶常见面试题总结](docs/java/multi-thread/2020最新Java并发进阶常见面试题总结.md)**
|
||||
|
||||
**面试常问知识点:**
|
||||
**重要知识点详解:**
|
||||
|
||||
1. [并发容器总结](docs/java/Multithread/并发容器总结.md)
|
||||
2. **线程池**:[Java 线程池学习总结](./docs/java/Multithread/java线程池学习总结.md)、[拿来即用的线程池最佳实践](./docs/java/Multithread/best-practice-of-threadpool.md)
|
||||
2. **线程池**:[Java 线程池学习总结](./docs/java/multi-thread/java线程池学习总结.md)、[拿来即用的线程池最佳实践](./docs/java/multi-thread/拿来即用的线程池最佳实践.md)
|
||||
3. [乐观锁与悲观锁](docs/essential-content-for-interview/面试必备之乐观锁与悲观锁.md)
|
||||
4. [万字图文深度解析 ThreadLocal](docs/java/Multithread/ThreadLocal.md)
|
||||
5. [JUC 中的 Atomic 原子类总结](docs/java/Multithread/Atomic.md)
|
||||
6. [AQS 原理以及 AQS 同步组件总结](docs/java/Multithread/AQS.md)
|
||||
4. [ ThreadLocal 关键字解析](docs/java/multi-thread/万字详解ThreadLocal关键字.md)
|
||||
4. [并发容器总结](docs/java/multi-thread/并发容器总结.md)
|
||||
5. [JUC 中的 Atomic 原子类总结](docs/java/multi-thread/Atomic原子类总结.md)
|
||||
6. [AQS 原理以及 AQS 同步组件总结](docs/java/multi-thread/AQS原理以及AQS同步组件总结.md)
|
||||
|
||||
### JVM
|
||||
|
||||
@ -160,14 +98,10 @@
|
||||
8. [JVM 配置常用参数和常用 GC 调优策略](docs/java/jvm/GC调优参数.md)
|
||||
9. **[【加餐】大白话带你认识 JVM](docs/java/jvm/[加餐]大白话带你认识JVM.md)**
|
||||
|
||||
### 其他
|
||||
### 新特性
|
||||
|
||||
1. **Linux IO** : [Linux IO](docs/java/Linux_IO.md)
|
||||
2. **I/O** :[BIO,NIO,AIO 总结 ](docs/java/BIO-NIO-AIO.md)
|
||||
3. **Java 8** :[Java 8 新特性总结](docs/java/What's%20New%20in%20JDK8/Java8Tutorial.md)、[Java 8 学习资源推荐](docs/java/What's%20New%20in%20JDK8/Java8教程推荐.md)、[Java8 forEach 指南](docs/java/What's%20New%20in%20JDK8/Java8foreach指南.md)
|
||||
4. **Java9~Java14** : [一文带你看遍 JDK9~14 的重要新特性!](./docs/java/jdk-new-features/new-features-from-jdk8-to-jdk14.md)
|
||||
5. Java 编程规范:**[Java 编程规范以及优雅 Java 代码实践总结](docs/java/Java编程规范.md)** 、[告别编码 5 分钟,命名 2 小时!史上最全的 Java 命名规范参考!](docs/java/java-naming-conventions.md)
|
||||
6. 设计模式 :[设计模式系列文章](docs/system-design/设计模式.md)
|
||||
1. **Java 8** :[Java 8 新特性总结](docs/java/What's%20New%20in%20JDK8/Java8Tutorial.md)、[Java 8 学习资源推荐](docs/java/What's%20New%20in%20JDK8/Java8教程推荐.md)、[Java8 forEach 指南](docs/java/What's%20New%20in%20JDK8/Java8foreach指南.md)
|
||||
2. **Java9~Java14** : [一文带你看遍 JDK9~14 的重要新特性!](./docs/java/jdk-new-features/new-features-from-jdk8-to-jdk14.md)
|
||||
|
||||
## 网络
|
||||
|
||||
@ -176,26 +110,22 @@
|
||||
|
||||
## 操作系统
|
||||
|
||||
[最硬核的操作系统常见问题总结!](docs/operating-system/basis.md)
|
||||
|
||||
### Linux
|
||||
|
||||
- [后端程序员必备的 Linux 基础知识](docs/operating-system/linux.md)
|
||||
- [Shell 编程入门](docs/operating-system/Shell.md)
|
||||
- [我为什么从 Windows 转到 Linux?](docs/operating-system/完全使用GNU_Linux学习.md)
|
||||
- [Linux IO 模型](docs/operating-system/Linux_IO.md)
|
||||
- [Linux 性能分析工具合集](docs/operating-system/Linux性能分析工具合集.md)
|
||||
1. [操作系统常见问题总结!](docs/operating-system/basis.md)
|
||||
2. [后端程序员必备的 Linux 基础知识](docs/operating-system/linux.md)
|
||||
3. [Shell 编程入门](docs/operating-system/Shell.md)
|
||||
4. [Linux 性能分析工具合集](docs/operating-system/Linux性能分析工具合集.md)
|
||||
|
||||
## 数据结构与算法
|
||||
|
||||
### 数据结构
|
||||
|
||||
- [不了解布隆过滤器?一文给你整的明明白白!](docs/dataStructures-algorithms/data-structure/bloom-filter.md)
|
||||
- [数据结构知识学习与面试](docs/dataStructures-algorithms/数据结构.md)
|
||||
1. [不了解布隆过滤器?一文给你整的明明白白!](docs/dataStructures-algorithms/data-structure/bloom-filter.md)
|
||||
2. [数据结构知识学习与面试](docs/dataStructures-algorithms/数据结构.md)
|
||||
|
||||
### 算法
|
||||
|
||||
- [硬核的算法学习书籍+资源推荐](docs/dataStructures-algorithms/算法学习资源推荐.md)
|
||||
算法这部分内容非常重要,如果你不知道如何学习算法的话,可以看下我写的:[《硬核的算法学习书籍+资源推荐》](docs/dataStructures-algorithms/算法学习资源推荐.md) 。
|
||||
|
||||
- 常见算法问题总结:
|
||||
- [几道常见的字符串算法题总结 ](docs/dataStructures-algorithms/几道常见的子符串算法题.md)
|
||||
- [几道常见的链表算法题总结 ](docs/dataStructures-algorithms/几道常见的链表算法题.md)
|
||||
@ -228,23 +158,31 @@
|
||||
|
||||
## 系统设计
|
||||
|
||||
### 必知
|
||||
### 编码规范
|
||||
|
||||
1. **[RestFul API 简明教程](docs/system-design/restful-api.md)**
|
||||
2. **[因为命名被 diss 无数次。Guide 简单聊聊编程最头疼的事情之一:命名](docs/system-design/naming.md)**
|
||||
1. [RestFul API 简明教程](docs/system-design/restful-api.md)
|
||||
2. [Java 编程规范以及优雅 Java 代码实践总结](docs/java/Java编程规范.md)
|
||||
3. [Java 命名之道](docs/system-design/naming.md)
|
||||
4. [设计模式系列文章](docs/system-design/设计模式.md)
|
||||
|
||||
### 常用框架
|
||||
|
||||
如果你没有接触过 Java Web 开发的话,可以先看一下我总结的 [《J2EE 基础知识》](docs/java/J2EE基础知识.md) 。虽然,这篇文章中的很多内容已经淘汰,但是可以让你对Java 后台技术发展有更深的认识。
|
||||
|
||||
#### Spring/SpringBoot
|
||||
|
||||
**知识点/面试题:**
|
||||
|
||||
1. **[Spring 常见问题总结](docs/system-design/framework/spring/SpringInterviewQuestions.md)**
|
||||
2. **[SpringBoot 指南/常见面试题总结](https://github.com/Snailclimb/springboot-guide)**
|
||||
3. **[Spring/Spring 常用注解总结!安排!](./docs/system-design/framework/spring/spring-annotations.md)**
|
||||
4. **[Spring 事务总结](docs/system-design/framework/spring/spring-transaction.md)**
|
||||
5. [Spring IoC 和 AOP 详解](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247486938&idx=1&sn=c99ef0233f39a5ffc1b98c81e02dfcd4&chksm=cea24211f9d5cb07fa901183ba4d96187820713a72387788408040822ffb2ed575d28e953ce7&token=1666190828&lang=zh_CN#rd)
|
||||
6. [Spring 中 Bean 的作用域与生命周期](docs/system-design/framework/spring/SpringBean.md)
|
||||
7. [SpringMVC 工作原理详解](docs/system-design/framework/spring/SpringMVC-Principle.md)
|
||||
8. [Spring 中都用到了那些设计模式?](docs/system-design/framework/spring/Spring-Design-Patterns.md)
|
||||
|
||||
**重要知识点详解:**
|
||||
|
||||
1. **[Spring/Spring 常用注解总结!安排!](./docs/system-design/framework/spring/spring-annotations.md)**
|
||||
2. **[Spring 事务总结](docs/system-design/framework/spring/spring-transaction.md)**
|
||||
3. [Spring 中都用到了那些设计模式?](docs/system-design/framework/spring/Spring-Design-Patterns.md)
|
||||
4. [Spring 中 Bean 的作用域与生命周期](docs/system-design/framework/spring/SpringBean.md)
|
||||
5. [SpringMVC 工作原理详解](docs/system-design/framework/spring/SpringMVC-Principle.md)
|
||||
|
||||
#### MyBatis
|
||||
|
||||
@ -272,39 +210,16 @@ SSO(Single Sign On)即单点登录说的是用户登陆多个子系统的其中
|
||||
|
||||
[分布式相关概念入门](docs/system-design/website-architecture/分布式.md)
|
||||
|
||||
#### 分布式搜索引擎
|
||||
#### 搜索引擎
|
||||
|
||||
提高搜索效率。常见于电商购物网站的商品搜索于分类。
|
||||
|
||||
比较常用的是 Elasticsearch 和 Solr。
|
||||
|
||||
代办。
|
||||
用于提高搜索效率,功能和浏览器搜索引擎类似。比较常见的搜索引擎是 Elasticsearch(推荐) 和 Solr。
|
||||
|
||||
#### RPC
|
||||
|
||||
让调用远程服务调用像调用本地方法那样简单。
|
||||
|
||||
- [Dubbo 总结:关于 Dubbo 的重要知识点](docs/system-design/data-communication/dubbo.md)
|
||||
- [服务之间的调用为啥不直接用 HTTP 而用 RPC?](docs/system-design/data-communication/why-use-rpc.md)
|
||||
|
||||
#### 消息队列
|
||||
|
||||
消息队列在分布式系统中主要是为了解耦和削峰。相关阅读: **[消息队列总结](docs/system-design/data-communication/message-queue.md)** 。
|
||||
|
||||
**RabbitMQ:**
|
||||
|
||||
1. [RabbitMQ 入门](docs/system-design/data-communication/rabbitmq.md)
|
||||
|
||||
**RocketMQ:**
|
||||
|
||||
1. [RocketMQ 入门](docs/system-design/data-communication/RocketMQ.md)
|
||||
2. [RocketMQ 的几个简单问题与答案](docs/system-design/data-communication/RocketMQ-Questions.md)
|
||||
|
||||
**Kafka:**
|
||||
|
||||
1. **[Kafka 入门+SpringBoot 整合 Kafka 系列](https://github.com/Snailclimb/springboot-kafka)**
|
||||
2. **[Kafka 常见面试题总结](docs/system-design/data-communication/kafka-inverview.md)**
|
||||
3. [【加餐】Kafka 入门看这一篇就够了](docs/system-design/data-communication/Kafka入门看这一篇就够了.md)
|
||||
1. [Dubbo 总结:关于 Dubbo 的重要知识点](docs/system-design/data-communication/dubbo.md)
|
||||
2. [服务之间的调用为啥不直接用 HTTP 而用 RPC?](docs/system-design/data-communication/why-use-rpc.md)
|
||||
|
||||
#### API 网关
|
||||
|
||||
@ -315,69 +230,84 @@ SSO(Single Sign On)即单点登录说的是用户登陆多个子系统的其中
|
||||
|
||||
#### 分布式 id
|
||||
|
||||
1. [为什么要分布式 id ?分布式 id 生成方案有哪些?](docs/system-design/micro-service/分布式id生成方案总结.md)
|
||||
|
||||
#### 分布式限流
|
||||
|
||||
1. [限流算法有哪些?](docs/system-design/micro-service/limit-request.md)
|
||||
|
||||
#### 分布式接口幂等性
|
||||
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。比如数据量太大之后,往往需要对进行对数据进行分库分表,分库分表后需要有一个唯一ID来标识一条数据或消息,数据库的自增ID显然不能满足需求。相关阅读:[为什么要分布式 id ?分布式 id 生成方案有哪些?](docs/system-design/micro-service/分布式id生成方案总结.md)
|
||||
|
||||
#### ZooKeeper
|
||||
|
||||
> 前两篇文章可能有内容重合部分,推荐都看一遍。
|
||||
|
||||
1. [【入门】ZooKeeper 相关概念总结 01](docs/system-design/framework/zookeeper/zookeeper-intro.md)
|
||||
2. [【进阶】ZooKeeper 相关概念总结 02](docs/system-design/framework/zookeeper/zookeeper-plus.md)
|
||||
1. [【入门】ZooKeeper 相关概念总结](docs/system-design/framework/zookeeper/zookeeper-intro.md)
|
||||
2. [【进阶】ZooKeeper 相关概念总结](docs/system-design/framework/zookeeper/zookeeper-plus.md)
|
||||
3. [【实战】ZooKeeper 实战](docs/system-design/framework/zookeeper/zookeeper-in-action.md)
|
||||
|
||||
#### 其他
|
||||
### 微服务
|
||||
|
||||
- 接口幂等性(代办):分布式系统必须要考虑接口的幂等性。
|
||||
1. [ 大白话入门 Spring Cloud](docs/system-design/micro-service/spring-cloud.md)
|
||||
|
||||
#### 数据库扩展
|
||||
### 高并发
|
||||
|
||||
读写分离、分库分表。
|
||||
#### 消息队列
|
||||
|
||||
代办.....
|
||||
消息队列在分布式系统中主要是为了解耦和削峰。相关阅读: **[消息队列总结](docs/system-design/data-communication/message-queue.md)** 。
|
||||
|
||||
1. **RabbitMQ** : [RabbitMQ 入门](docs/system-design/data-communication/rabbitmq.md)
|
||||
2. **RocketMQ** : [RocketMQ 入门](docs/system-design/data-communication/RocketMQ.md)、[RocketMQ 的几个简单问题与答案](docs/system-design/data-communication/RocketMQ-Questions.md)
|
||||
3. **Kafka** :**[Kafka 常见面试题总结](docs/system-design/data-communication/kafka-inverview.md)**
|
||||
|
||||
#### 读写分离
|
||||
|
||||
读写分离主要是为了将数据库的读和写操作分不到不同的数据库节点上。主服务器负责写,从服务器负责读。另外,一主一从或者一主多从都可以。
|
||||
|
||||
**读写分离可以大幅提高读性能,小幅提高写的性能。因此,读写分离更适合单机并发读请求比较多的场景。**
|
||||
|
||||
#### 分库分表
|
||||
|
||||
**分库分表是为了解决由于库、表数据量过大,而导致数据库性能持续下降的问题。** 常见的分库分表工具有:`sharding-jdbc`(当当)、`TSharding`(蘑菇街)、`MyCAT`(基于Cobar)、`Cobar`(阿里巴巴)...。
|
||||
|
||||
**推荐使用 `sharding-jdbc`** 。 因为,`sharding-jdbc` 是一款轻量级 `Java` 框架,以 `jar` 包形式提供服务,不要我们做额外的运维工作,并且兼容性也很好。
|
||||
|
||||
#### 负载均衡
|
||||
|
||||
### 高可用
|
||||
|
||||
高可用描述的是一个系统在大部分时间都是可用的,可以为我们提供服务的。高可用代表系统即使在发生硬件故障或者系统升级的时候,服务仍然是可用的 。相关阅读: **《[如何设计一个高可用系统?要考虑哪些地方?](docs/system-design/website-architecture/如何设计一个高可用系统?要考虑哪些地方?.md)》** 。
|
||||
|
||||
#### CAP理论
|
||||
|
||||
CAP 也就是 Consistency(一致性)、Availability(可用性)、Partition Tolerance(分区容错性) 这三个单词首字母组合。
|
||||
|
||||
#### BASE理论
|
||||
|
||||
**BASE** 是 **Basically Available(基本可用)** 、**Soft-state(软状态)** 和 **Eventually Consistent(最终一致性)** 三个短语的缩写。BASE理论是对CAP中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的总结,是基于CAP定理逐步演化而来的,它大大降低了我们对系统的要求。
|
||||
|
||||
#### 限流
|
||||
|
||||
限流为了对服务端的接口接受请求的频率进行限制,防止服务挂掉。比如某一接口的请求限制为 100 个每秒, 对超过限制的请求放弃处理或者放到队列中等待处理。限流可以有效应对突发请求过多。相关阅读:[限流算法有哪些?](docs/system-design/high-availability/limit-request.md)
|
||||
|
||||
#### 降级
|
||||
|
||||
限流是从用户访问压力的角度来考虑如何应对故障,降级是从系统功能优先级的角度考虑如何应对故障
|
||||
|
||||
服务降级指的是当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行。降级往往会指定不同的级别,面临不同的异常等级执行不同的处理。根据服务方式:可以拒接服务,可以延迟服务,也有时候可以随机服务。根据服务范围:可以砍掉某个功能,也可以砍掉某些模块。总之服务降级需要根据不同的业务需求采用不同的降级策略。主要的目的就是服务虽然有损但是总比没有好。
|
||||
|
||||
#### 熔断
|
||||
|
||||
熔断和降级是两个比较容易混淆的概念,因为单纯从名字上看好像都有禁止某个功能的意思,但其实内在含义是不同的,原因在于降级的目的是应对系统自身的故障,而熔断的目的是应对依赖的外部系统故障的情况。
|
||||
|
||||
#### 排队
|
||||
|
||||
另类的一种限流,类比于现实世界的排队。玩过英雄联盟的小伙伴应该有体会,每次一有活动,就要经历一波排队才能进入游戏。
|
||||
|
||||
### 大型网站架构
|
||||
|
||||
- [8 张图读懂大型网站技术架构](docs/system-design/website-architecture/8%20张图读懂大型网站技术架构.md)
|
||||
- [关于大型网站系统架构你不得不懂的 10 个问题](docs/system-design/website-architecture/关于大型网站系统架构你不得不懂的10个问题.md)
|
||||
|
||||
#### 性能测试
|
||||
## 工具
|
||||
|
||||
- [后端程序员也要懂的性能测试知识](https://articles.zsxq.com/id_lwl39teglv3d.html) (知识星球)
|
||||
|
||||
#### 高并发
|
||||
|
||||
待办......
|
||||
|
||||
#### 高可用
|
||||
|
||||
高可用描述的是一个系统在大部分时间都是可用的,可以为我们提供服务的。高可用代表系统即使在发生硬件故障或者系统升级的时候,服务仍然是可用的 。相关阅读: **《[如何设计一个高可用系统?要考虑哪些地方?](docs/system-design/website-architecture/如何设计一个高可用系统?要考虑哪些地方?.md)》** 。
|
||||
|
||||
### 微服务
|
||||
|
||||
#### Spring Cloud
|
||||
|
||||
- [ 大白话入门 Spring Cloud](docs/system-design/micro-service/spring-cloud.md)
|
||||
|
||||
## 必会工具
|
||||
|
||||
### Git
|
||||
|
||||
- [Git 入门](docs/tools/Git.md)
|
||||
|
||||
### Docker
|
||||
|
||||
1. [Docker 基本概念解读](docs/tools/Docker.md)
|
||||
2. [一文搞懂 Docker 镜像的常用操作!](docs/tools/Docker-Image.md)
|
||||
|
||||
### 其他
|
||||
|
||||
- [【原创】如何使用云服务器?希望这篇文章能够对你有帮助!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485738&idx=1&sn=f97e91a50e444944076c30b0717b303a&chksm=cea246e1f9d5cff73faf6a778b147ea85162d1f3ed55ca90473c6ebae1e2c4d13e89282aeb24&token=406194678&lang=zh_CN#rd)
|
||||
1. **Java** :[JAD 反编译](docs/java/JAD反编译tricks.md)、[手把手教你定位常见 Java 性能问题](./docs/java/手把手教你定位常见Java性能问题.md)
|
||||
2. **Git** :[Git 入门](docs/tools/Git.md)
|
||||
3. **Docker** : [Docker 基本概念解读](docs/tools/Docker.md) 、[一文搞懂 Docker 镜像的常用操作!](docs/tools/Docker-Image.md)
|
||||
|
||||
## 面试指南
|
||||
|
||||
@ -398,22 +328,9 @@ SSO(Single Sign On)即单点登录说的是用户登陆多个子系统的其中
|
||||
3. [新手学习 Java,有哪些 Java 相关的博客,专栏,和技术学习网站推荐?](docs/questions/java-learning-website-blog.md)
|
||||
4. [Java 还是大数据,你需要了解这些东西!](docs/questions/java-big-data.md)
|
||||
|
||||
## 资源
|
||||
## 书单
|
||||
|
||||
### Java 程序员必备书单
|
||||
|
||||
1. [「基础篇」Guide 的 Java 后端书架来啦!都是 Java 程序员必看的书籍?](./docs/books/java基础篇.md)
|
||||
|
||||
### 实战项目推荐
|
||||
|
||||
- **[Java、SpringBoot 实战项目推荐](https://github.com/Snailclimb/awesome-java#实战项目)**
|
||||
|
||||
### Github
|
||||
|
||||
- [Github 上非常棒的 Java 开源项目集合](https://github.com/Snailclimb/awesome-java)
|
||||
- [Github 上 Star 数最多的 10 个项目,看完之后很意外!](docs/tools/github/github-star-ranking.md)
|
||||
- [年末将至,值得你关注的 16 个 Java 开源项目!](docs/github-trending/2019-12.md)
|
||||
- [Java 项目历史月榜单](docs/github-trending/JavaGithubTrending.md)
|
||||
1. [「基础篇」Java书单](./docs/books/java基础篇.md)
|
||||
|
||||
---
|
||||
|
||||
|
||||
@ -83,14 +83,14 @@ JDK 1.5 以后的 `AtomicStampedReference 类`就提供了此种能力,其中
|
||||
|
||||
CAS 只对单个共享变量有效,当操作涉及跨多个共享变量时 CAS 无效。但是从 JDK 1.5开始,提供了`AtomicReference类`来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行 CAS 操作.所以我们可以使用锁或者利用`AtomicReference类`把多个共享变量合并成一个共享变量来操作。
|
||||
|
||||
### CAS与synchronized的使用情景
|
||||
### CAS与`synchronized`的使用情景
|
||||
|
||||
> **简单的来说CAS适用于写比较少的情况下(多读场景,冲突一般较少),synchronized适用于写比较多的情况下(多写场景,冲突一般较多)**
|
||||
|
||||
1. 对于资源竞争较少(线程冲突较轻)的情况,使用synchronized同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
|
||||
1. 对于资源竞争较少(线程冲突较轻)的情况,使用`synchronized`同步锁进行线程阻塞和唤醒切换以及用户态内核态间的切换操作额外浪费消耗cpu资源;而CAS基于硬件实现,不需要进入内核,不需要切换线程,操作自旋几率较少,因此可以获得更高的性能。
|
||||
2. 对于资源竞争严重(线程冲突严重)的情况,CAS自旋的概率会比较大,从而浪费更多的CPU资源,效率低于synchronized。
|
||||
|
||||
补充: Java并发编程这个领域中synchronized关键字一直都是元老级的角色,很久之前很多人都会称它为 **“重量级锁”** 。但是,在JavaSE 1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的 **偏向锁** 和 **轻量级锁** 以及其它**各种优化**之后变得在某些情况下并不是那么重了。synchronized的底层实现主要依靠 **Lock-Free** 的队列,基本思路是 **自旋后阻塞**,**竞争切换后继续竞争锁**,**稍微牺牲了公平性,但获得了高吞吐量**。在线程冲突较少的情况下,可以获得和CAS类似的性能;而线程冲突严重的情况下,性能远高于CAS。
|
||||
补充: Java并发编程这个领域中`synchronized`关键字一直都是元老级的角色,很久之前很多人都会称它为 **“重量级锁”** 。但是,在JavaSE 1.6之后进行了主要包括为了减少获得锁和释放锁带来的性能消耗而引入的 **偏向锁** 和 **轻量级锁** 以及其它**各种优化**之后变得在某些情况下并不是那么重了。`synchronized`的底层实现主要依靠 **Lock-Free** 的队列,基本思路是 **自旋后阻塞**,**竞争切换后继续竞争锁**,**稍微牺牲了公平性,但获得了高吞吐量**。在线程冲突较少的情况下,可以获得和CAS类似的性能;而线程冲突严重的情况下,性能远高于CAS。
|
||||
|
||||
## 公众号
|
||||
|
||||
|
||||
@ -1,78 +0,0 @@
|
||||
本文数据统计于 1.1 号凌晨,由 SnailClimb 整理。
|
||||
|
||||
### 1. JavaGuide
|
||||
|
||||
- **Github地址**: [https://github.com/Snailclimb/JavaGuide](https://github.com/Snailclimb/JavaGuide)
|
||||
- **star**: 18.2k
|
||||
- **介绍**: 【Java学习+面试指南】 一份涵盖大部分Java程序员所需要掌握的核心知识。
|
||||
|
||||
### 2. mall
|
||||
|
||||
- **Github地址**: [https://github.com/macrozheng/mall](https://github.com/macrozheng/mall)
|
||||
- **star**: 3.3k
|
||||
- **介绍**: mall项目是一套电商系统,包括前台商城系统及后台管理系统,基于SpringBoot+MyBatis实现。 前台商城系统包含首页门户、商品推荐、商品搜索、商品展示、购物车、订单流程、会员中心、客户服务、帮助中心等模块。 后台管理系统包含商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等模块。
|
||||
|
||||
### 3. advanced-java
|
||||
|
||||
- **Github地址**:[https://github.com/doocs/advanced-java](https://github.com/doocs/advanced-java)
|
||||
- **star**: 3.3k
|
||||
- **介绍**: 互联网 Java 工程师进阶知识完全扫盲
|
||||
|
||||
### 4. matrix
|
||||
|
||||
- **Github地址**:[https://github.com/Tencent/matrix](https://github.com/Tencent/matrix)
|
||||
- **star**: 2.5k
|
||||
- **介绍**: Matrix 是一款微信研发并日常使用的 APM(Application Performance Manage),当前主要运行在 Android 平台上。 Matrix 的目标是建立统一的应用性能接入框架,通过各种性能监控方案,对性能监控项的异常数据进行采集和分析,输出相应的问题分析、定位与优化建议,从而帮助开发者开发出更高质量的应用。
|
||||
|
||||
### 5. miaosha
|
||||
|
||||
- **Github地址**:[https://github.com/qiurunze123/miaosha](https://github.com/qiurunze123/miaosha)
|
||||
- **star**: 2.4k
|
||||
- **介绍**: 高并发大流量如何进行秒杀架构,我对这部分知识做了一个系统的整理,写了一套系统。
|
||||
|
||||
### 6. arthas
|
||||
|
||||
- **Github地址**:[https://github.com/alibaba/arthas](https://github.com/alibaba/arthas)
|
||||
- **star**: 8.2k
|
||||
- **介绍**: Arthas 是Alibaba开源的Java诊断工具,深受开发者喜爱。
|
||||
|
||||
### 7 spring-boot
|
||||
|
||||
- **Github地址**: [https://github.com/spring-projects/spring-boot](https://github.com/spring-projects/spring-boot)
|
||||
- **star:** 32.6k
|
||||
- **介绍**: 虽然Spring的组件代码是轻量级的,但它的配置却是重量级的(需要大量XML配置),不过Spring Boot 让这一切成为了过去。 另外Spring Cloud也是基于Spring Boot构建的,我个人非常有必要学习一下。
|
||||
|
||||
**关于Spring Boot官方的介绍:**
|
||||
|
||||
> Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can “just run”…Most Spring Boot applications need very little Spring configuration.(Spring Boot可以轻松创建独立的生产级基于Spring的应用程序,只要通过 “just run”(可能是run ‘Application’或java -jar 或 tomcat 或 maven插件run 或 shell脚本)便可以运行项目。大部分Spring Boot项目只需要少量的配置即可)
|
||||
|
||||
### 8. tutorials
|
||||
|
||||
- **Github地址**:[https://github.com/eugenp/tutorials](https://github.com/eugenp/tutorials)
|
||||
- **star**: 10k
|
||||
- **介绍**: 该项目是一系列小而专注的教程 - 每个教程都涵盖Java生态系统中单一且定义明确的开发领域。 当然,它们的重点是Spring Framework - Spring,Spring Boot和Spring Securiyt。 除了Spring之外,还有以下技术:核心Java,Jackson,HttpClient,Guava。
|
||||
|
||||
### 9. qmq
|
||||
|
||||
- **Github地址**:[https://github.com/qunarcorp/qmq](https://github.com/qunarcorp/qmq)
|
||||
- **star**: 1.1k
|
||||
- **介绍**: QMQ是去哪儿网内部广泛使用的消息中间件,自2012年诞生以来在去哪儿网所有业务场景中广泛的应用,包括跟交易息息相关的订单场景; 也包括报价搜索等高吞吐量场景。
|
||||
|
||||
|
||||
### 10. symphony
|
||||
|
||||
- **Github地址**:[https://github.com/b3log/symphony](https://github.com/b3log/symphony)
|
||||
- **star**: 9k
|
||||
- **介绍**: 一款用 Java 实现的现代化社区(论坛/BBS/社交网络/博客)平台。
|
||||
|
||||
### 11. incubator-dubbo
|
||||
|
||||
- **Github地址**:[https://github.com/apache/incubator-dubbo](https://github.com/apache/incubator-dubbo)
|
||||
- **star**: 23.6k
|
||||
- **介绍**: 阿里开源的一个基于Java的高性能开源RPC框架。
|
||||
|
||||
### 12. apollo
|
||||
|
||||
- **Github地址**:[https://github.com/ctripcorp/apollo](https://github.com/ctripcorp/apollo)
|
||||
- **star**: 10k
|
||||
- **介绍**: Apollo(阿波罗)是携程框架部门研发的分布式配置中心,能够集中化管理应用不同环境、不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性,适用于微服务配置管理场景。
|
||||
@ -1,76 +0,0 @@
|
||||
### 1. JavaGuide
|
||||
|
||||
- **Github地址**: [https://github.com/Snailclimb/JavaGuide](https://github.com/Snailclimb/JavaGuide)
|
||||
- **star**: 22.8k
|
||||
- **介绍**: 【Java学习+面试指南】 一份涵盖大部分Java程序员所需要掌握的核心知识。
|
||||
|
||||
### 2. advanced-java
|
||||
|
||||
- **Github地址**:[https://github.com/doocs/advanced-java](https://github.com/doocs/advanced-java)
|
||||
- **star**: 7.9k
|
||||
- **介绍**: 互联网 Java 工程师进阶知识完全扫盲
|
||||
|
||||
### 3. fescar
|
||||
|
||||
- **Github地址**:[https://github.com/alibaba/fescar](https://github.com/alibaba/fescar)
|
||||
- **star**: 4.6k
|
||||
- **介绍**: 具有 **高性能** 和 **易用性** 的 **微服务架构** 的 **分布式事务** 的解决方案。(特点:高性能且易于使用,旨在实现简单并快速的事务提交与回滚。
|
||||
|
||||
### 4. mall
|
||||
|
||||
- **Github地址**: [https://github.com/macrozheng/mall](https://github.com/macrozheng/mall)
|
||||
- **star**: 5.6 k
|
||||
- **介绍**: mall项目是一套电商系统,包括前台商城系统及后台管理系统,基于SpringBoot+MyBatis实现。 前台商城系统包含首页门户、商品推荐、商品搜索、商品展示、购物车、订单流程、会员中心、客户服务、帮助中心等模块。 后台管理系统包含商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等模块。
|
||||
|
||||
### 5. miaosha
|
||||
|
||||
- **Github地址**:[https://github.com/qiurunze123/miaosha](https://github.com/qiurunze123/miaosha)
|
||||
- **star**: 4.4k
|
||||
- **介绍**: 高并发大流量如何进行秒杀架构,我对这部分知识做了一个系统的整理,写了一套系统。
|
||||
|
||||
### 6. flink
|
||||
|
||||
- **Github地址**:[https://github.com/apache/flink](https://github.com/apache/flink)
|
||||
- **star**: 7.1 k
|
||||
- **介绍**: Apache Flink是一个开源流处理框架,具有强大的流和批处理功能。
|
||||
|
||||
### 7. cim
|
||||
|
||||
- **Github地址**:[https://github.com/crossoverJie/cim](https://github.com/crossoverJie/cim)
|
||||
- **star**: 1.8 k
|
||||
- **介绍**: cim(cross IM) 适用于开发者的即时通讯系统。
|
||||
|
||||
### 8. symphony
|
||||
|
||||
- **Github地址**:[https://github.com/b3log/symphony](https://github.com/b3log/symphony)
|
||||
- **star**: 10k
|
||||
- **介绍**: 一款用 Java 实现的现代化社区(论坛/BBS/社交网络/博客)平台。
|
||||
|
||||
### 9. spring-boot
|
||||
|
||||
- **Github地址**: [https://github.com/spring-projects/spring-boot](https://github.com/spring-projects/spring-boot)
|
||||
- **star:** 32.6k
|
||||
- **介绍**: 虽然Spring的组件代码是轻量级的,但它的配置却是重量级的(需要大量XML配置),不过Spring Boot 让这一切成为了过去。 另外Spring Cloud也是基于Spring Boot构建的,我个人非常有必要学习一下。
|
||||
|
||||
**关于Spring Boot官方的介绍:**
|
||||
|
||||
> Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can “just run”…Most Spring Boot applications need very little Spring configuration.(Spring Boot可以轻松创建独立的生产级基于Spring的应用程序,只要通过 “just run”(可能是run ‘Application’或java -jar 或 tomcat 或 maven插件run 或 shell脚本)便可以运行项目。大部分Spring Boot项目只需要少量的配置即可)
|
||||
|
||||
### 10. arthas
|
||||
|
||||
- **Github地址**:[https://github.com/alibaba/arthas](https://github.com/alibaba/arthas)
|
||||
- **star**: 9.5k
|
||||
- **介绍**: Arthas 是Alibaba开源的Java诊断工具。
|
||||
|
||||
**概览:**
|
||||
|
||||
当你遇到以下类似问题而束手无策时,`Arthas`可以帮助你解决:
|
||||
|
||||
0. 这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?
|
||||
1. 我改的代码为什么没有执行到?难道是我没 commit?分支搞错了?
|
||||
2. 遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
|
||||
3. 线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!
|
||||
4. 是否有一个全局视角来查看系统的运行状况?
|
||||
5. 有什么办法可以监控到JVM的实时运行状态?
|
||||
|
||||
`Arthas`支持JDK 6+,支持Linux/Mac/Winodws,采用命令行交互模式,同时提供丰富的 `Tab` 自动补全功能,进一步方便进行问题的定位和诊断。
|
||||
@ -1,144 +0,0 @@
|
||||
# 年末将至,值得你关注的16个Java 开源项目!
|
||||
|
||||
Star 的数量统计于 2019-12-29。
|
||||
|
||||
### 1.JavaGuide
|
||||
|
||||
Guide 哥大三开始维护的,目前算是纯 Java 类型项目中 Star 数量最多的项目了。但是,本仓库的价值远远(+N次 )比不上像 Spring Boot、Elasticsearch 等等这样非常非常非常优秀的项目。希望以后我也有能力为这些项目贡献一些有价值的代码。
|
||||
|
||||
- **Github 地址**:<https://github.com/Snailclimb/JavaGuide>
|
||||
- **Star**: 66.3k
|
||||
- **介绍**: 【Java 学习+面试指南】 一份涵盖大部分 Java 程序员所需要掌握的核心知识。
|
||||
|
||||
### 2.java-design-patterns
|
||||
|
||||
感觉还不错。根据官网介绍:
|
||||
|
||||
> 设计模式是程序员在设计应用程序或系统时可以用来解决常见问题的最佳形式化实践。 设计模式可以通过提供经过测试的,经过验证的开发范例来加快开发过程。 重用设计模式有助于防止引起重大问题的细微问题,并且还可以提高熟悉模式的编码人员和架构师的代码可读性。
|
||||
|
||||
|
||||
|
||||
- **Github 地址** : [https://github.com/iluwatar/java-design-patterns](https://github.com/iluwatar/java-design-patterns)
|
||||
- **Star**: 53.8k
|
||||
- **介绍**: 用 Java 实现的设计模式。[https://java-design-patterns.com](https://java-design-patterns.com/)。
|
||||
|
||||
### 3.elasticsearch
|
||||
|
||||
搜索引擎界的扛把子,但不仅仅是搜素引擎那么简单。
|
||||
|
||||
- **Github 地址** : [https://github.com/elastic/elasticsearch](https://github.com/elastic/elasticsearch)
|
||||
- **Star**: 46.2k
|
||||
- **介绍**: 开源,分布式,RESTful 搜索引擎。
|
||||
|
||||
### 4.spring-boot
|
||||
|
||||
必须好好学啊,一定要好好学!现在 Java 后端新项目有不用 Spring Boot 开发的有吗?如果有的话,请把这个人的联系方式告诉我,我有很多话想给他交流交流!
|
||||
|
||||
- **Github地址**: [https://github.com/spring-projects/spring-boot](https://github.com/spring-projects/spring-boot)
|
||||
- **star:** 34.8k (1,073 stars this month)
|
||||
- **介绍**: 虽然Spring的组件代码是轻量级的,但它的配置却是重量级的(需要大量XML配置),不过Spring Boot 让这一切成为了过去。 另外Spring Cloud也是基于Spring Boot构建的,我个人非常有必要学习一下。
|
||||
|
||||
### 5.RxJava
|
||||
|
||||
这个没怎么用过,不做太多评价。
|
||||
|
||||
- **Github 地址** : [https://github.com/ReactiveX/RxJava](https://github.com/ReactiveX/RxJava)
|
||||
- **Star**: 41.5k
|
||||
- **介绍**: `RxJava` 是一个 基于事件流、实现异步操作的库。
|
||||
|
||||
### 6.advanced-java
|
||||
|
||||
本项目大部分内容来自中华石杉的一个课程,内容涵盖高并发、分布式、高可用、微服务、海量数据处理等领域知识,非常不错了!
|
||||
|
||||
- **Github 地址**:[https://github.com/doocs/advanced-java](https://github.com/doocs/advanced-java)
|
||||
- **Star**: 36.7k
|
||||
- **介绍**: 互联网 Java 工程师进阶知识完全扫盲:涵盖高并发、分布式、高可用、微服务等领域知识,后端同学必看,前端同学也可学习。
|
||||
|
||||
### 7.mall
|
||||
|
||||
很牛逼的实战项目,还附有详细的文档,作为毕设或者练手项目都再好不过了。
|
||||
|
||||
- **Github地址**: [https://github.com/macrozheng/mall](https://github.com/macrozheng/mall)
|
||||
- **star**: 27.6k
|
||||
- **介绍**: mall项目是一套电商系统,包括前台商城系统及后台管理系统,基于SpringBoot+MyBatis实现。 前台商城系统包含首页门户、商品推荐、商品搜索、商品展示、购物车、订单流程、会员中心、客户服务、帮助中心等模块。 后台管理系统包含商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等模块。
|
||||
|
||||
### 8.okhttp
|
||||
|
||||
给我感觉是安卓项目中用的居多。当然,Java 后端项目也会经常用,但是一般使用 Spring Boot 进行开发的时候,如果需要远程调用的话建议使用 Spring 封装的 `RestTemplate `。
|
||||
|
||||
- **Github地址**:[https://github.com/square/okhttp](https://github.com/square/okhttp)
|
||||
- **star**: 35.4k
|
||||
- **介绍**: 适用于Android,Kotlin和Java的HTTP客户端。https://square.github.io/okhttp/。
|
||||
|
||||
### 9.guava
|
||||
|
||||
很厉害很厉害!提供了很多非常实用的工具类、更加实用的集合类、一些常用的数据结构比如布隆过滤器、缓存等等。
|
||||
|
||||
- **Github地址**:[https://github.com/google/guava](https://github.com/google/guava)
|
||||
- **star**: 35.3k
|
||||
- **介绍**: Guava是一组核心库,其中包括新的集合类型(例如 multimap 和 multiset),不可变集合,图形库以及用于并发,I / O,哈希,基元,字符串等的实用程序!
|
||||
|
||||
### 10.Spark
|
||||
|
||||
我木有用过,留下了没有技术的眼泪。
|
||||
|
||||
- **Github地址**:[https://github.com/apache/spark](https://github.com/apache/spark)
|
||||
- **star**: 24.7k
|
||||
- **介绍**: Spark 是一个快速、通用的大规模数据处理引擎,和Hadoop的MapReduce计算框架类似,但是相对于MapReduce,Spark凭借其可伸缩、基于内存计算等特点,以及可以直接读写Hadoop上任何格式数据的优势,进行批处理时更加高效,并有更低的延迟。
|
||||
|
||||
### 11.arthas
|
||||
|
||||
虽然我自己没有亲身用过,但是身边用过的朋友评价都还挺好的。根据官网介绍,这家伙可以解决下面这些让人脑壳疼的问题:
|
||||
|
||||
1. 这个类从哪个 jar 包加载的?为什么会报各种类相关的 Exception?
|
||||
2. 我改的代码为什么没有执行到?难道是我没 commit?分支搞错了?
|
||||
3. 遇到问题无法在线上 debug,难道只能通过加日志再重新发布吗?
|
||||
4. 线上遇到某个用户的数据处理有问题,但线上同样无法 debug,线下无法重现!
|
||||
5. 是否有一个全局视角来查看系统的运行状况?
|
||||
6. 有什么办法可以监控到JVM的实时运行状态?
|
||||
7. 怎么快速定位应用的热点,生成火焰图?
|
||||
|
||||
- **Github 地址**:[https://github.com/alibaba/arthas](https://github.com/alibaba/arthas)
|
||||
- **star**: 18.8 k
|
||||
- **介绍**: Arthas 是 Alibaba 开源的 Java 诊断工具。
|
||||
|
||||
### 12.spring-boot-examples
|
||||
|
||||
学习 Spring Boot 必备!配合上我的 **springboot-guide** :[https://github.com/Snailclimb/springboot-guide](https://github.com/Snailclimb/springboot-guide),效果杠杠滴!
|
||||
|
||||
- **Github 地址**:[https://github.com/ityouknow/spring-boot-examples](https://github.com/ityouknow/spring-boot-examples)
|
||||
- **star**: 20.2 k
|
||||
- **介绍**: Spring Boot 教程、技术栈示例代码,快速简单上手教程。
|
||||
|
||||
### 13.lombok
|
||||
|
||||
使用 Lombok 我们可以简化我们的 Java 代码,比如使用它之后我们通过注释就可以实现 getter/setter、equals等方法。
|
||||
|
||||
- **Github 地址**:[https://github.com/rzwitserloot/lombok](https://github.com/rzwitserloot/lombok)
|
||||
- **star**: 20.2 k
|
||||
- **介绍**: 对 Java 编程语言的非常刺激的补充。[https://projectlombok.org/](https://projectlombok.org/) 。
|
||||
|
||||
### 14.p3c
|
||||
|
||||
与我而言,没有特别惊艳,但是一些提供的一些代码规范确实挺有用的!
|
||||
|
||||
- **Github 地址**:[https://github.com/alibaba/p3c](https://github.com/alibaba/p3c)
|
||||
- **star**: 19.8 k
|
||||
- **介绍**: 阿里巴巴Java编码指南pmd实现和IDE插件。
|
||||
|
||||
### 15.spring-boot-demo
|
||||
|
||||
- **Github 地址**:[https://github.com/xkcoding/spring-boot-demo](https://github.com/xkcoding/spring-boot-demo)
|
||||
- **Star**: 8.8k
|
||||
- **介绍**: spring boot demo 是一个用来深度学习并实战 spring boot 的项目。
|
||||
|
||||
### 16. awesome-java
|
||||
|
||||
Guide 哥半个多月前开始维护的,虽然现在 Star 数量比较少,我相信后面一定会有更多人喜欢上这个项目,我也会继续认真维护下去。
|
||||
|
||||
- **Github 地址**:[https://github.com/Snailclimb/awesome-java](https://github.com/Snailclimb/awesome-java)
|
||||
- **Star**: 0.3 k
|
||||
- **介绍**: Github 上非常棒的 Java 开源项目集合。
|
||||
|
||||
|
||||
|
||||
@ -1,64 +0,0 @@
|
||||
### 1. JavaGuide
|
||||
|
||||
- **Github地址**: [https://github.com/Snailclimb/JavaGuide](https://github.com/Snailclimb/JavaGuide)
|
||||
- **Star**: 27.2k (4,437 stars this month)
|
||||
- **介绍**: 【Java学习+面试指南】 一份涵盖大部分Java程序员所需要掌握的核心知识。
|
||||
|
||||
### 2.DoraemonKit
|
||||
|
||||
- **Github地址**: <https://github.com/didi/DoraemonKit>
|
||||
- **Star**: 5.2k (3,786 stars this month)
|
||||
- **介绍**: 简称 "DoKit" 。一款功能齐全的客户端( iOS 、Android )研发助手,你值得拥有。
|
||||
|
||||
### 3.advanced-java
|
||||
|
||||
- **Github地址**:[https://github.com/doocs/advanced-java](https://github.com/doocs/advanced-java)
|
||||
- **Star**:11.2k (3,042 stars this month)
|
||||
- **介绍**: 互联网 Java 工程师进阶知识完全扫盲。
|
||||
|
||||
### 4. spring-boot-examples
|
||||
|
||||
- **Github地址**:<https://github.com/ityouknow/spring-boot-examples>
|
||||
- **star**: 9.6 k (1,764 stars this month)
|
||||
- **介绍**: Spring Boot 教程、技术栈示例代码,快速简单上手教程。
|
||||
|
||||
### 5. mall
|
||||
|
||||
- **Github地址**: [https://github.com/macrozheng/mall](https://github.com/macrozheng/mall)
|
||||
- **star**: 7.4 k (1,736 stars this month)
|
||||
- **介绍**: mall项目是一套电商系统,包括前台商城系统及后台管理系统,基于SpringBoot+MyBatis实现。 前台商城系统包含首页门户、商品推荐、商品搜索、商品展示、购物车、订单流程、会员中心、客户服务、帮助中心等模块。 后台管理系统包含商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等模块。
|
||||
|
||||
### 6. fescar
|
||||
|
||||
- **Github地址**:[https://github.com/alibaba/fescar](https://github.com/alibaba/fescar)
|
||||
- **star**: 6.0 k (1,308 stars this month)
|
||||
- **介绍**: 具有 **高性能** 和 **易用性** 的 **微服务架构** 的 **分布式事务** 的解决方案。(特点:高性能且易于使用,旨在实现简单并快速的事务提交与回滚。)
|
||||
|
||||
### 7. h4cker
|
||||
|
||||
- **Github地址**:<https://github.com/The-Art-of-Hacking/h4cker>
|
||||
- **star**: 2.1 k (1,303 stars this month)
|
||||
- **介绍**: 该仓库主要由Omar Santos维护,包括与道德黑客/渗透测试,数字取证和事件响应(DFIR),漏洞研究,漏洞利用开发,逆向工程等相关的资源。
|
||||
|
||||
### 8. spring-boot
|
||||
|
||||
- **Github地址**: [https://github.com/spring-projects/spring-boot](https://github.com/spring-projects/spring-boot)
|
||||
- **star:** 34.8k (1,073 stars this month)
|
||||
- **介绍**: 虽然Spring的组件代码是轻量级的,但它的配置却是重量级的(需要大量XML配置),不过Spring Boot 让这一切成为了过去。 另外Spring Cloud也是基于Spring Boot构建的,我个人非常有必要学习一下。
|
||||
|
||||
**关于Spring Boot官方的介绍:**
|
||||
|
||||
> Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can “just run”…Most Spring Boot applications need very little Spring configuration.(Spring Boot可以轻松创建独立的生产级基于Spring的应用程序,只要通过 “just run”(可能是run ‘Application’或java -jar 或 tomcat 或 maven插件run 或 shell脚本)便可以运行项目。大部分Spring Boot项目只需要少量的配置即可)
|
||||
|
||||
### 9. arthas
|
||||
|
||||
- **Github地址**:[https://github.com/alibaba/arthas](https://github.com/alibaba/arthas)
|
||||
- **star**: 10.5 k (970 stars this month)
|
||||
- **介绍**: Arthas 是Alibaba开源的Java诊断工具。
|
||||
|
||||
### 10. tutorials
|
||||
|
||||
- **Github地址**:[https://github.com/eugenp/tutorials](https://github.com/eugenp/tutorials)
|
||||
- **star**: 12.1 k (789 stars this month)
|
||||
- **介绍**: 该项目是一系列小而专注的教程 - 每个教程都涵盖Java生态系统中单一且定义明确的开发领域。 当然,它们的重点是Spring Framework - Spring,Spring Boot和Spring Securiyt。 除了Spring之外,还有以下技术:核心Java,Jackson,HttpClient,Guava。
|
||||
|
||||
@ -1,60 +0,0 @@
|
||||
### 1. JavaGuide
|
||||
|
||||
- **Github 地址**: [https://github.com/Snailclimb/JavaGuide](https://github.com/Snailclimb/JavaGuide)
|
||||
- **Star**: 32.9k (6,196 stars this month)
|
||||
- **介绍**: 【Java 学习+面试指南】 一份涵盖大部分 Java 程序员所需要掌握的核心知识。
|
||||
|
||||
### 2.advanced-java
|
||||
|
||||
- **Github 地址**:[https://github.com/doocs/advanced-java](https://github.com/doocs/advanced-java)
|
||||
- **Star**: 15.1k (4,012 stars this month)
|
||||
- **介绍**: 互联网 Java 工程师进阶知识完全扫盲。
|
||||
|
||||
### 3.spring-boot-examples
|
||||
|
||||
- **Github 地址**:[https://github.com/ityouknow/spring-boot-examples](https://github.com/ityouknow/spring-boot-examples)
|
||||
- **Star**: 12.8k (3,462 stars this month)
|
||||
- **介绍**: Spring Boot 教程、技术栈示例代码,快速简单上手教程。
|
||||
|
||||
### 4. mall
|
||||
|
||||
- **Github 地址**: [https://github.com/macrozheng/mall](https://github.com/macrozheng/mall)
|
||||
- **star**: 9.7 k (2,418 stars this month)
|
||||
- **介绍**: mall 项目是一套电商系统,包括前台商城系统及后台管理系统,基于 SpringBoot+MyBatis 实现。 前台商城系统包含首页门户、商品推荐、商品搜索、商品展示、购物车、订单流程、会员中心、客户服务、帮助中心等模块。 后台管理系统包含商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等模块。
|
||||
|
||||
### 5. seata
|
||||
|
||||
- **Github 地址** : [https://github.com/seata/seata](https://github.com/seata/seata)
|
||||
- **star**: 7.2 k (1359 stars this month)
|
||||
- **介绍**: Seata 是一种易于使用,高性能,基于 Java 的开源分布式事务解决方案。
|
||||
|
||||
### 6. quarkus
|
||||
|
||||
- **Github 地址**:[https://github.com/quarkusio/quarkus](https://github.com/quarkusio/quarkus)
|
||||
- **star**: 12 k (1,224 stars this month)
|
||||
- **介绍**: Quarkus 是为 GraalVM 和 HotSpot 量身定制的 Kubernetes Native Java 框架,由最佳的 Java 库和标准精心打造而成。Quarkus 的目标是使 Java 成为 Kubernetes 和无服务器环境中的领先平台,同时为开发人员提供统一的反应式和命令式编程模型,以优化地满足更广泛的分布式应用程序架构。
|
||||
|
||||
### 7. arthas
|
||||
|
||||
- **Github 地址**:[https://github.com/alibaba/arthas](https://github.com/alibaba/arthas)
|
||||
- **star**: 11.6 k (1,199 stars this month)
|
||||
- **介绍**: Arthas 是 Alibaba 开源的 Java 诊断工具。
|
||||
|
||||
### 8.DoraemonKit
|
||||
|
||||
- **Github 地址**: <https://github.com/didi/DoraemonKit>
|
||||
- **Star**: 6.2k (1,177 stars this month)
|
||||
- **介绍**: 简称 "DoKit" 。一款功能齐全的客户端( iOS 、Android )研发助手,你值得拥有。
|
||||
|
||||
### 9.elasticsearch
|
||||
|
||||
- **Github 地址** [https://github.com/elastic/elasticsearch](https://github.com/elastic/elasticsearch)
|
||||
- **Star**: 39.7k (1,069 stars this month)
|
||||
- **介绍**: 开源,分布式,RESTful 搜索引擎。
|
||||
|
||||
### 10. tutorials
|
||||
|
||||
- **Github 地址**:[https://github.com/eugenp/tutorials](https://github.com/eugenp/tutorials)
|
||||
- **star**: 13 k (998 stars this month)
|
||||
- **介绍**: 该项目是一系列小而专注的教程 - 每个教程都涵盖 Java 生态系统中单一且定义明确的开发领域。 当然,它们的重点是 Spring Framework - Spring,Spring Boot 和 Spring Securiyt。 除了 Spring 之外,还有以下技术:核心 Java,Jackson,HttpClient,Guava。
|
||||
|
||||
@ -1,98 +0,0 @@
|
||||
以下涉及到的数据统计与 2019 年 5 月 1 日 12 点,数据来源:<https://github.com/trending/java?since=monthly> 。
|
||||
|
||||
下面的内容从 Java 学习文档到最热门的框架再到热门的工具应有尽有,比如下面推荐到的开源项目 Hutool 就是近期比较热门的项目之一,它是 Java 工具包,能够帮助我们简化代码!我觉得下面这些项目对于学习 Java 的朋友还是很有帮助的!
|
||||
|
||||
|
||||
### 1. JavaGuide
|
||||
|
||||
- **Github 地址**: [https://github.com/Snailclimb/JavaGuide](https://github.com/Snailclimb/JavaGuide)
|
||||
- **Star**: 37.9k (5,660 stars this month)
|
||||
- **介绍**: 【Java 学习+面试指南】 一份涵盖大部分 Java 程序员所需要掌握的核心知识。
|
||||
|
||||
### 2. advanced-java
|
||||
|
||||
- **Github 地址**:[https://github.com/doocs/advanced-java](https://github.com/doocs/advanced-java)
|
||||
- **Star**: 15.1k (4,654 stars this month)
|
||||
- **介绍**: 互联网 Java 工程师进阶知识完全扫盲。
|
||||
|
||||
### 3. CS-Notes
|
||||
|
||||
- **Github 地址**:<https://github.com/CyC2018/CS-Notes>
|
||||
- **Star**: 59.2k (4,012 stars this month)
|
||||
- **介绍**: 技术面试必备基础知识。
|
||||
|
||||
### 4. ghidra
|
||||
|
||||
- **Github 地址**:<https://github.com/NationalSecurityAgency/ghidra>
|
||||
- **Star**: 15.0k (2,995 stars this month)
|
||||
- **介绍**: Ghidra是一个软件逆向工程(SRE)框架。
|
||||
|
||||
### 5. mall
|
||||
|
||||
- **Github 地址**: [https://github.com/macrozheng/mall](https://github.com/macrozheng/mall)
|
||||
- **star**: 11.6 k (2,100 stars this month)
|
||||
- **介绍**: mall 项目是一套电商系统,包括前台商城系统及后台管理系统,基于 SpringBoot+MyBatis 实现。 前台商城系统包含首页门户、商品推荐、商品搜索、商品展示、购物车、订单流程、会员中心、客户服务、帮助中心等模块。 后台管理系统包含商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等模块。
|
||||
|
||||
### 6. ZXBlog
|
||||
|
||||
- **Github 地址**: <https://github.com/ZXZxin/ZXBlog>
|
||||
- **star**: 2.1 k (2,086 stars this month)
|
||||
- **介绍**: 记录各种学习笔记(算法、Java、数据库、并发......)。
|
||||
|
||||
### 7.DoraemonKit
|
||||
|
||||
- **Github地址**: <https://github.com/didi/DoraemonKit>
|
||||
- **Star**: 7.6k (1,541 stars this month)
|
||||
- **介绍**: 简称 "DoKit" 。一款功能齐全的客户端( iOS 、Android )研发助手,你值得拥有。
|
||||
|
||||
### 8. spring-boot
|
||||
|
||||
- **Github地址**: [https://github.com/spring-projects/spring-boot](https://github.com/spring-projects/spring-boot)
|
||||
- **star:** 37.3k (1,489 stars this month)
|
||||
- **介绍**: 虽然Spring的组件代码是轻量级的,但它的配置却是重量级的(需要大量XML配置),不过Spring Boot 让这一切成为了过去。 另外Spring Cloud也是基于Spring Boot构建的,我个人非常有必要学习一下。
|
||||
|
||||
**Spring Boot官方的介绍:**
|
||||
|
||||
> Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can “just run”…Most Spring Boot applications need very little Spring configuration.(Spring Boot可以轻松创建独立的生产级基于Spring的应用程序,只要通过 “just run”(可能是run ‘Application’或java -jar 或 tomcat 或 maven插件run 或 shell脚本)便可以运行项目。大部分Spring Boot项目只需要少量的配置即可)
|
||||
|
||||
### 9. spring-boot-examples
|
||||
|
||||
- **Github 地址**:[https://github.com/ityouknow/spring-boot-examples](https://github.com/ityouknow/spring-boot-examples)
|
||||
- **Star**: 12.8k (1,453 stars this month)
|
||||
- **介绍**: Spring Boot 教程、技术栈示例代码,快速简单上手教程。
|
||||
|
||||
### 10. seata
|
||||
|
||||
- **Github 地址** : [https://github.com/seata/seata](https://github.com/seata/seata)
|
||||
- **star**: 8.4 k (1441 stars this month)
|
||||
- **介绍**: Seata 是一种易于使用,高性能,基于 Java 的开源分布式事务解决方案。
|
||||
|
||||
### 11. litemall
|
||||
|
||||
- **Github 地址**:[https://github.com/ityouknow/spring-boot-examples](https://github.com/ityouknow/spring-boot-examples)
|
||||
- **Star**: 6.0k (1,427 stars this month)
|
||||
- **介绍**: 又一个小商城。litemall = Spring Boot后端 + Vue管理员前端 + 微信小程序用户前端 + Vue用户移动端。
|
||||
|
||||
### 12. skywalking
|
||||
|
||||
- **Github 地址**:<https://github.com/apache/skywalking>
|
||||
- **Star**: 8.0k (1,381 stars this month)
|
||||
- **介绍**: 针对分布式系统的应用性能监控,尤其是针对微服务、云原生和面向容器的分布式系统架构。
|
||||
|
||||
### 13. elasticsearch
|
||||
|
||||
- **Github 地址** [https://github.com/elastic/elasticsearch](https://github.com/elastic/elasticsearch)
|
||||
- **Star**: 4.0k (1,068stars this month)
|
||||
- **介绍**: 开源,分布式,RESTful 搜索引擎。
|
||||
|
||||
### 14. arthas
|
||||
|
||||
- **Github地址**:[https://github.com/alibaba/arthas](https://github.com/alibaba/arthas)
|
||||
- **star**: 12.6 k (1,080 stars this month)
|
||||
- **介绍**: Arthas 是Alibaba开源的Java诊断工具。
|
||||
|
||||
### 15. hutool
|
||||
|
||||
- **Github地址**:<https://github.com/looly/hutool>
|
||||
- **star**: 4.5 k (1,031 stars this month)
|
||||
- **介绍**: Hutool是一个Java工具包,也只是一个工具包,它帮助我们简化每一行代码,减少每一个方法,让Java语言也可以“甜甜的”。Hutool最初是我项目中“util”包的一个整理,后来慢慢积累并加入更多非业务相关功能,并广泛学习其它开源项目精髓,经过自己整理修改,最终形成丰富的开源工具集。官网:<https://www.hutool.cn/> 。
|
||||
@ -1,125 +0,0 @@
|
||||
以下涉及到的数据统计与 2019 年 6 月 1 日 18 点,数据来源:<https://github.com/trending/java?since=monthly> 。下面推荐的内容从 Java 学习文档到最热门的框架再到热门的工具应有尽有,建议收藏+在看!
|
||||
|
||||
### 1.LeetCodeAnimation
|
||||
|
||||
- **Github 地址**: <https://github.com/MisterBooo/LeetCodeAnimation>
|
||||
- **Star**: 29.0k (11,492 stars this month)
|
||||
- **介绍**: Demonstrate all the questions on LeetCode in the form of animation.(用动画的形式呈现解LeetCode题目的思路)。
|
||||
|
||||
### 2.CS-Notes
|
||||
|
||||
- **Github 地址**:<https://github.com/CyC2018/CS-Notes>
|
||||
- **Star**: 64.4k (5513 stars this month)
|
||||
- **介绍**: 技术面试必备基础知识、Leetcode 题解、后端面试、Java 面试、春招、秋招、操作系统、计算机网络、系统设计。
|
||||
|
||||
### 3.JavaGuide
|
||||
|
||||
- **Github 地址**:<https://github.com/Snailclimb/JavaGuide>
|
||||
- **Star**: 42.0k (4,442 stars this month)
|
||||
- **介绍**: 【Java 学习+面试指南】 一份涵盖大部分 Java 程序员所需要掌握的核心知识。
|
||||
|
||||
### 4.mall
|
||||
|
||||
- **Github 地址**: [https://github.com/macrozheng/mall](https://github.com/macrozheng/mall)
|
||||
- **star**: 14.6 k (3,086 stars this month)
|
||||
- **介绍**: mall 项目是一套电商系统,包括前台商城系统及后台管理系统,基于 SpringBoot+MyBatis 实现。 前台商城系统包含首页门户、商品推荐、商品搜索、商品展示、购物车、订单流程、会员中心、客户服务、帮助中心等模块。 后台管理系统包含商品管理、订单管理、会员管理、促销管理、运营管理、内容管理、统计报表、财务管理、权限管理、设置等模块。
|
||||
|
||||
### 5.advanced-java
|
||||
|
||||
- **Github 地址**:[https://github.com/doocs/advanced-java](https://github.com/doocs/advanced-java)
|
||||
- **Star**: 20.8k (2,394 stars this month)
|
||||
- **介绍**: 互联网 Java 工程师进阶知识完全扫盲。
|
||||
|
||||
### 6.spring-boot
|
||||
|
||||
- **Github地址**: [https://github.com/spring-projects/spring-boot](https://github.com/spring-projects/spring-boot)
|
||||
- **star:** 38.5k (1,339 stars this month)
|
||||
- **介绍**: 虽然Spring的组件代码是轻量级的,但它的配置却是重量级的(需要大量XML配置),不过Spring Boot 让这一切成为了过去。 另外Spring Cloud也是基于Spring Boot构建的,我个人非常有必要学习一下。
|
||||
|
||||
**Spring Boot官方的介绍:**
|
||||
|
||||
> Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can “just run”…Most Spring Boot applications need very little Spring configuration.(Spring Boot可以轻松创建独立的生产级基于Spring的应用程序,只要通过 “just run”(可能是run ‘Application’或java -jar 或 tomcat 或 maven插件run 或 shell脚本)便可以运行项目。大部分Spring Boot项目只需要少量的配置即可)
|
||||
|
||||
### 7. Java
|
||||
|
||||
- **Github 地址**:<https://github.com/TheAlgorithms/Java>
|
||||
- **Star**:14.3k (1,334 stars this month)
|
||||
- **介绍**: All Algorithms implemented in Java。
|
||||
|
||||
### 8.server
|
||||
|
||||
- **Github 地址**:<https://github.com/wildfirechat/server>
|
||||
- **star**: 2.2 k (1,275 stars this month)
|
||||
- **介绍**: 全开源即时通讯(IM)系统。
|
||||
|
||||
### 9.litemall
|
||||
|
||||
- **Github 地址**:<https://github.com/linlinjava/litemall>
|
||||
- **Star**: 7.1k (1,114 stars this month)
|
||||
- **介绍**: 又一个小商城。litemall = Spring Boot后端 + Vue管理员前端 + 微信小程序用户前端 + Vue用户移动端。
|
||||
|
||||
### 10.Linkage-RecyclerView
|
||||
|
||||
- **Github 地址**:<https://github.com/KunMinX/Linkage-RecyclerView>
|
||||
- **Star**: 10.0k (1,093 stars this month)
|
||||
- **介绍**: 即使不用饿了么订餐,也请务必收藏好该库!🔥 一行代码即可接入,二级联动订餐列表 - Even if you don't order food by PrubHub, be sure to collect this library, please! 🔥 This secondary linkage list widget can be accessed by only one line of code. Supporting by RecyclerView & AndroidX.
|
||||
|
||||
### 11.toBeTopJavaer
|
||||
|
||||
- **Github 地址** : <https://github.com/hollischuang/toBeTopJavaer>
|
||||
- **Star**: 3.3k (1,007 stars this month)
|
||||
- **介绍**: To Be Top Javaer - Java工程师成神之路
|
||||
|
||||
### 12.elasticsearch
|
||||
|
||||
- **Github 地址** : [https://github.com/elastic/elasticsearch](https://github.com/elastic/elasticsearch)
|
||||
- **Star**: 48.0k (968 stars this month)
|
||||
- **介绍**: 开源,分布式,RESTful 搜索引擎。
|
||||
|
||||
### 13.java-design-patterns
|
||||
|
||||
- **Github 地址** : <https://github.com/iluwatar/java-design-patterns>
|
||||
- **Star**: 41.5k (955 stars this month)
|
||||
- **介绍**: Design patterns implemented in Java。
|
||||
|
||||
### 14.apollo
|
||||
|
||||
- **Github 地址** : <https://github.com/ctripcorp/apollo>
|
||||
- **Star**: 14.5k (927 stars this month)
|
||||
- **介绍**: Apollo(阿波罗)是携程框架部门研发的分布式配置中心,能够集中化管理应用不同环境、不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限、流程治理等特性,适用于微服务配置管理场景。
|
||||
|
||||
### 15.arthas
|
||||
|
||||
- **Github地址**:[https://github.com/alibaba/arthas](https://github.com/alibaba/arthas)
|
||||
- **star**: 13.5 k (933 stars this month)
|
||||
- **介绍**: Arthas 是Alibaba开源的Java诊断工具。
|
||||
|
||||
### 16.dubbo
|
||||
|
||||
- **Github地址**:<https://github.com/apache/dubbo>
|
||||
- **star**: 26.9 k (769 stars this month)
|
||||
- **介绍**: Apache Dubbo是一个基于Java的高性能开源RPC框架。
|
||||
|
||||
### 17.DoraemonKit
|
||||
|
||||
- **Github地址**: <https://github.com/didi/DoraemonKit>
|
||||
- **Star**: 8.5k (909 stars this month)
|
||||
- **介绍**: 简称 "DoKit" 。一款功能齐全的客户端( iOS 、Android )研发助手,你值得拥有。
|
||||
|
||||
### 18.halo
|
||||
|
||||
- **Github地址**: <https://github.com/halo-dev/halo>
|
||||
- **Star**: 4.1k (829 stars this month)
|
||||
- **介绍**: Halo 可能是最好的 Java 博客系统。
|
||||
|
||||
### 19.seata
|
||||
|
||||
- **Github 地址** : [https://github.com/seata/seata](https://github.com/seata/seata)
|
||||
- **star**: 9.2 k (776 stars this month)
|
||||
- **介绍**: Seata 是一种易于使用,高性能,基于 Java 的开源分布式事务解决方案。
|
||||
|
||||
### 20.hutool
|
||||
|
||||
- **Github地址**:<https://github.com/looly/hutool>
|
||||
- **star**: 5,3 k (812 stars this month)
|
||||
- **介绍**: Hutool是一个Java工具包,也只是一个工具包,它帮助我们简化每一行代码,减少每一个方法,让Java语言也可以“甜甜的”。Hutool最初是我项目中“util”包的一个整理,后来慢慢积累并加入更多非业务相关功能,并广泛学习其它开源项目精髓,经过自己整理修改,最终形成丰富的开源工具集。官网:<https://www.hutool.cn/> 。
|
||||
@ -1,119 +0,0 @@
|
||||
### 1.CS-Notes
|
||||
|
||||
- **Github 地址**:https://github.com/CyC2018/CS-Notes
|
||||
- **Star**: 69.8k
|
||||
- **介绍**: 技术面试必备基础知识、Leetcode 题解、后端面试、Java 面试、春招、秋招、操作系统、计算机网络、系统设计。
|
||||
|
||||
### 2.toBeTopJavaer
|
||||
|
||||
- **Github 地址:**[https://github.com/hollischuang/toBeTopJavaer](https://github.com/hollischuang/toBeTopJavaer)
|
||||
- **Star**: 4.7k
|
||||
- **介绍**: To Be Top Javaer - Java工程师成神之路。
|
||||
|
||||
### 3.p3c
|
||||
|
||||
- **Github 地址:** [https://github.com/alibaba/p3c](https://github.com/alibaba/p3c)
|
||||
- **Star**: 16.6k
|
||||
- **介绍**: Alibaba Java Coding Guidelines pmd implements and IDE plugin。Eclipse 和 IDEA 上都有该插件,推荐使用!
|
||||
|
||||
### 4.SpringCloudLearning
|
||||
|
||||
- **Github 地址:** [https://github.com/forezp/SpringCloudLearning](https://github.com/forezp/SpringCloudLearning)
|
||||
- **Star**: 8.7k
|
||||
- **介绍**: 史上最简单的Spring Cloud教程源码。
|
||||
|
||||
### 5.dubbo
|
||||
|
||||
- **Github地址**:<https://github.com/apache/dubbo>
|
||||
- **star**: 27.6 k
|
||||
- **介绍**: Apache Dubbo是一个基于Java的高性能开源RPC框架。
|
||||
|
||||
### 6.jeecg-boot
|
||||
|
||||
- **Github地址**: [https://github.com/zhangdaiscott/jeecg-boot](https://github.com/zhangdaiscott/jeecg-boot)
|
||||
- **star**: 3.3 k
|
||||
- **介绍**: 一款基于代码生成器的JAVA快速开发平台!全新架构前后端分离:SpringBoot 2.x,Ant Design&Vue,Mybatis,Shiro,JWT。强大的代码生成器让前后端代码一键生成,无需写任何代码,绝对是全栈开发福音!! JeecgBoot的宗旨是提高UI能力的同时,降低前后分离的开发成本,JeecgBoot还独创在线开发模式,No代码概念,一系列在线智能开发:在线配置表单、在线配置报表、在线设计流程等等。
|
||||
|
||||
### 7.advanced-java
|
||||
|
||||
- **Github 地址**:[https://github.com/doocs/advanced-java](https://github.com/doocs/advanced-java)
|
||||
- **Star**: 24.2k
|
||||
- **介绍**: 互联网 Java 工程师进阶知识完全扫盲:涵盖高并发、分布式、高可用、微服务等领域知识,后端同学必看,前端同学也可学习。
|
||||
|
||||
### 8.FEBS-Shiro
|
||||
|
||||
- **Github 地址**:[https://github.com/wuyouzhuguli/FEBS-Shiro](https://github.com/wuyouzhuguli/FEBS-Shiro)
|
||||
- **Star**: 2.6k
|
||||
- **介绍**: Spring Boot 2.1.3,Shiro1.4.0 & Layui 2.5.4 权限管理系统。预览地址:http://49.234.20.223:8080/login。
|
||||
|
||||
### 9.SpringAll
|
||||
|
||||
- **Github 地址**: [https://github.com/wuyouzhuguli/SpringAll](https://github.com/wuyouzhuguli/SpringAll)
|
||||
- **Star**: 5.4k
|
||||
- **介绍**: 循序渐进,学习Spring Boot、Spring Boot & Shiro、Spring Cloud、Spring Security & Spring Security OAuth2,博客Spring系列源码。
|
||||
|
||||
### 10.JavaGuide
|
||||
|
||||
- **Github 地址**:<https://github.com/Snailclimb/JavaGuide>
|
||||
- **Star**: 47.2k
|
||||
- **介绍**: 【Java 学习+面试指南】 一份涵盖大部分 Java 程序员所需要掌握的核心知识。
|
||||
|
||||
### 11.vhr
|
||||
|
||||
- **Github 地址**:[https://github.com/lenve/vhr](https://github.com/lenve/vhr)
|
||||
- **Star**: 4.9k
|
||||
- **介绍**: 微人事是一个前后端分离的人力资源管理系统,项目采用SpringBoot+Vue开发。
|
||||
|
||||
### 12. tutorials
|
||||
|
||||
- **Github 地址**:[https://github.com/eugenp/tutorials](https://github.com/eugenp/tutorials)
|
||||
- **star**: 15.4 k
|
||||
- **介绍**: 该项目是一系列小而专注的教程 - 每个教程都涵盖 Java 生态系统中单一且定义明确的开发领域。 当然,它们的重点是 Spring Framework - Spring,Spring Boot 和 Spring Securiyt。 除了 Spring 之外,还有以下技术:核心 Java,Jackson,HttpClient,Guava。
|
||||
|
||||
### 13.EasyScheduler
|
||||
|
||||
- **Github 地址**:[https://github.com/analysys/EasyScheduler](https://github.com/analysys/EasyScheduler)
|
||||
- **star**: 1.1 k
|
||||
- **介绍**: Easy Scheduler是一个分布式工作流任务调度系统,主要解决“复杂任务依赖但无法直接监控任务健康状态”的问题。Easy Scheduler以DAG方式组装任务,可以实时监控任务的运行状态。同时,它支持重试,重新运行等操作... 。https://analysys.github.io/easyscheduler_docs_cn/
|
||||
|
||||
### 14.thingsboard
|
||||
|
||||
- **Github 地址**:[https://github.com/thingsboard/thingsboard](https://github.com/thingsboard/thingsboard)
|
||||
- **star**: 3.7 k
|
||||
- **介绍**: 开源物联网平台 - 设备管理,数据收集,处理和可视化。 [https://thingsboard.io](https://thingsboard.io/)
|
||||
|
||||
### 15.mall-learning
|
||||
|
||||
- **Github 地址**: [https://github.com/macrozheng/mall-learning](https://github.com/macrozheng/mall-learning)
|
||||
- **star**: 0.6 k
|
||||
- **介绍**: mall学习教程,架构、业务、技术要点全方位解析。mall项目(16k+star)是一套电商系统,使用现阶段主流技术实现。 涵盖了SpringBoot2.1.3、MyBatis3.4.6、Elasticsearch6.2.2、RabbitMQ3.7.15、Redis3.2、Mongodb3.2、Mysql5.7等技术,采用Docker容器化部署。 https://github.com/macrozheng/mall
|
||||
|
||||
### 16. flink
|
||||
|
||||
- **Github地址**:[https://github.com/apache/flink](https://github.com/apache/flink)
|
||||
- **star**: 9.3 k
|
||||
- **介绍**: Apache Flink是一个开源流处理框架,具有强大的流和批处理功能。
|
||||
|
||||
### 17.spring-cloud-kubernetes
|
||||
|
||||
- **Github地址**:[https://github.com/spring-cloud/spring-cloud-kubernetes](https://github.com/spring-cloud/spring-cloud-kubernetes)
|
||||
- **star**: 1.4 k
|
||||
- **介绍**: Kubernetes 集成 Spring Cloud Discovery Client, Configuration, etc...
|
||||
|
||||
### 18.springboot-learning-example
|
||||
|
||||
- **Github地址**:[https://github.com/JeffLi1993/springboot-learning-example](https://github.com/JeffLi1993/springboot-learning-example)
|
||||
- **star**: 10.0 k
|
||||
- **介绍**: spring boot 实践学习案例,是 spring boot 初学者及核心技术巩固的最佳实践。
|
||||
|
||||
### 19.canal
|
||||
|
||||
- **Github地址**:[https://github.com/alibaba/canal](https://github.com/alibaba/canal)
|
||||
- **star**: 9.3 k
|
||||
- **介绍**: 阿里巴巴 MySQL binlog 增量订阅&消费组件。
|
||||
|
||||
### 20.react-native-device-info
|
||||
|
||||
- **Github地址**:[https://github.com/react-native-community/react-native-device-info](https://github.com/react-native-community/react-native-device-info)
|
||||
- **star**: 4.0 k
|
||||
- **介绍**: React Native iOS和Android的设备信息。
|
||||
@ -1,8 +0,0 @@
|
||||
- [2018 年 12 月](https://github.com/Snailclimb/JavaGuide/blob/master/docs/github-trending/2018-12.md)
|
||||
- [2019 年 1 月](https://github.com/Snailclimb/JavaGuide/blob/master/docs/github-trending/2019-1.md)
|
||||
- [2019 年 2 月](https://github.com/Snailclimb/JavaGuide/blob/master/docs/github-trending/2019-2.md)
|
||||
- [2019 年 3 月](https://github.com/Snailclimb/JavaGuide/blob/master/docs/github-trending/2019-3.md)
|
||||
- [2019 年 4 月](https://github.com/Snailclimb/JavaGuide/blob/master/docs/github-trending/2019-4.md)
|
||||
- [2019 年 5 月](https://github.com/Snailclimb/JavaGuide/blob/master/docs/github-trending/2019-5.md)
|
||||
- [2019 年 6 月](https://github.com/Snailclimb/JavaGuide/blob/master/docs/github-trending/2019-6.md)
|
||||
|
||||
@ -1,422 +0,0 @@
|
||||
## synchronized / Lock
|
||||
|
||||
1. JDK 1.5之前
|
||||
|
||||
,Java通过
|
||||
|
||||
synchronized
|
||||
|
||||
关键字来实现
|
||||
|
||||
锁
|
||||
|
||||
功能
|
||||
|
||||
- synchronized是JVM实现的**内置锁**,锁的获取和释放都是由JVM**隐式**实现的
|
||||
|
||||
2. JDK 1.5
|
||||
|
||||
,并发包中新增了
|
||||
|
||||
Lock接口
|
||||
|
||||
来实现锁功能
|
||||
|
||||
- 提供了与synchronized类似的同步功能,但需要**显式**获取和释放锁
|
||||
|
||||
3. Lock同步锁是基于
|
||||
|
||||
Java
|
||||
|
||||
实现的,而synchronized是基于底层操作系统的
|
||||
|
||||
Mutex Lock
|
||||
|
||||
实现的
|
||||
|
||||
- 每次获取和释放锁都会带来**用户态和内核态的切换**,从而增加系统的**性能开销**
|
||||
- 在锁竞争激烈的情况下,synchronized同步锁的性能很糟糕
|
||||
- 在**JDK 1.5**,在**单线程重复申请锁**的情况下,synchronized锁性能要比Lock的性能**差很多**
|
||||
|
||||
4. **JDK 1.6**,Java对synchronized同步锁做了**充分的优化**,甚至在某些场景下,它的性能已经超越了Lock同步锁
|
||||
|
||||
|
||||
|
||||
## 实现原理
|
||||
|
||||
复制
|
||||
|
||||
```
|
||||
public class SyncTest {
|
||||
public synchronized void method1() {
|
||||
}
|
||||
|
||||
public void method2() {
|
||||
Object o = new Object();
|
||||
synchronized (o) {
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
复制
|
||||
|
||||
```
|
||||
$ javac -encoding UTF-8 SyncTest.java
|
||||
$ javap -v SyncTest
|
||||
```
|
||||
|
||||
### 修饰方法
|
||||
|
||||
复制
|
||||
|
||||
```
|
||||
public synchronized void method1();
|
||||
descriptor: ()V
|
||||
flags: ACC_PUBLIC, ACC_SYNCHRONIZED
|
||||
Code:
|
||||
stack=0, locals=1, args_size=1
|
||||
0: return
|
||||
```
|
||||
|
||||
1. JVM使用**ACC_SYNCHRONIZED**访问标识来区分一个方法是否为**同步方法**
|
||||
|
||||
2. 在方法调用时,会检查方法是否被设置了
|
||||
|
||||
ACC_SYNCHRONIZED
|
||||
|
||||
访问标识
|
||||
|
||||
- 如果是,执行线程会将先尝试**持有Monitor对象**,再执行方法,方法执行完成后,最后**释放Monitor对象**
|
||||
|
||||
### 修饰代码块
|
||||
|
||||
复制
|
||||
|
||||
```
|
||||
public void method2();
|
||||
descriptor: ()V
|
||||
flags: ACC_PUBLIC
|
||||
Code:
|
||||
stack=2, locals=4, args_size=1
|
||||
0: new #2 // class java/lang/Object
|
||||
3: dup
|
||||
4: invokespecial #1 // Method java/lang/Object."<init>":()V
|
||||
7: astore_1
|
||||
8: aload_1
|
||||
9: dup
|
||||
10: astore_2
|
||||
11: monitorenter
|
||||
12: aload_2
|
||||
13: monitorexit
|
||||
14: goto 22
|
||||
17: astore_3
|
||||
18: aload_2
|
||||
19: monitorexit
|
||||
20: aload_3
|
||||
21: athrow
|
||||
22: return
|
||||
```
|
||||
|
||||
1. synchronized修饰同步代码块时,由**monitorenter**和**monitorexit**指令来实现同步
|
||||
2. 进入**monitorenter**指令后,线程将**持有**该**Monitor对象**,进入**monitorexit**指令,线程将**释放**该**Monitor对象**
|
||||
|
||||
### 管程模型
|
||||
|
||||
1. JVM中的**同步**是基于进入和退出**管程**(**Monitor**)对象实现的
|
||||
|
||||
2. **每个Java对象实例都会有一个Monitor**,Monitor可以和Java对象实例一起被创建和销毁
|
||||
|
||||
3. Monitor是由**ObjectMonitor**实现的,对应[ObjectMonitor.hpp](https://github.com/JetBrains/jdk8u_hotspot/blob/master/src/share/vm/runtime/objectMonitor.hpp)
|
||||
|
||||
4. 当多个线程同时访问一段同步代码时,会先被放在**EntryList**中
|
||||
|
||||
5. 当线程获取到Java对象的Monitor时(Monitor是依靠
|
||||
|
||||
底层操作系统
|
||||
|
||||
的
|
||||
|
||||
Mutex Lock
|
||||
|
||||
来实现
|
||||
|
||||
互斥
|
||||
|
||||
的)
|
||||
|
||||
- 线程申请Mutex成功,则持有该Mutex,其它线程将无法获取到该Mutex
|
||||
|
||||
6. 进入
|
||||
|
||||
WaitSet
|
||||
|
||||
- 竞争锁**失败**的线程会进入**WaitSet**
|
||||
- 竞争锁**成功**的线程如果调用**wait**方法,就会**释放当前持有的Mutex**,并且该线程会进入**WaitSet**
|
||||
- 进入**WaitSet**的进程会等待下一次唤醒,然后进入EntryList**重新排队**
|
||||
|
||||
7. 如果当前线程顺利执行完方法,也会释放Mutex
|
||||
|
||||
8. Monitor依赖于**底层操作系统**的实现,存在**用户态**和**内核态之间**的**切换**,所以增加了**性能开销**
|
||||
|
||||
[](https://java-performance-1253868755.cos.ap-guangzhou.myqcloud.com/java-performance-synchronized-monitor.png)
|
||||
|
||||
复制
|
||||
|
||||
```
|
||||
ObjectMonitor() {
|
||||
_header = NULL;
|
||||
_count = 0; // 记录个数
|
||||
_waiters = 0,
|
||||
_recursions = 0;
|
||||
_object = NULL;
|
||||
_owner = NULL; // 持有该Monitor的线程
|
||||
_WaitSet = NULL; // 处于wait状态的线程,会被加入 _WaitSet
|
||||
_WaitSetLock = 0 ;
|
||||
_Responsible = NULL ;
|
||||
_succ = NULL ;
|
||||
_cxq = NULL ;
|
||||
FreeNext = NULL ;
|
||||
_EntryList = NULL ; // 多个线程访问同步块或同步方法,会首先被加入 _EntryList
|
||||
_SpinFreq = 0 ;
|
||||
_SpinClock = 0 ;
|
||||
OwnerIsThread = 0 ;
|
||||
_previous_owner_tid = 0;
|
||||
}
|
||||
```
|
||||
|
||||
## 锁升级优化
|
||||
|
||||
1. 为了提升性能,在**JDK 1.6**引入**偏向锁、轻量级锁、重量级锁**,用来**减少锁竞争带来的上下文切换**
|
||||
2. 借助JDK 1.6新增的**Java对象头**,实现了**锁升级**功能
|
||||
|
||||
### Java对象头
|
||||
|
||||
1. 在**JDK 1.6**的JVM中,对象实例在**堆内存**中被分为三部分:**对象头**、**实例数据**、**对齐填充**
|
||||
2. 对象头的组成部分:**Mark Word**、**指向类的指针**、**数组长度**(可选,数组类型时才有)
|
||||
3. Mark Word记录了**对象**和**锁**有关的信息,在64位的JVM中,Mark Word为**64 bit**
|
||||
4. 锁升级功能主要依赖于Mark Word中**锁标志位**和**是否偏向锁标志位**
|
||||
5. synchronized同步锁的升级优化路径:***偏向锁** -> **轻量级锁** -> **重量级锁***
|
||||
|
||||
[](https://java-performance-1253868755.cos.ap-guangzhou.myqcloud.com/java-performance-synchronized-mark-word.jpg)
|
||||
|
||||
### 偏向锁
|
||||
|
||||
1. 偏向锁主要用来优化**同一线程多次申请同一个锁**的竞争,在某些情况下,大部分时间都是同一个线程竞争锁资源
|
||||
|
||||
2. 偏向锁的作用
|
||||
|
||||
- 当一个线程再次访问同一个同步代码时,该线程只需对该对象头的**Mark Word**中去判断是否有偏向锁指向它
|
||||
- **无需再进入Monitor去竞争对象**(避免用户态和内核态的**切换**)
|
||||
|
||||
3. 当对象被当做同步锁,并有一个线程抢到锁时
|
||||
|
||||
- 锁标志位还是**01**,是否偏向锁标志位设置为**1**,并且记录抢到锁的**线程ID**,进入***偏向锁状态***
|
||||
|
||||
4. 偏向锁
|
||||
|
||||
**不会主动释放锁**
|
||||
|
||||
- 当线程1再次获取锁时,会比较**当前线程的ID**与**锁对象头部的线程ID**是否一致,如果一致,无需CAS来抢占锁
|
||||
|
||||
- 如果不一致,需要查看
|
||||
|
||||
锁对象头部记录的线程
|
||||
|
||||
是否存活
|
||||
|
||||
- 如果**没有存活**,那么锁对象被重置为**无锁**状态(也是一种撤销),然后重新偏向线程2
|
||||
|
||||
- 如果
|
||||
|
||||
存活
|
||||
|
||||
,查找线程1的栈帧信息
|
||||
|
||||
- 如果线程1还是需要继续持有该锁对象,那么暂停线程1(**STW**),**撤销偏向锁**,**升级为轻量级锁**
|
||||
- 如果线程1不再使用该锁对象,那么将该锁对象设为**无锁**状态(也是一种撤销),然后重新偏向线程2
|
||||
|
||||
5. 一旦出现其他线程竞争锁资源时,偏向锁就会被
|
||||
|
||||
撤销
|
||||
|
||||
- 偏向锁的撤销**可能需要**等待**全局安全点**,暂停持有该锁的线程,同时检查该线程**是否还在执行该方法**
|
||||
- 如果还没有执行完,说明此刻有**多个线程**竞争,升级为**轻量级锁**;如果已经执行完毕,唤醒其他线程继续**CAS**抢占
|
||||
|
||||
6. 在
|
||||
|
||||
高并发
|
||||
|
||||
场景下,当
|
||||
|
||||
大量线程
|
||||
|
||||
同时竞争同一个锁资源时,偏向锁会被
|
||||
|
||||
撤销
|
||||
|
||||
,发生
|
||||
|
||||
STW
|
||||
|
||||
,加大了
|
||||
|
||||
性能开销
|
||||
|
||||
- 默认配置
|
||||
|
||||
- `-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=4000`
|
||||
- 默认开启偏向锁,并且**延迟生效**,因为JVM刚启动时竞争非常激烈
|
||||
|
||||
- 关闭偏向锁
|
||||
|
||||
- `-XX:-UseBiasedLocking`
|
||||
|
||||
- 直接
|
||||
|
||||
设置为重量级锁
|
||||
|
||||
- `-XX:+UseHeavyMonitors`
|
||||
|
||||
红线流程部分:偏向锁的**获取**和**撤销**
|
||||
[](https://java-performance-1253868755.cos.ap-guangzhou.myqcloud.com/java-performance-synchronized-lock-upgrade-1.png)
|
||||
|
||||
### 轻量级锁
|
||||
|
||||
1. 当有另外一个线程竞争锁时,由于该锁处于**偏向锁**状态
|
||||
|
||||
2. 发现对象头Mark Word中的线程ID不是自己的线程ID,该线程就会执行
|
||||
|
||||
CAS
|
||||
|
||||
操作获取锁
|
||||
|
||||
- 如果获取**成功**,直接替换Mark Word中的线程ID为自己的线程ID,该锁会***保持偏向锁状态***
|
||||
- 如果获取**失败**,说明当前锁有一定的竞争,将偏向锁**升级**为轻量级锁
|
||||
|
||||
3. 线程获取轻量级锁时会有两步
|
||||
|
||||
- 先把**锁对象的Mark Word**复制一份到线程的**栈帧**中(**DisplacedMarkWord**),主要为了**保留现场**!!
|
||||
- 然后使用**CAS**,把对象头中的内容替换为**线程栈帧中DisplacedMarkWord的地址**
|
||||
|
||||
4. 场景
|
||||
|
||||
- 在线程1复制对象头Mark Word的同时(CAS之前),线程2也准备获取锁,也复制了对象头Mark Word
|
||||
- 在线程2进行CAS时,发现线程1已经把对象头换了,线程2的CAS失败,线程2会尝试使用**自旋锁**来等待线程1释放锁
|
||||
|
||||
5. 轻量级锁的适用场景:线程**交替执行**同步块,***绝大部分的锁在整个同步周期内都不存在长时间的竞争***
|
||||
|
||||
红线流程部分:升级轻量级锁
|
||||
[](https://java-performance-1253868755.cos.ap-guangzhou.myqcloud.com/java-performance-synchronized-lock-upgrade-2.png)
|
||||
|
||||
### 自旋锁 / 重量级锁
|
||||
|
||||
1. 轻量级锁
|
||||
|
||||
CAS
|
||||
|
||||
抢占失败,线程将会被挂起进入
|
||||
|
||||
阻塞
|
||||
|
||||
状态
|
||||
|
||||
- 如果正在持有锁的线程在**很短的时间**内释放锁资源,那么进入**阻塞**状态的线程被**唤醒**后又要**重新抢占**锁资源
|
||||
|
||||
2. JVM提供了**自旋锁**,可以通过**自旋**的方式**不断尝试获取锁**,从而***避免线程被挂起阻塞***
|
||||
|
||||
3. 从
|
||||
|
||||
JDK 1.7
|
||||
|
||||
开始,
|
||||
|
||||
自旋锁默认启用
|
||||
|
||||
,自旋次数
|
||||
|
||||
不建议设置过大
|
||||
|
||||
(意味着
|
||||
|
||||
长时间占用CPU
|
||||
|
||||
)
|
||||
|
||||
- `-XX:+UseSpinning -XX:PreBlockSpin=10`
|
||||
|
||||
4. 自旋锁重试之后如果依然抢锁失败,同步锁会升级至
|
||||
|
||||
重量级锁
|
||||
|
||||
,锁标志位为
|
||||
|
||||
10
|
||||
|
||||
- 在这个状态下,未抢到锁的线程都会**进入Monitor**,之后会被阻塞在**WaitSet**中
|
||||
|
||||
5. 在
|
||||
|
||||
锁竞争不激烈
|
||||
|
||||
且
|
||||
|
||||
锁占用时间非常短
|
||||
|
||||
的场景下,自旋锁可以提高系统性能
|
||||
|
||||
- 一旦锁竞争激烈或者锁占用的时间过长,自旋锁将会导致大量的线程一直处于**CAS重试状态**,**占用CPU资源**
|
||||
|
||||
6. 在
|
||||
|
||||
高并发
|
||||
|
||||
的场景下,可以通过
|
||||
|
||||
关闭自旋锁
|
||||
|
||||
来优化系统性能
|
||||
|
||||
- ```
|
||||
-XX:-UseSpinning
|
||||
```
|
||||
|
||||
- 关闭自旋锁优化
|
||||
|
||||
- ```
|
||||
-XX:PreBlockSpin
|
||||
```
|
||||
|
||||
- 默认的自旋次数,在**JDK 1.7**后,**由JVM控制**
|
||||
|
||||
[](https://java-performance-1253868755.cos.ap-guangzhou.myqcloud.com/java-performance-synchronized-lock-upgrade-3.png)
|
||||
|
||||
## 小结
|
||||
|
||||
1. JVM在**JDK 1.6**中引入了**分级锁**机制来优化synchronized
|
||||
|
||||
2. 当一个线程获取锁时,首先对象锁成为一个
|
||||
|
||||
偏向锁
|
||||
|
||||
- 这是为了避免在**同一线程重复获取同一把锁**时,**用户态和内核态频繁切换**
|
||||
|
||||
3. 如果有多个线程竞争锁资源,锁将会升级为
|
||||
|
||||
轻量级锁
|
||||
|
||||
- 这适用于在**短时间**内持有锁,且分锁**交替切换**的场景
|
||||
- 轻量级锁还结合了**自旋锁**来**避免线程用户态与内核态的频繁切换**
|
||||
|
||||
4. 如果锁竞争太激烈(自旋锁失败),同步锁会升级为重量级锁
|
||||
|
||||
5. 优化synchronized同步锁的关键:
|
||||
|
||||
减少锁竞争
|
||||
|
||||
- 应该尽量使synchronized同步锁处于**轻量级锁**或**偏向锁**,这样才能提高synchronized同步锁的性能
|
||||
- 常用手段
|
||||
- **减少锁粒度**:降低锁竞争
|
||||
- **减少锁的持有时间**,提高synchronized同步锁在自旋时获取锁资源的成功率,**避免升级为重量级锁**
|
||||
|
||||
6. 在**锁竞争激烈**时,可以考虑**禁用偏向锁**和**禁用自旋锁**
|
||||
@ -1,383 +0,0 @@
|
||||
<!-- TOC -->
|
||||
|
||||
- [Collections 工具类和 Arrays 工具类常见方法](#collections-工具类和-arrays-工具类常见方法)
|
||||
- [Collections](#collections)
|
||||
- [排序操作](#排序操作)
|
||||
- [查找,替换操作](#查找替换操作)
|
||||
- [同步控制](#同步控制)
|
||||
- [Arrays类的常见操作](#arrays类的常见操作)
|
||||
- [排序 : `sort()`](#排序--sort)
|
||||
- [查找 : `binarySearch()`](#查找--binarysearch)
|
||||
- [比较: `equals()`](#比较-equals)
|
||||
- [填充 : `fill()`](#填充--fill)
|
||||
- [转列表 `asList()`](#转列表-aslist)
|
||||
- [转字符串 `toString()`](#转字符串-tostring)
|
||||
- [复制 `copyOf()`](#复制-copyof)
|
||||
|
||||
<!-- /TOC -->
|
||||
# Collections 工具类和 Arrays 工具类常见方法
|
||||
|
||||
## Collections
|
||||
|
||||
Collections 工具类常用方法:
|
||||
|
||||
1. 排序
|
||||
2. 查找,替换操作
|
||||
3. 同步控制(不推荐,需要线程安全的集合类型时请考虑使用 JUC 包下的并发集合)
|
||||
|
||||
### 排序操作
|
||||
|
||||
```java
|
||||
void reverse(List list)//反转
|
||||
void shuffle(List list)//随机排序
|
||||
void sort(List list)//按自然排序的升序排序
|
||||
void sort(List list, Comparator c)//定制排序,由Comparator控制排序逻辑
|
||||
void swap(List list, int i , int j)//交换两个索引位置的元素
|
||||
void rotate(List list, int distance)//旋转。当distance为正数时,将list后distance个元素整体移到前面。当distance为负数时,将 list的前distance个元素整体移到后面。
|
||||
```
|
||||
|
||||
**示例代码:**
|
||||
|
||||
```java
|
||||
ArrayList<Integer> arrayList = new ArrayList<Integer>();
|
||||
arrayList.add(-1);
|
||||
arrayList.add(3);
|
||||
arrayList.add(3);
|
||||
arrayList.add(-5);
|
||||
arrayList.add(7);
|
||||
arrayList.add(4);
|
||||
arrayList.add(-9);
|
||||
arrayList.add(-7);
|
||||
System.out.println("原始数组:");
|
||||
System.out.println(arrayList);
|
||||
// void reverse(List list):反转
|
||||
Collections.reverse(arrayList);
|
||||
System.out.println("Collections.reverse(arrayList):");
|
||||
System.out.println(arrayList);
|
||||
|
||||
|
||||
Collections.rotate(arrayList, 4);
|
||||
System.out.println("Collections.rotate(arrayList, 4):");
|
||||
System.out.println(arrayList);
|
||||
|
||||
// void sort(List list),按自然排序的升序排序
|
||||
Collections.sort(arrayList);
|
||||
System.out.println("Collections.sort(arrayList):");
|
||||
System.out.println(arrayList);
|
||||
|
||||
// void shuffle(List list),随机排序
|
||||
Collections.shuffle(arrayList);
|
||||
System.out.println("Collections.shuffle(arrayList):");
|
||||
System.out.println(arrayList);
|
||||
|
||||
// void swap(List list, int i , int j),交换两个索引位置的元素
|
||||
Collections.swap(arrayList, 2, 5);
|
||||
System.out.println("Collections.swap(arrayList, 2, 5):");
|
||||
System.out.println(arrayList);
|
||||
|
||||
// 定制排序的用法
|
||||
Collections.sort(arrayList, new Comparator<Integer>() {
|
||||
|
||||
@Override
|
||||
public int compare(Integer o1, Integer o2) {
|
||||
return o2.compareTo(o1);
|
||||
}
|
||||
});
|
||||
System.out.println("定制排序后:");
|
||||
System.out.println(arrayList);
|
||||
```
|
||||
|
||||
### 查找,替换操作
|
||||
|
||||
```java
|
||||
int binarySearch(List list, Object key)//对List进行二分查找,返回索引,注意List必须是有序的
|
||||
int max(Collection coll)//根据元素的自然顺序,返回最大的元素。 类比int min(Collection coll)
|
||||
int max(Collection coll, Comparator c)//根据定制排序,返回最大元素,排序规则由Comparatator类控制。类比int min(Collection coll, Comparator c)
|
||||
void fill(List list, Object obj)//用指定的元素代替指定list中的所有元素。
|
||||
int frequency(Collection c, Object o)//统计元素出现次数
|
||||
int indexOfSubList(List list, List target)//统计target在list中第一次出现的索引,找不到则返回-1,类比int lastIndexOfSubList(List source, list target).
|
||||
boolean replaceAll(List list, Object oldVal, Object newVal), 用新元素替换旧元素
|
||||
```
|
||||
|
||||
**示例代码:**
|
||||
|
||||
```java
|
||||
ArrayList<Integer> arrayList = new ArrayList<Integer>();
|
||||
arrayList.add(-1);
|
||||
arrayList.add(3);
|
||||
arrayList.add(3);
|
||||
arrayList.add(-5);
|
||||
arrayList.add(7);
|
||||
arrayList.add(4);
|
||||
arrayList.add(-9);
|
||||
arrayList.add(-7);
|
||||
ArrayList<Integer> arrayList2 = new ArrayList<Integer>();
|
||||
arrayList2.add(-3);
|
||||
arrayList2.add(-5);
|
||||
arrayList2.add(7);
|
||||
System.out.println("原始数组:");
|
||||
System.out.println(arrayList);
|
||||
|
||||
System.out.println("Collections.max(arrayList):");
|
||||
System.out.println(Collections.max(arrayList));
|
||||
|
||||
System.out.println("Collections.min(arrayList):");
|
||||
System.out.println(Collections.min(arrayList));
|
||||
|
||||
System.out.println("Collections.replaceAll(arrayList, 3, -3):");
|
||||
Collections.replaceAll(arrayList, 3, -3);
|
||||
System.out.println(arrayList);
|
||||
|
||||
System.out.println("Collections.frequency(arrayList, -3):");
|
||||
System.out.println(Collections.frequency(arrayList, -3));
|
||||
|
||||
System.out.println("Collections.indexOfSubList(arrayList, arrayList2):");
|
||||
System.out.println(Collections.indexOfSubList(arrayList, arrayList2));
|
||||
|
||||
System.out.println("Collections.binarySearch(arrayList, 7):");
|
||||
// 对List进行二分查找,返回索引,List必须是有序的
|
||||
Collections.sort(arrayList);
|
||||
System.out.println(Collections.binarySearch(arrayList, 7));
|
||||
```
|
||||
|
||||
### 同步控制
|
||||
|
||||
Collections提供了多个`synchronizedXxx()`方法·,该方法可以将指定集合包装成线程同步的集合,从而解决多线程并发访问集合时的线程安全问题。
|
||||
|
||||
我们知道 HashSet,TreeSet,ArrayList,LinkedList,HashMap,TreeMap 都是线程不安全的。Collections提供了多个静态方法可以把他们包装成线程同步的集合。
|
||||
|
||||
**最好不要用下面这些方法,效率非常低,需要线程安全的集合类型时请考虑使用 JUC 包下的并发集合。**
|
||||
|
||||
方法如下:
|
||||
|
||||
```java
|
||||
synchronizedCollection(Collection<T> c) //返回指定 collection 支持的同步(线程安全的)collection。
|
||||
synchronizedList(List<T> list)//返回指定列表支持的同步(线程安全的)List。
|
||||
synchronizedMap(Map<K,V> m) //返回由指定映射支持的同步(线程安全的)Map。
|
||||
synchronizedSet(Set<T> s) //返回指定 set 支持的同步(线程安全的)set。
|
||||
```
|
||||
|
||||
### Collections还可以设置不可变集合,提供了如下三类方法:
|
||||
|
||||
```java
|
||||
emptyXxx(): 返回一个空的、不可变的集合对象,此处的集合既可以是List,也可以是Set,还可以是Map。
|
||||
singletonXxx(): 返回一个只包含指定对象(只有一个或一个元素)的不可变的集合对象,此处的集合可以是:List,Set,Map。
|
||||
unmodifiableXxx(): 返回指定集合对象的不可变视图,此处的集合可以是:List,Set,Map。
|
||||
上面三类方法的参数是原有的集合对象,返回值是该集合的”只读“版本。
|
||||
```
|
||||
|
||||
**示例代码:**
|
||||
|
||||
```java
|
||||
ArrayList<Integer> arrayList = new ArrayList<Integer>();
|
||||
arrayList.add(-1);
|
||||
arrayList.add(3);
|
||||
arrayList.add(3);
|
||||
arrayList.add(-5);
|
||||
arrayList.add(7);
|
||||
arrayList.add(4);
|
||||
arrayList.add(-9);
|
||||
arrayList.add(-7);
|
||||
HashSet<Integer> integers1 = new HashSet<>();
|
||||
integers1.add(1);
|
||||
integers1.add(3);
|
||||
integers1.add(2);
|
||||
Map scores = new HashMap();
|
||||
scores.put("语文" , 80);
|
||||
scores.put("Java" , 82);
|
||||
|
||||
//Collections.emptyXXX();创建一个空的、不可改变的XXX对象
|
||||
List<Object> list = Collections.emptyList();
|
||||
System.out.println(list);//[]
|
||||
Set<Object> objects = Collections.emptySet();
|
||||
System.out.println(objects);//[]
|
||||
Map<Object, Object> objectObjectMap = Collections.emptyMap();
|
||||
System.out.println(objectObjectMap);//{}
|
||||
|
||||
//Collections.singletonXXX();
|
||||
List<ArrayList<Integer>> arrayLists = Collections.singletonList(arrayList);
|
||||
System.out.println(arrayLists);//[[-1, 3, 3, -5, 7, 4, -9, -7]]
|
||||
//创建一个只有一个元素,且不可改变的Set对象
|
||||
Set<ArrayList<Integer>> singleton = Collections.singleton(arrayList);
|
||||
System.out.println(singleton);//[[-1, 3, 3, -5, 7, 4, -9, -7]]
|
||||
Map<String, String> nihao = Collections.singletonMap("1", "nihao");
|
||||
System.out.println(nihao);//{1=nihao}
|
||||
|
||||
//unmodifiableXXX();创建普通XXX对象对应的不可变版本
|
||||
List<Integer> integers = Collections.unmodifiableList(arrayList);
|
||||
System.out.println(integers);//[-1, 3, 3, -5, 7, 4, -9, -7]
|
||||
Set<Integer> integers2 = Collections.unmodifiableSet(integers1);
|
||||
System.out.println(integers2);//[1, 2, 3]
|
||||
Map<Object, Object> objectObjectMap2 = Collections.unmodifiableMap(scores);
|
||||
System.out.println(objectObjectMap2);//{Java=82, 语文=80}
|
||||
|
||||
//添加出现异常:java.lang.UnsupportedOperationException
|
||||
// list.add(1);
|
||||
// arrayLists.add(arrayList);
|
||||
// integers.add(1);
|
||||
```
|
||||
|
||||
## Arrays类的常见操作
|
||||
1. 排序 : `sort()`
|
||||
2. 查找 : `binarySearch()`
|
||||
3. 比较: `equals()`
|
||||
4. 填充 : `fill()`
|
||||
5. 转列表: `asList()`
|
||||
6. 转字符串 : `toString()`
|
||||
7. 复制: `copyOf()`
|
||||
|
||||
|
||||
### 排序 : `sort()`
|
||||
|
||||
```java
|
||||
// *************排序 sort****************
|
||||
int a[] = { 1, 3, 2, 7, 6, 5, 4, 9 };
|
||||
// sort(int[] a)方法按照数字顺序排列指定的数组。
|
||||
Arrays.sort(a);
|
||||
System.out.println("Arrays.sort(a):");
|
||||
for (int i : a) {
|
||||
System.out.print(i);
|
||||
}
|
||||
// 换行
|
||||
System.out.println();
|
||||
|
||||
// sort(int[] a,int fromIndex,int toIndex)按升序排列数组的指定范围
|
||||
int b[] = { 1, 3, 2, 7, 6, 5, 4, 9 };
|
||||
Arrays.sort(b, 2, 6);
|
||||
System.out.println("Arrays.sort(b, 2, 6):");
|
||||
for (int i : b) {
|
||||
System.out.print(i);
|
||||
}
|
||||
// 换行
|
||||
System.out.println();
|
||||
|
||||
int c[] = { 1, 3, 2, 7, 6, 5, 4, 9 };
|
||||
// parallelSort(int[] a) 按照数字顺序排列指定的数组(并行的)。同sort方法一样也有按范围的排序
|
||||
Arrays.parallelSort(c);
|
||||
System.out.println("Arrays.parallelSort(c):");
|
||||
for (int i : c) {
|
||||
System.out.print(i);
|
||||
}
|
||||
// 换行
|
||||
System.out.println();
|
||||
|
||||
// parallelSort给字符数组排序,sort也可以
|
||||
char d[] = { 'a', 'f', 'b', 'c', 'e', 'A', 'C', 'B' };
|
||||
Arrays.parallelSort(d);
|
||||
System.out.println("Arrays.parallelSort(d):");
|
||||
for (char d2 : d) {
|
||||
System.out.print(d2);
|
||||
}
|
||||
// 换行
|
||||
System.out.println();
|
||||
|
||||
```
|
||||
|
||||
在做算法面试题的时候,我们还可能会经常遇到对字符串排序的情况,`Arrays.sort()` 对每个字符串的特定位置进行比较,然后按照升序排序。
|
||||
|
||||
```java
|
||||
String[] strs = { "abcdehg", "abcdefg", "abcdeag" };
|
||||
Arrays.sort(strs);
|
||||
System.out.println(Arrays.toString(strs));//[abcdeag, abcdefg, abcdehg]
|
||||
```
|
||||
|
||||
### 查找 : `binarySearch()`
|
||||
|
||||
```java
|
||||
// *************查找 binarySearch()****************
|
||||
char[] e = { 'a', 'f', 'b', 'c', 'e', 'A', 'C', 'B' };
|
||||
// 排序后再进行二分查找,否则找不到
|
||||
Arrays.sort(e);
|
||||
System.out.println("Arrays.sort(e)" + Arrays.toString(e));
|
||||
System.out.println("Arrays.binarySearch(e, 'c'):");
|
||||
int s = Arrays.binarySearch(e, 'c');
|
||||
System.out.println("字符c在数组的位置:" + s);
|
||||
```
|
||||
|
||||
### 比较: `equals()`
|
||||
|
||||
```java
|
||||
// *************比较 equals****************
|
||||
char[] e = { 'a', 'f', 'b', 'c', 'e', 'A', 'C', 'B' };
|
||||
char[] f = { 'a', 'f', 'b', 'c', 'e', 'A', 'C', 'B' };
|
||||
/*
|
||||
* 元素数量相同,并且相同位置的元素相同。 另外,如果两个数组引用都是null,则它们被认为是相等的 。
|
||||
*/
|
||||
// 输出true
|
||||
System.out.println("Arrays.equals(e, f):" + Arrays.equals(e, f));
|
||||
```
|
||||
|
||||
### 填充 : `fill()`
|
||||
|
||||
```java
|
||||
// *************填充fill(批量初始化)****************
|
||||
int[] g = { 1, 2, 3, 3, 3, 3, 6, 6, 6 };
|
||||
// 数组中所有元素重新分配值
|
||||
Arrays.fill(g, 3);
|
||||
System.out.println("Arrays.fill(g, 3):");
|
||||
// 输出结果:333333333
|
||||
for (int i : g) {
|
||||
System.out.print(i);
|
||||
}
|
||||
// 换行
|
||||
System.out.println();
|
||||
|
||||
int[] h = { 1, 2, 3, 3, 3, 3, 6, 6, 6, };
|
||||
// 数组中指定范围元素重新分配值
|
||||
Arrays.fill(h, 0, 2, 9);
|
||||
System.out.println("Arrays.fill(h, 0, 2, 9);:");
|
||||
// 输出结果:993333666
|
||||
for (int i : h) {
|
||||
System.out.print(i);
|
||||
}
|
||||
```
|
||||
|
||||
### 转列表 `asList()`
|
||||
|
||||
```java
|
||||
// *************转列表 asList()****************
|
||||
/*
|
||||
* 返回由指定数组支持的固定大小的列表。
|
||||
* (将返回的列表更改为“写入数组”。)该方法作为基于数组和基于集合的API之间的桥梁,与Collection.toArray()相结合 。
|
||||
* 返回的列表是可序列化的,并实现RandomAccess 。
|
||||
* 此方法还提供了一种方便的方式来创建一个初始化为包含几个元素的固定大小的列表如下:
|
||||
*/
|
||||
List<String> stooges = Arrays.asList("Larry", "Moe", "Curly");
|
||||
System.out.println(stooges);
|
||||
```
|
||||
|
||||
### 转字符串 `toString()`
|
||||
|
||||
```java
|
||||
// *************转字符串 toString()****************
|
||||
/*
|
||||
* 返回指定数组的内容的字符串表示形式。
|
||||
*/
|
||||
char[] k = { 'a', 'f', 'b', 'c', 'e', 'A', 'C', 'B' };
|
||||
System.out.println(Arrays.toString(k));// [a, f, b, c, e, A, C, B]
|
||||
```
|
||||
|
||||
### 复制 `copyOf()`
|
||||
|
||||
```java
|
||||
// *************复制 copy****************
|
||||
// copyOf 方法实现数组复制,h为数组,6为复制的长度
|
||||
int[] h = { 1, 2, 3, 3, 3, 3, 6, 6, 6, };
|
||||
int i[] = Arrays.copyOf(h, 6);
|
||||
System.out.println("Arrays.copyOf(h, 6);:");
|
||||
// 输出结果:123333
|
||||
for (int j : i) {
|
||||
System.out.print(j);
|
||||
}
|
||||
// 换行
|
||||
System.out.println();
|
||||
// copyOfRange将指定数组的指定范围复制到新数组中
|
||||
int j[] = Arrays.copyOfRange(h, 6, 11);
|
||||
System.out.println("Arrays.copyOfRange(h, 6, 11):");
|
||||
// 输出结果66600(h数组只有9个元素这里是从索引6到索引11复制所以不足的就为0)
|
||||
for (int j2 : j) {
|
||||
System.out.print(j2);
|
||||
}
|
||||
// 换行
|
||||
System.out.println();
|
||||
```
|
||||
@ -1173,11 +1173,32 @@ String s = input.readLine();
|
||||
|
||||
## 3. Java 核心技术
|
||||
|
||||
### 3.1. 集合
|
||||
### 3.1. 反射机制
|
||||
|
||||
#### 3.1.1. Collections 工具类和 Arrays 工具类常见方法总结
|
||||
JAVA 反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为 java 语言的反射机制。
|
||||
|
||||
详见笔主的这篇文章: https://gitee.com/SnailClimb/JavaGuide/blob/master/docs/java/basic/Arrays,CollectionsCommonMethods.md
|
||||
#### 3.1.1.静态编译和动态编译
|
||||
|
||||
- **静态编译:** 在编译时确定类型,绑定对象
|
||||
- **动态编译:** 运行时确定类型,绑定对象
|
||||
|
||||
#### 3.1.2.反射机制优缺点
|
||||
|
||||
- **优点:** 运行期类型的判断,动态加载类,提高代码灵活度。
|
||||
- **缺点:** 1,性能瓶颈:反射相当于一系列解释操作,通知 JVM 要做的事情,性能比直接的 java 代码要慢很多。2,安全问题,让我们可以动态操作改变类的属性同时也增加了类的安全隐患。
|
||||
|
||||
#### 3.1.3.反射的应用场景
|
||||
|
||||
**反射是框架设计的灵魂。**
|
||||
|
||||
在我们平时的项目开发过程中,基本上很少会直接使用到反射机制,但这不能说明反射机制没有用,实际上有很多设计、开发都与反射机制有关,例如模块化的开发,通过反射去调用对应的字节码;动态代理设计模式也采用了反射机制,还有我们日常使用的 Spring/Hibernate 等框架也大量使用到了反射机制。
|
||||
|
||||
举例:
|
||||
|
||||
1. 我们在使用 JDBC 连接数据库时使用 `Class.forName()`通过反射加载数据库的驱动程序;
|
||||
2. Spring 框架的 IOC(动态加载管理 Bean)创建对象以及 AOP(动态代理)功能都和反射有联系;
|
||||
3. 动态配置实例的属性;
|
||||
4. ......
|
||||
|
||||
### 3.2. 异常
|
||||
|
||||
@ -1,361 +0,0 @@
|
||||
|
||||
## 一 先从 ArrayList 的构造函数说起
|
||||
|
||||
**ArrayList有三种方式来初始化,构造方法源码如下:**
|
||||
|
||||
```java
|
||||
/**
|
||||
* 默认初始容量大小
|
||||
*/
|
||||
private static final int DEFAULT_CAPACITY = 10;
|
||||
|
||||
|
||||
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
|
||||
|
||||
/**
|
||||
*默认构造函数,使用初始容量10构造一个空列表(无参数构造)
|
||||
*/
|
||||
public ArrayList() {
|
||||
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
|
||||
}
|
||||
|
||||
/**
|
||||
* 带初始容量参数的构造函数。(用户自己指定容量)
|
||||
*/
|
||||
public ArrayList(int initialCapacity) {
|
||||
if (initialCapacity > 0) {//初始容量大于0
|
||||
//创建initialCapacity大小的数组
|
||||
this.elementData = new Object[initialCapacity];
|
||||
} else if (initialCapacity == 0) {//初始容量等于0
|
||||
//创建空数组
|
||||
this.elementData = EMPTY_ELEMENTDATA;
|
||||
} else {//初始容量小于0,抛出异常
|
||||
throw new IllegalArgumentException("Illegal Capacity: "+
|
||||
initialCapacity);
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
/**
|
||||
*构造包含指定collection元素的列表,这些元素利用该集合的迭代器按顺序返回
|
||||
*如果指定的集合为null,throws NullPointerException。
|
||||
*/
|
||||
public ArrayList(Collection<? extends E> c) {
|
||||
elementData = c.toArray();
|
||||
if ((size = elementData.length) != 0) {
|
||||
// c.toArray might (incorrectly) not return Object[] (see 6260652)
|
||||
if (elementData.getClass() != Object[].class)
|
||||
elementData = Arrays.copyOf(elementData, size, Object[].class);
|
||||
} else {
|
||||
// replace with empty array.
|
||||
this.elementData = EMPTY_ELEMENTDATA;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
细心的同学一定会发现 :**以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为10。** 下面在我们分析 ArrayList 扩容时会讲到这一点内容!
|
||||
|
||||
## 二 一步一步分析 ArrayList 扩容机制
|
||||
|
||||
这里以无参构造函数创建的 ArrayList 为例分析
|
||||
|
||||
### 1. 先来看 `add` 方法
|
||||
|
||||
```java
|
||||
/**
|
||||
* 将指定的元素追加到此列表的末尾。
|
||||
*/
|
||||
public boolean add(E e) {
|
||||
//添加元素之前,先调用ensureCapacityInternal方法
|
||||
ensureCapacityInternal(size + 1); // Increments modCount!!
|
||||
//这里看到ArrayList添加元素的实质就相当于为数组赋值
|
||||
elementData[size++] = e;
|
||||
return true;
|
||||
}
|
||||
```
|
||||
|
||||
> **注意** :JDK11 移除了 `ensureCapacityInternal()` 和 `ensureExplicitCapacity()` 方法
|
||||
|
||||
### 2. 再来看看 `ensureCapacityInternal()` 方法
|
||||
|
||||
可以看到 `add` 方法 首先调用了`ensureCapacityInternal(size + 1)`
|
||||
|
||||
```java
|
||||
//得到最小扩容量
|
||||
private void ensureCapacityInternal(int minCapacity) {
|
||||
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
|
||||
// 获取默认的容量和传入参数的较大值
|
||||
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
|
||||
}
|
||||
|
||||
ensureExplicitCapacity(minCapacity);
|
||||
}
|
||||
```
|
||||
**当 要 add 进第1个元素时,minCapacity为1,在Math.max()方法比较后,minCapacity 为10。**
|
||||
|
||||
### 3. `ensureExplicitCapacity()` 方法
|
||||
|
||||
如果调用 `ensureCapacityInternal()` 方法就一定会进过(执行)这个方法,下面我们来研究一下这个方法的源码!
|
||||
|
||||
```java
|
||||
//判断是否需要扩容
|
||||
private void ensureExplicitCapacity(int minCapacity) {
|
||||
modCount++;
|
||||
|
||||
// overflow-conscious code
|
||||
if (minCapacity - elementData.length > 0)
|
||||
//调用grow方法进行扩容,调用此方法代表已经开始扩容了
|
||||
grow(minCapacity);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
我们来仔细分析一下:
|
||||
|
||||
- 当我们要 add 进第1个元素到 ArrayList 时,elementData.length 为0 (因为还是一个空的 list),因为执行了 `ensureCapacityInternal()` 方法 ,所以 minCapacity 此时为10。此时,`minCapacity - elementData.length > 0 `成立,所以会进入 `grow(minCapacity)` 方法。
|
||||
- 当add第2个元素时,minCapacity 为2,此时e lementData.length(容量)在添加第一个元素后扩容成 10 了。此时,`minCapacity - elementData.length > 0 ` 不成立,所以不会进入 (执行)`grow(minCapacity)` 方法。
|
||||
- 添加第3、4···到第10个元素时,依然不会执行grow方法,数组容量都为10。
|
||||
|
||||
直到添加第11个元素,minCapacity(为11)比elementData.length(为10)要大。进入grow方法进行扩容。
|
||||
|
||||
### 4. `grow()` 方法
|
||||
|
||||
```java
|
||||
/**
|
||||
* 要分配的最大数组大小
|
||||
*/
|
||||
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
|
||||
|
||||
/**
|
||||
* ArrayList扩容的核心方法。
|
||||
*/
|
||||
private void grow(int minCapacity) {
|
||||
// oldCapacity为旧容量,newCapacity为新容量
|
||||
int oldCapacity = elementData.length;
|
||||
//将oldCapacity 右移一位,其效果相当于oldCapacity /2,
|
||||
//我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍,
|
||||
int newCapacity = oldCapacity + (oldCapacity >> 1);
|
||||
//然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,
|
||||
if (newCapacity - minCapacity < 0)
|
||||
newCapacity = minCapacity;
|
||||
// 如果新容量大于 MAX_ARRAY_SIZE,进入(执行) `hugeCapacity()` 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,
|
||||
//如果minCapacity大于最大容量,则新容量则为`Integer.MAX_VALUE`,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 `Integer.MAX_VALUE - 8`。
|
||||
if (newCapacity - MAX_ARRAY_SIZE > 0)
|
||||
newCapacity = hugeCapacity(minCapacity);
|
||||
// minCapacity is usually close to size, so this is a win:
|
||||
elementData = Arrays.copyOf(elementData, newCapacity);
|
||||
}
|
||||
```
|
||||
|
||||
**int newCapacity = oldCapacity + (oldCapacity >> 1),所以 ArrayList 每次扩容之后容量都会变为原来的 1.5 倍左右(oldCapacity为偶数就是1.5倍,否则是1.5倍左右)!** 奇偶不同,比如 :10+10/2 = 15, 33+33/2=49。如果是奇数的话会丢掉小数.
|
||||
|
||||
> ">>"(移位运算符):>>1 右移一位相当于除2,右移n位相当于除以 2 的 n 次方。这里 oldCapacity 明显右移了1位所以相当于oldCapacity /2。对于大数据的2进制运算,位移运算符比那些普通运算符的运算要快很多,因为程序仅仅移动一下而已,不去计算,这样提高了效率,节省了资源
|
||||
|
||||
**我们再来通过例子探究一下`grow()` 方法 :**
|
||||
|
||||
- 当add第1个元素时,oldCapacity 为0,经比较后第一个if判断成立,newCapacity = minCapacity(为10)。但是第二个if判断不会成立,即newCapacity 不比 MAX_ARRAY_SIZE大,则不会进入 `hugeCapacity` 方法。数组容量为10,add方法中 return true,size增为1。
|
||||
- 当add第11个元素进入grow方法时,newCapacity为15,比minCapacity(为11)大,第一个if判断不成立。新容量没有大于数组最大size,不会进入hugeCapacity方法。数组容量扩为15,add方法中return true,size增为11。
|
||||
- 以此类推······
|
||||
|
||||
**这里补充一点比较重要,但是容易被忽视掉的知识点:**
|
||||
|
||||
- java 中的 `length `属性是针对数组说的,比如说你声明了一个数组,想知道这个数组的长度则用到了 length 这个属性.
|
||||
- java 中的 `length()` 方法是针对字符串说的,如果想看这个字符串的长度则用到 `length()` 这个方法.
|
||||
- java 中的 `size()` 方法是针对泛型集合说的,如果想看这个泛型有多少个元素,就调用此方法来查看!
|
||||
|
||||
### 5. `hugeCapacity()` 方法。
|
||||
|
||||
从上面 `grow()` 方法源码我们知道: 如果新容量大于 MAX_ARRAY_SIZE,进入(执行) `hugeCapacity()` 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,如果minCapacity大于最大容量,则新容量则为`Integer.MAX_VALUE`,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 `Integer.MAX_VALUE - 8`。
|
||||
|
||||
|
||||
```java
|
||||
private static int hugeCapacity(int minCapacity) {
|
||||
if (minCapacity < 0) // overflow
|
||||
throw new OutOfMemoryError();
|
||||
//对minCapacity和MAX_ARRAY_SIZE进行比较
|
||||
//若minCapacity大,将Integer.MAX_VALUE作为新数组的大小
|
||||
//若MAX_ARRAY_SIZE大,将MAX_ARRAY_SIZE作为新数组的大小
|
||||
//MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
|
||||
return (minCapacity > MAX_ARRAY_SIZE) ?
|
||||
Integer.MAX_VALUE :
|
||||
MAX_ARRAY_SIZE;
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
|
||||
## 三 `System.arraycopy()` 和 `Arrays.copyOf()`方法
|
||||
|
||||
|
||||
阅读源码的话,我们就会发现 ArrayList 中大量调用了这两个方法。比如:我们上面讲的扩容操作以及`add(int index, E element)`、`toArray()` 等方法中都用到了该方法!
|
||||
|
||||
|
||||
### 3.1 `System.arraycopy()` 方法
|
||||
|
||||
```java
|
||||
/**
|
||||
* 在此列表中的指定位置插入指定的元素。
|
||||
*先调用 rangeCheckForAdd 对index进行界限检查;然后调用 ensureCapacityInternal 方法保证capacity足够大;
|
||||
*再将从index开始之后的所有成员后移一个位置;将element插入index位置;最后size加1。
|
||||
*/
|
||||
public void add(int index, E element) {
|
||||
rangeCheckForAdd(index);
|
||||
|
||||
ensureCapacityInternal(size + 1); // Increments modCount!!
|
||||
//arraycopy()方法实现数组自己复制自己
|
||||
//elementData:源数组;index:源数组中的起始位置;elementData:目标数组;index + 1:目标数组中的起始位置; size - index:要复制的数组元素的数量;
|
||||
System.arraycopy(elementData, index, elementData, index + 1, size - index);
|
||||
elementData[index] = element;
|
||||
size++;
|
||||
}
|
||||
```
|
||||
|
||||
我们写一个简单的方法测试以下:
|
||||
|
||||
```java
|
||||
public class ArraycopyTest {
|
||||
|
||||
public static void main(String[] args) {
|
||||
// TODO Auto-generated method stub
|
||||
int[] a = new int[10];
|
||||
a[0] = 0;
|
||||
a[1] = 1;
|
||||
a[2] = 2;
|
||||
a[3] = 3;
|
||||
System.arraycopy(a, 2, a, 3, 3);
|
||||
a[2]=99;
|
||||
for (int i = 0; i < a.length; i++) {
|
||||
System.out.print(a[i] + " ");
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
结果:
|
||||
|
||||
```
|
||||
0 1 99 2 3 0 0 0 0 0
|
||||
```
|
||||
|
||||
### 3.2 `Arrays.copyOf()`方法
|
||||
|
||||
```java
|
||||
/**
|
||||
以正确的顺序返回一个包含此列表中所有元素的数组(从第一个到最后一个元素); 返回的数组的运行时类型是指定数组的运行时类型。
|
||||
*/
|
||||
public Object[] toArray() {
|
||||
//elementData:要复制的数组;size:要复制的长度
|
||||
return Arrays.copyOf(elementData, size);
|
||||
}
|
||||
```
|
||||
|
||||
个人觉得使用 `Arrays.copyOf()`方法主要是为了给原有数组扩容,测试代码如下:
|
||||
|
||||
```java
|
||||
public class ArrayscopyOfTest {
|
||||
|
||||
public static void main(String[] args) {
|
||||
int[] a = new int[3];
|
||||
a[0] = 0;
|
||||
a[1] = 1;
|
||||
a[2] = 2;
|
||||
int[] b = Arrays.copyOf(a, 10);
|
||||
System.out.println("b.length"+b.length);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
结果:
|
||||
|
||||
```
|
||||
10
|
||||
```
|
||||
|
||||
### 3.3 两者联系和区别
|
||||
|
||||
**联系:**
|
||||
|
||||
看两者源代码可以发现 copyOf() 内部实际调用了 `System.arraycopy()` 方法
|
||||
|
||||
**区别:**
|
||||
|
||||
`arraycopy()` 需要目标数组,将原数组拷贝到你自己定义的数组里或者原数组,而且可以选择拷贝的起点和长度以及放入新数组中的位置 `copyOf()` 是系统自动在内部新建一个数组,并返回该数组。
|
||||
|
||||
## 四 `ensureCapacity`方法
|
||||
|
||||
ArrayList 源码中有一个 `ensureCapacity` 方法不知道大家注意到没有,这个方法 ArrayList 内部没有被调用过,所以很显然是提供给用户调用的,那么这个方法有什么作用呢?
|
||||
|
||||
```java
|
||||
/**
|
||||
如有必要,增加此 ArrayList 实例的容量,以确保它至少可以容纳由minimum capacity参数指定的元素数。
|
||||
*
|
||||
* @param minCapacity 所需的最小容量
|
||||
*/
|
||||
public void ensureCapacity(int minCapacity) {
|
||||
int minExpand = (elementData != DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
|
||||
// any size if not default element table
|
||||
? 0
|
||||
// larger than default for default empty table. It's already
|
||||
// supposed to be at default size.
|
||||
: DEFAULT_CAPACITY;
|
||||
|
||||
if (minCapacity > minExpand) {
|
||||
ensureExplicitCapacity(minCapacity);
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
**最好在 add 大量元素之前用 `ensureCapacity` 方法,以减少增量重新分配的次数**
|
||||
|
||||
我们通过下面的代码实际测试以下这个方法的效果:
|
||||
|
||||
```java
|
||||
public class EnsureCapacityTest {
|
||||
public static void main(String[] args) {
|
||||
ArrayList<Object> list = new ArrayList<Object>();
|
||||
final int N = 10000000;
|
||||
long startTime = System.currentTimeMillis();
|
||||
for (int i = 0; i < N; i++) {
|
||||
list.add(i);
|
||||
}
|
||||
long endTime = System.currentTimeMillis();
|
||||
System.out.println("使用ensureCapacity方法前:"+(endTime - startTime));
|
||||
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
运行结果:
|
||||
|
||||
```
|
||||
使用ensureCapacity方法前:2158
|
||||
```
|
||||
|
||||
```java
|
||||
public class EnsureCapacityTest {
|
||||
public static void main(String[] args) {
|
||||
ArrayList<Object> list = new ArrayList<Object>();
|
||||
final int N = 10000000;
|
||||
list = new ArrayList<Object>();
|
||||
long startTime1 = System.currentTimeMillis();
|
||||
list.ensureCapacity(N);
|
||||
for (int i = 0; i < N; i++) {
|
||||
list.add(i);
|
||||
}
|
||||
long endTime1 = System.currentTimeMillis();
|
||||
System.out.println("使用ensureCapacity方法后:"+(endTime1 - startTime1));
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
运行结果:
|
||||
|
||||
```
|
||||
|
||||
使用ensureCapacity方法前:1773
|
||||
```
|
||||
|
||||
通过运行结果,我们可以看出向 ArrayList 添加大量元素之前最好先使用`ensureCapacity` 方法,以减少增量重新分配的次数。
|
||||
@ -1,34 +1,35 @@
|
||||
<!-- MarkdownTOC -->
|
||||
## 1. ArrayList 简介
|
||||
|
||||
- [ArrayList简介](#arraylist简介)
|
||||
- [ArrayList核心源码](#arraylist核心源码)
|
||||
- [ArrayList源码分析](#arraylist源码分析)
|
||||
- [System.arraycopy\(\)和Arrays.copyOf\(\)方法](#systemarraycopy和arrayscopyof方法)
|
||||
- [两者联系与区别](#两者联系与区别)
|
||||
- [ArrayList核心扩容技术](#arraylist核心扩容技术)
|
||||
- [内部类](#内部类)
|
||||
- [ArrayList经典Demo](#arraylist经典demo)
|
||||
`ArrayList` 的底层是数组队列,相当于动态数组。与 Java 中的数组相比,它的容量能动态增长。在添加大量元素前,应用程序可以使用`ensureCapacity`操作来增加 `ArrayList` 实例的容量。这可以减少递增式再分配的数量。
|
||||
|
||||
<!-- /MarkdownTOC -->
|
||||
`ArrayList`继承于 **`AbstractList`**,实现了 **`List`**, **`RandomAccess`**, **`Cloneable`**, **`java.io.Serializable`** 这些接口。
|
||||
|
||||
```java
|
||||
|
||||
### ArrayList简介
|
||||
ArrayList 的底层是数组队列,相当于动态数组。与 Java 中的数组相比,它的容量能动态增长。在添加大量元素前,应用程序可以使用`ensureCapacity`操作来增加 ArrayList 实例的容量。这可以减少递增式再分配的数量。
|
||||
|
||||
它继承于 **AbstractList**,实现了 **List**, **RandomAccess**, **Cloneable**, **java.io.Serializable** 这些接口。
|
||||
|
||||
在我们学数据结构的时候就知道了线性表的顺序存储,插入删除元素的时间复杂度为**O(n)**,求表长以及增加元素,取第 i 元素的时间复杂度为**O(1)**
|
||||
public class ArrayList<E> extends AbstractList<E>
|
||||
implements List<E>, RandomAccess, Cloneable, java.io.Serializable{
|
||||
|
||||
ArrayList 继承了AbstractList,实现了List。它是一个数组队列,提供了相关的添加、删除、修改、遍历等功能。
|
||||
}
|
||||
```
|
||||
|
||||
ArrayList 实现了**RandomAccess 接口**, RandomAccess 是一个标志接口,表明实现这个这个接口的 List 集合是支持**快速随机访问**的。在 ArrayList 中,我们即可以通过元素的序号快速获取元素对象,这就是快速随机访问。
|
||||
- `RandomAccess` 是一个标志接口,表明实现这个这个接口的 List 集合是支持**快速随机访问**的。在 `ArrayList` 中,我们即可以通过元素的序号快速获取元素对象,这就是快速随机访问。
|
||||
- `ArrayList` 实现了 **`Cloneable` 接口** ,即覆盖了函数`clone()`,能被克隆。
|
||||
- `ArrayList` 实现了 java.io.Serializable `接口,这意味着`ArrayList`支持序列化,能通过序列化去传输。
|
||||
|
||||
ArrayList 实现了**Cloneable 接口**,即覆盖了函数 clone(),**能被克隆**。
|
||||
### 1.1. Arraylist 和 Vector 的区别?
|
||||
|
||||
ArrayList 实现**java.io.Serializable 接口**,这意味着ArrayList**支持序列化**,**能通过序列化去传输**。
|
||||
1. `ArrayList` 是 `List` 的主要实现类,底层使用 `Object[ ]`存储,适用于频繁的查找工作,线程不安全 ;
|
||||
2. `Vector` 是 `List` 的古老实现类,底层使用 `Object[ ]`存储,线程安全的。
|
||||
|
||||
和 Vector 不同,**ArrayList 中的操作不是线程安全的**!所以,建议在单线程中才使用 ArrayList,而在多线程中可以选择 Vector 或者 CopyOnWriteArrayList。
|
||||
### ArrayList核心源码
|
||||
### 1.2. Arraylist 与 LinkedList 区别?
|
||||
|
||||
1. **是否保证线程安全:** `ArrayList` 和 `LinkedList` 都是不同步的,也就是不保证线程安全;
|
||||
2. **底层数据结构:** `Arraylist` 底层使用的是 **`Object` 数组**;`LinkedList` 底层使用的是 **双向链表** 数据结构(JDK1.6 之前为循环链表,JDK1.7 取消了循环。注意双向链表和双向循环链表的区别,下面有介绍到!)
|
||||
3. **插入和删除是否受元素位置的影响:** ① **`ArrayList` 采用数组存储,所以插入和删除元素的时间复杂度受元素位置的影响。** 比如:执行`add(E e)`方法的时候, `ArrayList` 会默认在将指定的元素追加到此列表的末尾,这种情况时间复杂度就是 O(1)。但是如果要在指定位置 i 插入和删除元素的话(`add(int index, E element)`)时间复杂度就为 O(n-i)。因为在进行上述操作的时候集合中第 i 和第 i 个元素之后的(n-i)个元素都要执行向后位/向前移一位的操作。 ② **`LinkedList` 采用链表存储,所以对于`add(E e)`方法的插入,删除元素时间复杂度不受元素位置的影响,近似 O(1),如果是要在指定位置`i`插入和删除元素的话(`(add(int index, E element)`) 时间复杂度近似为`o(n))`因为需要先移动到指定位置再插入。**
|
||||
4. **是否支持快速随机访问:** `LinkedList` 不支持高效的随机元素访问,而 `ArrayList` 支持。快速随机访问就是通过元素的序号快速获取元素对象(对应于`get(int index)`方法)。
|
||||
5. **内存空间占用:** `ArrayList` 的空 间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 `LinkedList` 的空间花费则体现在它的每一个元素都需要消耗比 `ArrayList` 更多的空间(因为要存放直接后继和直接前驱以及数据)。
|
||||
|
||||
## 2. ArrayList 核心源码解读
|
||||
|
||||
```java
|
||||
package java.util;
|
||||
@ -100,7 +101,7 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
elementData = c.toArray();
|
||||
//如果elementData数组的长度不为0
|
||||
if ((size = elementData.length) != 0) {
|
||||
// 如果elementData不是Object类型数据(c.toArray可能返回的不是Object类型的数组所以加上下面的语句用于判断)
|
||||
// 如果elementData不是Object类型数据(c.toArray可能返回的不是Object类型的数组所以加上下面的语句用于判断)
|
||||
if (elementData.getClass() != Object[].class)
|
||||
//将原来不是Object类型的elementData数组的内容,赋值给新的Object类型的elementData数组
|
||||
elementData = Arrays.copyOf(elementData, size, Object[].class);
|
||||
@ -111,7 +112,7 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
}
|
||||
|
||||
/**
|
||||
* 修改这个ArrayList实例的容量是列表的当前大小。 应用程序可以使用此操作来最小化ArrayList实例的存储。
|
||||
* 修改这个ArrayList实例的容量是列表的当前大小。 应用程序可以使用此操作来最小化ArrayList实例的存储。
|
||||
*/
|
||||
public void trimToSize() {
|
||||
modCount++;
|
||||
@ -195,7 +196,7 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
}
|
||||
|
||||
/**
|
||||
*返回此列表中的元素数。
|
||||
*返回此列表中的元素数。
|
||||
*/
|
||||
public int size() {
|
||||
return size;
|
||||
@ -213,12 +214,12 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
* 如果此列表包含指定的元素,则返回true 。
|
||||
*/
|
||||
public boolean contains(Object o) {
|
||||
//indexOf()方法:返回此列表中指定元素的首次出现的索引,如果此列表不包含此元素,则为-1
|
||||
//indexOf()方法:返回此列表中指定元素的首次出现的索引,如果此列表不包含此元素,则为-1
|
||||
return indexOf(o) >= 0;
|
||||
}
|
||||
|
||||
/**
|
||||
*返回此列表中指定元素的首次出现的索引,如果此列表不包含此元素,则为-1
|
||||
*返回此列表中指定元素的首次出现的索引,如果此列表不包含此元素,则为-1
|
||||
*/
|
||||
public int indexOf(Object o) {
|
||||
if (o == null) {
|
||||
@ -251,7 +252,7 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
}
|
||||
|
||||
/**
|
||||
* 返回此ArrayList实例的浅拷贝。 (元素本身不被复制。)
|
||||
* 返回此ArrayList实例的浅拷贝。 (元素本身不被复制。)
|
||||
*/
|
||||
public Object clone() {
|
||||
try {
|
||||
@ -267,7 +268,7 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
}
|
||||
|
||||
/**
|
||||
*以正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。
|
||||
*以正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。
|
||||
*返回的数组将是“安全的”,因为该列表不保留对它的引用。 (换句话说,这个方法必须分配一个新的数组)。
|
||||
*因此,调用者可以自由地修改返回的数组。 此方法充当基于阵列和基于集合的API之间的桥梁。
|
||||
*/
|
||||
@ -276,11 +277,11 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
}
|
||||
|
||||
/**
|
||||
* 以正确的顺序返回一个包含此列表中所有元素的数组(从第一个到最后一个元素);
|
||||
*返回的数组的运行时类型是指定数组的运行时类型。 如果列表适合指定的数组,则返回其中。
|
||||
*否则,将为指定数组的运行时类型和此列表的大小分配一个新数组。
|
||||
* 以正确的顺序返回一个包含此列表中所有元素的数组(从第一个到最后一个元素);
|
||||
*返回的数组的运行时类型是指定数组的运行时类型。 如果列表适合指定的数组,则返回其中。
|
||||
*否则,将为指定数组的运行时类型和此列表的大小分配一个新数组。
|
||||
*如果列表适用于指定的数组,其余空间(即数组的列表数量多于此元素),则紧跟在集合结束后的数组中的元素设置为null 。
|
||||
*(这仅在调用者知道列表不包含任何空元素的情况下才能确定列表的长度。)
|
||||
*(这仅在调用者知道列表不包含任何空元素的情况下才能确定列表的长度。)
|
||||
*/
|
||||
@SuppressWarnings("unchecked")
|
||||
public <T> T[] toArray(T[] a) {
|
||||
@ -311,7 +312,7 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
}
|
||||
|
||||
/**
|
||||
* 用指定的元素替换此列表中指定位置的元素。
|
||||
* 用指定的元素替换此列表中指定位置的元素。
|
||||
*/
|
||||
public E set(int index, E element) {
|
||||
//对index进行界限检查
|
||||
@ -324,7 +325,7 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
}
|
||||
|
||||
/**
|
||||
* 将指定的元素追加到此列表的末尾。
|
||||
* 将指定的元素追加到此列表的末尾。
|
||||
*/
|
||||
public boolean add(E e) {
|
||||
ensureCapacityInternal(size + 1); // Increments modCount!!
|
||||
@ -334,7 +335,7 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
}
|
||||
|
||||
/**
|
||||
* 在此列表中的指定位置插入指定的元素。
|
||||
* 在此列表中的指定位置插入指定的元素。
|
||||
*先调用 rangeCheckForAdd 对index进行界限检查;然后调用 ensureCapacityInternal 方法保证capacity足够大;
|
||||
*再将从index开始之后的所有成员后移一个位置;将element插入index位置;最后size加1。
|
||||
*/
|
||||
@ -350,7 +351,7 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
}
|
||||
|
||||
/**
|
||||
* 删除该列表中指定位置的元素。 将任何后续元素移动到左侧(从其索引中减去一个元素)。
|
||||
* 删除该列表中指定位置的元素。 将任何后续元素移动到左侧(从其索引中减去一个元素)。
|
||||
*/
|
||||
public E remove(int index) {
|
||||
rangeCheck(index);
|
||||
@ -363,7 +364,7 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
System.arraycopy(elementData, index+1, elementData, index,
|
||||
numMoved);
|
||||
elementData[--size] = null; // clear to let GC do its work
|
||||
//从列表中删除的元素
|
||||
//从列表中删除的元素
|
||||
return oldValue;
|
||||
}
|
||||
|
||||
@ -402,7 +403,7 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
}
|
||||
|
||||
/**
|
||||
* 从列表中删除所有元素。
|
||||
* 从列表中删除所有元素。
|
||||
*/
|
||||
public void clear() {
|
||||
modCount++;
|
||||
@ -488,7 +489,7 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
}
|
||||
|
||||
/**
|
||||
* 从此列表中删除指定集合中包含的所有元素。
|
||||
* 从此列表中删除指定集合中包含的所有元素。
|
||||
*/
|
||||
public boolean removeAll(Collection<?> c) {
|
||||
Objects.requireNonNull(c);
|
||||
@ -498,7 +499,7 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
|
||||
/**
|
||||
* 仅保留此列表中包含在指定集合中的元素。
|
||||
*换句话说,从此列表中删除其中不包含在指定集合中的所有元素。
|
||||
*换句话说,从此列表中删除其中不包含在指定集合中的所有元素。
|
||||
*/
|
||||
public boolean retainAll(Collection<?> c) {
|
||||
Objects.requireNonNull(c);
|
||||
@ -508,8 +509,8 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
|
||||
/**
|
||||
* 从列表中的指定位置开始,返回列表中的元素(按正确顺序)的列表迭代器。
|
||||
*指定的索引表示初始调用将返回的第一个元素为next 。 初始调用previous将返回指定索引减1的元素。
|
||||
*返回的列表迭代器是fail-fast 。
|
||||
*指定的索引表示初始调用将返回的第一个元素为next 。 初始调用previous将返回指定索引减1的元素。
|
||||
*返回的列表迭代器是fail-fast 。
|
||||
*/
|
||||
public ListIterator<E> listIterator(int index) {
|
||||
if (index < 0 || index > size)
|
||||
@ -518,7 +519,7 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
}
|
||||
|
||||
/**
|
||||
*返回列表中的列表迭代器(按适当的顺序)。
|
||||
*返回列表中的列表迭代器(按适当的顺序)。
|
||||
*返回的列表迭代器是fail-fast 。
|
||||
*/
|
||||
public ListIterator<E> listIterator() {
|
||||
@ -526,21 +527,211 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
}
|
||||
|
||||
/**
|
||||
*以正确的顺序返回该列表中的元素的迭代器。
|
||||
*返回的迭代器是fail-fast 。
|
||||
*以正确的顺序返回该列表中的元素的迭代器。
|
||||
*返回的迭代器是fail-fast 。
|
||||
*/
|
||||
public Iterator<E> iterator() {
|
||||
return new Itr();
|
||||
}
|
||||
|
||||
|
||||
|
||||
```
|
||||
### <font face="楷体" id="1" id="5">ArrayList源码分析</font>
|
||||
#### System.arraycopy()和Arrays.copyOf()方法
|
||||
通过上面源码我们发现这两个实现数组复制的方法被广泛使用而且很多地方都特别巧妙。比如下面<font color="red">add(int index, E element)</font>方法就很巧妙的用到了<font color="red">arraycopy()方法</font>让数组自己复制自己实现让index开始之后的所有成员后移一个位置:
|
||||
```java
|
||||
|
||||
## 3. ArrayList 扩容机制分析
|
||||
|
||||
### 3.1. 先从 ArrayList 的构造函数说起
|
||||
|
||||
**ArrayList 有三种方式来初始化,构造方法源码如下:**
|
||||
|
||||
```java
|
||||
/**
|
||||
* 默认初始容量大小
|
||||
*/
|
||||
private static final int DEFAULT_CAPACITY = 10;
|
||||
|
||||
|
||||
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
|
||||
|
||||
/**
|
||||
* 在此列表中的指定位置插入指定的元素。
|
||||
*默认构造函数,使用初始容量10构造一个空列表(无参数构造)
|
||||
*/
|
||||
public ArrayList() {
|
||||
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
|
||||
}
|
||||
|
||||
/**
|
||||
* 带初始容量参数的构造函数。(用户自己指定容量)
|
||||
*/
|
||||
public ArrayList(int initialCapacity) {
|
||||
if (initialCapacity > 0) {//初始容量大于0
|
||||
//创建initialCapacity大小的数组
|
||||
this.elementData = new Object[initialCapacity];
|
||||
} else if (initialCapacity == 0) {//初始容量等于0
|
||||
//创建空数组
|
||||
this.elementData = EMPTY_ELEMENTDATA;
|
||||
} else {//初始容量小于0,抛出异常
|
||||
throw new IllegalArgumentException("Illegal Capacity: "+
|
||||
initialCapacity);
|
||||
}
|
||||
}
|
||||
|
||||
|
||||
/**
|
||||
*构造包含指定collection元素的列表,这些元素利用该集合的迭代器按顺序返回
|
||||
*如果指定的集合为null,throws NullPointerException。
|
||||
*/
|
||||
public ArrayList(Collection<? extends E> c) {
|
||||
elementData = c.toArray();
|
||||
if ((size = elementData.length) != 0) {
|
||||
// c.toArray might (incorrectly) not return Object[] (see 6260652)
|
||||
if (elementData.getClass() != Object[].class)
|
||||
elementData = Arrays.copyOf(elementData, size, Object[].class);
|
||||
} else {
|
||||
// replace with empty array.
|
||||
this.elementData = EMPTY_ELEMENTDATA;
|
||||
}
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
细心的同学一定会发现 :**以无参数构造方法创建 ArrayList 时,实际上初始化赋值的是一个空数组。当真正对数组进行添加元素操作时,才真正分配容量。即向数组中添加第一个元素时,数组容量扩为 10。** 下面在我们分析 ArrayList 扩容时会讲到这一点内容!
|
||||
|
||||
### 3.2. 一步一步分析 ArrayList 扩容机制
|
||||
|
||||
这里以无参构造函数创建的 ArrayList 为例分析
|
||||
|
||||
#### 3.2.1. 先来看 `add` 方法
|
||||
|
||||
```java
|
||||
/**
|
||||
* 将指定的元素追加到此列表的末尾。
|
||||
*/
|
||||
public boolean add(E e) {
|
||||
//添加元素之前,先调用ensureCapacityInternal方法
|
||||
ensureCapacityInternal(size + 1); // Increments modCount!!
|
||||
//这里看到ArrayList添加元素的实质就相当于为数组赋值
|
||||
elementData[size++] = e;
|
||||
return true;
|
||||
}
|
||||
```
|
||||
|
||||
> **注意** :JDK11 移除了 `ensureCapacityInternal()` 和 `ensureExplicitCapacity()` 方法
|
||||
|
||||
#### 3.2.2. 再来看看 `ensureCapacityInternal()` 方法
|
||||
|
||||
可以看到 `add` 方法 首先调用了`ensureCapacityInternal(size + 1)`
|
||||
|
||||
```java
|
||||
//得到最小扩容量
|
||||
private void ensureCapacityInternal(int minCapacity) {
|
||||
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
|
||||
// 获取默认的容量和传入参数的较大值
|
||||
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
|
||||
}
|
||||
|
||||
ensureExplicitCapacity(minCapacity);
|
||||
}
|
||||
```
|
||||
|
||||
**当 要 add 进第 1 个元素时,minCapacity 为 1,在 Math.max()方法比较后,minCapacity 为 10。**
|
||||
|
||||
#### 3.2.3. `ensureExplicitCapacity()` 方法
|
||||
|
||||
如果调用 `ensureCapacityInternal()` 方法就一定会进过(执行)这个方法,下面我们来研究一下这个方法的源码!
|
||||
|
||||
```java
|
||||
//判断是否需要扩容
|
||||
private void ensureExplicitCapacity(int minCapacity) {
|
||||
modCount++;
|
||||
|
||||
// overflow-conscious code
|
||||
if (minCapacity - elementData.length > 0)
|
||||
//调用grow方法进行扩容,调用此方法代表已经开始扩容了
|
||||
grow(minCapacity);
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
我们来仔细分析一下:
|
||||
|
||||
- 当我们要 add 进第 1 个元素到 ArrayList 时,elementData.length 为 0 (因为还是一个空的 list),因为执行了 `ensureCapacityInternal()` 方法 ,所以 minCapacity 此时为 10。此时,`minCapacity - elementData.length > 0`成立,所以会进入 `grow(minCapacity)` 方法。
|
||||
- 当 add 第 2 个元素时,minCapacity 为 2,此时 e lementData.length(容量)在添加第一个元素后扩容成 10 了。此时,`minCapacity - elementData.length > 0` 不成立,所以不会进入 (执行)`grow(minCapacity)` 方法。
|
||||
- 添加第 3、4···到第 10 个元素时,依然不会执行 grow 方法,数组容量都为 10。
|
||||
|
||||
直到添加第 11 个元素,minCapacity(为 11)比 elementData.length(为 10)要大。进入 grow 方法进行扩容。
|
||||
|
||||
#### 3.2.4. `grow()` 方法
|
||||
|
||||
```java
|
||||
/**
|
||||
* 要分配的最大数组大小
|
||||
*/
|
||||
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
|
||||
|
||||
/**
|
||||
* ArrayList扩容的核心方法。
|
||||
*/
|
||||
private void grow(int minCapacity) {
|
||||
// oldCapacity为旧容量,newCapacity为新容量
|
||||
int oldCapacity = elementData.length;
|
||||
//将oldCapacity 右移一位,其效果相当于oldCapacity /2,
|
||||
//我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍,
|
||||
int newCapacity = oldCapacity + (oldCapacity >> 1);
|
||||
//然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,
|
||||
if (newCapacity - minCapacity < 0)
|
||||
newCapacity = minCapacity;
|
||||
// 如果新容量大于 MAX_ARRAY_SIZE,进入(执行) `hugeCapacity()` 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,
|
||||
//如果minCapacity大于最大容量,则新容量则为`Integer.MAX_VALUE`,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 `Integer.MAX_VALUE - 8`。
|
||||
if (newCapacity - MAX_ARRAY_SIZE > 0)
|
||||
newCapacity = hugeCapacity(minCapacity);
|
||||
// minCapacity is usually close to size, so this is a win:
|
||||
elementData = Arrays.copyOf(elementData, newCapacity);
|
||||
}
|
||||
```
|
||||
|
||||
**int newCapacity = oldCapacity + (oldCapacity >> 1),所以 ArrayList 每次扩容之后容量都会变为原来的 1.5 倍左右(oldCapacity 为偶数就是 1.5 倍,否则是 1.5 倍左右)!** 奇偶不同,比如 :10+10/2 = 15, 33+33/2=49。如果是奇数的话会丢掉小数.
|
||||
|
||||
> ">>"(移位运算符):>>1 右移一位相当于除 2,右移 n 位相当于除以 2 的 n 次方。这里 oldCapacity 明显右移了 1 位所以相当于 oldCapacity /2。对于大数据的 2 进制运算,位移运算符比那些普通运算符的运算要快很多,因为程序仅仅移动一下而已,不去计算,这样提高了效率,节省了资源
|
||||
|
||||
**我们再来通过例子探究一下`grow()` 方法 :**
|
||||
|
||||
- 当 add 第 1 个元素时,oldCapacity 为 0,经比较后第一个 if 判断成立,newCapacity = minCapacity(为 10)。但是第二个 if 判断不会成立,即 newCapacity 不比 MAX_ARRAY_SIZE 大,则不会进入 `hugeCapacity` 方法。数组容量为 10,add 方法中 return true,size 增为 1。
|
||||
- 当 add 第 11 个元素进入 grow 方法时,newCapacity 为 15,比 minCapacity(为 11)大,第一个 if 判断不成立。新容量没有大于数组最大 size,不会进入 hugeCapacity 方法。数组容量扩为 15,add 方法中 return true,size 增为 11。
|
||||
- 以此类推······
|
||||
|
||||
**这里补充一点比较重要,但是容易被忽视掉的知识点:**
|
||||
|
||||
- java 中的 `length`属性是针对数组说的,比如说你声明了一个数组,想知道这个数组的长度则用到了 length 这个属性.
|
||||
- java 中的 `length()` 方法是针对字符串说的,如果想看这个字符串的长度则用到 `length()` 这个方法.
|
||||
- java 中的 `size()` 方法是针对泛型集合说的,如果想看这个泛型有多少个元素,就调用此方法来查看!
|
||||
|
||||
#### 3.2.5. `hugeCapacity()` 方法。
|
||||
|
||||
从上面 `grow()` 方法源码我们知道: 如果新容量大于 MAX_ARRAY_SIZE,进入(执行) `hugeCapacity()` 方法来比较 minCapacity 和 MAX_ARRAY_SIZE,如果 minCapacity 大于最大容量,则新容量则为`Integer.MAX_VALUE`,否则,新容量大小则为 MAX_ARRAY_SIZE 即为 `Integer.MAX_VALUE - 8`。
|
||||
|
||||
```java
|
||||
private static int hugeCapacity(int minCapacity) {
|
||||
if (minCapacity < 0) // overflow
|
||||
throw new OutOfMemoryError();
|
||||
//对minCapacity和MAX_ARRAY_SIZE进行比较
|
||||
//若minCapacity大,将Integer.MAX_VALUE作为新数组的大小
|
||||
//若MAX_ARRAY_SIZE大,将MAX_ARRAY_SIZE作为新数组的大小
|
||||
//MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
|
||||
return (minCapacity > MAX_ARRAY_SIZE) ?
|
||||
Integer.MAX_VALUE :
|
||||
MAX_ARRAY_SIZE;
|
||||
}
|
||||
```
|
||||
|
||||
### 3.3. `System.arraycopy()` 和 `Arrays.copyOf()`方法
|
||||
|
||||
阅读源码的话,我们就会发现 ArrayList 中大量调用了这两个方法。比如:我们上面讲的扩容操作以及`add(int index, E element)`、`toArray()` 等方法中都用到了该方法!
|
||||
|
||||
#### 3.3.1. `System.arraycopy()` 方法
|
||||
|
||||
```java
|
||||
/**
|
||||
* 在此列表中的指定位置插入指定的元素。
|
||||
*先调用 rangeCheckForAdd 对index进行界限检查;然后调用 ensureCapacityInternal 方法保证capacity足够大;
|
||||
*再将从index开始之后的所有成员后移一个位置;将element插入index位置;最后size加1。
|
||||
*/
|
||||
@ -555,32 +746,87 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
size++;
|
||||
}
|
||||
```
|
||||
又如toArray()方法中用到了copyOf()方法
|
||||
```java
|
||||
|
||||
/**
|
||||
*以正确的顺序(从第一个到最后一个元素)返回一个包含此列表中所有元素的数组。
|
||||
*返回的数组将是“安全的”,因为该列表不保留对它的引用。 (换句话说,这个方法必须分配一个新的数组)。
|
||||
*因此,调用者可以自由地修改返回的数组。 此方法充当基于阵列和基于集合的API之间的桥梁。
|
||||
我们写一个简单的方法测试以下:
|
||||
|
||||
```java
|
||||
public class ArraycopyTest {
|
||||
|
||||
public static void main(String[] args) {
|
||||
// TODO Auto-generated method stub
|
||||
int[] a = new int[10];
|
||||
a[0] = 0;
|
||||
a[1] = 1;
|
||||
a[2] = 2;
|
||||
a[3] = 3;
|
||||
System.arraycopy(a, 2, a, 3, 3);
|
||||
a[2]=99;
|
||||
for (int i = 0; i < a.length; i++) {
|
||||
System.out.print(a[i] + " ");
|
||||
}
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
结果:
|
||||
|
||||
```
|
||||
0 1 99 2 3 0 0 0 0 0
|
||||
```
|
||||
|
||||
#### 3.3.2. `Arrays.copyOf()`方法
|
||||
|
||||
```java
|
||||
/**
|
||||
以正确的顺序返回一个包含此列表中所有元素的数组(从第一个到最后一个元素); 返回的数组的运行时类型是指定数组的运行时类型。
|
||||
*/
|
||||
public Object[] toArray() {
|
||||
//elementData:要复制的数组;size:要复制的长度
|
||||
return Arrays.copyOf(elementData, size);
|
||||
}
|
||||
```
|
||||
##### 两者联系与区别
|
||||
**联系:**
|
||||
看两者源代码可以发现`copyOf()`内部调用了`System.arraycopy()`方法
|
||||
**区别:**
|
||||
1. arraycopy()需要目标数组,将原数组拷贝到你自己定义的数组里,而且可以选择拷贝的起点和长度以及放入新数组中的位置
|
||||
2. copyOf()是系统自动在内部新建一个数组,并返回该数组。
|
||||
#### ArrayList 核心扩容技术
|
||||
|
||||
个人觉得使用 `Arrays.copyOf()`方法主要是为了给原有数组扩容,测试代码如下:
|
||||
|
||||
```java
|
||||
public class ArrayscopyOfTest {
|
||||
|
||||
public static void main(String[] args) {
|
||||
int[] a = new int[3];
|
||||
a[0] = 0;
|
||||
a[1] = 1;
|
||||
a[2] = 2;
|
||||
int[] b = Arrays.copyOf(a, 10);
|
||||
System.out.println("b.length"+b.length);
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
结果:
|
||||
|
||||
```
|
||||
10
|
||||
```
|
||||
|
||||
#### 3.3.3. 两者联系和区别
|
||||
|
||||
**联系:**
|
||||
|
||||
看两者源代码可以发现 `copyOf()`内部实际调用了 `System.arraycopy()` 方法
|
||||
|
||||
**区别:**
|
||||
|
||||
`arraycopy()` 需要目标数组,将原数组拷贝到你自己定义的数组里或者原数组,而且可以选择拷贝的起点和长度以及放入新数组中的位置 `copyOf()` 是系统自动在内部新建一个数组,并返回该数组。
|
||||
|
||||
### 3.4. `ensureCapacity`方法
|
||||
|
||||
ArrayList 源码中有一个 `ensureCapacity` 方法不知道大家注意到没有,这个方法 ArrayList 内部没有被调用过,所以很显然是提供给用户调用的,那么这个方法有什么作用呢?
|
||||
|
||||
```java
|
||||
//下面是ArrayList的扩容机制
|
||||
//ArrayList的扩容机制提高了性能,如果每次只扩充一个,
|
||||
//那么频繁的插入会导致频繁的拷贝,降低性能,而ArrayList的扩容机制避免了这种情况。
|
||||
/**
|
||||
* 如有必要,增加此ArrayList实例的容量,以确保它至少能容纳元素的数量
|
||||
如有必要,增加此 ArrayList 实例的容量,以确保它至少可以容纳由minimum capacity参数指定的元素数。
|
||||
*
|
||||
* @param minCapacity 所需的最小容量
|
||||
*/
|
||||
public void ensureCapacity(int minCapacity) {
|
||||
@ -595,146 +841,56 @@ public class ArrayList<E> extends AbstractList<E>
|
||||
ensureExplicitCapacity(minCapacity);
|
||||
}
|
||||
}
|
||||
//得到最小扩容量
|
||||
private void ensureCapacityInternal(int minCapacity) {
|
||||
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
|
||||
// 获取默认的容量和传入参数的较大值
|
||||
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
|
||||
|
||||
```
|
||||
|
||||
**最好在 add 大量元素之前用 `ensureCapacity` 方法,以减少增量重新分配的次数**
|
||||
|
||||
我们通过下面的代码实际测试以下这个方法的效果:
|
||||
|
||||
```java
|
||||
public class EnsureCapacityTest {
|
||||
public static void main(String[] args) {
|
||||
ArrayList<Object> list = new ArrayList<Object>();
|
||||
final int N = 10000000;
|
||||
long startTime = System.currentTimeMillis();
|
||||
for (int i = 0; i < N; i++) {
|
||||
list.add(i);
|
||||
}
|
||||
long endTime = System.currentTimeMillis();
|
||||
System.out.println("使用ensureCapacity方法前:"+(endTime - startTime));
|
||||
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
运行结果:
|
||||
|
||||
```
|
||||
使用ensureCapacity方法前:2158
|
||||
```
|
||||
|
||||
```java
|
||||
public class EnsureCapacityTest {
|
||||
public static void main(String[] args) {
|
||||
ArrayList<Object> list = new ArrayList<Object>();
|
||||
final int N = 10000000;
|
||||
list = new ArrayList<Object>();
|
||||
long startTime1 = System.currentTimeMillis();
|
||||
list.ensureCapacity(N);
|
||||
for (int i = 0; i < N; i++) {
|
||||
list.add(i);
|
||||
}
|
||||
|
||||
ensureExplicitCapacity(minCapacity);
|
||||
}
|
||||
//判断是否需要扩容,上面两个方法都要调用
|
||||
private void ensureExplicitCapacity(int minCapacity) {
|
||||
modCount++;
|
||||
|
||||
// 如果说minCapacity也就是所需的最小容量大于保存ArrayList数据的数组的长度的话,就需要调用grow(minCapacity)方法扩容。
|
||||
//这个minCapacity到底为多少呢?举个例子在添加元素(add)方法中这个minCapacity的大小就为现在数组的长度加1
|
||||
if (minCapacity - elementData.length > 0)
|
||||
//调用grow方法进行扩容,调用此方法代表已经开始扩容了
|
||||
grow(minCapacity);
|
||||
}
|
||||
|
||||
```
|
||||
```java
|
||||
/**
|
||||
* ArrayList扩容的核心方法。
|
||||
*/
|
||||
private void grow(int minCapacity) {
|
||||
//elementData为保存ArrayList数据的数组
|
||||
///elementData.length求数组长度elementData.size是求数组中的元素个数
|
||||
// oldCapacity为旧容量,newCapacity为新容量
|
||||
int oldCapacity = elementData.length;
|
||||
//将oldCapacity 右移一位,其效果相当于oldCapacity /2,
|
||||
//我们知道位运算的速度远远快于整除运算,整句运算式的结果就是将新容量更新为旧容量的1.5倍,
|
||||
int newCapacity = oldCapacity + (oldCapacity >> 1);
|
||||
//然后检查新容量是否大于最小需要容量,若还是小于最小需要容量,那么就把最小需要容量当作数组的新容量,
|
||||
if (newCapacity - minCapacity < 0)
|
||||
newCapacity = minCapacity;
|
||||
//再检查新容量是否超出了ArrayList所定义的最大容量,
|
||||
//若超出了,则调用hugeCapacity()来比较minCapacity和 MAX_ARRAY_SIZE,
|
||||
//如果minCapacity大于MAX_ARRAY_SIZE,则新容量则为Interger.MAX_VALUE,否则,新容量大小则为 MAX_ARRAY_SIZE。
|
||||
if (newCapacity - MAX_ARRAY_SIZE > 0)
|
||||
newCapacity = hugeCapacity(minCapacity);
|
||||
// minCapacity is usually close to size, so this is a win:
|
||||
elementData = Arrays.copyOf(elementData, newCapacity);
|
||||
}
|
||||
|
||||
```
|
||||
扩容机制代码已经做了详细的解释。另外值得注意的是大家很容易忽略的一个运算符:**移位运算符**
|
||||
**简介**:移位运算符就是在二进制的基础上对数字进行平移。按照平移的方向和填充数字的规则分为三种:<font color="red"><<(左移)</font>、<font color="red">>>(带符号右移)</font>和<font color="red">>>>(无符号右移)</font>。
|
||||
**作用**:**对于大数据的2进制运算,位移运算符比那些普通运算符的运算要快很多,因为程序仅仅移动一下而已,不去计算,这样提高了效率,节省了资源**
|
||||
比如这里:int newCapacity = oldCapacity + (oldCapacity >> 1);
|
||||
右移一位相当于除2,右移n位相当于除以 2 的 n 次方。这里 oldCapacity 明显右移了1位所以相当于oldCapacity /2。
|
||||
|
||||
**另外需要注意的是:**
|
||||
|
||||
1. java 中的**length 属性**是针对数组说的,比如说你声明了一个数组,想知道这个数组的长度则用到了 length 这个属性.
|
||||
|
||||
2. java 中的**length()方法**是针对字 符串String说的,如果想看这个字符串的长度则用到 length()这个方法.
|
||||
|
||||
3. .java 中的**size()方法**是针对泛型集合说的,如果想看这个泛型有多少个元素,就调用此方法来查看!
|
||||
|
||||
|
||||
#### 内部类
|
||||
```java
|
||||
(1)private class Itr implements Iterator<E>
|
||||
(2)private class ListItr extends Itr implements ListIterator<E>
|
||||
(3)private class SubList extends AbstractList<E> implements RandomAccess
|
||||
(4)static final class ArrayListSpliterator<E> implements Spliterator<E>
|
||||
```
|
||||
ArrayList有四个内部类,其中的**Itr是实现了Iterator接口**,同时重写了里面的**hasNext()**, **next()**, **remove()** 等方法;其中的**ListItr** 继承 **Itr**,实现了**ListIterator接口**,同时重写了**hasPrevious()**, **nextIndex()**, **previousIndex()**, **previous()**, **set(E e)**, **add(E e)** 等方法,所以这也可以看出了 **Iterator和ListIterator的区别:** ListIterator在Iterator的基础上增加了添加对象,修改对象,逆向遍历等方法,这些是Iterator不能实现的。
|
||||
### <font face="楷体" id="6"> ArrayList经典Demo</font>
|
||||
|
||||
```java
|
||||
package list;
|
||||
import java.util.ArrayList;
|
||||
import java.util.Iterator;
|
||||
|
||||
public class ArrayListDemo {
|
||||
|
||||
public static void main(String[] srgs){
|
||||
ArrayList<Integer> arrayList = new ArrayList<Integer>();
|
||||
|
||||
System.out.printf("Before add:arrayList.size() = %d\n",arrayList.size());
|
||||
|
||||
arrayList.add(1);
|
||||
arrayList.add(3);
|
||||
arrayList.add(5);
|
||||
arrayList.add(7);
|
||||
arrayList.add(9);
|
||||
System.out.printf("After add:arrayList.size() = %d\n",arrayList.size());
|
||||
|
||||
System.out.println("Printing elements of arrayList");
|
||||
// 三种遍历方式打印元素
|
||||
// 第一种:通过迭代器遍历
|
||||
System.out.print("通过迭代器遍历:");
|
||||
Iterator<Integer> it = arrayList.iterator();
|
||||
while(it.hasNext()){
|
||||
System.out.print(it.next() + " ");
|
||||
}
|
||||
System.out.println();
|
||||
|
||||
// 第二种:通过索引值遍历
|
||||
System.out.print("通过索引值遍历:");
|
||||
for(int i = 0; i < arrayList.size(); i++){
|
||||
System.out.print(arrayList.get(i) + " ");
|
||||
}
|
||||
System.out.println();
|
||||
|
||||
// 第三种:for循环遍历
|
||||
System.out.print("for循环遍历:");
|
||||
for(Integer number : arrayList){
|
||||
System.out.print(number + " ");
|
||||
}
|
||||
|
||||
// toArray用法
|
||||
// 第一种方式(最常用)
|
||||
Integer[] integer = arrayList.toArray(new Integer[0]);
|
||||
|
||||
// 第二种方式(容易理解)
|
||||
Integer[] integer1 = new Integer[arrayList.size()];
|
||||
arrayList.toArray(integer1);
|
||||
|
||||
// 抛出异常,java不支持向下转型
|
||||
//Integer[] integer2 = new Integer[arrayList.size()];
|
||||
//integer2 = arrayList.toArray();
|
||||
System.out.println();
|
||||
|
||||
// 在指定位置添加元素
|
||||
arrayList.add(2,2);
|
||||
// 删除指定位置上的元素
|
||||
arrayList.remove(2);
|
||||
// 删除指定元素
|
||||
arrayList.remove((Object)3);
|
||||
// 判断arrayList是否包含5
|
||||
System.out.println("ArrayList contains 5 is: " + arrayList.contains(5));
|
||||
|
||||
// 清空ArrayList
|
||||
arrayList.clear();
|
||||
// 判断ArrayList是否为空
|
||||
System.out.println("ArrayList is empty: " + arrayList.isEmpty());
|
||||
long endTime1 = System.currentTimeMillis();
|
||||
System.out.println("使用ensureCapacity方法后:"+(endTime1 - startTime1));
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
运行结果:
|
||||
|
||||
```
|
||||
使用ensureCapacity方法前:1773
|
||||
```
|
||||
|
||||
通过运行结果,我们可以看出向 ArrayList 添加大量元素之前最好先使用`ensureCapacity` 方法,以减少增量重新分配的次数。
|
||||
@ -23,8 +23,10 @@ List list=Collections.synchronizedList(new LinkedList(...));
|
||||
```
|
||||
## <font face="楷体" id="2">内部结构分析</font>
|
||||
**如下图所示:**
|
||||

|
||||
|
||||

|
||||
看完了图之后,我们再看LinkedList类中的一个<font color="red">**内部私有类Node**</font>就很好理解了:
|
||||
|
||||
```java
|
||||
private static class Node<E> {
|
||||
E item;//节点值
|
||||
BIN
docs/java/collection/images/linkedlist/LinkedList内部结构.png
Normal file
{kind=link}
|
After Width: | Height: | Size: 18 KiB |
@ -1,416 +0,0 @@
|
||||
> 原文链接:https://www.cnblogs.com/liqiangchn/p/12000361.html
|
||||
|
||||
简洁清爽的代码风格应该是大多数工程师所期待的。在工作中笔者常常因为起名字而纠结,夸张点可以说是编程5分钟,命名两小时!究竟为什么命名成为了工作中的拦路虎。
|
||||
|
||||
每个公司都有不同的标准,目的是为了保持统一,减少沟通成本,提升团队研发效能。所以本文中是笔者结合阿里巴巴开发规范,以及工作中的见闻针对Java领域相关命名进行整理和总结,仅供参考。
|
||||
|
||||
## 一,Java中的命名规范
|
||||
|
||||
好的命名能体现出代码的特征,含义或者是用途,让阅读者可以根据名称的含义快速厘清程序的脉络。不同语言中采用的命名形式大相径庭,Java中常用到的命名形式共有三种,既首字母大写的UpperCamelCase,首字母小写的lowerCamelCase以及全部大写的并用下划线分割单词的UPPER_CAMEL_UNSER_SCORE。通常约定,**类一般采用大驼峰命名,方法和局部变量使用小驼峰命名,而大写下划线命名通常是常量和枚举中使用。**
|
||||
|
||||
| 类型 | 约束 | 例 |
|
||||
| :----: | :----------------------------------------------------------: | :--------------------------------------------: |
|
||||
| 项目名 | 全部小写,多个单词用中划线分隔‘-’ | spring-cloud |
|
||||
| 包名 | 全部小写 | com.alibaba.fastjson |
|
||||
| 类名 | 单词首字母大写 | Feature, ParserConfig,DefaultFieldDeserializer |
|
||||
| 变量名 | 首字母小写,多个单词组成时,除首个单词,其他单词首字母都要大写 | password, userName |
|
||||
| 常量名 | 全部大写,多个单词,用'_'分隔 | CACHE_EXPIRED_TIME |
|
||||
| 方法 | 同变量 | read(), readObject(), getById() |
|
||||
|
||||
## 二,包命名
|
||||
|
||||
**包名**统一使用**小写**,**点分隔符**之间有且仅有一个自然语义的英文单词或者多个单词自然连接到一块(如 springframework,deepspace不需要使用任何分割)。包名统一使用单数形式,如果类命有复数含义,则可以使用复数形式。
|
||||
|
||||
包名的构成可以分为以下几四部分【前缀】 【发起者名】【项目名】【模块名】。常见的前缀可以分为以下几种:
|
||||
|
||||
| 前缀名 | 例 | 含义 |
|
||||
| :-------------: | :----------------------------: | :----------------------------------------------------------: |
|
||||
| indi(或onem ) | indi.发起者名.项目名.模块名.…… | 个体项目,指个人发起,但非自己独自完成的项目,可公开或私有项目,copyright主要属于发起者。 |
|
||||
| pers | pers.个人名.项目名.模块名.…… | 个人项目,指个人发起,独自完成,可分享的项目,copyright主要属于个人 |
|
||||
| priv | priv.个人名.项目名.模块名.…… | 私有项目,指个人发起,独自完成,非公开的私人使用的项目,copyright属于个人。 |
|
||||
| team | team.团队名.项目名.模块名.…… | 团队项目,指由团队发起,并由该团队开发的项目,copyright属于该团队所有 |
|
||||
| 顶级域名 | com.公司名.项目名.模块名.…… | 公司项目,copyright由项目发起的公司所有 |
|
||||
|
||||
## 三,类命名
|
||||
|
||||
**类名使用大驼峰命名形式**,类命通常时**名词或名词短语**,接口名除了用名词和名词短语以外,还可以使用形容词或形容词短语,如Cloneable,Callable等,表示实现该接口的类有某种功能或能力。对于测试类则以它要测试的类开头,以Test结尾,如HashMapTest。
|
||||
|
||||
对于一些特殊特有名词缩写也可以使用全大写命名,比如XMLHttpRequest,不过笔者认为缩写三个字母以内都大写,超过三个字母则按照要给单词算。这个没有标准如阿里巴巴中fastjson用JSONObject作为类命,而google则使用JsonObjectRequest命名,对于这种特殊的缩写,原则是统一就好。
|
||||
|
||||
| 属性 | 约束 | 例 |
|
||||
| -------------- | ----------------------------------------- | ------------------------------------------------------------ |
|
||||
| 抽象类 | Abstract 或者 Base 开头 | BaseUserService |
|
||||
| 枚举类 | Enum 作为后缀 | GenderEnum |
|
||||
| 工具类 | Utils作为后缀 | StringUtils |
|
||||
| 异常类 | Exception结尾 | RuntimeException |
|
||||
| 接口实现类 | 接口名+ Impl | UserServiceImpl |
|
||||
| 领域模型相关 | /DO/DTO/VO/DAO | 正例:UserDAO 反例: UserDo, UserDao |
|
||||
| 设计模式相关类 | Builder,Factory等 | 当使用到设计模式时,需要使用对应的设计模式作为后缀,如ThreadFactory |
|
||||
| 处理特定功能的 | Handler,Predicate, Validator | 表示处理器,校验器,断言,这些类工厂还有配套的方法名如handle,predicate,validate |
|
||||
| 测试类 | Test结尾 | UserServiceTest, 表示用来测试UserService类的 |
|
||||
| MVC分层 | Controller,Service,ServiceImpl,DAO后缀 | UserManageController,UserManageDAO |
|
||||
|
||||
## 四,方法
|
||||
|
||||
**方法命名采用小驼峰的形式**,首字小写,往后的每个单词首字母都要大写。 和类名不同的是,方法命名一般为**动词或动词短语**,与参数或参数名共同组成动宾短语,即动词 + 名词。一个好的函数名一般能通过名字直接获知该函数实现什么样的功能。
|
||||
|
||||
### 4.1 返回真伪值的方法
|
||||
|
||||
注:Prefix-前缀,Suffix-后缀,Alone-单独使用
|
||||
|
||||
| 位置 | 单词 | 意义 | 例 |
|
||||
| ------ | ------ | ------------------------------------------------------------ | ------------- |
|
||||
| Prefix | is | 对象是否符合期待的状态 | isValid |
|
||||
| Prefix | can | 对象**能否执行**所期待的动作 | canRemove |
|
||||
| Prefix | should | 调用方执行某个命令或方法是**好还是不好**,**应不应该**,或者说**推荐还是不推荐** | shouldMigrate |
|
||||
| Prefix | has | 对象**是否持有**所期待的数据和属性 | hasObservers |
|
||||
| Prefix | needs | 调用方**是否需要**执行某个命令或方法 | needsMigrate |
|
||||
|
||||
### 4.2 用来检查的方法
|
||||
|
||||
| 单词 | 意义 | 例 |
|
||||
| -------- | ---------------------------------------------------- | -------------- |
|
||||
| ensure | 检查是否为期待的状态,不是则抛出异常或返回error code | ensureCapacity |
|
||||
| validate | 检查是否为正确的状态,不是则抛出异常或返回error code | validateInputs |
|
||||
|
||||
### 4.3 按需求才执行的方法
|
||||
|
||||
| 位置 | 单词 | 意义 | 例 |
|
||||
| ------ | --------- | ----------------------------------------- | ---------------------- |
|
||||
| Suffix | IfNeeded | 需要的时候执行,不需要的时候什么都不做 | drawIfNeeded |
|
||||
| Prefix | might | 同上 | mightCreate |
|
||||
| Prefix | try | 尝试执行,失败时抛出异常或是返回errorcode | tryCreate |
|
||||
| Suffix | OrDefault | 尝试执行,失败时返回默认值 | getOrDefault |
|
||||
| Suffix | OrElse | 尝试执行、失败时返回实际参数中指定的值 | getOrElse |
|
||||
| Prefix | force | 强制尝试执行。error抛出异常或是返回值 | forceCreate, forceStop |
|
||||
|
||||
### 4.4 异步相关方法
|
||||
|
||||
| 位置 | 单词 | 意义 | 例 |
|
||||
| --------------- | ------------ | -------------------------------------------- | --------------------- |
|
||||
| Prefix | blocking | 线程阻塞方法 | blockingGetUser |
|
||||
| Suffix | InBackground | 执行在后台的线程 | doInBackground |
|
||||
| Suffix | Async | 异步方法 | sendAsync |
|
||||
| Suffix | Sync | 对应已有异步方法的同步方法 | sendSync |
|
||||
| Prefix or Alone | schedule | Job和Task放入队列 | schedule, scheduleJob |
|
||||
| Prefix or Alone | post | 同上 | postJob |
|
||||
| Prefix or Alone | execute | 执行异步方法(注:我一般拿这个做同步方法名) | execute, executeTask |
|
||||
| Prefix or Alone | start | 同上 | start, startJob |
|
||||
| Prefix or Alone | cancel | 停止异步方法 | cancel, cancelJob |
|
||||
| Prefix or Alone | stop | 同上 | stop, stopJob |
|
||||
|
||||
### 4.5 回调方法
|
||||
|
||||
| 位置 | 单词 | 意义 | 例 |
|
||||
| ------ | ------ | -------------------------- | ------------ |
|
||||
| Prefix | on | 事件发生时执行 | onCompleted |
|
||||
| Prefix | before | 事件发生前执行 | beforeUpdate |
|
||||
| Prefix | pre | 同上 | preUpdate |
|
||||
| Prefix | will | 同上 | willUpdate |
|
||||
| Prefix | after | 事件发生后执行 | afterUpdate |
|
||||
| Prefix | post | 同上 | postUpdate |
|
||||
| Prefix | did | 同上 | didUpdate |
|
||||
| Prefix | should | 确认事件是否可以发生时执行 | shouldUpdate |
|
||||
|
||||
### 4.6 操作对象生命周期的方法
|
||||
|
||||
| 单词 | 意义 | 例 |
|
||||
| ---------- | ------------------------------ | --------------- |
|
||||
| initialize | 初始化。也可作为延迟初始化使用 | initialize |
|
||||
| pause | 暂停 | onPause ,pause |
|
||||
| stop | 停止 | onStop,stop |
|
||||
| abandon | 销毁的替代 | abandon |
|
||||
| destroy | 同上 | destroy |
|
||||
| dispose | 同上 | dispose |
|
||||
|
||||
### 4.7 与集合操作相关的方法
|
||||
|
||||
| 单词 | 意义 | 例 |
|
||||
| -------- | ---------------------------- | ---------- |
|
||||
| contains | 是否持有与指定对象相同的对象 | contains |
|
||||
| add | 添加 | addJob |
|
||||
| append | 添加 | appendJob |
|
||||
| insert | 插入到下标n | insertJob |
|
||||
| put | 添加与key对应的元素 | putJob |
|
||||
| remove | 移除元素 | removeJob |
|
||||
| enqueue | 添加到队列的最末位 | enqueueJob |
|
||||
| dequeue | 从队列中头部取出并移除 | dequeueJob |
|
||||
| push | 添加到栈头 | pushJob |
|
||||
| pop | 从栈头取出并移除 | popJob |
|
||||
| peek | 从栈头取出但不移除 | peekJob |
|
||||
| find | 寻找符合条件的某物 | findById |
|
||||
|
||||
### 4.8 与数据相关的方法
|
||||
|
||||
| 单词 | 意义 | 例 |
|
||||
| ------ | -------------------------------------- | ------------- |
|
||||
| create | 新创建 | createAccount |
|
||||
| new | 新创建 | newAccount |
|
||||
| from | 从既有的某物新建,或是从其他的数据新建 | fromConfig |
|
||||
| to | 转换 | toString |
|
||||
| update | 更新既有某物 | updateAccount |
|
||||
| load | 读取 | loadAccount |
|
||||
| fetch | 远程读取 | fetchAccount |
|
||||
| delete | 删除 | deleteAccount |
|
||||
| remove | 删除 | removeAccount |
|
||||
| save | 保存 | saveAccount |
|
||||
| store | 保存 | storeAccount |
|
||||
| commit | 保存 | commitChange |
|
||||
| apply | 保存或应用 | applyChange |
|
||||
| clear | 清除数据或是恢复到初始状态 | clearAll |
|
||||
| reset | 清除数据或是恢复到初始状态 | resetAll |
|
||||
|
||||
### 4.9 成对出现的动词
|
||||
|
||||
| 单词 | 意义 |
|
||||
| -------------- | ----------------- |
|
||||
| get获取 | set 设置 |
|
||||
| add 增加 | remove 删除 |
|
||||
| create 创建 | destory 移除 |
|
||||
| start 启动 | stop 停止 |
|
||||
| open 打开 | close 关闭 |
|
||||
| read 读取 | write 写入 |
|
||||
| load 载入 | save 保存 |
|
||||
| create 创建 | destroy 销毁 |
|
||||
| begin 开始 | end 结束 |
|
||||
| backup 备份 | restore 恢复 |
|
||||
| import 导入 | export 导出 |
|
||||
| split 分割 | merge 合并 |
|
||||
| inject 注入 | extract 提取 |
|
||||
| attach 附着 | detach 脱离 |
|
||||
| bind 绑定 | separate 分离 |
|
||||
| view 查看 | browse 浏览 |
|
||||
| edit 编辑 | modify 修改 |
|
||||
| select 选取 | mark 标记 |
|
||||
| copy 复制 | paste 粘贴 |
|
||||
| undo 撤销 | redo 重做 |
|
||||
| insert 插入 | delete 移除 |
|
||||
| add 加入 | append 添加 |
|
||||
| clean 清理 | clear 清除 |
|
||||
| index 索引 | sort 排序 |
|
||||
| find 查找 | search 搜索 |
|
||||
| increase 增加 | decrease 减少 |
|
||||
| play 播放 | pause 暂停 |
|
||||
| launch 启动 | run 运行 |
|
||||
| compile 编译 | execute 执行 |
|
||||
| debug 调试 | trace 跟踪 |
|
||||
| observe 观察 | listen 监听 |
|
||||
| build 构建 | publish 发布 |
|
||||
| input 输入 | output 输出 |
|
||||
| encode 编码 | decode 解码 |
|
||||
| encrypt 加密 | decrypt 解密 |
|
||||
| compress 压缩 | decompress 解压缩 |
|
||||
| pack 打包 | unpack 解包 |
|
||||
| parse 解析 | emit 生成 |
|
||||
| connect 连接 | disconnect 断开 |
|
||||
| send 发送 | receive 接收 |
|
||||
| download 下载 | upload 上传 |
|
||||
| refresh 刷新 | synchronize 同步 |
|
||||
| update 更新 | revert 复原 |
|
||||
| lock 锁定 | unlock 解锁 |
|
||||
| check out 签出 | check in 签入 |
|
||||
| submit 提交 | commit 交付 |
|
||||
| push 推 | pull 拉 |
|
||||
| expand 展开 | collapse 折叠 |
|
||||
| begin 起始 | end 结束 |
|
||||
| start 开始 | finish 完成 |
|
||||
| enter 进入 | exit 退出 |
|
||||
| abort 放弃 | quit 离开 |
|
||||
| obsolete 废弃 | depreciate 废旧 |
|
||||
| collect 收集 | aggregate 聚集 |
|
||||
|
||||
## 五,变量&常量命名
|
||||
|
||||
### 5.1 变量命名
|
||||
|
||||
变量是指在程序运行中可以改变其值的量,包括成员变量和局部变量。变量名由多单词组成时,第一个单词的首字母小写,其后单词的首字母大写,俗称骆驼式命名法(也称驼峰命名法),如 computedValues,index、变量命名时,尽量简短且能清楚的表达变量的作用,命名体现具体的业务含义即可。
|
||||
|
||||
变量名不应以下划线或美元符号开头,尽管这在语法上是允许的。变量名应简短且富于描述。变量名的选用应该易于记忆,即,能够指出其用途。尽量避免单个字符的变量名,除非是一次性的临时变量。pojo中的布尔变量,都不要加is(数据库中的布尔字段全都要加 is_ 前缀)。
|
||||
|
||||
### 5.2 常量命名
|
||||
|
||||
常量命名CONSTANT_CASE,一般采用全部大写(作为方法参数时除外),单词间用下划线分割。那么什么是常量呢?
|
||||
|
||||
常量是在作用域内保持不变的值,一般使用final进行修饰。一般分为三种,全局常量(public static final修饰),类内常量(private static final 修饰)以及局部常量(方法内,或者参数中的常量),局部常量比较特殊,通常采用小驼峰命名即可。
|
||||
|
||||
```java
|
||||
/**
|
||||
* 一个demo
|
||||
*
|
||||
* @author Jann Lee
|
||||
* @date 2019-12-07 00:25
|
||||
**/
|
||||
public class HelloWorld {
|
||||
|
||||
/**
|
||||
* 局部常量(正例)
|
||||
*/
|
||||
public static final long USER_MESSAGE_CACHE_EXPIRE_TIME = 3600;
|
||||
|
||||
/**
|
||||
* 局部常量(反例,命名不清晰)
|
||||
*/
|
||||
public static final long MESSAGE_CACHE_TIME = 3600;
|
||||
|
||||
/**
|
||||
* 全局常量
|
||||
*/
|
||||
private static final String ERROR_MESSAGE = " error message";
|
||||
|
||||
/**
|
||||
* 成员变量
|
||||
*/
|
||||
private int currentUserId;
|
||||
|
||||
/**
|
||||
* 控制台打印 {@code message} 信息
|
||||
*
|
||||
* @param message 消息体,局部常量
|
||||
*/
|
||||
public void sayHello(final String message){
|
||||
System.out.println("Hello world!");
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
常量一般都有自己的业务含义,**不要害怕长度过长而进行省略或者缩写**。如,用户消息缓存过期时间的表示,那种方式更佳清晰,交给你来评判。
|
||||
|
||||
## 通用命名规则[#](https://www.cnblogs.com/liqiangchn/p/12000361.html#450918152)
|
||||
|
||||
1. 尽量不要使用拼音;杜绝拼音和英文混用。对于一些通用的表示或者难以用英文描述的可以采用拼音,一旦采用拼音就坚决不能和英文混用。
|
||||
正例: BeiJing, HangZhou
|
||||
反例: validateCanShu
|
||||
2. 命名过程中尽量不要出现特殊的字符,常量除外。
|
||||
3. 尽量不要和jdk或者框架中已存在的类重名,也不能使用java中的关键字命名。
|
||||
4. 妙用介词,如for(可以用同音的4代替), to(可用同音的2代替), from, with,of等。
|
||||
如类名采用User4RedisDO,方法名getUserInfoFromRedis,convertJson2Map等。
|
||||
|
||||
## 六,代码注解
|
||||
|
||||
### 6.1 注解的原则
|
||||
|
||||
好的命名增加代码阅读性,代码的命名往往有严格的限制。而注解不同,程序员往往可以自由发挥,单并不意味着可以为所欲为之胡作非为。优雅的注解通常要满足三要素。
|
||||
|
||||
1. Nothing is strange
|
||||
没有注解的代码对于阅读者非常不友好,哪怕代码写的在清除,阅读者至少从心理上会有抵触,更何况代码中往往有许多复杂的逻辑,所以一定要写注解,不仅要记录代码的逻辑,还有说清楚修改的逻辑。
|
||||
2. Less is more
|
||||
从代码维护角度来讲,代码中的注解一定是精华中的精华。合理清晰的命名能让代码易于理解,对于逻辑简单且命名规范,能够清楚表达代码功能的代码不需要注解。滥用注解会增加额外的负担,更何况大部分都是废话。
|
||||
|
||||
```java
|
||||
// 根据id获取信息【废话注解】
|
||||
getMessageById(id)
|
||||
```
|
||||
|
||||
1. Advance with the time
|
||||
注解应该随着代码的变动而改变,注解表达的信息要与代码中完全一致。通常情况下修改代码后一定要修改注解。
|
||||
|
||||
### 6.2 注解格式
|
||||
|
||||
注解大体上可以分为两种,一种是javadoc注解,另一种是简单注解。javadoc注解可以生成JavaAPI为外部用户提供有效的支持javadoc注解通常在使用IDEA,或者Eclipse等开发工具时都可以自动生成,也支持自定义的注解模板,仅需要对对应的字段进行解释。参与同一项目开发的同学,尽量设置成相同的注解模板。
|
||||
|
||||
#### a. 包注解
|
||||
|
||||
包注解在工作中往往比较特殊,通过包注解可以快速知悉当前包下代码是用来实现哪些功能,强烈建议工作中加上,尤其是对于一些比较复杂的包,包注解一般在包的根目录下,名称统一为package-info.java。
|
||||
|
||||
```java
|
||||
/**
|
||||
* 落地也质量检测
|
||||
* 1. 用来解决什么问题
|
||||
* 对广告主投放的广告落地页进行性能检测,模拟不同的系统,如Android,IOS等; 模拟不同的网络:2G,3G,4G,wifi等
|
||||
*
|
||||
* 2. 如何实现
|
||||
* 基于chrome浏览器,用chromedriver驱动浏览器,设置对应的网络,OS参数,获取到浏览器返回结果。
|
||||
*
|
||||
* 注意: 网络环境配置信息{@link cn.mycookies.landingpagecheck.meta.NetWorkSpeedEnum}目前使用是常规速度,可以根据实际情况进行调整
|
||||
*
|
||||
* @author cruder
|
||||
* @time 2019/12/7 20:3 下午
|
||||
*/
|
||||
package cn.mycookies.landingpagecheck;
|
||||
```
|
||||
|
||||
#### b. 类注接
|
||||
|
||||
javadoc注解中,每个类都必须有注解。
|
||||
|
||||
```java
|
||||
/**
|
||||
* Copyright (C), 2019-2020, Jann balabala...
|
||||
*
|
||||
* 类的介绍:这是一个用来做什么事情的类,有哪些功能,用到的技术.....
|
||||
*
|
||||
* @author 类创建者姓名 保持对齐
|
||||
* @date 创建日期 保持对齐
|
||||
* @version 版本号 保持对齐
|
||||
*/
|
||||
```
|
||||
|
||||
#### c. 属性注解
|
||||
|
||||
在每个属性前面必须加上属性注释,通常有以下两种形式,至于怎么选择,你高兴就好,不过一个项目中要保持统一。
|
||||
|
||||
```java
|
||||
/** 提示信息 */
|
||||
private String userName;
|
||||
/**
|
||||
* 密码
|
||||
*/
|
||||
private String password;
|
||||
```
|
||||
|
||||
#### d. 方法注释
|
||||
|
||||
在每个方法前面必须加上方法注释,对于方法中的每个参数,以及返回值都要有说明。
|
||||
|
||||
```java
|
||||
/**
|
||||
* 方法的详细说明,能干嘛,怎么实现的,注意事项...
|
||||
*
|
||||
* @param xxx 参数1的使用说明, 能否为null
|
||||
* @return 返回结果的说明, 不同情况下会返回怎样的结果
|
||||
* @throws 异常类型 注明从此类方法中抛出异常的说明
|
||||
*/
|
||||
```
|
||||
|
||||
#### e. 构造方法注释
|
||||
|
||||
在每个构造方法前面必须加上注释,注释模板如下:
|
||||
|
||||
```java
|
||||
/**
|
||||
* 构造方法的详细说明
|
||||
*
|
||||
* @param xxx 参数1的使用说明, 能否为null
|
||||
* @throws 异常类型 注明从此类方法中抛出异常的说明
|
||||
*/
|
||||
```
|
||||
|
||||
而简单注解往往是需要工程师字节定义,在使用注解时应该注意以下几点:
|
||||
|
||||
1. 枚举类的各个属性值都要使用注解,枚举可以理解为是常量,通常不会发生改变,通常会被在多个地方引用,对枚举的修改和添加属性通常会带来很大的影响。
|
||||
2. 保持排版整洁,不要使用行尾注释;双斜杠和星号之后要用1个空格分隔。
|
||||
|
||||
```java
|
||||
id = 1;// 反例:不要使用行尾注释
|
||||
//反例:换行符与注释之间没有缩进
|
||||
int age = 18;
|
||||
// 正例:姓名
|
||||
String name;
|
||||
/**
|
||||
* 1. 多行注释
|
||||
*
|
||||
* 2. 对于不同的逻辑说明,可以用空行分隔
|
||||
*/
|
||||
```
|
||||
|
||||
## 总结
|
||||
|
||||
无论是命名和注解,他们的目的都是为了让代码和工程师进行对话,增强代码的可读性,可维护性。优秀的代码往往能够见名知意,注解往往是对命名的补充和完善。命名太南了!
|
||||
|
||||
参考文献:
|
||||
|
||||
- 《码出高效》
|
||||
- https://www.cnblogs.com/wangcp-2014/p/10215620.html
|
||||
- https://qiita.com/KeithYokoma/items/2193cf79ba76563e3db6
|
||||
- https://google.github.io/styleguide/javaguide.html#s2.1-file-name
|
||||
@ -1,130 +0,0 @@
|
||||
<!-- TOC -->
|
||||
|
||||
- [0.0.1. 泛型的实际应用:实现最小值函数](#001-%e6%b3%9b%e5%9e%8b%e7%9a%84%e5%ae%9e%e9%99%85%e5%ba%94%e7%94%a8%e5%ae%9e%e7%8e%b0%e6%9c%80%e5%b0%8f%e5%80%bc%e5%87%bd%e6%95%b0)
|
||||
- [0.0.2. 使用数组实现栈](#002-%e4%bd%bf%e7%94%a8%e6%95%b0%e7%bb%84%e5%ae%9e%e7%8e%b0%e6%a0%88)
|
||||
- [0.0.3. 实现线程安全的 LRU 缓存](#003-%e5%ae%9e%e7%8e%b0%e7%ba%bf%e7%a8%8b%e5%ae%89%e5%85%a8%e7%9a%84-lru-%e7%bc%93%e5%ad%98)
|
||||
|
||||
<!-- /TOC -->
|
||||
|
||||
### 0.0.1. 泛型的实际应用:实现最小值函数
|
||||
|
||||
自己设计一个泛型的获取数组最小值的函数.并且这个方法只能接受Number的子类并且实现了Comparable接口。
|
||||
|
||||
```java
|
||||
//注意:Number并没有实现Comparable
|
||||
private static <T extends Number & Comparable<? super T>> T min(T[] values) {
|
||||
if (values == null || values.length == 0) return null;
|
||||
T min = values[0];
|
||||
for (int i = 1; i < values.length; i++) {
|
||||
if (min.compareTo(values[i]) > 0) min = values[i];
|
||||
}
|
||||
return min;
|
||||
}
|
||||
```
|
||||
|
||||
测试:
|
||||
|
||||
```java
|
||||
int minInteger = min(new Integer[]{1, 2, 3});//result:1
|
||||
double minDouble = min(new Double[]{1.2, 2.2, -1d});//result:-1d
|
||||
String typeError = min(new String[]{"1","3"});//报错
|
||||
```
|
||||
### 0.0.2. 使用数组实现栈
|
||||
|
||||
**自己实现一个栈,要求这个栈具有`push()`、`pop()`(返回栈顶元素并出栈)、`peek()` (返回栈顶元素不出栈)、`isEmpty()`、`size()`这些基本的方法。**
|
||||
|
||||
提示:每次入栈之前先判断栈的容量是否够用,如果不够用就用`Arrays.copyOf()`进行扩容;
|
||||
|
||||
```java
|
||||
public class MyStack {
|
||||
private int[] storage;//存放栈中元素的数组
|
||||
private int capacity;//栈的容量
|
||||
private int count;//栈中元素数量
|
||||
private static final int GROW_FACTOR = 2;
|
||||
|
||||
//不带初始容量的构造方法。默认容量为8
|
||||
public MyStack() {
|
||||
this.capacity = 8;
|
||||
this.storage=new int[8];
|
||||
this.count = 0;
|
||||
}
|
||||
|
||||
//带初始容量的构造方法
|
||||
public MyStack(int initialCapacity) {
|
||||
if (initialCapacity < 1)
|
||||
throw new IllegalArgumentException("Capacity too small.");
|
||||
|
||||
this.capacity = initialCapacity;
|
||||
this.storage = new int[initialCapacity];
|
||||
this.count = 0;
|
||||
}
|
||||
|
||||
//入栈
|
||||
public void push(int value) {
|
||||
if (count == capacity) {
|
||||
ensureCapacity();
|
||||
}
|
||||
storage[count++] = value;
|
||||
}
|
||||
|
||||
//确保容量大小
|
||||
private void ensureCapacity() {
|
||||
int newCapacity = capacity * GROW_FACTOR;
|
||||
storage = Arrays.copyOf(storage, newCapacity);
|
||||
capacity = newCapacity;
|
||||
}
|
||||
|
||||
//返回栈顶元素并出栈
|
||||
private int pop() {
|
||||
if (count == 0)
|
||||
throw new IllegalArgumentException("Stack is empty.");
|
||||
count--;
|
||||
return storage[count];
|
||||
}
|
||||
|
||||
//返回栈顶元素不出栈
|
||||
private int peek() {
|
||||
if (count == 0){
|
||||
throw new IllegalArgumentException("Stack is empty.");
|
||||
}else {
|
||||
return storage[count-1];
|
||||
}
|
||||
}
|
||||
|
||||
//判断栈是否为空
|
||||
private boolean isEmpty() {
|
||||
return count == 0;
|
||||
}
|
||||
|
||||
//返回栈中元素的个数
|
||||
private int size() {
|
||||
return count;
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
验证
|
||||
|
||||
```java
|
||||
MyStack myStack = new MyStack(3);
|
||||
myStack.push(1);
|
||||
myStack.push(2);
|
||||
myStack.push(3);
|
||||
myStack.push(4);
|
||||
myStack.push(5);
|
||||
myStack.push(6);
|
||||
myStack.push(7);
|
||||
myStack.push(8);
|
||||
System.out.println(myStack.peek());//8
|
||||
System.out.println(myStack.size());//8
|
||||
for (int i = 0; i < 8; i++) {
|
||||
System.out.println(myStack.pop());
|
||||
}
|
||||
System.out.println(myStack.isEmpty());//true
|
||||
myStack.pop();//报错:java.lang.IllegalArgumentException: Stack is empty.
|
||||
```
|
||||
|
||||
|
||||
|
||||
@ -1,441 +0,0 @@
|
||||
<!-- TOC -->
|
||||
|
||||
- [1. LRU 缓存介绍](#1-lru-%e7%bc%93%e5%ad%98%e4%bb%8b%e7%bb%8d)
|
||||
- [2. ConcurrentLinkedQueue简单介绍](#2-concurrentlinkedqueue%e7%ae%80%e5%8d%95%e4%bb%8b%e7%bb%8d)
|
||||
- [3. ReadWriteLock简单介绍](#3-readwritelock%e7%ae%80%e5%8d%95%e4%bb%8b%e7%bb%8d)
|
||||
- [4. ScheduledExecutorService 简单介绍](#4-scheduledexecutorservice-%e7%ae%80%e5%8d%95%e4%bb%8b%e7%bb%8d)
|
||||
- [5. 徒手撸一个线程安全的 LRU 缓存](#5-%e5%be%92%e6%89%8b%e6%92%b8%e4%b8%80%e4%b8%aa%e7%ba%bf%e7%a8%8b%e5%ae%89%e5%85%a8%e7%9a%84-lru-%e7%bc%93%e5%ad%98)
|
||||
- [5.1. 实现方法](#51-%e5%ae%9e%e7%8e%b0%e6%96%b9%e6%b3%95)
|
||||
- [5.2. 原理](#52-%e5%8e%9f%e7%90%86)
|
||||
- [5.3. put方法具体流程分析](#53-put%e6%96%b9%e6%b3%95%e5%85%b7%e4%bd%93%e6%b5%81%e7%a8%8b%e5%88%86%e6%9e%90)
|
||||
- [5.4. 源码](#54-%e6%ba%90%e7%a0%81)
|
||||
- [6. 实现一个线程安全并且带有过期时间的 LRU 缓存](#6-%e5%ae%9e%e7%8e%b0%e4%b8%80%e4%b8%aa%e7%ba%bf%e7%a8%8b%e5%ae%89%e5%85%a8%e5%b9%b6%e4%b8%94%e5%b8%a6%e6%9c%89%e8%bf%87%e6%9c%9f%e6%97%b6%e9%97%b4%e7%9a%84-lru-%e7%bc%93%e5%ad%98)
|
||||
|
||||
<!-- /TOC -->
|
||||
|
||||
最近被读者问到“不用LinkedHashMap的话,如何实现一个线程安全的 LRU 缓存?网上的代码太杂太乱,Guide哥哥能不能帮忙写一个?”。
|
||||
|
||||
*划重点,手写一个 LRU 缓存在面试中还是挺常见的!*
|
||||
|
||||
很多人就会问了:“网上已经有这么多现成的缓存了!为什么面试官还要我们自己实现一个呢?” 。咳咳咳,当然是为了面试需要。哈哈!开个玩笑,我个人觉得更多地是为了学习吧!今天Guide哥教大家:
|
||||
|
||||
1. 实现一个线程安全的 LRU 缓存
|
||||
2. 实现一个线程安全并且带有过期时间的 LRU 缓存
|
||||
|
||||
考虑到了线程安全性我们使用了 `ConcurrentHashMap` 、`ConcurrentLinkedQueue` 这两个线程安全的集合。另外,还用到 `ReadWriteLock`(读写锁)。为了实现带有过期时间的缓存,我们用到了 `ScheduledExecutorService`来做定时任务执行。
|
||||
|
||||
如果有任何不对或者需要完善的地方,请帮忙指出!
|
||||
|
||||
### 1. LRU 缓存介绍
|
||||
|
||||
**LRU (Least Recently Used,最近最少使用)是一种缓存淘汰策略。**
|
||||
|
||||
LRU缓存指的是当缓存大小已达到最大分配容量的时候,如果再要去缓存新的对象数据的话,就需要将缓存中最近访问最少的对象删除掉以便给新来的数据腾出空间。
|
||||
|
||||
### 2. ConcurrentLinkedQueue简单介绍
|
||||
|
||||
**ConcurrentLinkedQueue是一个基于单向链表的无界无锁线程安全的队列,适合在高并发环境下使用,效率比较高。** 我们在使用的时候,可以就把它理解为我们经常接触的数据结构——队列,不过是增加了多线程下的安全性保证罢了。**和普通队列一样,它也是按照先进先出(FIFO)的规则对接点进行排序。** 另外,队列元素中不可以放置null元素。
|
||||
|
||||
`ConcurrentLinkedQueue` 整个继承关系如下图所示:
|
||||
|
||||

|
||||
|
||||
`ConcurrentLinkedQueue中`最主要的两个方法是:`offer(value)`和`poll()`,分别实现队列的两个重要的操作:入队和出队(`offer(value)`等价于 `add(value)`)。
|
||||
|
||||
我们添加一个元素到队列的时候,它会添加到队列的尾部,当我们获取一个元素时,它会返回队列头部的元素。
|
||||
|
||||
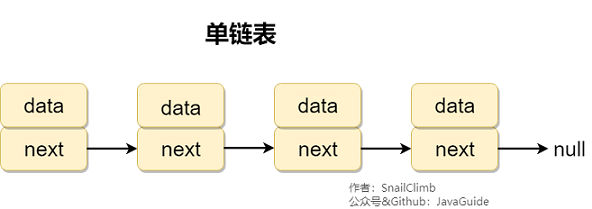
|
||||
|
||||
利用`ConcurrentLinkedQueue`队列先进先出的特性,每当我们 `put`/`get`(缓存被使用)元素的时候,我们就将这个元素存放在队列尾部,这样就能保证队列头部的元素是最近最少使用的。
|
||||
|
||||
### 3. ReadWriteLock简单介绍
|
||||
|
||||
`ReadWriteLock` 是一个接口,位于`java.util.concurrent.locks`包下,里面只有两个方法分别返回读锁和写锁:
|
||||
|
||||
```java
|
||||
public interface ReadWriteLock {
|
||||
/**
|
||||
* 返回读锁
|
||||
*/
|
||||
Lock readLock();
|
||||
|
||||
/**
|
||||
* 返回写锁
|
||||
*/
|
||||
Lock writeLock();
|
||||
}
|
||||
```
|
||||
|
||||
`ReentrantReadWriteLock` 是`ReadWriteLock`接口的具体实现类。
|
||||
|
||||
**读写锁还是比较适合缓存这种读多写少的场景。读写锁可以保证多个线程和同时读取,但是只有一个线程可以写入。**
|
||||
|
||||
读写锁的特点是:写锁和写锁互斥,读锁和写锁互斥,读锁之间不互斥。也就说:同一时刻只能有一个线程写,但是可以有多个线程
|
||||
读。读写之间是互斥的,两者不能同时发生(当进行写操作时,同一时刻其他线程的读操作会被阻塞;当进行读操作时,同一时刻所有线程的写操作会被阻塞)。
|
||||
|
||||
另外,**同一个线程持有写锁时是可以申请读锁,但是持有读锁的情况下不可以申请写锁。**
|
||||
|
||||
### 4. ScheduledExecutorService 简单介绍
|
||||
|
||||
`ScheduledExecutorService` 是一个接口,`ScheduledThreadPoolExecutor` 是其主要实现类。
|
||||
|
||||

|
||||
|
||||
**`ScheduledThreadPoolExecutor` 主要用来在给定的延迟后运行任务,或者定期执行任务。** 这个在实际项目用到的比较少,因为有其他方案选择比如`quartz`。但是,在一些需求比较简单的场景下还是非常有用的!
|
||||
|
||||
**`ScheduledThreadPoolExecutor` 使用的任务队列 `DelayQueue` 封装了一个 `PriorityQueue`,`PriorityQueue` 会对队列中的任务进行排序,执行所需时间短的放在前面先被执行,如果执行所需时间相同则先提交的任务将被先执行。**
|
||||
|
||||
### 5. 徒手撸一个线程安全的 LRU 缓存
|
||||
|
||||
#### 5.1. 实现方法
|
||||
|
||||
`ConcurrentHashMap` + `ConcurrentLinkedQueue` +`ReadWriteLock`
|
||||
|
||||
#### 5.2. 原理
|
||||
|
||||
`ConcurrentHashMap` 是线程安全的Map,我们可以利用它缓存 key,value形式的数据。`ConcurrentLinkedQueue`是一个线程安全的基于链表的队列(先进先出),我们可以用它来维护 key 。每当我们put/get(缓存被使用)元素的时候,我们就将这个元素对应的 key 存放在队列尾部,这样就能保证队列头部的元素是最近最少使用的。当我们的缓存容量不够的时候,我们直接移除队列头部对应的key以及这个key对应的缓存即可!
|
||||
|
||||
另外,我们用到了`ReadWriteLock`(读写锁)来保证线程安全。
|
||||
|
||||
#### 5.3. put方法具体流程分析
|
||||
|
||||
为了方便大家理解,我将代码中比较重要的 `put(key,value)`方法的原理图画了出来,如下图所示:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
#### 5.4. 源码
|
||||
|
||||
```java
|
||||
/**
|
||||
* @author shuang.kou
|
||||
* <p>
|
||||
* 使用 ConcurrentHashMap+ConcurrentLinkedQueue+ReadWriteLock实现线程安全的 LRU 缓存
|
||||
* 这里只是为了学习使用,本地缓存推荐使用 Guava 自带的,使用 Spring 的话,推荐使用Spring Cache
|
||||
*/
|
||||
public class MyLruCache<K, V> {
|
||||
|
||||
/**
|
||||
* 缓存的最大容量
|
||||
*/
|
||||
private final int maxCapacity;
|
||||
|
||||
private ConcurrentHashMap<K, V> cacheMap;
|
||||
private ConcurrentLinkedQueue<K> keys;
|
||||
/**
|
||||
* 读写锁
|
||||
*/
|
||||
private ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
|
||||
private Lock writeLock = readWriteLock.writeLock();
|
||||
private Lock readLock = readWriteLock.readLock();
|
||||
|
||||
public MyLruCache(int maxCapacity) {
|
||||
if (maxCapacity < 0) {
|
||||
throw new IllegalArgumentException("Illegal max capacity: " + maxCapacity);
|
||||
}
|
||||
this.maxCapacity = maxCapacity;
|
||||
cacheMap = new ConcurrentHashMap<>(maxCapacity);
|
||||
keys = new ConcurrentLinkedQueue<>();
|
||||
}
|
||||
|
||||
public V put(K key, V value) {
|
||||
// 加写锁
|
||||
writeLock.lock();
|
||||
try {
|
||||
//1.key是否存在于当前缓存
|
||||
if (cacheMap.containsKey(key)) {
|
||||
moveToTailOfQueue(key);
|
||||
cacheMap.put(key, value);
|
||||
return value;
|
||||
}
|
||||
//2.是否超出缓存容量,超出的话就移除队列头部的元素以及其对应的缓存
|
||||
if (cacheMap.size() == maxCapacity) {
|
||||
System.out.println("maxCapacity of cache reached");
|
||||
removeOldestKey();
|
||||
}
|
||||
//3.key不存在于当前缓存。将key添加到队列的尾部并且缓存key及其对应的元素
|
||||
keys.add(key);
|
||||
cacheMap.put(key, value);
|
||||
return value;
|
||||
} finally {
|
||||
writeLock.unlock();
|
||||
}
|
||||
}
|
||||
|
||||
public V get(K key) {
|
||||
//加读锁
|
||||
readLock.lock();
|
||||
try {
|
||||
//key是否存在于当前缓存
|
||||
if (cacheMap.containsKey(key)) {
|
||||
// 存在的话就将key移动到队列的尾部
|
||||
moveToTailOfQueue(key);
|
||||
return cacheMap.get(key);
|
||||
}
|
||||
//不存在于当前缓存中就返回Null
|
||||
return null;
|
||||
} finally {
|
||||
readLock.unlock();
|
||||
}
|
||||
}
|
||||
|
||||
public V remove(K key) {
|
||||
writeLock.lock();
|
||||
try {
|
||||
//key是否存在于当前缓存
|
||||
if (cacheMap.containsKey(key)) {
|
||||
// 存在移除队列和Map中对应的Key
|
||||
keys.remove(key);
|
||||
return cacheMap.remove(key);
|
||||
}
|
||||
//不存在于当前缓存中就返回Null
|
||||
return null;
|
||||
} finally {
|
||||
writeLock.unlock();
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* 将元素添加到队列的尾部(put/get的时候执行)
|
||||
*/
|
||||
private void moveToTailOfQueue(K key) {
|
||||
keys.remove(key);
|
||||
keys.add(key);
|
||||
}
|
||||
|
||||
/**
|
||||
* 移除队列头部的元素以及其对应的缓存 (缓存容量已满的时候执行)
|
||||
*/
|
||||
private void removeOldestKey() {
|
||||
K oldestKey = keys.poll();
|
||||
if (oldestKey != null) {
|
||||
cacheMap.remove(oldestKey);
|
||||
}
|
||||
}
|
||||
|
||||
public int size() {
|
||||
return cacheMap.size();
|
||||
}
|
||||
|
||||
}
|
||||
```
|
||||
|
||||
**非并发环境测试:**
|
||||
|
||||
```java
|
||||
MyLruCache<Integer, String> myLruCache = new MyLruCache<>(3);
|
||||
myLruCache.put(1, "Java");
|
||||
System.out.println(myLruCache.get(1));// Java
|
||||
myLruCache.remove(1);
|
||||
System.out.println(myLruCache.get(1));// null
|
||||
myLruCache.put(2, "C++");
|
||||
myLruCache.put(3, "Python");
|
||||
System.out.println(myLruCache.get(2));//C++
|
||||
myLruCache.put(4, "C");
|
||||
myLruCache.put(5, "PHP");
|
||||
System.out.println(myLruCache.get(2));// C++
|
||||
```
|
||||
|
||||
**并发环境测试:**
|
||||
|
||||
我们初始化了一个固定容量为 10 的线程池和count为10的`CountDownLatch`。我们将1000000次操作分10次添加到线程池,然后我们等待线程池执行完成这10次操作。
|
||||
|
||||
|
||||
```java
|
||||
int threadNum = 10;
|
||||
int batchSize = 100000;
|
||||
//init cache
|
||||
MyLruCache<String, Integer> myLruCache = new MyLruCache<>(batchSize * 10);
|
||||
//init thread pool with 10 threads
|
||||
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(threadNum);
|
||||
//init CountDownLatch with 10 count
|
||||
CountDownLatch latch = new CountDownLatch(threadNum);
|
||||
AtomicInteger atomicInteger = new AtomicInteger(0);
|
||||
long startTime = System.currentTimeMillis();
|
||||
for (int t = 0; t < threadNum; t++) {
|
||||
fixedThreadPool.submit(() -> {
|
||||
for (int i = 0; i < batchSize; i++) {
|
||||
int value = atomicInteger.incrementAndGet();
|
||||
myLruCache.put("id" + value, value);
|
||||
}
|
||||
latch.countDown();
|
||||
});
|
||||
}
|
||||
//wait for 10 threads to complete the task
|
||||
latch.await();
|
||||
fixedThreadPool.shutdown();
|
||||
System.out.println("Cache size:" + myLruCache.size());//Cache size:1000000
|
||||
long endTime = System.currentTimeMillis();
|
||||
long duration = endTime - startTime;
|
||||
System.out.println(String.format("Time cost:%dms", duration));//Time cost:511ms
|
||||
```
|
||||
|
||||
### 6. 实现一个线程安全并且带有过期时间的 LRU 缓存
|
||||
|
||||
实际上就是在我们上面时间的LRU缓存的基础上加上一个定时任务去删除缓存,单纯利用 JDK 提供的类,我们实现定时任务的方式有很多种:
|
||||
|
||||
1. `Timer` :不被推荐,多线程会存在问题。
|
||||
2. `ScheduledExecutorService` :定时器线程池,可以用来替代 `Timer`
|
||||
3. `DelayQueue` :延时队列
|
||||
4. `quartz` :一个很火的开源任务调度框架,很多其他框架都是基于 `quartz` 开发的,比如当当网的`elastic-job `就是基于`quartz`二次开发之后的分布式调度解决方案
|
||||
5. ......
|
||||
|
||||
最终我们选择了 `ScheduledExecutorService`,主要原因是它易用(基于`DelayQueue`做了很多封装)并且基本能满足我们的大部分需求。
|
||||
|
||||
我们在我们上面实现的线程安全的 LRU 缓存基础上,简单稍作修改即可!我们增加了一个方法:
|
||||
|
||||
```java
|
||||
private void removeAfterExpireTime(K key, long expireTime) {
|
||||
scheduledExecutorService.schedule(() -> {
|
||||
//过期后清除该键值对
|
||||
cacheMap.remove(key);
|
||||
keys.remove(key);
|
||||
}, expireTime, TimeUnit.MILLISECONDS);
|
||||
}
|
||||
```
|
||||
我们put元素的时候,如果通过这个方法就能直接设置过期时间。
|
||||
|
||||
|
||||
**完整源码如下:**
|
||||
|
||||
```java
|
||||
/**
|
||||
* @author shuang.kou
|
||||
* <p>
|
||||
* 使用 ConcurrentHashMap+ConcurrentLinkedQueue+ReadWriteLock+ScheduledExecutorService实现线程安全的 LRU 缓存
|
||||
* 这里只是为了学习使用,本地缓存推荐使用 Guava 自带的,使用 Spring 的话,推荐使用Spring Cache
|
||||
*/
|
||||
public class MyLruCacheWithExpireTime<K, V> {
|
||||
|
||||
/**
|
||||
* 缓存的最大容量
|
||||
*/
|
||||
private final int maxCapacity;
|
||||
|
||||
private ConcurrentHashMap<K, V> cacheMap;
|
||||
private ConcurrentLinkedQueue<K> keys;
|
||||
/**
|
||||
* 读写锁
|
||||
*/
|
||||
private ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
|
||||
private Lock writeLock = readWriteLock.writeLock();
|
||||
private Lock readLock = readWriteLock.readLock();
|
||||
|
||||
private ScheduledExecutorService scheduledExecutorService;
|
||||
|
||||
public MyLruCacheWithExpireTime(int maxCapacity) {
|
||||
if (maxCapacity < 0) {
|
||||
throw new IllegalArgumentException("Illegal max capacity: " + maxCapacity);
|
||||
}
|
||||
this.maxCapacity = maxCapacity;
|
||||
cacheMap = new ConcurrentHashMap<>(maxCapacity);
|
||||
keys = new ConcurrentLinkedQueue<>();
|
||||
scheduledExecutorService = Executors.newScheduledThreadPool(3);
|
||||
}
|
||||
|
||||
public V put(K key, V value, long expireTime) {
|
||||
// 加写锁
|
||||
writeLock.lock();
|
||||
try {
|
||||
//1.key是否存在于当前缓存
|
||||
if (cacheMap.containsKey(key)) {
|
||||
moveToTailOfQueue(key);
|
||||
cacheMap.put(key, value);
|
||||
return value;
|
||||
}
|
||||
//2.是否超出缓存容量,超出的话就移除队列头部的元素以及其对应的缓存
|
||||
if (cacheMap.size() == maxCapacity) {
|
||||
System.out.println("maxCapacity of cache reached");
|
||||
removeOldestKey();
|
||||
}
|
||||
//3.key不存在于当前缓存。将key添加到队列的尾部并且缓存key及其对应的元素
|
||||
keys.add(key);
|
||||
cacheMap.put(key, value);
|
||||
if (expireTime > 0) {
|
||||
removeAfterExpireTime(key, expireTime);
|
||||
}
|
||||
return value;
|
||||
} finally {
|
||||
writeLock.unlock();
|
||||
}
|
||||
}
|
||||
|
||||
public V get(K key) {
|
||||
//加读锁
|
||||
readLock.lock();
|
||||
try {
|
||||
//key是否存在于当前缓存
|
||||
if (cacheMap.containsKey(key)) {
|
||||
// 存在的话就将key移动到队列的尾部
|
||||
moveToTailOfQueue(key);
|
||||
return cacheMap.get(key);
|
||||
}
|
||||
//不存在于当前缓存中就返回Null
|
||||
return null;
|
||||
} finally {
|
||||
readLock.unlock();
|
||||
}
|
||||
}
|
||||
|
||||
public V remove(K key) {
|
||||
writeLock.lock();
|
||||
try {
|
||||
//key是否存在于当前缓存
|
||||
if (cacheMap.containsKey(key)) {
|
||||
// 存在移除队列和Map中对应的Key
|
||||
keys.remove(key);
|
||||
return cacheMap.remove(key);
|
||||
}
|
||||
//不存在于当前缓存中就返回Null
|
||||
return null;
|
||||
} finally {
|
||||
writeLock.unlock();
|
||||
}
|
||||
}
|
||||
|
||||
/**
|
||||
* 将元素添加到队列的尾部(put/get的时候执行)
|
||||
*/
|
||||
private void moveToTailOfQueue(K key) {
|
||||
keys.remove(key);
|
||||
keys.add(key);
|
||||
}
|
||||
|
||||
/**
|
||||
* 移除队列头部的元素以及其对应的缓存 (缓存容量已满的时候执行)
|
||||
*/
|
||||
private void removeOldestKey() {
|
||||
K oldestKey = keys.poll();
|
||||
if (oldestKey != null) {
|
||||
cacheMap.remove(oldestKey);
|
||||
}
|
||||
}
|
||||
|
||||
private void removeAfterExpireTime(K key, long expireTime) {
|
||||
scheduledExecutorService.schedule(() -> {
|
||||
//过期后清除该键值对
|
||||
cacheMap.remove(key);
|
||||
keys.remove(key);
|
||||
}, expireTime, TimeUnit.MILLISECONDS);
|
||||
}
|
||||
|
||||
public int size() {
|
||||
return cacheMap.size();
|
||||
}
|
||||
|
||||
}
|
||||
|
||||
```
|
||||
|
||||
**测试效果:**
|
||||
|
||||
```java
|
||||
MyLruCacheWithExpireTime<Integer,String> myLruCache = new MyLruCacheWithExpireTime<>(3);
|
||||
myLruCache.put(1,"Java",3000);
|
||||
myLruCache.put(2,"C++",3000);
|
||||
myLruCache.put(3,"Python",1500);
|
||||
System.out.println(myLruCache.size());//3
|
||||
Thread.sleep(2000);
|
||||
System.out.println(myLruCache.size());//2
|
||||
```
|
||||
{kind=link}
|
Before Width: | Height: | Size: 69 KiB After Width: | Height: | Size: 69 KiB |
{kind=link}
|
Before Width: | Height: | Size: 155 KiB After Width: | Height: | Size: 155 KiB |
{kind=link}
|
Before Width: | Height: | Size: 212 KiB After Width: | Height: | Size: 212 KiB |
{kind=link}
|
Before Width: | Height: | Size: 32 KiB After Width: | Height: | Size: 32 KiB |
{kind=link}
|
Before Width: | Height: | Size: 40 KiB After Width: | Height: | Size: 40 KiB |
{kind=link}
|
Before Width: | Height: | Size: 74 KiB After Width: | Height: | Size: 74 KiB |
{kind=link}
|
Before Width: | Height: | Size: 98 KiB After Width: | Height: | Size: 98 KiB |
{kind=link}
|
Before Width: | Height: | Size: 93 KiB After Width: | Height: | Size: 93 KiB |
{kind=link}
|
Before Width: | Height: | Size: 72 KiB After Width: | Height: | Size: 72 KiB |
{kind=link}
|
Before Width: | Height: | Size: 60 KiB After Width: | Height: | Size: 60 KiB |
{kind=link}
|
Before Width: | Height: | Size: 31 KiB After Width: | Height: | Size: 31 KiB |
{kind=link}
|
Before Width: | Height: | Size: 72 KiB After Width: | Height: | Size: 72 KiB |
{kind=link}
|
Before Width: | Height: | Size: 94 KiB After Width: | Height: | Size: 94 KiB |
{kind=link}
|
Before Width: | Height: | Size: 35 KiB After Width: | Height: | Size: 35 KiB |
{kind=link}
|
Before Width: | Height: | Size: 49 KiB After Width: | Height: | Size: 49 KiB |
{kind=link}
|
Before Width: | Height: | Size: 29 KiB After Width: | Height: | Size: 29 KiB |
{kind=link}
|
Before Width: | Height: | Size: 93 KiB After Width: | Height: | Size: 93 KiB |
{kind=link}
|
Before Width: | Height: | Size: 32 KiB After Width: | Height: | Size: 32 KiB |
{kind=link}
|
Before Width: | Height: | Size: 75 KiB After Width: | Height: | Size: 75 KiB |
{kind=link}
|
Before Width: | Height: | Size: 69 KiB After Width: | Height: | Size: 69 KiB |
{kind=link}
|
Before Width: | Height: | Size: 54 KiB After Width: | Height: | Size: 54 KiB |
{kind=link}
|
Before Width: | Height: | Size: 68 KiB After Width: | Height: | Size: 68 KiB |
{kind=link}
|
Before Width: | Height: | Size: 90 KiB After Width: | Height: | Size: 90 KiB |
{kind=link}
|
Before Width: | Height: | Size: 88 KiB After Width: | Height: | Size: 88 KiB |
{kind=link}
|
Before Width: | Height: | Size: 135 KiB After Width: | Height: | Size: 135 KiB |
{kind=link}
|
Before Width: | Height: | Size: 64 KiB After Width: | Height: | Size: 64 KiB |
{kind=link}
|
Before Width: | Height: | Size: 29 KiB After Width: | Height: | Size: 29 KiB |
{kind=link}
|
Before Width: | Height: | Size: 129 KiB After Width: | Height: | Size: 129 KiB |
{kind=link}
|
Before Width: | Height: | Size: 25 KiB After Width: | Height: | Size: 25 KiB |
{kind=link}
|
Before Width: | Height: | Size: 50 KiB After Width: | Height: | Size: 50 KiB |
{kind=link}
|
Before Width: | Height: | Size: 65 KiB After Width: | Height: | Size: 65 KiB |
{kind=link}
|
Before Width: | Height: | Size: 111 KiB After Width: | Height: | Size: 111 KiB |
{kind=link}
|
Before Width: | Height: | Size: 46 KiB After Width: | Height: | Size: 46 KiB |
{kind=link}
|
Before Width: | Height: | Size: 162 KiB After Width: | Height: | Size: 162 KiB |
{kind=link}
|
Before Width: | Height: | Size: 27 KiB After Width: | Height: | Size: 27 KiB |
{kind=link}
|
Before Width: | Height: | Size: 399 KiB After Width: | Height: | Size: 399 KiB |
{kind=link}
|
Before Width: | Height: | Size: 40 KiB After Width: | Height: | Size: 40 KiB |
{kind=link}
|
Before Width: | Height: | Size: 86 KiB After Width: | Height: | Size: 86 KiB |
{kind=link}
|
Before Width: | Height: | Size: 74 KiB After Width: | Height: | Size: 74 KiB |
{kind=link}
|
Before Width: | Height: | Size: 66 KiB After Width: | Height: | Size: 66 KiB |
{kind=link}
|
Before Width: | Height: | Size: 116 KiB After Width: | Height: | Size: 116 KiB |
{kind=link}
|
Before Width: | Height: | Size: 128 KiB After Width: | Height: | Size: 128 KiB |
{kind=link}
|
Before Width: | Height: | Size: 76 KiB After Width: | Height: | Size: 76 KiB |
{kind=link}
|
Before Width: | Height: | Size: 107 KiB After Width: | Height: | Size: 107 KiB |
{kind=link}
|
Before Width: | Height: | Size: 554 KiB After Width: | Height: | Size: 554 KiB |
@ -1,160 +0,0 @@
|
||||
<!-- TOC -->
|
||||
|
||||
- [Linux IO](#linux-io)
|
||||
- [操作系统的内核](#操作系统的内核)
|
||||
- [操作系统的用户态与内核态](#操作系统的用户态与内核态)
|
||||
- [为什么要有用户态与内核态?](#为什么要有用户态与内核态)
|
||||
- [用户态切换到内核态的几种方式](#用户态切换到内核态的几种方式)
|
||||
- [阻塞和非阻塞](#阻塞和非阻塞)
|
||||
- [同步与异步](#同步与异步)
|
||||
- [Linux IO 模型](#linux-io模型)
|
||||
- [阻塞 IO](#阻塞io)
|
||||
- [非阻塞 IO(网络 IO 模型)](#非阻塞io网络io模型)
|
||||
- [IO 多路复用(网络 IO 模型)](#io多路复用网络io模型)
|
||||
- [信号驱动 IO(网络 IO 模型)](#信号驱动io网络io模型)
|
||||
- [异步 IO](#异步io)
|
||||
|
||||
<!-- /TOC -->
|
||||
|
||||
# Linux IO
|
||||
|
||||
> 图源: https://www.jianshu.com/p/85e931636f27 (如有侵权,请联系俺,俺会立刻删除)
|
||||
|
||||
### 操作系统的内核
|
||||
|
||||
**操作系统的内核是操作系统的核心部分。它负责系统的内存,硬件设备,文件系统以及应用程序的管理。**
|
||||
|
||||
#### 操作系统的用户态与内核态
|
||||
|
||||
unix 与 linux 的体系架构:用户态与内核态。
|
||||
|
||||
用户态与内核态与内核态是操作系统对执行权限进行分级后的不同的运行模式。
|
||||
|
||||

|
||||
|
||||
#### 为什么要有用户态与内核态?
|
||||
|
||||
在 cpu 的所有指令中,有些指令是非常危险的,如果使用不当,将会造成系统崩溃等后果。为了避免这种情况发生,cpu 将指令划分为**特权级(内核态)指令**和**非特权级(用户态)指令。**
|
||||
|
||||
**对于那些危险的指令只允许内核及其相关模块调用,对于那些不会造成危险的指令,就允许用户应用程序调用。**
|
||||
|
||||
- 内核态(核心态,特权态): **内核态是操作系统内核运行的模式。** 内核态控制计算机的硬件资源,如硬件设备,文件系统等等,并为上层应用程序提供执行环境。
|
||||
- 用户态: **用户态是用户应用程序运行的状态。** 应用程序必须依托于内核态运行,因此用户态的态的操作权限比内核态是要低的,如磁盘,文件等,访问操作都是受限的。
|
||||
- 系统调用: 系统调用是操作系统为应用程序提供能够访问到内核态的资源的接口。
|
||||
|
||||
#### 用户态切换到内核态的几种方式
|
||||
|
||||
- 系统调用: 系统调用是用户态主动要求切换到内核态的一种方式,用户应用程序通过操作系统调用内核为上层应用程序开放的接口来执行程序。
|
||||
- 异常: 当 cpu 在执行用户态的应用程序时,发生了某些不可知的异常。于是当前用户态的应用进程切换到处理此异常的内核的程序中去。
|
||||
- 硬件设备的中断: 当硬件设备完成用户请求后,会向 cpu 发出相应的中断信号,这时 cpu 会暂停执行下一条即将要执行的指令,转而去执行与中断信号对应的应用程序,如果先前执行的指令是用户态下程序的指令,那么这个转换过程也是用户态到内核台的转换。
|
||||
|
||||
#### 阻塞和非阻塞
|
||||
|
||||
1. 阻塞: 一个线程调用一个方法计算 1 - 100 的和,如果该方法没有返回结果,
|
||||
那么调用方法的线程就一直等待直到该方法执行完毕。
|
||||
2. 非阻塞: 一个线程调用一个方法计算 1 - 100 的和,该方法立刻返回,如果方法返回没有结果,
|
||||
调用者线程也无需一直等待该方法的结果,可以执行其他任务,但是在方法返回结果之前,
|
||||
**线程仍然需要轮询的检查方法是否已经有结果。**
|
||||
|
||||
**结论: 阻塞与非阻塞针对调用者的立场而言。**
|
||||
|
||||
#### 同步与异步
|
||||
|
||||
1. **同步**: 一个线程调用一个方法计算 1 - 100 的和,如果方法没有计算完,就不返回。
|
||||
2. **异步**: 一个线程调用一个方法计算 1 - 100 的和,该方法立刻返回,但是由于方法没有返回结果,
|
||||
所以就需要被调用的这个方法来通知调用线程 1 - 100 的结果,
|
||||
或者线程在调用方法的时候指定一个回调函数来告诉被调用的方法执行完后就执行回调函数。
|
||||
|
||||
**结论:同步和异步是针对被调用者的立场而言的。**
|
||||
|
||||
### Linux IO 模型
|
||||
|
||||
Linux 下共有 5 种 IO 模型:
|
||||
|
||||
1. 阻塞 IO
|
||||
2. 非阻塞 IO
|
||||
3. IO 多路复用
|
||||
4. 信号驱动 IO
|
||||
5. 异步 IO
|
||||
|
||||
#### 阻塞 IO
|
||||
|
||||
阻塞 IO 是很常见的一种 IO 模型。在这种模型中,**用户态的应用程序会执行一个操作系统的调用,检查内核的数据是否准备好。如果内核的数据已经准备好,就把数据复制到用户应用进程。如果内核没有准备好数据,那么用户应用进程(线程)就阻塞,直到内核准备好数据并把数据从内核复制到用户应用进程,** 最后应用程序再处理数据。
|
||||
|
||||

|
||||
|
||||
**阻塞 IO 是同步阻塞的。**
|
||||
|
||||
1. 阻塞 IO 的同步体现在: **内核只有准备好数据并把数据复制到用户应用进程才会返回。**
|
||||
|
||||
2. 阻塞 IO 的阻塞体现在:**用户应用进程等待内核准备数据和把数据从用户态拷贝到内核态的这整个过程,
|
||||
用户应用进程都必须一直等待。** 当然,如果是本地磁盘 IO,内核准备数据的时间可能会很短。但网络 IO 就不一样了,因为服务端不知道客户端何时发送数据,内核就仍需要等待 socket 数据,时间就可能会很长。
|
||||
|
||||
**阻塞 IO 的优点是对于数据是能够保证无延时的,因为应用程序进程会一直阻塞直到 IO 完成。**但应用程序的阻塞就意味着应用程序进程无法执行其他任务,这会大大降低程序性能。一个不太可行的办法是为每个客户端 socket 都分配一个线程,这样就会提升 server 处理请求的能力。不过操作系统的线程资源是有限的,如果请求过多,可能造成线程资源耗尽,系统卡死等后果。
|
||||
|
||||
#### 非阻塞 IO(网络 IO 模型)
|
||||
|
||||
在非阻塞 IO 模型中,用户态的应用程序也会执行一个操作系统的调用,检查内核的数据是否准备完成。**如果内核没有准备好数据,
|
||||
内核会立刻返回结果,用户应用进程不用一直阻塞等待内核准备数据,而是可以执行其他任务,但仍需要不断的向内核发起系统调用,检测数据是否准备好,这个过程就叫轮询。** 轮询直到内核准备好数据,然后内核把数据拷贝到用户应用进程,再进行数据处理。
|
||||
|
||||

|
||||
|
||||
非阻塞 IO 的非阻塞体现在: **用户应用进程不用阻塞在对内核的系统调用上**
|
||||
|
||||
非阻塞 IO 的优点在于用户应用进程在轮询阶段可以执行其它任务。但这也是它的缺点,轮询就代表着用户应用进程不是时刻都会发起系统调用。
|
||||
**可能数据准备好了,而用户应用进程可能等待其它任务执行完毕才会发起系统调用,这就意味着数据可能会被延时获取。**
|
||||
|
||||
#### IO 多路复用(网络 IO 模型)
|
||||
|
||||
在 IO 多路复用模型中,**用户应用进程会调用操作系统的 select/poll/epoll 函数,它会使内核同步的轮询指定的 socket,
|
||||
(在 NIO 中,socket 就是注册到 Selector 上的 SocketChannel,可以允许多个)直至监听的 socket 有数据可读或可写,select/poll/epoll 函数才会返回,用户应用进程也会阻塞的等待 select/poll/epoll 函数返回。**
|
||||
|
||||
当 select/poll/epoll 函数返回后,即某个 socket 有事件发生了,用户应用进程就会发起系统调用,处理事件,将 socket 数据复制到用户进程内,然后进行数据处理。
|
||||
|
||||

|
||||
|
||||
**IO 多路复用模型是同步阻塞的**
|
||||
|
||||
1. IO 多路复用模型的同步体现在: **select 函数只有监听到某个 socket 有事件才会返回。**
|
||||
|
||||
2. IO 多路复用模型的阻塞体现在: **用户应用进程会阻塞在对 select 函数上的调用上。**
|
||||
|
||||
**IO 多路复用的优点在于内核可以处理多个 socket,相当于一个用户进程(线程)就可以处理多个 socket 连接。**
|
||||
|
||||
这样不仅降低了系统的开销,并且对于需要高并发的应用是非常有利的。而非阻塞 IO 和阻塞 IO 的一个用户应用进程只能处理一个 socket,要想处理多 socket,只能新开进程或线程,但这样很消耗系统资源。
|
||||
|
||||
**PS:
|
||||
在 IO 多路复用模型中, socket 一般应该为非阻塞的,这就是 Java 中 NIO 被称为非阻塞 IO 的原因。但实际上 NIO 属于 IO 多路复用,它是同步阻塞的 IO。具体原因见 [知乎讨论](https://www.zhihu.com/question/37271342)**
|
||||
|
||||
**PS:
|
||||
select/poll/epoll 函数是 IO 多路复用模型的基础,所以如果想深入了解 IO 多路复用模型,就需要了解这 3 个函数以及它们的优缺点。**
|
||||
|
||||
#### 信号驱动 IO(网络 IO 模型)
|
||||
|
||||
在信号驱动 IO 模型中,**用户应用进程发起 sigaction 系统调用,内核收到并立即返回。用户应用进程可以继续执行其他任务,不会阻塞。当内核准备好数据后向用户应用进程发送 SIGIO 信号,应用进程收到信号后,发起系统调用,将数据从内核拷贝到用户进程,** 然后进行数据处理。
|
||||
|
||||

|
||||
|
||||
个人感觉在内核收到系统调用就立刻返回这一点很像异步 IO 的方式了,不过与异步 IO 仍有很大差别。
|
||||
|
||||
#### 异步 IO
|
||||
|
||||
在异步 IO 模型中,**用户进程发起 aio_read 系统调用,无论内核的数据是否准备好,都会立即返回。用户应用进程不会阻塞,可以继续执行其他任务。当内核准备好数据,会直接把数据复制到用户应用进程。最后内核会通知用户应用进程 IO 完成。**
|
||||
|
||||

|
||||
|
||||
**异步 IO 的异步体现在:内核不用等待数据准备好就立刻返回,所以内核肯定需要在 IO 完成后通知用户应用进程。**
|
||||
|
||||
---
|
||||
|
||||
```text
|
||||
弄清楚了阻塞与非阻塞,同步与异步和上面5种IO模型,相信再看
|
||||
Java中的IO模型,也只是换汤不换药。
|
||||
```
|
||||
|
||||
- BIO : 阻塞 IO
|
||||
- NIO : IO 多路复用
|
||||
- AIO : 异步 IO
|
||||
|
||||
本来打算写 Java 中的 IO 模型的,发现上面几乎讲完了(剩 API 使用吧),没啥要写的了,
|
||||
所以暂时就这样吧。如果各位同学有好的建议,欢迎 pr 或 issue。
|
||||
@ -1,252 +0,0 @@
|
||||
<!-- TOC -->
|
||||
|
||||
* [完全使用GNU/Linux学习](#完全使用gnulinux学习)
|
||||
* [为什么要写这篇文章?](#为什么要写这篇文章)
|
||||
* [为什么我要从Windows切换到Linux?](#为什么我要从windows切换到linux)
|
||||
* [Linux作为日常使用的缺点](#linux作为日常使用的缺点)
|
||||
* [硬件驱动问题](#硬件驱动问题)
|
||||
* [软件问题](#软件问题)
|
||||
* [你真的需要完全使用Linux吗?](#你真的需要完全使用linux吗)
|
||||
* [结尾](#结尾)
|
||||
* [我使用Debian/Ubuntu时遇到的问题](#我使用debianubuntu时遇到的问题)
|
||||
* [IDEA编辑Markdown预渲染问题](#idea编辑markdown预渲染问题)
|
||||
* [wifi适配器找不到](#wifi适配器找不到)
|
||||
* [XMind安装](#xmind安装)
|
||||
* [Fcitx候选框的定位问题](#fcitx候选框的定位问题)
|
||||
|
||||
<!-- /TOC -->
|
||||
|
||||
# 完全使用GNU/Linux学习
|
||||
|
||||
喔,看到这个标题千万不要以为我要写和王垠前辈一样的内容啊,嘿嘿。不过在这里还是献上王垠前辈的那篇文章的链接吧:[完全用Linux工作](https://www.douban.com/group/topic/12121637/)。
|
||||
|
||||
## 为什么要写这篇文章?
|
||||
|
||||
首先介绍本篇文章产出的时间,现在是2020/04/06。在三,四天之前,我其实并没有写这篇文章的打算,但是这三,四天以来,我一直在忙活从Ubuntu18换到Debian10 Buster的事情,没有时间写代码,手确实有些痒了。你可能想象不到,我这个之前一直使用Ubuntu的人,只是切换到Debian就花这么长时间,你可能以为我是在劝退各位同学,其实不是的,我只是想表达:我对Linux并不熟悉,这其中一部分原因是我使用的是对用户较为友好的发行版Ubuntu,另一部分原因是我仍然没有那么大的动力去学习Linux,即使它一直作为我的日常使用。
|
||||
|
||||
这篇文章并不是吹嘘或贬低Windows和Linux系统,而是想记录一下我一直以来使用Linux作为日常学习的心得,以及这几天再度折腾Debian以来的感触。
|
||||
|
||||
|
||||
|
||||
## 为什么我要从Windows切换到Linux?
|
||||
|
||||
Windows是商业软件,这使它具备易用的性质。Linux是自由软件,这使得它拥有开源的性质。
|
||||
|
||||
易用软件通常带来的是对用户的友好度,以致于Windows发展至今,被许许多多的普通用户所采用。自由软件通常带来的是其社区的发展,所以你现在可以在网上看到许多如 ask ubuntu 这样的论坛。
|
||||
|
||||
我非常赞同《完全用Linux工作》中的一个观点: **UNIX 不是计算机专家的专利。**
|
||||
|
||||
我对这句话的理解就是:即使你学习或工作的方向不是计算机,但你仍然可以去学习Unix/Linux,如果你是计算机方向的同学,那么,你就更应该去学习Unix/Linux了。
|
||||
|
||||
但这只是我从Win切换到Linux的一部分原因,另一个很重要的原因是我受够了Windows的 “易用性”。这里的易用性并不是说我排斥Windows的人性化,而是因为人性化给我带来了很多学习上的困难。举个很简单的栗子:你在学习一项技术的时候,无论是否有面试造火箭的需要,你是否都会好奇想了解其原理和实现,即使你可能知道它很复杂。
|
||||
|
||||
**为什么你会好奇一个事物的源头?**
|
||||
|
||||
我个人认为的答案是:有趣的事情就在眼前,为什么不去了解它呢?
|
||||
|
||||
而Windows只是有趣,但它并不在“眼前”。
|
||||
|
||||
我个人的体验哈,不知道有没有同学和我一样的经历,在很多时候,你的Windows可能会出现一些莫名奇妙的问题,但你却不知道如何解决它,你只能求助搜索引擎,当你解决完问题后,你不会想要去了解为什么会发生这种问题,因为Windows太庞大了。
|
||||
|
||||
就比如: 我现在安装了Git,使用起来没有任何问题。但等到过一段时间后,Git莫名奇妙的不能使用了,明明你啥都没干。更甚之,有一些流氓问题或流氓软件不能被解决和被屏蔽。
|
||||
|
||||
问题出现了,总得要解决吧,所以此时你开始在互联网上查询相关问题的解决方法,如果你的运气好,那么有人可能遇到过和你出现相同的问题,你也因此可能会得到答案。不过一般的答案只是教你怎么解决的,如打开注册表,添加或删除某个key,你不会想要知道为什么做,因为对于初学者来说,当你看到注册表那么多的内容时,你只想着不出错就行了,哪还有心思去学习这玩意啊。如果你的运气不好,且并没有更换系统的打算,那么你可能会将就着使用,但此时,你的心里可能已经衍生了对Windows的厌烦情绪。
|
||||
|
||||
我对流氓软件的定义是:当你想让一个软件如你的想法停止运行或停止弹出广告的时候,这个软件不能或不能做的很好的达到你的要求时,这就是一个流氓软件。你也许会说,每个人都有不同的要求,软件怎么可能达到每个人的标准呢?但我指的是停止和停止弹出广告等这样最基本的诉求,如果一个软件连最基本的诉求都实现不了,又何必再使用它呢?
|
||||
|
||||
综上所述,我从Window切换到Linux的最主要的原因有:**学习和自由。**
|
||||
|
||||
是的,你不得不承认Linux是你学习计算机的非常好的环境,与C/C++天然的集成,比你在Windows上冷冰冰的安装一个IDE就开始敲起代码来,显得多了那么一点感觉。
|
||||
|
||||
还有一点,可能有的同学和我一样,刚接触Linux的时候,是在Windows上安装一个虚拟机环境或使用Docker来进行学习。不可否认,这确实是在Windows上学习Linux的主要途径了,但是你有没有感觉到,你在采取这种方式学习的时候,对Linux始终有种陌生感,似乎我只是在为了学习而学习。
|
||||
|
||||
产生这种想法的主要原因就是你没有融入到Linux环境之中,当你融入到Linux环境之中时,你不再只是需要学习那些操作命令,你会不可避免的遇到某个你从来没有接触过的问题,这个问题不是你在Windows上“丢失图标”的那种烦人问题,而可能是令你有些害怕的因为Nvidia的驱动而黑屏的问题。你也会在互联网上查询为什么会出现这种问题,但你得到的并不是“修改注册表”这种答案,而是会学习到:为什么Nvidia在Linux上会出现这种问题?我怎么做才能解决驱动问题?其他驱动是否也有类似Nvidia这种问题? 当你解决问题后,你的电脑开始正常工作了,你便开始使用它作为你的日常使用...
|
||||
|
||||
关于使用Linux学习的原因的最后一点是我认为自己不够慎独,不够克制。当我使用Windows的时候,并不能完全克制住自己接触那些新鲜游戏的念头,我玩起游戏来,通常会连续很长时间,可能是一天-_-。不过我并不是说Linux上没有游戏,相反,Linux是对很多游戏的支持是很好的,你可以玩到很多游戏,但你是否会因为使用Linux对游戏不再那么执着,至少我是如此了。这一点可以归结为“使用Linux对戒游戏有帮助吧” ,哈哈。
|
||||
|
||||
再谈谈自由:
|
||||
|
||||
我对自由的理解是:软件在你的掌控之中,你可以了解它的每一部分,你可以去到你想到达的地方,不受任何限制,这只取决于你愿不愿意。
|
||||
|
||||
来看看基本的Linux目录吧:
|
||||
|
||||

|
||||
|
||||
这些目录你可能有很多都不认识,但没关系,因为这就是Linux系统(大部分)所有的目录了,你稍微了解下,就知道这些目录里放的是什么文件了。
|
||||
|
||||
这也是我个人的体验而已,总之,Linux的自由是一种开源精神,比我描述的可大的多。至于Windows,我到现在连C盘的目录放了些什么都不太熟悉,但我并不是在贬低Windows,因为这就是Windows易用性的代价,相应的,Linux作为自由软件,它也有很多缺点。
|
||||
|
||||
|
||||
|
||||
## Linux作为日常使用的缺点
|
||||
|
||||
### 硬件驱动问题
|
||||
|
||||
硬件驱动问题一般是在安装Linux时会出现的问题,根据个人电脑配置的不同,你的电脑的硬件驱动可能与要安装的Linux发行版不兼容,导致系统出现相应的问题。我这几天对驱动问题最深刻的体会就明白了为啥Linus大神会吐槽: “Nvidia Fuck You”。很多驱动厂商对Linux系统是闭源的,你可以下载这些厂商的驱动,但是能不能用,或者用起来有什么毛病都得你自己买单。
|
||||
|
||||
随着Linux开始在普通用户中变得流行起来,我相信今后Linux的生态会发展的越来越好,且现在很多Linux发行版对各种硬件的兼容性也越来越好,就以我之前使用的Ubuntu18来说,Nvidia,Wifi,蓝牙等驱动使用都是没啥问题的。我现在使用的Debian10 Buster对Nvidia的支持可能还不是那么好,使用起来总有一些小毛病,不过无伤大雅,其实没毛病我还有点不适应,不是说Debian是Ubuntu的爸爸吗,哈哈。
|
||||
|
||||
|
||||
|
||||
### 软件问题
|
||||
|
||||
不得不承认的一点是Linux的软件生态确实没有Windows那么丰富,你在考虑切换系统之前,必须先调查清楚Linux上是否有你必需的软件,你所需的软件是否支持跨平台或者是否有可替代的应用。我个人对软件要求较为简单,大部分都是生产力工具,其他的应用如娱乐软件之类的都可以使用网页版作为替代。如果你在Linux系统上想尝试游戏的话,我认为也是OK的,因为我也尝试过Linux Dota2 ,体验非常好(不是广告-_-)。不过大多数国内游戏厂商对Linux的支持都是很差的,所以如果过不了这道坎,也不要切换系统了。
|
||||
|
||||
软件问题其实可以分为2部分看待,一部分就是刚刚介绍过的生态问题,另一部分就是当你在使用某些软件的时候,总会出现某些小Bug。
|
||||
|
||||
就以Fcitx来说,Fcitx是一款通用的Linux输入法框架,被称为小企鹅输入法,很多输入法都是在Fcitx之上开发的,如搜狗,Googlepinyin,Sunpinyin等。使用过Fcitx的同学可能会遇到这种问题:当你在使用Fcitx在某些软件上打字时,候选框并不会跟随你光标的位置,而是总会固定在某一个位置,并且你无法改变,这个问题是我目前见过的最大Bug。不过这个Bug只在部分软件上有,在Chrome,Typora上都没有这个问题,这让我怀疑是软件的国际化问题,而非Fcitx问题。
|
||||
|
||||
所以第二个部分总结起来就是某些软件可能会出现某些未知的Bug,你得寻求解决的办法,或者忍耐使用,使用Linux也是得牺牲一些代价的。
|
||||
|
||||
|
||||
|
||||
## 你真的需要完全使用Linux吗?
|
||||
|
||||
说到这里,其实我想借用知乎某位前辈的话来表达一下我的真实想法: “**Linux最好的地方在与开放自由,最大的毛病也是在这里。普通人没有能力去选择,也没有时间做选择。透明就一定好么?也有很多人喜欢被安排啊!**“ ([知乎 - 汉卿](https://www.zhihu.com/question/309704636))
|
||||
|
||||
就像我开头说过的: “我对Linux并不熟悉,这其中一部分原因是我使用的是对用户较为友好的发行版Ubuntu,另一部分原因是我仍然没有那么大的动力去学习Linux,即使它一直作为我的日常使用。”
|
||||
|
||||
我完全使用Linux是为了学习和自由,我确实在Linux上感受到了自由,且学到了很多东西,但我却一直沉溺在这种使用Linux带来的满足感之中,并不能真正理解Linux给我们带来的到底是什么。
|
||||
|
||||
这次从Ubuntu切换到Debian的原因是我想尝试换个新的环境,但是当我花了3,4天后,我明白了:我只是呆在一个地方久了,想换个新地方而已,但老地方不一定坏,因为我都没怎么了解过这个老地方,就像当初我从Windows换到Linux那样,我都没有深入的了解过Windows就换了,那一段时间我还抱怨Windows的各种缺点,现在看来,非常可笑。
|
||||
|
||||
|
||||
|
||||
#### 结尾
|
||||
|
||||
一文把想说的话几乎都给说了,个人文笔有限,且本文主观意识太强,如果觉得本文不符合您的胃口,就当看个笑话吧。
|
||||
|
||||
|
||||
---
|
||||
|
||||
## 我使用Debian/Ubuntu时遇到的问题
|
||||
|
||||
**以下内容是我在Debian10 Buster下遇到的问题以及相关解决办法,
|
||||
使用Ubuntu和Debian其他版本的同学也可借鉴。**
|
||||
|
||||
PS:欢迎各位同学在此处写下你遇到的问题和解决办法。
|
||||
|
||||
### IDEA编辑Markdown预渲染问题
|
||||
这个问题花了我很长时间。
|
||||
|
||||
当我安装IDEA后,使用它编辑markdown文件的时候,就出现了如下图所示的情况:
|
||||
|
||||

|
||||
|
||||
你可以看到右边渲染的画面明显有问题。刚开始的时候我一度怀疑是IDEA版本的问题,
|
||||
于是我又安装IDEA其他版本,但也没有任何作用,这时我怀疑是显卡的原因:
|
||||
|
||||

|
||||
|
||||
可以看到使用的是Intel的核显,于是当我查询相关资料,使用脚本将核显换为了独显,这里没留截图,当你换到独显后,
|
||||
图形会显示独显的配置,使用nvidia-smi命令可以查看独显使用状态。
|
||||
于是我满怀期待的打开IDEA,但还是无济于事。当我以为真的是Debian的Bug的时候,
|
||||
我又发现Bumblebee可以管理显卡,何不一试?于是我安装Bumblebee后,使用optirun命令启动IDEA,没想到啊,
|
||||
还真是可以:
|
||||
|
||||

|
||||
|
||||
我真的就很奇怪,同样是使用了独显,为什么optirun启动就可以正常显示。
|
||||
于是我后来又查询optirun是否开启了gpu加速,但很可惜,我并没有得到相关答案,不过这让我确定了这个问题出现在
|
||||
显卡上。如果有知道原因的同学,敬请告之,感激不尽。
|
||||
|
||||
|
||||
### wifi适配器找不到
|
||||
我猜(不确定)这个问题应该发生在大多数使用联想笔记本的同学的电脑上,不止Debian,且Ubuntu也有这个问题。
|
||||
当安装完系统后,我们打开设置会发现wifi一栏显示 “wifi适配器找不到” 此类的错误信息。
|
||||
这个问题的大概原因是:无线网络适配器被阻塞了,需要手动将电脑上的wifi开关打开,而在我的笔记本上并wifi开关,
|
||||
所以可以猜测是联想网络驱动的问题。
|
||||
可以使用 rfkill list all命令查询你的wlan是否被阻塞了,没有此命令的同学可以使用
|
||||
|
||||
````text
|
||||
sudo apt-get install rfkill
|
||||
````
|
||||
|
||||
安装,当wlan显示Hard blocked: true , 就证明你的无线驱动被阻塞了。
|
||||
解决办法是将阻塞无限驱动的那个模块从内核中移除掉,直接在 /etc/modprobe.d
|
||||
目录下编辑 blacklist.conf文件,其内容为:
|
||||
|
||||
````text
|
||||
blacklist ideapad_laptop
|
||||
````
|
||||
|
||||
文件名不一定要与我的一致,但是要以.conf结尾。
|
||||
你可以将modprobe.d目录下的文件理解为黑名单文件,
|
||||
当Linux启动时就不会加载conf文件指定的模块,
|
||||
这里的 ideapad_laptop 就是我们需要移除的那个无线模块。
|
||||
|
||||
**后遗症:
|
||||
当我们移除 ideapad_laptop 模块后,以后开机的时候,有时会出现
|
||||
蓝牙适配器找不到的情况,之前在Ubuntu上却并未发现这种问题,
|
||||
看来Debian在驱动方面没有Ubuntu做的好,不过这也是可以理解的,
|
||||
而且大多数时候还是可以正常使用的-_-。**
|
||||
|
||||
|
||||
### XMind安装
|
||||
XMind是使用Java编写的,依赖于Openjdk8。所以在Linux上使用XMind,
|
||||
首先需要有Openjdk8的环境。
|
||||
其次启动的时候需要编写Shell脚本来启动(不是唯一办法,但却是非常简单的办法),没想到吧,我也没想到,
|
||||
这也是我趟过很多坑才玩出来的。
|
||||
|
||||
首先我们需要准备一张XMind的软件启动图片:XMind.png,
|
||||
这个我已经放到[目录](https://github.com/guang19/framework-learning/tree/dev/img/linux)
|
||||
下了,需要的同学请自取。
|
||||
|
||||
其次我们进入XMind_amd64目录下,32位系统的同学进入XMind_i386目录,
|
||||
我们创建并编辑 start.sh 脚本,其内容为:
|
||||
|
||||
````text
|
||||
#!/bin/bash
|
||||
cd /home/guang19/SDK/xmind/XMind_amd64 (这个路径为你的XMind脚本的路径)
|
||||
./XMind
|
||||
````
|
||||
|
||||
这个脚本的内容很简单吧,当启动脚本的时候,进入目录,直接启动XMind。
|
||||
|
||||
脚本写完后需要让它能够被执行,使用
|
||||
|
||||
````text
|
||||
chmod +x start.sh
|
||||
````
|
||||
|
||||
命令让start.sh可以被执行。
|
||||
|
||||
此时你可以尝试执行 ./start.sh 命令来启动XMind,启动成功的话,
|
||||
就已经完成了99%了,如果启动不成功,可以再检测下前面的步骤是否有误。
|
||||
|
||||
如果以后你只想用Shell启动XMind的话,那么到此也就为止了,连上面所说的图片都不需要了。
|
||||
如果你想更方便的启动的话,那么就需要创建桌面文件启动。
|
||||
在Debian/Ubuntu下,你所看到的桌面文件,都存储在 /usr/share/applications
|
||||
目录下面(也有的在.local/share/applications目录下),这个目录下文件全是以.desktop结尾。
|
||||
我们现在就需要在这个目录下创建xmind.desktop文件(名字可以不叫xmind)。
|
||||
|
||||
其内容为:
|
||||
|
||||
````text
|
||||
[Desktop Entry]
|
||||
Encoding=UTF-8
|
||||
Name=XMind
|
||||
Type=Application
|
||||
Exec=sh /home/guang19/SDK/xmind/XMind_amd64/start.sh
|
||||
Icon=/home/guang19/SDK/xmind/XMind.png
|
||||
````
|
||||
|
||||
我们暂时只需要理解Icon和Exec属性。
|
||||
Icon就是你在桌面上看到的应用的图标,把Icon的路径改为你XMind.png的路径就行了。
|
||||
再看Exec属性,当我们在桌面上点击XMind的图标的时候,就会执行Exec对应的命令或脚本,
|
||||
我们把Exec改为start.sh文件的路径就行了,别掉了sh命令,因为start.sh是脚本,
|
||||
需要sh命令启动。
|
||||
|
||||
以上步骤完成,保存desktop文件后,你就可以在桌面上看到XMind应用了。
|
||||
|
||||
|
||||
### Fcitx候选框的定位问题
|
||||
这个问题贴一张我处境的截图就明白了:
|
||||
|
||||

|
||||
|
||||
可以看到我的光标定位在第207行,但是我输入法的候选框停留在IDEA的左下角。
|
||||
为什么我要说停留在IDEA的左下角?因为就目前我的使用而言,这个问题只在IDEA下存在,
|
||||
不仅是Debian,Ubuntu也存在这种问题,我个人认为这应该是IDEA的问题,
|
||||
查到的相关文章大部分都是说Swing的问题,看来这个问题还真是比较困难了。
|
||||
如果有同学知道解决办法,还请不吝分享,非常感谢。
|
||||
@ -1,323 +0,0 @@
|
||||
> 本文由 JavaGuide 读者推荐,JavaGuide 对文章进行了整理排版!原文地址:https://www.wmyskxz.com/2019/07/17/kafka-ru-men-jiu-zhe-yi-pian/ , 作者:我没有三颗心脏。
|
||||
|
||||
# 一、Kafka 简介
|
||||
|
||||
------
|
||||
|
||||
## Kafka 创建背景
|
||||
|
||||
**Kafka** 是一个消息系统,原本开发自 LinkedIn,用作 LinkedIn 的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础。现在它已被[多家不同类型的公司](https://cwiki.apache.org/confluence/display/KAFKA/Powered+By) 作为多种类型的数据管道和消息系统使用。
|
||||
|
||||
**活动流数据**是几乎所有站点在对其网站使用情况做报表时都要用到的数据中最常规的部分。活动数据包括页面访问量(Page View)、被查看内容方面的信息以及搜索情况等内容。这种数据通常的处理方式是先把各种活动以日志的形式写入某种文件,然后周期性地对这些文件进行统计分析。**运营数据**指的是服务器的性能数据(CPU、IO 使用率、请求时间、服务日志等等数据)。运营数据的统计方法种类繁多。
|
||||
|
||||
近年来,活动和运营数据处理已经成为了网站软件产品特性中一个至关重要的组成部分,这就需要一套稍微更加复杂的基础设施对其提供支持。
|
||||
|
||||
## Kafka 简介
|
||||
|
||||
**Kafka 是一种分布式的,基于发布 / 订阅的消息系统。**
|
||||
|
||||
主要设计目标如下:
|
||||
|
||||
- 以时间复杂度为 O(1) 的方式提供消息持久化能力,即使对 TB 级以上数据也能保证常数时间复杂度的访问性能。
|
||||
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒 100K 条以上消息的传输。
|
||||
- 支持 Kafka Server 间的消息分区,及分布式消费,同时保证每个 Partition 内的消息顺序传输。
|
||||
- 同时支持离线数据处理和实时数据处理。
|
||||
- Scale out:支持在线水平扩展。
|
||||
|
||||
## Kafka 基础概念
|
||||
|
||||
### 概念一:生产者与消费者
|
||||
|
||||

|
||||
|
||||
对于 Kafka 来说客户端有两种基本类型:
|
||||
|
||||
1. **生产者(Producer)**
|
||||
2. **消费者(Consumer)**。
|
||||
|
||||
除此之外,还有用来做数据集成的 Kafka Connect API 和流式处理的 Kafka Streams 等高阶客户端,但这些高阶客户端底层仍然是生产者和消费者API,它们只不过是在上层做了封装。
|
||||
|
||||
这很容易理解,生产者(也称为发布者)创建消息,而消费者(也称为订阅者)负责消费or读取消息。
|
||||
|
||||
### 概念二:主题(Topic)与分区(Partition)
|
||||
|
||||

|
||||
|
||||
在 Kafka 中,消息以**主题(Topic)**来分类,每一个主题都对应一个 **「消息队列」**,这有点儿类似于数据库中的表。但是如果我们把所有同类的消息都塞入到一个“中心”队列中,势必缺少可伸缩性,无论是生产者/消费者数目的增加,还是消息数量的增加,都可能耗尽系统的性能或存储。
|
||||
|
||||
我们使用一个生活中的例子来说明:现在 A 城市生产的某商品需要运输到 B 城市,走的是公路,那么单通道的高速公路不论是在「A 城市商品增多」还是「现在 C 城市也要往 B 城市运输东西」这样的情况下都会出现「吞吐量不足」的问题。所以我们现在引入**分区(Partition)**的概念,类似“允许多修几条道”的方式对我们的主题完成了水平扩展。
|
||||
|
||||
### 概念三:Broker 和集群(Cluster)
|
||||
|
||||
一个 Kafka 服务器也称为 Broker,它接受生产者发送的消息并存入磁盘;Broker 同时服务消费者拉取分区消息的请求,返回目前已经提交的消息。使用特定的机器硬件,一个 Broker 每秒可以处理成千上万的分区和百万量级的消息。(现在动不动就百万量级..我特地去查了一把,好像确实集群的情况下吞吐量挺高的..嗯..)
|
||||
|
||||
若干个 Broker 组成一个集群(Cluster),其中集群内某个 Broker 会成为集群控制器(Cluster Controller),它负责管理集群,包括分配分区到 Broker、监控 Broker 故障等。在集群内,一个分区由一个 Broker 负责,这个 Broker 也称为这个分区的 Leader;当然一个分区可以被复制到多个 Broker 上来实现冗余,这样当存在 Broker 故障时可以将其分区重新分配到其他 Broker 来负责。下图是一个样例:
|
||||
|
||||

|
||||
|
||||
Kafka 的一个关键性质是日志保留(retention),我们可以配置主题的消息保留策略,譬如只保留一段时间的日志或者只保留特定大小的日志。当超过这些限制时,老的消息会被删除。我们也可以针对某个主题单独设置消息过期策略,这样对于不同应用可以实现个性化。
|
||||
|
||||
### 概念四:多集群
|
||||
|
||||
随着业务发展,我们往往需要多集群,通常处于下面几个原因:
|
||||
|
||||
- 基于数据的隔离;
|
||||
- 基于安全的隔离;
|
||||
- 多数据中心(容灾)
|
||||
|
||||
当构建多个数据中心时,往往需要实现消息互通。举个例子,假如用户修改了个人资料,那么后续的请求无论被哪个数据中心处理,这个更新需要反映出来。又或者,多个数据中心的数据需要汇总到一个总控中心来做数据分析。
|
||||
|
||||
上面说的分区复制冗余机制只适用于同一个 Kafka 集群内部,对于多个 Kafka 集群消息同步可以使用 Kafka 提供的 MirrorMaker 工具。本质上来说,MirrorMaker 只是一个 Kafka 消费者和生产者,并使用一个队列连接起来而已。它从一个集群中消费消息,然后往另一个集群生产消息。
|
||||
|
||||
|
||||
# 二、Kafka 的设计与实现
|
||||
|
||||
------
|
||||
|
||||
上面我们知道了 Kafka 中的一些基本概念,但作为一个成熟的「消息队列」中间件,其中有许多有意思的设计值得我们思考,下面我们简单列举一些。
|
||||
|
||||
## 讨论一:Kafka 存储在文件系统上
|
||||
|
||||
是的,**您首先应该知道 Kafka 的消息是存在于文件系统之上的**。Kafka 高度依赖文件系统来存储和缓存消息,一般的人认为 “磁盘是缓慢的”,所以对这样的设计持有怀疑态度。实际上,磁盘比人们预想的快很多也慢很多,这取决于它们如何被使用;一个好的磁盘结构设计可以使之跟网络速度一样快。
|
||||
|
||||
现代的操作系统针对磁盘的读写已经做了一些优化方案来加快磁盘的访问速度。比如,**预读**会提前将一个比较大的磁盘快读入内存。**后写**会将很多小的逻辑写操作合并起来组合成一个大的物理写操作。并且,操作系统还会将主内存剩余的所有空闲内存空间都用作**磁盘缓存**,所有的磁盘读写操作都会经过统一的磁盘缓存(除了直接 I/O 会绕过磁盘缓存)。综合这几点优化特点,**如果是针对磁盘的顺序访问,某些情况下它可能比随机的内存访问都要快,甚至可以和网络的速度相差无几。**
|
||||
|
||||
**上述的 Topic 其实是逻辑上的概念,面相消费者和生产者,物理上存储的其实是 Partition**,每一个 Partition 最终对应一个目录,里面存储所有的消息和索引文件。默认情况下,每一个 Topic 在创建时如果不指定 Partition 数量时只会创建 1 个 Partition。比如,我创建了一个 Topic 名字为 test ,没有指定 Partition 的数量,那么会默认创建一个 test-0 的文件夹,这里的命名规则是:`<topic_name>-<partition_id>`。
|
||||
|
||||

|
||||
|
||||
任何发布到 Partition 的消息都会被追加到 Partition 数据文件的尾部,这样的顺序写磁盘操作让 Kafka 的效率非常高(经验证,顺序写磁盘效率比随机写内存还要高,这是 Kafka 高吞吐率的一个很重要的保证)。
|
||||
|
||||
每一条消息被发送到 Broker 中,会根据 Partition 规则选择被存储到哪一个 Partition。如果 Partition 规则设置的合理,所有消息可以均匀分布到不同的 Partition中。
|
||||
|
||||
## 讨论二:Kafka 中的底层存储设计
|
||||
|
||||
假设我们现在 Kafka 集群只有一个 Broker,我们创建 2 个 Topic 名称分别为:「topic1」和「topic2」,Partition 数量分别为 1、2,那么我们的根目录下就会创建如下三个文件夹:
|
||||
|
||||
```shell
|
||||
| --topic1-0
|
||||
| --topic2-0
|
||||
| --topic2-1
|
||||
```
|
||||
|
||||
在 Kafka 的文件存储中,同一个 Topic 下有多个不同的 Partition,每个 Partition 都为一个目录,而每一个目录又被平均分配成多个大小相等的 **Segment File** 中,Segment File 又由 index file 和 data file 组成,他们总是成对出现,后缀 “.index” 和 “.log” 分表表示 Segment 索引文件和数据文件。
|
||||
|
||||
现在假设我们设置每个 Segment 大小为 500 MB,并启动生产者向 topic1 中写入大量数据,topic1-0 文件夹中就会产生类似如下的一些文件:
|
||||
|
||||
```shell
|
||||
| --topic1-0
|
||||
| --00000000000000000000.index
|
||||
| --00000000000000000000.log
|
||||
| --00000000000000368769.index
|
||||
| --00000000000000368769.log
|
||||
| --00000000000000737337.index
|
||||
| --00000000000000737337.log
|
||||
| --00000000000001105814.index
|
||||
| --00000000000001105814.log
|
||||
| --topic2-0
|
||||
| --topic2-1
|
||||
|
||||
```
|
||||
|
||||
**Segment 是 Kafka 文件存储的最小单位。**Segment 文件命名规则:Partition 全局的第一个 Segment 从 0 开始,后续每个 Segment 文件名为上一个 Segment 文件最后一条消息的 offset 值。数值最大为 64 位 long 大小,19 位数字字符长度,没有数字用0填充。如 00000000000000368769.index 和 00000000000000368769.log。
|
||||
|
||||
以上面的一对 Segment File 为例,说明一下索引文件和数据文件对应关系:
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
其中以索引文件中元数据 `<3, 497>` 为例,依次在数据文件中表示第 3 个 message(在全局 Partition 表示第 368769 + 3 = 368772 个 message)以及该消息的物理偏移地址为 497。
|
||||
|
||||
注意该 index 文件并不是从0开始,也不是每次递增1的,这是因为 Kafka 采取稀疏索引存储的方式,每隔一定字节的数据建立一条索引,它减少了索引文件大小,使得能够把 index 映射到内存,降低了查询时的磁盘 IO 开销,同时也并没有给查询带来太多的时间消耗。
|
||||
|
||||
因为其文件名为上一个 Segment 最后一条消息的 offset ,所以当需要查找一个指定 offset 的 message 时,通过在所有 segment 的文件名中进行二分查找就能找到它归属的 segment ,再在其 index 文件中找到其对应到文件上的物理位置,就能拿出该 message 。
|
||||
|
||||
由于消息在 Partition 的 Segment 数据文件中是顺序读写的,且消息消费后不会删除(删除策略是针对过期的 Segment 文件),这种顺序磁盘 IO 存储设计师 Kafka 高性能很重要的原因。
|
||||
|
||||
> Kafka 是如何准确的知道 message 的偏移的呢?这是因为在 Kafka 定义了标准的数据存储结构,在 Partition 中的每一条 message 都包含了以下三个属性:
|
||||
>
|
||||
> - offset:表示 message 在当前 Partition 中的偏移量,是一个逻辑上的值,唯一确定了 Partition 中的一条 message,可以简单的认为是一个 id;
|
||||
> - MessageSize:表示 message 内容 data 的大小;
|
||||
> - data:message 的具体内容
|
||||
|
||||
## 讨论三:生产者设计概要
|
||||
|
||||
当我们发送消息之前,先问几个问题:每条消息都是很关键且不能容忍丢失么?偶尔重复消息可以么?我们关注的是消息延迟还是写入消息的吞吐量?
|
||||
|
||||
举个例子,有一个信用卡交易处理系统,当交易发生时会发送一条消息到 Kafka,另一个服务来读取消息并根据规则引擎来检查交易是否通过,将结果通过 Kafka 返回。对于这样的业务,消息既不能丢失也不能重复,由于交易量大因此吞吐量需要尽可能大,延迟可以稍微高一点。
|
||||
|
||||
再举个例子,假如我们需要收集用户在网页上的点击数据,对于这样的场景,少量消息丢失或者重复是可以容忍的,延迟多大都不重要只要不影响用户体验,吞吐则根据实时用户数来决定。
|
||||
|
||||
不同的业务需要使用不同的写入方式和配置。具体的方式我们在这里不做讨论,现在先看下生产者写消息的基本流程:
|
||||
|
||||

|
||||
|
||||
图片来源:[http://www.dengshenyu.com/%E5%88%86%E5%B8%83%E5%BC%8F%E7%B3%BB%E7%BB%9F/2017/11/12/kafka-producer.html](http://www.dengshenyu.com/分布式系统/2017/11/12/kafka-producer.html)
|
||||
|
||||
流程如下:
|
||||
|
||||
1. 首先,我们需要创建一个ProducerRecord,这个对象需要包含消息的主题(topic)和值(value),可以选择性指定一个键值(key)或者分区(partition)。
|
||||
2. 发送消息时,生产者会对键值和值序列化成字节数组,然后发送到分配器(partitioner)。
|
||||
3. 如果我们指定了分区,那么分配器返回该分区即可;否则,分配器将会基于键值来选择一个分区并返回。
|
||||
4. 选择完分区后,生产者知道了消息所属的主题和分区,它将这条记录添加到相同主题和分区的批量消息中,另一个线程负责发送这些批量消息到对应的Kafka broker。
|
||||
5. 当broker接收到消息后,如果成功写入则返回一个包含消息的主题、分区及位移的RecordMetadata对象,否则返回异常。
|
||||
6. 生产者接收到结果后,对于异常可能会进行重试。
|
||||
|
||||
|
||||
|
||||
## 讨论四:消费者设计概要
|
||||
|
||||
### 消费者与消费组
|
||||
|
||||
假设这么个场景:我们从Kafka中读取消息,并且进行检查,最后产生结果数据。我们可以创建一个消费者实例去做这件事情,但如果生产者写入消息的速度比消费者读取的速度快怎么办呢?这样随着时间增长,消息堆积越来越严重。对于这种场景,我们需要增加多个消费者来进行水平扩展。
|
||||
|
||||
Kafka消费者是**消费组**的一部分,当多个消费者形成一个消费组来消费主题时,每个消费者会收到不同分区的消息。假设有一个T1主题,该主题有4个分区;同时我们有一个消费组G1,这个消费组只有一个消费者C1。那么消费者C1将会收到这4个分区的消息,如下所示:
|
||||
|
||||

|
||||
|
||||
如果我们增加新的消费者C2到消费组G1,那么每个消费者将会分别收到两个分区的消息,如下所示:
|
||||
|
||||

|
||||
|
||||
如果增加到4个消费者,那么每个消费者将会分别收到一个分区的消息,如下所示:
|
||||
|
||||

|
||||
|
||||
但如果我们继续增加消费者到这个消费组,剩余的消费者将会空闲,不会收到任何消息:
|
||||
|
||||

|
||||
|
||||
总而言之,我们可以通过增加消费组的消费者来进行水平扩展提升消费能力。这也是为什么建议创建主题时使用比较多的分区数,这样可以在消费负载高的情况下增加消费者来提升性能。另外,消费者的数量不应该比分区数多,因为多出来的消费者是空闲的,没有任何帮助。
|
||||
|
||||
**Kafka一个很重要的特性就是,只需写入一次消息,可以支持任意多的应用读取这个消息。**换句话说,每个应用都可以读到全量的消息。为了使得每个应用都能读到全量消息,应用需要有不同的消费组。对于上面的例子,假如我们新增了一个新的消费组G2,而这个消费组有两个消费者,那么会是这样的:
|
||||
|
||||

|
||||
|
||||
在这个场景中,消费组G1和消费组G2都能收到T1主题的全量消息,在逻辑意义上来说它们属于不同的应用。
|
||||
|
||||
最后,总结起来就是:如果应用需要读取全量消息,那么请为该应用设置一个消费组;如果该应用消费能力不足,那么可以考虑在这个消费组里增加消费者。
|
||||
|
||||
### 消费组与分区重平衡
|
||||
|
||||
可以看到,当新的消费者加入消费组,它会消费一个或多个分区,而这些分区之前是由其他消费者负责的;另外,当消费者离开消费组(比如重启、宕机等)时,它所消费的分区会分配给其他分区。这种现象称为**重平衡(rebalance)**。重平衡是 Kafka 一个很重要的性质,这个性质保证了高可用和水平扩展。**不过也需要注意到,在重平衡期间,所有消费者都不能消费消息,因此会造成整个消费组短暂的不可用。**而且,将分区进行重平衡也会导致原来的消费者状态过期,从而导致消费者需要重新更新状态,这段期间也会降低消费性能。后面我们会讨论如何安全的进行重平衡以及如何尽可能避免。
|
||||
|
||||
消费者通过定期发送心跳(heartbeat)到一个作为组协调者(group coordinator)的 broker 来保持在消费组内存活。这个 broker 不是固定的,每个消费组都可能不同。当消费者拉取消息或者提交时,便会发送心跳。
|
||||
|
||||
如果消费者超过一定时间没有发送心跳,那么它的会话(session)就会过期,组协调者会认为该消费者已经宕机,然后触发重平衡。可以看到,从消费者宕机到会话过期是有一定时间的,这段时间内该消费者的分区都不能进行消息消费;通常情况下,我们可以进行优雅关闭,这样消费者会发送离开的消息到组协调者,这样组协调者可以立即进行重平衡而不需要等待会话过期。
|
||||
|
||||
在 0.10.1 版本,Kafka 对心跳机制进行了修改,将发送心跳与拉取消息进行分离,这样使得发送心跳的频率不受拉取的频率影响。另外更高版本的 Kafka 支持配置一个消费者多长时间不拉取消息但仍然保持存活,这个配置可以避免活锁(livelock)。活锁,是指应用没有故障但是由于某些原因不能进一步消费。
|
||||
|
||||
### Partition 与消费模型
|
||||
|
||||
上面提到,Kafka 中一个 topic 中的消息是被打散分配在多个 Partition(分区) 中存储的, Consumer Group 在消费时需要从不同的 Partition 获取消息,那最终如何重建出 Topic 中消息的顺序呢?
|
||||
|
||||
答案是:没有办法。Kafka 只会保证在 Partition 内消息是有序的,而不管全局的情况。
|
||||
|
||||
下一个问题是:Partition 中的消息可以被(不同的 Consumer Group)多次消费,那 Partition中被消费的消息是何时删除的? Partition 又是如何知道一个 Consumer Group 当前消费的位置呢?
|
||||
|
||||
无论消息是否被消费,除非消息到期 Partition 从不删除消息。例如设置保留时间为 2 天,则消息发布 2 天内任何 Group 都可以消费,2 天后,消息自动被删除。
|
||||
Partition 会为每个 Consumer Group 保存一个偏移量,记录 Group 消费到的位置。 如下图:
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
### 为什么 Kafka 是 pull 模型
|
||||
|
||||
消费者应该向 Broker 要数据(pull)还是 Broker 向消费者推送数据(push)?作为一个消息系统,Kafka 遵循了传统的方式,选择由 Producer 向 broker push 消息并由 Consumer 从 broker pull 消息。一些 logging-centric system,比如 Facebook 的[Scribe](https://github.com/facebookarchive/scribe)和 Cloudera 的[Flume](https://flume.apache.org/),采用 push 模式。事实上,push 模式和 pull 模式各有优劣。
|
||||
|
||||
**push 模式很难适应消费速率不同的消费者,因为消息发送速率是由 broker 决定的。**push 模式的目标是尽可能以最快速度传递消息,但是这样很容易造成 Consumer 来不及处理消息,典型的表现就是拒绝服务以及网络拥塞。**而 pull 模式则可以根据 Consumer 的消费能力以适当的速率消费消息。**
|
||||
|
||||
**对于 Kafka 而言,pull 模式更合适。**pull 模式可简化 broker 的设计,Consumer 可自主控制消费消息的速率,同时 Consumer 可以自己控制消费方式——即可批量消费也可逐条消费,同时还能选择不同的提交方式从而实现不同的传输语义。
|
||||
|
||||
## 讨论五:Kafka 如何保证可靠性
|
||||
|
||||
当我们讨论**可靠性**的时候,我们总会提到*保证**这个词语。可靠性保证是基础,我们基于这些基础之上构建我们的应用。比如关系型数据库的可靠性保证是ACID,也就是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。
|
||||
|
||||
Kafka 中的可靠性保证有如下四点:
|
||||
|
||||
- 对于一个分区来说,它的消息是有序的。如果一个生产者向一个分区先写入消息A,然后写入消息B,那么消费者会先读取消息A再读取消息B。
|
||||
- 当消息写入所有in-sync状态的副本后,消息才会认为**已提交(committed)**。这里的写入有可能只是写入到文件系统的缓存,不一定刷新到磁盘。生产者可以等待不同时机的确认,比如等待分区主副本写入即返回,后者等待所有in-sync状态副本写入才返回。
|
||||
- 一旦消息已提交,那么只要有一个副本存活,数据不会丢失。
|
||||
- 消费者只能读取到已提交的消息。
|
||||
|
||||
使用这些基础保证,我们构建一个可靠的系统,这时候需要考虑一个问题:究竟我们的应用需要多大程度的可靠性?可靠性不是无偿的,它与系统可用性、吞吐量、延迟和硬件价格息息相关,得此失彼。因此,我们往往需要做权衡,一味的追求可靠性并不实际。
|
||||
|
||||
> 想了解更多戳这里:http://www.dengshenyu.com/%E5%88%86%E5%B8%83%E5%BC%8F%E7%B3%BB%E7%BB%9F/2017/11/21/kafka-data-delivery.html
|
||||
|
||||
# 三、动手搭一个 Kafka
|
||||
|
||||
通过上面的描述,我们已经大致了解到了「Kafka」是何方神圣了,现在我们开始尝试自己动手本地搭一个来实际体验一把。
|
||||
|
||||
## 第一步:下载 Kafka
|
||||
|
||||
这里以 Mac OS 为例,在安装了 Homebrew 的情况下执行下列代码:
|
||||
|
||||
```shell
|
||||
brew install kafka
|
||||
```
|
||||
|
||||
由于 Kafka 依赖了 Zookeeper,所以在下载的时候会自动下载。
|
||||
|
||||
## 第二步:启动服务
|
||||
|
||||
我们在启动之前首先需要修改 Kafka 的监听地址和端口为 `localhost:9092`:
|
||||
|
||||
```shell
|
||||
vi /usr/local/etc/kafka/server.properties
|
||||
```
|
||||
|
||||
|
||||
然后修改成下图的样子:
|
||||
|
||||

|
||||
依次启动 Zookeeper 和 Kafka:
|
||||
|
||||
```shell
|
||||
brew services start zookeeper
|
||||
brew services start kafka
|
||||
```
|
||||
|
||||
然后执行下列语句来创建一个名字为 “test” 的 Topic:
|
||||
|
||||
```shell
|
||||
kafka-topics --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
|
||||
```
|
||||
|
||||
我们可以通过下列的命令查看我们的 Topic 列表:
|
||||
|
||||
```shell
|
||||
kafka-topics --list --zookeeper localhost:2181
|
||||
```
|
||||
|
||||
## 第三步:发送消息
|
||||
|
||||
然后我们新建一个控制台,运行下列命令创建一个消费者关注刚才创建的 Topic:
|
||||
|
||||
```shell
|
||||
kafka-console-consumer --bootstrap-server localhost:9092 --topic test --from-beginning
|
||||
```
|
||||
|
||||
用控制台往刚才创建的 Topic 中添加消息,并观察刚才创建的消费者窗口:
|
||||
|
||||
```shel
|
||||
kafka-console-producer --broker-list localhost:9092 --topic test
|
||||
```
|
||||
|
||||
能通过消费者窗口观察到正确的消息:
|
||||
|
||||

|
||||
|
||||
# 参考资料
|
||||
|
||||
------
|
||||
|
||||
1. https://www.infoq.cn/article/kafka-analysis-part-1 - Kafka 设计解析(一):Kafka 背景及架构介绍
|
||||
2. [http://www.dengshenyu.com/%E5%88%86%E5%B8%83%E5%BC%8F%E7%B3%BB%E7%BB%9F/2017/11/06/kafka-Meet-Kafka.html](http://www.dengshenyu.com/分布式系统/2017/11/06/kafka-Meet-Kafka.html) - Kafka系列(一)初识Kafka
|
||||
3. https://lotabout.me/2018/kafka-introduction/ - Kafka 入门介绍
|
||||
4. https://www.zhihu.com/question/28925721 - Kafka 中的 Topic 为什么要进行分区? - 知乎
|
||||
5. https://blog.joway.io/posts/kafka-design-practice/ - Kafka 的设计与实践思考
|
||||
6. [http://www.dengshenyu.com/%E5%88%86%E5%B8%83%E5%BC%8F%E7%B3%BB%E7%BB%9F/2017/11/21/kafka-data-delivery.html](http://www.dengshenyu.com/分布式系统/2017/11/21/kafka-data-delivery.html) - Kafka系列(六)可靠的数据传输
|
||||
|
||||
|
||||
@ -8,8 +8,6 @@ ID是数据的唯一标识,传统的做法是利用UUID和数据库的自增ID
|
||||
|
||||
这篇文章并不会分析的特别详细,主要是做一些总结,以后再出一些详细某个方案的文章。
|
||||
|
||||
|
||||
|
||||
## 数据库自增ID
|
||||
|
||||
第一种方案仍然还是基于数据库的自增ID,需要单独使用一个数据库实例,在这个实例中新建一个单独的表:
|
||||
|
||||
@ -209,5 +209,6 @@ Guide 制作了一个涵盖上面所有重要内容的思维导图,便于小
|
||||
1. 《阿里巴巴 Java 开发手册》
|
||||
2. 《Clean Code》
|
||||
3. Google Java 代码指南:https://google.github.io/styleguide/javaguide.html#s5.1-identifier-name
|
||||
4. 告别编码5分钟,命名2小时!史上最全的Java命名规范参考:https://www.cnblogs.com/liqiangchn/p/12000361.html
|
||||
|
||||
|
||||
|
||||
@ -1,84 +0,0 @@
|
||||
|
||||
|
||||
> 下面的 10 个项目还是很推荐的!JS 的项目占比挺大,其他基本都是文档/学习类型的仓库。
|
||||
|
||||
说明:数据统计于 2019-11-27。
|
||||
|
||||
### 1. freeCodeCamp
|
||||
|
||||
- **Github地址**:[https://github.com/freeCodeCamp/freeCodeCamp](https://github.com/freeCodeCamp/freeCodeCamp)
|
||||
- **star**: 307 k
|
||||
- **介绍**: 开放源码代码库和课程。与数百万人一起免费学习编程。网站:[https://www.freeCodeCamp.org](https://www.freecodecamp.org/) (一个友好的社区,您可以在这里免费学习编码。它由捐助者支持、非营利组织运营,以帮助数百万忙碌的成年人学习编程技术。这个社区已经帮助10,000多人获得了第一份开发人员的工作。这里的全栈Web开发课程是完全免费的,并且可以自行调整进度。这里还有数以千计的交互式编码挑战,可帮助您扩展技能。)
|
||||
|
||||
比如我想学习 ES6 的语法,学习界面是下面这样的,你可以很方便地边练习边学习:
|
||||
|
||||
|
||||
|
||||
### 2. 996.ICU
|
||||
|
||||
- **Github地址**:[https://github.com/996icu/996.ICU](https://github.com/996icu/996.ICU)
|
||||
- **star**: 248 k
|
||||
- **介绍**: `996.ICU` 是指“工作 996, 生病 ICU” 。这是中国程序员之间的一种自嘲说法,意思是如果按照 996 的模式工作,那以后就得进 ICU 了。这个项目最早是某个中国程序员发起的,然后就火遍全网,甚至火到了全世界很多其他国家,其网站被翻译成了多种语言。网站地址:[https://996.icu](https://996.icu/)。
|
||||
|
||||

|
||||
|
||||
### 3. vue
|
||||
|
||||
- **Github地址**:[https://github.com/vuejs/vue](https://github.com/vuejs/vue)
|
||||
- **star**: 153 k
|
||||
- **介绍**: 尤大的前端框架。国人用的最多(容易上手,文档比较丰富),所以 Star 数量比较多还是有道理的。Vue (读音 /vjuː/,类似于 **view**) 是一套用于构建用户界面的**渐进式框架**。与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用。Vue 的核心库只关注视图层,不仅易于上手,还便于与第三方库或既有项目整合。另一方面,当与[现代化的工具链](https://cn.vuejs.org/v2/guide/single-file-components.html)以及各种[支持类库](https://github.com/vuejs/awesome-vue#libraries--plugins)结合使用时,Vue 也完全能够为复杂的单页应用提供驱动。
|
||||
|
||||
### 4. React
|
||||
|
||||
- **Github地址**:[https://gitstar-ranking.com/facebook/react](https://gitstar-ranking.com/facebook/react)
|
||||
- **star**: 140 k
|
||||
- **介绍**: Facebook 开源的,大公司有保障。用于构建用户界面的声明式、基于组件开发,高效且灵活的JavaScript框架。我司大部分项目的前端都是 React ,我自己也用过一段时间,感觉还不错,但是也有一些小坑。
|
||||
|
||||
### 5. tensorflow
|
||||
|
||||
- **Github地址**:[https://github.com/tensorflow/tensorflow](https://github.com/tensorflow/tensorflow)
|
||||
- **star**: 138 k
|
||||
- **介绍**: 适用于所有人的开源机器学习框架。[TensorFlow](https://www.tensorflow.org/)是用于机器学习的端到端开源平台。TensorFlow最初是由Google机器智能研究组织内Google Brain团队的研究人员和工程师开发的,用于进行机器学习和深度神经网络研究。该系统具有足够的通用性,也可以适用于多种其他领域。TensorFlow提供了稳定的[Python](https://www.tensorflow.org/api_docs/python) 和[C ++](https://www.tensorflow.org/api_docs/cc) API,以及[其他语言的](https://www.tensorflow.org/api_docs)非保证的向后兼容API 。
|
||||
|
||||
### 6. bootstrap
|
||||
|
||||
- **Github地址**:[https://github.com/twbs/bootstrap](https://github.com/twbs/bootstrap)
|
||||
- **star**: 137 k
|
||||
- **介绍**: 相信初学前端的时候,大家一定或多或少地接触过这个框架。官网说它是最受欢迎的HTML,CSS和JavaScript框架,用于在网络上开发响应式,移动优先项目。
|
||||
|
||||
### 7. free-programming-books
|
||||
|
||||
- **Github地址**:[https://github.com/EbookFoundation/free-programming-books](https://github.com/EbookFoundation/free-programming-books)
|
||||
- **star**: 132 k
|
||||
- **介绍**: 免费提供的编程书籍。我自己没太搞懂为啥这个项目 Star 数这么多,知道的麻烦评论区吱一声。
|
||||
|
||||
### 8. Awesome
|
||||
|
||||
- **Github地址** : [https://github.com/sindresorhus/awesome](https://github.com/sindresorhus/awesome)
|
||||
- **star**: 120 k
|
||||
- **介绍**: github 上很多的各种 Awesome 系列合集。
|
||||
|
||||
下面是这个开源仓库的目录,可以看出其涵盖了很多方面的内容。
|
||||
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/awsome-contents.jpg" style="zoom:50%;" />
|
||||
|
||||
举个例子,这个仓库里面就有两个让你的电脑更好用的开源仓库,Mac 和 Windows都有:
|
||||
|
||||
- Awesome Mac:https://github.com/jaywcjlove/awesome-mac/blob/master/README-zh.m
|
||||
- Awsome Windows: https://github.com/Awesome-Windows/Awesome/blob/master/README-cn.md
|
||||
|
||||
### 9. You-Dont-Know-JS
|
||||
|
||||
- **Github地址**:[https://github.com/getify/You-Dont-Know-JS](https://github.com/getify/You-Dont-Know-JS)
|
||||
- **star**: 112 k
|
||||
- **介绍**: 您还不认识JS(书籍系列)-第二版
|
||||
|
||||
### 10. oh-my-zsh
|
||||
|
||||
- **Github地址**:[https://github.com/ohmyzsh/ohmyzsh](https://github.com/ohmyzsh/ohmyzsh)
|
||||
- **star**: 99.4 k
|
||||
- **介绍**: 一个令人愉快的社区驱动的框架(拥有近1500个贡献者),用于管理zsh配置。包括200多个可选插件(rails, git, OSX, hub, capistrano, brew, ant, php, python等),140多个主题,可为您的早晨增光添彩,以及一个自动更新工具,可让您轻松保持与来自社区的最新更新……
|
||||
|
||||
下面就是 oh-my-zsh 提供的一个花里胡哨的主题:
|
||||
|
||||
|
||||
@ -1,149 +0,0 @@
|
||||
最近很多阿里云双 11 做活动,优惠力度还挺大的,很多朋友都买以最低的价格买到了自己的云服务器。不论是作为学习机还是部署自己的小型网站或者服务来说都是很不错的!
|
||||
|
||||
但是,很多朋友都不知道如何正确去使用。下面我简单分享一下自己的使用经验。
|
||||
|
||||
总结一下,主要涉及下面几个部分,对于新手以及没有这么使用过云服务的朋友还是比较友好的:
|
||||
|
||||
1. 善用阿里云镜像市场节省安装 Java 环境的时间,相关说明都在根目录下的 readme.txt. 文件里面;
|
||||
2. 本地通过 SSH 连接阿里云服务器很容易,配置好 Host地址,通过 root 用户加上实例密码直接连接即可。
|
||||
3. 本地连接 MySQL 数据库需要简单配置一下安全组和并且允许 root 用户在任何地方进行远程登录。
|
||||
4. 通过 Alibaba Cloud Toolkit 部署 Spring Boot 项目到阿里云服务器真的很方便。
|
||||
|
||||
**[活动地址](https://www.aliyun.com/1111/2019/group-buying-share?ptCode=32AE103FC8249634736194795A3477C4647C88CF896EF535&userCode=hf47liqn&share_source=copy_link)** (仅限新人,老用户可以考虑使用家人或者朋友账号购买,推荐799/3年 2核4G 这个性价比和适用面更广)
|
||||
|
||||
### 善用阿里云镜像市场节省安装环境的时间
|
||||
|
||||
基本的购买流程这里就不多说了,另外这里需要注意的是:其实 Java 环境是不需要我们手动安装配置的,阿里云提供的镜像市场有一些常用的环境。
|
||||
|
||||
> 阿里云镜像市场是指阿里云建立的、由镜像服务商向用户提供其镜像及相关服务的网络平台。这些镜像在操作系统上整合了具体的软件环境和功能,比如Java、PHP运行环境、控制面板等,供有相关需求的用户开通实例时选用。
|
||||
|
||||
具体如何在购买云服务器的时候通过镜像创建实例或者已有ECS用户如何使用镜像可以查看官方详细的介绍,地址:
|
||||
|
||||
https://help.aliyun.com/knowledge_detail/41987.html?spm=a2c4g.11186631.2.1.561e2098dIdCGZ
|
||||
|
||||
### 当我们成功购买服务器之后如何通过 SSH 连接呢?
|
||||
|
||||
创建好 ECS 后,你绑定的手机会收到短信,会告知你初始密码的。你可以登录管理控制台对密码进行修改,修改密码需要在管理控制台重启服务器才能生效。
|
||||
|
||||
你也可以在阿里云 ECS 控制台重置实例密码,如下图所示。
|
||||
|
||||

|
||||
|
||||
**第一种连接方式是直接在阿里云服务器管理的网页上连接**。如上图所示, 点击远程连接,然后输入远程连接密码,这个并不是你重置实例密码得到的密码,如果忘记了直接修改远程连接密码即可。
|
||||
|
||||
**第二种方式是在本地通过命令或者软件连接。** 推荐使用这种方式,更加方便。
|
||||
|
||||
**Windows 推荐使用 Xshell 连接,具体方式如下:**
|
||||
|
||||
> Window电脑在家,这里直接用找到的一些图片给大家展示一个。
|
||||
|
||||
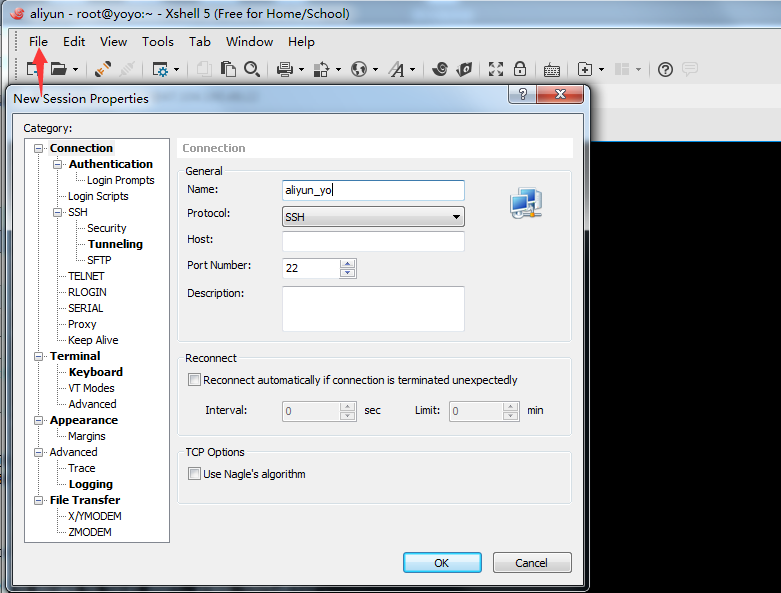
|
||||
|
||||

|
||||
|
||||
接着点开,输入账号:root,命名输入刚才设置的密码,点ok就可以了
|
||||
|
||||
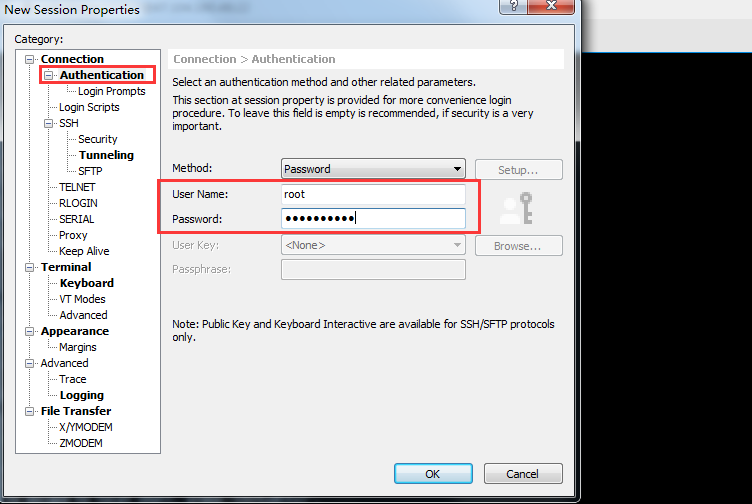
|
||||
|
||||
**Mac 或者 Linux 系统都可以直接使用 ssh 命令进行连接,非常方便。**
|
||||
|
||||
成功连接之后,控制台会打印出如下消息。
|
||||
|
||||
```shell
|
||||
➜ ~ ssh root@47.107.159.12 -p 22
|
||||
root@47.107.159.12's password:
|
||||
Last login: Wed Oct 30 09:31:31 2019 from 220.249.123.170
|
||||
|
||||
Welcome to Alibaba Cloud Elastic Compute Service !
|
||||
|
||||
欢迎使用 Tomcat8 JDK8 Mysql5.7 环境
|
||||
|
||||
使用说明请参考 /root/readme.txt 文件
|
||||
```
|
||||
|
||||
我当时选择是阿里云提供好的 Java 环境,自动就提供了 Tomcat、 JDK8 、Mysql5.7,所以不需要我们再进行安装配置了,节省了很多时间。另外,需要注意的是:**一定要看 /readme.txt ,Tomcat、 JDK8 、Mysql5.7相关配置以及安装路径等说明都在里面。**
|
||||
|
||||
### 如何连接数据库?
|
||||
|
||||
**如需外网远程访问mysql 请参考以上网址 设置mysql及阿里云安全组**。
|
||||
|
||||

|
||||
|
||||
Mysql为了安全性,在默认情况下用户只允许在本地登录,但是可以使用 SSH 方式连接。如果我们不想通过 SSH 方式连接的话就需要对 MySQL 进行简单的配置。
|
||||
|
||||
```shell
|
||||
#允许root用户在任何地方进行远程登录,并具有所有库任何操作权限:
|
||||
# *.*代表所有库表 “%”代表所有IP地址
|
||||
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY "自定义密码" WITH GRANT OPTION;
|
||||
Query OK, 0 rows affected, 1 warning (0.00 sec)
|
||||
#刷新权限。
|
||||
mysql>flush privileges;
|
||||
#退出mysql
|
||||
mysql>exit
|
||||
#重启MySQL生效
|
||||
[root@snailclimb]# systemctl restart mysql
|
||||
```
|
||||
|
||||
这样的话,我们就能在本地进行连接了。Windows 推荐使用Navicat或者SQLyog。
|
||||
|
||||
> Window电脑在家,这里用 Mac 上的MySQL可视化工具Sequel Pro给大家演示一下。
|
||||
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-7/Screen Shot 2019-10-30 at 11.02.26 AM.png" style="zoom:50%;" />
|
||||
|
||||
### 如何把一个Spring Boot 项目部署到服务器上呢?
|
||||
|
||||
默认大家都是用 IDEA 进行开发。另外,你要有一个简单的 Spring Boot Web 项目。如果还不了解 Spring Boot 的话,一个简单的 Spring Boot 版 "Hello World "项目,地址如下:
|
||||
|
||||
https://github.com/Snailclimb/springboot-guide/blob/master/docs/start/springboot-hello-world.md 。
|
||||
|
||||
**1.下载一个叫做 Alibaba Cloud Toolkit 的插件。**
|
||||
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-7/Alibaba-Cloud-Toolkit.png" style="zoom:50%;" />
|
||||
|
||||
**2.进入 Preference 配置一个 Access Key ID 和 Access Key Secret。**
|
||||
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-7/Screen Shot 2019-10-30 at 10.10.23 AM.png" style="zoom:50%;" />
|
||||
|
||||
**3.部署项目到 ECS 上。**
|
||||
|
||||
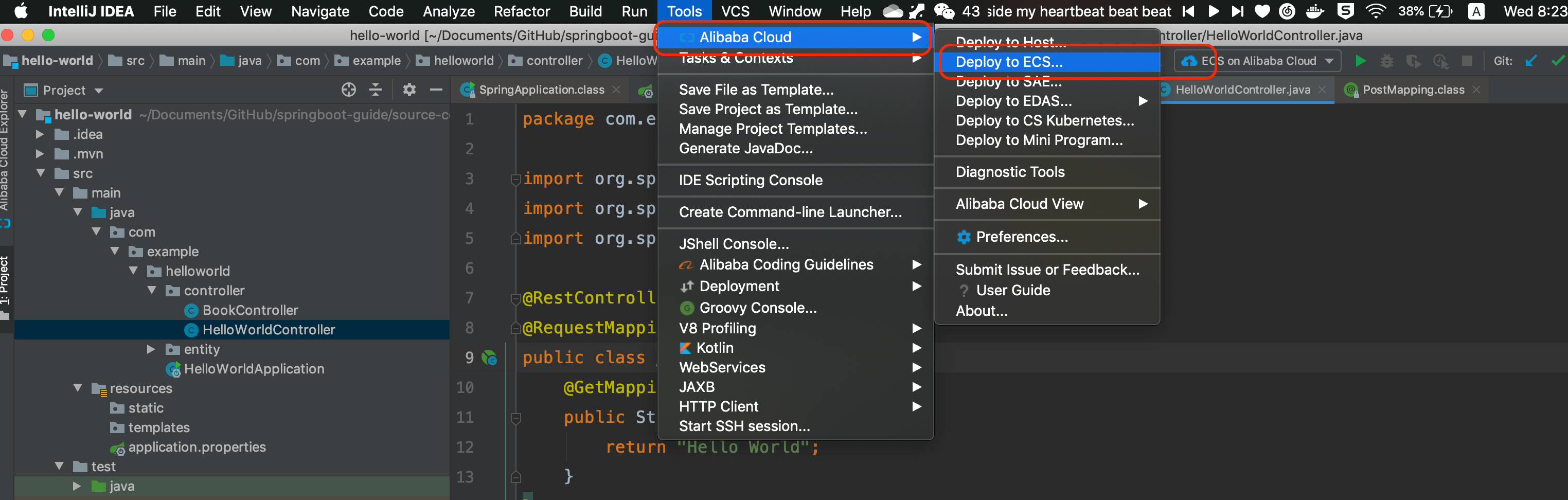
|
||||
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-7/deploy-to-ecs2.png" style="zoom:50%;" />
|
||||
|
||||
按照上面这样填写完基本配置之后,然后点击 run 运行即可。运行成功,控制台会打印出如下信息:
|
||||
|
||||
```shell
|
||||
[INFO] Deployment File is Uploading...
|
||||
[INFO] IDE Version:IntelliJ IDEA 2019.2
|
||||
[INFO] Alibaba Cloud Toolkit Version:2019.9.1
|
||||
[INFO] Start upload hello-world-0.0.1-SNAPSHOT.jar
|
||||
[INFO][##################################################] 100% (18609645/18609645)
|
||||
[INFO] Succeed to upload, 18609645 bytes have been uploaded.
|
||||
[INFO] Upload Deployment File to OSS Success
|
||||
[INFO] Target Deploy ECS: { 172.18.245.148 / 47.107.159.12 }
|
||||
[INFO] Command: { source /etc/profile; cd /springboot; }
|
||||
Tip: The deployment package will be temporarily stored in Alibaba Cloud Security OSS and will be
|
||||
deleted after the deployment is complete. Please be assured that no one can access it except you.
|
||||
|
||||
[INFO] Create Deploy Directory Success.
|
||||
|
||||
[INFO] Deployment File is Downloading...
|
||||
[INFO] Download Deployment File from OSS Success
|
||||
|
||||
[INFO] File Upload Total time: 16.676 s
|
||||
```
|
||||
|
||||
通过控制台答应出的信息可以看出:通过这个插件会自动把这个 Spring Boot 项目打包成一个 jar 包,然后上传到你的阿里云服务器中指定的文件夹中,你只需要登录你的阿里云服务器,然后通过 `java -jar hello-world-0.0.1-SNAPSHOT.jar`命令运行即可。
|
||||
|
||||
```shell
|
||||
[root@snailclimb springboot]# ll
|
||||
total 18176
|
||||
-rw-r--r-- 1 root root 18609645 Oct 30 08:25 hello-world-0.0.1-SNAPSHOT.jar
|
||||
[root@snailclimb springboot]# java -jar hello-world-0.0.1-SNAPSHOT.jar
|
||||
```
|
||||
|
||||
然后你就可以在本地访问访问部署在你的阿里云 ECS 上的服务了。
|
||||
|
||||
<img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-7/Screen Shot 2019-10-30 at 10.32.06 AM.png" style="zoom:50%;" />
|
||||
|
||||
**[推荐一下阿里云双11的活动:云服务器1折起,仅86元/年,限量抢购!](https://www.aliyun.com/1111/2019/group-buying-share?ptCode=32AE103FC8249634736194795A3477C4647C88CF896EF535&userCode=hf47liqn&share_source=copy_link)** (仅限新人,老用户可以考虑使用家人或者朋友账号购买,推荐799/3年 2核4G 这个性价比和适用面更广)
|
||||
{kind=link}
|
Before Width: | Height: | Size: 91 KiB |
{kind=link}
|
Before Width: | Height: | Size: 136 KiB |
{kind=link}
|
Before Width: | Height: | Size: 139 KiB |
{kind=link}
|
Before Width: | Height: | Size: 106 KiB |
{kind=link}
|
Before Width: | Height: | Size: 90 KiB |
{kind=link}
|
Before Width: | Height: | Size: 66 KiB |