 +
+
+
+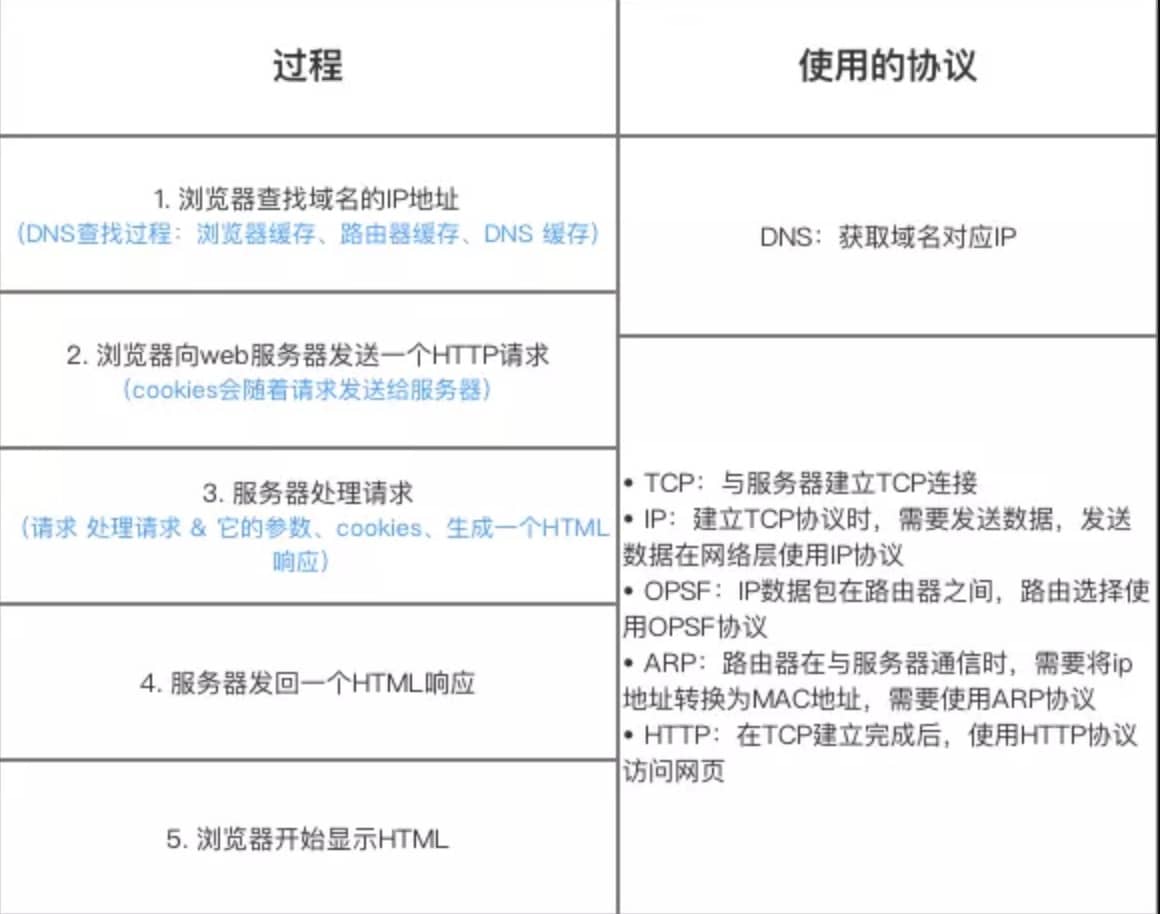 +
+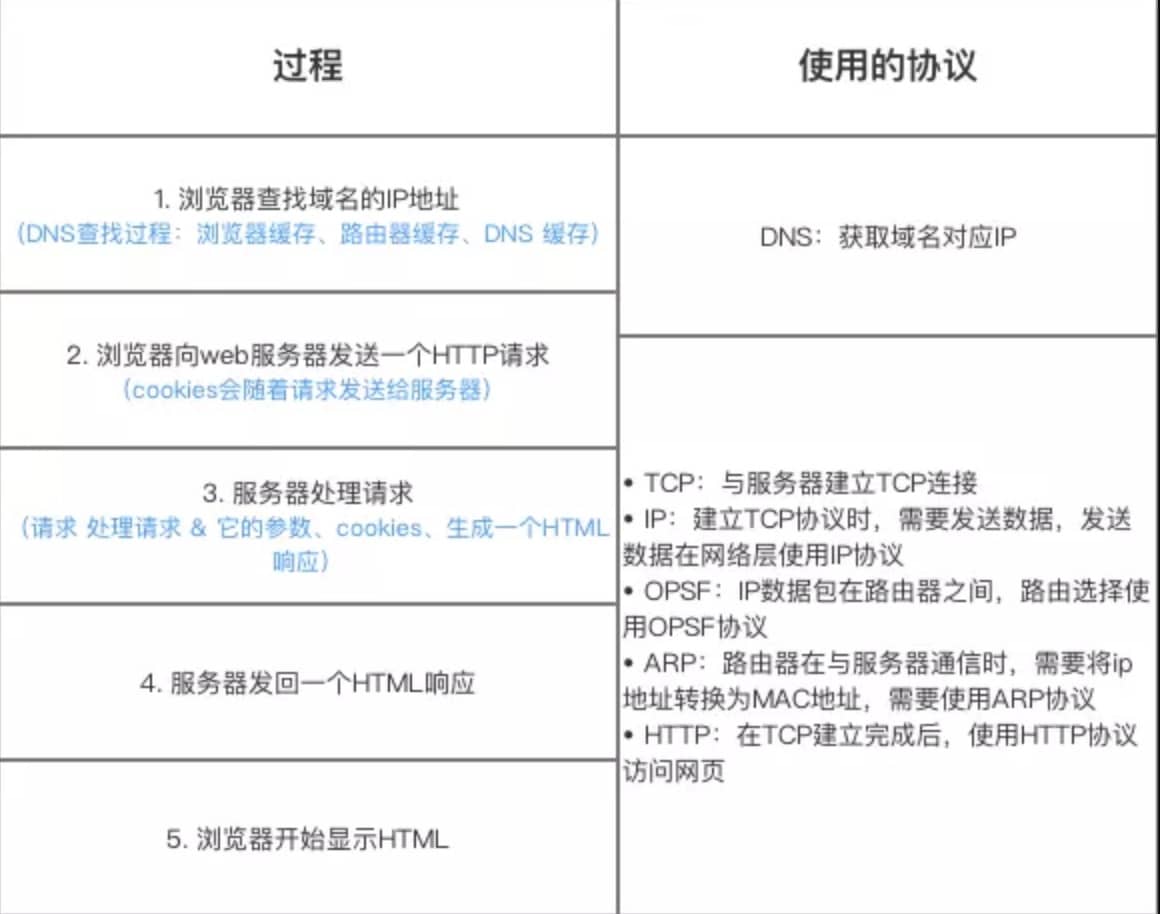 > 上图有一个错误,请注意,是 OSPF 不是 OPSF。 OSPF(Open Shortest Path First,ospf)开放最短路径优先协议, 是由 Internet 工程任务组开发的路由选择协议
@@ -130,7 +130,7 @@ tag:
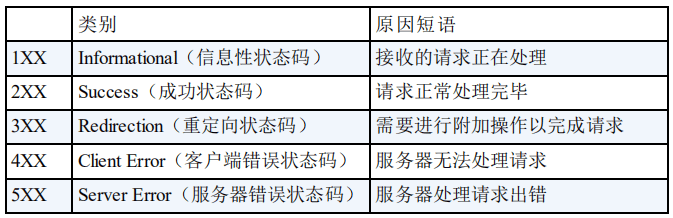
HTTP 状态码用于描述 HTTP 请求的结果,比如2xx 就代表请求被成功处理。
-
+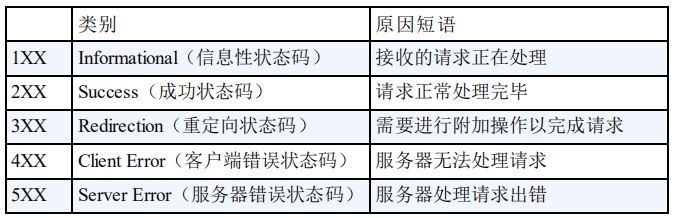
关于 HTTP 状态码更详细的总结,可以看我写的这篇文章:[HTTP 常见状态码总结(应用层)](./http-status-codes.md)。
diff --git a/docs/database/mysql/some-thoughts-on-database-storage-time.md b/docs/database/mysql/some-thoughts-on-database-storage-time.md
index 79ee0ac3..8abb358c 100644
--- a/docs/database/mysql/some-thoughts-on-database-storage-time.md
+++ b/docs/database/mysql/some-thoughts-on-database-storage-time.md
@@ -111,7 +111,7 @@ Timestamp 只需要使用 4 个字节的存储空间,但是 DateTime 需要耗
下图是 MySQL 5.6 版本中日期类型所占的存储空间:
-
+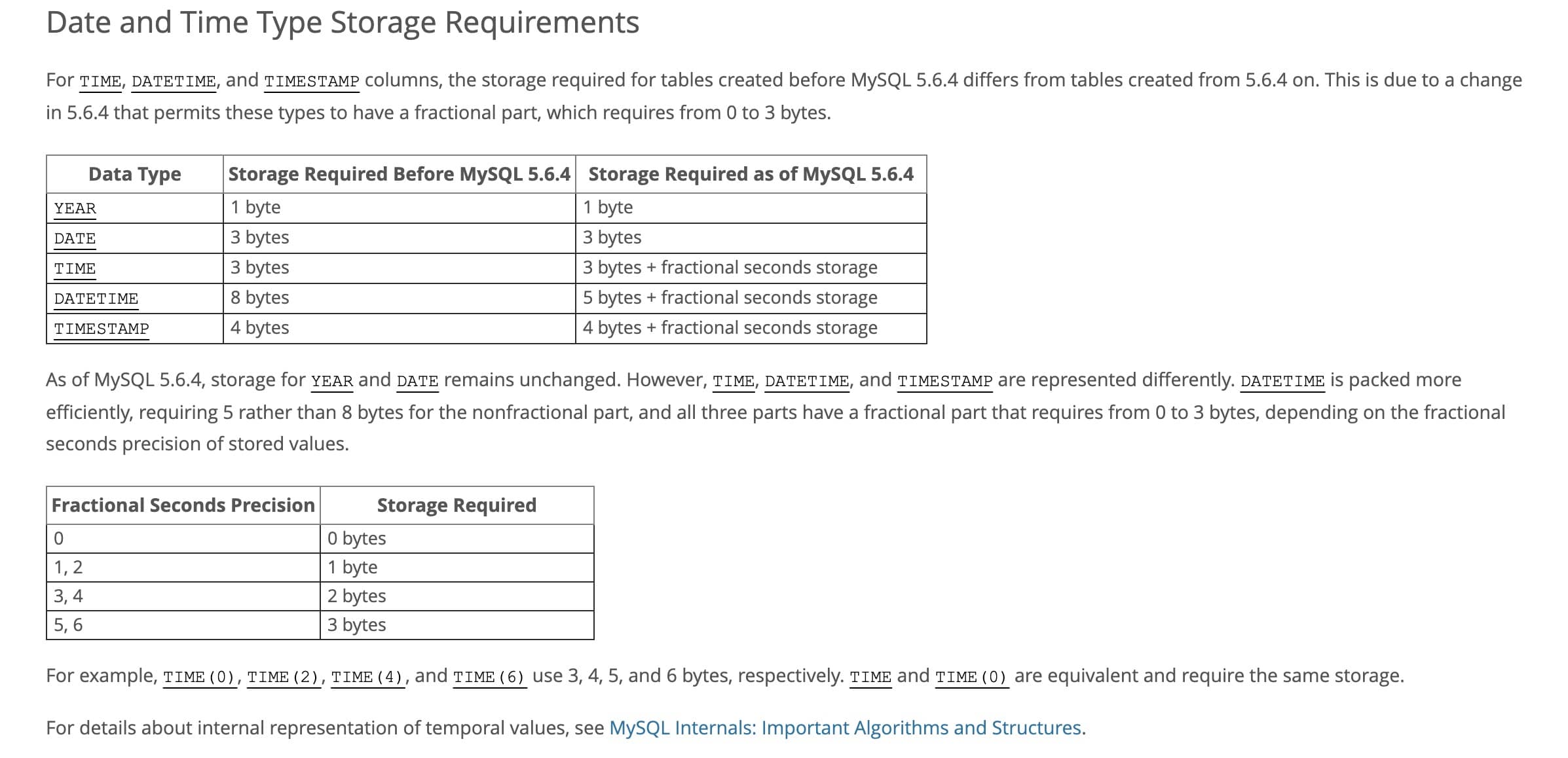
可以看出 5.6.4 之后的 MySQL 多出了一个需要 0 ~ 3 字节的小数位。DateTime 和 Timestamp 会有几种不同的存储空间占用。
@@ -153,7 +153,7 @@ MySQL 中时间到底怎么存储才好?Datetime?Timestamp? 数值保存的时
好像并没有一个银弹,很多程序员会觉得数值型时间戳是真的好,效率又高还各种兼容,但是很多人又觉得它表现的不够直观。这里插一嘴,《高性能 MySQL 》这本神书的作者就是推荐 Timestamp,原因是数值表示时间不够直观。下面是原文:
-
> 上图有一个错误,请注意,是 OSPF 不是 OPSF。 OSPF(Open Shortest Path First,ospf)开放最短路径优先协议, 是由 Internet 工程任务组开发的路由选择协议
@@ -130,7 +130,7 @@ tag:
HTTP 状态码用于描述 HTTP 请求的结果,比如2xx 就代表请求被成功处理。
-
+
关于 HTTP 状态码更详细的总结,可以看我写的这篇文章:[HTTP 常见状态码总结(应用层)](./http-status-codes.md)。
diff --git a/docs/database/mysql/some-thoughts-on-database-storage-time.md b/docs/database/mysql/some-thoughts-on-database-storage-time.md
index 79ee0ac3..8abb358c 100644
--- a/docs/database/mysql/some-thoughts-on-database-storage-time.md
+++ b/docs/database/mysql/some-thoughts-on-database-storage-time.md
@@ -111,7 +111,7 @@ Timestamp 只需要使用 4 个字节的存储空间,但是 DateTime 需要耗
下图是 MySQL 5.6 版本中日期类型所占的存储空间:
-
+
可以看出 5.6.4 之后的 MySQL 多出了一个需要 0 ~ 3 字节的小数位。DateTime 和 Timestamp 会有几种不同的存储空间占用。
@@ -153,7 +153,7 @@ MySQL 中时间到底怎么存储才好?Datetime?Timestamp? 数值保存的时
好像并没有一个银弹,很多程序员会觉得数值型时间戳是真的好,效率又高还各种兼容,但是很多人又觉得它表现的不够直观。这里插一嘴,《高性能 MySQL 》这本神书的作者就是推荐 Timestamp,原因是数值表示时间不够直观。下面是原文:
- +
+ 每种方式都有各自的优势,根据实际场景才是王道。下面再对这三种方式做一个简单的对比,以供大家实际开发中选择正确的存放时间的数据类型:
diff --git a/docs/database/mysql/transaction-isolation-level.md b/docs/database/mysql/transaction-isolation-level.md
index 4cbabae6..574c0b6b 100644
--- a/docs/database/mysql/transaction-isolation-level.md
+++ b/docs/database/mysql/transaction-isolation-level.md
@@ -73,27 +73,27 @@ SET [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL [READ UNCOMMITTED|READ COMMITTE
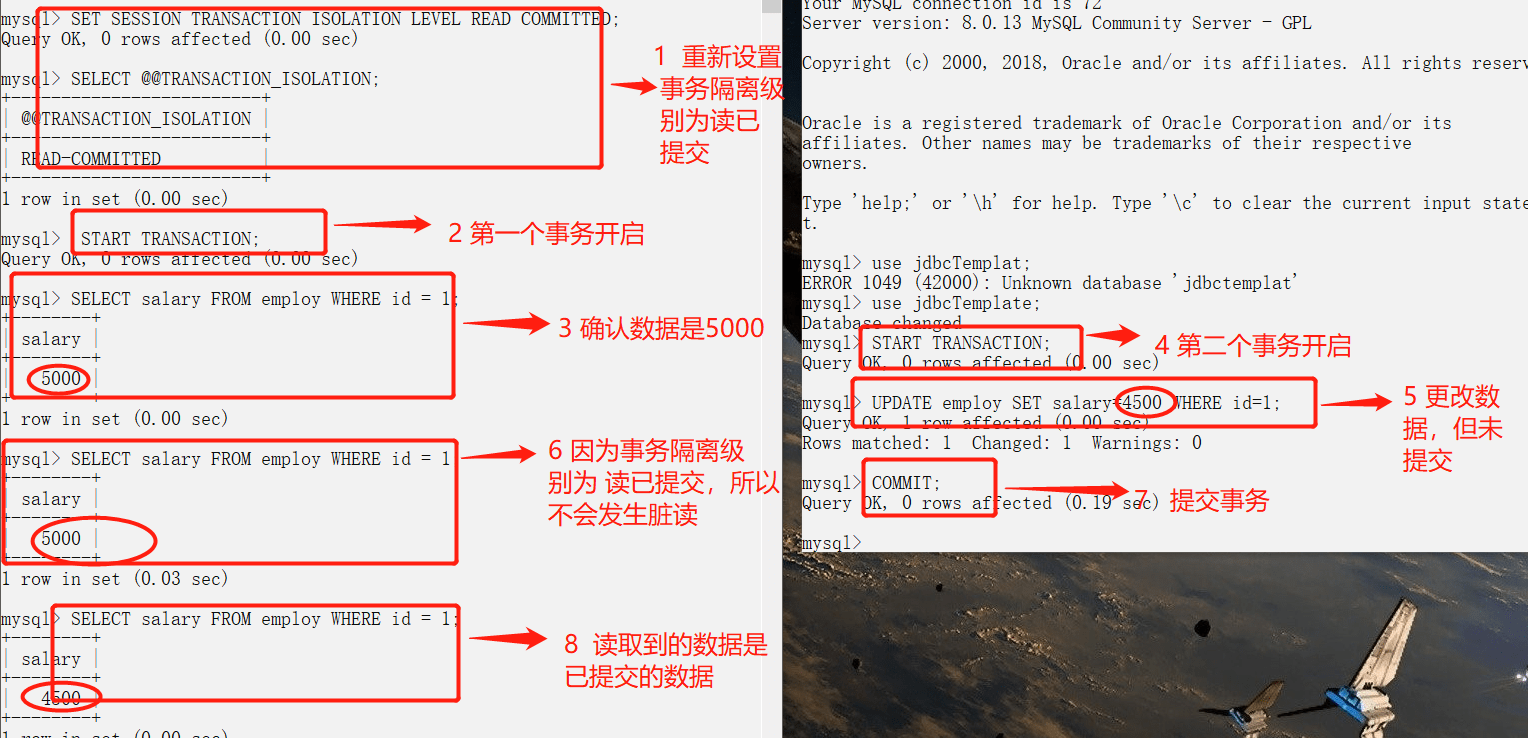
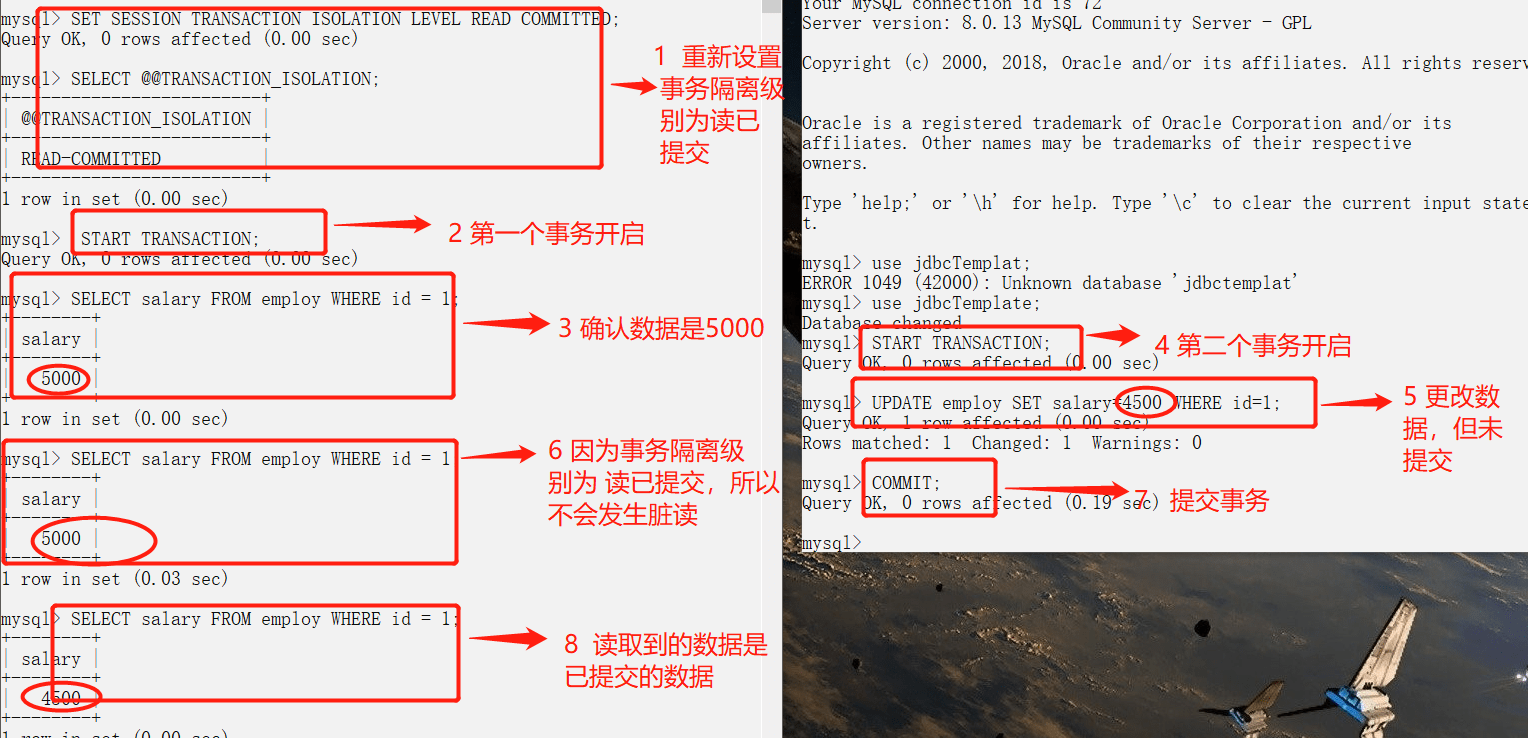
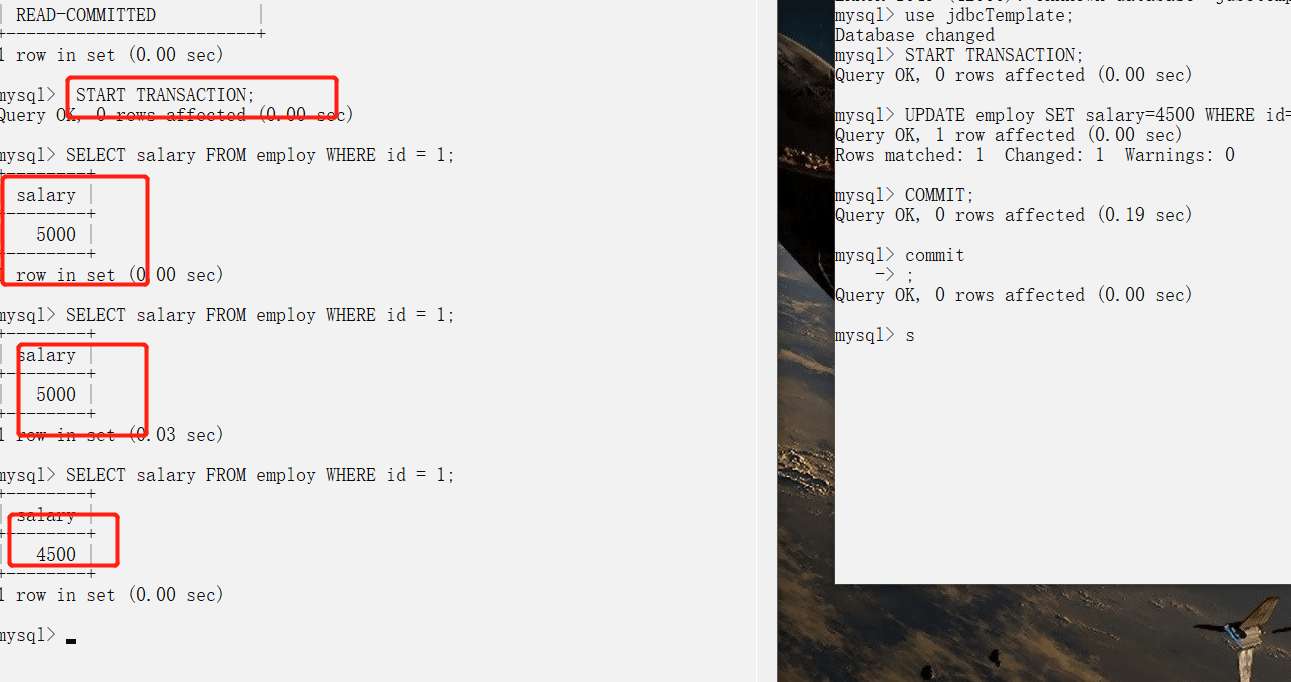
### 脏读(读未提交)
-实例.jpg)
+%E5%AE%9E%E4%BE%8B.jpg)
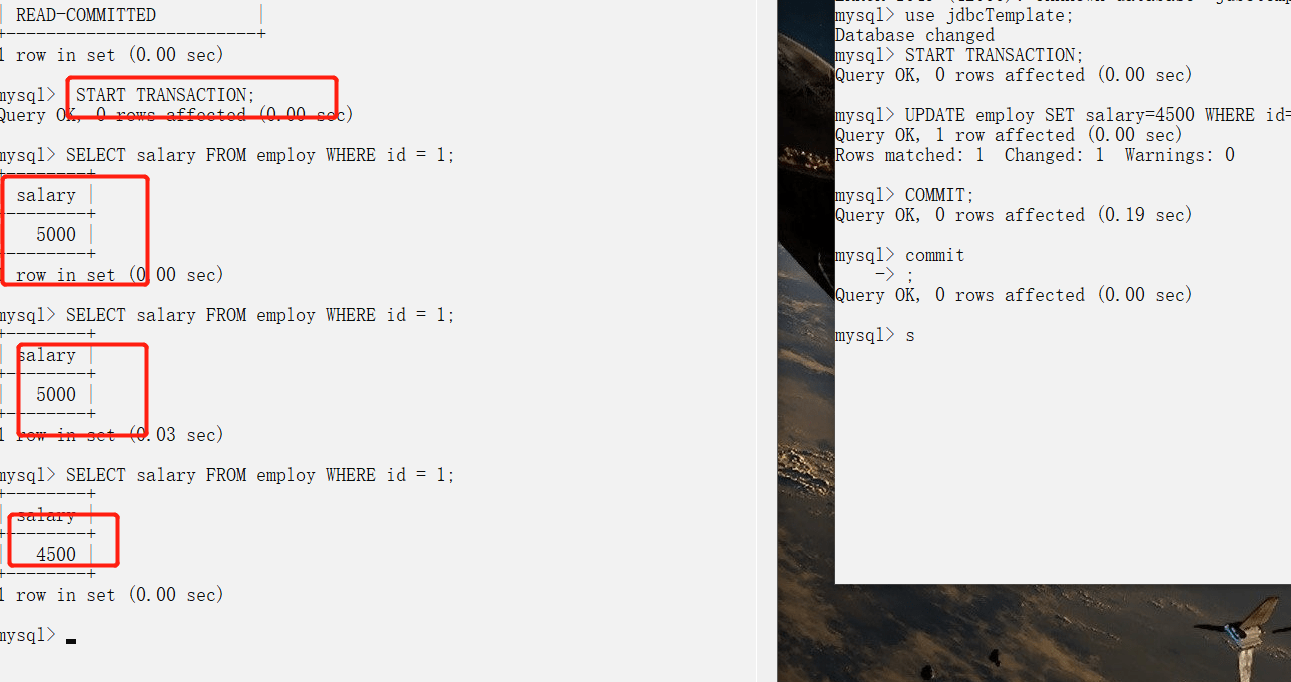
### 避免脏读(读已提交)
-
+
### 不可重复读
还是刚才上面的读已提交的图,虽然避免了读未提交,但是却出现了,一个事务还没有结束,就发生了 不可重复读问题。
-
+
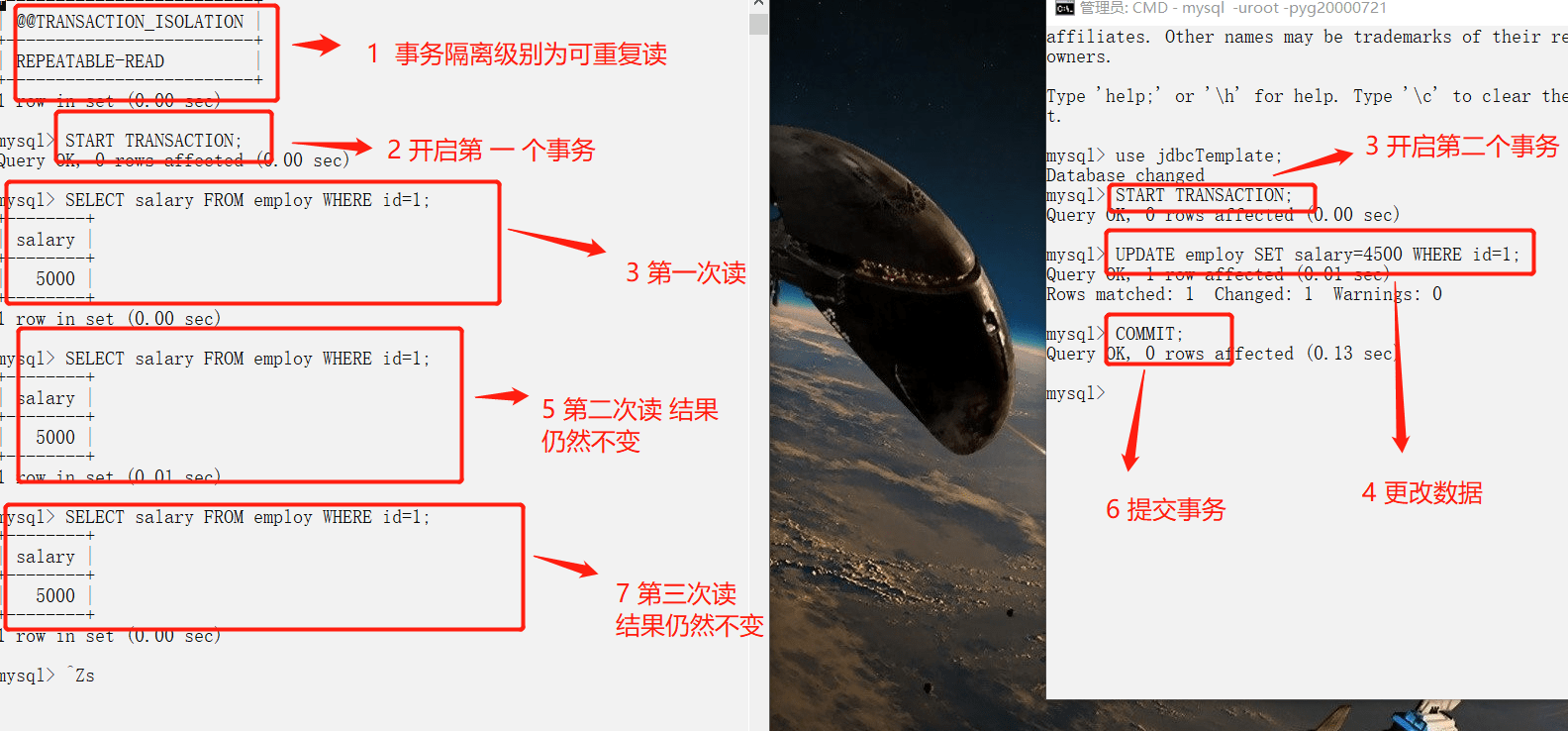
### 可重复读
-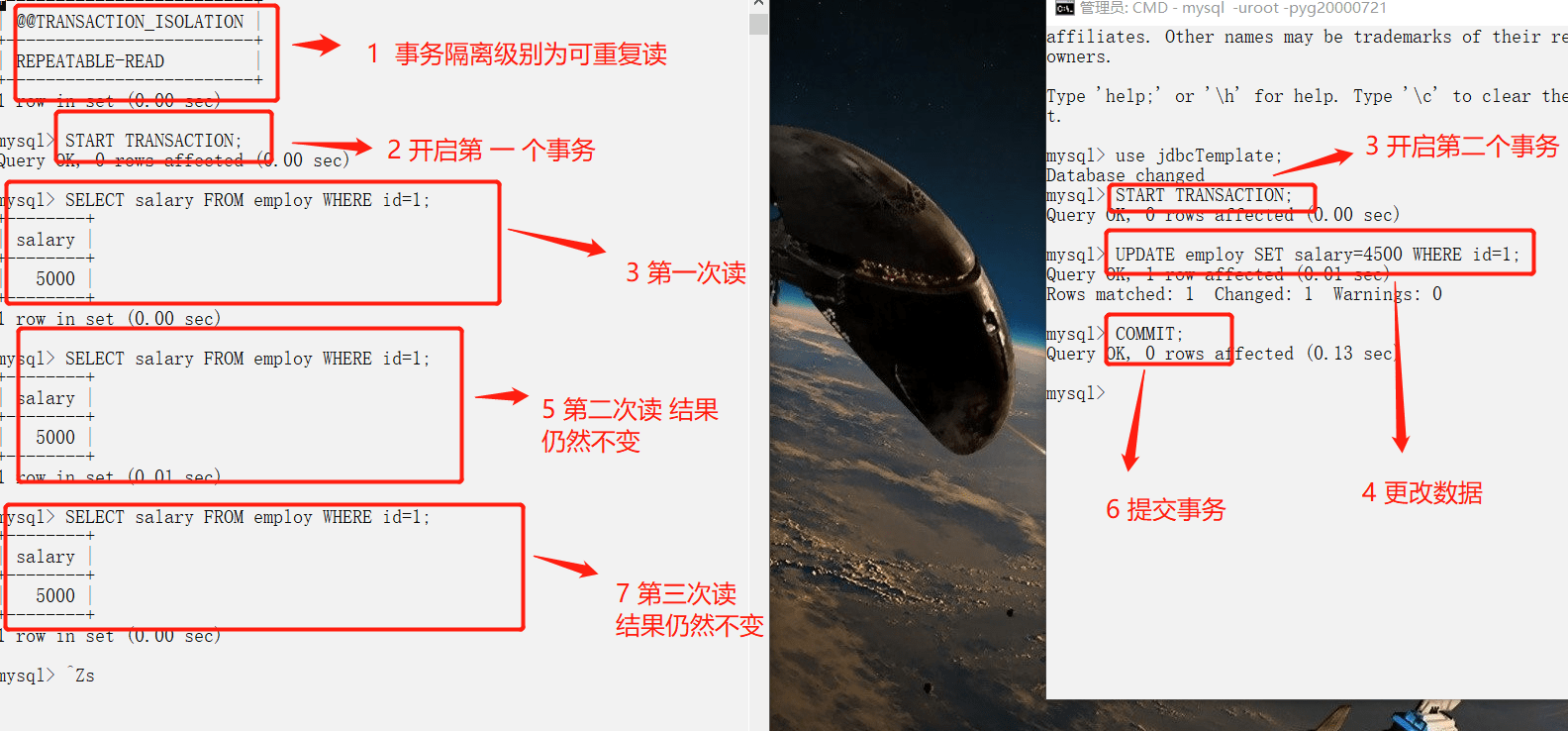
+
### 幻读
#### 演示幻读出现的情况
-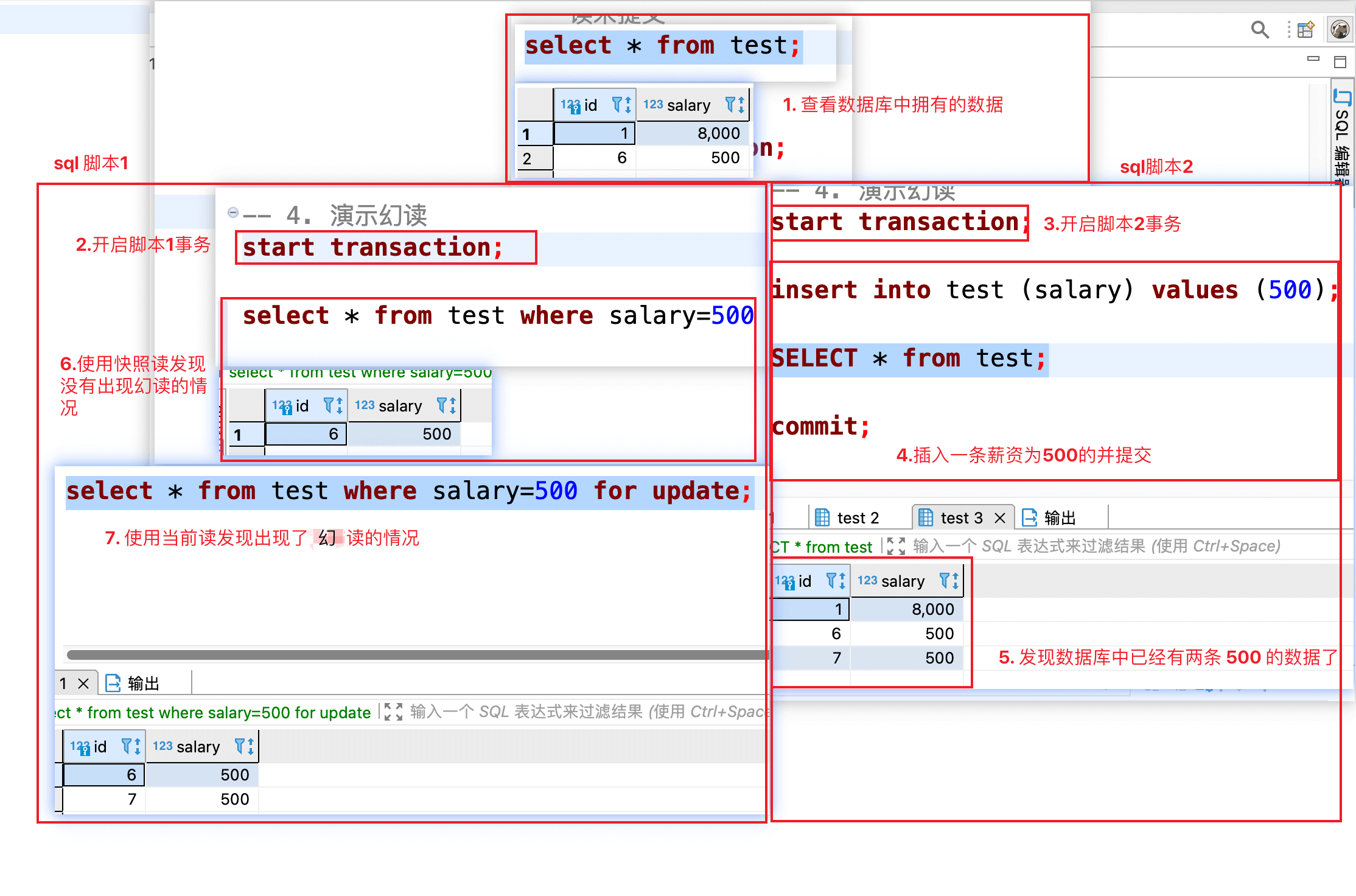
+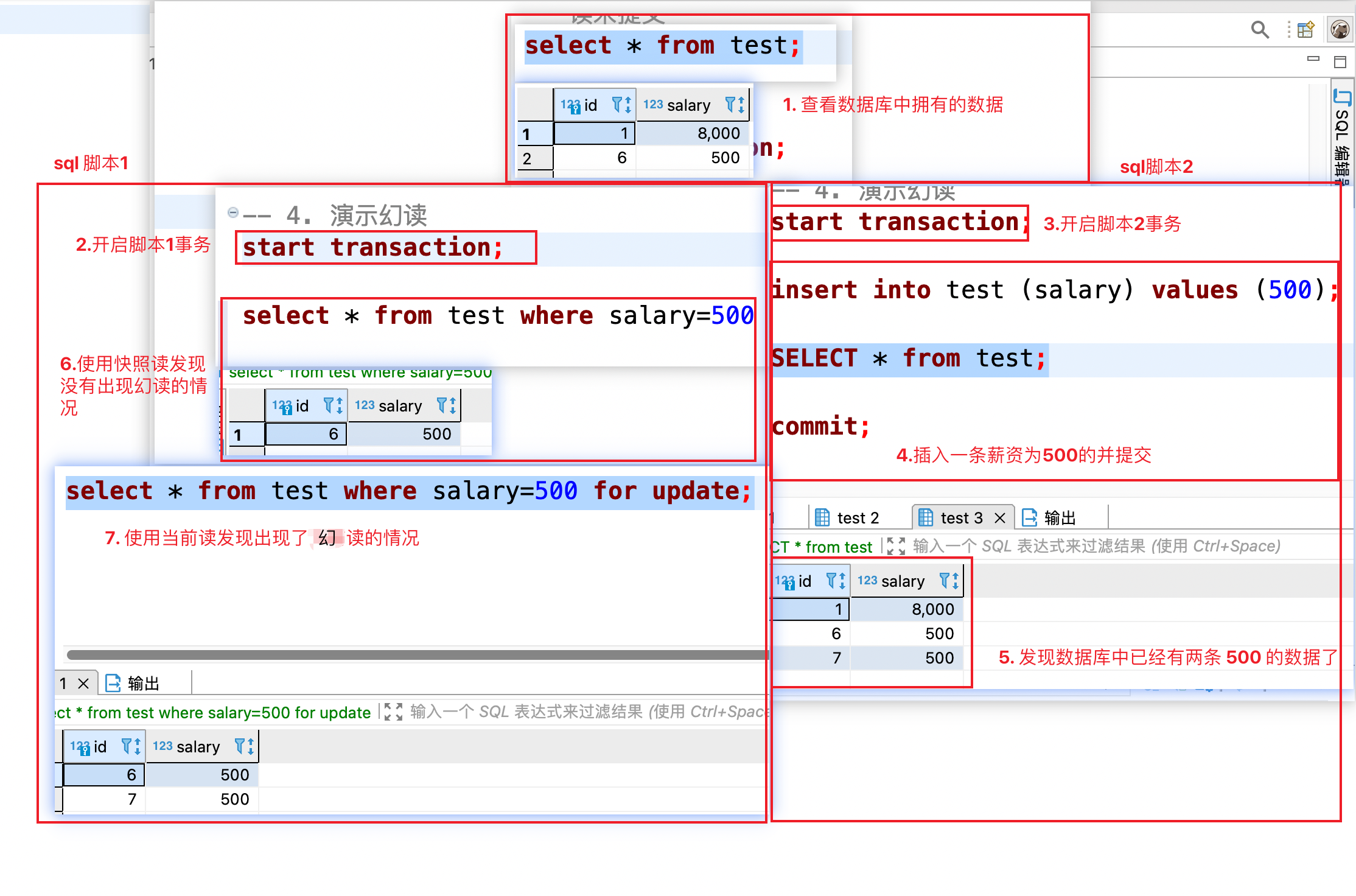
SQL 脚本 1 在第一次查询工资为 500 的记录时只有一条,SQL 脚本 2 插入了一条工资为 500 的记录,提交之后;SQL 脚本 1 在同一个事务中再次使用当前读查询发现出现了两条工资为 500 的记录这种就是幻读。
diff --git a/docs/distributed-system/distributed-configuration-center.md b/docs/distributed-system/distributed-configuration-center.md
index 10d27b51..7839e38d 100644
--- a/docs/distributed-system/distributed-configuration-center.md
+++ b/docs/distributed-system/distributed-configuration-center.md
@@ -4,8 +4,53 @@ category: 分布式
icon: "configuration"
---
-**分布式配置中心**
-
-
+**分布式配置中心** 相关的面试题为我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了《Java 面试指北》中。

+
+[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)(点击链接即可查看详细介绍)的部分内容展示如下,你可以将其看作是 [JavaGuide](https://javaguide.cn/#/) 的补充完善,两者可以配合使用。
+
+
+
+最近几年,市面上有越来越多的“技术大佬”开始办培训班/训练营,动辄成千上万的学费,却并没有什么干货,单纯的就是割韭菜。
+
+为了帮助更多同学准备 Java 面试以及学习 Java ,我创建了一个纯粹的知识星球。虽然收费只有培训班/训练营的百分之一,但是知识星球里的内容质量更高,提供的服务也更全面。
+
+欢迎准备 Java 面试以及学习 Java 的同学加入我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html),干货非常多,学习氛围也很不错!收费虽然是白菜价,但星球里的内容或许比你参加上万的培训班质量还要高。
+
+
每种方式都有各自的优势,根据实际场景才是王道。下面再对这三种方式做一个简单的对比,以供大家实际开发中选择正确的存放时间的数据类型:
diff --git a/docs/database/mysql/transaction-isolation-level.md b/docs/database/mysql/transaction-isolation-level.md
index 4cbabae6..574c0b6b 100644
--- a/docs/database/mysql/transaction-isolation-level.md
+++ b/docs/database/mysql/transaction-isolation-level.md
@@ -73,27 +73,27 @@ SET [SESSION|GLOBAL] TRANSACTION ISOLATION LEVEL [READ UNCOMMITTED|READ COMMITTE
### 脏读(读未提交)
-实例.jpg)
+%E5%AE%9E%E4%BE%8B.jpg)
### 避免脏读(读已提交)
-
+
### 不可重复读
还是刚才上面的读已提交的图,虽然避免了读未提交,但是却出现了,一个事务还没有结束,就发生了 不可重复读问题。
-
+
### 可重复读
-
+
### 幻读
#### 演示幻读出现的情况
-
+
SQL 脚本 1 在第一次查询工资为 500 的记录时只有一条,SQL 脚本 2 插入了一条工资为 500 的记录,提交之后;SQL 脚本 1 在同一个事务中再次使用当前读查询发现出现了两条工资为 500 的记录这种就是幻读。
diff --git a/docs/distributed-system/distributed-configuration-center.md b/docs/distributed-system/distributed-configuration-center.md
index 10d27b51..7839e38d 100644
--- a/docs/distributed-system/distributed-configuration-center.md
+++ b/docs/distributed-system/distributed-configuration-center.md
@@ -4,8 +4,53 @@ category: 分布式
icon: "configuration"
---
-**分布式配置中心**
-
-
+**分布式配置中心** 相关的面试题为我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html)(点击链接即可查看详细介绍以及加入方法)专属内容,已经整理到了《Java 面试指北》中。

+
+[《Java 面试指北》](https://javaguide.cn/zhuanlan/java-mian-shi-zhi-bei.html)(点击链接即可查看详细介绍)的部分内容展示如下,你可以将其看作是 [JavaGuide](https://javaguide.cn/#/) 的补充完善,两者可以配合使用。
+
+
+
+最近几年,市面上有越来越多的“技术大佬”开始办培训班/训练营,动辄成千上万的学费,却并没有什么干货,单纯的就是割韭菜。
+
+为了帮助更多同学准备 Java 面试以及学习 Java ,我创建了一个纯粹的知识星球。虽然收费只有培训班/训练营的百分之一,但是知识星球里的内容质量更高,提供的服务也更全面。
+
+欢迎准备 Java 面试以及学习 Java 的同学加入我的[知识星球](https://javaguide.cn/about-the-author/zhishixingqiu-two-years.html),干货非常多,学习氛围也很不错!收费虽然是白菜价,但星球里的内容或许比你参加上万的培训班质量还要高。
+
+ +
+
+
+ +
+
+
+ +
+
+
+ +
+
+
+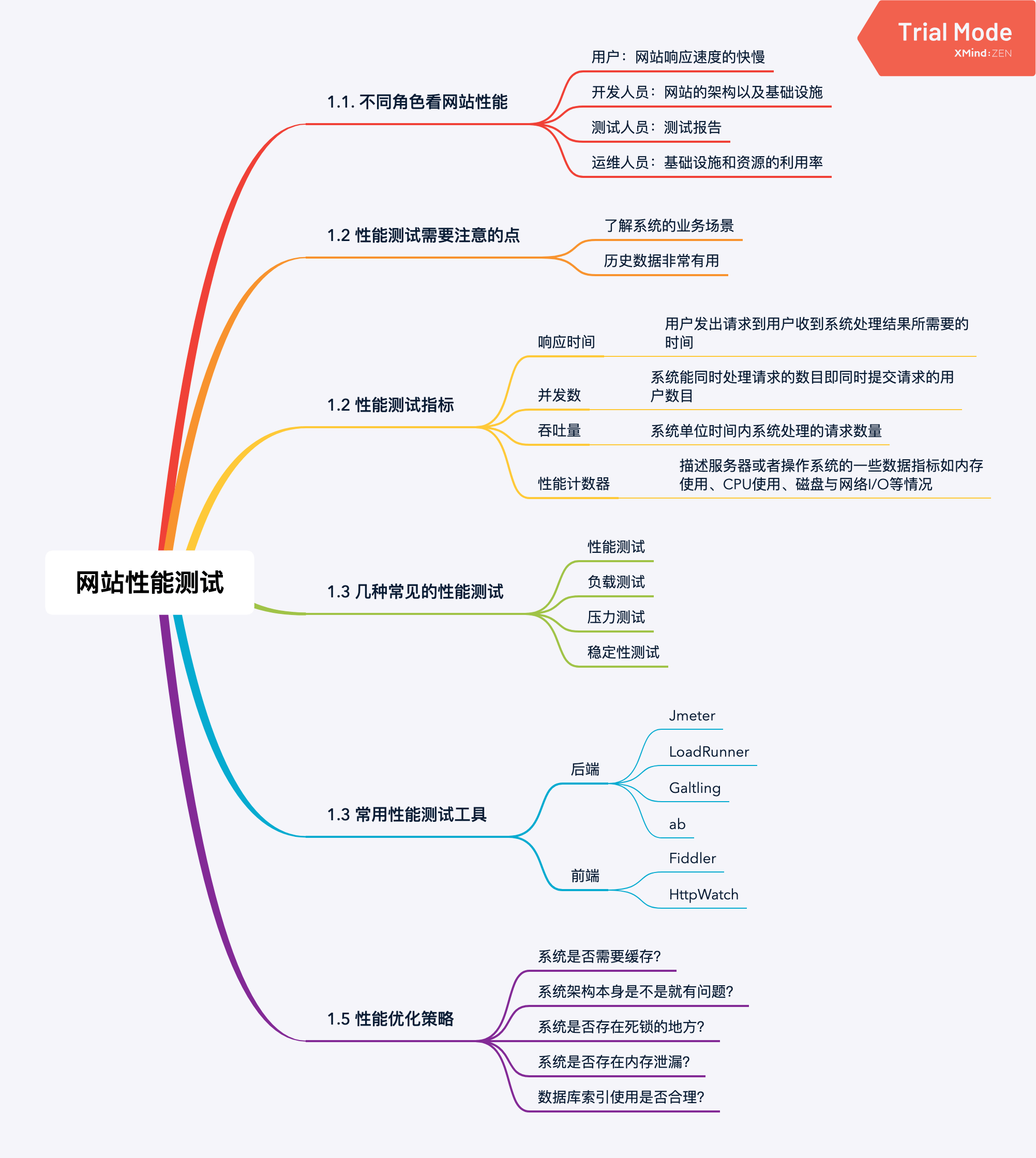 -
## 一 不同角色看网站性能
### 1.1 用户
diff --git a/docs/high-performance/message-queue/message-queue.md b/docs/high-performance/message-queue/message-queue.md
index d320265c..aca7f07a 100644
--- a/docs/high-performance/message-queue/message-queue.md
+++ b/docs/high-performance/message-queue/message-queue.md
@@ -45,7 +45,7 @@ tag:
### 通过异步处理提高系统性能(减少响应所需时间)
-
+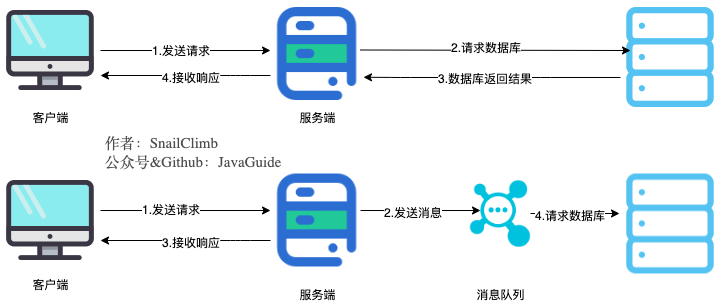
将用户的请求数据存储到消息队列之后就立即返回结果。随后,系统再对消息进行消费。
@@ -57,7 +57,7 @@ tag:
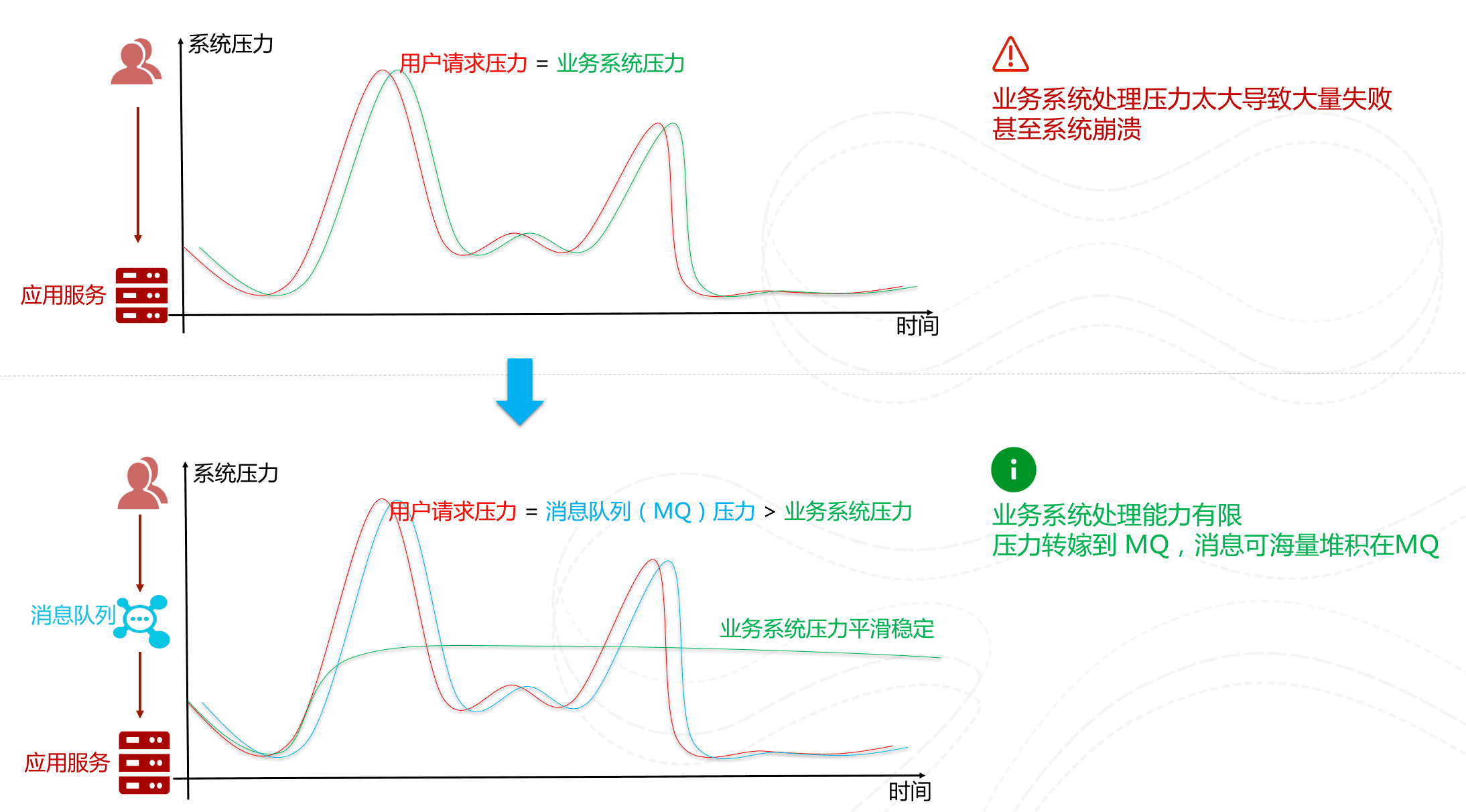
举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
-
+
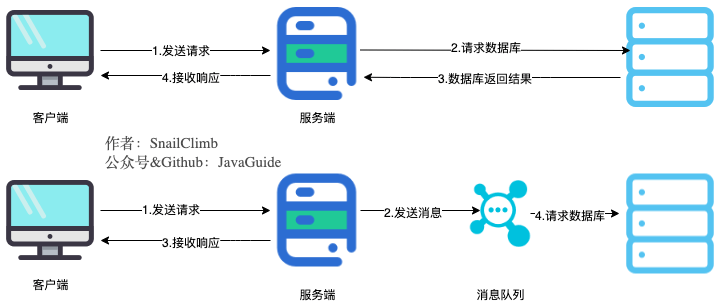
### 降低系统耦合性
diff --git a/docs/high-performance/message-queue/rabbitmq-intro.md b/docs/high-performance/message-queue/rabbitmq-intro.md
index 921fccd6..b15f5789 100644
--- a/docs/high-performance/message-queue/rabbitmq-intro.md
+++ b/docs/high-performance/message-queue/rabbitmq-intro.md
@@ -31,7 +31,7 @@ RabbitMQ 整体上是一个生产者与消费者模型,主要负责接收、
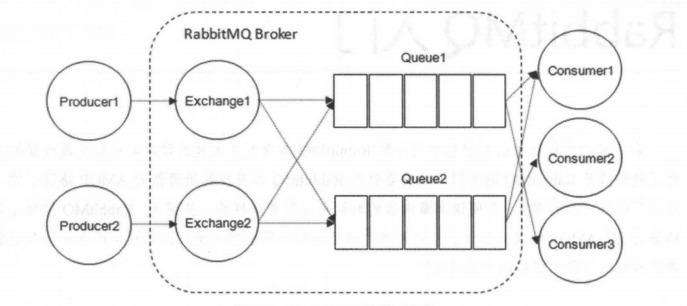
下面再来看看图1—— RabbitMQ 的整体模型架构。
-
+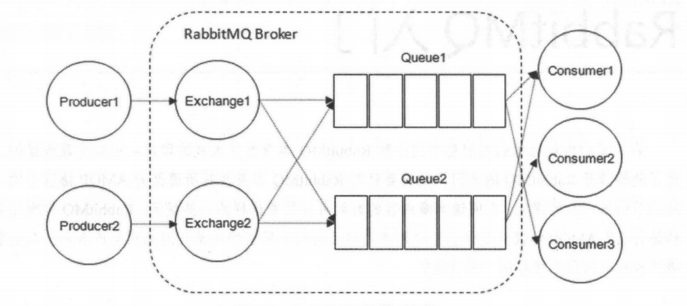
下面我会一一介绍上图中的一些概念。
@@ -52,7 +52,7 @@ RabbitMQ 整体上是一个生产者与消费者模型,主要负责接收、
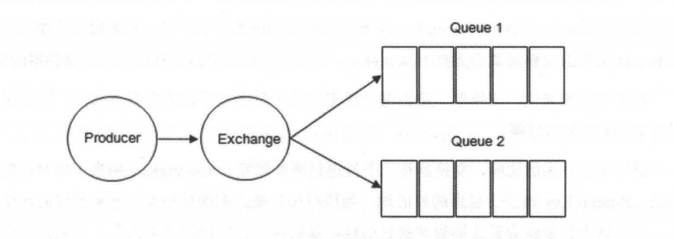
Exchange(交换器) 示意图如下:
-
+
生产者将消息发给交换器的时候,一般会指定一个 **RoutingKey(路由键)**,用来指定这个消息的路由规则,而这个 **RoutingKey 需要与交换器类型和绑定键(BindingKey)联合使用才能最终生效**。
@@ -60,7 +60,7 @@ RabbitMQ 中通过 **Binding(绑定)** 将 **Exchange(交换器)** 与 **Queue(
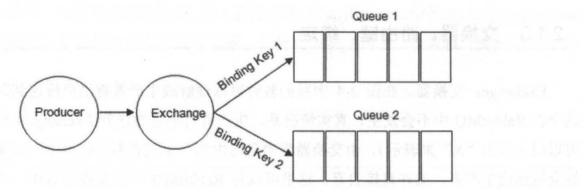
Binding(绑定) 示意图:
-
+
生产者将消息发送给交换器时,需要一个RoutingKey,当 BindingKey 和 RoutingKey 相匹配时,消息会被路由到对应的队列中。在绑定多个队列到同一个交换器的时候,这些绑定允许使用相同的 BindingKey。BindingKey 并不是在所有的情况下都生效,它依赖于交换器类型,比如fanout类型的交换器就会无视,而是将消息路由到所有绑定到该交换器的队列中。
@@ -80,7 +80,7 @@ Binding(绑定) 示意图:
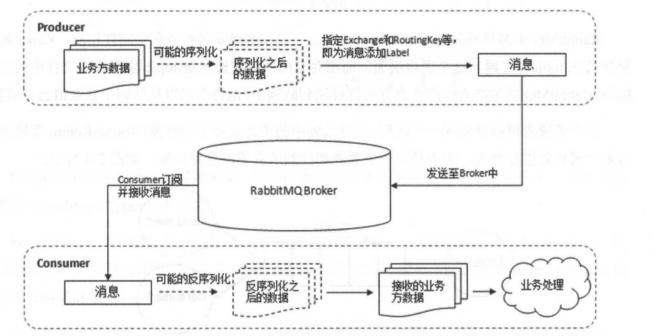
下图展示了生产者将消息存入 RabbitMQ Broker,以及消费者从Broker中消费数据的整个流程。
-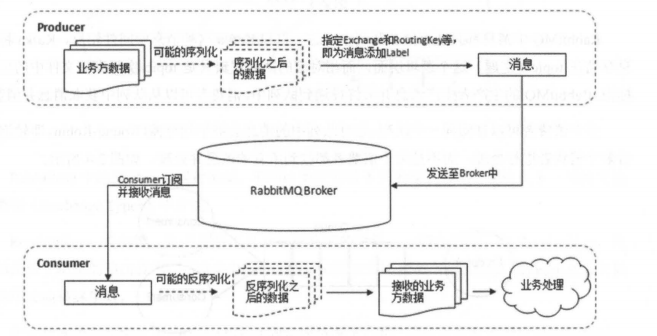
+
这样图1中的一些关于 RabbitMQ 的基本概念我们就介绍完毕了,下面再来介绍一下 **Exchange Types(交换器类型)** 。
@@ -96,7 +96,7 @@ fanout 类型的Exchange路由规则非常简单,它会把所有发送到该Ex
direct 类型的Exchange路由规则也很简单,它会把消息路由到那些 Bindingkey 与 RoutingKey 完全匹配的 Queue 中。
-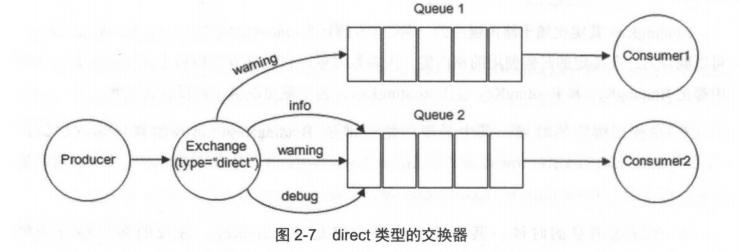
+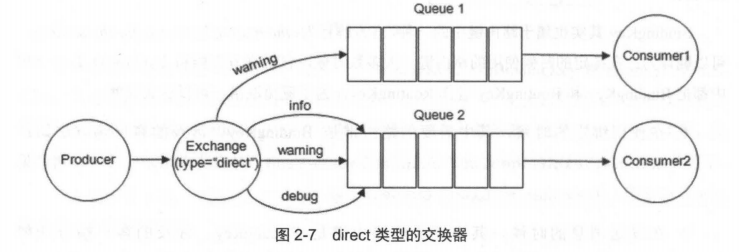
以上图为例,如果发送消息的时候设置路由键为“warning”,那么消息会路由到 Queue1 和 Queue2。如果在发送消息的时候设置路由键为"Info”或者"debug”,消息只会路由到Queue2。如果以其他的路由键发送消息,则消息不会路由到这两个队列中。
@@ -110,7 +110,7 @@ direct 类型常用在处理有优先级的任务,根据任务的优先级把
- BindingKey 和 RoutingKey 一样也是点号“.”分隔的字符串;
- BindingKey 中可以存在两种特殊字符串“\*”和“#”,用于做模糊匹配,其中“\*”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)。
-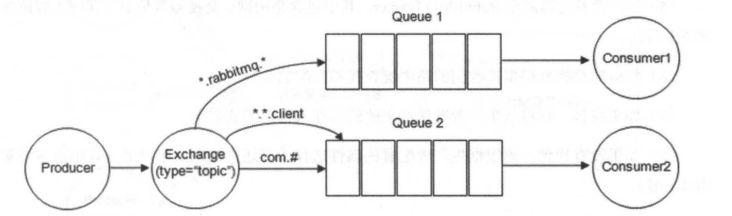
+
以上图为例:
@@ -132,7 +132,7 @@ headers 类型的交换器不依赖于路由键的匹配规则来路由消息,
注意:在安装 RabbitMQ 的时候需要注意 RabbitMQ 和 Erlang 的版本关系,如果不注意的话会导致出错,两者对应关系如下:
-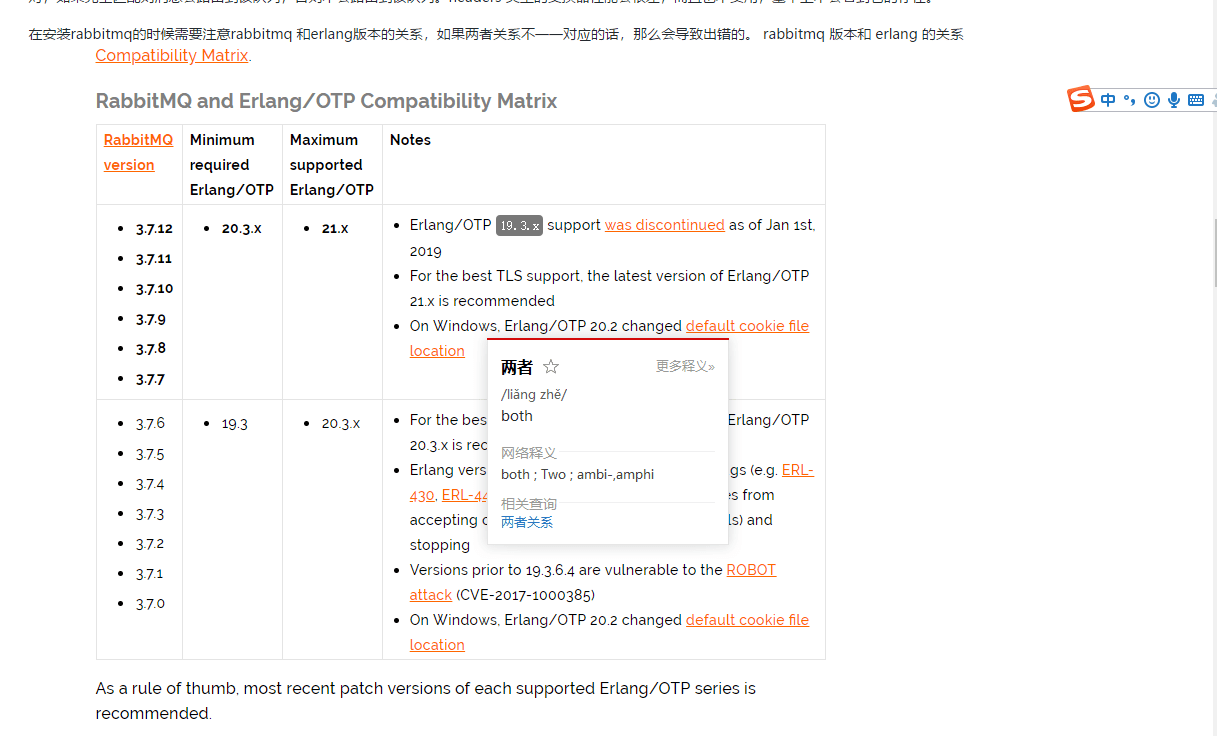
+
### 2.1 安装 erlang
@@ -196,7 +196,7 @@ make && make install
```erlang
io:format("hello world~n", []).
```
-
+
大功告成,我们的 erlang 已经安装完成。
@@ -304,6 +304,5 @@ Setting permissions for user "root" in vhost "/" ...
再次访问:http://你的ip地址:15672/ ,输入用户名和密码:root root
-
-
+
diff --git a/docs/java/basis/java-basic-questions-03.md b/docs/java/basis/java-basic-questions-03.md
index 3525eda3..49260542 100644
--- a/docs/java/basis/java-basic-questions-03.md
+++ b/docs/java/basis/java-basic-questions-03.md
@@ -468,7 +468,7 @@ SPI 将服务接口和具体的服务实现分离开来,将服务调用方和
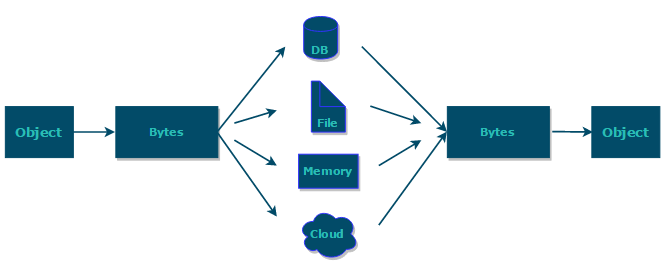
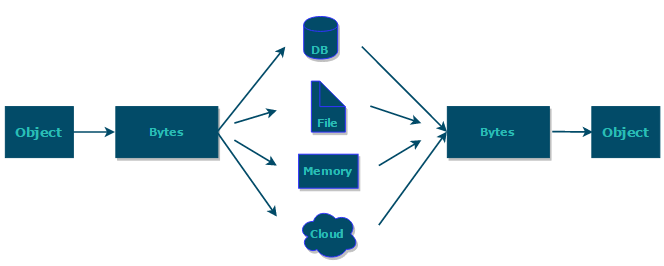
综上:**序列化的主要目的是通过网络传输对象或者说是将对象存储到文件系统、数据库、内存中。**
-
+
-
## 一 不同角色看网站性能
### 1.1 用户
diff --git a/docs/high-performance/message-queue/message-queue.md b/docs/high-performance/message-queue/message-queue.md
index d320265c..aca7f07a 100644
--- a/docs/high-performance/message-queue/message-queue.md
+++ b/docs/high-performance/message-queue/message-queue.md
@@ -45,7 +45,7 @@ tag:
### 通过异步处理提高系统性能(减少响应所需时间)
-
+
将用户的请求数据存储到消息队列之后就立即返回结果。随后,系统再对消息进行消费。
@@ -57,7 +57,7 @@ tag:
举例:在电子商务一些秒杀、促销活动中,合理使用消息队列可以有效抵御促销活动刚开始大量订单涌入对系统的冲击。如下图所示:
-
+
### 降低系统耦合性
diff --git a/docs/high-performance/message-queue/rabbitmq-intro.md b/docs/high-performance/message-queue/rabbitmq-intro.md
index 921fccd6..b15f5789 100644
--- a/docs/high-performance/message-queue/rabbitmq-intro.md
+++ b/docs/high-performance/message-queue/rabbitmq-intro.md
@@ -31,7 +31,7 @@ RabbitMQ 整体上是一个生产者与消费者模型,主要负责接收、
下面再来看看图1—— RabbitMQ 的整体模型架构。
-
+
下面我会一一介绍上图中的一些概念。
@@ -52,7 +52,7 @@ RabbitMQ 整体上是一个生产者与消费者模型,主要负责接收、
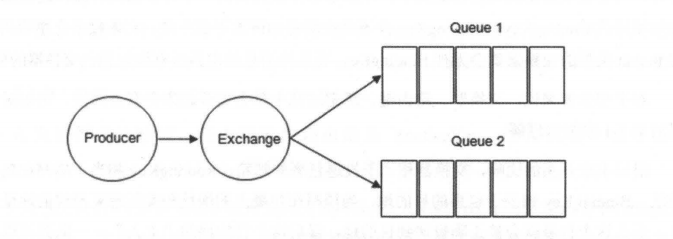
Exchange(交换器) 示意图如下:
-
+
生产者将消息发给交换器的时候,一般会指定一个 **RoutingKey(路由键)**,用来指定这个消息的路由规则,而这个 **RoutingKey 需要与交换器类型和绑定键(BindingKey)联合使用才能最终生效**。
@@ -60,7 +60,7 @@ RabbitMQ 中通过 **Binding(绑定)** 将 **Exchange(交换器)** 与 **Queue(
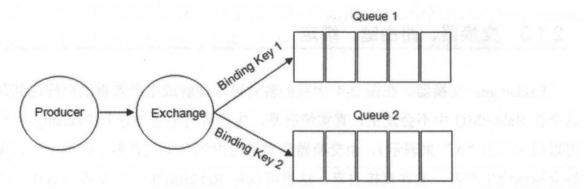
Binding(绑定) 示意图:
-
+
生产者将消息发送给交换器时,需要一个RoutingKey,当 BindingKey 和 RoutingKey 相匹配时,消息会被路由到对应的队列中。在绑定多个队列到同一个交换器的时候,这些绑定允许使用相同的 BindingKey。BindingKey 并不是在所有的情况下都生效,它依赖于交换器类型,比如fanout类型的交换器就会无视,而是将消息路由到所有绑定到该交换器的队列中。
@@ -80,7 +80,7 @@ Binding(绑定) 示意图:
下图展示了生产者将消息存入 RabbitMQ Broker,以及消费者从Broker中消费数据的整个流程。
-
+
这样图1中的一些关于 RabbitMQ 的基本概念我们就介绍完毕了,下面再来介绍一下 **Exchange Types(交换器类型)** 。
@@ -96,7 +96,7 @@ fanout 类型的Exchange路由规则非常简单,它会把所有发送到该Ex
direct 类型的Exchange路由规则也很简单,它会把消息路由到那些 Bindingkey 与 RoutingKey 完全匹配的 Queue 中。
-
+
以上图为例,如果发送消息的时候设置路由键为“warning”,那么消息会路由到 Queue1 和 Queue2。如果在发送消息的时候设置路由键为"Info”或者"debug”,消息只会路由到Queue2。如果以其他的路由键发送消息,则消息不会路由到这两个队列中。
@@ -110,7 +110,7 @@ direct 类型常用在处理有优先级的任务,根据任务的优先级把
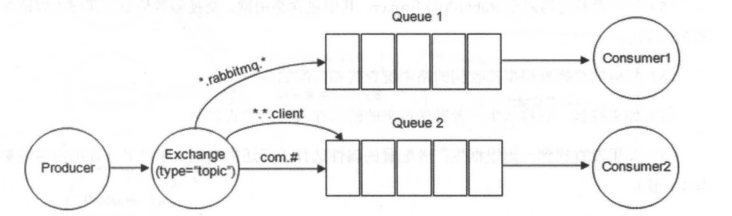
- BindingKey 和 RoutingKey 一样也是点号“.”分隔的字符串;
- BindingKey 中可以存在两种特殊字符串“\*”和“#”,用于做模糊匹配,其中“\*”用于匹配一个单词,“#”用于匹配多个单词(可以是零个)。
-
+
以上图为例:
@@ -132,7 +132,7 @@ headers 类型的交换器不依赖于路由键的匹配规则来路由消息,
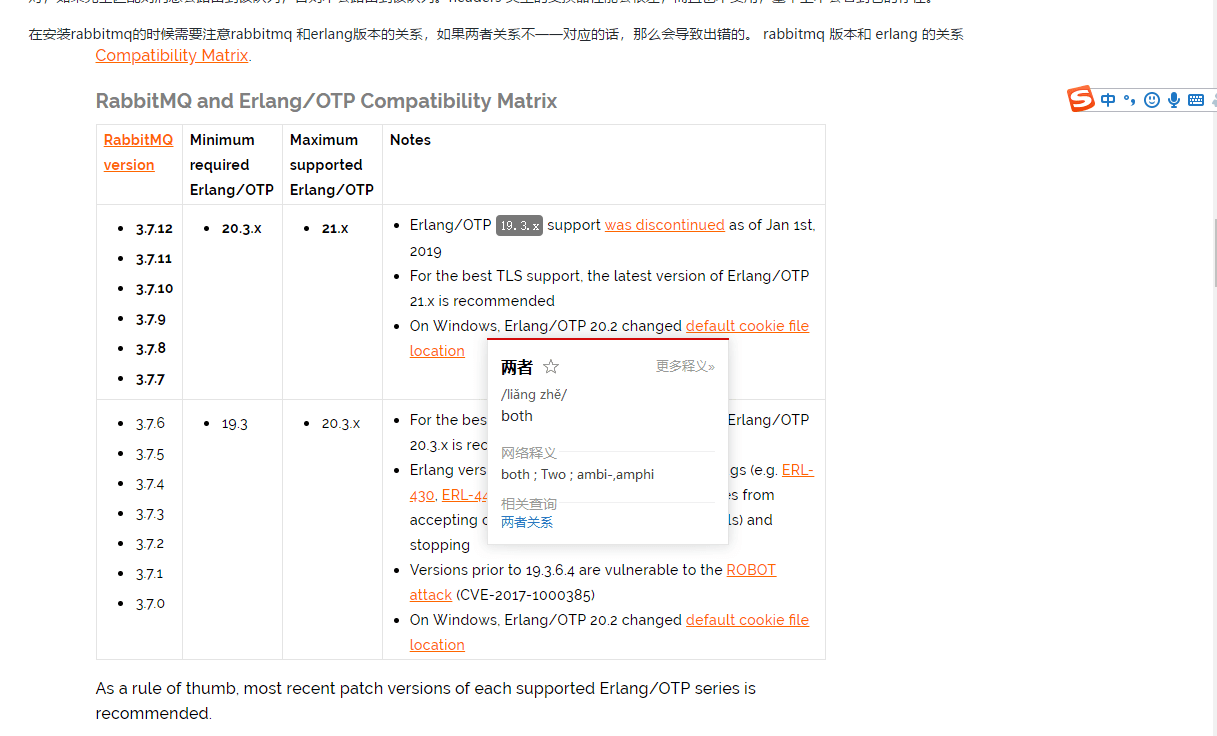
注意:在安装 RabbitMQ 的时候需要注意 RabbitMQ 和 Erlang 的版本关系,如果不注意的话会导致出错,两者对应关系如下:
-
+
### 2.1 安装 erlang
@@ -196,7 +196,7 @@ make && make install
```erlang
io:format("hello world~n", []).
```
-
+
大功告成,我们的 erlang 已经安装完成。
@@ -304,6 +304,5 @@ Setting permissions for user "root" in vhost "/" ...
再次访问:http://你的ip地址:15672/ ,输入用户名和密码:root root
-
-
+
diff --git a/docs/java/basis/java-basic-questions-03.md b/docs/java/basis/java-basic-questions-03.md
index 3525eda3..49260542 100644
--- a/docs/java/basis/java-basic-questions-03.md
+++ b/docs/java/basis/java-basic-questions-03.md
@@ -468,7 +468,7 @@ SPI 将服务接口和具体的服务实现分离开来,将服务调用方和
综上:**序列化的主要目的是通过网络传输对象或者说是将对象存储到文件系统、数据库、内存中。**
-
+
https://www.corejavaguru.com/java/serialization/interview-questions-1
diff --git a/docs/java/basis/java-keyword-summary.md b/docs/java/basis/java-keyword-summary.md index 141b6778..09113434 100644 --- a/docs/java/basis/java-keyword-summary.md +++ b/docs/java/basis/java-keyword-summary.md @@ -155,7 +155,7 @@ static { 一个类中的静态代码块可以有多个,位置可以随便放,它不在任何的方法体内,JVM 加载类时会执行这些静态的代码块,如果静态代码块有多个,JVM 将按照它们在类中出现的先后顺序依次执行它们,每个代码块只会被执行一次。 -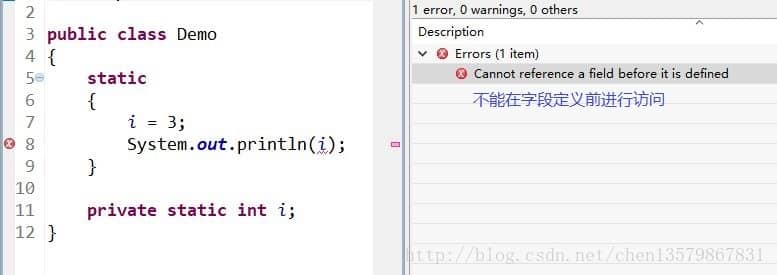 +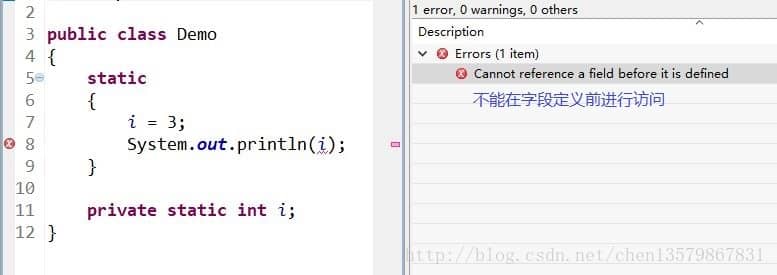 静态代码块对于定义在它之后的静态变量,可以赋值,但是不能访问. diff --git a/docs/java/basis/serialization.md b/docs/java/basis/serialization.md index 30d4d395..0f04d8a3 100644 --- a/docs/java/basis/serialization.md +++ b/docs/java/basis/serialization.md @@ -29,7 +29,7 @@ tag: 综上:**序列化的主要目的是通过网络传输对象或者说是将对象存储到文件系统、数据库、内存中。** - +https://www.corejavaguru.com/java/serialization/interview-questions-1
@@ -198,7 +198,7 @@ Github 地址:[https://github.com/protostuff/protostuff](https://github.com/pr Hessian 是一个轻量级的,自定义描述的二进制 RPC 协议。Hessian 是一个比较老的序列化实现了,并且同样也是跨语言的。 -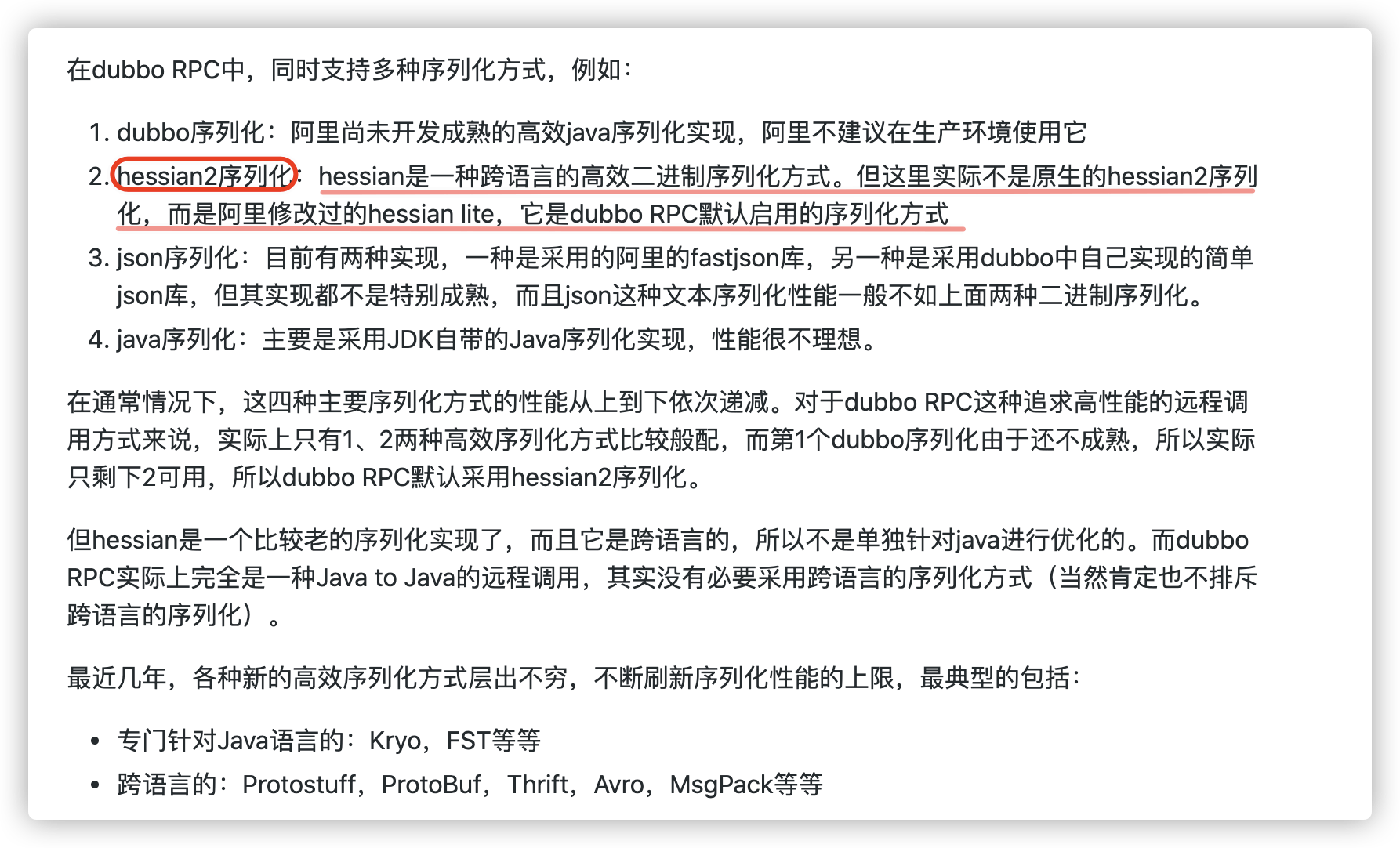 +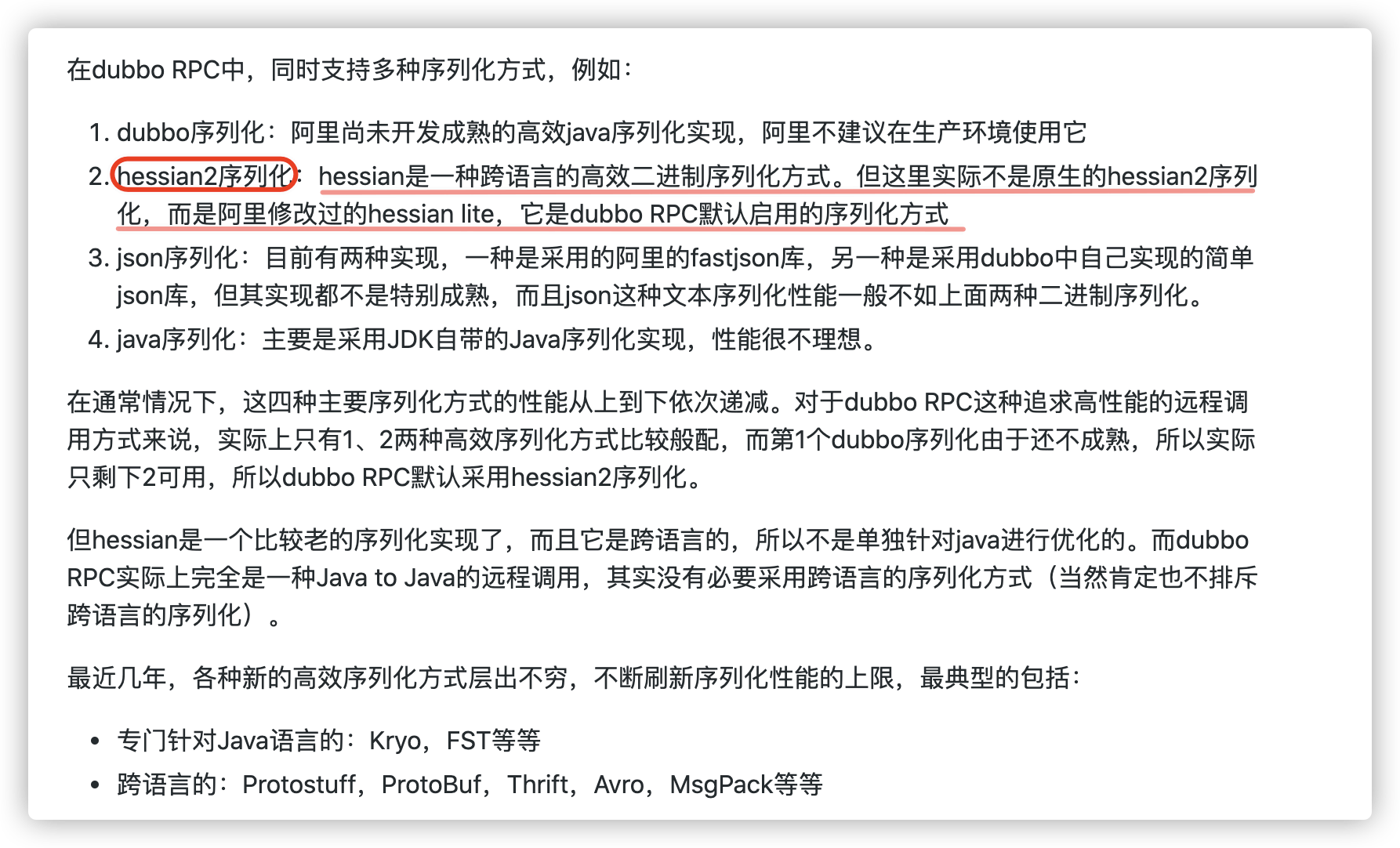 Dubbo2.x 默认启用的序列化方式是 Hessian2 ,但是,Dubbo 对 Hessian2 进行了修改,不过大体结构还是差不多。 diff --git a/docs/java/collection/hashmap-source-code.md b/docs/java/collection/hashmap-source-code.md index 5942dc31..c3af8193 100644 --- a/docs/java/collection/hashmap-source-code.md +++ b/docs/java/collection/hashmap-source-code.md @@ -59,7 +59,7 @@ static int hash(int h) { 所谓 **“拉链法”** 就是:将链表和数组相结合。也就是说创建一个链表数组,数组中每一格就是一个链表。若遇到哈希冲突,则将冲突的值加到链表中即可。 -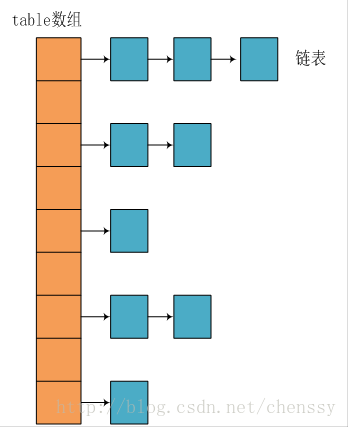 +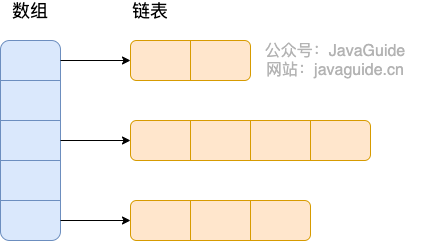 ### JDK1.8 之后 @@ -67,7 +67,7 @@ static int hash(int h) { 当链表长度大于阈值(默认为 8)时,会首先调用 `treeifyBin()`方法。这个方法会根据 HashMap 数组来决定是否转换为红黑树。只有当数组长度大于或者等于 64 的情况下,才会执行转换红黑树操作,以减少搜索时间。否则,就是只是执行 `resize()` 方法对数组扩容。相关源码这里就不贴了,重点关注 `treeifyBin()`方法即可! -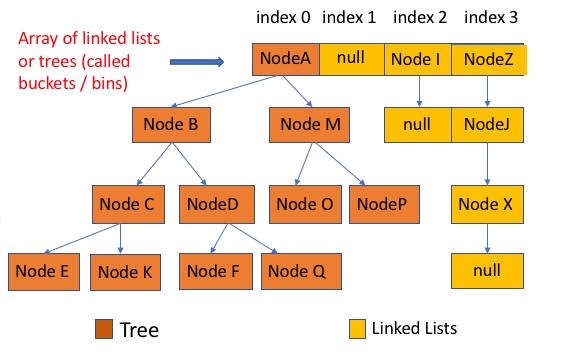 +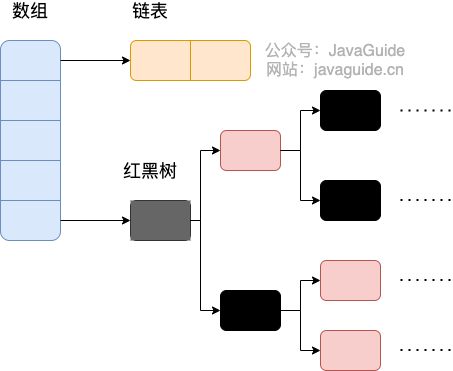 **类的属性:** diff --git a/docs/java/concurrent/aqs.md b/docs/java/concurrent/aqs.md index 616e9b8d..8181239b 100644 --- a/docs/java/concurrent/aqs.md +++ b/docs/java/concurrent/aqs.md @@ -9,7 +9,7 @@ tag: AQS 的全称为 `AbstractQueuedSynchronizer` ,翻译过来的意思就是抽象队列同步器。这个类在 `java.util.concurrent.locks` 包下面。 - + AQS 就是一个抽象类,主要用来构建锁和同步器。 @@ -38,7 +38,7 @@ CLH 队列锁结构如下图所示: AQS(`AbstractQueuedSynchronizer`)的核心原理图(图源[Java 并发之 AQS 详解](https://www.cnblogs.com/waterystone/p/4920797.html))如下: -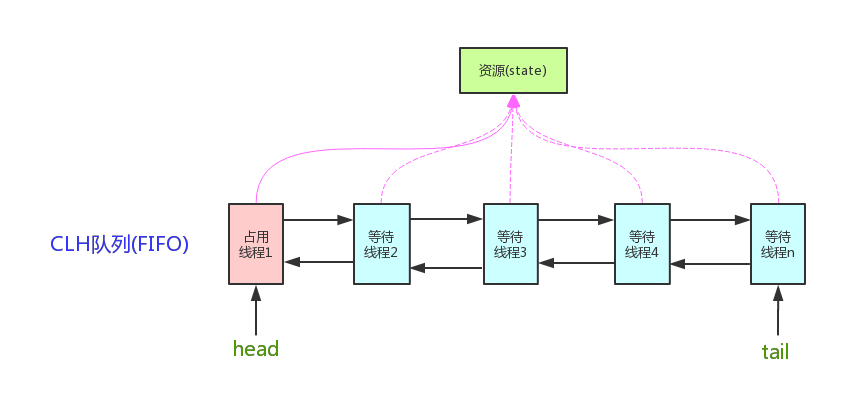 +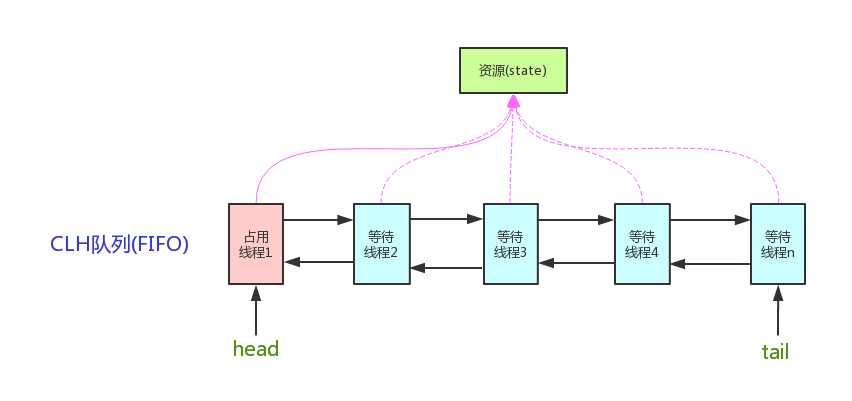 AQS 使用 **int 成员变量 `state` 表示同步状态**,通过内置的 **线程等待队列** 来完成获取资源线程的排队工作。 diff --git a/docs/java/concurrent/java-concurrent-questions-02.md b/docs/java/concurrent/java-concurrent-questions-02.md index ef7c99b4..55b6c676 100644 --- a/docs/java/concurrent/java-concurrent-questions-02.md +++ b/docs/java/concurrent/java-concurrent-questions-02.md @@ -378,7 +378,7 @@ public class SynchronizedDemo { 通过 JDK 自带的 `javap` 命令查看 `SynchronizedDemo` 类的相关字节码信息:首先切换到类的对应目录执行 `javac SynchronizedDemo.java` 命令生成编译后的 .class 文件,然后执行`javap -c -s -v -l SynchronizedDemo.class`。 - +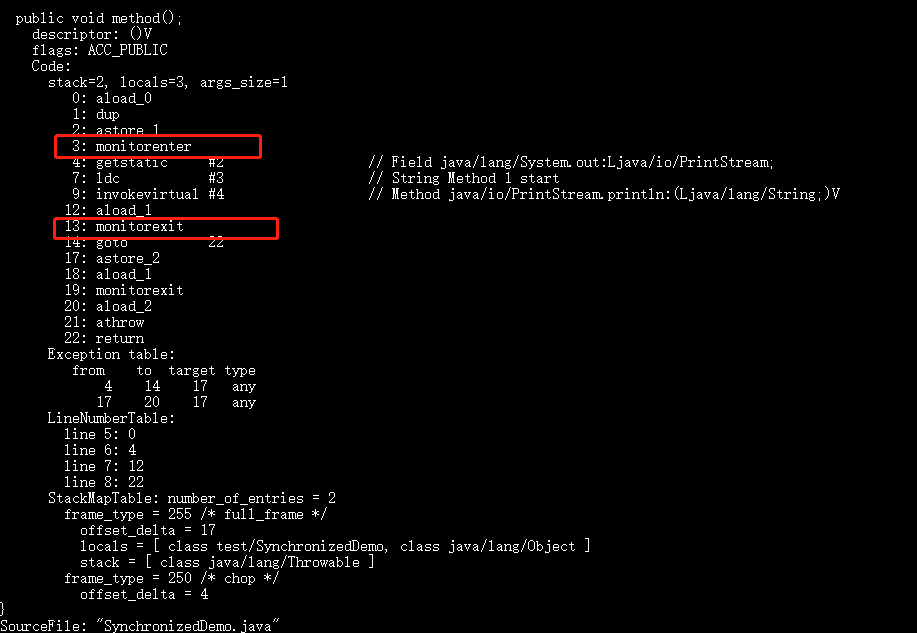 从上面我们可以看出:**`synchronized` 同步语句块的实现使用的是 `monitorenter` 和 `monitorexit` 指令,其中 `monitorenter` 指令指向同步代码块的开始位置,`monitorexit` 指令则指明同步代码块的结束位置。** @@ -409,7 +409,7 @@ public class SynchronizedDemo2 { ``` -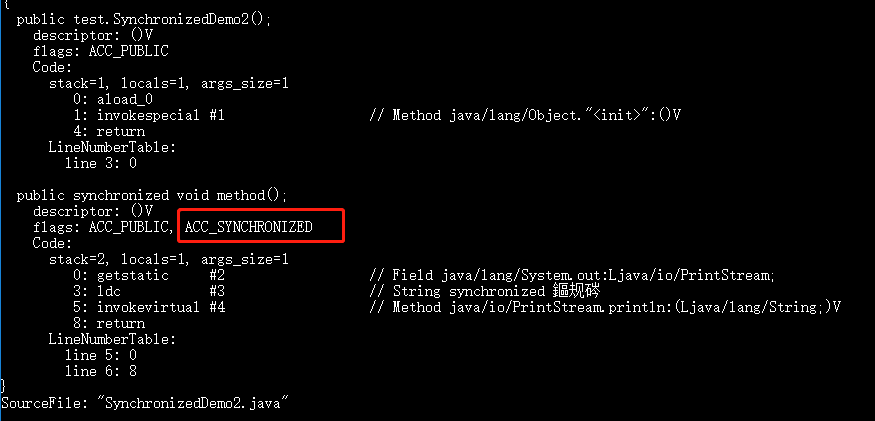 +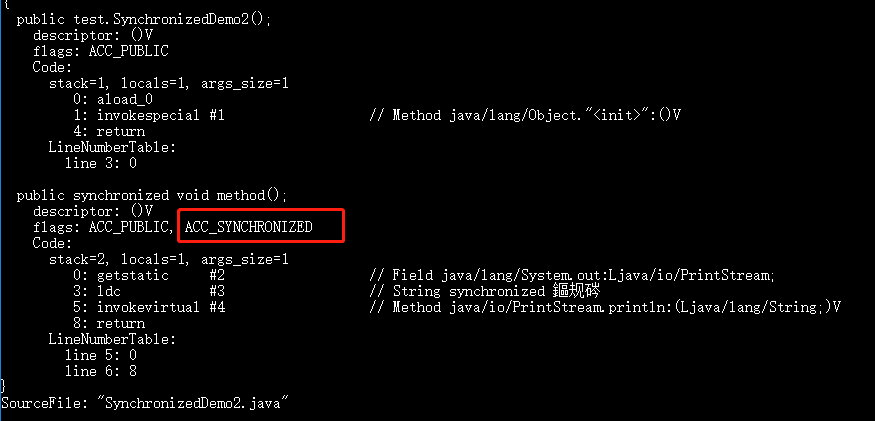 `synchronized` 修饰的方法并没有 `monitorenter` 指令和 `monitorexit` 指令,取得代之的确实是 `ACC_SYNCHRONIZED` 标识,该标识指明了该方法是一个同步方法。JVM 通过该 `ACC_SYNCHRONIZED` 访问标志来辨别一个方法是否声明为同步方法,从而执行相应的同步调用。 diff --git a/docs/system-design/J2EE基础知识.md b/docs/system-design/J2EE基础知识.md index 62f906a4..02e7215d 100644 --- a/docs/system-design/J2EE基础知识.md +++ b/docs/system-design/J2EE基础知识.md @@ -135,7 +135,9 @@ Response.setHeader("Refresh","5;URL=http://localhost:8080/servlet/example.htm"); JSP是一种Servlet,但是与HttpServlet的工作方式不太一样。HttpServlet是先由源代码编译为class文件后部署到服务器下,为先编译后部署。而JSP则是先部署后编译。JSP会在客户端第一次请求JSP文件时被编译为HttpJspPage类(接口Servlet的一个子类)。该类会被服务器临时存放在服务器工作目录里面。下面通过实例给大家介绍。 工程JspLoginDemo下有一个名为login.jsp的Jsp文件,把工程第一次部署到服务器上后访问这个Jsp文件,我们发现这个目录下多了下图这两个东东。 .class文件便是JSP对应的Servlet。编译完毕后再运行class文件来响应客户端请求。以后客户端访问login.jsp的时候,Tomcat将不再重新编译JSP文件,而是直接调用class文件来响应客户端请求。 -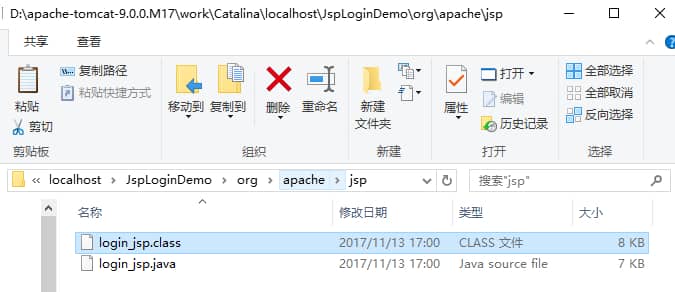 + + + 由于JSP只会在客户端第一次请求的时候被编译 ,因此第一次请求JSP时会感觉比较慢,之后就会感觉快很多。如果把服务器保存的class文件删除,服务器也会重新编译JSP。 开发Web程序时经常需要修改JSP。Tomcat能够自动检测到JSP程序的改动。如果检测到JSP源代码发生了改动。Tomcat会在下次客户端请求JSP时重新编译JSP,而不需要重启Tomcat。这种自动检测功能是默认开启的,检测改动会消耗少量的时间,在部署Web应用的时候可以在web.xml中将它关掉。 @@ -289,13 +291,3 @@ Cookie 和 Session都是用来跟踪浏览器用户身份的会话方式,但 Cookie 数据保存在客户端(浏览器端),Session 数据保存在服务器端。 Cookie 存储在客户端中,而Session存储在服务器上,相对来说 Session 安全性更高。如果使用 Cookie 的一些敏感信息不要写入 Cookie 中,最好能将 Cookie 信息加密然后使用到的时候再去服务器端解密。 - -## 公众号 - -如果大家想要实时关注我更新的文章以及分享的干货的话,可以关注我的公众号。 - -**《Java面试突击》:** 由本文档衍生的专为面试而生的《Java面试突击》V2.0 PDF 版本[公众号](#公众号)后台回复 **"Java面试突击"** 即可免费领取! - -**Java工程师必备学习资源:** 一些Java工程师常用学习资源公众号后台回复关键字 **“1”** 即可免费无套路获取。 - - diff --git a/docs/system-design/framework/spring/spring-design-patterns-summary.md b/docs/system-design/framework/spring/spring-design-patterns-summary.md index 885d7572..3a8d9d81 100644 --- a/docs/system-design/framework/spring/spring-design-patterns-summary.md +++ b/docs/system-design/framework/spring/spring-design-patterns-summary.md @@ -17,7 +17,7 @@ tag: **IoC 是一个原则,而不是一个模式,以下模式(但不限于)实现了 IoC 原则。** - + **Spring IoC 容器就像是一个工厂一样,当我们需要创建一个对象的时候,只需要配置好配置文件/注解即可,完全不用考虑对象是如何被创建出来的。** IoC 容器负责创建对象,将对象连接在一起,配置这些对象,并从创建中处理这些对象的整个生命周期,直到它们被完全销毁。 @@ -132,7 +132,7 @@ public Object getSingleton(String beanName, ObjectFactory singletonFactory) { **Spring AOP 就是基于动态代理的**,如果要代理的对象,实现了某个接口,那么 Spring AOP 会使用 **JDK Proxy** 去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候 Spring AOP 会使用 **Cglib** 生成一个被代理对象的子类来作为代理,如下图所示: - +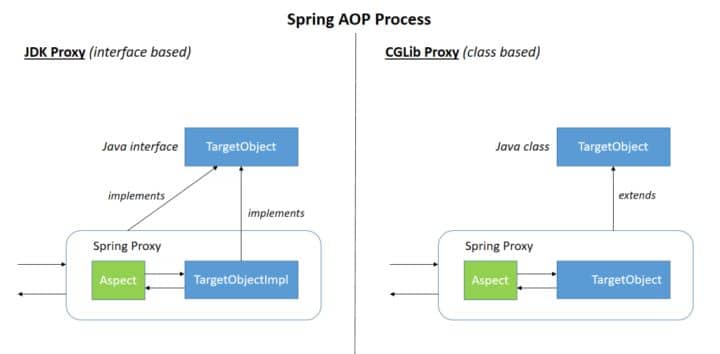 当然,你也可以使用 AspectJ ,Spring AOP 已经集成了 AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。 @@ -202,7 +202,7 @@ Spring 中默认存在以下事件,他们都是对 `ApplicationContextEvent` - `ContextRefreshedEvent`:`ApplicationContext` 初始化或刷新完成后触发的事件; - `ContextClosedEvent`:`ApplicationContext` 关闭后触发的事件。 -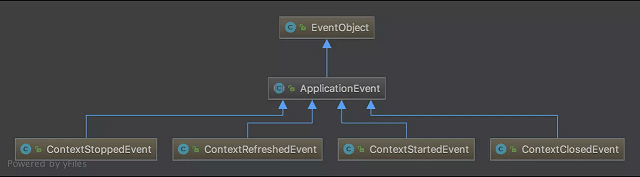 +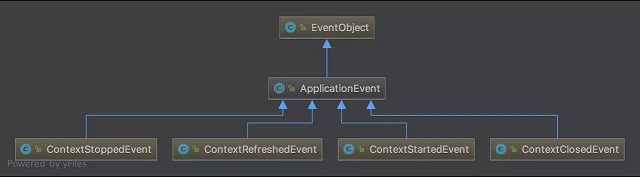 #### 事件监听者角色 @@ -325,7 +325,7 @@ if(mappedHandler.getHandler() instanceof MultiActionController){ 装饰者模式可以动态地给对象添加一些额外的属性或行为。相比于使用继承,装饰者模式更加灵活。简单点儿说就是当我们需要修改原有的功能,但我们又不愿直接去修改原有的代码时,设计一个 Decorator 套在原有代码外面。其实在 JDK 中就有很多地方用到了装饰者模式,比如 `InputStream`家族,`InputStream` 类下有 `FileInputStream` (读取文件)、`BufferedInputStream` (增加缓存,使读取文件速度大大提升)等子类都在不修改`InputStream` 代码的情况下扩展了它的功能。 -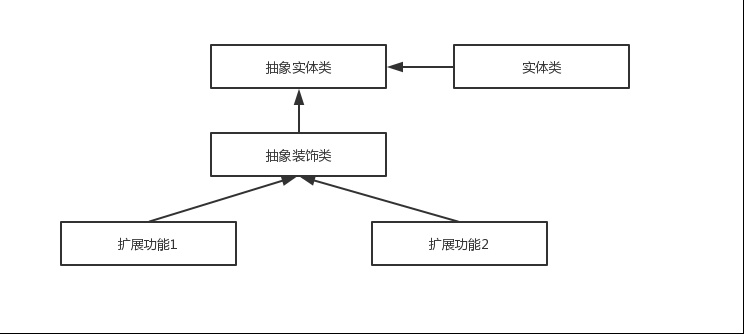 +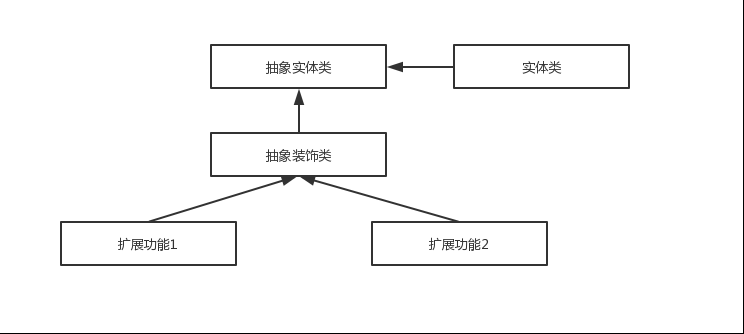 Spring 中配置 DataSource 的时候,DataSource 可能是不同的数据库和数据源。我们能否根据客户的需求在少修改原有类的代码下动态切换不同的数据源?这个时候就要用到装饰者模式(这一点我自己还没太理解具体原理)。Spring 中用到的包装器模式在类名上含有 `Wrapper`或者 `Decorator`。这些类基本上都是动态地给一个对象添加一些额外的职责