mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-06-16 18:10:13 +08:00
[docs update]格式修正&部分表述完善
This commit is contained in:
parent
2f3365cf94
commit
8e054e6c65
@ -182,7 +182,7 @@ HTTP 状态码用于描述 HTTP 请求的结果,比如 2xx 就代表请求被
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
- **连接方式** : HTTP/1.0 为短连接,HTTP/1.1 支持长连接。
|
- **连接方式** : HTTP/1.0 为短连接,HTTP/1.1 支持长连接。HTTP 协议的长连接和短连接,实质上是 TCP 协议的长连接和短连接。
|
||||||
- **状态响应码** : HTTP/1.1 中新加入了大量的状态码,光是错误响应状态码就新增了 24 种。比如说,`100 (Continue)`——在请求大资源前的预热请求,`206 (Partial Content)`——范围请求的标识码,`409 (Conflict)`——请求与当前资源的规定冲突,`410 (Gone)`——资源已被永久转移,而且没有任何已知的转发地址。
|
- **状态响应码** : HTTP/1.1 中新加入了大量的状态码,光是错误响应状态码就新增了 24 种。比如说,`100 (Continue)`——在请求大资源前的预热请求,`206 (Partial Content)`——范围请求的标识码,`409 (Conflict)`——请求与当前资源的规定冲突,`410 (Gone)`——资源已被永久转移,而且没有任何已知的转发地址。
|
||||||
- **缓存机制** : 在 HTTP/1.0 中主要使用 Header 里的 If-Modified-Since,Expires 来做为缓存判断的标准,HTTP/1.1 则引入了更多的缓存控制策略例如 Entity tag,If-Unmodified-Since, If-Match, If-None-Match 等更多可供选择的缓存头来控制缓存策略。
|
- **缓存机制** : 在 HTTP/1.0 中主要使用 Header 里的 If-Modified-Since,Expires 来做为缓存判断的标准,HTTP/1.1 则引入了更多的缓存控制策略例如 Entity tag,If-Unmodified-Since, If-Match, If-None-Match 等更多可供选择的缓存头来控制缓存策略。
|
||||||
- **带宽**:HTTP/1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP/1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
|
- **带宽**:HTTP/1.0 中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP/1.1 则在请求头引入了 range 头域,它允许只请求资源的某个部分,即返回码是 206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
|
||||||
|
|||||||
@ -23,7 +23,7 @@ tag:
|
|||||||
|
|
||||||
**优点**:
|
**优点**:
|
||||||
|
|
||||||
- 使用索引可以大大加快 数据的检索速度(大大减少检索的数据量), 这也是创建索引的最主要的原因。
|
- 使用索引可以大大加快数据的检索速度(大大减少检索的数据量), 减少 IO 次数,这也是创建索引的最主要的原因。
|
||||||
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
|
- 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。
|
||||||
|
|
||||||
**缺点**:
|
**缺点**:
|
||||||
|
|||||||
@ -84,24 +84,24 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
|
|||||||
|
|
||||||
相信看了上面的对比之后,我们已经没有什么理由可以选择使用 Memcached 来作为自己项目的分布式缓存了。
|
相信看了上面的对比之后,我们已经没有什么理由可以选择使用 Memcached 来作为自己项目的分布式缓存了。
|
||||||
|
|
||||||
### 为什么要用 Redis/为什么要用缓存?
|
### 为什么要用 Redis?
|
||||||
|
|
||||||
下面我们主要从“高性能”和“高并发”这两点来回答这个问题。
|
**1、访问速度更快**
|
||||||
|
|
||||||
**1、高性能**
|
传统数据库数据保存在磁盘,而 Redis 基于内存,内存的访问速度比磁盘快很多。引入 Redis 之后,我们可以把一些高频访问的数据放到 Redis 中,这样下次就可以直接从内存中读取,速度可以提升几十倍甚至上百倍。
|
||||||
|
|
||||||
假如用户第一次访问数据库中的某些数据的话,这个过程是比较慢,毕竟是从硬盘中读取的。但是,如果说,用户访问的数据属于高频数据并且不会经常改变的话,那么我们就可以很放心地将该用户访问的数据存在缓存中。
|
|
||||||
|
|
||||||
**这样有什么好处呢?** 那就是保证用户下一次再访问这些数据的时候就可以直接从缓存中获取了。操作缓存就是直接操作内存,所以速度相当快。
|
|
||||||
|
|
||||||
**2、高并发**
|
**2、高并发**
|
||||||
|
|
||||||
一般像 MySQL 这类的数据库的 QPS 大概都在 1w 左右(4 核 8g) ,但是使用 Redis 缓存之后很容易达到 10w+,甚至最高能达到 30w+(就单机 Redis 的情况,Redis 集群的话会更高)。
|
一般像 MySQL 这类的数据库的 QPS 大概都在 4k 左右(4 核 8g) ,但是使用 Redis 缓存之后很容易达到 5w+,甚至能达到 10w+(就单机 Redis 的情况,Redis 集群的话会更高)。
|
||||||
|
|
||||||
> QPS(Query Per Second):服务器每秒可以执行的查询次数;
|
> QPS(Query Per Second):服务器每秒可以执行的查询次数;
|
||||||
|
|
||||||
由此可见,直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高了系统整体的并发。
|
由此可见,直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高了系统整体的并发。
|
||||||
|
|
||||||
|
**3、功能全面**
|
||||||
|
|
||||||
|
Redis 除了可以用作缓存之外,还可以用于分布式锁、限流、消息队列、延时队列等场景,功能强大!
|
||||||
|
|
||||||
### 常见的缓存读写策略有哪些?
|
### 常见的缓存读写策略有哪些?
|
||||||
|
|
||||||
关于常见的缓存读写策略的详细介绍,可以看我写的这篇文章:[3 种常用的缓存读写策略详解](https://javaguide.cn/database/redis/3-commonly-used-cache-read-and-write-strategies.html) 。
|
关于常见的缓存读写策略的详细介绍,可以看我写的这篇文章:[3 种常用的缓存读写策略详解](https://javaguide.cn/database/redis/3-commonly-used-cache-read-and-write-strategies.html) 。
|
||||||
|
|||||||
@ -732,12 +732,12 @@ Bloom Filter 会使用一个较大的 bit 数组来保存所有的数据,数
|
|||||||
|
|
||||||
下面单独对 **Cache Aside Pattern(旁路缓存模式)** 来聊聊。
|
下面单独对 **Cache Aside Pattern(旁路缓存模式)** 来聊聊。
|
||||||
|
|
||||||
Cache Aside Pattern 中遇到写请求是这样的:更新 DB,然后直接删除 cache 。
|
Cache Aside Pattern 中遇到写请求是这样的:更新数据库,然后直接删除缓存 。
|
||||||
|
|
||||||
如果更新数据库成功,而删除缓存这一步失败的情况的话,简单说两个解决方案:
|
如果更新数据库成功,而删除缓存这一步失败的情况的话,简单说有两个解决方案:
|
||||||
|
|
||||||
1. **缓存失效时间变短(不推荐,治标不治本)**:我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
|
1. **缓存失效时间变短(不推荐,治标不治本)**:我们让缓存数据的过期时间变短,这样的话缓存就会从数据库中加载数据。另外,这种解决办法对于先操作缓存后操作数据库的场景不适用。
|
||||||
2. **增加 cache 更新重试机制(常用)**:如果 cache 服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。如果多次重试还是失败的话,我们可以把当前更新失败的 key 存入队列中,等缓存服务可用之后,再将缓存中对应的 key 删除即可。
|
2. **增加缓存更新重试机制(常用)**:如果缓存服务当前不可用导致缓存删除失败的话,我们就隔一段时间进行重试,重试次数可以自己定。不过,这里更适合引入消息队列实现异步重试,将删除缓存重试的消息投递到消息队列,然后由专门的消费者来重试,直到成功。虽然说多引入了一个消息队列,但其整体带来的收益还是要更高一些。
|
||||||
|
|
||||||
相关文章推荐:[缓存和数据库一致性问题,看这篇就够了 - 水滴与银弹](https://mp.weixin.qq.com/s?__biz=MzIyOTYxNDI5OA==&mid=2247487312&idx=1&sn=fa19566f5729d6598155b5c676eee62d&chksm=e8beb8e5dfc931f3e35655da9da0b61c79f2843101c130cf38996446975014f958a6481aacf1&scene=178&cur_album_id=1699766580538032128#rd)。
|
相关文章推荐:[缓存和数据库一致性问题,看这篇就够了 - 水滴与银弹](https://mp.weixin.qq.com/s?__biz=MzIyOTYxNDI5OA==&mid=2247487312&idx=1&sn=fa19566f5729d6598155b5c676eee62d&chksm=e8beb8e5dfc931f3e35655da9da0b61c79f2843101c130cf38996446975014f958a6481aacf1&scene=178&cur_album_id=1699766580538032128#rd)。
|
||||||
|
|
||||||
|
|||||||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 155 KiB |
{kind=link}
|
Before Width: | Height: | Size: 47 KiB After Width: | Height: | Size: 47 KiB |
@ -211,16 +211,16 @@ static class Entry extends WeakReference<ThreadLocal<?>> {
|
|||||||
|
|
||||||
**方式二:通过 `Executor` 框架的工具类 `Executors` 来创建。**
|
**方式二:通过 `Executor` 框架的工具类 `Executors` 来创建。**
|
||||||
|
|
||||||
我们可以创建多种类型的 `ThreadPoolExecutor`:
|
`Executors`工具类提供的创建线程池的方法如下图所示:
|
||||||
|
|
||||||
- **`FixedThreadPool`**:该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
|
|
||||||
- **`SingleThreadExecutor`:** 该方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
|
|
||||||
- **`CachedThreadPool`:** 该方法返回一个可根据实际情况调整线程数量的线程池。初始大小为 0。当有新任务提交时,如果当前线程池中没有线程可用,它会创建一个新的线程来处理该任务。如果在一段时间内(默认为 60 秒)没有新任务提交,核心线程会超时并被销毁,从而缩小线程池的大小。
|
|
||||||
- **`ScheduledThreadPool`**:该方法返回一个用来在给定的延迟后运行任务或者定期执行任务的线程池。
|
|
||||||
|
|
||||||
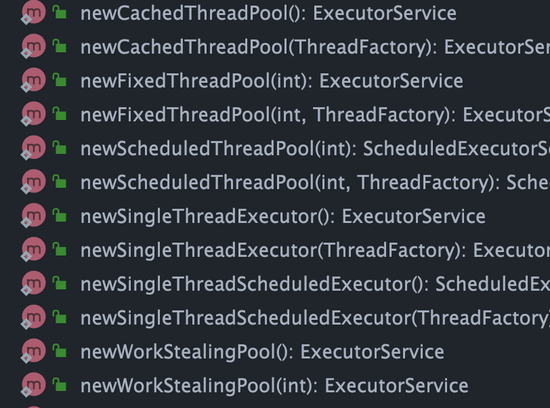
对应 `Executors` 工具类中的方法如图所示:
|
可以看出,通过`Executors`工具类可以创建多种类型的线程池,包括:
|
||||||
|
|
||||||
|
- `FixedThreadPool`:固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
|
||||||
|
- `SingleThreadExecutor`: 只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
|
||||||
|
- `CachedThreadPool`: 可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
|
||||||
|
- `ScheduledThreadPool`:给定的延迟后运行任务或者定期执行任务的线程池。
|
||||||
|
|
||||||
### 为什么不推荐使用内置线程池?
|
### 为什么不推荐使用内置线程池?
|
||||||
|
|
||||||
@ -234,9 +234,9 @@ static class Entry extends WeakReference<ThreadLocal<?>> {
|
|||||||
|
|
||||||
`Executors` 返回线程池对象的弊端如下:
|
`Executors` 返回线程池对象的弊端如下:
|
||||||
|
|
||||||
- **`FixedThreadPool` 和 `SingleThreadExecutor`**:使用的是无界的 `LinkedBlockingQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
|
- `FixedThreadPool` 和 `SingleThreadExecutor`:使用的是无界的 `LinkedBlockingQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
|
||||||
- **`CachedThreadPool`**:使用的是同步队列 `SynchronousQueue`, 允许创建的线程数量为 `Integer.MAX_VALUE` ,如果任务数量过多且执行速度较慢,可能会创建大量的线程,从而导致 OOM。
|
- `CachedThreadPool`:使用的是同步队列 `SynchronousQueue`, 允许创建的线程数量为 `Integer.MAX_VALUE` ,如果任务数量过多且执行速度较慢,可能会创建大量的线程,从而导致 OOM。
|
||||||
- **`ScheduledThreadPool` 和 `SingleThreadScheduledExecutor`**:使用的无界的延迟阻塞队列`DelayedWorkQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
|
- `ScheduledThreadPool` 和 `SingleThreadScheduledExecutor`:使用的无界的延迟阻塞队列`DelayedWorkQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
|
||||||
|
|
||||||
```java
|
```java
|
||||||
// 无界队列 LinkedBlockingQueue
|
// 无界队列 LinkedBlockingQueue
|
||||||
@ -300,31 +300,31 @@ public ScheduledThreadPoolExecutor(int corePoolSize) {
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
**`ThreadPoolExecutor` 3 个最重要的参数:**
|
`ThreadPoolExecutor` 3 个最重要的参数:
|
||||||
|
|
||||||
- **`corePoolSize` :** 任务队列未达到队列容量时,最大可以同时运行的线程数量。
|
- `corePoolSize` : 任务队列未达到队列容量时,最大可以同时运行的线程数量。
|
||||||
- **`maximumPoolSize` :** 任务队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。
|
- `maximumPoolSize` : 任务队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。
|
||||||
- **`workQueue`:** 新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
|
- `workQueue`: 新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
|
||||||
|
|
||||||
`ThreadPoolExecutor`其他常见参数 :
|
`ThreadPoolExecutor`其他常见参数 :
|
||||||
|
|
||||||
- **`keepAliveTime`**:线程池中的线程数量大于 `corePoolSize` 的时候,如果这时没有新的任务提交,多余的空闲线程不会立即销毁,而是会等待,直到等待的时间超过了 `keepAliveTime`才会被回收销毁,线程池回收线程时,会对核心线程和非核心线程一视同仁,直到线程池中线程的数量等于 `corePoolSize` ,回收过程才会停止。
|
- `keepAliveTime`:线程池中的线程数量大于 `corePoolSize` 的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了 `keepAliveTime`才会被回收销毁。
|
||||||
- **`unit`** : `keepAliveTime` 参数的时间单位。
|
- `unit` : `keepAliveTime` 参数的时间单位。
|
||||||
- **`threadFactory`** :executor 创建新线程的时候会用到。
|
- `threadFactory` :executor 创建新线程的时候会用到。
|
||||||
- **`handler`** :饱和策略。关于饱和策略下面单独介绍一下。
|
- `handler` :饱和策略(后面会单独详细介绍一下)。
|
||||||
|
|
||||||
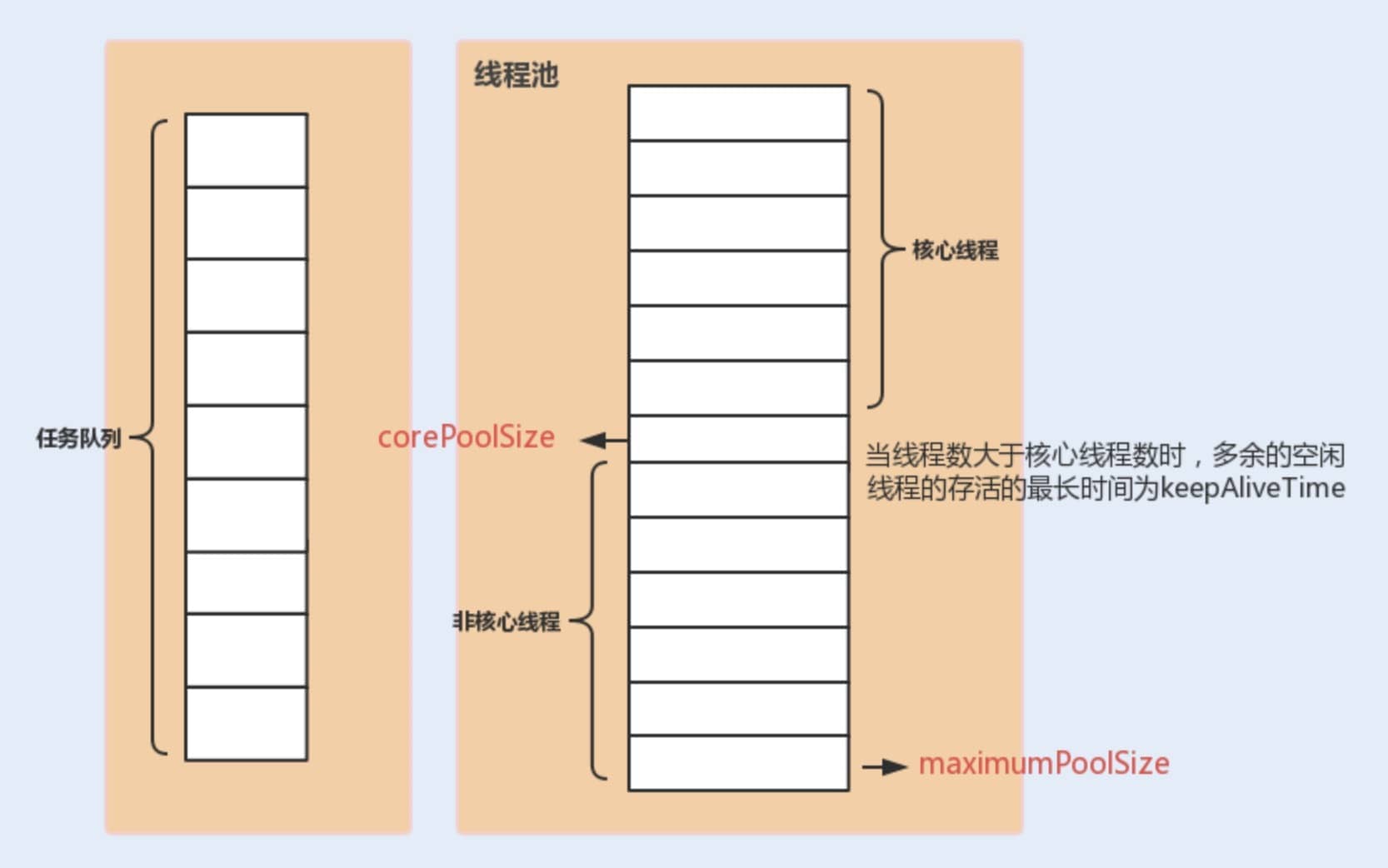
下面这张图可以加深你对线程池中各个参数的相互关系的理解(图片来源:《Java 性能调优实战》):
|
下面这张图可以加深你对线程池中各个参数的相互关系的理解(图片来源:《Java 性能调优实战》):
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
### 线程池的饱和策略有哪些?
|
### 线程池的饱和策略有哪些?
|
||||||
|
|
||||||
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,`ThreadPoolExecutor` 定义一些策略:
|
如果当前同时运行的线程数量达到最大线程数量并且队列也已经被放满了任务时,`ThreadPoolExecutor` 定义一些策略:
|
||||||
|
|
||||||
- **`ThreadPoolExecutor.AbortPolicy`:** 抛出 `RejectedExecutionException`来拒绝新任务的处理。
|
- `ThreadPoolExecutor.AbortPolicy`:抛出 `RejectedExecutionException`来拒绝新任务的处理。
|
||||||
- **`ThreadPoolExecutor.CallerRunsPolicy`:** 调用执行自己的线程运行任务,也就是直接在调用`execute`方法的线程中运行(`run`)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。
|
- `ThreadPoolExecutor.CallerRunsPolicy`:调用执行自己的线程运行任务,也就是直接在调用`execute`方法的线程中运行(`run`)被拒绝的任务,如果执行程序已关闭,则会丢弃该任务。因此这种策略会降低对于新任务提交速度,影响程序的整体性能。如果您的应用程序可以承受此延迟并且你要求任何一个任务请求都要被执行的话,你可以选择这个策略。
|
||||||
- **`ThreadPoolExecutor.DiscardPolicy`:** 不处理新任务,直接丢弃掉。
|
- `ThreadPoolExecutor.DiscardPolicy`:不处理新任务,直接丢弃掉。
|
||||||
- **`ThreadPoolExecutor.DiscardOldestPolicy`:** 此策略将丢弃最早的未处理的任务请求。
|
- `ThreadPoolExecutor.DiscardOldestPolicy`:此策略将丢弃最早的未处理的任务请求。
|
||||||
|
|
||||||
举个例子:Spring 通过 `ThreadPoolTaskExecutor` 或者我们直接通过 `ThreadPoolExecutor` 的构造函数创建线程池的时候,当我们不指定 `RejectedExecutionHandler` 饱和策略来配置线程池的时候,默认使用的是 `AbortPolicy`。在这种饱和策略下,如果队列满了,`ThreadPoolExecutor` 将抛出 `RejectedExecutionException` 异常来拒绝新来的任务 ,这代表你将丢失对这个任务的处理。如果不想丢弃任务的话,可以使用`CallerRunsPolicy`。`CallerRunsPolicy` 和其他的几个策略不同,它既不会抛弃任务,也不会抛出异常,而是将任务回退给调用者,使用调用者的线程来执行任务
|
举个例子:Spring 通过 `ThreadPoolTaskExecutor` 或者我们直接通过 `ThreadPoolExecutor` 的构造函数创建线程池的时候,当我们不指定 `RejectedExecutionHandler` 饱和策略来配置线程池的时候,默认使用的是 `AbortPolicy`。在这种饱和策略下,如果队列满了,`ThreadPoolExecutor` 将抛出 `RejectedExecutionException` 异常来拒绝新来的任务 ,这代表你将丢失对这个任务的处理。如果不想丢弃任务的话,可以使用`CallerRunsPolicy`。`CallerRunsPolicy` 和其他的几个策略不同,它既不会抛弃任务,也不会抛出异常,而是将任务回退给调用者,使用调用者的线程来执行任务
|
||||||
|
|
||||||
@ -354,7 +354,7 @@ public static class CallerRunsPolicy implements RejectedExecutionHandler {
|
|||||||
|
|
||||||
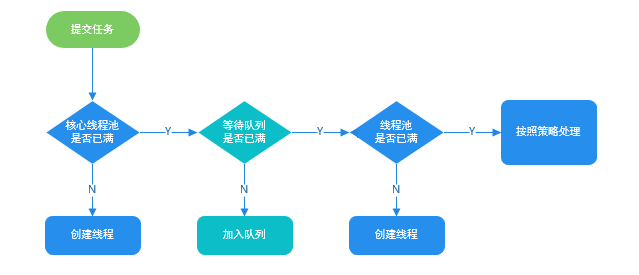
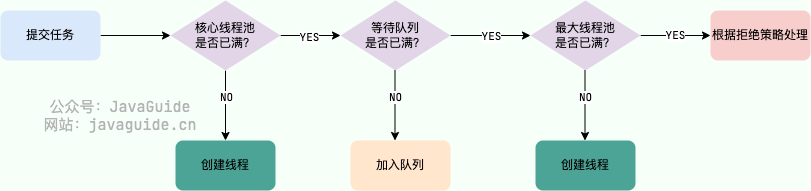
### 线程池处理任务的流程了解吗?
|
### 线程池处理任务的流程了解吗?
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
1. 如果当前运行的线程数小于核心线程数,那么就会新建一个线程来执行任务。
|
1. 如果当前运行的线程数小于核心线程数,那么就会新建一个线程来执行任务。
|
||||||
2. 如果当前运行的线程数等于或大于核心线程数,但是小于最大线程数,那么就把该任务放入到任务队列里等待执行。
|
2. 如果当前运行的线程数等于或大于核心线程数,但是小于最大线程数,那么就把该任务放入到任务队列里等待执行。
|
||||||
|
|||||||
@ -80,7 +80,7 @@ public class ScheduledThreadPoolExecutor
|
|||||||
|
|
||||||
线程池实现类 `ThreadPoolExecutor` 是 `Executor` 框架最核心的类。
|
线程池实现类 `ThreadPoolExecutor` 是 `Executor` 框架最核心的类。
|
||||||
|
|
||||||
### 构造方法介绍
|
### 线程池参数分析
|
||||||
|
|
||||||
`ThreadPoolExecutor` 类中提供的四个构造方法。我们来看最长的那个,其余三个都是在这个构造方法的基础上产生(其他几个构造方法说白点都是给定某些默认参数的构造方法比如默认制定拒绝策略是什么)。
|
`ThreadPoolExecutor` 类中提供的四个构造方法。我们来看最长的那个,其余三个都是在这个构造方法的基础上产生(其他几个构造方法说白点都是给定某些默认参数的构造方法比如默认制定拒绝策略是什么)。
|
||||||
|
|
||||||
@ -112,24 +112,24 @@ public class ScheduledThreadPoolExecutor
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
下面这些对创建非常重要,在后面使用线程池的过程中你一定会用到!所以,务必拿着小本本记清楚。
|
下面这些参数非常重要,在后面使用线程池的过程中你一定会用到!所以,务必拿着小本本记清楚。
|
||||||
|
|
||||||
**`ThreadPoolExecutor` 3 个最重要的参数:**
|
`ThreadPoolExecutor` 3 个最重要的参数:
|
||||||
|
|
||||||
- **`corePoolSize` :** 任务队列未达到队列容量时,最大可以同时运行的线程数量。
|
- `corePoolSize` : 任务队列未达到队列容量时,最大可以同时运行的线程数量。
|
||||||
- **`maximumPoolSize` :** 任务队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。
|
- `maximumPoolSize` : 任务队列中存放的任务达到队列容量的时候,当前可以同时运行的线程数量变为最大线程数。
|
||||||
- **`workQueue`:** 新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
|
- `workQueue`: 新任务来的时候会先判断当前运行的线程数量是否达到核心线程数,如果达到的话,新任务就会被存放在队列中。
|
||||||
|
|
||||||
`ThreadPoolExecutor`其他常见参数 :
|
`ThreadPoolExecutor`其他常见参数 :
|
||||||
|
|
||||||
- **`keepAliveTime`**:线程池中的线程数量大于 `corePoolSize` 的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了 `keepAliveTime`才会被回收销毁。
|
- `keepAliveTime`:线程池中的线程数量大于 `corePoolSize` 的时候,如果这时没有新的任务提交,核心线程外的线程不会立即销毁,而是会等待,直到等待的时间超过了 `keepAliveTime`才会被回收销毁。
|
||||||
- **`unit`** : `keepAliveTime` 参数的时间单位。
|
- `unit` : `keepAliveTime` 参数的时间单位。
|
||||||
- **`threadFactory`** :executor 创建新线程的时候会用到。
|
- `threadFactory` :executor 创建新线程的时候会用到。
|
||||||
- **`handler`** :饱和策略。关于饱和策略下面单独介绍一下。
|
- `handler` :饱和策略(后面会单独详细介绍一下)。
|
||||||
|
|
||||||
下面这张图可以加深你对线程池中各个参数的相互关系的理解(图片来源:《Java 性能调优实战》):
|
下面这张图可以加深你对线程池中各个参数的相互关系的理解(图片来源:《Java 性能调优实战》):
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
**`ThreadPoolExecutor` 饱和策略定义:**
|
**`ThreadPoolExecutor` 饱和策略定义:**
|
||||||
|
|
||||||
@ -142,9 +142,23 @@ public class ScheduledThreadPoolExecutor
|
|||||||
|
|
||||||
举个例子:
|
举个例子:
|
||||||
|
|
||||||
Spring 通过 `ThreadPoolTaskExecutor` 或者我们直接通过 `ThreadPoolExecutor` 的构造函数创建线程池的时候,当我们不指定 `RejectedExecutionHandler` 饱和策略的话来配置线程池的时候默认使用的是 `ThreadPoolExecutor.AbortPolicy`。在默认情况下,`ThreadPoolExecutor` 将抛出 `RejectedExecutionException` 来拒绝新来的任务 ,这代表你将丢失对这个任务的处理。 对于可伸缩的应用程序,建议使用 `ThreadPoolExecutor.CallerRunsPolicy`。当最大池被填满时,此策略为我们提供可伸缩队列(这个直接查看 `ThreadPoolExecutor` 的构造函数源码就可以看出,比较简单的原因,这里就不贴代码了)。
|
举个例子:Spring 通过 `ThreadPoolTaskExecutor` 或者我们直接通过 `ThreadPoolExecutor` 的构造函数创建线程池的时候,当我们不指定 `RejectedExecutionHandler` 饱和策略来配置线程池的时候,默认使用的是 `AbortPolicy`。在这种饱和策略下,如果队列满了,`ThreadPoolExecutor` 将抛出 `RejectedExecutionException` 异常来拒绝新来的任务 ,这代表你将丢失对这个任务的处理。如果不想丢弃任务的话,可以使用`CallerRunsPolicy`。`CallerRunsPolicy` 和其他的几个策略不同,它既不会抛弃任务,也不会抛出异常,而是将任务回退给调用者,使用调用者的线程来执行任务
|
||||||
|
|
||||||
### 线程池创建两种方式
|
```java
|
||||||
|
public static class CallerRunsPolicy implements RejectedExecutionHandler {
|
||||||
|
|
||||||
|
public CallerRunsPolicy() { }
|
||||||
|
|
||||||
|
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
|
||||||
|
if (!e.isShutdown()) {
|
||||||
|
// 直接主线程执行,而不是线程池中的线程执行
|
||||||
|
r.run();
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
### 线程池创建的两种方式
|
||||||
|
|
||||||
**方式一:通过`ThreadPoolExecutor`构造函数来创建(推荐)。**
|
**方式一:通过`ThreadPoolExecutor`构造函数来创建(推荐)。**
|
||||||
|
|
||||||
@ -152,24 +166,24 @@ Spring 通过 `ThreadPoolTaskExecutor` 或者我们直接通过 `ThreadPoolExecu
|
|||||||
|
|
||||||
**方式二:通过 `Executor` 框架的工具类 `Executors` 来创建。**
|
**方式二:通过 `Executor` 框架的工具类 `Executors` 来创建。**
|
||||||
|
|
||||||
我们可以创建多种类型的 `ThreadPoolExecutor`:
|
`Executors`工具类提供的创建线程池的方法如下图所示:
|
||||||
|
|
||||||
- **`FixedThreadPool`**:该方法返回一个固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
|

|
||||||
- **`SingleThreadExecutor`:** 该方法返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
|
|
||||||
- **`CachedThreadPool`:** 该方法返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
|
|
||||||
- **`ScheduledThreadPool`**:该返回一个用来在给定的延迟后运行任务或者定期执行任务的线程池。
|
|
||||||
|
|
||||||
对应 `Executors` 工具类中的方法如图所示:
|
可以看出,通过`Executors`工具类可以创建多种类型的线程池,包括:
|
||||||
|
|
||||||

|
- `FixedThreadPool`:固定线程数量的线程池。该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新的任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
|
||||||
|
- `SingleThreadExecutor`: 只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
|
||||||
|
- `CachedThreadPool`: 可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
|
||||||
|
- `ScheduledThreadPool`:给定的延迟后运行任务或者定期执行任务的线程池。
|
||||||
|
|
||||||
《阿里巴巴 Java 开发手册》强制线程池不允许使用 `Executors` 去创建,而是通过 `ThreadPoolExecutor` 构造函数的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
|
《阿里巴巴 Java 开发手册》强制线程池不允许使用 `Executors` 去创建,而是通过 `ThreadPoolExecutor` 构造函数的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
|
||||||
|
|
||||||
`Executors` 返回线程池对象的弊端如下(后文会详细介绍到):
|
`Executors` 返回线程池对象的弊端如下(后文会详细介绍到):
|
||||||
|
|
||||||
- **`FixedThreadPool` 和 `SingleThreadExecutor`**:使用的是无界的 `LinkedBlockingQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
|
- `FixedThreadPool` 和 `SingleThreadExecutor`:使用的是无界的 `LinkedBlockingQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
|
||||||
- **`CachedThreadPool`**:使用的是同步队列 `SynchronousQueue`, 允许创建的线程数量为 `Integer.MAX_VALUE` ,如果任务数量过多且执行速度较慢,可能会创建大量的线程,从而导致 OOM。
|
- `CachedThreadPool`:使用的是同步队列 `SynchronousQueue`, 允许创建的线程数量为 `Integer.MAX_VALUE` ,如果任务数量过多且执行速度较慢,可能会创建大量的线程,从而导致 OOM。
|
||||||
- **`ScheduledThreadPool` 和 `SingleThreadScheduledExecutor`**:使用的无界的延迟阻塞队列`DelayedWorkQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
|
- `ScheduledThreadPool` 和 `SingleThreadScheduledExecutor`:使用的无界的延迟阻塞队列`DelayedWorkQueue`,任务队列最大长度为 `Integer.MAX_VALUE`,可能堆积大量的请求,从而导致 OOM。
|
||||||
|
|
||||||
```java
|
```java
|
||||||
// 无界队列 LinkedBlockingQueue
|
// 无界队列 LinkedBlockingQueue
|
||||||
@ -217,7 +231,7 @@ public ScheduledThreadPoolExecutor(int corePoolSize) {
|
|||||||
|
|
||||||
我们上面讲解了 `Executor`框架以及 `ThreadPoolExecutor` 类,下面让我们实战一下,来通过写一个 `ThreadPoolExecutor` 的小 Demo 来回顾上面的内容。
|
我们上面讲解了 `Executor`框架以及 `ThreadPoolExecutor` 类,下面让我们实战一下,来通过写一个 `ThreadPoolExecutor` 的小 Demo 来回顾上面的内容。
|
||||||
|
|
||||||
### ThreadPoolExecutor 示例代码
|
### 线程池示例代码
|
||||||
|
|
||||||
首先创建一个 `Runnable` 接口的实现类(当然也可以是 `Callable` 接口,我们后面会介绍两者的区别。)
|
首先创建一个 `Runnable` 接口的实现类(当然也可以是 `Callable` 接口,我们后面会介绍两者的区别。)
|
||||||
|
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user