[] tab, int hash) {
`ConcurrentHashMap` 和 `Hashtable` 的区别主要体现在实现线程安全的方式上不同。
- **底层数据结构:** JDK1.7 的 `ConcurrentHashMap` 底层采用 **分段的数组+链表** 实现,JDK1.8 采用的数据结构跟 `HashMap1.8` 的结构一样,数组+链表/红黑二叉树。`Hashtable` 和 JDK1.8 之前的 `HashMap` 的底层数据结构类似都是采用 **数组+链表** 的形式,数组是 HashMap 的主体,链表则是主要为了解决哈希冲突而存在的;
-- **实现线程安全的方式(重要):** ① **在 JDK1.7 的时候,`ConcurrentHashMap`(分段锁)** 对整个桶数组进行了分割分段(`Segment`),每一把锁只锁容器其中一部分数据,多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。 **到了 JDK1.8 的时候已经摒弃了 `Segment` 的概念,而是直接用 `Node` 数组+链表+红黑树的数据结构来实现,并发控制使用 `synchronized` 和 CAS 来操作。(JDK1.6 以后 对 `synchronized` 锁做了很多优化)** 整个看起来就像是优化过且线程安全的 `HashMap`,虽然在 JDK1.8 中还能看到 `Segment` 的数据结构,但是已经简化了属性,只是为了兼容旧版本;② **`Hashtable`(同一把锁)** :使用 `synchronized` 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
+- **实现线程安全的方式(重要):**
+ - 在 JDK1.7 的时候,`ConcurrentHashMap` 对整个桶数组进行了分割分段(`Segment`,分段锁),每一把锁只锁容器其中一部分数据(下面有示意图),多线程访问容器里不同数据段的数据,就不会存在锁竞争,提高并发访问率。
+ - 到了 JDK1.8 的时候,`ConcurrentHashMap` 已经摒弃了 `Segment` 的概念,而是直接用 `Node` 数组+链表+红黑树的数据结构来实现,并发控制使用 `synchronized` 和 CAS 来操作。(JDK1.6 以后 `synchronized` 锁做了很多优化) 整个看起来就像是优化过且线程安全的 `HashMap`,虽然在 JDK1.8 中还能看到 `Segment` 的数据结构,但是已经简化了属性,只是为了兼容旧版本;
+ - **`Hashtable`(同一把锁)** :使用 `synchronized` 来保证线程安全,效率非常低下。当一个线程访问同步方法时,其他线程也访问同步方法,可能会进入阻塞或轮询状态,如使用 put 添加元素,另一个线程不能使用 put 添加元素,也不能使用 get,竞争会越来越激烈效率越低。
-**两者的对比图:**
+下面,我们再来看看两者底层数据结构的对比图。
-**Hashtable:**
+**Hashtable** :
-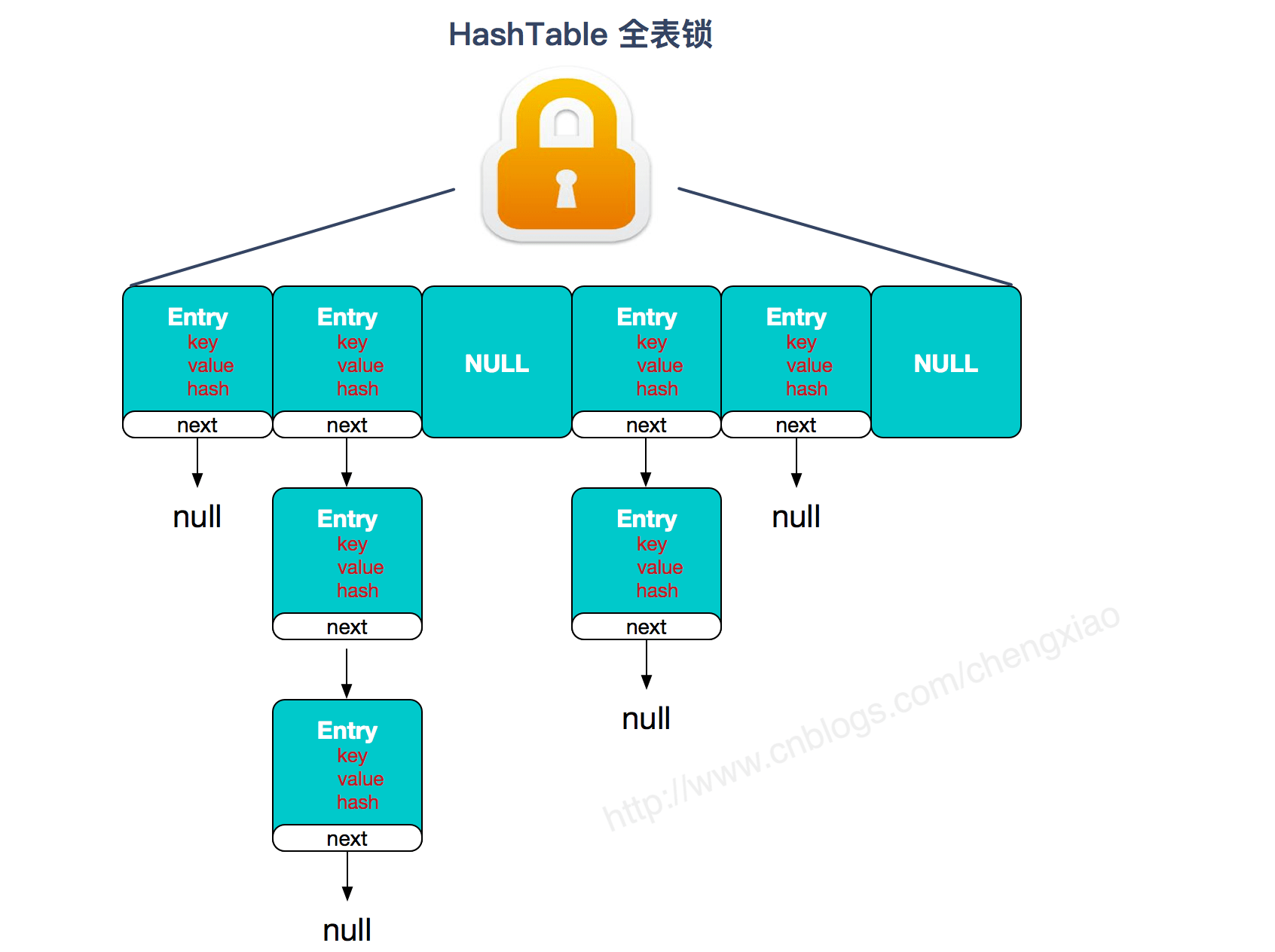
+
https://www.cnblogs.com/chengxiao/p/6842045.html>
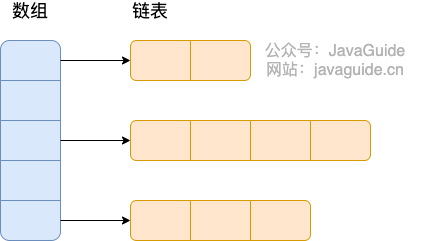
-**JDK1.7 的 ConcurrentHashMap:**
+**JDK1.7 的 ConcurrentHashMap** :
-
+
-**JDK1.8 的 ConcurrentHashMap:**
+`ConcurrentHashMap` 是由 `Segment` 数组结构和 `HashEntry` 数组结构组成。
-
+`Segment` 数组中的每个元素包含一个 `HashEntry` 数组,每个 `HashEntry` 数组属于链表结构。
+
+**JDK1.8 的 ConcurrentHashMap** :
+
+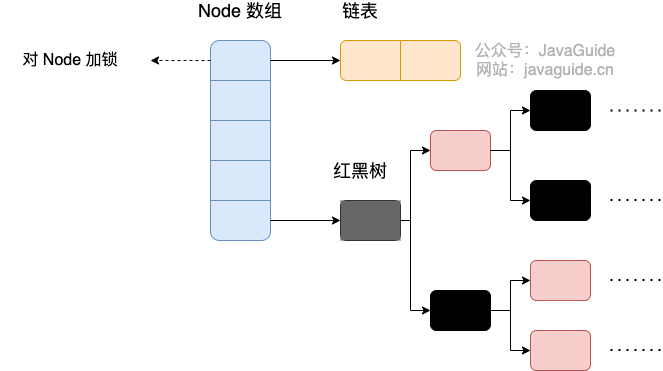
JDK1.8 的 `ConcurrentHashMap` 不再是 **Segment 数组 + HashEntry 数组 + 链表**,而是 **Node 数组 + 链表 / 红黑树**。不过,Node 只能用于链表的情况,红黑树的情况需要使用 **`TreeNode`**。当冲突链表达到一定长度时,链表会转换成红黑树。
+`TreeNode`是存储红黑树节点,被`TreeBin`包装。`TreeBin`通过`root`属性维护红黑树的根结点,因为红黑树在旋转的时候,根结点可能会被它原来的子节点替换掉,在这个时间点,如果有其他线程要写这棵红黑树就会发生线程不安全问题,所以在 `ConcurrentHashMap` 中`TreeBin`通过`waiter`属性维护当前使用这棵红黑树的线程,来防止其他线程的进入。
+
+```java
+static final class TreeBin extends Node {
+ TreeNode root;
+ volatile TreeNode first;
+ volatile Thread waiter;
+ volatile int lockState;
+ // values for lockState
+ static final int WRITER = 1; // set while holding write lock
+ static final int WAITER = 2; // set when waiting for write lock
+ static final int READER = 4; // increment value for setting read lock
+...
+}
+```
+
### ConcurrentHashMap 线程安全的具体实现方式/底层具体实现
-#### JDK1.7(上面有示意图)
+#### JDK1.8 之前
-首先将数据分为一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
+
+
+首先将数据分为一段一段(这个“段”就是 `Segment`)的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据时,其他段的数据也能被其他线程访问。
**`ConcurrentHashMap` 是由 `Segment` 数组结构和 `HashEntry` 数组结构组成**。
-Segment 继承了 `ReentrantLock`,所以 `Segment` 是一种可重入锁,扮演锁的角色。`HashEntry` 用于存储键值对数据。
+`Segment` 继承了 `ReentrantLock`,所以 `Segment` 是一种可重入锁,扮演锁的角色。`HashEntry` 用于存储键值对数据。
```java
static class Segment extends ReentrantLock implements Serializable {
}
```
-一个 `ConcurrentHashMap` 里包含一个 `Segment` 数组。`Segment` 的结构和 `HashMap` 类似,是一种数组和链表结构,一个 `Segment` 包含一个 `HashEntry` 数组,每个 `HashEntry` 是一个链表结构的元素,每个 `Segment` 守护着一个 `HashEntry` 数组里的元素,当对 `HashEntry` 数组的数据进行修改时,必须首先获得对应的 `Segment` 的锁。
+一个 `ConcurrentHashMap` 里包含一个 `Segment` 数组,`Segment` 的个数一旦**初始化就不能改变**。 `Segment` 数组的大小默认是 16,也就是说默认可以同时支持 16 个线程并发写。
-#### JDK1.8 (上面有示意图)
+`Segment` 的结构和 `HashMap` 类似,是一种数组和链表结构,一个 `Segment` 包含一个 `HashEntry` 数组,每个 `HashEntry` 是一个链表结构的元素,每个 `Segment` 守护着一个 `HashEntry` 数组里的元素,当对 `HashEntry` 数组的数据进行修改时,必须首先获得对应的 `Segment` 的锁。也就是说,对同一 `Segment` 的并发写入会被阻塞,不同 `Segment` 的写入是可以并发执行的。
-`ConcurrentHashMap` 取消了 `Segment` 分段锁,采用 CAS 和 `synchronized` 来保证并发安全。数据结构跟 HashMap1.8 的结构类似,数组+链表/红黑二叉树。Java 8 在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为 O(N))转换为红黑树(寻址时间复杂度为 O(log(N)))
+#### JDK1.8 之后
-`synchronized` 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,效率又提升 N 倍。
+
-## Collections 工具类
+Java 8 几乎完全重写了 `ConcurrentHashMap`,代码量从原来 Java 7 中的 1000 多行,变成了现在的 6000 多行。
-Collections 工具类常用方法:
+`ConcurrentHashMap` 取消了 `Segment` 分段锁,采用 `Node + CAS + synchronized` 来保证并发安全。数据结构跟 `HashMap` 1.8 的结构类似,数组+链表/红黑二叉树。Java 8 在链表长度超过一定阈值(8)时将链表(寻址时间复杂度为 O(N))转换为红黑树(寻址时间复杂度为 O(log(N)))。
-1. 排序
-2. 查找,替换操作
-3. 同步控制(不推荐,需要线程安全的集合类型时请考虑使用 JUC 包下的并发集合)
+Java 8 中,锁粒度更细,`synchronized` 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,就不会影响其他 Node 的读写,效率大幅提升。
+
+### JDK 1.7 和 JDK 1.8 的 ConcurrentHashMap 实现有什么不同?
+
+- **线程安全实现方式** :JDK 1.7 采用 `Segment` 分段锁来保证安全, `Segment` 是继承自 `ReentrantLock`。JDK1.8 放弃了 `Segment` 分段锁的设计,采用 `Node + CAS + synchronized` 保证线程安全,锁粒度更细,`synchronized` 只锁定当前链表或红黑二叉树的首节点。
+- **Hash 碰撞解决方法** : JDK 1.7 采用拉链法,JDK1.8 采用拉链法结合红黑树(链表长度超过一定阈值时,将链表转换为红黑树)。
+- **并发度** :JDK 1.7 最大并发度是 Segment 的个数,默认是 16。JDK 1.8 最大并发度是 Node 数组的大小,并发度更大。
+
+## Collections 工具类(不重要)
+
+**`Collections` 工具类常用方法**:
+
+- 排序
+- 查找,替换操作
+- 同步控制(不推荐,需要线程安全的集合类型时请考虑使用 JUC 包下的并发集合)
### 排序操作