mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
[docs update]完善 Redis常见面试题总结(上) - Redis 可以做消息队列么?
This commit is contained in:
parent
d06864ff0f
commit
8c48313596
@ -123,9 +123,9 @@ MySQL 8.x 中实现的索引新特性:
|
||||
|
||||
|
||||
|
||||
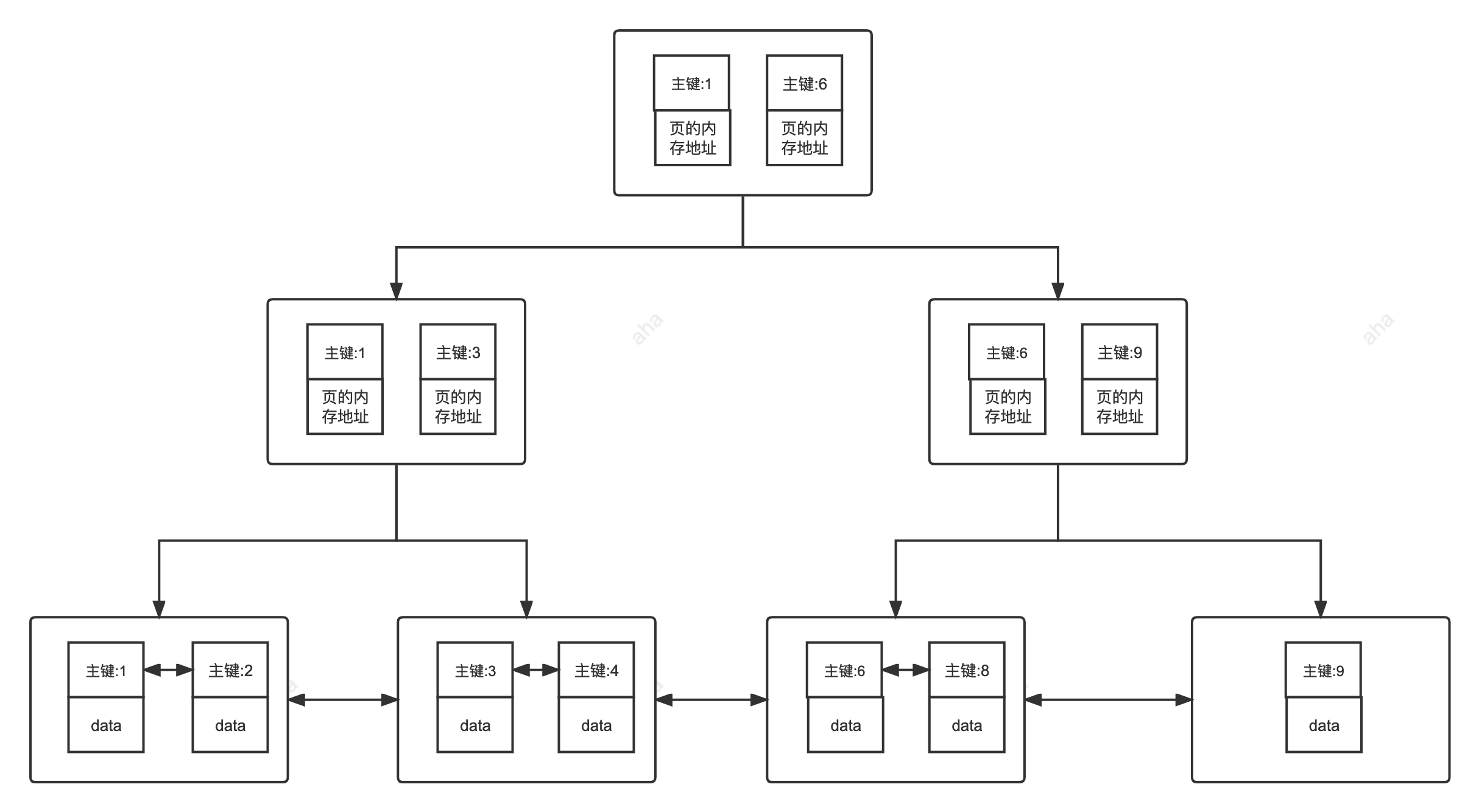
## 二级索引(辅助索引)
|
||||
## 二级索引
|
||||
|
||||
**二级索引又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。**
|
||||
**二级索引(Secondary Index)又称为辅助索引,是因为二级索引的叶子节点存储的数据是主键。也就是说,通过二级索引,可以定位主键的位置。**
|
||||
|
||||
唯一索引,普通索引,前缀索引等索引属于二级索引。
|
||||
|
||||
@ -147,7 +147,7 @@ PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
|
||||
|
||||
#### 聚簇索引介绍
|
||||
|
||||
**聚簇索引即索引结构和数据一起存放的索引,并不是一种单独的索引类型。InnoDB 中的主键索引就属于聚簇索引。**
|
||||
**聚簇索引(Clustered Index)即索引结构和数据一起存放的索引,并不是一种单独的索引类型。InnoDB 中的主键索引就属于聚簇索引。**
|
||||
|
||||
在 MySQL 中,InnoDB 引擎的表的 `.ibd`文件就包含了该表的索引和数据,对于 InnoDB 引擎表来说,该表的索引(B+树)的每个非叶子节点存储索引,叶子节点存储索引和索引对应的数据。
|
||||
|
||||
@ -167,7 +167,7 @@ PS: 不懂的同学可以暂存疑,慢慢往下看,后面会有答案的,
|
||||
|
||||
#### 非聚簇索引介绍
|
||||
|
||||
**非聚簇索引即索引结构和数据分开存放的索引,并不是一种单独的索引类型。二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。**
|
||||
**非聚簇索引(Non-Clustered Index)即索引结构和数据分开存放的索引,并不是一种单独的索引类型。二级索引(辅助索引)就属于非聚簇索引。MySQL 的 MyISAM 引擎,不管主键还是非主键,使用的都是非聚簇索引。**
|
||||
|
||||
非聚簇索引的叶子节点并不一定存放数据的指针,因为二级索引的叶子节点就存放的是主键,根据主键再回表查数据。
|
||||
|
||||
@ -214,21 +214,90 @@ SELECT id FROM table WHERE id=1;
|
||||
|
||||
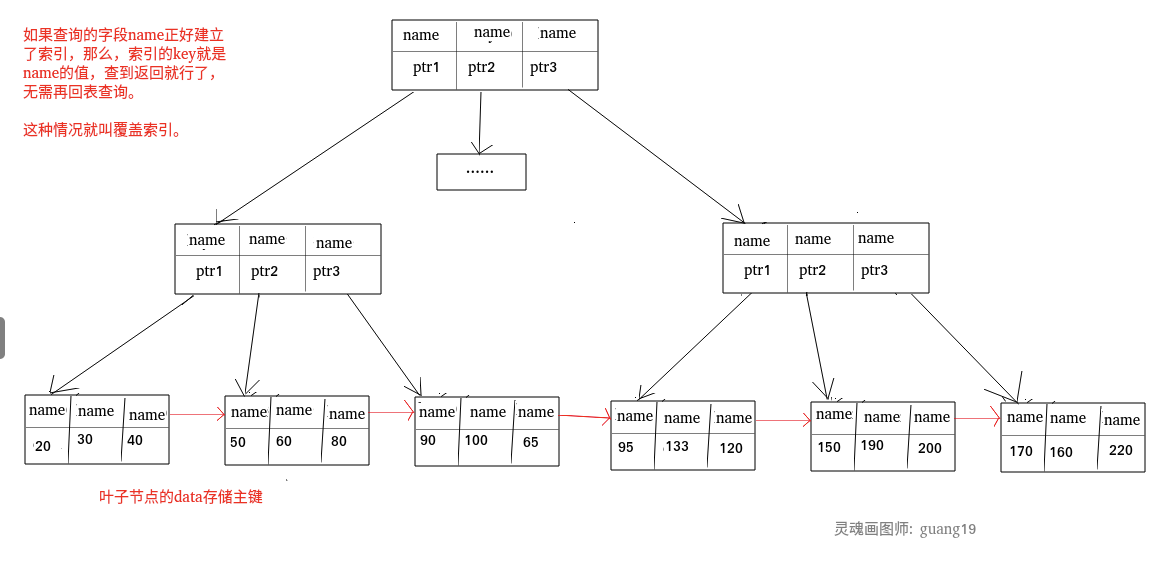
### 覆盖索引
|
||||
|
||||
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为“覆盖索引”。我们知道在 InnoDB 存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
|
||||
如果一个索引包含(或者说覆盖)所有需要查询的字段的值,我们就称之为 **覆盖索引(Covering Index)** 。我们知道在 InnoDB 存储引擎中,如果不是主键索引,叶子节点存储的是主键+列值。最终还是要“回表”,也就是要通过主键再查找一次。这样就会比较慢覆盖索引就是把要查询出的列和索引是对应的,不做回表操作!
|
||||
|
||||
**覆盖索引即需要查询的字段正好是索引的字段,那么直接根据该索引,就可以查到数据了,而无需回表查询。**
|
||||
|
||||
> 如主键索引,如果一条 SQL 需要查询主键,那么正好根据主键索引就可以查到主键。
|
||||
>
|
||||
> 再如普通索引,如果一条 SQL 需要查询 name,name 字段正好有索引,
|
||||
> 如主键索引,如果一条 SQL 需要查询主键,那么正好根据主键索引就可以查到主键。再如普通索引,如果一条 SQL 需要查询 name,name 字段正好有索引,
|
||||
> 那么直接根据这个索引就可以查到数据,也无需回表。
|
||||
|
||||
|
||||
|
||||
我们这里简单演示一下覆盖索引的效果。
|
||||
|
||||
1、创建一个名为 `cus_order` 的表,来实际测试一下这种排序方式。为了测试方便, `cus_order` 这张表只有 `id`、`score`、`name`这 3 个字段。
|
||||
|
||||
```sql
|
||||
CREATE TABLE `cus_order` (
|
||||
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
|
||||
`score` int(11) NOT NULL,
|
||||
`name` varchar(11) NOT NULL DEFAULT '',
|
||||
PRIMARY KEY (`id`)
|
||||
) ENGINE=InnoDB AUTO_INCREMENT=100000 DEFAULT CHARSET=utf8mb4;
|
||||
```
|
||||
|
||||
2、定义一个简单的存储过程(PROCEDURE)来插入 100w 测试数据。
|
||||
|
||||
```sql
|
||||
DELIMITER ;;
|
||||
CREATE DEFINER=`root`@`%` PROCEDURE `BatchinsertDataToCusOder`(IN start_num INT,IN max_num INT)
|
||||
BEGIN
|
||||
DECLARE i INT default start_num;
|
||||
WHILE i < max_num DO
|
||||
insert into `cus_order`(`id`, `score`, `name`)
|
||||
values (i,RAND() * 1000000,CONCAT('user', i));
|
||||
SET i = i + 1;
|
||||
END WHILE;
|
||||
END;;
|
||||
DELIMITER ;
|
||||
```
|
||||
|
||||
存储过程定义完成之后,我们执行存储过程即可!
|
||||
|
||||
```sql
|
||||
CALL BatchinsertDataToCusOder(1, 1000000); # 插入100w+的随机数据
|
||||
```
|
||||
|
||||
等待一会,100w 的测试数据就插入完成了!
|
||||
|
||||
3、创建覆盖索引并使用 `EXPLAIN` 命令分析。
|
||||
|
||||
为了能够对这 100w 数据按照 `score` 进行排序,我们需要执行下面的 SQL 语句。
|
||||
|
||||
```sql
|
||||
SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;#降序排序
|
||||
```
|
||||
|
||||
使用 `EXPLAIN` 命令分析这条 SQL 语句,通过 `Extra` 这一列的 `Using filesort` ,我们发现是没有用到覆盖索引的。
|
||||
|
||||

|
||||
|
||||
不过这也是理所应当,毕竟我们现在还没有创建索引呢!
|
||||
|
||||
我们这里以 `score` 和 `name` 两个字段建立联合索引:
|
||||
|
||||
```sql
|
||||
ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);
|
||||
```
|
||||
|
||||
创建完成之后,再用 `EXPLAIN` 命令分析再次分析这条 SQL 语句。
|
||||
|
||||

|
||||
|
||||
通过 `Extra` 这一列的 `Using index` ,说明这条 SQL 语句成功使用了覆盖索引。
|
||||
|
||||
关于 `EXPLAIN` 命令的详细介绍请看:[MySQL 执行计划分析](https://javaguide.cn/database/mysql/mysql-query-execution-plan.html)这篇文章。
|
||||
|
||||
### 联合索引
|
||||
|
||||
使用表中的多个字段创建索引,就是 **联合索引**,也叫 **组合索引** 或 **复合索引**。
|
||||
|
||||
以 `score` 和 `name` 两个字段建立联合索引:
|
||||
|
||||
```sql
|
||||
ALTER TABLE `cus_order` ADD INDEX id_score_name(score, name);
|
||||
```
|
||||
|
||||
### 最左前缀匹配原则
|
||||
|
||||
最左前缀匹配原则指的是,在使用联合索引时,**MySQL** 会根据联合索引中的字段顺序,从左到右依次到查询条件中去匹配,如果查询条件中存在与联合索引中最左侧字段相匹配的字段,则就会使用该字段过滤一批数据,直至联合索引中全部字段匹配完成,或者在执行过程中遇到范围查询(如 **`>`**、**`<`**)才会停止匹配。对于 **`>=`**、**`<=`**、**`BETWEEN`**、**`like`** 前缀匹配的范围查询,并不会停止匹配。所以,我们在使用联合索引时,可以将区分度高的字段放在最左边,这也可以过滤更多数据。
|
||||
@ -326,4 +395,4 @@ mysql> EXPLAIN SELECT `score`,`name` FROM `cus_order` ORDER BY `score` DESC;
|
||||
| filtered | 按表条件过滤后,留存的记录数的百分比 |
|
||||
| Extra | 附加信息 |
|
||||
|
||||
篇幅问题,我这里只是简单介绍了一下 MySQL 执行计划,详细介绍请看:[SQL 的执行计划](https://javaguide.cn/database/mysql/mysql-query-execution-plan.html)这篇文章。
|
||||
篇幅问题,我这里只是简单介绍了一下 MySQL 执行计划,详细介绍请看:[MySQL 执行计划分析](https://javaguide.cn/database/mysql/mysql-query-execution-plan.html)这篇文章。
|
||||
|
||||
@ -119,4 +119,4 @@ config set active-defrag-cycle-max 50
|
||||
|
||||
- Redis 官方文档:https://redis.io/topics/memory-optimization
|
||||
- Redis 核心技术与实战 - 极客时间 - 删除数据后,为什么内存占用率还是很高?:https://time.geekbang.org/column/article/289140
|
||||
- Redis 源码解析——内存分配:https://shinerio.cc/2020/05/17/redis/Redis%E6%BA%90%E7%A0%81%E8%A7%A3%E6%9E%90%E2%80%94%E2%80%94%E5%86%85%E5%AD%98%E7%AE%A1%E7%90%86/
|
||||
- Redis 源码解析——内存分配:<https://shinerio.cc/2020/05/17/redis/Redis源码解析——内存管理>
|
||||
@ -93,6 +93,12 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
|
||||
|
||||
由此可见,直接操作缓存能够承受的数据库请求数量是远远大于直接访问数据库的,所以我们可以考虑把数据库中的部分数据转移到缓存中去,这样用户的一部分请求会直接到缓存这里而不用经过数据库。进而,我们也就提高了系统整体的并发。
|
||||
|
||||
### 常见的缓存读写策略有哪些?
|
||||
|
||||
关于常见的缓存读写策略的详细介绍,可以看我写的这篇文章:[3 种常用的缓存读写策略详解](https://javaguide.cn/database/redis/3-commonly-used-cache-read-and-write-strategies.html) 。
|
||||
|
||||
## Redis 应用
|
||||
|
||||
### Redis 除了做缓存,还能做什么?
|
||||
|
||||
- **分布式锁** : 通过 Redis 来做分布式锁是一种比较常见的方式。通常情况下,我们都是基于 Redisson 来实现分布式锁。关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html) 。
|
||||
@ -101,33 +107,81 @@ Memcached 是分布式缓存最开始兴起的那会,比较常用的。后来
|
||||
- **复杂业务场景** :通过 Redis 以及 Redis 扩展(比如 Redisson)提供的数据结构,我们可以很方便地完成很多复杂的业务场景比如通过 bitmap 统计活跃用户、通过 sorted set 维护排行榜。
|
||||
- ......
|
||||
|
||||
### 如何基于 Redis 实现分布式锁?
|
||||
|
||||
关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html) 。
|
||||
|
||||
### Redis 可以做消息队列么?
|
||||
|
||||
Redis 5.0 新增加的一个数据结构 `Stream` 可以用来做消息队列,`Stream` 支持:
|
||||
> 实际项目中也没见谁使用 Redis 来做消息队列,对于这部分知识点大家了解就好了。
|
||||
|
||||
**Redis 2.0 之前,如果想要使用 Redis 来做消息队列的话,只能通过 List 来实现。**
|
||||
|
||||
通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`即可实现简易版消息队列 :
|
||||
|
||||
```bash
|
||||
# 生产者生产消息
|
||||
> RPUSH myList msg1 msg2
|
||||
(integer) 2
|
||||
> RPUSH myList msg3
|
||||
(integer) 3
|
||||
# 消费者消费消息
|
||||
> LPOP myList
|
||||
"msg1"
|
||||
```
|
||||
|
||||
不过,通过 `RPUSH/LPOP` 或者 `LPUSH/RPOP`这样的方式存在性能问题,我们需要不断轮询去调用 `RPOP` 或 `LPOP` 来消费消息。当 List 为空时,大部分的轮询的请求都是无效请求,这种方式大量浪费了系统资源。
|
||||
|
||||
因此,Redis 还提供了 `BLPOP`、`BRPOP` 这种阻塞式读取的命令(带 B-Bloking 的都是阻塞式),并且还支持一个超时参数。如果 List 为空,Redis 服务端不会立刻返回结果,它会等待 List 中有新数据后在返回或者是等待最多一个超时时间后返回空。如果将超时时间设置为 0 时,即可无限等待,直到弹出消息
|
||||
|
||||
```bash
|
||||
# 超时时间为 10s
|
||||
# 如果有数据立刻返回,否则最多等待10秒
|
||||
> BRPOP myList 10
|
||||
null
|
||||
```
|
||||
|
||||
**List 实现消息队列功能太简单,像消息确认机制等功能还需要我们自己实现,最要命的是没有广播机制,消息也只能被消费一次。**
|
||||
|
||||
**Redis 2.0 引入了 发布订阅 (pub/sub) 解决了 List 实现消息队列没有广播机制的问题。**
|
||||
|
||||
pub/sub 中引入了一个概念叫 channel(频道),发布订阅机制的实现就是基于这个 channel 来做的。
|
||||
|
||||
pub/sub 涉及发布者和订阅者(也叫消费者)两个角色:
|
||||
|
||||
- 发布者通过 `PUBLISH` 投递消息给指定 channel。
|
||||
- 订阅者通过`SUBSCRIBE`订阅它关心的 channel。并且,订阅者可以订阅一个或者多个 channel。
|
||||
|
||||
我们这里启动 3 个 Redis 客户端来简单演示一下:
|
||||
|
||||

|
||||
|
||||
pub/sub 既能单播又能广播,还支持 channel 的简单正则匹配。不过,消息丢失(客户端断开连接或者 Redis 宕机都会导致消息丢失)、消息堆积(发布者发布消息的时候不会管消费者的具体消费能力如何)等问题依然没有一个比较好的解决办法。
|
||||
|
||||
为此,Redis 5.0 新增加的一个数据结构 `Stream` 来做消息队列。`Stream` 支持:
|
||||
|
||||
- 发布 / 订阅模式
|
||||
- 按照消费者组进行消费
|
||||
- 消息持久化( RDB 和 AOF)
|
||||
|
||||
不过,和专业的消息队列相比,还是有很多欠缺的地方比如消息丢失和堆积问题不好解决。因此,我们通常建议是不使用 Redis 来做消息队列的,你完全可以选择市面上比较成熟的一些消息队列比如 RocketMQ、Kafka。
|
||||
`Stream` 使用起来相对要麻烦一些,这里就不演示了。而且,`Stream` 在实际使用中依然会有一些小问题不太好解决比如在 Redis 发生故障恢复后不能保证消息至少被消费一次。
|
||||
|
||||
相关文章推荐:[Redis 消息队列的三种方案(List、Streams、Pub/Sub)](https://javakeeper.starfish.ink/data-management/Redis/Redis-MQ.html)。
|
||||
综上,和专业的消息队列相比,使用 Redis 来实现消息队列还是有很多欠缺的地方比如消息丢失和堆积问题不好解决。因此,我们通常建议不要使用 Redis 来做消息队列,你完全可以选择市面上比较成熟的一些消息队列比如 RocketMQ、Kafka。
|
||||
|
||||
### 如何基于 Redis 实现分布式锁?
|
||||
|
||||
关于 Redis 实现分布式锁的详细介绍,可以看我写的这篇文章:[分布式锁详解](https://javaguide.cn/distributed-system/distributed-lock.html) 。
|
||||
相关阅读:[Redis 消息队列发展历程 - 阿里开发者 - 2022](https://mp.weixin.qq.com/s/gCUT5TcCQRAxYkTJfTRjJw)。
|
||||
|
||||
## Redis 数据结构
|
||||
|
||||
> 关于 Redis 5 种基础数据结构和 3 种特殊数据结构的详细介绍请看下面这两篇文章:
|
||||
>
|
||||
> - [Redis 5 种基本数据结构详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)
|
||||
> - [Redis 3 种特殊数据结构详解](https://javaguide.cn/database/redis/redis-data-structures-02.html)
|
||||
|
||||
### Redis 常用的数据结构有哪些?
|
||||
|
||||
- **5 种基础数据结构** :String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
|
||||
- **3 种特殊数据结构** :HyperLogLogs(基数统计)、Bitmap (位存储)、Geospatial (地理位置)。
|
||||
|
||||
关于 5 种基础数据结构的详细介绍请看这篇文章:[Redis 5 种基本数据结构详解](https://javaguide.cn/database/redis/redis-data-structures-01.html)。
|
||||
|
||||
关于 3 种特殊数据结构的详细介绍请看这篇文章:[Redis 3 种特殊数据结构详解](https://javaguide.cn/database/redis/redis-data-structures-02.html)。
|
||||
|
||||
### String 的应用场景有哪些?
|
||||
|
||||
- 常规数据(比如 session、token、、序列化后的对象)的缓存;
|
||||
@ -369,15 +423,18 @@ Redis6.0 的多线程默认是禁用的,只使用主线程。如需开启需
|
||||
```bash
|
||||
io-threads 4 #设置1的话只会开启主线程,官网建议4核的机器建议设置为2或3个线程,8核的建议设置为6个线程
|
||||
```
|
||||
|
||||
另外:
|
||||
- io-threads的个数一旦设置,不能通过config动态设置
|
||||
- 当设置ssl后,io-threads将不工作
|
||||
|
||||
- io-threads 的个数一旦设置,不能通过 config 动态设置。
|
||||
- 当设置 ssl 后,io-threads 将不工作。
|
||||
|
||||
开启多线程后,默认只会使用多线程进行 IO 写入 writes,即发送数据给客户端,如果需要开启多线程 IO 读取 reads,同样需要修改 redis 配置文件 `redis.conf` :
|
||||
|
||||
```bash
|
||||
io-threads-do-reads yes
|
||||
```
|
||||
|
||||
但是官网描述开启多线程读并不能有太大提升,因此一般情况下并不建议开启
|
||||
|
||||
相关阅读:
|
||||
|
||||
@ -162,72 +162,6 @@ Redis 从 2.6 版本开始支持执行 Lua 脚本,它的功能和事务非常
|
||||
|
||||
## Redis 性能优化
|
||||
|
||||
### Redis bigkey
|
||||
|
||||
#### 什么是 bigkey?
|
||||
|
||||
简单来说,如果一个 key 对应的 value 所占用的内存比较大,那这个 key 就可以看作是 bigkey。具体多大才算大呢?有一个不是特别精确的参考标准:string 类型的 value 超过 10 kb,复合类型的 value 包含的元素超过 5000 个(对于复合类型的 value 来说,不一定包含的元素越多,占用的内存就越多)。
|
||||
|
||||
#### bigkey 有什么危害?
|
||||
|
||||
除了会消耗更多的内存空间,bigkey 对性能也会有比较大的影响。
|
||||
|
||||
因此,我们应该尽量避免写入 bigkey!
|
||||
|
||||
#### 如何发现 bigkey?
|
||||
|
||||
**1、使用 Redis 自带的 `--bigkeys` 参数来查找。**
|
||||
|
||||
```bash
|
||||
# redis-cli -p 6379 --bigkeys
|
||||
|
||||
# Scanning the entire keyspace to find biggest keys as well as
|
||||
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
|
||||
# per 100 SCAN commands (not usually needed).
|
||||
|
||||
[00.00%] Biggest string found so far '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28057c20"' with 4437 bytes
|
||||
[00.00%] Biggest list found so far '"my-list"' with 17 items
|
||||
|
||||
-------- summary -------
|
||||
|
||||
Sampled 5 keys in the keyspace!
|
||||
Total key length in bytes is 264 (avg len 52.80)
|
||||
|
||||
Biggest list found '"my-list"' has 17 items
|
||||
Biggest string found '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28057c20"' has 4437 bytes
|
||||
|
||||
1 lists with 17 items (20.00% of keys, avg size 17.00)
|
||||
0 hashs with 0 fields (00.00% of keys, avg size 0.00)
|
||||
4 strings with 4831 bytes (80.00% of keys, avg size 1207.75)
|
||||
0 streams with 0 entries (00.00% of keys, avg size 0.00)
|
||||
0 sets with 0 members (00.00% of keys, avg size 0.00)
|
||||
0 zsets with 0 members (00.00% of keys, avg size 0.00
|
||||
```
|
||||
|
||||
从这个命令的运行结果,我们可以看出:这个命令会扫描(Scan) Redis 中的所有 key ,会对 Redis 的性能有一点影响。并且,这种方式只能找出每种数据结构 top 1 bigkey(占用内存最大的 string 数据类型,包含元素最多的复合数据类型)。
|
||||
|
||||
**2、分析 RDB 文件**
|
||||
|
||||
通过分析 RDB 文件来找出 big key。这种方案的前提是你的 Redis 采用的是 RDB 持久化。
|
||||
|
||||
网上有现成的代码/工具可以直接拿来使用:
|
||||
|
||||
- [redis-rdb-tools](https://github.com/sripathikrishnan/redis-rdb-tools) :Python 语言写的用来分析 Redis 的 RDB 快照文件用的工具
|
||||
- [rdb_bigkeys](https://github.com/weiyanwei412/rdb_bigkeys) : Go 语言写的用来分析 Redis 的 RDB 快照文件用的工具,性能更好。
|
||||
|
||||
### 大量 key 集中过期问题
|
||||
|
||||
我在上面提到过:对于过期 key,Redis 采用的是 **定期删除+惰性/懒汉式删除** 策略。
|
||||
|
||||
定期删除执行过程中,如果突然遇到大量过期 key 的话,客户端请求必须等待定期清理过期 key 任务线程执行完成,因为这个这个定期任务线程是在 Redis 主线程中执行的。这就导致客户端请求没办法被及时处理,响应速度会比较慢。
|
||||
|
||||
如何解决呢?下面是两种常见的方法:
|
||||
|
||||
1. 给 key 设置随机过期时间。
|
||||
2. 开启 lazy-free(惰性删除/延迟释放) 。lazy-free 特性是 Redis 4.0 开始引入的,指的是让 Redis 采用异步方式延迟释放 key 使用的内存,将该操作交给单独的子线程处理,避免阻塞主线程。
|
||||
|
||||
个人建议不管是否开启 lazy-free,我们都尽量给 key 设置随机过期时间。
|
||||
|
||||
### 使用批量操作减少网络传输
|
||||
|
||||
一个 Redis 命令的执行可以简化为以下 4 步:
|
||||
@ -286,6 +220,79 @@ Lua 脚本同样支持批量操作多条命令。一段 Lua 脚本可以视作
|
||||
|
||||
不过, Redis Cluster 下 Lua 脚本的原子操作也无法保证了,原因同样是无法保证所有的 key 都在同一个 **hash slot**(哈希槽)上。
|
||||
|
||||
### 大量 key 集中过期问题
|
||||
|
||||
我在前面提到过:对于过期 key,Redis 采用的是 **定期删除+惰性/懒汉式删除** 策略。
|
||||
|
||||
定期删除执行过程中,如果突然遇到大量过期 key 的话,客户端请求必须等待定期清理过期 key 任务线程执行完成,因为这个这个定期任务线程是在 Redis 主线程中执行的。这就导致客户端请求没办法被及时处理,响应速度会比较慢。
|
||||
|
||||
如何解决呢?下面是两种常见的方法:
|
||||
|
||||
1. 给 key 设置随机过期时间。
|
||||
2. 开启 lazy-free(惰性删除/延迟释放) 。lazy-free 特性是 Redis 4.0 开始引入的,指的是让 Redis 采用异步方式延迟释放 key 使用的内存,将该操作交给单独的子线程处理,避免阻塞主线程。
|
||||
|
||||
个人建议不管是否开启 lazy-free,我们都尽量给 key 设置随机过期时间。
|
||||
|
||||
### Redis bigkey
|
||||
|
||||
#### 什么是 bigkey?
|
||||
|
||||
简单来说,如果一个 key 对应的 value 所占用的内存比较大,那这个 key 就可以看作是 bigkey。具体多大才算大呢?有一个不是特别精确的参考标准:string 类型的 value 超过 10 kb,复合类型的 value 包含的元素超过 5000 个(对于复合类型的 value 来说,不一定包含的元素越多,占用的内存就越多)。
|
||||
|
||||
#### bigkey 有什么危害?
|
||||
|
||||
除了会消耗更多的内存空间,bigkey 对性能也会有比较大的影响。因此,我们应该尽量避免写入 bigkey!
|
||||
|
||||
#### 如何发现 bigkey?
|
||||
|
||||
**1、使用 Redis 自带的 `--bigkeys` 参数来查找。**
|
||||
|
||||
```bash
|
||||
# redis-cli -p 6379 --bigkeys
|
||||
|
||||
# Scanning the entire keyspace to find biggest keys as well as
|
||||
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
|
||||
# per 100 SCAN commands (not usually needed).
|
||||
|
||||
[00.00%] Biggest string found so far '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28057c20"' with 4437 bytes
|
||||
[00.00%] Biggest list found so far '"my-list"' with 17 items
|
||||
|
||||
-------- summary -------
|
||||
|
||||
Sampled 5 keys in the keyspace!
|
||||
Total key length in bytes is 264 (avg len 52.80)
|
||||
|
||||
Biggest list found '"my-list"' has 17 items
|
||||
Biggest string found '"ballcat:oauth:refresh_auth:f6cdb384-9a9d-4f2f-af01-dc3f28057c20"' has 4437 bytes
|
||||
|
||||
1 lists with 17 items (20.00% of keys, avg size 17.00)
|
||||
0 hashs with 0 fields (00.00% of keys, avg size 0.00)
|
||||
4 strings with 4831 bytes (80.00% of keys, avg size 1207.75)
|
||||
0 streams with 0 entries (00.00% of keys, avg size 0.00)
|
||||
0 sets with 0 members (00.00% of keys, avg size 0.00)
|
||||
0 zsets with 0 members (00.00% of keys, avg size 0.00
|
||||
```
|
||||
|
||||
从这个命令的运行结果,我们可以看出:这个命令会扫描(Scan) Redis 中的所有 key ,会对 Redis 的性能有一点影响。并且,这种方式只能找出每种数据结构 top 1 bigkey(占用内存最大的 string 数据类型,包含元素最多的复合数据类型)。
|
||||
|
||||
**2、分析 RDB 文件**
|
||||
|
||||
通过分析 RDB 文件来找出 big key。这种方案的前提是你的 Redis 采用的是 RDB 持久化。
|
||||
|
||||
网上有现成的代码/工具可以直接拿来使用:
|
||||
|
||||
- [redis-rdb-tools](https://github.com/sripathikrishnan/redis-rdb-tools) :Python 语言写的用来分析 Redis 的 RDB 快照文件用的工具
|
||||
- [rdb_bigkeys](https://github.com/weiyanwei412/rdb_bigkeys) : Go 语言写的用来分析 Redis 的 RDB 快照文件用的工具,性能更好。
|
||||
|
||||
### Redis 内存碎片
|
||||
|
||||
**相关问题** :
|
||||
|
||||
1. 什么是内存碎片?为什么会有 Redis 内存碎片?
|
||||
2. 如何清理 Redis 内存碎片?
|
||||
|
||||
**参考答案** :[Redis 内存碎片详解](https://javaguide.cn/database/redis/redis-memory-fragmentation.html)。
|
||||
|
||||
## Redis 生产问题
|
||||
|
||||
### 缓存穿透
|
||||
|
||||
@ -1,14 +1,12 @@
|
||||
# ZooKeeper 实战
|
||||
|
||||
## 1. 前言
|
||||
|
||||
这篇文章简单给演示一下 ZooKeeper 常见命令的使用以及 ZooKeeper Java客户端 Curator 的基本使用。介绍到的内容都是最基本的操作,能满足日常工作的基本需要。
|
||||
|
||||
如果文章有任何需要改善和完善的地方,欢迎在评论区指出,共同进步!
|
||||
|
||||
## 2. ZooKeeper 安装和使用
|
||||
## ZooKeeper 安装
|
||||
|
||||
### 2.1. 使用Docker 安装 zookeeper
|
||||
### 使用Docker 安装 zookeeper
|
||||
|
||||
**a.使用 Docker 下载 ZooKeeper**
|
||||
|
||||
@ -22,7 +20,7 @@ docker pull zookeeper:3.5.8
|
||||
docker run -d --name zookeeper -p 2181:2181 zookeeper:3.5.8
|
||||
```
|
||||
|
||||
### 2.2. 连接 ZooKeeper 服务
|
||||
### 连接 ZooKeeper 服务
|
||||
|
||||
**a.进入ZooKeeper容器中**
|
||||
|
||||
@ -38,13 +36,13 @@ root@eaf70fc620cb:/apache-zookeeper-3.5.8-bin# cd bin
|
||||
|
||||
|
||||
|
||||
### 2.3. 常用命令演示
|
||||
## ZooKeeper 常用命令演示
|
||||
|
||||
#### 2.3.1. 查看常用命令(help 命令)
|
||||
### 查看常用命令(help 命令)
|
||||
|
||||
通过 `help` 命令查看 ZooKeeper 常用命令
|
||||
|
||||
#### 2.3.2. 创建节点(create 命令)
|
||||
### 创建节点(create 命令)
|
||||
|
||||
通过 `create` 命令在根目录创建了 node1 节点,与它关联的字符串是"node1"
|
||||
|
||||
@ -59,13 +57,13 @@ root@eaf70fc620cb:/apache-zookeeper-3.5.8-bin# cd bin
|
||||
Created /node1/node1.1
|
||||
```
|
||||
|
||||
#### 2.3.3. 更新节点数据内容(set 命令)
|
||||
### 更新节点数据内容(set 命令)
|
||||
|
||||
```shell
|
||||
[zk: 127.0.0.1:2181(CONNECTED) 11] set /node1 "set node1"
|
||||
```
|
||||
|
||||
#### 2.3.4. 获取节点的数据(get 命令)
|
||||
### 获取节点的数据(get 命令)
|
||||
|
||||
`get` 命令可以获取指定节点的数据内容和节点的状态,可以看出我们通过 `set` 命令已经将节点数据内容改为 "set node1"。
|
||||
|
||||
@ -86,7 +84,7 @@ numChildren = 1
|
||||
|
||||
```
|
||||
|
||||
#### 2.3.5. 查看某个目录下的子节点(ls 命令)
|
||||
### 查看某个目录下的子节点(ls 命令)
|
||||
|
||||
通过 `ls` 命令查看根目录下的节点
|
||||
|
||||
@ -104,7 +102,7 @@ numChildren = 1
|
||||
|
||||
ZooKeeper 中的 ls 命令和 linux 命令中的 ls 类似, 这个命令将列出绝对路径 path 下的所有子节点信息(列出 1 级,并不递归)
|
||||
|
||||
#### 2.3.6. 查看节点状态(stat 命令)
|
||||
### 查看节点状态(stat 命令)
|
||||
|
||||
通过 `stat` 命令查看节点状态
|
||||
|
||||
@ -125,7 +123,7 @@ numChildren = 1
|
||||
|
||||
上面显示的一些信息比如 cversion、aclVersion、numChildren 等等,我在上面 “[ZooKeeper 相关概念总结(入门)](https://javaguide.cn/distributed-system/distributed-process-coordination/zookeeper/zookeeper-intro.html)” 这篇文章中已经介绍到。
|
||||
|
||||
#### 2.3.7. 查看节点信息和状态(ls2 命令)
|
||||
### 查看节点信息和状态(ls2 命令)
|
||||
|
||||
`ls2` 命令更像是 `ls` 命令和 `stat` 命令的结合。 `ls2` 命令返回的信息包括 2 部分:
|
||||
|
||||
@ -149,7 +147,7 @@ numChildren = 1
|
||||
|
||||
```
|
||||
|
||||
#### 2.3.8. 删除节点(delete 命令)
|
||||
### 删除节点(delete 命令)
|
||||
|
||||
这个命令很简单,但是需要注意的一点是如果你要删除某一个节点,那么这个节点必须无子节点才行。
|
||||
|
||||
@ -159,7 +157,7 @@ numChildren = 1
|
||||
|
||||
在后面我会介绍到 Java 客户端 API 的使用以及开源 ZooKeeper 客户端 ZkClient 和 Curator 的使用。
|
||||
|
||||
## 3. ZooKeeper Java客户端 Curator简单使用
|
||||
## ZooKeeper Java客户端 Curator简单使用
|
||||
|
||||
Curator 是Netflix公司开源的一套 ZooKeeper Java客户端框架,相比于 Zookeeper 自带的客户端 zookeeper 来说,Curator 的封装更加完善,各种 API 都可以比较方便地使用。
|
||||
|
||||
@ -182,7 +180,7 @@ Curator4.0+版本对ZooKeeper 3.5.x支持比较好。开始之前,请先将下
|
||||
</dependency>
|
||||
```
|
||||
|
||||
### 3.1. 连接 ZooKeeper 客户端
|
||||
### 连接 ZooKeeper 客户端
|
||||
|
||||
通过 `CuratorFrameworkFactory` 创建 `CuratorFramework` 对象,然后再调用 `CuratorFramework` 对象的 `start()` 方法即可!
|
||||
|
||||
@ -207,9 +205,9 @@ zkClient.start();
|
||||
- `connectString` :要连接的服务器列表
|
||||
- `retryPolicy` :重试策略
|
||||
|
||||
### 3.2. 数据节点的增删改查
|
||||
### 数据节点的增删改查
|
||||
|
||||
#### 3.2.1. 创建节点
|
||||
#### 创建节点
|
||||
|
||||
我们在 [ZooKeeper常见概念解读](./zookeeper-intro.md) 中介绍到,我们通常是将 znode 分为 4 大类:
|
||||
|
||||
@ -263,7 +261,7 @@ zkClient.getData().forPath("/node1/00001");//获取节点的数据内容,获
|
||||
zkClient.checkExists().forPath("/node1/00001");//不为null的话,说明节点创建成功
|
||||
```
|
||||
|
||||
#### 3.2.2. 删除节点
|
||||
#### 删除节点
|
||||
|
||||
**a.删除一个子节点**
|
||||
|
||||
@ -277,7 +275,7 @@ zkClient.delete().forPath("/node1/00001");
|
||||
zkClient.delete().deletingChildrenIfNeeded().forPath("/node1");
|
||||
```
|
||||
|
||||
#### 3.2.3. 获取/更新节点数据内容
|
||||
#### 获取/更新节点数据内容
|
||||
|
||||
```java
|
||||
zkClient.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath("/node1/00001","java".getBytes());
|
||||
@ -285,7 +283,7 @@ zkClient.getData().forPath("/node1/00001");//获取节点的数据内容
|
||||
zkClient.setData().forPath("/node1/00001","c++".getBytes());//更新节点数据内容
|
||||
```
|
||||
|
||||
#### 3.2.4. 获取某个节点的所有子节点路径
|
||||
#### 获取某个节点的所有子节点路径
|
||||
|
||||
```java
|
||||
List<String> childrenPaths = zkClient.getChildren().forPath("/node1");
|
||||
|
||||
@ -1,3 +1,5 @@
|
||||
|
||||
|
||||
# ZooKeeper 相关概念总结(入门)
|
||||
|
||||
相信大家对 ZooKeeper 应该不算陌生。但是你真的了解 ZooKeeper 到底有啥用不?如果别人/面试官让你给他讲讲对于 ZooKeeper 的认识,你能回答到什么地步呢?
|
||||
@ -182,7 +184,7 @@ Session 有一个属性叫做:`sessionTimeout` ,`sessionTimeout` 代表会
|
||||
|
||||
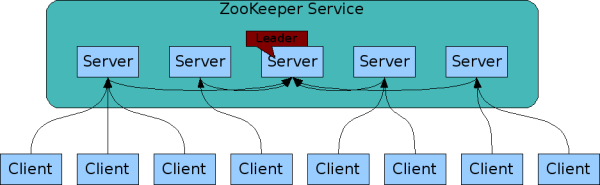
为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么 ZooKeeper 本身仍然是可用的。通常 3 台服务器就可以构成一个 ZooKeeper 集群了。ZooKeeper 官方提供的架构图就是一个 ZooKeeper 集群整体对外提供服务。
|
||||
|
||||
|
||||

|
||||
|
||||
上图中每一个 Server 代表一个安装 ZooKeeper 服务的服务器。组成 ZooKeeper 服务的服务器都会在内存中维护当前的服务器状态,并且每台服务器之间都互相保持着通信。集群间通过 ZAB 协议(ZooKeeper Atomic Broadcast)来保持数据的一致性。
|
||||
|
||||
@ -202,17 +204,18 @@ ZooKeeper 集群中的所有机器通过一个 **Leader 选举过程** 来选定
|
||||
| Follower | 为客户端提供读服务,如果是写服务则转发给 Leader。参与选举过程中的投票。 |
|
||||
| Observer | 为客户端提供读服务,如果是写服务则转发给 Leader。不参与选举过程中的投票,也不参与“过半写成功”策略。在不影响写性能的情况下提升集群的读性能。此角色于 ZooKeeper3.3 系列新增的角色。 |
|
||||
|
||||
### ZooKeeper 集群 Leader 选举过程
|
||||
|
||||
当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,就会进入 Leader 选举过程,这个过程会选举产生新的 Leader 服务器。
|
||||
|
||||
这个过程大致是这样的:
|
||||
|
||||
1. **Leader election(选举阶段)**:节点在一开始都处于选举阶段,只要有一个节点得到超半数节点的票数,它就可以当选准 leader。
|
||||
2. **Discovery(发现阶段)** :在这个阶段,followers 跟准 leader 进行通信,同步 followers 最近接收的事务提议。
|
||||
3. **Synchronization(同步阶段)** :同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后
|
||||
准 leader 才会成为真正的 leader。
|
||||
3. **Synchronization(同步阶段)** :同步阶段主要是利用 leader 前一阶段获得的最新提议历史,同步集群中所有的副本。同步完成之后准 leader 才会成为真正的 leader。
|
||||
4. **Broadcast(广播阶段)** :到了这个阶段,ZooKeeper 集群才能正式对外提供事务服务,并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
|
||||
|
||||
### ZooKeeper 集群中的服务器状态
|
||||
ZooKeeper 集群中的服务器状态有下面几种:
|
||||
|
||||
- **LOOKING** :寻找 Leader。
|
||||
- **LEADING** :Leader 状态,对应的节点为 Leader。
|
||||
|
||||
@ -139,7 +139,7 @@
|
||||
|
||||
那么如何解决呢?很简单,人多了容易吵架,我现在 **就允许一个能提案** 就行了。
|
||||
|
||||
## 引出 `ZAB`
|
||||
## 引出 ZAB
|
||||
|
||||
### Zookeeper 架构
|
||||
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user