mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
[docs update&fix]开源项目推荐完善&修复RocketMQ面试题图片问题
This commit is contained in:
parent
44acf3b8cc
commit
8c20a9b3e9
@ -768,7 +768,7 @@ public class ConsumerAddViewHistory implements RocketMQListener<Message> {
|
|||||||
|
|
||||||
### 传统 IO 方式
|
### 传统 IO 方式
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
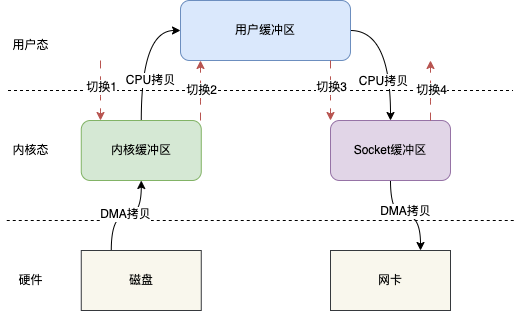
传统的 IO 读写其实就是 read + write 的操作,整个过程会分为如下几步
|
传统的 IO 读写其实就是 read + write 的操作,整个过程会分为如下几步
|
||||||
|
|
||||||
@ -791,7 +791,7 @@ mmap(memory map)是一种内存映射文件的方法,即将一个文件或
|
|||||||
|
|
||||||
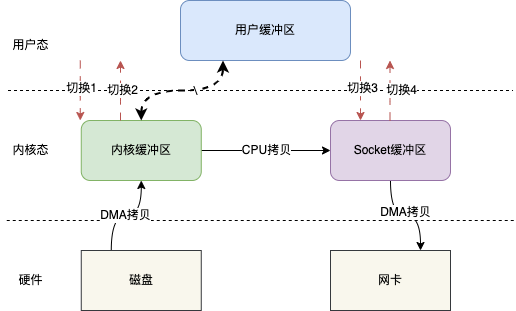
简单地说就是内核缓冲区和应用缓冲区共享,从而减少了从读缓冲区到用户缓冲区的一次 CPU 拷贝。基于此上述架构图可变为:
|
简单地说就是内核缓冲区和应用缓冲区共享,从而减少了从读缓冲区到用户缓冲区的一次 CPU 拷贝。基于此上述架构图可变为:
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
基于 mmap IO 读写其实就变成 mmap + write 的操作,也就是用 mmap 替代传统 IO 中的 read 操作。
|
基于 mmap IO 读写其实就变成 mmap + write 的操作,也就是用 mmap 替代传统 IO 中的 read 操作。
|
||||||
|
|
||||||
@ -808,7 +808,7 @@ MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRI
|
|||||||
|
|
||||||
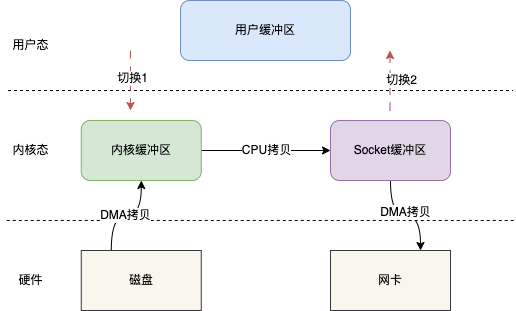
sendfile()跟 mmap()一样,也会减少一次 CPU 拷贝,但是它同时也会减少两次上下文切换。
|
sendfile()跟 mmap()一样,也会减少一次 CPU 拷贝,但是它同时也会减少两次上下文切换。
|
||||||
|
|
||||||

|
|
||||||
|
|
||||||
如图,用户在发起 sendfile()调用时会发生切换 1,之后数据通过 DMA 拷贝到内核缓冲区,之后再将内核缓冲区的数据 CPU 拷贝到 Socket 缓冲区,最后拷贝到网卡,sendfile()返回,发生切换 2。发生了 3 次拷贝和两次切换。Java 也提供了相应 api:
|
如图,用户在发起 sendfile()调用时会发生切换 1,之后数据通过 DMA 拷贝到内核缓冲区,之后再将内核缓冲区的数据 CPU 拷贝到 Socket 缓冲区,最后拷贝到网卡,sendfile()返回,发生切换 2。发生了 3 次拷贝和两次切换。Java 也提供了相应 api:
|
||||||
|
|
||||||
|
|||||||
@ -244,7 +244,7 @@ ShardingSphere 的优势如下(摘自 ShardingSphere 官方文档:<https://s
|
|||||||
|
|
||||||
另外,ShardingSphere 的生态体系完善,社区活跃,文档完善,更新和发布比较频繁。
|
另外,ShardingSphere 的生态体系完善,社区活跃,文档完善,更新和发布比较频繁。
|
||||||
|
|
||||||
艿艿之前写了一篇分库分表的实战文章,各位朋友可以看看:[《芋道 Spring Boot 分库分表入门》](https://mp.weixin.qq.com/s/A2MYOFT7SP-7kGOon8qJaw) 。
|
不过,还是要多提一句:**现在很多公司都是用的类似于 TiDB 这种分布式关系型数据库,不需要我们手动进行分库分表(数据库层面已经帮我们做了),也不需要解决手动分库分表引入的各种问题,直接一步到位,内置很多实用的功能(如无感扩容和缩容、冷热存储分离)!如果公司条件允许的话,个人也是比较推荐这种方式!**
|
||||||
|
|
||||||
### 分库分表后,数据怎么迁移呢?
|
### 分库分表后,数据怎么迁移呢?
|
||||||
|
|
||||||
@ -266,6 +266,7 @@ ShardingSphere 的优势如下(摘自 ShardingSphere 官方文档:<https://s
|
|||||||
- 读写分离基于主从复制,MySQL 主从复制是依赖于 binlog 。
|
- 读写分离基于主从复制,MySQL 主从复制是依赖于 binlog 。
|
||||||
- **分库** 就是将数据库中的数据分散到不同的数据库上。**分表** 就是对单表的数据进行拆分,可以是垂直拆分,也可以是水平拆分。
|
- **分库** 就是将数据库中的数据分散到不同的数据库上。**分表** 就是对单表的数据进行拆分,可以是垂直拆分,也可以是水平拆分。
|
||||||
- 引入分库分表之后,需要系统解决事务、分布式 id、无法 join 操作问题。
|
- 引入分库分表之后,需要系统解决事务、分布式 id、无法 join 操作问题。
|
||||||
- ShardingSphere 绝对可以说是当前分库分表的首选!ShardingSphere 的功能完善,除了支持读写分离和分库分表,还提供分布式事务、数据库治理等功能。另外,ShardingSphere 的生态体系完善,社区活跃,文档完善,更新和发布比较频繁。
|
- 现在很多公司都是用的类似于 TiDB 这种分布式关系型数据库,不需要我们手动进行分库分表(数据库层面已经帮我们做了),也不需要解决手动分库分表引入的各种问题,直接一步到位,内置很多实用的功能(如无感扩容和缩容、冷热存储分离)!如果公司条件允许的话,个人也是比较推荐这种方式!
|
||||||
|
- 如果必须要手动分库分表的话,ShardingSphere 是首选!ShardingSphere 的功能完善,除了支持读写分离和分库分表,还提供分布式事务、数据库治理等功能。另外,ShardingSphere 的生态体系完善,社区活跃,文档完善,更新和发布比较频繁。
|
||||||
|
|
||||||
<!-- @include: @article-footer.snippet.md -->
|
<!-- @include: @article-footer.snippet.md -->
|
||||||
|
|||||||
@ -267,7 +267,7 @@ public E take() throws InterruptedException {
|
|||||||
}
|
}
|
||||||
}
|
}
|
||||||
} finally {
|
} finally {
|
||||||
//收尾逻辑:如果leader不为空且q有元素,则说明有任务没人认领,直接发起通知唤醒因为锁被当前消费者持有而导致阻塞的生产者(即调用put、add、offer的线程)
|
//收尾逻辑:当leader为null,并且队列中有任务时,唤醒等待的获取元素的线程。
|
||||||
if (leader == null && q.peek() != null)
|
if (leader == null && q.peek() != null)
|
||||||
available.signal();
|
available.signal();
|
||||||
//释放锁
|
//释放锁
|
||||||
|
|||||||
@ -75,6 +75,7 @@ icon: "xitongsheji"
|
|||||||
## 搜索引擎
|
## 搜索引擎
|
||||||
|
|
||||||
- [Elasticsearch](https://github.com/elastic/elasticsearch "elasticsearch") (推荐):开源,分布式,RESTful 搜索引擎。
|
- [Elasticsearch](https://github.com/elastic/elasticsearch "elasticsearch") (推荐):开源,分布式,RESTful 搜索引擎。
|
||||||
|
- [Meilisearch](https://github.com/meilisearch/meilisearch):一个功能强大、快速、开源、易于使用和部署的搜索引擎,支持中文搜索(不需要添加额外的配置)。
|
||||||
- [Solr](https://lucene.apache.org/solr/) : Solr(读作“solar”)是 Apache Lucene 项目的开源企业搜索平台。
|
- [Solr](https://lucene.apache.org/solr/) : Solr(读作“solar”)是 Apache Lucene 项目的开源企业搜索平台。
|
||||||
- [Easy-ES](https://gitee.com/dromara/easy-es):傻瓜级 ElasticSearch 搜索引擎 ORM 框架。
|
- [Easy-ES](https://gitee.com/dromara/easy-es):傻瓜级 ElasticSearch 搜索引擎 ORM 框架。
|
||||||
|
|
||||||
@ -148,10 +149,23 @@ icon: "xitongsheji"
|
|||||||
|
|
||||||
### 缓存
|
### 缓存
|
||||||
|
|
||||||
|
#### 本地缓存
|
||||||
|
|
||||||
- [Caffeine](https://github.com/ben-manes/caffeine) : 一款强大的本地缓存解决方案,性能非常强大。
|
- [Caffeine](https://github.com/ben-manes/caffeine) : 一款强大的本地缓存解决方案,性能非常强大。
|
||||||
- [Redis](https://github.com/redis/redis):一个使用 C 语言开发的内存数据库,分布式缓存首选。
|
- [Guava](https://github.com/google/guava):Google Java 核心库,内置了比较完善的本地缓存实现。
|
||||||
- [OHC](https://github.com/snazy/ohc) :Java 堆外缓存解决方案(项目从 2021 年开始就不再进行维护了)。
|
- [OHC](https://github.com/snazy/ohc) :Java 堆外缓存解决方案(项目从 2021 年开始就不再进行维护了)。
|
||||||
|
|
||||||
|
#### 分布式缓存
|
||||||
|
|
||||||
|
- [Redis](https://github.com/redis/redis):一个使用 C 语言开发的内存数据库,分布式缓存首选。
|
||||||
|
- [Dragonfly](https://github.com/dragonflydb/dragonfly):一种针对现代应用程序负荷需求而构建的内存数据库,完全兼容Redis和Memcached的 API,迁移时无需修改任何代码,号称全世界最快的内存数据库。
|
||||||
|
- [KeyDB](https://github.com/Snapchat/KeyDB): Redis 的一个高性能分支,专注于多线程、内存效率和高吞吐量。
|
||||||
|
|
||||||
|
#### 多级缓存
|
||||||
|
|
||||||
|
- [J2Cache](https://gitee.com/ld/J2Cache):基于本地内存和 Redis 的两级 Java 缓存框架。
|
||||||
|
- [JetCache](https://github.com/alibaba/jetcache):阿里开源的缓存框架,支持多级缓存、分布式缓存自动刷新、 TTL 等功能。
|
||||||
|
|
||||||
### 消息队列
|
### 消息队列
|
||||||
|
|
||||||
**分布式队列**:
|
**分布式队列**:
|
||||||
|
|||||||
Loading…
x
Reference in New Issue
Block a user