mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
style: update linter
This commit is contained in:
parent
5e58e830eb
commit
7ea99a88d7
@ -26,8 +26,8 @@ tag:
|
||||
|
||||
上图存在错误:
|
||||
|
||||
1. 插入排序的最好时间复杂度为 O(n) 而不是 O(n^2) 。
|
||||
2. 希尔排序的平均时间复杂度为 O(nlogn)
|
||||
1. 插入排序的最好时间复杂度为 $O(n)$ 而不是 $O(n^2)$。
|
||||
2. 希尔排序的平均时间复杂度为 $O(nlogn)$。
|
||||
|
||||
**图片名词解释:**
|
||||
|
||||
@ -38,8 +38,8 @@ tag:
|
||||
|
||||
### 术语说明
|
||||
|
||||
- **稳定**:如果 A 原本在 B 前面,而 A=B,排序之后 A 仍然在 B 的前面。
|
||||
- **不稳定**:如果 A 原本在 B 的前面,而 A=B,排序之后 A 可能会出现在 B 的后面。
|
||||
- **稳定**:如果 A 原本在 B 前面,而 $A=B$,排序之后 A 仍然在 B 的前面。
|
||||
- **不稳定**:如果 A 原本在 B 的前面,而 $A=B$,排序之后 A 可能会出现在 B 的后面。
|
||||
- **内排序**:所有排序操作都在内存中完成。
|
||||
- **外排序**:由于数据太大,因此把数据放在磁盘中,而排序通过磁盘和内存的数据传输才能进行。
|
||||
- **时间复杂度**:定性描述一个算法执行所耗费的时间。
|
||||
@ -55,7 +55,7 @@ tag:
|
||||
|
||||
比较类排序的优势是,适用于各种规模的数据,也不在乎数据的分布,都能进行排序。可以说,比较排序适用于一切需要排序的情况。
|
||||
|
||||
而**计数排序**、**基数排序**、**桶排序**则属于**非比较类排序算法**。非比较排序不通过比较来决定元素间的相对次序,而是通过确定每个元素之前,应该有多少个元素来排序。由于它可以突破基于比较排序的时间下界,以线性时间运行,因此称为线性时间非比较类排序。 非比较排序只要确定每个元素之前的已有的元素个数即可,所有一次遍历即可解决。算法时间复杂度 `O(n)`。
|
||||
而**计数排序**、**基数排序**、**桶排序**则属于**非比较类排序算法**。非比较排序不通过比较来决定元素间的相对次序,而是通过确定每个元素之前,应该有多少个元素来排序。由于它可以突破基于比较排序的时间下界,以线性时间运行,因此称为线性时间非比较类排序。 非比较排序只要确定每个元素之前的已有的元素个数即可,所有一次遍历即可解决。算法时间复杂度 $O(n)$。
|
||||
|
||||
非比较排序时间复杂度底,但由于非比较排序需要占用空间来确定唯一位置。所以对数据规模和数据分布有一定的要求。
|
||||
|
||||
@ -109,13 +109,13 @@ public static int[] bubbleSort(int[] arr) {
|
||||
### 算法分析
|
||||
|
||||
- **稳定性**:稳定
|
||||
- **时间复杂度**:最佳:O(n) ,最差:O(n2), 平均:O(n2)
|
||||
- **空间复杂度**:O(1)
|
||||
- **时间复杂度**:最佳:$O(n)$ ,最差:$O(n^2)$, 平均:$O(n^2)$
|
||||
- **空间复杂度**:$O(1)$
|
||||
- **排序方式**:In-place
|
||||
|
||||
## 选择排序 (Selection Sort)
|
||||
|
||||
选择排序是一种简单直观的排序算法,无论什么数据进去都是 `O(n²)` 的时间复杂度。所以用到它的时候,数据规模越小越好。唯一的好处可能就是不占用额外的内存空间了吧。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
|
||||
选择排序是一种简单直观的排序算法,无论什么数据进去都是 $O(n^2)$ 的时间复杂度。所以用到它的时候,数据规模越小越好。唯一的好处可能就是不占用额外的内存空间了吧。它的工作原理:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
|
||||
|
||||
### 算法步骤
|
||||
|
||||
@ -156,13 +156,13 @@ public static int[] selectionSort(int[] arr) {
|
||||
### 算法分析
|
||||
|
||||
- **稳定性**:不稳定
|
||||
- **时间复杂度**:最佳:O(n2) ,最差:O(n2), 平均:O(n2)
|
||||
- **空间复杂度**:O(1)
|
||||
- **时间复杂度**:最佳:$O(n^2)$ ,最差:$O(n^2)$, 平均:$O(n^2)$
|
||||
- **空间复杂度**:$O(1)$
|
||||
- **排序方式**:In-place
|
||||
|
||||
## 插入排序 (Insertion Sort)
|
||||
|
||||
插入排序是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用 in-place 排序(即只需用到 `O(1)` 的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
|
||||
插入排序是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。插入排序在实现上,通常采用 in-place 排序(即只需用到 $O(1)$ 的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
|
||||
|
||||
插入排序的代码实现虽然没有冒泡排序和选择排序那么简单粗暴,但它的原理应该是最容易理解的了,因为只要打过扑克牌的人都应该能够秒懂。插入排序是一种最简单直观的排序算法,它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
|
||||
|
||||
@ -206,25 +206,25 @@ public static int[] insertionSort(int[] arr) {
|
||||
### 算法分析
|
||||
|
||||
- **稳定性**:稳定
|
||||
- **时间复杂度**:最佳:O(n) ,最差:O(n2), 平均:O(n2)
|
||||
- **空间复杂度**:O(1)
|
||||
- **时间复杂度**:最佳:$O(n)$ ,最差:$O(n^2)$, 平均:$O(n2)$
|
||||
- **空间复杂度**:O(1)$
|
||||
- **排序方式**:In-place
|
||||
|
||||
## 希尔排序 (Shell Sort)
|
||||
|
||||
希尔排序是希尔 (Donald Shell) 于 1959 年提出的一种排序算法。希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为递减增量排序算法,同时该算法是冲破 `O(n²)` 的第一批算法之一。
|
||||
希尔排序是希尔 (Donald Shell) 于 1959 年提出的一种排序算法。希尔排序也是一种插入排序,它是简单插入排序经过改进之后的一个更高效的版本,也称为递减增量排序算法,同时该算法是冲破 $O(n^2)$ 的第一批算法之一。
|
||||
|
||||
希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录 “基本有序” 时,再对全体记录进行依次直接插入排序。
|
||||
|
||||
### 算法步骤
|
||||
|
||||
我们来看下希尔排序的基本步骤,在此我们选择增量 `gap=length/2`,缩小增量继续以 `gap = gap/2` 的方式,这种增量选择我们可以用一个序列来表示,`{n/2, (n/2)/2, ..., 1}`,称为**增量序列**。希尔排序的增量序列的选择与证明是个数学难题,我们选择的这个增量序列是比较常用的,也是希尔建议的增量,称为希尔增量,但其实这个增量序列不是最优的。此处我们做示例使用希尔增量。
|
||||
我们来看下希尔排序的基本步骤,在此我们选择增量 $gap=length/2$,缩小增量继续以 $gap = gap/2$ 的方式,这种增量选择我们可以用一个序列来表示,$\lbrace \frac{n}{2}, \frac{(n/2)}{2}, \dots, 1 \rbrace$,称为**增量序列**。希尔排序的增量序列的选择与证明是个数学难题,我们选择的这个增量序列是比较常用的,也是希尔建议的增量,称为希尔增量,但其实这个增量序列不是最优的。此处我们做示例使用希尔增量。
|
||||
|
||||
先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,具体算法描述:
|
||||
|
||||
- 选择一个增量序列 `{t1, t2, …, tk}`,其中 `(ti>tj, i<j, tk=1)`;
|
||||
- 选择一个增量序列 $\lbrace t_1, t_2, \dots, t_k \rbrace$,其中 $t_i \gt t_j, i \lt j, t_k = 1$;
|
||||
- 按增量序列个数 k,对序列进行 k 趟排序;
|
||||
- 每趟排序,根据对应的增量 `t`,将待排序列分割成若干长度为 `m` 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
|
||||
- 每趟排序,根据对应的增量 $t$,将待排序列分割成若干长度为 $m$ 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
|
||||
|
||||
### 图解算法
|
||||
|
||||
@ -263,20 +263,20 @@ public static int[] shellSort(int[] arr) {
|
||||
### 算法分析
|
||||
|
||||
- **稳定性**:不稳定
|
||||
- **时间复杂度**:最佳:O(nlogn), 最差:O(n^2) 平均:O(nlogn)
|
||||
- **空间复杂度**:`O(1)`
|
||||
- **时间复杂度**:最佳:$O(nlogn)$, 最差:$O(n^2)$ 平均:$O(nlogn)$
|
||||
- **空间复杂度**:$O(1)$
|
||||
|
||||
## 归并排序 (Merge Sort)
|
||||
|
||||
归并排序是建立在归并操作上的一种有效的排序算法。该算法是采用分治法 (Divide and Conquer) 的一个非常典型的应用。归并排序是一种稳定的排序方法。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为 2 - 路归并。
|
||||
|
||||
和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是 `O(nlogn)` 的时间复杂度。代价是需要额外的内存空间。
|
||||
和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是 $O(nlogn)$ 的时间复杂度。代价是需要额外的内存空间。
|
||||
|
||||
### 算法步骤
|
||||
|
||||
归并排序算法是一个递归过程,边界条件为当输入序列仅有一个元素时,直接返回,具体过程如下:
|
||||
|
||||
1. 如果输入内只有一个元素,则直接返回,否则将长度为 `n` 的输入序列分成两个长度为 `n/2` 的子序列;
|
||||
1. 如果输入内只有一个元素,则直接返回,否则将长度为 $n$ 的输入序列分成两个长度为 $n/2$ 的子序列;
|
||||
2. 分别对这两个子序列进行归并排序,使子序列变为有序状态;
|
||||
3. 设定两个指针,分别指向两个已经排序子序列的起始位置;
|
||||
4. 比较两个指针所指向的元素,选择相对小的元素放入到合并空间(用于存放排序结果),并移动指针到下一位置;
|
||||
@ -346,8 +346,8 @@ public static int[] merge(int[] arr_1, int[] arr_2) {
|
||||
### 算法分析
|
||||
|
||||
- **稳定性**:稳定
|
||||
- **时间复杂度**:最佳:O(nlogn), 最差:O(nlogn), 平均:O(nlogn)
|
||||
- **空间复杂度**:O(n)
|
||||
- **时间复杂度**:最佳:$O(nlogn)$, 最差:$O(nlogn)$, 平均:$O(nlogn)$
|
||||
- **空间复杂度**:$O(n)$
|
||||
|
||||
## 快速排序 (Quick Sort)
|
||||
|
||||
@ -401,8 +401,8 @@ public static void quickSort(int[] array, int low, int high) {
|
||||
### 算法分析
|
||||
|
||||
- **稳定性**:不稳定
|
||||
- **时间复杂度**:最佳:O(nlogn), 最差:O(nlogn),平均:O(nlogn)
|
||||
- **空间复杂度**:O(logn)
|
||||
- **时间复杂度**:最佳:$O(nlogn)$, 最差:$O(nlogn)$,平均:$O(nlogn)$
|
||||
- **空间复杂度**:$O(logn)$
|
||||
|
||||
## 堆排序 (Heap Sort)
|
||||
|
||||
@ -410,9 +410,9 @@ public static void quickSort(int[] array, int low, int high) {
|
||||
|
||||
### 算法步骤
|
||||
|
||||
1. 将初始待排序列 `(R1, R2, ……, Rn)` 构建成大顶堆,此堆为初始的无序区;
|
||||
2. 将堆顶元素 `R[1]` 与最后一个元素 `R[n]` 交换,此时得到新的无序区 `(R1, R2, ……, Rn-1)` 和新的有序区 (Rn), 且满足 `R[1, 2, ……, n-1]<=R[n]`;
|
||||
3. 由于交换后新的堆顶 `R[1]` 可能违反堆的性质,因此需要对当前无序区 `(R1, R2, ……, Rn-1)` 调整为新堆,然后再次将 R [1] 与无序区最后一个元素交换,得到新的无序区 `(R1, R2, ……, Rn-2)` 和新的有序区 `(Rn-1, Rn)`。不断重复此过程直到有序区的元素个数为 `n-1`,则整个排序过程完成。
|
||||
1. 将初始待排序列 $(R_1, R_2, \dots, R_n)$ 构建成大顶堆,此堆为初始的无序区;
|
||||
2. 将堆顶元素 $R_1$ 与最后一个元素 $R_n$ 交换,此时得到新的无序区 $(R_1, R_2, \dots, R_{n-1})$ 和新的有序区 $R_n$, 且满足 $R_i \leqslant R_n (i \in 1, 2,\dots, n-1)$;
|
||||
3. 由于交换后新的堆顶 $R_1$ 可能违反堆的性质,因此需要对当前无序区 $(R_1, R_2, \dots, R_{n-1})$ 调整为新堆,然后再次将 $R_1$ 与无序区最后一个元素交换,得到新的无序区 $(R_1, R_2, \dots, R_{n-2})$ 和新的有序区 $(R_{n-1}, R_n)$。不断重复此过程直到有序区的元素个数为 $n-1$,则整个排序过程完成。
|
||||
|
||||
### 图解算法
|
||||
|
||||
@ -490,8 +490,8 @@ public static int[] heapSort(int[] arr) {
|
||||
### 算法分析
|
||||
|
||||
- **稳定性**:不稳定
|
||||
- **时间复杂度**:最佳:O(nlogn), 最差:O(nlogn), 平均:O(nlogn)
|
||||
- **空间复杂度**:O(1)
|
||||
- **时间复杂度**:最佳:$O(nlogn)$, 最差:$O(nlogn)$, 平均:$O(nlogn)$
|
||||
- **空间复杂度**:$O(1)$
|
||||
|
||||
## 计数排序 (Counting Sort)
|
||||
|
||||
@ -567,10 +567,10 @@ public static int[] countingSort(int[] arr) {
|
||||
|
||||
## 算法分析
|
||||
|
||||
当输入的元素是 `n` 个 `0` 到 `k` 之间的整数时,它的运行时间是 `O(n+k)`。计数排序不是比较排序,排序的速度快于任何比较排序算法。由于用来计数的数组 `C` 的长度取决于待排序数组中数据的范围(等于待排序数组的**最大值与最小值的差加上 1**),这使得计数排序对于数据范围很大的数组,需要大量额外内存空间。
|
||||
当输入的元素是 `n` 个 `0` 到 `k` 之间的整数时,它的运行时间是 $O(n+k)$。计数排序不是比较排序,排序的速度快于任何比较排序算法。由于用来计数的数组 `C` 的长度取决于待排序数组中数据的范围(等于待排序数组的**最大值与最小值的差加上 1**),这使得计数排序对于数据范围很大的数组,需要大量额外内存空间。
|
||||
|
||||
- **稳定性**:稳定
|
||||
- **时间复杂度**:最佳:`O(n+k)` 最差:`O(n+k)` 平均:`O(n+k)`
|
||||
- **时间复杂度**:最佳:$O(n+k)$ 最差:$O(n+k)$ 平均:$O(n+k)$
|
||||
- **空间复杂度**:`O(k)`
|
||||
|
||||
## 桶排序 (Bucket Sort)
|
||||
@ -653,22 +653,22 @@ public static List<Integer> bucketSort(List<Integer> arr, int bucket_size) {
|
||||
### 算法分析
|
||||
|
||||
- **稳定性**:稳定
|
||||
- **时间复杂度**:最佳:`O(n+k)` 最差:`O(n²)` 平均:`O(n+k)`
|
||||
- **空间复杂度**:`O(n+k)`
|
||||
- **时间复杂度**:最佳:$O(n+k)$ 最差:$O(n^2)$ 平均:$O(n+k)$
|
||||
- **空间复杂度**:$O(n+k)$
|
||||
|
||||
## 基数排序 (Radix Sort)
|
||||
|
||||
基数排序也是非比较的排序算法,对元素中的每一位数字进行排序,从最低位开始排序,复杂度为 `O(n×k)`,`n` 为数组长度,`k` 为数组中元素的最大的位数;
|
||||
基数排序也是非比较的排序算法,对元素中的每一位数字进行排序,从最低位开始排序,复杂度为 $O(n×k)$,$n$ 为数组长度,$k$ 为数组中元素的最大的位数;
|
||||
|
||||
基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。基数排序基于分别排序,分别收集,所以是稳定的。
|
||||
|
||||
### 算法步骤
|
||||
|
||||
1. 取得数组中的最大数,并取得位数,即为迭代次数 `N`(例如:数组中最大数值为 1000,则 `N=4`);
|
||||
1. 取得数组中的最大数,并取得位数,即为迭代次数 $N$(例如:数组中最大数值为 1000,则 $N=4$);
|
||||
2. `A` 为原始数组,从最低位开始取每个位组成 `radix` 数组;
|
||||
3. 对 `radix` 进行计数排序(利用计数排序适用于小范围数的特点);
|
||||
4. 将 `radix` 依次赋值给原数组;
|
||||
5. 重复 2~4 步骤 `N` 次
|
||||
5. 重复 2~4 步骤 $N$ 次
|
||||
|
||||
### 图解算法
|
||||
|
||||
@ -721,8 +721,8 @@ public static int[] radixSort(int[] arr) {
|
||||
### 算法分析
|
||||
|
||||
- **稳定性**:稳定
|
||||
- **时间复杂度**:最佳:`O(n×k)` 最差:`O(n×k)` 平均:`O(n×k)`
|
||||
- **空间复杂度**:`O(n+k)`
|
||||
- **时间复杂度**:最佳:$O(n×k)$ 最差:$O(n×k)$ 平均:$O(n×k)$
|
||||
- **空间复杂度**:$O(n+k)$
|
||||
|
||||
**基数排序 vs 计数排序 vs 桶排序**
|
||||
|
||||
|
||||
@ -167,5 +167,4 @@ MySQL 中时间到底怎么存储才好?Datetime?Timestamp?还是数值时间
|
||||
| TIMESTAMP | 4~7 字节 | YYYY-MM-DD hh:mm:ss[.fraction] | 1970-01-01 00:00:01[.000000] ~ 2038-01-19 03:14:07[.999999] | 是 |
|
||||
| 数值型时间戳 | 4 字节 | 全数字如 1578707612 | 1970-01-01 00:00:01 之后的时间 | 否 |
|
||||
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
@ -48,7 +48,7 @@ String 是一种二进制安全的数据类型,可以用来存储任何类型
|
||||
### 常用命令
|
||||
|
||||
| 命令 | 介绍 |
|
||||
| ------------------------------ | -------------------------------- |
|
||||
| ------------------------------- | -------------------------------- |
|
||||
| SET key value | 设置指定 key 的值 |
|
||||
| SETNX key value | 只有在 key 不存在时设置 key 的值 |
|
||||
| GET key | 获取指定 key 的值 |
|
||||
@ -486,7 +486,7 @@ value1
|
||||
## 总结
|
||||
|
||||
| 数据类型 | 说明 |
|
||||
| -------------------------------- | ------------------------------------------------- |
|
||||
| -------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| String | 一种二进制安全的数据类型,可以用来存储任何类型的数据比如字符串、整数、浮点数、图片(图片的 base64 编码或者解码或者图片的路径)、序列化后的对象。 |
|
||||
| List | Redis 的 List 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。 |
|
||||
| Hash | 一个 String 类型的 field-value(键值对) 的映射表,特别适合用于存储对象,后续操作的时候,你可以直接修改这个对象中的某些字段的值。 |
|
||||
|
||||
@ -212,7 +212,7 @@ user2
|
||||
## 总结
|
||||
|
||||
| 数据类型 | 说明 |
|
||||
| ---------------- | ------------------------------------------------------------ |
|
||||
| ---------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| Bitmap | 你可以将 Bitmap 看作是一个存储二进制数字(0 和 1)的数组,数组中每个元素的下标叫做 offset(偏移量)。通过 Bitmap, 只需要一个 bit 位来表示某个元素对应的值或者状态,key 就是对应元素本身 。我们知道 8 个 bit 可以组成一个 byte,所以 Bitmap 本身会极大的节省储存空间。 |
|
||||
| HyperLogLog | Redis 提供的 HyperLogLog 占用空间非常非常小,只需要 12k 的空间就能存储接近`2^64`个不同元素。不过,HyperLogLog 的计数结果并不是一个精确值,存在一定的误差(标准误差为 `0.81%` )。 |
|
||||
| Geospatial index | Geospatial index(地理空间索引,简称 GEO) 主要用于存储地理位置信息,基于 Sorted Set 实现。 |
|
||||
|
||||
@ -260,7 +260,7 @@ struct __attribute__ ((__packed__)) sdshdr64 {
|
||||
通过源码可以看出,SDS 共有五种实现方式 SDS_TYPE_5(并未用到)、SDS_TYPE_8、SDS_TYPE_16、SDS_TYPE_32、SDS_TYPE_64,其中只有后四种实际用到。Redis 会根据初始化的长度决定使用哪种类型,从而减少内存的使用。
|
||||
|
||||
| 类型 | 字节 | 位 |
|
||||
| -------- | ---- | ---- |
|
||||
| -------- | ---- | --- |
|
||||
| sdshdr5 | < 1 | <8 |
|
||||
| sdshdr8 | 1 | 8 |
|
||||
| sdshdr16 | 2 | 16 |
|
||||
|
||||
@ -190,7 +190,7 @@ ORDER BY vend_name DESC
|
||||
下面的运算符可以在 `WHERE` 子句中使用:
|
||||
|
||||
| 运算符 | 描述 |
|
||||
| :------ | :--------------------------------------------------------- |
|
||||
| :------ | :----------------------------------------------------------- |
|
||||
| = | 等于 |
|
||||
| <> | 不等于。 **注释:** 在 SQL 的一些版本中,该操作符可被写成 != |
|
||||
| > | 大于 |
|
||||
|
||||
@ -28,7 +28,7 @@ SQL 插入记录的方式汇总:
|
||||
试卷作答记录表`exam_record`中,表已建好,其结构如下,请用一条语句将这两条记录插入表中。
|
||||
|
||||
| Filed | Type | Null | Key | Extra | Default | Comment |
|
||||
| ----------- | ---------- | ---- | ---- | -------------- | ------- | -------- |
|
||||
| ----------- | ---------- | ---- | --- | -------------- | ------- | -------- |
|
||||
| id | int(11) | NO | PRI | auto_increment | (NULL) | 自增 ID |
|
||||
| uid | int(11) | NO | | | (NULL) | 用户 ID |
|
||||
| exam_id | int(11) | NO | | | (NULL) | 试卷 ID |
|
||||
@ -52,7 +52,7 @@ INSERT INTO exam_record (uid, exam_id, start_time, submit_time, score) VALUES
|
||||
表`exam_record`:
|
||||
|
||||
| Filed | Type | Null | Key | Extra | Default | Comment |
|
||||
| ----------- | ---------- | ---- | ---- | -------------- | ------- | -------- |
|
||||
| ----------- | ---------- | ---- | --- | -------------- | ------- | -------- |
|
||||
| id | int(11) | NO | PRI | auto_increment | (NULL) | 自增 ID |
|
||||
| uid | int(11) | NO | | | (NULL) | 用户 ID |
|
||||
| exam_id | int(11) | NO | | | (NULL) | 试卷 ID |
|
||||
@ -78,7 +78,7 @@ WHERE YEAR(submit_time) < 2021;
|
||||
试题信息表`examination_info`:
|
||||
|
||||
| Filed | Type | Null | Key | Extra | Default | Comment |
|
||||
| ------------ | ----------- | ---- | ---- | -------------- | ------- | ------------ |
|
||||
| ------------ | ----------- | ---- | --- | -------------- | ------- | ------------ |
|
||||
| id | int(11) | NO | PRI | auto_increment | (NULL) | 自增 ID |
|
||||
| exam_id | int(11) | NO | UNI | | (NULL) | 试卷 ID |
|
||||
| tag | varchar(32) | YES | | | (NULL) | 类别标签 |
|
||||
@ -98,7 +98,7 @@ REPLACE INTO examination_info VALUES
|
||||
**描述**:现在有一张试卷信息表 `examination_info`, 表结构如下图所示:
|
||||
|
||||
| Filed | Type | Null | Key | Extra | Default | Comment |
|
||||
| ------------ | -------- | ---- | ---- | -------------- | ------- | -------- |
|
||||
| ------------ | -------- | ---- | --- | -------------- | ------- | -------- |
|
||||
| id | int(11) | NO | PRI | auto_increment | (NULL) | 自增 ID |
|
||||
| exam_id | int(11) | NO | UNI | | (NULL) | 试卷 ID |
|
||||
| tag | char(32) | YES | | | (NULL) | 类别标签 |
|
||||
@ -130,7 +130,7 @@ SET tag = REPLACE(tag,'PYTHON','Python')
|
||||
**描述**:现有一张试卷作答记录表 exam_record,其中包含多年来的用户作答试卷记录,结构如下表:作答记录表 `exam_record`: **`submit_time`** 为 完成时间 (注意这句话)
|
||||
|
||||
| Filed | Type | Null | Key | Extra | Default | Comment |
|
||||
| ----------- | ---------- | ---- | ---- | -------------- | ------- | -------- |
|
||||
| ----------- | ---------- | ---- | --- | -------------- | ------- | -------- |
|
||||
| id | int(11) | NO | PRI | auto_increment | (NULL) | 自增 ID |
|
||||
| uid | int(11) | NO | | | (NULL) | 用户 ID |
|
||||
| exam_id | int(11) | NO | | | (NULL) | 试卷 ID |
|
||||
@ -155,7 +155,7 @@ UPDATE exam_record SET submit_time = '2099-01-01 00:00:00', score = 0 WHERE DATE
|
||||
作答记录表`exam_record:` **`start_time`** 是试卷开始时间`submit_time` 是交卷,即结束时间。
|
||||
|
||||
| Filed | Type | Null | Key | Extra | Default | Comment |
|
||||
| ----------- | ---------- | ---- | ---- | -------------- | ------- | -------- |
|
||||
| ----------- | ---------- | ---- | --- | -------------- | ------- | -------- |
|
||||
| id | int(11) | NO | PRI | auto_increment | (NULL) | 自增 ID |
|
||||
| uid | int(11) | NO | | | (NULL) | 用户 ID |
|
||||
| exam_id | int(11) | NO | | | (NULL) | 试卷 ID |
|
||||
@ -213,7 +213,7 @@ DELETE FROM exam_record WHERE TIMESTAMPDIFF(MINUTE, start_time, submit_time) < 5
|
||||
作答记录表`exam_record`:`start_time` 是试卷开始时间,`submit_time` 是交卷时间,即结束时间,如果未完成的话,则为空。
|
||||
|
||||
| Filed | Type | Null | Key | Extra | Default | Comment |
|
||||
| ----------- | ---------- | :--: | ---- | -------------- | ------- | -------- |
|
||||
| ----------- | ---------- | :--: | --- | -------------- | ------- | -------- |
|
||||
| id | int(11) | NO | PRI | auto_increment | (NULL) | 自增 ID |
|
||||
| uid | int(11) | NO | | | (NULL) | 用户 ID |
|
||||
| exam_id | int(11) | NO | | | (NULL) | 试卷 ID |
|
||||
@ -241,7 +241,7 @@ LIMIT 3
|
||||
**描述**:现有一张试卷作答记录表 exam_record,其中包含多年来的用户作答试卷记录,结构如下表:
|
||||
|
||||
| Filed | Type | Null | Key | Extra | Default | Comment |
|
||||
| ----------- | ---------- | :--: | ---- | -------------- | ------- | -------- |
|
||||
| ----------- | ---------- | :--: | --- | -------------- | ------- | -------- |
|
||||
| id | int(11) | NO | PRI | auto_increment | (NULL) | 自增 ID |
|
||||
| uid | int(11) | NO | | | (NULL) | 用户 ID |
|
||||
| exam_id | int(11) | NO | | | (NULL) | 试卷 ID |
|
||||
@ -278,7 +278,7 @@ TRUNCATE exam_record;
|
||||
原来的用户信息表:
|
||||
|
||||
| Filed | Type | Null | Key | Default | Extra | Comment |
|
||||
| ------------- | ----------- | ---- | ---- | ----------------- | -------------- | -------- |
|
||||
| ------------- | ----------- | ---- | --- | ----------------- | -------------- | -------- |
|
||||
| id | int(11) | NO | PRI | (NULL) | auto_increment | 自增 ID |
|
||||
| uid | int(11) | NO | UNI | (NULL) | | 用户 ID |
|
||||
| nick_name | varchar(64) | YES | | (NULL) | | 昵称 |
|
||||
@ -292,7 +292,7 @@ TRUNCATE exam_record;
|
||||
你应该返回的输出如下表格所示,请写出建表语句将表格中所有限制和说明记录到表里。
|
||||
|
||||
| Filed | Type | Null | Key | Default | Extra | Comment |
|
||||
| ------------- | ----------- | ---- | ---- | ----------------- | -------------- | -------- |
|
||||
| ------------- | ----------- | ---- | --- | ----------------- | -------------- | -------- |
|
||||
| id | int(11) | NO | PRI | (NULL) | auto_increment | 自增 ID |
|
||||
| uid | int(11) | NO | UNI | (NULL) | | 用户 ID |
|
||||
| nick_name | varchar(64) | YES | | (NULL) | | 昵称 |
|
||||
@ -324,7 +324,7 @@ CREATE TABLE IF NOT EXISTS user_info_vip(
|
||||
**用户信息表 `user_info`:**
|
||||
|
||||
| Filed | Type | Null | Key | Default | Extra | Comment |
|
||||
| ------------- | ----------- | ---- | ---- | ----------------- | -------------- | -------- |
|
||||
| ------------- | ----------- | ---- | --- | ----------------- | -------------- | -------- |
|
||||
| id | int(11) | NO | PRI | (NULL) | auto_increment | 自增 ID |
|
||||
| uid | int(11) | NO | UNI | (NULL) | | 用户 ID |
|
||||
| nick_name | varchar(64) | YES | | (NULL) | | 昵称 |
|
||||
@ -383,7 +383,7 @@ DROP TABLE IF EXISTS exam_record_2014;
|
||||
根据题意,将返回如下结果:
|
||||
|
||||
| examination_info | 0 | PRIMARY | 1 | id | A | 0 | | | | BTREE |
|
||||
| ---------------- | ---- | ---------------- | ---- | -------- | ---- | ---- | ---- | ---- | ---- | -------- |
|
||||
| ---------------- | --- | ---------------- | --- | -------- | --- | --- | --- | --- | --- | -------- |
|
||||
| examination_info | 0 | uniq_idx_exam_id | 1 | exam_id | A | 0 | | | YES | BTREE |
|
||||
| examination_info | 1 | idx_duration | 1 | duration | A | 0 | | | | BTREE |
|
||||
| examination_info | 1 | full_idx_tag | 1 | tag | | 0 | | | YES | FULLTEXT |
|
||||
|
||||
@ -21,14 +21,14 @@ tag:
|
||||
示例数据:`examination_info`(`exam_id` 试卷 ID, tag 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间)
|
||||
|
||||
| id | exam_id | tag | difficulty | duration | release_time |
|
||||
| ---- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| --- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
|
||||
| 2 | 9002 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
|
||||
|
||||
示例数据:`exam_record`(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分)
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
|
||||
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | 2021-05-02 10:30:01 | 81 |
|
||||
| 3 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:31:01 | 84 |
|
||||
@ -43,7 +43,7 @@ tag:
|
||||
根据输入你的查询结果如下:
|
||||
|
||||
| tag | difficulty | clip_avg_score |
|
||||
| ---- | ---------- | -------------- |
|
||||
| --- | ---------- | -------------- |
|
||||
| SQL | hard | 81.7 |
|
||||
|
||||
从`examination_info`表可知,试卷 9001 为高难度 SQL 试卷,该试卷被作答的得分有[80,81,84,90,50],去除最高分和最低分后为[80,81,84],平均分为 81.6666667,保留一位小数后为 81.7
|
||||
@ -200,7 +200,7 @@ WHERE info.exam_id = record.exam_id
|
||||
示例数据 `exam_record` 表(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
|
||||
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | 2021-05-02 10:30:01 | 81 |
|
||||
| 3 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:31:01 | 84 |
|
||||
@ -288,7 +288,7 @@ FROM
|
||||
示例数据 exam_record 表(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
|
||||
| 2 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 89 |
|
||||
| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
|
||||
@ -302,7 +302,7 @@ FROM
|
||||
`examination_info` 表(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间)
|
||||
|
||||
| id | exam_id | tag | difficulty | duration | release_time |
|
||||
| ---- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| --- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
|
||||
| 2 | 9002 | SQL | easy | 60 | 2020-02-01 10:00:00 |
|
||||
| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
|
||||
@ -364,7 +364,7 @@ WHERE info.exam_id = record.exam_id
|
||||
`exam_record` 表(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分)
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | 2021-07-02 09:21:01 | 80 |
|
||||
| 2 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 81 |
|
||||
| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
|
||||
@ -382,7 +382,7 @@ WHERE info.exam_id = record.exam_id
|
||||
请计算 2021 年每个月里试卷作答区用户平均月活跃天数 `avg_active_days` 和月度活跃人数 `mau`,上面数据的示例输出如下:
|
||||
|
||||
| month | avg_active_days | mau |
|
||||
| ------ | --------------- | ---- |
|
||||
| ------ | --------------- | --- |
|
||||
| 202107 | 1.50 | 2 |
|
||||
| 202109 | 1.25 | 4 |
|
||||
|
||||
@ -417,7 +417,7 @@ GROUP BY MONTH
|
||||
**描述**:现有一张题目练习记录表 `practice_record`,示例内容如下:
|
||||
|
||||
| id | uid | question_id | submit_time | score |
|
||||
| ---- | ---- | ----------- | ------------------- | ----- |
|
||||
| --- | ---- | ----------- | ------------------- | ----- |
|
||||
| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
|
||||
| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
|
||||
| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
|
||||
@ -496,7 +496,7 @@ ORDER BY submit_month
|
||||
**描述**:现有试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分),示例数据如下:
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | 2021-07-02 09:21:01 | 80 |
|
||||
| 2 | 1002 | 9001 | 2021-09-05 19:01:01 | 2021-09-05 19:40:01 | 81 |
|
||||
| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
|
||||
@ -514,7 +514,7 @@ ORDER BY submit_month
|
||||
还有一张试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间),示例数据如下:
|
||||
|
||||
| id | exam_id | tag | difficulty | duration | release_time |
|
||||
| ---- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| --- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
|
||||
| 2 | 9002 | SQL | easy | 60 | 2020-02-01 10:00:00 |
|
||||
| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
|
||||
@ -522,7 +522,7 @@ ORDER BY submit_month
|
||||
请统计 2021 年每个未完成试卷作答数大于 1 的有效用户的数据(有效用户指完成试卷作答数至少为 1 且未完成数小于 5),输出用户 ID、未完成试卷作答数、完成试卷作答数、作答过的试卷 tag 集合,按未完成试卷数量由多到少排序。示例数据的输出结果如下:
|
||||
|
||||
| uid | incomplete_cnt | complete_cnt | detail |
|
||||
| ---- | -------------- | ------------ | ------------------------------------------------------------ |
|
||||
| ---- | -------------- | ------------ | --------------------------------------------------------------------------- |
|
||||
| 1002 | 2 | 4 | 2021-09-01:算法;2021-07-02:SQL;2021-09-02:SQL;2021-09-05:SQL;2021-07-05:SQL |
|
||||
|
||||
**解释**:2021 年的作答记录中,除了 1004,其他用户均满足有效用户定义,但只有 1002 未完成试卷数大于 1,因此只输出 1002,detail 中是 1002 作答过的试卷{日期:tag}集合,日期和 tag 间用 **:** 连接,多元素间用 **;** 连接。
|
||||
@ -592,7 +592,7 @@ ORDER BY incomplete_cnt DESC
|
||||
**描述**:现有试卷作答记录表 `exam_record`(`uid`:用户 ID, `exam_id`:试卷 ID, `start_time`:开始作答时间, `submit_time`:交卷时间,没提交的话为 NULL, `score`:得分),示例数据如下:
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | (NULL) | (NULL) |
|
||||
| 2 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:21:01 | 60 |
|
||||
| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | 2021-09-02 12:31:01 | 70 |
|
||||
@ -610,7 +610,7 @@ ORDER BY incomplete_cnt DESC
|
||||
试卷信息表 `examination_info`(`exam_id`:试卷 ID, `tag`:试卷类别, `difficulty`:试卷难度, `duration`:考试时长, `release_time`:发布时间),示例数据如下:
|
||||
|
||||
| id | exam_id | tag | difficulty | duration | release_time |
|
||||
| ---- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| --- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
|
||||
| 2 | 9002 | C++ | easy | 60 | 2020-02-01 10:00:00 |
|
||||
| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
|
||||
@ -659,7 +659,7 @@ ORDER BY tag_cnt DESC
|
||||
**描述**:现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间),示例数据如下:
|
||||
|
||||
| id | uid | nick_name | achievement | level | job | register_time |
|
||||
| ---- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
|
||||
| --- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
|
||||
| 1 | 1001 | 牛客 1 号 | 3100 | 7 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 2 | 1002 | 牛客 2 号 | 2100 | 6 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 3 | 1003 | 牛客 3 号 | 1500 | 5 | 算法 | 2020-01-01 10:00:00 |
|
||||
@ -672,7 +672,7 @@ ORDER BY tag_cnt DESC
|
||||
试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间) 示例数据如下:
|
||||
|
||||
| id | exam_id | tag | difficulty | duration | release_time |
|
||||
| ---- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| --- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
|
||||
| 2 | 9002 | C++ | easy | 60 | 2020-02-01 10:00:00 |
|
||||
| 3 | 9003 | 算法 | medium | 80 | 2020-08-02 10:00:00 |
|
||||
@ -680,7 +680,7 @@ ORDER BY tag_cnt DESC
|
||||
试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分) 示例数据如下:
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1001 | 9001 | 2021-07-02 09:01:01 | 2021-09-01 09:41:01 | 70 |
|
||||
| 2 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:21:01 | 60 |
|
||||
| 3 | 1002 | 9002 | 2021-09-02 12:01:01 | 2021-09-02 12:31:01 | 70 |
|
||||
@ -701,7 +701,7 @@ ORDER BY tag_cnt DESC
|
||||
请计算每张 SQL 类别试卷发布后,当天 5 级以上的用户作答的人数 `uv` 和平均分 `avg_score`,按人数降序,相同人数的按平均分升序,示例数据结果输出如下:
|
||||
|
||||
| exam_id | uv | avg_score |
|
||||
| ------- | ---- | --------- |
|
||||
| ------- | --- | --------- |
|
||||
| 9001 | 3 | 81.3 |
|
||||
|
||||
解释:只有一张 SQL 类别的试卷,试卷 ID 为 9001,发布当天(2021-09-01)有 1001、1002、1003、1005 作答过,但是 1003 是 5 级用户,其他 3 位为 5 级以上,他们三的得分有[70,80,85,90],平均分为 81.3(保留 1 位小数)。
|
||||
@ -753,7 +753,7 @@ ORDER BY uv DESC,
|
||||
现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间):
|
||||
|
||||
| id | uid | nick_name | achievement | level | job | register_time |
|
||||
| ---- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
|
||||
| --- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
|
||||
| 1 | 1001 | 牛客 1 号 | 3100 | 7 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 2 | 1002 | 牛客 2 号 | 2100 | 6 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 3 | 1003 | 牛客 3 号 | 1500 | 5 | 算法 | 2020-01-01 10:00:00 |
|
||||
@ -764,7 +764,7 @@ ORDER BY uv DESC,
|
||||
试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
|
||||
|
||||
| id | exam_id | tag | difficulty | duration | release_time |
|
||||
| ---- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| --- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
|
||||
| 2 | 9002 | C++ | easy | 60 | 2021-09-01 06:00:00 |
|
||||
| 3 | 9003 | 算法 | medium | 80 | 2021-09-01 10:00:00 |
|
||||
@ -772,7 +772,7 @@ ORDER BY uv DESC,
|
||||
试卷作答信息表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:41:01 | 79 |
|
||||
| 2 | 1002 | 9003 | 2021-09-01 12:01:01 | 2021-09-01 12:21:01 | 60 |
|
||||
| 3 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
|
||||
@ -827,7 +827,7 @@ ORDER BY level_cnt DESC
|
||||
现有试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:41:01 | 81 |
|
||||
| 2 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
|
||||
| 3 | 1002 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 80 |
|
||||
@ -838,7 +838,7 @@ ORDER BY level_cnt DESC
|
||||
题目练习表 practice_record(uid 用户 ID, question_id 题目 ID, submit_time 提交时间, score 得分):
|
||||
|
||||
| id | uid | question_id | submit_time | score |
|
||||
| ---- | ---- | ----------- | ------------------- | ----- |
|
||||
| --- | ---- | ----------- | ------------------- | ----- |
|
||||
| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
|
||||
| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
|
||||
| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
|
||||
@ -850,7 +850,7 @@ ORDER BY level_cnt DESC
|
||||
请统计每个题目和每份试卷被作答的人数和次数,分别按照"试卷"和"题目"的 uv & pv 降序显示,示例数据结果输出如下:
|
||||
|
||||
| tid | uv | pv |
|
||||
| ---- | ---- | ---- |
|
||||
| ---- | --- | --- |
|
||||
| 9001 | 3 | 3 |
|
||||
| 9002 | 1 | 3 |
|
||||
| 8001 | 3 | 5 |
|
||||
@ -919,7 +919,7 @@ FROM
|
||||
现有试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
|
||||
|
||||
| id | exam_id | tag | difficulty | duration | release_time |
|
||||
| ---- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| --- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
|
||||
| 2 | 9002 | C++ | easy | 60 | 2021-09-01 06:00:00 |
|
||||
| 3 | 9003 | 算法 | medium | 80 | 2021-09-01 10:00:00 |
|
||||
@ -927,7 +927,7 @@ FROM
|
||||
试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
|
||||
| 2 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 70 |
|
||||
| 3 | 1003 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | **86** |
|
||||
@ -1012,7 +1012,7 @@ ORDER BY UID
|
||||
现有用户信息表 user_info(uid 用户 ID,nick_name 昵称, achievement 成就值, level 等级, job 职业方向, register_time 注册时间):
|
||||
|
||||
| id | uid | nick_name | achievement | level | job | register_time |
|
||||
| ---- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
|
||||
| --- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
|
||||
| 1 | 1001 | 牛客 1 号 | 3100 | 7 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 2 | 1002 | 牛客 2 号 | 2300 | 7 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 3 | 1003 | 牛客 3 号 | 2500 | 7 | 算法 | 2020-01-01 10:00:00 |
|
||||
@ -1023,7 +1023,7 @@ ORDER BY UID
|
||||
试卷信息表 examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间):
|
||||
|
||||
| id | exam_id | tag | difficulty | duration | release_time |
|
||||
| ---- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| --- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
|
||||
| 2 | 9002 | C++ | hard | 60 | 2021-09-01 06:00:00 |
|
||||
| 3 | 9003 | 算法 | medium | 80 | 2021-09-01 10:00:00 |
|
||||
@ -1031,7 +1031,7 @@ ORDER BY UID
|
||||
试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ----- |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ----- |
|
||||
| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
|
||||
| 2 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
|
||||
| 3 | 1003 | 9001 | 2021-09-01 19:01:01 | 2021-09-01 19:40:01 | 86 |
|
||||
@ -1044,7 +1044,7 @@ ORDER BY UID
|
||||
题目练习记录表 practice_record(uid 用户 ID, question_id 题目 ID, submit_time 提交时间, score 得分):
|
||||
|
||||
| id | uid | question_id | submit_time | score |
|
||||
| ---- | ---- | ----------- | ------------------- | ----- |
|
||||
| --- | ---- | ----------- | ------------------- | ----- |
|
||||
| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
|
||||
| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
|
||||
| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
|
||||
@ -1127,7 +1127,7 @@ ORDER BY exam_cnt,
|
||||
现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间):
|
||||
|
||||
| id | uid | nick_name | achievement | level | job | register_time |
|
||||
| ---- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
|
||||
| --- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
|
||||
| 1 | 1001 | 牛客 1 号 | 3100 | 7 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 2 | 1002 | 牛客 2 号 | 2300 | 7 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 3 | 1003 | 牛客 3 号 | 2500 | 7 | 算法 | 2020-01-01 10:00:00 |
|
||||
@ -1138,7 +1138,7 @@ ORDER BY exam_cnt,
|
||||
试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
|
||||
|
||||
| id | exam_id | tag | difficulty | duration | release_time |
|
||||
| ---- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| --- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
|
||||
| 2 | 9002 | C++ | easy | 60 | 2021-09-01 06:00:00 |
|
||||
| 3 | 9003 | 算法 | medium | 80 | 2021-09-01 10:00:00 |
|
||||
|
||||
@ -74,7 +74,7 @@ FROM table;
|
||||
现有试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
|
||||
|
||||
| id | exam_id | tag | difficulty | duration | release_time |
|
||||
| ---- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| --- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
|
||||
| 2 | 9002 | SQL | hard | 60 | 2021-09-01 06:00:00 |
|
||||
| 3 | 9003 | 算法 | medium | 80 | 2021-09-01 10:00:00 |
|
||||
@ -82,7 +82,7 @@ FROM table;
|
||||
试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, score 得分):
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 78 |
|
||||
| 2 | 1002 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
|
||||
| 3 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
|
||||
@ -135,7 +135,7 @@ WHERE ranking <= 3
|
||||
现有试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
|
||||
|
||||
| id | exam_id | tag | difficulty | duration | release_time |
|
||||
| ---- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| --- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| 1 | 9001 | SQL | hard | 60 | 2021-09-01 06:00:00 |
|
||||
| 2 | 9002 | C++ | hard | 60 | 2021-09-01 06:00:00 |
|
||||
| 3 | 9003 | 算法 | medium | 80 | 2021-09-01 10:00:00 |
|
||||
@ -143,7 +143,7 @@ WHERE ranking <= 3
|
||||
试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1001 | 9001 | 2021-09-01 09:01:01 | 2021-09-01 09:51:01 | 78 |
|
||||
| 2 | 1001 | 9002 | 2021-09-01 09:01:01 | 2021-09-01 09:31:00 | 81 |
|
||||
| 3 | 1002 | 9002 | 2021-09-01 12:01:01 | 2021-09-01 12:31:01 | 81 |
|
||||
@ -199,7 +199,7 @@ ORDER BY a.exam_id DESC
|
||||
现有试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ----- |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ----- |
|
||||
| 1 | 1006 | 9003 | 2021-09-07 10:01:01 | 2021-09-07 10:21:02 | 84 |
|
||||
| 2 | 1006 | 9001 | 2021-09-01 12:11:01 | 2021-09-01 12:31:01 | 89 |
|
||||
| 3 | 1006 | 9002 | 2021-09-06 10:01:01 | 2021-09-06 10:21:01 | 81 |
|
||||
@ -246,7 +246,7 @@ ORDER BY days_window DESC,
|
||||
现有试卷作答记录表 `exam_record`(`uid`:用户 ID, `exam_id`:试卷 ID, `start_time`:开始作答时间, `submit_time`:交卷时间,为空的话则代表未完成, `score`:得分):
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1006 | 9003 | 2021-09-06 10:01:01 | 2021-09-06 10:21:02 | 84 |
|
||||
| 2 | 1006 | 9001 | 2021-08-02 12:11:01 | 2021-08-02 12:31:01 | 89 |
|
||||
| 3 | 1006 | 9002 | 2021-06-06 10:01:01 | 2021-06-06 10:21:01 | 81 |
|
||||
@ -297,7 +297,7 @@ ORDER BY exam_complete_cnt DESC,
|
||||
现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间):
|
||||
|
||||
| id | uid | nick_name | achievement | level | job | register_time |
|
||||
| ---- | ---- | ----------- | ----------- | ----- | ---- | ------------------- |
|
||||
| --- | ---- | ------------ | ----------- | ----- | ---- | ------------------- |
|
||||
| 1 | 1001 | 牛客 1 号 | 3200 | 7 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 2 | 1002 | 牛客 2 号 | 2500 | 6 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 3 | 1003 | 牛客 3 号 ♂ | 2200 | 5 | 算法 | 2020-01-01 10:00:00 |
|
||||
@ -305,7 +305,7 @@ ORDER BY exam_complete_cnt DESC,
|
||||
试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
|
||||
|
||||
| id | exam_id | tag | difficulty | duration | release_time |
|
||||
| ---- | ------- | ------ | ---------- | -------- | ------------------- |
|
||||
| --- | ------- | ------ | ---------- | -------- | ------------------- |
|
||||
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
|
||||
| 2 | 9002 | SQL | hard | 80 | 2020-01-01 10:00:00 |
|
||||
| 3 | 9003 | 算法 | hard | 80 | 2020-01-01 10:00:00 |
|
||||
@ -314,7 +314,7 @@ ORDER BY exam_complete_cnt DESC,
|
||||
试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ----- |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ----- |
|
||||
| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 90 |
|
||||
| 15 | 1002 | 9001 | 2020-01-01 18:01:01 | 2020-01-01 18:59:02 | 90 |
|
||||
| 13 | 1001 | 9001 | 2020-01-02 10:01:01 | 2020-01-02 10:31:01 | 89 |
|
||||
@ -435,7 +435,7 @@ ORDER BY t1.uid,
|
||||
现有试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
|
||||
|
||||
| id | exam_id | tag | difficulty | duration | release_time |
|
||||
| ---- | ------- | ------ | ---------- | -------- | ------------------- |
|
||||
| --- | ------- | ------ | ---------- | -------- | ------------------- |
|
||||
| 1 | 9001 | SQL | hard | 60 | 2021-01-01 10:00:00 |
|
||||
| 2 | 9002 | C++ | hard | 80 | 2021-01-01 10:00:00 |
|
||||
| 3 | 9003 | 算法 | hard | 80 | 2021-01-01 10:00:00 |
|
||||
@ -444,7 +444,7 @@ ORDER BY t1.uid,
|
||||
试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ----- |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ----- |
|
||||
| 1 | 1001 | 9001 | 2020-08-02 10:01:01 | 2020-08-02 10:31:01 | 89 |
|
||||
| 2 | 1002 | 9001 | 2020-04-01 18:01:01 | 2020-04-01 18:59:02 | 90 |
|
||||
| 3 | 1001 | 9001 | 2020-04-01 09:01:01 | 2020-04-01 09:21:59 | 80 |
|
||||
@ -469,7 +469,7 @@ ORDER BY t1.uid,
|
||||
由示例数据结果输出如下:
|
||||
|
||||
| tag | exam_cnt_20 | exam_cnt_21 | growth_rate | exam_cnt_rank_20 | exam_cnt_rank_21 | rank_delta |
|
||||
| ---- | ----------- | ----------- | ----------- | ---------------- | ---------------- | ---------- |
|
||||
| --- | ----------- | ----------- | ----------- | ---------------- | ---------------- | ---------- |
|
||||
| SQL | 3 | 2 | -33.3% | 1 | 2 | 1 |
|
||||
|
||||
解释:2020 年上半年有 3 个 tag 有作答完成的记录,分别是 C++、SQL、PYTHON,它们被做完的次数分别是 3、3、2,做完次数排名为 1、1(并列)、3;
|
||||
@ -591,7 +591,7 @@ ORDER BY
|
||||
现有试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
|
||||
|
||||
| id | exam_id | tag | difficulty | duration | release_time |
|
||||
| ---- | ------- | ------ | ---------- | -------- | ------------------- |
|
||||
| --- | ------- | ------ | ---------- | -------- | ------------------- |
|
||||
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
|
||||
| 2 | 9002 | C++ | hard | 80 | 2020-01-01 10:00:00 |
|
||||
| 3 | 9003 | 算法 | hard | 80 | 2020-01-01 10:00:00 |
|
||||
@ -600,7 +600,7 @@ ORDER BY
|
||||
试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 6 | 1003 | 9001 | 2020-01-02 12:01:01 | 2020-01-02 12:31:01 | 68 |
|
||||
| 9 | 1001 | 9001 | 2020-01-02 10:01:01 | 2020-01-02 10:31:01 | 89 |
|
||||
| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 90 |
|
||||
@ -695,7 +695,7 @@ ORDER BY
|
||||
现有试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 90 |
|
||||
| 2 | 1002 | 9001 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 89 |
|
||||
| 3 | 1002 | 9001 | 2020-02-01 12:11:01 | 2020-02-01 12:31:01 | 83 |
|
||||
@ -748,7 +748,7 @@ GROUP BY exam_id,
|
||||
**描述**:现有试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 90 |
|
||||
| 2 | 1002 | 9001 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 89 |
|
||||
| 3 | 1002 | 9001 | 2020-02-01 12:11:01 | 2020-02-01 12:31:01 | 83 |
|
||||
@ -767,7 +767,7 @@ GROUP BY exam_id,
|
||||
由示例数据结果输出如下:
|
||||
|
||||
| start_month | mau | month_add_uv | max_month_add_uv | cum_sum_uv |
|
||||
| ----------- | ---- | ------------ | ---------------- | ---------- |
|
||||
| ----------- | --- | ------------ | ---------------- | ---------- |
|
||||
| 202001 | 2 | 2 | 2 | 2 |
|
||||
| 202002 | 4 | 2 | 2 | 4 |
|
||||
| 202003 | 3 | 0 | 2 | 4 |
|
||||
@ -829,5 +829,4 @@ ORDER BY
|
||||
start_month
|
||||
```
|
||||
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
@ -19,7 +19,7 @@ tag:
|
||||
现有试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分),数据如下:
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:01 | 80 |
|
||||
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | 2021-05-02 10:30:01 | 81 |
|
||||
| 3 | 1001 | 9001 | 2021-09-02 12:01:01 | (NULL) | (NULL) |
|
||||
@ -69,14 +69,14 @@ HAVING incomplete_cnt <> 0
|
||||
现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间),数据如下:
|
||||
|
||||
| id | uid | nick_name | achievement | level | job | register_time |
|
||||
| ---- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
|
||||
| --- | ---- | --------- | ----------- | ----- | ---- | ------------------- |
|
||||
| 1 | 1001 | 牛客 1 号 | 10 | 0 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 2 | 1002 | 牛客 2 号 | 2100 | 6 | 算法 | 2020-01-01 10:00:00 |
|
||||
|
||||
试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间),数据如下:
|
||||
|
||||
| id | exam_id | tag | difficulty | duration | release_time |
|
||||
| ---- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| --- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| 1 | 9001 | SQL | hard | 60 | 2020-01-01 10:00:00 |
|
||||
| 2 | 9002 | SQL | easy | 60 | 2020-01-01 10:00:00 |
|
||||
| 3 | 9004 | 算法 | medium | 80 | 2020-01-01 10:00:00 |
|
||||
@ -84,7 +84,7 @@ HAVING incomplete_cnt <> 0
|
||||
试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分),数据如下:
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
|
||||
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
|
||||
| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
|
||||
@ -130,7 +130,7 @@ ORDER BY UID
|
||||
现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间):
|
||||
|
||||
| id | uid | nick_name | achievement | level | job | register_time |
|
||||
| ---- | ---- | ----------- | ----------- | ----- | ---- | ------------------- |
|
||||
| --- | ---- | ----------- | ----------- | ----- | ---- | ------------------- |
|
||||
| 1 | 1001 | 牛客 1 号 | 1000 | 2 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 3 | 1003 | 进击的 3 号 | 2200 | 5 | 算法 | 2020-01-01 10:00:00 |
|
||||
@ -140,7 +140,7 @@ ORDER BY UID
|
||||
试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
|
||||
| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
|
||||
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
|
||||
@ -163,7 +163,7 @@ ORDER BY UID
|
||||
题目练习记录表 `practice_record`(`uid` 用户 ID, `question_id` 题目 ID, `submit_time` 提交时间, `score` 得分):
|
||||
|
||||
| id | uid | question_id | submit_time | score |
|
||||
| ---- | ---- | ----------- | ------------------- | ----- |
|
||||
| --- | ---- | ----------- | ------------------- | ----- |
|
||||
| 1 | 1001 | 8001 | 2021-08-02 11:41:01 | 60 |
|
||||
| 2 | 1002 | 8001 | 2021-09-02 19:30:01 | 50 |
|
||||
| 3 | 1002 | 8001 | 2021-09-02 19:20:01 | 70 |
|
||||
@ -218,7 +218,7 @@ GROUP BY u_info.uid
|
||||
现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间):
|
||||
|
||||
| id | uid | nick_name | achievement | level | job | register_time |
|
||||
| ---- | ---- | ----------- | ----------- | ----- | ---- | ------------------- |
|
||||
| --- | ---- | ------------ | ----------- | ----- | ---- | ------------------- |
|
||||
| 1 | 1001 | 牛客 1 号 | 1900 | 2 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 3 | 1003 | 牛客 3 号 ♂ | 2200 | 5 | 算法 | 2020-01-01 10:00:00 |
|
||||
@ -229,7 +229,7 @@ GROUP BY u_info.uid
|
||||
试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
|
||||
|
||||
| id | exam_id | tag | difficulty | duration | release_time |
|
||||
| ---- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| --- | ------- | --- | ---------- | -------- | ------------------- |
|
||||
| 1 | 9001 | C++ | hard | 60 | 2020-01-01 10:00:00 |
|
||||
| 2 | 9002 | c# | hard | 80 | 2020-01-01 10:00:00 |
|
||||
| 3 | 9003 | SQL | medium | 70 | 2020-01-01 10:00:00 |
|
||||
@ -237,7 +237,7 @@ GROUP BY u_info.uid
|
||||
试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
|
||||
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
|
||||
| 4 | 1001 | 9001 | 2021-06-02 19:01:01 | 2021-06-02 19:32:00 | 20 |
|
||||
@ -312,7 +312,7 @@ ORDER BY UID,avg_score;
|
||||
现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间):
|
||||
|
||||
| id | uid | nick_name | achievement | level | job | register_time |
|
||||
| ---- | ---- | ----------- | ----------- | ----- | ---- | ------------------- |
|
||||
| --- | ---- | ----------- | ----------- | ----- | ---- | ------------------- |
|
||||
| 1 | 1001 | 牛客 1 号 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 3 | 1003 | 进击的 3 号 | 22 | 0 | 算法 | 2020-01-01 10:00:00 |
|
||||
@ -323,7 +323,7 @@ ORDER BY UID,avg_score;
|
||||
试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
|
||||
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
|
||||
| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 87 |
|
||||
@ -538,7 +538,7 @@ CASE
|
||||
现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间):
|
||||
|
||||
| id | uid | nick_name | achievement | level | job | register_time |
|
||||
| ---- | ---- | ----------- | ----------- | ----- | ---- | ------------------- |
|
||||
| --- | ---- | ------------ | ----------- | ----- | ---- | ------------------- |
|
||||
| 1 | 1001 | 牛客 1 号 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 3 | 1003 | 牛客 3 号 ♂ | 22 | 0 | 算法 | 2020-01-01 10:00:00 |
|
||||
@ -549,7 +549,7 @@ CASE
|
||||
试卷作答记录表 exam_record(uid 用户 ID, exam_id 试卷 ID, start_time 开始作答时间, submit_time 交卷时间, score 得分):
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
|
||||
| 2 | 1001 | 9001 | 2021-05-02 10:01:01 | (NULL) | (NULL) |
|
||||
| 3 | 1001 | 9002 | 2021-02-02 19:01:01 | 2021-02-02 19:30:01 | 75 |
|
||||
@ -650,7 +650,7 @@ ORDER BY a.LEVEL DESC,
|
||||
现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间):
|
||||
|
||||
| id | uid | nick_name | achievement | level | job | register_time |
|
||||
| ---- | ---- | ----------- | ----------- | ----- | ---- | ------------------- |
|
||||
| --- | ---- | ------------ | ----------- | ----- | ---- | ------------------- |
|
||||
| 1 | 1001 | 牛客 1 号 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-02-01 10:00:00 |
|
||||
| 3 | 1003 | 牛客 3 号 ♂ | 22 | 0 | 算法 | 2020-01-02 10:00:00 |
|
||||
@ -661,7 +661,7 @@ ORDER BY a.LEVEL DESC,
|
||||
请从中找到注册时间最早的 3 个人。由示例数据结果输出如下:
|
||||
|
||||
| uid | nick_name | register_time |
|
||||
| ---- | ----------- | ------------------- |
|
||||
| ---- | ------------ | ------------------- |
|
||||
| 1001 | 牛客 1 | 2020-01-01 10:00:00 |
|
||||
| 1003 | 牛客 3 号 ♂ | 2020-01-02 10:00:00 |
|
||||
| 1004 | 牛客 4 号 | 2020-01-02 11:00:00 |
|
||||
@ -682,7 +682,7 @@ SELECT uid, nick_name, register_time
|
||||
**描述**:现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间):
|
||||
|
||||
| id | uid | nick_name | achievement | level | job | register_time |
|
||||
| ---- | ---- | ----------- | ----------- | ----- | ---- | ------------------- |
|
||||
| --- | ---- | ------------ | ----------- | ----- | ---- | ------------------- |
|
||||
| 1 | 1001 | 牛客 1 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 3 | 1003 | 牛客 3 号 ♂ | 22 | 0 | 算法 | 2020-01-01 10:00:00 |
|
||||
@ -698,7 +698,7 @@ SELECT uid, nick_name, register_time
|
||||
试卷信息表 examination_info(exam_id 试卷 ID, tag 试卷类别, difficulty 试卷难度, duration 考试时长, release_time 发布时间):
|
||||
|
||||
| id | exam_id | tag | difficulty | duration | release_time |
|
||||
| ---- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| --- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| 1 | 9001 | 算法 | hard | 60 | 2020-01-01 10:00:00 |
|
||||
| 2 | 9002 | 算法 | hard | 80 | 2020-01-01 10:00:00 |
|
||||
| 3 | 9003 | SQL | medium | 70 | 2020-01-01 10:00:00 |
|
||||
@ -706,7 +706,7 @@ SELECT uid, nick_name, register_time
|
||||
试卷作答记录表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ----- |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ----- |
|
||||
| 1 | 1001 | 9001 | 2020-01-02 09:01:01 | 2020-01-02 09:21:59 | 80 |
|
||||
| 2 | 1002 | 9003 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 81 |
|
||||
| 3 | 1002 | 9002 | 2020-01-01 12:11:01 | 2020-01-01 12:31:01 | 83 |
|
||||
@ -785,7 +785,7 @@ LIMIT 6,3
|
||||
**描述**:现有试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
|
||||
|
||||
| id | exam_id | tag | difficulty | duration | release_time |
|
||||
| ---- | ------- | -------------- | ---------- | -------- | ------------------- |
|
||||
| --- | ------- | -------------- | ---------- | -------- | ------------------- |
|
||||
| 1 | 9001 | 算法 | hard | 60 | 2021-01-01 10:00:00 |
|
||||
| 2 | 9002 | 算法 | hard | 80 | 2021-01-01 10:00:00 |
|
||||
| 3 | 9003 | SQL | medium | 70 | 2021-01-01 10:00:00 |
|
||||
@ -866,7 +866,7 @@ WHERE
|
||||
**描述**:现有用户信息表 `user_info`(`uid` 用户 ID,`nick_name` 昵称, `achievement` 成就值, `level` 等级, `job` 职业方向, `register_time` 注册时间):
|
||||
|
||||
| id | uid | nick_name | achievement | level | job | register_time |
|
||||
| ---- | ---- | ---------------------- | ----------- | ----- | ---- | ------------------- |
|
||||
| --- | ---- | ---------------------- | ----------- | ----- | ---- | ------------------- |
|
||||
| 1 | 1001 | 牛客 1 | 19 | 0 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 2 | 1002 | 牛客 2 号 | 1200 | 3 | 算法 | 2020-01-01 10:00:00 |
|
||||
| 3 | 1003 | 牛客 3 号 ♂ | 22 | 0 | 算法 | 2020-01-01 10:00:00 |
|
||||
@ -930,7 +930,7 @@ GROUP BY
|
||||
现有试卷信息表 `examination_info`(`exam_id` 试卷 ID, `tag` 试卷类别, `difficulty` 试卷难度, `duration` 考试时长, `release_time` 发布时间):
|
||||
|
||||
| id | exam_id | tag | difficulty | duration | release_time |
|
||||
| ---- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| --- | ------- | ---- | ---------- | -------- | ------------------- |
|
||||
| 1 | 9001 | 算法 | hard | 60 | 2021-01-01 10:00:00 |
|
||||
| 2 | 9002 | C++ | hard | 80 | 2021-01-01 10:00:00 |
|
||||
| 3 | 9003 | C++ | hard | 80 | 2021-01-01 10:00:00 |
|
||||
@ -945,7 +945,7 @@ GROUP BY
|
||||
试卷作答信息表 `exam_record`(`uid` 用户 ID, `exam_id` 试卷 ID, `start_time` 开始作答时间, `submit_time` 交卷时间, `score` 得分):
|
||||
|
||||
| id | uid | exam_id | start_time | submit_time | score |
|
||||
| ---- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| --- | ---- | ------- | ------------------- | ------------------- | ------ |
|
||||
| 1 | 1001 | 9001 | 2020-01-01 09:01:01 | 2020-01-01 09:21:59 | 80 |
|
||||
| 2 | 1002 | 9003 | 2020-01-20 10:01:01 | 2020-01-20 10:10:01 | 81 |
|
||||
| 3 | 1002 | 9002 | 2020-02-01 12:11:01 | 2020-02-01 12:31:01 | 83 |
|
||||
@ -967,7 +967,7 @@ GROUP BY
|
||||
由示例数据结果输出如下:
|
||||
|
||||
| tag | answer_cnt |
|
||||
| ---- | ---------- |
|
||||
| --- | ---------- |
|
||||
| C++ | 6 |
|
||||
|
||||
解释:被作答过的试卷有 9001、9002、9003、9004,他们的 tag 和被作答次数如下:
|
||||
|
||||
@ -141,9 +141,7 @@ CAP 理论这节我们也说过了:
|
||||
> 分布式一致性的 3 种级别:
|
||||
>
|
||||
> 1. **强一致性**:系统写入了什么,读出来的就是什么。
|
||||
>
|
||||
> 2. **弱一致性**:不一定可以读取到最新写入的值,也不保证多少时间之后读取到的数据是最新的,只是会尽量保证某个时刻达到数据一致的状态。
|
||||
>
|
||||
> 3. **最终一致性**:弱一致性的升级版,系统会保证在一定时间内达到数据一致的状态。
|
||||
>
|
||||
> **业界比较推崇是最终一致性级别,但是某些对数据一致要求十分严格的场景比如银行转账还是要保证强一致性。**
|
||||
|
||||
@ -197,8 +197,6 @@ tag:
|
||||
|
||||
你可以看到图中生产者组中的生产者会向主题发送消息,而 **主题中存在多个队列**,生产者每次生产消息之后是指定主题中的某个队列发送消息的。
|
||||
|
||||
|
||||
|
||||
每个主题中都有多个队列(分布在不同的 `Broker`中,如果是集群的话,`Broker`又分布在不同的服务器中),集群消费模式下,一个消费者集群多台机器共同消费一个 `topic` 的多个队列,**一个队列只会被一个消费者消费**。如果某个消费者挂掉,分组内其它消费者会接替挂掉的消费者继续消费。就像上图中 `Consumer1` 和 `Consumer2` 分别对应着两个队列,而 `Consumer3` 是没有队列对应的,所以一般来讲要控制 **消费者组中的消费者个数和主题中队列个数相同** 。
|
||||
|
||||
当然也可以消费者个数小于队列个数,只不过不太建议。如下图。
|
||||
@ -608,8 +606,6 @@ sendfile()跟 mmap()一样,也会减少一次 CPU 拷贝,但是它同时也
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
如图,用户在发起 sendfile()调用时会发生切换 1,之后数据通过 DMA 拷贝到内核缓冲区,之后再将内核缓冲区的数据 CPU 拷贝到 Socket 缓冲区,最后拷贝到网卡,sendfile()返回,发生切换 2。发生了 3 次拷贝和两次切换。Java 也提供了相应 api:
|
||||
|
||||
```java
|
||||
|
||||
@ -107,4 +107,5 @@ tag:
|
||||
人的精力是有限的,而且面对三十这个天花板,各种事件也会接连而至,在职场中学会合理安排时间并不断提升核心能力,这样才能保证自己的竞争力。
|
||||
|
||||
职场就像苦海无边,回首望去可能也没有岸边停泊,但是要具有换船的能力或者有个小木筏也就大差不差了。
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
@ -207,4 +207,3 @@ Java 后端面试复习的重点请看这篇文章:[Java 面试重点总结(
|
||||
6. 岗位匹配度很重要。校招通常会对你的项目经历的研究方向比较宽容,即使你的项目经历和对应公司的具体业务没有关系,影响其实也并不大。社招的话就不一样了,毕竟公司是要招聘可以直接来干活的人,你有相关的经验,公司会比较省事。
|
||||
|
||||
7. 面试之后及时复盘。面试就像是一场全新的征程,失败和胜利都是平常之事。所以,劝各位不要因为面试失败而灰心、丧失斗志。也不要因为面试通过而沾沾自喜,等待你的将是更美好的未来,继续加油!
|
||||
|
||||
|
||||
@ -351,7 +351,7 @@ public class BigDecimalUtil {
|
||||
}
|
||||
```
|
||||
|
||||
相关 issue:[建议对保留规则设置为 RoundingMode.HALF_EVEN,即四舍六入五成双]([#2129](https://github.com/Snailclimb/JavaGuide/issues/2129)) 。
|
||||
相关 issue:[建议对保留规则设置为 RoundingMode.HALF_EVEN,即四舍六入五成双](<[#2129](https://github.com/Snailclimb/JavaGuide/issues/2129)>) 。
|
||||
|
||||
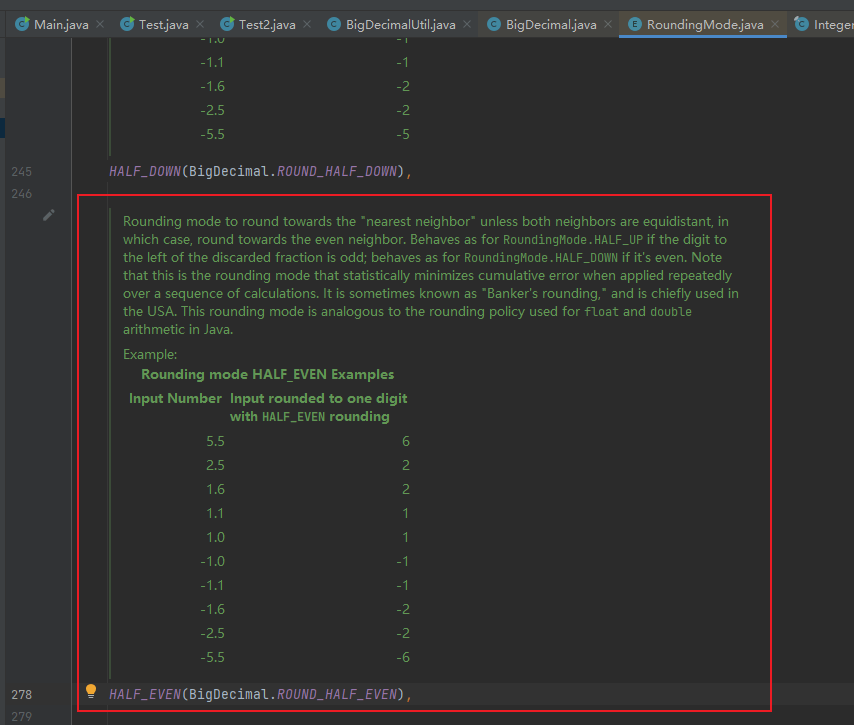
|
||||
|
||||
|
||||
@ -157,9 +157,7 @@ JDK 9 引入了一种新的编译模式 **AOT(Ahead of Time Compilation)** 。
|
||||
> 答:
|
||||
>
|
||||
> 1. OpenJDK 是开源的,开源意味着你可以对它根据你自己的需要进行修改、优化,比如 Alibaba 基于 OpenJDK 开发了 Dragonwell8:[https://github.com/alibaba/dragonwell8](https://github.com/alibaba/dragonwell8)
|
||||
>
|
||||
> 2. OpenJDK 是商业免费的(这也是为什么通过 yum 包管理器上默认安装的 JDK 是 OpenJDK 而不是 Oracle JDK)。虽然 Oracle JDK 也是商业免费(比如 JDK 8),但并不是所有版本都是免费的。
|
||||
>
|
||||
> 3. OpenJDK 更新频率更快。Oracle JDK 一般是每 6 个月发布一个新版本,而 OpenJDK 一般是每 3 个月发布一个新版本。(现在你知道为啥 Oracle JDK 更稳定了吧,先在 OpenJDK 试试水,把大部分问题都解决掉了才在 Oracle JDK 上发布)
|
||||
>
|
||||
> 基于以上这些原因,OpenJDK 还是有存在的必要的!
|
||||
@ -409,7 +407,7 @@ Java 中有 8 种基本数据类型,分别为:
|
||||
这 8 种基本数据类型的默认值以及所占空间的大小如下:
|
||||
|
||||
| 基本类型 | 位数 | 字节 | 默认值 | 取值范围 |
|
||||
| :-------- | :--- | :--- | :------ | ------------------------------------------------------------ |
|
||||
| :-------- | :--- | :--- | :------ | -------------------------------------------------------------- |
|
||||
| `byte` | 8 | 1 | 0 | -128 ~ 127 |
|
||||
| `short` | 16 | 2 | 0 | -32768(-2^15) ~ 32767(2^15 - 1) |
|
||||
| `int` | 32 | 4 | 0 | -2147483648 ~ 2147483647 |
|
||||
|
||||
@ -314,5 +314,4 @@ System.out.println("列表清空后为:" + list);
|
||||
列表清空后为:[]
|
||||
```
|
||||
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
@ -266,7 +266,6 @@ HashMap 只提供了 put 用于添加元素,putVal 方法只是给 put 方法
|
||||
|
||||
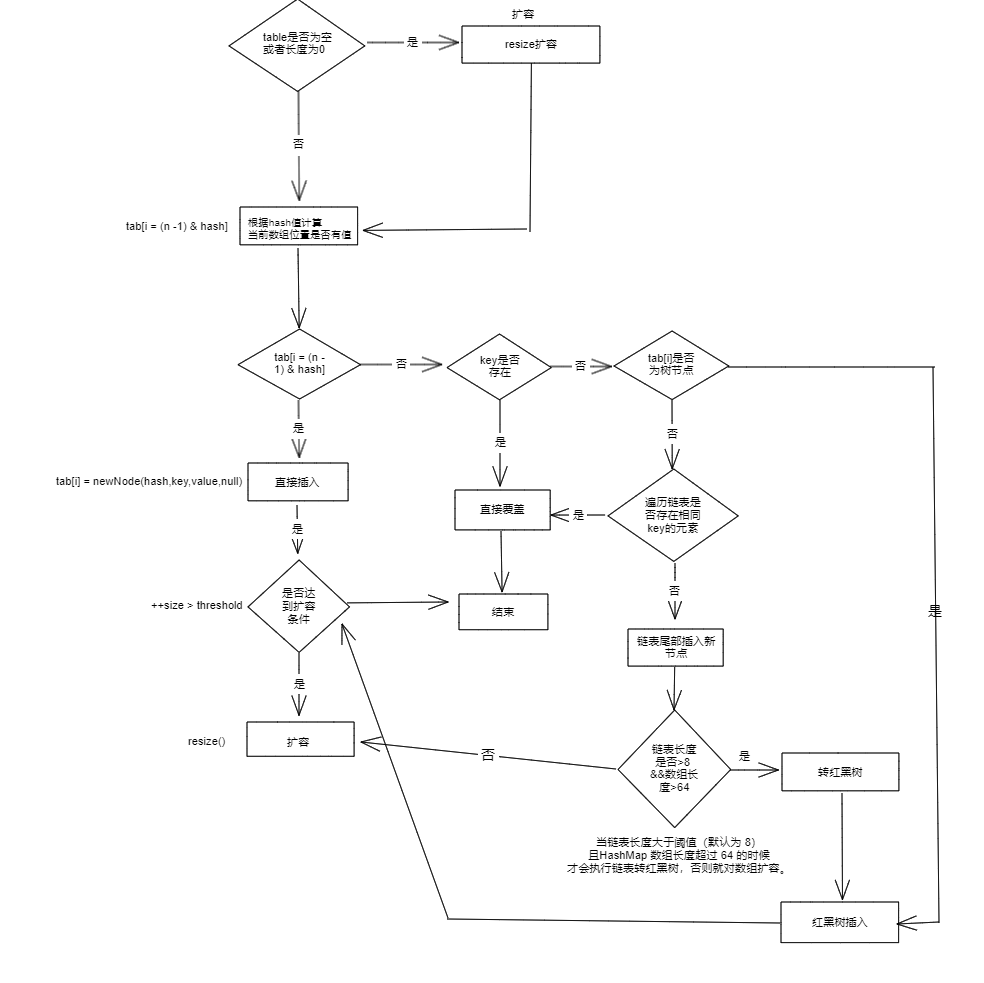
|
||||
|
||||
|
||||
```java
|
||||
public V put(K key, V value) {
|
||||
return putVal(hash(key), key, value, false, true);
|
||||
@ -499,7 +498,6 @@ final Node<K,V>[] resize() {
|
||||
}
|
||||
```
|
||||
|
||||
|
||||
## HashMap 常用方法测试
|
||||
|
||||
```java
|
||||
|
||||
@ -66,7 +66,7 @@ head:
|
||||
如果你看过 `HashSet` 源码的话就应该知道:`HashSet` 底层就是基于 `HashMap` 实现的。(`HashSet` 的源码非常非常少,因为除了 `clone()`、`writeObject()`、`readObject()`是 `HashSet` 自己不得不实现之外,其他方法都是直接调用 `HashMap` 中的方法。
|
||||
|
||||
| `HashMap` | `HashSet` |
|
||||
| :------------------------------------: | :----------------------------------------------------------: |
|
||||
| :------------------------------------: | :----------------------------------------------------------------------------------------------------------------------: |
|
||||
| 实现了 `Map` 接口 | 实现 `Set` 接口 |
|
||||
| 存储键值对 | 仅存储对象 |
|
||||
| 调用 `put()`向 map 中添加元素 | 调用 `add()`方法向 `Set` 中添加元素 |
|
||||
|
||||
@ -513,4 +513,5 @@ System.out.println("清空后的链表:" + list);
|
||||
链表长度:2
|
||||
清空后的链表:[]
|
||||
```
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
@ -11,5 +11,4 @@ tag:
|
||||
|
||||
<!-- @include: @yuanma.snippet.md -->
|
||||
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
@ -715,6 +715,4 @@ CompletableFuture.runAsync(() -> {
|
||||
|
||||
另外,建议 G 友们可以看看京东的 [asyncTool](https://gitee.com/jd-platform-opensource/asyncTool) 这个并发框架,里面大量使用到了 `CompletableFuture` 。
|
||||
|
||||
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
@ -26,11 +26,13 @@ tag:
|
||||
## 虚拟线程有什么优点和缺点?
|
||||
|
||||
### 优点
|
||||
|
||||
- 非常轻量级:可以在单个线程中创建成百上千个虚拟线程而不会导致过多的线程创建和上下文切换。
|
||||
- 简化异步编程: 虚拟线程可以简化异步编程,使代码更易于理解和维护。它可以将异步代码编写得更像同步代码,避免了回调地狱(Callback Hell)。
|
||||
- 减少资源开销: 相比于操作系统线程,虚拟线程的资源开销更小。本质上是提高了线程的执行效率,从而减少线程资源的创建和上下文切换。
|
||||
|
||||
### 缺点
|
||||
|
||||
- 不适用于计算密集型任务: 虚拟线程适用于 I/O 密集型任务,但不适用于计算密集型任务,因为密集型计算始终需要 CPU 资源作为支持。
|
||||
- 依赖于语言或库的支持: 协程需要编程语言或库提供支持。不是所有编程语言都原生支持协程。比如 Java 实现的虚拟线程。
|
||||
|
||||
@ -44,7 +46,6 @@ Java 21 已经正式支持虚拟线程,大家可以在官网下载使用,在
|
||||
2. 使用 `Thread.ofVirtual()` 创建
|
||||
3. 使用 `ThreadFactory` 创建
|
||||
|
||||
|
||||
#### 使用 Thread.startVirtualThread()创建
|
||||
|
||||
```java
|
||||
@ -123,6 +124,7 @@ static class CustomThread implements Runnable {
|
||||
```
|
||||
|
||||
## 虚拟线程和平台线程性能对比
|
||||
|
||||
通过多线程和虚拟线程的方式处理相同的任务,对比创建的系统线程数和处理耗时。
|
||||
|
||||
**说明**:统计创建的系统线程中部分为后台线程(比如 GC 线程),两种场景下都一样,所以并不影响对比。
|
||||
|
||||
@ -48,7 +48,7 @@ NIO 主要包括以下三个核心组件:
|
||||
|
||||
为了更清晰地认识缓冲区,我们来简单看看`Buffer` 类中定义的四个成员变量:
|
||||
|
||||
~~~java
|
||||
```java
|
||||
public abstract class Buffer {
|
||||
// Invariants: mark <= position <= limit <= capacity
|
||||
private int mark = -1;
|
||||
@ -56,7 +56,7 @@ public abstract class Buffer {
|
||||
private int limit;
|
||||
private int capacity;
|
||||
}
|
||||
~~~
|
||||
```
|
||||
|
||||
这四个成员变量的具体含义如下:
|
||||
|
||||
@ -77,12 +77,12 @@ public abstract class Buffer {
|
||||
|
||||
这里以 `ByteBuffer`为例进行介绍:
|
||||
|
||||
~~~java
|
||||
```java
|
||||
// 分配堆内存
|
||||
public static ByteBuffer allocate(int capacity);
|
||||
// 分配直接内存
|
||||
public static ByteBuffer allocateDirect(int capacity);
|
||||
~~~
|
||||
```
|
||||
|
||||
Buffer 最核心的两个方法:
|
||||
|
||||
@ -97,7 +97,7 @@ public static ByteBuffer allocateDirect(int capacity);
|
||||
|
||||
Buffer 中数据变化的过程:
|
||||
|
||||
~~~java
|
||||
```java
|
||||
import java.nio.*;
|
||||
|
||||
public class CharBufferDemo {
|
||||
@ -138,11 +138,11 @@ public class CharBufferDemo {
|
||||
System.out.println("\n");
|
||||
}
|
||||
}
|
||||
~~~
|
||||
```
|
||||
|
||||
输出:
|
||||
|
||||
~~~bash
|
||||
```bash
|
||||
初始状态:
|
||||
capacity: 8, limit: 8, position: 0
|
||||
|
||||
@ -158,7 +158,7 @@ capacity: 8, limit: 3, position: 0
|
||||
|
||||
调用clear()方法后的状态:
|
||||
capacity: 8, limit: 8, position: 0
|
||||
~~~
|
||||
```
|
||||
|
||||
为了帮助理解,我绘制了一张图片展示 `capacity`、`limit`和`position`每一阶段的变化。
|
||||
|
||||
@ -188,7 +188,6 @@ Channel 与前面介绍的 Buffer 打交道,读操作的时候将 Channel 中
|
||||
|
||||
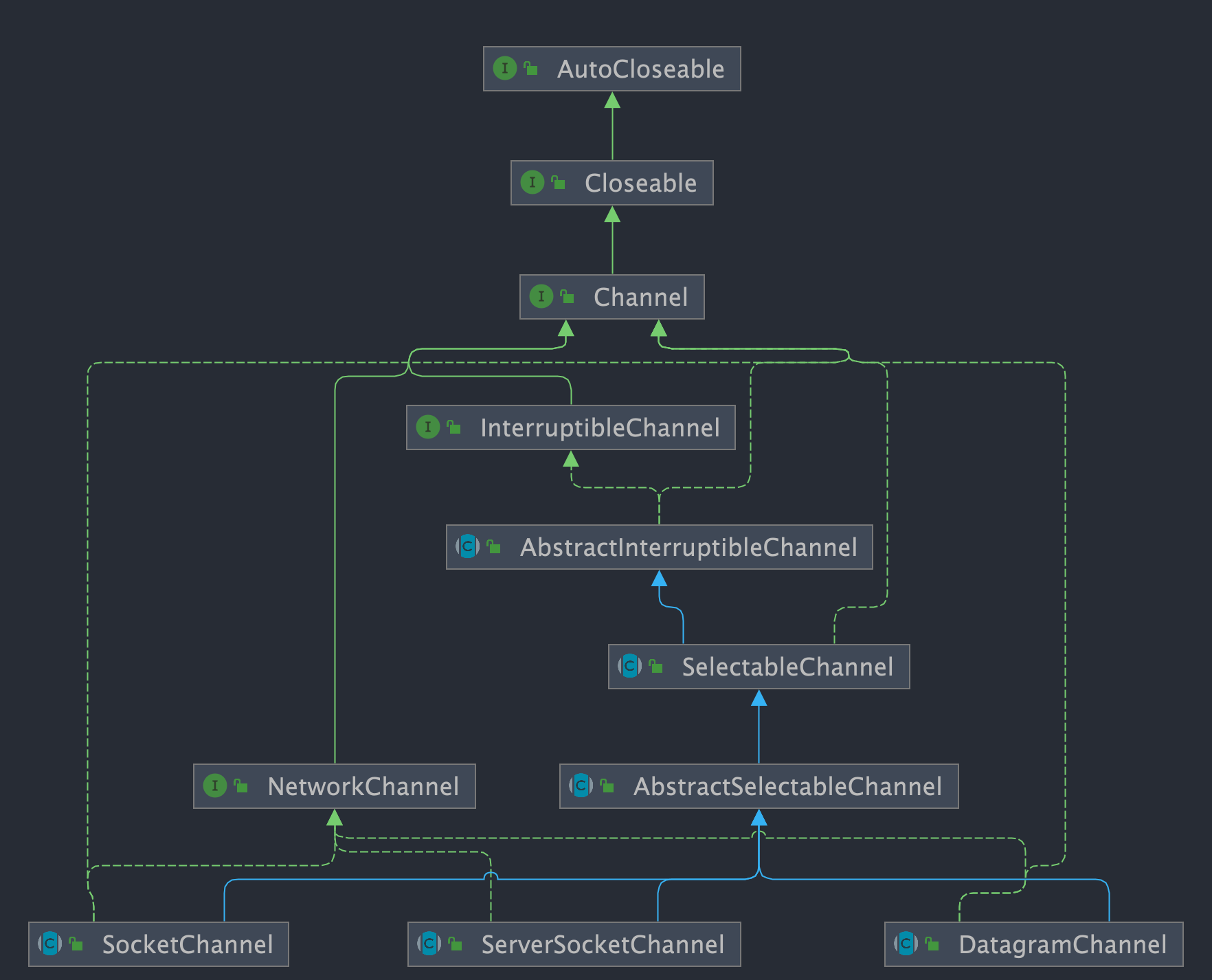
|
||||
|
||||
|
||||
Channel 最核心的两个方法:
|
||||
|
||||
1. `read` :读取数据并写入到 Buffer 中。
|
||||
@ -196,12 +195,12 @@ Channel 与前面介绍的 Buffer 打交道,读操作的时候将 Channel 中
|
||||
|
||||
这里我们以 `FileChannel` 为例演示一下是读取文件数据的。
|
||||
|
||||
~~~java
|
||||
```java
|
||||
RandomAccessFile reader = new RandomAccessFile("/Users/guide/Documents/test_read.in", "r"))
|
||||
FileChannel channel = reader.getChannel();
|
||||
ByteBuffer buffer = ByteBuffer.allocate(1024);
|
||||
channel.read(buffer);
|
||||
~~~
|
||||
```
|
||||
|
||||
### Selector(选择器)
|
||||
|
||||
@ -258,7 +257,7 @@ Selector 还提供了一系列和 `select()` 相关的方法:
|
||||
|
||||
使用 Selector 实现网络读写的简单示例:
|
||||
|
||||
~~~java
|
||||
```java
|
||||
import java.io.IOException;
|
||||
import java.net.InetSocketAddress;
|
||||
import java.nio.ByteBuffer;
|
||||
@ -335,7 +334,7 @@ public class NioSelectorExample {
|
||||
}
|
||||
}
|
||||
}
|
||||
~~~
|
||||
```
|
||||
|
||||
在示例中,我们创建了一个简单的服务器,监听 8080 端口,使用 Selector 处理连接、读取和写入事件。当接收到客户端的数据时,服务器将读取数据并将其打印到控制台,然后向客户端回复 "Hello, Client!"。
|
||||
|
||||
@ -390,5 +389,4 @@ private void loadFileIntoMemory(File xmlFile) throws IOException {
|
||||
|
||||
- Java NIO:Buffer、Channel 和 Selector:https://www.javadoop.com/post/java-nio
|
||||
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
@ -109,8 +109,8 @@ public class GCTest {
|
||||
|
||||
大对象直接进入老年代的行为是由虚拟机动态决定的,它与具体使用的垃圾回收器和相关参数有关。大对象直接进入老年代是一种优化策略,旨在避免将大对象放入新生代,从而减少新生代的垃圾回收频率和成本。
|
||||
|
||||
* G1 垃圾回收器会根据-XX:G1HeapRegionSize参数设置的堆区域大小和-XX:G1MixedGCLiveThresholdPercent参数设置的阈值,来决定哪些对象会直接进入老年代。
|
||||
* Parallel Scavenge 垃圾回收器中,默认情况下,并没有一个固定的阈值(XX:ThresholdTolerance是动态调整的)来决定何时直接在老年代分配大对象。而是由虚拟机根据当前的堆内存情况和历史数据动态决定。
|
||||
- G1 垃圾回收器会根据 `-XX:G1HeapRegionSize` 参数设置的堆区域大小和 `-XX:G1MixedGCLiveThresholdPercent` 参数设置的阈值,来决定哪些对象会直接进入老年代。
|
||||
- Parallel Scavenge 垃圾回收器中,默认情况下,并没有一个固定的阈值(`XX:ThresholdTolerance`是动态调整的)来决定何时直接在老年代分配大对象。而是由虚拟机根据当前的堆内存情况和历史数据动态决定。
|
||||
|
||||
### 长期存活的对象将进入老年代
|
||||
|
||||
@ -122,7 +122,7 @@ public class GCTest {
|
||||
|
||||
> 修正([issue552](https://github.com/Snailclimb/JavaGuide/issues/552)):“Hotspot 遍历所有对象时,按照年龄从小到大对其所占用的大小进行累积,当累积的某个年龄大小超过了 survivor 区的 50% 时(默认值是 50%,可以通过 `-XX:TargetSurvivorRatio=percent` 来设置,参见 [issue1199](https://github.com/Snailclimb/JavaGuide/issues/1199) ),取这个年龄和 MaxTenuringThreshold 中更小的一个值,作为新的晋升年龄阈值”。
|
||||
>
|
||||
> jdk8 官方文档引用:https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html 。
|
||||
> jdk8 官方文档引用:<https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html>。
|
||||
>
|
||||
> 
|
||||
>
|
||||
@ -234,7 +234,6 @@ public class ReferenceCountingGc {
|
||||
- 所有被同步锁持有的对象
|
||||
- JNI(Java Native Interface)引用的对象
|
||||
|
||||
|
||||
**对象可以被回收,就代表一定会被回收吗?**
|
||||
|
||||
即使在可达性分析法中不可达的对象,也并非是“非死不可”的,这时候它们暂时处于“缓刑阶段”,要真正宣告一个对象死亡,至少要经历两次标记过程;可达性分析法中不可达的对象被第一次标记并且进行一次筛选,筛选的条件是此对象是否有必要执行 `finalize` 方法。当对象没有覆盖 `finalize` 方法,或 `finalize` 方法已经被虚拟机调用过时,虚拟机将这两种情况视为没有必要执行。
|
||||
|
||||
@ -155,4 +155,3 @@ java -XX:+UseZGC -XX:+ZGenerational ...
|
||||
## 参考
|
||||
|
||||
- Java 21 String Templates:<https://howtodoinjava.com/java/java-string-templates/>
|
||||
|
||||
|
||||
@ -53,6 +53,7 @@ icon: tool
|
||||
- [zktools](https://zktools.readthedocs.io/en/latest/#installing):一个低延迟的 ZooKeeper 图形化管理客户端,颜值非常高,支持 Mac / Windows / Linux 。你可以使用 zktools 来实现对 ZooKeeper 的可视化增删改查。
|
||||
|
||||
## Kafka
|
||||
|
||||
- [Kafka UI](https://github.com/provectus/kafka-ui):免费的开源 Web UI,用于监控和管理 Apache Kafka 集群。
|
||||
- [Kafdrop](https://github.com/obsidiandynamics/kafdrop) : 一个用于查看 Kafka 主题和浏览消费者组的 Web UI。
|
||||
- [EFAK](https://github.com/smartloli/EFAK) (Eagle For Apache Kafka,以前叫做 Kafka Eagle):一个简单的高性能监控系统,用于对 Kafka 集群进行全面的监控和管理。
|
||||
@ -1,2 +1 @@
|
||||

|
||||
|
||||
|
||||
@ -4,8 +4,6 @@
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
下面是星球提供的部分服务(点击下方图片即可获取知识星球的详细介绍):
|
||||
|
||||
@ -25,4 +25,3 @@
|
||||
**无任何套路,无任何潜在收费项。用心做内容,不割韭菜!**
|
||||
|
||||
不过, **一定要确定需要再进** 。并且, **三天之内觉得内容不满意可以全额退款** 。
|
||||
|
||||
|
||||
@ -655,7 +655,6 @@ public class DefaultAopProxyFactory implements AopProxyFactory, Serializable {
|
||||
|
||||
#### Spring AOP 自调用问题
|
||||
|
||||
|
||||
当一个方法被标记了`@Transactional` 注解的时候,Spring 事务管理器只会在被其他类方法调用的时候生效,而不会在一个类中方法调用生效。
|
||||
|
||||
这是因为 Spring AOP 工作原理决定的。因为 Spring AOP 使用动态代理来实现事务的管理,它会在运行的时候为带有 `@Transactional` 注解的方法生成代理对象,并在方法调用的前后应用事物逻辑。如果该方法被其他类调用我们的代理对象就会拦截方法调用并处理事务。但是在一个类中的其他方法内部调用的时候,我们代理对象就无法拦截到这个内部调用,因此事务也就失效了。
|
||||
|
||||
@ -11,5 +11,4 @@ tag:
|
||||
|
||||
<!-- @include: @yuanma.snippet.md -->
|
||||
|
||||
|
||||
<!-- @include: @article-footer.snippet.md -->
|
||||
@ -358,7 +358,7 @@ public ReturnT<String> myAnnotationJobHandler(String param) throws Exception {
|
||||
由于 SchedulerX 属于人民币产品,我这里就不过多介绍。PowerJob 官方也对比过其和 QuartZ、XXL-JOB 以及 SchedulerX。
|
||||
|
||||
| | QuartZ | xxl-job | SchedulerX 2.0 | PowerJob |
|
||||
| -------------- | ------------------------------------------ | ---------------------------------------- | ------------------------------------------------- | ------------------------------------------------------------ |
|
||||
| -------------- | ------------------------------------------- | ------------------------------------------ | ---------------------------------------------------- | --------------------------------------------------------------- |
|
||||
| 定时类型 | CRON | CRON | CRON、固定频率、固定延迟、OpenAPI | **CRON、固定频率、固定延迟、OpenAPI** |
|
||||
| 任务类型 | 内置 Java | 内置 Java、GLUE Java、Shell、Python 等脚本 | 内置 Java、外置 Java(FatJar)、Shell、Python 等脚本 | **内置 Java、外置 Java(容器)、Shell、Python 等脚本** |
|
||||
| 分布式计算 | 无 | 静态分片 | MapReduce 动态分片 | **MapReduce 动态分片** |
|
||||
|
||||
@ -41,7 +41,7 @@ tag:
|
||||
Hutool 一个 Java 基础工具类,对文件、流、加密解密、转码、正则、线程、XML 等 JDK 方法进行封装,组成各种 Util 工具类,同时提供以下组件:
|
||||
|
||||
| 模块 | 介绍 |
|
||||
| :----------------: | :----------------------------------------------------------: |
|
||||
| :----------------: | :---------------------------------------------------------------------------: |
|
||||
| hutool-aop | JDK 动态代理封装,提供非 IOC 下的切面支持 |
|
||||
| hutool-bloomFilter | 布隆过滤,提供一些 Hash 算法的布隆过滤 |
|
||||
| hutool-cache | 简单缓存实现 |
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user