mirror of
https://github.com/Snailclimb/JavaGuide
synced 2025-08-01 16:28:03 +08:00
[docs update]内容修正
This commit is contained in:
parent
74fc413bcc
commit
7cf404ba59
@ -780,10 +780,15 @@ dynamic-hz yes
|
||||
|
||||
### 大量 key 集中过期怎么办?
|
||||
|
||||
如果存在大量 key 集中过期的问题,可能会使 Redis 的请求延迟变高。可以采用下面的可选方案来应对:
|
||||
当 Redis 中存在大量 key 在同一时间点集中过期时,可能会导致以下问题:
|
||||
|
||||
1. 尽量避免 key 集中过期,在设置键的过期时间时尽量随机一点。
|
||||
2. 对过期的 key 开启 lazyfree 机制(修改 `redis.conf` 中的 `lazyfree-lazy-expire`参数即可),这样会在后台异步删除过期的 key,不会阻塞主线程的运行。
|
||||
- **请求延迟增加:** Redis 在处理过期 key 时需要消耗 CPU 资源,如果过期 key 数量庞大,会导致 Redis 实例的 CPU 占用率升高,进而影响其他请求的处理速度,造成延迟增加。
|
||||
- **内存占用过高:** 过期的 key 虽然已经失效,但在 Redis 真正删除它们之前,仍然会占用内存空间。如果过期 key 没有及时清理,可能会导致内存占用过高,甚至引发内存溢出。
|
||||
|
||||
为了避免这些问题,可以采取以下方案:
|
||||
|
||||
1. **尽量避免 key 集中过期**: 在设置键的过期时间时尽量随机一点。
|
||||
2. **开启 lazy free 机制**: 修改 `redis.conf` 配置文件,将 `lazyfree-lazy-expire` 参数设置为 `yes`,即可开启 lazy free 机制。开启 lazy free 机制后,Redis 会在后台异步删除过期的 key,不会阻塞主线程的运行,从而降低对 Redis 性能的影响。
|
||||
|
||||
### Redis 内存淘汰策略了解么?
|
||||
|
||||
|
||||
@ -706,9 +706,14 @@ System.out.println(aa==bb); // true
|
||||
|
||||
### String s1 = new String("abc");这句话创建了几个字符串对象?
|
||||
|
||||
会创建 1 或 2 个字符串对象。
|
||||
先说答案:会创建 1 或 2 个字符串对象。
|
||||
|
||||
1、如果字符串常量池中不存在字符串对象 “abc”,那么它首先会在字符串常量池中创建字符串对象 "abc",然后在堆内存中再创建其中一个字符串对象 "abc"
|
||||
1. 字符串常量池中不存在 "abc":会创建 2 个 字符串对象。一个在字符串常量池中,由 `ldc` 指令触发创建。一个在堆中,由 `new String()` 创建,并使用常量池中的 "abc" 进行初始化。
|
||||
2. 字符串常量池中已存在 "abc":会创建 1 个 字符串对象。该对象在堆中,由 `new String()` 创建,并使用常量池中的 "abc" 进行初始化。
|
||||
|
||||
下面开始详细分析。
|
||||
|
||||
1、如果字符串常量池中不存在字符串对象 “abc”,那么它首先会在字符串常量池中创建字符串对象 "abc",然后在堆内存中再创建其中一个字符串对象 "abc"。
|
||||
|
||||
示例代码(JDK 1.8):
|
||||
|
||||
@ -718,9 +723,33 @@ String s1 = new String("abc");
|
||||
|
||||
对应的字节码:
|
||||
|
||||
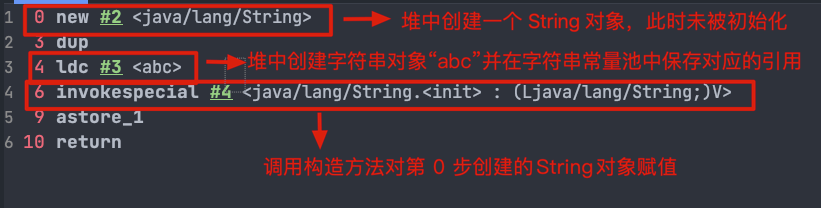
|
||||
```java
|
||||
// 在堆内存中分配一个尚未初始化的 String 对象。
|
||||
// #2 是常量池中的一个符号引用,指向 java/lang/String 类。
|
||||
// 在类加载的解析阶段,这个符号引用会被解析成直接引用,即指向实际的 java/lang/String 类。
|
||||
0 new #2 <java/lang/String>
|
||||
// 复制栈顶的 String 对象引用,为后续的构造函数调用做准备。
|
||||
// 此时操作数栈中有两个相同的对象引用:一个用于传递给构造函数,另一个用于保持对新对象的引用,后续将其存储到局部变量表。
|
||||
3 dup
|
||||
// JVM 先检查字符串常量池中是否存在 "abc"。
|
||||
// 如果常量池中已存在 "abc",则直接返回该字符串的引用;
|
||||
// 如果常量池中不存在 "abc",则 JVM 会在常量池中创建该字符串字面量并返回它的引用。
|
||||
// 这个引用被压入操作数栈,用作构造函数的参数。
|
||||
4 ldc #3 <abc>
|
||||
// 调用构造方法,使用从常量池中加载的 "abc" 初始化堆中的 String 对象
|
||||
// 新的 String 对象将包含与常量池中的 "abc" 相同的内容,但它是一个独立的对象,存储于堆中。
|
||||
6 invokespecial #4 <java/lang/String.<init> : (Ljava/lang/String;)V>
|
||||
// 将堆中的 String 对象引用存储到局部变量表
|
||||
9 astore_1
|
||||
// 返回,结束方法
|
||||
10 return
|
||||
```
|
||||
|
||||
`ldc (load constant)` 指令的作用是从常量池中加载常量,包括字符串常量、整数常量、浮点数常量、或者类引用。这里用于判断字符串常量池中是否保存了对应的字符串对象,如果保存了的话会将它的引用加载到操作数栈,如果没有保存的话,会在字符串常量池中创建对应的字符串对象,并将其引用加载到操作数栈中。
|
||||
`ldc (load constant)` 指令的确是从常量池中加载各种类型的常量,包括字符串常量、整数常量、浮点数常量,甚至类引用等。对于字符串常量,`ldc` 指令的行为如下:
|
||||
|
||||
1. **从常量池加载字符串**:`ldc` 首先检查字符串常量池中是否已经有内容相同的字符串对象。
|
||||
2. **复用已有字符串对象**:如果字符串常量池中已经存在内容相同的字符串对象,`ldc` 会将该对象的引用加载到操作数栈上。
|
||||
3. **没有则创建新对象并加入常量池**:如果字符串常量池中没有相同内容的字符串对象,JVM 会在常量池中创建一个新的字符串对象,并将其引用加载到操作数栈中。
|
||||
|
||||
2、如果字符串常量池中已存在字符串对象“abc”,则只会在堆中创建 1 个字符串对象“abc”。
|
||||
|
||||
@ -735,7 +764,16 @@ String s2 = new String("abc");
|
||||
|
||||
对应的字节码:
|
||||
|
||||
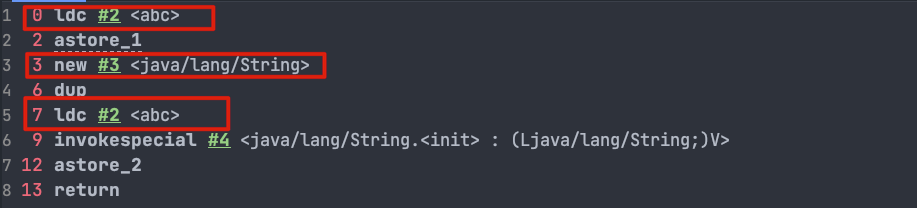
|
||||
```java
|
||||
0 ldc #2 <abc>
|
||||
2 astore_1
|
||||
3 new #3 <java/lang/String>
|
||||
6 dup
|
||||
7 ldc #2 <abc>
|
||||
9 invokespecial #4 <java/lang/String.<init> : (Ljava/lang/String;)V>
|
||||
12 astore_2
|
||||
13 return
|
||||
```
|
||||
|
||||
这里就不对上面的字节码进行详细注释了,7 这个位置的 `ldc` 命令不会在堆中创建新的字符串对象“abc”,这是因为 0 这个位置已经执行了一次 `ldc` 命令,已经在堆中创建过一次字符串对象“abc”了。7 这个位置执行 `ldc` 命令会直接返回字符串常量池中字符串对象“abc”对应的引用。
|
||||
|
||||
|
||||
@ -55,8 +55,8 @@ head:
|
||||
|
||||
### Throwable 类常用方法有哪些?
|
||||
|
||||
- `String getMessage()`: 返回异常发生时的简要描述
|
||||
- `String toString()`: 返回异常发生时的详细信息
|
||||
- `String getMessage()`: 返回异常发生时的详细信息
|
||||
- `String toString()`: 返回异常发生时的简要描述
|
||||
- `String getLocalizedMessage()`: 返回异常对象的本地化信息。使用 `Throwable` 的子类覆盖这个方法,可以生成本地化信息。如果子类没有覆盖该方法,则该方法返回的信息与 `getMessage()`返回的结果相同
|
||||
- `void printStackTrace()`: 在控制台上打印 `Throwable` 对象封装的异常信息
|
||||
|
||||
|
||||
@ -653,7 +653,15 @@ abc
|
||||
|
||||
我们上面的代码示例中,为了方便,都没有选择自定义线程池。实际项目中,这是不可取的。
|
||||
|
||||
`CompletableFuture` 默认使用`ForkJoinPool.commonPool()` 作为执行器,这个线程池是全局共享的,可能会被其他任务占用,导致性能下降或者饥饿。因此,建议使用自定义的线程池来执行 `CompletableFuture` 的异步任务,可以提高并发度和灵活性。
|
||||
`CompletableFuture` 默认使用全局共享的 `ForkJoinPool.commonPool()` 作为执行器,所有未指定执行器的异步任务都会使用该线程池。这意味着应用程序、多个库或框架(如 Spring、第三方库)若都依赖 `CompletableFuture`,默认情况下它们都会共享同一个线程池。
|
||||
|
||||
虽然 `ForkJoinPool` 效率很高,但当同时提交大量任务时,可能会导致资源竞争和线程饥饿,进而影响系统性能。
|
||||
|
||||
为避免这些问题,建议为 `CompletableFuture` 提供自定义线程池,带来以下优势:
|
||||
|
||||
- **隔离性**:为不同任务分配独立的线程池,避免全局线程池资源争夺。
|
||||
- **资源控制**:根据任务特性调整线程池大小和队列类型,优化性能表现。
|
||||
- **异常处理**:通过自定义 `ThreadFactory` 更好地处理线程中的异常情况。
|
||||
|
||||
```java
|
||||
private ThreadPoolExecutor executor = new ThreadPoolExecutor(10, 10,
|
||||
|
||||
Loading…
x
Reference in New Issue
Block a user